| Issue |
A&A
Volume 692, December 2024
|
|
|---|---|---|
| Article Number | A228 | |
| Number of page(s) | 23 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202451251 | |
| Published online | 16 December 2024 | |
Inferring stellar parameters and their uncertainties from high-resolution spectroscopy using invertible neural networks★
INAF – Arcetri Astrophysical Observatory,
Largo E. Fermi 5,
50125
Florence,
Italy
★★ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
25
June
2024
Accepted:
23
September
2024
Abstract
Context. New spectroscopic surveys will increase the number of astronomical objects in need of characterisation by more than an order of magnitude. Machine learning tools are required to address this data deluge in a fast and accurate fashion. Most machine learning algorithms cannot directly estimate error, making them unsuitable for reliable science.
Aims. We aim to train a supervised deep-learning algorithm tailored for high-resolution observational stellar spectra. This algorithm accurately infers precise estimates while providing coherent estimates of uncertainties by leveraging information from both the neural network and the spectra.
Methods. We trained a conditional invertible neural network (cINN) on observational spectroscopic data obtained from the GIRAFFE spectrograph (HR 10 and HR 21 setups) within the Gaia-ESO survey. A key feature of cINN is its ability to produce the Bayesian posterior distribution of parameters for each spectrum. By analysing this distribution, we inferred stellar parameters and their corresponding uncertainties. We carried out several tests to investigate how parameters are inferred and errors are estimated.
Results. We achieved an accuracy of 28 K in Teff, 0.06 dex in log ɡ, 0.03 dex in [Fe/H], and between 0.05 dex and 0.17 dex for the other abundances for high-quality spectra. Accuracy remains stable with low signal-to-noise ratio (between 5 and 25) spectra, with an accuracy of 39 K in Teff, 0.08 dex in log ɡ, and 0.05 dex in [Fe/H]. The uncertainties obtained are well within the same order of magnitude. The network accurately reproduces astrophysical relationships both on the scale of the Milky Way and within smaller star clusters. We created a table containing the new parameters generated by our cINN.
Conclusions. This neural network represents a compelling proposition for future astronomical surveys. These derived uncertainties are coherent and can therefore be reused in future works as Bayesian priors.
Key words: methods: data analysis / methods: numerical / techniques: spectroscopic / surveys / stars: abundances / stars: fundamental parameters
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Most of the recent progress in our understanding of the formation and evolution of the Milky Way is the result of exploration of the wealth of information contained within the catalogues produced by the Gaia space mission (Gaia Collaboration 2016) and provided by a series of ground-based stellar spectroscopic surveys, such as Gaia-ESO (GES; Randich et al. 2022), APOGEE (Majewski et al. 2017), and GALAH (De Silva et al. 2015). These surveys have gathered the spectra of hundreds of thousands of stars to derive radial velocities, standard stellar parameters (effective temperatures, surface gravities, and global metallicities), chemical abundances, and other stellar properties (e.g. projected rotational velocities, activity indices). The next generation of multi-object spectrographs and surveys (e.g. SDSS-V Kollmeier et al. 2017; WEAVE Jin et al. 2023; MOONS Gonzalez et al. 2020 and 4MOST de Jong et al. 2019) have begun or will soon begin to observe an even greater number of stars than the previous ones – greater by more than an order of magnitude.
Several new analysis tools based on machine learning techniques have been developed to analyse this huge wealth of data. Some of these new tools, like convolutional neural networks (CNNs; Ambrosch et al. 2023) and AstroNN (Leung & Bovy 2019), use artificial neural networks (ANNs) trained with previously analysed and labelled observed spectra to consistently measure stellar parameters and chemical abundances. We refer to this as the ‘data-driven’ approach. Alternatively, ANNs can be used to interpolate a set of synthetic models in a high-dimensional label space including both stellar parameters and abundances. Other than to infer astrophysical parameters from the spectra, ANNs have been used in stellar spectroscopy for other applications, for example to convert synthetic spectra into observational ones, including the effects of theoretical and instrumental systematic effects (Ting et al. 2019; O’Briain et al. 2021). Spectral analysis codes based on ANNs can process large numbers of spectra much faster than traditional codes, which fit observed data using a precomputed grid of synthetic spectra derived from atmospheric models (e.g. MATISSE Recio-Blanco et al. 2016; PySME Wehrhahn et al. 2023). Furthermore, they are more efficient at deriving parameters like abundances from low-resolution spectra and combining spectra with photometric and astrometric data (Wang et al. 2023; Guiglion, G. et al. 2020; Guiglion et al. 2024).
While conferring these advantages, this new generation of codes based on ANN for the analysis of stellar spectra are affected by a few limitations. Data-driven codes require training sets made of thousands of spectra that have been independently analysed. Such datasets are not easy to build, especially because they ought to include stars with non-standard properties (e.g. metal-poor or active stars). Also, the results from these codes may be biased because they use astrophysical correlations among parameters during the learning process. For example, the abundance from one element can be inferred from the combination of lines of other elements that are correlated for astrophysical reasons, which can lead to biased results (Ting & Weinberg 2022). Finally, there is no well-accepted method to calculate errors on the inferred parameters.
Invertible neural networks (INNs), a new ANN architecture proposed by Ardizzone et al. (2019a), are particularly well suited for estimating physical parameters from observations, because they are designed to provide a posterior probability distribution of the inferred labels. This architecture has already been tested for astrophysical problems ranging from the analysis of the internal structure of planets, to studying the merger history of galaxies, to photometric stellar parameter determination (Haldemann et al. 2023; Eisert et al. 2023; Ksoll et al. 2020). Kang et al. 2022, 2023a,b used a conditional INN to analyse emission lines in HII regions and stellar parameters from low-mass young stars).
In this study, we developed an INN model for the analysis of medium-resolution (R~20 000) spectra from GES and derived stellar parameters and some chemical abundances. The paper is organised as follows: in Section 2 we describe the dataset used for training, validation, and testing of the INN model. In Section 3 we present the network architecture, the training process, and the methods used for calculating the errors on the resultant astrophysical parameters. In Section 4 we present the results obtained from applying our code to the GES data, in Section 5 we validate our results through some astrophysical tests, and, finally, in Sections 6 and 7 we discuss our findings and draw conclusions.
2 Data
2.1 The GES GIRAFFE dataset
In this study, we used data from GES, a large public spectroscopic survey of almost 115 000 stars in the Galactic field and star clusters carried out between 2011 and 2018 with the multi-object spectrograph FLAMES at the VLT (Gilmore et al. 2022; Randich et al. 2022). All the reduced spectra and the astrophysical parameters derived by the GES consortium are available at the ESO website1. In particular, the final data release contains spectra observed by the GES consortium or retrieved from the archive with the two FLAMES spectrographs: UVES (R~47 000) and GIRAFFE (R~20000). Most of the available setups in both instruments were used during the survey. However, in this work, we used only spectra acquired with the GIRAFFE HR10 (5330–5610 Å, R=21 500) and HR21 (8480–8980 Å, R=18 000) setups, which were used for observing Milky Way field stars as well as clusters and special targets selected as calibrators. The astrophysical parameters used as labels for training, validation, and testing were all retrieved from the last public release (DR 5.1).
The targets catalogue, the data reduction process, the workflow for processing and analysing the data, and the content of the final catalogue of GES are described in Randich et al. (2022) and Gilmore et al. (2022), while the detailed methodologies used for deriving the stellar parameters and chemical abundances of the data release 5.1 are discussed in Worley et al. (2024) and Hourihane et al. (2023).
Absolute solar abundance and abundance amplitude relative to solar abundances for the stars and elements used in this work.
2.2 Dataset pre-processing
For our analysis, we retrieved the normalised spectra of the HR10 (6060 pixels) and HR21 (10 940 pixels) setups from the GES catalogue and combined them to create spectra with a total of 17 000 pixels. We tested the effect of using a buffer zone to avoid overlapping information between HR10 and HR21, but we found no significant difference in the results. We corrected for the Doppler shift caused by the stellar radial velocity by shifting all the spectra to a common rest frame and applying the flux-conserving method from the ASTROPY coordinated package SPECUTILS2 for resampling (Astropy Collaboration 2022). We then filled in any missing values in the normalised flux with the mean flux value.
We then selected only the spectra that have all the stellar parameters used in this work reported in data release 5.1, namely effective temperature (TEFF), surface gravity (LOGG), metal-licity (FEH), and elemental abundances of aluminium (AL1), magnesium (MG1), calcium (CA1), nickel (NI1), titanium (TI1), and silicon (SI1). We normalised these parameters to have zero mean and unit variance and fed them into the ANN. However, to facilitate the visualisation and comparison of our results, we adopted the relative abundance with respect to the solar abundance. The solar abundance values used in this work are taken from Grevesse et al. (2007) and listed in Table 1. Additionally, we may also express the relative abundance with respect to iron, as [element/Fe].
Among the ensemble of 114916 stars encompassed within the GES data release 5.1, a subset of 67 046 stars have been observed with both HR10 and HR21. Among these stars, 11 313 have values for the full set of nine labels used in our analysis. We further impose a cut on the median S/N of 25, empirically identified as offering the best compromise between the quantity and quality of our data. This leaves us with 8391 spectra, of which we use 80% (6688 spectra) for training and 20% (1703 spectra) for testing our machine learning models.
At times, we need to compute and analyse the entire dataset. For this, we use the full set of 49 858 stars, which includes all stars observed in HR10 and HR21, with an additional restriction to stars below 7000 K. While this approach might include stars from the training set – which is not ideal –, it becomes necessary due to the limited availability of data. When this occurs, we always compare the results against the GES dataset and look for improvements, as seen in Section 5.2. Additionally, if other restrictions are applied, they are detailed in the corresponding section. We refer to this dataset as the Catalogue dataset. We have made this catalogue available along with the inferences generated by OssicoNN.
To investigate the effects of noise degradation, we constructed a Noisy dataset that consists of 2592 spectra with a median S/N ranging from 5 to 25. Furthermore, with the aim of validating the results produced by the network, we created two specific datasets. The first, referred to as the Cluster dataset, includes stars belonging to the open clusters NGC 2420, NGC 2243, and Br 32 and globular clusters NGC 1904, NGC 2808, and NGC 362. These clusters include many stars observed with the setups HR10 and HR21, and are well studied and have reliable parameters in the literature (Pancino et al. 2017a). The second dataset, called Benchmark, contains benchmark stars with well-known parameters in the literature; these stars have been used to calibrate the GES parameters (Worley et al. 2024) and have been observed multiple times, resulting in varying S/N values for the same star. This dataset allows us to validate the reliability of our ANN against other independent methods and observations. The S/N distribution for each dataset is shown in Fig. 1.
 |
Fig. 1 Distribution of s/N for the various datasets used. |
2.3 Data space
In the Catalogue sample of stars, the effective temperature range is Teff = 3224–6999 K, the surface gravity log(g) spans from 0.39 to 5.00 dex, and the metallicity [Fe/H] varies from −3.47 to 0.49 dex. The chemical abundances also exhibit a wide range of values, which are listed in Table 1.
Figure 2 shows the distribution of these parameters and abundances. The distributions of effective temperatures and surface gravities are bimodal, while the abundance distributions are close to Gaussian, with negative skewness and a peak below zero. As expected, chemical abundances are positively correlated with each other. Most of the metal-poor stars included in the full dataset (blue contour) are absent from the dataset used for training and testing (orange contour) because some of their inferred chemical abundances are missing. In the training set (in orange), the temperature range becomes [3781–6915]K, the surface gravity spans from 0.51 and 4.84 dex, and the metallicity varies from −2.52 to 0.47 dex. Similarly, aluminium ranges from −1.60 to 1.06 dex, magnesium from −2.40 to 0.74 dex, calcium from −2.64 to 0.74 dex, nickel from −2.56 to 1.03 dex, titanium from −1.77 to 0.86 dex, and silicon from −1.92 to 3.31 dex. The distributions of the Test and Noisy datasets are similar to that of the Training dataset.
3 Neural network setup
In this section, we describe the architecture of our neural network and how it has been used to derive astrophysical parameters and their errors from the GES spectra. In the rest of the paper, we refer to our neural network model as OssicoNN, which takes inspiration from the word ossicones, which refers to the horn-like structures on the head of a giraffe.
3.1 Network architecture
3.1.1 A nontechnical summary of the architecture
In this subsection, we summarise the high-level features of the network architecture in nontechnical language. Readers familiar with machine learning terminology may wish to skip this summary and proceed to the following subsections, while readers more interested in the astrophysical applications of our methods may wish to read this summary and then proceed directly to Sect. 4.
The OssicoNN model consists of two linked networks (Fig. 3): (1) a conditioning network and (2) a conditional INN (cINN). The conditioning network takes as input the observed spectra and extracts high-level features that are then fed into the cINN. Its role is therefore only to process the spectra into a low-dimensional set of variables.
The cINN, on the other hand, is the core of the model and consists of a set of invertible transformations that link the input stellar parameters (labels) to an equal number of hidden variables in a so-called ‘latent space’. For computational simplicity, variables in the latent space are constrained to be distributed as multidimensional Gaussians. The latent space acts as a reservoir of diversity, allowing us to encode all the information available when moving from spectra to labels, allowing the network to be fully reversible.
The network is trained by feeding it the labels together with the associated spectra, that is, after processing the latter via the conditioning network. Because of the bijective nature of the cINN, the model also simultaneously learns the inverse transformation, which links spectra and latent space variables to the stellar parameters. When used for inference, OssicoNN exploits this inverse transformation. The inference therefore requires sampling over the Gaussian-distributed variables in the latent space, and, taking the spectra as inputs to the conditioning network, producing an output value for the stellar parameters.
This architecture natively takes parameter degeneracies into account. By repeatedly sampling from the latent space in inference mode, we can recover the posterior distribution function of the stellar parameters generated from a single input spectrum. The resulting (marginalised) uncertainty in the stellar parameters is called internal uncertainty. This uncertainty is linked to the nature of the inverse problem and the ability of the network to learn it, and is not related to the data quality.
We also consider the uncertainty in the model predictions resulting from noise in the data, which we refer to as external uncertainty. This uncertainty is not automatically taken into account by the network, and we explicitly model it by adding realistic noise to the input spectra when running OssicoNN in inverse mode. We model the total uncertainty by summing in quadrature the internal and external terms.
 |
Fig. 2 Stellar parameter distribution for the catalogue dataset (in blue) and the training dataset (in orange). The catalogue dataset comprises all stars observed in HR10 and HR21, with an additional restriction to stars below 7000 K, totalling 49 858 stars. The training dataset contains only the stars from the catalogue dataset used for training (6688 stars). |
3.1.2 The invertible neural network approach
Invertible neural networks are part of the family of normalising flow algorithms (Tabak & Vanden-Eijnden 2010). These algorithms are rooted in the foundational concept of transforming complex probability distributions into more tractable forms, akin to the familiar normal distribution. Normalising flows have found applications in the domain of machine learning, with auto-regressive flows standing out as the foremost examples (Kingma et al. 2016). While these normalising flows are theoretically bijective and allow explicit calculation of posterior probabilities, the practical implementation of the reverse transformation proves computationally prohibitive. Addressing this challenge, Ardizzone et al. (2019a) introduced INNs, endowing the framework with a comprehensive set of properties:
- (i)
The mapping from inputs to outputs is bijective, meaning that it has an inverse function.
- (ii)
Both the forward and inverse mapping can be computed efficiently.
- (iii)
Both mappings have a tractable Jacobian, which enables the explicit calculation of posterior probabilities.
The fundamental concept underpinning INNs is their ability to alleviate the inherent degeneracy between the spaces of output labels, denoted as x, and observations, denoted as y, during the inverse procedure. This is achieved by the introduction of an auxiliary set of variables, referred to as the latent space z. Consequently, the neural network transitions from the conventional relationship f(x) = y to a form denoted f(x) = [y, z]. The latent space serves as a reservoir, capturing the entirety of the information that becomes lost during the forward process. This augmentation allows a bijective transformation, thus enabling the inverse procedure expressed as 𝑔(y, z) = x.
To build such INNs, Ardizzone et al. (2019a) combined reversible coupling layers. Examples of these coupling layers are NICE (Non-linear Independent Components Estimation; Dinh et al. 2014), RealNVP (Real-valued Non-Volume Preserving; Dinh et al. 2016), and GLOW (Kingma & Dhariwal 2018; an evolution of RealNVP for image processing). These layers take a vector u as input, split it into two components [u1, u2], and apply the following transformation to produce the output vector v:
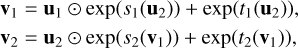 (1)
(1)
where ⊙ denotes element-wise multiplication and + is vector addition.
The block’s reversibility allows a straightforward conversion from the latent space vector v = [v1, v2] back to the original vector u through the following transformation:
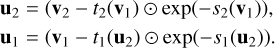 (2)
(2)
The reversible blocks in our model use the internal functions si and ti – which are neural networks of our design (typically composed of a linear layer and a rectified linear unit (ReLU) activation for simplicity) ent space (and back). The benefit of these blocks is that the si and ti networks always operate in the forward direction, regardless of whether we are performing the forward or the inverse transformation. Not only does this make it possible to calculate both forward and inverse transformations, but as the hyperparameters of the linear layers are the same in both forward and inverse modes, both transformations are learned simultaneously.
Subsequent to each reversible block, a deterministic permutation is systematically applied to the vector u (or v in the inverse mode), introducing a stochastic yet fixed rearrangement of vector elements. This permutation serves the dual purpose of enhancing interactions among vector elements, thereby enriching the expressiveness of the model, while maintaining a deterministic footing to ensure reproducibility and stability in the learning process. Ultimately, these computational blocks have the advantageous property of allowing for an easy computation of the determinant of the Jacobian matrix of the transformation.
 |
Fig. 3 Schematic representation of OssicoNN, the neural network for the inference of stellar parameters. The primary objective of the neural network is to encapsulate a transformative mapping between the hidden stellar parameters and an abstract latent space composed of an equivalent number of Gaussian distributions. This is done by the conditional network (in blue). The mapping is conditioned by the spectra first processed by the conditioning network (in red) that extracts the important features from the spectra. Each layer is shown as a box in a different colour, reflecting its nature, with key hyperparameters listed beside it. |
3.1.3 Conditional invertible neural networks
Invertible neural networks faced limitations due to rigid dimensionality requirements between x, y, and z. This was particularly challenging when x and y had significantly different dimensionality, like in the case where a few physical parameters are inferred from spectra with a large number of spectral channels. This limitation is alleviated in conditional invertible neural networks (cINNs, Ardizzone et al. 2019b). While the fundamental idea of building a transformation between spaces remains, the innovation of cINNs lies in constraining this transformation between hidden parameters x and the latent space z using a condition (c) derived from observations y.
During training, this transformation is expressed as z = f (x; c = y), and the subsequent inverse transformation recovers hidden parameters as x = 𝑔(y; c = y). This refined architecture enables flexibility by decoupling the dimensions of x and y, allowing work with a latent space z aligned with the dimensions of x.
Practically, this new condition c is seamlessly integrated into the si and ti neural networks in the reversible blocks. This is achieved by merely combining the condition vector c with the input vector (u during forward transformation, v in inverse mode) before entering the neural network. Therefore, the notation si·(uj) is replaced by the notation si(uj, c = y) in the cINN framework.
3.2 Implementation of conditional invertible neural networks
In scenarios involving observations with high-dimensional data, such as spectra and images, including them in reversible blocks becomes computationally expensive and inefficient. This is primarily due to the substantial number of pixels, many of which might not contribute useful information. Therefore, we introduce a conditioning neural network h, which is a function that maps the observations to a lower-dimensional representation. This representation captures the salient aspects of the data that are related to the hidden parameters x.
The whole cINN is represented in Fig. 3. The architecture consists of two distinct parts. The first is the conditional network, which is composed of different reversible blocks. During training, information travels in the forward direction through the conditional network along the blue arrows from star parameter labels to latent space. During inference, the conditional network operates in reverse mode and information travels along the red arrows. The second part of the architecture is the conditioning network. Comprising layers linked by green arrows, this network processes the input spectra and extracts relevant features. It enables efficient computation by injecting information at various stages within the coupling blocks of the conditional network.
We used FREIA3 (Ardizzone et al. 2018-2022), a library that facilitates the design of INNs (and cINNs) based on the PYTORCH library (Paszke et al. 2019), to construct the entire network. The GLOW blocks were implemented following the logic explained in the documentation, and we adopted the layers and logic of Pytorch.
Hyperparameters are the user-defined settings that control the learning process of a model, such as the number of hidden layers, the learning rate, and the regularisation strength. The choice of hyperparameters can have a significant impact on the performance and accuracy of a model, but it is often a time-consuming and tedious task to manually tune them. To overcome this challenge, we used OPTUNA (Akiba et al. 2019), a software framework for automated hyperparameter optimisation. OPTUNA provides a flexible and easy-to-use interface for defining and exploring the hyperparameter space and finds the best hyperparameters. In particular, we employed the Tree Structured Parzen Estimator (TPE) sampler – which is based on the Bayesian method – to systematically explore the parameter space with 100 distinct models.
We tasked OPTUNA with the objective of minimising the mean squared error (MSE) between GES values and inferred values. To attain this goal, we maintained the structure of the conditioning neural network while adjusting the parameters of the layers:
Convolutional layer:
Convolution_out [2i, i ∊ [2, 8]],
Convolution_kernel [2i, i ∊ [2, 8]],
Convolution_stride [1, 2].
Maxpool:
maxpool [1, 2, 3, 4].
Dense:
Dense_out [2i, i ∊ [2, 8]].
The selection of hyperparameters is thus grounded in either optimisation or, if explicitly indicated, the recommendations provided by the creators of the cINN (Ardizzone et al. 2019b).
3.2.1 Invertible network
The hidden data space and the latent space are bridged by the INN, which consists of four GLOW blocks. Each GLOW block contains two identical neural networks, s and t, which are composed of two dense layers with 512 neurons each with ReLU activations. The outputs of the cINNs are concatenated to these dense layers. Prior to each GLOW block, a random permutation block is inserted as previously mentioned, and subsequent to each block, a normalisation block is positioned. This design adheres to the guidelines proposed by the original authors of the cINN.
3.2.2 Conditioning network
The conditioning network follows a standard CNN setup, with 1D convolutional layers using ReLU activation. After the first convolutional layer, we also add a subsequent max-pooling to reduce output size. This structure repeats three times, followed by flattening and three linear layers with ReLU activation and dropout regularisation. The output then goes through a final linear layer before joining the last GLOW block.
Moreover, outputs from the second, third, and fourth convolutional layers are duplicated, flattened, and processed through two linear layers with ReLU activation (except for the first one, which also adds a max-pooling layer). These processed outputs serve as conditioning inputs for the first, second, and third GLOW blocks, respectively. The feature numbers at each convo-lutional layer stage are 256, 32, 256, and 32, respectively. These features play a key role in conveying relevant spectral information to the conditional network, influencing how data space is mapped to latent space. The complete set of hyperparameters of the different layers is shown in Fig. 3.
3.2.3 Training process
Ardizzone et al. (2019b) suggest that the cINNs be trained with a maximum likelihood loss based on input vector parameters, latent space parameters, and model parameters θ:
![Mathematical equation: ${\cal L} = {_i}\left[ {{{{{\left\| {f\left( {{x_i};\theta ,{y_i}} \right)} \right\|}^2}} \over 2} - \log \left( {\left| {{\mkern 1mu} \det \left( {{{\partial f} \over {\partial x}}} \right)} \right|} \right)} \right] + {1 \over {2{\sigma ^2}}}\theta {^2}.$](/articles/aa/full_html/2024/12/aa51251-24/aa51251-24-eq3.png) (3)
(3)
The final loss function therefore consists of two components: the first one is the maximum likelihood objective, and the second one is an L2 regularisation term. In practice, we only implement the maximum likelihood objective, and the regularisation term is added separately.
To facilitate the training process, we adopt the other techniques proposed by the cINN authors. First, we apply soft clamping of the hyperparameters by constraining the gradient norm below 10. We additionally use the ‘clamp’ parameter within the GLOW layer specifications. This parameter restricts the exponential term in Equations (2) and (3) to exp(± sc1amp). Following the Ardizzone et al. (2019b) recommendation we chose sclamp = 1.9. These decisions are driven by the consideration that the exponential function is employed in coupling layers, which poses a risk of amplifying the values of elements in u (or v), potentially resulting in divergence. Second, we use soft channel permutations (i.e. random orthogonal matrices) to allow the exchange of information between u1 and u2 within the blocks. Third, we use normal initialisation with a scaling factor of 0.01, which improves the initial stage of training. Moreover, when training, we introduce Gaussian noise with an amplitude of 0.05 to the hidden parameters in the training set to improve performance and general stability.
We train these hyperparameters using the loss function in Eq. (3), and we additionally compute the mean squared error (MSE) as another metric with which to monitor the training progress. We compute these two metrics for both the training and the validation dataset. During training, spectra are fed to the neural network in batches of 32 elements. We train for 60 epochs with a learning rate of lr = 10−3, which is reduced by a factor of ten at epoch 50. Furthermore, we apply a weight decay of 1e-5 to the model parameters as a form of L2 regularisation, which helps to prevent overfitting and improve generalisation performance.
The training of our neural network model with a NVIDIA RTX4090 takes approximately 25 minutes for 60 epochs. The evolution of these different metrics during training is shown in Fig. 4. The MSE exhibits instability, particularly within the initial 50 epochs when the learning rate is set to lr=0.001. This behaviour is not unexpected, considering the inherent dissimilarity between the MSE error metric and the likelihood function. While the MSE error term penalises larger deviations due to its quadratic nature, the likelihood function focuses on points that deviate from the underlying data probability distribution.
Training neural networks inherently involves randomness due to the different initial conditions and the random sequencing of training data exposure. To ensure the selection of a well-trained network, we trained five versions of the model and opted for the one that obtains the least loss.
 |
Fig. 4 Evolution of the loss function and the MSE during training. The learning rate was reduced from 103 to 104 in period 50, leading to a drop in overall losses. |
3.3 Uncertainties
Supervised machine learning algorithms represent a distinct paradigm compared to ‘classical’ algorithms. Classical algorithms derive results from predefined rules and observations, whereas in supervised machine learning algorithms, the results and observations are employed to deduce rules (and potentially generate new results). The nature and origin of uncertainties are therefore very different. Consequently, various methods have been suggested to address uncertainties within this alternative paradigm (Hüllermeier & Waegeman 2019). The theoretical approach to calculating these uncertainties relies on quantifying the disparity between an ideal transformation and one derived from our neural network and data.
This gap leads to the emergence of various types of uncertainty (Perreault Levasseur et al. 2017). Here, we primarily consider epistemic and aleatoric uncertainties. Epistemic uncertainties arise from errors inherent to the model, specifically due to the lack of knowledge about the perfect model. In an ideal scenario, these uncertainties can be reduced with additional information. Such uncertainties include, among other factors, model uncertainty, indicating that the neural network, constrained by the chosen architecture, may not precisely emulate the perfect transformation. For instance, a neural network composed solely of dense layers without activations might only model linear transformations, resulting in a mismatch with the perfect transformation when the mapping between observation space Y and output space X is not itself linear. Epistemic uncertainties also include approximation uncertainty, which arises due to limitations in the learning process, such as halting after a finite number of iterations or populations inadequately represented in the dataset with respect to X × Y.
Furthermore, aleatoric uncertainties emerge from the inherent variability caused by randomness. In the case of astrophysical spectra and INN, this will include factors such as photon noise, potential data corruption, calibration uncertainties, observational artefacts, potential errors in the hidden parameters, and the non-deterministic relation between observations and parameters. These uncertainties are similar in that improvements by adding new information – whether through alterations to architecture and training methods or by increasing the dataset – are ineffective in reducing them.
Addressing all uncertainties in our analysis is quite complex. We address this challenge by computing two types of uncertainties. The first, referred to here as internal uncertainty, is a combination of some epistemic and aleatoric uncertainties associated with the neural network. The second, which we call external uncertainty, accounts for uncertainties in data quality.
3.3.1 Internal uncertainties in cINN
Internal uncertainty encompasses the inherently non-deterministic relationship between spectrum and parameters. Even with complete information about spectrum, there remains uncertainty in the predicted parameters, which is considered as aleatoric uncertainty here. This effect is further amplified as data are observational (and therefore inherently noisy, even after curation) and parameters are derived from a classical pipeline that introduces its own biases. Additionally, internal uncertainty considers part of the approximation uncertainty created by the quality and density of the training data.
However, internal uncertainties do not encompass all components of epistemic uncertainty. For example, we do not account for the full range of model uncertainties or certain aspects of approximation uncertainties. This is because we maintain specific assumptions about the model, such as keeping the weights fixed and not measuring the impact of changes induced by adjusting the model’s weights.
Computing these internal errors is achieved by determining the posterior distribution of the parameters according to the observations p(x|y). To do this, we use the fact that cINN models a transformation between the distribution of the parameters and a normal distribution p(z) = N(z, 0, I). We can therefore obtain the posterior distribution by sampling the normal distribution in Ninternal samples and performing the inverse transformation x = 𝑔(z, c = y). This exploration of the full latent space through Ninteгnal samples allows us to capture the complete diversity of possible solutions for a given spectrum, thereby reconstructing the full Bayesian posterior for all parameters.
Marginalising along a small number (1 or 2) of parameters allows us to effectively explore the full multivariate posterior. For the sake of visualisation, we studied the pairwise distribution of all parameters. The distributions for three spectra are provided in Figs. B.1, B.2, B.3 on Zenodo (see data availability section).
The posterior distribution of each parameter is unimodal and approximately Gaussian, indicating that the problem we are addressing does not exhibit strong degeneracies. We studied the pairwise parameter distributions, finding unimodal, bivariate, Gaussian-like distributions, with pairs of parameters being weakly correlated or not at all. We calculated the Pearson coefficients for all stars in the test set (see Figs. 5 and B.4 on Zenodo for full coefficients) and determined that the most highly correlated parameters are temperature and surface gravity (weak linear correlation, median R = 0.3) and temperature and metal-licity (very weak correlation, median R = 0.18). The median Pearson coefficients for other parameter pairs are below 0.14.
3.3.2 External uncertainties in cINN
External uncertainties encompass all the sources of error in the data. In this study, we account for observational errors that affect the data quality, such as Poisson noise from photon counts on the CCD, cosmic-ray hits, atmospheric effects, and so on. However, we do not consider systematic errors that are intrinsic to the instrument and affect all spectra in a similar way. We also assume that the stellar parameters assigned to each spectrum by GES are accurate and reliable, without any bias or misclassification.
We estimated external uncertainties from the GES data products. The GES data reduction pipeline produces the inverse of the variance (IVAR) for each pixel. To obtain the standard deviation of the noise, we take the square root of the inverse of IVAR multiplied by the ratio between the normalised FLUX_NORM and the non-normalised flux (FLUX):
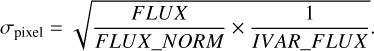 (4)
(4)
This ensures that we estimate the noise level of the normalised spectrum.
To account for external uncertainty in our machine learning models, we generated Nexteгnal noisy spectra for each observed spectrum by adding Gaussian noise with a mean of zero and a standard deviation σpixel (Eq. (4)) to each pixel 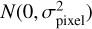 :
:
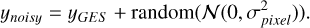 (5)
(5)
We assume that the pixels are independent and we neglect the covariance between the pixels. This procedure creates a distribution of spectra that represents the possible variations due to noise. This methodis similarto thatappliedby Kang etal. (2022) to the HII region, although our treatment of uncertainties is different, as we separate the internal and external uncertainties.
 |
Fig. 5 Distribution of the Pearson coefficients between pairs of parameters for test set stars derived from sampling latent space to obtain the posterior distribution for one spectrum. Temperature, metallicity, and gravity exhibit the strongest correlations (albeit weak), whereas abundances, such as [Al/H] and [Mg/H], show very poor correlations. Additional Pearson coefficient distributions are provided in Zenodo (Fig. B.4, see Data availability section). |
3.3.3 Total uncertainties
To estimate the total uncertainty, we combined the two sources of error: internal and external. We first generated Nexternal spectra with added noise, simulating the observational uncertainty. For each noisy spectrum, we drew Ninternal samples from the latent space, representing the diversity of the neural network. We then applied OssicoNN in inverse mode to infer the stellar parameters for each spectrum and latent sample. This gives us the posterior distribution of all the parameters for each Nexternal spectrum in the form tensor of shape (Nstars, Nexternal, Ninternal, Nparameters).
To find the total error for each parameter, we characterised the distribution differences. We first looked at external uncertainty, that is, how the distribution changes between Nexteгnal iterations of the same spectra. The most reliable method entails using kernel density estimation (KDE) and identifying the peak in the density distribution for each of the Nexteгnal spectra. To do this, we used the SCIKIT-LEARN kernel density function with a Gaussian kernel and a bandwidth determined by the Silver-man rule. We recorded the peak of the density for each spectrum. The external error is directly derived by computing the standard deviation on the subset composed of values linked with peak density:
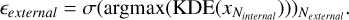 (6)
(6)
The internal uncertainty is derived by measuring the amplitude of the posterior distribution when sampling the latent space. We measured this global amplitude by calculating the interval u68/2 of each posterior distribution, where u68 denotes the interval between percentile 16 and percentile 86 of the distribution. The final value is determined by calculating the median along the Nexternal values:
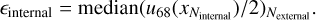 (7)
(7)
The overall uncertainty is computed by quadratically summing these two distinct uncertainties:
 (8)
(8)
3.4 Inference of the parameters
The algorithm offers two modes of inference that differ in their speed and accuracy. In the Fast mode, the algorithm randomly selects a single sample from the latent space for each dimension according to a Gaussian probability. This sample, together with the spectrum to be analysed, is fed to the neural network in inverse mode, which then infers all the parameters of the associated spectrum. On the other hand, the Precision mode allows more precise parameter estimation and measurement of the uncertainties discussed earlier. To estimate parameter values, both IVAR information and sampling of the latent space are employed to obtain the same tensor as previously described in Section 3.3.3. The final task involves converting the parameter distribution into a singular value. The most reliable method again entails using KDE and identifying the peak of the posterior distribution. Although this step is resource-intensive, it is indispensable when dealing with multimodal distributions resulting from certain physical degeneracies. However, in the case of the stellar parameters under investigation, this complexity is absent. Therefore, to validate our estimation, we could also have taken the median of the distribution to save time. Finally, the median is calculated over the Nexternal samples.
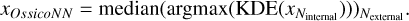 (9)
(9)
OssicoNN achieves a rate of 5000 iterations per second for parameter determination of a spectrum – random_latent_space pair. This efficiency enables rapid predictions during real-time analysis. In Fast mode, analysing a catalogue of about 50 000 stars takes roughly 10 seconds. However, switching to Precision mode incurs a significant increase in computational overheads. Given that we utilise Nexternal spectra and Ninternal samples from the latent space for each spectra, the computation time scales with the product of these two parameters. For instance, with Nexternal = 20 and Ninternal = 250, processing the same catalogue would require approximately 14 hours.
4 Results
4.1 Accuracy of predictions
4.1.1 Test set predictions
The neural network applied to the test set demonstrates no bias for either mode (1 K for temperature and >0.01 dex for both log gravity and abundances). The standard deviation of the residuals, which is indicative of the scatter in the direct comparison between the GES labels and OssicoNN predictions (Fig. 6), is relatively low. For the precision mode in particular, we obtain a standard deviation of 28 K for temperature, 0.06 dex for gravity, 0.03 for metallicity, and ranges from 0.06 to 0.17 for the element abundances. The standard deviation consistently exceeds the absolute values of the difference between the 15th percentile p15 and 85th percentile p85 after median adjustment. This indicates a distribution that deviates from a Gaussian and is characterised by a narrow core with few outliers, exhibiting significantly divergent predictions. Moreover, the congruence of the mean and median across all parameters indicates that the predictions made by OssicoNN are symmetrically distributed around the centre, where outliers are therefore few in number and are evenly distributed between overestimates and underestimates.
Table 2 and Fig. 6 demonstrate that the alignment quality between predictions and labels for each parameter can be categorised into three levels: very high, high, and medium. Temperature, gravity, and metallicity predictions are notably accurate, exhibiting minimal scatter (translating into a low standard deviation for residues). The predictions for aluminum and magnesium abundances are also highly accurate, though they show a slightly larger scatter (about 0.05 dex). For other abundances, prediction becomes more challenging, with larger scatter (in the range of 0.1–0.2 dex).
Figure 6 highlights a small set of stars with very low metallicity (around −1.5 dex), which is predicted with remarkable accuracy despite the limited number of low-metallicity stars in the training set. We interpret this as a result of likelihood training, which compels the neural network to focus on less densely populated regions of the full parameter distribution. The distribution of [Si/H] residuals deviates more strongly from a Gaussian, with a standard deviation that is 46% greater than the 15th and 85th percentiles, while the difference between these statistics for [Ca/H], [Ni/H], and [Ti/H] is around 20%. [Si/H] exhibits a narrow core and outliers for which the OssicoNN estimates are far from the GES labels. Overall, the agreement between the two estimates is good, although there are certain outliers where the OssicoNN predictions diverge from the GES labels.
4.1.2 Noisy dataset predictions
Figure 7 shows the comparison between the input labels and the model predictions (using the Precision mode) on the noisy dataset. The median of the residuals remains strikingly consistent (0 K for temperature, 0 dex for gravity, 0 dex for metallicity, and between −0.02 dex and +0.01 dex for abundances). However, there is a noticeable uptick in the standard deviation (39 for temperature, 0.08 dex for gravity, 0.05 dex for metallicity, and between 0.06 dex and 0.24 dex for abundances). This increase is still minimal, considering that the median S/N drops from 55 to 24. Similar to the findings in the test set, the estimates for temperature, gravity, and metallicity align more closely with those from GES compared to the estimates for abundances (especially for [Ca/H], [Ni/H], [Ti/H], and [Si/H]).
Compared to Fast mode, Precision mode decreases the u68 interval of the residuals between prediction and input labels (ranging between 0% and 60%) for various parameters. This improvement is particularly pronounced in noisy datasets.
Using OssicoNN, we generated new estimates for the nine output parameters for the Catalogue dataset, totalling 49 858 stars. The table, available at the CDS, includes the object name in the GES DR5 catalogue (denoted as OBJ), the nine parameters, along with their uncertainties (total, internal, and external), and a DATASET entry indicating the dataset to which the star belonged (specifically whether or not it was part of the training set).
 |
Fig. 6 Density distribution of parameters inferred by OssicoNN compared with the parameters given in GES for the test dataset. The average bias and the standard deviation, the 15th percentile, and 85th percentile of the residuals around the 1:1 relation are given in every panel. Dashed diagonal lines indicate the 1:1 relation. |
4.2 Uncertainties
To investigate uncertainties, we applied the following restrictions to the Catalogue dataset: inferred temperatures ranging from 4000 to 6915 K and metallicities between −1.5 and 0.5 dex. Additionally, we filtered out stars with temperatures of below 4500 K and surface gravities exceeding log (𝑔) = 4. This step is designed to exclude stars falling outside the training range, resulting in a dataset comprising 42 738 stars from various datasets and a wide range of S/Ns. We refer to this dataset as the ‘Reduced Catalogue’ dataset.
This dataset contains the stars from the training set. This decision arises from the realisation that excluding stars would result in the omission of a large number of high-S/N spectra. However, we do not perceive this as a concern, as our primary interest lies in assessing uncertainties and not in the inferred values. Using only the test set does not result in significantly different quantitative trends. In the following, it is worth remembering that OssicoNN operates without knowledge of the estimated uncertainties associated with GES parameter labels.
Statistics detailing uncertainty distributions are provided in Table 3. The overall temperature uncertainty distribution is shown in Fig. 8a, and distributions for all other parameters can be found in Fig. C.1 on Zenodo (see Data availability section). Across all distributions, we find that the uncertainty associated with each parameter is of the same order of magnitude as that estimated in GES. For example, in the case of temperature, the median of the uncertainty distribution is around 50 K for OssicoNN, compared to approximately 64 K for GES. The scale of the uncertainties in OssicoNN closely mirrors the errors observed between OssicoNN and GES, particularly for the Noisy dataset when OssicoNN is configured in Precision mode.
For temperature, surface gravity, and metallicity, we observe that the OssicoNN distribution is much wider, with a large tail and high uncertainties. For temperature, for example, this translates into a higher mean (101 K) in the OssicoNN distribution than the median and GES mean (64 K). An examination of the 670 stars with temperature uncertainties over 500 K shows an average S/N of five, highlighting the strong expected link between low S/N and high uncertainty estimations by the neural network. For other abundances, the GES and OssicoNN distributions are similar, with the peak of the OssicoNN distribution occurring earlier than the GES peak, resulting in lower median and mean uncertainties for OssicoNN. Silicon is the exception, showing a larger tail and higher uncertainties (p85 = 0.56 dex). Silicon is also the least available parameter in the GES catalogue. It is assumed that when uncertainties were too high, the abundance was not recorded in the GES catalogue. In OssicoNN, this leads to very high uncertainties for silicon, making the measurement unreliable.
The GES uncertainty distribution presents several distinct patterns (not visible in figures due to log scale). Firstly, the uncertainties in effective temperature, surface gravity, and metallicity exhibit discrete errors. For other parameters with continuous distributions, we observe non-physical patterns, such as over-density and under-density strips, caused by the method used to compute the classical label. Conversely, OssicoNN does not reproduce these patterns.
Figure 8b illustrates the distribution of normalised residuals for effective temperature, shown in red when considering only OssicoNN uncertainties and in grey when considering the quadratic sum of GES and OssicoNN uncertainties. Each distribution is fitted with a Gaussian with a fixed standard deviation of 1. According to the central limit theorem, this error-to-uncertainty ratio should follow a centred Gaussian distribution with a standard deviation of one if the relationship between GES and OssicoNN estimates is linearly homoscedastic and if the uncertainties are independently drawn from a normal distribution. Normalised residuals for all parameters are provided in Fig. C.2 on Zenodo (see Data availability section). Additionally, a similar figure using a reduced test set is also available. The Gaussian fits show that the errors are balanced, as indicated by the systematically zero means, regardless of the error and dataset considered. However, it is notable that some abundance distributions for the dataset of stars exhibit a tail towards negative values, with a very pronounced tail for metallicity and smaller tails for calcium, nickel, and titanium.
Based on the data, we propose that this tail results from two phenomena. Firstly, there is an overestimation of abundances because the training set contains few low-metal stars, leading to overestimation of these quantities (see Section 4). Secondly, as discussed in Section 5.1, the metallicities of stars with very low S/N are underestimated in the GES dataset. These tails are absent in the test set (Fig. C.3 on Zenodo) when the spectra are of good quality and fall within the training parameter space. When we normalise with respect to the sum in quadrature of OssicoNN and GES uncertainties, the distribution deviates from Gaussian. This deviation is expected, as the neural network is unaware of the uncertainties in the GES labels and assumes the labels provided to OssicoNN are absolutely true.
Nevertheless, this does not mean there is no relationship between the estimates, labels, and their respective uncertainties. Figure 8c shows the temperature estimates of GES and OssicoNN along with their uncertainties for a randomly selected subset of 200 stars (limited for clarity). Estimates are mutually compatible when accounting for measurement uncertainties as uncertainties almost universally overlap the 1:1 line. This concordance between estimates and labels is also illustrated by the large uncertainties attributed (by at least one of the estimators) when the pair (estimate and labels) deviates from the 1:1 relationship. The same plot for the other parameters is available in Fig. C.4 on Zenodo.
Figure 8d shows the distribution of inferred total uncertainties in temperature concerning the ‘Reduced Catalogue dataset’. Additionally, the figure illustrates the distribution of external (red) and internal (orange) errors in each temperature bin. For the corresponding bins, we also present the median S/N depicted in blue, alongside the distribution of the training set indicated in green. Comparable visualisations for additional parameters can be found in Fig. C.5 on Zenodo (see Data availability section).
First, for high uncertainties characterised by ϵTeff > 500 K, the errors exhibit a uniform distribution. This uniform distribution of high uncertainties is consistently observed across other parameters as well. Subsequently, we can decompose the total error into external and internal components. The external error demonstrates a strong anticorrelation with the S/N: it is inversely related, such that high S/N values correspond to low external errors, and conversely, low median S/N values result in high errors assigned by the neural network. Specifically for temperature, the external error reaches a minimum of 8 K around 4200 K when the median S/N exceeds 50, and it escalates to a maximum of 513 K at 6900 K when the median S/N falls below 10. This trend is consistently observed across all parameters.
The internal error manifests as a convex function, initially valued at 20 K, decreasing to 16 K at 4500 K, then rising to 83 K at 6350 K, and ultimately surging to 352 K at 6850 K. This error distribution is influenced, among other factors, by the distribution of the training set: a higher density of the training set at a specific temperature correlates with a lower external error. This relationship is particularly evident in the abundance parameters, where the minimum internal uncertainty coincides with the maximum training set distribution. Additionally, this function likely depends on the neural network’s capability to optimize hyperpa-rameters and accurately map the parameter space to the latent space, effectively performing a precise fit. It is anticipated that the contribution of this factor is minimal at the centre of the parameter distribution and maximal at the boundaries, though further investigation and quantification are necessary.
Nonetheless, this internal uncertainty is modulated by the S/N, as a high S/N suggests a higher proportion of training stars within a bin relative to the total star population in that bin, as well as an enhanced capability to extract useful information due to reduced noise. However, this analysis does not hold for temperature, where we would anticipate a minimum internal error at 4750K. This unexpected behaviour is attributed to the degeneracy (refer to Figures 5 and 10) between the main sequence and the red giant branch, which is obscured by marginalisation along the temperature axis. OssicoNN reflects this degeneracy as a high internal error. To verify this, we examined Fig. 8d to ensure that the stars of the giant branch and main sequence were not divided into distinct zones (one with low uncertainties and the other with high uncertainties) and observed an overlap between the populations. The other parameters do not exhibit such degeneracy and thus more accurately reflect the training set distribution.
In summary, both internal and external errors exhibit behaviours consistent with the uncertainties that have been included and listed in Section 3.3, namely dependencies on S/N, on the training distribution, potential degeneracies, and so on. Similar trends can be seen for all other parameters in Fig. C.5 on Zenodo (see Data availability section). The external error demonstrates a robust correlation with the S/N of the spectrum, with higher S/N associated with lower external error, and vice versa. Internal uncertainties are represented by a function that reflects the distribution observed in the training set, the geometry in parameter space, and the challenges due to the non-deterministic relations between spectra and parameters. In Gaussian training distribution with non-degeneracy, this distribution tends to be convex, with its minimum coinciding with the peak density of the training set.
Residual statistics between OssicoNN and GES for various datasets and two modes: Fast and Precision.
Statistics of the distribution of the uncertainties in OssicoNN and GES for the reduced catalogue dataset.
 |
Fig. 7 Density distribution of parameters inferred by GES and OssicoNN for the noisy dataset. The average bias and the standard deviation, the 15th percentile, and 85th percentile of the residue results around the 1:1 relation are given in every panel. Dashed diagonal lines indicate the 1:1 relation. For the sake of clarity, we have excluded three stars from the [Si/H] quadrant that deviate significantly from the expected 1:1 relationship. These particular stars were initially predicted to have abundances of 3.1, 3.7, and 4.5 in the GES model. However, when using OssicoNN, their predicted abundances were notably different, measuring only −0.3, 0.2, and 0.2. |
 |
Fig. 8 Different plot for effective temperature uncertainties in the ‘Reduced Catalogue dataset’ (totalling 42 738 stars), (a) Distribution of uncertainties in GES and OssicoNN. (b) Distribution of the residuals between OssicoNN and GES normalised with respect to the uncertainties of OssicoNN (red shadowed area) and the sum in quadrature of GES and OssicoNN errors (grey shadowed area). Dashed lines represent the fit of the distribution with a Gaussian function with standard deviation σ = 1. (c) Temperature estimates for 200 stars taken at random from the catalogue by GES and OssicoNN with their respective uncertainties, (d) Density distribution of total OssicoNN uncertainties with respect to inferred temperature. The red and orange lines represent the median external and internal uncertainties for each temperature bin. The blue curve and its scale on the right represent the median S/N per temperature bin. |
4.3 Interpreting the network with saliency maps
Given the nature of stellar physics, not every combination of stellar parameters is feasible, resulting in correlations between certain parameters. For instance, metal abundances exhibit correlations, and so, for example, a high iron content tends to coincide with a high aluminium abundance. These correlations are inherently present in our training dataset, along with any correlations arising from observational constraints such as instrumental ones, as well as choices made regarding the study of particular populations. During the neural network training process, access to these parameters enables the network to derive hyperparame-ters based on these correlations rather than solely from spectral data. While this approach may yield satisfactory results for many stars, it may falter for more unconventional cases.
To verify what features of the training set the network learnt from, we can examine the saliency map. A saliency map identifies the most influential regions or features of an input image that contribute to the network’s output. Briefly, this method computes the gradient of the output score concerning the input image and utilises this gradient information (saliency 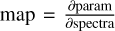 ) to pinpoint the regions of the input image exerting the greatest influence on the output. The saliency map is computed for all features and spectra within the test dataset and is then averaged across all spectra. Figure 9 illustrates the saliency map for all parameters. We then compute the absolute values of the saliency maps and determine the main peaks and their associated wavelengths. Using SCIKIT-LEARN Pedregosa et al. (2011) and the NearestNeighbors function, we match the wavelengths of the peaks with the theoretical lines in a catalogue of atomic lines pertinent to this domain (Heiter et al. 2021).
) to pinpoint the regions of the input image exerting the greatest influence on the output. The saliency map is computed for all features and spectra within the test dataset and is then averaged across all spectra. Figure 9 illustrates the saliency map for all parameters. We then compute the absolute values of the saliency maps and determine the main peaks and their associated wavelengths. Using SCIKIT-LEARN Pedregosa et al. (2011) and the NearestNeighbors function, we match the wavelengths of the peaks with the theoretical lines in a catalogue of atomic lines pertinent to this domain (Heiter et al. 2021).
As evident from Fig. 9, temperature (Teff) and surface gravity (log 𝑔) are typically not reliant on individual lines but rather on the entire spectrum. More specifically, the temperature estimate comprises a combination of several lines with approximately equal weights, including those associated with magnesium I, iron I, manganese I, titanium I, and calcium II.
Concerning surface gravity, OssicoNN primarily derives pertinent information from HR 10, focusing particularly on iron lines (with the ones at 5497.516 K and 5586.80 Å being the most crucial), as well as lines related to magnesium and calcium.
When examining the abundances, our expectation is for them to be deduced mostly from the lines associated with the respective elements. The saliency map for [Fe/H] captures information from numerous spectral lines. Specifically, the map identifies the 15 main peaks associated with 18 theoretical lines, with some peaks corresponding to multiple spectral lines due to the pair-matching algorithm erroneously assigning two theoretical lines to the same saliency map peak. Each of these peaks can be associated with one or more theoretical iron lines.
Similarly, when averaging over all spectra, the saliency map for aluminium, magnesium, and silicon is predominantly influenced by a select few lines corresponding to each element. Specifically, aluminium is primarily determined by the doublet at 8772.865 Å and 8773.896 Å, magnesium by the lines at 8717.825 Å, 8736.019 Å, 8806.757 Å, and 5528.405 Å, and silicon by the line at 8892.720 Å, although a handful of additional lines from other elements may contribute marginally.
A second group of elements, including nickel and calcium, primarily relies on their respective spectral lines (5581.965 Å for calcium and 5578.718 Å for nickel), as well as the silicon line at 8892.720Å. The saliency map also gives some importance to secondary contributions from other lines of the element under consideration (5587.858 Å for nickel and 5594.462 Å for calcium), as well as aforementioned lines from other elements (aluminium, magnesium and silicon).
Titanium poses a significant challenge as it is primarily determined by several lines originating from other elements, notably the ones mentioned above, and only to a limited extent by titanium-specific lines such as 5490.148 Å, 5514.343 Å, and 5514.533 Å.
Based on these findings, it appears that aluminium, magnesium, and silicon are determined independently of the other elements, while calcium and nickel show slight correlations with silicon. Titanium, on the other hand, seems to be influenced by a combination of other elements and may exhibit correlations with the abundances of other elements.
The saliency maps show that the information content of each spectral region is never zero. This effect is due to the use of convolutional layers with a large kernel, which aggregates information from a substantial number of pixels simultaneously, leading to a smoothing effect in the saliency map calculation.
Additionally, we examined the impact of sampling parameters based on their values. Spectra were sampled according to their aluminium abundance (−1 < [Al/H]; −1 ≤ [Al/H] < −0.5; −0.5 ≤ [Al/H] < 0;0 ≤ [Al/H] < 0.5; [Al/H] > 0.5). At higher abundances, reliance on the doublet 8772.865 Å and 8773.896 Å is evident.
5 Astrophysical validation
To further evaluate the precision and the accuracy of OssicoNN, we compared the parameters obtained by the pipeline with those derived from the GES workflow for three selected samples (field stars, star clusters, and benchmark stars) using some of the astro-physical tests used in Hourihane et al. (2023) to check the quality of the data.
 |
Fig. 9 Median saliency map across all test and noisy datasets. This is obtained by averaging the saliency maps for each parameter. The represented spectrum corresponds to the median of the test and noisy datasets spectra. The primary theoretical lines corresponding to a peak in the absolute value of the saliency map are indicated by vertical lines. The displayed iron lines are among the 15 most significant peaks for the iron saliency map. |
5.1 Field stars
From the Catalogue dataset, we selected stars that belong to the Milky Way field using the keyword GES_TYPE = ‘GE_MW’, where temperature, surface gravity, and metallicity were estimated by the GES pipeline. This selection includes stars from both the thin and thick Galactic disc, along with a small fraction of halo stars, totalling 44,756 stars.
Figure 10 shows the Kiel diagrams of this sample created with the OssicoNN (left panel) and GES (right panel) parameters. This diagram depicts the relationship between surface gravity, effective temperature, and metallicity, providing insight into stellar evolution. Comparing the diagrams reveals that OssicoNN accurately reproduces the structure observed in GES data. Notably, we can observe the presence of a well-populated main sequence (MS) region characterised by surface gravity of between 4.8 and 4.3, temperatures spanning from 4200 K to about 7000 K, and solar metallicity. Low-temperature stars (around 4000 K) and surface gravity higher than 3.5, thus located about the MS, are expected to pre-main sequence stars. The red giant branch (RGB, with Teff from about 4500–5500 K and log 𝑔 <3.5) is also well populated by stars of different metallicity. As expected, the more metal-rich stars at any given log g are the cooler ones. The trend is well reproduced with the OssicoNN parameters, in which the scatter is reduced – in particular on the left side of the RGB for the lower metallicity giant stars.
However, OssicoNN struggles to accurately replicate some stars with very low metallicity below [Fe/H] = −2, particularly those with high temperature and gravity (around 6500 K and 4.7 dex), or low temperature and medium gravity (around 4000 K and 4 dex). These stars are mainly characterised by spectra with S/N ranging between 5 and 10. Furthermore, as these stars were not included in the training dataset, OssicoNN did not learn to effectively distinguish between them. Moreover, we argue that the parameters measured for these stars in GES are not correct: for the upper MS stars, the low metallicities obtained are due to degeneracy between high temperature and low metallicity, while for the lower MS and PMS, this is to the presence of molecular bands that do not allow the stellar continuum to be correctly estimated. From a chemical evolution point of view, we do not expect to have upper MS (thus massive and young) stars in the disc with such low metallicity ([Fe/H]< −2). Along the same line of argument, the cool PMS stars representing the late stages of Galactic chemical evolution are expected to have at least solar metallicity (see e.g. Magrini et al. 2023).
On the other hand, the uncertainties assigned by OssicoNN to these stars are relatively low, particularly the internal uncertainty, despite the higher external uncertainty caused by the low S/N. This merits a significant level of confidence in the predictions made by OssicoNN. Similarly, when examining the placement of these stars in the Kiel diagram using OssicoNN, we observe a good alignment with the overall trend seen among stars with similar parameters. Whether any inaccuracies in our assessment of OssicoNN are due to limitations in the training set or errors in our evaluation of the GES pipeline because of the low S/N remains uncertain. Nonetheless, our analysis leans towards the latter hypothesis, highlighting once again the remarkable effectiveness of the neural network in the low-S/N domain.
Figure 11 shows the distributions of [Mg/Fe] versus [Fe/H] for all the stars with S/N greater than 25 obtained using the parameters derived with OssicoNN (on the left) and the GES workflow (on the right). To perform this task, it is essential to compare the same stars, requiring that both [Fe/H] and [Mg/H] be determined by the GES pipeline. As a result, the figure includes a total of 11 909 stars. This plot is classically used to separate the two disc populations (see e.g. Fuhrmann 1998; Bensby et al. 2003; Hayden et al. 2017): at a given metallicity, thick-disc stars are expected to have higher [Mg/Fe] due to their different star formation history. In Fig.11, the thin and thick disc are better separated when the OssicoNN abundances are used (left panel) than when the original GES ones are employed. This suggests that the abundances derived with our neural network are more precise than those obtained with classical analysis, improving the analysis of the low-S/N spectra and consequently improving the separation and reducing the scatter.
 |
Fig. 10 Kiel diagram: log g versus effective temperature colour coded according to metallicity for stars in the Milky Way field as derived using OssicoNN astrophysical parameters (left panel) and the GES recommended values (right panel). Superimposed are three isochrones for an age of 5 Gyr and three metallicities ([Fe/H]=0: orange, [Fe/H=1]: green, [Fe/H=1]: blue) with colours that match the colormap). generated using PARSEC version 1.2S (Bressan et al. 2012, Chen et al. 2014). Stars were selected from the Catalogue dataset where ‘GES_TYPE = GES_MW’, with temperature, surface gravity, and metallicity derived by the classical pipelines, totaling 44 756 stars. |
 |
Fig. 11 Abundance ratio of magnesium to iron ([Mg/Fe]) versus metallicity ([Fe/H]) for stars in the Milky Way field as derived using OssicoNN astrophysical parameters (left panel) and the GES recommended values (right). Stars were selected from the Catalogue dataset where ‘GES_TYPE = GES_MW’, with [Fe/H] and [Mg/H] derived by the classical pipelines, totalling 11 909 stars. |
5.2 Star clusters
Star clusters are often used for the calibration and the validation of pipelines used for the analysis of stellar spectra. This is because they are composed of coeval stars with known age that span a large range of effective temperatures and surface gravities and, depending on the elements and on the type of cluster, are chemically homogeneous within 0.02–0.05 dex (Bovy 2016; Poovelil et al. 2020). We note that, instead, globular clusters might show a large spread in some abundances, which is related to anti-correlations between the abundances of pairs of elements (see e.g. Pancino et al. 2017b).
Here, we compare the astrophysical parameters from OssicoNN and GES for three open clusters NGC 2243, NGC 2420, and Br 32, and three globular clusters NGC 1904, NGC 362, and NGC 2808. We chose these three open clusters because they include a significant number of stars observed with the HR10 and HR21 setups and the globular clusters because they allow us to test the pipeline within a range of metallicities (from [Fe/H] −1.55 to −0.82 dex) that is poorly covered in the training sample.
To identify the stars of a specific cluster in the GES catalogue, we used the keywords GES_FLD=CLUSTER_NAME and MEM3D > 0.9. The first keyword selects all the stars that were included in the GES target list as possible cluster members, while the latter identifies stars with a probability of greater than 90% of belonging to the cluster on the basis of Gaia proper motions and GES radial velocities.
The distributions of the stellar parameters and the abundances for the three open clusters are shown in Figs. 12, A.1 and A.2. The figures reveal that the predicted surface temperature and gravity exhibit a distribution mirroring that of GES. On average, the standard deviation of the chemical-abundance estimates by OssicoNN in open clusters is reduced by 33%, though this varies significantly from one abundance to another. For example, the dispersion for magnesium does not decrease, while the magnesium dispersion is reduced by 70%. For all elements, OssicoNN estimates show fewer outliers and a denser core. However, the clear reduction in the spread for titanium might be linked to the weak influence of titanium lines in determining abundance (see Section 4.3), leading to a less accurate estimate of titanium diversity compared to other elements. As such, extreme caution should be exercised when drawing conclusions regarding titanium, particularly when attempting to identify behaviour diverging from the norm.
We also display the Kiel diagram of each cluster with the isochrone corresponding to the age and metallicity derived by Cantat-Gaudin et al. (2020) and reported in Randich et al. (2022), which were generated using PARSEC version 1.2S (Bressan et al. 2012, Chen et al. 2014)4. For each cluster, we calculated the distance between the stars and the isochrone using a KD Tree. The RMSE (root mean square error) was then calculated. The RMSE of OssicoNN is reduced by 10% for NGC 2243, remains similar for NGC 420, and increases by 25% for Br32. Overall, the stars of the subgiant branch, the RGB, and the red giant clump are well positioned in relation to the isochrone by both GES and OssicoNN.
The differences between GES and OssicoNN are most pronounced in the main sequence and the main sequence turn-off regions. In NGC 2243, the turn-off is better defined by OssicoNN, while in Br32, the GES estimates are closer to the isochrone. In the more complex case of NGC 2420, there is a sequence of stars that appear to belong to the main sequence, where GES predicts a decrease in gravity starting from Teff ≈ 6600 K. Consequently, this star matches the isochrone section corresponding to the subgiant branch. If we exclude the subgiant branch from the isochrone and the other stars belonging to this branch, we obtain an RMSE of 35 for GES and 32 for OssicoNN, corresponding to a 10% reduction. Another issue observed in NGC2243 is the relationship between temperature and metallicity. In NGC2420, some high-temperature stars (particularly in GES) exhibit non-physical metallicities (too low compared to the rest of the open cluster). The presence of this trend in both labels and predictions (without being in the training set) indicates a potential issue in the spectra.
Globular clusters exhibit distinctive anticorrelations in some of their abundance ratios, a phenomenon that is likely indicative of chemical enrichment resulting from the nucleosynthetic processes undergone by preceding generations of stars. The manifestation of this chemical signature is particularly pronounced in the relationship between magnesium (Mg) and aluminium (Al) within these clusters (Pancino et al. 2017b).
These clusters serve as a robust benchmark for evaluating the neural network’s efficacy in replicating astrophysical phenomena, specifically through its interpretation of the Mg-Al relationship. Figure 13 shows the relation between [Mg/Fe] and [Al/Fe] abundances for the three globular clusters included in this test. The figure demonstrates the neural network’s adeptness in faithfully reproducing the anticipated anticorrelation between Mg and Al. We measured the Pearson coefficients between these two parameters across all clusters and found a good correspondence between the GES pipeline estimates and the OssicoNN estimates, with an average difference of 0.1, emphasising the network’s potential for enhanced precision in astrophysical analyses.
 |
Fig. 12 Parameters and abundances of stars belonging to the NGC 2243 cluster using the GES pipeline and the OssicoNN neural network. The number of GES stars varies across quadrants since it depends on how many stars could be successfully processed through the classical pipelines for the given set of parameters. We also display the Kiel diagram for and the isochrone corresponding to the age and metallicity of the cluster measured by Cantat-Gaudin et al. (2020). The isochrone was generated using PARSEC version 1.2S (Bressan et al. 2012, Chen et al. 2014). |
 |
Fig. 13 Anticorrelation of chemical abundances [Al/Fe] and [Mg/Fe] observed in globular clusters when parameters are inferred by OssicoNN (red) or GES (blue). |
5.3 Benchmark stars
In this section, we present a comparative analysis between the OssicoNN and GES predictions and measurements obtained from alternative studies, focusing on benchmark stars. Figure 14 provides a visual representation of the disparity between the GES/OssicoNN predictions and external estimates by Jofré et al. (2015) for temperature. Comparisons for the other parameters are shown on Zenodo in Fig. D.1 (see Data availability section). The depicted figures unequivocally illustrate the accuracy of the predictions.
Three groups emerge. The first consists of Alf Cet, Gam Sge, Alf Tau, Bet Ara, and HD 220009. These five stars exhibit erroneous predictions for several parameters, albeit with large uncertainties, highlighting the importance of cINN in assessing the quality of inference. This discrepancy is likely due to these low-temperature, low-gravity stars not being present in the training set, leading to incomplete inference on most parameters, except for temperature and metallicity. Similarly, the second group, comprising HD 122563 and HD 140283, which are characterised by low metallicity ([Fe/H] < −2, outside the training range), shows completely inaccurate inferences by OssicoNN, albeit with large uncertainties. The third group comprises the remaining stars, which are predicted quite well with a precision comparable to that of GES. For instance, the average difference between the OssicoNN predictions and the estimates of the reference for temperature is −52 K on average, compared to −15 K between GES and the reference, with a maximum difference of 186 K for OssicoNN versus 183 K for GES. Concerning gravity, the average difference between the reference and OssicoNN is 0.04, whereas it is −0.04 for GES. Abundance predictions are similarly accurate, with an average deviation between the neural network and the reference ranging from 0.02 dex for silicon to 0.06 dex for titanium. This deviation is slightly higher for OssicoNN than for GES, except for calcium and silicon, where the OssicoNN prediction shows closer agreement with the reference.
These findings underscore the data-driven nature of the neural network, highlighting that it lacks sufficient encapsulation of physical principles to differentiate itself from GES in favour of a more fundamentally grounded estimate. The analysis reveals that estimates of both surface gravity and abundance are less precise for low-temperature stars particularly those falling within the M star category. This observation underscores a potential limitation in the predictive capacity of the model, particularly in scenarios involving low-temperature stars.
 |
Fig. 14 Effective temperature estimations for selected Benchmark stars using the GES pipeline, the OssicoNN neural network, and Jofré et al. (2015), who combine spectral and spectral-independent analyses. The size of the Joſré + 2015 dots takes into account the measurement uncertainty. |
6 Discussion
Many of the limitations stem from the training dataset’s insufficient coverage of the full parameter space. The challenge arises from the necessity to retain only stars with the complete set of nine parameters for training, which significantly diminishes the available pool of stars. To address this issue, we experimented with estimating values for spectra missing up to two parameters (excluding temperature, gravity, and metallicity). This estimation involved interpolating the absent abundances based on metallicity (see Appendix F on Zenodo for more details). The rationale behind this approach is to save stars that lack only a few parameters, while the majority are well inferred by GES. By implementing this technique, we effectively doubled the size of the training dataset and substantially augmented its diversity. Consequently, this enhancement led to improvements in overall prediction accuracy and rectified issues observed in the Kiel diagram or with benchmark stars of M-type and low metallicity. However, by calculating the Pearson product-moment correlation coefficients for the GES and OssicoNN estimates with and without augmentation, we observed a discrepancy. Specifically, the coefficients for silicon and titanium showed a divergence when comparing GES and classic OssicoNN to augmented OssicoNN. This divergence is particularly severe for silicon, which is often among the primary missing elements, prompting us to discard this model. Nevertheless, we anticipate that forthcoming surveys with significantly larger sample sizes will mitigate this issue effectively.
The HR10 and HR21 spectra were processed in their normalised states, resulting in spectra containing 17 000 pixels. Consequently, the algorithms used are not particularly fast. As we have not yet reached the Nyquist-Shannon sampling level, there is significant potential to speed up the algorithm by following this criterion, retaining the structure while adjusting the hyperparameters accordingly.
While OssicoNN has demonstrated significant effectiveness in addressing neural network challenges, such as providing uncertainty measures, it still faces limitations inherent to supervised machine learning when applied to observational data. Primarily, OssicoNN relies on the input labels provided by GES, which may not always be accurate. Furthermore, when applied to stars that were excluded from the training due to incomplete parameter derivation, the resulting estimates are unreliable. This highlights the a limitation of algorithms trained on observational data: they are inherently limited to estimating quantities within the realm of existing knowledge, rendering them less effective tools for exploration and discovery.
We attempted to evaluate the inference on a different dataset, specifically the AMBRE synthetic spectra (de Laverny et al. 2012), which are tailored to match the GIRAFFE HR10-HR21 spectral shape. Regrettably, the results were highly unsatisfactory (e.g. the typical residual deviation is around 1000K for effective temperature). Therefore, it is more appropriate to consider OssicoNN as an estimator of the parameters assigned by GES for each star, rather than an independent parameter estimator.
Solving all this issues necessitates the exploration of various paths, including the advancement of domain adaptation techniques to minimise disparities between synthetic datasets (these techniques can leverage synthetic datasets encompassing a wider range of parameters, even those not yet observed) and observed datasets. Another possibility would be the exploration of unsupervised methods, which exhibit greater adaptability across multiple datasets.
7 Summary and conclusions
In this paper, we introduce OssicoNN, a neural network expressly devised to address challenges associated with the determination of stellar parameters. At its core lies the application of the conditional invertible neural network (cINN), an elegant framework developed by Ardizzone et al. (2019a). Leveraging the flux uncertainty present in the spectra and the properties of cINN, OssicoNN offers an estimation of the overall uncertainty derived during the inference process, encompassing both the internal error associated with the neural network and the external error intrinsic to the data. OssicoNN is trained on stellar observational data from the GIRAFFE dataset of the Gaia-ESO Survey to derive effective temperature, surface gravity, metallicity, and various elemental abundances (aluminium, magnesium, calcium, nickel, titanium, and silicon) from stellar spectra.
The appeal of cINNs lies in their ability to compute Bayesian posterior distributions for all parameters x given an observation y. This is facilitated by introducing auxiliary variables known as the latent space z, which serve as a reservoir of diversity built during training. During inference, this diversity is constrained by the observation to retain only the feasible possibilities.
The training set comprises 6688 high-quality stars (S /N > 25). The spectra encompass two spectral domains: HR 10 (5330–5610 Å, R = 21500) and HR21 (8480–8980 Å, R = 18 000). The training set predominantly includes stars with effective temperatures ranging Teff = 4000–6915K, surface gravities (log(𝑔)) spanning from 0.48 to 4.84 dex, and metallicities ([Fe/H]) varying from −1.5 to 0.47 dex.
We validated the performance of OssicoNN in various methods. Our main results can be summarised as follows:
The neural network demonstrates exceptional accuracy on the test set (S/N>25), achieving an accuracy of 28 K in Teff, 0.06 dex in log(𝑔), 0.03 dex in [Fe/H], and between 0.05 dex and 0.17 dex for other abundances.
Accuracy remains stable even for spectra with low S/N (of between 5 and 25), with an accuracy of 39K in Teff, 0.08 dex in log(𝑔), and 0.05 dex in [Fe/H].
To identify the spectral channels critical for inferring each parameter, we employed a saliency map (gradient analysis). The results indicate that the determination of abundance is based on the absorption lines of the element under consideration, such as the 8892.720 Å line for silicon or the 8773.896 Å and 8773.896 Å doublet for aluminium. This is not the case only for titanium, which is primarily determined by lines originating from other elements.
Utilising the capabilities of cINN, we can determine the distribution of parameter posteriors for a spectrum, thereby quantifying internal uncertainties. By employing the Monte Carlo method to vary the spectra, accounting for the variance of each spectrum, the external error is measured. The total error is then computed as the quadratic sum of the individual errors.
The error magnitude is comparable to the accuracy, with a median uncertainty of 55 K for temperature, 0.08 dex for log(𝑔), 0.05 dex for [Fe/H], and between 0.06 dex and 0.17 dex for chemical abundances.
The behaviour of the uncertainties aligns with expectations, which is evident in the residual/uncertainty ratio, which follows a Gaussian distribution 𝒩(0, 1), as predicted by the central limit theorem, assuming the uncertainties are independently drawn from a normal distribution and the relationship between GES and OssicoNN estimates is linearly homoscedastic. Additionally, the uncertainties are consistent with those determined by GES.
The study of external and internal uncertainties allowed us to identify the key parameters that contribute to error determination, even indirectly. The external error is strongly related to the S/N. The internal error depends on the distribution of the training set, potential degeneracies, and internal parameters of the neural network (establishing a precise relationship is more straightforward in the central regions of the parameter space than at its edges).
We then verified that the neural network accurately reproduces astrophysical relationships at both the Milky Way scale and within small star clusters. In the Milky Way, this verification was conducted at two levels. First, we examined the chemical separation between the stars of the thin disc and the thick disc in the [Mg/Fe]–[Fe/H] plane. OssicoNN achieves a clearer separation between the two discs compared to the labels in the GES catalogue. Second, we analysed the evolution of stars in the Milky Way using the Kiel diagram. The Kiel diagram of parameters inferred by OssicoNN correctly depicts the various branches and sequences. Additionally, there is an improvement in the Kiel diagram, with some low-S/N stars being correctly repo-sitioned with their appropriate metallicities. However, there are some weaker areas, particularly in regions where the training set is sparsely populated, leading to less precise inferences. This shortcoming is mitigated when the training set is artificially expanded.
Within the clusters, the relationships are accurately reproduced. The anticorrelation observed in globular clusters is well replicated. In open clusters, the parameters exhibit a tight Gaussian dispersion of abundances, with the distribution being 33% narrower than that of the labels. Additionally, stars plotted on the Kiel diagram follow the isochrone (fixed age–metallicity) of the cluster.
We compared OssicoNN with independent estimates of benchmark stars from Jofré et al. (2015). The two sets of estimates are similar when the parameters fall within the training set range; otherwise, deviations occur, such as at very low metallicity ([Fe/H]<−1.5). Within the training set range, the precision is −52 K for temperature, 0.04 dex for surface gravity, and less than 0.06 dex for abundance. Expanding the training set with augmentation resolves the issue of an insufficiently broad training range.
A new GES HR10 and HR21 survey catalogue has been derived using OssicoNN.
All these points emphasise that OssicoNN is highly suited for application with new instruments such as 4MOST and WEAVE.
Data availability
The additional figures are available on Zenodo: https://zenodo.org/records/13844177. The code is available on GitHub : https://github.com/nils-can/OssicoNN. The weights of the driven hyperparameters are available on request. The new GES HR10 and HR21 survey catalogue derived using OssicoNN is available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/692/A228
Acknowledgements
This work was supported by the INAF Techno grant 2022 MALSPEC (MAchine Learning for SPECtroscopy, PI: Sacco). This work is based on data obtained from the ESO Science Archive Facility with DOI(s): https://doi.org/10.18727/archive/25 (The Gaia-ESO Survey, co-PI: G. Gilmore and S. Randich). We would like to express our sincere gratitude to the anonymous reviewer for their thoughtful and constructive comments. Their insightful feedback has significantly contributed to the improvement of this manuscript.
Appendix A Additional Figures
 |
Fig. A.1 Parameters and abundances of stars belonging to the NGC2420 cluster using the GES pipeline and the OssicoNN neural network. The number of GES stars varies across quadrants since it depends on how many stars could be successfully processed through the classical pipelines for the given set of parameters. We also display the Kiel diagram and the isochrone corresponding to the age and metallicity of the cluster measured by Cantat-Gaudin et al. (2020). The isochrone is generated using PARSEC version 1.2S (Bressan et al. (2012))., Chen et al. (2014)). |
 |
Fig. A.2 Parameters and abundances of stars belonging to the Br32 cluster using the GES pipeline and the OssicoNN neural network. The number of GES stars varies across quadrants since it depends on how many stars could be successfully processed through the classical pipelines for the given set of parameters. We also display the Kiel diagram and the isochrone corresponding to the age and metallicity of the cluster measured by Cantat-Gaudin et al. (2020). THe isochrone is generated using PARSEC version 1.2S (Bressan et al. (2012), Chen et al. (2014)). |
References
- Akiba, T., Sano, S., Yanase, T., Ohta, T., & Koyama, M. 2019, in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining [Google Scholar]
- Ambrosch, M., Guiglion, G., Mikolaitis, Š., et al. 2023, A&A, 672, A46 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ardizzone, L., Bungert, T., Draxler, F., et al. 2018-2022, Framework for Easily Invertible Architectures (FrEIA) [Google Scholar]
- Ardizzone, L., Kruse, J., Wirkert, S., et al. 2019a, arXiv e-prints [arXiv:1808.04730] [Google Scholar]
- Ardizzone, L., Lüth, C., Kruse, J., Rother, C., & Köthe, U. 2019b, arXiv e-prints [arXiv:1907.02392] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Bensby, T., Feltzing, S., & Lundström, I. 2003, A&A, 410, 527 [CrossRef] [EDP Sciences] [Google Scholar]
- Bovy, J. 2016, ApJ, 817, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Bressan, A., Marigo, P., Girardi, L., et al. 2012, MNRAS, 427, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Cantat-Gaudin, T., Anders, F., Castro-Ginard, A., et al. 2020, A&A, 640, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chen, Y., Girardi, L., Bressan, A., et al. 2014, MNRAS, 444, 2525 [Google Scholar]
- de Jong, R. S., Agertz, O., Berbel, A. A., et al. 2019, The Messenger, 175, 3 [NASA ADS] [Google Scholar]
- de Laverny, P., Recio-Blanco, A., Worley, C. C., & Plez, B. 2012, A&A, 544, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Silva, G. M., Freeman, K. C., Bland-Hawthorn, J., et al. 2015, MNRAS, 449, 2604 [NASA ADS] [CrossRef] [Google Scholar]
- Dinh, L., Krueger, D., & Bengio, Y. 2014, arXiv e-prints [arXiv: 1410.8516] [Google Scholar]
- Dinh, L., Sohl-Dickstein, J., & Bengio, S. 2016, arXiv e-prints [arXiv:1605.08803] [Google Scholar]
- Eisert, L., Pillepich, A., Nelson, D., et al. 2023, MNRAS, 519, 2199 [Google Scholar]
- Fuhrmann, K. 1998, A&A, 338, 161 [NASA ADS] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gilmore, G., Randich, S., Worley, C. C., et al. 2022, A&A, 666, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gonzalez, O. A., Mucciarelli, A., Origlia, L., et al. 2020, The Messenger, 180, 18 [NASA ADS] [Google Scholar]
- Grevesse, N., Asplund, M., & Sauval, A. J. 2007, Space Sci. Rev., 130, 105 [Google Scholar]
- Guiglion, G., Matijevic, G., Queiroz, A. B. A., et al. 2020, A&A, 644, A168 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Guiglion, G., Nepal, S., Chiappini, C., et al. 2024, A&A, 682, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Haldemann, J., Ksoll, V., Walter, D., et al. 2023, A&A, 672, A180 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hayden, M. R., Recio-Blanco, A., de Laverny, P., Mikolaitis, S., & Worley, C. C. 2017, A&A, 608, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heiter, U., Lind, K., Bergemann, M., et al. 2021, A&A, 645, A106 [EDP Sciences] [Google Scholar]
- Hourihane, A., François, P., Worley, C. C., et al. 2023, A&A, 676, A129 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hüllermeier, E., & Waegeman, W. 2019, arXiv e-prints [arXiv: 1910.09457] [Google Scholar]
- Jin, S., Trager, S. C., Dalton, G. B., et al. 2023, MNRAS [arXiv:2212.03981] [Google Scholar]
- Jofré, P., Heiter, U., Soubiran, C., et al. 2015, A&A, 582, A81 [Google Scholar]
- Kang, D. E., Pellegrini, E. W., Ardizzone, L., et al. 2022, MNRAS, 512, 617 [CrossRef] [Google Scholar]
- Kang, D. E., Klessen, R. S., Ksoll, V. F., et al. 2023a, MNRAS, 520, 4981 [NASA ADS] [CrossRef] [Google Scholar]
- Kang, D. E., Ksoll, V. F., Itrich, D., et al. 2023b, A&A, 674, A175 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kingma, D. P., & Dhariwal, P. 2018, arXiv e-prints [arXiv: 1807.03039] [Google Scholar]
- Kingma, D. P., Salimans, T., Jozefowicz, R., et al. 2016, arXiv e-prints [arXiv: 1606.04934] [Google Scholar]
- Kollmeier, J. A., Zasowski, G., Rix, H.-W., et al. 2017, arXiv e-prints [arXiv:1711.03234] [Google Scholar]
- Ksoll, V. F., Ardizzone, L., Klessen, R., et al. 2020, MNRAS, 499, 5447 [NASA ADS] [CrossRef] [Google Scholar]
- Leung, H. W., & Bovy, J. 2019, MNRAS, 483, 3255 [NASA ADS] [Google Scholar]
- Magrini, L., Viscasillas Vázquez, C., Spina, L., et al. 2023, A&A, 669, A119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Majewski, S. R., Schiavon, R. P., Frinchaboy, P. M., et al. 2017, AJ, 154, 94 [NASA ADS] [CrossRef] [Google Scholar]
- O’Briain, T., Ting, Y.-S., Fabbro, S., et al. 2021, ApJ, 906, 130 [CrossRef] [Google Scholar]
- Pancino, E., Lardo, C., Altavilla, G., et al. 2017a, A&A, 598, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pancino, E., Romano, D., Tang, B., et al. 2017b, A&A, 601, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, arXiv e-prints [arXiv:1912.01703] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Perreault Levasseur, L., Hezaveh, Y. D., & Wechsler, R. H. 2017, ApJ, 850, L7 [Google Scholar]
- Poovelil, V. J., Zasowski, G., Hasselquist, S., et al. 2020, ApJ, 903, 55 [NASA ADS] [CrossRef] [Google Scholar]
- Randich, S., Gilmore, G., Magrini, L., et al. 2022, A&A, 666, A121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Recio-Blanco, A., de Laverny, P., Allende Prieto, C., et al. 2016, A&A, 585, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tabak, E. G., & Vanden-Eijnden, E. 2010, Commun. Math. Sci., 8, 217 [CrossRef] [Google Scholar]
- Ting, Y.-S., Conroy, C., Rix, H.-W., & Cargile, P. 2019, ApJ, 879, 69 [Google Scholar]
- Ting, Y.-S., & Weinberg, D. H. 2022, ApJ, 927, 209 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, R., Luo, A. L., Zhang, S., et al. 2023, ApJS, 266, 40 [NASA ADS] [CrossRef] [Google Scholar]
- Wehrhahn, A., Piskunov, N., & Ryabchikova, T. 2023, A&A, 671, A171 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Worley, C. C., Smiljanic, R., Magrini, L., et al. 2024, A&A, 684, A148 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
All Tables
Absolute solar abundance and abundance amplitude relative to solar abundances for the stars and elements used in this work.
Residual statistics between OssicoNN and GES for various datasets and two modes: Fast and Precision.
Statistics of the distribution of the uncertainties in OssicoNN and GES for the reduced catalogue dataset.
All Figures
|
Fig. 1 Distribution of s/N for the various datasets used. |
| In the text | |
|
Fig. 2 Stellar parameter distribution for the catalogue dataset (in blue) and the training dataset (in orange). The catalogue dataset comprises all stars observed in HR10 and HR21, with an additional restriction to stars below 7000 K, totalling 49 858 stars. The training dataset contains only the stars from the catalogue dataset used for training (6688 stars). |
| In the text | |
|
Fig. 3 Schematic representation of OssicoNN, the neural network for the inference of stellar parameters. The primary objective of the neural network is to encapsulate a transformative mapping between the hidden stellar parameters and an abstract latent space composed of an equivalent number of Gaussian distributions. This is done by the conditional network (in blue). The mapping is conditioned by the spectra first processed by the conditioning network (in red) that extracts the important features from the spectra. Each layer is shown as a box in a different colour, reflecting its nature, with key hyperparameters listed beside it. |
| In the text | |
|
Fig. 4 Evolution of the loss function and the MSE during training. The learning rate was reduced from 103 to 104 in period 50, leading to a drop in overall losses. |
| In the text | |
|
Fig. 5 Distribution of the Pearson coefficients between pairs of parameters for test set stars derived from sampling latent space to obtain the posterior distribution for one spectrum. Temperature, metallicity, and gravity exhibit the strongest correlations (albeit weak), whereas abundances, such as [Al/H] and [Mg/H], show very poor correlations. Additional Pearson coefficient distributions are provided in Zenodo (Fig. B.4, see Data availability section). |
| In the text | |
|
Fig. 6 Density distribution of parameters inferred by OssicoNN compared with the parameters given in GES for the test dataset. The average bias and the standard deviation, the 15th percentile, and 85th percentile of the residuals around the 1:1 relation are given in every panel. Dashed diagonal lines indicate the 1:1 relation. |
| In the text | |
|
Fig. 7 Density distribution of parameters inferred by GES and OssicoNN for the noisy dataset. The average bias and the standard deviation, the 15th percentile, and 85th percentile of the residue results around the 1:1 relation are given in every panel. Dashed diagonal lines indicate the 1:1 relation. For the sake of clarity, we have excluded three stars from the [Si/H] quadrant that deviate significantly from the expected 1:1 relationship. These particular stars were initially predicted to have abundances of 3.1, 3.7, and 4.5 in the GES model. However, when using OssicoNN, their predicted abundances were notably different, measuring only −0.3, 0.2, and 0.2. |
| In the text | |
|
Fig. 8 Different plot for effective temperature uncertainties in the ‘Reduced Catalogue dataset’ (totalling 42 738 stars), (a) Distribution of uncertainties in GES and OssicoNN. (b) Distribution of the residuals between OssicoNN and GES normalised with respect to the uncertainties of OssicoNN (red shadowed area) and the sum in quadrature of GES and OssicoNN errors (grey shadowed area). Dashed lines represent the fit of the distribution with a Gaussian function with standard deviation σ = 1. (c) Temperature estimates for 200 stars taken at random from the catalogue by GES and OssicoNN with their respective uncertainties, (d) Density distribution of total OssicoNN uncertainties with respect to inferred temperature. The red and orange lines represent the median external and internal uncertainties for each temperature bin. The blue curve and its scale on the right represent the median S/N per temperature bin. |
| In the text | |
|
Fig. 9 Median saliency map across all test and noisy datasets. This is obtained by averaging the saliency maps for each parameter. The represented spectrum corresponds to the median of the test and noisy datasets spectra. The primary theoretical lines corresponding to a peak in the absolute value of the saliency map are indicated by vertical lines. The displayed iron lines are among the 15 most significant peaks for the iron saliency map. |
| In the text | |
|
Fig. 10 Kiel diagram: log g versus effective temperature colour coded according to metallicity for stars in the Milky Way field as derived using OssicoNN astrophysical parameters (left panel) and the GES recommended values (right panel). Superimposed are three isochrones for an age of 5 Gyr and three metallicities ([Fe/H]=0: orange, [Fe/H=1]: green, [Fe/H=1]: blue) with colours that match the colormap). generated using PARSEC version 1.2S (Bressan et al. 2012, Chen et al. 2014). Stars were selected from the Catalogue dataset where ‘GES_TYPE = GES_MW’, with temperature, surface gravity, and metallicity derived by the classical pipelines, totaling 44 756 stars. |
| In the text | |
|
Fig. 11 Abundance ratio of magnesium to iron ([Mg/Fe]) versus metallicity ([Fe/H]) for stars in the Milky Way field as derived using OssicoNN astrophysical parameters (left panel) and the GES recommended values (right). Stars were selected from the Catalogue dataset where ‘GES_TYPE = GES_MW’, with [Fe/H] and [Mg/H] derived by the classical pipelines, totalling 11 909 stars. |
| In the text | |
|
Fig. 12 Parameters and abundances of stars belonging to the NGC 2243 cluster using the GES pipeline and the OssicoNN neural network. The number of GES stars varies across quadrants since it depends on how many stars could be successfully processed through the classical pipelines for the given set of parameters. We also display the Kiel diagram for and the isochrone corresponding to the age and metallicity of the cluster measured by Cantat-Gaudin et al. (2020). The isochrone was generated using PARSEC version 1.2S (Bressan et al. 2012, Chen et al. 2014). |
| In the text | |
|
Fig. 13 Anticorrelation of chemical abundances [Al/Fe] and [Mg/Fe] observed in globular clusters when parameters are inferred by OssicoNN (red) or GES (blue). |
| In the text | |
|
Fig. 14 Effective temperature estimations for selected Benchmark stars using the GES pipeline, the OssicoNN neural network, and Jofré et al. (2015), who combine spectral and spectral-independent analyses. The size of the Joſré + 2015 dots takes into account the measurement uncertainty. |
| In the text | |
|
Fig. A.1 Parameters and abundances of stars belonging to the NGC2420 cluster using the GES pipeline and the OssicoNN neural network. The number of GES stars varies across quadrants since it depends on how many stars could be successfully processed through the classical pipelines for the given set of parameters. We also display the Kiel diagram and the isochrone corresponding to the age and metallicity of the cluster measured by Cantat-Gaudin et al. (2020). The isochrone is generated using PARSEC version 1.2S (Bressan et al. (2012))., Chen et al. (2014)). |
| In the text | |
|
Fig. A.2 Parameters and abundances of stars belonging to the Br32 cluster using the GES pipeline and the OssicoNN neural network. The number of GES stars varies across quadrants since it depends on how many stars could be successfully processed through the classical pipelines for the given set of parameters. We also display the Kiel diagram and the isochrone corresponding to the age and metallicity of the cluster measured by Cantat-Gaudin et al. (2020). THe isochrone is generated using PARSEC version 1.2S (Bressan et al. (2012), Chen et al. (2014)). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.