| Issue |
A&A
Volume 693, January 2025
|
|
|---|---|---|
| Article Number | A73 | |
| Number of page(s) | 18 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202452799 | |
| Published online | 03 January 2025 | |
Inferring redshift and galaxy properties via a multi-task neural net with probabilistic outputs
An application to simulated MOONS spectra
1
Dipartimento di Fisica e Astronomia, Università di Firenze, Via G. Sansone 1, I-50019 Sesto F.no (Firenze), Italy
2
INAF – Osservatorio Astrofisico di Arcetri, Largo E. Fermi 5, I-50125 Florence, Italy
3
School of Physics and Astronomy, University of St Andrews, North Haugh, St Andrews KY16 9SS UK
4
INAF-Osservatorio di Astrofisica e Scienza dello Spazio di Bologna, Via Piero Gobetti 93/3, 40129 Bologna, Italy
5
GEPI, Observatoire de Paris, PSL University, CNRS, Meudon, France
6
Cavendish Laboratory, University of Cambridge, 19 J. J. Thomson Ave., Cambridge CB3 0HE UK
7
Kavli Institute for Cosmology, University of Cambridge, Madingley Road, Cambridge CB3 0HA UK
8
Department of Physics and Astronomy, University College London, Gower Street, London WC1E 6BT, UK
9
European Southern Observatory, Karl-Schwarzschild-Strasse 2, D-85748 Garching bei Muenchen, Germany
⋆ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
29
October
2024
Accepted:
25
November
2024
Abstract
The era of large-scale astronomical surveys demands innovative approaches for rapid and accurate analysis of extensive spectral data, and a promising direction in which to address this challenge is offered by machine learning. Here, we introduce a new pipeline, M-TOPnet (Multi-Task network Outputting Probabilities), which employs a convolutional neural network with residual learning to simultaneously derive redshift and other key physical properties of galaxies from their spectra. Our tool efficiently encodes spectral information into a latent space, employing distinct downstream branches for each physical quantity, thereby benefiting from multi-task learning. Notably, our method handles the redshift output as a probability distribution, allowing for a more refined and robust estimation of this critical parameter. We demonstrate preliminary results using simulated data from the MOONS instrument, which will soon be operating at the ESO/VLT. We highlight the effectiveness of our tool in accurately predicting the redshift, stellar mass, and star formation rate of galaxies at z ≳ 1 − 3, even for faint sources (mH ∼ 24) for which traditional methods often struggle. Through analysis of the output probability distributions, we demonstrate that our pipeline enables robust quality screening of the results, achieving accuracy rates of up to 99% in redshift determination (defined as predictions within |Δz|< 0.01 relative to the true redshift) with 8 h exposure spectra, while automatically identifying potentially problematic cases. Our pipeline thus emerges as a powerful solution for the upcoming challenges in observational astronomy, combining precision, interpretability, and efficiency, all aspects that are crucial for analysing the massive datasets expected from next-generation instruments.
Key words: methods: data analysis / techniques: spectroscopic / ISM: general / galaxies: evolution / galaxies: high-redshift / galaxies: ISM
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Spectra encode most of the information on the physical properties of galaxies; therefore, spectroscopy is an essential technique to probe the physical mechanisms that drive the formation and evolution of galaxies across cosmic time. The analysis of emission lines, absorption lines, and continuum in spectra across ultraviolet (UV), optical, and infrared (IR) wavelengths allows one to infer information about the internal structure and various physical properties of galaxies (see comprehensive reviews by Conroy 2013; Maiolino & Mannucci 2019 and Kewley et al. 2019). By applying stellar population synthesis models to the entire galaxy spectrum, it is possible to constrain the recent star formation history of galaxies (Madau et al. 1998; Bruzual & Charlot 2003; Cid Fernandes et al. 2005; Maraston 2005; Tojeiro et al. 2007; Carnall et al. 2018). Additionally, spectral energy distributions (SEDs) provide insights into key quantities like stellar masses (Mstar), star formation rates (SFRs), and dust extinction (Brinchmann et al. 2004; Conroy 2013; Boquien et al. 2019). Likewise, the analysis of key emission lines in the UV and optical spectra are particularly revealing: indeed, hydrogen lines, such as Lyman-alpha (Lyα) in the UV and recombination lines like Hα and Hβ in the optical range, effectively trace the ionising photon rate emitted by young, massive stars (Kennicutt 1998b; Buat 2002; Kennicutt & Evans 2012; Matthee et al. 2023). On the other hand, bright oxygen lines, including [OII] and [OIII], serve as powerful diagnostics for understanding the physical conditions within the ionised interstellar medium (Stasińska & Izotov 2003; Jones et al. 2015; Berg et al. 2016; Sanders et al. 2023). Moreover, the measurement of certain optical line ratios – for example, involving [OII], [OIII], [NII], and Hα – enables the determination of gas-phase metallicity via so-called strong-line methods (Nagao et al. 2006; Mannucci et al. 2009; Steidel et al. 2014; Maiolino & Mannucci 2019; Curti et al. 2023; Nakajima et al. 2023). Stellar metallicity, on the other hand, is typically assessed through absorption lines found in stellar spectra, such as those of iron and magnesium (Tantalo & Chiosi 2004; Gallazzi et al. 2005). These two types of measurements offer complementary perspectives on the chemical evolution of galaxies (Peng et al. 2015; Lian et al. 2018; Fraser-McKelvie et al. 2022; Looser et al. 2024).
A crucial piece of information gained from galaxy spectra is their redshift. Accurate spectroscopic redshifts not only anchor galaxies in both space and time but also allow for precise calculations of rest-frame properties like colour and luminosity (e.g. Alam et al. 2017; Schlafly et al. 2023). More importantly, redshift is key to tracking the evolutionary trends over cosmic time of physical properties like the above-mentioned luminosity, Mstar, metallicity, and the SFR (a notable example is the time evolution of the SFR density; see e.g. Madau & Dickinson 2014), as well as the time evolution of scaling relations like the galaxy main sequence (e.g. Speagle et al. 2014; Renzini & Peng 2015; Rinaldi et al. 2024), the mass-metallicity relation (e.g. Tremonti et al. 2004; Graziani et al. 2020; Langan et al. 2023; Heintz et al. 2023), and the fundamental metallicity relation (e.g. Mannucci et al. 2010). This information can serve as a benchmark for calibrating both analytical and numerical models of galaxy formation and evolution (see the reviews by Somerville & Davé 2015 and Crain & van de Voort 2023), allowing us to refine our understanding of the complex physical processes involved in the galaxy baryon cycle, including galaxy feedback and mechanisms of galaxy quenching (see e.g. Piotrowska et al. 2022; Kurinchi-Vendhan et al. 2024), the interplay between gas inflows and outflows driven by active galactic nuclei (AGNs) and supernovae (see e.g. Davé et al. 2011; Anglés-Alcázar et al. 2017), and the intricate balance between star formation efficiency and metal and dust enrichment (see e.g. Ginolfi et al. 2018, 2020; Graziani et al. 2020; Di Cesare et al. 2023).
However, despite the vast amounts of spectral data produced by large surveys, extracting physical quantities from these complex datasets in an accurate and quick way remains a challenge (e.g. Huertas-Company & Lanusse 2023; Zhong et al. 2024; Iglesias-Navarro et al. 2024). Traditional methods, such as those implemented in tools like redmonster (Hutchinson et al. 2016) and redrock (Lan et al. 2023), utilise cross-correlation (Tonry & Davis 1979) and template-fitting techniques to process spectral data and derive redshift and physical properties (see e.g. Bautista et al. 2018; Napolitano et al. 2023). Although these traditional methods are reliable, they tend to be computationally intensive and often struggle with low signal-to-noise ratios and sky subtraction residuals, leading to increased failure rates and inaccuracies with low-quality data (Bolton et al. 2012; Zhong et al. 2024). Moreover, the efficiency of these techniques can be severely limited by the need for extensive template libraries or optimal initial guesses to ensure accuracy, making them less scalable for the vast data volumes expected from forthcoming astronomical surveys (see e.g. Newman et al. 2013). Therefore, traditional methods will soon become a prohibitive bottleneck.
Over the next half-decade, large-multiplicity instruments like the Dark Energy Spectroscopic Instrument (DESI; DESI Collaboration 2022; Hahn et al. 2023), the 4-metre Multi-Object Spectroscopic Telescope (4MOST; de Jong et al. 2014, 2019), the Subaru Prime Focus Spectrograph (PFS; Tamura et al. 2022), and the Multi-Object Optical and Near-infrared Spectrograph (MOONS; Cirasuolo et al. 2020; Maiolino et al. 2020) will capture spectra from billions of galaxies, which would require tens or hundreds of billions of CPU hours for analysis (see e.g. Huertas-Company & Lanusse 2023). To optimise the scientific outcomes of these huge datasets, strategies to perform fast, efficient, and accurate automated analyses become mandatory. Constructing fully data-driven models and employing deep learning based methods offers advantages in terms of efficiency, scalability, and flexibility, making them ideal for processing the enormous volumes of data anticipated from future spectroscopic surveys.
For these reasons, it is not surprising that machine learning (ML) -based models are becoming increasingly prominent in the field of astronomy using both unsupervised and supervised learning methods, among which artificial neural networks (ANNs) are very popular (see e.g. three recent reviews by Baron 2019, Smith & Geach 2023, and Huertas-Company & Lanusse 2023 for a comprehensive overview of the state-of-the art of ML in astronomy and insights into the functioning of these popular methods). In the field of galaxy formation and evolution, these techniques have been particularly successful in vision tasks involving galaxy images. For instance, convolutional neural networks (CNN) have been successfully employed for galaxy morphology classification (e.g. Dieleman et al. 2015; Huertas-Company et al. 2015; Ghosh et al. 2020; Walmsley et al. 2022), the identification of merging systems (e.g. Ćiprijanović et al. 2020; Bickley et al. 2021; Ferreira et al. 2024), and the detection of strong gravitational lenses (e.g. Lanusse et al. 2018; Jacobs et al. 2019). Beyond classification, ML, and especially ANNs, has been applied to galaxy images to infer physical properties like photometric redshifts (e.g. Collister & Lahav 2004; Pasquet et al. 2019; Zhou et al. 2021) and resolved stellar populations (e.g. Buck & Wolf 2021), and to perform segmentation tasks like deblending (e.g. Boucaud et al. 2020; Melchior et al. 2021) and pixel-level morphological classifications using encoder-decoder architectures (e.g. Hausen & Robertson 2020).
From a spectroscopy perspective, while the integration of ML in spectral data analysis is also gaining traction, it is still less common than image-based applications, likely due to the higher complexity of spectral data and the established reliability of classical methods. Some works have focussed on classifying galaxy spectra and estimating spectroscopic redshifts using deep CNNs (e.g. Stivaktakis et al. 2018) or Bayesian networks (e.g. Podsztavek et al. 2022) to account for uncertainties, reaching human-expert precision in localising and classifying spectral features (e.g. Busca & Balland 2018), and outperforming standard methods in terms of speed and accuracy for redshift prediction (e.g. Zhong et al. 2024). Moreover, ANNs and other supervised ML techniques (like AdaBoost with Decision Trees; see e.g. Ucci et al. 2017) have been used to determine key physical properties of galaxies from their emission line spectra, such as density, metallicity, and the ionisation parameter in the ISM, training the models with a large library of synthetic spectra (e.g. Ucci et al. 2018) or with labels obtained through common full spectrum fitting routines (e.g. Wang et al. 2024). Also, probabilistic ML and simulation-based inference have been used to estimate the star formation histories of galaxies from their optical absorption spectra (see Iglesias-Navarro et al. 2024), and unsupervised learning techniques like auto-encoders have proven successful in reliably capturing spectral features, providing highly realistic reconstructions for galaxy spectra from an interpretable latent space, and detecting outliers (see Melchior et al. 2023; Liang et al. 2023).
Capitalising on these advancements in spectroscopic analysis and borrowing techniques from the broader ML research community, we have developed a novel pipeline, which we dub M-TOPnet (Multi-Task network Outputting Probabilities) to facilitate reading and for simplicity. M-TOPnet employs a CNN with residual learning (He et al. 2015; see applications to astronomical spectra in Li et al. 2018; Zhong et al. 2024, and Moradi et al. 2024) designed to simultaneously derive redshift, emission or absorption line locations, and key physical properties of galaxies (currently tested for Mstar and SFR) from their spectra within a unified framework. Our tool efficiently encodes spectral information (both from lines and continuum) into a shared embedding space. Distinct branches for each physical quantity depart from this common representation, leveraging the benefits of multi-task learning (e.g. Caruana 1997; Ruder 2017; Crawshaw 2020).
To address the critical aspect of prediction uncertainty, we followed a two-fold approach. First, we formulated the redshift prediction as a classification task by mapping real redshift values into small bins determined by the spectral resolution of our spectra (a similar approach has been tested by e.g. Carrasco Kind & Brunner 2013; Stivaktakis et al. 2018; Stewart et al. 2022; Pankaj & Chakraborty 2022). This method accounts for aleatoric uncertainty (uncertainty due to inherent noise in the data), allowing for the possibility of training the model with a probability distribution function (PDF) of the redshift (whose measurement can be influenced by the quality of the spectrum), and thus obtaining a PDF for the prediction. Second, we experimented with incorporating Monte Carlo (MC) dropout to account for epistemic uncertainty (uncertainty due to model parameters) and reconstruct the posterior distribution function by averaging multiple inferences. Monte Carlo dropout involves randomly dropping units during each forward pass at inference time (see a discussion in Sect. 3), simulating a form of Bayesian approximation to estimate model uncertainty (Gal & Ghahramani 2015; see also astronomical applications in Ferreira et al. 2020; Perreault Levasseur et al. 2017; Leung & Bovy 2019; Podsztavek et al. 2022).
A key feature of our methodology is its interpretability. By analysing the embedding layers, we demonstrate the ability of M-TOPnet to learn and distinguish between important, yet unlabelled, galaxy characteristics, such as differentiating between star-forming and passive galaxies.
We present preliminary results using simulated data for the fibre-fed multi-object spectrograph MOONS (Cirasuolo et al. 2020), which will soon begin operations at the Very Large Telescope (VLT). MOONS represents a transformative leap in our ability to study galaxy evolution, particularly around the epoch of cosmic noon (z ∼ 1 − 2.5). Its unique combination of large multiplexing (1000 fibers), high sensitivity, broad simultaneous spectral coverage extending in the near-IR (0.64 − 1.8 μm), and high spectral resolution (R ∼ 4000 − 7000) will enable SDSS-like surveys at high redshifts for the first time, revolutionising our understanding of galaxy mass assembly and chemical evolution around cosmic noon (Cirasuolo et al. 2020). In particular, the planned guaranteed time observation (GTO) survey MOONS Redshift-Intensive Survey Experiment (MOONRISE; Maiolino et al. 2020), utilising hundreds of nights of guaranteed time, aims to obtain high-quality spectra for up to half a million galaxies at 0.9 < z < 2.6. This unprecedented sample will allow for robust measurements of key physical properties including metallicity, SFRs, AGN activity, and stellar populations across a wide range of environments and galaxy masses. By accessing the same rest-frame optical diagnostics used in statistically significant studies of the local universe, MOONS will offer a consistent probe of galaxy evolution over cosmic time, critically constraining models of galaxy formation and transformation. We highlight the efficacy of M-TOPnet in accurately predicting the redshift, Mstar, and SFR from simulated MOONS spectra of galaxies at z ∼ 1 − 3, even for faint sources for which traditional methods often struggle. Our model proves to be a practical and adaptable approach to tackle the upcoming challenges in observational astronomy. By leveraging multi-task learning and the capability to handle uncertainties by outputting probabilities (see Sect. 3), it delivers the precision, the efficiency, and the flexibility needed to robustly analyse the massive, complex datasets expected from next-generation instruments.
This paper is organised as follows. Section 2 describes the origin and properties of the simulated MOONS dataset. In Sect. 3, we outline our methodologies, covering data processing, preparation, and the design and training of M-TOPnet. Section 4 presents the results, with further elaboration provided in the discussion (Sect. 5). Finally, Sect. 6 provides the conclusions.
2. The simulated MOONS dataset
In this work, we employ a dataset of simulated MOONS spectra to train and validate our M-TOPnet pipeline, in preparation of future real observations. The input mock spectra are generated by MAMBO (Mocks with Abundance Matching in BOlogna), a method devised to quickly paint galaxy properties (Mstar, SFR, photometry, dust, metallicity, size, decomposition bulge or disc, emission lines, and spectra) on top of Dark Matter (DM) sub-haloes and create realistic multi-wavelength mock data for the next generation of surveys (see a discussion on MAMBO in López-López et al. 2024). In the present work, we run the MAMBO workflow on a lightcone built by Henriques et al. (2015) on the Millennium Simulation (Springel et al. 2005), namely lightcone number 23, which has a mass function closest to the mean of all 25 available lightcones. The lightcone covers the redshift range 0 < z < 10 and contains DM haloes with Msub > 1.7 × 1010 M⊙ h−1, with an area of 3.14 deg2.
To assign properties to galaxies, MAMBO first assigns the Mstar using the Stellar-to-Halo Mass relation (Girelli et al. 2020) derived from the observed Stellar Mass Function (SMF) at z ∼ 0 from SDSS (Peng et al. 2010), the SMF in COSMOS for redshifts between 0.2 < z < 4 (Ilbert et al. 2013), and the SMF from CANDELS for z ≥ 4 (Grazian et al. 2015). Each galaxy is then classified as either quiescent or star-forming, with a small random fraction designated as starbursts, based on the relative proportions of SMFs for the red and blue populations. This assignment ensures that more massive, predominantly quiescent galaxies are linked to large sub-halos, typically located in the dense, central regions of massive halos, thus accurately reflecting the observed correlation between galaxy colour and environment (López-López et al. 2024).
All other galaxy properties are determined using a modified version of the open-source code EGG (Empirical Galaxy Generator; Schreiber et al. 2017)1, which has been thoroughly validated against extensive observations and distributions of physical properties (for a detailed description, see Girelli 2021, and López-López et al. 2024 for the AGN modelling). EGG applies observed scaling relations, such as the star-forming main sequence (Schreiber et al. 2015) to estimate SFR, distinguishing between UV-derived obscured SFR and IR-derived dust-free SFR. The Hα luminosity is inferred from the Kennicutt-Schmidt law (Kennicutt 1998a), and the hydrogen lines from line ratios for Case B recombination and T = 10 000 K as in Osterbrock & Ferland (2006). The other emission lines are generated using stellar masses and SFRs, and calibrated on the SDSS, assuming redshift evolution as in Shapley et al. (2015). Gaussian emission lines are simulated with a velocity dispersion with a mass-dependent σgas from Bezanson et al. (2018).
The code also generates rest-frame and observed photometry from UV to submillimetre wavelengths, based on the SEDs of both bulge and disc components and using specific broad-band filters for MOONRISE (Maiolino et al. 2020). At optical and near-IR wavelengths, the SEDs are drawn from a library of templates built from the Bruzual & Charlot (2003) models, dust-attenuated using Calzetti’s law (Calzetti et al. 2000), and cover the UVJ colour space (Williams et al. 2009) for both quiescent and star-forming galaxies. The attenuation of emission lines is differential compared to continuum, considering the redshift dependence derived in Pannella et al. (2015). From the full galaxy sample, we extracted a sub-sample that mimics the MOONSRISE selection. Specifically, we selected sources with apparent magnitude in the H band mH < 25 or both log(Mstar/M⊙) > 9 in the redshift range 0.7 < z < 3, and covering an area close to a single MOONS field of view. In total we selected about 40 000 galaxies, for which MAMBO creates also the observed spectra of the stellar continuum at vacuum wavelengths, to which we added emission lines according to catalogue fluxes, applied the assigned velocity dispersion and resampled according to MOONS pixel. We, therefore, assigned a size to each galaxy according to their mass using van der Wel et al. (2014) relations for passive and star forming, separately. We considered the light loss due to the MOONS fibre using Sérsic profiles, assuming Sérsic index n = 4 and n = 1, for passive and star-forming galaxies, respectively.
The final mock spectra used for this work are generated by running MAMBO templates through MOONS1D. The MOONS1D package2 is a Python-based 1D spectral simulator specifically designed by the MOONS collaboration for the MOONS instrument at the VLT. This tool generates simulated spectra based on observing conditions and input templates, including options for different observing bands (such as RI, YJ, and H) resolutions, and observing strategies (XSWITCH and STARE; see Maiolino et al. 2020). Users can specify parameters like seeing, airmass, and exposure time to simulate realistic observational conditions. The output is a FITS file containing the simulated spectrum. MOONS1D has been instrumental in testing the science pipelines, supporting the preparation for future observations by providing realistic mock spectra.
For the dataset used in this work, for any given MAMBO template, MOONS1D is ran using the low-resolution mode for all three MOONS spectral channels (RI, YJ, H), adopting a range of 2, 4 and 8 h of exposure time (assuming individual exposures of 300 s). Also, a seeing of 0.8″ and an airmass of 1.2 are assumed, and the spectra include the effects of fibre loss. We have also adopted a simulated XSWITCH observing strategy (see Maiolino et al. 2020), i.e, a technique for high-efficiency nodding observations. In this approach, two fibers are allocated per object: one fiber captures the target’s signal, while the other is positioned on a sky region. During the observation, the target and sky fibers alternate positions, allowing one to collect data from the target and the sky in the same fiber, which significantly improves sky subtraction accuracy. This strategy is planned to be adopted in the MOONRISE survey (Cirasuolo et al. 2020) as it will be particularly valuable for faint object observations.
As a result, we obtain a mock dataset of 118 194 spectra, each composed by 12 217 spectral elements, covering a wavelength domain (over the three RI, YJ, H spectral bands) from 0.64 to 1.8 μm, with a gap between about 1.35 and 1.45 μm. The redshift, Mstar, and SFR of each spectrum – that is, the physical properties that we aim to derive in this work – are taken as ground truths from MAMBO.
The distributions of the key quantities of galaxies in the simulated dataset are illustrated in Figure 1a. In detail, we show histograms of redshift, Mstar, SFR and mH. Redshift values range from approximately 0.7 to 2.9, although their distribution is not uniform and tend to peak towards the low-edge tail. Values of Mstar are distributed between about 108 M⊙ and 1011.2 M⊙, with a peak around 109 M⊙, while SFRs range between 10−2 M⊙/yr and 103 M⊙/yr, with a peak at about 2 − 3 M⊙/yr. Values of mH are mostly distributed between about 19 and 27, with mH ∼ 24 − 25 galaxies being the most represented. In the upper panel of Figure 1b, we report the distribution of our galaxies in the log(Mstar) versus log(SFR) diagram, showing that galaxies in our sample are representative of both populations of normal main-sequence star-forming galaxies and passive galaxies. Galaxies in this diagram are colour-coded according to their Hα line flux, whose distribution is shown in the lower panel of Figure 1b.
 |
Fig. 1. Properties of galaxies in the simulated dataset. (a) Distributions of key galaxy properties, including redshift (first panel), Mstar (second panel), SFR (third panel), and mH (bottom panel), arranged from top to bottom. (b) Upper panel: Distribution of galaxies in the log(Mstar) versus log(SFR) diagram, highlighting their representation of both main-sequence star-forming galaxies and passive galaxies. Galaxies are colour-coded by their Hα line flux. For reference, we show the trends of the main sequence at z = 0.5 − 1 (blue points) and at z = 1.5 − 2 (red points) reported by Whitaker et al. (2014), and the best fit for the main sequence at z ∼ 1 by Speagle et al. (2014). Lower panel: flux distribution of the Hα line. |
In Figure 2, we show three examples of simulated galaxy spectra in our sample, covering the entire spectral domain. The right panels provide a closer look at the zoomed spectrum around the Hα line. With Hα line fluxes of F(Hα) ∼ 10−15 erg/s/cm2 (upper panel), F(Hα) ∼ 10−16.5 erg/s/cm2 (central panel), and F(Hα) ∼ 10−17.5 erg/s/cm2 (lower panels), these spectra can be considered representative examples at z ∼ 1 of high-, average-, and low-quality spectra in our sample, respectively. These spectra were generated with a simulated exposure time of 2 h, resulting in a fixed noise level. Notably, the third spectrum represents a quiescent galaxy, indicating that such spectra are particularly challenging for this study.
 |
Fig. 2. Examples of simulated galaxy spectra from our sample, shown before any pre-processing required for input into our pipeline, covering the entire spectral range. Each row represents a different galaxy spectrum, with the left panels showing the full spectrum and the right panels providing a zoomed-in view around the Hα line. The spectra are positioned based on the Hα line flux: F(Hα) ∼ 10−15 erg/s/cm2 (upper row), F(Hα) ∼ 10−16.5 erg/s/cm2 (middle row), and F(Hα) ∼ 10−17.5 erg/s/cm2 (lower row), representing high-, average-, and low-quality spectra, respectively. Red vertical lines indicate the positions of key emission lines, including [OII], Hβ, [OIII], and Hα, with corresponding labels. The missing flux values around 14 000 Å are due to the gap between spectral bands (see Sect. 2). |
3. Methods
3.1. Data processing and preparation before training
After combining the RI, YJ, and H spectral bands (see Sect. 2), we performed several preprocessing steps on the spectra before training the M-TOPnet pipeline outlined in the subsequent sections. These steps were performed on the entire dataset (prior to splitting it for training, validation, and testing) and are intended to be applied to any new instances for future inference once the M-TOPnet pipeline is trained.
Initially, we applied sky masking to our spectra to mitigate the impact of strong sky lines, assuming a sky model provided by the simulations. This process involves masking spectral channels exceeding a conservative flux threshold of 10−4.8 photons/s/cm2/Å/arcsec2 in the pre-defined sky model, effectively ignoring channels where sky emission might dominate. This threshold corresponds to rejecting approximately 15% of the channels across our spectra. Variations in this threshold have been tested, demonstrating the robustness of our results with up to 25% channel exclusion.
Then, we removed the continuum from the spectra using a running median filtering technique, subtracting a median-filtered spectrum with a window size of 1000 channels from the original. This size was chosen to effectively capture the overall shape of the continuum emission. While more precise methods such as full spectral fitting exist (see Sect. 1, and references therein), they tend to be slower; our approach provides a practical balance of speed and accuracy. Subsequently, we normalised the continuum-subtracted spectra by dividing them by their maximum value in each spectrum. This two-step procedure ensures that the resulting spectra are free of continuum contribution and normalised, facilitating further analysis of spectral lines.
The continuum, estimated through running median filtering, was then rebinned into ten points using linear interpolation. This reduction in dimensionality of the continuum preserves essential shape characteristics, and complements the information contained in the continuum-subtracted and normalised spectra. These continuum points are used alongside the emission lines to derive physical properties of galaxies, providing a more comprehensive analysis of the spectral data. Our approach effectively captures the underlying continuum variations while simplifying the input features for subsequent modelling. As a result, for each spectrum, we generate a normalised continuum-subtracted spectrum to emphasise the spectral lines, and a ten-point vector encoding information on the continuum shape, which is not yet normalised but will be standardised according to the distribution of the training set, as is explained in the following paragraphs. We note that this modular design allows for future enhancements, such as incorporating photometric points from imaging into the continuum vector.
At this point, our dataset consists of 1) normalised, sky-masked, and continuum-subtracted spectra, 2) continuum vectors, and 3) galaxy property labels that we aim to predict; that is, redshift, Mstar, and SFR. To train and test M-TOPnet, we split the dataset into training, validation, and test sets. The training set accounts for 70% (82 736 examples) of the sample, while both the validation and test sets account for 15% each (17 729 spectra). We note that spectral and galaxy properties of instances in training, validation, and test sets follow the same distributions as are shown in Figure 1a and are thus representative of the total simulated MOONS dataset. After splitting, prior to training, the continuum vectors and labels for the logarithms of Mstar and SFR were standardised separately, based on the mean and standard deviation values from the training set. This standardisation was applied consistently across the training, validation, and test sets. By doing so, we preserve the relationships between the continuum and the physical properties like Mstar and SFR, while ensuring data consistency across the dynamic range, facilitating model training.
We do not need to normalise the redshift as it is not shown in training as a scalar value. Instead, as is explained in the following and anticipated in Sect. 1, we approached redshift prediction as a classification task by discretising continuous redshift values into finely spaced bins. We defined these bins with a resolution of dz = 0.003, optimising the balance between granularity and the limitations given by the spectral resolution. This choice corresponds to velocity bins ranging from approximately 200 to 500 km s−1 at z ∼ 0.7 − 3, which is somewhat broader than the < 100 km s−1 resolution expected for MOONS in low-resolution mode. However, we find it to be the optimal compromise between achieving sufficient accuracy for robust redshift determination and maintaining relatively compact discretised vectors of redshift elements, allowing us to conduct multiple tests on the pipeline. We note that similar results to those discussed in Sect. 4 were obtained in a single test using a finer bin width of dz = 0.0005, which is more consistent with the nominal instrumental resolution. However, this finer discretisation increased the vector size to nearly 5000 elements, significantly slowing down both training and inference processes, and making it infeasible to perform all the tests needed to fully characterise the pipeline and identify the best model. Therefore, we have opted for dz = 0.003 in this version of the pipeline, leaving further refinements for future work.
To represent redshift input values, we employed a modified one-hot vector representation, where each redshift is represented by a Gaussian distribution centred on its corresponding bin. This method allows us to adapt to the inherent uncertainty in real observational data, where lower-quality spectra may yield less precise redshift measurements. Typically, this is crucial for real data, where spectral quality can affect redshift accuracy. However, since our analysis uses simulated data with no error associated to the labels, we employed a standard Gaussian, setting its standard deviation σ to a fixed value of 0.001. We also tested with a σ of zero-channels (i.e. a Dirac Delta function) or by scaling the sigma linearly with the standard deviation of the continuum-subtracted spectra, but we did not see any significant change in the results. We note that these redshift PDFs are already normalised by definition, so they do not need further normalisation.
A final step in data preparation consisted of generating an auxiliary spectrum for each galaxy spectrum, which serves as a training tool for line-location tasks within our multi-task neural network (see a discussion in the following Sect. 3.2). This auxiliary spectrum was populated with zeros, except at positions corresponding to expected emission and absorption lines based on the redshift. To account for spectral dispersion and minor offsets in line positions, and thus help the identification of the line location, we also marked five adjacent channels on either side of each expected line with ones. This parameter was tested across a range from 1 to 10 adjacent channels, with negligible impact on results. The emission and absorption lines used to define the spectral line masks are reported in Table 1.
3.2. Neural network design and training
We designed a multi-task neural network model to simultaneously predict redshift, Mstar, SFR, and perform spectral line location. The architecture has been developed using Keras, a high-level neural network API that runs on top of TensorFlow (Chollet 2015; Abadi et al. 2016). The model architecture is tailored to process both the continuum-subtracted spectra and the ten-point continuum vectors, leveraging the strengths of convolutional layers. CNNs have been widely utilised in ML (Goodfellow et al. 2016), demonstrating substantial improvements in computer vision, and have become widely adopted in astronomy (see Sect. 1 and references therein). While their usage has been mostly focussed on the image domain (e.g. Dieleman et al. 2015; Zhu et al. 2019; Wu & Boada 2019; Smith & Geach 2023), CNNs are also particularly useful for galaxy spectra because they can capture hierarchical features at different scales. The convolution operations detect local patterns, while pooling operations help capture wider-scale dependencies, making them well suited for analysing spectral features that exist across various scales (see e.g. Stivaktakis et al. 2018; Melchior et al. 2023; Wu et al. 2023; Wang et al. 2024). The pipeline also makes use of multi-layer perceptrons (MLPs), which are fully connected neural networks consisting of multiple layers of neurons, each applying a non-linear activation function to its inputs.
3.2.1. Model architecture
Here, we discuss the architecture of our M-TOPnet model, sketched in Figure 3, outlining its fundamental parts.
-
Input layer – The model accepts two inputs: continuum-subtracted spectra and continuum points. These are processed separately due to their distinct nature and require transformations.
-
Spectral processing – The continuum-subtracted spectra undergo a series of convolutional residual blocks. Residual blocks, introduced by He et al. (2015), allow for the training of deeper networks by addressing the vanishing gradient problem. They achieve this by introducing skip connections that bypass one or more layers, enabling the network to learn residual functions with reference to the layer inputs (see an application to galaxy spectra in Moradi et al. 2024). In M-TOPnet, each residual block consists of two convolutional layers followed by an average pooling layer with a pool size of five, which means that each pooling operation reduces the spatial dimensions by a factor of five. The number of filters increases from 16 to 64 across the blocks. This approach enables the model to capture simple features in initial layers and progressively more complex patterns in deeper layers, exploiting the hierarchical nature of spectral data and improving its ability to represent intricate spectral characteristics. This strategy has been effectively employed in other cases using astronomical spectra (see e.g. Podsztavek et al. 2022; Ambrosch et al. 2023; Wang et al. 2024), and we found it to be the most efficient architecture for our tasks. The convolutional layers use the rectified linear unit (ReLU) activation function, which is widely used due to its ability to mitigate the vanishing gradient problem and accelerate convergence (Nair & Hinton 2010).
-
Continuum processing – The continuum points are processed through a dense layer, which consists of 32 neurons, converting the low-dimensional continuum information into a higher-dimensional representation.
-
Feature combination – The flattened output from the spectral processing branch, the encoded continuum information, and the intermediate output from the line location task are concatenated to form a ‘shared info’ layer. This layer is preceded by a batch normalisation layer, which helps to stabilise the learning process and reduce internal covariate shift. The ‘shared info’ layer efficiently encodes the information of the spectra and of the continuum. In Sect. 5, we show through a dimensionality reduced visualisation that this layer effectively learns a general representation of the spectra from which one can retrieve physical information that was not used as labels during training.
-
Task-specific branches – Each task-specific branch consists of an MLP with dropout layers, as follows.
-
Line location: an MLP with two hidden layers (64 and 128 neurons) and sigmoid activation in the output layer predicts the locations of spectral lines. We use sigmoid activation because each spectral channel in the input can be 0 or 1, making it a binary classification problem.
-
Redshift: an MLP with two hidden layers (64 and 128 neurons) and Softmax activation in the output layer performs redshift classification, outputting a probability distribution over the redshift bins. This discrete approach via Softmax provides an efficient solution for our classification task within the discretised redshift space.
-
Stellar mass: an MLP with two hidden layers (64 and 32 neurons) and linear activation in the output layer predicts log(Mstar).
-
Star formation rate: an MLP with two hidden layers (64 and 32 neurons) and linear activation in the output layer predicts log(SFR).
We note that both predictions for log(Mstar) and SFR are standardised and need to be scaled back to their original dynamic range using the inverse transformation of the standardisation before any analysis. Each hidden layer in these MLPs is followed by a dropout layer with a dropout rate of 0.2.
-
Dropout is a regularisation technique introduced that helps prevent overfitting by randomly dropping out a fraction of neurons during training (Hinton et al. 2012; Srivastava et al. 2014). This process helps to reduce the network’s reliance on any particular set of features. This leads to better generalisation and reduces overfitting. The technique has been shown to be particularly effective in deep neural networks and has become a standard tool in deep learning pipelines. In this work, we have experimented with keeping dropout switched on during inference as well, which is a technique known as MC dropout (Gal & Ghahramani 2015). This approach allows us to estimate the model’s epistemic uncertainty by performing multiple forward passes through the network with different dropout masks (see Sects. 1 and 4).
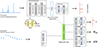 |
Fig. 3. Architecture of M-TOPnet, the deep learning pipeline used for the galaxy spectral analysis in this work. Our model accepts two inputs: a normalised, continuum-subtracted spectrum and a normalised continuum vector. The spectrum is processed through convolutional residual blocks to extract spectral features, while the continuum vector is encoded through a dense layer. Outputs from both branches, along with intermediate outputs from the line location task, are combined into a shared information layer. This shared layer feeds into task-specific branches consisting of MLPs to predict line locations, redshift, and normalised values of Mstar, and SFR. See a discussion on the different components in Sect. 3.2. |
3.2.2. Multi-task learning
The multi-task approach is particularly beneficial in our context. In general, multi-task learning has been proven to have several advantages (see e.g. Caruana 1997; Ruder 2017; Crawshaw 2020): it allows for parameter sharing across tasks, which can lead to better generalisation; it acts as a regulariser, reducing the risk of overfitting; it can leverage the commonalities and differences across tasks to improve learning efficiency; and it can potentially lead to better performance on all tasks compared to single-task models.
While our primary focus is on accurate redshift determination, we found that including the line location task significantly improves the overall performance, especially for redshift prediction. This auxiliary task helps the model develop a better internal representation of the spectral features, even though it may not always perform optimally on its own (as is discussed in Sect. 4). The inclusion of Mstar and SFR prediction tasks further enriches the shared representations, capturing more detailed spectral characteristics that indirectly benefit the redshift determination. This method leverages the existing physical relationships between the continuum (in terms of both its normalisation and shape) and spectral lines relative to Mstar and SFR, which, in turn, enhances the model’s ability to infer redshifts more effectively. We note that the multi-task approach is innovative because it involves strategically defining related auxiliary tasks (such as line location, in our case), which impose implicit constraints on the model. These tasks help the model learn physically relevant features, ultimately guiding it towards a more accurate redshift estimation.
It is worth mentioning that multi-task learning should not be confused with multi-output regression. Unlike multi-output regression, which typically handles multiple outputs with a single type of loss function, multi-task learning can integrate tasks of different natures with task-specific loss functions, as is demonstrated in our joint tasks of probability distribution estimation for the redshift, continuous regression for Mstar and SFR, and discrete line location. Multi-task learning thus provides added flexibility by allowing each task to have its own objective function, enabling the model to learn from distinct yet complementary tasks, which can enhance performance and generalisation. We discuss the impact of multi-task learning on our pipeline in Sect. 4.
3.2.3. Training process
The model was trained using a combined loss function, weighing the contributions from each task (see below). We employed an adaptive learning rate strategy, starting with an initial rate of 0.005 and decreasing it linearly to 0.0005 over 50 epochs, after which it remains constant. This approach follows fairly standard practice (Goodfellow et al. 2016; Defazio et al. 2023), where the initial and final learning rates are chosen to allow for a balanced combination of rapid convergence and stable refinement. The training process was set to run for a maximum of 100 epochs with early stopping based on validation loss, using a patience of 10 epochs. This approach helps prevent overfitting while allowing the model sufficient time to converge. Our best model converged after 60 epochs, although convergence generally oscillates by a factor of ±8 epochs, likely due to weight initialisation and data shuffling in the mini-batches.
The loss functions for each task are as follows: categorical cross-entropy for redshift, binary cross-entropy for line location, and mean squared error for stellar mass and SFR prediction. We assigned different weights to each task’s loss, with the emission line location task given a higher weight (10) compared to the others (1 each). This weighting scheme was determined to be optimal through experimentation. We also tested equal weighting across all tasks and other variations, but found that emphasising the line location task led to the best overall model performance. This approach makes intuitive sense: if the network cannot accurately identify emission lines, it will struggle to predict the redshift, whereas predictions for Mstar and SFR are less sensitive to precise line identification.
In conclusion, our M-TOPnet architecture leverages the strengths of both CNNs and MLPs, utilising residual blocks for efficient spectral processing and a multi-task learning approach to improve overall performance, particularly in redshift determination. The model design allows it to extract and combine information from both the spectral lines and the continuum, providing a comprehensive analysis of the input data. We shall make the code for our pipeline, including the M-TOPnet architecture, publicly available on GitHub after the paper is accepted.
4. Results
In this section, we present the results obtained by testing the ANN discussed in Sect. 3 on our test set (see Sect. 2). As was previously discussed, M-TOPnet takes as input pairs of normalised continuum-subtracted spectra and normalised ten-point continuum vectors, and it produces the following outputs:
-
A 12.217-sized 1D vector indicating the predicted locations of spectral lines reported in Table 1;
-
A 800-sized 1D vector representing the PDF of the redshift prediction, with minimum redshift bins of dz = 0.003;
-
A scalar value for the Mstar prediction;
-
A scalar value for the SFR prediction.
We note that we used scalar predictions for Mstar and SFR because calculating PDFs for these quantities would significantly slow down the training and inference processes due to the increased model complexity and computational demand. Given the importance of capturing potentially multi-peaked solutions, we prioritised generating a PDF for the redshift prediction. This approach serves as a proof of concept for our method: due to its modular design, our pipeline can easily be extended to produce PDFs for Mstar and SFR in future work.
The upper panels of Figure 4 display scatter plots comparing labelled values and predicted values for all 17 729 simulated MOONS galaxy spectra in our test set, considering exposure times of 2 h, 4 h, and 8 h. While the comparison for Mstar and SFR is straightforward as they are scalar values, the redshift comparison is less direct due to the adopted classification scheme where both labels and predictions are probability vectors. For this comparison, we use the peaks of both labelled and predicted PDFs.
 |
Fig. 4. Comparison of predicted and labelled values for redshift, Mstar, and SFR for all simulated MOONS galaxy spectra in the test set with exposure times of 2 h, 4 h, and 8 h. Upper panels: Scatter plots of predicted versus labelled values, with the dashed black line indicating perfect agreement. Solid black lines represent the contours of the joint probability density, corresponding to the 20th, 50th, 75th, and 95th percentiles of the distribution, estimated using a Gaussian kernel density estimator. Lower panels: Histograms of the residuals (‘predicted value – labelled value’; see Sect. 4) with Gaussian fits, showing the mean (μ) and standard deviation (σ) of the distributions. |
Our model demonstrates excellent agreement with the ground truth values, as is evidenced by the red points (representing instances in the test set) aligning closely with the one-to-one relation (black line, representing a perfect model). Notably, redshift predictions are highly accurate, with most points coinciding with the one-to-one relation and only a small fraction of outliers, confirming the effectiveness of training through a classification scheme and handling discretised distributions of continuous values.
The lower panels of Figure 4 present histograms (in violet) showing the distributions of residuals for the relations in the upper panels. These residual distributions, defined as ‘predicted value – labelled value’, are fitted with a Gaussian model (blue curve), and the best-fit values for μ and σ are also shown. For the redshift, we observe μ = 0, indicating no appreciable offset between predicted and labelled redshift. Mstar shows a μ = 0.02 dex, and SFR a μ = −0.005 dex, both demonstrating minimal offset. Regarding σ values, we find 0.15 dex for Mstar, 0.22 dex for SFR, and a remarkable 0.001 for redshift. These results confirm our earlier observations about the upper panels of Figure 4. It is important to note that for redshift, the Gaussian fit primarily represents the bulk of data points near the one-to-one relation and does not account for outliers, which will be discussed in detail in subsequent paragraphs.
One evident cause of outliers in the redshift determination is the spectrum quality, determined by the exposure time, texp. This is demonstrated in the left panel of Figure 5, where we restrict the model predictions to mock spectra with a simulated exposure time of 8 hours. This analysis clearly shows that most outliers, especially the most catastrophic ones, disappear (< 2%).
 |
Fig. 5. Comparison of redshift prediction accuracy for 8-hour spectra using two models: the multi-task model discussed in Sect. 3 on the left panel, and a single-task model (showing increased outliers, including catastrophic errors; see Sect. 4) on the right panel. The redshift range z = 2.7 − 3, where a significant relative excess of unsuccessful predictions is shown (see Sect. 5 for a discussion) is highlighted by the grey box. |
The right panel of Figure 5 presents the same analysis on the test set, but using a version of M-TOPnet where multi-task learning is artificially disabled by assigning a weight of 0 to all losses except the redshift determination one. This plot reveals a significant number of outliers, about 5% of which are catastrophic (with differences between labels and predictions up to Δz > 0.5), confirming the benefits of multi-task learning in achieving better representations, as is discussed in Sect. 3. Additionally, when we disable only the Mstar and SFR tasks, while keeping the line location task active, we still observe catastrophic outliers, with a fraction of about 4%, indicating that these quantities provide important constraints on the redshift solution space. This result highlights the intrinsic physical relationships among these quantities: the continuum, emission lines, Mstar, and SFR are interrelated, and leveraging these connections helps the model make more accurate redshift predictions.
To validate our model in a scenario more closely aligned with observational strategies, we conducted a test by applying physically motivated selection criteria to galaxies in our simulated test set. Specifically, we emulated the selection criteria anticipated by the planned GTO MOONS extragalactic survey MOONRISE (Maiolino et al. 2020). For this analysis, we first selected spectra of galaxies at z < 2.6 with mH < 25. For the latter criterion, we adopted a conservative approach by including fainter objects; however, this is still conservative, as the survey is expected to reach down to mH = 24 (Maiolino et al. 2020). Among these selected spectra, we further refined our selection based on the galaxy type and exposure time: spectra with simulated texp = 2 h for star-forming galaxies and texp = 8 h for passive galaxies (see Figure 1b; see also a thorough discussion on the justification of such selection criteria in Maiolino et al. 2020). Our MOONRISE-like sample comprise 5344 objects. Figure 6 presents scatter plots comparing labelled values and predicted values for redshift, Mstar, and SFR for this selected subset of the test sample. These plots show similar trends to those observed in the general case, as the applied selection criteria do not significantly alter the bulk properties of the simulated galaxy population. This similarity is also evidenced by the distributions of residuals, which closely resemble those of the full dataset. The μ and σ of these distributions, obtained by fitting Gaussian models, are displayed in the lower right corners of each panel in Figure 6. We provide additional quantitative analysis of M-TOPnet performance on the MOONRISE-like sample in the next sections, including specific metrics and comparisons to the full dataset results.
 |
Fig. 6. Same as the upper panels of Figure 4, but indicative of the subset of galaxies defined by selection criteria similar to the planned MOONS GTO survey MOONRISE (see Sect. 4). |
4.1. Spectroscopic redshift determination
From this point forward, we concentrate our analysis on the redshift predictions. This focus is warranted because redshift prediction is a particularly challenging task, as it relies heavily on complex information from the full spectrum. Additionally, achieving high accuracy in redshift predictions is crucial for most of the relevant measurements (see a discussion in Sect. 1). Importantly, M-TOPnet employs novel and sophisticated methods for redshift determination, which could potentially become standard in astronomical ML pipelines.
While previous analyses focussed on the fraction of test galaxy spectra for which redshift was ‘exactly’ determined (i.e. the peak of the predicted redshift PDF is in the same dz = 0.003 sized bin as the peak of the target redshift), another useful diagnostic is to determine the fraction of ‘successful predictions’ given varying thresholds of Δz. Figure 7 visualises this test using four increasing Δz thresholds: 0.003, 0.005, 0.01, and 0.1 (the last being consistent with typical photometric redshift uncertainties).
 |
Fig. 7. Fraction of successful redshift predictions as a function of varying Δz thresholds for different galaxy subsets. The subsets include a general division by exposure time (texp = 2 h, 4 h, 8 h, represented by dashed lines) and a more specific division by both exposure time and redshift range z = 0.8 − 1.7 (represented by solid lines in blue, green, and red). The MOONRISE-like selection is shown by the solid grey line, and bright galaxies with Hα flux greater than 10−17 erg/s/cm−2 are shown by the solid violet line. The Δz thresholds tested are 0.003, 0.005, 0.01, and 0.1. |
Here, it is crucial to note that the total dataset includes varying levels of noise (exposure times from 2 h to 8 h) and a wide distribution of physical properties (see Sect. 2), including quenched or green-valley galaxies with faint or absent emission lines, making accurate prediction challenging for some spectra: in Sect. 5, we shall expand on some crucial differences in terms of physical properties between successful and unsuccessful predictions.
Thus, we analysed the sample by splitting it by exposure time (dashed blue, green, and red lines for 2 h, 4 h, and 8 h observations, respectively), confirming that indeed mock galaxy spectra with a longer simulated exposure time reach higher fraction of successful predictions, ranging from about 0.85 at Δz < 0.003 up to 0.92 at Δz < 0.1. In grey (solid line), we present the trend for the subset of galaxies defined by selection criteria similar to those of the MOONRISE GTO survey (see the previous section). This subset exhibits approximately 76% successful predictions at a Δz threshold of 0.003, increasing to about 85% at a Δz threshold of 0.1. We also selected test galaxy spectra in the redshift range z = 0.8 − 1.7 (corresponding to about 60% of the test set) without any additional selection criteria: this is an interesting redshift range as it corresponds to the one at which most of the observations from MOONRISE have been planned (Maiolino et al. 2020), and offers an ideal target range for all future surveys. In fact, at these redshifts the Hα line falls above 1.2 μm, maximising the impact of the unique MOONS H-band channel. In addition, this range allows for simultaneous coverage of bright optical emission lines like the [OII] doublet at around 3728 Å, and the Hβ and the [OIII] lines at 4960 Å and 5008 Å, respectively. Focussing on this redshift range results in an approximately 5% improvement in successful predictions (see solid blue, green, and red lines). Lastly, we also examined ‘bright’ sources with Hα flux greater than 10−17 erg/s/cm−2 (solid violet line), a representative threshold close to the median value of the Hα flux distribution (see Figure 1). We find that these sources, irrespective of texp, show very high levels of successful predictions, ranging from 90% at Δz < 0.003 to 95% at Δz < 0.1.
Another useful check is to determine how the fraction of successful predictions, at a fixed Δz threshold, depends on critical observables that could be used to select target observations for MOONS. In Figure 8, we visualise this check using a Δz threshold of 0.01 and showing the fraction of successful predictions as a function of mH. We adopted a |Δz|< 0.01 threshold because it represents an acceptable uncertainty for most of the z-based measurements, and we chose mH due to its wide availability for most likely MOONS targets. As in Figure 7, we display the MOONRISE-like sample (solid grey lines) and different sub-samples based on exposure times (solid blue, green, and red lines for 2 h, 4 h, and 8 h exposures, respectively) and Hα flux (solid violet line). For very bright galaxies, mH < 22, the fraction of successful predictions is almost always above 90%, except for simulated 2 h exposures, which reach about 85% at mH = 21.5. Between mH 23 and 25, where most test galaxies lie (see histogram in the top panel), the gap between sub-samples increases: bright Hα galaxies and 8 h exposures consistently achieve above 90%, while the MOONRISE-like sample is positioned approximately between the 4-hour exposures, showing success rates of 80–90%, and the 2-hour exposure, ranging from 75–85%. At mH > 25, success fractions drop below 50%, although bright Hα galaxies and 8 h exposures still achieve about 90% and 65% success rates, respectively, down to mH ∼ 26.
 |
Fig. 8. Relationship between the fraction of successful redshift predictions (with |Δz|< 0.01) and the H-band magnitude mH. Top panel: Histogram of the number of objects as a function of mH. Bottom panel: Fraction of successful predictions as a function of mH for different subsets: galaxies with Hα flux greater than 10−17 erg/s/cm−2 (violet line), MOONRISE-like selection (grey line), and subsets with varying exposure times of 2 h (blue), 4 h (green), and 8 h (red), along with a simulated reference trend (dashed orange line). See Sect. 4 for a detailed discussion on the behaviour of the observed trends. |
For reference, the dashed orange line represents the results from a direct computation of the expected detection rate of star-forming galaxies based on observed properties of the COSMOS galaxies. In brief, COSMOS galaxy properties are derived by SED fitting from the COSMOS2020 catalogue (Weaver et al. 2022). The flux of the Hα line was derived from the measured SFR and dust extinction, assuming standard calibrations by Kennicutt & Evans (2012). The metallicity was estimated from the galaxy stellar mass and SFR, assuming that all the galaxies in the sample follow the fundamental metallicity relation (Mannucci et al. 2010), which is observed to be in place at least up to z ∼ 3 (Cresci et al. 2019). At each metallicity, line ratios were inferred using the calibrations presented in Curti et al. (2020). Galaxy sizes, important to estimate the fiber losses, were derived as a function of stellar mass and redshift from van der Wel et al. (2014). Finally, line widths were derived from the observed Tully-Fisher relation at z ∼ 1 from Di Teodoro et al. (2016). A redshift was considered to be successfully determined if at least two emission lines were well detected, one with S/N > 7 and the other with S/N > 5. Further details on these computations will be provided in an upcoming work. It can be seen that the results from the ML model are in good agreement with the expectations up to mH ∼ 25, and are above these values for fainter magnitudes.
Finally, in Figures 9 and 10, we showcase four examples of the output retrieved from M-TOPnet for four galaxy spectra in the test set. Figure 9 details two random examples of spectra for which we achieved a successful redshift prediction with the highest possible accuracy (|Δz|< 0.003). For both spectra, shown in grey in the upper panels, the redshift PDF is extremely narrow, and peaked at the location of the expected label redshift. Additionally, the line location task performed very well, accurately predicting the location of all the spectral lines defined in the spectral line masked vector (vertical light blue lines), as is indicated by the vertical dashed red lines. As was discussed in previous paragraphs, similar results are obtained for most spectra in the test set.
 |
Fig. 9. Examples of pipeline outputs for two random galaxy spectra with successful redshift predictions (|Δz|< 0.003). Top panels: Input spectra (grey) with predicted line locations (dashed red lines) and expected spectral lines (light blue lines). The expected and predicted locations of the Hα line are marked with a red and green arrow, respectively. Middle panels: Saliency maps for redshift prediction, indicating the most influential wavelengths for the model predictions. Bottom panels: Predicted (blue) and actual (red) redshift PDFs, highlighting the accuracy of the redshift predictions. |
 |
Fig. 10. Same as Figure 9, but showing the pipeline outputs for two random galaxy spectra with unsuccessful redshift predictions (see Sect. 4). |
Figure 9 also includes 1D saliency map vectors for the redshift prediction task (see central panels), obtained by computing the gradients of the model predictions with respect to the input spectrum tensor. A saliency map highlights the parts of the input that are most influential in determining the output. For our 1D spectra, the saliency map shows which wavelengths are most important for the redshift prediction. We note that the saliency map vectors peak not only at spectral positions where lines are present but also at positions where there are no lines. This suggests that the model also considers the absence of lines at certain positions as informative for determining the redshift, as the presence of a line in these locations would change the solution.
Figure 10 shows two random examples of unsuccessful redshift predictions, characterised by wider redshift PDFs with multiple peaks and failure in the line location task. Interestingly, in the first case (left panel), the secondary solution predicted by our model corresponds to the correct one, whereas this is not the case in the second example (right panel). By examining and visualising various outputs from the test set, we realise that the small fraction of spectra with large errors tend to have wider redshift PDFs, which become almost flat with numerous tiny peaks in instances of catastrophic errors (|Δz|> 0.5). This behaviour can be understood from a Bayesian perspective: when the spectral data provides insufficient evidence to strongly constrain the likelihood, the posterior distribution becomes broader and more uncertain, reflecting the lack of strong evidence to favour a single redshift solution. This behaviour highlights the ability of the model to express uncertainty in its predictions under ambiguous conditions.
As was mentioned in Sect. 3, we also experimented with MC dropout for redshift determination, by averaging results from 50 forward passes with dropout layers active during inference. This technique addresses epistemic uncertainty by approximating a Bayesian neural network (see Sects. 1 and 3 and references therein). We find that MC dropout does not provide a tangible improvement in the global results discussed above and shown in Figures 4, 7, and 8 (values remain similar within a relative factor of about 10%). This may be because the technique of discretising the redshift range and turning its prediction into a classification task accounts for most of the uncertainty, which thus appears to be primarily aleatoric rather than epistemic in this problem. However, by visually inspecting the difference between the averaged prediction obtained through MC dropout and the prediction from a single inference, we observe an appreciable net effect in a few cases. In these cases, the label redshift corresponds to the secondary solution of the predicted PDF in the single-inference case, and the situation improves with more forward passes, leading to a correct prediction. Thus, while the global effect of MC dropout is minimal, it has the potential to improve results on an individual case basis for certain types of spectra. This indicates potential, and we plan to conduct a more detailed examination of this technique in future work to identify the spectra classes for which it can have a more significant impact and determine the optimal balance between the number of forward passes and total computation time.
5. Discussion
The results presented in Sect. 4 clearly demonstrate the potential of ML in inferring information from spectral data of galaxies. In particular, our M-TOPnet pipeline has proven highly effective in accurately determining galaxy physical properties. These findings serve as a valuable benchmark for planning future observational strategies with MOONS.
5.1. Physical properties of galaxies with incorrectly predicted redshifts
We have conducted several analyses to test the precision of M-TOPnet for redshift determination. These tests reveal that a small fraction of test galaxy spectra (varying with exposure time) are not accurately predicted. This observation raises an intriguing question: whether we can identify and understand the causes of these prediction failures, and furthermore, whether these failures are driven by inherent properties of the data rather than model misspecification.
These questions connect to the broader topic of explainability in deep learning, which has become a central focus in ML research. Explainable ML aims to make the decision-making processes of complex models more transparent and interpretable. In the context of our study, understanding where and why our model fails can provide valuable insights into its limitations and potential areas for improvement.
To address these questions, we analysed the differences between the distributions of simulated MOONS galaxy spectra in the test set that are successfully predicted versus those that are not. We adopted the same threshold on the residuals of |Δz|< 0.01, as in Sect. 4, to define successful predictions.
Figure 11 illustrates the distributions of both sub-samples. To facilitate a fair comparison, given the significantly smaller number of poorly determined redshifts, we normalised each distribution to the same area. The histograms show the distributions of successfully predicted objects in blue and unsuccessfully predicted objects in red, as a function of redshift, SFR, Mstar, and fluxes of Hα and [OIII] emission lines. We observe clear offsets between the red and blue distributions in the case of SFR and emission line fluxes. The histograms of unsuccessful predictions peak at systematically lower SFR and emission line fluxes (similar behaviours are observed for other emission lines, provided in the simulated dataset). This finding is not surprising, as galaxies with lower SFR and lower emission line fluxes have fainter (or absent) spectral lines, presenting a challenge for accurate redshift determination. The distributions of Mstar show less obvious deviations; however, we note a relative excess of unsuccessful predictions at very low Mstar (< 109 M⊙), where galaxies tend to have very low SFR according to the galaxy main-sequence, and at very high Mstar (> 1010.5 M⊙), where a non-negligible fraction of the galaxy population is quenched, as is seen in the Mstar-SFR diagram (see Sect. 2).
 |
Fig. 11. Normalised distributions of well-classified (blue) and poorly classified (red) galaxy spectra based on various parameters (see Sect. 5 for a discussion). Top left to bottom right: Distributions as a function of redshift (z), SFR, stellar mass (Mstar), and fluxes of Hα and [OIII] emission lines. The threshold for a good prediction is set at |Δz|< 0.01. |
Another noteworthy finding emerges from the analysis of the redshift distributions. We observe a significant relative excess of unsuccessful predictions at redshifts between z = 2.7 − 3, also visible in the scatter plots of Figure 5 (see the grey squared box delineating the redshift range under examination). This behaviour can be explained by the simultaneous absence of bright Hydrogen and Oxygen emission lines, which in this redshift range fall outside the spectrum or in the gap between spectral bands.
5.2. Analysis and screening of the output redshift probability distribution functions
Having identified differences in physical properties between galaxy spectra with successfully and unsuccessfully determined redshifts, we now turn our attention to potential differences in the pipeline outputs themselves. M-TOPnet does not output a single scalar value for redshift but rather a probability vector. This raises the question of whether the shape of the PDF can be used to derive the quality of the prediction and, in particular, to identify the wrong redshift estimates. Intuitively, one might expect that galaxy spectra with unsuccessfully predicted redshifts (for instance, due to the reasons discussed above and visualised in Figure 11) would have broader or more dispersed PDFs with multiple peaks. This can be justified in the context of the Bayes’ theorem, as insufficient evidence in the spectral data leads to a poorly constrained likelihood, resulting in a dispersed posterior.
The challenge lies in quantifying this intuition objectively, potentially enabling further a posteriori screening of the output. To this end, we employed scipy.stats methods to compute the entropy and the skewness of the redshift PDFs obtained for the galaxy spectra in our sample. Entropy, in this context, quantifies the uncertainty or spread in the redshift probability distribution, indicating how concentrated or dispersed the predicted redshift values are. Skewness, on the other hand, measures the asymmetry of the redshift PDFs. In our context, we expect poorly classified spectra to produce broader, flatter PDFs with lower peak amplitudes, leading to skewness values closer to zero, while well-classified spectra should result in narrow, asymmetric PDFs with higher skewness values. Figure 12 presents the distributions and mutual relations of these metrics in corner plots, maintaining the colour coding from Figure 11 (red for poorly predicted redshifts, blue for successfully predicted spectra). For this analysis, we divide the test set into its two extreme exposure times, showing objects with texp = 2 h in the top panel and objects with texp = 8 h in the bottom panel. Interestingly, we find that the distributions are double-peaked, and the blue and red distributions are clearly separated in both proxies: poorly predicted objects show smaller skewness and larger entropy, with only a tiny fraction of false negatives (i.e. spectra for which the redshift is successfully determined but whose PDFs appear similar to those of poorly determined spectra).
 |
Fig. 12. Corner plots showing the distributions and mutual relations of skewness and entropy of redshift PDFs for well-classified (blue) and poorly classified (red) galaxy spectra. The threshold for a good prediction is set at |Δz|< 0.01. Top panel: Results for spectra with an exposure time of texp = 2 h. Bottom panel: Results for spectra with texp = 8 h. Well-classified spectra and poorly classified spectra are clearly distinguished by their skewness and entropy values (see a discussion in Sect. 5). The vertical orange lines indicate the separation threshold for skewness = 20 and entropy = 2. |
The clear separation exhibited in the distributions, which we identify to be around skewness = 20 and entropy = 2, allows for the following experiment. By using a threshold of entropy = 2 (see orange vertical lines in Figure 12), we can separate a posteriori – that is, after the process of inference and after obtaining the predictions – the bulk of good and poor predicted spectra. Applying this threshold, we find that the accuracy in redshift determination (using the usual |Δz|< 0.01 threshold) increases from 0.77 to 0.97 in the texp = 2 h case, and from 0.9 to a remarkable 0.99 in the texp = 8 h case. This improvement corresponds to filtering out about 27% of the spectra in the first case and about 12% in the second case.
As is visible in Figure 12, this process also rejects a small fraction of false negatives. However, if the specific kind of analysis is not adversely affected by filtering out a fraction of spectra of the order of the percentages reported, one can decide to apply this further screening to strongly enhance the model’s performance. We note that applying a threshold at skewness = 20 yields equivalent results, indicating that these metrics independently serve as effective proxies for distinguishing between well- and poorly predicted spectra. While one could consider adopting a threshold based on combinations of these metrics, this goes beyond the scope of this paper, and such a combined approach would likely be less interpretable.
We emphasise that this approach is only possible because M-TOPnet outputs probability vectors rather than single scalar values.
5.3. Exploration of the embedding space structure
Another central subject in ML is the interpretability of models, which involves understanding how a model achieves its tasks and what kind of information it uses and encodes. Interpretability is thus crucial for validating the decisions of a model and ensuring its reliability. One way to address this problem is to study the structure of the embedding spaces. The embedding space is a lower-dimensional representation of the input data learned by the model, which captures essential features for the task at hand. Several works in astronomy have explored this approach by visualising a dimensionality-reduced structure of key layers in their models (Portillo et al. 2020; Pat et al. 2020; Liang et al. 2023; Stoppa et al. 2023), for instance using techniques like UMAP (uniform manifold approximation and projection; McInnes et al. 2018) or t-SNE (t-distributed stochastic neighbour embedding; van der Maaten & Hinton 2008) to analyse latent spaces and gain insights into how these models organise and interpret data (see e.g. Sarmiento et al. 2021; Melchior et al. 2023).
Following a similar approach, we explored the structure of the concatenation of the three dense layers that follow the ‘shared info’ layer, from which the tasks for redshift, Mstar, and SFR determination depart (see Figure 3). The concatenation of these layers has a dimension of 64 × 3, but we reduced this to two dimensions for simpler visualisation using the UMAP algorithm. UMAP works by preserving the global structure of the data while maintaining the local relationships between points, making it an effective tool for visualising complex high-dimensional data (McInnes et al. 2018).
Figure 13 shows the UMAP-reduced 2D visualisations of these embedding layers, colour-coded by Mstar (top left), SFR (top centre), Hα flux (top right), redshift (bottom left), and Sérsic index (bottom right). The Sérsic index, provided by the simulation, is n = 1 for star-forming galaxies and n = 4 for quiescent galaxies.
 |
Fig. 13. UMAP-reduced 2D visualisations of the concatenated dense layers following the ‘shared info’ layer in M-TOPnet (see Figure 3 and a discussion in Sect. 5). Each panel shows the embedding space colour-coded by different parameters: from left to right, Mstar, SFR, Hα flux (upper panels) and redshift and Sérsic index (lower panels), which differentiates between star-forming galaxies (Sérsic index = 1) and quiescent galaxies (Sérsic index = 4). |
We find that the embedding space under examination successfully encodes information on these quantities, as is evidenced by clear trends and separation of colours. This occurs even for quantities like line fluxes (we tested other lines besides Hα, finding similar results) and star-forming or quiescent classes that were not seen during training and for which the model has no prior knowledge. This suggests that the model is building this knowledge by encoding all the necessary information from the spectral data. This finding is particularly significant as it demonstrates that, while our model may still function as a black box, it is learning to encode physically meaningful and interpretable information about galaxy properties. By correctly organising galaxies in the embedding space according to their physical properties – even those not explicitly used in training – the model shows that it has developed a meaningful internal representation of the relationship between spectral features and galaxy characteristics. We note that the redshift trend in the embedding space appears to be less smooth compared to other quantities. This is likely a result of the discretised nature of the task, which introduces step-like transitions in the latent space and affects continuity; this is why we used a more perceptually uniform colour map to better highlight the organisation of the data.
These results collectively demonstrate that our method, in addition to being fast and accurate, is also interpretable. This further emphasises the potential of well-designed deep learning pipelines for galaxy spectral fitting. By providing not just accurate predictions but also insights into the underlying data structure and relationships, such methods can become powerful tools in advancing our understanding of galactic properties and evolution. Also, the latent space, beyond encoding physically meaningful information about galaxy properties, can also be utilised for outlier detection (see e.g. Liang et al. 2023).
5.4. Alignment with real data
A final crucial point of discussion concerns the likely possibility that the current version of M-TOPnet may not perform as well on real data as it does on the simulated data it has been trained on, despite the simulations being designed to best reproduce real data. This phenomenon is well-known in ML as a domain gap between a source domain (in our case, the simulations) and a target domain (in our case, the real data). Domain gaps can be triggered by unavoidable offsets between the source and target distributions and are amplified when the model strongly relies on features of the source domain that are different or not present in the target domain. Ideally, if labels were available for the target domain, one could re-train or fine-tune the model using them to build more general representations. However, the problem arises when there are no labels, or very few labels, for the target domain. For the MOONS data, using labels derived from real data would require processing through standard astronomical tools and therefore transfer the limitations and biases of those tools to our ML pipeline.
In this situation, domain adaptation methods can help reduce the domain gap without prior knowledge of the target domain’s labels. Among these techniques, domain-adversarial neural networks (DANNs; Ganin et al. 2015) have been explored in astronomy, such as in the identification of galaxy morphology or galaxy mergers or using training data from cosmological simulations or different instruments (e.g. Ćiprijanović et al. 2020, 2021; Huertas-Company et al. 2024), or the classification of ionised nebulae (Belfiore et al. 2024). DANNs work by forcing the model to learn domain-invariant features that are common between source and target domains. This is typically achieved by incorporating a domain classifier into the network architecture. During training, the model learns to maximise the main task accuracy (e.g. redshift prediction) while simultaneously minimising the domain classifier’s ability to distinguish between source and target domain samples. This adversarial training process encourages the model to focus on features that are informative for the main task but invariant across domains. The application of such domain adaptation techniques could potentially enhance the robustness of M-TOPnet when applied to real MOONS data. It would allow the model to leverage the wealth of information in the simulated data while adapting to the specific characteristics of the observed spectra. This approach could be particularly valuable in the early stages of MOONS operations, enabling rapid and accurate analysis of the first batches of real data.
6. Conclusions
The advent of large spectroscopic surveys has revolutionised our understanding of galaxy evolution. However, the huge volume of data that will be produced by next-generation instruments like MOONS (Cirasuolo et al. 2020; Maiolino et al. 2020) presents significant challenges to data analysis and interpretation (see Sect. 1 and references therein) as traditional spectral fitting techniques, while accurate, can be time-consuming and computationally expensive (Hutchinson et al. 2016; Bautista et al. 2018; Napolitano et al. 2023; Zhong et al. 2024).
This study explores the potential of ML to efficiently and accurately extract key physical properties from galaxy spectra. Our work aims to develop a robust pipeline that can handle the complexities of spectral data while providing interpretable results, in preparation for the wealth of data expected from MOONS observations.
Our approach leverages a multi-task learning framework (Caruana 1997; Ruder 2017; Crawshaw 2020), developing a neural network architecture, dubbed M-TOPnet, which simultaneously predicts redshift, Mstar, SFR, and performs spectral line location. This integrated approach proves beneficial, improving overall performance, particularly for redshift determination. A key innovation in our method is the treatment of redshift prediction as a classification problem (see similar applications in e.g. Carrasco Kind & Brunner 2013; Stivaktakis et al. 2018; Stewart et al. 2022). By discretising the redshift range, we achieve high accuracy in redshift determination, while also enabling the output of PDFs rather than single scalar values.
When applied to simulated MOONS data, our pipeline demonstrates a promising performance. For a subset of galaxies defined by selection criteria similar to those of the MOONRISE GTO survey (see Sect. 4), we achieve approximately 76% successful redshift predictions with a stringent threshold of |Δz|< 0.003, improving to about 85% when relaxing the threshold to |Δz|< 0.1. The results are even more promising for longer exposure times, with 8 h exposures reaching success rates of 85% at |Δz|< 0.003 and 92% at |Δz|< 0.1. Notably, for bright sources with Hα flux greater than 10−17 erg/s/cm−2, our success rates further improve to 90–97%.
Our analysis has revealed several factors, in addition to simulated exposure times, that influence the prediction accuracy. We observe that galaxies with lower SFRs and fainter emission lines pose greater challenges for accurate redshift determination. We note a relative excess of unsuccessful predictions at redshifts between z = 2.7 − 3, due to the absence of bright emission lines in the observable spectrum at these redshifts.
To further enhance the reliability of our predictions, we developed metrics to assess the quality of output redshift PDFs, including root mean square, skewness, and entropy. Interestingly, we found that the distributions of these metrics are multi-peaked, with a clear separation between successfully and unsuccessfully predicted redshifts. The PDFs of poorly predicted redshifts are typically narrower, with larger entropy values and smaller skewness. This clear distinction, only possible because M-TOPnet outputs full PDFs rather than single scalar values, allows for effective a posteriori screening. By applying thresholds on these metrics, we are able to significantly increase redshift determination accuracy, from 77% to 97% for 2 h exposures, and from 90% to 99% for 8 h exposures. This additional screening step demonstrates the potential for post-processing to further improve the performance of the pipeline, highlighting the advantages of our probabilistic approach.
A key strength of our approach lies in its interpretability. Through exploration of the embedding space structure, we found that our model successfully encoded information on galaxy properties not explicitly used in training, such as emission line fluxes and galaxy types (star-forming vs quiescent). This finding is particularly significant as it demonstrates that the model is learning meaningful representations of galaxy characteristics from spectral features, rather than simply functioning as a black box.
Looking ahead, we acknowledge the potential challenges in applying M-TOPnet to real MOONS data due to the inevitable differences between simulated and observed spectra. To address this, we discuss the potential application of domain adaptation techniques, such as domain-adversarial neural networks (e.g. Ganin et al. 2015; Ćiprijanović et al. 2020, 2021; Huertas-Company & Lanusse 2023). These methods could enhance the robustness of our tool when applied to real data by learning domain-invariant features, thereby bridging the gap between simulations and observations.
In conclusion, our findings demonstrate the significant potential of ML techniques in spectroscopic analysis. By combining accuracy, efficiency, and interpretability, M-TOPnet offers a promising approach for handling the large datasets expected from next-generation instruments like MOONS. As we move forwards, this work provides a valuable foundation for advancing our understanding of galaxy evolution across cosmic time, clearing the path for new insights from the wealth of upcoming spectroscopic data.
Acknowledgments
F.B acknowledges support from the INAF ‘Fundamental Astrophysics‘ programs 2022 & 2023. E.D.T. was supported by the European Research Council (ERC) under grant agreement no. 10104075. A.M., F.M., F.B. and G.C. acknowledge support from grant PRIN-MUR 2020ACSP5K_002 financed by European Union – Next Generation EU. VW and NFB acknowledge Science and Technologies Facilities Council (STFC) grants ST/V000861/1 and ST/Y00275X/1.
References
- Abadi, M., Agarwal, A., Barham, P., et al. 2016, arXiv e-prints [arXiv:1603.04467] [Google Scholar]
- Alam, S., Ata, M., Bailey, S., et al. 2017, MNRAS, 470, 2617 [Google Scholar]
- Ambrosch, M., Guiglion, G., Mikolaitis, Š., et al. 2023, A&A, 672, A46 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Anglés-Alcázar, D., Faucher-Giguère, C.-A., Kereš, D., et al. 2017, MNRAS, 470, 4698 [CrossRef] [Google Scholar]
- Baron, D. 2019, arXiv e-prints [arXiv:1904.07248] [Google Scholar]
- Bautista, J. E., Vargas-Magaña, M., Dawson, K. S., et al. 2018, ApJ, 863, 110 [NASA ADS] [CrossRef] [Google Scholar]
- Belfiore, F., Ginolfi, M., Blanc, G., et al. 2024, A&A submitted [arXiv:2410.16370] [Google Scholar]
- Berg, D. A., Skillman, E. D., Henry, R. B. C., Erb, D. K., & Carigi, L. 2016, ApJ, 827, 126 [NASA ADS] [CrossRef] [Google Scholar]
- Bezanson, R., van der Wel, A., Pacifici, C., et al. 2018, ApJ, 858, 60 [NASA ADS] [CrossRef] [Google Scholar]
- Bickley, R. W., Bottrell, C., Hani, M. H., et al. 2021, MNRAS, 504, 372 [NASA ADS] [CrossRef] [Google Scholar]
- Bolton, A. S., Schlegel, D. J., Aubourg, É., et al. 2012, AJ, 144, 144 [NASA ADS] [CrossRef] [Google Scholar]
- Boquien, M., Burgarella, D., Roehlly, Y., et al. 2019, A&A, 622, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Boucaud, A., Huertas-Company, M., Heneka, C., et al. 2020, MNRAS, 491, 2481 [Google Scholar]
- Brinchmann, J., Charlot, S., White, S. D. M., et al. 2004, MNRAS, 351, 1151 [Google Scholar]
- Bruzual, G., & Charlot, S. 2003, MNRAS, 344, 1000 [NASA ADS] [CrossRef] [Google Scholar]
- Buat, V. 2002, Ap&SS, 281, 129 [NASA ADS] [CrossRef] [Google Scholar]
- Buck, T., & Wolf, S. 2021, arXiv e-prints [arXiv:2111.01154] [Google Scholar]
- Busca, N., & Balland, C. 2018, arXiv e-prints [arXiv:1808.09955] [Google Scholar]
- Calzetti, D., Armus, L., Bohlin, R. C., et al. 2000, ApJ, 533, 682 [NASA ADS] [CrossRef] [Google Scholar]
- Carnall, A. C., McLure, R. J., Dunlop, J. S., & Davé, R. 2018, MNRAS, 480, 4379 [Google Scholar]
- Carrasco Kind, M., & Brunner, R. J. 2013, MNRAS, 432, 1483 [Google Scholar]
- Caruana, R. 1997, Mach. Learn., 28, 41 [CrossRef] [Google Scholar]
- Chollet, F. 2015, https://github.com/fchollet/keras [Google Scholar]
- Cid Fernandes, R., Mateus, A., Sodré, L., Stasińska, G., & Gomes, J. M. 2005, MNRAS, 358, 363 [Google Scholar]
- Ćiprijanović, A., Snyder, G. F., Nord, B., & Peek, J. E. G. 2020, Astron. Comput., 32, 100390 [CrossRef] [Google Scholar]
- Ćiprijanović, A., Kafkes, D., Downey, K., et al. 2021, MNRAS, 506, 677 [CrossRef] [Google Scholar]
- Cirasuolo, M., Fairley, A., Rees, P., et al. 2020, The Messenger, 180, 10 [NASA ADS] [Google Scholar]
- Collister, A. A., & Lahav, O. 2004, PASP, 116, 345 [NASA ADS] [CrossRef] [Google Scholar]
- Conroy, C. 2013, ARA&A, 51, 393 [NASA ADS] [CrossRef] [Google Scholar]
- Crain, R. A., & van de Voort, F. 2023, ARA&A, 61, 473 [NASA ADS] [CrossRef] [Google Scholar]
- Crawshaw, M. 2020, arXiv e-prints [arXiv:2009.09796] [Google Scholar]
- Cresci, G., Mannucci, F., & Curti, M. 2019, A&A, 627, A42 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Curti, M., Mannucci, F., Cresci, G., & Maiolino, R. 2020, MNRAS, 491, 944 [Google Scholar]
- Curti, M., D’Eugenio, F., Carniani, S., et al. 2023, MNRAS, 518, 425 [Google Scholar]
- Davé, R., Finlator, K., & Oppenheimer, B. D. 2011, MNRAS, 416, 1354 [CrossRef] [Google Scholar]
- Defazio, A., Cutkosky, A., Mehta, H., & Mishchenko, K. 2023, arXiv e-prints [arXiv:2310.07831] [Google Scholar]
- de Jong, R. S., Barden, S., Bellido-Tirado, O., et al. 2014, SPIE Conf. Ser., 9147, 91470M [NASA ADS] [Google Scholar]
- de Jong, R. S., Agertz, O., Berbel, A. A., et al. 2019, The Messenger, 175, 3 [NASA ADS] [Google Scholar]
- DESI Collaboration (Abareshi, B., et al.) 2022, AJ, 164, 207 [NASA ADS] [CrossRef] [Google Scholar]
- Di Cesare, C., Graziani, L., Schneider, R., et al. 2023, MNRAS, 519, 4632 [Google Scholar]
- Dieleman, S., Willett, K. W., & Dambre, J. 2015, MNRAS, 450, 1441 [NASA ADS] [CrossRef] [Google Scholar]
- Di Teodoro, E. M., Fraternali, F., & Miller, S. H. 2016, A&A, 594, A77 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ferreira, L., Conselice, C. J., Duncan, K., et al. 2020, ApJ, 895, 115 [NASA ADS] [CrossRef] [Google Scholar]
- Ferreira, L., Bickley, R. W., Ellison, S. L., et al. 2024, MNRAS, 533, 2547 [NASA ADS] [CrossRef] [Google Scholar]
- Fraser-McKelvie, A., Cortese, L., Groves, B., et al. 2022, MNRAS, 510, 320 [Google Scholar]
- Gal, Y., & Ghahramani, Z. 2015, arXiv e-prints [arXiv:1506.02142] [Google Scholar]
- Gallazzi, A., Charlot, S., Brinchmann, J., White, S. D. M., & Tremonti, C. A. 2005, MNRAS, 362, 41 [Google Scholar]
- Ganin, Y., Ustinova, E., Ajakan, H., et al. 2015, arXiv e-prints [arXiv:1505.07818] [Google Scholar]
- Ghosh, A., Urry, C. M., Wang, Z., et al. 2020, ApJ, 895, 112 [NASA ADS] [CrossRef] [Google Scholar]
- Ginolfi, M., Graziani, L., Schneider, R., et al. 2018, MNRAS, 473, 4538 [NASA ADS] [CrossRef] [Google Scholar]
- Ginolfi, M., Hunt, L. K., Tortora, C., Schneider, R., & Cresci, G. 2020, A&A, 638, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Girelli, G. 2021, Ph.D. Thesis, Alma Mater Studiorum Università di Bologna, Italy, http://amsdottorato.unibo.it/9820/ [Google Scholar]
- Girelli, G., Pozzetti, L., Bolzonella, M., et al. 2020, A&A, 634, A135 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goodfellow, I., Bengio, Y., & Courville, A. 2016, Deep Learning (MIT Press) [Google Scholar]
- Grazian, A., Fontana, A., Santini, P., et al. 2015, A&A, 575, A96 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Graziani, L., Schneider, R., Ginolfi, M., et al. 2020, MNRAS, 494, 1071 [NASA ADS] [CrossRef] [Google Scholar]
- Hahn, C., Wilson, M. J., Ruiz-Macias, O., et al. 2023, AJ, 165, 253 [CrossRef] [Google Scholar]
- Hausen, R., & Robertson, B. E. 2020, ApJS, 248, 20 [CrossRef] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2015, arXiv e-prints [arXiv:1512.03385] [Google Scholar]
- Heintz, K. E., Brammer, G. B., Giménez-Arteaga, C., et al. 2023, Nat. Astron., 7, 1517 [NASA ADS] [CrossRef] [Google Scholar]
- Henriques, B. M. B., White, S. D. M., Thomas, P. A., et al. 2015, MNRAS, 451, 2663 [Google Scholar]
- Hinton, G. E., Srivastava, N., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. R. 2012, arXiv e-prints [arXiv:1207.0580] [Google Scholar]
- Huertas-Company, M., & Lanusse, F. 2023, PASA, 40 [CrossRef] [Google Scholar]
- Huertas-Company, M., Gravet, R., Cabrera-Vives, G., et al. 2015, ApJS, 221, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Huertas-Company, M., Iyer, K. G., Angeloudi, E., et al. 2024, A&A, 685, A48 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hutchinson, T. A., Bolton, A. S., Dawson, K. S., et al. 2016, AJ, 152, 205 [NASA ADS] [CrossRef] [Google Scholar]
- Iglesias-Navarro, P., Huertas-Company, M., Martín-Navarro, I., Knapen, J. H., & Pernet, E. 2024, A&A, 689, A58 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ilbert, O., McCracken, H. J., Le Fèvre, O., et al. 2013, A&A, 556, A55 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jacobs, C., Collett, T., Glazebrook, K., et al. 2019, ApJS, 243, 17 [Google Scholar]
- Jones, T., Martin, C., & Cooper, M. C. 2015, ApJ, 813, 126 [NASA ADS] [CrossRef] [Google Scholar]
- Kennicutt, R. C., Jr 1998a, ARA&A, 36, 189 [NASA ADS] [CrossRef] [Google Scholar]
- Kennicutt, R. C., Jr 1998b, ApJ, 498, 541 [Google Scholar]
- Kennicutt, R. C., & Evans, N. J. 2012, ARA&A, 50, 531 [NASA ADS] [CrossRef] [Google Scholar]
- Kewley, L. J., Nicholls, D. C., & Sutherland, R. S. 2019, ARA&A, 57, 511 [Google Scholar]
- Kurinchi-Vendhan, S., Farcy, M., Hirschmann, M., & Valentino, F. 2024, MNRAS, 534, 3974 [NASA ADS] [CrossRef] [Google Scholar]
- Lan, T.-W., Tojeiro, R., Armengaud, E., et al. 2023, ApJ, 943, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Langan, I., Zabl, J., Bouché, N. F., et al. 2023, MNRAS, 521, 546 [NASA ADS] [CrossRef] [Google Scholar]
- Lanusse, F., Ma, Q., Li, N., et al. 2018, MNRAS, 473, 3895 [Google Scholar]
- Leung, H. W., & Bovy, J. 2019, MNRAS, 483, 3255 [NASA ADS] [Google Scholar]
- Li, R., Shu, Y., Su, J., et al. 2018, MNRAS, 482, 313 [Google Scholar]
- Lian, J., Thomas, D., Maraston, C., et al. 2018, MNRAS, 474, 1143 [NASA ADS] [CrossRef] [Google Scholar]
- Liang, Y., Melchior, P., Lu, S., Goulding, A., & Ward, C. 2023, AJ, 166, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Looser, T. J., D’Eugenio, F., Piotrowska, J. M., et al. 2024, MNRAS, 532, 2832 [NASA ADS] [CrossRef] [Google Scholar]
- López-López, X., Bolzonella, M., Pozzetti, L., et al. 2024, A&A, 691, A136 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Madau, P., & Dickinson, M. 2014, ARA&A, 52, 415 [Google Scholar]
- Madau, P., Pozzetti, L., & Dickinson, M. 1998, ApJ, 498, 106 [NASA ADS] [CrossRef] [Google Scholar]
- Maiolino, R., & Mannucci, F. 2019, A&ARv, 27, 3 [Google Scholar]
- Maiolino, R., Cirasuolo, M., Afonso, J., et al. 2020, The Messenger, 180, 24 [NASA ADS] [Google Scholar]
- Mannucci, F., Cresci, G., Maiolino, R., et al. 2009, MNRAS, 398, 1915 [Google Scholar]
- Mannucci, F., Cresci, G., Maiolino, R., Marconi, A., & Gnerucci, A. 2010, MNRAS, 408, 2115 [NASA ADS] [CrossRef] [Google Scholar]
- Maraston, C. 2005, MNRAS, 362, 799 [NASA ADS] [CrossRef] [Google Scholar]
- Matthee, J., Mackenzie, R., Simcoe, R. A., et al. 2023, ApJ, 950, 67 [NASA ADS] [CrossRef] [Google Scholar]
- McInnes, L., Healy, J., & Melville, J. 2018, arXiv e-prints [arXiv:1802.03426] [Google Scholar]
- Melchior, P., Joseph, R., Sanchez, J., MacCrann, N., & Gruen, D. 2021, Nat. Rev. Phys., 3, 712 [NASA ADS] [CrossRef] [Google Scholar]
- Melchior, P., Liang, Y., Hahn, C., & Goulding, A. 2023, AJ, 166, 74 [NASA ADS] [CrossRef] [Google Scholar]
- Moradi, R., Rastegarnia, F., Wang, Y., & Mirtorabi, M. T. 2024, MNRAS, 533, 1976 [NASA ADS] [CrossRef] [Google Scholar]
- Nagao, T., Maiolino, R., & Marconi, A. 2006, A&A, 459, 85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nair, V., & Hinton, G. E. 2010, in Proceedings of the 27th International Conference on International Conference on Machine Learning, ICML’10 (Madison, WI, USA: Omnipress), 807 [Google Scholar]
- Nakajima, K., Ouchi, M., Isobe, Y., et al. 2023, ApJS, 269, 33 [NASA ADS] [CrossRef] [Google Scholar]
- Napolitano, L., Pandey, A., Myers, A. D., et al. 2023, AJ, 166, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Newman, J. A., Cooper, M. C., Davis, M., et al. 2013, ApJS, 208, 5 [Google Scholar]
- Osterbrock, D. E., & Ferland, G. J. 2006, Astrophysics of gaseous nebulae and active galactic nuclei (Sausalito, CA: University Science Books) [Google Scholar]
- Pankaj, S., & Chakraborty, P. 2022, in 2022 International Conference on Data Science, Agents& Artificial Intelligence (ICDSAAI), 01, 1 [Google Scholar]
- Pannella, M., Elbaz, D., Daddi, E., et al. 2015, ApJ, 807, 141 [Google Scholar]
- Pasquet, J., Bertin, E., Treyer, M., Arnouts, S., & Fouchez, D. 2019, A&A, 621, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pat, F., Juneau, S., Böhm, V., et al. 2020, in ASP Conf. Ser., 525, 67 [NASA ADS] [Google Scholar]
- Peng, Y.-J., Lilly, S. J., Kovač, K., et al. 2010, ApJ, 721, 193 [Google Scholar]
- Peng, Y., Maiolino, R., & Cochrane, R. 2015, Nature, 521, 192 [Google Scholar]
- Perreault Levasseur, L., Hezaveh, Y. D., & Wechsler, R. H. 2017, ApJ, 850, L7 [Google Scholar]
- Piotrowska, J. M., Bluck, A. F. L., Maiolino, R., & Peng, Y. 2022, MNRAS, 512, 1052 [NASA ADS] [CrossRef] [Google Scholar]
- Podsztavek, O., Škoda, P., & Tvrdík, P. 2022, Astron. Comput., 40, 100615 [NASA ADS] [CrossRef] [Google Scholar]
- Portillo, S. K. N., Parejko, J. K., Vergara, J. R., & Connolly, A. J. 2020, AJ, 160, 45 [Google Scholar]
- Renzini, A., & Peng, Y.-J. 2015, ApJ, 801, L29 [Google Scholar]
- Rinaldi, P., Navarro-Carrera, R., Caputi, K. I., et al. 2024, arXiv e-prints [arXiv:2406.13554] [Google Scholar]
- Ruder, S. 2017, arXiv e-prints [arXiv:1706.05098] [Google Scholar]
- Sanders, R. L., Shapley, A. E., Topping, M. W., Reddy, N. A., & Brammer, G. B. 2023, ApJ, 955, 54 [NASA ADS] [CrossRef] [Google Scholar]
- Sarmiento, R., Huertas-Company, M., Knapen, J. H., et al. 2021, ApJ, 921, 177 [NASA ADS] [CrossRef] [Google Scholar]
- Schlafly, E. F., Kirkby, D., Schlegel, D. J., et al. 2023, AJ, 166, 259 [NASA ADS] [CrossRef] [Google Scholar]
- Schreiber, C., Pannella, M., Elbaz, D., et al. 2015, A&A, 575, A74 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schreiber, C., Elbaz, D., Pannella, M., et al. 2017, A&A, 602, A96 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shapley, A. E., Reddy, N. A., Kriek, M., et al. 2015, ApJ, 801, 88 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, M. J., & Geach, J. E. 2023, R. Soc. Open Sci., 10, 221454 [NASA ADS] [CrossRef] [Google Scholar]
- Somerville, R. S., & Davé, R. 2015, ARA&A, 53, 51 [Google Scholar]
- Speagle, J. S., Steinhardt, C. L., Capak, P. L., & Silverman, J. D. 2014, ApJS, 214, 15 [Google Scholar]
- Springel, V., White, S. D. M., Jenkins, A., et al. 2005, Nature, 435, 629 [Google Scholar]
- Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. 2014, J. Mach. Learn. Res., 15, 1929 [Google Scholar]
- Stasińska, G., & Izotov, Y. 2003, A&A, 397, 71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Steidel, C. C., Rudie, G. C., Strom, A. L., et al. 2014, ApJ, 795, 165 [Google Scholar]
- Stewart, L., Bach, F., Berthet, Q., & Vert, J. P. 2022, arXiv e-prints [arXiv:2211.05641] [Google Scholar]
- Stivaktakis, R., Tsagkatakis, G., Moraes, B., et al. 2018, arXiv e-prints [arXiv:1809.09622] [Google Scholar]
- Stoppa, F., Bhattacharyya, S., Ruiz de Austri, R., et al. 2023, A&A, 680, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tamura, N., Moritani, Y., Yabe, K., et al. 2022, SPIE Conf. Ser., 12184, 1218410 [NASA ADS] [Google Scholar]
- Tantalo, R., & Chiosi, C. 2004, MNRAS, 353, 917 [NASA ADS] [CrossRef] [Google Scholar]
- Tojeiro, R., Heavens, A. F., Jimenez, R., & Panter, B. 2007, MNRAS, 381, 1252 [NASA ADS] [CrossRef] [Google Scholar]
- Tonry, J., & Davis, M. 1979, AJ, 84, 1511 [Google Scholar]
- Tremonti, C. A., Heckman, T. M., Kauffmann, G., et al. 2004, ApJ, 613, 898 [Google Scholar]
- Ucci, G., Ferrara, A., Gallerani, S., & Pallottini, A. 2017, MNRAS, 465, 1144 [Google Scholar]
- Ucci, G., Ferrara, A., Pallottini, A., & Gallerani, S. 2018, MNRAS, 477, 1484 [Google Scholar]
- van der Maaten, L., & Hinton, G. 2008, J. Mach. Learn. Res., 9, 2579 [Google Scholar]
- van der Wel, A., Franx, M., van Dokkum, P. G., et al. 2014, ApJ, 788, 28 [Google Scholar]
- Walmsley, M., Lintott, C., Géron, T., et al. 2022, MNRAS, 509, 3966 [Google Scholar]
- Wang, L.-L., Yang, G.-J., Zhang, J.-L., et al. 2024, MNRAS, 527, 10557 [Google Scholar]
- Weaver, J. R., Kauffmann, O. B., Ilbert, O., et al. 2022, ApJS, 258, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Whitaker, K. E., Franx, M., Leja, J., et al. 2014, ApJ, 795, 104 [NASA ADS] [CrossRef] [Google Scholar]
- Williams, R. J., Quadri, R. F., Franx, M., van Dokkum, P., & Labbé, I. 2009, ApJ, 691, 1879 [NASA ADS] [CrossRef] [Google Scholar]
- Wu, J. F., & Boada, S. 2019, MNRAS, 484, 4683 [NASA ADS] [CrossRef] [Google Scholar]
- Wu, Y., Tao, Y., Fan, D., Cui, C., & Zhang, Y. 2023, MNRAS, 527, 1163 [CrossRef] [Google Scholar]
- Zhong, F., Napolitano, N. R., Heneka, C., et al. 2024, MNRAS, 532, 643 [NASA ADS] [CrossRef] [Google Scholar]
- Zhou, X., Gong, Y., Meng, X.-M., et al. 2021, ApJ, 909, 53 [NASA ADS] [CrossRef] [Google Scholar]
- Zhu, X.-P., Dai, J.-M., Bian, C.-J., et al. 2019, Ap&SS, 364, 55 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
All Figures
|
Fig. 1. Properties of galaxies in the simulated dataset. (a) Distributions of key galaxy properties, including redshift (first panel), Mstar (second panel), SFR (third panel), and mH (bottom panel), arranged from top to bottom. (b) Upper panel: Distribution of galaxies in the log(Mstar) versus log(SFR) diagram, highlighting their representation of both main-sequence star-forming galaxies and passive galaxies. Galaxies are colour-coded by their Hα line flux. For reference, we show the trends of the main sequence at z = 0.5 − 1 (blue points) and at z = 1.5 − 2 (red points) reported by Whitaker et al. (2014), and the best fit for the main sequence at z ∼ 1 by Speagle et al. (2014). Lower panel: flux distribution of the Hα line. |
| In the text | |
|
Fig. 2. Examples of simulated galaxy spectra from our sample, shown before any pre-processing required for input into our pipeline, covering the entire spectral range. Each row represents a different galaxy spectrum, with the left panels showing the full spectrum and the right panels providing a zoomed-in view around the Hα line. The spectra are positioned based on the Hα line flux: F(Hα) ∼ 10−15 erg/s/cm2 (upper row), F(Hα) ∼ 10−16.5 erg/s/cm2 (middle row), and F(Hα) ∼ 10−17.5 erg/s/cm2 (lower row), representing high-, average-, and low-quality spectra, respectively. Red vertical lines indicate the positions of key emission lines, including [OII], Hβ, [OIII], and Hα, with corresponding labels. The missing flux values around 14 000 Å are due to the gap between spectral bands (see Sect. 2). |
| In the text | |
|
Fig. 3. Architecture of M-TOPnet, the deep learning pipeline used for the galaxy spectral analysis in this work. Our model accepts two inputs: a normalised, continuum-subtracted spectrum and a normalised continuum vector. The spectrum is processed through convolutional residual blocks to extract spectral features, while the continuum vector is encoded through a dense layer. Outputs from both branches, along with intermediate outputs from the line location task, are combined into a shared information layer. This shared layer feeds into task-specific branches consisting of MLPs to predict line locations, redshift, and normalised values of Mstar, and SFR. See a discussion on the different components in Sect. 3.2. |
| In the text | |
|
Fig. 4. Comparison of predicted and labelled values for redshift, Mstar, and SFR for all simulated MOONS galaxy spectra in the test set with exposure times of 2 h, 4 h, and 8 h. Upper panels: Scatter plots of predicted versus labelled values, with the dashed black line indicating perfect agreement. Solid black lines represent the contours of the joint probability density, corresponding to the 20th, 50th, 75th, and 95th percentiles of the distribution, estimated using a Gaussian kernel density estimator. Lower panels: Histograms of the residuals (‘predicted value – labelled value’; see Sect. 4) with Gaussian fits, showing the mean (μ) and standard deviation (σ) of the distributions. |
| In the text | |
|
Fig. 5. Comparison of redshift prediction accuracy for 8-hour spectra using two models: the multi-task model discussed in Sect. 3 on the left panel, and a single-task model (showing increased outliers, including catastrophic errors; see Sect. 4) on the right panel. The redshift range z = 2.7 − 3, where a significant relative excess of unsuccessful predictions is shown (see Sect. 5 for a discussion) is highlighted by the grey box. |
| In the text | |
|
Fig. 6. Same as the upper panels of Figure 4, but indicative of the subset of galaxies defined by selection criteria similar to the planned MOONS GTO survey MOONRISE (see Sect. 4). |
| In the text | |
|
Fig. 7. Fraction of successful redshift predictions as a function of varying Δz thresholds for different galaxy subsets. The subsets include a general division by exposure time (texp = 2 h, 4 h, 8 h, represented by dashed lines) and a more specific division by both exposure time and redshift range z = 0.8 − 1.7 (represented by solid lines in blue, green, and red). The MOONRISE-like selection is shown by the solid grey line, and bright galaxies with Hα flux greater than 10−17 erg/s/cm−2 are shown by the solid violet line. The Δz thresholds tested are 0.003, 0.005, 0.01, and 0.1. |
| In the text | |
|
Fig. 8. Relationship between the fraction of successful redshift predictions (with |Δz|< 0.01) and the H-band magnitude mH. Top panel: Histogram of the number of objects as a function of mH. Bottom panel: Fraction of successful predictions as a function of mH for different subsets: galaxies with Hα flux greater than 10−17 erg/s/cm−2 (violet line), MOONRISE-like selection (grey line), and subsets with varying exposure times of 2 h (blue), 4 h (green), and 8 h (red), along with a simulated reference trend (dashed orange line). See Sect. 4 for a detailed discussion on the behaviour of the observed trends. |
| In the text | |
|
Fig. 9. Examples of pipeline outputs for two random galaxy spectra with successful redshift predictions (|Δz|< 0.003). Top panels: Input spectra (grey) with predicted line locations (dashed red lines) and expected spectral lines (light blue lines). The expected and predicted locations of the Hα line are marked with a red and green arrow, respectively. Middle panels: Saliency maps for redshift prediction, indicating the most influential wavelengths for the model predictions. Bottom panels: Predicted (blue) and actual (red) redshift PDFs, highlighting the accuracy of the redshift predictions. |
| In the text | |
|
Fig. 10. Same as Figure 9, but showing the pipeline outputs for two random galaxy spectra with unsuccessful redshift predictions (see Sect. 4). |
| In the text | |
|
Fig. 11. Normalised distributions of well-classified (blue) and poorly classified (red) galaxy spectra based on various parameters (see Sect. 5 for a discussion). Top left to bottom right: Distributions as a function of redshift (z), SFR, stellar mass (Mstar), and fluxes of Hα and [OIII] emission lines. The threshold for a good prediction is set at |Δz|< 0.01. |
| In the text | |
|
Fig. 12. Corner plots showing the distributions and mutual relations of skewness and entropy of redshift PDFs for well-classified (blue) and poorly classified (red) galaxy spectra. The threshold for a good prediction is set at |Δz|< 0.01. Top panel: Results for spectra with an exposure time of texp = 2 h. Bottom panel: Results for spectra with texp = 8 h. Well-classified spectra and poorly classified spectra are clearly distinguished by their skewness and entropy values (see a discussion in Sect. 5). The vertical orange lines indicate the separation threshold for skewness = 20 and entropy = 2. |
| In the text | |
|
Fig. 13. UMAP-reduced 2D visualisations of the concatenated dense layers following the ‘shared info’ layer in M-TOPnet (see Figure 3 and a discussion in Sect. 5). Each panel shows the embedding space colour-coded by different parameters: from left to right, Mstar, SFR, Hα flux (upper panels) and redshift and Sérsic index (lower panels), which differentiates between star-forming galaxies (Sérsic index = 1) and quiescent galaxies (Sérsic index = 4). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.