| Issue |
A&A
Volume 617, September 2018
|
|
|---|---|---|
| Article Number | A48 | |
| Number of page(s) | 17 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201731489 | |
| Published online | 24 September 2018 | |
Planck intermediate results
LIII. Detection of velocity dispersion from the kinetic Sunyaev-Zeldovich effect
1
APC, AstroParticule et Cosmologie, Université Paris Diderot, CNRS/IN2P3, CEA/lrfu, Observatoire de Paris, Sorbonne Paris Cité, 10 rue Alice Domon et Léonie Duquet, 75205 Paris Cedex 13, France
2
African Institute for Mathematical Sciences, 6-8 Melrose Road, Muizenberg, Cape Town, South Africa
3
Agenzia Spaziale Italiana, Via del Politecnico snc, 00133 Roma, Italy
4
Astrophysics Group, Cavendish Laboratory, University of Cambridge, J J Thomson Avenue, Cambridge, CB3 0HE, UK
5
Astrophysics & Cosmology Research Unit, School of Mathematics, Statistics & Computer Science, University of KwaZulu-Natal, Westville Campus, Private Bag X54001, Durban, 4000, South Africa
6
CITA, University of Toronto, 60 St. George St., Toronto, ON M5S 3H8, Canada
7
CNRS, IRAP, 9 Av. colonel Roche, BP 44346, 31028 Toulouse Cedex 4, France
8
California Institute of Technology, Pasadena, California, USA
9
Computational Cosmology Center, Lawrence Berkeley National Laboratory, Berkeley, California, USA
10
DTU Space, National Space Institute, Technical University of Denmark, Elektrovej 327, DK-2800 Kgs., Lyngby, Denmark
11
Département de Physique Théorique, Université de Genève, 24, Quai E. Ansermet, 1211 Genève 4, Switzerland
12
Departamento de Astrofísica, Universidad de La Laguna (ULL), 38206 La Laguna, Tenerife, Spain
13
Departamento de Física, Universidad de Oviedo, C/Federico García Lorca 18, Oviedo, Spain
14
Department of Astrophysics/IMAPP, Radboud University, PO Box 9010, 6500 GL Nijmegen, The Netherlands
15
Department of Mathematics, University of Stellenbosch, Stellenbosch, 7602, South Africa
16
Department of Physics & Astronomy, University of British Columbia, 6224 Agricultural Road, Vancouver, British Columbia, Canada
17
Department of Physics & Astronomy, University of the Western Cape, Cape Town, 7535, South Africa
18
Department of Physics and Astronomy, University of Sussex, Brighton, BN1 9QH, UK
19
Department of Physics, Gustaf Hällströmin katu 2a, University of Helsinki, Helsinki, Finland
20
Department of Physics, Princeton University, Princeton, New Jersey, USA
21
Department of Physics, University of California, Santa Barbara, CA, USA
22
Department of Physics, University of Illinois at Urbana-Champaign, 1110 West Green Street, Urbana, IL, USA
23
Dipartimento di Fisica e Astronomia G. Galilei, Università degli Studi di Padova, via Marzolo 8, 35131 Padova, Italy
24
Dipartimento di Fisica e Scienze della Terra, Università di Ferrara, Via Saragat 1, 44122 Ferrara, Italy
25
Dipartimento di Fisica, Università La Sapienza, P. le A. Moro 2, Roma, Italy
26
Dipartimento di Fisica, Università degli Studi di Milano, Via Celoria, 16, Milano, Italy
27
Dipartimento di Fisica, Università degli Studi di Trieste, via A. Valerio 2, Trieste, Italy
28
Dipartimento di Fisica, Università di Roma Tor Vergata, Via della Ricerca Scientifica 1, Roma, Italy
29
European Space Agency, ESAC, Planck Science Office, Camino bajo del Castillo, s/n, Urbanización Villafranca del Castillo, Villanueva de la Cañada, Madrid, Spain
30
European Space Agency, ESTEC, Keplerlaan 1, 2201 AZ Noordwijk, The Netherlands
31
Gran Sasso Science Institute, INFN, viale F. Crispi 7, 67100 L’Aquila, Italy
32
HGSFP and University of Heidelberg, Theoretical Physics Department, Philosophenweg 16, 69120 Heidelberg, Germany
33
Haverford College Astronomy Department, 370 Lancaster Avenue, Haverford, Pennsylvania, USA
34
Helsinki Institute of Physics, Gustaf Hällströmin katu 2, University of Helsinki, Helsinki, Finland
35
INAF – OAS Bologna, Istituto Nazionale di Astrofisica - Osservatorio di Astrofisica e Scienza dello Spazio di Bologna, Area della Ricerca del CNR, Via Gobetti 101, 40129 Bologna, Italy
36
INAF – Osservatorio Astronomico di Padova, Vicolo dell’Osservatorio 5, Padova, Italy
37
INAF – Osservatorio Astronomico di Trieste, Via G.B. Tiepolo 11, Trieste, Italy
38
INAF, Istituto di Radioastronomia, Via Piero Gobetti 101, 40129 Bologna, Italy
39
INAF/IASF Milano, Via E. Bassini 15, Milano, Italy
40
INFN – CNAF, viale Berti Pichat 6/2, 40127 Bologna, Italy
41
INFN, Sezione di Bologna, viale Berti Pichat 6/2, 40127 Bologna, Italy
42
INFN, Sezione di Ferrara, Via Saragat 1, 44122 Ferrara, Italy
43
INFN, Sezione di Milano, Via Celoria 16, Milano, Italy
44
INFN, Sezione di Roma 1, Università di Roma Sapienza, Piazzale Aldo Moro 2, 00185 Roma, Italy
45
INFN, Sezione di Roma 2, Università di Roma Tor Vergata, Via della Ricerca Scientifica 1, Roma, Italy
46
INFN/National Institute for Nuclear Physics, Via Valerio 2, 34127 Trieste, Italy
47
Imperial College London, Astrophysics group, Blackett Laboratory, Prince Consort Road, London, SW7 2AZ, UK
48
Institut d’Astrophysique Spatiale, CNRS, Univ. Paris-Sud, Université Paris-Saclay, Bât. 121, 91405 Orsay Cedex, France
49
Institut d’Astrophysique de Paris, CNRS (UMR7095), 98 bis Boulevard Arago, 75014 Paris, France
50
Institute Lorentz, Leiden University, PO Box 9506, Leiden 2300 RA, The Netherlands
51
Institute of Theoretical Astrophysics, University of Oslo, Blindern, Oslo, Norway
52
Instituto de Astrofísica de Canarias, C/Vía Láctea s/n, La Laguna, Tenerife, Spain
53
Instituto de Física de Cantabria (CSIC-Universidad de Cantabria), Avda. de los Castros s/n, Santander, Spain
54
Istituto Nazionale di Fisica Nucleare, Sezione di Padova, via Marzolo 8, 35131 Padova, Italy
55
Jet Propulsion Laboratory, California Institute of Technology, 4800 Oak Grove Drive, Pasadena, California, USA
56
Jodrell Bank Centre for Astrophysics, Alan Turing Building, School of Physics and Astronomy, The University of Manchester, Oxford Road, Manchester, M13 9PL, UK
57
Kavli Institute for Cosmological Physics, University of Chicago, Chicago, IL 60637, USA
58
Kavli Institute for Cosmology Cambridge, Madingley Road, Cambridge, CB3 0HA, UK
59
LAL, Université Paris-Sud, CNRS/IN2P3, Orsay, France
60
LERMA, CNRS, Observatoire de Paris, 61 Avenue de l’Observatoire, Paris, France
61
Laboratoire de Physique Subatomique et Cosmologie, Université Grenoble-Alpes, CNRS/IN2P3, 53, rue des Martyrs, 38026 Grenoble Cedex, France
62
Laboratoire de Physique Théorique, Université Paris-Sud 11 & CNRS, Bâtiment 210, 91405 Orsay, France
63
Lawrence Berkeley National Laboratory, Berkeley, CA, USA
64
Low Temperature Laboratory, Department of Applied Physics, Aalto University, Espoo, 00076 AALTO, Finland
65
Max-Planck-Institut für Astrophysik, Karl-Schwarzschild-Str. 1, 85741 Garching, Germany
66
Mullard Space Science Laboratory, University College London, Surrey, H5 6NT, UK
67
NAOC-UKZN Computational Astrophysics Centre (NUCAC), University of KwaZulu-Natal, Durban, 4000 South Africa
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
68
Nicolaus Copernicus Astronomical Center, Polish Academy of Sciences, Bartycka 18, 00-716 Warsaw, Poland
69
Nordita (Nordic Institute for Theoretical Physics), Roslagstullsbacken 23, 106 91 Stockholm, Sweden
70
SISSA, Astrophysics Sector, via Bonomea 265, 34136 Trieste, Italy
71
San Diego Supercomputer Center, University of California, San Diego, 9500 Gilman Drive, La Jolla, CA, 92093, USA
72
School of Chemistry and Physics, University of KwaZulu-Natal, Westville Campus, Private Bag X54001, Durban, 4000, South Africa
73
School of Physics and Astronomy, Cardiff University, Queens Buildings, The Parade, Cardiff, CF24 3AA, UK
74
School of Physics and Astronomy, Sun Yat-Sen University, 135 Xingang Xi Road, Guangzhou, PR China
75
School of Physics, Indian Institute of Science Education and Research Thiruvananthapuram, Maruthamala PO, Vithura, Thiruvananthapuram, 695551 Kerala, India
76
Simon Fraser University, Department of Physics, 8888 University Drive, Burnaby BC, Canada
77
Sorbonne Université-UPMC, UMR7095, Institut d’Astrophysique de Paris, 98 bis Boulevard Arago, 75014 Paris, France
78
Space Research Institute (IKI), Russian Academy of Sciences, Profsoyuznaya Str, 84/32, Moscow, 117997, Russia
79
Space Science Data Center - Agenzia Spaziale Italiana, Via del Politecnico snc, 00133 Roma, Italy
80
Space Sciences Laboratory, University of California, Berkeley, California, USA
81
The Oskar Klein Centre for Cosmoparticle Physics, Department of Physics, Stockholm University, AlbaNova, 106 91 Stockholm, Sweden
82
UPMC Univ. Paris 06, UMR7095, 98 bis Boulevard Arago, 75014 Paris, France
83
Université de Toulouse, UPS-OMP, IRAP, 31028 Toulouse Cedex 4, France
84
Warsaw University Observatory, Aleje Ujazdowskie 4, 00-478 Warszawa, Poland
Received:
2
July
2017
Accepted:
12
June
2018
Abstract
Using the Planck full-mission data, we present a detection of the temperature (and therefore velocity) dispersion due to the kinetic Sunyaev-Zeldovich (kSZ) effect from clusters of galaxies. To suppress the primary CMB and instrumental noise we derive a matched filter and then convolve it with the Planck foreground-cleaned “2D-ILC” maps. By using the Meta Catalogue of X-ray detected Clusters of galaxies (MCXC), we determine the normalized rms dispersion of the temperature fluctuations at the positions of clusters, finding that this shows excess variance compared with the noise expectation. We then build an unbiased statistical estimator of the signal, determining that the normalized mean temperature dispersion of 1526 clusters is 〈(ΔT/T)2 〉 = (1.64 ± 0.48) × 10−11. However, comparison with analytic calculations and simulations suggest that around 0.7 σ of this result is due to cluster lensing rather than the kSZ effect. By correcting this, the temperature dispersion is measured to be 〈(ΔT/T)2〉 = (1.35 ± 0.48) × 10−11, which gives a detection at the 2.8 σ level. We further convert uniform-weight temperature dispersion into a measurement of the line-of-sight velocity dispersion, by using estimates of the optical depth of each cluster (which introduces additional uncertainty into the estimate). We find that the velocity dispersion is 〈υ2〉 = (123 000 ± 71 000) (km s−1)2, which is consistent with findings from other large-scale structure studies, and provides direct evidence of statistical homogeneity on scales of 600 h−1 Mpc. Our study shows the promise of using cross-correlations of the kSZ effect with large-scale structure in order to constrain the growth of structure.
Key words: cosmic background radiation / large-scale structure of Universe / galaxies: clusters: general / methods: data analysis
Corresponding author: Y.-Z. Ma, This email address is being protected from spambots. You need JavaScript enabled to view it.
© ESO 2018
1. Introduction
The kinetic Sunyaev-Zeldovich (hereafter kSZ; Sunyaev & Zeldovich 1972, 1980) effect describes the temperature anisotropy of the cosmic microwave background (CMB) radiation due to inverse Compton scattering of CMB photons off a moving cloud of electrons. The effect can be written as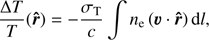 (1)
(1)
where σT is the Thomson cross-section, ne is the electron density, υ · r̂ is the velocity along the line-of-sight, and dl is the path length in the radial direction. By adopting a so-called “pairwise momentum estimator,” i.e., using the weights that quantify the difference in temperature between pairs of galaxies, the effect was first detected by Hand et al. (2012) using CMB maps from the Atacama Cosmology Telescope (ACT). The detection of the kSZ effect has been further solidified using the same pairwise momentum estimator with other CMB data, including Wilkinson Microwave Anisotropy Probe (WMAP) 9-year W-band data, and Planck’s four foreground-cleaned maps (Planck Collaboration Int. XXXVII 2016), and again more recently using a Fourier space analysis (Sugiyama et al. 2018). These measurements represent detections at the 2–3 σ level. In addition, De Bernardis et al. (2017) applied the pairwise momentum estimator to the ACT data and 50 000 bright galaxies from BOSS DR11 catalogue, and obtained 3.6–4.1 σ C.L. detection. By using the same estimator to the South Pole Telescope (SPT) data and Dark Energy Survey (DES) data, Soergel et al. (2016) achieved the detection of kSZ signal 4.2 σ C.L. More recently Li et al. (2018) detected the pairwise kSZ signal for BOSS DR13 low mass group (Mh ≲ 1012h−1M⊙) by using the 2D-ILC map (see Sect. 2.1.2). Besides the pairwise momentum estimator, in Planck Collaboration Int. XXXVII (2016) the kSZ temperature map (δT) was estimated from Planck full-mission data and cross-correlated with the reconstructed linear velocity field data (υ · r̂) from the Sloan Digital Sky Survey (SDSS-DR7) to compute the correlation function 〈 ΔT (υ · r̂)〉. For this cross-correlation, 3.0–3.2 σ detections were found for the foreground-cleaned Planck maps, and 3.8 σ for the Planck 217-GHz map. Following Planck Collaboration Int. XXXVII (2016), Schaan et al. (2016) detected the aggregated signal of the kSZ effect at 3.3 σ C.L. by cross-correlating the velocity field from BOSS samples with the kSZ map produced from ACT observations. More recently, Hill et al. (2016) cross-correlated the squared kSZ fields from WMAP and Planck, and the projected galaxy overdensity from the Wide-field Infrared Survey Explorer (WISE), which led to a 3.8 σ detection. With advanced ACTPol and a future Stage-IV CMB experiment, the signal-to-noise ratio (S/N) of the kSZ squared field and projected density field could reach 120 and 150, respectively (Ferraro et al. 2016), although these authors also cautioned that the results should be corrected for a bias due to lensing. These previous attempts to make various kinds of kSZ measurement are summarized in Table 1.
Recent measurements of the kinetic Sunyaev-Zeldovich effect with cross-correlations of various tracers of large-scale structure.
There has been a lot of previous work investigating how to use kSZ measurements to determine the peculiar velocity field. This idea was first proposed by Haehnelt & Tegmark (1996), suggesting that on small angular scales the peculiar velocities of clusters could be inferred from CMB observations. Aghanim et al. (2001) estimated the potential uncertainty of the kSZ measurements due to contamination by the primary CMB and thermal Sunyaev-Zeldovich (here-after tSZ) effect. In Holzapfel et al. (1997), the peculiar velocities of two distant galaxy clusters, namely Abell 2163 (z = 0.201) and Abell 1689 (z = 0.181), were estimated through millimetre-wavelength observations (the SZ Infrared Experiment, SuZIE). Furthermore, Benson et al. (2003) estimated the bulk flow using six galaxy clusters at z > 0.2 from the SuZIE II experiment in three frequency bands between 150 and 350 GHz, constraining the bulk flow to be <1410 km s−1 at 95% CL. In addition, Kashlinsky & Atrio-Barandela (2000) and Kashlinsky et al. (2008, 2009) estimated peculiar velocities on large scales and claimed a “dark flow” (>≳1000 km s−1) on Gpc scales. However, by combining galaxy cluster catalogues with Planck nominal mission foreground-cleaned maps, Planck Collaboration Int. XIII (2014) constrained the cluster velocity monopole to be 72 ± 60 km s−1 and the dipole (bulk flow) to be <254 km s−1 (95% CL) in the CMB rest frame. This indicates that the Universe is largely homogeneous on Gpc scales, consistent with the standard Λ cold dark matter (ΛCDM) scenario with adiabatic initial conditions1.
This work represents the third contribution of the Planck2 Collaboration to the study of the kSZ effect. In Planck Collaboration Int. XIII (2014) we focused on constraining the monopole and dipole of the peculiar velocity field, which gives constraints on the large-scale inhomogeneity of the Universe. In the second paper, Planck Collaboration Int. XXXVII (2016), we calculated the pairwise momentum of the kSZ effect and cross-correlated this with the reconstructed peculiar velocity field 〈 ΔT (υ · r̂)〉, obtaining direct evidence of unbound gas outside the virial radii of the clusters. A follow-up paper modelled these results to reconstruct the baryon fraction and suggested that this unbound gas corresponds to all baryons surrounding the galaxies (Hernández-Monteagudo et al. 2015). Even though the large-scale bulk flow and monopole flow were not detected in Planck Collaboration Int. XIII (2014), the small-scale velocity dispersion in the nearby Universe, determined by the local gravitational potential field, might still be measurable. This is because the velocity of each galaxy comprises two components, namely the bulk flow components, which reflect the large-scale perturbations, and a small-scale velocity dispersion component, which reflects perturbations due to the local gravitational potential (see, e.g., Watkins et al. 2009; Feldman et al. 2010; Ma & Scott 2013, 2014). Therefore, although the bulk flow of the galaxy clusters is constrained to be less than 254 km s−1, the total velocity dispersion can still be large enough to be detected. With that motivation, in this paper we will look at a different aspect than in the previous two papers, namely focusing on 1-point statistics of Planck data to constrain the temperature and velocity dispersion due to the kSZ effect. This topic is relevant for large-scale structure, since the velocity dispersion that we are trying to measure can be used as a sensitive test for galaxy formation models (Ostriker 1980; Davies et al. 1983; Kormendy & Bender 1996; Kormendy 2001; MacMillan et al. 2006) and moreover, a numerical value for the small-scale dispersion often has to be assumed in studies of large-scale flows (e.g., Ma et al. 2011; Turnbull et al. 2012). Providing such a statistical test through Planck’s full-mission foreground-cleaned maps is the main aim of the present paper.
This paper is organized as follows. In Sect. 2, we describe the Planck CMB data and the X-ray catalogue of detected clusters of galaxies. In Sect. 3, we discuss the filter that we develop to convolve the observational map, and the statistical methodology that we use for searching for the kSZ temperature-dispersion signal. Then we present the results of our search along with relevant statistical tests. In Sect. 4, we discuss the astrophysical implications of our result, the conclusions being presented in the last section. Throughout this work, we adopt a spatially flat, CDM cosmology model, with the best-fit cosmological parameters given by Planck Collaboration XIII (2016): Ωm = 0.309; ΩΛ = 0.691; ns = 0.9608; σ8 = 0.809; and h = 0.68, where the Hubble constant is H0 = 100 h km s−1 Mpc−1.
2. Data description
2.1. Planck maps
2.1.1. Maps from the Planck Legacy Archive
In this work we use the publicly released Planck 2015 data3. The kSZ effect gives rise to frequency-independent temperature fluctuations that are a source of secondary anisotropies. The kSZ effect should therefore be present in all CMB foreground-cleaned products. Here we investigate the four Planck 2015 foreground-cleaned maps, namely the Commander, NILC, SEVEM, and SMICA maps. These are the outputs of four different component-separation algorithms (Planck Collaboration Int. XXXVII 2016) and have a resolution of θFWHM = 5 arcmin. SMICA uses a spectral-matching approach, SEVEM adopts a template-fitting method to minimize the foregrounds, NILC is the result of an internal linear combination approach, and Commander uses a parametric, pixel-based Monte Carlo Markov chain technique to project out foregrounds (Planck Collaboration XII 2014; Planck Collaboration IX 2016; Planck Collaboration X 2015). All of these maps are produced with the intention of minimizing the foreground contribution, but there could nevertheless be some residual contamination from the tSZ effect, as well as other fore-grounds (e.g., the Galactic kSZ effect, see Waelkens et al. 2008). We use the HEALPix package (Górski et al. 2005) to visualize and mainpulate the maps.
2.1.2. The 2D-ILC map
The 2D-ILCPlanck CMB map has the additional benefit of being constructed to remove contamination from the tSZ effect, provided that the tSZ spectral energy distribution is perfectly known across the frequency channels. The 2D-ILC CMB map has been produced by taking the Planck 2015 data and implementing the “constrained ILC” method developed in Remazeilles et al. (2011a). This component-separation approach was specifically designed to cancel out in the CMB map any residual of the tSZ effect towards galaxy clusters by using spectral filtering, as we now describe.
For a given frequency band i, the Planck observation map xi can be modelled as the combination of different emission components: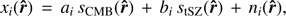 (2)
(2)
where sCMB(r̂) is the CMB temperature anisotropy at pixel r̂, stSZ(r̂) is the tSZ fluctuation in the same direction, and ni(p) is a “nuisance” term including instrumental noise and Galactic foregrounds at frequency i. The CMB fluctuations scale with frequency through a known emission law parameterized by the vector a, with nine components, accounting for the nine Planck frequency bands. The emission law of the tSZ fluctuations is also known and can be parameterized by the scaling vector b in the Planck frequency bands. The kSZ signal is implicitly included in the CMB fluctuations, since CMB anisotropies and kSZ fluctuations share the same spectral signature.
Similar to the standard NILC method (Basak & Delabrouille 2012, 2013), the 2D-ILC approach makes a minimum-variance-weighted linear combination of the Planck frequency maps. Specifically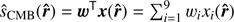 , under the condition that the scalar product of the weight vector w and the CMB scaling vector a is equal to unity, i.e.,
, under the condition that the scalar product of the weight vector w and the CMB scaling vector a is equal to unity, i.e., 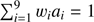 , which guarantees the conservation of CMB anisotropies in the filtering. However, 2D-ILC (Remazeilles et al. 2011a) generalizes the standard NILC method by offering an additional constraint for the ILC weights to be orthogonal to the tSZ emission law b, while guaranteeing the conservation of the CMB component. The 2D-ILC CMB estimate is thus given by
, which guarantees the conservation of CMB anisotropies in the filtering. However, 2D-ILC (Remazeilles et al. 2011a) generalizes the standard NILC method by offering an additional constraint for the ILC weights to be orthogonal to the tSZ emission law b, while guaranteeing the conservation of the CMB component. The 2D-ILC CMB estimate is thus given by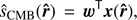 (3)
(3)
such that the variance of Eq. (3) is minimized, with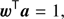 (4)
(4)
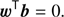 (5)
(5)
Benefiting from the knowledge of the CMB and tSZ spectral signatures, the weights of the 2D-ILC are constructed in order to simultaneously yield unit response to the CMB emission law a (Eq. (4)) and zero response to the tSZ emission law b (Eq. (5)). The residual contamination from Galactic foregrounds and instrumental noise is controlled through the condition (Eq. (3)). The exact expression for the 2D-ILC weights was derived in Remazeilles et al. (2011a) by solving the minimization problem (Eqs. (3)–(5)):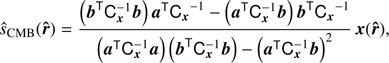 (6)
(6)
where 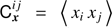 are the coefficients of the frequency-frequency covariance matrix of the Planck channel maps; in practice we compute this locally in each pixel p as
are the coefficients of the frequency-frequency covariance matrix of the Planck channel maps; in practice we compute this locally in each pixel p as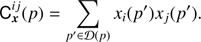 (7)
(7)
Here the pixel domain D(p) (referred to as “super pixels”) around the pixel p is determined by using the following procedure: the product of frequency maps xi and xj is convolved with a Gaussian kernel in pixel space in order to avoid sharp edges at the boundaries of super pixels that would create spurious power (Basak & Delabrouille 2012, 2013).
Before applying the 2D-ILC filter (Eq. (6)) to the Planck 2015 data, we first pre-process the data by performing point-source “in-painting” and wavelet decomposition, in order to optimize the foreground cleaning. In each Planck channel map we mask the point-sources detected at S/N > 5 in the Second Planck Catalogue of Compact Sources PCCS2 (Planck Collaboration XXVI 2016). The masked pixels are then filled in by interpolation with neighbouring pixels through a minimum curvature spline surface in-painting technique, as implemented in Remazeilles et al. (2015). This pre-processing of the point-source regions will guarantee reduction of the contamination from compact foregrounds in the kSZ measurement.
The in-painted Planck maps are then decomposed into a particular family of spherical wavelets called “needlets” (see, e.g., Narcowich et al. 2006; Guilloux et al. 2009). The needlet transform of the Planck maps is performed as follows. The spherical harmonic coefficients ai, ℓm of the Planck channel maps xi are bandpass filtered in multipole space in order to isolate the different ranges of angular scales in the data. The 2D-ILC weights (Eq. (6)) are then computed in pixel space from the inverse spherical harmonic transform of the bandpass-filtered ai, ℓm coefficients. The frequency-frequency covariance matrix in Eq. (7) is actually computed on the bandpass-filtered maps. In this way, component separation is performed for each needlet scale (i.e., range of multipoles) independently. Due to their localization properties, the needlets allow for a filtering in both pixel space and multipole space, therefore adapting the component-separation procedure to the local conditions of contamination in both spaces (see Delabrouille et al. 2009; Remazeilles et al. 2011b; Basak & Delabrouille 2012, 2013).
The top left panel of Fig. 1 shows the result of stacking 3° × 3° patches of the NILCPlanck CMB map in the direction of known galaxy clusters, while the top right panel shows the result of stacking the 2D-ILCPlanck CMB map in the direction of the same set of galaxy clusters4. The Planck SZ sample provides a very stringent test, because these are the places on the sky where Planck detected a significant y signature. We see that stacking of the NILC CMB map shows a significant tSZ residual effect in the direction of galaxy clusters. Conversely, the stacking of the 2D-ILCPlanck CMB map (right panel of Fig. 1) appears to show substantially reduced tSZ residuals, due to the 2D-ILC filtering. In the bottom panels of Fig. 1 we show the results of the stacking procedure for the specific cluster catalogue that we will be using for the main analysis in this paper (see next section for details).
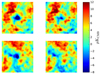 |
Fig. 1. Top left: stack of the NILC CMB map in the directions of Planck SZ (PSZ) galaxy clusters. Top right: stack of the 2D-ILC CMB map in the direction of PSZ galaxy clusters. This sample provides a very stringent test of the tSZ leakage, since the PSZ positions are the known places on the sky with detectable SZ signal. The stacked NILC CMB map clearly shows an excess in the centre, which is due to residual contamination from the tSZ effect, while the 2D-ILC CMB map has a signature in the centre that is consistent with the strength of other features in the stacked image. Bottom left: stack of the NILC CMB map in the directions of MCXC clusters. Bottom right: stack of the 2D-ILC CMB map in the direction of 1526 MCXC clusters (see Sect. 2.2 for the detail of the catalogue). For a different set of sky positions, the results are broadly consistent with those for the PSZ clusters. All these maps are 3° × 3° in size, and use the same colour scale. |
The profiles of the stacked patches are plotted in Fig. 2. The excess of power due to tSZ residuals in the NILC CMB map would clearly lead to a significant bias in any attempt to detect the kSZ signal at the positions of the galaxy clusters. As a baseline reference, the flux profile of the Planck 217-GHz map, stacked in the directions of these galaxy clusters, is also plotted in Fig. 2 (green squares). The tSZ signal should in principle vanish in observations at 217 GHz, since that is effectively the null frequency for the tSZ signature; in practice it is non-zero in the Planck 217-GHz map because of the broad spectral bandpass. In fact there is an offset of about 20 μ K in the flux profile of the stacked 217-GHz map at the position of PSZ clusters. There is also still a residual offset in the 2D-ILC CMB map; however, it is smaller by a factor of about 2 than the tSZ signal in the baseline Planck 217-GHz map (see top panel of Fig. 2), and dramatically better than for the NILC map. This suggests that the method employed for the 2D-ILC map was successful in removing the tSZ signal.
 |
Fig. 2. Profiles for stacked patches (see Fig. 1) of the NILC CMB map (black diamonds) and the 2D-ILC CMB map (blue triangles) at the positions of PSZ clusters (top panel) and MCXC clusters (bottom panel). The profile of the stacked Planck 217-GHz map is also shown as a reference (green squares). The central deficit in the flux profile of the stacked NILC CMB map (black diamonds) is due to residual tSZ contamination. |
The residual flux of the stacked 2D-ILC CMB map in the direction of galaxy clusters can be interpreted as the result of possibly imperfect assumptions in the 2D-ILC filter and the exact tSZ spectral shape across the Planck frequency bands. There may be several reasons behind incomplete knowledge of the tSZ spectrum: detector bandpass mismatch; calibration uncertainties; and also relativistic tSZ corrections. In addition, even if the kSZ flux is expected to vanish on average when stacking inward- and outward-moving clusters in a homogeneous universe, there is still a potential selection bias (since we use a selected subset of clusters for stacking) that may result in a non-zero average kSZ residual in the offset of the 2D-ILC map. Although it is not easy to estimate the size of all these effects, we are confident that they cannot be too large because the residual offset in the 2D-ILC map is negligible compared to the tSZ residuals in Planck CMB maps, and smaller by a factor of 2 with respect to the baseline Planck 217-GHz map.
Regarding residual Galactic foreground contamination, we checked that the angular power spectrum of the 2D-ILC CMB map on the 60% of the sky that is unmasked is consistent with the angular power spectrum of the PlanckSMICA CMB maps. There is therefore no obvious excess of power due to Galactic emission. We also checked the amount of residual dust contamination of the kSZ signal on small angular scales in the direction of the galaxy clusters, where dusty star-forming galaxies are present (Planck Collaboration Int. XLIII 2016). Considering the Planck 857-GHz map as a dust template, we scaled it across the Planck frequency bands using a modified blackbody spectrum with best-fit values from Planck Collaboration Int. XLIII (2016), i.e., β = 1.5 and T = 24.2 K. This provides dust maps at each frequency band. We then applied the ILC weights that go into the 2D-ILC CMB+kSZ map (Eq. (6)) to the thermal dust maps. This provides an estimate of the map of the residual dust contamination in the 2D-ILC map. We then stacked the residual dust map in the direction of the galaxy clusters from either the PSZ or the MCXC catalogue, and computed the profile of the stacked patch as in Fig. 2. We found that the residual flux from the dust stacked in the direction of the galaxy clusters is compatible with zero.
Residual cosmic infrared background (hereafter CIB) and instrumental noise in the CMB maps will add some scatter to the measured kSZ signals in the directions of galaxy clusters, but should not lead to any bias in the stacked profile. However, any additional source of extra noise will lead to bias in the variance of the stacked profile. Since CIB and noise are not spatially localized on the sky (unlike kSZ and tSZ signals) this bias can be estimated using off-cluster positions, e.g., for the matched-filtering analysis performed in Sect. 3.2.
In order to quantify the amount of residual noise in the 2D-ILC CMB map, we apply the 2D-ILC weights (calculated from the Planck full-survey maps) to the first and second halves of each stable pointing period (also called “rings”). In the half-difference of the resulting “first” and “second” 2D-ILC maps, the sky emission cancels out, therefore leaving an estimate of the noise contamination in the 2D-ILC CMB maps, constructed from the full-survey data set.
The 2D-ILC CMB map shows approximately 10% more noise than the NILC CMB map; this arises from the additional constraint imposed in the 2D-ILC of cancelling out the tSZ emission. At the cost of having a slightly higher noise level, the 2D-ILC CMB map benefits from the absence of bias due to tSZ in the directions of galaxy clusters. For this reason, the 2D-ILC CMB map is particularly well suited for the extraction of the kSZ signal in the direction of galaxy clusters and we shall focus on it for the main results of this paper.
2.2. The MCXC X-ray catalogue
To trace the underlying baryon distribution, we use the Meta Catalogue of X-ray detected Clusters of galaxies (MCXC), which is an all-sky compilation of 1743 all-sky ROSAT survey-based samples (BCS, Ebeling et al. 1998, 2000; CIZA, Ebeling et al. 2010; Kocevski et al. 2007; MACS, Ebeling et al. 2007; NEP, Henry et al. 2006; NORAS, Böhringer et al. 2000; REFLEX, Böhringer et al. 2004; SCP, Cruddace et al. 2002) along with a few other catalogues (160SD, Mullis et al. 2003; 400SD, Burenin et al. 2007; EMSS, Gioia & Luppino 1994; Henry 2004; SHARC, Romer et al. 2000; Burke et al. 2003; WARPS, Perlman et al. 2002; Horner et al. 2008). We show stacks and profiles for this catalogue on the Planck map in Figs. 1 and 2. While selecting sources from this catalogue, we use the luminosity within R500 (the radius of the cluster within which the density is 500 times the cosmic critical density), L500, and restrict the samples to have 1.5 × 1033 W < L500 < 3.7 × 1038 W within the band 0.1–2.4 keV (see Piffaretti et al. 2011). As well as L500, for each cluster the catalogue gives M500, the mass enclosed within R500 at redshift z, i.e., 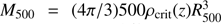 , estimated using the empirical relation
, estimated using the empirical relation 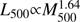 in Arnaud et al. (2010). Further details of catalogue homogenization and calibration are described in Piffaretti et al. (2011) and Planck Collaboration Int. XIII (2014).
in Arnaud et al. (2010). Further details of catalogue homogenization and calibration are described in Piffaretti et al. (2011) and Planck Collaboration Int. XIII (2014).
For each cluster in the MCXC catalogue, the properties we use in the rest of this paper are the sky position (Galactic coordinates l, b), the redshift z, and the mass M500. In Sect. 4 we will use M500 and z to estimate the optical depth for each cluster.
Since in the CMB map, the Galactic plane region is highly contaminated by foreground emission, we use the Planck Galactic and point-source mask to remove 40% of the sky area. The number of MCXC sources outside the sky mask is Nc = 1526 (which we use throughout the paper) and their spatial and red-shift distributions are shown in Fig. 3. The full-sky distribution is presented in the left panel of Fig. 3, and one can see that the distribution of MCXC clusters is roughly uniform outside the Galactic mask. The redshift of MCXC clusters peaks at z = 0.09, with a long tail towards higher redshift, z >≳ 0.4.
 |
Fig. 3. Left: full-sky distribution of 1526 MCXC X-ray clusters (Piffaretti et al. 2011; Planck Collaboration Int. XIII 2014) in Galactic coordinates. The dark blue area is the masked region, and the clusters are shown in orange. Right: redshift histogram of 1526 X-ray clusters, with bin width Δz = 0.025. |
3. Methodology and statistical tests
3.1. Matched-filter technique
The foreground-cleaned CMB maps (SEVEM, SMICA, NILC, Commander, and 2D-ILC) contain mainly the primary CMB and kSZ signals, so in order to optimally characterize the kSZ signal, we need to use a spatial filter to convolve the maps in order xto downweight the CMB signal. Here we use the matched-filter technique (e.g., Tegmark & de Oliveira-Costa 1998; Ma et al. 2013), which is an easily implemented approach for suppressing the primary CMB and instrumental noise.
Most of Planck’s SZ-clusters are unresolved, so we treat them as point sources on the sky. In this limit, if cluster i has flux Si at sky position r̂i, the sky temperature ΔT(r̂) can be written as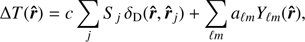 (8)
(8)
where δD is the Dirac delta function, c is the conversion factor between flux and temperature, and the spherical harmonics characterize the true CMB fluctuations. The sky signal, obtained from the Planck telescope, is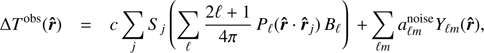 (9)
(9)
where 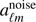 is the true CMB signal convolved with the beam plus the detector noise, i.e.,
is the true CMB signal convolved with the beam plus the detector noise, i.e., 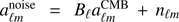 (assuming that this is the only source of noise). The beam function of Planck foreground-cleaned maps in ℓ-space is close to a Gaussian with θFWHM = 5 arcmin, i.e.,
(assuming that this is the only source of noise). The beam function of Planck foreground-cleaned maps in ℓ-space is close to a Gaussian with θFWHM = 5 arcmin, i.e., 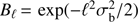 , with
, with 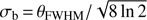 . Residual foregrounds in the Planck CMB maps and in the 2D-ILC CMB map have been minimized in the component-separation algorithms, as demonstrated in Planck Collaboration IX (2016) for the public Planck CMB maps and in Planck Collaboration Int. XIII (2014) for the 2D-ILC CMB map. Figure 4 compares the angular power spectrum, Cℓ, directly estimated from the map by using the pseudo-Cℓ estimator (Hivon et al. 2002), and the spectrum predicted by using the best-fit CDM model and noise template. One can see that the measured spectral data scatter around the predicted spectrum, and that the two spectra are quite consistent with each other.
. Residual foregrounds in the Planck CMB maps and in the 2D-ILC CMB map have been minimized in the component-separation algorithms, as demonstrated in Planck Collaboration IX (2016) for the public Planck CMB maps and in Planck Collaboration Int. XIII (2014) for the 2D-ILC CMB map. Figure 4 compares the angular power spectrum, Cℓ, directly estimated from the map by using the pseudo-Cℓ estimator (Hivon et al. 2002), and the spectrum predicted by using the best-fit CDM model and noise template. One can see that the measured spectral data scatter around the predicted spectrum, and that the two spectra are quite consistent with each other.
 |
Fig. 4. Measured (black dots) and predicted (red line) power spectra from the Planck2D-ILC map. The predicted spectrum is based on the best-fitting ΛCDM model convolved with the squared beam |
In order to maximize our sensitivity to SZ clusters, we further convolve ΔT obs(r̂) with an optimal filter Wℓ: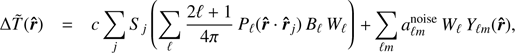 (10)
(10)
where we are seeking the form of Wℓ that will maximize cluster S/N. In the direction of each cluster, the filtered signal is![Mathematical equation: $$ \begin{eqnarray} \Delta \tilde{T}_{\rm c}({\hat{r}}_{j})=cS_{j}\left[\sum_{\ell}\left(\frac{2 \ell +1}{4 \pi} \right)B_{\ell}W_{\ell} \right] \equiv (cS_{j})A, \end{eqnarray}, $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq21.gif) (11)
(11)
and we want to vary Wℓ to minimize the ratio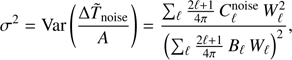 (12)
(12)
where 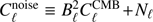 , and we take
, and we take 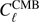 to be the CDM model power spectrum. Since A in Eq. (11) is a constant, we minimize Eq. (12) by adding a Lagrange multiplier to the numerator (see, e.g., Ma et al. 2013), i.e., we minimize
to be the CDM model power spectrum. Since A in Eq. (11) is a constant, we minimize Eq. (12) by adding a Lagrange multiplier to the numerator (see, e.g., Ma et al. 2013), i.e., we minimize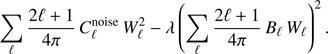 (13)
(13)
We then obtain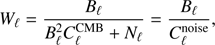 (14)
(14)
which we plot in Fig. 5 as a black line, along with the primary CMB Cℓ, the noise map, and their sum. In the filtering process, we use the normalized filter 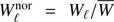 , where
, where 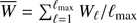 . One can see that the filter function Wℓ gives lower weight in the primary CMB domain while giving more weight in the cluster regime, ℓ >≳ 2000. We then convolve the five Planck foreground-cleaned maps with this Wℓ filter, noting that the noise power spectrum Nℓ in Eq. (14) of each foreground-cleaned map is estimated by using its corresponding noise map. After we perform this step, the primary CMB features are highly suppressed (Fig. 6), and the whole sky looks essentially like a noisy map, although it still contains the kSZ information of course.
. One can see that the filter function Wℓ gives lower weight in the primary CMB domain while giving more weight in the cluster regime, ℓ >≳ 2000. We then convolve the five Planck foreground-cleaned maps with this Wℓ filter, noting that the noise power spectrum Nℓ in Eq. (14) of each foreground-cleaned map is estimated by using its corresponding noise map. After we perform this step, the primary CMB features are highly suppressed (Fig. 6), and the whole sky looks essentially like a noisy map, although it still contains the kSZ information of course.
 |
Fig. 5. Optimal matched filter (black line) for point-source detection in the Planck2D-ILC map (Eq. (14)). For comparison, the power spectra of the CMB signal (red line) and noise map (blue dashed line) are shown, along with their sum (brown line). |
3.2. Statistical method and tests of robustness
We now proceed to estimate the kSZ temperature dispersion and perform various tests. The filtered map contains the kSZ signal and residual noise, and from this we plot the histogram of 1526 ΔT/T values at the cluster positions (see red bars in Fig. 7). We can also randomly select the same number of pixels on the sky and plot a histogram for that. The two histograms have almost zero mean value (Table 2), but in the real cluster positions yield a larger variance than the random selections, i.e., the real cluster positions give a slightly broader distribution than for the randomly selected positions (Table 2). We also show results for the skewness and kurtosis of the two samples in Table 2, and one can see that for these statistics the real cluster positions also give larger values than for the randomly-selected positions. This suggests that there may be additional tests that could be performed to distinguish the real cluster kSZ signals; however, we leave that for future studies, and for the rest of this paper we just focus on investigating whether the slight broadening of the distribution is due to the kSZ effect.
Statistics of the values of (ΔT/T) × 105 at the true 1526 cluster positions and for 1526 randomly-selected positions.
 |
Fig. 7. Histograms of 1526 ΔT/T values of 2D-ILC map at the cluster catalogue positions (red bars), and randomly selected positions (black bars). The statistics of the true cluster positions and random positions can be found in Table 2. |
3.2.1. Test of thermal Sunyaev-Zeldovich effect residuals
The first test we want to perform is to check whether the measured kSZ (ΔT/T) value at each cluster position suffers from residuals of the tSZ effect. The mapmaking procedures of SMICA, NILC, SEVEM, and Commander minimize the variance of all non-CMB contribution to the map, but they are not designed to null the tSZ component. By contrast, the 2D-ILC map is designed to also null the tSZ contribution, and therefore should provide a cleaner measurement of the kSZ effect (but with a slightly higher noise level).
We first choose 5000 randomly selected catalogues from each Planck foreground-cleaned map, each being a collection of 1526 random positions on the sky. We then calculate the average value of (ΔT/T) for each random catalogue and plot the resulting histograms in Fig. 8. The five different colours of (overlapping) histogram represent the different Planck maps. One can see that they are all centred on zero, with approximately the same widths. Since the 2D-ILC map has nulled the tSZ component in the map, it does not minimize the variance of all foreground components and as a result, its width in Fig. 8 (2.86 × 10−7) is slightly larger than for all other maps; in these units, the 1 σ width of the histograms for SMICA, NILC, SEVEM and Commander are 2.49 × 10−7, 2.48 × 10−7, 2.53 × 10−7, and 2.62 × 10−7, respectively. This indicates that the noise level in the filtered 2D-ILC map is slightly higher than for the other four maps.
 |
Fig. 8. Histogram of the |
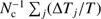
We then calculate the average value of ΔT/T at the true cluster positions for the five Planck foreground-cleaned maps as the vertical bars in Fig. 8. One can see that only the average value of the 2D-ILC map lies close to zero and within the 68% width of the noise histogram, while the values of all other maps are quite far from the centre of the noise distribution. This strongly suggests that at each of the true cluster positions the (ΔT/T) value contains some contribution from the tSZ effect, so that the tSZ effect contributes extra variance to the foreground-cleaned maps.
3.2.2. Test with random positions
We now want to test whether this slight broadening of the distribution is a statistically significant consequence of the kSZ effect. So for the 5000 randomly selected catalogues, we calculate the scatter of the 1526 (ΔT/T) values. We then plot (in Fig. 9) the histogram of 5000 rms values of these random catalogues, and mark the rms value of the true MCXC cluster positions for reference. One can see that the mean of the 5000 rms values of the random catalogues is 1.10 × 10−5, and that the scatter of the 5000 rms values of the random catalogue has a width around 2.15 × 10−7. The rms value of the 1526 true MCXC position is 1.17 × 10−5, larger than the mean value at more than the 3 σ level.
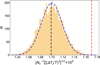 |
Fig. 9. Distribution of the rms for 5000 mock catalogues (yellow histogram); here each catalogue consists of Nc randomly chosen positions on the filtered 2D-ILC map. The mean and rms of the 5000 random catalogues are 1.10 × 10−5 (shown as the black dashed vertical line) and 2.15 × 10−7, respectively. For the Nc true MCXC cluster positions, the rms is 1.17 × 10−5 (red vertical dashed line). |
In Table 3, we list the rms value for the true sky positions of the 1526 MCXC catalogue sources (σMCXC, the mean (σran), and standard deviation (σ(σran)) for 5000 random catalogues for different foreground-cleaned maps. One can see that although the absolute value of each map varies somewhat, the second column (σran) is consistently smaller than the first column (σMCXC) by roughly 0.07–0.13 × 10−5, which, specifically for 2D-ILC is about 3 times the scatter of the rms among catalogues (σ(σran)). This consistency strongly suggests that the kSZ effect contributes to the extra dispersion in the convolved ΔT/T maps at the cluster positions (since the 2D-ILC map is constructed to remove the tSZ effect). If we use the SMICA, SEVEM, NILC, and Commander maps, the detailed values will vary slightly due to the different calibration schemes of the maps, but the detection remains consistently there. The difference between σMCXC and σran is slightly larger in the SMICA, NILC, and SEVEM maps due to residual tSZ contamination, shown as the vertical bars in Fig. 8.
rms values for the true sky positions of 1526 MCXC catalogue clusters (σMCXC), along with the mean (σran) and scatter (σ(σran)) of the values of the rms for 5000 random catalogues, where each catalogue consists of 1526 random positions on the sky.
This all points towards the broadening of the ΔT/T histogram being a consequence of the kSZ effect; hence we identify it as additional temperature dispersion arising from the scatter in cluster velocities detected through the kSZ effect. In Sect. 4, we will interpret this effect in terms of the line-of-sight velocity dispersion of the SZ clusters, which is an extra variance predicted in linear perturbation theory in the standard picture of structure formation (Peebles 1980).
3.2.3. Test with finite cluster size
We now want to test how much our results depend on the assumption that SZ clusters are point sources. A cluster on the sky appears to have a radius of θ500, which is equal to θ500 = R500/DA, where R500 is the radius from the centre of the cluster at which the density contrast is equal to 500 and DA is the angular diameter distance to the cluster. The peak in the distribution of θ500 values for the MCXC clusters lies at around 3 arcmin, so we multiply the filter function (Eq. (14)) with an additional “cluster beam function” 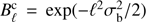 , where
, where 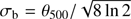 . We pick three different values for the cluster size, namely θ500 = 3, 5, and 7 arcmin, and see how our results change.
. We pick three different values for the cluster size, namely θ500 = 3, 5, and 7 arcmin, and see how our results change.
We list our findings in Table 4; one can see that the detailed values for three cases are slightly different from those of the point-source assumptions, but the changes are not dramatic. More importantly, the offsets between σMCXC and σran stay the same for various assumptions of cluster size. Therefore the detection of the temperature dispersion due to the kSZ effect does not strongly depend on the assumption of clusters being point sources.
3.3. Statistical results
3.3.1. Statistics with the uniform weight
We now want to perform a more quantitative calculation of the significance of detection. Since the convolved map mainly consists of the kSZ signal at the cluster positions plus residual noise, we write the observed temperature fluctuation at the cluster positions as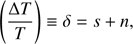 (15)
(15)
where δ, s, and n represent the observed ΔT/T value, the kSZ signal contribution, and the residual noise, respectively, all of which are dimensionless quantities. Now we define the estimator 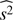 as
as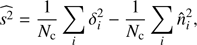 (16)
(16)
where the summation includes all of the Nc = 1526 cluster positions. For the first term δi, we use the Nc true cluster position as the measurement of each observed ΔT/T. For the second term, we randomly select Nc pixels outside the Galactic and point-source mask that are not cluster positions. The calculation of the first term is fixed, whereas the second term depends on the Nc random positions we choose. Each randomly selected set of Nc positions corresponds to a mock catalogue, which leads to one value of s2. We do this for 5000 such catalogues, where each mock catalogue has a different noise part (n̂i) in Eq. (16), but the same observed δi. Then we plot the histogram of s2 values for these catalogues in the left panel of Fig. 10. One can see that the s2 distribution is close to a Gaussian distribution with mean and error being s2 = (1.64 ± 0.48) × 10−11.
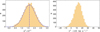 |
Fig. 10. Left: distribution of 5000 values of s2 with uniform weight (Eq. (16)) on each position for the 2D-ILC map. Right: distribution of υ2 calculated from Eq. (30), after subtracting the lensing shift. The distribution has P(υ2 < 0) = 5.3%, corresponding to a (1-sided) detection of 1.6 σ. We have tested with 50 000 values of s2 and the results are consistent with those from 5000 values. |
One can use a complementary method to obtain the mean and variance of 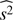 , i.e., E[s2] and V[s2]. We lay out this calculation in Appendix A, where we directly derive these results:
, i.e., E[s2] and V[s2]. We lay out this calculation in Appendix A, where we directly derive these results:![Mathematical equation: $$ \begin{array}{lll}E\left[s^2\right]&=&\overline{\delta^2}-\mu_2{(n)};\\V\left[s^2\right]&=&\frac1{N_\mathrm c}\left[\mu_4{(n)}-\mu_2^2{(n)}\right].\end{array} $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq36.gif) (17)
(17)
Here μ2 and μ4 are the second and fourth moments of the corresponding random variables.
For the moments of δ, we use the measurements at the 1526 cluster positions. For the estimate of the noise, we take all of the unmasked pixels of the convolved sky. In order to avoid selecting the real cluster positions, we remove all pixels inside a 10 arcmin aperture around each cluster. These “holes” at each cluster position constitute a negligible portion of the total unmasked pixels, and our results are not sensitive to the aperture size we choose. As a result, we have approximately 3 × 107 unmasked pixels to sample the noise. We then substitute the values into Eq. (17) to obtain the expectation values and variances.
In Table 5, we list the mean and rms value of 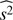 . Comparing with the 2D-ILC map, one can see that the SMICA, NILC, and SEVEM maps give larger values of E[s2] and therefore apparently higher significance levels, which we believe could be due to the fact that the residual tSZ effect in these maps contributes to the signal. However, the Commander map gives a reasonable estimate of the dispersion, since it appears to be less contaminated by tSZ residuals (see Fig. 8). As discussed in Sect. 2.1.2, the mapmaking procedure of the 2D-ILC product enables us to null the tSZ effect so that the final map should be free of tSZ, but with larger noise. This is the reason that we obtain a somewhat lower significance in Table 5 for 2D-ILC compared to some of the other maps. We will therefore mainly quote this conservative detection in the subsequent analysis.
. Comparing with the 2D-ILC map, one can see that the SMICA, NILC, and SEVEM maps give larger values of E[s2] and therefore apparently higher significance levels, which we believe could be due to the fact that the residual tSZ effect in these maps contributes to the signal. However, the Commander map gives a reasonable estimate of the dispersion, since it appears to be less contaminated by tSZ residuals (see Fig. 8). As discussed in Sect. 2.1.2, the mapmaking procedure of the 2D-ILC product enables us to null the tSZ effect so that the final map should be free of tSZ, but with larger noise. This is the reason that we obtain a somewhat lower significance in Table 5 for 2D-ILC compared to some of the other maps. We will therefore mainly quote this conservative detection in the subsequent analysis.
Statistics of the variables 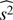 due to the kSZ effect for different CMB maps.
due to the kSZ effect for different CMB maps.
3.3.2. Statistics with different weights
The results so far have been found using the same weights for each cluster position. We now examine the stability of the detection using weighted stacking. In Eq. (16) we defined stacking with uniform weights, which can be generalized to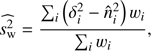 (18)
(18)
where wi is the weight function. We certainly expect “larger” clusters to contribute more to the signal, but it is not obvious what cluster property will be best to use. In Table 6, we try different weighting functions wi, with the first row being the uniform weight, which is equivalent to Eq. (16). In addition, we try as different choices of weighting function the optical depth τ and its square τ25, the angular size θ500 and its square 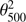 , the luminosity L500 and its square
, the luminosity L500 and its square 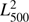 , and the mass M500 and its square
, and the mass M500 and its square 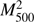 . Since some of these may give distributions of
. Since some of these may give distributions of 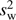 that deviate from Gaussians, we also calculate the frequencies for finding
that deviate from Gaussians, we also calculate the frequencies for finding 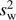 smaller than zero,
smaller than zero, 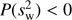 . The smaller this P-value is, the more significant is the detection.
. The smaller this P-value is, the more significant is the detection.
Statistics of the weighted variables 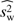 for different choices of weights in the 2D-ILC map.
for different choices of weights in the 2D-ILC map.
From Table 6, we see that most weighting choices are consistent with uniform weighting though with reduced significance of the detection, the exceptions being the choices of θ500 or 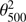 . For wi = θ500,i and
. For wi = θ500,i and 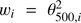 , we have P-values of 0.0002 and 0.0039, respectively, yielding (1-sided) significance levels of 3.5 σ and 2.7 σ. Their distributions deviate slightly from a Gaussian, with a tail toward smaller values.
, we have P-values of 0.0002 and 0.0039, respectively, yielding (1-sided) significance levels of 3.5 σ and 2.7 σ. Their distributions deviate slightly from a Gaussian, with a tail toward smaller values.
The increased detection of excess variance using θ500 weighting stems from our choice of using a single cluster beam function for all clusters. In Sect. 3.2.3 we tested the robustness of our results to the choice of cluster beam function, finding little dependence. Nevertheless, such a test assumed all clusters had the same angular size, while in reality there is a large spread in the angular sizes of the clusters. By weighting with θ500 we are able to recover some of this lost signal in a quick and simple way, which we tested by comparing results for larger clusters versus smaller clusters. Despite this, we find that the increased significance is mainly due to the increased value for ![Mathematical equation: $ \textstyle E{\left[ s_w^2\right]} $](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq57.gif) and not a decrease in the noise. This tension may be evidence of systematic effects in the data or potentially some noise coming from residual tSZ signal in the 2D-ILC map; this should be further investigated when better data become available.
and not a decrease in the noise. This tension may be evidence of systematic effects in the data or potentially some noise coming from residual tSZ signal in the 2D-ILC map; this should be further investigated when better data become available.
3.3.3. Statistics with split samples
We further split the samples into two groups, according to their median values of M500, R500 and L500. The distributions of these values are shown in Fig. 11. One can see that our samples span several orders of magnitude in mass, radius, and luminosity, but that the median values of the three quantities quite consistently split the samples into two. We re-calculate the 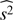 statistics as defined in Eq. (16) for the two sub-samples and list our results in Table 7.
statistics as defined in Eq. (16) for the two sub-samples and list our results in Table 7.
 |
Fig. 11. Left: R500 versus M500 for the sample. Right: L500 versus M500 for the sample. The vertical and horizontal lines show the median values of R500, M500, and L500. |
Statistics of split samples. Here the median values of the samples are (M500)mid = 1.68 × 1014M⊙, (L500)mid = 2.3 × 1010L⊙, and (R500)mid = 0.79 Mpc.
We see that the groups with lower values of L500, M500, and R500 give detections of the kSZ temperature dispersion at 1.1 σ, 1.2 σ, and 0.7 σ, whereas the higher value subsets give higher S/N detections. It is clear that the signal we see is dominated by the larger, more massive, and more luminous subset of clusters, as one might expect. In principle one could use this information (and that of the previous subsection) to devise an estimator that takes into account the variability of cluster properties in order to further maximize the kSZ signal; however, a cursory exploration found that, for our current data, improvements will not be dramatic. We therefore leave further investigations for future work.
3.4. Effect of lensing
An additional effect that could cause a correlation between our tSZ-free CMB maps and clusters comes from gravitational lensing (as discussed in Ferraro et al. 2016). It is therefore important to determine what fraction of our putative kSZ signal might come from lensing, and we estimate this in the following way. The MCMX CMB temperature variance is set by the integrated local CMB power spectrum at these positions. Lensing by the clusters magnifies the CMB, locally shifting scales with respect to the global average, potentially introducing a lensing signal in the variance shift. If we were to compare the CMB variance between cluster lensed and unlensed skies unlimited by resolution, no difference would be seen; lensing is merely a remapping of points on the sky, and hence does not affect one-point measures, with local shifts in scales in the power spectrum being compensated by subtle changes in amplitude, keeping the variance the same. However, as noted by Ferraro et al. (2016), the presence of finite beams and of the filtering breaks this invariance and the relevance of the lensing effects needs to be assessed. Crudely, the cluster-lensing signal α · ∇T (with α the deflection due to the cluster) can be as large as 5 μK (Lewis & Challinor 2006), hence potentially contributing ≃ 25 μK2 to the observed variance 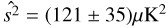 , i.e., around the 1 σ level.
, i.e., around the 1 σ level.
We obtain a more precise estimate with a CMB simulation as follows. After generating a Gaussian CMB sky with lensed CMB spectra, we lens the CMB at each cluster position according to the deflection field predicted for a standard halo profile (Navarro et al. 1996; Dodelson 2004) of the observed red-shift and estimated mass. We use for this operation a bicubic spline interpolation scheme, on a high-resolution grid of 0.4 arcmin (Nside = 8192), using the python lensing tools6. We then add the 2D-ILC noise-map estimate to the CMB. We can finally compare the temperature variance at the cluster positions before and after cluster lensing. We show our results in Fig. 12. The background (yellow) histogram shows the value of the dispersion of the 5000 random catalogues on the simulated map with 2D-ILC noise added. The purple (red) line indicates the value of dispersion of the map without (with) cluster lensing added. One can see that with cluster lensing added the value of dispersion is shifted to a higher value by 1.4 × 10−7, which is somewhat less than the rms of the random catalogue (2.1 × 10−7). This indicates that the lensing causes a roughly 0.7 σ shift in the width of histogram. From Fig. 12, we can calculate the lensing-shifted ŝ2 as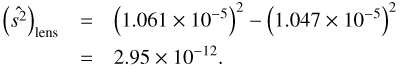 (19)
(19)
 |
Fig. 12. Histogram of the |
![Mathematical equation: $ \textstyle{\left[ N_\mathrm c^{-1}{\mathrm\Sigma}_j{(\mathrm\Delta T_j/T)}^2\right]}^{1/2} $](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq64.gif)
Therefore, using uniform weights, by subtracting the 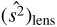 , the temperature dispersion
, the temperature dispersion 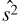 in the 2D-ILC map is measured to be
in the 2D-ILC map is measured to be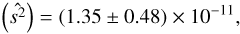 (20)
(20)
which is thus detected at the 2.8σ level.
3.5. Comparison with other kSZ studies
Table 1 summarizes all of the previous measurements of the kSZ effect coming from various cross-correlation studies. One can see that many investigations have used the pairwise temperature-difference estimator (Hand et al. 2012), which was inspired by the pairwise momentum estimator (Ferreira et al. 1999). However, in a different approach, recently Hill et al. (2016) and Ferraro et al. (2016) cross-correlated the squared kSZ field with the WISE galaxy projected density catalogue and obtained a roughly 4 σ detection. This approach has similarities with the temperature dispersion that we probe in this paper, but is different in several ways. Firstly, in terms of tracers, Hill et al. (2016) used the density field of the WISE-selected galaxies, of which only the radial distribution (Wg(η) kernel) is known, whereas in this work we use the MCXC X-ray catalogue in which each cluster’s exact position and redshift are already determined. Secondly, for the optical depth treatment Hill et al. (2016) used 46 million WISE galaxies, so the cross-correlation with the kSZ2 field contains the contribution of diffuse gas as well as virialized gas in groups; hence they assumed that their galaxies are tracing the velocity field with a uniform optical depth approximation (in their notation it is the fgas parameter). In this paper, on the other hand, we are explicitly probing the velocity dispersion around galaxy clusters, so our optical depth comes from each individual cluster. Thirdly, in Hill et al. (2016) and Ferraro et al. (2016) the angular scales of the kSZ2 and WISE projected density field correlation lie in the range ℓ = 400–3000, whereas in this work, the dispersion effectively comes from a narrower range of scales around 5′–10′. Lastly, the lensing contamination in our case is below 1 σ of our signal, while in Hill et al. (2016) and Ferraro et al. (2016), the lensing is correlated with the WISE projected density field, and so the detected signal has a larger lensing contribution (Fig. 1 in Hill et al. 2016).
It is evident therefore that the methods discussed in this paper and described in Hill et al. (2016) are complementary. As the mapping of the small-scale CMB sky continues to improve, we can imagine that the assumptions made in either approach will need to be revisited and more sophisticated methods will be needed to probe the kSZ statistics more thoroughly, e.g., through direct comparison with simulations.
4. Implications for the peculiar velocity field
We now want to investigate what the temperature dispersion indicates for the variance of the peculiar velocity field. As shown in Eq. (1), the dimensionless temperature fluctuation is different from the dimensionless velocity field through the line-of-sight optical depth factor τ. Since the coherence length of the velocity field is order 100 h−1 Mpc (Planck Collaboration Int. XXXVII 2016), i.e., much larger than the size of a cluster, the velocity can be taken out of the integral, giving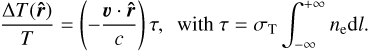 (21)
(21)
In order to convert the kSZ signal into a line-of-sight velocity we therefore need to obtain an estimate of τ for each cluster. In Planck Collaboration Int. XIII (2014), the values calculated are explicitly given as the optical depth per solid angle, obtained based on two scaling relations from Arnaud et al. (2005 and 2010). Here we adopt a slightly different approach, which is to determine the τ value at the central pixel of each galaxy cluster.
Many of the previous studies of the tSZ effect have used the “universal pressure profile” (UPP, Arnaud et al. 2010; Planck Collaboration Int. V 2013) and β isothermal model (Cavaliere & Fusco-Femiano 1976, 1978) to model the pressure and electron density profiles of the clusters (Grego et al. 2000; Benson et al. 2003, 2004; Hallman et al. 2007; Halverson et al. 2009; Plagge et al. 2010). Because the UPP is just a fitting function for pressure, it is difficult to separate out the electron density and the temperature unless we use the isothermal assumption. In fact, Battaglia et al. (2012) demonstrated that the UPP is not absolutely universal, and that feedback from an active galactic nucleus can change the profile in a significant way. The functional form of the β model can be derived from a parameterization of density under the assumption of isothermality of the profile (e.g., Sarazin 1986). However, since isothermality is a poor assumption for many clusters (Planck Collaboration Int. V 2013), we only consider the β model here as a fitting function. Measurements of cluster profiles from the South Pole Telescope (SPT) have found that the index β = 0.86 provides the best fit to the profiles of SZ clusters (Plagge et al. 2010), and therefore we use this value of β in the following discussion.
The electron density can be written as![Mathematical equation: $$ n_\mathrm e{(r)}=\frac{n_\mathrm e0}{{\left[1+{(r/r_\mathrm c)}^2\right]}^{3\beta/2}}, $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq69.gif) (22)
(22)
where rc = rvir/c is the core radius of each cluster, with c being the concentration parameter. Here we adopt the formula from Duffy et al. (2008) and Komatsu et al. (2011) to calculate the concentration parameter given the redshift and halo mass of the cluster: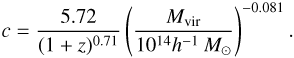 (23)
(23)
In the catalogue, M500 and redshift z are given, so one can use these two quantities to calculate the virial mass Mvir of the cluster. The calculation is contained in Appendix B.
The radius rvir is calculated through![Mathematical equation: $$ M_\text{vir}=\frac{4\pi}3{\left[\mathrm\Delta{(z)}\rho_\mathrm c{(z)}\right]}r_\text{vir}^3, $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq71.gif) (24)
(24)
where ρc(z) is the critical density of the Universe at redshift z, and Δ(z) depends on Ωm and ΩΛ as Bryan & Norman (1998)![Mathematical equation: $$ \mathrm\Delta{(z)}=18\pi^2+82{\left[\mathrm\Omega{(z)-1}\right]}-39{\left[\mathrm\Omega{(z)-1}\right]}^2,\text{with}\;\mathrm\Omega{(z)}={\mathrm\Omega}_\mathrm m{(1+z)}^2/\left[{\mathrm\Omega}_\mathrm m{(1+z)}^3+{\mathrm\Omega}_\mathrm\Lambda\right].\;\text{Thus,} $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq72.gif) (25)
(25)
with Ω(z) = Ωm(1 + z)2/[Ωm(1 + z)3 ΩΛ]. Thus,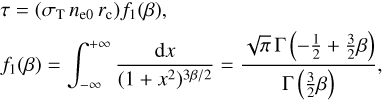 (26)
(26)
where Γ is the usual gamma function. To determine ne0, we use 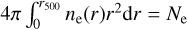 , where
, where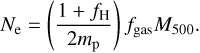 (27)
(27)
Here the quantity fH = 0.76 is the hydrogen mass fraction, mp is the proton mass, and fgas = (Ωb/Ωm) is the cosmic baryon fraction, while M500 is the cluster mass enclosed in the radius r500. Thus,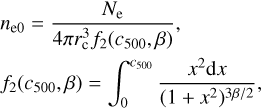 (28)
(28)
where c500 = r500/rc ≃ cvir/2.0 is the concentration parameter for R500.
Combining Eqs. (26), (27), and (28), we have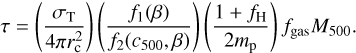 (29)
(29)
In Fig. 13, we plot the histogram of the optical depth values of the 1526 clusters in the sample. The mean and standard deviation are given by τ = (3.9 ± 1.2) × 10−3. This is very consistent with the quoted value τ = (3.75 ± 0.89) × 10−3 from the cross-correlation between the kSZ SPT data and the photometric data from DES survey by fitting to a template of pairwise kSZ field (Soergel et al. 2016). Note that the uncertainty quoted here describes the scatter in the mean τ values for the whole of the sample.
We convert the temperature dispersion data listed in Table 5 to the line-of-sight velocity dispersion measurement by using the modelled value of τ, after correcting by our estimate of the lensing effect. Our procedure is as follows. For each estimate of 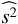 , we correct by the estimated shift caused by lensing, then calculate its υ2 value, and obtain an averaged value of υ2 via
, we correct by the estimated shift caused by lensing, then calculate its υ2 value, and obtain an averaged value of υ2 via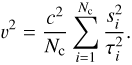 (30)
(30)
We then do this for the 5000 values of 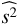 , and plot the distribution (after shifting by the lensing effect) in the right panel of Fig. 10 for the 2D-ILC map. We also present results for υ2 in Table 8, where we can see that for the conservative case, i.e., the 2D-ILC map, the velocity dispersion is measured to be υ2 = (12.3 ± 7.1) × (100 km s−1)2. From the right panel of Fig. 10, we can see that the distribution is not completely Gaussian, but has a tail towards smaller υ2. The frequency P(υ2 < 0) is 5.3%, which would correspond to a detection of the dispersion of peculiar velocity from 1526 MCXC clusters at the 1.7 σ level (using Appendix C).
, and plot the distribution (after shifting by the lensing effect) in the right panel of Fig. 10 for the 2D-ILC map. We also present results for υ2 in Table 8, where we can see that for the conservative case, i.e., the 2D-ILC map, the velocity dispersion is measured to be υ2 = (12.3 ± 7.1) × (100 km s−1)2. From the right panel of Fig. 10, we can see that the distribution is not completely Gaussian, but has a tail towards smaller υ2. The frequency P(υ2 < 0) is 5.3%, which would correspond to a detection of the dispersion of peculiar velocity from 1526 MCXC clusters at the 1.7 σ level (using Appendix C).
Statistics of the line-of-sight velocity dispersion υ2 (υ · r̂)2.
In studies of peculiar velocity fields, the most relevant quantity is the linear line-of-sight velocity (υ), or in other words 〈υ2〉1/2. We find7 〈υ2〉1/2 = (350 ± 100) km s−1 for the 2D-ILC map. One can see that the value we find is consistent with the velocity dispersion estimated through studies of the peculiar velocity field (e.g., Riess 2000; Turnbull et al. 2012; Ma & Scott 2013; Carrick et al. 2015).
Here we need to remember that what we measured is the line-of-sight velocity dispersion, which contains both the large-scale bulk flow, and the small-scale velocity and intrinsic dispersion (see, e.g., Ma & Scott 2014). The prediction for the rms bulk flow, Eq. (22) of Planck Collaboration Int. XIII (2014, or Eq. (4) in Ma & Pan 2014), is based on linear perturbation theory for the ΛCDM model and works only for the large-scale bulk flows. The small-scale motions and intrinsic dispersion are not fully predictable from linear perturbation theory because they depend on sub-Jeans scale structure evolution, which involves nonlinear effects. However, this small-scale velocity and intrinsic dispersion are nevertheless physical effects, which are non-negligible in general (Carrick et al. 2015). One should consider that the line-of-sight velocity dispersion that we have measured is a combination of two effects, namely large-scale bulk flows and small-scale intrinsic dispersion, where the second component is generally non-negligible.
We estimate that the histogram of separation distances between all pairs of cluster is peaked at d ≃ 600 Mpc. Since the bulk flow contributes to the velocity dispersion measurement here, then we can set an upper limit on the cosmic bulk flow on scales of 600 h−1 Mpc, 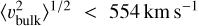 (95% CL).
(95% CL).
Such a constraint on large-scale bulk flows indicates that the Universe is statistically homogeneous on scales of 600 h−1 Mpc. This is consistent with the limits obtained from Type-Ia supernovae (Feindt et al. 2013), the Spiral Field I-band survey (Nusser & Davis 2011; Ma & Scott 2013), ROSAT galaxy clusters (Mody & Hajian 2012), and the Planck peculiar velocity study (Planck Collaboration Int. XIII 2014). However, it does not allow the very large “dark flow” claimed in Kashlinsky et al. (2008, 2010, 2012) and Atrio-Barandela et al. (2015). In addition to ruling out such models, improved measurements of the velocity dispersion in the future have the potential to set up interesting constraints on dark energy and modified gravity (Bhattacharya & Kosowsky 2007, 2008).
5. Conclusions
The kinetic Sunyaev-Zeldovich effect gives anisotropic perturbations of the CMB sky, particularly in the direction of clusters of galaxies. Previous studies have detected the kSZ effect through the pairwise momentum estimator and temperaturevelocity cross-correlation. In this paper, we have detected the kSZ effect through a measurement of the temperature dispersion and then we have interpreted this as a determination of the small-scale velocity dispersion of cosmological structure.
To do this, we first selected two sets of Planck foreground-cleaned maps. One set contains four Planck publicly available maps, namely SMICA, NILC, SEVEM and Commander, each being produced using a different algorithm to minimize foreground emission. The second set, is the Planck2D-ILC map, which nulls the tSZ component, while resulting in slightly larger residual noise in the map. We then apply a matched-filter technique to the maps, to suppress the primary CMB and instrumental noise. We specifically consider the MCXC cluster sample. Applying a Galactic and point-source mask to the maps, results in 1526 MCXC clusters remaining unmasked.
We measured the distribution of the ΔT/T values for the 1526 MCXC cluster positions, and also at 1526 randomly selected positions, to give a quantification of the noise level. We found that the 1526 true cluster positions give extra variance to the distribution, and identify this as being due to the kSZ temperature dispersion effect. We compare this signal to results from 5000 random catalogues on the sky, each composed of 1526 random positions. This extra dispersion signal is persistent in several tests that we carry out.
We then construct estimators 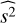 to quantify this effect. For the SMICA, NILC, and SEVEM maps, the significance of detection is stronger than in the 2D-ILC map, which is likely due to the fact that the residual tSZ effect in the map is correlated with the kSZ signal. In addition, an analytical estimate, supported by simulations, shows that about 0.7 σ of the temperature-dispersion effect comes from gravitational lensing. By subtracting this effect, quoting the conservative result from 2D-ILC, we obtain 〈s2〉 = (1.35 ± 0.48) × 10−11 (68% CL), where
to quantify this effect. For the SMICA, NILC, and SEVEM maps, the significance of detection is stronger than in the 2D-ILC map, which is likely due to the fact that the residual tSZ effect in the map is correlated with the kSZ signal. In addition, an analytical estimate, supported by simulations, shows that about 0.7 σ of the temperature-dispersion effect comes from gravitational lensing. By subtracting this effect, quoting the conservative result from 2D-ILC, we obtain 〈s2〉 = (1.35 ± 0.48) × 10−11 (68% CL), where 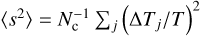 . This gives a detection of temperature dispersion at about the 2.8 σ level. We obtain largely consistent results when we obtain results by weighting clusters with their different observed properties.
. This gives a detection of temperature dispersion at about the 2.8 σ level. We obtain largely consistent results when we obtain results by weighting clusters with their different observed properties.
We further estimate the optical depth of each cluster, and thereby convert our (lensing-corrected) temperature dispersion measurement into a velocity dispersion measurement, obtaining 〈υ2〉 = (12.3 ± 7.1) × (100 km s−1)2 (68% CL) using a Gaussian approximation. The distribution has P(υ2 < 0) = 5.3%, and the best-fit value is consistent with findings from large-scale structure studies. This constraint implies that the Universe is statistically homogeneous on scales of 600 h−1 Mpc, with the bulk flow constrained to be 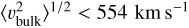 (95% CL).
(95% CL).
The measurement that we present here shows the promise of statistical kSZ studies for constraining the growth of structure in the Universe. To improve the results in the future, one needs to have better component-separation algorithms to down-weight the residual noise contained in the kSZ map, as well as having more sensitive and higher resolution CMB maps for removing the tSZ signal. One also needs larger cluster catalogues, with the uncertainty scaling roughly as 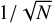 if the residual noise is Gaussian.
if the residual noise is Gaussian.
Although in principle one could still have an isocurvature perturbation on very large scales (Turner 1991; Ma et al. 2011).
Planck (http://www.esa.int/Planck) is a project of the European Space Agency (ESA) with instruments provided by two scientific consortia funded by ESA member states and led by Principal Investigators from France and Italy, telescope reflectors provided through a collaboration between ESA and a scientific consortium led and funded by Denmark, and additional contributions from NASA (USA).
From the Planck Legacy Archive, http://pla.esac.esa.int
The Planck PSZ1 catalogue of galaxy clusters from the 2013 Planck data release has been used to determine the position of known SZ clusters.
Available at https://github.com/carronj/LensIt
68% CL, although we caution that the distribution is not Gaussian.
Acknowledgments
The Planck Collaboration acknowledges the support of: ESA; CNES, and CNRS/INSU-IN2P3-INP (France); ASI, CNR, and INAF (Italy); NASA and DoE (USA); STFC and UKSA (UK); CSIC, MINECO, JA, and RES (Spain); Tekes, AoF, and CSC (Finland); DLR and MPG (Germany); CSA (Canada); DTU Space (Denmark); SER/SSO (Switzerland); RCN (Norway); SFI (Ireland); FCT/MCTES (Portugal); ERC and PRACE (EU). A description of the Planck Collaboration and a list of its members, indicating which technical or scientific activities they have been involved in, can be found at http://www.cosmos.esa.int/web/planck/planck-collaboration. This paper makes use of the HEALPix software package.
References
- Aghanim, N., Górski, K. M., & Puget, J.-L. 2001, A&A, 374, 1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Arnaud, M., Pointecouteau, E., & Pratt, G. W. 2005, A&A, 441, 893 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Arnaud, M., Pratt, G. W., Piffaretti, R., et al. 2010, A&A, 517, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Atrio-Barandela, F., Kashlinsky, A., Ebeling, H., Fixsen, D. J., & Kocevski, D. 2015, ApJ, 810, 143 [NASA ADS] [CrossRef] [Google Scholar]
- Basak, S., & Delabrouille, J. 2012, MNRAS, 419, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Basak, S., & Delabrouille, J. 2013, MNRAS, 435, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Battaglia, N., Bond, J. R., Pfrommer, C., & Sievers, J. L. 2012, ApJ, 758, 74 [NASA ADS] [CrossRef] [Google Scholar]
- Benson, B. A., Church, S. E., Ade, P. A. R., et al. 2003, ApJ, 592, 674 [NASA ADS] [CrossRef] [Google Scholar]
- Benson, B. A., Church, S. E., Ade, P. A. R., et al. 2004, ApJ, 617, 829 [NASA ADS] [CrossRef] [Google Scholar]
- Bhattacharya, S., & Kosowsky, A. 2007, ApJ, 659, L83 [NASA ADS] [CrossRef] [Google Scholar]
- Bhattacharya, S., & Kosowsky, A. 2008, Phys. Rev. D, 77, 083004 [NASA ADS] [CrossRef] [Google Scholar]
- Böhringer, H., Voges, W., Huchra, J. P., et al. 2000, ApJ, 129, 435 [Google Scholar]
- Böhringer, H., Schuecker, P., Guzzo, L., et al. 2004, A&A, 425, 367 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bryan, G. L., & Norman, M. L. 1998, ApJ, 495, 80 [NASA ADS] [CrossRef] [Google Scholar]
- Burenin, R. A., Vikhlinin, A., Hornstrup, A., et al. 2007, ApJ, 172, 561 [NASA ADS] [Google Scholar]
- Burke, D. J., Collins, C. A., Sharples, R. M., Romer, A. K., & Nichol, R. C. 2003, MNRAS, 341, 1093 [NASA ADS] [CrossRef] [Google Scholar]
- Carrick, J., Turnbull, S. J., Lavaux, G., & Hudson, M. J. 2015, MNRAS, 450, 317 [NASA ADS] [CrossRef] [Google Scholar]
- Cavaliere, A., & Fusco-Femiano, R. 1976, A&A, 49, 137 [NASA ADS] [Google Scholar]
- Cavaliere, A., & Fusco-Femiano, R. 1978, A&A, 70, 677 [NASA ADS] [Google Scholar]
- Cruddace, R., Voges, W., Böhringer, H., et al. 2002, ApJ, 140, 239 [NASA ADS] [Google Scholar]
- Davies, R. L., Efstathiou, G., Fall, S. M., Illingworth, G., & Schechter, P. L. 1983, ApJ, 266, 41 [NASA ADS] [CrossRef] [Google Scholar]
- De Bernardis, F., Aiola, S., Vavagiakis, E. M., et al. 2017, J. Cosmol. Astropart. Phys., 3, 008 [Google Scholar]
- Delabrouille, J., Cardoso, J.-F., Le Jeune, M., et al. 2009, A&A, 493, 835 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dodelson, S. 2004, Phys. Rev. D, 70, 023009 [NASA ADS] [CrossRef] [Google Scholar]
- Duffy, A. R., Schaye, J., Kay, S. T., & Dalla Vecchia, C. 2008, MNRAS, 390, L64 [NASA ADS] [CrossRef] [Google Scholar]
- Ebeling, H., Edge, A. C., Bohringer, H., et al. 1998, MNRAS, 301, 881 [NASA ADS] [CrossRef] [Google Scholar]
- Ebeling, H., Edge, A. C., Allen, S. W., et al. 2000, MNRAS, 318, 333 [NASA ADS] [CrossRef] [Google Scholar]
- Ebeling, H., Barrett, E., Donovan, D., et al. 2007, ApJ, 661, L33 [NASA ADS] [CrossRef] [Google Scholar]
- Ebeling, H., Edge, A. C., Mantz, A., et al. 2010, MNRAS, 407, 83 [NASA ADS] [CrossRef] [Google Scholar]
- Feindt, U., Kerschhaggl, M., Kowalski, M., et al. 2013, A&A, 560, A90 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Feldman, H. A., Watkins, R., & Hudson, M. J. 2010, MNRAS, 407, 2328 [NASA ADS] [CrossRef] [Google Scholar]
- Ferraro, S., Hill, J. C., Battaglia, N., Liu, J., & Spergel, D. N. 2016, Phys. Rev. D, 94, 123526 [NASA ADS] [CrossRef] [Google Scholar]
- Ferreira, P. G., Juszkiewicz, R., Feldman, H. A., Davis, M., & Jaffe, A. H. 1999, ApJ, 515, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Gioia, I. M., & Luppino, G. A. 1994, ApJ, 94, 583 [NASA ADS] [CrossRef] [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [NASA ADS] [CrossRef] [Google Scholar]
- Grego, L., Carlstrom, J. E., Joy, M. K., et al. 2000, ApJ, 539, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Guilloux, F., Faÿ, G., & Cardoso, J.-F. 2009, Appl. Comput. Harmon. Anal., 26, 143 [CrossRef] [Google Scholar]
- Haehnelt, M. G., & Tegmark, M. 1996, MNRAS, 279, 545 [NASA ADS] [CrossRef] [Google Scholar]
- Hallman, E. J., Burns, J. O., Motl, P. M., & Norman, M. L. 2007, ApJ, 665, 911 [NASA ADS] [CrossRef] [Google Scholar]
- Halverson, N. W., Lanting, T., Ade, P. A. R., et al. 2009, ApJ, 701, 42 [NASA ADS] [CrossRef] [Google Scholar]
- Hand, N., Addison, G. E., Aubourg, E., et al. 2012, Phys. Rev. Lett., 109, 041101 [NASA ADS] [CrossRef] [Google Scholar]
- Henry, J. P. 2004, ApJ, 609, 603 [NASA ADS] [CrossRef] [Google Scholar]
- Henry, J. P., Mullis, C. R., Voges, W., et al. 2006, ApJ, 162, 304 [NASA ADS] [Google Scholar]
- Hernández-Monteagudo, C., Ma, Y.-Z., Kitaura, F. S., et al. 2015, Phys. Rev. Lett., 115, 191301, [NASA ADS] [CrossRef] [Google Scholar]
- Hill, J. C., Ferraro, S., Battaglia, N., Liu, J., & Spergel, D. N. 2016, Phys. Rev. Lett., 117, 051301 [NASA ADS] [CrossRef] [Google Scholar]
- Hivon, E., Górski, K. M., Netterfield, C. B., et al. 2002, ApJ, 567, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Holzapfel, W. L., Ade, P. A. R., Church, S. E., et al. 1997, ApJ, 481, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Horner, D. J., Perlman, E. S., Ebeling, H., et al. 2008, ApJ, 176, 374 [NASA ADS] [Google Scholar]
- Kashlinsky, A., & Atrio-Barandela, F. 2000, ApJ, 536, L67 [NASA ADS] [CrossRef] [Google Scholar]
- Kashlinsky, A., Atrio-Barandela, F., Kocevski, D., & Ebeling, H. 2008, ApJ, 686, L49 [NASA ADS] [CrossRef] [Google Scholar]
- Kashlinsky, A., Atrio-Barandela, F., Kocevski, D., & Ebeling, H. 2009, ApJ, 691, 1479 [NASA ADS] [CrossRef] [Google Scholar]
- Kashlinsky, A., Atrio-Barandela, F., Ebeling, H., Edge, A., & Kocevski, D. 2010, ApJ, 712, L81 [NASA ADS] [CrossRef] [Google Scholar]
- Kashlinsky, A., Atrio-Barandela, F., & Ebeling, H. 2012, ArXiv e-prints [arXiv: 1202.0717] [Google Scholar]
- Kocevski, D. D., Ebeling, H., Mullis, C. R., & Tully, R. B. 2007, ApJ, 662, 224 [NASA ADS] [CrossRef] [Google Scholar]
- Komatsu, E., Smith, K. M., Dunkley, J., et al. 2011, ApJ, 192, 18 [NASA ADS] [Google Scholar]
- Kormendy, J. 2001, ASP Conf. Ser., 230, 247 [NASA ADS] [Google Scholar]
- Kormendy, J., & Bender, R. 1996, ApJ, 464, L119 [NASA ADS] [CrossRef] [Google Scholar]
- Lewis, A., & Challinor, A. 2006, Phys. Rept., 429, 1 [Google Scholar]
- Li, Y.-C., Ma, Y.-Z., Remazeilles, M., & Moodley, K. 2018, Phys. Rev. D, 97, 023514 [NASA ADS] [CrossRef] [Google Scholar]
- Ma, Y.-Z., & Pan, J. 2014, MNRAS, 437, 1996 [NASA ADS] [CrossRef] [Google Scholar]
- Ma, Y.-Z., & Scott, D. 2013, MNRAS, 428, 2017 [NASA ADS] [CrossRef] [Google Scholar]
- Ma, Y.-Z., & Scott, D. 2014, Astron. Geophys., 55, 030003 [CrossRef] [Google Scholar]
- Ma, Y.-Z., Gordon, C., & Feldman, H. A. 2011, Phys. Rev. D, 83, 103002 [NASA ADS] [CrossRef] [Google Scholar]
- Ma, Y.-Z., Hinshaw, G., & Scott, D. 2013, ApJ, 771, 137 [NASA ADS] [CrossRef] [Google Scholar]
- MacMillan, J. D., Widrow, L. M., & Henriksen, R. N. 2006, ApJ, 653, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Mody, K., & Hajian, A. 2012, ApJ, 758, 4 [NASA ADS] [CrossRef] [Google Scholar]
- Mullis, C. R., McNamara, B. R., Quintana, H., et al. 2003, ApJ, 594, 154 [NASA ADS] [CrossRef] [Google Scholar]
- Narcowich, F., Petrushev, P., & Ward, J. 2006, SIAM J. Math. Anal., 38, 574 [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1996, ApJ, 462, 563 [NASA ADS] [CrossRef] [Google Scholar]
- Nusser, A., & Davis, M. 2011, ApJ, 736, 93 [NASA ADS] [CrossRef] [Google Scholar]
- Ostriker, J. P. 1980, Comments Astrophys., 8, 177 [NASA ADS] [Google Scholar]
- Peebles, P. J. E. 1980, in The large-scale structure of the universe (Research supported by the National Science Foundation) (Princeton, NJ: Princeton University Press) [Google Scholar]
- Perlman, E. S., Horner, D. J., Jones, L. R., et al. 2002, ApJ, 140, 265 [NASA ADS] [Google Scholar]
- Piffaretti, R., Arnaud, M., Pratt, G. W., Pointecouteau, E., & Melin, J.-B. 2011, A&A, 534, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Plagge, T., Benson, B. A., Ade, P. A. R., et al. 2010, ApJ, 716, 1118 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration XII. 2014, A&A, 571, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration IX. 2016, A&A, 594, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration X. 2016, A&A, 594, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XIII. 2016, A&A, 594, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXVI. 2016, A&A, 594, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration Int. V. 2013, A&A, 550, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration Int. XIII. 2014, A&A, 561, A97 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration Int. XXXVII. 2016, A&A, 586, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration Int. XLIII. 2016, A&A, 596, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Remazeilles, M., Delabrouille, J., & Cardoso, J.-F. 2011a, MNRAS, 410, 2481 [NASA ADS] [CrossRef] [Google Scholar]
- Remazeilles, M., Delabrouille, J., & Cardoso, J.-F. 2011b, MNRAS, 418, 467 [NASA ADS] [CrossRef] [Google Scholar]
- Remazeilles, M., Dickinson, C., Banday, A. J., Bigot-Sazy, M.-A., & Ghosh, T. 2015, MNRAS, 451, 4311 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G. 2000, ASP Conf. Ser., 201, 80 [NASA ADS] [Google Scholar]
- Romer, A. K., Nichol, R. C., Holden, B. P., et al. 2000, ApJ, 126, 209 [NASA ADS] [Google Scholar]
- Sarazin, C. L. 1986, Rev. Mod. Phys., 58, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Schaan, E., Ferraro, S., Vargas-Magaña, M., et al. 2016, Phys. Rev. D, 93, 082002 [NASA ADS] [CrossRef] [Google Scholar]
- Soergel, B., Flender, S., Story, K. T., et al. 2016, MNRAS, 461, 3172 [NASA ADS] [CrossRef] [Google Scholar]
- Sugiyama, N. S., Okumura, T., & Spergel, D. N. 2018, MNRAS, 475, 3764 [NASA ADS] [CrossRef] [Google Scholar]
- Sunyaev, R. A., & Zeldovich, Y. B. 1972, Comments Astrophys. Space Phys., 4, 173 [NASA ADS] [EDP Sciences] [Google Scholar]
- Sunyaev, R. A., & Zeldovich, I. B. 1980, MNRAS, 190, 413 [NASA ADS] [CrossRef] [Google Scholar]
- Tegmark, M., & de Oliveira-Costa, A. 1998, ApJ, 500, L83 [NASA ADS] [CrossRef] [Google Scholar]
- Turnbull, S. J., Hudson, M. J., Feldman, H. A., et al. 2012, MNRAS, 420, 447 [NASA ADS] [CrossRef] [Google Scholar]
- Turner, M. S. 1991, Phys. Rev. D, 44, 3737 [NASA ADS] [CrossRef] [Google Scholar]
- Waelkens, A., Maturi, M., & Enßlin, T. 2008, MNRAS, 383, 1425 [NASA ADS] [CrossRef] [Google Scholar]
- Watkins, R., Feldman, H. A., & Hudson, M. J. 2009, MNRAS, 392, 743 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: The statistics of s2
Let us first define the kth moment of a distribution of a random variable x to be![Mathematical equation: $$ \mu_k{(x)}\equiv E\left[ x^k\right]=\frac1N\underset i{\mathrm\Sigma}\;x_i^k. $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq86.gif) (A.1)
(A.1)
The 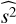 estimator is defined in Eq. (16). Note that the observed
estimator is defined in Eq. (16). Note that the observed 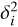 is always taken to be the value of kSZ on the true cluster position, so there is no randomness in
is always taken to be the value of kSZ on the true cluster position, so there is no randomness in 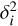 . We also define
. We also define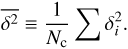 (A.2)
(A.2)
Therefore, the mean value of  is
is![Mathematical equation: $$ \begin{eqnarray}E[s^{2}] &=& \overline{\delta^{2}}- \left(\frac{1}{N_{\rm c}}\sum_{i}E[n_{i}^{2}] \right) \nonumber \\ &=& \overline{\delta^{2}} -\mu_{2}(n), \end{eqnarray} $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq92.gif) (A.3)
(A.3)
while the variance of  is
is![Mathematical equation: $$ V{\left[ s^2\right]}=E{\left[ s^4\right]}-{(E\left[ s^2\right])}^2. $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq94.gif) (A.4)
(A.4)
Therefore, we first calculate![Mathematical equation: $$ \begin{eqnarray}s^{4} &=& \left[ \overline{\delta^{2}}- \left(\frac{1}{N_{\rm c}}\sum_{i}n_{i}^{2} \right) \right]^{2} \nonumber \\&=& \left(\overline{\delta^{2}} \right)^{2}+\frac{1}{N^{2}_{\rm c}} \sum_{ij}n^{2}_{i}n^{2}_{j}-\frac{2}{N_{\rm c}}\overline{\delta^{2}} \left(\sum_{i} n^{2}_{i} \right) \nonumber \\&=& \left(\overline{\delta^{2}} \right)^{2}+\frac{1}{N_{\rm c}} \sum_{i}n^{4}_{i} +\frac{1}{N^{2}_{\rm c}}\sum_{i,j \,(i \neq j)}n^{2}_{i}n^{2}_{j} \nonumber \\&-& \frac{2}{N_{\rm c}}\overline{\delta^{2}} \left(\sum_{i} n^{2}_{i} \right). \end{eqnarray} $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq95.gif) (A.5)
(A.5)
And hence,![Mathematical equation: $$ \begin{eqnarray}E[s^{4}] &=& \left(\overline{\delta^{2}} \right)^{2}+\frac{1}{N_{\rm c}} \mu_{4}(n) +\frac{N_{\rm c}-1}{N_{\rm c}}\left(\mu_{2}(n) \right)^{2} \nonumber \\ &&-~2\overline{\delta^{2}} \mu_{2}(n),\end{eqnarray} $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq96.gif) (A.6)
(A.6)
where in the above derivation we have assumed that the residual noise samples in two different pixels are uncorrelated, i.e., 〈ninj〉 = 0. Finally,![Mathematical equation: $$ \begin{eqnarray}V[s^{2}]=\frac{1}{N_{\rm c}}\left(\mu_{4}(n)-\mu^{2}_{2}(n) \right).\end{eqnarray}$$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq97.gif) (A.7)
(A.7)
Appendix B: Converting M500 to Mvir
For each cluster, M500 is defined as the mass within the radius of R500, in which its average density is 500 times the critical density of the Universe,![Mathematical equation: $$ M_{500}=\frac{4\pi}3{\left[500\rho_\mathrm c{(z)}\right]}r_{500}^3, $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq98.gif) (B.1)
(B.1)
Where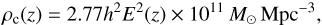 (B.2)
(B.2)
and E2(z) = Ω(1+z)3 + ΩΛ. The quantity Mvir is calculated via Eqs. (24) and (25), and the relationship between M500 and Mvir is Mody & Hajian (2012)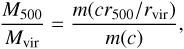 (B.3)
(B.3)
where c is the concentration parameter (Eq. (23)) and m(x) = ln(1 + x) − x/(1 + x). Given redshift z and mass M500, we can thus determine r500 through Eq. (B.1). If we substitute M500, z, and r500 into Eq. (B.3), this becomes an algebraic equation for Mvir. This is because rvir can be determined from Mvir through Eqs. (24) and (25), and c is related to Mvir through Eq. (23). Therefore, we can iteratively solve for Mvir, given the values of M500 and z.
Appendix C: Converting P values into S/Ns
Since the distribution of weighted s2 has a longer tail than a Gaussian distribution, instead of calculating the ratio between mean and rms values of the distribution, we calculate the p-values, and list them in the third column of Table 6. We now convert them into S/N in the following way. Suppose the variable x satisfies a Gaussian distribution, the normalized distribution is 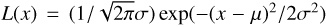 . Then the cumulative probability to find x < 0 is
. Then the cumulative probability to find x < 0 is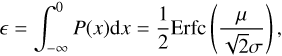 (C.1)
(C.1)
where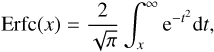 (C.2)
(C.2)
is the complimentary error function.
Therefore the equivalent S/N given the value of 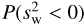 is
is![Mathematical equation: $$ \begin{eqnarray}{S/N}=\sqrt{2}\left\{{\rm Erfc}^{-1}\left[2P(s^{2}_{\rm w}<0) \right] \right\}.\end{eqnarray} $$](/articles/aa/full_html/2018/09/aa31489-17/aa31489-17-eq105.gif) (C.3)
(C.3)
We use Eq. (C.3) to obtain the fourth column of Table 6.
All Tables
Recent measurements of the kinetic Sunyaev-Zeldovich effect with cross-correlations of various tracers of large-scale structure.
Statistics of the values of (ΔT/T) × 105 at the true 1526 cluster positions and for 1526 randomly-selected positions.
rms values for the true sky positions of 1526 MCXC catalogue clusters (σMCXC), along with the mean (σran) and scatter (σ(σran)) of the values of the rms for 5000 random catalogues, where each catalogue consists of 1526 random positions on the sky.
Statistics of the weighted variables for different choices of weights in the 2D-ILC map.
Statistics of split samples. Here the median values of the samples are (M500)mid = 1.68 × 1014M⊙, (L500)mid = 2.3 × 1010L⊙, and (R500)mid = 0.79 Mpc.
All Figures
|
Fig. 1. Top left: stack of the NILC CMB map in the directions of Planck SZ (PSZ) galaxy clusters. Top right: stack of the 2D-ILC CMB map in the direction of PSZ galaxy clusters. This sample provides a very stringent test of the tSZ leakage, since the PSZ positions are the known places on the sky with detectable SZ signal. The stacked NILC CMB map clearly shows an excess in the centre, which is due to residual contamination from the tSZ effect, while the 2D-ILC CMB map has a signature in the centre that is consistent with the strength of other features in the stacked image. Bottom left: stack of the NILC CMB map in the directions of MCXC clusters. Bottom right: stack of the 2D-ILC CMB map in the direction of 1526 MCXC clusters (see Sect. 2.2 for the detail of the catalogue). For a different set of sky positions, the results are broadly consistent with those for the PSZ clusters. All these maps are 3° × 3° in size, and use the same colour scale. |
| In the text | |
|
Fig. 2. Profiles for stacked patches (see Fig. 1) of the NILC CMB map (black diamonds) and the 2D-ILC CMB map (blue triangles) at the positions of PSZ clusters (top panel) and MCXC clusters (bottom panel). The profile of the stacked Planck 217-GHz map is also shown as a reference (green squares). The central deficit in the flux profile of the stacked NILC CMB map (black diamonds) is due to residual tSZ contamination. |
| In the text | |
|
Fig. 3. Left: full-sky distribution of 1526 MCXC X-ray clusters (Piffaretti et al. 2011; Planck Collaboration Int. XIII 2014) in Galactic coordinates. The dark blue area is the masked region, and the clusters are shown in orange. Right: redshift histogram of 1526 X-ray clusters, with bin width Δz = 0.025. |
| In the text | |
|
Fig. 4. Measured (black dots) and predicted (red line) power spectra from the Planck2D-ILC map. The predicted spectrum is based on the best-fitting ΛCDM model convolved with the squared beam |
| In the text | |
|
Fig. 5. Optimal matched filter (black line) for point-source detection in the Planck2D-ILC map (Eq. (14)). For comparison, the power spectra of the CMB signal (red line) and noise map (blue dashed line) are shown, along with their sum (brown line). |
| In the text | |
 |
Fig. 6. Filtered (with Eq. (14)) and masked 2D-ILC map in dimensionless units (i.e., ΔT/T). |
| In the text | |
|
Fig. 7. Histograms of 1526 ΔT/T values of 2D-ILC map at the cluster catalogue positions (red bars), and randomly selected positions (black bars). The statistics of the true cluster positions and random positions can be found in Table 2. |
| In the text | |
|
Fig. 8. Histogram of the |
| In the text | |
|
Fig. 9. Distribution of the rms for 5000 mock catalogues (yellow histogram); here each catalogue consists of Nc randomly chosen positions on the filtered 2D-ILC map. The mean and rms of the 5000 random catalogues are 1.10 × 10−5 (shown as the black dashed vertical line) and 2.15 × 10−7, respectively. For the Nc true MCXC cluster positions, the rms is 1.17 × 10−5 (red vertical dashed line). |
| In the text | |
|
Fig. 10. Left: distribution of 5000 values of s2 with uniform weight (Eq. (16)) on each position for the 2D-ILC map. Right: distribution of υ2 calculated from Eq. (30), after subtracting the lensing shift. The distribution has P(υ2 < 0) = 5.3%, corresponding to a (1-sided) detection of 1.6 σ. We have tested with 50 000 values of s2 and the results are consistent with those from 5000 values. |
| In the text | |
|
Fig. 11. Left: R500 versus M500 for the sample. Right: L500 versus M500 for the sample. The vertical and horizontal lines show the median values of R500, M500, and L500. |
| In the text | |
|
Fig. 12. Histogram of the |
| In the text | |
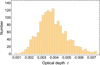 |
Fig. 13. Histogram of the optical depth τ derived using Eq. (29) for 1526 X-ray cluster positions. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.