| Issue |
A&A
Volume 686, June 2024
|
|
|---|---|---|
| Article Number | A80 | |
| Number of page(s) | 29 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202348152 | |
| Published online | 30 May 2024 | |
Total and dark mass from observations of galaxy centers with machine learning
1
School of Physics and Astronomy, Sun Yat-sen University, Zhuhai Campus, 2 Daxue Road, Tangjia, Zhuhai, Guangdong 519082, PR China
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
CSST Science Center for Guangdong-Hong Kong-Macau Great Bay Area, Zhuhai, Guangdong 519082, PR China
3
Department of Physics E. Pancini, University Federico II, Via Cinthia 6, 80126 Naples, Italy
4
INAF – Osservatorio Astronomico di Capodimonte, Salita Moiariello 16, 80131 Naples, Italy
5
Instituto de Física, Universidade Federal da Bahia, 40210-340 Salvador-BA, Brazil
6
PPGCosmo, Universidade Federal do Espírito Santo, 29075-910 Vitória, ES, Brazil
7
Department of Physics, Federal University of Sergipe, Avenida Marechal Rondon s/n, Jardim Rosa Elze, São Cristovão, SE 49100-000, Brazil
8
National Astronomical Observatories, Chinese Academy of Sciences, 20A Datun Road, Chaoyang District, Beijing 100012, PR China
9
School of Astronomy and Space Science, University of Chinese Academy of Sciences, Beijing 100049, PR China
Received:
4
October
2023
Accepted:
15
February
2024
Abstract
Context. The galaxy total mass inside the effective radius is a proxy of the galaxy dark matter content and the star formation efficiency. As such, it encodes important information on the dark matter and baryonic physics.
Aims. Total central masses can be inferred via galaxy dynamics or gravitational lensing, but these methods have limitations. We propose a novel approach based on machine learning to make predictions on total and dark matter content using simple observables from imaging and spectroscopic surveys.
Methods. We used catalogs of multiband photometry, sizes, stellar mass, kinematic measurements (features), and dark matter (targets) of simulated galaxies from the Illustris-TNG100 hydrodynamical simulation to train a Mass Estimate machine Learning Algorithm (MELA) based on random forests.
Results. We separated the simulated sample into passive early-type galaxies (ETGs), both normal and dwarf, and active late-type galaxies (LTGs) and showed that the mass estimator can accurately predict the galaxy dark masses inside the effective radius in all samples. We finally tested the mass estimator against the central mass estimates of a series of low-redshift (z ≲ 0.1) datasets, including SPIDER, MaNGA/DynPop, and SAMI dwarf galaxies, derived with standard dynamical methods based on the Jeans equations. We find that MELA predictions are fully consistent with the total dynamical mass of the real samples of ETGs, LTGs, and dwarf galaxies.
Conclusions. MELA learns from hydro-simulations how to predict the dark and total mass content of galaxies, provided that the real galaxy samples overlap with the training sample or show similar scaling relations in the feature and target parameter space. In this case, dynamical masses are reproduced within 0.30 dex (∼2σ), with a limited fraction of outliers and almost no bias. This is independent of the sophistication of the kinematical data collected (fiber vs. 3D spectroscopy) and the dynamical analysis adopted (radial vs. axisymmetric Jeans equations, virial theorem). This makes MELA a powerful alternative to predict the mass of galaxies of massive stage IV survey datasets using basic data, such as aperture photometry, stellar masses, fiber spectroscopy, and sizes. We finally discuss how to generalize these results to account for the variance of cosmological parameters and baryon physics using a more extensive variety of simulations and the further option of reverse engineering this approach and using model-free dark matter measurements (e.g., via strong lensing), plus visual observables, to predict the cosmology and the galaxy formation model.
Key words: methods: data analysis / galaxies: fundamental parameters / galaxies: kinematics and dynamics / dark matter
Publisher note: A missing funding grant was added in the acknowledgements on 9 February 2026.
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Galaxies originate within the gravitational confines of dark matter halos. They consist of baryonic matter, mostly in the form of stars and gas, as well as dark matter (DM). The spatial distribution and interplay of these two components play a major role in shaping the process of galaxy formation and evolution. Due to the elusiveness of the DM, a compelling characterization of its properties, from the very basic, such as the total dark mass (e.g., using virial theorem, Busarello et al. 1997), to the more complex, such as their mass density profiles (Burkert 1995; Navarro et al. 1996), remains unattainable.
The only approach to constrain DM distribution in galaxies relies on gravitational effects. Ever since the initial discoveries indicating the presence of DM in galaxies, rotation curves have been extensively utilized to investigate the mass distribution of (rotation-supported) spiral systems (e.g., Rubin et al. 1970; Lelli et al. 2016). For ellipticals, instead, typical probes are stellar velocity dispersion profiles and higher-order velocity moments (Kronawitter et al. 2000; Gerhard et al. 2001; Thomas et al. 2007; Romanowsky et al. 2003; Cappellari et al. 2006; Napolitano et al. 2009; Tortora et al. 2009), and strong gravitational lensing (Treu & Koopmans 2004; Koopmans et al. 2006; Auger et al. 2010; Tortora et al. 2010; Sonnenfeld et al. 2013).
Our comprehension of the physical processes contributing to the assembling of baryons and DM received a burst thanks to the advent of new techniques, allowing us to collect data for large galaxy samples or resolve their kinematics in detail. Multiobject spectrographs have been used to simultaneously obtain spectra from up to hundreds of objects in a single observation (e.g., SDSS; Blanton et al. 2003) and Integral Field Spectrographs (IFS) have provided full two-dimensional kinematical maps, including galaxy rotation, velocity dispersion and even higher-velocity moments, (see, e.g., ATLTAS3D, Cappellari et al. 2011; MaNGA, Bundy et al. 2015; SAMI, Croom et al. 2012)
The next-generation (photometric and spectroscopic) sky surveys (or stage IV surveys), such as the Chinese Survey Space Telescope (CSST; Zhan 2011), Vera-Rubin/Large Synoptic Survey Telescope (VR-LSST; Ivezić et al. 2019), Euclid mission (Laureijs et al. 2011), Dark Energy Spectroscopic Instrument (DESI; Levi et al. 2013; DESI Collaboration 2016), and 4-metre Multi-Object Spectrograph Telescope (4MOST; de Jong 2011; de Jong et al. 2019) will provide us with even more massive amounts of data, posing tremendous challenges for data modeling. Hence, finding methods that can swiftly obtain reliable results (e.g., to serve as crucial reference values for further analysis and more complex observations) without the need for complex modeling is very necessary.
Machine learning (ML) has become, in the last decade, an efficient solution in various astronomical applications. For example, it has been successfully applied in complex tasks where conventional analytical methods often proved to be challenging or computationally expensive. It has been used for predicting photometric redshifts (e.g., Amaro et al. 2019; Li et al. 2021b, 2022a); deriving structural parameters of galaxies from light profiles (Li et al. 2022b); performing star, galaxy, and quasar separation in both images and catalogs (Li et al. 2021a; von Marttens et al. 2024; Baqui et al. 2021); identifying and modeling strong gravitational lensing events (Li et al. 2020; Gentile et al. 2022); determining DM distribution of galaxies (de los Rios et al. 2023); and connecting properties of galaxies and DM halos (Moster et al. 2021).
Recently, we have proposed using ML algorithms, trained on cosmological simulations, to estimate the DM content of galaxies (von Marttens et al. 2022, vM+22 hereafter). Cosmological simulations are based on physical principles and realistic recipes for feedback processes, producing seemingly realistic galaxy distributions and scaling relations. Therefore they can be used to train ML algorithms to estimate the DM content of galaxies. In the first paper in this series, we used a Tree-based Pipeline Optimization Tool (TPOT; Olson et al. 2016) to find the optimal ML pipeline. We demonstrated that we can infer the DM properties of galaxies (e.g., central DM mass, DM half-mass radius) starting from general catalog properties, such as luminosity, size, kinematics, colors, and stellar masses in the IllustrisTNG simulation (Nelson et al. 2019, N+19 hereafter). There are other studies following a similar strategy: using the Cosmology and Astrophysics with MachinE Learning Simulation (CAMELS; Villaescusa-Navarro et al. 2023, VN+23 hereafter). For example, Villanueva-Domingo et al. (2022) infer halo mass given the positions, velocities, stellar masses, and radii of the hosted galaxies using graph neural networks. Shao et al. (2022) predict the total mass of a subhalo from their internal properties, such as velocity dispersion, radius, or star formation rate, using neural network and symbolic regression. However, these studies are solely conducted on simulations and have not been tested using real observational data1. On the other hand, utilizing cosmological simulations for replicating and comprehending observational data via ML represents a novel strategy imbued with unforeseeable potentialities.
For instance, we can constrain cosmological parameters and feedback processes comparing DM-related scaling relations from cosmological simulations with galaxy data, which has been envisioned within the CAMELS project (see, e.g., Villaescusa-Navarro et al. 2022), and has recently been shown to be feasible using classical statistical methods (e.g., Busillo et al. 2023). In this paper, we apply a random forest algorithm to predict central total mass and DM mass of galaxies from both simulations and observations. The Mass Estimate machine Learning Algorithm (MELA) is trained with simulation data to make predictions for the galaxies from observations that are compared with results from literature dynamical analyses.
The advantage of our novel method is that it is based on low-level photometric and kinematical information, including only aperture photometry and aperture kinematics. These are typical standardized data provided by photometric large sky surveys, for example, the CSST, VR-LSST, and Euclid, and spectroscopic surveys, such as fiber-aperture velocity dispersion (e.g., from DESI and 4MOST). If successful, this method can provide a significant advantage with respect to standard analysis tools generally based on much higher-level information in Jeans analysis, including accurate surface photometry analysis (Tortora et al. 2009, T+09 hereafter) and integral field spectroscopy (Cappellari 2008, 2020). More importantly, it provides physically motivated inferences because they are based on realistic cosmological simulations.
The other major novelty of the MELA project is that it is entirely data-driven. It provides, for the first time, a full application to real systems and a direct comparison of the predicted masses against classical dynamical methods on samples of early-type and late-type galaxies (Tortora et al. 2012; Zhu et al. 2023) and dwarf systems (Eftekhari et al. 2022) (see Sect. 2 for details).
The outline of the paper is as follows. In Sect. 2 we describe the data and the main physical quantities therein. In Sect. 3 we describe how MELA works and how to evaluate the performance of MELA’s predictions. In Sect. 4 we show the result of self-prediction and apply the trained MELA to real data. In Sect. 5 we discuss the robustness of the MELA and the possible reason for the errors. In Sect. 6 we draw conclusions and give future perspectives.
Throughout this work, we adopt a flat Universe with a ΛCDM model: (ΩΛ, Ωm, h) = (0.6911, 0.3089, 0.6774) based on Planck2015 (Planck Collaboration XIII 2016).
2. Simulation and observation data
In this section, we introduce the simulation datasets we want to use for the training and testing of the MELA and the different observational datasets we want to use as predictive samples. These latter are designated for testing only and are not utilized for model training. In fact, they are used for assessing the performance of the algorithm previously trained using the entire simulation dataset. As anticipated, one of the novelties of this paper is a direct application to dynamical samples to check if MELA can predict the mass content of galaxies consistently with standard dynamical analyses. For this reason, differently from our previous analysis, in vM+22, here we concentrate on the prediction of the central dark matter content of galaxies, namely the total mass Mtot(r1/2) and the dark matter within effective radius MDM(r1/2). In a future work, we will test the same methods against analyses based on extended datasets able to constraint more total dark matter quantities (e.g., based on planetary nebulae, see Napolitano et al. 2009).
The simulation data we use for the training of the machine learning algorithms is based on the IllustrisTNG simulation (N+19), a state-of-the-art magneto-hydrodynamic simulation.
As predictive samples, we consider datasets covering different mass ranges (from dwarf to massive ETG systems) and different dynamical approaches. In particular, we have collected dynamical masses of massive ETGs from Spheroids Panchromatic Investigation in Different Environmental Regions project (SPIDER; Tortora et al. 2012, T+12 hereafter) and combined analysis of the Dynamics and stellar Population for the MaNGA survey (MaNGA DynPop; Zhu et al. 2023, Z+23 hereafter), while we also use dwarf spheroidals from the SAMI Fornax Dwarf survey (Eftekhari et al. 2022, E+22 hereafter).
2.1. Features and targets: A necessary preamble
Before going into the details of the different datasets, we start by describing the physical quantities that we use throughout the paper, as they are differently defined in simulations and observations. This is an important semantic preamble to set the following discussion and motivate some of the choices we need to make when combining simulations and observation in a single analysis. “Observational realism” is a complex chapter of this comparison (see, e.g., Bottrell et al. 2019; Fortuni et al. 2023), which also involves the impact of inappropriate definitions of the observational-like parameters derived from simulations (see, e.g., Tang et al. 2021). Addressing these issues is beyond the scope of this paper, except for some relevant aspects concerning the measurement errors (see, e.g., Qiu et al. 2024, and Sect. 2.2.2). and will be fully addressed in future studies. However, here we need to discuss, and possibly quantify, all obvious mismatches of physical quantities in simulation and observation datasets and introduce some basic assumptions to align the two data types as much as possible.
In Table 1 we show the most important physical properties that we want to use as input of the machine learning algorithm (features) and the quantities we want to predict (targets), with their broad meaning in simulations and observations, face-to-face. We also add some accessory features, that are indirectly used for the target definitions. In particular, we remark the stellar mass inside the half-light radius, M⋆(r1/2) which we decided to exclude from the training/testing features because redundant with respect to the total stellar mass, M⋆, at least in simulations, where, by definition, M⋆(r1/2) = M⋆/2. Here below are some notes to save for the rest of the paper.
Definition of features and targets.
3D vs. 2D features and targets. Data dimensionality is a critical aspect of our study. On the one hand, simulations provide 3D quantities, inherently projection invariant. On the other hand, observational data are essentially 2D, derived from images; for example, they represent projection variant views of astronomical objects, meaning that some of their attributes can change depending on different observation angles. For “total” quantities (luminosity, stellar masses), the use of 2D or 3D does not make a real difference, but for sizes and partial quantities (r1/2, and stellar and total masses inside it) it does. Generally speaking, for real galaxies the dynamical masses (i.e., the ones coming from Jeans modeling or equivalent) can be easily modeled as projected, 2D, or de-projected, 3D, although this conversion comes along with some geometrical assumption (from spherical symmetry, e.g., Wolf et al. 2010; Tortora & Napolitano 2022, to axisymmetric, e.g., Z+23).
3D half-light (r1/2⋆) vs. half-mass (r1/2) radii. Half-light radii or effective radii are certainly the physical parameters that potentially carry the most complex systematics, due to their strong relation with galaxy masses and galaxy types (see, e.g., Shen et al. 2003). We stress in particular two of them: 1) the constant mass-to-light ratio, as in simulations the radius is computed on stellar mass particles; 2) 2D vs. 3D definition (see also above). However: 1) M/L gradients might have a little impact on the mass-size relation of galaxies with an average ratio of the mass weighted, Rm, with respect to the light weighted, Rl, that is of the order of Rm/Rl ∼ 0.6–0.7, from low redshift (see, e.g., Bernardi et al. 2023), up to about redshift 1 (e.g., Suess et al. 2019), although with a large scatter (and assuming uniform initial mass function inside galaxies); 2) the ratio between the 2D and the 3D half-light radii can be quantified to be ∼3/4 for pressure supported systems with a large variety of light distribution under spherical symmetry (see Wolf et al. 2010, W+10 hereafter), while it is basically bias-less for disks where the 3D radius can be obtained from simple thin disk deprojection. Putting these two arguments together we finally conclude that, as the M/L gradients are computed in real galaxies using 2D quantities (e.g., Bernardi et al. 2023, Eq. (4)), and being the 2D radii more compact than the 3D radii, these gradients are an upper limit for the equivalent 3D ones. Hence, the rm/rl (having used the r for 3D quantities) has to be closer to unity than the one measured on 2D gradients, making it reasonable to use the 3D half-mass radius (r1/2) in simulations as a good proxy of the half-light radius (r1/2⋆). In the following, we use the symbol r1/2 to indicate both ones, equivalently.
Predicting and comparing 3D targets. A consequence of the conclusion above is that we can use the 3D features of simulations to predict the 3D targets, and so we can for real galaxies if we use analogous 3D features and targets. These latter can be compared with the equivalent obtained from dynamical models, only under the conditions that the conversion of the 2D to 3D mass properties of real galaxies is free from systematics. Alternatively, to make use of more observation-like features, we should train on 2D features, which are not yet a standard product for hydro-simulations. We will address this in the forthcoming paper on this project.
Velocity dispersion. The velocity dispersion in simulations is defined over the full set of particles (i.e., DM, stellar, black hole, gas), which are distributed over a large range of radii. In observations, it is measured over a small aperture (Thomas et al. 2013; Napolitano et al. 2020) and possibly corrected with an empirical formula (e.g., Cappellari et al. 2006) to the effective radius, or directly derived at the r1/2 via integral field spectroscopy (e.g., Z+23). The question arises of how comparable these two quantities are. The Observed velocity dispersion of galaxies shows a strong negative slope generally confined within the central regions, up to a few effective radii (see, e.g., Gerhard et al. 2001; Coccato et al. 2009; Napolitano et al. 2009, 2011; Pulsoni et al. 2018). On the other hand, the softening length of the TNG100 (∼0.7 kpc h−1) likely suppresses the typical central peak of the velocity dispersion profile of galaxies. The net effect is that in mid-resolution simulations the overall σ, as in Table 1, is basically sensitive to the large radii flatter part of the velocity dispersion profile that is smaller than the one measured in the central galaxies (e.g., Pulsoni et al. 2018). This is expected to produce a systematic shift on the typical scaling relations involving σ, like the mass-velocity dispersion relation (e.g., Faber & Jackson 1976; Cappellari et al. 2013; Napolitano et al. 2020). This is shown in detail in Sect. 5.2. For dwarf galaxies, though, the typical velocity dispersion profiles look flatter at all radii (see E+22, Fig. 4), hence this effect might be mitigated and the σ from the simulations can be a realistic proxy of the real velocity dispersion (see also Sect. 5.2).
Dark matter in galaxies. This is naturally provided in the TNG100 catalog by the sum of all the DM particles inside a given 3D volume. In our case, this is the one enclosed in the effective radius, MDM(r1/2). For real galaxies, depending on the sample, it can be directly fitted assuming some form of dark matter halo (e.g., a Navarro et al. 1997 or Burkert 1995 profile), or, if only the total mass of the galaxy is inferred, by the equation MDM(r1/2) = Mdyn(r1/2)−M⋆(r1/2)– see Table 1. Either case, the underlying assumption is that the gas mass is negligible in the considered volume. This is somewhat reasonable for the regions inside r1/2 we want to consider in this analysis. However, this might have a nonnegligible impact on the comparison with the simulations. In these latter cases, if we can reasonably assume that Mdyn(r1/2) = Mtot(r1/2) = M⋆(r1/2) + MDM(r1/2) + Mgas(r1/2), the quantity Mdyn(r1/2) − M⋆(r1/2) equals, by definition, 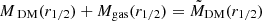 . Hence, this newly defined mass comes from the fact that in real galaxies the albeit limited, gas mass contributes as dark baryons to the MDM(r1/2). Thus, when explicitly checking the predictions of MELA against the DM in real data, we should use
. Hence, this newly defined mass comes from the fact that in real galaxies the albeit limited, gas mass contributes as dark baryons to the MDM(r1/2). Thus, when explicitly checking the predictions of MELA against the DM in real data, we should use 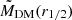 as a target (see Appendix A). For convention, we call this the “augmented” dark matter, meaning that it includes all the unaccounted mass contributions that exceed the stellar mass of a galaxy (aka “missing mass”).
as a target (see Appendix A). For convention, we call this the “augmented” dark matter, meaning that it includes all the unaccounted mass contributions that exceed the stellar mass of a galaxy (aka “missing mass”).
2.2. TNG100 simulation for training and testing
IllustrisTNG (N+19) is a series of state-of-the-art magneto-hydrodynamic simulations using different box sizes: 50 Mpc h−1, 100 Mpc h−1, and 300 Mpc h−1. In this work, we use TNG100-1 (TNG100, for short), which is the highest resolution simulation with a volume of 106.5 Mpc3 and 10243 dark matter particles. The mass resolution of dark matter particles is 7.5 × 106 M⊙, while the mean mass resolution of baryon particles is 1.4 × 106 M⊙. The Plummer equivalent gravitational softening of the collisionless component in the comoving units at z = 0 is Rp = 1.0 kpc h−1 (see N+19, Table 1) or 0.74 kpc h−1 in the physical units at z = 0. The cosmological parameters are based on Planck2015 (see Sect. 1), which is also the cosmology we use for all the observed data throughout the paper. The hydrodynamical part of the simulation includes updated recipes for star formation and evolution, chemical enrichment, cooling, and feedbacks (Weinberger et al. 2016; Pillepich et al. 2018; Nelson et al. 2018). It also accounts for AGN feedback (Weinberger et al. 2016) and galactic winds model (Pillepich et al. 2018), mimicking supernovae feedback.
The IllustrisTNG snapshots and Group catalogs in different redshift bins, from z = 0 to z = 127, are publicly available2. In the following, to illustrate the main properties of the simulations, we will use a reference redshift window from 0 to 0.1. In particular, we only use the information of Subfind Groups, which contain groups of particles recognized as individual objects for which a series of physical quantities have been assigned as the integral of all particles belonging to the group. The main properties we are interested in are indicated as TNG in Table 1 and previously described in Sect. 2.1. In the redshift range z ∈ [0,0.1], they include 9 snapshots, corresponding to z = 0.00, 0.01, 0.02, 0.03, 0.05, 0.06, 0.07, 0.08, 0.10. The Subfind Group Catalog represents the basic dataset to train our machine learning tools and subsequently test the performances, using the known target values as ground truth. If the galaxy-like systems belonging to the TNG simulations are a fair representation of the real galaxies, we can expect that the ML tool trained on the TNG galaxy catalog can predict the target quantities, specifically dark and total mass, not only on the simulated test sample, but also on the real galaxies. In the next section, we detail the selections needed to choose realistic galaxy systems from the Subfind Group Catalog.
2.2.1. Selection and properties of the galaxy sample from TNG100
The galaxy dataset from the Subfind Group Catalog contains subhalos from friend-of-friend (FOF) and subfind algorithms, that represent galaxy-like groups, but not all of them are well-defined, realistic systems. To select physically meaningful galaxies, we use the following criteria:
-
SubhaloFlag=True. This selects subhalos with cosmological origin (i.e., they have not been produced by fragmentation of larger halos by baryonic processes). TNG provides a Flag for these spurious satellite systems3.
-
The stellar half-mass (or effective) radius and dark matter half-mass radius are larger than 2 times of the Plummer radius Rp = 0.74 kpc. This is to avoid that the internal properties of small galaxies are fully dominated by numerical softening.
-
Number of both stellar and dark matter particles is larger than N = 200. This is a further criterion to have robust total quantities based on sufficiently large particle statistics in galaxies. This corresponds to a lower total stellar mass limit of M⋆ = 108.3 M⊙, which also implies M⋆(r1/2) > 108.0 M⊙.
-
We finally assume that every subhalo is a single galaxy.
We divide this galaxy sample into passive/early-type galaxies (ETGs) and active/late-type galaxies (LTGs) using the specific star formation rate as the criterion. Following observational analyses (Paspaliaris et al. 2023), we adopt log sSFR/yr−1 < −11 for ETGs and log sSFR/yr−1 > −11 for LTGs. This is possibly a more robust selection than one based on pure the color-stellar mass cut (see, e.g., Pulsoni et al. 2020), which yet allows us a sharp separation of the red sequence galaxies from the blue cloud systems. In the absence of other relevant structural parameters in the TNG catalogs suitable for morphological (e.g., the n-index of the Sersic 1968 profile) or kinematical selection criteria (e.g., galaxy spin, see Rodriguez-Gomez et al. 2022), the sSFR criterion remains the best physical argument we can use to make the ETG/LTG separation.
In Fig. 1 we show the correlations/distributions of some of the relevant properties (see Table 1) we will use in the rest of the paper as features and targets for these two classes. From the left panel, we clearly see the differences in the distributions of the ETGs and LTGs, which is also reflected in differences in the scaling relations, among the different quantities. We also remark the bimodal distribution of the ETGs, showing the presence of two populations of high-mass ETGs, at log M⋆(r1/2)/M⊙ ≳ 9.8, and “dwarf”, low-mass sample, at log M⋆(r1/2)/M⊙ ≲ 9.8, which is mirrored by the velocity dispersion distribution, which is also bimodal around log σ/km s−1 ∼ 1.9.
 |
Fig. 1. Distribution of relevant features and targets as in Table 1: total mass inside the stellar half-mass radius, augmented dark matter mass inside stellar half-mass radius, half-mass radius, stellar mass in half-mass radius, velocity dispersion, total and dark matter mass in half-light radius. Left: galaxies are divided into ETGs and LTGs on the basis of their SFR. Right: ETGs are further divided into normal and dwarf ETGs based on the classification criteria outlined in Table 2. The normalized distribution of the features and targets is shown along the diagonal. Units are as in Table 1. This is the original data from TNG100 without considering mock measurement errors. To get a comparative picture, a fixed value was set for the different types of galaxies. We randomly get a 20 000 galaxy subsample from the full dataset and from the three galaxy types. |
“Normal” ETGs (nETGs) and “dwarf” ETGs (dETGs) are known to have rather different scaling relations and possibly also different formation mechanisms (Koleva et al. 2009) which might reflect differences in their dark matter properties. Unsurprisingly, we also observe similar bimodalities in the total and DM masses. We then define nETGs as ETGs having log M⋆(r1/2)/M⊙ > 9.8 and log σ/km s−1 > 1.9, and dETGs all the remaining ETGs. With these criteria, the LTGs, and n/dETGs are distributed as shown in the right panel of Fig. 1, where we can use the Pearson correlation coefficient ρ:
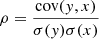 (1)
(1)
to quantify the linear relationship between different pairs of variables (i.e., the features and targets in Table 1). In Eq. (1), cov(y, x) represents the covariance of two variables, while the denominator σ(y) and σ(x) are the standard deviations of y and x. These values normalize the covariance, ensuring that ρ ranges between −1 (indicating a perfect negative linear relationship) and 1 (indicating a perfect positive linear relationship). From these correlation matrices, it is evident that the three classes have different distributions and scaling relations (see, e.g., mass-size relation, and the mass-σ relation). This is more clearly illustrated in the correlation heatmap presented in Fig. 2, where there are groups of physical parameters (i.e., M⋆, M⋆(r1/2), σ, MDM(r1/2), Mtot(r1/2)) that have a different level of correlation for the three distinct classes (three panels on the right). In particular, dwarfs show a looser correlations of the half-light radius, r1/2, with luminosity, mass, and σ, while the nETGs and LTG show tighter size-luminosity, mass-size relations, compatibly with observations (see also, Tang et al. 2021). Also looking at the target quantities, MDM(r1/2) and Mtot(r1/2), dETGs show shallower correlations with other parameters (e.g., luminosity, size, and stellar masses) with respect to nETGs and LTGs. When combined together, the full TNG galaxy sample (TNG_all) shows a correlation matrix (first panel on the left) which is very similar to the one of LTGs, which is the numerically dominant population with intermediate properties. We will come back to these correlations later, when interpreting the results of the mass predictions.
 |
Fig. 2. Correlation heat map of the different TNG galaxy samples defined in Sect. 2.2 when not considering (upper row) and considering (bottom row) the mock measurement errors, as in Sect. 2.2.2. The correlation coefficients are calculated using the Pearson correlation coefficient (see Eq. (1)). |
Due to these different features in the correlations highlighted by the Figs. 1 and 2, we will compare the mass predictions obtained by considering these three classes (i.e., nETGs, dETGs, LTGs) as separated and joined together, as done in vM+22. This will allow us to check whether MELA can perform better on the individual classes rather than all galaxies together.
In Table 2 we summarize the definition of the three galaxy classes from the TNG simulation. The number we collected in the different redshift bins is used in the next analysis to predict the total mass and the dark mass for the observed samples.
Classification criteria for simulated and observed galaxy samples.
2.2.2. Mock measurement errors for TNG100 galaxies
The physical quantities extracted from simulation usually are provided with no error (although they are themselves the product of a measurement process) and they ideally represent “exact predictions” of theoretical models. Statistically speaking they can be assumed to be the true value of physical quantities that, in observed galaxies, come along with measurement uncertainties. These measurement errors need to be taken into account when doing predictions, because their net effect is to dilute the correlations seen in Fig. 1, making also the predictions of the target broadened. This is a very basic form of “observational realism”, discussed in Sect. 2.1.
To include the effect of observing measurements on the simulated quantities, we have assumed Gaussian errors with typical relative uncertainties of 10% for the features (i.e., g and r magnitudes, M⋆, M⋆(r1/2), σ, r1/2) and 15% for the targets (i.e., MDM(r1/2) and Mtot(r1/2)) to be consistent with typical uncertainties found for galaxy observations and dynamical samples in the galaxy centers (see, e.g., T+09, Z+23, Cappellari et al. 2013). Note that the adoption of errors on targets is not strictly necessary, under the assumption that the targets represent some ground truth properties of galaxies. However, our choice intends to conservatively account for the fact that targets are extracted from the simulation with a measurement process that brings some uncertainties. Finally, the mock measurements are obtained by randomly drawing the “measured” quantities from a Gaussian centered in their original (true) value and with standard deviation corresponding to the adopted relative errors. The new “measured” quantity is taken inside 3σ from the original “true” value. This step is needed to fully account for the intrinsic errors of the observed features in the training phase, which should reproduce the distribution of the observed features one wants to use to make the predictions of the chosen targets.
In Fig. 2 we finally report the correlation matrices for the whole sample and the three galaxy classes after having added the measurement errors, face-to-face with the same matrices before the measurement errors. As seen the correlations have not been dramatically affected, although we can see a decrease of the correlation coefficients of the order of ∼5% or smaller for TNG_all and ∼10% or smaller for the n/dETG and LTG classes.
2.3. Observational data: The predictive sample
As mentioned in the introduction of this section, we use a variety of galaxy mass catalogs based on different dynamical methods as a predictive sample. These include SPIDER, MaNGA DynPop a SAMI Fornax Dwarf survey that we briefly describe below in this section. Here we anticipate that according to the independent and identically distributed hypothesis in machine learning inferences, to have reliable ML predictions, we need to ensure that the feature and target distributions of the test sample are comparable with those of the training sample. To do that we apply to observational samples above the same selection criteria of the TNG classes, as summarized in Table 2. Here we see that, for observations, we add the further condition that the dynamical mass inside the effective radius is larger than the stellar mass inside the effective radius (i.e., Mdyn(r1/2) > M⋆(r1/2)). This is because mass estimators, due to the statistical errors, might sometimes bring to such unphysical results. We also remark that the r1/2 ≳ 1.5 kpc criterion, imposed by the softening length of the simulations, is quite restrictive for observations as there are massive ultra-compact galaxies (UCMGs, e.g., Tortora et al. 2016, 2018; Scognamiglio et al. 2020; Spiniello et al. 2021) and dwarf galaxies (Graham & Guzmán 2003), having sizes generally smaller than the threshold used above. If, on one hand, the UCMGs are rare in the local universe (Trujillo et al. 2014; Tortora et al. 2016) and this selection does not impact the predictive sample, on the other hand, given the mass-size relation of dETGs (e.g., E+22) r1/2 > 1.5 kpc corresponds to stellar masses of the order of M⋆/M⊙ ∼ 109 or higher, thus strongly impacting the accessible lower mass limit of observations. As we are interested in pushing the predictions of the MELA toward low stellar masses, then we decide to add a secondary dwarf predictive sample for which we use the r1/2 = 1 kpc as a lower size limit and use a separate analogous training sample to make predictions for it.
2.3.1. SPIDER ETGs
The Spheroid’s Panchromatic Investigation in Different Environmental Regimes (SPIDER) is a sample of 39 993 bright ETGs in the redshift range of 0.05–0.095, possessing SDSS optical photometry and optical spectroscopy. 5080 galaxies also have YJHK photometric from DR2 of UKIDSS-LAS (see La Barbera et al. 2010). ETGs are defined as bulge-dominated systems, with passive spectra in their centers. Following Bernardi et al. (2003), they select ETGs with eClass < 0 and fracDevr > 0.8, where the SDSS spectroscopic parameter eClass gives the spectral type of a galaxy, while the SDSS photometric parameter fracDevr measures the fraction of galaxy light that is better fitted by a de Vaucouleurs (rather than an exponential) law. Here we are interested in a subsample of this catalog for which Jeans analysis has been used to derive the dynamical mass inside the r1/2 from T+12. We note that the selections are very effective in removing late-type systems (see La Barbera et al. 2010), but do not allow a clear separation of E and S0 galaxy types. However, this has no significant impact on the Jeans analysis results, as discussed in T+12. The final SPIDER sample contains 4260 galaxies for which information about the quantities as in Table 1 are available from T+12, and that we briefly summarize here below:
-
g- and r-band photometry from SDSS-DR6;
-
Re: effective radius obtained from the Sérsic fit to the SDSS imaging in the K-band. We convert it to 3D by r1/2 = 1.35 × Re;
-
M⋆: total stellar mass Swindle et al. (2011), obtained by fitting synthetic stellar population models from Bruzual & Charlot (2003) from SDSS (optical) + UKIDS (NIR) using the software LePhare (Ilbert et al. 2006), assuming a extinction law (Cardelli et al. 1989) and Chabrier IMF;
-
σ and σe: respectively, SDSS fiber velocity dispersion and aperture corrected velocity dispersion within 1r1/2 following Cappellari et al. (2006);
-
Mdyn(r1/2) and MDM(r1/2) respectively, dynamical mass from the Jeans equation and dynamical minus stellar mass in the 3D effective radius (see T+12).
In Fig. 3 we compare the distribution of the galaxy features and targets of the nETG sample against the same quantities from SPIDER ETGs selected according to the all set of criteria above. From the distribution, we can see that the SPIDER sample nicely overlaps with most of the distribution of the nETGs, except for the velocity dispersion. This is expected, as discussed in Sect. 2.1. All other deviations from the ETG simulated sample of the observed sample should be tracked to the difference of the definitions highlighted in Table 1. As anticipated in Sects. 2.1 and 2.2.2, this matter is related to the “observational realism” of simulations. Here we want to check whether the application of uniform selection criteria, such as the one introduced above in this section, can provide reasonably realistic mass predictions, or whether we need physically motivated corrections to empirically align observations and simulations (see, e.g., Pillepich et al. 2018).
 |
Fig. 3. Kernel density estimation (KDE) for each class of the dataset. Top row: KDE of the nETG dataset. Bottom row: KDE of the LTG and dETG dataset. The number of each class of datasets is indicated in Table 2. All the data points are within the x-axis limit. In the case of Fornax, an incompleteness of the smoothed estimate is evident due to the limited number of data points. |
2.3.2. MaNGA DynPop
Mapping Nearby Galaxies at APO (MaNGA4; Bundy et al. 2015) is a spectroscopic program included in the Sloan Digital Sky Survey, (SDSS), released in the final Data Release 17 (DR17). Unlike previous SDSS surveys based on fiber spectroscopy, MaNGA obtained 3D spectroscopy of ∼10 000 (10 k) nearby galaxies, hence providing two-dimensional maps of stellar velocity and velocity dispersion, mean stellar age, and star formation history for an unprecedented sample at z ∼ 0. As no preliminary selections on size, inclination, morphology, or environment were applied, MaNGA is a volume limited sample fully representative of the local universe galaxy population, eventually including all varieties of galaxies as ETGs, LTGs, and also irregular systems.
For our analysis, we are interested in the DynPop catalog (Z+23), combining the Jeans equation dynamical analysis with stellar population (Lu et al. 2023) for the full 10 k MaNGA sample5. The stellar dynamics is performed using the Jeans anisotropic modeling (JAM) method (Cappellari 2008, 2020), which was successfully adopted for extended analyses (e.g., Cappellari et al. 2013). The JAM method contains a final combination of eight different set-ups. Namely: two orientations of the velocity ellipsoid (cylindrically-aligned JAMcyl or spherically-aligned JAMsph) and four assumptions for the models’ dark versus luminous matter distribution: 1) mass-follows-light (e.g., Cappellari et al. 2012; Shetty et al. 2020), 2) free NFW dark halo (Navarro et al. 1996), 3) cosmologically-constrained NFW halo 4) generalized NFW dark halo (Wyithe et al. 2001) (i.e., using a free inner DM halo central slope). The catalog contains a series of parameters that we are interested in using in our analysis, and we briefly describe here below (see Z+23, their Appendix B):
-
M⋆: total stellar masses from K-correction fit for Sersic fluxes which is from the NSA catalog (Blanton & Roweis 2007; Blanton et al. 2011) with Chabrie IMF. In the DynPop catalog, they also provide the decomposition of the stellar mass from their total mass model.
-
r1/2: 3D radius of the sphere which encloses half the total luminosity, based on JAM.
-
σ: effective velocity dispersion within elliptical half-light isophote.
-
Mdyn(r1/2): dynamical masses derived via JAM.
-
“Qual” flag: this is a quality flag that classifies galaxies according to the “goodness” of the dynamical model fit. Qual = −1 means irregular galaxies; Qual = 0 no good fit for both velocity (V) and
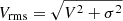 maps; Qual = 1 means acceptable fit for the Vrms map. Qual = 2 means have a good fit to the Vrms but a bad fit to the v. Qual = 3 means that both Vrms and V are well fitted (see Z+23, Sect 5.1).
maps; Qual = 1 means acceptable fit for the Vrms map. Qual = 2 means have a good fit to the Vrms but a bad fit to the v. Qual = 3 means that both Vrms and V are well fitted (see Z+23, Sect 5.1).
For our test, we choose as reference model the JAMsph with the generalized NFW as a reference and use the related Qual flag to select the predictive sample. We start by selecting a sample with quality flag Qual ≥ 1 (i.e., good fit to either the velocity map, or the velocity dispersion map, or both) from the original sample of 10 296 galaxies. However, we will also report the MELA predictions for all galaxies that are not clearly irregular (i.e., Qual ≥ 0) in Appendix C. In the same Appendix, we also show the predictions by MELA_ALL as compared against all other JAM models. The Redshift range of the DynPop sample is 0.00–0.17, so for consistency with the training sample used for SPIDER, we further select only the z < 0.1 systems to start with.
Using Qual ≥ 1 and z < 0.1, we are left with 5737 galaxies. To separate ETGs from LTGs, we adopt the criteria proposed by Domínguez Sánchez et al. (2021) and consistently adopted by Z+23:
-
E: (PLTG < 0.5) and (T-Type < 0) and (PS0 < 0.5) and (VC = 1) and (VF = 0)
-
S0: (PLTG < 0.5) and (T-Type < 0) and (PS0 > 0.5) and (VC = 2) and (VF = 0)
-
S: (PLTG > 0.5) and (T-Type > 0) and (VC = 3) and (VF = 0)
where PLTG, PS0 and PLTG are machine learning probabilities available as SDSS DR17 value added catalogs6.
We finally fixed the E+S0 sample as the final DynPop ETG sample. According to Z+23, MANGA is not suitable to be effectively used to study dwarf galaxies, due to the low spectral resolution. Although some low-velocity dispersion systems are present in the sample, we decided to discard these “dwarf” systems. We finally show the features and target distribution in Fig. 3, and find also in this case a good overlap with both the nETG and LTGs from TNG. We also see a nice overlap of the DynPop ETG sample with the SPIDER sample, especially looking at the central velocity dispersion distribution.
For the DynPop sample, Z+23 reports the use of Planck15 cosmology.
2.3.3. SAMI-Fornax Dwarf Survey
As a reference observational data on dwarf galaxies, we use the recent dynamical sample from the SAMI-Fornax Dwarf Survey (DSAMI, for short), reported in E+22. DSAMI is an integral field, high-resolution R ∼ 5000 survey of dwarf galaxies in the Fornax Cluster. The surveys provide spectroscopical data for the largest sample of low-mass (107 − 108 M⊙) galaxies in a cluster to date. The full description of the sample and the spatially resolved stellar radial velocity and velocity dispersion maps, together with their specific stellar angular momentum are given in Scott et al. (2020), and E+22 provides, in Table 1 and 5, the following parameters that we can use as predictive samples:
-
M⋆: the stellar mass within the effective radius, defined by the formula provided by Taylor et al. (2011, Eq. (3)) with Chabrie IMF:
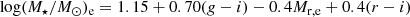 (2)
(2)where Mr, e is the absolute magnitude inside an effective radius, assuming Ωm = 0.3, ΩΛ = 0.7, h = 0.7, as cosmology;
-
Re: the effective radius obtained from r-band GALFIT model (Venhola et al. 2018). We convert it to 3D by r1/2 = 1.33 × Re;
-
σe: the velocity dispersion inside the effective radius. Due to the flat dispersion profile, they use the velocity dispersion with an aperture of 15″diameter as a proxy of the σe;
-
Mdyn(r1/2) and MDM(r1/2): respectively, the inferences of the total dynamical mass (see details below) and dark matter inside r1/2. The former is obtained via a simple mass estimator calibrated on the spherical Jeans equation from W+10 with h = 0.702 from WMAP5 cosmology:
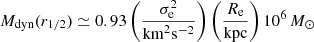 (3)
(3)where the MDM(r1/2) is a 3D mass in the 3D half-light radius, although σe and Re are both projected, according to W+10.
According to W+10, Eq. (3) is a rather robust estimator that is little sensitive to orbital anisotropy and is valid if the projected velocity dispersion profile is fairly flat near the half-light radius. This is a good approximation for most of the observed dwarf kinematics in the E+22 sample, hence we expect it to provide fairly unbiased Mtot(r1/2) estimates.
The total number of galaxies, which matches the training sample limits, in terms of stellar mass and effective radius, is 15 and the distribution is also shown in Fig. 3.
To convert all features and targets on the same scale as the TNG data, we use a distance of 19.7 Mpc for the Fornax cluster, which corresponds to z ∼ 0.005 in Planck15 cosmology, and rescale all dynamical quantities from WMAP5 to this latter cosmology.
3. The Mass Estimate machine Learning Algorithm
In this section we describe the principle of the Mass Estimate machine Learning Algorithm (MELA) we want to develop in this paper. We first introduce the main architecture and training strategy and then the statistical indicators we will use to assess its performances.
3.1. Random forests
As a first model for MELA we want to use random forests (RF). This is a powerful method for ensemble learning (the idea of combining the outputs of multiple models through some kind of voting or averaging). In particular, it is suitable for the specific goal of predicting the dark matter properties of galaxies, starting from a list of observations, as we have seen in vM+22, where RF has been the algorithm always picked by the Tree-based Pipeline Optimization Tool (TPOT; Olson et al. 2016). RF makes use of decision trees and, more specifically, for regression problems, it is based on CART trees. Compared to a simple decision tree, RF results, based on averages from all the decision trees which is made, are more robust and less prone to overfit. We use the package sklearn.ensemble.RandomForestRegressor and keep the default structural parameters, with 100 trees, after having tested that the performances would not significantly change with the adoption of any variation around the default set-up. Finally, in order to make the results reproducible, we set the structure parameters random_state=1.
3.2. Training MELA
In this section, we outline the various MELA configurations we will utilize throughout the paper, each corresponding to different training samples. As previously mentioned, while the pipeline remains consistent and relies on the same features and targets, we plan to employ distinct training samples. These samples are anticipated to offer more specialized and consequently accurate predictions for individual classes. To differentiate between the various configurations, we will use the following MELA extensions:
-
MELA_ALL. The MELA trained using the full original TNG100 sample, with no classes. Training size: 339 504 galaxies.
-
MELA_NETG. The MELA trained using the “normal” ETG sample. Training size: 21 416 galaxies.
-
MELA_DW. The MELA trained using the “dwarf” ETG sample. Training size: 70 859 galaxies.
-
MELA_LTG. The MELA trained using the LTG sample. Training size: 247 229 galaxies.
For the self-prediction (in Sect. 4.1), we allocate 80% of the complete training dataset as a training set and the remaining 20% as a test set to assess the performance of MELA. However, when applying the MELA to real observations, we use the entire dataset for training.
Looking at the training sample sizes of the different MELAs above, we remark that they seem rather unbalanced, being the LTG sample the largest one in the TNG_all sample. In principle, being the number counts of the individual classes a realistic representation of a complete sample of galaxies, their true distributions can be considered as a “prior” which realistically describes the observed samples. However, one can expect that such unbalanced training samples can affect the relative performances of the different trained MELAs above. To check that, we will also adopt a more “balanced” training/testing approach to verify if this can impact the different MELAs predictions. In particular, in Sect. 4.1, we will use a sample consisting of 21 000 galaxies per class, which is randomly selected from the complete dataset of each respective class. This balanced sample is aligned with the less abundant test set among the three classes (i.e., the nETGs, with 21 416 entries).
In this case, the class samples are divided into 16 800 galaxies for training and 4200 for testing. We will compare both training approaches, referred to as “full-counts” and “balanced-counts” training samples, against the respective test samples.
3.3. ML evaluator metrics
To evaluate the performance of the MELA, in terms of accuracy and precision, we use four different statistical estimators (see symbol definitions at the end of this list):
-
The coefficient of determination R2:
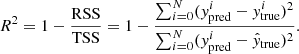 (4)
(4) -
The Mean Absolute Error (MAE):
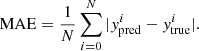 (5)
(5) -
The Mean Standard Error (MSE):
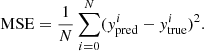 (6)
(6) -
The Pearson correlation coefficient ρ, already introduced in Eq. (1), but re-defined here as:
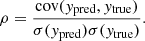 (7)
(7) -
The Median of Bias (MdBias), defined as:
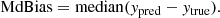 (8)
(8) -
The outlier fraction: the fraction of prediction exceeding ∼2σ errors of the typical mass estimates from dynamical analyses. In particular, we have found that this corresponds to ±0.3 dex for DynPop, being 0.15 dex about the average errors in that sample (see K+23). In case of log-normal errors, we expect a 5% outliers, as an acceptable outlier fraction.
In all equations above, N represents the total number of data points, while the variable y refers to the output of the MELA, which is also known as the target (hence, yi represents the value of the ith output), the subscripts “true” and “pred” indicate the true and predicted values respectively and 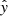 denotes the mean value of y. Furthermore, RSS indicates the residual sum of squares and TSS indicates the total sum of squares. R2 is a statistical measure used to assess the goodness of fit of a regression. By definition, R2 ranges from 0 to 1, with R2 = 1 meaning the perfect fit. However, in practical cases RSS can be larger than TSS, making R2 < 0. In these cases, the ML fails to make the prediction. It is important to note that R2 alone does not quantify the quality of a regression model; for example, it does not consider the complexity of the model, the significance of individual predictors, or the presence of overfitting. Therefore, R2 in used in conjunction with other metrics. MSE and MAE are both commonly used metrics for evaluating the performance of a regression model. They quantify the average magnitude of errors between the predicted values and the actual values. Both MSE and MAE are defined to be non-negative, with lower values indicating better performances of the ML tool. Finally, ρ describes the linear correlation between the true value and the predicted value. It ranges from −1 (perfect anti-correlation) to 1 (perfect correlation). For the purpose of our analysis, when comparing predictions with ground truth, the closer ρ and R2 are to 1 and the closer MAE and MSE to 0, the better the performances of the MELA are.
denotes the mean value of y. Furthermore, RSS indicates the residual sum of squares and TSS indicates the total sum of squares. R2 is a statistical measure used to assess the goodness of fit of a regression. By definition, R2 ranges from 0 to 1, with R2 = 1 meaning the perfect fit. However, in practical cases RSS can be larger than TSS, making R2 < 0. In these cases, the ML fails to make the prediction. It is important to note that R2 alone does not quantify the quality of a regression model; for example, it does not consider the complexity of the model, the significance of individual predictors, or the presence of overfitting. Therefore, R2 in used in conjunction with other metrics. MSE and MAE are both commonly used metrics for evaluating the performance of a regression model. They quantify the average magnitude of errors between the predicted values and the actual values. Both MSE and MAE are defined to be non-negative, with lower values indicating better performances of the ML tool. Finally, ρ describes the linear correlation between the true value and the predicted value. It ranges from −1 (perfect anti-correlation) to 1 (perfect correlation). For the purpose of our analysis, when comparing predictions with ground truth, the closer ρ and R2 are to 1 and the closer MAE and MSE to 0, the better the performances of the MELA are.
4. Results
In this section, we first evaluate the performance of the MELA to predict the total and the dark mass over a test sample derived by the TNG simulation. In our first analysis (see vM+22) we have demonstrated that ML can effectively predict the dark matter content of galaxies as a whole (i.e., without breaking these into different classes). Here, we want to check the performances of the MELA on the different galaxy types. We start by using test samples containing simulated galaxies from one of the three TNG100 classes and checking the predictions using the corresponding trained MELA (see Sect. 3.2) (i.e., the MELA_NETG, the MELA_DW, and the MELA_LTG) in turn, and compare these against the MELA_ALL trained over the full TNG sample. After having tested MELA which trained on the all features, we also checked the performance of the algorithm with different combinations of a smaller number of them. As discussed in vM+22 and in Sect. 1, some of the features reported in Table 1 might be redundant and bring little contribution to the accuracy of the predictions. Hence, we will check whether we can find a minimal sample of features that can provide accurate enough predictions, for each of the three galaxy classes.
4.1. Training and testing on TNG100: Self-prediction
In this section, we report the performances of MELA on the three test samples from the different classes of simulated TNG100 galaxies, using the full set of features: g, r, M⋆, r1/2, σ. Since the training and test samples are derived from the same simulated dataset, we dub this test “self-prediction”. For the sake of brevity, we illustrate here only the detailed results of the MELA trained with measurement errors included, while we will shortly report the results with no errors in Appendix B.
4.1.1. Self-prediction
We start by showing the results by the “full-counts” training sample defined in Sect. 3.2. In Fig. 4, we show the predicted values of the two targets vs. ground truth. Accuracy-wise, we can clearly see that nETGs and LTGs have R2 and ρ both larger than 0.9 for the two targets, although for Mtot(r1/2) the indicators are systematically better than the MDM(r1/2). For the dETGs, the R2 is ∼0.75 and ∼0.83, while ρ ∼ 0.87 and ∼0.91, for MDM(r1/2) and Mtot(r1/2), respectively (i.e., smaller than the other two classes). Looking at the same figure, all predictions look quite nicely aligned to the 1-to-1 relation with a negligible number of outliers (< 2%) consistent with a log-normal scatter. We argue that the lower R2 and ρ, for the dETGs, come from a lower correlation in the plots, due to the smaller mass range covered by the dETG sample. The scatter, on the other hand, as measured by the MAE and MSE, is rather similar for all the three classes (MAE ∼ 0.07 − 0.09, MSE ∼ 0.007 − 0.014) regardless of the target, suggesting very similar performances of MELA for all classes. We also note the emergence of a systematic deviation (within a few percent) at logMtot(r1/2)/M⊙ < 9.3, due to some incompleteness effect on objects close to the low-mass limit.
 |
Fig. 4. Self-prediction test using full features as indicated in Table 1, with the full-counts training sample incorporating added measurement errors, as described in Sect. 2.2.2. Top row: target is MDM(r1/2). Bottom row: target is Mtot(r1/2). The results without measurement errors are presented in Appendix B. The data is divided into 80% for training and 20% for testing. The x-axis represents the true values, while the y-axis represents the predicted values. “numofgal” is the number of the test set. The purple error bar represents the 16%, 50%, 84% percentiles as a function of Mtrue(r1/2), with a bin size of 0.2 dex. The red dashed line is ±0.30 dex (corresponding to ∼2σ errors, see text). Outliers are defined as the fraction of data outside the red dashed line. In the case of accurate predictions, the data points are expected to lie along the dotted 1-to-1 line. |
In vM+22 (see their Table 1), for TNG_all with target MDM(r1/2) they found R2 ∼ 0.98, ρ ∼ 0.99, MAE ∼ 0.04 and MSE ∼ 0.004 in the “joint analysis” (i.e., using all features). Our accuracy and overall scatter is obviously larger because we are now considering the measurement errors, which were not taken into account in vM+22. The inclusion of errors ultimately returns a more realistic forecast of the accuracy and scatter we might expect in real applications. In Appendix B, we will present our results without considering the measurement errors, to compare directly with what was done in vM+22, and show that these are in full agreement with the latter.
Next, we move to the results of the “balanced-counts” training sample, as shown in Fig. 5. Here we see that all self-predictions look almost unchanged, with all the statistical indicators remaining consistent with 1%, as seen by comparing the R2, MAE, MSE, and ρ values in the insets with the ones in Fig. 4. This shows significant stability of the MELAs with respect to the “prior” parameter distributions of the training samples. Most of all, the MELA_ALL performance remains insensitive to the relative balance of the three galaxy classes. This confirms the evidence that MELA can fully capture the diversity of the correlations of the three galaxy classes (nETG, dETGs, and LTGs) even if mixed together. To demonstrate that, in Fig. 6 we show the predictions of the Mtot(r1/2) for the same test sample of nETG, dETGs and LTGs, but using MELA_ALL for all classes. Compared to the same quantities predicted in Fig. 5 by MELA_NETG, MELA_DW and MELA_LTG, respectively, we find that the resulting R2 are almost indistinguishable for the three classes.
 |
Fig. 5. Self-prediction test performed using the full set of features and a balanced-counts training sample, which includes measurement errors. The training-test sample has been adjusted to maintain an equal number of entries across all samples in Fig. 4 through random selection, aligning with the less populated class (nETGs). The training set consists of 80% of the randomly selected subsample (16 800 entries), while the remaining 20% (4200 entries) is allocated for testing. Top row: target is MDM(r1/2). Bottom row: target is Mtot(r1/2). |
 |
Fig. 6. Self-prediction test of the MELA_ALL is performed using the full set of the features, and the Mtot(r1/2) as the target. As explained in Sect. 3.2, for this test the training utilizes balanced-counts training samples. These training samples comprise 21 000 × 80% = 16 800 galaxies for each class (i.e., dETGs, nETGs, LTGs), accompanied by 4200 galaxies for testing. The predictions of the entire TNG sample are presented as the self-prediction test in Fig. 5. |
This result seems rather surprising for two main reasons: 1) one could expect that the tilt of the different scaling relations in Fig. 1 should give more sensitivity to MELA to the different galaxy classes, in particular for the dETGs, showing the more deviating correlations in Fig. 1; 2) one would also expect that the different distributions of the galaxy observed quantities (features), in Fig. 3, should impact the prediction of MELA moving from one sample to the other. Instead, the result above seems to show that the MELA_ALL can use the combined information of all features from the different galaxy species, regardless of the specific correlations they have with the DM and the total mass, within the classes. Also, this result seems to show that MELA_ALL can correctly make predictions if the features and targets of a predictive sample are included in the dominion of the training sample, regardless of the detailed distribution of features and targets of the former of the two samples. We will return to this point in the discussion in Sect. 5.
As a final note of this section, one might guess that the equivalence of the performances of MELA_ALL and the customized MELAs can be a consequence of training over features (i.e., σ and M⋆) that are used to split the samples. First, this is true for the ETGs, for which we indeed use a condition on σ and M⋆ to separate the nETGs from the dETGs (see Table 2), but not for LTGs, which are selected only according to the sSFR. Second, as discussed above, the MELAs eventually learns from correlations among features and targets, and thresholds in the features only define the range of the correlations to use in training, which cannot tightly correlate with the mass of the individual galaxies. To check that, we conduct two tests. First, we compare the results obtained from MELA_ALL and MELA_ETG (where MELA was trained on the whole ETG sample) applying on the whole ETG sample (i.e., applying no selection based on the features used for the predictions). We find that the R2 values are nearly identical, meaning that MELA performs equally if any of the features used to split the sample is involved in the training. Second, we dig more into the details of the effect of the features in the splitting by predicting on the nETG, where we have used the σ and M⋆ in their selection, but predicting using the MELA_ETG above, trained on the whole nETG+dETG sample. Here we find, again, almost no change in the results, this also shows that the information used to split the sample is not used by the MELAs to predict.
4.1.2. Optimizing the features combination
One of the aims of this analysis is to find the optimal combination of the features needed to correctly predict the dark matter and/or the total mass of galaxies. In vM+22 we have grouped the canonical features one can collect from galaxy surveys into “Photometric” (including a series of broad optical and NIR bands), “Structural” (including the stellar mass and the r1/2), and “Kinematical” (including σ and a global circular velocity parameter), for a total of 14 features. We have shown that Structural and Photometric features are particularly effective in the prediction of MDM(r1/2), being typically R2 ∼ 0.88 − 0.94, and that the best predictions are found when using all groups of features (R2 ∼ 0.98 − 0.99). In vM+22 we did not try to optimize the feature selection, although we noticed that some groups of features might be more relevant than others in the feature importance analysis.
Here we want to check in detail the impact of the use of the individual features on the accuracy of the predictions. This is a heuristic “feature importance”, which is more oriented to accuracy optimization by avoiding redundant features that might add noise rather than effective predictive power. This becomes particularly important for real applications, where the predictions might suffer more from the feature noise introduced by measurement errors (see above). In Tables 3 and 4, we report the R2 estimator for MDM(r1/2) and Mtot(r1/2), respectively, obtained by changing the number of features considered and selecting the first ranked feature combination giving the highest accuracy among all possible combinations allowed for that particular number of features. The content of both tables is graphically summarized in Fig. 7, where we show the R2 as a function of the number of features in Tables 3 and 4, regardless the features.
 |
Fig. 7. Accuracy as a function of the number of features for MDM(r1/2) and Mtot(r1/2), taking measurement errors into account. This figure is based on Tables 3 and 4. The results without considering measurement errors can be found in Appendix B. |
Accuracy as a function of the number of features for the MDM(r1/2), considering measurement errors.
Accuracy as a function of the number of features for the Mtot(r1/2), considering measurement errors.
The first thing to notice from Fig. 7 is that the accuracy (R2) of both the targets, MDM(r1/2) and Mtot(r1/2), reaches a “plateau” for all the galaxy groups with just 3 features, which eventually are the same for all classes and for both targets (i.e., r1/2M⋆ and σ), although the two highest ranked features can be different for the different classes and targets (see num = 2 rows in Tables 3 and 4). According to the same tables, the stellar mass is the primary feature in almost all cases except the MDM(r1/2) predictions of the dETGs, where σ is the primary parameter. Interestingly, while σ appears to be important for the dETGs for both targets, it seems to be less important for the nETGs, LTGs, and the full sample, TNG_all, where it starts contributing to the predictions only after the stellar mass and the effective radius. The result of TNG_all, in particular, seems to be consistent with vM+22, which also discussed the kinematics to have a feature importance in the DM predictions at the r1/2 lower than the “structural” parameters (including M⋆ and r1/2).
A second important result is that differently from the dETGs, which, at least for Mtot(r1/2), clearly need three features to reach the “accuracy plateau”, the nETGs and LTGs both seem to need only two features (i.e., the stellar mass and the r1/2) to reach the same plateau. This finding has interesting implications, which we need to explore further, in particular, on the real galaxies (see Sect. 4.2). For instance, this might be a reflection of the strong correlation of the M⋆ and the MDM(r1/2), which scores the highest in the correlation matrix in Fig. 2. However, this might be a partial explanation, as we notice that there is no direct connection between the feature ranking in Tables 3 and 4, with the correlation coefficients. For instance, for the TNG_all sample in Fig. 2, the second highest correlation of the MDM(r1/2) is σ, but this latter, as commented before, is the third feature kicking in the feature ranking. Finally, we stress, that in selecting the features bringing the highest gain in accuracy in Tables 3 and 4, in some cases the difference among features is rather small, meaning that some features are just as good as others to make accurate predictions. This becomes clear when moving to the features that score fourth or higher. On the other hand, for the features ranked below the third, the feature ranking is rather robust (i.e., the first of the second-ranked features provides a larger gain in accuracy with respect to other features).
An obvious conclusion of this “feature ranking” test is that the MELAs do not need all the features in Table 1 to accurately predict the central total and dark matter content of galaxies. From Tables 3 and 4 we can see that the combination of the 3 features [r1/2, M⋆, σ] is sufficient for all galaxy classes.
Using only these 3 features, we also notice that MELA_ALL reaches the highest accuracy for both targets (i.e., R2 ≳ 0.93 for the MDM(r1/2) and R2 ≳ 0.96 for the Mtot(r1/2)). This copes with the result found in Fig. 6 about the superiority of the performances of MELA_ALL with respect to customized MELAs. Based on these results, for the test on the real galaxies in Sect. 4.2, we decide: 1) to use MELA_ALL as a unique tool for all galaxy species, unless otherwise specified; 2) to use only [r1/2, M⋆, σ] as training/testing features.
Although these latter are standard physical products of imaging and spectroscopic surveys, it is still interesting to check the effective ability of the MELA_ALL to minimize the input information needed to make reliable predictions of the MDM(r1/2) and Mtot(r1/2), with respect to the customized MELA_NETG, MELA_LTG, MELA_DW. In Fig. 8 we show the predictions of MELA_ALL, trained on the “balanced-counts” sample using only r1/2 and M⋆ as features. We can see that the prediction of dwarf galaxies has strongly degraded with respect to the same predictions using the 3 features in Fig. 6 as the R2 is decreased by ≳19% (0.687 vs. 0.815), the MAE increased by ≳24% (0.104 vs. 0.084), and the MSE increased up to ∼73% (0.019 vs. 0.011) for dETGs. On the other hand, as suggested by Table 4, for the nETGs and LTGs the R2 decreases by less than 3% (0.956 vs. 0.963 for nETGs and 0.924 vs. 0.943 for LTGs) and the MAE and MSE increase by < 9% (0.074 vs. 0.068 for nETGs and 0.095 vs. 0.082 for LTGs) and < 16% (0.009 vs. 0.007 for nETGs and 0.014 vs. 0.011 for LTGs), which are all much lower than the dETGs. Finally, the TNG_all sample, despite keeping the least accuracy degradation (< 2% in R2, i.e., 0.967 vs. 0.978), shows the largest increase in scatter (MAE: 0.094 vs. 0.078 and MSE: 0.015 vs. 0.010). This allows us to conclude that, when using M⋆, r1/2 and σ as features, or even adding other features like the photometry, we can have a better accuracy using the MELA_ALL vs. customized MELAs for each class, while the customized MELAs work equally accurately if the number of features is suboptimal (e.g., using only M⋆ and r1/2, at least for nETGs and LTGs).
 |
Fig. 8. Self-prediction test of the MELA_ALL with the target being Mtot(r1/2). This test uses the balanced-counts training sample and takes measurement errors into account. The test focuses on only two features: r1/2 and M⋆. |
Finally, following the same logic of feature optimization, in Sect. 4.3 we will explore other possible combinations of them, excluding some that are more difficult to measure (e.g., σ for dETGs) or more prone to systematics (e.g., stellar mass). To do that, we will test these combinations both on the TNG and the real datasets.
4.2. Prediction on real data
In this section, we can finally apply the MELA to the datasets introduced in Sect. 2. This is the first attempt we are aware of, a ML tool trained on simulations is applied to perform mass predictions of galaxies. The fundamental premise here is that simulations are based on complex physical processes, which serve as a physically motivated ground truth. Alternatively, we could use real mass estimates and observables (see, e.g., Sect. 5.1), but this would make MELA learn how to predict masses mimicking the process of dynamical modeling, including their assumptions and systematics. As discussed in Sect. 1 this is not our goal, as we want to rather provide an orthogonal method to use for comparison with standard tools.
As mentioned earlier, for the real galaxies, the obvious target to use is the Mtot(r1/2) as this is a rather standard diagnostic for classical dynamical analysis of galaxies. We have also discussed in Sect. 2.1 that, at least for the dynamical analysis of ETGs, the usual assumption is the absence of gas, which, instead, cannot be excluded in the simulations. This brought us to define the “augmented” dark mass, 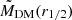 , in Sect. 2.1, that will be tested in Appendix A. Here we anticipate that the line of arguments we want to use is that, if we can demonstrate that MELA is able to 1) correctly predict the total mass in galaxies, under the assumption that the dynamical analyses provide unbiased estimates of the galaxy total masses, and 2) also predict the augmented dark matter, then 3) we will deliberately conclude that also the DM estimates are correct, specifically in the context of the cosmological framework provided by the TNG100 simulation.
, in Sect. 2.1, that will be tested in Appendix A. Here we anticipate that the line of arguments we want to use is that, if we can demonstrate that MELA is able to 1) correctly predict the total mass in galaxies, under the assumption that the dynamical analyses provide unbiased estimates of the galaxy total masses, and 2) also predict the augmented dark matter, then 3) we will deliberately conclude that also the DM estimates are correct, specifically in the context of the cosmological framework provided by the TNG100 simulation.
As discussed in the Sect. 1, the combination of stellar masses, baryonic mass, and dark matter in a galaxy is the complex interplay of the cosmological parameters and the galaxy formation recipes, driving the star formation efficiency in galaxies. Hence, the fact that MELA can provide consistent predictions of the total mass of real galaxies is not a trivial result. For sure the predictions of both the Mtot(r1/2) and MDM(r1/2) are model-dependent by definition (i.e., those expected exclusively in the cosmology + feedback model of the TNG100). Hence, if this cosmology/baryon physics mix is different than the one beyond the dynamical inferences of the real sample (e.g., the combination of the choice of the cosmological parameters and assumptions on the dark matter properties in the models), we should not expect MELA to return predictions consistently with the dynamical models. As far as the cosmological parameter choice concerned, we have uniformed the units of the quantities (e.g., the distances and the stellar masses) that have a direct dependence on the cosmological parameters, by aligning the real datasets to the TNG cosmology (i.e., Planck2015, see Sect. 1). Hence, we can expect that most of the deviation of the MELA predictions from the classical mass estimates can be tracked either to the assumptions behind the mass estimators from the real sample side, or the combination of the (cosmological + feedback) model + observational realism, from the simulation side. We will return to this point in detail in Sect. 5.
After this premise, we can now show the results on the real data. We have anticipated in Sect. 4.1.2 that for the application to the observed datasets, we can use the MELA_ALL trained using the three most important features [M⋆, r1/2, and σ]. In particular, we use the “full-counts” training set. The results are shown in Fig. 9.
 |
Fig. 9. MELA_ALL predictions of the central total mass, Mtot(r1/2), for the real galaxy dynamical samples. The optimal feature combination (i.e., r1/2, M⋆ and σ) is used, as discussed in Sect. 4.1 and Table 4. Shown (from left to right) are predictions of the SPIDER sample; the DynPop/nETG; the DynPop/LTG samples; and the DSAMI sample. The dynamical model used as representative of the MaNGA Dynpop results is the JAMsph+generalized NFW profile (see Sect. 2.3.2). For the DSAMI sample, the red triangles represent the data points from the secondary test sample (1 kpc < r1/2 < 2Rp). The legend provides an overview of the statistical estimators for the different samples. |
The immediate impression is a very good qualitative consistency of the MELA_ALL predictions with the dynamical estimates. The R2 ≳ 0.8 in all cases except for the DSAMI sample, which also shows an MAE more than twice larger than the other samples, indicating an exceedingly high scatter. We recall here that the DSAMI sample is fully confined in the low end of the mass range covered by the training sample, in a region where the scatter of the scaling relations is systematically larger, at the level that the same scaling relations (see, e.g., the size-stellar mass relation in Fig. 1) are almost washed away for dETGs. Despite that, we see that the MELA predictions are still nicely aligned around the 1-to-1 relation. The R2 values are in all cases smaller than the ones found in the self-predictions for nETGs, LTGs, and dETGs, if we use these latter as benchmarks. Looking at Fig. 4, bottom row (but also Fig. 5 for the balanced training sample), the R2 is smaller by 10% and 18%, respectively for the SPIDER and DynPop ETG samples with respect to the nETGs (R2 ≈ 0.96), by 4% for the DynPop LTG sample with respect to the self-predictions of the LTGs and by 35% for the DSAMI sample with respect to the dETGs. In this latter case, we have included also the “secondary” dwarf predictive sample (red dots) to increase the statistics. In terms of scatter, both the MAE and the MSE can be between 32% to 200% larger than the self-prediction cases in Fig. 4, although the maximum absolute values of both estimators (MAE ≲ 0.12 and MAE ≲ 0.03, if we exclude the DSAMI sample) is yet reasonably low. As comparison, in Fig. 9, we show the ±0.30 dex limits, corresponding to the ∼2σ errors of the DynPop estimates, to check that the majority (typically > 95%) of the MELA predictions are enclosed within these limits (i.e., the outlier fraction is below 5%). We also notice a small systematic effect, more evident in the MELA DynPop ETG estimates, that are 0.07 dex underestimated with respect to the corresponding classical estimates, with a tail of outliers below the −0.30 dex limit, which also exceeds the 5% expected for an unbiased log-normal distribution. We track this misalignment between the MELA predictions and the classical Jeans analysis method of the DynPop sample, most of the more severe degradation (i.e., 18%) of the R2 with respect to the self-predictions, discussed above. Indeed, if we just artificially compensate for this small offset (i.e., by adding +0.07 dex to the MELA predictions) the R2 would become 0.837 for DynPop ETGs, showing an improvement of 6%. We will discuss more quantitatively the robustness of these results in Sects. 5.1 and 5.2. Here we just anticipate that 1) the mentioned offsets seem statistically insignificant, as they are well within the scatter and 2) they partially come from the different definitions of the 3D structural quantities, which are difficult to align even between the observational samples.
The second, remarkable thing to notice, in Fig. 9, is that the good accuracy of the MELA predictions is insensitive to the methods adopted and, partially, to the sample adopted (i.e., DSAMI has a systematically lower accuracy, see above). In the figure, the classical dynamical methods adopted span from simple virial theorem (DSAMI), to the radial Jeans equation applied to fiber spectroscopy (SPIDER), to full 2D Jeans modeling of IFU rotation and velocity dispersion (DynPop). These methods are based on a variety of different data (deep imaging + multiobject spectroscopy, integral field spectroscopy) and contain a diversity of assumptions (e.g., geometry, orbital anisotropy, total mass model, if any), which potentially could bring a multiplicity of systematics. For these datasets, in the case of MELA estimates, we have adopted simple quantities characterizing the same systems. This is particularly impressive for the DynPop sample, which is, by far, the most complex predictive dataset. The dynamical analysis in K+23 is among the most sophisticated currently available on the market, and it is based on state-of-the-art observations, based on the largest IFU dataset ever observed, see Sect. 2.3.2. Despite that, MELA could use very basic information, like total stellar mass, size, and a single velocity dispersion values, to derive the mass of the DynPop sample with similar accuracy (see also Sect. 5.1). As discussed earlier M⋆r1/2 and σ are, nowadays, standard level 3 products of multiband photometric surveys (e.g., KiDS – de Jong et al. 2013, DES – Levi et al. 2013) or by large sky spectroscopic surveys (e.g., SDSS –Thomas et al. 2013, GAMA – Lange et al. 2015, LAMOST – Napolitano et al. 2020) for up to millions of galaxies, and will be obtained for hundreds of millions of galaxies by next-generations imaging surveys (e.g., LSST – Ivezić et al. 2019, Euclid – Laureijs et al. 2011, CSST – Zhan 2011, Roman – Spergel et al. 2015) or spectroscopic surveys (DESI – Levi et al. 2013; DESI Collaboration 2016, 4MOST – de Jong et al. 2019). This gives an idea of the great potential of MELA applications. This potential is not diminished by the only apparent shortcoming of this approach: the cosmology + feedback dependency. We will come back to this in detail in Sect. 5.2.
We conclude this section by showing the Mtot(r1/2) predictions for all the observational samples, based on the same three features but using the customized MELAs. These are shown in Fig. 10. By comparing this latter with Fig. 9, we see that all data samples show almost no changes in all statistical indicators. This confirms the conclusions based on the self-prediction tests based on TNG100 mock galaxies in Sect. 4.1.2, that MELA_ALL is as good as, or even better than, the customized MELAs.
4.3. Other relevant feature combinations on simulations and real galaxies
In this section, we finally test different feature combinations to check whether 1) they provide similar accuracy with respect to the optimal feature combination seen in the Sect. 4.2; 2) there are combinations of features easier to measure that can still provide sufficient accuracy on the targets and that can be considered for applications on real data.
4.3.1. Using two features: r1/2 and M⋆
The first obvious test is the “minimal feature” scenario anticipated in Sect. 4.1.2 (i.e., the use of two features, r1/2 and M⋆). The results for MELA_ALL and “full-counts” training are shown in Fig. 11. Overall we see again a remarkable agreement for SPIDER and DynPop (both nETGs and LTGs), with R2, MAE, MSE, and ρ only slightly degraded with respect to the case of the three features shown in Fig. 9. This is in line with the accuracy degradation reported in Table 4. However, we also notice that the very massive end of the SPIDER sample (log M⋆/M⊙ > 11.5) shows a large scatter and a positive offset than the much tighter estimates in Fig. 9. On the other hand, the predictions for DSAMI are much worse than the 3 feature case, which is also expected, as discussed in Sect. 4.1.2 and seen in Table 4. We see though that most of the poor R2 might come from a small but not insignificant fraction of notable exceptions (2/15, the two blue points on the left), while the majority of the prediction looks well predicted. This is yet promising and needs to be tested possibly on larger samples. Indeed, the possibility of predicting correctly the total mass of dwarf galaxies without kinematical measurements is interesting as these latter are notoriously difficult outside the local universe (Battaglia & Nipoti 2022). Finally, we have checked that for the MELA_DW the results are not significantly better (R2 = −0.100) than the MELA_ALL, although the self-prediction test shows otherwise (see, e.g., Table 4), again, very likely for the poor statistics.
 |
Fig. 11. MELA_ALL predictions of the central total mass, Mtot(r1/2), as in Fig. 9, but using only two features: r1/2 and M⋆. In the case of DSAMI, there are three obvious outliers above +0.30 dex. In the bottom right corner of the plot are shown the statistical estimators obtained excluding these outliers. |
4.3.2. Excluding the stellar mass
Moving forward, with tests beyond the “feature ranking” analysis, we want to check how good MELA can predict if one of the highest ranked features is missing (i.e., the M⋆ and the r1/2 in turn), still keeping all other features from our original catalog.
We start by excluding the M⋆, assuming that one does not possess enough data (either multiband photometry or spectroscopy) to have a robust estimate of the stellar mass. In this case, the features we can use are the two photometric bands (g and r), the size (r1/2), and the velocity dispersion (σ). We stress here that, as the TNG100 simulations are based on the Chabrier IMF, the mass prediction we derive even excluding M⋆ from the features, remains bound to the same IMF. This is to avoid explaining any difference we might find using total luminosity instead of the total mass, with an IMF variation.
In Fig. 12 we show both the self-prediction results, i.e., the prediction obtained using a random TNG100 test sample (upper row), using the MELA_ALL (left) and MELA_NETG (right), and the corresponding SPIDER predictions (bottom row), being this latter the only observed sample which provides all the features (included g and r band photometry) in a consistent way with the TNG100 (as in Table 1). For the self=prediction test, we find a very good accuracy, which is not far from what found for the results with all features, as in Figs. 4 and 5. This confirms the trend seen in Fig. 7 and Table 4, where the accuracy flattens to R2 > 0.95 if the number of features is larger than four. We notice that the result here is even better than in Table 4. This is because here we are using “balanced-counts” while in Table 4 we are using the “full counts” (The “full counts” results are R2 = 0.955, 0.949 for MELA_ALL and MELA_NETG). The fact that these good accuracies are found even in case the stellar mass is missing, though, seems in contrast with Table 4, showing that the M⋆ is the most relevant feature. In fact, there is no contradiction, as the total luminosity carries almost the same information as the total mass, if one can change one into another via a constant stellar mass-to-light ratio, M/L. This is clearly seen in the correlation matrices of all galaxy species in Fig. 2, where the largest correlation coefficients of the M⋆ are the ones with the g and r magnitudes.
 |
Fig. 12. MELA_ALL predictions of the central total mass, Mtot(r1/2), using four features: g, r, r1/2, and σ. Top row: self-prediction test with balanced-counts training sample. Bottom row: application of MELA_ALL and MELA_NETG on the SPIDER dataset. Only the SPIDER sample was used as a real data test as it is the only dataset providing the broadband luminosities. |
In the bottom row of Fig. 12, which shows our predictions of the SPIDER sample, we find an acceptable R2, MAE, and MSE, which are comparable with the ones found for the 2-feature test (Sect. 4.3.1). Most of the degradation of the estimator comes from the larger scatter and tendency of MELA to underestimate the masses at the high-mass end (log Mtot(r1/2)/M⊙ > 11.5). This tilt is not statistically significant. However, due to the tight correlation between the luminosity-stellar mass-total mass, we can argue that the mismatch might come from a steeper slope, α, of the M/L ∝ Lα relation (where L can be the luminosity of g or r-band in this case of the TNG100 nETGs with respect to the SPIDER ETGs). Given the adoption of the same IMF in the two samples, this has to be tracked to the stellar population parameters, star-formation history, and, ultimately, feedback in simulation. The reason this does not affect the stellar mass is that, generally, this latter is calibrated in simulation in order to reproduce the observed stellar mass function, while the consistency of the luminosity function with real observations, even introducing realistic calibrations, is yet disputable (Trčka et al. 2022).
As an extreme case of minimal information to use for predictions, we can limit to photometry-only observations and exclude the kinematical information. For instance, we can check if using g magnitude and r magnitude MELA can still provide reasonable estimates. We apply the trained MELA on the SPIDER sample. The prediction shows a tilt similar to that in Fig. 12 (bottom), but with a worse accuracy (R2 = 0.740 vs. 0.806), meaning that adding σ to photometry does improve the MELA performance, although not dramatically (in line with Table 4).
4.3.3. Excluding the effective radius
We conclude the round of feature combinations, with a note about excluding the r1/2. We do not extensively consider this case as this has no practical applications, because we cannot predict the total and dark matter quantities within the r1/2, if this latter is unknown. Anyways, we have tested this situation as this can provide further insight into the way MELA handles missing features, specifically the second most important feature after M⋆, as seen in Tables 3 and 4. Starting with self-predictions of the TNG100 galaxies, using g, r, M⋆, and σ as input, the predictions of the Mtot(r1/2) show accuracies and precisions of the order of the ones found for the missing M⋆. In particular, we find R2 = 0.951, 0.949 for self-prediction using MELA_ALL and MELA_NETG, once again in line with what is expected for 4 features from Fig. 7 and Table 4. Going to the prediction of the SPIDER sample (we remind this is the only sample for which there are explicit cataloged g and r magnitudes), besides a much lower R2 = 0.65 and very large MAE and MSE (∼0.16 and ∼0.04 respectively), once again, we register a tilt between the MELA_ALL predictions and the dynamical values from T+12, although this time it is statistically significant, which is shown in Fig. 13 (left panel). Here, the bulk of the predicted distribution, between log Mtot(r1/2)/M⊙ = 10 and 11, stays within the ±0.30 dex from the 1-to-1 relation, while strong deviations are seen above log Mtot(r1/2)/M⊙ = 11. This is mirrored by the behavior of the two datasets in the M⋆ − r1/2 relation, shown in the same Fig. 13 (right panel), where we see a steeper slope of the linear fit to the data for the SPIDER sample (orange line) with respect to the nETGs (blue line) of TNG100, that starts to strongly deviate at log Mtot(r1/2)/M⊙ ∼ 11. Overall, we notice that as long as the SPIDER galaxies remain consistent with the M⋆ − r1/2 of TNG100 galaxies (e.g., below the red curve as a qualitative example), also the predictions remain aligned along the 1-to-1 line (see the correspondent red line in the left panel). We believe these deviating galaxies explain the tilt in the predictions because MELA_ALL, in the absence of any knowledge about r1/2s, guesses their values from the TNG100 M⋆ − r1/2 relation, which, being shallower in slope, returns an underestimated r1/2. Due to the tight correlation between the r1/2 and Mtot(r1/2) (see, e.g., the correlation matrix in Fig. 2), this causes an underestimated Mtot(r1/2), particularly at log Mtot(r1/2)/M⊙ > 11, and the subsequent tilt.
 |
Fig. 13. MELA_ALL prediction and the scaling relation analysis of SPIDER. Left panel: result of applying MELA_ALL on SPIDER with four features (g, r, M⋆, σ) and missing the r1/2. The green circle is the median value for a given x-axis bin, where the bin size is 0.1 dex. The orange line represents the linear fit of the blue data points. Right panel: M⋆-r1/2 relation of nETGs and SPIDER. A linear fit line is displayed for both data points. The best linear fit of the SPIDER sample is determined by averaging the linear fit using log M⋆ and log r1/2 as independent variables. This approach compensates for the more unbalanced distribution observed towards log M⋆/M⊙ ≲ 11.2. Completeness effects on the M⋆-r1/2 relation are not considered here, as the focus is on understanding the origin of the tilt in the predictions (left panel). |
4.4. Final remarks
We want to conclude this section with a recap of the results we have collected using different test samples, that, we believe, have some profound implications.
1) The first clear evidence (Sect. 4.1) is that MELA can correctly predict the total mass of a galaxy (inside r1/2) if this belongs to the parent population of the training sample (self-prediction). This is true either if we separate the different galaxy types, or if we keep all species together (see also vM+22). Hence, MELA seems to be insensitive to the differences among the scaling relations of the different galaxy types, and able to predict independently the multiple correlations among the features and targets (i.e., stellar properties and DM/total mass).
2) The second evidence (Sect. 4.2) is that MELA can accurately predict the Mtot(r1/2) of the real sample, with a scatter which is consistent with the typical dynamical analysis errors, if a sufficient number of features is available. The minimal combination to keep the maximum accuracy includes the stellar mass, the effective radius, and the velocity dispersion (Sect. 4.1.2). This might not be surprising as these are the structural parameters that enter into the Virial theorem, which ultimately should govern the physics behind the equilibrium of gravitational systems.
3) The third evidence is that MELA cannot accurately predict the total masses of the real sample, if either the stellar mass or the effective radius are missed (i.e., using only two features in the training). These are the most important features providing high accuracy to the Mtot(r1/2) predictions (see Sect. 4.1.2) and missing either of them causes not only a larger scatter, but also a tilt in the predictions with respect to the real sample. Since the tilt is not present in the self-predictions test, this cannot be tracked to the inability of MELA to guess what is the true mass if any of these features are missing, but rather it has to be tracked to the differences (i.e., a tilt in the scaling relations between the simulation and the real data). We have given proof of that in Fig. 13. The question arises of why these tilted scaling relations do not affect the Mtot(r1/2) predictions whatever feature combinations are used, including the three-feature (M⋆, r1/2, σ) case.
4) To answer this question, we argue that the ML has indeed learned the physics behind the equilibrium of the galaxies in the TNG100. This is basically the Jeans equation, which can be written to explicit the total mass of stellar systems as (Binney & Tremaine 1987):
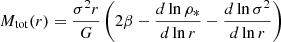 (9)
(9)
where G is the gravitational constant, ρ* is the 3D light density profile, σ is the radial component of the velocity dispersion7, and β is the anisotropy parameters. By incorporating all the bracket content in a single “virial factor”, k, which eventually depends on the slope of the light profile, n, and orbital anisotropy, as well as the slope of the velocity dispersion profile, γ, and also using the Faber & Jackson (1976), M⋆ ∝ σδ (where, canonically, δ ∼ 4), then Eq. (9) writes (e.g., at the 3D effective radius, r1/2):
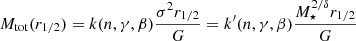 (10)
(10)
where, in the second equation, the new constant k′ incorporates the units of the conversions from the velocity dispersion to the stellar mass from the FJ.
These are the equations that MELA eventually learns from the training sample and that are behind all results seen in this section. The proof of this assertion is beyond the purpose of this paper but it can be traced back to the ability of the ML to find universal relations in subhalo properties (see, e.g., Shao et al. 2022). However, we note that the equation on the right seems consistent with M⋆ and r1/2 being the most important features for nETGs and LTGs found in Sect. 4.1.2 and also explains why the σ is the least important feature, in another word because it is needed only to set the slope of the FJ, δ, which is defined with a little scatter (Fig. 1, bottom right). If this interpretation is correct then MELA should be able to correctly predict the quantity 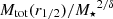 with δ = 4 in Eq. (10), using r1/2 only as a feature for the nETG sample. This is because we have fully incorporated the effect of σ by fixing δ = 4, as argued above. Indeed, in Fig. 14 we see that MELA predicts the
with δ = 4 in Eq. (10), using r1/2 only as a feature for the nETG sample. This is because we have fully incorporated the effect of σ by fixing δ = 4, as argued above. Indeed, in Fig. 14 we see that MELA predicts the 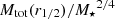 with a rather high accuracy, as expected, showing that it might have learned Eq. (10), where M⋆ is a fundamental quantity. On the other hand, for dwarf galaxies, the main driver of the feature importance is the poorer correlation between M⋆ and Mtot(r1/2) (and MDM(r1/2) see Figs. 1 and 2) than the σ-Mtot(r1/2), meaning that MELA becomes more accurate using the equation on the left in Eq. (10). This explains why σ and r1/2 or M⋆ and r1/2 are, in turns, the highest ranked features in Tables 3 and 4, for dETGs and nETGs, respectively. Finally, the reason this equation works also for the LTGs, which generally are rotation-dominated, can reside in the fact that the total mass of the galaxies is strongly correlated to the mass of their bulges, which are governed by Eq. (9).
with a rather high accuracy, as expected, showing that it might have learned Eq. (10), where M⋆ is a fundamental quantity. On the other hand, for dwarf galaxies, the main driver of the feature importance is the poorer correlation between M⋆ and Mtot(r1/2) (and MDM(r1/2) see Figs. 1 and 2) than the σ-Mtot(r1/2), meaning that MELA becomes more accurate using the equation on the left in Eq. (10). This explains why σ and r1/2 or M⋆ and r1/2 are, in turns, the highest ranked features in Tables 3 and 4, for dETGs and nETGs, respectively. Finally, the reason this equation works also for the LTGs, which generally are rotation-dominated, can reside in the fact that the total mass of the galaxies is strongly correlated to the mass of their bulges, which are governed by Eq. (9).
 |
Fig. 14. MELA predictions of |
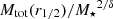
A first corollary of this assertion is that every time one of the three features is missing, the ML tool tries to replace it with other scaling relations it has also learned from the training sample. If these are consistent with the observations, then the predictions remain correct. If the scaling relations are tilted, then the predictions are tilted (Figs. 12 and 13). A second corollary of our assertion is that if there is an offset between the scaling relations of the observations and simulations, then one can expect an offset in the predictions. We will discuss this in more detail in Sect. 5.2, dedicated to systematics. In particular, we will demonstrate that this is a necessary but not sufficient condition for accurate predictions.
Finally, a last note about Eq. (10). The dependence of the k factor on the Sérsic suggests that the n-index is responsible for part of the scatter in the predictions. Hence, the accuracy and precision of the predictions would strongly benefit from the inclusion of this parameter in the training. We are currently working on this implementation in future analyses (De Araujo Ferrera et al., in prep.), however, we stress here that being the n-index generally known with little accuracy, this might also introduce some extra-scatter itself. Hence, here we acknowledge that, despite not knowing n, MELA can still return a reasonable scatter in its estimates.
5. Discussion
In this section, we want to revisit all the results discussed in the previous section and quantify the robustness and the source of the systematics of our machine learning mass estimator algorithm, where possible. In particular, we will discuss the impact of the results of this paper in a wider context of the use of galaxies to infer cosmology, using machine learning tools trained on hydro-dynamical cosmological simulations (see CAMELS; VN+23).
5.1. Robustness of the results
In Sect. 4, we have seen that typical accuracies obtained for the best combinations of features in the Mtot(r1/2) predictions of real data (e.g., the 3-feature cases) give typical R2 which are up to 18% worse that the self-predicting case for ETGs (e.g., DynPop) and up to 35% for dETGs (i.e., DSAMI), and even larger MAE and MSE degradation. However, the statistical indicators can be somehow too optimistic in the test on simulated data. To check this, we have let MELA_ALL make predictions on both the training and test sets of TNG100. We have found that all the evaluation metrics are nearly identical, confirming that there is no overfitting in MELA_ALL. Furthermore, to better assess whether the statistical indicators on real samples are still sufficient to claim a good accuracy and precision of MELA predictions, we have benchmarked them against the best accuracy the MELA can provide if effectively trained on real galaxies as ground truth (and not the TNG simulation as done in Sect. 3.2). This means we can simply use the self-predictions of the real datasets, to estimate the best indicators one can expect to achieve, in the ideal conditions of knowing the ground truth (accuracy) and taking into account all the uncertainties on the measurements (precision). This is done by training and testing using the same features from the observed datasets but using the classical mass estimates as a target. Due to the smaller training size, this “self-prediction test” on the real data can be performed only for the massive ETG samples and LTG samples which have up to thousands of galaxies, allowing training sets of several hundred entries, but not for the dwarf samples. The scope of this test is to find out the best R2 and MAE and MSE of the real sample as compared to the TNG100 self-predictions, which might be too idealized, even if accounting for realistic statistical errors. This is particularly important for the scatter, as measured by the MAE and MSE, that shows up much larger when moving from the TNG100 to the real sample, as discussed above. In Fig. 15, we can see the results of such a test from SPIDER and DynPop. All indicators of the real data self-prediction result in scores closer to the maximum scores found in the self-predictions with a R2 ∼ 3% smaller and MSE not more than 60% larger except for SPIDER8. Hence, based on the absolute values of the statistical indicators and the vicinity to the benchmarks found for the self-predictions of the real samples, we conclude that the overall accuracy and precision of the MELA predictions of the real sample based on the TNG100 training are rather satisfactory.
 |
Fig. 15. Self-prediction test for observation using three features: M⋆, r1/2, and σ with the balanced-counts training sample. The training–test sample has been re-scaled to ensure an equal number of entries across all samples through random selection, aligning with the less populated class (DynPop-nETGs). The training set consists of 80% of the randomly selected subsample (800 entries), while the remaining 20% (200 entries) is allocated for testing. The Fornax sample is too small, with fewer than 20 entries, making it impossible to conduct the self-prediction test. |
5.2. Source of systematics
In Sect. 2.1 we have listed a series of potential factors that can produce a misalignment between the simulation data and the observational data, which might introduce some systematic errors in the ML prediction based on simulations. We have also discussed that, by construction, the physical properties of galaxies in a single simulation are model (i.e., cosmology, feedback, DM flavor) dependent, this means that training on a single simulation might give a wrong answer about the true mass content of a galaxy. In Sect. 4 we have presented the first attempt at central mass content predictions of different observational datasets from MELA, a machine learning-based mass estimator trained to use a set of very basic observables from multiband imaging and spectroscopic surveys. It is worth mentioning that we have achieved an excellent agreement with classical mass, as shown in Fig. 9. This is noteworthy since there is a well-known misalignment between real galaxy data and simulations (Vogelsberger et al. 2020), which is also reported in the distributions of galaxy properties (Fig. 3) and the scaling relation (Fig. 13). However, here below we want to address, in a more quantitative, albeit not exhaustive way, some obvious sources of systematics and provide possible pathways for future improvements of the MELA results.
5.2.1. Simulations vs. observations
Following the discussion at point 4) of Sect. 4.4 we can now better understand the impact of the systematics of the feature definitions in the MELA predictions. In Sect. 2.1 we have mentioned that among the quantities involved in Eq. (10), the most prone to mismatch in definitions is the effective radius. As mentioned in Sect. 2.1, in this paper we make use of the 3D radius, consistently with the simulation. However, the definition of such a radius is different in SPIDER and DynPop. The former starts from the 2D effective radius from Sérsic fit to the r-band imaging from SDSS and then converts this to 3D using a simple formula (i.e., R3D = 1.35 × R2D from W+10). In DynPop, the effective radius is determined via multi-Gaussian expansion (see Z+23, their Appendix B) of the SDSS r-band imaging, and it is defined as the radius of the sphere enclosing half of the total light of the galaxy. Although the original data of both SPIDER and DynPop are the same (SDSS imaging), the techniques are different and the assumptions are also different, hence it is possible that the (small) difference in the prediction of the data (e.g., seen in Figs. 9–11) come from observed quantities’ definition. If so, according to the second corollary at the end of Sect. 4.4, we might expect an offset between the mass-size relations of the SPIDER and DynPop, with SPIDER being better aligned to the TNG galaxies M⋆-r1/2 relation. A proper analysis of the M⋆-r1/2 relation should take into account the completeness of the samples (Roy et al. 2018), which is beyond the purpose of this discussion that we want to keep yet qualitative at this stage.
In Fig. 16, we show the median mass-size relation of the TNG100, SPIDER, and DynPop galaxies, divided into ETGs and LTGs as a comparison, excluding the stellar mass ranges where there is a clear incompleteness, for example for the DynPop sample (ETG: log M⋆/M⊙ ≲ 10.8; LTG: log M⋆/M⊙ ≲ 10.3, see, e.g., Fig. 9). From the figure, we can see that there is a substantial agreement for the DynPop LTG and TNG100 LTG samples, which is somehow compatible with almost no-offstet in the LTG predictions, especially in Figs. 10 and 11. We also see an agreement between the SPIDER sample and the nETGs from TNG100, which corresponds also to quite unbiased predictions in the same figures. On the other hand, the DynPop ETG sample looks systematically offset with respect to the nETGs in the r1/2 direction by ∼0.10 dex, except for the most massive data points where all ETG relations seem to converge. Assuming that the DynPop offset is entirely due to a r1/2 bias, we can check whether by naively correcting the log r1/2 of the DynPop sample by +0.10 dex, we can also correct the 0.07 dex bias of the predictions discussed in Sect. 4.2. After adding a constant value 0.10 dex to the r1/2, we can see that in Fig. 16 nETGs (green circle) and DynPop nETG (red star) overlap nicely, which means we could correct the systematics error. We repeat the predictions using r1/2, M⋆, and σ as input and show the results in Fig. 17 left panel, using MELA_ALL. We observe indeed a much better agreement of the machine learning predictions with the K+23 ETG estimates, with the offset completely solved. We believe this is a confirmation of the second corollary in Sect. 4.4, although, in the specific case, a constant correction to the M⋆-r1/2 is just a rough approximation.
 |
Fig. 16. Median mass-size relation of the TNG100 simulated galaxies and the observed datasets. Top: ETG galaxies from TNG100 (nETGs), SPIDER, and DynPop_nETGs (see inset for legend). Bottom: LTG galaxies from TNG100 and DynPop_LTGs, as in the legend. Error bars represent the 0.16, 0.84 percentiles of the data within different bins. We use log M⋆/M⊙ = 10.8, as a reasonable completeness limit based on the DynPop_nETGs and log M⋆/M⊙ = 10.3 for the LTGs samples. |
We conclude this section by noticing that the velocity dispersion also has a different definition, especially because in simulations there is no attempt to subtract the rotation component. However, as discussed in Tortora et al. (2009), the rotation is expected to have an impact that cannot exceed the 10%, also for v/σ ∼ 1 systems. Furthermore, due to the least importance in the ranking of the features (Sect. 4.1.2), this is found to have a minor impact on the case of small systematics. For instance, we have seen in Sect. 4.3.2, that excluding the stellar mass, we can still find relatively good results, and having found the insignificant tilt mainly coming from the mass-to-light ratio and not from the σ. Indeed, luminosity is the feature substituting the stellar mass as a significant feature used to make predictions.
5.2.2. Feedback
In the previous subsection, we have discussed a first series of systematics causing a mismatch between the predictions of different datasets, residing on the definition of the measured quantities. However, assuming no definition mismatch, the scaling relations are expected to differ for the physics, especially the one of the baryons, behind them (Wechsler & Tinker 2018). In this case, the offset and tilt of the scaling relations discussed at point 4) of the Sect. 4.4, can be the consequence of the feedback model of the assumed simulation. If, on one side, this represents a problem if one wants to use ML tools trained on simulations to make total or dark mass predictions, on the other side, this also holds a great potential to reverse engineering the approach to use some “unbiased” dark or total mass measurements from galaxies as features and thus put some constraints on the feedback model. In this latter case the only unknown in Eq. (10) are the slopes and normalizations of the scaling relations like M⋆-r1/2 and M⋆-σ (Sect. 5.2.1), and M/L ∼ Lα (Sect. 4.3.2), that eventually depend on the feedback. This is the basic philosophy behind the recent experiments trying to use machine learning tools trained on multi-cosmology simulations, eventually including also a variation of the cosmological parameters (see also Sect. 5.2.3), to constrain the combination of the feedbacks model and the cosmology using galaxies (e.g., Villaescusa-Navarro et al. 2022), or galaxy clusters (e.g., Qiu et al. 2024).
To illustrate how a different series of predictions from simulations can produce a better agreement with observations, we use again the case of the DynPop ETGs, and put ourselves in the hypothesis that the K+23 are the ground truth and the TNG100 nETGs have the wrong feedback. Then we can imagine that to match the observation we need predictions that have a smaller M⋆ and a more compact radius in order to align the M⋆-r1/2 relation of the simulation with the DynPop in Fig. 16 (note that in the previous section we have increased the r1/2 of DynPop to make the same correction). This qualitatively would correspond to the impact of a lower AGN feedback that produces more stellar mass and possibly more concentrated in the central regions which (see, e.g., Ceverino et al. 2023). In Fig. 17 right panel, we have arbitrarly reduced the log M⋆ of the nETGs training sample by 0.03 dex and the log r1/2 by 0.14 dex in order to match the M⋆-r1/2 in Fig.16. After this adjustment, we can see the adjusted nETGs are aligned well with the DynPop nETGs. Then we used MELA_NETG to train and predict again the DynPop nETGs Mtot(r1/2). As it can be seen in Fig. 17 right panel, the prediction is much improved with respect to the one in Fig. 9, showing again the connection between the prediction and the scaling relations, but, most of all, the sensitivity of the method to the physics reproduced in the hydro-simulation used as training sample.
 |
Fig. 17. Prediction results of the DynPop_nETGs sample with three features: M⋆, r1/2, and σ, as indicated in Figs. 9 and 10. Left panel: prediction made by correcting the r1/2 of the Dynpop_nETGs by increasing 0.10 dex with MELA_ALL, as discussed in Sect. 5.2.1. This correction is applied due to a potential offset between observation and simulation, as shown in Fig. 16 top row. Right panel: prediction made by correcting both r1/2 and M⋆ of the nETGs (i.e., the training sample of MELA_NETG). Specifically, the r1/2 is decreased by 0.14 dex, and the M⋆ is decreased by 0.30 dex. The adjusted mass-size relation is shown in Fig. 16. This correction is applied because of the anticipated offset arising from different cosmology settings between simulation and observation, as discussed in Sect. 5.2.3. In comparison to Figs. 9 and 10, the prediction is observed to improve after these adjustments. |
5.2.3. Cosmology
In Sect. 4 we have commented that the results presented in this paper are model-dependent as all the mass predictions are based on TNG100 simulations which are characterized by a precise set of cosmological parameters (Planck15), plus a given feedback model (see Sect. 2.2).
As far as mass estimation is concerned, this is not a limitation as, broadly speaking, this is a more general and physically motivated approach than typical mass modeling analyses where one uses assumptions on the dark matter density profile (Navarro et al. 1996; Wyithe et al. 2001; Burkert 1995; Einasto 1965) that are generally based on DM only simulations. The advantage of this latter approaches is that one can predict the halo properties (e.g., concentration, virial mass) including either a certain variance on the cosmological parameters (see, e.g., Dutton & Macciò 2014) or even different DM “flavors” (e.g., Newton et al. 2021; Banerjee et al. 2020). More rarely, dynamical studies try to account for the effect of the baryonic physics (Napolitano et al. 2010, 2011).
The use of direct prediction from hydro-simulations, as proposed here, has the advantage of including all the physics of the interplay between DM and baryons. One can even generalize the results by considering simulations, with different cosmology, DM flavor, and feedback recipes. For example, CAMELS simulations9 have produced more than 5000 simulations where they have changed two cosmological parameters (namely the mass cosmic density, Ωm, the amplitude of the fluctuation within 8Mpc, σ8) and four astrophysical parameters regulating the supernova (ASN1, ASN2) and the AGN feedback (AGN1, AGN2). The combination of these parameters can produce a variety of scaling relations including baryonic and dark matter parameters. In this case, the caution to use is to adopt only those simulations showing baryonic scaling relations that do not systematically deviate from the ones of the real data, allowing some freedom to the “unresolved” biases between observations and simulations discussed in Sect. 5.2.1. In this latter case, one can train on a wider range of simulations and check the variance of the mass estimates from different cosmologies and feedback, then fully generalize the final results. Machine learning is an ideal environment to perform this, for its natural capability to handle very large and highly complex datasets, with tiny computational time. We will address this kind of application in a future analysis.
Another obvious application is the one proposed by the CAMELS team (Villaescusa-Navarro et al. 2022; Chawak et al. 2023), also known as cosmology with one or more galaxies, but it is not clear whether it would work. Answering this question in a quantitative way is beyond the purpose of this paper. However, we believe we have proved that this is possible using real data, as the ML tools are sensitive to small variations of the scaling relations, regardless these are introduced by feedback or cosmology. Of course, the sensitivity to the cosmology can be inferior to other more effective cosmological probes (see, e.g., galaxy clusters, Qiu et al. 2024). However, independent tests using more classical statistical methods have also shown that this is possible using galaxy observations (Busillo et al. 2023).
5.2.4. Centrals vs. satellites
A final possible source of systematics is the existence of differences in the predictions between central and satellite galaxies. This might be due to intrinsic different DM properties, due to the different assembly history, or the difficulty of extracting the physical quantities of satellites embedded into larger parent halos. To check for the presence of biases, we have performed a test by training MELA on central and satellite galaxies and comparing the self-predictions of the two classes against the cross-predictions (i.e., training on centrals and predicting the targets of the satellites and vice versa). For nETGs we have seen this to produce insignificant variation on the final R2, MSE, and MAE, and just the outlier fraction increasing from < 1% to ≳1%. Hence, we can exclude that this might have an impact on the final results of our analysis.
6. Conclusions
The next-generation photometric and spectroscopic surveys will collect high-quality multiband imaging and spectroscopy for billions of galaxies. For instance, we will be able to measure the sizes, stellar masses, stellar population properties, and internal kinematics for hundreds of millions of systems. To have access to their dark matter content, though, it is necessary to use dynamical methods, which have limitations due to modeling assumptions (e.g., geometry, orbital anisotropy) or complexity (e.g., jeans modeling vs. orbital superposition) that might require complementary data (e.g., 2D kinematics) to be compellingly fulfilled. This makes the direct estimates of the DM in such large galaxy samples prohibitive. On the other hand, indirect methods can be used based on semi-empirical scaling relations (e.g., from abundance matching; Macciò et al. 2020), but these also imply two types of biases: 1) the assumed cosmology, as these scaling relations are built on the expectation of the halo mass function which is cosmology dependent, and 2) the halo model (see, Asgari et al. 2023; Peacock & Smith 2000; Zheng et al. 2005), which is generally challenging to constrain. In either case (i.e., direct or indirect), the DM content of galaxies of the upcoming galaxy compilations will remain highly unconstrained or biased.
Nevertheless, such an unprecedented dataset holds an enormous potential to deeply answer fundamental questions of galaxy formation and evolution, especially related to the star-halo connection (Wechsler & Tinker 2018) and mass assembly across time (Tojeiro et al. 2017). Ultimately, these collections of data, in combination with their analogs from cosmological simulations, can allow us to break the contribution of the dark matter and the physics of baryons in galaxies and their dependence on cosmological parameters (Villaescusa-Navarro et al. 2023; Busillo et al. 2023). Hence, it is of pivotal importance to find effective ways to connect data and simulations in high-dimensional parameter spaces (e.g., Shao et al. 2022), and finally fully exploit the capability of ML to constrain cosmology and galaxy formation in a single framework (see also Qiu et al. 2024).
In this work, which follows the first test made in vM+22, we developed a novel mass estimator based on random forests, called MELA, which can learn the relation between luminous properties (namely the g- and r-band luminosity, the effective radius, the velocity dispersion, the stellar mass) and the mass of galaxies in hydrodynamical simulations and can predict the total and dark matter content of galaxies. For the first time, after having tested MELA on a sample of simulated galaxies (see von Marttens et al. 2022), we applied a ML-based estimator to different samples of real systems, including an ETG sample from SPIDER, an ETG/LTG sample from DynPop/MANGA, and a dwarf sample from the SAMI project. In order to implement some observational realism, we added Gaussian noise to the original simulation data used for the training of MELA to reproduce the observational errors, while we used the 3D mass inference from the dynamical models to consistently align the quantity to be predicted in real galaxies (targets).
We summarize here the major results of our analysis, based on tests on catalogs of simulated galaxies from TNG100 (self-predictions) and the different real dynamical samples (real-predictions):
-
In the self-prediction test, MELA achieved R2 = 0.933 for MDM(r1/2) and R2 = 0.959 for Mtot(r1/2) using all galaxies without separating them into classes. The predictions for Mtot(r1/2) are more accurate than MDM(r1/2), which mainly reflects the low scatter of the scaling relations of the former. Normal ETGs (nETGs) always have the highest accuracy when separating galaxies into classes, followed by the LTGs and dwarf ETGs (dETGs). In particular, the outlier fraction is less than 0.5% for dETGs and LTGs; and less than 0.2% for nETGs.
-
We also used the TNG100 mock catalog sample to investigate different combinations of features optimizing the R2. We found that for all classes of galaxies, using three features (i.e., r1/2, M⋆, and σ) we reach a plateau in the accuracy, R2 ∼ 0.93 for MDM(r1/2) and R2 ∼ 0.96 for Mtot(r1/2), that is a little improved using further features. We also found that these accuracies are almost equivalent if we use a customized MELA trained on the different classes or a generalized tool, MELA_ALL, trained on all classes mixed.
-
We finally applied both MELA_ALL and the customized MELA to the different classes of real galaxies with dynamical masses from different methods. We find that all the statistical indicators show almost no difference between MELA_ALL and MELA. The MELA_ALL performs well in the nETGs (SPIDER: R2 = 0.864, DynPop/nETGs: R2 = 0.790) and the LTGs (DynPop/LTGs: R2 = 0.905); it performs a little worse in the dETGs (Fornax: R2 = 0.529), possibly for the larger scatter of the dwarf galaxies’ size-mass relation. Outlier fractions are generally lower than 5%, consistent with log-normal errors of the MELA predictions.
-
We finally checked the robustness of the results by applying a self-prediction test on the observations. We find that if MELA is trained using the real galaxy catalog of features and targets, MELA correctly predicts the targets, and it does so with an accuracy slightly better than if trained on the TNG100 training sample. We also showed the impact of the bias between simulations and observations under the form of offset and tilt of the scaling relations. For instance, we tracked the statistically insignificant offset found on the DynPop/nETGs (< 0.07 dex) to the offset in the r1/2-M⋆ relation of this sample with respect to the TNG100 and the SPIDER sample (which is nicely aligned with simulations), perhaps due to the definition of DynPop r1/2. We also discussed the impact of the feedback model on the scaling relations, which is incorporated in the data, but that can be varied in the simulations, thus producing other sets of predictions that can closely match independent dynamical analyses.
-
From this point of view, taking the dynamical estimates at face value, and considering the surprising consistency of the MELA predictions with the dynamical masses, we conclude that the TNG100 feedback model is good enough to predict Mtot(r1/2) in real galaxies, having fixed the cosmological parameters to Planck15. We have made the MELA and MELA_ALL publicly available at this URL10 to be used to predict total and dark matter for other datasets having features consistent with those used in this paper (possibly r1/2, M⋆, and σ). Together with the code, we have also made available the catalog of the features and targets used for the three data samples analyzed in this paper: SPIDER, MaNGA/DynPop, and DSAMI.
-
We tested that MELA can equally well predict the augmented DM (or missing mass), MDM(r1/2) = Mtot(r1/2) − M⋆(r1/2), which is the only directly inferred with dynamics. This led us to conclude that it can also correctly predict the pure dark matter component, MDM(r1/2), in real galaxies (in simulations, it is trivial as this is a known quantity). In this latter case, the MDM(r1/2) is possibly more tightly dependent on the feedback model. Overall, the obvious advantage of MELA with respect to standard dynamical models is that it can estimate the dark mass of galaxies.
-
We finally discussed what equilibrium equations MELA might have learned during the training, although these are not used in simulations, but should be encoded in the physics of the collapse of baryons and dark matter. This led us to argue that ML can extract the physics from data. In a forthcoming paper, we will use symbolic regression to constrain a ML-based physical formula from MELA.
In terms of perspectives for future applications, we expect to extend the training of MELA to other cosmologies and feedback models, for example, using publicly available CAMELS simulations (Villaescusa-Navarro et al. 2023). We foresee the ability of the tool to provide mass predictions in multiple cosmology–feedback combinations. We also plan to train other MELA-like algorithms over catalogs of TNG100 simulated galaxies for which we have extracted the Sérsic parameters of the light and the DM density profiles, to predict the galaxy total slope and other DM halo density properties (De Araujo Ferrera et al., in prep.).
We believe this work has provided evidence that ML techniques are indeed mature enough to move to applications to real data, like those we expect to collect from next-generation surveys (Euclid, CSST, VR-LSST, DESI, 4MOST). We showed we can obtain robust predictions, provided that observations and simulations use homogeneous quantities for features and targets. For this “observational realism” step, in this paper, we have to make a significant effort to match data and simulations, and the results are very convincing. We believe that we are now motivated to take even another step, and use some unbiased dark matter estimate as a further feature (e.g., via strong gravitational lensing), and train a MELA-like tool, having cosmology and feedback parameters as a target, to finally try to address the cosmology with the multiple galaxies problem (Chawak et al. 2023), but using real data.
After the publication of the preprint of this article and during the referee process, the preprint of another paper was announced (Chu et al. 2024), also aiming at predicting the total and dark mass in galaxies, using convolutional neural networks (CNNs). Unlike this one, this work uses 2D kinematics as input and is explicitly meant not to be applied to real galaxies as it is based on idealistic simulated velocity fields. Although this approach is still at the proof-of-concept stage, it illustrates that deep learning is a promising method to explore further to infer galaxy masses.
The MaNGA DynPop catalogs are public on Github: https://manga-dynpop.github.io/pages/data_access/
https://www.sdss4.org/dr17/data_access/value-added-catalogs/?vac_id=manga-morphology-deep-learning-dr17-catalog
This is not equivalent to the observed velocity dispersion, which is the result of projection effects and the anisotropy parameter, but it can be reasonably be assumed proportional to the measured quantities.
This is possible because of the simpler dynamical method adopted by T+12.
Acknowledgments
We thank the anonymous referee for the stimulating report which helped to strengthen some of our results and improve the clarity of the paper. We thank Lanlan Qiu for insightful discussions. N.R.N. acknowledges that part of this work was supported by the National Science Foundation of China, the Research Fund for Excellent International Scholars (grant n. 12150710511), and from the research grant from China Manned Space Project n. CMS-CSST-2021-A01. N.R.N. also acknowledges support from the Guangdong Science Foundation grant (ID: 2022A1515012251). C.T. acknowledges the INAF grant 2022 LEMON. W.L. acknowledges the support from NSFC grant (No. 12073089).
References
- Amaro, V., Cavuoti, S., Brescia, M., et al. 2019, MNRAS, 482, 3116 [Google Scholar]
- Asgari, M., Mead, A. J., & Heymans, C. 2023, Open J. Astrophys., 6, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Auger, M. W., Treu, T., Bolton, A. S., et al. 2010, ApJ, 724, 511 [NASA ADS] [CrossRef] [Google Scholar]
- Banerjee, A., Adhikari, S., Dalal, N., More, S., & Kravtsov, A. 2020, JCAP, 2020, 024 [CrossRef] [Google Scholar]
- Baqui, P. O., Marra, V., Casarini, L., et al. 2021, A&A, 645, A87 [EDP Sciences] [Google Scholar]
- Battaglia, G., & Nipoti, C. 2022, Nat. Astron., 6, 659 [NASA ADS] [CrossRef] [Google Scholar]
- Bernardi, M., Sheth, R. K., Annis, J., et al. 2003, AJ, 125, 1817 [NASA ADS] [CrossRef] [Google Scholar]
- Bernardi, M., Sheth, R. K., Domínguez Sánchez, H., et al. 2023, MNRAS, 518, 3494 [Google Scholar]
- Binney, J., & Tremaine, S. 1987, Galactic Dynamics (Princeton, N.J: Princeton University Press) [Google Scholar]
- Blanton, M. R., & Roweis, S. 2007, AJ, 133, 734 [NASA ADS] [CrossRef] [Google Scholar]
- Blanton, M. R., Lin, H., Lupton, R. H., et al. 2003, AJ, 125, 2276 [NASA ADS] [CrossRef] [Google Scholar]
- Blanton, M. R., Kazin, E., Muna, D., Weaver, B. A., & Price-Whelan, A. 2011, AJ, 142, 31 [NASA ADS] [CrossRef] [Google Scholar]
- Bottrell, C., Hani, M. H., Teimoorinia, H., et al. 2019, MNRAS, 490, 5390 [NASA ADS] [CrossRef] [Google Scholar]
- Bruzual, G., & Charlot, S. 2003, MNRAS, 344, 1000 [NASA ADS] [CrossRef] [Google Scholar]
- Bundy, K., Bershady, M. A., Law, D. R., et al. 2015, ApJ, 798, 7 [Google Scholar]
- Burkert, A. 1995, ApJ, 447, L25 [NASA ADS] [Google Scholar]
- Busarello, G., Capaccioli, M., Capozziello, S., Longo, G., & Puddu, E. 1997, A&A, 320, 415 [NASA ADS] [Google Scholar]
- Busillo, V., Tortora, C., Napolitano, N. R., et al. 2023, MNRAS, 525, 6191 [NASA ADS] [CrossRef] [Google Scholar]
- Cappellari, M. 2008, MNRAS, 390, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Cappellari, M. 2020, MNRAS, 494, 4819 [NASA ADS] [CrossRef] [Google Scholar]
- Cappellari, M., Bacon, R., Bureau, M., et al. 2006, MNRAS, 366, 1126 [Google Scholar]
- Cappellari, M., Emsellem, E., Krajnović, D., et al. 2011, MNRAS, 413, 813 [Google Scholar]
- Cappellari, M., McDermid, R. M., Alatalo, K., et al. 2012, Nature, 484, 485 [Google Scholar]
- Cappellari, M., McDermid, R. M., Alatalo, K., et al. 2013, MNRAS, 432, 1862 [NASA ADS] [CrossRef] [Google Scholar]
- Cardelli, J. A., Clayton, G. C., & Mathis, J. S. 1989, ApJ, 345, 245 [Google Scholar]
- Ceverino, D., Mandelker, N., Snyder, G. F., et al. 2023, MNRAS, 522, 3912 [NASA ADS] [CrossRef] [Google Scholar]
- Chawak, C., Villaescusa-Navarro, F., Echeverri Rojas, N., et al. 2023, ArXiv e-prints [arXiv:2309.12048] [Google Scholar]
- Chu, J., Tang, H., Xu, D., Lu, S., & Long, R. 2024, MNRAS, 528, 6354 [NASA ADS] [CrossRef] [Google Scholar]
- Coccato, L., Gerhard, O., Arnaboldi, M., et al. 2009, MNRAS, 394, 1249 [Google Scholar]
- Croom, S. M., Lawrence, J. S., Bland-Hawthorn, J., et al. 2012, MNRAS, 421, 872 [NASA ADS] [Google Scholar]
- de Jong, R. 2011, The Messenger, 145, 14 [NASA ADS] [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Kuijken, K. H., & Valentijn, E. A. 2013, Exp. Astron., 35, 25 [Google Scholar]
- de Jong, R. S., Agertz, O., Berbel, A. A., et al. 2019, The Messenger, 175, 3 [NASA ADS] [Google Scholar]
- de los Rios, M., Petač, M., Zaldivar, B., et al. 2023, MNRAS, 525, 6015 [NASA ADS] [CrossRef] [Google Scholar]
- DESI Collaboration (Aghamousa, A., et al.) 2016, ArXiv e-prints [arXiv:1611.00036] [Google Scholar]
- Domínguez Sánchez, H., Margalef, B., Bernardi, M., & Huertas-Company, M. 2021, MNRAS, 509, 4024 [CrossRef] [Google Scholar]
- Dutton, A. A., & Macciò, A. V. 2014, MNRAS, 441, 3359 [Google Scholar]
- Eftekhari, F. S., Peletier, R. F., Scott, N., et al. 2022, MNRAS, 517, 4714 [NASA ADS] [CrossRef] [Google Scholar]
- Einasto, J. 1965, Trudy Astrofizicheskogo Instituta Alma-Ata, 5, 87 [NASA ADS] [Google Scholar]
- Faber, S. M., & Jackson, R. E. 1976, ApJ, 204, 668 [Google Scholar]
- Fortuni, F., Merlin, E., Fontana, A., et al. 2023, A&A, 677, A102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gentile, F., Tortora, C., Covone, G., et al. 2022, MNRAS, 510, 500 [Google Scholar]
- Gerhard, O., Kronawitter, A., Saglia, R. P., & Bender, R. 2001, AJ, 121, 1936 [Google Scholar]
- Graham, A. W., & Guzmán, R. 2003, AJ, 125, 2936 [Google Scholar]
- Ilbert, O., Arnouts, S., McCracken, H. J., et al. 2006, A&A, 457, 841 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Koleva, M., de Rijcke, S., Prugniel, P., Zeilinger, W. W., & Michielsen, D. 2009, MNRAS, 396, 2133 [CrossRef] [Google Scholar]
- Koopmans, L. V. E., Treu, T., Bolton, A. S., Burles, S., & Moustakas, L. A. 2006, ApJ, 649, 599 [Google Scholar]
- Kronawitter, A., Saglia, R. P., Gerhard, O., & Bender, R. 2000, A&AS, 144, 53 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- La Barbera, F., de Carvalho, R. R., de La Rosa, I. G., et al. 2010, MNRAS, 408, 1313 [CrossRef] [Google Scholar]
- Lange, R., Driver, S. P., Robotham, A. S. G., et al. 2015, MNRAS, 447, 2603 [CrossRef] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Lelli, F., McGaugh, S. S., & Schombert, J. M. 2016, AJ, 152, 157 [Google Scholar]
- Levi, M., Bebek, C., Beers, T., et al. 2013, ArXiv e-prints [arXiv:1308.0847] [Google Scholar]
- Li, R., Napolitano, N. R., Tortora, C., et al. 2020, ApJ, 899, 30 [Google Scholar]
- Li, C., Zhang, Y., Cui, C., et al. 2021a, MNRAS, 506, 1651 [NASA ADS] [CrossRef] [Google Scholar]
- Li, C., Zhang, Y., Cui, C., et al. 2021b, MNRAS, 509, 2289 [CrossRef] [Google Scholar]
- Li, R., Napolitano, N. R., Feng, H., et al. 2022a, A&A, 666, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Li, R., Napolitano, N. R., Roy, N., et al. 2022b, ApJ, 929, 152 [NASA ADS] [CrossRef] [Google Scholar]
- Lu, S., Zhu, K., Cappellari, M., et al. 2023, MNRAS, 526, 1022 [NASA ADS] [CrossRef] [Google Scholar]
- Macciò, A. V., Courteau, S., Ouellette, N. N. Q., & Dutton, A. A. 2020, MNRAS, 496, L101 [CrossRef] [Google Scholar]
- Moster, B. P., Naab, T., Lindström, M., & O’Leary, J. A. 2021, MNRAS, 507, 2115 [CrossRef] [Google Scholar]
- Napolitano, N. R., Romanowsky, A. J., Coccato, L., et al. 2009, MNRAS, 393, 329 [NASA ADS] [CrossRef] [Google Scholar]
- Napolitano, N. R., Romanowsky, A. J., & Tortora, C. 2010, MNRAS, 405, 2351 [NASA ADS] [Google Scholar]
- Napolitano, N. R., Romanowsky, A. J., Capaccioli, M., et al. 2011, MNRAS, 411, 2035 [Google Scholar]
- Napolitano, N. R., D’Ago, G., Tortora, C., et al. 2020, MNRAS, 498, 5704 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1996, ApJ, 462, 563 [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [Google Scholar]
- Nelson, D., Pillepich, A., Springel, V., et al. 2018, MNRAS, 475, 624 [Google Scholar]
- Nelson, D., Springel, V., Pillepich, A., et al. 2019, Comput. Astrophys. Cosmol., 6, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Newton, O., Leo, M., Cautun, M., et al. 2021, JCAP, 2021, 062 [CrossRef] [Google Scholar]
- Olson, R. S., Bartley, N., Urbanowicz, R. J., & Moore, J. H. 2016, in Proceedings of the Genetic and Evolutionary Computation Conference 2016, GECCO ’16 (New York, NY, USA: ACM), 485 [Google Scholar]
- Paspaliaris, E. D., Xilouris, E. M., Nersesian, A., et al. 2023, A&A, 669, A11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Peacock, J. A., & Smith, R. E. 2000, MNRAS, 318, 1144 [Google Scholar]
- Pillepich, A., Nelson, D., Hernquist, L., et al. 2018, MNRAS, 475, 648 [Google Scholar]
- Planck Collaboration XIII. 2016, A&A, 594, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pulsoni, C., Gerhard, O., Arnaboldi, M., et al. 2018, A&A, 618, A94 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pulsoni, C., Gerhard, O., Arnaboldi, M., et al. 2020, A&A, 641, A60 [EDP Sciences] [Google Scholar]
- Qiu, L., Napolitano, R. N., Borgani, S., et al. 2024, A&A, in press, https://doi.org/10.1051/0004-6361/202346683 [Google Scholar]
- Rodriguez-Gomez, V., Genel, S., Fall, S. M., et al. 2022, MNRAS, 512, 5978 [NASA ADS] [CrossRef] [Google Scholar]
- Romanowsky, A. J., Douglas, N. G., Arnaboldi, M., et al. 2003, Science, 301, 1696 [NASA ADS] [CrossRef] [Google Scholar]
- Roy, N., Napolitano, N. R., La Barbera, F., et al. 2018, MNRAS, 480, 1057 [Google Scholar]
- Rubin, V. C., Ford, W., & Kent, J. 1970, ApJ, 159, 379 [NASA ADS] [CrossRef] [Google Scholar]
- Scognamiglio, D., Tortora, C., Spavone, M., et al. 2020, ApJ, 893, 4 [Google Scholar]
- Scott, N., Eftekhari, F. S., Peletier, R. F., et al. 2020, MNRAS, 497, 1571 [Google Scholar]
- Sersic, J. L. 1968, Atlas de Galaxias Australes (Cordoba, Argentina: Observatorio Astronomico) [Google Scholar]
- Shao, H., Villaescusa-Navarro, F., Genel, S., et al. 2022, ApJ, 927, 85 [NASA ADS] [CrossRef] [Google Scholar]
- Shen, S., Mo, H. J., White, S. D. M., et al. 2003, MNRAS, 343, 978 [NASA ADS] [CrossRef] [Google Scholar]
- Shetty, S., Cappellari, M., McDermid, R. M., et al. 2020, MNRAS, 494, 5619 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Treu, T., Gavazzi, R., et al. 2013, ApJ, 777, 98 [Google Scholar]
- Spergel, D., Gehrels, N., Baltay, C., et al. 2015, ArXiv e-prints [arXiv:1503.03757] [Google Scholar]
- Spiniello, C., Tortora, C., D’Ago, G., et al. 2021, A&A, 646, A28 [EDP Sciences] [Google Scholar]
- Suess, K. A., Kriek, M., Price, S. H., & Barro, G. 2019, ApJ, 877, 103 [NASA ADS] [CrossRef] [Google Scholar]
- Swindle, R., Gal, R. R., La Barbera, F., & de Carvalho, R. R. 2011, AJ, 142, 118 [NASA ADS] [CrossRef] [Google Scholar]
- Tang, L., Lin, W., Wang, Y., & Napolitano, N. R. 2021, MNRAS, 508, 3321 [NASA ADS] [CrossRef] [Google Scholar]
- Taylor, E. N., Hopkins, A. M., Baldry, I. K., et al. 2011, MNRAS, 418, 1587 [Google Scholar]
- Thomas, J., Saglia, R. P., Bender, R., et al. 2007, MNRAS, 382, 657 [Google Scholar]
- Thomas, D., Steele, O., Maraston, C., et al. 2013, MNRAS, 431, 1383 [NASA ADS] [CrossRef] [Google Scholar]
- Tojeiro, R., Eardley, E., Peacock, J. A., et al. 2017, MNRAS, 470, 3720 [NASA ADS] [CrossRef] [Google Scholar]
- Tortora, C., & Napolitano, N. R. 2022, Front. Astron. Space Sci., 8, 197 [NASA ADS] [CrossRef] [Google Scholar]
- Tortora, C., Napolitano, N. R., Romanowsky, A. J., Capaccioli, M., & Covone, G. 2009, MNRAS, 396, 1132 [NASA ADS] [CrossRef] [Google Scholar]
- Tortora, C., Napolitano, N. R., Romanowsky, A. J., & Jetzer, P. 2010, ApJ, 721, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Tortora, C., La Barbera, F., Napolitano, N., de Carvalho, R., & Romanowsky, A. J. 2012, MNRAS, 425, 577 [NASA ADS] [CrossRef] [Google Scholar]
- Tortora, C., La Barbera, F., Napolitano, N. R., et al. 2016, MNRAS, 457, 2845 [NASA ADS] [CrossRef] [Google Scholar]
- Tortora, C., Napolitano, N. R., Spavone, M., et al. 2018, MNRAS, 481, 4728 [Google Scholar]
- Trčka, A., Baes, M., Camps, P., et al. 2022, MNRAS, 516, 3728 [CrossRef] [Google Scholar]
- Treu, T., & Koopmans, L. V. E. 2004, ApJ, 611, 739 [Google Scholar]
- Trujillo, I., Ferré-Mateu, A., Balcells, M., Vazdekis, A., & Sánchez-Blázquez, P. 2014, ApJ, 780, L20 [Google Scholar]
- Venhola, A., Peletier, R., Laurikainen, E., et al. 2018, A&A, 620, A165 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Villaescusa-Navarro, F., Ding, J., Genel, S., et al. 2022, ApJ, 929, 132 [NASA ADS] [CrossRef] [Google Scholar]
- Villaescusa-Navarro, F., Genel, S., Anglés-Alcázar, D., et al. 2023, ApJS, 265, 54 [NASA ADS] [CrossRef] [Google Scholar]
- Villanueva-Domingo, P., Villaescusa-Navarro, F., Anglés-Alcázar, D., et al. 2022, ApJ, 935, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Vogelsberger, M., Marinacci, F., Torrey, P., & Puchwein, E. 2020, Nat. Rev. Phys., 2, 42 [Google Scholar]
- von Marttens, R., Casarini, L., Napolitano, N. R., et al. 2022, MNRAS, 516, 3924 [NASA ADS] [CrossRef] [Google Scholar]
- von Marttens, R., Marra, V., Quartin, M., et al. 2024, MNRAS, 527, 3347 [Google Scholar]
- Wechsler, R. H., & Tinker, J. L. 2018, ARA&A, 56, 435 [NASA ADS] [CrossRef] [Google Scholar]
- Weinberger, R., Springel, V., Hernquist, L., et al. 2016, MNRAS, 465, 3291 [Google Scholar]
- Wolf, J., Martinez, G. D., Bullock, J. S., et al. 2010, MNRAS, 406, 1220 [NASA ADS] [Google Scholar]
- Wyithe, J. S. B., Turner, E. L., & Spergel, D. N. 2001, ApJ, 555, 504 [NASA ADS] [CrossRef] [Google Scholar]
- Zhan, H. 2011, Sci. Sin. Phys. Mech. Astron., 41, 1441 [NASA ADS] [CrossRef] [Google Scholar]
- Zheng, Z., Berlind, A. A., Weinberg, D. H., et al. 2005, ApJ, 633, 791 [NASA ADS] [CrossRef] [Google Scholar]
- Zhu, K., Lu, S., Cappellari, M., et al. 2023, MNRAS, 522, 6326 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Dark Matter predictions of the dynamical sample
In this Appendix, we show the dark matter predictions of the real dynamical sample, both the “augmented” one, 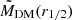 defined in Sect. 2.1, and the standard one, MDM(r1/2). As discussed in Sect. 2.1, the former corresponds to the standard definition in observational data, when there is no explicit estimate of the internal the gas content of galaxies. This is expected to produce a minimal impact on the ETG estimates, but it can give a larger bias in the LTGs. For this same reason, since we miss the information on the hidden baryons of the real galaxies, we cannot test whether the true DM mass inside the r1/2 predicted by MELA is consistent with the dynamical inferences. Hence, as introduced in Sect. 4.2, we will argue that if the augmented mass is correctly predicted, the pure DM content of the galaxy is correctly predicted too, despite the fact that this has to be feedback-dependent. In fact, as extensively discussed across this paper, both stars and gas content of galaxies depend on the baryonic physics adopted in TNG100.
defined in Sect. 2.1, and the standard one, MDM(r1/2). As discussed in Sect. 2.1, the former corresponds to the standard definition in observational data, when there is no explicit estimate of the internal the gas content of galaxies. This is expected to produce a minimal impact on the ETG estimates, but it can give a larger bias in the LTGs. For this same reason, since we miss the information on the hidden baryons of the real galaxies, we cannot test whether the true DM mass inside the r1/2 predicted by MELA is consistent with the dynamical inferences. Hence, as introduced in Sect. 4.2, we will argue that if the augmented mass is correctly predicted, the pure DM content of the galaxy is correctly predicted too, despite the fact that this has to be feedback-dependent. In fact, as extensively discussed across this paper, both stars and gas content of galaxies depend on the baryonic physics adopted in TNG100.
In Fig. A.1 we show the 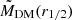 and the MDM(r1/2) predictions, using the minimal feature set as reference result and the MELA_ALL configuration. We compare them with the only DM estimate we have from observations in both cases, although we expect the MDM(r1/2) should miss the baryon part and show a negative offset. The first thing to note is that all the statistical estimators are degraded with respect to the analogous predictions of the total mass as in Fig. 9. This has, again, to do with the larger scatter of the scaling relations involving MDM(r1/2) discussed in Appendix B. However, we see a better accuracy of the
and the MDM(r1/2) predictions, using the minimal feature set as reference result and the MELA_ALL configuration. We compare them with the only DM estimate we have from observations in both cases, although we expect the MDM(r1/2) should miss the baryon part and show a negative offset. The first thing to note is that all the statistical estimators are degraded with respect to the analogous predictions of the total mass as in Fig. 9. This has, again, to do with the larger scatter of the scaling relations involving MDM(r1/2) discussed in Appendix B. However, we see a better accuracy of the 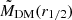 predictions with respect to the MDM(r1/2), as measured by the larger R2 and the smaller MAE and MSE, although the improvements in R2 are never larger than 10%, while the ρ is almost unchanged in all cases. This latter effect is due to the small offset of the predicted MDM(r1/2) with respect to the 1-to-1 relation, due to the missing baryons mentioned above and slightly visible in the plot, especially for the DynPop/LTG sample, which, by definition, is gas richer. We stress though that for the DynPop/ETG sample the R2 is particularly poor, due to the combination of a higher outlier fraction and, also a larger offset, that seems not to be resolved even in the
predictions with respect to the MDM(r1/2), as measured by the larger R2 and the smaller MAE and MSE, although the improvements in R2 are never larger than 10%, while the ρ is almost unchanged in all cases. This latter effect is due to the small offset of the predicted MDM(r1/2) with respect to the 1-to-1 relation, due to the missing baryons mentioned above and slightly visible in the plot, especially for the DynPop/LTG sample, which, by definition, is gas richer. We stress though that for the DynPop/ETG sample the R2 is particularly poor, due to the combination of a higher outlier fraction and, also a larger offset, that seems not to be resolved even in the 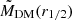 prediction. In fact, the residual offset has to be tracked back to the shift of the scaling relations discussed for the Mtot(r1/2) in Sect. 5.2, which is rather understood. We conclude this appendix with the claim that the accuracy of the augmented dark mass obtained for MELA predictions is in line with the one found for the total mass, Mtot(r1/2), in Sect. 4.2, except that the statistical estimators are poorer due to the larger scatter in the estimates, coming from the noisier DM scaling relations. As postulated above, we also claim that we provide the estimate of the “true” DM content of galaxies in the TNG100 cosmology+feedback framework (i.e., deprived of the gas content that is hidden in the dynamical inferences). These parameters will also be part of the catalog of MELA predictions which we make public (see Sect. 6).
prediction. In fact, the residual offset has to be tracked back to the shift of the scaling relations discussed for the Mtot(r1/2) in Sect. 5.2, which is rather understood. We conclude this appendix with the claim that the accuracy of the augmented dark mass obtained for MELA predictions is in line with the one found for the total mass, Mtot(r1/2), in Sect. 4.2, except that the statistical estimators are poorer due to the larger scatter in the estimates, coming from the noisier DM scaling relations. As postulated above, we also claim that we provide the estimate of the “true” DM content of galaxies in the TNG100 cosmology+feedback framework (i.e., deprived of the gas content that is hidden in the dynamical inferences). These parameters will also be part of the catalog of MELA predictions which we make public (see Sect. 6).
 |
Fig. A.1. MELA_ALL predictions of the central dark matter (MDM(r1/2), top row) and augmented DM ( |
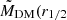
Appendix B: Self-predictions with no measurement errors
As mentioned in Sect. 4.1 we present here the results of the self-predictions excluding the measurement errors (i.e., taking the catalogs of the features and targets of the TNG100 at face value). This is a standard approach when comparing simulation and observations, but it might be eventually too idealized if one wants to use simulations to obtain realistic forecasts for real applications. In order to check the net impact of this idealized approach and to directly compare our results with similar literature analyses (e.g., Shao et al. 2022) and our previous results, in vM+22. The accuracy of both the MDM(r1/2) and Mtot(r1/2) are shown in Tables B.1 and B.2, in a similar way to what is shown in Tables 3 and 4, for the case with measurement errors included. From the comparison of these pairs of Tables, we see the same features noticed for the case of errors included, in particular, the growth of accuracy with the increasing number of features and also the same order in the “feature importance”. Also, the inclusions of the errors do not impact the number of features needed to reach the “plateau”, with r1/2, M⋆, and σ remaining the most important features. The only difference we see is that all accuracies increase at every step, meaning that the only impact of the errors, as expected, is to increase the scatter and then the overall accuracy of the predictions. With no errors, MELA reaches up to 98% accuracy for MDM(r1/2) and up to 99% for Mtot(r1/2). In particular, we can compare the new results with the one of vM+22, by looking at the TNG_all sample predictions for the DM mass in the r1/2. The closer experiments to compare are then the ones considering all the features in our self-predictions (last line in both Tables B.1 and B.2), showing R2 values of 0.98 and the result from vM+22 also reporting a R2 ∼ 0.981 (see their Table 1). In Fig. C.1 we also show the one-to-one plot of the same targets for the case of MELA_ALL configuration using the full-count training sample, which is again the closest experiment to vM+22 (e.g., their Fig. 4). Compared to our Fig. 6, we can visually see that the net effect of the absence of measurement errors is the extremely tight correlation with a much smaller scatter and a tiny outlier fraction. This turns out to be consistent with what we have previously found in vM+22, where the DM mass inside r1/2. We can also see that the scatter of the total mass is systematically smaller than the one of the DM. This is also seen in Fig. 6, although it does not show up as evident as it is in this no-error case. Overall, this reveals that the total mass is slightly better predicted by MELA than the dark mass. The reason for that can be the smaller scatter in the scaling relations shown by the Mtot(r1/2) with respect to the MDM(r1/2), for example, Mtot(r1/2)–M⋆(r1/2) or Mtot(r1/2)–σ vs. the same relations of the MDM(r1/2) in Fig. 1.
Accuracy as a function of the number of features for the MDM(r1/2), excluding measurement errors.
Accuracy as a function of the number of features for the Mtot(r1/2), excluding measurement errors.
Appendix C: Different settings of DynPop
In this Appendix, we briefly collect the results of all available settings (i.e., different Qual of galaxies and different assumptions of JAM analysis) of the DynPop dynamical sample. In Fig. C.2 we show the prediction of DynPop sample with Qual ≥0 for the reference dynamical analysis, i.e, the one based on the generalized NFW, that can be directly compared with the results based on the Qual≥1 of the same model, as in Fig. 9. As expected, we see a degradation of all the statistical estimators for both nETGs and, especially, LTGs. The indicators having more affected are the ones related to the scatter (MAE and MSE) and the outlier fraction, indeed suggesting a larger scatter of the poorer quality dynamical analysis estimates used as ground-truth. It is interesting that the nETG sample has R2 overall consistent with the one found for the Qual ≥ 1 predictions (R2 = 0.796 vs. 0.790, outliers fraction 8.10% vs. 7.47%.). We finally stress that galaxies with Qual = 0 are mainly concentrated in the small mass end and mainly in the LTG sample. This selection effect is rather obvious as because of their smaller masses (and luminosities), they are harder to observe and therefore have poorer image quality.
In Fig. C.3 we finally show the MELA_ALL predictions (see URL in the foornote 10) against all other mass estimates from the models as in K+23. The overall impression is that the MELA_ALL predictions are rather robust with respect to the majority of the dynamical models adopted. We stress here that in the different plots, the MELA estimates stay the same and only the DynPop, along the x-axis, change. In this respect this figure measures the level of fidelity of the DynPop model with respect to the TNG100 predictions, assuming that MELA produces realistic, observationally consistent estimates of the total mass of galaxies. In this perspective, LTGs are also the sample showing minimal differences as a function of the models, while nETGs show quite a large variation with the worse case provided by the sph/fNFW, while the Mass-Follows-Light (MLF) models, seem to be surprisingly consistent with TNG100, performing even better than our reference gNFW models. This might suggest that the DM in nETGs is steeper than typical NFW cusps (e.g., because of adiabatic contraction). This might not be a surprising result, as the dynamical models (consistently with simulations) make use of a Chabrier IMF, and lower normalization IMF has been found to require adiabatic contraction to fit both the central (e.g., Napolitano et al. 2010) and extended kinematics (e.g., Napolitano et al. 2011) of ETGs.
 |
Fig. C.1. Self-prediction test using full features as indicated in Table 1, with the full-counts training sample incorporating excluding measurement errors, as described in Sect. 2.2.2. Top row: Target is MDM(r1/2). Bottom row: Target is Mtot(r1/2) . The results including measurement errors are presented in Fig. 4. |
 |
Fig. C.2. MELA_ALL predictions of the central total mass, Mtot(r1/2), for the DynPop sample, but using quality flag Qual≥0. This can be compared to the corresponding result of Qual≥1 in Fig. 9. |
 |
Fig. C.3. MELA_ALL predictions of the central total mass, Mtot(r1/2), for all the JAM models from K+23, as mentioned in Sect. 2.3.2. These scenarios encompass different orientations of the velocity ellipsoid and the assumptions about the dark vs. luminous matter distribution. In detail, they combine the following assumptions: 1) cyl and sph make use of the orientations of the velocity ellipsoid along cylindrical and spherical coordinates, respectively; 2) MFL corresponds to the mass-follows-light assumption; 3) NFW corresponds to the free NFW dark halo assumption; 4) fNFW is the fixed NFW, using the cosmologically constrained NFW halo assumption; 5) gNFW is the generalized NFW dark halo. Our reference model is sph_gNFW, which are the last two plots (see also Fig. 9). |
All Tables
Accuracy as a function of the number of features for the MDM(r1/2), considering measurement errors.
Accuracy as a function of the number of features for the Mtot(r1/2), considering measurement errors.
Accuracy as a function of the number of features for the MDM(r1/2), excluding measurement errors.
Accuracy as a function of the number of features for the Mtot(r1/2), excluding measurement errors.
All Figures
|
Fig. 1. Distribution of relevant features and targets as in Table 1: total mass inside the stellar half-mass radius, augmented dark matter mass inside stellar half-mass radius, half-mass radius, stellar mass in half-mass radius, velocity dispersion, total and dark matter mass in half-light radius. Left: galaxies are divided into ETGs and LTGs on the basis of their SFR. Right: ETGs are further divided into normal and dwarf ETGs based on the classification criteria outlined in Table 2. The normalized distribution of the features and targets is shown along the diagonal. Units are as in Table 1. This is the original data from TNG100 without considering mock measurement errors. To get a comparative picture, a fixed value was set for the different types of galaxies. We randomly get a 20 000 galaxy subsample from the full dataset and from the three galaxy types. |
| In the text | |
|
Fig. 2. Correlation heat map of the different TNG galaxy samples defined in Sect. 2.2 when not considering (upper row) and considering (bottom row) the mock measurement errors, as in Sect. 2.2.2. The correlation coefficients are calculated using the Pearson correlation coefficient (see Eq. (1)). |
| In the text | |
|
Fig. 3. Kernel density estimation (KDE) for each class of the dataset. Top row: KDE of the nETG dataset. Bottom row: KDE of the LTG and dETG dataset. The number of each class of datasets is indicated in Table 2. All the data points are within the x-axis limit. In the case of Fornax, an incompleteness of the smoothed estimate is evident due to the limited number of data points. |
| In the text | |
|
Fig. 4. Self-prediction test using full features as indicated in Table 1, with the full-counts training sample incorporating added measurement errors, as described in Sect. 2.2.2. Top row: target is MDM(r1/2). Bottom row: target is Mtot(r1/2). The results without measurement errors are presented in Appendix B. The data is divided into 80% for training and 20% for testing. The x-axis represents the true values, while the y-axis represents the predicted values. “numofgal” is the number of the test set. The purple error bar represents the 16%, 50%, 84% percentiles as a function of Mtrue(r1/2), with a bin size of 0.2 dex. The red dashed line is ±0.30 dex (corresponding to ∼2σ errors, see text). Outliers are defined as the fraction of data outside the red dashed line. In the case of accurate predictions, the data points are expected to lie along the dotted 1-to-1 line. |
| In the text | |
|
Fig. 5. Self-prediction test performed using the full set of features and a balanced-counts training sample, which includes measurement errors. The training-test sample has been adjusted to maintain an equal number of entries across all samples in Fig. 4 through random selection, aligning with the less populated class (nETGs). The training set consists of 80% of the randomly selected subsample (16 800 entries), while the remaining 20% (4200 entries) is allocated for testing. Top row: target is MDM(r1/2). Bottom row: target is Mtot(r1/2). |
| In the text | |
|
Fig. 6. Self-prediction test of the MELA_ALL is performed using the full set of the features, and the Mtot(r1/2) as the target. As explained in Sect. 3.2, for this test the training utilizes balanced-counts training samples. These training samples comprise 21 000 × 80% = 16 800 galaxies for each class (i.e., dETGs, nETGs, LTGs), accompanied by 4200 galaxies for testing. The predictions of the entire TNG sample are presented as the self-prediction test in Fig. 5. |
| In the text | |
|
Fig. 7. Accuracy as a function of the number of features for MDM(r1/2) and Mtot(r1/2), taking measurement errors into account. This figure is based on Tables 3 and 4. The results without considering measurement errors can be found in Appendix B. |
| In the text | |
|
Fig. 8. Self-prediction test of the MELA_ALL with the target being Mtot(r1/2). This test uses the balanced-counts training sample and takes measurement errors into account. The test focuses on only two features: r1/2 and M⋆. |
| In the text | |
|
Fig. 9. MELA_ALL predictions of the central total mass, Mtot(r1/2), for the real galaxy dynamical samples. The optimal feature combination (i.e., r1/2, M⋆ and σ) is used, as discussed in Sect. 4.1 and Table 4. Shown (from left to right) are predictions of the SPIDER sample; the DynPop/nETG; the DynPop/LTG samples; and the DSAMI sample. The dynamical model used as representative of the MaNGA Dynpop results is the JAMsph+generalized NFW profile (see Sect. 2.3.2). For the DSAMI sample, the red triangles represent the data points from the secondary test sample (1 kpc < r1/2 < 2Rp). The legend provides an overview of the statistical estimators for the different samples. |
| In the text | |
 |
Fig. 10. As Fig. 9, but applying specialized MELAs on the different dynamical samples. |
| In the text | |
|
Fig. 11. MELA_ALL predictions of the central total mass, Mtot(r1/2), as in Fig. 9, but using only two features: r1/2 and M⋆. In the case of DSAMI, there are three obvious outliers above +0.30 dex. In the bottom right corner of the plot are shown the statistical estimators obtained excluding these outliers. |
| In the text | |
|
Fig. 12. MELA_ALL predictions of the central total mass, Mtot(r1/2), using four features: g, r, r1/2, and σ. Top row: self-prediction test with balanced-counts training sample. Bottom row: application of MELA_ALL and MELA_NETG on the SPIDER dataset. Only the SPIDER sample was used as a real data test as it is the only dataset providing the broadband luminosities. |
| In the text | |
|
Fig. 13. MELA_ALL prediction and the scaling relation analysis of SPIDER. Left panel: result of applying MELA_ALL on SPIDER with four features (g, r, M⋆, σ) and missing the r1/2. The green circle is the median value for a given x-axis bin, where the bin size is 0.1 dex. The orange line represents the linear fit of the blue data points. Right panel: M⋆-r1/2 relation of nETGs and SPIDER. A linear fit line is displayed for both data points. The best linear fit of the SPIDER sample is determined by averaging the linear fit using log M⋆ and log r1/2 as independent variables. This approach compensates for the more unbalanced distribution observed towards log M⋆/M⊙ ≲ 11.2. Completeness effects on the M⋆-r1/2 relation are not considered here, as the focus is on understanding the origin of the tilt in the predictions (left panel). |
| In the text | |
|
Fig. 14. MELA predictions of |
| In the text | |
|
Fig. 15. Self-prediction test for observation using three features: M⋆, r1/2, and σ with the balanced-counts training sample. The training–test sample has been re-scaled to ensure an equal number of entries across all samples through random selection, aligning with the less populated class (DynPop-nETGs). The training set consists of 80% of the randomly selected subsample (800 entries), while the remaining 20% (200 entries) is allocated for testing. The Fornax sample is too small, with fewer than 20 entries, making it impossible to conduct the self-prediction test. |
| In the text | |
|
Fig. 16. Median mass-size relation of the TNG100 simulated galaxies and the observed datasets. Top: ETG galaxies from TNG100 (nETGs), SPIDER, and DynPop_nETGs (see inset for legend). Bottom: LTG galaxies from TNG100 and DynPop_LTGs, as in the legend. Error bars represent the 0.16, 0.84 percentiles of the data within different bins. We use log M⋆/M⊙ = 10.8, as a reasonable completeness limit based on the DynPop_nETGs and log M⋆/M⊙ = 10.3 for the LTGs samples. |
| In the text | |
|
Fig. 17. Prediction results of the DynPop_nETGs sample with three features: M⋆, r1/2, and σ, as indicated in Figs. 9 and 10. Left panel: prediction made by correcting the r1/2 of the Dynpop_nETGs by increasing 0.10 dex with MELA_ALL, as discussed in Sect. 5.2.1. This correction is applied due to a potential offset between observation and simulation, as shown in Fig. 16 top row. Right panel: prediction made by correcting both r1/2 and M⋆ of the nETGs (i.e., the training sample of MELA_NETG). Specifically, the r1/2 is decreased by 0.14 dex, and the M⋆ is decreased by 0.30 dex. The adjusted mass-size relation is shown in Fig. 16. This correction is applied because of the anticipated offset arising from different cosmology settings between simulation and observation, as discussed in Sect. 5.2.3. In comparison to Figs. 9 and 10, the prediction is observed to improve after these adjustments. |
| In the text | |
|
Fig. A.1. MELA_ALL predictions of the central dark matter (MDM(r1/2), top row) and augmented DM ( |
| In the text | |
|
Fig. C.1. Self-prediction test using full features as indicated in Table 1, with the full-counts training sample incorporating excluding measurement errors, as described in Sect. 2.2.2. Top row: Target is MDM(r1/2). Bottom row: Target is Mtot(r1/2) . The results including measurement errors are presented in Fig. 4. |
| In the text | |
|
Fig. C.2. MELA_ALL predictions of the central total mass, Mtot(r1/2), for the DynPop sample, but using quality flag Qual≥0. This can be compared to the corresponding result of Qual≥1 in Fig. 9. |
| In the text | |
|
Fig. C.3. MELA_ALL predictions of the central total mass, Mtot(r1/2), for all the JAM models from K+23, as mentioned in Sect. 2.3.2. These scenarios encompass different orientations of the velocity ellipsoid and the assumptions about the dark vs. luminous matter distribution. In detail, they combine the following assumptions: 1) cyl and sph make use of the orientations of the velocity ellipsoid along cylindrical and spherical coordinates, respectively; 2) MFL corresponds to the mass-follows-light assumption; 3) NFW corresponds to the free NFW dark halo assumption; 4) fNFW is the fixed NFW, using the cosmologically constrained NFW halo assumption; 5) gNFW is the generalized NFW dark halo. Our reference model is sph_gNFW, which are the last two plots (see also Fig. 9). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.