| Issue |
A&A
Volume 697, May 2025
|
|
|---|---|---|
| Article Number | A148 | |
| Number of page(s) | 17 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202554196 | |
| Published online | 14 May 2025 | |
Classifying spectra of emission-line regions with neural networks
An application to integral field spectroscopic data of M33
1
Dipartimento di Fisica e Astronomia, Università di Firenze, Via G. Sansone 1, I-50019 Sesto F.no, (Firenze), Italy
2
INAF – Osservatorio Astrofisico di Arcetri, Largo E. Fermi 5, I-50125 Florence, Italy
3
INFN – Istituto Nazionale di Fisica Nucleare (INFN), Via Bruno Rossi 1, 50019 Sesto Fiorentino, (FI), Italy
4
ICSC – Centro Nazionale di Ricerca in High Performance Computing, Big Data & Quantum Computing, Via Magnanelli 2, 40033 Casalecchio di Reno, (BO), Italy
5
University of Trento, Via Sommarive 14, I-38123 Trento, Italy
6
Max-Planck-Institut für Extraterrestrische Physik (MPE), Gießenbachstraße 1, 85748 Garching, Germany
7
Scuola Normale Superiore, Piazza dei Cavalieri 7, I-56126 Pisa, Italy
⋆ Corresponding author: caterina.bracci@unifi.it
Received:
20
February
2025
Accepted:
26
March
2025
Emission-line regions are key to understanding the properties and evolution of galaxies, as they trace the exchange of matter and energy between stars and the interstellar medium (ISM). In nearby galaxies, individual nebulae can be resolved from the background, and classified through their optical spectral properties. Traditionally, the classification of these emission-line regions in H II regions, planetary nebulae (PNe), supernova remnants (SNRs), and diffuse ionised gas (DIG) relies on criteria based on single or multiple emission-line ratios. However, these methods face limitations due to the rigidity of the classification boundaries, the narrow scope of information they are based upon, and the inability to take line-of-sight superpositions of emission-line regions into account. In this work, we explore the use of artificial neural networks to classify emission-line regions using their optical spectra. Our training set consists of simulated optical spectra, obtained from photoionisation and shock models, and processed to match observations obtained with the MUSE integral field spectrograph at the ESO/VLT. We evaluate the performance of the network on simulated spectra exploring a range of signal-to-noise (S/N) levels, different values for dust extinction, and the superposition of different nebulae along the line of sight. At infinite S/N the network achieves perfect predictive performance, while, as the S/N decreases, the classification accuracy declines, reaching an average of ∼80% at S/N(Hα) = 20. We then apply our model to real spectra from MUSE observations of the Local Group galaxy M33. The network provides a robust classification of individual spaxels, even at low S/N, identifying H II regions and PNe and distinguishing them from SNRs and diffuse ionised gas, while identifying overlapping nebulae. Moreover, we compare the network’s classification with traditional diagnostics, finding a satisfactory level of agreement between the two approaches. We identify the emission lines that are most relevant for our classification tasks using activation maximisation maps. In particular, we find that at high S/N the model mainly relies on weak lines (e.g. auroral lines of metal ions and He recombination lines), while at the S/N level typical of our dataset the model effectively emulates traditional diagnostic methods by leveraging strong nebular lines. We discuss potential future developments focused on deriving segmentation maps for H II regions and other nebulae, and the extension of our method to new datasets and instruments.
Key words: methods: data analysis / methods: statistical / ISM: general / HII regions / planetary nebulae: general / ISM: supernova remnants
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1. Introduction
Ionised nebulae act as signposts of diverse astrophysical processes, including those governing the life cycle of stars, and feedback of stars into the interstellar medium (ISM). H II regions, ionised by young, massive O and B stars, for example, provide key information on chemical composition, star formation and feedback in galaxies through their emission-line-rich optical spectra (Stasińska 2004; Krumholz & Matzner 2009; Kreckel et al. 2018; Barnes et al. 2020; Santoro et al. 2022; Sanders et al. 2024). Planetary nebulae (PNe), on the other hand, are formed from gas ejected by intermediate-mass stars which ionise the surrounding material as they evolve from the asymptotic giant branch into white dwarfs. PNe have been used as tracers of galaxy dynamics, chemical composition, and to measure extragalactic distances via the planetary nebula luminosity function (Acker et al. 1992; Maciel 2013; Roth et al. 2021; Scheuermann et al. 2022). Supernova remnants (SNRs), are instead ionised by collisional shocks rather than photoionisation (Fesen et al. 1985; Iben & Tutukov 1984; Maciel 2013). Supernovae are amongst the main sources of feedback and chemical enrichment into the ISM. Therefore, understanding the evolution of SNRs and estimating the rate of supernovae in galaxies is essential for the study of the energetics and chemical evolution of the ISM (Blair & Long 2004; Kim & Ostriker 2018; Koo et al. 2020).
In nearby galaxies, it is possible to spatially resolve H II regions and other ionised nebulae, therefore morphologically isolating them from the background emission of the diffuse ionised gas (DIG). Traditional methods for identifying and classifying ionised regions rely on narrow-band imaging and single or multiple emission-line ratios. At solar metallicity, H II regions are generally traced by the Balmer Hα line, which is the most prominent in their emission-line-rich spectra. The most commonly used diagnostic diagrams, such as the Baldwin-Phillips-Terlevich (BPT, Baldwin et al. 1981; Veilleux & Osterbrock 1987) diagram, are based on ratios of pairs of strong optical emission lines (e.g. [N II]λ6584/Hα, [O III]λ5007/Hβ) to separate H II regions from other types of nebulae (Kreckel et al. 2019; Della Bruna et al. 2020; Santoro et al. 2022).
Overall, traditional methods for classifying ionised nebulae (see, for example, Maiolino & Mannucci 2019) come with significant limitations. Most of them are designed to identify a single type of nebula at the time, rather than enabling comparative classification. Moreover, these criteria also rely on sharp empirical or theoretical boundaries (Kewley et al. 2001; Kauffmann et al. 2003), which can lead to misclassification of objects with low S/N ratios or those near the edge of these limits. Overlap between different nebula types in the line-ratio space further complicates the classification (Frew & Parker 2010; Kopsacheili et al. 2020). These difficulties mean that such a classification often requires visual inspection to confirm morphological details or to link nebulae to their ionising sources (Rousseau-Nepton et al. 2018; Kreckel et al. 2019), which is particularly impractical in the context of large datasets.
‘Cloud-scale’ integral field spectroscopic (IFS) surveys, with spatial resolutions better than 100 pc, enable us to map and resolve individual structures involved in the star formation process (with sizes from a few parsecs to ∼100 parsecs; Sanders et al. 1985; Oey et al. 2003). These advances have revolutionised ISM studies, enabling detailed exploration across diverse galaxy samples (e.g. SIGNALS, Rousseau-Nepton et al. 2019; MAGNUM, Mingozzi et al. 2019; PHANGS, Emsellem et al. 2022), while emphasising the need for efficient classification methods to manage the increasingly large and complex datasets they provide.
For these reasons, in this work, we explore the use of machine learning (ML), and neural networks in particular, for the classification of emission-line regions. Several studies have applied ML techniques to identify different regions in galaxies (e.g. Rhea et al. 2023; Baron et al. 2024; Belfiore et al. 2025) and to determine their astrophysical properties (e.g. Ucci et al. 2017; Kang et al. 2023; Ginolfi et al. 2025). Recently, Rhea et al. (2023) classified H II regions, PNe, SNRs, and DIG by training a fully connected neural network on three key line ratios present in the optical spectra of these regions: [O III]λ5007/Hβ, [N II]λ6583/Hα, and [S II]/Hα. The line ratios for the training were obtained from photoionisation and shock models for each class of nebulae.
In Fig. 1, we show a schematic view of the approach introduced in this paper, which expands the approach of Rhea et al. (2023). Starting from photoionisation and shock models, we created a dataset of simulated optical spectra. We then fed the spectra (as opposed to a table of individual line ratios) to the network and trained a model to classify the different nebular spectra. This approach is advantageous because it allows us to self-consistently apply our classification algorithm to regions where certain emission lines are undetected. It also enables the network to exploit the additional information provided by weaker emission lines in regions of higher S/N, going beyond the more common optical diagnostics.
 |
Fig. 1. Schematic representation of the workflow presented in this paper. The diagram illustrates the key steps and processes involved in the analysis, from choosing the emission-line region models to the generation of the simulated dataset of spectra and the neural network’s classification. The leftmost image illustrates the model selection phase, depicting the distribution of our H II region, PN, SNR, and DIG models on a BPT diagnostic diagram (Baldwin et al. 1981). The central plot provides a representative simulated spectrum for each of the four classes. The rightmost panel presents a schematic of the neural network architecture, where the simulated spectra serve as input, and the network is trained to classify each spectrum into its corresponding nebular type. |
We also account for the potential superposition of nebulae along the line of sight by training our model on simulated spectra, which are constructed as linear combinations of different nebular classes. This approach not only addresses the complexity introduced by overlapping regions but also helps to reproduce the spectra of individual emitting regions better, which are typically more complex than those described by a single-cloud photoionisation model. Overall, our approach aims to enable the classification of nebulae with contamination from other nebulae (such as the superposition along the line of sight) and low S/N.
The Local Group galaxies are the ideal laboratory to develop, validate, and test classification methods for emission-line regions because these galaxies are close enough to allow us to observe and spatially resolve individual nebulae. M33 is the third largest galaxy in the Local Group and the second closest spiral to the Milky Way, located at a distance of approximately 840 kpc (Gieren et al. 2013; Breuval et al. 2023). Its proximity, combined with the data quality provided by MUSE, makes it an excellent target for testing the performance of our model on real data.
In this work, therefore, we present in Sect. 2 the M33 MUSE data. In Sect. 3, we describe the generation of the simulated spectra and our neural network model architecture. In Sect. 4, we evaluate the performance of the model on the simulated spectra, while in Sect. 5 we discuss the classifications of the MUSE M33 dataset. Finally, in Sect. 6, we discuss our results using interpretability techniques and compare them with traditional methods, while in Sect. 7, we present a summary of our results.
2. Data
In this work, we use MUSE IFS data of the nearby galaxy M33 and build simulated spectra to match the observational characteristics of this dataset. We present in the following sections the data acquisition and the processing methods used in this study.
The observations of M33 used in this work were obtained using MUSE in its seeing-limited, wide-field mode, and are part of the ESO programme ID 109.22XS.001 (PI: G. Cresci). A mosaic of 24 1′×1′ MUSE pointings covered a mostly contiguous region of 3′×8′ (0.7 × 1.9 kpc2) along the southern major axis of the galaxy, with an overlap of 2″ between adjacent pointings. The average seeing during observations was ∼0.7″, corresponding to ∼2.9 pc at the distance of M33 of 840 kpc. The MUSE data have a spectral resolution (R = λ/Δλ) ranging from 1770 at 4800 Å to 3590 at 9300 Å.
The observation and data reduction strategy is discussed in detail in Feltre et al. (in prep.), and was performed with the pymusepipe software framework1, a customised python wrapper to the MUSE data reduction pipeline (Weilbacher et al. 2020) developed by the PHANGS team (Emsellem et al. 2022) and optimised for processing large mosaics of extended objects. The final datacube, created by aligning the 24 pointings, contains ∼2.3 × 106 spectra, each consisting of 3682 wavelength channels. Feltre et al. (in prep.) also derived emission-line flux maps from the MUSE M33 datacube. These maps allowed us to compare the predictions from the ML models to standard diagnostics based on line ratios of optical lines.
3. Methods
3.1. Photoionisation and shock models
We created a set of synthetic emission-line region optical spectra, exploiting predictions from photoionisation and shock models for the types of nebula of interest. In particular, we selected grids of simulations from the Mexican Million Models database (3MdB, Morisset et al. 2015; Alarie & Morisset 2019), computed using the Cloudy v13 photoionisation code (Ferland et al. 2013) or the shock modelling code MAPPINGS V (Sutherland et al. 2018).
We took inspiration from Congiu et al. (2023) and Belfiore et al. (2025) in selecting a suitable set of H II regions, PNe, and SNRs models and parameters from those available in 3MdB. A detailed description of the model selection is provided in Appendix A. We added DIG models and refined the parameter selection for the models of the other three nebulae to better match those of observed nebulae in M33 (see Appendix B.1) in the [N II] and [S II]-BPT diagrams.
Fig. 2 shows the distribution of the final set of models in the [N II]-BPT and [S II]-BPT diagrams. These distributions are compared with the integrated spectra from the M33 nebulae, showing a reasonable overlap. The diagnostic lines from Kewley et al. (2001, 2006) and Kauffmann et al. (2003) are included to distinguish between different ionisation mechanisms, such as star formation and shocks, and roughly match the expected location with respect to the different model classes.
 |
Fig. 2. Two diagnostic diagrams ([N II]-BPT, Baldwin et al. 1981; [S II]-BPT, Veilleux & Osterbrock 1987) illustrating the relative positions of the emission-line region models and the observed nebulae in M33 across three different line ratio spaces. Green stars mark the identified M33 H II regions, blue squares the M33 PNe, and red circles the M33 SNRs. Similarly, green contours show the H II regions models, blue ones the PN models, pink-red ones the SNR models, and yellow-orange ones the DIG models. On the left, the [N II]-BPT diagram (Baldwin et al. 1981) includes the Kewley et al. (2001) and Kauffmann et al. (2003) (dashed line) diagnostic lines. On the right, the [S II]-BPT diagram includes the Kewley et al. (2006) diagnostic line. |
3.2. Generation of mock spectra
We used the photoionisation and shock models presented in Sect. 3.1 to generate ‘realistic’ H II regions, PNe, SNRs, and DIG mock spectra, matching the wavelength range, sampling, spectral resolution, noise, and other physical parameters of the MUSE data for M33. In this Section we describe the process in more detail.
We first restricted our analysis to emission lines that are covered by the wavelength range of MUSE and, for practical reasons, considered only a set of emission lines which can typically be detected in our dataset and in spectra of typical H II regions (e.g. Berg et al. 2020). Line intensities were then normalised to the Hα intensity.
We modelled each emission line with a Gaussian function centred at its rest-frame wavelength shifted to the systemic velocity of M33. The velocity dispersion for each emission line was computed as the quadrature sum of the MUSE line spread function and the intrinsic velocity dispersion of the ionised nebula. We adopted the MUSE line spread function from Bacon et al. (2017), which varies from σ ∼ 80 km s−1 at the blue end of the spectrum to ∼40 km s−1 at the red end. The intrinsic velocity dispersion, on the other hand, was randomly selected for each spectrum in the range [30 − 50] km s−1, which represents the expected range for PNe and H II regions (Magrini et al. 2016; Kewley et al. 2019). SNRs are expected to have larger velocity dispersion (which can exceed ∼100 km s−1; Li et al. 2024), especially when unresolved. However, such behaviour is not evident in our M33 data. We therefore did not use a different distribution of velocity dispersion for SNRs and DIG.
We added random Gaussian noise to the spectra to mimic the effect of observational noise. For the purpose of testing our classification models, we consider two different noise levels, S/N = 20 and S/N = 100. Since our mock spectra are normalised to an Hα flux of one, these values correspond to S/N values on the Hα line flux. These values are chosen because an Hα S/N = 20 corresponds to the 20th percentile of the S/N distribution in the M33 datacube, while S/N = 100 corresponds to the 99th percentile. From this point on, we refer to the S/N = 20 and S/N = 100 model set as ‘low S/N’ and ‘high S/N’ respectively. Additionally, we refer to the dataset with no added noise as ‘infinite S/N’.
We also model dust attenuation assuming the Cardelli et al. (1989) Galactic extinction law as revised by O’Donnell (1994), with RV = 3.1. We randomly extract E(B − V) values for each spectrum from a uniform distribution, ranging from E(B − V) = 0 to 0.4, where the latter value corresponds to the 90th percentile of the distribution of the E(B − V) values in the M33 MUSE datacube (see Sect. 5.3). Similarly to the addition of noise, this process adds variety to the dataset. For testing, we consider a dataset with dust attenuation and S/N = 100, which we refer to as ‘high S/N + extinction’.
3.3. Preprocessing of the mock spectra
Before feeding the mock spectra into our ML model, we experimented with different normalisation methods. Standardisation is a common preprocessing step in ML, where features are rescaled to have a mean of zero and a standard deviation of one, ensuring that the model does not favour features with larger numerical ranges. We also tested min-max normalisation, in which we scale data to a fixed range, such as [0, 1]. Both these methods are typically performed across all instances in the dataset for each feature (e.g. each wavelength channel in our spectra) to ensure consistent scaling of input features. In our case, we also explored normalising each input spectrum independently along the wavelength dimension. This approach ensures that the relative differences within each spectrum are preserved while removing variations in scale or offset between spectra.
We found that the performance of the network did not depend on the choice of normalisation so we opted for the standardisation of individual spectra across wavelength, which has the advantage of being trivial to apply to observational data and ensures that the spectra remain interpretable. Afterwards, we divided our mock spectra into training (70%), validation (15%) and testing (15%) subsets.
3.4. Neural network architecture
We tested different model architectures including both dense fully connected neural networks and 1D convolutional neural networks (CNN). While in a fully connected network every neuron in each layer is connected to every neuron in the next layer, a CNN uses convolutional layers to better detect features, reducing the number of parameters compared to dense connections. The key difference is therefore that the fully connected networks treat all input features (in our case wavelength channels) equally, while the convolutional ones exploit local relationships in the data. We found that the performances of our both models were similar, so we focus here on the results obtained using the fully connected network.
Our default neural network model consists of a fully connected network with two dense hidden layers interspersed with dropout layers. For the training with the infinite S/N dataset, we use a first hidden dense layer with 16 units, followed by a dropout layer (with a dropout rate of 5%), a second dense layer with four neurons, again followed by a 5% dropout layer, followed by the output layer. The output layer consists of four neurons with a softmax activation to calculate the probabilities of each output class. For the task of classifying noisy spectra we use a first dense layer of 128 neurons, and a second layer of 64. Each is followed by a dropout layer (with 10% dropout for the high S/N cases and 20% dropout for the low S/N case). These are followed by the usual output layer. A visual representation of the network’s architecture can be viewed in Fig. 1, right panel.
The models are fit with a batch size (the number of instances in the mini-batches used in the training) of 256. The learning is stopped with the EarlyStopping callback, after five epochs of patience in which the loss measured on the validation set does not decrease. We trained the model with cross-entropy loss and the Adam (Adaptive Moment Estimation) optimizer algorithm (Kingma & Ba 2014). We build the networks using keras (v2.14.0; Chollet et al. 2015) from tensorflow (v2.14.0; Abadi et al. 2016), implemented in python (v3.9.7).
4. Testing on mock spectra
In this section, we discuss the performance of the model on a subset of mock spectra by comparing its classifications with the known input labels. In particular, we evaluated the model using confusion matrices, which compare the input and predicted classes, and using the f1-score, which is the harmonic mean of precision and recall. In multi-class classification, precision for each class measures the proportion of true positives among all predicted positives for that class, while recall for each class measures the proportion of true positives among all positives for that class. The overall f1-score was computed as the unweighted average of the f1-scores for all classes since the number of instances is the same for each class.
4.1. The effect of noise and extinction
We compare performance metrics for models trained with the four different mock datasets described in Section 3.2: infinite S/N, high S/N, high S/N + extinction, and low S/N. For the infinite S/N case, the confusion matrix is perfectly diagonal (not shown), as the model is able to recognise the correct label for each instance of the test set. As visible in Fig. 3 and quantified in Table 1, the model’s performance deteriorates with the addition of noise and extinction effects, with f1-scores decreasing to 0.82 for the low S/N case. However, in the high S/N and high S/N + extinction cases, where the datasets consist of high-quality spectra, f1-scores above 90% can be achieved.
 |
Fig. 3. Confusion matrices comparing the networks’ predicted classification with the true classification for four different test mock datasets. The values shown are percentages. Top row: confusion matrices for the network trained with the single-label high S/N dataset without extinction (panel a) and for the network trained with the high S/N dataset with extinction (panel b). Bottom row: confusion matrices for the network trained with the low S/N dataset without extinction (panel c) and for the network trained with the multi-label dataset (panel d). |
The PN class is consistently more accurately recovered, whereas the classification performance for the H II region and DIG classes declines more significantly when adding noise and extinction (to 78% and 74% respectively in the low S/N case). Overall, we also find a higher misclassification rate between H II regions and DIG spectra, H II regions and PNe spectra, and SNR and DIG spectra.
4.2. Mock spectra of nebular line-of-sight superpositions (‘multi-label’)
Realistic observations along a line-of-sight might contain a superposition of nebulae of different classes and/or be contaminated by foreground and background diffuse emission. In this section we explore the ability of our ML model to recover the contributions of different components. To do this, we built a new set of mock spectra as a weighted sum of spectra from individual classes. We refer to the models obtained by linear combination as ‘multi-label’ and the original single-class models for H II regions, PNe, SNR, and DIG as ‘single-label’.
We built multi-label models by generating weighted sums of the line intensities of four single-label models, one for each of the four different classes. For example, a multi-cloud model described by the label [0.2, 0.6, 0.1, 0.1] is constituted by a random H II region model scaled by 0.2, a PN model scaled by 0.6, a SNR model scaled by 0.1, and a DIG model also scaled by 0.1. Because of their normalisation, these weights can be interpreted as probabilities. Therefore, we also set up the problem of the recovery of these weights as a multi-label classification problem.
In total, we generate 200 000 ‘multi-label’ models, selecting the single-label models randomly but making sure that each model is taken into account a few times. The number of multi-label instances significantly exceeds the number of ‘single-label’ ones in this dataset (they are 1/6 of the total number of models), because the task of classifying the multi-label spectra is more complex than that of classifying single-label spectra as the multi-label linear combinations can be extremely diverse among themselves. Therefore the network will need many examples to learn to correctly classify these instances. Starting from these emission-line region models, the mock spectra are created as described in Sect. 3.2 with a S/N = 100 and E(B − V) = 0 − 0.4 (matching the characteristics of the low-noise dataset with extinction). We chose the same network architecture as the one used for the classification of noisy spectra (Sect. 3).
To evaluate the network performance, we consider a test set of spectra where the prevalent contribution is higher than 50%, to mimic cases where a nebula, dominating the emission, is subject to some degree of contamination. The ‘true label’ is taken as the class with the highest contribution in each spectrum’s label and the ‘predicted label’ is taken as the class with the highest contribution (i.e. with the highest probability) as predicted by the network. The results are shown in Fig. 3, panel d. As for the single-label cases discussed above, we find that the PNe class is predicted most accurately, while the H II regions and DIG classes have lower accuracy. In particular, the network struggles to recover the true label of regions where the H II region class is the one with the highest contribution. Finally, we measure an f1-score of 0.82. This value is comparable with that of the low S/N single-label dataset (Sect. 4.1), even if the training sample has a higher S/N of 100. However, this is justifiable considering that the task has been considerably complicated by the mixture of different nebular models.
For a more comprehensive view of the network’s performance, we measure the difference, for each class, between the input weight and the model probability prediction of each spectrum of the test set. Then we calculate the median of the absolute values of the difference for each class. The median errors on the weights of the four classes are 8.9, 5.3, 7.2, and 8.2% respectively for H II regions, PNe, SNRs, and DIG. Since the sum of the weights is normalised to one, these numbers can be interpreted as median fractional errors. The network therefore generally achieves good performance, with fractional errors on class contributions of less than 9%. The PNe contribution is the better predicted one, while the contributions from H II regions and DIG are predicted a little less accurately.
Fig. 4 shows the discrepancy between the input weight and the model prediction for four example instances of the test set with different combinations of the four nebulae. The plot in panel a shows a single-label SNR spectrum, whose coefficients are well predicted by the network. The b and c panels show two multi-label cases in which the prevalent class has a contribution higher than 0.5: we notice that the network retrieves the prevalent class, even if with some error on the estimate (< 0.1).
 |
Fig. 4. Bar plots showing the median error made by the network trained on the multi-label dataset on each class contribution for three example instances. The coloured bars represent the network’s prediction, while the empty bars are the true labels. In panel a, we show the classification of a single-label PNe spectrum, whose coefficients are accurately predicted. In panel b, we show the results for a multi-label instance, with a prevalent contribution of DIG > 60%. In panel c, we show the results for another multi-label instance, with a prevalent contribution of H II region = 60%. |
5. Application to observational data of M33
5.1. Tailoring of the models to observed data
To apply our neural network to real observational data, we train new models using mock spectra tailored to match the specific S/N and extinction distributions of our M33 dataset.
Such an adjustment is necessary because variations in S/N significantly influence the model’s ability to classify or predict accurately (e.g. Kang et al. 2023; Ginolfi et al. 2025). In particular, if the S/N and extinction properties of the training data differ significantly from those of the test data, the model’s performance can degrade due to a mismatch in learned features. For instance, a model trained on high S/N spectra may struggle to classify low S/N data accurately and vice versa, as the noise characteristics can dominate or obscure the spectral features critical for classification.
For example, when low S/N instances (S/N = 20) are classified using our model trained on high S/N spectra (S/N = 100), a significant drop in performance is observed, with an f1-score of 0.56 compared to 0.82 (as shown in Table 1), achieved when the classification is performed using a model trained on data with the same S/N. Therefore, in Sect. 5.2 and Appendix B.2, we present the process of tailoring the models to classify the spectra in each spaxel of the M33 field. In Appendix B.1, we explore a different model tailored to match the characteristics of integrated nebulae rather than single spaxels.
f1-scores on the test set of the ANN model trained on different mock datasets.
5.2. The ‘single spaxel’ model
To apply our ML model to the MUSE M33 cube, we first pre-processed the input datacube, enhancing the S/N of the spectra by applying a spatial Gaussian smoothing with a kernel of σ = 1 spaxel. We then generated a new multi-label mock spectra dataset with a S/N distribution matching that of the data. In particular, we fit the Hα S/N distribution from the M33 datacube with a lognormal distribution (mean ∼ 37, σ ∼ 22). We then sampled suitable noise values from this distribution to generate mock spectra.
We recreated in our mock spectra the distribution of E(B − V) inferred from the Balmer decrement (Hα/Hβ) from each spectrum of the MUSE data. In particular, we calculated the dust attenuation applying a S/N > 5 cut on Hα and Hβ fluxes, assuming the case B theoretical ratio of Hα/Hβ = 2.87 and adopting the Cardelli et al. (1989) Galactic extinction law as revised by O’Donnell (1994), with RV = 3.1. We find the distribution of E(B − V) for the individual spaxels and fit it with a truncated normal distribution, which we use to sample random E(B − V) values for use in our mock training dataset. While this approach does not associate an E(B − V) value with low-S/N spaxels, these regions are likely to fall towards the range of extinction values already sampled by our distribution.
Due to the low peculiar velocity of M33, the [O I]λ6300 line is not sufficiently redshifted from its airglow counterpart and is therefore strongly affected by sky subtraction residuals and generally not recoverable in our MUSE data. We therefore removed it from the mock spectra to avoid the network interpreting airglow emission as [O I]λ6300 from the target.
The architecture of the network used in this case is akin to the one already described in the multi-label case (Sect. 4.2), with an increase of the dropout rate to 30% to help with the model’s generalisation. Since this network is trained with a multi-label type of dataset, we evaluate its performance as in Sect. 4.2. We find that the average median error on the prediction of each class’ contribution for the mock test dataset is ∼9%. We also measure an f1-score of 0.80 considering only the test instances with the prevalent class contributing to at least 50% of the spectrum and comparing that class with the dominant one predicted by the network. This performance is comparable to that of the previously described low S/N and the multi-label cases (Sect. 4).
Before testing the model on our data, we perform two additional pre-processing steps. Missing data (NaNs) in the spectra are set to zero, and the input spectra are standardised (the mean is subtracted and then they are divided by the standard deviation) before input into the network. This is the same standardisation process performed on the mock spectra and is a fundamental step because these spectra may have a non-negligible contribution from the continuum. However, this contribution is sufficiently small with respect to the emission lines, that standardising the spectrum makes a detailed continuum subtraction unnecessary. In total, it takes ∼20 hours to complete the classification for every spaxel in the datacube (2 356 584 spectra) on a single GPU.
5.3. Classification of the IFS datacube
We applied the ‘single spaxel’ model to the entire IFS datacube and show the result of the classification process in Fig. 5. In particular, the figure shows the predicted classification for each spaxel of the observed field of the M33 galaxy (panel a) compared to the map of the emission from three key lines, Hα, [S II]λ6716, 6731, and [O III]λ5007 (panel b). The prediction map is a three-colour rgb image, where the green colour scale is associated with the H II regions class, the blue one with PNe, and the red one with SNRs and DIG classes summed together. Each pixel in the image is coloured based on the neural network’s predicted probability for the spectrum within the corresponding spaxel, with the colour increasingly aligning with the representative colour of each class as its predicted contribution increases. The motivation for considering the SNR and DIG probabilities together is further discussed later in this section and is mostly driven by the network’s difficulty in clearly distinguishing between these two classes.
 |
Fig. 5. Comparison between the neural network classification of the single-spaxel spectra and a map of three key emission lines. On the left side (panel a), we show our neural network’s prediction map for the observed field of M33. Each colour quantitatively represents the predicted contribution to each pixel’s spectra from an H II region (green), a PN (blue), and a SNR plus DIG (red). We overlay a S/N map (in shades of grey), derived from the Hα flux map and its associated error map. On the right side (panel b), we show an RGB map of three key emission lines for the entire observed field of M33, with the red scale representing the [S II]λ6716, 6731 flux, the blue the [O III]λ5007 flux, and the green the Hα flux. The gold star symbols mark massive stars brighter than 20 mag in the F475W Hubble Space Telescope (HST) filter and the smaller orange stars those with magnitude between 21 and 20 in the same filter from Williams et al. (2021). The light blue star symbols mark Wolf-Rayet stars (Neugent & Massey 2011). In both images, the red circles mark SNRs from the Lee & Lee (2014) and Long et al. (2018) catalogues, while the smaller teal circles show the PNe selected by Ciardullo et al. (2004). |
In Fig. 5a, we also overlap a S/N map in grey scale for a better interpretation of the prediction map. Darker areas on the map indicate lower S/N levels. The square grid which is visible in the S/N map represents the edges of the MUSE pointings and becomes apparent because the overlap regions between pointing have intrinsically higher S/N because of their deeper integrations.
By comparing panels a and b in Fig. 5, we conclude that the network identifies H II regions across the entire field. In particular, regions classified as H II regions by the network correspond well to Hα-bright regions (which appear green in Fig. 5b) hosting ionising stars (Feltre et al., in prep.; Williams et al. 2021), which are shown with a star symbol in Fig. 5b.
To investigate where the model sets the H II region boundaries we examine two prototypical H II regions shown in Fig. 6 which are among the most luminous (4.4 and 9 × 1017 erg s−1, top and bottom, respectively) identified in our MUSE data. They show a nearly spherically symmetric geometry, with emission from higher/lower ionisation lines decreasing/increasing from the centre outwards, and exhibit clear ionisation fronts, as traced by the [S II]/[O III] ratio (Feltre et al., in prep.). More details on the spectral properties of these regions are provided in Pellegrini et al. (2012) and Feltre et al. (in prep.). Here we compare the neural network classification with the [S II]/[O III] line ratio map. The black, purple, and magenta contours in this map highlight where the model predicts a probability of H II region equal to 40%, 60%, and 90%, respectively. The comparison shows that the predicted H II regions extend up to the ionising front traced by the high [S II]/[O III] ratio. Thus, our H II region classification successfully classified the whole nebula, out to the ionisation front, when considering a probability of 0.6.
 |
Fig. 6. Zoom-in of a region of interest in the M33 field, focusing on two H II regions. In the left classification map, we quantitatively represent the predicted contribution to each pixel’s spectra from an H II region in green, a PN in blue, and a SNR/DIG in red. We overlay a S/N map (in shades of grey), derived from the Hα flux map and its associated error map. The right panel shows a [S II]λ6716, 6731/[O III]λ5007 ratio map. The black, purple, and magenta contours in this panel enclose a model-predicted H II region probability of 0.4, 0.6, and 0.9, respectively. |
We then test the ability of the network to detect the PNe previously identified in Ciardullo et al. (2004). Firstly, we consider the ‘isolated’ PNe, whose classification maps are visible in panels a–f of Fig. 7. We find that our model predicts a strong PN probability (≳75%) for four of these PNe and a 50% probability of another one (i.e. PN is still the dominant class). Only the PN in panel f has another class (H II region) as the prevalent one (∼50%). Additionally, where PNe occur in the vicinity of another bright region, and therefore some overlap along the line-of-sight seems probable, the network predicts a more mixed classification and a lower PN probability (∼30%). This is the case for the PNe in panels g and h of Fig. 7. For these, the prevalent class is H II region (40−50% probability). Furthermore, the network detects new PNe that were missed in the literature catalogues with very high probabilities (≳90%). Two examples are visible in panels i and j of Fig. 7.
 |
Fig. 7. Cutouts of the classification map focusing on the Ciardullo et al. (2004) PNe, identified by the light blue circles (panels a–h) and two additionally identified PNe, marked in grey (panels i, j). Each colour of the RBG map quantitatively represents the predicted contribution to each pixel’s spectra from an H II region (G), a PN (B), and a SNR/DIG (R). We overlay a S/N map (in shades of grey), derived from the Hα flux map and its associated error map. On the top right of each cutout, we write the PN contribution for the identified PNe averaged over an aperture of 1.5″ of diameter centred on the probability peak. On the bottom left, we specify whether the PN is isolated or its emission appears to be blended to that of other regions. The green circle in panel h marks a nearby SNR from the Lee & Lee (2014) and Long et al. (2018) catalogues. |
Aside from the confidently identified H II regions and PNe, the remainder of the field’s spectra are mainly classified as SNRs or DIG. However, we observe that the network struggles with distinguishing SNR from DIG spectra. Indeed, as shown in the confusion matrices in Fig. 3, we have already observed that the network exhibits some degree of confusion between SNRs and DIG spectra. Additionally, in this specific case, the [O I]λ6300 line is not considered in our model because of the overlap with airglow emission (Sect. 5.1). Both traditional diagnostics (Kopsacheili et al. 2020) and our neural network (as discussed in Sect. 6.1) identify [O I]λ6300 as a critical emission line for the classification of SNRs. In its absence, the network is compelled to rely predominantly on the [S II]λ6716, 6731 doublet, which proves insufficient to discriminate between the two classes. This limitation arises because the emission line ratios in the DIG are almost always consistent with low-ionisation emission regions (LIER), but also shock models (Allen et al. 2008) significantly overlap with the LIER region of the BPT diagram, as observed in our case (see Fig. 2). These considerations motivate our decision to sum the prediction probabilities for SNR and DIG when discussing our results.
Considering this, our model correctly classifies the SNRs documented in the literature (red circles in Fig. 5, from Lee & Lee 2014; Long et al. 2018) as belonging to the SNR+DIG class with varying degrees of confidence. Similarly, the spectra from part of the filamentary structure visible at low S/N in the line emission map are classified as H II region mixed with the SNR+DIG class.
We also observe some bright regions with a mix of contributions from both PNe and H II region (as in Fig. 8). Despite the fact that PN may be the most probable classification, these regions have an extended morphology and are clearly ionised by either Wolf-Rayet (WR) stars (Neugent & Massey 2011) or hot young stars (Williams et al. 2021). Indeed, the bright ultraviolet (UV) flux from WR stars (among the hottest and most luminous stars in the local Universe) creates a highly ionised H II region, or ‘WR nebula’ (e.g. Chu 1981; Tuquet et al. 2024). The WR star’s hard spectrum results in strong emission lines from high-ionisation species such as [O III], which is also a prominent feature in PNe. Because of their underlying spectral similarity, WR nebulae are often classified as PNe by our neural network.
 |
Fig. 8. Cutout of the classification map focusing on an [O III]λ5007 bright H II region hosting a Wolf-Rayet star (Neugent & Massey 2011), marked by the light blue star symbol. The colours in the map quantitatively represent the predicted contribution to each pixel’s spectra from an H II region (green scale), a PN (blue), and a SNR/DIG (red). We overlay a S/N map (in shades of grey). The additional star symbols in yellow and gold represent massive stars respectively brighter than 20 mag and between 21 and 20 mag in the F475W HST filter (Williams et al. 2021). |
Finally, we conclude that the neural network is good at distinguishing H II regions and PN spectra that show brighter high-ionisation line emission, from SNRs and DIG spectra, which are characterised by low-ionisation line emission. We compare these classifications with traditional diagnostics in Sect. 6.2.
6. Discussion
In this section, we explore the interpretation of our neural network approach through activation maximisation to identify the spectral features used for classification. We also discuss the limitations of our neural network model, in particular the misclassifications arising from photoionisation and shock model mismatches, and propose future work on domain adaptation to address these challenges.
6.1. Interpreting the model with activation maximisation
Activation maximisation is a method used to visualise and interpret the features in the data that specific neurons in a neural network have learned to recognise. By adjusting the input spectrum to enhance the activations of the target neurons, activation maximisation produces synthetic spectra that are optimised to trigger strong responses from those neurons. The generated spectra provide visual insights into the features that the resulting classification is based on.
We show activation maximisation maps (i.e. spectra) for three of our mock single-label datasets (infinite S/N, high S/N, low S/N) in Fig. 9. These ideal spectra show both positive and negative peaks located at the position of some of the emission lines present in the training dataset. Regardless of the sign of the values, the more prominent the peak, the larger influence that line will have on the network’s classification. In all cases, the network correctly neglects the channels devoid of emission lines.
 |
Fig. 9. Activation maximisation maps corresponding to three different mock datasets with different S/N for the four different classes of nebulae. For ease of visualisation, we show in colour the spectral channels where the absolute value of the activation is larger than 15% of the maximum value of the activation spectrum. The key emission lines are labelled. Panel a: activation map for the network trained with mock spectra with infinite S/N. Panel b: The high S/N mock spectra case. Panel c: the low S/N spectra case. |
When trained with the infinite S/N dataset, the network bases its classification on faint emission features, including the auroral lines of the main metal ions ([N II]λ5755, [S III]λ6321, [O II]λ7320, 30) and the He I recombination lines at λ6678, λ7065. Thus, according to our model, these faint lines are the most suitable to efficiently classify emission-line regions.
In the high S/N case, the network starts to shift its focus towards the brighter lines in the spectrum for all four classes. Indeed Fig. 9, panel b, shows that the lines the neural network uses to classify PNe, for example, are both some of the faint lines (such as He Iλ5876, [Ar III]λ7135, He Iλ7065), and some of the bright ones (such as Hα, [O III]λλ4959, 5007, [N II]λ6548, 84 and Hβ).
In the low S/N case, strong emission lines such as Hα, Hβ, [O III]λ4959, 5007, [N II]λ6584 become even more emphasised, while the fainter lines lose relevance (Fig. 9, panel c). Indeed, the network is now relying exclusively on Hα, Hβ, [N II]λ6548, 84, [O I]λ6300, [S II]λ6716, 6731, and the [S III]λ9069 lines to classify the mock spectra. In this last case, we find that the classification strategy learnt by the network tends to mirror that of the traditional techniques. For example, the characteristic features the network positively reacts to in H II regions spectra are the Balmer recombination lines, while it characterises DIG spectra by the lower ionisation lines of [N II] and [S II]. PNe are identified using [O III], Hα and [N II], as suggested by Ciardullo et al. (2002), and SNR by [O I]/Hα as suggested by Kopsacheili et al. (2020). The activation maps of the network trained on the high S/N dataset with extinction exhibit intermediate characteristics between those of the models trained on the high S/N and low S/N datasets.
These findings highlight important advantages of our neural-network-based approach over traditional diagnostic diagrams. While the network relies on spectral features similar to those employed in classical techniques, our method enables the emergence of new diagnostic trends in high-S/N regions. Unlike diagnostic diagrams that rely on pre-computed flux ratios in low-dimensional (2D or 3D) spaces, our approach directly ingests spectra. This allows the model to exploit the full information content of the spectrum, naturally exploring a multi-dimensional diagnostic space with potentially non-linear relationships between features. Consequently, the network can uncover subtle, complex patterns in the data that traditional approaches might overlook.
6.2. Evaluating the IFS data classification against traditional diagnostics
We further assess the IFS datacube classification by comparing it with the one performed with traditional methods. In particular, we consider two traditional diagnostic line ratios: ![$ R=[{\mathrm{O}\,{\small { {\text{ III}}}}}]\lambda5007 $](/articles/aa/full_html/2025/05/aa54196-25/aa54196-25-eq1.gif) /(H
/(H![$ \alpha+[{\mathrm{N}\,{\small { {\text{ II}}}}}]\lambda6548) $](/articles/aa/full_html/2025/05/aa54196-25/aa54196-25-eq2.gif) for PNe (Ciardullo et al. 2002), and [S II]λλ6717, 6730/Hα for SNRs and DIG (D’Odorico et al. 1980).
for PNe (Ciardullo et al. 2002), and [S II]λλ6717, 6730/Hα for SNRs and DIG (D’Odorico et al. 1980).
Fig. 10 shows the PNe probability map generated by the network alongside a map of the R value for a section of the M33 field. In the probability map, blue pixels indicate regions with a predicted probability of being PNe higher than 50%. Ciardullo et al. (2002) consider PNe all the nebulae with R > 1.6, which are coloured in blue in the right panel. The magenta contours on both maps highlight areas with a predicted PNe contribution of 50%, providing a direct visual comparison between the network predictions and the R-based classification. The two panels of Fig. 10 show how well the areas with a strong likelihood of being PNe trace the areas with higher R values, considering both PNe and [O III]λ5007 bright H II regions. In particular, this threshold on PNe probability traces most of the PNe in Ciardullo et al. (2004), with the exception of those embedded in more complex regions (those of panels e–g of Fig. 7). For a more quantitative comparison, we used the intersection over union (IoU) metric, which measures the overlap between two regions by dividing the area of their intersection by the area of their union (0 indicates no overlap, 1 perfect alignment). We do this considering the area of all the spaxels in the entire field with a PNe probability > 0.5 and that of all the spaxels with R > 1.6, obtaining a IoU value of ∼0.69.
 |
Fig. 10. Comparison between the PNe neural network classification and the one with a traditional method from the literature for a section of the observed M33 field. On the left is the PN contribution map as predicted by the network. Colours tending to blue show a higher probability of PN, while those tending to green show a lower one. On the right, a map coloured based on the R = [OIII]λ5007/(Hα + [NII]λ6584) ratio from Ciardullo et al. (2002), where all the pixels coloured in blue are predicted to be PNe. The yellow star symbols mark O type ionising stars from Williams et al. (2021), selected based on flux and colour. Instead, the light blue ones mark Wolf-Rayet stars (Neugent & Massey 2011). In both images, the blue circles show the Ciardullo et al. (2004) PNe, while the green circles mark the Lee & Lee (2014) and Long et al. (2018) SNRs. The pink contours mark the points with a predicted PN contribution of 0.5. |
Similarly, in Fig. 11 we study the SNR+DIG region probability map together with a map of the [S II]/Hα ratio in another section of the M33 MUSE field. We consider the fact that a [S II]/Hα ratio closer to one corresponds to regions that are more likely to be shock ionised (Mathewson & Clarke 1972; D’Odorico et al. 1980). Again, there is a satisfactory conformity between the two maps, especially considering (some) of the regions in the green circles which are SNR from the literature. We again measure the IoU for the entire field, considering the SNR+DIG probability threshold at 0.6 (so that the H II regions and PNe are clearly separated from the SNR/DIG) and the [S II]/Hα ratio threshold at 0.5, retrieving a IoU value of ∼0.73, confirming a good agreement between the two maps.
 |
Fig. 11. Comparison between the SNR+DIG neural network classification and the one with a traditional method from the literature for a section of the observed M33 field. On the left is the SNR+DIG contribution map as predicted by the network. Colours tending to red show a higher probability of SNR or DIG, while those tending to green a lower one. On the right, a map coloured based on the [S II]λ6716, 6731/Hα ratio. A higher value of the ratio suggests brighter [S II] emission with respect to Hα. The yellow star symbols mark O type ionising stars from Williams et al. (2021), selected based on flux and colour. Instead, the light blue ones mark Wolf-Rayet stars (Neugent & Massey 2011). In both images, the blue circles show the Ciardullo et al. (2004) PNe, while the green circles mark the Lee & Lee (2014) and Long et al. (2018) SNRs. The pink contours mark the points with a predicted SNR+DIG contribution of 0.6. |
6.3. Limitations and future work
The findings presented here are subject to certain limitations that warrant further investigation. Firstly, all the used emission-line region models are single-cloud models, that is, they describe the integrated spectrum of a single nebula (Pérez-Montero 2014; Delgado-Inglada et al. 2014). On the other hand, we compare them to spatially resolved spectra of these regions, which show complex structures within the observed nebulae (Feltre et al., in prep.), with the exception of PNe, which are unresolved. Therefore, the assumptions of single-cloud models (e.g. uniform density, spherical geometry) are not realistic in most cases and are not sufficient to interpret observations of spatially resolved nebulae. To address this limitation, it would be necessary to train our neural networks with photoionisation and shock models that better describe the elaborate structure of these nebulae, such as three-dimensional models (Ercolano et al. 2005, 2007; Jin et al. 2022) or state-of-the-art multi-cloud models (e.g. HOMERUN, Marconi et al. 2024). Nevertheless, despite these simplifications, single-cloud models still provide a meaningful classification, even if they do not capture the full complexity of spatially resolved structures. In Appendix B, we discuss the application of our ML method to integrated data.
Additionally, misclassifications can arise from a discrepancy between the photoionisation and shock models and observed nebulae. We have verified that this discrepancy is not large by comparing ∼2000 real spectra extracted randomly from the cube from areas with S/N ≥ 7 on the Hα line and finding the model for which the sum of the absolute value of the residuals is minimum. The reduced χ2 of these fits is always below 2, with average equal to 0.5, ensuring that there is at least one mock spectrum accurately reproducing a real one within twice the noise levels of the observed spectra.
To address the problem of model mismatch within an ML framework, Belfiore et al. (2025) implemented domain adaptation techniques (Ganin & Lempitsky 2015). Domain adaptation bridges the gap between photoionisation and shock models and observed ionised nebulae by learning representations valid across both domains. Implementing such techniques can significantly improve the robustness of neural network models, reducing the biases introduced when training only on theoretical predictions. This can be achieved with the use of a DANN (domain-adversarial neural network, Ganin et al. 2016). The goal of a DANN is to maximise the performance of a model trained on labelled data in the source domain (our synthetic spectra) on an unlabelled target domain (our observed spectra) by extracting domain-invariant features (those shared by both source and target domain).
Finally, we consider the resilience of the ‘single spaxel’ model to line shifts in the dataset since a fully connected neural network is not inherently shift invariant. To do so, we measure the f1-score as in Sect. 4.2 on multi-label mock test spectra with different velocity shifts (±50, 100, 150, 200, 250 km/s). For comparison, we apply the same test with a CNN trained on the same tailored mock dataset (Sect. 5.1). The CNN is composed of two convolutional layers (one with with five kernels of dimension equal to two wavelength channels and one with 50 kernels of dimension equal to ten channels) both followed by a max pooling layer with pooling size equal to four, a flattening layer, two dense layers composed of eight units each followed by a 10% dropout layer, and then the output layer. The results of this evaluation are presented in Fig. 12. The fully connected model maintains a strong performance (f1-score ∼ 70%) up to ∼100 km/s (equivalent to a shift of approximately two wavelength channels in our MUSE dataset), which corresponds to the maximum velocity shift observed in our M33 field. In contrast, due to its inherent translational invariance, the CNN outperforms the fully connected at larger shifts. Thus, for our dataset, we find the fully connected network to be sufficiently robust for the classification. However, a CNN should be considered for broader applications. Since this test is carried out at the inference stage, a better performance could be achieved by adding velocity shifts in the training dataset.
 |
Fig. 12. Evolution of the f1-score for different velocity shifts in the mock test dataset for the single spaxel fully connected model and a CNN trained on the same dataset. |
7. Summary and conclusions
The study of emission-line regions in extragalactic environments is critical for understanding galaxy evolution. We demonstrate the potential of using artificial neural networks to classify nebular regions by their spectra, overcoming some of the issues of traditional diagnostics. These limitations include rigid classification boundaries, the challenge of classifying spectra with low signal-to-noise ratios and intermediate properties (e.g. due to superposition), the limited use of the information contained in the data, and the time-consuming step of spectral line fittings.
We train and test our neural network with mock datasets created starting from emission-line intensities in photoionisation and shock models, emulating instrumental and physical observational effects, and simulating a range of noise and extinction levels. We also develop a multi-label dataset to train the network in recognising cases where the spectra may display features that overlap between different classes (e.g. caused by superposition along the line-of-sight). We evaluate the network’s performance across the different training datasets and use activation maximisation maps to investigate the features in the spectra on which the network relies to carry out its classification. Our main findings after the training and testing of the network are:
-
With high S/N spectra (S/N = 100) the network shows excellent classification performance (f1 = 0.97) and relies on faint spectral lines, such as [N II]λ5755, He Iλ5876, [S II]λ6312, He Iλ7065, [O II]λ7320, [O II]λ7330, and [Ar III]λ7751.
-
When noise and extinction are introduced, the network relies more on brighter lines to maintain classification accuracy. This approach resembles traditional techniques, as it draws on lines typically used in single- and multi-ratio diagnostic methods. This suggests that the model has, to some extent, learned features of traditional classification approaches (D’Odorico et al. 1980; Baldwin et al. 1981; Ciardullo et al. 2002; Kopsacheili et al. 2020).
We also run the network on real spectra extracted from a MUSE observation of a field of the nearby galaxy M33. We classify over two million single-pixel spectra. The key results from the tests on real data are:
-
The network is able to effectively distinguish H II regions and PNe spectra from SNRs and DIG ones across the entire observed field, confidently identifying most of the PNe from the literature (Ciardullo et al. 2004).
-
The difficulty in distinguishing between SNRs and DIG spectra possibly arises from the missing [O I]λ6300 line, which according to both our test and the literature (Kopsacheili et al. 2020) is key in this discrimination. Taking this into account, we also retrieve the literature SNRs (Lee & Lee 2014; Long et al. 2018).
-
The comparison of the spaxel-wise classification results with commonly used diagnostic line ratio maps (Ciardullo et al. 2002; D’Odorico et al. 1980) further supports the network’s alignment with traditional methods.
In conclusion, our approach demonstrates that neural networks can effectively classify emission-line regions by dynamically selecting different sets of spectral lines based on the available data quality. Additionally, by leveraging the three-dimensional nature of IFS data, our method allows for the definition of physically motivated spatial boundaries for the nebular regions and accounts for the effects of projection and line-of-sight superposition. These capabilities represent a significant advancement over traditional classification methods. More broadly, this work highlights the potential of ML as an invaluable tool for the analysis of large IFS data, paving the way for broader applications in the automated analysis of complex astrophysical datasets.
Acknowledgments
Based on observations obtained at the ESO/VLT Programme ID 109.22XS.001 (PI:Cresci). FB acknowledges support from the INAF-Fundamental Astrophysics programme 2022 & 2023. AF acknowledges the support from project “VLT- MOONS” CRAM 1.05.03.07, INAF Large Grant 2022 “The metal circle: a new sharp view of the baryon cycle up to Cosmic Dawn with the latest generation IFU facilities” and INAF Large Grant 2022 “Dual and binary SMBH in the multi-messenger era”. EB and GC acknowledges the support of the INAF Large Grant 2022 “The metal circle: a new sharp view of the baryon cycle up to Cosmic Dawn with the latest generation IFU facilities” The work of AB was funded by Progetto ICSC – Spoke 2 – Codice CN00000013 – CUP I53C21000340006 – Missione 4 Istruzione e ricerca – Componente 2 Dalla ricerca all’impresa – Investimento 1.4. GT acknowledges financial support from the European Research Council (ERC) Advanced Grant under the European Union’s Horizon Europe research and innovation programme (grant agreement AdG GALPHYS, No. 101055023). GV acknowledges support by European Union’s HE ERC Starting Grant No. 101040227 – WINGS.
References
- Abadi, M., Agarwal, A., Barham, P., et al. 2016, ArXiv e-prints [arXiv:1603.04467] [Google Scholar]
- Acker, A., Marcout, J., Ochsenbein, F., et al. 1992, The Strasbourg-ESO Catalogue of Galactic Planetary Nebulae. Parts I, II (Garching, Germany: European Southern Observatory) [Google Scholar]
- Alarie, A., & Morisset, C. 2019, RMxAA, 55, 377 [Google Scholar]
- Allen, M. G., Groves, B. A., Dopita, M. A., Sutherland, R. S., & Kewley, L. J. 2008, ApJS, 178, 20 [Google Scholar]
- Bacon, R., Conseil, S., Mary, D., et al. 2017, A&A, 608, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Baldwin, J. A., Phillips, M. M., & Terlevich, R. 1981, PASP, 93, 5 [Google Scholar]
- Barnes, A. T., Longmore, S. N., Dale, J. E., et al. 2020, MNRAS, 498, 4906 [NASA ADS] [CrossRef] [Google Scholar]
- Baron, D., Sandstrom, K. M., Rosolowsky, E., et al. 2024, ApJ, 968, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Belfiore, F., Ginolfi, M., Blanc, G., et al. 2025, A&A, 694, A212 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Berg, D. A., Pogge, R. W., Skillman, E. D., et al. 2020, ApJ, 893, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Blair, W. P., & Long, K. S. 2004, ApJS, 155, 101 [NASA ADS] [CrossRef] [Google Scholar]
- Breuval, L., Riess, A. G., Macri, L. M., et al. 2023, ApJ, 951, 118 [CrossRef] [Google Scholar]
- Cappellari, M., & Copin, Y. 2003, MNRAS, 342, 345 [Google Scholar]
- Cardelli, J. A., Clayton, G. C., & Mathis, J. S. 1989, ApJ, 345, 245 [Google Scholar]
- Chollet, F., et al. 2015, Keras, https://keras.io [Google Scholar]
- Chu, Y. H. 1981, ApJ, 249, 195 [NASA ADS] [CrossRef] [Google Scholar]
- Ciardullo, R., Feldmeier, J. J., Jacoby, G. H., et al. 2002, ApJ, 577, 31 [Google Scholar]
- Ciardullo, R., Durrell, P. R., Laychak, M. B., et al. 2004, ApJ, 614, 167 [Google Scholar]
- Congiu, E., Blanc, G. A., Belfiore, F., et al. 2023, A&A, 672, A148 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Delgado-Inglada, G., Morisset, C., & Stasińska, G. 2014, MNRAS, 440, 536 [Google Scholar]
- Della Bruna, L., Adamo, A., Bik, A., et al. 2020, A&A, 635, A134 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- D’Odorico, S., Dopita, M. A., & Benvenuti, P. 1980, A&AS, 40, 67 [Google Scholar]
- Emsellem, E., Schinnerer, E., Santoro, F., et al. 2022, A&A, 659, A191 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ercolano, B., Barlow, M. J., & Storey, P. J. 2005, MNRAS, 362, 1038 [Google Scholar]
- Ercolano, B., Bastian, N., & Stasińska, G. 2007, MNRAS, 379, 945 [Google Scholar]
- Ferland, G. J., Porter, R. L., van Hoof, P. A. M., et al. 2013, RMxAA, 49, 137 [NASA ADS] [Google Scholar]
- Fesen, R. A., Blair, W. P., & Kirshner, R. P. 1985, ApJ, 292, 29 [Google Scholar]
- Fioc, M., & Rocca-Volmerange, B. 1997, A&A, 326, 950 [NASA ADS] [Google Scholar]
- Flores-Fajardo, N., Morisset, C., Stasińska, G., & Binette, L. 2011, MNRAS, 415, 2182 [Google Scholar]
- Frew, D. J., & Parker, Q. A. 2010, PASA, 27, 129 [CrossRef] [Google Scholar]
- Ganin, Y., & Lempitsky, V. 2015, Proc. Mach. Learn. Res., 37, 1180 [Google Scholar]
- Ganin, Y., Ustinova, E., Ajakan, H., et al. 2016, J. Mach. Learn. Res., 17, 1 [Google Scholar]
- Gieren, W., Górski, M., Pietrzyński, G., et al. 2013, ApJ, 773, 69 [Google Scholar]
- Ginolfi, M., Mannucci, F., Belfiore, F., et al. 2025, A&A, 693, A73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Iben, I., & Tutukov, A. V. 1984, ApJS, 54, 335 [NASA ADS] [CrossRef] [Google Scholar]
- Jin, Y., Kewley, L. J., & Sutherland, R. S. 2022, ApJ, 934, L8 [NASA ADS] [CrossRef] [Google Scholar]
- Kang, D. E., Klessen, R. S., Ksoll, V. F., et al. 2023, MNRAS, 520, 4981 [NASA ADS] [CrossRef] [Google Scholar]
- Kauffmann, G., Heckman, T. M., Tremonti, C., et al. 2003, MNRAS, 346, 1055 [Google Scholar]
- Kewley, L. J., Dopita, M. A., Sutherland, R. S., Heisler, C. A., & Trevena, J. 2001, ApJ, 556, 121 [Google Scholar]
- Kewley, L. J., Groves, B., Kauffmann, G., & Heckman, T. 2006, MNRAS, 372, 961 [Google Scholar]
- Kewley, L. J., Nicholls, D. C., & Sutherland, R. S. 2019, ARA&A, 57, 511 [Google Scholar]
- Kim, C.-G., & Ostriker, E. C. 2018, ApJ, 853, 173 [NASA ADS] [CrossRef] [Google Scholar]
- Kingma, D., & Ba, J. 2014, arXiv e-prints [arXiv:1412.6980] [Google Scholar]
- Koo, B.-C., Kim, C.-G., Park, S., & Ostriker, E. C. 2020, ApJ, 905, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Kopsacheili, M., Zezas, A., & Leonidaki, I. 2020, MNRAS, 491, 889 [CrossRef] [Google Scholar]
- Kreckel, K., Faesi, C., Kruijssen, J. M. D., et al. 2018, ApJ, 863, L21 [NASA ADS] [CrossRef] [Google Scholar]
- Kreckel, K., Ho, I.-T., Blanc, G. A., et al. 2019, ApJ, 887, 80 [NASA ADS] [CrossRef] [Google Scholar]
- Krumholz, M. R., & Matzner, C. D. 2009, ApJ, 703, 1352 [NASA ADS] [CrossRef] [Google Scholar]
- Lee, J. H., & Lee, M. G. 2014, ApJ, 793, 134 [NASA ADS] [CrossRef] [Google Scholar]
- Leitherer, C., Schaerer, D., Goldader, J. D., et al. 1999, ApJS, 123, 3 [Google Scholar]
- Li, J., Kreckel, K., Sarbadhicary, S., et al. 2024, A&A, 690, A161 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Long, K. S., Blair, W. P., Milisavljevic, D., Raymond, J. C., & Winkler, P. F. 2018, ApJ, 855, 140 [NASA ADS] [CrossRef] [Google Scholar]
- Maciel, W. J. 2013, Astrophysics of the Interstellar Medium (New York, NY: Springer) [CrossRef] [Google Scholar]
- Magrini, L., Coccato, L., Stanghellini, L., Casasola, V., & Galli, D. 2016, A&A, 588, A91 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Maiolino, R., & Mannucci, F. 2019, A&ARv, 27, 3 [Google Scholar]
- Marconi, A., Amiri, A., Feltre, A., et al. 2024, A&A, 689, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mathewson, D. S., & Clarke, J. N. 1972, ApJ, 178, L105 [NASA ADS] [CrossRef] [Google Scholar]
- Mingozzi, M., Cresci, G., Venturi, G., et al. 2019, A&A, 622, A146 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mollá, M., García-Vargas, M. L., & Bressan, A. 2009, MNRAS, 398, 451 [CrossRef] [Google Scholar]
- Morisset, C., Delgado-Inglada, G., & Flores-Fajardo, N. 2015, RMxAA, 51, 103 [Google Scholar]
- Neugent, K. F., & Massey, P. 2011, ApJ, 733, 123 [NASA ADS] [CrossRef] [Google Scholar]
- O’Donnell, J. E. 1994, ApJ, 422, 158 [Google Scholar]
- Oey, M. S., Parker, J. S., Mikles, V. J., & Zhang, X. 2003, AJ, 126, 2317 [NASA ADS] [CrossRef] [Google Scholar]
- Pellegrini, E. W., Oey, M. S., Winkler, P. F., et al. 2012, ApJ, 755, 40 [NASA ADS] [CrossRef] [Google Scholar]
- Pérez-Montero, E. 2014, MNRAS, 441, 2663 [CrossRef] [Google Scholar]
- Rauch, T. 2003, A&A, 403, 709 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rhea, C. L., Rousseau-Nepton, L., Moumen, I., et al. 2023, RAS Tech. Instrum., 2, 345 [NASA ADS] [CrossRef] [Google Scholar]
- Roth, M. M., Jacoby, G. H., Ciardullo, R., et al. 2021, ApJ, 916, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Rousseau-Nepton, L., Robert, C., Martin, R. P., Drissen, L., & Martin, T. 2018, MNRAS, 477, 4152 [NASA ADS] [Google Scholar]
- Rousseau-Nepton, L., Martin, R. P., Robert, C., et al. 2019, MNRAS, 489, 5530 [NASA ADS] [CrossRef] [Google Scholar]
- Russell, S. C., & Dopita, M. A. 1992, ApJ, 384, 508 [NASA ADS] [CrossRef] [Google Scholar]
- Sanders, D. B., Scoville, N. Z., & Solomon, P. M. 1985, ApJ, 289, 373 [NASA ADS] [CrossRef] [Google Scholar]
- Sanders, R. L., Shapley, A. E., Topping, M. W., Reddy, N. A., & Brammer, G. B. 2024, ApJ, 962, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Santoro, F., Kreckel, K., Belfiore, F., et al. 2022, A&A, 658, A188 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Scheuermann, F., Kreckel, K., Anand, G. S., et al. 2022, MNRAS, 511, 6087 [NASA ADS] [CrossRef] [Google Scholar]
- Stasińska, G. 2004, Abundance Determinations in H II Regions and Planetary Nebulae (XIII Canary Islands Winter School of Astrophysics Subjects), 115 [Google Scholar]
- Sutherland, R., Dopita, M., Binette, L., & Groves, B. 2018, Astrophysics Source Code Library [record ascl:1807.005] [Google Scholar]
- Tuquet, S., St-Louis, N., Drissen, L., et al. 2024, MNRAS, 530, 4153 [Google Scholar]
- Ucci, G., Ferrara, A., Gallerani, S., & Pallottini, A. 2017, MNRAS, 465, 1144 [Google Scholar]
- Vazdekis, A., Koleva, M., Ricciardelli, E., Röck, B., & Falcón-Barroso, J. 2016, MNRAS, 463, 3409 [Google Scholar]
- Veilleux, S., & Osterbrock, D. E. 1987, ApJS, 63, 295 [Google Scholar]
- Weilbacher, P. M., Palsa, R., Streicher, O., et al. 2020, A&A, 641, A28 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Williams, B. F., Durbin, M. J., Dalcanton, J. J., et al. 2021, ApJS, 253, 53 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Selection of photoionisation and shock models
To model the line fluxes of H II regions, we used the HII_CHIm model grid from Pérez-Montero (2014). This is a small grid of H II region models, with input ionising spectra from POPSTAR models (Mollá et al. 2009) of a single instantaneous burst of star formation with an age of 1 Myr. The selected parameters and their values are shown in Table A.1, leading to a total of 452 models.
For PNe, we adopted the PNe_2014 grid (Delgado-Inglada et al. 2014), which covers a wide range of physical parameters and is representative of most of the observed PNe. The chosen input parameters are reported in Table A.1, leading to a selection of 216 PNe models.
Models for SNRs were taken from the 3MdBs (3MdB shock) table (Alarie & Morisset 2019). These models are not specifically designed to represent SNRs but rather radiative shocks in general. This may affect the classifications of real data, as shocks may also occur elsewhere in the ISM. We adopted the models from the Allen et al. (2008) grid using the parameters in Table A.1, leading to a total number of 297 shock models.
Lastly, DIG models were recovered from the DIG_HR grid (Flores-Fajardo et al. 2011) in 3MdB. The project consists of a grid of plane-parallel, ionisation-bounded models in which two ionisation sources are combined: O-B stars and hot low-mass evolved stars (HOLMES). The SED representing the O-B stars is taken from the evolutionary stellar population synthesis code STARBURST99 (Leitherer et al. 1999), while the SED representing HOLMES is from PEGASE.2 (Fioc & Rocca-Volmerange 1997). A sub-sample of the available models representing standard DIG conditions was selected as described in Table A.1, leading to the selection of 3928 DIG models.
Our selection criteria generated a small and unbalanced set of models for the different classes, with gaps between the models in the parameter space. For each class, we therefore generated new models using a linear combination of two models from the same class, with the combination weights chosen randomly. The resulting ensemble of interpolated models is capable of populating the observational parameter space more densely. The final set of models consisted of 35 000 models for each of the four types of emission-line regions.
Parameter selection for the photoionisation and shock models.
Appendix B: Classification of integrated nebular spectra
B.1. Integrated emission-line region spectra
Following Feltre et al. (in prep.), we identified line-emitting regions of interest (H II regions, PNe, and SNR) in the M33 MUSE datacube according to a two-step process. First, the hierarchical tree-based Python package astrodendro was used on the combined Hα+[O III]λ5007 line emission map. The astrodendro hyperparameters were chosen to produce a segmentation mask matching visual expectations and detections of individual nebulae from existing catalogues. We used slightly less restrictive parameters than those adopted in Feltre et al. (in prep.), which focused primarily on H II regions, in order to maximise the detection of SNR and PNe.
In a second step, the final segmentation mask was obtained by deblending adjacent regions using the watershed algorithm and requiring a minimum number of 100 pixels per region. This process yielded a total of 179 nebular regions. Integrated spectra were extracted from the MUSE data cube by summing the flux within the mask of each region. For these, we adopt the classification of these regions into H II regions, PNe, and SNRs as presented in Feltre et al. (in prep.), which is based on traditional diagnostics and takes into account literature studies of PNe and SNRs.
In addition to these 179 regions, we considered five PNe from the literature (Ciardullo et al. 2004) that were not identified by astrodendro and extracted spectra from apertures of 2″ around them. Furthermore we extracted spectra (which we label as DIG) from 16 apertures of 2″ in the field, specifically chosen to avoid correspondence with bright Hα, [O III], or [S II] emission, as well as known ionising stars (Williams et al. 2021). In total, we obtained 200 integrated spectra. The average S/N measured on the Hα line for all the 200 spectra is ∼370.
B.2. The ‘integrated nebulae’ ML model
We build a separate ML model to classify the spectra of the integrated regions in M33. Since these are very high S/N spectra (average of ≳300 on Hα), there is a significant stellar continuum contribution. We find that in this case the continuum affects the models’ performance. In particular, the fraction of misclassified instances decreased by ∼30% when classifying spectra after continuum subtraction. We therefore subtract the continuum from the data using pPXF (Cappellari & Copin 2003) and a set of eMILES simple stellar population models (Vazdekis et al. 2016).
The generation of the mock spectra follows the same steps as those described in Sec. 4.2. Since the real integrated spectra have very high S/N, we train the network with S/N = 370, the average value for the integrated spectra. We also evaluate the extinction affecting the integrated spectra by measuring the Balmer decrement from the Hα/Hβ flux ratio for all the spectra and replicate its distribution in the synthetic dataset, similarly to the procedure described in Sec. 5.2.
We test the model and find an average median error on the prediction of each class’ contribution of ∼8%. The measured f1-score is equal to 0.89, considering only the test instances with the prevalent class contributing to at least 50% of the spectrum and comparing that class with the dominant one predicted by the network. This performance is compatible with that of the previously described multi-label cases (Sec. 4.2), considering that the S/N in this mock dataset is five times higher.
B.3. Classification of integrated spectra
In this section, we test the classification of artificial neural networks on the integrated spectra of the M33 emission-line regions extracted from the dendrograms, using the tailored model presented in Sec. B.2. As ‘ground truth’ labels for emission-line regions in the M33 cube, we consider the classification carried out by Feltre et al. (in prep.) using traditional methods. In particular, they relied on the extensive literature classification of nebulae and ionising sources in M33, including catalogues of PNe (Ciardullo et al. 2004), SNRs (Lee & Lee 2014; Long et al. 2018), Wolf-Rayet stars (Neugent & Massey 2011) and their associated nebulae (Tuquet et al. 2024), and the position of hot young stars selected from the HST UV-optical-IR photometry presented in Williams et al. (2021). On the other hand, the DIG labelled spectra were specifically extracted (Appendix B.1) to avoid any of the other types of nebula from regions without Williams et al. (2021) ionising stars and bright Hα, [S II], or [O III] emission.
We now compare this classification with that of the neural network for all the 200 spectra. To evaluate the network’s performance we create confusion matrices comparing the traditional classification of each spectrum with the most probable class the model predicts for each spectrum. The number of spectra for each class is very inhomogeneous, with the majority of regions classified as H II regions. From the confusion matrix (Fig. B.1), we observe that the fraction of correctly classified dendrograms is 68% for those identified as H II regions, 87% for those identified as PNe, and 62% for those identified as DIG. However, of the SNR spectra, only 30% were classified as such. Considering the integrated spectra whose classification does not correspond to the one obtained with traditional diagnostics, we notice the recurring confusion between SNR, DIG, and H II region spectra, similar to that present also in the mock spectra classification (see Fig. 3).
 |
Fig. B.1. Confusion matrix comparing the traditional classification by Feltre et al. (in prep.) and the most probable class predicted by the neural network for the integrated spectra of the nebulae of M33. |
In Fig. B.2 we present a map of the regions from which the integrated spectra have been extracted, colour coded based on the classification assigned by the network (green for H II regions, blue for PNe, green for SNRs and gold for DIG). The majority of dendrograms identified as H II regions by traditional diagnostics but classified as SNRs or DIG by the neural network, exhibit comparatively higher fluxes of [O III]λ5007 or [S II]λ6716, 6731 compared to the other H II regions, identified by their hosting of ionising stars. Additionally, the network better identifies those H II regions with a prevalent Hα emission (compared to other lines), thus appearing red in the emission-line map in Fig. B.2. The misclassified PN occurs near a different type of bright nebula (specifically a SNR), which indeed leads the network towards an incorrect SNR classification. This PN is also misclassified by our single spaxel model (see Fig. 7, panel h), which predicts a higher H II region probability.
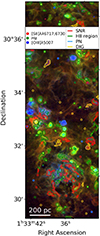 |
Fig. B.2. Map of the observed field of M33 showing the regions for the extraction of the integrated spectra and their neural network classification. We show the RGB map of three key emission lines for the entire observed field of M33, with the red scale representing the [S II]λ6716, 6731 flux, the blue the [O III]λ5007 flux, and the green the Hα flux. On top of this, we mark the contours of the regions of spectrum extraction coloured based on the model’s classification: green for H II region, blue for PNe, red for SNRs, and gold for DIG. |
Of all the H II regions, four are classified as PNe. Similarly to the case of the single spaxel model (Sect. 5.3), they are all characterised by bright [O III] emission. Furthermore, the many H II regions classified as SNR or DIG have low Hα emission, lie in lower S/N areas, or do not directly host an ionising star, therefore potentially challenging the validity of the label from Feltre et al. (in prep.). Conversely, the four SNRs identified as H II regions are characterised by brighter Hα emission with respect to the other dendrograms corresponding to SNRs found in the literature. Additionally, as in the single spaxel model (Sect. 5.3), there is a significant ‘confusion’ between SNRs and DIG spectra (see Fig. B.1). However, as discussed in Sec. 5.3, the model is not able to rely on the [O I]λ6300 line, which, according to both Kopsacheili et al. (2020) and our neural network models (Sec. 6.1), is crucial in identifying and distinguishing SNRs.
Finally, for many of the correctly identified integrated spectra, the second most probable classification is DIG. However, for the majority of the incorrectly classified instances, the second most probable class is the correct one.
All Tables
All Figures
|
Fig. 1. Schematic representation of the workflow presented in this paper. The diagram illustrates the key steps and processes involved in the analysis, from choosing the emission-line region models to the generation of the simulated dataset of spectra and the neural network’s classification. The leftmost image illustrates the model selection phase, depicting the distribution of our H II region, PN, SNR, and DIG models on a BPT diagnostic diagram (Baldwin et al. 1981). The central plot provides a representative simulated spectrum for each of the four classes. The rightmost panel presents a schematic of the neural network architecture, where the simulated spectra serve as input, and the network is trained to classify each spectrum into its corresponding nebular type. |
| In the text | |
|
Fig. 2. Two diagnostic diagrams ([N II]-BPT, Baldwin et al. 1981; [S II]-BPT, Veilleux & Osterbrock 1987) illustrating the relative positions of the emission-line region models and the observed nebulae in M33 across three different line ratio spaces. Green stars mark the identified M33 H II regions, blue squares the M33 PNe, and red circles the M33 SNRs. Similarly, green contours show the H II regions models, blue ones the PN models, pink-red ones the SNR models, and yellow-orange ones the DIG models. On the left, the [N II]-BPT diagram (Baldwin et al. 1981) includes the Kewley et al. (2001) and Kauffmann et al. (2003) (dashed line) diagnostic lines. On the right, the [S II]-BPT diagram includes the Kewley et al. (2006) diagnostic line. |
| In the text | |
|
Fig. 3. Confusion matrices comparing the networks’ predicted classification with the true classification for four different test mock datasets. The values shown are percentages. Top row: confusion matrices for the network trained with the single-label high S/N dataset without extinction (panel a) and for the network trained with the high S/N dataset with extinction (panel b). Bottom row: confusion matrices for the network trained with the low S/N dataset without extinction (panel c) and for the network trained with the multi-label dataset (panel d). |
| In the text | |
|
Fig. 4. Bar plots showing the median error made by the network trained on the multi-label dataset on each class contribution for three example instances. The coloured bars represent the network’s prediction, while the empty bars are the true labels. In panel a, we show the classification of a single-label PNe spectrum, whose coefficients are accurately predicted. In panel b, we show the results for a multi-label instance, with a prevalent contribution of DIG > 60%. In panel c, we show the results for another multi-label instance, with a prevalent contribution of H II region = 60%. |
| In the text | |
|
Fig. 5. Comparison between the neural network classification of the single-spaxel spectra and a map of three key emission lines. On the left side (panel a), we show our neural network’s prediction map for the observed field of M33. Each colour quantitatively represents the predicted contribution to each pixel’s spectra from an H II region (green), a PN (blue), and a SNR plus DIG (red). We overlay a S/N map (in shades of grey), derived from the Hα flux map and its associated error map. On the right side (panel b), we show an RGB map of three key emission lines for the entire observed field of M33, with the red scale representing the [S II]λ6716, 6731 flux, the blue the [O III]λ5007 flux, and the green the Hα flux. The gold star symbols mark massive stars brighter than 20 mag in the F475W Hubble Space Telescope (HST) filter and the smaller orange stars those with magnitude between 21 and 20 in the same filter from Williams et al. (2021). The light blue star symbols mark Wolf-Rayet stars (Neugent & Massey 2011). In both images, the red circles mark SNRs from the Lee & Lee (2014) and Long et al. (2018) catalogues, while the smaller teal circles show the PNe selected by Ciardullo et al. (2004). |
| In the text | |
|
Fig. 6. Zoom-in of a region of interest in the M33 field, focusing on two H II regions. In the left classification map, we quantitatively represent the predicted contribution to each pixel’s spectra from an H II region in green, a PN in blue, and a SNR/DIG in red. We overlay a S/N map (in shades of grey), derived from the Hα flux map and its associated error map. The right panel shows a [S II]λ6716, 6731/[O III]λ5007 ratio map. The black, purple, and magenta contours in this panel enclose a model-predicted H II region probability of 0.4, 0.6, and 0.9, respectively. |
| In the text | |
|
Fig. 7. Cutouts of the classification map focusing on the Ciardullo et al. (2004) PNe, identified by the light blue circles (panels a–h) and two additionally identified PNe, marked in grey (panels i, j). Each colour of the RBG map quantitatively represents the predicted contribution to each pixel’s spectra from an H II region (G), a PN (B), and a SNR/DIG (R). We overlay a S/N map (in shades of grey), derived from the Hα flux map and its associated error map. On the top right of each cutout, we write the PN contribution for the identified PNe averaged over an aperture of 1.5″ of diameter centred on the probability peak. On the bottom left, we specify whether the PN is isolated or its emission appears to be blended to that of other regions. The green circle in panel h marks a nearby SNR from the Lee & Lee (2014) and Long et al. (2018) catalogues. |
| In the text | |
|
Fig. 8. Cutout of the classification map focusing on an [O III]λ5007 bright H II region hosting a Wolf-Rayet star (Neugent & Massey 2011), marked by the light blue star symbol. The colours in the map quantitatively represent the predicted contribution to each pixel’s spectra from an H II region (green scale), a PN (blue), and a SNR/DIG (red). We overlay a S/N map (in shades of grey). The additional star symbols in yellow and gold represent massive stars respectively brighter than 20 mag and between 21 and 20 mag in the F475W HST filter (Williams et al. 2021). |
| In the text | |
|
Fig. 9. Activation maximisation maps corresponding to three different mock datasets with different S/N for the four different classes of nebulae. For ease of visualisation, we show in colour the spectral channels where the absolute value of the activation is larger than 15% of the maximum value of the activation spectrum. The key emission lines are labelled. Panel a: activation map for the network trained with mock spectra with infinite S/N. Panel b: The high S/N mock spectra case. Panel c: the low S/N spectra case. |
| In the text | |
|
Fig. 10. Comparison between the PNe neural network classification and the one with a traditional method from the literature for a section of the observed M33 field. On the left is the PN contribution map as predicted by the network. Colours tending to blue show a higher probability of PN, while those tending to green show a lower one. On the right, a map coloured based on the R = [OIII]λ5007/(Hα + [NII]λ6584) ratio from Ciardullo et al. (2002), where all the pixels coloured in blue are predicted to be PNe. The yellow star symbols mark O type ionising stars from Williams et al. (2021), selected based on flux and colour. Instead, the light blue ones mark Wolf-Rayet stars (Neugent & Massey 2011). In both images, the blue circles show the Ciardullo et al. (2004) PNe, while the green circles mark the Lee & Lee (2014) and Long et al. (2018) SNRs. The pink contours mark the points with a predicted PN contribution of 0.5. |
| In the text | |
|
Fig. 11. Comparison between the SNR+DIG neural network classification and the one with a traditional method from the literature for a section of the observed M33 field. On the left is the SNR+DIG contribution map as predicted by the network. Colours tending to red show a higher probability of SNR or DIG, while those tending to green a lower one. On the right, a map coloured based on the [S II]λ6716, 6731/Hα ratio. A higher value of the ratio suggests brighter [S II] emission with respect to Hα. The yellow star symbols mark O type ionising stars from Williams et al. (2021), selected based on flux and colour. Instead, the light blue ones mark Wolf-Rayet stars (Neugent & Massey 2011). In both images, the blue circles show the Ciardullo et al. (2004) PNe, while the green circles mark the Lee & Lee (2014) and Long et al. (2018) SNRs. The pink contours mark the points with a predicted SNR+DIG contribution of 0.6. |
| In the text | |
|
Fig. 12. Evolution of the f1-score for different velocity shifts in the mock test dataset for the single spaxel fully connected model and a CNN trained on the same dataset. |
| In the text | |
|
Fig. B.1. Confusion matrix comparing the traditional classification by Feltre et al. (in prep.) and the most probable class predicted by the neural network for the integrated spectra of the nebulae of M33. |
| In the text | |
|
Fig. B.2. Map of the observed field of M33 showing the regions for the extraction of the integrated spectra and their neural network classification. We show the RGB map of three key emission lines for the entire observed field of M33, with the red scale representing the [S II]λ6716, 6731 flux, the blue the [O III]λ5007 flux, and the green the Hα flux. On top of this, we mark the contours of the regions of spectrum extraction coloured based on the model’s classification: green for H II region, blue for PNe, red for SNRs, and gold for DIG. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.