| Issue |
A&A
Volume 691, November 2024
|
|
|---|---|---|
| Article Number | A331 | |
| Number of page(s) | 23 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202349113 | |
| Published online | 25 November 2024 | |
CLAP
I. Resolving miscalibration for deep learning-based galaxy photometric redshift estimation
1
Pengcheng Laboratory,
Nanshan District,
Shenzhen,
Guangdong
518000,
P.R. China
2
Aix-Marseille Université, CNRS/IN2P3, CPPM,
Marseille
13009,
France
3
School of Physics and Microelectronics, Zhengzhou University,
Zhengzhou,
Henan
450001,
P.R. China
4
Department of Physics E. Pancini, University Federico II,
Via Cinthia 6,
80126
Naples,
Italy
5
School of Physics and Astronomy, Sun Yat-sen University,
Zhuhai Campus, 2 Daxue Road, Tangjia,
Zhuhai,
Guangdong
519082,
P.R.China
6
CSST Science Center for Guangdong-Hong Kong-Macau Great Bay Area,
Zhuhai,
Guangdong
519082,
P.R. China
7
Department of Astronomy, The Ohio State University,
Columbus,
OH
43210,
USA
8
Center for Cosmology and AstroParticle Physics (CCAPP), The Ohio State University,
Columbus,
OH
43210,
USA
9
Research School of Astronomy & Astrophysics, Australian National University,
Cotter Rd.,
Weston,
ACT 2611,
Australia
10
School of Computing, Australian National University,
Acton,
ACT 2601,
Australia
★ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
28
December
2023
Accepted:
22
September
2024
Abstract
Obtaining well-calibrated photometric redshift probability densities for galaxies without a spectroscopic measurement remains a challenge. Deep learning discriminative models, typically fed with multi-band galaxy images, can produce outputs that mimic probability densities and achieve state-of-the-art accuracy. However, several previous studies have found that such models may be affected by miscalibration, an issue that would result in discrepancies between the model outputs and the actual distributions of true redshifts. Our work develops a novel method called the Contrastive Learning and Adaptive KNN for Photometric Redshift (CLAP) that resolves this issue. It leverages supervised contrastive learning (SCL) and k-nearest neighbours (KNN) to construct and calibrate raw probability density estimates, and implements a refitting procedure to resume end-to-end discriminative models ready to produce final estimates for large-scale imaging data, bypassing the intensive computation required for KNN. The harmonic mean is adopted to combine an ensemble of estimates from multiple realisations for improving accuracy. Our experiments demonstrate that CLAP takes advantage of both deep learning and KNN, outperforming benchmark methods on the calibration of probability density estimates and retaining high accuracy and computational efficiency. With reference to CLAP, a deeper investigation on miscalibration for conventional deep learning is presented. We point out that miscalibration is particularly sensitive to the method-induced excessive correlations among data instances in addition to the unaccounted-for epistemic uncertainties. Reducing the uncertainties may not guarantee the removal of miscalibration due to the presence of such excessive correlations, yet this is a problem for conventional methods rather than CLAP. These discussions underscore the robustness of CLAP for obtaining photometric redshift probability densities required by astrophysical and cosmological applications. This is the first paper in our series on CLAP.
Key words: methods: data analysis / techniques: image processing / surveys / galaxies: distances and redshifts
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
In cosmological and extragalactic studies, the cosmological redshift ɀ characterises the cosmic distance, and it is a crucial quantity for probing the properties of galaxies and the evolution of the Universe. The most direct and accurate way to measure redshift is through spectroscopy. However, spectroscopic redshifts (spec-ɀ) are highly time intensive to obtain. There have been multiple ongoing or planned galaxy imaging surveys in recent years, such as the Kilo-Degree Survey (KiDS; de Jong et al. 2013), the Dark Energy Survey (DES; Dark Energy Survey Collaboration 2016), the Euclid survey (Laureijs et al. 2011), the Hyper Suprime-Cam (HSC; Aihara et al. 2018), the Nancy Grace Roman Space Telescope (Spergel et al. 2015), the Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST; Ivezić et al. 2019), and the China Space Station Telescope (CSST; Zhan 2018). They require redshift estimates for hundreds of millions or billions of galaxies for which spectroscopic measurements are infeasible. Given such extremely rich datasets, photometric redshifts (photo-ɀ), measured typically using photometry, have become an alternative in order to meet the needs for large imaging surveys.
The idea behind photometric redshift estimation for individual galaxies lies in the mapping between the observed galaxy photometric or morphological properties and the redshift. Broadly speaking, two categories of methods are commonly leveraged for deriving individual redshift estimates (see Salvato et al. 2019 and Newman & Gruen 2022). Template-fitting methods (e.g. Arnouts et al. 1999; Benítez 2000; Feldmann et al. 2006; Ilbert et al. 2006; Greisel et al. 2015; Leistedt et al. 2019) determine redshifts by finding the best fit between the galaxy spectral energy distribution (SED) and a library of SED templates covering different physical and morphological properties such as galaxy types. Data driven or empirical methods determine redshifts by empirically learning the mapping from photometric data to redshift estimates without any theoretical modelling. These include unsupervised learning approaches in which known redshifts are given as external information, such as k-nearest neighbours (KNN; e.g. Zhang et al. 2013; Beck et al. 2016; De Vicente et al. 2016; Speagle et al. 2019; Han et al. 2021; Luken et al. 2022), self-organising maps (SOMs; e.g. Way & Klose 2012; Carrasco Kind & Brunner 2014; Speagle & Eisenstein 2017; Buchs et al. 2019; Wilson et al. 2020), and supervised learning approaches in which known redshifts are used as labels, such as artificial neural networks (ANNs; e.g. Collister & Lahav 2004; Brescia et al. 2014; Bonnett 2015; Cavuoti et al. 2015; Hoyle 2016; Sadeh et al. 2016; Cavuoti et al. 2017; Bilicki et al. 2018; D’Isanto & Polsterer 2018; Pasquet et al. 2019; Mu et al. 2020; Schuldt et al. 2021; Dey et al. 2022a; Ait Ouahmed et al. 2024; Treyer et al. 2024), decision trees and random forest (e.g. Carliles et al. 2010; Carrasco Kind & Brunner 2013; Luken et al. 2022), boosted decision trees (e.g. Gerdes et al. 2010), support vector machines (SVMs; e.g. Jones & Singal 2017), and Gaussian mixture models (GMMs; e.g. D’Isanto & Polsterer 2018; Jones & Heavens 2019; Hatfield et al. 2020; Ansari et al. 2021).
Thanks to the recent advances in deep learning, a few studies (e.g. D’Isanto & Polsterer 2018; Pasquet et al. 2019; Schuldt et al. 2021; Dey et al. 2022a; Ait Ouahmed et al. 2024; Treyer et al. 2024) have developed deep neural networks (DNNs) to predict photometric redshifts and achieve state-of-the-art predictive accuracy. These discriminative models, developed in a supervised end-to-end manner and usually having a large number of trainable weights, directly take multi-band stamp images of galaxies as inputs and produce redshift estimates. They are trained iteratively with mini-batches of training data, minimising a loss function via gradient descent in which spectroscopic redshifts are used as labels. In this way, the models can automatically establish a mapping from input images to the target redshifts. Studies such as Henghes et al. (2022), Li et al. (2022a), Zhou et al. (2022a), and Zhou et al. (2022b) explored hybrid networks that are fed with both images and multi-band photometry or fluxes. The outperformance of such image-based methods in accuracy over photometry-only methods suggests that other than photometry there may be extra information such as galaxy morphology encoded in images that helps improve redshift estimation (Soo et al. 2018).
Photometric redshift estimates for individual galaxies are usually considered in two forms: (a) the point estimate ɀphoto derived from photometric data d (i.e. photometry or images) and (b) the (posterior) probability density estimate p(ɀ|d) over possible values given photometric data d, accounting for imperfect knowledge in determining redshifts. This work concentrates on probability density estimation via deep learning.
Obtaining well-calibrated redshift probability density estimates is a challenging task, as reported for a large array of redshift estimation methods (e.g. Wittman et al. 2016; Tanaka et al. 2018; Amaro et al. 2019; Euclid Collaboration 2020; Schmidt et al. 2020; Kodra et al. 2023). There have been several techniques coupled with deep learning models used to express redshift probability densities, including the softmax function (Pasquet et al. 2019; Treyer et al. 2024), GMMs (D’Isanto & Polsterer 2018), and Bayesian neural networks (BNNs; Zhou et al. 2022b), outputting vectors covering a redshift range and normalised to unity. Despite their high accuracy, the calibration of such estimates produced by neural networks remains an open issue. From a statistical viewpoint, a well-calibrated probability density estimate should fulfil the frequentist definition: for a given sample of galaxies, the integrated probability within any arbitrary redshift range must describe the relative frequency of true redshifts falling in this range (Dey et al. 2021, 2022b). While there are proofs that ANNs are capable of providing reliable posterior probability estimates (Richard & Lippmann 1991; Rojas 1996), several studies have shown evidence that the probability density outputs from discriminative models especially those with high capacity may suffer from miscalibration, that is, a model’s confidence is not consistent with its accuracy (e.g. Guo et al. 2017; Thulasidasan et al. 2019; Minderer et al. 2021; Wen et al. 2021). In other words, miscalibration would lead to a deviation between the estimated p′(ɀ|d) and the empirically correct p(ɀ|d). Guo et al. (2017) pointed out that the extent of miscalibration generally grows with the model capacity for typical neural networks. As we show, neural networks similar to the one developed by Treyer et al. (2024) (with ~60 layers and ~7 million trainable parameters) already exhibit clear miscalibration behaviours. Furthermore, the variability stemming from the iterative training procedure would contribute additional uncertainties and increase the potential risk of miscalibration (Huang et al. 2021, 2023).
Unlike point estimates that only give the collapsed values, well-calibrated probability density estimates are capable of describing the intrinsic dispersions due to the complex many-to- many mapping from photometric data to redshift, and describing the uncertainties due to the method implemented for redshift estimation and errors in photometric data. They are thus preferred for precision cosmology, in which one needs to understand and incorporate the full uncertainties in photometric redshift estimation into analysis (e.g. Mandelbaum et al. 2008; Myers et al. 2009; Bonnett et al. 2016; Abruzzo & Haiman 2019; Ruiz-Zapatero et al. 2023; Zhang et al. 2023). On the other hand, this leads to a strong requirement for the calibration of probability density estimates. The potential miscalibration issue associated with conventional deep learning would result in unreliable characterisation of uncertainties and would bias the photometric redshift estimation, consequently degrading the cosmological inference. In particular, miscalibrated probability densities for individual galaxies may induce biases on the mean redshifts estimated in tomographic bins and lead to poorly reconstructed redshift distribution over a galaxy sample, which are severe for weak lensing tomography (e.g. Ma et al. 2006; Huterer et al. 2006; Laureijs et al. 2011; Joudaki et al. 2020; Hildebrandt et al. 2020; Euclid Collaboration 2021).
In our previous work (Lin et al. 2022) we developed a set of consecutive steps to correct biases in photometric redshift estimation with deep learning, potentially overcoming the impact of miscalibration on the mean redshifts in tomographic bins. However, this approach is limited to point estimate analysis, and suffers from a trade-off between constraining estimation errors and correcting biases, which originates from retraining a fraction of a network using a subset of training data and soft labels that enlarges estimation errors. We thus attempt to find a better solution to tackle the miscalibration issue for probability density estimation.
In this work we propose the Contrastive Learning and Adaptive KNN for Photometric Redshift (CLAP), a novel method that resolves the miscalibration encountered by conventional deep learning in the context of photometric redshift probability density estimation. CLAP leverages the gains from KNN and retains the advantages of deep learning simultaneously. It turns a discriminative model into a contrastive learning framework that projects galaxy images and additional input data to redshift-sensitive latent vectors, followed by an adaptive KNN algorithm and a KNN-enabled recalibration procedure to produce locally calibrated probability density estimates, which leverage diagnostics with the probability integral transform (PIT; Gass & Harris 2001). The contrastive learning is coupled with supervised learning in which spectroscopic redshifts are used as labels. We give a solution for alleviating the reliance on the expensive computation required for KNN, and suggest a proper way to combine an ensemble of probability density estimates for reducing uncertainties. We demonstrate CLAP using data separately from the Sloan Digital Sky Survey (SDSS; Eisenstein et al. 2011), the Canada-France-Hawaii Telescope Legacy Survey (CFHTLS; Gwyn 2012), and the Kilo-Degree Survey (KiDS; de Jong et al. 2013). As we show, the main advantages of CLAP include the following:
a substantial improvement on the calibration of probability density estimates thanks to KNN;
a high accuracy comparable to that obtained by conventional image-based deep learning methods, better than photometry- only KNN approaches such as Beck et al. (2016);
computational efficiency of end-to-end deep learning models retained by bypassing the intensive computation required for KNN.
This is in line with other works that demonstrate the merits of combining deep learning with KNN (e.g. Papernot & McDaniel 2018; Chen et al. 2020; Dwibedi et al. 2021; Sun et al. 2022; Liao et al. 2023). CLAP is analogous to likelihood-free inference approaches for parameter estimation and inference (e.g. Charnock et al. 2018; Fluri et al. 2021; Livet et al. 2021), but instead of exploiting simulated data for inference, we perform KNN on real data and labels to ensure the probability density estimates to be locally calibrated.
With CLAP as a reference, we delve into the miscalibration issue and showcase that it is a common shortcoming of conventional deep learning methods for probability density estimation. In particular, we present an illustration of miscalibration over different representative discriminative models, and reveal its association with uncertainties and correlations between data instances. In light of these findings, suggestions are given on circumventing miscalibration in deep learning in order to obtain reliable photometric redshift estimates applicable to actual astrophysical and cosmological analysis.
As a further note, another common issue for conventional methods is the mismatch between the spectroscopic sample used to train a model and the target (or test) sample to which the model is applied. As the learned distribution p(ɀ, d) is fixed in the model once the model is trained, applying it to a target sample with a different distribution would induce biases. In contrast, CLAP has the flexibility to match the target distribution by assigning different weights to the nearest neighbours for each data instance, offering a possible way to circumvent mismatches. This is another advantage of CLAP over conventional methods. We note that a mismatch may also lead to inconsistency between a model’s confidence and accuracy for the target sample, though we use ‘miscalibration’ to exclusively refer to the issue internal to the method implementation irrespective of mismatches. We will discuss the approaches built on CLAP for resolving mismatches in the next paper of our CLAP series, while in the current work we present the details of CLAP and solely focus on miscalibration.
In addition, we note that probability density estimates are denoted with probability density functions (PDFs) in most studies. From a rigorous statistical point, a PDF should characterise the dispersions intrinsic to a physical phenomenon, free from model assumptions, implementations, and noise in data. In actual applications, however, probability density estimates inevitably depend on the certain estimation method and the data quality. It is challenging to get rid of all those extra uncertainties, even after resolving miscalibration. We thus do not refer to probability density estimates as PDFs in order to avoid misuse of the terminology. For brevity, we adopt the expression p(ɀ|d) without adding extra terms to the condition unless otherwise noted.
This paper organised is as follows. Section 2 describes the data used in this work, primarily galaxy images and spectroscopic redshifts. Section 3 introduces our method, CLAP. The information about the network architectures is provided in Appendix A. In Sect. 4 we show our results on probability density estimation using CLAP. An investigation on miscalibration is presented in Sect. 5. Finally, we summarise our results and give concluding remarks in Sect. 6. In the section dedicated to Data and Code Availability, we provide supplementary appendices that contain more results and discussions; we also provide the photometric redshift catalogues produced by CLAP and the code used in this work.
2 Data
We took data from three imaging surveys, the Sloan Digital Sky Survey (SDSS), the Canada-France-Hawaii Telescope Legacy Survey (CFHTLS), and the Kilo-Degree Survey (KiDS), each of which covers a different redshift and magnitude range. The distributions of spectroscopic redshift and r-band magnitude for each dataset are shown in Fig. 1. The redshift coverage and sample division are detailed in Table 1.
2.1 Sloan Digital Sky Survey (SDSS)
The SDSS dataset used in this work contains 516 524 galaxies from the Main Galaxy Sample available from SDSS Data Release 12 (Alam et al. 2015). These data were retrieved by Pasquet et al. (2019) and also used in Lin et al. (2022), with detailed information provided in Pasquet et al. (2019). This dataset has a low-redshift coverage ɀ < 0.4 and a cut at 17.8 on dereddened r-band petrosian magnitude, providing a rich reservoir of data in a restricted parameter space. The galactic reddening E(B – V) for each galaxy along the line of sight is obtained using the dust map from Schlegel et al. (1998). Each galaxy is associated with a spectroscopically measured redshift. Five stamp images that cover five optical bands u, g, r, i, ɀ were made to have the galaxy located at the centre and encompass 64 × 64 pixels in spatial dimensions, with each pixel covering 0.396 arcsec. The five images together with the galactic reddening E(B – V) are regarded as a data instance and used as input data for CLAP. While previous work noticed that inputting the information of point spread functions (PSFs) to deep learning models would improve the estimation of galaxy properties (e.g. Umayahara et al. 2020; Li et al. 2022b), we did not find a strong impact of PSFs on photometric redshift estimation for the data used in our work. Therefore, we did not include the PSF information in the input data for CLAP.
Via complete random sampling, we selected 393 219 galaxies as a training sample, 20 000 galaxies as a validation sample, and 103 305 galaxies as a target sample, similar to the sample division by Pasquet et al. (2019). Such division imposes that all the samples follow the same parent redshift-data distribution in spite of different sample sizes. This is the assumption we hold in this work without considering mismatches.
 |
Fig. 1 Distributions of spectroscopic redshift and r-band magnitude for the SDSS, CFHTLS, and KiDS datasets used in our work. |
Data coverage in spectroscopic redshift and sample division.
2.2 Canada-France-Hawaii Telescope Legacy Survey (CFHTLS)
We took the CFHTLS dataset that was described in detail in Treyer et al. (in prep.) and also used in Lin et al. (2022). It contains 158 193 galaxies observed in either the CFHTLS-Deep survey or the CFHTLS-Wide survey (Hudelot et al. 2012), with spectroscopic redshift up to ɀ ~ 4.0 and dereddened r-band petrosian magnitude up to r – 27.0.
Since CFHTLS had no spectroscopic observations, the spectroscopic redshifts were retrieved from a few other spectroscopic surveys. The majority is a collection of high-quality redshifts measured with high S/N spectra or multiple spectral features, obtained from the COSMOS Lyman-Alpha Mapping And Mapping Observations survey (CLAMATO; Data Release 1; Lee et al. 2018), the DEEP2 Galaxy Redshift Survey (Data Release 4; Newman et al. 2013), the Galaxy And Mass Assembly survey (GAMA; Data Release 3; Baldry et al. 2018), the SDSS survey (Data Release 12), the UKIDSS Ultra-Deep Survey (UDS; McLure et al. 2013; Bradshaw et al. 2013), the VANDELS ESO public spectroscopic survey (Data Release 4; Garilli et al. 2021), the VIMOS Public Extragalactic Redshift Survey (VIPERS; Data Release 2; Scodeggio et al. 2018), the VIMOS Ultra-Deep Survey (VUDS; Le Fèvre et al. 2015), the VIMOS VLT Deep Survey (VVDS; Le Fèvre et al. 2013), the WiggleZ Dark Energy Survey (Final Release; Drinkwater et al. 2018), and the zCOS- MOS survey (Lilly et al. 2007). There is also a collection of low-resolution redshifts, acquired from the secure low-resolution prism redshift measurements from the PRIsm MUlti-object Survey (PRIMUS; Data Release 1; Coil et al. 2011; Cool et al. 2013) and the grism redshift measurements from the 3D-HST survey (Data Release v4.1.5; Skelton et al. 2014; Momcheva et al. 2016). In the 158 193 CFHTLS galaxies, 134 759 have high- quality spectroscopic redshifts and 23 434 have low-resolution redshifts. Similar to the SDSS images, the stamp images of each CFHTLS galaxy cover five optical bands u, g, r, i, ɀ and have 64 × 64 pixels with a pixel scale of 0.187 arcsec. The galactic reddening E(B – V) is also included as a part of the data.
We randomly selected 14 759 galaxies as a validation sample and 20 000 galaxies as a target sample, both from the high-quality collection. The remaining 100 000 galaxies and the low-resolution collection of 23 434 galaxies form a training sample. That is, for testing the results we only use the high-quality redshifts that are assumed to be secure, while the low-resolution redshifts are just used to increase statistics in training. In addition, we do not treat the CFHTLS-DEEP sample and the CFHTLS-WIDE sample separately as in Lin et al. (2022).
 |
Fig. 2 Graphic illustration of our method CLAP for photometric redshift probability density estimation. The development of a CLAP model consists of several procedures, including supervised contrastive learning (SCL), adaptive KNN, reconstruction, and refitting. The SCL framework is based on neural networks. It uses an encoder network to project multi-band galaxy images and additional input data (i.e. galactic reddening E(B – V), magnitudes) to low-dimensional latent vectors, which form a latent space that encodes redshift information and has a distance metric defined. The spectroscopic redshift labels are leveraged to supervise the redshift outputs predicted by an estimator network for extracting redshift information, but the trained estimator and its outputs are no longer used once the latent space is established (indicated by the shaded region). These outputs are uncalibrated, and should not be regarded as the final estimates produced by CLAP. The adaptive KNN and the KNN-enabled recalibration are implemented locally on the latent space via diagnostics with the probability integral transform (PIT), constructing raw probability density estimates using the known redshifts of the PIT-selected nearest neighbours. The raw estimates are then used as labels to retrain the estimator from scratch in a refitting procedure with the trained encoder fixed, resuming an end-to-end model ready to process imaging data and produce the desired estimates. Lastly, we combine the estimates from an ensemble of CLAP models developed following these procedures (not shown in the figure). |
2.3 Kilo-Degree Survey (KiDS)
We used the KiDS dataset retrieved by Li et al. (2022a) from the KiDS Data Release 4 (Kuijken et al. 2019). There are 134 147 galaxies in this dataset, with spectroscopic redshift up to ɀ ~ 3.0 and dereddened r-band ‘Gaussian Aperture and Point spread function (GAaP)’ magnitude up to r ~ 24.5. The detailed description can be found in Li et al. (2022a). Similar to the CFHTLS dataset, the spectroscopic redshifts of the KiDS galaxies were acquired from other surveys including the Chandra Deep Field South (CDFS; Szokoly et al. 2004), the DEEP2 Galaxy Redshift Survey, the Galaxy And Mass Assembly survey (GAMA), and the zCOSMOS survey. The stamp images from KiDS cover four optical bands u, g, r, i and have a pixel scale of 0.2 arcsec. Again, we set the spatial dimensions to be 64 × 64.
In addition to the KiDS images, this dataset includes the dereddened GAaP magnitudes in the five near-infrared (NIR) bands Z, Y, J, H, Ks from the VISTA Kilo-degree Infrared Galaxy Survey (VIKING; Edge et al. 2014), as well as the galactic reddening E(B – V). Nonetheless, we refer to this dataset as ‘the KiDS dataset’ for brevity throughout the paper.
Similar to Li et al. (2022a), we randomly selected 100 000 galaxies as a training sample, 14 147 galaxies as a validation sample, and 20 000 galaxies as a target sample.
Supervised contrastive learning: Compress high-dimensional input data to low-dimensional redshift-sensitive latent vectors so that the subsequent KNN can be performed.
Adaptive KNN: Obtain the optimal number of nearest neighbours for each data instance via local PIT diagnostics, whose known spectroscopic redshifts are used to construct an initial probability density estimate.
Recalibration: Ensure that the obtained probability density estimates are locally calibrated.
Refitting: Resume an end-to-end model in order to bypass the expensive computation of KNN and regain the computational efficiency of deep learning.
Combining an ensemble of estimates: use the harmonic mean to combine the probability density estimates from an ensemble of models developed following the procedures above.
3 Our method: CLAP
3.1 Overview
This section introduces our method CLAP. As illustrated in Fig. 2 and summarised in Algorithm 1, a CLAP model is developed via supervised contrastive learning (SCL), adaptive KNN, reconstruction, and refitting, based on deep learning neural networks. For the model inputs, we prefer multi-band galaxy images rather than magnitudes or colours alone, because the images contain more information than photometry and potentially enable better accuracy to be achieved in photometric redshift estimation. On the other hand, as we demonstrate, the KNN algorithm is a key component of CLAP in resolving miscalibration, while the multi-band images have a large number of dimensions such that directly implementing the KNN on the images is infeasible. Therefore, CLAP first leverages contrastive learning to project the multi-band images and additional input data (i.e. galactic reddening E(B – V), magnitudes) to low-dimensional redshiftsensitive latent vectors that form a latent space with a defined distance metric, enabling the subsequent KNN to be performed. It is essentially a deep learning-based compression of complex high-dimensional data. The contrastive learning is coupled with supervised learning using the spectroscopic redshift labels for better extraction of redshift information.
The adaptive KNN is implemented on the obtained latent space. For each data instance from the target sample or the validation sample, the optimal k value (i.e. the number of the nearest neighbours), which defines its neighbourhood, is determined via diagnostics based on the local PIT distributions. The PIT values are computed using the known spectroscopic redshifts of the selected nearest neighbours from the training sample. Once the k value is determined, the known redshifts of the k nearest neighbours within the neighbourhood are used to construct a probability density estimate, which is then recalibrated via local PIT diagnostics on the nearest neighbours again. The PIT values used for recalibration may be computed using the known redshifts from the validation sample. In essence, with the adaptive KNN and the KNN-enabled recalibration, the joint distribution p(ɀ, d) for the given dataset is modelled locally by leveraging the neighbourhood of the projection Φ(d) in the latent space, where Φ stands for the implemented model for projecting data in SCL that has been omitted in the expression p(ɀ|d) for brevity.
The computational complexity of KNN precludes its use for processing large amounts of data envisioned by future imaging surveys. In order to avoid running computationally expensive KNN for every data instance from a potentially large target sample, a refitting procedure is implemented to resume an end-to-end model ready to directly produce the desired probability density estimates given input images, which regains the efficiency of deep learning.
Finally, for reducing uncertainties and improving accuracy, we develop an ensemble of CLAP models following the procedures above and combine the estimates from the ensemble. We propose that using the harmonic mean is a proper way for performing such combination.
The details of CLAP are elaborated in the following subsections.
3.2 Supervised contrastive learning
We adopted a contrastive learning technique to establish a latent space that encodes redshift information (see Huertas-Company et al. 2023 for a review of contrastive learning in astrophysics). The essence of contrastive learning is to have positive pairs and negative pairs simultaneously, minimising the contrast between positive pairs and maximising the contrast between negative pairs. A naive choice of generating positive pairs would be to modify the images on the pixel level such as colour jittering, resizing, smoothing, and adding noise, such that contrastive learning is performed in an unsupervised manner (e.g. Hayat et al. 2021; Wei et al. 2022). However, our initial experiments showed that unsupervised contrastive learning with such pixellevel operations failed to produce a good representation for redshift, presumably because redshift is complex high-order information in a multi-dimensional spectroscopic and photometric parameter space, and may have exquisite dependence on pixel intensities (Campagne 2020). Therefore, we propose to incorporate supervised learning in the contrastive learning technique using spectroscopic redshift labels, so that meaningful redshift information can propagate from input data to the latent space. We also consider implementing a deep learningbased reconstruction of redshift-informed images to provide positive counterparts for the original images to avoid performing pixel-level operations.
In addition, we do not perturb input data to account for the noise in data (or ‘aleatoric’ uncertainties) like that applied in MLPQNA (Brescia et al. 2014; Cavuoti et al. 2015, 2017), because, again, this may destruct redshift information. In fact, the errors in the input data from the training sample can be encoded in the latent space in the training process, and then encapsulated in the obtained probability density estimates by KNN for the target sample. Assuming that the errors in the training data are representative of those in the target data, these errors can be well accounted for without any particular treatment. While we assume that the spectroscopic redshifts used in this work are noiseless (except the low-resolution redshifts from the CFHTLS dataset), the possible errors in the spectroscopic redshifts from the training sample can also be encapsulated in the same way.
With these considerations, we developed a supervised contrastive learning (SCL) framework customised for the given problem (illustrated in Fig. 3). It consists of an encoder network, an estimator network, and a decoder network. The encoder is fed with multi-band galaxy images (denoted with I) and additional input data, and outputs two low-dimensional vectors vA and vB . The vector vA is used to encode redshift information, which we refer to as the ‘latent vector’ that is taken to form a latent space, while the vector vB is used to encode other information extracted from the input data needed for reconstructing images. The vector vA is inputted to the estimator that produces a redshift output having the form of a probability density (denoted with q(ɀ|d)), which is expressed in a series of bins given by the softmax function applied on the last fully connected layer and trained in a classification setting (i.e. considering each redshift bin as a class). The vectors vA and vB are concatenated and inputted to the decoder, reconstructing images that resemble the original inputs I . The reconstructed images (denoted with Ir) together with the original additional input data are re-inputted to the encoder, producing vectors 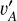 and
and 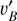 , and subsequently a redshift output q′(ɀ|d) and images
, and subsequently a redshift output q′(ɀ|d) and images 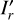 . In this second pass, the encoder, the estimator, and the decoder all use shared weights. Furthermore, we inputted the images I* that are original but reshaped with random flipping and rotation by 90 deg steps, yet the redshift is not modified under the assumption of spatial invariance. Correspondingly,
. In this second pass, the encoder, the estimator, and the decoder all use shared weights. Furthermore, we inputted the images I* that are original but reshaped with random flipping and rotation by 90 deg steps, yet the redshift is not modified under the assumption of spatial invariance. Correspondingly, 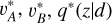 , and
, and 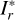 were obtained.
were obtained.
In this framework, we regarded the images Ir and I (or equivalently, the latent vectors 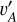 and va) for the same galaxy as a positive pair on condition that redshift information has been passed to vA,
and va) for the same galaxy as a positive pair on condition that redshift information has been passed to vA, 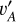 , and Ir. I* and I (or
, and Ir. I* and I (or 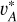 and vA ) for the same galaxy were regarded as another positive pair, though this would not extract meaningful redshift information but only disentangle spatially variant information such as galaxy morphology. Lastly, the original images I1 and I2 for any two different galaxies (or the corresponding latent vectors vA1 and vA2) were regarded as a negative pair.
and vA ) for the same galaxy were regarded as another positive pair, though this would not extract meaningful redshift information but only disentangle spatially variant information such as galaxy morphology. Lastly, the original images I1 and I2 for any two different galaxies (or the corresponding latent vectors vA1 and vA2) were regarded as a negative pair.
We adopted the Euclidean distance as a metric to characterise the contrast between two latent vectors vA1 and vA2,
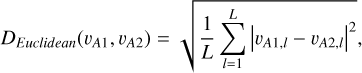 (1)
(1)
where the index l runs over the L dimensions of the latent vectors. For a mini-batch of n data instances from the training sample, we obtained the latent vectors {vA,i}, {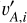 }, and {
}, and {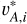 }, where the index i runs over all the data instances. Both (
}, where the index i runs over all the data instances. Both (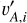 , vA,i) and (
, vA,i) and (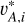 , vA,i) for each data instance were used as positive pairs, having 2n pairs in total. The similarity function for all the positive pairs was defined as
, vA,i) for each data instance were used as positive pairs, having 2n pairs in total. The similarity function for all the positive pairs was defined as
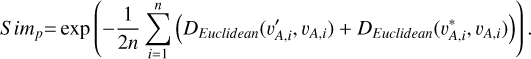 (2)
(2)
We generated n/2 negative pairs from {vA,i} each having two different galaxies (denoted with (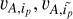 )). The similarity function for all the negative pairs was defined as
)). The similarity function for all the negative pairs was defined as
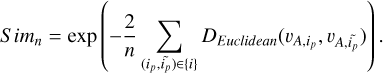 (3)
(3)
We then defined the contrastive loss function as
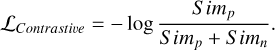 (4)
(4)
We converted the spectroscopic redshifts into one-hot labels using the same binning as the softmax output, assuming no spectroscopic errors beyond the bin size. The same one-hot label (denoted with y) was used to supervise both q(ɀ| d) and q′(ɀ| d) via the cross-entropy loss function
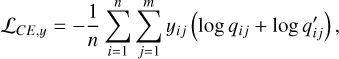 (5)
(5)
where the index i runs over the n data instances in the mini-batch; the index j runs over the m redshift bins for each data instance. We also used the cross-entropy to impose mutual consistency between q(ɀ|d), q′ (ɀ|d), and q* (ɀ|d),
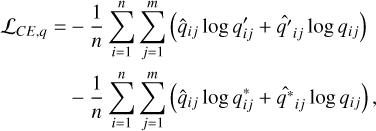 (6)
(6)
where the hat ˆ on top of q(ɀ|d), q′ (ɀ|d), and q*(ɀ|d) refers to gradient stopping in training when they are used as labels in front of the log terms. Equations (5) and (6) ensure redshift information to be encoded in vA, 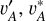 , and Ir.
, and Ir.
We adopted the pixel-wise mean square error (MSE) to constrain the reconstructed images Ir, 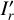 , and
, and 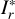 ,
,
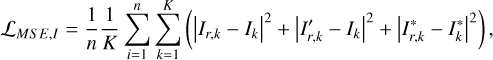 (7)
(7)
where the index k runs over a total number of K pixels of the images over multiple bands. The different MSE constraints for Ir and 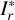 ensure spatially variant information to be encoded in the vector vB. We note that Ir is required to be not identical to I, otherwise vA and
ensure spatially variant information to be encoded in the vector vB. We note that Ir is required to be not identical to I, otherwise vA and 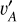 would collapse to a single point in the latent space, making the contrast between any different data instances uncontrollable and nullifying the contrastive learning. This requirement is naturally fulfilled since the random noise on I cannot be fully recovered given a compression of information by the encoder.
would collapse to a single point in the latent space, making the contrast between any different data instances uncontrollable and nullifying the contrastive learning. This requirement is naturally fulfilled since the random noise on I cannot be fully recovered given a compression of information by the encoder.
Finally, we had the total loss function to perform SCL by summing up all the aforementioned loss functions,
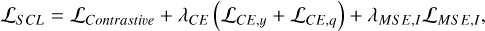 (8)
(8)
where the coefficients λCE and λMS E,I define the relative weights among different terms. With a trained SCL framework, we can obtain the projection of each data instance (i.e. the latent vector) from a sample and establish a latent space.
As an additional note, having the estimator produce redshift outputs q(z|d) in SCL is not yet to make estimation but only to let redshift information propagate to the latent vectors. These outputs are not used once the latent space is established. As we show, they are typically not calibrated, and should not be confused with the final estimates given by the complete implementation of CLAP that we introduce later, but they are compared in our analysis.
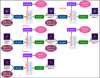 |
Fig. 3 Supervised contrastive learning (SCL) framework. It contains an encoder, an estimator, and a decoder. The encoder, the same as that shown in Fig. 2, takes multi-band galaxy images and additional data as inputs, and produces two vectors vA and vB. The vector vA is used to encode redshift information and is referred to as the ‘latent vector’ throughout this work. It is inputted to the estimator that produces a redshift output supervised by the spectroscopic redshift label for extracting redshift information. The concatenation of vA and vB is inputted to the decoder to reconstruct images that resemble the input images. With the reconstructed images as inputs, this process is conducted again using the three networks with shared weights, producing the vector vA. Furthermore, the images reshaped with random flipping and rotation by 90 deg steps are exploited as inputs, producing the vector vA. For contrastive learning, the contrast between vA and vA and the contrast between vA and vA for the same galaxy are minimised (i.e. positive pairs), which are characterised by the Euclidean distance. The contrast between the latent vectors for any two different galaxies is maximised (i.e. a negative pair). |
3.3 Adaptive KNN
We performed KNN to retrieve a group of nearest neighbours for the projection of any query data instance in an established latent space, whose known redshifts were used to construct an initial probability density estimate. This idea is based on the topology of the latent space, that is, the data instances with neighbouring projections would have similar redshift-related properties and can be approximated as random draws from a common redshift probability density. The neighbourhood for a data instance in the latent space is represented by its nearest neighbours. We note that a neighbourhood would typically encapsulate different redshifts; at the same time, different neighbourhoods would overlap, having shared nearest neighbours that provide the same redshifts. In other words, the topology of the latent space naturally depicts the many-to-many mapping between photometric data and redshift.
Since the data are not uniformly distributed, the conventional KNN with a constant k value as performed by Wei et al. (2022) may not define the neighbourhood properly for every query data instance. Therefore, we proposed an ‘adaptive’ KNN algorithm with varying k values for different data instances. To be specific, we relied on local PIT diagnostics to determine the optimal k for each data instance. The PIT for a data instance is defined as
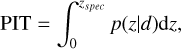 (9)
(9)
where ɀspec stands for its spectroscopic redshift. If a neighbourhood is properly defined that best describes the local properties and gives well-calibrated probability density estimates, the distribution of the PIT values computed for the data instances within the neighbourhood should be uniform between 0 and 1 (see also Dey et al. 2021; Zhao et al. 2021; Dey et al. 2022b). Therefore, the optimal k can be found when the PIT distribution constructed by the corresponding number of nearest neighbours is closest to uniformity (i.e. via PIT diagnostics).
The adaptive KNN algorithm consists of two rounds of gridsearch from a grid of k values. The first round is performed to find the k nearest neighbours for each query data instance with each k selected from the grid. The query data instances and the nearest neighbours are all from the training sample. We adopt the Euclidean distance for KNN, the distance metric used in SCL. The known spectroscopic redshifts of the k nearest neighbours provide a probability density; then with the known redshift of the query data instance, a PIT value for each given k can be computed (denoted with PITk). The second round of search, for each query data instance from the target sample or the validation sample, is performed to find its k nearest neighbours from the training sample with each given k. Then with the PITk values of the k nearest neighbours obtained from the first round, a distribution of PITk can be constructed that represents the local PIT distribution for the query data instance within a neighbourhood whose scale is characterised by the given k.
To quantify the discrepancy between uniformity and the PITk distribution for each k, we adopted the 1-Wasserstein distance (Villani 2009; Panaretos & Zemel 2019) defined as
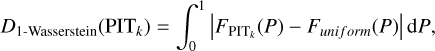 (10)
(10)
where 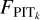 (P) and Funi form (P) stand for the cumulative versions of the normalised PITk distribution and the uniform distribution, respectively. The 1-Wasserstein distance mainly captures the deviation between the broad shapes of the two distribution and is insensitive to random fluctuations in the PITk distribution. Using it as a metric, we searched for the optimal k for each query data instance from the target sample or the validation sample, for which the corresponding D1-Wasserstein (PITk) reaches the minimum. Then the spectroscopic redshifts of the k nearest neighbours were collected to construct an initial probability density estimate pini(ɀ|d), using the same binning as the softmax output in SCL.
(P) and Funi form (P) stand for the cumulative versions of the normalised PITk distribution and the uniform distribution, respectively. The 1-Wasserstein distance mainly captures the deviation between the broad shapes of the two distribution and is insensitive to random fluctuations in the PITk distribution. Using it as a metric, we searched for the optimal k for each query data instance from the target sample or the validation sample, for which the corresponding D1-Wasserstein (PITk) reaches the minimum. Then the spectroscopic redshifts of the k nearest neighbours were collected to construct an initial probability density estimate pini(ɀ|d), using the same binning as the softmax output in SCL.
3.4 Recalibration
A PIT distribution closest to uniformity is not necessarily uniform. To ensure good calibration of the to-be-obtained probability density estimates, after determining the optimal k and constructing pini(ɀ|d), we performed a (first-order) recalibration procedure similar to Bordoloi et al. (2010) using the local PITk distribution for the given k,
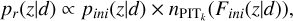 (11)
(11)
where pr(ɀ|d) is the recalibrated probability density estimate; Fini (ɀ|d) stands for the cumulative density estimate given by Pini(ɀ|d); 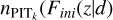 ) stands for the PITk number density at Fini(ɀ|d). We note that this is a local recalibration procedure for every data instance enabled by KNN, rather than global calibration over the whole sample as performed by Bordoloi et al. (2010).
) stands for the PITk number density at Fini(ɀ|d). We note that this is a local recalibration procedure for every data instance enabled by KNN, rather than global calibration over the whole sample as performed by Bordoloi et al. (2010).
A robust recovery of 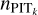 is crucial for recalibration. Naturally,
is crucial for recalibration. Naturally, 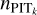 can be approximated using the training sample alone,
can be approximated using the training sample alone,
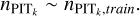 (12)
(12)
Given possible overfitting in SCL, the distributions of the projections p(Φ(d)|ɀ) for the data seen and unseen in the training process may mildly differ, thus 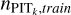 may not perfectly reflect the actual PIT distribution within the defined neighbourhood of an unseen data instance. Therefore, we re-computed the PITk value for each data instance from the training sample, but with ɀspec in Eq. (9) being the redshift of its nearest instance from the validation sample. The distribution of such PITk values is denoted with
may not perfectly reflect the actual PIT distribution within the defined neighbourhood of an unseen data instance. Therefore, we re-computed the PITk value for each data instance from the training sample, but with ɀspec in Eq. (9) being the redshift of its nearest instance from the validation sample. The distribution of such PITk values is denoted with 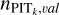 . With this, we propose another estimate of
. With this, we propose another estimate of 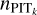 as
as
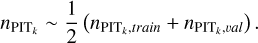 (13)
(13)
Combining 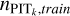 and
and 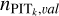 is due to the consideration that using
is due to the consideration that using 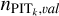 alone would introduce large errors because of limited statistics. For each dataset, we checked the recalibration results with either Eq. (12) or Eq. (13) using the validation sample, and applied the better one for the target sample. The KNN-calibrated raw probability density estimates pr(ɀ|d) for the target sample produced by Eq. (11) are used for refitting described in the next subsection.
alone would introduce large errors because of limited statistics. For each dataset, we checked the recalibration results with either Eq. (12) or Eq. (13) using the validation sample, and applied the better one for the target sample. The KNN-calibrated raw probability density estimates pr(ɀ|d) for the target sample produced by Eq. (11) are used for refitting described in the next subsection.
Essentially, this recalibration procedure determines the weights assigned to the nearest neighbours of each data instance that better characterise the local redshift-data distribution p(ɀ, d). An assessment on recalibration is presented in the supplementary appendices (see Data and Code Availability).
3.5 Refitting
To bypass the intensive computation required for KNN, we implemented a refitting procedure that resumed an end-to-end discriminative model ready to be applied directly to imaging data and produce probability density estimates p(ɀ|d). To be specific, for a SCL framework developed in Sect. 3.2, we discarded the decoder, fixed the trained encoder and refit the estimator from scratch in a simple supervised manner with the KNN-calibrated raw probability density estimates pr(ɀ|d) as labels. This is equivalent to retraining only the estimator using the obtained latent vectors as inputs. Both the inputs and the KNN-calibrated labels for refitting are now from the target sample. We note that the KNN-calibrated labels have no access to the actual spectroscopic redshifts from the target sample, thus there is no leakage of target redshift information to the model.
To better constrain the shapes of the probability density estimates p(ɀ|d), we adopted a hybrid loss function that consists of the cross-entropy and the 1-Wasserstein distance between p(ɀ|d) and pr(ɀ|d),
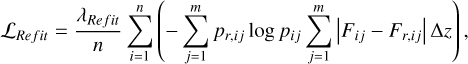 (14)
(14)
where the index i runs over the n data instances in a mini-batch; the index j runs over the m redshift bins for each data instance. Fij and Fr,ij stand for the two cumulative density estimates. ∆ɀ is the size of a redshift bin (i.e. ∆ɀ = (ɀmax – 0)/m). The coefficient λRefit controls the overall amplitude of the loss.
The model resumed this way has no difference from conventional end-to-end discriminative models but its outputs have been calibrated thanks to KNN. We demonstrate that refitting using the KNN-calibrated labels rather than the one-hot labels does not introduce apparent biases (Sect. 4.6) or miscalibration (Sect. 5).
The output probability density estimates may be unfavourably discretised due to sparse data coverage in redshift bins. Hence, once a model was resumed, each output estimate was further smoothed with a Gaussian filter, whose dispersion was determined as 5% of the standard deviation of the unsmoothed estimate. We found that this choice would effectively reduce the degree of discretisation but have negligible impact on the width of each probability density estimate (see Data and Code Availability for a few examples).
In practice, when a target sample is too large to perform KNN, we can select a representative subset from the target sample as a reference subsample, implement the refitting procedure, and apply the resumed model to the remaining data for inference. We test the outcomes of inference using the SDSS dataset in Sect. 4.6.
3.6 Combining probability density estimates
Combining probability density estimates from an ensemble of measurements would reduce uncertainties and improve accuracy (Treyer et al. 2024). Pasquet et al. (2019) took the arithmetic mean over individual probability density estimates from six realisations of the same network to obtain the final estimates. Though seemingly intuitive, such combination tends to produce overdispersed probability density estimates. This is because 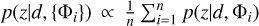 does not hold true in general for any models {Φi} to be combined (see Sect. 5.3 for more discussions).
does not hold true in general for any models {Φi} to be combined (see Sect. 5.3 for more discussions).
In this work, we suggest that a proper way to combine estimates from an ensemble of models is via the harmonic mean. To prove this, we first assume that the projection of a data instance d (with a particular redshift z) via any individual model Φi to the latent space (i.e. Φi(d)) is a random draw from the hypothetical neighbourhood of the projection via the combined model Φc, though these individual projections do not need to be enclosed in an actual common neighbourhood. We also assume that the probability of getting the projection Φc (d) can be computed by averaging the probabilities of getting each individual projection Φi(d) under the linear approximation,
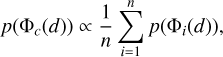 (15)
(15)
or equivalently,
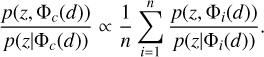 (16)
(16)
Since the data instance d with the given redshift z falls in the neighbourhoods of all the projections {Φi(d)} and Φc(d), the probability of ɀ belonging to any neighbourhood remains constant, i.e. p(Φc(d)|ɀ) = p(Φi(d)|ɀ) for any model Φi. This leads to the conclusion that
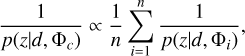 (17)
(17)
for which p(ɀ|Φc(d)) and p(ɀ|Φi(d)) have been rewritten as p(ɀ|d, Φc) and p(ɀ|d, Φi), respectively, where ɀ is now considered as any redshift bins. Therefore, we propose to use the harmonic mean for combining an ensemble of probability density estimates. The combined estimates should be renormalised to unity if using the harmonic mean. For brevity in the text, we do not mention this explicitly hereafter. We show a few examples of probability densities before and after combination in the supplementary appendices (see Data and Code Availability).
3.7 Implementing CLAP
We implemented CLAP following all the procedures introduced in the previous subsections, using the SDSS, CFHTLS, and KiDS datasets separately. With each dataset, we used the training sample and the validation sample to develop the SCL framework, then included the target sample in the downstream procedures. For the CFHTLS dataset, both the galaxies with high-quality and low-resolution spectroscopic redshifts from the training sample were used in SCL, while only those with high-quality spectroscopic redshifts were used after SCL. This removes the mismatch between the initial training sample and the target sample.
For the encoder and the estimator in SCL, we adopted a modified version of the inception network developed by Treyer et al. (2024). It falls in the category of convolutional neural networks (CNNs), featured by a set of multi-scale inception modules (Szegedy et al. 2015) accompanied with convolutional layers and pooling layers. They produce feature maps that are then flattened and fed into a set of fully connected layers for predicting redshifts. Between the first two fully connected layers in this network, we inserted two new parallel layers to produce the vectors vA and vB. The whole part of the network before the vectors is regarded as the encoder. The last fully connected layers, only linked to vA, form the estimator. For it, we discarded the regression branch and only kept the classification branch (with a softmax function) from the original implementation by Treyer et al. (2024). The redshift bin size we used in the softmax output and the one-hot spectroscopic redshift labels for each dataset is listed in Table 1. The concatenation of vA and vB is fed into the decoder that has convolutional layers and bilinear interpolation for upsampling and reconstructing images. The latent vector vA has 16 dimensions for encoding redshift information, and vB has 512 dimensions. These numbers were chosen to ensure computational efficiency and no major loss of information. For the SDSS dataset and the CFHTLS dataset, we included the galactic reddening E(B – V) as an extra channel to the multi-band images inputted to the encoder. For the KiDS dataset, the 5-band NIR magnitudes from VIKING were further included as extra channels. More details about the network architectures can be found in Appendix A.
The raw SDSS and CFHTLS images have AB magnitude zeropoints of 22.5 and 30, respectively. The KiDS images were redefined to have a zeropoint of 25. In order to lessen the significance of the galaxy peak flux, we then rescaled the images from all the datasets using the formula
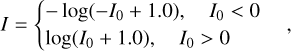 (18)
(18)
where I and I0 stand for the rescaled and the original pixel intensities, respectively.
In Eq. (8), we set the coefficient λMSE,I = 100 for the SDSS and KiDS datasets while λMSE,I = 1 for the CFHTLS dataset. λCE = 1 was set for all the datasets. With each dataset, we trained our SCL framework from scratch using the mini-batch gradient descent implemented with the default Adam optimiser (Kingma & Ba 2015). In each training iteration, a mini-batch of 64 images- label pairs was randomly selected from the training sample. The images were randomly flipped and rotated with 90 deg steps before being used as the initial inputs I. We adopted an initial learning rate of 10–4, which was reduced by a factor of 5 after 60 000 training iterations. By monitoring the loss with the validation sample, we decided to conduct 150 000, 120 000, 120 000 training iterations in total for the SDSS, CFHTLS, and KiDS datasets, respectively. The SCL framework for each dataset was properly trained with these numbers, while we note that mild underfitting or overfitting would not have a significant impact on the results.
For the adaptive KNN and the recalibration procedures, we used 100 bins from 0 to 1 to express the PIT distributions for all the datasets. We note that a small number of bins would enlarge quantisation errors, while a large number of bins would make the data insufficient to fill in the bins, leading to shot noise. An intermediate number such as 100 is a compromise between reducing quantisation errors and limiting shot noise. For efficient grid search, we selected discrete k values from four consecutive ranges: 5–200 with a step of 5, 200–600 with a step of 10, 600–1000 with a step of 20, and 1000–2000 with a step of 50. The maximum k is set to be 2000, large enough to avoid finding too small (sub-optimal) k values while still ensuring locality of each obtained neighbourhood and circumventing unnecessary intensive computation. The medians of the distributions of the obtained optimal k are 660, 110, and 145 for the SDSS, CFHTLS, and KiDS target samples, respectively. The majority of data have optimal k well below 2000, while only a minor fraction of the obtained optimal k values (2.9, 0.2, and 0.5%, respectively) are equal to this maximum value and thus may potentially exceed the defined k range. We note that small k values may be disfavoured because of large shot noise, but this potential bias can be corrected by recalibration (see Data and Code Availability for an assessment on recalibration).
In order to obtain the PIT distributions 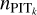 for recalibration, by checking the validation samples, we chose to use Eq. (13) for the SDSS and CFHTLS datasets, and Eq. (12) for the KiDS dataset. We performed the second-order polynomial fit to remove random fluctuations in
for recalibration, by checking the validation samples, we chose to use Eq. (13) for the SDSS and CFHTLS datasets, and Eq. (12) for the KiDS dataset. We performed the second-order polynomial fit to remove random fluctuations in 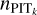 and used the fit
and used the fit 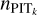 in Eq. (11) for recalibration.
in Eq. (11) for recalibration.
In the refitting procedure, in order to test whether the resumed end-to-end models are capable of making inference for held-out data, we split the SDSS target sample into a reference subsample and an inference subsample, used for refitting and inference, respectively, while the CFHTLS and KiDS target samples are only used as reference samples due to limited statistics. We set λRefit = 100 in Eq. (14). For each dataset, we set the minibatch size to be 128, took 40 000 training iterations in total, and adopted a constant learning rate of 10−4. The mini-batch gradient descent with the default Adam optimiser was used again.
For the hyperparameters and coefficients involved in the implementation of CLAP, we tested a few different values around the aforementioned chosen values and found negligible impact on the results, indicating that the CLAP models established with the current implementation have converged. We refer to Lin et al. (2022) for detailed discussions on the impacts of varying implementing conditions, involving, for example, the training sample size, the redshift bin size, the number of training iterations, and the mini-batch size.
Finally, we leveraged the strategy of combining an ensemble of models to improve accuracy. Following the aforementioned procedures, we implemented CLAP ten times. Each time, the SCL and the refitting were conducted in the same way but with a different initialisation of trainable weights and different selections of mini-batches. The outcomes of adaptive KNN and recalibration may consequently be different due to such stochas- ticity. The output probability density estimates from the ten CLAP models were combined using the harmonic mean.
We compared the models developed with the full range of data for each dataset illustrated in Fig. 1 and those developed with segmented ranges of redshift and r-band magnitude. The results produced by these ‘sub-models’ generally follow the evolution trends of biases and accuracy obtained by the ‘fullmodels’ shown in Sect. 4.5. Therefore, we only discuss the results from the full-models in the remainder of the paper.
4 Results on probability density estimation
Throughout this section, we present our results on photometric redshift estimation by CLAP using the target samples from the SDSS, CFHTLS, and KiDS datasets. Comparisons are made with a few benchmark methods. In Sects. 4.3, 4.4, and 4.5, we use the whole SDSS target sample without separating the reference and the inference subsamples, while in Sect. 4.6 we make this separation when assessing the resumption of end-to-end models by refitting. We demonstrate that the reference and the inference subsamples have consistent results produced by CLAP and thus they can be combined. A few examples of probability density estimates obtained by CLAP are presented in the supplementary appendices (see Data and Code Availability).
4.1 Assessment techniques
Before further discussions in the next subsections, we present the techniques used for assessing the probability density estimates and the density-derived point estimates.
Firstly, we discuss our choice of point estimates, which is important for our analysis. There are several possible definitions of point estimates that can be derived from probability density estimates, such as ɀmean (i.e. the probability-weighted mean redshift), ɀmode (i.e. the redshift at the peak probability), and ɀmedian (i.e. the median redshift at which the cumulative probability is 0.5). Different definitions have been discussed in many studies such as Tanaka et al. (2018), Pasquet et al. (2019), Lin et al. (2022), Treyer et al. (2024), and Treyer et al. (in prep.). For template-fitting methods, the best-fitting redshifts are usually adopted as point estimates, analogous to ɀmode. In our work, we chose ɀmean as point estimates. Our consideration for this links back to the frequentist definition: if a probability density accurately describes the actual rate of occurrence of true redshifts, the empirical mean of the true redshifts should be equal to the expected mean redshift weighted by the probability density, i.e. ɀmean. In other words, with sufficient statistics, perfect probability density estimates lead to zero mean redshift residuals if estimated with ɀmean (though the reverse is not necessarily true). Other choices of point estimates do not have such property in general. Therefore, ɀmean is taken as our exclusive choice of point estimates ɀphoto for CLAP hereafter.
To have an inspection over the properties of the probability density estimates, we checked a few summary statistics defined using the individual probability densities and the corresponding spectroscopic redshifts ɀspec, including the probability integral transform (PIT), the 1-Wasserstein distance, the continuous ranked probability score (CRPS), the cross-entropy, the entropy, the standard deviation, the skewness, and the kurtosis. Regarding the point estimates, we characterised the mean redshift biases using δ<ɀ>, the residuals of mean redshifts estimated in redshift or magnitude bins, and quantified the estimation accuracy using σMAD, the estimate of deviation based on the median absolute deviation (MAD). The definitions of all these metrics are shown in Table 2.
Knowing that each individual probability density has only one realisation (i.e. a unique spectroscopic redshift for a given galaxy), we also considered a distribution offset analysis with a stacking technique to assess the global behaviour of the probability density estimates over a sample. Specifically, we recentred each probability density estimate by shifting the point estimate ɀphoto to ɀ = 0 and stacked all such recentred estimates over a sample (denoted with pΣ(ɀ – ɀphoto)); we also drew the histogram of ɀspec – ɀphoto. If the probability density estimates are well- calibrated, these two distributions should be consistent given sufficient statistics (though the reverse is not necessarily true). Hence, we checked the cumulative offset of the stacked recentred probability density pΣ(ɀ – ɀphoto) relative to the ɀspec – ɀphoto histogram (denote with ∆FpΣ–h). Such cumulative offset is sensitive to any inconsistency between the two distributions to be compared.
Although many studies stacked the original probability density estimates and made a comparison with the actual ɀspec distribution, we note that such stacked probability density and the ɀspec distribution are usually not directly comparable. In other words, for probability densities p(ɀ|d1), p(z|d2),…, p(ɀ|dn) to be stacked, there may exist a data instance with any particular redshift ɀ enclosed in the neighbourhoods of d1, d2,…, dn simultaneously, making the selections of (ɀ, d1), (ɀ, d2),…, (ɀ, dn) not mutually exclusive, such that 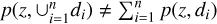 (see also Malz 2021). However, the connections among d1, d2,…, dn through the shared data instance with ɀ can be broken by instead using ∆ɀi = ɀ – ɀphoto,i for each di. This is because (ɀ, d1), (ɀ, d2),…, (ɀ, dn) that initially had the shared ɀ are now reassigned to different {∆ɀi} bins since {ɀphoto,i} are different. Now the selections of (∆ɀ, d1), (∆ɀ, d2),…, (∆ɀ, dn) for the same ∆ɀ are statistically mutually exclusive, since ∆ɀ is no longer contributed by a shared data instance in the neighbourhoods of d1, d2,…, dn. Hence, the stacked recentred probability density pΣ(ɀ – ɀphoto) and the ɀspec –ɀphoto distribution are now comparable provided with sufficient statistics. Admittedly, this stacking technique is not rigorously mathematically meaningful, but it serves as a tool to check the reliability of the probability density estimates globally over a sample.
(see also Malz 2021). However, the connections among d1, d2,…, dn through the shared data instance with ɀ can be broken by instead using ∆ɀi = ɀ – ɀphoto,i for each di. This is because (ɀ, d1), (ɀ, d2),…, (ɀ, dn) that initially had the shared ɀ are now reassigned to different {∆ɀi} bins since {ɀphoto,i} are different. Now the selections of (∆ɀ, d1), (∆ɀ, d2),…, (∆ɀ, dn) for the same ∆ɀ are statistically mutually exclusive, since ∆ɀ is no longer contributed by a shared data instance in the neighbourhoods of d1, d2,…, dn. Hence, the stacked recentred probability density pΣ(ɀ – ɀphoto) and the ɀspec –ɀphoto distribution are now comparable provided with sufficient statistics. Admittedly, this stacking technique is not rigorously mathematically meaningful, but it serves as a tool to check the reliability of the probability density estimates globally over a sample.
Similarly, we checked the cumulative offset between the zspec − zphoto histograms for two methods (denote with ∆Fh–h), which can be used to demonstrate their relative accuracy and biases, irrespective of whether or not they have probability density estimation.
Estimates and summary statistics derived from probability densities.
4.2 Benchmark methods
We compared CLAP with a few benchmark methods for the three datasets. The results predicted by our SCL framework (i.e. the softmax outputs q(z|d) from SCL rather than refitting) are shown for the first comparison. We reiterate that the SCL prediction is only regarded as a baseline and should not be confused with the results from the complete implementation of CLAP. For the KiDS dataset, we also show the results produced by CLAP but without including the 5-band NIR magnitudes from VIKING as inputs, demonstrating the impact of the NIR data on photometric redshift estimation. For both CLAP and the SCL prediction, the ensemble of ten probability density estimates are combined using the harmonic mean unless otherwise noted.
For further comparison, we present the results obtained by several image-based deep learning methods collected from different studies, including inception networks from Pasquet et al. (2019) and Treyer et al. (in prep.), a bias correlation approach based on inception networks from Lin et al. (2022), a capsule network from Dey et al. (2022a), as well as a VGG network (using the 4-band KiDS images as inputs) and a hybrid network (using the 4-band KiDS images and the 5-band VIKING photometry as inputs) from Li et al. (2022a). Regarding photometry-only methods, we show the results from Beck et al. (2016) who applied KNN and local regression, the results obtained using Le Phare (Arnouts et al. 1999; Ilbert et al. 2006), as well as those retrieved from the public KiDS catalogues1 produced by MLPQNA (Brescia et al. 2014; Cavuoti et al. 2015, 2017), ANNz2 (Sadeh et al. 2016; Bilicki et al. 2018), and BPZ (Benítez 2000).
We show the results from Lin et al. (2022), Pasquet et al. (2019), Dey et al. (2022a), Treyer et al. (in prep.), and Li et al. (2022a) using their test samples. All but the CFHTLS test sample from Lin et al. (2022) essentially have the same redshift-data distributions as our target samples in spite of different sample divisions. We use the results provided by Lin et al. (2022) for which the zphoto-dependent mean redshift biases have been corrected, bypassing the impact of the mismatch in distributions. The results from Beck et al. (2016) and Le Phare are shown using our target samples, while those from MLPQNA, ANNz2, and BPZ are shown using the test sample provided by Li et al. (2022a). These results are directly compared despite that different choices of point estimates were adopted by different studies. Pasquet et al. (2019), MLPQNA, and BPZ have probability density estimates available for comparison, while the other methods only provide point estimates. The probability density estimates provided by Pasquet et al. (2019) have the same redshift coverage and binning as ours. For consistency with our analysis on the KiDS dataset selected with zspec < 3, the original probability density estimates given by MLPQNA and BPZ were truncated at z = 3, rebinned, and renormalised. We further caution that the VGG network, MLPQNA, ANNz2, and BPZ for the KiDS dataset did not use the five NIR bands, thus they can be treated as a direct reference for the ‘No-NIR’ CLAP implementation, but not the default implementation with the NIR data included. These results are all shown to enrich the comparison among various methods.
4.3 Calibration of probability density estimates
In the upper panels of Fig. 4, the dashed curves show the zspec – zphoto histograms for CLAP and the benchmark methods for the SDSS, CFHTLS, and KiDS datasets. The solid curves show the stacked recentred probability densities (z − zphoto) when the probability density estimates are available. Their cumulative offsets 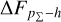 are shown as the solid curves in the lower panels. The first column of Fig. 5 shows the PIT distributions. The cumulative offset
are shown as the solid curves in the lower panels. The first column of Fig. 5 shows the PIT distributions. The cumulative offset 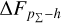 and the PIT distribution are complementary and offer a cross-check over the calibration of a given set of probability density estimates.
and the PIT distribution are complementary and offer a cross-check over the calibration of a given set of probability density estimates.
For all the three datasets, the cumulative offsets 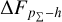 given by CLAP (including the No-NIR implementation for the KiDS dataset) are constrained within low levels (i.e. 0.005, 0.01, and 0.01, respectively), better than those given by the SCL prediction and the other benchmark methods. CLAP also produces nearly flat PIT distributions, though the PIT distributions obtained for the CFHTLS dataset and by the No-NIR implementation for the KiDS dataset are slightly convex, in addition to some fluctuations probably as a result of estimation errors. The exclusion of the NIR data for the KiDS dataset degrades the estimation accuracy (see Sect. 4.5), but hardly influences the calibration of probability densities. In particular, No-NIR CLAP outperforms the SCL prediction for which the NIR data were used. Both the small offsets and the nearly flat PIT distributions gain evidence that the probability density estimates obtained by CLAP are well-calibrated.
given by CLAP (including the No-NIR implementation for the KiDS dataset) are constrained within low levels (i.e. 0.005, 0.01, and 0.01, respectively), better than those given by the SCL prediction and the other benchmark methods. CLAP also produces nearly flat PIT distributions, though the PIT distributions obtained for the CFHTLS dataset and by the No-NIR implementation for the KiDS dataset are slightly convex, in addition to some fluctuations probably as a result of estimation errors. The exclusion of the NIR data for the KiDS dataset degrades the estimation accuracy (see Sect. 4.5), but hardly influences the calibration of probability densities. In particular, No-NIR CLAP outperforms the SCL prediction for which the NIR data were used. Both the small offsets and the nearly flat PIT distributions gain evidence that the probability density estimates obtained by CLAP are well-calibrated.
In contrast, for either the CFHTLS dataset or the KiDS dataset, the tilde around zero in the cumulative offset 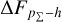 given by the SCL prediction indicates that the stacking of the recentred probability density estimates is narrower than the zspec − zphoto histogram, reflecting that the probability density estimates are underdispersed (or overconfident), as also implied by the convex PIT distributions. This is a sign of miscalibra-tion caused internally by the estimation method. The probability density estimates given by MLPQNA and BPZ are significantly uncalibrated, producing large cumulative offsets
given by the SCL prediction indicates that the stacking of the recentred probability density estimates is narrower than the zspec − zphoto histogram, reflecting that the probability density estimates are underdispersed (or overconfident), as also implied by the convex PIT distributions. This is a sign of miscalibra-tion caused internally by the estimation method. The probability density estimates given by MLPQNA and BPZ are significantly uncalibrated, producing large cumulative offsets 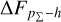 . For the SDSS dataset, the trough centred at zero in the cumulative offset
. For the SDSS dataset, the trough centred at zero in the cumulative offset 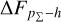 given by the SCL prediction indicates that the probability density estimates are on average shifted towards higher redshift, resulting in overestimated zphoto and the slightly tilted PIT distribution, though the PIT distribution is already close to flatness thanks to high accuracy. For Pasquet et al. (2019), the reversed tilde and the concave PIT distribution indicate that the probability density estimates are overdispersed, which is an artefact erroneously introduced by combining probability density estimates using the arithmetic mean (discussed in Sect. 5.3).
given by the SCL prediction indicates that the probability density estimates are on average shifted towards higher redshift, resulting in overestimated zphoto and the slightly tilted PIT distribution, though the PIT distribution is already close to flatness thanks to high accuracy. For Pasquet et al. (2019), the reversed tilde and the concave PIT distribution indicate that the probability density estimates are overdispersed, which is an artefact erroneously introduced by combining probability density estimates using the arithmetic mean (discussed in Sect. 5.3).
These results indicate that CLAP is more robust than the other methods in obtaining well-calibrated probability density estimates. We present a deeper investigation on miscalibra-tion in Sect. 5. We note that the adaptive KNN algorithm and recalibration are both key parts of CLAP for ensuring good calibration for each data instance. An assessment on recalibration is presented in the supplementary appendices (see Data and Code Availability).
 |
Fig. 4 Distribution offset analysis for the SDSS, CFHTLS, and KiDS target samples. The results obtained by CLAP are compared with the prediction from our supervised contrastive learning (SCL) framework, and those produced by a few benchmark image-based methods including inception networks from Pasquet et al. (2019) and Treyer et al. (in prep.), network-based bias correlation from Lin et al. (2022), a capsule network from Dey et al. (2022a), a VGG network, and a hybrid network from Li et al. (2022a), and the photometry-only methods including KNN & regression from Beck et al. (2016), Le Phare (Arnouts et al. 1999; Ilbert et al. 2006), as well as MLPQNA (Brescia et al. 2014; Cavuoti et al. 2015, 2017), ANNz2 (Sadeh et al. 2016; Bilicki et al. 2018), and BPZ (Benítez 2000) retrieved from the public KiDS catalogues. For the KiDS dataset, the results obtained by CLAP but without the NIR data are also shown (‘No NIR’). For both CLAP and the SCL prediction, the ensemble of ten probability density estimates are combined using the harmonic mean. Upper panels: z − zphoto distributions. The solid curves show the stacked recentred probability densities pΣ (z − zphoto) for the methods that have probability density estimation. The dashed curves show the zspec − zphoto histograms for all the methods. The error bands are estimated using bootstrap. The vertical dashed lines show the median of zspec − zphoto for each method, indicating the centre of each zspec − zphoto distribution regardless of the random errors due to limited statistics at high redshift. Lower panels: Cumulative z − zphoto distribution offsets. The solid curves show the cumulative offset of the stacked recentred probability density pΣ(z − zphoto) relative to the corresponding zspec − zphoto histogram for each method that has a probability density estimation (i.e. |
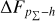
 |
Fig. 5 Distributions of summary statistics of photometric redshift probability density estimates illustrated for the SDSS, CFHTLS, and KiDS target samples. Comparison is made among the results from CLAP and the methods for which the probability density estimates are available, as in Fig. 4. The definitions of the shown summary statistics can be found in Table 2. For both CLAP and the SCL prediction, the ensemble of ten probability density estimates are combined using the harmonic mean. For the PIT, the y-axis in each panel is truncated at 0.5 for clearer illustration; the horizontal dashed lines indicate normalised uniform distributions. The PIT distributions produced by MLPQNA and BPZ are dramatically non-flat and are not shown in the figure. For the kurtosis, the vertical dashed lines indicate the value for Gaussian-like distributions (i.e. 3). |
4.4 Properties of probability density estimates
Figure 5 illustrates the distributions of the summary statistics other than PIT for the methods that have probability density estimation. For CLAP, the SCL prediction, and Pasquet et al. (2019), the distributions of the 1-Wasserstein distance, the CRPS, the cross-entropy, and the standard deviation all have heavy tails towards large values, resulting from the wide probability densities and the large uncertainties at high magnitude. The distributions of these summary statistics obtained by No-NIR CLAP for the KiDS dataset are all slightly shifted towards higher values due to enlarged estimation errors compared to the results from default CLAP. Both the distributions of the cross-entropy and the entropy are peaked around 3, meaning that the probability at the redshift bin that zspec falls in is most likely to be exp(−3) ~ 0.05, which is consistent with the probability that has the largest contribution to the entropy. The subtle double peaks in the entropy distribution for CFHTLS dataset reflects the two populations clearly seen in the r-band magnitude distribution in Fig. 1, an artefact introduced by combining disparate spectroscopic surveys. The slightly excessive tails in the entropy distributions obtained by CLAP for the CFHTLS and KiDS datasets are due to the smoothing applied on the probability densities in the refitting procedure. In contrast to the image-based methods, MLPQNA and BPZ tend to produce higher values for these summary statistics due to lower accuracy and wider probability densities.
The bulk of the skewness distribution for the SDSS dataset is located at positive values, showing that the majority of probability density estimates are right skewed as a result of the skewed redshift distribution for the training sample. The skewness distributions for the CFHTLS and KiDS datasets are also centred above zero, whereas there are much heavier tails than those for the SDSS dataset. The tails of the kurtosis distributions are all above 3, indicating that the majority of probability density estimates have fatter tails than Gaussian-like distributions. Significantly higher values are present for the CFHTLS and KiDS datasets, reaching up to 30.9 and 56.4 at the 90th percentile, respectively. The variety of the skewness and the kurtosis reveals the diversity of photometric redshift probability densities estimated over broad redshift and magnitude ranges.
4.5 Mean redshift biases and accuracy of point estimates
Using the point estimates derived from the probability density estimates, we evaluated the mean redshift biases and the accuracy, characterised by δ<z> and σMAD, respectively, which are important indicators of the quality of photometric redshift estimation. Accurate mean redshift determination is crucial for weak lensing tomography analysis (e.g. Ma et al. 2006; Huterer et al. 2006; Euclid Collaboration 2021). For modern cosmological surveys such as Euclid and LSST, the error of the mean redshift determined in a tomographic bin is required to be no more than 0.002 (Laureijs et al. 2011). This is a demanding requirement that necessitates careful evaluation on the photometric redshift estimation results.
Figure 6 illustrates how δ<z> and σMAD evolve as a function of zphoto or r-band magnitude for CLAP and the other methods. These results are also summarised in the supplementary appendices (see Data and Code Availability). As a further comparison, the dashed curves in the lower panels of Fig. 4 show the cumulative offset of the zspec − zphoto histogram for each of all the methods (including No-NIR CLAP for the KiDS dataset) relative to that for default CLAP (i.e. ∆Fh–h).
At first glance, the results obtained by the image-based methods are in general better than those obtained by the photometry-only methods. Most image-based methods achieve higher accuracy characterised by σMAD, which might primarily result from the exploitation of information in addition to galaxy photometry. The lower accuracy obtained by No-NIR CLAP and the VGG network compared to that by the other image-based methods for the KiDS dataset indicates the need for the 5-band NIR magnitudes as inputs. We notice that there seems to be no significant difference among most image-based methods in constraining the mean redshift biases. In particular, the results from all the image-based methods shown for the SDSS dataset fulfil the requirement |δ<z>| < 0.002 over zphoto < 0.25, associated with high accuracy due to the good quality of the magnitude-limited low-redshift SDSS data and a large training sample size. For the CFHTLS and KiDS datasets, although there are large scatters at high red-shift and high magnitude due to limited statistics and low S/N, the mean redshift residuals produced by most image-based methods generally exhibit no drastic evolving trend as a function of zphoto over the full redshift range. The photometry-only methods, on the contrary, typically produce higher σMAD, as also implied by the strong tildes in their cumulative offsets ∆Fh–h relative to CLAP, though the accuracy achieved by MLPQNA is only mildly different from that by the VGG network. ANNz2 and BPZ produce much stronger biases. The mutually enhanced errors and biases may primarily stem from the photometry-redshift degeneracies and the photometric errors. The template-fitting methods (i.e. Le Phare and BPZ) may additionally suffer from a shortage of representative templates.
In spite of similar results given by the image-based methods, we point out that CLAP performs better in constraining the mean redshift biases given sufficient statistics. For each of the CFHTLS and KiDS datasets, we show the mean redshift residuals in a restricted redshift range (i.e. zphoto < 1.0 and zphoto < 0.6, respectively) in addition to the full range, which contains roughly 90% of the full sample. As can be seen, the residuals produced by default CLAP are marginally consistent with the requirement |Δ<z>| < 0.002, better than those by the conventional discriminative models such as the inception network from Treyer et al. (in prep.) and the hybrid network from Li et al. (2022a). The outputs by these conventional methods at low redshift would probably be compromised in order to accommodate the large errors at high redshift. The non-zero residuals at low redshift might also be compounded by stochasticity in the training process and exhibit variations if there were multiple realisations of the same network (further discussed in Sect. 5.1). Similar behaviours can be noticed for residuals shown as a function of r-band magnitude. This is in line with the fact that the zspec − zphoto histograms obtained by these methods all have centres slightly deviating from zero, as indicated by the vertical dotted lines overplotted on the zspec − zphoto histograms and also the troughs in the cumulative offsets ΔFh−h. The results given by the SCL prediction have similar but weaker behaviours. In contrast, No-NIR CLAP, though having lower accuracy, still produces a zspec − zphoto histogram centred at zero and has a good constraint on the mean redshift biases. For the SDSS dataset, we see a clear drop at around zphoto ~ 0.25 for the results from Pasquet et al. (2019), which was also illustrated in Fig. 8 therein. The cumulative offset ΔFh−h for the SCL prediction has a bump around zero, echoing with the trough in 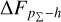 , indicating that the zphoto estimates given by the SCL prediction are on average shifted towards higher values.
, indicating that the zphoto estimates given by the SCL prediction are on average shifted towards higher values.
In general, we note that the conventional discriminative models cannot always guarantee near-zero mean redshift residuals. This may be due to, for example, the joint impact of overfitting, data imbalance, and stochasticity in the training process, which are all related to the phenomenon of miscalibration. While the effect of miscalibration on the point estimates is insignificant for the SDSS dataset as indicated by the good bias constraints over zphoto < 0.25, this is no longer the case for the CFHTLS and KiDS datasets. However, instead of relying on direct model outputs, CLAP leverages known redshifts to construct and calibrate probability density estimates, thus it has a better ability in reducing the mean redshift biases. While Lin et al. (2022) also tackled the mean redshift biases and potentially the impact of miscali-bration, the accuracy might be compromised for bias correction. This is illustrated by the conspicuous boost in σMAD and the strong tilde in ΔFh−h for the CFHTLS dataset. In contrast, this trade-off is no longer a problem for CLAP, thus CLAP achieves high accuracy comparable to other image-based methods.
Furthermore, we point out that the results produced by the image-based methods but the ones from Lin et al. (2022) are all shown in a simple scenario in which the distribution for the target sample matches that for the training sample, giving an impression that CLAP does not noticeably outperform the other conventional methods especially for the SDSS dataset. In general scenarios, however, the mean redshift residuals obtained by the other methods would deviate from zero if shown for a target sample with a different distribution, as the distribution learned from the training sample is fixed in the trained model. On the contrary, CLAP is flexible to adjust the learned distribution, outperforming the other methods in resolving the mean redshift biases induced by mismatches. The next paper on CLAP will discuss how to estimate an unknown target distribution and resolve mismatches based on the CLAP implementation.
Despite the merits, CLAP inevitably suffers from non-negligible errors at high redshift owing to low S/N and insufficient spectroscopic data, the same as other deep learning methods. The errors at high redshift might be the cause for uncontrolled mean redshift biases such as the drop of Δ<z> at r > 22 for the CFHTLS dataset and the mild decreasing trend as a function of r-band magnitude for the KiDS dataset. We suggest that a good control of errors is crucial for ensuring the robustness of CLAP. This would require a larger collection of good-quality spectroscopic data at the high-redshift regime, which are expected to be available from future spectroscopic surveys. Furthermore, in order to optimise the exploitation of available data, it is promising to extend CLAP by exploring the hybridisation of complementary methods (e.g. Sánchez & Bernstein 2018; Alarcon et al. 2020; Rau et al. 2022) as well as domain knowledge-motivated algorithms, which would bring in improvements in high redshift estimation.
 |
Fig. 6 Mean redshift residuals and accuracy of photometric redshift point estimates shown for the SDSS, CFHTLS, and KiDS target samples. The results obtained by CLAP are compared with those produced by other methods, as in Fig. 4. For both CLAP and the SCL prediction, the ensemble of ten probability density estimates are combined using the harmonic mean. Upper panels: mean redshift residuals as a function of photometric redshift zphoto. The error bars are estimated using the root mean square error (RMSE) of residuals in each photometric redshift bin. The requirement for the accuracy of photometric redshift estimation (i.e. |δ<z> | < 0.002) is indicated by the shaded bands. The horizontal dashed lines indicate zero residuals. The results for the CFHTLS and KiDS datasets are shown in both the full and the restricted redshift ranges; the restricted range (i.e. zphoto < 1.0 and zphoto < 0.6, respectively) roughly covers 90% of the full sample for each dataset. For the KiDS dataset, the results produced by ANNZ2 and BPZ are not shown in the restricted range due to large biases. Middle panels: same as the upper panels, but showing mean redshift residuals as a function of r-band magnitude for the full data. Lower panels: σMAD as a function of r-band magnitude. The error bars are estimated using bootstrap. |
4.6 Resumption of end-to-end models by refitting
Refitting has been implemented in CLAP to resume end-to-end discriminative models in order to avoid running computationally expensive KNN for large-scale imaging data. In Fig. 7, we illustrate the outcomes of refitting for the SDSS, CFHTLS, and KiDS target samples that are used as reference samples, and also the results for the SDSS inference subsample. The results obtained by No-NIR CLAP for the KiDS dataset are similar to those obtained by default CLAP and are thus not shown in order to avoid redundancy. With no loss of generality, for each dataset we only selected one of the ten CLAP models in the ensemble for demonstration. It can be seen that the mean redshift residuals Δ<z>, σMAD, the cumulative offsets 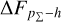 , and the PIT distributions for each reference sample with and without refitting and for the SDSS inference subsample are all in good consistency. In particular, the deviations in the cumulative offsets
, and the PIT distributions for each reference sample with and without refitting and for the SDSS inference subsample are all in good consistency. In particular, the deviations in the cumulative offsets 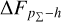 are considered insignificant since they are no more than the upper levels set for each dataset in Fig. 4 (i.e. 0.005, 0.01, and 0.01, respectively). The PIT distributions remain nearly flat regardless of refitting or inference.
are considered insignificant since they are no more than the upper levels set for each dataset in Fig. 4 (i.e. 0.005, 0.01, and 0.01, respectively). The PIT distributions remain nearly flat regardless of refitting or inference.
We thus confirm that no apparent biases were introduced in our refitting procedure or the inference process. The resumption of end-to-end models by refitting holds promises as it not only preserves the advantages of conventional deep learning methods (i.e. accuracy and efficiency), but also retains all the gains from KNN. In addition, the smoothing applied on the probability density estimates effectively remove the unrealistic spikes due to insufficient data coverage (see Data and Code Availability for a few examples).
5 Investigation on miscalibration
Miscalibration is a problem that jeopardises reliable probability density estimation. We attempted to illustrate and analyse miscalibration in the context of deep learning-based photometric redshift estimation with CLAP as a reference. Without losing generality, this analysis was conducted using the SDSS target sample alone. The reference and the inference subsamples are not separated.
5.1 Illustration of miscalibration
We illustrated miscalibration via a comparison among CLAP, the SCL prediction, and a few representative conventional deep learning methods, including:
a vanilla CNN in which we kept the encoder and the estimator from CLAP but without implementing the SCL scheme, trained using the one-hot spectroscopic redshift labels and the softmax cross-entropy loss function only, similar to Pasquet et al. (2019);
a network same as the vanilla CNN, but the output layer was replaced by a mixture of five Gaussian components (i.e. GMM), and trained using the one-hot redshift labels and the CRPS loss function, following the implementation by D’Isanto & Polsterer (2018);
a network same as the vanilla CNN, but Monte Carlo (MC) dropout (Gal & Ghahramani 2016) was applied on two fully connected layers with a dropout rate of 0.5, and the harmonic means of MC estimates (i.e. softmax outputs) were taken as the final probability density estimates, which is an implementation of BNN.
For each of these methods, we trained ten models using the same number of training iterations, mini-batch size, and learning rate as used in SCL for implementing CLAP.
In Fig. 8, we show the PIT distribution and the cumulative offset 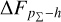 for each of the ten (uncombined) models obtained by each method. Same as those shown in Fig. 4, the cumulative offset
for each of the ten (uncombined) models obtained by each method. Same as those shown in Fig. 4, the cumulative offset 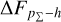 characterises the normalised deviation of the stacked recentred probability density pΣ(z − zphoto) relative to the corresponding zspec − zphoto histogram. It can be clearly seen that CLAP provides robust results for all of the ten models in the ensemble, whereas the other methods all produce non-negligible deviations from uniform PIT distributions and zero offsets. These deviations typically have large variations among the ten realisations for each of the methods, exhibiting different degrees of miscalibration, despite that the models for each method were developed in the same manner. The variable deviations may originate from different sources of stochasticity introduced in the training process such as random initialisation and random selections of mini-batches, on top of the impacts of overfitting and data imbalance. They offer an evident indication that the probability density estimates produced by the conventional methods are prone to miscalibration (see also Guo et al. 2017; Thulasidasan et al. 2019; Minderer et al. 2021; Wen et al. 2021). Furthermore, Fig. 8 shows the outcomes of combining the ensemble of ten estimates using the harmonic mean (H.M.) or the arithmetic mean (A.M.). With this, we demonstrate that properly combining probability density estimates (i.e. using the harmonic mean) would lessen the degree of miscalibration, yet it cannot guarantee a complete removal. In contrast, the estimates from CLAP do not suffer from apparent miscalibration either before or after combination using the harmonic mean.
characterises the normalised deviation of the stacked recentred probability density pΣ(z − zphoto) relative to the corresponding zspec − zphoto histogram. It can be clearly seen that CLAP provides robust results for all of the ten models in the ensemble, whereas the other methods all produce non-negligible deviations from uniform PIT distributions and zero offsets. These deviations typically have large variations among the ten realisations for each of the methods, exhibiting different degrees of miscalibration, despite that the models for each method were developed in the same manner. The variable deviations may originate from different sources of stochasticity introduced in the training process such as random initialisation and random selections of mini-batches, on top of the impacts of overfitting and data imbalance. They offer an evident indication that the probability density estimates produced by the conventional methods are prone to miscalibration (see also Guo et al. 2017; Thulasidasan et al. 2019; Minderer et al. 2021; Wen et al. 2021). Furthermore, Fig. 8 shows the outcomes of combining the ensemble of ten estimates using the harmonic mean (H.M.) or the arithmetic mean (A.M.). With this, we demonstrate that properly combining probability density estimates (i.e. using the harmonic mean) would lessen the degree of miscalibration, yet it cannot guarantee a complete removal. In contrast, the estimates from CLAP do not suffer from apparent miscalibration either before or after combination using the harmonic mean.
A deeper understanding of these findings is discussed in the next subsection. Additionally, remarks on combining probability density estimates using the harmonic mean or the arithmetic mean are given in Sect. 5.3.
 |
Fig. 7 Outcomes of resuming end-to-end discriminative models by refitting in CLAP illustrated for the SDSS, CFHTLS, and KiDS target samples. The SDSS target sample is split into a reference subsample (used to refit the model) and an inference subsample (held out for inference), while the CFHTLS and KiDS target samples are only used as reference samples. The results obtained by No-NIR CLAP for the KiDS dataset are not shown in order to avoid redundancy. For each dataset, only one of the ten CLAP models in the ensemble is selected for demonstration. First row: mean redshift residuals as a function of photometric redshift zphoto computed using the reference samples with and without refitting. The results for the SDSS inference subsample are also shown. As in Fig. 6, the results for the CFHTLS and KiDS datasets are shown in the low redshift ranges in addition to the full ranges. Second row: σMAD as a function of r-band magnitude. Third row: cumulative offsets |
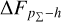
 |
Fig. 8 PIT distributions and cumulative offsets |
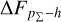
5.2 Association with uncertainties and correlations
Other than the dispersions intrinsic to the mapping between photometric data and redshift, a reliable probability density should typically encompass two types of uncertainties: ‘aleatoric’ uncertainties due to intrinsic stochastic noise in data and ‘epistemic’ uncertainties due to incomplete knowledge or limitations of the method implementation. There are several components in epistemic uncertainties. One component reflects the incapability or limit of an estimation method that has a certain configuration (e.g. the network architecture, the learning rate, the number of training iterations). For example, a shallow network would not be as capable as a deep network in extracting redshift information from galaxy images, thus the shallow network would produce larger uncertainties. We anticipate that both this component of epistemic uncertainties and aleatoric uncertainties are encapsulated in uncombined probability density estimates from CLAP given sufficient statistics, as both the errors due to model incapability and the errors in data are propagated to the latent space in the training process and taken into account by KNN. There are other components of epistemic uncertainties that stem from stochasticity in the method implementation, such as a particular random initialisation, variability in the iterative training procedure, and particular overfitted features. We argue that these components are often not accounted for by uncombined probability density estimates from a single measurement. This leads to the consequence that the probability densities produced by two models with the same network architecture but different parametrisations may not be identical. Nonetheless, we expect these unaccounted-for uncertainties to be reduced by properly combining different measurements.
On the other side, the self-adaptive training procedure of a deep learning model would correlate its outputs for different data instances, as the outputs are conditioned on the same network with a certain parametrisation. This would induce an excess of correlated errors in bulk that cannot be cancelled out and may be problematic for downstream astrophysical and cosmological analysis.
In this subsection, we attempted to investigate how miscal-ibration is associated with both unaccounted-for uncertainties and correlations between data instances induced by the estimation method. We first analysed the correlations of PIT and zphoto estimated using the ensemble of probability density estimates. With each quantity, every data instance can be regarded as a ten-dimensional vector. We computed the correlation between every two data instances over the whole sample. Then for each data instance, we drew three percentiles (i.e. 10th, 50th, 90th) from the distribution of correlations with all the other instances.
In the upper panels of Fig. 9, we show the distributions of the three correlation percentiles for PIT and zphoto, comparing CLAP and the other methods listed in Sect. 5.1. A sharp contrast is noteworthy: the percentile distributions for CLAP are all narrow spikes, with the 50th percentiles located precisely at zero, whereas the distributions for the other methods are much more dispersed and favour positive correlations (though the use of MC dropout may reduce the dispersions to some extent). This contrast marks an excess of method-induced correlations for the conventional methods. The existence of such excessive correlations implies that there would be bulk shifts in response to perturbing the measurement for any particular data instance that has non-zero net correlations with the whole sample, resulting in correlated miscalibration behaviours among data instances and aggravating the variations of the non-uniform PIT distributions and the non-zero cumulative offsets 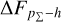 as manifested in Fig. 8. In other words, miscalibration is sensitive to the excessive correlations. They may be produced because the one-hot labels used for training these conventional methods are devoid of power in constraining the actual shapes of the probability densities, leaving the freedom for generating correlated errors in bulk. On the contrary, CLAP adopts KNN-calibrated labels for refitting that have much better constraining power and strongly suppress correlations induced by the self-adaptive training procedure. The resulting correlation distributions are thus symmetric and steady for the whole sample, and no significant non-zero net correlations are present.
as manifested in Fig. 8. In other words, miscalibration is sensitive to the excessive correlations. They may be produced because the one-hot labels used for training these conventional methods are devoid of power in constraining the actual shapes of the probability densities, leaving the freedom for generating correlated errors in bulk. On the contrary, CLAP adopts KNN-calibrated labels for refitting that have much better constraining power and strongly suppress correlations induced by the self-adaptive training procedure. The resulting correlation distributions are thus symmetric and steady for the whole sample, and no significant non-zero net correlations are present.
Next, we analysed the uncertainties of PIT and zphoto. For each data instance, we randomly selected two measurements out of the ensemble and computed their absolute difference. The distribution of the differences over the sample can be viewed as a manifestation of the typical epistemic uncertainties not accounted for by uncombined probability density estimates. Randomly selecting estimates from the ensemble can average the contributions from correlated errors between data instances. Similarly, for each data instance, we computed the absolute difference between two measurements, one obtained by combining five randomly selected probability density estimates using the harmonic mean while the other by combining the remaining five estimates, which would manifest the unaccounted-for epistemic uncertainties for a combination of five estimates.
The lower panels of Fig. 9 present the cumulative distributions for the uncombined and combined cases. We confirmed that the unaccounted-for uncertainties can indeed be reduced by combining the ensemble of estimates, which in turn lowers the degree of miscalibration for the other methods. For CLAP, the unaccounted-for uncertainties approximately shrink by two times when five estimates are combined. We found that the unaccounted-for uncertainties mildly evolve with r-band magnitude, as there tend to be large estimation errors for high-magnitude galaxies. Nonetheless, by combining ten estimates as in our main experiments, we anticipate that the unaccounted-for uncertainties can be further reduced and reach Δzphoto ~ 0.001 for individual data instances at the 90th percentile for the SDSS sample.
Furthermore, there are larger uncertainties for the other methods compared to CLAP, roughly 10, 40, 50, and 40% larger for the SCL prediction, the vanilla CNN, the GMM, and the MC dropout, respectively. These ratios remain nearly unchanged when the overall uncertainties are reduced. This indicates that the excessive uncertainties may be contributed from the excessive method-induced correlations. These correlations remain approximately constant such that the excessive uncertainties scale with the overall uncertainties. As a result, the apparent miscalibration may be alleviated but it is hard to be eliminated for the other methods provided that a reduction of uncertainties does not lead to a reduction of correlations. For the SCL prediction in particular, while a 10% excess of uncertainties seems insignificant, the presence of excessive correlations still results in obvious miscalibration behaviours that cannot be removed completely by combining the ensemble of estimates, as already shown in Fig. 8.
To summarise, both unaccounted-for uncertainties and excessive correlations induced by the method would exacerbate miscalibration. We speculate that the excessive correlations may stem from the use of one-hot labels that lack constraining power. They would stay unchanged when the uncertainties are reduced, and cause correlated miscalibration behaviours and contribute to the overall unaccounted-for uncertainties. Owing to their existence, reducing the uncertainties may not guarantee to remove miscalibration. Unlike the conventional methods, CLAP does not suffer from the issue of excessive correlations or apparent miscalibration.
Hence, for developing deep learning methods to obtain well-calibrated probability density estimates suitable for astrophysical and cosmological applications, we suggest that one has to pay attention to the interplay between miscalibration, unaccounted-for uncertainties, and method-induced correlations, with a particular focus on the negative impact of correlated errors. In principle, miscalibration may be reduced by, for example, carefully fine-tuning a discriminative model with an optimised training procedure and checking the outputs using a validation sample, yet we note that this may be difficult to effectively circumvent the issue of excessive correlations. In this regard, we suggest that it would be favourable to replace one-hot labels with more informative labels that have better access to the actual shapes of probability densities for training deep learning models. Such informative labels may be constructed using KNN-based methods such as CLAP, or extended with complementary approaches that are independent of the exploitation of photometric data, such as spatial cross-correlation for individual galaxies (e.g. Rahman et al. 2015; Morrison et al. 2017; Sánchez & Bernstein 2018; Scottez et al. 2018). Furthermore, using informative labels bypasses the need for a particular fine-tuning procedure.
 |
Fig. 9 Correlation and uncertainty analysis for CLAP, the SCL prediction, the vanilla CNN, the GMM, and the MC dropout (detailed in the text). Upper panels: 10th, 50th, and 90th percentiles drawn from the distributions of PIT and zphoto correlations between each data instance (viewed as a ten-dimensional vector) and all the other data instances from the sample. Lower panels: distributions of PIT and zphoto uncertainties that are not accounted for by uncombined probability density estimates (dashed curves) or by a combination of five estimates (solid curves). |
5.3 Harmonic mean versus arithmetic mean for combining probability density estimates
Finally in this subsection, we give some remarks on combining an ensemble of probability density estimates using the harmonic mean or the arithmetic mean, as it also concerns the miscali-bration issue. Conceptually speaking, there are specific errors introduced by each model Φ from the ensemble, which are propagated to the learned joint distribution p(z, Φ(d)) of redshifts and the projections of data. If combining probability density estimates using the arithmetic mean as suggested by Pasquet et al. (2019), Φ(d) is treated as a fixed quantity; the specific errors from all the models to be combined would not be removed but projected and aggregated along the z dimension. Therefore, using the arithmetic mean would artificially increase epistemic uncertainties, broaden the probability density estimates, and introduce miscalibration, though the unaccounted-for uncertainties can be reduced. This has been illustrated in Fig. 8. However, we suggest that using the harmonic mean would essentially project the specific errors on the Φ(d) dimension in each z bin. Then the errors in any z bins can be reduced by averaging the probabilities p(Φ(d)) under the first-order approximation, as proved in Sect. 3.6. It turns out that no miscalibration appears as a result of using the harmonic mean, thus it deserves to be a proper way to combine probability density estimates. As combining non-identical estimates is a non-trivial task, while other approaches are possible to use (e.g. Dahlen et al. 2013), care must be taken to ensure statistical soundness and avoid violating the frequentist definition.
6 Conclusion
We developed a novel method called the Contrastive Learning and Adaptive KNN for Photometric Redshift (CLAP), which empowers state-of-the-art image-based deep learning methods with the advantages of k-nearest neighbours (KNN) for photometric redshift probability density estimation. With CLAP, we have resolved the miscalibration encountered by conventional deep learning, the inconsistency between accuracy and confidence that leads to a disagreement between the estimated and the empirical probability densities. This is crucial for obtaining probability density estimates that are required to be well-calibrated and suitable for downstream astrophysical and cosmological inference.
The main idea of CLAP is to transform a conventional discriminative model into a supervised contrastive learning (SCL) framework that establishes a latent space encoding redshift information, and then KNN can be applied to substitute the conventional uncalibrated network output (e.g. softmax) for probability density estimation. The deep learning-based contrastive learning is combined with supervised learning using spectroscopic red-shifts as labels, so that meaningful redshift information can be extracted from images and propagate to the latent space, enabling CLAP to achieve much higher accuracy than by photometry-only KNN approaches. The adaptive KNN algorithm and the KNN-enabled recalibration procedure rely on diagnostics based on the local distributions of the probability integral transform (PIT) values, which naturally ensures that each probability density estimate is locally calibrated.
We applied CLAP to the SDSS, CFHTLS, and KiDS datasets that have different redshift coverages (i.e. zspec < 0.4, zspec < 4.0, and zspec < 3.0, respectively). To evaluate the obtained probability density estimates according to the frequentist definition, the probability-weighted mean redshifts were taken as point estimates. Compared to benchmark methods, we found that CLAP is indeed capable of giving smaller distribution offsets (i.e. between the stacked recentred probability density pΣ(z − zphoto) and the zspec − zphoto histogram), producing better PIT distributions, and having a better control of mean redshift biases. Our experiments also verified that CLAP does not suffer from the bias-variance trade-off faced by Lin et al. (2022). It achieves high accuracy comparable to that by conventional image-based deep learning methods.
Furthermore, we demonstrated that the resumption of end-to-end discriminative models via refitting retains the benefits from KNN, but bypasses its expensive computation for processing large-scale data, regaining the computational efficiency of deep learning. Therefore, we confirmed that CLAP can leverage the advantages of both deep learning and KNN at the same time. For practical purposes, we suggest that such resumed models can be used to make inference for a large target sample, while the computationally intensive KNN may only be needed to obtain labels for a small representative subset used for refitting.
With reference to CLAP, we investigated the miscalibration issue for conventional deep learning discriminative models. We experimented on a few representative conventional methods, and found that they all exhibit various degrees of miscalibra-tion with large variations among different realisations. For these methods, we note that miscalibration is particularly sensitive to an excess of method-induced correlations among data instances other than unaccounted-for epistemic uncertainties, which may be due to the use of one-hot labels that do not have access to the actual shapes of probability densities. On the contrary, CLAP is not affected by excessive correlations or apparent miscalibration because the probability density estimates are directly calibrated using the nearest neighbours whose spectroscopic redshifts are known.
We also confirmed that combining the probability density estimates produced by an ensemble of realisations can indeed reduce unaccounted-for epistemic uncertainties and improve accuracy. However, a proper way of combining probability density estimates should be applied in order to avoid artificially introducing epistemic uncertainties and miscalibration. Contrary to the seemingly intuitive arithmetic mean, we proved that the harmonic mean should be considered as a better choice.
In summary, by efficaciously resolving miscalibration in the context of photometric redshift estimation, our method CLAP has made a promising step towards developing robust and reliable deep learning methods for astrophysical problems. In the next paper in our series, we will leverage CLAP to tackle the mismatch issue, another common but challenging shortcoming of conventional deep learning, and more broadly, data driven methods. In general, we anticipate that hybrid methods may be developed and integrated with domain knowledge to provide complementary information for photometric redshift estimation and extend our current implementation of CLAP. This is essential for alleviating the difficulty in controlling errors and biases at high redshift due to low S/N and insufficient spectroscopic data. We also expect CLAP to be used in applications that involve probability density estimation not limited to photometric redshift. The extension of CLAP is left for future endeavours.
Data and code availability
We provide more results and discussions in the supplementary appendices available at https://zenodo.org/records/13954481. These appendices present examples of probability density estimates obtained by default CLAP, an assessment on recalibration, statistics for point estimates obtained by all the methods discussed in Sect. 4, and an assessment on the local spatial distribution of the nearest neighbours. The photometric redshift catalogues produced by default CLAP are also provided. The code used in this work is available at https://github.com/QiufanLin/CLAP-I.
Acknowledgements
This work is supported by ‘The Major Key Project of PCL’ and makes use of the Cloud Brain System at PCL for computing resources. H.X.R. acknowledges financial support from the National Natural Science Foundation of China (62201306). Y.S.T. acknowledges financial support from the Australian Research Council through DECRA Fellowship DE220101520. The authors thank Stéphane Arnouts and Marie Treyer for access to the CFHTLS imaging data and catalogues. This work makes use of Sloan Digital Sky Survey (SDSS) data. Funding for SDSS-III has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, and the U.S. Department of Energy Office of Science. The SDSS-III web site is http://www.sdss3.org/. SDSS-III is managed by the Astro-physical Research Consortium for the Participating Institutions of the SDSS-III Collaboration including the University of Arizona, the Brazilian Participation Group, Brookhaven National Laboratory, Carnegie Mellon University, University of Florida, the French Participation Group, the German Participation Group, Harvard University, the Instituto de Astrofisica de Canarias, the Michigan State/Notre Dame/JINA Participation Group, Johns Hopkins University, Lawrence Berkeley National Laboratory, Max Planck Institute for Astrophysics, Max Planck Institute for Extraterrestrial Physics, New Mexico State University, New York University, Ohio State University, Pennsylvania State University, University of Portsmouth, Princeton University, the Spanish Participation Group, University of Tokyo, University of Utah, Vanderbilt University, University of Virginia, University of Washington, and Yale University. This work is based on observations obtained with MegaPrime/MegaCam, a joint project of CFHT and CEA/DAPNIA, at the Canada-France-Hawaii Telescope (CFHT) which is operated by the National Research Council (NRC) of Canada, the Institut National des Sciences de l’Univers of the Centre National de la Recherche Scientifique (CNRS) of France, and the University of Hawaii. This work is based in part on data products produced at Terapix and the Canadian Astronomy Data Centre as part of the Canada-France-Hawaii Telescope Legacy Survey, a collaborative project of NRC and CNRS. This work is based on observations made with ESO Telescopes at the La Silla Paranal Observatory under programme IDs 177.A-3016,177.A-3017,177.A-3018 and 179.A-2004, and on data products produced by the KiDS consortium. The KiDS production team acknowledges support from: Deutsche Forschungsgemeinschaft, ERC, NOVA and NWO-M grants; Target; the University of Padova, and the University Federico II (Naples).
Appendix A Network architectures
We adopted a modified version of the inception network developed by Treyer et al. (2024) for the encoder network and the estimator network in our SCL framework. The detailed description of the inception network is presented therein. We designed a decoder that leverages bilinear interpolation for upsampling images. The architectures of the encoder, the estimator, and the decoder are presented in Fig. A.1.
 |
Fig. A.1 Network architectures of the encoder, the estimator, and the decoder used in our work. The kernel size, the padding type, the activation function, and the output shape for each layer are specified when necessary. k and s refer to the kernel size and the output shape, respectively. In the encoder, c stands for the total number of channels after concatenating multi-band images and additional input (c = 6 for the SDSS dataset and the CFHTLS dataset; c = 10 for the KiDS dataset). The encoder outputs the latent vector υA and the vector υB with parallel fully connected layers. In the decoder, b stands for the number of optical bands for images (b = 5 for the SDSS dataset and the CFHTLS dataset; b = 4 for the KiDS dataset). The Leaky ReLU activation has a leaky ratio of 0.2. In the estimator, m stands for the number of redshift bins in the output (quoted in Table 1). |
References
- Abruzzo, M. W., & Haiman, Z. 2019, MNRAS, 486, 2730 [NASA ADS] [CrossRef] [Google Scholar]
- Aihara, H., Arimoto, N., Armstrong, R., et al. 2018, PASJ, 70, S4 [NASA ADS] [Google Scholar]
- Ait Ouahmed, R., Arnouts, S., Pasquet, J., Treyer, M., & Bertin, E. 2024, A&A, 683, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Alam, S., Albareti, F. D., Allende Prieto, C., et al. 2015, ApJS, 219, 12 [Google Scholar]
- Alarcon, A., Sánchez, C., Bernstein, G. M., & Gaztañaga, E. 2020, MNRAS, 498, 2614 [NASA ADS] [CrossRef] [Google Scholar]
- Amaro, V., Cavuoti, S., Brescia, M., et al. 2019, MNRAS, 482, 3116 [Google Scholar]
- Ansari, Z., Agnello, A., & Gall, C. 2021, A&A, 650, A90 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Arnouts, S., Cristiani, S., Moscardini, L., et al. 1999, MNRAS, 310, 540 [Google Scholar]
- Baldry, I. K., Liske, J., Brown, M. J. I., et al. 2018, MNRAS, 474, 3875 [Google Scholar]
- Beck, R., Dobos, L., Budavári, T., Szalay, A. S., & Csabai, I. 2016, MNRAS, 460, 1371 [Google Scholar]
- Benítez, N. 2000, ApJ, 536, 571 [Google Scholar]
- Bilicki, M., Hoekstra, H., Brown, M. J. I., et al. 2018, A&A, 616, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bonnett, C. 2015, MNRAS, 449, 1043 [NASA ADS] [CrossRef] [Google Scholar]
- Bonnett, C., Troxel, M. A., Hartley, W., et al. 2016, Phys. Rev. D, 94, 042005 [Google Scholar]
- Bordoloi, R., Lilly, S. J., & Amara, A. 2010, MNRAS, 406, 881 [NASA ADS] [Google Scholar]
- Bradshaw, E. J., Almaini, O., Hartley, W. G., et al. 2013, MNRAS, 433, 194 [NASA ADS] [CrossRef] [Google Scholar]
- Brescia, M., Cavuoti, S., Longo, G., & De Stefano, V. 2014, A&A, 568, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Buchs, R., Davis, C., Gruen, D., et al. 2019, MNRAS, 489, 820 [Google Scholar]
- Campagne, J.-E. 2020, arXiv e-prints [arXiv:2002.10154] [Google Scholar]
- Carliles, S., Budavári, T., Heinis, S., Priebe, C., & Szalay, A. S. 2010, ApJ, 712, 511 [NASA ADS] [CrossRef] [Google Scholar]
- Carrasco Kind, M., & Brunner, R. J. 2013, MNRAS, 432, 1483 [Google Scholar]
- Carrasco Kind, M., & Brunner, R. J. 2014, MNRAS, 438, 3409 [NASA ADS] [CrossRef] [Google Scholar]
- Cavuoti, S., Brescia, M., Tortora, C., et al. 2015, MNRAS, 452, 3100 [NASA ADS] [CrossRef] [Google Scholar]
- Cavuoti, S., Amaro, V., Brescia, M., et al. 2017, MNRAS, 465, 1959 [Google Scholar]
- Charnock, T., Lavaux, G., & Wandelt, B. D. 2018, Phys. Rev. D, 97, 083004 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, G., Lu, Y., Lu, J., & Zhou, J. 2020, in Computer Vision – ECCV 2020, eds. A. Vedaldi, H. Bischof, T. Brox, & J.-M. Frahm (Cham: Springer International Publishing), 643 [Google Scholar]
- Coil, A. L., Blanton, M. R., Burles, S. M., et al. 2011, ApJ, 741, 8 [Google Scholar]
- Collister, A. A., & Lahav, O. 2004, PASP, 116, 345 [NASA ADS] [CrossRef] [Google Scholar]
- Cool, R. J., Moustakas, J., Blanton, M. R., et al. 2013, ApJ, 767, 118 [NASA ADS] [CrossRef] [Google Scholar]
- Dahlen, T., Mobasher, B., Faber, S. M., et al. 2013, ApJ, 775, 93 [Google Scholar]
- Dark Energy Survey Collaboration (Abbott, T., et al.) 2016, MNRAS, 460, 1270 [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Kuijken, K. H., & Valentijn, E. A. 2013, Exp. Astron., 35, 25 [Google Scholar]
- De Vicente, J., Sánchez, E., & Sevilla-Noarbe, I. 2016, MNRAS, 459, 3078 [NASA ADS] [CrossRef] [Google Scholar]
- Dey, B., Newman, J. A., Andrews, B. H., et al. 2021, arXiv e-prints [arXiv:2110.15209] [Google Scholar]
- Dey, B., Andrews, B. H., Newman, J. A., et al. 2022a, MNRAS, 515, 5285 [NASA ADS] [CrossRef] [Google Scholar]
- Dey, B., Zhao, D., Andrews, B., et al. 2022b, in Machine Learning for Astrophysics, proceedings of the Thirty-ninth International Conference on Machine Learning (ICML 2022) (Berlin: Springer), 39 [Google Scholar]
- D’Isanto, A., & Polsterer, K. L. 2018, A&A, 609, A111 [Google Scholar]
- Drinkwater, M. J., Byrne, Z. J., Blake, C., et al. 2018, MNRAS, 474, 4151 [Google Scholar]
- Dwibedi, D., Aytar, Y., Tompson, J., Sermanet, P., & Zisserman, A. 2021, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 9568 [CrossRef] [Google Scholar]
- Edge, A., Sutherland, W., & VIKING Team. 2014, VizieR Online Data Catalog: II/329 [Google Scholar]
- Eisenstein, D. J., Weinberg, D. H., Agol, E., et al. 2011, AJ, 142, 72 [Google Scholar]
- Euclid Collaboration (Desprez, G., et al.) 2020, A&A, 644, A31 [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Ilbert, O., et al.) 2021, A&A, 647, A117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Feldmann, R., Carollo, C. M., Porciani, C., et al. 2006, MNRAS, 372, 565 [NASA ADS] [CrossRef] [Google Scholar]
- Fluri, J., Kacprzak, T., Refregier, A., Lucchi, A., & Hofmann, T. 2021, Phys. Rev. D, 104, 123526 [NASA ADS] [CrossRef] [Google Scholar]
- Gal, Y., & Ghahramani, Z. 2016, Proc. Mach. Learn. Res., 48, 1050 [Google Scholar]
- Garilli, B., McLure, R., Pentericci, L., et al. 2021, A&A, 647, A150 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gass, S. I., & Harris, C. M. 2001, Probability Integral Transformation Method (New York, NY: Springer US), 635 [Google Scholar]
- Gerdes, D. W., Sypniewski, A. J., McKay, T. A., et al. 2010, ApJ, 715, 823 [Google Scholar]
- Greisel, N., Seitz, S., Drory, N., et al. 2015, MNRAS, 451, 1848 [NASA ADS] [CrossRef] [Google Scholar]
- Guo, C., Pleiss, G., Sun, Y., & Weinberger, K. Q. 2017, Proc. Mach. Learn. Res., 70, 1321 [Google Scholar]
- Gwyn, S. D. J. 2012, AJ, 143, 38 [Google Scholar]
- Han, B., Qiao, L.-N., Chen, J.-L., et al. 2021, Res. Astron. Astrophys., 21, 017 [CrossRef] [Google Scholar]
- Hatfield, P. W., Almosallam, I. A., Jarvis, M. J., et al. 2020, MNRAS, 498, 5498 [NASA ADS] [CrossRef] [Google Scholar]
- Hayat, M. A., Stein, G., Harrington, P., Lukic´, Z., & Mustafa, M. 2021, ApJ, 911, L33 [NASA ADS] [CrossRef] [Google Scholar]
- Henghes, B., Thiyagalingam, J., Pettitt, C., Hey, T., & Lahav, O. 2022, MNRAS, 512, 1696 [NASA ADS] [CrossRef] [Google Scholar]
- Hildebrandt, H., Köhlinger, F., van den Busch, J. L., et al. 2020, A&A, 633, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hoyle, B. 2016, Astron. Comput., 16, 34 [NASA ADS] [CrossRef] [Google Scholar]
- Huang, Z., Lam, H., & Zhang, H. 2021, arXiv e-prints [arXiv:2110.12122] [Google Scholar]
- Huang, Z., Lam, H., & Zhang, H. 2023, arXiv e-prints [arXiv:2306.05674] [Google Scholar]
- Hudelot, P., Cuillandre, J. C., Withington, K., et al. 2012, VizieR Online Data Catalog: II/317 [Google Scholar]
- Huertas-Company, M., Sarmiento, R., & Knapen, J. H. 2023, RAS Techniq. Instrum., 2, 441 [CrossRef] [Google Scholar]
- Huterer, D., Takada, M., Bernstein, G., & Jain, B. 2006, MNRAS, 366, 101 [Google Scholar]
- Ilbert, O., Arnouts, S., McCracken, H. J., et al. 2006, A&A, 457, 841 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jones, D. M., & Heavens, A. F. 2019, MNRAS, 490, 3966 [NASA ADS] [CrossRef] [Google Scholar]
- Jones, E., & Singal, J. 2017, A&A, 600, A113 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Joudaki, S., Hildebrandt, H., Traykova, D., et al. 2020, A&A, 638, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kingma, D. P., & Ba, J. 2015, in 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, eds. Y. Bengio, & Y. LeCun [Google Scholar]
- Kodra, D., Andrews, B. H., Newman, J. A., et al. 2023, ApJ, 942, 36 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., Heymans, C., Dvornik, A., et al. 2019, A&A, 625, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, arXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Le Fèvre, O., Cassata, P., Cucciati, O., et al. 2013, A&A, 559, A14 [Google Scholar]
- Le Fèvre, O., Tasca, L. A. M., Cassata, P., et al. 2015, A&A, 576, A79 [Google Scholar]
- Lee, K.-G., Krolewski, A., White, M., et al. 2018, ApJS, 237, 31 [Google Scholar]
- Leistedt, B., Hogg, D. W., Wechsler, R. H., & DeRose, J. 2019, ApJ, 881, 80 [Google Scholar]
- Li, R., Napolitano, N. R., Feng, H., et al. 2022a, A&A, 666, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Li, R., Napolitano, N. R., Roy, N., et al. 2022b, ApJ, 929, 152 [NASA ADS] [CrossRef] [Google Scholar]
- Liao, T., Lei, Z., Zhu, T., et al. 2023, IEEE Trans. Knowledge Data Eng., 35, 264 [Google Scholar]
- Lilly, S. J., Le Fèvre, O., Renzini, A., et al. 2007, ApJS, 172, 70 [Google Scholar]
- Lin, Q., Fouchez, D., Pasquet, J., et al. 2022, A&A, 662, A36 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Livet, F., Charnock, T., Le Borgne, D., & de Lapparent, V. 2021, A&A, 652, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Luken, K. J., Norris, R. P., Park, L. A. F., Wang, X. R., &Filipovic´, M. D. 2022, Astron. Comput., 39, 100557 [NASA ADS] [CrossRef] [Google Scholar]
- Ma, Z., Hu, W., & Huterer, D. 2006, ApJ, 636, 21 [Google Scholar]
- Malz, A. I. 2021, Phys. Rev. D, 103, 083502 [NASA ADS] [CrossRef] [Google Scholar]
- Mandelbaum, R., Seljak, U., Hirata, C. M., et al. 2008, MNRAS, 386, 781 [NASA ADS] [CrossRef] [Google Scholar]
- McLure, R. J., Pearce, H. J., Dunlop, J. S., et al. 2013, MNRAS, 428, 1088 [NASA ADS] [CrossRef] [Google Scholar]
- Minderer, M., Djolonga, J., Romijnders, R., et al. 2021, in Advances in Neural Information Processing Systems, eds. M. Ranzato, A. Beygelzimer, Y. Dauphin, P. Liang, & J. W. Vaughan, (New Yprk: Curran Associates, Inc.), 34, 15682 [Google Scholar]
- Momcheva, I. G., Brammer, G. B., van Dokkum, P. G., et al. 2016, ApJS, 225, 27 [Google Scholar]
- Morrison, C. B., Hildebrandt, H., Schmidt, S. J., et al. 2017, MNRAS, 467, 3576 [Google Scholar]
- Mu, Y.-H., Qiu, B., Zhang, J.-N., Ma, J.-C., & Fan, X.-D. 2020, Res. Astron. Astrophys., 20, 089 [Google Scholar]
- Myers, A. D., White, M., & Ball, N. M. 2009, MNRAS, 399, 2279 [NASA ADS] [CrossRef] [Google Scholar]
- Newman, J. A., & Gruen, D. 2022, ARA&A, 60, 363 [NASA ADS] [CrossRef] [Google Scholar]
- Newman, J. A., Cooper, M. C., Davis, M., et al. 2013, ApJS, 208, 5 [Google Scholar]
- Panaretos, V. M., & Zemel, Y. 2019, Ann. Rev. Stat. Appl., 6, 405 [CrossRef] [Google Scholar]
- Papernot, N., & McDaniel, P. 2018, arXiv e-prints [arXiv:1803.04765] [Google Scholar]
- Pasquet, J., Bertin, E., Treyer, M., Arnouts, S., & Fouchez, D. 2019, A&A, 621, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rahman, M., Ménard, B., Scranton, R., Schmidt, S. J., & Morrison, C. B. 2015, MNRAS, 447, 3500 [CrossRef] [Google Scholar]
- Rau, M. M., Morrison, C. B., Schmidt, S. J., et al. 2022, MNRAS, 509, 4886 [Google Scholar]
- Richard, M. D., & Lippmann, R. P. 1991, Neural Comput., 3, 461 [CrossRef] [Google Scholar]
- Rojas, R. 1996, Neural Comput., 8, 41 [CrossRef] [Google Scholar]
- Ruiz-Zapatero, J., Hadzhiyska, B., Alonso, D., et al. 2023, MNRAS, 522, 5037 [CrossRef] [Google Scholar]
- Sadeh, I., Abdalla, F. B., & Lahav, O. 2016, PASP, 128, 104502 [NASA ADS] [CrossRef] [Google Scholar]
- Salvato, M., Ilbert, O., & Hoyle, B. 2019, Nat. Astron., 3, 212 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez, C., & Bernstein, G. M. 2018, MNRAS, 483, 2801 [Google Scholar]
- Schlegel, D. J., Finkbeiner, D. P., & Davis, M. 1998, ApJ, 500, 525 [Google Scholar]
- Schmidt, S. J., Malz, A. I., Soo, J. Y. H., et al. 2020, MNRAS, 499, 1587 [Google Scholar]
- Schuldt, S., Suyu, S. H., Cañameras, R., et al. 2021, A&A, 651, A55 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Scodeggio, M., Guzzo, L., Garilli, B., et al. 2018, A&A, 609, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Scottez, V., Benoit-Lévy, A., Coupon, J., Ilbert, O., & Mellier, Y. 2018, MNRAS, 474, 3921 [Google Scholar]
- Skelton, R. E., Whitaker, K. E., Momcheva, I. G., et al. 2014, ApJS, 214, 24 [Google Scholar]
- Soo, J. Y. H., Moraes, B., Joachimi, B., et al. 2018, MNRAS, 475, 3613 [NASA ADS] [CrossRef] [Google Scholar]
- Speagle, J. S., & Eisenstein, D. J. 2017, MNRAS, 469, 1205 [NASA ADS] [CrossRef] [Google Scholar]
- Speagle, J. S., Leauthaud, A., Huang, S., et al. 2019, MNRAS, 490, 5658 [NASA ADS] [CrossRef] [Google Scholar]
- Spergel, D., Gehrels, N., Baltay, C., et al. 2015, arXiv e-prints [arXiv:1503.03757] [Google Scholar]
- Sun, Y., Ming, Y., Zhu, X., & Li, Y. 2022, Proc. Mach. Learn. Res., 162, 20827 [Google Scholar]
- Szegedy, C., Liu, W., Jia, Y., et al. 2015, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) [Google Scholar]
- Szokoly, G. P., Bergeron, J., Hasinger, G., et al. 2004, ApJS, 155, 271 [NASA ADS] [CrossRef] [Google Scholar]
- Tanaka, M., Coupon, J., Hsieh, B.-C., et al. 2018, PASJ, 70, S9 [Google Scholar]
- Thulasidasan, S., Chennupati, G., Bilmes, J. A., Bhattacharya, T., & Michalak, S. 2019, in Advances in Neural Information Processing Systems, ed. H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. Fox, & R. Garnett (New York: Curran Associates, Inc.) [Google Scholar]
- Treyer, M., Ait Ouahmed, R., Pasquet, J., et al. 2024, MNRAS, 527, 651 [Google Scholar]
- Umayahara, T., Shibuya, T., Miura, N., et al. 2020, SPIE Conf. Ser., 11452, 1145223 [NASA ADS] [Google Scholar]
- Villani, C. 2009, The Wasserstein Distances (Berlin, Heidelberg: Springer Berlin Heidelberg), 93 [Google Scholar]
- Way, M. J., & Klose, C. D. 2012, PASP, 124, 274 [NASA ADS] [CrossRef] [Google Scholar]
- Wei, S., Li, Y., Lu, W., et al. 2022, PASP, 134, 114508 [CrossRef] [Google Scholar]
- Wen, Y., Jerfel, G., Muller, R., et al. 2021, in International Conference on Learning Representations [Google Scholar]
- Wilson, D., Nayyeri, H., Cooray, A., & Hußler, B. 2020, ApJ, 888, 83 [NASA ADS] [CrossRef] [Google Scholar]
- Wittman, D., Bhaskar, R., & Tobin, R. 2016, MNRAS, 457, 4005 [Google Scholar]
- Zhan, H. 2018, COSPAR Sci. Assembly, 42, 16 [Google Scholar]
- Zhang, Y., Ma, H., Peng, N., Zhao, Y., & Wu, X.-b. 2013, AJ, 146, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, T., Rau, M. M., Mandelbaum, R., Li, X., & Moews, B. 2023, MNRAS, 518, 709 [Google Scholar]
- Zhao, D., Dalmasso, N., Izbicki, R., & Lee, A. B. 2021, Proc. Mach. Learn. Res., 161, 1830 [Google Scholar]
- Zhou, X., Gong, Y., Meng, X.-M., et al. 2022a, MNRAS, 512, 4593 [NASA ADS] [CrossRef] [Google Scholar]
- Zhou, X., Gong, Y., Meng, X.-M., et al. 2022b, Res. Astron. Astrophys., 22, 115017 [CrossRef] [Google Scholar]
All Tables
All Figures
|
Fig. 1 Distributions of spectroscopic redshift and r-band magnitude for the SDSS, CFHTLS, and KiDS datasets used in our work. |
| In the text | |
|
Fig. 2 Graphic illustration of our method CLAP for photometric redshift probability density estimation. The development of a CLAP model consists of several procedures, including supervised contrastive learning (SCL), adaptive KNN, reconstruction, and refitting. The SCL framework is based on neural networks. It uses an encoder network to project multi-band galaxy images and additional input data (i.e. galactic reddening E(B – V), magnitudes) to low-dimensional latent vectors, which form a latent space that encodes redshift information and has a distance metric defined. The spectroscopic redshift labels are leveraged to supervise the redshift outputs predicted by an estimator network for extracting redshift information, but the trained estimator and its outputs are no longer used once the latent space is established (indicated by the shaded region). These outputs are uncalibrated, and should not be regarded as the final estimates produced by CLAP. The adaptive KNN and the KNN-enabled recalibration are implemented locally on the latent space via diagnostics with the probability integral transform (PIT), constructing raw probability density estimates using the known redshifts of the PIT-selected nearest neighbours. The raw estimates are then used as labels to retrain the estimator from scratch in a refitting procedure with the trained encoder fixed, resuming an end-to-end model ready to process imaging data and produce the desired estimates. Lastly, we combine the estimates from an ensemble of CLAP models developed following these procedures (not shown in the figure). |
| In the text | |
|
Fig. 3 Supervised contrastive learning (SCL) framework. It contains an encoder, an estimator, and a decoder. The encoder, the same as that shown in Fig. 2, takes multi-band galaxy images and additional data as inputs, and produces two vectors vA and vB. The vector vA is used to encode redshift information and is referred to as the ‘latent vector’ throughout this work. It is inputted to the estimator that produces a redshift output supervised by the spectroscopic redshift label for extracting redshift information. The concatenation of vA and vB is inputted to the decoder to reconstruct images that resemble the input images. With the reconstructed images as inputs, this process is conducted again using the three networks with shared weights, producing the vector vA. Furthermore, the images reshaped with random flipping and rotation by 90 deg steps are exploited as inputs, producing the vector vA. For contrastive learning, the contrast between vA and vA and the contrast between vA and vA for the same galaxy are minimised (i.e. positive pairs), which are characterised by the Euclidean distance. The contrast between the latent vectors for any two different galaxies is maximised (i.e. a negative pair). |
| In the text | |
|
Fig. 4 Distribution offset analysis for the SDSS, CFHTLS, and KiDS target samples. The results obtained by CLAP are compared with the prediction from our supervised contrastive learning (SCL) framework, and those produced by a few benchmark image-based methods including inception networks from Pasquet et al. (2019) and Treyer et al. (in prep.), network-based bias correlation from Lin et al. (2022), a capsule network from Dey et al. (2022a), a VGG network, and a hybrid network from Li et al. (2022a), and the photometry-only methods including KNN & regression from Beck et al. (2016), Le Phare (Arnouts et al. 1999; Ilbert et al. 2006), as well as MLPQNA (Brescia et al. 2014; Cavuoti et al. 2015, 2017), ANNz2 (Sadeh et al. 2016; Bilicki et al. 2018), and BPZ (Benítez 2000) retrieved from the public KiDS catalogues. For the KiDS dataset, the results obtained by CLAP but without the NIR data are also shown (‘No NIR’). For both CLAP and the SCL prediction, the ensemble of ten probability density estimates are combined using the harmonic mean. Upper panels: z − zphoto distributions. The solid curves show the stacked recentred probability densities pΣ (z − zphoto) for the methods that have probability density estimation. The dashed curves show the zspec − zphoto histograms for all the methods. The error bands are estimated using bootstrap. The vertical dashed lines show the median of zspec − zphoto for each method, indicating the centre of each zspec − zphoto distribution regardless of the random errors due to limited statistics at high redshift. Lower panels: Cumulative z − zphoto distribution offsets. The solid curves show the cumulative offset of the stacked recentred probability density pΣ(z − zphoto) relative to the corresponding zspec − zphoto histogram for each method that has a probability density estimation (i.e. |
| In the text | |
|
Fig. 5 Distributions of summary statistics of photometric redshift probability density estimates illustrated for the SDSS, CFHTLS, and KiDS target samples. Comparison is made among the results from CLAP and the methods for which the probability density estimates are available, as in Fig. 4. The definitions of the shown summary statistics can be found in Table 2. For both CLAP and the SCL prediction, the ensemble of ten probability density estimates are combined using the harmonic mean. For the PIT, the y-axis in each panel is truncated at 0.5 for clearer illustration; the horizontal dashed lines indicate normalised uniform distributions. The PIT distributions produced by MLPQNA and BPZ are dramatically non-flat and are not shown in the figure. For the kurtosis, the vertical dashed lines indicate the value for Gaussian-like distributions (i.e. 3). |
| In the text | |
|
Fig. 6 Mean redshift residuals and accuracy of photometric redshift point estimates shown for the SDSS, CFHTLS, and KiDS target samples. The results obtained by CLAP are compared with those produced by other methods, as in Fig. 4. For both CLAP and the SCL prediction, the ensemble of ten probability density estimates are combined using the harmonic mean. Upper panels: mean redshift residuals as a function of photometric redshift zphoto. The error bars are estimated using the root mean square error (RMSE) of residuals in each photometric redshift bin. The requirement for the accuracy of photometric redshift estimation (i.e. |δ<z> | < 0.002) is indicated by the shaded bands. The horizontal dashed lines indicate zero residuals. The results for the CFHTLS and KiDS datasets are shown in both the full and the restricted redshift ranges; the restricted range (i.e. zphoto < 1.0 and zphoto < 0.6, respectively) roughly covers 90% of the full sample for each dataset. For the KiDS dataset, the results produced by ANNZ2 and BPZ are not shown in the restricted range due to large biases. Middle panels: same as the upper panels, but showing mean redshift residuals as a function of r-band magnitude for the full data. Lower panels: σMAD as a function of r-band magnitude. The error bars are estimated using bootstrap. |
| In the text | |
|
Fig. 7 Outcomes of resuming end-to-end discriminative models by refitting in CLAP illustrated for the SDSS, CFHTLS, and KiDS target samples. The SDSS target sample is split into a reference subsample (used to refit the model) and an inference subsample (held out for inference), while the CFHTLS and KiDS target samples are only used as reference samples. The results obtained by No-NIR CLAP for the KiDS dataset are not shown in order to avoid redundancy. For each dataset, only one of the ten CLAP models in the ensemble is selected for demonstration. First row: mean redshift residuals as a function of photometric redshift zphoto computed using the reference samples with and without refitting. The results for the SDSS inference subsample are also shown. As in Fig. 6, the results for the CFHTLS and KiDS datasets are shown in the low redshift ranges in addition to the full ranges. Second row: σMAD as a function of r-band magnitude. Third row: cumulative offsets |
| In the text | |
|
Fig. 8 PIT distributions and cumulative offsets |
| In the text | |
|
Fig. 9 Correlation and uncertainty analysis for CLAP, the SCL prediction, the vanilla CNN, the GMM, and the MC dropout (detailed in the text). Upper panels: 10th, 50th, and 90th percentiles drawn from the distributions of PIT and zphoto correlations between each data instance (viewed as a ten-dimensional vector) and all the other data instances from the sample. Lower panels: distributions of PIT and zphoto uncertainties that are not accounted for by uncombined probability density estimates (dashed curves) or by a combination of five estimates (solid curves). |
| In the text | |
|
Fig. A.1 Network architectures of the encoder, the estimator, and the decoder used in our work. The kernel size, the padding type, the activation function, and the output shape for each layer are specified when necessary. k and s refer to the kernel size and the output shape, respectively. In the encoder, c stands for the total number of channels after concatenating multi-band images and additional input (c = 6 for the SDSS dataset and the CFHTLS dataset; c = 10 for the KiDS dataset). The encoder outputs the latent vector υA and the vector υB with parallel fully connected layers. In the decoder, b stands for the number of optical bands for images (b = 5 for the SDSS dataset and the CFHTLS dataset; b = 4 for the KiDS dataset). The Leaky ReLU activation has a leaky ratio of 0.2. In the estimator, m stands for the number of redshift bins in the output (quoted in Table 1). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.