Fig. 3
Download original image
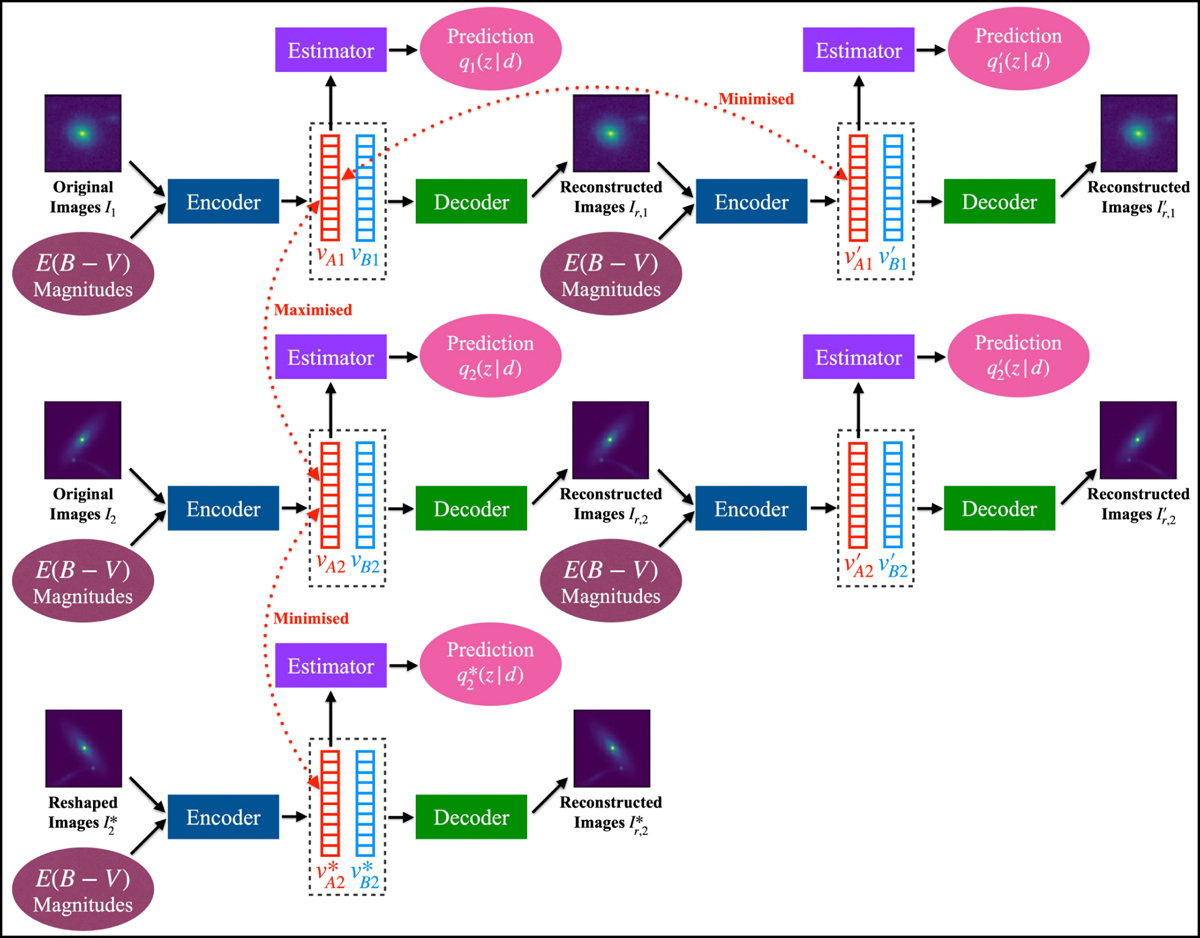
Supervised contrastive learning (SCL) framework. It contains an encoder, an estimator, and a decoder. The encoder, the same as that shown in Fig. 2, takes multi-band galaxy images and additional data as inputs, and produces two vectors vA and vB. The vector vA is used to encode redshift information and is referred to as the ‘latent vector’ throughout this work. It is inputted to the estimator that produces a redshift output supervised by the spectroscopic redshift label for extracting redshift information. The concatenation of vA and vB is inputted to the decoder to reconstruct images that resemble the input images. With the reconstructed images as inputs, this process is conducted again using the three networks with shared weights, producing the vector vA. Furthermore, the images reshaped with random flipping and rotation by 90 deg steps are exploited as inputs, producing the vector vA. For contrastive learning, the contrast between vA and vA and the contrast between vA and vA for the same galaxy are minimised (i.e. positive pairs), which are characterised by the Euclidean distance. The contrast between the latent vectors for any two different galaxies is maximised (i.e. a negative pair).
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.