| Issue |
A&A
Volume 699, July 2025
|
|
|---|---|---|
| Article Number | A54 | |
| Number of page(s) | 17 | |
| Section | The Sun and the Heliosphere | |
| DOI | https://doi.org/10.1051/0004-6361/202453524 | |
| Published online | 01 July 2025 | |
Automatic detection of Ellerman bombs using deep learning
1
Institute of Theoretical Astrophysics, University of Oslo, PO Box 1029 Blindern, N-0315 Oslo, Norway
2
Rosseland Centre for Solar Physics, University of Oslo, PO Box 1029 Blindern, N-0315 Oslo, Norway
3
TNO, Oude Waalsdorperweg 63, 2597 AK Den Haag, The Netherlands
⋆ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
19
December
2024
Accepted:
6
May
2025
Abstract
Context. Ellerman bombs (EBs) are observable signatures of photospheric small-scale magnetic reconnection events. They can be seen as intensity enhancements of the Hα 6563 Å line wings and as brightenings in the SDO/AIA 1600 Å and 1700 Å passbands. Reliable automatic and systematic detection of EBs would enable the study of the impact of magnetic reconnection on the Sun’s dynamics.
Aims. We aim to develop a method to automatically detect EBs in Hα observations from the Swedish 1-m Solar Telescope (SST) and in SDO/AIA observations using the 1600 Å, 1700 Å, 171 Å, and 304 Å passbands.
Methods. We trained models based on neural networks (NNs) to perform automatic detection of EBs. Additionally, we used different types of NNs to study how different properties – such as local spatial information, the spectral shape of each pixel, or the center-to-limb variation – contribute to the detection of EBs.
Results. We find that for SST observations, the NN-based models are proficient at detecting EBs. With sufficiently high spectral resolution, the spatial context is not required to detect EBs. However, as we degrade the spectral and spatial resolution, the spatial information becomes more important. Models that include both dimensions perform best. For SDO/AIA, the models struggle to reliably distinguish between EBs and bright patches of different origin. Permutation feature importance revealed that the Hα line wings (around ± 1 Å from line center) are the most informative features for EB detection. For the SDO/AIA case, the 1600 Å channel is the most relevant one when used in combination with 171 Å and 304 Å.
Conclusions. The combination of the four different SDO/AIA passbands is not informative enough to accurately classify EBs. From our analysis of a few sample SDO/AIA 1600 Å and 1700 Å light curves, we conclude that inclusion of the temporal variation may be a significant step towards establishing an effective EB detection method that can be applied to the extensive SDO/AIA database of observations.
Key words: methods: data analysis / methods: observational / techniques: image processing / Sun: activity / Sun: magnetic fields / Sun: photosphere
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Small-scale magnetic reconnection events play a fundamental role in the dynamics of active regions. Magnetic reconnection is believed to be one of the main mechanisms for releasing energy stored in the magnetic field, heating the solar atmosphere, and accelerating particles (Priest 1990). Since magnetic reconnection cannot be observed directly, we have to use markers to study it. A prominent marker is the so-called Ellerman bomb (EB). This phenomenon were first observed by Ellerman (1917) and appear as a compact and dynamic brightening in active regions. Ellerman bombs are classically identified as enhancements on the wings of the Hα 6563 Å line, while the core remains unaffected.
Although the main tracer of EBs is the Hα line, similar spectral signatures are observed in other hydrogen lines, such as the Hβ or Hε lines (Joshi & Rouppe van der Voort 2022; Krikova et al. 2023), and wing enhancements have been observed in other chromospheric lines, such as Ca II 8542 Å and Ca II H & K lines (Socas-Navarro et al. 2005; Pariat et al. 2007; Matsumoto et al. 2008; Vissers et al. 2013). These events exhibit a flame-like morphology when seen close to the limb with sufficient spatial resolution, as first shown by Watanabe et al. (2011). The fact that the Hα line core remains in absorption and they are not visible in the continuum indicates that EBs occur in the upper photosphere (Rutten et al. 2013; Rouppe van der Voort et al. 2023). Ellerman bombs are predominantly observed near polarity inversion lines, where small magnetic field concentrations with opposite polarity meet (Georgoulis et al. 2002; Pariat et al. 2007; Watanabe et al. 2011; Vissers et al. 2013, 2019a; Rouppe van der Voort et al. 2024). Some statistical studies have been performed on the general properties of EBs, though their results vary depending on the constraints used (e.g., Georgoulis et al. 2002; Watanabe et al. 2011; Vissers et al. 2013; Nelson et al. 2013; Vissers et al. 2019b). According to these studies, EBs are sub-arcsecond events, ranging from 0.1 to around 0.7 arcsec2 in size, and have lifetimes of around 3 minutes, with some cases lasting up to about 10 minutes. Ellerman bomb signatures can also be observed in the mid-UV 1600 Å and 1700 Å continua (Qiu et al. 2000; Pariat et al. 2007; Herlender & Berlicki 2011; Rutten et al. 2013; Vissers et al. 2019b, 2013). Some of these studies (e.g., Vissers et al. 2013, 2019b) have shown that the strongest EBs (when observed in the Hα line) exhibit a strong spatial and temporal correlation with the associated co-spatial middle-UV brightenings. Simulations have also been used to study the EB triggering mechanism, height of formation, and the required temperature to produce their spectral signatures (e.g., Hansteen et al. 2019; Hong et al. 2021).
Ellerman bombs have been detected in many studies using intensity criteria (e.g., Qiu et al. 2000; Georgoulis et al. 2002; Watanabe et al. 2011; Vissers et al. 2013, 2019b). In these cases, an intensity threshold is applied over one wing of Hα (or other spectral lines sensitive to EBs) or a combination of both wings, depending on the work. Pixels exceeding a given threshold are proposed as EB candidates. Temporal and spatial requirements are then used to select the final EBs. The threshold value is often related to the average intensity of the field of view (FOV). This value varies from study to study due to factors such as different instrumentation, the contrast in the data, or the observed region. A comprehensive study of this variability is detailed in Table 2 of Vissers et al. (2019b). An important consideration regarding threshold-based methods is that they primarly rely on pixel intensity to detect EBs. Other studies use clustering techniques to detect EB candidates (Joshi et al. 2020; Rouppe van der Voort et al. 2021; Joshi & Rouppe van der Voort 2022; Bhatnagar et al. 2024). They used the k-means algorithm (Lloyd 1982) to cluster spectral profiles into groups with similar properties. Once the data is sorted into the different clusters, one has to manually select which clusters contain representative properties of EBs. This method has the advantage of using all the information encoded in the spectral line; however, it does not provide a probability of belonging to a particular group or category.
Although the mentioned methods work well for detecting EBs, they are typically tailored to individual observations and are not easily applicable across different datasets. Additionally, the observations where EBs are detected are usually conducted using ground-based telescopes, which generally cover a small FOV and have limited temporal coverage. This poses a significant limitation for studying EBs over larger spatial and temporal domains, as well as for understanding their impact on the long-term evolution of active regions. One potential solution to this problem is detecting EBs in the passbands of the Solar Dynamics Observatory’s Atmospheric Imaging Assembly (SDO/AIA) at 1600 Å and 1700 Å. This approach could open a new avenue for studying the role of small-scale magnetic reconnection events over longer periods and across the full solar disk. However, detecting EBs in SDO/AIA presents significant challenges. Firstly, the pixel resolution of SDO/AIA is 0 6 (Lemen et al. 2012), which means that the telescope will only capture the larger EBs. Secondly, SDO/AIA provides passband images instead of detailed spectral information. This is a major drawback because spectral lines have key features for detecting EBs. An additional difficulty is the similarity between EBs and other phenomena such as magnetic concentrations (also referred to as pseudo EBs in Rutten et al. 2013). Vissers et al. (2019b) attempted to extend EB detection to the SDO/AIA 1600 Å and 1700 Å passbands on ten different datasets, using an approach primarily based on intensity thresholding. They used EB detections from co-aligned Hα observations taken by the Swedish 1-m Solar Telescope (SST; Scharmer et al. 2003) as ground-truth data. However, their result showed that the use of the 1600 Å or 1700 Å intensity channels is not enough to precisely recover all the EBs present in the data. This highlights the considerable challenge of this task, suggesting the need for more advanced methods or alternative techniques that combine all the different data available in the observations.
6 (Lemen et al. 2012), which means that the telescope will only capture the larger EBs. Secondly, SDO/AIA provides passband images instead of detailed spectral information. This is a major drawback because spectral lines have key features for detecting EBs. An additional difficulty is the similarity between EBs and other phenomena such as magnetic concentrations (also referred to as pseudo EBs in Rutten et al. 2013). Vissers et al. (2019b) attempted to extend EB detection to the SDO/AIA 1600 Å and 1700 Å passbands on ten different datasets, using an approach primarily based on intensity thresholding. They used EB detections from co-aligned Hα observations taken by the Swedish 1-m Solar Telescope (SST; Scharmer et al. 2003) as ground-truth data. However, their result showed that the use of the 1600 Å or 1700 Å intensity channels is not enough to precisely recover all the EBs present in the data. This highlights the considerable challenge of this task, suggesting the need for more advanced methods or alternative techniques that combine all the different data available in the observations.
Deep learning techniques have been extensively used to study the Sun, as reviewed by Asensio Ramos et al. (2023). Among other achievements (e.g., Díaz Baso et al. 2022), these techniques – based on the optimization of complex neural networks (NNs) – have recently demonstrated their effectiveness in automatically detecting various features in solar images, such as coronal holes (Illarionov & Tlatov 2018; Jarolim et al. 2021), solar filaments (Zhu et al. 2019; Guo et al. 2022), and sub-granular structures (Díaz Castillo et al. 2022). Other studies have used them to detect and differentiate between various solar phenomena such as flare ribbons, prominences, and sunspots (e.g., Armstrong & Fletcher 2019). Motivated by those advances and the flexibility of these techniques to combine diverse wavelength channels in a non-linear way, we developed a method to identify EBs in Hα observations from the SST and in SDO/AIA datasets using deep learning. We aim to create models that are generalizable, meaning that they are applicable to any other dataset from the same observatory once they are trained. Moreover, by testing the method in different scenarios, we can quantify the importance of the input information for detecting EBs.
The paper is organized as follows. Section 2 contains and explanation of the methodology used to build the models, covering the approach taken, the data used, and the specific architecture and assessment of the models. Results are presented in Sect. 3 and discussed in Sect. 4.
2. Semantic segmentation of EBs
2.1. Segmentation process
Our objective is to determine whether a pixel belongs to an EB or not. This task of assigning a label to each pixel of the image based on the object it belongs to is called semantic segmentation (Prince 2023; Csurka et al. 2023). To perform the segmentation, we used methods based on NNs (Goodfellow et al. 2016). The primary motivation for using NNs in this work is their capability to uncover deeper patterns and relationships within the data, potentially leading to more effective solutions than traditional methods (see e.g., Díaz Baso et al. 2023, 2025). Additionally, NNs allow the incorporation of a wider range of features, including spatial information, spectral information, and the observer’s line-of-sight information.
A sketch of the full semantic segmentation process is depicted in Fig. 1. From left to right, the input image is processed by the NN, which outputs a value between zero and one for each pixel. This output is refined by a calibrator that adjusts each value to a probability of a given pixel being an EB. Finally, we applied a threshold to these probabilities, and all pixels with values above the selected probability threshold were classified as EBs. From now on, we refer to this probability threshold simply as “probability”.
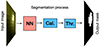 |
Fig. 1. Sketch of the semantic segmentation process for the determination of whether a pixel in the input image belongs to an EB. After being processed by the NN and the calibrator (Cal.) and after application of a probability threshold (Thr.), the output mask shows which pixels belong to an EB (white). |
2.2. Ground-truth data
To optimize a NN for any given task, we need ground-truth data, i.e., observations where EBs have been pre-detected and each pixel is already labeled. Part of this data is also used later to assess the model’s performance. Our goal is to develop a model capable of generalization, meaning it can be applied to observations from the same telescope but targeting different regions of the Sun. To achieve this, the ground-truth data must be as diverse as possible. Since our objective is to detect EBs in both SST and SDO observations, we need two different groups of datasets. One group with SST observations and the other one with SDO/AIA observations. Each group of datasets is composed of several observations, as explained in Sect. 2.2.1 and Sect. 2.2.2. We also want these datasets to be co-spatial and co-temporal between SST and SDO/AIA, so we can translate the SST EB Hα signatures to SDO/AIA channels.
2.2.1. SST datasets
The SST dataset is composed of data labeled by Vissers et al. (2019b), where EBs were detected in SST Hα high-spatial resolution observations. The main characteristics of these datasets used are summarized in Table 1 of that paper, and we adopted the same numbering to refer to each different observation. The criteria used in Vissers et al. (2019b) to classify a candidate as an EB involved a brightness threshold of 145% for the EB’s core and 140% for its halo over the average quiet-Sun in at least one of the wings of the Hα line. Regarding the size and lifetime, a minimum area of ∼0.035 arcsec2 and a minimum lifetime of 60 s were considered. These datasets cover a wide range of heliocentric angles (θ), with μ = cos θ ranging from 0.93 to 0.2. They also include three main types of regions: moat flows, decaying active regions, and emerging flux regions. This variety suits the requirements for diverse data. The spectral coverage of each observation differs, ranging from ± 1.4 Å to ± 2.1 Å with respect to the Hα line core at 6563 Å.
To combine the data from different observations, we had to move all the data into a common frame. First, we normalized each dataset with the average intensity of all the quiet-Sun pixels for each observation, following Vissers et al. (2019b). We opted to keep only the observations with a spectral coverage up to ± 1.5 Å from Hα line core to avoid possible confusion with network bright points (Rutten et al. 2013). We then interpolated the data to the following wavelengths with respect to the line core 6563 Å: [±1.5, ±1.2, ±1.0, ±0.8, ±0.6, ±0.3, ±0.2, 0.0] Å, to ensure the same spectral points across all the observations. This process excluded sets B and F from Vissers et al. (2019b) because their spectral sampling does not reach ± 1.5 Å. We also excluded set C because it was not available. Therefore, we used sets A, D, E, G, H, I, and J. The input features used for SST detections include all the spectral points of the Hα line. We also experimented with the inclusion of spatial information and the line-of-sight parameter μ to study the quality of the classification. All the SST data that we analyzed were obtained with the CRisp Imaging Spectropolarimeter (CRISP; Scharmer et al. 2008), with a pixel resolution of 0 057 pixel−1. Those datasets have been processed with different versions of the SST data reduction pipeline (de la Cruz Rodríguez et al. 2015) including the Multi-Object Multi-Frame Blind Deconvolution image restoration technique (MOMFBD; Van Noort et al. 2005). To illustrate how the detections and the analysis would be carried out in a real-world context, we applied our trained models on a new unseen dataset which lacks ground-truth labels. This dataset consists of an Hα observation of the AR 13679 observed at the SST. This observation was carried out on 2024 May 15 from 08:44:46 to 09:11:57 UT. We used the Hα 6563 Å scans, obtained with the new CRISP cameras with a pixel scale of 0
057 pixel−1. Those datasets have been processed with different versions of the SST data reduction pipeline (de la Cruz Rodríguez et al. 2015) including the Multi-Object Multi-Frame Blind Deconvolution image restoration technique (MOMFBD; Van Noort et al. 2005). To illustrate how the detections and the analysis would be carried out in a real-world context, we applied our trained models on a new unseen dataset which lacks ground-truth labels. This dataset consists of an Hα observation of the AR 13679 observed at the SST. This observation was carried out on 2024 May 15 from 08:44:46 to 09:11:57 UT. We used the Hα 6563 Å scans, obtained with the new CRISP cameras with a pixel scale of 0 044 pixel−1. The line was sampled at 33 positions in the range ± 2 Å with respect to the line core at 6563 Å, with 0.1 Å steps. The cadence of the instrument for this configuration was 37 s (the scan also included the Fe I 6173 Å and Ca II 8542 Å lines, but we do not use them here). The dataset was processed using the SSTRED reduction pipeline (Löfdahl et al. 2021). We will refer to this dataset as the “new dataset”.
044 pixel−1. The line was sampled at 33 positions in the range ± 2 Å with respect to the line core at 6563 Å, with 0.1 Å steps. The cadence of the instrument for this configuration was 37 s (the scan also included the Fe I 6173 Å and Ca II 8542 Å lines, but we do not use them here). The dataset was processed using the SSTRED reduction pipeline (Löfdahl et al. 2021). We will refer to this dataset as the “new dataset”.
2.2.2. SDO datasets
The channels we used to detect EBs in SDO/AIA are the 1600 Å, 1700 Å, 171 Å, and 304 Å passbands. The first two passbands present clear EBs signatures. Additionally, the 1600 Å passband also displays signatures from flaring active region fibrils and transition-region transients due to a large C IV line contribution (Young et al. 2018; Vissers et al. 2019b; Simões et al. 2019). These signatures are also visible in 171 Å and 304 Å, so we used these passbands to discard false positives in the 1600 Å channel. Therefore, we used these four passbands as inputs for the SDO/AIA model. Futhermore, similar to our approach with SST, we also investigated the inclusion of spatial information and the viewing parameter μ.
Unlike the SST case, we do not have pre-labeled SDO data with detected EBs. Therefore, we have to label SDO data based on SST observations. To achieve this, we downloaded co-temporal SDO/AIA observations for each SST dataset. These observations interpolated to the same pixel scale of 0 6 pixel−1, normalized by the exposure time and corrected from time-dependent degradation using the AIAPY python package (Barnes et al. 2020). Then, we made cutouts of the corresponding regions to obtain co-spatial SDO/AIA data that matched SST observations. The process to create the masks is illustrated in Fig. 2. First, we downsampled the SST data and masks by means of pixel binning to match the pixel resolution of SDO/AIA (from ∼0
6 pixel−1, normalized by the exposure time and corrected from time-dependent degradation using the AIAPY python package (Barnes et al. 2020). Then, we made cutouts of the corresponding regions to obtain co-spatial SDO/AIA data that matched SST observations. The process to create the masks is illustrated in Fig. 2. First, we downsampled the SST data and masks by means of pixel binning to match the pixel resolution of SDO/AIA (from ∼0 06 to ∼0
06 to ∼0 6). Next, we coaligned the SST data with the SDO data using the Hα blue wing and the SDO/AIA 1700 Å passband (panels a and b), so SST Hα EB masks can be applied to the SDO data. Given the lower resolution of SDO/AIA, only the brighter EBs are visible in the UV passbands (see e.g., Vissers et al. 2019b). Hence, smaller EBs will not show any signature in UV channels. If we directly use the SST masks as they are, we risk considering SDO pixels as EBs when they do not show any signature, reducing the reliability of the method. Therefore, we had to refine the mask definition for SDO. To re-identify signatures of EBs in UV channels, we search for UV brightenings that overlaped with the EB masks.
6). Next, we coaligned the SST data with the SDO data using the Hα blue wing and the SDO/AIA 1700 Å passband (panels a and b), so SST Hα EB masks can be applied to the SDO data. Given the lower resolution of SDO/AIA, only the brighter EBs are visible in the UV passbands (see e.g., Vissers et al. 2019b). Hence, smaller EBs will not show any signature in UV channels. If we directly use the SST masks as they are, we risk considering SDO pixels as EBs when they do not show any signature, reducing the reliability of the method. Therefore, we had to refine the mask definition for SDO. To re-identify signatures of EBs in UV channels, we search for UV brightenings that overlaped with the EB masks.
 |
Fig. 2. Illustration of the process used to compute SDO/AIA labeled data for an arbitrary frame of dataset E. Panel (a) displays the SST Hα blue wing and EBs highlighted by blue contours. Panel (b) shows the same data as the previous panel but downsampled and coaligned with SDO data of the same target region. Panel (c) shows the square root of the product of SDO/AIA 1600 Å and 1700 Å. Red contours indicate pixels above the threshold and blue contours represent the EBs from the SST. Panel (d) shows SDO/AIA 1700 Å passband for the target region with the resulting masks in yellow contours. These yellow contours are selected as the red contours in panel (c) which overlap with the blue contours. Panel (a) is displayed using its data coordinate system. The arrows at the top left of this panel point towards solar north (red), and west (blue) for this reference frame. Panels (b), (c), and (d) are displayed using heliocentric coordinates. |
To identify these UV brightenings, we applied an intensity threshold to the SDO datasets using the square root of the product of the 1600 Å and 1700 Å channels. We used this combination to enhance the signal of the brightenings. The value for the intensity threshold is different for each dataset and has been fine-tuned to isolate the brighter regions as indicated by the red contours on panel c of Fig. 2. Finally, we selected the UV brightenings contours that overlap with EB masks from the SST as final SDO mask, i.e., the red contours that coincide with blue contours on panel c of Fig. 2. This mask is shown on panel d in yellow.
2.3. Training, validation, and test set
To build and assess the models we used three different datasets: training, validation and test. Training and validation sets were used during the model training process. The training set was employed in the optimization of the NN, while the validation set was utilized to evaluate the model’s ability to generalize rather than memorize the labels from the training data. Once the models were built, the test set was used to assess their performance using ground-truth data which was not incorporated during the training process.
To create the training, validation, and test sets, we carefully selected data that include instances of all events seen in the observations (e.g., plages, bright points, flaring (arch)filaments, umbras). This helps the model distinguish EBs from other phenomena. Without this step, the models may only correctly classify clear-cut cases of EBs or non-EBs and struggle with brighter events such as magnetic bright points or flare ribbons.
To create the datasets we used subsamples of the data with dimensions (m, n, f), where m and n are the spatial dimensions and f includes the spectral information and additional features. We refer to these subsamples as image patches and we used square image patches (m = n) in the following. The advantage of using image patches is that they can capture whole events or parts of them, unlike single pixels. Each image patch includes all image channels and spectral positions from their respective observation. This is shown in Fig. 3 for an arbitrary image patch of the SST dataset and in Fig. 4 for an arbitrary image patch of the SDO dataset. In both figures, the last panel shows the mask, marking the pixels that belong to an EB candidate.
 |
Fig. 3. Example SST image patch with all the channels. All this information forms one SST image patch, which serves as input for the CNN SST models. Each image is scaled individually. Offsets are given with respect to nominal Hα line center. The size of the area of SST is 20 × 20 pixels. |
 |
Fig. 4. Example SDO image patch with all the AIA channels included for the segmentation process, which serves as input for the CNN SDO models. Here the EB is clearly visible in 1600 Å and 1700 Å while there are no signatures in the 171 Å or 304 Å passbands. The size of the area of SDO image patch is 10 × 10 pixels. |
A key challenge in this process is automatically selecting the centers of the image patches to ensure an adequate representation of both EBs and other types of events/regions. As discussed, we aim for the image patches to capture EBs along with other phenomena. However, an important issue to address is the strong data imbalance. The data balance, ℛ, was defined as the ratio between the number of valid and invalid events:
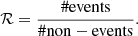 (1)
(1)
In our case, an event is a pixel that is part of an EB and a non-event a pixel that is not part of an EB. There are significantly more non-events than events in our dataset so ℛ is very small. This behavior is very common in classification of energetic phenomena (e.g., Bobra & Couvidat 2015). In particular, ℛ = 0.001 for the SST datasets and ℛ = 0.003 for SDO datasets. Randomly selecting positions from those datasets would make it highly unlikely to sample an EB due to this high imbalance. As a result, the model might focus more on non-events rather than the small fraction of EBs. To mitigate this, we developed an algorithm to iteratively select the centers of the image patches based on Eq. (1). This algorithm, starting in a random location, selects the center of the next image patch based on a probability distribution function ℒ that is updated at each step to maintain a balanced ℛ, i.e., to keep ℛ as close to 1 as possible. Additionally, each time an image patch is created, we apply random transformations (rotation, mirroring, and transposing) to avoid having identical or very similar image patches. The algorithm is explained in more detail in Appendix A.
For both SST and SDO data, we generated 20 image patches per frame, using 20 frames from each of the seven different datasets. For SST, the image patch size is 20 × 20 pixels (generating a total of 1.1 × 106 pixels) and ℛ is 0.185 using the new algorithm. For the SDO dataset, the image patch size is 10 × 10 pixels (a total of 2.8 × 105 pixels) and ℛ is 0.117. For both cases, the algorithm for image patch selection increased ℛ by two orders of magnitude. These new ℛ values show the great improvement in the composition of the datasets, although there still being some unbalance to be addressed. This is solved in Sect. 2.5. Once the image patches for each dataset are created, we combined them into a single full dataset, which we split into train (70%) and validation (30% of the image patches) sets. Additionally, we created the test set by generating 10 image patches per frame from 20 frames for each set. To avoid data leakage, we used frames that were not included in the training and validation sets to produce the test set. Table 1 summarizes the number of image patches and ℛ for all the sets produced.
Description of the training, validation, and test set used for the SST and SDO models.
2.4. NN architectures
To evaluate when the model requires spatial information to detect EB, we employed different NN architectures. When spatial information, including all channels, is essential, we used convolutional neural networks (CNNs). The functioning of CNNs consists on the concatenation of multiple convolutional layers, where the input of each layer is convolved with a matrix called a kernel, producing an output. The weights of these kernels are updated iteratively during training. For this task, we specifically used fully convolutional neural networks (Shelhamer et al. 2017), which only include convolutional layers (including the activation function). In contrast, when spatial information is not necessary and only spectral information from individual pixels is required, we employed fully connected neural networks (FNNs; Goodfellow et al. 2016). In this approach, each pixel is treated independently, disregarding spatial coherence.
To train these models, we used image patches as input for the CNNs, preserving their spatial structure. For the FNNs, we flatten the image patches into one-dimensional arrays. All models used the Exponential Linear Unit (ELU; Clevert et al. 2015) as the activation function. We selected ELU and not the popular Rectified Linear Unit (ReLU; Nair & Hinton 2010) because, after testing both, the former proved to be more suitable for the calibration process. The Sigmoid function was used as the final activation function to map outputs to the range ]0, 1[.
The particular architectures for SST and SDO differ due to their different input features. Different architectures were tested, resulting in the ones showed below. Architectures with more or larger hidden layers did not present a large improvement on the final trained models. For SST, the FNN architecture is
![Mathematical equation: $$ \begin{aligned} \overset{\mathrm{Input}(\mathrm {Spectrum})}{15]}&\rightarrow [12,32]\rightarrow \mathrm{ELU}\rightarrow [32,20] \rightarrow \mathrm{ELU}\nonumber \\&\rightarrow [20,10]\rightarrow \mathrm{ELU}\rightarrow [10,1]\\&\rightarrow \mathrm{Sigmoid}\rightarrow \underset{\mathrm{Output}}{[1},\nonumber \end{aligned} $$](/articles/aa/full_html/2025/07/aa53524-24/aa53524-24-eq8.gif) (2)
(2)
where each tuple [a, b] represents a hidden layer, with a as the number of inputs for the layer and b as the number of outputs. For SST, the CNN architecture is
![Mathematical equation: $$ \begin{aligned} \overset{\mathrm{Input\,(Image\,patch)}}{20,20,15]}&\rightarrow [15,32,3]\rightarrow \mathrm{ELU}\rightarrow [32,32, 3]\rightarrow \mathrm{ELU}\nonumber \\&\rightarrow [32,12,3]\rightarrow \mathrm{ELU}\rightarrow [12,1,1]\\&\rightarrow \mathrm{Sigmoid}\rightarrow \underset{\mathrm{Output}}{[20, 20,1}.\nonumber \end{aligned} $$](/articles/aa/full_html/2025/07/aa53524-24/aa53524-24-eq9.gif) (3)
(3)
Each triplet [a, b, c] represents the input number of channels a, the output number of channels b, and the size of the kernel used c for every hidden layer. The input [a, b, c] is an image patch of size a × b with c channels. In the cases where we also include μ, the input becomes 16 (15 spectral points + μ).
For SDO/AIA, the FNN architecture is
![Mathematical equation: $$ \begin{aligned} \overset{\mathrm{Input (Spectrum)}}{4]}&\rightarrow [4,10]\rightarrow \mathrm{ELU}\rightarrow [10,10] \rightarrow \mathrm{ELU}\nonumber \\&\rightarrow [10,6]\rightarrow \mathrm{ELU}\rightarrow [6,3]\rightarrow \mathrm{ELU}\rightarrow [3,1]\\&\rightarrow \mathrm{Sigmoid}\rightarrow \underset{\mathrm{Output}}{[1}.\nonumber \end{aligned} $$](/articles/aa/full_html/2025/07/aa53524-24/aa53524-24-eq10.gif) (4)
(4)
For SDO/AIA, the CNN architecture is:
![Mathematical equation: $$ \begin{aligned} \overset{\mathrm{Input\,(Image\,patch)}}{10,10,4]}&\rightarrow [4,10,3]\rightarrow \mathrm{ELU}\rightarrow [10,50, 3]\rightarrow \mathrm{ELU}\nonumber \\&\rightarrow [50,50,3]\rightarrow \mathrm{ELU}\rightarrow [50,10,3]\rightarrow \mathrm{ELU}\\&\rightarrow [10,1,1]\rightarrow \mathrm{Sigmoid}\rightarrow \underset{\mathrm{Output}}{[10,10,1}.\nonumber \end{aligned} $$](/articles/aa/full_html/2025/07/aa53524-24/aa53524-24-eq11.gif) (5)
(5)
Similar to the case of SST, for SDO, the models where we also included μ, the input and first layers becomes five (four passbands + μ). The models are trained and tested using image patches to reduce computational costs. When making predictions with new observations, it is not necessary to use image patches; the models can be applied directly to the full-resolution data.
We tested more sophisticated architectures, but they did not offer any improvement over the models we ultimately selected. This outcome suggests that incorporating an encoder-decoder architecture, typical in U-Net models (Ronneberger et al. 2015; Díaz Baso et al. 2019), would not offer additional benefits.
2.5. Training process
The models were trained for several hundred epochs (around 500) until they no longer improved. The batch size was chosen to be 126 for the SST and 500 for the SDO to achieve a good balance between memory consumption and performance. We used the Adam optimizer (Kingma & Ba 2017) for training the neural networks. Different learning rates were tested for each model, selecting the ones that presented the best performance. All the selected learning rates are between 10−2 and 10−3. We used a weighted binary cross-entropy (BCE) as the loss function to address the class imbalance in the data:
![Mathematical equation: $$ \begin{aligned} \text{ BCE} = \sum _{n}^N -{ w}_n\left[ { y}_n\log {\hat{y}_n} + (1 - { y}_n)\log (1-\hat{{ y}}_n)\right], \end{aligned} $$](/articles/aa/full_html/2025/07/aa53524-24/aa53524-24-eq12.gif) (6)
(6)
where 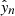 is the output of the NN model and yn is the ground-truth data for the nth pixel, and N is the total number of pixels. The BCE is a loss function used in binary classification tasks that measure the difference between the ground-truth labels and the predicted probabilities, employing logarithms to penalize incorrect predictions more severely. Unlike mean squared error, which is used for regression, BCE is tailored for classification, effectively handling the probabilistic discrepancy between predicted and actual class labels. The weights (wn) were employed because models trained with the plain Binary Cross-entropy tend to develop a bias toward the majority class in imbalanced datasets. By incorporating these weights, we assigned different levels of importance to event and non-event pixels, ensuring a balanced training process (Goodfellow et al. 2016; Csurka et al. 2023). The weight for each class was computed using the formula:
is the output of the NN model and yn is the ground-truth data for the nth pixel, and N is the total number of pixels. The BCE is a loss function used in binary classification tasks that measure the difference between the ground-truth labels and the predicted probabilities, employing logarithms to penalize incorrect predictions more severely. Unlike mean squared error, which is used for regression, BCE is tailored for classification, effectively handling the probabilistic discrepancy between predicted and actual class labels. The weights (wn) were employed because models trained with the plain Binary Cross-entropy tend to develop a bias toward the majority class in imbalanced datasets. By incorporating these weights, we assigned different levels of importance to event and non-event pixels, ensuring a balanced training process (Goodfellow et al. 2016; Csurka et al. 2023). The weight for each class was computed using the formula:
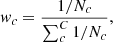 (7)
(7)
where Nc is the number of pixels of class c, and C denotes the total number of classes, which is 2 in our case. Each pixel is assigned a weight based on its class. During the training, the weight of each pixel within a batch is normalized by the sum of the weights of all pixels in that batch. One might assume that these weights alone would adequately address any class imbalance issue; however, the original imbalance was so extreme that a combination of weighted BCE and the implemented resampling techniques, as described in Sect. 2.3, was necessary to achieve satisfactory performance.
2.6. Calibration
After obtaining the NN output, we proceeded with the calibration process (see Fig. 1). The output of the NN is a number between 0 and 1 that we wish to interpret as the probability of being an EB. For instance, an output of 0.6 should reflect a 60% chance of belonging to the EB class. If the model’s output closely matches to the actual probability, the model is considered calibrated. Although the loss function used in the training process includes a probabilistic interpretation, the NN output is often not calibrated (Guo et al. 2017).
The calibration process of a NN can be addressed as a post-processing step. The most common method consists of fitting a function that maps the output of the NN to a true probability. Following Guo et al. (2017), we chose to fit a isotonic step-wise function (Kruskal 1964) to calibrate the models. This function is a non-parametric regression that maps the output of the NN to the true probability. The calibration process is performed using the training and validation sets together because the calibration process requires as much data as possible to sample all the possible outputs. The calibration process does not affect the performance of the model, but it significantly improves the interpretability of the predictions. The calibration process is explained in more detail in Appendix B.
2.7. Probability
After the calibration process, the NN produces a continuous output in the range ]0, 1[ for each pixel, which can be interpreted as probabilities. To determine the final decision on whether a pixel is an EB or not, a probability value has to be chosen. Pixels with values above this probability will be considered as EBs. For instance, by selecting a probability of 0.8 (indicating an 80% probability of being an EB), all the pixels with a probability of 0.8 or higher will be classified as EBs. This final step, shown in Fig. 1 as Thr., results in the output binary mask, where 1 indicates EB, and 0 indicates non-EB.
2.8. Performance metrics
After building and training the model, we evaluated its performance on the test set. This evaluation involved comparing the model’s predictions 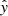 to the ground-truth labels y in the validation set. The predictions were classified into the following categories:
to the ground-truth labels y in the validation set. The predictions were classified into the following categories:
-
True positive (TP): The model correctly predicts an event that is indeed present. This means that both the predicted label and the actual label are 1 (
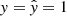 ).
). -
False positive (FP): The model incorrectly predicts an event that is not present. In this case, the actual label is 0, but the predicted label is 1 (y = 0 but
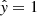 ).
). -
True negative (TN): The model correctly predicts that there is no event. Here, both the predicted label and the actual label are 0 (
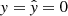 ).
). -
False negative (FN): The model fails to predict an event that is actually present. In this scenario, the actual label is 1, but the predicted label is 0 (y = 1 but
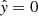 ).
).
These four quantities are considered as the elements of the confusion matrix or contingency table of any binary classification task.
By categorizing the predictions in this manner, several metrics can be computed. For example, recall measures how many events are recovered over the total number of true events:
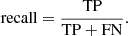 (8)
(8)
A recall of 1 means that we correctly classified all the EBs present in the data.
The precision measures the fraction of correct predictions over the total number of predicted events:
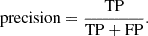 (9)
(9)
A precision of 1 means that among all the predictions of EBs there is no prediction that is not an actual EB. Recall and precision are anti-correlated except in the case of a perfect classifier. If the precision of a model is increased, the model becomes more conservative to reduce the chances of misclassifying the positive class, thus decreasing the ability of the model to recover all the positive examples (i.e., the recall), and vice versa. Therefore, a useful quantity to balance recall and precision is their harmonic mean, the F1 score:
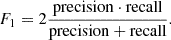 (10)
(10)
The F1 score and the precision are metrics that are strongly influenced by the class imbalance in the datasets. Therefore, they should not be used to compare models that are trained on datasets with different ℛ. However, since we are comparing models trained with the same dataset, this does not pose an issue for our comparison. Although more complex metrics exist (see e.g., Bobra & Couvidat 2015; Asensio Ramos et al. 2023), we decided to use these fundamental metrics due to their simplicity and ease of interpretation.
2.9. Spatial degradation
To investigate the impact of a lower spatial resolution on the detection of EB, we degraded the SST data to match the spatial pixel size of SDO/AIA, which is ten times larger. To achieve this, we first downsampled the SST data to the SDO pixel size and then upsampled it back to the original SST dimensions using nearest-neighbor interpolation, ensuring the size of the original EB masks was preserved.
By creating these degraded datasets, we could systematically assess how the reduced spatial resolution affected the performance of our EB detection models. This step is crucial to disentangle the impact of the spectral and spatial information in this identification. When using SDO, both the spatial resolution and the wavelength information differ from the original SST observations. Therefore, it is important to quantify how each factor - spatial resolution and spectral characteristics – contributes to the effectiveness of EB detection.
2.10. Feature importance
Finally, we conducted an analysis to identify which channels or input characteristics are the most relevant for detecting EBs. For that we used a model inspection technique called permutation feature importance (Fisher et al. 2018). Permutation feature importance measures the decrease in a model’s performance when the values of a single feature are randomly shuffled. This procedure disrupts the relationship between the feature and the target variable, and the resulting decrease in the model’s performance indicates how much the model relies on that particular feature.
We used the validation set to calculate the feature importance for the SST and SDO segmentation. For each channel under assessment, we shuffled the values of that specific feature across all pixels while keeping other features unchanged. The model then made predictions using these modified validation sets, and we computed the F1 score to quantify the impact of shuffling each feature.
3. Results
3.1. SST EB segmentation
Figure 5 shows the recall, precision, and F1 score and their dependence on the selected probability for all the models trained to detect EB in SST observations. The recall, precision, and F1 score are all functions of the probability threshold applied to the model’s output. As the probability increases, the model becomes more restrictive and selects only the most probable events, leaving many real events out of the selection. This is reflected in the recall, which decreases (ratio of recovered events over total events) and the precision, which increases (ratio of correct predictions over total predictions). The F1 score, being the harmonic mean of recall and precision, provides a balanced metric that considers both false positives and false negatives.
 |
Fig. 5. Metrics of recall, precision, and their harmonic mean, the F1 score, for the models trained to perform EB detection in SST Hα observations. The metric scores are shown as a function of probability of a detection being an EB. From left to right, the metrics are for models trained using: all the spectral points, all spectral points plus μ, and all spectral points for the spatially degraded dataset. Dashed lines represent CNN models, while solid lines indicate FNN models. Blue, orange, and red colors correspond to recall, precision, and F1 score, respectively. These metrics have been computed using the test set. |
Regarding the general trends of different models, the metrics for the CNN and the FNN are very similar in the two first panels of Fig. 5. The recall (blue lines) of the CNN is higher than that of FNN at most points, indicating that the CNN slightly recovers a few more events. In contrast, the FNN models show a higher precision, meaning that they fail less than the CNN when they classifiy a pixel as EB. Despite these differences, the F1 score is almost identical across all probabilities, suggesting similar overall performance for the CNN and FNN models. The inclusion of μ (second panel) does not seem to add significant information, as the metrics remain similar with or without it. The maximum F1 score reached in both panels is 0.9, achieved at 40 − 50% probability, indicating the optimal balance between precision and recall. However, with a 90% probability, the models reach a precision of ∼0.99, at the cost of lowering the recall to values between 0.66 and 0.74 depending on the particular model. Thus, although almost all the EB detected are correct, only about a 70% of the present EB in the data are retrieved. In the third panel, showing the models trained with spatially degraded data, there is a significant difference between CNN and FNN models. The CNN models (dashed lines) achieve better results than FNN models (solid lines) for all three metrics. This behavior indicates that the inclusion of spatial information in the CNN model, clearly improves the detection of EBs. Nonetheless, the maximum F1 score is 0.69 for the CNN and 0.63 for the FNN, at 0.3–0.4 probabilities, 0.27 points lower than the maximum F1 achieved by the models with the original SST resolution. At a 0.9 probability, precisions are 0.95 and 0.96, with recalls of 0.14 and 0.12 for CNN and FNN, respectively.
To demonstrate the models’ ability to handle unseen data, we used them to detect EB in the new dataset. Figure 6 shows normalized histograms of the area of the EBs classified in each frame by the CNN and the FNN models, using a probability of 0.5. This value provides the best trade-off between precision and recall for all three panels in Fig. 5. To compute the histograms, we selected detections with an area larger than 0.035 arcsec2 and a minimum linear extent of about 2″, consistent with the criteria applied in Vissers et al. (2019b). It is evident our models detect smaller features than those identified in Vissers et al. (2019b). The total number of detections are 4483 and 3094 for the FNN and CNN models respectively (without constraints).
 |
Fig. 6. Histograms of the area of EB predictions in the new dataset by the CNN and FNN models, using a probability of 0.5. Red bars correspond to the detections made by the FNN model and blue bars to the CNN model. Filled bars represent the area of EBs that meet the size criteria explained in the text. Dark blue color represents the overlap between red and blue bars. Unfilled bars show all the detected EBs, without size constraints. The dashed line marks the area cutoff used in the criteria. The y-axis presents the fraction of each bin with respect to the total number of detections. For clarity, the x-axis is limited to 0.80, although the histogram tails extend up to approximately 1.2 arcsec2 with near-zero counts. |
The average area for EBs detected with the criteria is 0.118 arcsec2 for the FNN model and 0.143 arcsec2 for the CNN model. For all the detected EBs (without the criteria) the average area is 0.050 arcsec2 for the FNN model and 0.030 arcsec2 for the CNN model. It is important to note that we did not apply any temporal criteria to the EB detection. We considered the areas of EBs detected at each frame independently of the other ones. Since EBs increase and decrease in size during their lifetime, all the previous and later smaller sizes after a given EB reaches a maximum size, displaces the average towards lower values. The inclusion of temporal evolution could modify the result presented in Fig. 6, and would reduce the number of detected EBs by connecting them between frames and treating them as single events.
Figure 7 shows a cutout of an SST Hα frame of the new dataset. The left panel shows the intensity image at +1 Å from the Hα core where the EBs appear as intensity enhancements brighter than their surroundings. The middle and right panels show the EBs predictions made by the CNN and the FNN models, respectively, indicating with different colors the probability assigned to each pixel. CNN detections are smoother than FNN ones. The change from 0% (dark blue) to 100% (dark red) is gradual for the CNN while the FNN prediction map shows abrupt changes from 0 to 1.
 |
Fig. 7. Example of EB predictions done by the CNN and FNN SST models over a cutout of the new dataset. The left panel shows the intensity image in the red wing of Hα at +1 Å offset. The middle and right panels show the predictions done by the CNN and FNN models respectively. The colormap indicates the probability assigned by the models to each pixel of being an EB. The white dashed contours mark the 0.1 probability of the CNN prediction and are drawn in all panels to facilitate spatial comparison. An animation of this figure that shows the probability maps over the full time sequence is available in the online material. |
3.2. SDO EB segmentation
Figure 8 presents the performance metrics for SDO/AIA models. The top panel shows the metrics for the models trained using all the passbands, while the bottom panel shows the metrics from the models trained with all the passbands including μ. The inclusion of μ does not significantly affect the metrics, consistent with the SST results in Fig. 5.
 |
Fig. 8. Metrics of recall, precision, and F1 score for the models trained to perform EB detection in SDO/AIA. The upper and lower panel shows the metrics for the models trained with all the passbands and passbands plus μ respectively. The metric scores are shown as a function of the probability of a detection being an EB. These metrics have been computed using the test set. |
Comparing the performance of the FNN and CNN models, the CNN metrics (dashed lines) generally achieve better scores across most probabilities. The CNN models achieve a maximum F1 score of approximately 0.77 for a probability of 0.5. The FNN models peak at around 0.66 for a probability of 0.25. At the highest probability, the precision for both models in both panels reaches around 0.97, with recalls between 0.20 and 0.33. This behavior indicates that the model only recovers between 20 and 30% of all the events, missing more than half of them. These scores indicate that SDO models cannot accurately recover EBs without making a strong compromise in the number of events detected. Finally, Fig. 9 shows the predictions made by the CNN model over dataset E. Different contours represent different levels of probability. This illustrates how the model’s detection performance varies with different probabilities.
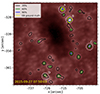 |
Fig. 9. Example AIA 1700 Å frame with EBs detected by the SDO/AIA CNN model. Detections are outlined by black, green, and blue contours, corresponding to probabilities of 0.2, 0.6, and 0.9 respectively. Yellow contours indicate EBs detected in Hα SST observations at the same time. White dashed circles and white letters indicate the bright patches selected for the study presented in Fig. 12. The movie online shows the detections for all the frames of the observation. |
3.3. Feature importance analysis
The results of the permutation feature importance experiment are presented in Fig. 10. This figure shows the impact on the F1 score when the data for each individual wavelength feature is shuffled. As a result, the features for which the F1 score decreases the most are the most important ones. We used a 0.5 probability for both SST and SDO CNN models to carry out this section, as this value yields the highest F1 score for the models. Left and right panels show the F1 score obtained for SST and SDO CNN models, respectively. The dashed lines in both panels indicate the original F1 score without shuffling. For the SST, data show a sombrero profile, where the scores decrease for the line wings around ± 1 Å offset and increase for the most external points and the line core wavelengths. The feature at + 1.2 Å offset is the most important with a F1 score of 0.74, followed by the blue wing wavelengths at −1, − 1.2 and −0.8 Å offsets. The rest of the values, mostly belonging to the line core, lie around 0.89, very close to the score without shuffling (0.9). We performed the same experiment with the SST FNN model, and the result showed a similar trend, giving a larger importance to the red and blue wings.
In the right panel of Fig. 10, the results for the SDO model show a different relation between the channels. The lowest score is achieved by the 1600 Å channel, with a value of 0.21. The original F1 CNN score without shuffling is 0.76, meaning that the permutation of the 1600 Å reduces it by 0.54 points, more than half of the total value. The values for 1700 Å, 171 Å, and 304 Å are 0.67, 0.74 and 0.75, respectively. The gap between 1600 Å and the rest indicates that 1600 Å channel is very dominant in the classification compared to the other passbands.
 |
Fig. 10. Computed F1 score for each input channel in the permutation feature importance assessment. The evaluated channel is shuffled to measure performance loss, where a lower score indicates higher importance. The left panel shows the results for the SST input features (wavelength offsets in Hα) and the right panel displays the results for the SDO/AIA passbands. Both panels show the results for the CNN architecture. A dashed vertical line indicates the score without shuffling the input features. |
3.4. EB segmentation versus intensity threshold
To evaluate the effectiveness of the method developed, we aim to compare our trained models with a simple intensity threshold method evaluated in the test set. For the SST models, this comparison is not possible because the ground-truth data used for the training was produced using an intensity threshold in Vissers et al. (2019b). Thus, it is redundant by definition to compare the SST models with the intensity threshold method using the test set. For the SDO models, this comparison is possible because we have re-defined our own ground-truth data as explained in Sect. 2.2.2.
To evaluate the effectiveness of our SDO models, we have compared these results with a simple intensity threshold method evaluated in the test set. We applied a minimum brightness threshold over the 1700 Å channel. We used different threshold values, ranging from 1 to 9 standard deviations (σ) above the local quiet-Sun average, as carried out by Vissers et al. (2019b). The result is shown in Fig. 11. The best F1 score is 0.75 for a threshold of 2σ over the quiet-Sun average intensity, with a recall and a precision of 0.73 and 0.78 respectively. For comparison, the FNN and the CNN achieved a maximum F1 0.66 and 0.76. This means that the threshold performs better than the FNN model and is very close to the CNN model.
 |
Fig. 11. Recall, precision, and F1 score for the brightness intensity threshold used to perform EB detection in SDO/AIA. The metric scores are shown as a function of the applied intensity threshold. The units of the thresholds is the number of standard deviation values (σ) above the local quiet-Sun average. For comparison, dashed and solid red lines indicate the maximum F1 score achieved by the FNN and CNN SDO models respectively. The gray vertical line indicates the threshold value suggested by Vissers et al. (2019b) at 5σ. These metrics have been computed using the test set. |
4. Discussion
4.1. SST detections
For the models trained with the datasets at the original SST spatial resolution, both CNN and FNN models show proficient detection and classification of EBs, with very similar performance metrics (see Fig. 5). Notably, the F1 scores for both models are almost identical, with the FNN demonstrating slightly higher precision and lower recall, possibly related to the way both models handle the input information and other differences in the neural network architectures. The F1 score value does not vary much for the different probabilities except for 0.1 in the two first panels of Fig. 5. This indicates that the recall decreases at the same rhythm as the precision increases. As we increase the probability, the models are more restrictive at selecting events to become more precise. The similarity in the scores between CNN and FNN models indicates that the spectral information is enough to classify EBs, regardless of the spatial information. However, for the spatially degraded SST observations, CNN models achieve better scores than FNN models, highlighting the importance of having access to the spatial information in this context. During the degradation process, ten pixels are interpolated into one, significantly weakening the EB spectral signature and typical spectral shape. According to Vissers et al. (2019b), the typical size of an EB in these datasets is about 0.15 arcsec2. The pixel scale of SST/CRISP is 0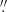 057 so a typical EB will extend around 6.8 pixels. In addition, EBs tend to be elongated, so their signature is greatly affected by the spatial degradation. The spatial extension of an EB is used by the CNN models to improve identification. As the quality of spectral information decreases, the use of intensity spatial patterns increases. Regarding the dependency on μ, no substantial differences are observed between models using or not using this information, as shown in the first and second panels of Fig. 5. These models use spectral points as the primary information, with the spatial information (in the case of CNN) playing a secondary role. The observer’s parameter μ could be relevant if we only use single-channel intensity images, as EB appearance depends on the location on the disk. EBs may appear more distinct towards the limb due to higher contrast and increased projected area, displaying a flame morphology, as explained by Watanabe et al. (2011) and Vissers et al. (2019b).
057 so a typical EB will extend around 6.8 pixels. In addition, EBs tend to be elongated, so their signature is greatly affected by the spatial degradation. The spatial extension of an EB is used by the CNN models to improve identification. As the quality of spectral information decreases, the use of intensity spatial patterns increases. Regarding the dependency on μ, no substantial differences are observed between models using or not using this information, as shown in the first and second panels of Fig. 5. These models use spectral points as the primary information, with the spatial information (in the case of CNN) playing a secondary role. The observer’s parameter μ could be relevant if we only use single-channel intensity images, as EB appearance depends on the location on the disk. EBs may appear more distinct towards the limb due to higher contrast and increased projected area, displaying a flame morphology, as explained by Watanabe et al. (2011) and Vissers et al. (2019b).
The inclusion of spatial information in the detection also impacts the properties and quantity of detected EBs in the new dataset. Indeed, Fig. 6 reveals a difference in behavior between CNN and FNN models. The FNN and CNN models detected a total of 4483 and 3094 EBs respectively, resulting in a difference of 1389 events. The FNN model detected more small-area events than the CNN model, as captured by the size of the bars for the CNN and FNN from around 0.1 arcsec2 onwards. In contrast, the FNN model detects more small events in relation to all its detections. The CNN model imposes some spatial coherence and is more restrictive for small candidates, indicating that the CNN model also incorporates some spatial information (from the training set) when detecting EBs. The EBs present in the ground-truth data have a minimum area constraint of 0.035 arcsec2, which is softly learned by the CNN model during the training process. Since the spectral information dominates, the size requirement is probably applied by the model when the predictions are dubious. However, the differences between the CNN and FNN detections are not very significant. For the FNN, 89% of all detections are below 0.1 arcsec2, while for the CNN, they are about 80% of the total. These conclusions are specific to this dataset and may not be generalizable.
To compare the areas of the EBs detected by our models with the ones reported in Vissers et al. (2019b), we applied the same area and linear extent constraints, represented by the color-filled bars in Fig. 6. With this, we got an average EB area of 0.14 and 0.12 arcsec2 for the CNN and FNN models. This agrees with the average EB area of 0.14 arcsec2 found by Vissers et al. (2019b). However, if we remove the size constraints for the detected EBs, we obtain average areas of 0.05 and 0.072 arcsec2 for FNN and CNN models, respectively. Sub 0 1 events also present EB signature. Therefore, depending on the definition, those events can be classified or not as EB. As we obtain higher spatial resolution observations, we can expect to find even smaller events showing EB signatures, emphasizing the importance of high-resolution observations.
1 events also present EB signature. Therefore, depending on the definition, those events can be classified or not as EB. As we obtain higher spatial resolution observations, we can expect to find even smaller events showing EB signatures, emphasizing the importance of high-resolution observations.
Figure 7 shows the probability map predicted by the CNN and the FNN over a cutout of the new dataset. CNN predictions exhibit a smooth transition from non-EB to EB. This smooth transition is very natural since the borders of the EBs are diffuse. In contrast, FNN predictions show abrupt borders, with no probability gradient between 0% and 100% except for some single pixels. These different behaviors are explained by the different architectures. The CNN model’s ability to use spatial information allows it to exploit information from adjacent pixels, resulting in smoother transitions in its predictions. On the other hand, the FNN model’s pixel-wise approach requires an effective threshold, because it cannot use any extra information. This idea supports why the FNN models classify more small-scale events than the CNN models, as seen in Fig. 6.
The result of the permutation feature importance experiment for the SST CNN model indicates that the red and blue wings are the most important spectral points to detect EBs. While the model relies on the entire spectrum for its predictions, the information at the wings of the Hα line is essential for the correct classification. This result confirms the choice of previous methods based on a combination of both wings for EB detection (see e.g., Vissers et al. 2013, 2015; Reid et al. 2016; Vissers et al. 2019b) and aligns with the spectral EB definition (e.g., Watanabe et al. 2011). The enhancement of the Hα wings is the main signature of EBs, so it is expected that the wavelengths close to the wings are the most important features for the classification. However, this does not mean that the other features do not contribute. If the pseudo-continuum wavelengths (farthest wavelength points) or the core are extremely bright, this will tell the model that this is not an EB event. The fact that many of these points show a very small decrease in F1 score when randomized, suggests that we could potentially remove some of them without significantly affecting the model’s performance.
4.2. SDO/AIA detections
The results for the SDO models are shown in Fig. 8. The higher F1 values are 0.66 and 0.77 for the FNN and CNN models, respectively. These values indicate that the best performance of these models is poorer than the SST models, although a direct comparison is not feasible since they are not trained on the same data. The F1 score is sensitive to ℛ, so a different ℛ on the used datasets would scale the obtained metrics (Brabec et al. 2020).
Another interesting aspect is that CNN models generally outperform FNN models, and the gap is very well visible with a difference of about 0.1–0.2 in all metrics on average, except for the precision at higher probabilities. This behavior is similar but more pronounced than the one observed for the SST models under the spatially degraded dataset (right panel of Fig. 5). We speculate that this is due to the difference in the spectral information (passbands instead of detailed spectra) and the lower spatial resolution of SDO/AIA (about ten times lower than SST). Our interpretation is that, similar to the SST models under lower spatial resolution, the CNN models use all the available spatial information to detect EBs. The lower spatial resolution of SDO/AIA results in only the largest EBs being visible. Additionally, the lack of detailed spectral information in the SDO/AIA passbands makes it more challenging to differentiate EBs from other bright events. An example of the predictions made by the CNN model over the SDO/AIA dataset is shown in Fig. 9. At 60% probability, the CNN model detects a large number of bright patches, which are not EBs. This result indicates that the model struggles to differentiate EBs from other bright events. This behavior is observed in all the frames of this observation (see movie in Fig. 9).
Additionally, the feature importance analysis in Fig. 10 shows that the 1600 Å passband is the most relevant feature to detect EBs. This is consistent with previous findings that the SDO/AIA 1600 Å passband shows the highest contrast for EB (e.g., Rutten et al. 2013; Vissers et al. 2013). However, the 1700 Å passband presents a similar importance as 171 Å and 304 Å in Fig. 10. This conclusion differs from Vissers et al. (2019b), which reported that 1700 Å passband is better than the 1600 Å passband for detecting EBs. The difference arises from the detection method used. In Vissers et al. (2019b), single passbands observations were used to detect EBs by applying a threshold on the intensity of each band. Given that the 1600 Å passband presents a contribution of hotter-atmospheric signatures in addition to EBs, the 1700 Å passband, which does not have that issue, contains fewer sources of error. This makes the use of the 1700 Å passband more precise than the 1600 Å passband, as shown in Figs. 8 and 10 of Vissers et al. (2019b). In the method developed in this work we combined 1600 Å, 1700 Å, 171 Å and 304 Å passbands. This allows our models to filter out transition-region or flaring events thanks to the information provided by the 171 Å and 304 Å passbands. We speculate that this makes the model to rely on high-contrast brightenings produced by the EBs in the 1600 Å passband, making the 1700 Å information redundant. This also indicates that the SDO models apply an intensity threshold over a non-linear combination of the passbands for the classification task. Although the model recovers some EB candidates, this approach is insufficient to accurately discern EBs while keeping a good ratio between the number of events detected and the precision of the detections.
The misidentification of EBs in SDO is mainly due to the similar intensity patterns produced by network bright points and EBs in the SDO/AIA passbands. Network bright points mark strong magnetic field concentrations, which also appear bright in the wings of Hα line. These magnetic field concentrations manifest in the mid-UV channels of SDO as bright patches, which the SDO models also classify as EBs (see Fig. 9). The relationship between these magnetic field concentrations and bright patches has been statistically studied by Tähtinen et al. (2022). Most of the Hα EBs coincide with bright patches in 1600 Å and 1700 Å, that are not clearly distinguishable from those produced by network bright points. Only the strongest EBs induce a noticeable enhancement in the passbands. Rutten et al. (2013) also warned about the misidentification caused by the magnetic field concentrations, referring to them as pseudo-EBs. Another possible error source is the presence of UV-bursts, which can be mistaken with EBs. As shown in Kleint & Panos (2022), UV-bursts can produce a signature in both AIA 1600 Å and AIA 1700 Å passbands, with the 1600 Å channel statistically displaying a higher enhancement than in 1700 Å. Therefore, using intensity alone is insufficient to detect EBs using SDO/AIA passbands. This work demonstrates that NN-based models are unable to find reliable patterns (spatial or spectral) to differentiate between EBs and other bright events in SDO/AIA data based solely on the intensity maps.
4.3. Intensity threshold versus NN models
For the SST case, the use of ground-truth data produced by an intensity threshold does not allow us to compare the NN methods with an intensity threshold. To make the comparison, we would require a new labeled dataset generated independently of the existing ground-truth criteria. However, this would require a new labeling method (with its own bias), making comparisons against a third criterion. For the SDO models, we can make the comparison with the intensity threshold method because we created our own ground-truth data. The results for the intensity threshold method are shown in Fig. 11. The best F1 score obtained, of 0.75 for 2σ, is similar to the best result of the CNN model and surpasses the FNN model. However, if we use a value for the intensity threshold of 5σ, as suggested by the final recipe given by Vissers et al. (2019b), the F1 decreases to 0.2. The first conclusion from this result is the evident dependence of the threshold value to the observation and a consequence of the method followed to build the ground-truth data for the SDO train, validation and test sets, explained in Sect. 2.2.2. This conclusion also explains why CNN models outperform FNNs. Convolutional NNs employ a small context window, which helps them contextualize the properties of the observed pixels, whereas FNN models operate on a pixel-by-pixel basis without utilizing any spatial information. The second conclusion is that the comparable performance of a non-linear classification technique such as CNNs to a thresholding method may suggest that the current approach does not provide significant information for solving the classification problem.
4.4. Temporal evolution
A dimension that has not been explored in this work is the temporal evolution of bright patches. If an EB produces a distinct signature in the time domain, this could be used to differentiate it from other bright events and improve the detection. Ellerman bombs are dynamic events that evolve in time, producing larger and faster changes in intensity than the typical network bright points. This behavior has been observed in previous studies (e.g., Qiu et al. 2000; Pariat et al. 2007; Herlender & Berlicki 2011), where the light curves of EBs detected in Hα correlated with the temporal evolution of co-spatial brightenings in the mid-UV continua.
To test this hypothesis, we analyzed the intensity evolution (or light curve) of the bright patches indicated with white dashed circles in Fig. 9. We then studied the correlation between their evolution and the occurrence of co-temporal and co-spatial Hα EBs in the SST datasets. Figure 12 shows the light curve of these bright patches for the 1600 Å passband, extending the temporal domain to include 2 h before and 2 h after the SST observations. The varying lengths of the light curves are given by the different lifetimes of the bright patches. To compute the intensity at each time, we averaged over 36 pixels around the brightest point of each bright patch. The two first panels show the light curve for the bright patches A and B, which have an associated EB. The red and blue shaded areas indicate the EBs detected in Hα observations associated with bright patches A and B. The light curves at 1600 Å reveal an important increase in intensity during the EBs’ lifetime (about 1.5–2.0 larger in amplitude compared to the minimum intensity at the same location). These EBs are exceptional cases with a very long lifetime, but similar trends also appear in other observations, such as EB-2 in Vissers et al. (2015). A question arises whether we should consider the entire duration of the event as a single EB, or the concatenation of several EBs at the same location. In contrast, the two last panels present the light curve for the bright patches C and D, which have no EB associated. Their light curves do not show any strong intensity variations, but the average intensity could be as high as some of the EBs. For example, in panel D, the intensity is comparable with the intensity reached in the panel A during the associated EB. This indicates that the study of the temporal evolution of AIA bright patches could be the key to detecting EBs effectively using SDO/AIA data. Thus, the study of the light curve of the bright patches identified by the SDO CNN model can be used as next step to identify EBs with more precision. Indeed, there is a popular type of neural network for spatio-temporal predictions (ConvLSTM; Shi et al. 2015) which has proven to be a key part to improve the detection of solar far-side active regions by exploiting the temporal information (Broock et al. 2022).
 |
Fig. 12. Temporal variation of the 1600 Å passband of SDO/AIA bright patches indicated in Fig. 9. Gray lines indicate the interval with SST co-temporal and co-spatial observations. Red and blue shaded areas in the two first panels indicate the EBs detected in Hα observations associated with bright patches A and B. An offset is applied to the x-axis to have 0 at the start of the SST observation. |
5. Summary and conclusions
This study explores the automatic detection of EBs in solar observations using NNs, with the aim of developing a generalizable method applicable to different datasets. The models were trained using high-resolution Hα observations from the SST and data from the 1600 Å, 1700 Å, 171 Å and 304 Å channels of SDO/AIA.
For the SST observations, NN-based models (both CNN and FNN) proved to be effective in detecting EBs. Spatial information is not crucial for detection when sufficiently high spectral resolution is available. However, as spectral and spatial resolution degrades, spatial information becomes more relevant, as indicated by the CNN models, which incorporate spatial information, and outperform FNN models in these scenarios. The inclusion of μ did not significantly improve the detection accuracy. Finally, the feature importance analysis revealed that the Hα line wings at ±1 Å offset are the most informative for detection.
For the SDO/AIA models, the detection of EBs was more challenging due to the lower spatial resolution and the lack of detailed spectral information. The models failed to adequately distinguish between EBs and bright events of different origin. This suggests that the combined intensity of the different channels does not provide enough information to classify EBs. The CNN models generally outperformed the FNN models, indicating that spatial information is crucial for detection when the spatial resolution is lower (as indicated by the spatially degraded SST dataset).
The feature importance analysis showed that the 1600 Å and 1700 Å channels are the most important for EB detection (with 1600 Å being the most relevant of these two). The 171 Å and 304 Å channels are mainly used to filter out transition-region events or flares with a strong lower-atmosphere component.
The comparison between the intensity threshold method and the SDO models pointed out the importance of using the context information of each observation to detect EBs. Both the intensity threshold method based on the local background and the SDO/CNN model, which use spatial information, outperform the SDO/FNN model, which does not use any spatial information.
Finally, this study explored the diagnostic potential of the temporal evolution of bright patches to differentiate EBs from other bright events. Preliminary analysis of the light curves suggests that time evolution could be key to detecting EBs. Ellerman bombs exhibit significant intensity variations on short timescales during their lifetime compared to network magnetic concentrations, indicating that incorporating temporal information could improve SDO/AIA detection models. This result offers a promising avenue towards developing a reliable EB detection method that can be applied to the full SDO/AIA database. For instance, it could be added to the output of the SDO CNN models to further improve the detection. Such a method would, for example, allow for analysis of long-term variations in EB occurrence and the impact of small-scale reconnection events in the formation of active regions to be established (Díaz Baso et al. 2021).
Models trained to detect EBs in SST observations provide the capability to automatically process large amounts of data in a reliable and precise manner. With the advent of new observatories such as Solar Orbiter (SolO; Müller et al. 2020), the Daniel K. Inouye Solar Telescope (DKIST; Rimmele et al. 2020), the upcoming European Solar Telescope (EST; Quintero Noda et al. 2022), and the Multi-Slit Solar Explorer (MUSE; De Pontieu et al. 2019), the solar community is embracing the big data paradigm. Methods such as the one presented in this paper will be crucial for properly exploiting the data produced by these new facilities and understanding the contribution of small-scale energetic events to the energy balance of the Sun.
Data availability
Movies associated to Figs. 7 and 9 are available at https://www.aanda.org
Acknowledgments
We would like to thank the anonymous referee for their comments and suggestions. This research is supported by the Research Council of Norway, project number 325491, through its Centres of Excellence scheme, project number 262622. This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement N° 945371. The Swedish 1-m Solar Telescope is operated on the island of La Palma by the institute for Solar Physics of Stockholm University in the Spanish Observatorio del Roque de los Muchachos of the Instituto de Astrofisica de Canarias. The Swedish 1-m Solar Telescope, SST, is co-funded by the Swedish Research Council as a national research infrastructure (registration number 4.3-2021-00169). We acknowledge the community effort devoted to the development of the following open-source packages that were used in this work: numpy (https://numpy.org/), matplotlib (https://matplotlib.org), scipy (https://scipy.org), astropy (https://astropy.org), sunpy (https://sunpy.org), pytrack (Tortora et al. 2022), and pytorch (Paszke et al. 2019). This research has made use of NASA’s Astrophysics Data System Bibliographic Services.
References
- Armstrong, J. A., & Fletcher, L. 2019, Sol. Phys., 294, 80 [NASA ADS] [CrossRef] [Google Scholar]
- Asensio Ramos, A., Cheung, M. C. M., Chifu, I., & Gafeira, R. 2023, Liv. Rev. Sol. Phys., 20, 4 [NASA ADS] [CrossRef] [Google Scholar]
- Barnes, W. T., Cheung, M. C. M., Bobra, M. G., et al. 2020, Journal of Open Source Software, 5, 5 [Google Scholar]
- Bhatnagar, A., Rouppe van der Voort, L., & Joshi, J. 2024, A&A, 689, A156 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bobra, M. G., & Couvidat, S. 2015, ApJ, 798, 135 [Google Scholar]
- Brabec, J., Komárek, T., Franc, V., & Machlica, L. 2020, in Computational Science - ICCS 2020, eds. V. V. Krzhizhanovskaya, G. Závodszky, M. H. Lees, J. J. Dongarra, P. M. A. Sloot, S. Brissos, & J. Teixeira (Cham: Springer International Publishing), 74 [Google Scholar]
- Broock, E. G., Asensio Ramos, A., & Felipe, T. 2022, A&A, 667, A132 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Clevert, D. A., Unterthiner, T., & Hochreiter, S. 2015, ArXiv e-prints [arXiv:1511.07289] [Google Scholar]
- Csurka, G., Volpi, R., & Chidlovskii, B. 2023, ArXiv e-prints [arXiv:2302.06378] [Google Scholar]
- de la Cruz Rodríguez, J., Löfdahl, M. G., Sütterlin, P., Hillberg, T., & Rouppe van der Voort, L. 2015, A&A, 573, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Pontieu, B., Lemen, J. R., & Cheung, C. M. M. 2019, AGU Fall Meeting Abstracts, 2019, SH33A-07 [Google Scholar]
- Díaz Baso, C. J., de la Cruz Rodríguez, J., & Danilovic, S. 2019, A&A, 629, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Díaz Baso, C. J., de la Cruz Rodríguez, J., & Leenaarts, J. 2021, A&A, 647, A188 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Díaz Baso, C. J., Asensio Ramos, A., & de la Cruz Rodríguez, J. 2022, A&A, 659, A165 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Díaz Baso, C. J., Rouppe van der Voort, L., de la Cruz Rodríguez, J., & Leenaarts, J. 2023, A&A, 673, A35 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Díaz Baso, C. J., Asensio Ramos, A., de la Cruz Rodríguez, J., da Silva Santos, J. M., & Rouppe van der Voort, L. 2025, A&A, 693, A170 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Díaz Castillo, S. M., Asensio Ramos, A., Fischer, C. E., & Berdyugina, S. V. 2022, Front. Astron. Space Sci., 9 [Google Scholar]
- Ellerman, F. 1917, ApJ, 46, 46 [Google Scholar]
- Fawcett, T. 2006, Pattern Recognition Letters, 27, 27 [Google Scholar]
- Fisher, A., Rudin, C., & Dominici, F. 2018, J. Mach. Learn. Res., 20, 1 [Google Scholar]
- Georgoulis, M. K., Rust, D. M., Bernasconi, P. N., & Schmieder, B. 2002, ApJ, 575, 506 [Google Scholar]
- Goodfellow, I., Bengio, Y., & Courville, A. 2016, Deep Learning (MIT Press), http://www.deeplearningbook.org [Google Scholar]
- Guo, C., Pleiss, G., Sun, Y., & Weinberger, K. Q. 2017, arXiv e-prints [arXiv:1706.04599] [Google Scholar]
- Guo, X., Yang, Y., Feng, S., et al. 2022, Sol. Phys., 297, 104 [NASA ADS] [CrossRef] [Google Scholar]
- Hansteen, V., Ortiz, A., Archontis, V., et al. 2019, A&A, 626, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Herlender, M., & Berlicki, A. 2011, Centr. Eur. Astrophys. Bull., 35, 181 [Google Scholar]
- Hong, J., Li, Y., Ding, M. D., & Hao, Q. 2021, ApJ, 921, 50 [NASA ADS] [CrossRef] [Google Scholar]
- Illarionov, E. A., & Tlatov, A. G. 2018, MNRAS, 481, 5014 [Google Scholar]
- Jarolim, R., Veronig, A. M., Hofmeister, S., et al. 2021, A&A, 652, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Joshi, J., Rouppe van der Voort, L. H. M., & de la Cruz Rodríguez, J. 2020, A&A, 641, L5 [EDP Sciences] [Google Scholar]
- Joshi, J., & Rouppe van der Voort, L. H. M. 2022, A&A, 664, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kingma, D. P., & Ba, J. 2017, arXiv e-prints [arXiv:1412.6980] [Google Scholar]
- Kleint, L., & Panos, B. 2022, A&A, 657, 657 [Google Scholar]
- Krikova, K., Pereira, T. M. D., & Rouppe van der Voort, L. H. M. 2023, A&A, 677, A52 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kruskal, J. B. 1964, Psychometrika, 29, 29 [Google Scholar]
- Lemen, J. R., Title, A. M., Akin, D. J., et al. 2012, Sol. Phys., 275, 17 [Google Scholar]
- Lloyd, S. 1982, IEEE Transactions on Information Theory, 28, 28 [Google Scholar]
- Löfdahl, M. G., Hillberg, T., Cruz Rodríguez, J., et al. 2021, A&A, 653, A68 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Matsumoto, T., Kitai, R., Shibata, K., et al. 2008, PASJ, 60, 60 [Google Scholar]
- Müller, D., St. Cyr, O. C., Zouganelis, I., et al. 2020, A&A, 642, A1 [Google Scholar]
- Nair, V., & Hinton, G. E. 2010, Proceedings of the 27th International Conference on International Conference on Machine Learning, ICML’10 (Madison: Omnipress), 807 [Google Scholar]
- Nelson, C. J., Doyle, J. G., Erdélyi, R., et al. 2013, Sol. Phys., 283, 307 [Google Scholar]
- Pariat, E., Schmieder, B., Berlicki, A., et al. 2007, A&A, 473, 279 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, Advances in Neural Information Processing Systems 32 (Curran Associates, Inc.), 8024 [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 12 [Google Scholar]
- Priest, E. 1990, Mitteilungen der Astronomischen Gesellschaft Hamburg, 65, 65 [Google Scholar]
- Prince, S. J. 2023, Understanding Deep Learning (The MIT Press) [Google Scholar]
- Qiu, J., Ding, M. D., Wang, H., Denker, C., & Goode, P. R. 2000, ApJ, 544, L157 [NASA ADS] [CrossRef] [Google Scholar]
- Quintero Noda, C., Schlichenmaier, R., Bellot Rubio, L. R., et al. 2022, A&A, 666, A21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Reid, A., Mathioudakis, M., Doyle, J. G., et al. 2016, ApJ, 823, 110 [Google Scholar]
- Rimmele, T. R., Warner, M., Keil, S. L., et al. 2020, Sol. Phys., 295, 172 [Google Scholar]
- Ronneberger, O., Fischer, P., & Brox, T. 2015, arXiv e-prints [arXiv:1505.04597] [Google Scholar]
- Rouppe van der Voort, L. H. M., Joshi, J., Henriques, V. M. J., & Bose, S. 2021, A&A, 648, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rouppe van der Voort, L. H. M., van Noort, M., & de la Cruz Rodríguez, J. 2023, A&A, 673, A11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rouppe van der Voort, L. H. M., Joshi, J., & Krikova, K. 2024, A&A, 683, A190 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rutten, R. J., Vissers, G. J. M., Rouppe van der Voort, L. H. M., Sütterlin, P., & Vitas, N. 2013, J. Phys. Conf. Ser., 440, 012007 [Google Scholar]
- Scharmer, G. B., Bjelksjo, K., Korhonen, T. K., Lindberg, B., & Petterson, B. 2003, in Innovative Telescopes and Instrumentation for Solar Astrophysics, eds. S. L. Keil, & S. V. Avakyan, SPIE Conf. Ser., 4853, 341 [NASA ADS] [CrossRef] [Google Scholar]
- Scharmer, G. B., Narayan, G., Hillberg, T., et al. 2008, ApJ, 689, L69 [Google Scholar]
- Shelhamer, E., Long, J., & Darrell, T. 2017, IEEE Trans. Pattern Anal. Mach. Intell., 39, 39 [Google Scholar]
- Shi, X., Chen, Z., Wang, H., et al. 2015, ArXiv e-prints [arXiv:1506.04214] [Google Scholar]
- Simões, P. J. A., Reid, H. A. S., Milligan, R. O., & Fletcher, L. 2019, ApJ, 870, 114 [Google Scholar]
- Socas-Navarro, H., Martínez-Pillet, V., Elmore, D., et al. 2005, Sol. Phys., 235, 235 [Google Scholar]
- Tähtinen, I., Virtanen, I. I., Pevtsov, A. A., & Mursula, K. 2022, A&A, 664, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tortora, M., Cordelli, E., & Soda, P. 2022, IEEE Access, 10, 10 [Google Scholar]
- Van Noort, M., Rouppe van der Voort, L., & Löfdahl, M. G. 2005, Sol. Phys., 228, 191 [Google Scholar]
- Vissers, G. J. M., Rouppe van der Voort, L. H. M., & Rutten, R. J. 2013, ApJ, 774, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Vissers, G. J. M., Rouppe van der Voort, L. H. M., Rutten, R. J., Carlsson, M., & De Pontieu, B. 2015, ApJ, 812, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Vissers, G. J. M., de la Cruz Rodríguez, J., Libbrecht, T., et al. 2019a, A&A, 627, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vissers, G. J. M., Rouppe van der Voort, L. H. M., & Rutten, R. J. 2019b, A&A, 626, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Watanabe, H., Vissers, G., Kitai, R., Rouppe van der Voort, L., & Rutten, R. J. 2011, ApJ, 736, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Young, P. R., Tian, H., Peter, H., et al. 2018, Space Sci. Rev., 214, 120 [Google Scholar]
- Zhu, G., Lin, G., Wang, D., Liu, S., & Yang, X. 2019, Sol. Phys., 294, 117 [CrossRef] [Google Scholar]
Appendix
Image patches selection algorithm
The following algorithm outlines the process for selecting image patch centers to address the data imbalance issue. This algorithm ensures that the selected points adequately represent both EBs and non-EBs, thereby facilitating a more balanced dataset for training the model. To achieve this, the algorithm proceeds through the following steps:
-
Step 1: Define matrix W. This matrix is a copy of the ground-truth mask, with values of 1 at EB locations and 0 elsewhere. Optionally, this mask can be smoothed. The matrix is then normalized so that the total sum is 1.
-
Step 2: Define value w. We assume that we have n image patches. The value w represents the sum of the number of 0s and 1s in all the image patches, i.e., pixels event and non-event. Each 0 counts as −1 and each 1 as +1. Thus, if there is an equal number of 0s and 1s, w = 0. Initially, since n = 0, w = 0.
-
Step 3: Define the probability density function (PDF) as ℒ = A−|W + w|. The parameter A is chosen based on the desired sharpness of the probability to select events. In this case, we use A = e.
-
Step 4: Iteratively select the image patches. For each new image patch, w is recomputed and L is updated to select the next point until the desired amount of image patches N is achieved.
To avoid image patch repetition, we do not allow the code to use the same image patch centroid twice. We also apply to each new image patch random transformations, which include flipping, rotation and transposing. To clarify these steps, we present the pseudocode for the image patch selection algorithm:
Input: Number of image patches N
Input: Probability density function (PDF) W
Initialize w = 0
Select random point x0
Initialize number of selected image patches n = 1
while n < N do
Update ℒ with w
Select next point x′ ∼ ℒ
Compute new w
n = n + 1
end while
Figure A.1 shows the image patches selected for an arbitrary frame of Set E.
 |
Fig. A.1. Image patches selected by the image patch selection algorithm in an arbitrary frame of Set E. Image patches are represented by black contour rectangles. Red contours outline the locations of EBs. |
Appendix B: Calibration process
The output of the neural network is a value between 0 and 1. This value, as mapped by the network, may not necessarily represent a true probability. Therefore, it is crucial to ensure that these values correspond to actual probabilities. If they do not, we aim to map these outputs into a real probability space. When the outputs of the model represent true probabilities, the model is said to be calibrated. In this context, a value of 0.7 for a pixel should be interpreted as a 70% chance of being an EB, and a 30% chance of being a non-EB. An uncalibrated model can still be used, but in such cases, the only property that holds is that a higher score indicates a higher probability (Fawcett 2006). As shown in Guo et al. (2017), deeper models tend to show higher levels of miscalibration. Thus, this issue becomes more pronounced with deeper models. Although our models are not particularly deep, we nonetheless address their calibration following the methodology outlined in Guo et al. (2017). It is crucial to note that calibration does not affect the model’s capacity but rather improves the interpretability of its predictions.
For the calibration process, we first grouped the outputs of the neural network into M bins, each one with the same size. In our case, we used intervals defined by the following limits: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]. For each bin, we included the lower limit and exclude the upper limit, except for the last bin where both limits are included.
The calibration process is based on two metrics: accuracy (acc) and confidence (conf), defined as:
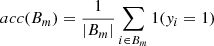 (B.1)
(B.1)
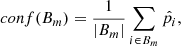 (B.2)
(B.2)
where Bm denotes the mth bin and |Bm| indicates the number of outputs in the given bin. Variables yi and pi are the ground-truth label and the associated probability of the output i. The metric acc measures the proportion of correctly classified outputs within a given bin, reflecting the neural network’s accuracy. If the third bin ([0.2, 0.3[) has 100 samples, we would expect that about 20 to 30 of those samples are correctly identified as EBs. The metric conf is the average predicted probability within each bin. For a perfect calibration, acc(Bm) = conf(Bm). At this points, we could define the distance between these two quantities as the (average) expected calibration error (ECE):
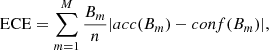 (B.3)
(B.3)
where n is the total number of outputs. We use this metric to quantify how good is the calibration of a given model. A perfect calibration would have ECE = 0. At this point, a non-parametric regression is used to find the mapping function to obtain true probabilities given the output of the neural network, in other words, to find the function which minimizes the ECE. This step is implemented using the sklearn python package (Pedregosa et al. 2011). After this step, this new mapping is “attached” to the neural network as the Calibrator step.
The reliability diagram is a way to visualize the degree of calibration of a model and it compares the deviation of the real confidence w.r.t the theoretical value of each bin defined by:
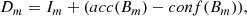 (B.4)
(B.4)
where Im is the value at the middle of the interval m. For example, the third bin comprises the interval [2,3[, so I3 = 2.5. For a perfect calibration, Dm = Im, so the center of each bin should coincide with the diagonal. Figure B.1 displays the reliability diagram for the CNN model of the SST EB identification, before (orange) and after (blue) the calibration procedure, together with the isotonic mapping curve.
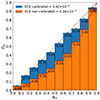 |
Fig. B.1. Reliability diagram of the CNN model for SST. Orange and blue bars represent the non-calibrated and calibrated model respectively. The number below the head of each bin represents the real conf of that bin. ECE and ECE_C are the ECE errors for the non-calibrated and calibrated model respectively. The red curve represents the isotonic fitting. |
All Tables
Description of the training, validation, and test set used for the SST and SDO models.
All Figures
|
Fig. 1. Sketch of the semantic segmentation process for the determination of whether a pixel in the input image belongs to an EB. After being processed by the NN and the calibrator (Cal.) and after application of a probability threshold (Thr.), the output mask shows which pixels belong to an EB (white). |
| In the text | |
|
Fig. 2. Illustration of the process used to compute SDO/AIA labeled data for an arbitrary frame of dataset E. Panel (a) displays the SST Hα blue wing and EBs highlighted by blue contours. Panel (b) shows the same data as the previous panel but downsampled and coaligned with SDO data of the same target region. Panel (c) shows the square root of the product of SDO/AIA 1600 Å and 1700 Å. Red contours indicate pixels above the threshold and blue contours represent the EBs from the SST. Panel (d) shows SDO/AIA 1700 Å passband for the target region with the resulting masks in yellow contours. These yellow contours are selected as the red contours in panel (c) which overlap with the blue contours. Panel (a) is displayed using its data coordinate system. The arrows at the top left of this panel point towards solar north (red), and west (blue) for this reference frame. Panels (b), (c), and (d) are displayed using heliocentric coordinates. |
| In the text | |
|
Fig. 3. Example SST image patch with all the channels. All this information forms one SST image patch, which serves as input for the CNN SST models. Each image is scaled individually. Offsets are given with respect to nominal Hα line center. The size of the area of SST is 20 × 20 pixels. |
| In the text | |
|
Fig. 4. Example SDO image patch with all the AIA channels included for the segmentation process, which serves as input for the CNN SDO models. Here the EB is clearly visible in 1600 Å and 1700 Å while there are no signatures in the 171 Å or 304 Å passbands. The size of the area of SDO image patch is 10 × 10 pixels. |
| In the text | |
|
Fig. 5. Metrics of recall, precision, and their harmonic mean, the F1 score, for the models trained to perform EB detection in SST Hα observations. The metric scores are shown as a function of probability of a detection being an EB. From left to right, the metrics are for models trained using: all the spectral points, all spectral points plus μ, and all spectral points for the spatially degraded dataset. Dashed lines represent CNN models, while solid lines indicate FNN models. Blue, orange, and red colors correspond to recall, precision, and F1 score, respectively. These metrics have been computed using the test set. |
| In the text | |
|
Fig. 6. Histograms of the area of EB predictions in the new dataset by the CNN and FNN models, using a probability of 0.5. Red bars correspond to the detections made by the FNN model and blue bars to the CNN model. Filled bars represent the area of EBs that meet the size criteria explained in the text. Dark blue color represents the overlap between red and blue bars. Unfilled bars show all the detected EBs, without size constraints. The dashed line marks the area cutoff used in the criteria. The y-axis presents the fraction of each bin with respect to the total number of detections. For clarity, the x-axis is limited to 0.80, although the histogram tails extend up to approximately 1.2 arcsec2 with near-zero counts. |
| In the text | |
|
Fig. 7. Example of EB predictions done by the CNN and FNN SST models over a cutout of the new dataset. The left panel shows the intensity image in the red wing of Hα at +1 Å offset. The middle and right panels show the predictions done by the CNN and FNN models respectively. The colormap indicates the probability assigned by the models to each pixel of being an EB. The white dashed contours mark the 0.1 probability of the CNN prediction and are drawn in all panels to facilitate spatial comparison. An animation of this figure that shows the probability maps over the full time sequence is available in the online material. |
| In the text | |
|
Fig. 8. Metrics of recall, precision, and F1 score for the models trained to perform EB detection in SDO/AIA. The upper and lower panel shows the metrics for the models trained with all the passbands and passbands plus μ respectively. The metric scores are shown as a function of the probability of a detection being an EB. These metrics have been computed using the test set. |
| In the text | |
|
Fig. 9. Example AIA 1700 Å frame with EBs detected by the SDO/AIA CNN model. Detections are outlined by black, green, and blue contours, corresponding to probabilities of 0.2, 0.6, and 0.9 respectively. Yellow contours indicate EBs detected in Hα SST observations at the same time. White dashed circles and white letters indicate the bright patches selected for the study presented in Fig. 12. The movie online shows the detections for all the frames of the observation. |
| In the text | |
|
Fig. 10. Computed F1 score for each input channel in the permutation feature importance assessment. The evaluated channel is shuffled to measure performance loss, where a lower score indicates higher importance. The left panel shows the results for the SST input features (wavelength offsets in Hα) and the right panel displays the results for the SDO/AIA passbands. Both panels show the results for the CNN architecture. A dashed vertical line indicates the score without shuffling the input features. |
| In the text | |
|
Fig. 11. Recall, precision, and F1 score for the brightness intensity threshold used to perform EB detection in SDO/AIA. The metric scores are shown as a function of the applied intensity threshold. The units of the thresholds is the number of standard deviation values (σ) above the local quiet-Sun average. For comparison, dashed and solid red lines indicate the maximum F1 score achieved by the FNN and CNN SDO models respectively. The gray vertical line indicates the threshold value suggested by Vissers et al. (2019b) at 5σ. These metrics have been computed using the test set. |
| In the text | |
|
Fig. 12. Temporal variation of the 1600 Å passband of SDO/AIA bright patches indicated in Fig. 9. Gray lines indicate the interval with SST co-temporal and co-spatial observations. Red and blue shaded areas in the two first panels indicate the EBs detected in Hα observations associated with bright patches A and B. An offset is applied to the x-axis to have 0 at the start of the SST observation. |
| In the text | |
|
Fig. A.1. Image patches selected by the image patch selection algorithm in an arbitrary frame of Set E. Image patches are represented by black contour rectangles. Red contours outline the locations of EBs. |
| In the text | |
|
Fig. B.1. Reliability diagram of the CNN model for SST. Orange and blue bars represent the non-calibrated and calibrated model respectively. The number below the head of each bin represents the real conf of that bin. ECE and ECE_C are the ECE errors for the non-calibrated and calibrated model respectively. The red curve represents the isotonic fitting. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.