| Issue |
A&A
Volume 691, November 2024
|
|
|---|---|---|
| Article Number | A348 | |
| Number of page(s) | 23 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202450975 | |
| Published online | 26 November 2024 | |
Constrained cosmological simulations of the Local Group using Bayesian hierarchical field-level inference
1
Kapteyn Astronomical Institute, University of Groningen, P.O Box 800 9700 AV, Groningen, The Netherlands
2
CNRS & Sorbonne Université, UMR 7095, Institut d’Astrophysique de Paris, 98 bis boulevard Arago, F-75014 Paris, France
3
Max-Planck-Institut für Astrophysik, Karl-Schwarzschild-Straße 1, 85748 Garching, Germany
4
The Oskar Klein Centre, Department of Physics, Stockholm University, Albanova University Center, SE 106 91 Stockholm, Sweden
⋆ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
3
June
2024
Accepted:
1
October
2024
Abstract
We present a novel approach based on Bayesian field-level inference that provides representative ΛCDM initial conditions for simulation of the Local Group (LG) of galaxies and its neighbourhood, constrained by present-day observations. We extended the Bayesian Origin Reconstruction from Galaxies (BORG) algorithm with a multi-resolution approach, allowing us to reach the smaller scales needed to apply the constraints. Our data model simultaneously accounts for observations of mass tracers within the dark haloes of the Milky Way (MW) and M31, for their observed separation and relative velocity, and for the quiet surrounding Hubble flow, represented by the positions and velocities of 31 galaxies at distances between one and four megaparsec. Our approach delivers representative posterior samples of ΛCDM realisations that are statistically and simultaneously consistent with all of these observations, leading to significantly tighter mass constraints than found if the individual datasets are considered separately. In particular, we estimate the virial masses of the MW and M31 to be log10(M200c/M⊙) = 12.07 ± 0.08 and 12.33 ± 0.10, respectively, their sum to be log10(ΣM200c/M⊙) = 12.52 ± 0.07, and the enclosed mass within spheres of radius R to be log10(M(R)/M⊙) = 12.71 ± 0.06 and 12.96 ± 0.08 for R = 1 Mpc and 3 Mpc, respectively. The M31-MW orbit is nearly radial for most of our ΛCDM realisations, and most of them feature a dark matter sheet aligning approximately with the supergalactic plane, despite the surrounding density field not being used explicitly as a constraint. High-resolution, high-fidelity resimulations from initial conditions identified using the approximate simulations of our inference scheme continue to satisfy the observational constraints, demonstrating a route to future high-resolution, full-physics ΛCDM simulations of ensembles of LG look-alikes, all of which closely mirror the observed properties of the real system and its immediate environment.
Key words: methods: numerical / galaxies: evolution / galaxies: formation / Local Group / dark matter
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Abundant and very detailed observational information is available for the Local Group (LG) of galaxies. It thus provides a unique laboratory to study the physics of galaxy formation, galactic dynamics, and even cosmology. For instance, the LG has a complete sample of dwarf galaxies down to low luminosity, and the sample’s properties have led to controversies such as the ‘missing satellite’ and ‘too-big-to-fail’ problems (Bullock & Boylan-Kolchin 2017, and references therein) which highlight apparent differences between the observed dwarf luminosity function and that predicted by cosmological simulations. This has driven refinements of galaxy formation modelling on small scales involving more realistic treatments of baryonic processes such as star formation and feedback, but it has also motivated the exploration of alternative particle physics candidates for dark matter (Sales et al. 2022, and references therein). Another observed peculiarity of the LG is the co-planar spatial and orbital configuration of the satellites surrounding the two major galaxies, which has led to debates on whether this can plausibly occur in a ΛCDM universe (Libeskind et al. 2005; Pawlowski 2018). Some authors have argued that this configuration is transient and of low statistical significance (Sawala et al. 2023a) and that the clustering of orbital planes may reflect coordinated infall of groups of satellites (Li & Helmi 2008; Taibi et al. 2024). The LG is also the only place where we can use detailed kinematic and chemical information for individual stars to deduce the detailed assembly history of a galaxy, an area in which substantial progress has been made since the latest data release of Gaia (Helmi 2020).
Cosmological simulations are central to addressing these problems, as they provide realistic models for the formation of structure, which allows us to evaluate observations in the context of a specific physical model such as the ΛCDM paradigm. To understand whether particular observed properties of our LG are consistent with this paradigm, and to explore its predictions for the formation history of LG galaxies, it is valuable to construct a representative ensemble of ΛCDM simulations tuned to match closely the well-observed properties of the two main galaxies and their environment.
Much effort has been made on modelling the formation of the LG, initially using two-body models (Kahn & Woltjer 1959; Gott & Thuan 1978; Mishra 1985), later using Numerical Action Methods (Peebles et al. 1989; Peebles 1990; Peebles & Tully 2013), and recently the community has developed several full cosmological simulation programmes aimed at the LG (some recent ones include Gottloeber et al. 2010; Fattahi et al. 2016; Sawala et al. 2016; Garrison-Kimmel et al. 2014, 2019; Libeskind et al. 2020; Sawala et al. 2022; McAlpine et al. 2022). However, obtaining a representative sample of LG analogues that closely match relevant observed properties such as the masses of the two main galaxies, their separation and relative velocity, as well as their somewhat larger-scale environment, has turned out to be challenging. Many studies have started with a cosmological simulation with unconstrained initial conditions, and have picked out LG analogues in the simulation volume (Li & White 2008; González et al. 2014; Fattahi et al. 2016; Carlesi et al. 2017; Zhai et al. 2020; Pillepich et al. 2024), but this approach has limited ability to match the LG at the present day because the number of analogues that one finds is directly related to the total parameter volume allowed by the selection criteria. Hence, tightening the criteria rapidly reduces the number of analogues found. This can be partially mitigated by utilising large volume simulations or by running many simulations with different random initial conditions to increase the volume surveyed, but finding a system that matches all desired properties of the LG accurately is not feasible. This can be seen in Table 1 which provides the number of LG analogues found by different studies, as well as the strictness of the selection criteria. For example, we note that, in the APOSTLE suite, only 12 LG analogues were found to satisfy relatively loose criteria within a (100 Mpc)3 simulation volume.
A summary of the selection requirements of some notable past Local Group simulations.
A more direct and potentially more powerful approach is to use constrained simulations, in which one reconstructs initial conditions given some present-day constraints. Two commonly applied methods exist. One is based on Wiener Filter reconstructions (Hoffman & Ribak 1991; Zaroubi et al. 1999), while the second and more recent is based on Bayesian inference, using Hamiltonian Monte Carlo (HMC) methods. Both have been very successful on large scales (Mathis et al. 2002; Courtois et al. 2012; Sorce et al. 2016; Tully et al. 2019; Jasche et al. 2015; Jasche & Lavaux 2019; Lavaux et al. 2019), reproducing cosmic large-scale structures that match in detail those observed. Bayesian forward modelling schemes are generally preferable because the Hoffman & Ribak (1991) method only exactly samples from the posterior distribution for constraints that are linear in the initial condition field. Bayesian forward modelling with HMC is more versatile in dealing with complex observational data and it can be extended to deal with non-linear scales.
So far, these techniques have only been applied with constraints based on datasets suited to constrain structure on a relatively large scale, such as galaxy redshift surveys, and peculiar velocity catalogues. They have never been applied to generate constrained simulations that match the properties of the LG and its immediate environment. For example, the 2019 analysis of 2M++ with BORG (Jasche & Lavaux 2019) constrains realisations of cosmic structure to match the observed galaxy distribution binned in (4 Mpc)3 voxels, and constrained simulations based on peculiar velocity datasets (e.g. Carlesi et al. 2016) have a similar or larger effective filter scale, because of the requirement that the velocities are well-described by linear theory. Both methods are thus still far from what is required for a constrained simulation of the LG.
Several recent programmes use these large-scale constrained simulations as a base. They then do trial-and-error runs to identify LG analogues with roughly the observed properties. This is done by first generating initial conditions using large-scale constraints. This sets the large-scale Fourier components of the initial density fields. The Fourier components on small scales remain unconstrained and are set at random. One then resimulates many different realisations and picks out those which produce a galaxy pair that is Local-Group-like. For example, in the Clues (Gottloeber et al. 2010; Carlesi et al. 2016; Sorce et al. 2016) and more recent Hestia simulations (Libeskind et al. 2020), one starts from large-scale initial conditions based on a Wiener Filter reconstruction of peculiar velocity data from the CosmicFlows-2 catalogue (Tully et al. 2013). Subsequently, for Hestia, 1000 realisations with randomised small-scale initial conditions are created, resulting in 13 realisations with a halo pair that matches their relatively coarse Local Group criteria, as summarised in Table 1.
For the Sibelius simulations, Sawala et al. (2022) go a step further, using for the large scale structure a realisation from the 2M++ galaxy count data-based reconstructions from BORG (Jasche & Lavaux 2019). They also randomised the small-scale unconstrained structure and found a few good matches, although they did not satisfy their full ‘wish list’ of LG analogue selection criteria, which is briefly listed in Table 1 and is more strict than that for the HESTIA simulations. To get higher-fidelity realisations, they refined promising sets of initial conditions by iteratively randomising smaller and smaller scales, at each stage picking the ‘best’ simulation and then refining even smaller scales. With some careful selection of promising candidates, this allowed them to obtain a small number of initial condition sets that match their strictest LG requirements (see Table 1). However, with such a hierarchical, manual approach, the results cannot be assumed to be an unbiased and fair sample of the posterior distribution of ΛCDM universes subject to the adopted LG constraints.
Such a sample of representative histories for the LG would however be extremely valuable. One could then infer the expected distribution of LG properties in a ΛCDM universe, conditional on its present-day configuration. For instance, one could check expectations for anisotropies in the satellite distribution (i.e. satellite planes), for the immediate environment of the LG, for the distribution of mass on various scales, for the inter-group and circum-group baryon distribution, and even for the detailed assembly history of the system.
In this work, we will use the Hamiltonian Monte Carlo (HMC) methods already used successfully on larger scales to generate constrained simulations of the LG (Jasche & Wandelt 2013; Lavaux & Jasche 2016; Jasche & Lavaux 2019). These methods come with some difficulties, however. Notably the HMC algorithm requires the availability of an efficient evaluation for the derivatives of the posterior probability. In other words, one needs to be able to back-propagate the gradient of the likelihood to the cosmological initial conditions. Additionally, the HMC requires generating many simulations. Keeping computational time feasible requires individual simulations to be efficient. Because of this, constrained simulations cannot be built directly on top of state-of-the-art N-body simulation codes such as Gadget-4 (Springel et al. 2021) or Swift (Schaller et al. 2024) without major modification. Instead, the relevant community has developed custom cosmological simulation codes with hand-coded derivatives, usually based on Lagrangian perturbation theory (Jasche & Wandelt 2013; Kitaura 2013; Wang et al. 2013), or using Particle Mesh (PM) gravity (Wang et al. 2014; Jasche & Lavaux 2019; Li et al. 2022). Particle mesh simulations are particularly attractive because they can be much improved and with marginal additional cost by utilising integration techniques informed by Lagrangian Perturbation theory, for example, COLA (Tassev et al. 2013), which is used in BORG, or FastPM (Feng et al. 2016), which is used by Modi et al. (2021). The existing single-mesh integrator in BORG is still, however, insufficiently accurate to achieve the resolution we require in a reasonable computation time, which is why we implement a zoom method in this paper.
This paper proceeds with Section 2, where the HMC methodology for finding a representative sample of LG initial conditions is described, together with the observational data on the LG that we will use to constrain our inference. Then, in Section 3, we present the results of this inference and the properties of the realistic and representative sample of Local Groups that it produces. In Section 4 we explore how the initial conditions can be used to perform resimulations with Gadget-4. In Section 5 we discuss how our results compare to previous studies, we highlight some of its limitations, and we sketch some future research directions. Finally, in Section 6 we conclude.
2. Methods and setup
For this work, we wish to obtain a fair statistical sample of ΛCDM simulations, all of which reproduce with high fidelity the main observed characteristics of the two largest LG galaxy haloes, as well as the smooth and weakly perturbed Hubble flow in their immediate environment. Since a simulation is determined fully by forward integration from its initial conditions, obtaining a fair sample of simulations is equivalent to obtaining a fair sample of initial condition sets conditional on well-established observational constraints on the present-day system. This motivates us to set up a Bayesian inference problem: we wish to sample the initial conditions, following a ΛCDM prior, conditional on a likelihood that describes our observational knowledge of the LG and its environment. The posterior initial conditions will then generate a fair statistical sample of simulations of LG analogues. To build this machinery, we split this section into three parts: in Section 2.1, we describe the inference process, which uses Hamiltonian Monte Carlo, in Section 2.2, we describe the forward model, which is the cosmological simulation from a Gaussian random initial density field to the present-day particle distribution, and in Section 2.3, we describe the likelihood we adopt to summarise the observational knowledge we have of the LG and its immediate environment. Figure 1 provides an overall summary of the process.
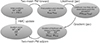 |
Fig. 1. Schematic diagram of our Hamiltonian Monte Carlo method. The procedure starts with a white noise initial condition field s, then uses a nested, double-mesh particle-mesh (PM) integrator to obtain the final particle phase-space coordinates (xfinal and vfinal). The likelihood is implemented in Python using the JAX package (Bradbury et al. 2018), which automatically implements the gradient. We compute the gradient of the likelihood and back-propagate it through the double-mesh integrator steps to the initial condition field. Using this gradient, we then do a Hamiltonian Monte Carlo (HMC) update on the initial condition field and iterate the whole procedure many times to obtain our sample of initial condition fields. |
2.1. Bayesian inference of large-scale structure formation
In cosmological simulations, the initial conditions on particles are created by Gaussian random numbers s, which, assuming a power spectrum and Lagrangian perturbation theory, are then used to determine the initial high-redshift particle positions and velocities (Angulo & Hahn 2022, and references therein). We wish to carry out Bayesian inference on the Gaussian white noise field that generates the initial conditions of our simulation, sampling from the posterior
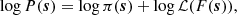 (1)
(1)
where π is the prior probability, s indicates the Gaussian random field that generates the initial conditions, F(s) is the result of the forward model, that is, our particle-mesh simulations, and ℒ indicates the likelihood function which describes how likely the observed properties of the LG are, given the result of a simulation (see Section 2.3).
2.1.1. Hamiltonian Monte Carlo
For the inference, we utilise Hamiltonian Monte Carlo (HMC, Duane et al. 1987; Neal 1993), a sampling method that works well for high-dimensional problems and has been successfully used to make large-scale structure inference (Jasche & Wandelt 2013; Lavaux & Jasche 2016; Jasche & Lavaux 2019). The process is well-described in Brooks et al. (2011), and we summarise it briefly here. Conceptually, it means solving numerically the equations of motion for a fictitious physical system, where the potential is minus the log-posterior of the problem. In our case, we consider the motion of our initial condition field vector s, inside the potential defined by the log-posterior of our problem:
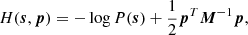 (2)
(2)
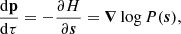 (3)
(3)
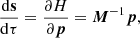 (4)
(4)
where p is the momentum and M is the mass matrix. Each iteration of the Hamiltonian Monte Carlo sampler consists of three steps. One first (step 1) integrates the equations of motion (Equations (3) and (4)) for a given number of steps Nsteps using a step size ϵ. The integrator must be symplectic. Then (step 2) after the integration, the proposed result is rejected or accepted based on a Metropolis-Hastings criterion:
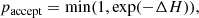 (5)
(5)
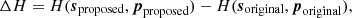 (6)
(6)
and the new state becomes (sproposed, pproposed) upon acceptance, and (soriginal, −poriginal) upon rejection. And lastly (step 3), the momentum is refreshed
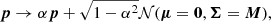 (7)
(7)
where 𝒩(μ = 0, Σ = M) is a multivariate Gaussian distribution with mean μ and covariance matrix Σ.
This gives the HMC algorithm several hyperparameters that must be chosen. We opt for a leapfrog scheme to integrate Hamilton’s equations of motion, with a fixed number of steps Nsteps, and where the step size drawn is uniformly between [0.9ϵmax, ϵmax]. We set the mass matrix M to be an identity matrix, and we set the momentum conservation ratio α to zero; that is, we do a full momentum refreshment each step.
The parameters ϵmax and Nsteps have to be tuned, and we tune them to achieve acceptance rates around 50 % to 70 %, while maximising the integration length per step – this is required to keep random-walk behaviour to a minimum (Brooks et al. 2011). Although adopting a different mass matrix can help sampling performance, it is not practical to find one, especially in high-dimensional problems like ours. Similarly, tuning α can also benefit sampling performance in some situations; we found no measurable improvement in some exploratory tests, so we kept it to zero. Lastly, we have tried replacing the leapfrog integrator with higher-order schemes as suggested by Hernández-Sánchez et al. (2021), but some cursory tests showed a simple leapfrog integration to perform the best for this problem. More complete testing is left for future work.
2.1.2. Two-grid sampling
In our procedure, we use a zoom setup, in which our Gaussian white noise field s is actually composed of two white noise fields for a low-resolution (LR) grid sLR and a high-resolution (HR) grid sHR. These are NLR3 and NHR3 grids with each element being a 𝒩(0, 1) standard Gaussian random variable. In our procedure, we jointly sample these fields.
2.2. The forward model
In our case, the forward model is the gravity simulation that takes in the Gaussian white noise fields s and outputs the particle positions and velocities at the present time. Four steps are involved. (i) We convolve the Gaussian white noise field s with (the square root of) the (appropriately scaled) power spectrum, in our case the linear matter power spectrum P(k) with the backscaling method (Angulo & Hahn 2022). This gets us the initial condition of the matter field at z = 63. (ii) We compute the Lagrangian displacement field given the generated Gaussian random field at z = 63 and interpolate this displacement onto our particle load that is initially placed on two cartesian grids. In particular, we place high-resolution particles at the centres of each voxel of the high-resolution grid and place low-resolution particles at the centres of each voxel in the low-resolution grid that is not in the high-resolution region. This results in 643 high-resolution particles and 643 − 163 low-resolution particles1. (iii) We perturb the positions and velocities using the Lagrangian displacement field to obtain the particle initial conditions at z = 63. (iv) We run a gravity simulation given these particles down to z = 0, for which we use a two-level particle-mesh method.
2.2.1. Particle mesh simulations
To compute particle forces, in the usual single-mesh particle mesh simulations (Hockney & Eastwood 1988), one also has to do four steps. (i) We compute the density field by depositing particles onto a mesh, distributing the mass of each particle on the nearest mesh cells with the piecewise linear Cloud-In-Cell (CIC) kernel. (ii) We obtain the potential field from this density field by solving the Poisson equation on a mesh. In practice, we convolve the density field with the Green’s function in Fourier space (this is denoted as Δ−1 because, on the mesh, this operation can be thought of as the inverse of the Laplacian). (iii) We compute a force field from the potential field by finite differentiation. (iv) We interpolate the forces onto the particles using a CIC kernel. When taking derivatives of the potential, which must be consistent with the choice of Green’s function, we use a 2nd-order finite-difference approximation of the gradient compatible with our treatment of the inverse Laplacian (see Hahn & Abel 2011, for an overview of alternative higher-order approximations). Using the forces, the equations of motion are then integrated in time using a leapfrog integrator. In this work, we build on the implementation existing in BORG, as described in Jasche & Lavaux (2019).
The computational effort of particle deposition onto a density grid scales with the number of particles, and the computational effort of the Fourier transform with the number of voxels 𝒪(Nlog N), where N = (L/Δx)3, with L the box size and Δx the voxel size. Thus, the computational effort is determined by the required box size, resolution and particle mass.
2.2.2. Zoom simulations
In practice, single-mesh simulations result in a rather limited dynamic range. This is why many improved algorithms have been proposed, for instance, tree-based codes, codes using the fast multipole method, and zoom methods. Here we will use a zoom method because we require high enough spatial resolution to resolve the haloes of the MW and M31 (which have virial radii of order 200 kpc) within a region large enough to avoid artefacts from imposed periodic boundary conditions. In our zoom simulations, a fixed-position high-resolution (HR) zoom region populated with high-resolution (i.e. low-mass) particles is embedded within a lower resolution (LR) but larger region populated with more massive particles.
The particular zoom method we employ is a relatively simple extension of the single-grid particle-mesh method. The forces are split into two parts: a long-range and a short-range part, where the long-range force is computed from the LR grid, and the short-range force is computed from the HR grid. The force on each particle i is
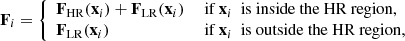
where FLR(x) is the tri-linearly interpolated force vector at position x of the LR region’s force field, and FHR(x) is the equivalent interpolated high-resolution force within the HR region.
To carry out the force splitting faithfully, we convolve the LR potential with a Gaussian filter,
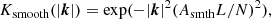 (8)
(8)
where we set Asmth = 1.25, which is the default value when matching the PM and tree forces in Gadget-4 (Springel et al. 2021). We also convolve the HR potential field with a high-pass filter which is the complement of this Gaussian filter, such that at each frequency in k-space, the total power is preserved. Additionally, since some power is lost in the low-resolution force field as a result of CIC deposition and interpolation, we recover this power from the HR field. We also zero-pad the HR grid in order to achieve vacuum boundary conditions. We found that we require 16 cells of padding, corresponding to eight cells on each side, in order to have convergence on the final positions of the MW-M31 pair.
The final result is that our ‘effective’ gravitational potential – the potential from which the force fields FLR and FHR are calculated – is, in Fourier space
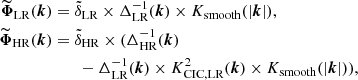 (9)
(9)
where δLR is the density field of the low-resolution region, deposited with the grid size of the low-resolution region, and Δ−1 is the inverse Laplacian. It is understood that KCIC,LR is set to be zero beyond the Nyquist frequency of the LR grid.
For the initial conditions, we consider two initial Gaussian random fields, ΦLR(k) and a ΦHR(k). These are both simply white noise fields convolved with the matter power spectrum with the appropriate linear scaling. From these we obtain the Lagrangian displacement fields ΨLR, i and ΨHR, i, similarly as the force fields, except that now the total of the squares of the two filters must sum to one (Equation 5 in Stopyra et al. 2021). This results in the displacement fields
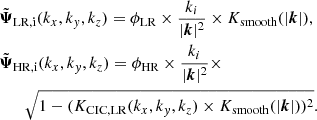 (10)
(10)
To get the actual particle displacements, we do a CIC interpolation of the initial particle grids onto this grid.
Because we use this zoom simulation algorithm inside a Hamiltonian Monte Carlo sampler, we also need to derive its adjoint gradient. This calculation is analogous to Appendix C of Jasche & Lavaux (2019), with the inclusion of the different particle masses for the low- and high-resolution particles; this is just an extra constant factor on the mass deposition end. Additionally, the force adjoint gradient will now have contributions from both the LR and HR grids.
The parallelisation strategy is also similar to BORG. In the single-mesh particle-mesh code of the BORG framework, each MPI task handles a slab of the full simulation box as well as the particles in this slab. At each timestep, we transfer particles that move into a different slab to their new MPI task. This allows for simple parallelisation of the FFTs as well as the CIC assignment and interpolation. In our zoom algorithm, the process is similar, except that each MPI node owns both a slab of the LR box and a slab of the HR box.
2.3. The Local Group likelihood
The likelihood indicates how ‘Local-Group-like’ the final state of a simulation is, or, more precisely, it quantifies the level of consistency between the observational constraints and each particular simulated LG analogue, given the observational uncertainties. To define this likelihood, we first introduce the concept of filtered masses, positions and velocities in Section 2.3.1 as a simple means to extract robust and differentiable values for such quantities from the particle data of our simulation. Our total Local Group likelihood is
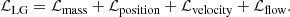 (11)
(11)
We include observational constraints on the masses and position of the two haloes (ℒmass and ℒposition, Section 2.3.2). We also constrain the relative MW-M31 velocity vector (ℒvelocity, Section 2.3.3). Finally, we require that the local Hubble flow as traced by individual galaxies in the Local Group’s immediate surroundings should be reproduced within the observational uncertainties (ℒflow, Section 2.3.4).
2.3.1. Filtered masses, positions and velocities
To be able to compare the output of our simulation to observations, we need to consider some quantities that are easy to measure both in simulations and through observation. We consider therefore the masses, positions and velocities of the objects of interest, averaged over some fixed filter. The filtered mass is defined as a function of position,
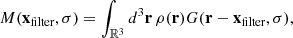 (12)
(12)
where G(Δr, σ) = e−Δr2/2σ2 is an isotropic Gaussian filter with standard deviation σ. Although it might seem desirable to use a tophat filter so that one can use observationally inferred enclosed masses, the result would not be differentiable with respect to the particle positions, which would make the gradients non-informative and reduce the HMC’s efficiency. In the case of particles at locations ri, ρ(r)≈∑imiδ(r − ri), so this becomes:
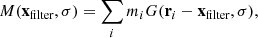
where mi is the mass of particle i. We also constrain the offset of the filtered centre of mass from the filter centre.
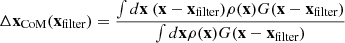 (13)
(13)
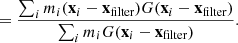 (14)
(14)
Lastly, we can define the filtered velocity, which is the average velocity within the filter:
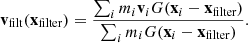 (15)
(15)
2.3.2. Mass and position
Observational estimates of the masses of the Milky Way and Andromeda give rise to the mass likelihood ℒmass, which consists of the terms2
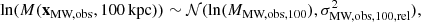 (16)
(16)
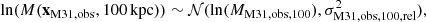 (17)
(17)
where MMW,obs is the observational estimate of the 100 kpc filtered mass of the Milky Way and MM31,obs that of M31. σMW,obs,rel and σMW,obs,rel are the associated relative errors. The filter size of 100 kpc was chosen because halo masses are well converged on this scale at our simulation resolution and because observational estimates on this scale have reasonably low uncertainty. The estimates we use come from the joint fitting of several observational tracers of the mass profiles of the Milky Way and Andromeda. The data used and assumptions made to obtain them are described in Appendix A, and the final values with associated uncertainties are summarised in Table 2. We note that the uncertainties are mainly the observational uncertainties, but we have also added another 5 % in quadrature to account for halo-to-halo scatter in the relation used to convert the mass found for our fitted contracted NFW profiles to the equivalent mass for a dark-matter-only halo (we follow the recipe of Cautun et al. 2020).
We use a heliocentric coordinate frame that is rotated to have M31 on the x-axis, that is xM31,obs = (780, 0, 0) kpc (our assumed distance to M31 is 780 kpc, see Appendix B). In this coordinate frame, xMW,obs ≈ ( − 3.9, −6.9, −1.8) kpc.
Our mass likelihood (Equations (16) and (17)) is insufficient on its own, because the observed filtered mass could be matched by an overly massive but substantially offset halo. We therefore introduce an additional likelihood term, ℒposition, that forces the filtered centre of mass to be close to the filter centre. Specifically, we constrain the offset in position to be consistent with
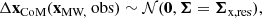 (18)
(18)
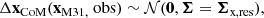 (19)
(19)
where we set the covariance matrix Σx,res to be isotropic with dispersion σ of 30 kpc per direction, which allows for some spread in the simulations but does not lead to significant bias in estimations of the mass.
2.3.3. Velocity likelihood
We also wish to use the relative velocity of the Milky Way and M31 as a constraint. In our setup, we assume the distance between the Milky Way and M31 to be known. Therefore we translate the measured proper motion vector with its uncertainties into a transverse velocity vector with associated uncertainties. This allows us to describe the likelihood ℒvelocity for the 3D relative velocity of the barycentres of the two haloes as a 3D multivariate Gaussian:
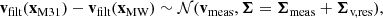 (20)
(20)
where Σmeas is the covariance matrix that incorporates the observational errors on the radial velocity and proper motions, and Σv,res is some additional uncertainty that we include because adopting overly precise values for the constraints would result in inefficient sampling. Moreover, in reality, M31’s 100-kpc filtered halo velocity may be offset from the galaxy’s velocity. We choose Σv,res to be isotropic: 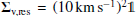 , where
, where 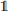 is the identity matrix. We give the observational values adopted in Appendix B.
is the identity matrix. We give the observational values adopted in Appendix B.
Although it would, in principle, be better to compare the proper motions directly to the simulated data, this does not matter in practice: the positions of the two haloes are allowed a dispersion of 30 kpc, namely a ∼5 % scatter in the distance. The uncertainties on the transverse velocities due to proper motion uncertainties are, however, much larger.
2.3.4. Local galaxy flow likelihood
Lastly, we utilise peculiar velocity measurements of galaxies in the immediate environment of the LG. Such measurements have shown that the Hubble flow is particularly quiet in our surroundings (Sandage & Tammann 1975; Schlegel et al. 1994; Karachentsev et al. 2009; Aragon-Calvo et al. 2023). This has implications for the mass of the LG, as it shows that there is no large unresolved mass apart from the Milky Way and M31 in our neighbourhood and puts bounds on the possible total mass of the LG (Peñarrubia et al. 2014). This makes it an ideal constraint for our purposes because it naturally enforces a dynamically quiet environment around the MW and M31 without need for an explicit isolation criterion of the kind usually imposed when identifying LG analogues in simulations (Gottloeber et al. 2010; Libeskind et al. 2020; Sawala et al. 2022). In particular, we constrain the radial component of the velocity at the location of our sample of galaxies (which we describe below). Each galaxy gives us the following constraint for the flow likelihood ℒflow:
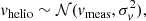 (21)
(21)
 (22)
(22)
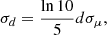 (23)
(23)
where vhelio is the simulation-derived velocity at the galaxy’s location converted to the heliocentric frame, vmeas is the measured heliocentric velocity, d is the distance, σd is the (linearised) uncertainty on the distance, σμ is the error on the distance modulus, and σint is some intrinsic scatter reflecting residual peculiar velocities. To compute the velocity in heliocentric frame vhelio, we evaluate the 3D filtered velocities at the locations of the galaxy in question, as well as the 3D filtered velocity at the location of our Milky Way (from Equation (15)). We compute from their difference a simulated Galactocentric velocity and then convert this to a heliocentric frame.
In order to compute filtered velocities for distant galaxies, we use a filter size of (250 kpc)×(d/Mpc), where d is the distance. The increasing filter size ensures that we have enough particles inside our filter, also at larger distances where we might only have a few particles because the corresponding Lagrangian region can be (partly) outside the zoom region.
We require the residual intrinsic scatter σint in our setup because we only put in the Milky Way and M31 as matter density constraints. Thus, many structures that contribute to the peculiar velocities of more distant galaxies are missing in our simulations. Some of these structures could, in principle, be included, at the cost of making our inference more complex. However, our simulations do not resolve lower mass structures and the observational data on known higher mass structures such as the M81, Centaurus and Maffei groups are uncertain; hence we prefer, for now, to ignore them. We adopt σint = 35 km s−1 since Peñarrubia et al. (2014) estimated 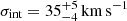 for the residual scatter around their spherical infall model, based on a very similar sample of galaxies.
for the residual scatter around their spherical infall model, based on a very similar sample of galaxies.
To build our sample, we join the galaxies from two sources: the catalogue of local volume galaxies (Karachentsev et al. 2013),3 and the CosmicFlows-1 catalogue (Tully et al. 2009),4 in order to get a complete and up-to-date sample which combines as many independent distance measurements per galaxy as possible. For measurement errors, we follow CosmicFlows-1, which assumes a distance modulus error of 0.2 for a TRGB-only measurement, 0.16 for a TRGB + Cepheid measurement, and similar for other distance measurement methods. In our sample, we include only isolated galaxies, because these are expected to trace well the underlying flow field. Galaxies that have an interaction with a nearby massive perturber would need to be modelled more carefully.
Additionally, we only include galaxies with relatively small distance errors to ensure a reliable estimate of the velocity at the galaxy’s position. To be specific, we use the following criteria to build our sample of galaxies:
-
The distance error must be less than 0.25 Mpc. Given the error estimates we have adopted, this limits the sample to be within
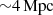 .
. -
There must not be a more luminous galaxy within 0.5 Mpc that has K < −15. The 2MASS K magnitude is used for this. If no K-band magnitude is measured, the estimate from Karachentsev et al. (2013) is used.
-
We exclude the data points for the MW and M31 because they are already treated.
-
We exclude the data point for M81, because of its interaction with M82 and NGC 3077. The three galaxies are strongly interacting and their velocities cover a range of more than 200 km s−1, so including them would require a more thorough dynamical analysis of the group.
-
To filter out satellites, we exclude any galaxy within 800 kpc of: The Milky Way, Andromeda, M81, Maffei 1 / IC 342, Centaurus A (NGC5128).
-
The measurement error on the velocity must be less than 20 km s−1. In practice, this cuts out one galaxy (ESO006-001) which has a radial velocity uncertainty of 58 km s−1.
We are left with a sample of 31 galaxies. Their Hubble diagram is plotted in a Local-Group-centric reference frame in Figure 2, while their on-sky distribution is shown in Figure 3. We note that the spatial distribution of galaxies more distant than 2 Mpc follows the Supergalactic plane quite closely. We note that because our likelihood is conditioned on the flow velocity at the position of each galaxy, we should not be biased due to the inhomogeneity and incompleteness of the sky distribution of our sample. Analyses that assume spherical symmetry of the tracer populations and of the surrounding Hubble flow when determining quantities such as the LG mass and turnaround radius may be biased by such issues (see also Santos-Santos et al. 2024).
 |
Fig. 2. The catalogue of galaxies used as flow tracers in this analysis, analogous to Fig. 11 in Peñarrubia et al. (2014). The x-axis is the Local-Group-centric distance, where the centre of the LG is the centre of mass of the Milky Way-M31 pair when assuming a mass ratio of MM31/MMW = 2. The y-axis is the radial velocity projected in the LG-centric frame, where the offset is computed by interpolating the velocity field along the line between the two galaxies linearly. The different lines indicate spherical Kepler-like velocity models of the recession velocity (Equation (9) of Peñarrubia et al. 2014). |
 |
Fig. 3. Sky distribution in Supergalactic coordinates of the catalogue of the galaxies used as flow tracers in this analysis. Symbol type indicates distance from the LG’s barycentre, and colour indicates velocity with respect to the spherical model shown as a red line in Figure 2. Units are in Mpc and km s−1. The blue line shows the Galactic plane. |
2.3.5. Correcting masses for resolution effects
For our purposes, the main effect of low numerical resolution in our simulations is that haloes become less concentrated so that the mass within a Gaussian filter is biased low. This bias is quite systematic and can be well described by a simple power law: 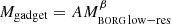 , with some log-normal scatter σlnM. Hence, if we identify simulation parameters for which σlnM is small, we can adequately correct for the effect of lowered resolution. To this end, we ran unconstrained simulations similar to the one shown in Appendix C, but with varying spatial, time and mass resolution. We then cross-matched individual haloes in the BORG and Gadget simulations, and fit power-laws linking the halo masses in the two schemes, determining the mean relation and the scatter for these cross-matched haloes.
, with some log-normal scatter σlnM. Hence, if we identify simulation parameters for which σlnM is small, we can adequately correct for the effect of lowered resolution. To this end, we ran unconstrained simulations similar to the one shown in Appendix C, but with varying spatial, time and mass resolution. We then cross-matched individual haloes in the BORG and Gadget simulations, and fit power-laws linking the halo masses in the two schemes, determining the mean relation and the scatter for these cross-matched haloes.
2.3.6. Velocity reference frame
To compare observational data to our simulations using the velocity likelihoods above, we had to find the velocity offset between the real heliocentric frame and the simulation reference frame. This is done by assuming that the real Galactocentric frame coincides with the simulation reference frame in which the simulated Milky Way has a zero 100 kpc filtered velocity. However, in reality, there might be a difference between the 100 kpc filtered velocity and the velocity of the Galactic centre, and additionally, there is some uncertainty in the Solar Galactocentric velocity vector. We incorporate these uncertainties by marginalising over a possible offset velocity, voff which we assume to have zero mean and a 10 km s−1 isotropic scatter (see Appendix D). Since all our velocity likelihoods are multivariate normal distributions, this marginalisation can be done analytically. The derivation is shown in Appendix D.
3. Results
To present our results, we first describe the experimentation and reasoning underlying the particular simulation parameters we end up using. (Section 3.1). We then present some results derived from the analysis of our chains in Section 3.2, we quantify the resulting autocorrelation in Section 3.3, and we provide some noteworthy quantitative predictions in Section 3.4 and in Section 3.5.
3.1. Simulation parameters
Our set-up incorporates constraints from different aspects: model uncertainties, numerical accuracy, and resolution. We summarise here the considerations for each parameter.
In the first place, there is the log-likelihood itself, which we would like to represent the data as closely as possible. Ideally, we would like to match the positions of the Milky Way and M31, and their relative radial velocity to within the observational uncertainties. However, the measurement errors for these data are very small. This leads to large numerical inaccuracies in the HMC algorithm, in turn requiring very small timesteps in order to reach acceptable acceptance rates (we aim for 50 % to 70 %, which is optimal for Gaussian distributions, Brooks et al. 2011), resulting in greater autocorrelation lengths, and so substantially longer computation time to reach the same effective number of samples. To overcome this problem, in Section 2.3.2 and 2.3.3 we purposely degraded the precision of the constraints on halo positions and relative radial velocity to a level that is compatible with the accuracy of our simulation, taking into account its resolution and the lack of baryonic effects.
To tune the resolution and the particle masses, we require that simulations at high resolution carried out with Gadget match lower resolution runs carried out with our Zoom algorithm. In practice, we found that our filtered halo masses are most sensitive to lowering resolution. Therefore, we tune our resolution parameters to minimise runtime, while still being able to correct for the effect of low resolution on the masses. In practice, we choose parameters for which the uncertainty in the halo mass bias correction σ is below 10% (see Appendix C for the size and uncertainty of the correction for our preferred parameters).
We note that we verify in Section 4 that for our chosen spatial, mass and time resolutions, our final masses, positions and velocities are sufficiently accurate for our problem. The choice of resolution has multiple consequences and it is important to limit it for two reasons: higher resolution leads to more costly computations, but it also leads to a rougher probability landscape which impacts negatively the statistical performance of the HMC. One possible explanation for this might be that higher resolution in space and time allows for more complicated particle trajectories which are then less linear, making the problem harder to sample from.
The sizes of the low- and high-resolution regions were determined by requiring the outer box to be large enough to be able to fit the local Hubble flow while being small enough that the Lagrangian region at its centre does not move substantially. If the bulk flow were too large compared to the size of the high-resolution box, there would be substantial leakage of low-resolution particles, or of particles that have a major part of their history inside the low-resolution region, into the region of interest (the MW-M31 pair and its immediate surroundings). The high-resolution region must be large enough to allow some flexibility, yet small enough that a computationally affordable grid (1283 is currently feasible) can resolve the formation of the MW and M31 haloes.
The initial Gaussian white noise fields themselves are on a 643 grid for the LR field and a 803 grid for the HR field, due to the need for zero-padding. This gives our inference problem a total dimensionality of Ndim = 643 + 803 = 774 144. The particles themselves are placed at the centres of the voxels of two 643 grids. The forces are calculated on grids of twice this size, namely a 1283 grid and a 1603 grid respectively.
To integrate the equations of motion of our N-body simulations, we use the default scheme in BORG (Jasche & Lavaux 2019) for which timesteps are linearly spaced in the cosmological scale factor a.
The resulting numerical parameters are summarised in Table 3. With these settings, we then proceed to sample from our initial condition field s.
A summary of the simulation settings.
3.2. Markov chains
For the work presented in this paper, we have run in parallel 12 Markov chains. A trace plot of the different contributions to the posterior of one HMC chain is shown in the left panel of Figure 4. In this plot, the different terms that make up the likelihood are shown with different colours, namely the log-likelihood of the individual halo masses (red and purple, Equations (16) and (17)) and positions (orange and green, Equations (18) and (19)) for a 100 kpc filter, the 3D M31-MW relative velocity (brown, Equation (20)), and the total likelihood of the Hubble flow tracers (pink, Equation (21)). After burn-in these are expected to vary according to a chi-square distribution (scaled by −1/2) with one degree of freedom (masses), 3 degrees of freedom (positions and 3d-velocity), or 31 degrees of freedom (flow tracers, since we include 31 galaxies).
 |
Fig. 4. Trace plots of an example chain, chain number 10. Left: the likelihood values of the observational constraints. The solid blue line is the total likelihood, which is the sum of all other solid lines that indicate components of the likelihood. The dashed lines are the prior on the initial white noise fields sLR and sHR. Right: The masses of the Milky Way and M31 along the chain. The greyed-out lines indicate values of the masses before applying the correction from Figure C.1. This particular chain was considered warmed up by sample 760 according to the criterion of Section 3.3. |
Also shown is the value of the prior log-likelihood (dashed blue and dashed orange), the χ2/2 of the initial Gaussian random fields that generate the initial conditions. During warm-up, the Gaussian random numbers that generate the initial conditions were set to start at zero for all voxels. This procedure is commonly used within BORG to speed up the warm-up process; we aim to improve it in future. Since this prior is just the sum of squares of Gaussian random numbers, after warm-up its value should follow a chi-square distribution (up to a division by two) hence have mean Ndim/2, where, in our case, Ndim/2 = 387 072. That is why the dashed lines in the left panel of Figure 4, which indicate the value of the prior, start at 0 and then converge around 387 000.
Figure 4 shows that a hierarchy exists, where small-scale constraints such as the individual halo properties warm up very quickly, followed by constraints on larger scales such as the MW-M31 velocity (brown) the local Hubble flow (pink), and finally the field as a whole (the dashed lines showing the prior). All the observational constraints get to within a few σ of their required observational values by about 200 HMC steps, the last being the flow tracer velocities (pink curve) which should scatter within a scaled χ2-distribution with a mean value half the number of galaxies we consider, so 31/2 = 15.5.
In the right panel of Figure 4, the simulation-derived masses are shown. We reach convergence within a few hundred samples, and the masses for both the Milky Way and M31 are biased slightly low, even after applying the Appendix C correction which accounts both for the low spatial and time resolution of the simulation, and for the fact that we determine masses for fixed filter positions which do not coincide exactly with the centres of the simulated haloes. In principle, one could avoid the problem of haloes being offset from the filter centre by first ‘finding’ the centre of the halo at each step, but this is not straightforward: one would have to make sure that the procedure stays differentiable, and also that the centre of mass varies continuously as a function of initial conditions. Failing to require these two properties would cause the log-likelihood to be discontinuous, resulting in poor sampling performance.
3.3. Autocorrelation analysis
In Figure 5 we show images of the final state of nine simulations spaced evenly along the chain of Figure 4. The present-day density field reflects directly the initial conditions, and one can see correlations in structure between neighbouring images in Figure 5; present-day density fields (and therefore the corresponding initial conditions) do not fully decorrelate between samples that are not spaced sufficiently far apart. For instance, in consecutive images, one can see large haloes repeating, some of which highlighted by coloured circles, shifted only by relatively small amounts. Some coherence between nearby samples is also visible in the behaviour of the flow tracer likelihood (the pink curve in Figure 4).
 |
Fig. 5. Final density fields of the low-resolution box as chain 10 evolves. This chain has Feff = 411, so every Feff sample (going vertically down each column) can be considered as an independent sample. The circles highlight a few haloes that do not shift by much between consecutive samples, illustrating the substantial autocorrelation between samples separated by significantly less than Feff. We note that sample 0 (which occurs after one iteration of the HMC) is almost completely uniform because we start our chains from a uniform field. Visualisation here was done using pySPHViewer (Benitez-Llambay 2015). |
It is helpful to quantify correlation as a function of lag within a chain, which we choose to do by computing correlations between initial condition fields s. These decorrelate the slowest among all the quantities we have considered, so this is a conservative choice. We compute the autocorrelation along the chain of the vector si, representing both the HR and LR initial conditions, which we calculate for a lag t as
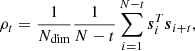 (24)
(24)
which is equivalent to the average fictitious time autocorrelation of the individual components of s. We use only samples after the chains are warmed up. Since the effective sample size is (Brooks et al. 2011)
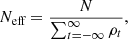 (25)
(25)
we can find the effective sample size through an estimate of ρt. One would ideally use directly estimated values for ρt; unfortunately, if t is too large, we are limited by the length of the chain. In practice, ρt has exponential behaviour, which is common for HMC where each step has a small integration length. Thus, for each chain, we fit an exponential curve, and from this fit, we can obtain a good estimate of ρt for all t. We show the correlation functions ρt for our different chains in Figure 6, giving also the Neff derived from exponential fits.
 |
Fig. 6. Autocorrelation functions as computed using Equation (24) for our twelve different chains, each indicated by a different colour. |
The number of samples per effective sample, Feff, is
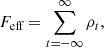 (26)
(26)
so to obtain independent samples, we can thin each chain with the corresponding Feff, taking samples separated by Feff, starting from the last sample in the chain. Proceeding in this way, we obtain 27 independent samples across all chains. In Figure 5, an example chain is shown, where one can verify by eye that samples separated by Feff = 411 appear fully decorrelated. This decorrelation number varies from chain to chain as can be seen seen in Figure 6.
Since the initial condition field decorrelates the slowest, we can use this to provide a simple criterion to indicate when the chain has warmed up. If the prior, (which started at zero) is above 98 % of its final value (this means that the power spectrum is within a few per cent of the cosmological expectation) we consider the chain to be sufficiently warmed-up.
For this paper, we create two sets of samples:
-
An ‘independent’ set of simulations, where each chain has been thinned by the factor Feff above, that is, first taking the sample at the end of the chain, then the sample Feff before that, then repeatedly stepping back by Feff until we reach the warm-up phase.
-
A ‘semi-independent’ set of simulations, which is the same, but thinned by a factor Feff/20 rather than Feff. Despite large scales being more correlated in nearby members of this set, quantities determined primarily by small-scale power, such as individual halo masses, are largely independent.
We believe that we are rather conservative in our estimate of the true effective number of samples: when visually inspecting a chain, one can see almost no correlation when considering two samples separated by Feff. We note that the inter-chain variation is similar to the intra-chain variation.
We note that, in any MCMC analysis, the posterior mean of any inferred quantity q has a corresponding error due to Monte Carlo integration. This error is 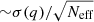 (Brooks et al. 2011). In practice, this error for Neff = 27, is of the order of 19 %. Adding in quadrature to the full posterior width σ(q) gives a total error of
(Brooks et al. 2011). In practice, this error for Neff = 27, is of the order of 19 %. Adding in quadrature to the full posterior width σ(q) gives a total error of 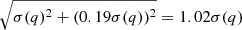 , a change of 2 % which barely changes the resulting uncertainty. A typical case in this work is the estimation of masses.
, a change of 2 % which barely changes the resulting uncertainty. A typical case in this work is the estimation of masses.
3.4. Posterior quantities for the individual galaxies
With a reasonable set of independent samples, we can make a variety of quantitative statements based on our chains. A few examples of ‘independent’ samples of the Local Group environment (each from a different chain) are shown in Figure 7. In every sample, the Milky Way and M31 lie within a connecting filament. On a larger scale, the LG lives in a relatively quiet, underdense, environment, in a wall-like structure that is approximately aligned with the Local Sheet: most structures live close to the xy-plane in Supergalactic Coordinates. This is a priori somewhat surprising, since we have not explicitly constrained the density field surrounding the LG, only the peculiar velocity field, which appears close to isotropic.
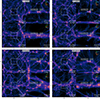 |
Fig. 7. Final density fields in simulation coordinates of evolution from four of our independent sets of initial conditions (each from a different chain). Each pane corresponds to a single set of initial conditions. Within each pane, the left column shows the full box and the right column the central 10 Mpc zoom box, while the two rows show orthogonal projections. The name at the top of each pane indicates the chain it came from (after C), and its sample index (after S). The visualisations are made using the Lagrangian Sheet density estimation method of the r3d package* (Powell & Abel 2015). The unit vectors of the Supergalactic reference frame are shown at the top right of each high-resolution panel. (* Since our two-grid initial condition layout is not a pure cubic grid, in particular, at the zoom-region boundary, we cannot use the recipe where every cube is divided into 6 tetrahedra as in e.g. Abel et al. (2012). Instead, we use a Delaunay tetrahedralisation to create the simplex tracers.) |
In Figure 8, we show posterior distributions for various quantities along our chains. These histograms indicate plausible values for quantities such as the filtered halo masses of the Milky Way and Andromeda, given our full set of constraints and our specific assumed ΛCDM model, whereas the dashed lines show the observationally based constraints that we adopted as priors for each quantity, as described in Section 2.3; for the filtered halo masses, these are already the result of Appendix A’s quasi-Bayesian analysis of observational data for halo mass tracers surrounding the two galaxies under a ΛCDM prior.
 |
Fig. 8. Posterior distributions of LG properties from our Markov chains. In each panel, the histogram is of samples from our chains and therefore indicates the posterior distribution. The dashed lines are the injected observational constraints. The top left panel indicates the centre-of-mass position of the Milky Way, and the top middle panel M31. The right panel shows the relative velocity of the MW-M31 pair. The bottom left and middle panels indicate the 100 kpc filtered masses of the Milky Way and M31. The bottom right panel shows the total log-likelihood of the flow tracers, with on top the χ2-distribution (scaled by |
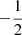
The centre-of-mass distributions of the two main haloes match well with the likelihood constraints we have put on their positions. In fact, they are less tail-heavy than the input, which is expected, because moving the centre of mass too far away would also impact other terms in the likelihood, in particular, the mass likelihood.
While the 100 kpc-filtered M31 mass matches the injected observational constraint quite well, with only a small downward bias, the filtered Milky Way mass is biased more substantially low. These biases are however mostly a consequence of the halo centres not aligning perfectly with the filter centres; the biases decrease to within a few per cent of the observational prior when re-centring the filters at the precise halo centre. Our chains imply virial mass estimates for the two haloes of log10(M200c/M⊙) = 12.07 ± 0.08 and 12.33 ± 0.10, for the MW and M31, respectively.5 This is very similar to the implied M200c’s we obtain from our NFW-like fitting to observation in Appendix A. It is important to note the small error bars resulting from the need to satisfy all observational constraints simultaneously. The fact that these masses are near the lower end of the range quoted in earlier studies is mainly a consequence of the Hubble flow constraint, which not only requires a relatively small total mass for the LG but also approximately determines its centre of mass, thereby implying a mass ratio for the two main galaxies (see Peñarrubia et al. 2014). With their simple spherical model, these authors found a mass ratio of 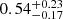 (mean and 16th/84th percentiles) whereas we find a mass ratio of
(mean and 16th/84th percentiles) whereas we find a mass ratio of 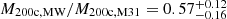 , similar to the value 0.58 ± 0.19 implied for this ratio by the analysis of Appendix A. These results are discussed further in Section 5.2 below.
, similar to the value 0.58 ± 0.19 implied for this ratio by the analysis of Appendix A. These results are discussed further in Section 5.2 below.
3.5. The environment and mass of the Local Group
Visual inspection of our chains shows that they all produce first-approach trajectories for the MW-M31 pair. Furthermore, in Figure 8, we find that orbits for the pair are almost perfectly radial, that is, along vx. The tangential components in the (α, δ) directions are (vα, vδ) = (12.7 ± 21.3, −6.7 ± 18.7) km s−1, while the velocity in the radial direction has a posterior of vx = ( − 102 ± 13) km s−1. We note that although the histograms showing the tangential velocity distributions from our chains are not centred on the observational constraints, these posteriors are statistically compatible with the observed tangential velocity. The posterior is approximately radial, and the Salomon et al. (2021) M31 proper motions that we have decided to use, which are based on Gaia EDR3 data, are ∼1σ off from a radial orbit in the R.A. direction, and ∼2σ in the Dec. direction. Independent measurements of M31’s transverse velocity, done with for example HST (van der Marel et al. 2012) or through modelling the dynamics of M31’s satellites (van der Marel & Guhathakurta 2008; Salomon et al. 2016) show significant scatter compared to the values of Salomon et al. (2021), and overall a radial orbit is well within the range spanned by the different measurements as can be seen from the comparison in Figure 6 of Salomon et al. (2021). The bias of our posterior distribution towards small tangential motion is likely a result of the constraints on the local Hubble flow that we have applied because a significantly non-radial orbit would require a nearby massive object in order to produce sufficient tidal torque to generate the orbital angular momentum. The presence of such an object is disfavoured by the quiet and at most weakly distorted Hubble expansion indicated by our flow tracers. We can see in Figure 9 that the velocities of our isolated galaxy catalogue are generally well matched by our simulations, with one or two possible exceptions (e.g. Tucana) which would be worth more detailed investigation.
 |
Fig. 9. Similar to Figure 2, but now with the purple points showing the line-of-sight velocities from our simulations at the 3D location of each galaxy. Each purple point is an independent sample from our chains, specifically, we plot the ‘independent’ set as defined in Section 3.3. |
Inference on the mass profiles is shown in Figure 10. We find posterior distributions for the enclosed Local Group mass, M(< 1 Mpc) = (5.20 ± 0.67)×1012 M⊙ and M(< 2.5 Mpc) = (7.77 ± 1.27)×1012 M⊙, when measured from the LG barycentre6. Within the larger radius, the LG is only overdense by a factor of about 3.00 ± 0.49. By a radius of 4 Mpc, the distance of the most distant flow tracers we have used, this factor has dropped to 1.33 ± 0.35. If the Local Group mass is instead defined as the sum of the virial masses M200c of the two objects, we find 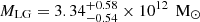 . It is interesting to compare these numbers to previous work. From the Timing Argument alone, Li & White (2008) found the sum of the two M200c values to be
. It is interesting to compare these numbers to previous work. From the Timing Argument alone, Li & White (2008) found the sum of the two M200c values to be 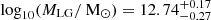 for a ΛCDM prior. This is substantially larger than our value (although consistent with it at about 1σ) reflecting the fact that the quiet local Hubble flow is not consistent with the upper end of their Timing Argument range. In contrast, using local Hubble flow observations alone, Peñarrubia et al. (2014) estimated the mass of the LG within about 0.8 Mpc to be M(< 0.8 Mpc) = (2.3 ± 0.7)×1012 M⊙, consistent only at about 2.8σ with the mass, M(< 0.8 M⊙) = (4.82 ± 0.58)×1012 M⊙, that we find; such a low mass is strongly disfavoured by the Timing Argument. Combining the two types of data, namely the MW’s and M31’s orbital and halo properties together with the quiet Hubble flow, leads to our own tighter constraints.
for a ΛCDM prior. This is substantially larger than our value (although consistent with it at about 1σ) reflecting the fact that the quiet local Hubble flow is not consistent with the upper end of their Timing Argument range. In contrast, using local Hubble flow observations alone, Peñarrubia et al. (2014) estimated the mass of the LG within about 0.8 Mpc to be M(< 0.8 Mpc) = (2.3 ± 0.7)×1012 M⊙, consistent only at about 2.8σ with the mass, M(< 0.8 M⊙) = (4.82 ± 0.58)×1012 M⊙, that we find; such a low mass is strongly disfavoured by the Timing Argument. Combining the two types of data, namely the MW’s and M31’s orbital and halo properties together with the quiet Hubble flow, leads to our own tighter constraints.
 |
Fig. 10. Enclosed mass profiles in our simulations, centred on the Local Group’s centre of mass, on the Milky Way, and on M31. The lines indicate the posterior mean, and the shaded regions are the 1σ region of the ‘semi-independent’ sample set (see Section 3.3, we use this to avoid being affected by shot noise coming from thinning the chains). |
Finally, in the bottom right panel of Figure 8, we see that the distribution of total log-likelihood values for galaxy velocities in the Local Group’s immediate environment is consistent with the expected χ2-distribution. Since the uncertainties entering this estimate are dominated by the 35 km s−1 residual scatter assumed in our likelihood, the fact that we obtain fully acceptable χ2 values means that our ΛCDM simulations match the observational data as well as the simple spherical model of Peñarrubia et al. (2014).
4. Resimulations with Gadget-4
The simulations discussed so far are based on a zoom scheme with a relatively small grid size for the two nested meshes. This is optimised for computational speed but is relatively low-resolution. In particular, the spatial and time resolution are sub-optimal for studies of the small-scale structure and detailed temporal evolution of the LG galaxies. To enable such studies, it is necessary to carry out higher-resolution simulations from our initial conditions. However, our constraints were applied to simulations executed using the low-resolution BORG scheme, so it is necessary to see if the constraints are still satisfied when the resolution in space, time and mass is improved and high-resolution simulations are carried out with state-of-the-art software. Here we begin by using Gadget-4 (Springel et al. 2021) in a simple Tree-PM setting (non-zoom) but with the same initial particle masses, positions and velocities as in the corresponding BORG simulation. Hence, these runs test only the effect of reducing the timesteps and the softening to values comparable to those usually used in high-resolution calculations. The (comoving) force softenings that we adopt are 6 kpc/h for HR-particles and 24 kpc/h for LR-particles. This approximately follows the rule of thumb proposed by Power et al. (2003), namely 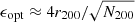 , which for a 1.5 × 1012 M⊙ halo with virial radius ∼250 kpc and particle mass 1.5 × 108 M⊙ leads to ∼10 kpc. Using the initial condition fields s that we found from our chains, we generate the particle’s initial positions and velocities using the technique described in Section 2, specifically Equation (10). We put into Gadget the particle masses, positions and velocities that the original BORG scheme generated at its starting redshift, z = 63.
, which for a 1.5 × 1012 M⊙ halo with virial radius ∼250 kpc and particle mass 1.5 × 108 M⊙ leads to ∼10 kpc. Using the initial condition fields s that we found from our chains, we generate the particle’s initial positions and velocities using the technique described in Section 2, specifically Equation (10). We put into Gadget the particle masses, positions and velocities that the original BORG scheme generated at its starting redshift, z = 63.
Four such resimulations are compared with the BORG originals in Figure 11 where the present-day particle distributions in the LG region are plotted on top of each other. Although the two integration schemes do produce similar LG analogues, there are sometimes noticeable offsets between the halo positions of the Milky Way and Andromeda. In these cases, the corresponding velocities are biased oppositely, suggesting that this difference affects mostly the phase of the orbit and not the overall properties. We discuss the amplitude of these differences in more detail below.
 |
Fig. 11. LG region (a box of (2 Mpc)3 centred at the Milky Way) in some resimulations with Gadget-4. The blue dots indicate particles in the BORG simulations, and the orange dots indicate particles in the gadget re-simulations. Each panel indicates one simulation, with two projections being shown. |
The filtered masses of the BORG run and the Gadget run match quite well after correcting the BORG masses following the prescription of Appendix C. This can be seen in Figure 12, where the corrected 100 kpc filtered masses of the Milky Way and M31 in the BORG simulation are compared with the corresponding masses in the Gadget re-runs. To be able to compare masses properly, we filter based on the actual halo centres, as determined by a shrinking-spheres procedure (Power et al. 2003) for both the Gadget and the BORG runs. The filtered mass ratios are generally close to one, with some small spread, which is, however, expected (about 6.5 % is expected, see Figure C.1).
 |
Fig. 12. Filtered mass ratios of the Gadget resimulations compared to BORG (after applying the correction from Appendix C). Each symbol indicates a different set of initial conditions. For five simulations, we also show the result with higher Gadget resolution (with particle masses 64× smaller, softening 16× smaller and power included in the initial conditions to 4× smaller scale) in darker colours. Points referring to simulations with the same initial conditions but different resolutions are connected with a blue line. |
Positional offsets between the main haloes in the BORG-Gadget simulation pairs are typically at the level of 100 kpc and in a few realisations up to 300 kpc, as can be seen in Figure 13, where the three components of the MW-M31 position difference are shown. The peculiar velocity difference between the two haloes also differs somewhat between BORG and Gadget, as can be seen in Figure 14, where the symbols are the same as in Figure 13. We note that cases with a large relative position offset also have a large relative velocity offset, and furthermore, these offsets are strongly correlated: where Gadget gives larger separations, it gives a smaller relative velocity, and vice versa. Forward (or backward) integration of the offset Gadget simulations into their relatively near future (or past) would likely bring them into substantially better agreement with the observational constraints.
 |
Fig. 13. Position differences of the M31 and MW analogues in the Gadget resimulations plotted against the same difference in the BORG simulations. The x-axis is the Sun-M31 axis, and y and z are R.A. and Dec. directions at the position of M31. As in Figure 12, pairs of symbols joined by lines refer to the five cases with an additional higher resolution Gadget resimulation. |
For five of the cases, we have also carried out simulations with substantially improved mass and spatial resolution. Specifically, for the HR particles these additional resimulations use a 64× smaller particle mass and a 16× smaller softening length; furthermore, they extend the power in the initial conditions to 4× higher spatial frequency7. This may be expected to add further random offsets in the evolutionary phase of the MW-M31 orbit on top of those found for our main set of resimulations. (See Sawala et al. (2022) for further discussion of the influence of initial conditions on phase offsets in the orbits of LG analogues.) We tested that the effects of the increase in mass resolution and of the extra small-scale power on the masses, positions and velocities of the two main haloes are relatively minor, as may be seen in Figures 12 to 14. Finally we show in Figure 15 how these various resolutions affect the end result; the increasing resolution and the addition of small-scale power allows us to model smaller-scale structures in our simulations.
 |
Fig. 14. Peculiar velocity differences between the M31 and MW analogues in the Gadget resimulations plotted component by component against the same quantity for the BORG simulations. The x-axis is the Sun-M31 axis, and y and z are oriented orthogonally in directions of increasing R.A. and Dec. at the position of M31. As in Figure 12, pairs of symbols joined by lines refer to the five cases with an additional higher resolution Gadget resimulation. |
 |
Fig. 15. Comparison of the density fields of the LG when integrating the same initial conditions (C6 S1530) with the BORG zoom particle-mesh scheme used in our Markov chains, with Gadget at the same mass resolution (particle mass of m = 1.5 × 108 M⊙ and softening of b = 10 kpc), and with Gadget with a higher resolution (m = 2.4 × 106 M⊙, b = 0.56 kpc). |
5. Discussion
In Table 1, we listed some major recent simulation studies of Local Group analogues in their observed cosmological context. These studies found their analogues by carrying out large numbers of ΛCDM simulations constrained to reproduce nearby large-scale structures (smoothed over scales of ∼5 Mpc) and then selecting the few that, by chance, produced systems approximately matching the observed LG. Because we use the observed properties of the LG and its environment as explicit constraints in our ΛCDM sampling, we match or surpass the requirements of the most precise previous programme, while including additional constraints, for example, requiring a match to the observed quiet Hubble flow in the environment of the LG out to 4 Mpc. Further constraints could easily be included, for example, on the spin orientation of the MW and M31 haloes, or on the properties of well-observed massive nearby groups such as M81 or Centaurus. Our current effective sample size, (∼27 quasi-independent realisations) is relatively small, but additional realisations can be generated simply by continuing the sampling chains as long as is needed. Although the resolution of these simulations is quite low, offsets when resimulating at higher resolution are relatively small.
5.1. Comparison to previous Local Group simulations
In comparison to the simulations listed in Table 1, our simulations generally enforce more precise constraints on MW and M31 properties such as halo masses, separation, and velocity. The one exception is the radial velocity constraint of Sibelius-‘Strict’ (Sawala et al. 2022). They require a relative radial velocity in the range 99 to 109 km s−1, whereas we adopt a Gaussian uncertainty of dispersion 14 km s−1. We have also not placed any constraints on the presence of a massive satellite like the LMC or M33, which was done when refining the selection of LG candidates in for example ELVIS (Garrison-Kimmel et al. 2014). For the Local Group’s environment, we constrained the (quiet) local Hubble flow using 31 observed flow tracers. Only APOSTLE (Fattahi et al. 2016) has a related constraint, which they put on the mean Hubble flow magnitude at 2.5 Mpc. We have placed no constraints on structure more distant than 4 Mpc (unlike Clues, Hestia and Sibelius Carlesi et al. 2016; Libeskind et al. 2020; Sawala et al. 2022). As a result, our simulations do not generally have a Virgo cluster analogue, although an appropriate large-scale tidal field at the Local Group’s position is enforced by our detailed fitting of the local (perturbed) Hubble flow. Finally, our current simulations are gravity-only/dark-matter-only; we intend to carry out higher resolution, full physics resimulations in future work.
5.2. The mass distribution in and around the Local Group
We use four classes of observations to constrain our analysis: dynamical tracers in the MW halo, dynamical tracers in the M31 halo, the relative 3D position and velocity of the MW/M31 pair, and the perturbed Hubble flow in the immediate environment of the LG. Much previous work has addressed each of these topics. Some of the authors of previous work directly or indirectly adopt a ΛCDM prior, but most prefer more idealised and less specific model assumptions. As a result, it is not easy to compare masses obtained by different methods and in different regions to decide whether they are compatible. In contrast, our procedure randomly samples realisations subject to all the constraints simultaneously, leading to consistent estimates of the mass in all regions of the LG and its environment under a ΛCDM prior.
For technical reasons, we have expressed prior observational constraints on the masses of the individual MW and M31 haloes in terms of their mass profiles filtered with a Gaussian of dispersion 100 kpc. Because of the limited resolution of our forward modelling, the mass on smaller scales is not well reproduced by our current scheme, and a bias correction is still needed even for 100 kpc-filtered masses. We thus limit the quantitative comparison with earlier work to similar scales. In their recent exhaustive review of the MW case Wang et al. (2020) convert all previous studies to estimates of the virial mass of the MW halo, finding results in the range 11.75 < log10(M200c/M⊙) < 12.42 when all results are considered, or 11.89 < log10(M200c/M⊙) < 12.12 using only recent results that make use of proper motion information from Gaia-DR2. Different results in the first set are incompatible according to their published errors, which may be due to unknown systematics, whereas those in the second set are mutually compatible and appear to exclude log10(M200c/M⊙) > 12.2 at about 2σ. From our chains, we find log10(M200c/M⊙) = 12.075 ± 0.079, which is similar to our adopted constraint on the mass; our analysis of a limited set of observational data in Appendix A leads to log10(M200c/M⊙) = 12.053 ± 0.081. For M31, the three outer halo mass estimates discussed in Appendix A, are consistent with each other within their quoted error bars, and combining them assuming an NFW-like profile gives a virial mass estimate log10(M200c/M⊙) = 12.31 ± 0.13. For comparison, the result from our chains is log10(M200c/M⊙) = 12.331 ± 0.092. Thus, the posterior mass estimates are not pulled far from the direct observational constraints, derived and reported in Appendix A. This is remarkable as constraints from the other galaxy, from the Timing Argument and from the surrounding Hubble flow were not enforced in the estimates from Appendix A.
The separation and relative velocity of the MW/M31 pair were first used to estimate its total mass by Kahn & Woltjer (1959). Their Timing Argument idealised the system as a pair of point masses, and more recent work has often quoted masses based on a similar underlying model (e.g. van der Marel & Guhathakurta 2008; Peñarrubia et al. 2016, the latter include the LMC as a third subdominant point mass, and treat the surrounding Hubble flow as perturbed only by the sum of these three masses). Given the extended nature of the matter distribution in the LG, it is unclear what region the mass returned by such analyses should be considered to apply to. This difficulty can be avoided by adopting an explicit ΛCDM prior. Li & White (2008) searched a large ΛCDM simulation and identified many isolated pairs of haloes comparable in individual halo mass, separation and relative velocity to the LG. They then used these pairs to calibrate the relation between the mass inferred from the Timing Argument and the sum of the virial masses of the two haloes, finding the two to be similar8 and to be proportional to each other with fairly small scatter, arriving at the final estimate log10(ΣM200c/M⊙) = 12.72 ± 0.185. We find with our analysis log10(ΣM200c/M⊙) = 12.53 ± 0.07, which is in tension at 1σ with the above past results. Although formally still consistent, this demonstrates that including the additional constraints on individual halo masses and the surrounding Hubble flow pulls the Timing Argument mass as derived from just properties of the individual haloes by Li & White (2008) to substantially lower values. We note that our results have a much-reduced uncertainty. van der Marel et al. (2012) pointed out both the lower mean value and the smaller uncertainty found when Timing Argument results are combined with mass estimates for the individual haloes, but they did not consider data on the nearby Hubble flow, nor did they explicitly require simultaneous consistency with all observed data in a ΛCDM cosmology; nevertheless, their final estimate of the total LG mass converts to log10(ΣM200c/M⊙) = 12.42 ± 0.08, slightly lower than our result here.
More recently, Benisty et al. (2022) and Chamberlain et al. (2023) have pointed out that mass estimates from the Timing Argument are biased high by the reflex motion induced by the LMC: the gravitational pull of the LMC causes the inner Milky Way disc and halo to travel relative to the overall halo barycentre. For instance, Chamberlain et al. (2023) find that accounting for this reflex motion reduces the Timing Argument mass by ∼10 %. Specifically, in our work, we assume that the Galactic Center is at rest with respect to the average velocity within a 100 kpc Gaussian filter, allowing a 10 km s−1 gaussian uncertainty in this central velocity. A possible extension of our work would be to allow for an arbitrary relative ‘travel velocity’ of the Milky Way’s disc with respect to the overall halo, thereby obtaining independent bounds on the LMC-induced reflex motion Peñarrubia et al. (2016) do this in the context of a spherical model).
Peñarrubia et al. (2014) use a catalogue of nearby galaxies very similar to that of Figure 2 to estimate the total mass of the LG. In their model, all deviations from uniform undecelerated expansion are due entirely to the attraction of a point mass put at the LG barycentre. Perhaps surprisingly, this model provides a reasonable fit to the observed velocities of galaxies lying between 0.8 and 3 Mpc from the LG-barycentre, even though it assumes that all mass within 3 Mpc is contained in the LG itself (see Figure 2). It leads to an estimated total LG mass, log10(MLG/M⊙) = 12.36 ± 0.14. This is much smaller than the masses log10(M(< 0.8 Mpc)/M⊙) = 12.68 ± 0.05 and log10(M(< 3.0 Mpc)/M⊙) = 12.96 ± 0.08 derived from our analysis within the inner and outer radii of the nearby galaxy sample they used. These estimates are, respectively, factors of 2 and 4 larger than our estimate ΣM200c for the sum of the MW and M31 virial masses, showing that ΛCDM analogues of the Local group typically have substantial additional mass in these larger regions. Despite this, Figure 9 shows that our ΛCDM realisations fit the quiet local Hubble flow about as well as the model of Peñarrubia et al. (2014). The latter must clearly fail at larger distances since already at 3 Mpc material spread uniformly at the mean cosmic density would contribute about half of the enclosed mass (see Figure 10). On the other hand, the velocities of nearby galaxies are clearly not compatible with values of ΣM200c at the upper end of the range allowed by the ΛCDM-calibrated Timing Argument analysis of Li & White (2008), and so must contribute substantially to the strong downward pull noted in the last paragraph.
5.3. Improvements and future directions
In the future, we could consider many different avenues for improving our HMC methods. Firstly, a more accurate gravity solver could improve the accuracy of the reconstructions. This could be achieved in the first instance by higher resolution at the cost of increased computational cost, but there may be scope to develop more sophisticated approaches that still allow the adjoint gradient to be calculated. To run all the chains presented in this paper, we used a total of about 800 000 core-hours (logical, i.e. with hyperthreading/SMT, physical: 400 000). This could reduced by more careful tuning of the code, for instance, an improved method for load-balancing. The resimulations at unchanged mass resolution presented in this paper are very cheap, requiring only about 25 core-hours per simulation, but a real resimulation programme would, of course, substantially improve the mass resolution in addition to the spatial and time resolution, leading to increased computational cost (the simulations at 64× improved mass resolution mentioned at the end of Section 4 each took about 2000 core-hours).
Improvements could also be made to the sampling method. At the moment, the HMC mass matrix is diagonal; for instance, tuning the mass ratio between the LR and HR cells (this is currently unity) might be beneficial. Replacing the HMC altogether with a more efficient algorithm might also be possible, for example, the No-U-turn sampler might be worth exploring, which can, in some circumstances, outperform even a well-tuned HMC (Hoffman & Gelman 2011). The algorithm suggested by Bayer et al. (2023) might also be worth exploring but would require additional work to quantify its bias in our setup since it is not generally guaranteed to give unbiased results.
In terms of getting closer to observation, there are many more things to explore. For instance, a goal might be to incorporate the Large Scale Structure reproduced in previous BORG applications. This could be done either by sampling fully or by optimising small-scale fields overlaid on fixed large-scale initial conditions predetermined by BORG. On smaller scales, one could envision extending the likelihood to include the LMC and M33. However, their haloes currently overlap substantially with the Milky Way and Andromeda respectively, so careful thought would be needed to implement such constraints optimally. For instance, one might apply the constraints a few Gyr back in time, when the haloes had less overlap.
The current method for computing the velocity field at the locations of the galaxies is also not optimal: we consider the velocity field as a single-valued function, but in reality, dark matter motions are multi-valued, with multiple ‘streams’ at many locations due to complex folding of the dark matter sheet in phase-space (Abel et al. 2012). Additionally, one should also marginalise over distance uncertainties. Implementing a better method would require a substantial amount of work, especially considering the need for any estimator to be differentiable.
6. Conclusion
We have extended the BORG framework, a Hamiltonian Monte Carlo scheme, by adding a zoom component to the gravity simulation and incorporating a robust Local Group likelihood based on observed mass tracers in the Milky Way and M31 haloes, on their relative position and velocity, and on the peculiar velocities of surrounding galaxies out to 4 Mpc. Using these constraints we have inferred a fair and representative sample of ΛCDM initial conditions which evolve to produce a sizable sample of high-fidelity LG analogues.
Almost all these analogues live in a wall-like structure that is roughly aligned with the Supergalactic Plane and have a MW-M31 orbit which is very nearly radial; the mean and rms scatter of the posterior tangential velocity distribution is (vy, vz) = (12.7 ± 2.13, −6.7 ± 18.7) km s−1, where y and z directions are pointed orthogonally to directions of increasing R.A. and Dec at the position of M31. Requiring simultaneous consistency with all our dynamical constraints results in masses of log10(M200c/M⊙) = 12.07 ± 0.08 and 12.33 ± 0.10 for the Milky Way and Andromeda, consistent with the injected estimates based on halo mass tracers alone. Our combined analysis estimates the sum of the two halo masses to be log10(ΣM200c/M⊙) = 12.46 ± 0.07 and their ratio to be 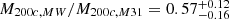 . For the spherically enclosed mass of the LG, we find M(< 1 Mpc) = (5.20 ± 0.67)×1012 M⊙ and M(< 2.5 Mpc) = (7.77 ± 1.27)×1012 M⊙.
. For the spherically enclosed mass of the LG, we find M(< 1 Mpc) = (5.20 ± 0.67)×1012 M⊙ and M(< 2.5 Mpc) = (7.77 ± 1.27)×1012 M⊙.
We also find that in high-resolution resimulations of our initial conditions, we match halo masses for the two big galaxies within 10 % and positions within 100 kpc or so. Some direct applications of such simulations include investigating the spatial and dynamical distributions of the satellites of the Milky Way and Andromeda galaxies, and the range of predicted growth histories for the two galaxies in the context of ΛCDM.
Since the zoom region has a side length of 1/4 of the full box, (64/4)3 = 163 low-resolution particles are replaced by the high-resolution particles.
In this work, we use the notation x ∼ 𝒩(μ, σ2) to mean that x follows a normal distribution with mean μ and standard deviation σ. In practice, quantities of this form appear as quadratic terms in the log-likelihood of our inference problem.
This is defined as the mass within a sphere that has an average density of 200 times the critical density of the universe. The centre of the sphere is chosen to be the shrinking-spheres centre. We correct for the effect of limited resolution inside BORG using the correction for M200c in Appendix C.
In this case, the barycentre is found by finding the centre of mass of all particles within a 1 Mpc sphere centred at the point between the Milky Way and M31, although in practice the masses are rather insensitive to the exact chosen centre when considering radii beyond 1 Mpc.
Considerable care is needed to include this extra small-scale power consistently while retaining the amplitudes of the longer wavelength modes from the lower resolution simulation. We will describe this in detail in a future publication dedicated to such high-resolution resimulations.
Sawala et al. (2023b) show that this is only true for systems which are similar to the LG in that the sum of the two virial radii is similar to the separation of the haloes.
When computing the filtered masses, we derive them at the cell centres, instead of at the halo centres. This leads to small offsets between the filter and halo centre, which will bias the masses slightly low, but since the offset is always less than Δx/2 = 13 kpc, we found it to be negligible.
Acknowledgments
We are grateful to the referee for their constructive report, which has meaningfully improved the quality of this manuscript. This work has been financially supported by a Spinoza Prize from NWO to AH. GL acknowledges support from the Simons Foundation "Learning the Universe" Collaboration, the CNES Euclid, and the International Emerging Action (IEA) "Manticore" from CNRS. JJ gratefully acknowledges support from the Swedish Research Council (VR) under project 2020-05143, ’Deciphering the Dynamics of Cosmic Structure,’ and from the Simons Collaboration on ’Learning the Universe.’ Additionally, JJ appreciates the hospitality of the Aspen Center for Physics, supported by National Science Foundation grant PHY-1607611, with participation funding provided by the Simons Foundation. The computations were enabled by resources provided by the Swedish National Infrastructure for Computing (SNIC) at the PDC Center for High Performance Computing, KTH Royal Institute of Technology, partially funded by the Swedish Research Council through grant agreement no. 2018-05973. SS was supported by the Göran Gustafsson Foundation for Research in Natural Sciences and Medicine. EW thanks Tom Callingham, Akshara Viswanathan, Andrija Kostić and Vincent Souveton for helpful discussions. This work has been done in part within the Aquila Consortium (https://www.aquila-consortium.org). Software: During this work, we have made use of various software packages. This includes BORG(Jasche & Wandelt 2013; Jasche & Lavaux 2019), GADGET-4 (Springel et al. 2021), XTENSOR (https://github.com/xtensor-stack/xtensor), ONETBB (https://github.com/oneapi-src/oneTBB), FFTW (Frigo & Johnson 2005), OPENMPI (Gabriel et al. 2004), MPICH (https://www.mpich.org), JAX (Bradbury et al. 2018), MPI4PY (Dalcin & Fang 2021), MPI4JAX (Häfner & Vicentini 2021), XARRAY (Hoyer & Hamman 2017; Hoyer et al. 2023), NUMPY (Harris et al. 2020), SCIPY (Virtanen et al. 2020), MATPLOTLIB (Hunter 2007), H5PY (https://www.h5py.org/), ASTROPY (Astropy Collaboration 2018, 2022), R3D (Powell 2015), ADJUSTTEXT (Flyamer et al. 2023).
References
- Abel, T., Hahn, O., & Kaehler, R. 2012, MNRAS, 427, 61 [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Angulo, R. E., & Hahn, O. 2022, Liv. Rev. Comput. Astrophys., 8, 1 [CrossRef] [Google Scholar]
- Aragon-Calvo, M. A., Silk, J., & Neyrinck, M. 2023, MNRAS, 520, L28 [Google Scholar]
- Bayer, A. E., Seljak, U., & Modi, C. 2023, ArXiv e-prints [arXiv:2307.09504] [Google Scholar]
- Benisty, D., Vasiliev, E., Evans, N. W., et al. 2022, ApJ, 928, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Benitez-Llambay, A. 2015, https://doi.org/10.5281/zenodo.21703 [Google Scholar]
- Bennett, M., & Bovy, J. 2019, MNRAS, 482, 1417 [NASA ADS] [CrossRef] [Google Scholar]
- Bradbury, J., Frostig, R., Hawkins, P., et al. 2018, http://github.com/jax-ml/jax [Google Scholar]
- Brooks, S., Gelman, A., Jones, G. L., & Meng, X.-L. 2011, Handbook of Markov Chain Monte Carlo (CRC Press) [CrossRef] [Google Scholar]
- Bullock, J. S., & Boylan-Kolchin, M. 2017, ARA&A, 55, 343 [Google Scholar]
- Callingham, T. M., Cautun, M., Deason, A. J., et al. 2019, MNRAS, 484, 5453 [Google Scholar]
- Carignan, C., Chemin, L., Huchtmeier, W. K., & Lockman, F. J. 2006, ApJ, 641, L109 [NASA ADS] [CrossRef] [Google Scholar]
- Carlesi, E., Sorce, J. G., Hoffman, Y., et al. 2016, MNRAS, 458, 900 [NASA ADS] [CrossRef] [Google Scholar]
- Carlesi, E., Hoffman, Y., Sorce, J. G., & Gottlöber, S. 2017, MNRAS, 465, 4886 [NASA ADS] [CrossRef] [Google Scholar]
- Cautun, M., Benítez-Llambay, A., Deason, A. J., et al. 2020, MNRAS, 494, 4291 [Google Scholar]
- Chamberlain, K., Price-Whelan, A. M., Besla, G., et al. 2023, ApJ, 942, 18 [CrossRef] [Google Scholar]
- Chemin, L., Carignan, C., & Foster, T. 2009, ApJ, 705, 1395 [NASA ADS] [CrossRef] [Google Scholar]
- Corbelli, E., Lorenzoni, S., Walterbos, R., Braun, R., & Thilker, D. 2010, A&A, 511, A89 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Courtois, H. M., Hoffman, Y., Tully, R. B., & Gottlöber, S. 2012, ApJ, 744, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Dalcin, L., & Fang, Y.-L. L. 2021, Comput. Sci. Eng., 23, 47 [NASA ADS] [CrossRef] [Google Scholar]
- de Grijs, R., & Bono, G. 2014, AJ, 148, 17 [NASA ADS] [CrossRef] [Google Scholar]
- Drimmel, R., & Poggio, E. 2018, Res. Notes Am. Astron. Soc., 2, 210 [Google Scholar]
- Duane, S., Kennedy, A. D., Pendleton, B. J., & Roweth, D. 1987, Phys. Lett. B, 195, 216 [CrossRef] [Google Scholar]
- Eilers, A.-C., Hogg, D. W., Rix, H.-W., & Ness, M. K. 2019, ApJ, 871, 120 [Google Scholar]
- Errani, R., & Navarro, J. F. 2021, MNRAS, 505, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Fardal, M. A., Weinberg, M. D., Babul, A., et al. 2013, MNRAS, 434, 2779 [Google Scholar]
- Fattahi, A., Navarro, J. F., Sawala, T., et al. 2016, MNRAS, 457, 844 [NASA ADS] [CrossRef] [Google Scholar]
- Feng, Y., Chu, M.-Y., Seljak, U., & McDonald, P. 2016, MNRAS, 463, 2273 [NASA ADS] [CrossRef] [Google Scholar]
- Flyamer, I., Xue, Z., Colin, et al. 2023, https://doi.org/10.5281/zenodo.10016869 [Google Scholar]
- Frigo, M., & Johnson, S. 2005, Proc. IEEE, 93, 216 [NASA ADS] [CrossRef] [Google Scholar]
- Gabriel, E., Fagg, G. E., Bosilca, G., et al. 2004, Proceedings, 11th European PVM/MPI Users’ Group Meeting (Budapest, Hungary: Euro PVM/MPI), 97 [Google Scholar]
- Garrison-Kimmel, S., Boylan-Kolchin, M., Bullock, J. S., & Lee, K. 2014, MNRAS, 438, 2578 [NASA ADS] [CrossRef] [Google Scholar]
- Garrison-Kimmel, S., Hopkins, P. F., Wetzel, A., et al. 2019, MNRAS, 487, 1380 [NASA ADS] [CrossRef] [Google Scholar]
- Geehan, J. J., Fardal, M. A., Babul, A., & Guhathakurta, P. 2006, MNRAS, 366, 996 [NASA ADS] [CrossRef] [Google Scholar]
- González, R. E., Kravtsov, A. V., & Gnedin, N. Y. 2014, ApJ, 793, 91 [CrossRef] [Google Scholar]
- Gott, J. R., III, & Thuan, T. X. 1978, ApJ, 223, 426 [NASA ADS] [CrossRef] [Google Scholar]
- Gottloeber, S., Hoffman, Y., & Yepes, G. 2010, Constrained Local Universe Simulations (CLUES) [Google Scholar]
- GRAVITY Collaboration (Abuter, R., et al.) 2018, A&A, 615, L15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Häfner, D., & Vicentini, F. 2021, J. Open Source Softw., 6, 3419 [CrossRef] [Google Scholar]
- Hahn, O., & Abel, T. 2011, MNRAS, 415, 2101 [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Helmi, A. 2020, ARA&A, 58, 205 [Google Scholar]
- Hernández-Sánchez, M., Kitaura, F.-S., Ata, M., & Vecchia, C. D. 2021, MNRAS, 502, 3976 [CrossRef] [Google Scholar]
- Hockney, R. W., & Eastwood, J. W. 1988, Computer Simulation Using Particles, (Taylor & Francis Group) [Google Scholar]
- Hoffman, M. D., & Gelman, A. 2011, arXiv e-prints [arXiv:1111.4246] [Google Scholar]
- Hoffman, Y., & Ribak, E. 1991, ApJ, 380, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Hoyer, S., & Hamman, J. 2017, Journal of Open Research Software, 5, 1 [Google Scholar]
- Hoyer, S., Roos, M., Joseph, H., et al. 2023, https://doi.org/10.5281/zenodo.10023467 [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Jasche, J., & Lavaux, G. 2019, A&A, 625, A64 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jasche, J., & Wandelt, B. D. 2013, MNRAS, 432, 894 [Google Scholar]
- Jasche, J., Leclercq, F., & Wandelt, B. D. 2015, JCAP, 2015, 036 [Google Scholar]
- Kafle, P. R., Sharma, S., Lewis, G. F., Robotham, A. S. G., & Driver, S. P. 2018, MNRAS, 475, 4043 [CrossRef] [Google Scholar]
- Kahn, F. D., & Woltjer, L. 1959, ApJ, 130, 705 [NASA ADS] [CrossRef] [Google Scholar]
- Karachentsev, I. D., Kashibadze, O. G., Makarov, D. I., & Tully, R. B. 2009, MNRAS, 393, 1265 [NASA ADS] [CrossRef] [Google Scholar]
- Karachentsev, I. D., Makarov, D. I., & Kaisina, E. I. 2013, AJ, 145, 101 [Google Scholar]
- Karukes, E. V., Benito, M., Iocco, F., Trotta, R., & Geringer-Sameth, A. 2020, JCAP, 2020, 033 [Google Scholar]
- Kitaura, F. S. 2013, MNRAS, 429, L84 [NASA ADS] [CrossRef] [Google Scholar]
- Lavaux, G., & Jasche, J. 2016, MNRAS, 455, 3169 [Google Scholar]
- Lavaux, G., Jasche, J., & Leclercq, F. 2019, arXiv e-prints [arXiv:1909.06396] [Google Scholar]
- Li, Y.-S., & Helmi, A. 2008, MNRAS, 385, 1365 [NASA ADS] [CrossRef] [Google Scholar]
- Li, Y.-S., & White, S. D. M. 2008, MNRAS, 384, 1459 [CrossRef] [Google Scholar]
- Li, Y., Lu, L., Modi, C., et al. 2022, arXiv e-prints [arXiv:2211.09958] [Google Scholar]
- Libeskind, N. I., Frenk, C. S., Cole, S., et al. 2005, MNRAS, 363, 146 [NASA ADS] [CrossRef] [Google Scholar]
- Libeskind, N. I., Carlesi, E., Grand, R. J. J., et al. 2020, MNRAS, 498, 2968 [NASA ADS] [CrossRef] [Google Scholar]
- Mathis, H., Lemson, G., Springel, V., et al. 2002, MNRAS, 333, 739 [NASA ADS] [CrossRef] [Google Scholar]
- McAlpine, S., Helly, J. C., Schaller, M., et al. 2022, MNRAS, 512, 5823 [CrossRef] [Google Scholar]
- McMillan, P. J. 2017, MNRAS, 465, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Mishra, R. 1985, MNRAS, 212, 163 [NASA ADS] [CrossRef] [Google Scholar]
- Modi, C., Lanusse, F., & Seljak, U. 2021, Astron. Comput., 37, 100505 [NASA ADS] [CrossRef] [Google Scholar]
- Neal, R. M. 1993, Probabilistic Inference Using Markov Chain Monte Carlo Methods Technical Report CRG-TR-93-1, University of Toronto [Google Scholar]
- Oman, K. A., & Riley, A. H. 2024, MNRAS, 532, L48 [NASA ADS] [CrossRef] [Google Scholar]
- Ou, X., Eilers, A.-C., Necib, L., & Frebel, A. 2024, MNRAS, 528, 693 [NASA ADS] [CrossRef] [Google Scholar]
- Patel, E., & Mandel, K. S. 2023, ApJ, 948, 104 [NASA ADS] [CrossRef] [Google Scholar]
- Pawlowski, M. S. 2018, Mod. Phys. Lett. A, 33, 1830004 [NASA ADS] [CrossRef] [Google Scholar]
- Peebles, P. J. E. 1990, ApJ, 362, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Peebles, P. J. E., & Tully, R. B. 2013, arXiv e-prints [arXiv:1302.6982] [Google Scholar]
- Peebles, P. J. E., Melott, A. L., Holmes, M. R., & Jiang, L. R. 1989, ApJ, 345, 108 [CrossRef] [Google Scholar]
- Peñarrubia, J., Ma, Y.-Z., Walker, M. G., & McConnachie, A. 2014, MNRAS, 443, 2204 [Google Scholar]
- Peñarrubia, J., Gómez, F. A., Besla, G., Erkal, D., & Ma, Y.-Z. 2016, MNRAS, 456, L54 [CrossRef] [Google Scholar]
- Pillepich, A., Sotillo-Ramos, D., Ramesh, R., et al. 2024, MNRAS, 535, 1721 [NASA ADS] [CrossRef] [Google Scholar]
- Powell, D. 2015, https://github.com/devonmpowell/r3d/blob/master/la-ur-15-26964.pdf [Google Scholar]
- Powell, D., & Abel, T. 2015, J. Comput. Phys., 297, 340 [NASA ADS] [CrossRef] [Google Scholar]
- Power, C., Navarro, J. F., Jenkins, A., et al. 2003, MNRAS, 338, 14 [Google Scholar]
- Reid, M. J., & Brunthaler, A. 2004, ApJ, 616, 872 [Google Scholar]
- Sales, L. V., Wetzel, A., & Fattahi, A. 2022, Nat. Astron., 6, 897 [NASA ADS] [CrossRef] [Google Scholar]
- Salomon, J. B., Ibata, R. A., Famaey, B., Martin, N. F., & Lewis, G. F. 2016, MNRAS, 456, 4432 [CrossRef] [Google Scholar]
- Salomon, J. B., Ibata, R., Reylé, C., et al. 2021, MNRAS, 507, 2592 [NASA ADS] [Google Scholar]
- Sandage, A., & Tammann, G. A. 1975, ApJ, 196, 313 [NASA ADS] [CrossRef] [Google Scholar]
- Santos-Santos, I. M. E., Navarro, J. F., & McConnachie, A. 2024, MNRAS, 532, 2490 [NASA ADS] [CrossRef] [Google Scholar]
- Sawala, T., Frenk, C. S., Fattahi, A., et al. 2016, MNRAS, 457, 1931 [Google Scholar]
- Sawala, T., McAlpine, S., Jasche, J., et al. 2022, MNRAS, 509, 1432 [Google Scholar]
- Sawala, T., Cautun, M., Frenk, C., et al. 2023a, Nat. Astron., 7, 481 [Google Scholar]
- Sawala, T., Peñarrubia, J., Liao, S., & Johansson, P. H. 2023b, MNRAS, 526, L77 [NASA ADS] [CrossRef] [Google Scholar]
- Schaller, M., Borrow, J., Draper, P. W., et al. 2024, MNRAS, 530, 2378 [NASA ADS] [CrossRef] [Google Scholar]
- Schlegel, D., Davis, M., Summers, F., & Holtzman, J. A. 1994, ApJ, 427, 527 [NASA ADS] [CrossRef] [Google Scholar]
- Sohn, S. T., Anderson, J., & van der Marel, R. P. 2012, ApJ, 753, 7 [NASA ADS] [CrossRef] [Google Scholar]
- Sorce, J. G., Gottlöber, S., Yepes, G., et al. 2016, MNRAS, 455, 2078 [NASA ADS] [CrossRef] [Google Scholar]
- Springel, V., Pakmor, R., Zier, O., & Reinecke, M. 2021, MNRAS, 506, 2871 [NASA ADS] [CrossRef] [Google Scholar]
- Stopyra, S., Pontzen, A., Peiris, H., Roth, N., & Rey, M. 2021, ApJS, 252, 28 [CrossRef] [Google Scholar]
- Taibi, S., Pawlowski, M. S., Khoperskov, S., Steinmetz, M., & Libeskind, N. I. 2024, A&A, 681, A73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tamm, A., Tempel, E., Tenjes, P., Tihhonova, O., & Tuvikene, T. 2012, A&A, 546, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tassev, S., Zaldarriaga, M., & Eisenstein, D. 2013, JCAP, 2013, 036 [CrossRef] [Google Scholar]
- Tollerud, E. J., Beaton, R. L., Geha, M. C., et al. 2012, ApJ, 752, 45 [NASA ADS] [CrossRef] [Google Scholar]
- Tully, R. B., Rizzi, L., Shaya, E. J., et al. 2009, AJ, 138, 323 [NASA ADS] [CrossRef] [Google Scholar]
- Tully, R. B., Courtois, H. M., Dolphin, A. E., et al. 2013, AJ, 146, 86 [NASA ADS] [CrossRef] [Google Scholar]
- Tully, R. B., Pomarède, D., Graziani, R., et al. 2019, ApJ, 880, 24 [Google Scholar]
- van der Marel, R. P., & Guhathakurta, P. 2008, ApJ, 678, 187 [CrossRef] [Google Scholar]
- van der Marel, R. P., Fardal, M., Besla, G., et al. 2012, ApJ, 753, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Vasiliev, E., Belokurov, V., & Erkal, D. 2021, MNRAS, 501, 2279 [NASA ADS] [CrossRef] [Google Scholar]
- Veljanoski, J., Mackey, A. D., Ferguson, A. M. N., et al. 2014, MNRAS, 442, 2929 [NASA ADS] [CrossRef] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Meth., 17, 261 [Google Scholar]
- Wang, H., Mo, H. J., Yang, X., & van den Bosch, F. C. 2013, ApJ, 772, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, H., Mo, H. J., Yang, X., Jing, Y. P., & Lin, W. P. 2014, ApJ, 794, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, W., Han, J., Cautun, M., Li, Z., Ishigaki, M. N., et al. 2020, Sci. China Phys. Mech. Astron., 63, 109801 [NASA ADS] [CrossRef] [Google Scholar]
- Watkins, L. L., Evans, N. W., & van de Ven, G. 2013, MNRAS, 430, 971 [NASA ADS] [CrossRef] [Google Scholar]
- Zaroubi, S., Hoffman, Y., & Dekel, A. 1999, ApJ, 520, 413 [NASA ADS] [CrossRef] [Google Scholar]
- Zhai, M., Guo, Q., Zhao, G., Gu, Q., & Liu, A. 2020, ApJ, 890, 27 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Milky Way and M31 mass estimates
In our framework, we require filtered masses, as defined by Equation (12), together with their observational uncertainties. It is not straightforward to find good estimates for these quantities from the literature based on independent mass tracers across a wide range of radii. In most analyses of specific mass tracers corresponding enclosed masses are quoted, but because different analyses tend to be based on different models and assumptions, combining these results takes some care. We, therefore, present here a new analysis of a subset of the available mass tracers for the Milky Way and Andromeda in an attempt to obtain robust and conservative estimates of their filtered halo masses with a ΛCDM prior.
A.1. Milky Way
For the Milky Way, there exist several joint analyses that constrain the mass profile using a heterogeneous set of mass tracers that go out to large radius (McMillan 2017; Karukes et al. 2020; Wang et al. 2020). We choose a procedure, described below, which follows Cautun et al. (2020), with a few minor alterations and additions to the data. The mass model is the same as in Cautun et al. (2020) and consists of a bulge, a thin and thick disc, a circumgalactic medium, and a contracted NFW dark matter profile. We refer to the original paper for details. As constraints, we incorporate the following changes with respect to the fitting in Cautun et al. (2020):
-
We use the Ou et al. (2024) circular velocity curve. This is an update of the Eilers et al. (2019) curve that was used by Cautun et al. (2020). We only utilise the data points within < 21.5 kpc, because the (systematic) errors become very large at larger radii. Since systematic errors dominate statistical errors in this analysis, we add to the statistical errors a covariance matrix that is modelled by a Gaussian Process (see also Oman & Riley 2024). We assume a rational quadratic covariance function; the covariance due to systematic errors between data points i and j is assumed to be C(dij) = A2(1 + dij2/2αk2)−α, where the width k and power-law index α are allowed to vary, and where the amplitude A is set to 6 km s−1, which is the amplitude that Ou et al. (2024) estimate as the magnitude of their systematic error. For the distance metric dij between data points i and j, we use the difference in logarithm of Galactocentric radii ri and rj, that is, dij = |log ri/rj|. We verified that the results obtained are robust against reasonable variation of covariance function and distance metric. One can see that with this treatment, the uncertainty of the final fit (Figure A.1) reflects well the systematic uncertainty in the inner region, something that is not achieved when simply adding the systematic uncertainty in quadrature with the statistical uncertainty.
-
We add mass estimates from Sagittarius stream modelling by Vasiliev et al. (2021). Although they have a different (more flexible) dark matter profile, the enclosed masses are given too. They quote two spherically enclosed masses (the constraint is put on the integrated density within this sphere): M(50 kpc) = (3.85 ± 0.10)×1011 M⊙ and M(100 kpc) = (5.7 ± 0.3)×1011 M⊙. However, their model is triaxial and includes an LMC. Since we limit ourselves to a simple spherical model, we opt for an error of 20 % to be able to generalise the masses to our spherical model.
 |
Fig. A.1. Our assumed circular velocity curve for the Milky Way, together with a band showing the 1σ scatter in the posterior distribution of ΛCDM models constrained by the observational data points shown, with their adopted error bars, in orange, red, and green. The solid blue curve is the mean of the posterior circular velocity distribution at each radius. The error bar of the Callingham et al. (2019) estimate is diagonal since they estimated the virial mass and a lower mass results in a lower virial radius. |
The fit and the model velocity profiles are shown in Figure A.1. For the dark matter profile, we have sampled the NFW parameters of the dark-matter-only analogue, that, after using the recipe from Cautun et al. (2020) resulted in the contracted NFW profile we have used in our mass model. Since our simulations are dark-matter-only, this sample of implied dark-matter-only analogues is ideal for constraining our simulations. We scale up these sample profiles by a factor (1 − fbar)−1 to account for the baryon fraction, fbar = 0.157. For each of these scaled NFW profiles, we then compute the implied 100 kpc filtered mass following Equation (12) as Mfilt(100 kpc) = ∫0∞ρNFW(r)exp(−r2/2σ2)4πr2dr. We find ln(Mfilt(100 kpc)) = ln(1.085 × 1012 M⊙)±0.1291, the value listed in Table 2 as our constraint, where we also include an additional 5 % in quadrature to account for the halo-to-halo scatter that Cautun et al. (2020) found.
A.2. M31
For M31, we carry out an analysis similar to that for the Milky Way, also with a contracted halo.
-
We use a stellar + gas mass model from Tamm et al. (2012), derived purely from stellar population modelling. This model consists of a nucleus, a bulge, a stellar disc, a star-forming young disc and a stellar halo. Since different choices in the stellar population models allow for up to 50 % extra stellar mass (this freedom mostly stems from the choice of stellar initial mass function) (Tamm et al. 2012), we include an unknown multiplicative factor A, giving ρ = Aρtamm, min, where A ∼ 𝒰(1, 1.5) and ρtamm, min is their minimum stellar-mass model.
-
The NFW dark matter profile is contracted, following the procedure of Cautun et al. (2020)
We derive constraints as follows:
-
We consider the rotation curves derived by Chemin et al. (2009), Corbelli et al. (2010), Carignan et al. (2006). There is some scatter within the literature on measurements of the rotation curve. Since we are interested only in the total mass within our rather large Gaussian filter, it is not useful to model the full internal structure of M31. We therefore use only one data point as a constraint, which we choose to put at r = 35 kpc, since the datasets do not go beyond this. In order to smooth out small-scale structure, we average velocity measurements within a 5 kpc window centred at 35 kpc for each dataset. Although reported uncertainties are typically small, they often do not include the systematic difference between the two sides of the galaxy, which we do not attempt to model and hence must include as an uncertainty. However, the errors reported by Corbelli et al. (2010) do include these, so we adopt their average uncertainty within the window. This results in our chosen constraint, vc(35 kpc) = (239 ± 25) km s−1.
-
Fardal et al. (2013) used a Bayesian sampling method based on N-body modelling of the giant stellar stream to estimate M31’s halo mass. Since any quoted M200c is model-dependent, we convert this to an enclosed-mass estimate within their fitted apocentre, M(rapo = 55.5 kpc) = (5.92 ± 0.03)×1011 M⊙, which we expect to be robust. This uncertainty is an underestimate, however, because the halo scale radius, disc and bulge mass were not taken as free parameters; rather, Fardal et al. (2013) determined them as a function of halo mass, such that in total the model roughly matches the rotation curve. This is done by assuming that the parameters lie exactly on the maximum-likelihood curve of the fit by Geehan et al. (2006). To get the true uncertainty we should therefore propagate the uncertainty of the Geehan et al. (2006) model and add it to our uncertainty estimate. Although doing this exactly is impractical, we can get a conservative estimate on the error of M(rapo) by assuming that it is only known as well the the rotation curve itself. Hence, we use the same relative error on this data point as on the rotation curve point discussed above, leading to the constraint M(< 55.5 kpc) = (5.92 ± 1.24)×1011 M⊙.
-
Veljanoski et al. (2014) use outer-halo globular clusters as mass tracers. They estimate an enclosed mass of M(< 200 kpc) = (1.2 ± 0.2)×1012 M⊙ for an NFW-like potential.
-
Tollerud et al. (2012) estimate a halo mass from satellite galaxy data. They utilise an estimator of the form M(< r) = C(r)σ2r/G, tuning C(r) to match simulation data. This leads to an estimated enclosed mass within the satellite median distance of M(< 139 kpc) = (8.0 ± 3.9)×1011 M⊙.
-
Patel & Mandel (2023) compare satellite dynamics directly with simulations to infer a virial mass (defined as the mass within a sphere of mean density 18π2ρcrit) of
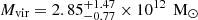 . We convert this to a log-normal constraint on the virial mass, setting the standard deviation to be σlnM = (ln(2.85 + 1.47)−ln(2.85 − 0.77))/2.
. We convert this to a log-normal constraint on the virial mass, setting the standard deviation to be σlnM = (ln(2.85 + 1.47)−ln(2.85 − 0.77))/2.
The circular velocity curve of our model is shown in Figure A.2. The final constraint on the filtered mass, listed in Table 2, is derived completely analogously to the one for the Milky Way described in the previous section.
 |
Fig. A.2. Our assumed ΛCDM circular velocity curve for M31, together with a band showing the 1σ scatter in allowed models. The data points used for the fitting are also shown. |
Appendix B: Positions and velocities of the Milky Way and M31
B.1. Milky Way
For the position and velocity of the Sun with respect to the Milky Way, we use the default parameters of Astropy (Astropy Collaboration 2018, 2022), which use measurements of the position and motion of the Sagittarius A* by Reid & Brunthaler (2004), GRAVITY Collaboration (2018), Drimmel & Poggio (2018). The height above the plane is from Bennett & Bovy (2019). Specifically, this is a solar Galactocentric velocity of v⊙ = (12.9, 245.6, 7.78) km s−1, with a Galactocentric distance of 8.122 kpc, and a disc-height of z⊙ = 20.6 pc. The measurement uncertainties are of the order of a few km s−1, and hence we neglect them compared to the other sources of uncertainty in our analysis. In particular, we include an isotropic uncertainty of 10 km s−1 in the offset from the Solar frame of reference to that of the barycentre of the MW’s filtered halo mass (see Section 2.3.6).
B.2. Andromeda
The position on the sky of M31 is (α, δ) = (00h42m44.33s, 41d16m07.5s) (Kafle et al. 2018), and we take its distance modulus to be μ = 24.46 ± 0.10 (de Grijs & Bono 2014), which corresponds to a distance of dM31 = (780 ± 46) kpc.
The heliocentric radial velocity of M31 is v = ( − 301 ± 1) km s−1 (Watkins et al. 2013). For the proper motions, we use the recent measurement by Salomon et al. (2021) based on Gaia EDR3 data, specifically (μα cos δ, μδ) = ((48.9 ± 10.5) μas/yr, (−36.9 ± 8.1) μas/yr). We use this in preference to the HST proper motion by Sohn et al. (2012), van der Marel et al. (2012), because the HST measurement is based on only a small part of the galaxy (because HST has a small field of view), and therefore, for the global motion, the result is quite sensitive to modelling choices for the internal dynamics (van der Marel et al. 2012). The resulting values for our constraints are quoted in Table 2.
Appendix C: Low-resolution mass bias correction
The integrator in our Hamiltonian Monte Carlo sampler requires a full particle-mesh simulation to be run at each step. To build a sufficiently large MCMC sample size, we require very fast, and therefore low-resolution simulations. To give a practical number, each independent sample needs about 500 HMC rejection/acceptance steps. Each step requires about 200 leapfrog steps. Thus, for each independent sample, we need to run 100 000 evolutionary simulations. Unfortunately at low resolution, the inner regions of our haloes are not well-resolved and so are less concentrated than they should be. This was already noted in the literature as a systematic effect (e.g. Errani & Navarro 2021) and as such we may account for it relatively accurately by an appropriate correction.
For this purpose, we have run two unconstrained simulations with the same initial conditions. One has the same spatial, temporal, and mass resolution as the HR region in our inference set-up, while the other is a high-resolution Gadget simulation from the same initial conditions. Their properties are listed in Table C.1. We then create a density field (with a mesh size of Δx = 26 kpc), and find all local maxima of the 100 kpc filtered mass field in the two simulations. Each maximum corresponds to a halo, so we obtain a catalogue of halo masses9 and positions. We then select the haloes with filtered mass > 2.5 × 1011 M⊙. We lastly require isolation (no halo > 1 × 1011 M⊙ within 2 Mpc) to filter out close pairs, which might not have well-defined masses. We cross-match the two catalogues to get a relationship between low-resolution and high-resolution haloes, requiring a position difference of less than 200 kpc when matching.
Simulation settings used for the halo mass bias correction.
The resulting fits are shown in Figure C.1. Although there is some freedom in the choice of selection, isolation requirement, and cross-match precision, the results are robust against reasonable variation; the simple power-law fits given in the figure work quite well and are used in our main analysis.
 |
Fig. C.1. Halo masses in the high-resolution Gadget simulation compared to those in the low-resolution BORG simulation. We note that MHR, 12 is the 100 kpc filtered mass (blue) or M200c value (orange) in the Gadget resimulation in units of 1 × 1012 M⊙, while MLR, 12 indicates the corresponding quantities for the BORG simulation. σ indicates the scatter around the power-law fits to the relations given in the figure legend. |
Appendix D: Marginalisation of the velocity frame
Our velocity likelihoods consist of the 31 Gaussian distributions from the external galaxies and three Gaussian distributions for the three velocity components of M31. This can be written as a single multivariate Gaussian, vmod ∼ 𝒩(vobs, Σobs), where the components of the v vectors are either the radial velocities of external galaxies, or one of the 3 components of the M31 velocity vector. The covariance matrix Σobs is diagonal. As described in Section 2.3.6, we wish to marginalise over a latent parameter, the velocity frame offset voff between the true Galactocentric reference frame, and the simulation-derived Galactocentric frame (which is defined such that the Milky Way’s 100 kpc filtered velocity is zero). In practice, we allow for a dispersion of σoff = 10 km s−1, because this is the standard deviation of the difference between 100 kpc filtered velocity and the 5 kpc filtered velocity of Gadget resimulations of our Milky Way of an earlier version of the chain that did not incorporate this additional uncertainty.
If Z = X + Y where X ∼ 𝒩(μX, ΣX) and Y ∼ 𝒩(μY, ΣY), then Z ∼ 𝒩(μX + μY, ΣX + ΣY). Moreover, if a scalar random variable R ∼ 𝒩(μ, σ2) and a vector random variable V ∼ 𝒩(μV, ΣV), are combined into a vector random variable Y = V + Rα, where α is a constant vector, then Y will follow Y ∼ 𝒩(μV + αμ, ΣV + σ2(ααT)).
Assume that there is an offset voff between the assumed heliocentric reference frame in the simulation and the true one and that each component has voff,k ∼ 𝒩(0, σoff2). The corrected radial velocity will be  . In the case of M31, where we also have constraints on the tangential velocity, the corrected 3d-velocity would be vM31,corr = vM31 + voff. Now, if we define
. In the case of M31, where we also have constraints on the tangential velocity, the corrected 3d-velocity would be vM31,corr = vM31 + voff. Now, if we define
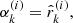 (D.1)
(D.1)
where 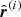 is the unit vector in the direction of the measured velocity giving rise to velocity constraint i, we can write
is the unit vector in the direction of the measured velocity giving rise to velocity constraint i, we can write
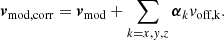 (D.2)
(D.2)
So, making use of the above, we have the following
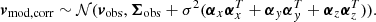 (D.3)
(D.3)
All Tables
A summary of the selection requirements of some notable past Local Group simulations.
All Figures
|
Fig. 1. Schematic diagram of our Hamiltonian Monte Carlo method. The procedure starts with a white noise initial condition field s, then uses a nested, double-mesh particle-mesh (PM) integrator to obtain the final particle phase-space coordinates (xfinal and vfinal). The likelihood is implemented in Python using the JAX package (Bradbury et al. 2018), which automatically implements the gradient. We compute the gradient of the likelihood and back-propagate it through the double-mesh integrator steps to the initial condition field. Using this gradient, we then do a Hamiltonian Monte Carlo (HMC) update on the initial condition field and iterate the whole procedure many times to obtain our sample of initial condition fields. |
| In the text | |
|
Fig. 2. The catalogue of galaxies used as flow tracers in this analysis, analogous to Fig. 11 in Peñarrubia et al. (2014). The x-axis is the Local-Group-centric distance, where the centre of the LG is the centre of mass of the Milky Way-M31 pair when assuming a mass ratio of MM31/MMW = 2. The y-axis is the radial velocity projected in the LG-centric frame, where the offset is computed by interpolating the velocity field along the line between the two galaxies linearly. The different lines indicate spherical Kepler-like velocity models of the recession velocity (Equation (9) of Peñarrubia et al. 2014). |
| In the text | |
|
Fig. 3. Sky distribution in Supergalactic coordinates of the catalogue of the galaxies used as flow tracers in this analysis. Symbol type indicates distance from the LG’s barycentre, and colour indicates velocity with respect to the spherical model shown as a red line in Figure 2. Units are in Mpc and km s−1. The blue line shows the Galactic plane. |
| In the text | |
|
Fig. 4. Trace plots of an example chain, chain number 10. Left: the likelihood values of the observational constraints. The solid blue line is the total likelihood, which is the sum of all other solid lines that indicate components of the likelihood. The dashed lines are the prior on the initial white noise fields sLR and sHR. Right: The masses of the Milky Way and M31 along the chain. The greyed-out lines indicate values of the masses before applying the correction from Figure C.1. This particular chain was considered warmed up by sample 760 according to the criterion of Section 3.3. |
| In the text | |
|
Fig. 5. Final density fields of the low-resolution box as chain 10 evolves. This chain has Feff = 411, so every Feff sample (going vertically down each column) can be considered as an independent sample. The circles highlight a few haloes that do not shift by much between consecutive samples, illustrating the substantial autocorrelation between samples separated by significantly less than Feff. We note that sample 0 (which occurs after one iteration of the HMC) is almost completely uniform because we start our chains from a uniform field. Visualisation here was done using pySPHViewer (Benitez-Llambay 2015). |
| In the text | |
|
Fig. 6. Autocorrelation functions as computed using Equation (24) for our twelve different chains, each indicated by a different colour. |
| In the text | |
|
Fig. 7. Final density fields in simulation coordinates of evolution from four of our independent sets of initial conditions (each from a different chain). Each pane corresponds to a single set of initial conditions. Within each pane, the left column shows the full box and the right column the central 10 Mpc zoom box, while the two rows show orthogonal projections. The name at the top of each pane indicates the chain it came from (after C), and its sample index (after S). The visualisations are made using the Lagrangian Sheet density estimation method of the r3d package* (Powell & Abel 2015). The unit vectors of the Supergalactic reference frame are shown at the top right of each high-resolution panel. (* Since our two-grid initial condition layout is not a pure cubic grid, in particular, at the zoom-region boundary, we cannot use the recipe where every cube is divided into 6 tetrahedra as in e.g. Abel et al. (2012). Instead, we use a Delaunay tetrahedralisation to create the simplex tracers.) |
| In the text | |
|
Fig. 8. Posterior distributions of LG properties from our Markov chains. In each panel, the histogram is of samples from our chains and therefore indicates the posterior distribution. The dashed lines are the injected observational constraints. The top left panel indicates the centre-of-mass position of the Milky Way, and the top middle panel M31. The right panel shows the relative velocity of the MW-M31 pair. The bottom left and middle panels indicate the 100 kpc filtered masses of the Milky Way and M31. The bottom right panel shows the total log-likelihood of the flow tracers, with on top the χ2-distribution (scaled by |
| In the text | |
|
Fig. 9. Similar to Figure 2, but now with the purple points showing the line-of-sight velocities from our simulations at the 3D location of each galaxy. Each purple point is an independent sample from our chains, specifically, we plot the ‘independent’ set as defined in Section 3.3. |
| In the text | |
|
Fig. 10. Enclosed mass profiles in our simulations, centred on the Local Group’s centre of mass, on the Milky Way, and on M31. The lines indicate the posterior mean, and the shaded regions are the 1σ region of the ‘semi-independent’ sample set (see Section 3.3, we use this to avoid being affected by shot noise coming from thinning the chains). |
| In the text | |
|
Fig. 11. LG region (a box of (2 Mpc)3 centred at the Milky Way) in some resimulations with Gadget-4. The blue dots indicate particles in the BORG simulations, and the orange dots indicate particles in the gadget re-simulations. Each panel indicates one simulation, with two projections being shown. |
| In the text | |
|
Fig. 12. Filtered mass ratios of the Gadget resimulations compared to BORG (after applying the correction from Appendix C). Each symbol indicates a different set of initial conditions. For five simulations, we also show the result with higher Gadget resolution (with particle masses 64× smaller, softening 16× smaller and power included in the initial conditions to 4× smaller scale) in darker colours. Points referring to simulations with the same initial conditions but different resolutions are connected with a blue line. |
| In the text | |
|
Fig. 13. Position differences of the M31 and MW analogues in the Gadget resimulations plotted against the same difference in the BORG simulations. The x-axis is the Sun-M31 axis, and y and z are R.A. and Dec. directions at the position of M31. As in Figure 12, pairs of symbols joined by lines refer to the five cases with an additional higher resolution Gadget resimulation. |
| In the text | |
|
Fig. 14. Peculiar velocity differences between the M31 and MW analogues in the Gadget resimulations plotted component by component against the same quantity for the BORG simulations. The x-axis is the Sun-M31 axis, and y and z are oriented orthogonally in directions of increasing R.A. and Dec. at the position of M31. As in Figure 12, pairs of symbols joined by lines refer to the five cases with an additional higher resolution Gadget resimulation. |
| In the text | |
|
Fig. 15. Comparison of the density fields of the LG when integrating the same initial conditions (C6 S1530) with the BORG zoom particle-mesh scheme used in our Markov chains, with Gadget at the same mass resolution (particle mass of m = 1.5 × 108 M⊙ and softening of b = 10 kpc), and with Gadget with a higher resolution (m = 2.4 × 106 M⊙, b = 0.56 kpc). |
| In the text | |
|
Fig. A.1. Our assumed circular velocity curve for the Milky Way, together with a band showing the 1σ scatter in the posterior distribution of ΛCDM models constrained by the observational data points shown, with their adopted error bars, in orange, red, and green. The solid blue curve is the mean of the posterior circular velocity distribution at each radius. The error bar of the Callingham et al. (2019) estimate is diagonal since they estimated the virial mass and a lower mass results in a lower virial radius. |
| In the text | |
|
Fig. A.2. Our assumed ΛCDM circular velocity curve for M31, together with a band showing the 1σ scatter in allowed models. The data points used for the fitting are also shown. |
| In the text | |
|
Fig. C.1. Halo masses in the high-resolution Gadget simulation compared to those in the low-resolution BORG simulation. We note that MHR, 12 is the 100 kpc filtered mass (blue) or M200c value (orange) in the Gadget resimulation in units of 1 × 1012 M⊙, while MLR, 12 indicates the corresponding quantities for the BORG simulation. σ indicates the scatter around the power-law fits to the relations given in the figure legend. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.