| Issue |
A&A
Volume 661, May 2022
The Early Data Release of eROSITA and Mikhail Pavlinsky ART-XC on the SRG mission
|
|
|---|---|---|
| Article Number | A2 | |
| Number of page(s) | 25 | |
| Section | Catalogs and data | |
| DOI | https://doi.org/10.1051/0004-6361/202141120 | |
| Published online | 18 May 2022 | |
The eROSITA Final Equatorial-Depth Survey (eFEDS)
Catalog of galaxy clusters and groups★
1
Max Planck Institute for Extraterrestrial Physics,
Giessenbachstrasse 1,
85748
Garching,
Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Universitaets-Sternwarte Muenchen, Fakultaet fuer Physik, LMU Munich,
Scheinerstr. 1,
81679
Munich,
Germany
3
IRAP, Université de Toulouse, CNRS, UPS, CNES,
Toulouse,
France
4
Argelander-Institut für Astronomie (AIfA), Universität Bonn,
Auf dem Hügel 71,
53121
Bonn,
Germany
5
Physics Program, Graduate School of Advanced Science and Engineering, Hiroshima University,
1-3-1 Kagamiyama, Higashi-Hiroshima,
Hiroshima
739-8526,
Japan
6
Hiroshima Astrophysical Science Center, Hiroshima University,
1-3-1 Kagamiyama, Higashi-Hiroshima,
Hiroshima
739-8526,
Japan
7
Core Research for Energetic Universe, Hiroshima University,
1-3-1, Kagamiyama, Higashi-Hiroshima,
Hiroshima
739-8526,
Japan
8
INAF – Osservatorio Astronomico di Trieste,
via Tiepolo 11,
34143
Trieste,
Italy
9
IFPU – Institute for Fundamental Physics of the Universe,
Via Beirut 2,
34014
Trieste,
Italy
10
University of Hamburg, Hamburger Sternwarte,
Gojenbergsweg 112,
21029
Hamburg,
Germany
11
Tsung-Dao Lee Institute, and Key Laboratory for Particle Physics, Astrophysics and Cosmology, Ministry of Education, Shanghai Jiao Tong University,
Shanghai
200240,
PR China
12
Department of Astronomy, School of Physics and Astronomy, and Shanghai Key Laboratory for Particle Physics and Cosmology, Shanghai Jiao Tong University,
Shanghai
200240,
PR China
13
Academia Sinica Institute of Astronomy and Astrophysics (ASIAA),
11F of AS/NTU Astronomy-Mathematics Building, No.1, Sec. 4, Roosevelt Rd,
Taipei
10617,
Taiwan
14
Leibniz-Institut für Astrophysik Potsdam (AIP),
An der Sternwarte 16,
14482
Potsdam,
Germany
15
Research Center for the Early Universe, The University of Tokyo,
7-3-1 Hongo, Bunkyo-ku,
Tokyo
113-0033,
Japan
16
Department of Physics, The University of Tokyo,
7-3-1 Hongo, Bunkyo-ku,
Tokyo
113-0033,
Japan
17
Kavli Institute for the Physics and Mathematics of the Universe (Kavli IPMU, WPI), The University of Tokyo,
5-1-5 Kashiwanoha, Kashiwa,
Chiba
277-8582,
Japan
18
Department of Physics, Nara Women's University, Kitauoyanishimachi,
Nara
630-8506,
Japan
Received:
19
April
2021
Accepted:
7
July
2021
Abstract
Aims. The eROSITA Final Equatorial-Depth Survey has been carried out during the performance verification phase of the Spectrum-Roentgen-Gamma/eROSITA telescope and was completed in November 2019. This survey is designed to provide the first eROSITA-selected sample of clusters and groups and to test the predictions for the all-sky survey in the context of cosmological studies with clusters of galaxies.
Methods. In the area of ~140 square degrees covered by eFEDS, 542 candidate clusters and groups of galaxies were detected as extended X-ray sources with the eSASS source detection algorithm. We performed imaging and spectral analysis of the 542 cluster candidates with eROSITA X-ray data and studied the properties of the sample.
Results. We provide the catalog of candidate galaxy clusters and groups detected by eROSITA in the eFEDS field down to a flux of ~10–14 erg s–1 cm–2 in the soft band (0.5–2 keV) within 1’. The clusters are distributed in the redshift range ɀ = [0.01, 1.3] with a median redshift ɀmedian = 0.35. With eROSITA X-ray data, we measured the temperature of the intracluster medium within two radii, 300 kpc and 500 kpc, and constrained the temperature with >2σ confidence level for ~1/5 (102 out of 542) of the sample. The average temperature of these clusters is ~2 keV. Radial profiles of flux, luminosity, electron density, and gas mass were measured from the precise modeling of the imaging data. The selection function, the purity, and the completeness of the catalog are examined and discussed in detail. The contamination fraction is ~1/5 in this sample and is dominated by misidentified point sources. The X-ray luminosity function of the clusters agrees well with the results obtained from other recent X-ray surveys. We also find 19 supercluster candidates in this field, most of which are located at redshifts between 0.1 and 0.5, including one cluster at ɀ ~ 0.36 that was presented previously.
Conclusions. The eFEDS cluster and group catalog at the final eRASS equatorial depth provides a benchmark proof of concept for the eROSITA All-Sky Survey extended source detection and characterization. We confirm the excellent performance of eROSITA for cluster science and expect no significant deviations from our pre-launch expectations for the final all-sky survey.
Key words: surveys / galaxies: clusters: general / galaxies: clusters: intracluster medium / X-rays: galaxies: clusters
The full cluster catalog is only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/cat/J/A+A/661/A2
© A. Liu et al. 2022
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access funding provided by Max Planck Society.
1 Introduction
The extended ROentgen Survey with an Imaging Telescope Array (eROSITA, Predehl et al. 2021) on board the Spectrum-Roentgen-Gamma (SRG) mission is a German-Russian X-ray telescope launched on July 13, 2019. With the large collecting area (1365 cm2 at 1 keV), moderate angular resolution (on-axis half-energy width, HEW, ~18” at 1.49 keV), and wide energy band coverage (0.2–10 keV) (Predehl et al. 2021), eROSITA will provide an X-ray all-sky survey with unprecedented sensitivity. The complete eROSITA All-Sky Survey (eRASS) will be about 25 times more sensitive than the ROSAT All-Sky Survey (RASS, Voges et al. 1999) in the soft X-ray band (0.2–2.3 keV), and will be the first ever true X-ray imaging all-sky survey in the hard band (2.3–10 keV) (Merloni et al. 2012). The final eROSITA All-Sky Survey will consist of eight complete scans of the X-ray sky by the end of 2023, each lasting for six months. The first and second scans have already been completed in June and December 2020.
One of the main science goals of eROSITA is to study cosmology by detecting a large number of galaxy clusters and groups (for simplicity, we use the term “clusters” to refer to the assembly of X-ray emitting galaxy clusters and groups unless noted otherwise), which are the main extended sources in the X-ray sky. Clusters are the most massive gravitationally bound systems in the Universe. Located in the area of science where cosmology and astrophysics meet, clusters play a unique role in tracing the formation and evolution of the large-scale structure (see Allen et al. 2011, for a review) and the various astrophysical processes on smaller scales (e.g., Rosati et al. 2002). Studies on cluster-related cosmology and astrophysics require a large sample of clusters with a clean selection function and an accurate mass calibration (see, e.g., Pratt et al. 2019).
The first X-ray imaging all-sky survey, RASS, was performed by ROSAT in the 1990s (Voges et al. 1999). It surveyed the X-ray sky in the soft (0.1-2.4 keV) band. RASS-based catalogs, such as ROSAT Brightest Cluster Sample (BCS, Ebeling et al. 1998), Northern ROSAT All-Sky Galaxy Cluster Survey (NORAS, Böhringer et al. 2000), ROSAT-ESO Flux Limited X-ray Galaxy Cluster Survey (REFLEX, Böhringer et al. 2001), Massive Cluster Survey (MACS, Ebeling et al. 2001), Clusters In the Zone of Avoidance (CIZA, Ebeling et al. 2002), and several other catalogs compiled in more recent years (see, e.g., Piffaretti et al. 2011; Böhringer et al. 2014, Böhringer et al. 2017; Klein et al. 2019; Finoguenov et al. 2020), contain a few thousand clusters in total, reaching a flux limit of ~10–12 erg s–1 cm–2. However, the sensitivity of ROSAT limits its capability of detecting high-redshift and low-mass clusters. In the past ten years, the Sunyaev-Zeldovich (SZ) effect surveys, such as South Pole Telescope (SPT, Bleem et al. 2015), Atacama Cosmology Telescope (ACT, Hasselfield et al. 2013), and Planck (Planck Collaboration XXIX 2014), have also made a remarkable contribution to increase the ICM-based cluster sample. Nevertheless, the ther-modynamical and chemical properties of the SZ selected clusters also need to be measured based on X-ray follow-up observations. Moreover, X-ray surveys are more sensitive in detecting low-mass nearby clusters compared to other bands such as SZ and optical, and they are less affected by projection effects. It is therefore necessary to establish a larger and deeper X-ray cluster sample that effectively extends to high-redshift and low-mass regimes.
In the years after RASS, a number of small- and medium-area X-ray surveys have been conducted based on XMM-Newton and Chandra (see, e.g., Hasinger et al. 2007; Cappelluti et al. 2007; Finoguenov et al. 2007, 2010, 2015; Pierre et al. 2007, 2016; Clerc et al. 2012; Gozaliasl et al. 2019; Koulouridis et al. 2021). Although the sky coverage of most of these surveys is smaller than 100 square degrees, hundreds of clusters have been detected, reaching fluxes of 10–15 erg s–1 cm–2, because of the high sensitivity of the instruments and the sufficient depth of the surveys. With well-understood selection functions and extensive follow-up observations, these samples play an important role in the study of cluster physics and the constraints of cosmology (see, e.g., Pacaud et al. 2016, 2018; Ridl et al. 2017; Adami et al. 2018) and fill the gap between RASS and the next generation of X-ray all-sky survey. As the successor of ROSAT, one of the main design goals of eROSITA is to provide a larger X-ray selected sample of clusters. eROSITA is expected to detect ~105 clusters in the complete all-sky survey (Merloni et al. 2012; Pillepich et al. 2012), up to redshifts ɀ ~ 1.5, down to masses of M500 ~ 1013 M⊙, and reaching a flux limit of f0.5-2 kev ~ 10–14 erg s–1 cm–2. This cluster catalog will inevitably be a valuable resource for testing and constraining cosmological models with the aim to trace the evolution of the large-scale structure and to study cluster-related astrophysics.
A proof-of-concept mini-survey, the eROSITA Final Equatorial-Depth Survey (eFEDS), was designed to demonstrate the survey science capabilities of eROSITA. The observations of the eFEDS field were performed between November 4 and 7, 2019, during the performance verification phase. The eFEDS field is located at 126° < RA < 146° and –3° < Dec < +6°, covering a solid angle of approximately 140 square degrees (137.9 deg2 have a vignetting-corrected exposure time in the 0.5-2 keV band of 0.1 ks or more), with the similar depth as the full eROSITA All-Sky Survey in the equatorial regions. The average exposure times are ~2.2 and ~1.2 ks before and after correcting for vignetting effects. The eFEDS field has also been observed with a broad array of multiwavelength survey instruments from optical to radio bands. In particular the photometric data from the Hyper Suprime-Cam (HSC) Subaru Strategic Program (HSC-SSP; Aihara et al. 2018a,b, 2019; Miyazaki et al. 2018; Komiyama et al. 2018; Kawanomoto et al. 2018; Furusawa et al. 2018; Bosch et al. 2018; Huang et al. 2018; Coupon et al. 2018; Oguri et al. 2018), DECaLS (Dark Energy Camera Legacy Survey, Dey et al. 2019), SDSS (Sloan Digital Sky Survey, Blanton et al. 2017), 2MRS (2MASS Redshift Survey, Huchra et al. 2012), and GAMA (Galaxy And Mass Assembly, Driver et al. 2009) surveys are used for optical confirmation and redshift determination of the clusters, and HSC, in particular, will provide weak-lensing masses for eFEDS clusters (Klein et al. 2022; Chiu et al. 2022). A combination of these with the X-ray properties measured with eROSITA data will enable the calibration of scaling relations between X-ray observables and cluster halo mass (Ghirardini et al. 2022; Bahar et al. 2022). Being the largest contiguous survey at the final Equatorial depth, it provides an ideal setup for testing the predictions for the cluster number density in the survey and offers rich cluster science through its multiwavelength coverage (e.g., Ghirardini et al. 2021; Pasini et al. 2022).
In this paper, we present the catalog of candidate galaxy clusters and groups detected in eFEDS, and provide the first results of the X-ray analysis on these clusters based on eROSITA data. More detailed studies of the eFEDS clusters will also be presented in a series of accompanying and forthcoming papers. Klein et al. (2022) present the optical identification of the eFEDS cluster candidates. Chiu et al. (2022); Ramos-Ceja et al. (2022), and Ota et al. (in prep.) perform an optical and weak-lensing analysis on the eFEDS clusters. Radio properties of the clusters are studied in Pasini et al. (2022). ICM morphology and X-ray scaling relations based on eROSITA data are studied in Ghirardini et al. (2022) and Bahar et al. (2022), respectively. Spectroscopic follow-up results will be provided in Ider Chitham et al. (in prep.). The catalog of cluster candidates that are misidentified as point sources will be presented in Bulbul et al. (2022). Moreover, the main eFEDS X-ray source catalog is provided in Brunner et al. (2022). The eFEDS simulation results are introduced in detail in Liu et al. (2022).
The paper is organized as follows. In Sect. 2 we describe the eROSITA observations of the eFEDS field and the source detection in detail and discuss the potential contamination in the sample. We also summarize in this section the optical confirmation and redshift determination of the clusters on the basis of optical photometric and spectroscopic survey data. In Sect. 3 we examine the selection function of the cluster sample. In Sect. 4 we provide the details of the X-ray data analysis we performed in this work and of the X-ray observables. In Sect. 5 we compute the X-ray luminosity function of the cluster sample. In Sect. 6 we perform a search for superclusters in the eFEDS field on the basis of the spatial distribution and redshifts of the clusters. Our conclusions are summarized in Sect. 7. Throughout this paper, we adopt the concordance ACDM cosmology with ΩA = 0.7, Ωm = 0.3, and H0 = 70 km s–1 Mpc–1. Quoted error bars correspond to a 1σ confidence level unless noted otherwise.
2 eFEDS extended source catalog
2.1 eROSITA observation and data calibration
The data are processed with the eROSITA Standard Analysis Software System (eSASS, Brunner et al. 2022)1. The details of the data reduction and calibration are described in Brunner et al. (2022) and Dennerl et al. (2020). We here provide a short summary of the analysis steps. Pattern recognition and energy calibration are applied for all the seven eROSITA telescope modules (TMs) to produce calibrated event lists. The event lists are then filtered after the determination of good time intervals, dead times, corrupted events and frames, and bad pixels. Using star-tracker and gyro data, we assign celestial coordinates to the reconstructed X-ray photons, which can then be projected on the sky so that images and exposure maps can be produced. We select all valid pixel patterns here, that is, single, double, triple, and quadruple events, but use only photons that are detected at off-axis angles ≤30’. By doing this, we remove the photons in the corners of the square CCDs where the vignetting and point spread function (PSF) calibrations are currently less accurate.
 |
Fig. 1 Exposure-corrected point-source-free 0.2–2.3 keV adaptively smoothed eROSITA image of the eFEDS field. In detail, a point source mask is constructed by excluding regions around each point source in which the surface brightness is above 10% of the background surface brightness. The accumulate_counts program from the contour binning package (Sanders & Fabian 2006) is used to calculate a map containing the radius around each pixel (including those in masked areas) that encloses at least 36 counts (excluding masked sources). This map is used to smooth the input image and exposure map with Gaussians, excluding masked areas, where σ is given by the radius in each pixel. The smoothed image and exposure map were divided to create the exposure-corrected image shown here. |
2.2 Source detection strategy
The details of the source detection for eFEDS are presented in Brunner et al. (2022). We briefly summarize the compilation of the extended source catalog. The source detection was performed using the tool erbox in eSASS on the merged 0.2–2.3 keV image of all seven eROSITA TMs. erbox is a modified sliding-box algorithm that searches for sources on the input image that are brighter than the expected background fluctuation at a given image position. The source detection procedure contains the following steps. As the first step, erbox is applied to scan the X-ray image with a local sliding window and returns a list of candidate sources that are enhancements with respect to the background above a certain threshold. The background is interpolated from a frame-shaped region around the detection window. The candidate sources identified in the first step are then excised from the original image. The resulting source-free image is then used to create a background map through adaptive filtering using the erbackmap tool in eSASS. The source detection with erbox is then repeated, but using the new background map created in the last step, producing a new list of candidate sources. The erbox+erbackmap iteration is run three times to enhance the reliability of the background map and the sensitivity of the detection algorithm.
In the second step, the source parameters for each candidate, such as the detection likelihood, the extent likelihood, and the extent, are determined by fitting the image with the source model, which is aβ-model convolved with the calibrated PSF, in which rc equals to the extent of the source, and is set free to vary between 8” and 60” for extended sources. This step is performed using the ermldet tool in eSASS.
We applied these source detection procedures on the 0.2–2.3 keV image of the eFEDS field. Setting the minimum detection likelihood, ℒdet = ln(P), at 5 and the minimum extent likelihood ℒext at 6, we detect 542 candidate extended sources over the full eFEDS field. This corresponds to an extended source density of about four sources per square degree at the equatorial depth. The eROSITA image of the eFEDS field in which the extended sources are highlighted is shown in Fig. 1. The distribution of the sources in the field with redshift information (see Sect. 2.3) is shown in Fig. 2.
2.3 Optical confirmation and redshift determination
The photometric redshifts of the clusters are determined based on the multicomponent matched filter (MCMF) cluster confirmation tool (see Klein et al. 2018, Klein et al. 2019, for more details). The MCMF tool takes optical photometric datasets and searches for galaxy overdensities along the line of sight at the position of a cluster candidate. To do this, the galaxy cluster richness is measured as a function of redshift using a red-sequence technique and within an aperture defined from the X-ray count rate. Peaks in richness versus redshift space are fit by specific peak profiles, and redshift and richnesses are recorded for multiple possible counterparts along the line of sight. MCMF is then run on random lines of sight excluding regions around X-ray candidates. MCMF on eFEDS was run on two photometric datasets with different optical filters and depth: DECaLS ɡ, r, ɀ and unWISE W1 bands, and HSC ɡ, r, ɀ bands. DECaLS is free from strong calibration issues and provides full coverage of the eFEDS field, but is ~2 magnitudes shallower than HSC-SSP data. The deep HSC-SSP data in the ɡ, r, i, ɀ bands provide good photometric redshifts out to high redshifts (ɀ ~ 1.3), where DECaLS has shallower data and misses the i band. The results of both MCMF runs were then combined to the final catalog. Spectroscopic redshifts, on the other hand, were then derived by cross-matching the clusters with public spectroscopic redshifts including SDSS up to DR16 (Blanton et al. 2017), GAMA (Driver et al. 2009), and 2MRS (Huchra et al. 2012) and requiring either three or more redshifts consistent with the photo-ɀ estimate and within R500 (estimated using the relation between X-ray count rate and mass, see Klein et al. 2022) or a spectroscopic redshift of the brightest cluster galaxy (BCG). We note that the searching radius of R500 is large enough because it is well beyond the typical offsets between the X-ray and optical center or the BCG of galaxy clusters (e.g., Seppi et al. 2021). In total, we provide spectroscopic redshifts for 297 clusters.
In Fig. 3 we plot the histogram of the 542 redshifts. The red-shift of the clusters in the sample ranges from 0.01 to 1.3, and the median value is ɀmedian = 0.35. The redshift distribution is very close to the prediction of Pillepich et al. (2012) when a mass cut at M500 = 5 × 1013 M⊙ is assumed (see their Fig. 3).
In our companion paper on the optical confirmation and red-shifts (Klein et al. 2022), we provide a detailed description of the follow-up and analysis of its results. We refer to that paper for more details.
 |
Fig. 2 Distribution of the 542 cluster candidates in eFEDS. The color code represents the redshift of the cluster, provided by MCMF (Klein et al. 2018, 2019). The radius of the circle is equal to R500, within which the average density is 500 times the critical density at the cluster redshift. |
 |
Fig. 3 Redshift histogram of the 542 cluster candidates in the redshift range of 0.01–1.3. The median redshift of the sample ɀmedian = 0.35 is shown as the vertical dashed line. We also plot the results after cutting the sample with different thresholds on the extent likelihood ℒext. |
2.4 Crossmatch with published X-ray and SZ cluster catalogs
The eFEDS field is also covered by other X-ray and SZ surveys. We therefore matched our catalog to the published cluster catalogs. For X-ray clusters, we used the MCXC (Meta-Catalogue of X-ray detected Clusters of galaxies, Piffaretti et al. 2011) and the CODEX (COnstrain Dark Energy with X-ray clusters, Finoguenov et al. 2020), both of which are mainly based on the ROSAT all-sky survey (MCXC also contains clusters from ROSAT pointed observations and XMM-Newton observations). For SZ clusters, we used the most recent ACT-DR5 cluster catalog (Hilton et al. 2021) and the PLANCKSZ2 catalog (Planck Collaboration XXVII 2016b). The matching distance was determined as 2’ for X-ray catalogs and the ACT catalog and 3’ for the PLANCKSZ2 catalog. We do not present the crossmatch results with optical cluster catalogs here because the selection of clusters in optical surveys is quite different from that of ICM-based surveys (see, e.g., Wen et al. 2012; Rykoff et al. 2016). The results of the match are listed in Table 1. In summary, we find 1 and 43 matches with the MCXC and CODEX catalogs and 10 and 57 matches with the PLANCKSZ2 and ACT catalogs, also including multiple-to-one matches. After removing the cases that were matched in multiple catalogs, we find 86 matches in total between the 542 eFEDS clusters and these published catalogs, corresponding to ~16% of the whole sample. This indicates that the majority of the clusters are detected for the first time in ICM-based surveys. The redshift comparisons of the common clusters are given in Klein et al. (2022).
We briefly compare the luminosity (L500 in the 0.1–2.4 keV band) provided in the CODEX catalog and measured in this work (see Sect. 4 for the measurement of luminosity) for the clusters in common. Out of the 43 common clusters, we find 13 clusters with a luminosity difference larger than 2c. CODEX measured a higher luminosity than our results for all these 13 clusters. Clearly, this disagreement can be due to many possible reasons. First, the redshifts are different: in 4 out of the 13 clusters, the redshifts we adopt in this work are different by >15% from those used in the CODEX catalog. Second, the centers of the clusters and the radii on which the luminosity was measured differ strongly in the two catalogs: the offsets in the center of the 13 clusters range from ~30” to 2’. eROSITA has a better angular resolution than ROSAT, therefore the luminosity measured with ROSAT for these 13 clusters might be biased by unresolved active galactic nuclei (AGN). However, we did not further compare the measurements of X-ray observables in the two catalogs because this would require revisiting the details in the analysis of the CODEX clusters, which is beyond the goal of this paper.
Results of crossmatching with published cluster catalogs.
2.5 Contamination in the catalog
We used a set of realistic simulations of the eFEDS field using sixte-2.6.22 (Dauser et al. 2019) and simput-2.4.10 to assess the contamination fraction in our catalog. The details of these simulations and their results are provided in Liu et al. (2022) and Brunner et al. (2022). The source detection and matching were performed on the simulated field in the same way as described in detail in Sect. 2.2. Here we use the simulations to estimate the total contamination in the catalog.
We divided the detected sources into the following five classes. Class 1 includes unique point sources, which are classified as counterparts of input AGN or stars. Class 2 includes unique extended sources, which are classified as counterparts of input extended sources. Class 3 consists of point source residuals. In this case, the input point source associated with the detected source has already been detected as a point source or an extended source. However, a part of its signal, likely in the outer wing of the PSF that cannot be perfectly fit by the source detection algorithm, is detected as another point source. Class 4 sources are extended source residuals, which are similar to class 3, but the input source is an extended source. The input extended source has already been detected, but a part of its photons, which probably represents the signal from substructures or fluctuations in its outskirts, is detected as another extended source. Finally, class 5 includes sources without input counterparts, and classified as spurious sources due to background fluctuation.
We plot the detection fraction of the sources in each class as a function of the extent likelihood in Fig. 4. A cut at ℒext > 6 is applied to be consistent with our catalog. In Fig. 4 we consider classes 1, 3, and 5, the unique point source, point source residual, and background fluctuation, as contamination sources (i.e., noncluster sources) in the catalog. Classes 2 and 4, the unique extended source and extended source residual, are classified as real clusters. In particular, we remark that we considered class 4 as real extended sources instead of spurious detections because substructures in cluster outskirts are commonly observed and it is reasonable to identify them as separated sources. The total fractions of contamination sources and clusters are also plotted in Fig. 4 as solid lines. The top panel of Fig. 4 shows that the contamination fraction can reach ~50% at ℒext = 6 and decreases to <20% at ℒext = 15. We also found that the contamination in the catalog is dominated by class 1, namely, the unique point sources, which are mostly AGN that are misidentified as extended sources. This is consistent with our previous simulation results (see Clerc et al. 2018, Fig. 9), which show that sources with a low extent and a low extent likelihood have a higher probability of being point sources that are misidentified as extended. Combining the result with the distribution of ℒext of our sample (see the middle and lower panels of Fig. 4), we find that the total contamination fraction in our sample is ~1/5, corresponding to a total number of ~110 noncluster sources. Because most of these noncluster sources have low ℒext, they can be excluded by setting an Lext threshold much higher than 6. For example, a simple cut at ℒext ≥ 15 delivers a subsample of ~270 clusters with a purity >90%, even though the sample volume is unavoidably reduced. We list in Table 2 the properties of the subsamples corresponding to different thresholds of ℒext. The redshift distributions of the subsamples are plotted in Fig. 3. We remark that with the current eFEDS X-ray data alone, we are not able to perfectly clean the sample without significantly decreasing the sample volume. Deeper X-ray observations and multiwavelength follow-ups are needed to further clean the sample. For example, Klein et al. (2022) presented an approach to clean the sample that uses the optical information. This approach is found to remove a significant part of the contaminants. We refer to this paper for more details about the results and discussion of the optical cleaning of the sample.
We stress that our selection function is built based on the simulations of the X-ray sky coupled with the standard extended source detection procedure. Currently, the selection function does not include any information about the optical cleaning. The modeling of the total selection function including both X-ray and optical information and cross-talk between them is being developed and subject to future work (Clerc et al., in prep.). To be consistent with our selection function, we include all the 542 cluster candidates in our further analysis in this paper unless noted otherwise. We recommend using the X-ray extent and detection likelihood selections where the provided selection function is used for sample studies.
 |
Fig. 4 Contamination fraction assessment in our sample based on simulations. Upper panel: cumulative detection fraction of sources in the five classes as a function of extent likelihood. The orange solid line shows the total fraction of sources classified as real clusters, namely, the sum of unique extended source and extended source residual. The total contamination is plotted with the solid gray line based on summing all the other three classes. Middle panel: cumulative detecting fraction of sources in the five classes. Lower panel: distribution of extent likelihood of the clusters in our catalog. The clean sample after removing the fraction of contamination is shown in orange. The gray bar represents the contamination in each bin. |
Properties of the subsamples corresponding to different thresholds of ℒext.
3 Selection function
This section describes how the cluster sample completeness and the parameters it depends on were inferred. Simulations of the eFEDS field accounting for the instrument response function and the scanning strategy are described in Liu et al. (2022). This relies on realistic methods to simulate the emission of galaxy clusters and AGN (Comparat et al. 2019, Comparat et al. 2020).
3.1 eFEDS field simulations
We recall here the main steps for producing the simulations. Eighteen independent realizations of the field were simulated in order to increase the statistics in the selection function derivation. A full-sky light cone of dark matter halos was created based on the numerical N-body simulation (UNIT 1 inverse, Chuang et al. 2019), which assumes a Planck-CMB cosmology (Planck Collaboration XIII 2016a). The halos were associated with X-ray emitting sources, namely AGN and galaxy clusters. The model of the X-ray emitting black hole population is empirical and inherits from the halo abundance matching technique, which is particularly efficient at reproducing the observed stellar mass, the luminosity and specific accretion rates distributions (Comparat et al. 2019). AGN fluxes were derived from a set of template spectra folded with a redshift- and luminosity-dependent obscuration model. For halos and subhalos with masses M500c above 5 × 1013 M⊙, cluster images were drawn from a library of emission measure profiles inferred from actual datasets, leading to a reproduction of the observed scaling relations between mass, luminosity, and temperature (Comparat et al. 2020). The assignment of halos and profiles depends on their mass, redshift, and dynamical state; a large positional offset between the dark matter center of mass and its highest density peak will preferentially lead to a low central value of the emission measure profile. An ellipsoidal shape is given to cluster images that follows the halo triaxial shape. Halos of lower masses are simulated with the same method, but we decreased their flux to obtain realistic fluxes for groups. The method suffers from the existing Malmquist bias in the library of profiles we used and creates groups that are too bright. The source spectra are absorbed by an amount depending on the local Galactic absorption column density. Stellar sources as well as cosmic X-ray background and emission from the Galaxy are accounted for using measurements acquired during the calibration and performance verification phases. The SIXTE simulation software (Dauser et al. 2019) is fed with the actual spacecraft attitude file during the eFEDS mapping, hence the simulations faithfully reproduce the exposure variations in the field. The resulting event lists are processed similarly to the true eFEDS event lists, see Sect. 2.1. In particular, extended sources are identified using identical thresholds in detection and extent likelihood as in the real catalog.
3.2 Finding source counterparts
Matching the input galaxy cluster catalogs and the extended source lists poses a challenge because the sky density of the input galaxy cluster catalogs is higher than that of the extended source lists. Fixing a matching radius or performing a nearest neighbor search might lead to unrealistic matches because of projection effects. In order to mitigate this issue, we applied a Bayesian matching procedure that is based on the NWAY software and formalism (Salvato et al. 2018). Cross-correlation between the two catalogs avoids specifying an explicit scale length, except for a maximum radial search of 3' around each source, which is set to save computational cost. We accounted for angular extents by artificially increasing the positional uncertainties of input and detected sources. These uncertainties were set to 10% of a cluster virial radius and to the best-fit source extent. The NWAY algorithm was run twice, according to whether the input cluster list or the detection list was considered as the parent catalog. During the two independent runs, a probability value p; for an association to be valid was assigned to each pair composed of an input cluster and a detected source. An additional value pany representing the probability for a source from the parent catalog to have at least one counterpart in the other catalog was also issued. These probabilities account for chance associations and provide a ranking of the most likely counterparts. Their values depend on the position of the sources, their positional uncertainties, the solid angle of the survey field, and the source density in both catalogs. In order to distinguish complex cases involving multiple substructures, heavy projection effects, or substantial source splitting by the detection algorithms, we introduced a prior on the true flux distribution of detected sources. This prior updates the values of pi and pany. It was obtained by multiplying a loose version of the selection functions presented in Clerc et al. (2018) by the input flux distribution. When this prior was applied, NWAY favored brighter sources when it searched for counterparts to a detected source in the input cluster catalog. Finally, thresholds on pany and pi (two sets of thresholds for both runs) enabled selecting valid matches. The final list of matches is found to be rather insensitive to the exact value of these thresholds: many of the pany values are distributed either around zero or around one, and choosing pi > 0.1 proved to be efficient in selecting the correct counterpart. Valid matches with the highest pi among all possible associations were denoted as primary matches; the matches that were primary in both runs were considered solid matches between the input and detection lists.
3.3 Training classifiers
The main outcome of the matching procedure is a list of simulated clusters with associated properties and a flag indicating whether a source is reliably matched to a detection. These properties are either intrinsic to a cluster (e.g., luminosity, redshift, and central emission measure) or extrinsic (e.g., local exposure time and absorbing column density). We reformulated the problem of cluster selection into a binary classification problem and explored two methods to predict the detection probability of a cluster as a function of its properties.
The first set of selection functions relies on a random forest algorithm (e.g., Breiman 2001). We used the implementation present in the scikit-learn package3 (Pedregosa et al. 2011). Properties attached to clusters or features were normalized, and their one-dimensional distribution was rendered as flat as possible through histogram equalization. A subsample from the initial list was created by randomly selecting two-thirds of the detected and undetected clusters. The remaining sources were kept for testing and evaluation purposes. The random forest classifier randomly drew 1001 decision trees and averaged their results in order to provide a low-variance estimator of the probability of detection, pdet. Each tree was built by sampling the initial list of clusters with replacements. The thresholds at each node of a tree were chosen by minimizing the Gini impurity. The uncertainty on the value of pdet was obtained with a custom implementation of the unbiased infinitesimal jackknife variance estimator proposed by Wager et al. (2014). Various algorithm parameters were tested and optimized by balancing execution time and classifier scores. These scores measure the fractional number of objects in the validation subsample that are correctly classified (with pdet = 0.5 selected as classification threshold). Scores of our classifiers typically reach 80–90%, depending on the nature and the number of selected features. In order to prevent the classifier from extrapolating out of the training zone, we used a simple convex-hull algorithm (Barber et al. 1996).
The selection of features relevant for cluster selection functions was based on practical concerns as well as on careful examination of the classifier outcome. Of the variables we tested, the cluster (true) 0.5–2 keV X-ray counts, its flux in the same band, the redshift, mass, and luminosity were found to be the most discriminating, as expected from earlier sensitivity studies. We re-formed our choice of parameters by examining the feature importance of the random forest classifier, and we found that the central emission measure as well as the local exposure time play additional roles in the selection.
The second set of selection functions relied on Gaussian processes (e.g., Rasmussen & Williams 2006). This classifier constructs a latent variable, modeled as a Gaussian process whose covariance function (kernel) is a squared exponential function. It is transformed into a probability by means of a sigmoid (inverse probit) function, and the algorithm uses the Bernoulli likelihood of the training sample in order to maximize the marginal likelihood and find the best hyperparameters for the kernel, namely its amplitude and scale lengths along each feature dimension. In order to increase speed in execution time, we used the stochastic variational Gaussian process (SVGP) algorithm (Hensman et al. 2015) implemented in the GPy library4. Among the additional modeling hypotheses, this algorithm imposes ten inducing points to create an auxiliary random process summarizing the latent function. The selection probability pdet was obtained by integrating out the latent variable distribution against the link function (the sigmoid); uncertainties on pdet were approximated by folding the 1σ envelope of the latent function into the link function. The resulting selection functions appear smoother than those trained with random forests and their uncertainty range is better controlled; however, they cannot capturing small-scale variations in the feature space as well as selection functions trained with random forests. Nevertheless, both flavors of the selection function provide equivalent performances. In Fig. 5 we show the selection probability as a function of cluster luminosity and redshift using Gaussian processes.
4 X-ray analysis and cluster X-ray properties
In this section we describe the X-ray analysis of the 542 cluster candidates we performed on the basis of the performance verification phase eROSITA observations. The analysis mainly consists of two parts, imaging analysis and spectral analysis. These parts aim at providing a measurement of the average cluster temperature and the radial profiles of other observables such as flux, luminosity, electron density, and gas mass. As an example, the image, spectrum, and the measured electron density profile of one of the most massive clusters in the field, eFEDS J092121.2+031726, are shown in Fig. 6.
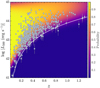 |
Fig. 5 Detection probability as a function of luminosity L500 in the 0.5–2 keV band and redshift ɀ. The data points with error bars are the L500 for the clusters with >2σ measurements. Details of the computation of L500 are presented in Sect. 5. The white curve shows the flux limit at 1.5 × 10–14 erg s–1 cm–2, corresponding to an average completeness level of ~40%. |
4.1 Imaging analysis, luminosity, and gas mass
The X-ray imaging analysis for the eFEDS field has been extensively described in Ghirardini et al. (2021). We only highlight the main steps here. We note that in the imaging analysis of this work, we do not conduct further analyses of the morphology and dynamical status of the clusters. An in-depth study of the morphological parameters of the eFEDS clusters will be performed in Ghirardini et al. (2022).
The imaging analysis in this work is based on a direct image fitting, building a cluster model, projecting it onto the plane of the sky, and adding to it the model images of instrumental and sky backgrounds. Images and exposure maps (vignetted and unvignetted) were extracted in the soft 0.5-2 keV energy band using the eSASS tools evtool and expmap.
To model the image for each cluster, we adopted a forward modeling approach. We started from the Vikhlinin et al. (2006) electron number density model,
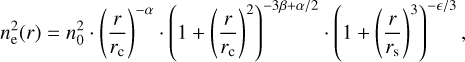 (1)
(1)
where n0 is the normalization factor, rc and rs are core and scale radii, a controls the slope of the density profile in core and intermediate radii, and ϵ controls the change of slope at large radii. The priors on our parameters were ϵ < 5 (as suggested by Vikhlinin et al. 2006), β > 1/3, and a > 0, and we froze rs = rc. The number density model was then projected onto the 2D image plane, convolved with the eROSITA PSF and multiplied by the vignetted exposure map. The resulting cluster model image was finally matched to the count image to obtain the best fit,
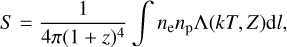 (2)
(2)
where ne and np are the number density of electron and proton, respectively, and we assumed ne = 1.2np. ∆(kT, Z) is the band-averaged cooling function, dependent on temperature and metallicity, and dl is the integral along the line of sight (Bulbul et al. 2010).
To compute the ICM mass of a cluster from the electron density profile, we used the enclosed ICM mass within a given aperture obtained by integrating the best-fit density model,
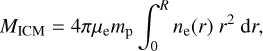 (3)
(3)
where we assumed 0.3 solar abundance of the ICM, adopting the solar abundance table, including the He abundance, from Asplund et al. (2009). The average nuclear charge and mass are A ~ 1.4 and Z ~ 1.2, and μe = A/Z ~ 1.17.
The particle background map was obtained by folding the instrumental background parameter to the unvignetted exposure map. The sky-background component, including contribution from the cosmic X-ray background, Galactic halo, and the Local Bubble, was added to the particle background after being folded by the vignetted exposure map to create the total background model.
The faint point sources within the images were excised, while the bright ones were modeled as delta functions convolved with the PSF to eliminate residual emission due to the wings of the PSF. The resultant model image was fit with the soft-band image of eFEDS observations using the Monte Carlo Markov chain (MCMC) code emcee (Foreman-Mackey et al. 2013) to find the best-fit parameters, consisting of the parameters of the number density model. We integrated the surface brightness profile and converted it into luminosity and flux by constructing an apec model in Xspec, adopting the ICM temperature measured from the spectral analysis. Clearly, the energy conversion factor (ECF) depends on the temperature, which itself varies with radial distance from the cluster center. Taking advantage of the weak dependence of this conversion on temperature (Pacaud et al. 2016), we simply adopted the temperature measured within 500 kpc to compute the ECF for any radius. The MCMC chains for spectral and imaging analysis were used to compute the ECF. By integrating the full probability distributions of temperature and surface brightness, we self-consistently estimated the uncertainties on the luminosity and flux measurements.
We obtained significant (>2σ) luminosity measurements for ~90% of the clusters although we only obtained temperature measurements with the same significance level for a much lower fraction (see Sect. 4.2) because the imaging data were used to measure the luminosity, and because conversion factor from surface brightness to luminosity depends only weakly on temperature. The luminosity-redshift distribution of the eFEDS cluster sample is shown in Fig. 7. For clarity, we only plot the data points with >2σ significance for each measurement. The figure clearly shows the flux-limited nature of the sample and the absence of high-luminosity clusters at low redshift due to the small volume, both of which are common for a flux-limited survey such as eFEDS. These biases should be taken into account for further analyses of cosmological parameters and scaling relations.
 |
Fig. 6 Results of imaging and spectral analysis for cluster eFEDS J092121.2+031726 at redshift 0.333 (spectroscopic) as an example. This cluster is detected with ℒext = 478.6 and ℒdet = 1729.8 and has one of the highest S/Ns in our sample. The temperature and soft-band luminosity within 500 kpc are |
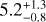
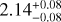
4.2 Spectral analysis
We extracted spectra and computed ancillary response files (ARFs) and redistribution matrix files (RMFs) from the seven TMs using the eSASS algorithm srctool with the latest version of the calibration database. For the extraction radius that we used for the spectral analysis, we opted for two fixed physical apertures, 300 and 500 kpc. The first was chosen for a fair comparison with similar flux-limited surveys, for instance, the XXL survey (Pacaud et al. 2016). The second is a compromise between the aim to include more photons and the rapidly decreasing signal-to-noise ratio (S/N) in the cluster outskirts. In Fig. 8 we verify the selection of the two extraction radii by plotting the S/N in the soft band as a function of extraction radius. We remark that while the radius of 300 kpc was determined regardless of the S/N, most of the clusters reach maximum S/N around 500 kpc. We note that due to the wide PSF of the eROSITA mirrors, photons originating from particular regions in the sky may become detected in the adjacent regions on the detector. This is known as the PSF spilling effect. This effect is particularly strong for high-redshift clusters (ɀ > 1.5), where the 300 kpc regions are comparable to the 26” FOV average PSF HEW of eROSITA. Because we do not have clusters at ɀ > 1.5 in this sample, we omitted the systematic uncertainties due to PSF spilling in this work.
The background spectra were extracted within a [2500–4000] kpc annulus centered at each cluster centroid after masking the emission from point sources and other clusters. The inner radius of the background region corresponds to ~3R500 for a cluster with M500 = 2 × 1014 M⊙ at ɀ = 0.3. We verified this choice of background radius on the eFEDS image and confirm that the inner radius of 2500 kpc extended well beyond the ICM emission in our data for all the clusters. The background spectra include the contribution from unvignetted instrumental background due to galactic cosmic rays (Freyberg et al. 2020) and vignetted cosmic X-ray background due to unresolved point sources, local hot bubble and Galactic halo emission. Our final total background model then includes an unabsorbed apec model for the local hot bubble and two absorbed apec models for the Galactic halo and the Local Group at ~0.25 keV and at a slightly higher temperature at ~0.75 keV (Kuntz & Snowden 2000; Snowden et al. 2008; Bulbul et al. 2012). The cosmic X-ray background due to unresolved sources was modeled by an absorbed power-law, where the index was frozen to 1.46 (see, e.g., Luo et al. 2017) and the normalization was determined by fitting the local background spectra. The fitting band was restricted to 0.8-9 keV for the TMs affected by the light leak (TM5 and TM7, see Predehl et al. 2021), while the 0.6–9 keV spectrum was used for all the other TMs. A more conservative way to remove the light leak is to entirely ignore the spectra of TMs 5 and 7. However, this will lose a significant fraction of good photons and further reduces the S/N. We compared our fitting results with those obtained by ignoring TMs 5 and 7 for a sample of 50 clusters with the highest S/N. We find that the temperatures measured with and without TMs 5 and 7 are consistent within 1c statistical uncertainty for all the cases. The normalization of spectra of TMs 5 and 7 is more affected by the calibration issues and light leak. However, we find that the difference in normalization with and without TMs 5 and 7 is also within 2c. Because the electron number density and luminosity are not directly determined from the spectroscopy (and the normalization) but from the imaging analysis, we do not expect that our measurements are significantly affected by calibration issues related to TMs 5 and 7. We therefore decided to keep TMs 5 and 7 in the spectral fitting and only ignored the energy range below 0.8 keV, as already mentioned.
Because most of our detected clusters lie in the low-count regime, we strictly used C-statistics in our fits (Cash 1979) and modeled our background instead of subtracting it from the total spectrum. The ICM emission was fit with the apec thermal plasma emission model (Smith et al. 2001; Foster et al. 2012). The solar abundance table from Asplund et al. (2009) was adopted. The Galactic hydrogen absorption was modeled using tbabs (Wilms et al. 2000), where the column density nH was fixed to nH, tot provided by Willingale et al. (2013) at the cluster position. This value takes neutral hydrogen and also molecular hydrogen into account. The current version of the tbabs model includes the most accurate atomic data available for neutral species (e.g., they consider the smearing of the K-photoabsorption edge through Auger decay)5. The spectral fitting was done using Xspec version 12.11.1 (Arnaud 1996).
Due to the shallow depth of the eFEDS survey, we do not have significant metallicity measurements for all clusters in the sample (see Fig. 6 for an example). Therefore we fixed the metallicity to 0.3 Z⊙ (see, e.g., Liu et al. 2020) for all clusters for a uniform treatment of the data. The redshift of the cluster was set at the value provided by MCMF, as described in Sect. 2.3. We used spectroscopic redshifts where available and adopted photometric redshifts for the rest of the clusters. We note that the redshifts of the ICM and member galaxies may be slightly different, especially in disturbed clusters (e.g., Liu et al. 2015), therefore an ideal approach is to allow the redshift to vary within a small range. However, given the low number of photons in our spectra (only a few clusters in our sample have ~ 1000 net counts in the full band within 500 kpc), we were unable to obtain a significant constraint on the redshift from the X-ray spectral analysis for the vast majority of the sample. Thawing the redshift in the model does not improve the spectral fitting. We therefore fixed the redshift parameter to the MCMF values mentioned above for all the clusters. Moreover, the measurement of redshift from X-ray spectra requires well-understood gain calibration of the CCD (see, e.g., Sanders et al. 2020). Therefore we will explore the X-ray redshift determination in future studies. We also note that we ignored the multiple phase nature of the ICM within our extraction radii by using a single apec model in the spectral fitting. This would unavoidably result in larger residuals particularly in the soft band (see Fig. 6, lower left panel). However, considering the low S/N in our data, we argue that an averaged spectroscopic-like temperature is the only quantity we can measure, and that constraining the multitemperature structures in the ICM is well beyond the data quality and the goal of this paper.
Due to the shallow survey data, we were unable to obtain a robust constraint on temperature for most of the clusters for which we only detected fewer than 100 counts in the 0.5–2 keV band within 500 kpc. Another problem in temperature measurement is the contamination of misidentified AGN in the sample. Finally, we were able to measure accurate temperatures of only 102 clusters (~ 1/5 of the full sample) at >2σ significance level. All these clusters have >100 counts in the 0.5–2 keV band within 500 kpc. Most of them (100/102) have Lext > 10, thus the contamination level of this subsample is much lower than the average of the full sample. We plot the L - T relations for 300 and 500 kpc in Fig. 9. The ICM temperature of these 102 clusters ranges from -0.5 to ~7 keV, and the average temperature is ~2 keV, implying that they are dominated by low-mass clusters and groups (see, e.g., Borm et al. 2014, Fig. 3). As expected owing to the large effective area in the soft band, we are more sensitive to low-mass cluster and group populations than other surveys. Moreover, our ability to measure hot clusters at >5 keV is limited due to the reduced sensitivity of eROSITA in the energy band >3 keV. This is clearly reflected in Fig. 9: the ICM temperatures of hot clusters are poorly constrained. Figure 9 also shows that several outliers appear at high luminosity but relatively low temperature. For example, eFEDS J083811.8-015934, eFEDS J092339.0+052654, and eFEDS J093520.9+023234 have 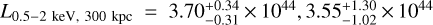 , and
, and 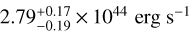 , and
, and 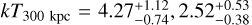 , and
, and 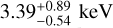 . We verified the X-ray and optical data for these cases and found that they are all massive clusters, with estimated R500 (see Sect. 5) of >1.2 Mpc, much larger than the 300 kpc and 500 kpc extraction radii we chose. The low temperatures we measured are probably due to the cool core that dominates the emission within our extraction radii. This also reminds us that a meaningful research of the relations between the X-ray observables can only be made after an accurate measurement of the R500 of the clusters, from which both the core-included and core-excluded X-ray observables can be measured. A detailed study of the scaling relations between different X-ray observables, for example, L - T and L - Mgas measured within R500, will be performed in a future work by Bahar et al. (2022).
. We verified the X-ray and optical data for these cases and found that they are all massive clusters, with estimated R500 (see Sect. 5) of >1.2 Mpc, much larger than the 300 kpc and 500 kpc extraction radii we chose. The low temperatures we measured are probably due to the cool core that dominates the emission within our extraction radii. This also reminds us that a meaningful research of the relations between the X-ray observables can only be made after an accurate measurement of the R500 of the clusters, from which both the core-included and core-excluded X-ray observables can be measured. A detailed study of the scaling relations between different X-ray observables, for example, L - T and L - Mgas measured within R500, will be performed in a future work by Bahar et al. (2022).
We provide in Table B.1 the main X-ray observables of the 102 clusters with >2σ temperature measurements within either 300 or 500 kpc. The full table containing the X-ray analysis results of all the 542 clusters is available at https://erosita.mpe.mpg.de/edr/eROSITAObservations/Catalogues, and at the CDS.
 |
Fig. 7 Luminosity redshift distribution of the clusters with significant luminosity measurements (>2σ) for 300 kpc (upperpanel) and 500 kpc (lower panel). The black curve shows the flux limit: 10–14 erg s–1 cm–2 for 300 kpc and 1.5 × 10–14 erg s–1 cm–2 for 500 kpc (without a K correction). |
 |
Fig. 8 Signal-to-noise ratio profiles for all the clusters. The net count rates are computed from the best-fit model of the soft-band image (see Sect. 4.1 for more details). For each cluster, the S/N as a function of radius is shown as a curve color-coded by its maximum value. The maximum S/N and the corresponding radii for all clusters are marked with blue dots. Clusters with maximum S/N lower than 3 are plotted in dark gray. The histogram in the upper left panel shows the distribution of the maximum S/N, only considering clusters with maximum S/N higher than 3, in order to remove the contamination from low-significance clusters. |
 |
Fig. 9 Luminosity plotted as a function of temperature for the clusters with >2σ temperature measurements in either of the two radii. |
5 X-ray luminosity function
The X-ray luminosity function (XLF) of a galaxy cluster survey is defined as the count of clusters per effective survey volume as a function of cluster luminosity. A widely adopted strategy is to measure XLF by dividing the cluster sample into luminosity bins (see Böhringer et al. 2014, for example), the XLF can be written as
![Mathematical equation: ${{dn} \over {dL}}\left({\left\langle {{L_i}} \right\rangle} \right) = {1 \over {\Delta {L_i}}}\sum\limits_j {{1 \over {{V_{{\rm{eff}}}}\left[{{L_j},{F_{\lim}},A\left({{F_j}} \right)} \right]/P\left({{L_j},{z_j}} \right)}},,} $](/articles/aa/full_html/2022/05/aa41120-21/aa41120-21-eq10.png) (4)
(4)
where (Li) and ∆Li are the center luminosity (we used L500 in 0.5–2 keV) and the width of the ith luminosity bin, Lj is the luminosity of the jth cluster in the ith bin. P(Lj, ɀj) is the detection probability of a cluster with luminosity Lj at redshift ɀj, obtained from the selection function (see Sect. 3). Veff [Lj, Flim, A(Fj)] is the survey-effective volume as a function of Lj and the flux limit and sky coverage of the survey. The flux limit was set as Flim = 1.5 × 10–14 erg s–1 cm–2 (see Fig. 5). Because the exposure is nearly uniform across the whole eFEDS field above the flux limit, we used a constant sky coverage A = 126 deg2, determined as the sky area with vignetted exposure higher than 0.5 ks, which is the lowest exposure at which a cluster with flux close to the flux limit is detected. Veff was then computed as the comov-ing shell volume between redshift 0 and the redshift at which the cluster can be detected at the flux limit, scaled by the sky coverage. Because our sample has an average contamination fraction of ~1/5, we finally scaled the dn/dL by a factor of 0.8.
To be able to calculate the XLF of the eFEDS sample, the luminosity L500 measured within R500 must be known. There are several ways to measure the mass, thus computing the R500, for a cluster, such as a dedicated weak-lensing analysis (see Umetsu 2020, for a review), and a measurement of hydrostatic mass on the basis of deeper X-ray observation (see, e.g., Ettori et al. 2019). We estimated the R500 in another way: the R500 of each cluster was determined as the radius within which the mass M500 and luminosity L500 are consistent with cluster L - M scaling relation. While the majority of the published L - M scaling relations in the literature focus on massive clusters (e.g., Pratt et al. 2009; Vikhlinin et al. 2009; Bulbul et al. 2019; Andrade-Santos et al. 2021), a few studies also involved the lower end of the mass scale (see, e.g., Eckmiller et al. 2011; Lovisari et al. 2015; Sereno et al. 2020). Because the eFEDS sample consists of mostly low-mass clusters, we adopted the Lovisari et al. (2015) L - M scaling relation, which is based on an X-ray selected bias-corrected sample of 20 galaxy groups and 62 massive HIFLUGCS clusters. We note that Lovisari et al. (2015) calculated the masses based on X-ray data and hydrostatic equilibrium assumption. The value of R500 obtained from this approach is just a rough estimation. We discuss the impact of the choice of scaling relations on our results in Sect. 5.1. The Lovisari et al. (2015) L - M relation is
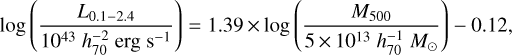 (5)
(5)
where L0.1–2.4 is the luminosity in 0.1–2.4 keV energy range within R500, and is computed for each cluster in our sample using the same method as described in Sect. 4.1. We note that the 0.1–2.4 keV band luminosity is only used to estimate R500 with the above scaling relation. We use the 0.5–2 keV band luminosity to compute the luminosity function.
The luminosity range [5 × 1041–3 x 1044] erg s–1 cm–2 was divided into several bins with equal logarithmic width. The bins at low-L and high-L edges were then slightly adjusted in order to ensure that each bin included at least 10 clusters. The center of each bin was determined as the weighted-average luminosity of the clusters within it. The errors in dn/dL were computed from 1000 bootstrapped samples for which the luminosity of each cluster was randomized considering the statistical uncertainty. This error was then added in quadrature with the Poisson error for the number of clusters in each bin. We investigated the evolution of the XLF by splitting the sample into two redshift bins, 0.01–0.35, and 0.35–1.3, each including ~250 clusters. The XLFs of the full sample and the two redshift bins are listed in Table 3 and plotted in Fig. 10.
The XLF of galaxy clusters are available in the literature for a variety of samples (see, e.g., Rosati et al. 1998; Vikhlinin et al. 1998; De Grandi et al. 1999; Allen et al. 2003; Mullis et al. 2004; Böhringer et al. 2007, 2014; Koens et al. 2013; Pacaud et al. 2016; Adami et al. 2018; Finoguenov et al. 2020). Here we compare our XLF with the results in several recent works based on different cluster samples, namely the WARPS (Koens et al. 2013), the XXL-100 (Pacaud et al. 2016), and the XXL-C1 sample (Adami et al. 2018). The comparison is shown in Fig. 10. We find good agreement in the XLFs of the full eFEDS sample and of the XXL-100 and XXL-C1 clusters. In particular, the eFEDS XLF is relatively closer to the result based on the XXL-100 sample, especially for low luminosities. When we divide the eFEDS cluster sample into two redshift bins, we do not observe any significant evolution of the XLF with redshift, consistent with the literature, as shown in the right panel of Fig. 10). However, we note that the contamination in the full eFEDS sample at different luminosity and redshift bins may induce a bias in the XLF measurements. Therefore we also computed the XLF with a purer subsample that we obtained by selecting the eFEDS clusters with extent likelihood ℒext ≥ 15. This subsample contains~250 clusters in the luminosity range in which the XLF is computed, with an estimated purity >90%. The selection function was also recomputed for this subsample according to the corresponding thresholds. As a result, the XLF of the subsample is fully consistent with that of the full sample, as shown in Fig. 10).
X-ray luminosity function of the eFEDS clusters for the full sample and in two redshift bins.
5.1 Effect of the scaling relation on the luminosity function
Because R500 and L500 were determined using L – M scaling relation, the XLF is dependent on the choice of L – M relation we adopt. In this section we assess this effect by comparing the current XLF with the result we obtain with other L – M relations. The general form of cluster L – M relation reads log (L) = a • log (M) + b, where the slope a varies in the range [1, 2] in different works, depending on the cluster population that were studied (Pratt et al. 2009; Arnaud et al. 2010; Giodini et al. 2013; Lovisari et al. 2015; Bulbul et al. 2019; Sereno et al. 2020). Several works have found that the L - M relation for galaxy groups is steeper than for massive clusters (see, e.g., Lovisari et al. 2015). This adds complexity to our selection of the L – M relation for our sample, which includes both low-mass groups and clusters. Even though we finally chose the result reported by Lovisari et al. (2015) based on a combined sample of groups and clusters, with a = 1.39, it is necessary to examine the result when we adopt a steeper relation. We therefore recomputed R500, L500, and the corresponding XLF using the scaling relation in Bulbul et al. (2019),
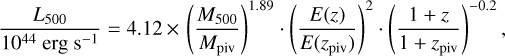 (6)
(6)
where L500 is the 0.5–2 keV band luminosity within R500, Mpiv = 6.35 x 1014 M0 and ɀpiv = 0.45. We found that while the large difference in the slopes of the two scaling relations (1.39 and 1.89) changed R500 by about 10% on average, the value of L500 was only affected by a few percent. The XLFs also agree well. Clearly, the cluster sample based on which the scaling relation is obtained in either Lovisari et al. (2015) or Bulbul et al. (2019) does not perfectly fit the cluster population in our sample, thus preventing us from having a more precise assessment of this bias. The accurate measurements of the quantities R500, L500, and M500, of these clusters will have to rely on a weak-lensing analysis with high quality or on hydrostatic mass measurement on basis of deeper X-ray observations. Before submitting this paper, we obtained the mass M500 derived from the scaling relation of count rate, mass, and redshift with a weak-lensing calibration, which will be presented in detail in Chiu et al. (2022). The L500 are different by less than a few percent with respect to our results, and the change in the XLF is negligible.
6 Superclusters in the eFEDS field
We further analyzed the spatial distribution of our sample of 542 galaxy clusters to search for superclusters. Early supercluster searches used optically detected catalogs of galaxy clusters such as Abell/ACO clusters (see, e.g., Zucca et al. 1993; Einasto et al. 1994). The first supercluster catalog based on X-ray selected clusters was presented in Einasto et al. (2001), where 19 super-clusters with multiplicity (the multiplicity (Ncl) of a supercluster is defined as the number of its member clusters) ≥2 were detected based on the early RASS catalog. In recent years, more superclusters have been discovered thanks to the increase in the volume and depth of X-ray cluster samples. For instance, Chon et al. (2013) detected 164 superclusters with Ncl ≥ 2 at z ≤ 0.4 based on the ROSAT-ESO FluxLimited X-ray (REFLEX II) cluster catalog. Adami et al. (2018) detected 35 superclusters with Ncl ≥ 3 and 39 cluster pairs out to ɀ ~ 0.8 based on the 365-cluster catalog from the XXL survey.
We employed a friends-of-friends (FoF) algorithm to identify superclusters with an evolving linking length. This method that has been widely used in previous works (Zucca et al. 1993; Einasto et al. 2001; Chon et al. 2013; Chow-Martínez et al. 2014; Adami et al. 2018). This method is well suited for detecting superclusters because they are not virialized objects and thus often have irregular shapes. Our FoF algorithm starts by searching for neighboring clusters (the “friends”) with a distance smaller than the linking length for a cluster in the sample. Then for each of the friends, the algorithm continues to search for friends of friends until no new friends can be found. Because the linking length varies with cluster redshift, we use the average linking length of the two clusters when we compute their relation to ensure that the search result is stable.
The linking length of the FoF algorithm in comoving distances can be computed as follows (see, e.g., Chon et al. 2013,
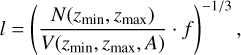
where N is the number of clusters in the redshift bin, V is the comoving volume of the shell as a function of the lower and upper bounds of the bin and the eFEDS survey area A. f is the over-density factor. Therefore the linking length at a specific red-shift corresponds to the maximum distance between two clusters defining a region that is f times overdense with respect to the average cluster number density at that redshift. The resulting linking length evolves with the redshift distribution of clusters and allows us to detect similar overdensities throughout the red-shift range. We set ∆ɀ = 0.05 and f = 10, as was commonly used in previous works. In Fig. 11 we plot the linking length as a function of cluster redshift in our sample. The linking length increases from ~20 Mpc at low-ɀ to >50 Mpc at high-ɀ due to the low number density of high-ɀ clusters in our catalog (see Fig. 3).
We classify the cluster systems found by the FoF algorithm with at least four members as supercluster candidates.
Clearly, systems with two or three member clusters are also possible objects of interest, and the thresholds of supercluster multiplicity are usually lower than 4 (e.g., Chon et al. 2013; Adami et al. 2018). However, our cluster sample has a contamination fraction of ~1/5, which decreases the reliability of the superclusters with low multiplicity. We therefore determined Ncl > 4 as our threshold. Figure 11 also shows that the linking length starts to increase abnormally beyond redshift z ~ 0.8. Clearly, the density of clusters at this high redshift in our sample is too low for superclusters to be detected. We therefore set an upper limit on the linking length: lmax = 70 Mpc, to avoid incorrect detections at high redshifts.
With this approach, we detected 19 supercluster candidates in the eFEDS field. We list them in Table 4. The multiplicities of these 19 superclusters range from 4 to 10. The cut out X-ray images of these superclusters and the properties of their member clusters are provided in the appendix (see Table A.1 and Fig. A.1). The galaxy density maps from the HSC-SSP survey data at the corresponding redshifts for all the superclusters are presented in Fig. A.2. The association of the galaxy density maps and the X-ray images of the superclusters is good. Moreover, we also identified 46 and 14 cluster systems with two and three member clusters, respectively. As a comparison, Adami et al. (2018) detected 39 cluster pairs and 35 superclusters with Ncl > 3 in the XXL 365-cluster catalog. Considering the difference between eFEDS and XXL in sky coverage (140 deg2 vs. 50 deg2), sample size (542 vs. 365), and flux limit (10–14 erg s–1 cm–2 vs. a few 10–15 erg s–1 cm–2), we do not find a significant inconsistency between the number of superclusters in eFEDS and XXL.
We estimated the mass for each supercluster by summing the virial mass of its member clusters. The virial masses of the clusters in our sample were estimated using the M500 obtained from the Lovisari et al. (2015) L – M scaling relation (see Sect. 5). We then converted M500 into Mvir by assuming a Navarro-Ferenk-White (NFW) profile (Navarro et al. 1997) with concentration c = r200/rs = 4, which approximately gives Mvir ≈ 2M500 (Reiprich et al. 2013).
We also adopted a new parameter, the compactness, C, to describe the spatial distribution of member clusters within the supercluster. C is defined in the following way. We considered a sphere whose diameter is equal to the linking length. The position of this sphere was adjusted until the total mass of the enclosed member clusters reached its maximum value. C is then defined as the ratio of the maximum enclosed mass to the total mass of the supercluster. If all the member clusters are distributed within the linking length, the compactness is accordingly 1. Clearly, C is very sensitive to the reliability of the distance between member clusters and thus is affected by the uncertainties in photometric redshift measurements. The precision of C is also dependent on the multiplicity of a super-cluster. Among the 19 superclusters candidates, we measure a compactness C = 1 for 6 candidates. Most of them have a compactness higher than 0.5. Limited by the sample size and the narrow redshift span (most of the supercluster candidates are below z = 0.5), we are not able to further analyze the compactness. On the other hand, an increasing supercluster compactness from high-z to low-z can be anticipated and can be investigated in future works, provided that a larger and more complete supercluster sample is available, especially at high redshift.
With the 3D distribution of member clusters and their total mass, we further explored the collapsing probability for each supercluster candidate. When a ACDM cosmology is assumed, an object with an overdensity δc = p/pc higher than ~1.7 will finally collapse. Clearly, because superclusters do not have regular shapes, their volume cannot be measured directly. Moreover, we only know the mass in the most massive member clusters that are detectable, while the fraction of mass in filaments and low-mass subhalos is unavailable. Therefore the density within a supercluster cannot be measured accurately. Nevertheless, we can obtain a very conservative lower limit of the density by dividing the total virial masses of the member clusters by the volume of the smallest sphere that encloses all the member clusters.
Interestingly, we still found two superclusters with this very conservative estimation: eFEDS-SC12 and eFEDS-SC13, with δc = 2.2 and 4.7, implying that they will finally collapse with a high probability. The radii of the smallest sphere are 11.8 Mpc and 8.4 Mpc, respectively. This is consistent with their compactness: the two superclusters have a compactness equal to 1. Table A.1 and Fig. A.1 show that the cluster members of these two super-clusters are distributed very closely to each other. On the other hand, we are not able to constrain the collapsing time of the two superclusters, which obviously should take into account not only gravity, but also the effect of dark energy and the 3D distribution of mass within the supercluster. We therefore defer this study to a future work.
We also confirm the detection of the supercluster discovered by Ghirardini et al. (2021). However, this supercluster is found to be fragmented into two parts, eFEDS-SC11 and eFEDS-SC12, with four members each. This is due to the change in the member cluster redshift. Ghirardini et al. (2021) adopted the photometric redshifts from HSC survey data that were available at the time of submission, while here in this work we use the latest spectro-scopic redshifts (see Sect. 2.3). This difference also highlights the importance of using the most accurate spectroscopic red-shifts in the search for superclusters. We also note that although the supercluster discovered in Ghirardini et al. (2021) is fragmented into eFEDS-SC11 and eFEDS-SC12 in this work, they are still very close to each other. The closest members of eFEDS-SC11 and eFEDS-SC12 are separated by ~29 Mpc, which only slightly exceeds the linking length at their redshift, ~28 Mpc. This ~1 Mpc difference is within the virial radius of a cluster, therefore eFEDS-SC11 and eFEDS-SC12 probably belong to the same structure. We therefore confirm that our results are fully consistent with Ghirardini et al. (2021).
Most of the supercluster candidates are located in the redshift range [0.1–0.5]. Four high-z candidates lie beyond redshift 0.5: eFEDS-SC16 at 0.565, eFEDS-SC17 at 0.579, eFEDS-SC18 at 0.619, and eFEDS-SC19 at 0.803. However, we note that we only have photometric redshifts for most members of these super-clusters (see Table A.1). Moreover, the linking length rapidly increases to >50 Mpc at high redshifts due to the low number density of high-redshift clusters in our catalog. Considering the relatively large uncertainty in the photometric redshift and the low statistics at high-z, we note that these candidates need to be verified by future spectroscopic follow-up observations.
 |
Fig. 10 X-ray luminosity function of the eFEDS cluster sample. Left panel: results for the full sample. Right panel: results in two redshift bins. The number of clusters in each bin is indicated in the lower panel. Some literature results are plotted as the shaded area for comparison: XXL-C1 (Adami et al. 2018), XXL-100 (Pacaud et al. 2016), and WARPS (Koens et al. 2013). Thick error bars show the results of the ℒext ≥ 15 subsample. |
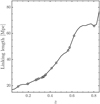 |
Fig. 11 Linking length in comoving distances as a function of cluster redshift in our sample. The circles mark the positions of the 19 supercluster candidates we detected. |
Supercluster candidates detected in the eFEDS field.
7 Conclusions
We have presented the first catalog of eROSITA-selected galaxy cluster and group candidates and their physical properties as detected in the sky area covered by the eROSITA Final Equatorial-Depth Survey (eFEDS). The optical follow-up for redshift and confirmation was performed using the MCMF tool on the basis of data from the HSC-SSP survey and the DECaLS survey. Our conclusions are summarized below.
In the area of 140 square degrees that is covered by eFEDS, we detected 542 candidate clusters and groups of galaxies down to the flux limit of ~10–14 erg s–1 cm–2 in the soft band (0.5–2 keV) within 1′. The clusters are distributed in the redshift range ɀ = [0.01, 1.3], and the median redshift is ɀmedian = 0.35. The contamination fraction of noncluster sources in the sample, dominated by AGN misidentified as extended sources, is ~1/5, as obtained from simulations. After accounting for the contamination, we find a cluster density of ~3.2 per square degree at this depth, in agreement with the expectations in Merloni et al. (2012). Our simulations suggest that it is possible to obtain a sample with a purity of >90% if a simple cut at ℒext ≥ 15 is applied. This further selection delivers a subsample of ~270 clusters. However, we note that the sample volume is unavoidably reduced as the high-redshift tail of the sample will have a smaller extent and will therefore be more severely cut by a higher ℒext threshold. Most of these high-redshift clusters are real, however, and the simulations predict that a few more of them will be found among the point-source-detected population. In a following paper (Bulbul et al. 2022), we will present a detailed assessment of the contribution of unresolved clusters to the eFEDS point-sources catalog. Further improvement of the characterization of the high-redshift clusters will be obtained through the recently completed SDSS-IV and SDSS-V spectro-scopic follow-up campaign, which will be presented elsewhere (Ider Chitham et al., in prep.). We also found that ~16% of the clusters can be matched with a counterpart in the published X-ray or SZ cluster catalogs, indicating that the majority of the clusters in the sample are detected through their ICM emission for the first time.
We measured the ICM temperature within two parametric radii, 300 kpc and 500 kpc. Radial profiles of flux, luminosity, electron density, and gas mass were measured from the soft-band surface brightness image. For ~1/5 of the clusters in the sample (102/542), we obtain >2σ constraints on temperature. The average temperature of these clusters is -2 keV. The clusters span the luminosity range [1041 erg s–1, ~1044 erg s–1]. According to the L – M scaling relation in Lovisari et al. (2015), ~40% of the clusters have M500 < 1014 M⊙, indicating that our sample is dominated by galaxy groups and low-mass clusters, as expected.
The selection function, the purity, and completeness of the catalog were examined and discussed in detail using the most recent simulations of the eFEDS field. The X-ray luminosity function of the sample is found to agree well with the results obtained from other recent X-ray surveys, such as the XXL and the WARPS surveys. We find no significant evolution of the cluster XLF in the redshift range [0.01, 1.3].
Using the redshifts and spatial distribution of the clusters, we performed a search for superclusters in the eFEDS field and detected 19 supercluster candidates, most of which are located at redshifts between 0.1 and 0.5, including the one at ɀ ~ 0.36 that has been published in Ghirardini et al. (2021). Another four high-ɀ supercluster candidates are detected at redshifts higher than 0.5, but need further spectroscopic confirmation as the errors on the photometric redshifts may bias the linking length calculations.
The eFEDS cluster and group catalog at the final eRASS equatorial depth provides a benchmark proof-of-concept for the eROSITA All-Sky Survey extended source detection and characterization. We confirm the excellent performance of eROSITA for cluster science and expect no significant deviations from our pre-launch expectations for the final all-sky survey.
Acknowledgement
This work is based on data from eROSITA, the soft X-ray instrument aboard SRG, a joint Russian-German science mission supported by the Russian Space Agency (Roskosmos), in the interests of the Russian Academy of Sciences represented by its Space Research Institute (IKI), and the Deutsches Zentrum für Luft- und Raumfahrt (DLR). The SRG spacecraft was built by Lav-ochkin Association (NPOL) and its subcontractors, and is operated by NPOL with support from the Max Planck Institute for Extraterrestrial Physics (MPE). The development and construction of the eROSITA X-ray instrument was led by MPE, with contributions from the Dr. Karl Remeis Observatory Bamberg & ECAP (FAU Erlangen-Nuernberg), the University of Hamburg Observatory, the Leibniz Institute for Astrophysics Potsdam (AIP), and the Institute for Astronomy and Astrophysics of the University of Tubingen, with the support of DLR and the Max Planck Society. The Argelander Institute for Astronomy of the University of Bonn and the Ludwig Maximilians Universität Munich also participated in the science preparation for eROSITA. The eROSITA data shown here were processed using the eSASS/NRTA software system developed by the German eROSITA consortium. The Hyper Suprime-Cam (HSC) collaboration includes the astronomical communities of Japan and Taiwan, and Princeton University. The HSC instrumentation and software were developed by the National Astronomical Observatory of Japan (NAOJ), the Kavli Institute for the Physics and Mathematics of the Universe (Kavli IPMU), the University of Tokyo, the High Energy Accelerator Research Organization (KEK), the Academia Sinica Institute for Astronomy and Astrophysics in Taiwan (ASIAA), and Princeton University. Funding was contributed by the FIRST program from the Japanese Cabinet Office, the Ministry of Education, Culture, Sports, Science and Technology (MEXT), the Japan Society for the Promotion of Science (JSPS), Japan Science and Technology Agency (JST), the Toray Science Foundation, NAOJ, Kavli IPMU, KEK, ASIAA, and Princeton University. This paper makes use of software developed for the Large Synoptic Survey Telescope. We thank the LSST Project for making their code available as free software at http://dm.lsst.org. This paper is based [in part] on data collected at the Subaru Telescope and retrieved from the HSC data archive system, which is operated by Subaru Telescope and Astronomy Data Center (ADC) at NAOJ. Data analysis was in part carried out with the cooperation of Center for Computational Astrophysics (CfCA), NAOJ. This work was supported in part by World Premier International Research Center Initiative (WPI Initiative), MEXT, Japan, and JSPS KAKENHI Grant Number JP19KK0076. This work was supported in part by CNES. This work was supported in part by the Fund for the Promotion of Joint International Research, JSPS KAKENHI Grant Number 16KK0101. The authors thank Dominique Eckert for useful discussions. DNH acknowledges support from the ERC through the grant ERC-Stg DRANOEL n. 714245. E.B. acknowledges financial support from the European Research Council (ERC) Consolidator Grant under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 101002585).
Appendix A Properties of supercluster candidates
We list in Table A.1 the member clusters of the supercluster candidates detected in the eFEDS field, as described in Sect. 6. In Fig. A.1 we show the X-ray images of these superclusters. The galaxy density maps from the HSC-SSP survey data at the corresponding redshifts for all the superclusters are shown in Fig. A.2.
The member clusters of the 19 superclusters in the eFEDS field.
 |
Fig. A.1 X-ray images of the 19 superclusters we detected in the eFEDS field. The images are generated in the same way as for Fig. 1. The white circles mark the estimated virial radii of the member clusters of each supercluster. The thick bar in the lower right corner indicates the linking length at the supercluster redshift. |
 |
Fig. A.2 Galaxy density map from HSC-SSP survey data at the locations and redshifts of the 19 supercluster candidates. They are obtained by integrating the full probability function of the MIZUKI (Tanaka 2015) photometric redshifts (P(z)) of each galaxy (the S19A catalog; Nishizawa et al. 2020) with a width of the redshift slice of |
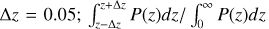
Appendix B Main results of the X-ray analysis
In this section we list the main results of the X-ray analysis. Instead of providing the results for all the 542 clusters, we specifically selected a subsample of 102 clusters with > 2σ temperature measurements within either 300 kpc or 500 kpc. The results of the clusters in the subsample are listed in Table B.1.
Main results of the X-ray analysis for the 102 clusters in the subsample with > 2σ- temperature measurements within either 300 kpc or 500 kpc.
References
- Adami, C., Giles, P., Koulouridis, E., et al. 2018, A&A, 620, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Aihara, H., Armstrong, R., Bickerton, S., et al. 2018a, PASJ, 70, S8 [NASA ADS] [Google Scholar]
- Aihara, H., Arimoto, N., Armstrong, R., et al. 2018b, PASJ, 70, S4 [NASA ADS] [Google Scholar]
- Aihara, H., AlSayyad, Y., Ando, M., et al. 2019, PASJ, 71, 114 [Google Scholar]
- Allen, S. W., Schmidt, R. W., Fabian, A. C., & Ebeling, H. 2003, MNRAS, 342, 287 [NASA ADS] [CrossRef] [Google Scholar]
- Allen, S. W., Evrard, A. E., & Mantz, A. B. 2011, ARA&A, 49, 409 [Google Scholar]
- Andrade-Santos, F., Pratt, G. W., Melin, J.-B., et al. 2021, ApJ, 914, 58 [NASA ADS] [CrossRef] [Google Scholar]
- Arnaud, K. A. 1996, ASP Conf. Ser., 101, 17 [Google Scholar]
- Arnaud, M., Pratt, G. W., Piffaretti, R., et al. 2010, A&A, 517, A92 [CrossRef] [EDP Sciences] [Google Scholar]
- Asplund, M., Grevesse, N., Sauval, A. J., & Scott, P. 2009, ARA&A, 47, 481 [NASA ADS] [CrossRef] [Google Scholar]
- Bahar, Y. E., Bulbul, E., Clerc, N., et al. 2022, A&A, 661, A7 (eROSITA EDR SI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Barber, C. B., Dobkin, D. P., & Huhdanpaa, H. 1996, ACM Trans. Math. Softw., 22, 469 [CrossRef] [Google Scholar]
- Blanton, M. R., Bershady, M. A., Abolfathi, B., et al. 2017, AJ, 154, 28 [Google Scholar]
- Bleem, L. E., Stalder, B., de Haan, T., et al. 2015, ApJS, 216, 27 [Google Scholar]
- Böhringer, H., Voges, W., Huchra, J. P., et al. 2000, ApJS, 129, 435 [Google Scholar]
- Böhringer, H., Schuecker, P., Guzzo, L., et al. 2001, A&A, 369, 826 [Google Scholar]
- Böhringer, H., Schuecker, P., Pratt, G. W., et al. 2007, A&A, 469, 363 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Böhringer, H., Chon, G., & Collins, C. A. 2014, A&A, 570, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Böhringer, H., Chon, G., Retzlaff, J., et al. 2017, AJ, 153, 220 [Google Scholar]
- Borm, K., Reiprich, T. H., Mohammed, I., & Lovisari, L. 2014, A&A, 567, A65 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bosch, J., Armstrong, R., Bickerton, S., et al. 2018, PASJ, 70, S5 [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [Google Scholar]
- Brunner, H., Liu, T., Lamer, G., et al. 2022, A&A, 661, A1 (eROSITA EDR SI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bulbul, G. E., Hasler, N., Bonamente, M., & Joy, M. 2010, ApJ, 720, 1038 [NASA ADS] [CrossRef] [Google Scholar]
- Bulbul, G. E., Smith, R. K., Foster, A., et al. 2012, ApJ, 747, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Bulbul, E., Chiu, I. N., Mohr, J. J., et al. 2019, ApJ, 871, 50 [Google Scholar]
- Bulbul, E., Liu, A., Pasini, T., et al. 2022, A&A, 661, A10 (eROSITA EDR SI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cappelluti, N., Hasinger, G., Brusa, M., et al. 2007, ApJS, 172, 341 [NASA ADS] [CrossRef] [Google Scholar]
- Cash, W. 1979, ApJ, 228, 939 [Google Scholar]
- Chiu, I.N., Ghirardini, V., Liu, A., et al. 2022, A&A, 661, A11 (eROSITA EDR SI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chon, G., Böhringer, H., & Nowak, N. 2013, MNRAS, 429, 3272 [Google Scholar]
- Chow-Martínez, M., Andernach, H., Caretta, C. A., & Trejo-Alonso, J. J. 2014, MNRAS, 445, 4073 [Google Scholar]
- Chuang, C.-H., Yepes, G., Kitaura, F.-S., et al. 2019, MNRAS, 487, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Clerc, N., Sadibekova, T., Pierre, M., et al. 2012, MNRAS, 423, 3561 [NASA ADS] [CrossRef] [Google Scholar]
- Clerc, N., Ramos-Ceja, M. E., Ridl, J., et al. 2018, A&A, 617, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Comparat, J., Merloni, A., Salvato, M., et al. 2019, MNRAS, 487, 2005 [Google Scholar]
- Comparat, J., Eckert, D., Finoguenov, A., et al. 2020, Open J. Astrophys., 3, 13 [Google Scholar]
- Coupon, J., Czakon, N., Bosch, J., et al. 2018, PASJ, 70, S7 [Google Scholar]
- Dauser, T., Falkner, S., Lorenz, M., et al. 2019, A&A, 630, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Grandi, S., Böhringer, H., Guzzo, L., et al. 1999, ApJ, 514, 148 [NASA ADS] [CrossRef] [Google Scholar]
- Dennerl, K., Andritschke, R., Bräuninger, H., et al. 2020, SPIE Conf. Ser., 11444, 114444Q [NASA ADS] [Google Scholar]
- Dey, A., Schlegel, D. J., Lang, D., et al. 2019, AJ, 157, 168 [Google Scholar]
- Driver, S. P., Norberg, P., Baldry, I. K., et al. 2009, Astron. Geophys., 50, 5.12 [NASA ADS] [CrossRef] [Google Scholar]
- Ebeling, H., Edge, A. C., Böhringer, H., et al. 1998, MNRAS, 301, 881 [NASA ADS] [CrossRef] [Google Scholar]
- Ebeling, H., Edge, A. C., & Henry, J. P. 2001, ApJ, 553, 668 [Google Scholar]
- Ebeling, H., Mullis, C. R., & Tully, R. B. 2002, ApJ, 580, 774 [Google Scholar]
- Eckmiller, H. J., Hudson, D. S., & Reiprich, T. H. 2011, A&A, 535, A105 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, M., Einasto, J., Tago, E., Dalton, G. B., & Andernach, H. 1994, MNRAS, 269, 301 [Google Scholar]
- Einasto, M., Einasto, J., Tago, E., Müller, V., & Andernach, H. 2001, AJ, 122, 2222 [NASA ADS] [CrossRef] [Google Scholar]
- Ettori, S., Ghirardini, V., Eckert, D., et al. 2019, A&A, 621, A39 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Finoguenov, A., Guzzo, L., Hasinger, G., et al. 2007, ApJS, 172, 182 [Google Scholar]
- Finoguenov, A., Watson, M. G., Tanaka, M., et al. 2010, MNRAS, 403, 2063 [NASA ADS] [CrossRef] [Google Scholar]
- Finoguenov, A., Tanaka, M., Cooper, M., et al. 2015, A&A, 576, A130 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Finoguenov, A., Rykoff, E., Clerc, N., et al. 2020, A&A, 638, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Foster, A. R., Ji, L., Smith, R. K., & Brickhouse, N. S. 2012, ApJ, 756, 128 [Google Scholar]
- Freyberg, M., Perinati, E., Pacaud, F., et al. 2020, SPIE Conf. Ser., 11444, 114441O [Google Scholar]
- Furusawa, H., Koike, M., Takata, T., et al. 2018, PASJ, 70, S3 [Google Scholar]
- Ghirardini, V., Bulbul, E., Hoang, D. N., et al. 2021, A&A, 647, A4 [EDP Sciences] [Google Scholar]
- Ghirardini, V., Bahar, Y. E., Bulbul, E., et al. 2022, A&A, 661, A12 (eROSITA EDR SI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Giodini, S., Lovisari, L., Pointecouteau, E., et al. 2013, Space Sci. Rev., 177, 247 [Google Scholar]
- Gozaliasl, G., Finoguenov, A., Tanaka, M., et al. 2019, MNRAS, 483, 3545 [Google Scholar]
- Hasinger, G., Cappelluti, N., Brunner, H., et al. 2007, ApJS, 172, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Hasselfield, M., Hilton, M., Marriage, T. A., et al. 2013, J. Cosmol. Astropart. Phys., 2013, 008 [Google Scholar]
- Hensman, J., Matthews, A., & Ghahramani, Z. 2015, in Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, ed. G. Guy Lebanon & S. V. N. Vishwanathan, 38, 351 [Google Scholar]
- Hilton, M., Sifón, C., Naess, S., et al. 2021, ApJS, 253, 3 [Google Scholar]
- Huang, S., Leauthaud, A., Murata, R., et al. 2018, PASJ, 70, S6 [CrossRef] [Google Scholar]
- Huchra, J. P., Macri, L. M., Masters, K. L., et al. 2012, ApJS, 199, 26 [Google Scholar]
- Kawanomoto, S., Uraguchi, F., Komiyama, Y., et al. 2018, PASJ, 70, 66 [Google Scholar]
- Klein, M., Mohr, J. J., Desai, S., et al. 2018, MNRAS, 474, 3324 [Google Scholar]
- Klein, M., Grandis, S., Mohr, J. J., et al. 2019, MNRAS, 488, 739 [Google Scholar]
- Klein, M., Oguri, M., Mohr, J. J., et al. 2022, A&A, 661, A4 (eROSITA EDR SI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Koens, L. A., Maughan, B. J., Jones, L. R., et al. 2013, MNRAS, 435, 3231 [CrossRef] [Google Scholar]
- Komiyama, Y., Chiba, M., Tanaka, M., et al. 2018, ApJ, 853, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Koulouridis, E., Clerc, N., Sadibekova, T., et al. 2021, A&A, 652, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kuntz, K. D., & Snowden, S. L. 2000, ApJ, 543, 195 [Google Scholar]
- Liu, A., Yu, H., Tozzi, P., & Zhu, Z.-H. 2015, ApJ, 809, 27 [Google Scholar]
- Liu, A., Tozzi, P., Ettori, S., et al. 2020, A&A, 637, A58 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liu, T., Merloni, A., Comparat, J., et al. 2022, A&A, 661, A27 (eROSITA EDR SI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lovisari, L., Reiprich, T. H., & Schellenberger, G. 2015, A&A, 573, A118 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Luo, B., Brandt, W. N., Xue, Y. Q., et al. 2017, ApJS, 228, 2 [Google Scholar]
- Merloni, A., Predehl, P., Becker, W., et al. 2012, ArXiv e-prints [arXiv:1209.3114] [Google Scholar]
- Miyazaki, S., Komiyama, Y., Kawanomoto, S., et al. 2018, PASJ, 70, S1 [NASA ADS] [Google Scholar]
- Mullis, C. R., Vikhlinin, A., Henry, J. P., et al. 2004, ApJ, 607, 175 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [Google Scholar]
- Nishizawa, A. J., Hsieh, B.-C., Tanaka, M., & Takata, T. 2020, ArXiv e-prints [arXiv:2003.01511] [Google Scholar]
- Oguri, M., Lin, Y.-T., Lin, S.-C., et al. 2018, PASJ, 70, S20 [NASA ADS] [Google Scholar]
- Okabe, N., Dicker, S., Eckert, D., et al. 2021, MNRAS, 501, 1701 [Google Scholar]
- Pacaud, F., Clerc, N., Giles, P. A., et al. 2016, A&A, 592, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pacaud, F., Pierre, M., Melin, J. B., et al. 2018, A&A, 620, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pasini, T., Brüggen, M., Hoang, D. N., et al. 2022, A&A, 661, A13 (eROSITA EDR SI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Pierre, M., Chiappetti, L., Pacaud, F., et al. 2007, MNRAS, 382, 279 [NASA ADS] [CrossRef] [Google Scholar]
- Pierre, M., Pacaud, F., Adami, C., et al. 2016, A&A, 592, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Piffaretti, R., Arnaud, M., Pratt, G. W., Pointecouteau, E., & Melin, J.-B. 2011, A&A, 534, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pillepich, A., Porciani, C., & Reiprich, T. H. 2012, MNRAS, 422, 44 [Google Scholar]
- Planck Collaboration XXIX. 2014, A&A, 571, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XIII. 2016a, A&A, 594, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXVII. 2016b, A&A, 594, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pratt, G. W., Croston, J. H., Arnaud, M., & Böhringer, H. 2009, A&A, 498, 361 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pratt, G. W., Arnaud, M., Biviano, A., et al. 2019, Space Sci. Rev., 215, 25 [Google Scholar]
- Predehl, P., Andritschke, R., Arefiev, V., et al. 2021, A&A, 647, A1 [EDP Sciences] [Google Scholar]
- Ramos-Ceja, M. E., Oguri, M., Miyazaki, S., et al. 2022, A&A, 661, A14 (eROSITA EDR SI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rasmussen, C. E., & Williams, C. K. I. 2006, Gaussian Processes for Machine Learning (Cambridge, Massachusetts: MIT Press) [Google Scholar]
- Reiprich, T. H., Basu, K., Ettori, S., et al. 2013, Space Sci. Rev., 177, 195 [Google Scholar]
- Ridl, J., Clerc, N., Sadibekova, T., et al. 2017, MNRAS, 468, 662 [NASA ADS] [CrossRef] [Google Scholar]
- Rosati, P., Della Ceca, R., Norman, C., & Giacconi, R. 1998, ApJ, 492, L21 [NASA ADS] [CrossRef] [Google Scholar]
- Rosati, P., Borgani, S., & Norman, C. 2002, ARA&A, 40, 539 [Google Scholar]
- Rykoff, E. S., Rozo, E., Hollowood, D., et al. 2016, ApJS, 224, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Salvato, M., Buchner, J., Budavári, T., et al. 2018, MNRAS, 473, 4937 [Google Scholar]
- Sanders, J. S., & Fabian, A. C. 2006, MNRAS, 370, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Sanders, J. S., Dennerl, K., Russell, H. R., et al. 2020, A&A, 633, A42 [EDP Sciences] [Google Scholar]
- Seppi, R., Comparat, J., Nandra, K., et al. 2021, A&A, 652, A155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sereno, M., Umetsu, K., Ettori, S., et al. 2020, MNRAS, 492, 4528 [CrossRef] [Google Scholar]
- Smith, R. K., Brickhouse, N. S., Liedahl, D. A., & Raymond, J. C. 2001, ApJ, 556, L91 [Google Scholar]
- Snowden, S. L., Mushotzky, R. F., Kuntz, K. D., & Davis, D. S. 2008, A&A, 478, 615 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tanaka, M. 2015, ApJ, 801, 20 [Google Scholar]
- Umetsu, K. 2020, A&ARv, 28, 7 [Google Scholar]
- Vikhlinin, A., McNamara, B. R., Forman, W., et al. 1998, ApJ, 498, L21 [NASA ADS] [CrossRef] [Google Scholar]
- Vikhlinin, A., Kravtsov, A., Forman, W., et al. 2006, ApJ, 640, 691 [Google Scholar]
- Vikhlinin, A., Burenin, R. A., Ebeling, H., et al. 2009, ApJ, 692, 1033 [Google Scholar]
- Voges, W., Aschenbach, B., Boller, T., et al. 1999, A&A, 349, 389 [NASA ADS] [Google Scholar]
- Wager, S., Hastie, T., & Efron, B. 2014, J. Mach. Learn. Res., 15, 1625 [Google Scholar]
- Wen, Z. L., Han, J. L., & Liu, F. S. 2012, ApJS, 199, 34 [Google Scholar]
- Willingale, R., Starling, R. L. C., Beardmore, A. P., Tanvir, N. R., & O’Brien, P. T. 2013, MNRAS, 431, 394 [Google Scholar]
- Wilms, J., Allen, A., & McCray, R. 2000, ApJ, 542, 914 [Google Scholar]
- Zucca, E., Zamorani, G., Scaramella, R., & Vettolani, G. 1993, ApJ, 407, 470 [Google Scholar]
version eSASSusers_281889.
Version 0.23.2.
GPy, since 2012: a Gaussian process framework in Python; Version 1.9.9; http://github.com/SheffieldML/GPy
All Tables
X-ray luminosity function of the eFEDS clusters for the full sample and in two redshift bins.
Main results of the X-ray analysis for the 102 clusters in the subsample with > 2σ- temperature measurements within either 300 kpc or 500 kpc.
All Figures
|
Fig. 1 Exposure-corrected point-source-free 0.2–2.3 keV adaptively smoothed eROSITA image of the eFEDS field. In detail, a point source mask is constructed by excluding regions around each point source in which the surface brightness is above 10% of the background surface brightness. The accumulate_counts program from the contour binning package (Sanders & Fabian 2006) is used to calculate a map containing the radius around each pixel (including those in masked areas) that encloses at least 36 counts (excluding masked sources). This map is used to smooth the input image and exposure map with Gaussians, excluding masked areas, where σ is given by the radius in each pixel. The smoothed image and exposure map were divided to create the exposure-corrected image shown here. |
| In the text | |
|
Fig. 2 Distribution of the 542 cluster candidates in eFEDS. The color code represents the redshift of the cluster, provided by MCMF (Klein et al. 2018, 2019). The radius of the circle is equal to R500, within which the average density is 500 times the critical density at the cluster redshift. |
| In the text | |
|
Fig. 3 Redshift histogram of the 542 cluster candidates in the redshift range of 0.01–1.3. The median redshift of the sample ɀmedian = 0.35 is shown as the vertical dashed line. We also plot the results after cutting the sample with different thresholds on the extent likelihood ℒext. |
| In the text | |
|
Fig. 4 Contamination fraction assessment in our sample based on simulations. Upper panel: cumulative detection fraction of sources in the five classes as a function of extent likelihood. The orange solid line shows the total fraction of sources classified as real clusters, namely, the sum of unique extended source and extended source residual. The total contamination is plotted with the solid gray line based on summing all the other three classes. Middle panel: cumulative detecting fraction of sources in the five classes. Lower panel: distribution of extent likelihood of the clusters in our catalog. The clean sample after removing the fraction of contamination is shown in orange. The gray bar represents the contamination in each bin. |
| In the text | |
|
Fig. 5 Detection probability as a function of luminosity L500 in the 0.5–2 keV band and redshift ɀ. The data points with error bars are the L500 for the clusters with >2σ measurements. Details of the computation of L500 are presented in Sect. 5. The white curve shows the flux limit at 1.5 × 10–14 erg s–1 cm–2, corresponding to an average completeness level of ~40%. |
| In the text | |
|
Fig. 6 Results of imaging and spectral analysis for cluster eFEDS J092121.2+031726 at redshift 0.333 (spectroscopic) as an example. This cluster is detected with ℒext = 478.6 and ℒdet = 1729.8 and has one of the highest S/Ns in our sample. The temperature and soft-band luminosity within 500 kpc are |
| In the text | |
|
Fig. 7 Luminosity redshift distribution of the clusters with significant luminosity measurements (>2σ) for 300 kpc (upperpanel) and 500 kpc (lower panel). The black curve shows the flux limit: 10–14 erg s–1 cm–2 for 300 kpc and 1.5 × 10–14 erg s–1 cm–2 for 500 kpc (without a K correction). |
| In the text | |
|
Fig. 8 Signal-to-noise ratio profiles for all the clusters. The net count rates are computed from the best-fit model of the soft-band image (see Sect. 4.1 for more details). For each cluster, the S/N as a function of radius is shown as a curve color-coded by its maximum value. The maximum S/N and the corresponding radii for all clusters are marked with blue dots. Clusters with maximum S/N lower than 3 are plotted in dark gray. The histogram in the upper left panel shows the distribution of the maximum S/N, only considering clusters with maximum S/N higher than 3, in order to remove the contamination from low-significance clusters. |
| In the text | |
|
Fig. 9 Luminosity plotted as a function of temperature for the clusters with >2σ temperature measurements in either of the two radii. |
| In the text | |
|
Fig. 10 X-ray luminosity function of the eFEDS cluster sample. Left panel: results for the full sample. Right panel: results in two redshift bins. The number of clusters in each bin is indicated in the lower panel. Some literature results are plotted as the shaded area for comparison: XXL-C1 (Adami et al. 2018), XXL-100 (Pacaud et al. 2016), and WARPS (Koens et al. 2013). Thick error bars show the results of the ℒext ≥ 15 subsample. |
| In the text | |
|
Fig. 11 Linking length in comoving distances as a function of cluster redshift in our sample. The circles mark the positions of the 19 supercluster candidates we detected. |
| In the text | |
|
Fig. A.1 X-ray images of the 19 superclusters we detected in the eFEDS field. The images are generated in the same way as for Fig. 1. The white circles mark the estimated virial radii of the member clusters of each supercluster. The thick bar in the lower right corner indicates the linking length at the supercluster redshift. |
| In the text | |
|
Fig. A.2 Galaxy density map from HSC-SSP survey data at the locations and redshifts of the 19 supercluster candidates. They are obtained by integrating the full probability function of the MIZUKI (Tanaka 2015) photometric redshifts (P(z)) of each galaxy (the S19A catalog; Nishizawa et al. 2020) with a width of the redshift slice of |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.