| Issue |
A&A
Volume 696, April 2025
|
|
|---|---|---|
| Article Number | A217 | |
| Number of page(s) | 21 | |
| Section | Interstellar and circumstellar matter | |
| DOI | https://doi.org/10.1051/0004-6361/202451493 | |
| Published online | 25 April 2025 | |
Comparing the morphology of molecular clouds without supervision
1
Laboratoire de Physique de l’École normale supérieure, ENS, Université PSL, CNRS, Sorbonne Université, Université Paris Cité,
75005
Paris,
France
2
Observatoire de Paris, Université PSL, Sorbonne Université, LERMA,
CNRS UMR 8112,
75014
Paris,
France
★ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
13
July
2024
Accepted:
4
March
2025
Abstract
Molecular clouds are astrophysical objects whose complex nonlinear dynamics are reflected in their complex morphological features. Many studies investigating the bridge between higher-order statistics and physical properties have highlighted the value of non-Gaussian morphological features in capturing physical information. Yet, as this bridge is usually characterized in the supervised world of simulations, transferring it to observations can be hazardous, especially when the discrepancy between simulations and observations remains unknown. In this paper, we aim to evaluate, directly from the observation data, the discriminating ability of a set of statistics. To do so, we developed a test that allowed us to compare the informative power of two sets of summary statistics for a given unlabeled dataset. Contrary to supervised approaches, this test does not require knowledge of any class label or parameter associated with the data. Instead, it evaluates and compares the degeneracy levels of the summary statistics based on a notion of statistical compatibility. We applied this test to column density maps of 14 nearby molecular clouds observed by Herschel and iteratively compared different sets of typical summary statistics. We show that a standard Gaussian description of these clouds is highly degenerate but can be substantially improved when being estimated on the logarithm of the maps. This illustrates that low-order statistics, when properly used, remain a very powerful tool. We further show that such descriptions still exhibit a small quantity of degeneracies, some of which are lifted by the higher-order statistics provided by reduced wavelet scattering transforms. These degeneracies quantitatively differ between observations and state-of-the-art simulations of dense molecular cloud collapse, and they are not present for log-fractional Brownian motion models. Finally, we show how the summary statistics identified can be cooperatively used to build a morphological distance, which is evaluated visually and gives convincing results.
Key words: methods: statistical / ISM: clouds / ISM: structure / submillimeter: ISM
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Molecular clouds (MCs) play a key role in star formation. Their highly nonlinear dynamics tend to couple spatial scales over a wide range, creating dense filamentary structures in which clumps form, and these eventually lead to prestellar cores (McKee & Ostriker 2007). However, the precise role of each physical ingredient (such as turbulence, magnetic fields, and gravity, to name but a few) in these dynamics still remains to be fully understood.
A key step toward such an understanding certainly resides in the ability to decipher, in the morphology of these structured clouds, some signature of the physical processes at play. For instance, the power-law shape of the power spectrum (PS) in emission maps may trace properties of the turbulence (Miville-Deschênes et al. 2007; Federrath & Klessen 2013), or the shape of the probability distribution function (PDF) of column density maps (Vázquez-Semadeni et al. 1997; Hennebelle & Chabrier 2008; Kainulainen et al. 2009; Federrath & Klessen 2013; Schneider et al. 2022; Appel et al. 2022) may trace the impact of gravitational collapse or stellar feedback as it transitions from a log-normal shape to the development of a heavy tail.
However, the strong nonlinear interplay between the physical processes at work leads to the emergence of non-Gaussian structures, such as filaments, in the interstellar medium (ISM). This has motivated numerous studies to capture physical information beyond one-point and two-point statistics. Many approaches have been investigated, including diagnostics of the phase coherence of Fourier modes (Levrier et al. 2006; Burkhart & Lazarian 2016), bispectrum (Burkhart et al. 2009), structure functions (Heyer & Brunt 2004), dendograms (Goodman et al. 2009), multiscale segmentation (Robitaille et al. 2019), scattering transforms (Allys et al. 2019; Regaldo-Saint Blancard et al. 2020; Allys et al. 2020; Saydjari et al. 2021), and neural networks (Peek & Burkhart 2019; Zavagno et al. 2023).
If higher-order statistics represent an appealing way to refine the morphological description of complex ISM structures, they are nevertheless subject to the following caveats:
They should not undermine the potential of low-order statistics but rather be regarded as complementary diagnostics (Burkhart & Lazarian 2016). Low-order descriptors should not be underestimated; it is not because the processes under study are highly non-Gaussian that low-order statistics are only marginally informative. Yet, in numerous studies, such easy-access information is not considered (at times, it is even intentionally discarded1) in order to emphasize the contribution of higher-order statistics.
Refining the statistical description with higher-order terms complicates the connection between the statistical descriptions and the physical processes and associated parameters. Thus, such a connection is usually learned in the supervised world of simulations, typically via a Fisher analysis (Allys et al. 2020) or a classification task (Saydjari et al. 2021). But transferring this connection to observations can be hazardous, especially when their similarity to simulations remains unknown (Falgarone et al. 2004; Peek & Burkhart 2019). Indeed, the informativeness of a set of summary statistics can be highly dataset dependent (Nunes & Balding 2010; Blum et al. 2013).
In this paper, we aim to identify which sets of summary statistics are relevant to characterize the diversity of observed molecular clouds without relying on simulations or prior knowledge. In such an unsupervised framework, various observations cannot be grouped a priori in a similar class, so one often has to work in a very low data regime, which dramatically restricts the range of tools that can be used. This unsupervised and prior-knowledge-free framework excludes features that require significant tuning to extract information, such as neural networks. This priority shift from theoretical informativeness to actual information retrievable in this framework might reshuffle the cards regarding the various sets of summary statistics to consider. This led us to wonder to what extent non-Gaussian statistics can actually bring meaningful contributions in a fully observation-driven and unsupervised framework.
To answer this question, we rely on a dataset of column density maps constructed from a survey of nearby molecular clouds. Our approach is to identify the amount of degeneracy that a set of summary statistics can have on this dataset, that is, finding a pair of maps in this dataset that are compatible according to this set of statistics but that actually have a different morphology. A simplified illustration of such a degeneracy is given in Figs. 1 and 2, where we compare an observed column density map with a realization of a field, called logFBM, whose logarithm is sampled from a fractional Brownian motion (FBM), which is a specific type of Gaussian process with a power-law PS. In this example, the PDFs of these maps, their power spectra, and the power spectra of their logarithms all appear compatible, even though the maps clearly have different structures. For instance, the Perseus cloud shows filamentary features that are absent in the logFBM sample. This illustration underlines the limitation of these statistics, but only for this specific comparison, where we compare one observation to a specific known model. However, in an unsupervised framework, when working solely with unlabeled observations, we exhibit these limitations by introducing additional statistics that could be used to lift these degeneracies.
In this work, we use such a degeneracy diagnostic on the observed molecular clouds dataset to progressively build a set of summary statistics that allows us to characterize their diversity, even in a low data regime. We start with basic statistics, such as the PS and one-point statistics. We evidence strong limitations that we investigate and substantially mitigate by applying a logarithmic transformation to the maps beforehand. We exhibit further but moderate limitations of this improved set, leveraging higher-order statistics through the reduced wavelet scattering transform (RWST). This study, initially carried out only on the observational dataset, is then extended to logFBM data as well as to a set of magnetohydrodynamics (MHD) simulations intended to reproduce observations of dense star-forming molecular clouds. We conclude by discussing the relevance and limitations of the final set of statistics we have constructed and show how it can be used to assess the distance, in a statistical sense, between different maps of the ISM.
The paper is structured as follows:
In Sect. 2, we present the set of MCs considered in this work and the corresponding column density maps as well as the numerical simulations and the logFBM models.
We present in Sect. 3 the diagnostic of statistical compatibility on which we rely and our general methodology.
We present in Sect. 4 the sets of statistics that are confronted.
We apply this methodology in Sect. 5 to confront these sets of statistics on observations, and from these results, we design an informative and low-dimensional set of summary statistics ϕfinal.
We finally define, in Sect. 6, a morphological distance based on ϕfinal that allows us to compare datasets, such as observations and simulations.
 |
Fig. 1 Column density map of a region in Perseus (top row) and sample of a log-fractional Brownian motion (logFBM) field (bottom row). Each image has 256 × 512 pixels but is tiled into two complementary patches of size 256 × 256 on which the statistics shown in Fig. 2 are computed. While these one-point and two-point statistics (some being non-Gaussian) are clearly compatible, these two images have manifestly different morphologies. |
 |
Fig. 2 Statistical properties of the maps from Fig. 1: PDFs (top), power spectra (center), and power spectra of the logarithms of the maps (bottom). The dashed vertical line in the power spectra plots is located at the 18.2″ resolution of the column density map from the observational dataset. Power spectra are apodized as explained in Sect. 4. We see that the logFBM process is compatible with this observed portion of MC for all these statistics (some of theme being non-Gaussian), while having a manifestly different morphology, as revealed in Fig. 1. All these statistics are thus degenerate for such a comparison. |
2 Data
In this section, we present the main dataset that we use for this study: an ensemble of ~550 molecular hydrogen (H2) column density maps from a survey of nearby MCs. Three other datasets are used in this paper:
A set of ~230 H2 column density maps built from magnetohydrodynamical numerical simulations of dense molecular clouds, classified into three subsets with varying values of the magnetic field, from null (“Hydro high res”), to medium (“MHD”), and high (“MHD high B”). These simulations are used in this work as an example of state-of-the-art attempts to reproduce the physics at play in the early stages of star formation, including self-gravity and decaying turbulence. As it is often the case in studies of complex multi-physics ISM systems such as molecular clouds, these simulations focus on, and account only for, a partial variety of the physical processes at stake. For instance the set of simulations chosen here do not include any form of stellar feedback, that is nevertheless present in some regions of our observational dataset.
A set of ~500 synthetic maps sampled from logFBM models, whose parameters reproduce the diversity of the observational dataset. This type of purely synthetic fields has already been extensively used to model the ISM (see, e.g., Elmegreen 2002; Brunt & Heyer 2002; Miville-Deschênes et al. 2007; Levrier et al. 2018).
A set of ~1000 images from a large collection of everyday textures, the Describable Texture Dataset (DTD, Cimpoi et al. 2014). We use these to emphasize the specificity of ISM fields in the context of image texture analysis.
More details about these sets are provided in Appendix A. All these maps have a size of 512 × 512 pixels.
2.1 Observations: Column density maps from the HGBS
We focus our study on a set of MCs targeted by the Gould Belt Survey (HGBS) (André et al. 2010) with the Herschel Space Observatory (Pilbratt et al. 2010), whose footprints on the sky are shown in Fig. A.1. The HGBS fulfills the two main criteria we require for this work:
It sampled numerous MCs with a diversity of physical and environmental conditions, from diffuse and quiescent regions with no sign of star formation activity such as the Polaris Flare (Heithausen & Thaddeus 1990; André et al. 2010; Miville-Deschênes et al. 2010) to very dense and active ones such as Orion B (Schneider et al. 2013) or the Aquila Rift cloud (Könyves et al. 2015). Examples of molecular column density maps from the HGBS are shown in Fig. 3. However, we emphasize that this survey is limited to local clouds (distances d ≤ 500 pc) and does not encompass the full range of conditions expected in Galactic molecular clouds2.
It imaged a broad range of scales, from the full cloud size (~10 pc, corresponding to a few degrees for these nearby clouds) down to the ~0.1 pc scale of filaments (Arzoumanian et al. 2011; André et al. 2014), which is spatially resolved for the nearest clouds3, thus covering more than two orders of magnitude in spatial scales. This allows us to perform an in-depth morphological analysis, based on a local description of multiscale interactions.
We consider the high resolution (18″) H2 column density maps of 14 regions, produced with the procedure described in appendix A of Palmeirim et al. (2013) and publicly available from the Herschel Gould Belt Survey Archive4. This 18″ angular resolution corresponds to a 12 mpc spatial resolution for the nearest clouds, such as Ophiuchus and Taurus (d ~ 145 pc), and up to 40 mpc for the most distant clouds, such as Orion B (d ~ 450 pc). The main properties of these clouds are given in Table 1. At small scales and low density, these observations are contaminated by the Cosmic Infrared Background (CIB) and the noise. This partly impedes the intercomparison of diffuse observations and their comparison with logFBM models. However, these contaminations are negligible for dense regions, which are the ones targeted by the set of simulations considered in this study.
 |
Fig. 3 Three examples of H2 column density maps from the HGBS. The spatial resolution of the maps is 18″, sampled with a pixel size of 3″. As a reference, a white dot with diameter 90″ (which amounts to five times the resolution) is shown at the bottom right corner of each map. Estimates of spatial scales, also shown on the maps, are based on reported distances (see Table 1). The Polaris Flare is an example of a diffuse and quiescent cloud, while Aquila and Orion B are dense and very active star-forming regions. |
Summary of the properties of the different MCs studied in this paper, as well as their division into patches at different sampling.
2.2 Subsampling and tiling
The presence of physical processes such as gravity in the dynamics of MCs implies spatial variations of their statistical properties, which prevents us from modeling them as stationary stochastic processes. For instance, they often exhibit strong local overdensities, while being surrounded by diffuse borders. This inhomogeneity makes it difficult to compare such objects as a whole, as well as to properly estimate their statistical properties, when seen as realizations of a random process, as these properties will, for instance, depend heavily on the identification of the cloud boundary, or on the precise definition of what a cloud is. Furthermore, variance estimates for random processes generally rely on a homogeneity assumption to estimate the intrinsic variability of a process from its spatial variations. More broadly, the estimation of the statistical moments and properties of a process is usually based on spatial averaging, which assumes the homogeneity of the sample.
To avoid this problem, we choose to restrict the comparison to local patches of these MCs, assuming statistical homogeneity within each individual patch. This requires the identification of a characteristic stationarity length over which it can be assumed that the statistical properties of the cloud do not vary significantly. Different patches extracted from the same cloud may have different statistical properties, which will be representative of the inhomogeneity of the cloud as a whole. This encourages us to use small patches. However, an additional difficulty is that these patches must be large enough to make statistical estimates. In particular, variance estimates require sampling beyond the correlation length of the process under study.
In this paper, we have chosen to cut patches with angular sizes ranging from 0.85° to 2.55°, which correspond respectively to 3 pc and 9 pc for a cloud at a typical distance of 200 pc. We believe this represents a good compromise with regard to the trade-off mentioned above. However, we are aware that there may not be an ideal solution, especially as we have no precise estimate of either the stationarity length or the correlation length. This means that we cannot rule out potential confusion between local intrinsic variability and large-scale variations in the statistical properties of the clouds. However, we believe that, for lack of a better solution, this does not undermine the relevance of this study.
More precisely, we make multiple versions of the original (18″ resolution, 3″ pixel size) column density maps at different pixel sizes (6″, 9″, 12″, and 18″). The subsampling is done using a bivariate spline approximation of order three of the original maps. Then, we cut from these maps patches of size in pixels 512 × 512, with a step size of 256 pixels, such that two neighboring patches have 50% of their pixels in common. In the following, these patches are tiled into four subpatches of size 256 × 256 to perform a variability estimation. The choice of 6″ for the finest sampling allows us to exploit the 18″ resolution of these maps with mitigated sampling artifacts. We note furthermore that the smallest scales that we probe with the two-point-based statistics presented in Sect. 4.2 remain above 24″. This prevents the finite 18″ resolution to significantly affect the results. The 9″, 12″, and 18″ pixel sizes respectively correspond to a relative shrinking of the 6″ pixel maps with ratios of 1.5, 2, and 3, which allows us to accommodate for the significant and quite uncertain range of distances of the different MCs in the HGBS. This entire procedure, which is illustrated in Fig. 4, and summarized in Table 1, leads to a total of 551 patches with size 512 × 512 pixels, each of which is then subdivided into four 256 × 256 subpatches.
3 Quantifying informative power of summary statistics on an unlabeled dataset
3.1 General methodology
We want to quantify and compare the informative power of different sets of statistics on a given dataset, that is, their ability to distinguish between patches of different physical properties. However, because we work with unlabeled data, we cannot use supervised frameworks, such as Fisher analysis, that have a label-based approach to quantify information. For instance, when working with simulations, each data sample xi can be labeled by its corresponding physical parameters θi. In our case, we have to deal with an ensemble of unlabeled maps, for which we have a priori no notion of similarity between pairs.
In this paper, we choose to rely on a notion of compatibility between patches, computed from their summary statistics, and that can be estimated for any set of statistics. This approach allows us to be quantitative, even in such an unsupervised setting. Nevertheless, without supervision, it remains difficult to interpret a compatibility result between two patches for a given set of summary statistics. Indeed, it is unclear whether the two patches actually have similar properties or if they possess genuinely distinct properties whose differences are not effectively captured by the statistics.
To overcome this difficulty, we compare the results obtained from complementary sets of statistics. Indeed, we assume that if two patches are distinguished by a first set of statistics, this is sufficient to assess that these patches have different physical properties5 and therefore to highlight the degeneracies of another set of statistics. It is this comparative approach, which is all the more relevant when the panel of statistics compared is comprehensive, that we use in this paper.
We also emphasize that the informative power of a set of statistics strongly depends on the family of processes studied. For instance, we know that the empirical mean and PS are sufficient statistics for stationary Gaussian fields (Cover & Thomas 2006), which is not the case for physical processes in general. In this paper, we apply our approach to the dataset of observations defined above as well as to numerical simulations and synthetic logFBM models. In addition, we note that this diagnostic can also be used to compare maps from two different datasets.
In the rest of this section, we introduce the compatibility criterion, and explain how we extend it from a level of pair of patches to a dataset level. The sets of statistics used in this paper are presented in the following section.
3.2 Statistical compatibility for a pair of patches
We aim to measure a notion of compatibility, according to a given set of summary statistics ϕ, between the two processes that generated the patches (xi, xj). To estimate this ϕ-compatibility, we need to make a number of simplifications, given the low data regime, that will bring us back to a simplified case of statistical hypothesis testing. To do so, we tiled each patch xi into four subpatches ![Mathematical equation: $\[\{x_{i}^{(l)}\}_{1 \leq l \leq 4}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq1.png) , as illustrated in Fig. 4. We then computed the statistics at this subpatch level,
, as illustrated in Fig. 4. We then computed the statistics at this subpatch level, ![Mathematical equation: $\[\{\phi(x_{i}^{(l)})\}_{1 \leq l \leq 4}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq2.png) , and we assumed that these random variables can be considered as independent samples of the same distribution, which we furthermore modeled as a multivariate normal distribution6 of mean μi and variance Σi:
, and we assumed that these random variables can be considered as independent samples of the same distribution, which we furthermore modeled as a multivariate normal distribution6 of mean μi and variance Σi:
![Mathematical equation: $\[\phi(x_i^{(l)}) \sim \mathcal{N}(\mu_i, \Sigma_i).\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq3.png) (1)
(1)
Under these assumptions, the problem of estimating the compatibility between the distributions of ![Mathematical equation: $\[\phi(x_{i}^{(l)})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq4.png) and
and ![Mathematical equation: $\[\phi(x_{j}^{(l)})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq5.png) boils down to testing the compatibility between the two normal distributions, that is, to test the hypothesis: μi = μj and Σi = Σj. In our case, however, we have to estimate this compatibility from very few samples, most of the time fewer than the dimension of the vector of statistics ϕ. Thus, we choose to focus only on testing if the means μi and μj are statistically compatible, but not Σi and Σj, a problem known as the multivariate two-sample mean test. The most widely used test statistic for this problem is Hotelling’s two-sample T2-statistic, a multivariate extension of Student’s t-test (Hotelling 1931). However, this test statistic requires to invert an estimation S of the full covariance matrix Σi + Σj, which is usually intractable in our low data regime.
boils down to testing the compatibility between the two normal distributions, that is, to test the hypothesis: μi = μj and Σi = Σj. In our case, however, we have to estimate this compatibility from very few samples, most of the time fewer than the dimension of the vector of statistics ϕ. Thus, we choose to focus only on testing if the means μi and μj are statistically compatible, but not Σi and Σj, a problem known as the multivariate two-sample mean test. The most widely used test statistic for this problem is Hotelling’s two-sample T2-statistic, a multivariate extension of Student’s t-test (Hotelling 1931). However, this test statistic requires to invert an estimation S of the full covariance matrix Σi + Σj, which is usually intractable in our low data regime.
To overcome this, Srivastava & Du (2008) proposed a test statistic based only on the diagonal DS of the covariance estimator S (defined in Appendix B), and on the trace of the square of its associated correlation matrix ![Mathematical equation: $\[R \equiv D_{S}^{-1 / 2} S ~D_{S}^{-1 / 2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq6.png) :
:
![Mathematical equation: $\[d_\phi^2\left(x_i, x_j\right) \equiv \alpha\left[\left(\hat{\mu}_i-\hat{\mu}_j\right)^T D_S^{-1}\left(\hat{\mu}_i-\hat{\mu}_j\right)-\beta\right],\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq7.png) (2)
(2)
where ![Mathematical equation: $\[\hat{\mu}_{i}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq8.png) is the estimator of μi obtained through an average over the four subpatches
is the estimator of μi obtained through an average over the four subpatches ![Mathematical equation: $\[x_{i}^{(l)}, \alpha\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq9.png) is an overall factor to normalize the variance of
is an overall factor to normalize the variance of ![Mathematical equation: $\[d_{\phi}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq10.png) , and β is a debiasing term. We emphasize that, through a dependence on tr(R2), the α factor accounts, at least partially, for the correlation structure of ϕ. Further details about these terms are provided in Appendix B.
, and β is a debiasing term. We emphasize that, through a dependence on tr(R2), the α factor accounts, at least partially, for the correlation structure of ϕ. Further details about these terms are provided in Appendix B.
Under the assumption that Σi = Σj, the ![Mathematical equation: $\[d_{\phi}^{2}(x_{i}, x_{j})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq11.png) test statistic has a variance of order unity. Thus, when it is much larger than one, μi and μj cannot be considered compatible:
test statistic has a variance of order unity. Thus, when it is much larger than one, μi and μj cannot be considered compatible:
![Mathematical equation: $\[d_\phi^2\left(x_i, x_j\right) \gg 1 \Longrightarrow \mu_i \text { and } \mu_j \text { are incompatible;}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq12.png) (3)
(3)
whereas when it is of the order of one or less, it is not possible to detect a discrepancy between the two means μi and μj with the available amount of data:
![Mathematical equation: $\[\begin{aligned}d_\phi^2(x_i, x_j) \lessapprox 1 \Longrightarrow \mu_i ~\text{and} \mu_j \text{are not incompatible based on}\\\text{the available amount of data.}\end{aligned}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq13.png) (4)
(4)
3.3 Comparing summary statistics on a dataset
By extending the ϕ-compatibility test introduced above, we set up a comparison between two sets of summary statistics ϕA and ϕB on a given dataset. This comparison consists in studying whether each set of summary statistics has degeneracies that the other set can lift. These degeneracies are evidenced by the presence in the dataset of pairs of maps that are clearly incompatible for ϕA, but for which ϕB detects no incompatibility, or vice versa. For this comparison to be relevant, the dataset must contain maps with genuinely different properties, which is the case for the sets studied below.
In practice, we suggest the following algorithm:
Step 1: For every patch xi of the dataset, compute the statistics ϕA and ϕB of its corresponding subpatches
![Mathematical equation: $\[\{x_{i}^{(l)}\}_{l}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq14.png) .
.Step 2: For every pair {xi, xj} with i ≠ j, compute
![Mathematical equation: $\[d_{\phi_{A}}^{2}(x_{i}, x_{j})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq15.png) and
and ![Mathematical equation: $\[d_{\phi_{B}}^{2}(x_{i}, x_{j})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq16.png) from the quantities derived in step 1.
from the quantities derived in step 1.Step 3: Place every pair as a point on a 2D scatter plot showing
![Mathematical equation: $\[d_{\phi_{A}}^{2}(x_{i}, x_{j})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq17.png) against
against ![Mathematical equation: $\[d_{\phi_{B}}^{2}(x_{i}, x_{j})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq18.png) , such as Fig. 5.
, such as Fig. 5.
The resulting scatter plot can then be used to detect whether there are some pairs of processes in the dataset that are degenerate for ϕA but not for ϕB (or vice versa), as explained in Fig. 5. In such plots, the presence of points in the bottom right region, that is, where dϕA ≫ 1 and dϕB ⪅ 1, reveals that some pairs of this dataset are identified by ϕA as incompatible but not by ϕB: such pairs thus evidence degeneracies of ϕB lifted by ϕA (panel a). Conversely, the presence of points in the top left region evidences degeneracies of ϕA lifted by ϕB. Hence, if all the points land mainly in the subdiagonal part (panel b), this evidences that ϕA is better suited than ϕB to compare the pairs of this dataset. If, on the contrary, the points are spread both in the upper left and bottom right regions of the plot (panel c), this shows that both ϕA and ϕB are individually insufficient to describe the processes of this dataset.
4 Summary statistics
We present below the different summary statistics that are used in this paper. In the following, x is an image, x(u) is the value of the image at pixel ![Mathematical equation: $\[\boldsymbol{u}, \tilde{x}(\boldsymbol{k})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq19.png) is the discrete Fourier transform of the image x evaluated at wavevector k, ⋆ stands for the convolution operator, and ⟨⟩u for the averaging over pixels. When ϕ(x) is multivariate, ϕ(x)[i] is the value of its i-th dimension.
is the discrete Fourier transform of the image x evaluated at wavevector k, ⋆ stands for the convolution operator, and ⟨⟩u for the averaging over pixels. When ϕ(x) is multivariate, ϕ(x)[i] is the value of its i-th dimension. ![Mathematical equation: $\[\bar{x}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq20.png) designates the following normalization of
designates the following normalization of ![Mathematical equation: $\[x: \bar{x} \equiv x / \operatorname{std}(x)\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq21.png) where
where ![Mathematical equation: $\[\operatorname{std}(x) \equiv \sqrt{\langle\left[x-\langle x\rangle_{u}\right]^{2}\rangle_{u}}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq22.png) .
.
We note that the authors consider the logarithms of some typical statistics, instead of their raw values. For instance, we use log ⟨x⟩u instead of ⟨x⟩u. This is possible when we work with positive-valued statistics. We made this choice to better fit the Gaussianity assumption given in Eq. (1). In addition, ϕ(x) and log ϕ(x) should hold the same amount of information as one can be retrieved from the other, see Appendix C for more details. For readability, we name in the following “ϕ” instead of “log of ϕ”. We note, however, that neither ϕ(x) nor log (ϕ(x)) should be mistaken for ϕ(log x), and we name the latter “ϕ of log”. If no precision is made, log designates the logarithm in base ten.
 |
Fig. 5 Illustration of the proposed test to confront two sets of summary statistics, ϕA versus ϕB, on their degeneracy level for a given dataset. Each star represents a pair of patches. Panel a: the presence of stars in the bottom right region, i.e., where dϕA ≫ 1 and dϕB ⪅ 1, reveals that some pairs of this dataset are identified by ϕA as incompatible but not by ϕB: such pairs thus evidence degeneracies of ϕB lifted by ϕA. Conversely, the presence of stars in the top left region evidences degeneracies of ϕA lifted by ϕB. Hence, if all the points land mainly in the sub-diagonal part (panel b), this evidences that ϕA is better suited than ϕB to compare the pairs of this dataset. If on the contrary the points are spread both in the upper left and bottom right regions of the plot (panel c), this shows that both ϕA and ϕB are individually not sufficient to describe the processes of this dataset. |
4.1 One-point based statistics
We list below the one-point statistics that are used in this paper. Even though some of these statistics can probe non-Gaussian information such as sparsity, they are all pointwise statistics. This means in particular that they cannot capture spatial arrangement in the maps.
The mean:
![Mathematical equation: $\[\boxed{\phi_{\text {mean }}(x) \equiv \log \langle x\rangle_u.}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq23.png) (5)
(5)The variance:
![Mathematical equation: $\[\boxed{\phi_{\mathrm{var}}(x) \equiv \log \langle\left[x-\langle x\rangle_u]^2\right\rangle_u.}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq24.png) (6)
(6)The mean of the logarithm:
![Mathematical equation: $\[\boxed{\phi_{\text {mean of } \log }(x) \equiv\langle\log x\rangle_u.}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq25.png) (7)
(7)The variance of the logarithm:
![Mathematical equation: $\[\boxed{\phi_{\text {var of } \log }(x) \equiv \log \langle\left[\log x-\langle\log x\rangle_u]^2\right\rangle_u.}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq26.png) (8)
(8)-
The quantile functions7 (QF) normalized by the median:
![Mathematical equation: $\[\boxed{\phi_{\mathrm{QF}}(x)[i] \equiv \log \left[q_{\alpha_i}(x) / q_{1 / 2}(x)\right],}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq27.png) (9)
(9)where qα(x) designates the α-quantile of the distribution of values {x(u)}u. Hence q1/2 stands for the median operator. We consider ten quantiles {αi}i such that 1 − αi are logarithmically spaced between 10−4 and 0.4. Low quantiles are not considered, because, for diffuse observational data, they are contaminated by the noise and the CIB (Ossenkopf-Okada et al. 2016). This logarithmic binning of the high column density values is motivated by the log-normal to power-law behavior of the tail of MCs’ PDFs. See for instance Pouteau et al. (2023) and references therein. Using quantile functions also allows the description to be very robust to outlying pixels, which in practice only drive the last quantile.
4.2 Two-point based statistics
A very popular way to describe spatial properties of a process is through the PS. It is defined as the Fourier transform of the autocorrelation function, and describes the energy distribution scale by scale in the process studied. In this paper, we consider the isotropic PS, defined as
![Mathematical equation: $\[P S[k] \equiv\langle\mathbb{E}[\tilde{x}(\boldsymbol{k})|^2]\rangle_{\|\boldsymbol{k}\|=k.}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq28.png)
A power-law behavior PS[k] ∝ k−β is expected for fields arising in turbulent MHD (Schekochihin 2022). Thus we adopted a log-log representation to linearize it and for stability purposes (Bruna & Mallat 2013):
![Mathematical equation: $\[\boxed{\phi_{\mathrm{PS}}(x)[i] \equiv \log \langle | x_{\mathrm{apo}} \star \psi_i|^2\rangle_u,}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq29.png) (10)
(10)
where xapo is apodized to mitigate non periodic boundary conditions (PBC) as explained in Appendix D. We use six band-pass filters {ψi}1≤i≤6 defined as
![Mathematical equation: $\[\tilde{\psi}_i[\boldsymbol{k}]=1_{\|\boldsymbol{k}\| \in[k_i, k_{i+1}[},\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq30.png) (11)
(11)
where ki is logarithmically spaced between kmin = 1/256 pix−1 and kmax = 1/4 pix−1. For the finest maps with pixel size 6″, this kmax corresponds to a smallest angular scale of 24″, which remains above the 18″ resolution of the observations.
Because some MCs tend to have log-normal behavior in their one-point statistics, we also consider PS statistics of the logarithm of the maps:
![Mathematical equation: $\[\boxed{\phi_{\mathrm{PS ~of ~log}} (x)[i] \equiv \log \langle |(\log x)_{\text {apo }} \star \psi_i|^2\rangle_u.}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq31.png) (12)
(12)
4.3 Scattering statistics
The wavelet scattering transform (WST) is a set of non-Gaussian descriptors with a hierarchical and multiscale structure (Bruna & Mallat 2013). It has been shown to be highly effective in describing astrophysical fields (see, for instance, Allys et al. 2019; Saydjari et al. 2021). The usual WST consists in two layers of statistics, the first of which depends on a single scale of length ≃2j pixels with orientation θ:
![Mathematical equation: $\[S_1(x)[j, \theta] \equiv\langle | x \star \psi_{j, \theta}| \rangle_u.\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq32.png)
The second layer probes a coupling between two oriented scales (j1, θ1), and (j2, θ2), with j1 < j2:
![Mathematical equation: $\[S_2(x)\left[j_1, j_2, \theta_1, \theta_2\right] \equiv\langle |\left|x \star \psi_{j_1, \theta_1}\right| \star \psi_{j_2, \theta_2}| \rangle_u / S_1(x)\left[j_1, \theta_1\right].\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq33.png)
Then, observing that many processes of interest in astrophysics and cosmology exhibit strong regularities in their angular dependencies, Allys et al. (2019) proposed the reduced WST (RWST): an angular compression of WST statistics for 2D data. We are going to use three of the main descriptors they introduced (we refer to the above reference for more details):
-
![Mathematical equation: $\[S_{1}^{I s o}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq34.png) , a scale-by-scale isotropic descriptor, that we normalize by estimating it on
, a scale-by-scale isotropic descriptor, that we normalize by estimating it on ![Mathematical equation: $\[\bar{x}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq35.png) instead of x:
instead of x:
![Mathematical equation: $\[\boxed{\left.S_1^{I s o}(x)[j] \equiv\left\langle\log _2\langle | \bar{x} \star \psi_{j, \theta} \mid\right\rangle_u\right\rangle_\theta.}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq36.png) (13)
(13)We note that it computes a L1 norm of the filtered field, in contrast with the PS that probes a L2 norm.
-
![Mathematical equation: $\[-S_{2}^{I s o 1}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq37.png) and
and ![Mathematical equation: $\[S_{2}^{I s o 2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq38.png) , that measure an isotropic coupling between scales and are obtained by a nonlinear fit of the following model (Allys et al. 2019):
, that measure an isotropic coupling between scales and are obtained by a nonlinear fit of the following model (Allys et al. 2019):
![Mathematical equation: $\[\begin{aligned}& \log _2 S_2(x)\left[j_1, j_2, \theta_1, \theta_2\right]=S_2^{I s o 1}(x)\left[j_1, j_2\right] \\&\qquad\qquad\qquad\qquad+S_2^{I s o 2}(x)\left[j_1, j_2\right] \cos \left[2\left(\theta_2-\theta_1\right)\right].\end{aligned}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq39.png) (14)
(14)They characterize, respectively, a coupling between non-oriented scales and the relative coupling between parallel and perpendicular scales.
In this paper, we furthermore compress both ![Mathematical equation: $\[S_{2}^{I s o 1}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq40.png) and
and ![Mathematical equation: $\[S_{2}^{I s o 2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq41.png) coefficients that depend on two scales (2j1, 2j2) by only keeping their j2 − j1 dependency, that is, a dependency on their ratio, by considering the following average:
coefficients that depend on two scales (2j1, 2j2) by only keeping their j2 − j1 dependency, that is, a dependency on their ratio, by considering the following average:
![Mathematical equation: $\[\boxed{\langle S_2^{I s o 1}\rangle_{j_2-j_1}(x)[\delta] \equiv\langle S_2^{I s o 1}(x)[j_1, j_2]\rangle_{j_2-j_1=\delta},}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq42.png) (15)
(15)
and
![Mathematical equation: $\[\boxed{\langle S_2^{I s o 2}\rangle_{j_2-j_1}(x)[\delta] \equiv\langle S_2^{I s o 2}(x)[j_1, j_2]\rangle_{j_2-j_1=\delta}.}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq43.png) (16)
(16)
In practice, we divided the half-plane [0, π[ in eight different θ angles, and we considered four scales8 between jmin = 2 and jmax = 5. This leads to the three possible values 1 ≤ δ ≤ 3 for our reduced S 2 coefficients. These computations are performed using the pywst9 Python package (Regaldo-Saint Blancard et al. 2020).
Overview of the sets of summary statistics used.
Aggregated sets of summary statistics used in this work.
4.4 Overview
The statistics introduced above are compiled in Table 2. In the following, in addition to the sets of summary statistics defined above, we also consider some aggregated sets of summary statistics that are made from groups of these building blocks. For instance, we refer to ϕGaussian statistics to mean the joint set of {ϕmean, ϕPS}. These groups are defined in Table 3.
5 Toward a low-degeneracy set of statistics
We wanted to construct a set of informative summary statistics for the observational dataset. To do so, we followed a bottomup approach, starting with the typical low-order statistics and increasingly trying to improve on them by exhibiting and lifting potential degeneracies. The underlying idea is that low-order statistics are good candidates to concentrate most of the informative power into a few coefficients. Such a concentration property is of interest, especially as our low data regime prevents us from learning many features. Another benefit of this approach is to first promote simple statistics, and use more elaborate ones only if they add a significant contribution.
5.1 Molecular clouds have Gaussian degeneracies
To begin with, we investigate whether Gaussian statistics (i.e., the set made of mean and PS statistics) are degenerate for the observational data. To point out such potential degeneracies, we confront these Gaussian statistics, starting with a low-order non-Gaussian set of statistics, the quantile function QF, using the methodology introduced in Sect. 3.3. As shown in Fig. 6, this first confrontation on observational data already underlines a strong degeneracy level for both Gaussian and QF features, showing that neither statistics is by itself sufficient, according to the compatibility diagnostic we introduced. In particular, the quantile statistics extract a significant amount of information that cannot be efficiently captured by Gaussian statistics.
In addition to this dataset-wide diagnostic, we display in Fig. 7 three randomly selected pairs of 512 × 512 patches degenerate for Gaussian statistics but with increasing QF incompatibility. The locations of these pairs on the scatter plot of Fig. 6 are given there by the red stars. For these three pairs of patches, we show in Fig. 8 the two sets of statistics used in the diagnostic: QF statistics and Gaussian statistics.
In Fig. 8, the orange filled lines (resp. bands) correspond to the mean (resp. standard deviation) of the statistics computed over the four 256 × 256 subpatches of the top patch of each pair of Fig. 7, and the corresponding blue lines and areas refer to the bottom patch of the pair. To better highlight the discrepancies between the two patches of a given pair, the offsets of the orange and blue filled lines with respect to their common mean are also shown in the middle rows of Fig. 8.
These results illustrate the ability of QF statistics to distinguish between images with the same Gaussian statistics, which confirms that our compatibility diagnostic works as expected. We emphasize here that the ϕQF statistics are complementary to the one-point properties probed by Gaussian statistics.
This behavior is not particularly surprising as one-point properties of column density maps of MCs are expected to be at least log-normal, if not with a power-law tail. Hence, estimating such properties directly from the logarithm of the maps, as does ϕQF but not ϕGaussian, might enhance the discriminative power. To test this idea, we study in the first column of Fig. 9 the degeneracy level of the set of mean and variance statistics estimated respectively on the raw maps and their logarithm. More precisely, top row plots confront QF statistics with {ϕmean, ϕvar}, while bottom row plots confront QF statistics with {ϕmean of log, ϕvar of log}. We see in this figure that the pairs of observations are clearly better discriminated when using the mean and variance computed on the logarithm of the maps (d) rather than directly (a). This effect is very well reproduced by logFBM data (middle column), but does not hold in general, as shown with the DTD (right column).
These results suggest that the specific Gaussian degeneracies evidenced in Fig. 6 are mainly explained by the inefficiency of Gaussian one-point statistics {ϕmean, ϕvar} to characterize one-point properties of processes that have a log-normal (or heavier tail) nature.
Surprisingly, this analysis also shows that, for datasets such as observations or logFBMs, probing the PDF properties through the prism of a mean and a variance is more discriminative than probing its shape. Indeed, in both plots (d) and (e) of Fig. 9, our suitably constructed set {ϕmean of log, ϕvar of log}, of dimension two, performs almost always a better discrimination than the set ϕQF, of dimension ten. This emphasizes the importance of suitably constructed low-dimensional descriptions in such analysis. The effectiveness of such low-dimensional features in the diagnostic we introduced reflects their ability to exploit underlying regularities in the processes at play, enabling data compression with only moderate loss of information. However, when dealing with datasets made of a wide diversity of irregular processes, such as everyday life textures (e.g., DTD), it is hard to identify a compression that does not lead, for some pairs, to poorer performances (c, f).
 |
Fig. 6 Confronting Gaussian statistics with QF statistics on observational data, based on the test presented in Fig. 5. Each set of statistics has strong degeneracies lifted by the other set. To investigate the Gaussian confusions, we pick three pairs of 512 × 512 patches, whose locations on the scatter plot are given by the red stars. These pairs are shown in Fig. 7. |
 |
Fig. 7 Examples of Gaussian confusions. Three pairs of 512 × 512 patches are chosen, whose locations on the scatter plot of Fig. 6 are given there by the red stars. The column density maps are shown in units of 1020cm−2. For each patch, we report: s the subsampling factor from the original 3″/pix map, d and b the approximated distance and Galactic latitude of the cloud. The pixel size (in mpc) of a patch is thus proportional to s × d. If a pair has patches (i, j) with incompatible pixel sizes, that we define according to the following criterion |
![Mathematical equation: $\[\max \{\frac{s_{i} d_{i}}{s_{j} d_{j}}, \frac{s_{j} d_{j}}{s_{i} d_{i}}\} \geq 3 / 2\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq48.png)
 |
Fig. 8 Statistics for the examples of Gaussian confusions shown in Fig. 7. In each row, the orange filled line (resp. band) corresponds to the mean (resp. standard deviation) of the statistics computed over the four 256 × 256 subpatches of the top patch of each pair of Fig. 7, and the corresponding blue lines and areas refer to the bottom patch of the pair. The top row corresponds to the statistics used in the x-axis of the scatter plot of Fig. 6, i.e., QF statistics, plotted with ten increasing quantile values, while the bottom row corresponds to the y-axis, i.e., Gaussian statistics, plotted starting with mean and followed by the binned PS with six decreasing scales. To better highlight the discrepancies between the two patches of a given pair, we report in second and third rows the offsets of the orange and blue filled lines with respect to their common mean. |
 |
Fig. 9 Top row: plots confronting QF statistics with {ϕmean, ϕvar}. Bottom row: plots confronting QF statistics with {ϕmean of log, ϕvar of log}. These results evidence that taking the logarithm of the map enhances the discriminative power of the mean and variance statistics on both observation and logFBM data (left and middle columns) but not on DTD (right column). |
5.2 Molecular clouds have log-Gaussian degeneracies
The ability of Gaussian one-point statistics to grasp efficiently one-point properties of observations from the logarithm of the column density maps, shown in Fig. 9, suggests to shift toward log-Gaussian statistics, that is, mean and PS estimated on the logarithms of the maps. We thus investigate now whether we may point out some degeneracies of these statistics on observational data. However, if we confront this set with QF statistics, as we did previously for Gaussian statistics, we do not expect to lift significant log-Gaussian degeneracies. Instead, we suggest searching for such degeneracies using a set of higher-order statistics: the RWST. We confront, in Fig. 10, log-Gaussian statistics with the RWST statistics, on three datasets: logFBM in (a), observations in (b) and simulations in (c).
For logFBM data (Fig. 10a), we see that the RWST diagnostic does not provide any additional information beyond what is already captured by log-Gaussian statistics. Indeed, as expected for such a dataset, log-Gaussian statistics are sufficient (Cover & Thomas 2006). This result, without being a complete validation, is a clear success of our compatibility diagnostic and supports its relevance. We note that the authors do not include one-point statistics in the set of RWST coefficients, which explains why this descriptor is extremely degenerate for this dataset.
When applying the same analysis on observation data (Fig. 10b), we see again that the log-Gaussian statistics lift strong RWST degeneracies. However, contrary to logFBM data, we now see that the RWST also lift some degeneracies of the log-Gaussian statistics. To investigate more these degeneracies, we show, in Appendix E, six examples of degenerate pairs in Fig. E.1 and the statistics of these patches in Fig. E.2. In most of these pairs, the ![Mathematical equation: $\[S_{1}^{I s o}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq49.png) coefficients heavily contribute to lift the log-Gaussian degeneracy. In the first and last pairs,
coefficients heavily contribute to lift the log-Gaussian degeneracy. In the first and last pairs, ![Mathematical equation: $\[\langle S_{2}^{I s o 2}\rangle_{j_{2}-j_{1}}[\delta]\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq50.png) and respectively
and respectively ![Mathematical equation: $\[\langle S_{2}^{I s o 1}\rangle_{j_{2}-j_{1}}[\delta]\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq51.png) are also very discriminative.
are also very discriminative.
Finally, simulations yield yet another result (Fig. 10c). Although this case leads to the same qualitative conclusions as observations, namely underlining the insufficiency of log-Gaussian statistics, it differs from it quantitatively. This shows that the distribution of simulations in the space of summary statistics is different from that of observations. In particular, the scatter plots (b) and (c) of Fig. 10 show that the structures of these distributions, that is, the dependency between the statistics for each of them, are not the same. This supports the caveat of simulation-based inference according to which observations and simulations of such ISM processes have different statistical structures, and motivates the observation-based approach of this paper.
To complement the previous results, we show the scatter plot obtained by directly comparing patches from observations and simulations (Fig. 10d). This plot reveals even greater degeneracies than those observed previously, further highlighting the difference between observations and simulations. We note that this also leaves open the question of whether the set of log-Gaussian + RWST statistics also has degeneracies of its own to make such a comparison. This could be further investigated by confronting it with other sets of statistics using the diagnostic introduced in this paper.
 |
Fig. 10 Confrontation of log-Gaussian statistics with RWST statistics on logFBM synthetic data (a), observations (b), simulations (c), and observation-simulation pairs (d). As expected, no log-Gaussian degeneracies are found for the logFBM data (a). However, some are found for the other cases (b,c,d). To investigate the log-Gaussian degeneracies in the observations, six pairs of patches, whose locations on the scatter plot (b) are given by the red stars, are shown in Fig. E.1. Only five stars are actually visible, but two of them are overlapped at the horizontal coordinate x = 10. |
6 Comparing pairs and datasets
In the previous section, we confronted multiple sets of statistics to assess their information content through their level of degeneracy. In this section, we fixed the set of statistics: ϕ = ϕfinal, composed of 17 coefficients (seven log-Gaussian descriptors and ten RWST statistics), and used it to define a morphological distance between maps. We illustrate this distance by exhibiting closest pairs of images in a dataset, as well as between different datasets such as observations and simulations.
6.1 Defining a morphological distance
Our objective is to define a morphological distance between two patches based on ϕfinal. One of our requirements is to enable a comparison between distance values for different pairs, so that these pairs can be ordered according to the morphological proximity of their patches. This requirement prevents us from using the statistical compatibility diagnostic introduced earlier. Indeed, since it is weighted by the local variance of each patch’s statistics, this can lead, for example, to some patches in a dataset being compatible with almost all the others simply because their spatial variance is very high. This could also encourage a simulation to approach an observation, following this criterion, by arbitrarily increasing its variance Var ϕ(xSIM) without focusing on reducing the discrepancy of its average statistical properties ![Mathematical equation: $\[\hat{\phi}(x_{\text {SIM}})-\hat{\phi}(x_{\text {OBS}})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq52.png) . This property was purposely used to act as a penalization when confronting different sets of statistics in the previous section, but is no longer desired for pairs’ ordering, once ϕ is fixed.
. This property was purposely used to act as a penalization when confronting different sets of statistics in the previous section, but is no longer desired for pairs’ ordering, once ϕ is fixed.
To build a morphological distance that avoids this drawback, we choose instead to normalize it by the variability of the statistics evaluated over the entire observational dataset. We thus use the following distance:
![Mathematical equation: $\[d_{\mathcal{D}}^2\left(x_i, x_j\right) \equiv\left(\hat{\mu}_i-\hat{\mu}_j\right)^T\left(\operatorname{diag} M_{\mathcal{D}}\right)^{-1}\left(\hat{\mu}_i-\hat{\mu}_j\right),\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq53.png) (17)
(17)
which is normalized by the variance of ![Mathematical equation: $\[\hat{\mu}_{i}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq54.png) over all maps of a given dataset 𝒟:
over all maps of a given dataset 𝒟:
![Mathematical equation: $\[M_{\mathcal{D}} \equiv\langle(\hat{\mu}_i-\langle\hat{\mu}_j\rangle_j)(\hat{\mu}_i-\langle\hat{\mu}_j\rangle_j)^T\rangle_i,\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq55.png) (18)
(18)
where the brackets indicate an average over 𝒟. We note, however, that it is difficult to interpret the value of ![Mathematical equation: $\[d_{\mathcal{D}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq56.png) in absolute terms. Indeed, the M𝒟 term does not describe a typical variance for a given process, but describes the variety of morphologies encountered accross the entire dataset, that can be broad, as seen in the MC data investigated here. Unlike statistical compatibility diagnostics, the
in absolute terms. Indeed, the M𝒟 term does not describe a typical variance for a given process, but describes the variety of morphologies encountered accross the entire dataset, that can be broad, as seen in the MC data investigated here. Unlike statistical compatibility diagnostics, the ![Mathematical equation: $\[d_{\mathcal{D}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq57.png) distance is therefore modified by the addition or removal of maps in the dataset 𝒟, and can be affected by the presence of outliers.
distance is therefore modified by the addition or removal of maps in the dataset 𝒟, and can be affected by the presence of outliers.
In the following, we work with different datasets. For instance, we aim at comparing the minimum distance between observations and simulations to the typical distance of the closest pairs of observations. To do so, we use in this paper a unique metric, Mobs, computed on the observation dataset, as well as its associated ![Mathematical equation: $\[d_{\text {obs }}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq58.png) distance.
distance.
6.2 Closest pairs
We use the ![Mathematical equation: $\[d_{\text {obs }}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq59.png) morphological distance to identify the closest pairs of patches that can be found between two datasets. To do so, we report in Fig. 11 the cumulative distributions of distances associated with pairs of observation patches (in gray), as well as with pairs consisting of one observation patch and one logFBM, DTD, and simulation patch (in red, purple, and blue, respectively). For each case, we select six of the typical closest pairs10, as well as six relatively distant pairs, that we show in Fig. 12. In dashed lines with the same colors, we also report the cumulative distributions of distances associated to pairs of patches from a common dataset (logFBM, DTD11, and simulation patches, respectively).
morphological distance to identify the closest pairs of patches that can be found between two datasets. To do so, we report in Fig. 11 the cumulative distributions of distances associated with pairs of observation patches (in gray), as well as with pairs consisting of one observation patch and one logFBM, DTD, and simulation patch (in red, purple, and blue, respectively). For each case, we select six of the typical closest pairs10, as well as six relatively distant pairs, that we show in Fig. 12. In dashed lines with the same colors, we also report the cumulative distributions of distances associated to pairs of patches from a common dataset (logFBM, DTD11, and simulation patches, respectively).
Closest (OBS, OBS) pairs and (OBS, logFBM) pairs are visually rather similar, while distant pairs look very different. This relative agreement between the morphological proximity, as probed by our statistical distance and by human vision, is encouraging, because it should be satisfied by an ideal distance. However, it remains far from being an exhaustive diagnostic.
The closest (OBS, logFBM) pairs have a distance ![Mathematical equation: $\[d_{\mathrm{obs}}^{2} \sim 2\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq61.png) , which corresponds to a high agreement. Indeed, only ~0.5% of (OBS, OBS) or (logFBM, logFBM) pairs exhibit smaller distance values, and we have already mentioned10 that the closest 1% of (OBS, OBS) pairs are very similar by construction. In comparison, simulations are farther from observations: the closest pairs between observations and simulations have a distance
, which corresponds to a high agreement. Indeed, only ~0.5% of (OBS, OBS) or (logFBM, logFBM) pairs exhibit smaller distance values, and we have already mentioned10 that the closest 1% of (OBS, OBS) pairs are very similar by construction. In comparison, simulations are farther from observations: the closest pairs between observations and simulations have a distance ![Mathematical equation: $\[d_{\text {obs }}^{2} \sim 8\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq62.png) , four times larger than the closest (OBS, logFBM) pairs, when already ~10% of pairs of observations exhibit smaller distances (see Sect. 6.3 for more details on this interpretation). These closest (OBS, SIM) pairs seem to us visually less similar than the closest (OBS, OBS) or (OBS, logFBM) pairs (left panels of Fig. 12), but are still not so different, for instance with respect to the more distant pairs, that can be seen in the right panels of Fig. 12.
, four times larger than the closest (OBS, logFBM) pairs, when already ~10% of pairs of observations exhibit smaller distances (see Sect. 6.3 for more details on this interpretation). These closest (OBS, SIM) pairs seem to us visually less similar than the closest (OBS, OBS) or (OBS, logFBM) pairs (left panels of Fig. 12), but are still not so different, for instance with respect to the more distant pairs, that can be seen in the right panels of Fig. 12.
The closest (OBS, logFBM) samples obtained here are very diffuse regions of MCs such as Corona Australis, Polaris Flare, and Ophiuchus. This is not surprising because, for MCs, diffuse regions are closer to logFBM models than dense regions, whose PDFs are known to deviate from log-normality. However, these diffuse regions are still supposed to exhibit coherent structures that should induce deviations from logFBM models. Here, such deviations are found to be small. We note, however, that this proximity only means that certain diffuse regions are close to logFBM processes relative to the total variability of the observational dataset, and not necessarily that they are well described by such models, or could not be distinguished by the previous compatibility diagnostic. Moreover, this proximity to logFBM models is also partly due to contamination by the CIB which has non-negligible power at such low levels of column density, and is expected to Gaussianize the data, including their RWST statistics (Auclair et al. 2024). Incidentally, we remind that the observational dataset has some artifacts that make it deviate from an “ideal” MC column density dataset, even if we try to limit as much as possible their effects (noise, finite resolution), as discussed in Sect. 4.
On the contrary, the observations that are closest to the simulations of dense MCs correspond, unsurprisingly, to dense regions of MCs such as Ophiuchus, Aquila, and Serpens. We note that Ophiuchus exhibits patches that are close to these dense simulations, but also at least one patch that is close to a logFBM model, underlining the spatial variability of molecular cloud morphologies. This illustrates the difficulty to treat a MC as a single entity, and emphasizes the relevance of our local approach.
The comparison between observations and DTD shows the limitations of our morphological distance diagnostic. Indeed, the closest (OBS, DTD) pairs are found at a distance ![Mathematical equation: $\[d_{\mathrm{obs}}^{2} \sim 2\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq65.png) that is the typical distance between close (OBS, OBS) pairs or close (OBS, logFBM) pairs, although they are visually very different. This illustrates that, for a diagnostic based on a low-dimensional set of statistics, it is difficult to probe a distance over a family of processes that has such a wide variety of textures as DTD. On the contrary, because the simulations closest to the observations are more distant (
that is the typical distance between close (OBS, OBS) pairs or close (OBS, logFBM) pairs, although they are visually very different. This illustrates that, for a diagnostic based on a low-dimensional set of statistics, it is difficult to probe a distance over a family of processes that has such a wide variety of textures as DTD. On the contrary, because the simulations closest to the observations are more distant (![Mathematical equation: $\[d_{\mathrm{obs}}^{2} \sim 8\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq66.png) ), this suggests that the set of simulations does not intersect the set of observations and that ϕfinal is able to pinpoint this discrepancy, as discussed in the following subsection.
), this suggests that the set of simulations does not intersect the set of observations and that ϕfinal is able to pinpoint this discrepancy, as discussed in the following subsection.
Finally, it is quite impressive to see that we can build a distance diagnostic from a representation of dimension 17 only that still manages to identify morphological similarity between maps quite satisfactorily. This illustrates the possibility of constructing a highly informative but low-dimensional description tailored to a family of processes from an ensemble of compressed sets of typical statistics. It should be stressed, however, that this study remains partial, notably because it is based mainly on the observation of a few close pairs in our dataset. Yet, the confrontation diagnostics studied in Sect. 5 showed that degenerate counterexamples remain largely in the minority. In addition, we lack solid baselines since it is inherently difficult to quantify visual impressions of morphological proximity, although some work has been done in this direction (Peek & White 2021).
 |
Fig. 11 Cumulative distributions of |
![Mathematical equation: $\[d_{\mathrm{obs}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq60.png)
 |
Fig. 12 Closest (left) and more distant (right) pairs extracted from distributions of morphological distances reported in Fig. 11. Column density maps are shown in units of 1020cm−2. The colorbars can change from a pair to another. We see that the closest (OBS, SIM) pairs are much more distant |
![Mathematical equation: $\[(d_{\mathrm{obs}}^{2} \sim 7)\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq63.png)
![Mathematical equation: $\[d_{\mathrm{obs}}^{2} \sim 0.7\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq64.png)
 |
Fig. 13 Comparison of closest (OBS, SIM) pairs (i, j) (gray boxes) to neighboring (OBS, OBS) pairs (i, i′). The top row focuses on the closest observation to simulations, which corresponds to a patch of Ophiuchus, while the bottom row focuses on the second closest patch, which is in Aquila. In the latter case, neighboring (but independent) observations of Aquila are significantly closer than the closest simulations. The maps are shown in units of 1020cm−2 but the colorbars can change from a pair to another. |
6.3 Interpreting the minimal distance between observations and simulations
A last question we tackle is whether the relatively high value of the minimal distance ![Mathematical equation: $\[d_{\text {obs }}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq67.png) that we get between observations and simulations indeed indicates that these two sets of processes do not overlap.
that we get between observations and simulations indeed indicates that these two sets of processes do not overlap.
In order to do so, we select the observations that are closest to the simulations. As shown in Fig. 12, these correspond to patches of Ophiuchus and Aquila. Then, we report in Fig. 13 the closest observations to these patches, and sort them by proximity, according to ![Mathematical equation: $\[d_{\mathrm{obs}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq68.png) .
.
Concerning the Ophiuchus patch (top row), only three observations patches seem to be closer
![Mathematical equation: $\[(d_{\mathrm{obs}}^{2} \in\{6.5,7.2,7.3\})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq69.png) to it than the closest simulation (
to it than the closest simulation (![Mathematical equation: $\[d_{\mathrm{obs}}^{2}=7.3\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq70.png) ), and the difference in
), and the difference in ![Mathematical equation: $\[d_{\text {obs }}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq71.png) is small.
is small.However, concerning the Aquila patch (bottom row), there are numerous observations closer to it than the closest simulation (
![Mathematical equation: $\[d_{\mathrm{obs}}^{2}=8\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq72.png) ), and their distance is much smaller (down to
), and their distance is much smaller (down to ![Mathematical equation: $\[d_{\mathrm{obs}}^{2}=3.1\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq73.png) ).
).
We further interpret this discrepancy between distances in Appendix F. We conclude that the minimum (OBS, SIM) distance value, obtained on all possible pairs between those datasets, evidences a meaningful but moderate distinction between these datasets. We note that the ϕfinal statistics set may still have some degeneracies, particularly for the (OBS, SIM) comparison, and that accounting for these should likely deepen this gap. However, we believe that the current analysis illustrates the usefulness of such a morphological distance, and leave a more detailed study for future work.
7 Conclusions
In this paper, we aim to study the diversity of morphologies of observed molecular clouds. To do so, we construct a set of ~500 patches of size 512 × 512 pixels, extracted at different resolutions from column density maps of 14 nearby clouds derived from the HGBS dust emission observations. We compute several sets of statistics (mean, variance, quantile function, power spectrum and scattering transform) from these maps, and we compare their informative power. To do so, we introduce a new methodology (Fig. 5) that allows us to confront, without any supervision, two sets of summary statistics on their respective abilities to detect statistical incompatibility between pairs of stochastic processes of a given family.
Applying this methodology to this set of observations, we find that Gaussian statistics have degeneracies for the observational dataset, some of which can be lifted by one-point statistics (Fig. 6). We then show that even if log-Gaussian statistics are much less degenerate, a compressed set of scattering statistics still succeeds to demonstrate further degeneracies (Fig. 10b). This confirms that the diversity of morphologies arising in these observed clouds cannot be sufficiently described by either Gaussian or log-Gaussian statistics. This means that using such descriptions, typically to compare numerical simulations with observational data, can lead to misleading conclusions: in addition to missing potential absolute discrepancies, observations with different statistical properties can still be matched to the same simulation.
We apply the same diagnostic to simulations (Fig. 10c) and to the set of logFBMs (Fig. 10a), and find deviations from the statistical structure of the set of observations. In particular, the outcome of this diagnostic strikingly supports the sufficiency of log-Gaussian statistics to discriminate between logFBM patches. Regarding observations and simulations, there remain deviations between their respective statistical structures, even though great care has been taken in this work to design robust and low-dimensional sets of summary statistics. This supports the difficulty of transferring statistical properties learned on simulations to observations, especially those properties relative to higher-order moments, as mentioned in the caveat n°1 in the introduction. This also buttresses the supervision-detached approach developed in this paper, along with the choice to work with compressed and robust summary statistics.
From these results, we introduce a morphological distance ![Mathematical equation: $\[d_{\mathrm{obs}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq74.png) based on a set of summary statistics ϕfinal composed of seven log-Gaussian and ten RWST coefficients. The similarity probed by this distance is in agreement with visual impression when comparing observations with themselves, with logFBMs and with simulations (Fig. 12). However, it remains insufficient to operate on datasets made of a wider diversity of textures such as DTD.
based on a set of summary statistics ϕfinal composed of seven log-Gaussian and ten RWST coefficients. The similarity probed by this distance is in agreement with visual impression when comparing observations with themselves, with logFBMs and with simulations (Fig. 12). However, it remains insufficient to operate on datasets made of a wider diversity of textures such as DTD.
This work opens multiple perspectives:
The methodology we developed to confront summary statistics requires very few assumptions: it can operate in an unsupervised and very low data regime. Hence, such methodology can easily be assimilated by the ISM community and applied on a wider set of statistics and physical fields (velocities, polarization, temperature);
The low-dimensional and analytical morphological embedding ϕfinal developed here allows us for a statistically interpretable comparison, for instance between different observed clouds, between observations and simulations or statistical models. It also paves the way for the use of more sophisticated unsupervised learning techniques;
Leveraging saliency maps
![Mathematical equation: $\[\nabla_{\text {pixels}} d_{\mathrm{obs}}^{2}(x_{i}, x_{j})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq75.png) , the morphological distance
, the morphological distance ![Mathematical equation: $\[d_{\mathrm{obs}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq76.png) can be used to highlight the main areas responsible for morphological discrepancies between two patches (xi, xj), broadening the scope of the work initiated by Peek & Burkhart (2019) to the unsupervised world of observations;
can be used to highlight the main areas responsible for morphological discrepancies between two patches (xi, xj), broadening the scope of the work initiated by Peek & Burkhart (2019) to the unsupervised world of observations;The present work focuses on the statistical properties of molecular clouds. In particular, it assumes that patches with incompatible statistics should be considered as realizations of different processes. However, a potential caveat of this approach, when applied to nonstationary processes such as dense molecular clouds, could be to find statistical incompatibilities between patches which are not particularly relevant from a physical point of view. While we do not further discuss this issue in the present paper, we think it could deserve further work;
The confrontation methodology can be used to make a feature selection algorithm, in the spirit of the FRAME model developed by Zhu et al. (1998), but designed to optimize the comparison task of a nonparametric collection of processes {pi}i, instead of modeling a single process.
The following improvements could also be of great benefit:
Reduce the uncertainty in the compatibility diagnostic
![Mathematical equation: $\[d_{\phi}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq77.png) due to the precision matrix estimation. A promising idea is to use a maximum entropy model conditioned on the data (Bruna & Mallat 2019; Allys et al. 2019; Zhang & Mallat 2021) on which to perform the precision estimation;
due to the precision matrix estimation. A promising idea is to use a maximum entropy model conditioned on the data (Bruna & Mallat 2019; Allys et al. 2019; Zhang & Mallat 2021) on which to perform the precision estimation;Reduce the overall dependency of the morphological distance
![Mathematical equation: $\[d_{\mathcal{D}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq78.png) on the dataset 𝒟, and in particular on its outliers. This can be done by building a localized metric, reducing the scope of the averages in Eq. (18) from 𝒟 to 𝒟loc[i], the set of neighbors of a given process i.
on the dataset 𝒟, and in particular on its outliers. This can be done by building a localized metric, reducing the scope of the averages in Eq. (18) from 𝒟 to 𝒟loc[i], the set of neighbors of a given process i.
Acknowledgements
We thank the anonymous referee for his careful reading of the manuscript, detailed comments and useful recommendations that helped us to improve the quality of the paper. This research has made use of data from the Herschel Gould Belt survey (HGBS) project (http://gouldbelt-herschel.cea.fr). The HGBS is a Herschel Key Programme jointly carried out by SPIRE Specialist Astronomy Group 3 (SAG 3), scientists of several institutes in the PACS Consortium (CEA Saclay, INAF-IFSI Rome and INAF-Arcetri, KU Leuven, MPIA Heidelberg), and scientists of the Herschel Science Center (HSC). This work reused datasets available on the Galactica simulations database (http://www.galactica-simulations.eu). This work used the Describable Textures Dataset (https://www.robots.ox.ac.uk/~vgg/data/dtd/).
Appendix A Further details on the datasets
A.1 Observations
Fig. A.1 presents the footprints on the sky of the set of observations used in this work.
 |
Fig. A.1 Footprints of the Herschel Gould Belt Survey (HGBS) fields used in this study, overlaid on the total thermal dust intensity at 353 GHz from the GNILC (Remazeilles et al. 2011) variable resolution data of Planck (Planck Collaboration XII 2020). |
A.2 Numerical simulations
The set of numerical simulations used in this paper as an example of state-of-the-art attempts to reproduce the physics of the ISM in silico is taken from the ORION project of the Galactica database12. Using the adaptive mesh refinement (AMR) code RAMSES (Teyssier 2002; Fromang et al. 2006), the data simulates the collapse of a dense molecular cloud under self-gravity, including decaying MHD turbulence but without stellar feedback. The focus of these simulations is to study the early stages of the star formation process in a molecular cloud (105 M⊙ in a 66 pc cubic box), and so fits in well with the HGBS observational data used in this paper.
Three classes of simulations are considered, one without magnetic field (“Hydro high res”), one with a typical magnetic field of order 5–10 μG (“MHD”), and one with a higher value of the magnetic field of order 10–25 μG (“MHD high B”). With the adaptive mesh refinement scheme, the spatial resolution of the models can reach down to 1 mpc (~200 au), and even 100 au for the “Hydro high res” model. For more details about these simulations, we refer the reader to Ntormousi & Hennebelle (2019).
For each of these models, we take two snapshots, integrate along the three axes, and crop the resulting column density images to keep the central 33 pc × 33 pc field, on a regular 4096 × 4096 grid. Examples of such images are shown in Fig. A.2. As we did for observations, we cut these panels into 512 × 512 patches, keeping only the ones where the effective resolution is fine enough, to avoid artifacts due to the AMR scheme affecting our morphological analysis. The pixels in the resulting patches have sizes 8 mpc. This is in accordance with the typical spatial sampling found in our observational dataset. Indeed, this corresponds to the finest pixels (6″) of intermediate-distance clouds d ~ 300 pc, but also to the closest clouds d ~ 150 pc sampled at 12″.
 |
Fig. A.2 Overview of the simulations. One snapshot is shown for each model (“Hydro high res”, “MHD”, and “MHD high B”), and the maps show the central 33 pc × 33 pc field for H2 column density integrated along the y-axis. |
A.3 logFBM models
To perform our analysis of observational data, we also considered purely synthetic, parametric models of column density maps, derived from exponentiations of FBMs. Such fields have been previously studied by the ISM community (Elmegreen 2002; Brunt & Heyer 2002; Miville-Deschênes et al. 2007; Levrier et al. 2018). It is indeed a convenient class of models that allows us to simultaneously reproduce exactly the log-normal one-point properties (encountered in quiescent regions) and power-law power spectra to a good approximation. An example is given in Fig. 1.
In this paper, we consider the following model:
![Mathematical equation: $\[X \equiv e^{\sigma F_\beta \star Z+\mu}, \quad\text { with } Z \sim \mathcal{N}(\mathbf{0}, I),\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq79.png) (A.1)
(A.1)
parametrized by μ, σ and β, corresponding respectively to the mean, standard deviation and spectral index of the FBM. The latter is generated by sampling a 512 × 512 Gaussian white noise map Z, which is then filtered with Fβ, that is defined in Fourier space as:
![Mathematical equation: $\[\tilde{F}_\beta(\boldsymbol{k}) \equiv \begin{cases}\propto k^{-\beta / 2} & \text { if } \boldsymbol{k} \neq \mathbf{0}, \\ 1 & \text { if } \boldsymbol{k}=\mathbf{0},\end{cases}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq80.png) (A.2)
(A.2)
such that σFβ ⋆ Z + μ is a real valued Gaussian process with mean μ, variance σ2 and β-decaying PS power-law.
The parameters (μ, σ, β) are fitted from the observations. More precisely, for each 512 × 512 column density patch that has no negative pixel (that is about 87% of the 550 observational patches), we estimate the mean μ, variance σ2 and spectral index β on the logarithm of the column density patch, expressed in 1022 cm−2 units. This procedure leads to a distribution of ~480 estimated parameters triplets (μ, σ, β) that is reported in Fig. A.3. For each triplet, we then sample one 512 × 512 logFBM patch. Contrary to the other patches considered in this paper (observations, simulations, everyday textures), these samples have PBCs, by construction. However, their 256 × 256 subpatches, that are the only ones on which the various summary statistics are applied, do not, just as the rest of the data.
We dub these synthetic maps logFBM models, to recall that the statistics of their logarithms are those of FBM fields. In the literature, emission maps are often produced by integrating a 3D generated field. In this paper, for simplicity and computational efficiency, we directly generate 2D fields. Even though integrated 3D fields could be expected to better model MCs’ column density maps, they do not differ much in morphology from 2D models and both are far from reproducing MCs’ morphology. Thus, the 2D logFBM models used here are suited to the scope of this paper.
A.4 Describable textures dataset
To better understand the peculiarities of MCs’ statistical properties, we compare them with a very wide set of everyday textures: the DTD (Cimpoi et al. 2014). This dataset is openly accessible13. In this paper, we keep only images with a smaller edge size larger than 512 pixels. We then crop these ~1050 resulting pictures into 512 × 512 patches. Next, each patch is converted to grayscale by summing its three RGB channels. These maps have integer values ranging from 0 to 3 × 255 = 765 that we finally divide by a factor 103 to match the typical values of the other datasets.
 |
Fig. A.3 log-Gaussian parameters fitted on the observations used to sample logFBM data. |
Appendix B Srivastava and Du test statistic
The test statistic ![Mathematical equation: $\[d_{\phi}^{2}(x_{i}, x_{j})\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq81.png) we introduce in Eq. 2 is derived from Srivastava & Du (2008). We apply this test on the two collections of summary statistics
we introduce in Eq. 2 is derived from Srivastava & Du (2008). We apply this test on the two collections of summary statistics ![Mathematical equation: $\[\{\phi(x_{i}^{(l)})\}_{1 \leq l \leq N_{i}}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq82.png) and
and ![Mathematical equation: $\[\{\phi(x_{j}^{(l)})\}_{1 \leq l \leq N_{j}}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq83.png) computed on the subpatches (indexed by l) of the patch xi and the patch xj. In our case, Ni = Nj = 4. We recall Eq. 2 here:
computed on the subpatches (indexed by l) of the patch xi and the patch xj. In our case, Ni = Nj = 4. We recall Eq. 2 here:
![Mathematical equation: $\[d_\phi^2(x_i, x_j) \equiv \alpha[(\hat{\mu}_i-\hat{\mu}_j)^T D_S^{-1}(\hat{\mu}_i-\hat{\mu}_j)-\beta].\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq84.png) (B.1)
(B.1)
This equation is based on the following quantities:
![Mathematical equation: $\[\begin{gathered} \hat{\mu}_{i} \equiv\left\langle\phi\left(x_{i}^{(l)}\right)\right\rangle_{1 \leq l \leq N_{i},} \\ p=\operatorname{dim} \phi, \text { and } n=N_{i}+N_{j}-2, \\ \left\{\begin{array}{l} S_{i} \equiv\left\langle\left[\phi\left(x_{i}^{(l)}\right)-\hat{\mu}_{i}\right]\left[\phi\left(x_{i}^{(l)}\right)-\hat{\mu}_{i}\right]^{T}\right\rangle_{1 \leq l \leq N_{i},} \\ S \equiv \frac{1}{n}\left(N_{i} S_{i}+N_{j} S_{j}\right), \\ D_{S} \equiv \operatorname{diag} S, \end{array}\right. \\ \left\{\begin{array}{l}R \equiv D_{S}^{-1 / 2} S D_{S}^{-1 / 2}, \\c_{p, n} \equiv 1+\text{tr} ~R^{2} / p^{3 / 2}, \\\alpha \equiv \frac{N_{i} N_{j}}{N_{i}+N_{j}} \frac{1}{\sqrt{2\left(\text{tr} ~R^{2}-p^{2} / n\right) c_{p, n}}}, \\\beta \equiv \frac{N_{i}+N_{j}}{N_{i} N_{j}} \frac{n p}{n-2}.\end{array}\right.\end{gathered}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq85.png)
Appendix C Rationale for using the logarithm of some standard statistics
In theory, because the mapping ψ ↦ log ψ is invertible, the same amount of information should be contained in ϕ(x) and in log ϕ(x) (when the latter is well defined). However, for the compatibility diagnostic we chose, these two options might perform differently. Such issues are not specific to this test and also occur with standard diagnostics such as Fisher analysis (Park et al. 2023).
First, this nonlinear mapping can change the fulfillment level of the test assumptions. In the Srivastava and Du test used here, the two input distributions to be compared are assumed to be normally distributed and with equal variance. In many cases, typically when ϕ(x) > 0, taking the logarithm of ϕ(x) decreases the deviation to normality and decreases the relative deviations between the variances of ϕ(xi) and ϕ(xj).
Second, this could lead to dramatic improvement in incompatibility detection, as illustrated in Fig. C.1 for ϕ = ϕvar (provided that the assumptions of the test are not too discarded in both cases for these results to be appropriately interpreted).
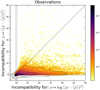 |
Fig. C.1 Effect of logarithmic rescaling after computing variance statistics on observation data. Provided that the assumptions of the test are not too discarded in both cases for these results to be appropriately interpreted on both axes, this shows that ⟨[x − ⟨x⟩u]2⟩u is strictly more degenerate than log ⟨[x − ⟨x⟩u]2⟩u. |
Appendix D Apodization
The 256 × 256 subpatches on which we perform 2D Fourier transform do not have PBCs. Thus, before applying such transform during PS estimation on a given subpatch x, we first apodize it as follows:
![Mathematical equation: $\[x \mapsto r w \cdot\left(x-\langle x\rangle_u\right),\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq86.png)
where w· denotes the pixel-wise multiplication by the window w, reported in Fig. D.1 and r is a scalar factor depending on the input map x such that the output apodized map has same variance as the input. The resulting map does not share the same mean with the input but this property is not regarded by the Fourierbased statistics used here.
 |
Fig. D.1 256 × 256 apodization window w used. The orange line is a 1D slice of the middle of the window. |
Appendix E Additional examples of degeneracies
We show six examples of pairs of patches in Fig. E.1 that have compatible log-Gaussian statistics but incompatible RWST statistics, as shown in Fig. E.2.
 |
Fig. E.1 Examples of log-Gaussian degeneracies. Six pairs of 512 × 512 patches are chosen, whose locations on the scatter plot of Fig. 10b are given there by the red stars. The column density maps are shown in units of 1020cm−2. For each patch, we report: s the subsampling factor from the original 3″/pix map, d and b the approximated distance and Galactic latitude of the cloud. If a pair has patches (i, j) with incompatible pixel sizes according to the following criterion |
![Mathematical equation: $\[\max \{\frac{s_{i} d_{i}}{s_{j} d_{j}}, \frac{s_{j} d_{j}}{s_{i} d_{i}}\} \geq 3 / 2\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq87.png)
 |
Fig. E.2 Statistics for the examples of log-Gaussian confusions shown in Fig. E.1. In each row, the orange filled line (resp. band) corresponds to the mean (resp. standard deviation) of the statistics computed over the four 256 × 256 subpatches of the top patch of each pair of Fig. E.1, and the corresponding blue lines and areas refer to the bottom patch of the pair. The top row corresponds to the RWST, starting with |
![Mathematical equation: $\[S_{1}^{I s o}[j]\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq88.png)
![Mathematical equation: $\[\langle S_{2}^{I s o 1}\rangle_{j_{2}-j_{1}}[\delta]\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq89.png)
![Mathematical equation: $\[\langle S_{2}^{I s o 2}\rangle_{j_{2}-j_{1}}[\delta]\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq90.png)
Appendix F Lower bound of the gap between observations and simulations
In Sect. 6.3, we investigate whether observations and simulations do intersect. Ideally, we would like to check whether the set of observations’ moments ![Mathematical equation: $\[\{\bar{\mu}_{i}\}_{i \in \mathrm{obs}}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq91.png) overlaps that of simulations
overlaps that of simulations ![Mathematical equation: $\[\{\bar{\mu}_{j}\}_{j \in \operatorname{sim}}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq92.png) , where
, where ![Mathematical equation: $\[\bar{\mu}_{i} \equiv \mathbb{E}[\phi_{\text {final}}(x_{i})]\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq93.png) stands for the expected value over a given process i. In practice, we would aim at retrieving the minimal distance
stands for the expected value over a given process i. In practice, we would aim at retrieving the minimal distance
![Mathematical equation: $\[\bar{d}_{i j}^2 \equiv\left(\bar{\mu}_i-\bar{\mu}_j\right)^T\left(\operatorname{diag} M_{\mathrm{obs}}\right)^{-1}\left(\bar{\mu}_i-\bar{\mu}_j\right)\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq94.png) (F.1)
(F.1)
between ![Mathematical equation: $\[\bar{\mu}_i\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq95.png) and
and ![Mathematical equation: $\[\bar{\mu}_j\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq96.png) over (OBS, SIM) pairs (i, j).
over (OBS, SIM) pairs (i, j).
However, the distance ![Mathematical equation: $\[d_{\text {obs }}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq97.png) introduced previously is a statistical estimator so that, in general,
introduced previously is a statistical estimator so that, in general,
![Mathematical equation: $\[d_{i j}^2 \neq d_{i j}^2,\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq98.png)
and in particular: ![Mathematical equation: $\[\mathbb{E}[d_{i j}^{2}]>\bar{d}_{i j}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq99.png) . Indeed, the variance of the estimator
. Indeed, the variance of the estimator ![Mathematical equation: $\[\hat{\mu}_{i}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq100.png) biases
biases ![Mathematical equation: $\[d_{i j}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq101.png) with respect to
with respect to ![Mathematical equation: $\[\bar{d}_{i j}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq102.png) :
:
![Mathematical equation: $\[\mathbb{E}[d_{i j}^2] \equiv d_{i j}^2+b_{i j}.\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq103.png) (F.2)
(F.2)
This non-negative bias, which boils down to
![Mathematical equation: $\[b_{i j}=\operatorname{tr}\{\operatorname{cov}~[(\operatorname{diag} M_{\mathrm{obs}})^{-1 / 2}(\hat{\mu}_i-\hat{\mu}_j)]\},\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq104.png) (F.3)
(F.3)
prevents us from interpreting directly the value of ![Mathematical equation: $\[d_{i j}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq105.png) as
as ![Mathematical equation: $\[\bar{d}_{i j}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq106.png) . Furthermore, its value increases with the amplitude of the fluctuations of
. Furthermore, its value increases with the amplitude of the fluctuations of ![Mathematical equation: $\[\hat{\mu}_{i}-\hat{\mu}_{j}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq107.png) and can thus change depending on the pair (i, j) considered. This dependency on the pair also prevents us, without further check, from actually comparing
and can thus change depending on the pair (i, j) considered. This dependency on the pair also prevents us, without further check, from actually comparing ![Mathematical equation: $\[\bar{d}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq108.png) between different pairs based on the estimations d2.
between different pairs based on the estimations d2.
To probe and interpret the minimal distance between observations and simulations, we propose the following strategy:
Find an observation i and a simulation j that minimize the biased estimation
![Mathematical equation: $\[d_{i j}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq109.png) . Such pairs are already reported in Fig. 12 and are good candidates to minimize
. Such pairs are already reported in Fig. 12 and are good candidates to minimize ![Mathematical equation: $\[\bar{d}_{i j}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq110.png) . The goal then becomes to compare
. The goal then becomes to compare ![Mathematical equation: $\[\bar{d}_{i j}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq111.png) with the minimal value
with the minimal value ![Mathematical equation: $\[\bar{d}_{i i^{\prime}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq112.png) , for i′ another observation, independent of i. But
, for i′ another observation, independent of i. But ![Mathematical equation: $\[\bar{d}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq113.png) is unknown. Instead:
is unknown. Instead:Find an observation i′, that minimizes the biased distance
![Mathematical equation: $\[d_{i i}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq114.png) , while checking it does not overlap i in the sky to assume them independent.
, while checking it does not overlap i in the sky to assume them independent.Since
![Mathematical equation: $\[\bar{d}_{i j}^{2}-\bar{d}_{i i^{\prime}}^{2}=\mathbb{E}[d_{i j}^{2}]-\mathbb{E}[d_{i i^{\prime}}^{2}]+b_{i i^{\prime}}-b_{i j}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq115.png) , the discrepancy between
, the discrepancy between ![Mathematical equation: $\[\bar{d}_{i j}^{2}-\bar{d}_{i i^{\prime}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq116.png) can be estimated based on the measured discrepancy
can be estimated based on the measured discrepancy ![Mathematical equation: $\[d_{i j}^{2}-d_{i i^{\prime}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq117.png) up to the unknown bias shift bii′ − bij.
up to the unknown bias shift bii′ − bij.If, in addition the observation patch xi′ is such that spatial fluctuations of ϕfinal over its subpatches are at least of the order of those estimated from the subpatches of the simulation patch xj, then based on Eq. F.3, we have bii′ ⪆ bij. This allows us then to use
![Mathematical equation: $\[d_{i j}^{2}-d_{i i^{\prime}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq118.png) as an estimated lower bound for
as an estimated lower bound for ![Mathematical equation: $\[\bar{d}_{i j}^{2}-\bar{d}_{i i^{\prime}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq119.png) .
.
We report in Fig. 13 such independent14 pairs (i, i′). In the first row, we fix i associated with the patch from Ophiuchus xi that is the closest observation to simulations (![Mathematical equation: $\[d_{i j}^{2}=7\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq120.png) , Fig. 12). For this choice of patch, the reported distances
, Fig. 12). For this choice of patch, the reported distances ![Mathematical equation: $\[d_{i i^{\prime}}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq121.png) of neighboring observations i′ are rather similar to
of neighboring observations i′ are rather similar to ![Mathematical equation: $\[d_{i j}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq122.png) . However, in the second row, where i is associated with the patch from Aquila that is the second closest observation to simulations (as shown in Fig. 12), we see other observations i′, such as Serpens or Orion B, that are closer than the closest simulation:
. However, in the second row, where i is associated with the patch from Aquila that is the second closest observation to simulations (as shown in Fig. 12), we see other observations i′, such as Serpens or Orion B, that are closer than the closest simulation: ![Mathematical equation: $\[d_{i i^{\prime}}^{2}=3< d_{i j}^{2}=8\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq123.png) . We checked that the fluctuations of i′ are comparable to those of j so that bii′ ⪆ bij. This implies then
. We checked that the fluctuations of i′ are comparable to those of j so that bii′ ⪆ bij. This implies then ![Mathematical equation: $\[\bar{d}_{i j}^2-\bar{d}_{i i^{\prime}}^2 \lessapprox 5\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq124.png) while
while ![Mathematical equation: $\[\bar{d}_{i i^{\prime}}^{2} \leq d_{i i^{\prime}}^{2}=3\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq125.png) . Hence,
. Hence, ![Mathematical equation: $\[\bar{d}_{i j}^{2} / \bar{d}_{i i^{\prime}}^{2} \lessapprox 8 / 3\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq126.png) . This second case shows that one of the closest (OBS, SIM) pairs is definitely further apart than this specific observation is with other observations, at least according to ϕfinal. This example also supports that the potential bias on the
. This second case shows that one of the closest (OBS, SIM) pairs is definitely further apart than this specific observation is with other observations, at least according to ϕfinal. This example also supports that the potential bias on the ![Mathematical equation: $\[d_{\text {obs }}^{2}\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq127.png) estimators remains moderate for the study of (OBS, SIM) pairs (
estimators remains moderate for the study of (OBS, SIM) pairs (![Mathematical equation: $\[\bar{d}_{i j}^{2} \lessapprox 5\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq128.png) and
and ![Mathematical equation: $\[d_{i j}^{2}=8\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq129.png) implies bij ⪅ 3).
implies bij ⪅ 3).
References
- Allys, E., Levrier, F., Zhang, S., et al. 2019, A&A, 629, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Allys, E., Marchand, T., Cardoso, J.-F., et al. 2020, Phys. Rev. D, 102, 103506 [NASA ADS] [CrossRef] [Google Scholar]
- André, P., Men’shchikov, A., Bontemps, S., et al. 2010, A&A, 518, L102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- André, P., Di Francesco, J., Ward-Thompson, D., et al. 2014, Protostars and Planets VI, 27 [Google Scholar]
- Appel, S. M., Burkhart, B., Semenov, V. A., Federrath, C., & Rosen, A. L. 2022, ApJ, 927, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Arzoumanian, D., André, P., Didelon, P., et al. 2011, A&A, 529, L6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Auclair, C., Allys, E., Boulanger, F., et al. 2024, A&A, 681, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blum, M., Nunes, M., Prangle, D., & Sisson, S. 2013, Statist. Sci., 28, 189 [Google Scholar]
- Bruna, J., & Mallat, S. 2013, IEEE Trans. Pattern Anal. Mach. Intellig., 35, 1872 [Google Scholar]
- Bruna, J., & Mallat, S. 2019, Math. Statist. Learn., 1, 257 [CrossRef] [Google Scholar]
- Brunt, C. M., & Heyer, M. H. 2002, ApJ, 566, 276 [Google Scholar]
- Burkhart, B., & Lazarian, A. 2016, ApJ, 827, 26 [Google Scholar]
- Burkhart, B., Falceta-Gonçalves, D., Kowal, G., & Lazarian, A. 2009, ApJ, 693, 250 [Google Scholar]
- Cimpoi, M., Maji, S., Kokkinos, I., et al. 2014, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) [Google Scholar]
- Cover, T., & Thomas, J. 2006, Elements of Information Theory (WileyInterscience) [Google Scholar]
- Elmegreen, B. G. 2002, ApJ, 564, 773 [NASA ADS] [CrossRef] [Google Scholar]
- Falgarone, E., Hily-Blant, P., & Levrier, F. 2004, Ap&SS, 292, 89 [Google Scholar]
- Federrath, C., & Klessen, R. S. 2013, ApJ, 763, 51 [Google Scholar]
- Fromang, S., Hennebelle, P., & Teyssier, R. 2006, A&A, 457, 371 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Galli, P. A. B., Bertout, C., Teixeira, R., & Ducourant, C. 2013, A&A, 558, A77 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goodman, A. A., Rosolowsky, E. W., Borkin, M. A., et al. 2009, Nature, 457, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Heithausen, A., & Thaddeus, P. 1990, ApJ, 353, L49 [NASA ADS] [CrossRef] [Google Scholar]
- Hennebelle, P., & Chabrier, G. 2008, ApJ, 684, 395 [Google Scholar]
- Heyer, M. H., & Brunt, C. M. 2004, ApJ, 615, L45 [NASA ADS] [CrossRef] [Google Scholar]
- Hotelling, H. 1931, The Annals of Mathematical Statistics, 2, 360 [Google Scholar]
- Kainulainen, J., Beuther, H., Henning, T., & Plume, R. 2009, A&A, 508, L35 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Knude, J., & Hog, E. 1998, A&A, 338, 897 [NASA ADS] [Google Scholar]
- Könyves, V., André, P., Men’Shchikov, A., et al. 2015, A&A, 584, A91 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Levrier, F., Falgarone, E., & Viallefond, F. 2006, A&A, 456, 205 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Levrier, F., Neveu, J., Falgarone, E., et al. 2018, A&A, 614, A124 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mamajek, E. E. 2008, Astron. Nachr., 329, 10 [Google Scholar]
- McKee, C. F., & Ostriker, E. C. 2007, ARA&A, 45, 565 [Google Scholar]
- Miville-Deschênes, M.-A., Lagache, G., Boulanger, F., & Puget, J.-L. 2007, A&A, 469, 595 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miville-Deschênes, M. A., Martin, P. G., Abergel, A., et al. 2010, A&A, 518, L104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ntormousi, E., & Hennebelle, P. 2019, A&A, 625, A82 [EDP Sciences] [Google Scholar]
- Nunes, M. A., & Balding, D. J. 2010, Statist. Appl. Genet. Mol. Biol., 9 [Google Scholar]
- Ortiz-León, G. N., Loinard, L., Dzib, S. A., et al. 2018, ApJ, 869, L33 [Google Scholar]
- Ossenkopf-Okada, V., Csengeri, T., Schneider, N., Federrath, C., & Klessen, R. S. 2016, A&A, 590, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Palmeirim, P. a., André, P., Kirk, J., et al. 2013, A&A, 550, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Park, C. F., Allys, E., Villaescusa-Navarro, F., & Finkbeiner, D. 2023, ApJ, 946, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Peek, J., & Burkhart, B. 2019, ApJ, 882, L12 [Google Scholar]
- Peek, J., & White, R. 2021, Bull. AAS, 53, 6 [Google Scholar]
- Pilbratt, G. L., Riedinger, J. R., Passvogel, T., et al. 2010, A&A, 518, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XII. 2020, A&A, 641, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pouteau, Y., Motte, F., Nony, T., et al. 2023, A&A, 674, A76 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Regaldo-Saint Blancard, B., Levrier, F., Allys, E., Bellomi, E., & Boulanger, F. 2020, A&A, 642, A217 [EDP Sciences] [Google Scholar]
- Remazeilles, M., Delabrouille, J., & Cardoso, J.-F. 2011, MNRAS, 418, 467 [Google Scholar]
- Robitaille, J.-F., Motte, F., Schneider, N., Elia, D., & Bontemps, S. 2019, A&A, 628, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Saydjari, A. K., Portillo, S. K., Slepian, Z., et al. 2021, ApJ, 910, 122 [Google Scholar]
- Schekochihin, A. A. 2022, J. Plasma Phys., 88, 155880501 [NASA ADS] [CrossRef] [Google Scholar]
- Schlafly, E. F., Green, G., Finkbeiner, D. P., et al. 2014, ApJ, 786, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, N., André, P., Könyves, V., et al. 2013, ApJ, 766, L17 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, N., Ossenkopf-Okada, V., Clarke, S., et al. 2022, A&A, 666, A165 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Srivastava, M. S., & Du, M. 2008, J. Multivariate Anal., 99, 386 [Google Scholar]
- Teyssier, R. 2002, A&A, 385, 337 [CrossRef] [EDP Sciences] [Google Scholar]
- Vázquez-Semadeni, E., Ballesteros-Paredes, J., & Rodríguez, L. F. 1997, ApJ, 474, 292 [Google Scholar]
- Yan, Q.-Z., Zhang, B., Xu, Y., et al. 2019, A&A, 624, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zavagno, A., Dupé, F.-X., Bensaid, S., et al. 2023, A&A, 669, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zhang, S., & Mallat, S. 2021, Appl. Computat. Harmonic Anal., 53, 199 [CrossRef] [Google Scholar]
- Zhu, S. C., Wu, Y., & Mumford, D. 1998, Int. J. Comput. Vis., 27, 107 [Google Scholar]
- Zucker, C., Speagle, J. S., Schlafly, E. F., et al. 2020, A&A, 633, A51 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
The mean and variance of the data may be normalized, the power spectra flattened, and histograms (nonlinearly) equalized.
A further study could target more distant, more massive star forming regions with interferometric observations. We postpone such a study to a future paper.
The typical resolutions range from 10″ at 70 μm to 36″ at 500 μm.
Indeed, this implication, from statistical to physical incompatibility, is ensured for patches that undergo stationary dynamics, both in space and time. However, for dense molecular clouds, this assumption is not entirely satisfied when nonstationary processes such as self-gravity come into play. A potential caveat could then be to find incompatibilities between summary statistics which are not particularly relevant from a physical point of view. While we do not further discuss this issue in the present paper, we think it could deserve further work.
This assumption is not far from being true when the law of large numbers can be applied to the distribution of ϕ(x). This is for instance the case when ϕ(x) is defined as an average over the image pixels of a certain local distortion (such as filtering, possibly nonlinear) ϕloc(x) of x: ϕ(x) = ⟨ϕloc(x)[u]⟩u and when the process ϕloc(x) is stationary with a correlation length that is small compared to the image length.
We consider quantile functions rather than probability distribution functions, as the difficulty of defining a unique binning range makes comparisons less efficient. Indeed, to define a range in terms of quantiles allows us for a natural adaptation to each MCs ’ regions.
This choice of jmin is such that, for the finest maps of pixel size 6″, the dyadic scale jmin corresponds to 24″, which remains above the 18″ resolution of the observations. Choosing a larger jmax would allow us to consider larger scales. However, such scales often bring limited additional information due to their large variance, while for computational purposes, a larger jmax leads to a significant loss of the surface used in the image x to estimate the scattering coefficients in the non PBC case. Indeed, to mitigate the latter, convolutions are done with local wavelets and then corrupted edges are cropped with a margin size ∝ 2jmax.
We do not investigate the ~1% closest pairs of observations, since the comparison between observations is slightly biased with respect to the other ones. The reason is that, in that case only, we have pairs made of non-independent patches, such as neighboring patches in the sky or two slightly different scaled versions of the same region. This corresponds to approximately 1% of the pairs, which we therefore exclude.
We note that the ~10 closest pairs of DTD images, located at ![Mathematical equation: $\[d_{\text {obs }}^{2} \lessapprox 1\]$](/articles/aa/full_html/2025/04/aa51493-24/aa51493-24-eq130.png) are artifacts in this dataset corresponding in practice to almost identical images.
are artifacts in this dataset corresponding in practice to almost identical images.
Indeed, only one of these pairs is made of patches retrieved from the same MC (Ophiuchus), but these patches do not overlap.
All Tables
Summary of the properties of the different MCs studied in this paper, as well as their division into patches at different sampling.
All Figures
|
Fig. 1 Column density map of a region in Perseus (top row) and sample of a log-fractional Brownian motion (logFBM) field (bottom row). Each image has 256 × 512 pixels but is tiled into two complementary patches of size 256 × 256 on which the statistics shown in Fig. 2 are computed. While these one-point and two-point statistics (some being non-Gaussian) are clearly compatible, these two images have manifestly different morphologies. |
| In the text | |
|
Fig. 2 Statistical properties of the maps from Fig. 1: PDFs (top), power spectra (center), and power spectra of the logarithms of the maps (bottom). The dashed vertical line in the power spectra plots is located at the 18.2″ resolution of the column density map from the observational dataset. Power spectra are apodized as explained in Sect. 4. We see that the logFBM process is compatible with this observed portion of MC for all these statistics (some of theme being non-Gaussian), while having a manifestly different morphology, as revealed in Fig. 1. All these statistics are thus degenerate for such a comparison. |
| In the text | |
|
Fig. 3 Three examples of H2 column density maps from the HGBS. The spatial resolution of the maps is 18″, sampled with a pixel size of 3″. As a reference, a white dot with diameter 90″ (which amounts to five times the resolution) is shown at the bottom right corner of each map. Estimates of spatial scales, also shown on the maps, are based on reported distances (see Table 1). The Polaris Flare is an example of a diffuse and quiescent cloud, while Aquila and Orion B are dense and very active star-forming regions. |
| In the text | |
 |
Fig. 4 Illustration of the preprocessing of observational data. Details are given in Sect. 2.2. |
| In the text | |
|
Fig. 5 Illustration of the proposed test to confront two sets of summary statistics, ϕA versus ϕB, on their degeneracy level for a given dataset. Each star represents a pair of patches. Panel a: the presence of stars in the bottom right region, i.e., where dϕA ≫ 1 and dϕB ⪅ 1, reveals that some pairs of this dataset are identified by ϕA as incompatible but not by ϕB: such pairs thus evidence degeneracies of ϕB lifted by ϕA. Conversely, the presence of stars in the top left region evidences degeneracies of ϕA lifted by ϕB. Hence, if all the points land mainly in the sub-diagonal part (panel b), this evidences that ϕA is better suited than ϕB to compare the pairs of this dataset. If on the contrary the points are spread both in the upper left and bottom right regions of the plot (panel c), this shows that both ϕA and ϕB are individually not sufficient to describe the processes of this dataset. |
| In the text | |
|
Fig. 6 Confronting Gaussian statistics with QF statistics on observational data, based on the test presented in Fig. 5. Each set of statistics has strong degeneracies lifted by the other set. To investigate the Gaussian confusions, we pick three pairs of 512 × 512 patches, whose locations on the scatter plot are given by the red stars. These pairs are shown in Fig. 7. |
| In the text | |
|
Fig. 7 Examples of Gaussian confusions. Three pairs of 512 × 512 patches are chosen, whose locations on the scatter plot of Fig. 6 are given there by the red stars. The column density maps are shown in units of 1020cm−2. For each patch, we report: s the subsampling factor from the original 3″/pix map, d and b the approximated distance and Galactic latitude of the cloud. The pixel size (in mpc) of a patch is thus proportional to s × d. If a pair has patches (i, j) with incompatible pixel sizes, that we define according to the following criterion |
| In the text | |
|
Fig. 8 Statistics for the examples of Gaussian confusions shown in Fig. 7. In each row, the orange filled line (resp. band) corresponds to the mean (resp. standard deviation) of the statistics computed over the four 256 × 256 subpatches of the top patch of each pair of Fig. 7, and the corresponding blue lines and areas refer to the bottom patch of the pair. The top row corresponds to the statistics used in the x-axis of the scatter plot of Fig. 6, i.e., QF statistics, plotted with ten increasing quantile values, while the bottom row corresponds to the y-axis, i.e., Gaussian statistics, plotted starting with mean and followed by the binned PS with six decreasing scales. To better highlight the discrepancies between the two patches of a given pair, we report in second and third rows the offsets of the orange and blue filled lines with respect to their common mean. |
| In the text | |
|
Fig. 9 Top row: plots confronting QF statistics with {ϕmean, ϕvar}. Bottom row: plots confronting QF statistics with {ϕmean of log, ϕvar of log}. These results evidence that taking the logarithm of the map enhances the discriminative power of the mean and variance statistics on both observation and logFBM data (left and middle columns) but not on DTD (right column). |
| In the text | |
|
Fig. 10 Confrontation of log-Gaussian statistics with RWST statistics on logFBM synthetic data (a), observations (b), simulations (c), and observation-simulation pairs (d). As expected, no log-Gaussian degeneracies are found for the logFBM data (a). However, some are found for the other cases (b,c,d). To investigate the log-Gaussian degeneracies in the observations, six pairs of patches, whose locations on the scatter plot (b) are given by the red stars, are shown in Fig. E.1. Only five stars are actually visible, but two of them are overlapped at the horizontal coordinate x = 10. |
| In the text | |
|
Fig. 11 Cumulative distributions of |
| In the text | |
|
Fig. 12 Closest (left) and more distant (right) pairs extracted from distributions of morphological distances reported in Fig. 11. Column density maps are shown in units of 1020cm−2. The colorbars can change from a pair to another. We see that the closest (OBS, SIM) pairs are much more distant |
| In the text | |
|
Fig. 13 Comparison of closest (OBS, SIM) pairs (i, j) (gray boxes) to neighboring (OBS, OBS) pairs (i, i′). The top row focuses on the closest observation to simulations, which corresponds to a patch of Ophiuchus, while the bottom row focuses on the second closest patch, which is in Aquila. In the latter case, neighboring (but independent) observations of Aquila are significantly closer than the closest simulations. The maps are shown in units of 1020cm−2 but the colorbars can change from a pair to another. |
| In the text | |
|
Fig. A.1 Footprints of the Herschel Gould Belt Survey (HGBS) fields used in this study, overlaid on the total thermal dust intensity at 353 GHz from the GNILC (Remazeilles et al. 2011) variable resolution data of Planck (Planck Collaboration XII 2020). |
| In the text | |
|
Fig. A.2 Overview of the simulations. One snapshot is shown for each model (“Hydro high res”, “MHD”, and “MHD high B”), and the maps show the central 33 pc × 33 pc field for H2 column density integrated along the y-axis. |
| In the text | |
|
Fig. A.3 log-Gaussian parameters fitted on the observations used to sample logFBM data. |
| In the text | |
|
Fig. C.1 Effect of logarithmic rescaling after computing variance statistics on observation data. Provided that the assumptions of the test are not too discarded in both cases for these results to be appropriately interpreted on both axes, this shows that ⟨[x − ⟨x⟩u]2⟩u is strictly more degenerate than log ⟨[x − ⟨x⟩u]2⟩u. |
| In the text | |
|
Fig. D.1 256 × 256 apodization window w used. The orange line is a 1D slice of the middle of the window. |
| In the text | |
|
Fig. E.1 Examples of log-Gaussian degeneracies. Six pairs of 512 × 512 patches are chosen, whose locations on the scatter plot of Fig. 10b are given there by the red stars. The column density maps are shown in units of 1020cm−2. For each patch, we report: s the subsampling factor from the original 3″/pix map, d and b the approximated distance and Galactic latitude of the cloud. If a pair has patches (i, j) with incompatible pixel sizes according to the following criterion |
| In the text | |
|
Fig. E.2 Statistics for the examples of log-Gaussian confusions shown in Fig. E.1. In each row, the orange filled line (resp. band) corresponds to the mean (resp. standard deviation) of the statistics computed over the four 256 × 256 subpatches of the top patch of each pair of Fig. E.1, and the corresponding blue lines and areas refer to the bottom patch of the pair. The top row corresponds to the RWST, starting with |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.