| Issue |
A&A
Volume 667, November 2022
|
|
|---|---|---|
| Article Number | A34 | |
| Number of page(s) | 29 | |
| Section | Interstellar and circumstellar matter | |
| DOI | https://doi.org/10.1051/0004-6361/202243865 | |
| Published online | 03 November 2022 | |
Topological models to infer multiphase interstellar medium properties
Université Paris-Saclay, Université Paris-Cité, CEA, CNRS, AIM,
91191,
Gif-sur-Yvette, France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
26
April
2022
Accepted:
1
July
2022
Abstract
Context. Spectroscopic observations of high-redshift galaxies slowly reveal the same complexity of the interstellar medium (ISM) as expected from resolved observations in nearby galaxies. While providing, in principle, a wealth of diagnostics concerning galaxy evolution, star formation, or the nature and influence of compact objects, such high-z spectra are often spatially and spectrally unresolved, and inferring reliable diagnostics represents a major obstacle. Bright, nearby, unresolved galaxies observed in the optical and infrared domains provide many constraints to design methods to infer ISM properties, but they have so far been limited to deterministic methods and/or with simple topological assumptions (e.g., single 1D model).
Aims. It is urgent to build upon previous ISM multiphase and multicomponent methods by using a probabilistic approach that makes it possible to derive probability density functions for relevant parameters while also enabling a large number of free parameters with potential priors. The goal is to provide a flexible statistical framework that is agnostic to the model grid and that considers either a few discrete components defined by their parameter values and/or statistical distributions of parameters. In this paper, we present a first application with the objective to infer probability distributions of several physical parameters (e.g., the mass of H0, H2, escape fraction of ionizing photons, and metallicity) for the star-forming regions of the metal-poor dwarf galaxy I Zw 18 in order to confirm the low molecular gas content and high escape fraction of ionizing photons from H ii regions.
Methods. We present a Bayesian approach to model a suite of spectral lines using a sequential Monte Carlo method provided by the Python package PyMC which combines several concepts such as tempered likelihoods, importance sampling, and independent Metropolis-Hastings chains. The algorithm, provided by the associated code MULTIGRIS, accepts a few components which can be represented as sectors around one or several stellar clusters, or continuous (e.g., power-law, normal) distributions for any given parameter. We applied this approach to a grid of models calculated with the photoionization and photodissociation code Cloudy in order to produce topological models of I Zw 18.
Results. The statistical framework we present makes it possible to consider a large number of spectroscopic tracers, with the extinction and systematic uncertainties as potential additional random variables. We applied this technique to the galaxy I Zw 18 in order to reproduce and go beyond previous topological models specifically tailored to this object. While our grid is designed for global properties of low-metallicity star-forming galaxies, we were able to calculate accurate values for the metallicity, number of ionizing photons, masses of ionized and neutral hydrogen, as well as the dust mass and the dust-to-gas mass ratio in I Zw 18. We find a relatively modest amount of H2 (~105 M⊙) which is predominantly CO-dark and traced by C+ rather than C0. Nevertheless, more than 90% of the [C ii] emission is associated with the neutral atomic gas. Our models confirm the necessity to include an X-ray source with an inferred luminosity in good agreement with direct X-ray observations. Finally, we investigate the escape fraction of ionizing photons for different energy ranges. While the escape fraction for the main H ii region lies around 50–65%, we show that most of the soft X-ray photons are able to escape and may play a role in the ionization and heating of the circumgalactic or intergalactic medium.
Conclusions. Multicomponent ISM models associate a complex enough distribution of matter and phases with a simple enough topological description to be constrained with probabilistic frameworks. Despite ignoring effects such as reflected light, the diffuse radiation field, or ionization by several non-cospatial sources, they remain well adapted to individual H ii regions and to star-forming galaxies dominated by one or a few H ii regions, and the improvement due to the combination of several components largely compensates for other secondary effects.
Key words: HII regions / ISM: general / ISM: structure / galaxies: ISM / galaxies: individual: IZw 18 / methods: numerical
© V. Lebouteiller and L. Ramambason 2022
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe-to-Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Spectroscopic observations of very high redshift (z ≳ 7) galaxies have become routinely available (e.g., Harikane et al. 2018; Wagg et al. 2020; Lee et al. 2021), with an increasing number of tracers arising from different phases of the interstellar medium (ISM), enabling numerous diagnostics (e.g., star formation rate, active galactic nuclei, and molecular gas content) that had been so far limited to galaxy surveys around or after the cosmic noon (z ≲ 2–3). The integrated emission-line spectrum of galaxies, in particular, makes it possible to infer chemical abundances, physical conditions, and relative contributions of energetic sources at work in galaxies, which in turn provide useful constraints on cosmological evolution of galaxies (e.g., Spinoglio et al. 2017) or to examine specific processes such as the escape of ionizing photons (e.g., Harikane et al. 2020) and the nature and influence of compact objects in low-metallicity environments (e.g., Lebouteiller et al. 2017).
The integrated spectrum reflects a combination of (1) many interstellar components with different properties (e.g., ionization parameter, abundances, column density, and incident radiation field) that need to be disentangled, and (2) tracers with different emission conditions (e.g., critical density and excitation temperature) that need to be consistently accounted for. It is often assumed either that integrated measurements can be linked to some kind of loosely defined “average” parameter or that some regions with specific properties (e.g., H ii regions) dominate the galaxy emission. The modeling of integrated spectra is thus often limited to a single cloud hypothesis (i.e., assuming that the physical conditions of a single cloud correspond to the average conditions of the galaxy). Specific diagnostics involving only a few tracers are sometimes considered to isolate a specific parameter (e.g., density measurements with optical [S ii] lines, ionization parameter, or metallicity; e.g., Kewley et al. 2019) or to isolate a specific region or phase (e.g., low-density ionized gas with far-IR [N ii] lines; e.g., Lee et al. 2019). Nevertheless, the derived conditions may not always represent a meaningful average galaxy value due to multiple nonlinear effects that produce integrated emission lines.
Possible ways forward include global approaches treating all observables coherently, such as what is done for the full spectral energy distribution (SED) with, for example, MAGPHYS (da Cunha et al. 2008) or BEAST (Gordon et al. 2016). While many tools are available to infer physical conditions from the SED (see review in Walcher et al. 2011), the treatment of emission lines is, however, not systematic and emission lines are sometimes included only to decontaminate observed photometry bands for full SED modeling (Burgarella et al. 2005). Using a large number of emission lines as constraints is a difficult task due to the complex, multiphase nature of the ISM. For instance, efforts are underway to consider photodissociation regions or molecular gas in CIGALE (Boquien et al. 2019). Concerning emission lines models specifically, efforts to treat many lines at once have been mostly focused on the ionized gas, including with modern statistical frameworks (e.g., BOND, Vale Asari et al. 2016; NebulaBayes, Thomas et al. 2019; and WARPFIELD, Kang et al. 2022). Still, some excitation mechanisms are often not considered (e.g., shocks and X-rays) and a single-sector approach is often preferred due to the quickly overwhelming number of free parameters and the difficulty in defining the distribution of parameters.
It is thus urgent to continue and build upon such efforts especially since multiwavelength and multiphase ISM studies in external galaxies have been facilitated by the advent of infrared space instruments enabling access to neutral gas tracers such as the Infrared Spectrograph (IRS; Houck et al. 2004) onboard Spitzer (Werner et al. 2004), the Photodetector Array Camera and Spectrometer (PACS; Poglitsch et al. 2010) onboard Herschel (Pilbratt et al. 2010) and airborne ones such as FIFI-LS onboard SOFIA (Fischer et al. 2018), as well as millimeter observatories that provide multiphase tracers at high-z (e.g., ALMA and IRAM/NOEMA).
Several projects have been undergone over recent years to infer physical parameters from IR and optical spectra of nearby galaxies. Studies focusing on low-metallicity dwarf galaxies from the Dwarf Galaxy Survey (Madden et al. 2013) pioneered the multiphase models of the ISM in external galaxies. We modeled simultaneously the ionized and neutral (atomic and molecular) gas with the photoionization and photodissociation code Cloudy (Ferland et al. 2013) while considering increasingly complex arrangements of regions with different characteristics. Since a realistic description of the ISM structure for a given galaxy is impossible to infer, simplifications are necessary. For instance, one can assume that the ionizing sources are cospatial. Assuming galaxies are dominated by one or a few massive H ii regions, our approach has then been to consider a stellar cluster surrounded by a small number of sectors defined by their covering factor (fraction of the total solid angle seen by the cluster), with the incident radiation field propagating into each – independent – sector. The various iterations are described in detail in Sect. 2. This approach had been devised by Péquignot (2008), who showed that difficulties in explaining Te([O iii]) in the dwarf galaxy I Zw 18 can be lifted using radiation-bounded condensations embedded in a low-density matter-bounded diffuse medium. Following the approach of Péquignot (2008), the principle is to constrain an ISM topology, which represents the relative contribution to the total integrated emission from discrete sectors having different physical conditions. In other words, same results will be obtained for a given topology representing different geometries (i.e., the way in which these sectors are distributed, intertwined, or split; Sect. 4.3).
In most cases, the number of available tracers and their different origins (e.g., ionized/neutral and diffuse/dense phases) require at least two sectors with different properties even when the integrated spectrum appears to be dominated by a single H ii region. In our studies, the reflected and diffuse light were not accounted for but the associated uncertainties are largely compensated for by improvements enabled by a multiphase/sector approach. While the ISM topology description above is adapted to H ii region-dominated galaxies, several efforts are underway to extend the sectors into a diffuse component and to combine several H ii regions. Our approach has been so far to combine a rather small number of discrete sectors, but another approach considers that the integrated emission-line spectrum effectively corresponds to an vast ensemble of clouds whose properties (i.e., distribution of density and distance to source) are described and linked through a specific parameterized law (e.g., power law; Richardson et al. 2014, 2016). The observed emission is then the result of strong selection effects due to the fact that some lines emit preferentially under some physical conditions.
As such models become increasingly complex, it is interesting to realize how they complement 3D simulations. While simulations do consider self-consistent and realistic ISM structures, the treatment of the radiative transfer is often too calculation-intensive. On the other hand, state-of-the-art radiative transfer codes (e.g., Ercolano et al. 2005; Bisbas et al. 2012, 2015; Jin et al. 2022) are difficult to scale to 3D (Morisset 2011, 2013) or even to adapt to multiple components since the exact distribution of matter and ionizing/energetic sources has to be predefined. Simulations and models could eventually meet halfway provided the latter are able to consider complex geometries. As the complexity increases (e.g., by increasing the number of sectors, stellar populations, or excitation mechanisms), however, it becomes important to implement a statistically robust method to identify high-probability regions in the parameter space. Previous efforts to model galaxies with multiple sectors and phases have mostly relied on χ2 methods, with several limitations described in Sect. 2. We have thus designed a new statistical framework to evaluate solutions in a multidimensional grid and to quantify confidence intervals in a multiphase/sector approach. The approach is close to NebulaBayes (Thomas et al. 2019) but here adapted to complex configurations with several sectors with varying escape fraction of ionizing photons, that is with high dimensionality and several continuous variables that can be implemented in a customized environment. The tool we present is agnostic to the grid of models used as input (i.e., it is possible to use grids from different photoionization codes or any grid for which sets of input parameters and output values can be tabulated). We present here ISM applications, with a focus on the low-metallicity dwarf galaxy I Zw 18. The latter has been extensively studied and open questions include in particular the amount and distribution of the elusive molecular gas.
We summarize the various steps and results using topological models of galaxies in Sect. 2. We then describe the new probabilistic method in Sect. 3 and present specific applications to ISM studies in Sect. 4. Benchmark results are presented in Sect. 5. Finally, we illustrate the use of the new method with the dwarf galaxy I Zw 18 in Sect. 6.
2 Modeling approach and previous results
In order to motivate the general approach presented in this study, we illustrate below recent progresses in the modeling approach with multiple phases and sectors (summarized in Fig. 1). The first step was to study spatially-unresolved emission lines in the dwarf galaxy Haro 11 (Cormier et al. 2012). We were able to construct a model with Cloudy that matches the flux of 17 IR emission lines. The full model implements the propagation of the radiation field into a single sector from a dense ionized gas into the photodissociation region (PDR). Since the model includes only one sector, the modeled “PDR covering factor” is one by definition. However, the model is constrained using only unambiguous H ii region lines and the predictions for the PDR lines [C ii] and [O i] are compared to the observations a posteriori to calculate an effective PDR covering factor. The model suggests that the PDR covering factor is about 10% in this galaxy. A diffuse ionized/neutral phase was included a posteriori to fully explain the emission of [N ii], [Ne ii], and [C ii]. Structure-wise, the volume filling factors of the diffuse component, H ii region, and the PDR are ≳90%, ~0.2%, and ≲0.01% respectively, hinting at a “porous” ISM (small filling factor of the dense phase) which could be linked to the relatively low-metallicity environment.
In Cormier et al. (2019), the technique was improved and applied to most of the DGS targets which were fully covered by the IRS and PACS spectrograph apertures (38 spatially-unresolved galaxies; Madden et al. 2013). The IR emission lines are modeled with two radiation-bounded sectors distinguished by their ionization parameter and densities. The PDR is assumed to be associated with the high-ionization parameter sector (i.e., the PDR is clipped from the low-ionization parameter sector). Possible PDR covering factor values, corresponding to a scaling factor of all PDR lines, are then tabulated along with other physical parameters (e.g., density and ionization parameter). Contrary to the iterative process to characterize the components needed in Haro 11, all sector parameter values are determined simultaneously. The main result shows that the PDR covering factor increases with metallicity, strengthening the result that the ISM porosity increases at low metallicity. However, it was not possible to convert this parameter into a fraction of escaping ionizing photons.
In Polles et al. (2019), we studied IR spectral cubes of the nearby (≈700 kpc) galaxy IC 10. The H ii region lines are modeled with a single sector, as in Haro 11, but the sector is allowed to be matter-bounded. As such, the physical depth of the sector is another free parameter in addition to cluster age, density etc. This new parameter allowed us to determine that regions are more and more radiation-bounded as the spatial aperture over which the emission lines are integrated increases. In other words, H 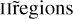 are systematically matter-bounded and the full optically body scale is mostly radiation-bounded. While this should translate into a similar conclusion for the escape of ionizing photons, the calculation of the latter was unfortunately not possible.
are systematically matter-bounded and the full optically body scale is mostly radiation-bounded. While this should translate into a similar conclusion for the escape of ionizing photons, the calculation of the latter was unfortunately not possible.
We have also examined IR emission lines in star-forming regions in the Magellanic Clouds (Lambert-Huyghe et al. 2022). The observations are spatially resolved and individual pixels are modeled with Cloudy with a single sector that can be matter-bounded. The particularity of the approach is that each Cloudy model is split between its H ii region and PDR counterparts and each pixel is modeled with a mix of these. As an illustration, a pixel can be a naked H ii region (matter-bounded) or a pure PDR with no associated ionized gas emission (reflecting the fact that the ionizing sources may be located in another pixel). Any combination in between is possible, but, for the sake of this specific project, the H ii region and PDR counterparts for any given pixel originate from the same Cloudy model.
Finally, the study of I Zw 18 (Lebouteiller et al. 2017) was inspired by the work of Péquignot (2008), with a conversion of the Nebu radiative transfer code to Cloudy, and with the inclusion of new IR emission lines, X-ray constraints, and dust treatment. Several sectors are used, some of them matter-bounded, and both optical and IR emission lines were used. While the model is relatively more complex compared to other efforts, the topology has not been inferred statistically but rather from a partly-manual and specific convergence process. Structure-wise, the model shows that the covering factor of the sector reaching into the molecular gas must be lower than ~0.1%, corresponding to subparsec size clumps, thereby confirming the low porosity of the ISM in an extremely metal-poor environment.
The studies described above allowed us to make considerable progress for ISM studies. As far as the technique is concerned, calibration uncertainties and other correlated uncertainties have been successfully accounted for with a covariance matrix. However, several limitations have been identified, concerning in particular the χ2 minimization technique to evaluate the solution and associated error bars. Firstly, upper limits were often ignored or else treated in a binary way (i.e., either the model is above or below the upper limit). Secondly, the number of degrees of freedom is difficult to estimate, even for linear models (Andrae et al. 2010), and some observations may trace the same physical parameter while a given observation may constrain several parameters (this difficulty increases when priors need to be considered). Degeneracy and correlation between parameters are generally difficult to account for. Due to the large number of free parameters and to the difficulty in assessing similar or degenerate solutions, it was difficult to consider combinations of more than two components (i.e., either dealing with more sectors and/or more stellar populations). Thirdly, the type of constraints (ratios and/or absolute values) and choice of tracers (ignoring or adding some tracers) often produce erratic probability density functions with solutions that are not compatible with each other within errors. Fourthly, the χ2 distribution is difficult to translate robustly into a confidence/credible interval. Finally, priors could not be used to inform the model of known quantities with uncertainties.
In the present study, we present a new probabilistic tool called MULTIGRIS1 to solve most of the issues above. The underlying objective is to derive automatically a configuration as complex as the one illustrated in Fig. 1e without the need to tabulate some parameters (in particular the mixing weight of components (i.e., their relative contributions) which can be treated as continuous variables instead. For a more general discussion of deterministic and Bayesian approaches in astrophysics we refer to Galliano (2022).
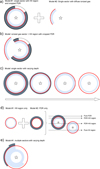 |
Fig. 1 Illustration of the topological configurations considered in previous studies. For each approach, we show the relative contributions of sectors each corresponding to a specific Cloudy model. These contributions are equivalent to the fraction of the total solid angle in 3D. The light blue shell corresponds to the ionized gas, the dark gray shell to the neutral gas, and the red arc to the photoionization front. In Cormier (2012) (a), the model used an H ii region connected with a PDR, with the PDR covering factor scaled a posteriori (cropped shell in white), and an additional model is considered a posteriori to account for the diffuse ionized gas. In Cormier et al. (2019) (b), two sectors are considered with the PDR associated only with the high-ionization parameter sector. In Polles et al. (2019) (c), models use a single sector with a varying depth. In Lambert-Huyghe et al. (2022) (d), observations are compared to a mix of pure H ii region and PDR components drawn from the same Cloudy radiation-bounded model. In Lebouteiller et al. (2017) (e), up to four sectors were considered with different depths. |
3 Methodology
3.1 General principle
The goal is to evaluate the posterior distribution of parameters from a multidimensional grid of individual precalculated models, with a series of observations (measured values with uncertainties) as constraints. Primary parameters that define a unique set of models are used for the inference, with each parameter value drawn from a Monte-Carlo Markov Chain (MCMC). Mixing weights may be used as additional inference parameters to combine model prediction sets. Predicted observations are then computed as a linear combination of prediction sets and compared to measured values accounting for their error bars (and potentially upper/lower limits). MULTIGRIS is completely agnostic to the grid of precomputed models used as long as predicted observations can be expressed as a linear combination of prediction sets. In practice, the code can therefore perform on any kind of grid for which input (primary) parameters and output values (predictions) are tabulated.
Although one would prefer to independently compute predicted values on-the-fly for each set of drawn parameter values, the computing time may be too long for a time-efficient MCMC sampling. In our approach, the sampler explores the grid of precomputed models either with nearest neighbor or linear interpolation and with several additional continuous variables (e.g., mixing weights for the relative contribution of components or any nuisance variables). The sampling process, which is required to draw continuous random variables such as the mixing weight or any nuisance variable, is much slower than algorithms such as NebulaBayes (Thomas et al. 2019), for which likelihoods are evaluated at a predefined number of grid points, with or without interpolation. Such “brute-force” algorithms remain ideal when the dimensionality is relatively low and/or when all combination of parameters can be precalculated and tabulated. The main advantage of the sampling is to consider continuous or discrete variables without the need to tabulate them and the ability to implement new on-the-fly distributions using the same input grid.
3.2 Inference
The Bayesian inference is performed with PyMC2 which implements and enables gradient-based MCMC algorithms in an intuitive and relatively abstract way (Salvatier et al. 2016). The predicted value for each observation i is defined as:
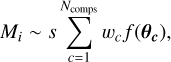 (1)
(1)
where f is a function that retrieves the predicted observation for any set of primary parameters from a grid using a given interpolation method, wc are the mixing weights of each component, θc are the primary parameters uniquely identifying a precomputed model in the grid, and the scaling factor s is described as a Normal distribution with mean µ and standard deviation σ:
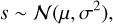 (2)
(2)
with
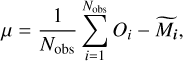 (3)
(3)
where Nobs is the total number of observations, Oi is the measured value of observation i and 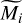 is the median of the predicted values for the corresponding observation, and
is the median of the predicted values for the corresponding observation, and
![Mathematical equation: $\sigma = \sqrt {{1 \over {{N_{{\rm{obs}}}} - 1}}\sum\limits_{i = 1}^{{N_{{\rm{obs}}}}} {{{\left[ {{O_i} - \widetilde {{M_i}} - \mu } \right]}^2}} } .$](/articles/aa/full_html/2022/11/aa43865-22/aa43865-22-eq6.png) (4)
(4)
By default, the model is scaled globally to match the set of observed values, making the scaling factor one of the inferred parameters (see Table 1 for the list of parameters used for inference). The use of the median of predicted values ensures that quantities do not reach large numbers while optimizing the computing time for sampling random variables.
The mixing weights are described as a Dirichlet distribution:
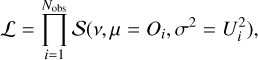 (5)
(5)
Primary parameters are described with Normal distributions truncated to the minimum/maximum values in the grid:
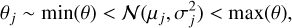 (6)
(6)
with µj the average parameter value in the grid and σj spans the entire parameter value range by default for a weakly informative prior when no user-provided prior is set. The model likelihood is calculated as the product of asymmetric Student-T distributions S centered on the observation for each draw of model values Mi:
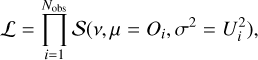 (7)
(7)
with v the normality parameter (with a default value corresponding to a Normal distribution) and Ui the asymmetric uncertainty on the observed value. The normality parameter v may be changed to account for outliers, but if there are no outliers, decreasing the normality parameter effectively increases the number of high-probability regions. The model is then allowed to scan wider ranges and find that other solutions are acceptable.
The posterior probability distribution for a given model M is then defined as
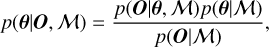 (8)
(8)
with p(O|θ, M) the likelihood, p(θ, M) the prior probability, and p(O, M) the marginal likelihood which integrates all parameter combinations:
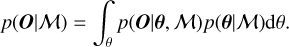 (9)
(9)
For lower and upper limits we use a half-Student-T likelihood with the same normality parameter v as for Eq. (7), with a default value corresponding to a Normal distribution. Systematic uncertainties on observations are treated as nuisance variables encompassing a set of one or several observations, distributed by default as a Normal distribution.
Priors on, or between, parameters are meant to be implemented in an intuitive way. Built-in priors currently allow constraining parameter values between components (e.g., value in component 1 lower than in component 2), constraining absolute parameter values as Normal distributions, upper or lower limits, and using literal equations binding parameter values to each other.
Summary of inference model parameters.
3.3 Input data grid
A model table is required with each row defining a unique pre-computed model prediction. The model table is then transformed to produce a grid spanning all possible combination of parameters. If some parameter combinations are not available, the invalid data is accounted for during the inference process with zero likelihood. A mask is used to track the regions where the modeled values are not finite, either due to grid completion (but also due to model upper limits).
A preprocessing script may be used to manipulate the grid before the inference step. This is useful, for instance to create new observations based on existing ones in order to be later used as constraints.
It is possible to upsample the grid, for instance with a linear interpolation. The inference (Sect. 3.2) enables on-the-fly interpolation for each MCMC draw but nonlinear interpolation that are calculation-intensive would need to be performed beforehand in order to generate a refined grid. The default grid interpolation method uses nearest neighbors, as it allows a relatively quick solution to be found. A multidimensional linear interpolation is also implemented that can be used for either all parameters or a subset. For performance issues the code samples fractional grid indices by default with nearest neighbor or linear interpolation but it is possible to force sampling real values instead.
The conversion of the initial model table into a multidimensional grid may produce many nonvalid values. For this reason, the linear interpolation often deals with an n-dimensional cell with nonfinite vertices. The current performance-driven workaround is to perform a discrete interpolation (upsample) in order to force the sampler to probe vertices instead of exploring around it. This is done by introducing a categorical random variable.
It is also expected that the grid is sampled well enough in each dimension so that the variation of the likelihood function across each grid node is accurately described with a linear interpolation (see an illustration and the discussion in Galliano et al. 2021). Potential solutions to better sample the likelihood function include computing new models possibly thanks to an adaptative grid, using a quadratic interpolation to force smooth variations of the likelihood function, or to perform a linear regression using Machine Learning techniques (Morisset et al. in prep.).
As for all grid search algorithms, there can be some edge effects. The inference model needs to probe around the high probability regions, and if the latter happen to lie on the edge of the grid or on the edge of an invalid data region (which is more likely to occur as the number of dimensions increases), the posterior mean will be slightly offset from the edge even if the maximum likelihood lies in principle at the edge. Edge effects can be mitigated in part by using the median or the mode of the chain.
Finally, the inference is performed on the primary parameters themselves by default, but it is possible to consider power-law, broken power-law, normal, or double-normal distributions instead. In such cases, the slopes and pivot point (power-law distributions) or means and standard deviations (normal distributions) as well as lower- and upper-boundaries are described as random variables.
3.4 Sampling methods
Several MCMC step methods are implemented in PyMC, some of which we have benchmarked for our purpose. The Sequential Monte Carlo (SMC) sampler is a method that progresses by a series of successive annealed sequences from the prior to the posterior. The PyMC implementation is based on Ching & Chen (2007) and Minson et al. (2013). The No U-turn sampler (NUTS) works on continuous variables with Hamiltonian mechanics (Hoffman & Gelman 2011). Other methods include Metropolis-Hastings (e.g., Robert 2015) and Adaptive Differential Evolution Metropolis, the latter which uses the past chain values to inform and generate jumps (ter Braak & Vrugt 2008). Other methods may be investigated in the future.
Random walkers such as NUTS need long enough chains to authorize excursions either to or from the high-probability region. In comparison, SMC identifies the high-likelihood regions by running in parallel a large number of chains starting from random values sampled from the prior distribution. Among the many advantages of SMC, it can sample from distributions with multiple peaks and does not have a burn-in phase. Random walkers are more likely to be stuck around one peak. While several methods have been included in MULTIGRIS, the envisioned use for ISM studies implies that the probability distribution is expected to be multipeaked and we thus describe the SMC method further below.
SMC uses a combination of various techniques, with in particular tempered likelihoods and importance sampling. The tempered posterior is proportional to the product of the tempered likelihood and the prior. For a given model M this translates as
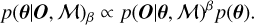 (10)
(10)
SMC first samples the prior (β = 0), calculates a new β value to match a predefined effective sample size (by default half the number of draws), computes importance weights using the tempered likelihood p(O|θ, M)β, computes a new set of samples by resampling according to importance weights, computes the mean/covariance of the proposed distribution, runs relatively short (on the order of a few to a few dozens) independent Metropolis-Hastings chains from the proposed distribution to explore the tempered posterior. The importance weights increasingly account for the likelihood as the stages increase. The stages continue until the true posterior is sampled (β ≥ 1). The overall process is illustrated in Fig. 2.
Since SMC samples a large number of chains exploring the entire parameter space instead of a single chain, it is important to have enough samples to probe the prior parameter space. Furthermore, since each individual chain walks with independent Metropolis-Hastings, it is in principle possible to have only few samples per parameter but better results are obtained when using a large number of chains per parameter combination to either obtain an average probability density function (PDF) if the chains have significantly different distributions and/or to evaluate whether all chains have converged to the same distribution. While the number of samples may seem appropriate for the considered prior distribution, they also need to be numerous enough to probe the posterior distribution, which may show multiple peaks. If a small number of samples is considered, this may lead to significant stochasticity between independent model runs. SMC runs several jobs in parallel, and in the following we always show the combined chain result. The inference result contains the posterior distribution of the parameters, which are then processed for further analysis.
 |
Fig. 2 Illustration of Sequential Importance Resampling Particle Filter. From top to bottom, the distribution is sampled from the prior, reweighted and resampled according to the tempered posterior density. Surviving samples seed new Markov chains and walk through a number of Metropolis steps. |
3.5 Component identification
When the configuration requires more than one component, an important postsampling step is to identify them. By default, drawn values of primary parameters (used for the inference) are not assigned to any specific component (i.e., components are not explicitly identified or tied to any given parameter or parameter set). This is meant to assert whether inferred parameters have indeed significantly different values between each component. If parameter values are not significantly different between components, the components are thus allowed to switch back and forth while the solution should remain stable (specifically, for the NUTS/Metropolis samplers this means that draws may switch with time, while for the SMC sampler this means that each draw at any given stage may probe any component).
If the main objective is to derive PDFs of secondary parameters (those not used for inference and calculated in the postprocessing step; Sect. 3.8), there is no need to identify explicitly each component. Nevertheless, if the parameter value for each component is difficult to disentangle, some samples may be wasted to switch from one component to the other and the probability distributions may not be as smooth as possible.
In some cases, it may be interesting to examine the posterior distribution of primary parameters for each component individually. MULTIGRIS performs a processing step to identify and characterize individual components from the chain, by redistributing components through a minimization of the standard deviation for all parameters for individual chains and components (Fig. 3). This is an iterative process, redistributing components for each draw along the entire chain several times. This redistribution bears some uncertainties and the individual component properties may still have some level of degeneracy. The global solution (combination of the components) is, however, not affected by the redistribution of components since all parameters are switched together.
Depending on the solution, it may be difficult to redistribute components a posteriori, which may indicate a need for more constraints. For this reason, it may be useful to force the identification of components a priori. In MULTIGRIS, components can be sorted using a prior constraint on any given parameter. Sorting with a prior constraint will obviously affect the inference, and the result will be different depending on which parameter is used for sorting.
 |
Fig. 3 Posterior distribution of parameters for a model with two components. One parameter (age) has been purposefully forced to be the same of the two components. The raw posterior distribution is shown on the left, for which the two components may switch during inference, and the final result is shown on the right, in which the individual component parameter values have been redistributed a posteriori. For visual purposes only a subset of the parameters are shown. |
3.6 Diagnostics
PyMC automatically returns useful statistics for each parameter (e.g., effective sample size, autocorrelation, Gelman–Rubin convergence test using multiple chains, and marginal likelihood for SMC). Several diagnostics are available in particular to check the model convergence. To calculate the final posterior distribution, we draw a random set of values from the chains (and, depending on the step method, removing the tuning steps). We also compute posterior predictive p-values for each parameter and for all parameters combined following the method in Galliano et al. (2021). Figures 4–5 provide some illustrations of some available diagnostic plots (see also Sect. 6).
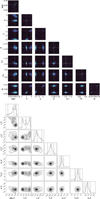 |
Fig. 4 Example of results for a 2-component model. The kernel density estimate (nonparametric method to estimate a PDF) is shown on top and a corner plot for one of the two components on the bottom. We note that some parameters have been forced to have identical values for the two components. |
3.7 Model selection and comparison
Model selection methods in PyMC include WAIC (widely-applicable Information Criterion; Watanabe 2010) and LOO (Leave-one-out cross-validation; Vehtari et al. 2017). LOO cross-validation, in particular, repeatedly extracts a training set to fit the model and evaluates the fit using the remainder data. Approximations based on importance sampling make it possible to perform the iterations without having to refit the data.
The SMC sampler also provides the marginal likelihood p(O|M) (Eq. (8)), that is the probability of the observed data given the model (where parameters are integrated out). While the χ2 asymptotically reaches a minimum value when the number of components increases, reflecting the fact that the fit does not improve significantly anymore (the reduced χ2 is difficult to estimate; Sect. 2), the marginal likelihood reaches a maximum and decreases as the number of potential solutions increases through the larger number of components (see details in Sect. 5.2). Even though increasing the number of components increases the number of potential solutions, such models become less and less likely as the overall number of parameter sets increases (spreading the prior), implying that the probability of the data given the model decreases.
To compare models, we are eventually interested in computing for each model:
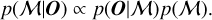 (11)
(11)
One can then compare models directly with different priors or models with a different number of components by using the marginal likelihood p(O|M) as long as models have the same a priori probability p(M) under all circumstances.
Model comparison may be used to select one preferred model or to combine models through averaging:
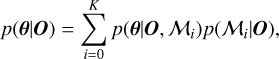 (12)
(12)
where K is the number of models. An alternative to weighing through the marginal likelihood is to use information criteria methods such as WAIC or LOO with the Akaike weight for a model i as
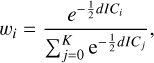 (13)
(13)
with dIC = −2 × elpdLOO,WAIC where elpd is the expected log pointwise predictive density for either LOO or WAIC.
 |
Fig. 5 Example of the posterior distributions for the primary parameters (two leftmost columns) and for the observations (two rightmost columns). For each quantity, the left plot shows the PDF (with the vertical line indicating the reference measured value for observations), and the right plot shows the sequence of samples. For these plots individual jobs are combined. We note that some parameters have been forced to have identical values for the two components. |
3.8 Postprocessing
Primary parameters, that uniquely define precomputed model predictions in the grid, are the ones used for inference. From the posterior distribution of primary parameters, we can obtain the corresponding distribution for any other parameter in the grid. The postprocessing step uses the PDF of primary parameters in order to deduce secondary parameters that completely depend on the primary parameters, or new observations that were not used as constraints. The semantic distinction between new observations to predict and secondary parameters is only due to the assumption that secondary parameters can never be observed.
4 Application to ISM studies
While MULTIGRIS is agnostic to the grid of precomputed models, it has been initially designed for the purpose of combining ISM components corresponding to sectors around stellar clusters or to several clusters surrounded with one or several sectors. In that vein, the mixing weight described in Sect. 3.2 is interpreted as the integrated covering factor of lines of sight (or equivalently as the fraction of the total solid angle) corresponding to the same 1D model. More complex configurations are described in Sect. 4.3. If a single cluster is considered with several ISM components, we refer to the components as sectors in the following.
Other configurations can also be considered, for instance considering a large number of clouds whose parameters are linked with a distribution (e.g., power-law and normal; Richardson et al. 2014). In the latter cases, the distribution parameters (e.g., slope and boundaries) need to be inferred (instead of primary parameters for a discrete number of clouds/components). It is of course possible to simply tabulate the statistical cloud distribution parameters as a preprocessing step but the ability to infer these parameters on-the-fly through the sampling process of continuous random variables makes it easier to consider many dimensions (e.g., varying the lower- and upper-boundaries).
Although MULTIGRIS can consider power-law or normal distributions, we illustrate here the applications for a multi-sector approach building on previous works using the same approach. Following our previous efforts, we consider that star-forming dwarf galaxies are dominated by one or a few giant H ii regions. The ISM topology is then defined as a group of sectors around a given cluster including thermal and possibly nonthermal sources.
MULTIGRIS includes by default part of the publicly available BOND database (Vale Asari et al. 2016) and a specific model database calculated with the photoionization/photodissociation code Cloudy (SFGX; Ramambason et al. 2022). The SFGX database is especially adapted to low-metallicity ISM studies and includes predictions for UV to IR emission lines and X-ray sources. This model database consists of a table with each row corresponding to a specific model outcome computed with Cloudy (Ferland et al. 2017). Primary parameters defined in MULTIGRIS are the luminosity and age of the stellar cluster, the luminosity and temperature of a potential X-ray source, the ionization parameter, the gas density, the metallicity, the dust-to-gas mass ratio, and the physical depth of the cloud. Secondary parameters include in particular masses of dust and of various gas phases as well as the escape fraction of ionizing photons. We briefly describe the database below with the details available in Ramambason et al. (2022).
4.1 Cluster properties
Stellar clusters are defined by their age and luminosity, as well as the temperature/luminosity of a potential X-ray component. The latter is described by a multicolor blackbody parameterized by the temperature at the inner radius of the accretion disk and by the total luminosity.
We consider Cloudy runs with a 107 or 109 L⊙ cluster. A single scaling factor is used to match the observed fluxes (the scaling factor may use all observations like in Cormier et al. 2019 or a single observation, such as the total IR emission). The scaling factor together with the model luminosity provide the effective luminosity. This means that a 1010 L⊙ galaxy is effectively considered to be a sum of a thousand 107 L⊙ or ten 109 L⊙ H ii regions rather than a 1010 L⊙ H ii region. These two reference luminosities are considered to avoid variations due to shape and degeneracies between luminosity and scaling factor (filled sphere vs. thin shell; see Ramambason et al. 2022).
There is no degeneracy between the stellar luminosity and the scaling factor used to reproduce the lines, since the relative line fluxes do change with luminosity while the scaling factor simply scales up or down all lines from the inferred luminosity. Line ratios are not affected by the scaling factor, contrary to topological factors like the depth of each sector (Sect. 4.2).
4.2 ISM properties
The ISM properties for each sector are defined by the density, ionization parameter, and cloud depth. The density parameter is set by the density at the illuminated front. The density profile is then constant until the ionization front and then scales with the total H column density.
An ISM parameter of interest to study the neutral gas, low-ionization H ii region species, or the escape of ionizing photons is the physical depth of the shells. We need a general definition for the depth cuts that applies to all models, in particular because the scaling of parameters such as visual extinction AV as a function of depth varies depending on metallicity. We introduce in the SFGX model database a “cut” parameter whose variation depends on observables, described as
cut = 0: inner radius (illuminated edge).
cut = 1: H+−H0 transition (i.e., ionization front; electron fraction 0.5).
cut = 2: H0−H2 transition (photodissociation front; molecular gas fraction 0.5).
cut = 3: C0−CO transition (photodissociation front; molecular gas fraction 0.5).
cut = 4: full depth corresponding to stopping criterion AV = 10.
Fractional cut values are considered by sampling the extinction AV profile. With this definition, radiation-bounded models have cut ≳1. The last cut value is somewhat less trivial as the corresponding stopping criterion is the maximum model AV = 10 which vary dramatically between models with different metallicities.
4.3 ISM topology
Possible configurations enabled by MULTIGRIS include any combination of components, either as a discrete number of sectors around several clusters with the inferred mixing weight defining the relative contribution of each sector or as a statistical distribution of clouds parameterized by, for instance, a power-law or a normal distribution. In the following, we focus on a discrete number of sectors.
The contexts enabled by MULTIGRIS make it possible to use predefined sets of priors, for instance, one cluster (defined by the age of the stellar population and by the X-ray source properties) surrounded with n sectors (possibly matter-bounded), a set of n clusters each associated with one sector (in practice, we mix models with different stellar population ages and/or different X-ray source properties), or a combination of several clusters and several sectors around each cluster. When several sectors are considered, their covering factor is not tabulated a priori, contrary to Cormier et al. (2019). It is instead inferred on-the-fly through the mixing weight continuous random variable.
Figure 6 shows an illustration of inferred mixing weights. The default representation is simply a pie chart indicating the contributions of each sector that is the fraction of solid angle around the cluster that corresponds to a given sector. Another representation randomly distributes the sectors around the cluster according to their covering factor and reflects the fact that the ISM topology alone is constrained and that all the random distributions of sectors (different geometries) are thus equivalent. Finally, it is possible to illustrate a 3D distribution by creating a spherical random map to distribute all sectors based on their covering factor and by populating a line emissivity cube with each line of sight from the cube center toward a given angle corresponding to a given sector. The projected result is shown in Fig. 6.
A caveat exists when dealing with two sectors including one with negligible flux contribution for all lines (e.g., very small depth). There is then a degeneracy between the covering factor of the main sector and the model scaling factor. This is important only for parameters that heavily depend on the topology (see also Sect.5.3). This problem is exacerbated if using a single observation that arises mostly from one sector. For these reasons, it is advised to check whether a second sector is in fact necessary through model selection methods (Sect. 3.7).
As discussed in Ramambason et al. (2022), the overall topology and the depth of each sector may have a significant impact on the metallicity and SFR determinations, and an even stronger impact on the escape fraction of ionizing photons (see also Sect. 5.3). The escape fraction is constrained by line ratios from tracers originating at various depths and also depends on the total cluster luminosity determination (Sect. 4.1).
 |
Fig. 6 Configuration of inferred sectors for an example model. Top: the left plot shows the integrated covering factors while the right plot shows the same topology but with a different, random, geometry. The color scales from yellow to red as the gas volume density increases. Different inner radii indicate different ionization parameter (U) values, with dotted arcs showing U = 0, 1, …. The gray arcs show the photoionization and photodissociation fronts. The depth is not drawn to scale. Bottom: sectors are distributed randomly in 3D according to their relative covering factors and then projected in 2D. Screening/extinction effects are ignored. Stars are added for visual purposes only. |
4.4 Observations
Any spectral line or photometric band can be used as observational constraint as long as Cloudy is able to compute it. The SFGX database includes several hundred tracers mostly in the optical and IR domains. While extinction-corrected fluxes can be used as constraints, MULTIGRIS may include extinction or attenuation law parameters as random variables, therefore consistently matching observations and models. This is especially useful when comparing optical and IR datasets because optical datasets only consider extinction within the layer from which optical lines arise while IR datasets may probe more embedded regions.
Nuisance variables can be added to reflect systematic uncertainties on observations. For instance, a systematic uncertainty can be considered for elemental abundances. On first order, line fluxes scale with the elemental abundance for small variations that do not modify significantly the physical conditions (e.g., cool ingrates; see Cormier et al. 2019) and a systematic factor can thus be used to scale all species of a given element. Other nuisance variables may consider calibration errors between several groups of tracers.
Several observation sets can be defined with some tracer potentially appearing in several sets (e.g., observed with different instruments and requiring a different scaling factor). As new observations become available, it is therefore possible to update the posterior distributions.
5 Benchmark
MULTIGRIS is designed to run on standard multicore personal computers, with the ability to use large grids. The SFGX grid currently contains more than a billion values and can be read in less than a second.
With the SMC sampler, relatively short individual chains are sampled with independent Metropolis-Hastings (Sect. 3.4). Depending on the parameter variation across the grid, the minimum number of chains per parameter may range from two to a few. From our benchmark studies, good results are obtained with the SFGX context with about two chains per parameter. For a configuration with a single cluster with two or three matter-bounded sectors, this translates into a few 103–4 samples. The inference time scales with the number of parameters to explore, and, to a somewhat lesser extent, with the number of observations due to the likelihood calculation.
5.1 Multimodal solutions
A common issue with ISM grids is the existence of multiple potential solutions across the grid. Random MCMC walkers are not particularly adapted because the sampler may not be able to probe multiple peaks if the latter are too distant from each other, unless the chain is sufficiently long. On the other hand, the SMC step method initially samples from the prior and is able to probe multiple peaks through the convergence process to the posterior distribution (Sect. 3.4).
We show in Fig. 7 a model run with the SMC and NUTS samplers with similar execution time. The grid was modified to introduce a degeneracy for the age and metallicity with two equivalent solutions. SMC is able to explore the two peaks in the posterior distribution while individual chains in NUTS may be stuck to one or the other peak.
 |
Fig. 7 Benchmark model run with a degeneracy artificially introduced for the age (idx_age_0) and metallicity (idx_Z_0). The SMC step method is shown on the left (each individual line corresponding to a given job) and NUTS on the right (each line corresponding to a given chain). The x-axes in the two columns have different ranges. |
5.2 Number of sectors
Another common issue with multisector models is to estimate the most likely, or at least minimum, number of sectors required. Model comparison metrics help in making a choice to estimate how many components are necessary (Sect. 3.7). One can either choose a frequentist tests by computing likelihood ratios (testing how well the models explains the data using the most likely parameter set) or hypothesis tests by computing the marginal likelihood (testing how much belief one should have in each model given the data and the priors). In Cormier et al. (2019), the decision was based on the χ2 value but this only indicated the minimum number of sectors to obtain a satisfactory agreement between observations and models, that is from a pure frequentist point of view.
In principle, the marginal likelihood reaches a maximum for the most likely number of sectors given the data and the priors. In other words, a higher number of sectors is less likely to reproduce the data because the latter is overfitted. In that vein, the Bayes factor, which computes the marginal likelihood ratio is a useful metrics, but the actual probability we are interested in to compare models is p(M|O), which supposes the knowledge of the overall a priori probability of the model, p(M) (Sect. 3.7).
Another model comparison method is to run a model with n sectors and infer whether up to n − 1 sectors can be ignored by setting their covering factor to zero during inference. The n − 1 sectors that can be ignored are described with a categorical random variable. This allows for an on-the-fly estimate of the most likely number of components, with the advantage of inferring a probability for each number of components. On important caveat though is that this method is adapted only in cases when potential additional sectors do not change significantly the properties of the other sectors in order to prevent erratic jumps during inference.
In Fig. 8, we show a benchmark test for estimating the number of sectors. We start from a model with a given number of sectors (from one to three) and run the MCMC model fixing the number of sectors from one to three. We also show the results when letting the number of sectors free (but limited to two or three). One can see that all metrics (LOO, WAIC, SMC marginal likelihood) reach a maximum for the expected number of sectors. When the number of sectors is itself allowed to vary, the expected number is inferred (obviously as long as the maximum number of sectors is enough). We note that such methods are reliable only if (1) all models have passed the burn-in phase (for random walkers), (2) all chains have converged toward an identical solution, and (3) there are significantly more observations that parameters. Furthermore, we made the implicit assumption that there is no intrinsic reason to prefer any specific configuration for all possible combinations of parameters and data (i.e., p(M) is the same for all models).
While the benchmark test performs as expected, the application for ISM components is much less straightforward. Models are supposed to represent any given number of sectors around a single cluster or possibly even several clusters (Sect. 4.3). However, depending on the complexity of the dataset (e.g., observations coming from different phases) and the complexity of the studied object (e.g., single H ii region or a full galaxy) the model may not be fully adapted a priori, resulting in posterior probabilities that need to be regarded with caution. Moreover, models may not have the same a priori probability p(M). For a multisector approach, p(M) can be somewhat subjective and cannot be computed rigorously since we know the model does not correspond to the reality of a galaxy or a stellar cluster. At the very least, p(M) is expected to be low for a single sector with a given density/pressure profile.
The systematic uncertainties related to the model description as a few sectors may motivate the use of more statistically appropriate models with a large number of clouds whose physical conditions can be parameterized. In that vein, it is important to consider and compare various types of distributions (Sect. 6).
5.3 Influence of topology on parameters
While it is possible to compare models with different number of sectors based on the available observations (Sect. 5.2), it must be noted that some parameters are particularly sensitive to the number of sectors used. First and foremost, it is generally assumed here that all sectors contribute significantly to the emission of at least one tracer. This is to avoid having to consider an empty or unconstrained sector (model with holes), which would effectively change the covering factors of the other sectors. If we were to assume empty sectors, it is possible to calculate the effective total covering factor of nonempty sectors provided the input stellar cluster luminosity (i.e., the bolometric luminosity) is constrained independently (Sect. 4.3). In the following we always assume only nonempty sectors.
Figure 9 shows the variation of inferred parameters as a function of the number of sectors used for the same series of typical benchmark models as in Sect. 5.2. When the true solution corresponds to a single sector, using a model with two or three sectors does not change significantly the parameter values except for the escape fraction of ionizing photons. However, such models become more and more unlikely as the number of sectors increases. Similarly, using three sectors for a true solution with two sectors leads to a good agreement with expected results, this time even for the escape fraction. More generally, using a larger than necessary number of sectors usually does not impact significantly the results except for the escape fraction in some cases. On the other hand, using a lower than necessary number of sectors may result in significant differences for all parameters, but keeping in mind that the model is likely unsatisfactory (Fig. 8). In summary and unsurprisingly, the parameters which depend the most on the topology are the ones which depend on the depth of each sector, that is the escape fraction of ionizing photons but also the mass of H2.
 |
Fig. 8 Model comparison to estimate the number of sectors required. We show models with an input of one, two, and three sectors from left to right. In the top panel we show the log values of LOO, WAIC, and the SMC marginal likelihood (“lml”) for MCMC runs with a number of sectors from one to three. In the middle panel we show the likelihood weights (not to be confused with the mixing weight) of each sector when the number of sectors is allowed to vary. Each horizontal line corresponds to a model with the number of sectors allowed to vary up to two or three. For each horizontal line, the filled circles show the inferred weight and the circled one highlights the number of sectors with the largest weight. In the bottom panel we show the fraction of draws that agree with the observed value within 2- and 3-σ. |
5.4 Selection of observations
In Figs. 10–11 we show a benchmark test analyzing the evolution of the solution with an increasing number of lines. For this illustration, the series of lines we consider is sorted based on their detection or potential detection in high-z sources. The first set of three lines includes [C ii], [O iii] 88 µm, and [O i] 63 µm. We then add [N ii] 205 µm and [O i] 145 µm, then [Ne ii] 12.8 µm, [Ne iii] 15.6 µm, [N iii] 57 µm and [Ar ii] 7 µm, then [Ar iii] 9 µm, H2 17 µm, [Si ii] 34 µm, and [Ne v] 14 µm. As the figures show, the solution naturally improves with the number of lines considered. In the radiation-bounded case (eight parameters; Fig. 10), a satisfactory solution is found even with three lines. For the matter-bounded case (ten parameters), for which there is an added degeneracy due to the inclusion of the depth parameter, a satisfactory solution is found with nine lines.
While it may seem that considering as many lines as possible would be the best option, there are several important caveats to take into account when dealing with actual observations. Since one is looking for an approximate/simplified topological model, it is may be somewhat illusory to search a model that will reproduce many observations at once. There is a risk of diluting the actual solution if the configuration is not adapted and/or if the systematic uncertainties (e.g., instrumental, atomic data, and abundances) are not properly accounted for. For instance, a model may be controlled by the likelihoods of a subset of many observations corresponding to lines arising in similar physical conditions – though in slight disagreement – at the expense of other few observations constraining potentially interesting/complementary parameters. Furthermore, outliers or observations with abnormally small error bars may produce a pathological posterior with local probability peaks where the sampler gets stuck (either preventing excursions for random walkers or affecting the computation of important samples for SMC). Unfortunately, this prevents the sampler from exploring other regions in the parameter space and, as a result, the sampler may be stuck in a global (all observations combined) low-probability region. Inversely, this also means that a global high-probability region may be dominated by an outlier or and observation with an abnormally small uncertainty. The 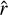 diagnostic (comparing means and variances of chains; Vehtari et al. 2021) may be useful to examine whether one observation dominates the likelihood calculation.
diagnostic (comparing means and variances of chains; Vehtari et al. 2021) may be useful to examine whether one observation dominates the likelihood calculation.
Since these issues intrinsically depend on which observations are considered and with what uncertainties, the Bayesian approach by itself does not perform necessarily better than the χ2 approach and great care must be taken to adapt the model configuration to the set of observations and to account for all possible systematic uncertainties. Nevertheless, we can use the PDF to analyze the dependencies between parameters and predicted observations. Once the sampler converges, the values drawn according to the primary parameter PDFs make it possible to investigate correlations between parameters, between parameters and predicted observations, and between predicted observations themselves. With this in mind, it may be useful to include all available observations at first and, (1) identify observations that are not well reproduced in order to consider potential missing systematic uncertainties and/or incorrect model assumptions (e.g., number of parameters and specific configuration), (2) check if some observations effectively constrain at least one parameter, and inversely, if every parameter is constrained by at least one observation, and (3) check if some observations constrain the same parameter(s), in which case redundant observations may be removed to prevent that the likelihood is controlled only by few parameters without changing significantly the solution.
Figure 12 shows the map of the correlation coefficients between predicted observations for a given run. For each set of two observations, we compare the correlation coefficients with each parameter for all MCMC draws (i.e., around the solution). The final correlation coefficient between the two predicted observations is zero if the two predicted observations constrain entirely different parameters and one if the two predicted observations constrain precisely the same parameters. The correlations do not account for the observed values/uncertainties and are calculated using the input grid values. Nevertheless, they may help in choosing an optimal set of observations.
 |
Fig. 9 Output parameters for the benchmark model comparison. We show models with an input of one, two, and three sectors and for radiation-bounded (“rb”) or matter-bounded (“mb”) template models. Each plot shows a standard boxplot configuration with the median value in red, with the box spanning from the first to third quartile, and the horizontal gray bars extending to 1.5 times the inter-quartile range. Faint open circles show the data that extend beyond the horizontal gray bars. In each panel we show the results forcing the number of components from one to three. The two top panels show the marginal likelihood (“lml”) and the likelihood while the other panels below show several parameters (from top to bottom the number of ionizing photons, the mass of H+, the mass of H2 traced by CO, the mass of H2 traced by C+, the X-ray luminosity, the metallicity, and the escape fraction of ionizing photons). The horizontal lines show the expected value, except for the marginal likelihood where it indicates the highest value. |
 |
Fig. 10 Evolution of the solution with the number of lines considered for a benchmark run. Each row corresponds to a parameter, and each column represents a different number of lines from three to 13 ([C ii]+[O iii] 88 µm+[O i] 63 µm, +[N ii] 205 µm+[O i] 145 µm, +[Ne ii] 12.8 µm+[Ne iii] 15.6 µm+[N iii] 57 µm+[Ar ii] 7 µm, +[Ar iii] 9 µm+H2 17 µm+[Si ii] 34 µm+[Ne v] 14 µm. The horizontal black lines indicate the expected solution. The model used here is radiation-bounded. |
6 Modeling of the low-metallicity star-forming dwarf galaxy I Zw 18
The low-metallicity star-forming dwarf galaxy I Zw 18 has been extensively studied with topological models in Péquignot (2008, hereafter P08) and Lebouteiller et al. (2017, hereafter L17). Among the most pressing questions concerning this object are the amount and distribution of the molecular gas and the influence of the known bright X-ray source on the ISM properties.
We use the SFGX grid (Sect. 4) with a linear interpolation for the metallicity and luminosity parameters. The interpolation is particularly useful for the luminosity which is not well sampled with only two values (Sect. 4.1). Output parameter values are provided as the median and highest density intervals with 94% confidence level. The full list of observations used is shown in Table 2. We note that the observed values for IR lines have been completely revised in L17 compared to P08, but these lines had not been used for the convergence process in the latter. Furthermore, the fluxes used here are tailored to the study of the NW H ii region in I Zw 18 and differ slightly from the uniform dataset used for the DGS sample in Ramambason et al. (2022).
 |
Fig. 12 Map of the correlation coefficients between predicted observations for a benchmark run. Here one can see that, according to the input grid, most H lines trace the same parameters around the solution (the same applies to He or [S ii]). |
6.1 Reproducing the modeling strategy of Péquignot (2008) with optical lines: Model MI,opt
We first build model MI,opt to illustrate how MULTIGRIS may reproduce the results in P08 with the use of a general photoionization grid. P08 used an iterative and partly-manual convergence process specifically tailored to I Zw 18. The observed spectrum used in P08 is close to Izotov et al. (1999) but includes a correction from E(B − V) = 0.08 to 0.04, which in turn provides a different value and a constraint on the Hα/Hβ ratio as compared to Izotov et al. (1999).
While P08 used 12.97 Mpc for the distance, we use here 18.2 Mpc (Aloisi et al. 2007) to be consistent with L17. Predicted physical quantities in P08 are modified accordingly here. Contrary to P08 we use error bars as they are naturally required to produce random draws in the MCMC process. In order to prevent the sampler from being stuck in local high-probability regions (Sect. 5.4), we introduce a default minimum 10% error on all lines.
Instead of using the [S ii] line ratio as a specific observation to constrain the density around the ionization front as in P08, we use the absolute fluxes of all lines including both [S ii] lines. The lines used for inference depend on the densities at various depths, which all translate into a constraint for the density at the illuminated front, which is the only parameter defining the density (Sect. 4.2). While we could use the known X-ray luminosity (Kaaret & Feng 2013) and dust-to-gas mass ratio (Galliano et al. 2021) in I Zw 18 as observed values together with the spectral line fluxes, we chose to predict them instead and compare them with observations a posteriori.
The helium abundance in the SFGX database is He/H = 0.098 and does not scale with metallicity. We tentatively scale all helium line intensities using a nuisance variable with the assumption that (1) on first order all line fluxes scale with the abundance as long as the scaling factor is small enough and (2) the chemical and physical conditions of the model are not significantly impacted by the abundance variation. In all results below, we find He/H between 0.07 and 0.08 for all runs, compared to 0.08 used in P08. Helium is the only element for which we force the abundance. The other elemental abundances scale with O/H depending on several prescriptions described in Ramambason et al. (2022).
Since our goal is to compare to P08, we first use a similar three-sector configuration with an identical inner radius for all sectors, with no prior. We allow the cloud depth to reach slightly beyond the ionization front in order to fully consider the ionized layer. The primary parameters that we use for inference as well as predicted (secondary) parameters are listed in Table 3.
We show the comparison between the observations and the predictions of model MI,opt in Table 2 and Fig. 13. Results for parameters are shown in Table 4. P08 derived one sector as a matter-bounded “veil” with covering factor (CF) 44% to account for the fact that absorbing gas is expected for any line of sight from the cluster, best corresponding to our sector #1, one sector as a matter-bounded sector with CF = 30%, best corresponding to our sector #2, and one sector as a radiation-bounded sector with CF = 26% best corresponding to our sector #3. The inner radius in model MI,opt is 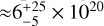 cm as compared to a fixed value of 5.6 × 1020 cm in P08 (18.2Mpc). Sector #1 contributes little to the total line emission but contributes significant fraction of He ii 4686Å, which is the brightest line in this sector (Fig. 14), as in P08.
cm as compared to a fixed value of 5.6 × 1020 cm in P08 (18.2Mpc). Sector #1 contributes little to the total line emission but contributes significant fraction of He ii 4686Å, which is the brightest line in this sector (Fig. 14), as in P08.
We find good agreements for the number of ionizing photons go and the ionized gas mass M(H+) compared to P08. The escape fraction is calculated using the ionizing continuum output from Cloudy and is also in good agreement, although it is by far the parameter with the largest relative uncertainty. In P08, the fraction of photons absorbed within the H ii regions, Qabs/Q, was estimated a priori to be 0.37 ± 0.03 and at least 0.30 based on the observed vs. expected Hα emission and assuming that all ionizing photons are eventually absorbed in the galaxy. This leads to an expected escape fraction fesc ≈ 63% and at most 70% for the H ii regions and the best models in P08 agree with these values. The escaping photons are responsible for the diffuse Hα halo emission in the galaxy.
While the dust-to-gas mass ratio has little impact on the predicted emission lines in the H ii region, it is interesting that the model is still able to recover the expected value. The range of [−1, 1] for Zdust corresponds to the 95% envelope around the median relationship of Zdust vs. Zgas in Galliano et al. (2021). I Zw 18 lies only slightly above the median relationship in that study while the SFGX models are allowed to reach up to five times below or above (Table 3).
The X-ray luminosity we infer is difficult to compare to P08. In P08, a stellar radiation field including an ad-hoc EUV component was used and an X-ray blackbody was added to explain the neutral gas emission lines. The stellar model BPASS (Eldridge et al. 2017) does not have enough energy in the EUV range to explain the He ii emission so there is a need to include the X-ray multicolor blackbody model from the SFGX database.
Relatively, He ii is the main line emission in sector #1 (Fig. 14). The X-ray luminosity we derive, 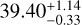 (log erg s−1), agrees with the value measured by Thuan et al. (2004), ≈39.48, with Chandra in the 0.5–10 keV range. It is somewhat lower than the XMM-Newton value in Kaaret & Feng (2013) of 40.15 (log erg s−1) but still within uncertainties.
(log erg s−1), agrees with the value measured by Thuan et al. (2004), ≈39.48, with Chandra in the 0.5–10 keV range. It is somewhat lower than the XMM-Newton value in Kaaret & Feng (2013) of 40.15 (log erg s−1) but still within uncertainties.
The fact that we obtain globally similar results to P08 is remarkable considering that we use different pressure profiles and a general prescription for the abundance patterns vs. metallicity. However, the automatic approach obviously cannot pretend to reach the same level of fine-tuning as specific studies.
Not surprisingly, the predicted [C ii] in model MI,opt, 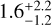 , is much lower than the observed value (
, is much lower than the observed value (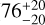 ) because [C ii] is expected to emit deeper while we restricted ourselves to models reaching the ionization front. This is an indication that the fraction of observed [C ii] in the ionized gas is small, which is confirmed by models accounting for the neutral gas (Sect. 6.2).
) because [C ii] is expected to emit deeper while we restricted ourselves to models reaching the ionization front. This is an indication that the fraction of observed [C ii] in the ionized gas is small, which is confirmed by models accounting for the neutral gas (Sect. 6.2).
 |
Fig. 13 Comparison between observed and modeled fluxes for the ionized gas model MI,opt of I Zw 18. Plotted values in red are the difference between observations and models normalized by the model value. MULTIGRIS produces this plot in cartesian and polar coordinates, we show here the latter for illustration and because it is better adapted to a large number of observations. The black circle, black dots, and orthogonal black lines indicate the model and the red points and red error bars indicate the observations. The color of the sector is green if observations and models agree within errors and yellow if the model agrees within the observed error bar. |
Observations and predictions for the ionized and neutral gas models of I Zw 18.
 |
Fig. 14 Origin of each line emission in the MULTIGRIS model for the ionized gas model MI,opt (left), the neutral atomic gas model MNA (middle), and the neutral molecular gas model MNM (right). |
ISM model parameters.
6.2 New topological models
We now attempt to update the results in L17 who converted the P08 modeling approach to Cloudy. The use of the latter was motivated by the need to account for dust in order to compare the relative importance of the photoelectric effect heating and X-ray photoionization in the neutral gas. To this effect L17 introduced several neutral atomic and molecular lines in the model but parameters were adjusted manually and there was no convergence test. Apart from an exploratory model with four sectors including a deep sector with constant pressure to investigate the molecular gas, the sector configuration in L17 was precisely the same as in P08.
For all the models described below, in addition to new IR constraints probing the ionized or neutral gas, we also relax some of the constraints on the topology, notably by letting the inner radius free for each sector. Furthermore, while we fixed the number of components in model MI,opt to reproduce the results of P08 in Sect. 6.1, we now test different number of components. All model predictions are provided for convenience in the appendix (Figs. A.1–A.3; Table A.1).
I Zw 18 model parameters.
6.2.1 Ionized gas: Model MI,opt+IR
For model MI,opt+IR we consider the ionized gas again but this time considering IR lines in addition to optical ones. Results are shown in Table2 and Fig. 13. Some newly added observations arise from the same physical conditions as the optical lines and thus provide further constraints to the model, but some other observations provide new constraints, such as [O iii] 88 µm for the rather diffuse highly-ionized gas Fig. 15 confirms that the optical and IR [O iii] lines do not trace the same physical conditions.
The model comparison metrics indicate that the most likely number of sectors is one but this does not account for the fact that the prior odds for a model with a single sector is expected to be low (Sect. 3.7). It turns out, however, that the predictions are in good agreement with models with more than one sector (Fig. A.1). We also tested various combinations with the ionization parameter U and gas density n as power-law distributions and the cut parameter as either a power-law or normal distribution (model MI,power−law). Results are shown in Fig. A.1 and Table A.1. Globally, even though those latter models have a somewhat lower probability, the predictions for all secondary parameters are in agreement with the values inferred with a small, discrete, number of components.
Using the model MI,opt+IR as an illustration (i.e., with three sectors), the X-ray luminosity is now slightly larger compared to MI,opt. The predicted value, 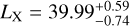 (log erg s−1), is now in better agreement with the XMM-Newton value in Kaaret & Feng (2013) of 40.15 (log erg s−1).
(log erg s−1), is now in better agreement with the XMM-Newton value in Kaaret & Feng (2013) of 40.15 (log erg s−1).
Other notable differences with model MI,opt include the mass of neutral atomic hydrogen M(H0) and the dust mass Mdust which become somewhat lower. However, the values have large uncertainties reflecting the fact that model MI,opt+IR holds little information on the neutral gas.
 |
Fig. 15 Map of the correlation coefficients between predicted values for the ionized gas model MI,opt of I Zw 18 (see Fig. 12 for the plot description). We can see for instance that [O iii] 88 µm does not correlate with the same parameters compared to other lines. |
6.2.2 Neutral atomic gas: Model MNA
For the neutral atomic gas model MNA, we include [C ii], [O i], [Si ii], and [Fe ii] as additional constraints. We also include the total IR emission (which, according to L17’s models originates from dust emission in the H ii region, a moderate contribution from dust in the H i region, and a small but significant contribution from free-free emission). We allow the cloud depth to reach slightly beyond the H/H2 transition in order to fully consider the neutral atomic layer.
The model comparison metrics (Sect. 3.7) indicate that model with a single sector is highly unlikely (Fig. A.2). Results with more than one sector are in good agreement. As for the ionized gas model (MI,opt,+IR; Sect. 6.2.1), we also tested various combinations with U and n as power-law distributions and the cut parameter as a broken power-law (model MNA,power−law). The use of a broken power-law instead of a single power-law is motivated by the fact that the extrapolation of the distribution of depth values for matter-bounded regions does not have to hold for the radiation-bounded regions. Not surprisingly, we find a pivot cut around one, that is at the ionization front, with significantly different slopes below and above (Table A.1). The corresponding model MNA,power−law has a relatively lower probability as compared to the models with a small, discrete, number of components, indicating that more complex distributions may be needed. Nevertheless, the predictions are globally in good agreement with model MNA (Fig. A.1).
Parameter values for model MNA are shown in Tables 2 and 4. Most global parameters (e.g., metallicity and mass) are unchanged when compared to model MI,opt+IR with only ionized gas observations. However, the mixing weights and depth of the sectors are significantly different compared to the ionized gas model, which explains the change in the escape fraction values, which strongly depends on the topology (Sect. 5.3). The escape fraction somewhat decreased compared to MI,opt+IR, and, while the difference is relatively small, this could imply that some of the neutral gas emission arises on somewhat larger spatial scales than the H ii region.
The mass of atomic hydrogen is now much larger compared to MI,opt+IR and in agreement with expectations (Table 4). We find a mass of molecular gas of about ≈103.8 M⊙. L17 had evaluated the molecular gas mass assuming the same topology as MI,opt, that is with the same covering factors as in P08. This effectively corresponded to a rather diffuse molecular medium as opposed to clumps that were considered in a specific, separate, four-sector model. The H2 mass distributed in the large-scale radiation-bounded sector in L17 was extremely low, on the order of 1 M⊙. We find a much larger value in our model MNA because the topology is different (sector mixing weight and different inner radii) and the H2 mass is furthermore controlled by the somewhat arbitrary maximum depth criterion (which we fix to slightly beyond the H/H2 transition for MNA). This rather small H2 mass of ≈103.8 M⊙ exists in the C+ zone and is therefore CO-dark with a CO-dark H2 fraction of ≈100% (but the overall [C ii] emission is still dominated by the neutral atomic gas). The dust mass is also close to the observed value and the dust-togas mass ratio is now slightly larger compared to MI,opt+IR and in better agreement with Galliano et al. (2021), which is not surprising since the dust mass mostly comes from the neutral phase. However, by comparing models MI,opt (or MI,opt+IR) and MNA we find that ≈2/3 of the TIR emission comes from the ionized phase, which is in agreement with L17 who found that TIR can be decomposed as ≈20% free-free emission, ≈15% dust in the H i region, and ≈65% dust in the H ii region.
The [C ii] emission is much larger compared to MI,opt+IR (Table 2) confirming that most of the predicted [C ii] emission arises in the neutral atomic gas. We find a fraction of [C ii] arising in the neutral atomic gas, fCII,H of about 94%. The deep narrow sector #3 is responsible for most of the [C ii], [O i], [Si ii], [Fe ii], and H2 line emission and also dominates the [Ar ii] and [Ne ii] emission (Fig. 14; Table 4). We note that the relative fluxes predicted for [C ii], [O i], and [Si ii] differ somewhat compared to observations, which is likely due to the density profile assumed in the models. The model MNA predicts an essentially null CO emission.
6.2.3 Neutral molecular gas: model MNM
We now add molecular gas observations as constraints for model MNM. For CO, we use the recently claimed CO(2–1) detection of Zhou et al. (2021), corresponding to a CO(1–0) luminosity of 0.18 L⊙ (≈3.5σ detection). Even though the signal is quite uncertain, the new observation is much deeper than previous studies and provides at the very least a useful upper limit. We also include several upper limits for near-IR and mid-IR H2 lines (see L17).
The model comparison metrics (Sect. 3.7) indicate that the model with a single sector is highly unlikely (Fig. A.3). As for model MNA, we also tested various combinations with U and n as power-law distributions and the cut parameter as a broken power-law. The corresponding model MNM,power−law reproduces better the observed CO but has a much lower probability as compared to the models with a small, discrete, number of components, indicating that more complex distributions of the cut parameter throughout the ionized, neutral atomic, and neutral molecular gas may be needed (Fig. A.1). In the following we discuss the model MNM composed of 4 sectors.
In Table 4, we can see that the narrowest sector now reaches somewhat deeper, but with a most likely value not quite reaching the H0-H2 transition. Otherwise the other primary parameters are mostly unchanged compared to MNA.
In Fig. 16, we see that the most likely values for I(CO) are much lower than the observed value even within uncertainties. CO being the only observation constraining such depths and the detection level being so low, the model is mostly constrained by other lines, in particular those arising mostly in the neutral atomic gas as well as TIR. In other words, the CO detection is in fact unlikely within the model topological assumptions in model MNM. There is a solution agreeing with the observed CO intensity, corresponding to an H2 mass ≈107 M⊙, but with a relatively low probability of ≲20%. This large value coincides with the upper limit on the H2 mass of L17 based on the observed CO(1–0) upper limit of <8 × 10−3 (normalized to Hβ = 1000) from Leroy et al. (2007).
When the observed CO flux is well reproduced, the H0 mass becomes somewhat too large, being significantly above 107 M⊙ (Fig. 16) and the total IR emission starts deviating from the observed value (Fig. 17). Adding CO tends to make a deeper narrower sector as the CO emission is better and better reproduced (though these models are unlikely). The mixing weight of the deep sector ought to be lower otherwise it would produce too much [O i] and H2 in particular. Even with four sectors (model MNM), the CO emission always come from the same sector as [C ii] and [O i]. In other words, if we need to account for CO then we need a deep narrow sector and this sector produces a significant/dominant emission of [C ii] and [O i]. This implies that the [C ii] and [O i] emission should be probing a mostly neutral atomic medium associated to the CO clumps if they do exist, since the maximum fraction of [C ii] associated with H2 is ≈15% (Fig. 16).
A more stringent observational constraint would be useful either to confirm that the CO emission is in fact much lower or to constrain a better topological model. Nevertheless, the predicted H2 mass is about 105.4 M⊙ and anticorrelates with the covering factor of the dense sector (top panel of Fig. 16). As for model MNA, the small H2 mass is better traced by C+ than C0 or CO (Table 4), and the CO-dark H2 gas fraction is therefore ≈100%. However, most of the [C ii] emission is not associated with H2 but with H0, in agreement with L17.
The CO luminosity we predict is ≈3500 times lower than Zhou et al. (2021), implying αCO = M(H2)/L(CO) = 9 × 104 M⊙ (K km s−1)−1. For the metallicity of I Zw 18, together with the reference solar value for αCO = 4.3 M⊙pc−2(K km s−1)−1 (e.g., Bolatto et al. 2013), this translates into a slope of y = − 3.1 with αCO ∝ (Z/Z⊙)y. This coefficient is on the high end of metallicity-dependent αCO studies but quite close to the value derived by Madden et al. (2020) of −3.39 and the extrapolation of Schruba et al. (2012; Fig. 18). If we consider instead the less likely solution at M(H2) ~ 107 M⊙ corresponding to the CO observation in Zhou et al. (2021), we obtain a αCO ≈ 2200 M⊙ pc−2(K km s−1)−1, implying y ≈ −2. The calculation and discussion of αCO for the full DGS sample will be discussed in Ramambason et al. (in prep.).
 |
Fig. 16 Properties of the molecular sector in model MNM. From top to bottom, we show as a function of the total predicted H2 mass, the mixing weight of the molecular sector, the mass of H0, of dust, the CO(1–0) intensity (scaled to 4.56 × 1036 erg s−1; with the horizontal lines showing the observed range in Zhou et al. 2021), and the fraction of [C ii] originating from the molecular sector. |
6.2.4 Escape fraction of ionizing photons
In all models, more than half of the global escape fraction is due to sector #1 which is always matter-bounded, and with the largest mixing weight (Fig. 19). The observed fluxes correspond to the NW H ii region of I Zw 18 and the global escape fraction therefore also corresponds to that region, while the galaxy escape fraction is probably significantly lower (P08). We refer to Ramambason et al. (2022) for a more general discussion of the escape fractions in the Dwarf Galaxy Survey.
Our models include the presence of an X-ray source associated with the H ii region (L17). For the first time we are now able to calculate the escape fraction for different photon energy ranges and evaluate the escape fraction of He-ionizing photons, which have received much less attention than H-ionizing photons (Benson et al. 2013). The escape fractions of photons in our models is saved in the energy ranges 1 − ∞, 1−1.8, 1.8−4 (He0-ionizing photons), 4–20 (He+-ionizing photons), and 20 − ∞ Ryd (Table 2). In model MI,opt+IR (Sect. 6.2.1), the escape fraction fesc(1 – ∞) ≈ 59% lies between fesc(1–1.8) ≈ 52% and fesc(1.8–4) ≈ 78%, that is in the range where most of the input radiation field energy lies. The escape fraction fesc(4–20), on the other hand, is remarkably lower (≈26%), which is due to the absorption by He2+ close to the illuminated edge of the cloud (Fig. 20). Nevertheless, the fesc(4–20) values remains significant due to the fact that the medium gradually becomes more transparent to photons significantly above 4 Ryd. As a matter of fact, fesc(20 – ∞), which traces the escape of soft to hard X-ray photons is ≈87% in the model. Even though soft X-ray photons deposit their energy in the neutral gas (L17), fesc(20 − ∞) remains large even in model MNA (≈80%), which is due to the fact that the mixing weight of the radiation-bounded sector is relatively low. Most X-ray photons therefore escape the H ii region, but the global X-ray escape fraction reaching the IGM ultimately depends on the distribution of diffuse H i gas. Since low-metallicity star-forming dwarf galaxies are known to harbor bright X-ray sources (e.g., Basu-Zych et al. 2016; Ponnada et al. 2019; Lehmer et al. 2020), this makes such sources interesting suspects for the IGM heating at z > 10 (Mirabel et al. 2011).
 |
Fig. 17 Variation of the observed fluxes as a function of I(CO). From top to bottom we show the IR flux, the [O i] flux, and the H2 S(l) line flux. Fluxes are scaled to 4.56 × l036 ergs−1. Horizontal and vertical lines show the observed uncertainties or the upper limit (for H2). |
 |
Fig. 18 Variation of αCO as a function of metallicity compared to Schruba et al. (2012); Sandstrom et al. (2013); Amorín et al. (2016); Madden et al. (2020). The red data points and upper limits are from Madden et al. (2020). We also show on top the most likely solution (empty black circle with the gray circle indicating the standard deviation) with M(H2) = 105.4 M⊙ and CO 3500 times fainter than in Zhou et al. (2021) and on bottom the secondary, less likely, solution with 107 M⊙ and CO in agreement with Zhou et al. (2021). |
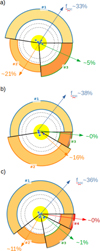 |
Fig. 19 Sector configurations for models MI,opt+IR (a), MNA (b), and MNM (c) for I Zw 18. See Fig. 6 for the plot description. The arrows indicate the escape fraction (1 − ∞ Ryd) for each sector. |
 |
Fig. 20 Absorption of the ionizing radiation throughout the gas slab. Top: shape of the radiation field spectrum for each zone calculated in Cloudy for the radiation-bounded sector of model MNM, from the illuminated edge of the cloud (blue) to the last zone (green). The vertical lines show the 1, 1.8, 4, 8, 20, and 2000 Ryd energy values. The spectrum is heavily and rapidly absorbed right above 4 Ryd due to He2+ absorption. Bottom: evolution of the integrated flux across the cloud depth (normalized to the value at the illuminated edge) for different energy ranges in Rydberg. The vertical lines show the ionization front, PDR, and C/CO transitions from left to right. The radiation field >20 Ryd is able to penetrate in the neutral gas (top panel) but this contributes little to the total escape fraction (bottom panel). The kink for the 1.8−4 Ryd range is due to secondary ionization following He recombination. |
7 Conclusions
In this study, we present a new statistical framework to infer probability density functions (PDFs) of parameters constrained by observations with uncertainties. While the method and associated code, MULTIGRIS, are agnostic to the input grid used, the method was developed in particular for ISM studies with the objective of inferring a topology representing either a discrete number of ISM components around one or several stellar clusters or a continuous distribution of clouds whose physical conditions are parameterized by power- or normal-laws.
The inference is performed using a sequential Monte Carlo method that is well adapted to multipeaked posterior distributions. Primary parameters are sampled using either a nearest neighbor or linear interpolation on the grid values. Built-in priors are available to use predefined configurations flexible enough to various combinations of components.
We illustrate the method with a grid of models calculated with Cloudy. Primary parameters describe the stellar clusters and potential X-ray sources as well as the surrounding ISM distribution. The grid, described in Ramambason et al. (2022) includes a free parameter defining the cloud depth. While the inference is performed on these primary parameters, the algorithm is able to calculate PDFs of secondary parameters, that is any parameter not considered as an observation and which Cloudy can compute. A large number of random variables and observations can be accommodated. Observations may be gathered in observation sets with associated systematic uncertainties, and upper/lower limits are fully considered. For ISM studies, the extinction may be included as one additional random variable.
We first apply this method to the well-known low-metallicity star-forming dwarf galaxy I Zw 18, whose ISM has been modeled extensively using optical and IR lines in particular. Our objective is to reproduce previous results with a general grid that is not tailored to any specific object and to provide PDFs for the most important parameters. We first consider only ionized gas observations, then add neutral atomic and finally neutral molecular gas observations in order to test the robustness of the diagnostics adding/removing some observations while examine physical parameters related to specific ISM phases.
We are able to reproduce the metallicity, number of ionizing photons, as well as the mass of H+ and H0, the dust mass and the dust-to-gas mass ratio. We confirm that an X-ray source with luminosity ≈1040 erg s−1 is necessary to explain the ionized and neutral gas emission, with properties similar to those observed in specific X-ray studies. This implies interesting prospects for constraining the presence, properties, and nature of compact objects from their signatures in the ISM. Such a method is only possible if the topology is well constrained by many observations, with at least some of them themselves influenced by the X-ray source.
We examine the H2 mass, using in particular the mid-IR H2 upper limits as well as the recently claimed detection of CO(1−0) by Zhou et al. (2021). With the topology used, we find that the CO(1-0) emission is likely much lower than the observed value. It is possible, however, that CO exists in small dense clumps that we are not able to model. Nevertheless, we derive a most likely mass of H2 of ≈105.4 M⊙, leading to αCO = 9 × 104 M⊙ pc−2 (K km s−1)−1 and to a metallicity coefficient of y = −3.1 with αCO ∝ (Z/Z⊙)y, in excellent agreement with Madden et al. (2020) and Schruba et al. (2012). The calculation and discussion of αCO for the full DGS sample will be discussed in Ramambason et al. (in prep.).
The H2 mass is better traced by C+ than C0 or CO and the CO-dark H2 mass is therefore ≈100%. However, the fraction of [C ii] arising from the molecular gas is small and most of the [C ii] emission is associated with H0. Assuming CO clumps exist, the predicted [C ii] and [O i] emission arise from the same sector as CO, implying that [C ii] and [O i] lines probe a mostly neutral atomic medium directly associated with the hypothetical CO clumps.
Finally we investigate the escape fraction of ionizing photons and find values around 50–65% in agreement with expectations. We decompose the photons by energy range and find that most (≳80%) soft X-ray photons are able to escape. This has potential implications for the ionization and heating of the IGM as such photons can escape the diffuse H i gas halo.
Acknowledgements
This work has greatly benefited from the environment provided by the FACE Foundation Thomas Jefferson Fund (award TJF21_053). We would like to thank Frédéric Galliano for insightful and inspiring discussions about Bayesian statistics, and the anonymous referee for constructive feedback and encouraging comments.
Appendix A Other models
In this appendix we show the results for the ionized, neutral-atomic, and neutral-molecular gas models with a varying number of sectors and with a power- or normal-law distribution for some parameters.
I Zw 18 model parameters for other considered models.
References
- Aloisi, A., Clementini, G., Tosi, M., et al. 2007, ApJ, 667, L151 [NASA ADS] [CrossRef] [Google Scholar]
- Amorín, R., Muñoz-Tuñón, C., Aguerri, J. A. L., & Planesas, P. 2016, A&A, 588, A23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Andrae, R., Schulze-Hartung, T., & Melchior, P. 2010, ArXiv e-prints [arXiv:1012.3754] [Google Scholar]
- Basu-Zych, A. R., Lehmer, B., Fragos, T., et al. 2016, ApJ, 818, 140 [NASA ADS] [CrossRef] [Google Scholar]
- Benson, A., Venkatesan, A., & Shull, J. M. 2013, ApJ, 770, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Bisbas, T. G., Bell, T. A., Viti, S., Yates, J., & Barlow, M. J. 2012, MNRAS, 427, 2100 [NASA ADS] [CrossRef] [Google Scholar]
- Bisbas, T. G., Haworth, T. J., Barlow, M. J., et al. 2015, MNRAS, 454, 2828 [NASA ADS] [CrossRef] [Google Scholar]
- Bolatto, A. D., Wolfire, M., & Leroy, A. K. 2013, ARA&A, 51, 207 [CrossRef] [Google Scholar]
- Boquien, M., Burgarella, D., Roehlly, Y., et al. 2019, A&A, 622, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Burgarella, D., Buat, V., & Iglesias-Páramo, J. 2005, MNRAS, 360, 1413 [NASA ADS] [CrossRef] [Google Scholar]
- Ching, J., & Chen, Y.-C. 2007, J. Eng. Mech., 133, 816 [Google Scholar]
- Cormier, D. 2012, Ph.D. Thesis, Université Paris-Diderot, France [Google Scholar]
- Cormier, D., Lebouteiller, V., Madden, S. C., et al. 2012, A&A, 548, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cormier, D., Abel, N. P., Hony, S., et al. 2019, A&A, 626, A23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- da Cunha, E., Charlot, S., & Elbaz, D. 2008, MNRAS, 388, 1595 [Google Scholar]
- Eldridge, J. J., Stanway, E. R., Xiao, L., et al. 2017, PASA, 34, e058 [Google Scholar]
- Ercolano, B., Barlow, M. J., & Storey, P. J. 2005, MNRAS, 362, 1038 [Google Scholar]
- Ferland, G. J., Porter, R. L., van Hoof, P. A. M., et al. 2013, Rev. Mex. Astron. Astrofis., 49, 137 [Google Scholar]
- Ferland, G. J., Chatzikos, M., Guzmán, F., et al. 2017, Rev. Mex. Astron. Astrofis., 53, 385 [NASA ADS] [Google Scholar]
- Fischer, C., Beckmann, S., Bryant, A., et al. 2018, J. Astron. Instrum., 7, 1840003 [Google Scholar]
- Galliano, F. 2022, Habilitation Thesis, Université Paris-Saclay, France [Google Scholar]
- Galliano, F., Nersesian, A., Bianchi, S., et al. 2021, A&A, 649, A18 [EDP Sciences] [Google Scholar]
- Gordon, K. D., Fouesneau, M., Arab, H., et al. 2016, ApJ, 826, 104 [NASA ADS] [CrossRef] [Google Scholar]
- Harikane, Y., Ouchi, M., Shibuya, T., et al. 2018, ApJ, 859, 84 [NASA ADS] [CrossRef] [Google Scholar]
- Harikane, Y., Ouchi, M., Inoue, A. K., et al. 2020, ApJ, 896, 93 [Google Scholar]
- Hoffman, M. D., & Gelman, A. 2011, ArXiv e-prints [arXiv:1111.4246] [Google Scholar]
- Houck, J. R., Roellig, T. L., van Cleve, J., et al. 2004, ApJS, 154, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Izotov, Y. I., Chaffee, F. H., Foltz, C. B., et al. 1999, ApJ, 527, 757 [NASA ADS] [CrossRef] [Google Scholar]
- Jin, Y., Kewley, L. J., & Sutherland, R. 2022, ApJ, 927, 37 [NASA ADS] [CrossRef] [Google Scholar]
- Kaaret, P., & Feng, H. 2013, ApJ, 770, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Kang, D. E., Pellegrini, E. W., Ardizzone, L., et al. 2022, MNRAS, 512, 617 [CrossRef] [Google Scholar]
- Kewley, L. J., Nicholls, D. C., & Sutherland, R. S. 2019, ARA&A, 57, 511 [Google Scholar]
- Lambert-Huyghe, A., Madden, S. C., Lebouteiller, V., et al. 2022, A&A, in press, https://doi.org/10.1051/0004-6361/202243353 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lebouteiller, V., Péquignot, D., Cormier, D., et al. 2017, A&A, 602, A45 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lee, M. M., Nagao, T., De Breuck, C., et al. 2019, ApJ, 883, L29 [NASA ADS] [CrossRef] [Google Scholar]
- Lee, M. M., Nagao, T., De Breuck, C., et al. 2021, ApJ, 913, 41 [NASA ADS] [CrossRef] [Google Scholar]
- Lehmer, B. D., Ferrell, A. P., Doore, K., et al. 2020, ApJS, 248, 31 [NASA ADS] [CrossRef] [Google Scholar]
- Leroy, A., Bolatto, A., Stanimirovic, S., et al. 2007, ApJ, 658, 1027 [NASA ADS] [CrossRef] [Google Scholar]
- Madden, S. C., Rémy-Ruyer, A., Galametz, M., et al. 2013, PASP, 125, 600 [NASA ADS] [CrossRef] [Google Scholar]
- Madden, S. C., Cormier, D., Hony, S., et al. 2020, A&A, 643, A141 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Minson, S. E., Simons, M., & Beck, J. L. 2013, Geophys. J. Int., 194, 1701 [Google Scholar]
- Mirabel, I. F., Dijkstra, M., Laurent, P., Loeb, A., & Pritchard, J. R. 2011, A&A, 528, A149 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Morisset, C. 2011, Cloudy_3D: Quick Pseudo-3D Photoionization Code [Google Scholar]
- Morisset, C. 2013, Pycloudy: Tools to manage astronomical Cloudy photoionization code [Google Scholar]
- Péquignot, D. 2008, A&A, 478, 371 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pilbratt, G. L., Riedinger, J. R., Passvogel, T., et al. 2010, A&A, 518, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Poglitsch, A., Waelkens, C., Geis, N., et al. 2010, A&A, 518, A2 [Google Scholar]
- Polles, F. L., Madden, S. C., Lebouteiller, V., et al. 2019, A&A, 622, A119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ponnada, S., Brorby, M., & Kaaret, P. 2019, MNRAS, 2537 [Google Scholar]
- Ramambason, L., Lebouteiller, V., Bik, A., et al. 2022, A&A, in press https://doi.org/10.1051/0004-6361/202243866 [Google Scholar]
- Rémy-Ruyer, A., Madden, S. C., Galliano, F., et al. 2015, A&A, 582, A121 [Google Scholar]
- Richardson, C. T., Allen, J. T., Baldwin, J. A., Hewett, P. C., & Ferland, G. J. 2014, MNRAS, 437, 2376 [NASA ADS] [CrossRef] [Google Scholar]
- Richardson, C. T., Allen, J. T., Baldwin, J. A., et al. 2016, MNRAS, 458, 988 [NASA ADS] [CrossRef] [Google Scholar]
- Robert, C. P. 2015, ArXiv e-prints [arXiv:1504.01896] [Google Scholar]
- Salvatier, J., Wiecki, T. V., & Fonnesbeck, C. 2016, Peer J Comput. Sci., 2, e55 [CrossRef] [Google Scholar]
- Sandstrom, K. M., Leroy, A. K., Walter, F., et al. 2013, ApJ, 777, 5 [Google Scholar]
- Schruba, A., Leroy, A. K., Walter, F., et al. 2012, AJ, 143, 138 [NASA ADS] [CrossRef] [Google Scholar]
- Spinoglio, L., Alonso-Herrero, A., Armus, L., et al. 2017, PASA, 34, e057 [NASA ADS] [CrossRef] [Google Scholar]
- ter Braak, C. J. F., & Vrugt, J. A. 2008, Stat. Comput., 18, 435 [CrossRef] [Google Scholar]
- Thomas, A. D., Kewley, L. J., Dopita, M. A., et al. 2019, ApJ, 874, 100 [NASA ADS] [CrossRef] [Google Scholar]
- Thuan, T. X., Bauer, F. E., Papaderos, P., & Izotov, Y. I. 2004, ApJ, 606, 213 [NASA ADS] [CrossRef] [Google Scholar]
- Vale Asari, N., Stasińska, G., Morisset, C., & Cid Fernandes, R. 2016, MNRAS, 460, 1739 [NASA ADS] [CrossRef] [Google Scholar]
- Vehtari, A., Gelman, A., & Gabry, J. 2017, Stat. Comput., 27, 1413 [Google Scholar]
- Vehtari, A., Gelman, A., Simpson, D., Carpenter, B., & Bürkner, P.-C. 2021, Bayesian Anal., 16, 667 [CrossRef] [Google Scholar]
- Wagg, J., Aravena, M., Brisbin, D., et al. 2020, MNRAS, 499, 1788 [NASA ADS] [CrossRef] [Google Scholar]
- Walcher, J., Groves, B., Budavári, T., & Dale, D. 2011, Ap&SS, 331, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Watanabe, S. 2010, J. Mach. Learn. Res., 11, 3571 [Google Scholar]
- Werner, M. W., Roellig, T. L., Low, F. J., et al. 2004, ApJS, 154, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Zhou, L., Shi, Y., Zhang, Z.-Y., & Wang, J. 2021, A&A, 653, A10 [Google Scholar]
All Tables
All Figures
|
Fig. 1 Illustration of the topological configurations considered in previous studies. For each approach, we show the relative contributions of sectors each corresponding to a specific Cloudy model. These contributions are equivalent to the fraction of the total solid angle in 3D. The light blue shell corresponds to the ionized gas, the dark gray shell to the neutral gas, and the red arc to the photoionization front. In Cormier (2012) (a), the model used an H ii region connected with a PDR, with the PDR covering factor scaled a posteriori (cropped shell in white), and an additional model is considered a posteriori to account for the diffuse ionized gas. In Cormier et al. (2019) (b), two sectors are considered with the PDR associated only with the high-ionization parameter sector. In Polles et al. (2019) (c), models use a single sector with a varying depth. In Lambert-Huyghe et al. (2022) (d), observations are compared to a mix of pure H ii region and PDR components drawn from the same Cloudy radiation-bounded model. In Lebouteiller et al. (2017) (e), up to four sectors were considered with different depths. |
| In the text | |
|
Fig. 2 Illustration of Sequential Importance Resampling Particle Filter. From top to bottom, the distribution is sampled from the prior, reweighted and resampled according to the tempered posterior density. Surviving samples seed new Markov chains and walk through a number of Metropolis steps. |
| In the text | |
|
Fig. 3 Posterior distribution of parameters for a model with two components. One parameter (age) has been purposefully forced to be the same of the two components. The raw posterior distribution is shown on the left, for which the two components may switch during inference, and the final result is shown on the right, in which the individual component parameter values have been redistributed a posteriori. For visual purposes only a subset of the parameters are shown. |
| In the text | |
|
Fig. 4 Example of results for a 2-component model. The kernel density estimate (nonparametric method to estimate a PDF) is shown on top and a corner plot for one of the two components on the bottom. We note that some parameters have been forced to have identical values for the two components. |
| In the text | |
|
Fig. 5 Example of the posterior distributions for the primary parameters (two leftmost columns) and for the observations (two rightmost columns). For each quantity, the left plot shows the PDF (with the vertical line indicating the reference measured value for observations), and the right plot shows the sequence of samples. For these plots individual jobs are combined. We note that some parameters have been forced to have identical values for the two components. |
| In the text | |
|
Fig. 6 Configuration of inferred sectors for an example model. Top: the left plot shows the integrated covering factors while the right plot shows the same topology but with a different, random, geometry. The color scales from yellow to red as the gas volume density increases. Different inner radii indicate different ionization parameter (U) values, with dotted arcs showing U = 0, 1, …. The gray arcs show the photoionization and photodissociation fronts. The depth is not drawn to scale. Bottom: sectors are distributed randomly in 3D according to their relative covering factors and then projected in 2D. Screening/extinction effects are ignored. Stars are added for visual purposes only. |
| In the text | |
|
Fig. 7 Benchmark model run with a degeneracy artificially introduced for the age (idx_age_0) and metallicity (idx_Z_0). The SMC step method is shown on the left (each individual line corresponding to a given job) and NUTS on the right (each line corresponding to a given chain). The x-axes in the two columns have different ranges. |
| In the text | |
|
Fig. 8 Model comparison to estimate the number of sectors required. We show models with an input of one, two, and three sectors from left to right. In the top panel we show the log values of LOO, WAIC, and the SMC marginal likelihood (“lml”) for MCMC runs with a number of sectors from one to three. In the middle panel we show the likelihood weights (not to be confused with the mixing weight) of each sector when the number of sectors is allowed to vary. Each horizontal line corresponds to a model with the number of sectors allowed to vary up to two or three. For each horizontal line, the filled circles show the inferred weight and the circled one highlights the number of sectors with the largest weight. In the bottom panel we show the fraction of draws that agree with the observed value within 2- and 3-σ. |
| In the text | |
|
Fig. 9 Output parameters for the benchmark model comparison. We show models with an input of one, two, and three sectors and for radiation-bounded (“rb”) or matter-bounded (“mb”) template models. Each plot shows a standard boxplot configuration with the median value in red, with the box spanning from the first to third quartile, and the horizontal gray bars extending to 1.5 times the inter-quartile range. Faint open circles show the data that extend beyond the horizontal gray bars. In each panel we show the results forcing the number of components from one to three. The two top panels show the marginal likelihood (“lml”) and the likelihood while the other panels below show several parameters (from top to bottom the number of ionizing photons, the mass of H+, the mass of H2 traced by CO, the mass of H2 traced by C+, the X-ray luminosity, the metallicity, and the escape fraction of ionizing photons). The horizontal lines show the expected value, except for the marginal likelihood where it indicates the highest value. |
| In the text | |
|
Fig. 10 Evolution of the solution with the number of lines considered for a benchmark run. Each row corresponds to a parameter, and each column represents a different number of lines from three to 13 ([C ii]+[O iii] 88 µm+[O i] 63 µm, +[N ii] 205 µm+[O i] 145 µm, +[Ne ii] 12.8 µm+[Ne iii] 15.6 µm+[N iii] 57 µm+[Ar ii] 7 µm, +[Ar iii] 9 µm+H2 17 µm+[Si ii] 34 µm+[Ne v] 14 µm. The horizontal black lines indicate the expected solution. The model used here is radiation-bounded. |
| In the text | |
 |
Fig. 11 Same as Fig. 10, but for a matter-bounded model. |
| In the text | |
|
Fig. 12 Map of the correlation coefficients between predicted observations for a benchmark run. Here one can see that, according to the input grid, most H lines trace the same parameters around the solution (the same applies to He or [S ii]). |
| In the text | |
|
Fig. 13 Comparison between observed and modeled fluxes for the ionized gas model MI,opt of I Zw 18. Plotted values in red are the difference between observations and models normalized by the model value. MULTIGRIS produces this plot in cartesian and polar coordinates, we show here the latter for illustration and because it is better adapted to a large number of observations. The black circle, black dots, and orthogonal black lines indicate the model and the red points and red error bars indicate the observations. The color of the sector is green if observations and models agree within errors and yellow if the model agrees within the observed error bar. |
| In the text | |
|
Fig. 14 Origin of each line emission in the MULTIGRIS model for the ionized gas model MI,opt (left), the neutral atomic gas model MNA (middle), and the neutral molecular gas model MNM (right). |
| In the text | |
|
Fig. 15 Map of the correlation coefficients between predicted values for the ionized gas model MI,opt of I Zw 18 (see Fig. 12 for the plot description). We can see for instance that [O iii] 88 µm does not correlate with the same parameters compared to other lines. |
| In the text | |
|
Fig. 16 Properties of the molecular sector in model MNM. From top to bottom, we show as a function of the total predicted H2 mass, the mixing weight of the molecular sector, the mass of H0, of dust, the CO(1–0) intensity (scaled to 4.56 × 1036 erg s−1; with the horizontal lines showing the observed range in Zhou et al. 2021), and the fraction of [C ii] originating from the molecular sector. |
| In the text | |
|
Fig. 17 Variation of the observed fluxes as a function of I(CO). From top to bottom we show the IR flux, the [O i] flux, and the H2 S(l) line flux. Fluxes are scaled to 4.56 × l036 ergs−1. Horizontal and vertical lines show the observed uncertainties or the upper limit (for H2). |
| In the text | |
|
Fig. 18 Variation of αCO as a function of metallicity compared to Schruba et al. (2012); Sandstrom et al. (2013); Amorín et al. (2016); Madden et al. (2020). The red data points and upper limits are from Madden et al. (2020). We also show on top the most likely solution (empty black circle with the gray circle indicating the standard deviation) with M(H2) = 105.4 M⊙ and CO 3500 times fainter than in Zhou et al. (2021) and on bottom the secondary, less likely, solution with 107 M⊙ and CO in agreement with Zhou et al. (2021). |
| In the text | |
|
Fig. 19 Sector configurations for models MI,opt+IR (a), MNA (b), and MNM (c) for I Zw 18. See Fig. 6 for the plot description. The arrows indicate the escape fraction (1 − ∞ Ryd) for each sector. |
| In the text | |
|
Fig. 20 Absorption of the ionizing radiation throughout the gas slab. Top: shape of the radiation field spectrum for each zone calculated in Cloudy for the radiation-bounded sector of model MNM, from the illuminated edge of the cloud (blue) to the last zone (green). The vertical lines show the 1, 1.8, 4, 8, 20, and 2000 Ryd energy values. The spectrum is heavily and rapidly absorbed right above 4 Ryd due to He2+ absorption. Bottom: evolution of the integrated flux across the cloud depth (normalized to the value at the illuminated edge) for different energy ranges in Rydberg. The vertical lines show the ionization front, PDR, and C/CO transitions from left to right. The radiation field >20 Ryd is able to penetrate in the neutral gas (top panel) but this contributes little to the total escape fraction (bottom panel). The kink for the 1.8−4 Ryd range is due to secondary ionization following He recombination. |
| In the text | |
 |
Fig. A.1 Results for model MI,opt+IR See Figure 9 for the plot description. |
| In the text | |
 |
Fig. A.2 Results for model MNA. See Figure 9 for the plot description. |
| In the text | |
 |
Fig. A.3 Results for model MNM. See Figure 9 for the plot description. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.