| Issue |
A&A
Volume 662, June 2022
|
|
|---|---|---|
| Article Number | A109 | |
| Number of page(s) | 8 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202243250 | |
| Published online | 28 June 2022 | |
AutoSourceID-Light
Fast optical source localization via U-Net and Laplacian of Gaussian
1
Department of Astrophysics/IMAPP, Radboud University,
PO Box 9010,
6500 GL
The Netherlands
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Center for Astrophysics and Cosmology, University of Nova Gorica,
Vipavska 13,
5000
Nova Gorica,
Slovenia
3
High Energy Physics/IMAPP, Radboud University,
PO Box 9010,
6500 GL
Nijmegen,
The Netherlands
4
Nikhef,
Science Park 105,
1098 XG
Amsterdam,
The Netherlands
5
Science Institute, University of Iceland,
IS-107
Reykjavik,
Iceland
6
Instituto de Física Corpuscular, IFIC-UV/CSIC,
Valencia,
Spain
7
Department of Mathematics/IMAPP, Radboud University,
PO Box 9010,
6500 GL
Nijmegen,
The Netherlands
8
Department of Astronomy, University of Cape Town,
Private Bag X3,
Rondebosch
7701,
South Africa
9
South African Astronomical Observatory,
PO Box 9, Observatory,
7935
Cape Town,
South Africa
10
The Inter-University Institute for Data Intensive Astronomy, University of Cape Town,
Private Bag X3,
Rondebosch
7701,
South Africa
11
SRON, Netherlands Institute for Space Research,
Sorbonnelaan 2,
3584 CA
Utrecht,
The Netherlands
12
Institute of Astronomy, KU Leuven,
Celestijnenlaan 200D,
3001
Leuven,
Belgium
13
Institute for Fundamental Physics of the Universe,
Via Beirut 2,
34151
Trieste,
Italy
Received:
2
February
2022
Accepted:
11
May
2022
Abstract
Aims. With the ever-increasing survey speed of optical wide-field telescopes and the importance of discovering transients when they are still young, rapid and reliable source localization is paramount. We present AutoSourceID-Light (ASID-L), an innovative framework that uses computer vision techniques that can naturally deal with large amounts of data and rapidly localize sources in optical images.
Methods. We show that the ASID-L algorithm based on U-shaped networks and enhanced with a Laplacian of Gaussian filter provides outstanding performance in the localization of sources. A U-Net network discerns the sources in the images from many different artifacts and passes the result to a Laplacian of Gaussian filter that then estimates the exact location.
Results. Using ASID-L on the optical images of the MeerLICHT telescope demonstrates the great speed and localization power of the method. We compare the results with SExtractor and show that our method outperforms this more widely used method. ASID-L rapidly detects more sources not only in low- and mid-density fields, but particularly in areas with more than 150 sources per square arcminute. The training set and code used in this paper are publicly available.
Key words: astronomical databases: miscellaneous / methods: data analysis / stars: imaging / techniques: image processing
© F. Stoppa et al. 2022
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe-to-Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
The increased capabilities of many telescopes both on Earth, for example the Zwicky Transient Facility (ZTF, Bellm 2014; Bellm et al. 2019) and the Vera C. Rubin Observatory (Ivezić et al. 2019), and in orbit, such as Gaia (Gaia Collaboration 2016) and the recently launched James Webb Space Telescope (JWST, Gardner et al. 2006), are and will be able to provide large amounts of data at a staggeringly increasing rate. Synoptic telescopes can already take images of the size of 100 Mpixels every 15–60 seconds; this processing speed creates a real bottleneck, and thus there is a need for analysis techniques that can efficiently keep up with this trend and can naturally deal with large amounts of data.
There is a long list of methods used in the astronomical community for source localization. Among the most famous are SExtractor (Bertin & Arnouts 1996), Daophot (Stetson 1987), Mopex (Makovoz & Marleau 2005), SourceMiner (Savage & Oliver 2007), and Astrometry.net (Lang et al. 2010). Most of these methods use a combination of image transformation and detection criteria to first estimate the background and then perform thresholding and deblending to separate overlapping sources. However, when the density of sources exceeds a certain level, these multi-step processes can struggle and their performance can degenerate both in computation time and localization accuracy.
In this paper we propose a new way to analyze optical imaging data that uses computer vision techniques to rapidly localize sources. This method is also extendable to different parts of the electromagnetic spectrum, and therefore naturally leads to the possibility of simultaneous multi-wavelength source analysis.
Some of us developed the AutoSourceID (ASID) code, targeted at automatic sources localization and classification in gamma-ray data (Panes et al. 2021). ASID showed significant promise; the source detection threshold was comparable to that of the traditional catalogs (e.g., 4FGL) (Abdollahi et al. 2020), but with the added advantage that source detection proved to be more robust to uncertainties of the diffuse gamma-ray background.
The code presented in this paper uses a similar baseline structure and is focused on the rapid localization of sources in optical images, the reason behind naming it AutoSourceID-Light (ASID-L). ASID-L uses a U-Net (Ronneberger et al. 2015) network to construct a segmented mask where each pixel in the input image is assigned a value between 0 (background) and 1 (source). A Laplacian of Gaussian filter (Chen et al. 1987) is then applied to the mask predicted by the U-Net to identify the individual sources. The result is a fast automatic way to go from images to a catalog of sources.
Moreover, the problems encountered by the previously mentioned source detection methods can be solved by deep learning algorithms whose computation time does not depend on the number of sources in the images and which, if well trained, can retrieve more sources in crowded regions.
In this work we use wide-field optical images taken with the MeerLICHT telescope, a 65 cm telescope located in Sutherland, South Africa (Bloemen et al. 2016; Groot 2019).
To train the U-Net we also need the true locations of the sources in the images; since the main interest in the context of MeerLICHT is the rapid localization of point sources, we retrieved these locations from the Gaia Early Data Release 3 catalog (EDR3, Gaia Collaboration 2016, 2021). As in the case of any supervised machine learning algorithm, the choice of the training set is fundamental and deeply related to what the network will learn; in our case this means that only point sources will be recognized by the network as targets for its localization. The ASID-L framework is not limited to point sources, however; the U-Net creates a circular segmentation mask for each source that it is trained to localize regardless of its shape, opening up the possibility of localizing extended sources such as galaxies if they are part of the training process.
Finally, we compare the results of ASID-L with SExtractor (Bertin & Arnouts 1996). We chose this method not only because it is widely used in the community, but also because it is already part of the optical images processing pipeline of the MeerLICHT telescope.
2 Method
ASID-L, like its gamma-ray counterpart ASID, works with a chain of networks and tools to rapidly create a catalog of sources from an image. For optical images, the pivotal steps are to detect and find the precise location of the sources; therefore, ASID-L is divided into the following steps: mask generation and source localization. We describe each step in more detail below.
2.1 Mask generation: U-Net image segmentation
Evolved from the well-known convolutional neural network (CNN) architecture (LeCun et al. 1999), U-Net was first designed and applied in 2015 to process biomedical images. The U-Net architecture is primarily used for semantic segmentation, where for each pixel of an image, a corresponding class label is predicted, and helps provide the pixel-level contextual information. Apart from biomedical image segmentation, U-Net was also applied to a wide range of case studies such as lunar crater detection (Wang et al. 2020), radio astronomy (Akeret et al. 2017), and cosmology (Bonjean 2020).
U-Net follows a symmetric encoder–decoder structure. In the encoding path, the image dimension is halved at each stage, and the number of channels are increased in the convolution operation. The channels can be thought of as feature detectors where, low-level features are detected in the initial part of the network and high-level features are detected as the image size reduces and thus we can obtain a dense feature map. This part of the network is similar to a regular fully CNN (FCN Long et al. 2015) and provides classification information.
The obtained dense feature map is then increased back in size in the decoder path to obtain the full-scale segmented image, which is the reason behind the “U” in the network name. In the decoder path, each convolutional layer is connected to its equal-sized counterpart of the encoding path, which helps to combine the small-scale and the large-scale structure and propagate the contextual information along the network to make accurate small-scale predictions on the obtained final segmentation map.
During the training of the network, the weights and biases of the convolutional kernels are optimized based on the loss function described in Sect. 2.2.
The input for the training set of a U-Net algorithm are the images to be segmented and their known segmentations, called masks. After the training process, the U-Net only needs an image as input and will predict its segmentation mask. U-Net networks are typically used to cut out a few relatively large structures (e.g., in biology or galaxy images); our use-case, discerning many small objects, is largely unexplored in fundamental science.
In our application to MeerLICHT, the input images for the training set are pairs of 256 × 256 pixel patches obtained from full field images and their corresponding masks. More details about the location of the sources and the choice of a fixed size mask is in Sect. 3.2.
The training process is straightforward. At epoch 1 the U-Net is fed with thousands of pairs of optical images and their associated masks; an example is shown in Fig. 1. Starting only from the optical image of the pair, the U-Net predicts a mask similar to the one shown in Fig. 2. In reality, at epoch 1 the U-Net does not know anything about what a mask looks like, so the result would be much worse than that shown in Fig. 2. Comparing predicted and training masks with the loss function of Sect. 2.2, the U-Net gradually learns where and how to improve its prediction for the next epoch. By repeating this process for multiple epochs, the U-Net is able to reconstruct mask patches that closely resemble those in the training set, such as the one shown in Fig. 2.
The main difference between a training mask and the output of the U-net is that in the latter the predictions are continuous values in the range [0, 1] for each pixel (instead of integers {0, 1}). Thus, the need for an additional method to discern which groups of pixels should be considered sources and where their centers are located.
 |
Fig. 1 U-Net input, optical image patch on the left and associated mask patch on the right. |
2.2 Loss function
To optimize the model during training, we applied a combination of binary cross-entropy (BCE, Mannor et al. 2005) loss and Dice (Sudre et al. 2017) loss.
Binary cross-entropy loss is defined as
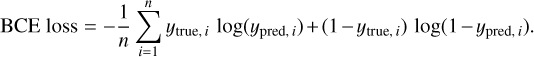 (1)
(1)
This loss examines each pixel individually, comparing ytrue (the true mask value, either 0 or 1) assigned to a specific pixel to ypred (the mask value predicted by the U-Net), and then averages over all n = 256 × 256 pixels.
The second loss function is based on the Dice coefficient (Dice 1945), which is a measure of the overlap between two samples. In 2017 it was adapted as a loss function known as Dice loss, and it is defined as
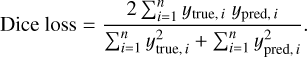 (2)
(2)
The BCE loss works best for equal data distribution among classes, while the Dice loss is particularly suitable for segmentation tasks. The combination of these two losses, also known as Combo loss (Taghanaki et al. 2018), was shown to improve performance in medical image segmentation tasks with a classimbalanced dataset. Inspired by this, we employed in ASID-L the sum of these two losses as the loss function.
2.3 Source localization: Laplacian of Gaussian
Once we have a predicted mask like that in Fig. 2, we apply the Laplacian of Gaussian (LoG) algorithm to determine the exact location and number of sources.
The LoG is a computer vision method for the detection of blobs, based on the combination of a Laplacian filter and a Gaussian blurring step (Sotak & Boyer 1989; Lindeberg 1992). A Laplacian filter is a derivative filter used to find areas of rapid change in images and, for an image with pixel intensity values I(x, y), is given by
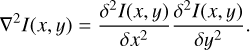 (3)
(3)
Since the Laplacian is a second-order derivative filter, it is quite sensitive to noise. For this reason a Gaussian blurring step is needed to mitigate the problem. Both the Gaussian kernel and the Laplacian filter can be applied simultaneously due to the associative property of the convolution operation, and this two-in-one process is called LoG. The result is a great tool for blob localization that identifies regions that differ in properties from surrounding areas.
A 2D LoG function centered on zero and with standard deviation σ has the form
![Mathematical equation: ${\rm{LoG}}\left({x,y;{\sigma ^2}} \right) = - {1 \over {\pi {\sigma ^4}}}\left[{1 - {{{x^2} + {y^2}} \over {2{\sigma ^2}}}} \right]{e^{- {{{x^2} + {y^2}} \over {2{\sigma ^2}}}}}.$](/articles/aa/full_html/2022/06/aa43250-22/aa43250-22-eq4.png) (4)
(4)
The LoG is strongly dependent on the choice of σ due to the relationship between the size of the blob structures in the image and the Gaussian kernel. As constructed, the LoG results in high positive values for blobs of radius close to 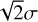 . In general, to capture blobs of different sizes a multi-scale approach is needed where the LoG is applied multiple times with a set of different values for σ (Lindeberg 1998, 2013). However, this is not the case for us; in fact, we exploit the fixed size of our masks to find the single best σ to localize our blobs, improving both accuracy and speed of ASID-L (for more details, see Sect. 4.2). Figure 3 shows an example of what the LoG filter identifies as sources and their locations for the predicted mask of Fig. 2.
. In general, to capture blobs of different sizes a multi-scale approach is needed where the LoG is applied multiple times with a set of different values for σ (Lindeberg 1998, 2013). However, this is not the case for us; in fact, we exploit the fixed size of our masks to find the single best σ to localize our blobs, improving both accuracy and speed of ASID-L (for more details, see Sect. 4.2). Figure 3 shows an example of what the LoG filter identifies as sources and their locations for the predicted mask of Fig. 2.
This is the final output of ASID-L, the locations identified by the LoG are reported as a list of pixel coordinates, but can easily be converted to any coordinate system. We can see the results of ASID-L superimposed on the original optical image in Fig. 4.
 |
Fig. 3 Sources localized by the LoG (red circles) in the U-Net predicted mask. |
3 Application
We now show how we built ASID-L on images taken with an optical telescope, in our case the MeerLICHT telescope (Bloemen et al. 2016; Groot 2019).
3.1 MeerLICHT
The MeerLICHT telescope is a 65 cm optical telescope with a field of view of 2.7 square degrees and a 10.5k × 10.5k pixel CCD. The main aim of MeerLICHT is to follow the pointings of the MeerKAT radio telescope (Jonas & MeerKAT Team 2016) to enable the simultaneous detection of transients at radio and optical wavelengths. The filter set available is the SDSS ugriz set and an additional wide g+r filter named q. The images taken are immediately transferred to the IDIA/ilifu facility, where the image processing software BlackBOX1 (Vreeswijk et al., in prep.) processes the images in the standard fashion before continuing with the source detection (currently using SExtrac-tor), the astrometric and photometric calibration, the derivation of the position-dependent image point spread function (PSF), the image subtraction, and transient detection.
The code presented here is the second deep learning algorithm developed in the context of MeerLICHT, following Meer-CRAB, an algorithm used to classify real and bogus transients in optical images (Hosenie et al. 2021).
 |
Fig. 4 Sources localized by ASID-L (red circles) superimposed on the optical image. |
3.2 Training set
To build and evaluate ASID-L, we selected MeerLICHT q-band images of fields with different source densities: (1) a field centered on the Omega Cen globular cluster, (2) a field of the Fornax galaxy cluster and (3) an “empty” field centered on the Chandra Deep Field-South (CDF-S, Giacconi et al. 2002). We used the Gaia Early Data Release 3 catalog (EDR3, Gaia Collaboration 2016, 2021) to infer the presence of real sources for the training set. For each of the above fields we selected the relevant Gaia EDR3 sources and converted the G-band magnitude of the Gaia source to the q-band flux (in electrons per second) that the source would have on a specific image, using the image zero-point determined in the MeerLICHT photometric calibration. Together with the image background noise, consisting of a combination of the sky background noise and the read noise, and the PSF shape at the source position on the image, we were then able to determine the signal-to-noise ratio (S/N) that the Gaia source would have on a specific MeerLICHT image. The number of sources per square arcminute as a function of the S/N for each field is shown in Table 1.
Variability in the brightness of the point sources and colour terms (MeerLICHT q-band is much narrower than Gaia G) lead to differences between predicted S/N of a source based on Gaia and the true S/N in the MeerLICHT image. The sharp cut-off at the predicted S/N in reality becomes a soft cut-off around that S/N.
For the training, test, and validation sets, we used the three fields described above and the masks built from Gaia sources with a S/N above 3. In Sect. 4.1 we come back to our S/N cut-off choice.
Each field is divided into 1681 patches of 256 × 256 pixels, for a total of 5043 patches of optical images. The choice behind the size of the patches was determined by having a reasonable number of trainable parameters in the U-Net, approximately two million, and at the same time enough memory to load the images. With dedicated hardware the size of the images can be increased. We then created a field mask for each field; at every Gaia EDR3 source location we created a mask made of a central 3 × 3 square of pixels and an additional pixel in every cardinal direction. This is the smallest number of pixels such that the mask still resembles a circle and for overlapping to be minimized in very crowded regions. Each field mask was then split in the same way as for the optical images, resulting in 5043 256 × 256 mask patches. We assigned 80% of the patches to the training set, 10% to the test set, and 10% to the validation set.
Number of sources with different S/N thresholds.
4 Results
To evaluate the performance of ASID-L in terms oflocalized and non-localized sources with respect to the Gaia EDR3 catalog we use the Dice coefficient. In confusion matrix settings, the Dice coefficient can be framed via the following formula:
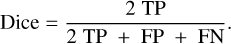 (5)
(5)
Here true positive (TP) is the total number of sources that are both localized by ASID-L and in the Gaia catalog, false positive (FP) is the total number of sources where ASID-L localized something that was not in the Gaia catalog, and false negative (FN) is the total number of sources missed by our method that instead were in the Gaia catalog.
In particular, we evaluate the results of ASID-L on the 165 test patches belonging to the Omega Cen globular cluster; we chose this specific field due to the high variability in the number of sources in each patch. Outside the cluster, an average of a few dozen sources can be identified in each patch, while closer to its center hundreds or even thousands of sources can be found in a 256 × 256 patch.
4.1 S/N cut-off choice
The choice of the S/N cut-off for the training set locations influences the results of ASID-L and has to be well thought out. A cut-off that is too high in Gaia EDR3 means losing sources that are actually in the images, and consequentially, ASID-L will learn to ignore anything below the cut-off. On the contrary, a cutoff that is too low will create masks in locations with no sources in the optical image resulting in a very high number of FPs in the output of ASID-L. In Table 2 we report the number of localized sources per square arcminute as a function of the S/N cut-off of the training set; based on this information we chose the S/N cutoff that results in the highest Dice coefficient and lowest S/N: S/N = 3.
Training results with different S/N cut-off.
Detected sources with different LoG thresholds.
4.2 LoG parameters choice
There are three parameters to optimize for our LoG step: the standard deviation σ, a threshold τ, and an overlap index ω.
As introduced in Sect. 2.3, we exploited the fixed size of the masks to estimate the optimal σ parameter. Evaluating multiple values of σ we found that σ = 1.43 is the optimal choice to localize blobs of the exact size and shape of our masks. As a consequence, we improved the accuracy of the LoG ensuring that only the U-Net’s predicted blobs of the correct size are localized and substantially increasing the speed by not having to evaluate multiple values of σ at every iteration.
To simplify the job of the LoG, a threshold τ is set to remove any predicted pixel with a value below it. An immediate way to see the influence of the threshold τ on the LoG result is the number of FPs. The information in Table 3 suggested that a LoG threshold of 0.2 is the optimal choice.
The last parameter is the maximum amount of overlap ω between adjacent sources. We set this parameter to 0.8, meaning that if two adjacent sources overlap by more than 80% only one central source is localized. For our test set, this parameter has no influence on the resulting number of TPs, FNs, and FPs.
4.3 Final results
We now present the results of ASID-L with the specific choices of S/N cut-off and LoG parameters introduced in the previous sections. At the same time, we compare the results with SExtractor, one of the most applied algorithms for source localization in optical images. The SExtractor results were obtained with the default parameters; the only exceptions were DETECT_MINAREA = 3 and BACK_SIZE = 60.
In Table 4, for the Omega Cen test set, we compare the number of sources per square arcminute in the Gaia EDR3 catalog, and the sources localized by SExtractor and ASID-L.
Gaia has the highest number of sources by far, and it is what we use as the ground truth for all the comparisons. However, the Gaia catalog is not perfect; it does not include small galaxies and might include sources that are not visible in the optical images for the reasons explained in Sect. 3.2.
For the Omega Cen test set, SExtractor ideally has a few FPs per square arcminute; however, the overall number of TPs is low, resulting in a Dice coefficient of 0.5653. ASID-L, on the contrary, has an higher number of FPs, but it correctly localizes almost twice as many sources with respect to SExtractor, resulting in a Dice coefficient of 0.8075.
We now evaluate the reason behind this substantial difference in the results of the two methods. In Fig. 5, we show the Dice coefficient, as in Eq. (5), for all 165 patches of the test set belonging to the Omega Cen globular cluster field.
ASID-L scores are between 0.75 and 0.9 for any number of sources in the patches, proving that a high number of sources is not a concern for the method. ASID-L recovers more sources than SExtractor, although the influence of the FPs in low-density regions affects the resulting Dice coefficient value, as can be seen at the top left of the plot. SExtractor, instead, suffers in very crowded regions: the higher the number of sources, the lower its Dice coefficient.
For the two patches of Figs. 6–8 show the results of ASID-L and SExtractor with respect to Gaia EDR3 in terms of TP, FN, and FP.
In uncrowded regions ASID-L recovers a few sources more than SExtractor, while for very crowded regions (as in Fig. 8), ASID-L localizes many more sources.
Comparison of detected sources.
 |
Fig. 5 Dice coefficient of the Omega Cen test set patches as a function of the number of sources per square arcminute in each patch (ASID-L in blue and SExtractor in orange). |
 |
Fig. 6 Optical patches with two different densities of sources. |
 |
Fig. 7 Comparison between ASID-L and SExtractor with respect to Gaia EDR3 for the uncrowded patch in Fig. 6. |
 |
Fig. 8 Comparison between ASID-L and SExtractor with respect to Gaia EDR3 for the crowded patch in Fig. 6. |
5 Speed and additional features
With the increased capabilities of many telescopes, large amounts of data will have to be processed at a staggeringly increasing rate. Thus, there is a need for computationally efficient methods that not only can keep up with this trend, but can also help to reduce the carbon footprint of this process.
We now evaluate the processing time of ASID-L and SEx-tractor on an Alienware Area 51M, Intel Core i9-9900K, 32GB DDR4/2400, Nvidia GeForce RTX 2080.
We estimated the processing time of SExtractor in the Python library Source Extractor and Photometry (SEP, Barbary 2016; Barbary et al. 2017). SEP uses the same core algorithms of SEx-tractor, it is written in C, and it has a Python module to wrap it in a Pythonic API. This additional step makes SEP slower than SExtractor, but within acceptable limits.
ASID-L was also tested in Python. It was developed with Tensorflow and Scikit-Image, runs on GPU, and was parallelized on multiple cores, although the use of a GPU or parallelization is not needed.
In Table 5, we evaluate the time performance of both methods on 3 2560 × 2560 pixels (580 square arcminutes) MeerLICHT images with different densities of sources.
The striking difference between ASID-L and SExtractor is that the ASID-L processing time does not depend on the number of sources in the images; SExtractor, on the contrary, does. For fields with approximately ten sources per square arcminute ASID-L runs seven times faster than SEP; however, SEP provides a set of additional information for each source that makes it preferable for the accurate exploration of uncrowded fields. SExtractor is a great tool, but it also heavily depends on the input parameters, which makes it unsuitable for the automatic localization of sources. ASID-L, on the contrary, does not need any prior information about the field and can be applied without supervision in a live-stream manner. ASID-L not only speeds up the source localization task, but its additional features make the preprocessing of the optical images unnecessary, which increases the time gain and reduces the carbon footprint of the entire process.
ASID-L is trained and can thus predict on images where the background has not been subtracted and where differences between the channels of the CCD have not been corrected, effectively removing these steps from the preprocessing completely. ASID-L can also discern between real sources and a series of artifacts, such as diffraction spikes and cosmic rays. The cosmic-ray removal was previously performed using the Astro-scrappy2 implementation of L.A. Cosmic (Van Dokkum 2001; Van Dokkum et al. 2012) and required a few minutes per Meer-LICHT/BlackGEM (Groot et al. 2019) image. This is now taken care of directly during the prediction step.
Last but not least, ASID-L can recognize satellite trails and correctly discard them. With the increasing number of low-Earth-orbit (LEO) satellites such as SpaceX’s Starlink, this is a vital feature. It has been calculated that once the size of the Starlink constellation reaches 10 000, essentially all ZTF images taken during twilight may be affected (Mróz et al. 2022). In Fig. 9, we show the prediction of ASID-L on two images affected by cosmic rays, satellite trails and diffraction spikes.
Computation time comparison.
 |
Fig. 9 Sources localized by ASID-L (red circle) superimposed on two optical images in the presence of multiple artifacts. |
 |
Fig. 10 Star cluster image retrieved from the Hubble Space Telescope archive (GO-10396, PI: J.S. Gallagher). In red are the sources localized by ASID-L. |
6 Transfer learning and application to different telescopes
An open question that we want to address in the future is how the resolution of the images affects the localization results. A promising first test can be found in Figs. 10 and 11, where we applied ASID-L, trained on MeerLICHT images, to images from the Hubble Space Telescope. The HST has a full width at half maximum (FWHM) PSF of about 0.11 arcseconds, much better than the 2-3 arcsec of MeerLICHT.
Although this is an early study, it appears that ASID-L is capable of localizing many sources without the need to retrain the U-Net on HST images. The main difference between MeerLICHT and HST, the resolution of the images, does not seem to affect the results of the method. However, there may be artifacts in HST images that differ from those ASID-L ever encountered in MeerLICHT, one example being the diffraction spikes that are much brighter for HST.
Moreover, in Fig. 11 we can see that some small sources are not localized by ASID-L; two possible reasons could be the peculiar background or the fact that in MeerLICHT sources of that size are most likely cosmic rays that ASID-L is trained to automatically remove.
ASID-L was created for optical images, but we are also interested in its performance for different parts of the EM spectrum. In Fig. 12 we show the result of ASID-L applied to an infrared image from the Wide-field Infrared Survey Explorer (WISE, Wright et al. 2010) space telescope. ASID-L seems to hold localization power also in the infrared; although the background is quite different from that of the MeerLICHT images, many sources are localized. A deeper exploration of these images with a ground truth catalog, like we did with Gaia EDR3, will give us many insights into what the differences are in applying ASID-L to different parts of the EM spectrum.
A great result for the future would be proving that ASID-L can be applied to different telescopes without the need of retraining for each specific instrument, effectively opening a path toward transfer learning for a broad range of telescopes.
 |
Fig. 11 Messier 16 (Eagle Nebula) image retrieved from the Hubble Space Telescope archive. In red are the sources localized by ASID-L. |
7 Conclusions
In this paper we presented the building blocks of ASID-L and applied it to real images taken with the MeerLICHT telescope. Born from the combination of a U-Net network and a computer vision tool called Laplacian of Gaussian, ASID-L has been trained and evaluated with the Gaia EDR3 catalog. The result is a clean framework for significantly increasing the speed and accuracy of optical source localization in any field, crowded or not.
Because it does not depend on any prior knowledge, ASID-L can be used on archival images or live as soon as a telescope takes the image. An iterative use of ASID-L can be applied to the search for specific objects like transients and variable stars. ASID-L not only identifies faint sources, it also handles a few well-known optical image problems: cosmic rays, diffraction spikes, and artificial trails.
The dataset used in this paper for training, test, and validation set is available on Zenodo (Stoppa & Vreeswijk 20223). ASID-L is directly accessible on GitHub and Zenodo (Stoppa 2022; Stoppa et al. 20224), and will be included in the pipeline of the MeerLICHT telescope.
Our next project will be to expand ASID-L and make its output broader by including additional information about the localized sources. The current output of ASID-L is suitable to be used as input for additional networks; one example is cutting 32 × 32 pixel patches around each localized source and applying a classifier to discern between different types of sources or simply to discern between true positives and false positives and improving the performance of ASID-L. Another deep learning algorithm can be applied to each localized source to extract their features such as flux, PSF, ellipticity, the pixels they occupy, and a more accurate estimate of the center. All these additional steps and the compatibility with multiple telescopes will further enhance the competitiveness of ASID-L in the astronomical community.
 |
Fig. 12 Infrared image of the NGC 31 field taken with the WISE space telescope. In red are the sources localized by ASID-L. |
Acknowledgements
F.S. and G.N. acknowledge support from the Dutch Science Foundation NWO. S.B. and G.Z. acknowledge the financial support from the Slovenian Research Agency (grants P1-0031, I0-0033 and J1-1700). R.R. acknowledges support from the Ministerio de Ciencia e Innovación (PID2020-113644GB-I00). P.J.G. is supported by NRF SARChI (grant 111692). The MeerLICHT telescope is a collaboration between Radboud University, the University of Cape Town, the South African Astronomical Observatory, the University of Oxford, the University of Manchester and the University of Amsterdam, and supported by the NWO and NRF Funding agencies. We thank the anonymous reviewer whose comments and suggestions helped to improve and clarify this paper.
References
- Abdollahi, S., Acero, F., Ackermann, M., et al. 2020, ApJS, 247, 33 [Google Scholar]
- Akeret, J., Chang, C., Lucchi, A., & Refregier, A. 2017, Astron. Comput., 18, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Barbary, K. 2016, J. Open Source Softw., 1, 58 [Google Scholar]
- Barbary, K., Boone, K., Craig, M., Deil, C., & Rose, B. 2017, https://doi.org/10.5281/zenodo.896928 [Google Scholar]
- Bellm, E. 2014, in The Third Hot-wiring the Transient Universe Workshop, eds. P.R. Wozniak, M.J. Graham, A.A. Mahabal, & R. Seaman, 27 [Google Scholar]
- Bellm, E. C., Kulkarni, S. R., Graham, M. J., et al. 2019, PASP, 131, 018002 [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, A&AS, 117, 393 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bloemen, S., Groot, P., Woudt, P., et al. 2016, SPIE Conf. Ser., 9906, 990664 [NASA ADS] [Google Scholar]
- Bonjean, V. 2020, A&A 634, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chen, J. S., Huertas, A., & Medioni, G. 1987, IEEE Transac. Patt. Anal. Mach. Intell., 9, 584 [CrossRef] [Google Scholar]
- Dice, L. R. 1945, Ecology, 26, 297 [CrossRef] [Google Scholar]
- Gaia Collaboration ( Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration ( Brown, A.G.A., et al.) 2021, A&A, 649, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gardner, J. P., Mather, J. C., Clampin, M., et al. 2006, Space Sci. Rev., 123, 485 [Google Scholar]
- Giacconi, R., Zirm, A., Wang, J., et al. 2002, ApJS, 139, 369 [Google Scholar]
- Groot, P. J. 2019, Nat. Astron., 3, 1160 [NASA ADS] [CrossRef] [Google Scholar]
- Groot, P., Bloemen, S., & Jonker, P. 2019, https://doi.org/10.5281/zenodo.3471366 [Google Scholar]
- Hosenie, Z., Bloemen, S., Groot, P., et al. 2021, Exp. Astron., 51, 319 [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jonas, J., & MeerKAT Team. 2016, MeerKAT Science: On the Pathway to the SKA 1 [Google Scholar]
- Lang, D., Hogg, D. W., Mierle, K., Blanton, M., & Roweis, S. 2010, AJ, 139, 1782 [Google Scholar]
- LeCun, Y., Haffner, Patrickand Bottou, L., & Bengio, Y. 1999, Object Recognition with Gradient-Based Learning (Berlin, Heidelberg: Springer Berlin Heidelberg), 319 [Google Scholar]
- Lindeberg, T. 1992, J. Math. Imaging Vision, 1, 65 [CrossRef] [Google Scholar]
- Lindeberg, T. 1998, Int. J. Comput. Vision, 30, 79 [CrossRef] [Google Scholar]
- Lindeberg, T. 2013, J. Math. Imaging Vis., 46, 177 [CrossRef] [Google Scholar]
- Long, J., Shelhamer, E., & Darrell, T. 2015, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Los Alamitos, CA, USA: IEEE Computer Society), 3431 [CrossRef] [Google Scholar]
- Makovoz, D., & Marleau, F. R. 2005, PASP, 117, 1113 [NASA ADS] [CrossRef] [Google Scholar]
- Mannor, S., Peleg, D., & Rubinstein, R. 2005, in Proceedings of the 22nd International Conference on Machine Learning, ICML ’05 (New York, NY, USA: Association for Computing Machinery), 561 [Google Scholar]
- Mróz, P., Otarola, A., Prince, T. A., et al. 2022, ApJ, 924, L30 [CrossRef] [Google Scholar]
- Panes, B., Eckner, C., Hendriks, L., et al. 2021, A&A, 656, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ronneberger, O., Fischer, P., & Brox, T. 2015, in Medical Image Computing and Computer-Assisted Intervention - MICCAI 2015, eds. N. Navab, J. Hornegger, W.M. Wells, & A.F. Frangi (Cham: Springer International Publishing), 234 [CrossRef] [Google Scholar]
- Savage, R. S., & Oliver, S. 2007, ApJ, 661, 1339 [NASA ADS] [CrossRef] [Google Scholar]
- Sotak, G., & Boyer, K. 1989, Comput. Vision Graphics Image Process., 48, 147 [CrossRef] [Google Scholar]
- Stetson, P. B. 1987, PASP, 99, 191 [Google Scholar]
- Stoppa, F. 2022, https://doi.org/10.5281/zenodo.5938341 [Google Scholar]
- Stoppa, & Vreeswijk 2022, https://doi.org/10.5281/zenodo.5902893 [Google Scholar]
- Stoppa, F., Vreeswijk, P., Bloemen, S., et al. 2022, Astrophysics Source Code Library [record ascl:2203.014] [Google Scholar]
- Sudre, C. H., Li, W., Vercauteren, T., Ourselin, S., & Jorge Cardoso, M. 2017, Lecture Notes in Computer Science (Berlin: Springer), 240 [CrossRef] [Google Scholar]
- Taghanaki, S. A., Zheng, Y., Zhou, S. K., et al. 2018, CoRR, abs/1805.02798 [Google Scholar]
- Van Dokkum, P. G. 2001, PASP, 113, 1420 [CrossRef] [Google Scholar]
- Van Dokkum, P. G., Bloom, J., & Tewes, M. 2012, Astrophysics Source Code Library [record ascl:1207.005] [Google Scholar]
- Wang, S., Fan, Z., Li, Z., Zhang, H., & Wei, C. 2020, Remote Sens., 12, 2460 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868 [Google Scholar]
All Tables
All Figures
|
Fig. 1 U-Net input, optical image patch on the left and associated mask patch on the right. |
| In the text | |
 |
Fig. 2 U-Net output, predicted mask for the left image of Fig. 1. |
| In the text | |
|
Fig. 3 Sources localized by the LoG (red circles) in the U-Net predicted mask. |
| In the text | |
|
Fig. 4 Sources localized by ASID-L (red circles) superimposed on the optical image. |
| In the text | |
|
Fig. 5 Dice coefficient of the Omega Cen test set patches as a function of the number of sources per square arcminute in each patch (ASID-L in blue and SExtractor in orange). |
| In the text | |
|
Fig. 6 Optical patches with two different densities of sources. |
| In the text | |
|
Fig. 7 Comparison between ASID-L and SExtractor with respect to Gaia EDR3 for the uncrowded patch in Fig. 6. |
| In the text | |
|
Fig. 8 Comparison between ASID-L and SExtractor with respect to Gaia EDR3 for the crowded patch in Fig. 6. |
| In the text | |
|
Fig. 9 Sources localized by ASID-L (red circle) superimposed on two optical images in the presence of multiple artifacts. |
| In the text | |
|
Fig. 10 Star cluster image retrieved from the Hubble Space Telescope archive (GO-10396, PI: J.S. Gallagher). In red are the sources localized by ASID-L. |
| In the text | |
|
Fig. 11 Messier 16 (Eagle Nebula) image retrieved from the Hubble Space Telescope archive. In red are the sources localized by ASID-L. |
| In the text | |
|
Fig. 12 Infrared image of the NGC 31 field taken with the WISE space telescope. In red are the sources localized by ASID-L. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.