| Issue |
A&A
Volume 692, December 2024
|
|
|---|---|---|
| Article Number | A161 | |
| Number of page(s) | 38 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202449372 | |
| Published online | 13 December 2024 | |
Genuine Retrieval of the AGN Host Stellar Population (GRAHSP)
1
Max Planck Institute for Extraterrestrial Physics, Giessenbachstrasse, 85741 Garching, Germany
2
Excellence Cluster Universe, Boltzmannstr. 2, D-85748 Garching, Germany
3
School of Physics and Astronomy, Tel Aviv University, Tel Aviv, 69978, Israel
4
Institute for Astronomy & Astrophysics, National Observatory of Athens, V. Paulou & I. Metaxa, 11532 Athens, Greece
5
Centre for Extragalactic Astronomy, Department of Physics, Durham University, Durham, United Kingdom
6
Institute of Astronomy and Astrophysics, University of Tübingen, Sand 1, 72076 Tübingen, Germany
7
Ludwig-Maximilians-Universität München, Faculty of Physics, Scheinerstrasse 1, D-81679 München, Germany
8
Department of Astronomy, University of Illinois at Urbana-Champaign, Urbana, IL, 61801, USA
9
Kavli Institute for the Physics and Mathematics of the Universe, The University of Tokyo, Kashiwa, 277-8583 (Kavli IPMU, WPI), Japan
⋆ Corresponding author; mara@mpe.mpg.de
Received:
29
January
2024
Accepted:
2
July
2024
Context. The assembly and co-evolution of super-massive black holes (SMBHs) and their host galaxy stellar population is one of the key open questions in modern galaxy evolution. Observationally constraining this question is challenging. Important parameters of galaxies, such as the stellar mass (M⋆) and star formation rate (SFR), are inferred by modeling the spectral energy distribution (SED), with templates constructed on the basis of various assumptions on stellar evolution. In the case of galaxies triggering SMBH activity, the active galactic nucleus (AGN) contaminates the light of the host galaxy at all wavelengths, hampering inferences of host galaxy parameters. Underestimating the AGN contribution due to incomplete AGN templates results in a systematic overestimation of the stellar mass, biasing our understanding of AGN and galaxy co-evolution. This challenge has gained further attention with the advent of sensitive wide-area surveys with millions of newly detected luminous AGN, including those by eROSITA, Euclid, and LSST.
Aims. We aim to robustly estimate the accuracy, bias, scatter, and uncertainty of AGN host galaxy parameters, including stellar masses, and improve these measurements relative to previously used techniques.
Methods. This work makes two important contributions. Firstly, we present a new SED fitting code, GRAHSP, with an AGN model composed of a flexible power-law continuum with empirically determined broad and narrow lines and a FeII forest component, a flexible infrared torus that can reproduce the diverse dust temperature distributions, and appropriate attenuation on the galaxy and AGN light components. We verify that this model reproduces published X-ray to infrared SEDs of AGN to better than 20% accuracy. A fully Bayesian fit includes uncertainties in the model and the data, making the inference highly robust. The model is constrained with a fast nested sampling inference procedure supporting the many free model parameters. Secondly, we created a benchmark photometric data set where optically selected pure quasars are paired with non-AGN pure galaxies at the same redshift. Their photometry flux is summed into a hybrid (Chimera) object but with known galaxy and AGN properties. Based on this data-driven benchmark, true and retrieved stellar masses, SFR, and AGN luminosities can be compared, allowing for the evaluation and quantification of biases and uncertainties inherent in any given SED fitting methodology.
Results. The Chimera benchmark, which we release with this paper, shows that previous codes systematically overestimate M⋆ and SFR by 0.5 dex with a wide scatter of 0.7 dex at AGN luminosities above 1044 erg s−1. In 20% of cases, the estimated error bars lie completely outside a 1 dex-wide band centreed around the true value, which we consider an outlier. In contrast, GRAHSP shows no measurable bias on M⋆ and SFR, with an outlier fraction of only about 5%. GRAHSP also estimates more realistic uncertainties.
Conclusions. Unbiased characterization of galaxies hosting AGN enables characterization of the environmental conditions conducive to black hole growth, whether star formation is suppressed at high black hole activity, and identifying the mechanisms that prevent overluminous AGN relative to the host galaxy mass. It can also shed light on the long-standing questions of whether AGN obscuration is primarily an orientation effect or related to phases in galaxy evolution.
Key words: methods: data analysis / techniques: photometric / galaxies: general / galaxies: nuclei / quasars: general / galaxies: Seyfert
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model.
Open Access funding provided by Max Planck Society.
1. Introduction
The scaling relations of supermassive black holes (SMBHs) at the centre of massive, passive galaxies presented in Magorrian et al. (1998), together with the recognition that these are grown by active galactic nuclei (AGN) episodes (Soltan 1982) triggered a revolution in studies of galaxy evolution. They imply that galaxies and AGN are merely experiencing varying levels of SMBH accretion activity. Only when combined do these phases give a full picture of galaxy evolution. Further studies extended SMBH scaling relations to all types of galaxies (e.g. early- and late-type, dwarf and active galaxies Gebhardt et al. 2000; Ferrarese & Merritt 2000; Xiao et al. 2011; Gültekin et al. 2011; Kormendy & Ho 2013; Schutte et al. 2019), finding correlations between the black hole mass (MBH) and host physical parameters (e.g. stellar mass and velocity dispersion). These facts, combined with the similarity of the cosmic star formation rate (SFR) and BH accretion history (e.g., Aird et al. 2012; Madau & Dickinson 2014) point toward the interconnection between the SMBHs and their host and require considering the AGN phase in galaxy evolution studies. Indeed, models have been proposed in which the energy produced during SMBH growth episodes can modulate the formation of stars in the host galaxy (e.g., Sanders et al. 1988), thereby establishing AGN as an important component for our understanding of galaxy evolution (e.g., Di Matteo et al. 2005; Hopkins et al. 2008). In turn, this complicates a task that was already difficult for inactive galaxies. Unlike redshift, estimates of a galaxy’s physical parameters such as stellar mass (M⋆), star formation rate (SFR), and bolometric luminosity cannot be measured directly. Known degeneracies, such as age-metallicity (Worthey et al. 1994) or color-redshift (Masters et al. 2015), are hard to break with SED fitting, in part because the number of parameters in the fit is usually larger than the number of photometric data points.
For galaxies hosting an active SMBH, the need to account for the nuclear emission at various wavelengths complicates things further. The relative host-to-AGN contribution is unknown, and the AGN contribution at various wavelengths changes, depending on whether or not the nuclear emission is obscured by dust. Thus, basic questions such as, whether the physical properties are different for galaxies hosting inactive and active SMBHs, whether differences between obscured and unobscured sources arise due to orientation or evolution, remain unanswered. Not correctly accounting for the nuclear component can result in inaccurate or biased galaxy parameters and hence interpretations. This could be the origin of conflicting results reported in the literature so far. For example, Stemo et al. (2020), using a sample of about 2500 X-ray selected AGN, found that AGN host galaxies tend to have lower SFRs than normal galaxies of equal mass. This result is in contrast with what was found in Mountrichas et al. (2022), Pouliasis et al. (2022) and Suh et al. (2019) for the same type of AGN. It has also been reported that the stellar mass of AGN host galaxies depends on their level of obscuration (suggesting an evolutionary link; Koutoulidis et al. 2022; Zou et al. 2019), and other work has suggested that it does not (consistent with the AGN unification model; Masoura et al. 2021). If there is an evolution in place from obscured to unobscured objects as suggested by Hopkins et al. (2008), raises the question of why hosts of obscured AGN are more massive than the hosts of the unobscured ones (Koutoulidis et al. 2022). This uncertainty in the actual stellar mass of AGN host galaxies indirectly affects other parameters, such as specific accretion rate (used to estimate the rate at which the BH accrete material Aird et al. 2012; Georgakakis et al. 2017) and specific star formation.
The increased availability of wide- and all-sky areas allows the selection of bright, unobscured AGN. Contrary to typical pencil-beam surveys (e.g. Lockman Hole Fotopoulou et al. 2016), Chandra deep-field south (Hsu et al. 2014; Luo et al. 2017), where bright, unobscured AGN are virtually absent, they are abundant in all-sky surveys. Existing surveys include optical spectroscopy by the Sloan Digital Sky Survey (SDSS; Eisenstein et al. 2011), photometry imaging in the optical by the Dark Energy Spectroscopic Instrument Legacy Surveys (Dey et al. 2019) and mid-infrared by WISE (Wright et al. 2010; Mainzer et al. 2011; Meisner et al. 2023), astrometry by Gaia (e.g., Gaia Collaboration 2023), X-rays by 4XMM (Webb et al. 2020), XMMSlew (Saxton et al. 2008), and eROSITA (Predehl et al. 2021). Therefore, a major effort is required to develop algorithms that provide more reliable physical parameters for unobscured AGN, making inclusive galaxy evolutionary studies finally possible. In recent years an increasing number of algorithms have been developed (and often made public) for this purpose, such as AGNFitter (Calistro Rivera et al. 2016), MAGPHYS (da Cunha et al. 2008), PROSPECTOR (Johnson et al. 2021), CIGALE (Boquien et al. 2019), X-CIGALE (extending CIGALE to X-ray emission; Yang et al. 2020), FAST (Aird et al. 2017), among others (see review by Pacifici et al. 2023). Figure 1 of Thorne et al. (2022) nicely summarises the basic ingredients of the most used codes1.
This paper demonstrates that the existing approaches are insufficient in the new parameter space, and thus we present a new code, GRAHSP (Genuine Retrieval of the AGN Host Stellar Population). GRAHSP differs substantially through a more complete model description of the AGN component and more realistic uncertainty estimation. GRAHSP has been developed by the eROSITA team specifically for measuring the physical parameters of the millions of AGN that eROSITA started to detect in 2020 (see Merloni et al. 2024, which presents the first all-sky survey data release). The reliability of measurements obtained with GRAHSP at different host-to-AGN ratios has been tested thoroughly by measuring the physical parameters of AGN constructed by combining galaxies with a known stellar mass from COSMOS with a quasi-stellar object (QSO). We have defined this testing sample as the Chimera sample, an ideal benchmark for reference. For non-AGN galaxies, we verified that the GRAHSP results are consistent with published results. This ensures that the use can be generalised to any sample of extragalactic sources. In addition to stellar mass, GRAHSP estimates key galaxy parameters such as the SFR, AGN parameters such as the bolometric luminosity, the power-law continuum slope, the torus covering factor, and the system’s dust attenuation.
In Section 2 we present GRAHSP. The samples and data sets used in this work are described in Section 3, which includes AGN-free galaxy samples and infrared, X-ray, and optically selected AGN samples. Section 4 describes a novel benchmark data set, where the true decomposition between galaxy and AGN light is known by construction. In Section 5, the model is vetted with initial tests. Based on the benchmark data set, Section 6 demonstrates the key result: GRAHSP’s stellar mass estimates are unbiased and outperform literature methods, even in the difficult case of unobscured, luminous AGN. Throughout the paper, we assume AB magnitudes unless stated otherwise and consistently use the cosmology of Planck Collaboration VI (2020).
2. Method
The modeling of multi-wavelength photometry of AGN candidates can be driven by several goals: (1) the determination of redshifts (photo-z); (2) the identification of whether an AGN is present; (3) the measurement of AGN parameters, such as luminosities, and (4) the measurement of galaxy parameters.
If the goal is to estimate redshifts, the colour-redshift relation can be mapped with a small set of galaxy, AGN, and hybrid templates (e.g., Salvato et al. 2009, 2019). If the goal is to identify AGN, light at any wavelength in excess of that expected by galaxy emission needs to be detected, for example by the statistical preference for an additional blue power-law (associated with the accretion disk) or the presence of mid-infrared bump components (related nuclear dust heated by the AGN). Two commonly adopted models for these two components are those proposed by Richards et al. (2006) and Dale et al. (2014), respectively; see Thorne et al. (2022) for a recent work. The goal can also be achieved with diagnostic colour plots in the UV (e.g., Richards et al. 2009) or infrared (e.g., Lacy et al. 2004).
If the goal is the inference of AGN parameters, such as those of a clumpy torus (Nenkova et al. 2008a; Hönig & Kishimoto 2010; Stalevski et al. 2016) or the estimation of the black hole spin assuming a certain accretion flow model (Netzer & Trakhtenbrot 2014), one may assume an AGN model and interpret the inferred parameters within this framework for the scope of the study. The most challenging goal is the robust inference of galaxy parameters under the presence of AGN light. This is the goal tackled in this work.
Suppose, for example, the case of photometry from an extremely luminous quasar being modelled by an AGN template library2. If any residuals remain at this stage due to an imperfect AGN modelling, and a galaxy template library is added and optimized to fit the residuals, the stellar population will be extremely massive (to reach quasar luminosities) and either red (to fix residuals in the near-infrared) or blue (to fix residuals in the UV-optical). The inferred parameters will be driven by the AGN mis-modelling and have nothing to do with the underlying galaxy. In Section 6, we will show that this hypothetical scenario occurs in real applications leading to biased measurements of key physical parameters. While the inference would be wrong, this may not be detectable by residual diagnostics such as reduced χ2, since there may not be any residuals remaining. Also, the true stellar mass cannot be easily verified by other, independent methods. The overestimated galaxy template normalisation cannot be resolved by refining the AGN template normalisation further with data from longer and shorter wavelengths, because the AGN template is already in the right place. This includes incorporating X-ray information (e.g., Yang et al. 2020). This failure mode has the worrying potential to induce spurious correlations between host galaxy mass and AGN accretion rate.
In addition to the challenges above, AGN are ubiquitously variable (Bershady et al. 1998; Klesman & Sarajedini 2007; Sesar et al. 2007; Trevese et al. 2008). While galaxies are, for the most part, static light emitters on human time scales; and their SEDs can be modelled with a single static template, AGN break this assumption. Therefore, residuals caused by non-simultaneously collected photometry should also be considered in the modelling.
In the absence of a physical model that accurately reproduces the AGN-plus galaxy photometry without significant residuals, two broad approaches have been followed in the literature: (1) The photometry can be degraded (by increasing the errors) until the model provides a sufficient description. This approach is implemented in CIGALE v2022.1 (Yang et al. 2022), for example. (2) A suitable AGN template library can be derived empirically, for instance, from spectroscopy. Some examples of this approach include the infrared modelling of Mullaney et al. (2011), Mor & Netzer (2012), Kirkpatrick et al. (2012), and the recent parametric Seyfert 1 model of Temple et al. (2021). These templates still have to be constructed to be flexible enough to capture the full diversity of the AGN phenomenon. While such an empirical AGN model may not be directly associated with physical properties, it is effective at “deleting” the AGN light contribution so that the host galaxy light can be analysed, with realistic uncertainty estimates. The necessary flexibility of the AGN model leads to many free fitting parameters, in addition to the galaxy parameters. It is then easily possible that the number of parameters exceeds the number of data points. Such overparametrisation leads to degeneracies which need to be explored computationally. Bayesian inference methods can address this (see e.g. Calistro Rivera et al. 2016).
We are primarily following the second approach. In Section 2.1, we describe our flexible parametric AGN model and detail its components. Section 2.2 validates the model’s capability to predict high-quality AGN-galaxy hybrid spectra. The parameter ranges are also calibrated there. Model parameters are typeset in monospace, as are code module names in the section headers. For analysing photometry, GRAHSP builds on some of the open source infrastructure from CIGALE and accepts similar input and configuration files. However, the computational methods for achieving rapid model evaluation are substantially different (Section 2.3). For fitting, GRAHSP is paired with an advanced inference procedure for uncertainty quantification, which considers model limitations and AGN variability (Section 2.4).
2.1. Model
The spectral model implemented in GRAHSP consists of several components. The AGN components include a continuum (Section 2.1.1) with emission lines (Section 2.1.2) and an infrared torus (Section 2.1.3). Bolometric AGN luminosities are defined in Section 2.1.4. The galaxy components are presented in Section 2.1.5. Both the AGN and galaxy components can undergo dust attenuation (Section 2.1.6) and finally redshifting (Section 2.3.1). Figure 1 gives a visual overview of the model components, which are now introduced in order.
 |
Fig. 1. Overview of how the individual model components contribute to the summed emission (black). The AGN power-law continuum (blue; accretion disk, or BBB) is enhanced by emission lines including an iron forest (red). The disk model is normalised at the monochromatic luminosity at 5100 Å (blue square), here |
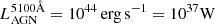
2.1.1. The big blue bump continuum (activatepl)
We adopt a flexible model motivated by theoretical and observational considerations. Thin accretion disk models (Shakura & Sunyaev 1973) predict a power-law emission spectrum in the UV to the optical range with a smooth UV bend-over that depends on the spin, black hole mass, and Eddington ratio (e.g., Netzer & Trakhtenbrot 2014). In observed SEDs, the bend towards the far-UV is wider than predicted (e.g., Blaes et al. 2001), that is, it is UV-brighter. This can be partially addressed by assuming strongly inhomogeneous thin disks that locally fluctuate in temperature (Dexter & Agol 2011). Because of these complications, we avoid assuming a specific physical accretion flow model and instead model the big blue bump (BBB) phenomenologically. From Lyα to 1 μm, observed stacked spectra (e.g., Zheng et al. 1997; Selsing et al. 2016) show a power-law spectral density Fλ ∝ λλα with typical indices αλ between −1.3 and −2.2. There is substantial object-to-object diversity (Richards et al. 2006) not attributed to dust attenuation. Additionally, the power-law continuum can change its slope on time scales of hundreds of days, as demonstrated by optical difference spectra in Ruan et al. (2014). Above 1 μm, emission by the torus (discussed further in Section 2.1.3) adds to the SED of the big blue bump. Only thanks to polarization-spectroscopy by Kishimoto et al. (2008) could this transition be directly disentangled free of any additional contributions by reprocessing (emission lines, dusty torus). They showed that the big blue bump emission continues a power-law decline at least until 2 μm with αλ ≈ −1.7 for the observed source.
To encompass this diversity in continua, we adopt the smooth bending power-law (SBPL) parameterisation of Ryde (1999). This formulation transitions from a power-law with index α1 (uvslope parameter) to one with index α2 (plslope) at a break wavelength λbreak (plbendloc). The width of the bend can be controlled with the parameter Λ (plbendwidth). The key L_AGN parameter 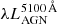 sets the power-law normalisation at λ0 = 5100 Å. The luminosity spectral density is:
sets the power-law normalisation at λ0 = 5100 Å. The luminosity spectral density is:
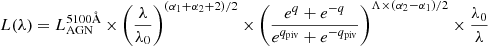
with q = ln(λ/λbreak)/Λ and qpiv = ln(λ0/λbreak)/Λ. We verified that recent state-of-the-art relativistic accretion disk simulations (e.g. Hagen & Done 2023) can be approximated with Eq. (1). The smooth bend-over towards the UV is illustrated by the blue curve in Figure 1.
2.1.2. AGN emission lines activatelines
AGN emission lines are superimposed on the continuum. Their contribution to the observed narrow or broad-band photometry can be substantial (see e.g. Temple et al. 2021)3. The line luminosity of Hβ is set by default to 2 per cent of 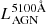 for the broad line component and to 0.2 per cent for the narrow line component. This can be modified by the linestrength_boost_factor parameter. The luminosity ratio of the other lines relative to Hβ is set based on the broad and narrow line list of Netzer (1990), listed in Table 1. Hγ is added based on Rakshit et al. (2020). With the luminosity ratio defined, the full-width-half-maximum (FWHM; linewidth parameter) of the lines can be chosen somewhat arbitrarily between hundreds and tens of thousands km s, since this cannot be distinguished with photometry.
for the broad line component and to 0.2 per cent for the narrow line component. This can be modified by the linestrength_boost_factor parameter. The luminosity ratio of the other lines relative to Hβ is set based on the broad and narrow line list of Netzer (1990), listed in Table 1. Hγ is added based on Rakshit et al. (2020). With the luminosity ratio defined, the full-width-half-maximum (FWHM; linewidth parameter) of the lines can be chosen somewhat arbitrarily between hundreds and tens of thousands km s, since this cannot be distinguished with photometry.
List of broad and narrow emission lines.
In addition to the individual lines, a FeII forest template is added. Following Merloni et al. (2010), we select from Bruhweiler & Verner (2008) the template with density nH = 1011 cm3, microturbulence ξ = 20 km s−1 and ionising flux ϕH = 1020.5 cm−2s−1, and de-redshift it from z = 0.004. The template luminosity is normalised at λ = 4593.4 Å relative to the Hβ line luminosity (see above) with ratio AFeII (AFeII). We also tested inclusion of a Balmer continuum component, however, the improvements to the presented results were negligible.
Figure 1 illustrates the importance of these features. The total SED (black) is elevated in the optical wavelengths above the power-law component (blue) by the Fe forest and lines (red). Figure 2 compares the AGN model with different slope (gray shades) to the empirical steep and flat quasar templates by Richards et al. (2006) (blue and red curves) and the higher redshift stacked quasar spectrum of Selsing et al. (2016) (pink curve). The key emission features, shown here with Alines = 1, AFeII = 6 and Wlines = 10 000 km s−1, are present in the model and reproduce the observations. At the shortest wavelengths below 2000 Å, the current FeII template is potentially missing emission. At wavelengths above 1 μm, the power law continues downwards (dashed line) as required by the spectral-polarimetric observations (blue circles), which were anchored to the dashed line in this figure at the lowest measured wavelengths. Above 1 μm, the emission begins to be dominated by the emission of the torus, which is discussed in the next section.
 |
Fig. 2. Detailed view of the optical continuum and emission lines. The model continuum bending power-law (yellow dashed line) reproduces the polarization measurements of Kishimoto et al. (2008) (dark blue data points). The full model including a torus and emission lines is shown in solid lines. Variations of the power-law slope (light grey to black) reproduce SDSS steep and flat unabsorbed spectra from Richards et al. (2006) and Selsing et al. (2016) (red, blue and pink lines). Towards the infrared, the torus component dominates the continuum. |
2.1.3. AGN torus activategtorus
The AGN infrared emission is associated with the reprocessing of UV emission by dust (see e.g. the review by Netzer 2015). The infrared emission is composed of at least two components, one dominating in the mid-infrared (cold dust) and one dominating in the near-infrared (hot dust). At long wavelengths, the infrared emission has recently been imaged in nearby galaxies (e.g., García-Burillo et al. 2021) and is associated with parsec-scale, cold molecular dust (the torus). In addition to the cold dust, a near-universal component is hot dust (e.g., Mor & Netzer 2012). Through interferometry observations, the hot dust was associated with polar regions relative to the torus (Tristram et al. 2014; Asmus et al. 2016). However, Lyu et al. (2017) found that there is a substantial population (30–40 per cent) of AGN deficient in warm or hot dust. This suggests that the covering factors, geometries, or dust properties are diverse.
The properties of the dust, chemical composition and grain size distribution are also not fully understood (e.g., Packham et al. 2012). In empirical studies, the SED is often approximated by a grey body. Towards short wavelengths, such parameterisations are flexible, while at the longest wavelength, typically a λ−4 power-law decline is assumed (Rayleigh-Jeans tail). The average shape at the longest wavelength is debated, for example, in Xue et al. (2011) and Symeonidis (2022). Direct observations with Herschel by Bernhard et al. (2021) show a wide, log-quadratic bend peaking around 30 − 50 μm that is completely dominated by the host galaxy already at ≥70 μm.
We use a parameterised empirical template that can emulate this diversity. The hot dust components can be approximated by black bodies with a temperature distribution. The peak and low-wavelength distribution is then well described by a log-quadratic curve. This functional form is sub-optimal at the longest wavelength, where the Rayleigh-Jeans law motivates a linear rather than quadratic decline in a log-log plot. However, the tail of the torus hot dust component is typically dominated by cold galaxy-scale dust emission. As a result, deviations of the log-quadratic at the long-wavelength regime are negligible for the modelling (we verify this below in Section 2.2). The same argument applies to the tail of the hot dust, which is dominated by the cold dust component. We therefore use the sum of two log-quadratic curves for the hot and cold dust, which are:
![$$ \begin{aligned} L_\mathrm{cool}&\propto \exp [-(\lambda - \lambda _\mathrm{COOL} )^2 / (2W_\mathrm{COOL} ^2)],\nonumber \\ L_\mathrm{hot}&\propto \exp [-(\lambda - \lambda _\mathrm{HOT} \, \, \,)^2 /(2W_\mathrm{HOT} ^2)]. \end{aligned} $$](/articles/aa/full_html/2024/12/aa49372-24/aa49372-24-eq5.gif)
The parameters include the peak λCOOL (COOLlam) and width WCOOL (in dex; COOLwidth) of the Gaussian-like form for the spectrum (and analogously for the hot dust component). These parameters are related to the temperature distribution of the dust. The normalisation of the hot dust peak relative to the cold dust peak in λLλ is a parameter that we term the hot factor:
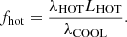
With the two log-quadratic curves fixed, the normalisation of the torus to the AGN powerlaw has to be defined. The ratio of the near to mid-infrared continuum torus template amplitude to that of the UV to optical power-law template, fcov (fcov), is commonly referred to as the torus covering factor:
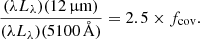
However, the translation to a geometric covering factor of a physical structure is complicated by anisotropy in the emission profile and distribution of dust clumps (Stalevski et al. 2016). Section 2.2 below demonstrates that the model can reproduce torus spectral templates derived by other works, including those of Lyu et al. (2017), Mor & Netzer (2012), Mullaney et al. (2011) and Kirkpatrick et al. (2012), as well as individual AGN in the local Universe.
An important feature in the mid-infrared is the absorption and emission by Si dust at 12 μm. Because the Si feature is not as pronounced as smooth models suggest, this has been interpreted as evidence for a clumpy torus (Nenkova et al. 2008b). However, it was later shown that similar effects can be produced with smooth geometries (Feltre et al. 2012). Goulding et al. (2012) showed that deep Si absorption features are associated with edge-on galaxies, suggesting that non-nuclear dust imprints this feature.
We allow the model to place Si in absorption or emission. An Si template is created by taking the difference between the average templates of faint (on average in absorption) and luminous (on average in emission) AGN in the 8–18 μm range from Mullaney et al. (2011). The template is normalised at 12 μm. The Si parameter then controls the amplitude of this contribution, with zero corresponding to it not being present. The effect of this parameter is very localised, as shown by comparing the dotted and solid dark yellow curves in Fig. 3. Indeed, this parameter is inconsequential if no photometry filter covers the 8–18 μm rest-frame wavelengths.
 |
Fig. 3. Overview of the AGN model parameters and how they configure the spectrum, shown here in Lλ with arbitrary units. The power law (blue) is normalised at 5100 Å, where it has a power law slope of β. The power law bends over at λbend towards the UV, where it has slope βUV. The width of this transition is set by Wbend. Emission lines with FWHM Wlines and an FeII template are added and can be further scaled by Alines and AFeII, respectively. The torus component (dark yellow) is normalised by the ratio of 12 μm and 5100 ÅλLλ luminosities, fcov (see Eq. (4)). It consists of the sum of two log-quadratic curves, with width Wcool and Whot and location λcool and λhot. The peak-to-peak λLλ ratio is set by fhot (see Eq. (3)). The depth of the Si feature, in emission if positive or in absorption if negative (here: −1), is set by Si. The flexibility of these 15 parameters is restricted in Section 2.2. |
2.1.4. Bolometric luminosities
The luminosity integrated over the entire wavelength range is a crucial measure of the radiative energy budget in the circum-nuclear environments of supermassive black holes. However, since some radiation is absorbed and then re-emitted (as emission lines or in the torus), some care is needed to define what to compute to avoid double-counting. Furthermore, because our conversion between fluxes and luminosities assumes the luminosity distance, we compute isotropic luminosities, that is under the assumption of an isotropic radiation profile. Converting to more realistic, anisotropic emission luminosities requires a physical model (see, e.g. Stalevski et al. 2016, for a detailed discussion).
GRAHSP computes two bolometric AGN luminosities. Both are intrinsic, that is, before applying attenuation, rest-frame, isotropic luminosities. The first, lumBolBBB, integrates all AGN SED components except for the torus upwards of 91.2nm. The substantial contribution of the ionising far-UV and X-rays are not included in lumBolBBB. This is because the wavelength range is rarely directly measured. The user should apply a model-dependent correction factor to obtain the true bolometric luminosity. The second is the bolometric luminosity of the torus, lumBolTOR, integrated over the entire wavelength range. While lumBolBBB is primarily informed by data in UV to optical rest-frame wavelengths, lumBolTOR is informed by infrared data. Both bolometric luminosities are reported, as well as the ratio between them, ratioTORBBB=lumBolTOR/lumBolBBB. How to interpret such a ratio of instantaneous, isotropic luminosities as a covering factor of a light-year-sized torus that reprocesses the radiation from an anisotropically emitting accretion disk is discussed extensively in Stalevski et al. (2016).
2.1.5. Galaxy model
For the host stellar population, we adopt standard CIGALE modules Boquien et al. (2019), Yang et al. (2022). These implement stellar population synthesis (SPS) by Bruzual & Charlot (2003) (bc03) and Maraston (2005) (m2005) combined with a parametric star formation history (SFH) model. The stellar population is scaled to a total stellar mass of M⋆, a key parameter setting the normalisation of the galaxy emission spectrum. In the SPS, a metallicity needs to be assumed. The effects of metallicity on the resulting SED are well known to be degenerate with stellar age. Instead of exploring this degeneracy, we follow previous work and choose to measure the effective stellar age, assuming a fixed metallicity, and interpret the results in this context.
The galaxy evolution field has recently developed non-parametric SFHs (e.g., Iyer et al. 2019), which can approximate complex SFHs seen in cosmological simulations. Leja et al. (2019) demonstrated that non-parametric SFHs can more faithfully reconstruct the stellar mass build-up even in individual galaxies, given precision photometry. However, both parametric and non-parametric approaches agree within 0.1 dex on present-time properties, such as the current stellar mass and the average star formation rate (SFR) in the last 100 Myr (Leja et al. 2019). In this work (see also Ciesla et al. 2015), we demonstrate that contamination by AGN light creates much larger uncertainties when inferring SFR. To compare results on stellar mass from the literature, it is beneficial to stick with a simple parametric SFH. In GRAHSP, any SFH models implemented in CIGALE (see Boquien et al. 2019) can be enabled. For this work, we adopt a tau-delayed SFH (sfhdelayed), where the SFH rises linearly with time t and is then truncated with an exponential cut-off time scale τ:
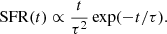
Figure 4 illustrates galaxy spectra of different SFHs (inset) for completeness. A maximum age for the oldest stars, t0, can be set (main_age), which defines the start of the SFH.
 |
Fig. 4. Example galaxy SEDs of stellar populations with different star formation histories. The star formation rate (see inset) rises linearly towards the present (right), with an exponential cutoff timescale τ. At low τ, the yellow SFR curve truncates quickly, indicating it is dominated by old stars. The corresponding yellow SED in the main panel peaks between 0.3 − 3 μm. The blue curve in the inset corresponds to continuously rising star formation. The corresponding blue SED in the main panel is dominated by luminous young stars, nebular emission lines and infrared dust emission. Minimal attenuation, E(B − V)=0.01, is applied. |
We point out that this parameterisation induces a characteristic SFR prior. The current SFR (averaged over the last 10 Myr for example) can be read off as the right-most point of each curve in the inset of Fig. 4. The maximum (highest τ) values are near SFR(10 Myr) = M⋆/10 Myr (and similar for SFR defined over other time windows), where most stellar mass was built relatively recently. A uniform or log-uniform grid on τ then induces an SFR prior that declines exponentially to arbitrarily low SFR (lowest τ). The endpoints of the inset of Fig. 4 indeed show a bimodality, with few points in the middle. This means that even if a random τ and M⋆ were picked, a main sequence can emerge. A red cloud can emerge by imposing a SFR floor.
As for the AGN component, emission lines may contribute a substantial flux in galaxy spectra (Ilbert et al. 2006; Hsu et al. 2014). Nebular emission lines are added with the nebular CIGALE module (Boquien et al. 2013, 2019). Their effect is clearly seen in recently star-forming templates in Fig. 4.
For gauging the relative importance of AGN and host galaxy emission, GRAHSP also computes an AGN fraction. Following Dale et al. (2014), fracAGNDale is the AGN luminosity fraction from 5 − 20 μm. Additionally, the bolometric AGN fraction fracAGNTOR is the ratio of lumBolTOR to the bolometric galaxy luminosity. These are also computed before applying attenuation (next section, Section 2.1.6), and for consistency, the bolometric galaxy luminosity does not include galaxy dust re-emission. From our key model parameters, 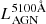 and M⋆, we can also consider a rough contrast ratio of AGN to host galaxy, after converting the stellar mass with a mass-to-light ratio Υ:
and M⋆, we can also consider a rough contrast ratio of AGN to host galaxy, after converting the stellar mass with a mass-to-light ratio Υ:
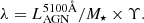
For simplicity, for Υ we adopt the solar bolometric mass-to-light ratio Υ0 = M⊙/L⊙ = M⊙/3.83 × 1033 erg s−1, which is close to the Milky Way V-band mass-to-light ratio ΥV, MW = 1.5 (e.g., Flynn et al. 2006). If we assume the same bolometric corrections for X-ray and 5100 Å (justified in Section 5.4), from black hole mass scaling relations λ = 2.7 is the approximate Eddington limit (Aird et al. 2017).
2.1.6. Attenuation model (biattenuation)
The spectra of AGN and galaxies are frequently attenuated by dust along the line of sight. Dust attenuation can be modelled by a variety of empirical laws. Salvato et al. (2009) and Hopkins et al. (2004), analysing large photometric and spectroscopic AGN samples, respectively, find a preference for the dust attenuation law of Prevot et al. (1984) derived from the Small Magellanic Cloud (SMC), ASMC(λ). There is still debate whether steeper and even entirely feature-less (power-law like) attenuation may be preferable (Fynbo et al. 2013; Zafar et al. 2015). Because the reddening of the continuum is dependent on the assumed intrinsic AGN continuum model, for which we chose a flexible parameterisation, we remain with a SMC-like dust attenuation model. The level of attenuation is parameterised with E(B − V):
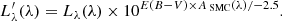
We approximate the SMC attenuation curve as a broken power law:
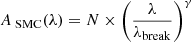
where γ = γOPT (default: −1.2) below λbreak and γ = γNIR (default: −3) above. The normalisation is N = 1.2 at λbreak = 1100 nm.
In our implementation, the AGN and galaxy components are attenuated differently. The galaxy attenuation level is parameterized by the E(B-V) color excess parameter, and the total galaxy luminosity absorbed is recorded. Enforcing energy balance, the luminosity is then re-emitted in the infrared following the Dale et al. (2014) model of galactic dust emission (galdale2014). Figure 5 illustrates this, and how the model approximates a dusty star-burst galaxy. For the AGN light, the situation is different (see also Calistro Rivera et al. 2016). The dust emission is already empirically modelled with the torus component (Section 2.1.3 above). The energy may not be balanced due to variability and anisotropy, as the line-of-sight absorption differs from geometrically averaged absorption. Since the AGN is embedded in the host galaxy dust but also nuclear dust, it may undergo additional attenuation. Therefore, we attenuate the AGN components not only with E(B-V), but with E(B-V) + E(B-V)-AGN, where E(B-V)-AGN is a parameter giving the nuclear attenuation color excess.
 |
Fig. 5. Effect of attenuation on the galaxy model. Models are shown from intrinsic (dark blue) to strongly attenuated (dark red). For illustration, the extremely attenuated local low-metallicity star-bursting galaxy Haro 11 from Lyu et al. (2016) is overplotted as a dashed red curve. |
The E(B-V)-AGN parameter also allows the AGN model to transition from a Sy1 to a Sy2. Figure 6 illustrates how the blue continuum, its lines and ultimately also the torus are attenuated by increasing values of E(B-V)-AGN. In our model, narrow and broad emission lines are both attenuated to the same extent, while in reality, narrow emission lines should remain visible in Sy2. However, this approximation is sufficient because in the relevant wavelength range, the photometry of Sy2 galaxies is dominated by host galaxy light (Hickox et al. 2017).
 |
Fig. 6. Effect of attenuation on the AGN model. Models are shown from intrinsic (blue top curves) to strongly attenuated (red bottom curves). The intrinsic torus model component (see Section 2.1.3) is shown in dashed black. The dark red curves illustrate that the most heavily attenuation can also suppress the torus. |
2.2. Model validation and parameter range calibration
This section tests and validates the performance of the GRAHSP model. Additionally, for each model parameter we identify the range required to reproduce the observations, to be used as prior knowledge when fitting lower-quality and noisier photometric observations typical of distant AGN samples. For this purpose, consistent, high-quality UV to far-IR spectra of galaxies hosting AGN are needed. Brown et al. (2019) compiled spectroscopic and photometric data from 0.09 to 30 μm on a diverse set of 41 local AGN. For each AGN, they carefully cross-calibrated and aperture-corrected the observations into one continuous broad-band SED. Figure 7 shows these data-driven model spectra in red. This AGN SED atlas was created to demonstrate the diversity of galaxies with AGN, including different host-AGN contrasts and infrared torus shapes. We use the AGN SED Atlas to identify reasonable ranges for each fitting parameter to restrict our otherwise very flexible model. We also include the empirical AGN templates of Elvis et al. (1994), Mullaney et al. (2011) and the hot-dust deficient and warm-dust deficient templates of Lyu et al. (2017) derived from 87 Palomar-Green quasars.
 |
Fig. 7. Atlas of AGN spectra (red) from Brown et al. (2019). The black curve shows our best-fit GRAHSP model. Dashed curves show model components. |
We optimize our model parameters to best approximate each spectrum. The best-fit model is overlaid in black in Figure 7. Individual model components are presented as dashed curves. Overall, the fit is very good, and the model captures the diversity of AGN-galaxy SED shapes. The model quality can be quantified by looking at the fit residuals in Figure 8. These were computed by averaging the model and data in windows of Δλ = 0.2λ, as relevant to broad-band photometry. The residuals remain below 20 per cent across the entire wavelength range considered, with few (3.4%) exceptions. In 2MASXJ13000533+1632151, the reddened galaxy continuum is not perfectly approximated near 300nm. IRAS-F16156+0146 shows an extremely deep Si absorption feature, which is not modelled well in the wings. NGC 7469 and NGC 5728 show complex galaxy polycyclic aromatic hydrocarbon emission features which are not fully captured by the Dale et al. (2014) templates adopted here.
 |
Fig. 8. Relative residuals of the fits of Fig. 7 are shown as curves. Four individual cases with the largest deviations are highlighted in colours and labelled. The distribution of residuals is presented on the right-hand side as a histogram. The vast majority of residuals (96.6%) are concentrated to smaller than 20 per cent deviations. |
The best-fit model parameters for each AGN are listed in the appendix in Table A.1. The diversity of the AGN Atlas can only be captured by allowing all listed parameters to vary. However, we can use the typical values to restrict the allowed parameter range. The last rows in Table A.1 list the 10 and 90 per cent quantile for each parameter. For example, for the attenuation of the AGN, E(B − V) values ranging from 0.01 to 1 mag are found, and for the galaxy, E(B − V) values ranging from 0.01 to 0.1 mag are found. The best-fit model parameters for four empirical templates are listed in Table 2. Here we see that the normal AGN template of Elvis et al. (1994) has a covering factor of 60 per cent with cool and hot torus components centred at 14 and 2.5 μm, of widths 0.4 and 0.5 dex, respectively. This is very similar to the Mullaney et al. (2011) template in the last row. In contrast, the warm-dust deficient template of Lyu et al. (2017) is decomposed with a narrower cold dust energy distribution, while the hot-dust deficient template contains a hot dust component centred at shorter wavelengths. The amplitude factor of the hot dust component (last column) also varies from 0.3 to 6. We cannot rule out the possibility that parameter degeneracies influence the values listed in Table 2, however, the found ranges from Table A.1 and Table 2 motivate the parameter ranges when fitting the model to data. To achieve efficient fits with the remaining 21 free model parameters requires an advanced inference engine.
Best-fit parameters for popular AGN SED templates.
2.3. Inference engine
2.3.1. Photometric flux prediction
The composed model is redshifted and converted into observable flux Fλ using the luminosity distance DL: Fλ(λ)=Lλ(λ)/(4πDL2)/(1 + z). For these steps, the implementation is taken from CIGALE (Boquien et al. 2013, redshifting module), which also applies absorption by the inter-galactic medium (Madau 1992). Finally, the flux of a photometric filter band i of interest is predicted with the filter transmission curve T(λ) as Fi = λpivot2∫F(λ)T(λ) dλ with the pivot wavelength λpivot = (∫T(λ)×λdλ)/(∫T(λ)/λ dλ). See Appendix A2 of Bessell & Murphy (2012) for a discussion why the pivot wavelength, rather than the mean filter wavelength, is relevant here. The model filter flux Fi is a function of all model parameters, Fi = f(LAGN,M⋆,⋯).
2.3.2. Computational optimisations
GRAHSP includes several optimisations that allow for the fitting of a single galaxy in 2–3 minutes on a typical single computing core. This includes the generation of visualisations of the SED fit and the inferred parameter uncertainties. This speed enables processing large samples, or experimentation and variation of models and data processing of individual objects. For rapid evaluation of a model with a substantial number of components, and fitting that fully explores the degeneracies between the many model parameters, GRAHSP departs substantially from existing approaches. We review some of these first.
In CIGALE, the model is implemented as a pipeline of modules that successively build up the SED. Each module has parameters. Each parameter can take a set of possible values, which is specified by the user as a list of numbers. CIGALE then creates an n-dimensional grid of all possible parameter combinations and instantiates each model spectrum. Because of the curse of dimensionality and limited computing resources (in memory and computation budget), this requires the user to sparsely choose the grid points for each parameter. This problem is exacerbated by the fact that an AGN+galaxy model is a linear combination of two models. However, CIGALE is unaware of this and thus builds the full model grid inefficiently, with the frac_agn specifying the relative normalisation of the AGN and galaxy components. The AGNFitter (Calistro Rivera et al. 2016) and FortesFit (Rosario 2019) instead first build two grids and linearly combine them during fitting, with stellar mass and AGN luminosity as normalisations. The parameterisation can be important because a log-uniform prior on stellar mass and AGN luminosity, each, prefers a much wider specific accretion rate distribution than setting a uniform prior on frac_agn. The latter can induce a bias to a narrow range of specific accretion rates, which may affect galaxy-AGN co-evolution studies. To test a new model variant (e.g. for a new filter set or redshift) with the two-grid precomputation approach, the user needs to write custom code to create the grids, and to balance the possible science goals with the grid size and computational cost. Another approach is to generate models on-the-fly, including instantiating the stellar population, attenuation, redshifting, and filter flux computation. Crucially, this enables full exploration of degenerate parameters, such as the E(B − V) and power-law slopes, with arbitrarily fine resolution.
GRAHSP takes a hybrid approach. It uses the pipeline-of-modules approach of CIGALE, but computes models on-the-fly. Models are cached using a hash map, which retrieves the output of the last module where all parameters matched. Therefore, while sampling, GRAHSP progressively builds up an implied grid. However, the grid is not necessarily fully constructed. The cache keeps only a user-defined maximum number of models (the CACHE_MAX environment variable), dismissing from memory models that have become uninteresting as the fit proceeds. The caching speeds up computation when the available machine memory is large. More specifically, the main run script of GRAHSP, dualsampler.py, entertains two pipelines, as illustrated in Figure 9. One pipeline creates the AGN components with mock galaxy components and a second one the galaxy components with mock AGN components. The mocked components only permit a single value for each module parameter. This means that the implied grid for each of the two pipelines is, as in AGNfitter or FortesFit, only concerned with either the galaxy or AGN parameter space. In the final model evaluation, the AGN components from the AGN pipelines and the galaxy component from the galaxy pipeline are scaled and added together. These pipelines include the module list that can be freely chosen by the user at run time. After the combination of the galaxy and AGN components, several modules can be applied relatively cheaply on-the-fly afterwards (see Fig. 9). This includes flux computation, redshifting, biattenuation and also activepl. The expensive computation of attenuation for each filter band is disabled during fitting, and re-enabled during the analysis of the results. Since these modules are evaluated on-the-fly, their parameter grids can be arbitrarily fine. This enables a detailed exploration of the degeneracies between continuum shape (activatepl) and its attenuation (biattenuation). It also enables the incorporation of redshift uncertainties, either as a free fitting parameter or with an informative prior from photometric redshift estimation.
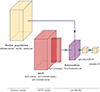 |
Fig. 9. GRAHSP computation pipeline. One sub-pipeline (yellow) produces the galaxy SED (large yellow box), one sub-pipeline (red large box) produces the AGN SED. Each sub-pipeline has a separate cache. Subsequent modules are applied on-the-fly, including the AGN power-law, attenuating the AGN and the galaxy components, summing and transforming into observed-frame fluxes. |
GRAHSP is also parallelised. SED analysis can be trivially split across computing cores without communication when analysing more objects than computing cores (known as an embarrassingly parallel problem). The user can set the number of cores to use (–cores command-line option) and choose among several parallelisation backends provided by the joblib and multiprocessing python libraries. Here, a further modification to CIGALE is necessary. CIGALE stores its database of model templates in a sqlite file on disk. However, mutual locking of multiple parallel runs accessing the sqlite file can cause substantial delays on shared file systems, as typically happens in computing centres. To avoid this, if the environment variable DB_IN_MEMORY is set to 1, the database (2GB) is copied to memory on start-up, which brings substantial speed-ups on large machines.
2.3.3. Module Pipeline
The order of execution of the modules is: sfhdelayed, bc03 (or m2005), nebular, activate, activatelines, activatetorus, activatepl, biattenuation, galdale2014, redshifting. The module galdale2014 has to be placed after biattenuation to receive the attenuated luminosity.
2.3.4. Parameters and priors
Table 3 summarises the modules (in square brackets) and their parameters introduced in the previous sections. Figure 1 gives an impression of the shapes of the model components with arbitrarily chosen galaxy and AGN parameters. For stellar mass, AGN luminosity and redshift, a continuous parameter space is explored, and the user can specify priors through the data file and command line options. The redshift can be constrained with a fixed (spectroscopic) value, or with uncertainties4 (photometric), or left unconstrained. The AGN luminosity can be constrained by providing a log-normal flux prior, for example from an X-ray detection. To test fits without a host galaxy, the upper limit on the stellar mass can be lowered through a command-line option. The other parameters are specified through a configuration file (pcigale.ini). The meaning of the AGN parameters is illustrated in Fig. 3. The effect of the two E(B − V) parameters is shown in Figs. 5 and 6. As in CIGALE, the specified grid parameter values also define a prior. numpy functions can be used to generate log-uniform grids, for example.
Modules and their parameters.
The values chosen for the tests in this work are listed in the right-most column of Table 3. For the galaxy, these follow previous CIGALE-based fits by Ciesla et al. (2015) and Yang et al. (2020). For the AGN component, we generally follow the ranges found in Section 2.2.
2.4. Fitting method
This section describes the procedure for constraining model parameters from observational data. In many fields of astronomy, low signal-to-noise ratio data can be interpreted by fitting parametric physical models using Bayesian fitting algorithms. In contrast, in SED fitting and today’s precision photometry surveys, it is common that the data quality exceeds that of the model. This situation is known as inference under model mis-specification. There is little benefit from advanced algorithms when the results are primarily limited by the quality of the model. Instead, it is more important to achieve fast fits, test robustness by varying assumptions, and understand the systematics in the results. In this work, we include improvements in the model (previous section), the likelihood (Section 2.4.1), model uncertainties (Section 2.4.2) and the Bayesian sampling algorithm exploring the parameter space (Section 2.4.3). Finally, Section 2.4.4 illustrates the outputs of the fit.
2.4.1. Likelihood
First, we review the χ2 likelihood implemented in CIGALE and LePhare (Arnouts et al. 1999). Assuming photometric fluxes fi were measured with associated uncertainties σi for a set of bands i ∈ ℬ, the usual Gaussian likelihood ℒ is adopted:
![$$ \begin{aligned} {\mathcal{L} }=\prod _i\frac{1}{\sqrt{2\pi \sigma ^2_i}}\times \exp \left[{-\frac{1}{2}\left(\frac{F_i-f_i}{\sigma _i}\right)^2}\right]. \end{aligned} $$](/articles/aa/full_html/2024/12/aa49372-24/aa49372-24-eq13.gif)
If the σi are fixed during the analysis, one can rewrite this as
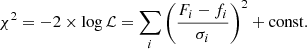
To maximise the likelihood (and minimise the χ2), the optimal model normalisation factor can be found analytically. The profile likelihood variant χprof2 is then:
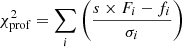
with
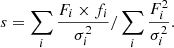
This is how CIGALE and LePhare optimise the normalisation analytically without exploring this additional parameter. In particular, for each model, CIGALE computes the optimal normalisation, and scales proportional parameters, including the stellar mass and AGN luminosity. Thus, the posterior distribution of stellar masses is determined primarily by the model template shapes, but does not fully consider the flux uncertainties. This can be demonstrated by fitting a single photometry data point with 20% flux error in CIGALE with a single template model (all parameters fixed). The uncertainties on the stellar mass should then trivially be 20%. However, CIGALE finds an uncertainty of 0%, which is then heuristically raised to 5%5. This shows that the CIGALE uncertainties on normalisation-related parameters can be severely underestimated. In GRAHSP, we instead use a Bayesian approach and resolve this issue with the full likelihood (Eq. (7)) instead of a profile likelihood. The normalisation(s) are free model parameter(s), as for example in FortesFit or AGNFitter.
GRAHSP supports flux upper limits. Upper limits are a property of the detection process (see Kashyap et al. 2010), and describe the probability distribution that a source of a flux f escaped detection by chance. We assume that the cumulative probability distribution up to flux f can be described by the cumulative probability density of a Gaussian with mean fj and width σj, for each band j ∈ ℬ with a non-detection. These are consistently incorporated in the likelihood as additional multiplication terms:
![$$ \begin{aligned} {\mathcal{L} }\prime ={\mathcal{L} }\times \prod _j\int _0^{f_j}{\frac{1}{\sqrt{2\pi \sigma _j^2}}\times \exp {\left[-\frac{1}{2}\left(\frac{F_j-f}{\sigma _j}\right)^2\right]}\, \mathrm{d}f}. \end{aligned} $$](/articles/aa/full_html/2024/12/aa49372-24/aa49372-24-eq17.gif)
This is the same treatment as implemented in CIGALE. Users provide upper limits by setting in the data file the flux uncertainty to −σj (negative values) and the flux to fj. Forced photometry at a position known from another band, may indicate a non-significant flux detection for that band. Following Kashyap et al. (2010), such upper bounds are treated as normal flux measurements (see the beginning of this section). In addition to measurement uncertainties, additional systematic uncertainties have to be considered.
2.4.2. Variability and model uncertainties
This section discusses the three types of uncertainties that GRAHSP considers: measurement uncertainties, model uncertainties, and stochasticity introduced by AGN variability. In the implementation, the total σ used in the Gaussian likelihood (Eqs. (7) and (9)) is a combination with Bienaymé’s identity of three contributions:
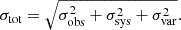
The flux measurement uncertainty σobs is provided by the input photometric catalogue. The model uncertainty σsys is computed for each filter as:
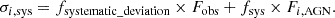
The first term is already used in CIGALE to account for systematic uncertainty in the galaxy model, with fsystematic_deviation set to 10 per cent by default and also here. In addition, in GRAHSP the systematic fractional AGN model uncertainty, fsys, is a free-fitting parameter (labeled systematics in the output). It scales the uncertainty with the photometric band’s model flux, Fi, AGN, considering only AGN components. Large values of fsys provide small χ2 values, however, due to the normalisation terms in Eq. (7), these are disfavored by their low probability density. We assign fsys an exponential prior distribution centreed at zero with a user-definable scale, set to systematics_width=0.2% in this work. The heavy tails allow poorly fitted data to increase the parameter to values much larger than systematics_width (see e.g. discussion in Gelman 2006).
The inclusion of this systematic uncertainty has important implications. In standard practice, when the model produces a poor fit (large χ2 values), the model parameter uncertainties are typically too small. The fit then either has to be discarded (like in LePhare) or the resulting parameter distributions cannot be trusted. Here, instead, when the model fits the data poorly, fsys becomes large, which in turn produces larger uncertainties on the fit parameters. Therefore, even in situations where the model poorly describes the data, the estimates and uncertainties by GRAHSP can be meaningful. This enables systematic analyses of samples and the direct use of the fitting results. Additionally, fsys can indicate when the model is a poor fit.
The third term in Eq. (10) is the variance introduced by AGN variability. It is active when variability_uncertainty is set to True in the configuration. This term is also proportional to the AGN model fluxes, σvar = Fi, AGN × Fvar(LAGN). From studying the year-to-year multi-band photometry variability of a sample of X-ray selected AGN in Pan-STARRS1, Simm et al. (2016) found a relation for the fractional variability independent of wavelength and black hole mass, which we adopt as:
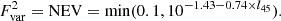
Here, l45 is the logarithm of the bolometric AGN BBB luminosity Lbol in units of 1045 erg/s. To summarise, the AGN variability uncertainty term depends on the AGN luminosity, with low-luminosity AGN having the largest variations. The practical implication is that photometry in similar wavelengths collected over several years from multiple surveys can be consistently included. Indeed, if the photometry shows statistically significant variability, this will make the model fit prefer an AGN-dominant model, because only the AGN components can induce additional variance.
2.4.3. Bayesian sampling algorithm
The continuous and discrete parameters listed in Table 3, plus the systematic model uncertainty parameter, define a challenging 21-dimensional parameter space. The model parameter space is likely to involve non-trivial degeneracies that should be fully explored. This is evident from the flexibility of the model illustrated in Fig. 3 pinned down by perhaps only a small number of photometric observations.
The nested sampling (Skilling 2004; Ashton et al. 2022) Monte Carlo algorithm can perform well in this setting. Nested sampling estimates the parameter posterior probability distribution and the Bayesian evidence (useful for model comparison), by maintaining a population of live points sampled from the prior. At each nested sampling iteration, the lowest likelihood live point is discarded, and the sampling continues, however, with the constraint that any new prior samples must exceed the likelihood of the discarded point. This has two effects: at each step, the likelihood threshold is raised such that the prior volume shrinks by a factor of K/(K + 1), where K is the number of live points. Secondly, the population of live points initially globally samples the parameter space, but gradually focuses more towards the likelihood peak. The posterior probability distribution is estimated by posterior samples. These are the discarded points, weighted by the volume discarded at the corresponding iteration i, Vi = 1/K × (K/(K + 1))i, and the likelihood of the point, wi = ℒi × Vi. The evidence is estimated as Z = ∫ℒ × π(θ) dθ ≈ ∑iwi. In practice, after many iteration the likelihood peak is reached and ℒ plateaus while Vi declines exponentially; thus the iterations can be stopped. The remainder of the live points is also added to the posterior and evidence integrals. For rapid progress towards the posterior peak, we choose K = 50 live points.
Iterative progress is made in nested sampling by adding a new live point sampled from the prior, with the requirement that its likelihood is higher than that of the discarded live point. In the first few nested sampling iterations, the likelihood-restricted prior is similar to the entire prior. Therefore, it is efficient to sample directly from the prior using rejection sampling. We adopt the ellipsoidal rejection sampling technique of Mukherjee et al. (2006) for the first 10 000 model evaluations, and then switch to slice sampling. Slice sampling (e.g., Jasa & Xiang 2012; Handley et al. 2015) efficiently samples from a likelihood-restricted prior in high-dimensional parameter spaces. We start from a randomly selected live point and perform 20 slice sampling steps before the point is accepted as a new live point. A slice sampling step proposes a direction vector, and along this direction, proposal points are drawn until the proposal exceeds the likelihood threshold. This can be made efficient (see Kiatsupaibul et al. 2011) by a stepping-out procedure identifying slice end points. For a literature review of techniques, see Buchner (2023). For proposing a direction vector, Buchner (2022) compared various proposals with a diverse set of test problems. The most rapidly converging proposal alternates randomly between differential vectors of random pairs of live points and randomly chosen principal axes of the live point distribution. We adopt this slice sampling technique until the posterior weight of the remaining live points is negligible (< 1%).
The nested sampling procedure described above is implemented in the open-source Python library UltraNest6. We connect GRAHSP to UltraNest to obtain posterior samples, Bayesian evidence estimates, diagnostics and visualisations of the posterior. UltraNest allows GRAHSP to resume from previously started runs, which enables modifying post-processing analysis outputs (see the next section) without refitting from scratch.
2.4.4. Uncertainty quantification
For each analysed source, an output folder is created. UltraNest places the posterior samples and other nested sampling outputs7 there. From the posterior samples the corresponding SED model is calculated. For computational efficiency, by default GRAHSP process only 50 posterior samples (--num-posterior-samples command line option). Posterior predictions of the individual model components are made and visualised. For each photometric band selected in the configuration file, predicted model fluxes for the entire model, and the AGN and galaxy components alone, are computed. This allows comparisons to other data sets not used in the fit or predictions for future observations. The fit parameters and marginal posterior distributions of derived quantities, such as the star formation rate within the last 100 Myr, the 12 μm AGN luminosity or the NEV, are also created, and corner plots can be optionally created. For all visualisations, the information is stored in text files, so that the user can replot the data. Finally, an output file listing all the analysed sources with the inferred parameter values and derived quantities, is created. The posterior probability distribution is summarised with the median (suffix _med to the analysed parameter name), standard deviation (_std), arithmetic mean (_mean), geometric mean (_lmean), and 2-sigma equivalent lower and upper quantiles (_lo, _hi). The geometric mean can be beneficial for log-quantities such as luminosities and masses.
3. Data
We aim to thoroughly test our code and model with diverse data sets. These include pure galaxies (without detected AGN activity) from deep pencil-beam surveys, and large samples of AGN selected in X-ray, optical and infrared wavelengths. Table D1 presents an overview of the sample sizes, photometric bands and depths.
3.1. Data set from COSMOS
The 2 deg2 COSMOS survey field (Scoville et al. 2007) is one of the prime extragalactic survey fields. Deep multiwavelength observations from UV/optical (down to 26 mag) and infrared enable the study of faint and distant galaxies. In X-rays, it has been fully observed with XMM first (Hasinger 2008) and Chandra later (Civano et al. 2015) down to a flux limit of 2 × 10−16 erg/cm2/s in the 0.5–2 keV band, making it easy to detect also faint AGN (Brusa et al. 2010; Marchesi et al. 2016). Furthermore, extensive and deep spectroscopy campaigns (COSMOS Deep, zCOSMOS, MOSFIRE, DEIMOS, LEGA-C, just to name a few) were conducted over the years, making COSMOS the ideal benchmark for testing SED fitting techniques. For the spectroscopy, we used the compilation that was available within the COSMOS collaboration in 2017 and considered only extragalactic sources with secure redshift (reliability 100%), following the ranking introduced by Lilly et al. (2009). We take UV to mid-IR photometry from the COSMOS2015 catalog (Laigle et al. 2016), namely near-UV from Galex, optical from Subaru broad (BVrizy), intermediate and narrow-band filters, near-infrared from the wide-field camera (WFCAM, J band), Canada-France Hawaii Telescope (CFHT, H and Ks band), and mid-infrared bands 1–4 of Spitzer’s infrared camera (IRAC). We further cleaned the sample by discarding all sources with a flag indicating any flux extraction problems such as saturation, and those with neighbors within 2 arc seconds in HST i-band imaging to avoid deblending problems. Fluxes from 3 arcsec apertures are preferred, which is sufficiently large to encompass most galaxies. AB magnitudes are converted into fluxes. Magnitude errors are conservatively converted into flux errors by comparing the difference between the flux of the nominal magnitude and the flux obtained for a 1σ lower magnitude. Flux measurements are corrected for Milky Way extinction with the values listed in Table 3 of Laigle et al. (2016) for each band, multiplied by the catalogued galactic E(B − V) values.
After this basic cleaning, we have created two sub-samples:
– COSMOS-pure-galaxies: in this sub-sample, all AGN candidates have been removed based on either (a) broad emission lines in the optical VLT (Lilly et al. 2009) and DEIMOS (Hasinger et al. 2018) spectra, (b) detection by XMM-Newton (Brusa et al. 2010) or Chandra (Civano et al. 2012; Marchesi et al. 2016, (c) an entry in Simbad marking it as an AGN or AGN candidate, (d) the IRAC-based infrared AGN selection criterion of Donley et al. (2012). While some AGN may remain in this sample, they are likely limited to low luminosities. The final pure galaxy sample contains 3367 galaxies.
– X-ray detected AGN: The second sub-sample instead consists of X-ray selected AGN taken from the homogeneous catalog of Marchesi et al. (2016) based on the Chandra (Civano et al. 2012) and Chandra-Legacy (Civano et al. 2015) surveys of the COSMOS area. Out of the 4016 sources listed there, we retain 225 AGN.
The sample of X-ray-detected AGN is used to quantify the stellar mass estimation as a function of: a) redshift accuracy: Often spectroscopic redshifts are not available and photometric redshift are challenging to obtain for AGN (e.g., Salvato et al. 2019). For the spectroscopic redshift sample, we compute masses adopting the spectroscopic redshift. Additionally, to test the impact of uncertainty induced by photometric redshifts, we also estimated the masses adopting the photometric redshift value from Marchesi et al. (2016) computed as in Salvato et al. (2011). Their accuracy and fraction of redshift outliers are at the few per cent level. b) depth of the multiwavelength data: Unlike deep pencil-beam surveys, wide-area surveys are characterised by a limited number of shallow photometric points. To emulate this situation, the photometry of these 225 AGN is modified in two steps: first, when the observed flux falls below the flux limits of current all-sky surveys, the measurement was discarded. The limiting depth in AB magnitudes was assumed to be: Galex/near-UV 20.8, B (23.15), r (22.70), i (22.20), z (20.70), yHSC (20.5+0.6348), J (20+0.938), Hw (18.8+1.379), Ksw (18.4+1.9), IRAC1 (16.6+2.699), IRAC2 (15.6+3.339), IRAC3 (11.3+5.174) and IRAC4 (8+6.620). Secondly, the photometric errors were increased by setting the flux errors to a fraction of the measured flux. That fraction is chosen from the mean fractional flux error in COSMOS of the respective band. This simple approach follows the assumption that both COSMOS and the emulated surveys are signal-to-noise limited, and the vast majority of sources are found at the faint end.
3.2. All-sky selected AGN
The AGN detected in X-ray pencil-beam surveys are not capturing the entire range of the AGN population, especially those with the most vigorously accreting black holes. For this reason, we test GRAHSP on AGN samples from wide- or all-sky surveys, selected in infrared, X-rays and optical. The following Section 3.2.1 and Section 3.2.2 provide the details for the construction of the samples and the extraction of photometry.
3.2.1. DR16QWX and eFEDS: all-sky infrared and X-ray AGN
In this section, we identify a complementary X-ray and mid-infrared sample of spectroscopic type 1 quasars. For our DR16QWX sample, the starting point is the QSO data release 16 (DR16Q) from SDSS, presented in Lyke et al. (2020). The DR16Q lists quasars targeted because of infrared and X-ray selection, but also includes previously targeted quasars that have X-ray counterparts. In terms of infrared selection, the DR16Q includes WISE (Wright et al. 2010) AGN selected in the Stripe82X survey field (LaMassa et al. 2019). In terms of X-ray selection, the DR16Q includes quasars that Salvato et al. (2019) identified as WISE counterparts to the X-ray all-sky ROSAT/2RXS (Boller et al. 2016) and XMMSLEW2 (Saxton et al. 2008; XMM-SSC 2018). For combining XMMSLEW2 with DR16Q, we find the Salvato et al. (2019) counterpart by a 1′′ position match of the respective WISE counterparts. For 2RXS, the Salvato et al. (2019) counterparts are listed directly in DR16Q. In addition, the DR16Q also includes the optical counterparts to XMM sources from XMMPZCAT (Ruiz et al. 2018) and the 3XMM-DR8, both based on the third version of the XMM-Newton Serendipitous Source Catalog (Rosen et al. 2016). Therefore, from the DR16Q, we select quasars selected by WISE, ROSAT or XMM. Only quasars (classified as normal quasar or broad-absorption-line quasar in Table 2 of Lyke et al. 2020) were kept. Furthermore, the b-band galactic extinction is required to be less than 0.1 magnitudes, which limits the sample to high galactic latitudes. Of the remaining sources, all show high redshift confidence (above 0.35). The vast majority of these (80%) were not targeted by the optical selection of SDSS DR7 (Schneider et al. 2010), making the selection complementary to bright, blue quasars. We restrict the sample to high quality redshifts (ZWARNING=0 and SN_MEDIAN_ALL> 1.6, see for example Menzel et al. 2016), and to not be in DR7 (IS_QSO_DR7Q< 1). This leaves 2349 sources. Finally, to focus on non-jetted AGN, sources within one arc second of source positions listed in the CRATES flat-spectrum radio source catalog (Healey et al. 2007) or the BZCAT blazar catalog (Massaro et al. 2015) are removed. Our final DR16QWX sample includes 2296 AGN.
For an eROSITA sample, we adopt the extragalactic sources from the eROSITA Final Equatorial-Depth Survey (eFEDS Brunner et al. 2022; Salvato et al. 2022). We focus on sources with spectroscopic redshifts above 0.002, and remove jetted AGN as described above.
Next, the UV to infrared photometry is collated with a one arcsecond search radius around the optical position. We carefully construct photometry from near-UV to mid-IR with matched apertures. Our implementation is released with this paper as RainbowLasso9. Near-UV magnitudes from Galex (Bianchi et al. 2017) are converted into fluxes (see Section 3.1). Measurements below 20.8 AB mag, the nominal Galex survey depth, are discarded. Co-extracted optical (g, r, i, z) and WISE (W1-W4) photometry is obtained from the Legacy Survey data release 10 (LS10 Dey et al. 2019). Sources were discarded if the photometry extraction fit was forced, hit limits, or the parameters had to be held fixed10. Heavily blended sources are also discarded. If a multi-source fit assigned less than 10 per cent of flux in the g, r or W2 bands to other sources (fracflux_* columns), the source is considered isolated. Final sample sizes are listed in the first row of Table D1. Because of the large point-spread function in the W3 and W4 bands, we discard W3 and W4 photometry if other sources dominate in either band or the contribution in W1 or W2 exceeds 10%. We consider point sources those where a point-spread function model provided the best fit (TYPE=“PSF”), and the remainder extended sources. For extended sources, we use fluxes extracted from 5 arcsecond apertures (apflux column 7 for the optical bands and column 5 for WISE bands), while for point sources, we use the model flux. Fluxes are corrected for galactic attenuation by dividing by the respective MW_TRANSMISSION columns. Near-infrared photometry is added from the Visible and Infrared Survey Telescope for Astronomy (VISTA) Hemisphere survey (VHS) data release 5 (McMahon et al. 2013, 2021), the United Kingdom Infrared Telescope (UKIRT) and InfraRed Deep Sky Survey (UKIDSS) (Lawrence et al. 2007; Warren et al. 2007). For point sources, we use aperture-corrected PSF model fluxes extracted from 2.8 arcsecond diameter apertures (apermag4), while for extended sources, we use not-aperture corrected fluxes from 5.6′′ diameters (aper*corr6). We also retain the X-ray flux from the source X-ray catalogs, where available, and convert it to a 2 − 10 keV luminosity assuming a power law index of 1.8, as most sources are only mildly absorbed.
3.2.2. SDSS-DR7Q: pure quasar sample
We construct a pure quasar sample that complements the COSMOS pure-galaxy sample in Section 3.1. By “pure” we mean here that the emission is dominated by AGN processes at essentially all wavelengths, and galaxy contribution is negligible. Ultraviolet and optically selected quasars were targeted by SDSS up to data release 7 catalogue (DR7 Schneider et al. 2010). Shen et al. (2011, 2012) selected sources where the i-band absolute magnitude exceeds −22 and the SDSS spectra show at least one broad emission line. This resulted in 105 783 extremely luminous, unobscured quasars. We assume that these are completely dominated by the AGN process and can be treated as point sources. We use the Milky Way-corrected AB magnitudes in the catalogue of Shen et al. (2011). Besides the optical bands (ugriz), the catalogue also provides near-infrared Vega magnitudes (JHKs) from the Two Micron All Sky Survey (2MASS) (Skrutskie et al. 2006) and infrared Vega magnitudes from WISE. The magnitudes and errors (see Section 3.1) were converted into fluxes.
4. The Chimera benchmark data set
To date, no benchmark exists for characterising the bias and variance of AGN host galaxy properties. These include fundamental physical quantities such as stellar masses, star formation rates, and stellar ages. The fundamental reason is that, unlike in the problem of estimating redshifts from photometry, true labels are generally not available even with more costly observations (spectroscopy). Comparisons of outputs from various codes and different models indicate that the results vary with model assumptions (Mobasher et al. 2015; Santini et al. 2012). Works on AGN hosts usually exclude from the analysis the unobscured AGN (e.g., Aird et al. 2015), because they present large uncertainties (e.g., Bongiorno et al. 2012). Ciesla et al. (2015) demonstrated with simulated unobscured AGN how stellar mass and SFR are respectively over and underestimated, already with a 40 per cent light contribution by the AGN. Reliable retrieval becomes even more challenging the fewer photometric bands are available. However, because the model assumed for simulating data was the same as the model for inference, such tests provide limited insight into the true bias and scatter of estimated host parameters.
To account for these issues, we aim to design a benchmark data set in which fiducial truth physical galaxy properties are known. The Chimera11 benchmark for AGN-galaxy decomposition is derived from real-world data without assuming a true model for AGN. We rely on the inference of physical properties in pure galaxies (non-AGN), as validated in Mobasher et al. (2015). We verified that the stellar masses determined by GRAHSP are consistent with those presented in the COSMOS2015 catalog (see the next section) and other codes (Section 5.5), so that any of these methods can be used as a reference value. This establishes fiducial truth physical galaxy properties, in the sense that we know what would have been measured if the galactic nucleus were inactive. In the second step, pure quasars from the DR7Q data set (Section 3.2.2) are randomly paired with pure galaxies (Section 3.1), under the constraint that the spectroscopic redshifts are within 0.01 of each other. The fluxes in each photometry band are then summed. For this step, the optical and near-infrared bands (urizJHK) can be summed directly, as the filter curves are in close agreement. For IRAC and WISE bands 1 and 2, tiny conversions from Stern et al. (2012) are applied. The higher IRAC bands substantially differ from WISE 3 and 4, and we do not consider them. The fluxes are summed, with a weighting factor applied to the quasar light, which controls how luminous a quasar is added. Uncertainties are propagated assuming Gaussian noise. Fluxes are only provided for bands where both the galaxy and the quasar had a measurement. The distribution of magnitudes of the Chimera benchmark is shown in Figure 10 (optical) and Figure 11 (infrared).
 |
Fig. 10. r magnitude as a function of redshift for the samples considered in this work. The COSMOS X-ray selected AGN (big blue circles) are, on average, fainter and at higher redshifts than all-sky WISE or X-ray selected quasars (red). The Chimera objects (crosses) combine COSMOS galaxies (pink) with different levels (colour bar) of quasar light (from optically selected quasars). |
 |
Fig. 11. WISE diagnostic plot for the same samples as shown in Fig. 10. Sources dominated by galaxy light tend to lie towards the bottom-right. With increasing AGN luminosities (colour bar), sources move to the upper-left. Magnitudes are in AB. |
The Chimera benchmark data set is enriched with reference galaxy and AGN properties. These are the galaxy properties (stellar mass, SFR, stellar age, attenuation, etc.) from COSMOS2015 and AGN properties (bolometric and 5100 Å quasar luminosities, black hole mass) from Shen et al. (2011). The Chimera benchmark is released12 with this paper, so that it can be used as a reference for comparing physical parameter estimates for AGN in codes currently in use or under development.
5. Preliminary Tests on GRAHSP
5.1. Model plausibility
As a first check, model colours are verified against colours of observed samples of AGN and galaxies. Fig. 12 shows the g-r-z-W1 colour-colour diagnostic plot presented in Salvato et al. (2022). We draw random samples from the GRAHSP model prior, construct the template and present the model colours as dots in Fig. 12. These cover the entire parameter space and beyond. The model dots envelop the distribution of quasars from DR16QWX and eFEDS AGN, which are illustrated as contours in Fig. 12. The locus of stars (see Salvato et al. 2022) is below the dashed line, and as expected, few galaxy model templates are in this region. Appendix E extensively tests the model colours against four observational samples (DR16QWX, eFEDS, COSMOS AGN and COSMOS pure galaxies). There it is shown that emission lines and the FeII template are an important contributor, without which the observed colours cannot be reproduced. This has also been noted in Temple et al. (2021), which studied the mean quasar colour over a wide redshift range. Here, we demonstrate that the GRAHSP model is capable of reproducing not only the mean colour but also the wide diversity of colours in the galaxy and AGN population.
 |
Fig. 12. Colour diagnostic plot. The GRAHSP templates (coloured dots as a function of redshift) cover the entire plane. The observations are illustrated by coloured contours containing 99% of each sample. At the centre-left, quasars dominate (red outline, DR16QWX), while the eFEDS sample includes a wider distribution. The dashed diagonal line demarks the separation of Salvato et al. (2022) between galaxies (above) and stars (below the line). |
5.2. Retrieving stellar masses for COSMOS-pure-galaxies sample
We first test GRAHSP on the COSMOS-pure-galaxy sample, using only galaxy models. The top panel of Fig. 13 compares the resulting stellar mass estimates to those published by Laigle et al. (2016). To ensure consistent assumptions, we show only sources where their adopted redshift agrees with the spectroscopic redshift within 1 per cent. The stellar mass estimates agree well at all redshifts and at all stellar masses.
 |
Fig. 13. COSMOS comparisons. Stellar masses from COSMOS2015 are compared with those from GRAHSP, with the AGN component turned OFF (top panel) or ON (middle panel), for various redshift bins. In both cases, the agreement is extremely good, with very little scatter around the 1:1 relation. For the case with the AGN component turned ON, the GRAHSP AGN luminosity is plotted as a function of stellar mass. As expected, in all sources the AGN component is well below 10% in all cases but two. |
Secondly, we test the impact of introducing our AGN model components, even if it is not required. On the same COSMOS-pure-galaxy sample, the middle panel of Fig. 13 compares two runs: once without AGN from the previous experiment and once with the full GRAHSP setup described in Section 2. The estimates show close agreement, indicating that the added model complexity does not bias the measurement. In most cases, the upper error bar of the AGN luminosity is well below 1042 erg/s, allowing for low-luminosity AGN, at most. In the SED, the AGN is always sub-dominant compared to the host. This can be quantified with the AGN-to-galaxy light contrast ratio, 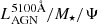 , where Ψ is the solar light-to-mass ratio (see Section 2.1.4). The bottom panel of Fig. 13 shows that the contrast lies well below 10% in the vast majority of cases. From the entire sample, only few have a blue SED that can be fit with a star-burst or a luminous AGN, giving rise to large (but correct) uncertainties in the contrast ratio. These can also be seen in the middle panel.
, where Ψ is the solar light-to-mass ratio (see Section 2.1.4). The bottom panel of Fig. 13 shows that the contrast lies well below 10% in the vast majority of cases. From the entire sample, only few have a blue SED that can be fit with a star-burst or a luminous AGN, giving rise to large (but correct) uncertainties in the contrast ratio. These can also be seen in the middle panel.
5.3. Template fit test
Next, the ability to describe SEDs from a diverse sample of AGN by the models in GRAHSP, is tested. We use here the DR16QWX sample of infrared and X-ray selected AGN (Section 3.2.1) and show two extreme cases in Figures 14 and 15. Firstly, Fig. 14 shows an AGN-dominated case. The model follows the data points closely. The Hα emission line at 0.653 μm substantially contributes to the measured flux in the relevant filter (blue square), which is also reflected in the model flux (red point). This demonstrates the importance of emission features in the templates. Figure 14 shows the total model and its components. Because the fit is fully Bayesian with continuous amplitude parameters, the posterior (shaded areas) is smooth. The corresponding parameter constraints are shown in Figure 16 as blue histograms. In particular, the stellar mass (top left panel) posterior is a flat distribution reaching up to approximately 1010 M⊙, indicating that for this AGN-dominated source only an upper limit can be estimated. A host-galaxy-dominated source is presented in Fig. 15 as a second example. The galaxy template is constrained well. Comparing the thin cap error bars with the wide cap blue error bars, we see that the data uncertainties were slightly enlarged by the fit (see Section 2.4.4). The parameter constraints are shown in red in Fig. 16. The panels marked ‘log_stellar_mass‘ and ‘sfh.sfr‘ show that stellar mass and star formation rate could be constrained, respectively. The AGN luminosity (second panel in the top row) is constrained to less than 1044 erg s−1. Degeneracies between all model parameters can also be explored. The bottom right panel of Fig. 16 only shows the conditional distribution of stellar mass and AGN luminosity, with the obtained posterior samples.
 |
Fig. 14. Example of an AGN-dominated SED fit from the DR16QWX sample. The total model (black) and the individual components (colours, see legend) are presented with the posterior mean (solid line) and 2 sigma equivalent uncertainties (shaded areas). Observed fluxes are shown as blue data points with blue squares and wide blue capped 3σ error bars. The overlaid blue error bars with thin caps show the enlarged total error budget after the fit. The filter curves of observed photometric bands are shown at the top, grouped to the same colours by instrument. Predicted model fluxes are shown as red points. These can deviate from the black curve because of the averaging over the filter curve. The bottom panel presents the relative residuals of model and observations. The title lists the source ID, redshift, χ2 (Eq. (8)) per number of data points and Bayesian model evidence. On the right, key values are shown, including the stellar mass (in M⊙), star formation rate (in M⊙/yr), the galactic and AGN extinction, and the 5100 Å AGN luminosity (in erg/s). Lower case variables are logarithmic. Below 2 μm, the model is dominated by the AGN disk, and above by the torus. The third data point (z-band) is raised compared to the neighboring data points, which can be understood by the Hα emission line at that redshift. The galaxy component has an extremely wide luminosity range (purple), that is, the stellar mass is unconstrained (see the first number on the right) in this luminous AGN (see the fourth number on the right). |
 |
Fig. 15. Example of a host-galaxy-dominated SED, with elements as in Fig. 14. Here, the SED is dominated by galaxy components (purple and green curves), including nebular emission lines (grey). The stellar mass and star formation rate are well constrained (numbers on the right), while the AGN luminosity has more than an order of magnitude uncertainty around a low value of 1041 erg s−1. Here, model uncertainties (thin cap error bars) were only slightly increased without requiring an AGN component. |
 |
Fig. 16. Parameter posterior probability distributions for two different objects: One AGN-dominated source (blue) of Fig. 14 and one host-galaxy-dominated source (red) of Fig. 15. Panels with thick histograms are model parameters. Panels with thin histograms are derived parameters. The large bottom-right panel shows the joint posterior distribution of AGN luminosity and stellar mass as posterior samples. |
We investigate this a bit closer by looking at the inferred systematic uncertainty parameter values. Figure 17 presents the distribution of posterior medians on the systematic model error parameter fsys for the entire DR16QWX sample. The median of the prior is 0.2 (vertical black dashed line). This indicates that, for most sources, no additional model uncertainty had to be introduced during fitting. For reference, the cases from Fig. 14 and Fig. 15 have a median fsys of approximately 0.08.
 |
Fig. 17. Distribution of posterior medians of the systematic model error parameter fsys (see Eq. (10)). |
5.4. Extension to X-ray data
Yang et al. (2022) investigated the use of X-ray constraints to improve the model fit. As illustrated with the galaxy-dominated case (Fig. 15), in particular low-luminosity and obscured AGN sources can benefit from additional constraints on the AGN component. GRAHSP supports placing priors on the AGN luminosity. Here we investigate whether X-ray observations are appropriate to constrain the 5100 Å luminosity parameter of our model.
The upper panel of Fig. 18 shows the correlation between SED-inferred 5100 Å luminosities and X-ray-based luminosities. The X-ray luminosities were not used in the fit and are taken by conversion from X-ray survey catalog fluxes (see Section 3.2.1). They show a 1:1 correlation with some scatter, particularly due to sources with large uncertainties. We investigate the intrinsic scatter by considering the luminosity ratio (blue histogram in the bottom panel of Fig. 18). The distribution is compared to results from the local Universe in the literature, where Koss et al. (2018) reported a 0.43 ± 0.47 log-ratio distribution between the 5100 Å and 14 − 195 keV luminosities, which the authors relate to the 2 − 10 keV luminosity with a shift of 0.42 dex. Fortunately, the two shifts almost cancel out, making the 5100 Å luminosity approximately equal the 2 − 10 keV luminosity, with a scatter of 0.5 dex (gray distribution in the bottom panel of Fig. 18). This agrees with our distribution of mean ratios. This demonstrates that measured X-ray fluxes, blurred with a 0.5 dex Gaussian, can be used as AGN luminosity priors in GRAHSP fits. Practically, this is achieved by providing the necessary columns in the input file (see Table 3).
 |
Fig. 18. Extension to X-rays. Top panel: The AGN luminosity at 5100 Å inferred from GRAHSP is compared to the 2 − 10 keV luminosity from X-ray observations in the DR16QWX sample. Points are colour-coded by redshift, with yellow indicating the highest redshifts. Bottom panel: The ratio is shown as a black histogram. For comparison, the grey dashed curve represents the mean ratio and scatter observed by Koss et al. (2018). |
5.5. Literature model setups
In the subsequent sections we test GRAHSP. We compare the results from GRAHSP to those derived from three alternative methodologies that have been described in the literature. All of these are based on CIGALE, and for our analysis we adopt the latest version of that code (2022.1). We adopt broadly the same setups that are described in the literature except that in all cases we use a Planck cosmology Planck Collaboration VI (2020) and the Maraston (2005) SPS model, noting however that adopting the Bruzual & Charlot (2003) models produces similar results.
The first model, “D14”, adds the AGN model of Dale et al. (2014) to the stellar population. The slope is allowed to vary (values: 0.0625, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0), and so is the AGN fraction (values: 0.01, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.99). Since the AGN model has only two parameters, the galaxy parameters can be evaluated on a fine grid while retaining an acceptable computational cost, with τ taking values of 1, 50, 500, 1000, 2000, 2500, 3000, 3500, 4000, 4500, 5000, 5500, 6000, 7000, 8000 Myr and the age ranges from 100 to 13 Gyr in 15 logarithmic steps. A modified starburst attenuation law is applied.
The second model, “C15”, follows the setup of (Ciesla et al. 2015). The AGN is modelled with the Fritz et al. (2006) template library. The full list of parameters is given in Appendix B. Due to the high number of AGN parameters, the galaxy parameters need to be more coarsely gridded in CIGALE, with τ taking values of 500, 1000, 3000, 5000, 10 000 Myr and age taking values of 500, 1000, 3000, 5000, 7000, 10 000. A Calzetti-Leiterer attenuation law is applied (Calzetti et al. 2000; Leitherer et al. 2002).
The third model, “Y19”, follows the setup of Yang et al. (2019). The AGN model is SKIRTOR (Stalevski et al. 2016), which also has many free parameters listed in Table B1. The galaxy parameters are coarsely gridded, with τ taking values of 100, 500, 1000, 5000 Myr and age taking values of 500, 1000, 3000, 5000, 7000.
The comparison of GRAHSP and the three CIGALE model setups is shown in Section 6. For a fair comparison, we compute the Chimera fiducial truth from COSMOS with the galaxy model setup exactly matching the respective model setup. However, adopting the COSMOS2015 results as fiducial truth does not change the results, as there is good agreement on pure galaxy inference (see, e.g. the top panel of Fig. 13).
GRAHSP has many more free parameters than the above setups do. For example, SKIRTOR is the model with the largest number of free parameters, but for computationally feasible fits with CIGALE, many need to be fixed. Appendix F investigates whether having all parameters free can resolve any differences between GRAHSP and CIGALE. In particular, similar to Section 2.2, we fit SKIRTOR against the Brown et al. (2019) Atlas of AGN spectra in Appendix F, and find substantial residuals.
5.6. Validation of the Chimera benchmark
Before applying GRAHSP to the Chimera benchmark and evaluating the results, we perform a sanity check on the created low-luminosity AGN objects. At luminosities of L(AGN)< 1042 erg/s (i.e. typically corresponding to quasar flux weights of 0.1 per cent), the Chimera objects have essentially the same fluxes as those from the original COSMOS-pure-galaxy sample, but with two differences. Firstly, the number of filters is much more limited compared to the COSMOS filter set used to establish the fiducial truth stellar mass. Secondly, the filter curves are taken from SDSS, which do not exactly correspond to the COSMOS filters where the galaxy fluxes are from (Subaru and CFHT). To establish that this is not a concern, and that the Chimeras have usable fluxes, Fig. 19 compares the stellar mass computed by GRAHSP on these Chimeras to the original stellar mass from Laigle et al. (2016). The stellar masses from the two analyses are consistent, with a mean of 0.0 dex and a scatter of 0.2 dex. Similar results are found for the comparison of CIGALE with the D14, C15 and Y19 models. There are a few (0.2%) outliers, however.
 |
Fig. 19. Chimera sanity check at low AGN luminosities. Comparison of stellar masses measured from COSMOS-pure-galaxies sample to that measured by GRAHSP for the Chimeras built using the same galaxies and with low AGN contribution. The measurements are consistent; for some cases, the uncertainties are very large. |
One outlier is shown in Fig. 20. The top panel shows the analysis of the original COSMOS data with CIGALE. The subsequent panel shows the Chimera object with CIGALE (middle) and with GRAHSP (bottom panel). The COSMOS data are fitted with a strongly star-forming galaxy template, which is required because of the longest-wavelength infrared data points. Heavy attenuation then suppresses the UV (compare the blue curve to the black curve). The model is not a good fit, with a reduced χ2 of 3.9. The infrared colours are not indicative of an AGN, following Assef et al. (2013). Instead, this indicates that the galaxy model may be incomplete. The stellar mass in units of 1010 M⊙, when analysing the COSMOS photometry, is 5 in the COSMOS2015 catalogue, but 0.14 in CIGALE and 0.18 in GRAHSP when run without an AGN component. When an AGN component is used to fit the Chimera object, the infrared excess is modelled with an AGN component (Fig. 20, CIGALE: middle panel; GRAHSP: bottom panel). This differs slightly in shape between the D14, C15 and Y19 models, but the results are similar. The middle panel of Fig. 20 demonstrates this point: galaxy light is assigned to the AGN component. The resulting stellar masses are now an order of magnitude higher, between 1 and 2.2 × 1010 M⊙, as much less attenuation is needed.
 |
Fig. 20. Example of an outlier at the lowest Chimera quasar weight (0.0001). This should be galaxy-dominated with very low AGN luminosity. The top panel shows the original COSMOS galaxy. The observed fluxes (purple) are reproduced with a high reduced χ2 (see title) by the galaxy model (black curve), with substantial residuals in the near-infrared and optical wavelengths. The middle panel presents the constructed Chimera fluxes (purple), fitted with the C15 model’s galaxy (yellow curve) and AGN (orange curve) mixture model, using CIGALE. The AGN component models the data in the infrared. The stellar mass has become eight times larger than in the top panel. The bottom panel presents the analysis of the same Chimera data with GRAHSP. Here the fit is dominated by a low-luminosity AGN, and the stellar mass is poorly constrained. The x-axis range is wider in this panel. |
We include such cases where even the galaxy is not perfectly modelled. These are realistic, and would be difficult to recognise if the uncertainties were larger or fewer bands were used. They are relevant as the inference is unstable when measuring a stellar mass of galaxies for comparison to AGN samples. Nevertheless, such cases are rare. An order of magnitude or more difference to the COSMOS reference masses are present in four per cent of the Chimeras in the case of CIGALE, and six per cent with GRAHSP, as shown in Fig. 20. Their rarity implies that the COSMOS data analysis is valid as a fiducial truth for Chimera objects. In the subsequent sections, larger AGN luminosities are also considered, and the impact on the stellar mass estimate reliability is determined.
6. Results
The Chimera benchmark described in Section 4 provides galaxy properties true values that can be used for testing the capabilities of SED fitting methods. In this section we test GRAHSP. We also compare it to CIGALE with the three model setups (D14, C15, Y19; described in Section 7.3).
6.1. Stellar mass retrieval
First, we investigate the retrieval of stellar masses. We split the Chimera sample into bins of true AGN bolometric luminosity. In Fig. 21, we compare the true values against results from runs of GRAHSP and three CIGALE setups. At low luminosities (first column), all estimates have relatively small uncertainties, and centre around the true value (near zero deviation Δ = logMestimated/Mtrue). The content of the bottom left panel was already presented in Fig. 19 as a correlation. In the following, the mean of the deviations is referred to as the bias, and the standard deviation as the scatter of the estimator. We weight the mean and standard deviation by the error bar size. Finally, we mark outliers with circles. These are defined as cases where the error bar excludes the 1 dex wide band centred around the true value, illustrated with grey dotted horizontal lines. Section 5.6 already discussed one example outlier in the lowest luminosity bin from the D14, C15 and Y19 models.
The bias, scatter and outlier fraction are noted in the upper-right corner of each panel. At higher luminosities (last column of Fig. 21), the settings most commonly used in literature show a positive bias of +0.5 dex. This is most pronounced at lower stellar masses, where the mass is overestimated by an order of magnitude or more. The outlier fraction is 20 per cent. In contrast, GRAHSP (bottom row), has outlier fractions below 5 per cent and near-zero bias (≤0.2 dex). The scatter is comparable across all methods.
 |
Fig. 21. Retrieval of stellar masses on the Chimera benchmark data set. The y-axis always shows the ratio of the estimated stellar mass to the true stellar mass (x-axis), in log units of M⊙. The first three rows are AGN models in CIGALE, the last row is GRAHSP. The sample is split into four bins (panel columns) of true AGN bolometric luminosity (in erg/s, log). Results with large error bars (> 1 dex) are in grey. If the measured stellar mass deviates from the expectation (dotted grey horizontal lines) by more than 0.5 dex, it is considered an outlier and indicated with a circle. In each bin, the mean and standard deviation are quoted, together with the fraction of outliers in brackets. CIGALE models show a 0.2–0.5 dex bias at L > 43. For GRAHSP, the bias is below 0.1 dex. The GRAHSP fraction of outliers is also lower. The downward-pointing triangles at the very top of the figure indicate where the AGN and galaxy luminosities are approximately equal (λ = 1 in Eq. (6)). The CIGALE models start to deviate to the left of these markers, corresponding to λ > 1. |
An example fit result for such an outlier is illustrated in Fig. 22. The top-left panel shows the true COSMOS galaxy, modelled with the many photometric bands in COSMOS. In the subsequent panels, the constructed Chimera object is shown, with all luminosities about one order of magnitude higher (1 × 1036W instead of 1 × 1035W), due to the AGN. Even though the galaxy should therefore be ten times fainter than the AGN, the Chimera object is fitted by the D14, C15 and Y19 models (see panels) with approximately equal luminosity between AGN (orange) and galaxy (yellow) contribution. The bottom panel shows the result from GRAHSP. The more flexible AGN model of GRAHSP, together with its fine parameter space sampling and consideration of systematic uncertainties, can describe the data with an AGN-dominated combination (bottom panel of Fig. 22), where the host galaxy stellar mass is consistent with that of the COSMOS fiducial truth.
 |
Fig. 22. Example of outlier in CIGALE-based analyses from the 1043 − 44 erg/s AGN luminosity bin. Panel (a) shows the original COSMOS data (CosmosId: 420968 at z = 0.33), where a M⋆ = 108 M⊙ galaxy-only model (black) reproduces the observed fluxes (purple) with small residuals (χred2 = 0.4). Panels (b), (c) and (d) present CIGALE fit to the Chimera fluxes (purple) with D14, C15 and Y19 settings. In all three models, the galaxy template is incorrectly placed at 1036 W instead of < 1035 W as in panel (a). In the C15 and Y19 models, the best-fit model is dominated by the AGN component (orange). The bottom panel (e) shows the fit by GRAHSP for the same object. The galaxy component has very large uncertainties (purple shade at the bottom), but includes the true stellar contribution (compare the purple curve here to the black curve in the top left panel). The error budget has slightly increased during the analysis from the blue error bars with wider caps to those with thin caps. The power-law AGN model (blue) dominates the fit at all wavelengths. |
We caution that such failures could not be recognised from the fit alone. Firstly, Fig. 22 shows χ2 values comparable to unity for some of the models. Secondly, we implemented the cleaning criteria proposed by Mountrichas et al. (2021), which require the maximum-likelihood stellar mass to agree with the posterior mean stellar mass within a factor of five. This occurs in 100 per cent of the sample. Therefore, the criterion does not improve the outlier fractions, which range from 5 to 20 per cent. Thirdly, agreement between different model assumptions also does not resolve incorrect solutions, as illustrated by the example of Fig. 22 and Fig. 20, which give across three different CIGALE AGN models a consistent but incorrect high stellar mass.
6.2. Star formation rate
The next host galaxy property considered is the star formation rate (SFR). SFR is known to be difficult to estimate in individual galaxies (e.g., Ciesla et al. 2015). Nevertheless, works such as Aird et al. (2019) rely on sample-averaged stellar masses, so quantifying the bias and scatter of estimators is important. Here, the SFR in the last Myr is expressed in M⊙/yr, and again compared to the true SFR from the Chimera benchmark sample in Fig. 23. We only consider those objects where in the reference COSMOS galaxy, the fiducial truth SFR could be constrained to better than an order of magnitude by all models.
At the lowest true SFRs, the inferred SFR is overpredicted by one to three orders of magnitude. At the highest SFR (> 10 M⊙, the retrieval is unbiased at least to the right order of magnitude. At the highest AGN luminosities, GRAHSP shows the lowest bias. The D14 model (top panels) shows an erratic behaviour at the highest SFR for AGN luminosities of logL > 43. The other two CIGALE models, have a larger positive bias than GRAHSP. In the CIGALE models, the outlier fraction lies between 20 and 30 per cent, while the outlier fractions of GRAHSP remain below 10 per cent even at the highest luminosity bin.
6.3. Luminosity-dependence of estimators
The trends with AGN luminosity are summarised in Fig. 24. The left panels show the outlier fraction, bias and scatter of the stellar mass estimator, from top to bottom panel. The outlier fraction is much lower in GRAHSP than the other methods, and does not strongly increase with luminosity. Indeed, the outlier fraction (top left panel in Fig. 24) approximately corresponds to the probability expected outside the error bars. This is not the case for the Y19, C15 and D14 CIGALE models, for which the outlier rates rise up to 20 per cent at high luminosities. While the bias (centre left panel in Fig. 24) of the D14, C15 and Y19 methods starts near zero in low-luminosity AGN, it rises steeply with luminosities, up to 0.4 dex. This means that any sample-averaged stellar masses are systematically raised by this amount.
 |
Fig. 23. Star formation rate retrieval on the Chimera benchmark data set. As in Fig. 21. Each panel shows the deviation of the estimated SFR from the true SFR (in log units of M⊙/yr, x-axis). The first three rows’ right panels show the performance of current models at moderate AGN luminosities. Overestimates by 1–2 dex are common at low star formation rates, with outlier fractions between 10–30 per cent. The bias of GRAHSP (last row) is lower and the outlier fraction consistently below 10 per cent. |
 |
Fig. 24. Comparison of codes and models on the Chimera benchmark data sets. The panel rows show the outlier fraction (see Fig. 21), the bias and scatter in dex. The first column shows stellar mass estimation (from Fig. 21), the second column star-formation rate estimation (from Fig. 23). Each curve as a function of AGN bolometric luminosity (log, in erg/s) represents one method. The outlier fraction of GRAHSP is lower than those of other methods. The bias of GRAHSP is near-zero. Other methods systematically overestimate the masses in luminous AGN (middle left panel), and star-formation rates (middle right panel). |
The right column of Fig. 24 presents trends of the SFR estimator. The range (right axis) of the bias panel had to be increased compared with the stellar masses (left column), indicating how much more uncertain this measurement is. While the scatter is comparable between methods, the bias and outlier fraction are lowest in GRAHSP. The latter indicates that CIGALE-based reported SFR error bars are too small, whereas GRAHSP produces realistic error bars.
6.4. AGN luminosity
The last comparison from the Chimera benchmark compares the retrieval of luminosities. The top panel of Fig. 25 shows the retrieval of bolometric luminosity by the Y19 model across all Chimeras. We excluded cases where the fiducial truth luminosity listed in Shen et al. (2012) is larger than 1 dex. The bias is small (0.1 dex) with small scatter (0.5 dex), with 19 per cent lying outside the 1 dex-wide band of the true value. Some of this scatter is likely due to differences in modelling assumptions of the Shen et al. (2011) bolometric computation and AGN model. The second panel shows the results for the BBB luminosity of GRAHSP. The bias is slightly negative and luminosity-independent. The outlier fraction is only 3 per cent. The third panel shows the bolometric luminosity estimated from the torus, with comparable results.
 |
Fig. 25. Luminosity retrieval on the Chimera benchmark data set. The top panel shows the deviation from the AGN bolometric luminosity (in log units of erg/s). Current methods (top panel) show an upward bias at Lbol < 1043 erg s−1, and an outlier fraction of 15 per cent. The bolometric luminosity (see Section 2.1.4) from the BBB and the torus are presented in the second and third panels, respectively. The bottom panel compares the retrieval of 5100 Å luminosity. In all cases, the average bias of GRAHSP is close to zero, with an outlier fraction lower than 5 per cent. |
The bottom panel of Fig. 25 evaluates the 5100 Å luminosity retrieval of GRAHSP. The estimator has a very low bias (−0.1 dex) with a scatter of 0.4 dex. A low fraction, three per cent, are outliers.
7. Discussion
This work makes two major contributions to the field of host galaxy studies of AGN. Firstly, the Chimeras, a data-driven benchmark data set with fiducial truth of the AGN and galaxy decomposition, is made publicly available to the community. Secondly, GRAHSP, an SED analysis method that is unbiased in the estimation of stellar mass and AGN luminosity, is presented. We now discuss these contributions in turn.
7.1. The Chimera benchmark data set
The Chimera benchmark data set covers an enormous range of galaxies that could hypothetically exist in the Universe. The AGN luminosities range from 1041 − 48 erg/s, the redshifts from 0.08 to 3.5, the stellar masses from 107 to 1011.2 M⊙, the star formation rates from 0.01 to 100 M⊙/yr, and the black hole masses from 107 to 1010 M⊙. The galaxies and AGN are randomly mixed, which likely results in situations that do not, or only extremely rarely, occur in nature. However, only if our analysis methods provide reasonable inferences in these situations can we be certain that these situations do not occur.
The Chimera benchmark is a novel data-driven, model-agnostic approach. Generating mock observations from models (e.g., Ciesla et al. 2015) tests the internal validity of these models, and the constraining power of data under the assumption that the model is correct. However, in reality, the diversity of AGN and galaxy phenomenology is not covered by any current model (see e.g. Fig. 20), since it requires understanding stellar population evolutionary models and re-emission by the inter-stellar medium, and even less certain for AGN, the emission of the accretion flow (see e.g. Antonucci 2018) and the infrared re-processing by a multi-scale, multi-temperature nuclear obscurer (see e.g. Netzer 2015; Hönig 2016).
Alternative approaches to vet the inferred stellar mass and SFR have been proposed. These include considering the fit quality (reduced χ2) and the asymmetry of the posterior, and consistency between several codes with different assumptions. These are incomplete indicators, as demonstrated in Fig. 21, as multiple codes and models may give comparable, but incorrect decomposition, with acceptable fit quality.
Generating a benchmark data set of AGN-galaxy hybrids from observational data alone sidesteps these issues. Fits with simplified, computationally feasible models can then be evaluated without assuming a generating model.
Currently, the Chimera benchmark focuses on the mixture of type 1 quasars with typical galaxies. This is the most challenging situation, and thus the centre of this work. A future modification could be to introduce a variety of empirical attenuation laws onto the type 1 quasar SED to emulate type 2 AGN.
At low AGN contamination the galaxy stellar mass is retrieved correctly for the vast majority of Chimera objects by all methods. This validates two assumptions of the Chimera benchmark. Firstly, it demonstrates that the stellar mass inferred with fewer bands (the Chimera bands) agrees with the assumed fiducial truth measured from many bands (COSMOS, including intermediate bands). Secondly, that it is acceptable to sum fluxes from similar bands (ugrz filters of SDSS vs. CFHT/Subaru) without correcting for the slightly different filter curves.
The Chimera benchmark could also be used to train a machine-learning model to infer host and AGN properties. However, two serious concerns need to be considered: Firstly, the method would be limited to the bands of Chimera, and thus would not be able to handle slightly different filter bands. Secondly, to reliably characterise the performance of such a method would require an independent test data set with known fiducial truth. A random hold-out subset of Chimera would not reflect the capability to unseen samples. An example independent test data set with fiducial truth is shown below in Section 7.3.
7.2. Unbiased estimates of galaxy stellar mass and SFR with GRAHSP
In this work we consider an estimator unbiased despite contamination of AGN light, if the bias is negligible compared to other sources of uncertainty. For example, Mobasher et al. (2015) demonstrated that the stellar mass estimation of non-AGN galaxies is uncertain to 0.14 dex due to variations in assumptions by different methods, but increases to 0.3 if the nebular emission or population model is varied. The scatter needs to be considered when analysing individual sources, and may make the bias negligible. In sample studies however, especially those comparing AGN to non-AGN samples, the bias is crucial.
We demonstrate that GRAHSP surpasses the capabilities of existing SED analysis methods. GRAHSP is unbiased in estimating stellar masses up to high AGN luminosities. The scatter and catastrophic outlier rates are drastically smaller at all AGN luminosities compared to commonly used CIGALE models. We speculate that other SED fitting packages not tested here suffer from the same biases if they employ limited (single-parameter) BBB and torus models, or the Fritz and Dale AGN templates, as compared with ours. With the release of the Chimera benchmark, any code developer or user can assess the validity of their code for host galaxy characterisation.
We confirm previous results indicating that estimating star formation rates is challenging in active galaxies. The large scatter present in all methods indicates that for individual galaxies the SFR can be overestimated by 1–2 orders of magnitude. GRAHSP provides unbiased estimates on average. In individual bins of SFR and AGN luminosity, GRAHSP is also unbiased over a wider range of SFRs and luminosities. However, in the high AGN luminosity bins at SFR below 1 M⊙/yr, all methods overestimate the SFR.
The method characterisations could also be inverted to correct methods for their biases. For this, one would need to estimate the bias and scatter in bins of inferred properties instead of the fiducial truth values, since the latter are not available when applying to real data. This, in turn, requires assuming a sample distribution.
GRAHSP opens the door to a new field of study connecting host galaxies with their black holes. For the vast majority of AGN, the properties of super-massive black holes, such as black hole mass or spin can only be measured through spectroscopy of broad lines, that is, in type 1. Now, this information can be reliably connected to the host galaxy properties, which are demonstrated to be measured by GRAHSP in an unbiased fashion. This will enable answering the long-standing question of whether type 1 AGN live in different host galaxies than those of type 2.
7.3. Comparison with literature results for eROSITA AGN
The 140 square degree eROSITA full-depth equatorial field (eFEDS) was observed by eROSITA in Dec 2019 (Brunner et al. 2022). This revealed approximately 20 000 luminous AGN (Salvato et al. 2022). We computed the stellar masses with GRAHSP for AGN with known spectroscopic redshifts, based on the catalogues of Salvato et al. (2022), combined with multiwavelength photometry collated in the same way as described in Section 3.2.1. For consistency, we ran GRAHSP with Bruzual & Charlot (2003) stellar population models assuming a Chabrier initial mass function.
A subset of eFEDS was observed by the Hyper Suprime-Cam (HSC) Subaru Strategic Program (Aihara et al. 2019). Li et al. (2021) developed a spatial decomposition technique that separates nuclear, PSF-like light (including the AGN) from extended emission (the majority of the host galaxy). The isolated host galaxy photometric fluxes were then assembled into an SED and fitted with a galaxy model by Li et al. (2024). We compare their stellar masses, for overlapping sources with the same spectroscopic redshifts, in Fig. 26. These show consistent stellar masses. Only cases where the GRAHSP uncertainties are smaller than 1 dex are shown. The remainder is also consistent with the 1:1 line within the uncertainties.
 |
Fig. 26. HSC test. Comparison of GRAHSP stellar mass estimates (x-axis) to those based on deeper and spatially decomposed HSC photometry modelled with a galaxy (y-axis). The stellar masses are consistent. Squares and circles indicate point-like and extended sources, respectively, in LegacySurvey. |
Secondly, a subset of eFEDS was observed by the Galaxy And Mass Assembly (GAMA) survey field G09 (Driver et al. 2022). The optical (ugriz) photometry data reach 19th magnitude and are complemented by multiwavelength data (GALEX UV, KiDS NIR, WISE MIR, Herschel FIR Bellstedt et al. 2020, 2021), to compute stellar masses with ProSpect (Robotham et al. 2020). The assumed model does not include an AGN component. We match their sources by position to the catalogue of Salvato et al. (2022), discard sources where different redshifts were assumed, and focus again on the ones where the stellar mass could be constrained with GRAHSP. Figure 27 shows that the GAMA stellar masses are consistent with those inferred by GRAHSP, if the AGN is faint compared to the galaxy (yellow). In more luminous AGN (purple), the GAMA stellar masses are much higher. Similar to the example of Fig. 22, this is likely due to the GAMA model fit attributing AGN light to the stellar population.
 |
Fig. 27. GAMA test. Comparison of GRAHSP stellar mass estimates (x-axis) to those based on a galaxy-only model with deeper GAMA photometry (y-axis). The color bar indicates the 5100 Å AGN luminosity from GRAHSP. For host-dominated sources (yellow), the stellar mass estimates are in agreement. For more AGN-dominated sources (purple), the stellar mass of GAMA (without an AGN model) lies significantly above that inferred by GRAHSP. |
7.4. The importance of unbiased inference
Understanding biases in the inference of key galaxy parameters is crucial to making progress in galaxy evolution. We briefly discuss some potential impacts of the systematic overestimation of stellar masses and SFR in the presence of AGN. Firstly, such biases can induce a spurious correlation between AGN luminosity and stellar mass and between AGN luminosity and SFR. The former may be interpreted as the galaxy’s gravitational potential being conducive to feeding the AGN, the latter as a co-feeding of stars and black holes from the same gas reservoir. Secondly, if the stellar mass in AGN is overestimated at high AGN luminosities, then SAR = Lbol(AGN)/M⋆ will be underestimated. A resulting dearth of sources with high SAR may appear as a bend or break of the SAR distribution. This may be interpreted as a feedback effect preventing high accretion rates. A related effect is that dwarf galaxies hosting luminous AGN may be systematically absent from SED fitting catalogues. For the high redshift Universe, D’Silva et al. (2023) recently argued that JWST-discovered extremely massive galaxies may be caused by SED fitting issues related to modelling of the AGN component. Finally, there are second-order effects. For example, a selection that picks up a relatively narrow range of Eddington ratios, combined with a bias of increased stellar mass with AGN luminosity, can induce a spurious black hole mass – stellar mass correlation.
With these complications in mind, it is essential to tackle the problem of unbiased inference. Unbiased inference enables a clear interpretation of the complex, multi-dimensional parameter space of AGN-galaxy co-evolution, which includes Lbol(AGN), M⋆, SFR, redshift, obscuration, and other parameters. Realistic uncertainties are also essential. Because the aforementioned parameters are inferred from the same SED fit, they can have complex degeneracies. For example, the photometry fluxes set the sum of AGN luminosity and luminosity by stars (SFR or stellar mass parameter), see for example Fig. 16. To ensure the secure discovery of parameter correlations, the covariance of these parameters needs to be considered. As pointed out in Section 2.1.5, uninformative SFR inference can spuriously introduce a main sequence in AGN-hosts. Such effects can be avoided by carefully considering uncertainties and their degeneracies, which can indicate whether τ, SFR, M⋆ could indeed be constrained.
While the identified difficulties in the inference of host galaxy parameters can lead to artificial correlations, this does not imply that the conclusions drawn in the literature have to be reversed. Rather, the absence of such biases needs to be demonstrated. Addressing inference biases, together with cautious interpretation and careful data preparation, is a continued effort to refine our understanding of AGN-galaxy co-evolution.
8. Summary
The long-standing problem of understanding the host galaxy’s stellar population of AGN is tackled in this work. Firstly, in Section 4 we carefully designed a benchmark of galaxy-AGN hybrid objects that allows us to investigate galaxy parameter retrieval introduced by the contamination by AGN light. We demonstrate that previous methods are systematically biased towards high stellar masses in Fig. 21 and high star formation rates in Fig. 23, especially when the AGN light is on par with or dominates the stellar emission. This is important for interpreting the AGN host galaxy literature to date.
Secondly, we develop a new code, GRAHSP, which is unbiased and has lower variance in estimating basic galaxy and AGN properties. The SED-fitting combines (1) a modern galaxy stellar population and nebular emission model with self-consistent dust re-emission dependent on its attenuation, (2) a flexible, empirically validated AGN model consisting of a BBB with emission lines and an infrared component, (3) sources of data variance including AGN variability and systematic model uncertainty, (4) a fast Bayesian inference algorithm capable of exploring the extensive parameter space degeneracies.
The AGN model of GRAHSP, activate, is validated on a battery of five stringent observational tests: 1) The 0.1–50 μm spectra of a diverse set of 41 local AGN, 2) stacked average optical and infrared AGN spectra, 3) spectral polarimetry up to 1 μm for the transition between BBB and torus, 4) the range of photometric colours from redshift z = 0 to 6 and 5) typical emission line equivalent width ratios. Our model passes these tests and is able to reproduce the AGN population with deviations in flux below 20 per cent. Crucial for robust host galaxy analysis, our model not only reproduces a mean SED or mean colours at each redshift, but also the full diversity observed.
A variety of tests in real-world applications demonstrates that GRAHSP genuinely retrieves the AGN host stellar population. The improved modelling will enable next-generation AGN host galaxy and co-evolution studies.
More illustrations are available at https://www.astrojess.com/graphics/interactive-sed-diagram
Already the same consideration was done in the past for the contribution of emission lines in the SED fitting of normal galaxies (e.g., Ilbert et al. 2006; Cardamone et al. 2010; Hsu et al. 2014; Ananna et al. 2017).
Acknowledgments
JB thanks Sophia G. H. Waddell for improving the acronym. AG acknowledges support from the Hellenic Foundation for Research and Innovation (HFRI) project “4MOVE-U” grant agreement 2688, which is part of the programme “2nd Call for HFRI Research Projects to support Faculty Members and Researchers”. BL acknowledges funding from the EU H2020-MSCA-ITN-2019 Project 860744 “BiD4BESt: Big Data applications for black hole Evolution STudies”. Services: This research uses services or data provided by the Astro Data Lab at NSF’s National Optical-Infrared Astronomy Research Laboratory. NOIRLab is operated by the Association of Universities for Research in Astronomy (AURA), Inc., under a cooperative agreement with the National Science Foundation.This research has made use of the SIMBAD database Wenger et al. (2000) and the VizieR catalogue access tool Ochsenbein et al. (2000), operated at CDS, Strasbourg, France. Software: astropy (Astropy Collaboration 2013, 2018), topcat (Taylor 2005), stilts (https://www.star.bris.ac.uk), Sciserver (Taghizadeh-Popp et al. 2020, implemented at MPE, following), ultranest (Buchner 2021), matplotlib (Hunter 2007), scipy (Jones et al. 2001). Photometric survey data: This work is based on data from eROSITA, the soft X-ray instrument aboard SRG, a joint Russian-German science mission supported by the Russian Space Agency (Roskosmos), in the interests of the Russian Academy of Sciences represented by its Space Research Institute (IKI), and the Deutsches Zentrum für Luft- und Raumfahrt (DLR). The SRG spacecraft was built by Lavochkin Association (NPOL) and its subcontractors and is operated by NPOL with support from the Max Planck Institute for Extraterrestrial Physics (MPE). The development and construction of the eROSITA X-ray instrument was led by MPE, with contributions from the Dr. Karl Remeis Observatory Bamberg & ECAP (FAU Erlangen-Nuernberg), the University of Hamburg Observatory, the Leibniz Institute for Astrophysics Potsdam (AIP), and the Institute for Astronomy and Astrophysics of the University of Tübingen, with the support of DLR and the Max Planck Society. The Argelander Institute for Astronomy of the University of Bonn and the Ludwig Maximilians Universität Munich also participated in the science preparation for eROSITA. The UKIDSS source tables were provided by the WIde Field Astronomy Unit (WFAU) of the University of Edinburgh and originate from UKIDSS DR11 of the WFCAM science archive (Hambly et al. 2008). The UKIDSS project is defined in (Lawrence et al. 2007). UKIDSS uses the UKIRT Wide Field Camera (WFCAM; (WFCAM; Casali et al. 2007) and a photometric system described in Hewett et al. (2006). The VISTA Hemisphere Survey is based on observations collected at the European Organisation for Astronomical Research in the Southern Hemisphere at the La Silla or Paranal Observatories under programme ID(s) 179.A-2010(A), 179.A-2010(B), 179.A-2010(C), 179.A-2010(D), 179.A-2010(E), 179.A-2010(F), 179.A-2010(G), 179.A-2010(H), 179.A-2010(I), 179.A-2010(J), 179.A-2010(K), 179.A-2010(L), 179.A-2010(M), 179.A-2010(N), 179.A-2010(O). This publication makes use of data products from the Two Micron All Sky Survey, which is a joint project of the University of Massachusetts and the Infrared Processing and Analysis Center/California Institute of Technology, funded by the National Aeronautics and Space Administration and the National Science Foundation. The Legacy Surveys consist of three individual and complementary projects: the Dark Energy Camera Legacy Survey (DECaLS; Proposal ID #2014B-0404; PIs: David Schlegel and Arjun Dey), the Beijing-Arizona Sky Survey (BASS; NOAO Prop. ID #2015A-0801; PIs: Zhou Xu and Xiaohui Fan), and the Mayall z-band Legacy Survey (MzLS; Prop. ID #2016A-0453; PI: Arjun Dey). DECaLS, BASS and MzLS together include data obtained, respectively, at the Blanco telescope, Cerro Tololo Inter-American Observatory, NSF’s NOIRLab; the Bok telescope, Steward Observatory, University of Arizona; and the Mayall telescope, Kitt Peak National Observatory, NOIRLab. Pipeline processing and analyses of the data were supported by NOIRLab and the Lawrence Berkeley National Laboratory (LBNL). The Legacy Surveys project is honored to be permitted to conduct astronomical research on Iolkam Du’ag (Kitt Peak), a mountain with particular significance to the Tohono O’odham Nation. NOIRLab is operated by the Association of Universities for Research in Astronomy (AURA) under a cooperative agreement with the National Science Foundation. LBNL is managed by the Regents of the University of California under contract to the U.S. Department of Energy. This project used data obtained with the Dark Energy Camera (DECam), which was constructed by the collaboration of the Dark Energy Survey (DES). Funding for the DES Projects has been provided by the U.S. Department of Energy, the U.S. National Science Foundation, the Ministry of Science and Education of Spain, the Science and Technology Facilities Council of the United Kingdom, the Higher Education Funding Council for England, the National Center for Supercomputing Applications at the University of Illinois at Urbana-Champaign, the Kavli Institute of Cosmological Physics at the University of Chicago, Center for Cosmology and Astro-Particle Physics at the Ohio State University, the Mitchell Institute for Fundamental Physics and Astronomy at Texas A&M University, Financiadora de Estudos e Projetos, Fundacao Carlos Chagas Filho de Amparo, Financiadora de Estudos e Projetos, Fundacao Carlos Chagas Filho de Amparo a Pesquisa do Estado do Rio de Janeiro, Conselho Nacional de Desenvolvimento Cientifico e Tecnologico and the Ministerio da Ciencia, Tecnologia e Inovacao, the Deutsche Forschungsgemeinschaft and the Collaborating Institutions in the Dark Energy Survey. The Collaborating Institutions are Argonne National Laboratory, the University of California at Santa Cruz, the University of Cambridge, Centro de Investigaciones Energeticas, Medioambientales y Tecnologicas-Madrid, the University of Chicago, University College London, the DES-Brazil Consortium, the University of Edinburgh, the Eidgenossische Technische Hochschule (ETH) Zurich, Fermi National Accelerator Laboratory, the University of Illinois at Urbana-Champaign, the Institut de Ciencies de l’Espai (IEEC/CSIC), the Institut de Fisica d’Altes Energies, Lawrence Berkeley National Laboratory, the Ludwig Maximilians Universitat Munchen and the associated Excellence Cluster Universe, the University of Michigan, NSF’s NOIRLab, the University of Nottingham, the Ohio State University, the University of Pennsylvania, the University of Portsmouth, SLAC National Accelerator Laboratory, Stanford University, the University of Sussex, and Texas A&M University. BASS is a key project of the Telescope Access Program (TAP), which has been funded by the National Astronomical Observatories of China, the Chinese Academy of Sciences (the Strategic Priority Research Program “The Emergence of Cosmological Structures” Grant #XDB09000000), and the Special Fund for Astronomy from the Ministry of Finance. The BASS is also supported by the External Cooperation Program of the Chinese Academy of Sciences (Grant #114A11KYSB20160057), and the Chinese National Natural Science Foundation (Grant #12120101003, #11433005). The Legacy Survey team makes use of data products from the Near-Earth Object Wide-field Infrared Survey Explorer (NEOWISE), which is a project of the Jet Propulsion Laboratory/California Institute of Technology. NEOWISE is funded by the National Aeronautics and Space Administration. The Legacy Surveys imaging of the DESI footprint is supported by the Director, Office of Science, Office of High Energy Physics of the U.S. Department of Energy under Contract No. DE-AC02-05CH1123, by the National Energy Research Scientific Computing Center, a DOE Office of Science User Facility under the same contract, and by the U.S. National Science Foundation, Division of Astronomical Sciences under Contract No. AST-0950945 to NOAO. The Hyper Suprime-Cam (HSC) collaboration includes Japan, Taiwan’s astronomical communities, and Princeton University. The HSC instrumentation and software were developed by the National Astronomical Observatory of Japan (NAOJ), the Kavli Institute for the Physics and Mathematics of the Universe (Kavli IPMU), the University of Tokyo, the High Energy Accelerator Research Organization (KEK), the Academia Sinica Institute for Astronomy and Astrophysics in Taiwan (ASIAA), and Princeton University. Funding was contributed by the FIRST program from the Japanese Cabinet Office, the Ministry of Education, Culture, Sports, Science and Technology (MEXT), the Japan Society for the Promotion of Science (JSPS), Japan Science and Technology Agency (JST), the Toray Science Foundation, NAOJ, Kavli IPMU, KEK,ASIAA, and Princeton University. Spectroscopic survey data: Funding for the Sloan Digital Sky Survey (SDSS) has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Aeronautics and Space Administration, the National Science Foundation, the US Department of Energy, the Japanese Monbukagakusho, and the Max Planck Society. The SDSS Web site is http://www.sdss.org/. The SDSS is managed by the Astrophysical Research Consortium (ARC) for the Participating Institutions. The Participating Institutions are The University of Chicago, Fermilab, the Institute for Advanced Study, the Japan Participation Group, The Johns Hopkins University, Los Alamos National Laboratory, the Max-Planck-Institute for Astronomy (MPIA), the Max-Planck-Institute for Astrophysics (MPA), New Mexico State University, University of Pittsburgh, Princeton University, the United States Naval Observatory, and the University of Washington.
References
- Aihara, H., AlSayyad, Y., Ando, M., et al. 2019, PASJ, 71, 114 [Google Scholar]
- Aird, J., Coil, A. L., Moustakas, J., et al. 2012, ApJ, 746, 90 [CrossRef] [Google Scholar]
- Aird, J., Coil, A. L., Georgakakis, A., et al. 2015, MNRAS, 451, 1892 [Google Scholar]
- Aird, J., Coil, A. L., & Georgakakis, A. 2017, MNRAS, 465, 3390 [NASA ADS] [CrossRef] [Google Scholar]
- Aird, J., Coil, A. L., & Georgakakis, A. 2019, MNRAS, 484, 4360 [NASA ADS] [CrossRef] [Google Scholar]
- Ananna, T. T., Salvato, M., LaMassa, S., et al. 2017, ApJ, 850, 66 [Google Scholar]
- Antonucci, R. 2018, Nat. Astron., 2, 504 [NASA ADS] [CrossRef] [Google Scholar]
- Arnouts, S., Cristiani, S., Moscardini, L., et al. 1999, MNRAS, 310, 540 [Google Scholar]
- Ashton, G., Bernstein, N., Buchner, J., et al. 2022, Nat. Rev. Methods Primers, 2, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Asmus, D., Hönig, S. F., & Gandhi, P. 2016, ApJ, 822, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Assef, R. J., Stern, D., Kochanek, C. S., et al. 2013, ApJ, 772, 26 [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Bellstedt, S., Robotham, A. S. G., Driver, S. P., et al. 2020, MNRAS, 498, 5581 [NASA ADS] [CrossRef] [Google Scholar]
- Bellstedt, S., Robotham, A. S. G., Driver, S. P., et al. 2021, MNRAS, 503, 3309 [NASA ADS] [CrossRef] [Google Scholar]
- Bernhard, E., Tadhunter, C., Mullaney, J. R., et al. 2021, MNRAS, 503, 2598 [NASA ADS] [CrossRef] [Google Scholar]
- Bershady, M. A., Trevese, D., & Kron, R. G. 1998, ApJ, 496, 103 [NASA ADS] [CrossRef] [Google Scholar]
- Bessell, M., & Murphy, S. 2012, PASP, 124, 140 [NASA ADS] [CrossRef] [Google Scholar]
- Bianchi, L., Shiao, B., & Thilker, D. 2017, ApJS, 230, 24 [Google Scholar]
- Blaes, O., Hubeny, I., Agol, E., & Krolik, J. H. 2001, ApJ, 563, 560 [NASA ADS] [CrossRef] [Google Scholar]
- Boller, T., Freyberg, M. J., Trümper, J., et al. 2016, A&A, 588, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bongiorno, A., Merloni, A., Brusa, M., et al. 2012, MNRAS, 427, 3103 [Google Scholar]
- Boquien, M., Boselli, A., Buat, V., et al. 2013, A&A, 554, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Boquien, M., Burgarella, D., Roehlly, Y., et al. 2019, A&A, 622, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brown, M. J. I., Duncan, K. J., Landt, H., et al. 2019, MNRAS, 489, 3351 [Google Scholar]
- Bruhweiler, F., & Verner, E. 2008, ApJ, 675, 83 [NASA ADS] [CrossRef] [Google Scholar]
- Brunner, H., Liu, T., Lamer, G., et al. 2022, A&A, 661, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brusa, M., Civano, F., Comastri, A., et al. 2010, ApJ, 716, 348 [NASA ADS] [CrossRef] [Google Scholar]
- Bruzual, G., & Charlot, S. 2003, MNRAS, 344, 1000 [NASA ADS] [CrossRef] [Google Scholar]
- Buchner, J. 2021, J. Open Source Software, 6, 3001 [CrossRef] [Google Scholar]
- Buchner, J. 2022, Phys. Sci. Forum, 5, 46 [NASA ADS] [Google Scholar]
- Buchner, J. 2023, Stat. Surv., 17, 169 [NASA ADS] [CrossRef] [Google Scholar]
- Calistro Rivera, G., Lusso, E., Hennawi, J. F., & Hogg, D. W. 2016, ApJ, 833, 98 [Google Scholar]
- Calzetti, D., Armus, L., Bohlin, R. C., et al. 2000, ApJ, 533, 682 [NASA ADS] [CrossRef] [Google Scholar]
- Cardamone, C. N., van Dokkum, P. G., Urry, C. M., et al. 2010, ApJS, 189, 270 [Google Scholar]
- Casali, M., Adamson, A., Alves de Oliveira, C., et al. 2007, A&A, 467, 777 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ciesla, L., Charmandaris, V., Georgakakis, A., et al. 2015, A&A, 576, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Civano, F., Elvis, M., Brusa, M., et al. 2012, ApJS, 201, 30 [Google Scholar]
- Civano, F., Hickox, R. C., Puccetti, S., et al. 2015, ApJ, 808, 185 [Google Scholar]
- da Cunha, E., Charlot, S., & Elbaz, D. 2008, MNRAS, 388, 1595 [Google Scholar]
- Dale, D. A., Helou, G., Magdis, G. E., et al. 2014, ApJ, 784, 83 [Google Scholar]
- Dexter, J., & Agol, E. 2011, ApJ, 727, L24 [Google Scholar]
- Dey, A., Schlegel, D. J., Lang, D., et al. 2019, AJ, 157, 168 [Google Scholar]
- Di Matteo, T., Springel, V., & Hernquist, L. 2005, Nature, 433, 604 [NASA ADS] [CrossRef] [Google Scholar]
- Donley, J. L., Koekemoer, A. M., Brusa, M., et al. 2012, ApJ, 748, 142 [Google Scholar]
- Driver, S. P., Bellstedt, S., Robotham, A. S. G., et al. 2022, MNRAS, 513, 439 [NASA ADS] [CrossRef] [Google Scholar]
- D’Silva, J. C. J., Driver, S. P., Lagos, C. D. P., et al. 2023, ApJ, 959, L18 [CrossRef] [Google Scholar]
- Eisenstein, D. J., Weinberg, D. H., Agol, E., et al. 2011, AJ, 142, 72 [Google Scholar]
- Elvis, M., Wilkes, B. J., McDowell, J. C., et al. 1994, ApJS, 95, 1 [Google Scholar]
- Feltre, A., Hatziminaoglou, E., Fritz, J., & Franceschini, A. 2012, MNRAS, 426, 120 [Google Scholar]
- Ferrarese, L., & Merritt, D. 2000, ApJ, 539, L9 [Google Scholar]
- Flynn, C., Holmberg, J., Portinari, L., Fuchs, B., & Jahreiß, H. 2006, MNRAS, 372, 1149 [NASA ADS] [CrossRef] [Google Scholar]
- Fotopoulou, S., Buchner, J., Georgantopoulos, I., et al. 2016, A&A, 587, A142 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fritz, J., Franceschini, A., & Hatziminaoglou, E. 2006, MNRAS, 366, 767 [Google Scholar]
- Fynbo, J. P. U., Krogager, J. K., Venemans, B., et al. 2013, ApJS, 204, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- García-Burillo, S., Alonso-Herrero, A., Ramos Almeida, C., et al. 2021, A&A, 652, A98 [NASA ADS] [CrossRef] [Google Scholar]
- Gebhardt, K., Bender, R., Bower, G., et al. 2000, ApJ, 539, L13 [Google Scholar]
- Gelman, A. 2006, Bayesian Anal., 1, 515 [Google Scholar]
- Georgakakis, A., Aird, J., Schulze, A., et al. 2017, MNRAS, 471, 1976 [NASA ADS] [CrossRef] [Google Scholar]
- Goulding, A. D., Alexander, D. M., Bauer, F. E., et al. 2012, ApJ, 755, 5 [Google Scholar]
- Gültekin, K., Tremaine, S., Loeb, A., & Richstone, D. O. 2011, ApJ, 738, 17 [CrossRef] [Google Scholar]
- Hagen, S., & Done, C. 2023, MNRAS, 525, 3455 [NASA ADS] [CrossRef] [Google Scholar]
- Hambly, N. C., Collins, R. S., Cross, N. J. G., et al. 2008, MNRAS, 384, 637 [NASA ADS] [CrossRef] [Google Scholar]
- Handley, W. J., Hobson, M. P., & Lasenby, A. N. 2015, MNRAS, 453, 4384 [Google Scholar]
- Hasinger, G. 2008, A&A, 490, 905 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hasinger, G., Capak, P., Salvato, M., et al. 2018, ApJ, 858, 77 [Google Scholar]
- Healey, S. E., Romani, R. W., Taylor, G. B., et al. 2007, ApJS, 171, 61 [Google Scholar]
- Hewett, P. C., Warren, S. J., Leggett, S. K., & Hodgkin, S. T. 2006, MNRAS, 367, 454 [Google Scholar]
- Hickox, R. C., Myers, A. D., Greene, J. E., et al. 2017, ApJ, 849, 53 [NASA ADS] [CrossRef] [Google Scholar]
- Hönig, S. F. 2016, Astrophys. Space Sci. Lib., 439, 95 [CrossRef] [Google Scholar]
- Hönig, S. F., & Kishimoto, M. 2010, A&A, 523, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hopkins, P. F., Strauss, M. A., Hall, P. B., et al. 2004, AJ, 128, 1112 [Google Scholar]
- Hopkins, P. F., Hernquist, L., Cox, T. J., & Kereš, D. 2008, ApJS, 175, 356 [Google Scholar]
- Hsu, L.-T., Salvato, M., Nandra, K., et al. 2014, ApJ, 796, 60 [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Ilbert, O., Arnouts, S., McCracken, H. J., et al. 2006, A&A, 457, 841 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Iyer, K. G., Gawiser, E., Faber, S. M., et al. 2019, ApJ, 879, 116 [NASA ADS] [CrossRef] [Google Scholar]
- Jasa, T., & Xiang, N. 2012, J. Acoust. Soc. Am., 132, 3251 [NASA ADS] [CrossRef] [Google Scholar]
- Johnson, B. D., Leja, J., Conroy, C., & Speagle, J. S. 2021, ApJS, 254, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Jones, E., Oliphant, T., Peterson, P., et al. 2001, SciPy: Open source scientific tools for Python, http://www.scipy.org [Google Scholar]
- Kashyap, V. L., van Dyk, D. A., Connors, A., et al. 2010, ApJ, 719, 900 [NASA ADS] [CrossRef] [Google Scholar]
- Kiatsupaibul, S., Smith, R. L., & Zabinsky, Z. B. 2011, ACM Trans. Model. Comput. Simul., 21, 16:1 [CrossRef] [Google Scholar]
- Kirkpatrick, A., Pope, A., Alexander, D. M., et al. 2012, ApJ, 759, 139 [Google Scholar]
- Kishimoto, M., Antonucci, R., Blaes, O., et al. 2008, Nature, 454, 492 [NASA ADS] [CrossRef] [Google Scholar]
- Klesman, A., & Sarajedini, V. 2007, ApJ, 665, 225 [NASA ADS] [CrossRef] [Google Scholar]
- Kormendy, J., & Ho, L. C. 2013, ARA&A, 51, 511 [Google Scholar]
- Koss, M. J., Blecha, L., Bernhard, P., et al. 2018, Nature, 563, 214 [Google Scholar]
- Koutoulidis, L., Mountrichas, G., Georgantopoulos, I., Pouliasis, E., & Plionis, M. 2022, A&A, 658, A35 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lacy, M., Storrie-Lombardi, L. J., Sajina, A., et al. 2004, ApJS, 154, 166 [Google Scholar]
- Laigle, C., McCracken, H. J., Ilbert, O., et al. 2016, ApJS, 224, 24 [Google Scholar]
- LaMassa, S. M., Georgakakis, A., Vivek, M., et al. 2019, ApJ, 876, 50 [NASA ADS] [CrossRef] [Google Scholar]
- Lawrence, A., Warren, S. J., Almaini, O., et al. 2007, MNRAS, 379, 1599 [Google Scholar]
- Leitherer, C., Calzetti, D., & Martins, L. P. 2002, ApJ, 574, 114 [NASA ADS] [CrossRef] [Google Scholar]
- Leja, J., Carnall, A. C., Johnson, B. D., Conroy, C., & Speagle, J. S. 2019, ApJ, 876, 3 [Google Scholar]
- Li, J., Silverman, J. D., Ding, X., et al. 2021, ApJ, 918, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Li, J., Silverman, J. D., Merloni, A., et al. 2024, MNRAS, 527, 4690 [Google Scholar]
- Lilly, S. J., Le Brun, V., Maier, C., et al. 2009, ApJS, 184, 218 [Google Scholar]
- Luo, B., Brandt, W. N., Xue, Y. Q., et al. 2017, ApJS, 228, 2 [Google Scholar]
- Lyke, B. W., Higley, A. N., McLane, J. N., et al. 2020, ApJS, 250, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Lyu, J., Rieke, G. H., & Alberts, S. 2016, ApJ, 816, 85 [NASA ADS] [CrossRef] [Google Scholar]
- Lyu, J., Rieke, G. H., & Shi, Y. 2017, ApJ, 835, 257 [NASA ADS] [CrossRef] [Google Scholar]
- Madau, P. 1992, ApJ, 389, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Madau, P., & Dickinson, M. 2014, ARA&A, 52, 415 [Google Scholar]
- Magorrian, J., Tremaine, S., Richstone, D., et al. 1998, AJ, 115, 2285 [Google Scholar]
- Mainzer, A., Bauer, J., Grav, T., et al. 2011, ApJ, 731, 53 [Google Scholar]
- Maraston, C. 2005, MNRAS, 362, 799 [NASA ADS] [CrossRef] [Google Scholar]
- Marchesi, S., Lanzuisi, G., Civano, F., et al. 2016, ApJ, 830, 100 [Google Scholar]
- Masoura, V. A., Mountrichas, G., Georgantopoulos, I., & Plionis, M. 2021, A&A, 646, A167 [EDP Sciences] [Google Scholar]
- Massaro, E., Maselli, A., Leto, C., et al. 2015, Ap&SS, 357, 75 [Google Scholar]
- Masters, D., Capak, P., Stern, D., et al. 2015, ApJ, 813, 53 [Google Scholar]
- McMahon, R. G., Banerji, M., Gonzalez, E., et al. 2013, The Messenger, 154, 35 [NASA ADS] [Google Scholar]
- McMahon, R.G., Banerji, M., Gonzalez, E., et al. 2021, VizieR Online Data Catalog, II/367 [Google Scholar]
- Meisner, A. M., Caselden, D., Schlafly, E. F., & Kiwy, F. 2023, AJ, 165, 36 [NASA ADS] [CrossRef] [Google Scholar]
- Menzel, M. L., Merloni, A., Georgakakis, A., et al. 2016, MNRAS, 457, 110 [NASA ADS] [CrossRef] [Google Scholar]
- Merloni, A., Bongiorno, A., Bolzonella, M., et al. 2010, ApJ, 708, 137 [Google Scholar]
- Merloni, A., Lamer, G., Liu, T., et al. 2024, A&A, 682, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mobasher, B., Dahlen, T., Ferguson, H. C., et al. 2015, ApJ, 808, 101 [NASA ADS] [CrossRef] [Google Scholar]
- Mor, R., & Netzer, H. 2012, MNRAS, 420, 526 [NASA ADS] [CrossRef] [Google Scholar]
- Mountrichas, G., Buat, V., Georgantopoulos, I., et al. 2021, A&A, 653, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mountrichas, G., Buat, V., Yang, G., et al. 2022, A&A, 663, A130 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mukherjee, P., Parkinson, D., & Liddle, A. R. 2006, ApJ, 638, L51 [NASA ADS] [CrossRef] [Google Scholar]
- Mullaney, J. R., Alexander, D. M., Goulding, A. D., & Hickox, R. C. 2011, MNRAS, 414, 1082 [Google Scholar]
- Nenkova, M., Sirocky, M. M., Ivezić, Ž., & Elitzur, M. 2008a, ApJ, 685, 147 [Google Scholar]
- Nenkova, M., Sirocky, M. M., Nikutta, R., Ivezić, Ž., & Elitzur, M. 2008b, ApJ, 685, 160 [Google Scholar]
- Netzer, H. 1990, in Active Galactic Nuclei, eds. R. D. Blandford, H. Netzer, L. Woltjer, T. J. L. Courvoisier, & M. Mayor, 57 [Google Scholar]
- Netzer, H. 2015, ARA&A, 53, 365 [Google Scholar]
- Netzer, H., & Trakhtenbrot, B. 2014, MNRAS, 438, 672 [NASA ADS] [CrossRef] [Google Scholar]
- Ochsenbein, F., Bauer, P., & Marcout, J. 2000, A&AS, 143, 23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pacifici, C., Iyer, K. G., Mobasher, B., et al. 2023, ApJ, 944, 141 [NASA ADS] [CrossRef] [Google Scholar]
- Packham, C., Mason, R., & Alonso-Herrero, A. 2012, On donuts and Crumbs: A Brief History of Torus Models (University of Texas at San Antonio) [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pouliasis, E., Mountrichas, G., Georgantopoulos, I., et al. 2022, A&A, 667, A56 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Predehl, P., Andritschke, R., Arefiev, V., et al. 2021, A&A, 647, A1 [EDP Sciences] [Google Scholar]
- Prevot, M. L., Lequeux, J., Maurice, E., Prevot, L., & Rocca-Volmerange, B. 1984, A&A, 132, 389 [Google Scholar]
- Rakshit, S., Stalin, C. S., & Kotilainen, J. 2020, ApJS, 249, 17 [Google Scholar]
- Richards, G. T., Strauss, M. A., Fan, X., et al. 2006, AJ, 131, 2766 [Google Scholar]
- Richards, G. T., Myers, A. D., Gray, A. G., et al. 2009, ApJS, 180, 67 [Google Scholar]
- Robotham, A. S. G., Bellstedt, S., Lagos, C. d. P., et al. 2020, MNRAS, 495, 905 [NASA ADS] [CrossRef] [Google Scholar]
- Rosario, D. J. 2019, FortesFit: Flexible spectral energydistribution modelling with a Bayesian backbone, Astrophysics Source Code Library [record ascl:1904.011] [Google Scholar]
- Rosen, S. R., Webb, N. A., Watson, M. G., et al. 2016, A&A, 590, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ruan, J. J., Anderson, S. F., Dexter, J., & Agol, E. 2014, ApJ, 783, 105 [Google Scholar]
- Ruiz, A., Corral, A., Mountrichas, G., & Georgantopoulos, I. 2018, A&A, 618, A52 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ryde, F. 1999, Astrophys. Lett. Commun., 39, 281 [NASA ADS] [Google Scholar]
- Salvato, M., Hasinger, G., Ilbert, O., et al. 2009, ApJ, 690, 1250 [CrossRef] [Google Scholar]
- Salvato, M., Ilbert, O., Hasinger, G., et al. 2011, ApJ, 742, 61 [Google Scholar]
- Salvato, M., Ilbert, O., & Hoyle, B. 2019, Nat. Astron., 3, 212 [NASA ADS] [CrossRef] [Google Scholar]
- Salvato, M., Wolf, J., Dwelly, T., et al. 2022, A&A, 661, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sanders, D. B., Soifer, B. T., Elias, J. H., et al. 1988, ApJ, 325, 74 [Google Scholar]
- Santini, P., Rosario, D. J., Shao, L., et al. 2012, A&A, 540, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Saxton, R. D., Read, A. M., Esquej, P., et al. 2008, A&A, 480, 611 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schneider, D. P., Richards, G. T., Hall, P. B., et al. 2010, AJ, 139, 2360 [Google Scholar]
- Schutte, Z., Reines, A. E., & Greene, J. E. 2019, ApJ, 887, 245 [NASA ADS] [CrossRef] [Google Scholar]
- Scoville, N., Aussel, H., Brusa, M., et al. 2007, ApJS, 172, 1 [Google Scholar]
- Selsing, J., Fynbo, J. P. U., Christensen, L., & Krogager, J. K. 2016, A&A, 585, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sesar, B., Ivezić, Ž., Lupton, R. H., et al. 2007, AJ, 134, 2236 [NASA ADS] [CrossRef] [Google Scholar]
- Shakura, N. I., & Sunyaev, R. A. 1973, A&A, 24, 337 [NASA ADS] [Google Scholar]
- Shen, Y., Richards, G. T., Strauss, M. A., et al. 2011, ApJS, 194, 45 [Google Scholar]
- Shen, Y., Richards, G. T., Strauss, M. A., et al. 2012, VizieR Online Data Catalog, J/ApJS/194/45 [Google Scholar]
- Simm, T., Salvato, M., Saglia, R., et al. 2016, A&A, 585, A129 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Skilling, J. 2004, AIP Conf. Proc., 735, 395 [Google Scholar]
- Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, 131, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Soltan, A. 1982, MNRAS, 200, 115 [Google Scholar]
- Stalevski, M., Ricci, C., Ueda, Y., et al. 2016, MNRAS, 458, 2288 [Google Scholar]
- Stemo, A., Comerford, J. M., Barrows, R. S., et al. 2020, ApJ, 888, 78 [NASA ADS] [CrossRef] [Google Scholar]
- Stern, D., Assef, R. J., Benford, D. J., et al. 2012, ApJ, 753, 30 [Google Scholar]
- Suh, H., Civano, F., Hasinger, G., et al. 2019, ApJ, 872, 168 [Google Scholar]
- Symeonidis, M. 2022, MNRAS, 509, 3209 [Google Scholar]
- Taghizadeh-Popp, M., Kim, J. W., Lemson, G., et al. 2020, Astron. Comput., 33, 100412 [NASA ADS] [CrossRef] [Google Scholar]
- Taylor, M. B. 2005, ASP Conf. Ser., 347, 29 [Google Scholar]
- Temple, M. J., Hewett, P. C., & Banerji, M. 2021, MNRAS, 508, 737 [NASA ADS] [CrossRef] [Google Scholar]
- Thorne, J. E., Robotham, A. S. G., Davies, L. J. M., et al. 2022, MNRAS, 509, 4940 [Google Scholar]
- Trevese, D., Boutsia, K., Vagnetti, F., Cappellaro, E., & Puccetti, S. 2008, A&A, 488, 73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tristram, K. R. W., Burtscher, L., Jaffe, W., et al. 2014, A&A, 563, A82 [CrossRef] [EDP Sciences] [Google Scholar]
- Warren, S. J., Cross, N. J. G., Dye, S., et al. 2007, ArXiv e-prints [arXiv:astro-ph/0703037] [Google Scholar]
- Webb, N. A., Coriat, M., Traulsen, I., et al. 2020, A&A, 641, A136 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wenger, M., Ochsenbein, F., Egret, D., et al. 2000, A&AS, 143, 9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Worthey, G., Faber, S. M., Gonzalez, J. J., & Burstein, D. 1994, ApJS, 94, 687 [Google Scholar]
- Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868 [Google Scholar]
- Xiao, T., Barth, A. J., Greene, J. E., et al. 2011, ApJ, 739, 28 [NASA ADS] [CrossRef] [Google Scholar]
- XMM-SSC 2018, VizieR Online Data Catalog, IX/53 [Google Scholar]
- Xue, Y. Q., Luo, B., Brandt, W. N., et al. 2011, ApJS, 195, 10 [Google Scholar]
- Yang, G., Brandt, W. N., Alexander, D. M., et al. 2019, MNRAS, 485, 3721 [Google Scholar]
- Yang, G., Boquien, M., Buat, V., et al. 2020, MNRAS, 491, 740 [Google Scholar]
- Yang, G., Boquien, M., Brandt, W. N., et al. 2022, ApJ, 927, 192 [NASA ADS] [CrossRef] [Google Scholar]
- Zafar, T., Møller, P., Watson, D., et al. 2015, A&A, 584, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zheng, W., Kriss, G. A., Telfer, R. C., Grimes, J. P., & Davidsen, A. F. 1997, ApJ, 475, 469 [NASA ADS] [CrossRef] [Google Scholar]
- Zou, F., Yang, G., Brandt, W. N., & Xue, Y. 2019, ApJ, 878, 11 [Google Scholar]
Appendix A: GRAHSP AGN SED Atlas
For the fits of the AGN SED Atlas of spectra compiled by Brown et al. (2019), Table A.1 presents the best-fit parameters.
Best fit model parameters for the AGN SED Atlas of Brown et al..
Appendix B: Literature CIGALE setups
For the comparison with CIGALE, Table B1 specifies the AGN model configuration of the setups considered. These are described in more detail in Section 5.5.
CIGALE model setups from the literature.
Appendix C: The effect of photometric redshifts
In this section, we investigate the effect of photometric redshifts on stellar mass estimates. The SED fitting to characterise the host galaxy, as presented in this paper, relies on knowledge of the redshift. Dedicated methods have been developed to estimate photometric redshifts for AGN (see the review of Salvato et al. 2022). The quality of photometric redshift estimation is typically quantified with a spectroscopic test sample through a catastrophic outlier fraction (|zphot − zspec|/(1 + zspec)> 0.15) and a scatter around the spectroscopic redshift: σNMAD = 1.48 × median(|zphot − zspec|/(1 + zspec). Depending on the precision and number of photometric filter bands, the scatter can range from 0.01-0.02 (low to mid-luminosity Chandra-COSMOS AGN Salvato et al. 2011), all the way to more than 0.1 (eFEDS luminous AGN survey, outside KiDS and HSC survey areas Salvato et al. 2022). In this section, we investigate how such a scatter in the redshift estimate impacts the stellar mass estimate.
For this purpose, we use the COSMOS AGN sample which features many photometric bands. We modify the assumed redshifts by z′=zspec + 0.01 × ×(1 + zspec), and repeat this exercise with shifts of 0.02 and 0.04. We re-run GRAHSP with these redshifts and compare the estimated stellar masses. We only consider the cases where the 2σ uncertainties in the reference fit were smaller than an order of magnitude. Figure C.1 presents the impact on stellar masses. Here, the difference in posterior mean stellar mass is shown, without considering the uncertainty further. There are 5 (4) cases that have changed in stellar mass by more than a factor of 3, when the photometric redshift is changed by 0.04 (0.02) times (1+z). Surprisingly, the stellar mass predominantly becomes smaller, although the same source fluxes are explained by a source placed at larger distances. At a photometric redshift change of 0.01 times (1+z), there are only 2 such outliers. Also, the distribution is narrower, with a standard deviation of 0.14 dex rather than 0.26 (0.21) dex for the 0.02 (0.04) photometry error case. The results underline that precision photometric redshifts are important for SED fitting studies. Such precision photometric redshifts will enable the application of robust SED fitting across complete samples without requiring costly follow-up spectroscopy. Alternatively, the effect of photo-z deviations can be modelled by considering the distribution presented in Fig. C.1.
 |
Fig. C.1. Change in the stellar mass estimate when the redshift is inaccurate. The x-axis shows the change in stellar mass from a reference run at the spectroscopic redshift, and another run assuming z + Δ × (1 + z) as the redshift, with Δ values of 0.01 (blue), 0.02 (red) and 0.04 (yellow). The red and yellow histograms are similar, with a tail to the left. The blue histogram is narrower and lacks the long tails present in the other two histograms. |
Appendix D: Overview of samples
Table D1 presents an overview of the samples fitted in this work. For each sample and filter, the table lists the number of sources with flux measurements and the median magnitudes.
Sample and filter set overview.
Appendix E: Model photometry plots
 |
Fig. E.1. WISE W1-W2 colour diagnostic plot. Observed colours for different samples are shown in contours encompassing 99 per cent of the sample. The GRAHSP templates (coloured dots) cover the area of the samples. |
 |
Fig. E.2. i-z colour evolution. The colour range evolution of the model is tested against observations (coloured dots). The model range is shown in grey, for three configurations: the dotted curve is a fiducial model with fixed FeII template and emission line strength. There is good overlap, except near z=0.6, z=1.2 and z=1.5 at negative i-z colours. Increasing the emission line strength range creates an overlap at z=0.6 and z=1.5 (dashed curve). Additionally increasing the FeII template strength range (grey curve, full model range) also produces a good overlap at z=1.2. However, at z=0.8, some observed eFEDS colours are lower than the model. |
 |
Fig. E.3. Colour evolution with redshift. Each row shows one colour. Observations are shown in dots for different samples. At each redshift, the model templates cover the observed range, illustrated by the grey area. |
This section compares colours derived from the GRAHSP model templates to those observed in the samples used in this work. Figure E.1 presents the WISE W1-W2 colour diagnostic plot. The entire space relevant for AGN and galaxies is covered well by the model. Most DR16QWX objects that lie above the W1-W2>0.7 infrared quasar selection (Assef et al. 2013). There is an absence of model and data points near 0 on the left side of the plot, where stars typically dominate the surveys (not shown).
Figure E.2 shows a notable disagreement between data and model in the i-z colour with a fiducial model (grey area above the dotted curve) using the empirical emission line strengths listed in Table 1 and the FeII template. At redshifts z = 0.6 − 1.5, much lower i-z colours are observed, namely that the i-band is brighter than the z-band. This can be explained by emission lines. The dashed curve shows the results of allowing the FeII template amplitude to be higher, which eases the tension at all redshifts. Some low colours remain, which can be partially improved by also allowing the line emission strength to increase. However, there is still room for improvement at z=0.8. This could be addressed by varying the adopted FeII template. The remaining disagreements are of the order of 10 per cent in magnitude and therefore also flux, a typical systematic uncertainty of models, as also shown in Section 2.2.
 |
Fig. E.4. Colour evolution with redshift (continued from Fig. E.3). Each row shows one colour. Observations are shown in dots for different samples. At each redshift, the model templates cover the observed range, illustrated by the grey area. Filters are from DECAM/UltraVista/WISE for eFEDS, DR16QWX and the model, but from Subaru/HSC/WFCAM/CFHT/IRAC for COSMOS, making the comparison slightly inconsistent. |
Figures E.3 and E.4 presents the colour evolution as a function of redshift for a high number of bands. Only objects with spectroscopic redshift are shown, and all magnitudes are in AB. Filters are from DECAM/UltraVista/WISE for eFEDS, DR16QWX and the model, but from Subaru/HSC/WFCAM/CFHT/IRAC for COSMOS, making the comparison inconsistent because the filter curves differ slightly. The fourth panel of Fig. E.3 shows g-r colours, which reach negative values at redshift z = 0.6. Values below -0.2 can only be achieved when the emission line strength (Alines) is allowed to vary. This can be seen by comparing the dotted curve, which marks the lower end of the model range with Alines = 1, with the dashed curve, where Alines can vary. At most redshifts, the model covers the data well. The unobscured, fiducial model range (dark grey), with both E(B-V) parameters below 0.03 and a limited line diversity (Alines = 1, AFeII ≤ 10), follows the colour evolution of the bulk of the observations. There are some data points outside this range, but they are within the full model range (light grey). There are some small remaining differences in the r-z colours near z = 0.8 and in the J-H colours (third panel of Fig. E.4) near z = 2.5. These correspond to differences of less than 20 per cent in flux. In the W1-W2 panel of Figure E.4, a small number of galaxies at low W1-W2 are outside the model colour range at z = 1.5 − 3. These can also be seen in Figure E.1 on the bottom right end. The model templates thin out, but appear to still cover the necessary colour-magnitude space.
With the caveat that colours can be contaminated by nearby objects, the photometry test shown here corroborates the findings of Section 2.2 that the model captures the diversity of the AGN-host galaxy population at most redshifts.
Appendix F: Testing CIGALE/SKIRTOR on the Brown SED Atlas
In this section, we test the fidelity of CIGALE’s SED model against the Brown SED Atlas.
We start with the same approach as in Section 2.2, but use the Y19 model setup. Unlike in Section 7.3, all SKIRTOR parameters (t, pl, q, oa, R, i, delta, fracAGN, E(B-V)-polar, temperature and emissivity) are left free to vary with all its permitted values. Further parameters include M⋆, τ, age, α and E(B-V). This gives a total of 16 free parameters. To find the best-fit parameter values for each source, we minimise a χ2 statistic as in Section 2.2 with scipy’s differential evolution algorithm with default settings.
Figure F.1 presents the best fits. Because this model lacks AGN emission lines, in the UV-opt range, the lines are not reproduced. Further, at 10 μm, the model typically overestimating the emission. For some sources (such as Mrk926, 3C351, Mrk590, Ark120) the continuum also has deviations in the 2–10 μm range, which are not present in Fig. 7.
The model residuals are presented in Fig. F.2. Here, discrepancies of 25 per cent are apparent from 10 (negative) to 15 μm (positive), indicating that the Si feature is imperfectly modelled. Near 2–4 μm, a hump is apparent, indicating that the hot dust model is incomplete. Near 200–400 nm, structure is also apparent in the residual, possibly related to unmodelled emission lines (FeII forest), giving rise to a 20 per cent discrepancy.
In contrast to the residuals shown in Fig. 7, the residuals in Fig. F.2 are not random from object to object, but show a systematic pattern. This implies that photometric model colours will be systematically shifted with CIGALE when modelling galaxies hosting AGN. As discussed in Section 2, we suspect such residuals to be the cause for the stellar mass and SFR bias identified in the CIGALE results of this paper. The correlated residuals cannot be fully resolved by adding independent uncertainties to each measured flux. For the reduced bias of GRAHSP when compared to CIGALE, the number of parameters are not the only difference. Here, we have left 16 parameters free to vary but residuals remain. However, the computation and memory usage of CIGALE cannot handle such a high number of parameters when fitting photometry.
 |
Fig. F.1. Like Fig. 7, but comparing CIGALE’s SKIRTOR model (black) with the Atlas of AGN spectra (red) from Brown et al. (2019). |
All Tables
All Figures
|
Fig. 1. Overview of how the individual model components contribute to the summed emission (black). The AGN power-law continuum (blue; accretion disk, or BBB) is enhanced by emission lines including an iron forest (red). The disk model is normalised at the monochromatic luminosity at 5100 Å (blue square), here |
| In the text | |
|
Fig. 2. Detailed view of the optical continuum and emission lines. The model continuum bending power-law (yellow dashed line) reproduces the polarization measurements of Kishimoto et al. (2008) (dark blue data points). The full model including a torus and emission lines is shown in solid lines. Variations of the power-law slope (light grey to black) reproduce SDSS steep and flat unabsorbed spectra from Richards et al. (2006) and Selsing et al. (2016) (red, blue and pink lines). Towards the infrared, the torus component dominates the continuum. |
| In the text | |
|
Fig. 3. Overview of the AGN model parameters and how they configure the spectrum, shown here in Lλ with arbitrary units. The power law (blue) is normalised at 5100 Å, where it has a power law slope of β. The power law bends over at λbend towards the UV, where it has slope βUV. The width of this transition is set by Wbend. Emission lines with FWHM Wlines and an FeII template are added and can be further scaled by Alines and AFeII, respectively. The torus component (dark yellow) is normalised by the ratio of 12 μm and 5100 ÅλLλ luminosities, fcov (see Eq. (4)). It consists of the sum of two log-quadratic curves, with width Wcool and Whot and location λcool and λhot. The peak-to-peak λLλ ratio is set by fhot (see Eq. (3)). The depth of the Si feature, in emission if positive or in absorption if negative (here: −1), is set by Si. The flexibility of these 15 parameters is restricted in Section 2.2. |
| In the text | |
|
Fig. 4. Example galaxy SEDs of stellar populations with different star formation histories. The star formation rate (see inset) rises linearly towards the present (right), with an exponential cutoff timescale τ. At low τ, the yellow SFR curve truncates quickly, indicating it is dominated by old stars. The corresponding yellow SED in the main panel peaks between 0.3 − 3 μm. The blue curve in the inset corresponds to continuously rising star formation. The corresponding blue SED in the main panel is dominated by luminous young stars, nebular emission lines and infrared dust emission. Minimal attenuation, E(B − V)=0.01, is applied. |
| In the text | |
|
Fig. 5. Effect of attenuation on the galaxy model. Models are shown from intrinsic (dark blue) to strongly attenuated (dark red). For illustration, the extremely attenuated local low-metallicity star-bursting galaxy Haro 11 from Lyu et al. (2016) is overplotted as a dashed red curve. |
| In the text | |
|
Fig. 6. Effect of attenuation on the AGN model. Models are shown from intrinsic (blue top curves) to strongly attenuated (red bottom curves). The intrinsic torus model component (see Section 2.1.3) is shown in dashed black. The dark red curves illustrate that the most heavily attenuation can also suppress the torus. |
| In the text | |
|
Fig. 7. Atlas of AGN spectra (red) from Brown et al. (2019). The black curve shows our best-fit GRAHSP model. Dashed curves show model components. |
| In the text | |
|
Fig. 8. Relative residuals of the fits of Fig. 7 are shown as curves. Four individual cases with the largest deviations are highlighted in colours and labelled. The distribution of residuals is presented on the right-hand side as a histogram. The vast majority of residuals (96.6%) are concentrated to smaller than 20 per cent deviations. |
| In the text | |
|
Fig. 9. GRAHSP computation pipeline. One sub-pipeline (yellow) produces the galaxy SED (large yellow box), one sub-pipeline (red large box) produces the AGN SED. Each sub-pipeline has a separate cache. Subsequent modules are applied on-the-fly, including the AGN power-law, attenuating the AGN and the galaxy components, summing and transforming into observed-frame fluxes. |
| In the text | |
|
Fig. 10. r magnitude as a function of redshift for the samples considered in this work. The COSMOS X-ray selected AGN (big blue circles) are, on average, fainter and at higher redshifts than all-sky WISE or X-ray selected quasars (red). The Chimera objects (crosses) combine COSMOS galaxies (pink) with different levels (colour bar) of quasar light (from optically selected quasars). |
| In the text | |
|
Fig. 11. WISE diagnostic plot for the same samples as shown in Fig. 10. Sources dominated by galaxy light tend to lie towards the bottom-right. With increasing AGN luminosities (colour bar), sources move to the upper-left. Magnitudes are in AB. |
| In the text | |
|
Fig. 12. Colour diagnostic plot. The GRAHSP templates (coloured dots as a function of redshift) cover the entire plane. The observations are illustrated by coloured contours containing 99% of each sample. At the centre-left, quasars dominate (red outline, DR16QWX), while the eFEDS sample includes a wider distribution. The dashed diagonal line demarks the separation of Salvato et al. (2022) between galaxies (above) and stars (below the line). |
| In the text | |
|
Fig. 13. COSMOS comparisons. Stellar masses from COSMOS2015 are compared with those from GRAHSP, with the AGN component turned OFF (top panel) or ON (middle panel), for various redshift bins. In both cases, the agreement is extremely good, with very little scatter around the 1:1 relation. For the case with the AGN component turned ON, the GRAHSP AGN luminosity is plotted as a function of stellar mass. As expected, in all sources the AGN component is well below 10% in all cases but two. |
| In the text | |
|
Fig. 14. Example of an AGN-dominated SED fit from the DR16QWX sample. The total model (black) and the individual components (colours, see legend) are presented with the posterior mean (solid line) and 2 sigma equivalent uncertainties (shaded areas). Observed fluxes are shown as blue data points with blue squares and wide blue capped 3σ error bars. The overlaid blue error bars with thin caps show the enlarged total error budget after the fit. The filter curves of observed photometric bands are shown at the top, grouped to the same colours by instrument. Predicted model fluxes are shown as red points. These can deviate from the black curve because of the averaging over the filter curve. The bottom panel presents the relative residuals of model and observations. The title lists the source ID, redshift, χ2 (Eq. (8)) per number of data points and Bayesian model evidence. On the right, key values are shown, including the stellar mass (in M⊙), star formation rate (in M⊙/yr), the galactic and AGN extinction, and the 5100 Å AGN luminosity (in erg/s). Lower case variables are logarithmic. Below 2 μm, the model is dominated by the AGN disk, and above by the torus. The third data point (z-band) is raised compared to the neighboring data points, which can be understood by the Hα emission line at that redshift. The galaxy component has an extremely wide luminosity range (purple), that is, the stellar mass is unconstrained (see the first number on the right) in this luminous AGN (see the fourth number on the right). |
| In the text | |
|
Fig. 15. Example of a host-galaxy-dominated SED, with elements as in Fig. 14. Here, the SED is dominated by galaxy components (purple and green curves), including nebular emission lines (grey). The stellar mass and star formation rate are well constrained (numbers on the right), while the AGN luminosity has more than an order of magnitude uncertainty around a low value of 1041 erg s−1. Here, model uncertainties (thin cap error bars) were only slightly increased without requiring an AGN component. |
| In the text | |
|
Fig. 16. Parameter posterior probability distributions for two different objects: One AGN-dominated source (blue) of Fig. 14 and one host-galaxy-dominated source (red) of Fig. 15. Panels with thick histograms are model parameters. Panels with thin histograms are derived parameters. The large bottom-right panel shows the joint posterior distribution of AGN luminosity and stellar mass as posterior samples. |
| In the text | |
|
Fig. 17. Distribution of posterior medians of the systematic model error parameter fsys (see Eq. (10)). |
| In the text | |
|
Fig. 18. Extension to X-rays. Top panel: The AGN luminosity at 5100 Å inferred from GRAHSP is compared to the 2 − 10 keV luminosity from X-ray observations in the DR16QWX sample. Points are colour-coded by redshift, with yellow indicating the highest redshifts. Bottom panel: The ratio is shown as a black histogram. For comparison, the grey dashed curve represents the mean ratio and scatter observed by Koss et al. (2018). |
| In the text | |
|
Fig. 19. Chimera sanity check at low AGN luminosities. Comparison of stellar masses measured from COSMOS-pure-galaxies sample to that measured by GRAHSP for the Chimeras built using the same galaxies and with low AGN contribution. The measurements are consistent; for some cases, the uncertainties are very large. |
| In the text | |
|
Fig. 20. Example of an outlier at the lowest Chimera quasar weight (0.0001). This should be galaxy-dominated with very low AGN luminosity. The top panel shows the original COSMOS galaxy. The observed fluxes (purple) are reproduced with a high reduced χ2 (see title) by the galaxy model (black curve), with substantial residuals in the near-infrared and optical wavelengths. The middle panel presents the constructed Chimera fluxes (purple), fitted with the C15 model’s galaxy (yellow curve) and AGN (orange curve) mixture model, using CIGALE. The AGN component models the data in the infrared. The stellar mass has become eight times larger than in the top panel. The bottom panel presents the analysis of the same Chimera data with GRAHSP. Here the fit is dominated by a low-luminosity AGN, and the stellar mass is poorly constrained. The x-axis range is wider in this panel. |
| In the text | |
|
Fig. 21. Retrieval of stellar masses on the Chimera benchmark data set. The y-axis always shows the ratio of the estimated stellar mass to the true stellar mass (x-axis), in log units of M⊙. The first three rows are AGN models in CIGALE, the last row is GRAHSP. The sample is split into four bins (panel columns) of true AGN bolometric luminosity (in erg/s, log). Results with large error bars (> 1 dex) are in grey. If the measured stellar mass deviates from the expectation (dotted grey horizontal lines) by more than 0.5 dex, it is considered an outlier and indicated with a circle. In each bin, the mean and standard deviation are quoted, together with the fraction of outliers in brackets. CIGALE models show a 0.2–0.5 dex bias at L > 43. For GRAHSP, the bias is below 0.1 dex. The GRAHSP fraction of outliers is also lower. The downward-pointing triangles at the very top of the figure indicate where the AGN and galaxy luminosities are approximately equal (λ = 1 in Eq. (6)). The CIGALE models start to deviate to the left of these markers, corresponding to λ > 1. |
| In the text | |
|
Fig. 22. Example of outlier in CIGALE-based analyses from the 1043 − 44 erg/s AGN luminosity bin. Panel (a) shows the original COSMOS data (CosmosId: 420968 at z = 0.33), where a M⋆ = 108 M⊙ galaxy-only model (black) reproduces the observed fluxes (purple) with small residuals (χred2 = 0.4). Panels (b), (c) and (d) present CIGALE fit to the Chimera fluxes (purple) with D14, C15 and Y19 settings. In all three models, the galaxy template is incorrectly placed at 1036 W instead of < 1035 W as in panel (a). In the C15 and Y19 models, the best-fit model is dominated by the AGN component (orange). The bottom panel (e) shows the fit by GRAHSP for the same object. The galaxy component has very large uncertainties (purple shade at the bottom), but includes the true stellar contribution (compare the purple curve here to the black curve in the top left panel). The error budget has slightly increased during the analysis from the blue error bars with wider caps to those with thin caps. The power-law AGN model (blue) dominates the fit at all wavelengths. |
| In the text | |
|
Fig. 23. Star formation rate retrieval on the Chimera benchmark data set. As in Fig. 21. Each panel shows the deviation of the estimated SFR from the true SFR (in log units of M⊙/yr, x-axis). The first three rows’ right panels show the performance of current models at moderate AGN luminosities. Overestimates by 1–2 dex are common at low star formation rates, with outlier fractions between 10–30 per cent. The bias of GRAHSP (last row) is lower and the outlier fraction consistently below 10 per cent. |
| In the text | |
|
Fig. 24. Comparison of codes and models on the Chimera benchmark data sets. The panel rows show the outlier fraction (see Fig. 21), the bias and scatter in dex. The first column shows stellar mass estimation (from Fig. 21), the second column star-formation rate estimation (from Fig. 23). Each curve as a function of AGN bolometric luminosity (log, in erg/s) represents one method. The outlier fraction of GRAHSP is lower than those of other methods. The bias of GRAHSP is near-zero. Other methods systematically overestimate the masses in luminous AGN (middle left panel), and star-formation rates (middle right panel). |
| In the text | |
|
Fig. 25. Luminosity retrieval on the Chimera benchmark data set. The top panel shows the deviation from the AGN bolometric luminosity (in log units of erg/s). Current methods (top panel) show an upward bias at Lbol < 1043 erg s−1, and an outlier fraction of 15 per cent. The bolometric luminosity (see Section 2.1.4) from the BBB and the torus are presented in the second and third panels, respectively. The bottom panel compares the retrieval of 5100 Å luminosity. In all cases, the average bias of GRAHSP is close to zero, with an outlier fraction lower than 5 per cent. |
| In the text | |
|
Fig. 26. HSC test. Comparison of GRAHSP stellar mass estimates (x-axis) to those based on deeper and spatially decomposed HSC photometry modelled with a galaxy (y-axis). The stellar masses are consistent. Squares and circles indicate point-like and extended sources, respectively, in LegacySurvey. |
| In the text | |
|
Fig. 27. GAMA test. Comparison of GRAHSP stellar mass estimates (x-axis) to those based on a galaxy-only model with deeper GAMA photometry (y-axis). The color bar indicates the 5100 Å AGN luminosity from GRAHSP. For host-dominated sources (yellow), the stellar mass estimates are in agreement. For more AGN-dominated sources (purple), the stellar mass of GAMA (without an AGN model) lies significantly above that inferred by GRAHSP. |
| In the text | |
|
Fig. C.1. Change in the stellar mass estimate when the redshift is inaccurate. The x-axis shows the change in stellar mass from a reference run at the spectroscopic redshift, and another run assuming z + Δ × (1 + z) as the redshift, with Δ values of 0.01 (blue), 0.02 (red) and 0.04 (yellow). The red and yellow histograms are similar, with a tail to the left. The blue histogram is narrower and lacks the long tails present in the other two histograms. |
| In the text | |
|
Fig. E.1. WISE W1-W2 colour diagnostic plot. Observed colours for different samples are shown in contours encompassing 99 per cent of the sample. The GRAHSP templates (coloured dots) cover the area of the samples. |
| In the text | |
|
Fig. E.2. i-z colour evolution. The colour range evolution of the model is tested against observations (coloured dots). The model range is shown in grey, for three configurations: the dotted curve is a fiducial model with fixed FeII template and emission line strength. There is good overlap, except near z=0.6, z=1.2 and z=1.5 at negative i-z colours. Increasing the emission line strength range creates an overlap at z=0.6 and z=1.5 (dashed curve). Additionally increasing the FeII template strength range (grey curve, full model range) also produces a good overlap at z=1.2. However, at z=0.8, some observed eFEDS colours are lower than the model. |
| In the text | |
|
Fig. E.3. Colour evolution with redshift. Each row shows one colour. Observations are shown in dots for different samples. At each redshift, the model templates cover the observed range, illustrated by the grey area. |
| In the text | |
|
Fig. E.4. Colour evolution with redshift (continued from Fig. E.3). Each row shows one colour. Observations are shown in dots for different samples. At each redshift, the model templates cover the observed range, illustrated by the grey area. Filters are from DECAM/UltraVista/WISE for eFEDS, DR16QWX and the model, but from Subaru/HSC/WFCAM/CFHT/IRAC for COSMOS, making the comparison slightly inconsistent. |
| In the text | |
|
Fig. F.1. Like Fig. 7, but comparing CIGALE’s SKIRTOR model (black) with the Atlas of AGN spectra (red) from Brown et al. (2019). |
| In the text | |
 |
Fig. F.2. Like Fig. 8, but with CIGALE’s SKIRTOR model. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.