| Issue |
A&A
Volume 675, July 2023
|
|
|---|---|---|
| Article Number | A120 | |
| Number of page(s) | 32 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202346017 | |
| Published online | 07 July 2023 | |
Euclid preparation
XXVIII. Forecasts for ten different higher-order weak lensing statistics
1
Université Paris-Saclay, Université Paris Cité, CEA, CNRS, Astrophysique, Instrumentation et Modélisation Paris-Saclay, 91191 Gif-sur-Yvette, France
2
Institute for Particle Physics and Astrophysics, Dept. of Physics, ETH Zurich, Wolfgang-Pauli-Strasse 27, 8093 Zurich, Switzerland
3
Dipartimento di Fisica e Astronomia “Augusto Righi” – Alma Mater Studiorum Università di Bologna, Via Piero Gobetti 93/2, 40129 Bologna, Italy
4
INAF-Osservatorio di Astrofisica e Scienza dello Spazio di Bologna, Via Piero Gobetti 93/3, 40129 Bologna, Italy
5
INFN-Sezione di Bologna, Viale Berti Pichat 6/2, 40127 Bologna, Italy
6
University Observatory, Faculty of Physics, Ludwig-Maximilians-Universität, Scheinerstr. 1, 81679 Munich, Germany
7
AIM, CEA, CNRS, Université Paris-Saclay, Université de Paris, 91191 Gif-sur-Yvette, France
8
Argelander-Institut für Astronomie, Universität Bonn, Auf dem Hügel 71, 53121 Bonn, Germany
9
INFN-Sezione di Roma, Piazzale Aldo Moro, 2 – c/o Dipartimento di Fisica, Edificio G. Marconi, 00185 Roma, Italy
10
INAF-Osservatorio Astronomico di Roma, Via Frascati 33, 00078 Monteporzio Catone, Italy
11
Johns Hopkins University, 3400 North Charles Street, Baltimore, MD 21218, USA
12
School of Mathematics, Statistics and Physics, Newcastle University, Herschel Building, Newcastle-upon-Tyne NE1 7RU, UK
13
Departamento de Física, Faculdade de Ciências, Universidade de Lisboa, Edifício C8, Campo Grande, 1749-016 Lisboa, Portugal
14
Instituto de Astrofísica e Ciências do Espaço, Faculdade de Ciências, Universidade de Lisboa, Tapada da Ajuda, 1349-018 Lisboa, Portugal
15
Aix-Marseille Université, CNRS, CNES, LAM, Marseille, France
16
Institute of Physics, Laboratory of Astrophysics, École Polytechnique Fédérale de Lausanne (EPFL), Observatoire de Sauverny, 1290 Versoix, Switzerland
17
Dipartimento di Fisica, Sapienza Università di Roma, Piazzale Aldo Moro 2, 00185 Roma, Italy
18
Université Paris-Saclay, CNRS, Institut d’astrophysique spatiale, 91405 Orsay, France
19
INAF-Osservatorio Astrofisico di Torino, Via Osservatorio 20, 10025 Pino Torinese, (TO), Italy
20
Dipartimento di Fisica, Università di Genova, Via Dodecaneso 33, 16146 Genova, Italy
21
INFN-Sezione di Roma Tre, Via della Vasca Navale 84, 00146 Roma, Italy
22
Department of Physics “E. Pancini”, University Federico II, Via Cinthia 6, 80126 Napoli, Italy
23
Instituto de Astrofísica e Ciências do Espaço, Universidade do Porto, CAUP, Rua das Estrelas, 4150-762 Porto, Portugal
24
Dipartimento di Fisica, Universitá degli Studi di Torino, Via P. Giuria 1, 10125 Torino, Italy
25
INFN-Sezione di Torino, Via P. Giuria 1, 10125 Torino, Italy
26
INAF-IASF Milano, Via Alfonso Corti 12, 20133 Milano, Italy
27
Institut de Física d’Altes Energies (IFAE), The Barcelona Institute of Science and Technology, Campus UAB, 08193 Bellaterra, (Barcelona), Spain
28
Port d’Informació Científica, Campus UAB, C. Albareda s/n, 08193 Bellaterra, (Barcelona), Spain
29
Institut d’Estudis Espacials de Catalunya (IEEC), Carrer Gran Capitá 2-4, 08034 Barcelona, Spain
30
Institute of Space Sciences (ICE, CSIC), Campus UAB, Carrer de Can Magrans, s/n, 08193 Barcelona, Spain
31
INAF-Osservatorio Astronomico di Capodimonte, Via Moiariello 16, 80131 Napoli, Italy
32
INFN section of Naples, Via Cinthia 6, 80126 Napoli, Italy
33
Dipartimento di Fisica e Astronomia “Augusto Righi” – Alma Mater Studiorum Universitá di Bologna, Viale Berti Pichat 6/2, 40127 Bologna, Italy
34
Centre National d’Études Spatiales, Toulouse, France
35
Institut national de physique nucléaire et de physique des particules, 3 rue Michel-Ange, 75794 Paris Cédex 16, France
36
Institute for Astronomy, University of Edinburgh, Royal Observatory, Blackford Hill, Edinburgh EH9 3HJ, UK
37
Jodrell Bank Centre for Astrophysics, Department of Physics and Astronomy, University of Manchester, Oxford Road, Manchester M13 9PL, UK
38
ESAC/ESA, Camino Bajo del Castillo, s/n., Urb. Villafranca del Castillo, 28692 Villanueva de la Cañada, Madrid, Spain
39
European Space Agency/ESRIN, Largo Galileo Galilei 1, 00044 Frascati, Roma, Italy
40
Mullard Space Science Laboratory, University College London, Holmbury St Mary, Dorking, Surrey RH5 6NT, UK
41
Instituto de Astrofísica e Ciências do Espaço, Faculdade de Ciências, Universidade de Lisboa, Campo Grande, 1749-016 Lisboa, Portugal
42
Department of Astronomy, University of Geneva, ch. d’Ecogia 16, 1290 Versoix, Switzerland
43
INAF-Istituto di Astrofisica e Planetologia Spaziali, Via del Fosso del Cavaliere, 100, 00100 Roma, Italy
44
Univ. Lyon, Univ. Claude Bernard Lyon 1, CNRS/IN2P3, IP2I Lyon, UMR 5822, 69622 Villeurbanne, France
45
INAF-Osservatorio Astronomico di Trieste, Via G. B. Tiepolo 11, 34143 Trieste, Italy
46
INAF-Osservatorio Astronomico di Padova, Via dell’Osservatorio 5, 35122 Padova, Italy
47
Max Planck Institute for Extraterrestrial Physics, Giessenbachstr. 1, 85748 Garching, Germany
48
Universitäts-Sternwarte München, Fakultät für Physik, Ludwig-Maximilians-Universität München, Scheinerstrasse 1, 81679 München, Germany
49
Leiden Observatory, Leiden University, Niels Bohrweg 2, 2333 CA, Leiden, The Netherlands
50
Jet Propulsion Laboratory, California Institute of Technology, 4800 Oak Grove Drive, Pasadena, CA 91109, USA
51
Technical University of Denmark, Elektrovej 327, 2800 Kgs. Lyngby, Denmark
52
Cosmic Dawn Center (DAWN), Copenhagen, Denmark
53
Institut d’Astrophysique de Paris, 98bis Boulevard Arago, 75014 Paris, France
54
Max-Planck-Institut für Astronomie, Königstuhl 17, 69117 Heidelberg, Germany
55
NASA Goddard Space Flight Center, Greenbelt, MD 20771, USA
56
Université de Genève, Département de Physique Théorique and Centre for Astroparticle Physics, 24 quai Ernest-Ansermet, 1211 Genève 4, Switzerland
57
Department of Physics, PO Box 64, 00014 University of Helsinki, Finland
58
Helsinki Institute of Physics, Gustaf Hällströmin katu 2, University of Helsinki, Helsinki, Finland
59
Institute of Theoretical Astrophysics, University of Oslo, PO Box 1029 Blindern, 0315 Oslo, Norway
60
NOVA optical infrared instrumentation group at ASTRON, Oude Hoogeveensedijk 4, 7991 PD Dwingeloo, The Netherlands
61
Department of Physics, Institute for Computational Cosmology, Durham University, South Road DH1 3LE, UK
62
Université Paris Cité, CNRS, Astroparticule et Cosmologie, 75013 Paris, France
63
Institut d’Astrophysique de Paris, UMR 7095, CNRS, and Sorbonne Université, 98 bis boulevard Arago, 75014 Paris, France
64
European Space Agency/ESTEC, Keplerlaan 1, 2201 AZ Noordwijk, The Netherlands
65
Kapteyn Astronomical Institute, University of Groningen, PO Box 800, 9700 AV Groningen, The Netherlands
66
Department of Physics and Astronomy, University of Aarhus, Ny Munkegade 120, 8000 Aarhus C, Denmark
67
Space Science Data Center, Italian Space Agency, Via del Politecnico snc, 00133 Roma, Italy
68
Institute of Space Science, Bucharest 077125, Romania
69
Dipartimento di Fisica e Astronomia “G.Galilei”, Universitá di Padova, Via Marzolo 8, 35131 Padova, Italy
70
INFN-Padova, Via Marzolo 8, 35131 Padova, Italy
71
Dipartimento di Fisica e Astronomia, Universitá di Bologna, Via Gobetti 93/2, 40129 Bologna, Italy
72
Departamento de Física, FCFM, Universidad de Chile, Blanco Encalada 2008, Santiago, Chile
73
Institut für Astro- und Teilchenphysik, Universität Innsbruck, Technikerstr. 25/8, 6020 Innsbruck, Austria
74
Aix-Marseille Université, CNRS/IN2P3, CPPM, Marseille, France
75
Institut de Ciencies de l’Espai (IEEC-CSIC), Campus UAB, Carrer de Can Magrans, s/n Cerdanyola del Vallés, 08193 Barcelona, Spain
76
Centro de Investigaciones Energéticas, Medioambientales y Tecnológicas (CIEMAT), Avenida Complutense 40, 28040 Madrid, Spain
77
Universidad Politécnica de Cartagena, Departamento de Electrónica y Tecnología de Computadoras, 30202 Cartagena, Spain
78
Institut de Recherche en Astrophysique et Planétologie (IRAP), Université de Toulouse, CNRS, UPS, CNES, 14 Av. Édouard Belin, 31400 Toulouse, France
79
Infrared Processing and Analysis Center, California Institute of Technology, Pasadena, CA 91125, USA
80
INAF-Osservatorio Astronomico di Brera, Via Brera 28, 20122 Milano, Italy
81
Instituto de Astrofísica de Canarias, Calle Vía Láctea s/n, 38204 San Cristóbal de La Laguna, Tenerife, Spain
82
Center for Computational Astrophysics, Flatiron Institute, 162 5th Avenue, 10010 New York, NY, USA
83
School of Physics and Astronomy, Cardiff University, The Parade, Cardiff CF24 3AA, UK
84
Department of Physics and Helsinki Institute of Physics, Gustaf Hällströmin katu 2, 00014 University of Helsinki, Finland
85
Dipartimento di Fisica “Aldo Pontremoli”, Universitá degli Studi di Milano, Via Celoria 16, 20133 Milano, Italy
86
INFN-Sezione di Milano, Via Celoria 16, 20133 Milano, Italy
87
Junia, EPA department, 59000 Lille, France
88
Instituto de Física Teórica UAM-CSIC, Campus de Cantoblanco, 28049 Madrid, Spain
89
CERCA/ISO, Department of Physics, Case Western Reserve University, 10900 Euclid Avenue, Cleveland, OH 44106, USA
90
Laboratoire de Physique de l’École Normale Supérieure, ENS, Université PSL, CNRS, Sorbonne Université, 75005 Paris, France
91
Observatoire de Paris, Université PSL, Sorbonne Université, LERMA, 75005 Paris, France
92
Astrophysics Group, Blackett Laboratory, Imperial College London, London SW7 2AZ, UK
93
SISSA, International School for Advanced Studies, Via Bonomea 265, 34136 Trieste, TS, Italy
94
IFPU, Institute for Fundamental Physics of the Universe, Via Beirut 2, 34151 Trieste, Italy
95
INFN, Sezione di Trieste, Via Valerio 2, 34127 Trieste, TS, Italy
96
Departamento de Astrofísica, Universidad de La Laguna, 38206 La Laguna, Tenerife, Spain
97
Dipartimento di Fisica e Scienze della Terra, Universitá degli Studi di Ferrara, Via Giuseppe Saragat 1, 44122 Ferrara, Italy
98
Istituto Nazionale di Fisica Nucleare, Sezione di Ferrara, Via Giuseppe Saragat 1, 44122 Ferrara, Italy
99
Institut de Physique Théorique, CEA, CNRS, Université Paris-Saclay, 91191 Gif-sur-Yvette Cedex, France
100
Dipartimento di Fisica – Sezione di Astronomia, Universitá di Trieste, Via Tiepolo 11, 34131 Trieste, Italy
101
NASA Ames Research Center, Moffett Field, CA 94035, USA
102
INAF, Istituto di Radioastronomia, Via Piero Gobetti 101, 40129 Bologna, Italy
103
INFN-Bologna, Via Irnerio 46, 40126 Bologna, Italy
104
Université Côte d’Azur, Observatoire de la Côte d’Azur, CNRS, Laboratoire Lagrange, Bd de l’Observatoire, CS 34229, 06304 Nice cedex 4, France
105
Institute for Theoretical Particle Physics and Cosmology (TTK), RWTH Aachen University, 52056 Aachen, Germany
106
Institute for Astronomy, University of Hawaii, 2680 Woodlawn Drive, Honolulu, HI 96822, USA
107
Department of Physics & Astronomy, University of California Irvine, Irvine, CA 92697, USA
108
University of Lyon, UCB Lyon 1, CNRS/IN2P3, IUF, IP2I Lyon, France
109
INFN-Sezione di Genova, Via Dodecaneso 33, 16146 Genova, Italy
110
Department of Astronomy & Physics and Institute for Computational Astrophysics, Saint Mary’s University, 923 Robie Street, Halifax Nova Scotia B3H 3C3, Canada
111
Ruhr University Bochum, Faculty of Physics and Astronomy, Astronomical Institute (AIRUB), German Centre for Cosmological Lensing (GCCL), 44780 Bochum, Germany
112
Univ. Grenoble Alpes, CNRS, Grenoble INP, LPSC-IN2P3, 53, Avenue des Martyrs, 38000 Grenoble, France
113
Department of Physics and Astronomy, University College London, Gower Street, London WC1E 6BT, UK
114
Department of Physics and Astronomy, Vesilinnantie 5, 20014 University of Turku, Finland
115
University of Applied Sciences and Arts of Northwestern Switzerland, School of Engineering, 5210 Windisch, Switzerland
116
Centro de Astrofísica da Universidade do Porto, Rua das Estrelas, 4150-762 Porto, Portugal
117
Institute of Cosmology and Gravitation, University of Portsmouth, Portsmouth PO1 3FX, UK
118
Department of Mathematics and Physics E. De Giorgi, University of Salento, Via per Arnesano, CP-I93, 73100 Lecce, Italy
119
INFN, Sezione di Lecce, Via per Arnesano, CP-193, 73100 Lecce, Italy
120
INAF-Sezione di Lecce, c/o Dipartimento Matematica e Fisica, Via per Arnesano, 73100 Lecce, Italy
121
Institute for Computational Science, University of Zurich, Winterthurerstrasse 190, 8057 Zurich, Switzerland
122
Higgs Centre for Theoretical Physics, School of Physics and Astronomy, The University of Edinburgh, Edinburgh EH9 3FD, UK
123
Université St Joseph; Faculty of Sciences, Beirut, Lebanon
124
Institut für Theoretische Physik, University of Heidelberg, Philosophenweg 16, 69120 Heidelberg, Germany
125
Department of Astrophysical Sciences, Peyton Hall, Princeton University, Princeton, NJ 08544, USA
Received:
30
January
2023
Accepted:
11
April
2023
Recent cosmic shear studies have shown that higher-order statistics (HOS) developed by independent teams now outperform standard two-point estimators in terms of statistical precision thanks to their sensitivity to the non-Gaussian features of large-scale structure. The aim of the Higher-Order Weak Lensing Statistics (HOWLS) project is to assess, compare, and combine the constraining power of ten different HOS on a common set of Euclid-like mocks, derived from N-body simulations. In this first paper of the HOWLS series, we computed the nontomographic (Ωm, σ8) Fisher information for the one-point probability distribution function, peak counts, Minkowski functionals, Betti numbers, persistent homology Betti numbers and heatmap, and scattering transform coefficients, and we compare them to the shear and convergence two-point correlation functions in the absence of any systematic bias. We also include forecasts for three implementations of higher-order moments, but these cannot be robustly interpreted as the Gaussian likelihood assumption breaks down for these statistics. Taken individually, we find that each HOS outperforms the two-point statistics by a factor of around two in the precision of the forecasts with some variations across statistics and cosmological parameters. When combining all the HOS, this increases to a 4.5 times improvement, highlighting the immense potential of HOS for cosmic shear cosmological analyses with Euclid. The data used in this analysis are publicly released with the paper.
Key words: gravitational lensing: weak / methods: statistical / surveys / large-scale structure of Universe / cosmological parameters
© ESO 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1. Introduction
It is a well-established fact that the Universe is undergoing a phase of accelerated expansion (e.g., Riess et al. 1998; Perlmutter et al. 1999). Understanding what is driving this acceleration in the framework of a spatially flat universe is one of the (if not the) greatest challenges of modern-day cosmology. The concordance Λ cold dark matter (ΛCDM) model performs excellently in fitting the available data, yet the cosmological constant Λ is far from satisfactory from a theoretical point of view. To make things harder for ΛCDM, recent tensions have emerged due to an inconsistency between the values of some parameters from independent data measuring the same quantities in radically different ways. The most debated case is the discrepancy between the Hubble constant H0 as measured from local probes and as inferred from cosmological data sets (see, e.g., Di Valentino et al. 2021, for a review). Another, albeit less significant, example is the disagreement between the cosmic microwave background (CMB) and lensing estimates of the growth of structure parameter, 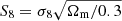 (e.g., Hildebrandt et al. 2017; Heymans et al. 2021; Amon et al. 2022). Although some unknown systematic effects could have been missed in the analysis, such tensions may also be the first signs that alternative models are needed, relying on either dark energy in a general relativity framework or based on modified gravity (see, e.g., Joyce et al. 2016, and references therein). Discriminating among the plethora of viable candidates is the aim of Stage IV surveys such as the Dark Energy Spectroscopic Instrument (DESI, DESI Collaboration 2016), the Prime Focus Spectrograph (PFS, Takada et al. 2014), the Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST, Ivezić et al. 2019), Euclid (Laureijs et al. 2011), SPHEREx (Doré et al. 2014), and the Nancy Grace Roman Space Telescope (Spergel et al. 2015).
(e.g., Hildebrandt et al. 2017; Heymans et al. 2021; Amon et al. 2022). Although some unknown systematic effects could have been missed in the analysis, such tensions may also be the first signs that alternative models are needed, relying on either dark energy in a general relativity framework or based on modified gravity (see, e.g., Joyce et al. 2016, and references therein). Discriminating among the plethora of viable candidates is the aim of Stage IV surveys such as the Dark Energy Spectroscopic Instrument (DESI, DESI Collaboration 2016), the Prime Focus Spectrograph (PFS, Takada et al. 2014), the Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST, Ivezić et al. 2019), Euclid (Laureijs et al. 2011), SPHEREx (Doré et al. 2014), and the Nancy Grace Roman Space Telescope (Spergel et al. 2015).
In this context, the Euclid mission will play a pivotal role in cosmology by measuring the dark energy equation of state w and the S8 parameter with exquisite precision and accuracy (see, e.g., Laureijs et al. 2011; Euclid Collaboration 2020). This will be achieved by exploiting the clustering of galaxies as well as cosmic shear: the Weak gravitational Lensing (WL) signal of galaxies due to the deflection of light rays by the large-scale structure. In this article, we focus on optimizing the extraction of cosmological information from the cosmic shear probe.
The classical cosmic shear analysis involves measuring the correlations between ellipticities of pairs of galaxies as a function of their separation; an estimator called the two-point correlation functions of the shear (γ-2PCF). Although it benefits from a comprehensive theoretical description, this estimator is only sensitive to the multiscale variance of the lensing field. However, the gravitational collapse of the matter perturbations introduces non-Gaussian features in the shear field. As a consequence, the γ-2PCF and any estimator probing the field up to second order do not contain all cosmological information. This is seen, for example, in the degeneracies between parameters, such as the one between Ωm and σ8, which means the γ-2PCF can only efficiently constrain their combination 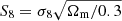 . To recover the extra information contained in nonlinear scales, many non-Gaussian estimators – also referred as higher-order statistics (HOS) in contrast to two-point statistics – have been introduced in the literature. Such HOS include higher-order moments (e.g., Van Waerbeke et al. 2013; Gatti et al. 2022; Porth & Smith 2021), peak counts (e.g., Marian et al. 2009; Dietrich & Hartlap 2010; Kacprzak et al. 2016; Martinet et al. 2018, 2021b; Harnois-Déraps et al. 2021), one-point probability distributions (e.g., Barthelemy et al. 2020; Boyle et al. 2021; Liu & Madhavacheril 2019; Thiele et al. 2020), Minkowski functionals (e.g., Kratochvil et al. 2012; Petri et al. 2015; Vicinanza et al. 2019; Parroni et al. 2020), Betti numbers (e.g., Feldbrugge et al. 2019; Parroni et al. 2021), persistent homology (e.g., Heydenreich et al. 2021, 2022), scattering transform coefficients (e.g., Cheng et al. 2020; Cheng & Ménard 2021b), as well as map-level inference (Porqueres et al. 2022; Boruah et al. 2022). Despite their increased complexity, which often requires resorting to numerical simulations to model their cosmology dependence, all the references above have demonstrated that these new statistics have superior constraining power compared to the γ-2PCF. However, each of these new HOS is usually developed and studied by independent teams, which renders a fair comparison between them extremely difficult.
. To recover the extra information contained in nonlinear scales, many non-Gaussian estimators – also referred as higher-order statistics (HOS) in contrast to two-point statistics – have been introduced in the literature. Such HOS include higher-order moments (e.g., Van Waerbeke et al. 2013; Gatti et al. 2022; Porth & Smith 2021), peak counts (e.g., Marian et al. 2009; Dietrich & Hartlap 2010; Kacprzak et al. 2016; Martinet et al. 2018, 2021b; Harnois-Déraps et al. 2021), one-point probability distributions (e.g., Barthelemy et al. 2020; Boyle et al. 2021; Liu & Madhavacheril 2019; Thiele et al. 2020), Minkowski functionals (e.g., Kratochvil et al. 2012; Petri et al. 2015; Vicinanza et al. 2019; Parroni et al. 2020), Betti numbers (e.g., Feldbrugge et al. 2019; Parroni et al. 2021), persistent homology (e.g., Heydenreich et al. 2021, 2022), scattering transform coefficients (e.g., Cheng et al. 2020; Cheng & Ménard 2021b), as well as map-level inference (Porqueres et al. 2022; Boruah et al. 2022). Despite their increased complexity, which often requires resorting to numerical simulations to model their cosmology dependence, all the references above have demonstrated that these new statistics have superior constraining power compared to the γ-2PCF. However, each of these new HOS is usually developed and studied by independent teams, which renders a fair comparison between them extremely difficult.
The Higher-Order Weak Lensing Statistics (HOWLS) project has been initiated to remedy this situation. One of its main aims is, indeed, to test HOS probes by relying on the same mock data, here mimicking those that Euclid will make available. In contrast to some early (e.g., Pires et al. 2009; Hilbert et al. 2012) and recent efforts in the literature (e.g., Zürcher et al. 2022), HOWLS was designed as a challenge to the community, thus attracting contributions from the largest team of HOS experts ever. Individual teams within the Euclid community have applied 24 different algorithms to the same mocks for a total of two second-order statistics (the shear and convergence two-point correlation functions γ-2PCF and κ-2PCF) and ten different HOS: convergence one-point probability distribution (κ-PDF), higher-order convergence moments (HOM), n-th order aperture mass moments 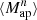 , aperture mass peak counts (peaks), convergence Minkowski functionals (MFs), convergence Betti numbers (BNs), aperture mass persistent homology Betti numbers (pers. BNs) and heatmap (pers. heat.), and convergence scattering transform coefficients (ST). Such a large number is unprecedented and offers the possibility of investigating which one (or which combination) is best suited to be coupled with the standard γ-2PCF probe to narrow down the constraints on cosmological parameters (CPs). Different HOS are in fact sensitive to different scales and features in the convergence (κ) maps and thus they couple to the γ-2PCF in their own way. Moreover, HOWLS can also check for correlations among the various HOS probes, revealing which ones are sufficiently uncorrelated such that their combination does indeed improve the total constraining power. It is also worth stressing that the present paper is only the first in a series. HOWLS will actually serve as a preparation for the application of WL HOS to the Euclid Survey, defining common tools and pipelines for the consortium.
, aperture mass peak counts (peaks), convergence Minkowski functionals (MFs), convergence Betti numbers (BNs), aperture mass persistent homology Betti numbers (pers. BNs) and heatmap (pers. heat.), and convergence scattering transform coefficients (ST). Such a large number is unprecedented and offers the possibility of investigating which one (or which combination) is best suited to be coupled with the standard γ-2PCF probe to narrow down the constraints on cosmological parameters (CPs). Different HOS are in fact sensitive to different scales and features in the convergence (κ) maps and thus they couple to the γ-2PCF in their own way. Moreover, HOWLS can also check for correlations among the various HOS probes, revealing which ones are sufficiently uncorrelated such that their combination does indeed improve the total constraining power. It is also worth stressing that the present paper is only the first in a series. HOWLS will actually serve as a preparation for the application of WL HOS to the Euclid Survey, defining common tools and pipelines for the consortium.
The HOWLS data set is based on the DUSTGRAIN-pathfinder simulations (Giocoli et al. 2018a), designed to model the cosmological dependence of every statistic, and on the Scinet LIght-Cones Simulations (SLICS, Harnois-Déraps et al. 2018) for estimating covariances. We have built realistic Euclid mocks out of these simulations, in particular mimicking the expected galaxy density, intrinsic ellipticities, and redshift distribution. For every mock, we built a convergence map following the Kaiser & Squires (1993) implementation described in Pires et al. (2020). We measured the γ-2PCF in the ellipticity catalogs; the κ-2PCF, κ-PDF, MFs, BNs, ST, and HOM from the convergence maps; 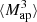 ,
, 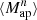 , and pers. BNs and pers. heat. from the aperture mass calculated from the shear field; and peaks of aperture mass maps calculated from the reconstructed convergence fields. We then developed two independent analysis pipelines to compute the Fisher information and thus forecast the constraining power of HOS compared to two-point statistics.
, and pers. BNs and pers. heat. from the aperture mass calculated from the shear field; and peaks of aperture mass maps calculated from the reconstructed convergence fields. We then developed two independent analysis pipelines to compute the Fisher information and thus forecast the constraining power of HOS compared to two-point statistics.
This first paper in the HOWLS series is intended to introduce the data set (Sect. 2) and HOS (Sect. 3), and to conduct a Fisher analysis (Sect. 4) to compare them. Forecasts are presented and discussed in Sect. 5. We conclude in Sect. 6 by listing the refinements that we will include in the following HOWLS publications. The HOWLS data set and applied statistics are publicly released with this article1.
2. HOWLS data set
To perform a Fisher analysis, one needs to compute data vector (DV) derivatives with respect to individual CPs. We therefore run the DUSTGRAIN-pathfinder simulations, varying one parameter at a time among Ωm, σ8, and w, for four different values around the fiducial ones. We additionally used the DUSTGRAIN-pathfinder and SLICS to build the covariance matrix necessary to forecast parameter constraints. The simulations are summarized in Table 1 and described in detail below in Sect. 2.1 for DUSTGRAIN-pathfinder and Sect. 2.2 for SLICS.
Simulations used in HOWLS with CP values for Ωm, σ8, and w, and the numbers of realizations.
2.1. DUSTGRAIN-pathfinder simulations
The DUSTGRAIN-pathfinder suite consists of N-body simulations of volume (750 h−1 Mpc)3 filled with Np = 7683 particles, corresponding to a particle mass resolution mp of approximately 8 × 1010h−1 M⊙ (Giocoli et al. 2018a). The standard reference CPs have been set to values consistent with the results of the Planck-2015 (Planck Collaboration I 2016) cosmological data analysis, namely a matter density Ωm of 0.31345, a baryon density Ωb of 0.0491, Hubble constant H0 of 67.31 km s−1 Mpc−1, a scalar spectral index ns of 0.9658, and mean amplitude σ8 of the linear density fluctuations on the 8 h−1 Mpc scale of 0.842. Since the DUSTGRAIN-pathfinder simulations are part of a cosmological data set that also accounts for modified gravity models, the simulations (including those assuming standard general relativity) were carried out with the MG-Gadget code (Puchwein et al. 2013).
For the analyses performed for this work, in addition to the reference ΛCDM, we used 12 other cosmological runs. In particular, we considered cosmological simulations where only one of the CPs Ωm, σ8, and w was varied, either by ±4% and ±16% for σ8 and w, or by +28%/−36% for Ωm to allow for existing data to be reused. When varying Ωm the value of the physical baryon density Ωbh2 was kept fixed in the computation of the linear matter power spectrum adopted in the initial conditions, which was performed by means of the Boltzmann code CAMB (Lewis et al. 2000).
For each cosmological simulation, we built up mass density planes and then shooting-rays in light cones for 128 different line-of-sight realizations (256 in the case of the fiducial cosmology). The past light cones were built using the MapSim routine (Giocoli et al. 2015) following a pyramidal geometry. This method has been used and tested on a variety of cosmological simulations (Tessore et al. 2015; Castro et al. 2018; Giocoli et al. 2018b) and recently compared with other algorithms (Hilbert et al. 2020) finding only percent-level differences for both cosmic shear two-point and peak statistics. The approach we follow in MapSim is based on using several snapshots from a single realization of an N-body simulation to build a light-cone up to a redshift of 4. For the DUSTGRAIN-pathfinder suite there are 21 snapshots available in this redshift range. Given the box length of 750 h−1Mpc, roughly 7 (5) boxes are needed to cover the comoving distance of about 5 (3.6) h−1 Gpc to a source redshift zs of 4 (2). To obtain better redshift sampling, the volume required to construct the light-cone is divided along the line-of-sight into multiple contiguous redshift slices obtained from the individual snapshots. If the redshift slice reaches beyond the boundary of a single box, two lens planes are constructed from a single snapshot. The total number of lens planes up to zs = 4 (zs = 2) is 27 (19). To avoid replicating the same structure along the line of sight, the 7 boxes needed to cover the light-cone are randomized. This randomization procedure allows us to extract multiple realizations from a single simulation. Randomization is achieved by using seeds that act on the simulation boxes based on: (i) changing the location of the observer, typically placed on the center of one of the faces of the box, (ii) redefining the center of the box (taking advantage of periodic boundary conditions), and (iii) changing the signs of the box axes. From each line of sight realization, we then project, using the Born approximation, to construct convergence and shear maps of 5 × 5 deg2 at various source redshifts.
In Fig. 1 we exhibit the κ maps for our 13 simulations considering sources at redshift zs = 2. As can be seen, we display the same line-of-sight realization for the different cosmological simulations: in each subpanel we can recognize by eye the same large-scale structure distribution. More detailed and quantitative statistical information can now be extracted from these maps, for example in Fig. 2 we show the corresponding convergence power spectra, averaged over 128 lines of sight. The left, central and right panels display the Ωm, σ8, and w variations, respectively. The black solid line and gray shaded region – the same in all panels – exhibit the average convergence power spectra and the corresponding dispersion for the reference ΛCDM run.
 |
Fig. 1. Convergence maps for sources at zs = 2 of the same light-cone random realization constructed from the DUSTGRAIN-pathfinder simulations used in this work. The region displayed covers a region of approximately 2.5 × 2.5 deg2. |
 |
Fig. 2. Convergence power spectra for sources at zs = 2. From left to right, we exhibit the runs that account for Ωm, σ8 and w variations, respectively. The curves show the average over all 128 line of sight realizations, and the gray areas show the scatter of the convergence power spectrum around the mean value for the reference ΛCDM simulation (256 lines of sight) considering a field of view of 5 deg on a side. |
2.2. SLICS simulations
The SLICS are a suite of 924 fully independent N-body simulations specifically designed for the estimation of covariance matrices describing WL observables. They were produced by cubep3m, a Poisson solver that computes the nonlinear evolution of 15363 particles starting from initial conditions created at z = 120 under the Zeldovich approximation (Harnois-Déraps et al. 2013), in boxes of 505 h−1 Mpc on a side. Every run shares the same CPs2 but embodies a unique noise realization, thereby providing a large ensemble ideally suited for sample variance estimation. The matter power spectrum agrees to within 2 percent with the COSMIC EMULATOR (Heitmann et al. 2014) up to k = 3.0 h−1 Mpc at z = 0.6 (Harnois-Déraps & van Waerbeke 2015).
As detailed in Harnois-Déraps et al. (2018), the particles were collapsed on-the-fly into mass sheets at 18 predetermined redshifts, from which WL light-cones were constructed up to a redshift of 3.0 following the standard multiple-plane technique. Specifically, convergence and shear maps of 100 deg2 were constructed under the Born approximation at 18 source planes, and subsequently sampled to generate Euclid-like galaxy mocks with properties listed in Sect. 2.3, similarly to the methods presented in Sect. 2.1. Each plane has a thickness of 257.5 h−1 Mpc, which, according to Zorrilla Matilla et al. (2020), results in sub-dominant biases on cosmic shear statistics for upcoming surveys.
The SLICS simulations are publicly available3 and were used in a number of cosmic shear data analyses including CFHTLenS (e.g., Joudaki et al. 2017), Kilo Degree Survey (Hildebrandt et al. 2017) and Dark Energy Survey (Harnois-Déraps et al. 2021) data, as well as clustering data analyses including 2dFLenS (Blake et al. 2016), GAMA (van Uitert et al. 2018) and BOSS (Xia et al. 2020). Notably, the covariance matrix estimates of two-point functions have been shown to match well the analytical calculations in Hildebrandt et al. (2017) and Harnois-Déraps et al. (2019), leading to comparable constraints on CPs.
Some dissimilarities between the SLICS and the DUSTGRAIN-pathfinder simulations are worth noting here, as they might have a small but nonnegligible impact on the results presented in this paper. The two suites are based on distinct N-body codes, which results in residual differences in the nonlinear clustering. In addition, we note differences in particle count and mass resolution, in the light-cone opening angles, in pixel sizes4 and in the lens randomization procedure. Finally, the shear maps construction pipelines differ in that they are computed directly from the convergence field of view for DUSTGRAIN-pathfinder, but over the full periodic box for SLICS, which eliminates residual edge effects and B-mode leakage. It is worth mentioning that for the DUSTGRAIN-pathfinder runs, we assume void boundary condition, with κ = 0 outside the field of view, when computing the shear field. The only scales that are affected are angular modes l ∼ 105 and change is below one percent. This last caveat has been also highlighted in Hilbert et al. (2020), for a lower resolution map, to have little impact on two-point statistics as also suggested from the good agreement between numerical and theoretical forecasts for γ-2PCF and κ-PDF in the present analysis (see Sect. 4.5).
2.3. Mock galaxy catalogs
We generate mock galaxy catalogs by sampling the shear and convergence planes defined earlier from the DUSTGRAIN-pathfinder and SLICS simulations. This is to achieve a high degree of realism, allowing us to reproduce Euclid survey properties such as the redshift distribution, galaxy density, and shape noise. The procedure closely follows the implementation of Martinet et al. (2021b), but additionally considers magnitudes in the IE band of the Euclid VIS instrument for sampling the redshift distribution in the case of DUSTGRAIN-pathfinder. In contrast to the mentioned article, we do not present results including tomography in the present work. This is delayed to a future HOWLS paper but our mocks already support any tomographic slicing by construction.
The redshift distributions n(z) of the DUSTGRAIN-pathfinder and SLICS simulations are shown in Fig. 3. They are built from the COSMOS2015 photometric redshift catalogs (Laigle et al. 2016) after a cut in magnitudes IE ≤ 24.5 in the case of DUSTGRAIN-pathfinder and i′≤24.5 for SLICS. This difference is explained by the fact the SLICS mocks were built earlier for Martinet et al. (2021b) than DUSTGRAIN-pathfinder and did not yet include the information about the Euclid VIS magnitudes (computed as a combination of the r, i′, and z′ magnitudes in the present work). Therefore, the DUSTGRAIN-pathfinder n(z) is closer to the expected Euclid n(z). The difference is, however, less than 5%, except in the redshift range z ≤ 0.2, which contains little information with regard to lensing. Additionally, the model of the dependence on cosmology is built from DUSTGRAIN-pathfinder while SLICS enters in the computation of the covariance matrix. This distinction lowers the risk of any impact of the n(z) difference between the two sets of data on the cosmological inference. After the magnitude cut, the COSMOS2015 n(z) is smoothed by fitting the parametrization from Fu et al. (2008) as it was shown in Martinet et al. (2021b) to capture the high-redshift tail better than the standard Smail et al. (1994) fit. The redshift distributions of the DUSTGRAIN-pathfinder and SLICS mocks are fully characterized by
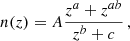
 |
Fig. 3. Top: Redshift distributions of the mocks built from the DUSTGRAIN-pathfinder (red dots) and SLICS (blue dots) simulations, normalized to 30 galaxies per arcmin2. These correspond to a Fu et al. (2008) fit to the Laigle et al. (2016) COSMOS2015 catalog after removing galaxies with magnitudes IE ≥ 24.5 and i′≥24.5 for DUSTGRAIN-pathfinder and SLICS, respectively (red and blue histograms). Bottom: Fractional difference between the DUSTGRAIN-pathfinder and SLICS redshift distributions. The difference is always below 5% except for redshifts lower than 0.2. |
and the parameters listed in Table 2.
Parameters of the Fu et al. (2008) redshift distributions of Eq. (1) for the DUSTGRAIN-pathfinder and SLICS mocks, normalized to 30 galaxies per arcmin2.
Shape noise is included by assigning an intrinsic ellipticity to each galaxy. Specifically, we draw each ellipticity component (ϵi, i = {1, 2}) from a Gaussian random distribution centered on 0 and with a dispersion σϵi = 0.26. This reference value (e.g., Euclid Collaboration 2019b) has been measured for a sample of galaxies observed with the Hubble Space Telescope and with similar photometric properties to the expected VIS sample (magnitudes I814 ∼ 24.5, Schrabback et al. 2018).
The impact of shape noise on the cosmological model is minimized by using the same random realization of galaxy intrinsic ellipticities and positions across all cosmologies for a given mock. This means that we have 128 independent realizations of shape noise for the DUSTGRAIN-pathfinder mocks, but these are identical for the 12 cosmologies probed. Conversely, the positions and ellipticities are fully random for any realization used in the covariance matrix computation, either with the DUSTGRAIN-pathfinder or SLICS simulations. This ensures the shape noise contribution to the error budget is faithfully captured. This process of fixing shape noise in the model and leaving it free in the covariance has become standard practice for simulation-based inference with higher-order mass map estimators (e.g., Kacprzak et al. 2016; Martinet et al. 2018; Harnois-Déraps et al. 2021).
These galaxy catalogs are then fed to the Euclid convergence map reconstruction pipeline described in Pires et al. (2020) and in Sect. 2.4 to produce the convergence maps on which most HOS will be measured. These catalogs are also used to compute direct statistics from the shear, specifically γ-2PCFs (Sect. 3.1) and aperture masses (Map, see Sects. 3.4 and 3.8).
2.4. Mass mapping
The statistical properties of the WL field can be assessed by a statistical analysis either of the shear field or of the convergence field. Many HOS are traditionally computed from the κ field. This requires solving a mass inversion problem that consists of reconstructing the convergence κ from the measured shear field γ. Using complex notation, the shear field is written as γ = γ1 + iγ2, and the convergence field as κ = κE + iκB, with κE and κB respectively corresponding to the E- and B-mode components of the field, by analogy with the electromagnetic field.
We can derive the relation between the shear field γ and the convergence field κ in the Fourier domain (Kaiser & Squires 1993) with
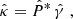
where the hat symbol denotes Fourier transforms, 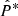 is the complex conjugate, and
is the complex conjugate, and 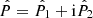 with
with
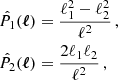
with 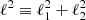 and ℓi the Fourier counterparts of the angular coordinates θi. The convergence can only be determined up to an additive constant because there is a degeneracy when ℓ1 = ℓ2 = 0 (see e.g., Bartelmann 1995). In practice, we impose that the mean convergence vanishes across the field by setting the reconstructed ℓ = 0 mode to zero.
and ℓi the Fourier counterparts of the angular coordinates θi. The convergence can only be determined up to an additive constant because there is a degeneracy when ℓ1 = ℓ2 = 0 (see e.g., Bartelmann 1995). In practice, we impose that the mean convergence vanishes across the field by setting the reconstructed ℓ = 0 mode to zero.
Assuming the mass inversion is conducted without noise regularization, the same information is contained in the shear field as in the convergence maps. However, it is well known that the Kaiser-Squires inversion creates undesirable artifacts at the borders of the reconstructed convergence maps (see e.g., Seitz & Schneider 1996, 2001; Pires et al. 2020). This is due to the fact that the discrete Fourier transform implicitly assumes periodicity of the image along both dimensions. In a future work, mass mapping systematic effects will be further mitigated and their impact quantified by propagating the errors into CP forecasts using HOS. In addition to border effects and masks, we will test the impact of reduced shear. In this article, however, we assume that the mean ellipticity is an unbiased estimator of the mean shear instead of reduced shear such that we can replace γ by ϵ in Eq. (2), an assumption only correct in the weak regime.
The shear is sampled only at the positions of the galaxies. Therefore, the first step of the mass inversion method is to bin the observed ellipticities of galaxies on a regular pixel grid to create the shear maps. In practice, we bin the galaxies in pixels of size of 0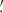 59, resulting in shear maps of 512 × 512 pixels (for DUSTGRAIN-pathfinder) and 1024 × 1024 pixels (for SLICS) that are then converted into convergence maps using Eq. (2). The statistical analysis is performed only on the E-modes convergence maps because WL only produces E-modes. However, the application of the HOS to the B-modes map can be used to test for residual systematic effects.
59, resulting in shear maps of 512 × 512 pixels (for DUSTGRAIN-pathfinder) and 1024 × 1024 pixels (for SLICS) that are then converted into convergence maps using Eq. (2). The statistical analysis is performed only on the E-modes convergence maps because WL only produces E-modes. However, the application of the HOS to the B-modes map can be used to test for residual systematic effects.
3. Statistics
Many higher-order probes have been proposed, tested, and measured on present-day Stage III lensing maps with promising preliminary results (e.g., Martinet et al. 2018; Gatti et al. 2022; Harnois-Déraps et al. 2021; Heydenreich et al. 2022; Zürcher et al. 2022; Burger et al. 2023). This consideration motivated us to focus our analysis on HOS of scalar fields derived from the shear: convergence and aperture mass. In the following paragraphs, we review the probes we consider, referring the interested reader to the quoted papers for further details. Far from being fully exhaustive, this short review aims at presenting the tools we have used and giving the reader an overview of the many roads that open up when going beyond second-order statistics. A short description of theoretical predictions is given for the 2PCF and the κ-PDF as they are used to validate the simulated derivatives entering the Fisher analysis, see Sect. 4.5. The impatient reader can directly look at Table 3, where we list the HOS we have used together with their abbreviations, the number of independent teams that applied them, and the subsections in which they are described. The fact that each statistic was computed by a different team led to a variety of choices in terms of the filtering of the shear or convergence field. For this publication we do not try to homogenize these choices as we consider it part of each method and list these differences in Table 3.
Statistics that have been applied to the HOWLS data set, with their abbreviation in the present article, the filter and smoothing scale employed, the number of independent teams for each statistic and links to the corresponding subsections.
3.1. Two-point correlation functions
Although useful on their own, HOS are at their best when used in combination with standard second-order statistics, coupling the typically larger signal-to-noise ratio (S/N) of lower-order statistics with the degeneracy-breaking power of HOS. In the following, we therefore quantify both the constraints from each HOS probe alone and the improvement of the constraints from joint second- and higher-order statistics with respect to the second-order-only case.
The most basic cosmic shear observable is the real-space shear two-point correlation functions (γ-2PCF), since it can be estimated by simply multiplying the ellipticities of galaxy pairs and averaging. The shear can conveniently be decomposed into a tangential, γt, and cross – component, γ×, such that
![$$ \begin{aligned} \gamma _{\rm t}({\boldsymbol{\vartheta }}^\prime ,{\boldsymbol{\vartheta }}) = -{\boldsymbol{\mathfrak{R} }} [ \gamma ({\boldsymbol{\vartheta }}^\prime ) \mathrm{e}^{-2 \mathrm{i} \phi } ] \qquad \gamma _{\times }({\boldsymbol{\vartheta }}^\prime ,{\boldsymbol{\vartheta }}) = -{\boldsymbol{\mathfrak{I} }}[\gamma ({\boldsymbol{\vartheta }}^\prime ) \mathrm{e}^{-2 \mathrm{i} \phi }] \;, \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq37.gif)
with ℜ and ℑ the real and imaginary parts, ϕ the polar angle of the direction vector between the galaxy position ϑ′ and a reference point ϑ, and the minus sign a convention to have the tangential shear positive around a mass overdensity. The two shear components can then be combined to get two 2PCFs (see, e.g., Kilbinger 2015, and references therein)
![$$ \begin{aligned} \left\{ \begin{array}{l} \displaystyle {\xi _{+}(\theta ) = \langle \gamma \gamma ^* \rangle (\theta ) = \langle \gamma _{\rm t} \gamma _{\rm t} \rangle (\theta ) + \langle \gamma _{\times } \gamma _{\times } \rangle (\theta )} \\ \\ \displaystyle {\xi _{-}(\theta ) = {\boldsymbol{\mathfrak{R} }}[\langle \gamma \gamma \rangle (\theta ) {e}^{-4 \mathrm{i} \phi }] = \langle \gamma _{\rm t} \gamma _{\rm t} \rangle (\theta ) - \langle \gamma _{\times } \gamma _{\times } \rangle (\theta )} \\ \end{array} \right. , \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq38.gif)
where the dependence is only on the angular separation θ on the sky because under the Cosmological Principle cosmic fields are statistically invariant under translation and rotation.
The main virtue of these γ-2PCF is that they can be straightforwardly estimated from the measured ellipticities εi as
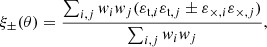
where the sum runs over the galaxy pairs with positions on the sky (θi, θj) having angular separation |θi − θj| in a bin centered on θ. The weight wi of the ellipticity εi can be related to the measurement error, and set to zero if the galaxy is in a masked region. In the present article the lensing weights are set to 1, as the impact of masks and shear measurement methods are beyond the scope of this analyis.
The γ-2PCF can be easily computed for a given cosmological model by first going to Fourier space and then converting back into real space. The final result is
![$$ \begin{aligned} \left\{ \begin{array}{l} \displaystyle {\xi _{+}(\theta ) = \frac{1}{2 \pi } \int {\left[P_{\kappa }^{E}(\ell ) + P_{\kappa }^{B}(\ell )\right] \, J_0(\ell \theta ) \,\ell \, \mathrm{d}\ell }} \\ \displaystyle {\xi _{-}(\theta ) = \frac{1}{2 \pi } \int {\left[P_{\kappa }^{E}(\ell ) - P_{\kappa }^{B}(\ell ) \right] \, J_4(\ell \theta )\, \ell \, \mathrm{d}\ell }} \\ \end{array} \right. \;, \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq40.gif)
where 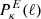 and
and 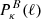 are the power spectra of the convergence E and B modes, while Jn(x) is the n-th order spherical Bessel function of the first kind. We note that, in the absence of systematics and neglecting higher-order effects, WL does not produce B modes so that
are the power spectra of the convergence E and B modes, while Jn(x) is the n-th order spherical Bessel function of the first kind. We note that, in the absence of systematics and neglecting higher-order effects, WL does not produce B modes so that 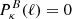 , and ξ± reduce to different Hankel transforms of the same quantity, which can be derived from the matter power spectrum Pδ(ℓ).
, and ξ± reduce to different Hankel transforms of the same quantity, which can be derived from the matter power spectrum Pδ(ℓ).
As done for the shear, we can similarly define the κ-2PCF for the convergence. In particular, this will inherit the same properties of translation and rotation invariance as in the shear case. The main difference is that, with the convergence being a scalar quantity, there is only one single correlation function. In Fourier space, this can be related to the convergence power spectrum as
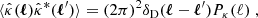
where δD is the Dirac-δ function and the convergence power spectrum depends only on the modulus of ℓ due to the statistical homogeneity and isotropy. It is then possible to show that 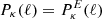 , and the κ-2PCF is given by
, and the κ-2PCF is given by
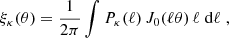
which is the same as ξ+(θ). In the following, we keep this different label in order to distinguish between the γ-2PCF and κ-2PCF.
In this article, the γ-2PCF has been computed with the ATHENA software (Kilbinger et al. 2014) using 10 logarithmic bins between 0 1 and 300′. The κ-2PCF has been measured using the public code TreeCorr (Jarvis et al. 2004). The minimum separation considered is 0
1 and 300′. The κ-2PCF has been measured using the public code TreeCorr (Jarvis et al. 2004). The minimum separation considered is 0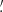 59 (corresponding to the pixel scale) and the maximum separation is approximately 424′ (corresponding to the DUSTGRAIN-pathfinder map diagonal), with 25 bins. As discussed in Sect. 4 several bins are later removed to pass our quality criteria, with the final scale range described in Table 3. We also show these DVs as well as their standard Fisher derivatives with respect to Ωm, σ8, and w in Figs. 4 and 5 for γ-2PCF and κ-2PCF respectively. Finally, we note some difference in the chosen binning by the different teams computing the 2PCFs which leads to some artificial difference between ξ+ and ξκ, for example.
59 (corresponding to the pixel scale) and the maximum separation is approximately 424′ (corresponding to the DUSTGRAIN-pathfinder map diagonal), with 25 bins. As discussed in Sect. 4 several bins are later removed to pass our quality criteria, with the final scale range described in Table 3. We also show these DVs as well as their standard Fisher derivatives with respect to Ωm, σ8, and w in Figs. 4 and 5 for γ-2PCF and κ-2PCF respectively. Finally, we note some difference in the chosen binning by the different teams computing the 2PCFs which leads to some artificial difference between ξ+ and ξκ, for example.
 |
Fig. 4. γ-2PCF ξ+ (top) and ξ− (bottom) DVs and derivatives. The gray lines, whose scale is given by the second axis, correspond to the average DVs computed from the 924 SLICS realizations. The Fisher derivatives (defined in Eq. (47)) are computed from the DUSTGRAIN-pathfinder simulations with large variations of Ωm (orange), σ8 (green), and w (blue). The solid, dashed, and dotted lines respectively correspond to the average over 128, 64, and 32 realizations. The shaded areas represent the uncertainty computed from the 128 DUSTGRAIN-pathfinder realizations, and the gray error bars those of the 924 SLICS realizations. The inclusion of the dashed and dotted lines within the shaded areas highlights the low numerical noise. |
 |
Fig. 5. Fiducial DV for κ-2PCF (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue). |
3.2. Convergence PDF
The one-point probability distribution function (PDF) of the WL convergence κ encodes vital information about the non-Gaussian late-time density field. In the presence of shape noise, which dominates on small scales, this information can be extracted most conveniently from the PDF of the convergence after smoothing on an angular scale big enough that the variance set by the gravitational clustering is larger than the shape noise contribution. As a one-point statistic, the PDF is straightforward to measure from simulated and real data, as evidenced by recent analyses of density-split statistics and weak lensing moments in the Dark Energy Survey (Friedrich et al. 2018; Gruen et al. 2018; Gatti et al. 2020, 2022), which carry PDF information in a compressed way and can deal with survey mask effects.
When focusing on mildly nonlinear scales, typically corresponding to smoothing scales of about 10′ at low redshifts, this one-point PDF also admits accurate theoretical predictions (see for example Barthelemy et al. 2020; Boyle et al. 2021). The main idea of this theoretical model relies on the fact that, within the Limber approximation, since the WL convergence probes the matter density in a cone whose opening angle is set by the smoothing scale, the κ-PDF can be predicted using cylindrical collapse applied to the 2D slices of the density in the circular cross-sections. Hence, for a set of sources regrouped in redshift bins and with a certain source distribution across the survey n(z), we recall that the theoretical cumulant generating function (CGF) ϕκ, θ at a given angular smoothing scale θ can be expressed as
![$$ \begin{aligned} \phi _{\kappa ,\theta }(\lambda ) = \int \frac{\mathrm{d}z \, c}{H(z)} \, \phi _{\rm cyl}[\omega _{n(z)}(z) \lambda ,z]\;, \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq49.gif)
with ϕcyl the CGF of the density in each individual 2D slice of radius χ(z)θ, and ωn(z) the generalized lensing kernel given a wide distribution of sources following the normalized distribution n(z)
![$$ \begin{aligned} \omega _{n(z)}(z) = \frac{3\Omega _{\rm m} H_0^2}{2 c^2}\!\!\int \!\! \mathrm{d}z_{\rm s} n(z_{\rm s}) \frac{[\chi (z_{\rm s})-\chi (z)]\,\chi (z)}{\chi (z_{\rm s})}\,\mathcal{H} (z_{\rm s}-z)\,(1+z)\;, \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq50.gif)
where the Heaviside ℋ ensures that the integrand vanishes for z ≥ zs. ϕcyl is obtained from the cylindrical collapse dynamics as a proxy for the whole nonlinear evolution in cylindrically symmetric configurations (top-hat smoothing) and enforces a specific hierarchy of cumulants. The PDF is then recovered through the inverse Laplace transform of the exponential of the κ CGF as
![$$ \begin{aligned} \mathcal{P} _{\theta }(\kappa )=\int _{-i \infty }^{+i \infty } \frac{\mathrm{d} \lambda }{2 \pi \mathrm{i} } \exp \left[-\lambda \kappa +\phi _{\kappa , \theta }(\lambda )\right]\;. \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq51.gif)
Note that the cylindrical collapse model is accurate enough to predict the so-called reduced cumulants of the (2D) density field 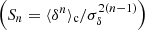 , where ⟨δn⟩c are the cumulants of the matter density. This means that the model also requires an external input for the prediction of the nonlinear variance of all the 2D slices of the density along the line of sight. Fortunately, the emulation of the matter power spectrum has received lots of attention these past years and can be estimated rather accurately, for example by using the revised Halofit model (Takahashi et al. 2012) or the Euclid Emulator (Euclid Collaboration 2019a). Galaxy shape noise can be included in the theoretical prediction through a convolution of the noiseless PDF as described in Boyle et al. (2021) or directly at the level of the CGF by simple addition of – for example – an associated shape noise variance
, where ⟨δn⟩c are the cumulants of the matter density. This means that the model also requires an external input for the prediction of the nonlinear variance of all the 2D slices of the density along the line of sight. Fortunately, the emulation of the matter power spectrum has received lots of attention these past years and can be estimated rather accurately, for example by using the revised Halofit model (Takahashi et al. 2012) or the Euclid Emulator (Euclid Collaboration 2019a). Galaxy shape noise can be included in the theoretical prediction through a convolution of the noiseless PDF as described in Boyle et al. (2021) or directly at the level of the CGF by simple addition of – for example – an associated shape noise variance  .
.
We extracted the κ-PDF from the simulated maps for two top-hat filters with smoothing scales θs ∈ {4 69, 9
69, 9 37}, corresponding to 8/16 pixels in the DUSTGRAIN-pathfinder simulations. After smoothing the maps with the appropriate top-hat filter, we excluded all pixels whose smoothing circle of radius θs would intersect the patch boundary.5 The PDF was obtained from a histogram using 201 linearly spaced bins in the range κ ∈ [ − 0.1, 0.1]. Cuts were made in the considered range of κ to exclude the extreme tails and keep the DV close to Gaussian as discussed in Sect. 4.2. The precise κ values are given in Fig. 6. The cuts exclude 0.05% and 0.25% of the cumulative probability from the low-κ and high-κ tails, respectively, for the smaller smoothing scale. We subsequently compare the theoretical predictions to the measurements in the simulation in Sect. 4.5.
37}, corresponding to 8/16 pixels in the DUSTGRAIN-pathfinder simulations. After smoothing the maps with the appropriate top-hat filter, we excluded all pixels whose smoothing circle of radius θs would intersect the patch boundary.5 The PDF was obtained from a histogram using 201 linearly spaced bins in the range κ ∈ [ − 0.1, 0.1]. Cuts were made in the considered range of κ to exclude the extreme tails and keep the DV close to Gaussian as discussed in Sect. 4.2. The precise κ values are given in Fig. 6. The cuts exclude 0.05% and 0.25% of the cumulative probability from the low-κ and high-κ tails, respectively, for the smaller smoothing scale. We subsequently compare the theoretical predictions to the measurements in the simulation in Sect. 4.5.
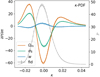 |
Fig. 6. Fiducial DV for κ-PDF (gray) along with its Fisher derivatives with respect to Ωm (orange), σ8 (green), and w (blue). The κ-PDF was computed on κ maps smoothed with a top-hat filter with a scale of 4 |
One alternative to the κ-PDF is to turn to the (slightly) more involved – but also more easily accessible through observations – modeling of the one-point PDF of the aperture mass from Eq. (13) discussed in Sect. 3.4. The analogous theoretical model was developed in Barthelemy et al. (2021). The next extension would be to include some tomographic information in the analysis. At the level of the PDF one could rely on the ideas developed in Barthelemy et al. (2022) for the joint PDF between – built to be – independent lensing kernels that probe structures along the line of sight, but the generalization to any other lensing observables should be straightforward.
3.3. Higher-order convergence moments
The shear and convergence 2PCF and their harmonic space counterparts, the power spectra, are related to the variance of the lensing fields. It is then natural to ask whether additional information is encoded in moments higher than two, given that they are indicators of the non-Gaussianity of the field. We consider here the second, third, and fourth moments of the convergence field.
Moments of the smoothed WL convergence field κθ can be calculated from weighted averages of the lensing PDF as 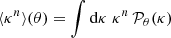 , assuming a lensing convergence field of zero mean. The variance ⟨κ2⟩=σ2 fully characterizes a Gaussian one-point distribution, while the skewness ⟨κ3⟩/σ3 and kurtosis ⟨κ4⟩/σ4 − 3 are the most common examples encoding non-Gaussian information. While an analysis of the variance, skewness, and kurtosis promises a significant compression of the κ-PDF DV, higher-order cumulants are known to be very sensitive to the tails of the distribution, rendering their signal and likelihood hard to predict.
, assuming a lensing convergence field of zero mean. The variance ⟨κ2⟩=σ2 fully characterizes a Gaussian one-point distribution, while the skewness ⟨κ3⟩/σ3 and kurtosis ⟨κ4⟩/σ4 − 3 are the most common examples encoding non-Gaussian information. While an analysis of the variance, skewness, and kurtosis promises a significant compression of the κ-PDF DV, higher-order cumulants are known to be very sensitive to the tails of the distribution, rendering their signal and likelihood hard to predict.
An approximated yet accurate formula for the moments can be obtained under the hierarchical ansatz (Bernardeau & Schaeffer 1992; Szapudi & Szalay 1993), using this ansatz to express the bispectrum and trispectrum in terms of the power spectrum and plugging them into the general expression for the convergence moments (see Munshi & Jain 2001; Vicinanza et al. 2019, for details).
It is worth noting that moments are a function of smoothing radius, so one typically considers as a cosmological probe their scaling with θ. In contrast, here we use them for a fixed θ since, in a preliminary analysis, we have found moments obtained from different smoothing radii to be highly correlated. Although some information is still present in the correlated moments, we prefer here to first focus on the choice of the filter radius in our two parameter analysis for which combining moments at different radii is not essential. We, therefore, measure them like the κ-PDF using a top-hat filter with two different values of the aperture radius, namely θ ∈ {4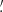 69, 9
69, 9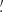 37}, and take {⟨κ2⟩(θ),⟨κ3⟩(θ),⟨κ4⟩(θ)} for a fixed θ as our DV (see Fig. 7). To this end, we first define
37}, and take {⟨κ2⟩(θ),⟨κ3⟩(θ),⟨κ4⟩(θ)} for a fixed θ as our DV (see Fig. 7). To this end, we first define
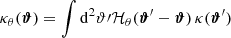
 |
Fig. 7. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for HOM computed on κ maps smoothed with a top-hat filter with a scale of 4 |
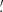
as the smoothed convergence field. We then take it to the second, third, fourth power and compute its average value over the pixels to compute the data vector for every single map. The mean over the different realizations of the simulations makes up our final DV.
3.4. Higher-order aperture mass moments
Higher-order moments as introduced before were extracted for the smoothed convergence maps. However, it is also possible to compute them for the aperture mass Map map, at sky location ϑ and scale θ given by (Schneider et al. 1998):
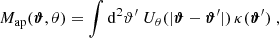
where Uθ is a compensated filter function with
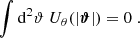
The higher-order aperture maps statistics 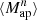 correlate the aperture masses on n different scales θ1, ⋯, θn, and are defined as
correlate the aperture masses on n different scales θ1, ⋯, θn, and are defined as
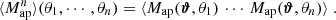
The 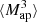 is closely related to the third-order moment of the convergence maps since both of them are sensitive to the matter bispectrum (Schneider et al. 2005). However, in contrast to other HOS considered in this work, the
is closely related to the third-order moment of the convergence maps since both of them are sensitive to the matter bispectrum (Schneider et al. 2005). However, in contrast to other HOS considered in this work, the 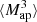 can be directly inferred from the shear and are therefore not affected by systematics induced by the convergence reconstruction. Additionally
can be directly inferred from the shear and are therefore not affected by systematics induced by the convergence reconstruction. Additionally 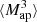 can be inferred from the shear three-point correlation functions Γ0 = ⟨γ γ γ⟩ and Γ1 = ⟨γ* γ γ⟩, which can be easily estimated even for irregular survey geometries and in the presence of masks (Schneider & Lombardi 2003; Heydenreich et al. 2023). Consequently,
can be inferred from the shear three-point correlation functions Γ0 = ⟨γ γ γ⟩ and Γ1 = ⟨γ* γ γ⟩, which can be easily estimated even for irregular survey geometries and in the presence of masks (Schneider & Lombardi 2003; Heydenreich et al. 2023). Consequently, 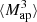 is more straightforward to measure in a realistic survey setting than HOS of κ.
is more straightforward to measure in a realistic survey setting than HOS of κ.
We infer the 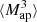 from the tangential shear γt(ϑ′;ϑ) at position ϑ′ with respect to ϑ. This inference is possible because each filter Uθ is associated with a function Qθ for which
from the tangential shear γt(ϑ′;ϑ) at position ϑ′ with respect to ϑ. This inference is possible because each filter Uθ is associated with a function Qθ for which
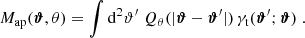
The function Qθ is given by
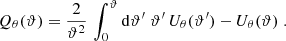
To mimic the application of the 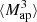 statistics to a survey, we use Eq. (16) and work directly with the simulated shear catalogs. We use the filter function Uθ from Crittenden et al. (2002),
statistics to a survey, we use Eq. (16) and work directly with the simulated shear catalogs. We use the filter function Uθ from Crittenden et al. (2002),
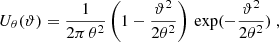
and the scale radii θ ∈ {1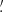 17, 2
17, 2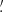 34, 4
34, 4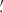 69, 9
69, 9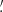 37}.
37}.
Our measurement of 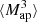 proceeds in two steps following the procedure in Sect. 5.3.1 of Heydenreich et al. (2023). First, we measure Map(ϑ, θ). For this, we employ the convolution theorem to solve the convolution of Qθ and γt in Fourier space. Since the tangential shear γt can be written as
proceeds in two steps following the procedure in Sect. 5.3.1 of Heydenreich et al. (2023). First, we measure Map(ϑ, θ). For this, we employ the convolution theorem to solve the convolution of Qθ and γt in Fourier space. Since the tangential shear γt can be written as
![$$ \begin{aligned} \gamma _{\rm t}({\boldsymbol{\vartheta }}^\prime ,{\boldsymbol{\vartheta }}) = - {\boldsymbol{\mathfrak{R} }} \left[ \gamma ({\boldsymbol{\vartheta }}^\prime )\frac{({\boldsymbol{\vartheta }}-{\boldsymbol{\vartheta }}^\prime )^*}{{\boldsymbol{\vartheta }}-{\boldsymbol{\vartheta }}^\prime } \right] \; , \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq80.gif)
where the vectors are interpreted as complex numbers ϑ = ϑ1 + iϑ2, Eq. (16) transforms into
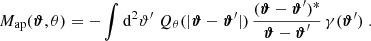
Therefore, we can calculate both 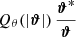 and γ(ϑ) on a grid, and solve the convolution in Eq. (20) using the Fast Fourier Transform (FFT). To avoid border effects, we cut off a strip of width of 4θ from each border. This large cut-off is needed because the exponential aperture filter is not exactly zero for ϑ > θ, so at distance θ, we still experience border effects from each side of the Map(ϑ, θ) map. Our cut-off means we neglect 0.07% of the total filter power, which we deem acceptable. Second, we measure
and γ(ϑ) on a grid, and solve the convolution in Eq. (20) using the Fast Fourier Transform (FFT). To avoid border effects, we cut off a strip of width of 4θ from each border. This large cut-off is needed because the exponential aperture filter is not exactly zero for ϑ > θ, so at distance θ, we still experience border effects from each side of the Map(ϑ, θ) map. Our cut-off means we neglect 0.07% of the total filter power, which we deem acceptable. Second, we measure 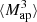 (θ1, θ2, θ3). For this, we multiply Map(ϑ, θ1), Map(ϑ, θ2), and Map(ϑ, θ3) for each line-of-sight and each position ϑ. Then, we average over ϑ, which gives
(θ1, θ2, θ3). For this, we multiply Map(ϑ, θ1), Map(ϑ, θ2), and Map(ϑ, θ3) for each line-of-sight and each position ϑ. Then, we average over ϑ, which gives 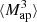 (θ1, θ2, θ3) for each line-of-sight. This DV is shown in Fig. 8.
(θ1, θ2, θ3) for each line-of-sight. This DV is shown in Fig. 8.
 |
Fig. 8. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for |
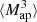
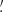
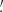
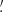
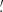
We estimate the n-th order moments 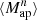 (Fig. 9) with a different approach. For this we cover the survey footprint with apertures and estimate
(Fig. 9) with a different approach. For this we cover the survey footprint with apertures and estimate 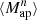 within each aperture (Schneider et al. 1998) as
within each aperture (Schneider et al. 1998) as
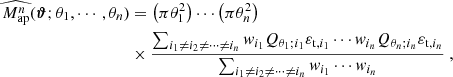
 |
Fig. 9. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for |
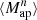
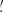
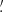
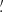
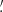
where each wi is the weight of the ellipticity εi and we abbreviated Qθj(|ϑij − ϑ|) ≡ Qθj; ij for an aperture centered at ϑ. Note that the index ik in the kth sum in (21) only considers galaxies that lie within the support of Qθk. By averaging over all apertures in the footprint with appropriate weights wap, one then obtains an unbiased estimate for 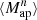 . As shown in Porth et al. (2020) and Porth & Smith (2021), one can decompose the nested sums appearing in (21), so that the full estimation process scales linearly with the number of galaxies. In this work, we estimate the connected parts of the aperture-mass statistics for n ∈ {2, 3, 4, 5}, where for n = 3 we take into account all of the different combinations of aperture radii and in the other cases only consider the components for which θ1 = … = θn. In contrast to the FFT-based estimation procedure described above, we employ a polynomial filter function introduced in Schneider et al. (1998) for the direct estimator method,
. As shown in Porth et al. (2020) and Porth & Smith (2021), one can decompose the nested sums appearing in (21), so that the full estimation process scales linearly with the number of galaxies. In this work, we estimate the connected parts of the aperture-mass statistics for n ∈ {2, 3, 4, 5}, where for n = 3 we take into account all of the different combinations of aperture radii and in the other cases only consider the components for which θ1 = … = θn. In contrast to the FFT-based estimation procedure described above, we employ a polynomial filter function introduced in Schneider et al. (1998) for the direct estimator method,
![$$ \begin{aligned} Q_\theta (\vartheta ) = \frac{6}{\pi \theta ^2} \left(\frac{\vartheta }{\theta }\right)^2\left[1-\left(\frac{\vartheta }{\theta }\right)^2\right]\mathcal{H} (\theta -\vartheta ) \ , \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq99.gif)
where ℋ(x) denotes the Heaviside function. For our choice of wap, we follow Porth & Smith (2021) who propose a form that approximates an inverse variance weighting scheme. As the mocks used in this work have wi ≡ 1, it can be shown that in this case the weight of an aperture centered at ϑ is equal to the number of multiplet counts within its configuration of aperture radii,
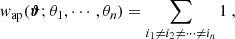
where the indices are bound to the same constraints as in (21). Analogous to the FFT-based estimation procedure we need to avoid border effects; with our choice (22) for the filter function this results in cutting off a strip of width of max({θ1,⋯,θn}) from each border. In the resulting DV (Fig. 9) the first twelve elements correspond to the equal scale statistics of order {2, 4, 5} while the final 20 elements correspond to the third order statistics and are ordered as the DV in Fig. 8.
3.5. Aperture mass peak counts
A different way to probe the convergence field at all statistical orders in a single step is to consider peak counts. As the name itself implies, one is now searching for peaks (i.e., local over-densities) on the smoothed convergence maps.
Some studies only focus on peaks with very large S/N because they are good tracers of massive galaxy clusters (Kruse & Schneider 1999; Marian & Bernstein 2006; Gavazzi & Soucail 2006; Hamana et al. 2015; Miyazaki et al. 2017). The advantage of this approach is that the dependence on cosmology of the WL cluster abundance can be accurately predicted by theoretical models (see e.g., Kruse & Schneider 2000; Bartelmann etal. 2001; Hamana et al. 2004; Marian et al. 2009). Another approach consists of also considering low-amplitude peaks. Since there is no analytical prediction for the full range of S/N peaks, it is necessary to run a large number of N-body simulations to calibrate the dependence of the peak count statistics on cosmology. However, a significant fraction of these peaks arise from large-scale structure projections, and as such, carry additional cosmological information (see e.g., Yang et al. 2013; Lin et al. 2016). Over the past two decades, many cosmological studies have been performed based on the second approach (see e.g., Pires et al. 2009; Dietrich & Hartlap 2010; Martinet et al. 2018, 2021a,b; Peel et al. 2018; Li et al. 2019; Ajani et al. 2020; Harnois-Déraps et al. 2021) and have shown the strength of peak counts in discriminating between cosmological models. In a preliminary Fisher analysis, we tested the two approaches and, as expected, the best results were obtained when including the full range of S/N peaks, which is therefore what we present in the following.
The computation of the peak count statistics requires filtering the convergence maps because of galaxy shape noise. In practice, the peak count can be evaluated at a given scale by convolving the convergence maps with a filter function of a specific scale (i.e., aperture radius). We choose to filter the maps using compensated filters defined in Eq. (14). Compensated filters (e.g., aperture mass filters or wavelet filters) have been preferred over low-pass filters (e.g., Gaussian filters) due to their shapes, which reduce the overlap between different scales and then the correlations between them (see e.g., Lin et al. 2016; Ajani et al. 2020). In Leonard et al. (2012), it is demonstrated that the aperture mass is formally identical to a wavelet transform at a specific scale.
As such, we use the starlet transform (Starck et al. 2007; Leonard et al. 2012) to simultaneously compute five aperture mass maps corresponding to scales of {1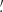 17, 2
17, 2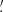 34, 4
34, 4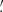 69, 9
69, 9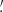 37, 18
37, 18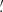 74}. The starlet transform decomposes the convergence as follows:
74}. The starlet transform decomposes the convergence as follows:
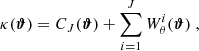
where CJ is a smooth version of the convergence κ and 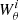 are the wavelet maps corresponding to a scale of θ = 2i pixels.
are the wavelet maps corresponding to a scale of θ = 2i pixels.
The starlet transform is equivalent to applying the following aperture mass filter to the convergence map (Leonard et al. 2012):
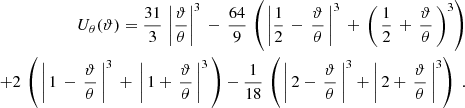
In the aperture mass maps, the peaks are identified as individual pixels higher than their eight neighbors. The edges are discarded from the computation. Once the peaks are detected on each aperture mass map, they are classified depending on their amplitudes with respect to the shape noise. Several implementations of the peaks have been tested. The main differences between the implementations are in the range of the amplitudes of the peaks that are considered, the number of equidistant bins and the size of the edges to be discarded.
The results for the peak counts presented in this study are obtained by sorting the peaks into 14 equidistant bins between −1 and 6 times the dispersion value (see Table 4 and Fig. 10) to ensure it is Gaussian distributed for the Fisher analysis and by discarding a stripe of 1 pixel on each side of the Map map before counting peaks.
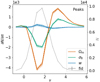 |
Fig. 10. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for peaks of aperture mass maps, computed from κ-fields smoothed with a starlet filter with a scale of 2 |
Verification of the Gaussian hypothesis.
3.6. Convergence Minkowski functionals
The HOS probes previously described can be considered extensions of the standard second-order probes since they all aim at probing the convergence field at higher orders to sort out the information contained in its non-Gaussianity. A different way to access this additional constraining power is represented by topological indicators.
Topology is the branch of mathematics that addresses the shapes, boundaries and connectivity of structural features in a field. More precisely, it is concerned with the properties of a geometric object that are preserved under continuous deformations, such as stretching, twisting, crumpling, and bending. Basic examples of topological properties are: the dimension distinguishing between a line and a surface; the compactness differentiating between a straight line and a circle; and connectedness, which separates a circle from two nonintersecting circles.
The first topological statistics we use as a cosmological tool are the Minkowski functionals (MFs). According to Hadwiger’s theorem (Hadwiger 1957), under a few simple requirements, any morphological descriptor of a d-dimensional scalar field is a linear combination of d + 1 MFs Vn with n ranging from 0 to d. The geometrical interpretation of each functional depends on the considered dimension d. Therefore, the morphology of the 2-dimensional convergence scalar field κ(ϑ) = κ(ϑ1, ϑ2) with variance σ2 will be described by the first three MFs6 as
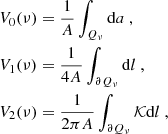
where A represents the map area, ∂Qν is the boundary of the excursion set Qν = {(ϑ1, ϑ2)∣κ(ϑ1, ϑ2)/σ ≥ ν} at a given threshold ν, da and dl are respectively the surface and the line element along ∂Qν, and 𝒦 is the local geodesic curvature of ∂Qν. Qualitatively, one can say that V0(ν) and V1(ν) quantify, respectively, the area and the perimeter of the excursion set Qν, while V2(ν) gives the Euler characteristic, which is the topological quantity measuring the connectivity of the field. For an orientable surface, the latter is defined as χ = 2(𝒜 − ℬ), that is the difference between the number 𝒜 of disconnected regions above the threshold ν and the number ℬ of those below ν, that is the number of holes. We note that in Morse theory the Euler characteristics are also given by the alternating sum of critical point counts and hence related to the peak counts described in the previous section.
Equation (26), applied to the convergence field, can be rewritten in an operative form as
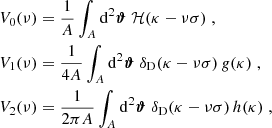
where
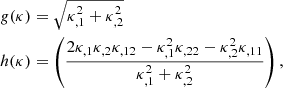
with κ,i and κ,ij the first- and second-order partial derivatives of the convergence field with respect to ϑi and ϑiϑj and for i, j = 1, 2.
Equation (27) suggests that the zeroth MF V0 can be evaluated by the integration of the Heaviside step function over the whole excursion set Qν. The other MFs V1, V2 have been transformed from line integrals into surface integrals by inserting a delta function δD and the appropriate Jacobian. The integrands of the first and second MFs, including the geodesic curvature 𝒦, are then given by second-order invariants that depend solely on the threshold ν, the field value κ and functions of its first- and second-order derivatives κ,i, κ,ij defined in Eq. (28), (see Sect. 2.3 of Schmalzing & Górski 1998, for a detailed calculation)7.
Equation (27) is the basis for developing an algorithm able to numerically measure MFs for a given threshold on a given convergence map. For our analysis, we make use of the code proposed and implemented in Vicinanza et al. (2019), Parroni et al. (2020). We apply it to the convergence map after performing a Gaussian smoothing with four different apertures, namely (1 17, 2
17, 2 34, 4
34, 4 69, 9
69, 9 37). Figure 11 shows the corresponding DV for the 2
37). Figure 11 shows the corresponding DV for the 2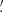 34 smoothing. The code has been validated by measuring MFs on simulated Gaussian maps since, in this case, it is possible to analytically predict the expected values of Vn(ν). This is no longer the case for non-Gaussian fields. A perturbative approach can be used when deviations from Gaussianity are very small (see e.g., Pogosyan et al. 2016), but it gives approximate results that require the evaluation of high-order polyspectra to be more accurate. Moreover, this formulation does not account for the presence of noise and systematics from the convergence reconstruction from biased shear data. We refer the reader to Parroni et al. (2020) and references therein for the derivation and testing of an approximate formulation dealing with these issues. However, in that same paper, it has been shown that a large number of nuisance parameters must be introduced, so it is desirable to rely on direct measurements from simulated convergence maps as we do here, which can be used to develop future emulators.
34 smoothing. The code has been validated by measuring MFs on simulated Gaussian maps since, in this case, it is possible to analytically predict the expected values of Vn(ν). This is no longer the case for non-Gaussian fields. A perturbative approach can be used when deviations from Gaussianity are very small (see e.g., Pogosyan et al. 2016), but it gives approximate results that require the evaluation of high-order polyspectra to be more accurate. Moreover, this formulation does not account for the presence of noise and systematics from the convergence reconstruction from biased shear data. We refer the reader to Parroni et al. (2020) and references therein for the derivation and testing of an approximate formulation dealing with these issues. However, in that same paper, it has been shown that a large number of nuisance parameters must be introduced, so it is desirable to rely on direct measurements from simulated convergence maps as we do here, which can be used to develop future emulators.
 |
Fig. 11. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for MFs V0 (top), V1 (center), and V2 (bottom) computed on κ maps smoothed with a Gaussian filter with a scale of 2 |
3.7. Convergence Betti numbers
In order to individually study the different topological features in the maps (holes, islands), one can rely on the Betti Numbers (BNs) βi(ν), (whose alternating sum gives back the Euler characteristics). BNs consist of topological invariants that formalize the pure topological information in a given field through the relationship between singularity structure and connectivity. They represent homology measures since they describe the spatial distribution of the critical points of the field and their connectivity. The homology of a 3-dimensional manifold M of a 2-dimensional scalar field such as the convergence κ(ϑ) = κ(ϑ1, ϑ2) is characterized by the first three BNs8, βi:ℝ↦ℤ ∣ i = 0, 1, 2. The manifold M of κ is a subset of ℝ3 defined by the relation
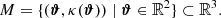
In particular, similarly to the excursion set Qν introduced in Sect. 3.6, it is useful to construct a superlevel set filtration at a threshold ν formally defined as
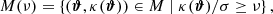
with σ2 the variance of the convergence field. For all the thresholds ν1 ≥ ν2 made inline M(ν1)⊆M(ν2) Indeed, lowering the threshold ν from ∞ to −∞, new points are included into the manifold M(ν). It is trivial to show that M(∞) = ∅ and M(−∞) = M.
Following the Morse–Smale theoretical approach introduced in Feldbrugge et al. (2019), it is possible to infer integral relations for BNs valid for an arbitrary 2-dimensional random field (not necessarily Gaussian):
![$$ \begin{aligned} \beta _{0}(\nu )&= \int _{\nu }^{\infty } \left\{ \mathcal{N} _{\rm max}(\nu ) - [ 1 - g(\nu ) ]\, \mathcal{N} _{\rm saddle}(\nu ) \right\} \, {\mathrm{d}}{\nu }, \nonumber \\ \beta _{1}(\nu )&= \int _{\nu }^{\infty } \left[ g(\nu )\, \mathcal{N} _{\rm saddle}(\nu ) - \mathcal{N} _{\rm min}(\nu ) \right]\, {\mathrm{d}}{\nu }, \\ \beta _{2}(\nu )&= 0,\nonumber \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq128.gif)
with 𝒩min,𝒩saddle,𝒩max:ℝ↦ℝ respectively the minima, saddle points and maxima density at threshold ν. The function g(ν):ℝ↦[0,1] and the opposite 1 − g(ν) respectively represent the probability of two different topological transitions caused by the introduction of a saddle point of the field at threshold ν. These latter affect the value of β1 or β0 as described in the incremental algorithm introduced in Feldbrugge et al. (2019). As is evident in Eq. (31), BNs depend solely on the diagnostic parameter ν, similarly to MFs. Furthermore, in the 2 - dimensional case, only the first two BNs β0(ν),β1(ν) are relevant since β2(ν) will increase only when the lowest minimum exceeds the threshold ν. Unfortunately, there is no analytical expression for g(ν) in either the Gaussian or non-Gaussian case. In fact, only an approximated form has been found by Feldbrugge et al. (2019) for Gaussian 2 - dimensional fields. On the other hand, by relying on the incremental algorithm presented in Feldbrugge et al. (2019), codes can be developed in order to numerically count BNs. For our analysis, we measure BNs through a code developed in Parroni et al. (2021) and tested against Gaussian maps. As done for the MFs, the convergence field is smoothed with the same Gaussian filter and with identical apertures {1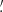 17, 2
17, 2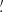 34, 4
34, 4 69, 9
69, 9 37}. The 2
37}. The 2 34 scale DV used for the Fisher forecasts is displayed in Fig. 12.
34 scale DV used for the Fisher forecasts is displayed in Fig. 12.
 |
Fig. 12. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for BNs β0 (top) and β1 (bottom) computed on κ maps smoothed with a Gaussian filter with a scale of 2 |
3.8. Persistent homology of aperture mass
Persistent homology is a tool from topological data analysis to quantify the topological structure of data in the presence of noise. We briefly introduce the method here. Further details can be found in Heydenreich et al. (2021, 2022).
As in Sect. 3.7, we construct excursion sets on a manifold M; here, M is represented by the S/N map of aperture masses Map/σ(Map) on a square patch on the sky, seen as a subset of ℝ2. The filter function of the aperture mass map was optimized to detect dark matter halos and reads (Schirmer et al. 2007)
![$$ \begin{aligned} Q_\theta (\vartheta ) =&\left[1 + \exp \left(6 -150 \frac{\vartheta }{\theta }\right) + \exp \left(-47 +50 \frac{\vartheta }{\theta }\right)\right]^{-1} \nonumber \\&\quad \times \left(\frac{\vartheta }{x_{\rm c}\theta }\right)^{-1} \tanh \left(\frac{\vartheta }{x_{\rm c}\theta }\right)\, . \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq135.gif)
Here we use the filter scale of θ = 2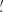 34 and a concentration index of xc = 0.15 (Hetterscheidt et al. 2005). By varying the threshold, topological features such as connected components and holes emerge. The number of these features at varying threshold levels depends on the topological structure of the aperture mass map. The topological features also have a physical interpretation: Connected components correspond to local minima of the aperture mass map, and thus to underdensities in the integrated matter distribution. On the other hand, holes correspond to local maxima of the aperture mass map, or overdensities in the integrated matter distribution.
34 and a concentration index of xc = 0.15 (Hetterscheidt et al. 2005). By varying the threshold, topological features such as connected components and holes emerge. The number of these features at varying threshold levels depends on the topological structure of the aperture mass map. The topological features also have a physical interpretation: Connected components correspond to local minima of the aperture mass map, and thus to underdensities in the integrated matter distribution. On the other hand, holes correspond to local maxima of the aperture mass map, or overdensities in the integrated matter distribution.
In contrast to BNs, which just count the number of features at each filtration level, persistent homology tracks the birth b and death d of each topological feature. The “persistence” of a feature, defined as its “lifetime” d − b, is a measure of how far a topological feature protrudes from its surroundings. In other words, features with low persistence are more likely to be attributed to noise (Sousbie 2011).
To visualize a persistent homology statistic, the features (b, d) are shown in a scatter plot, which is called a “persistence diagram”. Here, we distinguish between two summary statistics that we generate from the persistence diagram. The first are the “persistent Betti numbers” (pers. BNs) βi(νb, νd). In contrast to regular Betti numbers βi(ν), which just count the number of features alive at threshold ν, persistent Betti numbers βi(νb, νd) count all features that were born before νb and die after νd. This allows us to take into account the persistence of topological features and disregard the features that are only short-lived (for more detail, see Heydenreich et al. 2021). As a more robust summary statistic, we generate “persistent heatmaps” (pers. heat.) by replacing each point in the persistence diagram by a Gaussian of width σ = 0.2.9 For both summary statistics, we then construct a data vector by employing the χ2-maximiser method discussed in Heydenreich et al. (2022). This method evaluates how much a pers. BNs or pers. heat. varies between different cosmologies with respect to the expected standard deviation across realizations, and then picks a sample of evaluation points that maximize the cosmological information content. For both pers. BNs and pers. heat., we generate a DV containing 30 entries each and show them in Fig. 13. The jagged features in these DVs are due to the ordering of the x-axis which is dictated by the cosmological information content of the respective point in the heatmap, and not by its value.
 |
Fig. 13. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for pers. BNs (top) and pers. heat. (bottom) computed on aperture mass maps from γ, smoothed with a 2 |
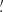
3.9. Scattering transform coefficients
The scattering transform (Mallat 2012) was invented as a novel summary statistic which borrows ideas from convolutional neural networks but does not need training. It was first applied in computer vision, and shortly after introduced to cosmology in Cheng et al. (2020), it has gained an increasing attention for various applications (e.g., Cheng & Ménard 2021b; Valogiannis & Dvorkin 2022a,b; Chung 2022; Delouis et al. 2022; Greig et al. 2023). Below, we present a brief description of the ST. A nontechnical guide to this new statistic and more intuitive understandings and details can be found in Cheng & Ménard (2021a) and references therein.
The ST statistics is similar to a lower order and compressed version of the N-point polyspectra. It keeps the ability to describe different morphological configurations without raising the power of variables by multiplication, thus numerically much more stable. In addition, it also uses logarithmic binning of frequencies, which significantly reduces the size without losing much information for fields with multiscale structures in comparison to polyspectra.
In this study, we use up to second order ST, which resembles up to some binned tri-spectrum and is defined in the following way:
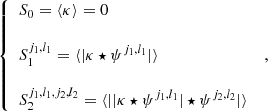
where we apply the ST to the lensing convergence field κ. In the above equations, κ ⋆ ψ is a convolution with wavelets ψ labeled by a size index j and orientation index l. Wavelets are localized band-pass filters, so convolution with a wavelet selects Fourier modes in a wide frequency bin. The wavelets chosen here are qualitatively similar to the aperture mass filters, but they are oriented instead of isotropic and thus also complex-valued, and we use wavelets with a wide range of sizes. | ⋅ | denotes the modulus of the complex-valued fields, which is the key operation in the design of the ST. Finally, S0, 1, 2 are the zeroth, first, and second order scattering coefficients, which are translation invariant.
Following Cheng et al. (2020), we use Morlet wavelets and sample L = 4 different orientations. Morlet wavelets is a sinusoidal wave multiplied by a Gaussian profile and modified to be strictly band-pass:
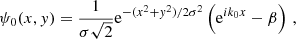
where 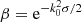 , σ = 0.8 pixel,
, σ = 0.8 pixel, 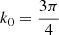 pixel−1. The whole library of wavelet ψ is obtained by dilating this prototype wavelet by factors of 2 for j times and rotating it by l × 45 degrees.
pixel−1. The whole library of wavelet ψ is obtained by dilating this prototype wavelet by factors of 2 for j times and rotating it by l × 45 degrees.
Now we explain the meaning of the ST in some detail. Those coefficients are obtained by first nonlinearly transforming the input field in a nested way and then taking the spatial average. In Fourier space, wavelets are wide window functions with different sizes (labeled by j) and orientations (labeled by l), so wavelet convolution will select Fourier modes around a frequency. The nonlinear operation, modulus, is not common in traditional statistics but proves useful in computer vision. Note that the modulus is applied in real space to each pixel (not to Fourier coefficients), similar to the pointwise nonlinearity used in convolutional neural networks. One intuitive way to understand the role of modulus is by noticing that for any field 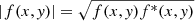 is the square root of a quadratic form of f. Cheng & Ménard (2021a) explained that the field |κ ⋆ ψ| is similar to a map of locally measured square root of the power spectrum averaged over the pass-band of filter ψ. So S1 resembles a binned power spectrum, and S2 resembles the spatial variance of power spectrum (4-point information), but all in a low-order form.
is the square root of a quadratic form of f. Cheng & Ménard (2021a) explained that the field |κ ⋆ ψ| is similar to a map of locally measured square root of the power spectrum averaged over the pass-band of filter ψ. So S1 resembles a binned power spectrum, and S2 resembles the spatial variance of power spectrum (4-point information), but all in a low-order form.
The total number of scattering coefficients depends on the number of distinct wavelets used. We find that the orientation dependence and the coefficients with j1 ≤ j2 contain little cosmological information for weak lensing, so the scattering coefficients can be reduced to a smaller set by averaging over all orientations:
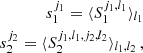
with j1 ≤ j2. If in total J dyadic scales (spaced by power of 2 in size) are used, the first and second-order scattering coefficients have sizes of J and J(J + 1)/2, respectively. In our study, we explore J = 8 dyadic scales, resulting in a compact set of 44 scattering coefficients used as the summary statistic. In Fig. 14, we show the mean and dispersion of the scattering transform coefficients in fiducial cosmology and its cosmological sensitivity. The jagged features are again due to the ordering of the x-axis. ST is a function of two scales, and would be a smooth function on a two-dimension space; however to display it in one dimension, we need to slice it along one direction, creating these wiggles. Besides compactness, the ST statistics also have the desirable properties of being informative and numerically stable, which is confirmed in the cosmological forecast analysis and reliability tests of the following sections.
 |
Fig. 14. Fiducial data vector (gray) along with its derivatives with respect to Ωm (red), σ8 (green), and w (blue) for ST computed on κ maps smoothed with a Gaussian filter with a scale of 2 |
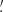
4. Fisher analysis
The aim of this paper is to estimate the constraints on (a subset of) CPs for each of the HOS probes described in Sect. 3. To this end, one could perform a Monte Carlo Markov chain (MCMC) analysis fitting the data as measured on, for example, the SLICS simulated maps. For this approach to be feasible, a mandatory ingredient would be a way to estimate the expected HOS value for any given set of CPs – in other words, a theoretical model and/or an emulator-like method. For most of the probes of interest here, these are not available, and so we need to look for an alternative approach that can be implemented for all the statistics. This is the Fisher matrix method, which is routinely used to forecast the accuracy that a probe can achieve on constraining CPs given the specifics of the survey at hand. In the following, we first give a brief introduction to the method, highlighting the key quantities, and then discuss in some more detail how we estimate them and the necessary caveats.
4.1. Fisher formalism
According to Bayes’ theorem, the posterior distribution P(p | Dobs) of the model parameters p given the observed data Dobs is given by
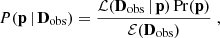
where ℒ(Dobs | p) is the likelihood of the data Dobs for the parameters p, Pr(p) is the prior on the model parameters, and ℰ(Dobs) is the evidence. The Fisher matrix F is defined as the expectation value of the second derivative of the likelihood function, that is its elements are (Bunn 1995; Vogeley & Szalay 1996; Tegmark et al. 1997)
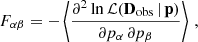
where (α, β) label the parameters of interest, and the derivatives are evaluated at a fiducial point pfid assumed to be the maximum of the likelihood function. The Fisher matrix is then the Hessian of the logarithmic likelihood, thus estimating how fast it decreases from the maximum.
Under the usual assumption of a Gaussian likelihood function, the Fisher matrix elements reduce to
![$$ \begin{aligned} F_{\alpha \beta }&= \frac{1}{2} \mathrm{tr}{\left[ \frac{\partial \mathsf C _{\rm d}}{\partial p_{\alpha }} \mathsf C _{\rm d}^{-1} \frac{\partial \mathsf C _{\rm d}}{\partial p_{\beta }} \mathsf C _{\rm d}^{-1} \right]} \nonumber \\&+ \frac{\partial \mathbf{D}_{\rm fid}(\mathbf{p})}{\partial p_{\alpha }} \ \mathsf C _{\rm d}^{-1} \ \frac{\partial \mathbf{D}_{\rm fid}(\mathbf{p})}{\partial p_{\beta }}\;, \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq147.gif)
where
is the data covariance matrix, and we have assumed that the mean of the data ⟨D⟩ coincides with the theoretical DV Dfid computed for the fiducial parameters. As in most lensing studies, we assume that the covariance matrix is model independent so that the Fisher matrix reduces to the second term only in Eq. (38). Strictly speaking, the Fisher matrix is the expectation of the likelihood Hessian, while in Eq. (38), we have implicitly assumed that this is the same as computing the derivatives at the fiducial point. Because of the Cramer–Rao inequality, this means that the inverse of the Fisher matrix gives a lower limit to the full expected parameter covariance matrix of the CPs. That is to say, the marginalized errors (i.e., having included all of the degeneracies with respect to other parameters) estimated from the diagonal elements Cαα of C as
![$$ \begin{aligned} \sigma (p_{\alpha }) = C_{\alpha \alpha }^{1/2} = \left[ (\mathsf F ^{-1})_{\alpha \alpha } \right]^{1/2}, \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq149.gif)
are a lower limit to the actual errors on the CPs.
The Fisher matrix is also useful for estimating the degeneracy directions in parameter space. The correlation coefficient among the parameters (pα, pβ) is given by
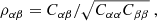
while the angle ϕαβ defining the degeneracy direction in the 2D plane (pα, pβ) may be estimated as
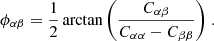
Both Eqs. (41) and (42) show that two parameters are completely independent if Cαβ = 0, that is the corresponding off-diagonal term of the Fisher matrix vanishes.
The above description of the Fisher matrix formalism makes it clear that three assumptions are implicitly used when computing the Fisher matrix: i. the likelihood may be approximated as Gaussian; ii. a reliable estimate of the covariance matrix is available; iii. one knows how to compute the derivatives of the DV with respect to the CPs. We subsequently discuss in the next few paragraphs the caveats associated with each of these points and how we deal with them.
4.2. Gaussian likelihood and data selection
Equation (38) has been obtained under the assumption that the likelihood is Gaussian. However, such an assumption must be tested for each particular probe at hand since it is manifestly violated for some of them under certain conditions. As an example, one can think of the number of peaks at very large κ, which is expected to be zero in the absence of noise. Similarly, the value of the zeroth order MF V0(κ) is identically 1 for very small κ. As a consequence, every measurement of these quantities will give the same value so that the distribution of repeated measurements would definitely be non-Gaussian. Should we include them in the DV, the Gaussian assumption of the likelihood would break down, introducing a systematic error that is hard to quantify. We therefore need to perform data selection to be confident that the likelihood can be well approximated by a Gaussian.
To this end, we note that if the likelihood is indeed Gaussian, the quantity
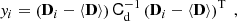
with Di the DV measured on the i-th SLICS map, and ⟨D⟩ the mean over the 924 realizations, must be distributed as a χ2 distribution with Nd degrees of freedom (Nd being the length of the DV). For each HOS probe, we therefore compare the yi distribution to the χ2 one, and quantify the agreement by computing the weighted average SMAPE (Symmetrized Mean Absolute Percentage Deviation) defined as (Rizzato & Sellentin 2023)
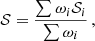
with
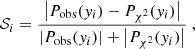
and
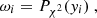
where Pobs(yi) and Pχ2(yi) are the measured and χ2 distribution in yi, and the sum is over the points used to sample the y distribution.10 Note that we have defined the weights ωi in such a way that we ask for a better match in the central regions of the distributions, reducing the sensitivity to outliers. There is no general rule to define a limiting value for 𝒮, but it is clear that the closer it is to zero, the more the two distributions match. For each probe and configuration, we therefore implement a four-step procedure to decide whether the distribution is compatible with the one expected for a Gaussian probe according to the following scheme: i. We first remove all the elements in the DV that are consistent with zero within 2σ, with σ estimated from the corresponding diagonal element of the covariance matrix. Note that this step is equivalent to saying that we are removing points with S/N < 2, so that we are actually deleting those elements carrying no valuable information; ii. We recompute the weighted average SMAPE defined above using only the surviving elements and comparing them with a χ2 distribution with Nobs degrees of freedom, and with Nobs ≤ Nd the number of surviving elements of the full DV; iii. We generate 924 mock realizations of the DV sampling from a Gaussian distribution with a mean and covariance matrix equal to the observed one, and compute the corresponding 𝒮mock value; iv. We repeat the above step 500 times, and estimate the 95% confidence limit (CL) range of the distribution of 𝒮mock, finally considering the observed DV Gaussian if its 𝒮obs is within this range.11 This was empirically found to roughly correspond to a limit of 𝒮obs ≤ 0.15.
Applying this procedure to the full list of probes is, however, nontrivial given the different peculiarities. Roughly speaking, we can divide them into two classes. First, we have the κ-PDF as a function of κ, the number of peaks as a function of S/N ν, the BNs and the MFs versus the threshold ν. All are measured by first choosing a range (xmin, xmax), and splitting it into Nx bins (with x = κ, ν). Second, we have other probes that are measured for a given fixed configuration so that they are set once for all by the measurement pipeline. In the first case, we can vary (xmin, xmax, Nx) until the Gaussianity criterion has been successfully passed. We investigate, in particular, configurations with (κmin, κmax) in the range ( − 0.1, 0.1) and (νmin, νmax) in the range ( − 5, 10), varying the number of bins from 10 to 70 in steps of 5. We then retain the configurations passing the SMAPE test according to the above procedure. This is illustrated in Fig. 15, where we can appreciate the correspondence between the measured and theoretical χ2 distribution for all probes but moments in configurations where 𝒮 ≤ 0.15.
 |
Fig. 15. Verification of the Gaussian hypothesis for all statistics computed in this analysis. For a Gaussian-distributed DV, the histogram of χ2 values from the SLICS simulations (red) should match the theoretical prediction (black) modulo the sampling noise across the finite set of 924 realizations. The corresponding SMAPE value (Eq. (45)) is given in the top left quadrant of each panel. 𝒮 ≤ 0.15 indicates compatibility with the Gaussian hypothesis, which is verified for all statistics but the three bottom panels with gray shaded background. The y-axes correspond to the frequency of each χ2 bin value across the SLICS and are different for each panel. |
For the other family of HOS probes, we could only compute the value of the average SMAPE, and checked whether it passed our Gaussianity criterion. We computed the Fisher matrix forecasts for all the probes, but left a warning if the SMAPE value is outside the expected 95% CL range, that is if the yi distribution is too different from a χ2 one. This is the case for all moments-based statistics: HOM, 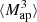 ,
, 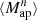 (gray shaded panels in Fig. 15), which have significant non-Gaussian distributions across the different realizations, rendering them unsuitable for a Fisher analysis. This issue, which seems partially related to the small patch sizes considered here, could be mitigated by considering "bulk" moments obtained from integrating the κ-PDF over a limited range using the tail cuts employed for the PDF. We nonetheless prefer to report the forecasts for these probes too since the fact that their likelihood is non Gaussian does not prevent one from using them in the future. Indeed, should the corresponding data be available, one can simply run an MCMC analysis based on a non-Gaussian likelihood. The classification of Gaussian and non-Gaussian DVs is given in Table 4, together with the selected range of scales, convergence, or S/N that allows each probe to pass the Gaussianity test.
(gray shaded panels in Fig. 15), which have significant non-Gaussian distributions across the different realizations, rendering them unsuitable for a Fisher analysis. This issue, which seems partially related to the small patch sizes considered here, could be mitigated by considering "bulk" moments obtained from integrating the κ-PDF over a limited range using the tail cuts employed for the PDF. We nonetheless prefer to report the forecasts for these probes too since the fact that their likelihood is non Gaussian does not prevent one from using them in the future. Indeed, should the corresponding data be available, one can simply run an MCMC analysis based on a non-Gaussian likelihood. The classification of Gaussian and non-Gaussian DVs is given in Table 4, together with the selected range of scales, convergence, or S/N that allows each probe to pass the Gaussianity test.
As a final remark, we note that the implemented criterion looks at the overall properties of the DV. However, one could also apply a more stringent criterion looking at the distribution of each single element of the DV. A way to quantitatively implement this approach is based on the D’Agostino–Pearson test. It turns out that this approach is, however, overly restrictive, cutting a large part of the DV for most probes. This is because this method looks for a perfect match with a Gaussian likelihood even in the tail of the distributions, which are actually not of interest for the computation of the Fisher matrix. Indeed, the Fisher matrix requires that the likelihood can be approximated as Gaussian in the neighborhood of its peak, so one is not really interested in what happens in the tails. This is why we finally prefer to rely on the yi distribution rather than the D’Agostino–Pearson test. This choice is also supported by the results of Lin et al. (2020), who found that the skewness and kurtosis of the γ-2PCF in LSST-like mocks have little impact on forecasts when computed with a Gaussian or an Edgeworth non-Gaussian likelihood.
4.3. Covariance matrices
The covariance matrix for each HOS probe can be estimated using the SLICS ellipticity mocks and convergence maps. To this end, we simply measure each probe on all realizations, take the mean as our fiducial DV, and use the definition (39) to compute the data covariance matrix Cd. We also use this simple method when investigating the joint use of second and HOS, or of more HOS probes at the same time. We then just concatenate the individual DVs into a single DV, which we then measure on the different mock realizations for the estimate of the covariance matrix. Unless otherwise stated, however, we focus first on single HOS probes and later combine them with the γ-2PCF. Moreover, to reduce the number of possible combinations, we choose a reference smoothing angle of 4 pixels for all probes, except for the convergence PDF and moments, which we evaluate from maps smoothed with an 8 pixel radius.12 We have checked that, for each probe, there is indeed a strong correlation between values estimated from the same map with different smoothing radii, so that using one smoothing angle per statistics captures most of the cosmological information.
Using a finite number of realizations alters the accuracy of the inverse covariance matrix (e.g., Hartlap et al. 2007). This arises from the fact that the DV cannot be considered as Gaussian distributed (this is only the case for an infinite number of realizations according to the central limit theorem) but rather follows a student-t distribution. Sellentin & Heavens (2017) propagated the impact of using a student-t likelihood in the Fisher formalism instead of the Gaussian likelihood, deriving a simple correction factor to this effect to be applied to the inverse Fisher matrix, which depends on the number of realizations used in the computation of the covariance matrix Nf, the number of degrees of freedom, that is the DV size Nd, and the number of CPs to be determined Np: c = (Nf − 1)/(Nf − Nd + Np − 1), (see Eq. (28) of Sellentin & Heavens 2017).
Although we use the Nf = 924 SLICS maps to compute the covariance in our analysis, we also use the 256 DUSTGRAIN-pathfinder realizations as a cross-check. However, the fact that the DUSTGRAIN-pathfinder realizations are pseudo-independent (i.e., derived from a single simulation) renders the comparison with the truly independent SLICS difficult. This nonetheless allows us to quantify the impact of the choice of a simulation set on the covariance computation and to a lesser extent on the possible cosmology dependence of the covariance as the SLICS and DUSTGRAIN-pathfinder have slightly different CPs. This comparison is done at the level of the Fisher forecasts, keeping the derivatives fixed and using three different covariance matrices: computed from the 256 pseudo-independent DUSTGRAIN-pathfinder simulations, and 256 and 924 SLICS simulations. We find perfect agreement between the SLICS for the different number of realizations when factoring in the Sellentin & Heavens (2017) correction factor, highlighting the robustness of our covariance estimate in terms of the number of realizations used. However, we see some variations between SLICS and DUSTGRAIN-pathfinder. Overall, the order of magnitude of the forecasts remains the same and it is difficult to attribute the difference we measure to a particular effect. This could stem from the simulations themselves, in particular the differences in the computation of the lensing quantities discussed in Sect. 2, the differing fiducial cosmologies, the different area of the mocks (25 deg2 for DUSTGRAIN-pathfinder and 100 deg2 for SLICS), or to the level of independence of the realizations in the DUSTGRAIN-pathfinder simulations. To specifically assess whether this difference could be due to the different field of view of the SLICS and DUSTGRAIN-pathfinder mocks, we also tried the following experiment. We computed the covariance from the central 5 × 5 deg2 region of each of the 924 SLICS mocks, scaled the covariance matrix by four, and compared it with the 10 × 10 deg2 result. We found excellent agreement showing that the difference with the DUSTGRAIN-pathfinder 5 × 5 deg2 covariance is not due to the change in area. The good agreement between the SLICS covariance for both areas also supports our decision to scale up the survey area to the nominal 15 000 deg2 expected for Euclid. In the case of the κ-PDF, it has also been shown that the numerical DUSTGRAIN-pathfinder covariances agree with those obtained from shifted lognormal maps created with FLASK (Xavier et al. 2016) for a fixed source redshift, which can be created in large quantities and tuned to replicate the desired skewness thus exquisitely matching the more expensive simulated covariances (Boyle et al. 2021).
Ultimately we chose to use the SLICS covariance because of the larger field-of-view and number of realizations, and the independence of each realization of this simulation set. We also rescale the covariance to 15 000 deg2. We note that our simulated covariances from small patches with vanishing mean density neglect the super-sample covariance effect. As its impact depends on the specific summary statistic, including it in the analysis is beyond the scope of this work. In the future, those effects can be estimated by treating the full data covariance as a sum of the simulated covariance and a super-sample term built from the response of the summary to a background density, as done for angular power spectra (Lacasa & Grain 2019) and the κ-PDF (Uhlemann et al. 2023). Alternatively, an analytic covariance model including super-sample effects can be derived from the estimator, as done for the κ-PDF (Uhlemann et al. 2023) and 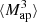 (Linke et al. 2023).
(Linke et al. 2023).
4.4. Derivatives and numerical noise
Computing the derivatives of the observable is a key step in the estimate of the Fisher matrix. This would be a trivial task should a theoretical procedure be available to compute the HOS corresponding to a given set of CPs. Unfortunately, this is not the case for most of the probes of interest here. For some of them, a theoretical formulation has been developed, but this typically does not account for noise in the data, and assumes that the κ map is perfectly reconstructed from the γ data.
Here, we must therefore compute derivatives numerically using the DUSTGRAIN-pathfinder simulations for shifted values of (Ωm, σ8, w). For each given probe, we first measure the DV as the mean over the Nc = 128 mocks available for each model. We then use four different methods to estimate numerical derivatives. First, we consider the simple 3 - point stencil derivatives defined as
with D(pα) the DV measured on the maps generated from simulations with all CPs but pα set to the fiducial values. Two choices are possible for the shift ε, the small and large increments, respectively corresponding to 4 and 16% except for the large increment of Ωm for which ε takes the values +28%/−36%. Alternatively, we can use all four values as entries in a linear fit, taking the best fit slope as an estimate of the first derivative. We perform both an unweighted fit and a weighted fit with weights given by
![$$ \begin{aligned} { w}^\mathrm{fit}_{i} = \left[ 1 - \left( \frac{| \varepsilon _i - \varepsilon _{\rm ref} |}{1.1 \varepsilon _{\rm ref}} \right)^3 \right]^3 \;, \end{aligned} $$](/articles/aa/full_html/2023/07/aa46017-23/aa46017-23-eq160.gif)
with εref = 0.12, and εi = ( − 0.16, −0.04, 0.04, 0.16), again with adapted values for the large increment of Ωm. In practice, we find that the weighted and unweighted fits are both equal to the large increment derivatives so we only discuss the large and small increment cases in the following.
As an example, we show in Figs. 4–14 the numerical derivatives for the large CP variation of all probes with respect to Ωm, σ8, and w in red, green, and blue, respectively. Shaded areas correspond to the noise computed as the dispersion over the Nc = 128 DUSTGRAIN-pathfinder realizations at each cosmology. We also show in gray the mean DV over the Nf = 924 SLICS realizations with error bars corresponding to the diagonal elements of the SLICS covariance matrix to better visualize the trend of the derivatives on the DV. We note from these figures that the derivatives with respect to w are close to 0, suggesting that we actually measure very little information on this parameter. This could be alleviated in the future for instance by increasing the number of realizations in the simulation, by adding simulations with a larger step in w in order to strengthen its effect, or by including a tomographic decomposition. On the other hand, there is a strong signal for the other two parameters and we therefore focus the forecasts on Ωm and σ8 in the remainder of the paper.
As a further check on the reliability of the numerical derivatives, one can investigate whether they are stable against the number of DUSTGRAIN-pathfinder maps used to compute them. In Figs. 4–14, we therefore add the derivatives computed for Nc = 32 and 64 realizations as dotted and dashed lines, respectively. For the large variation derivatives, these lines are within the error bars computed from the 128 realizations, highlighting the robustness against numerical noise. This is, however, not always the case at the level of the Fisher forecasts. In Fig. 16, the covariance matrix is held fixed to the 924 SLICS realizations and the dotted, dashed, and solid ellipses correspond to the forecasts computed with Fisher derivatives of 32, 64, and 128 DUSTGRAIN-pathfinder realizations, respectively. We note that several probes suffer from a slow convergence, for example κ-PDF, MFs, BNs, and pers. heat.. The fact that the forecasts are not yet fully converged is due to the complex interplay between the errors on the derivatives and that of the covariance matrix, which can amplify some noise fluctuations in the derivatives. We demonstrate the trustworthiness of the not fully converged κ-PDF derivatives through a comparison with theoretical predictions that lead to marginally wider and slightly tilted Fisher contours as shown in Sect. 4.5.2. Although one could try to develop some numerical methods to correct for this bias, we did not do so because of the three following reasons. First, the convergence of the numerical derivatives is different for each probe with only half of them being affected with the current number of realizations of the DUSTGRAIN-pathfinder simulations, suggesting a nontrivial correction scheme that would introduce individual differences in the analysis of each probe. Second, the effect remains small as shown by the smaller difference between the 64 and 128 realizations than between the 32 and 64. Finally, the comparison with theoretical predictions in the case of the κ-PDF strongly suggests that convergence has been reached in spite of the small variation still being seen between the 64 and 128 realizations in Fig. 16. Although we are confident in the forecasts when using the large CP increment to compute the derivatives, when considering the small increment derivatives, these are not even converged at the level of the Fisher derivatives. This is due to the CP step being too small, so that the change in the observable due to the shift from the fiducial CPs gets partially lost into the numerical noise. Apart from a few additional tests when comparing numerical and theoretical derivatives in Sect. 4.5, we therefore only consider the ±16% derivatives in the rest of this paper.
 |
Fig. 16. Fisher forecasts for all probes computed for a Euclid-like survey without tomography. The different ellipses refer to different numbers of DUSTGRAIN-pathfinder realizations Nc used to compute the DV derivatives: dotted, dashed, and solid lines, respectively for 32, 64, and 128 realizations. The covariance matrix is held fixed to SLICS with Nf = 924 realizations. For γ-2PCF and κ-PDF we separately assess the convergence of derivatives by a comparison with theoretical predictions in Figs. 17 and 18. |
4.5. Theory versus numerical forecasts
For assessing the robustness of our method in creating reliable Fisher forecasts from the simulated maps, we compare them to the theoretical results for a set of statistics for which such a description is available, namely the γ-2PCF, κ-2PCF, κ-PDF, MFs, HOM, and  . We here only report on two of them: the γ-2PCF in Sect. 4.5.1 and κ-PDF in Sect. 4.5.2, but the general conclusions are the following. Numerical noise in the Fisher derivatives can generate some artificial degeneracy breaking in the forecasts from the simulation-based model compared to the theoretical ones. Except for moments where we could not reconcile the theory and simulations due to the small field-of-view of our mocks, we find a fair agreement for other probes when applying some restrictions to our analysis:
. We here only report on two of them: the γ-2PCF in Sect. 4.5.1 and κ-PDF in Sect. 4.5.2, but the general conclusions are the following. Numerical noise in the Fisher derivatives can generate some artificial degeneracy breaking in the forecasts from the simulation-based model compared to the theoretical ones. Except for moments where we could not reconcile the theory and simulations due to the small field-of-view of our mocks, we find a fair agreement for other probes when applying some restrictions to our analysis:
-
we only consider Fisher forecasts for the two parameters Ωm and σ8 as the derivatives with respect to w are too noisy in our nontomographic setup;
-
we use only the large variations of the CPs (±16%) as the small variation (±4%) is too small to capture the signal compared to the numerical noise;
-
we further restrict the range of scales used in the 2PCFs because of the resolution and field-of-view of the DUSTGRAIN-pathfinder mocks.
4.5.1. Shear two-point correlation functions
As a first example, we choose the γ-2PCF introduced in Sect. 3.1. For computing the theoretical prediction, we use a modified version of the public software NICAEA (Kilbinger et al. 2009) and choose the transfer function from Eisenstein & Hu (1998) and the revised Halofit prescription of Takahashi et al. (2012) for the modeling of the nonlinear power spectrum. We also account for finite field effects in the ray-tracing of the DUSTGRAIN-pathfinder mocks by restricting the support of the convergence power spectrum in Eq. (7) to the accessible field-of-view; in particular we reweight Pκ by the fraction of inverse ℓ-modes that can be confined to a 5 × 5 deg2 region. This modification introduces a strong ringing effect in the γ-2PCF which becomes significant at around 5′/150′ for ξ−/ξ+. In the upper panels of Fig. 17, we compare the theoretical and numerical derivatives and we see that there is a nonnegligible discrepancy on small scales for both ξ+ and ξ− and an additional discrepancy on large scales for ξ+.
 |
Fig. 17. Upper row: Comparison of the derivatives of the γ-2PCF as predicted from theory (solid lines) and as measured from the DUSTGRAIN-pathfinder simulations (dots). The errorbars are scaled to a single line-of-sight in the DUSTGRAIN-pathfinder ensemble. The shaded regions display the scales that were discarded from the Fisher analysis presented in this work. In the lower panel we plot the relative deviation between the measured quantities and the theoretical predictions when accounting for (solid lines) or neglecting (dotted lines) finite field effects. The gray dashed lines display the 10 percent errorband. Lower row: Comparison of the Fisher forecast using the theoretical model (orange dashed) or the simulation measurements (blue dashed). The thin solid lines correspond to simulated analyses that are used to test the stability of the ellipses given the numerical noise in the derivatives. For the panel on the left we use all available scales on the γ-2PCF while for the figure on the right only the scales with realistic numerical derivatives (i.e., removing the gray shaded area of the upper panel) are included in the forecast. In the figure on the right we show for reference again the constraints of the theoretical model with all scales included. |
In the lower-left panel of Fig. 17, we show how these biases propagate in the forecasts with fixed w. In particular, when including a broad range of scales, we find that the simulation-based constraints seem much stronger as the different level of bias in the derivatives artificially breaks parameter degeneracies. When using only the scales for which the numerical derivatives are in reasonable agreement with their theoretical counterparts, this effect disappears at the cost of overall reduced constraining power. From the theoretical point of view this reduction remains small as shown by comparing the orange and black ellipses in Fig. 17. Besides the bias, noise in the simulation-based derivatives can also lead to artificial degeneracy breaking. To assess the magnitude of the latter effect, we first estimate the covariance matrix of the simulation-based derivatives and, from there, generate 100 noise realizations. When adding these realizations to the theoretical derivatives, we can assess the stability of our forecast in the ideal case, that is when no bias is present in the simulations. On the other hand, when adding the noise on top of the numerical derivatives, we get an upper bound on the instability of the actual forecast, even without a theoretical description of the observables underlying the analysis. For the γ-2PCF, we find that the ellipses are stable in all cases. For our subsequent analysis we limit ourselves to those scales in which the mean bias on the derivatives in (Ωm, σ8) is less than 10%. This range corresponds to the scales displayed in Table 4. We note that it is more restrictive than the range used in Martinet et al. (2021b,a) based on the same SLICS mocks for the covariance because of the better resolution and larger field-of-view of the cosmo-SLICS used for the model compared to the DUSTGRAIN-pathfinder simulations here.
4.5.2. Convergence PDF
We can use the theoretical model for the κ-PDF discussed in Sect. 3.2 to obtain the PDF at different cosmologies and cross-validate it with the PDFs measured from the simulations, which are also used to obtain the PDF covariance matrix entering the Fisher forecast.
We compare the mean of the measured κ-PDF for the fiducial cosmology with the theoretical predictions (including shape noise) in the top part of Fig. 18 (gray points and solid line) for a smoothing scale of θ = 4 69. We see that for the chosen cuts in the tails of the PDF and the measured error bars (standard deviation across all realizations) the theory does perform pretty well, which is reinforced by the fact that the derivatives with respect to the CPs are also well captured. Measured derivatives for both smaller increment sizes (shown as stars) and larger increment sizes (shown as points) in the CP variation are compared with our theoretical model for the κ-PDF, where the nonlinear variances along the line of sight are set externally. For σ8 (green), we see very good agreement between the theoretical and simulated derivatives. We also show the results for Ωm (red). In this case, a more substantial degree of discrepancy is seen between the theoretical and measured derivatives. The underprediction of the amplitude of the derivative stems from an underprediction of the difference in variances between the two cosmologies as predicted by Halofit. This is consistent with the simulations predicting a stronger response to Ωm than the theory in Fig. 17. We found a similar discrepancy in the Ωm derivatives when cross-checking with a larger smoothing scale of 9
69. We see that for the chosen cuts in the tails of the PDF and the measured error bars (standard deviation across all realizations) the theory does perform pretty well, which is reinforced by the fact that the derivatives with respect to the CPs are also well captured. Measured derivatives for both smaller increment sizes (shown as stars) and larger increment sizes (shown as points) in the CP variation are compared with our theoretical model for the κ-PDF, where the nonlinear variances along the line of sight are set externally. For σ8 (green), we see very good agreement between the theoretical and simulated derivatives. We also show the results for Ωm (red). In this case, a more substantial degree of discrepancy is seen between the theoretical and measured derivatives. The underprediction of the amplitude of the derivative stems from an underprediction of the difference in variances between the two cosmologies as predicted by Halofit. This is consistent with the simulations predicting a stronger response to Ωm than the theory in Fig. 17. We found a similar discrepancy in the Ωm derivatives when cross-checking with a larger smoothing scale of 9 37. We observe a similar underprediction for the w derivative (blue), which is also consistent with results for the γ-2PCF in Fig. 17. We also checked that replacing the input Halofit nonlinear variance with that from the Euclid emulator in each case resulted in minor changes of the predictions.
37. We observe a similar underprediction for the w derivative (blue), which is also consistent with results for the γ-2PCF in Fig. 17. We also checked that replacing the input Halofit nonlinear variance with that from the Euclid emulator in each case resulted in minor changes of the predictions.
 |
Fig. 18. Top: Overall shape of the lensing κ-PDF, smoothed with a top-hat filter of radius 4 |
Having discussed the theoretical modeling and measurement of the WL κ-PDF, we perform a Fisher forecast for the two parameters Ωm and σ8 using the central region of the WL κ-PDF at a single scale assuming a Euclid-like survey area, shape and source redshift distribution as discussed before. The result shown in the bottom part of Fig. 18 shows reasonably good convergence between the theoretical and numerical results, which reinforces the validity of both sets of forecasts. When adding w to the forecast, the simulated DVs would lead to unrealistically tight constraints compared to the predicted DVs. To avoid an artificial degeneracy breaking due to numerical noise, we limit the following analysis to two CPs.
5. Results
We now discuss the results of the Fisher analysis. We start by considering each probe independently (Sect. 5.1), then quantify the gain on CPs from our statistics when combined with the γ-2PCF alone (Sect. 5.2), and finally investigate the correlations between probes and their combinations (Sect. 5.3). For all results in this section of the paper, we consider a Euclid-like nontomographic analysis of 15 000 deg2 and vary only Ωm and σ8, as the Fisher derivatives are too noisy for constraining all three parameters (i.e., including w) in the nontomographic setup. We also present forecasts for the growth of structure parameter Σ8 = σ8(Ωm/0.3)α (equivalent to S8 when α = 0.5) in Appendix A to ease comparison with other analyses; however these results lead to similar conclusions as for σ8. The mass maps are smoothed with a 2 34 Gaussian, wavelet or Map filter except for moments and the κ-PDF where a 4
34 Gaussian, wavelet or Map filter except for moments and the κ-PDF where a 4 69 top-hat filter is used, thus probing larger scales. The derivatives are computed with the large variation of CPs in the DUSTGRAIN-pathfinder simulations and the covariance from the 924 SLICS simulations. We also note that these results were cross-checked by running two independent Fisher analysis pipelines that obtained the same output. Finally, we make a distinction between results for Gaussian-distributed DVs, for which the Fisher forecasts can be robustly computed, and results for non-Gaussian DVs, where the Fisher formalism cannot be trusted. The latter are included for consistency of the HOWLS project and because they can be used in future analyses by using a non-Gaussian likelihood.
69 top-hat filter is used, thus probing larger scales. The derivatives are computed with the large variation of CPs in the DUSTGRAIN-pathfinder simulations and the covariance from the 924 SLICS simulations. We also note that these results were cross-checked by running two independent Fisher analysis pipelines that obtained the same output. Finally, we make a distinction between results for Gaussian-distributed DVs, for which the Fisher forecasts can be robustly computed, and results for non-Gaussian DVs, where the Fisher formalism cannot be trusted. The latter are included for consistency of the HOWLS project and because they can be used in future analyses by using a non-Gaussian likelihood.
5.1. Individual forecasts
Individual Fisher forecasts are displayed in columns 2 and 3 of Table 5 and correspond to the 1σ marginalized parameter errors given as percentages of the CP fiducial values: δσ8/σ8 and δΩm/Ωm. These forecasts can also be visually appreciated as the orange Fisher ellipses in the Ωm − σ8 planes of Fig. 19.
 |
Fig. 19. Individual Fisher forecasts in the σ8 − Ωm plane for a nontomographic Euclid-like survey for the 11 statistics (orange) and γ-2PCF (blue), as well as their combination (green). The corresponding marginalized precision on CPs can be found in Table 5. The black dashed line in the first quadrant indicates constant |
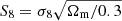
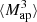
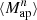
Fisher forecasts for a Euclid-like nontomographic analysis.
If we first focus on second-order statistics, we see that the forecasts are on the order of one percent on both parameters. This is the same order of magnitude as the forecasts from Euclid Collaboration (2020). A quantitative comparison is, however, not possible due to large differences in both analyses: we vary only 2 CPs in a nontomographic setup while they use a minimum of 5 parameters and a tomographic setup. Additionally, their analysis is based on theoretical predictions, while we are affected by numerical noise because we need to rely on simulations for a fair comparison among HOS. If we compare to analyses more similar to ours, for instance, the cosmo-SLICS based likelihood inference of Martinet et al. (2021b) for 4 CPs in their nontomographic setup, we also find a good agreement: rescaling the forecasts of their Table 1 to 15 000 deg2 gives a 1.9% precision on Ωm to be compared with the 1.2% of the present analysis. Our Fisher forecasts are tighter because we neglect the degeneracies between our two parameters and the additional two (w and h) probed in the aforementioned analysis. Additionally, we know that degeneracies between pairs of CPs, which are treated as simple ellipses in the Fisher formalism, are usually more complex. Looking at the orientation of the blue Fisher ellipse in the top-left quadrant of Fig. 19, we also see the usual lensing degeneracy shown by the dashed black line of constant S8. As expected, the κ-2PCF forecasts are of the same order as the γ-2PCF, but weaker due to the pixelization of the κ map, which destroys signal below the pixel size of 0 59.
59.
The κ-PDF forecasts are shown as the orange ellipse in the top-right quadrant of Fig. 19. The forecasts in this case are on the order of half a percent and are therefore tighter than those of the γ-2PCF thanks to the non-Gaussian small-scale information that this statistic is able to probe. The forecasts in this case also show different degeneracy directions. This is also the case for other HOS, with some diversity between DVs ranging from forecasts on the order of a third of a percent to about one percent, and various degeneracy orientations as shown by the different Fisher ellipses of Fig. 19. In the left part of Fig. 20 we also make an attempt to rank the statistics in terms of constraining power. We see a plateau in this figure where most of the statistics reach similar forecast values, about twice as good as that from the γ-2PCF. It is therefore hard to identify a single superior statistic, with notably pers. BNs, MFs, ST, κ-PDF, peaks, and pers. heat. all performing very well.
 |
Fig. 20. Fisher forecasts for σ8 and Ωm for a nontomographic Euclid-like survey for all statistics. The black crosses (left) show the individual forecasts and the gray circles (right) the forecasts combined with the γ-2PCF. Forecasts are ranked within 3 categories: two-point statistics, higher-order Gaussian statistics, and higher-order non-Gaussian statistics. The latter are displayed on a gray background as they should be confirmed with a non-Gaussian likelihood framework. The corresponding marginalized precision on CPs can be found in Table 5. |
Finally, we also display the forecasts for the statistics which are not Gaussian distributed at the end of Table 5 and with a gray shaded background in Figs. 19 and 20: HOM, 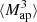 , and
, and 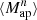 . These are only displayed for the consistency of the HOWLS challenge but must be interpreted with caution as the Gaussian likelihood assumption is required for the Fisher formalism. There is possible strong constraining power but a refined analysis that goes beyond the simple Fisher method is needed to assess the robustness of these results. We however note that in the case of
. These are only displayed for the consistency of the HOWLS challenge but must be interpreted with caution as the Gaussian likelihood assumption is required for the Fisher formalism. There is possible strong constraining power but a refined analysis that goes beyond the simple Fisher method is needed to assess the robustness of these results. We however note that in the case of 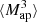 our results are consistent with that of the full MCMC implementation of Heydenreich et al. (2022).
our results are consistent with that of the full MCMC implementation of Heydenreich et al. (2022).
5.2. Combination with γ-2PCF
One striking conclusion of the last section is that almost all of the HOS outperform the γ-2PCF in terms of constraining power in our analysis. Although this can be in part due to the range of scales available in our simulations, it supports all the recent findings in the HOS literature mentioned in the introduction as well as in Sect. 3. One additional interesting question is the gain that these probes can provide when combined with the standard two-point analysis that is planned for Euclid.
This gain is displayed in Table 5, where we show the forecasts for each statistic combined with the γ-2PCF in columns 4 and 5 and the gain associated with these combined forecasts with respect to the γ-2PCF alone in the last two columns. We also show the combined Fisher ellipses in green in the Ωm − σ8 planes of Fig. 19.
As expected, the κ-2PCF brings very little additional information (a factor of 1.06) compared to the γ-2PCF. In theory there should be no gain at all as ξκ is equivalent to ξ+ in the absence of systematic B modes. However, the coarser binning of the ξκ (10 bins between 0 6 < θ < 9
6 < θ < 9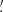 23) compared to that of ξ+ (5 bins between 0
23) compared to that of ξ+ (5 bins between 0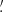 24 < θ < 8
24 < θ < 8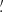 55) allows the former to probe a small fraction of cosmological information not captured by the latter in the present analysis. Moreover, each of the HOS improves the forecasts by a factor of about 1.5 to 2.5 depending on the considered statistic and CP. In some cases, the gain is dominated by the tighter constraints of the HOS, and in others, by the change in the Ωm-σ8 degeneracy direction. Most of the time it is due to a combination of the latter two effects.
55) allows the former to probe a small fraction of cosmological information not captured by the latter in the present analysis. Moreover, each of the HOS improves the forecasts by a factor of about 1.5 to 2.5 depending on the considered statistic and CP. In some cases, the gain is dominated by the tighter constraints of the HOS, and in others, by the change in the Ωm-σ8 degeneracy direction. Most of the time it is due to a combination of the latter two effects.
The ranking order of these combined forecasts, displayed in the right panel of Fig. 20, roughly follows the same order as for the individual forecasts. Here again, most statistics follow a similar trend in the gains provided, with ST, MFs and pers. BNs slightly outperforming other HOS, but closely followed by the κ-PDF, peaks, and pers. heat..
As a conclusion to this section, we note that the combined forecasts are always around two to three times tighter than that from the γ-2PCF alone, highlighting that HOS are able to extract the small-scale non-Gaussian information inaccessible to standard two-point estimators.
5.3. Probe combination
Finally, one can wonder whether all these HOS probe independent information or if their combination can extract even more of the non-Gaussian small-scale information. To answer this question, we first consider the correlation matrix of the concatenated DV made of all individual DVs. This has been computed from the 924 independent SLICS simulations and is shown in Fig. 21. We see strong correlations between the different statistics with amplitude affected by the filtering of the κ map or γ field. In addition, we can identify patterns that are common to the probes that are of the same nature: for instance, the γ-2PCF and κ-2PCF, the HOM and the 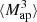 , or the peaks and the κ-PDF. All these correlations suggest that one could use a data compression scheme to create a DV that optimally combines the information from these different statistics. This is, however, left for a future article in the HOWLS series.
, or the peaks and the κ-PDF. All these correlations suggest that one could use a data compression scheme to create a DV that optimally combines the information from these different statistics. This is, however, left for a future article in the HOWLS series.
 |
Fig. 21. Correlation matrix for all 12 statistics tested in our analysis and referenced in Table 3, computed from the same 924 SLICS simulations. We note the complex correlations between the different statistics due to their expressions as well as to different filtering shapes and scales in the post-processing of the mass maps. The bin sizes of the κ-PDF, MFs, and BNs DVs have been increased in the figure for visualization purposes. |
Instead, we simply use the concatenated DV to compute the Fisher forecasts here. This increases the noise compared to the aforementioned optimal setting but the large number of realizations used for the covariance matrix still allows us to derive robust forecasts. These results are also checked against numerical noise as for the individual probes, finding converged forecasts when using 64 or 128 DUSTGRAIN-pathfinder realizations, as shown in Fig. 22. In more detail, we combine the κ-PDF, peaks, MFs, BNs, pers. BNs, pers. heat., and ST and perform a comparison with and without the γ-2PCF in Fig. 23. This DV consists of 511 elements, that is about half the number of SLICS realizations and gives a Sellentin & Heavens (2017) correction factor of 0.461. The corresponding forecast values are given in Table 5 and ranked compared to the individual probes in Fig. 20. We find an improvement by a factor of four to five in that case compared to the γ-2PCF alone. This improvement is mainly driven by the combination of forecasts with slight different degeneracies, which manage to partially break the classical lensing degeneracy. This was already suggested in several analyses showing that HOS present different degeneracies to the γ-2PCF, but this is the first time that so many statistics have been combined to further lift the lensing degeneracy. Furthermore, the addition of the γ-2PCF to this combined DV only marginally improves the forecast precision, suggesting that the information contained in the γ-2PCF has also been captured by the combined HOS with the scales considered here.
 |
Fig. 22. Same as Fig. 16, but for all Gaussian HOS together: κ-PDF, peaks, MFs, BNs, pers. BNs, pers. heat., and ST. Note the change of scales compared to other Fisher contour plots for better visualization. |
 |
Fig. 23. Same as Fig. 19, but for all Gaussian HOS together: κ-PDF, peaks, MFs, BNs, pers. BNs, pers. heat., and ST. The green and orange ellipses overlap almost exactly. |
6. Conclusion
HOWLS is a collaborative effort to explore the use of weak-lensing HOS for the interpretation of Euclid data. With this aim, we have compared two two-point statistics and ten HOS from the same set of Euclid-like mocks: the shear two-point correlation functions (γ-2PCF), the convergence two-point correlation function (κ-2PCF), the convergence one-point probability distribution (κ-PDF), convergence Minkowski functionals (MFs), convergence Betti numbers (BNs), aperture mass peak counts (peaks), higher-order convergence moments (HOM), third order aperture mass moments (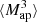 ), n-th order aperture mass moments (
), n-th order aperture mass moments (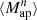 ), aperture mass persistent homology Betti numbers (pers. BNs), aperture mass persistent homology heatmap (pers. heat.), and convergence scattering transform coefficients (ST). Our mocks are based on the DUSTGRAIN-pathfinder N-body simulations, consisting of 12 simulations varying Ωm, σ8, and w, with 128 light cones for each of these plus one simulation at our fiducial cosmology with 256 light cones for covariance estimation. We also used the 924 independent SLICS simulations to improve the accuracy of our covariance matrix. In total, we generated 2460 mocks, which are all representative of the Euclid survey in terms of galaxy density, redshift distribution, and shape noise. For the fiducial analysis though we used only 1436, focusing on the four DUSTGRAIN-pathfinder simulations with large variation of Ωm and σ8, and the SLICS set for the covariance. We then built κ maps for all mocks with the internal Euclid mass mapping pipeline and computed each statistic from them, except for the γ-2PCF and the aperture masses, which were computed at the ellipticity catalog level. We performed a Fisher analysis to forecast the constraining power of all these statistics for a 15 000 deg2Euclid-like survey. The generated mass maps, DVs, and inverse Fisher matrices are being publicly released13 with the paper to ensure reproducibility and to allow for a fair comparison with future new HOS.
), aperture mass persistent homology Betti numbers (pers. BNs), aperture mass persistent homology heatmap (pers. heat.), and convergence scattering transform coefficients (ST). Our mocks are based on the DUSTGRAIN-pathfinder N-body simulations, consisting of 12 simulations varying Ωm, σ8, and w, with 128 light cones for each of these plus one simulation at our fiducial cosmology with 256 light cones for covariance estimation. We also used the 924 independent SLICS simulations to improve the accuracy of our covariance matrix. In total, we generated 2460 mocks, which are all representative of the Euclid survey in terms of galaxy density, redshift distribution, and shape noise. For the fiducial analysis though we used only 1436, focusing on the four DUSTGRAIN-pathfinder simulations with large variation of Ωm and σ8, and the SLICS set for the covariance. We then built κ maps for all mocks with the internal Euclid mass mapping pipeline and computed each statistic from them, except for the γ-2PCF and the aperture masses, which were computed at the ellipticity catalog level. We performed a Fisher analysis to forecast the constraining power of all these statistics for a 15 000 deg2Euclid-like survey. The generated mass maps, DVs, and inverse Fisher matrices are being publicly released13 with the paper to ensure reproducibility and to allow for a fair comparison with future new HOS.
We applied more than twice as many HOS as in any other publication to date, offering the first comprehensive overview of almost all WL statistics studied in the literature today. We found that combining any of these statistics with the standard γ-2PCF improves the precision of the individual forecasts on Ωm and σ8 by a factor of ∼2 to 3, highlighting the ability of HOS to probe non-Gaussian small-scale information missed by two-point estimators. Combining these HOS further increases the gain to a factor of 4.5 compared to the γ-2PCF thanks to the different degeneracy direction of each statistic in the Ωm − σ8 plane, which helps lift the classical lensing degeneracy.
Finally, while performing our analysis, we identified several points that require further investigation and will be addressed in future publications of the HOWLS series. First, we found that numerical noise in the Fisher derivatives could artificially break degeneracies between parameters, which prevented us from measuring robust forecasts for w and from using simulations with very small CP variations. Although this might be solved by a tomographic approach in the specific case of w, it also encourages more independent N-body simulations to be run at each cosmology, and not only at the fiducial one used for covariance estimates. We note that this could also be linked to the Fisher formalism and that this difficulty could be less of a problem in approaches where degeneracies are better explored in a CP hypercube. Second, we note that some statistics do not follow a multivariate Gaussian distribution, namely the HOM, 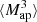 , and
, and 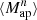 . The Fisher formalism breaks down for these statistics. They were included in the paper for consistency but not discussed on equal footing with other more robust results. This issue will be solved when moving from the Fisher formalism to an emulator-based model sampling the CP hypercube, which is a necessary step for measuring cosmological constraints from HOS in observations. Third, we calculated large correlations with complex patterns between all statistics. Although in a nontomographic setup it was possible to keep a large correlated DV in the joint analysis, this will no longer be the case when including tomography, requiring the development of a robust DV compression scheme. Finally, no systematic effects beyond shape noise were included in the present paper. Working with mass maps will notably introduce some new systematic effects related to masks and the κ reconstruction, and different HOS will have different responses to astrophysical biases such as intrinsic alignments and baryons that are particularly important on small scales (e.g., Semboloni et al. 2013). Besides the impressive gain in precision that we found, there is therefore also the hope that adding HOS to the γ-2PCF might help break degeneracies between systematics and CPs thanks to the different nature of these probes (e.g., Patton et al. 2017; Pyne & Joachimi 2021).
. The Fisher formalism breaks down for these statistics. They were included in the paper for consistency but not discussed on equal footing with other more robust results. This issue will be solved when moving from the Fisher formalism to an emulator-based model sampling the CP hypercube, which is a necessary step for measuring cosmological constraints from HOS in observations. Third, we calculated large correlations with complex patterns between all statistics. Although in a nontomographic setup it was possible to keep a large correlated DV in the joint analysis, this will no longer be the case when including tomography, requiring the development of a robust DV compression scheme. Finally, no systematic effects beyond shape noise were included in the present paper. Working with mass maps will notably introduce some new systematic effects related to masks and the κ reconstruction, and different HOS will have different responses to astrophysical biases such as intrinsic alignments and baryons that are particularly important on small scales (e.g., Semboloni et al. 2013). Besides the impressive gain in precision that we found, there is therefore also the hope that adding HOS to the γ-2PCF might help break degeneracies between systematics and CPs thanks to the different nature of these probes (e.g., Patton et al. 2017; Pyne & Joachimi 2021).
SLICS: https://slics.roe.ac.uk
When dealing with masks, this process can be replaced by only removing pixels whose smoothing circle covers less than a given threshold value (like 90%) in the considered patch and reweighting the κ values in the cells according to the coverage, as done in Friedrich et al. (2018), Gruen et al. (2018).
We have decided to use the 95 rather than the narrower 68% CL range although this choice makes it easier to pass the cut. The use of 95% range is, however, a more conservative choice to account for the noise in the estimate of the 𝒮mock distribution inherited from the finite number of values, and the use of a covariance matrix inferred from a finite number of simulations.
Note that, although the smoothing angle is the same, the smoothing filter can change from one probe to another so that a straightforward comparison among different probes should be avoided. We consider the filter choice as part of the probe itself, so we do not ask different contributors to use the same filter.
Acknowledgments
NM acknowledges support from a fellowship of the Centre National d’Etudes Spatiales (CNES). CG acknowledges the support from the grant PRIN-MIUR 2017 WSCC32 ZOOMING, from the grant ASI n.2018-23-HH.0, from the Italian National Institute of Astrophysics under the grant “Bando PrIN 2019”, PI: Viola Allevato, from the HPC-Europa3 Transnational Access programme HPC17VDILO, from INAF theory Grant 2022: Illuminating Dark Matter using Weak Lensing by Cluster Satellites, PI: Carlo Giocoli. IT acknowledges support from the Fundacao para a Ciencia e a Tecnologia (FCT) through the projects UIDB/04434/2020, UIDP/04434/2020 and the Investigador FCT Contract No. IF/01518/2014 and POCH/FSE (EC). The Euclid Consortium acknowledges the European Space Agency and a number of agencies and institutes that have supported the development of Euclid, in particular the Academy of Finland, the Agenzia Spaziale Italiana, the Belgian Science Policy, the Canadian Euclid Consortium, the French Centre National d’Etudes Spatiales, the Deutsches Zentrum für Luft- und Raumfahrt, the Danish Space Research Institute, the Fundação para a Ciência e a Tecnologia, the Ministerio de Ciencia e Innovación, the National Aeronautics and Space Administration, the National Astronomical Observatory of Japan, the Netherlandse Onderzoekschool Voor Astronomie, the Norwegian Space Agency, the Romanian Space Agency, the State Secretariat for Education, Research and Innovation (SERI) at the Swiss Space Office (SSO), and the United Kingdom Space Agency. A complete and detailed list is available on the Euclid web site (http://www.euclid-ec.org). Authors’ contributions: All authors have significantly contributed to this publication and/or made multiyear essential contributions to the Euclid project which made this work possible. The paper-specific main contributions of the lead authors are as follows: HOWLS project management: V. Cardone, C. Giocoli, N. Martinet, S. Pires, and I. Tereno; DUSTGRAIN-pathfinder simulations: M. Baldi and C. Giocoli; SLICS simulations: J. Harnois-Déraps; mocks and convergence maps: S. Pires and N. Martinet; Fisher analysis and paper writing coordination: V. Cardone and N. Martinet; theoretical predictions: A. Barthelemy, A. Boyle, V. Cardone, S. Heydenreich, L. Linke, L. Porth, and C. Uhlemann; γ-2PCF: N. Martinet; κ-2PCF, MFs, and BNs: S. Vinciguerra and V. Cardone; κ-PDF: A. Barthelemy, A. Boyle, S. Codis, and C. Uhlemann; peaks: S. Pires; pers. BNs and pers. heat.: S. Heydenreich and P. Burger; ST: S. Cheng; HOM: A. Boyle, A. Barthelemy, S. Codis, V. Cardone, C. Uhlemann, and S. Vinciguerra; 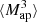 : L. Linke, S. Heydenreich, and P. Burger;
: L. Linke, S. Heydenreich, and P. Burger; 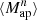 : L. Porth; earlier development of HOWLS: V. Ajani, M. Kilbinger, F. Lanusse, C. Llinares, C. Parroni, A. Peel, and M. Vicinanza.
: L. Porth; earlier development of HOWLS: V. Ajani, M. Kilbinger, F. Lanusse, C. Llinares, C. Parroni, A. Peel, and M. Vicinanza.
References
- Ajani, V., Peel, A., Pettorino, V., et al. 2020, Phys. Rev. D, 102, 103531 [Google Scholar]
- Albrecht, A., Bernstein, G., Cahn, R., et al. 2006, ArXiv e-prints [arXiv:astro-ph/0609591] [Google Scholar]
- Amon, A., Gruen, D., Troxel, M. A., et al. 2022, Phys. Rev. D, 105, 023514 [NASA ADS] [CrossRef] [Google Scholar]
- Bartelmann, M. 1995, A&A, 303, 643 [NASA ADS] [Google Scholar]
- Bartelmann, M., King, L. J., & Schneider, P. 2001, A&A, 378, 361 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Barthelemy, A., Codis, S., Uhlemann, C., Bernardeau, F., & Gavazzi, R. 2020, MNRAS, 492, 3420 [Google Scholar]
- Barthelemy, A., Codis, S., & Bernardeau, F. 2021, MNRAS, 503, 5204 [Google Scholar]
- Barthelemy, A., Bernardeau, F., Codis, S., & Uhlemann, C. 2022, Phys. Rev. D, 105, 043537 [NASA ADS] [CrossRef] [Google Scholar]
- Bernardeau, F., & Schaeffer, R. 1992, A&A, 255, 1 [NASA ADS] [Google Scholar]
- Blake, C., Amon, A., Childress, M., et al. 2016, MNRAS, 462, 4240 [NASA ADS] [CrossRef] [Google Scholar]
- Boruah, S. S., Rozo, E., & Fiedorowicz, P. 2022, MNRAS, 516, 4111 [NASA ADS] [CrossRef] [Google Scholar]
- Boyle, A., Uhlemann, C., Friedrich, O., et al. 2021, MNRAS, 505, 2886 [NASA ADS] [CrossRef] [Google Scholar]
- Bunn, E. F. 1995, Ph.D. Thesis, University of California, Berkeley, USA [Google Scholar]
- Burger, P. A., Friedrich, O., Harnois-Déraps, J., et al. 2023, A&A, 669, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Castro, T., Quartin, M., Giocoli, C., Borgani, S., & Dolag, K. 2018, MNRAS, 478, 1305 [Google Scholar]
- Cheng, S., & Ménard, B. 2021a, ArXiv e-prints [arXiv:2112.01288] [Google Scholar]
- Cheng, S., & Ménard, B. 2021b, MNRAS, 507, 1012 [NASA ADS] [CrossRef] [Google Scholar]
- Cheng, S., Ting, Y.-S., Ménard, B., & Bruna, J. 2020, MNRAS, 499, 5902 [Google Scholar]
- Chung, D. T. 2022, MNRAS, 517, 1625 [NASA ADS] [CrossRef] [Google Scholar]
- Coe, D. 2009, ArXiv e-prints [arXiv:0906.4123] [Google Scholar]
- Crittenden, R. G., Natarajan, P., Pen, U.-L., & Theuns, T. 2002, ApJ, 568, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Delouis, J. M., Allys, E., Gauvrit, E., & Boulanger, F. 2022, A&A, 668, A122 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- DESI Collaboration (Aghamousa, A., et al.) 2016, ArXiv e-prints [arXiv:1611.00036] [Google Scholar]
- Dietrich, J. P., & Hartlap, J. 2010, MNRAS, 402, 1049 [Google Scholar]
- Di Valentino, E., Mena, O., Pan, S., et al. 2021, CQG, 38, 153001 [NASA ADS] [CrossRef] [Google Scholar]
- Doré, O., Bock, J., Ashby, M., et al. 2014, ArXiv e-prints [arXiv:1412.4872] [Google Scholar]
- Eisenstein, D. J., & Hu, W. 1998, ApJ, 496, 605 [Google Scholar]
- Euclid Collaboration (Knabenhans, M., et al.) 2019a, MNRAS, 484, 5509 [Google Scholar]
- Euclid Collaboration (Martinet, N., et al.) 2019b, A&A, 627, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Blanchard, A., et al.) 2020, A&A, 642, A191 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Feldbrugge, J., van Engelen, M., van de Weygaert, R., Pranav, P., & Vegter, G. 2019, J. Cosmol. Astropart. Phys., 2019, 052 [CrossRef] [Google Scholar]
- Friedrich, O., Gruen, D., DeRose, J., et al. 2018, Phys. Rev. D, 98, 023508 [Google Scholar]
- Fu, L., Semboloni, E., Hoekstra, H., et al. 2008, A&A, 479, 9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gatti, M., Chang, C., Friedrich, O., et al. 2020, MNRAS, 498, 4060 [Google Scholar]
- Gatti, M., Jain, B., Chang, C., et al. 2022, Phys. Rev. D, 106, 083509 [NASA ADS] [CrossRef] [Google Scholar]
- Gavazzi, R., & Soucail, G. 2006, A&A, 462, 459 [Google Scholar]
- Giocoli, C., Metcalf, R. B., Baldi, M., et al. 2015, MNRAS, 452, 2757 [Google Scholar]
- Giocoli, C., Baldi, M., & Moscardini, L. 2018a, MNRAS, 481, 2813 [Google Scholar]
- Giocoli, C., Moscardini, L., Baldi, M., Meneghetti, M., & Metcalf, R. B. 2018b, MNRAS, 478, 5436 [Google Scholar]
- Greig, B., Ting, Y.-S., & Kaurov, A. A. 2023, MNRAS, 519, 5288 [NASA ADS] [CrossRef] [Google Scholar]
- Gruen, D., Friedrich, O., Krause, E., et al. 2018, Phys. Rev. D, 98, 023507 [Google Scholar]
- Hadwiger, H. 1957, Vorlesungen ueber Inhalt, Oberflache und Isoperimetrie, Die Grundlehren der mathematischen Wissenschaften (Springer) [CrossRef] [Google Scholar]
- Hamana, T., Takada, M., & Yoshida, N. 2004, MNRAS, 350, 893 [NASA ADS] [CrossRef] [Google Scholar]
- Hamana, T., Sakurai, J., Koike, M., & Miller, L. 2015, PASJ, 67, 34 [NASA ADS] [Google Scholar]
- Harnois-Déraps, J., & van Waerbeke, L. 2015, MNRAS, 450, 2857 [Google Scholar]
- Harnois-Déraps, J., Pen, U.-L., Iliev, I. T., et al. 2013, MNRAS, 436, 540 [Google Scholar]
- Harnois-Déraps, J., Amon, A., Choi, A., et al. 2018, MNRAS, 481, 1337 [Google Scholar]
- Harnois-Déraps, J., Giblin, B., & Joachimi, B. 2019, A&A, 631, A160 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harnois-Déraps, J., Martinet, N., Castro, T., et al. 2021, MNRAS, 506, 1623 [CrossRef] [Google Scholar]
- Hartlap, J., Simon, P., & Schneider, P. 2007, A&A, 464, 399 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heitmann, K., Lawrence, E., Kwan, J., Habib, S., & Higdon, D. 2014, ApJ, 780, 111 [Google Scholar]
- Hetterscheidt, M., Erben, T., Schneider, P., et al. 2005, A&A, 442, 43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heydenreich, S., Brück, B., & Harnois-Déraps, J. 2021, A&A, 648, A74 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heydenreich, S., Brück, B., Burger, P., et al. 2022, A&A, 667, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heydenreich, S., Linke, L., Burger, P., & Schneider, P. 2023, A&A, 672, A44 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heymans, C., Tröster, T., Asgari, M., et al. 2021, A&A, 646, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hilbert, S., Marian, L., Smith, R. E., & Desjacques, V. 2012, MNRAS, 426, 2870 [Google Scholar]
- Hilbert, S., Barreira, A., Fabbian, G., et al. 2020, MNRAS, 493, 305 [Google Scholar]
- Hildebrandt, H., Viola, M., Heymans, C., et al. 2017, MNRAS, 465, 1454 [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jarvis, M., Bernstein, G., & Jain, B. 2004, MNRAS, 352, 338 [Google Scholar]
- Joudaki, S., Blake, C., Heymans, C., et al. 2017, MNRAS, 465, 2033 [Google Scholar]
- Joyce, A., Lombriser, L., & Schmidt, F. 2016, Ann. Rev. Nucl. Part. Sci., 66, 95 [NASA ADS] [CrossRef] [Google Scholar]
- Kacprzak, T., Kirk, D., Friedrich, O., et al. 2016, MNRAS, 463, 3653 [Google Scholar]
- Kaiser, N., & Squires, G. 1993, ApJ, 404, 441 [Google Scholar]
- Kilbinger, M. 2015, Rep. Prog. Phys., 78, 086901 [Google Scholar]
- Kilbinger, M., Benabed, K., Guy, J., et al. 2009, A&A, 497, 677 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kilbinger, M., Bonnett, C., & Coupon, J. 2014, Astrophysics Source Code Library [record ascl:1402.026] [Google Scholar]
- Kratochvil, J. M., Lim, E. A., Wang, S., et al. 2012, Phys. Rev. D, 85, 103513 [Google Scholar]
- Kruse, G., & Schneider, P. 1999, MNRAS, 302, 821 [Google Scholar]
- Kruse, G., & Schneider, P. 2000, MNRAS, 318, 321 [Google Scholar]
- Lacasa, F., & Grain, J. 2019, A&A, 624, A61 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Laigle, C., McCracken, H. J., Ilbert, O., et al. 2016, ApJS, 224, 24 [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Leonard, A., Pires, S., & Starck, J.-L. 2012, MNRAS, 423, 3405 [NASA ADS] [CrossRef] [Google Scholar]
- Lewis, A., Challinor, A., & Lasenby, A. 2000, ApJ, 538, 473 [Google Scholar]
- Li, Z., Liu, J., Matilla, J. M. Z., & Coulton, W. R. 2019, Phys. Rev. D, 99, 063527 [Google Scholar]
- Lin, C.-A., Kilbinger, M., & Pires, S. 2016, A&A, 593, A88 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lin, C.-H., Harnois-Déraps, J., Eifler, T., et al. 2020, MNRAS, 499, 2977 [NASA ADS] [CrossRef] [Google Scholar]
- Linke, L., Heydenreich, S., Burger, P. A., & Schneider, P. 2023, A&A, 672, A185 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liu, J., & Madhavacheril, M. S. 2019, Phys. Rev. D, 99, 083508 [Google Scholar]
- Mallat, S. 2012, Commun. Pure Appl. Math., 65, 1331 [CrossRef] [Google Scholar]
- Marian, L., & Bernstein, G. M. 2006, Phys. Rev. D, 73, 043512 [NASA ADS] [CrossRef] [Google Scholar]
- Marian, L., Smith, R. E., & Bernstein, G. M. 2009, ApJ, 698, L33 [NASA ADS] [CrossRef] [Google Scholar]
- Martinet, N., Schneider, P., Hildebrandt, H., et al. 2018, MNRAS, 474, 712 [Google Scholar]
- Martinet, N., Castro, T., Harnois-Déraps, J., et al. 2021a, A&A, 648, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Martinet, N., Harnois-Déraps, J., Jullo, E., & Schneider, P. 2021b, A&A, 646, A62 [EDP Sciences] [Google Scholar]
- Miyazaki, S., Oguri, M., Hamana, T., et al. 2017, PASJ, 70, S27 [NASA ADS] [Google Scholar]
- Munshi, D., & Jain, B. 2001, MNRAS, 322, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Parroni, C., Cardone, V. F., Maoli, R., & Scaramella, R. 2020, A&A, 633, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Parroni, C., Tollet, É., Cardone, V. F., Maoli, R., & Scaramella, R. 2021, A&A, 645, A123 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Patton, K., Blazek, J., Honscheid, K., et al. 2017, MNRAS, 472, 439 [Google Scholar]
- Peel, A., Pettorino, V., Giocoli, C., Starck, J.-L., & Baldi, M. 2018, A&A, 619, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Perlmutter, S., Aldering, G., Goldhaber, G., et al. 1999, ApJ, 517, 565 [Google Scholar]
- Petri, A., Liu, J., Haiman, Z., et al. 2015, Phys. Rev. D, 91, 103511 [Google Scholar]
- Pires, S., Starck, J.-L., Amara, A., Réfrégier, A., & Teyssier, R. 2009, A&A, 505, 969 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pires, S., Vandenbussche, V., Kansal, V., et al. 2020, A&A, 638, A141 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration I. 2016, A&A, 594, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pogosyan, D., Codis, S., & Pichon, C. 2016, in The Zeldovich Universe: Genesis and Growth of the Cosmic Web, eds. R. van de Weygaert, S. Shandarin, E. Saar, & J. Einasto, 308, 61 [NASA ADS] [Google Scholar]
- Porqueres, N., Heavens, A., Mortlock, D., & Lavaux, G. 2022, MNRAS, 509, 3194 [Google Scholar]
- Porth, L., & Smith, R. E. 2021, MNRAS, 508, 3474 [NASA ADS] [CrossRef] [Google Scholar]
- Porth, L., Smith, R. E., Simon, P., Marian, L., & Hilbert, S. 2020, MNRAS, 499, 2474 [CrossRef] [Google Scholar]
- Puchwein, E., Baldi, M., & Springel, V. 2013, MNRAS, 436, 348 [NASA ADS] [CrossRef] [Google Scholar]
- Pyne, S., & Joachimi, B. 2021, MNRAS, 503, 2300 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G., Filippenko, A. V., Challis, P., et al. 1998, AJ, 116, 1009 [Google Scholar]
- Rizzato, M., & Sellentin, E. 2023, MNRAS, 521, 1152 [NASA ADS] [CrossRef] [Google Scholar]
- Schirmer, M., Erben, T., Hetterscheidt, M., & Schneider, P. 2007, A&A, 462, 875 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schmalzing, J., & Górski, K. M. 1998, MNRAS, 297, 355 [CrossRef] [Google Scholar]
- Schneider, P., & Lombardi, M. 2003, A&A, 397, 809 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schneider, P., van Waerbeke, L., Jain, B., & Kruse, G. 1998, MNRAS, 296, 873 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, P., Kilbinger, M., & Lombardi, M. 2005, A&A, 431, 9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schrabback, T., Applegate, D., Dietrich, J. P., et al. 2018, MNRAS, 474, 2635 [Google Scholar]
- Seitz, S., & Schneider, P. 1996, A&A, 305, 383 [NASA ADS] [Google Scholar]
- Seitz, S., & Schneider, P. 2001, A&A, 374, 740 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sellentin, E., & Heavens, A. F. 2017, MNRAS, 464, 4658 [Google Scholar]
- Semboloni, E., Hoekstra, H., & Schaye, J. 2013, MNRAS, 434, 148 [CrossRef] [Google Scholar]
- Smail, I., Ellis, R. S., & Fitchett, M. J. 1994, MNRAS, 270, 245 [Google Scholar]
- Sousbie, T. 2011, MNRAS, 414, 350 [NASA ADS] [CrossRef] [Google Scholar]
- Spergel, D., Gehrels, N., Baltay, C., et al. 2015, ArXiv e-prints [arXiv:1503.03757] [Google Scholar]
- Starck, J. L., & Murtagh, F. 2007, in Astronomical Image and Data Analysis, ed. O. Scherzer (Springer) [Google Scholar]
- Szapudi, I., & Szalay, A. S. 1993, ApJ, 408, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Takada, M., Ellis, R. S., Chiba, M., et al. 2014, PASJ, 66, R1 [Google Scholar]
- Takahashi, R., Sato, M., Nishimichi, T., Taruya, A., & Oguri, M. 2012, ApJ, 761, 152 [Google Scholar]
- Tegmark, M., Taylor, A. N., & Heavens, A. F. 1997, ApJ, 480, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Tessore, N., Winther, H. A., Metcalf, R. B., Ferreira, P. G., & Giocoli, C. 2015, J. Cosmology Astropart. Phys., 10, 036 [CrossRef] [Google Scholar]
- Thiele, L., Hill, J. C., & Smith, K. M. 2020, Phys. Rev. D, 102, 123545 [NASA ADS] [CrossRef] [Google Scholar]
- Uhlemann, C., Friedrich, O., Boyle, A., et al. 2023, Open J. Astrophys., 6, 2023 [NASA ADS] [CrossRef] [Google Scholar]
- Valogiannis, G., & Dvorkin, C. 2022a, Phys. Rev. D, 106, 103509 [Google Scholar]
- Valogiannis, G., & Dvorkin, C. 2022b, Phys. Rev. D, 105, 103534 [Google Scholar]
- van Uitert, E., Joachimi, B., Joudaki, S., et al. 2018, MNRAS, 476, 4662 [NASA ADS] [CrossRef] [Google Scholar]
- Van Waerbeke, L., Benjamin, J., Erben, T., et al. 2013, MNRAS, 433, 3373 [Google Scholar]
- Vicinanza, M., Cardone, V. F., Maoli, R., et al. 2019, Phys. Rev. D, 99, 043534 [Google Scholar]
- Vogeley, M. S., & Szalay, A. S. 1996, ApJ, 465, 34 [NASA ADS] [CrossRef] [Google Scholar]
- Xavier, H. S., Abdalla, F. B., & Joachimi, B. 2016, MNRAS, 459, 3693 [NASA ADS] [CrossRef] [Google Scholar]
- Xia, Q., Robertson, N., Heymans, C., et al. 2020, A&A, 633, A89 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Yang, X., Kratochvil, J. M., Huffenberger, K., Haiman, Z., & May, M. 2013, Phys. Rev. D, 87, 023511 [Google Scholar]
- Zorrilla Matilla, J. M., Waterval, S., & Haiman, Z. 2020, AJ, 159, 284 [Google Scholar]
- Zürcher, D., Fluri, J., Ajani, V., et al. 2022, ArXiv e-prints [arXiv:2206.01450] [Google Scholar]
Appendix A: Forecasts for Σ8
In order to ease comparison with the existing literature we also produce forecasts in the Σ8-Ωm plane in addition to the σ8-Ωm in the rest of the paper. We use the general definition of the growth of structure parameter Σ8 = σ8(Ωm/0.3)α and choose the optimal α value for the γ-2PCF, that is the one that coincides with the semi-minor axis of the corresponding Fisher ellipse. We find α = 0.63 slightly different from the α = 0.5 value of S8 as the lensing degeneracy is not fully captured by the simplistic Fisher formalism. We compute the transformation matrix (e.g., Coe 2009) between the two sets of parameters to derive the Fisher matrix for Σ8-Ωm, assuming that σ8 depends on Ωm and Σ8 through σ8 = Σ8(0.3/Ωm)α and that Ωm is independent:
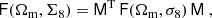
with
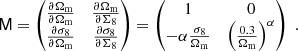
In the above equations, Ωm and σ8 are evaluated at the fiducial cosmology of the DUSTGRAIN-pathfinder simulations (see Table 1).
The results in the new set of parameters are presented in Fig. A.1 and Table A.1 which are respectively analogous to Fig. 19 and Table 5. The transformation of CPs implies reading Fig. 19 along the semi-major axis of the γ-2PCF Fisher ellipse (we note that for S8 that would be equivalent to reading this figure along the dashed black line of the top left quadrant). All ellipses appear rotated in the new CPs plane. Hence the gain on the FoM is preserved compared to the original case. As expected as well the forecasts of Σ8 are tighter than on the other two parameters. The general ranking of the statistics is the same whether one considers Σ8-Ωm or σ8-Ωm. However, the gain from combining a given HOS with the γ-2PCF is less important for Σ8, ranging from a factor 1.1 to 1.45 improvement in precision. This is because we probe the direction perpendicular to the lensing degeneracy while HOS are complementary to the γ-2PCF as they present different degeneracy directions. The FoM, which quantifies the improved precision for the set of probed parameters remains the same whether we consider Σ8-Ωm or σ8-Ωm.
 |
Fig. A.1. Same as Fig. 19, but for (Ωm, Σ8) instead of (Ωm, σ8), with Σ8 = σ8(Ωm/0.3)α and α = 0.63. Individual Fisher forecasts in the Σ8-Ωm plane for a nontomographic Euclid-like survey for the 11 statistics (orange) and γ-2PCF (blue), as well as their combination (green). The corresponding marginalized precision on CPs can be found in Table A.1. The bottom row with the gray shaded backgrounds displays probes that are not Gaussian distributed and cannot be robustly interpreted with Fisher forecasts. The abbreviated name of each summary statistic is displayed in the top-right part of each panel: γ-2PCF and κ-2PCF for the shear and convergence two-point correlation functions, κ-PDF for the convergence one-point probability distribution, peaks for aperture mass peak counts, MFs for convergence Minkowski functionals, BNs for convergence Betti numbers, pers. BNs and pers. heat. for aperture mass persistent homology Betti numbers and heatmap, ST for convergence scattering transform coefficients, HOM for higher-order convergence moments, and |
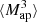
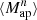
Same as Table. 5, but for (Ωm, Σ8) instead of (Ωm, σ8), with Σ8 = σ8(Ωm/0.3)α and α = 0.63. Fisher forecasts for a Euclid-like nontomographic analysis. The precision on Σ8 and Ωm is given as a percentage of the fiducial values for the probes taken individually and when combined with the γ-2PCF. We also report the figure of merit (FoM) as defined in the Dark Energy Task Force (Albrecht et al. 2006). The last columns display the expected gain over the γ-2PCF analysis for the scales available in the DUSTGRAIN-pathfinder simulations. Results for non-Gaussian statistics are also presented as part of the HOWLS project; we stress, however, that a non-Gaussian likelihood would be necessary to assess the robustness of these three probes.
All Tables
Simulations used in HOWLS with CP values for Ωm, σ8, and w, and the numbers of realizations.
Parameters of the Fu et al. (2008) redshift distributions of Eq. (1) for the DUSTGRAIN-pathfinder and SLICS mocks, normalized to 30 galaxies per arcmin2.
Statistics that have been applied to the HOWLS data set, with their abbreviation in the present article, the filter and smoothing scale employed, the number of independent teams for each statistic and links to the corresponding subsections.
Same as Table. 5, but for (Ωm, Σ8) instead of (Ωm, σ8), with Σ8 = σ8(Ωm/0.3)α and α = 0.63. Fisher forecasts for a Euclid-like nontomographic analysis. The precision on Σ8 and Ωm is given as a percentage of the fiducial values for the probes taken individually and when combined with the γ-2PCF. We also report the figure of merit (FoM) as defined in the Dark Energy Task Force (Albrecht et al. 2006). The last columns display the expected gain over the γ-2PCF analysis for the scales available in the DUSTGRAIN-pathfinder simulations. Results for non-Gaussian statistics are also presented as part of the HOWLS project; we stress, however, that a non-Gaussian likelihood would be necessary to assess the robustness of these three probes.
All Figures
|
Fig. 1. Convergence maps for sources at zs = 2 of the same light-cone random realization constructed from the DUSTGRAIN-pathfinder simulations used in this work. The region displayed covers a region of approximately 2.5 × 2.5 deg2. |
| In the text | |
|
Fig. 2. Convergence power spectra for sources at zs = 2. From left to right, we exhibit the runs that account for Ωm, σ8 and w variations, respectively. The curves show the average over all 128 line of sight realizations, and the gray areas show the scatter of the convergence power spectrum around the mean value for the reference ΛCDM simulation (256 lines of sight) considering a field of view of 5 deg on a side. |
| In the text | |
|
Fig. 3. Top: Redshift distributions of the mocks built from the DUSTGRAIN-pathfinder (red dots) and SLICS (blue dots) simulations, normalized to 30 galaxies per arcmin2. These correspond to a Fu et al. (2008) fit to the Laigle et al. (2016) COSMOS2015 catalog after removing galaxies with magnitudes IE ≥ 24.5 and i′≥24.5 for DUSTGRAIN-pathfinder and SLICS, respectively (red and blue histograms). Bottom: Fractional difference between the DUSTGRAIN-pathfinder and SLICS redshift distributions. The difference is always below 5% except for redshifts lower than 0.2. |
| In the text | |
|
Fig. 4. γ-2PCF ξ+ (top) and ξ− (bottom) DVs and derivatives. The gray lines, whose scale is given by the second axis, correspond to the average DVs computed from the 924 SLICS realizations. The Fisher derivatives (defined in Eq. (47)) are computed from the DUSTGRAIN-pathfinder simulations with large variations of Ωm (orange), σ8 (green), and w (blue). The solid, dashed, and dotted lines respectively correspond to the average over 128, 64, and 32 realizations. The shaded areas represent the uncertainty computed from the 128 DUSTGRAIN-pathfinder realizations, and the gray error bars those of the 924 SLICS realizations. The inclusion of the dashed and dotted lines within the shaded areas highlights the low numerical noise. |
| In the text | |
|
Fig. 5. Fiducial DV for κ-2PCF (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue). |
| In the text | |
|
Fig. 6. Fiducial DV for κ-PDF (gray) along with its Fisher derivatives with respect to Ωm (orange), σ8 (green), and w (blue). The κ-PDF was computed on κ maps smoothed with a top-hat filter with a scale of 4 |
| In the text | |
|
Fig. 7. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for HOM computed on κ maps smoothed with a top-hat filter with a scale of 4 |
| In the text | |
|
Fig. 8. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for |
| In the text | |
|
Fig. 9. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for |
| In the text | |
|
Fig. 10. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for peaks of aperture mass maps, computed from κ-fields smoothed with a starlet filter with a scale of 2 |
| In the text | |
|
Fig. 11. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for MFs V0 (top), V1 (center), and V2 (bottom) computed on κ maps smoothed with a Gaussian filter with a scale of 2 |
| In the text | |
|
Fig. 12. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for BNs β0 (top) and β1 (bottom) computed on κ maps smoothed with a Gaussian filter with a scale of 2 |
| In the text | |
|
Fig. 13. Fiducial DV (gray) along with its derivatives with respect to Ωm (orange), σ8 (green), and w (blue) for pers. BNs (top) and pers. heat. (bottom) computed on aperture mass maps from γ, smoothed with a 2 |
| In the text | |
|
Fig. 14. Fiducial data vector (gray) along with its derivatives with respect to Ωm (red), σ8 (green), and w (blue) for ST computed on κ maps smoothed with a Gaussian filter with a scale of 2 |
| In the text | |
|
Fig. 15. Verification of the Gaussian hypothesis for all statistics computed in this analysis. For a Gaussian-distributed DV, the histogram of χ2 values from the SLICS simulations (red) should match the theoretical prediction (black) modulo the sampling noise across the finite set of 924 realizations. The corresponding SMAPE value (Eq. (45)) is given in the top left quadrant of each panel. 𝒮 ≤ 0.15 indicates compatibility with the Gaussian hypothesis, which is verified for all statistics but the three bottom panels with gray shaded background. The y-axes correspond to the frequency of each χ2 bin value across the SLICS and are different for each panel. |
| In the text | |
|
Fig. 16. Fisher forecasts for all probes computed for a Euclid-like survey without tomography. The different ellipses refer to different numbers of DUSTGRAIN-pathfinder realizations Nc used to compute the DV derivatives: dotted, dashed, and solid lines, respectively for 32, 64, and 128 realizations. The covariance matrix is held fixed to SLICS with Nf = 924 realizations. For γ-2PCF and κ-PDF we separately assess the convergence of derivatives by a comparison with theoretical predictions in Figs. 17 and 18. |
| In the text | |
|
Fig. 17. Upper row: Comparison of the derivatives of the γ-2PCF as predicted from theory (solid lines) and as measured from the DUSTGRAIN-pathfinder simulations (dots). The errorbars are scaled to a single line-of-sight in the DUSTGRAIN-pathfinder ensemble. The shaded regions display the scales that were discarded from the Fisher analysis presented in this work. In the lower panel we plot the relative deviation between the measured quantities and the theoretical predictions when accounting for (solid lines) or neglecting (dotted lines) finite field effects. The gray dashed lines display the 10 percent errorband. Lower row: Comparison of the Fisher forecast using the theoretical model (orange dashed) or the simulation measurements (blue dashed). The thin solid lines correspond to simulated analyses that are used to test the stability of the ellipses given the numerical noise in the derivatives. For the panel on the left we use all available scales on the γ-2PCF while for the figure on the right only the scales with realistic numerical derivatives (i.e., removing the gray shaded area of the upper panel) are included in the forecast. In the figure on the right we show for reference again the constraints of the theoretical model with all scales included. |
| In the text | |
|
Fig. 18. Top: Overall shape of the lensing κ-PDF, smoothed with a top-hat filter of radius 4 |
| In the text | |
|
Fig. 19. Individual Fisher forecasts in the σ8 − Ωm plane for a nontomographic Euclid-like survey for the 11 statistics (orange) and γ-2PCF (blue), as well as their combination (green). The corresponding marginalized precision on CPs can be found in Table 5. The black dashed line in the first quadrant indicates constant |
| In the text | |
|
Fig. 20. Fisher forecasts for σ8 and Ωm for a nontomographic Euclid-like survey for all statistics. The black crosses (left) show the individual forecasts and the gray circles (right) the forecasts combined with the γ-2PCF. Forecasts are ranked within 3 categories: two-point statistics, higher-order Gaussian statistics, and higher-order non-Gaussian statistics. The latter are displayed on a gray background as they should be confirmed with a non-Gaussian likelihood framework. The corresponding marginalized precision on CPs can be found in Table 5. |
| In the text | |
|
Fig. 21. Correlation matrix for all 12 statistics tested in our analysis and referenced in Table 3, computed from the same 924 SLICS simulations. We note the complex correlations between the different statistics due to their expressions as well as to different filtering shapes and scales in the post-processing of the mass maps. The bin sizes of the κ-PDF, MFs, and BNs DVs have been increased in the figure for visualization purposes. |
| In the text | |
|
Fig. 22. Same as Fig. 16, but for all Gaussian HOS together: κ-PDF, peaks, MFs, BNs, pers. BNs, pers. heat., and ST. Note the change of scales compared to other Fisher contour plots for better visualization. |
| In the text | |
|
Fig. 23. Same as Fig. 19, but for all Gaussian HOS together: κ-PDF, peaks, MFs, BNs, pers. BNs, pers. heat., and ST. The green and orange ellipses overlap almost exactly. |
| In the text | |
|
Fig. A.1. Same as Fig. 19, but for (Ωm, Σ8) instead of (Ωm, σ8), with Σ8 = σ8(Ωm/0.3)α and α = 0.63. Individual Fisher forecasts in the Σ8-Ωm plane for a nontomographic Euclid-like survey for the 11 statistics (orange) and γ-2PCF (blue), as well as their combination (green). The corresponding marginalized precision on CPs can be found in Table A.1. The bottom row with the gray shaded backgrounds displays probes that are not Gaussian distributed and cannot be robustly interpreted with Fisher forecasts. The abbreviated name of each summary statistic is displayed in the top-right part of each panel: γ-2PCF and κ-2PCF for the shear and convergence two-point correlation functions, κ-PDF for the convergence one-point probability distribution, peaks for aperture mass peak counts, MFs for convergence Minkowski functionals, BNs for convergence Betti numbers, pers. BNs and pers. heat. for aperture mass persistent homology Betti numbers and heatmap, ST for convergence scattering transform coefficients, HOM for higher-order convergence moments, and |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.