| Issue |
A&A
Volume 697, May 2025
|
|
|---|---|---|
| Article Number | A39 | |
| Number of page(s) | 33 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202450394 | |
| Published online | 05 May 2025 | |
Spectral classification of young stars using conditional invertible neural networks
II. Application to Trumpler 14 in Carina
1 Alma Mater Studiorum Università di Bologna, Dipartimento di Fisica e Astronomia (DIFA),
Via Gobetti 93/2,
40129
Bologna,
Italy
2 Universität Heidelberg, Zentrum für Astronomie, Institut für Theoretische Astrophysik,
Albert-Ueberle-Straße 2,
69120
Heidelberg,
Germany
3 European Southern Observatory,
Karl-Schwarzschild-Str. 2,
85748
Garching bei München,
Germany
4 Universitäts-Sternwarte, Ludwig-Maximilians-Universität,
Scheinerstrasse 1,
81679
München,
Germany
5 Steward Observatory, The University of Arizona,
Tucson, AZ
85721,
USA
6 INAF – Osservatorio Astrofisico di Arcetri,
Largo E. Fermi 5,
50125
Firenze,
Italy
7 Universität Heidelberg, Interdisziplinäres Zentrum für Wissenschaftliches Rechnen,
Im Neuenheimer Feld 205,
69120
Heidelberg,
Germany
8 Harvard-Smithsonian Center for Astrophysics,
60 Garden Street,
Cambridge,
MA
02138,
USA
9 Elizabeth S. and Richard M. Cashin Fellow at the Radcliffe Institute for Advanced Studies at Harvard University,
10 Garden Street,
Cambridge,
MA
02138,
USA
10 INAF – Istituto di Astrofisica e Planetologia Spaziali,
Via Fosso del Cavaliere 100,
00133
Roma,
Italy
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
15
April
2024
Accepted:
20
March
2025
Abstract
Aims. We introduce an updated version of our deep learning tool that predicts effective temperature, surface gravity, extinction, and veiling from the optical spectra of young low-mass stars with intermediate spectral resolution. We determine the stellar parameters of 2051 stars in Trumpler 14 (Tr14) in the Carina Nebula Complex observed with VLT/MUSE.
Methods. We adopted a conditional invertible neural network (cINN) architecture to infer the posterior distribution of stellar parameters and train our cINN on two Phoenix stellar atmosphere model libraries (Settl and Dusty). Compared to the cINNs presented in our first study, the updated cINN considers the influence of the relative flux error on the parameter estimation and predicts an additional fourth parameter, veiling. We tested the prediction performance of cINN on synthetic test models to quantify the intrinsic error of the cINN as a function of relative flux error and on 36 class III template stars to validate the performance on real spectra. Using our cINN, we estimated the stellar parameters of young stars in Tr14 and compared them with those derived using the classical template fitting method applied to the same data in a previous study.
Results. We provide Teff, log g, AV, and rveil values of 2051 stars in Tr14 measured by our cINN as well as stellar ages and masses derived from the Hertzsprung–Russell diagram based on the measured parameters. Our parameter estimates generally agree well with those measured by template fitting. However, for K- and G-type stars, the Teff derived from template fitting is, on average, two to three subclasses hotter than the cINN estimates, while the corresponding veiling values from template fitting appear to be underestimated compared to the cINN predictions. We obtained an average age of 0.7−0.6+3.2 Myr for the Tr14 stars. By examining the impact of veiling on the equivalent width-based classification, we demonstrate that the main cause of temperature overestimation for K- and G-type stars in the previous study is that veiling and effective temperature are not considered simultaneously in their process.
Conclusions. Our cINN performs comparably to the multi-dimensional template fitting method while being significantly faster and capable of consistently analysing stars across a wide temperature range (2600–7000 K).
Key words: methods: statistical / stars: late-type / stars: pre-main sequence / HII regions / open clusters and associations: individual: Trumpler 14 / open clusters and associations: individual: Carina Nebula Complex
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Low-mass stars, whose masses are similar to or lower than the solar mass, account for the majority of the stars in star-forming regions (Bochanski et al. 2010) and about half of the total stellar mass (Kroupa 2001; Chabrier 2003). As low-mass stars remain in the pre-main-sequence phase even when the massive stars are dead, studying low-mass stars is key to understanding the early phases of stellar evolution as well as protoplanetary disk and planet formation. Therefore, it is essential to accurately determine the fundamental physical parameters of low-mass stars to gain insights into their structure and evolutionary processes.
Stellar parameters are estimated from photometric or spectroscopic data by using characteristic features (i.e. spectral indices) that appear differently depending on the type of star (e.g. Luhman et al. 1997; Luhman 1999; Luhman et al. 2003; Riddick et al. 2007; Herczeg & Hillenbrand 2014; Rugel et al. 2018) or by fitting the observed spectrum with already well-analysed stars, referred to as templates (e.g. Fang et al. 2021; Itrich et al. 2024). Thus, selecting the appropriate spectral indices tailored to the star under consideration is important in these methodologies. In addition, the range of applicable methods may be restricted by the wavelength and specification of the instrument. In this study, we apply a deep learning-based method to consistently analyse young low-mass stars over a wide temperature range.
Recently, numerous studies have utilised artificial neural networks (NNs; Goodfellow et al. 2016) in various ways to predict physical parameters (e.g. Fabbro et al. 2018; Ksoll et al. 2020; Olney et al. 2020; Rhea et al. 2020; Sharma et al. 2020; Kang et al. 2022; Shen et al. 2022); efficiently analyse images such as identifying structures and exoplanets (e.g. Abraham et al. 2018; De Beurs et al. 2022); and classify observations (e.g. Wu et al. 2019; Wei et al. 2020; Whitmore et al. 2021; Walmsley et al. 2021). In addition to the time-efficient nature of machine learning techniques, NNs are advantageous when solving complicated problems that are difficult to solve with classical methods. In this study, we adopt the conditional invertible neural network (cINN) architecture (Ardizzone et al. 2019b). Based on a supervised learning approach, the cINN is suitable for tasks such as regression or classification because it finds the complex links between the observable quantities and physical properties hidden in the training data. Moreover, another advantage of the cINN is that it always provides a posterior distribution for the target parameters without any additional calculations. For this reason, the cINN is especially well suited for solving degenerate inverse problems and has been used to analyse various complicated observations in astronomy (e.g. Ksoll et al. 2020, 2024; Bister et al. 2022; Kang et al. 2022, 2023a; Haldemann et al. 2023; Candebat et al. 2024).
We have developed a cINN that estimates four stellar parameters (Teff, log g, AV, and rveil) from the optical stellar spectrum with intermediate spectral resolution, and we used it to analyse numerous low-mass stars in Trumpler 14 (Tr14) in the Carina Nebula Complex (CNC) observed with the Multi Unit Spectroscopic Explorer (MUSE) of the Very Large Telescope (VLT). As a first step, in Kang et al. (2023b, hereafter Paper I), we pretested whether a cINN can extract physical properties well from the stellar spectrum. In Paper I, we introduced three cINNs trained on different Phoenix stellar atmosphere model libraries (Settl, NextGen, and Dusty) and examined the performance of these networks on 36 class III template stars that are well analysed in the literature (Manara et al. 2013b; Stelzer et al. 2013; Manara et al. 2017). We confirmed that cINNs estimated basic stellar parameters (Teff, log g, and AV) from the optical spectrum with a sufficiently high accuracy; they achieved an average error of 3%, with a maximum error range of 5–10%.
In this paper, we introduce a new cINN to estimate the stellar parameters of 2051 low-mass stars in Tr14. The new cINN additionally estimates spectrum veiling (rveil) due to the excess emission by the accretion or disk emission. Moreover, it considers the influence of the flux error on the parameter estimation because the signal-to-noise ratios (S/N) of the spectra analysed in this study are on average lower than that of the template stars used in Paper I, so that the influence of the flux error is no longer negligible anymore. We first test the overall performance of the new cINN using synthetic test models and 36 class III template stars and then determine the stellar parameters of Tr14 stars. We compare the parameters estimated by our cINN with those obtained in Itrich et al. (2024, hereafter IT24), which were derived using classical template fitting methods on the same observational data.
The paper is structured as follows. We describe the observational data of Tr14 and the template fitting method used in IT24 in Sect. 2 and introduce the structure of the cINN, our network setup, and training methodologies in Sect. 3. Sect. 4 presents the compilation of our training data. We test and validate the performance of our new cINN in Sect. 5. In Sect. 6, we present our overall results on Tr14 stars. In Sect. 7, we further discuss the methodological limitations of both the cINN and template fitting method and the validity of the measured veiling. We summarise the results in Sect. 8.
2 Young stars in Tr14
2.1 Observation and samples
The CNC is one of the most massive star-forming regions in the Galaxy, containing more than 70 O-type stars (Smith 2006; Berlanas et al. 2023), emitting intense ultraviolet radiation (Smith 2006), and located at a distance of 2.35 kpc (Göppl & Preibisch 2022) from the Sun in the plane of the Galactic disk. Interstellar extinction towards the CNC is known to be low but exhibits an abnormal reddening law, especially around Trumpler 14 and 16 (RV = 4–5, e.g. Tapia et al. 2003; Carraro et al. 2004; Hur et al. 2012; Hur et al. 2023). Among the three main star clusters in the CNC (Trumpler 14, 15, and 16), Tr14 is the youngest and most compact, with an age estimated to be around 1 Myr (Penny et al. 1993; Vazquez et al. 1996; Carraro et al. 2004; Smith & Brooks 2008, IT24).
Trumpler 14 has been observed with the MUSE (Bacon et al. 2010) on the VLT under the programme ID 097.C-0137 (PI: A. McLeod). MUSE is an integral-field unit (IFU) instrument and offers spatially sampled medium-resolution spectroscopy (R ~ 4000) in the optical regime (4650–9300 Å) with a relative wavelength accuracy expected to be below 0.1Å (Weilbacher et al. 2020). Observations were performed in Wide Field Mode with a field of view of 1′ × 1′ and a total integration time of 39 min per pointing. The whole mosaic covering the Tr14 cluster consists of 22 pointings, with the seeing ranging from 0.5” to 1.6”. IT24 reduced the observations with the dedicated European Southern Observatory (ESO) pipeline v. 2.8.3 (Weilbacher et al. 2020), which is part of the EsoReflex environment (Freudling et al. 2013). The data reduction included wavelength and flux calibration as well as astrometry correction. Stellar spectra were extracted from datacubes using Source-Extractor (Bertin & Arnouts 1996) with the 50% level of completeness at 15.5 mag based on the J-band HAWK-I magnitudes matched to the sources (IT24). IT24 estimated stellar parameters (Teff , AV, and rveil) from the stellar spectra using class III template stars observed with VLT/X-Shooter and analysed by Manara et al. (2013b, 2017). In this paper, we refer to measurements of IT24 as TF parameters (template-fitting parameters) or TF values and compare them to the stellar parameters obtained in this work.
The CNC is a bright HII region with spatially highly variable nebular emission. This emission hinders spectral analysis because nebular lines contaminate the stellar ones and make their measurement particularly challenging. IT24 adopted a conservative approach to this problem. After removing spurious sources (e.g. objects with I-band photometric uncertainty >0.1 mag, when one or more pixels were saturated, or when the position of the object was too close to the edge of the image, etc.), IT24 excluded sources where nebular emission variation around the star was too large compared to the stellar flux. They measured the fluctuation of I-band nebular emission within a radius of 20″ and compared it to the stellar emission. IT24 then applied an S/N cut (mean S/N >10) for the robustness and derived a “Clean” sample consisting of all the sources whose I-band flux is higher than three times the fluctuation of nebular emission.
Among the ~800 Clean samples, IT24 excluded foreground and background stars based on parallaxes corrected for bias (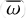 ), as described in Lindegren et al. (2021). First, IT24 selected stars from the Clean samples with good Gaia astrometry (Gaia Collaboration 2016, 2023) to establish an exclusion condition using the following criteria: goodness of fit parameter, RUWE < 1.4 (Lindegren 2018), astrometric_gof_al ≤ 5 (Lindegren et al. 2021), a parallax over error larger than 5, and uncertainty of the proper motion below 20%1. The distribution of corrected parallaxes for the selected 175 stars satisfying the above criteria was then fitted with a Gaussian profile (see Fig. 3 of IT24) which centre value fell on 0.43 mas, which corresponds well to the distance of 2.35 kpc found in Göppl & Preibisch (2022), and a 1-σ width of 0.04 mas. Here, the exclusion criteria,
), as described in Lindegren et al. (2021). First, IT24 selected stars from the Clean samples with good Gaia astrometry (Gaia Collaboration 2016, 2023) to establish an exclusion condition using the following criteria: goodness of fit parameter, RUWE < 1.4 (Lindegren 2018), astrometric_gof_al ≤ 5 (Lindegren et al. 2021), a parallax over error larger than 5, and uncertainty of the proper motion below 20%1. The distribution of corrected parallaxes for the selected 175 stars satisfying the above criteria was then fitted with a Gaussian profile (see Fig. 3 of IT24) which centre value fell on 0.43 mas, which corresponds well to the distance of 2.35 kpc found in Göppl & Preibisch (2022), and a 1-σ width of 0.04 mas. Here, the exclusion criteria, 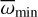 and
and 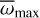 , are set to values ∓1-σ away from the centre, which correspond to 2.61 kpc and 2.13 kpc, respectively. Stars whose parallax values considering the 3-sigma uncertainty were lower than
, are set to values ∓1-σ away from the centre, which correspond to 2.61 kpc and 2.13 kpc, respectively. Stars whose parallax values considering the 3-sigma uncertainty were lower than 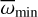 or larger than
or larger than 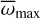 were defined as background stars or foreground stars, respectively. After excluding foreground and background stars, 780 stars remained in the final Clean sample in IT24.
were defined as background stars or foreground stars, respectively. After excluding foreground and background stars, 780 stars remained in the final Clean sample in IT24.
Due to the strict limits on contamination by nebular emission described above, more than 1800 sources were excluded in the main analysis of IT24, mostly stars with M* < 1 M⊙. However, IT24 also identified probable members among these sources, characterised their stellar parameters, and reported a separate catalogue for these stars (see Table D.1 of IT24), following the same member selection approach and the template fitting method used for the Clean samples. IT24 did not apply an additional S/N cut to these sources but confirmed that they have mean S/N > 2, with approximately 80% having mean S/N > 10. This “Uncertain” sample of 1867 objects constitutes a significant fraction of the “All” sample (71%) which could add to the statistical significance of the study of IT24. Here, we aim to enhance these previous efforts, use the full potential of MUSE capabilities with our updated neural network architecture and classify all Tr14 sources observed with MUSE.
Among the 780 Clean samples and 1867 Uncertain samples reported by IT24, we only use stars that have J-band magnitudes from the HAWK-I (Preibisch et al. 2011a,b) or VISTA (Preibisch et al. 2014) catalogues and also have spectral type assessed by IT24 for a direct comparison. This retains 727 and 1324 sources in the Clean and Uncertain samples, respectively. Because of several quality cuts applied in IT24, the I-band magnitudes of the final samples range from 12.7 to 22.3 mag. This corresponds to a lower mass limit of ~0.06 M⊙ (~2850 K, M7) at 1 Myr (Baraffe et al. 2015) when applying a distance modulus of 11.86 mag, equivalent to 2.35 kpc (Göppl & Preibisch 2022), and a global visual extinction towards Tr14 of ~2.6 mag (IT24) with RV of 4.4 (Hur et al. 2012).
As the stellar spectra of several Tr14 sources exhibit low S/Ns, we design a cINN that takes both the flux and flux error into account in this paper (see Sect. 3.2 for more details). This cINN adopts the dimensionless relative flux error (σλ), that is the flux error divided by the flux, σλ = ΔFlux(λ)/Flux(λ), the same as noise-to-signal ratio. The bottom panel of Fig. 1 shows the σλ distributions of the Clean and Uncertain samples as a function of wavelength. Although σλ is sensitive to wavelength, we decided to use a representative value, the median value across the wavelength range (σmed), in the following, because we encountered issues in training the cINN (see Sect. 3.2) and difficulties in modelling σλ. The top panels of Fig. 1 present the σmed distributions for Clean and Uncertain samples, respectively. σmed is widely distributed on a logarithmic scale from 10−4 to 100 (0.01– 10%). The Uncertain samples have on average about 1 dex higher σmed than the Clean samples. The median of σmed for the Clean samples is about 1%. We provide in Table 1 the measured σmed of all sources.
With this approach, σλ can be underestimated at shorter wavelengths, because σmed is mostly determined at 6500–7500 Å for Tr14 data. To assess this, we calculate the median σλ at 4750–5500 Å (σ5000) per star. Using spectral classifications from IT24, we find that M-type stars have an average σ5000/σmed of 13, which decreases to 7.5 for the Clean sample. In contrast, K- and G-type stars show lower ratios of 4.8 and 2.8, respectively, indicating a smaller S/N variation across the spectrum. K/G-type stars also exhibit higher overall S/Ns, with median σmed values of 0.88% (K-type) and 0.27% (G-type), compared to 9.84% for M-type stars. The median σλ at λ < 5500 Å is 3.8% (K-type) and 0.66% (G-type), both lower than the 3.4% median σλ at λ > 8500 Å for M-type stars. While underestimating σλ at shorter wavelengths could impact parameter accuracy, this effect is likely minor for earlier-type stars, given their higher S/Ns and smaller spectral S/N variation. In future studies, we will improve our approach to account for wavelength-dependent flux errors.
 |
Fig. 1 Upper panels: histograms of median relative flux error (σmed) for the spectra in the Clean samples (left) and the Uncertain samples (right). Dashed lines and purple shaded areas indicate the median values and ±1 standard deviations of the distributions. Lower panel: distribution of relative flux error at each spectral bin (σλ = ΔFlux(λ)/Flux(λ)) for the Clean (red) and Uncertain (blue) groups. The shaded areas indicate the interquantile ranges from 16% to 84%. The red and blue dashed lines show the median of σmed for each group as shown in the upper panels and the black dashed line shows the median σmed for all 2051 spectra. The green dotted line indicates the upper boundary of the training range (log σ = -0.5) of our cINN. The narrow grey-shaded vertical areas indicate the masked spectral bins not used in our network due to the presence of emission lines. |
2.2 Spectral classification used in IT24
In this section, we briefly summarise the spectral classification methods used in IT24. Some approaches such as for veiling and reddening are applied identically to the training data of our cINN in this paper. IT24 found the best-matching template for the observed spectra using 37 class III template stars, which cover a range from M9.5 to G8 type and are all subject to a negligible amount of extinction of below 0.3 mag. These stars are observed with VLT/X-shooter and published by Manara et al. (2013b, 2017). Because of the difference in spectral coverage between MUSE and the optical arm of X-Shooter, IT24 convolved the template spectra with a Gaussian kernel to match the MUSE resolution and re-sampled them to the common spectral range between 5600 and 9350 Å, which is a bit narrower than the entire spectral range of the MUSE spectra (4750–9350 Å). Spectra of both Tr14 samples and template stars are normalised by the flux at 7500 Å.
IT24 preselected M-type stars by using the spectral indices based on the TiO and VO absorption bands (Riddick et al. 2007; Jeffries et al. 2007; Herczeg & Hillenbrand 2014) and then applied different classification methods to M-type stars and K/G-type stars. For M-type stars, IT24 found the best-fit template simultaneously considering the spectral type, extinction, and veiling from a grid of template spectra with extinction (AV) covering a range from 0 to 7 mag in steps of 0.1 mag and veiling (rveil) covering an interval from 0 to 1.9 in steps of 0.02. They adopted a simple constant veiling model, similar to the approach used in Fang et al. (2021), where the additional flux is determined by a veiling factor at 7500 Å (rveil) and the flux at 7500 Å (F7500):
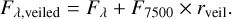 (1)
(1)
They first veiled the spectrum and redden it with a given visual extinction value (AV) following the extinction law of Cardelli et al. (1989), adopting the RV = 4.4 for Tr14 (Hur et al. 2012).
On the other hand, for K- or G-type stars, IT24 first determined the spectral type using the equivalent widths (EWs) of absorption lines and then determined AV and rveil using the template star with the closest spectral type. Assuming a linear relationship between EWs and spectral types, IT24 derived the correlation from the template stars and then applied it to the Tr14 data. Spectral types were translated into effective temperatures, Teff, using scales from Luhman et al. (2003) for M-type stars, and from Kenyon & Hartmann (1995) for earlier type stars.
Catalogue of low-mass stars in Tr14 with stellar parameters measured by cINN.
3 Neural network
Following the approach introduced in Paper I, we employ a conditional invertible neural network (cINN; Ardizzone et al. 2019a,b) in this study. cINNs belong to the family of deep learning architectures called Normalising Flows (NFs, Tabak & Vanden-Eijnden 2010; Tabak & Turner 2013; Dinh et al. 2015; Rezende & Mohamed 2015), encompassing methods that employ sequences of invertible transformations of simple known probability distributions to model complex target distributions (for a review see e.g. Kobyzev et al. 2021).
3.1 The conditional invertible neural network
The cINN marks a NF variant that is particularly well-tailored towards solving degenerate inverse problems, that is tasks where the underlying physical properties x of a system are to be recovered from a set of observable quantities y. In nature, this inverse mapping x ← y is often subject to degeneracy due to an inherent loss of information in the corresponding forward process x → y, such that different sets of physical properties may appear similar or even entirely the same in observations, rendering attempts to solve the inverse problem highly challenging.
The cINN approach tackles these challenges by encoding the information loss of the forward mapping in a set of unobservable, latent variables z that follow a known prior distribution P(z). To do so, the cINN learns a mapping f from the physical parameters x to the latent variables z conditioned on the observations y, that is,
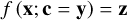 (2)
(2)
such that z captures the variance of x that is not explained by y, while maintaining the prescribed shape P(z) for the prior of z. To characterise a new observation y′ at prediction time, the encoded variance can then be queried by sampling the latent space according to P(z), allowing the cINN to estimate the full posterior distribution p (x|y′) by running in reverse following
 (3)
(3)
where f−1(·, c) = g(·, c) denotes the inverse of the learned forward mapping for fixed condition c. In practise a multivariate normal distribution with zero mean and unit covariance is the simplest choice for the prior P(z), while the dimension of the latent space is by design of the cINN equal to that of the target parameter space, that is dim(z) = dim(x).
3.2 Noise-Net
In Paper I, we applied our approach to class III template stars, for which the flux uncertainties are mostly low enough because of their high S/Ns. On the other hand, the stellar spectra of most Tr14 sources in this paper have lower S/Ns than the class III templates, so we cannot ignore the flux error. Therefore, we use a type of cINN called Noise-Net (Kang et al. 2023a) designed to consider the errors in the observable.
The Noise-Net, first introduced in Kang et al. (2023a), is a version of the cINN that estimates posterior distributions p(x | y, σ) that account for the error (i.e. random noise, σ) in observations by adding them as an additional condition to the network and learning the influence of the noise during the training process. Kang et al. (2023a) showed that the Noise-Net reflects the observational error well in the predicted posterior distribution while maintaining a good overall performance. By comparing the Noise-Net with the regular cINN that treats observational error via post-processing, Kang et al. (2023a) showed that Noise-Net achieves higher accuracy than the regular cINN for observations with non-negligible errors. On this account, we adopt the Noise-Net to build the cINN for our analysis in this paper.
There are two general differences between the Noise-Net and the regular cINN. Firstly, in the Noise-Net, both observations y = {y1,...,yM} and corresponding errors σ = {σ1,...,σM} are used as the condition (c) of the cINN. We define the error (σ) as the dimensionless relative error, that is the one-sigma Gaussian error divided by the observation. In this paper, as we use stellar spectra with 3433 spectral bins, σi is obtained by dividing the flux error by the flux for each spectral bin. Accordingly, the dimension of the condition (c) of the Noise-Net is twice that of the regular cINN. Secondly, two new steps are added in the training process for the Noise-Net to account for the uncertainties. The first step is to randomly sample errors for the training models at each training epoch. In order for the Noise-Net to learn a wide range of error values, we sampled the errors in a logarithmic scale from the uniform distribution,
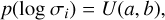 (4)
(4)
where the upper and lower bounds a and b are fixed during the training. Considering the relative flux error of the Tr14 spectra, we choose a lower bound of 10−5 and an upper bound of 10−0.5.
The next step is to perturb the flux by adding random Gaussian noise based on the error sampled in the first step. The true flux y* from the original training data is perturbed following
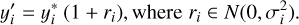 (5)
(5)
We clipped the perturbed fluxes to the minimum flux value of the given spectrum to avoid generating negative fluxes. Finally, the Noise-Net is trained to learn the forward process, that is the mapping from the target parameter values (x*) to the latent variables (z) using the combination of the perturbed spectrum and corresponding randomly sampled errors as the conditioning input for the cINN, c = [y′, σ]. The two random sampling processes in the training procedure ensure that the Noise-Net learns about different errors and flux values in every training epoch, which has a similar effect as extending the overall size of the training data.
In the first step, we can sample the errors of each spectral bin (σi) in various ways, such as sampling all bins independently or having the errors following a correlation function. In this paper, we decide to use one single value for all spectral bins per one model (i.e. σi = σ). The relative error in the real data depends on the wavelength as shown in Fig. 1 but modelling the correlation function of σλ is not easy. By sampling errors at all spectral bins independently, the network can in principle learn about the widest cases, but in our experiments, we found that training fails with this setup because the observable space becomes too complex. Therefore, we decided to sample one value and use the same relative error for all spectral bins per observation. As we perturb the observation (flux) at each spectral bin in the second step, the network learns about different perturbations at different wavelengths even though we use the same relative error. We plan to improve the error sampling and training methodology in the follow-up study to consider the correlations between errors.
When applying the trained Noise-Net to new observations, we always need to provide both the flux (y) and corresponding relative error (σ) as an input to the Noise-Net. The Noise-Net then returns the error-considered posterior distribution of the parameters p(x | y, σ). We can either feed errors differently at each spectral bin or feed the representative error value. In this paper, when we apply our network to Tr14 stars, we use the median relative error along the wavelength (σi = σmed) per observation instead of using the error at each spectral bin. Using synthetic test models and Tr14 stars in the Clean samples, we tested and confirmed that the change in the results is negligible whether we use the median relative error or different errors at each bin.
3.3 Network setup
3.3.1 Network construction
As in Paper I, we employed so-called (conditional) affine coupling blocks (Dinh et al. 2016) in order to build an invertible network architecture for the cINN. Given the halves u1 and u2 of the block input vector u, each of these blocks performs two complementary affine transformations,
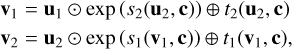 (6)
(6)
which are easily inverted given the halves v1, v2 of the output vector v following
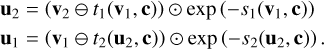 (7)
(7)
Here si and ti (i ∈ {1,2}) denote arbitrarily complex transformations that do not need to be invertible themselves (being only evaluated in the forward direction in both Eqs. (6) and (7) and can also be learned directly by the cINN itself when represented by small sub-networks (Ardizzone et al. 2019a,b).
In this paper, we construct a cINN consisting of 8 conditional affine coupling blocks in the GLOW (Generative Flow; Kingma & Dhariwal 2018) configuration, where a single subnetwork is adopted as the internal transformation of each affine coupling block. For each subnetwork, we employ a simple fully connected architecture with 3 layers and a width of 512, using the rectified linear units (ReLU, ReLU( x) = max(0, x)) as the activation functions. After each affine coupling block, we add an invertible random permutation layer to mix the information streams (u1 and u2). The permutation layer is a random orthogonal matrix and is fixed during the training (Ardizzone et al. 2019a,b).
With the flux and corresponding errors entering as a condition and simply being concatenated to the input of the subnetworks si and ti in each affine coupling layer, the cINN architecture has the additional advantage that a) the dimension of the input c can become arbitrarily large and b) a conditioning network h can be introduced (trained together with the cINN itself), which transforms the input condition into a learned, more informative representation 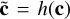 for the cINN (Ardizzone et al. 2019b). For the conditioning network h, we also adopt a simple fully connected feed-forward network with four layers and a width of 256 that extracts 256 features in the final layer.
for the cINN (Ardizzone et al. 2019b). For the conditioning network h, we also adopt a simple fully connected feed-forward network with four layers and a width of 256 that extracts 256 features in the final layer.
After constructing the network based on this setup, we train the network by minimising the maximum log-likelihood loss as described in Ardizzone et al. (2019b), using the Adam (Kingma & Ba 2014) optimiser for stochastic gradient descent with a step-wise learning rate adjustment.
3.3.2 Data pre-processing
Following the same approach introduced in Paper I, we transform both parameters x = {x1, .. ., xN} and observations y = {y1, ..., yM} by using linear transformations, prior to the training, to ensure the distributions of parameters and observables have zero mean and unit standard deviation. Each target property xi and input observable yi was rescaled following,
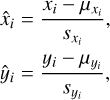 (8)
(8)
where μxi, μyi and xxi, syi, denote the means and standard deviations of the respective parameter or observable across the training data.
In the case of the relative flux errors σ = {σ1,...,σM}, we first convert each component σi into a logarithmic scale because they are sampled from a wide distribution in the log space during the training. Then we rescale them using a similar form of linear transformation as Eq. (8). Because the relative flux errors are randomly sampled from p(logσ) during the training (Eq. (4)), we use the mean and the standard deviation of Eq. (4) for μσi and sσi. The transformation coefficients (μxi, μyi, μσi, and sxi, syi, sσi) determined from the training data are applied in the same way to new query data.
4 Training data
As in Paper I, we train the cINN based on the Phoenix stellar atmosphere model (Allard et al. 2011, 2012) with solar abundances, which covers a wide range of temperature and gravity appropriate for pre-main-sequence stars and provides a sufficient spectral resolution. We generate training data by using the same Phoenix libraries and interpolation pipeline used in Paper I. Each Phoenix library is spaced uniformly with a 100 K interval for Teff and 0.5 for log(g/cms−2). For a given temperature and gravity values, we first interpolate linearly in log g for the two nearest temperatures for the given Teff and then interpolate in the temperature linearly between the two resulting spectra. Next, we add veiling and redden the spectra, adopting the same approaches used in IT24, which is described in Sect. 2.2. In our simple veiling model, the flux excess due to the accretion or disk emission is constant along the wavelength and determined by the flux at 7500 Å and a veiling factor, rveil (Eq. (1)). Lastly, the spectrum is reddened with a given visual extinction value (AV) following the extinction law of Cardelli et al. (1989), adopting the RV = 4.4 for Tr14 (Hur et al. 2012).
In Paper I, we tested three spectral libraries, namely Settl (i.e. BT-Settl CIFIST), NextGen and Dusty, for training our cINN and found that a cINN trained on the Settl library provided the best overall performance and widest parameter coverage. However, we also found that a cINN based on the Dusty library performs very well within the more limited temperature range (Teff < 4000 K). Based on this, we adopt a hybrid approach for this work, combining Settl and Dusty libraries for our training data set, instead of using a single spectral library. We first sample a large list of in total 131 072 different combinations of log(g/cms−2) and log(Teff/K), following Paper I, with uniform random sampling in log space: log(g) from 2.5 to 5 and log(Teff) from 3.415 to 3.845 (2600–7000 K). Afterwards, we synthesise the corresponding spectra using the interpolation scheme. For log(g)–log(Teff) combinations where Dusty models exist (3 ≤ log(g) ≤ 5 and 2600 ≤ Teff ≤ 4000 K), we randomly select between Dusty and Settl models, ensuring equal representation. Outside this range, only Settl models are used. To keep track of the library origin we add a flag to each training instance indicating the model used to synthesise a given spectrum, where a flag of 0 indicates a Settl origin and 1 denotes Dusty-based spectra. This flag is also treated as a target parameter, allowing the cINN to infer the most suitable model for a given query spectrum. We split this database and use 80% of it as a training set and the rest as a test set.
Unlike effective temperature and surface gravity, the extinction (AV) and the veiling (rveil) are sampled and applied to the synthetic spectra during the training. As AV and rveil values differ in every training epoch, the cINN can learn more diverse cases with a limited number of models. We sample rveil from 0 to 2 and sample AV from 0 to 10 mag. When we randomly sample the parameters within the given ranges, the cINN tends to perform poorly at the boundaries of the training range. To improve the cINN performance at the boundary values without giving unphysical values such as negative extinction, we assign boundary values to a certain fraction of the training data while randomly sampling the rest. For veiling, we expect some stars in Tr14 may not have veiling (rveil = 0) and most of their veiling values to remain below 2, based on IT24. Thus, we set rveil of 0 for 30% of the training data and sample the rest uniformly from 0 to 2. For extinction, AV is set to 0 for 10% of the training data. These assignments are randomised at each training epoch.
For the synthesised spectra, we initially cover a wavelength range from 4750Å to 9350Å, matching the spectral resolution of MUSE, that is we cover the wavelength interval with a total of 3681 spectral bins with a width of 1.25Å. Afterwards, we mask a few wavelength intervals, which correspond to prominent emission line features that can occur in the real observed data from Tr14. We have to exclude these spectral bins because neither the Settl nor Dusty spectral libraries account for emission lines in their synthetic spectra. Consequently, the cINN cannot properly fit the data in these wavelength intervals when applied to the real observations as it has never seen examples with emission lines during training. Properly modelling the emission lines for the training data is a complex issue and at this stage out of the scope of this study. The omitted wavelength ranges are the following: 4853–4868, 4955–4963, 5002–5011.5, 5575–5582, 5872–5881, 6297–6303, 6544–6552, 6553–6587.5, 6673–6680, 6710–6722, 6729–6735, 7064–7067, 7130–7140, 7279–7282.5, 7316–7323, 7327–7331, 7745.5–7753, 7768–7780, 8441–8453, 8495–8504, 8536–8552, 8597–8605, 8659–8670, 8747–8758, 8858–8867, 9009–9016, 9064–9073 and 9222–9235 Å (see grey areas in Fig. 1). Before we feed the spectrum into the cINN, we normalise the spectrum by the sum of flux at all spectral bins, excluding the masked bins listed above.
Once trained, our network can sample posterior estimates very efficiently. When tested with an NVIDIA H100 graphics card, the network generates a posterior distribution with 4096 posterior samples per observation for 100 observations in 0.4 seconds (249 observations/s). When tested with an M2 pro CPU, the speed is about 13 observation/s.
 |
Fig. 2 Histograms of the MAP accuracy for the five target parameters measured using 26241 synthetic test models at 11 different relative flux errors (σ). The blue plus symbol indicates the median value of each histogram. The grey horizontal dashed line and shaded area represent the median (1.12%) and standard deviation (0.77 dex) of the median relative flux error of Tr14 samples in the Clean group (see Fig. 1). |
 |
Fig. 3 RMSE of the MAP estimates (blue) and the entire posterior estimates (orange) for synthetic test models at 11 different median relative flux errors. The grey lines and shaded areas are the same as in Fig. 2. |
5 Validation
5.1 Performance test on synthetic models
We first investigate the performance of our trained network using synthetic models. The accuracy of the Noise-Net varies according to the amount of the error of measured observables. Kang et al. (2023a) showed that the average accuracy and precision of the Noise-Net gradually deteriorated as a function of error. In this section, we examine how large the intrinsic estimation error is as a function of the relative flux error by using the test set of our database (i.e. models not used in the training).
We use the entire 26 214 models in the test set for this experiment. As the synthetic model spectra are by definition pure without any flux error, we produce mock flux errors under a simple assumption. Although the flux error in the real spectra varies with wavelength (see Fig. 1), we simply use a fixed σ value at all wavelengths (σi = σfix). This means the ratio of flux error to flux is fixed, but not the flux error in the physical unit. Considering the training range of σ of our cINN (10−5–10−0.5) and the range of σmed of Tr14 stars in Fig. 1, we select eleven σfix values from 10−3 to 10−0.5 in 0.25 dex intervals on a logarithmic scale. We sample 4096 posterior estimates to obtain a posterior distribution for each test model at each σfix value. The maximum a posteriori (MAP) point estimate of each parameter is determined by performing a Gaussian kernel density estimation on the corresponding marginalised 1D posterior distribution (see Kang et al. 2022 for the detailed method). MAP estimates are used as representative estimates in this paper in many cases.
We investigate how much the MAP estimates differ from the ground truth of the test models. Fig. 2 shows the distribution of the MAP accuracy, the error between the MAP estimate and the ground truth, of the cINN for our five target parameters for 11 different σfix values. The distribution broadens with increasing σfix, which is a common trend for all five parameters. This is a typical characteristic of a Noise-Net as shown in the previous study (Kang et al. 2023a), where the overall accuracy deteriorates with increasing observational error. However, although the distribution widens, the overall error value is very small even at the highest σfix value. Moreover, the median of the MAP accuracy, denoted by the plus symbol, reveals that the cINN is on average very accurate.
We calculate the root mean squared error (RMSE) of the posterior estimate with respect to the ground truth in order to quantitatively measure the expected accuracy of the cINN as a function of σfix. The blue curve in Fig. 3 is the RMSE of the MAP estimates, while the orange curve shows the RMSE of all posterior samples in the posterior distributions, which is generally larger than the RMSE of the MAP estimates. In both curves, the RMSE increases slowly when σfix is smaller than about 1%, but after 1%, the RMSE increases more rapidly than before. This trend is common for all five target parameters.
Additionally, we split the test models into three groups, M type (2600–4000 K), K type (4000–5250 K), and G type (5250–6000 K), and examine how the RMSE curves vary with Teff of the models. Figure A.1 shows the RMSE curves for the three groups along with the one for the entire sample (the same as the blue curve in Fig. 3). For the four main parameters (Teff, log g, AV, and rveil), the RMSEs for the K/G-type models are significantly larger than that of the M-type models at the same σfix. The RMSE for the entire test model is closer to that of the K/G-type models but is smaller than the RMSE of the G-type models when σfix is larger than 10%. In particular, the RMSE of log g for the G-type models is more than 0.2 dex larger than that of the later types even when σfix is small. On the other hand, the M-type models show a much smaller RMSE than the earlier types, especially when σfix is large. These results imply that it is more difficult for cINN to measure parameters accurately for hotter stars, especially when the relative flux error is large. In the case of the library origin flag, RMSE is only observed for the M-type models, because only the models with Teff below 4000 K can have a choice of either Dusty or Settl.
When applying the cINN to real observations, it is important to interpret the obtained posterior estimates considering the intrinsic error of the cINN at the given relative flux error based on the result of this experiment. On this account, we indicate the median relative flux error of the Tr14 stars in the Clean group in Figs. 2 and 3 (grey dashed lines). The grey shade denotes the interval of ±1 standard deviation. As the σmed of the Tr14 spectra is widely distributed (see Fig. 1), the range of the corresponding RMSE is also wide. We choose three σfix values (0.1, 1 and 10%) close to the range of the Tr14 errors and list the RMSE of the MAP estimate at these errors in Table 2. Taking a 1% value close to the median error of the Tr14 observations, the expected error of our cINN is sufficiently small, on the order of 10−3–10−2. However, at large errors above 10%, the intrinsic error of the cINN is not negligible, especially in the case of surface gravity, extinction and veiling.
The half-width of the posterior distribution is usually used as an uncertainty of the MAP estimates, but the predicted posterior distributions of our cINNs in this paper and in Paper I are very narrow and mostly negligible. This is due to a large number of input data points (about 3000 data points) per observation containing sufficient information to predict precise stellar parameters. As we determine the average intrinsic error of the MAP estimate as a function of the relative flux error in this section, we take this into account when applying our cINN to real observations. In the following sections, the uncertainty of the MAP estimate is determined by combining the half-width of the posterior distribution and the intrinsic parameter estimation error at the corresponding relative flux error. We determine the width of the 68% confidence interval (i.e. u68) and use half of it as a half-width of the 1D posterior distribution. Using the median relative flux error along the wavelength (σmed), we find the closest one among the 11 σfix values and use the intrinsic errors of stellar parameters at the corresponding σfix. The final uncertainty of the MAP estimate is calculated as
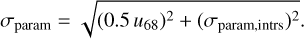 (9)
(9)
RMSE of the MAP estimates with respect to the ground truth for 26 214 synthetic test models for three different relative flux errors.
5.2 Test on class III template stars
We test the performance of the cINN using the 36 class III template stars observed with VLT/X-shooter and analysed by Manara et al. (2013b); Stelzer et al. (2013); Manara et al. (2017). While we validated the prediction accuracy of cINNs for three parameters (Teff, log g, and AV) in Paper I, using the same 36 stars, we perform similar examinations again because we introduce a new cINN including veiling as a fourth parameter and taking relative flux errors into account. Unlike the previous networks that used the common spectral range between the MUSE and X-shooter VIS arm (~5600–9350 Å), the cINN in this work employs the full MUSE wavelength range (4750– 9350 Å). Therefore, we combine the VIS and UV arm spectra of the template stars and degrade them to match MUSE spectral resolution and wavelength sampling. Since flux error information per spectral bin is not available for these data, we measure the standard deviation of flux at 20 Å intervals within the 6500–7500 Å range. The median of these standard deviations, normalised by the flux at 7000 Å, is utilised as σmed of the template spectrum. The average σmed calculated in this way is 3.81% for M-type stars, 1.7% for K-type stars, and 1.11% for G-type stars, which correspond well to the average S/Ns reported in Manara et al. (2017).
Fig. 4 shows comparisons between the MAP estimates measured by the cINN and the stellar parameters obtained in literature (Manara et al. 2013b; Stelzer et al. 2013; Manara et al. 2017). In Table A.1, we listed the literature stellar parameters and measured MAP estimates of these stars. We regard the literature extinction and veiling values as zero because previous studies reported that these stars are class III and have negligible extinction, mostly less than 0.2 mag and of up to 0.5 mag, with an extinction uncertainty of about 0.2 mag. Since the veiling of these stars was not measured in those studies, we arbitrarily assume the uncertainty of the literature veiling as 0.1. The estimation uncertainty of the MAP estimate is calculated following Eq. (9). Similar to Paper I, the new network accurately estimates effective temperature and surface gravity. For Teff, the mean absolute error (MAE) is about 130 K and the relative error is about 3.5%, equivalent to a subclass difference of about 0.95. For log g, the average error is about 0.3 dex, similar to the uncertainty of gravity measurements in the literature.
In the case of extinction, the network performs accurately for stars above 5000 K but overestimates extinction for cooler stars, particularly for stars below 3300 K, where the mean measurement is approximately 1.5 mag higher than the literature value. This trend was observed identically in Paper I, even when we used other Phoenix models to train the cINN (Settl, NextGen, and Dusty). We interpret this as a limitation of the Phoenix models in accurately representing lower-temperature stars, that is a large simulation gap, rather than a problem in the predictive ability of the cINN architecture because we confirmed in Paper I that the Phoenix spectra, synthesised based on the predicted parameters, agree well with the observed input spectra. However, the cINN in this study overestimates AV by approximately 0.6 mag for stars within the range of 3300–4200 K (M3.5 to K6), whereas the networks in Paper I accurately measured AV to within 0.2 mag for these stars. This difference is related to the additional parameter, veiling, in the new network. For the 36 stars, the mean absolute error of the veiling measurement is about 0.13. Stars below 3300 K exhibit a lower average error, under 0.1, whereas those in the 3300–4200 K range show a higher average error of 0.17. For stars between 3300– 4200 K, the network appears to overestimate veiling relative to the other stars, which results in larger extinction measurements as a compensatory effect.
We further investigate how the parameter estimates change when the relative flux error (σmed) is increased by a factor of 5 and 10. For Teff, log g, and AV, the MAP values do not change significantly except for stars above 5000 K. For these stars, the MAP estimates of Teff decrease slightly and become closer to the literature values. As a result, the mean error decreases from 131.6 K to 119.5 K and then to 105.3 K as σmed increases. On the other hand, the most noticeable change is observed in the veiling measurements (Fig. A.2). For stars over 4200 K, as σmed increases, the veiling estimates approach zero, while the veiling of the other stars does not change. The decrease in veiling for these stars results in a decrease in Teff but no noticeable change in AV.
Through the tests, we validated that the new network performs well for real spectra similar to those in Paper I. For the newly added parameter, rveil, we confirmed that the average error is 0.13, but for stars within the temperature range of 3300– 4200 K, the rveil error is higher around 0.17, thus overestimating extinction.
 |
Fig. 4 Comparison of MAP estimates with literature values for 36 class III template stars. The colour indicates the temperature difference between MAP estimates and literature values and the dotted green lines indicate the training range of the cINN. The texts in each panel show the root mean square errors and mean absolute errors between the MAP estimates and the literature values. Since these template stars are class III and have negligible extinction (AV < 0.5 mag) with an estimation uncertainty of 0.2 mag (Manara et al. 2017), we regard |
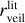
6 Application to Tr14
6.1 Stellar parameter estimation
This section outlines the parameter estimation process for the Tr14 observational data. We feed the stellar spectrum (fλ) normalised by the sum of fluxes at all spectral bins, excluding the masked bins (see Sect. 4), and a median relative flux error (σmed) as an input to the network and generate 4096 posterior samples per observation to get a posterior distribution. We measure the MAP estimates from the marginalised, one-dimensional posterior distribution for each stellar parameter and use them as a representative estimate. However, if degeneracy remains in the prediction, resulting in a multimodal posterior distribution, measuring the representative values from 1D posterior distributions may be problematic. Because the posterior estimates of each stellar parameter correlate to each other, MAP estimates independently measured from the marginalised 1D posterior distribution do not guarantee that they are from the same mode of the multimodal multivariate distribution. By examining the number of peaks (i.e. local maxima) in each 1D posterior distribution, we confirm that we can use the MAP estimate as a reasonable representative value in this work. The detailed analysis of the remaining degeneracy in the posterior distributions is described in Appendix C, providing some example posterior distributions.
Next, we investigate whether the MAP estimates fall well within its training range or if the predictions fall in unlearned areas. As mentioned in Sect. 4, our network is trained on 2600– 7000 K for Teff and 2.5–5.0 for log(g/cms−2) in the case of Settl models and 2600–4000 K for Teff and 3.0–5.0 for log(g/cms−2) in the case of Dusty models, and all models are trained on AV of 0–10 mag and rveil of 0–2. To distinguish the library, we labelled Settl models as 0 and Dusty models as 1. However, the cINN returns continuous values, not a perfect integer, so we consider MAP estimates of the library origin within –0.5 to 1.5 to be valid measurements. In the case of AV and rveil, the cINN can return negative values very close to 0 if the ground truth is either 0 or very close to 0. Therefore, we accept predictions that fall within a ±0.1 mag margin at the boundary condition for AV and within ±0.05 at the boundary for rveil.
In the entire sample, 90% of sources have MAP estimates within the training ranges for all five parameters. The other 10% of the sample have at least one extrapolated MAP estimate with most extrapolations happening in log g. We checked the extrapolated parameters and confirmed that there are no extreme outliers. Most of the extrapolated values are close to the boundary of the training range. For example, MAP estimates of log g larger than 5.0 are mostly distributed near 5.0–5.2 with a maximum of 5.5. For the effective temperature, there are 19 cases of extrapolation in total, with a maximum MAP estimate of 7790 K and a minimum value of 2495 K. However, most of the high Teff values are lower than 7500 K and most of the low Teff values are higher than 2580 K. We found 12 stars having either negative AV or negative rveil values with a minimum AV of –0.9 mag and a minimum rveil of –0.06; however, these do not appear to be extreme outliers. We confirmed that this was caused by the low quality of the spectra rather than cINN performance, so that IT24 measured zero values for these stars as well. Accordingly, we conclude not to exclude these extrapolated MAP estimates in our analysis.
Next, we measure the uncertainty of the stellar parameter estimates (i.e. estimation error) by combining the half-width of the posterior distribution and the intrinsic estimation error of the cINN at the corresponding observation error (Eq. (9)). By including the intrinsic errors, the uncertainty increased by a factor of 2 ~ 4 compared to the half-width of the posterior distribution on average. The uncertainty of stellar parameters is small overall. For the entire sample, the median uncertainties of effective temperature and extinction are 80.6 K and 0.0738 mag, respectively. The amount of uncertainty for the Clean group is even smaller than the other samples. The median uncertainty of each parameter for different sample groups is listed in Table 3. However, it is important to note that while cINN can distinguish very small variations between synthetic models, resulting in small estimation uncertainty listed in Table 3, this uncertainty does not quantitatively reflect the gap between the Phoneix models and real spectra. The measured stellar parameters and their uncertainties are listed in Table 1.
6.2 Stellar parameter comparison
In this section, we compare the stellar parameters estimated by our cINN with those measured by template fitting in IT24 (i.e. TF parameters) from the same MUSE spectra. IT24 could not measure surface gravity because it usually requires higher spectral resolution than that of MUSE to measure surface gravity. Therefore, we only use Teff, AV, and rveil when comparing our MAP estimates with the TF parameters obtained in IT24. We discuss the surface gravity of Tr14 stars estimated by our cINN separately in Appendix B. Additionally, in this section, we exclude 75 stars classified as G8 type in IT24 because their Teff measured in IT24 are just a lower limit.
Fig.5 shows the 1-to-1 comparison of the three stellar parameters (Teff, AV, and rveil) for the Clean and Uncertain groups, where the colour coding denotes the median relative flux error of each star (σmed) used as an input to our cINN. The stellar parameters measured by the two different methods are similar overall, but, for Tr14 stars, the difference between the TF parameters and MAP values is on average larger than that observed for the class III template stars presented in Sect. 5.2 and Paper I. The RMSE of Teff across all stars is 365 K, which is ~2.5 times larger than that we measured for the template stars. However, it is important to note that the TF parameters are not a perfect ground truth and their uncertainty is not negligible, unlike the class III template stars. The average uncertainty of the TF parameters for the Clean samples is about 155 K, 0.48 mag, and 0.42 for Teff, AV, and rveil, respectively. The scatter between MAP estimates and TF parameters for Teff is smaller for cooler stars than for hotter stars. Across the Clean and Uncertain sets combined, the RMSE of Teff for cooler stars (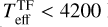 K) is 237 K whereas the RMSE for hotter stars (
K) is 237 K whereas the RMSE for hotter stars (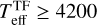 K) is 659 K.
K) is 659 K.
Fig. 5 shows that Teff from template fitting (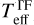 ) are discretised due to the limited number of template stars, whereas the MAP estimates of Teff lie on the interval between different subclasses. Interestingly, IT24 lacked templates between K6 and K4 types (4197–4561 K) so they could not measure the temperature within this range, whereas the cINN measured temperatures between K6 and K4 types for several stars whose
) are discretised due to the limited number of template stars, whereas the MAP estimates of Teff lie on the interval between different subclasses. Interestingly, IT24 lacked templates between K6 and K4 types (4197–4561 K) so they could not measure the temperature within this range, whereas the cINN measured temperatures between K6 and K4 types for several stars whose 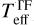 are mostly higher than their
are mostly higher than their 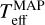 . IT24 also lacked templates hotter than G8 type (5430 K). There are 33 stars whose MAP-based Teff are higher than 5430 K in the Clean samples. 27 of them were classified as G8 type, which are excluded in Fig. 5, 4 of them were classified as G9 type, and the remaining 2 were classified as K0 type by IT24. It is highly likely that IT24 underestimated the temperature of these stars due to the absence of hotter template stars.
. IT24 also lacked templates hotter than G8 type (5430 K). There are 33 stars whose MAP-based Teff are higher than 5430 K in the Clean samples. 27 of them were classified as G8 type, which are excluded in Fig. 5, 4 of them were classified as G9 type, and the remaining 2 were classified as K0 type by IT24. It is highly likely that IT24 underestimated the temperature of these stars due to the absence of hotter template stars.
In the case of extinction, the RMSE between the cINN estimates and TF parameters is 0.67–0.9 mag depending on the sample groups, but for most samples, the cINN estimates agree well with the TF parameters within 1-σ estimation uncertainty. For the veiling factor, we find that TF parameters and MAP values for several stars fall nicely on the one-to-one line, while some stars lie along the y-axis. We found that IT24 measured zero veiling (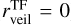 ) for 84% of stars classified as K- or G-types (i.e.
) for 84% of stars classified as K- or G-types (i.e. 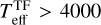 K), whereas the cINN measured a non-negligible amount of veiling (
K), whereas the cINN measured a non-negligible amount of veiling (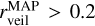 ) for half of them. The RMSE of rveil between TF parameters and MAP values is 0.3 for stars cooler than 4000 K and 0.46 for stars hotter than 4000 K. This large rveil difference for stars hotter than 4000 K is related to large Teff difference in corresponding stars, which is discussed in Sect. 7.2. It is important to note that both IT24 and this study utilise a wavelength-independent veiling model (Eq. (1)), which can be problematic, particularly for stars with high veiling. Therefore, we consider that veiling values are relatively less reliable for cases where rveil > 1 despite the low measurement uncertainty and accurate performance of cINN shown in Sect. 5. This consideration also applies to the veiling values from IT24. The relative flux error represented by σmed is usually smaller for hotter stars than cold stars. We could not find any relation between σmed and the difference between TF parameters and MAP values within the similar temperature groups.
) for half of them. The RMSE of rveil between TF parameters and MAP values is 0.3 for stars cooler than 4000 K and 0.46 for stars hotter than 4000 K. This large rveil difference for stars hotter than 4000 K is related to large Teff difference in corresponding stars, which is discussed in Sect. 7.2. It is important to note that both IT24 and this study utilise a wavelength-independent veiling model (Eq. (1)), which can be problematic, particularly for stars with high veiling. Therefore, we consider that veiling values are relatively less reliable for cases where rveil > 1 despite the low measurement uncertainty and accurate performance of cINN shown in Sect. 5. This consideration also applies to the veiling values from IT24. The relative flux error represented by σmed is usually smaller for hotter stars than cold stars. We could not find any relation between σmed and the difference between TF parameters and MAP values within the similar temperature groups.
We further investigate the difference between MAP estimates and TF parameters for each spectral type group as our samples cover a wide range of spectral types. In this analysis, we only use samples in the Clean group which have relatively small parameter estimation errors. In Fig. 6, we present the fraction of samples where the difference between the TF parameter and the MAP value is either smaller or larger than the indicated criteria in each spectral type group. For Teff, we use the parameter difference normalised by the sum of their 1-σ estimation uncertainties, that is 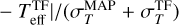 . We check if the Teff difference normalised by their uncertainty is smaller than 1 or larger than 1.5 to evaluate whether the MAP values are in good or bad agreement with the TF parameters. On the other hand, in the case of AV and rveil, we used fixed values for the evaluation, considering the average 1-σ error of AV and rveil.
. We check if the Teff difference normalised by their uncertainty is smaller than 1 or larger than 1.5 to evaluate whether the MAP values are in good or bad agreement with the TF parameters. On the other hand, in the case of AV and rveil, we used fixed values for the evaluation, considering the average 1-σ error of AV and rveil.
In Fig. 6, the spectral types with small temperature differences and those with large temperature differences are clearly separated. Later-type stars up to K6 type (4197 K) mostly have normalised differences below 1, while earlier types from K4 type (4561 K) onwards show more samples with differences above 1.5. The difference in extinction is less dependent on the spectral type compared to the effective temperature, except for M5.5 (3060 K) and M4.5 (3200 K) types, where AV differences above 1 mag are more frequent. This is a systematic trend already shown in Sect. 5.2 and Paper I that cINNs overestimate AV by about 1 mag for cold stars (Teff < 3200 K) even though estimates of the other parameters are accurate. In the case of rveil, cool stars up to K3 type (4733 K) have smaller differences than earlier type stars, similar to the case of Teff. The fractions of samples with a rveil difference larger than 0.4 are higher for earlier type stars above K0 (5172 K), but they are mostly lower than 40%. Based on Figs. 5 and 6, the MAP estimates and TF parameters show good agreement in all three stellar parameters for stars within M4–K6 types which corresponds to 3270–4197 K. Although it depends on the parameters, cool stars (Teff < 4500 K) show generally a good agreement.
To investigate if the degeneracy between stellar parameters affects the difference between MAP values and TF parameters, we examine the correlation between parameter deviations in Fig. 7, only using the Clean samples. The deviation in temperature and the deviation in extinction show a clear positive correlation: for M-types (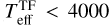 K), the cINN predicts higher Teff and AV than template fitting, while for K/G-type stars (
K), the cINN predicts higher Teff and AV than template fitting, while for K/G-type stars (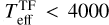 K), the trend reverses. Interestingly, K/G-type stars exhibit a tighter correlation, whereas M-type stars show more scatter with two distinct trends, as seen in the right panel of Fig. 7, where colour indicates rveil differences. For K/G-type stars, cINN tends to predict higher rveil than template fitting, forming a clear correlation: ΔTeff < 0, ΔAV < 0, and Δrveil > 0. Among M-type stars, one group (red circles) follows this trend with Δrveil < 0, while another group, where Δrveil > 0 but small, clusters near the y-axis, meaning AV deviations remain large despite small rveil and Teff deviations. As noted earlier, this aligns with a systematic trend in cINN seen in this study and Paper I, where extinction is overestimated for Teff < 3200 K, even when other parameters are accurately predicted.
K), the trend reverses. Interestingly, K/G-type stars exhibit a tighter correlation, whereas M-type stars show more scatter with two distinct trends, as seen in the right panel of Fig. 7, where colour indicates rveil differences. For K/G-type stars, cINN tends to predict higher rveil than template fitting, forming a clear correlation: ΔTeff < 0, ΔAV < 0, and Δrveil > 0. Among M-type stars, one group (red circles) follows this trend with Δrveil < 0, while another group, where Δrveil > 0 but small, clusters near the y-axis, meaning AV deviations remain large despite small rveil and Teff deviations. As noted earlier, this aligns with a systematic trend in cINN seen in this study and Paper I, where extinction is overestimated for Teff < 3200 K, even when other parameters are accurately predicted.
Median estimation uncertainty of MAP estimates for Tr14 samples in three different sample groups.
 |
Fig. 5 Comparison of the effective temperature (Teff), extinction (AV), and veiling factor (rveil) of stars in Tr14 from TF parameters (IT24) with our corresponding cINN-MAP estimates for the samples in the Clean (top) and Uncertain (bottom) groups. The colour code denotes the median relative flux error along the wavelength of each star which is used as an additional input to our cINN. |
 |
Fig. 6 Calculate fraction of samples where the difference between TF parameter and the MAP value is either smaller than the given criterion (left panels) or larger than the given criterion (right panels) within each spectral type group based on the Teff from TF parameters. We only use the Clean samples in this figure. The y-axis labels present the corresponding spectral type and the number of samples belonging to the spectral type group. We highlight the bar in blue (left panels) or red (right panels) when the fraction is higher than 50%. |
6.3 Hertzsprung-Russell diagram
We further estimate the bolometric luminosities of individual stars following the same procedure as IT24 did. To measure the bolometric luminosity, we first draw the J-band photometry from either the VISTA catalogue (Preibisch et al. 2014) or the HAWK-I catalogue (Preibisch et al. 2011a,b). We chose the one with smaller uncertainty if the J-band magnitude is available in both catalogues. The J-band photometry is the most suitable for deriving bolometric luminosities of young stars. Ongoing accretion onto the star and the presence of a circumstellar disk can cause a near-infrared (NIR) excess of their spectral energy distributions making most of the NIR photometry unreliable for derivation of stellar parameters. At the same time, young stars are heavily extincted which affects short-wavelength photometry. These effects cannot be fully avoided but can be minimised by using the J-band filter (e.g. Kenyon & Hartmann 1995; Luhman 1999).
The bolometric magnitude was calculated following the equation (IT24),
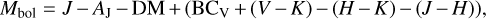 (10)
(10)
where colours and correction values are taken from Kenyon & Hartmann (1995). We calculate the J-band extinction (AJ) using the measured visual extinction (AV) and the extinction law from Cardelli et al. (1989) and apply the distance modulus (DM) of 11.86 mag for Tr14, equivalent to a distance of 2.35 kpc (Göppl & Preibisch 2022, IT24). The final bolometric luminosity was calculated by subtracting the solar bolometric luminosity of 4.74 (Cox 2002) from the bolometric magnitude:
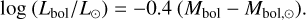 (11)
(11)
The difference in the bolometric luminosity between this work and IT24 arises only from the difference in AV and Teff because all the other values, such as the J-band photometry, are the same.
In the upper panels of Fig. 8, we present 2D histograms of all samples on the Hertzsprung-Russell (HR) diagram, where the left panel is based on the stellar parameters from IT24 and the right panel is based on the stellar parameters from this work. In the lower panels, we present the distribution of each sample group as red (Clean) and blue (Uncertain) contours. PARSEC theoretical isochrones (solid lines) and isomasses (dashed lines; Bressan et al. 2012) are plotted on each HR diagram. The HR diagram from this work appears smoother than that from TF parameters due to the non-discretised temperature measurements. The luminosity for each given spectral type exhibits a considerable spread of about 1.5 dex in both studies. The scatter of the TF parameter-based luminosities for K1–G8 type stars spans 2 dex, covering isochrones from 0.2 to 20 Myr. Since our cINN assigns different Teff to these stars, they shift on the HR diagram, forming two distinct groups: one group of stars lying close to the 1 Myr isochrone and the other group of a few stars around the 20 Myr isochrone. The luminosity spread is broader for Uncertain samples and M-type stars than for Clean samples or K/G-type stars for both the MAP-based luminosity and TF parameter-based luminosity. This spread observed in the HR diagrams can be attributed to several factors such as stellar parameter uncertainties, intrinsic age spread, stellar variability, or unresolved multiplicity (Hartmann 2001; Peterson et al. 2008; Baraffe et al. 2009; Costigan et al. 2014; Venuti et al. 2014; Claes et al. 2022).
One of the distinctive features in the HR diagram based on the MAP values is the high number density around the K5 type. As shown in Fig. 5, many stars classified as K4–K0 type by IT24 are classified as around K5 type by our cINN. This results in the vertical distribution along a temperature of about 4250 K. Based on the isomass lines, most stars have stellar mass lower than 1 M⊙, while the HR diagram based on the TF parameters shows more massive stars up to 3 M⊙. We discuss the distribution of the mass in more detail in the following section.
 |
Fig. 7 Extinction and temperature differences between cINN-MAP estimates and TF parameters for stars in the Clean group using the different colour codes: Teff measured by template fitting (left) and the difference in rveil between MAP estimates and TF parameters (right). The size of the symbol indicates the extinction from TF parameters. |
6.4 Stellar age and mass
By interpolating the PARSEC theoretical evolutionary tracks (Bressan et al. 2012), we calculate the ages and masses of individual stars from their effective temperatures and bolometric luminosities. We note that we only use evolutionary tracks from Bressan et al. (2012) in this paper and that the stellar age and mass can vary depending on the choice of the evolutionary track. In Fig. 9, we compare the distribution of stellar ages from IT24 with that from our work. The purple lines are based on all samples, while the red and blue lines show the distribution for the Clean and Uncertain groups, respectively. The first and the last bins of the histogram are overdense because of the lower and upper limits of the PARSEC theoretical models. We exclude these two bins when calculating the average age of the samples. The purple shading in Fig. 9 indicates the area we used to calculate the average stellar age for all samples. Following the same methodology as IT24, we fit the histogram with a log-normal function and use the peak and standard deviation of the best-fit function (black curves) as the average age and its uncertainty.
Based on the stellar parameters estimated by the cINN, the average stellar age of all samples is 0.7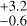 Myr. It is 0.26 dex lower than the average age calculated based on the TF parameters (1.4
Myr. It is 0.26 dex lower than the average age calculated based on the TF parameters (1.4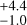 Myr). However, their average ages are still in good agreement within the 1-σ error range because both age values are widely distributed. The individual stellar ages based on the TF parameters and MAP values are different because of different stellar parameters, but the overall distribution and mean value are similar. The Clean samples tend to be at a younger age in comparison to the Uncertain samples in both MAP-based ages and TF parameter-based ages.
Myr). However, their average ages are still in good agreement within the 1-σ error range because both age values are widely distributed. The individual stellar ages based on the TF parameters and MAP values are different because of different stellar parameters, but the overall distribution and mean value are similar. The Clean samples tend to be at a younger age in comparison to the Uncertain samples in both MAP-based ages and TF parameter-based ages.
In the MAP-based HR diagram (Fig. 8), the distribution of stars hotter than ~3600 K (i.e. log Teff > 3.56) is divided roughly around the 5 Myr isochrone. When we examine the age distribution for these 874 stars, a break occurs in the age distribution at log t* of around 6.7 (~5 Myr). About 16% of the 874 stars have log t* > 6.7, showing an age distribution with a peak at log t* ~ 7.2 and an average age of 14.7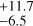 Myr. On the other hand, the average age of the other stars (log t* < 6.7) is 0.5
Myr. On the other hand, the average age of the other stars (log t* < 6.7) is 0.5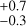 Myr, which is similar to the average age of the entire sample, but the standard deviation is smaller. The age break is not noticeable in the age distribution of lower-temperature stars. It is uncertain whether this break reflects two stellar populations with an age difference of ~ 10 Myr or whether the observed separation is a spurious feature because stellar ages are subject to significant uncertainties due to several factors (e.g. parameter uncertainty, evolutionary tracks).
Myr, which is similar to the average age of the entire sample, but the standard deviation is smaller. The age break is not noticeable in the age distribution of lower-temperature stars. It is uncertain whether this break reflects two stellar populations with an age difference of ~ 10 Myr or whether the observed separation is a spurious feature because stellar ages are subject to significant uncertainties due to several factors (e.g. parameter uncertainty, evolutionary tracks).
In Fig. 10, we present the distributions of stellar masses obtained from the TF parameters and MAP estimates. The mass of the Tr14 sources ranges from 0.1 M⊙ to 5 M⊙. To compare the mass distribution with well-known initial mass functions (IMFs; Kroupa 2001; Chabrier 2003), we calculate the number density of the star at the given mass bin. In the TF parameter-based mass distribution, there is a valley around 0.8–1 M⊙, which is also exhibited on the HR diagram (Fig. 8). This feature is attributed to the lack of templates between K4 and K6 types. On the other hand, there is no such limitation in the MAP-based masses, but the MAP-based stellar masses show an overdense region around 0.7–0.8 M⊙.
Both TF parameter-based and MAP-based stellar mass distributions follow the initial mass functions relatively well for m* > 0.3 M⊙. On the other hand, the number density decreases in the lower mass range m* < 0.3 M⊙ unlike the IMFs. This is because of the selection bias rather than physical reasons. As it is difficult to detect cold and faint stars with enough S/N, we suspect that most of these stars are not observed or are excluded from the catalogue of IT24. Even if they are observed with enough S/N, our classification methods cannot classify these stars properly because the lower limit of the template stars used in IT24 is M9 type (2400 K) and the lower training limit of our cINN is 2600 K. Therefore, very low-mass stars below 0.2–0.3 M⊙ are out of our scope and we lack the samples in this mass range. We do not focus much on the comparison of the mass distributions with the two IMFs because the stellar mass range of Tr14 samples in this study is too narrow to cover the overall mass range of the IMF.
 |
Fig. 8 Hertzsprung-Russell diagrams of Tr14 stars based on the stellar parameters from IT24 (left panels) and the stellar parameters from this work (right panels). In the upper panels, we plot 2D histograms using all samples, while in the lower panels, we plot contours dividing the samples into the Clean (red) and the Uncertain (blue) groups. We overplot PARSEC theoretical evolutionary tracks (Bressan et al. 2012) where solid lines indicate isochrones from 0.2 to 20 Myr and dashed lines indicate isomasses of 0.3, 0.7, 1, and 3 M⊙. |
 |
Fig. 9 Histograms of stellar age calculated from the TF parameters (left) and stellar age derived from the MAP values (right). The red and blue lines show the distribution of the Clean and Uncertain sample groups, respectively. We fit the purple shaded area with a log-normal function and plot the best-fit curve as the black solid line. The peak of the best-fit curve, denoted by a vertical black dotted line, is used as an average stellar age. |
 |
Fig. 10 Number density of stars within a given mass bin as a function of stellar mass from the TF parameters (left) and from the MAP values (right). The red and blue lines show the distribution of the Clean and Uncertain sample groups, while the purple lines and purple-shaded areas indicate the distribution of all samples. We present the initial mass functions from Kroupa (2001) and Chabrier (2003) with pink and cyan lines, respectively. |
6.5 Which method fits better
In this section, we verify whether the estimated parameters from each method reproduce the original input observation (i.e. stellar spectrum) well and investigate which method better explains the given observation. We reproduce the modified template spectra used in IT24 and the synthetic Phoenix spectra based on the MAP estimates. We first select the appropriate Phoenix library by rounding off the MAP estimate of the library flag to either 0 (Settl) or 1 (Dusty). If the library flag estimate is between 0.2 ~ 0.8, we define this as an ambiguous case and produce two spectra using both Settl and Dusty, respectively. We feed the MAP estimates of effective temperature and surface gravity to our Phoenix interpolation pipeline and add the veiling effect and extinction. Here, we call this synthetic spectrum generated based on MAP estimates a resimulation or a resimulated spectrum.
About 8% of the Tr14 samples had MAP estimates of either Teff or log g outside of the training range, where most of them were outliers in surface gravity. However, our interpolation pipeline is not able to extrapolate spectra for these cases. Considering that surface gravity has a comparatively small influence on the overall shape of the spectrum in contrast to Teff, AV, and rveil and that the degree of log g extrapolation is small enough (see Sect. 6.1), we reproduce synthetic spectra for these cases by clipping the extrapolated log g values to the upper or lower limit. In the case of Dusty model-based resimulated spectra, we computed resimulated spectra for log g predictions of up to 5.5, even though that exceeds the formal upper limit of 5 because Dusty models with a log g of up to 5.5 exist in our recent version of the interpolation pipeline. We exclude 15 stars with extrapolated Teff estimates that we could not generate synthetic spectra.
On the other hand, to compare the cINN performance with the template fitting, we reproduce the modified template spectrum following the same process as implemented in IT24, by choosing the same template star, adding the veiling effect, and reddening the spectrum using the rveil and AV values of TF parameters. We normalise the spectra by the sum of the fluxes across the spectral bins within the common wavelength range between the template spectra and the MUSE spectra (i.e. 5600– 9350 Å) excluding the bins masked due to the presence of emission lines (grey areas in Figs. 1 and 13). This is different to the normalisation used in IT24 for the template fitting (i.e. the normalisation by the flux at 7500Å).
To evaluate the goodness-of-fit, we compute the RMS of the residual between the input spectra and resimulated spectra or the input spectra and modified templates. When calculating this evaluation index, we only use the overlapping wavelength range between the template spectra and the MUSE spectra (5600– 9350Å). We exclude spectral bins with emission lines, listed in Sect. 4, because the Phoenix model does not produce the emission lines and so those ranges were excluded in the input of the cINN as well. The calculated RMSEs are weighted by the S/N at each spectral bin to consider the flux error.
The average RMSE of the resimulated spectra is (2.5 ± 1.1) × 10−5 for the Clean samples and (6.2 ± 4.9) × 10−5 for the Uncertain samples. The average RMSE of the modified templates is (2.7 ± 1.2) × 10−5 and (6.3 ± 4.9) × 10−5 for the Clean and Uncertain samples, respectively. The RMSEs are sufficiently small in general because both methods found their best-fit results. In both methods, there is a common trend where the lower the temperature of the stars, the larger the overall RMSE values are. For instance, in the Clean samples, the average RMSE for M-type stars is approximately 3 × 10−5, for K-types it is about 2 × 10−5, and for G-types, it is about 1.7 × 10−5. Regardless of methodological differences, stars with lower temperatures inherently exhibit larger RMSEs, but also their spectra are the most noisy. This trend has also been reported in Paper I.
Considering the smaller RMSE in the observational space as indicative of a better fit, we investigate whether a resimulated spectrum or a modified template spectrum is chosen as a better fit for each star. The histogram in Fig. 11 shows the distribution of the differences between the RMSE of the resimulated spectra and the RMSE of the modified templates. The median for the Clean group is -0.09 × 10−5, while it is -0.08 × 10−5 for the Uncertain group. As the RMSEs of both methods are small, their difference is also minor. The RMSEs of the resimulated spectra are slightly smaller than those of the modified template spectra. The bar plot in the right panel of Fig. 11 examines the frequency of which method is chosen as the better fit. If the absolute RMSE difference is smaller than 0.3 × 10−5, we consider it difficult to determine which of the two is superior and mark them as similar (purple bar). For 61% of the Clean samples, the two methods show comparable RMSE, while for the other 29% of the samples, the resimulated spectrum has a smaller RMSE than the modified template, meaning that the resimulated spectrum is closer to the original input spectrum. Only in 10% of the samples, the modified template is better than the resimulated spectrum. In the case of the Uncertain group, the modified template shows better fit for 21.5% of the samples but the resimulation spectrum is still better for more samples (30.5%). These results show that statistically both methods find the best fit at a similar level for more than half of the samples, but for the rest, the resimulated spectra are slightly more likely to match the original spectra better than modified templates.
For the detailed analysis, we split the samples into two groups based on the stellar parameter differences: small dX and large dX. We expect one method to have a much smaller RMSE than the other if the parameter difference is large. If |ΔTeff| > 500 K or |ΔAV| > 1 mag or |Δrveil| > 0.5, it is classified as large dX, meaning that the parameter difference is large and otherwise as small dX. Here we exclude 75 stars classified as G8-type in IT24 because their Teff are just a lower limit. Then we further divide the sample groups according to the spectral type. In Fig. 12, we present the comparison of the goodness-of-fit as shown in Fig. 11 by dividing the samples into small dX and large dX groups and separating them into three categories based on 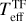 : M types, late K types (up to K6 type), early K and late G types (K6–G9). Additionally, we present four examples of MUSE spectra selected from the Clean samples, together with the modified template spectra and the resimulated spectra in Fig. 13.
: M types, late K types (up to K6 type), early K and late G types (K6–G9). Additionally, we present four examples of MUSE spectra selected from the Clean samples, together with the modified template spectra and the resimulated spectra in Fig. 13.
Fig. 12 shows that while the results in the large dX and small dX groups are similar, the results vary significantly with spectral types. In the case of M-type stars, the RMSE of the resimulated spectrum and that of the modified template are similar for about half of the samples. For the remaining samples, neither method is dominant in the bar plot and has a similar amount of around 25%. The first example in Fig. 13 (upper left panel) shows the spectrum of an M2 star. In this case, the stellar parameters derived from template fitting and those from cINN are in good agreement and both the modified template spectrum and the resimulated spectrum satisfy the observed spectrum well with a similar RMSE.
For late K-type stars (up to K6 type), there is almost no difference between the small dX and large dX groups. Interestingly, for 65% of the samples, the resimulated spectrum fits better than the modified template, which is a significantly larger fraction compared to M-types. The second example in Fig. 13 (upper right panel) is one of the K6-type stars classified as a small dX group. The resimulated spectrum of this star fits better with the observed spectrum than the modified template spectrum.
Fig. 5 showed that stars earlier than K6 type often have large differences in Teff and rveil, where the cINN predicts smaller Teff and larger rveil values compared to TF parameters. When parameter differences are small for early K or late G type stars, the resimulated spectra and modified template spectra show similar RMSE for 65% of the samples, while resimulated spectra have smaller RMSE for the majority of the other samples. On the other hand, when the parameter difference is large, it is more likely that the resimulated spectrum has a much smaller RMSE than the modified template spectrum.
The third and fourth panels (lower panels) in Fig. 13 show examples of early K-type stars, where differences between MAP estimates and TF parameters are large. In the former case (lower left panel), the parameter differences are considerably large whereas the RMSEs of the modified template spectrum and the resimulated spectra are similar. Both spectra satisfy the observation well, but the template spectrum fits better for λ > 8000 Å, whereas the resimulated spectrum fits better for the rest of the wavelength range. The latter case (bottom right panel in Fig. 13) is one where the parameter difference is large and one method clearly shows a better fit than the other. This star classified as K2 by template fitting is classified as M0.4 by the cINN and the corresponding resimulated spectrum satisfies the observation better than the template spectrum.
Summarising these results, for 53% of the total samples, both methods satisfy the observed spectrum to a similar level. But for the other cases, it is more common that the resimulated spectrum fits the input spectrum better than the modified template. If the stellar parameter differences between the two methods are large, the fraction of samples whose resimulation has a smaller RMSE slightly increases, especially for the case of stars earlier than K6 type.
 |
Fig. 11 Left: Comparison of the goodness-of-fit on the observational space: the difference between the RMSEs of the resimulated Phoenix spectra and the RMSEs of the modified template spectra. Right panel: Number of samples where the corresponding method has a better fit (i.e. a smaller RMSE) to the original input spectrum. If the difference between the RMSEs is within 0.3 × 10−5, they are classified as “similar”. These cases are indicated by the purple shaded area in the left panel and a purple bar in the right panel. We use the Clean group in the upper panels and the Uncertain group in the lower panels. |
 |
Fig. 12 Comparison of RMSE on the observational space for small dX and large dX groups for different |
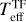
 |
Fig. 13 Four examples of MUSE spectra (solid black line) together with the best-matching modified template spectra (solid blue line) chosen in IT24 and the resimulated Pheonix model spectra based on the cINN predictions (MAP estimates). The resimulated spectrum is described by either a red (Settl) or green (Dusty) dash-dot line depending on the MAP estimate of the library flag. For both the template fitting and cINN-based result, we present RMSEs between the fitted spectra and the original MUSE spectrum in the legend and list the measured stellar parameters in the table. All the spectra are normalised by the sum of the fluxes across all spectral bins within the common wavelength range between the template spectrum and MUSE spectrum (i.e. 5600–9350 Å) excluding the bins masked due to emission lines (grey shades). The surface gravity value for the template is the log g value of the corresponding template star, not measured from the Tr14 spectrum. |
7 Discussion
7.1 Sources of uncertainty: cINN
We discuss the methodological limitations and weaknesses of the two different parameter estimation methods, the cINN and template fitting method used in IT24, and outline the sources of uncertainty and inaccuracies in the estimation. The main factors that influence the accuracy and reliability of the estimation by our cINN include the basic predictive performance, targets outside the training range, flux error, and the simulation gap.
The basic predictive performance refers to how well the cINN captures the underlying physical rules in the Phoenix models. This performance is validated immediately after the training by evaluating the performance of the cINN on the synthetic test models which follow the same physical rules as the training models but are not used in the training. The network may fail to fully learn from the training data if the underlying physics of the training data is too complex relative to the capacity of the network (e.g. depth of the network). Training difficulty is influenced by several factors such as the complexity of the physical laws and whether the observational data contains sufficient information to constrain the target parameters. In our studies, we have demonstrated the excellent predictive performance of our cINNs. In Paper I, the cINNs exhibited remarkable accuracy on the test models, demonstrating their capability to capture the physics of the Phoenix models. In this paper, we also demonstrated the good predictive performance of our cINN on the test set as a function of the relative flux error in Sect. 5.1. Therefore, in Paper I and this paper, the predictive performance of our cINN is highly reliable, with minimal impact on the estimation uncertainty. In addition, we demonstrated that the synthetic spectra resimulated based on the estimated parameters for Tr14 stars fit the input observations well, further confirming that the cINN effectively interprets the input observations based on the knowledge acquired during training.
Secondly, if the cINN encounters an unforeseen target, that is a star with properties outside the training range, its parameter estimates may be uncertain. Our cINN is trained on Teff between 2600 and 7000 K (M8–F3 types), log g of 2.5–5, AV of 0–10 mag, and rveil between 0 and 2. The accuracy of the cINN for stars outside these ranges is currently untested and therefore uncertain. Plus, since the metallicity of our training data is fixed to solar metallicity, stars whose metallicity deviates significantly may also result in uncertain estimations. However, we suggest that our training ranges sufficiently cover the characteristics of the Tr14 stars in this study and the young, low-mass stars we are interested in. The AV and rveil ranges span a sufficiently wide interval, encompassing the values reported in IT24 and the log g range also includes most of the probable log g values of young stellar objects found in the literature (e.g. Frasca et al. 2017; Manara et al. 2017; Olney et al. 2020). Furthermore, we obtain parameter predictions falling well within the training ranges for most Tr14 stars in this study.
Still, about 10% of Tr14 stars have at least one parameter outside the training range (Sect. 6.1). This may be due to the properties of those stars falling outside the training range, although the exact cause cannot be determined. We do not guarantee that the cINN can extrapolate accurately because we did not test on Phoenix models beyond the current Teff-log g space. Nevertheless, we cautiously claim that the extrapolated values presented in this study are reliable as most of the extrapolations in this work are log g values only slightly larger than the upper training limit of 5, falling mostly below 5.2. Given the log g values measured between 5 and 5.5, it is worth extending the training range of log g up to 5.5 in future studies.
The third factor is the relative flux error. Our cINN, the Noise-Net, accounts for the uncertainty caused by flux errors in parameter estimation. In Sect. 5.1, we demonstrated that although the parameter estimation error increases with relative flux error (σmed), our cINN remains accurate at typical σmed value of our Tr14 samples (1–10%, see Table 2 for detailed values). Since the training is limited to log σmed between –5 and –0.5, performance beyond this range is uncertain. We set this training range based on the relative flux errors in the Tr14 data so that for most Tr14 samples, the relative flux error falls within it (Fig. 1). In the Clean samples, only one star exceeds the log σmed limit, while in the Uncertain samples, there are 164 cases (12.4%), though most of their log σmed are below 0 and are not excessively large. Kang et al. (2023a), which first proposed the setup of the Noise-Net, tested the performance of the Noise-Net on errors beyond its training limit and found that parameters obtained by feeding errors exceeding the upper limit are similar to those obtained by clipping the error to the upper limit. The posterior distribution for the former case was slightly wider than that for the latter, though the difference was negligible overall. Kang et al. (2023a) concluded that the Noise-Net does not produce erratic predictions, even for unexpectedly large observational errors but instead estimates parameters by self-clipping the observational error close to the upper limit. Therefore, even for log σmed > –0.5, we suggest that the measured MAP value is reliable, although the width of the posterior distribution (i.e. estimation error) may be underestimated.
Additionally, we used one σ value per spectrum, that is σmed, at all spectral bins because of the difficulties in training, which may affect the parameter estimation by underestimating or overestimating σλ especially at outer wavelength ranges. In Sect. 2.1, we confirmed that the level of underestimation at bluer wavelength ranges was relatively small for the earlier types which should be more sensitive to this issue. However, concerning the underestimation of relative flux errors, we further investigated how cINN prediction changes if we increase σmed of Tr14 samples and confirmed that the changes in MAP estimates were not significant enough to affect the overall results in this study. The RMSE between the original MAP estimates and the MAP estimates obtained at five times larger σmed values was 53 K, 0.082 dex, 0.044 mag, and 0.071, for Teff, log g, AV, and rveil, respectively, when we use the entire 2051 stars. We suggest that our methodological limitation may influence parameter estimation, but the impact is unlikely to be significant in the present study. We will adopt a better approach to handle wavelength-dependent relative flux errors in future studies.
The last factor, the simulation gap, has the most significant impact on the reliability of the parameters obtained by cINN. We proved through several experiments that the cINN effectively learned from the training data and correctly interpreted the observed data. However, the cINN cannot overcome the gap between the training data (i.e. Phoenix models) and actual observations. In most astronomical problems, it is common to use synthetic observations for training machine learning models because it is very difficult to collect a sufficient number of real data with highly accurate parameters and high-quality observations at the same time. In Paper I, we roughly quantified the simulation gap between the Phoenix models and the class III template spectra and found that the gap is larger in M-type stars than in hotter stars.
The simulation gap is an inherent limitation not only for our cINN but also for all methodologies that use theoretical models to analyse real data. For example, estimating stellar masses and ages using evolutionary tracks or spectral energy distribution (SED) fitting using synthetic spectra are both subject to the limitations of the simulation gap. However, interpreting real observations using theoretical models is a widely used and accepted methodology in many studies. Moreover, the Phoenix models used in this paper have also been used in numerous other studies to obtain stellar parameters from observations. For example, Frasca et al. (2017) and Manara et al. (2017) measured the stellar parameters of young stars by fitting the observed spectra with the Settl model and validated that the measured parameters agreed well with the spectral type measured using spectral indices. Bayo et al. (2017) also used Settl models for SED fitting and Rajpurohit et al. (2018) classified M dwarfs using Settl models and demonstrated that the Settl model accurately reproduces the characteristic features of the stellar spectrum. Since we demonstrated that our cINN effectively captures the underlying rules in the Phoenix models, the uncertainty resulting from the simulation gap in our cINN is comparable to that in other studies using the same Phoenix models.
7.2 Sources of uncertainty: Template fitting in IT24
In this section, we discuss the limitations and weaknesses of the classification method used in IT24 that can affect the reliability of the estimated parameters. In particular, we focus on the classification method used for K- or G-type stars where three parameters (Teff, AV, and rveil) were not considered simultaneously. The details of the method are described in Sect. 2.2.
The main sources of uncertainty in IT24 include the low density of the template grid, the uncertainty of the template parameters, and the failure to consider all three parameters simultaneously for K/G-type stars. The first two factors represent the general limitations of the template fitting method. The grid of templates based on real data is less dense than the training data of cINN unless interpolation-like techniques (e.g. Fang et al. 2021; Claes et al. 2024) are employed. IT24 used 37 template stars ranging from M9.5 to G8, most of which have 0.5 subclass intervals for M types and 1 subclass intervals for K/G types. However, IT24 lacked a template between K6 and K4, corresponding to a temperature interval of approximately 350 K, and could not analyse the stars within this temperature range (see Figs. 8 and 10). Additionally, the maximum temperature of the template grid was G8 (5430 K), which is too low for some hotter stars. Several stars were classified as between K4–K6 type or as hotter than G8 by the cINN, highlighting the importance of the diversity of templates in improving the accuracy of parameter estimation in the template fitting method. Furthermore, as the template grid had only one or two stars per spectral type, the influence of surface gravity was neglected in IT24.
The most critical factor we focus on is that for K- and G-type stars, the temperature was determined independently, without considering other parameters, particularly veiling. The equivalent widths (EWs) of absorption lines decrease in the presence of veiling (Herczeg & Hillenbrand 2014). According to the constant veiling model used in both IT24 and this paper (Eq. (1)), the EWs decrease by about 50% when rveil is 1. Since EWs are sensitive to veiling, measuring the spectral type without accounting for veiling may result in incorrect spectral classification. Rugel et al. (2018) highlighted the importance of considering the degeneracy between spectral type, extinction, and accretion of pre-main-sequence stars, and Fang et al. (2021) showed that the temperature is overestimated if the veiling is not considered in the classification process. If veiling is determined after fixing the spectral type, we are likely to measure very small or zero veiling because the spectral type is already determined based on the veiled spectrum. This trend is revealed in the fact that about 84% of the hot stars have rveil of 0 when estimated by template fitting.
To investigate the influence of veiling on the spectral type determination based on EWs, we examine the change of spectral type by increasing the veiling on the class III template stars used in IT24 within the K7–G8 range. We first calculate the spectral type on a pure template spectrum without any extinction and veiling, that is SpT(r = 0). Next, we add veiling to the template spectrum following Eq. (1) and measure the spectral type again, where rveil increases from 0 to 2 in 0.1 intervals. Fig. 14 exhibits how dramatically the spectral type changes under the influence of veiling. A difference of 1 in the y-axis corresponds to a one-subclass difference. The impact of veiling varies depending on the original spectral type. Late K types are more sensitive to veiling than earlier types. According to this experiment, at a rveil of 0.5, the spectral type of K6 and K7 types is overestimated by about four subclasses (about 700 K higher) and for early K types, it is overestimated by 2–3 subclasses (200–300 K). In the case of G types, the spectral type increases by about 1–2 subclasses (100–200 K).
We suspect that the temperature difference between the TF parameters and the MAP values in K/G-types is highly affected by this veiling problem because the MAP values are mostly smaller than the TF parameters by ~600 K whereas the difference in Teff for M-type stars is about 200 K. Therefore, we convert each temperature value into spectral type (SpTTF and SpTMAP) and compare the SpT difference with MAP-based veiling (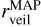 ). In Fig. 15, we split the Clean samples into two groups depending on the MAP-based SpT and present the correlations between SpT difference and veiling in Tr14 samples. Here, we exclude stars classified as G8 type by template fitting. The reason for using MAP-based veiling is that if SpTTF was influenced by veiling, it is highly probable that
). In Fig. 15, we split the Clean samples into two groups depending on the MAP-based SpT and present the correlations between SpT difference and veiling in Tr14 samples. Here, we exclude stars classified as G8 type by template fitting. The reason for using MAP-based veiling is that if SpTTF was influenced by veiling, it is highly probable that 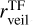 was underestimated. We also compared SpT difference with veiling difference (
was underestimated. We also compared SpT difference with veiling difference (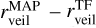 ) and found no significant change from Fig. 15, as most of
) and found no significant change from Fig. 15, as most of 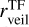 is 0. Generally, the higher the veiling, the larger the SpT difference, as we showed in Sect. 6.2 (see Fig. 7). In each panel, we plot the SpT difference in comparison to the curves of the template stars presented in Fig. 14, for corresponding SpTMAP ranges. Interestingly, the overall distribution of the Tr14 stars follows the SpT difference curves of the templates well. The change of SpT is more dramatic in late K types than earlier types in both Tr14 stars and templates. Despite the scatter in individual stars (blue circles), the average trends marked with the blue squares are almost identical to the curves obtained from the templates. The average values are calculated within a veiling interval of 0.2. We exclude stars in the average calculations whose MAP-based SpT are earlier than G8 (5430 K), the maximum temperature of the template fitting, because their temperature differences may be due to the lack of hotter templates.
is 0. Generally, the higher the veiling, the larger the SpT difference, as we showed in Sect. 6.2 (see Fig. 7). In each panel, we plot the SpT difference in comparison to the curves of the template stars presented in Fig. 14, for corresponding SpTMAP ranges. Interestingly, the overall distribution of the Tr14 stars follows the SpT difference curves of the templates well. The change of SpT is more dramatic in late K types than earlier types in both Tr14 stars and templates. Despite the scatter in individual stars (blue circles), the average trends marked with the blue squares are almost identical to the curves obtained from the templates. The average values are calculated within a veiling interval of 0.2. We exclude stars in the average calculations whose MAP-based SpT are earlier than G8 (5430 K), the maximum temperature of the template fitting, because their temperature differences may be due to the lack of hotter templates.
The overall results in Fig. 15 support our hypothesis that the main cause of the temperature differences in K/G-type stars is because the veiling is not considered in the SpT determination in IT24. This may not be the only cause of the temperature difference considering the scatter shown in Fig. 15. However, the distributions varying on the spectral type match well with the results of templates at the same temperature range, implying that the veiling is a major cause of the temperature difference. Moreover, in the case of the M-type stars, MAP-based temperature and template fitting-based temperature agree well even though non-neglectable veiling exists (Fig. 6). We claim that this is because IT24 considered temperature and veiling simultaneously for M-type stars.
In the case of K/G-type stars, extinction is not considered simultaneously with temperature either, but we expect the impact of neglecting extinction to be smaller than veiling because reddening the spectrum does not significantly change the EWs. We also examine the SpT change as a function of the extinction using the template stars, in the same way we tested the influence of veiling. We redden the template spectrum by increasing the AV from 0 to 5 mag in 0.2 mag intervals. Fig. A.3 shows that the influence of extinction on SpT is very small compared to the veiling. The trend varies a lot depending on the original SpT but the SpT changes within 0.3 subclass in AV of 1–4 mag, the typical AV range of the Tr14 samples. As the maximum SpT difference is about 0.4 subclass, below the precision level of SpT measured in IT24, we expect that extinction does not significantly affect the measured SpT in IT24.
 |
Fig. 14 Difference of spectral type measured for veiled templates to the spectral type measured for pure templates without veiling as a function of the veiling factor. We measure the spectral types using the same methodology used in IT24, which is based on the equivalent width of several absorption lines. The colour denotes the Teff of the template. |
 |
Fig. 15 Comparison of spectral type differences between TF parameters and MAP values to the MAP veiling values for the Clean samples of Tr14 (blue dots). The samples are divided into two groups depending on the spectral type based on the MAP values. Stars classified as G8 by template fitting are excluded. The blue squares represent the average values calculated within the veiling interval of 0.2. When calculating the average values, we exclude stars whose MAP-based temperature exceeds the maximum template fitting temperature of 5430 K (G8 type). The coloured lines correspond to the curves presented in Fig. 14, which show the change of the spectral type as a function of the veiling tested on the template stars. |
7.3 Veiling and NIR excess
Factors contributing to the observed veiling include ultraviolet and optical emission from the mass accretion process of young stars, as well as infrared (IR) emission from the protoplanetary disk. The continuum emission by accreting young stars is more easily detected as Balmer continuum emission and characteristic Balmer jump (Gullbring et al. 1998; Herczeg & Hillenbrand 2008; Rigliaco et al. 2012; Alcalá et al. 2014), but neither are observable within the MUSE wavelength range. Given the MUSE spectral range (4750–9350 Å), the veiling observed in our sample primarily results from Paschen continuum emission (3646–8203 Å), which is dimmer than the Balmer emission (Alcalá et al. 2014). Although mass accretion generates various emission lines (e.g. helium and calcium lines and Paschen series), neither IT24 nor our study utilised these lines for rveil measurements. IR emission from the disk can partially affect the longest wavelengths of the spectrum. Therefore, the veiling measured in IT24 and this study primarily reflects mass accretion rather than contributions from the disk.
One of the key limitations of the veiling values measured in both IT24 and this study is the assumption of a wavelength-independent veiling model (Eq. (1)). While this approximation can be applicable within the MUSE spectral range (4750– 9350 Å), which does not include the Balmer jump, it has clear limitations that become particularly significant for stars with high veiling. Both IT24 and this study limited the veiling factor, rveil, to 0–2. As a result, heavily veiled stars requiring rveil > 2 may not have been properly classified and were likely excluded from the final catalogue in IT24 although such stars could exist given the age of Tr14. However, we note that there may be some heavily veiled stars remaining in our samples with underestimated veiling values, although clearly identifying such cases is challenging. As the measured high veiling values may be uncertain due to limitations in the current simple veiling model, we consider that the reliability of veiling measurements, both from template fitting and cINN, is relatively low for high veiling values (rveil > 1). However, in Tr14 samples, only 110 stars (5%) exhibited MAP-based veiling values larger than 1, with just 27 stars among the Clean sample. Similarly, veiling values larger than 1 obtained in IT24 also constituted about 4% of the total sample, indicating that high veiling values are relatively rare in this study.
Additionally, the measured veiling values from both the cINN and in IT24 are less reliable for early K and G-type stars because veiling becomes less influential in changing the overall shape of the spectra for these stars compared to that of M-type stars. The average error of rveil from IT24 is 0.67 for K/G-type stars while it is 0.27 for M-type stars. This implies that veiling has minimal impact on chi-square fitting for K/G types, making accurate veiling measurements challenging. Fig. A.1 shows that the average intrinsic error of rveil from cINN is also higher for K/G-type models than M-type models at the same level of relative flux error, indicating that measuring rveil becomes challenging for hotter stars. To improve the veiling measurement, we need a more complex, wavelength-dependent model, such as the hydrogen slab model which has been widely used in many studies (e.g. Valenti et al. 1993; Herczeg & Hillenbrand 2008; Rigliaco et al. 2012; Manara et al. 2013a; Alcalá et al. 2014). Although improving the model might not entirely overcome the difficulties in measuring veiling within the MUSE spectral range due to the absence of distinct features such as the Balmer jump, we will adopt a more sophisticated veiling model in future studies.
IT24 determined whether stars exhibited NIR excess based on NIR photometry data (J-, H-, K-bands) by matching with the HAWK-I (Preibisch et al. 2011a) and VISTA (Preibisch et al. 2014) catalogues and following the definition from Zeidler et al. (2016). We use this NIR excess flag and check the validity of the measured veiling values in this study and IT24. However, it is important to note that this flag is only based on NIR photometry data and we need MIR data to accurately detect IR excess by protoplanetary disks. We also investigate the fraction of stars with a non-negligible amount of veiling (fveil) by setting a threshold of 0.2 (i.e. rveil > 0.2). The average estimation uncertainty for rveil of around 0.1 from the cINN is very small, but it does not quantitatively reflect other uncertainty factors such as the simulation gap. Therefore, when calculating fveil, we adopted the 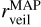 error of 0.15 for all Tr14 stars based on our test results on class III template stars (Sect. 5.2).
error of 0.15 for all Tr14 stars based on our test results on class III template stars (Sect. 5.2).
In the entire sample, only 25% of stars exhibit NIR excess (fNIR), while fveil is 0.45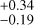 and 0.26
and 0.26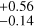 based on MAP estimates and TF parameters, respectively. The low fNIR is surprising given the age of Tr14 and Preibisch et al. (2011b) interpreted itas an impact of the harsh environment accelerating disk dispersal. We found that both template fitting and cINN results show a decreasing trend in fNIR and fveil for M type stars. Based on TF parameters, fveil decreases from 0.64 to 0.25 and fNIR decreases from 0.68 to 0.16 when
based on MAP estimates and TF parameters, respectively. The low fNIR is surprising given the age of Tr14 and Preibisch et al. (2011b) interpreted itas an impact of the harsh environment accelerating disk dispersal. We found that both template fitting and cINN results show a decreasing trend in fNIR and fveil for M type stars. Based on TF parameters, fveil decreases from 0.64 to 0.25 and fNIR decreases from 0.68 to 0.16 when 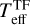 increases from 2700 to 4000 K. When using MAP estimates, fveil is overall higher than when derived from TF parameters, but it similarly decreases from 0.84 to 0.31 with increasing
increases from 2700 to 4000 K. When using MAP estimates, fveil is overall higher than when derived from TF parameters, but it similarly decreases from 0.84 to 0.31 with increasing 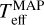 , while fNIR decreases from 0.49 to 0.24. However, for Teff > 4000 K, fveil and fNIR exhibit different trends depending on the methods used. Based on MAP estimates, fNIR gradually decreases from 0.24 to 0.1 with increasing
, while fNIR decreases from 0.49 to 0.24. However, for Teff > 4000 K, fveil and fNIR exhibit different trends depending on the methods used. Based on MAP estimates, fNIR gradually decreases from 0.24 to 0.1 with increasing 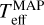 , whereas fveil increases from 0.31 to 0.65. However, high values of fveil at around 0.6 for stars with Teff > 4800 K are less reliable due to the small sample size. On the other hand, when using TF parameters, fNIR gradually increases from 0.16 to 0.35 within the K7–G9 type interval. Within this temperature range, fveil based on
, whereas fveil increases from 0.31 to 0.65. However, high values of fveil at around 0.6 for stars with Teff > 4800 K are less reliable due to the small sample size. On the other hand, when using TF parameters, fNIR gradually increases from 0.16 to 0.35 within the K7–G9 type interval. Within this temperature range, fveil based on 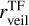 is small with a value of 0.08
is small with a value of 0.08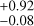 and without significant change but the uncertainty is too −large to for a meaningful interpretation.
and without significant change but the uncertainty is too −large to for a meaningful interpretation.
We examined how the distribution of stars on the colour– colour diagram varies with the spectral type (M or K/G types) and rveil using the NIR colours from the HAWK-I catalogue (Preibisch et al. 2011a). For this analysis, we only use the Clean sample, where stellar parameters are expected to be more reliable. In both IT24 and this study, most M-type stars with rveil < 0.1 do not exhibit NIR excess ( fNIR = 0.06), suggesting that rveil < 0.1 is a reliable indicator of minimal extra emission from either accretion or a disk. In Fig. A.5, 20% of K/G-type stars with 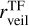 < 0.1 still exhibit NIR excess with large H - K colour. As discussed in Sect. 7.2, this supports our hypothesis that IT24 likely underestimated the veiling of these stars.
< 0.1 still exhibit NIR excess with large H - K colour. As discussed in Sect. 7.2, this supports our hypothesis that IT24 likely underestimated the veiling of these stars.
In Figs. A.4 and A.5, stars with higher veiling tend to have a higher fNIR. This trend appears consistently across spectral types in the MAP-based results (Fig. A.4). However, even among M-type stars with rveil > 0.3, nearly half do not show NIR excess. Given that the stellar parameters for M-type stars are reliable, as shown by the consistency between template fitting and cINN results, it is likely that a significant fraction of these stars have correctly measured veiling but undetected IR excess. In the case of K/G-type stars, some stars with high veiling but without NIR excess may have inaccurate veiling measurements because of the limitations of the veiling model and difficulty in veiling measurement for K/G types. However, some K/G-type stars do show clear excess and fNIR is also higher for stars with high veiling. As in the case ofM-type stars, it is still likely that veiling is correctly measured for a significant number of stars without NIR excess.
We examined the validity of the measured rveil using the NIR photometry but could not filter out misclassified veiling values. We suspect that the NIR excess flag did not fully capture the presence of actual IR excess because it is based on NIR photometry. The fact that the average rveil is higher for stars with NIR excess than those without suggests that the NIR excess does indicate a higher probability of a disk and accretion. However, more than 30% of stars without NIR excess still have veiling values larger than 0.2 in this study and IT24. Although the NIR excess flag offers some insight into the validity of veiling, it has the following limitations: it is based solely on NIR photometry without MIR data, and rveil likely traces mass accretion rather than IR excess. A more detailed comparison, incorporating MIR data for accurate IR excess measurement and other accretion tracers such as emission lines, is necessary but beyond the scope of this study so we leave this for future work.
8 Summary
In this paper, we present an updated version of the cINN for young low-mass stars and apply it to 2051 young stars in Tr14. In the previous study (Paper I), we introduced a cINN approach to estimate stellar parameters (Teff, log g, AV) from optical stellar spectra. cINNs were trained on Phoenix stellar atmosphere models and pretested on the class III template stars well-analysed in the literature. After confirming the applicability of the cINN in the study of low-mass stars in Paper I, we upgraded the cINN in this study for the application to the spectra of young stars observed with VLT/MUSE.
The major updates in the new cINN include a Noise-Net setup, the addition of veiling, and the combination of two Phoenix libraries for training. Firstly, the cINN in this paper adopts a Noise-Net architecture which reflects the influence of random noise of observation on the parameter prediction. This update is motivated by the fact that the S/Ns of Tr14 spectra in this study are on average lower than the template stars used in Paper I. We feed the stellar spectrum and a median relative flux error (σmed), calculated across the wavelength range, together to the cINN as an input. Secondly, we added the veiling factor as a fourth target parameter to measure the influence of veiling on the observed spectra. The third update constitutes the construction of a new training dataset by combining two Phoenix libraries, Settl and Dusty. As the new cINN is trained on two libraries, the last target parameter of the new cINN is a library origin label which distinguishes Settl and Dusty models.
We tested the performance of the new cINN on synthetic test models, confirming that although relative flux errors widen the posterior distributions, the network still provides very accurate predictions within the typical error range of our Tr14 data (Sect. 5.1). Then, we tested the network on 36 class III template stars well-interpreted by Manara et al. (2013b, 2017) and Stelzer et al. (2013), and confirmed that our new cINN estimates Teff and log g well within 1-σ estimation uncertainty, similar to previous cINNs presented in Paper I. The average error of the new parameter, veiling, was about 0.13–0.15.
Using our new cINN, we measured the stellar parameters (Teff, log g, AV, and rveil) of young stars in Tr14 and compared them with those measured by IT24 using the template fitting method on the same data. We only compare Teff, AV, and rveil because IT24 could not measure log g. Our main results of the comparison between cINN estimates (MAP values) and values obtained by IT24 (TF parameters) are the following.
The MAP values and TF parameters are in good agreement in general, but there is a non-negligible difference for earlier type stars (early K types and G types), especially in the case of Teff and rveil. All three parameters show good agreements for stars within M4– K6 types (3270–4197 K);
We found correlations between parameter differences. For example, when the cINN-based temperature is larger than the TF parameter, the cINN-based extinction is larger whereas the cINN-based veiling is smaller than the TF parameters. This trend is exhibited in K/G types, while the trend is the opposite in M-type stars;
The temperature values from template fitting are discrete because of the limited number of templates, whereas the cINN-based temperature estimates are continuous. As IT24 lacked templates between K6–K4 types and templates hotter than G8, the template fitting-based temperature is missing in these ranges, whereas many stars have temperatures between K6–K4 types and temperatures hotter than G8 when measured by the cINN;
Using the HR diagram and evolutionary tracks, we determine the average stellar age of the Tr14 stars to be 0.7
 Myr, which is slightly smaller than the template fitti−ng-based value, but still in good agreement within a 1-σ error;
Myr, which is slightly smaller than the template fitti−ng-based value, but still in good agreement within a 1-σ error;Both the resimulated Phoenix spectra based on the MAP values and the modified template spectra based on the TF parameters match the original input spectra well. When we evaluate the goodness-of-fit with the RMSE, the two methods had similar RMSE for half of the samples. However, for most of the other half, the resimulated spectra fit better to the input spectra than the modified templates;
The simulation gap, the gap between the synthetic models and reality, is the most influential factor affecting the reliability of the cINN outputs. This is because the cINN cannot overcome the intrinsic discrepancy between the Phoenix model and reality, even though the cINN can perfectly capture the underlying rules in the training models. However, this is a common limitation of all methodologies that apply theoretical models to real observations;
-
We found that the parameter differences for K/G-type stars are affected by the limitation of the spectral type classification method used in IT24 based on equivalent widths of absorption lines. Using the template stars, we demonstrated that neglecting the veiling in the spectral type classification leads to an overestimation of the temperature. For example, the spectral type of a K6-type star is measured as four subclasses earlier if rveil is about 0.5. The temperature difference between the MAP values and the TF parameters agrees well with the amount of overestimation incurred by ignoring the amount of veiling measured by the cINN.
Our cINN performs comparably to the multi-dimensional template fitting method used in IT24 and is more advantageous in some aspects: The cINN is overwhelmingly faster than the multi-dimensional fitting, it analyses stars over a wide temperature range (2600–7000 K) in a consistent manner, and it provides a posterior distribution. We suggest that our cINN is a useful enough tool for analysing large amounts of data observed with VLT/MUSE.
Data availability
A full version of Table 1 and spectra images similar to Fig. 13 for all sources are available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/697/A39
Acknowledgements
We thank the anonymous referee for insightful comments that helped to improve the flow of argument. This work was partly supported by European Union’s Horizon 2020 Research and Innovation Program and the European Research Council via the ERC Synergy Grant “ECOGAL” (project ID 855130), by the Marie Sklodowska-Curie grant DUSTBUSTERS (project No 823823), by the Heidelberg Cluster of Excellence (EXC 2181 – 390900948) “STRUCTURES”, funded by the German Excellence Strategy, and by the German Ministry for Economic Affairs and Climate Action in project “MAINN” (funding ID 50OO2206). We also thank for computing resources provided by the Ministry of Science, Research and the Arts (MWK) of the State of Baden- Württemberg through bwHPC and DFG through grants INST 35/1134-1 FUGG and INST 35/1597-1 FUGG, as well as for data storage at SDS@hd through grants INST 35/1314-1 FUGG and INST 35/1503-1 FUGG. RSK is greatful to the 2024/25 Class of Radcliffe Fellows for highly interesting and stimulating discussions. DI acknowledges support from collaborations and/or information exchange within NASA’s Nexus for Exoplanet System Science (NExSS) research coordination network sponsored by NASA’s Science Mission Directorate under Agreement No. 80NSSC21K0593 for the program “Alien Earths”.
Appendix A Supplemental materials
In this appendix, we present supplementary figures mentioned in the main contents.
A.1 Validation ofcINNon synthetic test models andclass III stars
We evaluated the performance of our network on 26 214 synthetic test models and 36 class III template stars observed with VLT/X-shooter in Sect. 5. By splitting the test models into three groups, M type (2600 – 4000 K), K type (4000 – 5250 K), and G type (5250 – 6000 K), we investigated how the prediction performance varies with Teff of the models. Figure A.1 shows the cINN performance as a function of relative flux error (σmed) for the three groups along with the one for the entire test models (the same as the blue curve in Fig. 3).
We examined the performance of our network on class III template stars in Sect. 5.2. In Table A.1, we listed the stellar parameters of the template stars obtained in literature (Manara et al. 2013b, 2017; Stelzer et al. 2013) and stellar parameters measured in this work by cINN. We tested the network performance at different levels of flux error by increasing the σmed o feach star, which we measured from the spectrum within the 6500–7500 Å range. Fig. A.2 shows the change of the veiling measurements with increasing σmed, which is the most noticeable between the four stellar parameters.
A.2 Influence of extinction on spectral type classification
In Sect. 7.2, to examine the influence of extinction (AV) on the spectral type classification method used in IT24, we redden the spectra of template stars between K7 type to G8 type artificially applying AV from 0 to 5 mag in 0.2 mag intervals. We measure the spectral type from each reddened spectrum and compare it with the spectral type measured from the unreddened, pure template spectrum where AV is 0 mag (SpT(AV = 0)). In Fig. A.3, we plot the difference between the spectral type of the reddened spectrum and the pure spectrum as a function of AV. Unlike the case of veiling (Fig. 14), the reddening changes the spectral type measurement mostly within 0.3 subclass and up to 0.4 subclass. We conclude that the influence of AV on the spectral type classification is negligible in our AV range.
A.3 NIR colour-colour diagram
In Sect. 7.3, we investigate the distribution of the Clean samples on the colour-colour diagrams using their NIR photometry data (J-, H-, and K-bands) obtained from HAWK-I catalouge (Preibisch et al. 2011a). Among 727 Clean samples, we only use the 694 stars with matched HAWK-I counterparts. In Fig. A.4, we divide the samples into 6 groups depending on their spectral type classification (i.e. M-type or K/G types) and rveil ranges based on MAP estimates. The colour code indicates the corresponding Teff. In Fig. A.5, we present similar diagrams but classify the samples according to stellar parameters from IT24.
 |
Fig. A.1 RMSE of the MAP estimates for all synthetic test models (black), M-type test models (blue, 2600 K ≤ Teff ≤ 4000 K), K-type test models (orange, 4000 K < Teff ≤ 5250 K), and G-type test models (green, 5250 K < Teff ≤ 6000 K) at 11 different relative flux errors. The grey horizontal dashed line and shaded area represent the median (1.12%) and standard deviation (0.77 dex) of the relative flux error (σmed) of Tr14 samples in the Clean group. |
 |
Fig. A.2 Comparison of MAP estimates of rveil measured by cINN with the literature Teff values for 36 template stars. For the second and third panels, we increase σmed values by a factor of 5 and 10, respectively. |
 |
Fig. A.3 Difference of spectral type measured for reddened templates to the spectral type measured for the corresponding, pure template without extinction as a function of extinction. Spectral types are measured using the same methodology used in IT24, which is based on the equivalent width of several absorption lines. The colour denotes the Teff of the template. |
 |
Fig. A.4 Colour–colour diagrams for the Clean samples using the NIR photometry data from HAWK-I catalouge (Preibisch et al. 2011a). We divide samples into six groups using MAP estimates: M-type stars (Teff < 4000 K), K/G-type stars (Teff ≥ 4000 K), rveil < 0.1, 0.1 ≤ rveil < 0.3, and rveil > 0.3. The colour of each star indicates the corresponding Teff value. The black dashed lines with a slope of 1.86 indicate the NIR excess selection threshold from Zeidler et al. (2016), where stars located to the right of the dashed line are classified as having NIR excess in IT24. We present the fraction of stars with NIR excess at the upper left corner of each panel (fNIR). |
 |
Fig. A.5 Colour–colour diagrams of the Clean samples, similar to Fig. A.4 but with sample groups divided based on TF parameters from IT24. The colour of each star indicates the corresponding Teff value. The black lines and the numbers on the upper left corner indicate the NIR excess selection threshold from Zeidler et al. (2016) and the fraction of stars with NIR excess, respectively. |
Stellar parameters of class III template stars obtained in literature and in this work by cINN.
Appendix B Surface gravity
In this section, we analyse the surface gravity (log g) of Tr14 stars measured by our cINN, which were excluded from the main sections. Fig. B.1 presents the distributions of surface gravities for different sample groups (Clean, Uncertain, and All). The log g of Tr14 stars mostly ranges from 3 to 5.5, matching well with the typical range of log g of pre-main sequence stars (Herczeg & Hillenbrand 2014; Stelzer et al. 2013; Frasca et al. 2017; Manara et al. 2017; Olney et al. 2020). The average log g for all samples is about 4.2. The overall distributions and mean values are almost the same for Clean and Uncertain groups.
For 39 stars (about 2% of the entire sample), we measure a relatively small log g values of 2–3 but considering the 1-σ estimation uncertainty, only 15 of them have log g values less than 3. Among these, log g values of 6 stars are below 2.5, the lower limit of the training range. These low surface gravities may be wrong estimates, especially for cases outside the training range. One possible explanation for the low surface gravity is that they are background giant stars whose luminosity is underestimated. The background stars may have higher extinction than other stars and we found that 6 of 15 stars have high extinction (AV > 4), much higher than the average of 2.6 mag for the entire sample and IT24 also measured high AV values for these stars. On the other hand, for about 7% of the sample, log g is larger than 5, the upper training limit. Nevertheless, as shown in Fig. B.1, log g values exceeding the upper limit of 5 are not significantly extrapolated and are all below 5.5. These values are relatively uncertain in that they are extrapolated and a bit high for the surface gravity of young stars. We discuss these stars later in Appendix B.1.
Fig. B.2 shows the distribution of Teff and log g as a 2D histogram for the Clean and Uncertain samples, respectively. Interestingly, we find a V-shaped distribution in both sample groups. Centred at 3800~4000 K, the cooler stars tend to have higher gravity with lower temperatures, whereas the hotter stars have higher gravity with higher temperatures. This feature reveals that there are fewer or no stars around 3800~4000 K with log g below 4.0. A similar V-shaped distribution in the T-g plot has been reported in Frasca et al. (2017) and Manara et al. (2017) as well. We overplot the isochrone and isomass lines from the PARSEC evolutionary tracks (Bressan et al. 2012). Below one solar mass, isomass lines are nearly vertical, meaning that the stellar mass varies with Teff rather than log g, while isochrones are mostly horizontal, varying with log g. Because log g increases with stellar age due to the photospheric contraction, it is often used as a tracer of stellar age instead of luminosity (Takagi et al. 2010). However, in Fig. B.2, most stars are distributed near the isochrones much older than the ~1 Myr ages derived from HR diagrams (Fig.8). To obtain a similar range of stellar age around 1 Myr, log g should be less than 3.5, but log g are mostly higher than this. Moreover, between log g of 4 and 4.5, the stellar age changes rapidly from 5 to 100 Myr depending on gravity.
Similar to Sect. 6.4, we calculate the stellar masses and ages by interpolating the same evolutionary tracks along Teff and log g and compare these values with those inferred from Teff-Lbol relation. The difference between the two masses (m*,Tg and m*,TL), is the smallest for K-type stars (0.12 dex). For M-type stars, m*,Tg is consistently larger than m*,TL by about 0.23 dex, whereas for G-type stars, the scatter is large. Meanwhile, the scatter is too large to find a correlation between the two ages obtained from the different relations (t*,Tg and t*,TL) and the RMSE between them is large (1.3 dex). As shown in Fig. B.2, t*,Tg is in general older than t*,TL. The stellar ages of individual stars, both t*,Tg and t*,TL, may have large uncertainties because of various factors but we also find a large difference in the mean stellar age obtained through the distribution of individual ages. In Fig. 9, the mean age of Tr14 stars obtained through Teff and Lbol is 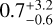 Myr (5.87±0.73 in log scale), whereas the mean age measured through Teff and log g using the same methodology is
Myr (5.87±0.73 in log scale), whereas the mean age measured through Teff and log g using the same methodology is 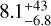 Myr (6.91±0.80 in log scale), where the difference between the two is more than 1 sigma. Frasca et al. (2017) and Manara et al. (2017) also reported the ages inferred from Teff-log g higher than those inferred from Teff-Lbol.
Myr (6.91±0.80 in log scale), where the difference between the two is more than 1 sigma. Frasca et al. (2017) and Manara et al. (2017) also reported the ages inferred from Teff-log g higher than those inferred from Teff-Lbol.
 |
Fig. B.1 Distribution of log g measured by the cINN for each sample group: Clean, Uncertain, and All. The blue vertical line indicates the mean value of the samples. |
 |
Fig. B.2 Kiel diagrams of the Clean samples (left) and the Uncertain samples (right) based on the stellar parameters obtained by the cINN in this work. The colour indicates the number density of the stars. We overplot PARSEC theoretical evolutionary tracks (Bressan et al. 2012) where solid lines indicate isochrones from 0.2 to 100 Myr and dashed lines indicate isomasses of 0.3, 0.7, 1, and 3 M⊙. |
B.1 High surface gravity
As shown in Fig. B.1, some stars exhibit surface gravity higher than the typical values for pre-main sequence stars. Specifically, 20% of the sample (410 stars) have log g values higher than 4.5 when considering the 1-σ estimation uncertainty, and this fraction decreases to 8.6% (177 stars) when considering the 3-σ uncertainty. We further examine the 177 stars classified as having higher log g than typical pre-main sequence stars.
In Fig. B.3, we present HR diagrams with log g values represented by colour and log g – Teff diagrams where age estimates derived from the HR diagram are colour-coded. The first row shows the entire sample, while the second row shows only the 177 stars with log g values above 4.5. These high-surface gravity stars split into two groups on the HR diagram: stars near the 20 Myr isochrone and stars appearing younger with estimated ages around 1 Myr. Of the 177 stars, approximately 55% (i.e. 98 stars) have t*,TL below 5 Myr, while the remaining 45% are older than 5 Myr. When we increase the log g threshold from 4.5 to 5, the proportion of high-log g stars with younger age estimates decreases to 30–40%. Thus, for about half of the stars with high log g the ages inferred from the HR diagram are also relatively higher than the average stellar age of Tr14 (~1 Myr). Stars with high log g but young age estimates generally lie near the vertex of the V-shaped distribution on the log g – Teff diagram, corresponding to Teff between 3400 and 4500 K (M3–K5).
For these 98 stars with high log g but low age estimates (t*,TL < 5 Myr), we can consider three cases: 1) log g is overestimated 2) t*,TL is underestimated or 3) both measurements are accurate. First, if the surface gravity is overestimated, potential causes are the log g accuracy of cINN, the simulation gap of the Phoenix model, and spectral features that mimic higher surface gravity. Surface gravity is typically measured based on line broadening in the spectrum with higher spectral resolution than that of MUSE. Our network, however, uses spectra with R~4000, which is generally considered insufficient for precise gravity measurements. Nevertheless, as demonstrated in Sect. 5, our network accurately measured log g from both synthetic and real spectra. Despite the relatively low spectral resolution, the log g estimates for template stars were consistent with literature values measured from X-shooter spectra with higher spectral resolution within 1-σ uncertainty.
Additionally, in Paper I, we showed which spectral features the network relies on to estimate log g (see Sect. 6 of Paper I for more detail) and found that important spectral features varied depending on the spectral type of the target star and that the network prioritised several spectral lines known as typical stellar parameter tracers. For example, the Na I doublet 8183, 8195 Å lines and the K I doublet 7665, 7699 Å lines were important for M-type stars, while for hotter stars, the importance of the KI doublet lines decreased and the Na I doublet 5890, 5896 Å lines became more important. Since the measured surface gravity for Tr14 stars also falls mostly within the expected range for premain sequence stars, we suggest that the overall surface gravity accuracy of our cINN is sufficient and reliable.
The second potential cause is related to the simulation gap in the Phoenix model. As shown in Table A.1, cINN measured log g over 4.7 for some class III template stars whose spectral types (M3.5–M0) are similar to those of 98 high-log g stars with low age estimates. Our estimates still agree well with the literature values since the literature (Stelzer et al. 2013) also measured high log g values above 4.5 for these template stars. We note that log g of these template stars are also measured by using Phoenix models (BT-Settl). Notably, the V-shaped log g – Teff distribution with high log g near 4000 K has also been reported by Manara et al. (2017) and Frasca et al. (2017), where both used Phoneix models to measure log g. It is possible that the effects of log g were not fully reflected in the Phoenix synthetic spectra at these temperatures, potentially leading to the overestimation of log g when applying Phoenix models to real observations. The third possibility is that spectral features sensitive to surface gravity could be influenced by factors other than the surface gravity itself, mimicking signatures of high surface gravity. In such cases, even alternative methods other than cINN might yield similarly high log g values.
 |
Fig. B.3 Hertzsprung-Russell diagrams (left) and Kiel diagrams (right) based on parameters obtained by cINN in this work using all 2051 Tr14 samples (upper panels) and using only 177 stars with surface gravities higher than 4.5 considering 3-σ estimation uncertainty. The colour in the HR diagrams indicates log g estimates while the colour in the log g – Teff diagrams represents stellar age derived from bolometric luminosity and Teff using PARSEC evolutionary tracks (Bressan et al. 2012). We overplot PARSEC theoretical evolutionary tracks (Bressan et al. 2012) where solid lines indicate isochrones from 0.2 to 100 Myr and dashed lines indicate isomasses of 0.3, 0.7, 1, and 3 M⊙. |
On the other hand, the age estimates based on luminosity may also be underestimated. The luminosity spread at the same temperature on the HR diagram is commonly observed and is attributed to several factors such as uncertainties in stellar parameters, intrinsic age spread, stellar variability, etc. However, the observed positions of these young high-log g stars on the HR diagram deviate non-negligibly from their expected positions based on log g estimates. We propose that the main sequence foreground stars may have been incorrectly measured as young stars because of the overestimated luminosity. As mentioned in IT24, significant contamination by foreground stars is expected because of the large distance of 2.35 kpc to Tr14 and because our samples with good Gaia astrometric measurements were limited.
Lastly, some stars may have higher surface gravity than expected for their age. If a star has undergone a slightly different evolutionary process than other stars in the cluster, its photospheric parameters may differ from those of stars with the same age and mass. If the stellar mass significantly increased due to strong accretion before the radius expanded, this could result in high log g. Such cases would likely exhibit characteristics of strong accretors, such as veiling or prominent emission lines. However, the average rveil for the 98 stars is 0.31, which is neither small nor extremely high. Among these stars, only 12 have rveil larger than 0.5, and only 8 exceed 0.7, suggesting that strong accretors are relatively rare among these 98 stars.
Appendix C Degeneracy in posterior distributions
In this paper, we sample 4096 posterior estimates per observation to get a posterior distribution and use a MAP estimate as a representative value from a marginalised, one-dimensional posterior distribution of each stellar parameter. To use the most probable estimate (i.e. peak value) as a representative, we need to check if degeneracy remains in the posterior distribution which is usually exhibited as a multimodal distribution. We check the number of peaks (i.e. local maxima) in each posterior distribution for Tr14 samples to investigate how often the degeneracy remains.
Using the same methodology as in Kang et al. (2022), we fit the marginalised 1D posterior distributions with multiple Gaussians and describe the posterior distribution with a maximum of 6 Gaussian components. Then we count the number of local maxima using the first derivative of the fitted function. For the entire Tr14 samples, 93.7% of them have a clear single peak in their posterior distributions for all parameters. Only 6 samples in the Clean group have multiple peaks in at least one parameter while 124 samples in the Uncertain group (i.e. 9.4% of the group) have multiple peaks. We found that multi-peaks arise from the estimation of the Phoenix library origin flag and that the double modes in the posterior distribution of the other stellar parameters are clearly separated based on the posterior estimates of the Phoenix library origin. In most of the multimodal posterior distributions, one mode is clearly more dominant than the other mode so we can use the MAP estimate as a representative which is determined from the dominant mode.
There are 13 samples (three from the Clean group and ten from the Uncertain group) which have two distinct modes with a comparable probability in the posterior distribution of stellar parameters (i.e. Teff, log g, AV, and rveil). For 11 of them, we confirm that the MAP estimates are determined from the same mode in all parameters. However, for the other two samples, which all belong to the Uncertain group, the MAP estimates are determined in different modes for each parameter. It is better not to use a MAP estimate as a representative in these cases. Still, we include these samples in our statistical analysis of the Uncertain group, considering that the difference between the two modes is almost negligible because of the very narrow width of the posterior distribution even in the multimodal cases. From the experiment, we conclude that we can use the MAP estimate as a representative in this paper.
In Fig. C.1, we present the posterior distributions of the five target parameters for three examples selected from the Clean group. The first example (the first column of Fig. C.1) shows the most common case, an unimodal posterior distribution with a clear single peak, where we determine a MAP estimate. The second and third examples represent the cases of a multimodal posterior distribution, where the different modes can be separated depending on the posterior estimate of the Phoenix library origin flag. In the second example, the mode of one library is more dominant than the other one so MAP estimates are determined by the dominant one. The third one is an example of multimodal posterior distributions where two modes have a comparable probability. By dividing the posterior distribution into two groups depending on the posterior estimate of the Phoenix library origin (Settl and Dusty), we confirm that the two peaks in the posterior distribution are due to the degeneracy in the library origin estimate.
 |
Fig. C.1 Posterior probability distributions (grey) of the five target parameters. Each column corresponds to a different sample drawn from the Clean group. The first column shows an example of an unimodal posterior distribution with a clear single peak (i.e. MAP estimate), which is the most common case in our results. The other columns represent degenerate cases where the posterior distribution of some parameters has a multimodal shape. In these cases, we divide the posterior distribution into two groups depending on the posterior estimate of the Phoenix library origin: a library value of 0 denotes Settl (blue shading) and a value of 1 denotes Dusty (orange shading). In each panel, we present the MAP estimate and the uncertainty at 68% confidence interval (u68) in the text box. |
References
- Abraham, S., Aniyan, A. K., Kembhavi, A. K., Philip, N. S., & Vaghmare, K. 2018, MNRAS, 477, 894 [NASA ADS] [CrossRef] [Google Scholar]
- Alcalá, J. M., Natta, A., Manara, C. F., et al. 2014, A&A, 561, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Allard, F., Homeier, D., & Freytag, B. 2011, in Astronomical Society of the Pacific Conference Series, 448, 16th Cambridge Workshop on Cool Stars, Stellar Systems, and the Sun, eds. C. Johns-Krull, M. K. Browning, & A. A. West, 91 [Google Scholar]
- Allard, F., Homeier, D., & Freytag, B. 2012, Philos. Trans. Roy. Soc. Lond. Ser. A, 370, 2765 [NASA ADS] [Google Scholar]
- Ardizzone, L., Kruse, J., Rother, C., & Köthe, U. 2019a, in International Conference on Learning Representations, https://openreview.net/forum?id=rJed6j0cKX [Google Scholar]
- Ardizzone, L., Lüth, C., Kruse, J., Rother, C., & Köthe, U. 2019b, arXiv e-prints [arXiv:1907.02392] [Google Scholar]
- Bacon, R., Accardo, M., Adjali, L., et al. 2010, SPIE Conf. Ser., 7735, 773508 [Google Scholar]
- Baraffe, I., Chabrier, G., & Gallardo, J. 2009, ApJ, 702, L27 [NASA ADS] [CrossRef] [Google Scholar]
- Baraffe, I., Homeier, D., Allard, F., & Chabrier, G. 2015, A&A, 577, A42 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bayo, A., Barrado, D., Allard, F., et al. 2017, MNRAS, 465, 760 [Google Scholar]
- Berlanas, S. R., Maíz Apellániz, J., Herrero, A., et al. 2023, A&A, 671, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, A&AS, 117, 393 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bister, T., Erdmann, M., Köthe, U., & Schulte, J. 2022, Eur. Phys. J. C, 82, 171 [NASA ADS] [CrossRef] [Google Scholar]
- Bochanski, J. J., Hawley, S. L., Covey, K. R., et al. 2010, AJ, 139, 2679 [NASA ADS] [CrossRef] [Google Scholar]
- Bressan, A., Marigo, P., Girardi, L., et al. 2012, MNRAS, 427, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Candebat, N., Germano Sacco, G., Magrini, L., et al. 2024, A&A, 692, A228 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cardelli, J. A., Clayton, G. C., & Mathis, J. S. 1989, ApJ, 345, 245 [Google Scholar]
- Carraro, G., Romaniello, M., Ventura, P., & Patat, F. 2004, A&A, 418, 525 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chabrier, G. 2003, PASP, 115, 763 [Google Scholar]
- Claes, R. A. B., Manara, C. F., Garcia-Lopez, R., et al. 2022, A&A, 664, L7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Claes, R. A. B., Campbell-White, J., Manara, C. F., et al. 2024, A&A, 690, A122 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Costigan, G., Vink, J. S., Scholz, A., Ray, T., & Testi, L. 2014, MNRAS, 440, 3444 [NASA ADS] [CrossRef] [Google Scholar]
- Cox, A. N. 2002, Allen’s Astrophysical Quantities, ed. A. N. Cox (New York, NY: Springer New York) [CrossRef] [Google Scholar]
- De Beurs, Zoe. L., Vanderburg, A., Shallue, C. J., et al. 2022, AJ, 164, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Dinh, L., Krueger, D., & Bengio, Y. 2015, in 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Workshop Track Proceedings, eds. Y. Bengio & Y. LeCun [Google Scholar]
- Dinh, L., Sohl-Dickstein, J., & Bengio, S. 2016, arXiv e-prints, [arXiv:1605.08803] [Google Scholar]
- Fabbro, S., Venn, K. A., O’Briain, T., et al. 2018, MNRAS, 475, 2978 [Google Scholar]
- Fang, M., Kim, J. S., Pascucci, I., & Apai, D. 2021, ApJ, 908, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Frasca, A., Biazzo, K., Alcalá, J. M., et al. 2017, A&A, 602, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Freudling, W., Romaniello, M., Bramich, D. M., et al. 2013, A&A, 559, A96 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goodfellow, I., Bengio, Y., & Courville, A. 2016, Deep Learning (Cambridge, MA: MIT Press) [Google Scholar]
- Göppl, C., & Preibisch, T. 2022, A&A, 660, A11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gullbring, E., Hartmann, L., Briceño, C., & Calvet, N. 1998, ApJ, 492, 323 [Google Scholar]
- Haldemann, J., Ksoll, V., Walter, D., et al. 2023, A&A, 672, A180 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hartmann, L. 2001, AJ, 121, 1030 [NASA ADS] [CrossRef] [Google Scholar]
- Herczeg, G. J., & Hillenbrand, L. A. 2008, ApJ, 681, 594 [Google Scholar]
- Herczeg, G. J., & Hillenbrand, L. A. 2014, ApJ, 786, 97 [Google Scholar]
- Hur, H., Sung, H., & Bessell, M. S. 2012, AJ, 143, 41 [NASA ADS] [CrossRef] [Google Scholar]
- Hur, H., Lim, B., & Chun, M.-Y. 2023, J. Korean Astron. Soc., 56, 97 [NASA ADS] [Google Scholar]
- Itrich, D., Testi, L., Beccari, G., et al. 2024, A&A, 685, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jeffries, R. D., Oliveira, J. M., Naylor, T., Mayne, N. J., & Littlefair, S. P. 2007, MNRAS, 376, 580 [NASA ADS] [CrossRef] [Google Scholar]
- Kang, D. E., Pellegrini, E. W., Ardizzone, L., et al. 2022, MNRAS, 512, 617 [CrossRef] [Google Scholar]
- Kang, D. E., Klessen, R. S., Ksoll, V. F., et al. 2023a, MNRAS, 520, 4981 [NASA ADS] [CrossRef] [Google Scholar]
- Kang, D. E., Ksoll, V. F., Itrich, D., et al. 2023b, A&A, 674, A175 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kenyon, S. J., & Hartmann, L. 1995, ApJS, 101, 117 [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, arXiv e-prints, [arXiv:1412.6980] [Google Scholar]
- Kingma, D. P., & Dhariwal, P. 2018, arXiv e-prints, [arXiv:1807.03039] [Google Scholar]
- Kobyzev, I., Prince, S. J., & Brubaker, M. A. 2021, IEEE Trans. Pattern Anal. Mach. Intell., 43, 3964 [NASA ADS] [CrossRef] [Google Scholar]
- Kroupa, P. 2001, MNRAS, 322, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Ksoll, V. F., Ardizzone, L., Klessen, R., et al. 2020, MNRAS, 499, 5447 [NASA ADS] [CrossRef] [Google Scholar]
- Ksoll, V. F., Reissl, S., Klessen, R. S., et al. 2024, A&A, 683, A246 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lindegren, L. 2018, Gaia technical note gAIA-C3-TN-LU-LL-124, http://www.rssd.esa.int/doc_fetch.php?id=3757412 [Google Scholar]
- Lindegren, L., Bastian, U., Biermann, M., et al. 2021, A&A, 649, A4 [EDP Sciences] [Google Scholar]
- Luhman, K. L. 1999, ApJ, 525, 466 [Google Scholar]
- Luhman, K. L., Liebert, J., & Rieke, G. H. 1997, ApJ, 489, L165 [Google Scholar]
- Luhman, K. L., Stauffer, J. R., Muench, A. A., et al. 2003, ApJ, 593, 1093 [Google Scholar]
- Manara, C. F., Beccari, G., Da Rio, N., et al. 2013a, A&A, 558, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Manara, C. F., Testi, L., Rigliaco, E., et al. 2013b, A&A, 551, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Manara, C. F., Frasca, A., Alcalá, J. M., et al. 2017, A&A, 605, A86 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Olney, R., Kounkel, M., Schillinger, C., et al. 2020, AJ, 159, 182 [NASA ADS] [CrossRef] [Google Scholar]
- Penny, L. R., Gies, D. R., Hartkopf, W. I., Mason, B. D., & Turner, N. H. 1993, PASP, 105, 588 [NASA ADS] [CrossRef] [Google Scholar]
- Peterson, D. E., Megeath, S. T., Luhman, K. L., et al. 2008, ApJ, 685, 313 [CrossRef] [Google Scholar]
- Preibisch, T., Hodgkin, S., Irwin, M., et al. 2011a, ApJS, 194, 10 [Google Scholar]
- Preibisch, T., Ratzka, T., Kuderna, B., et al. 2011b, A&A, 530, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Preibisch, T., Zeidler, P., Ratzka, T., Roccatagliata, V., & Petr-Gotzens, M. G. 2014, A&A, 572, A116 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rajpurohit, A. S., Allard, F., Teixeira, G. D. C., et al. 2018, A&A, 610, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rezende, D., & Mohamed, S. 2015, in Proceedings of Machine Learning Research, 37, Proceedings of the 32nd International Conference on Machine Learning, ed. F. Bach & D. Blei (Lille, France: PMLR), 1530 [Google Scholar]
- Rhea, C., Rousseau-Nepton, L., Prunet, S., Hlavacek-Larrondo, J., & Fabbro, S. 2020, ApJ, 901, 152 [Google Scholar]
- Riddick, F. C., Roche, P. F., & Lucas, P. W. 2007, MNRAS, 381, 1067 [Google Scholar]
- Rigliaco, E., Natta, A., Testi, L., et al. 2012, A&A, 548, A56 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rugel, M., Fedele, D., & Herczeg, G. 2018, A&A, 609, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sharma, K., Kembhavi, A., Kembhavi, A., et al. 2020, MNRAS, 491, 2280 [NASA ADS] [CrossRef] [Google Scholar]
- Shen, H., Huerta, E. A., O’Shea, E., Kumar, P., & Zhao, Z. 2022, Mach. Learn. Sci. Technol., 3, 015007 [Google Scholar]
- Smith, N. 2006, MNRAS, 367, 763 [Google Scholar]
- Smith, N., & Brooks, K. J. 2008, in Handbook of Star Forming Regions, Volume II, 5, ed. B. Reipurth, 138 [Google Scholar]
- Stelzer, B., Frasca, A., Alcalá, J. M., et al. 2013, A&A, 558, A141 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tabak, E., & Turner, C. 2013, Commun. Pure Appl. Math., 66, 145 [CrossRef] [Google Scholar]
- Tabak, E., & Vanden-Eijnden, E. 2010, Commun. Math. Sci., 8, 217 [CrossRef] [Google Scholar]
- Takagi, Y., Itoh, Y., & Oasa, Y. 2010, PASJ, 62, 501 [Google Scholar]
- Tapia, M., Roth, M., Vázquez, R. A., & Feinstein, A. 2003, MNRAS, 339, 44 [CrossRef] [Google Scholar]
- Valenti, J. A., Basri, G., & Johns, C. M. 1993, AJ, 106, 2024 [NASA ADS] [CrossRef] [Google Scholar]
- Vazquez, R. A., Baume, G., Feinstein, A., & Prado, P. 1996, A&AS, 116, 75 [NASA ADS] [Google Scholar]
- Venuti, L., Bouvier, J., Flaccomio, E., et al. 2014, A&A, 570, A82 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Walmsley, M., Lintott, C., Géron, T., et al. 2021, MNRAS, 509, 3966 [NASA ADS] [CrossRef] [Google Scholar]
- Wei, W., Huerta, E. A., Whitmore, B. C., et al. 2020, MNRAS, 493, 3178 [NASA ADS] [CrossRef] [Google Scholar]
- Weilbacher, P. M., Palsa, R., Streicher, O., et al. 2020, A&A, 641, A28 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Whitmore, B. C., Lee, J. C., Chandar, R., et al. 2021, MNRAS, 506, 5294 [NASA ADS] [CrossRef] [Google Scholar]
- Wu, C., Wong, O. I., Rudnick, L., et al. 2019, MNRAS, 482, 1211 [NASA ADS] [CrossRef] [Google Scholar]
- Zeidler, P., Preibisch, T., Ratzka, T., Roccatagliata, V., & Petr-Gotzens, M. G. 2016, A&A, 585, A49 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
We confirmed that the change of proper motion quality cut to proper motion error smaller than 0.2 mas/yr does not change the final good astrometry sample of Gaia counterparts.
All Tables
RMSE of the MAP estimates with respect to the ground truth for 26 214 synthetic test models for three different relative flux errors.
Median estimation uncertainty of MAP estimates for Tr14 samples in three different sample groups.
Stellar parameters of class III template stars obtained in literature and in this work by cINN.
All Figures
|
Fig. 1 Upper panels: histograms of median relative flux error (σmed) for the spectra in the Clean samples (left) and the Uncertain samples (right). Dashed lines and purple shaded areas indicate the median values and ±1 standard deviations of the distributions. Lower panel: distribution of relative flux error at each spectral bin (σλ = ΔFlux(λ)/Flux(λ)) for the Clean (red) and Uncertain (blue) groups. The shaded areas indicate the interquantile ranges from 16% to 84%. The red and blue dashed lines show the median of σmed for each group as shown in the upper panels and the black dashed line shows the median σmed for all 2051 spectra. The green dotted line indicates the upper boundary of the training range (log σ = -0.5) of our cINN. The narrow grey-shaded vertical areas indicate the masked spectral bins not used in our network due to the presence of emission lines. |
| In the text | |
|
Fig. 2 Histograms of the MAP accuracy for the five target parameters measured using 26241 synthetic test models at 11 different relative flux errors (σ). The blue plus symbol indicates the median value of each histogram. The grey horizontal dashed line and shaded area represent the median (1.12%) and standard deviation (0.77 dex) of the median relative flux error of Tr14 samples in the Clean group (see Fig. 1). |
| In the text | |
|
Fig. 3 RMSE of the MAP estimates (blue) and the entire posterior estimates (orange) for synthetic test models at 11 different median relative flux errors. The grey lines and shaded areas are the same as in Fig. 2. |
| In the text | |
|
Fig. 4 Comparison of MAP estimates with literature values for 36 class III template stars. The colour indicates the temperature difference between MAP estimates and literature values and the dotted green lines indicate the training range of the cINN. The texts in each panel show the root mean square errors and mean absolute errors between the MAP estimates and the literature values. Since these template stars are class III and have negligible extinction (AV < 0.5 mag) with an estimation uncertainty of 0.2 mag (Manara et al. 2017), we regard |
| In the text | |
|
Fig. 5 Comparison of the effective temperature (Teff), extinction (AV), and veiling factor (rveil) of stars in Tr14 from TF parameters (IT24) with our corresponding cINN-MAP estimates for the samples in the Clean (top) and Uncertain (bottom) groups. The colour code denotes the median relative flux error along the wavelength of each star which is used as an additional input to our cINN. |
| In the text | |
|
Fig. 6 Calculate fraction of samples where the difference between TF parameter and the MAP value is either smaller than the given criterion (left panels) or larger than the given criterion (right panels) within each spectral type group based on the Teff from TF parameters. We only use the Clean samples in this figure. The y-axis labels present the corresponding spectral type and the number of samples belonging to the spectral type group. We highlight the bar in blue (left panels) or red (right panels) when the fraction is higher than 50%. |
| In the text | |
|
Fig. 7 Extinction and temperature differences between cINN-MAP estimates and TF parameters for stars in the Clean group using the different colour codes: Teff measured by template fitting (left) and the difference in rveil between MAP estimates and TF parameters (right). The size of the symbol indicates the extinction from TF parameters. |
| In the text | |
|
Fig. 8 Hertzsprung-Russell diagrams of Tr14 stars based on the stellar parameters from IT24 (left panels) and the stellar parameters from this work (right panels). In the upper panels, we plot 2D histograms using all samples, while in the lower panels, we plot contours dividing the samples into the Clean (red) and the Uncertain (blue) groups. We overplot PARSEC theoretical evolutionary tracks (Bressan et al. 2012) where solid lines indicate isochrones from 0.2 to 20 Myr and dashed lines indicate isomasses of 0.3, 0.7, 1, and 3 M⊙. |
| In the text | |
|
Fig. 9 Histograms of stellar age calculated from the TF parameters (left) and stellar age derived from the MAP values (right). The red and blue lines show the distribution of the Clean and Uncertain sample groups, respectively. We fit the purple shaded area with a log-normal function and plot the best-fit curve as the black solid line. The peak of the best-fit curve, denoted by a vertical black dotted line, is used as an average stellar age. |
| In the text | |
|
Fig. 10 Number density of stars within a given mass bin as a function of stellar mass from the TF parameters (left) and from the MAP values (right). The red and blue lines show the distribution of the Clean and Uncertain sample groups, while the purple lines and purple-shaded areas indicate the distribution of all samples. We present the initial mass functions from Kroupa (2001) and Chabrier (2003) with pink and cyan lines, respectively. |
| In the text | |
|
Fig. 11 Left: Comparison of the goodness-of-fit on the observational space: the difference between the RMSEs of the resimulated Phoenix spectra and the RMSEs of the modified template spectra. Right panel: Number of samples where the corresponding method has a better fit (i.e. a smaller RMSE) to the original input spectrum. If the difference between the RMSEs is within 0.3 × 10−5, they are classified as “similar”. These cases are indicated by the purple shaded area in the left panel and a purple bar in the right panel. We use the Clean group in the upper panels and the Uncertain group in the lower panels. |
| In the text | |
|
Fig. 12 Comparison of RMSE on the observational space for small dX and large dX groups for different |
| In the text | |
|
Fig. 13 Four examples of MUSE spectra (solid black line) together with the best-matching modified template spectra (solid blue line) chosen in IT24 and the resimulated Pheonix model spectra based on the cINN predictions (MAP estimates). The resimulated spectrum is described by either a red (Settl) or green (Dusty) dash-dot line depending on the MAP estimate of the library flag. For both the template fitting and cINN-based result, we present RMSEs between the fitted spectra and the original MUSE spectrum in the legend and list the measured stellar parameters in the table. All the spectra are normalised by the sum of the fluxes across all spectral bins within the common wavelength range between the template spectrum and MUSE spectrum (i.e. 5600–9350 Å) excluding the bins masked due to emission lines (grey shades). The surface gravity value for the template is the log g value of the corresponding template star, not measured from the Tr14 spectrum. |
| In the text | |
|
Fig. 14 Difference of spectral type measured for veiled templates to the spectral type measured for pure templates without veiling as a function of the veiling factor. We measure the spectral types using the same methodology used in IT24, which is based on the equivalent width of several absorption lines. The colour denotes the Teff of the template. |
| In the text | |
|
Fig. 15 Comparison of spectral type differences between TF parameters and MAP values to the MAP veiling values for the Clean samples of Tr14 (blue dots). The samples are divided into two groups depending on the spectral type based on the MAP values. Stars classified as G8 by template fitting are excluded. The blue squares represent the average values calculated within the veiling interval of 0.2. When calculating the average values, we exclude stars whose MAP-based temperature exceeds the maximum template fitting temperature of 5430 K (G8 type). The coloured lines correspond to the curves presented in Fig. 14, which show the change of the spectral type as a function of the veiling tested on the template stars. |
| In the text | |
|
Fig. A.1 RMSE of the MAP estimates for all synthetic test models (black), M-type test models (blue, 2600 K ≤ Teff ≤ 4000 K), K-type test models (orange, 4000 K < Teff ≤ 5250 K), and G-type test models (green, 5250 K < Teff ≤ 6000 K) at 11 different relative flux errors. The grey horizontal dashed line and shaded area represent the median (1.12%) and standard deviation (0.77 dex) of the relative flux error (σmed) of Tr14 samples in the Clean group. |
| In the text | |
|
Fig. A.2 Comparison of MAP estimates of rveil measured by cINN with the literature Teff values for 36 template stars. For the second and third panels, we increase σmed values by a factor of 5 and 10, respectively. |
| In the text | |
|
Fig. A.3 Difference of spectral type measured for reddened templates to the spectral type measured for the corresponding, pure template without extinction as a function of extinction. Spectral types are measured using the same methodology used in IT24, which is based on the equivalent width of several absorption lines. The colour denotes the Teff of the template. |
| In the text | |
|
Fig. A.4 Colour–colour diagrams for the Clean samples using the NIR photometry data from HAWK-I catalouge (Preibisch et al. 2011a). We divide samples into six groups using MAP estimates: M-type stars (Teff < 4000 K), K/G-type stars (Teff ≥ 4000 K), rveil < 0.1, 0.1 ≤ rveil < 0.3, and rveil > 0.3. The colour of each star indicates the corresponding Teff value. The black dashed lines with a slope of 1.86 indicate the NIR excess selection threshold from Zeidler et al. (2016), where stars located to the right of the dashed line are classified as having NIR excess in IT24. We present the fraction of stars with NIR excess at the upper left corner of each panel (fNIR). |
| In the text | |
|
Fig. A.5 Colour–colour diagrams of the Clean samples, similar to Fig. A.4 but with sample groups divided based on TF parameters from IT24. The colour of each star indicates the corresponding Teff value. The black lines and the numbers on the upper left corner indicate the NIR excess selection threshold from Zeidler et al. (2016) and the fraction of stars with NIR excess, respectively. |
| In the text | |
|
Fig. B.1 Distribution of log g measured by the cINN for each sample group: Clean, Uncertain, and All. The blue vertical line indicates the mean value of the samples. |
| In the text | |
|
Fig. B.2 Kiel diagrams of the Clean samples (left) and the Uncertain samples (right) based on the stellar parameters obtained by the cINN in this work. The colour indicates the number density of the stars. We overplot PARSEC theoretical evolutionary tracks (Bressan et al. 2012) where solid lines indicate isochrones from 0.2 to 100 Myr and dashed lines indicate isomasses of 0.3, 0.7, 1, and 3 M⊙. |
| In the text | |
|
Fig. B.3 Hertzsprung-Russell diagrams (left) and Kiel diagrams (right) based on parameters obtained by cINN in this work using all 2051 Tr14 samples (upper panels) and using only 177 stars with surface gravities higher than 4.5 considering 3-σ estimation uncertainty. The colour in the HR diagrams indicates log g estimates while the colour in the log g – Teff diagrams represents stellar age derived from bolometric luminosity and Teff using PARSEC evolutionary tracks (Bressan et al. 2012). We overplot PARSEC theoretical evolutionary tracks (Bressan et al. 2012) where solid lines indicate isochrones from 0.2 to 100 Myr and dashed lines indicate isomasses of 0.3, 0.7, 1, and 3 M⊙. |
| In the text | |
|
Fig. C.1 Posterior probability distributions (grey) of the five target parameters. Each column corresponds to a different sample drawn from the Clean group. The first column shows an example of an unimodal posterior distribution with a clear single peak (i.e. MAP estimate), which is the most common case in our results. The other columns represent degenerate cases where the posterior distribution of some parameters has a multimodal shape. In these cases, we divide the posterior distribution into two groups depending on the posterior estimate of the Phoenix library origin: a library value of 0 denotes Settl (blue shading) and a value of 1 denotes Dusty (orange shading). In each panel, we present the MAP estimate and the uncertainty at 68% confidence interval (u68) in the text box. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.