| Issue |
A&A
Volume 683, March 2024
|
|
|---|---|---|
| Article Number | A130 | |
| Number of page(s) | 14 | |
| Section | Catalogs and data | |
| DOI | https://doi.org/10.1051/0004-6361/202348884 | |
| Published online | 13 March 2024 | |
The SRG/eROSITA All-Sky Survey
First catalog of superclusters in the western Galactic hemisphere★
1
Max Planck Institute for Extraterrestrial Physics,
Giessenbachstrasse 1,
85748
Garching,
Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Hamburger Sternwarte, Universität Hamburg,
Gojenbergsweg 112,
21029
Hamburg,
Germany
3
IRAP, Université de Toulouse, CNRS, UPS, CNES,
31028
Toulouse,
France
4
Institute for Astro- and Particle Physics, University of Innsbruck,
Technikerstr. 25,
6020
Innsbruck,
Austria
5
Leibniz-Institut für Astrophysik Potsdam (AIP),
An der Sternwarte 16,
14482
Potsdam,
Germany
6
Leiden Observatory, Leiden University,
PO Box 9513,
2300 RA
Leiden,
The Netherlands
7
Argelander-Institut für Astronomie, Universität Bonn,
Auf dem Hügel 71,
53121
Bonn,
Germany
Received:
8
December
2023
Accepted:
4
January
2024
Abstract
Superclusters of galaxies mark the large-scale overdense regions in the Universe. Superclusters provide an ideal environment to study structure formation and to search for the emission of the intergalactic medium such as cosmic filaments and WHIM. In this work, we present the largest-to-date catalog of X-ray-selected superclusters identified in the first SRG/eROSITA All-Sky Survey (eRASS1). By applying the Friends-of-Friends (FoF) method on the galaxy clusters detected in eRASS1, we identified 1338 supercluster systems in the western Galactic hemisphere up to redshift 0.8, including 818 cluster pairs and 520 rich superclusters with ≥3 members. The most massive and richest supercluster system is the Shapley supercluster at redshift 0.05 with 45 members and a total mass of 2.58 ± 0.51 × 1016M⊙. The most extensive system has a projected length of 127 Mpc. The sizes of the superclusters we identified in this work are comparable to the structures found with galaxy survey data. We also found a good association between the eRASS1 superclusters and the large-scale structures formed by optical galaxies. We note that 3948 clusters, corresponding to 45% of the cluster sample, were identified as supercluster members. The reliability of each supercluster was estimated by considering the uncertainties in the redshifts of the galaxy clusters and the peculiar velocities of clusters. Furthermore, 63% of the systems have a reliability larger than 0.7. The eRASS1 supercluster catalog provided in this work represents the most extensive sample of superclusters selected in the X-ray band in terms of the unprecedented sample volume, sky coverage, redshift range, the availability of X-ray properties, and the well-understood selection function of the parent cluster sample, which enables direct comparisons with numerical simulations. This legacy catalog will greatly advance our understanding of superclusters and the cosmic large-scale structure.
Key words: galaxies: clusters: general / large-scale structure of Universe / X-rays: galaxies: clusters
Full Tables 1, 2, A.1, and A.2 are available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/683/A130
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model.
Open Access funding provided by Max Planck Society.
1 Introduction
In the hierarchical structure formation picture, galaxy clusters emerge from the rarest and highest density peaks of initial fluctuations and become gravitationally bound after going through several merging and accretion processes (see Kravtsov & Borgani 2012, for a review). While clusters are widely used to study cosmology and structure formation, their spatial distribution also traces the cosmic overdense regions on a larger scale, such as superclusters. As components of the cosmic web, clusters and superclusters mark the density peaks in the large-scale structure. They are connected by other elements, such as filaments, sheets, and walls, and are separated by low-density regions, such as cosmic voids.
Superclusters are groups of galaxy clusters consisting of more than one member cluster. Superclusters will not necessarily collapse in the future as they are not gravitationally bound, and the physical connections between their member clusters are relatively weak compared to virialized systems. Except for some cases of merging clusters, in most of the supercluster systems, their members have not yet interacted with other members and lie beyond the virial radius of each other. These features make it difficult to define and identify superclusters in observations quantitatively. Although the concept of a supercluster was introduced about seventy years ago (de Vaucouleurs 1953), a precise and widely accepted definition of superclusters is still absent. Tully et al. (2014) and Einasto et al. (2019) proposed to define superclusters based on their dynamic effect on the cosmic environment, calling them “basins of attraction” and “cocoons”; Chon et al. (2015) suggested to call the superclusters that will survive the cosmic expansion and eventually collapse in the future "superstes-clusters", to distinguish them from traditional superclusters. In fact, some traditional superclusters, such as Laniakea (Tully et al. 2014), are essentially compilations of several smaller superclusters, and the whole system will disperse in the future (Chon et al. 2015).
Despite the difficulties in defining superclusters, there have been numerous works aiming at finding superclusters based on optical galaxy surveys or optical-selected cluster catalogs for decades (see, e.g., Abell 1961; Zucca et al. 1993; Einasto et al. 1994, for some early attempts). Most of the works where superclusters have been identified with galaxy catalogs used the method of galaxy density field. They computed the density of galaxies across the sky and searched for peaks of galaxy densities. For example, Einasto et al. (2007) found 543 super-clusters with the Two-degree-Field Galaxy Redshift Survey data by selecting the peaks in the galaxy density field. Using the Sloan Digital Sky Survey Data Release 7 galaxy catalog, Liivamägi et al. (2012) constructed a set of supercluster catalogs by searching for regions with densities over a selected threshold. Using a fixed density threshold and an adaptive local density threshold, they found 982 and 1313 superclusters, respectively. On the other hand, the works where superclusters were identified directly from cluster catalogs prefer the Friends-of-Friends (FoF) method, mostly due to the difficulties in precisely computing the density field of clusters as they are much rarer than galaxies. For example, Sankhyayan et al. (2023) identified 662 superclusters in the redshift range [0.05, 0.42] by applying a modified FoF method on the Wen-Han-Liu (WHL) SDSS cluster catalog (Wen et al. 2012). In summary, the number of known optical superclusters up to now is on the order of 103.
Compared to optical cluster surveys, X-ray cluster surveys have the advantage in terms of sample purity, as the former often suffers from projection effects (e.g., Costanzi et al. 2019; Myles et al. 2021). As clusters are more highly biased than galaxies (see, e.g., Seppi et al. 2024), fewer of them are needed to significantly trace the same underlying structure. Thanks to the availability of large-area X-ray surveys, in the past decades, there have been an increasing number of efforts in detecting super-clusters directly using X-ray cluster samples (Einasto et al. 2001; Chon et al. 2013; Adami et al. 2018; Böhringer & Chon 2021; Liu et al. 2022). The first X-ray flux-limited supercluster sample was constructed by Chon et al. (2013), with the extended ROSAT-ESO Flux-Limited X-ray (REFLEX II) galaxy cluster sample. They found 164 superclusters below redshift 0.4. In recent years, supercluster catalogs have become important products of X-ray cluster surveys. In the XXL survey, Adami et al. (2018) detected 35 superclusters with Ncl ≥ 3, and 39 cluster pairs, out to redshift 0.8. In the eROSITA Final Equatorial-Depth Survey (eFEDS, Brunner et al. 2022), Liu et al. (2022) detected 84 superclusters including 19 rich systems with Ncl ≥ 4. Böhringer & Chon (2021) identified eight superclusters in the local Universe (z ≤ 0.03) from the Cosmic Large-Scale Structure in X-rays cluster survey, compiled from the X-ray clusters in the ROSAT All-Sky Survey.
Most of these works used the FoF algorithm to identify superclusters, where the linking length was determined based on a specific local overdensity ratio at a specific redshift with respect to the sample average. It should be noted, however, that the overdensity ratio f can vary in different works (e.g., Chon et al. 2013; Böhringer & Chon 2021), and the detection of super-clusters is sensitive to the choice of f (see, e.g., Chon et al. 2013). In the nearby Universe, since the X-ray cluster surveys are almost complete at high fluxes, one can also use the cluster X-ray luminosity function (XLF) to compute the local overden-sity with respect to the cosmic average (e.g., Böhringer & Chon 2021), which would ideally give the same results as using the sample average. Other methods, such as the Voronoi tessellation, have also been used in the identification of superclusters and are found to give similar results as FoF (Adami et al. 2018). Recently, another novel technique based on the dendrogram of galaxies was developed and applied to the identification of clustering patterns of stars and galaxies (Liu et al. 2018; Yu & Hou 2022), which also has promising prospects of application in supercluster detection.
A large and representative sample of superclusters will advance the studies on both cosmology and astrophysics in many aspects. As the largest elements in the cosmic web, superclusters retain the history of the formation and evolution of the web. As "clusters of clusters", they are ideal laboratories to investigate the environmental effect on the evolution of galaxy clusters and galaxies. Superclusters can also play essential roles in the search for warm-hot intergalactic medium (WHIM) thanks to their association with cosmic structures. Moreover, nonthermal physics such as magnetic fields and cosmic rays can be studied in these dynamic systems. The amount of attempts to directly use superclusters as cosmology probes is quite limited. This is owing mostly to the difficulties in precisely identifying super-clusters, such as their centers, masses, and edges, and also to the sample volume: the total number of X-ray superclusters is on the order of 102 (Einasto et al. 2001; Chon et al. 2013; Adami et al. 2018; Liu et al. 2022). On the other hand, some well-known supercluster systems have already been used to study the large-scale structure, for example, mapping the structures in the nearby Universe (e.g., Böhringer & Chon 2021; Böhringer et al. 2021), and detecting or characterizing the inter-cluster filaments within supercluster systems (e.g., Ursino et al. 2015; Bulbul et al. 2016; Reiprich et al. 2021; Ghirardini et al. 2021; Hoang et al. 2023).
A precondition of finding superclusters is large samples of clusters with high sample purity and precise redshifts. These are available thanks to the recent large-area surveys in X-ray, Sunyaev-Zeldovich (SZ), and optical bands. In particular, the eROSITA (extended ROentgen Survey with an Imaging Telescope Array, Predehl et al. 2021) X-ray telescope onboard Spectrum Roentgen Gamma (SRG) will detect about 105 clusters and groups during its lifetime (Merloni et al. 2012; Liu et al. 2022; Bulbul et al. 2022), which will substantially increase the sample size of X-ray clusters. In eFEDS, 84 supercluster systems are detected in the ~140 deg2 survey area (Liu et al. 2022). Projected from the eFEDS results, the final eROSITA All-Sky Survey (eRASS) is expected to detect thousands of superclus-ters in the western Galactic hemisphere. In particular, thanks to the unprecedented sensitivity in the soft X-ray band, eROSITA will detect a large number of galaxy groups, which trace the large-scale structure even better than massive clusters owing to the overwhelming advantage in numbers. In the eROSITA and eRASS era, we can trace the large-scale structure with comparable power to the optical galaxy surveys for the first time. The large sample of superclusters detected by eROSITA will expand the study of superclusters from nearby Universe to higher red-shifts (z ≈ 1), from single targets to representative populations, and will greatly advance our understanding of superclusters and the related cosmological and astrophysical topics.
In this work, we search for supercluster systems based on the galaxy cluster catalog from the first eROSITA All-Sky Survey (eRASS1, Merloni et al. 2024; Bulbul et al. 2024; Kluge et al. 2024). Leveraging this largest-ever X-ray galaxy cluster sample, we aim to present the biggest X-ray supercluster catalog to be used for further explorations of superclusters. The paper is organized as follows. In Sect. 2, we introduce the eRASS1 galaxy cluster sample used for supercluster detection. In Sect. 3, we describe the identification of eRASS1 superclusters. In Sect. 4, we study the properties of the eRASS1 superclusters and their members. Our conclusions are summarized in Sect. 5. Throughout this paper, we adopt the concordance ΛCDM cosmology with Ωλ = 0.7, Ωm = 0.3, and H0 = 70 km s−1 Mpc−1. However, we note that the exact choice of cosmological parameters does not affect the results significantly. Quoted error bars correspond to a 1σ confidence level. To avoid confusion, we refer to the supercluster systems with two member clusters as "cluster pairs", and the systems with more than two member clusters as "rich superclusters", unless noted otherwise.
2 Galaxy cluster sample
2.1 eRASS1 galaxy cluster catalog
The first eROSITA All-Sky Survey was completed on June 11, 2020. In the western Galactic hemisphere1, nearly 9.3 × 105 X-ray sources are detected in the 0.2–2.3 keV energy range where eROSITA is most sensitive (Merloni et al. 2024). Among them, about 2.7 × 104 are classified as extended sources, namely, galaxy cluster candidates, according to a simple cut on X-ray extent likelihood: ℒext > 3 (Bulbul et al. 2024).
Optical identification of the cluster candidates is performed with eROMaPPer, a highly parallelized version of the red-sequence-based cluster finder tool redMaPPer (Rykoff et al. 2014, 2016). The public photometric data of the DESI Legacy Imaging Surveys DR9 and DR10 (Dey et al. 2019) are used for the confirmation of clusters and the computation of photometric redshifts zλ. Where possible, we also derive the spectroscopic redshifts of the eRASS1 clusters using publicly available galaxy spectroscopic redshifts. The final choice of cluster redshift BEST_Z is made as follows. If the cluster has at least three spectroscopic members, we determine its BEST_Z as zspec, which is the mean of the spectroscopic redshifts of the members. Otherwise, if the optical central galaxy has a spectroscopic redshift zspec,cg, we determine BEST_Z as zspec,cg. When neither of the above conditions is met, we adopt the photometric redshift zλ as the BEST_Z. Finally, for a few hundred clusters without spectro-scopic or photometric redshifts, we adopt the literature redshifts zlit by matching with public cluster catalogs using a matching radius of 2′. In summary, the eRASS1 galaxy cluster catalog contains 12247 optically confirmed clusters up to redshift 1.32. The details of the optical follow-up methodology are presented in Kluge et al. (2024).
To obtain the X-ray properties of the eRASS1 clusters, a multi-band X-ray imaging analysis is performed for each cluster, using the tool MBProj2D (Sanders et al. 2018). By forward-fitting cluster’s X-ray images in seven bands from 0.3 keV to 7 keV, MBProj2D provides the best-fit cluster physical model. Products for each cluster include the azimuthally-averaged electron density profile described in the form of the model in Vikhlinin et al. (2006), a single global temperature under the isothermal assumption, and other derived quantities such as flux, luminosity, count rate, gas mass, etc. In particular, the above quantities are given as a function of radius and in multiple energy ranges (see, e.g., Liu et al. 2023, for a recent application of MBProj2D). Masses within R5002 of the clusters are computed based on the scaling relation between X-ray count rate, redshift, and mass, after calibrated with weak lensing shear signal (see more details in Grandis et al. 2024; Ghirardini et al. 2024). The masses of eRASS1 clusters span a range 5 × 1012M⊙ < M500 < 2 × 1015M⊙.
A contamination probability estimator, Pcont, is also computed for each eRASS1 cluster. The calculation of Pcont is based on a mixture model that takes into account the cluster’s redshift, X-ray count rate, and optical richness. It gives the probability of a cluster to be a contaminant. According to the results of Pcont for each cluster, we estimate that around 1700 of the 12247 eRASS1 clusters are spurious. This is computed by Σ Pcont. Thus the purity of the eRASS1 cluster sample, Σ(1 – Pcont)/Ncl, is about 86%. Most of the contaminants in the catalog are AGN, misclas-sified as extended sources due to the sizable PSF of eROSITA. More details about the eRASS1 cluster catalog are provided in Bulbul et al. (2024) and Kluge et al. (2024).
2.2 Sample selection
We apply several additional selections on the primary eRASS1 cluster catalog published in Bulbul et al. (2024) to obtain a sub-sample of clusters with higher purity and more reliable redshifts, which is suitable for supercluster detection. Firstly, about 1900 clusters with Pcont larger than 0.3 are ignored to enhance the purity of the sample. Secondly, since the detection of super-clusters is sensitive to cluster redshifts, we exclude the clusters with unreliable redshifts. These include about 900 cases when the errorbar in redshift is large (δz/(1 + z) > 0.02) or when the photometric redshift exceeds the limiting redshift at cluster’s sky position (see Bulbul et al. 2024; Kluge et al. 2024, for more details). Thirdly, about 300 clusters are found to be duplicates based on the optical data. Namely, more than 70% of their members are also identified as members of another cluster, which has a higher extent likelihood (see Kluge et al. 2024, and the optical follow-up catalog, for more information). These clusters are also excluded from the sample. Fourthly, we exclude about 200 clusters with less than 5 X-ray photons within R500 to further reduce the contamination level. Finally, a few nearby clusters below red-shift 0.005, such as Virgo, are not considered. With the above selections, we obtain a subsample of 8862 clusters in the red-shift range of [0.0056, 1.32], with a purity of 96.4% estimated from the Pcont of the remaining clusters in the subsample.
In Fig. 1, we present the mass M500 and redshift distribution of the cluster sample. Most high redshift clusters do not pass the selection criteria due to the larger error bar in their photometric redshifts. Among the 8862 clusters in the sample, 2758 have spectroscopic redshifts as BEST_Z, 5885 and 219 have photometric and literature redshifts respectively. The median redshift of the sample is 0.28, slightly lower than the overall eRASS1 cluster sample, where zmedian ≈ 0.31. The loss of high redshift clusters will limit our supercluster identification to below z ≈ 1.
3 Supercluster identification
To identify superclusters in eRASS1, we adopt the similar FoF method as Liu et al. (2022). For a random cluster in the sample, the algorithm searches for neighboring clusters (namely, "friends") closer than a specific distance, called the "linking length" l. Then, for each of the "friends", the algorithm continues to search for "friends of friends" until no new neighboring clusters are found. The co-moving distances between clusters are computed using their redshifts and X-ray centroids (RA_XFIT, DEC_XFIT) obtained from the fit of MBProj2D. The 3D comov-ing distance between two clusters, assuming a flat universe with Ωk = 0, can be computed as:
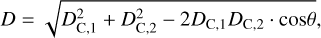 (1)
(1)
where DC,1 and DC,2 are the line-of-sight co-moving distances of the two clusters at (RA = α1, Dec = δ1, z = z1) and (RA = α2, Dec = δ2, z = z2), θ is the angular separation of the clusters. The line-of-sight co-moving distance of a cluster at redshift z can be written as:
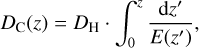 (2)
(2)
where DH = c/H0 is the Hubble distance, and the function E(z) is defined as:
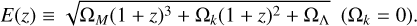 (3)
(3)
The angular separation of the two clusters θ can be computed as:
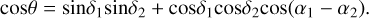 (4)
(4)
The linking length, in co-moving 3D distance, is computed as a function of the average cluster number density n and the desired overdensity ratio f: l = (n × f)–1/3. Here, n–1/3 is simply the average distance between two neighboring clusters assuming that the clusters are uniformly distributed in a 3D space without structures such as superclusters. Thus multiplying n with the overdensity ratio f implies that the cluster density in a super-cluster is f times that of the space average. In some other works, a factor of 4π/3 is included in the computation of local cluster density, by assuming spherical collapse, so that the linking length becomes l = (4πnf /3)–1/3 (e.g., Zucca et al. 1993). However, we note that most supercluster systems, especially cluster pairs, do not have regular shapes. Estimating the volume of a low-multiplicity supercluster with a sphere of radius l will likely overestimate the volume and underestimate the density. We therefore use the more general definition of l without the assumption of spherical collapse: (n × f)–1/3.
The selection of eRASS1 clusters is a strong function of X-ray count rate, which confines the detection of high-redshift clusters to the high-luminosity regime, known as the Malmquist bias, a common selection bias for flux-limited surveys. Additionally, surface brightness patterns also have non-negligible effects on the selection of X-ray clusters: high redshift clusters with bright cores are more likely to be misidentified as point sources because of their smaller angular sizes and the large PSF of X-ray telescopes (e.g., Bulbul et al. 2022). The combination of these selection effects leads to a decrease in the number density of eRASS1 clusters, and thus a rapid increase in linking length, at high redshifts. Additionally, as the survey depth of eRASS1 is not uniform, where the ecliptic pole areas have longer exposure than the equatorial areas, the distribution of eRASS1 clusters generally shows the same pattern of nonuniformity as the eRASS1 exposure map. The magnitude of this nonuniformity is much lower compared to the evolution of cluster number density with redshift. However, for some studies on superclusters, for example, the comparison between supercluster members and isolated clusters, one would prefer a more uniform selection after accounting for the nonuniformity of the parent cluster sample. Therefore, in the computation of cluster number density, we consider not only the dependency on redshift but also the influence of exposure time. This is different than what Liu et al. (2022) have done on eFEDS clusters, where cluster density is computed only as a function of redshift because the survey depth of eFEDS is nearly uniform. Our linking length is then defined as:
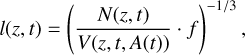 (5)
(5)
where N and V are the number of clusters and the corresponding survey volume in the redshift range [z – δz, z + δz] and exposure range [t – δt, t + δt]. The thickness of the shell, 2δz, is fixed at 0.01. δt is adjusted to make sure the corresponding survey area is larger than 100 deg2. A(t) is the eRASS1 depth curve (Bulbul et al. 2024). f is the overdensity ratio, and we adopt f = 10, which is a common choice in many previous works (e.g., Chon et al. 2013; Adami et al. 2018; Liu et al. 2022).
Since our cluster density decreases rapidly at high redshifts, we empirically set an upper limit on linking length: l <= 50 Mpc, to avoid spurious detections at high redshifts. Namely, we set 50 Mpc as the maximum distance between two clusters that are believed to be connected with each other. We note that the choice of 50 Mpc as the upper limit of linking length is relatively conservative compared to previous works. This will help reduce false detections and systems with very large distances between members. As a comparison, the linking length can be as large as 70-80 Mpc in XXL (Adami et al. 2018) and eFEDS (Liu et al. 2022). We also note that the thickness of the volume shell for computing the local cluster density in Eq. (5), 2δz = 0.01, ranges between 27 Mpc (at z = 0.8) and 42 Mpc (at z = 0.05), both are smaller than the upper limit of linking length. We plot in Fig. 2 the cluster density and linking length as functions of redshift and exposure time. As expected, the linking length shows a much stronger dependence on redshift than the exposure time. In summary, our selection of superclusters includes the cluster sample selection described in Sect. 2.2, and the linking length plotted in the right panel of Fig. 2. These selection procedures need to be accounted for in statistical studies of superclusters and in the comparison with numerical simulations.
In the identification of superclusters, we use the bestredshifts of the eRASS1 clusters (BEST_Z column in the eRASS1 cluster catalog) to compute the distance between clusters. However, the 3D distance between clusters is sensitive to the precision of cluster redshifts. Therefore, for each supercluster system detected using BEST_Z, we must check how robust the detection is over the clusters’ redshift uncertainties. In addition to that, the peculiar velocities of clusters can also contribute to their redshifts and are also an important source of uncertainties in the distances. For clusters with spectroscopic redshifts, the distance uncertainties might be dominated by peculiar motions. The peculiar velocities of clusters are not well-constrained, except for the very nearby Universe. We, therefore, adopt a typical value of upec = czpec = 400 km s–1 (see, e.g., Dolag & Sunyaev 2013) and add this component to the uncertainties of redshift in quadrature with the original redshift uncertainties. We then perform the following simulations to estimate the reliability of each super-cluster over the total uncertainties of the clusters’ redshifts. In each simulation, we randomly vary the redshift of each cluster in the sample over its total uncertainty. The same FoF method is then employed to identify superclusters in each simulated cluster sample. The simulations are performed 1000 times. We note that directly comparing the superclusters in each simulation by simply matching the central coordinates is not straightforward, and might bring misleading results. For instance, the addition or subtraction of a single member in the outskirts of a rich super-cluster can cause a significant shift in its central position, even if the dominant part of the superclusters is robustly detected in both cases. Therefore, instead of estimating the detection rate of the superclusters in the simulations, we compute for each cluster the frequency of being a supercluster member. Then, for each supercluster detected using BEST_Z, we define its reliability as the average frequency of its member clusters.
Another important point to note is that our supercluster identification, similar to all the other supercluster catalogs in both optical and X-ray bands, is clearly affected by the selection of the parent eRASS1 cluster sample and the detection algorithm. In principle, there is no universal division between superclus-ter members and isolated clusters. Obviously, an isolated cluster identified in a shallower survey can become a supercluster member in a deeper survey, when its faint neighbors are detected. Therefore, one has to specify the selection of the cluster sample and the detection criteria associated with a supercluster sample. Similarly, the comparison between supercluster members and isolated clusters also requires that the two classes of clusters have consistent selection functions, despite that the division of the two classes might differ in different surveys.
With the 8862 eRASS1 clusters and the linking length defined in Eq. (5), we identify 1338 supercluster systems in eRASS1, including 818 cluster pairs and 520 rich superclusters with >= 3 members. 3948 clusters are identified as members of these supercluster systems. In addition to this primary superclus-ter catalog obtained with f = 10, we also employ the same FoF method to search for supercluster systems with a lower overden-sity ratio f = 3 and a higher overdensity ratio f = 50. As a result, we detect 1270 and 929 superclusters corresponding to f = 3 and f = 50, respectively. In both cases, the numbers of super-clusters are lower than that of f = 10. This result is consistent with Chon et al. (2013) where the authors show in their Fig. 2 that the number of detected superclusters reaches its maximum value between f = 5 and f = 10. We also note that 4867 and 2205 clusters are identified as supercluster members for f = 3 and f= 50, consistent with the trend that the lower the overden-sity ratio, the more clusters are linked as superclusters. We base our following analysis on the primary supercluster catalog with f= 10.
 |
Fig. 1 Mass and redshift distribution of the cluster sample used for supercluster identification. Blue, yellow, and red histograms indicate photometric, spectroscopic, and literature redshifts, respectively. The black dashed line shows the redshift distribution of the overall eRASS1 cluster sample. |
 |
Fig. 2 Cluster number density (N / V, left panel) and linking length (l, right panel) plotted as functions of both redshift and exposure time, computed using Eq. (5), with f = 10. |
4 Properties of the eRASS1 superclusters
We present in this section the properties of the primary eRASS1 supercluster catalog. The spatial distribution of the rich super-clusters is presented in Fig. 3. Although we have accounted for the dependency of cluster density on exposure time, there is still a slight overdensity of identified supercluster systems around the South Ecliptic Pole, where eRASS1 is deeper than other regions.
Among the 8862 clusters in the sample, 3948 (45%) are identified as supercluster members. This fraction is only slightly lower than the result in Böhringer & Chon (2021), where 51% of the clusters are found to be supercluster members. The difference is likely due to the fact that Böhringer & Chon (2021) adopt a much lower overdensity ratio (ƒ = 2). The distribution of multiplicity, defined as the number of member clusters in a supercluster, is shown in Fig. 4. The richest system we identify, leRASS-SC J1307-3016, also known as the Shapley supercluster, has 45 members with a median redshift of 0.050. For each supercluster system, we compute the average distance of its members to the center of the system (dmem, where the center is defined as the algebraic mean coordinate of the members), and the total length (L), which is defined as the maximum distance between its members. Both quantities are computed in the projected 2D distance. The distribution of the average separation and length are shown in Fig. 5. dmem can be used to quantify how compact is a super-cluster system. For rich superclusters, the distribution of dmem reaches a peak value at around 15 Mpc, and extends to 40 Mpc (see the left panel of Fig. 5). The median dmem of rich superclusters is 12.9 Mpc. On the other hand, most of the cluster pairs have a low ámem smaller than 15 Mpc, with a small fraction extending to 25 Mpc, due to the upper limit of 50 Mpc on linking length. The median dmem of cluster pairs is 8.4 Mpc, much lower than rich superclusters. A similar trend can be found in the distribution of total length L (see the right panel of Fig. 5). The L of rich superclusters peaks at around 30 Mpc, with a median value of 33.5 Mpc, while the median L of cluster pairs is 16.9 Mpc. The most extensive system we detect in eRASS 1, leRASS-SC J1140-1939 at redshift 0.303, consisting of 10 member clusters, has a projected comoving length of 127 Mpc. As a comparison, the superclusters identified with SDSS DR7 data (Liivamägi et al. 2012) have average and maximum diameters of 22 Mpc and 120 Mpc, similar to the sizes of the eRASS 1 X-ray superclusters.
We also estimate the total cluster mass of the supercluster systems by simply summing up the virial masses M200 of its member clusters, where we adopt the approximation M200 ≈ 1.46 × M500 by assuming a Navarro-Ferenk-White (NFW) profile (Navarro et al. 1997) with concentration c = r200/rs = 4 (Reiprich et al. 2013). The total cluster mass is then converted to the total supercluster mass by adopting the relation found by Chon et al. (2014) with cosmological N-body simulations: Mtot, Cl = 0.39 + 0.077 × Mtot,SC. The most massive eRASS1 supercluster is the Shapley supercluster, 1eRASS-SC J1307-3016, with a total mass of 2.58 ± 0.51 × 1016M⊙ and a length of L = 111 Mpc. The mass estimation of the Shapley super-cluster is available in several previous works. For example, Reisenegger et al. (2000) reported a total mass of 1.9 × 1016M⊙ within 12 Mpc, using a caustic method of galaxies, and assuming a spherical collapse model. Ragone et al. (2006) measured a total mass of 2.3 × 1016M⊙, using 122 galaxy systems in a area of 12 × 15 deg2, with the masses outside the galaxy systems corrected. More recently, Chon et al. (2014) found a total mass of 1.91 × 1016M⊙ within 17.7 Mpc. We note that, given the difference in radius, data, and methods, our result is in broad agreement with the values reported by the previous works. A dedicated analysis on the Shapley supercluster with eROSITA will be performed in another work (Sanders et al., in prep.).
The redshift distribution of the supercluster systems is shown in Fig. 6. The supercluster systems at high redshifts are dominated by cluster pairs, owing to the decrease in the number density of clusters in the sample. Also shown in Fig. 6 in the right panel is the mass-redshift relation of rich superclusters with ≥3 members, where the masses of the systems span a range of [6 × 1013 – 2 × 1016M⊙]. The most distant system, 1eRASS-SC J0530-4138, is a cluster pair at redshift 0.802, consisting of two members, 1eRASS J052957.4-413822 and 1eRASS J053040.8-413904. We show in Fig. 7 the optical image of this cluster pair from the Legacy Imaging Survey. The photometric redshifts of the two members are 0.811 ± 0.007 and 0.793 ± 0.012, and the masses (M500) are 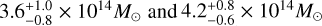 Due to the large error bar in redshifts, we are not able to precisely constrain the 3D distance between the two members. Therefore, this system has relatively low reliability, P = 0.50. The projected distance is about 3.7 Mpc, implying that the two members will probably merge as a massive cluster. Although this cluster pair is identified for the first time in this work, the two member clusters are already detected in Sunyaev–Zeldovich (SZ) surveys by the Atacama Cosmology Telescope (ACT, Hilton et al. 2021) and the South Pole Telescope (SPT, Bocquet et al. 2019). The reported photometric redshifts of 1eRASS J052957.4-413822 and 1eRASS J053040.8-413904 are 0.793 ± 0.0\0 and 0.795 ± 0.0\0 in ACT, and 0.775 ± 0.050 and 0.775 ± 0.048 in SPT. Therefore, our redshifts are consistent with both SZ surveys within 2σ, indicating that the detection of this cluster pair is reliable. Also shown in Fig. 7 is another example of a rich eRASS1 supercluster: 1eRASS-SC J0529-2226 consisting of four members at an average redshift of 0.17.
Due to the large error bar in redshifts, we are not able to precisely constrain the 3D distance between the two members. Therefore, this system has relatively low reliability, P = 0.50. The projected distance is about 3.7 Mpc, implying that the two members will probably merge as a massive cluster. Although this cluster pair is identified for the first time in this work, the two member clusters are already detected in Sunyaev–Zeldovich (SZ) surveys by the Atacama Cosmology Telescope (ACT, Hilton et al. 2021) and the South Pole Telescope (SPT, Bocquet et al. 2019). The reported photometric redshifts of 1eRASS J052957.4-413822 and 1eRASS J053040.8-413904 are 0.793 ± 0.0\0 and 0.795 ± 0.0\0 in ACT, and 0.775 ± 0.050 and 0.775 ± 0.048 in SPT. Therefore, our redshifts are consistent with both SZ surveys within 2σ, indicating that the detection of this cluster pair is reliable. Also shown in Fig. 7 is another example of a rich eRASS1 supercluster: 1eRASS-SC J0529-2226 consisting of four members at an average redshift of 0.17.
The reliabilities of the supercluster systems are computed using the method described in Sect. 3, and are presented in Fig. 8. Among the 1338 systems, 841 (63%) have reliability larger than 0.7. For rich superclusters with ≥3 members and cluster pairs, this fraction is 87 and 48%, indicating that the identification of rich superclusters is generally more reliable than cluster pairs. On average, low-redshift systems have higher reliability than high-redshift ones, as can be seen from the left panel of Fig. 8. This is probably due to the fact that the fraction of spectroscopic redshift is larger at low redshifts (see Fig. 1), which is about 10× more precise than photometric redshift. Dedicated spectroscopic follow-up of the eROSITA clusters is ongoing or planned with SDSS-V (Kollmeier et al. 2017; Almeida et al. 2023) and 4MOST (Finoguenov et al. 2019). It is expected that the reliability of the superclusters will be further improved when more spectroscopic redshifts are available.
The properties of the eRASS1 superclusters, including the average redshift, coordinate, multiplicity, total mass, average member separation dmem, and total length L, are present in Table 1. Since most of the superclusters do not have a regular shape, the average redshift and coordinate alone cannot locate the supercluster precisely. We, therefore, provide in Table 2 the properties of the member clusters for all the superclusters.
In addition to the primary supercluster catalog obtained with f = 10, we also provide in the appendix a supplementary super-cluster catalog with the information of members, corresponding to f= 50.
We compare our eRASS1 supercluster catalog with the known superclusters published in the literature. In many of the published supercluster catalogs, the location of superclusters is given as an average coordinate of the members. As superclusters are not bounded systems with irregular shapes, and they often span an area of several square degrees, it is almost infeasible to directly match the superclusters with the central coordinates. A practical way is to match the member clusters.
We first compare the eRASS1 supercluster catalog with eFEDS. As eFEDS is almost 10 times deeper than eRASS1, only a small fraction (63 out of 542) of eFEDS clusters are detected in eRASS1. In the eFEDS survey, Liu et al. (2022) detected 19 rich superclusters with ≥4 members. In this work, using the eRASS1 cluster sample, we detect 8 superclusters (including cluster pairs) in the eFEDS footprint. Most of them are already found in the eFEDS survey, despite that we report lower multiplicities for some systems in this work than the values in Liu et al. (2022) due to the much lower source density in eRASS1 compared to eFEDS. For example, eFEDS-SC3 (z = 0.196, N = 10) is identified as 1eRASS-SC J0859+0306 (z = 0.197, N = 3) in this work; eFEDS-SC5 (z = 0.269, N = 7) is identified as 1eRASS-SC J0841-0036 (z = 0.267, N = 2) in this work; eFEDS-SC6 (z = 0.281, N = 4) is identified as 1eRASS-SC J0921+0221 (z = 0.283, N = 2) in this work; eFEDS-SC12 (z = 0.358, N = 4) is identified as 1eRASS-SC J0935+0051 (z = 0.359, N = 2) in this work. The only exception is 1eRASS-SC J0932-0110, a cluster pair at z = 0.238. The two members of this system both have counterparts in the eFEDS cluster sample. However, one of its members, 1eRASS J093024.6-020635 (eFEDS J093025.7-020507), has a lower redshift in the eFEDS cluster catalog: 0.220±0.006, while the redshift measured in the eRASS1 cluster catalog is 0.241±0.006. Both results are photometric redshifts. Therefore, it is not identified as a cluster pair in eFEDS. We note that the optical confirmation of eFEDS clusters was performed with the multi-component matched filter cluster confirmation tool (MCMF, Klein et al. 2022) and the data from HSC-SSP, Legacy Survey DR8, and unWISE. In eRASS1, we use the eROMaPPer tool on Legacy Survey DR9 and DR10 (Kluge et al. 2024). The slight difference in the redshift of this cluster is probably because we use different optical survey data and methods for cluster confirmation in eFEDS and eRASS1.
35 rich supercluster systems and 39 cluster pairs are detected using the XXL365 cluster catalog (Adami et al. 2018). In eRASS1, we only detect 11 XXL clusters (Bulbul et al. 2024) due to the relatively shallow depth of eRASS1 compared to XXL, thus consequently limiting the detection rate of XXL superclusters. Only one cluster pair is identified in eRASS1: Id17 in the XXL cluster pair catalog at redshift 0.378. In eRASS1, we identify this cluster pair as a rich system: 1eRASS-SC J2321-5326, with four member clusters at a median redshift of 0.369. Except for the two members reported in Adami et al. (2018), XLSSC513 and XLSSC525, we find two additional members: 1eRASS J232541.0-531638 at z = 0.370 (XLSSC547) and 1eRASS J232708.1-513733 at z = 0.364.
We also make a general comparison with large-area optical spectroscopic surveys. In Fig. 9, we plot a slice of cosmic volume at z < 0.2 and −3° < Dec < 3°. A few more examples for different slices are shown in Fig. B.1. We find abroad association in the large-scale structures formed by galaxies and traced by the X-ray superclusters we identified in this work. We further compare the eRASS1 superclusters with the cosmic filaments detected with SDSS galaxies (Malavasi et al. 2020) in Fig. 10. To reduce overlapping between optical filaments, only a small part of the sky (125º < RA < 210º, 3° < Dec < 30°) and redshift range 0.15 < z < 0.25 are shown in Fig. 10. As a result, most of the eRASS1 superclusters are associated with the filaments. Most of the supercluster members are connected by galaxy filaments.
 |
Fig. 3 Distribution of the eRASS 1 supercluster systems color-coded by redshift. Each point represents a supercluster member. For clarity purposes, only rich superclusters with ≥3 member clusters are plotted. |
 |
Fig. 4 Multiplicity of the eRASS1 superclusters. Cluster pairs and superclusters (with ≥3 member clusters) are plotted in yellow and blue, respectively. |
 |
Fig. 5 Average separation and total length of the superclusters. Both quantities are given in projected co-moving distance. Cluster pairs and rich superclusters are plotted in yellow and blue, respectively. |
 |
Fig. 6 General properties of the supercluster systems identified in eRASS1. Left panel: redshift distribution of eRASS1 superclusters. Cluster pairs and superclusters (with ≥3 member clusters) are plotted in yellow and blue, respectively. Right panel: supercluster total mass versus redshift. Color code denotes the number of member clusters. For clarity, only rich superclusters with >3 members are shown in this plot. |
 |
Fig. 7 Examples of supercluster systems detected in eRASS1. Upper panels: the most distant supercluster system identified in eRASS1: 1eRASS-SC J0530-4138, a cluster pair at redshift 0.802. The red crosses mark the position of the two member clusters: 1eRASS J052957.4-413822 at z = 0.811 ± 0.007 and 1eRASS J053040.8-413904 at z = 0.793 ± 0.012. Lower panels: a rich supercluster 1eRASS-SC J0529-2226 detected at redshift 0.17, with the four member clusters marked as red crosses. The left panels show the eROSITA X-ray exposure-corrected images in the 0.2–2.3 keV band, after smoothing with a Gaussian of σ = 12″. The right panels show the optical images from the Legacy Survey, with the X-ray emission overlaid as white contours. |
 |
Fig. 8 Reliability of the eRASS1 superclusters accounting for cluster redshift uncertainties. In the left panel, each data point represents a super-cluster system color-coded by its multiplicity. Shown in the right panel is the histogram of reliability for all the systems (black), superclusters with ≥3 members (blue), and cluster pairs (yellow). |
General properties of superclusters identified in eRASS1.
Properties of member clusters of the eRASS1 superclusters.
 |
Fig. 9 Comparison of the large-scale structures traced by galaxies (gray dots) and X-ray superclusters identified in this work. The redshifts and positions of the galaxies are from a spectroscopic galaxy compilation of published catalogs (see Kluge et al. 2024). Each yellow triangle represents a supercluster member. Plotted is the slice −3° < Dec < 3°. |
 |
Fig. 10 Comparison of the filaments detected with SDSS galaxies (Malavasi et al. 2020 curves) and the eRASS1 X-ray superclusters. The supercluster members are plotted with dots. Color codes denote redshifts for both the filaments and supercluster members. To reduce overlapping between optical filaments, only the region (125º < RA < 210º, 3° < Dec < 30°) and redshift range 0.15 < z < 0.25 are plotted in the figure. |
5 Conclusions
We present in this work the first catalog of superclusters in the western Galactic hemisphere detected from the eRASS1 survey. We base our supercluster detection on the optically-confirmed galaxy clusters detected in eRASS1 (Bulbul et al. 2024). By applying several additional filters on the primary eRASS1 cluster catalog, with the aim of obtaining a purer subsample of clusters with more reliable redshifts, we select a subsample of 8862 eRASS1 clusters. Based on a contamination estimator Pcont computed using the cluster’s X-ray count rate, redshift, and optical richness, this cluster subsample has a high purity of 96.4%. A Friends-of-Friends method is employed to identify superclus-ter systems, where the linking length as a function of redshift and exposure time is computed to make sure that the local cluster density in superclusters is at least 10 times that of the average value of the sample. The false detection rate at high redshifts where the cluster density is too low is controlled by conservatively setting an upper limit of 50 Mpc on the linking length.
With the above data and method, we identify 1338 superclus-ter systems up to redshift 0.8, including 818 cluster pairs and 520 rich superclusters with ≥3 members. Among the 8862 selected clusters, 3948 clusters (about 45% of the sample) are members of these supercluster systems. The most massive and richest system, 1eRASS-SC J1307-3016, also known as the Shapley superclus-ter, consists of 45 members at an average redshift 0.050, and has a total mass of 2.58 ± 0.51 × 1016M⊙. The most extensive system, 1eRASS-SC J1140-1939 at redshift 0.303, has a total length of 127 Mpc. The sizes of the superclusters we identify in this work are comparable to the structures found with galaxy survey data. A good association is found between the eRASS1 superclusters and the large-scale structures formed by optical galaxies. We compute the reliability of each supercluster by accounting for the uncertainties in cluster redshifts and the peculiar velocities of the clusters. Thanks to the high accuracy of eRASS1 clusters’ redshifts, 63% of the supercluster systems have a reliability larger than 0.7. This will be further improved when more spectroscopic redshifts of the eRASS1 clusters are available from SDSS-V (Kollmeier et al. 2017; Almeida et al. 2023) and 4MOST (Finoguenov et al. 2019).
The eRASS1 supercluster catalog presented in this work represents the most extensive sample of superclusters detected in the X-ray band in terms of sample volume, sky coverage, red-shift range, and the availability of X-ray properties. Another advantage of the eRASS1 supercluster catalog is that the super-clusters are identified on the basis of a cluster sample with a well-understood selection function, thus making it convenient to compare with large numerical simulations. This legacy catalog will greatly advance our understanding of the evolution of the cosmic large-scale structure.
In a forthcoming paper (Liu et al., in prep.), we will utilize the eRASS1 supercluster catalog to investigate the environmental effects on the evolution of galaxy clusters. This can be done by simply comparing the X-ray properties of supercluster members and isolated clusters after accounting for selection effects (see, e.g., Manolopoulou et al. 2021). As these two classes of clusters naturally have different clustering magnitudes, such a comparison can also be used to test the dark matter halo formation theories, such as the halo assembly bias (Gao et al. 2005; Gao & White 2007).
A task for X-ray astronomy in the next decade is to find the "missing baryons", which account for 30–40% of the total baryonic mass in the Universe (e.g., Bregman 2007; Shull et al. 2012). These "missing baryons" are probably residing in the vast space between the nodes of the cosmic web, namely, galaxies and clusters, in the form of a low-density and X-ray emitting gas, with a temperature of ~106 K (e.g., Fang 2018; Nicastro et al. 2018). They can be detected either from their emission in the soft X-ray band (e.g., Eckert et al. 2015; Bulbul et al. 2016; Veronica et al. 2024) or through their absorption on bright background sources (Nicastro et al. 2022; Štofanová et al. 2024). Detecting and characterizing the intergalactic medium (IGM) and circum-galactic medium (CGM) are important science goals for X-ray missions in the near future, such as the Hot Universe Baryon Surveyor (HUBS, Bregman et al. 2023) and Athena (Nandra et al. 2013). Superclusters are the most probable reservoirs of the missing baryons. Therefore, the eRASS1 X-ray supercluster catalog will provide promising targets for future X-ray missions. Limited by the survey depth of eROSITA, the IGM emission in most of the individual supercluster systems is expected to be fainter than the detection limit of eRASS. Thus we need to apply image and spectrum stacking techniques to search for possible X-ray emissions from these cosmic filaments. The results of this work are presented in a separate paper (Zhang et al., in prep.). Dedicated multiwavelength analysis of individual systems, for example, the Shapley supercluster, will also be performed, to investigate the merging processes in member clusters (Sanders et al., in prep.; di Gennaro et al., in prep.).
Acknowledgement
We greatly thank the anonymous referee for his/her constructive comments that helped improve the paper. This work is based on data from eROSITA, the soft X-ray instrument aboard SRG, a joint Russian-German science mission supported by the Russian Space Agency (Roskosmos), in the interests of the Russian Academy of Sciences represented by its Space Research Institute (IKI), and the Deutsches Zentrum für Luft- und Raumfahrt (DLR). The SRG spacecraft was built by Lavochkin Association (NPOL) and its subcontractors and is operated by NPOL with support from the Max Planck Institute for Extraterrestrial Physics (MPE). The development and construction of the eROSITA X-ray instrument was led by MPE, with contributions from the Dr. Karl Remeis Observatory Bamberg & ECAP (FAU Erlangen-Nuernberg), the University of Hamburg Observatory, the Leibniz Institute for Astrophysics Potsdam (AIP), and the Institute for Astronomy and Astrophysics of the University of Tubingen, with the support of DLR and the Max Planck Society. The Argelander Institute for Astronomy of the University of Bonn and the Ludwig Maximilians Universität Munich also participated in the science preparation for eROSITA. The eROSITA data shown here were processed using the eSASS/NRTA software system developed by the German eROSITA consortium. A.L, E.B., V.G., C.G., S.Z., and X.Z. acknowledge financial support from the European Research Council (ERC) Consolidator Grant under the European Union’s Horizon 2020 research and innovation program (grant agreement CoG DarkQuest No 101002585). M.B. acknowledges support from the DFG under Germany’s Excellence Strategy -EXC 2121 "Quantum Universe" – 390833306. This work made use of SciPy (Jones et al. 2001), Matplotlib, a Python library for publication-quality graphics (Hunter 2007), Astropy, a community-developed core Python package for Astronomy (Astropy Collaboration 2013), NumPy (Van Der Walt et al. 2011).
Appendix A Supplementary catalog of superclusters identified with f = 50
General properties of superclusters identified in eRASS1 with overdensity ratio f = 50.
Properties of member clusters of the eRASS1 superclusters identified with overdensity ratio f = 50.
Appendix B A few more examples of comparison between eRASS1 superclusters and optical LSS
 |
Fig. B.1 Same as Fig. 9, but for different slices. Top left: 45° < R.A. < 100°, −55° < Dec. < −45°. Top right: 60° < R.A. < 95°, −22° < Dec. < −15°. Bottom: 180° < R.A. < 220°, −35° < Dec. < −25°. |
References
- Abell, G. O. 1961, AJ, 66, 607 [CrossRef] [Google Scholar]
- Adami, C., Giles, P., Koulouridis, E., et al. 2018, A&A, 620, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Almeida, A., Anderson, S. F., Argudo-Fernández, M., et al. 2023, ApJS, 267, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bocquet, S., Dietrich, J. P., Schrabback, T., et al. 2019, ApJ, 878, 55 [Google Scholar]
- Böhringer, H., & Chon, G. 2021, A&A, 656, A144 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Böhringer, H., Chon, G., & Trümper, J. 2021, A&A, 651, A15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bregman, J. N. 2007, ARA&A, 45, 221 [Google Scholar]
- Bregman, J., Cen, R., Chen, Y., et al. 2023, Sci. China Phys. Mech. Astron., 66, 299513 [NASA ADS] [CrossRef] [Google Scholar]
- Brunner, H., Liu, T., Lamer, G., et al. 2022, A&A, 661, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bulbul, E., Randall, S. W., Bayliss, M., et al. 2016, ApJ, 818, 131 [Google Scholar]
- Bulbul, E., Liu, A., Pasini, T., et al. 2022, A&A, 661, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bulbul, E., Liu, A., Kluge, M., et al. 2024, A&A, in press https://doi.org/10.1051/0004-6361/202348264 [Google Scholar]
- Chon, G., Böhringer, H., & Nowak, N. 2013, MNRAS, 429, 3272 [Google Scholar]
- Chon, G., Böhringer, H., Collins, C. A., & Krause, M. 2014, A&A, 567, A144 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chon, G., Böhringer, H., & Zaroubi, S. 2015, A&A, 575, L14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Costanzi, M., Rozo, E., Rykoff, E. S., et al. 2019, MNRAS, 482, 490 [CrossRef] [Google Scholar]
- de Vaucouleurs, G. 1953, AJ, 58, 30 [Google Scholar]
- Dey, A., Schlegel, D. J., Lang, D., et al. 2019, AJ, 157, 168 [Google Scholar]
- Dolag, K., & Sunyaev, R. 2013, MNRAS, 432, 1600 [NASA ADS] [CrossRef] [Google Scholar]
- Eckert, D., Roncarelli, M., Ettori, S., et al. 2015, MNRAS, 447, 2198 [Google Scholar]
- Einasto, M., Einasto, J., Tago, E., Dalton, G. B., & Andernach, H. 1994, MNRAS, 269, 301 [Google Scholar]
- Einasto, M., Einasto, J., Tago, E., Müller, V., & Andernach, H. 2001, AJ, 122, 2222 [NASA ADS] [CrossRef] [Google Scholar]
- Einasto, J., Einasto, M., Tago, E., et al. 2007, A&A, 462, 811 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, J., Suhhonenko, I., Liivamägi, L. J., & Einasto, M. 2019, A&A, 623, A97 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fang, T. 2018, Nature, 558, 375 [NASA ADS] [CrossRef] [Google Scholar]
- Finoguenov, A., Merloni, A., Comparat, J., et al. 2019, The Messenger, 175, 39 [NASA ADS] [Google Scholar]
- Gao, L., & White, S. D. M. 2007, MNRAS, 377, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Gao, L., Springel, V., & White, S. D. M. 2005, MNRAS, 363, L66 [NASA ADS] [CrossRef] [Google Scholar]
- Ghirardini, V., Bulbul, E., Hoang, D. N., et al. 2021, A&A, 647, A4 [EDP Sciences] [Google Scholar]
- Ghirardini, V., Bulbul, E., Artis, et al. 2024, A&A, submitted [arXiv:2402.08458] [Google Scholar]
- Grandis, S., Ghirardini, V., Bocquet, S., et al. 2024, A&A, submitted [arXiv:2482.88455] [Google Scholar]
- Hilton, M., Sifón, C., Naess, S., et al. 2021, ApJS, 253, 3 [Google Scholar]
- Hoang, D. N., Brüggen, M., Zhang, X., et al. 2023, MNRAS, 523, 6320 [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Jones, E., Oliphant, T., Peterson, P., et al. 2001, SciPy: Open source scientific tools for Python, http://www.scipy.org [Google Scholar]
- Klein, M., Oguri, M., Mohr, J. J., et al. 2022, A&A, 661, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kluge, M., Comparat, J., Liu, A., et al. 2024, A&A, submitted [arXiv:2402.08453] [Google Scholar]
- Kollmeier, J. A., Zasowski, G., Rix, H.-W., et al. 2017, arXiv e-prints [arXiv:1711.03234] [Google Scholar]
- Kravtsov, A. V., & Borgani, S. 2012, ARA&A, 50, 353 [Google Scholar]
- Liivamägi, L. J., Tempel, E., & Saar, E. 2012, A&A, 539, A80 [Google Scholar]
- Liu, A., Yu, H., Diaferio, A., et al. 2018, ApJ, 863, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, A., Bulbul, E., Ghirardini, V., et al. 2022, A&A, 661, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liu, A., Bulbul, E., Ramos-Ceja, M. E., et al. 2023, A&A, 670, A96 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Malavasi, N., Aghanim, N., Douspis, M., Tanimura, H., & Bonjean, V. 2020, A&A, 642, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Manolopoulou, M., Hoyle, B., Mann, R. G., Sahlén, M., & Nadathur, S. 2021, MNRAS, 500, 1953 [Google Scholar]
- Merloni, A., Predehl, P., Becker, W., et al. 2012, arXiv e-prints [arXiv:1209.3114] [Google Scholar]
- Merloni, A., Lamer, G., Liu, T., et al. 2024, A&A, 682, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Myles, J., Gruen, D., Mantz, A. B., et al. 2021, MNRAS, 505, 33 [NASA ADS] [CrossRef] [Google Scholar]
- Nandra, K., Barret, D., Barcons, X., et al. 2013, arXiv e-prints [arXiv:1306.2307] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [Google Scholar]
- Nicastro, F., Kaastra, J., Krongold, Y., et al. 2018, Nature, 558, 406 [Google Scholar]
- Nicastro, F., Fang, T., & Mathur, S. 2022, arXiv e-prints [arXiv:2203.15666] [Google Scholar]
- Predehl, P., Andritschke, R., Arefiev, V., et al. 2021, A&A, 647, A1 [EDP Sciences] [Google Scholar]
- Ragone, C. J., Muriel, H., Proust, D., Reisenegger, A., & Quintana, H. 2006, A&A, 445, 819 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Reiprich, T. H., Basu, K., Ettori, S., et al. 2013, Space Sci. Rev., 177, 195 [Google Scholar]
- Reiprich, T. H., Veronica, A., Pacaud, F., et al. 2021, A&A, 647, A2 [EDP Sciences] [Google Scholar]
- Reisenegger, A., Quintana, H., Carrasco, E. R., & Maze, J. 2000, AJ, 120, 523 [Google Scholar]
- Rykoff, E. S., Rozo, E., Busha, M. T., et al. 2014, ApJ, 785, 104 [Google Scholar]
- Rykoff, E. S., Rozo, E., Hollowood, D., et al. 2016, ApJS, 224, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Sanders, J. S., Fabian, A. C., Russell, H. R., & Walker, S. A. 2018, MNRAS, 474, 1065 [NASA ADS] [CrossRef] [Google Scholar]
- Sankhyayan, S., Bagchi, J., Tempel, E., et al. 2023, ApJ, 958, 62 [NASA ADS] [CrossRef] [Google Scholar]
- Seppi, R., Comparat, J., Ghirardini, V., et al. 2024, A&A, submitted [arXiv:2402.08460] [Google Scholar]
- Shull, J. M., Smith, B. D., & Danforth, C. W. 2012, ApJ, 759, 23 [NASA ADS] [CrossRef] [Google Scholar]
- Štofanová, L., Simionescu, A., Wijers, N. A., et al. 2024, MNRAS, 527, 5776 [Google Scholar]
- Tully, R. B., Courtois, H., Hoffman, Y., & Pomarède, D. 2014, Nature, 513, 71 [Google Scholar]
- Ursino, E., Galeazzi, M., Gupta, A., et al. 2015, ApJ, 806, 211 [NASA ADS] [CrossRef] [Google Scholar]
- Van Der Walt, S., Colbert, S. C., & Varoquaux, G. 2011, Comput. Sci. Eng., 13, 22 [Google Scholar]
- Veronica, A., Reiprich, T. H., Pacaud, F., et al. 2024, A&A, 681, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vikhlinin, A., Kravtsov, A., Forman, W., et al. 2006, ApJ, 640, 691 [Google Scholar]
- Wen, Z. L., Han, J. L., & Liu, F. S. 2012, ApJS, 199, 34 [Google Scholar]
- Yu, H., & Hou, X. 2022, Astron. Comput., 41, 100662 [NASA ADS] [CrossRef] [Google Scholar]
- Zucca, E., Zamorani, G., Scaramella, R., & Vettolani, G. 1993, ApJ, 407, 470 [Google Scholar]
Defined as (179.9442° < l < 359.9442°).
R500 is the radius within which the average matter density is 500 times the critical density at cluster’s redshift.
All Tables
General properties of superclusters identified in eRASS1 with overdensity ratio f = 50.
Properties of member clusters of the eRASS1 superclusters identified with overdensity ratio f = 50.
All Figures
|
Fig. 1 Mass and redshift distribution of the cluster sample used for supercluster identification. Blue, yellow, and red histograms indicate photometric, spectroscopic, and literature redshifts, respectively. The black dashed line shows the redshift distribution of the overall eRASS1 cluster sample. |
| In the text | |
|
Fig. 2 Cluster number density (N / V, left panel) and linking length (l, right panel) plotted as functions of both redshift and exposure time, computed using Eq. (5), with f = 10. |
| In the text | |
|
Fig. 3 Distribution of the eRASS 1 supercluster systems color-coded by redshift. Each point represents a supercluster member. For clarity purposes, only rich superclusters with ≥3 member clusters are plotted. |
| In the text | |
|
Fig. 4 Multiplicity of the eRASS1 superclusters. Cluster pairs and superclusters (with ≥3 member clusters) are plotted in yellow and blue, respectively. |
| In the text | |
|
Fig. 5 Average separation and total length of the superclusters. Both quantities are given in projected co-moving distance. Cluster pairs and rich superclusters are plotted in yellow and blue, respectively. |
| In the text | |
|
Fig. 6 General properties of the supercluster systems identified in eRASS1. Left panel: redshift distribution of eRASS1 superclusters. Cluster pairs and superclusters (with ≥3 member clusters) are plotted in yellow and blue, respectively. Right panel: supercluster total mass versus redshift. Color code denotes the number of member clusters. For clarity, only rich superclusters with >3 members are shown in this plot. |
| In the text | |
|
Fig. 7 Examples of supercluster systems detected in eRASS1. Upper panels: the most distant supercluster system identified in eRASS1: 1eRASS-SC J0530-4138, a cluster pair at redshift 0.802. The red crosses mark the position of the two member clusters: 1eRASS J052957.4-413822 at z = 0.811 ± 0.007 and 1eRASS J053040.8-413904 at z = 0.793 ± 0.012. Lower panels: a rich supercluster 1eRASS-SC J0529-2226 detected at redshift 0.17, with the four member clusters marked as red crosses. The left panels show the eROSITA X-ray exposure-corrected images in the 0.2–2.3 keV band, after smoothing with a Gaussian of σ = 12″. The right panels show the optical images from the Legacy Survey, with the X-ray emission overlaid as white contours. |
| In the text | |
|
Fig. 8 Reliability of the eRASS1 superclusters accounting for cluster redshift uncertainties. In the left panel, each data point represents a super-cluster system color-coded by its multiplicity. Shown in the right panel is the histogram of reliability for all the systems (black), superclusters with ≥3 members (blue), and cluster pairs (yellow). |
| In the text | |
|
Fig. 9 Comparison of the large-scale structures traced by galaxies (gray dots) and X-ray superclusters identified in this work. The redshifts and positions of the galaxies are from a spectroscopic galaxy compilation of published catalogs (see Kluge et al. 2024). Each yellow triangle represents a supercluster member. Plotted is the slice −3° < Dec < 3°. |
| In the text | |
|
Fig. 10 Comparison of the filaments detected with SDSS galaxies (Malavasi et al. 2020 curves) and the eRASS1 X-ray superclusters. The supercluster members are plotted with dots. Color codes denote redshifts for both the filaments and supercluster members. To reduce overlapping between optical filaments, only the region (125º < RA < 210º, 3° < Dec < 30°) and redshift range 0.15 < z < 0.25 are plotted in the figure. |
| In the text | |
|
Fig. B.1 Same as Fig. 9, but for different slices. Top left: 45° < R.A. < 100°, −55° < Dec. < −45°. Top right: 60° < R.A. < 95°, −22° < Dec. < −15°. Bottom: 180° < R.A. < 220°, −35° < Dec. < −25°. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.