| Issue |
A&A
Volume 665, September 2022
|
|
|---|---|---|
| Article Number | A78 | |
| Number of page(s) | 34 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202243824 | |
| Published online | 13 September 2022 | |
Detecting clusters of galaxies and active galactic nuclei in an eROSITA all-sky survey digital twin⋆
1
Max-Planck-Institut für extraterrestrische Physik (MPE), Giessenbachstrasse 1, 85748 Garching bei München, Germany
e-mail: rseppi@mpe.mpg.de
2
IRAP, Université de Toulouse, CNRS, UPS, CNES, Toulouse, France
3
Dr. Karl-Remeis-Sternwarte and ECAP, Sternwartstr. 7, 96049 Bamberg, Germany
4
Argelander-Institut für Astronomie (AIfA), Universität Bonn, Auf dem Hügel 71, 53121 Bonn, Germany
Received:
20
April
2022
Accepted:
6
July
2022
Context. The extended ROentgen Survey with an Imaging Telescope Array (eROSITA) on board the Spectrum-Roentgen-Gamma (SRG) observatory is revolutionizing X-ray astronomy. The mission provides unprecedented samples of active galactic nuclei (AGN) and clusters of galaxies, with the potential of studying astrophysical properties of X-ray sources and measuring cosmological parameters using X-ray-selected samples with higher precision than ever before.
Aims. We aim to study the detection, and the selection of AGN and clusters of galaxies in the first eROSITA all-sky survey, and to characterize the properties of the source catalog.
Methods. We produced a half-sky simulation at the depth of the first eROSITA survey (eRASS1), by combining models that truthfully represent the population of clusters and AGN. In total, we simulated 1 116 758 clusters and 225 583 320 AGN. We ran the standard eROSITA detection algorithm, optimized for extragalactic sources. We matched the input and the source catalogs with a photon-based matching algorithm.
Results. We perfectly recovered the bright AGN and clusters. We detected half of the simulated AGN with flux larger than 2 × 10−14 erg s−1 cm−2 as point sources and half of the simulated clusters with flux larger than 3 × 10−13 erg s−1 cm−2 as extended sources in the 0.5–2.0 keV band. We quantified the detection performance in terms of completeness, false detection rate, and contamination. We studied the population in the source catalog according to multiple cuts of source detection and extension likelihood. We find that the latter is suitable for removing contamination, and the former is very efficient in minimizing the false detection rate. We find that the detection of clusters of galaxies is mainly driven by flux and exposure time. It additionally depends on secondary effects, such as the size of the clusters on the sky plane and their dynamical state. The cool core bias mostly affects faint clusters classified as point sources, while its impact on the extent-selected sample is small. We measured the fraction of the area covered by our simulation as a function of limiting flux. We measured the X-ray luminosity of the detected clusters and find that it is compatible with the simulated values.
Conclusions. We discuss how to best build samples of galaxy clusters for cosmological purposes, accounting for the nonuniform depth of eROSITA. This simulation provides a digital twin of the real eRASS1.
Key words: surveys / catalogs / X-rays: galaxies: clusters / galaxies: active / methods: data analysis / large-scale structure of Universe
Full Tables A.1–A.3 are only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/cat/J/A+A/665/A78
© R. Seppi et al. 2022
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe-to-Open model.
Open Access funding provided by Max Planck Society.
1. Introduction
Our knowledge of the large-scale structure (LSS) of the Universe has dramatically improved in the past decades thanks to a variety of surveys at different wavelengths. A wealth of information about the matter distribution on cosmological scales is obtained by optical data from galaxy clustering, measured by the Two-degree-Field Galaxy Redshift Survey (2dFGRS, Colless et al. 2001), the Galaxy and Mass Assembly (GAMA) Survey (Driver et al. 2009), the VIMOS Public Extragalactic Redshift Survey (VIPERS, de la Torre et al. 2013), the Dark Energy Survey (DES, Abbott et al. 2018), the Kilo-Degree Survey (KiDS, Joudaki et al. 2018), the Hyper Suprime-Cam Subaru Strategic Program (HSC-SSP, Hikage et al. 2019), and the Sloan Digital Sky Survey (SDSS, Alam et al. 2021). Complementary data in the millimeter range trace the large-scale distribution of matter thanks to the lensing of the cosmic microwave background (CMB, Sherwin et al. 2012; Planck Collaboration XVII 2014). In addition, large samples of extragalactic sources are provided by X-ray surveys, such as ROSAT (Boller et al. 2016) and the extended ROentgen Survey with an Imaging Telescope Array (eROSITA, Merloni et al. 2012; Predehl et al. 2021). It is important to consider both galaxy clusters and active galactic nuclei (AGN) in this context: they both trace the LSS. They are fundamental to shedding light on the hot and energetic large-scale structure of the Universe.
Clusters of galaxies populate the most massive bound dark matter haloes in the Universe. They are the largest known virialized structures (Kravtsov & Borgani 2012; Pratt et al. 2019). In the context of hierarchical structure formation (White & Frenk 1991), they assemble at late times and reside in the nodes of the cosmic large-scale structure (Lacey & Cole 1993; Springel et al. 2005; Angulo et al. 2012; Klypin et al. 2016; Ishiyama et al. 2021). Their abundance as a function of mass and redshift (i.e., the measure of the halo mass function) is dependent on cosmological parameters (Tinker et al. 2008; Allen et al. 2011; Lesci et al. 2022; Clerc & Finoguenov 2022). This makes them a great tool for cosmological studies. Galaxy clusters are observed in optical data as an over-density of red galaxies (e.g., Rykoff et al. 2014; Abbott et al. 2020) or as peaks in weak-lensing convergence maps (e.g., Miyazaki et al. 2018), by distortion of the CMB due to the Sunyaev-Zel’dovich (SZ) effect in the millimeter band (e.g., Staniszewski et al. 2009; Planck Collaboration XXVII 2016) and by extended emission in the X-ray band (e.g., Böhringer et al. 2004; Adami et al. 2018; Finoguenov et al. 2020; Liu et al. 2022a). The combination of multiwavelength data is key for a complete description of galaxy clusters. On the one hand, optical surveys have the highest source density, which provides the largest samples of clusters using photometric data (Oguri 2014; Bleem et al. 2015a). On the other hand, pointed observations with interferometers in the radio and millimeter bands provide observations with extremely high angular resolution (Pasini et al. 2021). In addition, SZ surveys with telescopes such as Planck (Planck Collaboration XI 2014), the South Pole Telescope (SPT, Bleem et al. 2015b), or the Atacama Cosmology Telescope (ACT, Hilton et al. 2021) are effective in detecting high-redshift objects, thanks to the redshift-independent SZ signal. X-ray observations are particularly suitable to study clusters of galaxies. Clusters are the brightest extragalactic extended sources in the X-ray band (Rosati et al. 2002), they emit mainly due to thermal bremsstrahlung from the hot intra-cluster medium (Cavaliere & Fusco-Femiano 1976) and their emissivity depends on the radial density profile.
Active galactic nuclei (AGN) are very luminous objects, powered by the accretion of rich gas reservoirs onto super-massive black holes, and constitute the majority of the extragalactic sources detected in X-ray surveys (see Padovani et al. 2017, for a review). A large sample of AGN enables studies of the general evolution of supermassive black holes (Kauffmann & Haehnelt 2000), the properties of the host galaxy (Ferrarese & Merritt 2000), the AGN clustering properties (Koutoulidis et al. 2013; Viitanen et al. 2019), and their link to the underlying dark matter large-scale structure (Fanidakis et al. 2011; Georgakakis et al. 2019), as well as different channels through which these objects are formed (Mayer & Bonoli 2019), and the mechanisms triggering bursts of X-ray radiation (Arcodia et al. 2021).
With eROSITA onboard Spectrum-Roentgen-Gamma (SRG), a new era in X-ray astronomy is now unfolding (Merloni et al. 2012; Predehl et al. 2021). It has seven telescope modules with 54 nested mirror shells each. The Half Energy Width (HEW) of the point spread function (PSF) is about 15″ for each module. eROSITA will scan the full X-ray sky eight times in four years, resulting in a set of eight all-sky surveys. The sensitivity of the final cumulative all-sky survey (eRASS:8) will be 25 times higher than its predecessor the ROSAT all-sky survey (Voges et al. 1999; Boller et al. 2016). During its performance verification phase, SRG-eROSITA successfully completed a mini-survey in the ∼140 square degrees eROSITA Final Equatorial Depth Survey (eFEDS, Brunner et al. 2022). Since December 2019, eROSITA is performing all-sky surveys. The sky is split in half between the German (eROSITA_DE) and Russian consortium (eROSITA_RU). The eROSITA_DE area is split into 2447 tiles with a small overlap for data processing purposes. Of these, 2248 are uniquely owned by the German consortium, and the additional 199 are shared. Each tile covers a unique area of ∼8.7 square degrees.
eROSITA is predicted to ultimately detect a total of about 105 clusters of galaxies after the final cumulative all-sky survey (eRASS:8), the largest sample of X-ray-selected galaxy clusters to date. This will allow a variety of studies involving the cluster X-ray luminosity function (Mullis et al. 2004; Koens et al. 2013; Finoguenov et al. 2015; Adami et al. 2018; Clerc et al. 2020; Liu et al. 2022a), the clustering of galaxy clusters (Veropalumbo et al. 2014; Marulli et al. 2018, 2021; Lindholm et al. 2021), and provide powerful constraints on cosmological parameters such as the normalization of the power spectrum σ8 and the matter content of the Universe ΩM (Borgani 2008; Vikhlinin et al. 2009; Mantz et al. 2015; Pierre et al. 2016; Schellenberger & Reiprich 2017b; Pacaud et al. 2018; Ider Chitham et al. 2020; Garrel et al. 2021). A prediction of the eROSITA cluster count cosmology capabilities is studied by Pillepich et al. (2012, 2018). A total number of about three million sources, most of which are AGN, are expected to be detected in eRASS:8, a factor of 20 better than ROSAT.
An efficient and accurate detection of extragalactic sources is key to properly sampling the cosmic web and making the most out of the large samples provided by eROSITA.
The identification of galaxy clusters in X-ray surveys like eROSITA is affected by Poisson count noise in the low photon count regime and by the redshift-dimming effect on the cluster surface brightness. Cluster samples selected from X-ray surveys are primarily flux-limited (e.g., REFLEX, Böhringer et al. 2004). The detection of clusters also depends on secondary effects, such as their extent on the sky, or the low surface brightness of very extended objects (Pacaud et al. 2006; Burenin et al. 2007; Finoguenov et al. 2020). In this context, the cool core bias and the dynamical state of galaxy clusters have also been studied in recent years (Hudson et al. 2010; Eckert et al. 2011; Rossetti et al. 2016; Andrade-Santos et al. 2017; Käfer et al. 2019; Ghirardini et al. 2021a). Relaxed clusters develop an efficient cooling toward their center, which enhances the X-ray emission in the inner region. Such peaked surface brightness profiles possibly bias the detection toward relaxed structures. This has an impact on cosmological studies using the halo mass function (Seppi et al. 2021).
The cross-correlation between clusters and AGN in the LSS creates an interplay between point and extended sources in the detection process. A detailed understanding of the point sources is fundamental to investigate not only the X-ray background and the completeness of the observed sample (Georgakakis et al. 2008), but also the fraction of clusters that are misclassified as a point source (Pacaud et al. 2006; Burenin et al. 2007). This happens because of the small size of high redshift clusters, the peaked emission from compact nearby groups, or the presence of a central AGN in the cluster, which can boost the detection of high redshift clusters (McDonald et al. 2012; Trudeau et al. 2020). This misclassification is mitigated by multiwavelength follow-up observations. For instance, Salvato et al. (2022) found 346 cluster candidates in the eFEDS point-source catalog by the identification of the red sequence using optical data. An extensive study of these objects is provided by Bulbul et al. (2022).
An effective way of investigating the detection and selection effects in surveys is to simulate the observational process in its greatest detail. This approach has been explored using mocks in different wavelengths, from the optical band (Jimeno et al. 2017; Oguri et al. 2018), to the X-rays (Liu et al. 2013; Pierre et al. 2016; Clerc et al. 2018), and the microwave sky (Sehgal et al. 2010), or injecting simulated sources into real images (Suchyta et al. 2016; Everett et al. 2022). It allows accounting for instrumental effects and the observing strategy. Studying and quantifying effects that have an impact on the detection is then possible, comparing catalogs of simulated sources and the population that is detected in the simulation. Constant improvements in computational power and efficiency provide more detailed mocks. Recent progress in dark matter simulations allows to minimize the impact of cosmic variance thanks to the ability to simulate large volumes, but also resolve galaxy-like halos because of the small resolution (e.g., Klypin et al. 2016; Chuang et al. 2019; Ishiyama et al. 2021).
We study the eROSITA capabilities in the detection of extragalactic sources following this approach. Our goal is to understand the details of AGN and cluster detection and selection effects. These are two important subsequent steps. First, the detection should be optimized to maximize the ability to identify clusters and AGN, and make sure that the algorithm in question is detecting as many real sources as possible. After that, one can focus on selection criteria to clean the catalog of detected sources and obtain a certain sample according to the scientific goal.
In this paper, we use realistic end-to-end simulations to predict the population of objects observed by eROSITA, with a particular interest in extended sources, that are clusters of galaxies, and AGN. We focus on the eROSITA_DE sky area. We start from the simulations described by Comparat et al. (2019, 2020). We generate a half-sky simulation at the depth of the first eROSITA all-sky survey (eRASS1), the one reached after six months of operations. We follow the eROSITA scanning strategy. Photons are generated for 2438 eROSITA_DE tiles. The background is directly resampled from the eRASS1 observations. We extend the cluster model from Comparat et al. (2020) to galaxy groups down to 2 × 1013 M⊙ using the relation between X-ray luminosity and stellar mass (Anderson et al. 2015). Comparat et al. (2022) showed that such correction allows matching the relation between projected luminosity around eFEDS central galaxies and their stellar mass remarkably well. We run the eSASS (extended Science Analysis Software System) detection algorithm described by Brunner et al. (2022). We build a one-to-one association between simulated objects and the source catalog using the source ID of each simulated photon (Liu et al. 2022b), properly linked to a cluster, AGN, star, or the background. We assess the performance of the detection in terms of completeness (fraction of simulated objects that are recovered in the source catalog) and purity (fraction of entries in the source catalogs that are assigned to the correct simulated object). Our study follows up on the work of Liu et al. (2022b) on the eFEDS simulations. We take one step further, accounting for the larger variations of exposure and background level in eRASS1.
This paper is organized as follows. We summarize the main features of the simulation and the X-ray model in Sect. 2. We describe the detection process, the handling of the catalogs, and the classification of the sources in Sect. 3. We provide our results in Sect. 4. We study the population in the source catalog, the cumulative number density of AGN and clusters as a function of flux, the completeness of these samples, their relation with purity and contamination, and measure the X-ray luminosity of clusters. We further discuss our results in Sect. 5, including the best strategy to build samples of clusters detected by eROSITA, accounting for the different exposure across the sky. Finally, we summarize our findings in Sect. 6.
2. Simulated data
We follow the approach described by Comparat et al. (2020) and create all-sky simulations. A dark matter light cone is built with snapshots at different redshifts. Cluster and AGN models are used to predict X-ray emission (Comparat et al. 2019, 2020). We upgrade the cluster model to the galaxy groups regime. In this section, we review the main features of the simulations and models that are relevant for this analysis. The simulated data is released along with the article, see the description in Appendix A.
2.1. Light cones from N-body dark matter simulations
A light cone is created with the UNIT1i N-body simulations (Chuang et al. 2019). These are computed in a Flat ΛCDM cosmology (Planck Collaboration XXIV 2016). The fiducial parameters are H0 = 67.74 km s−1 Mpc−1, Ωm0 = 0.308900, Ωb0 = 0.048206. The size of the simulation box is 1 Gpc h−11 and the mass resolution is 1.2 × 109 M⊙ h−1. It allows a detailed modeling of both clusters and AGN. It is suited for studying low mass structures down to 1011 M⊙, AGN up to z ∼ 6, and the eROSITA selection function (Liu et al. 2022b).
2.2. X-ray model components
These simulations combine different source and X-ray background components. We describe each one of them in the following section.
2.2.1. Galaxy clusters
Comparat et al. (2020) introduce a new method to simulate the X-ray emission from galaxy clusters. The principle is to build mock observations using real data as a starting point (e.g., Kong et al. 2020; Everett et al. 2022). A total sample of 326 clusters is obtained by combining XMM-XXL (Pierre et al. 2016), HIFLUGCS (Reiprich & Böhringer 2002), X-COP (Eckert et al. 2019) and SPT-Chandra (Sanders et al. 2018). Their combination constitutes a relatively fair benchmark for eROSITA observations. Their X-ray properties are well measured inside R500c, the radius encompassing an average density that is 500 times the critical density of the Universe at the redshift of the cluster ρc = 3H2/8πG, where H is the Hubble parameter and G is the universal gravitational constant. From these clusters, a covariance matrix between redshift, temperature, hydrostatic masses, and emissivity is constructed. Simulated emissivity profiles are drawn from the covariance matrix by a Gaussian random process. These profiles are assigned to dark matter haloes by a nearest neighbor process, considering mass and redshift. The brightness of the cluster core is linked to the dynamical state of the dark matter halo. The initial model is constructed using clusters with high counts and signal-to-noise ratio, making it reliable down to masses of M500c ∼ 5 × 1013 M⊙.
In this article, we extend this model to galaxy groups for the eRASS1 simulation as follows. We use the relation between stellar mass and X-ray luminosity from Anderson et al. (2015) as a reference. The stellar mass is assigned to halos by an abundance matching scheme (see Comparat et al. 2019, and Sect. 2.2.2). We infer an average correction as a function of mass to align the scaling relation of the simulation to that of Anderson et al. (2015). The goal scaling relation between X-ray luminosity and the stellar mass of the central galaxy in each halo reads
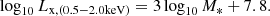
This average correction bends the scaling relation predicted by Comparat et al. (2020) at low mass to predict lower luminosities for lower mass haloes. Importantly, it preserves the scatter in the LX–mass scaling relation. These values substitute the ones obtained by integrating the emissivity profiles from the original covariance matrix. For haloes with a mass larger than M500c > 1014 M⊙ the correction is negligible, but it becomes very important in the mass range 1013–5 × 1013 M⊙. Both panels in Fig. B.1 highlight the improvement of the model after applying the correction. The number density of sources as a function of X-ray flux (logN–logS) predicted for masses above log10M/M⊙ > 13 is in excellent agreement with observations (Finoguenov et al. 2007, 2015, 2020; Liu et al. 2022a; Chiu et al. 2021; Bahar et al. 2021). With the eFEDS sample, the method is further validated. It offers a more complete picture of the cluster population. The relation between X-ray luminosity and M500c in the second panel of Fig. B.1 shows the impact of the correction, especially for groups. The predicted values of log10Lx reach reasonable values of ∼41 (and below) at log10M/M⊙ ∼ 13. The improved model is in line with different sets of observations, considering that these are flux-limited samples, whereas the orange curve is built with the complete simulated clusters population (Lovisari et al. 2015; Schellenberger & Reiprich 2017a; Bulbul et al. 2019; Lovisari et al. 2020; Chiu et al. 2021; Bahar et al. 2021). In general, our correction provides an excellent agreement between the new model and eFEDS clusters sample. We provide further details in Appendix B. In total, we simulate 1 116 758 clusters.
2.2.2. Active galactic nuclei
Active galactic nuclei are simulated by an empirical model that reliably reproduces their number density as a function of X-ray luminosity, clustering, and redshift (Georgakakis et al. 2019; Comparat et al. 2019). It is based on stellar mass to halo mass relations (Moster et al. 2013) and abundance matching to reproduce the hard X-ray AGN luminosity function (Aird et al. 2015; Buchner et al. 2015) and their number density as a function of flux up to z = 6. It matches the observed AGN duty cycle (fraction of galaxies hosting an active nucleus) by construction (Georgakakis et al. 2019). The model extends to very low X-ray fluxes ∼1 × 10−17 erg s−1 cm−2, well under the eROSITA flux limit, which enable a prediction of the X-ray background due to faint AGN. For the construction of the AGN population in the eRASS1 simulation, the sky is first divided into 768 HEALPix2 fields, which ensures faster processing, but also a smaller volume, sampling the luminosity function down to about 10−7 sources per Mpc3. This prevents the simulation of extremely bright sources. The model of the AGN spectra is an absorbed power-law with Compton reflection and a soft scattered component by cold matter (in Xspec tbabs*(plcabs+pexrav)+zpowerlw)*tbabs). The spectral index of the power-law is equal to Γ = 1.9. Finally, a fine-grained K-correction is applied to the AGN population (Hogg et al. 2002). The simulation accounts for a cross-correlation between clusters and AGN since they are both generated from the same N-body simulation. We neglect secondary effects regarding the population of halos hosting AGN in cluster environments. Further observational studies involving the fraction of active galaxies in clusters as a function of redshift and a comparison to field galaxies are required to develop such a model (see Martini et al. 2013; Koulouridis et al. 2014; Noordeh et al. 2020). In total, we simulate 225 583 320 AGN, about 200 times more than the clusters. Among them, 93 311 810 produce at least one count within 60″ from the center.
2.2.3. Stars
Fluxes to be assigned to stars are drawn from the eFEDS logN–logS. We assign them to Gaia DR2 (Gaia Collaboration 2018) true positions randomly. The spectrum is a 0.8 keV APEC model at redshift 0. This model is simple, but nonetheless sufficient to mimic the increase of stellar density toward the Milky Way for this simulation at the eRASS1 depth (Schneider et al. 2021; Salvato et al. 2022). In total, we simulate 373 316 stars.
2.2.4. Background
Our approach is similar to the one detailed by Liu et al. (2022b), who decompose and re-simulate the eFEDS background, subtracting the contribution from the simulated faint AGN, that partially contribute to the cosmic X-ray background (CXB). However, this is not feasible in eRASS1, due to the nonuniform coverage of the sky and background emission. We update such a method for the eRASS1 simulation. Background photons are obtained by resampling the observed eROSITA background maps, masking identified point and extended sources. This allows the introduction of spatially varying background, that closely follows real data. We start from the eROSITA_DE eRASS1 event lists and source catalogs. Following the masking scheme devised by Comparat et al. (in prep.), the photons are split into two groups. First, we consider source photons: events located within 1.4 times the source radius of a detected source (see Sect. 3 for a definition of the source radius). Secondly, we select background photons: events located further than 1.4 times the source radius of any detected source. These thresholds guarantee conservative masking of the sources in the event list to obtain a background event list. The complementary set of events constitutes the source event list. The whole dataset is mirrored in the eROSITA_RU sky, to obtain an all-sky map. This is divided into 49 125 HEALPix regions, each of them covering ∼0.84 deg2. The X-ray spectrum and the images of the background events are extracted from these regions. All the spectra are merged into a single mean background spectrum. These inputs are combined to generate a specific SIMPUT3 file for the mock background, that provides by construction a faithful reproduction of the observed eRASS1 background.
2.3. Mock observation
Photons are simulated with the SIXTE4 software (Dauser et al. 2019), a dedicated end-to-end X-ray simulator. SIXTE is the official simulator for eROSITA. The result is a list of events with energy, position, and arrival time. This approach allows accounting for instrumental effects because the simulator relies on vignetting, energy-dependent PSF, ancillary response file (ARF), and redistribution matrix file (RMF) as input from calibration data. The setup follows the eROSITA all-sky scan strategy (Merloni et al. 2012; Predehl et al. 2021).
We use the same attitude file from the real observations for the eRASS1 simulation. The attitude file specifies the details of the scanning by the spacecraft. It follows the planned observing strategy, scanning one full great circle every four hours. In addition, we use the same good time intervals (gti) of the real survey. This allows us to account for details such as orbit corrections, when the cameras are switched off, or camera failures, making the simulation an ideal digital twin of the real eRASS1. The total number of events in the simulation, covering about 20 618 square degrees, with energy of 0.2–10 keV is 187 486 754. There are 118 905 555 photons in the soft band (0.2–2.3 keV). These numbers are indeed very similar to the real data, respectively equal to 194 350 024 and 118 815 616 counts. The ratios between these numbers are 0.965 and 1.001 respectively.
3. Data analysis method
In this section, we describe how the simulated event files are processed and analyzed. The final result is a catalog of sources identified by the detection algorithm. We refer to the latter as the source catalog in the rest of this work. Only event files in the eROSITA_DE sky are processed. We first generate the photons on the sky plane divided into 768 HEALPix regions and then create specific catalogs for each field. This way we do not simulate the same photons twice in the overlapping regions of different eROSITA tiles. Given our interest in cluster detection, we focus on a single band detection in the soft X-rays (0.2–2.3 keV), where the eROSITA effective area is the highest (Predehl et al. 2021).
3.1. eSASS detection
Each simulated tile is processed with the eROSITA Standard Analysis Software System (eSASS, version eSASSusers_201009; Brunner et al. 2022). Starting from the calibrated event file, we produce 3.6 ° ×3.6° images for the eRASS1 simulation and the corresponding exposure maps, using all 7 telescope modules, in the soft X-ray band 0.2–2.3 keV. The detection relies on a sliding box algorithm, that looks for overdensities of photons over the background map. It follows the subsequent steps.
-
erbox: the image is scanned by a sliding cell, which marks potential sources if the signal-to-noise ratio is higher than a given threshold. This initial list of potential sources contains a large number of false detection, but maximizes the completeness.
-
erbackmap: the potential sources are masked by constructing a detection mask and the image is interpolated to create an adaptively smoothed background image. This process is iterated three times, to converge toward a more robust background map (Brunner et al. 2022; Liu et al. 2022b).
-
ermldet: each box marked as a potential source is analyzed by a maximum likelihood PSF-fitting algorithm, based on the position, count rate, and extent of the source. It compares the distribution of counts to a β model (Cavaliere & Fusco-Femiano 1976) convolved with the eROSITA PSF. It allows a simultaneous fitting of multiple sources. Different choices of the minimum likelihood threshold control the purity of the sample, decreasing the false detection rate when increasing the threshold. This task produces a catalog of sources and a source map.
Sources are assigned a significance of the detection (detection likelihood), extension of the best fitting β model (extent) and significance of the extended model over the point-like one (extension likelihood). These parameters are computed by minimizing the C-statistic (Cash 1979) in Eq. (2):
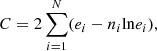
where ni is the measured number of events in each pixel and ei is the expected value from the model. The significance of each source is computed by comparing the best fitting model to the zero count case ΔC = Cnull − Cfit (see Brunner et al. 2022, Sect. A.5). The probability that a source arises from a random background fluctuation is computed using the regularized incomplete Gamma function PΓ.
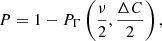
where ν is the number of degrees of freedom in the model. This is equal to three (four) for point (extended) sources, corresponding to positions on the pixels X and Y, count rate (and core radius of the β model) for our study, which only uses one detection band. The likelihood for each source is finally related to the natural logarithm of such probability:
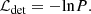
This gives a set of two fundamental parameters for each detection: DET_LIKE (ℒDET), and EXT_LIKE (ℒEXT). The first (second) one is related to the probability of identifying a spurious point (extended) source, exponentially proportional to −DET_LIKE (−EXT_LIKE). The core radius of the best-fitting extended beta model is also provided. It is set to zero for point sources, its minimum and maximum values are 8″ and 60″. A constant β = 2/3 is assumed for the model so that the slope of the profile is equal to −35. We show that on average our model generates profiles that are compatible with this assumption in Appendix B. The minimum thresholds of DET_LIKE and EXT_LIKE are extremely important in this step. They have a significant impact on the completeness and purity of the source catalog, see Sect. 4.4. We follow the same task processing as the eFEDS data, choosing values of detlikemin = 5 and extlikemin = 6 (Brunner et al. 2022). The values of detection and extension likelihood are correlated to the number of events from a given source and from the local background by construction. AGN producing five counts on average are detected with DET_LIKE = 10. Clusters of galaxies require a larger amount of events to be detected. A value of DET_LIKE = 5 is measured for clusters with nine source counts and ten background counts inside half R500c. Classifying the clusters as extended sources requires a larger number of events. A value of EXT_LIKE = 6 is measured for clusters with about 30 counts inside half R500c. When the ratio between source and background photons increases, the detection and extension likelihood rise as well. A value of EXT_LIKE (DET_LIKE) of 25 is measured on average for clusters with 91 (37) counts against 42 (24) events generated by the background. We provide a summary in Table 1. It shows the average number of counts generated by all sources, including clusters, agn, stars, and background, and the ones only generated by clusters (AGN) and background in the top left (right) panels at fixed values of detection likelihood. The bottom panel displays the counts at given extension likelihood value.
-
apetool: we perform source aperture photometry and compute the sensitivity map for each simulated tile. This gives the minimum number of counts necessary to detect a point-like source as a function of position in the sky, and at a given Poisson false detection probability threshold.
-
srctool: we measure the radius that maximizes the signal-to-noise ratio for each source. We refer to this parameter as source radius (srcRAD).
-
ersenmap: we compute the sensitivity map for extended sources. This gives the minimum flux necessary for a source to be detected at a given DET_LIKE threshold.
-
apetool: we perform again source aperture photometry focusing on the extended sources and different apertures of 60, 90, 120, 150, 180, 240, 300, and 600″.
Number of counts by sources detected with given values of detection and extension likelihood.
We perform the source detection in the soft (0.2–2.3 keV) X-ray band. In principle, one could choose specific detection and extension likelihood threshold according to different needs. We choose to characterize the extended sources without additional selections, using detlikemin = 5 and extlikemin = 6. This keeps our cluster catalog reasonably complete (down to some flux limit), without rejecting faint sources that are potentially interesting. Fig. 1 shows an example of this whole process. It displays a wedge of the simulated light cone in the top panel, showing galaxies that trace the large-scale structure in grey and how this is populated by AGN in blue, and clusters and groups in red. The bottom panel shows the projection on the sky plane of the events emitted by the sources in the wedge. It displays simulated photons in the soft X-ray band (black dots), the simulated stars (green circles), AGN (blue circles), clusters (red circles), extended detections (magenta squares), and point-like detections (cyan squares). This tile gives a typical view of different possible cases. Red circles within a magenta square identify simulated clusters that are detected as extended, whereas red circles within a cyan square denote clusters detected as point sources. Similarly, input AGN and stars detected as point sources are shown by blue and green circles within cyan squares. Every circle (red, blue, or green) without a corresponding square denotes a simulated object that has not been detected. We show clusters and AGN respectively down to low flux limits of 3 × 10−14 erg s−1 cm−2 and 8 × 10−15 erg s−1 cm−2. This explains the undetected objects in Fig. 1. Finally, background fluctuations that are detected as spurious sources are identified by squares without any circle.
 |
Fig. 1. Large-scale distribution of extragalactic sources and their X-ray view in the simulation. Top panel: light cone of the UNIT1i-eRASS1 simulation. The wedge shows the fraction of the sky enclosed by the same RA and Dec of the bottom panel as a function of redshift and lookback time. The galaxies tracing the large-scale structure are shown in grey. The AGN are denoted in blue. The red circles show clusters and groups. The size of the circle is proportional to the mass of the object. Bottom panel: central regions of tile 202105 of the eRASS1 simulation. This is the projection on the plane of the sky of light cone shown in the top panel. Photons with energies between 0.2 to 2.3 keV are shown by black dots, simulated stars by green circles, simulated AGN by blue circles, simulated clusters by red circles, eSASS extended detections by magenta squares, and eSASS point-like detections by cyan squares. |
The X-ray background drives the detection process, especially for faint sources. We compare the background maps computed on the simulation and on the real eRASS1 data. We find that the simulated background is overestimated by ∼10% compared to the observations. This is expected, because the cosmic X-ray background due to faint AGN is present both in the real eRASS1 background maps used to generate the background model, and as the simulated population of low-flux AGN.
We evaluate the impact of this 10% over-estimate of the background on the measured values of detection likelihood. We consider a wide range of counts per pixel values generated by a source (between 0.04 and 0.4) and by the background (between 0.001 and 0.009). These intervals are compatible with the source maps and background maps produced by eSASS. We expand these counts on a grid of 5 × 5 pixels, covering an area slightly larger than the eROSITA PSF. We compute the analytical value of detection likelihood by plugging these values into Eqs. (2)–(4). We repeat the process by increasing the background by 10%, computing the new value of ℒdet, and comparing it to the initial result with the unbiased background. We find that an overestimation of the background biases the detection likelihood to lower values. We measure a ∼4% negative impact on the calculation of detection likelihood for faint sources with DET_LIKE ∼ 5 and a 2.5% negative impact on more clear sources with DET_LIKE ∼20 due to a 10% overestimation of the background. We conclude that these effects have a minimal impact on the detection and characterization of faint sources around the detection limit, and do not significantly affect the study of more secure detections and the overall analysis of the population in the catalog. We provide further details and figures in Appendix C.
3.2. Catalog description
We summarize the simulations and source catalog statistics in Table 2. The catalogs described above have been further cleaned because of the following reasons. The generation of event files was not completed correctly because of numerical issues in 6 HEALPix fields in the simulation, covering about 320 square degrees. These have not been considered in the analysis presented in the rest of this work. In addition, an area of about 260 square degrees around the southern ecliptic pole (RA ∼ 93°, Dec ∼ −66°, where the exposure is maximal due to the survey scan mode) has been masked in the eRASS1 simulation. The generation of cluster events was not successful.
Summary statistics of eSASS catalog for the eRASS1 simulation.
We focus on the extragalactic sky, masking the areas with galactic latitude |glat| < 10 deg. The final area taken into consideration corresponds to 17 703.4 square degrees for the eRASS1 simulations.
Following the example of Liu et al. (2022b), we merge simulated catalogs and source catalogs according to the integer identifier (ID) of each photon. Every simulated count has an ID that links it to the source that produced it. This method is more reliable than simply matching the catalogs (input and output) with coordinates, because it uses the origin of each simulated photon: a cluster, AGN, star, or the background. We summarize the algorithm in the following paragraph.
First of all, we assess whether a detected source has a simulated counterpart or not. For point (extended) sources detected by eSASS, we study the photons within aperture radii of 20″ (60″). Their origin is stored in each photon ID. The entry in the source catalog is associated with the simulated source that issued the largest number of photons in the aperture radius. This assigns the ID of the simulated counterpart to the entry in the source catalog. We call this ID_Any. One caveat is that the simulation contains a large number of objects fainter than the eROSITA detection limit. Therefore, we only consider input sources that have at least two photons emitted during the mock observation. In addition, we set a lower counts threshold related to the local background counts, given by the counts corresponding to the 0.8 percentile point of the Poisson distribution, whose mean is equal to the number of background photons inside the given aperture radius.
Secondly, if an additional simulated counterpart is found, the one emitting the highest number of photons is assigned to ID_Any. The secondary counterpart is saved as ID_Any2.
Finally, a simulated source can be split into multiple detected sources. This results in copies of the same ID_Any. We select the detection where the simulated object provides the highest photons count and consider a unique matching between the two (ID_Uniq). If ID_Any does not refer to a unique counterpart, in cases where there are multiple entries in the source catalog pointing to the same ID_Any, we use ID_Any2 if it is available. A one-to-one matching between the simulated objects and the source catalog can be obtained with ID_Uniq. We divide the source catalog into five classes using the IDs just assigned, following the example of Liu et al. (2022b).
-
Primary counterpart of a simulated point source (PNT): detected source assigned to an ID_Uniq of an AGN or star. This is a secure point source detection.
-
Primary counterpart of a simulated extended source (EXT): detected source assigned to an ID_Uniq of a cluster. This is a secure cluster detection.
-
Secondary counterpart of a simulated point source (PNT2): detected source without an ID_Uniq, but assigned to an ID_Any of an AGN or star. This is a detection that corresponds to a fraction of a simulated point source but is not its primary counterpart. We refer to these as split sources corresponding to an AGN or star.
-
Secondary counterpart of a simulated extended source (EXT2): detected source without an ID_Uniq, but assigned to an ID_Any of a cluster. This is a detection that corresponds to a fraction of a simulated extended source but is not its primary counterpart. We refer to these are split sources corresponding to a cluster.
-
Background fluctuation (BKG): entry in the source catalog that is not associated with an ID_Any. This is a false detection, due to a random fluctuation of the background, and is classified as a spurious source.
The first two classes are additionally divided into three subclasses to study whether the source emission is contaminated by a secondary source. To quantify this, we analyze the photons within 60″ around every input source (denoted as ID_1). If we find at least three photons emitted by a source different than the target, and this number of counts is larger than the square root of the target number counts, we consider the source emitting such photons as contaminating. In this case, we save the ID of the contaminating source as ID_contam to the ID_1 source. This allows separating isolated (not contaminated) sources from clusters and AGN contaminated by another cluster and or AGN. These cases potentially lead to source blending.
We summarize the simulations and source catalog statistics in Table 2.
We show different examples of classification of the sources in Fig. 2. The top left panel a shows an example of a simulated cluster that is detected as extended with DET_LIKE = 10. The position of the detection is well aligned with the position of the simulated object. The dashed red circle encloses 0.5 × R500c. The point detection in the center of the panel b is assigned to the bright simulated cluster just below, but it is not the primary detection, that is the extended one closer to the cluster center. This is the case of a split source. The third panel c highlights a simulated AGN (blue circle) properly detected as a point source (cyan square). The fourth panel d shows an example of contamination in the extent-selected catalog: an AGN detected as an extended source. Finally, the fifth panel e contains an extended detection without any simulated counterpart: a spurious source. In this case, most of the photons around the detection are coming from the background. This shows how background fluctuations end up decreasing the purity of the source catalog. The second row of the figure (panels f, g, h, i, and l) shows the same type of objects, but with a higher value of detection likelihood equal to 20. We notice how the distribution of photons around faint detected clusters or AGN and spurious sources is very similar.
 |
Fig. 2. Examples of the eSASS catalog classification. Red (blue) solid circles show simulated clusters (AGN). Magenta (cyan) squares denote extended (point-like) eSASS entries, like in Fig. 1. The dashed red circles enclose 0.5 × R500c of a simulated cluster. Soft X-ray photons from simulated sources are represented by black dots, the green ones come from the background. The first (second) row shows examples for sources with DET_LIKE = 10 (20). Columns show respectively: an extended detection uniquely assigned to a simulated cluster, a secondary detection assigned to an input cluster, a point detection uniquely assigned to an AGN, an extended detection uniquely assigned to an AGN, and a detection without any simulated input. All panels have the same physical size. A ruler of 60 arcsec is shown in the top-left one. |
We compare the eSASS source catalog from the eRASS1 simulation to real eRASS1 data in Appendix C.
3.3. Imaging and spectral analysis
We measure the temperature and luminosity of the simulated clusters detected as extended in the eRASS1 simulation, assuming the value of R500c from the simulation. We compare them to the simulated quantities. We focus on secure clusters detected with EXT_LIKE > 20, spanning different ranges of exposure without additional selection on the sky area. Our approach is the same as the one described by Ghirardini et al. (2021a,b) and is summarized in this section.
1. Source masking: for each extended detection uniquely matched to a cluster, we mask every other source inside a circular region of 4 × R500c. For extended sources, the masking radius is equal to the extent measured by eSASS. For point-like ones, it corresponds to the point where the count rate convolved with the eROSITA PSF is consistent with the background within 1σ. This value is fixed to 10 arcsec when it is lower than such threshold.
2. Background extraction and modeling: we use the srctool command to extract the source spectrum in a circular region inside R500c and the background spectrum in a circular annulus between 3 − 4 × R500c. We model these two spectra simultaneously with the XSPEC software (v 12.10.1f, Arnaud 1996), using C-statistic (Cash 1979). The cluster emission is fitted by APEC model (Smith et al. 2001) and the Galactic absorption is modeled by TBabs (Wilms et al. 2000). The background model consists of a vignetted sky component and an unvignetted particle-induced one. The first describes photons focused by the telescope mirror and contains contributions from the Local Hot Bubble (apec), the Galactic Halo (tbabs×apec), and faint unresolved AGNs (tbabs×power-law). The second is due to instrumental effects and cosmic rays hitting the detector directly and is described by a combination of power-laws and Gaussian lines (Liu et al. 2022b). We fix redshift and galactic column density to the simulated values and fit for temperature.
3. Surface brightness fitting: we proceed by measuring the cluster surface brightness inside R500c and fitting the density profile following Vikhlinin et al. (2006) model, convolved with the PSF and projected onto the 2D image plane. The sky (particle) background model is folded with the vignetted (unvignetted) exposure map and added to the total model. The image is fit using the Monte Carlo Markov chain (MCMC) code emcee (Foreman-Mackey et al. 2013). We integrate the fitted 2D profile along the line of sight to obtain the surface brightness radial profile.
4. Luminosity: we finally convert the surface brightness radial profile to X-ray luminosity using an absorbed apec model in XSPEC. Given the measured temperature of a cluster, this provides the conversion factor from count rate to luminosity.
4. Results
In this section, we present our main findings about the detection process. We start from the point of view of the catalog of sources detected by eSASS. We refer to it as the source catalog. We focus on the cleaned catalog, see Table 2 and Sect. 3.2 for complete details.
We give an overview of how the source catalog is populated by clusters, AGN, stars, and spurious sources (Sect. 4.1). We then move to the standpoint of the simulated sources and study which of them are detected. We demonstrate how the method is able to recover clusters and AGN as a function of their simulated flux (Sects. 4.2 and 4.3). We detail how the detection of galaxy clusters depends on size and dynamical state.
We then combine these two points of view, quantifying the performance of the method (completeness, contamination, and spurious fractions), also accounting for the uneven depth of the survey (Sect. 4.4).
We study the sensitive area in the eRASS1 simulation as a function of limiting flux (Sect. 4.5) and finally verify that our measurement of the X-ray luminosity of clusters are compatible with simulated values (Sect. 4.6).
4.1. Population in the source catalog
We study the source population in the eSASS source catalog using fractions as a function of different cuts in detection and extension likelihood, using the classes defined in Sect. 3.2. We consider the full source catalog and the extent-selected sample (with positive values of EXT_LIKE). The result is shown in Fig. 3. We report the fraction corresponding to each class for different thresholds of detection and extension likelihood in Table 3. The histograms of the total number of sources and the fractional histograms in linear scales are collected in Appendix D.
 |
Fig. 3. Population in the eSASS catalog. The total number of sources detected by eSASS in the eRASS1 simulation (cleaned, see Sect. 3.2) is 1 133 807 (901 812). The number of extended sources is 7731 (5615). Top panel: fraction of sources in the full catalog as a function of minimum detection likelihood. Central panel: fraction of sources in the extent-selected sample (EXT_LIKE > = 6) as a function of minimum detection likelihood. Bottom panel: population in the source catalog as a function of minimum extension likelihood. Lines of different colors show the classes defined in Sect. 3. The dash-dotted lines denote sources that are not contaminated by photons of a secondary source (no blending), the dashed ones identify sources contaminated by a point source, and the dotted ones show sources contaminated by a cluster. |
Population in the cleaned eSASS source catalog for different cuts of detection and extension likelihood.
4.1.1. Full source catalog
The cleaned source catalog of the eRASS1 simulation contains 901 812 sources in total. Among them, 5615 are classified as extended.
4.1.2. Fraction of point sources
The majority of the catalog consists of point sources, mostly AGN and a few stars. They make up 93.8% of the catalog for detection likelihood larger than 10 in the eRASS1 simulation. For detection likelihood greater than 25, this fraction increases to 94.1%. This is driven by the predominant number density of the AGN population compared to other sources. In the whole cleaned catalog, 574 733 entries are associated with an AGN.
Fraction of clusters in source catalog. In the eRASS1 simulation, clusters of galaxies only consist of about 4.3% of the whole catalog for DET_LIKE > 5. Even when most of the false detections are removed, above DET_LIKE = 25, this fraction remains low, at about 6%. This difference between the fraction of AGN and clusters is driven by the intrinsic number density per square degree of these sources. For example, we simulate 18 clusters per square degree with flux larger than 10−14 erg s−1 cm−2. At the same flux value, the input AGN are 100 per square degree (see Sect. 4.2). In addition, clusters need a larger amount of counts to be detected, especially as extended, compared to point sources: their extended emission requires a larger exposure to emerge over the background.
Fraction of spurious detections. A fraction of sources in the eSASS catalog is not matched to any input simulated object. These spurious detections are due to background fluctuations, that mimic the emission of a source. The detection likelihood encodes by definition the probability for each entry in the source catalog of being a false detection, as explained in Sect. 3. However, the analytical derivation does not account for additional effects during the measurement process. These include uncertainty in the background estimation, errors in the PSF-fitting, or issues related to hardware and calibration. Consequently, the false detection rate is larger than the one predicted by Eq. (3).
The fraction of spurious sources drops significantly while increasing the detection likelihood threshold. We measure a spurious fraction of 25.4% for DET_LIKE > 5 and 14% for DET_LIKE > 6. The false detection rate is further reduced to 4% at DET_LIKE > 8 and 0.001% for DET_LIKE > 25. Progressive cuts in detection likelihood are therefore efficient in removing background fluctuations from the source catalog.
4.1.3. Fraction of split sources
Very bright and or extended input sources are possibly split into multiple detections. These are the one marked as secondary matches (PNT2, EXT2) in our classification scheme (see Sect. 3.2). The fraction of entries in the source catalog marked as a secondary match to a point source (PNT2) is always under 0.5%. Clusters are instead slightly more easily split into multiple sources, giving about 0.8% of entries cataloged as secondary matches to an extended source (EXT2). Together with decreasing the spurious fraction, increasing the DET_LIKE threshold gets rid of these low significance secondary detections, as this fraction decreases to ∼0.2% at DET_LIKE > 25. A total of 4627 clusters are split into more than one (point or extended) source in the eRASS1 simulation. About 70% of these are split into only two sources. Among the clusters that are split, the average number of split sources is 2.76. We find that the number of sources into which a cluster is split mainly depends on its flux, and secondary the size on the sky plane of the cluster itself. For example, more than 90% of the clusters with R500c larger than 350 arcsec are split into multiple sources. However, only the brightest objects are split into a large number of sources. A very bright and extended cluster with flux ∼10−11 erg s−1 cm−2 and R500c ∼ 500″ is split into 24 sources by eSASS on average. There is one particular case of an extremely bright and extended cluster (FX = 3.10 × 10−11 erg s−1 cm−2, R500c = 13.5′) in the pole region that is split into 65 sources. These trends are highlighted in Fig. 4. The left-hand panel shows the fraction of clusters that are split into multiple sources as a function of flux and R500c. The average number of sources that a cluster is split into is displayed on the right-hand panel.
 |
Fig. 4. Number of split sources as a function of flux and R500c. The left-hand panel shows the fraction of detected clusters that are split into multiple sources, the right-hand one displays the average number of sources which a cluster with given flux and size is split into. The blank spaces contain no input clusters. |
4.1.4. Blends
We study the sources that are blended with a secondary one, according to the criteria defined in Sect. 3 to find objects whose emission is contaminated by another object. Most of the sources detected by eSASS are not contaminated by the emission of a secondary nearby object. 92% of the detected point sources are isolated. This number for clusters is 94%. In the full cleaned catalog, about 4% of the population consists of point sources contaminated by other point sources. This number increases to 6% for DET_LIKE > 10, because of the drastic drop of spurious sources. For point sources contaminated by clusters (i.e., detections whose primary match is an AGN or a star, but that contain photons emitted by a cluster) this fraction reduces to 1%. About 7% of the clusters in the full catalog are contaminated by other point sources. In such cases, the presence of the bright AGN enhances the emission from a physical source and helps the detection algorithm in the identification of a source at that position. The flux measured by eSASS for these sources will be biased (see Bulbul et al. 2022). More detailed modeling of the cross-correlation between AGN and clusters is required to reach conclusive statements about blending.
4.1.5. Extended source catalog
We now focus on the extent-selected sample, selected by EXT_LIKE > = 6. This is the minimum value of extension likelihood fixed by the choice of the parameter extlikemin = 6 (Sect. 3). Different values of this parameter impact the properties of the extent-selected catalog. We detect a total of 5615 sources as extended in the full cleaned eSASS catalog of the eRASS1 simulation.
4.1.6. Fraction of clusters
The eRASS1 extent-selected catalog is dominated in numbers by clusters of galaxies: 75.2% of the eSASS sources are uniquely matched to a cluster, with a 21.2% point source contamination. When increasing the detection likelihood threshold to 25, clusters make up 79.8% of the catalog. These numbers increase more significantly when cutting in extension likelihood rather than detection likelihood. For EXT_LIKE > 25, 95.6% of the eRASS1 sources are clusters. This is partially related to the significant decrement of background fluctuations, which is completely canceled at this value of extension likelihood. However, the main contribution is given by the drop of AGN that are mistakenly classified as extended sources, which reduces contamination significantly. This fraction changes from 21.2% for EXT_LIKE > 6 to 1.6% for EXT_LIKE > 25 in the eRASS1 simulation.
4.1.7. Fraction of AGN
The fraction of AGN in the extent-selected sample (EXT_LIKE > = 6) is constant at around 20% as a function of detection likelihood cuts. Even for DET_LIKE greater than 25, it still reaches 18.7%. It means that progressive thresholds of detection likelihood are not efficient in reducing the fraction of AGN detected as extended.
The contribution of detections that contain a fraction of point source signal (PNT2, split point sources) is minimal in the extended select sample. It is well below 1% for any cut in detection or extension likelihood. The fraction of entries classified as cluster signal (EXT2, split clusters) is around 2.6% for eRASS1. Increasing the extension likelihood does not have a significant impact on this number. This is due to the fact that the scaling of these secondary matches with EXT_LIKE is more similar to the one of primary matches, compared to the random background fluctuations. This is not true for cuts in detection likelihood, which keep a higher number of AGN in the extent-selected sample, reducing the relative contribution of both primary and secondary matches in the catalog. In fact, by increasing the DET_LIKE threshold in the eRASS1 catalog from 5 to 25, the fraction of secondary matches also drops from 2.6 to 1.4% for extended sources and from 0.071% to 0.025% for point-like ones respectively.
4.1.8. Fraction of spurious sources
Random background fluctuations in the extent-selected catalog are efficiently removed using different thresholds of DET_LIKE and EXT_LIKE. For the former, the spurious fraction drops from 0.85% to 0.34% for detection likelihood larger than 5 and 10. The latter drops to 0.26% for EXT_LIKE > 10. There are no spurious sources above detection likelihood larger than 25 and extension likelihood larger than 20 in the extent-selected sample of eRASS1. The decrement of the false detection rate is steeper as a function of EXT_LIKE cuts. It means that, on top of reducing contamination, extension likelihood thresholds remove background fluctuations more efficiently than detection likelihood ones in the extent-selected sample.
4.1.9. Blends
We study sources blended with another source in the extent-selected catalog (EXT_LIKE > = 6). Focusing on the AGN that leak into the extent-selected sample, one can understand what caused the misclassification. For the whole extended eRASS1 sample, 6% of the catalog consists of AGN contaminated by another point source. This fraction is dominant over the ones contaminated by a cluster (2.5%). However, when increasing the EXT_LIKE threshold, the relation between these two classes changes significantly, to the point where for EXT_LIKE > 40, all the detections assigned to an AGN by our matching algorithm are actually blended with a cluster. Follow-up observations in the optical band have the potential to confirm these clusters, which lowers our estimate of contamination in the extended select sample due to bright point sources by ∼1%.
4.2. Simulated and detected sources
We now study which simulated sources are detected by eSASS. The detection process mainly depends on the net count rate of each source. Bright sources with large flux values provide a larger number of photons on the detector. Therefore, it is easier for the detection algorithm to identify them, compared to fainter objects dispersed in the local background. We investigate which simulated sources are detected by studying the number density as a function of the input flux threshold for AGN in Sect. 4.2.1, and for clusters in Sect. 4.2.2.
4.2.1. AGN logN–logS
We measure the cumulative number of detected AGN per square degree as a function of the input flux (0.5–2 keV band). We compare with the distribution of the simulated AGN (Comparat et al. 2019), with the observations from Gilli et al. (2007) and Georgakakis et al. (2008), and the collection from Merloni et al. (2012). The result is shown in the upper panel of Fig. 5. At the high flux end, the different shapes of the function denoting eRASS1 and other samples are expected due to the AGN simulation method in HEALPix fields as described in Sect. 2. It reduces the volume probed by the model and the total number of the brightest AGN consequently decreases, but this method guarantees a significant gain in computation time. Given our goal of studying the simulated objects that are detected, this has no impact on our purpose. In the lower panel, we show the ratio between the logN–logS built with the detected and simulated populations of AGN. Below the predicted eROSITA flux limits at ∼4 × 10−14 erg s−1 cm−2 for eRASS1 (see Merloni et al. 2012, Fig. 4.3.1), the number density of detected AGN deviates from the simulated one (solid curves depart from the dashed ones). Toward high fluxes, the number density of detected AGN converges to the simulated one. The ratio between these two curves reaches a value of 0.5 at ∼2 × 10−14 erg s−1 cm−2 for eRASS1. These numbers rise to ∼3.5 × 10−14 erg s−1 cm−2 and a ratio of 0.8 between the logN–logS of detected and simulated AGN. This is in excellent agreement with the prediction of the eRASS1 sensitivity for point sources in the same soft band 0.5–2.0 keV from Merloni et al. (2012). The completeness of the source catalog behaves smoothly as a function of flux and is in line with the expectations. We study the completeness fraction of AGN in more detail and provide analytical fits in Appendix E.
 |
Fig. 5. Cumulative number density of the AGN population. Top panel: blue (orange) line shows the logN–logS built with the sample of detected (simulated) AGN. The green, red, violet dashed lines show the distributions from Gilli et al. (2007), Georgakakis et al. (2008) and Merloni et al. (2012). The brown and pink vertical lines locate the eROSITA flux value where the ratio between the detected and simulated populations is equal to 0.5 and 0.8, respectively. Bottom panel: ratio between the logN–logS of detected and simulated AGN. A black dashed line denotes a ratio equal to 1.0. |
4.2.2. Cluster logN–logS
We study the cumulative number density of clusters as a function of the input flux. We detect 0.1 clusters per square degree with flux larger than 4 × 10−13 erg s−1 cm−2 in the eRASS1 simulation. We detect all the clusters at the brightest flux end, as the ratio between the logN–logS built with detected and simulated clusters reaches a value of 1.0 for the eRASS1 simulation. It is equal to 0.5 for flux values of ∼3 × 10−13 erg s−1 cm−2. For the same flux limit, about 70% of the clusters with mass larger than M500c > 3 × 1014 M⊙ are detected as extended sources. A ratio of 0.8 is reached for flux values of ∼1.5 × 10−12 erg s−1 cm−2 for eRASS1. These flux limit values are larger compared to the AGN ones. A different flux limit is thus expected between the two populations. The extension of the cluster model to galaxy groups allows a smooth transition between the faintest clusters that are not detected and the ones above the survey flux limit. The detection method is able to fully recover the bright end of the cluster sample. Around the flux limit, additional selection effects, such as the cool core bias or the size of the object on the sky plane, influence the detection process. In addition, at fixed simulated flux, due to their spatial extent, clusters will be detected with a lower likelihood compared to a point source with the same flux. We report the cumulative clusters number density as a function of flux in Fig. 6. In the upper panel, we show the cluster logN–logS for eRASS1. The blue line denotes the detected cluster population, while the orange line the simulated one. The green one adds a comparison to the eFEDS logN–logS (Liu et al. 2022a). We additionally compare our result to The SPectroscopic IDentification of eROSITA Sources observational program (SPIDERS, Clerc et al. 2016; Finoguenov et al. 2020) denoted by the red dashed line, and the Extended Chandra Deep Field South (ECDF-S, Finoguenov et al. 2015), indicated by the purple dashed line. There is good agreement within these samples. The bottom panel shows the ratio between the detected and the simulated populations. All clusters with high flux are detected as extended. We present the challenges of the detection of extended sources in Sect. 4.3.
 |
Fig. 6. Cumulative number of clusters per square degree as a function of flux. Top panel: solid blue (orange) line shows the logN–logS built with the sample of detected (simulated) clusters. The green dashed line shows the distributions of the eFEDS sample (Liu et al. 2022a), the red one denotes the SPIDERS sample (Finoguenov et al. 2020), and the pink one the ECDF-S (Finoguenov et al. 2015). The brown and pink vertical lines locate the eROSITA flux value where the ratio between the detected and simulated populations is equal to 0.5 and 0.8, respectively. Bottom panel: ratio between the logN–logS of detected and simulated clusters. A black dashed line denotes a ratio equal to 1.0. |
4.3. Cluster completeness
The completeness is defined as the ratio between the number of detected and simulated objects, see Eq. (5):
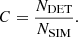
We measure the completeness of our source catalog as a function of the input flux in the 0.5–2 keV band. We study areas in the sky covered by different depths. We expect to measure higher completeness where the exposure is longer, which allows detecting a higher number of clusters. We consider four exposure time bins in this work, defining shallow, medium, deep, and pole regions. The respective intervals are < 110 s, 110 s–150 s, 150 s–400 s, > 400 s for the mock eRASS1. Such intervals are designed to identify three regions covering roughly a similar area on the sky, and a fourth, smaller one that encloses the pole with large exposure. Additional details are provided in Table 4. With this approach, we can quantify the gain of detected clusters thanks to deeper observations. We show the result for eRASS1 in Fig. 7. The lines are color-coded according to exposure time intervals. The solid lines show clusters of galaxies detected as extended, dashed ones additionally consider clusters detected as point sources with EXT_LIKE = 0. Adding the latter population increases completeness at a fixed value of flux. Focusing on the objects detected as extended, we measure a completeness fraction of 0.5 at 3.3 × 10−13 erg s−1 cm−2 for regions around the average eRASS1 exposure of about 275 s, denoted by the green solid line. This result is comparable with previous predictions by Clerc et al. (2018), who measured a completeness value of 0.5 at ∼5 × 10−14 erg s−1 cm−2 in equatorial fields with eRASS:8 depth of about 2.0 ks. The decrement of completeness in the 150 s–400 s range is due to a merging system, where only one eSASS detection with EXT_LIKE > 6 is present. The latter is assigned to one of the two clusters, the one providing most of the counts around the detection. The second cluster is assigned to a nearby point-like detection instead. Adding the clusters detected as point sources increases completeness. For the depth interval 150 s–400 s in eRASS1, the 50% completeness is reached at flux equal to 8 × 10−14 erg s−1 cm−2. There is a flux difference of about 0.7 dex with the addition of this population.
 |
Fig. 7. Fraction of simulated clusters with a counterpart in the eSASS catalog as a function of simulated soft X-ray flux. We do not apply any additional likelihood selection. Each color identifies an exposure time range. Solid lines denote clusters only detected as extended, while dashed ones include the ones detected as point sources. |
Different exposure and properties of the eRASS1 simulations.
The measure of completeness is positively correlated with exposure time. In the eRASS1 simulation, the fraction of clusters with flux ∼5 × 10−13 erg s−1 cm−2 that are detected as extended goes from 0.39 (exposure < 110 s) to 0.8 (exposure > 400 s).
The increase in the number of detected objects between the shallow and deep regions is expected, but nevertheless remarkable. It translates into an increment of the number density of clusters detected as extended with exposure time. In the former, we detect and properly classify as extended 0.13 clusters per square degree (exposure < 110 s). In the latter, such number increases to 1.05. Our result is in agreement with previous works (Pacaud et al. 2006; Clerc et al. 2012, 2018). This only means that we recover a larger number of simulated clusters in deep areas, not that the detection is necessarily more efficient. A different fraction of spurious sources is also detected in areas with large exposure because the background has lower fluctuations. Its overall level might be larger, but its lower variability may also reduce the false detection rate. Such deep areas additionally suffer from a higher degeneracy between blended point sources and proper extended ones, as well as between AGN in clusters and cluster substructures, which has an impact on the measure of contamination. A detailed discussion is presented in the next Sect. 4.4. We do a similar study for AGN and provide details and analytical fits in Appendix E.
4.3.1. Completeness and apparent cluster size
We investigate the impact of the apparent physical size of the clusters on the sky on the detection. This information is encoded in the critical radius R500c. We compare the number of detected objects to the simulated one on a 2D grid of flux and R500c. Considering the angular size of the cluster on the sky (e.g., in arcseconds) instead of its physical size (in kpc) allows to additionally account for the impact of redshift, which makes distant massive large clusters appear smaller than nearby ones with similar mass.
We find that the detection of extended sources is not solely a simple function of flux and exposure time. At fixed flux and exposure time, the completeness varies as a function of the size of the clusters on the sky. In the eRASS1 simulation, bright clusters with flux ∼1 × 10−12 erg s−1 cm−2, located in an area covered by exposure 150 s–400 s, and R500c = 180″ are detected as extended with a completeness of 0.75. The rest of these sources are actually detected but misclassified as point sources. In fact, the completeness reaches a value of 1.0 when adding the population of clusters detected as point-like objects. At the same value of flux, for larger objects with R500c = 300″, we measure a completeness of 0.84. The characterization of extremely large clusters is also challenging, because these can be split into multiple sources. In fact, the completeness decreases for large values of R500c, above 400″ and flux of 1 × 10−12 erg s−1 cm−2. As R500c increases, the surface brightness goes down rapidly. Therefore these cases represent the population of clusters which are very extended but with very low surface brightness, therefore they are harder to be detected. This is shown in Fig. 8. It displays the number of the simulated clusters population in the upper panels, the fraction of these objects that are detected as extended or point sources in the central ones, and finally only the ones classified as extended in the lower panels. It focuses on exposure intervals containing the average depth for our simulation, in the 150 s–400 s range for eRASS1. This figure confirms the trends of increasing completeness with flux (see Fig. 7). In addition, it demonstrates how the selection of extended sources is not a simple function of flux and exposure, but also of the size the object on the sky, encoded in our measure of R500c.
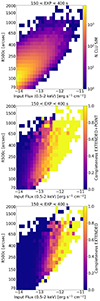 |
Fig. 8. Simulated and detected clusters population as a function of the input flux and size on the sky. The figures refer to areas of the eRASS1 simulation covered by an exposure between 150 s and 400 s. The blank spaces contain no input clusters. Top panel: number of simulated clusters in the flux–R500c space. Central panel: fraction of simulated clusters that is detected by eSASS, either as extended or point source. Bottom panel: fraction of simulated clusters that is only detected as extended. |
4.3.2. Completeness as a function of the central emissivity
We study the impact of the clusters dynamical state on the detection. Such property is related to the central cluster emission. In the simulations, we relate the emissivity in the central region of the cluster to a parameter of the dark matter halo (Xoff) which encodes its dynamical state. The offset parameter, Xoff, is the displacement between the halo center of mass and its peak of the density profile (Klypin et al. 2016; Seppi et al. 2021). The negative log10 of the central emissivity (EM0) is proportionally related to Xoff (see Comparat et al. 2020, for more details). Dynamically relaxed dark matter halos (with low offset parameter) host clusters with peaked emissivity profiles (cool cores with high central emissivity, and low EM0 in this formulation). Conversely, disturbed halos (with large offset parameter) host noncool core clusters with flatter emissivity profiles. We measure the completeness fraction as a function of EM0 for clusters in different bins of flux (Fig. 9). This allows quantifying the impact of the cool core bias, which makes the detection more efficient toward clusters with a peaked emission in the core. We describe the results for the eRASS1 simulation in the following paragraph.
 |
Fig. 9. Population of simulated and detected clusters as a function of the input flux and dynamical state. The panels show areas of the eRASS1 simulation covered by an exposure between 150 s and 400 s. The blank spaces contain no input clusters. Top panel: number of simulated clusters in the flux–EM0 space. Central panel: fraction of simulated clusters that is detected by eSASS, either as extended or point source. Bottom panel: fraction of simulated clusters that is only detected as extended. |
We find that clusters with low flux are hardly detected as extended. In this regime, where few objects are detected, they are mostly characterized as point sources. About 25% of the simulated objects with a flux of ∼3 × 10−14 erg s−1 cm−2, EM0 ∼5, and covered by an exposure between 150 s and 400s are detected, but none of them is classified as extended. At these low fluxes, we see evidence of the cool core bias. In fact, we detect only 7% of the extremely unrelaxed simulated clusters with EM0 = 6 at this flux value, as the completeness drops by a factor of ∼3.5 from relaxed to disturbed structures. The detection is generally more efficient for brighter objects. 82% of disturbed structures (EM0 = 5.5) and flux ∼3 × 10−13 erg s−1 cm−2 are identified by eSASS and 39% of them are characterized as extended. In addition, in this regime the cool core clusters are still detected as extended sources. For instance, at the value of EM0 = 5, every cluster brighter than ∼1 × 10−12 erg s−1 cm−2 is properly classified as extended. There is a smooth transition between these two regimes: 85% of the extreme cool cores (EM0 = 4.5) with flux ∼1 × 10−13 erg s−1 cm−2 are detected, but only 14% is identified as extended. Moving to the bright end of the flux distribution, the sample becomes less affected by the cool core bias. Among the clusters with flux ∼1 × 10−12 erg s−1 cm−2, relaxed (disturbed) ones with EM0 = 4.5 (EM0 = 5.5) are detected as extended in 100% (91%) of the cases. This transition is clear by comparing the central and bottom panels of Fig. 9. They remark the different behavior of the completeness for simulated bright cool cores between the clusters only identified as extended and the sample with the addition of the point-like detections in the eRASS1 simulation. When including the clusters detected as point sources (central panel), the population is skewed toward lower values of EM0, especially at low flux. This effect is mitigated in the extent-selected sample (bottom panel). We further discuss an explanation in Sect. 5.1.2. We conclude that the cool core bias strongly affects only the faint clusters detected as point sources. Its impact on brighter objects detected as extended is reduced. Our results suggest that a stricter selection focused on bright eROSITA clusters with larger values of extension likelihood provides a sample that is barely affected by the cool core bias. This is in agreement with Ghirardini et al. (2021a), who do not find a clear preference for cool core clusters in the extent-selected eFEDS clusters, and Bulbul et al. (2022), who find steeper emissivity profiles and more concentrated objects only within the sample of eFEDS clusters detected as point sources.
4.4. Detection efficiency
Different aspects come into play when evaluating the performance of a detection algorithm. We quantify the ability to recover simulated sources, to properly classify them as point-like or extended, and to minimize the false identification of background fluctuations.
The first one is completeness, that is the fraction of simulated objects with a given flux that have been detected, see Eq. (5). When measuring this number, we choose different flux thresholds according to exposure time in the two simulations. We consider the same depth bins described in previous sections (see Table 4). We work with exposure intervals and flux values identifying the 50% completeness for clusters detected as extended from Fig. 7, and the 80% completeness for AGN. These are also reported in Table 4. We use these limits as thresholds and consider all the objects brighter than such values.
Secondly, one needs to account for contamination given by objects that should not be in the catalog of interest. For instance, contamination in a cluster catalog is given by bright AGN that are mistakenly classified as extended sources. This is measured by the fraction of entries in the extended source catalog that are assigned to a simulated AGN or star. For an AGN catalog instead, contamination is caused by faint and or cool core clusters that are erroneously detected as point sources.
Finally, it is important to consider the false detections, that are entries in the source catalog related to a random background fluctuation, not to a physical source. This causes a fraction of spurious sources in the eSASS catalog. Contamination and false detection rate are usually enclosed in the notion of purity. The purer a catalog, the fewer contaminants and spurious sources it contains.
We combine these aspects in a single concept: the detection efficiency, which encodes the completeness and purity of the source catalog. We measure completeness, contamination, and the fraction of spurious sources in the eRASS1 simulation for different intervals of exposure time, defined in Table 4. In addition, we account for different thresholds of the detection and extension likelihood to cut the catalogs and study how they impact the eSASS performance in terms of detection efficiency for AGN identified as point-like and clusters of galaxies characterized as extended. We report our results in the next paragraphs.
4.4.1. AGN
Increasing exposure time allows detecting a fixed fraction of sources down to lower fluxes. In the full catalog with DET_LIKE > 5, we measure similar values of the completeness fraction in distinct exposure bins, thanks to the choices of different flux limits. The values are larger than 90% for eRASS1. These numbers will depend on the given flux limit. Our choice of the value where the fraction of detected AGN is equal to 0.8 leads to measuring a higher completeness fraction when using such values as thresholds. In general, we measure a lower fraction of spurious sources in areas with larger exposure. This is because even though the total number of background photons is higher, their fluctuations are suppressed, which results in a lower false detection rate. In the shallow areas, about 32% of the full source catalog does not have a simulated counterpart and is classified as spurious. This number is reduced to 13% in regions around the southern ecliptic pole with the deepest exposure. We provide an analytical fit for the false detection rate as a function of DET_LIKE cuts and exposure time in Appendix E (see Eq. (E.2) and Table E.1). Progressive cuts in detection likelihood clean the source catalog from these false detections but reduce the fraction of simulated AGN that are detected. Given our choices of flux thresholds, the completeness drops from 94.4% (94.9%) to 82.4% (86.5%) from DET_LIKE > 5 to DET_LIKE > 10 in the shallow (polar) region of eRASS1.
The fraction of clusters that leak into the point source sample is around 4%. A higher detection likelihood cut of 20 reduces this contamination to 2.2% in shallow areas and 1.5% in the pole, but this results in a significant loss in terms of completeness, which respectively drops to 50% and 63%. At fixed completeness, we measure higher contamination in areas with lower depth. This means that a larger exposure time is key to properly distinguish AGN detected as point sources from clusters contaminating the point-like sample, that should be classified as extended ones instead. All these trends are clear in the top panels of Fig. 10. The left-hand one shows the fraction of detected AGN as a function of the false detection rate. The lines are color-coded by exposure time and the dots and numbers denote different cuts in detection likelihood. The right-hand panel displays the correlation between AGN completeness and the fraction of clusters wrongly detected as point-like objects.
 |
Fig. 10. Efficiency of the eSASS detection for extragalactic sources in the eRASS1 simulation. The completeness is measured for simulated objects above the different flux limits for each exposure interval defined in Table 4. Top panels: detection efficiency for AGN detected as point sources (EXT_LIKE = 0). The numbers denote DET_LIKE thresholds. Bottom panels: detection efficiency for clusters. The numbers denote EXT_LIKE thresholds. No additional cuts of DET_LIKE are applied. Left-hand panels: completeness as a function of spurious fraction. Right-hand panels: completeness as a function of contamination. Different exposure intervals are shown in different colors. |
4.4.2. Clusters
We perform a similar analysis for the population of clusters in the source catalog at different cuts of extension likelihood. The choice of flux limits corresponding to the 50% completeness in each exposure interval translates into completeness values of around 65% when using them as thresholds. The qualitative efficiency trends are slightly different from the AGN ones. For instance, we progressively measure a lower false detection rate from regions with exposure lower than 110 s (1.5%) to the ones covered by 150 s–400 s (0.6%). However, the behavior of the spurious fraction in the pole region is different. In fact, it increases from extension likelihood larger than 6 to 8 and then drops as expected. This trend is related to the close interplay between the removal of false detections and bright AGN that leak into the extent-selected sample. Progressive cuts in extension likelihood are very effective for the latter case so that the number of spurious sources with respect to the total increases from EXT_LIKE > 6 to EXT_LIKE > 8, but it still decreases with respect to the number of real sources. Increasing to EXT_LIKE > 10 brings the false detection rate to 0.5% in the shallow areas and 0.1% in deep regions. Together with rejecting spurious sources, increasing EXT_LIKE thresholds are very effective in reducing the fraction of contamination. The latter goes from about 30% for EXT_LIKE > 6 in the pole region of eRASS1 to 4% at EXT_LIKE > 20. In regions covered by the average depth of the survey, with exposure 150 s–400 s for eRASS1, contamination goes from 23% to 1% for the same extension likelihood cuts of 6 and 20. Deep regions suffer from contamination more than shallower ones. This value goes from about 15% in shallow areas to 32% in the pole region for eRASS1. This is due to the larger amount of bright AGN photons that can be mistaken for extended objects, but also due to the higher chance of merging nearby point sources into a single extended detection.
In eRASS1, we measure similar contamination of about 15% on shallow areas (< 110 s) cutting the catalog with EXT_LIKE > 6 and the pole region (> 400 s) with EXT_LIKE > 10. The completeness is also close to 60% with these cuts. The average exposure of eRASS1 corresponding to roughly ∼275 s is included in the green curves. Cutting the catalogs at EXT_LIKE > 20 provides about 50% of the simulated cluster above the chosen flux thresholds, with 2% contamination, and a null false detection rate in eRASS1.
The completeness-spurious fraction and contamination curves for clusters are shown in the bottom panels of Fig. 10. The figure is color-coded according to the exposure time. It highlights the results described above. Progressive EXT_LIKE cuts of 6, 8, 10, 15, 20, and 30 are written as text.
These are key steps toward selecting a sample of clusters of galaxies to measure cosmological parameters with eROSITA, which has to be as pure and complete as possible. We discuss an alternative way of characterizing clusters of galaxies using the maximum signal-to-noise radius (srcRAD) in Appendix F.
4.5. Sensitivity
We compute the sensitivity maps for point sources in each simulated tile, using the apetool task, part of the eSASS chain described in Sect. 3. The sensitivity map is related to the probability of identifying a detection in a given energy band and at a given position on the detector. Our sensitivity maps are given in units of counts. These values depend on the Poisson false detection probability, which is defined as the probability of detecting photons generated by a random background fluctuation inside a radius of a given value as a source. We set this threshold to a standard value of P = 4 × 10−6, which corresponds to DET_LIKE ∼ 12 (see Eq. (4)). We consider apertures enclosing a local PSF encircled energy fraction equal to 60% (Brunner et al. 2022). Given the definition of detection likelihood (Sect. 3), these two quantities are related by DET_LIKE = − < SPSDOUBLEDOLLAR > ln(P). The final sensitivity map depends on the estimated background map, the detection mask, and the exposure map. Additional details are provided by Georgakakis et al. (2008). For each simulated tile in the simulation, we obtain the lower count rate detection threshold by dividing sensitivity and exposure maps. We convert to flux by dividing the count rate by the energy conversion factor (ECF) in the soft X-ray band between 0.2 and 2.3 keV. The ECF is computed following Brunner et al. (2022), with an absorbed power-law model of slope equal to 2.0 and varying galactic absorbing column density (nH) equal to the average value in each tile. It is equal to 1.074 × 1012 cm2 erg−1 for an nH value of 3 × 1020 cm−2. The result is the survey flux limit in areas of the sky covered with different exposure. We compute the cumulative distribution function of the flux limit for each tile and normalize it by the unique area covered by the sensitivity map. We sum up such quantity for all the simulated tiles. The result is the Area covered by the simulated first eROSITA all-sky survey as a function of limiting flux.
We show the normalized survey area in Fig. 11. It displays the area curve for the eRASS1 simulation and a comparison to the eRASS:8 sensitivity prediction from Merloni et al. (2012). The dashed orange line is an extrapolation of the eRASS:8 prediction to the depth of eRASS1, obtained by re-scaling the curve to the predicted eRASS1 limiting flux (see Table 4.4.1 in Merloni et al. 2012), and multiplying by an additional factor of 1.403, converting the flux of an ideal absorbed power-law AGN model with NH = 3 × 1020 cm−2 and photon index Γ = 1.8 from the 0.5–2.0 keV band to the 0.2–2.3 keV one. The agreement between the prediction and our measurement at the faint end is excellent. An offset at larger fluxes is expected because the former is based on an analytical derivation of the Poisson probability for false detections (see Sect. 4.3.1 of Merloni et al. 2012). A number of assumptions are taken into account to compute the final sensitivity, related to the background, the foreground absorption, and the exposure. Moreover, a further contribution is given by different Poisson probability thresholds, equal to 3 × 10−7 against 4 × 10−6 for this work. Our measure using the sensitivity maps computed by eSASS additionally accounts for a diverse and more realistic treatment of the X-ray background, as well as the true exposure derived from the real eRASS1 scanning process. This allows accounting for the nonuniform depth of the survey, compared to the prediction that is carried out at a fixed exposure equal to the average value for eRASS1 and does not include the higher sensitivity in deeper regions. This causes the difference between our measure and the prediction at the bright flux end. We find that 50% of the area is covered with a flux limit of 4.7 × 10−14 erg s−1 cm−2 in the 0.2–2.3 keV band in the eRASS1 simulation.
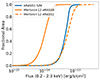 |
Fig. 11. Simulated eROSITA fractional survey area as a function of flux limit. The eRASS1 simulation is denoted by the blue line, the prediction by Merloni et al. (2012) for eRASS:8 is shown in orange. The dashed line denotes an extrapolation of the eRASS:8 prediction to the depth of eRASS1. |
4.6. Imaging and spectral analysis
We measure temperature and X-ray luminosity for a subsample of randomly selected clusters that have been detected as extended by eSASS. Our approach follows Ghirardini et al. (2021b) and is described in Sect. 3.3. This sample spans a wide range of exposure times, from equatorial shallow regions to deeper ones close to the southern ecliptic pole. It consists of 873 objects. In order to test our measurements, we compute a weighted mean of the measured luminosity in input luminosity bins with 0.1 dex width. We use weights that are equal to the inverse of the uncertainty on the value of measured X-ray luminosity. The result is shown in Fig. 12.
 |
Fig. 12. Measure of X-ray luminosity. Top panel: comparison between average values of measured X-ray luminosity as a function of input ones. The blue shaded area encloses the average measured luminosity within 1σ uncertainties. The dashed orange line shows a perfect one-to-one relation. Lower panel: residual plot normalized by the input luminosity. |
The blue shaded area shows the average value of the recovered X-ray luminosity, enclosing the LX standard deviation in each bin. This is always compatible with a perfect one-to-one relation, shown by the orange dashed line, and with a linear fit6 in the form of log10LX, M = m log10LX, SIM + q, denoted by the green dashed line. The lower panel displays the residual plot.
We notice that the residuals of the linear fit slightly shifts from negative to positive values for increasing luminosity. The slope of the linear relation is m = 1.026 ± 0.001. First of all, the fit of the density profile for faint clusters is more challenging, because they provide a lower amount of counts than bright objects. In addition, the temperature spectral fitting also requires a larger amount of photons to be precise. For fainter objects, this makes the conversion factor between count rate and luminosity more uncertain. This effect is partially mitigated by the fact that system with lower luminosity show also on average a lower gas temperature. These systems have more emission lines and a bremsstrahlung cutoff at a photon energy with high effective area, which partially reduces the number of counts needed to ultimately measure the temperature. The combination of these two factors biases the recovered X-ray luminosity toward lower values. The scatter slightly shifts toward positive values for luminous clusters. Bright structures are more probable to be extended on the sky, which increases the total net count of events that are not generated by the cluster itself but are potentially considered in the surface brightness fitting. This happens if point sources or other extended sources are not properly masked or if the background is not perfectly modeled. An additional component of the scatter in the relation between simulated and measured X-ray luminosity is given by bright nearby clusters. For these objects, the background extraction region is very large and can span areas with nH fluctuations. This may bias the temperature measure and ultimately the X-ray luminosity. These are all minor effects that do not affect our results on average. We find an excellent agreement between the input luminosity values and the measured ones.
5. Discussion
In the following section, we further discuss the importance of a proper characterization of source samples in the eROSITA surveys, and different strategies to build cluster samples for eRASS1.
5.1. Biases of the survey sample properties
Understanding the properties of large samples of sources from surveys such as eROSITA is crucial to exploit their scientific potential to the fullest. Accurate and precise detection and classification of sources in astronomical surveys is, therefore, an essential task. A multitude of factors make the process complex: the nature of the sources themselves, the characteristic of the telescope, and the detection pipeline. In general, it is important to understand and quantify the causes of errors and misclassification.
For instance, fluctuations of the X-ray background are potentially detected and classified as a source by eSASS. In this context, a biased measure of the X-ray background impacts not only the number of false detections, but also the detection likelihood of identified sources, because photons emitted from a source might be mistaken for background photons, or vice versa. An accurate estimate of the false detection rate is crucial to assess the fraction of spurious sources in a given sample. We showed that this can be achieved with realistic end-to-end simulations, identifying entries in the source catalog that are not matched to a simulated counterpart.
Another key factor is the contamination in the extent-selected sample (see Fig. 3). It is important to figure out why it occurs and how it can be reduced. Contamination is caused by different aspects. The main contribution is given by bright point sources, that are classified as extended. In the cleaned eSASS catalog of our simulation, 1017 extended detections are assigned to a simulated AGN, about 18% of the total extent-selected catalog. Secondary effects include close pairs of bright AGN, that can mimic the emission of an extended object when the detection algorithm is not able to resolve and disentangle the point sources. 446 among the 1017 AGN detected as extended are contaminated by another point source in our simulation (see Sect. 3.2). In addition, bright nearby stars can appear extended on the sky, further contaminating the cluster sample. 178 extended detections are assigned to a star in the cleaned catalog of our simulation. Areas around bright known stars from the optical band can easily be masked in the real survey, which minimize the contamination due to stars. This effect is even magnified in areas with deep exposure, where random background fluctuations have a higher chance of being identified as an extended source. We find a total of 48 extended false detections.
Such cases end up in secure extended detections with large values of DET_LIKE, which explains why choosing extremely high thresholds of detection likelihood do not lower contamination. Instead, a cut in EXT_LIKE is needed to reduce the contamination due to point sources in the extent-selected catalog. This is clear in the bottom panel of Fig. 3. It is possible to argue that a direct comparison of the population in the catalog after cutting at the same value of extension or detection likelihood is misleading, due to the intrinsic difference between them. In particular, EXT_LIKE has typically smaller values than DET_LIKE for extended detections. In the extent-selected sample, the 0.25, 0.5, 0.75, and 0.90 quantiles for EXT_LIKE (DET_LIKE) are 7.95 (22.69), 12.05 (37.19), 22.85 (65.22), 41.35 (114.99). For instance, if we focus on the 0.5 quantile, the AGN contamination is equal to 4.6% for EXT_LIKE = 12.05 and to 18.2% at DET_LIKE = 37.19. Therefore, we still conclude that applying extension likelihood cuts is a more efficient way of decreasing contamination. In observations, this can also be solved by a multiband approach, for example doing an optical follow-up of extended X-ray sources (see Salvato et al. 2022, for an example). This allows keeping all the cluster candidates in the catalog, that has the highest possible completeness. In a second step, one can look for overdensities of red galaxies around each X-ray detected cluster. If there is evidence of a red sequence, the cluster will be confirmed (see Finoguenov et al. 2020, for an example). Otherwise, the catalog will be cleaned from a spurious or contaminating source, increasing the purity of the sample, while keeping the completeness level unchanged. This is a key ingredient toward precision cosmology with X-ray-selected clusters (Ider Chitham et al. 2020).
With optical follow-up observations, one can not only find contaminating point sources classified as extended but also identify real clusters of galaxies that are misclassified as point sources (Green et al. 2016; Bulbul et al. 2022). Understanding why extended sources are classified as point-like ones is key to correct this bias and properly characterize as many clusters as possible. A cluster ends up classified as a point source because of different reasons. The first one is brightness. These are usually faint objects, whose extended emission at the outskirts struggles to emerge over the local background. The second one is related to their cores. Clusters with a peaked emission in the center are possibly mistaken for point sources. In fact, we find that clusters with low flux and cool core are detected as point sources (see Fig. 9). Furthermore, high redshift clusters, even if intrinsically bright and extended, cover a tiny area on the sky, possibly smaller than the PSF of the telescope. Finally, clusters of galaxies hosting an AGN are potentially dominated by the emission of the latter. All these cases give rise to contamination and or misclassification for clusters of galaxies that leak into the point source sample. A purer cluster sample affected by less systematics may be obtained by a detection algorithm that excises the core region. This is because the cluster’s outskirts have been shown to evolve in a self-similar way, with low scatter (McDonald et al. 2017; Käfer et al. 2019; Ghirardini et al. 2019). A more direct definition of the sample in terms of cluster mass is therefore achievable this way. This idea was implemented in clusters studies by Vikhlinin et al. (1998). A recent implementation is described by Käfer et al. (2020), where the X-ray images are filtered by a series of spatial wavelet filters with different scales, which allows isolating the extended emission from galaxy clusters. However, such a method requires a larger amount of counts to detect a cluster, which lowers the completeness of the sample.
The misclassification and contamination of clusters are additionally relevant for AGN. Simply selecting AGN from the point-like catalog means missing the bright objects that are mistakenly classified as extended, and accounting for faint clusters contaminating the point source catalog. However, we showed that this can be addressed by estimating completeness and contamination from realistic simulations, which provides the fraction of false detections, the contaminants, and the sources missed by the detection scheme according to desired selection criteria.
5.1.1. Completeness purity trade-off
Perfectly complete and pure samples of sources are ideally desired for astrophysical and cosmological studies. This means that, above the flux limit for a given experiment, a perfectly efficient detection and selection scheme should provide all the physical sources, making the source catalog as complete as technically feasible, identifying also very faint objects. Depending on the scientific application, it should also produce a catalog containing only the sources of interest, making the sample as pure and clean as possible. This means minimizing the rate of false detection: background fluctuations that are classified as physical sources. The concept of purity also includes contamination. For instance, in the extent-selected sample contamination is caused by bright AGN or stars, which should be classified as point sources instead. The number of such objects should also be minimized. The concepts of completeness and purity are closely related: maximizing the first means pushing the limits of the algorithm, and trying to identify the faintest physical objects. These are easily mistaken for random background fluctuations, which ultimately ends up costing a higher fraction of spurious sources in the final catalog.
In the context of the eROSITA surveys, the trade-off between completeness and purity is affected by various parameter choices made to select clusters. Different extension likelihood cuts are an example. Choosing a very low threshold will keep the catalog complete on the one hand, but on the other, the risk of introducing AGN in the catalog is higher, which increases contamination. Instead, higher likelihood thresholds will give a cleaner sample, at the cost of reducing the fraction of detected objects. This is evident in Fig. 10, where progressive EXT_LIKE cuts degrade completeness, but improve purity, reducing the false detections and contamination. We stress that our choice of various flux limits for different exposure times guarantees a comparable benchmark between areas covered by varying depth.
Different choices regarding the parameters characterizing the source catalog should be taken according to the specific scientific goal. For example, if the goal is to work with a secure catalog from the start, higher thresholds should be chosen. This will minimize the spurious sources and the contamination, making such cluster sample pure. However, the completeness will also be reduced. Instead, if the goal is to select the highest possible number of clusters at first, a very low EXT_LIKE limit is best. Such studies may involve the evolution of the luminosity function. A secondary step might then be required to clean the catalog, for example with multiwavelength observations such as an optical follow-up, allowing the confirmation of cluster candidates if there is evidence for a galaxy red sequence. This approach allows reducing contamination thanks to the multiwavelength information, while keeping the completeness level high, because no additional X-ray selection is applied. It also makes the cluster sample more secure, because it probes two distinct properties: the intra-cluster medium through X-rays, and the galaxy members in the optical and infrared bands. Samples defined in this way are particularly suitable for cosmological experiments. In this context, it is important to model the contamination and completeness levels together. For example, Aguena & Lima (2018) quantified the bias on the measure of cosmological parameters due to the imperfect modeling of completeness and purity in a cluster count experiment. They assumed a DES-like survey and found that a proper description of completeness and purity is key to measure unbiased cosmological parameters without degrading the constraining power especially when including low-mass clusters. A detailed description of the cluster selection (see Fig. 10) is therefore essential, since eROSITA will discover many new low-mass clusters and groups. Finally, other studies such as clustering may require a sample of objects contained in a well-defined volume. These can be constructed by rejecting faint and distant sources (see Sect. 5.2).
5.1.2. Impact of source size and cool core bias
Given the morphological complexity of clusters of galaxies, their detection is not a simple function of flux and exposure time.
For example, it has been shown that the size of the cluster on the sky does have an impact on the identification (Pacaud et al. 2006; Burenin et al. 2007; Clerc et al. 2018). On the one hand, the detection algorithm can easily detect bright nearby clusters and characterize them as extended. On the other hand, high redshift clusters, even if bright and large, may cover an area on the sky that is close to or smaller than the telescope PSF. The same holds for nearby groups with very low mass. Such objects are easily mistaken for point sources in the detection process. This makes the detection of clusters more complex. In Fig. 8, we show that the fraction of clusters detected as extended is not only a function of flux and exposure, but it additionally depends on the size of R500c on the sky, even fixing the former two variables. This effect is more visible for clusters with a smaller radius, whose extended emission struggles to emerge over the background, compared to larger clusters with a similar flux. These objects are actually detected by eSASS, but classified as point sources, as expected.
Furthermore, the dynamical state of the clusters plays a role in the detection and classification. Dynamically relaxed structures have had time to develop an efficient cooling toward the central regions, which enhances their central X-ray emission, resulting in a peaked surface brightness profile. This makes it easier for these types of objects to emerge over the background and biases the detection toward them. This is the notion of cool core bias (Eckert et al. 2011). However, clusters with a peaked profile can resemble the emission from a point source. In such cases, the peaked emission toward the central regions dominates over the tail at larger radii. This is not easily identified by eSASS, which ends up classifying the cluster as a point source. The net effect is that the detection is biased toward cool core clusters, but they might be easily misclassified as point sources.
The link between this effect, the exposure time, and the background has a significant impact on the detection process. On the one hand, a large exposure for a cool core cluster makes the large ratio between photons from the core and photons from the outskirts more clear over the background, making them look more similar to point sources than analogous objects covered by a shallow exposure. This will increase the probability to misclassify such clusters as point-like objects. On the other hand, with increasing depth the signal-to-noise ratio of the cluster outskirts will increase relative to the local background. In principle, a more accurate estimate of the background is also possible in this regime, thanks to the lower variability. These aspects should instead help the identification of clusters as extended. The characterization of the cool-core fraction in a cluster population also depends on the selection of the sample. Ghirardini et al. (2021a) measured the dynamical state of eFEDS clusters combining a set of quantities (such as concentration, central density, photons asymmetry, ellipticity) and did not find a prominent cool-core bias on the extent-selected sample. More detailed simulations at deeper exposures (e.g., eRASS:8) are needed to investigate this topic. Nonetheless, most of the brightest clusters are properly identified as extended (Fig. 9). We conclude that the eSASS algorithm minimizes the impact of the cool core bias on the vast majority of the sample of clusters detected as extended sources. It mostly affects the low-flux clusters, where only the cool cores are detected, but classified as point sources.
5.2. Construction of volume-limited samples
In the context of cosmological experiments, a well-defined sample of galaxy clusters is crucial. The eROSITA all-sky surveys naturally produce samples that are mainly flux-limited. Such samples are made up of clusters that reach the survey flux limit, which mainly depends on the telescope sensitivity and the scanning strategy. Therefore, a higher number density of objects is detected at low redshift and luminosity, compared to the high-z regime where only the brightest sources are detected. In addition, given that the sky coverage by eROSITA is not uniform in terms of depth, fainter objects can be detected in deep areas with a higher probability. Therefore, the source catalog will have different properties in regions with different exposure. These differences can be mitigated by building volume-limited samples, made up of clusters with a given set of properties inside a well-identified volume, that is encoded in the choice of the maximum distance (or redshift) up to which one is interested to build the sample. Then, in order to obtain an unbiased sample of objects, one can only consider sources whose luminosity is larger than the value corresponding to the flux limit at the chosen redshift. This provides a sample with a constant distribution of the number density as a function of redshift. Practically, a volume-limited sample is built from a flux-limited one by getting rid of the sources that are less luminous than a given threshold and further away than a certain distance (or redshift). The relation between these values of luminosity and redshift is set by the flux limit of the survey (see Eq. (6)), where dL denotes the luminosity distance, that depends on redshift:
Within such ranges of luminosity and redshift, a selection function built from simulations is less uncertain and allows unbiased results in cosmology experiments. A volume-limited sample provides an even sampling of the large-scale structure, accounting for the observational limits of the survey.
Because eROSITA does not cover the sky with a uniform depth, we build different volume-limited samples applying higher flux limits in areas with lower exposure. We use z = 0.1 as the lower redshift boundary and consider the exposure intervals and flux limits corresponding to 50% completeness defined in Table 4. We account for the K-correction in the relation between flux and luminosity (Eq. (6)). It guarantees that the flux is always measured in the same energy band for clusters at different redshift. We start by considering all the clean extragalactic eROSITA_DE sky (see Sect. 3.2) and applying the largest flux limit, identifying the 50% completeness in the shallowest areas of the survey. We proceed by reducing the area, gradually excluding shallower regions, and applying deeper flux cuts. The result is shown in Fig. 13. The first panel shows the cluster population in areas covered by a different exposure, that have been used to construct the volume-limited samples. The other four panels show how simulated (in blue) and detected clusters (in orange) populate the luminosity–redshift plane. The black dashed lines denote deeper flux limits as the area shrinks. The red dashed lines locate regions of this plane where the clusters are luminous enough to be above the flux limit at a given redshift. The volume-limited samples are finally built by considering the clusters inside the areas identified by these lines. Table 5 reports the number of clusters in the volume-limited samples and the corresponding flux-limited ones.
 |
Fig. 13. Selection of a volume-limited cluster sample in the eRASS1 simulation. Top panel: sky map with the cluster population in areas covered by different depth. Areas 0, 1, 2, and 3 respectively cover regions with exposure larger than 0 s, 110 s, 150 s, and 400 s. They are cumulative areas with respect to the ones defined in Table 4. Bottom panels: population of simulated and detected clusters in the luminosity–redshift plane. The black dashed lines denote the chosen flux threshold at each depth (see Table 4). The red dashed lines locate different areas above the given flux limits. The volume-limited sample is constructed with the objects within the regions delimited by these lines. |
Number of clusters in the volume-limited and flux-limited samples for areas covered with different depth.
This method provides a collection of clusters detected as extended sources that are an even subsample of all the simulated clusters within the same ranges of luminosity and redshift. This is shown in Fig. 14. The two top panels show how the volume-limited samples built with clusters detected as extended (dashed lines) compare to the one made up of simulated clusters (solid lines). The plot is color-coded according to the exposure time. The relation between the two samples in terms of redshift and M500c is shown in the right-hand and left-hand panels, respectively. The bottom panels show the corresponding flux-limited samples. The ratio between the number density distribution of detected and simulated clusters as a function of redshift is roughly constant for the volume-limited samples, and the majority of clusters with masses down to M500c ∼1014 M⊙ within our selection are detected. This means that our method has the potential to identify a cluster sample that provides an even sampling of the large-scale structure at different redshift and exposure time. The same trends of the cluster number density as a function of mass and redshift for the flux-limited samples are qualitatively similar. For the second one, the completeness is lower compared to the volume-limited case, because the cuts in luminosity and redshift exclude clusters that are close to the flux limit and have a lower probability of being detected. Using the full flux-limited sample to measure cosmological parameters maximizes the number of clusters, but a robust selection function around the upper redshift limit of the survey is required. The advantage for the volume-limited samples is that they are contained in a well-defined cosmological volume. This potentially makes the definition of the survey volume less uncertain in a cluster counts cosmological experiment.
 |
Fig. 14. Comparison between the volume-limited and flux-limited samples built with clusters detected as extended and simulated ones. The top panels display the volume-limited samples, the bottom panels show the flux-limited ones. Left-hand panels: relative contribution to the total cluster number density as a function of redshift for the four different populations. The lower plot shows the ratio between the N(z) built with the samples of detected and simulated clusters. Right-hand panels: relative contribution to the total cluster number density as a function of mass for the four different populations. The lower plot shows the ratio between the N(z) built with the samples of detected and simulated clusters. |
6. Summary and conclusions
Thanks to the eROSITA X-ray telescope, we are detecting clusters of galaxies and active galactic nuclei in the X-ray band at an extraordinary rate. This has a multitude of science applications, from the evolution of accreting supermassive black holes (Fanidakis et al. 2011), to major steps forward in cosmological studies with X-ray-selected clusters samples (Pillepich et al. 2018). In this context, it is key to deeply understand the detection and selection of these objects, alongside the properties of the sources recovered by a given detection scheme. Using the models described by Comparat et al. (2019, 2020) we produce a half-sky simulation following the observational strategy of eROSITA, to the depth of the first all-sky survey. The simulated objects include clusters of galaxies, AGN, and stars. The population of simulated clusters is a truthful representation of real clusters of galaxies because the model is built from real observations. The background is simulated following an approach similar to the one detailed by Liu et al. (2022b). For the eRASS1 simulation, we resample directly the real background maps. This provides an accurate digital twin of real eROSITA data. The result is shown in Fig. 1. We run the eSASS detection algorithm on the simulation. We compare the background maps measured on the simulation and the real eRASS1 data. The simulated background is overestimated by ∼10%, but this has a minor impact on the computation of the detection likelihood of each source (see Fig. C.2). We build a one-to-one correspondence between the source catalog and simulated objects thanks to a photon-based matching algorithm. We classify sources with five different labels: (i) uniquely identified with an AGN or star (PNT), (ii) uniquely identified with a cluster (EXT), (iii) fraction of AGN or star (PNT2), (iv) fraction of a cluster (EXT2), (v) background fluctuation (BKG). Various examples at values of detection likelihood equal to 10 and 20 are shown in Fig. 2.
We study the population in the source catalog as a function of different cuts in detection and extension likelihood. We find that the former is efficient in removing spurious sources from the catalog, which reduces the false detection rate. However, it does not reduce the contamination in the extended select sample due to bright AGN. Instead, progressive EXT_LIKE thresholds are better suited for this task. In addition, at large values of EXT_LIKE > 35 in eRASS1, all the contaminating AGN contain cluster emission. This reduces our estimate of contamination by ∼1%. These results are shown in Fig. 3.
Our detection algorithm perfectly recovers the bright end of the number density of objects as a function of flux for both clusters and AGN (see Figs. 5 and 6). The eSASS detection scheme is suitable for detecting clusters of galaxies. We compare the number of simulated and detected clusters in four different intervals of exposure time. Three of them cover a similar sky area, the fourth one is smaller and centered around the ecliptic poles with extremely high depth. In areas covered by the average simulation depth, we detect half of the simulated structures at flux values of 3.3 × 10−13 erg s−1 cm−2 for eRASS1 (see Fig. 7). We show how the selection of clusters is not a simple function of flux and exposure time, but the objects with different angular sizes on the sky plane are also detected differently, for instance clusters with smaller extent can be detected as point sources (see Fig. 8). This is in agreement with previous work (Pacaud et al. 2006; Burenin et al. 2007; Clerc et al. 2018; Finoguenov et al. 2020). We study how the relaxation state impacts the detection, by exploiting the central emission parameter EM0. The detection is biased toward relaxed clusters with a low EM0. However, the effect is mostly relevant for clusters detected as point sources, as eSASS tends to classify some of these relaxed clusters with EXT_LIKE = 0. This is particularly evident in the low flux regime around 10−13 erg s−1 cm−2, where a high fraction of simulated objects has a counterpart in the source catalog, but such counterpart is extended (EXT_LIKE > = 6) for only a few of them. The overall detection and characterization of clusters of galaxies are more efficient at the bright flux end, where they are still detected as extended sources (see Fig. 9). In the extent-selected sample, the impact of the cool core bias is minimal. These results are in agreement with the eFEDS sample (Ghirardini et al. 2021a; Bulbul et al. 2022).
We combine completeness and purity into the single concept of detection efficiency. We see how choosing specific flux thresholds for varying exposure times (see Table 4) allows detecting AGN and clusters with similar levels of completeness in areas covered with different depths. Figure 10 shows that the false detection rate in shallower areas is larger. This is due to the lower signal-to-noise ratio, which causes higher relative fluctuations of the background. This is clear for the point-like sample. Progressive cuts in detection likelihood remove the majority of the spurious sources in the point-like sample. The false detection rate drops from 21.5% in areas covered by 150–400 s exposure at DET_LIKE > 5 to < 1% for DET_LIKE > 10. The fraction of clusters mistakenly assigned to the point sample is low, below 4% for every DET_LIKE cut. Similar considerations can be done using thresholds of extension likelihood for clusters. In this case, the pole region shows different behavior of the false detection rate due to the cut in extension likelihood that is very efficient in removing spurious sources and also contaminating AGN in the extent-selected sample. Higher thresholds of extension likelihood are required to lower this value. Progressive EXT_LIKE cuts are very effective in reducing contamination. In the region around the eRASS1 southern ecliptic pole, it drops by 26% from EXT_LIKE > 6 to EXT_LIKE > 20 (see Fig. 10).
We provide area curves as a function of limiting flux built from sensitivity maps in Fig. 11. Our measurement is in agreement with the prediction from Merloni et al. (2012), especially at the faint end, but the ability of our method to account for the different exposures guarantees a better sensitivity at the bright flux end. We finally compute the X-ray luminosity of galaxy clusters in the eRASS1 simulation by fitting the surface brightness profile of each object, following the approach described by Ghirardini et al. (2021b). We show that on average we recover the simulated values of X-ray luminosity in Fig. 12.
We discuss how to best construct volume-limited samples applying different flux limits in areas covered with varying depth by eROSITA (see Fig. 13). This translates into different samples of clusters according to the values of luminosity and redshift. It guarantees an even sampling of the large-scale structure of the Universe also in a case of nonuniform coverage. The selection of these samples and their relative contribution to the cluster number density distribution as a function of redshift and mass is shown in Fig. 14.
We presented and analyzed a precise digital twin of the first eROSITA all-sky survey. Performing such a high-level simulation significantly increases our understanding of real data, allowing us to analyze how a realistically complex population of sources is observed by eROSITA. We studied the detection rate of galaxy clusters and AGN, accounting for the fraction of simulated objects that are detected by the eSASS pipeline, together with quantifying the false detection rate and contamination levels in the source catalog for point-like and extended sources. Using these results, one can control the fraction of false detections and or contaminants according to specific cuts of detection and extension likelihood in the real eRASS1 catalog. For example, this is useful for constructing different cluster samples, allowing for a precise contamination fraction. We addressed additional effects impacting the detection of clusters, such as their dynamical state and their physical size. This work is key toward characterizing the population of extragalactic sources in real eROSITA data.
Acknowledgments
This work is based on data from eROSITA, the soft X-ray instrument aboard SRG, a joint Russian-German science mission supported by the Russian Space Agency (Roskosmos), in the interests of the Russian Academy of Sciences represented by its Space Research Institute (IKI), and the Deutsches Zentrum für Luft- und Raumfahrt (DLR). The SRG spacecraft was built by Lavochkin Association (NPOL) and its subcontractors, and is operated by NPOL with support from the Max Planck Institute for Extraterrestrial Physics (MPE). The development and construction of the eROSITA X-ray instrument was led by MPE, with contributions from the Dr. Karl Remeis Observatory Bamberg & ECAP (FAU Erlangen-Nuernberg), the University of Hamburg Observatory, the Leibniz Institute for Astrophysics Potsdam (AIP), and the Institute for Astronomy and Astrophysics of the University of Tübingen, with the support of DLR and the Max Planck Society. The Argelander Institute for Astronomy of the University of Bonn and the Ludwig Maximilians Universität Munich also participated in the science preparation for eROSITA. The eROSITA data shown here were processed using the eSASS/NRTA software system developed by the German eROSITA consortium. The authors thank the referee for providing very useful comments that improved the paper.
References
- Abbott, T. M. C., Abdalla, F. B., Alarcon, A., et al. 2018, Phys. Rev. D, 98, 043526 [NASA ADS] [CrossRef] [Google Scholar]
- Abbott, T. M. C., Aguena, M., Alarcon, A., et al. 2020, Phys. Rev. D, 102, 023509 [Google Scholar]
- Adami, C., Giles, P., Koulouridis, E., et al. 2018, A&A, 620, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Aguena, M., & Lima, M. 2018, Phys. Rev. D, 98, 123529 [NASA ADS] [CrossRef] [Google Scholar]
- Aird, J., Coil, A. L., Georgakakis, A., et al. 2015, MNRAS, 451, 1892 [Google Scholar]
- Alam, S., Aubert, M., Avila, S., et al. 2021, Phys. Rev. D, 103, 083533 [NASA ADS] [CrossRef] [Google Scholar]
- Allen, S. W., Evrard, A. E., & Mantz, A. B. 2011, ARA&A, 49, 409 [Google Scholar]
- Anderson, M. E., Gaspari, M., White, S. D. M., Wang, W., & Dai, X. 2015, MNRAS, 449, 3806 [NASA ADS] [CrossRef] [Google Scholar]
- Andrade-Santos, F., Jones, C., Forman, W. R., et al. 2017, ApJ, 843, 76 [Google Scholar]
- Angulo, R. E., Springel, V., White, S. D. M., et al. 2012, MNRAS, 426, 2046 [NASA ADS] [CrossRef] [Google Scholar]
- Arcodia, R., Merloni, A., Nandra, K., et al. 2021, Nature, 592, 704 [NASA ADS] [CrossRef] [Google Scholar]
- Arnaud, K. A. 1996, in Astronomical Data Analysis Software and Systems V, eds. G. H. Jacoby, & J. Barnes, ASP Conf. Ser., 101, 17 [NASA ADS] [Google Scholar]
- Bahar, Y. E., Bulbul, E., Clerc, N., et al. 2021, A&A, 661, A7 [Google Scholar]
- Bleem, L. E., Stalder, B., Brodwin, M., et al. 2015a, ApJS, 216, 20 [Google Scholar]
- Bleem, L. E., Stalder, B., de Haan, T., et al. 2015b, ApJS, 216, 27 [Google Scholar]
- Böhringer, H., Schuecker, P., Guzzo, L., et al. 2004, A&A, 425, 367 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Boller, T., Freyberg, M. J., Trümper, J., et al. 2016, A&A, 588, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Borgani, S. 2008, in Cosmology with Clusters of Galaxies, eds. M. Plionis, O. López-Cruz, & D. Hughes, 740, 24 [NASA ADS] [Google Scholar]
- Brunner, H., Liu, T., Lamer, G., et al. 2022, A&A, 661, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Buchner, J., Georgakakis, A., Nandra, K., et al. 2015, ApJ, 802, 89 [Google Scholar]
- Bulbul, E., Chiu, I. N., Mohr, J. J., et al. 2019, ApJ, 871, 50 [Google Scholar]
- Bulbul, E., Liu, A., Pasini, T., et al. 2022, A&A, 661, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Burenin, R. A., Vikhlinin, A., Hornstrup, A., et al. 2007, ApJS, 172, 561 [Google Scholar]
- Cash, W. 1979, ApJ, 228, 939 [Google Scholar]
- Cavaliere, A., & Fusco-Femiano, R. 1976, A&A, 49, 137 [NASA ADS] [Google Scholar]
- Chiu, I.-N., Ghirardini, V., Liu, A., et al. 2021, A&A, 661, A11 [Google Scholar]
- Chuang, C.-H., Yepes, G., Kitaura, F.-S., et al. 2019, MNRAS, 487, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Clerc, N., & Finoguenov, A. 2022, ArXiv e-prints [arXiv:2203.11906] [Google Scholar]
- Clerc, N., Pierre, M., Pacaud, F., & Sadibekova, T. 2012, MNRAS, 423, 3545 [NASA ADS] [CrossRef] [Google Scholar]
- Clerc, N., Merloni, A., Zhang, Y. Y., et al. 2016, MNRAS, 463, 4490 [NASA ADS] [CrossRef] [Google Scholar]
- Clerc, N., Ramos-Ceja, M. E., Ridl, J., et al. 2018, A&A, 617, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Clerc, N., Kirkpatrick, C. C., Finoguenov, A., et al. 2020, MNRAS, 497, 3976 [NASA ADS] [CrossRef] [Google Scholar]
- Colless, M., Dalton, G., Maddox, S., et al. 2001, MNRAS, 328, 1039 [Google Scholar]
- Comparat, J., Merloni, A., Salvato, M., et al. 2019, MNRAS, 487, 2005 [Google Scholar]
- Comparat, J., Eckert, D., Finoguenov, A., et al. 2020, Open J. Astrophys., 3, 13 [Google Scholar]
- Comparat, J., Truong, N., Merloni, A., et al. 2022, A&A, in press, https://doi.org/10.1051/0004-6361/202243101 [Google Scholar]
- Dauser, T., Falkner, S., Lorenz, M., et al. 2019, A&A, 630, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de la Torre, S., Guzzo, L., Peacock, J. A., et al. 2013, A&A, 557, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Driver, S. P., Norberg, P., Baldry, I. K., et al. 2009, Astron. Geophys., 50, 5.12 [NASA ADS] [CrossRef] [Google Scholar]
- Eckert, D., Molendi, S., & Paltani, S. 2011, A&A, 526, A79 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Eckert, D., Ghirardini, V., Ettori, S., et al. 2019, A&A, 621, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Everett, S., Yanny, B., Kuropatkin, N., et al. 2022, ApJS, 258, 46 [Google Scholar]
- Fanidakis, N., Baugh, C. M., Benson, A. J., et al. 2011, MNRAS, 410, 53 [NASA ADS] [CrossRef] [Google Scholar]
- Ferrarese, L., & Merritt, D. 2000, ApJ, 539, L9 [Google Scholar]
- Finoguenov, A., Guzzo, L., Hasinger, G., et al. 2007, ApJS, 172, 182 [Google Scholar]
- Finoguenov, A., Tanaka, M., Cooper, M., et al. 2015, A&A, 576, A130 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Finoguenov, A., Rykoff, E., Clerc, N., et al. 2020, A&A, 638, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garrel, C., Pierre, M., Valageas, P., et al. 2021, A&A, 663, A3 [Google Scholar]
- Georgakakis, A., Nandra, K., Laird, E. S., Aird, J., & Trichas, M. 2008, MNRAS, 388, 1205 [Google Scholar]
- Georgakakis, A., Comparat, J., Merloni, A., et al. 2019, MNRAS, 487, 275 [NASA ADS] [CrossRef] [Google Scholar]
- Ghirardini, V., Eckert, D., Ettori, S., et al. 2019, A&A, 621, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ghirardini, V., Bahar, E., Bulbul, E., et al. 2021a, A&A, 661, A12 [Google Scholar]
- Ghirardini, V., Bulbul, E., Hoang, D. N., et al. 2021b, A&A, 647, A4 [EDP Sciences] [Google Scholar]
- Gilli, R., Comastri, A., & Hasinger, G. 2007, A&A, 463, 79 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Green, T. S., Edge, A. C., Ebeling, H., et al. 2016, MNRAS, 465, 4872 [Google Scholar]
- Hikage, C., Oguri, M., Hamana, T., et al. 2019, PASJ, 71, 43 [Google Scholar]
- Hilton, M., Sifón, C., Naess, S., et al. 2021, ApJS, 253, 3 [Google Scholar]
- Hogg, D. W., Baldry, I. K., Blanton, M. R., & Eisenstein, D. J. 2002, ArXiv e-prints [arXiv:astro-ph/0210394] [Google Scholar]
- Hudson, D. S., Mittal, R., Reiprich, T. H., et al. 2010, A&A, 513, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ider Chitham, J., Comparat, J., Finoguenov, A., et al. 2020, MNRAS, 499, 4768 [NASA ADS] [CrossRef] [Google Scholar]
- Ishiyama, T., Prada, F., Klypin, A. A., et al. 2021, MNRAS, 506, 4210 [NASA ADS] [CrossRef] [Google Scholar]
- Jimeno, P., Broadhurst, T., Lazkoz, R., et al. 2017, MNRAS, 466, 2658 [NASA ADS] [CrossRef] [Google Scholar]
- Joudaki, S., Blake, C., Johnson, A., et al. 2018, MNRAS, 474, 4894 [NASA ADS] [CrossRef] [Google Scholar]
- Käfer, F., Finoguenov, A., Eckert, D., et al. 2019, A&A, 628, A43 [Google Scholar]
- Käfer, F., Finoguenov, A., Eckert, D., et al. 2020, A&A, 634, A8 [Google Scholar]
- Kauffmann, G., & Haehnelt, M. 2000, MNRAS, 311, 576 [Google Scholar]
- Klypin, A., Yepes, G., Gottlöber, S., Prada, F., & Heß, S. 2016, MNRAS, 457, 4340 [Google Scholar]
- Koens, L. A., Maughan, B. J., Jones, L. R., et al. 2013, MNRAS, 435, 3231 [CrossRef] [Google Scholar]
- Kong, H., Burleigh, K. J., Ross, A., et al. 2020, MNRAS, 499, 3943 [NASA ADS] [CrossRef] [Google Scholar]
- Koutoulidis, L., Plionis, M., Georgantopoulos, I., & Fanidakis, N. 2013, MNRAS, 428, 1382 [NASA ADS] [CrossRef] [Google Scholar]
- Koulouridis, E., Plionis, M., Melnyk, O., et al. 2014, A&A, 567, A83 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kravtsov, A. V., & Borgani, S. 2012, ARA&A, 50, 353 [Google Scholar]
- Lacey, C., & Cole, S. 1993, MNRAS, 262, 627 [NASA ADS] [CrossRef] [Google Scholar]
- Le Brun, A. M. C., McCarthy, I. G., Schaye, J., & Ponman, T. J. 2014, MNRAS, 441, 1270 [NASA ADS] [CrossRef] [Google Scholar]
- Lesci, G. F., Marulli, F., Moscardini, L., et al. 2022, A&A, 659, A88 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lindholm, V., Finoguenov, A., Comparat, J., et al. 2021, A&A, 646, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liu, T., Tozzi, P., Tundo, E., et al. 2013, A&A, 549, A143 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liu, A., Bulbul, E., Ghirardini, V., et al. 2022a, A&A, 661, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liu, T., Merloni, A., Comparat, J., et al. 2022b, A&A, 661, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lovisari, L., Reiprich, T. H., & Schellenberger, G. 2015, A&A, 573, A118 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lovisari, L., Schellenberger, G., Sereno, M., et al. 2020, ApJ, 892, 102 [Google Scholar]
- Mantz, A. B., von der Linden, A., Allen, S. W., et al. 2015, MNRAS, 446, 2205 [Google Scholar]
- Mantz, A. B., Allen, S. W., Morris, R. G., et al. 2016, MNRAS, 463, 3582 [NASA ADS] [CrossRef] [Google Scholar]
- Martini, P., Miller, E. D., Brodwin, M., et al. 2013, ApJ, 768, 1 [Google Scholar]
- Marulli, F., Veropalumbo, A., Sereno, M., et al. 2018, A&A, 620, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Marulli, F., Veropalumbo, A., García-Farieta, J. E., et al. 2021, ApJ, 920, 13 [Google Scholar]
- Mayer, L., & Bonoli, S. 2019, Rep. Prog. Phys., 82, 016901 [Google Scholar]
- McDonald, M., Bayliss, M., Benson, B. A., et al. 2012, Nature, 488, 349 [Google Scholar]
- McDonald, M., Allen, S. W., Bayliss, M., et al. 2017, ApJ, 843, 28 [Google Scholar]
- Merloni, A., Predehl, P., Becker, W., et al. 2012, ArXiv e-prints [arXiv:1209.3114] [Google Scholar]
- Miyazaki, S., Oguri, M., Hamana, T., et al. 2018, PASJ, 70, S27 [NASA ADS] [Google Scholar]
- Moster, B. P., Naab, T., & White, S. D. M. 2013, MNRAS, 428, 3121 [Google Scholar]
- Mullis, C. R., Vikhlinin, A., Henry, J. P., et al. 2004, ApJ, 607, 175 [NASA ADS] [CrossRef] [Google Scholar]
- Noordeh, E., Canning, R. E. A., King, A., et al. 2020, MNRAS, 498, 4095 [NASA ADS] [CrossRef] [Google Scholar]
- Oguri, M. 2014, MNRAS, 444, 147 [NASA ADS] [CrossRef] [Google Scholar]
- Oguri, M., Lin, Y.-T., Lin, S.-C., et al. 2018, PASJ, 70, S20 [NASA ADS] [Google Scholar]
- Pacaud, F., Pierre, M., Refregier, A., et al. 2006, MNRAS, 372, 578 [NASA ADS] [CrossRef] [Google Scholar]
- Pacaud, F., Pierre, M., Melin, J. B., et al. 2018, A&A, 620, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Padovani, P., Alexander, D. M., Assef, R. J., et al. 2017, A&ARv, 25, 2 [Google Scholar]
- Pasini, T., Brüggen, M., Hoang, D. N., et al. 2021, A&A, 661, A13 [Google Scholar]
- Pierre, M., Pacaud, F., Adami, C., et al. 2016, A&A, 592, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pillepich, A., Porciani, C., & Reiprich, T. H. 2012, MNRAS, 422, 44 [Google Scholar]
- Pillepich, A., Reiprich, T. H., Porciani, C., Borm, K., & Merloni, A. 2018, MNRAS, 481, 613 [Google Scholar]
- Planck Collaboration XI. 2014, A&A, 571, A11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XVII. 2014, A&A, 571, A17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXIV. 2016, A&A, 594, A24 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXVII. 2016, A&A, 594, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pratt, G. W., Arnaud, M., Biviano, A., et al. 2019, Space Sci. Rev., 215, 25 [Google Scholar]
- Predehl, P., Andritschke, R., Arefiev, V., et al. 2021, A&A, 647, A1 [EDP Sciences] [Google Scholar]
- Reiprich, T. H., & Böhringer, H. 2002, ApJ, 567, 716 [Google Scholar]
- Rosati, P., Borgani, S., & Norman, C. 2002, ARA&A, 40, 539 [Google Scholar]
- Rossetti, M., Gastaldello, F., Ferioli, G., et al. 2016, MNRAS, 457, 4515 [Google Scholar]
- Rykoff, E. S., Rozo, E., Busha, M. T., et al. 2014, ApJ, 785, 104 [Google Scholar]
- Salvato, M., Wolf, J., Dwelly, T., et al. 2022, A&A, 661, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sanders, J. S., Fabian, A. C., Russell, H. R., & Walker, S. A. 2018, MNRAS, 474, 1065 [NASA ADS] [CrossRef] [Google Scholar]
- Schellenberger, G., & Reiprich, T. H. 2017a, MNRAS, 471, 1370 [Google Scholar]
- Schellenberger, G., & Reiprich, T. H. 2017b, MNRAS, 469, 3738 [CrossRef] [Google Scholar]
- Schneider, P. C., Freund, S., Czesla, S., et al. 2021, A&A, 661, A6 [Google Scholar]
- Sehgal, N., Bode, P., Das, S., et al. 2010, ApJ, 709, 920 [NASA ADS] [CrossRef] [Google Scholar]
- Seppi, R., Comparat, J., Nandra, K., et al. 2021, A&A, 652, A155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sherwin, B. D., Das, S., Hajian, A., et al. 2012, Phys. Rev. D, 86, 083006 [Google Scholar]
- Smith, R. K., Brickhouse, N. S., Liedahl, D. A., & Raymond, J. C. 2001, ApJ, 556, L91 [Google Scholar]
- Springel, V., White, S. D. M., Jenkins, A., et al. 2005, Nature, 435, 629 [Google Scholar]
- Staniszewski, Z., Ade, P. A. R., Aird, K. A., et al. 2009, ApJ, 701, 32 [CrossRef] [Google Scholar]
- Suchyta, E., Huff, E. M., Aleksić, J., et al. 2016, MNRAS, 457, 786 [Google Scholar]
- Tinker, J., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [Google Scholar]
- Trudeau, A., Garrel, C., Willis, J., et al. 2020, A&A, 642, A124 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Veropalumbo, A., Marulli, F., Moscardini, L., Moresco, M., & Cimatti, A. 2014, MNRAS, 442, 3275 [NASA ADS] [CrossRef] [Google Scholar]
- Viitanen, A., Allevato, V., Finoguenov, A., et al. 2019, A&A, 629, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vikhlinin, A., McNamara, B. R., Forman, W., et al. 1998, ApJ, 502, 558 [Google Scholar]
- Vikhlinin, A., Kravtsov, A., Forman, W., et al. 2006, ApJ, 640, 691 [Google Scholar]
- Vikhlinin, A., Kravtsov, A. V., Burenin, R. A., et al. 2009, ApJ, 692, 1060 [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Voges, W., Aschenbach, B., Boller, T., et al. 1999, A&A, 349, 389 [NASA ADS] [Google Scholar]
- White, S. D. M., & Frenk, C. S. 1991, ApJ, 379, 52 [Google Scholar]
- Wilms, J., Allen, A., & McCray, R. 2000, ApJ, 542, 914 [Google Scholar]
Appendix A: Simulated products
We provide the input catalogs of simulated clusters, AGN, and stars, the events generated by the simulated sources, and the output source catalog from eSASS. They are available publicly at the CDS and at 7. We also provide the catalog for the three band detection, using the 0.2–0.6, 0.6–2.3, 2.3–5.0 keV bands (see Liu et al. 2022b; Brunner et al. 2022, for more details). The association between input and output can be built using the ID_Uniq and the ID_Any (see Sect. 3.2). The IDs of stars are >= 107 and < 4×108, the ones for clusters are >= 4×108 and < 109, and the ones for AGN are >= 109. The source IDs are assigned on the HEALPix fields. The IDs of the contaminating sources are saved as ID_Contam. See Sect. 3.2 for the definition of the classes and additional details. The description of the columns for each file is given in Tables A.1 and A.2.
Description of the columns for the input catalogs of the eRASS1 simulation.
Description of the columns for the output catalogs of the eRASS1 simulation.
Description of the columns for the catalogs of events in the eRASS1 simulation.
Appendix B: Extension of the model to galaxy groups
In this section, we provide further details about the extension of our improved cluster model to lower masses (see Sect. 2), comparing it to the eFEDS cluster sample. Along with the (Anderson et al. 2015, AN15) correction using stellar mass, we also tested an improvement exploiting the X-ray luminosity - halo mass relation, following Le Brun et al. (2014) (LB14). Such correction reads:
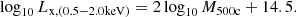
This correction gives a shallower slope in the cluster logN–logS (see Fig. 6) than AN15. AN15 provides a better agreement to observations than LB14, especially at low luminosities < 1×1043 erg/s. LB14 underestimates observed values by a factor of ∼ 2 at 1×1042 erg/s. AN15 provides a great correction for the X-ray luminosity to stellar mass relation by construction, while LB14 does not align well with observations. The same holds for the X-ray luminosity to temperature relation. The AN15 version gives excellent agreement to eFEDS data for low luminosity clusters. The Lx–Tx relation obtained from LB14 is too steep. We ultimately choose the AN15 correction over LB14, as it produces a logN–logS and scaling relations that align better with observations (see Fig. B.1). The prediction of the LX–M500c relation is slightly underestimated at the high mass end compared to data, see Fig. B.1. This makes our approach conservative, since the most massive and luminous objects are detected more easily, see also Fig. 7. On the other hand, the fact that observations suffer from the Malmquist bias at the low mass end possibly affects our correction using AN15. Nonetheless, the addition of the eFEDS cluster sample shows the ability of the model to reproduce observations also in the regime of galaxy groups.
 |
Fig. B.1. Improved cluster model. Top panel: number density of sources as function of flux. The solid orange (red) line shows the prediction of the model before (after) applying the correction. The shaded areas in blue, orange, and red denote the logN–logS from Finoguenov et al. (2007, 2015, 2020). The green and blue lines show a comparison to Le Brun et al. (2014) and Liu et al. (2022a). The dashed pink and brown lines denote the model corrected for higher mass thresholds. Bottom panel: relation between X-ray luminosity and mass. The blue (orange) shaded area shows the prediction of the model before (after) applying the correction. The green shaded area denotes the relation from Le Brun et al. (2014). Additional samples are shown by blue circles (Lovisari et al. 2020), orange circles (Adami et al. 2018), green squares (Lovisari et al. 2015), red circles (Schellenberger & Reiprich 2017a), pink stars (Bulbul et al. 2019), and brown squares (Mantz et al. 2016). |
We verify that the shape of the cluster profiles generated with the new model is on average compatible with a beta model. We measure the radial profile of events generated by three samples of 100 simulated clusters with masses of 2×1013, 5×1013, and 3×1014 M⊙ as a function of R500c. We fit each one of them with a beta model (see Sect. 3). The result is shown in Fig. B.2. The solid lines show the average surface brightness profile for each one of the three samples, the shaded areas denote the 1σ scatter around the mean value. The dashed lines denote the best-fitting beta model to each average profile. We fix β = 2/3, leaving the core radius as a free parameter. This is the same assumption taken by the ermldet task (see Sect. 3). The agreement between the average profile and the beta models is good. Even if the profile of a single object can significantly deviate from a beta model, our model generates profiles that are on average compatible with the assumptions taken by eSASS in the source detection chain.
 |
Fig. B.2. Surface brightness profiles of the simulated clusters. The radius is normalized to R500c. The solid lines show the average profile, the shaded areas denote the 1σ scatter around the mean. The dashed lines show the best-fitting beta model for each average profile. |
Appendix C: Comparison to data
We compare the source catalog of the eRASS1 simulation to the one obtained by processing the real data with the same eSASS set-up, described in Sect. 3. There is good agreement between the mock and the real data. This is shown in Fig. C.1. The mock is denoted by the blue solid line and the real data by the orange one. The distributions of the photon energy shown in the top panel are in excellent agreement, especially for the soft energy range in our interest. The central and bottom panels show the cumulative distributions of detection and extension likelihood. A small difference between the two is expected, caused by the fewer number of bright simulated AGN due to the steep logN–logS at high flux (see Fig. 5). This also contributes to the difference between the photon energy distributions at the hard end, above 5 keV. Nonetheless, the cumulative distributions show that the mock catalog and the real one have similar properties.
 |
Fig. C.1. Comparison between the eRASS1 simulation and the real data. These are respectively denoted by the blue and the orange solid lines. Top panel: distribution of the photon energy. Central panel: cumulative distribution of the sources as a function of detection likelihood. Bottom panel: cumulative distribution of the sources as a function of extension likelihood. |
In addition, we compare the background maps measured on the eRASS1 simulation to the ones obtained from real data (see Sect. 3). Figure C.2 shows the total number of pixels with a given value of the background map, expressed in counts per pixel. The real data is identified by the orange line and the simulation by the solid blue one. On the one hand, the peaks of these two curves differ by about 10%. In fact, a re-scaling of the simulated background by a factor of 0.9 (denoted by the dashed blue line) aligns well with the real eRASS1 maps. This is expected because the cosmic X-ray background component is slightly over-estimated in the simulation. The mock data contains the population of faint simulated AGN. However, this contribution is partially present also in the real eRASS1 maps that are used to create the background model. On the other hand, in some areas, the real background is higher than the mock data. This is because the model has been generated using a mean spectrum but in the eRASS1 data some local instabilities cause such higher background level.
 |
Fig. C.2. Background evaluation in the eRASS1 simulation. Top panel: comparison between the mock and real background maps. The lines identify the number of pixels showing a given value of the background map. The mock data is denoted in blue, the real eRASS1 in orange. The dashed blue line shows the simulated background re-scaled by 0.9. The lower panel shows the ratio between the mock and real data. Bottom panels: impact of a 10% overestimation of the background on the analytically computed value of detection likelihood. The left-hand panel shows DET_LIKE as a function of counts in each pixel given by a source and by the background. The panel on the right shows the corresponding percentage error on detection likelihood caused by a 10% larger background. The blue and the green solid lines respectively denote DET_LIKE = 5 and 20. |
In Sect. 3 we verified that such overestimation of the background has a negligible impact on the measured values of detection likelihood. This is reported in the bottom panels of Fig. C.2. We show the value of detection likelihood as a function of source and background counts per pixel (on the left), and the corresponding relative error due to the background over-estimate (on the right). The relative error is computed as
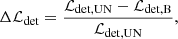
where ℒdet, UN is the unbiased value of detection likelihood, and ℒdet, B is the value of detection likelihood biased by a 10% overestimation of the background. The solid lines in blue and green denote values of ℒdet = 5 and 20, respectively. There is a ∼4% impact on the value of detection likelihood for faint sources with DET_LIKE∼5.
Finally, we quantify whether the 10% overestimate of the background significantly impacts our prediction of the false detection rate for the eRASS1 data using the digital twin. For this goal, we measure the spurious fraction on a two-dimensional grid of exposure time and background level. At fixed exposure, we build a binning scheme for the background level such that successive bins are 10% greater than the previous one, according to Xi + 1 = 1.1 × Xi, where X represents the background level bins. The upper panel of Fig. C.3 shows the spurious fraction in the exposure-background level plane. The grid contains 95% of the real eRASS1 catalog. At fixed background level, the spurious fraction decreases as a function of exposure time. Indeed the deeper data allows suppressing fluctuations of the background. At fixed exposure time, the false detection rate increases as a function of the background level, because the probability of picking up a random fluctuation is larger. This makes our prediction of the false detection rate conservative, because at fixed exposure, the real eRASS1 has a lower background compared to the simulation.
 |
Fig. C.3. Evolution of the false detection rate in the eRASS1 simulation. Top panel: spurious fraction as a function exposure time and background level in the eRASS1 simulation. Each bin containing more than 100 sources is color-coded by the false detection rate. Lower panel: correction of the prediction of the spurious fraction for the eRASS1 data using the simulation due to the 10% overestimate of the background. The x-axis is binned with a progressive 10% increment. The total number of spurious sources in each bin is written as text. |
Given our choice of the binning scheme, we can compare successive background level bins at fixed exposure time to estimate a correction for the prediction of the spurious fraction in the eRASS1 data using the simulation. We compute the relative difference between the bins (fspur, i + 1-fspur, i)/fspur, i + 1, where the index i runs on the background level bins for each exposure. The correction for each bin is shown the lower panel of Fig. C.3. We average over the bins containing more than 100 spurious sources, in order not to be affected by noise. We find a mean correction of 5.7%. We conclude that our measure of the spurious fraction in the digital twin is a conservative prediction of the false detection rate in the real data, and it is not significantly affected by the 10% overestimate of the background.
Appendix D: Population histograms
In this appendix, we collect panels showing the histograms and linear fractions relative to the population in the source catalog, described in Sect. 4.1 and Fig. 3. These are shown in Fig. D.1. The panels on the left show the total number of sources for different cuts in detection or extension likelihood. The panels on the right show the relative fraction for each source class.
 |
Fig. D.1. Population in the detected source catalog. The total number of sources in the cleaned catalog of the eRASS1 simulation is 901 812. The number of extended sources is 5615. Top panels: number of sources in the full catalog and fractions of the population classes in linear scale as a function of minimum detection likelihood. Central panels: number of sources and fractions of the population classes in linear scale in the extent-selected sample (EXT_LIKE >= 6) as a function of minimum detection likelihood. Bottom panels: population in the source catalog and fractions of the population classes in linear scale as a function of minimum extension likelihood. Lines of different colors show the classes defined in Sect. 3. The dashed-dotted lines denote sources that are not contaminated by photons of a secondary source (no blending), the dashed ones identify sources contaminated by a point source, and the dotted ones show sources blended with a cluster. |
Appendix E: AGN
We provide analytical fits to the completeness fraction of the sample of simulated AGN that are detected as point sources. Similarly to Sect. 4, we measure the detected fraction in terms of input flux and exposure time. We model these trends according to a modified sigmoid function. Our model reads:
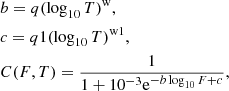
where q = 4.59, w = 0.41, q1 = 11.01, w1 = 0.16 for eRASS1. We measure the exposure time T in seconds and the flux F in erg/s/cm2. We show the result in Fig. E.1. The values extracted by matching the source catalog and the simulated AGN are identified by circles, the best-fit model is shown by the solid lines, color coded by exposure time. This model is not intended to provide a complete description of the AGN selection function, but it gives a useful benchmark. We notice that it works particularly well for exposure times between 160 s and 600 s for eRASS1, containing most of the eROSITA coverage in terms of observing time.
 |
Fig. E.1. The point source sample. Top panel: fraction of AGN detected as point-like objects as a function of the input flux in the soft X-ray band for different exposure times. The circles show the values measured comparing input and source catalogs, the solid lines our best fit model in Eq. E.1. Bottom panel: fraction of spurious sources in the point source sample as a function of detection likelihood cuts for different exposure times. The full circles denote the false detection rate measured in the simulation, the solid lines identify the model described by Equation E.2 computed at the average exposure time corresponding to each bin. |
In addition, we provide a functional form to describe the fraction of false detections for different cuts of detection likelihood and exposure time in the point-source sample. This is described by the following equation:
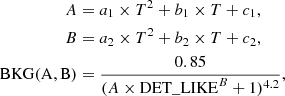
where T is the exposure time in seconds, DET_LIKE is a cut in detection likelihood, and the values of the parameters are reported in Table E.1. Such a model grasps the details of this trend. It is shown in the bottom panel of Fig. E.1. The dots denote the false detection rate measured in the simulation in each exposure time interval as a function DET_LIKE threshold, while the solid lines denote the model computed at the average exposure time corresponding to each interval.
Parameters describing the spurious fraction in the point source sample as a function of detection likelihood thresholds and exposure time.
Finally, we study the accuracy of the position of AGN detected as point sources (EXT_LIKE = 0). We study the offset between the simulated and detected positions and how it relates to the positional error computed by eSASS. Such error is the sum in quadrature of the error on the pixel position multiplied by the pixel scale and is named RADEC_ERR. We find that 99.48% (99.75%) of these point sources are contained by a ratio between the offset and RADEC_ERR lower than 5 (6). This is especially true for secure detections with DET_LIKE > 10, whereas sources with smaller values of detection likelihood show larger positional errors and populate the bottom right corner of Fig. E.2, which displays how AGN detected as point-like occupy the DET_LIKE – Offset/RADEC_ERR parameter space. The figure is color-coded according to the number of sources in each bin.
 |
Fig. E.2. Positional accuracy of the AGN detected as point-like (EXT_LIKE = 0). This figure shows a 2D histogram in the Offset/RADEC_ERR – DET_LIKE parameter space, and the black dashed line denotes a cut at Offset/RADEC_ERR = 5. The bins are color-coded according to the number of detected AGN in each bin. |
Appendix F: Cluster characterization
Our goal is to characterize a cluster sample that is as pure and complete as possible. On the one hand, we want to maximize the clusters detection rate, making sure that most of the simulated ones are recovered by eSASS. On the other hand, we want to keep the contamination low. This means not only rejecting spurious sources, that are entries in the source catalog that do not correspond to any physical object, but also reducing the contamination due to bright AGN and stars detected as extended objects. Simply applying a high threshold of detection likelihood is not enough to do this, as explained in Sect. 3 and Fig. 3. Therefore, we now focus on the catalog of extended sources, with detection likelihood larger than 6. It contains 7731 entries, 75.2% are clusters, 21.2% are AGN, 3.6% are either spurious sources or secondary matches to simulated objects (∼ 0.9% and 2.7% respectively, see Fig. 3), and 5% are stars. Our goal is to single out a complete and pure cluster sample in terms of observables, such as properties measured by the eSASS detection algorithm. We focus on two parameters: the source radius and the extension likelihood. We show the entire source population in this parameter space in the left-hand panel of Fig. F.1. Clusters are identified by blue circles, AGN by yellow triangles, stars by green squares, and spurious sources by red diamonds. Although most of the sources seem to span the entire srcRAD interval, only clusters reach very high values larger than 200 arcseconds. In addition, galaxy clusters populate the high EXT_LIKE end of this panel. We conclude that a double selection in terms of source radius and extension likelihood is relevant for future cosmological experiments using eROSITA galaxy clusters. We further study the population of detected clusters in terms of extension likelihood, srcRAD and counts in the right-hand panel of Fig. F.1.
 |
Fig. F.1. Distribution of the eSASS sources as a function of srcRAD and EXT_LIKE. Top panel: entire source catalog for the eRASS1 simulation in the srcRAD-EXT_LIKE parameter space. Clusters are identified by blue circles, AGN by yellow triangles, stars by green squares, and spurious sources plus secondary matches to simulated objects by red diamonds. Bottom panel: detected clusters color-coded by simulated counts in the 0.2–2.3 keV band inside R500c. |
Clusters with a larger amount of counts are detected at higher values of EXT_LIKE and show a larger srcRAD. This suggests once again how focusing on the top-right corner of this parameter space, selecting sources with large extension likelihood and source radius, allows one to identify secure clusters emitting a large number of photons. Such correlation also shows the impact on clusters selection of srcRAD. In particular, high count clusters are all located at the high srcRAD end: there are 255 detections with srcRAD > 200 arcseconds and 250 are uniquely matched to a cluster. However, objects with less than 100 counts are detected at different values of srcRAD, indicating that this parameter is less relevant in the selection of low count clusters.
All Tables
Number of counts by sources detected with given values of detection and extension likelihood.
Population in the cleaned eSASS source catalog for different cuts of detection and extension likelihood.
Number of clusters in the volume-limited and flux-limited samples for areas covered with different depth.
Description of the columns for the catalogs of events in the eRASS1 simulation.
Parameters describing the spurious fraction in the point source sample as a function of detection likelihood thresholds and exposure time.
All Figures
|
Fig. 1. Large-scale distribution of extragalactic sources and their X-ray view in the simulation. Top panel: light cone of the UNIT1i-eRASS1 simulation. The wedge shows the fraction of the sky enclosed by the same RA and Dec of the bottom panel as a function of redshift and lookback time. The galaxies tracing the large-scale structure are shown in grey. The AGN are denoted in blue. The red circles show clusters and groups. The size of the circle is proportional to the mass of the object. Bottom panel: central regions of tile 202105 of the eRASS1 simulation. This is the projection on the plane of the sky of light cone shown in the top panel. Photons with energies between 0.2 to 2.3 keV are shown by black dots, simulated stars by green circles, simulated AGN by blue circles, simulated clusters by red circles, eSASS extended detections by magenta squares, and eSASS point-like detections by cyan squares. |
| In the text | |
|
Fig. 2. Examples of the eSASS catalog classification. Red (blue) solid circles show simulated clusters (AGN). Magenta (cyan) squares denote extended (point-like) eSASS entries, like in Fig. 1. The dashed red circles enclose 0.5 × R500c of a simulated cluster. Soft X-ray photons from simulated sources are represented by black dots, the green ones come from the background. The first (second) row shows examples for sources with DET_LIKE = 10 (20). Columns show respectively: an extended detection uniquely assigned to a simulated cluster, a secondary detection assigned to an input cluster, a point detection uniquely assigned to an AGN, an extended detection uniquely assigned to an AGN, and a detection without any simulated input. All panels have the same physical size. A ruler of 60 arcsec is shown in the top-left one. |
| In the text | |
|
Fig. 3. Population in the eSASS catalog. The total number of sources detected by eSASS in the eRASS1 simulation (cleaned, see Sect. 3.2) is 1 133 807 (901 812). The number of extended sources is 7731 (5615). Top panel: fraction of sources in the full catalog as a function of minimum detection likelihood. Central panel: fraction of sources in the extent-selected sample (EXT_LIKE > = 6) as a function of minimum detection likelihood. Bottom panel: population in the source catalog as a function of minimum extension likelihood. Lines of different colors show the classes defined in Sect. 3. The dash-dotted lines denote sources that are not contaminated by photons of a secondary source (no blending), the dashed ones identify sources contaminated by a point source, and the dotted ones show sources contaminated by a cluster. |
| In the text | |
|
Fig. 4. Number of split sources as a function of flux and R500c. The left-hand panel shows the fraction of detected clusters that are split into multiple sources, the right-hand one displays the average number of sources which a cluster with given flux and size is split into. The blank spaces contain no input clusters. |
| In the text | |
|
Fig. 5. Cumulative number density of the AGN population. Top panel: blue (orange) line shows the logN–logS built with the sample of detected (simulated) AGN. The green, red, violet dashed lines show the distributions from Gilli et al. (2007), Georgakakis et al. (2008) and Merloni et al. (2012). The brown and pink vertical lines locate the eROSITA flux value where the ratio between the detected and simulated populations is equal to 0.5 and 0.8, respectively. Bottom panel: ratio between the logN–logS of detected and simulated AGN. A black dashed line denotes a ratio equal to 1.0. |
| In the text | |
|
Fig. 6. Cumulative number of clusters per square degree as a function of flux. Top panel: solid blue (orange) line shows the logN–logS built with the sample of detected (simulated) clusters. The green dashed line shows the distributions of the eFEDS sample (Liu et al. 2022a), the red one denotes the SPIDERS sample (Finoguenov et al. 2020), and the pink one the ECDF-S (Finoguenov et al. 2015). The brown and pink vertical lines locate the eROSITA flux value where the ratio between the detected and simulated populations is equal to 0.5 and 0.8, respectively. Bottom panel: ratio between the logN–logS of detected and simulated clusters. A black dashed line denotes a ratio equal to 1.0. |
| In the text | |
|
Fig. 7. Fraction of simulated clusters with a counterpart in the eSASS catalog as a function of simulated soft X-ray flux. We do not apply any additional likelihood selection. Each color identifies an exposure time range. Solid lines denote clusters only detected as extended, while dashed ones include the ones detected as point sources. |
| In the text | |
|
Fig. 8. Simulated and detected clusters population as a function of the input flux and size on the sky. The figures refer to areas of the eRASS1 simulation covered by an exposure between 150 s and 400 s. The blank spaces contain no input clusters. Top panel: number of simulated clusters in the flux–R500c space. Central panel: fraction of simulated clusters that is detected by eSASS, either as extended or point source. Bottom panel: fraction of simulated clusters that is only detected as extended. |
| In the text | |
|
Fig. 9. Population of simulated and detected clusters as a function of the input flux and dynamical state. The panels show areas of the eRASS1 simulation covered by an exposure between 150 s and 400 s. The blank spaces contain no input clusters. Top panel: number of simulated clusters in the flux–EM0 space. Central panel: fraction of simulated clusters that is detected by eSASS, either as extended or point source. Bottom panel: fraction of simulated clusters that is only detected as extended. |
| In the text | |
|
Fig. 10. Efficiency of the eSASS detection for extragalactic sources in the eRASS1 simulation. The completeness is measured for simulated objects above the different flux limits for each exposure interval defined in Table 4. Top panels: detection efficiency for AGN detected as point sources (EXT_LIKE = 0). The numbers denote DET_LIKE thresholds. Bottom panels: detection efficiency for clusters. The numbers denote EXT_LIKE thresholds. No additional cuts of DET_LIKE are applied. Left-hand panels: completeness as a function of spurious fraction. Right-hand panels: completeness as a function of contamination. Different exposure intervals are shown in different colors. |
| In the text | |
|
Fig. 11. Simulated eROSITA fractional survey area as a function of flux limit. The eRASS1 simulation is denoted by the blue line, the prediction by Merloni et al. (2012) for eRASS:8 is shown in orange. The dashed line denotes an extrapolation of the eRASS:8 prediction to the depth of eRASS1. |
| In the text | |
|
Fig. 12. Measure of X-ray luminosity. Top panel: comparison between average values of measured X-ray luminosity as a function of input ones. The blue shaded area encloses the average measured luminosity within 1σ uncertainties. The dashed orange line shows a perfect one-to-one relation. Lower panel: residual plot normalized by the input luminosity. |
| In the text | |
|
Fig. 13. Selection of a volume-limited cluster sample in the eRASS1 simulation. Top panel: sky map with the cluster population in areas covered by different depth. Areas 0, 1, 2, and 3 respectively cover regions with exposure larger than 0 s, 110 s, 150 s, and 400 s. They are cumulative areas with respect to the ones defined in Table 4. Bottom panels: population of simulated and detected clusters in the luminosity–redshift plane. The black dashed lines denote the chosen flux threshold at each depth (see Table 4). The red dashed lines locate different areas above the given flux limits. The volume-limited sample is constructed with the objects within the regions delimited by these lines. |
| In the text | |
|
Fig. 14. Comparison between the volume-limited and flux-limited samples built with clusters detected as extended and simulated ones. The top panels display the volume-limited samples, the bottom panels show the flux-limited ones. Left-hand panels: relative contribution to the total cluster number density as a function of redshift for the four different populations. The lower plot shows the ratio between the N(z) built with the samples of detected and simulated clusters. Right-hand panels: relative contribution to the total cluster number density as a function of mass for the four different populations. The lower plot shows the ratio between the N(z) built with the samples of detected and simulated clusters. |
| In the text | |
|
Fig. B.1. Improved cluster model. Top panel: number density of sources as function of flux. The solid orange (red) line shows the prediction of the model before (after) applying the correction. The shaded areas in blue, orange, and red denote the logN–logS from Finoguenov et al. (2007, 2015, 2020). The green and blue lines show a comparison to Le Brun et al. (2014) and Liu et al. (2022a). The dashed pink and brown lines denote the model corrected for higher mass thresholds. Bottom panel: relation between X-ray luminosity and mass. The blue (orange) shaded area shows the prediction of the model before (after) applying the correction. The green shaded area denotes the relation from Le Brun et al. (2014). Additional samples are shown by blue circles (Lovisari et al. 2020), orange circles (Adami et al. 2018), green squares (Lovisari et al. 2015), red circles (Schellenberger & Reiprich 2017a), pink stars (Bulbul et al. 2019), and brown squares (Mantz et al. 2016). |
| In the text | |
|
Fig. B.2. Surface brightness profiles of the simulated clusters. The radius is normalized to R500c. The solid lines show the average profile, the shaded areas denote the 1σ scatter around the mean. The dashed lines show the best-fitting beta model for each average profile. |
| In the text | |
|
Fig. C.1. Comparison between the eRASS1 simulation and the real data. These are respectively denoted by the blue and the orange solid lines. Top panel: distribution of the photon energy. Central panel: cumulative distribution of the sources as a function of detection likelihood. Bottom panel: cumulative distribution of the sources as a function of extension likelihood. |
| In the text | |
|
Fig. C.2. Background evaluation in the eRASS1 simulation. Top panel: comparison between the mock and real background maps. The lines identify the number of pixels showing a given value of the background map. The mock data is denoted in blue, the real eRASS1 in orange. The dashed blue line shows the simulated background re-scaled by 0.9. The lower panel shows the ratio between the mock and real data. Bottom panels: impact of a 10% overestimation of the background on the analytically computed value of detection likelihood. The left-hand panel shows DET_LIKE as a function of counts in each pixel given by a source and by the background. The panel on the right shows the corresponding percentage error on detection likelihood caused by a 10% larger background. The blue and the green solid lines respectively denote DET_LIKE = 5 and 20. |
| In the text | |
|
Fig. C.3. Evolution of the false detection rate in the eRASS1 simulation. Top panel: spurious fraction as a function exposure time and background level in the eRASS1 simulation. Each bin containing more than 100 sources is color-coded by the false detection rate. Lower panel: correction of the prediction of the spurious fraction for the eRASS1 data using the simulation due to the 10% overestimate of the background. The x-axis is binned with a progressive 10% increment. The total number of spurious sources in each bin is written as text. |
| In the text | |
|
Fig. D.1. Population in the detected source catalog. The total number of sources in the cleaned catalog of the eRASS1 simulation is 901 812. The number of extended sources is 5615. Top panels: number of sources in the full catalog and fractions of the population classes in linear scale as a function of minimum detection likelihood. Central panels: number of sources and fractions of the population classes in linear scale in the extent-selected sample (EXT_LIKE >= 6) as a function of minimum detection likelihood. Bottom panels: population in the source catalog and fractions of the population classes in linear scale as a function of minimum extension likelihood. Lines of different colors show the classes defined in Sect. 3. The dashed-dotted lines denote sources that are not contaminated by photons of a secondary source (no blending), the dashed ones identify sources contaminated by a point source, and the dotted ones show sources blended with a cluster. |
| In the text | |
|
Fig. E.1. The point source sample. Top panel: fraction of AGN detected as point-like objects as a function of the input flux in the soft X-ray band for different exposure times. The circles show the values measured comparing input and source catalogs, the solid lines our best fit model in Eq. E.1. Bottom panel: fraction of spurious sources in the point source sample as a function of detection likelihood cuts for different exposure times. The full circles denote the false detection rate measured in the simulation, the solid lines identify the model described by Equation E.2 computed at the average exposure time corresponding to each bin. |
| In the text | |
|
Fig. E.2. Positional accuracy of the AGN detected as point-like (EXT_LIKE = 0). This figure shows a 2D histogram in the Offset/RADEC_ERR – DET_LIKE parameter space, and the black dashed line denotes a cut at Offset/RADEC_ERR = 5. The bins are color-coded according to the number of detected AGN in each bin. |
| In the text | |
|
Fig. F.1. Distribution of the eSASS sources as a function of srcRAD and EXT_LIKE. Top panel: entire source catalog for the eRASS1 simulation in the srcRAD-EXT_LIKE parameter space. Clusters are identified by blue circles, AGN by yellow triangles, stars by green squares, and spurious sources plus secondary matches to simulated objects by red diamonds. Bottom panel: detected clusters color-coded by simulated counts in the 0.2–2.3 keV band inside R500c. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.