| Issue |
A&A
Volume 678, October 2023
|
|
|---|---|---|
| Article Number | A194 | |
| Number of page(s) | 73 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/202245429 | |
| Published online | 24 October 2023 | |
ALMA-IMF
VII. First release of the full spectral line cubes: Core kinematics traced by DCN J = (3−2)
1
Université Grenoble Alpes, CNRS, Institut de Planétologie et d’Astrophysique de Grenoble, 38000 Grenoble, France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Department of Astronomy, University of Florida, PO Box 112055 Gainesville, USA
3
Instituto de Radioastronomía y Astrofísica, Universidad Nacional Autónoma de México, Morelia, Michoacán 58089, Mexico
4
Laboratoire d’astrophysique de Bordeaux, Univ. Bordeaux, CNRS, B18N allée Geoffroy Saint-Hilaire, 33615 Pessac, France
5
Departamento de Astronomía, Universidad de Concepción, Casilla 160-C, 4030000 Concepción, Chile
6
Instituto Argentino de Radioastronomí a (CCT-La Plata, CONICET; CICPBA), C.C. No. 5, 1894 Villa Elisa, Buenos Aires, Argentina
7
Laboratoire de Physique de l’École Normale Supérieure, ENS, Université PSL, CNRS, Sorbonne Université, Université Paris Cité, 75005 Paris, France
8
Observatoire de Paris, PSL University, Sorbonne Université, LERMA, 75014 Paris, France
9
S. N. Bose National Centre for Basic Sciences, Block JD, Sector III, Salt Lake, Kolkata 700106, India
10
Department de Frisca Quantica i Astrofrisca, Universitat de Barcelona (UB), c. Martí i Franquès, 1, 08028 Barcelona, Catalonia, Spain
11
Instituto de Cièncias del Cosmos (ICCUB), Universitat de Barcelona (UB), c. Martí i Franquès, 1, 08028 Barcelona, Catalonia, Spain
12
Institut d’Estudis Espacials de Catalunya (IEEC), Gran Capita, 2-4, 08340 Barcelona, Catalonia, Spain
13
Institut de Radioastronomie Millimétrique (IRAM), 300 rue de la Piscine, 38406 Saint-Martin-d’Hères, France
14
ESO Headquarters, Karl-Schwarzchild-Str 2, 85748 Garching, Germany
15
Institute of Astronomy, National Tsing Hua University, Hsinchu 30013, Taiwan
16
National Astronomical Observatory of Japan, National Institutes of Natural Sciences, 2-21-1 Osawa, Mitaka, Tokyo 181-8588, Japan
17
Astronomical Science Program, Graduate Institute for Advanced Studies, SOKENDAI, 2-21-1 Osawa, Mitaka, Tokyo 181-8588, Japan
18
Herzberg Astronomy and Astrophysics Research Centre, National Research Council of Canada, 5071 West Saanich Road, Victoria, BC V9E 2E7, Canada
19
Department of Astronomy, Yunnan University, Kunming 650091, PR China
20
Shanghai Astronomical Observatory, Chinese Academy of Sciences, 80 Nandan Road, Shanghai 200030, PR China
21
Department of Astronomy, University of Virginia, Charlottesville, VA 22904, USA
22
DAS, Universidad de Chile, 1515 camino el observatorio, Las Condes, Santiago, Chile
Received:
10
November
2022
Accepted:
26
May
2023
Abstract
ALMA-IMF is an Atacama Large Millimeter/submillimeter Array (ALMA) Large Program designed to measure the core mass function (CMF) of 15 protoclusters chosen to span their early evolutionary stages. It further aims to understand their kinematics, chemistry, and the impact of gas inflow, accretion, and dynamics on the CMF. We present here the first release of the ALMA-IMF line data cubes (DR1), produced from the combination of two ALMA 12 m-array configurations. The data include 12 spectral windows, with eight at 1.3 mm and four at 3 mm. The broad spectral coverage of ALMA-IMF (∼6.7 GHz bandwidth coverage per field) hosts a wealth of simple atomic, molecular, ionised, and complex organic molecular lines. We describe the line cube calibration done by ALMA and the subsequent calibration and imaging we performed. We discuss our choice of calibration parameters and optimisation of the cleaning parameters, and we demonstrate the utility and necessity of additional processing compared to the ALMA archive pipeline. As a demonstration of the scientific potential of these data, we present a first analysis of the DCN (3–2) line. We find that DCN (3–2) traces a diversity of morphologies and complex velocity structures, which tend to be more filamentary and widespread in evolved regions and are more compact in the young and intermediate-stage protoclusters. Furthermore, we used the DCN (3–2) emission as a tracer of the gas associated with 595 continuum cores across the 15 protoclusters, providing the first estimates of the core systemic velocities and linewidths within the sample. We find that DCN (3–2) is detected towards a higher percentage of cores in evolved regions than the young and intermediate-stage protoclusters and is likely a more complete tracer of the core population in more evolved protoclusters. The full ALMA 12m-array cubes for the ALMA-IMF Large Program are provided with this DR1 release.
Key words: instrumentation: interferometers / stars: formation / stars: massive / stars: kinematics and dynamics / ISM: structure / ISM: molecules
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
The relative number of stars born with different masses between 0.01 M⊙ and > 100 M⊙, described by the initial mass function (IMF), is thought to be universal in studies of the cosmic history of star formation, including within our own Galaxy (e.g. Bastian et al. 2010; Kroupa et al. 2013). Early studies of the core mass distribution in local star-forming regions (SFRs) found distributions with shapes similar to the stellar IMF, suggesting a direct mapping of the core mass function (CMF) to the IMF with a constant efficiency factor (e.g. Motte et al. 1998, 2001; Testi & Sargent 1998; Alves et al. 2007; Enoch et al. 2008; Könyves et al. 2015). These studies, however, were based on nearby star-forming clouds, where the core mass was limited to < 5 M⊙. More recent studies on a larger selection of clouds (e.g. Zhang et al. 2015; Ohashi et al. 2016; Csengeri et al. 2017a; Lu et al. 2020) and the pilot studies of the ALMA-IMF Large Program (e.g. Ginsburg et al. 2017; Motte et al. 2018, and Sanhueza et al. 2019) identified varying CMF shapes, with evidence for top-heavy CMFs towards regions forming massive stars. Moreover, the dependence of the IMF on the environment remains the subject of debate (see reviews by Offner et al. 2014; Krumholz 2015; Ballesteros-Paredes et al. 2020; Lee et al. 2020). These circumstances highlighted the need for a larger, more statistically robust sample of protoclusters in different environments to test the universality of the CMF and determine if the cloud characteristics impact its shape.
ALMA-IMF is an ALMA Large Program (#2017.1.01355.L, PIs: Motte, Ginsburg, Louvet, Sanhueza) to survey 15 nearby high-mass SFRs in the Galactic plane with the goal of characterising the CMF and its evolution. To understand the CMF fully, it is imperative to also investigate the distribution, dynamics, and kinematics of the gas from clumps to clusters down to core scales and determine if inflows, outflows, or the formation of filaments may be correlated with the CMF shape or impact its shape over time. One of the main objectives of the ALMA-IMF Large Program is to discriminate between the quasi-static and dynamic scenarios of cloud-scale star formation by quantifying the role of cloud and core kinematics in defining core mass and core mass growth over time.
An overview of ALMA-IMF is presented in Paper I by Motte et al. (2022), who describes the sample selection, classification of the evolutionary nature of individual protoclusters in the three subgroups (i.e. young, intermediate, and evolved), and early results, highlighting the complex velocity and filamentary structures in the protoclusters. In Paper II, Ginsburg et al. (2022a) describes the first data release of the continuum images and presents an analysis of the spectral indices on the continuum data. Paper III, Pouteau et al. (2022), and Louvet et al. (2023) utilise the ALMA-IMF continuum data to characterise the continuum cores, providing the first core catalogues and building the first individual region and global CMFs for the 15 protoclusters. The next step in understanding the origin of the CMF is to measure the internal kinematics with evolution and determine their importance on the shape and evolution of the CMF over time. The ALMA-IMF spectral setup hosts a wealth of molecular emission well suited for this purpose, such as the 12CO (2–1), SiO (5–4), and SO (6–5), which can be used to explore the outflow population and provide a means to characterise further the nature of the cores as being pre- or proto-stellar (see Nony et al. 2023). The core population, gas inflow, and filamentary structure towards the 15 protoclusters will be probed using dense gas tracers in the ALMA-IMF spectral coverage, such as 13CS (5–4), DCN (3–2), N2H+ (1–0), and N2D+ (3–2) to understand further inflow onto the cores and characterise core mass growth with time and its implications on the CMF. In addition, the multitude of emission lines, from species tracing ionised gas to the interstellar complex organic molecules (iCOMs) present in the ALMA-IMF spectral coverage, will provide the community with an unprecedented database with high legacy value for cores, hot cores, shocks, and outflows. We present the data reduction steps and imaging strategies implemented to obtain the ALMA-IMF spectral line cubes. This DR1 data release provides the position-position-velocity image cubes of the 12 spectral windows (spws), ∼6.7 GHz of bandwidth coverage per protocluster, resulting in 180 image cubes for the whole ALMA-IMF sample. As a demonstration of the scientific potential of these data, we also present a first analysis of the DCN (3–2) emission towards the 15 protoclusters. As DCN (3–2) is expected to be an optically thin, dense gas tracer, we further utilised the DCN emission to explore the core kinematics of the ∼600 thermal dust cores identified and described in Louvet et al. (2023).
This paper is organised as follows: in Sect. 2, we report a summary of the observations taken by ALMA and an overview of the target regions. Section 3 describes the data processing and imaging strategy performed to produce the final deconvolved line cubes, the data products, and the post-processing steps. In Sects. 4, and 5 we provide an analysis and discussion of DCN line emission towards the 15 protoclusters. In Sect. 6, we give a summary of the DR1 release and the results obtained.
2. Observations
ALMA-IMF1 (the ALMA Large Program #2017.1.01355.L, PIs: Motte, Ginsburg, Louvet, Sanhueza), targets 15 protocluster clouds in our Galaxy using ALMA with its 12 m, 7 m arrays and total power (TP) observations and in two frequency bands; Band-3 (B3; ∼91–106 GHz) and Band-6 (B6; ∼216–234 GHz). We combine Tables 1 and 2 from Motte et al. (2022) to provide here a global overview of the 15 observed protoclusters in Table 1, listing their central positions, VLSR estimates, distances from the Sun, evolutionary nature, and imaged areas of the mosaics in ALMA’s B3 (3 mm) and B6 (1 mm). In addition, Table 1 lists the fraction of the bandwidth containing bright line emission (fBW line). This is the fraction of bandwidth that was excluded from making the cleanest continuum images (taken from Table 3 of Ginsburg et al. 2022a) and which highlights, to first order, the relative amount of molecular line emission present in the brightest regions of the protoclusters. A detailed description of the observing details and target selection for ALMA-IMF is provided in Ginsburg et al. (2022a) and Motte et al. (2022), respectively. ALMA-IMF was designed to observe homogeneously 15 of the most extreme and massive Galactic clouds within a distance range of 2–5.5 kpc. This distance range allows coverage of ≳1 × 1 pc2 of the highest column density regions towards each protocluster determined from ATLASGAL imaging (Csengeri et al. 2017b), while also allowing for a reasonable observing time towards the more distant protoclusters in the sample. The observing setup and array configurations were chosen to achieve a spatial resolution of ∼2000 au for all protoclusters, regardless of distance. In B3, all targets were observed with two 12m array configurations. In B6, the more distant regions were observed in two configurations (see Ginsburg et al. 2022a for the full description of the 12m array configurations per protocluster). The released cubes are produced from the combination of the two ALMA 12m-array configurations. The resulting angular resolutions of the continuum data are between 0.3″ and 1.5″ using a robust weighting of 0 for the Briggs weighting. The major and minor axis of the synthesised beam for each spectral window towards each protocluster is provided in Table A.2.
Overview of the ALMA-IMF protocluster clouds and their evolutionary stage.
An overview of the spectral setup of the 12 ALMA spectral windows is displayed in Fig. 1. The corresponding bandwidth, spectral resolution, along with main spectral lines in their respective spectral windows are also provided in Table 22. For W43-MM1, the B6 data were taken as part of the pilot program, 2013.1.01365.S (Motte et al. 2018). The exact frequency coverage for each spectral window and field are given in Table A.3.
 |
Fig. 1. Overview of the bandwidth covered by the spectral windows (spws, grey boxes), four in B3 (left panels) and eight in B6 (right panels) towards the 15 ALMA-IMF fields. The black line represents the central frequency for each spectral window. The numbers at the top denote the spectral windows as described in Table 2. The exact frequency coverage is provided in Table A.3. The blue line is the atmospheric transmission at a precipitable water vapour (PWV; The values over the observed frequency range are taken from https://www.apex-telescope.org/sites/chajnantor/atmosphere/transpwv/index_ns.php) of 1.796 mm in B6 and 5.18 mm in B3 (the typical values used in the ALMA sensitivity calculator), for a source at an elevation of 45 degrees. The coverage of the ALMA-IMF pilot program (B6 spectral window 7 for the W43-MM1 field) is offset by 1 GHz. |
Spectral setups of the ALMA-IMF Large Program.
3. Data products
Together with this paper, we provide access to the DR1 line cube release3, which includes the calibrated and imaged full spectral windows (both in B3 and B6) of the 12m array configurations towards the 15 protoclusters. ALMA-IMF also includes 7m array and TP observations using the same spectral setup. The combination of these data, which is particularly important for lines with significant extended emission, is ongoing, and those cubes will be added to the repository as they are created for future planned studies. For spectral window 0 in B3, which includes the N2H+ line, the 12 m only data still contain artefacts due to the extended emission and missing short spacings, we thus exclude this window from this DR1 release. The combined N2H+ data for this spectral window will be added to the repository as part of future works (e.g. Stutz et al., in prep.; Álvarez-Gutiérrez et al., in prep.; Sandoval et al., in prep.). We include the properties of spectral window 0 in B3 (e.g. beam size, and noise estimates) in this paper for completeness.
The data were restored to measurement sets using the scriptForPI.py files provided by the ALMA archive, and further batch processed with the custom scripts and imaging parameters of the ALMA-IMF data pipeline (Ginsburg et al. 2022a). All measurement sets underwent QA3 reprocessing: the FAUST Large Program (Project code: 2018.1.01205.L, Codella et al. 2021) reported that the calibration of the system temperature adopted by ALMA could result in the artificial suppression of bright lines4. The ALMA-IMF data were also affected by these issues, particularly spectral window 5 in B6 and spectral window 0 in B3, containing the brightest emission lines of CO (2–1) and N2H+ (1–0), respectively. The measurement sets were returned to the Joint ALMA Observatory for further QA3 processing in November 2020, and the reprocessing was completed in March 2021. The W43-MM1 B6 data from the pilot program 2013.1.01365.S (Motte et al. 2018) were also reprocessed following the same QA3 procedure as for the 2017.1.01355.L data.
3.1. ALMA-IMF data pipeline
The custom ALMA-IMF data pipeline developed to produce the calibrated and imaged continuum data (as described in Ginsburg et al. 2022a) was subsequently adapted to process the full spectral line windows. It runs in the CASA (McMullin et al. 2007) environment and is described in the following eight steps. The full data pipeline and custom python scripts can be found on the ALMA-IMF GitHub repository5.
1. Retrieve and extract the data from the ALMA archive using astroquery (Ginsburg et al. 2019).
2. Run scriptForPI.py to restore the measurement sets.
3. Separate the continuum and line measurement sets with split_windows.py5 and combine the different 12m array configurations.
4. Run the continuum_imaging_selfcal.py script5 to perform the continuum imaging and self calibration6.
5. Produce the continuum start model from the continuum data.
6. Run the line_imaging.py script5 to perform the line imaging.
7. Apply the ‘JvM’ correction (Jorsater & van Moorsel 1995) to the cleaned cubes (see Sect. 3.3 for more details).
8. Run statcont (Sánchez-Monge et al. 2017) on the imaged line cubes to produce the continuum subtracted cubes (this step is optional).
For illustration, Fig. 2 displays a flow diagram of the ALMA-IMF imaging pipeline and image processing steps taken to obtain the final line cubes provided in this release. The initial four steps are identical to the continuum data processing as detailed in Sect. 3.1.1 of Ginsburg et al. (2022a). Step 5) onward details the processing of the line cubes. In Step 5) the input start model for the line cleaning is derived from the output model of the continuum cleaning (see Sect. 3.2.1). To produce the optimal tclean parameters in CASA used for these data, we performed several internal quality assessments (QAs) of the tclean products and several iterations to test a range of tclean parameters (see Sect. 3.2 for more details). As with the continuum cleaning, the most important input file is imaging_parameters.py5, which includes the user-specified tclean parameters for both the continuum and now the line cubes for all fields and spectral windows. Finally, the last two steps, 7 and 8, refer to post-processing actions after the final CASA cubes are produced. The optional continuum subtraction on the line cubes described in Step 8 is performed in the image plane using the statcont procedure, as described in Sánchez-Monge et al. (2017). The statcont continuum-subtracted cubes are included in the data release. We also provide the continuum estimates and the primary beam responses for each field and spectral window so that the unsubtracted and non-primary beam-corrected cubes can be reproduced if required.
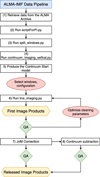 |
Fig. 2. Flow chart providing an overview of the framework of the ALMA-IMF data pipeline employed to produce the line cubes provided in this release. The white boxes labelled from 1–8 describe the steps in the pipeline that are defined by running scripts or procedures (as described in more detail in Sect. 3.1). Red ellipses highlight points where manual input was required to either select which line, spectral window, or configuration on which to perform tclean, or to optimise the tclean parameters after internal quality assessments (green diamonds). |
3.2. Optimisation of cleaning and imaging parameters
The ALMA-IMF dataset covers a multitude of molecular lines with varying dynamic ranges and morphologies across the 15 protoclusters. Therefore, the tclean parameters are optimised to be as homogeneous as possible, allowing the pipeline to run in an automated way. In the following, we discuss the selection of tclean parameters implemented to reach the imaged line cubes of the released ALMA-IMF dataset.
3.2.1. Continuum start-model
Given the large extent of the mosaic coverage, the complexity of the data, and the varying dynamic range across an individual field, we chose not to perform a simple continuum subtraction in the uv-plane before running tclean. This choice led to difficulties, however, with tclean diverging for some fields. Thus, we use a continuum model cube as the input startmodel parameter in tclean. This model cube is constructed from the .tt0 and .tt1 products of the mostly line-free cleanest continuum imaging (see Ginsburg et al. 2022a), tclean then stores this as an initial model and subtracts it from the visibilities at the beginning of the deconvolution process.
3.2.2. Cleaning optimisation and masking
We performed several iterations of tclean using the Hogbom and multi-scale deconvolvers and tested methods to mask the line emission: (1) an internally developed auto-masking, (2) the CASA auto multi-threshold masking, and (3) a primary beam mask. Multi-scale deconvolution with a primary beam mask produced the most stable and optimal results over the full set of spectral windows. In spectral windows with bright and extended emission, the routines that mask in an automated way could not adequately cover the full extent of the emission. Furthermore, auto multi-threshold had additional convergence problems when working with multi-scale deconvolution. For these reasons, we opted to use the primary beam mask (pbmask) as our tclean mask, setting its limit to 10% of the primary beam response. For the deconvolver, we found that multi-scale clean performed better at recovering larger-scale emission than Hogbom deconvolution. This difference was expected since the latter uses only point sources as a model. We defined the scales used in multi-scale tclean using a geometric series starting at 0 and increasing by ∼ × 2 the ratio of the minor beam axis to the cell size until a scale of ∼5.5″ is reached. This largest scale is selected to be a factor of 2–3 smaller than the typical largest recoverable scale in the data. The scales used for each field and spectral window are provided in the imaging_parameters.py file5.
3.2.3. Cleaning threshold
During the QA of the line cubes, we iterated over several cleaning thresholds. We found that using a relatively shallow threshold of 5σ resulted in the most stable outcomes, that is, mitigating the effects of divergence and ‘stippling’ over the full dataset. As described in Czekala et al. (2021) for the ALMA MAPS Large Program, a stippling pattern can be present in deeply cleaned cubes (≤3σ), which then results in artificial clean components appearing as spurious sources – of order the beam size – in the deconvolved image cubes. In Fig. 3, we show an example of this stippling effect in one of the ALMA-IMF line cubes. When cleaning down to 3σ, a bright model component was found in only one channel and pixel, resulting in a spurious emission peak in the cleaned cube, present in only a single channel. A Jupyter notebook describing this effect can be found in the ALMA-IMF pipeline repository7. We estimate that this issue only affects < 0.1% of the pixels in the cubes of this data release. In addition to the stippling, we found that cleaning to levels of 4σ or deeper also resulted in divergence across multiple spectral windows, compared with setting the noise threshold to ≥5σ. For the latter thresholds, however, we still find divergence in a few channels towards spectral windows containing bright and extended emission. These are mainly identified around the VLSR of the 12CO (2–1) and C18O (2–1) transitions. In these cases, we chose to mask the channels that showed divergence and re-run the tclean, leaving those channels uncleaned in the final cubes (the masked channel ranges can be obtained in the imaging_parameters.py file5). Towards the protocluster G351.77, we still identify divergences in several spectral windows. In the end, we ran tclean only down to 10σ level for this region for all spectral windows. The full set of cleaning parameters and masked channels can be found in the imaging_parameters.py file5.
 |
Fig. 3. Example of the ‘stippling’ effect as previously described in Czekala et al. (2021). The top panel shows nine channels of a zoomed-in region in a restored image cube, cleaned using a 3σ threshold. The central channel shows the resulting spurious emission peak. This bright emission, of order the beam size, is only present in a single channel, while the neighbouring pixels show no equivalent emission. The bottom panel shows the model extracted at the central pixel, where the bright model component (green line) is only found in a single pixel and channel. This model component is then convolved with the Gaussian clean beam during the tclean run to produce the restored image, resulting in spurious compact emission in a single channel. |
3.3. JvM correction
The JvM correction (Jorsater & van Moorsel 1995) is applied to the CASA-generated cubes to correct the flux scale of the residuals, and thus of the restored image, since the volumes of the clean and dirty beams are not the same (see also Walter et al. 2008; Czekala et al. 2021). Figure 4 illustrates this correction for the G333.60 region’s peak channel of the H41α line (situated in spectral window 1 of Band 3). The top panels show that a Gaussian clean beam is a reasonable approximation for the central part of the original PSF (dirty beam) but not beyond ∼50% of its FWHM. A factor ϵ is defined as the ratio of the clean-to-dirty beam volumes. The dirty beam is only considered up to its first null since this is the part approximated to a Gaussian during deconvolution and because the volume of a dirty beam without zero spacing integrated over its full domain is formally zero. The output CASA cubes are the channel-by-channel addition of a .model image convolved with the Gaussian clean beam (resulting in units of Jy per clean beam), the residuals contained in the .residual file, which are still in units of Jy per dirty beam, are then added. The JvM correction rescales the residuals to the same units (Jy per clean beam) by multiplying them by the ϵ factor before the final image restoration8.
 |
Fig. 4. Example of the JvM correction for the peak channel of the H41α line in spectral window 1 of Band 3 for protocluster G333.60. The top left panel shows the original PSF (i.e. the dirty beam), where the red circle marks the first null. The top right panel shows the absolute value of the radial profile of the beam (black solid line) and the corresponding approximation to a Gaussian clean beam (blue dashed line). The ϵ factor, defined as the ratio of the clean-to-dirty beam volumes, is 0.32 in this example. The residuals are shown for the original image (middle left panel) and after (middle right), the JvM correction is applied. The red rectangle shows the aperture where the quoted fluxes are measured. The restored images without (bottom left) and with JvM (bottom right) correction are shown in the bottom panels. |
Figure 4 shows a case where ϵ is as low as 0.32 (typically ϵ > 0.5). The mean, median and standard deviation for ϵ over all spectral windows and fields are 0.62, 0.60, and 0.17, respectively. The effect of the JvM correction on the flux in a restored-image is minimal when the line is relatively bright and deeply cleaned. The JvM correction becomes important as the flux in the residuals becomes larger than the flux in the model and as ϵ decreases. The first condition can occur in cubes with very bright and extended line emission that cannot be cleaned too deeply or for faint lines that reside in the same cube of a much brighter line. A small ϵ appears when the dirty beam has a substantial plateau beyond its core, which might occur due to the combination of different array configurations. The ϵ factor for each protocluster and spectral window can be found in its FITS header and in Table A.5. The CASA-generated cubes generally have a different beam for every channel. The common beam found by radio-beam is the minimum beam that contains all of the per-channel beams, excluding outliers (which sometimes occur at the edge of spectral windows). Although the channel-to-channel beam should vary smoothly with frequency, sometimes significant jumps in beam size can occur due to software instabilities. To make the cubes more readily usable, we convolve the model in every channel to a common Gaussian beam per spectral window using the radio-beam tool9. Using a common beam has the advantage of eliminating channel-to-channel variations, resulting in a cube with the same spatial resolution across all channels and allowing direct comparisons of full-bandwidth spectra in units of brightness temperature.
The JvM cubes are in a common unit (Jy per clean beam), meaning flux measurements from these cubes can be interpreted. As discussed previously, these cubes are not deeply cleaned due to divergence and stippling issues over the full bandwidth, which can result in significant real emission remaining in the residuals. Thus, the JvM correction provides a more accurate estimation of the flux in our data. An important consequence, however, of performing the JvM correction is that the noise in the residual is also scaled by the ϵ factor. The most conservative approach to obtaining the noise, which we adopt here, is to estimate the noise from emission and line-free regions in the JvM cubes (in units of Jy per clean beam) and scale by 1/ϵ factor (see Sect. 3.5), thus, taking the higher noise estimates in units of Jy per dirty beam. In other words, we assume the noise estimated from a smaller clean beam should be larger by the ratio of the dirty and clean beam areas. This conservative approach means we adopt a higher noise level (in units of Jy per dirty beam), reducing the number of sources we consider significant. Still, we suggest further investigation of noise behaviour with non-Gaussian beams would be helpful. We note that Walter et al. (2008) and Czekala et al. (2021) adopt the noise in Jy per dirty beam and Jy per clean beam as their noise levels, respectively. The latter is more representative of the telescope sensitivity for point-source detection prior to deconvolution.
3.4. Beam sizes
In Table A.1, we present the proposed beam and the average recovered continuum beam for all fields. In Table A.2, we provide the major and minor axes along with the beam position angle for all spectral windows towards all protoclusters. Plots of the continuum PSFs and central average frequencies are presented in Ginsburg et al. (2022a). In Fig. 5, we show the ratio of the average recovered beam for each spectral window and protocluster compared to the average continuum beam. We further scale the beam ratio by the frequency difference between the central frequency in the given spectral window to the frequency used to determine the continuum beam to account for any beam size differences due to frequency. The average ratio of the line beams and continuum beam is ∼1.2, except for B3, spectral window 0 (which includes the N2H+ transition), where the ratio is on average ∼1.4. The larger beams recovered in this spectral window are due to a plateau in the PSF, which may have occurred due to the combination of two considerably different array configurations, which resulted in a broader Gaussian fit during the determination of the synthesised beam in tclean. An example of the PSF profiles and synthesised beams for all spectral windows towards G012.80 is shown in Fig. 6. Additional broadening can be seen in B3, particularly in spectral window 0.
 |
Fig. 5. Ratio of the average line to continuum beam for each protocluster and spectral window (B3 top; B6 bottom panels). Where the average beam is defined as |
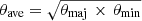
 |
Fig. 6. Absolute value of the radial mean of the PSF (dirty beam) for the protocluster G012.80 as a function of the distance from the PSF centre (in arcseconds). B3 spectral windows are shown on the left and B6 spectral windows are on the right. The solid lines use the .psf outputs from tclean and the dashed lines are the expected Gaussian clean beams (the FWHM is taken from the geometric mean of the beam major and minor axes). For the B3 spectral windows, the Gaussian clean beam is a good approximation to the PSF only within ∼50% of its FWHM. B3 spectral window 0 shows the largest deviation, resulting in a larger estimation of the respective Gaussian clean beam in tclean. The B6 spectral windows typically show a better correspondence between the PSFs and the Gaussian clean beam. |
3.5. Noise estimation
Estimating the noise homogeneously over the full sample of protoclusters and spectral windows is non-trivial, given that several lines are present in the same spectral window, with varying morphology and intensity across a given protocluster. To estimate noise levels, we use the median-absolute-deviation (MAD) estimator10 and take a threshold cut in intensity so that the noise is estimated using only the 25% of the channels with the lowest intensity across the full spectral window, and using the manually defined regions11 which were created for the continuum estimates of the noise in Ginsburg et al. (2022a). The noise estimates for each field and spectral window are taken on the non-continuum subtracted line cubes with the JvM correction applied but uncorrected by the primary beam response. As described in Sect. 3.3, we adopt the noise in units of Jy per dirty beam and provide the noise estimates for all fields and spectral windows (in units of mJy per dirty beam) in Table A.4. We also provide the requested (theoretical) noise in Table A.4 from the original ALMA-IMF proposal scaled to the obtained channel width and central frequency. In Fig. 7, we compare the requested to the achieved noise in brightness temperature units. To provide a direct comparison between the achieved noise (taken from Table A.4) and the requested noise, we scaled the requested noise to the same spectral resolution, beam size, and central frequency as those obtained in the observed data cubes for all spectral windows. We show in Fig. 7 that the achieved noise is better than expected (in all but one case) and, on average, ∼2.3 times lower than anticipated, accounting for the larger beam sizes achieved. We note that the data were observed in better conditions for most fields and with lower system temperatures (typically 20–30% better, but in some cases up to ∼50%) than those used for the sensitivity calculator’s noise estimates. The continuum noise is typically within a factor of two (Ginsburg et al. 2022a) of the theoretical value.
 |
Fig. 7. Expected thermal noise from the observations vs the achieved noise in the cubes for each spectral window in Kelvin (B3 left panel and B6 right panel). The Y-axis shows the measured noise in the released cubes in Jy per dirty beam converted to brightness temperature as described in Sect. 3.4. The X-axis shows the expected brightness temperature sensitivity for the proposed beam sizes (see Table A.1). Furthermore, to directly compare the achieved noise in the data to the expected noise from the proposed observations, we scale the expected noise by the frequency difference between the requested representative frequency and the central frequency of each spectral window. We also scale the expected noise by the difference in the representative channel width and the achieved channel width for each spectral window. As shown in Fig. 5, the achieved beam area is typically larger than the continuum beam by ∼1–1.5×. Thus, the expected noise is also scaled to account for the difference in the beam areas between the achieved and proposed beams (see Table A.2 for the exact proposed beams and achieved beams per field). The shaded regions show a noise within a factor of two (pink) and four (blue) from the expected noise, and the dashed line represents a 1 to 1 ratio. We typically achieve a noise on average ∼2–2.5 times lower than expected. |
3.6. Released line cubes and post-processed image products
The DR1 line cube release discussed here is made available with this work12. We provide the continuum-subtracted cubes corrected for their respective primary beam response and the JvM correction. The STATCONT procedure employed simultaneously over the full spectral window can satisfactorily remove the continuum for most of the bandwidth and fields, however, towards, the positions of hot core candidates or bright outflows, the continuum subtraction could be improved. For completeness, we also include the continuum estimates from the cubes, the models, residuals and primary beam files in this release. The naming structure of the cubes is given as the protocluster name, the ALMA band (i.e. B3 or B6), array configuration (we release here only the 12m array data), and spectral window (see Table 2 for reference). Meanwhile .JvM refers to the JvM correction (we have applied the correction to all released cubes; the ϵ factors used can be found in Table A.4), .image.pbcor refers to the primary beam correction, and .statcont.contsub refers to the continuum subtraction applied using the STATCONT procedure. The cubes range from the smallest at several MBs to the largest, which are ∼50 GB. The full DR1 dataset is ∼5 TB.
4. Analysis
The full set of ALMA-IMF line cubes contains a wealth of emission from a variety of molecular line species (see Table 2) and will provide the community with an unprecedented database with high legacy value for cores, hot cores (e.g. Bonfand et al. 2023; Brouillet et al. 2022), outflows, and inflows. To illustrate the richness of the ALMA-IMF survey data, we present a first look at the DCN (3–2) emission towards the 15 protoclusters, along with an analysis of the DCN (3–2) emission extracted from the compact continuum core population. We utilise the molecular transition DCN (3–2) as a proxy for the gas associated with the core as it is typically an optically thin tracer with a critical density of ∼107 cm−3. Furthermore, towards several low, intermediate, and massive star-forming regions DCN (3–2) emission has been previously observed to coincide well with the thermal dust emission associated with star-forming cores (see, e.g. Cunningham et al. 2016; Tatematsu et al. 2020; Sakai et al. 2022) and is not typically observed as an outflow tracer (however, it has been associated with shocks in, e.g. L1157-B1: Busquet et al. 2017).
4.1. Global scale DCN (3–2) morphology
DCN (3–2) has a rest frequency of 217.23854 GHz (Müller et al. 2001, 2005) and is located in B6, spectral window 1, with a spectral resolution of 0.34 km s−1. We use the continuum subtracted (STATCONT) line cubes provided in this release and do not perform any additional baseline subtraction. We then extract a 50 km s−1 wide subset of channels around the VLSR reported in Motte et al. (2022) and create the first three moment maps towards the 15 protoclusters, using the non-primary beam corrected cubes. The DCN (3–2) emission is integrated over a manually determined velocity range for each protocluster, using a 4σ threshold to identify channels where DCN (3–2) emission is present over an area larger than the beam size (the velocity ranges used for each protocluster are provided in the figure captions). The σ level is the noise estimated for spectral window 1 as described in Sect. 3.5 (i.e. in units of mJy per dirty beam) and listed for each protocluster in Table A.4. Furthermore, for the first and second-moment maps, we take an additional threshold cut per channel and include only pixels that contain emission > 4σ, preventing noisy pixels from being added into them. To highlight the contrast in the DCN (3–2) emission across the sample, we selected two protoclusters with different evolutionary classifications: young G338.93 and evolved G333.60, and display their first three moments in Fig. 8. Towards G338.93, there are two prominent ∼0.2 pc clumps of emission with a spread of ∼10 km s−1 in velocity. On the other hand, towards G333.60, the emission is tracing a more filamentary structure spread over a larger extent, that is, over ∼2 pc. This morphological difference appears to be part of a general trend (see Fig. D.1), where dense gas is less widespread in the young regions. Still, the trend needs to be confirmed using various gas tracers (Cunningham et al., in prep.). The full set of moment maps towards all protoclusters is presented in Fig. D.1. We note that in a few regions (e.g. G327.29 and G351.77), the moment 0 maps display negative bowls, resulting from the missing short spacings in this 12m-array only data.
 |
Fig. 8. Moment maps (moment 0, 1, and 2 in the left, centre, and right panels, respectively) of DCN (3–2) emission towards two example protoclusters with different evolutionary classifications, the young protocluster G338.93 (top), and the evolved G333.60 (bottom). All three moments have been determined over a velocity range of −53.4 to −68.6 km s−1 and −40 to −52.7 km s−1 for G338.93 and G333.60, respectively. For the moment 0 and moment 2 maps, we overlay the core positions and sizes (red ellipses) from the continuum core catalogue described in Louvet et al. (2023). For the moment 1 and moment 2 maps, we show a zoom-in of the area highlighted by the yellow dashed box overlaid on the moment 0 map. The moment 1 and moment 2 maps have an additional threshold cut per channel of 4σ. The synthesised beam is shown in the bottom left corner of each image. These maps highlight differences in the morphology traced by the DCN (3–2) emission, where the emission is more widespread and filamentary towards the evolved region G333.60 than in the young region G338.93. This trend in the DCN (3–2) emission morphology with the evolutionary stage is consistent across the full ALMA-IMF sample. |
4.2. DCN (3–2) line extraction and fitting
The DCN (3–2) line emission is extracted from each core using spectral-cube13 (Ginsburg et al. 2019). We use an elliptical aperture with a major (minor) axis length twice that of the continuum source major (minor) FWHM to extract the spectrum, where the continuum core sizes are taken from Louvet et al. (2023)14. As with the continuum cores, where the background is filtered to estimate the core properties more accurately, we chose to perform background subtraction on the DCN (3–2) emission to limit contamination from background and foreground DCN (3–2) within the dense regions of the protocluster. We extract the background emission from an elliptical annulus with an inner major (minor) axis size equal to the size of the spectral aperture (i.e. twice the continuum source major (minor) FWHM) and outer radius size 1.5x larger (i.e. three times the continuum source major (minor) FWHM). In these complex regions, particularly towards the densest parts of the protoclusters, nearby cores can overlap with the background annulus. We excluded pixels from neighbouring cores that spatially overlap with the background annulus in these instances. An example of the core spectral aperture and resulting background annulus is given in Appendix E. A core-averaged spectrum is then extracted for each of the 595 cores across the 15 ALMA-IMF clouds, and the average spectrum from its background annulus is subtracted from it. The resulting core-averaged, background-subtracted spectrum for each core is then fitted using a single component hyperfine structure model (HFS) adapted for the DCN (3–2) transition in PySpecKit (Ginsburg & Mirocha 2011; Ginsburg et al. 2022b). The methodology of the line extraction, background subtraction, and HSF fitting are discussed further in Appendix E.
4.3. DCN (3–2) detection of cores
A core is determined to have a DCN (3–2) detection if a velocity dispersion of > 0.2 km s−1 and a signal-to-noise ratio (S/N) > 4σ are found in the core averaged, background-subtracted spectrum. The noise in the spectrum is estimated from the MAD10 in 30 continuous channels (∼10 km s−1) from either the lower or upper part of the spectrum that were identified by eye to be in a line free part of the spectrum. Furthermore, as described in Sect. 3.3, we use the higher noise estimates in units of mJy per dirty beam.
Of the 595 continuum cores, 357 (60%) have a DCN (3–2) detection. Within each protocluster, however, several detected cores display complex spectra (91 over the full sample), thus not well fit by the single component HFS. We classify spectra as complex-type if multiple components or clear signs of structure affecting the single component fits are present in the spectrum. This is done manually by visually inspecting all fitted DCN (3–2) spectra. While the VLSR from complex-type spectral fits are provided for reference, the linewidths are not given, and these cores are excluded from the following analysis. Only cores determined to be well fit by a single component (e.g. listed as single in Table 3) are considered further. The complex-type spectra may harbour multiple velocity components or arise from line self-absorption due to optical depth effects. We note that a few of the DCN (3–2) spectra (i.e. core 3, G338.93) show broad wings, which may indicate that it is tracing shocked gas (e.g. Busquet et al. 2017). Additional work is required, however, to understand the nature of the complex-type spectra fully and extract accurate fits, which is beyond this paper’s scope. After filtering out the cores with a complex DCN (3–2) spectrum, the sample is reduced to 266 continuum cores, that is, ∼45% of the continuum cores have a single component HFS fit.
Example of the DCN fits towards the first 15 cores of the young protocluster G338.93.
We show examples of the single- and complex-type DCN (3–2) spectra in Figs. 9 and 10, respectively, extracted towards a sample of cores in the protocluster G338.93. In Table 3, we give an example of the resulting linewidth and VLSR from the hyperfine fitting for G338.93. The linewidths are taken as 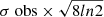 , where σ obs is the observed velocity dispersion from single component HFS fits to the core-averaged, background-subtracted spectra. The full set of single- and complex-type spectra and tables for G338.93 and all protoclusters can be found in Appendix F. Towards G338.93, 26 of its 42 cores have DCN (3–2) detections (∼62%), with 8 of these cores displaying complex spectra, thus after filtering, ∼43% of the cores in G338.93 have a single-type DCN (3–2) detection. In the evolved region G333.60, 38 of its 52 cores have DCN (3–2) detections (∼73%), with 10 of these cores displaying complex spectra, filtering out the complex-type spectra, ∼54% of the cores have single-type detection. In Table 4, we show the detection rate of the DCN (3–2) fits for both the single- and complex-type spectra extracted from all cores in all protoclusters. We find that DCN (3–2) is detected more often in cores situated in evolved regions with an average detection rate of 62% for cores with single-type spectra, compared to a lower average detection rate (< 35%) in the young and intermediate regions. This difference is seen whether the complex-type spectra are included or not, suggesting DCN detects a higher fraction of the continuum cores in the evolved protoclusters. This trend is in line with the more widespread detection of the DCN (3–2) emission in evolved protoclusters, as described in Sect. 4.1.
, where σ obs is the observed velocity dispersion from single component HFS fits to the core-averaged, background-subtracted spectra. The full set of single- and complex-type spectra and tables for G338.93 and all protoclusters can be found in Appendix F. Towards G338.93, 26 of its 42 cores have DCN (3–2) detections (∼62%), with 8 of these cores displaying complex spectra, thus after filtering, ∼43% of the cores in G338.93 have a single-type DCN (3–2) detection. In the evolved region G333.60, 38 of its 52 cores have DCN (3–2) detections (∼73%), with 10 of these cores displaying complex spectra, filtering out the complex-type spectra, ∼54% of the cores have single-type detection. In Table 4, we show the detection rate of the DCN (3–2) fits for both the single- and complex-type spectra extracted from all cores in all protoclusters. We find that DCN (3–2) is detected more often in cores situated in evolved regions with an average detection rate of 62% for cores with single-type spectra, compared to a lower average detection rate (< 35%) in the young and intermediate regions. This difference is seen whether the complex-type spectra are included or not, suggesting DCN detects a higher fraction of the continuum cores in the evolved protoclusters. This trend is in line with the more widespread detection of the DCN (3–2) emission in evolved protoclusters, as described in Sect. 4.1.
 |
Fig. 9. Example of the core-averaged, background-subtracted DCN (3–2) single-type spectra for six cores in the young protocluster G338.93. The associated continuum core number is given in the top left of each panel (the core numbering is taken from Louvet et al. 2023). The core VLSR (V) and velocity dispersion (σ) in units of km s−1 from the HSF fit are given in the top right. The line fit parameters for each core are also presented in Table 3. The pink-shaded region represents the part of the spectrum used to estimate the MAD noise. |
 |
Fig. 10. Example of the core-averaged, background-subtracted DCN (3–2) complex-type spectra for six cores in the young protocluster G338.93. The associated continuum core number is given in the top left of each panel (the core numbering is taken from Louvet et al. 2023). The core VLSR (V) and velocity dispersion (σ) in units of km s−1 from the HSF fit are given in the top right. Given the complex structure in their spectra, the resulting fits are excluded from the analysis and labelled as complex-type spectra. The pink-shaded region represents the part of the spectrum used to estimate the MAD noise. |
To assess if the background subtraction could bias the results, we also perform an extraction on the non-background subtracted DCN (3–2) spectra towards each core in Appendix E. While more cores are detected overall with single-type spectra (∼56%), DCN still detects a higher fraction of the continuum cores in evolved protoclusters (∼72%) compared with young and intermediate regions (< 50%). We also note that the absorption features in several spectra may come from the background subtraction (e.g. core 2, G338.93). Absorption features are, however, still present in the non-background subtracted spectra and are likely a consequence of the missing short spacings in these 12m array only data.
4.4. Protocluster VLSR estimates from the DCN (3-2) fits
In Table 4, we also provide the average VLSR and velocity ranges for the detected cores in each protocluster using only the fits from single-type DCN (3–2) spectra. For most protoclusters, we find that the VLSR estimates given in Table 1 (Motte et al. 2022) are consistent with the average centroid core VLSR for each protocluster. For W51-IRS2, W43-MM2, and W43-MM3, however, there is a shift of 5–7 km s−1 between the average core VLSR and that of the VLSR estimates from Motte et al. (2022). The shift in W51-IRS2 is likely due to the two distinct velocity distributions of its cores (which can be seen in the moment maps for W51-IRS2 in Fig. D.1) and has been observed previously (Ginsburg et al. 2015). Furthermore, both W43-MM2 and W43-MM3 reside in the same complex (W43), along with W43-MM1, and the few km s−1 velocity offset in these regions is likely due to differences between the average bulk motions on larger scales compared to the internal motions of the embedded protoclusters. The VLSR distribution for the cores situated within a given region span a range of values from 2.5 < ΔvLSR < 13.7 km s−1; however, the higher values are produced by outliers (see Fig. 11). In Fig. 11, we display the distribution of the core velocities per evolutionary stage. We estimate the velocity offset for each core by taking the central velocity of the fit and subtracting from it the average protocluster velocity (estimated from the average of the DCN (3–2) moment 1 maps). While the evolved protoclusters have cores with a larger velocity spread, that sample is dominated by the protocluster W51-IRS2, which likely has two distinct velocity distributions for its cores. Thus, we find no apparent difference in the spread of the core VLSR with the evolutionary stage of the host region.
Characteristic parameters of the DCN (3–2) hyperfine fits.
 |
Fig. 11. Distribution of the core velocities from the DCN line fits split by evolutionary stage. The velocity offset is determined as the central velocity of the fit and subtracting from it the average protocluster velocity (estimated from the average of the DCN (3–2) moment 1 maps). The vertical dashed lines are the average values for each subgroup (0.13 km s−1, −0.29 km s−1, and 0.44 km s−1 for the young, intermediate and evolved regions, respectively). We find no obvious dependence on the distribution of the core velocities over the sample. |
4.5. Comparison with other molecular lines
We compare here the DCN (3–2) emission extracted towards the protocluster G338.93 to other molecular lines (situated within the ALMA-IMF spectral coverage) that have previously been used to study core properties and kinematics, such as DCO+ (3–2), 13CS (5–4), OCS (19–18), C18O (2–1), and N2D+ (3–2) (e.g. Li et al. 2022; Sakai et al. 2022; Nony et al. 2020; Cunningham et al. 2016; Maud et al. 2015). They are fitted and classified as single- or complex-type spectra in the same way as for DCN (3–2) (described in Sect. 4.3), but using only a single component Gaussian fit in pyspeckit. To be consistent, for lines (e.g. DCO+) situated in spectral windows with higher spectral resolution than B6 spectral window 1, we smooth these cubes to have the same spectral resolution as DCN. In Table 5, we show the detection rate of several molecular transitions towards the core population of G338.93 along with their critical densities and the energies of their respective lower level above ground (in K). DCN (3–2) exhibits single-type spectra towards the highest percentile (∼43%) of continuum cores in G338.93, versus 5–31% for the other species. While C18O (2–1) is detected towards 1.3 times more cores overall (∼81%), a large fraction of those spectra (62%) contains complex-type spectra, which exhibit multiple peaks or non-Gaussian profiles (see Sect. 4.3). In Fig. 12, we show the extracted linewidths for each molecular species as a function of the associated continuum core masses (taken from Louvet et al. 2023) for the protocluster G338.93. DCN (3–2) is extracted with a single-type spectrum across the majority of the mass distribution of the cores. In comparison, 13CS (5–4) and OCS (19–18) are found predominantly towards the higher-mass continuum cores. Meanwhile, N2D+ (3–2) and DCO+ (3–2) trace cores in the low/intermediate mass range with a single-type spectrum. We note that several of the lowest mass cores in this region are not traced by DCN (3–2), but are traced by either C18O (2–1), N2D+ (3–2) and DCO+ (3–2), thus, DCN (3–2) may not be sensitive to the lowest mass cores (see Sect. 5.4 for further discussion). Furthermore, N2D+ (3–2) predominantly traces different cores than DCN (3-2) in G338.93 and could provide a complementary tracer of the low/intermediate mass core population. For the ALMA-IMF protoclusters, N2D+ may not be the optimal tracer of high-mass prestellar cores, contrary to the picture in infrared dark clouds (e.g. Tan et al. 2013, Barnes et al. 2023) where N2D+ is observed towards massive prestellar cores. While Fig. 12 highlights the need for a multi-line analysis to recover the full core population in these protoclusters, such a task is beyond the scope of this paper. It will be performed on individual regions in the future (e.g. Cunningham et al., in prep.). DCN (3–2) recovers the highest percentage of continuum cores with single-type spectra compared to other dense gas tracers. Thus, using only a single tracer, DCN (3–2) likely still provides the best proxy of the dense gas associated with the continuum cores in the ALMA-IMF bandwidth coverage.
Comparison of molecular line detection towards the continuum core population of G338.93.
 |
Fig. 12. Linewidths extracted towards the core population of G338.93 for the molecules listed in Table 5 as a function of the continuum core masses taken from Louvet et al. (2023), assuming the core dust temperature estimates as given in Table 3. The linewidths shown are from fits classified as single-type which can be well approximated by a single Gaussian (or single HFS fit for DCN) component fit to the extracted spectrum. The grey vertical lines represent the masses of all 42 cores in the G338.93 protocluster. DCN (3–2) well represents the full mass range of the cores in the protocluster. |
5. Discussion
5.1. Global DCN (3–2) morphology and kinematics
The DCN (3–2) emission displays a diversity of morphology and velocity structure across the ALMA-IMF fields. For the evolved regions, the emission traces more elongated, filamentary structures (e.g. W51-IRS2, G333.60, and G012.80) compared with more compact and less elongated emission for the young protoclusters (e.g. G328.25, and G338.93). The difference may be caused by a time evolution of density and temperature, where the evolved regions have had more time to concentrate gas, reaching temperatures and densities sufficient to produce DCN (3–2) emission, perhaps due to the development of expanding H II regions in the evolved protoclusters, which adds heating and compression and can shape their surrounding cloud (such as in G5.89-0.39, Fernández-López et al. 2021). The DCN (3–2) moment 1 maps display a broad range of velocity dispersion across the protoclusters, typically around 12 km s−1 and up to 16 km s−1 in W51-IRS2. We use here the spread of core velocities and the global DCN (3–2) emission to identify two protoclusters in the sample, W51-IRS2 and W51-E, which likely consist of multiple clouds along the line of sight that may not be spatially coherent structures in position-velocity space (e.g. Ginsburg et al. 2015).
5.2. Core distribution and kinematics in individual protoclusters
In Fig. 13, we show the positions of the detected cores and their respective core VLSR and linewidths overlaid on their DCN (3–2) moment 0 contour maps for the two example protoclusters, G338.93 and G333.60. The entire sample is shown in Appendix G. We estimate their core-to-core velocity dispersions (i.e. the standard deviation of the core VLSR) and find values of ∼2 km s−1 for both the young (G338.93) and evolved (G333.60) regions. In G338.93, however, the cores with DCN (3–2) detections are distributed in two separated ≤0.5 pc size hubs with different average bulk velocities, −60.2 km s−1 and −62.6 km s−1 for the north and south hub, respectively, compared to the global average of −61 km s−1. If we consider these core populations separately, the estimated core-to-core velocity dispersion is smaller ∼1.5 km s−1. In G333.60, the distribution of the detected cores is more widespread, over ∼3 pc. While it is less obvious to split the cores based on the DCN (3–2) emission, if we split the cores into three subgroups, the central ∼0.5 pc and the two filaments in the north-east and south-west, we obtain core-to-core velocities of ∼1.2 km s−1, ∼1.9 km s−1, ∼1.0 km s−1, respectively. We find no striking difference between the two regions, however, depending on how the cores are grouped, the core-to-core velocities can change by up to a factor of 2. The core-to-core velocity dispersions for the sub-groups in G338.93 and G333.60 are still larger than nearby star-forming regions (e.g. < 0.6 km s−1 Kirk et al. 2010), but they are in line with those found by Cheng et al. (2020) in the massive star-forming region, G286, on similar ∼1 pc scales.
 |
Fig. 13. Core VLSR (left) and DCN (3–2) linewidths (right) estimated from the DCN (3–2) fits to the continuum cores towards examples of a young and an evolved protocluster G338.93 (top) and G333.60 (bottom), respectively. The circles and stars represent the detected cores with mass estimates below and above 8 M⊙, respectively, with the colour scale displaying the fitted parameters from the DCN (3–2) fits (left: core VLSR, right: linewidth). The core VLSR is the centroid velocity of the DCN (3–2) fit minus the cloud VLSR (taken as −62 km s−1, and −47 km s−1 for G338.93, and G333.60, respectively). The grey contours are the 4σ level of the DCN (3–2) moment 0 map. In the right panels, the positions of cores without a DCN (3–2) detection are marked with a black cross and with a black star for cores with a mass estimate below and above 8 M⊙, respectively, and green triangles and stars represent cores with a complex-type DCN (3–2) spectra, with a mass estimate below and above 8 M⊙, respectively. |
Furthermore, if we consider the DCN (3–2) linewidths of cores situated within the two < 0.5 pc size hubs in G338.93, we find an average linewidth with a standard deviation of ∼1.6 km s−1 and ∼0.7 km s−1, respectively, whereas the cores outside of these main hubs (which are low and intermediate-mass) are not detected. Towards the evolved protocluster G333.60, around the central ∼0.5 pc close to the positions of the known H II region (e.g. Fujiyoshi et al. 2006), the linewidths are similar to G338.93 (average and standard deviation of ∼1.5 km s−1 and ∼0.5 km s−1, respectively) or associated with complex-type spectra (green points). In contrast, cores with a DCN (3-2) detection outside of the central region are typically lower-mass and situated along the filamentary structures and have smaller linewidths (with an average and standard deviation of ∼1.2 km s−1 and ∼0.3 km s−1, respectively).
5.3. Core kinematics and distribution with evolutionary classification
5.3.1. Core-to-core velocity distribution
In Fig. 14, we plot the core-to-core velocity dispersion vs the spatial spread (following, e.g. Stutz & Gould 2016) for each core grouped by their host region’s evolutionary stage. The radial spatial offset for each core is determined by taking the position of the core and subtracting from it the mean position of all cores in its protocluster and assuming the distances given in Table 1 for each region. The velocity offset for each core is determined by subtracting the centroid VLSR found from all cores with single-type spectra in a given region from it. We find core-to-core velocity dispersions of 1.8 ± 0.2 km s−1, 2.6 ± 0.4 km s−1, and 2.2 ± 0.2 km s−1 for the young, intermediate, and evolved protoclusters, respectively. This suggests that the young protoclusters have a slightly smaller core-to-core velocity dispersion compared with the intermediate and evolved protoclusters; however, a Kolmogorov-Smirnov (KS) test between the core-to-core velocities of the evolutionary stages does not give Pvalues < 0.05. Furthermore, as discussed in Sect. 5.2 for G338.93, and G333.60, the core-to-core velocities can change by a factor of 2 depending on how cores are separated. Thus, we would need to separate the cores spatially and by velocity in each region to assess the core-to-core velocity and spatial distribution fully. In Fig. 14, we also find that the most massive cores (red stars) are not necessarily at the central velocity or average central position of the protocluster, although we have a small number of statistics for the most massive cores. However, this also depends on how the cores are sub-clustered in a given protocluster. A complete analysis of the core-to-envelope dispersion will be done in future works, along with the separation of cores in individual protoclusters to estimate the core-to-core velocities more accurately.
 |
Fig. 14. Core VLSR vs the core radial offset grouped by evolutionary classification of the host protocluster; young, intermediate and evolved (Y: left, I: centre, and E: right, respectively). The radial spatial offset for each core is determined by taking the position of the core and subtracting from it the mean position of all cores in its protocluster and assuming the distances given in Table 1 for each region. The velocity offset for each core is determined by subtracting the centroid VLSR found from all cores with single-type spectra in a given region from it. The cores are colour-coded by their mass estimates taken from Louvet et al. (2023), and star symbols represent those cores with mass estimates > 8 M⊙. Cores with a declination smaller than the average position have a negative offset. For the young and intermediate regions, the spatial distribution of the cores is more compact compared to cores in evolved protoclusters, where the cores can be spatially distributed over larger areas (> 2.0 pc). |
Figure 14 highlights again that the cores in evolved protoclusters have a more widespread spatial distribution than those in the young and intermediate regions. The standard deviation of the spatial spread for the young, intermediate, and evolved regions are 0.33 pc, 0.39 pc, and 0.60 pc, respectively, with standard errors < 0.06 pc. A KS test on the core offsets in the young and intermediate regions suggests they are drawn from a different population than cores in evolved regions. Thus, the cores detected in DCN (3–2) are typically more concentrated in the young and intermediate regions. This is also the case if we consider the full core populations, not just those with DCN (3–2) detections. This suggests that the spatial distribution is inherent to the evolutionary stage and not biased by the cores with DCN (3–2) detections. Furthermore, we find that cores with large spatial offsets in evolved regions (i.e. > 0.5 pc) are predominantly lower mass. As discussed above, this depends on where the spatial centre of the protocluster is defined and if the cores are further sub-clustered. However, if we take ten random cores in each protocluster as the central position, the evolved protoclusters always have larger standard deviations in their spatial spread, which is significant with a KS-test. Thus, the larger values are likely not due to a bias in the definition of the cluster centre. A full assessment of the sub-clustering or separation of core populations as done in (e.g. Pouteau et al. 2023) should be performed to confirm this.
5.3.2. DCN (3–2) linewidths
Considering the DCN (3–2) linewidths grouped by evolutionary classification, we find slightly smaller average linewidths in the evolved regions of ∼1.2 km s−1 compared to the young and intermediate protoclusters of ∼1.5 km s−1, and standard deviations of ∼0.5, and ∼0.7 km s−1 respectively. In Fig. 15, we show the histogram of the DCN (3–2) linewidths extracted from the continuum cores as a function of the evolutionary stage. Furthermore, a KS test on the DCN (3–2) linewidths of those cores situated in the evolved regions, when compared with the DCN (3–2) linewidths of cores from intermediate + young regions, gives a Pvalues < 0.001, suggesting that they are not drawn from the same population. We note, however, that we do not have linewidth estimates with DCN (3–2) for all cores, thus, this trend would need to be confirmed with additional lines.
 |
Fig. 15. Distribution of the core linewidths from DCN single-type line fits as a function of protocluster distance (left). The red triangles, blue plusses, and black crosses represent the linewidths of core emission associated with evolved, intermediate, and young protoclusters, respectively. There is no obvious dependence on the protocluster distance and the linewidths. Right: Histogram of the linewidths from the DCN line fits grouped by evolutionary stage, where the solid red, blue dot-dashed, and black dashed lines represent the evolved, intermediate, and young protoclusters, respectively. The vertical lines display the mean linewidth for each evolutionary stage with the same colours described above. The evolved regions have a slightly smaller average linewidth (1.2 km s−1) than young and intermediate regions (∼1.5 km s−1), significant within the standard errors. |
While evolved protoclusters are typically at a slightly larger distance (∼4.2 kpc) compared with the young and intermediate regions (∼3.7 kpc), as our data are taken at a constant linear resolution, there is no reason to expect differences in the linewidths with protocluster distance, as shown in Fig. 15. Furthermore, if we consider the size-linewidth relation, we may expect an increase in the DCN linewidths with the core size. In Fig. 16, we show the non-thermal velocity dispersion-size relation for the 266 cores in our sample from all 15 protoclusters, where the non-thermal velocity dispersion (σNT) is estimated assuming:
 |
Fig. 16. Distribution of the core-size as a function of the respective non-thermal velocity dispersion from the DCN (3-2) spectra. The red triangles, blue plusses, and black crosses represent evolved, intermediate, and young protoclusters, respectively. The red, blue, and black squares are the average values (0.50 km s−1, 0.63 km s−1, and 0.63 km s−1) for the collective evolved, intermediate and young values, respectively, where the error bars represent the standard deviations (0.22 km s−1, 0.27 km s−1, and 0.33 km s−1, respectively). The black dashed line is the Larson relation (Larson 1981), and nearly all cores are above it. The black circle and error bar provide an estimate of the typical errors on the linewidth estimates. We find no correlation between the non-thermal velocity dispersion with core-size in the ranges of values sampled here. |
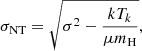
where k is the Boltzmann constant, Tk is the gas kinetic temperature used for DCN (3–2), which is taken to be equal to the dust temperature assumed by Louvet et al. (2023) and has a range from 18 K to be 300 K for all cores (the assumed temperatures for individual cores are shown in, e.g. Table 3), mH is the hydrogen mass, and μ is the molecular weight of the DCN molecule. The core sizes are the geometric mean of the major and minor continuum core FWHMs from Louvet et al. (2023) deconvolved by the smoothed beam15. We fit Pearson’s correlation coefficient (ρ), which measures the linear correlation between two variables, and find a value of 0.18, indicating no correlation exists between the dispersion and core sizes in these data. A similar lack of correlation between the non-thermal velocity dispersion and radius was found by Traficante et al. (2018) towards a sample of Hi-Gal clumps, albeit on the larger size scales of 0.1-1 pc. If we consider the different evolutionary stages independently, there is similarly no correlation for any individual subgroup. However, we note that we are sampling a very small range of core sizes (i.e. a factor of ∼3).
5.4. Nature of the core population traced by DCN (3-2)
In Fig. 17, we show the distribution of core masses taken from Louvet et al. (2023; assuming the core dust temperature estimates as given in e.g. Table 3) separated by their DCN classification (i.e. single-, complex-type and non-detected). We find that the complex-type spectra are typically extracted in cores with higher masses and densities on average (∼17 M⊙, and ∼2.5 × 107 cm−3, respectively) than those with single-type DCN (3-2) spectra (∼5 M⊙, and ∼1 × 107 cm−3, respectively). Since complexity is associated with higher mass cores, we suggest the complex-type spectra may be caused by high optical depths, either through self-absorption of the line or absorption of the background continuum. However, the presence of multiple velocity components cannot be ruled out. If we consider the non-detected cores, the average masses and densities are slightly lower, ∼3 M⊙, and ∼0.8 × 107cm−3, respectively. Moreover, there is a higher proportion of non-detected cores with masses less than a few M⊙ in the young and intermediate regions than the evolved protoclusters. As shown previously, towards the young protocluster, G338.93 (see Fig. 12), DCN (3–2) is not detected towards cores with masses below ∼1 M⊙, which could indicate a sensitivity bias for the lowest mass cores. We note that in G338.93, several of the lowest mass cores that are not detected by DCN (3–2) are, however, detected in other species (i.e. N2D+ (3–2) at ∼1 M⊙). If we consider recent DCN (3–2) observations by Hsieh et al. (2023) towards SVS13A, a low mass protobinary system harbouring two subsolar protostars at 293 pc, where they find peak brightness temperatures of around 15 K, we would not be sensitive to those cores at the distance of G338.93. We would expect, however, to detect them towards the ALMA-IMF protoclusters at distances < 3kpc (e.g. G337.92), suggesting that a sensitivity bias does not account for all of the non-detected low mass cores. Furthermore, if we include all non-detected cores with a mass below 1 M⊙ into the detected core statistics, the evolved protoclusters would still have ∼27% more DCN (3–2) detections. While the sensitivity limit has an impact on the DCN (3–2) detections and should be explored further, it does not fully explain the higher fraction of cores with a DCN detection in the evolved regions.
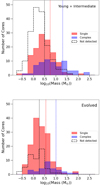 |
Fig. 17. Histograms of the mass distribution (in log scale) of the cores in the combined young + intermediate regions (top panel) and evolved regions (bottom panel). The shaded red and blue areas show the cores with single-type DCN (3–2) and complex-type spectra, respectively. The dashed black line represents cores with a DCN (3–2) non-detection. The red, blue, and black dashed vertical lines represent the average mass values (top: 5.6 M⊙, 20.1 M⊙, and 3.1 M⊙; bottom: 3.6 M⊙, 10.2 M⊙, and 1.8 M⊙) for the single-, complex-type, and non-detections, respectively. We find that the complex-type cores have an average mass nearly an order of magnitude higher than those without a DCN (3–2) detection and around three times higher than cores with a single-type DCN detection, regardless of evolutionary class. |
The detection of a deuterated species is typically associated with cold temperatures and high densities (e.g. Roberts & Millar 2000); however, DCN can form through both cold and high-temperature reaction channels, with reactions at higher temperatures being the dominant pathway (e.g. Turner 2001; Roueff et al. 2013). The abundance of DCN is enhanced in warmer gas up to and even above 70K (e.g. Millar et al. 1989; Turner 2001, Roueff et al. 2007, 2013). Thus, unlike other deuterated species such as N2D+, where the abundance is enhanced in the cold (< 25 K) dense environments, (where CO is frozen out) and destroyed in higher temperatures, DCN (3–2) emission also traces warmer gas. The higher number of DCN (3–2) detected cores in evolved protoclusters may be due to temperature, with the evolved regions having higher temperatures over a larger fraction of the cloud than young and intermediate regions. Perhaps due to the presence of H II regions in the evolved protoclusters, which can add heating and compression in the surrounding cloud. We should also note the possibility that DCN enhancement may result from sputtering. In particular, for high-mass protostellar cores with powerful outflows and shocks, DCN emission frozen in the dust grains could be released back to the gas phase by the passage of strong shocks (e.g. Busquet et al. 2017).
Cores with an N2D+ (3–2) detection but without a DCN detection are typically located outside the central hubs in G338.93 and may be in colder, more quiescent parts of the clouds. This has been observed in other works (e.g. Tatematsu et al. 2020; Cheng et al. 2020, Li et al. 2022; Sakai et al. 2022) where the spatial distribution between DCN (3–2) and N2D+ (3–2) is observed to be different. Sakai et al. (2022) found DCN (3–2) traced regions associated with more active signs of ongoing star formation, compared to N2D+ (3–2), which they observed to be tracing the more quiescent, colder regions in their sample of infrared dark clouds. This spatial dichotomy between DCN (3–2) emission and N2D+/DCO+ was similarly found in the young massive star-forming region G286 (Cheng et al. 2020) where they identified the DCN emission to be again concentrated around the more active, likely warmer parts of the cloud compared with other deuterated species. To assess the dichotomy and nature of the cores fully across the ALMA-IMF regions requires a multi-line analysis, which will be performed in future works (e.g. Cunningham et al., in prep.).
6. Summary
We have presented an overview of the calibration and imaging steps performed to produce the full set of ALMA-IMF 12m-only line cubes provided as part of the DR1 release with this paper. We have described the internal ALMA-IMF data pipeline available on the ALMA-IMF GitHub. We used the custom ALMA-IMF pipeline to produce a homogeneous and reproducible set of imaged line cubes for the 12 spectral windows and 6.7 GHz of total spectral coverage, containing a multitude of key molecular tracers that will provide a lasting legacy value to the community.
In addition, we provide an overview of the DCN (3–2) emission across the ALMA-IMF protoclusters, where the global DCN (3–2) emission displays a diversity of morphologies and kinematics across the sample, tracing more widespread, filamentary structures in the evolved regions, compared to young protoclusters where the DCN emission is found in more compact hub-type structures. We also extracted the DCN spectra from the 595 continuum cores, where DCN (3–2) emission is detected in ∼60% of the continuum cores, of which ∼45% have a single-type DCN spectrum. The evolved protoclusters have a higher percentage of DCN-detected cores, suggesting that the DCN (3–2) transition is likely a more complete tracer of the core population in evolved protoclusters. Furthermore, the cores with DCN (3–2) detections in evolved regions tend to be more spatially extended over the region than in the younger protoclusters. This may be due to the time evolution of the gas temperature and density, where the evolved regions are warmer over a larger portion of the cloud. We provide first estimates of the core linewidths and core VLSR from the DCN (3–2) fits and find an average core-to-core velocity and linewidth for cores with single-type DCN spectra of ∼2.2 km s−1 and ∼1.3 km s−1, respectively, across the 15 protoclusters. We find no obvious difference between the average core-to-core velocities and only a tentative difference in linewidths with the protocluster evolutionary stage. This may, however, be biased by the fact that we do not have estimates for all of the cores.
This is the same as Table 3 of Motte et al. (2022) but with slightly updated values for the achieved spectral resolutions.
The ALMA-IMF project page is at https://www.almaimf.com/data.html. This Data Release is hosted at Harvard Dataverse https://dataverse.harvard.edu/dataverse/alma-imf
We note that the self-calibration solutions were not applied to the line data.
A public tool to apply the JvM correction to interferometric images will be released in https://github.com/radio-astro-tools/beam-volume-tools
Implemented in astropy.stats.median_abs_deviation and we scale this by 1.4826 such that the reported value is equivalent to the standard deviation if the underlying data are normally distributed.
See the ALMA-IMF website; https://www.almaimf.com/data.html and is hosted by Harvard Dataverse; https://dataverse.harvard.edu/dataverse/alma-imf
We use here the smoothed core catalogue, where the continuum maps are smoothed to the same angular resolution of 2700 au. The extraction is done with v210414 of getsf (Men’shchikov 2021).
Unless the deconvolved size is less than half of the smoothed beam size, then the non-deconvolved source size is used.
Acknowledgments
We are grateful to the anonymous referee for their comments which improved this manuscript. This paper makes use of the following ALMA data: ADS/JAO.ALMA 2017.1.01355.L, 2013.1.01365.S, and 2015.1.01273.S. ALMA is a partnership of ESO (representing its member states), NSF (USA) and NINS (Japan), together with NRC (Canada), MOST and ASIAA (Taiwan), and KASI (Republic of Korea), in cooperation with the Republic of Chile. The Joint ALMA Observatory is operated by ESO, AUI/NRAO and NAOJ. This work and N.C. have received funding from the European Research Council (ERC) via the ERC Synergy Grant ECOGAL (grant 855130), from the French Agence Nationale de la Recherche (ANR) through the project COSMHIC (ANR-20- CE31-0009). The project leading to this publication has received support from ORP, which is funded by the European Union’s Horizon 2020 research and innovation programme under grant agreement No 101004719 [ORP]. A.G. acknowledges support from the National Science Foundation under grants AST-2008101 and CAREER 2142300. T.Cs. has received financial support from the French State in the framework of the IdEx Université de Bordeaux Investments for the future Program. R.G.-M. acknowledges support from UNAM-PAPIIT project IN108822 and from CONACyT Ciencia de Frontera project ID: 86372. A.S. gratefully acknowledges support by the Fondecyt Regular (projectcode 1220610), and ANID BASAL projects ACE210002 and FB210003. R.A. gratefully acknowledges support from ANID Beca Doctorado Nacional 21200897. T. B. acknowledges the support from S. N. Bose National Centre for Basic Sciences under the Department of Science and Technology, Govt. of India. M.B. has received financial support from the French State in the framework of the IdEx Université de Bordeaux Investments for the future Program. S.B. acknowledges support by the French Agence Nationale de la Recherche (ANR) through the project GENESIS (ANR-16-CE92-0035-01). A.L.S. and Y.P. acknowledge funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme, for the project ’the Dawn of Organic Chemistry’ (DOC), grant agreement No 741002. G.B. acknowledges support by the grant PID2020-117710GB-I00 (MCI-AEI-FEDER,UE).
References
- Alves, J., Lombardi, M., & Lada, C. J. 2007, A&A, 462, L17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ballesteros-Paredes, J., André, P., Hennebelle, P., et al. 2020, Space Sci. Rev., 216, 76 [Google Scholar]
- Barnes, A. T., Liu, J., Zhang, Q., et al. 2023, A&A, 675, A53 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bastian, N., Covey, K. R., & Meyer, M. R. 2010, ARA&A, 48, 339 [Google Scholar]
- Bonfand, M., Csengeri, T., Bontemps, S., et al. 2023, A&A, submitted [Google Scholar]
- Bosco, F., Beuther, H., Ahmadi, A., et al. 2019, A&A, 629, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brouillet, N., Despois, D., Molet, J., et al. 2022, A&A, 665, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Busquet, G., Fontani, F., Viti, S., et al. 2017, A&A, 604, A20 [CrossRef] [EDP Sciences] [Google Scholar]
- Cheng, Y., Tan, J. C., Liu, M., Lim, W., & Andersen, M. 2020, ApJ, 894, 87 [NASA ADS] [CrossRef] [Google Scholar]
- Codella, C., Ceccarelli, C., Chandler, C., et al. 2021, Front. Astron. Space Sci., 8, 227 [NASA ADS] [CrossRef] [Google Scholar]
- Csengeri, T., Bontemps, S., Wyrowski, F., et al. 2017a, A&A, 600, L10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Csengeri, T., Bontemps, S., Wyrowski, F., et al. 2017b, A&A, 601, A60 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cunningham, N., Lumsden, S. L., Cyganowski, C. J., Maud, L. T., & Purcell, C. 2016, MNRAS, 458, 1742 [NASA ADS] [CrossRef] [Google Scholar]
- Czekala, I., Loomis, R. A., Teague, R., et al. 2021, ApJS, 257, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Endres, C. P., Schlemmer, S., Schilke, P., et al. 2016, J. Mol. Spectrosc., 327, 95 [NASA ADS] [CrossRef] [Google Scholar]
- Enoch, M. L., Evans, N. J. I., Sargent, A. I., et al. 2008, ApJ, 684, 1240 [NASA ADS] [CrossRef] [Google Scholar]
- Fernández-López, M., Sanhueza, P., Zapata, L. A., et al. 2021, ApJ, 913, 29 [CrossRef] [Google Scholar]
- Fujiyoshi, T., Smith, C. H., Caswell, J. L., et al. 2006, MNRAS, 368, 1843 [NASA ADS] [CrossRef] [Google Scholar]
- Ginsburg, A., & Mirocha, J. 2011, Astrophysics Source Code Library [record ascl:1109.001] [Google Scholar]
- Ginsburg, A., Bally, J., Battersby, C., et al. 2015, A&A, 573, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ginsburg, A., Goddi, C., Kruijssen, J. M. D., et al. 2017, ApJ, 842, 92 [Google Scholar]
- Ginsburg, A., Koch, E., Robitaille, T., et al. 2019, https://doi.org/10.5281/zenodo.3558614 [Google Scholar]
- Ginsburg, A., Csengeri, T., Galván-Madrid, R., et al. 2022a, A&A, 662, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ginsburg, A., Sokolov, V., de Val-Borro, M., et al. 2022b, AJ, 163, 291 [NASA ADS] [CrossRef] [Google Scholar]
- Hsieh, T. H., Segura-Cox, D. M., Pineda, J. E., et al. 2023, A&A, 669, A137 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Immer, K., Galván-Madrid, R., König, C., Liu, H. B., & Menten, K. M. 2014, A&A, 572, A63 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jorsater, S., & van Moorsel, G. A. 1995, AJ, 110, 2037 [Google Scholar]
- Kirk, H., Pineda, J. E., Johnstone, D., & Goodman, A. 2010, ApJ, 723, 457 [NASA ADS] [CrossRef] [Google Scholar]
- Könyves, V., André, P., Men’shchikov, A., et al. 2015, A&A, 584, A91 [Google Scholar]
- Kroupa, P., Weidner, C., Pflamm-Altenburg, J., et al. 2013, in Planets, Stars and Stellar Systems. Volume 5: Galactic Structure and Stellar Populations, eds. T. D. Oswalt, & G. Gilmore, 115 [Google Scholar]
- Krumholz, M. R. 2015, in Very Massive Stars in the Local Universe, ed. J. S. Vink, Astrophys. Space Sci. Libr., 412, 43 [Google Scholar]
- Larson, R. B. 1981, MNRAS, 194, 809 [Google Scholar]
- Lee, Y.-N., Offner, S. S. R., Hennebelle, P., et al. 2020, Space Sci. Rev., 216, 70 [NASA ADS] [CrossRef] [Google Scholar]
- Li, S., Sanhueza, P., Lu, X., et al. 2022, ApJ, 939, 102 [CrossRef] [Google Scholar]
- Louvet, F., Sanhueza, P., Stutz, A., et al. 2023, A&A, submitted [Google Scholar]
- Lu, X., Cheng, Y., Ginsburg, A., et al. 2020, ApJ, 894, L14 [NASA ADS] [CrossRef] [Google Scholar]
- Maud, L. T., Lumsden, S. L., Moore, T. J. T., et al. 2015, MNRAS, 452, 637 [Google Scholar]
- McMullin, J. P., Waters, B., Schiebel, D., Young, W., & Golap, K. 2007, ASP Conf. Ser., 376, 127 [Google Scholar]
- Men’shchikov, A. 2021, A&A, 649, A89 [EDP Sciences] [Google Scholar]
- Millar, T. J., Bennett, A., & Herbst, E. 1989, ApJ, 340, 906 [NASA ADS] [CrossRef] [Google Scholar]
- Molet, J., Brouillet, N., Nony, T., et al. 2019, A&A, 626, A132 [EDP Sciences] [Google Scholar]
- Motte, F., Andre, P., & Neri, R. 1998, A&A, 336, 150 [NASA ADS] [Google Scholar]
- Motte, F., André, P., Ward-Thompson, D., & Bontemps, S. 2001, A&A, 372, L41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Motte, F., Nony, T., Louvet, F., et al. 2018, Nat. Astron., 2, 478 [Google Scholar]
- Motte, F., Bontemps, S., Csengeri, T., et al. 2022, A&A, 662, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Müller, H. S. P., Thorwirth, S., Roth, D. A., & Winnewisser, G. 2001, A&A, 370, L49 [Google Scholar]
- Müller, H. S. P., Schlöder, F., Stutzki, J., & Winnewisser, G. 2005, J. Mol. Struct., 742, 215 [Google Scholar]
- Nguyen-Luong, Q., Motte, F., Carlhoff, P., et al. 2013, ApJ, 775, 88 [CrossRef] [Google Scholar]
- Nony, T., Motte, F., Louvet, F., et al. 2020, A&A, 636, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nony, T., Galván-Madrid, R., Motte, F., et al. 2023, A&A, 674, A75 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Offner, S. S. R., Clark, P. C., Hennebelle, P., et al. 2014, Protostars and Planets VI, 53 [Google Scholar]
- Ohashi, S., Sanhueza, P., Chen, H.-R. V., et al. 2016, ApJ, 833, 209 [NASA ADS] [CrossRef] [Google Scholar]
- Pouteau, Y., Motte, F., Nony, T., et al. 2022, A&A, 664, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pouteau, Y., Motte, F., Nony, T., et al. 2023, A&A, 674, A76 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Roberts, H., & Millar, T. J. 2000, A&A, 364, 780 [NASA ADS] [Google Scholar]
- Roueff, E., Parise, B., & Herbst, E. 2007, A&A, 464, 245 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Roueff, E., Gerin, M., Lis, D. C., et al. 2013, J. Phys. Chem. A, 117, 9959 [Google Scholar]
- Sakai, T., Sanhueza, P., Furuya, K., et al. 2022, ApJ, 925, 144 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez-Monge, Á., Schilke, P., Schmiedeke, A., et al. 2017, A&A, 604, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sanhueza, P., Contreras, Y., Wu, B., et al. 2019, ApJ, 886, 102 [Google Scholar]
- Schöier, F. L., van der Tak, F. F. S., van Dishoeck, E. F., & Black, J. H. 2005, A&A, 432, 369 [Google Scholar]
- Shirley, Y. L. 2015, PASP, 127, 299 [Google Scholar]
- Stutz, A. M., & Gould, A. 2016, A&A, 590, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tan, J. C., Kong, S., Butler, M. J., Caselli, P., & Fontani, F. 2013, ApJ, 779, 96 [Google Scholar]
- Tatematsu, K., Liu, T., Kim, G., et al. 2020, ApJ, 895, 119 [NASA ADS] [CrossRef] [Google Scholar]
- Testi, L., & Sargent, A. I. 1998, ApJ, 508, L91 [NASA ADS] [CrossRef] [Google Scholar]
- Traficante, A., Duarte-Cabral, A., Elia, D., et al. 2018, MNRAS, 477, 2220 [NASA ADS] [CrossRef] [Google Scholar]
- Turner, B. E. 2001, ApJS, 136, 579 [Google Scholar]
- Walter, F., Brinks, E., de Blok, W. J. G., et al. 2008, AJ, 136, 2563 [Google Scholar]
- Wienen, M., Wyrowski, F., Menten, K. M., et al. 2015, A&A, 579, A91 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zhang, Q., Wang, K., Lu, X., & Jiménez-Serra, I. 2015, ApJ, 804, 141 [Google Scholar]
Appendix A: Properties of the line cubes and overview of spectral setups
In Table A.1 the geometric average of the expected continuum beam from the proposal (θprop) and the obtained beams (θcont) are given. In Table A.2, we provide the beam major and minor axes, along with the position angle for all observed protoclusters and spectral windows. In Table A.3, we provide the exact range of the frequency setups for each spectral window towards all 15 protoclusters. In Table A.4, we provide the rms noise extracted for each spectral window (in units of mJy per dirty beam) as well as the noise expected from the proposed observations, scaled to the same spectral resolution and central frequency. In Table A.5, we provide the ϵ factors used in the JvM correction for each spectral window.
Proposed and actual continuum beams for all spectral windows.
Obtained beams for B3 spectral windows (0-3).
continued: Obtained beams for B6 spectral windows (0-3).
continued: Obtained beams for B6 spectral windows (4-7).
Minimum and maximum frequency ranges [GHz] for the spectral window setups for B3 spws (0-3).
continued: Minimum and maximum frequency ranges [GHz] for the spectral window setups for B6 spws (0-3).
continued: Minimum and maximum frequency ranges [GHz] for the spectral window setups for B6 spws (4-7).
Spectral window noise estimates for B3 spws (0-3).
Spectral window noise estimates for B6 spws (0-3).
Spectral window noise estimates for B6 spws (4-7).
ϵ values used for the JvM correction for B3 spws (0-3) and B6 spws (0-7).
Appendix B: Known data issues
Towards several regions that contain bright hot cores, there can be a slight overestimation of the continuum startmodel at the positions of the hot cores, resulting in localised negative features in some of the residuals. This overestimate is likely due to rich line emission (line forests) across the spectrum at those positions. Often the negative residuals are < 10% of the flux in the restored image, but in some cases with faint (real) continuum and bright line emission, they are larger. We also note that in some instances the sidelobes can remain particularly bright in the final imaged cubes (e.g. G327 in B6).
Appendix C: Special cases
Several regions required additional special attention in early 2022 because tclean failed for a variety of reasons related to software configurations. We were never able to fully determine what the underlying causes of the failures were, but they manifested as CASA like the following:
MPICommandServer:: command_request_handler _service:: SynthesisImagerVi2:: CubeMajorCycle::MPIServer-23 (file src/code/synthesis/ImagerObjects/ CubeMajorCycleAlgorithm.cc, line 336) Exception for chan range [1921, 1921] — Error in running Major Cycle: A nasty Visbuffer2 error occurred...wait for CNGI W51-E_B3_fullcube_12M_0_34232805.log: Exception: Error in running Major Cycle: A nasty Visbuffer2 error occurred...wait for CNGI
or
SEVERE tclean::::casa Task tclean raised an exception of class RuntimeError with the following message: Error in making PSF : One or more of the cube section failed in de/gridding. Return values for the sections: [1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] Two combinations of field and band, W51-E B3 spw0 and G333.60 B6 spw 1, proved particularly difficult to run tclean to completion. We, therefore, modified the W51-E B3 spw0 imaging parameters to specify the number of channels by hand. For G333.60, we found that the final model exhibited ‘zigzag’ spectral patterns, in which, at the end of cleaning, adjacent spectral channels oscillated from −1t to +1t, where t is the final clean threshold. These oscillations manifest strongly in the image and spectra and render the data unusable for science, even though technically the clean threshold has been met. To correct this issue, we re-processed the final .model file by applying a 3-pixel maximum spectral filter, that is, replacing the value at each pixel in the cube with the maximum of the ±1 pixel range surrounding it in the spectral dimension. This approach has the effect of retaining the spectral peaks, but slightly over-predicting the values to either edge of the peaks.
Appendix D: DCN moment maps
In Figure D.1 we present the first three moment maps for the remaining 13 protoclusters. G338.93 and G333.60 are presented in the main body of the text in Figure 8.
 |
Fig. D.1. Moment maps (moment 0, 1, and 2 in the left, centre, and right panels, respectively) of DCN (3-2) emission towards the protoclusters G008.67 (top), G010.62 (middle), and G012.80 (bottom). All three moments have been determined over a velocity range of 31.7 to 43 km s−1, −9.3 to 5.8 km s−1, and 30.7 to 43 km s−1 for G008.67, G010.62, and G012.80, respectively. For the moment 0 and moment 2 maps, we overlay the core positions and sizes (red ellipses) from the continuum core catalogue described in Louvet et al. (2023). For the moment 1 and moment 2 maps, we show a zoom-in of the area highlighted by the yellow dashed box overlaid on the moment 0 map. The moment 1 and moment 2 maps have an additional threshold cut per channel of 4 σ. The synthesised beam is shown in the bottom left corner of each image. |
 |
Fig. D.1. continued. Moment maps (Moment 0, 1, and 2 in the left, centre, and right panels, respectively) of DCN (3-2) for G327.29 (top), G328.25 (middle), and G337.92 (bottom). Maps were calculated over a velocity range of −50.2 to −39.7 km s−1, −47.5 to −41 km s−1, and −30.8 to −45 km s−1, respectively. |
 |
Fig. D.1. continued. Moment maps (Moment 0, 1, and 2 in the left, centre, and right panels, respectively) of DCN (3-2) for G351.77 (top), G353.41 (middle), and W43-MM1 (bottom). Maps were calculated over a velocity range of −9.8 to 3.2 km s−1, −20.5 to −12.7 km s−1, and 92.7 to 105 km s−1, respectively. |
 |
Fig. D.1. continued. Moment maps (Moment 0, 1, and 2 in the left, centre, and right panels, respectively) of DCN (3-2) for W43-MM2 (top), W43-MM3 (middle), and W51-E (bottom). Maps were calculated over a velocity range of 85.7 to 94 km s−1, 90.4 to 95.8 km s−1, and 46 to 64 km s−1, respectively. |
 |
Fig. D.1. continued. Moment maps (Moment 0, 1, and 2 in the left, centre and right panels, respectively) of DCN (3-2) for W51-IRS2. Maps were calculated over a velocity range of 52.4 to 68 km s−1. |
Appendix E: DCN line extraction, background subtraction, and hyperfine fitting
We used spectral-cube16 (Ginsburg et al. 2019) to extract the DCN (3-2) emission from the Band 6 spectral window 1 cube. First, we shifted the cubes into the frequency rest frame of the DCN (3-2) transition, and then for each protocluster, we extracted a subcube with a 50 km s−1 width centred on the VLSR of the protocluster. We then extracted a core-averaged, background-subtracted DCN (3-2) spectrum for each continuum core. We used the smoothed core catalogue from Louvet et al. (2023) to obtain the positions and core sizes for the 595 continuum cores over the 15 ALMA-IMF protoclusters. We extracted the core-averaged DCN (3-2) spectrum from all pixels within an elliptical aperture with a major (minor) axis length twice that of the continuum source major (minor) FWHM. We subtracted from this an average background spectrum taken from within an elliptical annulus with an inner major (minor) axis size equal to the size of the spectral aperture (i.e. twice the continuum source major (minor) FWHM) and outer radius size 1.5x larger (i.e. three times the continuum source major (minor) FWHM). As nearby cores can overlap with the background annulus, we excluded those pixels from neighbouring cores that spatially overlap with the background annulus, creating a background ‘crown’. An example of the core and background annulus-crown definition can be seen in Fig. E.1. The resulting core-averaged, background-subtracted spectrum for each core was then fitted using PySpecKit (Ginsburg & Mirocha 2011; Ginsburg et al. 2022b) with an adapted single component hyperfine model (HFS), to account for the hyperfine structure in the DCN (3-2) line. The values for the specified hyperfine model were taken from the CDMS catalogue to define the frequencies and relative weights of the hyperfine lines (Endres et al. 2016; Müller et al. 2001, 2005). They are presented in Table E.2. An example of the positions of the hyperfine components overlaid on an example DCN spectrum is presented in Fig. E.2.
E.1. Single- and complex-type spectral classification
To classify a spectrum as either detection or non-detection, we require an S/N of at least 4 σ between its peak and estimated noise and a velocity dispersion of > 0.2 km s−1. The noise in the spectrum is estimated from the MAD10 in 30 continuous channels (∼10 km s−1) from either the lower or upper part of the spectrum (shaded pink regions in the DCN spectra) that were identified by eye to be in a line free part of the spectrum. We then split the detected spectra into single- or complex-type. This is done manually by visually inspecting the DCN (3-2) spectra after fitting. Again, we use the higher noise estimates in units of mJy per dirty beam. If multiple components are present in the spectrum, we also classify them as complex-type and remove them from the analysis. The extracted single- and complex-type DCN spectra for each core in each protocluster are shown in Appendix F.
E.2. Comparison of the background and non-background subtracted DCN spectra
In Figures F.11, and E.3, we show the DCN (3-2) detected single- and complex-type spectra identified when performing background-subtraction, and non-background subtraction, respectively, for G338.93. In Figure E.4, for reference, we also show the background spectra. Some of the ’absorption features’ in the background-subtracted spectra result from the background subtraction (e.g. core 13 and 29). The background subtraction also results in some cores with initially complex-type spectra due to the background contamination becoming single-type spectra (e.g. core 16). The background and non-background subtraction detection rates are similar in G338.93, with 18 and 21 detected single-type cores, respectively (with slight differences between which cores are single-type in the two sets), and eight cores with complex-type spectra in both. Furthermore, the average VLSR extracted from all cores is the same (-61 km s−1) when considering either background- or non-background-subtraction. The average linewidth of the fits, however, is smaller (∼1.6 km s−1) for the background-subtracted compared with (∼2.1 km s−1) for the non-background subtracted, which is due to the removal of the background contribution. These background-subtracted spectra are likely more representative of the gas associated with the cores. In Table E.1, we show the same table as in Table 4 but from fitting the non-background subtracted spectra for all cores in each protocluster. This highlights that the general trends across the sample are the same regardless of whether the background or non-background spectra are used.
Characteristic parameters of the DCN (3-2) hyperfine fits for the non-background subtracted.
 |
Fig. E.1. Zoom in towards cores 14 (top-left panel) and 45 (top-right panel) overlaid on the DCN moment 0 map in the protocluster G333.60. The red ellipses are 2 times the major (minor) FWHM of the continuum cores. In the bottom panels, we show examples of the masks (shaded blue areas) and their respective annulus (for core 14) or crown (for core 45), that is used to estimate the core-averaged, background-subtracted DCN (3-2) spectra. The background annulus is defined as 2-3 times the core major (minor) FWHMs from Louvet et al. (2023), with pixels from overlapping cores being masked out (i.e. the resulting crown in core 45). |
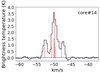 |
Fig. E.2. Example of the DCN (3-2) core-averaged, background-subtracted spectrum extracted for core 14, in G333.60 with the DCN hyperfine model (see Table E.2) overlaid in red vertical dashed lines and are set relative to the central core VLSR. |
DCN hyperfine model.
 |
Fig. E.3. Single-type non-background subtracted spectra in the young protocluster G338.93. They are classified in the same way as the background-subtracted spectra. The associated continuum core number is given in the top left of each panel (the core numbering is taken from Louvet et al. 2023) the core VLSR (V) and velocity dispersion (σ) both in units of km s−1 from the HSF fit are given in the top right. The pink shaded region represents the part of the spectrum used to estimate the MAD noise. |
 |
Fig. E.4. continued: Complex-type, non-background subtracted spectra towards the young protocluster G338.93. |
 |
Fig. E.4. Background spectra which are the average spectra from the background annulus or crown towards the positions of the single-type cores shown in Fig. E.3 in the young protocluster G338.93. The associated core numbers are provided in the top left of each panel. |
 |
Fig. E.4. continued: Background spectra which are the average spectra from the background annulus towards the positions of the complex-type cores shown in Fig. E.3 in the young protocluster G338.93. |
Appendix F: DCN line fits and spectra
We show the extracted single- and complex-type DCN (3-2) spectra for all cores in each of the 15 protoclusters in the ALMA-IMF survey. We also provide the tables of the associated core number, core name, position, and major and minor axes taken from Louvet et al. (2023) along with the DCN line fits extracted for each respective core. If no fit parameters are provided or the name single or complex is not provided, the core was not detected in DCN.
 |
Fig. F.1. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster G008.67. See Table F.1 for the line fit parameters for each core. The associated continuum core number is given in the top left of each panel (the core numbering is taken from Louvet et al. 2023) the core VLSR (V) and velocity dispersion (σ) both in units of km s−1 from the HSF fit are given in the top right. The pink shaded region represents the part of the spectrum used to estimate the MAD noise. |
 |
Fig. F.2. Complex-type core-averaged, background-subtracted DCN spectra extracted from cores in the intermediate protocluster G008.67. See Table F.1 for the line fit parameters for each core. |
DCN fits towards the core population of the intermediate protocluster G008.67.
DCN fits towards the core population of the evolved protocluster G010.62.
 |
Fig. F.3. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G010.62. See Table F.2 for the line fit parameters for each core. |
 |
Fig. F.3. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G010.62. See Table F.2 for the line fit parameters for each core. |
DCN fits towards the core population of the evolved protocluster G012.80.
 |
Fig. F.4. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G012.80. See Table F.3 for the line fit parameters for each core. |
 |
Fig. F.4. continued: Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G012.80. See Table F.3 for the line fit parameters for each core. |
 |
Fig. F.5. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G012.80. See Table F.3 for the line fit parameters for each core. |
DCN fits towards the core population of the young protocluster G327.29.
 |
Fig. F.6. single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G327.29. See Table F.4 for the line fit parameters for each core. |
 |
Fig. F.6. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G327.29. See Table F.4 for the line fit parameters for each core. |
DCN fits towards the core population of the young protocluster G328.25.
 |
Fig. F.7. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G328.25. See Table F.5 for the line fit parameters for each core. |
 |
Fig. F.8. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G328.25. See Table F.5 for the line fit parameters for each core. |
DCN fits towards the core population of the young protocluster G337.92.
 |
Fig. F.9. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G337.92. See Table F.6 for the line fit parameters for each core. |
 |
Fig. F.10. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G337.92. See Table F.6 for the line fit parameters for each core. |
DCN fits towards the core population of the young protocluster G338.93.
 |
Fig. F.11. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G338.93. See Table F.7 for the line fit parameters for each core. |
 |
Fig. F.12. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G338.93. See Table F.7 for the line fit parameters for each core. |
DCN fits towards the core population of the evolved protocluster G333.60.
 |
Fig. F.13. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G333.60. See Table F.8 for the line fit parameters extracted for each core. |
 |
Fig. F.14. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G333.60. See Table F.8 for the line fit parameters extracted for each core. |
DCN fits towards the core population of the intermediate protocluster G351.77.
 |
Fig. F.15. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster G351.77. See Table F.9 for the line fit parameters for each core. |
 |
Fig. F.16. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster G351.77. See Table F.9 for the line fit parameters for each core. |
DCN fits towards the core population of the intermediate protocluster G353.41.
 |
Fig. F.17. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster G353.41. See Table F.10 for the line fit parameters for each core. |
 |
Fig. F.18. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster G353.41. See Table F.10 for the line fit parameters for each core. |
DCN fits towards the core population of the young protocluster W43-MM1.
continued DCN fits towards the core population of the young protocluster W43-MM1.
 |
Fig. F.19. single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster W43-MM1. Readers can refer to Table F.11 for the line fit parameters for each core. |
 |
Fig. F.20. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster W43-MM1. Readers can refer to Table F.11 for the line fit parameters for each core. labelfigf20 |
DCN fits towards the core population of the young protocluster W43-MM2.
 |
Fig. F.21. single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster W43-MM2. Readers can refer to Table F.12 for the line fit parameters for each core. |
 |
Fig. F.22. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster W43-MM2. Readers can refer to Table F.12 for the line fit parameters for each core. |
DCN fits towards the core population of the intermediate protocluster W43-MM3.
 |
Fig. F.23. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster W43-MM3. Readers can refer to Table F.13 for the line fit parameters for each core. |
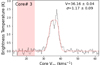 |
Fig. F.24. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster W43-MM3. Readers can refer to Table F.13 for the line fit parameters for each core. |
DCN fits towards the core population of the intermediate protocluster W51-E.
 |
Fig. F.25. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster W51-E. Readers can refer to Table F.14 for the line fit parameters for each core. |
DCN fits towards the core population of the evolved protocluster W51-IRS2.
continued DCN fits towards the core population of the evolved protocluster W51-IRS2.
 |
Fig. F.26. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster W51-E. Readers can refer to Table F.14 for the line fit parameters for each core. |
 |
Fig. F.27. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster W51-IRS2. Readers can refer to Table F.15 for the line fit parameters for each core. |
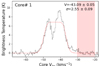 |
Fig. F.27. continued: Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster W51-IRS2. Readers can refer to Table F.15 for the line fit parameters for each core. |
 |
Fig. F.28. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster W51-IRS2. Readers can refer to Table F.15 for the line fit parameters for each core. |
Appendix G: DCN core kinematics
We present the core VLSR and linewidth of the cores with DCN (3-2) detections for the remaining 13 protoclusters. G338.93 and G333.60 are presented in the main body of the text.
 |
Fig. G.1. Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the intermediate, and evolved protocluster G008.67 (top) and G010.62 (bottom), respectively. The circles and stars represent the detected cores with mass estimates below and above 8 M⊙, respectively, with the colour scale displaying the fitted parameters from the DCN (3-2) fits (left: core VLSR, right: linewidth). The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as 37 km s−1, and -2 km s−1 for G008.67, and G010.62, respectively). The grey contours are the 4 σ level of the DCN (3-2) moment 0 map. In the right panels, the positions of cores without a DCN (3-2) detection are marked with a black cross and black star for cores with a mass estimate below and above 8 M⊙, respectively, and green triangles and stars represent cores with a complex-type DCN (3-2) spectra, with a mass estimate below and above 8 M⊙, respectively. |
 |
Fig. G.2. continued: Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the evolved and young protocluster G012.80 (top) and G327.29 (bottom), respectively. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as 37 km s−1 and -45 km s−1 for G012.80 and G327.29, respectively). |
 |
Fig. G.3. continued: Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the young protoclusters G328.25 (top) and G337.92 (bottom), respectively. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as -43 km s−1 and -40 km s−1 for G328.25 and G337.92, respectively). |
 |
Fig. G.4. Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the intermediate protoclusters G351.77 (top) and G353.41 (bottom), respectively. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as -3 km s−1, and -17 km s−1 for G351.77 and G353.41, respectively). |
 |
Fig. G.5. continued: Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the young protoclusters W43-MM1 (top) and W43-MM2 (bottom), respectively. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as 97 km s−1, and 91 km s−1 for W43-MM1, and W43-MM2, respectively). |
 |
Fig. G.6. continued: Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the evolved protocluster W51-IRS2. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as 61 km s−1 for W51-IRS2). |
 |
Fig. G.7. continued: Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the intermediate protoclusters W43-MM3 (top) and W51-E (bottom), respectively. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as 93 km s−1, and 55 km s−1 for W43-MM3, and W51-E, respectively). |
All Tables
Example of the DCN fits towards the first 15 cores of the young protocluster G338.93.
Comparison of molecular line detection towards the continuum core population of G338.93.
Minimum and maximum frequency ranges [GHz] for the spectral window setups for B3 spws (0-3).
continued: Minimum and maximum frequency ranges [GHz] for the spectral window setups for B6 spws (0-3).
continued: Minimum and maximum frequency ranges [GHz] for the spectral window setups for B6 spws (4-7).
Characteristic parameters of the DCN (3-2) hyperfine fits for the non-background subtracted.
DCN fits towards the core population of the intermediate protocluster G008.67.
DCN fits towards the core population of the intermediate protocluster G351.77.
DCN fits towards the core population of the intermediate protocluster G353.41.
continued DCN fits towards the core population of the young protocluster W43-MM1.
DCN fits towards the core population of the intermediate protocluster W43-MM3.
continued DCN fits towards the core population of the evolved protocluster W51-IRS2.
All Figures
|
Fig. 1. Overview of the bandwidth covered by the spectral windows (spws, grey boxes), four in B3 (left panels) and eight in B6 (right panels) towards the 15 ALMA-IMF fields. The black line represents the central frequency for each spectral window. The numbers at the top denote the spectral windows as described in Table 2. The exact frequency coverage is provided in Table A.3. The blue line is the atmospheric transmission at a precipitable water vapour (PWV; The values over the observed frequency range are taken from https://www.apex-telescope.org/sites/chajnantor/atmosphere/transpwv/index_ns.php) of 1.796 mm in B6 and 5.18 mm in B3 (the typical values used in the ALMA sensitivity calculator), for a source at an elevation of 45 degrees. The coverage of the ALMA-IMF pilot program (B6 spectral window 7 for the W43-MM1 field) is offset by 1 GHz. |
| In the text | |
|
Fig. 2. Flow chart providing an overview of the framework of the ALMA-IMF data pipeline employed to produce the line cubes provided in this release. The white boxes labelled from 1–8 describe the steps in the pipeline that are defined by running scripts or procedures (as described in more detail in Sect. 3.1). Red ellipses highlight points where manual input was required to either select which line, spectral window, or configuration on which to perform tclean, or to optimise the tclean parameters after internal quality assessments (green diamonds). |
| In the text | |
|
Fig. 3. Example of the ‘stippling’ effect as previously described in Czekala et al. (2021). The top panel shows nine channels of a zoomed-in region in a restored image cube, cleaned using a 3σ threshold. The central channel shows the resulting spurious emission peak. This bright emission, of order the beam size, is only present in a single channel, while the neighbouring pixels show no equivalent emission. The bottom panel shows the model extracted at the central pixel, where the bright model component (green line) is only found in a single pixel and channel. This model component is then convolved with the Gaussian clean beam during the tclean run to produce the restored image, resulting in spurious compact emission in a single channel. |
| In the text | |
|
Fig. 4. Example of the JvM correction for the peak channel of the H41α line in spectral window 1 of Band 3 for protocluster G333.60. The top left panel shows the original PSF (i.e. the dirty beam), where the red circle marks the first null. The top right panel shows the absolute value of the radial profile of the beam (black solid line) and the corresponding approximation to a Gaussian clean beam (blue dashed line). The ϵ factor, defined as the ratio of the clean-to-dirty beam volumes, is 0.32 in this example. The residuals are shown for the original image (middle left panel) and after (middle right), the JvM correction is applied. The red rectangle shows the aperture where the quoted fluxes are measured. The restored images without (bottom left) and with JvM (bottom right) correction are shown in the bottom panels. |
| In the text | |
|
Fig. 5. Ratio of the average line to continuum beam for each protocluster and spectral window (B3 top; B6 bottom panels). Where the average beam is defined as |
| In the text | |
|
Fig. 6. Absolute value of the radial mean of the PSF (dirty beam) for the protocluster G012.80 as a function of the distance from the PSF centre (in arcseconds). B3 spectral windows are shown on the left and B6 spectral windows are on the right. The solid lines use the .psf outputs from tclean and the dashed lines are the expected Gaussian clean beams (the FWHM is taken from the geometric mean of the beam major and minor axes). For the B3 spectral windows, the Gaussian clean beam is a good approximation to the PSF only within ∼50% of its FWHM. B3 spectral window 0 shows the largest deviation, resulting in a larger estimation of the respective Gaussian clean beam in tclean. The B6 spectral windows typically show a better correspondence between the PSFs and the Gaussian clean beam. |
| In the text | |
|
Fig. 7. Expected thermal noise from the observations vs the achieved noise in the cubes for each spectral window in Kelvin (B3 left panel and B6 right panel). The Y-axis shows the measured noise in the released cubes in Jy per dirty beam converted to brightness temperature as described in Sect. 3.4. The X-axis shows the expected brightness temperature sensitivity for the proposed beam sizes (see Table A.1). Furthermore, to directly compare the achieved noise in the data to the expected noise from the proposed observations, we scale the expected noise by the frequency difference between the requested representative frequency and the central frequency of each spectral window. We also scale the expected noise by the difference in the representative channel width and the achieved channel width for each spectral window. As shown in Fig. 5, the achieved beam area is typically larger than the continuum beam by ∼1–1.5×. Thus, the expected noise is also scaled to account for the difference in the beam areas between the achieved and proposed beams (see Table A.2 for the exact proposed beams and achieved beams per field). The shaded regions show a noise within a factor of two (pink) and four (blue) from the expected noise, and the dashed line represents a 1 to 1 ratio. We typically achieve a noise on average ∼2–2.5 times lower than expected. |
| In the text | |
|
Fig. 8. Moment maps (moment 0, 1, and 2 in the left, centre, and right panels, respectively) of DCN (3–2) emission towards two example protoclusters with different evolutionary classifications, the young protocluster G338.93 (top), and the evolved G333.60 (bottom). All three moments have been determined over a velocity range of −53.4 to −68.6 km s−1 and −40 to −52.7 km s−1 for G338.93 and G333.60, respectively. For the moment 0 and moment 2 maps, we overlay the core positions and sizes (red ellipses) from the continuum core catalogue described in Louvet et al. (2023). For the moment 1 and moment 2 maps, we show a zoom-in of the area highlighted by the yellow dashed box overlaid on the moment 0 map. The moment 1 and moment 2 maps have an additional threshold cut per channel of 4σ. The synthesised beam is shown in the bottom left corner of each image. These maps highlight differences in the morphology traced by the DCN (3–2) emission, where the emission is more widespread and filamentary towards the evolved region G333.60 than in the young region G338.93. This trend in the DCN (3–2) emission morphology with the evolutionary stage is consistent across the full ALMA-IMF sample. |
| In the text | |
|
Fig. 9. Example of the core-averaged, background-subtracted DCN (3–2) single-type spectra for six cores in the young protocluster G338.93. The associated continuum core number is given in the top left of each panel (the core numbering is taken from Louvet et al. 2023). The core VLSR (V) and velocity dispersion (σ) in units of km s−1 from the HSF fit are given in the top right. The line fit parameters for each core are also presented in Table 3. The pink-shaded region represents the part of the spectrum used to estimate the MAD noise. |
| In the text | |
|
Fig. 10. Example of the core-averaged, background-subtracted DCN (3–2) complex-type spectra for six cores in the young protocluster G338.93. The associated continuum core number is given in the top left of each panel (the core numbering is taken from Louvet et al. 2023). The core VLSR (V) and velocity dispersion (σ) in units of km s−1 from the HSF fit are given in the top right. Given the complex structure in their spectra, the resulting fits are excluded from the analysis and labelled as complex-type spectra. The pink-shaded region represents the part of the spectrum used to estimate the MAD noise. |
| In the text | |
|
Fig. 11. Distribution of the core velocities from the DCN line fits split by evolutionary stage. The velocity offset is determined as the central velocity of the fit and subtracting from it the average protocluster velocity (estimated from the average of the DCN (3–2) moment 1 maps). The vertical dashed lines are the average values for each subgroup (0.13 km s−1, −0.29 km s−1, and 0.44 km s−1 for the young, intermediate and evolved regions, respectively). We find no obvious dependence on the distribution of the core velocities over the sample. |
| In the text | |
|
Fig. 12. Linewidths extracted towards the core population of G338.93 for the molecules listed in Table 5 as a function of the continuum core masses taken from Louvet et al. (2023), assuming the core dust temperature estimates as given in Table 3. The linewidths shown are from fits classified as single-type which can be well approximated by a single Gaussian (or single HFS fit for DCN) component fit to the extracted spectrum. The grey vertical lines represent the masses of all 42 cores in the G338.93 protocluster. DCN (3–2) well represents the full mass range of the cores in the protocluster. |
| In the text | |
|
Fig. 13. Core VLSR (left) and DCN (3–2) linewidths (right) estimated from the DCN (3–2) fits to the continuum cores towards examples of a young and an evolved protocluster G338.93 (top) and G333.60 (bottom), respectively. The circles and stars represent the detected cores with mass estimates below and above 8 M⊙, respectively, with the colour scale displaying the fitted parameters from the DCN (3–2) fits (left: core VLSR, right: linewidth). The core VLSR is the centroid velocity of the DCN (3–2) fit minus the cloud VLSR (taken as −62 km s−1, and −47 km s−1 for G338.93, and G333.60, respectively). The grey contours are the 4σ level of the DCN (3–2) moment 0 map. In the right panels, the positions of cores without a DCN (3–2) detection are marked with a black cross and with a black star for cores with a mass estimate below and above 8 M⊙, respectively, and green triangles and stars represent cores with a complex-type DCN (3–2) spectra, with a mass estimate below and above 8 M⊙, respectively. |
| In the text | |
|
Fig. 14. Core VLSR vs the core radial offset grouped by evolutionary classification of the host protocluster; young, intermediate and evolved (Y: left, I: centre, and E: right, respectively). The radial spatial offset for each core is determined by taking the position of the core and subtracting from it the mean position of all cores in its protocluster and assuming the distances given in Table 1 for each region. The velocity offset for each core is determined by subtracting the centroid VLSR found from all cores with single-type spectra in a given region from it. The cores are colour-coded by their mass estimates taken from Louvet et al. (2023), and star symbols represent those cores with mass estimates > 8 M⊙. Cores with a declination smaller than the average position have a negative offset. For the young and intermediate regions, the spatial distribution of the cores is more compact compared to cores in evolved protoclusters, where the cores can be spatially distributed over larger areas (> 2.0 pc). |
| In the text | |
|
Fig. 15. Distribution of the core linewidths from DCN single-type line fits as a function of protocluster distance (left). The red triangles, blue plusses, and black crosses represent the linewidths of core emission associated with evolved, intermediate, and young protoclusters, respectively. There is no obvious dependence on the protocluster distance and the linewidths. Right: Histogram of the linewidths from the DCN line fits grouped by evolutionary stage, where the solid red, blue dot-dashed, and black dashed lines represent the evolved, intermediate, and young protoclusters, respectively. The vertical lines display the mean linewidth for each evolutionary stage with the same colours described above. The evolved regions have a slightly smaller average linewidth (1.2 km s−1) than young and intermediate regions (∼1.5 km s−1), significant within the standard errors. |
| In the text | |
|
Fig. 16. Distribution of the core-size as a function of the respective non-thermal velocity dispersion from the DCN (3-2) spectra. The red triangles, blue plusses, and black crosses represent evolved, intermediate, and young protoclusters, respectively. The red, blue, and black squares are the average values (0.50 km s−1, 0.63 km s−1, and 0.63 km s−1) for the collective evolved, intermediate and young values, respectively, where the error bars represent the standard deviations (0.22 km s−1, 0.27 km s−1, and 0.33 km s−1, respectively). The black dashed line is the Larson relation (Larson 1981), and nearly all cores are above it. The black circle and error bar provide an estimate of the typical errors on the linewidth estimates. We find no correlation between the non-thermal velocity dispersion with core-size in the ranges of values sampled here. |
| In the text | |
|
Fig. 17. Histograms of the mass distribution (in log scale) of the cores in the combined young + intermediate regions (top panel) and evolved regions (bottom panel). The shaded red and blue areas show the cores with single-type DCN (3–2) and complex-type spectra, respectively. The dashed black line represents cores with a DCN (3–2) non-detection. The red, blue, and black dashed vertical lines represent the average mass values (top: 5.6 M⊙, 20.1 M⊙, and 3.1 M⊙; bottom: 3.6 M⊙, 10.2 M⊙, and 1.8 M⊙) for the single-, complex-type, and non-detections, respectively. We find that the complex-type cores have an average mass nearly an order of magnitude higher than those without a DCN (3–2) detection and around three times higher than cores with a single-type DCN detection, regardless of evolutionary class. |
| In the text | |
|
Fig. D.1. Moment maps (moment 0, 1, and 2 in the left, centre, and right panels, respectively) of DCN (3-2) emission towards the protoclusters G008.67 (top), G010.62 (middle), and G012.80 (bottom). All three moments have been determined over a velocity range of 31.7 to 43 km s−1, −9.3 to 5.8 km s−1, and 30.7 to 43 km s−1 for G008.67, G010.62, and G012.80, respectively. For the moment 0 and moment 2 maps, we overlay the core positions and sizes (red ellipses) from the continuum core catalogue described in Louvet et al. (2023). For the moment 1 and moment 2 maps, we show a zoom-in of the area highlighted by the yellow dashed box overlaid on the moment 0 map. The moment 1 and moment 2 maps have an additional threshold cut per channel of 4 σ. The synthesised beam is shown in the bottom left corner of each image. |
| In the text | |
|
Fig. D.1. continued. Moment maps (Moment 0, 1, and 2 in the left, centre, and right panels, respectively) of DCN (3-2) for G327.29 (top), G328.25 (middle), and G337.92 (bottom). Maps were calculated over a velocity range of −50.2 to −39.7 km s−1, −47.5 to −41 km s−1, and −30.8 to −45 km s−1, respectively. |
| In the text | |
|
Fig. D.1. continued. Moment maps (Moment 0, 1, and 2 in the left, centre, and right panels, respectively) of DCN (3-2) for G351.77 (top), G353.41 (middle), and W43-MM1 (bottom). Maps were calculated over a velocity range of −9.8 to 3.2 km s−1, −20.5 to −12.7 km s−1, and 92.7 to 105 km s−1, respectively. |
| In the text | |
|
Fig. D.1. continued. Moment maps (Moment 0, 1, and 2 in the left, centre, and right panels, respectively) of DCN (3-2) for W43-MM2 (top), W43-MM3 (middle), and W51-E (bottom). Maps were calculated over a velocity range of 85.7 to 94 km s−1, 90.4 to 95.8 km s−1, and 46 to 64 km s−1, respectively. |
| In the text | |
|
Fig. D.1. continued. Moment maps (Moment 0, 1, and 2 in the left, centre and right panels, respectively) of DCN (3-2) for W51-IRS2. Maps were calculated over a velocity range of 52.4 to 68 km s−1. |
| In the text | |
|
Fig. E.1. Zoom in towards cores 14 (top-left panel) and 45 (top-right panel) overlaid on the DCN moment 0 map in the protocluster G333.60. The red ellipses are 2 times the major (minor) FWHM of the continuum cores. In the bottom panels, we show examples of the masks (shaded blue areas) and their respective annulus (for core 14) or crown (for core 45), that is used to estimate the core-averaged, background-subtracted DCN (3-2) spectra. The background annulus is defined as 2-3 times the core major (minor) FWHMs from Louvet et al. (2023), with pixels from overlapping cores being masked out (i.e. the resulting crown in core 45). |
| In the text | |
|
Fig. E.2. Example of the DCN (3-2) core-averaged, background-subtracted spectrum extracted for core 14, in G333.60 with the DCN hyperfine model (see Table E.2) overlaid in red vertical dashed lines and are set relative to the central core VLSR. |
| In the text | |
|
Fig. E.3. Single-type non-background subtracted spectra in the young protocluster G338.93. They are classified in the same way as the background-subtracted spectra. The associated continuum core number is given in the top left of each panel (the core numbering is taken from Louvet et al. 2023) the core VLSR (V) and velocity dispersion (σ) both in units of km s−1 from the HSF fit are given in the top right. The pink shaded region represents the part of the spectrum used to estimate the MAD noise. |
| In the text | |
|
Fig. E.4. continued: Complex-type, non-background subtracted spectra towards the young protocluster G338.93. |
| In the text | |
|
Fig. E.4. Background spectra which are the average spectra from the background annulus or crown towards the positions of the single-type cores shown in Fig. E.3 in the young protocluster G338.93. The associated core numbers are provided in the top left of each panel. |
| In the text | |
|
Fig. E.4. continued: Background spectra which are the average spectra from the background annulus towards the positions of the complex-type cores shown in Fig. E.3 in the young protocluster G338.93. |
| In the text | |
|
Fig. F.1. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster G008.67. See Table F.1 for the line fit parameters for each core. The associated continuum core number is given in the top left of each panel (the core numbering is taken from Louvet et al. 2023) the core VLSR (V) and velocity dispersion (σ) both in units of km s−1 from the HSF fit are given in the top right. The pink shaded region represents the part of the spectrum used to estimate the MAD noise. |
| In the text | |
|
Fig. F.2. Complex-type core-averaged, background-subtracted DCN spectra extracted from cores in the intermediate protocluster G008.67. See Table F.1 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.3. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G010.62. See Table F.2 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.3. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G010.62. See Table F.2 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.4. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G012.80. See Table F.3 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.4. continued: Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G012.80. See Table F.3 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.5. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G012.80. See Table F.3 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.6. single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G327.29. See Table F.4 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.6. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G327.29. See Table F.4 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.7. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G328.25. See Table F.5 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.8. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G328.25. See Table F.5 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.9. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G337.92. See Table F.6 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.10. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G337.92. See Table F.6 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.11. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G338.93. See Table F.7 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.12. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster G338.93. See Table F.7 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.13. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G333.60. See Table F.8 for the line fit parameters extracted for each core. |
| In the text | |
|
Fig. F.14. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster G333.60. See Table F.8 for the line fit parameters extracted for each core. |
| In the text | |
|
Fig. F.15. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster G351.77. See Table F.9 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.16. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster G351.77. See Table F.9 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.17. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster G353.41. See Table F.10 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.18. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster G353.41. See Table F.10 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.19. single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster W43-MM1. Readers can refer to Table F.11 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.20. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster W43-MM1. Readers can refer to Table F.11 for the line fit parameters for each core. labelfigf20 |
| In the text | |
|
Fig. F.21. single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster W43-MM2. Readers can refer to Table F.12 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.22. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the young protocluster W43-MM2. Readers can refer to Table F.12 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.23. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster W43-MM3. Readers can refer to Table F.13 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.24. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster W43-MM3. Readers can refer to Table F.13 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.25. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster W51-E. Readers can refer to Table F.14 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.26. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the intermediate protocluster W51-E. Readers can refer to Table F.14 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.27. Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster W51-IRS2. Readers can refer to Table F.15 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.27. continued: Single-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster W51-IRS2. Readers can refer to Table F.15 for the line fit parameters for each core. |
| In the text | |
|
Fig. F.28. Complex-type core-averaged, background-subtracted DCN spectra extracted from the cores in the evolved protocluster W51-IRS2. Readers can refer to Table F.15 for the line fit parameters for each core. |
| In the text | |
|
Fig. G.1. Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the intermediate, and evolved protocluster G008.67 (top) and G010.62 (bottom), respectively. The circles and stars represent the detected cores with mass estimates below and above 8 M⊙, respectively, with the colour scale displaying the fitted parameters from the DCN (3-2) fits (left: core VLSR, right: linewidth). The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as 37 km s−1, and -2 km s−1 for G008.67, and G010.62, respectively). The grey contours are the 4 σ level of the DCN (3-2) moment 0 map. In the right panels, the positions of cores without a DCN (3-2) detection are marked with a black cross and black star for cores with a mass estimate below and above 8 M⊙, respectively, and green triangles and stars represent cores with a complex-type DCN (3-2) spectra, with a mass estimate below and above 8 M⊙, respectively. |
| In the text | |
|
Fig. G.2. continued: Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the evolved and young protocluster G012.80 (top) and G327.29 (bottom), respectively. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as 37 km s−1 and -45 km s−1 for G012.80 and G327.29, respectively). |
| In the text | |
|
Fig. G.3. continued: Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the young protoclusters G328.25 (top) and G337.92 (bottom), respectively. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as -43 km s−1 and -40 km s−1 for G328.25 and G337.92, respectively). |
| In the text | |
|
Fig. G.4. Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the intermediate protoclusters G351.77 (top) and G353.41 (bottom), respectively. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as -3 km s−1, and -17 km s−1 for G351.77 and G353.41, respectively). |
| In the text | |
|
Fig. G.5. continued: Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the young protoclusters W43-MM1 (top) and W43-MM2 (bottom), respectively. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as 97 km s−1, and 91 km s−1 for W43-MM1, and W43-MM2, respectively). |
| In the text | |
|
Fig. G.6. continued: Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the evolved protocluster W51-IRS2. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as 61 km s−1 for W51-IRS2). |
| In the text | |
|
Fig. G.7. continued: Core VLSR (left) and DCN (3-2) linewidths (right) estimated from the DCN (3-2) fits to the continuum cores towards the intermediate protoclusters W43-MM3 (top) and W51-E (bottom), respectively. The core VLSR is the centroid velocity of the DCN (3-2) fit minus the cloud VLSR (taken as 93 km s−1, and 55 km s−1 for W43-MM3, and W51-E, respectively). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.