| Issue |
A&A
Volume 672, April 2023
|
|
|---|---|---|
| Article Number | A69 | |
| Number of page(s) | 24 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/202245560 | |
| Published online | 30 March 2023 | |
Identifying and characterising the population of hot sub-luminous stars with multi-colour MeerLICHT data⋆
1
Department of Astrophysics/IMAPP, Radboud University, PO Box 9010 6500 GL Nijmegen, The Netherlands
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Instituut voor Sterrenkunde, KU Leuven, Celestijnenlaan 200D, 3001 Leuven, Belgium
3
South African Astronomical Observatory, PO Box 9, Observatory, 7935 Cape Town, South Africa
4
Department of Astronomy & Inter-University Institute for Data Intensive Astronomy, University of Cape Town, Private Bag X3, 7701 Rondebosch, South Africa
5
Max Planck Institute for Astronomy, Koenigstuhl 17, 69117 Heidelberg, Germany
6
Guest Researcher, Center for Computational Astrophysics, Flatiron Institute, 162 Fifth Ave, New York, NY 10010, USA
7
Leiden Observatory, Leiden University, PO Box 9513 2300 RA Leiden, The Netherlands
Received:
28
November
2022
Accepted:
5
February
2023
Abstract
Context. Colour–magnitude diagrams reveal a population of blue (hot) sub-luminous objects with respect to the main sequence. These hot sub-luminous stars are the result of evolutionary processes that require stars to expel their obscuring, hydrogen-rich envelopes to reveal the hot helium core. As such, these objects offer a direct window into the hearts of stars that are otherwise inaccessible to direct observation.
Aims. MeerLICHT is a wide-field optical telescope that collects multi-band photometric data in six band filters (u, g, r, i, z, and q), whose primary goals are to study transient phenomena, gravitational wave counterparts, and variable stars. We showcase MeerLICHT’s capabilities of detecting faint hot subdwarfs and identifying the dominant frequency in the photometric variability of these compact hot stars, in comparison to their Gaia DR3 data. We hunt for oscillations, which will be an essential ingredient for accurately probing stellar interiors in future asteroseismology.
Methods. Comparative MeerLICHT and Gaia colour–magnitude diagrams are presented as a way to select hot subdwarfs from our sample. A dedicated frequency determination technique is developed and applied to the selected candidates to determine their dominant variability using time-series data from MeerLICHT and Gaia DR3. We explore the power of both datasets in determining the dominant frequency.
Results. Using the g − i colour, MeerLICHT offers a colour–magnitude diagram that is comparable in quality to that of Gaia DR3. The former, however, is more sensitive to fainter objects. The MeerLICHT colour–colour diagrams allow for the study of different stellar populations. The frequency analysis of MeerLICHT and Gaia DR3 data demonstrates the superiority of our MeerLICHT multi-colour photometry in estimating the dominant frequency compared to the sparse Gaia DR3 data.
Conclusions. MeerLICHT’s multi-band photometry leads to the discovery of high-frequency faint subdwarfs. Continued observations tuned to asteroseismology will allow for mode identification using the method of amplitude ratios. Our MeerLICHT results are a proof-of-concept of the capacity of the BlackGEM instrument currently in the commissioning stage at ESO’s La Silla Observatory in Chile.
Key words: surveys / subdwarfs / stars: variables: general / Hertzsprung–Russell and C-M diagrams / techniques: photometric / methods: data analysis
A full list of the candidates with their derived periods (full Table A.1) is only available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/672/A69
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Hot subdwarf O- and B-type stars (sdOs and sdBs, respectively) are a class of sub-luminous, high gravity (∼4.8 < log g < 5.5), post-main-sequence stars that have been relieved of their opaque hydrogen envelopes. As low-mass, core-burning helium stars with a thin hydrogen envelope (Heber 2009), they are located at the extreme horizontal branch (EHB): the bluest end of the horizontal branch in the Hertzsprung–Russell diagram. Decades of research has shown that these objects are ideally suited for providing information for multiple sub-fields of astrophysics. For instance, with their high surface temperatures (20 000 < Teff < 80 000 K), sdOB stars are potential sources of ionising ultraviolet radiation (e.g., Dorman et al. 1995; Han et al. 2007). Additionally, sdOB stars serve as tracers of the evolutionary pathways of horizontal branch stars in general, and due to their lack of an obscuring hydrogen envelope, they offer a direct probe into the core of core helium-burning objects that followed a standard evolution (Lee & Demarque 1990; Dotter et al. 2007; Heber 2009, 2016).
Numerous studies have found that a high fraction of sdOBs exist in close binaries, implying the importance of binary interaction in the creation of these objects (e.g., Maxted et al. 2001; Han et al. 2002, 2003; Geier et al. 2022). As such, characterising them and their companions can help constrain the still poorly understood processes of mass transfer and common-envelope evolution (e.g., Toonen et al. 2012; Ivanova et al. 2013). Typically, the companions of sdOB stars are white dwarfs, late-type main-sequence stars, or brown dwarfs (Heber 2016). However, studies have also revealed that sdOB stars can be found around early-type Be stars (Wang et al. 2021; El-Badry et al. 2022; Klement et al. 2022; Nazé et al. 2022). Furthermore, studies have claimed the detection of planetary (Silvotti et al. 2014) and neutron star (Wu et al. 2018) companions to sdOB stars, highlighting the importance of sdOB stars to multiple aspects of stellar and planetary evolution. Subdwarf stars are also thought to contribute to the population of close, double white-dwarf binaries capable of generating gravitational waves and type-Ia supernovae (Wang et al. 2009; Kupfer et al. 2018; Götberg et al. 2020). In addition to the extrinsic variability caused by their binary companions (e.g., eclipses, reflection effects, and ellipsoidal modulation), sdOB stars have been observed to exhibit both pressure (p) and gravity (g) mode oscillations, with amplitudes ranging from micro- to milli-magnitudes (Kilkenny et al. 1997; Charpinet et al. 1997; Green et al. 2003; Fontaine et al. 2003). The presence of pulsations has enabled asteroseismology to characterise the rotation rates of these stars, determine their internal (chemical) structures, and estimate the mass of the thin hydrogen envelope (Telting & Østensen 2006; Hu et al. 2007; Vučković et al. 2009; Randall et al. 2010; Van Grootel et al. 2010; Charpinet et al. 2011; Pablo et al. 2012; Østensen et al. 2014; Zong et al. 2016; Ghasemi et al. 2017; Lynas-Gray 2021).
Given the wide diversity of seemingly single and binary subdwarfs, as well as intrinsically variable and apparently non-variable subdwarfs, identifying proper populations has been a challenge over the years. Initial populations were identified and characterised through time-consuming ground-based spectroscopic and photometric campaigns (Green et al. 1986, 2008; Edelmann et al. 2003; Brown et al. 2005; Jester et al. 2005; Lisker et al. 2005; Morales-Rueda et al. 2006b; Geier et al. 2011). The advent of space-based missions boosted the discovery of subdwarfs thanks to ultraviolet data, such as those from the Galaxy Evolution Explorer (GALEX) survey (Vennes et al. 2011). This remained the predominant avenue for discovery until the launch of Gaia (Gaia Collaboration 2016), a space mission that has uncovered a substantial number of new hot subdwarfs. For example, Geier et al. (2019) compiled a catalogue of ∼40 000 hot sub-luminous stars from Gaia Data Release 2 (DR2; Gaia Collaboration 2018) and introduced classification schemes for hot sub-luminous star candidates based on colour, absolute magnitude, and reduced proper motion cuts. Their methodology was designed for the identification of new subdwarfs in future surveys. The release of the Gaia early Data Release 3 (eDR3; Gaia Collaboration 2021) increased this catalogue to 60 000 hot sub-luminous stars (Culpan et al. 2022).
Beyond the initial identification, the most challenging barrier to fully exploiting the binary and asteroseismic potential of sdOB stars remains the time-series characterisation of large samples of sdOB stars. The launch of the Kepler space mission saw the rapid development of sdOB asteroseismology with the identification of tens of new p- and g-mode pulsating sdB stars as well as a handful of close binaries (Kawaler et al. 2010; Østensen et al. 2011; Reed et al. 2021). This success has continued with the launch of the Transiting Exoplanet Survey Satellite (TESS; Ricker et al. 2015), thanks to which dozens more pulsators and close binaries have been observed with high-cadence, high duty-cycle observations (Uzundag et al. 2021; Baran et al. 2021; Barlow et al. 2022). While the Kepler, Kepler-2 (K2), and TESS missions have enabled great advances in the study of subdwarfs, these missions are limited in terms of their position in the sky, time base, or magnitude range. To that end, numerous ground-based photometric surveys, such as the Palomar Transient Factory (PTF), the Zwicky Transient Facility (ZTF), the OmegaWhite Survey, the Asteroid Terrestrial-impact Last Alert System (ATLAS), the All-Sky Automated Survey for Supernovae (ASAS-SN), and the Massive Unseen Companions to Hot Faint Underluminous Stars from SDSS (MUCHFUSS) project, amongst others, have been successful in identifying and characterising (sub-)populations of subdwarfs that show high frequency variability (Ramsay & Hakala 2005; Huber et al. 2006; Law et al. 2009; Macfarlane et al. 2015; Kupfer et al. 2017, 2021; Heinze et al. 2018; Jayasinghe et al. 2018; Schaffenroth et al. 2018; Coughlin et al. 2021). Although such surveys cover a larger area in the sky and have deeper magnitude limits compared to the current generation of space-based photometric missions, they are still limited in terms of colour characterisation and suffer from irregular observing cadences. Posing a further challenge, the characterisation of the sub-population of sdOB stars with wide companions on multiple-year-long orbits requires dedicated radial velocity monitoring (Vos et al. 2017, 2020).
In order to perform an unbiased and in-depth study of subdwarfs and their sub-populations, it is necessary to use high-precision data from all-sky observations, ideally combining ground- and space-based surveys. Our current work is a step in this direction. We assess the capacity of the MeerLICHT telescope (Bloemen et al. 2016; Groot et al. 2019a) in the study of subdwarfs. We show that MeerLICHT, and by implication the more powerful BlackGEM instrument currently in its commissioning stage (Bloemen et al. 2016; Groot et al. 2019b), will play a large role in discovering and characterising hot subdwarfs in the southern sky. In this paper we present the current MeerLICHT catalogue and explore how it can be used to study the population of sdB stars. Section 2 describes the MeerLICHT data and their colour properties in comparison with the Gaia DR3 data. Our MeerLICHT colour-magnitude diagrams (CMDs) reveal a population of hot, sub-luminous stars with multi-colour observations, whose variability we quantify using a dedicated time-series code (Sect. 3). The variability results are discussed in Sect. 4, and we conclude the paper in Sect. 5.
2. Data and observation
MeerLICHT is an ongoing southern all-sky survey (with declination < 30°), which started its full-time operations in May 2019 (Bloemen et al. 2016; Groot et al. 2019a). The survey aims to study transients, variable stars, and gravitational wave counterparts by co-observing with the Square Kilometre Array (SKA) precursor radio telescope, MeerKAT (Jonas 2009). MeerLICHT is a fully robotic 0.6 m optical telescope installed at the Sutherland Observatory, South Africa. The telescope offers a field of view of 2.7 square degrees, sampled at 0.56 arcsec/pixel. It provides multi-band photometric data in five filters (u, g, r, i, z) similar to those in the Sloan Digital Sky Survey (SDSS, Fukugita et al. 1996), with an additional broad filter, referred to as the q band. Their passband wavelengths are summarised in Table 1.
BlackGEM and MeerLICHT passband ranges.
The data used in this work were retrieved from the so-called MeerLICHT reference images database, part of the forthcoming MeerLICHT Southern All Sky Survey, in all six filter bands. The BlackGEM and MeerLICHT observations were obtained on a regular grid, where 12 740 fields tile the available sky. The time coverage across all fields is heterogeneous, largely due to the various surveys that dictate the observing strategy. When MeerLICHT is not paired with MeerKAT, observations are split between trying to build reference images for the MeerLICHT Southern All Sky Survey, follow-up of high interest targets, or a back-up programme. The back-up programme consists of a small subset of 140 fields (with field identification numbers > 16 000) that are directed towards Local Universe mass over-densities, and often receive higher duty-cycle observations in multiple filters.
In this work we use a dataset of about 5.5 million objects whose brightness is measured in the u, g, r, q, and i filters. This dataset is extracted from 5137 fields (as of July 2022) that contain at least one observation, with the positions and apparent magnitudes of the object, in each of the five filters. In order to obtain parallaxes for our sources, we cross-match the positions of the sources in our data with that of Gaia DR3, considering objects to correspond when they are situated within a radial distance of ρ < 1 arcsec. MeerLICHT astrometry is done on the Gaia DR2 astrometric frame and shows a systematic rms-error on the frame solution of ≲50 milli-arcsec. The positional accuracy on a given source depends on the signal-to-noise ratio of the object but is better than 0.2 arcsec at the limiting magnitude. Given its larger wavelength coverage, the q band has the most precise photometric measurements for a given integration time. However, the precision does drop off as a function of magnitude, and is further affected by the atmospheric transparency during a given exposure.
Since the traditional 1/parallax method is only valid when the parallax measurements are free from uncertainties (Bailer-Jones 2015), we converted parallax into distance (in parsec) using the methodology described in Bailer-Jones (2015) and Astraatmadja & Bailer-Jones (2016) and implemented in the TOPCAT software (Taylor 2005). In brief, this method estimates the distance based on the mode of a posterior distribution drawn from an exponentially decreasing volume density prior and by assuming the parallax follows a Gaussian distribution (Bailer-Jones 2015). As the mode of the posterior depends on a parameter, L, known as a scale length, we adopted a value of L = 1.35 kpc, which provides the best estimate on the distance for true fractional parallaxes < 2.5 (Astraatmadja & Bailer-Jones 2016). The mode of the posterior distribution is given by (Bailer-Jones 2015)
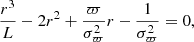 (1)
(1)
where r is the estimated distance (pc), L the scale length (pc), and ϖ (arcsec) and σϖ (arcsec) refer to the measured parallax and its uncertainty, respectively. We only retain sources for which the fractional parallax error is better than 20% (i.e., σϖ/ϖ < 0.2; Bailer-Jones 2015). Additionally, to make a more robust selection, Gaia quality flags are applied to the data, including renormalised unit weight error (RUWE) < 1.4 (Lindegren et al. 2021) and fidelity_v2 > 0.5 (e.g., Rybizki et al. 2022). We use these quality cuts to ensure that our sample consists of stars with reliable astrometric solutions. After applying these cuts, we are left with ∼4.6 million cross-matched objects, which are used to construct our CMDs and colour–colour diagrams discussed in Sect. 2.2.
2.1. MeerLICHT photometry
In this section we briefly discuss the extraction of MeerLICHT photometry, compare it to Gaia photometry, and use it to construct diagnostic diagrams. As previously mentioned, the astrometric solution for a given observed MeerLICHT image is calculated using the Gaia DR2 astrometric frame (Lindegren et al. 2018). All sources in a given image are detected using SourceExtractor (Bertin & Arnouts 1996). Subsequently, the flux of each source is measured using optimal photometry based on position-dependent point spread function shape (Naylor 1998; Horne 1986). All of the flux measurements are then associated with existing sources using a 1 arcsec association radius. If there is no existing source within 1 arcsec, then a new entry will be created in the MeerLICHT database. At set dates, a reference image for each filter has been created for each field in the database by performing a median combination of all available images in that filter. In addition to improving the overall signal-to-noise ratio in the reference image, most slow moving transients such as asteroids, comets, and other faint Solar System objects are removed via this process.
Extracting only stellar sources in the reference images with the q band gives us about 150 million stellar sources (as of July 2022), across ∼11 000 fields. It should be noted that these are high fidelity sources, meaning they have a star class probability above 0.8 (Source Extractor classification flag; star = 1; extended source = 0). To compare the distribution of observed MeerLICHT sources with that of Gaia, we randomly selected two MeerLICHT fields centred at a Galactic latitude |b|> 20°. We made a box query of the Gaia DR3 archive1 using the corners of each MeerLICHT field. Figures 1 and 2 illustrate the distributions of both datasets with b = 21.08° and b = −45.06°, respectively, using a magnitude bin width of 0.5 mag. We applied several cuts to the Gaia data using the parallax over parallax error (ϖ/σϖ) and the RUWE parameters to quantify their effects on the number of detected sources. We note that the RUWE parameter is expected to be around 1 for single sources (Lindegren 2017), which drives us to use its median value in the cuts (middle bottom panels of Figs. 1 and 2). Both figures show that the parallax error cuts are more sensitive to fainter objects, while lower values of RUWE most likely remove bright, non-stellar objects. It is worth noting that we applied these two cuts independently, such that when RUWE cuts are applied, there is no restriction on the parallax error, and vice versa.
 |
Fig. 1. Magnitude distribution of the MeerLICHT (ML) q band and the Gaia G band in a field with a galactic latitude above 20° (b = 21.08°), using a magnitude bin width of Δmag = 0.5 mag. The y-axis represents the number of data points per magnitude bin, and the x-axis corresponds to MeerLICHT’s q-band magnitude (qmag) and Gaia G-band magnitude (Gmag). The parallax over parallax error (ϖ/σϖ) and the RUWE cuts are applied independently to the Gaia data. The value in the middle bottom panel corresponds to the median of the RUWE. |
We find general agreement between the MeerLICHT and Gaia sources within magnitudes between 14 and 19, with RUWE values ≲1.0. For higher values of parallax error and RUWE cuts, we lose a significant number of Gaia data points, especially due to the parallax error cuts. Furthermore, both figures show that for fainter MeerLICHT objects with q-band magnitude ≳17 mag, we are likely to find fewer Gaia object matches with good astrometric solutions, ϖ/σϖ > 5. We note that the significant drop in the number of data points in the brighter and fainter ends of the distributions represents MeerLICHT’s limiting magnitude (∼20 mag) and saturation limit (∼12 mag) in the q band, respectively.
2.2. Colour-magnitude diagrams
We constructed our CMDs for the cross-matched and filtered list of ∼4.6 million sources. The resulting CMDs for MeerLICHT and Gaia are shown in Fig. 3. The left panel depicts the MeerLICHT (g − i) colour versus the q-band absolute magnitude, while the right panel represents the Gaia (BP − RP) versus the G-band absolute magnitude. The MeerLICHT and Gaia CMDs show a high degree of similarity, which illustrates the power of the MeerLICHT multi-colour photometry to define and extract stellar populations over a wide magnitude range. The CMDs of both datasets clearly reveal the longest stellar evolution phases, such as the main sequence, the giant branch, the EHB, and the white dwarf cooling track.
 |
Fig. 3. CMDs of both MeerLICHT (left) and Gaia DR3 (right) data. The blue data points represent the selected sdB candidates from the colour classification schemes. The open orange circles represent EBs identified from the sdB candidates, while the red stars correspond to candidates with sinusoidal variations. Even though white dwarfs are also selected, we do not exclude them from our analysis as they could be relevant to the study of sdB-white dwarf binary systems. |
2.3. sdB candidate selection
Colour–colour diagrams (CCDs) help us further visualise and identify different stellar populations through their different colour properties. Figure 4 shows four different MeerLICHT CCDs, revealing different sub-populations of stars depending on the colours used. We exploit these CCDs to identify sdB candidates in the MeerLICHT data using the colour classification schemes developed by Geier (2020) for the SDSS filter set. Geier (2020) define the class of hot subdwarfs by SDSS colours as follows:
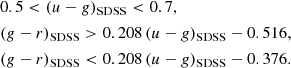
 |
Fig. 4. CCDs using different MeerLICHT colours. The sdB candidates shown in Fig. 3 are highlighted in orange here. |
To apply these colour selection criteria to our data, we first transform the MeerLICHT colours (denoted as ML) to SDSS colours using the following conversions, derived from areas where there is overlap between the two surveys:

Applying the above selection criteria yields 2188 sdB candidates within the cross-matched and quality-flag filtered MeerLICHT data. These candidates are shown in blue in Figs. 3 and 4. We note that the selection criteria do not discriminate against white dwarf stars. Furthermore, these cuts do not account for systems that contain sdB stars and a bright MS companion whose composite colour would locate the system closer to the MS.
2.4. Light curves
We extracted light curves of the sdB candidates and analysed their time-series behaviour. This extraction was done using the forced photometry package for MeerLICHT (Vreeswijk et al., in prep). In this case, we took the coordinates of the 2188 sdB candidates and performed optimal photometry at the average location of the closest matching source that exists in the database. We only retained flux estimates extracted from images that do not have a ‘red’ flag (i.e., excluding sources with large photometric zero-point uncertainties). The distribution of the number of observations in the q band for each of the 2188 sdB candidates is shown in Fig. 5. This distribution highlights the heterogeneity in the number of observations per target that is introduced by the schedule priorities. Based on Fig. 5, and following the requirement adopted by Gaia Collaboration (2023) in their analysis of the Gaia DR3 time-series photometry to hunt for non-radial oscillations in main-sequence stars, we only retained sdB candidates that had at least 40 observations in the q band. This limit is more conservative than that of Morales-Rueda et al. (2006a), who suggested that only 25 data points are needed to conclude that a star is variable. This left us with 610 final sdB candidates, with at least 40 MeerLICHT q-band measurements, to be treated by our time-series analysis methods. An example light curve for a typical sdB candidate with sparse and gapped data in multiple filters is shown in Fig. 6.
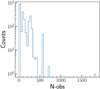 |
Fig. 5. Distribution of the number of observations in the q-band filter (N-obs) for the 2188 sdB candidates. The y-axis corresponds to the number of objects per N-obs bin and is represented on a logarithmic scale. The vertical dashed grey line indicates the cutoff at N-obs = 40 in MeerLICHT q-band observations. All objects to the right of this cutoff line are selected to be in our sdB candidate sample. |
 |
Fig. 6. Illustration of the nature of MeerLCIHT’s light curve for the target in the second panel of Figs. 12 and 13. The irregularity in the sampling and the gapped observations can be clearly seen in this plot. |
Among the 610 candidates, 44 were already identified as variables from the Gaia DR3 catalogue (Gaia Collaboration 2022). Our results from the frequency analysis (Sect. 3) allow us to make a preliminary classification of these variables based on their phase light curve shapes. Their periodograms and phase light curves are described in Appendix A. We summarise the characteristics of these candidates in Table A.1, including their photometric measurements and derived periods. In this table, we leave the variability class blank for candidates that show no evident periodic variability. The positions of the stars with a clearly variable phase curve are indicated in the CMDs in Fig. 3. This includes some tens of eclipsing binaries (EBs; open orange circles) and a few candidate variables with sinusoidal light curves (red stars).
With more than 40 observations in a single band, we hope to mitigate the chance that we misclassify a star as variable due to instrumental or other noise. In order to understand the behaviour of the noise in our sample, we compute the standard deviation for the q-band light curves for our final candidates, as shown in Fig. 7. As a comparison, we mark the targets that were flagged as VARIABLE in the Gaia catalogue in orange. We find that, generally, the light curves of the MeerLICHT sources have similar scatter compared to those of the validated Gaia variables, indicating that the ground-based MeerLICHT data are suitable for identifying and characterising the time-series variability of compact stars.
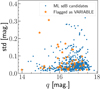 |
Fig. 7. Magnitude in the q band (qmag) versus standard deviation (std). Data points flagged as VARIABLE in the Gaia DR3 catalogue are marked in orange. |
3. Frequency analysis of sparsely sampled multi-colour data
Since sdB stars are known both to exist in binaries and to host self-driven stellar oscillations, we aim to identify the dominant variability in our sdB candidates. The limitations of frequency analysis, notably the iterative process of identifying and removing dominant periodic signals (also known as pre-whitening), are determined by the quality of the astronomical dataset, for example, the time base of the data, the regularity and duty-cycle of the data, and the precision of the data. As previously discussed, MeerLICHT data was irregularly gapped and suffer from variable local weather conditions. Additionally, MeerLICHT takes data in multiple filters, which presents a challenge to traditional Fourier-based frequency analysis methods that assume homoskedastic, regularly sampled data from a single passband.
In this section we first discuss statistical methods that have been developed for applications in the time domain (e.g., Stellingwerf 1978; Reimann 1994), as well as in the Fourier domain (e.g., Lomb 1976; Scargle 1982). Although these methods have been shown to work very well for dedicated asteroseismic ground-based campaigns (e.g., Breger et al. 1993), it remains challenging to capture the frequency information from sparsely sampled and multi-colour light curves of faint objects such as those treated in this work. Specifically, we develop a better technique that works for the most challenging time-series data in astronomy. Our method relies on a combination of statistical time-domain and Fourier-based techniques inspired by the work of Saha & Vivas (2017) and VanderPlas (2018), to which we refer for details and motivation on why such a scheme is beneficial for data as treated here. In the following sections we highlight the key points of the method while focusing on the improvements made in our new implementation of this technique.
3.1. The Lafler–Kinman Θ statistic
The Lafler–Kinman (LK) statistic is a non-parametric method for searching for periodicity in time-series data that was originally developed to find the pulsation periods of RR Lyrae stars from single-band data (Lafler & Kinman 1965). Based on the underlying principle of the LK statistic, the true pulsation period P in a light curve is the one that shows minimal scatter in the phased light curve when folded with the candidate period. For a given period P, the LK statistic as formulated by Lafler & Kinman (1965) is given by
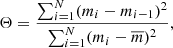 (2)
(2)
where N corresponds to the number of observations, mi are the magnitudes at times ti, and 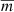 is the mean of mi. The magnitudes mi in this equation are sorted in ascending order of the time series folded with the period P as
is the mean of mi. The magnitudes mi in this equation are sorted in ascending order of the time series folded with the period P as
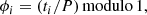 (3)
(3)
where ϕi is the phase for a given mi.
Finding the correct period in a light curve is the subject of numerous studies building on the original LK statistic. One of those is the well-known phase-dispersion minimisation (PDM) introduced by Stellingwerf (1978). With this PDM method, the dispersion is computed by binning the phase light curve into a certain number of bins. The sum of the scatter in each bin provides the general level of periodic variability present in the light curve. The LK statistic is a limiting case of PDM, where each bin contains a minimal number of two data points. This choice is preferable for sparse datasets (Saha & Vivas 2017).
In case of noisy sparse observations such as in MeerLICHT, it is important to include the uncertainties of the measurements, σi, into the computation of the statistic, denoted here as Θ. We implemented this by adding weights wi to each data point. Following Saha & Vivas (2017), the weights wi and the modified LK statistic are given by
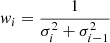 (4)
(4)
and
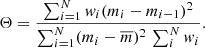 (5)
(5)
Here, 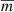 is the weighted average of mi. The period that gives the smallest value of Θ is considered to be the best estimate of the correct period. However, this is not always true in the case of noisy and unevenly sampled data, because strong false alias peaks may occur in the periodogram.
is the weighted average of mi. The period that gives the smallest value of Θ is considered to be the best estimate of the correct period. However, this is not always true in the case of noisy and unevenly sampled data, because strong false alias peaks may occur in the periodogram.
3.2. The Lomb-Scargle periodogram
Fourier analysis is a widely used method for searching for frequency in time-series data. This approach has been shown to be effective for uniformly sampled data. Considering a continuous time series of data x(t), its Fourier transform is given by
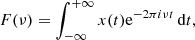 (6)
(6)
where ν is the cyclic frequency and i2 = −1 the imaginary unit. The so-called power spectral density, or PSD(ν), is defined as the squared amplitude of F(ν):
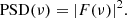 (7)
(7)
The PSD(ν) contains all the frequency information in the data in the case of a perfect and continuous signal. In ground-based astronomy, observations are taken on an irregular basis due to observational constraints such as telescope scheduling, weather, and seasonal cycles. These constraints lead to unevenly sampled time-series data with frequent large gaps.
A first approach for coping with such discrete time-series data (referred to as xn), known as the Schuster periodogram (or classical periodogram), was proposed by Schuster (1898):
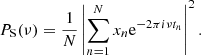 (8)
(8)
For uniformly sampled data, the Schuster periodogram can recover all the frequency information contained in the data. In a statistical sense, this periodogram is an estimator of the PSD (Scargle 1982).
For non-uniform sampling, Scargle (1982) proposed a generalisation of the classical periodogram. Following the notation in VanderPlas (2018), the Lomb–Scargle (LS) periodogram is given by
![Mathematical equation: $$ \begin{aligned} P_{\rm LS}(\nu )&= \frac{1}{2} \Bigg \{ \bigg (\sum _n x_n \cos (2\pi \nu [t_n-\tau ])\bigg )^2 \bigg / \sum _n \cos ^2(2\pi \nu [t_n-\tau ])&\nonumber \\&\quad + \bigg (\sum _n x_n \sin (2\pi \nu [t_n-\tau ])\bigg )^2 \bigg / \sum _n \sin ^2(2\pi \nu [t_n-\tau ]) \Bigg \} , \end{aligned} $$](/articles/aa/full_html/2023/04/aa45560-22/aa45560-22-eq13.gif) (9)
(9)
where τ is defined as
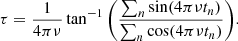 (10)
(10)
This formulation was constructed in such a way that the periodogram is not dependent on the chosen zero-point for the time stamps of the data.
An interesting aspect of the LS Periodogram in Eq. (9) is its connection to a least-squares regression (Lomb 1976) of a harmonic model fitted to the data at a given frequency ν (see VanderPlas & Ivezić 2015; VanderPlas 2018, for in-depth discussion). In other words, the resulting periodogram constructed from the χ2 goodness-of-fit is equivalent to the LS periodogram. Based on this connection, VanderPlas & Ivezić (2015) developed a generalised and multi-band periodogram derived from minimising the χ2 of a sinusoidal model yk(t|ω, θ) with ω = 2πν the angular frequency and θ the model parameters. This periodogram is given by
![Mathematical equation: $$ \begin{aligned} \chi ^2_{\rm min} = \chi _0^2 [1 - P_{\rm N}(\nu )], \end{aligned} $$](/articles/aa/full_html/2023/04/aa45560-22/aa45560-22-eq15.gif) (11)
(11)
where PN(ν) is a normalised version of the periodogram in Eq. (9). In this expression, 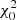 is called the reference model, with
is called the reference model, with 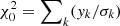 , where σk denotes the error associated with the observation yk. The sinusoidal model yk(t | ω, θ),
, where σk denotes the error associated with the observation yk. The sinusoidal model yk(t | ω, θ), 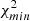 , as well as the other parameters are described in VanderPlas & Ivezić (2015). In their work, the authors also provide a matrix formulation of the periodogram for easy implementation.
, as well as the other parameters are described in VanderPlas & Ivezić (2015). In their work, the authors also provide a matrix formulation of the periodogram for easy implementation.
This formulation can further be generalised to consider data of the same object taken in different photometric bands, either simultaneously or contemporaneously. In the generalised form, yk(t | ω, θ) is a combination of: (i) Nbase number of Fourier components, known as the base model, which treats and fits the data as a single time series by ignoring filter labels; (ii) a set of Nband Fourier components, which fits each filter independently (VanderPlas & Ivezić 2015). This combination ensures that the model does not under-fit (if using only a single standard LS model) or over-fit the data (if we only compute a standard LS periodogram for each filter and use their combined χ2 to obtain the multi-band periodogram). For each filter k, yk(t | ω, θ) is expressed as
![Mathematical equation: $$ \begin{aligned} y_k(t|\omega ,\theta ) =&\theta _0 + \sum _{n=1}^{N_{\rm base}} \left[\theta _{2n - 1}\sin (n\omega t) + \theta _{2n}\cos (n\omega t)\right]\ \nonumber \\&+ \theta ^{(k)}_0 + \sum _{n=1}^{N_{band}} \left[\theta ^{(k)}_{2n - 1}\sin (n\omega t) + \theta ^{(k)}_{2n}\cos (n\omega t)\right], \end{aligned} $$](/articles/aa/full_html/2023/04/aa45560-22/aa45560-22-eq19.gif) (12)
(12)
where, θ0 and 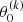 denote the model offsets, Nbase is the number of sinusoidal components of the base model, and Nband the number of sinusoidal components that fit the data for each filter k.
denote the model offsets, Nbase is the number of sinusoidal components of the base model, and Nband the number of sinusoidal components that fit the data for each filter k.
3.3. A hybrid method: The Ψ statistic
Combining the time-domain and Fourier-based methods is efficient for searching frequencies in time-series data that present an irregular (i.e., non-sinusoidal) shape and are sparsely sampled. For this reason Saha & Vivas (2017) introduced the so-called Ψ statistics, defined as
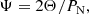 (13)
(13)
where Θ and PN are derived from Eqs. (5) and (11), respectively. Normalised periodograms have been used before in the exploitation of combined sparse datasets of the same variable star (e.g., Aerts et al. 2006, 2017) but this was done without relying on a firm mathematical basis. With our introduction of the normalised periodogram into the framework as in Eq. (13) we improve upon the use of such a quantity in applications to multiple time series of a star. Since the window function behaves differently in the LK statistic and the normalised periodogram, the combined Ψ statistic effectively suppresses aliased frequencies, resulting in a cleaner periodogram compared to each of Θ and PN separately, as illustrated in the columns of Fig. 8. In summary, we made use of the following new implementations to perform frequency analysis.
 |
Fig. 8. Illustration of the difference between scaling the magnitudes to have the same amplitude before computing the periodogram (bottom panel) and without scaling the magnitudes (top panel). The improvement in the cleanliness of the periodogram using Ψ is shown in the right panels. These plots correspond to the second target in Table 2 or a zoomed-in version of the top middle panel in Fig. 12. |
First, we used the so-called generalised multi-band periodogram developed by VanderPlas & Ivezić (2015) and adopted an implementation with a Fourier-based component as a hybrid period search method. This generalised method is optimised to take the sparse and irregular nature of our observations into account and, most importantly, allows for an easy exploration of the multi-band filters we have. It also includes the uncertainties in the flux or magnitude measurements in the computation of the periodogram, which is crucial in the case of noisy observations.
Second, the frequency grid search is defined in such a way that our algorithm can search for high-frequency variability.
Finally, with the goal of improving the quality of the periodogram, we scaled the magnitude values such that each filter has the same amplitude before we computed the periodogram.
Following our tests and science goals, our periodicity search was conducted using the scaled composite light curve for both the LK statistic and the LS periodogram, and setting Nbase = 1 and Nband = 0 for the LS periodogram (i.e., we ignore the two terms 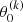 and Nband in Eq. (12)). Since MeerLICHT has narrower time spacing (time difference between two consecutive observations), particularly in the composite light curves, we can search for short-period variability in the sdOB candidates.
and Nband in Eq. (12)). Since MeerLICHT has narrower time spacing (time difference between two consecutive observations), particularly in the composite light curves, we can search for short-period variability in the sdOB candidates.
3.4. Defining the frequency grid
After defining the two elements (Θ and Π) of the Ψ statistic, we must now define the trial frequencies at which we want to search for periodicities in the data. Establishing a universal method for defining this frequency range is not trivial, particularly for irregularly sampled data. Therefore, it is crucial to choose the optimal frequency grid and the maximum frequency (Nyquist frequency) such that we: (i) optimally and robustly probe the highest frequency regimes, (ii) have a small enough frequency step as to not miss any periodic signals, and (iii) minimise the computational cost.
In this work, and following Chapt. 5 in Aerts et al. (2010), we adopted the minimum frequency as the inverse of the total time base (tbase = tmax − tmin). In practice, since our data are unevenly sampled and exhibit some wide gaps across the time base, we multiplied this value by a factor of 4. This implies that we searched for a frequency of a signal that repeats at least four times within the time base. The frequency step is defined as the inverse of the time base, divided by an oversampling factor (10 in our case). Lastly, the maximum frequency is determined based on the maximum sampling rate MeerLICHT can achieve in one day. It takes the integration time (60 s) and the overhead time (30 s) into account. The above parameters are defined as follows:
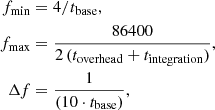 (14)
(14)
where the value 86 400 corresponds to the number of seconds in one day, Δf the frequency step, and toverhead and tintegration are the overhead and integration times, respectively. Both fmin and fmax are expressed in the number of cycles per day (d−1). We note that using this definition of fmax gives us a maximum frequency of 480 (d−1).
We used slightly different frequency grid settings for the Gaia data since it has different observational characteristics: as described in Aerts et al. (2010), the minimum frequency is kept as the inverse of the time base (fmin = 1/tbase); the maximum frequency as half the inverse of the median of the difference of two consecutive observations (fmax = 1/(2 × median(ti + 1 − ti))); and the frequency step as the ratio between fmin and an oversampling factor of 10 (Δf = fmin/10).
3.5. Multi-colour versus composite light curves
Since we have data in multiple passbands, we test how to best incorporate the multiple data streams into our periodicity search. The generalised LS periodogram allows for the direct inclusion of data in multiple passbands via the Nband term. However, it has been shown that adding more Fourier terms to the model increases its complexity and the background noise of the resulting LS periodogram (VanderPlas & Ivezić 2015). In particular, VanderPlas & Ivezić (2015) demonstrate that the best results are obtained when Nbase > Nband. As we want to fully exploit our data, we devise a scheme whereby we scale the light curves of each filter to have the same root-mean-square (RMS) scatter as the q-band light curve, then merge all of the light curves into a single, scaled composite light curve, sorted by ascending time. We use the single scaled composite light curve to calculate both the LK statistic and the LS periodogram. We compare the resulting Θ-statistic, LS, and Ψ-statistic periodograms using the multiple light curves and the generalised LS periodogram and the scaled composite single light curve in the top and bottom panels of Fig. 8. We note that there is a clear improvement in the resulting Θ-statistic periodogram when using the single scaled composite light curve, which in turn produces a Ψ-statistic periodogram with a lower noise level.
Our RMS scaling scheme is not without consequence, however. The light curve scaling is not perfect, and therefore results in a small, but still present amplitude offset between data points in different filters. When paired with MeerKAT or while on the backup fields, MeerLICHT observes in a repeated uqi filter sequence. The exposure time, readout, and filter changing result in a repeated measurement in a given filter roughly every five minutes. This introduces a five-minute signal into the window function of targets with observations following this sequence. This window pattern can be seen in periodograms for the majority of our targets, including the remaining figures shown in this work.
3.6. Window function pattern
It is crucial to study the window function to better understand different patterns occurring in the resulting periodograms. In other words, knowing the nature of the window function helps us detect aliases in our periodograms. With this in mind, we built an averaged periodogram of the candidates’ window functions, where the spectral powers, PN, are averaged per frequency bin width of 1 d−1. Here, we examine the window functions of the composite uqi-band light curves and those of the q band alone (in which objects are most observed), such that we can investigate the effects of combining the light curves on the window function pattern. Additionally, we included the uncertainties in the magnitudes while computing the periodograms to reveal their possible contributions to the shape of the window function. The resulting periodograms are presented in Fig. 9, where the blue and green solid lines are obtained from the periodograms of the standard window functions, whereas the orange and grey dashed lines are obtained from the introduction of the magnitude uncertainties in the calculation of the periodograms. These periodograms reveal several interesting frequency peaks:
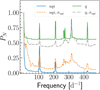 |
Fig. 9. Averaged LS periodograms of the candidates’ window functions using a frequency bin width of 1 cycle per day. The solid blue and green lines correspond to the window functions in the composite uqi-band filters and the q band, respectively. The dashed orange and grey lines represent the same window functions, but with the contribution of the uncertainties of the magnitude values included in the calculation of the periodograms. |
Peaks at 1, 100, and 200 d−1. Both the combined uqi-bands and the q-band window functions peak at ∼1 d−1, which is the result of daily observation sequences; and at ∼ 100 and 200 d−1, which are probably the harmonics of the 1 d−1 peak.
Peaks at 280 and 300 d−1. The frequency peak at ∼280 d−1, particularly for the q band, corresponds to a period of about 5 minutes, could be explained by the consecutive measurements in a given filter discussed in the previous section. This peak is more evident when the q-band filter alone is considered. As the time resolution increases when the three filters are used, this peak is suppressed. However, this peak interestingly appears in the uqi window function, along with the one at 300 d−1, when the uncertainties are introduced in the periodograms. Moreover, the pattern of this window function (a somewhat wide hump around 300 d−1) appears more often in the periodograms of our candidates (see Appendix A for more illustrations).
Peak at 400 d−1. This peak appears in all of the four cases and is most probably an alias of the 100 d−1 peak.
In general, combination frequencies occur due to the integration and readout times, the effects of which on the window function depend on whether a composite light curve is used. Since the mentioned frequency peaks represent the general pattern of all candidates’ window functions, each candidate may have a slightly different pattern. It is therefore necessary to examine each candidate’s window function to explain the source of the large bump around 300 d−1 and its correlation to the magnitude uncertainties (which is not covered in this paper). Overall, these uncertainties increase the noise levels of the periodograms at all frequencies, as shown in Fig. 9. Regardless of the magnitude uncertainties, increasing the data sampling will alleviate the aliases caused by the window functions. This is demonstrated by the uqi composite light curve (blue line) and the q-band window functions (green line) in Fig. 9, where we have three large peaks in the uqi periodogram compared to six in the q band.
Furthermore, in Fig. 10, we build a histogram of the dominant frequencies found by our algorithm for the 610 candidates. Some of the frequencies around 300 d−1 are most probably aliases due to the window function pattern in Fig. 9 (the orange dashed line).
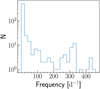 |
Fig. 10. Histogram of the candidates’ dominant frequencies found by the Ψ statistic. The y-axis is on a logarithmic scale. |
3.7. Influence of the number of Fourier terms
While PDM methods are well suited for detecting periodicities of non-sinusoidal signals, Fourier-based methods such as the LS periodogram are not. Typically, such Fourier-based methods require multiple harmonic terms to represent non-sinusoidal signals, like those produced by EBs. It is then a non-trivial task to select the base period from the resulting series of harmonics without direct intervention.
The generalised LS periodogram presented by VanderPlas (2018) enables the inclusion of multiple harmonic terms in addition to the single base sinusoid with the term Nbase. The inclusion of additional Fourier terms increases the likelihood that the true period of a non-sinusoidal signal is identified as the most dominant signal without manual intervention. An example of this is demonstrated in Fig. 11, with the Nbase = 1 model on the left and the Nbase = 2 model on the right. We note that the periodograms for this example are calculated using the scaled composite light curve. In this example, we see how the Nbase = 2 model easily identifies the true period of the EB, whereas the Nbase = 1 incorrectly identifies the first harmonic (2forb = 1/2 Porb) as the dominant periodicity. However, it has been demonstrated that the inclusion of additional Fourier terms generally results in the production of a noisier periodogram (VanderPlas 2018). In terms of goodness of fit, in Fig. 11 for instance, the two-term model slightly improves the root-mean-square error (RMSE) values in the q and u bands (or RMSEq and RMSEu, respectively), with RMSEq = 0.076 and RMSEu = 0.086, compared to the one-term model with RMSEq = 0.082 and RMSEu = 0.094.
 |
Fig. 11. Periodograms and phase diagrams comparing one-term (left panel) and two-term (right panel) models. The black curve represents the model fit to the data using the dominant frequency found using the LS periodogram. |
We further test the Nbase = 1, 2 term models on three known variables that were observed by MeerLICHT and Gaia, and have been previously studied by Graczyk et al. (2011). The resulting periodograms for the Nbase = 1 term model are shown in Fig. 12 and the resulting periodograms for the Nbase = 2 term model are shown in Fig. 13. The resulting dominant periodicities found for each object are listed in Table 2. In two of the three cases, we find that there is no difference between the identified dominant periodicities for the Nbase = 1 and 2 term models in the MeerLICHT data. We also find that we recover the true period, or a harmonic thereof, in all cases when using the MeerLICHT data. The third object returns unrelated periods, likely due to the fewer data points obtained by Gaia.
 |
Fig. 12. Comparison of MeerLICHT and Gaia periodograms and phase-folded light curves for Nbase = 1. Each column represents one of the three sdB candidates. The first and second rows represent the periodograms and phase-folded light curves for MeerLICHT data, respectively, whereas the last two rows correspond to that of Gaia data. The black curve is the model fit to the data using the LS model. For illustration purposes, the phase is plotted twice. |
Summary of the derived periods.
As expected, using Nbase = 2 results in higher noise level in the periodograms. To quantify this noise, we use a method similar to that used by Breger et al. (1993), averaging the square root of the power (Ψ) across all frequencies except the dominant frequency peak. It is worth noting that, in Breger et al. (1993), this noise is computed over a frequency window width of a few cycles per day around the dominant frequency. However, most of the candidates in this work exhibit somewhat high peaks at all frequencies; therefore, we compute the signal-to-noise ratio (S/N) based on the amplitude of the highest peak over the averaged noise across all frequencies. To illustrate the noise level difference between the one- and two-term models, we annotate each candidate S/N in Figs. 12 and 13. In these figures, the one- and two-term models for the first MeerLICHT target have a S/N of 15.86 and 11.09, respectively.
In their analysis, VanderPlas (2018) observed a similar case and interpreted the increased background noise as directly related to the flexibility of the model in fitting the data. This explains the increase in the amplitude of the periodogram at any frequencies, not only at the true frequency, as shown in Fig. 13. VanderPlas (2018) further pointed out that, in some cases, the background noise could also be harmonics, which we expect to occur at f1/2 for Nbase = 2, and at f1/2 and f1/3 for Nbase = 3, where f1 is the dominant frequency.
While the model with Nbase = 2 has greater flexibility in identifying the true period of EB targets, it shows little benefit in the case of sinusoidal signals such as those produced by stellar pulsations. Furthermore, including more terms greatly increases the computation time. For instance, a one-term model (∼11 min) is about 1.45 times faster than a two-term model (∼16 min) for ∼6 million trial frequencies. Considering that we are searching for general periodicities including both eclipses and pulsations, combined with the computation time and generally increased noise level in the periodogram when using Nbase = 2, we decide on using Nbase = 1 for the remainder of this work. A follow-up paper will be devoted to the derivation of the full frequency content of the light curves. Here, we focus on the dominant frequency.
4. Sample variability characteristics
In addition to identifying the dominant period of variability, we also characterise the time-series variability of each object (i.e., the kurtosis, skewness, magnitude of variability, etc.). We calculate these variability indices using the composite light curve, and record the scaling factor between the u and i bands to better understand the properties of our sample of sdOB candidates.
Gaining prior knowledge of the nature of the variability of our candidates before proceeding to the frequency analysis is helpful as we can focus on the most promising candidates. To characterise the variability of the candidates, we compute diverse variability indices from their time series. For several reasons, however, we only focus on two indices: the magnitude of variability (V) and the median absolute deviation (MAD; Rindskopf et al. 2010). One reason is that our data contain a wide range of observations per light curve, from 40 to hundreds of observations, which might introduce a bias into the derived statistical properties. Another reason is that since the light curves are subject to outliers, we need a statistical tool that is less sensitive to outliers.
The magnitude of variability is defined as the standard deviation of the flux over the average flux. The larger this value, the higher the level of variability of a given object. On the other hand, the MAD is a robust statistical tool for measuring the variance of data, which is less sensitive to outliers compared to the standard deviation (e.g., Eyer et al. 2023; Rindskopf et al. 2010). We computed these two indices for the 610 candidates using flux values in the q band. As their resulting values are somewhat skewed, we plot them on a logarithmic scale in Fig. 14. This figure shows that the two indices are independent of the number of observations and reveals that our candidates have a varied range of variability. By visually inspecting the candidates’ phase-folded light curves, we plot in the same figure those candidates that are found to be EBs. The majority of these EB candidates have higher values of the MAD and V indices, which suggests that, although no evident clusters can be found in the figure, these two variability indices might provide us with constraints on the variability of the candidates. Furthermore, the resulting correlations between various variability indices are presented in Appendix B.
 |
Fig. 14. MAD vs. the magnitude of variability index (V). The open blue circles represent objects with a number of data points N < 200 in the q band; the grey squares represent those with N > 200. Candidates observed as EBs are represented in orange. |
5. Conclusion
MeerLICHT observations allow us to study stellar populations in the southern sky, with approximately 5.5 million objects observed in the u, g, r, q, and i filters. From Gaia DR3 parallaxes, we were able to estimate the distance to these objects as well as their absolute magnitudes. Our hot-subdwarf candidates are drawn from colour classification schemes, which yields ∼2000 sdB candidates. A minimum number of observations per light curve and quality flags were applied to these candidates, producing our final set of 610 sdB candidates. The frequency search algorithms developed in this work have led to the discovery of dozens of potential EBs from these candidates, which are found at the brighter end of the EHB in the CMDs, suggesting that these objects are potentially hot massive main-sequence stars. This number would increase if we further examined ambiguous candidates. We also tested our algorithm with three known variables among our candidates, previously studied by Graczyk et al. (2011). The extraction of the Gaia light curves for these three variables enabled us to compare their periodograms and phase-folded light curves. In most of the cases, we find the same periods using both datasets. For MeerLICHT, different patterns in the periodograms and aliases were identified by means of the window functions. Finally, we attempted to statistically characterise our candidates using variability indices, with the aim of finding any structures in the light curves.
The purposes of the current study were to evaluate the capabilities of MeerLICHT in detecting faint hot subdwarfs and to develop efficient techniques for finding periodicity in unevenly sampled time-series data. This paper has shown that:
-
With MeerLICHT, we can effectively characterise different stellar populations in the CMDs and CCDs, notably the hot subdwarf population. A comparison of the MeerLICHT CMD with that of Gaia reveals significant similarities in terms of how the two CMDs represent various stages of stellar evolution.
-
MeerLICHT and Gaia have a comparable number of observations for objects with magnitudes between 14 and 19 mag and RUWE ≲ 1. In other words, under these conditions, it is most likely that there will be many matches between the two sorts of observations.
-
The hybrid implementation of both statistical and Fourier-based methods coupled with the amplitude scaling of the composite light curves are effective approaches for finding the dominant frequency.
-
Taking the uncertainties in the magnitudes into account when examining the window functions is important, at least for MeerLICHT data, as it reveals various aliases in the candidates’ periodograms.
-
The MAD and the magnitude of the variability indices allow us to find the most probable variable among the candidates.
As mentioned previously, the aim of this work was to evaluate the value of MeerLICHT data in characterising the variability properties of known sdB stars in the Southern Hemisphere. To that end, we have developed tools to investigate the variability of sdB stars and other variable stars within the MeerLICHT data, and we have demonstrated the value of contemporaneous multi-colour photometry for understanding stellar variability. It is also important to note that the uncertainty determination of the frequencies found was not fully explored in this work due to several main factors: the evaluation of this type of uncertainty is not straightforward due to the correlated and heteroscedastic nature of our data, the aliases present at different frequencies, and the irregularities of the data sampling affect the pattern of the window function and the resulting periodograms. Considering all of these constraints, further analyses are needed to properly assess the uncertainties, such as those discussed in Van Beeck et al. (2021). These limitations imply that the significance of the frequency reported here is only based on the S/N. The higher the S/N, the more we rely on its corresponding frequency.
Future research will concentrate on the examination of well-chosen candidates using asteroseismology and the use of spectroscopic and time-series data from other surveys, such as TESS, to enhance the frequency analysis and validation of the candidates. These candidates might not only be restricted to the sdB candidates but also include the sdO population (e.g., by following the classification schemes for sdO stars discussed in Geier 2020). Overall, the present work makes several noteworthy contributions to MeerLICHT observations of sdB stars and data analysis techniques that could be applied to related research, including the study and characterisation of variable stars that will be observed with the BlackGEM telescopes once it is fully operational.
Acknowledgments
The research leading to these results has received funding from the KU Leuven Research Council (grant C16/18/005: PARADISE), from the Research Foundation Flanders (FWO) under grant agreements G0A2917N (BlackGEM) and K802922N (Sabbatical leave awarded to CA), as well as from the BELgian federal Science Policy Office (BELSPO) through PRODEX grants for Gaia data exploitation. CA and CJ are grateful for the kind hospitality offered by the staff of the Center for Computational Astrophysics at the Flatiron Institute of the Simons Foundation in New York City during their work visit in the fall of 2022. PJG is supported by NRF SARChI grant 111692. The MeerLICHT telescope is designed, built and operated by a consortium consisting of Radboud University, the University of Cape Town, the South African Astronomical Observatory, the University of Oxford, the University of Manchester and the University of Amsterdam, supported by NWO, NRF and the European Research Council.
References
- Aerts, C., Marchenko, S. V., Matthews, J. M., et al. 2006, ApJ, 642, 470 [NASA ADS] [CrossRef] [Google Scholar]
- Aerts, C., Christensen-Dalsgaard, J., & Kurtz, D. W. 2010, Asteroseismology (Dordrecht: Springer) [Google Scholar]
- Aerts, C., Símon-Díaz, S., Bloemen, S., et al. 2017, A&A, 602, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astraatmadja, T. L., & Bailer-Jones, C. A. L. 2016, ApJ, 833, 119 [NASA ADS] [CrossRef] [Google Scholar]
- Bailer-Jones, C. A. L. 2015, PASP, 127, 994 [Google Scholar]
- Baran, A. S., Sahoo, S. K., Sanjayan, S., & Ostrowski, J. 2021, MNRAS, 503, 3828 [NASA ADS] [CrossRef] [Google Scholar]
- Barlow, B. N., Corcoran, K. A., Parker, I. M., et al. 2022, ApJ, 928, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, A&AS, 117, 393 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bloemen, S., Groot, P., Woudt, P., et al. 2016, SPIE Conf. Ser., 9906, 990664 [NASA ADS] [Google Scholar]
- Breger, M., Stich, J., Garrido, R., et al. 1993, A&A, 271, 482 [NASA ADS] [Google Scholar]
- Brown, W. R., Geller, M. J., Kenyon, S. J., et al. 2005, AJ, 130, 1097 [NASA ADS] [CrossRef] [Google Scholar]
- Charpinet, S., Fontaine, G., Brassard, P., et al. 1997, ApJ, 483, L123 [Google Scholar]
- Charpinet, S., Van Grootel, V., Fontaine, G., et al. 2011, A&A, 530, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Coughlin, M. W., Burdge, K., Duev, D. A., et al. 2021, MNRAS, 505, 2954 [CrossRef] [Google Scholar]
- Culpan, R., Geier, S., Reindl, N., et al. 2022, A&A, 662, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dorman, B., O’Connell, R. W., & Rood, R. T. 1995, ApJ, 442, 105 [NASA ADS] [CrossRef] [Google Scholar]
- Dotter, A., Chaboyer, B., Jevremović, D., et al. 2007, AJ, 134, 376 [NASA ADS] [CrossRef] [Google Scholar]
- Edelmann, H., Heber, U., Hagen, H. J., et al. 2003, A&A, 400, 939 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- El-Badry, K., Conroy, C., Quataert, E., et al. 2022, MNRAS, 516, 3602 [NASA ADS] [CrossRef] [Google Scholar]
- Eyer, L., Audard, M., Holl, B., et al. 2023, A&A, in press https://doi.org/10.1051/0004-6361/202244242 [Google Scholar]
- Fontaine, G., Brassard, P., Charpinet, S., et al. 2003, ApJ, 597, 518 [Google Scholar]
- Friedrich, S., Koenig, M., & Wicenec, A. 1997, ESA Spec. Publ., 402, 441 [Google Scholar]
- Fukugita, M., Ichikawa, T., Gunn, J. E., et al. 1996, AJ, 111, 1748 [Google Scholar]
- Gaia Collaboration 2022, VizieR Online Data Catalog, I/355 [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2021, A&A, 649, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (De Ridder, J., et al.) 2023, A&A, in press, https://doi.org/10.1051/0004-6361/202243767 [Google Scholar]
- Geier, S. 2020, A&A, 635, A193 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Geier, S., Hirsch, H., Tillich, A., et al. 2011, A&A, 530, A28 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Geier, S., Raddi, R., Gentile Fusillo, N. P., & Marsh, T. R. 2019, A&A, 621, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Geier, S., Dorsch, M., Pelisoli, I., et al. 2022, A&A, 661, A113 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ghasemi, H., Moravveji, E., Aerts, C., Safari, H., & Vučković, M. 2017, MNRAS, 465, 1518 [Google Scholar]
- Götberg, Y., Korol, V., Lamberts, A., et al. 2020, ApJ, 904, 56 [CrossRef] [Google Scholar]
- Graczyk, D., Soszyński, I., Poleski, R., et al. 2011, Acta Astron., 61, 103 [Google Scholar]
- Green, R. F., Schmidt, M., & Liebert, J. 1986, ApJS, 61, 305 [NASA ADS] [CrossRef] [Google Scholar]
- Green, E. M., Fontaine, G., Reed, M. D., et al. 2003, ApJ, 583, L31 [Google Scholar]
- Green, E. M., Fontaine, G., Hyde, E. A., For, B. Q., & Chayer, P. 2008, ASP Conf. Ser., 392, 75 [NASA ADS] [Google Scholar]
- Groot, P., Bloemen, S., & Jonker, P. 2019a, https://doi.org/10.5281/zenodo.3471366 [Google Scholar]
- Groot, P., Vreeswijk, P., Bloemen, S., et al. 2019b, GRB Coordinates Network, 25340, 1 [NASA ADS] [Google Scholar]
- Han, Z., Podsiadlowski, P., Maxted, P. F. L., Marsh, T. R., & Ivanova, N. 2002, MNRAS, 336, 449 [Google Scholar]
- Han, Z., Podsiadlowski, P., Maxted, P. F. L., & Marsh, T. R. 2003, MNRAS, 341, 669 [NASA ADS] [CrossRef] [Google Scholar]
- Han, Z., Podsiadlowski, P., & Lynas-Gray, A. E. 2007, MNRAS, 380, 1098 [NASA ADS] [CrossRef] [Google Scholar]
- Heber, U. 2009, ARA&A, 47, 211 [Google Scholar]
- Heber, U. 2016, PASP, 128, 082001 [Google Scholar]
- Heinze, A. N., Tonry, J. L., Denneau, L., et al. 2018, AJ, 156, 241 [Google Scholar]
- Horne, K. 1986, PASP, 98, 609 [Google Scholar]
- Hu, H., Nelemans, G., Østensen, R., et al. 2007, A&A, 473, 569 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Huber, M. E., Everett, M. E., & Howell, S. B. 2006, AJ, 132, 633 [NASA ADS] [CrossRef] [Google Scholar]
- Ivanova, N., Justham, S., Chen, X., et al. 2013, A&A Rev., 21, 59 [NASA ADS] [CrossRef] [Google Scholar]
- Jayasinghe, T., Kochanek, C. S., Stanek, K. Z., et al. 2018, MNRAS, 477, 3145 [Google Scholar]
- Jester, S., Schneider, D. P., Richards, G. T., et al. 2005, AJ, 130, 873 [Google Scholar]
- Jonas, J. L. 2009, Proc. IEEE, 97, 1522 [NASA ADS] [CrossRef] [Google Scholar]
- Kawaler, S. D., Reed, M. D., Østensen, R. H., et al. 2010, MNRAS, 409, 1509 [NASA ADS] [CrossRef] [Google Scholar]
- Kilkenny, D., Koen, C., O’Donoghue, D., & Stobie, R. S. 1997, MNRAS, 285, 640 [Google Scholar]
- Klement, R., Schaefer, G. H., Gies, D. R., et al. 2022, ApJ, 926, 213 [NASA ADS] [CrossRef] [Google Scholar]
- Kupfer, T., Ramsay, G., van Roestel, J., et al. 2017, ApJ, 851, 28 [NASA ADS] [CrossRef] [Google Scholar]
- Kupfer, T., Korol, V., Shah, S., et al. 2018, MNRAS, 480, 302 [NASA ADS] [CrossRef] [Google Scholar]
- Kupfer, T., Prince, T. A., van Roestel, J., et al. 2021, MNRAS, 505, 1254 [NASA ADS] [CrossRef] [Google Scholar]
- Lafler, J., & Kinman, T. D. 1965, ApJS, 11, 216 [NASA ADS] [CrossRef] [Google Scholar]
- Law, N. M., Kulkarni, S. R., Dekany, R. G., et al. 2009, PASP, 121, 1395 [NASA ADS] [CrossRef] [Google Scholar]
- Lee, Y.-W., & Demarque, P. 1990, ApJS, 73, 709 [NASA ADS] [CrossRef] [Google Scholar]
- Lindegren, L. 2017, Gaia technical note GAIA-C3-TN-LU-LL-124. http://www.rssd.esa.int/doc_fetch.php?id=3757412 [Google Scholar]
- Lindegren, L., Hernández, J., Bombrun, A., et al. 2018, A&A, 616, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lindegren, L., Bastian, U., Biermann, M., et al. 2021, A&A, 649, A4 [EDP Sciences] [Google Scholar]
- Lisker, T., Heber, U., Napiwotzki, R., et al. 2005, A&A, 430, 223 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lomb, N. R. 1976, Ap&SS, 39, 447 [Google Scholar]
- Lynas-Gray, A. E. 2021, Front. Astron. Space Sci., 8, 19 [NASA ADS] [Google Scholar]
- Macfarlane, S. A., Toma, R., Ramsay, G., et al. 2015, MNRAS, 454, 507 [NASA ADS] [CrossRef] [Google Scholar]
- Maxted, P. F. L., Heber, U., Marsh, T. R., & North, R. C. 2001, MNRAS, 326, 1391 [CrossRef] [Google Scholar]
- Morales-Rueda, L., Groot, P. J., Augusteijn, T., et al. 2006a, MNRAS, 371, 1681 [NASA ADS] [CrossRef] [Google Scholar]
- Morales-Rueda, L., Maxted, P. F. L., Marsh, T. R., Kilkenny, D., & O’Donoghue, D. 2006b, Baltic Astron., 15, 187 [NASA ADS] [Google Scholar]
- Naylor, T. 1998, MNRAS, 296, 339 [NASA ADS] [CrossRef] [Google Scholar]
- Nazé, Y., Rauw, G., Czesla, S., Smith, M. A., & Robrade, J. 2022, MNRAS, 510, 2286 [CrossRef] [Google Scholar]
- Østensen, R. H., Silvotti, R., Charpinet, S., et al. 2011, MNRAS, 414, 2860 [CrossRef] [Google Scholar]
- Østensen, R. H., Telting, J. H., Reed, M. D., et al. 2014, A&A, 569, A15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pablo, H., Kawaler, S. D., Reed, M. D., et al. 2012, MNRAS, 422, 1343 [NASA ADS] [CrossRef] [Google Scholar]
- Ramsay, G., & Hakala, P. 2005, MNRAS, 360, 314 [NASA ADS] [CrossRef] [Google Scholar]
- Randall, S. K., Fontaine, G., Brassard, P., & Van Grootel, V. 2010, A&A, 522, A48 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Reed, M. D., Slayton, A., Baran, A. S., et al. 2021, MNRAS, 507, 4178 [NASA ADS] [CrossRef] [Google Scholar]
- Reimann, J. D. 1994, PhD Thesis, University of California, Berkeley, USA [Google Scholar]
- Ricker, G. R., Winn, J. N., Vanderspek, R., et al. 2015, J. Astron. Telesc. Instrum. Syst., 1, 014003 [Google Scholar]
- Rindskopf, D., & Shiyko, M. 2010, in International Encyclopedia of Education, 3rd edn., eds. P. Peterson, E. Baker, & B. McGaw (Oxford: Elsevier), 267 [CrossRef] [Google Scholar]
- Rybizki, J., Green, G. M., Rix, H.-W., et al. 2022, MNRAS, 510, 2597 [NASA ADS] [CrossRef] [Google Scholar]
- Saha, A., & Vivas, A. K. 2017, AJ, 154, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Scargle, J. D. 1982, ApJ, 263, 835 [Google Scholar]
- Schaffenroth, V., Geier, S., Heber, U., et al. 2018, A&A, 614, A77 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuster, A. 1898, Terrest. Mag. (J. Geophys. Res.), 3, 13 [NASA ADS] [Google Scholar]
- Silvotti, R., Östensen, R., Telting, J., & Lovis, C. 2014, ASP Conf. Ser., 481, 13 [NASA ADS] [Google Scholar]
- Stellingwerf, R. F. 1978, ApJ, 224, 953 [Google Scholar]
- Taylor, M. B. 2005, ASP Conf. Ser., 347, 29 [Google Scholar]
- Telting, J. H., & Østensen, R. H. 2006, A&A, 450, 1149 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Toonen, S., Nelemans, G., & Portegies Zwart, S. 2012, A&A, 546, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Uzundag, M., Vučković, M., Németh, P., et al. 2021, A&A, 651, A121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Van Beeck, J., Bowman, D. M., Pedersen, M. G., et al. 2021, A&A, 655, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Van Grootel, V., Charpinet, S., Fontaine, G., et al. 2010, ApJ, 718, L97 [NASA ADS] [CrossRef] [Google Scholar]
- VanderPlas, J. T. 2018, ApJS, 236, 16 [Google Scholar]
- VanderPlas, J. T., & Ivezić, Ž. 2015, ApJ, 812, 18 [Google Scholar]
- Vennes, S., Kawka, A., & Németh, P. 2011, MNRAS, 410, 2095 [NASA ADS] [Google Scholar]
- Vos, J., Østensen, R. H., Vučković, M., & Van Winckel, H. 2017, A&A, 605, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vos, J., Bobrick, A., & Vučković, M. 2020, A&A, 641, A163 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vučković, M., Østensen, R. H., Aerts, C., et al. 2009, A&A, 505, 239 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wang, B., Meng, X., Chen, X., & Han, Z. 2009, MNRAS, 395, 847 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, L., Gies, D. R., Peters, G. J., et al. 2021, AJ, 161, 248 [Google Scholar]
- Wu, Y., Chen, X., Li, Z., & Han, Z. 2018, A&A, 618, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zong, W., Charpinet, S., Vauclair, G., Giammichele, N., & Van Grootel, V. 2016, A&A, 585, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: MeerLICHT’s sdB candidates flagged as VARIABLE in Gaia DR3
This section describes sdB candidates identified already as Variables in Gaia DR3 (Gaia Collaboration 2022). These candidates are among the 610 sdB candidates discussed in Sects. 2.3 and 2.4. Running the frequency search algorithm (see Sect. 4) on these candidates allows us to derive the periods and possible variability classes based on their phase light curve shapes. The same approaches described in Sect. 4 are applied to derive their periods using a one-term model. Visual inspection of the candidate phase light curves (Figs. A.1−A.5) reveals that 13 of them are EBs and 4 reveal sinusoidal variability. A summary of their photometric measurements and periods can be found in Table A.1 by referring to the ID value on top of each plot. This table contains the coordinates, averaged magnitude in the three band filters (u, q, i), number of observations in each filter (Nq, Nu, Ni), period, S/N, and a preliminary classification of the variability type of each candidate. We note that most of the candidates have no assigned class as their variability type is not obvious from the light curve shapes.
 |
Fig. A.1. Periodograms and phase diagrams of MeerLICHT’s candidates flagged as VARIABLE in Gaia DR3. |
 |
Fig. A.2. Periodograms and phase diagrams of MeerLICHT’s candidates flagged as VARIABLE in Gaia DR3. |
 |
Fig. A.3. Periodograms and phase diagrams of MeerLICHT’s candidates flagged as VARIABLE in Gaia DR3. |
 |
Fig. A.4. Periodograms and phase diagrams of MeerLICHT’s candidates flagged as VARIABLE in Gaia DR3. |
 |
Fig. A.5. Periodograms and phase diagrams of MeerLICHT’s candidates flagged as VARIABLE in Gaia DR3. |
MeerLICHT candidates flagged as VARIABLE in Gaia DR3.
Appendix B: Candidates’ variability indices plots and full catalogue
 |
Fig. B.1. Plots of the 610 sdB candidates’ variability indices. Au/Ai is the phase-folded models’ amplitude ratio between the u- and i-band filters for the dominant frequency, whereas sigvar is the significance of variability (also known as the reduced weighted χ2) computed from candidates’ fluxes in the q-band filter. The skewness and kurtosis (Friedrich et al. 1997) are obtained from the q-band fluxes, while the MAD and magnitude of variability (V), defined in Sect. 4, are derived from the q-band magnitudes. |
All Tables
All Figures
|
Fig. 1. Magnitude distribution of the MeerLICHT (ML) q band and the Gaia G band in a field with a galactic latitude above 20° (b = 21.08°), using a magnitude bin width of Δmag = 0.5 mag. The y-axis represents the number of data points per magnitude bin, and the x-axis corresponds to MeerLICHT’s q-band magnitude (qmag) and Gaia G-band magnitude (Gmag). The parallax over parallax error (ϖ/σϖ) and the RUWE cuts are applied independently to the Gaia data. The value in the middle bottom panel corresponds to the median of the RUWE. |
| In the text | |
 |
Fig. 2. Same as Fig. 1, but for a field centred at a galactic latitude below 20° (b = −45.06°). |
| In the text | |
|
Fig. 3. CMDs of both MeerLICHT (left) and Gaia DR3 (right) data. The blue data points represent the selected sdB candidates from the colour classification schemes. The open orange circles represent EBs identified from the sdB candidates, while the red stars correspond to candidates with sinusoidal variations. Even though white dwarfs are also selected, we do not exclude them from our analysis as they could be relevant to the study of sdB-white dwarf binary systems. |
| In the text | |
|
Fig. 4. CCDs using different MeerLICHT colours. The sdB candidates shown in Fig. 3 are highlighted in orange here. |
| In the text | |
|
Fig. 5. Distribution of the number of observations in the q-band filter (N-obs) for the 2188 sdB candidates. The y-axis corresponds to the number of objects per N-obs bin and is represented on a logarithmic scale. The vertical dashed grey line indicates the cutoff at N-obs = 40 in MeerLICHT q-band observations. All objects to the right of this cutoff line are selected to be in our sdB candidate sample. |
| In the text | |
|
Fig. 6. Illustration of the nature of MeerLCIHT’s light curve for the target in the second panel of Figs. 12 and 13. The irregularity in the sampling and the gapped observations can be clearly seen in this plot. |
| In the text | |
|
Fig. 7. Magnitude in the q band (qmag) versus standard deviation (std). Data points flagged as VARIABLE in the Gaia DR3 catalogue are marked in orange. |
| In the text | |
|
Fig. 8. Illustration of the difference between scaling the magnitudes to have the same amplitude before computing the periodogram (bottom panel) and without scaling the magnitudes (top panel). The improvement in the cleanliness of the periodogram using Ψ is shown in the right panels. These plots correspond to the second target in Table 2 or a zoomed-in version of the top middle panel in Fig. 12. |
| In the text | |
|
Fig. 9. Averaged LS periodograms of the candidates’ window functions using a frequency bin width of 1 cycle per day. The solid blue and green lines correspond to the window functions in the composite uqi-band filters and the q band, respectively. The dashed orange and grey lines represent the same window functions, but with the contribution of the uncertainties of the magnitude values included in the calculation of the periodograms. |
| In the text | |
|
Fig. 10. Histogram of the candidates’ dominant frequencies found by the Ψ statistic. The y-axis is on a logarithmic scale. |
| In the text | |
|
Fig. 11. Periodograms and phase diagrams comparing one-term (left panel) and two-term (right panel) models. The black curve represents the model fit to the data using the dominant frequency found using the LS periodogram. |
| In the text | |
|
Fig. 12. Comparison of MeerLICHT and Gaia periodograms and phase-folded light curves for Nbase = 1. Each column represents one of the three sdB candidates. The first and second rows represent the periodograms and phase-folded light curves for MeerLICHT data, respectively, whereas the last two rows correspond to that of Gaia data. The black curve is the model fit to the data using the LS model. For illustration purposes, the phase is plotted twice. |
| In the text | |
 |
Fig. 13. Same as Fig. 12, but using Nbase = 2. |
| In the text | |
|
Fig. 14. MAD vs. the magnitude of variability index (V). The open blue circles represent objects with a number of data points N < 200 in the q band; the grey squares represent those with N > 200. Candidates observed as EBs are represented in orange. |
| In the text | |
|
Fig. A.1. Periodograms and phase diagrams of MeerLICHT’s candidates flagged as VARIABLE in Gaia DR3. |
| In the text | |
|
Fig. A.2. Periodograms and phase diagrams of MeerLICHT’s candidates flagged as VARIABLE in Gaia DR3. |
| In the text | |
|
Fig. A.3. Periodograms and phase diagrams of MeerLICHT’s candidates flagged as VARIABLE in Gaia DR3. |
| In the text | |
|
Fig. A.4. Periodograms and phase diagrams of MeerLICHT’s candidates flagged as VARIABLE in Gaia DR3. |
| In the text | |
|
Fig. A.5. Periodograms and phase diagrams of MeerLICHT’s candidates flagged as VARIABLE in Gaia DR3. |
| In the text | |
|
Fig. B.1. Plots of the 610 sdB candidates’ variability indices. Au/Ai is the phase-folded models’ amplitude ratio between the u- and i-band filters for the dominant frequency, whereas sigvar is the significance of variability (also known as the reduced weighted χ2) computed from candidates’ fluxes in the q-band filter. The skewness and kurtosis (Friedrich et al. 1997) are obtained from the q-band fluxes, while the MAD and magnitude of variability (V), defined in Sect. 4, are derived from the q-band magnitudes. |
| In the text | |
 |
Fig. B.2. Same as Fig. B.1, but the x- and y-axis are represented on a logarithmic scale. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.