| Issue |
A&A
Volume 685, May 2024
|
|
|---|---|---|
| Article Number | A62 | |
| Number of page(s) | 41 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202349079 | |
| Published online | 14 May 2024 | |
Automated eccentricity measurement from raw eclipsing binary light curves with intrinsic variability★
1
Institute of Astronomy, KU Leuven,
Celestijnenlaan 200D,
3001
Leuven,
Belgium
e-mail: luc.ijspeert@kuleuven.be
2
Department of Astrophysics, IMAPP, Radboud University Nijmegen,
PO Box 9010,
6500 GL
Nijmegen,
The Netherlands
3
Max-Planck-Institut für Astrophysik,
Karl-Schwarzschild-Straße 1,
85741
Garching bei München,
Germany
4
Villanova University, Department of Astrophysics and Planetary Sciences,
800 East Lancaster Avenue, Villanova,
PA 19085
USA
5
Max Planck Institute for Astronomy,
Königstuhl 17,
69117
Heidelberg,
Germany
Received:
22
December
2023
Accepted:
2
February
2024
Context. Eclipsing binary systems provide the opportunity to measure the fundamental parameters of their component stars in a stellar-model-independent way. This makes them ideal candidates for testing and calibrating theories of stellar structure and (tidal) evolution. Large photometric (space) surveys provide a wealth of data for both the discovery and the analysis of these systems. Even without spectroscopic follow-up there is often enough information in their photometric time series to warrant analysis, especially if there is an added value present in the form of intrinsic variability, such as pulsations.
Aims. Our goal is to implement and validate a framework for the homogeneous analysis of large numbers of eclipsing binary light curves, such as the numerous high-duty-cycle observations from space missions like TESS. The aim of this framework is to be quick and simple to run and to limit the user's time investment when obtaining, amongst other parameters, orbital eccentricities.
Methods. We developed a new and fully automated methodology for the analysis of eclipsing binary light curves with or without additional intrinsic variability. Our method includes a fast iterative pre-whitening procedure that results in a list of extracted sinusoids that is broadly applicable for purposes other than eclipses. After eclipses are identified and measured, orbital and stellar parameters are measured under the assumption of spherical stars of uniform brightness.
Results. We tested our methodology in two settings: a set of synthetic light curves with known input and the catalogue of Kepler eclipsing binaries. The synthetic tests show that we can reliably recover the frequencies and amplitudes of the sinusoids included in the signal as well as the input binary parameters, albeit to varying degrees of accuracy. Recovery of the tangential component of eccentricity is the most accurate and precise. Kepler results confirm a robust determination of orbital periods, with 80.5% of periods matching the catalogued ones. We present the eccentricities for this analysis and show that they broadly follow the theoretically expected pattern as a function of the orbital period.
Conclusions. Our analysis methodology is shown to be capable of analysing large numbers of eclipsing binary light curves with no user intervention, and in doing so provide a basis for a further in-depth analysis of systems of particular interest as well as for statistical analysis at the sample level. Furthermore, the computational performance of the frequency analysis, extracting hundreds of sinusoids from Kepler light curves in a few hours, demonstrates its value as a tool for a field like asteroseismology.
Key words: asteroseismology / methods: data analysis / methods: statistical / ephemerides / binaries: eclipsing
★ The summarising catalogue of our Kepler analysis results is available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/685/A62
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
Eclipsing binary (EB) systems are an important source for determining the physical properties of stars (Torres et al. 2010). By being locked in a gravitational dance they provide the opportunity to directly measure individual stellar masses, and by eclipsing each other they provide the opportunity to measure the stellar radii (see Southworth 2012, for a brief but clear introduction to the topic). To achieve these measurements, the right observational data are needed: high-precision photometric time series of the brightness of the EB and enough data points of the radial velocities of both stars obtained through spectroscopy. Due to the nature of the observations, obtaining spectra is a lot more time-intensive than photometry, although both types of observations are seeing big boosts in the available amount of data: for example, from the Convection, Rotation and planetary Transits (CoRoT; Auvergne et al. 2009), Kepler (Koch et al. 2010), and Transiting Exoplanet Survey Satellite (TESS; Ricker et al. 2015) missions for photometry and the Gaia-ESO (Gilmore et al. 2012), GALactic Archaeology with HERMES (GALAH; De Silva et al. 2015), SDSS-IV Apache Point Observatory Galactic Evolution Experiment 2 (APOGEE-2; Blanton et al. 2017), and forthcoming SDSS-V Milky Way Mapper (MWM; Kollmeier et al. 2017) surveys for spectroscopy.
Large photometric surveys are an ideal source for discovering variable stars such as EBs (see e.g. Prša et al. 2011, 2022; Armstrong et al. 2016; IJspeert et al. 2021; Howard et al. 2022; Rowan et al. 2022). This means that there are large numbers of EBs with available photometric time series data that lack the multiple epochs of spectroscopic data needed to construct radial velocity curves. However, while less powerful, high-precision photometry alone can still provide valuable information about the physical properties of the system. To start, the orbital period determined from the eclipses can inform spectroscopic follow-up, and it is also an important ingredient in a further analysis of the system. Orbital eccentricities give the shape of the orbit and, by being tied to dissipation within the stars, provide a window into the stellar properties. The argument of periastron and inclination define two of the three angles of the orientation of the orbit1. The sum of the radii scaled by the semi-major axis and the ratio of radii provide the sizes of the stars relative to the size of the orbit, which also ties back to dissipative processes. The surface brightness ratio is related to the effective temperature ratio and, when combined with the scaled radii, tells us whether the two stars are more like twins or distant cousins.
There are several more properties that influence the shape of the light curve, one example being limb darkening, but they are usually subtler effects. Furthermore, many stars, including those in binaries, are found to exhibit intrinsic variability, such as pulsations (Lampens 2021, and citations therein). Systems that show both eclipses and pulsations offer the biggest opportunity to learn by virtue of the information encoded in their light variations (Huber 2015). Various studies have taken advantage of this, as shown by the in-depth analyses by, for example, Maceroni et al. (2009), Schmid et al. (2015), Johnston et al. (2019b, 2021, 2023), Maxted et al. (2020), Sekaran et al. (2020, 2021), Guo et al. (2022), Southworth & Bowman (2022), and Southworth & Van Reeth (2022). However, these studies only treated between one and several dozen systems. The analysis of these systems is often complicated: the amplitudes of pulsations can be comparable to or even exceed the depth of eclipses in the light curve, rendering it impossible to treat a single source of light variation separately. Any generalised approach should therefore account for both the eclipses present and any intrinsic variability that one or both stars exhibit.
Many interesting eclipsing systems have been manually investigated in depth to great effect, providing physical insights on a case-by-case basis (e.g. Schmid & Aerts 2016; Johnston et al. 2019a; Jennings et al. 2023; Pavlovski et al. 2023; Rosu et al. 2023, to name just a few). It is through these kinds of studies that we can calibrate in detail our models of stars, for example with regards to the discrepancy between the dynamical and evolutionary masses of intermediate- to high-mass stars (e.g. Burkholder et al. 1997; Guinan et al. 2000; Weidner & Vink 2010; Massey et al. 2012; Tkachenko et al. 2020; Johnston 2021). This underlines the value of these systems for the calibration of stellar models. With the number of known EBs in the thousands and increasing, investigating every one of them by hand in a reasonable amount of time is infeasible. If a portion of the analysis could be done in an automated way, this would give the researcher more time to take a more detailed look at a select number of promising systems. Additionally, there is a lot of power in numbers, as certain aspects of stellar physics can only be constrained by being compared with the population as a whole (see e.g. Van Eylen et al. 2016; Lurie et al. 2017; Wells & Prša 2021). Altogether, high levels of automation in data analysis are needed to achieve many of the goals in stellar astrophysical research today.
Notable work towards automated pipelines for EB analysis includes Detached Eclipsing Binary Light curve fitter (DEBiL; Devor 2005), Eclipsing Binary Automated Solver (EBAS; Tamuz et al. 2006), and Eclipsing Binaries via Artificial Intelligence (EBAI; Prša et al. 2008). The DEBiL analysis code is part of a larger EB detection pipeline and uses simulated annealing and the downhill simplex method (Nelder & Mead 1965) to solve the inverse problem. EBAS has a strategy for making an initial guess of the parameters using grid searches, gradient descent, and light curve geometry and then employs simulated annealing as well. DEBiL uses its own light curve model implementation of limb-darkened spherical stars, whereas EBAS uses the more complex EBOP light curve generator. With EBAI, Prša et al. (2008) took a different approach and used machine learning with neural networks trained on the rigorous Wilson & Devinney (Wilson & Devinney 1971) model to arrive at a fast estimator for EB parameters. All three pipelines were applied to the published database of Optical Gravitational Lensing Experiment (OGLE; Udalski et al. 1992) EBs (Wyrzykowski et al. 2003), which at the time typically had of the order of a few hundred data points per target. However, while two of the pipelines include a measure of ellipsoidal variability, none account for the intrinsic variability in the form of pulsations that we are specifically pursuing in this work, given its high astrophysical value.
We present a new and fully automated method and its implementation, STAR SHADOW, for the analysis of EB light curves with and without intrinsic variability. Starting from an input light curve, the algorithm can provide the orbital period, several orbit-and eclipse-specific parameters such as eccentricity, and a set of sinusoids that are added to the model of eclipses to fully describe the light variations in the time series. If further investigation into a system's eclipses or the remaining variability is desired, the removal of the other signal, be it the eclipses or the pulsations, is greatly simplified. We validated our method on artificial data and applied it to a population of EBs from the Kepler database (Prša et al. 2011; Slawson et al. 2011; Kirk et al. 2016) to further validate the computed orbital periods. For the Kepler population, we determined the orbital configurations, in particular eccentricities, and the properties of the variability intrinsic to the binary components. We provide a detailed description of the method and its application to a number of realistic synthetic test cases in this paper.
2 Light curve analysis
We developed an automated recipe for the analysis of EB light curves to handle large numbers of targets in a consistent, time-efficient way and without manual involvement. The implementation of the recipe, called STAR SHADOW (Satellite Time series Analysis Routine using Sinusoids and Harmonics Automatedly for Double stars with Occultations and Waves), is publicly available on GitHub2 (version 1.1.7a was used here) and comes with a short guide to get started. Since one of the main aims is the application to data from the TESS mission, the algorithm works best for high-duty-cycle satellite time series photometry and there are a few TESS-specific features like loading in TESS data products and recognition of TESS observing sectors. The algorithm is otherwise fully agnostic to the source of the input light curve, so in the following text if we mention 'sectors', this can be taken to mean any subdivision of the data in the time domain. The method is meant to be applied to known EBs with space-based time series data of tens of ppm precision, which covers the TESS, Kepler, and PLAnetary Transits and Oscillations of stars (PLATO; Rauer et al. 2022) missions, and it is assumed that care has been taken in detrending the raw light curves. Our own two main goals are the determination of the orbital eccentricity and a measure for the significance of variability in the light curve after subtraction of the eclipses.
2.1 Top level overview
We provide a visual representation of the flow of the analysis steps in Fig. 1, with additional example analysis output given in Appendix B. The recipe starts with an iterative pre-whitening procedure meant to capture all the statistically relevant (with regards to the Bayesian information criterion) variability in the light curve in a mathematical model of sine waves. The parameters of the sinusoids are optimised and, if not given beforehand, the orbital period is determined. Frequencies in the previously extracted list that match a theoretical orbital harmonic within a tolerance are forced to the exact multiple of the orbital frequency, thus replacing all frequencies within the tolerance with a single harmonic. If frequencies are closely spaced around the harmonics, this approach will remove too many frequencies from the model: an additional round of iterative pre-whitening ensures that the model of the light curve is complete. The model is again optimised, now including the orbital period as a free parameter, although its value tends to only change by a fraction of the period error estimate at this point, if at all.
The eclipses are located in the time series using their signatures in the first and second time derivatives, using only the model of harmonic sinusoids for the time derivatives to reduce the chance of mistaking intrinsic variability for eclipses. Examples of what is meant by such eclipse signatures can be seen in Fig. 2. The eclipse timings and depths are measured by finding specific extrema and zero points in the two time derivatives. The eclipse detection is based on the methodology described in IJspeert et al. (2021, Sec. 3).
The eclipse timings and depths are translated into some of the orbital and physical parameters of the system: eccentricity, argument of periastron, inclination, sum of the scaled radii, ratio of radii, and ratio of surface brightness. This is done using Kepler's second law and by iteratively solving a set of equations that relate specific points in the orbit to the system's properties. This is discussed further in Sect. 2.2.3.
The orbital and physical parameters are used as a starting point to fit a simple light curve model of eclipses to the data, to potentially increase the accuracy of some of the parameters. The model assumes spherical stars of uniform surface brightness and we refer to it later as just the 'eclipse model' for brevity. The fit is done in three steps: fit only the eclipse model to the original light curve, subtract the eclipse model and iteratively pre-whiten the residuals, and then optimise the full model of eclipses and sinusoids together.
Finally, the ratios of eclipse depth to variability amplitude are computed to have a quick statistic of the balance between the two signals. At every step that adds, removes, or otherwise alters sinusoids, the extracted sinusoids are checked for significance against a signal-to-noise threshold, but not removed based on this check.
2.2 Detailed description
The model of the light curve constructed during the iterative pre-whitening procedure also includes a linear trend for each sector. For TESS data, the linear trend is split up according to the first and second half of each sector; each piece is described by an independent slope and a y-intercept. This captures the average level of the light curve as well as remaining linear instrumental trends in the TESS data products, which may include sudden jumps in the light curve of a sector due to momentum dumps of the gyroscopes. Where the linear trend is split up can be defined by the user. The slope and y-intercept are calculated through their maximum likelihood estimators (MLEs), and updated at each step of the subsequent iterations of the pre-whitening as well as during optimisation procedures. The formulae of the MLEs are provided in Appendix A.1.
The time axis of the data is mean-subtracted throughout the analysis, which ensures a minimal correlation between parameters such as the slope and the y-intercept, and between the frequency and the phase. This means that sinusoid phases and eclipse times are measured with respect to this reference time. For the linear trends, the mean is computed for each separate sector, so their y-intercepts are with respect to those time points.
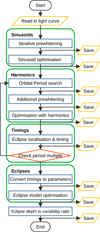 |
Fig. 1 Flowchart of the STAR SHADOW analysis steps. Blue rectangles contain analysis steps that are themselves grouped into four more general functionalities. Read and write operations are in yellow parallelograms, and the orange diamond denotes a decision point to redo a number of steps concerning the orbital period. |
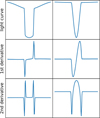 |
Fig. 2 Typical eclipse signatures in the derivatives of the light curve. The left column shows a flat-bottomed eclipse resulting in two separated features in the derivatives, while the V-shaped eclipse on the right leads to peaks merged into one feature. Adapted with permission from IJspeert et al. (2021). |
2.2.1 Frequency analysis
This subsection discusses the 'sinusoids' block in the flow diagram (Fig. 1) and the visualisation in Fig. B.1. In the iterative pre-whitening procedure, we build a model of the light curve in terms of sine waves:
![$\[y(t)=\sum_{i}A_{i}\sin(2\pi f_{i}(t-t_{\text{mean}})+\phi_{i}),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq1.png) (1)
(1)
where t is time, f is frequency, A is amplitude, and ϕ is phase. In this procedure, the next sinusoid to be subtracted is picked by finding the highest amplitude peak in the Lomb–Scargle periodogram (Lomb 1976; Scargle 1982). The periodogram is over-sampled by a factor of 10 with respect to the Rayleigh criterion given by 1/T, where T stands for the total time base of observations3. The highest peak in the periodogram is oversampled by an additional factor of 100 to obtain a precise position (i.e. frequency) and amplitude. The phase of the sinusoid is determined directly from the periodogram as well, using the formula described by Hocke (1998, Eq. (12)).
A sinusoid is only accepted if the Bayesian information criterion (BIC) of the residuals is reduced by at least two, indicating at least positive evidence of its presence by rule of thumb (Raftery 1995; Kass & Raftery 1995). The BIC decreases with more white-noise-like residuals (i.e. containing less information) but increases with additional free parameters, of which each sinusoid initially has three (see Appendix A.2 for a brief derivation). If the next sinusoid does not meet the requirement, the iteration is stopped. This was found to be a suitable procedure for CoRoT space photometry (Degroote et al. 2009). In the case red noise is present, and depending on its power spectral density, it is possible that frequency peaks of high enough signal-to-noise are missed if they have a frequency above the regime affected by the red noise but an amplitude below the amplitude of the red noise.
If at any point during the iterative pre-whitening a frequency is found within 1.5 times the Rayleigh criterion (Loumos & Deeming 1978) of a previously extracted frequency, their peaks in the periodogram will have been blended prior to subtraction. This blending means that the top of the true peak in the periodogram got shifted and the extracted frequency is in a different location. A mechanism is introduced to counteract this shift, which checks each frequency that is being extracted for closely spaced frequencies in the previously extracted list. If a chain of closely spaced frequencies is found around the currently extracted frequency, all frequencies in the chain are iteratively updated by removing one of them at a time and re-extracting it from the updated periodogram around that frequency. Here 'chain' is used to mean any consecutive set of frequencies that are closer than the frequency resolution (1.5/T) to their direct neighbour. This extends to frequencies that are further than the frequency resolution of the currently extracted frequency. The iteration of this sub-loop is terminated when the BIC of the residuals no longer decreases.
The sinusoid parameters may now have shifted with respect to their initial extraction, and the algorithm may have to remove some sinusoids again based on the BIC. This is done in two parts, starting with removing individual sinusoids one by one and checking whether it results in a decrease in the BIC of more than two. Secondly, it is checked whether chains of closely spaced frequencies (or any consecutive sub-chains) can be replaced by a single frequency and yield an improvement.
At the end of each step that involves extracting or updating sinusoid parameters, their significance is checked based on several criteria and stored alongside the parameters. This has no further effect on the analysis process. Sinusoids with an amplitude that is consistent with zero within three sigma are marked insignificant, and for frequencies that fall within three sigma of each other, the lowest amplitude sine wave is marked insignificant. The frequency-dependent periodogram noise level is computed by taking a running average over the Lomb–Scargle periodogram of the residuals of the light curve using a frequency window of one per day, as is common in the literature. The signal-to-noise for each sinusoid is the amplitude divided by this periodogram noise level and those not meeting the threshold are marked insignificant. We used the signal-to-noise threshold as determined by Baran & Koen (2021, Eq. (6)), which is a function of the number of data points and computed for a false alarm probability of 0.1%. We selected candidate harmonics as well, marking only the sinusoids that are within three sigma of a theoretical harmonic frequency (this selection is only relevant later in the analysis).
At the end of the frequency extraction, it is necessary to do a multi-sinusoid non-linear optimisation to get closer still to the real frequencies present in the light curve (Bowman & Michielsen 2021, Sect. 3). We implemented the minimize function from the Scipy (Virtanen et al. 2020) optimisation module and used the limited–memory Broyden–Fletcher–Goldfarb–Shanno bounds (L-BFGS-B) method with analytical gradients (see Appendix C for more insight into the choice of method and the mentioned gradient formulae). Doing such an optimisation whereby all sinusoids are simultaneously fitted is extremely time-consuming. Therefore, to limit the time taken the algorithm fits in groups of 20 to 25 sinusoids. This reduces the fit performance in terms of the final BIC value by about one-quarter of what it could have reached with a fully simultaneous fit in small-scale simulated tests, but the time saved is highly disproportional to this performance decrease (orders of magnitude). Groups are based on the amplitude of the sinusoids, bundling those with similar amplitudes together with the idea that those will have a similar level of influence on each other and on the likelihood function. The division between groups is made by sorting the amplitudes in descending order and making the cut where the largest jump in amplitude occurs within the given constraints of minimum and maximum group size. Group size is not fixed to one number in order to increase amplitude disparity between groups. Frequencies, amplitudes, and phases of the sinusoids in each group are fitted as free parameters in turn until all sinusoids have been optimised. Slopes and y-intercepts of all linear trends always remain free parameters throughout the fitting process.
2.2.2 Frequency analysis with harmonics
This subsection discusses the 'harmonics' block in the flow diagram (Fig. 1) and the visualisation in Fig. B.2. We now introduce the orbital period as a free parameter4. If known, an initial period can be provided, which is then further optimised. Alternatively, a period-finding algorithm is used to obtain the unknown orbital period.
The period-finding algorithm makes use of the already obtained information of sinusoids by only searching at the extracted frequencies and fractions of those. A combined phase dispersion minimisation measure (Stellingwerf 1978) and Lomb–Scargle amplitude statistic is computed as described in Saha & Vivas (2017). In addition, this is multiplied with two more statistics that use the known list of frequencies and are geared towards improving the odds of finding the correct EB orbital period. These two statistics are calculated as follows: (1) The number of harmonic sinusoids present in the extracted frequencies. At each tested orbital frequency, the theoretical orbital harmonic frequencies are computed and compared to the list of extracted frequencies. Those extracted frequencies that fall within the frequency resolution (1.5/T) of a theoretical harmonic are selected and count towards the length of the harmonic series for that orbital frequency. (2) The filling factor of the harmonic series. The second statistic is also based on the harmonic series and captures the filling factor calculated as the number of harmonics present in the extracted frequency list divided by the total number of theoretically possible harmonics below the Nyquist frequency. The Nyquist frequency is defined as the sampling rate divided by two; we used one over the minimum time step for the sampling rate.
After multiplying these four statistics the highest scoring frequency is taken as the initial orbital frequency. The best orbital frequency is further refined locally by minimising the sum of squared distances between the series of extracted harmonic frequencies and the theoretical harmonic frequencies in a grid with a sampling of 0.001% over a 1% interval around the orbital frequency.
As a final check, the two statistics on the series of harmonics as described above are calculated for several multiples of the orbital period: factors of 1/2, 2, 3, 4, and 5. There are two conditions for changing the period multiple, concerning both the filling factor itself and the multiplication of the two statistics of the filling factor and harmonic series length. If the multiplication of the two statistics results in more than 1.1 times the value in this statistic than for the original period and the filling factor is at least 0.85 times that of the original period, the final orbital period is set to the multiple achieving the best score. Alternatively, if both the mentioned values exceed 0.95 specifically for doubling the period, the period is doubled. The threshold values for this decision are empirically determined based on the tests described in Sects. 3 and 4.
The error on the period is estimated by taking the simple linear regression (SLR) uncertainty where each observed eclipse is represented by a single timestamp. This error is only a function of the number of observed eclipses and the uncertainty on the individual timestamps, which is taken to be half the integration time for the observations at this stage. The number of observed eclipses is approximated by rounding down the time base divided by the orbital period, and thus assuming no gaps.
Once the algorithm has a binary period, it selects the orbital harmonic frequencies. All frequencies falling within 1.5 times the Rayleigh criterion of the theoretical harmonics are removed and replaced by exact multiples of the orbital frequency. The new amplitudes and phases are obtained from the periodogram. From this point, the orbital harmonics will have a reduced number of free parameters (from three for unconstrained sinusoids to two, for example), and the orbital period is one additional free parameter. Despite the reduction in parameters and updated harmonic sinusoids, it is possible for this step to increase the overall BIC of the residuals, as too many sinusoids may have been removed.
Since harmonics have one free parameter fewer than their base frequency, it is possible that additional harmonics can be extracted from the periodogram while decreasing the BIC of the residuals by more than two. This is attempted by calculating the amplitude and phase at harmonic frequencies not yet occupied in the frequency list, up to the Nyquist frequency, and checking the significance criterion before they are added to the sinusoidal model of the light curve. Additionally, due to the removal of candidate harmonics, it is likely that more unconstrained sinusoids can be extracted analogously to the initial pre-whitening. After adding sinusoids to the list, the algorithm checks again whether individual frequencies have to be removed, or whether closely spaced chains of frequencies can be replaced by a single frequency based on the BIC of the residuals. If a chain of close frequencies contains a coupled harmonic sinusoid, the algorithm attempts to replace the chain with the harmonic (and therefore does not remove the harmonic). The harmonic does not change in frequency, but its amplitude and phase can change.
Finally, a second multi-sinusoid non-linear optimisation that is more or less analogous to the first is performed. The only differences are that a set of harmonic sinusoids is now coupled to the orbital period and the period is optimised along with the amplitudes and phases of the harmonics.
 |
Fig. 3 Typical eclipse signatures in the derivatives of the light curve, with markers pointing to important features for the automated eclipse detection and timing measurement. Note that points 7 in the left panel of first derivatives are not truly local minima but marked as such for illustrative purposes. Adapted with permission from IJspeert et al. (2021). |
2.2.3 Eclipse timing measurements
This subsection discusses the 'timings' block in the flow diagram (Fig. 1) and the visualisation in Fig. B.3. For the purpose of locating the eclipses, the eclipses are separated out from other variability in the light curve as much as possible by only using the model of orbital harmonic sinusoids (henceforth: harmonic model). Variability at the harmonic frequencies other than the eclipses cannot be separated yet, which can cause problems when that variability has high frequencies relative to the orbital frequency. For this reason, the algorithm initially determines the approximate eclipse positions using orbital harmonics up to and including the twentieth harmonic. Including fewer harmonics does not help as the eclipses lose too much detail. If this fails, it is attempted again with the first forty harmonics and finally with all the orbital harmonics. We provide a visualisation in Fig. 3 to aid in the explanation of the analysis steps below, matching the markers in the figure with numbers and letters between brackets in the text.
The first and second analytically computed time derivatives of the harmonic model inform the automated recognition of the eclipse signatures. The highest peaks in the absolute first derivative belong to the steepest slopes, which in most EB light curves will mean an eclipse ingress or egress. The sign of the first derivative at these locations allows the algorithm to distinguish the start of the eclipse from the end of the eclipse. The algorithm proceeds by determining the first and last contact points5 of the eclipses by following several steps, as described below. Starting from the extrema in the first derivative (1) and moving away from the centre of the eclipse, we find its first zero point (2). Between the extrema and these zero points, there is a minimum in the second derivative (3) where the curvature of the eclipse is greatest (most negative). The minima in the second derivative are taken to be the inner limits for the position of the first and last contact points. The algorithm checks for the presence of local minima in the absolute first derivative (4) between the zero points in the first derivative and the minima in the second derivative. If present, these local minima replace the zero points in the first derivative as the outer limit for the position of the first and last contact points. The times of first and last contact (a) are taken to be midway between the described inner and outer limits, and the interval (3–4) is taken to be the three sigma error region.
Towards the centre of the eclipse, the algorithm determines the first and last internal tangency points6, analogously to the contact points albeit in the opposite direction. Starting again from the extrema in the first derivative (1) and moving towards the centre of the eclipse, we find its first inner zero point (5). Between the extrema and these zero points, there is a maximum in the second derivative (6) where the curvature of the eclipse is greatest (most positive). The maxima in the second derivative are taken to be the outer limits for the position of the first and last tangency points. The algorithm checks for the presence of local minima in the absolute first derivative (7) between the zero points in the first derivative and the maxima in the second derivative. If present, these local minima replace the inner zero points in the first derivative as the inner limit for the position of the first and last tangency points. If the algorithm finds two distinct maxima in the second derivative and the second derivative reaches zero in between them, the first and last internal tangency points (b) are defined as the midway between their respective limits and the interval (6–7) is taken to be the three sigma error region. The internal tangency points now delimit the flattened-off bottom of the eclipse. If instead the algorithm finds that these two maxima coincide, or the curvature does not reach zero in between them, no such flat bottom is defined. In the case of a highly slanted (asymmetric) eclipse, the second derivative might not reach a strong enough maximum on one side of the eclipse for the algorithm to identify that edge.
The eclipse minima (c) are defined to be in the middle between the internal tangency points, and not as the actual minimum in the harmonic model. This is more robust in any cases with variability at harmonic frequencies that does not belong to the eclipses, and more closely corresponds to the time of conjunction. Possible asymmetry can still be accounted for because the internal tangency points may be anywhere between the contact points.
The best consecutive primary and secondary eclipse combination is chosen by taking those with the largest combined depth. If no secondary is found, or no eclipses are found at all, the analysis is stopped. The method for determination of the orbital eccentricity does not hold for systems with no detected secondary eclipse. This method of locating the eclipses was already described in IJspeert et al. (2021, Sect. 3), but was adapted and simplified to analytic sums of sine waves instead of raw data. We note that in the left panel of first derivatives in Fig. 3, points 7 are not truly local minima in the portrayed derivative of the theoretical eclipse model. Using finite sums of sine waves generally results in many more local minima and maxima than is the case for a theoretical model of eclipses, because of the inflection points around (sharp) bends, thus allowing for the simple identification of points 7 as local minima in the figure if a flat eclipse bottom is present.
Once two eclipses have been detected their timing measurements are refined using all significant harmonics. Limiting to lower harmonics works to make detection more robust, but the downside is that eclipses look wider and shallower. An altered version of the eclipse detection algorithm is used that has the benefit of starting from the previously detected positions and is more robust against high-frequency interference. The characteristic points measured are the same, but the method of arriving at them is different.
Starting off from previously determined inner zero points in the first derivative (5), the algorithm adjusts them to the different number of sinusoids included in the first derivative by moving to the nearest zero point. Subsequently, the algorithm determines the updated extrema in the first derivative (1) by searching between the inner zero points and the previous extrema in the first derivative. Moving away from the eclipse centre from the newly found extrema in the first derivative, we find the outer zero points (2). If secondary (local) extrema occur within the outer zero points, and these are sufficiently high (>80% of the height), the extrema in the first derivative (1) are shifted to those locations. The minima in the second derivative (3) are now found between the extrema and outer zero points in the first derivative. Local minima in the first derivative (4) are found by moving outwards from the minima in the second derivative. The inner zero points (5) are now adjusted again, by moving inwards to zero from the extrema in the first derivative. The maxima in the second derivative (6) are found between the extrema and inner zero points in the first derivative. Inner local minima in the first derivative (7) are obtained by moving inwards along the first derivative curve from the maxima in the second derivative. If the ingresses or egresses are found to be less than a quarter of the width of initial localisations (obtained with fewer harmonics), it may indicate that the algorithm did not capture the full extent of the eclipse due to variability not related to the eclipses. The algorithm adjusts the outer eclipse points (1, 2, 3, and 4) farther outwards by moving to the next extrema in the first derivative (1) and repeating the steps to find the other points. This adjustment is only accepted if it does not cross the original outer edges (4) as determined in the localisation step, and if it increases the depth by more than 20%. If the depth is not substantially increased, we are likely already outside of the eclipse.
Improved error estimates for the individual timings and error estimates for the individual depths are determined using the noise level and the slope of the eclipse in- and egress. The noise level is calculated as the standard deviation of the residuals of the light curve. For errors in the individual eclipse times of ingress and egress, the algorithm determines an average slope of each ingress and egress by fitting a straight line to each side of the eclipse. Dividing the noise level by this slope gives the time it takes the flux level to cross the noise level, thus providing an estimate of the timing precision for contact points. Errors in the individual eclipse times are derived from this by taking half and adding in quadrature to the error estimates obtained during eclipse detection:
![$\[\sigma_{\text{t, in/egress}} =\sqrt{\frac{1}{4}\sigma^2_{\text{t, noise/slope}}+\sigma^2_{\text{t, detection}}.}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq2.png) (2)
(2)
The factor 1/4 comes from halving the 'noise-crossing time' to make an error estimate out of it. Analogous to the orbital period error the error on the final eclipse timings, over all observed eclipses, is determined from the SLR uncertainty, which is only a function of the number of observed eclipses and the uncertainty on the individual timings given by Eq. (2). The error for the orbital period is also recalculated, now using the averaged error on the primary and secondary eclipse times as input instead of the time stamp error.
The error in the flux level at first and last contact is estimated as being the noise level, and the error at the bottom of the eclipse is either the noise level (if there is no flat bottom) or the standard deviation of the flux measurements from first to last internal tangency (if there is a flat bottom). These flux level errors then translate into depth errors by adding them in quadrature:
![$\[\sigma_{\text{depth}}=\sqrt{\frac{1}{4}\sigma^2_{\text{first contact}}\frac{1}{4}\sigma^2_{\text{last contact}}+\sigma^2_{\text{bottom}}.}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq3.png) (3)
(3)
The factor 1/4 comes from averaging the flux levels for the first and last contact points in the calculation for the eclipse depth. To obtain the error on the final eclipse depths, over all observed eclipses, we divided Eq. (3) by the square root of the number of eclipses.
Eclipses are rejected under certain conditions, at the end of the detection phase but also at points during the determination of the best candidates for primary and secondary eclipse. Most notably the algorithm applies a significance criterion to the depth and duration of the eclipses based on the estimated errors and a signal-to-noise threshold. The depth must exceed one sigma of the estimated error and one-half the standard deviation of the residuals, whereas the duration must exceed three sigma of the estimated error. Examples of other criteria, applied during the selection of candidate eclipses, look at differences between overlapping candidates and whether a candidate greatly changes in depth between harmonic models with all or only low-frequency harmonics (indicating the occurrence of unrelated signal). These selection criteria are meant to filter out as many false positive candidates as possible before choosing the final set of eclipses to use in the rest of the analysis. However, these criteria or the conditions applied at the end may result in only a primary eclipse (or none), in which case this is logged and the analysis ends.
2.2.4 Eclipse analysis
This subsection discusses the 'eclipses' block in the flow diagram (Fig. 1) and the visualisation in Fig. B.4. Determination of orbital and physical properties – including the eccentricity, argument of periastron, orbital inclination, sum of the scaled radii, ratio of the radii, and surface brightness ratio – is initially done through the use of formulae coupling these properties to the timings and depths of the primary and secondary eclipse. These formulae can be found in, for example, Kopal (1959), but some will be repeated here in altered form for completeness. As the main link between time and orbital elements, we need Kepler's second law in integral form:
![$\[\frac{2\pi(t_{b} - t_{a})}{P}=\left(1-e^{2}\right)^{\frac{3}{2}}\int\nolimits_{v_a}^{v_b}\frac{\text{d}v}{(1+e\cos (v))^{2}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq4.png) (4)
(4)
where ta and tb represent time points in the orbit, P is the orbital period, e the eccentricity and va and vb the true anomaly angles corresponding to the time points. This equation has an analytic solution, which we show in Eq. (A.32). Since we do not know the true anomaly (ν) angles beforehand, we have broken it down into argument of periastron (ω) and phase angle (θ):
![$\[v=\frac{\pi}{2}-\omega+\theta.\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq5.png) (5)
(5)
The argument of periastron is a free parameter defining part of the orbital orientation in the sky, the phase angle gives the position along the orbit and is zero near primary minimum and π near secondary minimum. The algorithm now only needs to determine the phase angles at several strategic points in the orbit to calculate useful values with the integral (4). These points constitute the times of minima, times of contact and for certain cases times of internal tangency as well. Times of minima are reached when the projected orbital separation reaches a minimum, hence when its derivative becomes zero:
![$\[0 = e\, \cos(\theta - \omega) + \sin^2(i) \cos(\theta) (\sin(\theta) - e\, \cos(\omega)),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq6.png) (6)
(6)
with i the orbital inclination. From this formula, we can see that in circular orbits the minima are at phase angles of exactly zero and π. Times of contact are reached when the projected distance between the two stars is equal to the sum of both radii (scaled by the semi-major axis), leading to the equation
![$\[\sqrt{1-\sin^2(i) \cos^2(\phi)}=\frac{r_1+r_2}{a(1-e^2)}(1\pm e\, \sin(\omega\pm \phi)),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq7.png) (7)
(7)
where we introduce the angles ϕ, which are the phase angles of the contact points as measured from zero and from π for the primary and secondary eclipse, respectively. In their exact form, Eqs. (6) and (7) do not have analytical solutions. Approximate analytical solutions do exist, but these are only valid for low eccentricities.
To be able to obtain accurate results for all eccentricities, we used an iterative form of Kepler's second law and let the algorithm solve it numerically for ψ:
![$\[\frac{2\pi(t_2-t_1)}{P}=\psi-\sin(\psi),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq8.png) (8)
(8)
where ψ relates to the component e cos(ω) of the eccentricity. We write
![$\[e\, \cos(\omega) = \frac{\tan\left(\frac{\psi-\pi}{2}\right)\sqrt{1-(e\, \sin(\omega))^2}}{\sqrt{1+\tan^2\left(\frac{\psi - \pi}{2}\right)}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq9.png) (9)
(9)
which depends on an estimate of e sin(ω). For e sin(ω) we write a formula with explicit dependence on inclination, as well as auxiliary angle ϕ0, which further simplifies with the assumption of small ϕ0 and i = 90°:
![$\[\begin{align*}e\, \sin (\omega)& = \displaystyle{\frac{\pi(\tau_{1,1} + \tau_{1,2} - \tau_{2,1} - \tau_{2,2})}{2P\,\sin(\phi_{0})}\frac{\sin^2(i)\sin^2(\phi_0)}{1-\sin^{2}(i)(1+\sin^2(\phi_0))}},\end{align*}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq10.png) (10)
(10)
![$\[\approx \displaystyle{\frac{d_2 - d_1}{d_2 + d_1}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq11.png) (11)
(11)
introducing the notation τ as the time duration from conjunction to either contact point and the subscript τn,m is used to indicate primary (n = 1) or secondary (n = 2) eclipse and first (m = 1) or last (m = 2) contact. Eclipse durations are denoted with dn here. We used formula (10) with i = 90° and the approximate formula for the auxiliary angle, ϕ0, as in Kopal (1959):
![$\[\phi_{0}\approx \frac{\pi}{2P}(\tau_{1,1}+\tau_{1,2}+\tau_{2,1}+\tau_{2,2}).\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq12.png) (12)
(12)
Angle ϕ0 relates to the sum of the scaled radii in the following manner:
![$\[\sqrt{1-\sin^2(i)\cos^2(\phi_0)}=\frac{r_1+r_2}{a(1 - e^2)},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq13.png) (13)
(13)
with a the semi-major axis. After obtaining the components of the eccentricity, the algorithm uses an iterative procedure to improve the value of ϕ0 by computing the sum of eclipse durations using Kepler's second law (Eq. (A.32)) and Eq. (7). A fast global minimisation method is used to find inclination, ratio of radii and ratio of surface brightness by comparing measured eclipse times and depths against the values computed using Eqs. (A.32), (6), (7), and (14).
All of the above assumes spherical stars of uniform brightness. Error estimates are made using a combination of analytical error formulae and the Monte Carlo approach of importance sampling. We provide more details for this step and the error formulae in Appendix C.5.
Fitting eclipse models to a light curve with no prior information usually does not work since the parameter space is degenerate and the optimisation is prone to getting stuck in local minima. Having obtained the parameters from the eclipse timings and depths in the previous step, our pipeline avoids this problem by being able to start close to the optimal solution.
We constructed a simple physical eclipse model by assuming spherical stars of uniform surface brightness and calculating the fraction of light lost due to one star covering the other, which we refer to as the eclipse model. We have not included light from a third body in this model. Subtracting the fractional light loss from one gives us the leftover normalised flux, l:
![$\[l=1-\frac{A_{\text{covered}}}{\pi\, r_1^2+\pi\, r_2^2\frac{sb_2}{sb_1}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq14.png) (14)
(14)
where sb1 and sb2 stand for the surface brightness of stars 1 and 2, respectively. This formula gives the normalised flux for the primary eclipse: we have multiplied the right-hand fraction by ![$\[\\frac{sb_{2}}{s b_{1}}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq15.png) to obtain the flux for the secondary eclipse. The covered area Acovered is the result of two overlapping circles as a function of the distance between their centres s and is computed as follows:
to obtain the flux for the secondary eclipse. The covered area Acovered is the result of two overlapping circles as a function of the distance between their centres s and is computed as follows:
![$\[\begin{align*}A=& r_1^2\ {\text{arccos}}\displaystyle{\left(\frac{s^2+r^2_1+r^2_2}{2sr_1}\right)}\\& + r_2^2\ {\text{arccos}}\displaystyle{\left(\frac{s^2+r^2_2+r^2_1}{2sr_2}\right)}\\&-r_1r_2\displaystyle{\sqrt{1-\left(\frac{r^2_1+r^2_2 - s^2}{2r_1r_2}\right)^2}}.\end{align*}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq16.png) (15)
(15)
The separation between the two centres is expressed in terms of the orbital parameters and as a function of the phase angle (Kopal 1959):
![$\[s=\displaystyle{\sqrt{\frac{(1 - e^2)^2\left(1-\sin^2(i)\, \cos^2(\theta)\right)}{(1-e\, \sin(\theta - \omega))^2}}}.\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq17.png) (16)
(16)
In the three equations above the stellar radii ri and the separation s are in units of the semi-major axis a, but this is left implicit for the simplicity of the formulae. The model is calculated at a regular interval of 0.001 rad in θ, which is converted into times using Kepler's law (Eq. (A.32)). Linear interpolation is used to get the values at the times of the observations.
This eclipse model is first fit to the data, starting from the previously obtained parameters, after which it is subtracted from the light curve and the residuals are pre-whitened analogously to the earlier steps. The obtained model of sinusoids, the linear model and the eclipse model are then optimised simultaneously. We implemented two approaches here: Markov chain Monte Carlo (MCMC) sampling with PyMC3 (Salvatier et al. 2016a) and Scipy minimize with method L-BFGS-B as before (default option)7. Since MCMC can deal with high dimensionality, it gives the full correlation structure as an output and thus additionally provides statistical error estimates. However, these estimates are found to be small compared to our other error estimates (and are thus underestimated; see Sec. 3). This procedure is slower than the fitting method. We note that the orbital period and time of primary minimum are fixed and no longer free parameters at this point. As time-dependent parameters are not included in our model of eclipses at this moment, we recommend to perform the analysis of the light curve in parts. This can reveal possible time dependence of the parameters due to a changing orbit.
2.3 Remaining variability
The level of intrinsic variability compared to the eclipse depths is computed to get an insight into the strength of the presence of potential pulsations or the harmonic sinusoids that are not captured by the eclipse model. Standard deviations are computed for the residuals of four different regression models: an eclipse model with no extra sinusoids, a model with only the first and second harmonic sinusoids, a model with only non-harmonic sinusoids and the full model including all sinusoids. All four models include the linear trend and the eclipse model. Then the algorithm takes the ratio of primary and secondary eclipse depth to each of these four standard deviations. While we have not further explored the variability in this work, additional steps of analysis on the remaining variability could be easily integrated into the framework.
3 Application to synthetic data
We produced a set of 100 synthetic test light curves with randomly sampled parameters, including orbital period, eccentricity, argument of periastron, inclination, scaled radii, surface brightness ratio, third light and a number of pulsations represented by sinusoids. Light curves of a single TESS sector (27.4 days) and a full year (13 sectors) at a 30-min cadence were constructed to mimic some of the TESS time series. The EB light curve models were produced with ellc (Maxted 2016) and sine waves were added to represent the intrinsic variability of various frequencies and amplitudes, finally adding Gaussian noise to imitate real data. Table 1 summarises the ranges of input parameters considered. Appendix D.2 includes examples of some of the generated light curves; all light curves and their parameters are made available through the GitHub page of STAR SHADOW.
Due to the random nature of the generated parameters, some of the synthetic light curves contain no eclipses or have such shallow eclipses that they are impossible to spot by eye. These systems are marked in Fig. 4 and later removed for a cleaner overview of the results. From the viewpoint of the analysis, there are several indicators for such difficult cases, most importantly the completion of all stages of the analysis. If the analysis was completed, the following parameters provide a handle on possible erroneous results: the number of eclipse cycles (period over time base) and depth of the secondary eclipse. We go into some more detail on both of these in the following.
The analysis algorithm was run with no prior knowledge of the orbital period, which is the most important parameter for the rest of the analysis to produce accurate results. We show the performance of the global period search in Fig. 4. In all relevant cases (ncycles ≥ 2, visible eclipses), the algorithm was able to pick the correct multiple of the input period to better than 0.34% precision. More specifically, using the same selection criteria, the mean absolute deviation from the input period is 0.031%, with a median of 0.0009%. Further restricting our selection to cases that have more than ten eclipse cycles reduces those numbers to a mean of 0.0011% and median of 0.00048%.
As Fig. 4 is sorted by the number of cycles, we can see the importance of this parameter as an indicator of the accuracy in the orbital period. This dependence on the number of cycles is taken into account in determining error values, and in the majority of cases, the estimated SLR errors include the input period value within one or two sigma. Figure 5 shows the difference between the measured and input period divided by the SLR errors (χp)in a histogram and kernel density estimation (KDE); the KDE is scaled such that its height is comparable to the histogram. The distribution has a broad peak at zero (width >1), indicating accurate period measurements with estimates of their precision that are overall underestimating the true errors made.
Ranges of synthetic light curve parameters.
Eccentricities
Further analysis depends on the secondary eclipse and thus its correct identification and the measurements of time of minimum, points of in- and egress and depth. Figure 6 shows the eccentricity measurements and inputs versus the depth of the secondary eclipse in the top panel and the deviation from the input in the bottom panel. The identification of the secondary becomes more difficult with decreasing secondary eclipse depth, as evidenced by the increasing scatter to the left in Fig. 6. What actually causes the measurements to be more difficult for lower secondary depths is both the decrease in signal-to-noise and the ratio between the secondary eclipse depth and the amplitude of any intrinsic variability with high-frequency compared to the orbital frequency. Both of these affect the precision with which we can localise the eclipse. Intrinsic variability can additionally impact the accuracy by either shifting the eclipse position or outright causing the method to miss the second eclipse entirely in the most extreme of cases. We refer to Fig. D.26 for the tangential components of the eccentricity. Specifically looking into the few cases with large (negative) eccentricity offsets at eclipse depths above 0.05 we see that the tangential components only constitute a fraction of the difference, up to about 0.03 in e cos(ω).
Deviations in eccentricity generally stay within 0.1. Although error estimates are representative in most cases, we also see cases with underestimated errors that are not explained by their secondary eclipse depth. We see a second maximum in the distribution of absolute differences between measured and input eccentricities (see Fig. 7), between values of −0.2 and −0.1, underestimating the input eccentricities. Inspecting these cases, we find no overarching indicator for their deviation, as their eclipses are correctly identified. We do find their deviations to stem nearly completely from the radial component, e sin(ω). This is caused by an inaccurate determination of eclipse start and end times. They are in some cases easily seen in their analysis output, but not in others (see Figs. D.28 and D.31 for examples). Figure 8 shows the distribution of the true deviations relative to the estimated errors, χe = (emeasured – einput/σe, which has a large width (> 1), meaning errors are underestimated. The bi-modality of the former distribution has largely disappeared, which indicates that the errors are sufficiently large for the second maximum to be incorporated into the main distribution of points. The eccentricities obtained from translating the timings (not shown here; see Appendix D.1) and those obtained from the eclipse model (shown here) have a similar spread. The mean for both distributions lies at zero, suggesting no significant bias towards lower or higher values.
The MCMC method also provides error values (not shown here). These are generally smaller than the previous estimates and more often than not missing the input values. This shows that while the MCMC sampling provides an overview of the full correlation structure, it does not capture the full extent of the error; it only captures the statistical error made when fitting a model with no uncertainties to noisy data. Results obtained using the L-BFGS-B fitting method are qualitatively the same as those obtained through the MCMC sampling method.
Distributions for the deviations from the input of the parameters argument of periastron, inclination, sum of the scaled radii, ratio of radii, and ratio of surface brightness are given in Appendix D.1. We note a few key takeaway points from those figures. There is a good agreement between the overall distributions of the parameter values from translating the timings and those obtained after the eclipse model optimisation step. Two exceptions seem to be the radial component of eccentricity, where the distribution for the eclipse model is shifted slightly towards overestimating this parameter by about two percent, and the auxiliary angle ϕ0, which is slightly underestimated by the eclipse model by less than a percent. The tangential component of the eccentricity is accurate and precise with a distribution width of about 0.01, but errors in a minority of cases are underestimated, resulting in long tails for its distribution of true deviations relative to the estimated errors. The sum of the scaled radii shows good agreement with the inputs: its distribution is less than 0.05 in width, be it with a heavy tail on the high end. The orbital inclination shows a slightly wider spread, and no correlation is seen between inclination deviations and third light. The ratio of radii measurement performs worst overall: we attribute this to the fact that for grazing eclipses, and ignoring limb darkening, there is not enough information in the light curve to strongly constrain the individual stellar radii. We do note that the errors the for ratio of radii appear overestimated for the majority of cases, narrowing down the central peak in its distribution of deviations relative to the error estimates. The addition of limb darkening to our eclipse model may improve the predictive power in this area, but for this specific set of synthetic light curves, other variability would dominate over this effect in most cases. The surface brightness ratio performs better than the radii ratio on an absolute scale, but its error estimates are more underestimated and this gives it a poor result on the relative scale.
We also note that we see no correlation between ϕ0 (or similarly sum of radii) and deviation in eccentricity across our parameter space, with maximum ϕ0 = 0.63. The limitation of the spherical eclipse model is not a simple function of one parameter, but rather depends on the shape of the eclipses as well as on the shape of the light curve at out-of-eclipse phases.
The number of sinusoids used in generating the synthetic light curves is randomly generated as well as their parameters. It is not evident a priori that we would recover this number: iterative pre-whitening procedures tend to vary in the number of sinusoids found based on stopping criteria and other aspects (e.g. Van Beeck et al. 2021). Our approach is to rely on a statistical measure for the information held in the data (the BIC) during pre-whitening, and only select based on significance criteria at the very end. Our final light curve model constitutes an eclipse model, a linear trend and a sum of sinusoids. We now look only at those sinusoids in the final model that pass the significance criteria, which includes the signal-to-noise threshold. Most of the harmonics found in this filtered list contain the leftovers of the eclipse signal not captured by the eclipse model, like ellipsoidal variability and effects of limb darkening. Therefore, it makes sense that we do not see a correlation with the number of harmonics in this list and the number of input sinusoids. We subtract the number of harmonics (nh) from the total number of filtered sinusoids (n) to arrive at the number of independent frequencies (n – nh), which is shown in Fig. 9. We find that this number strongly correlates with the input number of frequencies and that the results for longer time series tend to lie closer to the diagonal over all.
We take the square root of n – nh as the error estimate and compute the histogram and KDE for the deviations from the input value divided by the error to arrive at the distribution shown in Fig. 10. When separated into cases with month-long and year-long light curves, the former have consistently slightly underestimated numbers of sinusoids while the latter have unbiased estimates centred at zero.
One case with a large number of added sinusoids is picked out to look further into the accuracy of the parameters of the extracted sinusoids. We compare the input frequency values with the measured ones by pairing the closest matches together. Figure 11 shows the accuracy and precision of measured frequencies, showing that the error formulae agree with the deviations from the input. The same is true for the amplitudes and, to a lesser degree, for the phase measurements; the distribution of the latter is wider by about 50%. Figures D.32 and D.33 depict the light curve model and the periodogram for this synthetic test case.
 |
Fig. 4 Performance of the period search algorithm as a function of the number of orbital cycles. The blue points with error bars represent the fractional difference between the measured and the input orbital period with SLR error estimates, sorted by descending number of cycles. The grey line with points shows the number of cycles, calculated as the period divided by the time base, plotted on the right axis. The period error scales strongly with the number of cycles. Note that the number of cycles for cases ~60–100 is close to one, and cases that are shaded grey and hatched do not show eclipses. |
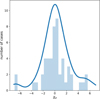 |
Fig. 5 Histogram and KDE of the orbital period χ values ((Pmeasured – Pinput)/σP). using the SLR uncertainties. The KDE is scaled to the height of the histogram. |
 |
Fig. 6 Eccentricity results for the synthetic test cases. Top panel: input (grey) and measured (coloured) eccentricities. Bottom panel: deviation from the input eccentricity against the secondary eclipse depth. The scatter in the bottom panel is seen to increase to the left, with decreasing eclipse depth, as the eccentricity depends critically on the identification and measurement of the secondary eclipse. |
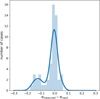 |
Fig. 7 Histogram and KDE of the differences between measured and input eccentricity. Next to the sharp peak at zero, and within the 0.1 deviation, there is a relatively small second maximum where eccentricities are underestimated by between −0.2 and −0.1. The KDE is scaled to the height of the histogram. |
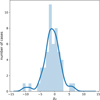 |
Fig. 8 Histogram and KDE of the eccentricity χ values ((emeasured – einput)/σe), using the error formula uncertainties. The bi-modality seen in the absolute differences has largely disappeared. The KDE is scaled to the height of the histogram. |
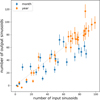 |
Fig. 9 Number of extracted independent sinusoids (n – nh) versus the input number of sinusoids put into the light curve (ninput). Harmonic sinusoids are filtered out as they capture residuals related to the eclipse model that are unrelated to the number of input sinusoids. Points are divided into month-long time series (blue) and year-long time series (orange), and the error bars are calculated as the square root of the number n – nh. |
 |
Fig. 10 Histogram and KDE of the χ values of the number of sinusoids. Errors are taken to be the square root of the amount (n – nh). The histogram is split into light curves of a month in length and those of a year in length: the shorter time base tends to lead to an underestimation of the number of sinusoids present. The KDE is scaled to the height of the histogram. |
4 Kepler EB Catalog
For the purpose of further testing the period-finding capability of STAR SHADOW against a vetted sample of real stars, we apply our methods to the 30-min cadence light curves for the Kepler EB Catalog targets collected by Prša et al. (2011), Slawson et al. (2011), and Kirk et al. (2016)8. In addition we present the results for the eccentricities found for this dataset. Of the 2920 detrended light curves in the catalogue, all completed analysis at least up to and including the period measurement and for 2001 of those we obtained an eccentricity measurement with our analysis (for all morphologies in the catalogue).
Generally, we see a high level of agreement between the periods found by our method and the periods reported in the catalogue. The proportion of targets where the period is within 1% of the reported period is 80.5%. The amount of targets where the period is within a percent of half the reported period is 7.9%, while other close multiplicative factors together constitute 1.3%, adding to a total agreement level of 89.7%. Cases where half the period is designated as the orbital period consist of systems with a primary and secondary eclipse that look very similar, and thus create only weak evidence in Fourier space and in phase dispersion for the correct multiple of the period. Figure 12 shows the fractional differences between measured and catalogue periods, around the zero point: we see a very sharp central peak and wide but low tails extending to around 7e-5 that are imperceptible on the scale of the plot. In the subset with the correct period multiple, we see a mean absolute fractional difference of 0.0027% and a median of 0.00010%. We divide the differences from the catalogue period by our estimated errors to get the distribution shown in Fig. 13. The strong central peak seen in the fractional differences remains but the wings of the distribution become more pronounced, indicating an underestimation of a subset of period errors.
The remaining 10.3% of cases that did not have a multiple of the catalogued period consist of three groups of light curves: (1) very low signal-to-noise cases (62%), (2) those where the binary signal is close to a pure sinusoid, which does not result in a strong series of harmonics to pick up on (36%), and (3) those from multiple systems that have more than one period reported in the catalogue; for these systems, the strongest periodic signal is found (correctly), but we then miss the other periods as we do not continue to search for signals caused by higher-order multiples (4%).
The residuals of the 2001 fully analysed light curves show a range in noise level (standard deviation) from 24 ppm to 8.8 ppt, with a median of 526 ppm and mean of 731 ppm. The signal-to-noise, measured as the smallest eclipse depth divided by the noise level, has a minimum of 0.4, a median of 68, and a mean of 151.
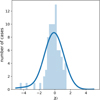 |
Fig. 11 Histogram and KDE of the frequency χ values ((fmeasured – finput)/σf) for one case of the synthetic light curves. Errors are calculated with the standard formulae. The KDE is scaled to the height of the histogram. |
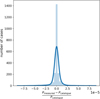 |
Fig. 12 Histogram and KDE of the fractional difference between the Kepler catalogue orbital periods and those measured in this work. Here we select the periods within 1% of the catalogue values. The KDE is scaled to the height of the histogram. |
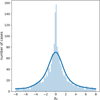 |
Fig. 13 Histogram and KDE of the orbital period χ values ((Pmeasured – Pcatalogue)/σP) comparing the Kepler catalogue values to those measured in this work. We select the periods within 1% of the catalogue values. The relatively pronounced wings of the distribution indicate underestimated period errors for a portion of systems. The KDE is scaled to the height of the histogram. |
Eccentricities
The Kepler EB Catalog does not provide eccentricity measurements to directly compare ours against. However, we can present our results in an eccentricity-versus-period plot that gives an idea of whether our measured eccentricity values are globally as we expect them to be. Generally speaking the orbital circularisation timescale is strongly dependent on the orbital period (Tassoul & Tassoul 1990), which means we would expect all short-period binaries to have zero or otherwise small eccentricity. Conversely we expect a wide distribution of eccentricities at the high period end as these systems are still at their birth configurations.
Figure 14 shows the eccentricity results for a selection of Kepler targets. The selection criteria are an eccentricity measurement error below 0.1 and a catalogue morphology parameter below 0.5, leaving 715 targets of the 2001 systems with an eccentricity measurement. The catalogue morphology parameter is an indicator of the level of detachment between the stars in the system, running from zero to one, with lower values being more detached. We show results that include all morphologies in Fig. D.38. As an integral part of our methodology, we analyse the sinusoidal content in the light curve that is present in addition to the eclipses. To separate targets that are likely pulsating at independent frequencies, we compute the standard deviation of the residuals after subtracting the eclipse model and all harmonic sinusoids from the light curve and dividing this by the standard deviation of the residuals of the full light curve model. This is interpreted as a measure of signal-to-noise of the intrinsic variability at non-harmonic frequencies, and we select targets above a value of 6. These are shown in Fig. 15. Grey markers indicate systems that were found to either be wrongly assigned to this selection of variables due to an ill-fitting eclipse model or have faulty eccentricity measurement due to the absence of one or both eclipses by manual inspection.
The overall picture is consistent with expectation: we see a buildup of systems at zero eccentricity below a period of some ten days, and a large range above that period. There are a few clear outliers among the lowest periods that have significant eccentricity measurements, the majority of which are due to an inaccurate identification or measurement of the secondary eclipse. As mentioned in Van Eylen et al. (2016), the measurement of the radial component of eccentricity, e sin(ω), is less straightforward than that of the tangential component, e cos(ω). This is also apparent in our methodology, which becomes visible when we take a look at the measurements of the tangential component in Fig. 16. Apart from the much smaller error estimates, the scatter around zero tangential eccentricity of the stars below ten days orbital period is tight.
The theory of close binary tides predicts the circularisation timescales of binary orbits (see e.g. Zahn 1975, 1977, 1989; Zahn & Bouchet 1989; Goldreich & Nicholson 1977; Savonije & Papaloizou 1983, 1984). Circularisation is the result of dissipation mechanisms (tidal friction) in the stellar interior, which in turn decrease the orbital energy. Mechanisms include, but are not limited to, damping of the tidal deformation through turbulent flow in a convective region, and the damping of tidally forced oscillations through radiative diffusion. The state of circularisation for a single binary depends on its age, which is generally not straightforward to constrain. Instead, the timescales on which binaries of certain types are expected to circularise can be used to predict the distribution of eccentricities in a population of binary systems. As explained by Van Eylen et al. (2016), age is involved as a factor for high-temperature stars. Due to their much shorter lifespans, comparable to or shorter than the circularisation timescale, they have not had time to circularise even at short periods where tidal friction is strongest. Additionally, hot stars with radiative envelopes have a different mechanism for circularisation than cool stars with convective envelopes. Therefore, we expect hot stars to exhibit larger eccentricities at shorter orbital periods than cool stars.
The Kepler sample studied by Van Eylen et al. (2016), and revisited here, has a majority of cool stars. If we use the same differentiating temperature of 6250 K only one-sixth of the selected eccentricity measurements remain in the high-temperature group. In that publication, the authors used the tangential component of eccentricity, e cos(ω) as a proxy for eccentricity, whereas we determine both components in our analysis. The two temperature groups look broadly consistent with each other in our measurements, due in part to outliers that may or may not be at correct measurement values. We looked in more detail at some of the clear outliers at low periods with eccentricity measurements at or above 0.1. Most of these measurements arise from misidentifications of noise as a secondary eclipse, or broad ellipsoidal variability as an eclipse (the Kepler EB Catalog includes singly eclipsing and even non-eclipsing systems with ellipsoidal variability). Nevertheless, there is a small number of correctly identified systems in this regime, around an eccentricity of 0.15 with well-fitting light curve solutions9: KIC 4544587, 7943535, 8196180, and 11867071 (orange points in Fig. 14). Using the temperatures provided by the Kepler EB Catalog, all four of these systems fall in the high-temperature category, two of them having temperatures above 7000 K. This seems to support the conclusion by Van Eylen et al. (2016), who reported an observed difference between the tangential eccentricity distributions of hot-hot binaries as compared to cool-hot and cool-cool binaries, where hot-hot systems are more eccentric at shorter periods. This is in broad lines consistent with theory.
We use a simple formula from Halbwachs et al. (2005, Eq. (3)), based on the strength of tides varying with distance as 1/r6 (Lecar et al. 1976), to visualise the envelope of maximum eccentricity in Fig. 14 more clearly. The cut-off period, or circularisation period, was set to the value reported by Van Eylen et al. (2016), calculated for cool stars. Apart from the outliers, both those misidentified and the hot stars discussed above, this envelope qualitatively fits the sample. We see the same extension of the low eccentricity cluster towards periods longer than 5 days as in the Van Eylen et al. (2016) sample, which may arise from dependences on age and/or temperature of the circularisation timescale. Our selection of systems with intrinsic variability at non-harmonic frequencies, Fig. 15, contains 108 systems. Even though only a few systems constrain the maximum eccentricity envelope in this selection, we may visually fit a line at a slightly longer cut-off period of 6.5 days. This could be an effect of the low numbers, but it may be a physical effect if pulsations aid the redistribution of orbital angular momentum, increasing the effectiveness of tides. We will investigate this effect further in a future study based on a TESS sample with a factor of about 4 more systems.
The summarising catalogue of our Kepler analysis results is available at the CDS. The results are also made available through the Kepler EB Catalog main web page10.
 |
Fig. 14 Eccentricity measurements for a subset of targets from the Kepler EB Catalog. Selections were made in eccentricity error (<0.1) and morphology parameter (<0.5), the latter being the more stringent criterion. We use the maximum eccentricity as a function of orbital period in Halbwachs et al. (2005, Eq. (3)) with the cut-off period set to 5 days to plot the dashed line. Orange points indicate four systems of interest, with well-fitting models. |
 |
Fig. 15 Eccentricity measurements for a subset of targets from the Kepler EB Catalog. Selections were made in eccentricity error (<0.1) and morphology parameter (<0.5), and measure of signal-to-noise of the intrinsic variability at non-harmonic frequencies (>6). We use the maximum eccentricity as a function of orbital period in Halbwachs et al. (2005, Eq. (3)) with the cut-off period set to 5 and 6.5 days to plot the dashed black and grey lines. Grey points indicate systems that do not belong in this selection or have otherwise faulty measurements. |
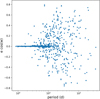 |
Fig. 16 Measurements of the tangential component of eccentricity for a subset of targets from the Kepler EB Catalog. The subset results from cut-offs in eccentricity error (<0.1) and morphology parameter (<0.5), the latter being the more stringent criterion. |
5 Conclusions
We have presented a novel photometric time series analysis methodology and its implementation, STAR SHADOW. Its aim is, in the first place, to analyse large numbers of EBs homogeneously, but it is also broadly applicable for computationally efficient iterative pre-whitening. The method has been tested against a set of synthetic light curves with known input parameters and high levels of intrinsic variability from sources other than eclipses. We find good levels of agreement between the input and extracted sinusoidal frequencies and amplitudes, as well as between the input and computed binary parameters. The accuracy and precision of the binary parameters vary, with the tangential component of eccentricity being the most accurate and precise and the radial component approximately an order of magnitude less well constrained. This is unsurprising as most of the information about the radial component is in radial velocity curves. The number of extracted frequencies after the subtraction of orbital harmonics and after filtering with significance criteria strongly correlates with the number of input sinusoids for the 1-year-long simulated light curves. The number is underestimated for shorter light curves of one month durations.
We further tested the period-finding capabilities of our implementation against the Kepler EB Catalog and examined the eccentricities obtained for this sample. The method finds the correct orbital period multiple, or half the orbital period, in 90% of cases, showing its capability to be used with minimal predetermined knowledge of the data. Cases where it finds half the period are those where the primary and secondary eclipses are nearly identical. Period error estimates are found to be appropriate for the vast majority of targets, with heavy tails on the distribution of the deviation over the error revealing an underestimation for a fraction of targets.
A few of our Kepler eccentricity determinations were compared to results obtained during an in-depth analysis by Kjurkchieva & Vasileva (2015, 2018) as a benchmark. Out of 13 targets, all but two eccentricity values agree within two sigma of our error estimates. The mean absolute deviation in eccentricity is 0.015, giving us confidence in the precision of the method for this parameter. We plot the eccentricities and the two components of eccentricity of our result against those found in the literature in separate panels of Fig. 17. Inspecting the output of our methodology, we find one clear outlier (KIC 8111622) for which the secondary eclipse is misidentified; this measurement is indicated in red. The reason for this misidentification is a very narrow eclipse that is also shallow; because of this, determining its positioning based on the time derivatives of the time series (limited to low frequencies) is difficult. The linear regression coefficient of the eccentricities, excluding this outlier, is 1.00 ± 0.41. In the bottom panel of Fig. 17, the diagonal with a negative slope indicates the position where points are expected if the definition of the primary and secondary eclipse is swapped. The one system where this is the case (KIC 6949550) happens to have equally deep eclipses, so assigning the tag primary or secondary to its eclipses is an ambiguous choice.
The eccentricities obtained for the Kepler targets generally follow the expected pattern as a function of the orbital period. Below around 10 days, eccentricities are broadly consistent with zero, and above 10 days there is a wide distribution of higher eccentricities. We do see a few outliers that are caused by a misidentification of the secondary eclipse, due to a combination of its low eclipse depth and the presence of other variability in the out-of-eclipse part of the light curve. Our methodology was developed with the TESS mission in mind, since our aim is to apply it to the sample of EBs from IJspeert et al. (2021).
We qualitatively compared our Kepler results to the work by Van Eylen et al. (2016), who analysed their own selection of Kepler EBs to obtain the tangential part of the eccentricities. Our results support their conclusion that, at low orbital periods, hot stars (>6250 K) have higher eccentricities than cool stars, which is broadly consistent with theory. Our eccentricity distribution (for cool stars) looks qualitatively consistent with the cut-off period of 5 days computed by Van Eylen et al. (2016) for cool stars with convective envelopes.
The average run time of the analysis was 10 min for one-year time base simulated light curves, with an average of 2 min of that spent on the frequency analysis. For the Kepler light curves, the recorded average time to completion is just over 2 h, including 1 h for frequency analysis. The scaling with the time series length (4 yr for Kepler) is not linear since the number of extracted sinusoids also increases with the time base. This rapid performance is achieved through various optimisations in the algorithm of iterative pre-whitening and multi-sinusoid non-linear optimisation; the main optimisations are further described in Appendix C. We encourage others to implement a gradient-based approach for sinusoid optimisation for the free performance boost it gives, in order to save on both time and energy.
 |
Fig. 17 Comparison of eccentricity measurements for 13 Kepler targets. Top panel: eccentricity measurements from this work versus those obtained in Kjurkchieva & Vasileva (2015, 2018), along the diagonal (grey line). The linear regression model is plotted as a black dotted line. Bottom panel: comparison between the tangential and radial components of eccentricity. The dashed line indicates where points occur if the definition of primary and secondary eclipse is swapped. |
Acknowledgements
The research leading to these results has received funding from the KU Leuven Research Council (grant C16/18/005: PARADISE), from the Research Foundation Flanders (FWO) under grant agreements 1124321N (Aspirant Fellowship to LIJ), G089422N (AT), as well as from the BELgian federal Science Policy Office (BELSPO) through PRODEX grant PLATO. CJ gratefully acknowledges support from the Netherlands Research School of Astronomy (NOVA) and from the Research Foundation Flanders (FWO) under grant agreement G0A2917N (BlackGEM). AP acknowledges support of the NSF grant #2306996 and NASA 23-ADAP23-0068. CA acknowledges funding by the European Research Council under grant ERC SyG 101071505. Funded by the European Union. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council. Neither the European Union nor the granting authority can be held responsible for them. This paper includes data collected by the Kepler mission, which are publicly available from the Mikulski Archive for Space Telescopes (MAST) at the Space Telescope Science Institute (STScI). Funding for the Kepler mission is provided by the NASA Science Mission Directorate. STScI is operated by the Association of Universities for Research in Astronomy, Inc., under NASA contract NAS 5-26555. Some of the computing resources and services used in this work were provided by the VSC (Flemish Supercomputer Center), funded by the Research Foundation - Flanders (FWO) and the Flemish Government. Software: This work and the presented code (STAR SHADOW) make use of Python (Python Software Foundation. Python Language Reference, version 3.7. Available at www.python.org) and the Python packages Numpy (Harris et al. 2020), Numba (Lam et al. 2015), Scipy (Virtanen et al. 2020), Astropy (Astropy Collaboration 2013, 2018, 2022), PyMC3 (Salvatier et al. 2016a,b), Theano (The Theano Development Team 2016), Arviz (Kumar et al. 2019), h5py (Collette 2013), Matplotlib (Hunter 2007) and corner (Foreman-Mackey 2016). The authors thank A. Kemp and D. Fritzewski for their valuable input as beta testers of parts of the code presented in this work.
Appendix A Additional formulae
A.1 Maximum likelihood estimators
Model parameters can sometimes be determined via direct calculation using MLEs under the assumption that our observations are independent and identically distributed according to a normal distribution. We could do this for the two parameters needed to capture linear trends, as well as for higher-order polynomials; we have gone up to third order here.
We can describe each observation as being drawn from a normal distribution (our first assumption):
![$\[f(x\vert\mu, \sigma)=\displaystyle{\frac{1}{\sqrt{2\pi\sigma^2}}exp \left(\frac{-(x - \mu)^2}{2\sigma^2}\right),}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq18.png) (A.1)
(A.1)
where x are the observations, μ the mean, and σ the standard deviation. The likelihood function is the joint probability density of our observations, which under the assumption that our observations are independent, can be written as the multiplication of the individual distributions:
![$\[L(\theta)=\displaystyle{\Pi_i f(x_i\vert \theta)=\left(\frac{1}{\sqrt{2\pi \sigma^{2}}}\right)^n exp \left(\frac{-\sum_{i}(x_i-\mu)^2}{2\sigma^2}\right),}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq19.png) (A.2)
(A.2)
with θ representing the model parameters and n is the number of data points. An MLE is obtained by maximising the likelihood, or taking the derivative of the likelihood with respect to each model parameter θ and setting this to zero. We take the (natural) logarithm of the likelihood because summation is easier to work with and the location of the maximum is conserved. Another advantage in the case of an iterative use of the likelihood is that it is computationally more stable to use the logarithm:
![$\[l(\theta)\equiv (ln(L(\theta))=- \displaystyle{\frac{n}{2}}ln\left(2\pi\sigma^2\right)-\displaystyle{\frac{\sum\nolimits_{i}(x_i-\mu)^2}{2\sigma^2}}.\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq20.png) (A.3)
(A.3)
We can now confirm that indeed the sample mean ![$\[\({\frac{1}{n}}\textstyle\sum_{i}x_{i}={\bar{x}})\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq21.png) is the MLE of the mean (μ) and the square root of the sample variance
is the MLE of the mean (μ) and the square root of the sample variance ![$\[\(\surd \frac{1}{n}\textstyle\sum_{i}(x_i - \bar{x})^2)\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq22.png) is the MLE of the standard deviation (σ) by taking the derivative of l to μ and σ, respectively, and setting this to zero. Substituting these parameters for their estimators, we obtain
is the MLE of the standard deviation (σ) by taking the derivative of l to μ and σ, respectively, and setting this to zero. Substituting these parameters for their estimators, we obtain
![$\[l(\theta)=-\displaystyle{\frac{n}{2}}ln\displaystyle{\left(\frac{2\pi}{n}\sum\limits_i(x_i-\bar{x})^2\right)-\frac{n}{2}}.\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq23.png) (A.4)
(A.4)
The light curve model that we use, whether that is a straight line, sinusoid or more complex, can be seen as the mean of the normal distributions that each observation follows, in the sense that subtracting the model from the data results in a zero mean for all data points. With y our observations and ŷ the model, we can then write
![$\[l(\theta)=\displaystyle{-\frac{n}{2}\left(ln\left(2\pi \sigma_r^2\right)+1\right),}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq24.png) (A.5)
(A.5)
and σ2r is the variance of the residuals, estimated as
![$\[\sigma_r^2=\displaystyle{\frac{1}{n}\sum_i(y_i - {\hat{y}}_i)^2}.\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq25.png)
We now need an analytical model to work out the estimators for the model parameters. A linear trend is used extensively in this work, but we also include the quadratic and cubic case here for completeness:
![$\[\begin{align*}\hat{y} & = \theta_1 x+\theta_0,\\\hat{y}_q & = \theta_2 x^2 +\theta_1 x+\theta_{0},\\\hat{y}_c & = \theta_3 x^3 +\theta_2 x^2 + \theta_{1}x+ \theta_{0}.\end{align*}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq26.png)
To shorten the following formulae, we define several sums using subscripts denoting the power of the variable within each term as follows:
![$\[S_{\hat{y}}=\sum_i(y_i -{\hat y}_i)^2=n\sigma_r^2,\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq27.png) (A.6)
(A.6)
![$\[S_{xx}=\sum_i(x_i -{\bar x})^2,\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq28.png) (A.7)
(A.7)
![$\[S_{x2x2}=\sum\limits_i(x_i^2 -{\bar x}^2)(x_i - {\bar x}),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq29.png) (A.8)
(A.8)
![$\[S_{x2x2}=\sum\limits_i(x_i^2 -{\bar x}^2)^2,\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq30.png) (A.9)
(A.9)
![$\[S_{x3x}=\sum\limits_i(x_i^3 -{\bar x}^3)(x_i-{\bar x}),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq31.png) (A.10)
(A.10)
![$\[S_{x3x2}=\sum\limits_i(x_i^3 -{\bar x}^3)(x_i^2-{\bar x}^2),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq32.png) (A.11)
(A.11)
![$\[S_{x3x3}=\sum\limits_i(x_i^3 -{\bar x}^3)^2,\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq33.png) (A.12)
(A.12)
![$\[S_{xy}=\sum\limits_i(x_i -{\bar x})(y_i- {\bar{y}}),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq34.png) (A.13)
(A.13)
![$\[S_{x2y}=\sum\limits_i(x_i^2 -{\bar x}^2)(y_i- {\bar{y}}),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq35.png) (A.14)
(A.14)
![$\[S_{x3y}=\sum\limits_i(x_i^3 -{\bar x}^3)(y_i- {\bar{y}}),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq36.png) (A.15)
(A.15)
where ![$\[\$\textstyle{\bar{x}}^{2}$\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq37.png) is the mean of squares and
is the mean of squares and ![$\[\\textstyle{\bar{x}}^{3}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq38.png) is the mean of cubes.
is the mean of cubes.
Setting ∂l/∂θ0 equal to zero for the linear case we find
![$\[\theta_0={\bar y}- \theta_1 {\bar x}.\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq39.png) (A.16)
(A.16)
Setting ∂l/∂θ1 equal to zero and substituting A.16 we find
![$\[\theta_1=\displaystyle{\frac{S_{xy}}{S_{xx}}}.\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq40.png) (A.17)
(A.17)
Maximum likelihood estimators for the standard deviations of the above estimators are
![$\[S_{\theta_0}^2=S_{y,x}^2\displaystyle{\left(\frac{1}{n_{data}}+\frac{{\bar x}^2}{S_{xx}}\right)},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq41.png) (A.18)
(A.18)
![$\[S_{\theta_1}^2 = \displaystyle{\frac{S_{y,x}^2}{S_{xx}}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq42.png) (A.19)
(A.19)
where the (corrected) standard deviation of y(x) is
![$\[S_{y,x}^2=\displaystyle{\frac{S_{\hat{y}}}{n_{dof}}}.\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq43.png) (A.20)
(A.20)
The quadratic case yields
![$\[\theta_2 = \displaystyle{\frac{S_{x2y}S_{xx}-S_{xy}S_{x2x}}{S_{x2x2}S_{xx}-S_{x2x}^{2}}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq44.png) (A.21)
(A.21)
![$\[\theta_1 = \displaystyle{\frac{S_{xy}-\theta_2S_{x2x}}{S_{xx}}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq45.png) (A.22)
(A.22)
![$\[\theta_0={\bar y} - \theta_2{\bar x}^2-\theta_1\bar{x}.\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq46.png) (A.23)
(A.23)
For the cubic case, we broke up θ3 into its numerator and denominator:
![$\[\begin{align*}\theta_{3,a} = & S_{x3y}\left(S_{x2x2}S_{xx} - S_{x2x}^2\right)\\& - S_{x2y}\, (S_{x3x2}S_{xx} - S_{x3x}S_{x2x})\\& + S_{xy}\, (S_{x3x2}S_{x2x} - S_{x3x}S_{x2x2}),\\\theta_{3,b} = & S_{x3x3}\left(S_{x2x2}S_{xx}-S_{x2x}^2\right)\\& - S_{x3x2}\, (S_{x3x2}S_{xx} - 2S_{x3x}S_{x2x})\\&- S^2_{x3x}S_{x2x2}\end{align*}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq47.png)
and obtain the following results:
![$\[\theta_3=\displaystyle{\frac{\theta_{3,a}}{\theta_{3,b}}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq48.png) (A.24)
(A.24)
![$\[\theta_2=\displaystyle{\frac{S_{x2y}S_{xx} - S_{xy}S_{x2x} - \theta_{3} (S_{x3x2}S_{xx}-S_{x3x}S_{x2x})}{S_{x2x2}S_{xx} - S^{2}_{x2x}}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq49.png) (A.25)
(A.25)
![$\[\theta_1= \displaystyle{\frac{S_{xy} - \theta_3S_{x3x} - \theta_{2}S_{x2x}}{S_{xx}}}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq50.png) (A.26)
(A.26)
![$\[\theta_0={\bar y}- \theta_3{\bar x}^3-\theta_2{\bar x}^2 - \theta_1{\bar x}.\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq51.png) (A.27)
(A.27)
A.2 Bayesian information criterion
The BIC of the residuals decreases with more white-noise-like residuals (i.e. containing less information), but increases with additional free parameters of which each sinusoid initially has three:
![$\[BIC = -2 \cdot ln(L(\theta)) + k \cdot ln(n),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq52.png) (A.28)
(A.28)
where L is the likelihood as a function of the parameters θ, n the number of data points and k the number of free parameters. Under the simplifying assumption that the observations are independent and identically distributed according to a normal distribution, the likelihood as in A.5 can be plugged in to get
![$\[BIC = n\cdot ln\left(2\pi\sigma_r^2\right)+n+k\cdot ln(n).\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq53.png) (A.29)
(A.29)
A.3 Kepler's second law
The law of equal swept-out areas, or Kepler's second law, couples the orbital properties to time intervals. This means it enables the computation of said properties if we can measure enough 'special' time points along the orbit. Special here means that we know something about the geometric configuration of the binary at that specific time. For example, at the time of eclipse minimum, we know that the star in front is covering a maximal portion of the surface area of the star in the back and thus the projected (in the plane of the sky) distance between their centres is minimal.
For an eccentric orbit, the instantaneous distance between the centres of the two stars is
![$\[R=\displaystyle{\frac{a\left(1-e^2\right)}{1+e\ cos(v)}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq54.png) (A.30)
(A.30)
with a the semi-major axis, e the eccentricity, and ν the true anomaly indicating in what phase of the orbit we are. Plugging this into Kepler's second law in integral form, we obtain
![$\[\displaystyle{\frac{2\pi (t_b-t_a)}{P}=\int\nolimits_{v_a}^{v_b}\frac{R^2dv}{a^2\sqrt{1-e^2}}=\left(1-e^2\right)^{\frac{3}{2}}\int_{v_a}^{v_b}\frac{dv}{(1+e\ cos (v))^2}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq55.png) (A.31)
(A.31)
where P is the orbital period and (tb − ta) is a time interval corresponding to the integral boundary values of ν. As can be read in more detail in Kopal (1959), this integral has an analytic solution:
![$\[\displaystyle{\frac{2\pi(t_b - t_a)}{P}=\left[2\cdot arctan\left(\frac{\sqrt{1-e}\, sin \left(\frac{v}{2}\right)}{\sqrt{1+e}\, cos \left(\frac{v}{2}\right)}\right)-\frac{e\sqrt{1-e^2}\, sin(v)}{\sqrt{1+e}\, cos(v)}\right]_{v_a}^{v_b}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq56.png) (A.32)
(A.32)
written in a slightly different form than in the aforementioned book. It follows naturally that the time interval is a function of eccentricity and argument of periastron (see Equation 5). What is not immediately apparent from this is the dependence on other properties like inclination and sum of the scaled radii. As described in the main text, these properties appear in Equations 6 and 7, which are used to calculate the true anomaly of our special time points that we need to plug into the integral bounds.
An auxiliary angle ϕ0 is defined corresponding to the sum of the scaled radii as in Equation 13, which does not a priori have any physical meaning11. This equation replaces the identical factor in Equation 7 to make
![$\[\sqrt{1-sin^2(i)cos^2(\phi)}=\sqrt{1-sin^2(i)cos^2(\phi_{0})}(1\pm e\ sin(\omega\pm \phi)),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq57.png) (A.33)
(A.33)
which is in fact four equations for four different ϕ angles corresponding to the first and last contact of the primary and secondary eclipse. Thus, these angles correspond to four additional special time points where we know the orbital configuration. These equations do not have analytical solutions.
In every formula above we assume spherical stars, or rather, circular projections of the stars, which is a decent approximation in the context of eclipses where the stars are always nearly aligned with the line of sight12. It is in the phases in between the eclipses that we see the stars 'side-on' and their deformation as a result of each other's gravity can be significant.
Appendix B Schematic method overview
 |
Fig. B.1 'Sinusoid' part of the analysis. The input light curve is iteratively pre-whitened, and the resulting parameters are non-linearly optimised. This step results in a mathematical model of the light curve in terms of a sum of sine waves and a linear trend for each sector (separately) and is applicable to any time series. In the second to last panel is the sum of sinusoids light curve model in orange and the bottom panel shows the residuals. |
 |
Fig. B.2 'Harmonic' part of the analysis. The orbital period is determined (if not given), and the orbital harmonics found in the extracted list of frequencies are coupled to the orbital frequency, after which another non-linear optimisation is done. This step is broadly applicable to EBs and other light curves of periodic, non-sinusoidal signal that results in a series of harmonics in the periodogram. The second to last panel shows the orbital harmonic sinusoid model in orange and the bottom panel shows all non-harmonic sinusoids. |
 |
Fig. B.3 'Timings' part of the analysis. The eclipses are detected and their positions, durations, and depths are measured through the use of the model of orbital harmonic sinusoids and time derivatives thereof. Also included is a check for the multiplicity of the period that checks for the number of identical eclipses found in one cycle. The bottom panel shows the light curve folded over the orbital period in blue, the harmonic model in red and the non-harmonic model subtracted light curve in orange. The horizontal and vertical dashed lines indicate the eclipse measurements. |
 |
Fig. B.4 'Eclipses' part of the analysis. The measurements of eclipse timings and depths are translated to orbital and physical parameters of the system using formulae, and the resulting parameters are used as a starting point for fitting an eclipse model of spherical and uniformly bright stars to the data. The eclipse model is supplemented with a sum of sinusoids, obtained by subtracting the initial eclipse model from the data and pre-whitening the residuals. The second to last panel shows the eclipse model in red and the bottom panel shows the supplemental sinusoid model. |
Appendix C Details of the method implementation
Appendix C.1 Iterative pre-whitening
As already eluded to in the main text, the next frequency, picked by its highest amplitude, is over-sampled in frequency space by a factor of 100 over the default sampling of the full periodogram. To spend as little computation time as possible on calculating periodograms, we use the 'fast' implementation of the Astropy Lomb–Scargle periodogram (Press & Rybicki 1989). This method extrapolates from a fast Fourier transform and thus is not ideal for high precision. Additionally, it cannot be used on sub-domains in frequency space as it will produce unphysical results. However, since we are using a two-step approach, this poses no problems. The oversampling step makes use of the traditional Lomb–Scargle periodogram, albeit an efficient implementation of it by Cuypers, translated by the authors to Python+Numba from the Fortran implementation in the IvS Python Repository (GitHub)13. The 100 times over-sampled periodogram is only computed for the domain between the point to the left and the point to the right of the topmost point in the original periodogram (the one at the highest amplitude), saving on unnecessary computations. The phase is computed only at the final determined frequency (using the formula from Hocke 1998), adding very little extra computational cost.
Another optimisation in all of the algorithms where sinusoids are iteratively added to or subtracted from a light curve model is to keep a copy of the model as well instead of just keeping a copy of each sinusoid parameter. Calculating sine waves is very time-consuming computationally speaking, so by replacing calculations of sine waves with simple addition and subtraction to the model in memory, we save a lot of computation time. Another benefit is that this step of the iterative process no longer scales in time with the number of sinusoids in the model. The additional step of iterating over closely spaced frequencies does still add a level of dependence on the number of sinusoids, making the overall scaling of iterative pre-whitening with the number of sinusoids slightly more than linear (with the dependence being a function of frequency density in the periodogram). The overall increase in efficiency is large enough that for the data used in testing for the speed (a fairly short light curve), the process even becomes memory-bound instead of CPU-bound, meaning that the speed of the computer memory is now the bottleneck for this part of the process in that scenario.
Appendix C.2 Minimisation with Scipy
Nelder-Mead (NM; Nelder & Mead 1965) is a robust gradientfree method that was tested extensively in this framework, and it performs well in terms of the final objective function value reached. However, it requires many function evaluations and thus is computationally expensive. The optimisation steps in the algorithm are (were) the computational bottleneck, so we looked for an effective way of decreasing this computational cost. Scipy offers a wide range of minimisation methods: in search of a faster but still robust method in our application, we tested all of them. Some methods require a Jacobian or both a Jacobian and a Hessian to be provided, and several cannot handle boundaries. For our application of fitting a sum of sine waves to the light curve, we can compute the partial derivatives constituting the Jacobian and Hessian, and our testing described below refers to this application. Table C.1 summarises the features of each minimisation method.
Scipy minimize method features.
Although it is not strictly necessary for every minimisation step in the algorithm, we do want to impose boundaries on our parameters. We tested methods that have the option to numerically compute gradients with and without the analytical Jacobian to see what the performance gain would be. Both Powell and sequential least squares programming (SLSQP) (without Jacobian) are more than an order of magnitude faster than NM, but both diverge from the true solution instead of converging on it. SLSQP becomes slightly faster when the Jacobian is provided and diverges slightly less dramatically. Method trust-constr (without Jacobian) takes a factor of a few longer than NM, while reaching worse cost-function values. However, when provided with the Jacobian it redeems itself by becoming faster than NM by a factor of 2 and obtaining the same cost-function value. Unfortunately providing the Hessian as well makes it much slower again; this could be due to the high computational cost of the Hessian function. Methods conjugate gradient (CG), Broyden–Fletcher–Goldfarb–Shanno (BFGS), L-BFGS-B, and truncated Newton constrained (TNC) perform similar to NM in terms of cost function, but only BFGS and L-BFGS-B are faster by a noticeable factor of a few without the Jacobian. CG does not benefit time-wise from the Jacobian, but the three others do: they reach similar speeds of more than an order of magnitude faster than NM. Also, Newton-CG, which required the Jacobian to function, falls into the same performance category as the three others in terms of both cost function and speed. It does not benefit meaningfully from the Hessian. All four of the methods that require the Hessian take a longer time than NM, by a factor of more than 2. Since CG, BFGS, and Newton-CG cannot handle bounds or constraints, L-BFGS-B and TNC go on to a second round of testing. Constrained optimization by linear approximation (COBYLA) also makes it to the second round by being fast and only marginally worse in terms of the cost function, and its lack of support for bounds can be mitigated by its support for constraints.
In a more demanding test with a longer light curve, the COBYLA method (which does not use a Jacobian) shows comparable speed to L-BFGS-B and TNC (with Jacobian), but diverges and does not return a sensible result. L-BFGS-B and TNC (both compared with and without Jacobian) perform very similarly: the final choice for L-BFGS-B is made based on its faster speed, and even though the cost-function value it reaches is not quite as good, the difference in the actual light curve model is imperceptibly small.
Appendix C.3 Analytical gradients
As mentioned above, the optimisation makes good use of analytical gradient information. We include their mathematical form here. Our objective function is the negative log-likelihood:
![$\[f=-In(l)=\frac n2\left[In\left(\frac{2\mathrm\pi}n\sum_i{(y_i-{\widehat y}_i)}^2\right)+1\right],\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq58.png) (C.1)
(C.1)
with symbol definitions as in Appendix A. The Jacobian is defined as
![$\[J=\left[\frac{\partial f}{\partial\theta_1},\frac{\partial f}{\partial\theta_2},\dots,\frac{\partial f}{\partial\theta_n}\right],\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq59.png) (C.2)
(C.2)
where each θj stands for one of the model parameters. Using the generalised product rule the derivatives can be written as
![$\[\frac{\partial f}{\partial\theta_j}=\sum_i\frac{\partial f}{\partial{\widehat y}_i}\frac{\partial{\widehat y}_i}{\partial\theta_j},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq60.png) (C.3)
(C.3)
![$\[\frac{\partial f}{\partial{\widehat y}_i}=\frac{-n(y_i-{\widehat y}_i)}{\sum_i{(y_i-{\widehat y}_i)}^2},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq61.png) (C.4)
(C.4)
![$\[\frac{\partial{\widehat y}_i}{\partial\theta_j}=\frac\partial{\partial\theta_j}a_jsin\left(2\mathrm\pi f_j(t_i-t_{mean})+\phi_j\right).\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq62.png) (C.5)
(C.5)
Making the derivatives explicit, we get
![$\[\frac{\partial\hat{y}_{i}}{\partial f_{j}}=2\pi(t_{i}-t_{m e a n})a_{j}c o s\left(2\pi f_{j}(t_{i}-t_{m e a n})+\phi_{j}\right),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq63.png) (C.6)
(C.6)
![$\[\frac{\partial\hat{y}_{i}}{\partial a_{j}}=\,s i n\left(2\pi f_{j}(t_{i}-t_{m e a n})+\phi_{j}\right),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq64.png) (C.7)
(C.7)
![$\[\frac{\partial\hat{y}_{i}}{\partial\phi_{j}}=a_{j}c o s\left(2\pi f_{j}(t_{i}-t_{m e a n})+\phi_{j}\right),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq65.png) (C.8)
(C.8)
And for the orbital period,
![$\[\frac{\partial\hat{y_{i}}}{\partial p_{o r b}}=\sum_{h}2\pi\frac{-n_{h}}{p_{o r b}^{2}}(t_{i}-t_{m e a n})a_{h}c o s\biggl(2\pi\frac{n_{h}}{p_{o r b}}(t_{i}-t_{m e a n})+\phi_{h}\biggr),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq66.png) (C.9)
(C.9)
in which we are now summing over all harmonic sinusoids. We note that for the eclipse model parameters we cannot compute gradients analytically. However, this does not prevent us from using the gradients that we do know during the optimisation of the eclipse model plus sinusoids. We use the scipy.optimize.approx_fprime to obtain numerical gradients for the 6 parameters of the eclipse model and fill those in at their respective locations in the Jacobian. This provides a similar, although smaller, speed increase as for the pure sinusoid optimisations.
Appendix C.4 Parameter space
The parameter space we work in for the six free parameters in our eclipse model is made up of ecos(ω), e sin(ω), cos(i), ϕ0, log10 ![$\[\\left({\frac{r_{\mathrm{2}}}{r_{\mathrm{1}}}}\right)\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq67.png) , and log10
, and log10 ![$\[\\left({\frac{s b_{2}}{s b_{1}}}\right)\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq68.png) . This choice of parameters ensures two things: minimal correlation between the free parameters and a flatter space across the relevant domain. In the case of ecos(ω), e sin(ω), and ϕ0 both of these reasons apply, while the reduction of correlation is the driving factor compared to their counterparts e, ω and rsum. Reducing correlation has a strong effect on the ability of optimisation algorithms to accurately and quickly converge. Another benefit is that our correlation structures, and thus error estimates, in the least correlated parameter space are most reliable and simple to interpret.
. This choice of parameters ensures two things: minimal correlation between the free parameters and a flatter space across the relevant domain. In the case of ecos(ω), e sin(ω), and ϕ0 both of these reasons apply, while the reduction of correlation is the driving factor compared to their counterparts e, ω and rsum. Reducing correlation has a strong effect on the ability of optimisation algorithms to accurately and quickly converge. Another benefit is that our correlation structures, and thus error estimates, in the least correlated parameter space are most reliable and simple to interpret.
Parameters ![$\[\{\frac{r_{\mathrm{2}}}{r_{\mathrm{1}}}}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq69.png) and
and ![$\[\{\frac{s b_{2}}{s b_{1}}}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq70.png) have an extremely curved parameter space in the sense that a step of 0.1 has a completely different meaning depending on where in the parameter domain we are situated. Using logarithms, log10
have an extremely curved parameter space in the sense that a step of 0.1 has a completely different meaning depending on where in the parameter domain we are situated. Using logarithms, log10 ![$\[\\left({\frac{r_{2}}{r_{1}}}\right)\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq71.png) and log10
and log10 ![$\[\\left({\frac{s b_{2}}{s b_{1}}}\right)\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq72.png) , has two main advantages that are similar to the ones mentioned for the reduction in correlation. It makes it simpler for many optimisation algorithms to traverse the parameter space for a more accurate and sometimes speedier result, as well as improving the reliability and interpretability of the error estimates (in that parameter space).
, has two main advantages that are similar to the ones mentioned for the reduction in correlation. It makes it simpler for many optimisation algorithms to traverse the parameter space for a more accurate and sometimes speedier result, as well as improving the reliability and interpretability of the error estimates (in that parameter space).
Appendix C.5 Translating eclipse timings to eccentricity
Here, we describe the steps for obtaining physical parameters from time measurements in more detail.
Although a multitude of approaches was tested, we settled on one that provides the best combination of speed and accuracy. The initial step is to set cos(i) = 0 and compute the approximate ϕ0 with Equation 12. Sufficient accuracy is retained when solving Equation 8 and plugging in the approximate Equations 9 and 10. Iteratively updating ϕ0 using exact formulae for the eclipse durations does, however, provide a noticeable improvement in the measurement of the sum of the scaled radii through Equation 13.
To find inclination, ratio of radii and ratio of surface brightness we construct a cost function based on iteratively solving Equations 6 and A.33 and plugging the obtained angles into 5 and then A.32 to obtain accurate theoretical eclipse times, and computing theoretical depths with Equation 14. Minimisation is done with a global optimiser from Scipy, called simplicial14 homology global optimisation (SHGO), with reasonable boundaries on the parameters for feasible systems.
Minimisation is performed in the parameter space: ![$\[\cos({i}),log_{10}\left(\frac{r_{2}}{r_{1}}\right),\,log_{10}\left(\frac{s b_{2}}{s b_{1}}\right)\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq73.png) . This has the benefit of homogenising the step size across the parameter space, where especially the two parameter ratios suffer from a large difference in step size on either end of their physical ranges. Since we also compute components of eccentricity ecos(ω) and e sin(ω), we also need to convert them to e and ω:
. This has the benefit of homogenising the step size across the parameter space, where especially the two parameter ratios suffer from a large difference in step size on either end of their physical ranges. Since we also compute components of eccentricity ecos(ω) and e sin(ω), we also need to convert them to e and ω:
![$\[\begin{array}{ccc}e&=&\sqrt{\left(e\;cos\mathit{\left(\omega\right)}\right)^2+\left(e\;sin\mathit{\left(\omega\right)}\right)^2,}\\\omega&=&arc\tan\;\left(\frac{e\;sin\mathit{\left(\omega\right)}}{e\;cos\mathit{\left(\omega\right)}}\right),\end{array}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq74.png) (C.10)
(C.10)
where code-wise an arctan2 function is used instead of arctan to obtain correct angles across the full range. ϕ0 is converted to the sum of radii with
![$\[r_{sum}=\sqrt{1-sin^2\left(i\right)cos^2\left({\phi}_{\mathit0}\right)}\left(1-e^2\right).\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq75.png) (C.11)
(C.11)
Error estimation was done with a combination of analytical error formulae and the Monte Carlo approach of importance sampling. The analytical formulae are used as minimum error estimates, but we do not have approximate analytical formulae for all parameters. Furthermore, for the analytical error formulae, we do not have an a priori value for the inclination error, so we estimate one that is informed by the tests on synthetic light curves. Starting with an error estimate of 0.035 radians in inclination (2 degrees), we use the following formulae as errors on the given subset of parameters:
![$\[\begin{array}\sigma_{e c o s(w)}=\;\sqrt{\partial_{p}^{2}\sigma_{p}^{2}+\partial_{t}^{2}\left(\sigma_{t,1}^{2}+\sigma_{t,2}^{2}\right)+\partial_{\dot{t}}^{2}\sigma_{\dot{t}}^{2}},\\\partial_{p}=\frac{-\pi(t_{2}-t_{1})s i n^{2}(i)}{p_{o r b}^{2}(1+s i n^{2}(i))},\\\partial_{t}=\frac{\pi s i n^{2}(i)}{p_{o r b}(1+s i n^{2}(i))},\\\partial_{i}=\frac{2s i n(i)c o s(i)}{(1+s i n^{2}(i))^{2}},\end{array}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq76.png) (C.12)
(C.12)
where we abbreviated the partial derivatives: ![$\[\\partial_{x}\equiv\frac{\partial_{y}}{\partial_{x}}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq77.png) .
.
![$\[\begin{aligned}\sigma_{e s i n(w)} & =\sqrt{\partial_p^2 \sigma_p^2+\sum_{m, n} \partial_\tau^2 \sigma_{\tau, m, n}^2+\partial_i^2 \sigma_i^2+\partial_{\phi, 0}^2 \sigma_{\phi, 0}^2}, \\\partial_p & =\frac{-\pi\left(\tau_{1,2}+\tau_{1,1}-\tau_{2,1}-\tau_{2,1}\right) sin ^2(i) cos ^2\left(\phi_0\right)}{2 sin \left(\phi_0\right) p_{o r b}^2\left(1+sin ^2(i)\left(1+cos ^2\left(\phi_0\right)\right)\right)}, \\\partial_\tau & =\frac{\pi sin ^2(i) cos ^2\left(\phi_0\right)}{2 sin \left(\phi_0\right) p_{\text orb }\left(1-sin ^2(i)\left(1+cos ^2\left(\phi_0\right)\right)\right)}, \\\partial_i & =\frac{2 sin (i) cos (i) cos ^2\left(\phi_0\right)}{\left(1-sin ^2(i)\left(1+cos ^2\left(\phi_0\right)\right)\right)^2}, \\\partial_{\phi, 0} & =\frac{2 sin ^2(i)\left(1-sin ^2(i)\right) sin \left(\phi_0\right) cos \left(\phi_0\right)}{\left(1-sin ^2(i)\left(1+cos ^2\left(\phi_0\right)\right)\right)^2}\end{aligned}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq78.png) (C.13)
(C.13)
where the sum goes over primary (m = 1) and secondary (m = 2) ingress (n = 1) and egress (n = 2).
![$\[\sigma_{e}=\;\sqrt{c o s^{2}(w)\sigma_{e c o s(w)}^{2}+\,s i n^{2}(w)\sigma_{e s i n(w)}^{2}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq79.png) (C.14)
(C.14)
![$\[\sigma_{w}=\sqrt{\frac{s i n^{2}(w)}{e^{2}}\sigma_{e c o s(w)}^{2}+\frac{c o s^{2}(w)}{e^{2}}\sigma_{e s i n(w)}^{2}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq80.png) (C.15)
(C.15)
![$\[\begin{aligned}\sigma_{\phi, 0} & =\sqrt{\partial_p^2 \sigma_p^2+\sum_{m, n} \partial_\tau^2 \sigma_{\tau, m, n}^2}, \\\partial_p & =\frac{\pi\left(\tau_{1,2}+\tau_{1,1}+\tau_{2,1}+\tau_{2,1}\right)}{2 p_{\text {orb }}^2}, \\\partial_\tau & =\frac{\pi}{2 p_{\text {orb }}},\end{aligned}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq81.png) (C.16)
(C.16)
![$\[\begin{aligned}\sigma_{r, s u m} & =\sqrt{\partial_e^2 \sigma_e^2+\partial_i^2 \sigma_i^2+\partial_{\phi, 0}^2 \sigma_{\phi, 0}^2}, \\\partial_e & =2 e \sqrt{1-sin ^2(i) cos ^2\left(\phi_0\right)}, \\\partial_i & =\frac{sin (i) cos (i) cos ^2\left(\phi_0\right)\left(1-e^2\right)}{\sqrt{1-sin ^2(i) cos ^2\left(\phi_0\right)}}, \\\partial_{\phi, 0} & =\frac{sin ^2(i) sin \left(\phi_0\right) cos \left(\phi_0\right)\left(1-e^2\right)}{\sqrt{1-sin ^2(i) cos ^2\left(\phi_0\right)}},\end{aligned}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq82.png) (C.17)
(C.17)
The error formulae for e sin(ω) and ϕ0 are found lacking in an earlier version of our synthetic test (Section 3), which likely is because they both rely on the measurement of the widths of the eclipses, which can be inaccurate and is more easily disturbed by additional variability. Based on the same test, we constructed simple scaling relations that apply to the minimum error in the concerned parameters. Their functional form is
![$\[minimum\,error=C\cdot e x p\left(-{\frac{d e p t h_{2}}{0.3\sum_{h}a_{h}}}\right),\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq83.png) (C.18)
(C.18)
where the constant C is 0.2 for e sin(ω) and 0.05 for ϕ0. The specific scaling variable used in the exponent was found to correlate strongest with absolute deviation from the input of these parameters (correlation of -0.45 for e sin(ω)), much more so than secondary eclipse depth alone (correlation of -0.24 for e sin(ω)). The inclusion of the depth of the secondary eclipse is intuitive as shallower secondary eclipses are harder to measure. The other parameter is less intuitive: it is the sum over amplitudes of low and high-frequency harmonics. The sum actually goes over harmonic orders up to and including 5, and harmonic orders above 15. Dependence on the higher frequency harmonics may be understood in terms of the presence of additional variability in the light curve, which reduces the accuracy of the measurements of eclipse edge points. The dependence on the low-frequency harmonics is likely to do with a stronger presence of these harmonics, indicating either very wide eclipses or out-of-eclipse variability, which cross over into the regime where the simplified physics of the applied formulae starts to lose accuracy.
To obtain minimum error values for the two ratios and their logarithms, we compute a scale factor by dividing the computed value for σe by the error estimate obtained for e in the importance sampling (explained below). We take the maximum of the upper and lower error value for this, and multiply the importance sampling errors of the logarithm of radius ratio and the logarithm of surface brightness ratio, again taking the maximum of upper and lower error value. Finally, computing the relative error scaling in log space, and multiplying by the respective parameters in linear space, we obtain the minimal errors for both representations of these two parameters.
In the importance sampling, we generated input normal distributions of a thousand samples for the measured values of eclipse times (minima, contact, and tangency) within their respective error regions and computed the output of the iterative 'translation' scheme outlined above for each of the generated input vectors. This results in a set of output distributions for each computed parameter. Estimates of the errors are then obtained using the highest density interval at 0.683 probability. We note that the resulting error region can exclude the point estimate made before. This is fixed by imposing the minimum errors. The choice not to use the mean of the distribution as a point estimate is made because the distributions are often multi-modal and may not accurately represent the optimal solution.
Appendix D Additional plots
Appendix D.1 Synthetic test set
These additional figures aim to give a more complete view of the output of our analysis of the synthetic light curves discussed in Section 3. The first, Figure D.1, shows the same period measurements as Figure 4, except now ordered by primary eclipse depth. We note that the eclipse depth does not have any significant influence on the period accuracy except in the most extreme cases where no eclipses can be made out (shaded and hatched dark grey area).
The majority of the remaining figures show the absolute and relative distributions of the parameter outputs compared to the input values. The relative distributions (denoted with χ) use the estimated error values obtained from the importance sampling and after imposing our error minima (from the formal error calculations and scaling relations). The two colours, blue and orange, in each plot show values obtained at the eclipse timing translation step and the eclipse model fitting step, respectively.
Finally, we show obtained inclinations versus the third light that was added to the artificial light curves. Third light is not modelled, but Figure D.27 shows no sign of a correlation between third light and inclination. These parameters are mutually degenerate, so such a correlation would be expected: possibly the overall (low) accuracy of our inclination measurements hides this dependence.
 |
Fig. D.1 Performance of the period search algorithm as a function of the primary eclipse depth. Blue points with error bars show the fractional difference between the measured and the input orbital period with SLR error estimates, sorted by descending primary eclipse depth. The grey line with points shows primary eclipse depths, plotted on the right axis. Note that cases shaded grey and hatched do not show eclipses, and cases shaded orange have fewer than three eclipse cycles. |
 |
Fig. D.2 Histogram and KDE of the eccentricity deviations from the input. |
 |
Fig. D.3 Histogram and KDE of the eccentricity χ values (deviation from the input divided by the error estimate). |
 |
Fig. D.4 Histogram and KDE of the argument of periastron deviations from the input. |
 |
Fig. D.5 Histogram and KDE of the argument of periastron χ values (deviation from the input divided by the error estimate). |
 |
Fig. D.6 Histogram and KDE of the inclination deviations from the input. |
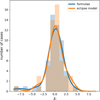 |
Fig. D.7 Histogram and KDE of the inclination χ values (deviation from the input divided by the error estimate). |
 |
Fig. D.8 Histogram and KDE of the sum of scaled radius deviations from the input. |
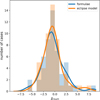 |
Fig. D.9 Histogram and KDE of the sum of scaled radius χ values (deviation from the input divided by the error estimate). |
 |
Fig. D.10 Histogram and KDE of the ratio of radius deviations from the input. |
 |
Fig. D.11 Histogram and KDE of the ratio of radius χ values (deviation from the input divided by the error estimate). |
 |
Fig. D.12 Histogram and KDE of the ratio of surface brightness deviations from the input. |
 |
Fig. D.13 Histogram and KDE of the ratio of surface brightness χ values (deviation from the input divided by the error estimate). |
 |
Fig. D.14 Histogram and KDE of the tangential component of eccentricity deviations from the input. |
 |
Fig. D.15 Histogram and KDE of the tangential component of eccentricity χ values (deviation from the input divided by the error estimate). |
 |
Fig. D.16 Histogram and KDE of the radial component of eccentricity deviations from the input. |
 |
Fig. D.17 Histogram and KDE of the radial component of eccentricity χ values (deviation from the input divided by the error estimate). |
 |
Fig. D.18 Histogram and KDE of the cosine of inclination deviations from the input. |
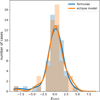 |
Fig. D.19 Histogram and KDE of the cosine of inclination χ values (deviation from the input divided by the error estimate). |
 |
Fig. D.20 Histogram and KDE of the auxiliary angle, ϕ0, deviations from the input. |
 |
Fig. D.21 Histogram and KDE of the auxiliary angle, ϕ0, χ values (deviation from the input divided by the error estimate). |
 |
Fig. D.22 Histogram and KDE of the logarithm of the ratio of radius deviations from the input. |
 |
Fig. D.23 Histogram and KDE of the logarithm of the ratio of radius χ values (deviation from the input divided by the error estimate). |
 |
Fig. D.24 Histogram and KDE of the logarithm of the ratio of surface brightness deviations from the input. |
 |
Fig. D.25 Histogram and KDE of the logarithm of the ratio of surface brightness χ values (deviation from the input divided by the error estimate). |
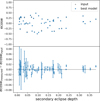 |
Fig. D.26 Tangential part of eccentricity (top panel) and deviation from input (bottom panel) versus secondary eclipse depth. |
 |
Fig. D.27 Inclinations (top panel) and deviation from input (bottom panel) versus third light (fraction of total light). Note the absence of an apparent correlation between the accuracy of inclination and third light. |
Appendix D.2 Example light curves
Here we show a few examples of the analysis results from the synthetic set of test light curves discussed in Section 3. The average level of added sinusoid amplitudes is high in this set, challenging the algorithm for eclipse detection and measurement. In Figure D.28 the algorithm was successful in detecting and measuring the eclipses, perhaps with the exception of a remaining residual spike on the egress of the primary. Figures D.32 and D.33 show the eclipse model of the final stage of the analysis and the periodogram with extracted sinusoids, respectively. This is the synthetic case used for the analysis of the accuracy and precision of the recovery of input sinusoids (most of them pink in the periodogram).
We see better how the added variability affects the measurement in Figure D.34, where the primary is wider to one side than it should be. The resulting large residuals are captured by the sinusoids that are complementary to the eclipse model to make up the full variability of the light curve. This results in harmonic sinusoids that in this case model artificial signals, but in other cases can also help model, for example, the physical shape of the eclipses or the ellipsoidal variability not captured by the eclipse model (see Figure D.35).
 |
Fig. D.28 Example (full) synthetic light curve of case 7. The top panel shows the final eclipse model of the eclipses in red and the full model of the light curve including sinusoids in grey. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here. The slight overestimation of the primary eclipse width can be identified by sharp residual peaks here and leads to an underestimation of the radial part of eccentricity of about 0.2 for this case. |
 |
Fig. D.29 Fourier amplitude spectrum of case 7. In red and pink are the extracted sinusoids, of which the red ones qualify as harmonics. At an orbital period of 16.56, the spacing of harmonics is quite dense (grey grid lines). |
 |
Fig. D.30 Fourier amplitude spectrum of case 7 after subtracting the eclipse model. In red are the extracted sinusoids that pass all criteria, including the signal-to-noise threshold shown in green (calculated in a window of 1d−1). |
 |
Fig. D.31 Example synthetic light curve of case 99 folded over the orbital period. The top panel shows the final eclipse model of the eclipses in red and the full model of the light curve including sinusoids in grey. The orange model is the starting point for the light curve fit. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here. The model starts from an overestimated primary eclipse width, and the fit is unable to fully correct for this as the residuals show. This leads to and underestimated tangential eccentricity by about 0.2 for this case. |
 |
Fig. D.32 Synthetic light curve of case 26 folded over the orbital period. The top panel shows the final eclipse model of the eclipses in red and the full model of the light curve including sinusoids in grey. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here and covers up the data points. |
 |
Fig. D.33 Fourier amplitude spectrum of case 26. In red and pink are the extracted sinusoids, of which the red ones qualify as harmonics. The peaks around 5 to 10 cycles per day are from sine waves put into the synthetic light curve and recovered accurately and precisely by our analysis pipeline. |
 |
Fig. D.34 Example (full) synthetic light curve of case 23. The top panel shows the final eclipse model in red and the full model of the light curve including sinusoids in grey. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here. We can see that the primary eclipse is too wide as the detection algorithm picked up on other variability close to it. |
 |
Fig. D.35 Example (folded over the period) synthetic light curve of case 24. The top panel shows the final eclipse model in red and the full model of the light curve including sinusoids in grey. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here. The eclipse model has trouble fitting these wide eclipses and does not capture any out-of-eclipse variability. |
 |
Fig. D.36 Example (folded over the period) synthetic light curve of case 88. The top panel shows the final eclipse model in red and the full model of the light curve including sinusoids in grey. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here. |
 |
Fig. D.37 Histogram and KDE of the orbital period χ values, comparing orbital periods measured in this work to those from the Kepler catalogue. Here we select the periods within 1% of half the catalogue values and the errors are taken to be the SLR uncertainties. The KDE is scaled to the height of the histogram. |
Appendix D.3 Kepler EB Catalog
Figure D.37 is complementary to Figure 13: it shows the distribution of measured periods around half the catalogue values. The shape of the distribution differs little from the one around the catalogue period, with a sharp central peak and heavy tails.
Adding all morphologies from the Kepler EB Catalog to the eccentricity-period plot, Figure D.38, extends it substantially to lower periods. We now include 1399 of 2001 targets with an eccentricity measurement, as compared to the 715 we had when limiting to morphologies below 0.5. We see that the majority of additional systems fall at around zero eccentricity, and while the error bars are relatively large, there is more scatter than for the previous selection of targets below ten days orbital period. Especially noticeable are the systems at periods around a day and high eccentricity. These do not indicate physical peculiarities, but rather inaccurate determination of eclipse times. For these low period systems, eclipses are often not sharply defined making it harder for our derivative-based method to accurately determine the edges.
We see from Figure D.39 that most of these outlier systems are not due to large ecos(ω) values: even though the scatter around the zero line for the tangential component of eccentricity is markedly larger for these high morphology targets, it stays within a value of 0.1 for most of them. That means inaccurate e sin(ω) measurement is the driving factor for these outliers.
 |
Fig. D.38 Eccentricity measurements for a subset of targets from the Kepler EB Catalog. A cut-off was made in eccentricity error (<0.1) but all morphology values were included. We use the maximum eccentricity as a function of orbital period in Halbwachs et al. (2005, Equation 3) with the cut-off period set to 5 days to plot the dashed line. |
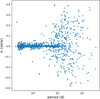 |
Fig. D.39 Measurements of the tangential component of eccentricity for a subset of targets from the Kepler EB Catalog. The subset results from a cut-off in eccentricity error (<0.1) but all morphology values were included. |
Appendix E Correlation reduction
Reducing the correlation between optimisation parameters can strongly benefit the ease and accuracy with which the optimisation is done. It may be possible to transform a parameter to this end; one such example is the use of auxiliary angle ϕ0 as mentioned in the main text. For the reason that we are trying to solve the general case of an EB light curve, it may not always make sense to use a certain re-parametrisation. For example: when eclipses are grazing, instead of showing the flattened-off phase of either total eclipses or transits, we lose information about the eclipsing stars. In this case, a grazing eclipse provides less information on the radii, but we do not lose all. It may then be appealing to keep the ratio of radii fixed at one, while only fitting for the sum of the scaled radii. We can, however, do better. The only information we actually lose completely is which star is bigger and which is smaller, but we can still recover information about the size of the bigger star and the size of the smaller star. We can represent this loss of knowledge in a new free parameter, which replaces the ratio of radii:
![$\[\rho=\frac{r_{1}^{2}+r_{2}^{2}}{a^{2}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq84.png) (E.1)
(E.1)
where ri is each star's radius and a the semi-major axis, similar to the sum of radii. We keep the sum of radii,
![$\[r_{s u m}={\frac{r_{1}+r_{2}}{a}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq85.png) (E.2)
(E.2)
or, alternatively, angle ϕ0 can be chosen. We cannot recover the individual radii r1 and r2 from this combination of parameters, representing the lack of information in the light curve. What we can recover is
![$\[r_{s,l}=\,\frac{1}{2}r_{sum}\pm\frac{1}{2}\,\sqrt{{{2}}\rho-\,{r}_{s u m}^{2}},\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq86.png) (E.3)
(E.3)
with which we find a small and a large radius (implicitly scaled by a). Clearly, for the systems where we have the information available, we would not want to artificially limit ourselves, in addition to actually increasing correlations between the parameters in those cases. Therefore, we chose to accept sub-optimal correlation structures in return for a more generally and homogeneously applicable method. However, for an analysis of a specific binary with grazing eclipses (which is a large fraction of all EBs for geometrical reasons), this approach may aid the specific optimisation procedure utilised, increasing accuracy and potentially speed.
References
- Armstrong, D. J., Kirk, J., Lam, K. W. F., et al. 2016, MNRAS, 456, 2260 [NASA ADS] [CrossRef] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Auvergne, M., Bodin, P., Boisnard, L., et al. 2009, A&A, 506, 411 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Baran, A. S., & Koen, C. 2021, Acta Astron., 71, 113 [Google Scholar]
- Blanton, M. R., Bershady, M. A., Abolfathi, B., et al. 2017, AJ, 154, 28 [Google Scholar]
- Bowman, D. M., & Michielsen, M. 2021, A&A, 656, A158 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Burkholder, V., Massey, P., & Morrell, N. 1997, ApJ, 490, 328 [NASA ADS] [CrossRef] [Google Scholar]
- Collette, A. 2013, Python and HDF5 (O'Reilly) [Google Scholar]
- Degroote, P., Briquet, M., Catala, C., et al. 2009, A&A, 506, 111 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Silva, G. M., Freeman, K. C., Bland-Hawthorn, J., et al. 2015, MNRAS, 449, 2604 [NASA ADS] [CrossRef] [Google Scholar]
- Devor, J. 2005, ApJ, 628, 411 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D. 2016, J. Open Source Softw., 1, 24 [Google Scholar]
- Gilmore, G., Randich, S., Asplund, M., et al. 2012, The Messenger, 147, 25 [NASA ADS] [Google Scholar]
- Goldreich, P., & Nicholson, P. D. 1977, Icarus, 30, 301 [NASA ADS] [CrossRef] [Google Scholar]
- Guinan, E. F., Ribas, I., Fitzpatrick, E. L., et al. 2000, ApJ, 544, 409 [NASA ADS] [CrossRef] [Google Scholar]
- Guo, Z., Ogilvie, G. I., Li, G., Townsend, R. H. D., & Sun, M. 2022, MNRAS, 517, 437 [NASA ADS] [CrossRef] [Google Scholar]
- Halbwachs, J. L., Mayor, M., & Udry, S. 2005, A&A, 431, 1129 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Hocke, K. 1998, Ann. Geophys., 16, 356 [Google Scholar]
- Howard, E. L., Davenport, J. R. A., & Covey, K. R. 2022, RNAAS, 6, 96 [NASA ADS] [Google Scholar]
- Huber, D. 2015, Giants of Eclipse: The zeta; Aurigae Stars and Other Binary Systems, eds. T. B. Ake & E. Griffin, Astrophys. Space Sci. Lib., 408, 169 [NASA ADS] [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- IJspeert, L. W., Tkachenko, A., Johnston, C., et al. 2021, A&A, 652, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jennings, Z., Southworth, J., Maxted, P. F. L., & Mancini, L. 2023, MNRAS, 521, 3405 [NASA ADS] [CrossRef] [Google Scholar]
- Johnston, C. 2021, A&A, 655, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Johnston, C., Pavlovski, K., & Tkachenko, A. 2019a, A&A, 628, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Johnston, C., Tkachenko, A., Aerts, C., et al. 2019b, MNRAS, 482, 1231 [Google Scholar]
- Johnston, C., Aimar, N., Abdul-Masih, M., et al. 2021, MNRAS, 503, 1124 [NASA ADS] [CrossRef] [Google Scholar]
- Johnston, C., Tkachenko, A., Van Reeth, T., et al. 2023, A&A, 670, A167 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kass, R. E., & Raftery, A. E. 1995, J. Am. Stat. Assoc., 90, 773 [Google Scholar]
- Kirk, B., Conroy, K., Prša, A., et al. 2016, AJ, 151, 68 [Google Scholar]
- Kjurkchieva, D., & Vasileva, D. 2015, PASA, 32, e023 [NASA ADS] [CrossRef] [Google Scholar]
- Kjurkchieva, D. P., & Vasileva, D. L. 2018, Ap&SS, 363, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Koch, D. G., Borucki, W. J., Basri, G., et al. 2010, ApJ, 713, L79 [Google Scholar]
- Kollmeier, J. A., Zasowski, G., Rix, H.-W., et al. 2017, arXiv e-prints [arXiv:1711.03234] [Google Scholar]
- Kopal, Z. 1959, CLOSE binary Systems (John Wiley & Sons) [Google Scholar]
- Kumar, R., Carroll, C., Hartikainen, A., & Martin, O. 2019, J. Open Source Softw., 4, 1143 [Google Scholar]
- Lam, S. K., Pitrou, A., & Seibert, S. 2015, in Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, LLVM '15 (New York, NY, USA: Association for Computing Machinery) [Google Scholar]
- Lampens, P. 2021, Galaxies, 9, 28 [NASA ADS] [CrossRef] [Google Scholar]
- Lecar, M., Wheeler, J. C., & McKee, C. F. 1976, ApJ, 205, 556 [NASA ADS] [CrossRef] [Google Scholar]
- Lomb, N. R. 1976, Ap&SS, 39, 447 [Google Scholar]
- Loumos, G. L., & Deeming, T. J. 1978, Ap&SS, 56, 285 [NASA ADS] [CrossRef] [Google Scholar]
- Lurie, J. C., Vyhmeister, K., Hawley, S. L., et al. 2017, AJ, 154, 250 [Google Scholar]
- Maceroni, C., Montalbán, J., Michel, E., et al. 2009, A&A, 508, 1375 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Massey, P., Morrell, N. I., Neugent, K. F., et al. 2012, ApJ, 748, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Maxted, P. F. L. 2016, A&A, 591, A111 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Maxted, P. F. L., Gaulme, P., Graczyk, D., et al. 2020, MNRAS, 498, 332 [Google Scholar]
- Nelder, J. A., & Mead, R. 1965, Comput. J., 7, 308 [Google Scholar]
- Pavlovski, K., Southworth, J., Tkachenko, A., Van Reeth, T., & Tamajo, E. 2023, A&A, 671, A139 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Press, W. H., & Rybicki, G. B. 1989, ApJ, 338, 277 [Google Scholar]
- Prša, A., Guinan, E. F., Devinney, E. J., et al. 2008, ApJ, 687, 542 [CrossRef] [Google Scholar]
- Prša, A., Batalha, N., Slawson, R. W., et al. 2011, AJ, 141, 83 [Google Scholar]
- Prša, A., Kochoska, A., Conroy, K. E., et al. 2022, ApJS, 258, 16 [CrossRef] [Google Scholar]
- Raftery, A. E. 1995, Sociol. Methodol., 25, 111 [CrossRef] [Google Scholar]
- Rauer, H., Aerts, C., Deleuil, M., et al. 2022, in European Planetary Science Congress, EPSC2022-453 [Google Scholar]
- Ricker, G. R., Winn, J. N., Vanderspek, R., et al. 2015, J. Astron. Telesc. Instrum. Syst., 1, 014003 [Google Scholar]
- Rosu, S., Quintero, E. A., Rauw, G., & Eenens, P. 2023, MNRAS, 521, 2988 [NASA ADS] [CrossRef] [Google Scholar]
- Rowan, D. M., Jayasinghe, T., Stanek, K. Z., et al. 2022, MNRAS, 517, 2190 [NASA ADS] [CrossRef] [Google Scholar]
- Saha, A., & Vivas, A. K. 2017, AJ, 154, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Salvatier, J., Wiecki, T. V., & Fonnesbeck, C. 2016a, PeerJ Comput. Sci., 2, e55 [Google Scholar]
- Salvatier, J., Wiecki, T. V., & Fonnesbeck, C. 2016b, Astrophysics Source Code Library [record ascl:1610.016] [Google Scholar]
- Savonije, G. J., & Papaloizou, J. C. B. 1983, MNRAS, 203, 581 [Google Scholar]
- Savonije, G. J., & Papaloizou, J. C. B. 1984, MNRAS, 207, 685 [Google Scholar]
- Scargle, J. D. 1982, ApJ, 263, 835 [Google Scholar]
- Schmid, V. S., & Aerts, C. 2016, A&A, 592, A116 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schmid, V. S., Tkachenko, A., Aerts, C., et al. 2015, A&A, 584, A35 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sekaran, S., Tkachenko, A., Abdul-Masih, M., et al. 2020, A&A, 643, A162 [EDP Sciences] [Google Scholar]
- Sekaran, S., Tkachenko, A., Johnston, C., & Aerts, C. 2021, A&A, 648, A91 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Slawson, R. W., Prša, A., Welsh, W. F., et al. 2011, AJ, 142, 160 [Google Scholar]
- Southworth, J. 2012, in Orbital Couples: Pas de Deux in the Solar System and the Milky Way, eds. F. Arenou, & D. Hestroffer, 51 [Google Scholar]
- Southworth, J., & Bowman, D. M. 2022, MNRAS, 513, 3191 [Google Scholar]
- Southworth, J., & Van Reeth, T. 2022, MNRAS, 515, 2755 [NASA ADS] [CrossRef] [Google Scholar]
- Stellingwerf, R. F. 1978, ApJ, 224, 953 [Google Scholar]
- Tamuz, O., Mazeh, T., & North, P. 2006, MNRAS, 367, 1521 [NASA ADS] [CrossRef] [Google Scholar]
- Tassoul, J.-L., & Tassoul, M. 1990, ApJ, 359, 155 [NASA ADS] [CrossRef] [Google Scholar]
- The Theano Development Team (Al-Rfou, R., et al.) 2016, arXiv e-prints [arXiv:1605.02688] [Google Scholar]
- Tkachenko, A., Pavlovski, K., Johnston, C., et al. 2020, A&A, 637, A60 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Torres, G., Andersen, J., & Giménez, A. 2010, A&ARv, 18, 67 [Google Scholar]
- Udalski, A., Szymanski, M., Kaluzny, J., Kubiak, M., & Mateo, M. 1992, Acta Astron., 42, 253 [NASA ADS] [Google Scholar]
- Van Beeck, J., Bowman, D. M., Pedersen, M. G., et al. 2021, A&A, 655, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Van Eylen, V., Winn, J. N., & Albrecht, S. 2016, ApJ, 824, 15 [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Weidner, C., & Vink, J. S. 2010, A&A, 524, A98 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wells, M. A., & Prša, A. 2021, ApJS, 253, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Wilson, R. E., & Devinney, E. J. 1971, ApJ, 166, 605 [Google Scholar]
- Wyrzykowski, L., Udalski, A., Kubiak, M., et al. 2003, Acta Astron., 53, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Zahn, J. P. 1975, A&A, 41, 329 [NASA ADS] [Google Scholar]
- Zahn, J. P. 1977, A&A, 57, 383 [Google Scholar]
- Zahn, J. P. 1989, A&A, 220, 112 [Google Scholar]
- Zahn, J. P., & Bouchet, L. 1989, A&A, 223, 112 [NASA ADS] [Google Scholar]
Found at keplerebs.villanova.edu
Note that this equation differs by a factor ![$\[\\sqrt{1-e^{2}}\]$](/articles/aa/full_html/2024/05/aa49079-23/aa49079-23-eq87.png) from the one given in Kopal (1959).
from the one given in Kopal (1959).
All Tables
All Figures
|
Fig. 1 Flowchart of the STAR SHADOW analysis steps. Blue rectangles contain analysis steps that are themselves grouped into four more general functionalities. Read and write operations are in yellow parallelograms, and the orange diamond denotes a decision point to redo a number of steps concerning the orbital period. |
| In the text | |
|
Fig. 2 Typical eclipse signatures in the derivatives of the light curve. The left column shows a flat-bottomed eclipse resulting in two separated features in the derivatives, while the V-shaped eclipse on the right leads to peaks merged into one feature. Adapted with permission from IJspeert et al. (2021). |
| In the text | |
|
Fig. 3 Typical eclipse signatures in the derivatives of the light curve, with markers pointing to important features for the automated eclipse detection and timing measurement. Note that points 7 in the left panel of first derivatives are not truly local minima but marked as such for illustrative purposes. Adapted with permission from IJspeert et al. (2021). |
| In the text | |
|
Fig. 4 Performance of the period search algorithm as a function of the number of orbital cycles. The blue points with error bars represent the fractional difference between the measured and the input orbital period with SLR error estimates, sorted by descending number of cycles. The grey line with points shows the number of cycles, calculated as the period divided by the time base, plotted on the right axis. The period error scales strongly with the number of cycles. Note that the number of cycles for cases ~60–100 is close to one, and cases that are shaded grey and hatched do not show eclipses. |
| In the text | |
|
Fig. 5 Histogram and KDE of the orbital period χ values ((Pmeasured – Pinput)/σP). using the SLR uncertainties. The KDE is scaled to the height of the histogram. |
| In the text | |
|
Fig. 6 Eccentricity results for the synthetic test cases. Top panel: input (grey) and measured (coloured) eccentricities. Bottom panel: deviation from the input eccentricity against the secondary eclipse depth. The scatter in the bottom panel is seen to increase to the left, with decreasing eclipse depth, as the eccentricity depends critically on the identification and measurement of the secondary eclipse. |
| In the text | |
|
Fig. 7 Histogram and KDE of the differences between measured and input eccentricity. Next to the sharp peak at zero, and within the 0.1 deviation, there is a relatively small second maximum where eccentricities are underestimated by between −0.2 and −0.1. The KDE is scaled to the height of the histogram. |
| In the text | |
|
Fig. 8 Histogram and KDE of the eccentricity χ values ((emeasured – einput)/σe), using the error formula uncertainties. The bi-modality seen in the absolute differences has largely disappeared. The KDE is scaled to the height of the histogram. |
| In the text | |
|
Fig. 9 Number of extracted independent sinusoids (n – nh) versus the input number of sinusoids put into the light curve (ninput). Harmonic sinusoids are filtered out as they capture residuals related to the eclipse model that are unrelated to the number of input sinusoids. Points are divided into month-long time series (blue) and year-long time series (orange), and the error bars are calculated as the square root of the number n – nh. |
| In the text | |
|
Fig. 10 Histogram and KDE of the χ values of the number of sinusoids. Errors are taken to be the square root of the amount (n – nh). The histogram is split into light curves of a month in length and those of a year in length: the shorter time base tends to lead to an underestimation of the number of sinusoids present. The KDE is scaled to the height of the histogram. |
| In the text | |
|
Fig. 11 Histogram and KDE of the frequency χ values ((fmeasured – finput)/σf) for one case of the synthetic light curves. Errors are calculated with the standard formulae. The KDE is scaled to the height of the histogram. |
| In the text | |
|
Fig. 12 Histogram and KDE of the fractional difference between the Kepler catalogue orbital periods and those measured in this work. Here we select the periods within 1% of the catalogue values. The KDE is scaled to the height of the histogram. |
| In the text | |
|
Fig. 13 Histogram and KDE of the orbital period χ values ((Pmeasured – Pcatalogue)/σP) comparing the Kepler catalogue values to those measured in this work. We select the periods within 1% of the catalogue values. The relatively pronounced wings of the distribution indicate underestimated period errors for a portion of systems. The KDE is scaled to the height of the histogram. |
| In the text | |
|
Fig. 14 Eccentricity measurements for a subset of targets from the Kepler EB Catalog. Selections were made in eccentricity error (<0.1) and morphology parameter (<0.5), the latter being the more stringent criterion. We use the maximum eccentricity as a function of orbital period in Halbwachs et al. (2005, Eq. (3)) with the cut-off period set to 5 days to plot the dashed line. Orange points indicate four systems of interest, with well-fitting models. |
| In the text | |
|
Fig. 15 Eccentricity measurements for a subset of targets from the Kepler EB Catalog. Selections were made in eccentricity error (<0.1) and morphology parameter (<0.5), and measure of signal-to-noise of the intrinsic variability at non-harmonic frequencies (>6). We use the maximum eccentricity as a function of orbital period in Halbwachs et al. (2005, Eq. (3)) with the cut-off period set to 5 and 6.5 days to plot the dashed black and grey lines. Grey points indicate systems that do not belong in this selection or have otherwise faulty measurements. |
| In the text | |
|
Fig. 16 Measurements of the tangential component of eccentricity for a subset of targets from the Kepler EB Catalog. The subset results from cut-offs in eccentricity error (<0.1) and morphology parameter (<0.5), the latter being the more stringent criterion. |
| In the text | |
|
Fig. 17 Comparison of eccentricity measurements for 13 Kepler targets. Top panel: eccentricity measurements from this work versus those obtained in Kjurkchieva & Vasileva (2015, 2018), along the diagonal (grey line). The linear regression model is plotted as a black dotted line. Bottom panel: comparison between the tangential and radial components of eccentricity. The dashed line indicates where points occur if the definition of primary and secondary eclipse is swapped. |
| In the text | |
|
Fig. B.1 'Sinusoid' part of the analysis. The input light curve is iteratively pre-whitened, and the resulting parameters are non-linearly optimised. This step results in a mathematical model of the light curve in terms of a sum of sine waves and a linear trend for each sector (separately) and is applicable to any time series. In the second to last panel is the sum of sinusoids light curve model in orange and the bottom panel shows the residuals. |
| In the text | |
|
Fig. B.2 'Harmonic' part of the analysis. The orbital period is determined (if not given), and the orbital harmonics found in the extracted list of frequencies are coupled to the orbital frequency, after which another non-linear optimisation is done. This step is broadly applicable to EBs and other light curves of periodic, non-sinusoidal signal that results in a series of harmonics in the periodogram. The second to last panel shows the orbital harmonic sinusoid model in orange and the bottom panel shows all non-harmonic sinusoids. |
| In the text | |
|
Fig. B.3 'Timings' part of the analysis. The eclipses are detected and their positions, durations, and depths are measured through the use of the model of orbital harmonic sinusoids and time derivatives thereof. Also included is a check for the multiplicity of the period that checks for the number of identical eclipses found in one cycle. The bottom panel shows the light curve folded over the orbital period in blue, the harmonic model in red and the non-harmonic model subtracted light curve in orange. The horizontal and vertical dashed lines indicate the eclipse measurements. |
| In the text | |
|
Fig. B.4 'Eclipses' part of the analysis. The measurements of eclipse timings and depths are translated to orbital and physical parameters of the system using formulae, and the resulting parameters are used as a starting point for fitting an eclipse model of spherical and uniformly bright stars to the data. The eclipse model is supplemented with a sum of sinusoids, obtained by subtracting the initial eclipse model from the data and pre-whitening the residuals. The second to last panel shows the eclipse model in red and the bottom panel shows the supplemental sinusoid model. |
| In the text | |
|
Fig. D.1 Performance of the period search algorithm as a function of the primary eclipse depth. Blue points with error bars show the fractional difference between the measured and the input orbital period with SLR error estimates, sorted by descending primary eclipse depth. The grey line with points shows primary eclipse depths, plotted on the right axis. Note that cases shaded grey and hatched do not show eclipses, and cases shaded orange have fewer than three eclipse cycles. |
| In the text | |
|
Fig. D.2 Histogram and KDE of the eccentricity deviations from the input. |
| In the text | |
|
Fig. D.3 Histogram and KDE of the eccentricity χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.4 Histogram and KDE of the argument of periastron deviations from the input. |
| In the text | |
|
Fig. D.5 Histogram and KDE of the argument of periastron χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.6 Histogram and KDE of the inclination deviations from the input. |
| In the text | |
|
Fig. D.7 Histogram and KDE of the inclination χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.8 Histogram and KDE of the sum of scaled radius deviations from the input. |
| In the text | |
|
Fig. D.9 Histogram and KDE of the sum of scaled radius χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.10 Histogram and KDE of the ratio of radius deviations from the input. |
| In the text | |
|
Fig. D.11 Histogram and KDE of the ratio of radius χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.12 Histogram and KDE of the ratio of surface brightness deviations from the input. |
| In the text | |
|
Fig. D.13 Histogram and KDE of the ratio of surface brightness χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.14 Histogram and KDE of the tangential component of eccentricity deviations from the input. |
| In the text | |
|
Fig. D.15 Histogram and KDE of the tangential component of eccentricity χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.16 Histogram and KDE of the radial component of eccentricity deviations from the input. |
| In the text | |
|
Fig. D.17 Histogram and KDE of the radial component of eccentricity χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.18 Histogram and KDE of the cosine of inclination deviations from the input. |
| In the text | |
|
Fig. D.19 Histogram and KDE of the cosine of inclination χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.20 Histogram and KDE of the auxiliary angle, ϕ0, deviations from the input. |
| In the text | |
|
Fig. D.21 Histogram and KDE of the auxiliary angle, ϕ0, χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.22 Histogram and KDE of the logarithm of the ratio of radius deviations from the input. |
| In the text | |
|
Fig. D.23 Histogram and KDE of the logarithm of the ratio of radius χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.24 Histogram and KDE of the logarithm of the ratio of surface brightness deviations from the input. |
| In the text | |
|
Fig. D.25 Histogram and KDE of the logarithm of the ratio of surface brightness χ values (deviation from the input divided by the error estimate). |
| In the text | |
|
Fig. D.26 Tangential part of eccentricity (top panel) and deviation from input (bottom panel) versus secondary eclipse depth. |
| In the text | |
|
Fig. D.27 Inclinations (top panel) and deviation from input (bottom panel) versus third light (fraction of total light). Note the absence of an apparent correlation between the accuracy of inclination and third light. |
| In the text | |
|
Fig. D.28 Example (full) synthetic light curve of case 7. The top panel shows the final eclipse model of the eclipses in red and the full model of the light curve including sinusoids in grey. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here. The slight overestimation of the primary eclipse width can be identified by sharp residual peaks here and leads to an underestimation of the radial part of eccentricity of about 0.2 for this case. |
| In the text | |
|
Fig. D.29 Fourier amplitude spectrum of case 7. In red and pink are the extracted sinusoids, of which the red ones qualify as harmonics. At an orbital period of 16.56, the spacing of harmonics is quite dense (grey grid lines). |
| In the text | |
|
Fig. D.30 Fourier amplitude spectrum of case 7 after subtracting the eclipse model. In red are the extracted sinusoids that pass all criteria, including the signal-to-noise threshold shown in green (calculated in a window of 1d−1). |
| In the text | |
|
Fig. D.31 Example synthetic light curve of case 99 folded over the orbital period. The top panel shows the final eclipse model of the eclipses in red and the full model of the light curve including sinusoids in grey. The orange model is the starting point for the light curve fit. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here. The model starts from an overestimated primary eclipse width, and the fit is unable to fully correct for this as the residuals show. This leads to and underestimated tangential eccentricity by about 0.2 for this case. |
| In the text | |
|
Fig. D.32 Synthetic light curve of case 26 folded over the orbital period. The top panel shows the final eclipse model of the eclipses in red and the full model of the light curve including sinusoids in grey. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here and covers up the data points. |
| In the text | |
|
Fig. D.33 Fourier amplitude spectrum of case 26. In red and pink are the extracted sinusoids, of which the red ones qualify as harmonics. The peaks around 5 to 10 cycles per day are from sine waves put into the synthetic light curve and recovered accurately and precisely by our analysis pipeline. |
| In the text | |
|
Fig. D.34 Example (full) synthetic light curve of case 23. The top panel shows the final eclipse model in red and the full model of the light curve including sinusoids in grey. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here. We can see that the primary eclipse is too wide as the detection algorithm picked up on other variability close to it. |
| In the text | |
|
Fig. D.35 Example (folded over the period) synthetic light curve of case 24. The top panel shows the final eclipse model in red and the full model of the light curve including sinusoids in grey. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here. The eclipse model has trouble fitting these wide eclipses and does not capture any out-of-eclipse variability. |
| In the text | |
|
Fig. D.36 Example (folded over the period) synthetic light curve of case 88. The top panel shows the final eclipse model in red and the full model of the light curve including sinusoids in grey. The bottom panel shows the residuals of subtracting the eclipse model (blue) and those of subtracting the full model (orange). The model of sinusoids is also plotted separately in red here. |
| In the text | |
|
Fig. D.37 Histogram and KDE of the orbital period χ values, comparing orbital periods measured in this work to those from the Kepler catalogue. Here we select the periods within 1% of half the catalogue values and the errors are taken to be the SLR uncertainties. The KDE is scaled to the height of the histogram. |
| In the text | |
|
Fig. D.38 Eccentricity measurements for a subset of targets from the Kepler EB Catalog. A cut-off was made in eccentricity error (<0.1) but all morphology values were included. We use the maximum eccentricity as a function of orbital period in Halbwachs et al. (2005, Equation 3) with the cut-off period set to 5 days to plot the dashed line. |
| In the text | |
|
Fig. D.39 Measurements of the tangential component of eccentricity for a subset of targets from the Kepler EB Catalog. The subset results from a cut-off in eccentricity error (<0.1) but all morphology values were included. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.