| Issue |
A&A
Volume 670, February 2023
|
|
|---|---|---|
| Article Number | A55 | |
| Number of page(s) | 16 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202244708 | |
| Published online | 03 February 2023 | |
A comparative study of source-finding techniques in H I emission line cubes using SoFiA, MTObjects, and supervised deep learning
1
Kapteyn Astronomical Institute, University of Groningen,
Landleven 12,
9747 AD
Groningen, The Netherlands
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Data Management & Bionetrics (DMB), University of Twente,
Drienerlolaan 5,
7522 NB
Enschede, The Netherlands
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
3
Bernoulli Institute for Mathematics, Computer Science and Artificial Intelligence, University of Groningen,
Nijenborgh 9,
9747 AG
Groningen, The Netherlands
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
6
August
2022
Accepted:
9
November
2022
Abstract
Context. The 21 cm spectral line emission of atomic neutral hydrogen (H I) is one of the primary wavelengths observed in radio astronomy. However, the signal is intrinsically faint and the H I content of galaxies depends on the cosmic environment, requiring large survey volumes and survey depth to investigate the H I Universe. As the amount of data coming from these surveys continues to increase with technological improvements, so does the need for automatic techniques for identifying and characterising H I sources while considering the tradeoff between completeness and purity.
Aims. This study aimed to find the optimal pipeline for finding and masking the most sources with the best mask quality and the fewest artefacts in 3D neutral hydrogen cubes. Various existing methods were explored, including the traditional statistical approaches and machine learning techniques, in an attempt to create a pipeline to optimally identify and mask the sources in 3D neutral hydrogen (H I) 21 cm spectral line data cubes.
Methods. Two traditional source-finding methods were tested first: the well-established H I source-finding software SoFiA and one of the most recent, best performing optical source-finding pieces of software, MTObjects. A new supervised deep learning approach was also tested, in which a 3D convolutional neural network architecture, known as V-Net, which was originally designed for medical imaging, was used. These three source-finding methods were further improved by adding a classical machine learning classifier as a post-processing step to remove false positive detections. The pipelines were tested on H I data cubes from the Westerbork Synthesis Radio Telescope with additional inserted mock galaxies.
Results. Following what has been learned from work in other fields, such as medical imaging, it was expected that the best pipeline would involve the V-Net network combined with a random forest classifier. This, however, was not the case: SoFiA combined with a random forest classifier provided the best results, with the V-Net–random forest combination a close second. We suspect this is due to the fact that there are many more mock sources in the training set than real sources. There is, therefore, room to improve the quality of the V-Net network with better-labelled data such that it can potentially outperform SoFiA.
Key words: techniques: image processing / methods: data analysis / surveys
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe-to-Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Large-area astronomical imaging surveys map the skies without a specific target, resulting in images that contain many astronomical objects. As the technology used to create these surveys improves with projects such as the Square Kilometre Array (SKA; Weltman et al. 2020), an unprecedented amount of data will become available. In addition to the difficulty of identifying low-intensity sources with close proximity to the level of noise, the time that it would require an experienced astronomer to manually identify sources in data sets of such volumes would be unfeasible (Haigh et al. 2021), hence the need for fast and accurate techniques for identifying and masking sources in astronomical imaging survey data.
The 21 cm spectral line emission of atomic neutral hydrogen (H I) is one of the primary wavelengths observed in radio astronomy. It is detected via the emission of a photon due to the energy level transition of the hydrogen atom at 21 cm. H I gas is observed as clouds in galaxies, which can be used to determine their structure, as well as free-floating gas outside of galaxies (see for example Hibbard et al. 2001 and the references therein). However, it is intrinsically faint and sensitive to its environment, requiring large volume coverage and depth to map the H I Universe, hence the need for large redshift range surveys that use radio telescopes such as the precursors to the SKA (Weltman et al. 2020). This includes the Meer Karoo Array Telescope (MeerKAT; Jonas 2009), a 64-dish array in South Africa, the Australian Square Kilometre Array Pathfinder (ASKAP; De Boer et al. 2009), which consists of 36 dishes in Western Australia, and the APERture Tile in Focus (Apertif; van Cappellen et al. 2022), a 12-dish array upgrade of the Westerbork Synthesis Radio Telescope (WSRT; Hogbom & Brouw 1974) in the Netherlands.
The 21 cm spectral line emission of galaxies is captured and processed into floating point values whose intensities represent flux in a 3D (mosaicked) H I data cube. The cube consists of two positional dimensions (right ascension and declination) and one spectral dimension (frequency or velocity), with a high data volume of the order of hundreds of gigavoxels (Moschini 2016). A schematic of such a data cube containing an H I emitting galaxy, without noise, can be seen in Fig. 1. Despite the growing knowledge and tools available for source-finding in 2D images, it is still considered a challenge in astronomy, particularly when considering the same task in 3D data cubes.
Astronomical source-finding is limited by the necessary tradeoff between accepting false positives and excluding true sources. This is only heightened by the lack of well-defined boundaries and low signal-to-noise ratios of H I sources (Aniyan & Thorat 2017). In addition, most H I sources are faint and extended (Punzo et al. 2015), and sometimes the surrounding noise that needs to be differentiated from the actual sources is very similar to the signal of the sources (Gheller et al. 2018).
The problem at hand can be seen as an overlap between astronomy and computer vision, where existing advances in computer vision could be used to solve the struggle of finding and masking sources in astronomy. While computer vision makes use of different terminologies, such as object segmentation, the task of finding and masking astronomical sources can be defined as locating and highlighting pixels in an image that belong to different objects.
Many astronomers explore source-finding solutions using simple statistical techniques (Jarvis & Tyson 1981; Bertin & Arnouts 1996; Andreon et al. 2000). However, these approaches are very sensitive to the input parameters and struggle to differentiate between faint sources and noise. The challenge lies in the absence of the boundaries of sources, with many having intensities very close to the noise, especially in the case of 21 cm data (Punzo et al. 2015). As a result, these approaches require a tradeoff between completeness and purity.
This study, therefore, aimed to address the dilemma of this tradeoff by determining the optimal source-finding pipeline, with better completeness, purity, and mask quality than previous methods. To this aim, the contributions of this work are fourfold.
First, this is the first published work, to our knowledge, that provides the training and testing of a deep learning source-finding and masking architecture on 3D H I emission data. This model could be adapted for data from different telescopes and could be used as a source-finding method in future H I surveys.
Second, a classical machine learning solution has been proposed for improving the purity of the catalogues created by source finders. It was trained on various methods to ensure its ability to be used on any H I source catalogue.
Third, a new pipeline for finding and masking H I sources in data cubes has been introduced. This was achieved by comparing statistical and deep learning methods using the well-known tool Source Finding Application (SoFiA; Serra et al. 2015; Westmeier et al. 2021) as the baseline for the experiments. The final pipeline consists of a source-finding method followed by a machine learning model for post-processing.
Finally, a catalogue of detections by various source finders of mock H I galaxies and their associated properties has been made available for future use1. These detections were made via the various experiments and can be used for training classification models in the future.
Section 2 begins by outlining the existing source-finding methods and an explanation of the algorithms that were tested in this paper. This is followed by an explanation of the data used and the experimental setup in Sect. 3. The results of each source-finding pipeline can be found in Sect. 4 and are discussed and compared in Sect. 5. Finally, some concluding statements are made and the potential for future work is explored in Sect. 6.
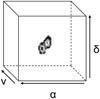 |
Fig. 1 Schematic of a noiseless 3D H I emission cube containing a galaxy. The cube consists of two positional dimensions (right ascension, α, and declination, δ) and one spectral dimension (frequency, υ). |
2 Source-finding methods
In this section, several existing astronomical source-finding methods are discussed, including their strengths and weaknesses. This is followed by the theoretical backgrounds of the source-finding software that were compared in this paper.
2.1 Existing methods
Existing source-finding techniques can be categorised into three types of approaches. The first is traditional methods, which use statistical techniques to identify sources, followed by classical machine learning techniques and deep learning approaches. Since most source-finding techniques are originally designed for 2D images, pixels will often be mentioned, but it is important to note that 3D data cubes are made up of voxels.
2.1.1 Traditional methods
The two most common traditional source-finding techniques in astronomy are thresholding and local peak search (Masias et al. 2012). The simplest of the two is thresholding, where a collection of connected pixels are masked as a source if they are above a specified threshold value. The threshold can be global to the image but due to background variations it is often chosen locally, depending on the neighbourhood, and in some cases, an adaptive threshold is used. However, despite their high speeds and simplicity, thresholding methods have difficulty finding faint sources. SExtractor (Bertin & Arnouts 1996) is one of the most well-known source-finding programmes in astronomy that uses a thresholding method.
The other most widely used traditional method is local peak search, which finds sources by creating a list of candidate pixels for the central points of sources, chosen by the local maxima. The sources are then masked by taking the pixels around each central point candidate that decrease in intensity. While local peak search has already been in use since the late 1970s (Argueso et al. 2006), it is more suited for detecting point sources and struggles to find extended sources. A common weakness of both thresholding and local peak search methods is their difficulty in de-blending or differentiating between multiple sources (Haigh et al. 2021).
While thresholding and local peak search are the most common classical source-finding techniques developed, in recent years a variety of methods have been applied, inspired by other computer vision applications. A popular classical source-finding technique in computer vision is edge-based source-finding and masking. This algorithm detects the edges of a source by finding discontinuities in the characteristics of the pixels, such as the brightness. These edges are then connected to create a border around the mask of the located source (Alamri et al. 2010). However, this approach is more appropriate for objects with well-defined edges and therefore is not suitable for the detection of diffuse H I emission sources.
Another popular classical source-finding method is the watershed transform (Bandara 2018). This method treats the image as a topographic surface and interprets the gradient of the pixel intensity as the elevation. It then locates and masks sources in the image by acting as if water is poured into the minima and treats the boundaries as where the puddles would merge. This is used for source-finding in astronomy by Aptoula et al. (2006), resulting in masks with continuous boundaries. Although the watershed approach is more stable than edge-based methods, it suffers from its computational complexity (Kaur & Kaur 2014).
Region-based detection locates sources and creates masks by grouping pixels with similar characteristics. While these region-based methods are popular among computer vision tasks, they have only recently been introduced in the context of astronomical source-finding. These methods have the advantage of being less sensitive to noise, particularly when prior knowledge can be used to define which characteristics to compare the pixels. However, region-based methods are also known to be memory and time-intensive (Zaitoun & Aqel 2015). A recent example of region-based source-finding software used in astronomy is Max-Tree Object (MTObjects or MTO; Teeninga et al. 2013, 2016), which makes use of max-trees (see Sect. 2.2.2). This software was originally designed for 2D optical data. However, since diffuse optical sources similarly suffer from the tradeoff between completeness and purity, MTO has been extended further for H I emission cubes by Arnoldus (2015).
Weighing up the pros and cons of each of these methods, the best source-finding solution, therefore, depends on the astronomical data itself. Hence the creation of general source-finding software, the flexible SoFiA (Serra et al. 2015; Westmeier et al. 2021). SoFiA is designed to be independent of the source of H I emission line data used and is currently the most used pipeline for source-finding in H I emission cubes. It was therefore used as the benchmark for our experiments.
2.1.2 Classical machine learning methods
In addition to the traditional statistical methods used for source-finding, there are many machine learning approaches. Classical machine learning methods learn from the characteristics of the observational data, such as the brightness of a pixel, also known as features. On the other hand, deep learning takes the raw data itself as input and then determines the features. These features are chosen to represent the physical properties of the system and therefore their quality determines the efficiency of the learning algorithm. It is therefore important to have a good understanding of the data being used, and in this case radio astronomy, to implement these techniques.
Both classical and deep machine learning methods can be either supervised or unsupervised. Unsupervised methods find the boundaries of objects using their intensity or a gradient analysis, which makes them better suited for identifying sources with well-defined boundaries. Supervised methods instead use prior knowledge through training samples. Since the H I sources in the data cubes are known to have ill-defined boundaries (Punzo et al. 2015), supervised machine learning techniques are better suited.
The most well-researched techniques use classification as a way to find sources, including support vector machines (Vapnik 1995), K-nearest neighbours (Cunningham & Delany 2007), decision trees (Breiman et al. 1984), and random forests (Ho 1995). While these techniques were not used directly as source finders, the random forest (Ho 1995) classifier was used as a postprocessor to improve the purity of the catalogues created by the source-finding methods, since it is one of the best-performing algorithms for classification (Fernandez-Delgado et al. 2014).
The random forest (Ho 1995) algorithm, as its name suggests, creates a random forest of uncorrelated decision trees (Breiman et al. 1984), which essentially build trees based on the features of a data set. To reduce variance, the decision trees are each trained on a subset of the training data and input features are selected randomly with replacement, also known as bootstrapping. The bias in the learning error is reduced by merging the decision trees and taking the average result or the result with the most votes. Random forests are therefore advantageous in their accuracy, stability, and few tuning parameters, but they can be very slow compared to other classical machine learning classifiers if a large number of trees are used (Fernandez-Delgado et al. 2014).
2.1.3 Deep learning methods
Deep learning is a type of machine learning that learns directly from observational data rather than its features. In recent years it has been the primary method used for finding and masking sources in computer vision due to its high accuracy above traditional methods (Fernandez-Delgado et al. 2014). Since deep learning takes the raw data as its input, it requires less prior knowledge of the data for training and therefore makes it most advantageous when the features do not provide enough information to create an accurate model. The main drawbacks of deep learning methods are their lack of transparency, their computational expense, and the need for large training data sets with already located and masked sources (O’Mahony et al. 2019). However, there is already a lot of work done to overcome the latter two challenges (Samudre et al. 2022; Zhi et al. 2018; Bochkovskiy et al. 2020).
The most frequently used deep learning method for image processing is the convolutional neural network (CNN; Goodfellow et al. 2016). A CNN is a type of artificial neural network that contains one or more convolutional layers. An advantage of CNNs is their ability to be re-trained on custom data sets, which allows for more flexibility while classical machine learning methods tend to be more domain-specific (O’Mahony et al. 2019). It is not only widely used in the field of computer vision but has recently become a popular method for source-finding in 21 cm astronomy images (Gheller et al. 2018; Lukic et al. 2019; Aniyan & Thorat 2017), and is found to out-perform other machine learning methods when used for optical 2D galaxy classification (Cheng et al. 2020; Alhassan et al. 2018).
While the use of CNNs for 2D images is well explored, the application of CNNs on 3D data cubes is still very new. The main challenge is that CNNs require a fixed-dimension grid input. Many of the existing methods use 2D data to train the network due to the lack of 3D data containing masks available for training. Many different techniques exist that essentially slice the cube into multiple 2D slices and then fuse them back together to create a masked cube, for example, Çiçek et al. (2016) and Yang et al. (2021). The identification of sources in each slice is done based on the top-ranking medical imaging CNN architecture called U-Net (Ronneberger et al. 2015).
Applying 2D CNNs to slices of the data has the advantage of being able to make use of previously trained weights from studies such as Gheller et al. (2018) and Lukic et al. (2019), which find sources in 2D radio data. However, while this saves computational costs, it is very important that the data are sliced in a way that preserves the shape of the sources, which is not so simple with asymmetric sources. An alternative approach is using an architecture that takes a 3D volume as its input, as opposed to 2D slices, and uses volumetric convolutions. V-Net (Milletari et al. 2016) is an architecture that does just that, following the architecture of U-Net (Ronneberger et al. 2015).
2.2 Comparing source-finding software
While there are a variety of source-finding techniques that exist, the traditional methods require extensive prior knowledge and still have been found to fail at differentiating many faint H I sources from surrounding noise. Although both classical machine learning methods and even deep learning have begun to be explored in astronomical source-finding, there is very little work done that uses these techniques on 3D H I emission data. In addition, the 3D CNN architectures that do exist have not yet been tested for finding astronomical sources. We, therefore, investigated the use of a 3D CNN architecture, namely V-Net (Milletari et al. 2016), to locate and mask H I sources in 3D data cubes. This was then evaluated and compared to software that makes use of traditional methods, SoFiA (Serra et al. 2015; Westmeier et al. 2021) and MTO (Teeninga et al. 2016), which will be discussed first.
2.2.1 SoFiA
Comparing the strengths of the best traditional algorithms used for source-finding, it is clear that the optimal source finder depends on the properties of the astronomical data itself. This has led to the creation of general source-finding software, the flexible SoFiA (Serra et al. 2015; Westmeier et al. 2021). SoFiA enables the choice of a variety of source-finding techniques and has been designed to be independent of the type of H I emission line data used. Currently, this is the most used pipeline for source-finding in H I emission data and is, therefore, the benchmark for the experiments for this study. The pipeline begins by removing any variation in the noise to ensure the assumption of uniform noise. This is done by normalising the cube with a weights cube made up of the local noise.
Version 2.3.1 of SoFiA (Serra et al. 2015; Westmeier et al. 2021) makes use of the smooth and clip method since this technique has been found to be the best source-finding method for extended sources (Popping et al. 2012) in H I data cubes. This algorithm uses 3D kernels to iteratively smooth the cube and find sources on multiple scales, both spatially and spectrally. For each resolution, voxels are added to the mask on the condition that they have a flux relative to the global root mean square (RMS) noise level above the chosen signal-to-noise threshold. Since H I sources are known to have an exponential radial surface brightness profile (Wright 1974) and a double-horned spectral profile, a Gaussian filter is used in the spatial domain and a boxcar filter in the spectral domain.
Once the voxels associated with sources are identified, an algorithm equivalent to the friends-of-friends algorithm (Jurek 2012) is used to merge them into sources. This is done by looping over the segmented binary mask and assigning a label to unlabelled source-containing voxels as well as the neighbouring voxels within a chosen merging or linking length. In this process, sources that do not fit the given size criteria are rejected.
The reliability of the sources is then determined following Serra et al. (2012). This works by assuming that a true source is positive and that the noise in the cube is symmetric. With this assumption, it is implied that there is an equal number of noise peaks with a negative intensity as there are with a positive intensity. The reliability of a source can therefore be evaluated in a 3D parameter space by measuring the density of positive and negative sources and calculating the probability that a positive source is not just a noise peak. Detections that are found to have an integrated signal-to-noise (S/N) ratio below an assigned S/N limit are designated a reliability score of zero. The resulting reliability score can be thresholded to remove unreliable sources.
2.2.2 MTObjects
MTObjects (Teeninga et al. 2013, 2016) is region-based source-finding software that makes use of max-trees. Max-trees are a special case of a component tree, a tree built from connected components of threshold sets. Connected components are classically defined as path-connected groups of voxels with the same intensity, foreground or background in the thresholded case, of maximal extent (Serra 1988). The definition of a max-tree, according to Salembier et al. (1998), is a representation of an image as a tree structure with the maxima as its leaves. The root of the max-tree consists of the entire image domain, while the leaves represent the voxels with the local maxima values. The nodes of the max-tree represent connected components of threshold sets of the image, where it is the grey scale of the image that is thresholded. Therefore, there can never be more nodes than there are voxels in the image. Each connected component of the max-tree can be assigned attributes such as the volume and flux density, which allows for filtering based on a threshold for these attributes.
A max-tree is much more compact than a classical component tree, saving memory by not storing the elements of their children and consisting of only those component tree nodes that have at least one voxel at the appropriate threshold level. The advantage of max-trees is that they can filter the cubes without distorting any edge information because it operates on the connected components of an image rather than individual voxels (Salembier et al. 1998). The version of MTObjects implemented by Arnoldus (2015) was used, as it was designed for 3D radio cubes. The pipeline consists of four steps that can be seen in the flowchart in Fig. 2.
The first step of the MTO pipeline is the pre-processing of the cube to create a max-tree mask. First, the cube is smoothed with a Gaussian filter to stabilise the gradient approximation. This is followed by the application of spatially adaptive smoothing to ensure the preservation of the edges of sources. The adaptive smoothing technique used is known as the Perona–Malik diffusion filter (Perona & Malik 1990). The filter models the smoothing as an anisotropic diffusion process.
Both smoothing steps are used to increase the signal-to-noise ratio and are followed by a background estimation to create a max-tree mask. The background is calculated as the mean of the regions that contain no sources. The background is then subtracted from the smoothed image and the resulting negative values are set to zero to ensure the lack of negative-total-flux nodes in the max-tree.
Once the cube has been smoothed and the background subtracted, the next step of the pipeline is the construction of the max-tree. During the construction of the max-tree, the node attributes are also calculated to inform the removal of false detections at a later stage.
Due to the limited classical definition of connectivity, Ouzounis & Wilkinson (2007) presented a new approach known as mask-based connectivity that instead relies on the pre-processed connectivity mask. However, Arnoldus (2015) adapts this definition of connectivity further still by storing the full original volume to calculate component attributes or properties at a later stage in the max-tree data structure. This allows for the enhancement of its source-finding by using the pre-processed image while maintaining the original image for the statistical model.
Once the max-tree is constructed, MTO finds and labels the nodes that belong to a source, this is the object detection step in Fig. 2, which filters the max-tree and chooses the nodes based on their attributes using statistical tests. Since the simple χ2 method from Teeninga et al. (2016) would not suffice in modelling the correlated noise in the H I cubes, the statistical tests have been modified for radio data (Teeninga et al. 2013). The attribute used to detect sources was chosen to be the flux density, as it is less sensitive to outliers (Arnoldus 2015). The flux density is defined as follows:
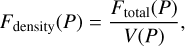 (1)
(1)
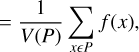 (2)
(2)
where P is a peak component of the max-tree mask, V(P) is its volume, and f is the original volume. A node or part of the volume is included in a source mask if it has a greater value of this attribute than other children of its parent node or if it has no significant parent.
 |
Fig. 2 Schematic diagram of the source-finding pipeline of MTObjects (Arnoldus 2015). An H I emission sub-cube, which contains a source, is transformed into a max-tree mask with the use of both Gaussian and adaptive smoothing. A max-tree is then built from the max-tree mask, and the source nodes are labelled using the attributes of the smoothed cube. Finally, post-processing is used to remove false detections. |
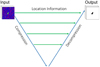 |
Fig. 3 Illustration of the V-Net architecture, based on the architecture of Milletari et al. (2016). The compression path is shown on the left and the decompression path on the right, and the two are horizontally linked by the location information. |
2.2.3 V-Net
As mentioned, the most used deep learning method for image processing is the CNN. While CNNs can be designed from scratch, there are many already existing architectures that have been optimised for source-finding tasks (Long et al. 2014; Christ et al. 2016; Milletari et al. 2016). These architectures can be adapted to a variety of source-finding tasks and data sets, and can either be re-trained from scratch or the weights from previous tasks can be selectively updated.
The CNN architecture chosen for this project was the novel V-Net (Milletari et al. 2016) network. V-Net is originally designed for locating and masking objects in medical images (Milletari et al. 2016) and was chosen due to its ability to take full data volumes as its input as opposed to slices of 3D images. V-Net is a fully volumetric CNN built following the well-known architecture of U-Net (Christ et al. 2016).
A schematic diagram of the V-Net architecture is shown in Fig. 3. Following Fig. 3 left to right, the model is composed of a compression and decompression path, much like U-Net. Each path is composed of multiple stages containing one to three convolutional layers each, which enable the learning of a residual function that ensures convergence, unlike U-Net. The convolutional layers in the stages of the compression path have a volumetric kernel of 5 × 5 × 5 voxels. In between each stage, a 2 × 2 × 2 voxels filter is applied with a stride of two voxels to halve the spatial sizes of the output feature maps and double the number of feature channels. This step is followed by the use of the Parametric Rectified Linear Unit (PReLU; He et al. 2015) as an activation function. This is a modification of the well-known Rectified Linear Unit (ReLU; Fukushima 1975), which directly outputs the input if it is positive and otherwise outputs zero. PReLU simply generalises this by using a slope for negative values.
The decompression path increases the spatial size of the input of each layer using de-convolutions, which are followed by one to three convolutional layers with filters the same size as those used in the compression path. With each convolutional layer, the number of filters is doubled and again a residual function is learnt. As a result, two output feature maps are produced with the same dimensions as the volume inputted into the network. These two probabilistic maps of the foreground and background regions are produced using voxel-wise softmax regression (Bridle 1990), which normalises the map so that the voxel values follow a probability distribution. As in U-Net, horizontal links are used at each stage to propagate the extracted features to the decompression paths in order to recover the location information lost in the compression path.
The sources aimed to be found occupy only a very small region of the volume, which only increases the risk of the training process getting stuck in a local minimum of the loss function. This could result in predictions that are biased to the noise and the model may miss or partially detect sources. Since this is an issue for medical imaging (Valverde et al. 2017), sample re-weighting-based loss functions can be employed (Long et al. 2014; Christ et al. 2016). These types of functions favour the sources during the learning phase. However, another approach to counter-act this imbalance is to use a loss function and evaluation metric that is inherently balanced. The most common of these is the Dice coefficient (Dice 1945; Sørensen 1948), also known as the F-score (van Rijsbergen 1979). The F-score maximises the measure of the overlap of two masks, ranging from 0 to 1. With A and B being two overlapping masks, the F-score is defined as twice the intersection divided by the union of each mask as follows:
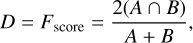 (3)
(3)
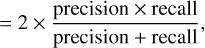 (4)
(4)
where the recall or the completeness measures the proportion of detected sources and the precision or purity measures the proportion of segments that match the ground truth or target masks as follows:
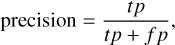 (5)
(5)
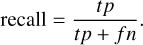 (6)
(6)
Here tp, tn, fp, and fn are the true positives, true negatives, false positives, and false negatives, respectively. An adaption of the Dice coefficient is used for the loss function of the V-Net network and is defined as follows (Milletari et al. 2016):
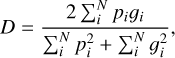 (7)
(7)
where N is the number of voxels in the detection mask, pi, with the ground truth mask gi. The gradient with respect to the jth voxel is therefore defined as
![Mathematical equation: $ {{\partial D} \over {\partial {p_j}}} = 2\left[ {{{{_j}\left( {\sum _i^Np_i^2 + \sum _i^N_i^2} \right) - 2{p_j}\left( {\sum _i^N{p_i}{_i}} \right)} \over {{{\left( {\sum _i^Np_i^2 + \sum _i^N_i^2} \right)}^2}}}} \right]. $](/articles/aa/full_html/2023/02/aa44708-22/aa44708-22-eq8.png) (8)
(8)
This allows a balance between the foreground and background voxels without the need to assign them weights. Moreover, this loss function is shown to outperform those with sample re-weighting methods (Milletari et al. 2016).
3 Methodology
This section describes both the observed and synthetic data used to compare the source-finding methods described in the previous section. This is followed by an explanation of the experimental setup, including the machines used for the experiments and the parameters used for each source-finding software.
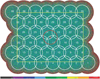 |
Fig. 4 Example of a single channel of an Apertif H I emission cube, prior to noise normalisation. The colour scale represents the noise balanced on 0, which is non-uniform and increases towards the edges of the cube. The layout of the Apertif compound beams mosaicked into a hexagonal shape is overlaid in white, following van Cappellen et al. (2022). Note that the cubes were cropped spatially, here indicated by the yellow rectangle, resulting in 1000 × 1600 pixels in dimension, representing the declination and right ascension, respectively. |
3.1 Data
Supervised machine learning methods, especially CNNs, require a large sample of labelled training data, which is not easily available for radio images. Previous approaches, such as Galaxy Zoo (Lintott et al. 2008), make use of crowdsourcing to create manually labelled data via visual inspection. However, even if manually labelled data were available, the ground truth or target mask is not known and some labels could be missed or incorrect, due to the difficulty of interpreting the 3D data cubes. Additionally, many of the sources of interest are rare and are therefore very difficult to train to detect (Haigh et al. 2021). To tackle this problem simulated cubes of H I emission containing galaxies with labelled masks were used for this project.
3.1.1 Observed data
To prevent the need to simulate noise, existing observed data cubes were taken from the H I medium-deep imaging survey from Apertif (Apertif Science Team 2016) receivers on the WSRT (Hogbom & Brouw 1974). Apertif collects data from 40 beams on the sky simultaneously, which are then combined into a single mosaic data cube. Each of the individual, nearly circular, beams covers 36′ of the sky, resulting in the final mosaic covering about 6.2 square degrees. The observations cover 1279.9–1425.1 MHz, which are then split into seven spectral windows of 23.84 Hz, for parallel computation, each with 652 channels. These windows were split in such a way that they overlap in frequency to account for the frequency width of galaxies.
Not every beam is equally sensitive and therefore the observations contain significant variations in the noise. In order to correct for these noise variations and allow for better source-finding, the noise was normalised by dividing the H I emission cube by the spectral RMS noise at each pixel. Figure 4 shows both the layout of the beams that form the mosaic and an example of a single channel taken from one of the data cubes prior to its noise normalisation. Due to the high intensity of noise at the edges and the blank voxels in the corners of the H I emission cubes, the corners and edges were cropped to prevent any errors from the source finders in case they could not take blank voxels in their input.
The observed areas of the sky in the imaging surveys performed with Apertif were chosen to include regions with publicly available spectroscopic and optical observations. Of the two major imaging surveys, the data was taken from the medium-deep survey (Apertif Science Team 2016), which covers an area including the Perseus-Pisces Supercluster (Böhringer et al. 2021). This area consists of nine pointings, each observed 10 times for 11.5 h to reduce the noise by a factor of 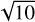 and increase the sensitivity when combining them. Due to the partial completion of the observations at the start of this project, two out of the nine pointings were used, one for training purposes and one for testing, each containing six spectral windows. The pointing used for training purposes ranges from 1h45m 10.91s–2h5m26.57s in right ascension and 34°51′04.49″–37°50′56.31″ in declination with a resolution of 25″ in the north-south direction. The pointing used for testing purposes covers 1h45m19.81s–1h5m7.69s in right ascension and 31°15′16.19″–35°15′08.58″ in declination with a resolution of 27″ in the north-south direction. At the rest frequency of 1420 MHz, applying a robust weighting of zero, the angular resolution in the east-west direction for both pointings is 15″.
and increase the sensitivity when combining them. Due to the partial completion of the observations at the start of this project, two out of the nine pointings were used, one for training purposes and one for testing, each containing six spectral windows. The pointing used for training purposes ranges from 1h45m 10.91s–2h5m26.57s in right ascension and 34°51′04.49″–37°50′56.31″ in declination with a resolution of 25″ in the north-south direction. The pointing used for testing purposes covers 1h45m19.81s–1h5m7.69s in right ascension and 31°15′16.19″–35°15′08.58″ in declination with a resolution of 27″ in the north-south direction. At the rest frequency of 1420 MHz, applying a robust weighting of zero, the angular resolution in the east-west direction for both pointings is 15″.
Once cropped, each of the spectral windows from each pointing makes up a data cube with 651 × 1000 × 1600 voxels in dimension, representing the frequency, declination and right ascension, respectively. The angular size of the pixels is 6″ and the spectral width of the channels is 36.611 kHz. The properties of the six spectral windows for the two pointings can be found in Table 1. The RMS of the noise prior to normalisation shows how the noise varies with the frequency range, increasing for more distant spectral windows.
Properties of the seven spectral windows of the two pointings chosen from the Apertif medium-deep survey.
3.1.2 Creating and inserting the mock galaxies
The 3000 mock galaxies created by Gogate (2022) were used as a parent library for the insertion into the H I emission cubes, similar to that shown in Fig. 4. These galaxies were created following empirical scaling relations and by assuming a A cold dark matter cosmology with H0 = 70 km s−1 Mpc−1 and Ωm = 0.3 using Galaxy Model (GalMod), which is part of the Groningen Image Processing SYstem (GIPSY; van der Hulst et al. 1992). In order to create the mock galaxies, GalMod requires a rotation curve and a radial H I density distribution for each galaxy. The universal rotation curve prescription by Persic et al. (1996) was used to calculate the rotational velocities of the mock sources. The radial H I surface density distributions were based on the prescription by Martinsson et al. (2016) and slightly modified by Gogate (2022). We refer to Gogate (2022) for further details.
From the available library of 3000 mock galaxy cubes, 300 were randomly selected and inserted into each of the twelve Apertif data cubes, resulting in a total of 1800 mock galaxies inserted in the six training cubes, and 1800 inserted in the six test cubes. The insertion of the mock galaxies into the observed Apertif cubes guarantees that the CNN was trained to find sources in the presence of noise with realistic properties.
As mentioned, the mock galaxies were scaled in size and flux as if observed at a distance of 50 Mpc, corresponding to a red-shift of z = 0.011675, assuming a quiet Hubble flow with H0 = 70 km s−1 Mpc−1, and an observed frequency of 1404.014 MHz. The mock galaxy cubes have pixels of 5″ or 1.212 kpc, and a channel width of 24.206 kHz or a rest frame velocity width of 5.169 km s−1. Furthermore, the cubes were smoothed to mimic a Gaussian synthesised beam with an angular resolution of Θ =15″×25″ corresponding to 3.6×6.1 kpc2.
Inserting a mock galaxy into one of the Apertif cubes that were corrected for primary beam attenuation, consisted of multiple preparatory steps. First, a random position and channel were chosen. The frequency, fobs, of the chosen channel corresponds to a redshift of zobs = (frest/fobs)−1, where frest = 1420.405 MHz is the rest frequency of the H I emission line, which in turn corresponds to a distance of Dobs = cz/H0 Mpc, where c = 299 792.458 km s−1 is the speed of light. It should be noted that since the angular resolution of the pre-existing mock galaxy cubes can only be reduced and not improved, the observing frequency corresponding to the distance of 50 Mpc was also the maximum frequency at which the mock galaxies could be inserted into the Apertif cubes.
Second, the angular resolution of the mock galaxy cube was reduced by smoothing to a Gaussian synthesised beam of Θobs = (1+zobs)15″×(1+zobs)25″, after which the channels were re-gridded to pixels of size (1+zobs)6″. Third, the mock galaxy cube was re-sampled in the spectral direction to a channel width of 36.621 kHz, while accounting for the corresponding rest frame channel width in km s−1, at the observing frequency fobs. Fourth, the flux density of the signal in the mock galaxy cube was scaled to the distance, Dobs, and beam size, Θobs, such that the measured total H I mass of the mock galaxy would be preserved.
Finally, for the purpose of labelling the ground truth in the training process for the 3D CNN and for evaluating all three source-finding methods, a binary mask cube was also made for each mock galaxy cube by converting all positive flux voxels to one and the rest of the voxels to zero. These binary mask cubes were then inserted into a duplicated Apertif cube in which all the voxels were first set to zero. Figure 5 illustrates a channel from an Apertif data cube after insertion of the mock galaxies, along with the corresponding binary mask.
The smoothing of the mock galaxy cubes, the resampling of the voxels, and the scaling of the flux allowed a voxel-by-voxel insertion of the mock galaxy cube into the Apertif data cube around the randomly selected channel. It should be noted, however, that the resulting data cubes with realistic noise properties not only contain the 300 inserted mock galaxies but also dozens of unknown and unlabelled real sources. Section 4.2 discusses how these real sources were identified and treated in the training process.
 |
Fig. 5 Zoomed-in, z-scaled (Tody 1986) single channel of an example of an Apertif cube (a) and the corresponding binary mask of the inserted mock galaxies (b). The cube has been noise-normalised, and mock galaxies have been inserted. The colour bars represent the intensity of the simulated emission. |
3.2 Experimental setup
All three source-finding algorithms were executed on the same compute architecture, a single machine consisting of two Intel Xeon E5-2698 v3 central processing units (CPU), each with 16 cores and 32 threads, and equipped with 24×32 = 768 GB DDR4 2133 MT/s of RAM. The training of the V-Net network, however, was done using the Peregrine high-performance computing (HPC) cluster of the University of Groningen2, consisting of 5740 CPU cores and 220 000 compute unified device architecture (CUDA) cores (Cook 2012). The training of the V-Net network used only one of these CUDA nodes with an allocated memory of 9GB.
Version 2.3.1 of the SoFiA software (Serra et al. 2015; Westmeier et al. 2021) was used for this experiment. This version was written in C, making it much faster than previous versions implemented in Python. For MTObjects, the code developed by Arnoldus (2015) was used, since it is designed for 3D radio data cubes. The V-Net network was implemented in PyTorch (Paszke et al. 2019) and is available through MedicalZooPytorch3 (Nikolaos 2019), an open-source 3D medical segmentation library. PyTorch is an open-source machine learning Python library that supports CUDA tensor types. It can therefore utilise graphics processing units (GPU) for computational purposes, which is advantageous for computer vision tasks.
The details of the parameters used for the implementation of SoFiA, MTO, and the V-Net network can be found in the Appendix. The move-up factor and the connectivity of MTO were chosen following Arnoldus (2015). The smoothing kernels used for SoFiA were chosen based on astrophysical considerations, such as the expected physical size and line width of galaxies (for example Westmeier et al. 2021). In addition, the minimum spatial and spectral widths for both MTO and SoFiA were chosen based on the mask sizes of the mock galaxies. The parameters of MTO and SoFiA were then manually optimised for the Apertif data cubes, by visually inspecting the resulting masks and comparing them to the ground truth masks of only the mock galaxies such that the parameters were optimised for purity without compromising the completeness.
The V-Net network, as with other neural networks, makes use of an optimiser to automatically modify its parameters to reduce its loss score. Using the adaption of the Dice coefficient as the loss function, explained in Sect. 2.2.3, the loss score is calculated by comparing the predictions to the targets and minimising the loss function with each epoch. For the implementation of V-Net, the adaptive moment estimation (Kingma & Ba 2015) was chosen as the optimiser because it combines the best properties of resilient backpropagation (Igel & Hüsken 2000) with those of another optimiser called an adaptive learning rate method. It has also been found to outperform the well-known stochastic gradient descent (Sebastian 2016) when many parameters are used and when saddle points are encountered. Through experimentation, a learning rate of 1×10−3 was chosen to minimize the loss score without drastically slowing down the learning process.
Prior to testing the source finders, V-Net was trained using a ground truth containing the masks of only the mock galaxies, since the location of real sources in the data cubes was not yet known. All three source-finding methods were run on the six Apertif cubes of each of the two pointings, containing real sources, realistic noise and the inserted mock galaxies. The V-Net network expects an input of dimensions 128 × 128 × 64 voxels, with the channels as the last dimension as opposed to the first. Therefore, a sliding window was used to create the input for the network with an overlap of size 15 × 20 × 20 voxels. Due to the high memory usage of MTO, a sliding window was also used to run the source finder on smaller inputs. Since the size of the windows was only limited by the memory of the machine used, the largest windows possible were taken. The windows therefore each consisted of 652 × 200 × 300 channels and pixels, respectively.
Each method yielded a catalogue of sources consisting of mock galaxies, potential real sources and false positives. Mock galaxies in the catalogue were identified by cross-matching against the mask cube and labelled as true positives. Real sources in the output catalogues of the three methods were differentiated from false positives by checking for the presence of an optical counterpart in the Panoramic Survey Telescope and Rapid Response System (Pan-STARRS) survey (Flewelling et al. 2020; see Sect. 4.2). Real sources were labelled as such and sources in the output catalogue not labelled as mock galaxies and that were without an optical counterpart were labelled as false positives. The masks of the identified real sources were created by taking the union of all the masks from the catalogues of the three source-finding methods. The masks for the real sources were then added to the ground truth and used to train V-Net’s network, now with both real sources and mock galaxies in the training pointing. The newly trained network was then run on the test pointing and evaluated in comparison to SoFiA and MTO, using the ground truth containing both real sources and mock galaxies.
In an attempt to improve the purity of the source catalogues produced by all three methods, a post-processing step was implemented to remove as many false positive detections as possible. The rejection of false detections could have been based directly on the astrophysical plausibility of the attributes, such as the size of the galaxy. However, for large volumes like the Apertif survey cubes analysed here, many false positive detections have attributes very close to the attributes of sources. Therefore, a shallow machine learning approach was used instead, postprocessing the source-finding catalogues with a random forest classifier (Ho 1995), as it is one of the best performing algorithms for classification (Fernandez-Delgado et al. 2014).
All three source-finding methods were run on both Apertif pointings. The three resulting catalogues of detected sources from the Apertif training pointing were combined and used as a single catalogue to train the random forest classifier, taken from scikit-learn (Pedregosa et al. 2011). This single catalogue was used to create a model that was generalisable to all three different source-finding methods. Due to the over-representation of false positive sources compared to true positive detections, the training catalogue had the potential to be imbalanced. In order to prevent this from creating a bias in the random forest classifier, the weights associated with each class, false positive detections and true positive sources, were automatically adjusted according to the frequency of that class by a factor of
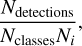 (9)
(9)
where Ndetections is the number of detections in the catalogue, Nclasses is the number of classes, in this case being two, and Ni is the number of detections in class i. The Gini index (Analyttica Datalab 2018) was chosen to measure the quality of the splits in the decision trees of the random forest because it yielded the best improvement in the purity of the catalogues.
The volume in voxels, the total and peak fluxes in Jy km s−1, the velocity width in km s−1, the spatial dimensions in kpc, the H I mass, and the spatial elongation of each detection in the Apertif training pointing catalogue was then used to train the random forest classification model. Once trained, the classification model was run on the catalogues of the Apertif test pointing, and the detections classified by the random forest classifier as false positive detections were removed from the catalogue to investigate if this improved the purity.
4 Results
This section compares and evaluates the merits of all three source-finding methods, SoFiA, MTO, and the V-Net network, using their relative compute times and results.
4.1 Compute times
Before the V-Net network could be used as a source finder, the network was first trained using the masks of the mock galaxies and identified real sources as the ground truth. The learning progress of the network is illustrated in Fig. 6, showing both the training and validation loss scores as a function of the compute epoch on the Peregrine HPC cluster, as mentioned in Sect. 3.2. About five epochs of the learning process could be completed per day. The trained network was taken from the 34th epoch, to be used as a source-finding method. The trained network was taken from the 34th epoch, to be used as a source-finding method. This epoch achieved the lowest combination of the training and validation loss score, obtained within the time frame of a week. It should be noted, however, that the time required to train the V-Net network is specific to the Peregrine cluster used, which was the most capable machine at our disposal.
After the training of the V-Net network, it was applied to the Apertif test pointing on the same machine as the MTO and SoFiA software. The V-Net network was found to be the slowest, taking just over twice as long as MTO to complete and more than 12 times longer than SoFiA. Again, it should be noted that these relative compute times depend on the parameter settings of the source-finding algorithms as listed in the Appendix. For instance, reducing or increasing the number of smoothing kernels for SoFiA will significantly affect the time it takes SoFiA to complete the task. The number and sizes of the smoothing kernels used by SoFiA, however, were deemed a good match to typical sizes of the sources in the Apertif cubes.
These relative compute times to completion were somewhat expected. While SoFiA could load an entire Apertif cube into memory, MTO had to work on sub-cubes sequentially, stitching together the masks of the detections from each sub-cube. The V-Net network had to work sequentially on even smaller subcubes than MTO due to the design of its architecture. It is important to recall that this evaluation of relative compute times only considers the process of source-finding for all three approaches. It does not include the time that was required to train the V-Net network.
 |
Fig. 6 Training and validation loss scores of the V-Net network per epoch during the training process. The blue line shows the validation loss score and the orange line the training loss score, with the dashed red line indicating the point where the model was taken for inference. |
4.2 Identifying real sources
During the evaluation of these methods, the location of the brightest voxel (see Sect. 4.3) for each of the detected sources was used to cross-reference it with the ground truth masks of the mock galaxies. This allowed us to mark the detected sources as true or false positive detections accordingly. As previously mentioned, the collection of ground truth masks based on the inserted mock galaxies is incomplete, as it does not include the real sources that also exist within the cubes. Therefore, the false positives returned by each method were inspected by eye, by overlaying their moment-0 H I emission maps as contours on optical images from Pan-STARRS (Flewelling et al. 2020). It should be noted that the 2D moment-0 maps were created by integrating the H I emission over all the channels within the 3D masks generated by each source-finding method. It is important to emphasise here that each of the three methods may generate a different mask, and therefore a different moment-0 map, for the same detected source.
To reduce the effort of visually inspecting the false positive detections, they were first filtered according to their spatial and spectral extent to ensure only astrophysically plausible H I sources were cross-referenced with the Pan-STARRS images. Only sources with spatial sizes smaller than 0.3 Mpc, and with spectral widths between 7 and 750 km s−1 were considered for visual inspection. Only detected sources that appeared to have an optical counterpart or to be realistic H I emission sources were subsequently labelled as real sources, taking the union of the detected masks from each source-finding method as the ground truth mask for these real sources.
Figure 7 presents examples of contoured H I moment-0 maps overlaid on optical images of the same area of the sky for three real sources from three different spectral windows. In these examples, the real sources appear to show some asymmetry in their moment-0 maps as generated by SoFiA and MTO. For instance, considering the top and middle rows of Fig. 7, the moment-0 maps of source (a) appear to show signs of the H I gas being stripped from the galaxy by ram pressure stripping, while source (c) appears to consist of two galaxies that are possibly interacting. However, these asymmetries are not recovered in the moment-0 maps generated by the V-Net network, as illustrated by the images in the bottom row of Fig. 7. This demonstrates that the V-Net network struggles to properly mask intrinsically asymmetric sources, which is expected as the network was primarily trained on symmetric mock galaxies and only the few identified real sources.
The number of mock galaxies, real sources and false positives as detected by each method can be found in Table 2. We note that V-Net performs significantly better at locating mock galaxies in the training pointing than in the test pointing. This is expected, since the network was trained with the training pointing and was not exposed to the test pointing until it was tested. In order to visually summarise these results, Fig. 8 shows Venn (Suppes 1957) diagrams with the total number of detections from all six spectral windows of the Apertif test pointing.
Considering the detections from the test pointing, SoFiA appears to be the most successful at finding the real sources, with 49 real sources exclusively detected by SoFiA (Fig. 8a). Comparing the physical properties of these 49 real sources to those of the real sources detected by all three source finders, it appears that SoFiA is better able to find sources that are spatially unresolved. On the contrary, the real sources detected by all three source-finding methods remain within a more conservative range for their spatial and spectral sizes. The V-Net network succeeds best at finding the mock galaxies, with 89 exclusively picked up by the V-Net network (Fig. 8b).
MTO picks up the most false positives, with as many as 3428 false positives that neither SoFiA nor V-Net picked up. However, Table 2 demonstrates that 90% of these false positive detections are taken from the most distant spectral window. Similarly, around 88% of the false positives detected by the V-Net network are located in this spectral window. This suggests that SoFiA’s local noise scaling provides it with a significant advantage over the other source-finding methods in data cubes with higher RMS noise (see Table 1). The false positives located in the other five spectral windows show no clear difference in their properties when comparing the detections of SoFiA and V-Net, but MTO appears to be more vulnerable to artefacts with spectral widths below 25 km s−1.
It is relevant to note here that the different source-finding methods respond differently to deviations from uniform noise. For example, due to radio frequency interference (RFI) that was not fully flagged, due to an imperfect subtraction of astrophysical radio continuum sources or due to calibration errors. For instance, SoFiA is sensitive to very local enhancements of the noise that could not be adequately normalised, as may happen at locations of poorly subtracted continuum sources or near the edges of the spectral windows. MTO, on the other hand, tends to pick up more extended artefacts and sharp-edged geometric artefacts related to calibration errors. V-Net appears to favour artefacts similar to those picked up by MTO, but with more elongation, such as ripples due to RFI residuals. Each method, therefore, has its own shortcomings, which is expected due to the differences in their approaches.
Number of mock galaxies, real sources, and false positives detected by each source-finding method prior to applying the random forest classifier.
 |
Fig. 7 Examples of masked H I moment-0 maps of detections of real sources, overlaid on their optical counterparts for each source-finding method. From left to right we show an example from different spectral windows of the Apertif test pointing with, from top to bottom, the mask from SoFiA, MTO, and the V-Net network. All the examples were matched across the methods by their brightest voxel. |
 |
Fig. 8 Venn diagrams of the total number of each kind of detection for all six spectral windows of the Apertif test pointing by each source-finding method prior to applying the random forest classifier. (a) Number of detected mock galaxies. (b) Number of detected real sources. (c) Number of detected false positives. SoFiA is represented by the blue circle, MTO is represented by the orange circle, and the V-Net network is represented by the green circle. |
4.3 Evaluating the source finders
In order to compare and evaluate each of the source-finding methods in each experiment, the resulting 3D masks, as produced by each source-finding method, were mapped one-to-one to the ground truth masks for each mock galaxy using the brightest voxel of each source. If a mask from a detection contained the brightest voxel of more than one source within the ground truth masks, the source with the voxel of the highest flux was chosen. Two metrics were used to measure how well the detections of a source finder masked the sources. The under-merging metric, UM, measures the extent to which a masking method breaks up sources that should be contained within single masks. The over-masking metric, OM, measures the extent to which a masking method masks more than just the source. Both metrics are defined by Haigh et al. (2021), who adapted the work of Levine & Nazif (1981), and are extended to three dimensions as follows:
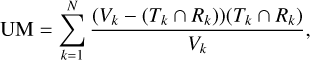 (10)
(10)
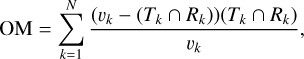 (11)
(11)
where N is the number of one-to-one mapped detections to a ground truth mask. Rk is the ground truth mask, with volume Vk, and Tk is the mask of the detected source, with volume υk. Tk ∩ Rk is, therefore, the intersection of these two masks. The combination of the two metrics results in the volume score, which indicates the quality of the mask of a detected source. The volume score is defined as follows (Haigh et al. 2021):
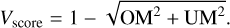 (12)
(12)
A final combined score was used and the mean of this value for each of the six spectral windows was calculated to rank and compare all three source-finding methods. This score takes the purity and completeness of the source finders into account by using the Fscore from Eq. (3), as well as the merging scores as follows:
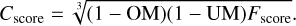 (13)
(13)
These evaluation metrics, for each source finder at each frequency range, can be found in Fig. 9, represented by the dashed lines. From these plots, it is clear that all the methods improve both their completeness and purity with frequency, as the spectral windows are closer to the observer and therefore contain seemingly brighter and larger sources. In addition, all the methods have very high volume scores above 0.8, demonstrating the high mask quality of them all.
When comparing the methods, the V-Net network appears to be the best performing method, with the most consistent purity across the different spectral windows. MTO, on the other hand, while a close competitor with the other methods in its mask quality, indicated by the volume score, seems to struggle most with its completeness and purity. This is most likely due to the way in which the noise was modelled, allowing MTO to identify the noise as sources. The addition of the random forest classifier, to improve the purity of all source-finding methods, is indicated in Fig. 9 by the solid lines. While this largely improves the purity, seen in the upper right plot, this comes at the expense of the completeness for all methods but MTO, seen in the upper-left plot.
Despite having a built-in reliability filter, the results indicate that the random forest classifier also succeeds in improving the purity of SoFiA’s catalogue. Comparing the properties of the false positives detected by SoFiA but rejected by the random forest classifier to those that are selected by the random forest classifier, the largest difference is the distribution of the mask volumes. The number of false positive detections rejected by the random forest suddenly increases for a mask volume below 40 voxels. Since the reliability measurements of SoFiA are calculated using only the values of the voxels within the mask, these results suggest the reliability algorithm could better filter unreliable sources by using the volume and shapes of the masks as additional parameters.
 |
Fig. 9 Various evaluation metrics of the three source finders evaluated with both the mock galaxies and the real sources as a function of the frequency range corresponding to each spectral window. For each plot, the results of SoFiA are shown in blue, the results of MTO in orange, and the results of the V-Net network in green, and the ground truth is shown as a dashed black line. The panel at the top left shows the completeness and the top right shows the purity. The mask quality is shown with the volume score in the bottom-left plot, and the combination of all merging scores, purity, and completeness is shown with the combined score in the bottom-right plot. For all the plots the x-axis shows the frequency range associated with each of the spectral windows of the Apertif test pointing. |
4.4 Comparing the physical properties
The physical properties of the masks created by each source-finding method were calculated to compare and search for any significant differences between the methods. The spatial sizes of the masks, Δx and Δy, as well as the velocity width, Δυ, were calculated following Meyer et al. (2017). In addition to the physical size of the object, the spatial elongation of each mask was calculated following the description in Sect. 2.2.2. The peak and total fluxes, and the H I mass were calculated following Meyer et al. (2017).
The 25th, 50th, and 75th percentiles of the physical properties of the masked mock galaxies were investigated in order to further compare the quality of the masks. In Fig. 10 the spatial dimensions and the total flux of the masked mock galaxies detected by all the methods appear to be almost in agreement, only slightly veering away from each other and the ground truth at the lower frequencies. While SoFiA appears to be the least accurate at masking the spatial sizes and elongation of the mock galaxies, the V-Net network is the most accurate. However, this is only true for the mock galaxies, on which the V-Net network was trained since Fig. 7 shows that it is less accurate at masking less regular real sources.
5 Discussion
In the search for the optimal pipeline to locate and mask H I sources in a 3D H I emission cube, three source-finding methods were compared, namely SoFiA, MTO, and a 3D CNN using the V-Net architecture. In an attempt to improve the purity of these methods, a random forest classifier was then used to post-process the resulting catalogues.
 |
Fig. 10 25th, 50th, and 75th percentiles of the physical properties of the masked mock galaxies detected by each method per spectral window. For all the plots the x-axis shows the frequency range associated with each spectral window, and the markers indicate the median or 50th percentile. The orange triangles show the detections of SoFiA, the green triangles show the detections of MTO, the red circles show the detections of the V-Net network, and the blue crosses show the ground truth masks. The lines below and above each marker indicate the 25th and 75th percentiles, respectively. The top panel shows the two spatial dimensions, Δx and Δy, in kpc, the second panel shows the peak flux and the total flux, the third panel shows the velocity width, Δv, in km s−1 and the spatial elongation, and the last panel shows the log of the H I mass. |
Mean combined scores of all source-finding pipelines.
5.1 Which is the optimal source-finding pipeline?
For a final comparison of all the source-finding pipelines proposed, the mean combined score across the spectral windows was calculated for each. The resulting scores can be found in Table 3. Evaluating the three source-finding methods on their own, the V-Net network is found to rank best overall, shown by the ‘Total’ column. However, the overall score does not account for the fact that there are far fewer real sources than mock galaxies in the data set and so these detections were then evaluated separately. SoFiA is found to rank the best regarding real source detections, while the V-Net network ranks the best at detecting mock galaxies. To account for this imbalance, the mean of the ‘Real’ and ‘Mock’ scores was calculated, resulting in SoFiA as the optimal source finder.
Since SoFiA is the most widely used and optimised source-finding software for H I emission data, it makes sense that of all the source-finding methods it is most suited to the data set used. This is perhaps due to its ability to perform local noise scaling, as well as its reliability filter, which reduces the false detection of noise and artefacts. In addition, the struggle of the V-Net network to mask real sources is likely due to the fact that it was trained with majority symmetric mock galaxies and could be overfitting to them (O’Mahony et al. 2019).
Of all the methods, SoFiA also takes the least amount of compute time, while the V-Net network was found to be the slowest (see Table 4). It is also important to point out the large number of computational resources used and the time taken for the training of the V-Net network. Therefore, it is suggested that in future work the sliding window is applied in parallel or the architecture is modified to take larger inputs since both would reduce the time spent on the training and source-finding.
However, investigating the physical properties of the masked mock galaxies detected, the V-Net network is found to yield the closest values to the ground truth. Outperforming the other source-finding methods at masking the mock galaxies suggests the potential for the V-Net network to outperform SoFiA overall, with an even better mask quality, should it be trained on more real sources. Alternatively, to remove the difficulty of not having enough labelled real sources, there is potential to investigate an unsupervised deep learning solution. It is also important to note the advantage of the V-Net network is that it is less sensitive to input parameters than the other source-finding methods.
Although MTO struggles with a low purity on its own, this was expected since Arnoldus (2015) used the reliability filter from SoFiA to tackle this and remove artefacts and noise detections. This low purity is most likely due to the way in which the background is estimated, which is not suitable for radio data with a mean near zero. This noise modelling could be the cause of the struggle of MTO to differentiate sources from the noise, which is suggested by the fact that 90% of the false positive detections are located in the spectral window with the highest RMS noise. While the completeness of MTO was not necessarily expected to overtake SoFiA, it is not as competitive in this regard as found in Arnoldus (2015), reaching up to 30% difference at some spectral windows when compared to SoFiA. While this could be simply due to the different sets of data used, it could also be caused by the lack of spectral smoothing, since only the spatial dimensions were smoothed anisotropically during the pre-processing.
As Arnoldus (2015) suggests, this could perhaps be improved with some experimentation with spectral smoothing, including the use of isotropic smoothing. Since the mask quality of MTO is very competitive with the other methods, improving the purity and completeness could also potentially enable it to overtake as the optimal source-finding method.
Elapsed real time in seconds for each of the three source-finding methods.
5.2 Can the addition of a classical machine learning classifier improve the results of the source finders?
The addition of a random forest classifier as a post-processor of the source-finding catalogues is found to improve the purity of all the source-finding methods. Besides MTO, it also causes a slight drop in completeness. This results in the overall improvement, measured by the combined score, for all the source finders. This improves the purity of MTO further than the reliability filter used in Arnoldus (2015), such that it outperforms the other source-finding methods in terms of purity, with little to no effect on the completeness. This suggests that implementing the random forest classifier within the max-tree could make the purity of MTO competitive on its own.
The top features ranked according to the random forest classifier are found to be the velocity width and the H I mass, demonstrating the importance of the physical size and flux of the detections for their reality. This could help inform the filtering process in rule-based methods like MTO. In addition, the purity of the SoFiA catalogue is also improved with the addition of the random forest classifier. This suggests that taking the shape and volume of detected masks into account could improve the reliability algorithm of SoFiA. However, it would also be interesting in future work to compare the results of SoFiA with and without the reliability filter to better understand how the random forest classifier improves the purity of the catalogue.
5.3 What are the limitations of these results?
The locating of real sources in the H I emission cubes enabled a separate evaluation of the methods with both real sources and mock galaxies. However, manually finding the real sources during the cross-matching process was very time-consuming and still resulted in an over-representation of the mock galaxies relative to the real sources. This indicates that this approach to labelling the ground truth was not the most effective. The over-representation of mock galaxies not only biased the training of the V-Net network but also could have biased the evaluation of all the pipelines for more symmetric, bright sources.
An additional limitation of the data used was the partial labelling of the data set since there is no guarantee that all the real sources existing prior to the mock galaxy insertion were labelled. The limitations of manually optimising the parameters for SoFiA and MTO must also be considered. Not only is this limited as a subjective approach, but identifying false positives can be a prohibitive process. We, therefore, suggest that further works make use of automatic optimisation algorithms when comparing different source-finding methods.
6 Conclusion
Due to improvements in technology, the amount of data coming from astronomical surveys continues to increase, and therefore so does the need for fast and accurate techniques for detecting and characterising sources. The challenge lies in the lack of clarity in the boundaries of sources, with many having intensities very close to the noise. This project, therefore, aimed to find the best pipeline for finding and masking the most sources with the best mask quality and the fewest artefacts in 3D neutral hydrogen cubes. This was done by testing two existing statistical methods, SoFiA and MTObjects, and a well-known medical imaging 3D CNN architecture called V-Net on H I emission data taken from the Apertif medium-deep survey with inserted mock galaxies.
The highest performing source finder of the methods tested is SoFiA. This is due to this pipeline’s ability to best find and mask real sources, as well as the small amount of time and computational resources needed relative to the other methods. However, the V-Net network ranks a close second, thanks to its ability to detect mock galaxies better than real sources. The addition of a random forest classifier is found to improve the purity of all the source-finding methods. SoFiA could therefore benefit from adding a built-in random forest classifier to improve the ease of use of this post-processing step.
As the everyday applications of computer vision continue to increase, so does the amount of astronomical data produced by ever-improving telescopes. With this progress grows the need for astronomers to keep up to date with the advances in computer vision. In this paper, a computer vision solution was applied to an astronomical task and found to be competitive with traditional software. In addition, with the implementation of suggested improvements, it is likely to even overtake the traditional astronomy methods. This demonstrates that the interchangeability of solutions between the two fields will become fundamental to the growth of data analysis in future astronomy.
Acknowledgements
We thank the Center for Information Technology of the University of Groningen for their support and for providing access to the Peregrine high-performance computing cluster. This work was funded by the Nederlandse Onderzoekschool Voor Astronomie (NOVA).
Appendix A Parameters of the source-finding methods
Chosen parameters for SoFiA when applied to the nearest spectral window.
Chosen parameters for MTObjects.
Chosen parameters for V-Net.
References
- Alamri, S., Kalyankar, N., & Khamitkar, S. 2010, Int. J. Comput. Sci. Eng., 2, 3 [Google Scholar]
- Alhassan, W., Taylor, A., & Vaccari, M. 2018, MNRAS, 480, 2085 [NASA ADS] [CrossRef] [Google Scholar]
- Analyttica Datalab 2018, Gini Coefficient or Gini Index in our Data Science & Analytics platform [Google Scholar]
- Andreon, S., Gargiulo, G., Longo, G., Tagliaferri, R., & Capuano, N. 2000, MNRAS, 319, 700 [Google Scholar]
- Aniyan, A., & Thorat, K. 2017, ApJS, 230, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Apertif Science Team 2016, Apertif Survey Plan II, (Accessed on 06/30/2021) [Google Scholar]
- Aptoula, E., Lefèvre, S., & Collet, C. 2006, in 2006 14th European Signal Processing Conference, 1 [Google Scholar]
- Argueso, F., Sanz, J., Barreiro, R., Herranz, D., & Gonzalez-Nuevo, J. 2006, MNRAS, 373, 311 [NASA ADS] [CrossRef] [Google Scholar]
- Arnoldus, C. 2015, Master’s thesis, University of Groningen, The Netherlands [Google Scholar]
- Bandara, R. 2018, ArXiv e-prints [arXiv: 1509.06851] [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, A&AS, 117, 393 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bochkovskiy, A., Wang, C., & Liao, H. 2020, ArXiv e-prints [arXiv: 2004.10934] [Google Scholar]
- Böhringer, H., Chon, G., & Trümper, G. 2021, A&A, 651, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Breiman, L., Friedman, J., Stone, C., & Olshen, R. 1984, Classification and Regression Trees (UK: Chapman and Hall/CRC) [Google Scholar]
- Bridle, J. 1990, in Neurocomputing, eds. F. Soulié, & J. Hérault (Berlin, Heidelberg: Springer Berlin Heidelberg), 227 [CrossRef] [Google Scholar]
- Cheng, T., Conselice, C. J., Aragón-Salamanca, A., et al. 2020, MNRAS, 493, 4209 [NASA ADS] [CrossRef] [Google Scholar]
- Christ, P., Elshaer, M. E. A., Ettlinger, F., et al. 2016, in Medical Image Computing and Computer-Assisted Intervention - MICCAI 2016, eds. S. Ourselin, L. Joskowicz, M. Sabuncu, G. Unal, & W. Wells (Cham: Springer International Publishing), 415 [Google Scholar]
- Çiçek, Ö., Abdulkadir, A., Lienkamp, S., Brox, T., & Ronneberger, O. 2016, 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation (Cham: Springer International Publishing), 424 [Google Scholar]
- Cook, S. 2012, CUDA Programming: A Developer’s Guide to Parallel Computing with GPUs, 1st edn, (San Francisco, CA: Morgan Kaufmann Publishers Inc.) [Google Scholar]
- Cunningham, P., & Delany, S. 2007, ACM Comput. Surveys, 54, 1 [Google Scholar]
- De Boer, D., Gough, R. G., Bunton, J. D., et al. 2009, Proc. IEEE, 97, 1507 [NASA ADS] [CrossRef] [Google Scholar]
- Dice, L. 1945, Ecology, 26, 297 [CrossRef] [Google Scholar]
- Fernandez-Delgado, M., Cernadas, E., Barro, S., & Amorim, D. 2014, J. Mach. Learn. Res., 15, 3133 [Google Scholar]
- Flewelling, H., Magnier, E. A., Chambers, K. C., et al. 2020, ApJS 251, 7 [NASA ADS] [CrossRef] [Google Scholar]
- Fukushima, K. 1975, Biological Cybernetics, 20, 121 [CrossRef] [Google Scholar]
- Gheller, C., Vazza, F., & Bonafede, A. 2018, MNRAS, 480, 3749 [NASA ADS] [CrossRef] [Google Scholar]
- Gogate, A. 2022, PhD thesis, University of Groningen, The Netherlands [Google Scholar]
- Goodfellow, I., Bengio, Y., & Courville, A. 2016, Deep Learning (USA: MIT Press) [Google Scholar]
- Haigh, C., Chamba, N., Venhola, A., et al. 2021, A&A, 645, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2015, ArXiv e-prints [arXiv:1502.01852] [Google Scholar]
- Hibbard, J. E., van Gorkom, J. H., Rupen, M. P., & Schiminovich, D. 2001, ASP Conf. Ser., 240, 657 [NASA ADS] [Google Scholar]
- Ho, T. 1995, Proceedings of 3rd International Conference on Document Analysis and Recognition, 1, 278 [Google Scholar]
- Hogbom, J., & Brouw, W. 1974, A&A, 33, 289 [NASA ADS] [Google Scholar]
- Igel, C., & Hüsken, M. 2000, Improving the Rprop Learning Algorithm [Google Scholar]
- Jarvis, J., & Tyson, J. 1981, AJ, 86, 476 [NASA ADS] [CrossRef] [Google Scholar]
- Jonas, J. L. 2009, Proc. IEEE, 97, 1522 [NASA ADS] [CrossRef] [Google Scholar]
- Jurek, R. 2012, PASA, 29, 251 [NASA ADS] [CrossRef] [Google Scholar]
- Kaur, D., & Kaur, Y. 2014, Int. J. Comput. Sci. Mobile Comput., 3, 809 [Google Scholar]
- Kingma, D., & Ba, J. 2015, in 3rd International Conference for Learning Representations, San Diego [Google Scholar]
- Levine, M., & Nazif, A. 1981, An Experimental Rule-based System for Testing Low Level Segmentation Strategies (Canada: McGill University) [Google Scholar]
- Lintott, C., et al. 2008, MNRAS, 389, 1179 [NASA ADS] [CrossRef] [Google Scholar]
- Long, J., Shelhamer, E., & Darrell, T. 2014, ArXiv e-prints [arXiv: 1411.4038] [Google Scholar]
- Lukic, V., De Gasperin, F., & Brüggen, M. 2019, Galaxies, 8, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Martinsson, T., Verheijen, M., Bershady, M. A., et al. 2016, A&A, 585, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Masias, M., Freixenet, J., Lladó, X., & Peracaula, M. 2012, MNRAS, 422, 1674 [NASA ADS] [CrossRef] [Google Scholar]
- Meyer, M., Robotham, A., Obreschkow, D., et al. 2017, PASA, 34, 52 [Google Scholar]
- Milletari, F., Navab, N., & Ahmadi, S. 2016, Proceedings - 2016 4th International Conference on 3D Vision, 565 [Google Scholar]
- Moschini, U. 2016, PhD thesis, University of Groningen, The Netherlands [Google Scholar]
- Nikolaos, A. 2019, Master’s thesis, University of Patras, Greece [Google Scholar]
- O’Mahony, N., Campbell, S., Carvalho, A., et al. 2019, ArXiv e-prints [arXiv:1910.13796] [Google Scholar]
- Ouzounis, G. K., & Wilkinson, M. H. F. 2007, IEEE Transac. Pattern Anal. Mach. Intell., 29, 990 [CrossRef] [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, in Advances in Neural Information Processing Systems 32, eds. H. Wallach, H. Larochelle, A. Beygelzimer, et al. (Curran Associates, Inc.), 8024 [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Perona, P., & Malik, J. 1990, IEEE Transac. Pattern Anal. Mach. Intell., 12, 629 [CrossRef] [Google Scholar]
- Persic, M., Salucci, P., & Ste, F. 1996, MNRAS, 281, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Popping, A., Jurek, R., Westmeier, T., et al. 2012, PASA, 29, 318 [NASA ADS] [CrossRef] [Google Scholar]
- Punzo, D., van der Hulst, J., Roerdink, J., et al. 2015, Astron. Comput., 12, 86 [NASA ADS] [CrossRef] [Google Scholar]
- Ronneberger, O., Fischer, P., & Brox, T. 2015, in Medical Image Computing and Computer-Assisted Intervention - MICCAI 2015, eds. N. Navab, J. Hornegger, & A. Wells, W. M. Frangi (Cham: Springer International Publishing), 234 [CrossRef] [Google Scholar]
- Salembier, P., Oliveras, A., & Garrido, L. 1998, IEEE Transac. Image Process., 7, 555 [CrossRef] [Google Scholar]
- Samudre, A., George, L., Bansal, M., & Wadadekar, Y. 2022, MNRAS, 509, 2269 [NASA ADS] [Google Scholar]
- Sebastian, R. 2016, ArXiv e-prints [arXiv: 1609.04747] [Google Scholar]
- Serra, J. 1988, Image Analysis and Mathematical Morphology, Theoretical Advances (New York: Academic Press), 2 [Google Scholar]
- Serra, P., Westmeier, T., Giese, N., et al. 2015, MNRAS, 448, 1922 [Google Scholar]
- Serra, P., Jurek, R., & Flöer, L. 2012, PASA, 29, 296 [Google Scholar]
- Sørensen, T. 1948, Kongelige Danske Videnskabernes Selskab [Google Scholar]
- Suppes, P. 1957, Introduction to Logic (New York: Van Nostrand), 312 [Google Scholar]
- Teeninga, P., Moschini, U., Trager, S. C., & Wilkinson, M. H. F. 2013, in 11th International Conference, Pattern Recognition and Image Analysis: New Information Technologies (PRIA-11-2013), 746 [Google Scholar]
- Teeninga, P., Moschini, U., Trager, S. C., & Wilkinson, M. H. F. 2016, Mathematical Morphology - Theory and Applications (Hoboken: John Wiley & Sons), 1, 100 [Google Scholar]
- Tody, D. 1986, SPIE Conf. Ser., 627, 733 [Google Scholar]
- Valverde, S., Cabezas, M., Roura, E., et al. 2017, ArXiv e-prints [arXiv:1702.04869] [Google Scholar]
- van Cappellen, W. A., Oosterloo, T. A., Verheijen, M. A. W., et al. 2022, A&A, 658, A146 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van der Hulst, J., Terlouw, J., Begeman, K., Zwitser, W., & Roelfsema, P. 1992, Astronomical Data Analysis Software and Systems I, 25, 131 [NASA ADS] [Google Scholar]
- van Rijsbergen, C. 1979, Information Retrieval (London: Butterworths), 2 [Google Scholar]
- Vapnik, V. 1995, Support-Vector Networks [Google Scholar]
- Weltman, A., Bull, P., Camera, S., et al. 2020, PASA, 37, e002 [Google Scholar]
- Westmeier, T., Kitaeff, S., Pallot, D., et al. 2021, MNRAS, 506, 3962 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, M. 1974, Galactic and Extragalactic Radio Astronomy (Berlin: Springer) [Google Scholar]
- Yang, A., Pan, F., Saragadam, V., et al. 2021, in Proceedings of the IeEe/CvF Winter Conference on Applications of Computer Vision (WACV), 335 [Google Scholar]
- Zaitoun, N. M., & Aqel, M.J. 2015, Procedia Comput. Sci., 65, 797 [CrossRef] [Google Scholar]
- Zhi, S., Liu, Y., Li, X., & Guo, Y. 2018, Comput. Graph., 71, 199 [CrossRef] [Google Scholar]
All Tables
Properties of the seven spectral windows of the two pointings chosen from the Apertif medium-deep survey.
Number of mock galaxies, real sources, and false positives detected by each source-finding method prior to applying the random forest classifier.
All Figures
|
Fig. 1 Schematic of a noiseless 3D H I emission cube containing a galaxy. The cube consists of two positional dimensions (right ascension, α, and declination, δ) and one spectral dimension (frequency, υ). |
| In the text | |
|
Fig. 2 Schematic diagram of the source-finding pipeline of MTObjects (Arnoldus 2015). An H I emission sub-cube, which contains a source, is transformed into a max-tree mask with the use of both Gaussian and adaptive smoothing. A max-tree is then built from the max-tree mask, and the source nodes are labelled using the attributes of the smoothed cube. Finally, post-processing is used to remove false detections. |
| In the text | |
|
Fig. 3 Illustration of the V-Net architecture, based on the architecture of Milletari et al. (2016). The compression path is shown on the left and the decompression path on the right, and the two are horizontally linked by the location information. |
| In the text | |
|
Fig. 4 Example of a single channel of an Apertif H I emission cube, prior to noise normalisation. The colour scale represents the noise balanced on 0, which is non-uniform and increases towards the edges of the cube. The layout of the Apertif compound beams mosaicked into a hexagonal shape is overlaid in white, following van Cappellen et al. (2022). Note that the cubes were cropped spatially, here indicated by the yellow rectangle, resulting in 1000 × 1600 pixels in dimension, representing the declination and right ascension, respectively. |
| In the text | |
|
Fig. 5 Zoomed-in, z-scaled (Tody 1986) single channel of an example of an Apertif cube (a) and the corresponding binary mask of the inserted mock galaxies (b). The cube has been noise-normalised, and mock galaxies have been inserted. The colour bars represent the intensity of the simulated emission. |
| In the text | |
|
Fig. 6 Training and validation loss scores of the V-Net network per epoch during the training process. The blue line shows the validation loss score and the orange line the training loss score, with the dashed red line indicating the point where the model was taken for inference. |
| In the text | |
|
Fig. 7 Examples of masked H I moment-0 maps of detections of real sources, overlaid on their optical counterparts for each source-finding method. From left to right we show an example from different spectral windows of the Apertif test pointing with, from top to bottom, the mask from SoFiA, MTO, and the V-Net network. All the examples were matched across the methods by their brightest voxel. |
| In the text | |
|
Fig. 8 Venn diagrams of the total number of each kind of detection for all six spectral windows of the Apertif test pointing by each source-finding method prior to applying the random forest classifier. (a) Number of detected mock galaxies. (b) Number of detected real sources. (c) Number of detected false positives. SoFiA is represented by the blue circle, MTO is represented by the orange circle, and the V-Net network is represented by the green circle. |
| In the text | |
|
Fig. 9 Various evaluation metrics of the three source finders evaluated with both the mock galaxies and the real sources as a function of the frequency range corresponding to each spectral window. For each plot, the results of SoFiA are shown in blue, the results of MTO in orange, and the results of the V-Net network in green, and the ground truth is shown as a dashed black line. The panel at the top left shows the completeness and the top right shows the purity. The mask quality is shown with the volume score in the bottom-left plot, and the combination of all merging scores, purity, and completeness is shown with the combined score in the bottom-right plot. For all the plots the x-axis shows the frequency range associated with each of the spectral windows of the Apertif test pointing. |
| In the text | |
|
Fig. 10 25th, 50th, and 75th percentiles of the physical properties of the masked mock galaxies detected by each method per spectral window. For all the plots the x-axis shows the frequency range associated with each spectral window, and the markers indicate the median or 50th percentile. The orange triangles show the detections of SoFiA, the green triangles show the detections of MTO, the red circles show the detections of the V-Net network, and the blue crosses show the ground truth masks. The lines below and above each marker indicate the 25th and 75th percentiles, respectively. The top panel shows the two spatial dimensions, Δx and Δy, in kpc, the second panel shows the peak flux and the total flux, the third panel shows the velocity width, Δv, in km s−1 and the spatial elongation, and the last panel shows the log of the H I mass. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.