| Issue |
A&A
Volume 686, June 2024
|
|
|---|---|---|
| Article Number | A158 | |
| Number of page(s) | 16 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202348848 | |
| Published online | 07 June 2024 | |
FINKER: Frequency Identification through Nonparametric KErnel Regression in astronomical time series
1
Department of Astrophysics/IMAPP, Radboud University,
PO Box 9010,
6500 GL
Nijmegen,
The Netherlands
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Department of Mathematics/IMAPP, Radboud University,
PO Box 9010,
6500 GL
Nijmegen,
The Netherlands
3
Max-Planck-Institut für Astrophysik,
Karl-Schwarzschild-Straße 1,
85741
Garching bei München,
Germany
4
Institute of Astronomy, KU Leuven,
Celestijnenlaan 200D,
3001
Leuven,
Belgium
5
SRON, Netherlands Institute for Space Research,
Sorbonnelaan 2,
3584 CA
Utrecht,
The Netherlands
6
Department of Astronomy and Inter-University Institute for Data Intensive Astronomy, University of Cape Town,
Private Bag X3,
Rondebosch,
7701,
South Africa
7
South African Astronomical Observatory,
PO Box 9,
Observatory
7935,
South Africa
Received:
5
December
2023
Accepted:
18
March
2024
Abstract
Context. Optimal frequency identification in astronomical datasets is crucial for variable star studies, exoplanet detection, and astero-seismology. Traditional period-finding methods often rely on specific parametric assumptions, employ binning procedures, or overlook the regression nature of the problem, limiting their applicability and precision.
Aims. We introduce a universal- nonparametric kernel regression method for optimal frequency determination that is generalizable, efficient, and robust across various astronomical data types.
Methods. FINKER uses nonparametric kernel regression on folded datasets at different frequencies, selecting the optimal frequency by minimising squared residuals. This technique inherently incorporates a weighting system that accounts for measurement uncertainties and facilitates multi-band data analysis. We evaluated our method’s performance across a range of frequencies pertinent to diverse data types and compared it with an established period-finding algorithm, conditional entropy.
Results. The method demonstrates superior performance in accuracy and robustness compared to existing algorithms, requiring fewer observations to reliably identify significant frequencies. It exhibits resilience against noise and adapts well to datasets with varying complexity.
Key words: methods: data analysis / methods: statistical / techniques: radial velocities / binaries: eclipsing / stars: variables: RR Lyrae
Equal contribution.
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
In astronomy, periodic signals buried within time series of flux (photometric light curves) or radial velocity measurements serve as important carriers of scientific information. Their detection is essential for various scientific pursuits, from exoplanet characterisation to the study of variable stars. A plethora of period-finding algorithms exist, from standard techniques such as the classical Lomb-Scargle periodogram (Lomb 1976; Scargle 1982), the generalised Lomb-Scargle (Zechmeister & Kürster 2009; VanderPlas 2018), and the discrete Fourier transform (Deeming 1975) to popular nonparametric methods such as string length (Dworetsky 1983), analysis of variance (Schwarzenberg-Czerny 1989, 1996), and phase dispersion minimisation (Stellingwerf 1978). In addition to these, smoothing algorithms and statistical hypothesis testing based on regression models and confidence sets have been employed to detect periodicities in radial velocity measurements (McDonald 1986; Toulis & Bean 2021), highlighting the potential of regression techniques for periodicity detection in astronomical data. These methods can be used to search for periodicity via either a grid search or direct optimisation (Reimann 1994).
Recent advancements have also seen the application of Gaussian process regression with specified kernels as a promising approach for analysing periodic data, offering a flexible framework for accounting for the noise characteristics and underlying trends in the time series (Barros et al. 2020; Nicholson & Aigrain 2022; Barragán et al. 2021; Matesic et al. 2024). Furthermore, the introduction of information theory-based methods, such as conditional entropy (Graham et al. 2013a) and quadratic mutual information (Huijse et al. 2018), has made significant contributions to this field. While these methodologies align with our work in aiming to identify periodic signals, they differ in terms of application and framework. We discuss these differences in our paper, highlighting the unique advantages and considerations of our approach, which we called Frequency Identification through Nonparametric KErnel Regression (FINKER), compared to these recent advancements.
Comparative analyses have been instrumental in enhancing our understanding of various period-finding algorithms’ capabilities and limitations (Graham et al. 2013b). Such studies emphasise the dependence of these methods on the quality of the light curve data. Graham et al. (2013b) advocate for a bimodal observation approach, where pairs of observations are taken rapidly each night to retain a high sampling frequency.
They also emphasise that algorithms perform notably well for specific types of variables, such as pulsating and eclipsing classes, but find that ensemble methods (e.g. Saha & Vivas 2017; Ranaivomanana et al. 2023), which combine multiple algorithms, do not generally outperform single algorithms. Among the array of algorithms studied, conditional entropy stands out in terms of period recovery and computational time, with analyses of variance and phase dispersion minimisation also showing promise.
Despite these advancements, the search for a universally applicable and assumption-free period-finding method continues. A noteworthy yet underdeveloped method presented by Hall et al. (2000) pioneered the exploration of nonparametric kernel regression techniques for period detection through grid search least-squares optimisation. Despite its potential, the method went largely unused in astronomical applications due to the technological and computational limitations of the time. This work was later expanded in a series of papers to apply the framework of nonparametric regression estimation to periodograms using single and multiple sine and cosine components to circumvent the alias problem (Hall & Li 2006; Genton & Hall 2007). While this body of earlier work serves as a conceptual underpinning for our current research, with our approach we have substantially extended the methodology by developing a more advanced, non-parametric kernel regression algorithm tailored for astronomical applications. With it, we can further investigate the behaviour of the kernel bandwidth when estimating frequencies.
We aim to establish nonparametric kernel regression as a robust and versatile method for optimal frequency identification, setting the stage for more precise and efficient analyses in both astronomical and potentially interdisciplinary fields. The structure of this paper is as follows: Sect. 2 contains the mathematical foundations and computational aspects of our proposed method. Section 3 describes the experimental setup and presents a comparative analysis with existing methodologies. Section 4 presents the results of FINKER applied to a set of real examples, such as classical pulsators, short period transiting compact binaries, and radial velocity variations in binaries. Finally, Sect. 5 offers conclusions and explores avenues for future developments.
To promote open and reproducible research, FINKER is publicly available on GitHub1 (Stoppa 2024).
2 Method
Nonparametric kernel regression (Nadaraya 1964; Watson 1964; Hall et al. 2000) serves as the core of our approach. However, before delving deeper into our method, it is crucial to consider the work of Schwarzenberg-Czerny (1999) on the comparative capabilities of parametric and non-parametric methods in optimum period search analyses. Their work highlights that parametric methods, when aligned with an accurately specified model that closely mirrors the data’s underlying structure, can yield superior efficiency and predictive power. However, the effectiveness of these methods can significantly diminish in scenarios where such a precise model alignment is lacking, leading to potential misinterpretations or overlooked data characteristics. In contrast, non-parametric methods, not being confined to a predefined model, stand out for their robust adaptability and resilience and thus their broader applicability across diverse settings. This inherent flexibility makes nonparametric methods especially valuable in situations where the underlying periodic signals in astronomical time series are complex and not modelled well by standard parametric forms.
Following the selection of nonparametric kernel regression for its adaptability and flexibility, this section details the methodology employed for nonparametric kernel regression based frequency identification. We discuss the relevant data pre-processing, the technical implementation of the nonparametric regression model, and the determination of the optimal frequency of variability in the time series. Each subsection delves into the specifics of these steps, elucidating the underlying principles and computational strategies.
In general, we considered an arbitrary, sparsely sampled astronomical time series, consisting of N observations yi with corresponding uncertainties σi taken at discrete times ti (with i = 1,…, N). This pertains to both photometric flux and radial velocity time series.
2.1 Phase folding
Astronomical time series are often sparsely sampled, leading to situations where successive observations may not provide direct insights into the periodically correlated nature of the phenomena under study.
To overcome this, we employed a common processing step in the analysis of periodic signals within astronomical data called phase folding. It involves transforming the time-series observations into a phase diagram by folding the data over a chosen frequency, vj, such that the phase of a given observation, ϕi, is given by
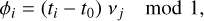 (1)
(1)
where t0 is the chosen reference epoch2, and νj is the candidate frequency for folding. This technique aligns the repeating patterns in the data, which can be obscured in the time domain due to irregular sampling intervals or noise. The periodic signal becomes more discernible by folding the data at the correct or assumed frequency, facilitating the analysis of its structure and properties.
It is important to note that this phase-folding technique intrinsically assumes the stationarity of the time series.
The phase-folded curve is particularly useful for visualising and analysing periodic variations in the brightness of variable stars or exoplanets transiting their host stars and for radial velocity variations of multiple star systems or exoplanetary systems. To illustrate this, Figure 1 showcases a real light curve alongside its phase-folded counterpart at the literature frequency (Torrealba et al. 2015). Upon examining this example, we notice that by folding the light curve on the underlying period of variability, we reduce the scatter between two adjacent points. This is the basis for various nonparametric frequency determination routines, including the analysis of variance method (Schwarzenberg-Czerny 1989), the Lafler–Kinman statistic (Clarke 2002), the conditional entropy periodogram (Graham et al. 2013a), and our proposed nonparametric kernel regression technique.
2.2 Nonparametric kernel regression
Once the astronomical time series is transformed into a phase diagram via phase folding, we apply nonparametric kernel regression to the folded light curve. This application is fundamental to our methodology, enabling the identification of the optimal frequency of variability by analysing the periodic signal’s structure and properties within the phase-flux relationship.
Local constant regression is the simplest variant and most efficient version of kernel regression. The regression function, 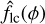 , at any given phase, ϕ, calculated for a given proposed frequency, vj, is computed as
, at any given phase, ϕ, calculated for a given proposed frequency, vj, is computed as
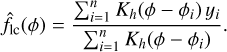 (2)
(2)
Here, yi represents the observed flux corresponding to the phase ϕi, and the estimated function value 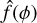 is a weighted average of these fluxes. The weights are determined by the kernel function Kh, which measures the closeness of each observed phase ϕi to the phase ϕ of interest. This approach is computationally straightforward and only requires one parameter, the bandwidth h of the kernel Kh. Section 2.4 explores this parameter in detail.
is a weighted average of these fluxes. The weights are determined by the kernel function Kh, which measures the closeness of each observed phase ϕi to the phase ϕ of interest. This approach is computationally straightforward and only requires one parameter, the bandwidth h of the kernel Kh. Section 2.4 explores this parameter in detail.
A simple extension to local constant, local linear regression (Fan & Gijbels 1994), enhances the local constant model by incorporating a linear trend within the kernel’s scope at each phase ϕ. This method is particularly famous for its ability to better manage boundary problems, an advantage in typical scenarios. However, in our approach, this boundary issue is already effectively addressed by using a common trick of extending the phase-folded light curve to both sides. This extension effectively mitigates boundary issues, allowing for a more accurate estimation of the regression function near the edges.
Local linear regression, while offering a refined analysis by including linear trends, necessitates the calculation of two additional parameters at each phase: the intercept and slope of the local linear model. Given its considerable computational load and the fact that our extensive frequency folding requirements do not show marked improvements over local constant regression, we opted for the latter. The computational simplicity and efficiency of local constant regression make it the more suitable choice for our frequency optimisation framework.
 |
Fig. 1 MeerLICHT (Bloemen et al. 2016) telescope’s light curve of CRTS J033427.7–271223 on the left and phase-folded version at the literature frequency (Torrealba et al. 2015) on the right. Associated with each observation is an estimated measurement uncertainty. |
2.3 Choice of kernel
The array of kernel functions available to researchers is rich, with each kernel bringing its own unique advantages to different data challenges (Epanechnikov 1969; Gasser et al. 1985; Izenman 1991). Despite this variety, our investigation specifically leverages the Gaussian kernel. This decision is informed by the kernel’s prevalent application across various fields and the observation that, for the problems at hand, it tends to provide results that are not significantly different from those obtained using other kernels. The Gaussian kernel is mathematically expressed as
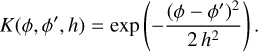 (3)
(3)
In this equation, ϕ and ϕ′ are points in the feature space, and h is the bandwidth, or relevant length scale, and can be optimised for specific applications.
One of the primary advantages of the Gaussian kernel is its smoothness. Being infinitely differentiable, it ensures that the estimated function is smooth. This is particularly beneficial for capturing underlying trends in astronomical data, which are often smooth in nature. The Gaussian kernel also has the property of localised influence, assigning significant weight only to points that are close to the target point in the feature space. Overall, the Gaussian kernel is a versatile tool for a wide range of applications.
2.4 Bandwidth selection
In kernel regression, the choice of bandwidth h is critical, as it directly impacts the estimator’s bias and variance. A well-chosen bandwidth balances the trade-off between the smoothness of the estimated function and the fidelity to the data points.
Scott’s rule (Scott 1979) and Silverman’s rule (Silverman 1986) are both prevalent methods for determining the bandwidth of a kernel density estimate. Scott’s rule is typically represented as
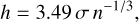 (4)
(4)
where n is the sample size and σ is the standard deviation of the observations. This bandwidth aims to minimise the mean integrated squared error (MISE) for data that approximates a normal distribution, yielding a smoother density estimate suitable for elucidating the data’s overall structure. Conversely, Silverman’s rule, which is often given by
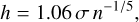 (5)
(5)
employs a slightly different formula tailored for Gaussian-like data but allowing for a tighter bandwidth, enhancing the detection of finer structural details within the data distribution.
Both rules presuppose a normal distribution and might not be optimal for datasets that are multi-modal or exhibit heavytailed distributions. Given the unique characteristics of our data, we adopted a custom bandwidth formula that better aligns with the non-Gaussian, periodic nature of such datasets:
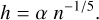 (6)
(6)
This formula is derived from the same principle of minimising the MISE, where the n−1/5 term balances the estimator’s bias and variance as the sample size n increases. The constant α replaces the standard deviation component from Silverman’s and Scott’s rules, allowing for adjustment based on the specific characteristics of the periodic data under study. This approach does not assume a Gaussian distribution, making it more adaptable to the heteroskedasticity and periodicity inherent in astronomical time-series data. Section 3.2 explains in more depth how we found an empiric optimal α for folded light curves.
Additionally, we built and tested a more accurate yet computationally expensive adaptive bandwidth strategy that assigns a different bandwidth to each data point, similar to the methodology proposed in Terrell & Scott (1992) and Orava (2012). The bandwidth is calculated as the average distance of each point to its k nearest neighbours, allowing the model to adapt to different levels of sparseness in the data.
We chose the number of neighbours, k, as a function of the sample size, n, specifically ln(n). This choice of k differs from the asymptotic value of k = n4/5 suggested in Orava (2012); however, it allows us to adapt more effectively to varying data densities, especially for small datasets. In datasets with thousands of observations, this choice would lead to overfitting; however, at those sample sizes, the use of an adaptive bandwidth is anyway impeded by the computational cost.
The algorithm used for effectively finding the nearest neighbours is the ball tree algorithm (Omohundro 2009); however, having to repeat this operation for each folding makes the adaptive bandwidth method more computationally expensive than the custom (fixed) bandwidth.
2.5 Role of weighted residuals in frequency determination
The sum of squared residuals (SSR) is a commonly used metric for assessing the goodness of fit. In the specific context of this work, it serves as a specialised objective to compare how the fit of the kernel regression behaves for data folded at different periods. The central premise is that a lower SSR indicates a more compact, smoother folded light curve, suggesting a more accurate fit to the inherent periodicity in the data. The SSR is defined as
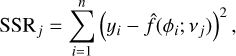 (7)
(7)
where, 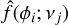 represents the estimated value at phase ϕi when the time-series data are folded at frequency vj, as obtained through a nonparametric regression model.
represents the estimated value at phase ϕi when the time-series data are folded at frequency vj, as obtained through a nonparametric regression model.
However, the standard SSR gives equal weight to all residuals, ignoring measurement uncertainties associated with the observations. To address this, we simply used a weighted sum of squared residuals, denoted as SSRw, that incorporates these uncertainties:
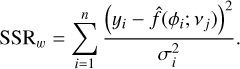 (8)
(8)
This weighted SSRw accounts for the heterogeneity in observational data quality, making the frequency selection more robust. Moreover, the number of estimated parameters, in our case, the bandwidth, is consistent across each dataset’s folding. This is crucial for mitigating the risk of overfitting, and it allows the use of SSR as a reliable metric for comparison across different foldings.
2.6 Uncertainty estimation in frequency determination via bootstrapping
To enhance the reliability of FINKER, we employed a bootstrap methodology (Efron 1979; Efron & Tibshirani 1986) that provides an estimate of the uncertainty of the predicted frequency.
This entails generating multiple datasets from the original by random sampling with replacement, after which FINKER is applied to a finely tuned grid centring on the initial frequency estimate. We use the standard deviation of the bootstrap results as an estimate of the prediction reliability.
In Sect. 3.3, we validate this approach on a set of simulations and show its reliability, comparing it to the known true errors in frequency.
It is crucial to acknowledge that the applicability of bootstrapping for uncertainty estimation in frequency determination rests on specific assumptions regarding the noise characteristics within the data. Particularly, this method assumes that the noise affecting the data is uncorrelated. Violations of this assumption may introduce bias into the bootstrap results, potentially compromising the accuracy of uncertainty estimates.
Furthermore, although a valid and informative method, its results are only meaningful if a frequency value has already been found with a certain degree of accuracy. Suppose the frequency value has been wrongly estimated. In that case, the measure of its uncertainty will remain small due to the search in a localised space around the found minimum, but the resulting value will be meaningless. We do not yet have a solution for this eventuality but will be subject to more in depth statistical research in the future.
2.7 FINKER’s steps for optimal frequency identification
The algorithm for optimisation is outlined as follows:
Generate a set of candidate frequencies v1, v2,…, vm.
For each candidate frequency, vj:
Identify the frequency vopt that minimises the SSRw.
Repeat B times:
- (a)
Sample with replacement from the original dataset.
- (b)
Apply nonparametric kernel regression to a small range around vopt.
- (c)
Identify the frequency vb that minimises the SSRw.
- (a)
Estimate the uncertainty of vopt, σv, as the standard deviation of all the vbs.
By automating this sequence of operations, FINKER provides a reliable estimation of the intrinsic periodic nature of the data, focusing on the frequency that yields the minimum SSRw.
3 Application to synthetic data and benchmarking
This section presents an empirical validation of FINKER and shows its performance on synthetic data mimicking various astronomical phenomena.
3.1 Synthetic data
The generation of synthetic light curves is a critical component of our simulation framework, allowing us to test the robustness and effectiveness of our frequency optimisation algorithm under controlled conditions. These simulations are characterised by several adjustable parameters, each designed to replicate diverse observational scenarios and attributes of astronomical entities.
First, we adjusted the number of data points to emulate both sparsely and densely sampled observations, mirroring the variability encountered in astronomical data acquisition. The total duration of these observations is also configurable and sets the temporal extent for the generated light curves.
Central to our simulations is the emulation of the light curve’s frequency components. We simulated the dominant periodic signal within the data through a primary frequency and its corresponding amplitude, which denotes the strength of this signal. Additionally, a secondary frequency and its amplitude are included to model objects exhibiting multiple periodic behaviours.
A baseline brightness level can be selected for the simulated astronomical object, representing its average brightness. Additionally, we incorporated a realistic level of photometric uncertainty through Gaussian white noise, informed by data obtained from the MeerLICHT telescope in Sutherland, South Africa (Bloemen et al. 2016). We built a function from real data that approximates the relation between the observations’ uncertainty and their magnitude. So, for a fixed baseline magnitude, varying the amplitude is equivalent to having a varying amplitude-to-noise ratio. Figure 2 shows, for a baseline magnitude of 17, three levels of amplitudes and their significant variability in amplitude-to-noise. At m = 17, we expect 0.007 mag, or <1% scatter due to intrinsic noise. Therefore, the top, middle, and lower panels of Fig. 2 correspond to the cases where the signal-to-noise ratio of the variation is 1.4, 7.1, and 14.3, respectively.
 |
Fig. 2 Simulated light curves at three S/N levels, based on the Meer-LICHT telescope data-derived σ-magnitude function. |
3.2 Optimisation of custom bandwidth parameter
As discussed in Sect. 2.4, in our application, the only parameter influencing the performance of the kernel regression model is the kernel bandwidth h. As such, we analysed the effect of varying this parameter to find an optimal value that (i) can be fixed for most types of light curves and (ii) would not require any parameters to be fine-tuned when using FINKER.
Our proposed bandwidth, h = α n−1/5, is modulated by the multiplicative constant α, which scales the base bandwidth, n−1/5. The scaling factor based on the sample size n allows us to account for different light curve sizes, and, since the phase space is always in the range [0,1], it also modulates the value of the bandwidth for different levels of δϕ, the average distance between observations in phase. This, of course, assumes that in phase space, on average, observations are equidistant. In astronomical time series, this is not always the case, and for these scenarios, we propose a solution later on in this section.
The other bandwidth component, α, determines the smoothness of the regression estimate for a light curve folded at a specific frequency- thereby affecting the trade-off between over-fitting and underfitting. Figure 3 demonstrates the relationship between the folding frequencies and the residual sum of squares for three α values. An α value of 0.1, around 10% of the phase range ([0,1]), typically achieves a good balance.
Since the sample size is fixed in real scenarios and the phase space is always in the range [0,1], we only need to find an α value that works in most situations. To do so, we built a set of simulations varying different signal-to-noise ratios (S/N) and sample sizes and searched for the alpha value that leads to the smallest estimated frequency error. We found that, on average, an α of 0.06 will allow for an accurate frequency identification and consequentially remove the burden of hand-picking this parameter. This α value will be employed for the subsequent analyses in this study.
Our custom bandwidth approach is an adequate solution for a wide range of scenarios. However, in situations characterised by a limited number of observations, significant sparsity, or data concentrated in specific regions of the phase space, an adaptive bandwidth strategy emerges as a more effective alternative, enhancing accuracy in these particular conditions. This adaptive method, while significantly more computationally intensive, dynamically adjusts the bandwidth in response to local data density- thereby offering a more tailored fit to the underlying structure of the data. In Sect. 4, we show how, for a select number of examples, an adaptive bandwidth allows the optimal frequency to be recovered with as few as ten observations.
 |
Fig. 3 Folding frequencies and squared residuals for kernel regression with different α values. The vertical dashed line indicates the true frequency of 1 day−1. All α values lead to frequency estimates that closely converge to the true value. |
 |
Fig. 4 Kernel density estimations of bootstrap-estimated frequencies for a single synthetic light curve across varying sample sizes and S/N levels. Each subplot represents the bootstrap frequency distribution of the estimated best frequency juxtaposed with the true frequency of the synthetic light curve. As expected, with larger sample sizes and S/N, FINKER is more accurate, and its bootstrap density better resembles a Gaussian. Consequentially, the estimated frequency uncertainty is more reliable. |
3.3 Bootstrap uncertainty reliability
After having identified the best frequency, FINKER performs a bootstrap resampling of the original light curve and repeats the search process in a small grid around the best frequency. Repeating this process multiple times gives an estimate of the variability of the estimated frequency that can be used as an uncertainty estimate.
In this section, we illustrate the application of FINKER’s bootstrap-based uncertainty estimation method to a synthetic light curve. We demonstrate the method’s potential in providing an uncertainty estimate around the determined frequency and visually assess the nature of these uncertainties in relation to various sample sizes and S/N.
Figure 4 presents a series of kernel density estimations of the frequencies obtained through the bootstrap method for different combinations of sample size and S/N for a synthetic light curve. The alignment of the best frequency with the bootstrap distribution’s mean suggests an unbiased nature of the estimation process. Notably, the bootstrap distribution deviates from the expected Gaussian shape at a S/N = 7.1 with a sample size of 50, indicating that low-S/N signals or a small sample size may pose challenges to the reliability of the bootstrap method.
The standard deviation of the bootstrap frequencies, serving as the uncertainty measure, appears to offer a conservative estimate. This conservatism ensures that the estimated uncertainty is not understated, yet it also hints at the opportunity to refine the method to more accurately capture the true variation. Future iterations of FINKER will focus on improving the uncertainty estimation to ensure a more precise reflection of the underlying variability, particularly in challenging observational scenarios characterised by low S/N and limited sample sizes.
3.4 Optimal frequency identification
To validate the accuracy of FINKER, we conducted experiments using synthetic light curves with known true frequencies. Our kernel regression method is benchmarked against the commonly used conditional entropy (Graham et al. 2013a), which we employed for a comparative analysis.
In short, conditional entropy gauges the variability of one variable, say the light curve’s flux, given that we have knowledge of another, such as the phase. For a specific folding frequency, a low conditional entropy implies a reduced level of sparseness in the flux for a given phase, consequentially hinting that the frequency value chosen is correct.
In the computation of conditional entropy, a binning process via partition schemes is employed. This involves organising the data into distinct bins or partitions, which aids in the accurate estimation of the probability distributions involved in the formula. Particularly, a simple rectangular partitioning scheme, with i = 1,…, N bins in flux space and j = 1,…, M bins in phase space is commonly adopted for computational efficiency during the analysis. The conditional entropy H(m| ϕ) is defined as
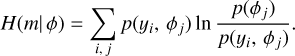 (9)
(9)
Here, p(yi, ϕj) denotes the estimated probability of a data point occupying the ith flux bin and the jth phase bin simultaneously, while p(ϕj) signifies the estimated probability of a data point falling within the jth phase bin, irrespective of its flux. In the context of analysing light curves, conditional entropy is used to infer the frequency value that minimises this entropy. Algorithmically, frequency identification using conditional entropy follows an approach similar to what is laid out in Sect. 2.7, but with a different objective function. We fixed the binning size for all subsequent analyses to N = 10 and M = 10.
Figures 5 and 6 illustrate the results of the conditional entropy and FINKER, respectively, for the search of the optimal frequency on a sinusoidal light curve. The left figure shows the range of frequencies tested and the objective function values for each method, the SSR for ours and conditional entropy for the benchmark method. The two objective values are not directly comparable, but for visual clarity, we rescaled both metrics in a [0,1] range for all subsequent plots. The right figure shows the light curve folded at the estimated best frequency and, for FINKER, the associated kernel regression fit.
As shown in Fig. 6, FINKER yields an accurate frequency prediction and has a smooth behaviour in its estimator. The noisy results of the conditional entropy are instead likely attributable to the binning process needed for the calculation of its metric.
Furthermore, our methodology inherently mitigates the common pitfall of mistaking harmonic frequencies for the fundamental frequency – a frequent issue with both other nonparametric approaches and standard parametric approaches. Specifically, when a frequency is an integer multiple of the true frequency, the light curve maintains a semblance of order and, consequentially, a relatively low entropy. Kernel regression, however, evaluates the goodness-of-fit for a frequency by analysing the residuals post-smoothing. Harmonic frequencies, which introduce regular oscillations, are neutralised by the smoothing process, leading to high residuals similar to those from an incorrect frequency. This unique attribute of kernel regression allows it to identify the true frequency more accurately. This behaviour is demonstrated in Fig. 7.
Despite its robustness against harmonic frequencies, kernel regression seems more sensitive to sub-harmonic frequencies with respect to the conditional entropy method. However, these are usually not misidentified since additional periodicity in the folded light curve will have an overly smoothed estimator and, consequentially, a higher residual. Furthermore, to counter this behaviour, our implementation includes a verification step to examine whether twice the identified optimal frequency yields a significant result. If the doubled frequency also presents a low residual sum of squares, it suggests that the true fundamental frequency may indeed be twice the initially identified one. This additional check enhances the method’s accuracy and is a standard option in our code.
Overall, this additional property of kernel regression not only enhances its reliability in frequency estimation but also reduces the likelihood of the need for manual inspection or secondary validation methods to confirm the fundamental frequency. This robustness is particularly valuable in automated analysis pipelines where large volumes of data preclude detailed individual review.
 |
Fig. 5 Conditional entropy’s results across a range of frequencies for a sinusoidal light curve with 100 observations, a baseline magnitude of 17, and an amplitude of 0.1 (S/N = 14.3). The plot on the left shows the frequency range searched, and the inset at the minimum entropy shows the noisy behaviour of the estimator. The estimated best frequency and its uncertainty are shown with a black error bar. The plot on the right shows the light curve folded at the found frequency. |
 |
Fig. 6 FINKER’s results across a range of frequencies for a sinusoidal light curve with 100 observations, a baseline magnitude of 17, and an amplitude of 0.1 (S/N = 14.3). The plot on the left shows the frequency range searched, and the inset illustrates the smooth behaviour of the residuals around the minimum. The estimated best frequency and its uncertainty are shown with a black error bar. The plot on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid, illustrating the algorithm’s capability to model the periodic signal accurately. |
 |
Fig. 7 Kernel regression’s fits (red lines) for harmonics and sub-harmonics of the true frequency. The light curve is folded at four different frequencies: half the true frequency (top left), the true frequency (top right), twice the true frequency (bottom left), and a random frequency (bottom right). Conveniently, for multiples of the true frequency, kernel regression will badly fit the observations resulting in high residuals. |
3.5 Sensitivity analysis with small sample sizes
To rigorously assess the robustness and performance of our frequency optimisation algorithm, a sensitivity analysis is conducted. This analysis focuses on two key parameters: the number of data points (npoints) and the amplitude of the primary frequency of variability. These parameters are systematically varied over a predefined range to simulate different observational conditions. For each combination of npoints and amplitude, the algorithm is executed using two different methods: kernel regression with custom bandwidth and conditional entropy. All simulations are calculated using the same baseline magnitude (17), such that changing the amplitude of the variability will result in different signal-to-noise levels.
The results are visualised for our kernel regression periodogram and the conditional entropy periodogram in Figs. 8 and 9, respectively. For both figures, the x-axis represents the amplitude levels, and the y-axis represents the number of observations simulated. The colour intensity on each heat map indicates the absolute error between the estimated and true frequency (of 1 day−1), |ftrue – fpred|.
The heat maps reveal a distinct contrast in performance between the methods. For a sinusoidal light curve, our kernel regression method demonstrates remarkable accuracy, with a clear trend of improvement as sample size and amplitude increase. In contrast, the conditional entropy method exhibits a dependence on larger datasets to attain comparable levels of accuracy, requiring at least twofold the number of observations to match the accuracy of our kernel regression technique. This robustness is critical for practical applications with scarce and sparse observational data.
4 Application to real data
The efficacy of our frequency optimisation algorithm is further substantiated through its application to a diverse array of real astronomical datasets. These datasets encompass light curves from variable stars, radial velocity measurements, and photometric data of transiting exoplanets. The sources of these datasets are diverse, originating from various telescopes and surveys, including the MeerLICHT (Bloemen et al. 2016) and Zwicky Transient Factory (ZTF; Bellm et al. 2019) photometric missions and the HERMES spectrograph (Raskin et al. 2011).
 |
Fig. 8 Heat map of the conditional entropy sensitivity analysis, illustrating the absolute error in frequency estimation relative to sample size (y-axis) and amplitude (x-axis). Lighter shades correspond to lower absolute errors, with cells marked by a red cross representing an average absolute error above 0.03, deemed as unreliable estimates. This analysis indicates that at least 20 observations are necessary for reliable frequency estimation at most amplitude levels, excluding the lowest one. |
 |
Fig. 9 Heat map of the kernel regression sensitivity analysis, depicting the absolute error in frequency estimation as a function of sample size (y-axis) and amplitude (x-axis). Lighter shades correspond to lower absolute errors, with cells marked by a red cross representing an average absolute error above 0.03, deemed as unreliable estimates. The heat map suggests that approximately ten observations are sufficient for a reliable frequency estimate across various amplitude levels, with the only exception being the lowest amplitude level. |
4.1 Photometric time series
MeerLICHT is a fully robotic telescope located in Sutherland Observatory in South Africa and is equipped with five Sloan u𝑔riɀ photometric filters with an additional custom q filter that is a combination of the ɀ and r filters (Bloemen et al. 2016). MeerLICHT nominally integrates for 60 s and has several observing strategies aimed at identifying and characterising transients in multiple wavelengths. The combination of these observing strategies has resulted in a large database of heterogeneously sampled, (sometimes) contemporaneous multi-colour photometric time series of millions of objects compiled over the mission 5-yr runtime. As the MeerLICHT light curves are highly irregularly sampled, they are ideal candidates for testing the performance of our algorithm.
Prior to analysis, the MeerLICHT data were subjected to a standard pre-processing pipeline. This includes the removal of outliers, correction for atmospheric extinction, and normalisation to account for instrumental variations (we refer the readers to de Wet et al. 2021 and Ranaivomanana et al. 2023 for a complete description of the data reduction process).
In addition to MeerLICHT data, we also made use of ZTF data in the case of compact transiting binaries. ZTF is a robotic telescope equipped with three photometric filters that surveys the night sky for transients and periodic variable stars with 30 second exposures in each filter (Bellm et al. 2019). While the majority of the data was obtained in the 𝑔 and r filters, we only considered data in the 𝑔 filter for this work. Due to its observing strategy, these data are irregularly sampled, but are less sparsely sampled than the MeerLICHT data. Additionally, ZTF has occasional deep drilling campaigns that cover select fields with a high cadence over a short period of time. Thus, the ZTF data have a highly irregular sampling that spans several years.
Table 1 lists a set of known light curves and their literature frequencies. We also show frequencies and uncertainties determined by the conditional entropy and nonparametric kernel regression periodograms. To ensure a fair comparison of the two methods, when a frequency is identified for both methods, half and double of that frequency are further investigated, and the final frequency is the one that minimises the respective metrics. Below is some more information on the type of light curves shown.
Classical pulsators: Classical pulsators are large amplitude, radially pulsating stars that exist in the classical instability strip, including δ Scuti variables, RR Lyrae variables, and Cepheid variables (Aerts et al. 2010; Kurtz 2022). We tested our algorithm on two classical pulsators from the MeerLICHT data and benchmarked it against the conditional entropy periodogram. In both cases, FINKER finds a similar optimal frequency as the conditional entropy periodogram, with a smaller estimated uncertainty. Crucially, these frequencies are in close agreement with values reported in the literature, which are often derived from datasets with higher resolution or more favourable observation conditions than those available from MeerLICHT. We plot the kernel regression periodogram for one classical pulsator target (CRTS J033427.7–271223) in Fig. 10.
Eclipsing binaries: The majority of stars exist in binaries or higher order multiples (Moe & Di Stefano 2017; Offner et al. 2023). If the orbital plane is inclined favourably with respect to us, we can see the stars eclipse one another as they move through their orbit. This produces periodic decreases in light that can range from less than 1% to blocking nearly all of the light from one star. As most stars are in binaries, eclipsing binaries are commonly found in photometric time series. Here, we look at two eclipsing binaries to demonstrate our method’s ability to reliably identify binaries with more complicated phase behaviour than classical pulsators and sinusoidal variables. Figure 11 illustrates the kernel regression periodograms for the eclipsing binary MLT J033147.60–281307.9.
Short period transiting compact binaries: Ultra short period binaries that contain at least one compact component (e.g. a white dwarf) are important contributors to gravitational wave events and exotic transient phenomena. In particular, we considered binaries where a white dwarf and M-dwarf star orbit each other with a very short period (often <1 day). Due to the relative brightness of the components, nearly all of the light in the system originates from the white dwarf. Because of the relative sizes of these objects and their light contributions, they exhibit transits in which a large amount of light of the white dwarf is blocked when the M-dwarf passes in front of the white dwarf. Additionally, due to their short orbital periods, these systems often spend very little time in transit, with transit times being of order minutes. Thus, these systems often have very few data points in transit, making them difficult to detect and their periods difficult to quantify, Here, we demonstrate that our nonparametric method, which inherently makes no assumption on the underlying morphology of variability, is able to robustly determine the frequency of variability of transit like signals in addition to eclipses and more sinusoidal-like variability. In Table 1, we include three white dwarf plus M-dwarf binaries with published periods that were observed by ZTF (Brown et al. 2023). The FINKER results for ZTF J041016.82–083419.5 are shown in Fig. 12. We notice that while the shape of the regression does not completely match the transit, the methodology is robust identifying the correct period. We further note that a smaller bandwidth may be more appropriate when hunting for periodic phenomena that have extremely short durations in phase space.
Comparison of optimal frequencies.
 |
Fig. 10 FINKER’s frequency search for CRTS J033427.7–271223. The panel on the left shows the frequency range searched, and the inset illustrates the smooth behaviour of the residuals around the minimum. The estimated best frequency and its uncertainty are shown with a black error bar. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid, illustrating the algorithm’s capability to model the periodic signal accurately. |
 |
Fig. 11 FINKER’s frequency search for MLT J033147.60–281307.9. The panel on the left shows the frequency range searched, and the inset illustrates the smooth behaviour of the residuals around the minimum. The estimated best frequency and its uncertainty are shown with a black error bar. FINKER’s framework allowed for a search of both the harmonic and sub-harmonic of the best frequency and correctly identified that there is a difference in the eclipses. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid, illustrating the algorithm’s capability to model the eclipsing signal accurately. |
4.2 Radial velocity time series
In addition to photometric time series, binary stars and exoplanet systems experience periodic radial velocity shifts due to orbital motion. Except for dedicated cases, radial velocity time series are often sparsely sampled due to various scheduling and weather condition requirements. In addition to variability arising from orbital motion, several other phenomena can result in actual or apparent Doppler shifts at the stellar surface, including stellar pulsations (Aerts et al. 2010), rotation, and winds. As a result, there are often multiple sources of variability with different amplitudes in radial velocity measurements. In this work, we considered radial velocity time series for a series of known spectroscopic binaries that were obtained via spectro-scopic observations with the HERMES Echelle spectrograph on the Mercator Telescope in La Palma, Spain (Raskin et al. 2011). These data were obtained with various observing strategies and are spaced out over several months in some cases and several years in others.
We find that this method is extremely powerful for searching sparsely sampled radial velocity time series for periodicities. In the cases listed in Table 1, the regression periodogram unambiguously identifies the orbital frequency despite the different cases having various amounts of data and signal to noise ratios for different measurements. Furthermore, as our method does not make assumptions on the morphology of the signal, it can identify periodic signals originating from both circular and eccentric orbits. Finally, while we did not attempt it here, this methodology is directly applicable to searches for periodic signals arising from exoplanets as well.
Figures 13 and 14 illustrate the kernel regression periodograms for HD 114520 and V772 Cas. For the latter, FINKER finds a frequency close to the literature value with only 10 observations; however, due to the low number of observations, the uncertainty estimate is unreliable.
To provide a comprehensive evaluation of our method, we have included in Appendix D a detailed comparison with the Lomb–Scargle periodogram for all the objects analysed in Sect. 4.
 |
Fig. 12 FINKER’s frequency search for ZTF J041016.82–083419.5. The panel on the left shows the frequency range searched, and the inset illustrates the behaviour of the residuals around the minimum. Transit data shows a less smooth behaviour of the residuals around the minimum, but the frequency and its uncertainty, shown as a black error bar, are consistent with the literature value. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid. |
5 Conclusion and future outlooks
We present FINKER, a nonparametric periodogram for determining the frequencies of variability in astronomical time series, specifically sparsely sampled light curves and radial velocity measurements. At its core, this method performs kernel regression on a time series that has been folded over a proposed frequency and calculates the SSR of the data points with respect to the regression fit. A smaller SSR means a more coherent structure and, therefore, corresponds to the likely period of variability. This method’s main strength is its adaptability to localised data structures and inherent robustness to noise. These features enable the method to capture complex, non-sinusoidal periodic trends arising from numerous different physical mechanisms that faster parametric methods may miss.
We evaluated and benchmarked our method by applying it to synthetic datasets, demonstrating a more accurate frequency estimation than the widely used conditional entropy. Moreover, the robustness of kernel regression against the misidentification of harmonic frequencies is highlighted in Sect. 3.4. The empirical analysis of real-world datasets from the MeerLICHT telescope and other sources further validates the algorithm’s efficacy, showcasing its potential as a reliable tool for period determination in the field of astronomy.
Despite its strengths, the method is not without limitations. It is computationally more demanding than some traditional methods, which may restrict its use in processing extremely large datasets or in applications requiring real-time analysis. Additionally, while the method’s susceptibility to half-frequency errors is mitigated by a simple check for significant doubled frequencies, this step requires additional computation and may not be foolproof in all cases. Specifically, this is the case for eclipsing binaries with similar eclipse depths. Future work will investigate whether a hybrid parametric–nonparametric method such as that proposed by Saha & Vivas (2017) can mitigate this. Furthermore, there are clear failure cases. These cases are limited to the situation where we do not achieve a quasi-uniform distribution of observations in the phase space for a given proposed frequency in the search. When this occurs, the regression can find several suitably similar configurations when comparing SSR values.
Looking ahead, there are several promising directions for future research. First, we can investigate methods for increasing the computational efficiency of this method, for example a two-step approach using a faster method to first calculate a coarse frequency grid before using our kernel regression method to more finely sample the promising regions. Second, our method employs local constant regression, but we also tested local linear regression and find some improvement in complex features in phase space; however, as of now, this improvement does not outweigh the additional computational cost. We briefly discuss the use of a grid in phase space to speed up computations in Appendix B.
Future work could also concentrate on the use of measurement uncertainties directly in the kernel regression estimation. This is a complex problem that has still not been completely resolved in the statistics community. The use of errors-invariable estimators and kernel deconvolution regression will be the first methods to explore in this regard (Delaigle et al. 2006; Delaigle 2014; Marzio et al. 2023). Furthermore, as the majority of stars exhibit more than a single periodic signal in photometry, expanding the algorithm’s capabilities to automatically handle multi-periodic signals without manual intervention would be a valuable enhancement.
Finally, given the impending increase in data volume from upcoming multi-colour photometric missions such as Black-GEM (Groot et al. 2019, 2022) and the Vera Rubin Observatory (Ivezić et al. 2019), we will need new methods that are (i) flexible, (ii) do not make assumptions on the underlying signals, and (iii) can efficiently search for periodicities in highly sparsely sampled data. FINKER promises to be an excellent method for use with such data.
 |
Fig. 13 FINKER’s frequency search for HD 114520. The panel on the left shows the frequency range searched, and the inset illustrates the smooth behaviour of the residuals around the minimum. The estimated best frequency and its uncertainty are shown with a black error bar. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid, illustrating the algorithm’s capability to model the periodic signal accurately. |
 |
Fig. 14 FINKER’s frequency search for V772 Cas with an adaptive bandwidth. The panel on the left shows the frequency range searched and the wild behaviour of the residuals due to the low number of points. The inset shows that the best frequency agrees with the literature values; however, the estimated uncertainty is unreliable due to the really low number of observations. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid. |
Acknowledgements
C.J. gratefully acknowledges support from the Netherlands Research School of Astronomy (NOVA) and from the Research Foundation Flanders (FWO) under grant agreement G0A2917N (BlackGEM). P.J.G. is partly supported by SARChI Grant 111692 from the South African National Research Foundation.
Appendix A Asymptotic properties
The asymptotic properties of the nonparametric kernel regression models are critical for understanding the large-sample behaviour. These have been thoroughly studied in Fan 1993 and Fan & Gijbels 1994. We summarise the key parameters: bias, variance, and mean squared error (MSE) to assess the asymptotic optimality of our methodology.
Bias For our local constant regression model, the bias is of O(h2), where h is the bandwidth. In practice, the bias can be significantly reduced by choosing an optimal bandwidth through cross-validation methods:
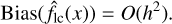 (A.1)
(A.1)
Variance The variance of the estimator can be described as 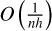 for both local constant and local linear models:
for both local constant and local linear models:
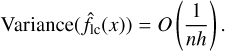 (A.2)
(A.2)
Mean squared error The MSE is a function of both bias and variance and is given by
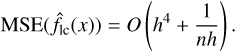 (A.3)
(A.3)
The optima bandwidth minimises this MSE, and cross-validation techniques are commonly employed to find this balance between bias and variance.
Asymptotic normality As shown in Martins-Filho & Saraiva 2012, under mild regularity conditions, the local constant regression is asymptotically normal. These asymptotic properties confirm that our nonparametric kernel regression models are statistically sound and efficient for large datasets.
Appendix B Computational efficiency of grid-based kernel regression
Nonparametric kernel regression can be computationally intensive with large datasets. To improve efficiency, we tested a grid-based method. This approach evaluates the regression function at predetermined grid points rather than at every data point. We first created a grid over the data’s range and computed the regression at these points. Then, we interpolated these values to estimate the regression function for the entire dataset.
We evaluated the computation times of kernel regression across various grid sizes using multiple synthetic light curves, both with and without the implementation of the grid method. The results showed that using a grid significantly reduces computation time, especially for large datasets. However, choosing the right grid size is important to ensure accuracy. We analysed how the grid size affects the variability of residuals and found that a grid with about 300 points is sufficient for stable and consistent squared residuals, regardless of sample size, as shown in Figure B.1.
Figure B.2 presents the average computation times without grid and with grids of different sizes. For smaller sample sizes, direct evaluation on the observations is quicker. But for larger samples, using a grid speeds up the process without affecting the regression’s accuracy.
All tests were run on an Alienware Area 51M, Intel Core i9-9900K- 32GB DDR4/2400, Nvidia GeForce RTX 2080.
 |
Fig. B.1 Stability of squared residuals across various grid sizes, indicating a plateau at a grid size of approximately 300 points. |
 |
Fig. B.2 Execution times comparing direct evaluation of the kernel regression on the points and on grids of different sizes, showing efficiency gains with grid sizes beyond 300 points. |
Appendix C Controversial cases
In this appendix- we delve into specific instances where FINKER encountered challenges or yielded results that diverged from established literature.
Case study: KIC 5217733 For KIC 5217733, FINKER’s frequency identification process did not align with the frequencies reported in literature (Kirk et al. 2016). As shown in Figure C.1, the algorithm’s search spanned the expected frequency range but failed to accurately recover the known frequency. This discrepancy is possibly attributed to the underestimation of uncertainties and the presence of numerous g-mode pulsations, which introduced additional variations in the line profile.
Case study: MLT J162036.64–614110.5 Another intriguing case is MLT J162036.64–614110.5, where FINKER’s results diverged from established literature findings. As depicted in Figure C.2, the algorithm executed a comprehensive search, including analyses of both the main frequency it found and its sub-harmonic. Interestingly, FINKER did not observe any significant difference in the eclipses, in contrast to literature reports. The light curve, when folded at the frequency identified by FINKER, and overlaid with our kernel regression fit, suggests a different interpretation of the data compared to traditional analyses. This case underscores the potential for FINKER’s framework to provide alternative insights into celestial phenomena, although it also highlights the need for cautious interpretation, especially in instances where results significantly deviate from established knowledge.
 |
Fig. C.1 FINKER’s frequency search for KIC 5217733 (Kirk et al. 2016). The panel on the left shows the frequency range searched, and the inset illustrates the failed recovery of the literature frequency. The panel on the right shows the light curve folded at the literature frequency (0.006201d−1) with the kernel regression fit (green line) overlaid. |
 |
Fig. C.2 FINKER’s frequency search for MLT J162036.64–614110.5. The panel on the left shows the frequency range searched and the thorough evaluation around the best frequency and its sub-harmonic. In disagreement with the results in the literature, FINKER did not find a significant difference in the eclipses. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid. |
Appendix D Comparison between FINKER and Lomb-Scargle periodogram
This appendix presents a comparative analysis of the frequency identification results obtained using the nonparametric kernel regression method implemented in FINKER and those derived from the Lomb-Scargle periodogram.
The datasets used for this comparison are those discussed in Section 4. For the Lomb-Scargle analysis, we used the implementation provided by the Astropy package in Python.
Specifically, we conducted the Lomb-Scargle periodogram analysis over the same frequency range used for FINKER. However, taking advantage of the Lomb-Scargle periodogram’s relatively low computational demands, we employed a denser frequency grid of 5 million points to ensure a thorough and detailed frequency search. The frequency identification process for FINKER was conducted as detailed in Section 3.
Table D.1 summarises the outcomes of this comparison, presenting the absolute differences between the frequencies identified by both methods and the established literature frequencies. Overall, FINKER’s nonparametric kernel regression shows lower absolute errors with respect to the literature values than the Lomb-Scargle periodogram. Notably, FINKER shows superior accuracy in identifying the correct frequencies for classical pulsators and eclipsing binaries. Conversely, for compact binaries and certain radial velocity targets, both methods yielded comparable results, with exceptions noted for ZTF J140702.57+211559.7 and HD 114520. In these cases, the Lomb-Scargle periodogram identified an incorrect frequency or double the correct frequency. However, for V772 Cas with only ten observations, the Lomb-Scargle periodogram identified a frequency closer to the literature value than FINKER, illustrating scenarios where parametric methods can outperform nonparametric if the underlying signal closely matches the assumed model.
Differences in optimal frequencies.
The comparison between FINKER and the Lomb-Scargle periodogram highlights the strengths and limitations of both methods. FINKER offers advantages in handling complex and noisy data, while the Lomb-Scargle periodogram remains a valuable tool for quick periodicity searches, especially when computational resources are limited. Future work could explore hybrid approaches that combine the robustness of nonparametric methods with the efficiency of parametric periodograms to enhance the accuracy and speed of frequency identification in astronomy.
References
- Aerts, C., Christensen-Dalsgaard, J., & Kurtz, D. W. 2010, Asteroseismology (Dordrecht: Springer) [Google Scholar]
- Barragán, O., Aigrain, S., Rajpaul, V. M., & Zicher, N. 2021, MNRAS, 509, 866 [CrossRef] [Google Scholar]
- Barros, S. C. C., Demangeon, O., Díaz, R. F., et al. 2020, A&A, 634, A75 [EDP Sciences] [Google Scholar]
- Bellm, E. C., Kulkarni, S. R., Graham, M. J., et al. 2019, PASP, 131, 018002 [Google Scholar]
- Bloemen, S., Groot, P., Woudt, P., et al. 2016, SPIE Conf. Ser., 9906, 990664 [NASA ADS] [Google Scholar]
- Brown, A. J., Parsons, S. G., van Roestel, J., et al. 2023, MNRAS, 521, 1880 [NASA ADS] [CrossRef] [Google Scholar]
- Clarke, D. 2002, A&A, 386, 763 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Wet, S., Groot, P. J., Bloemen, S., et al. 2021, A&A, 649, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Deeming, T. J. 1975, Ap&SS, 36, 137 [Google Scholar]
- Delaigle, A. 2014, Aust. N. Z. J. Stat., 56 [Google Scholar]
- Delaigle, A., Hall, P., & Qiu, P. 2006, J. Roy. Stat. Soc. Ser. B (Stat. Methodol.), 68 [Google Scholar]
- Dworetsky, M. M. 1983, MNRAS, 203, 917 [NASA ADS] [Google Scholar]
- Efron, B. 1979, Ann. Stat., 7, 1 [Google Scholar]
- Efron, B., & Tibshirani, R. 1986, Stat. Sci., 1, 54 [Google Scholar]
- Epanechnikov, V. A. 1969, Theory Probab. Appl., 14, 153 [Google Scholar]
- Escorza, A., Karinkuzhi, D., Jorissen, A., et al. 2019, A&A, 626, A128 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fan, J. 1993, Ann. Stat., 21, 196 [Google Scholar]
- Fan, J., & Gijbels, I. 1994, in Local Polynomial Modelling and its Applications [CrossRef] [Google Scholar]
- Gasser, T., Muller, H.-G., & Mammitzsch, V. 1985, J. Roy. Stat. Soc. Ser. B (Methodol.), 47, 238 [CrossRef] [Google Scholar]
- Genton, M. G., & Hall, P. 2007, J. Roy. Stat. Soc. Ser. B (Methodol.), 69, 643 [CrossRef] [Google Scholar]
- Graham, M. J., Drake, A. J., Djorgovski, S. G., Mahabal, A. A., & Donalek, C. 2013a, MNRAS, 434, 2629 [NASA ADS] [CrossRef] [Google Scholar]
- Graham, M. J., Drake, A. J., Djorgovski, S. G., et al. 2013b, MNRAS, 434, 3423 [NASA ADS] [CrossRef] [Google Scholar]
- Groot, P., Bloemen, S., & Jonker, P. 2019, in The La Silla Observatory - From the Inauguration to the Future, 33 [Google Scholar]
- Groot, P. J., Bloemen, S., Vreeswijk, P. M., et al. 2022, SPIE Conf. Ser., 12182, 121821V [NASA ADS] [Google Scholar]
- Hall, P., & Li, M. 2006, Biometrika, 93, 411 [CrossRef] [Google Scholar]
- Hall, P., Reimann, J. D., & Rice, J. P. 2000, Biometrika, 87, 545 [CrossRef] [Google Scholar]
- Huijse, P., Estévez, P. A., Förster, F., et al. 2018, ApJS, 236, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Izenman, A. J. 1991, J. Am. Stat. Assoc., 86, 205 [Google Scholar]
- Johnston, C., Aimar, N., Abdul-Masih, M., et al. 2021, MNRAS, 503, 1124 [NASA ADS] [CrossRef] [Google Scholar]
- Kirk, B., Conroy, K., Prša, A., et al. 2016, AJ, 151, 68 [Google Scholar]
- Kochukhov, O., Johnston, C., Labadie-Bartz, J., et al. 2021, MNRAS, 500, 2577 [Google Scholar]
- Kurtz, D. W. 2022, ARA&A, 60, 31 [NASA ADS] [CrossRef] [Google Scholar]
- Lomb, N. R. 1976, Ap&SS, 39, 447 [Google Scholar]
- Martins-Filho, C., & Saraiva, P. 2012, Commun. Stat. Theory Methods, 41, 1052 [CrossRef] [Google Scholar]
- Marzio, M. D., Fensore, S., & Taylor, C. C. 2023, Stat. Methods Appl., 32, 1217 [CrossRef] [Google Scholar]
- Matesic, M. R. B., Rowe, J. F., Livingston, J. H., et al. 2024, AJ, 167, 68 [NASA ADS] [CrossRef] [Google Scholar]
- McDonald, J. L. 1986, SIAM J. Sci. Stat. Comput., 7 [Google Scholar]
- Moe, M., & Di Stefano, R. 2017, ApJS, 230, 15 [Google Scholar]
- Nadaraya, E. A. 1964, Theory Probab. Applic., 9, 141 [CrossRef] [Google Scholar]
- Nicholson, B. A., & Aigrain, S. 2022, MNRAS, 515, 5251 [NASA ADS] [CrossRef] [Google Scholar]
- Offner, S. S. R., Moe, M., Kratter, K. M., et al. 2023, in Protostars and Planets VII, eds. S. Inutsuka, Y. Aikawa, T. Muto, K. Tomida, & M. Tamura, Astronomical Society of the Pacific Conference Series, 534, 275 [NASA ADS] [Google Scholar]
- Omohundro, S. M. 2009, in Five Balltree Construction Algorithms [Google Scholar]
- Orava, J. 2012, Tatra Mountains Math. Publ., 50, 39 [Google Scholar]
- Ranaivomanana, P., Johnston, C., Groot, P. J., et al. 2023, A&A, 672, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Raskin, G., van Winckel, H., Hensberge, H., et al. 2011, A&A, 526, A69 [CrossRef] [EDP Sciences] [Google Scholar]
- Reimann, J. D. 1994, PhD thesis, University of California, Berkeley, USA [Google Scholar]
- Saha, A., & Vivas, A. K. 2017, AJ, 154, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Scargle, J. D. 1982, ApJ, 263, 835 [Google Scholar]
- Schwarzenberg-Czerny, A. 1989, MNRAS, 241, 153 [Google Scholar]
- Schwarzenberg-Czerny, A. 1996, ApJ, 460, L107 [NASA ADS] [Google Scholar]
- Schwarzenberg-Czerny, A. 1999, ApJ, 516, 315 [NASA ADS] [CrossRef] [Google Scholar]
- Scott, D. W. 1979, Biometrika, 66, 605 [CrossRef] [Google Scholar]
- Silverman, B. W. 1986, Density Estimation for Statistics and Data Analysis (London, Chapman & Hall) [Google Scholar]
- Stellingwerf, R. F. 1978, ApJ, 224, 953 [Google Scholar]
- Stoppa, F. 2024, FINKER: v1.0.0 [Google Scholar]
- Terrell, G. R., & Scott, D. W. 1992, Ann. Stat., 20, 1236 [CrossRef] [Google Scholar]
- Torrealba, G., Catelan, M., Drake, A. J., et al. 2015, MNRAS, 446, 2251 [NASA ADS] [CrossRef] [Google Scholar]
- Toulis, P., & Bean, J. 2021, arXiv e-prints [arXiv:2105.14222] [Google Scholar]
- VanderPlas, J. T. 2018, ApJS, 236, 16 [Google Scholar]
- Watson, G. S. 1964, Sankhya, 26, 359 [Google Scholar]
- Zechmeister, M., & Kürster, M. 2009, A&A, 496, 577 [CrossRef] [EDP Sciences] [Google Scholar]
We note that the reference epoch refers to different moments for different types of data. For example, with eclipsing binaries and transiting systems t0 is set to coincide with the time of superior conjunction, whereas in spectroscopic binaries t0 refers to the time of periastron passage.
All Tables
All Figures
|
Fig. 1 MeerLICHT (Bloemen et al. 2016) telescope’s light curve of CRTS J033427.7–271223 on the left and phase-folded version at the literature frequency (Torrealba et al. 2015) on the right. Associated with each observation is an estimated measurement uncertainty. |
| In the text | |
|
Fig. 2 Simulated light curves at three S/N levels, based on the Meer-LICHT telescope data-derived σ-magnitude function. |
| In the text | |
|
Fig. 3 Folding frequencies and squared residuals for kernel regression with different α values. The vertical dashed line indicates the true frequency of 1 day−1. All α values lead to frequency estimates that closely converge to the true value. |
| In the text | |
|
Fig. 4 Kernel density estimations of bootstrap-estimated frequencies for a single synthetic light curve across varying sample sizes and S/N levels. Each subplot represents the bootstrap frequency distribution of the estimated best frequency juxtaposed with the true frequency of the synthetic light curve. As expected, with larger sample sizes and S/N, FINKER is more accurate, and its bootstrap density better resembles a Gaussian. Consequentially, the estimated frequency uncertainty is more reliable. |
| In the text | |
|
Fig. 5 Conditional entropy’s results across a range of frequencies for a sinusoidal light curve with 100 observations, a baseline magnitude of 17, and an amplitude of 0.1 (S/N = 14.3). The plot on the left shows the frequency range searched, and the inset at the minimum entropy shows the noisy behaviour of the estimator. The estimated best frequency and its uncertainty are shown with a black error bar. The plot on the right shows the light curve folded at the found frequency. |
| In the text | |
|
Fig. 6 FINKER’s results across a range of frequencies for a sinusoidal light curve with 100 observations, a baseline magnitude of 17, and an amplitude of 0.1 (S/N = 14.3). The plot on the left shows the frequency range searched, and the inset illustrates the smooth behaviour of the residuals around the minimum. The estimated best frequency and its uncertainty are shown with a black error bar. The plot on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid, illustrating the algorithm’s capability to model the periodic signal accurately. |
| In the text | |
|
Fig. 7 Kernel regression’s fits (red lines) for harmonics and sub-harmonics of the true frequency. The light curve is folded at four different frequencies: half the true frequency (top left), the true frequency (top right), twice the true frequency (bottom left), and a random frequency (bottom right). Conveniently, for multiples of the true frequency, kernel regression will badly fit the observations resulting in high residuals. |
| In the text | |
|
Fig. 8 Heat map of the conditional entropy sensitivity analysis, illustrating the absolute error in frequency estimation relative to sample size (y-axis) and amplitude (x-axis). Lighter shades correspond to lower absolute errors, with cells marked by a red cross representing an average absolute error above 0.03, deemed as unreliable estimates. This analysis indicates that at least 20 observations are necessary for reliable frequency estimation at most amplitude levels, excluding the lowest one. |
| In the text | |
|
Fig. 9 Heat map of the kernel regression sensitivity analysis, depicting the absolute error in frequency estimation as a function of sample size (y-axis) and amplitude (x-axis). Lighter shades correspond to lower absolute errors, with cells marked by a red cross representing an average absolute error above 0.03, deemed as unreliable estimates. The heat map suggests that approximately ten observations are sufficient for a reliable frequency estimate across various amplitude levels, with the only exception being the lowest amplitude level. |
| In the text | |
|
Fig. 10 FINKER’s frequency search for CRTS J033427.7–271223. The panel on the left shows the frequency range searched, and the inset illustrates the smooth behaviour of the residuals around the minimum. The estimated best frequency and its uncertainty are shown with a black error bar. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid, illustrating the algorithm’s capability to model the periodic signal accurately. |
| In the text | |
|
Fig. 11 FINKER’s frequency search for MLT J033147.60–281307.9. The panel on the left shows the frequency range searched, and the inset illustrates the smooth behaviour of the residuals around the minimum. The estimated best frequency and its uncertainty are shown with a black error bar. FINKER’s framework allowed for a search of both the harmonic and sub-harmonic of the best frequency and correctly identified that there is a difference in the eclipses. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid, illustrating the algorithm’s capability to model the eclipsing signal accurately. |
| In the text | |
|
Fig. 12 FINKER’s frequency search for ZTF J041016.82–083419.5. The panel on the left shows the frequency range searched, and the inset illustrates the behaviour of the residuals around the minimum. Transit data shows a less smooth behaviour of the residuals around the minimum, but the frequency and its uncertainty, shown as a black error bar, are consistent with the literature value. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid. |
| In the text | |
|
Fig. 13 FINKER’s frequency search for HD 114520. The panel on the left shows the frequency range searched, and the inset illustrates the smooth behaviour of the residuals around the minimum. The estimated best frequency and its uncertainty are shown with a black error bar. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid, illustrating the algorithm’s capability to model the periodic signal accurately. |
| In the text | |
|
Fig. 14 FINKER’s frequency search for V772 Cas with an adaptive bandwidth. The panel on the left shows the frequency range searched and the wild behaviour of the residuals due to the low number of points. The inset shows that the best frequency agrees with the literature values; however, the estimated uncertainty is unreliable due to the really low number of observations. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid. |
| In the text | |
|
Fig. B.1 Stability of squared residuals across various grid sizes, indicating a plateau at a grid size of approximately 300 points. |
| In the text | |
|
Fig. B.2 Execution times comparing direct evaluation of the kernel regression on the points and on grids of different sizes, showing efficiency gains with grid sizes beyond 300 points. |
| In the text | |
|
Fig. C.1 FINKER’s frequency search for KIC 5217733 (Kirk et al. 2016). The panel on the left shows the frequency range searched, and the inset illustrates the failed recovery of the literature frequency. The panel on the right shows the light curve folded at the literature frequency (0.006201d−1) with the kernel regression fit (green line) overlaid. |
| In the text | |
|
Fig. C.2 FINKER’s frequency search for MLT J162036.64–614110.5. The panel on the left shows the frequency range searched and the thorough evaluation around the best frequency and its sub-harmonic. In disagreement with the results in the literature, FINKER did not find a significant difference in the eclipses. The panel on the right shows the light curve folded at the found frequency with the kernel regression fit (green line) overlaid. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.