| Issue |
A&A
Volume 694, February 2025
|
|
|---|---|---|
| Article Number | A212 | |
| Number of page(s) | 11 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202451934 | |
| Published online | 14 February 2025 | |
Machine learning the gap between real and simulated nebulae
A domain-adaptation approach to classify ionised nebulae in nearby galaxies
1
INAF – Arcetri Astrophysical Observatory, Largo E. Fermi 5, I-50125 Florence, Italy
2
Università di Firenze, Dipartimento di Fisica e Astronomia, via G. Sansone 1, 50019 Sesto Fiorentino, Florence, Italy
3
The Observatories of the Carnegie Institution for Science, 813 Santa Barbara St, Pasadena, CA 91101, USA
4
Departamento de Astronomía, Universidad de Chile, Camino del Observatorio, 1515 Las Condes, Santiago, Chile
5
Université Côte d’Azur, Observatoire de la Côte d’Azur, CNRS, Laboratoire Lagrange, 06000 Nice, France
6
Universität Heidelberg, Zentrum für Astronomie, Institut für Theoretische Astrophysik, Albert-Ueberle-Straße 2, D-69120 Heidelberg, Germany
7
European Southern Observatory (ESO), Alonso de Córdova 3107, Casilla 19, Santiago 19001, Chile
8
International Centre for Radio Astronomy Research, University of Western Australia, 7 Fairway, Crawley, 6009 WA, Australia
9
Astronomisches Rechen-Institut, Zentrum für Astronomie der Universität Heidelberg, Mönchhofstraße 12-14, D-69120 Heidelberg, Germany
10
Universität Heidelberg, Interdisziplinäres Zentrum für Wissenschaftliches Rechnen, Im Neuenheimer Feld 225, 69120 Heidelberg, Germany
11
Center for Astrophysics | Harvard & Smithsonian, 60 Garden Street, Cambridge MA 02138, USA
12
Radcliffe Institute for Advanced Studies at Harvard University, 10 Garden Street, Cambridge, MA 02138, USA
13
Sub-department of Astrophysics, Department of Physics, University of Oxford, Keble Road, Oxford OX1 3RH, UK
⋆ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
20
August
2024
Accepted:
15
January
2025
Abstract
Classifying ionised nebulae in nearby galaxies is crucial to studying stellar feedback mechanisms and understanding the physical conditions of the interstellar medium. This classification task is generally performed by comparing observed line ratios with photoionisation simulations of different types of nebulae (H II regions, planetary nebulae, and supernova remnants). However, due to simplifying assumptions, such simulations are generally unable to fully reproduce the line ratios in observed nebulae. This discrepancy limits the performance of the classical machine-learning approach, where a model is trained on the simulated data and then used to classify real nebulae. For this study, we used a domain-adversarial neural network (DANN) to bridge the gap between photoionisation models (source domain) and observed ionised nebulae from the PHANGS-MUSE survey (target domain). The DANN is an example of a domain-adaptation algorithm, whose goal is to maximise the performance of a model trained on labelled data in the source domain on an unlabelled target domain by extracting domain-invariant features. Our results indicate a significant improvement in classification performance in the target domain when employing the DANN framework compared to a classical neural network (NN) classifier. Additionally, we investigated the impact of adding noise to the source dataset, finding that noise injection acts as a form of regularisation, further enhancing the performances of both the NN and DANN models on the observational data. The combined use of domain adaptation and noise injection improved the classification accuracy in the target domain by 23%. This study highlights the potential of domain adaptation methods in tackling the domain-shift challenge when using theoretical models to train machine-learning pipelines in astronomy.
Key words: methods: data analysis / methods: statistical / HII regions / galaxies: ISM
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Ionised nebulae are cosmic spotlights that provide us with a view of the properties of nearby as well as distant galaxies. H II regions, where young stars ionise the surrounding interstellar medium (ISM), are key probes of stellar feedback (Lopez et al. 2014; Pellegrini et al. 2020b; Barnes et al. 2020; Chevance et al. 2023) and tracers of the physical conditions and chemical abundances of the ISM (Peimbert et al. 2017; Kewley et al. 2019; Maiolino & Mannucci 2019). Given their importance for a wider range of astrophysical studies, a large body of work has been dedicated to the classification of ionised ISM emission in galaxies in order to separate H II regions from other ionising sources, including active galactic nuclei (Kewley et al. 2001; Kauffmann et al. 2003), shocks (Allen et al. 2008), hot evolved stars (Binette et al. 2012; Byler et al. 2019), and diffuse ionised gas (Cid Fernandes et al. 2011; Zhang et al. 2017; Belfiore et al. 2022).
Observations capable of resolving individual nebulae are particularly useful to test the physics of the ionised ISM and refine our classification strategies. The required resolution (∼100 pc) can be obtained using ground-based observations in galaxies closer than ∼20 Mpc. Several surveys (PHANGS, Emsellem et al. 2022; SIGNALS, Rousseau-Nepton et al. 2019; and MAUVE, e.g. Watts et al. 2024) have used wide-field integral field spectrography to map ionised gas in nearby galaxies at such a high resolution to study the physics of the small-scale star formation cycle in its galactic context. In these datasets, one can confidently separate high-density nebular structures from the ionised gas background (Roth et al. 2018; McLeod et al. 2021; Santoro et al. 2022; Belfiore et al. 2022). The classification task for ionised ISM structures is therefore simplified to distinguishing between H II regions, planetary nebulae (PNe), and supernova remnants (SNRs). Recent literature has leveraged both Bayesian methods and machine-learning algorithms for this classification problem (Kopsacheili et al. 2020; Micheva et al. 2022; Congiu et al. 2023; Rhea et al. 2023), and to infer the physical properties of H II regions (Kang et al. 2022, 2023).
This classical approach to classifying ionised nebulae is based on comparing measured emission-line ratios with those predicted by photoionisation simulations1 of the different classes of objects. Widely used line-ratio diagnostic diagrams, such as the Baldwin-Phillips-Terlevich (BPT, Baldwin et al. 1981) diagram, represent useful simplified projections. However, in the BPT two-dimensional planes, substantial overlap exists between the locations inhabited by the different classes, leading to ambiguous classifications. Such limitations can be overcome by using Bayesian methods, where the full set of available line ratios is used to infer the final classification (Congiu et al. 2023, hereafter C23).
Nonetheless, the classification approach based on comparison with simulations is fundamentally limited because the current generation of simulations cannot fully match the data across all observed line ratios. These limitations may be due to the simple geometries assumed in most simulations. In the case of H II regions, for example, density (or temperature) substructures have been invoked to explain the measured discrepancy between abundances measured from recombination lines and collisionally excited ones (Méndez-Delgado et al. 2023a,b). Limitations in geometry also do not take into account the possible presence of low-density paths, which may lead to the escape of ionising photons. Real nebulae may also feature multiple ionisation sources with non-trivial spatial distributions. While more complex three-dimensional models of H II regions have been constructed (Bisbas et al. 2009; Walch et al. 2012; Jin et al. 2022), such approaches cannot yet produce a sufficiently large and varied dataset for training machine-learning models.
This mismatch between theoretical simulations and empirical data leads to what in the language of machine learning is referred to as a ‘domain adaptation problem’. Here, a model needs to be trained on a labelled set of data (instances) and then applied to a different domain of interest in which the instances are unlabelled. The two domains are referred to as the ‘source domain’ (the one that includes labels, in our case the theory), and the ‘target domain’ (the unlabelled, empirical data). A schematic representation of the situation is presented in Fig. 1. A classical, supervised machine-learning approach (e.g. a classifier neural network) relies on training a model on the source domain, the only one for which we have labels, and then applying the same trained model for inference on the unlabelled target domain. However, because of the differences between the two domains, this approach generally leads to models that do not perform well on the target domain.
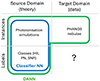 |
Fig. 1. Schematic representation of the domain-adaptation problem tackled in this work. The task consists in inferring the classification of PHANGS nebulae, given a set of photoionisation simulations from nebulae of different classes. The source domain (theory) contains the labels, while the target domain (data) is unlabelled. A classical, supervised machine-learning algorithm (e.g. a classifier neural network, in blue) is trained on the instances and labels of the source domain, but may perform poorly on the target domain, because of the differences between simulated and real data. In this work we employed a DANN, a domain-adaptation algorithm that uses as input (in green) both the labelled source domain and the unlabelled target domain instances. This approach allows the model to learn domain-invariant features and perform better on the target domain. |
In domain adaptation, on the other hand, an algorithm is trained on both the labelled source and unlabelled target domain instances. By learning so-called ‘domain-invariant’ features, shared by both source and target domain, such an algorithm can perform significantly better, effectively reconciling the differences between theory and empirical data. In this work we will use a DANN (domain adversarial neural network, Ganin et al. 2016) to perform the required domain adaptation.
Domain adaptation has found some early applications in astronomy, especially in the context of classifying images. The task of recognising galaxy mergers in large imaging surveys, for example, has attracted some attention in the literature. Since mergers are rare, training on simulations is mandatory to obtain a suitably large dataset. Early studies have demonstrated, however, that training on simulations without taking observational effects into account results in poor performance (Bottrell et al. 2019; Pearson et al. 2019). Using domain-adaptation algorithms, on the other hand, leads to substantial improvements (Ciprijanovic et al. 2021).
In this work, we test the ability of domain-adaptation techniques to handle the problem of classification of ionised nebulae based on their observed line ratios. For this proof-of-concept analysis, we focus on the well-studied problem of classifying ionised nebulae in nearby galaxies into H II regions, PNe, and SNRs using the catalogue of C23, based on optical integral field spectroscopy from the PHANGS-MUSE survey. We adopt standard machine-learning terminology, referring to the vector containing the line ratios for each nebula as an ‘instance’, the individual line ratios as ‘features’, and the classifications as ‘labels’. We present the implementation of a DANN and compare its performance against a classical artificial neural network (NN) classifier, in both the source and target domains. Additionally, we explore the impact of introducing noise to the source domain in order to more closely mimic realistic observations.
In detail, in Sec. 2 we present the datasets associated with the source and target domains. In Sec. 3 we describe our NN and DANN model architectures. In Sec. 4 we present the results obtained with both the classical NN and the DANN classifier, compare their performance, and discuss the impact of our proof-of-concept analysis. In Sec. 5 we present a summary of our results.
2. Data
2.1. Source domain: photoionisation simulations
The source domain in this work is represented by simulations of ionised nebulae generated by the photoionisation code CLOUDY (Ferland et al. 1994, 2017) and photoionisation and shock-modelling code MAPPINGS (Sutherland et al. 2018). These codes model the state of the ionised gas from first principles and predict the emerging spectrum of a nebula, but the resulting simulations suffer from limitations due to simplifying assumptions (all simulations are one-dimensional and homogeneous) and from missing or inaccurate physics (e.g. in their input ionising stellar spectra). Moreover, while simulation grids can be run for a wide range of input parameters (e.g. density, chemical abundances, ionisation parameters), real ionised nebulae generally only cover a part of this parameter space. In previous works, such unrealistic simulations were often excluded from the grid ‘by hand’ (Amayo et al. 2021) to reduce their impact on inference. Alternatively, more physical simulations can be constructed by coupling photoionisation models with physical models for the time evolution of ionised nebulae (Pellegrini et al. 2020a,b). Considering these factors, we expect simulations to show some mismatch with respect to observations of ionised nebulae, motivating our domain-adaptation approach.
For ease of comparison with the classifications performed by C23 we selected similar grids of simulations for H II regions, PNe, and shocks. Shock simulations were used to identify SNRs, although regions shocked by active galactic nuclei or shock networks in the diffuse ionised gas are also compatible with these simulations. Nonetheless, in this work we employ the term shock and SNR interchangeably. We considered a slightly more extended grid than C23 by including a wider range of possible values of N/O for H II regions and a wider range of possible densities for PNe. These parameters directly affect the line ratios of interest in this work, and we preferred to avoid ‘by-hand’ model pruning since the domain adaptation step should be able to account for any potential shifts between models and data.
The photoionisation simulations adopted in this work were taken from Perez-Montero (2014) for H II regions, Delgado-Inglada et al. (2014) for PNe, and Allen et al. (2008) for shocks. The range of simulation input parameters selected for our grids are summarised in Table 1. The line fluxes for these simulations were retrieved from the Mexican Million Models database (Morisset et al. 2015)2. We considered the emission line fluxes of a set of key optical emission lines, namely Hα, Hβ, [O III] λ5007, [N II]λ6584, [S II] λ6717, [S II] λ6731, and [O I] λ6300. The choice of emission lines to consider was motivated by their observability, as discussed in the next section.
Summary of the photoionisation simulation parameters
In our machine-learning analyses, we randomly selected a subset of simulations so that each class was equally represented, leading to a total of 2016 instances. We selected a balanced set of instances for the source domain even though the target domain is likely to be unbalanced, since observational samples generally contain a majority of H II regions.
In Fig. 2 (top row) we show the position of the subsample of selected simulations in the classical BPT diagnostic diagrams, together with demarcation lines from the literature (Kewley et al. 2001, 2006; Law et al. 2021). The Kauffmann et al. (2003) corresponds closely to the Law et al. (2021) in the [N II]-BPT. H II regions occupy the bottom-left corner of these diagrams, as expected, and generally lie below the Law et al. (2021) line, except in the [N II]-BPT, where H II regions with non-canonical N/O ratios extend to the top right of the demarcation. PNe populate preferentially the top left of the BPT diagrams, lying mostly above the H II demarcation lines except in the [O I]-BPT. Shocks populate the region of the diagrams sometimes associated with low-ionisation emission-line regions (LIERs, Belfiore et al. 2016), and are better separated from other classes in the [S II] and [O I]-BPT.
 |
Fig. 2. Location in three BPT diagrams of photoionisation simulations (top row) and ionised nebulae from PHANGS-MUSE (C23, bottom row). In each panel, the colour-coding represents class labels (green: H II regions, blue: PNe, and red: SNRs). The class labels for the observed nebulae are based on the Bayesian methodology of C23 and are never used in the training, as we treat the target domain as unlabelled. Only the subset of the C23 catalogue used to train the classification algorithm presented in this work is shown. In each BPT diagram we show the demarcation lines of Law et al. (2021) (L21, solid line) and Kewley et al. (2001, 2006) (K01, dashed line). The Kauffmann et al. (2003) line in the [N II]-BPT is almost coincident with the Law et al. (2021) line. The figure demonstrates that there is only a limited overlap in parameter space between simulations and data. |
2.2. Target domain: PHANGS-MUSE ionised nebulae
We applied our classification task to the catalogue of ionised nebulae presented in C23 and retrieved from the Canadian Astronomical Society Data Centre3. This catalogue contains emission-line fluxes for 40920 nebulae across a sample of 19 nearby (D < 20 Mpc) star-forming galaxies observed by the PHANGS-MUSE programme (Emsellem et al. 2022). Details on the catalogue generation are given in C23, and we summarise here the key steps. First, a detection image was generated using a combination of line maps for the [O III]λ5007, Hα, and [S II] λ6717,31 emission lines. The CLUMPFIND (Williams et al. 1994) algorithm was run on this image to produce a first iteration of the segmentation maps. This segmentation was refined by identifying the isophotes containing 90% of the region flux (after subtracting a local background), which was then chosen as the new region boundary. The catalogue was then cleaned to reject false detections by applying cuts in signal-to-noise ratio (S/N) and size. The line fluxes for each nebula were computed by fitting the integrated spectrum extracted from the datacube. Finally, a local background extracted in an annulus around the region was subtracted from the nebular flux to account for the contamination of diffuse ionised gas (DIG) along the line of sight. While this latter correction can be significantly uncertain for fainter nebulae, we chose to nonetheless use the background-subtracted fluxes for ease of comparison with the classifications performed by C23.
C23 classified ionised gas nebulae using a Bayesian approach based on a data-model comparison across a set of the brightest emission lines in the MUSE wavelength range (Hα, Hβ, [O III] λ5007, [S II] λ6717, [S II] λ6731, and [O I] λ6300, and [S III]λ 9068). However, in this work we considered the nebulae from the C23 catalogue as an unlabelled target domain, that is, we did not use the class labels during training. We nonetheless used the labels inferred by C23 as a post-facto check on the performance of our classifications.
From the C23 catalogue we selected a sub-sample of nebulae where the background-subtracted nebular line flux is larger than its error in the Hα, Hβ, [N II], and [O III] emission lines. For the sake of simplicity we also removed nebulae that were classified as ‘ambiguous’ by C23, which were usually objects with a very low S/N. This cut reduced the sample to 17 431 objects. Our sample is strongly unbalanced in terms of class membership, comprising of 14 042 (80.5%) H II regions, 270 (1.5%) PNe, and 3119 (18%) SNRs.
In this work we did not experiment with probabilistic models (Kang et al. 2023), so our machine-learning approach is not able to account for uncertainties and upper limits on data. Unfortunately, this fact represents a significant limitation for the catalogue under study. In particular, ∼50% of the objects classified as PNe by C23 are not detected in [S II] or [O I], and only 23% are detected in both. To avoid further curtailment of our sample of PNe, we decided to retain the objects with undetected [S II] or [O I], and used the measured 1σ error as their flux. We do not expect this choice to have a significant effect on our classification because, as evident from Fig. 2 (upper row), the PNe models cover a wide range of [S II]/Hα and [O I]/Hα. We also opted to exclude the [S III]λ9068 line in our analysis because of its limited detection statistics and because the [S III]λ9068 line has so far been difficult to reproduce in photoionisation models of H II regions (Mingozzi et al. 2019).
Finally, we corrected the observed data for dust attenuation along the line of sight because photoionisation models do not include any foreground dust screen model. We calculated the dust correction using the Balmer decrement, assuming case B recombination at a temperature of T = 104 K, and the attenuation law of O’Donnell (1994). We excluded regions where the measured Hα/Hβ ratio is lower than the theoretically expected ratio of 2.86, resulting in a final catalogue size of 15 652 nebulae. Our approach to dust extinction here is different from that followed in C23, who compared observed fluxes with photoionisation models reddened via a dust screen. We did not use the E(B − V) values from C23 directly because they were an output of their Bayesian analysis, and we preferred to keep the dataset free from any influence of the models. Using the extinction corrections from C23, however, did not lead to significant differences.
In Fig. 2 (lower panel) we show the position of the ionised nebulae selected for analysis in this work in the canonical BPT diagrams, together with the demarcation lines from the literature. It is evident that real H II regions and PNe populate only a fraction of the total space populated by models, while nebulae that have a best-fit classification as SNR extend in a wider section of parameter space than populated by the models.
3. Methods
3.1. Overview
In this section we summarise our machine-learning approach to classification. In this work we compare the performances of a simple NN classifier (trained only on the source domain) and a DANN (Ganin et al. 2016). A DANN is a ‘feature-based’ domain-adaptation architecture. This class of algorithms derive a set of features which are consistent across both the source and target domains (Ajakan et al. 2014). This domain-invariant representation is then used for classification.
Specifically, in a DANN both source and target domain instances are used as input to the network. An encoder network transforms the input data into a latent feature space (embeddings layer in Fig. 3). An additional neural network, called the discriminator, is passed the embeddings from the encoder. The discriminator’s goal is to classify instances as belonging to either the source or the target domain.
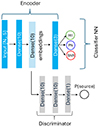 |
Fig. 3. Illustration of the network architecture of the simple NN classifier (top row only, blue layers) and the DANN (full figure). Through the cooperation of both the encoder and the discriminator network, the DANN learns domain-invariant features in the embeddings layer (light blue). The DANN is trained adversarially to deceive its discriminator into being unable to distinguish source from target domain instances. The figure also shows the dimensionality of the input (number of instances, Ni, by 5) and the number of neurons in each layer (in bracket next to each layer name). |
The model is trained adversarially, with the goal of deceiving its discriminator, in a similar fashion to generative adversarial networks (GANs, Goodfellow et al. 2014). In particular, for each iteration of the training loop, the DANN is fed both source and target domain instances. The parameters of the encoder network are optimised both for correct classification of source domain instances and for fooling the discriminator. Tricking the discriminator requires the embeddings to minimise any information content that could distinguish the two domains, therefore encoding only features shared by both. This allows the DANN to perform a classification task on domain-invariant features.
The next subsections (Secs. 3.2–3.4) summarise the algorithmic choices for both networks. Readers less familiar with machine-learning terminology may wish to proceed to the results and astrophysical validation in Sec. 4.
3.2. Data preprocessing
Before feeding the data into our machine-learning pipelines we subdivided the source-domain instances into a training (55%), validation (20%), and test (25%) set. The validation set was used to monitor the model performance during training, perform early stopping, and drive hyper-parameter choices. The test set, on the other hand, was only used to evaluate the model after training. The target domain is unlabelled, so its instances were not subdivided. All fluxes were normalised to that of Hβ and we consider the log of the value of the line ratio, so that each instance consists of a vector of five features, namely log([O III]λ5007/Hβ), log([N II]λ6584/Hβ), log([S II]λ6717/Hβ), log([S II]λ6731/Hβ), and log([O I]λ6300/Hβ). We did not consider Hα/Hβ since, after extinction correction, this ratio is fixed to 2.86 in all the observed line fluxes. We tested the effect of standardising (subtracting the mean and dividing by the standard deviation) the features before inputting them into the network, but found that adding a batch normalisation layer (see the next section) immediately after the input had comparable performance. We therefore did not standardise the input features.
3.3. Architecture of the NN classifier
We designed a simple NN to classify the instances within the source domain. After experimentation, we converged on a simple architecture, comprising an input layer followed by batch normalisation (Ioffe & Szegedy 2015), two dense hidden layers each with ten neurons, followed each by batch normalisation, and an output dense layer with three neurons, as required for our classification task. We adopt an exponential linear unit (ELU, Clevert et al. 2015) activation function for the nodes in the hidden layers, and apply a softmax activation to the output layer to ensure that the network’s output represents the probability of categorising each instance into the three target classes.
A sketch of the architecture of the NN is provided in Fig. 3, where the NN corresponds only to the layers in the top part of the diagram. The network was compiled utilising a cross-entropy loss function along with the Adam optimiser (Kingma & Ba 2014) with a learning rate of 10−3, and with the initial weights being determined by a He-Normal distribution (He et al. 2015). The network was built using the flexible KERAS API with the TENSORFLOW backend.
3.4. Architecture of the DANN
We constructed a DANN using an encoder network similar to the one in Sec. 3.3 and adding a discriminator and linking it to the last hidden layer of the classifier (the layers whose output constitutes the embeddings). We experimented with various architectures for the discriminator and obtained the best results by mirroring the encoder’s architecture. We made one modification to the network with respect to the previous section by adding dropout layers (rate of 0.2) between each two hidden layers. We found that this addition improved performance by reducing overfitting. We also fix the batch size to 128. The output layer of the discriminator consists of a single neuron with a sigmoid activation function, as required by the binary classification task of distinguishing between the two domains. We use the implementation of DANN available via the ADAPT python package4.
The total loss function of the DANN is given by
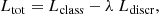 (1)
(1)
where Lclass is the classifier cross-entropy loss, Ldiscr is the discriminator binary entropy loss and λ is a hyper-parameter indicating the relative weight of the two components. The network was trained with the Adam optimiser and a slower learning rate (10−4) than in Sec. 3.3, as we found in our experiments that a higher learning rate can lead to instabilities. We used a default λ = 1. We experimented changing λ by four orders of magnitude around the default value and found λ = 1 to lead to the best performance on the target domain.
3.5. Training the models
We trained the NN classifier on the labelled source domain, while the DANN was trained on both the labelled source domain and the unlabelled target domain. In particular, the DANN was fed input batches which consisted of half source and half target domain instances. In all cases, training was halted when the validation loss no longer decreased, employing early stopping and a patience of 20 epochs to prevent overfitting. Each model was trained 20 times with different starting conditions and the results of this ensemble of models were averaged to provide better stability.
4. Results
In this section, we present the results of our experiments with domain adaptation and discuss how they compare with those obtained with a simple NN classifier.
4.1. Benchmarking domain adaptation
In Fig. 4 we show the confusion matrices obtained when applying the NN and the DANN on the test set of the source domain (left panels) and the target domain (right panels). Each element of the confusion matrix represents the percentage of instances of the input where an instance of a given class is predicted to belong to each of the possible classes. A fully diagonal matrix represents a perfect classifier. In this work, we calculate the confusion matrices considering the average predictions from an ensemble of 20 identical models, trained with different initial conditions.
 |
Fig. 4. Confusion matrices showing the performance of the NN (top row) and the DANN (bottom row) in classifying H II regions, PNe, and SNRs, evaluated over the test set of the source domain (left column) and the target domain (right column). Values of the f1 score and accuracy (acc) are reported at the top of each panel. |
A simple NN classifier performed extremely well on the test set of the source domain, reaching ∼100% accuracy. This demonstrates that the three considered classes are sufficiently distinct in the five-dimensional line ratio space considered in this work to always lead to accurate classifications by a simple NN. This result is in general agreement with the analysis of Rhea et al. (2023), who set up a similar experiment, but considered fewer (three or four) line ratios. Kang et al. (2022) obtained equally good reconstructions using an invertible neural network architecture.
While we do not have ground truth labels for the target domain (observed data), we nonetheless computed confusion matrices considering the classifications provided by C23 as ground truth. These classifications are not fully independent of the source domain, since they are based on a Bayesian data-model comparison. They nonetheless correspond to state-of-the-art classifications and we therefore compare against them to benchmark the ability of different models to generalise into the target domain.
The simple NN model did not translate well into the target domain (accuracy 0.67 and f1 score5 of 0.62). The network particularly struggled to classify SNR and PNe, which were often misclassified as H II regions, while still correctly classifying most true H II regions as such. The overall disappointing behaviour of the NN classifier on the target domain, despite its excellent performance on the test set of the source domain, clearly demonstrates the existence of a domain shift.
The DANN classifier sacrificed some accuracy in the source domain to improve the performance of the task on the target domain. We trained the DANN 20 times randomly varying the initial weights and show the result of the best model in Fig. 4 (bottom panels). This DANN model obtained accuracy of 0.97 in the source domain, and significantly improved in the target domain with respect to the NN classifier, reaching an accuracy score of 0.73. In particular, the DANN improved the behaviour of the classifier for PNe and SNRs in the target domain, which were less commonly confused for H II regions.
4.2. The effect of adding noise
We explored the impact of adding noise to the training set of the source domain to determine whether this could enhance the performance of the networks in the target domain. Introducing noise can be considered a simplistic form of domain adaptation, as noise can mimic observational effects, and potentially enforce a form of regularisation, guiding the network to learn more generalisable, domain-invariant features.
For this test we therefore added Gaussian noise to the training data. In particular, we tested ten noise values logarithmically spaced between 0.01 and 0.5. Since the instances were normalised to an Hβ flux of one, these noise level correspond to an Hβ S/N ranging from 0.5 to 100. Other lines would have a different S/N ratio, depending on their brightness with respect to Hβ. Such a simplified noise model was therefore assumed to be constant across wavelength.
This approach was not meant to represent a realistic noise distribution, which would be much more complex to simulate, given that H II regions, PNe, and SNRs have different luminosities and S/N ratios in their Balmer line emission. In particular, the S/N ratio on Hβ for our target sample is ∼200 on average, but varies from an average of 300 for H II regions, to 6 for PNe, and 35 for SNRs using the C23 labels. A more realistic noise distribution for the different classes in the source domain could be simulated assuming relevant luminosity functions and simulating the expected S/N given the observing parameters of our dataset. This is beyond the scope of our experiment here. However, the noise level does not need to closely match that of our dataset, since domain adaptation should contribute to mitigate the effect of the domain shift even if the noise model is not fully realistic.
We therefore generated a new set of augmented training data consisting of 20 160 source instances by adding Gaussian noise, with each instance from the original source domain perturbed ten times. We ensured instances from the same simulation but with different noise realizations were assigned to the same split (train/validation/test) when creating the noise-augmented dataset to avoid potential information leakage.
We trained the same NN and DANN models using this noise-augmented dataset 20 times for each noise value with different initial random values of the weights. For each ensemble of 20 models we calculated the average prediction probability and used that to compute the accuracy. We obtained errors on this accuracy by bootstrap resampling the distribution 100 times and considering as errors the 10th and 90th percentiles of the distribution. Fig. 5 shows the resulting average accuracy for the NN and the DANN on the test set of the source domain and on the target domain, with the shaded areas representing the errors. For comparison we also plot the accuracy values for the case with no noise (Sec. 4.1), labelled as S/N = ∞.
 |
Fig. 5. Accuracy on the test set of the source domain and target domain as a function of S/N for the NN (blue) and DANN (green) models. The lines correspond to the average of an ensemble of 20 models and the shaded areas represent the 10th and 90th percentiles of the distribution. The accuracy on the target domain for both NN and DANN peaks at S/N ∼ 40 (grey dashed line). |
The NN was only trained on the source domain and its performance on the test set increases almost monotonically with S/N. The results were virtually identical for all 20 runs. The performance on the NN on the target domain, on the other hand, was much poorer than on the source domain. Moreover the response was not monotonic, peaking at S/N ∼ 10–20 and decreasing for both lower and higher values of S/N. The worst worst performance of the NN on the target set was obtained with no noise.
For the DANN, the source domain accuracy, as quantified on the test set, also increased with increasing S/N. The target accuracy, however, peaked between S/N = 10–40, while decreasing for both lower and higher S/N, following a similar trend to the target accuracy of the NN, but shifted to overall higher accuracy values. In the case of no noise, discussed in the previous section, the DANN target performance was lower than its accuracy on the test set, and the results were plagued by instability, as demonstrated by the larger error bar.
These trends match the expectation that adding noise helps the model to generalise, but adding too much noise starts to erase features in the source domain, driving a decrease in accuracy for both source and target domain at S/N ≲ 10. We selected the best model to roughly match the peak of the target accuracy curves, corresponding to S/N ∼ 40.
Using S/N ∼ 40, we show the confusion matrices for the performance of the NN and DANN of a representative model (Fig. 6). If we compare directly to the no-noise model, the accuracy of the NN in the target domain increased to 0.82 (compared to 0.67 in the absence of noise). Planetary nebulae are now much better classified, but the model still struggles with SNR. Overall, however, the enhanced performance makes the simple NN classifier even more accurate than the DANN trained in the absence of noise.
 |
Fig. 6. Same plots as in Fig. 4, but considering both the NN and the DANN trained over a noise-augmented dataset with S/N ∼ 40 on Hβ in the source domain (see text in Sec. 4.2). Noise augmentation leads to better performances on the target domain for both the NN and the DANN. |
The performance of the DANN also increased with the noisy source dataset, reaching an accuracy score in the target domain of 0.90 (compared to 0.73 in the absence of noise), and an f1 score of 0.66. These results show that noise addition can act as a form of regularisation, helping the DANN to learn more robust representations that generalise better across domains.
4.3. Visualising domain-invariant features
To visually demonstrate the impact of the domain-adaptation strategy employed, we generated t-SNE (t-Distributed Stochastic Neighbour Embedding; van der Maaten & Hinton 2008) plots to show the distribution of instances from both the source and target domains. t-SNE is a dimensionality-reduction technique particularly suited for visualising high-dimensional datasets. It works by minimising the divergence between two distributions: a distribution that measures pairwise similarities of the input objects and a distribution that measures pairwise similarities of the corresponding low-dimensional points in the embedding. In our two-dimensional t-SNE, representations points that are similar in high-dimensional space are therefore found nearby in two-dimensional space.
We used t-SNE to visualise the similarities between source and target domain instances, which are five-dimensional vectors of line ratios in Fig. 7a. We use light-colour (light green, light blue, and light red) circles to represent the three classes in the source domain (H II regions, PN, and SNR, respectively), and three dark-colour squares (dark green, dark blue, and dark red) for the same three classes in the target domain. Fig. 7a demonstrates a clear separation between the source and target domains. In particular the H II regions and PNe target domain instances fall within gaps of the parameter space not covered by source domain instances, indicating a domain shift, and the overlap is only partial for SNRs.
 |
Fig. 7. Two-dimensional representations of the input data and the embeddings from the DANN obtained using t-SNE, illustrating the distribution of instances from both the source and target domains. For ease of visualisation we plot only a random subset of the target domain that homogeneously populates the three classes. The quantities on the axes represent the output of t-SNE and do not have a physical meaning, and they represent a different projection in each panel. Light colours (light blue, light red, and light green) represent the three classes in the source domain (H II regions, PNe, and SNRs, respectively), while dark colours (dark blue, dark red, and dark green) represent the same three classes in the target domain. Left: Input vectors show a clear separation between the source and target domains, pointing to the presence of a domain shift. Middle: Embedding vectors from the DANN model show a closer alignment of instances, showcasing the effectiveness of DANN in reducing domain shift. Right: The alignment is further enhanced with noise augmentation in the training set. Dark-coloured outliers in source domain clusters reflect the imperfect accuracy of the DANN model. Their existence is reflected in the non-diagonal confusion matrices discussed in Sec. 4.1. |
We repeated this analysis using the embedding vectors from the DANN model, which are ten-dimensional, in Fig. 7b. As discussed in the previous sections, the DANN model aligns the distributions of the source and target domain features in the embeddings space. As shown in Fig. 7b, a closer alignment between the source and target domain instances is observed, demonstrated by the overlap of light and dark points within the same clusters, indicating the effectiveness of DANN in reducing the domain shift.
Introducing noise in the training set enhanced the domain-adaptation capability of the DANN, inducing a better alignment of the embeddings from both domains, as shown in Fig. 7c. For this example we show a representative S/N ∼ 40 DANN model and demonstrate that light (source) and dark (target domain) data points now largely occupy the same regions of the two-dimensional space. Nonetheless, a slight ‘contamination’ of classes is observed, evidenced by dark-coloured outliers situated within the source domain clusters. In fact, we find that these instances correspond to cases where the DANN does not predict the correct class.
This visual analysis provides a tangible demonstration of how domain adaptation, as implemented by a DANN and further enhanced by noise augmentation, aids in aligning the distributions of the source and target domains, thus addressing the domain-shift challenge.
4.4. Interpreting the DANN embeddings
We used the dimensionality-reduced output of the DANN embedding layer discussed in the previous section to gain qualitative insights into what information the model has encoded. Visualising the low-dimensional output of key layers in a neural network is a well-established interpretability technique, which has also been used in an unsupervised fashion to learn about the underlying structure in the data (Portillo et al. 2020; Sarmiento et al. 2021; Baron et al. 2024; Ginolfi et al. 2025).
In Fig. 8 we present the dimensionality-reduced DANN embeddings of the source domain colour-coded by the line ratios which are used as input to our model or combinations thereof. To ease interpretability, in the case of the sulphur line doublet we consider their sum as ([S II] λ6717+ [S II]λ6731)/Hα and their density-sensitive ratio ([S II]λ6717/[S II]λ6731) instead. For reference we also plot in the top-left panel the source domain classes (same as Fig. 7c).
 |
Fig. 8. Two-dimensional representations of the DANN embeddings (a representative model with S/N ∼ 40) colour-coded by the source domain classes, and various line ratios (which are either the input features themselves or a combination of input features), shown as the titles of each panel. The colourbar goes from blue (low) to yellow (high) and in each panel is normalised to the 2nd and 98th percentiles of the quantity. The arrow emerging from the origin shows the direction of steepest increase in the colour-coded quantity, measured clockwise from the positive x-axis. |
We observe coherent gradients in key line ratios across the two-dimensional space considered. We quantified the direction of these gradients by calculating the partial correlation coefficients between the quantities on the x and y-axis (X and Y) and the quantity we use for colour-coding (Z). In particular we followed Baker et al. (2023) and determined the angle of maximum gradient (θ) by calculating
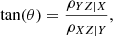 (2)
(2)
where ρYZ|X is the partial correlation coefficient between X and Y controlling for X. In each panel of Fig. 8 the arrows emerging from the origin show these angles, which are measured clockwise from the positive horizontal direction and evidently point towards the increasing gradient of the colour-coded quantity.
We found that the [O III]/Hβ ratio increases towards the bottom-right (θ = −130.1°) and high values are therefore mostly associated with PNe, as expected. The low-ionisation line ratios ([O I]/Hα, [N II]/Hα and [S II]/Hα) increase fastest towards the bottom-right, with [N II]/Hα (θ = −38.4°) being more similar to [S II]/Hα (θ = −28.1°) than [O I]/Hα (θ = −8.8°). These differences can mostly be attributed to the fact that the lowest line ratios in both [N II]/Hα and [S II]/Hα are found at the boundary between the H II and PNe classes, while the lowest [O I]/Hα occur in PNe only. Finally the density-sensitive [S II]λ6717/[S II]λ6731 ratio only shows some enhancement for the high-density H II region and PNe models but no overall gradient. Interestingly, the direction of maximum change for [O III]/Hβ and [N II]/Hα are nearly perpendicular (difference of 92°), highlighting the ability of these two line ratios to efficiently span the two-dimensional space considered and therefore confirming the usefulness of the [N II]-BPT in performing classifications of ionised nebulae.
4.5. Astrophysical validation with specialised catalogues
Because of the substantial difficulties in addressing the general problem of detection and classification of nebulae, some authors have produced catalogues aimed at a specific class of objects, using selection criteria fine-turned for that particular class. Scheuermann et al. (2022), for example, produced a catalogue of PNe from the PHANGS-MUSE dataset specifically selecting unresolved [O III] sources and applying additional cuts in line-ratio diagrams. Li et al. (2024) generated a catalogue of SNRs from the same dataset. They selected candidate regions based on a source-finding algorithm using the line ratios [S II]/Hα and [O I]/Hα after correcting for diffuse ionised gas emission (Belfiore et al. 2022), and considered additional kinematic (velocity dispersion), and line-ratio information.
We tested our models on the PNe catalogue of Scheuermann et al. (2022) and the SNRs catalogue of Li et al. (2024). To do so, we cross-matched these catalogues to the one of C23, matching objects with a distance of < 0.4″. We then pre-processed these catalogues in the same way as the C23 data. We show the resulting (binary) accuracy results in Fig. 9. We did not re-train the models but simply consider the accuracy of the predictions between the class of interest and all other classes.
 |
Fig. 9. Accuracy of the NN and DANN models (trained both on the noise-free and the noisy source domain) on the target domain, taking as ground truth the classifications of C23 (the default in this work), the PNe catalogue of Scheuermann et al. (2022), and the SNR catalogue of Li et al. (2024), respectively. The DANN+noise model reaches the highest levels of accuracy for both PNe and SNRs across all catalogues. |
Fig. 9 shows that both domain adaptation and noise addition lead to improvements in classification accuracy, although in different ways for different classes. For PNe, for example, both the addition of noise and the DANN contribute substantially to the increase in accuracy. The performance on the Scheuermann et al. (2022) catalogue remains slightly lower than on the C23 catalogue, however. For SNRs, on the other hand, all models perform better on the Li et al. (2024) catalogue than on C23, and the addition of noise does not improve performance substantially. For the DANN+noise case, the model reached an accuracy > 79% for all the catalogues of both PNe and SNRs.
5. Summary and conclusions
Several astrophysical science cases require the classification of objects based on a comparison between imperfect models and observational data. This class of problems can be tackled by machine-learning methods using domain adaptation, where a model is trained on labelled source-domain data (the theory) with the goal of optimising its performance on the unlabelled target domain (the observational data). In this work we presented a proof-of-concept application of domain-adaptation techniques to the challenge of classifying ionised nebulae into H II regions, planetary nebulae and supernova remnants based on their line ratios. Our source domain is represented by a set of libraries of photoionisation and shock simulations from the literature (Perez-Montero 2014; Delgado-Inglada et al. 2014; Allen et al. 2008). We chose as target domain the line ratios measured in the sample of nearby PHANGS-MUSE galaxies by C23.
We showed that a primary obstacle to an accurate classification is the domain shift that occurs when applying existing photoionisation simulations to real-world astronomical data. To address this, we employed a domain-adversarial neural network (DANN) framework and compared its performance to that of a vanilla feed-forward network classifier (NN). Our main conclusions are described below.
-
The NN classifier showed excellent performance on the source domain (100% accuracy on the test set), but considering the classifications carried out in C23 as the ground truth, its performance on the target domain was severely affected by domain shift (67% accuracy and f1 score of 0.62).
-
The DANN demonstrated superior performance over a classical NN classifier on the target domain (reaching 73% accuracy), indicating the effectiveness of domain-adaptation techniques in countering the domain-shift challenge. This comes at the cost of lower accuracy on the source domain.
-
Adding noise to the input models acts as a form of regularisation, enhancing the performance of both the NN classifier and the DANN on the target domain. In particular, the best performance on the target domain was obtained with S/N = 10–40, while very high noise leads to decreased classification accuracy, presumably as information is erased from the weaker features in the source domain.
-
By combining the use of a DANN and artificial noise injection in the models we achieved a notable improvement in classification accuracy, with our DANN best model reaching a classification accuracy of 90% (f1 score of 0.66) on the target domain.
-
We demonstrated that the DANN leads to closer alignment of the source and target domain instances by projecting their embeddings onto a two-dimensional parameter space via t-SNE. We also showed using this low-dimensional representation that the information learnt by the DANN can be interpreted in terms of input line ratios.
-
We applied our best DANN+noise model to specialised PNe (Scheuermann et al. 2022) and SNRs (Li et al. 2024) catalogues and found that both noise addition and domain adaptation lead to substantial improvement in the accuracy of classifying nebulae of these two classes also for these specialised catalogues.
Even for the relatively simple problem we have studied in this work, the combination of domain adaptation and noise injection in the models resulted in an increase in accuracy in the target domain of 23% over the naive application of a NN on the noise-free models. While the combination of domain adaptation and noise injection led to the best solution, domain adaptation on the noise-free models already represented a substantial improvement over the use of the NN on noise-free data. This highlights the potential of domain-adaptation techniques to a wide variety of astrophysical problems, where no simple recipe may exist to mimic observational realism. As astrophysics proceeds into the era of big data and large survey projects, domain adaptation is likely to become a fundamental component of ML-powered data analysis pipelines.
To avoid confusion, in this work we refer to photoionisation models as ‘simulations’, and use the term ‘model’ only to refer to a machine-learning model.
https://sites.google.com/site/mexicanmillionmodels, for H II regions and PNe and http://3mdb.astro.unam.mx:3686/ for shocks.
The f1 score for a binary classification problem is the harmonic mean of precision and recall. For our multiclass problem we used the average of the f1 scores for each label.
Acknowledgments
We thank the referee for the thoughtful comments which improved the quality of the paper. F.B thanks Ricarda Sontag for stimulating discussions that have improved the quality of this work. This work has been carried out as part of the PHANGS collaboration. Based on observations from the PHANGS-MUSE programme, collected at the European Southern Observatory under ESO programmes 094.C-0623 (PI: Kreckel), 095.C-0473, 098.C-0484 (PI: Blanc), 1100.B-0651 (PHANGS-MUSE; PI: Schinnerer), as well as 094.B-0321 (MAGNUM; PI: Marconi), 099.B-0242, 0100.B-0116, 098.B-0551 (MAD; PI: Carollo) and 097.B-0640 (TIMER; PI: Gadotti). FB acknowledges support from the INAF Fundamental Astrophysics programme 2022. G.A.B. acknowledge support from the ANID Basal project FB210003. RSK acknowledges financial support from the European Research Council via the ERC Synergy Grant “ECOGAL” (project ID 855130), from the German Excellence Strategy via the Heidelberg Cluster of Excellence (EXC 2181 - 390900948) “STRUCTURES”, and from the German Ministry for Economic Affairs and Climate Action in project “MAINN” (funding ID 50OO2206). RSK is grateful for computing resources provided by the Ministry of Science, Research and the Arts (MWK) of the State of Baden-Württemberg through bwHPC and the German Science Foundation (DFG) through grants INST 35/1134-1 FUGG and 35/1597-1 FUGG, and also for data storage at SDShd funded through grants INST 35/1314-1 FUGG and INST 35/1503-1 FUGG. RSK also thanks the Harvard-Smithsonian Center for Astrophysics and the Radcliffe Institute for Advanced Studies for their hospitality during his sabbatical, and the 2024/25 Class of Radcliffe Fellows for highly interesting and stimulating discussions. MB gratefully acknowledges support from the ANID BASAL project FB210003 and from the FONDECYT regular grant 1211000. This work was supported by the French government through the France 2030 investment plan managed by the National Research Agency (ANR), as part of the Initiative of Excellence of Université Côte d’Azur under reference number ANR-15-IDEX-01.
References
- Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., & Marchand, M. 2014, ArXiv e-prints [arXiv:1412.4446] [Google Scholar]
- Allen, M., Groves, B., Dopita, M., Sutherland, R., & Kewley, L. 2008, ApJS, 178, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Amayo, A., Delgado-Inglada, G., & Stasinska, G. 2021, MNRAS, 505, 2361 [CrossRef] [Google Scholar]
- Baker, W. M., Maiolino, R., Belfiore, F., et al. 2023, MNRAS, 519, 1149 [Google Scholar]
- Baldwin, J. A., Phillips, M. M., & Terlevich, R. 1981, PASP, 93, 5 [Google Scholar]
- Barnes, A. T., Longmore, S. N., Dale, J. E., et al. 2020, MNRAS, 498, 4906 [NASA ADS] [CrossRef] [Google Scholar]
- Baron, D., Sandstrom, K. M., Rosolowsky, E., et al. 2024, ApJ, 968, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Belfiore, F., Maiolino, R., & Bothwell, M. 2016, MNRAS, 455, 1218 [CrossRef] [Google Scholar]
- Belfiore, F., Santoro, F., Groves, B., et al. 2022, A&A, 659, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Binette, L., Matadamas, R., Hägele, G. F., Nicholls, D. C., & Magris, G. C. 2012, A&A, 547, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bisbas, T. G., Wünsch, R., Whitworth, A. P., & Hubber, D. A. 2009, A&A, 497, 649 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bottrell, C., Hani, M. H., Teimoorinia, H., et al. 2019, MNRAS, 490, 5390 [NASA ADS] [CrossRef] [Google Scholar]
- Byler, N., Dalcanton, J. J., Conroy, C., et al. 2019, AJ, 158, 2 [Google Scholar]
- Chevance, M., Krumholz, M., McLeod, A., et al. 2023, in Protostars Planets VII, eds. S. Inutsuka, Y. Aikawa, T. Muto, K. Tomida, & M. Tamura, ASP Conf. Ser., 534, 1 [Google Scholar]
- Cid Fernandes, R., Stasińska, G., Mateus, A., & Vale Asari, N. 2011, MNRAS, 413, 1687 [Google Scholar]
- Ciprijanovic, A., Kafkes, D., Downey, K., et al. 2021, MNRAS, 506, 677 [CrossRef] [Google Scholar]
- Clevert, D. A., Unterthiner, T., & Hochreiter, S. 2015, ArXiv e-prints [arXiv:1511.07289] [Google Scholar]
- Congiu, E., Blanc, G. A., Belfiore, F., et al. 2023, A&A, 672, A148 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Delgado-Inglada, G., Morisset, C., & Stasińska, G. 2014, MNRAS, 440, 536 [Google Scholar]
- Emsellem, E., Schinnerer, E., Santoro, F., et al. 2022, A&A, 659, A191 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ferland, G., Binette, L., Contini, M., et al. 1994, Anal (Lines: Emiss), 83 [Google Scholar]
- Ferland, G. J., Chatzikos, M., Guzmán, F., et al. 2017, RMxAA, 53, 385 [NASA ADS] [Google Scholar]
- Ganin, Y., Ustinova, E., Ajakan, H., et al. 2016, J. Mach. Learn. Res., 17, 1 [Google Scholar]
- Ginolfi, M., Mannucci, F., Belfiore, F., et al. 2025, A&A, 693, A73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., et al. 2014, ArXiv e-prints [arXiv:1406.2661] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2015, ArXiv e-prints [arXiv:1502.01852] [Google Scholar]
- Ioffe, S., & Szegedy, C. 2015, ArXiv e-prints [arXiv:1502.03167] [Google Scholar]
- Jin, Y., Kewley, L. J., & Sutherland, R. S. 2022, ApJ, 934, L8 [NASA ADS] [CrossRef] [Google Scholar]
- Kang, D. E., Pellegrini, E. W., Ardizzone, L., et al. 2022, MNRAS, 512, 617 [CrossRef] [Google Scholar]
- Kang, D. E., Klessen, R. S., Ksoll, V. F., et al. 2023, MNRAS, 520, 4981 [NASA ADS] [CrossRef] [Google Scholar]
- Kauffmann, G., Heckman, T. M., Tremonti, C., et al. 2003, MNRAS, 346, 1055 [Google Scholar]
- Kewley, L. J., Dopita, M. A., Sutherland, R. S., Heisler, C. A., & Trevena, J. 2001, ApJ, 556, 121 [Google Scholar]
- Kewley, L. J., Groves, B., Kauffmann, G., & Heckman, T. 2006, MNRAS, 372, 961 [Google Scholar]
- Kewley, L. J., Nicholls, D. C., Sutherland, R., et al. 2019, ApJ, 880, 16 [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, ArXiv e-prints [arXiv:1412.6980] [Google Scholar]
- Kopsacheili, M., Zezas, A., & Leonidaki, I. 2020, MNRAS, 491, 889 [CrossRef] [Google Scholar]
- Law, K.-H., Gordon, K. D., & Misselt, K. A. 2021, ApJ, 920, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Li, J., Kreckel, K., Sarbadhicary, S., et al. 2024, A&A, 690, A161 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lopez, L. A., Krumholz, M. R., Bolatto, A. D., et al. 2014, ApJ, 795, 121 [NASA ADS] [CrossRef] [Google Scholar]
- Maiolino, R., & Mannucci, F. 2019, A&ARv, 27, 3 [Google Scholar]
- McLeod, A. F., Ali, A. A., Chevance, M., et al. 2021, MNRAS, 508, 5425 [NASA ADS] [CrossRef] [Google Scholar]
- Méndez-Delgado, J. E., Esteban, C., García-Rojas, J., Kreckel, K., & Peimbert, M. 2023a, Natur, 618, 249 [CrossRef] [Google Scholar]
- Méndez-Delgado, J. E., Esteban, C., García-Rojas, J., et al. 2023b, MNRAS, 523, 2952 [CrossRef] [Google Scholar]
- Micheva, G., Roth, M. M., Weilbacher, P. M., et al. 2022, A&A, 668, 1 [Google Scholar]
- Mingozzi, M., Cresci, G., Venturi, G., et al. 2019, A&A, 622, A146 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Morisset, C., Delgado-Inglada, G., & Flores-Fajardo, N. 2015, RMxAA, 51, 101 [Google Scholar]
- O’Donnell, J. E. 1994, ApJ, 422, 158 [Google Scholar]
- Pearson, W. J., Wang, L., Trayford, J. W., Petrillo, C. E., & Van Der Tak, F. F. 2019, A&A, 626, 1 [Google Scholar]
- Peimbert, M., Peimbert, A., & Delgado-Inglada, G. 2017, PASP, 129, 82001 [Google Scholar]
- Pellegrini, E. W., Rahner, D., Reissl, S., et al. 2020a, MNRAS, 496, 339 [Google Scholar]
- Pellegrini, E. W., Reissl, S., Rahner, D., et al. 2020b, MNRAS, 498, 3193 [NASA ADS] [CrossRef] [Google Scholar]
- Perez-Montero, E. 2014, MNRAS, 441, 2663 [CrossRef] [Google Scholar]
- Portillo, S. K. N., Parejko, J. K., Vergara, J. R., & Connolly, A. J. 2020, AJ, 160, 45 [Google Scholar]
- Rhea, C. L., Rousseau-Nepton, L., Moumen, I., et al. 2023, RASTI, 2, 345 [NASA ADS] [Google Scholar]
- Roth, M. M., Sandin, C., Kamann, S., et al. 2018, A&A, 618, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rousseau-Nepton, L., Martin, R. P., Robert, C., et al. 2019, MNRAS, 489, 5530 [NASA ADS] [CrossRef] [Google Scholar]
- Santoro, F., Kreckel, K., Belfiore, F., et al. 2022, A&A, 658, 1 [Google Scholar]
- Sarmiento, R., Huertas-Company, M., Knapen, J. H., et al. 2021, ApJ, 921, 177 [NASA ADS] [CrossRef] [Google Scholar]
- Scheuermann, F., Kreckel, K., Anand, G. S., et al. 2022, MNRAS, 511, 6087 [NASA ADS] [CrossRef] [Google Scholar]
- Sutherland, R., Dopita, M., Binette, L., & Groves, B. 2018, Astrophysics Source Code Library [record ascl:1807.005] [Google Scholar]
- van der Maaten, L., & Hinton, G. 2008, J. Mach. Learn. Res., 9, 2579 [Google Scholar]
- Walch, S. K., Whitworth, A. P., Bisbas, T., Wünsch, R., & Hubber, D. 2012, MNRAS, 427, 625 [NASA ADS] [CrossRef] [Google Scholar]
- Watts, A. B., Cortese, L., Catinella, B., et al. 2024, MNRAS, 530, 1968 [NASA ADS] [CrossRef] [Google Scholar]
- Williams, J., de Geus, E. J., & Blitz, L. 1994, ApJ, 428, 693 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, K., Yan, R., Bundy, K., et al. 2017, MNRAS, 466, 3217 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
All Figures
|
Fig. 1. Schematic representation of the domain-adaptation problem tackled in this work. The task consists in inferring the classification of PHANGS nebulae, given a set of photoionisation simulations from nebulae of different classes. The source domain (theory) contains the labels, while the target domain (data) is unlabelled. A classical, supervised machine-learning algorithm (e.g. a classifier neural network, in blue) is trained on the instances and labels of the source domain, but may perform poorly on the target domain, because of the differences between simulated and real data. In this work we employed a DANN, a domain-adaptation algorithm that uses as input (in green) both the labelled source domain and the unlabelled target domain instances. This approach allows the model to learn domain-invariant features and perform better on the target domain. |
| In the text | |
|
Fig. 2. Location in three BPT diagrams of photoionisation simulations (top row) and ionised nebulae from PHANGS-MUSE (C23, bottom row). In each panel, the colour-coding represents class labels (green: H II regions, blue: PNe, and red: SNRs). The class labels for the observed nebulae are based on the Bayesian methodology of C23 and are never used in the training, as we treat the target domain as unlabelled. Only the subset of the C23 catalogue used to train the classification algorithm presented in this work is shown. In each BPT diagram we show the demarcation lines of Law et al. (2021) (L21, solid line) and Kewley et al. (2001, 2006) (K01, dashed line). The Kauffmann et al. (2003) line in the [N II]-BPT is almost coincident with the Law et al. (2021) line. The figure demonstrates that there is only a limited overlap in parameter space between simulations and data. |
| In the text | |
|
Fig. 3. Illustration of the network architecture of the simple NN classifier (top row only, blue layers) and the DANN (full figure). Through the cooperation of both the encoder and the discriminator network, the DANN learns domain-invariant features in the embeddings layer (light blue). The DANN is trained adversarially to deceive its discriminator into being unable to distinguish source from target domain instances. The figure also shows the dimensionality of the input (number of instances, Ni, by 5) and the number of neurons in each layer (in bracket next to each layer name). |
| In the text | |
|
Fig. 4. Confusion matrices showing the performance of the NN (top row) and the DANN (bottom row) in classifying H II regions, PNe, and SNRs, evaluated over the test set of the source domain (left column) and the target domain (right column). Values of the f1 score and accuracy (acc) are reported at the top of each panel. |
| In the text | |
|
Fig. 5. Accuracy on the test set of the source domain and target domain as a function of S/N for the NN (blue) and DANN (green) models. The lines correspond to the average of an ensemble of 20 models and the shaded areas represent the 10th and 90th percentiles of the distribution. The accuracy on the target domain for both NN and DANN peaks at S/N ∼ 40 (grey dashed line). |
| In the text | |
|
Fig. 6. Same plots as in Fig. 4, but considering both the NN and the DANN trained over a noise-augmented dataset with S/N ∼ 40 on Hβ in the source domain (see text in Sec. 4.2). Noise augmentation leads to better performances on the target domain for both the NN and the DANN. |
| In the text | |
|
Fig. 7. Two-dimensional representations of the input data and the embeddings from the DANN obtained using t-SNE, illustrating the distribution of instances from both the source and target domains. For ease of visualisation we plot only a random subset of the target domain that homogeneously populates the three classes. The quantities on the axes represent the output of t-SNE and do not have a physical meaning, and they represent a different projection in each panel. Light colours (light blue, light red, and light green) represent the three classes in the source domain (H II regions, PNe, and SNRs, respectively), while dark colours (dark blue, dark red, and dark green) represent the same three classes in the target domain. Left: Input vectors show a clear separation between the source and target domains, pointing to the presence of a domain shift. Middle: Embedding vectors from the DANN model show a closer alignment of instances, showcasing the effectiveness of DANN in reducing domain shift. Right: The alignment is further enhanced with noise augmentation in the training set. Dark-coloured outliers in source domain clusters reflect the imperfect accuracy of the DANN model. Their existence is reflected in the non-diagonal confusion matrices discussed in Sec. 4.1. |
| In the text | |
|
Fig. 8. Two-dimensional representations of the DANN embeddings (a representative model with S/N ∼ 40) colour-coded by the source domain classes, and various line ratios (which are either the input features themselves or a combination of input features), shown as the titles of each panel. The colourbar goes from blue (low) to yellow (high) and in each panel is normalised to the 2nd and 98th percentiles of the quantity. The arrow emerging from the origin shows the direction of steepest increase in the colour-coded quantity, measured clockwise from the positive x-axis. |
| In the text | |
|
Fig. 9. Accuracy of the NN and DANN models (trained both on the noise-free and the noisy source domain) on the target domain, taking as ground truth the classifications of C23 (the default in this work), the PNe catalogue of Scheuermann et al. (2022), and the SNR catalogue of Li et al. (2024), respectively. The DANN+noise model reaches the highest levels of accuracy for both PNe and SNRs across all catalogues. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.