| Issue |
A&A
Volume 668, December 2022
|
|
|---|---|---|
| Article Number | A134 | |
| Number of page(s) | 18 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/202243545 | |
| Published online | 14 December 2022 | |
Photometric detection of internal gravity waves in upper main-sequence stars
III. Comparison of amplitude spectrum fitting and Gaussian process regression using CELERITE2
1
Institute of Astronomy, KU Leuven, Celestijnenlaan 200D, 3001 Leuven, Belgium
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Kavli Institute for Theoretical Physics, University of California, Santa Barbara, CA 93106, USA
3
University of Washington Astronomy Department, Physics and Astronomy Building, 3910 15th Ave NE, Seattle, WA 98105, USA
4
Observatories of the Carnegie Institution for Science, 813 Santa Barbara Street, Pasadena, CA 91101, USA
Received:
14
March
2022
Accepted:
14
November
2022
Abstract
Context. Recent studies of massive stars using high-precision space photometry have revealed that they commonly exhibit stochastic low-frequency (SLF) variability. This has been interpreted as being caused by internal gravity waves excited at the interface of convective and radiative regions within stellar interiors, such as the convective core or sub-surface convection zones, or being caused by dynamic turbulence associated with sub-surface convection zones within the envelopes of main-sequence massive stars.
Aims. We aim to compare the properties of SLF variability in massive main-sequence stars observed by the Transiting Exoplanet Survey Satellite (TESS) mission determined by different statistical methods, and confirm the correlation between the morphology of SLF variability and a star’s location in the Hertzsprung–Russell (HR) diagram. We also aim to quantify the impact of data quality on the inferred SLF morphologies using both fitting methodologies.
Methods. From a sample of 30 previously observed and characterised galactic massive stars observed by TESS, we compare the resultant parameters of SLF variability, in particular the characteristic frequency, obtained from fitting the amplitude spectrum of the light curve with those inferred from fitting the covariance structure of the light curve using the CELERITE2 Gaussian process (GP) regression software and a damped simple harmonic oscillator (SHO) kernel.
Results. We find a difference in the characteristic frequency obtained from the amplitude spectrum fitting and from fitting the covariance structure of the light curve using a GP regression with CELERITE2 for only a minority of the considered sample. However, the trends among mass, age, and the properties of SLF variability previously reported remain unaffected. We also find that the method of GP regression is more efficient in terms of computation time and, on average, more robust against the quality and noise properties of the input time series data in determining the properties of SLF variability.
Conclusions. GP regression is a useful and novel methodology to efficiently characterise SLF variability in massive stars compared to previous techniques used in the literature. We conclude that the correlation between a star’s SLF variability, in particular the characteristic frequency, and its location in the HR diagram is robust for main-sequence massive stars. There also exists a distribution in the stochasticity of SLF variability in massive stars, which indicates that the coherency of SLF variability is also a function of mass and age in massive stars.
Key words: stars: early-type / stars: fundamental parameters / stars: massive / stars: rotation / stars: oscillations
© The Authors 2022
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe-to-Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
The treasure trove of time series photometric data assembled by space telescopes including CoRoT (Auvergne et al. 2009), Kepler/K2 (Borucki et al. 2010; Koch et al. 2010; Howell et al. 2014) and TESS (Ricker et al. 2015) in the last decade has revealed a remarkable range of diverse variability mechanisms in massive stars (Bowman 2020). A recent discovery is that essentially all early-type main-sequence stars show stochastic low-frequency (SLF) variability in time series photometry (Bowman et al. 2019a,b, 2020), in addition to other variability mechanisms including coherent heat-driven pulsation modes, rotational modulation, and the photometric signatures of binarity (Degroote et al. 2009a; Blomme et al. 2011; Pedersen et al. 2019; Burssens et al. 2020). Similarly, SLF variability has also been reported in later evolutionary stages of massive stars (see e.g. Bowman et al. 2019b; Dorn-Wallenstein et al. 2019, 2020; Nazé et al. 2021; Elliott et al. 2022; Lenoir-Craig et al. 2022), which shows similar morphologies to main sequence stars. It currently remains unclear which of the several plausible mechanisms that can generate SLF variability dominate in particular parameter regimes. Hence the investigation of SLF variability has opened up a novel method to understanding the interiors of massive stars (Bowman 2020).
Coupled with spectroscopy, the analysis of time series photometry is able to extract detailed and precise constraints on the physics of stellar interiors thanks to asteroseismology (Aerts et al. 2010; Aerts 2021). In early-type stars, a heat-engine excitation mechanism operating in the iron opacity bump at 200 000 K gives rise to pressure (p) and gravity (g) modes (Dziembowski & Pamyatnykh 1993; Dziembowski et al. 1993; Miglio et al. 2007; Szewczuk & Daszyńska-Daszkiewicz 2017), which probe predominantly the envelope and near-core physics, respectively. The analysis of coherent pulsations has revealed the interior rotation profiles and a diversity in the amounts of convective boundary and envelope mixing profiles in late-B stars (Degroote et al. 2009b, 2010; Daszyńska-Daszkiewicz et al. 2013; Moravveji et al. 2015, 2016; Szewczuk & Daszyńska-Daszkiewicz 2018; Szewczuk et al. 2022; Pedersen et al. 2021; Michielsen et al. 2021; Bowman & Michielsen 2021), in addition to tight constraints on differential radial rotation profiles, (core) masses and ages for late-O and early-B stars (Aerts et al. 2003; Pamyatnykh et al. 2004; Dziembowski & Pamyatnykh 2008; Burssens et al. 2022).
Similarly to asteroseismology of coherent pulsation modes, the exploitation of SLF variability in time series photometry, which is seen across a wide range in mass, age, and metallicity in massive stars, offers us the opportunity to improve our understanding of stellar structure and evolution (Bowman 2020). In their original methodology and characterisation study, Bowman et al. (2019a) used a sample of 35 early-type stars observed by the CoRoT mission to demonstrate how scaling laws based on solar granulation are inconsistent with the observed SLF variability1 (Paper I). Based on a much larger sample of more than 160 massive stars observed by Kepler/K2 and TESS, which included metal-rich galactic stars and metal-poor stars in the Large Magellanic Cloud (LMC) galaxy, Bowman et al. (2019b) have demonstrated that a common morphology in the SLF variability is observed for essentially all stars with M ≳ 3 M⊙. The SLF variability was determined to be dependent on the brightness of the star and by extension also its luminosity, and hence its location in the Hertzsprung–Russell (HR) diagram. More recently, Bowman et al. (2020) used a sample of galactic O and B stars observed by the TESS mission and combined it with high resolution spectroscopy (Simón-Díaz et al. 2011; Burssens et al. 2020) to show that the morphology of SLF variability is correlated with a star’s mass, age, and amount of macroturbulence (Paper II).
The detection of SLF variability in massive stars has inspired various theoretical works to explain this new type of observational signal. Motivated by the omnipresence of a convective core during the main-sequence evolution of a massive star led Aerts & Rogers (2015) to postulate that SLF variability observed at the surface of three O-type stars could be explained by convectively driven internal gravity waves (IGWs) excited by core convection. This conclusion was supported based on the qualitatively similar frequency spectra observed for these stars with those predicted from 2D hydrodynamical simulations (Rogers et al. 2013; Rogers 2015; Rogers & McElwaine 2017). More recent 2D and 3D simulations of core convection with different numerical setups also show that IGWs excited by core convection produce detectable velocity and temperature perturbations (Edelmann et al. 2019; Horst et al. 2020; Ratnasingam et al. 2020; Varghese et al. 2022; Vanon et al. 2022; Herwig et al. 2022; Thompson et al. 2022). On the other hand, other studies have postulated that the cause of SLF variability in massive stars is IGWs excited by sub-surface convection zones (Cantiello et al. 2009, 2021) since IGWs excited from core convection may be damped before they reach the surface (Lecoanet et al. 2019, 2021). Using simulations the dynamics of turbulent convection in massive star envelopes has also been shown to be another plausible cause of SLF variability (Jiang et al. 2015, 2018; Schultz et al. 2022). However, the efficiency of convection in sub-surface zones, and hence the driving of IGWs from these regions, is strongly metallicity dependent (Jermyn et al. 2022). Finally, another plausible mechanism for SLF variability, which is especially important for evolved (i.e post-main sequence) massive stars, is clumping in their optically thick winds (see e.g. Krtička & Feldmeier 2018, 2021).
It remains an open question as to which excitation mechanism(s) dominates in specific parameter regimes of the HR diagram, as the properties of (sub-surface) convection, winds, and the driving and propagation of IGWs depend on stellar properties such as mass, radius, metallicity, and rotation. What is clear is that a mechanism that aims to unanimously explain SLF variability in main-sequence early-type stars must do so for stars that span a broad range of masses (i.e. 3 ≲ M ≲ 100 M⊙), ages from the zero-age main sequence (ZAMS) to the terminal-age main sequence (TAMS) and beyond, rotation rates between essentially zero and close to critical, and for both metal-poor (i.e. Z ≤ 0.002) and metal-rich stars (i.e. Z ≥ 0.014). A mechanism must also explain the broad frequency range of SLF variability and how its properties correlate with mass and age (Bowman et al. 2019b, 2020).
In this paper, we compare the difference in the measured properties of SLF variability when using different fitting methods: directly fitting the amplitude spectrum of the light curve as previously performed by Bowman et al. (2020), and covariance structure fitting of the light curve using the CELERITE2 Gaussian process (GP) regression software package (Foreman-Mackey et al. 2017, 2021; Foreman-Mackey 2018). Our goal is to demonstrate a more efficient method for extracting the characteristic frequency of the SLF variability for a large number of massive stars observed by the ongoing TESS mission. In Sect. 2, we outline the approach to using GP regression and briefly describe the stellar sample. In Sect. 3, we present the results of our comparison and we conclude in Sect. 4.
2. Method
Given that SLF variability observed in massive stars is inherently a representation of a stochastic process, it is difficult to parametrise it with a physically motivated function in the time domain. This has led previous studies to characterise SLF variability instead in the Fourier domain (Blomme et al. 2011; Bowman et al. 2019a,b, 2020; Dorn-Wallenstein et al. 2019, 2020; Nazé et al. 2021; Elliott et al. 2022). However, there are various statistical tools and methodologies, such as GP regression (Rasmussen & Williams 2006; Aigrain & Foreman-Mackey 2022), low-order linear stochastic differential equations (Koen 2005), and continuous-time autoregressive moving average models (Kelly et al. 2014), that yield a model for stochastic signals in the time domain based on the statistical properties of time-series data.
2.1. Previous studies parameterising SLF variability
Previous efforts in parameterising SLF variability in massive stars have used a semi-Lorentzian function to fit the amplitude spectrum of the light curve with a from similar to:
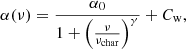 (1)
(1)
where α0 represents the amplitude at a frequency of zero, γ is the logarithmic amplitude gradient, νchar is the characteristic frequency, and Cw is a frequency-independent (i.e. white) noise term (Bowman et al. 2019a). We note that Cw is a parameter used to evaluate the white noise floor when fitting an amplitude spectrum, which is set by Poisson and instrumental errors and is not part of the spectrum of SLF variability. Hence, stars can have significantly different Cw values dependent on the quality of their light curves.
Typically, to avoid potential bias in the resultant fit when comparing various stars using Eq. (1), the light curves of massive stars have undergone iterative pre-whitening to remove dominant periodicities a priori. This means that periodic variability caused by coherent pulsation modes or rotational modulation is removed from the light curve by means of subtracting sinusoids with optimised amplitudes, frequencies and phases to create a residual light curve (Bowman et al. 2019a; Bowman & Michielsen 2021). This is particularly important for B-type stars, such as β Cep and SPB stars, which are commonly multi-periodic pulsators in addition to having SLF variability (Bowman et al. 2019b; Burssens et al. 2020). On the other hand, a two-step process of pre-whitening pulsation modes a priori and determining their frequencies, amplitudes, and phases may yield differences in the inferred morphology of the SLF variability compared to fitting the coherent modes and SLF variability simultaneously. Investigating the impact of this is beyond the scope of the current paper but will be explored in future work.
The fitting of the amplitude spectrum in previous studies has been achieved using a Markov chain Monte Carlo (MCMC) numerical framework (e.g. using the pythonEMCEE package; Foreman-Mackey et al. 2013, 2019a). It was used to sample the posterior probability distribution to determine the optimum parameters for Eq. (1) using the amplitude spectrum of a star’s light curve as observables. Yet the calculation of an amplitude spectrum and subsequent MCMC numerical framework is relatively computationally expensive and is also potentially quite sensitive to the explicit algorithm used to transform the light curve data from the time domain into the frequency domain. For example, the choices for the frequency over-sampling factor, frequency range, normalisation constant being the number of data points and/or the data set length when using the numerical implementation of a (discrete) Fourier transform (e.g. Deeming 1975; Kurtz 1985) or (variant of) a Lomb-Scargle periodogram (e.g. Scargle 1982; Press & Rybicki 1989) should ideally not impact the results. Not all studies in the literature make comparable choices – see discussion by Bowman & Michielsen (2021). Moreover, differences in approaches to gap-filling a light curve to maximise its duty cycle, remove aliases and aim to minimise the noise floor in the amplitude spectrum, but different forms of post-processing data such as smoothing the amplitude spectrum prior to fitting may lead to different results. Although useful, these amplitude spectrum fitting methods implicitly include assumptions for the signal and noise components of a light curve and can affect subsequent (asteroseismic) inference.
2.2. Advantages of GP regression
The application of GP regression has been highly successful in modelling radial velocity time series data, the light curves of transiting exoplanet host stars, and stellar variability including spot modulation in low-mass stars (Brewer & Stello 2009; Barclay et al. 2015; Grunblatt et al. 2017; Pereira et al. 2019; Nicholson & Aigrain 2022). In particular, a GP regression framework has been shown to be very effective at characterising stellar variability with periods shorter than the total time span of a time series, even in the case of degraded and noisy data sets (e.g. Nicholson & Aigrain 2022). As pointed out by Pereira et al. (2019), previous applications of GP regression in astrophysical contexts have typically focussed on determining accurate non-parametric models for time series data without particularly paying close attention to the physical processes that cause the variability. However, GP regression can be used under certain conditions to estimate physical parameters (e.g. such as characteristic timescales) that set the stochastic processes in time series data, such as modelling the signatures of granulation in the light curves of evolved low-mass stars (Pereira et al. 2019). In this work, we extend and test the application of covariance structure fitting of a light curve within a GP regression framework to extract physical parameters, in particular the characteristic frequency, of SLF variability in massive stars.
Because of the potential impact of different choices when calculating amplitude spectra, it can be argued that fitting the covariance structure of a light curve with a GP regression framework, such as the CELERITE2 software package, is the more robust strategy since it is directly fitting the original measurement data set (i.e. the light curve). Relying on the light curve as the data set and avoiding transformations into the Fourier domain, a GP regression method avoids these potential discrepancies. See also the application and discussion of the advantages of GP regression regarding the window function of a time series by Nicholson & Aigrain (2022). On the other hand, covariance structure fitting methods also include assumptions, such as that the mean of the light curve is constant and stationary, hence they have their own limitations.
In this work, we investigate the efficacy of using GP regression for determining the properties of SLF variability in massive star light curves. In so doing, we restrict our sample to the 30 galactic O-type stars from the TESS sample previously studied by Bowman et al. (2020) that seemingly do not have significant coherent pulsation modes and thus do not require iterative pre-whitening prior to fitting Eq. (1). Therefore, our comparison of fitting the amplitude spectrum and GP regression of the light curve is not influenced by any post-processing of the light curves, such as iterative pre-whitening.
2.3. Defining a GP kernel
A GP regression model is a non-parametric model that describes correlated stochastic variability in a time series by fitting hyperparameters to define a covariance matrix. Each data point in a time series is described as a correlated random variable with a mean and a variance, for which any finite collection of variables has a multi-variate Gaussian distribution (Rasmussen & Williams 2006; Aigrain & Foreman-Mackey 2022). In GP regression, a function is not directly fitted to a data set, but rather hyperparameters are fit to define a covariance matrix. This yields a posterior distribution that is a representation of a distribution of functions with a given structure in their covariance matrices, which are then conditioned on the data to evaluate the best representation of the input time series. In this work, it is assumed that the variance of the input time series is constant and generally that the observed SLF variability is stationary.
In the application of GP regression, a kernel to describe the correlation among data points is chosen, which is then applied to determine the best set of parameters to reproduce the observed time series (see e.g. Pereira et al. 2019). Posterior probability distributions for the relevant hyperparameters of the GP can be sampled using suitable priors, and the GP likelihood function (see Eq. (1) of Foreman-Mackey 2018). Computing the likelihood function is typically the computational bottleneck, therefore the selection of an appropriate kernel, GP implementation, and sampling algorithm is crucial (Foreman-Mackey et al. 2017).
In this work, we use the pythonCELERITE2 and EXOPLANET software packages (Foreman-Mackey et al. 2017, 2021; Foreman-Mackey 2018)2 to fit a covariance structure for TESS light curves within a GP regression framework. Inspired by Pereira et al. (2019) in their application of GP regression to study the granulation signal of pulsating red giants and guided by the excellent documentation of the CELERITE2 software package, we utilise a GP kernel that corresponds to a damped simple harmonic oscillator (SHO), whose power spectral density is given by
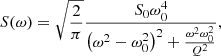 (2)
(2)
where ω0 is the natural frequency of the oscillator, S0 is related to the amplitude of the variability, and Q is the quality factor. For very large values of Q, Eq. (2) corresponds to an undamped SHO. As stated in Eq. (23) of Foreman-Mackey et al. (2017), the kernel in the time domain is given by
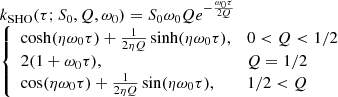 (3)
(3)
where η = |1 − (4Q2)−1|1/2, and τ is the (absolute) time separation between measurements needed to construct the covariance matrix (i.e. the ij element of the covariance matrix uses τ = |ti − tj|). In the limit of 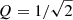 (see Foreman-Mackey et al. 2017 for the derivation; omitted here for brevity), the power spectral density in Eq. (2) reduces to
(see Foreman-Mackey et al. 2017 for the derivation; omitted here for brevity), the power spectral density in Eq. (2) reduces to
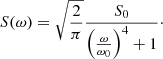 (4)
(4)
A GP regression of a time series can be parameterised using a characteristic variability timescale, ρchar = 2π/ω0, a characteristic amplitude3, 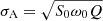 , and a characteristic damping timescale, τdamp = 2Q/ω0. The form of Eq. (4) is similar to the semi-Lorentzian function used to fit SLF variability in massive stars (cf. Eq. (1)). Furthermore, a damped SHO kernel is a convenient starting point when a physically motivated kernel may not be known (see Foreman-Mackey et al. 2017). Given that SLF variability represents a stochastic oscillatory process, we deem this kernel appropriate for modelling TESS light curves of massive stars. Testing its efficacy to extract effective timescales (e.g. νchar) from light curves is one of the goals of this work.
, and a characteristic damping timescale, τdamp = 2Q/ω0. The form of Eq. (4) is similar to the semi-Lorentzian function used to fit SLF variability in massive stars (cf. Eq. (1)). Furthermore, a damped SHO kernel is a convenient starting point when a physically motivated kernel may not be known (see Foreman-Mackey et al. 2017). Given that SLF variability represents a stochastic oscillatory process, we deem this kernel appropriate for modelling TESS light curves of massive stars. Testing its efficacy to extract effective timescales (e.g. νchar) from light curves is one of the goals of this work.
2.4. Input parameter guesses and priors
In our framework we use the kernel of a damped SHO and input guesses for its parameters as follows: ω0 as the characteristic angular frequency (i.e. 2 π νchar); 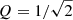 ; and
; and 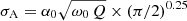 based on roughly matching terms between Eqs. (1) and (4). We note that our results are in fact not sensitive to the input guesses for these parameters as long as the domains of the priors are large enough to contain the true value.
based on roughly matching terms between Eqs. (1) and (4). We note that our results are in fact not sensitive to the input guesses for these parameters as long as the domains of the priors are large enough to contain the true value.
Given the pristine quality of space photometry and the dominance of the astrophysical variability signal over measurement errors, in this work we assume that all possible sources of instrumental noise are white (see e.g. Kallinger et al. 2014). This may not be generally true for all stars observed by the TESS mission, but is a valid assumption for the bright massive stars dominated by SLF variability studied in this work. We emulate a white noise floor in the Fourier domain by including a noise jitter term in the GP regression following Pereira et al. (2019). The jitter term is a constant added in quadrature to the diagonal of the covariance matrix and has a kernel function of:
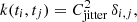 (5)
(5)
where i and j are matrix indices and 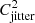 is the GP regression jitter term. Physically, the jitter term is used to represent uncorrelated noise in the data that cannot be captured by the GP regression, and hence represents a proxy of the measurement uncertainties in a light curve (Foreman-Mackey et al. 2017, 2021; Foreman-Mackey 2018).
is the GP regression jitter term. Physically, the jitter term is used to represent uncorrelated noise in the data that cannot be captured by the GP regression, and hence represents a proxy of the measurement uncertainties in a light curve (Foreman-Mackey et al. 2017, 2021; Foreman-Mackey 2018).
In running a GP regression for a given star, there are five main parameters to be determined: (i) the characteristic timescale, ρchar (from which the characteristic frequency can be determined: ω0 = 2πνchar, where νchar = 1/ρchar); (ii) the characteristic damping timescale, τdamp (from which the characteristic damping frequency can be calculated: νdamp = 1/τdamp); (iii) the characteristic amplitude, σA; (iv) a jitter term to emulate uncorrelated noise in the observations, Cjitter; and (v) the mean of the light curve. We take the νchar parameters from Bowman et al. (2020) multiplied by 2π to calculate ω0, guess as input guesses, and assign non-informative (i.e. uniform) priors in logarithmic space to all input parameter guesses except the mean of the light curve, which is assigned a normal prior based on the measured mean of the TESS light curve, which a priori has been set to be zero. We specify liberal lower and upper bounds for the four uniform priors as given in Table 1, but are results are not sensitive to these choices as long as the domains of the priors are sufficiently large. An input guess of the quality factor of the GP regression model is set as 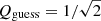 , and is evaluated as Q = πτdamp/ρchar.
, and is evaluated as Q = πτdamp/ρchar.
Lower and upper limits of the four uniform logarithmic priors used in this work.
2.5. Parameter and uncertainty estimation
To estimate the best-fitting model parameters and their uncertainties, we use the pythonPYMC3 software package (Salvatier et al. 2016)4 and perform a Hamiltonian Monte-Carlo with a no U-turn sampler to determine parameter confidence intervals. In a standard MCMC approach, parameter chains make stochastic walks within the multi-dimensional parameter space, whereas a no U-turn sampler employs a Hamiltonian description of the probability distribution to sample the posterior probability distribution for the model parameters following Bayes’ theorem. This makes a Hamiltonian Monte-Carlo no U-turn samplers typically much more efficient in finding global minima (Salvatier et al. 2016).
The best-fitting GP regression model is evaluated on the hyperparameters with maximum a posteriori probability. We use PYMC3 and the maximum a posteriori parameters as an initial trial point to begin sampling the posterior. In our implementation of the Hamiltonian Monte-Carlo with a no U-turn sampler, we use four parameter chains, and at each iteration each chain is used to construct a model subject to a GP marginalised log likelihood function within the PYMC3 model that also includes the log priors. A burn-in period of fewer than 1000 iterations is typically needed, which are discarded before parameter and uncertainty estimation are performed using another 1000 iterations. Convergence of the parameter chains is confirmed using the parameter variance criteria from Gelman & Rubin (1992). We use the highest density interval (HDI) and 94% of the posterior probability density to estimate the lower and upper confidence intervals for each marginalised parameter distribution.
Goodness of fit is assessed both by ensuring that good convergence statistics are obtained following parameter variance criteria (Gelman & Rubin 1992) and visual inspection of the marginalised posterior distributions (i.e. corner plots; Foreman-Mackey 2016). We also visually inspect the posterior probability distribution, GP regression model and its corresponding power spectral density in the time and Fourier domain, respectively.
We emphasise that our GP regression framework is a fit to the light curve and not a fit to an amplitude spectrum. But to aid in making our results visually comparable to the amplitude spectrum fitting results of Bowman et al. (2020), we calculate the power spectral density (i.e. amplitude squared per unit frequency as a function of frequency) of the TESS light curve and the resultant GP regression model, which are normalised using Parseval’s theorem following Pereira et al. (2019). Similarly, we also convert the fits from Bowman et al. (2020) into units of power spectral density. We normalise all power spectral density figures to have the same amplitude at zero frequency (i.e. α0 = 1), such that they converge at unity at zero frequency for ease of visual comparison. This is necessary to allow a consistent comparison of the power spectral density of the GP regression model including the jitter term, the power spectral density of the TESS data, and the converted fits of Bowman et al. (2020) in the Fourier domain. Furthermore, this approach allows us to perform a sanity check judgement of the quality of the best-fitting GP regression model to the data, since poor fits are more obvious in the Fourier domain5. The conversion of the results into a power spectral density does not impact the inferred parameters, such as νchar, as these are determined by the GP regression in the time domain.
3. Results
We apply our GP regression framework to the exact same TESS light curves of 30 massive stars previously analysed by Bowman et al. (2020). For each star, we provide a summary figure in Appendix A, which contains the TESS observations and the best-fitting GP regression model in the top panel, and the power spectral densities of the TESS observations, the converted best-fitting model from Bowman et al. (2020), and the GP regression model in the bottom panel. A full summary of our parameter results from the GP regression and the upper and lower confidence intervals for each parameter from the Hamiltonian Monte-Carlo with no U-turn sampler is given in Table B.1. We note that for all summary figures in Appendix A that the minimal informative frequency of the data set (i.e. resolution set by the inverse of the TESS light curve time span of ≥28 d) is significantly smaller than the chosen 0.1 d−1 lower limit of the x-axes.
An immediate major advantage of using a damped SHO model within a covariance structure fitting framework with the GP regression CELERITE2 software is that it provides additional useful inferred parameters of the SLF variability in massive stars, such as νdamp and Q, which are not provided by fitting Eq. (1) to an amplitude spectrum. Therefore, in addition to the characteristic timescale of the SLF variability, we are able to make inferences on its coherency and quasi-periodicity. We show the histogram of the inferred Q values for the sample of 30 massive stars in Fig. 1, which has been colour-coded by the spectroscopic effective luminosity of each star defined as 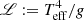 (Langer & Kudritzki 2014). We find a range of Q values spanning from 0.18 to 2.15 that cluster around a value approximately equal to
(Langer & Kudritzki 2014). We find a range of Q values spanning from 0.18 to 2.15 that cluster around a value approximately equal to 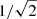 and have a median value of 0.48. The inferred Q values represent a wide range in the coherency of SLF variability of massive stars. The two stars with the largest Q values are HD 154368 (TIC 41792209) and HD 152424 (TIC 247267245). Both of these stars have large amplitude and quasi-coherent SLF variability in their light curves (see Fig. A.3) and are among the most massive and luminous stars in our sample.
and have a median value of 0.48. The inferred Q values represent a wide range in the coherency of SLF variability of massive stars. The two stars with the largest Q values are HD 154368 (TIC 41792209) and HD 152424 (TIC 247267245). Both of these stars have large amplitude and quasi-coherent SLF variability in their light curves (see Fig. A.3) and are among the most massive and luminous stars in our sample.
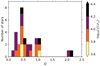 |
Fig. 1. Histogram of inferred Q values from the GP regression colour coded by their spectroscopic effective luminosity. The determined values are clustered around |
3.1. Comparison of Bowman et al. (2020) and GP regression
In the top- and bottom-left panels of Fig. 2, we show the pairwise comparison of the νchar values determined in this work using GP regression and those determined by Bowman et al. (2020), which are colour coded by the σA and νdamp GP regression parameters, respectively. On average, a fairly good agreement is seen between the two sets of νchar values. Yet a small fraction of the sample of stars have νchar values that differ by more than a factor of two. In some cases this leads to significant differences when considering the relatively small uncertainties on this parameter, but this varies from star to star. The discrepancies in some stars are not necessarily systematic with νchar. However, we note that stars with a significant difference in νchar values between the two methods have lower σA and higher νdamp values (i.e. the SLF variability is relatively low amplitude and more stochastic). Also, in cases when a significant difference is found, the GP regression value for νchar is typically larger than that of Bowman et al. (2020). This is likely related to the difference between a GP regression incorporating a different model and being a fit to the light curve rather than a fit to the amplitude spectrum. In other words, the sensitivity of the GP regression to the window function of the time series data is in the time domain rather than the Fourier domain, such that stars with lower amplitude SLF variability have larger discrepancies between the two methods. However, a much larger sample than the 30 stars considered in this work is needed to further investigate this if this effect is astrophysical or methodological in origin.
 |
Fig. 2. Comparison of GP regression parameters determined in this work and equivalent parameters from Bowman et al. (2020). Top-left panel: νchar values colour coded by σA. Top-right panel: τdamp values from the GP regression and the steepness of the amplitude spectrum, γ, colour coded by σA. Bottom-left panel: νchar values colour coded by νdamp. Bottom-right panel: σA values from the GP regression and α0 colour coded by νdamp. |
In the top-right panel of Fig. 2, we show the relationship between the steepness of the SLF variability in the amplitude spectrum, γ, as determined by Bowman et al. (2020) and the τdamp timescale colour-coded by σA as determined using GP regression in this work. Whilst there is considerable scatter between these two parameters, a positive correlation between γ and τdamp can be seen. This correlation is caused by stars with SLF variability characterised with longer damping timescales, τdamp, being less stochastic and more quasi-periodic (i.e. higher values of Q). In turn this leads to larger values of γ, and the majority of power in the SLF variability being concentrated near νchar as opposed to being spread over a wide range in frequency.
In the bottom-right panel of Fig. 2, we show the relationship between the amplitude of the SLF variability at zero frequency, α0, as determined by Bowman et al. (2020) and the characteristic amplitude, σA, in this work. A clear correlation between these parameters is seen, which demonstrates that they can serve as proxies of each other. We note that the relationship is almost linear in log-log space, with a linear regression of α0 and σA yielding a Pearson correlation coefficient of r = 0.97 (p < 10−10) and a gradient of 0.73 ± 0.03. This is expected given the equivalence of these parameters in both methodologies, but the gradient of order unity and the extremely high degree of correlation is a useful sanity check.
Our comparison of the GP regression parameters and those of Bowman et al. (2020) leads us to define two sub-groups of stars: (i) those with high α0 (i.e. high σA), low νchar (i.e. high τchar), and low νdamp values; and conversely (ii) those with low σA, high νchar, and high νdamp values. We term these the ‘yellow’ and ‘blue’ sub-groups, respectively, as indicated by the colour coding in Fig. 2. In other words, stars in the yellow sub-group typically have high-amplitude, quasi-periodic low-frequency variability, and stars in the blue group have low-amplitude, stochastic variability spanning a broad range in frequency, on average. These are not distinct populations and our sample in fact covers the transition between these two extremes. However, the definition of these two sub-groups serves to highlight the differences in the properties of SLF variability among a sample of massive stars.
3.2. Correlations with mass and age in the HR diagram
In Fig. 3 we show the spectroscopic HR diagram for the 30 galactic O stars studied by Bowman et al. (2020), which we have re-modelled using GP regression in this work. As discussed in Sect. 3.1, there are some star-to-star differences in the determined νchar parameters between the results of Bowman et al. (2020) and from our GP regression. However, an important result from this work is that the dependence of νchar on the mass and age of a star remains unaffected since both independent fitting methods yield the same correlation. Therefore, as demonstrated by comparing the left and right panels of Fig. 3, our new modelling approach further strengthens the conclusion of Bowman et al. (2020) that the light curve of a massive star encodes valuable constraints on its mass and age. More specifically, younger stars near the ZAMS have larger νchar values of approximately 7 d−1, on average, whereas older stars near the TAMS have smaller νchar values of approximately 1 d−1.
 |
Fig. 3. Spectroscopic HR diagram of 30 O stars determined by Bowman et al. (2020) to be dominated by SLF variability in their TESS light curves (left panel) that we re-model using GP regression in this work (right panel), which are colour-coded by their corresponding νchar values. Evolutionary tracks from Burssens et al. (2020) are shown as solid grey lines and labelled in units of M⊙, and the dashed grey line represents the ZAMS. A typical spectroscopic error bar for the sample is shown in the top-left corner. |
Furthermore, we note that the yellow sub-group of stars (cf. Sect. 3.1) are typically higher mass and more evolved and the blue sub-group of stars are closer to the ZAMS on average. This is a new result of our work. Not only does the value of νchar of a star’s SLF variability probe its mass and age, but the degree of coherency and stochasticity of a massive star’s light curve is also a function of age. More specifically, more massive and more evolved stars typically have larger Q values, as shown in Fig. 4.
 |
Fig. 4. Spectroscopic HR diagram of the same O stars as in Fig. 3 but colour-coded by the quality factor, Q, of the variability as determined in our GP regression. |
The larger the Q value in an oscillator, the narrower and sharper the peak in the power spectral density becomes because the system is more selective of what range of frequencies are driven to resonance. For example, systems with low quality factors (i.e. 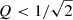 ) are referred to as ‘overdamped’ because damping dominates over driving. After a perturbation, such a system is returned asymptotically to its equilibrium steady state by means of an exponential decay. Whereas systems with high quality factors (i.e.
) are referred to as ‘overdamped’ because damping dominates over driving. After a perturbation, such a system is returned asymptotically to its equilibrium steady state by means of an exponential decay. Whereas systems with high quality factors (i.e. 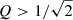 ) are referred to as ‘underdamped’, which means they continue to oscillate at their resonant frequency whilst experiencing a decaying signal amplitude. This is because an underdamped system has driving that is able to overcome damping. For a perfect oscillation with zero damping the quality factor is infinite. Hence, coherent pulsators driven by the heat-engine mechanism, would have extremely high Q values.
) are referred to as ‘underdamped’, which means they continue to oscillate at their resonant frequency whilst experiencing a decaying signal amplitude. This is because an underdamped system has driving that is able to overcome damping. For a perfect oscillation with zero damping the quality factor is infinite. Hence, coherent pulsators driven by the heat-engine mechanism, would have extremely high Q values.
Given the measured Q values of the stars shown in Fig. 4, our results demonstrate that SLF variability in massive stars transitions from being well described as an overdamped SHO to an underdamped SHO between the ZAMS and the TAMS in the HR diagram. Therefore, the coherency of SLF variability as inferred using GP regression is a new avenue for constraining the responsible physical mechanism in different parameter regimes of the HR diagram.
3.3. SLF variability as a quasi-periodic or stochastic phenomenon
Two prime examples of stars in the yellow sub-group are HD 152424 (TIC 247267245) and HD 154368 (TIC 41792209), which have 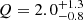 and
and 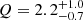 , respectively (see Table B.1). We note that there are relatively large uncertainties for the Q values, the largest of all the stars, but place the stars in the underdamped regime. These stars have almost ‘perfect’ GP regression fits to their light curves (see Appendix A), and have light curves that are clearly dominated by astrophysical signal and negligible instrumental noise. Stars in the yellow sub-group are those that deserve special attention for the purpose of identifying and extracting quasi-coherent pulsation modes from their apparent SLF variability for the purpose of asteroseismology (see e.g. Bowman 2020). However, such an attempt would require long-term light curves spanning dozens of TESS sectors to resolve individual modes owing to their apparent intrinsically damped nature. This is beyond the scope of our current paper but is the subject of future work.
, respectively (see Table B.1). We note that there are relatively large uncertainties for the Q values, the largest of all the stars, but place the stars in the underdamped regime. These stars have almost ‘perfect’ GP regression fits to their light curves (see Appendix A), and have light curves that are clearly dominated by astrophysical signal and negligible instrumental noise. Stars in the yellow sub-group are those that deserve special attention for the purpose of identifying and extracting quasi-coherent pulsation modes from their apparent SLF variability for the purpose of asteroseismology (see e.g. Bowman 2020). However, such an attempt would require long-term light curves spanning dozens of TESS sectors to resolve individual modes owing to their apparent intrinsically damped nature. This is beyond the scope of our current paper but is the subject of future work.
We also perform a second modelling setup and perform GP regression for all stars in which we fix the quality factor to be 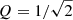 . As a consequence, the damping timescale, τdamp, is no longer included as a parameter. This allows for a better understanding of the measured Q values when it is an inferred parameter and of the power spectral density predictions derived from the GP regression. We provide the parameters from the fixed-Q GP regression in Table B.2. Fixing Q as a parameter forces the shape of the power spectral density prediction to be similar to that of Eq. (1). This has the potential to explain the differences in νchar values between those from Bowman et al. (2020) and from the non-fixed Q-value GP regression. However, the νchar values from the GP regressions with fixed and non-fixed Q values are within 1σ of each other, which demonstrates that we are somewhat insensitive to Q when using GP regression or there is significant degeneracy between the Q and νchar parameters.
. As a consequence, the damping timescale, τdamp, is no longer included as a parameter. This allows for a better understanding of the measured Q values when it is an inferred parameter and of the power spectral density predictions derived from the GP regression. We provide the parameters from the fixed-Q GP regression in Table B.2. Fixing Q as a parameter forces the shape of the power spectral density prediction to be similar to that of Eq. (1). This has the potential to explain the differences in νchar values between those from Bowman et al. (2020) and from the non-fixed Q-value GP regression. However, the νchar values from the GP regressions with fixed and non-fixed Q values are within 1σ of each other, which demonstrates that we are somewhat insensitive to Q when using GP regression or there is significant degeneracy between the Q and νchar parameters.
We also calculate and compare the Bayesian Information Criteria (BIC) values, which penalises models based on their complexity, using the GP log likelihood value returned by CELERITE2 software for the GP regression models when Q is a free and a fixed parameter. In most cases, 20 of the 30 TESS light curves, the BIC values indicate that the solutions with Q as a free parameter are strongly preferred. This is understandable since the added complexity is needed to more accurately describe the morphology of SLF variability in the time domain. A damped SHO model with a fixed Q value is less flexible, with the light curves of massive stars containing added complexity that is not well captured in this overly simplistic model. Moreover, the 10 stars in which the model with a fixed Q value is preferred are generally the stars with noisier light curves (i.e. blue subgroup members) and have generally poorer fits, as can be seen when comparing the power spectral density of the GP solution and the TESS data in the Fourier domain. Therefore, in order to accurately capture the shape of SLF variability we conclude that the use of GP regression with Q (and thus also τdamp) as a free parameter is the more robust approach, on average.
3.4. Testing the impact of poorer quality observations
We have demonstrated that the best-fitting parameters characterising SLF variability in massive stars are sometimes dependent on the choice of methodology, but this affects each star differently. This is expected because we are comparing the results of two different models each with different fitting methods. On the other hand, there is a general consistency in νchar values obtained from the two methods, but it generally depends on the amplitude of the SLF variability and the noise properties of the TESS light curve. For the yellow sub-group of stars, the astrophysical signal (i.e. SLF variability) strongly dominates over the white noise. Whereas, some stars in the blue sub-group have SLF variability that is comparable to the white noise, and only detected because of the high precision and long duration of TESS light curves. It is the blue sub-group of stars that have, on average, larger inconsistencies in their inferred νchar values between the two methods (cf. Fig. 2). In order to study SLF variability across a wide range of masses and ages, thus including the full range of SLF variability amplitudes (i.e. tens of μmag to tens of mmag; Bowman et al. 2019a,b), high-photometric precision and short-cadence space light curves are necessary to yield the necessarily low instrumental noise.
For the sample at large, there is fairly good agreement between the results in this work and the alternative approach taken previously by Bowman et al. (2020). This leads us to wonder which of the two approaches is more sensitive to the quality of the observations and perhaps less robust considering the notable difference in νchar values for some stars. For example, not all stars in our sample are the same brightness, such that the underlying random and instrumental noise contributions in their light curves are different. Perhaps the covariance structure fitting of a light curve is more sensitive to these noise properties compared to the amplitude spectrum fitting in the Fourier domain.
To test the sensitivity of the GP regression to the quality of the input time series, we degrade the quality of the TESS light curves of the 30 massive stars by adding additional frequency independent (i.e. white) noise. This increases the value of Cw (cf. Eq. (1)) in the amplitude spectrum and consequently also the contribution of the jitter term in the GP regression. For each star in our sample, we create four additional light curves which have 0.5, 1, 2 and 3 times the standard deviation of the original light curve added to them as white noise to emulate increasingly noisier data sets. The latter of which can be considered an extremely and unrealistic noise-dominated light curve, but we include it for completeness. We re-model these noisy light curves using our GP regression framework and the method of Bowman et al. (2020) and compare the resultant νchar values.
In Fig. 5, we show examples of the results of the yellow (left) and blue (right) sub-group members, HD 112244 (TIC 406050497) and HD 96715 (TIC 306491594), respectively. The GP regression typically returns the same νchar value for all noisy light curves of a star within the respective uncertainties, which are indicated by shaded regions that denote the 94% confidence interval for νchar from each fitting method. Naturally, the confidence intervals become larger for noisier light curves, but we note that they are always much smaller for the MCMC amplitude spectrum method compared to those from the GP regression framework. Importantly, there is considerably larger scatter in νchar values determined from the amplitude spectrum fitting methodology of Bowman et al. (2020) to the same artificially noise-enhanced data sets. The values of νchar of the latter are significantly different from each other because of the typically much smaller uncertainties returned by the method of amplitude spectrum fitting. In almost all cases, and as demonstrated by the example stars in Fig. 5, the νchar value returned by the amplitude spectrum fitting methodology systematically decreases to lower values when the white noise contribution is larger. Whereas, the νchar value from the GP regression stays the same within its (much larger) uncertainties, hence not significantly different among the noise-enhanced data sets given its relatively large uncertainties.
 |
Fig. 5. Results of GP regression and amplitude spectrum fitting for the noise-enhanced light curves of HD 112244 (TIC 406050497) and HD 96715 (TIC 306491594), which are typical yellow and blue subgroup members, are shown in the left and right columns, respectively. From top to bottom, increasingly larger amounts of white noise has been added. The blue and green shaded regions denote the 94% confidence interval for νchar for each method. The νchar values from the GP regression are more consistent, on average, than those from fitting the amplitude spectrum. |
Given the consistency of the νchar values of the GP regression, regardless of the underlying signal-to-noise ratio of SLF variability over the white noise, we conclude that it is the more robust methodology. The reason for this is because of the fundamental difference between the two fitting methods. The GP regression is a fit of the covariance structure in the light curve and incorporates a different model, in which the implemented jitter term more effectively handles the included white noise compared to directly fitting the amplitude spectrum. Therefore, large differences in the Cw term in Eq. (1) can lead to significantly different νchar values, especially given the small uncertainties typically returned from this method.
3.5. Application to synthetic data
Considering that our tests in Sect. 3.4 are applied to observed data sets of real stars with unknown underlying frequency spectra, it is possible that the GP regression fitting and amplitude spectrum include different biases. In this section, we test this hypothesis using synthetic light curve data sets generated from different combinations of hyperparameters for the damped SHO kernel generated using CELERITE2. We apply both fitting methods and compare the derived νchar values to investigate which approach is more robust in returning the true input value for νchar.
We generate 100 artificial light curves that span 26 d in length, consist of 1000 data points, and contain a 1-d gap in the middle to emulate one sector of TESS data. Each light curve is generated containing different noise properties and hyperparameters for a damped SHO kernel. We apply our covariance structure fitting method within a GP regression framework and the amplitude spectrum fitting method of Bowman et al. (2020) to these 100 synthetic light curves. For all cases, the derived νchar values are comparable between the two fitting methods and are approximately within a factor of two of each other, as was the case in Sect. 3.4 when applied to real and noise-enhanced TESS light curves. However, the νchar values determined from the methodology of Bowman et al. (2020) are sometimes up to approximately a factor of 1.4−1.7 larger than the true input values. As before, this difference is caused by the two approaches employing two different models and fitting methods. Moreover, the GP regression returns νchar values that are completely consistent with the true input values. Therefore, we conclude that the GP regression methodology is generally more robust, especially in cases of noisier input light curves. We show several examples of the fitted synthetic light curves and corresponding power density spectra in Fig. 6, which include the power spectral density of the noiseless damped SHO input model for comparison to the two fitting methods.
 |
Fig. 6. Examples of results of GP regression and amplitude spectrum fitting for synthetic light curves. The left and right columns show three examples that resemble yellow and blue subgroup members in terms of their quality factor, respectively. The blue and green shaded regions denote the 94% confidence interval for νchar for each method. In all cases, the true input value of νchar is recovered well by the GP model with CELERITE2, whereas the MCMC method of Bowman et al. (2020) sometimes overestimates the value of νchar because of the more rigid profile imposed in the Fourier domain, as demonstrated by a comparison with the noiseless input SHO model. |
We note that even though the GP regression is a fit to the light curve, and the method of Bowman et al. (2020) is a fit to the amplitude spectrum, the normalised power density spectra from the best-fitting GP regression models are typically better (visual) fits in the cases when Q > 1 (i.e. left panels of Fig. 6). This is because the shape of Eq. (1) is quite rigid and unable to capture the complete morphology of the SLF variability in the Fourier domain. For low-Q data sets, the form of Eq. (1) and the resultant power density spectrum of the best-fitting GP regression model are similar in shape, as shown in the right column panels of Fig. 6. However, the amplitude spectrum fitting methodology typically overestimates the true input value of νchar by a factor of ∼1.5. We refer the interested reader to Foreman-Mackey et al. (2017) for similar hare-and-hound exercises with CELERITE2 using simulated time series data.
4. Discussion and conclusions
The vast majority of massive stars have SLF variability in time series photometric observations, if not all when sufficiently high enough quality data are available, which probes the physical properties of the star, such as mass and age. In this work, we have tested the use of GP regression, specifically by fitting a covariance structure with the CELERITE2 software package and a damped SHO kernel (Foreman-Mackey et al. 2017, 2021; Foreman-Mackey 2018), to the time series photometric observations for a sample of 30 galactic massive stars observed by the TESS mission and previously studied by Bowman et al. (2020). We use the same input light curves from the TESS mission and compare our GP regression results, paying particular attention to the characteristic frequency of the SLF variability, νchar, to the previous amplitude spectrum fitting method by Bowman et al. (2020). We find that the νchar determinations by the two different methods are the same, within their uncertainties, for the majority of massive stars observed by TESS. This is encouraging and demonstrates that the previously found correlation of νchar with mass and age is robust given that the GP regression method is a fit to the light curve using a damped SHO model, and the method of Bowman et al. (2020) is a fit to the amplitude spectrum using a semi-Lorentzian (i.e. Harvey-like; Harvey 1985) model that is not necessarily physically motivated. A minority of stars have different and systematically higher values of νchar by up to a factor two when using the GP regression compared to amplitude spectrum fitting, as demonstrated by the examples shown in Fig. 6. Specifically, the damped SHO model of the GP regression is more flexible in fitting the SLF variability in the time domain compared to the rigid shape imposed by the semi-Lorentzian profile in the Fourier domain given in Eq. (1).
We have demonstrated that GP regression is a viable method for characterising SLF variability in time series photometry of massive stars. Our work lends further support to the conclusion of Bowman et al. (2020) that SLF variability probes the mass and age of a massive star, demonstrated by the correlation between νchar and a star’s location in the HR diagram, as shown in Fig. 3. Therefore, we conclude that the absence of coherent, heat-driven pulsation modes is not necessarily a prerequisite for asteroseismology of massive stars, given the probing power of νchar on bulk properties like mass and age. Furthermore, we have shown that a fraction of massive stars with SLF variability exhibit the characteristics of underdamped quasi-periodic variability, suggesting the presence of damped pulsations (i.e. stochastic IGWs). Although a range of quality factors exist in the SLF variability of massive stars, a transition from overdamped to underdamped variability is found to coincide with a transition from the ZAMS to the TAMS, as shown in Fig. 4. We have also demonstrated that a GP regression is more robust against noisier input time series data, especially in the cases where the SLF variability is comparable in amplitude to the white noise.
Numerous recent theoretical studies have focussed on understanding the possible physical causes that give rise to SLF variability in time series photometry. One possible mechanism is that stochastically excited IGWs from the convective core reach the surface with detectable amplitudes and produce a broad frequency spectrum of damped modes (Rogers et al. 2013; Rogers 2015; Rogers & McElwaine 2017; Edelmann et al. 2019; Horst et al. 2020; Ratnasingam et al. 2020; Varghese et al. 2022; Vanon et al. 2022; Herwig et al. 2022; Thompson et al. 2022). However, such an interpretation has been challenged by other studies employing numerical simulations showing that core-excited IGWs are likely damped before they reach the surface (Lecoanet et al. 2019, 2021). This latter result hence supports instead that SLF variability originates from sub-surface convection zones (Cantiello et al. 2021; Schultz et al. 2022). The presence and location of sub-surface convection zones and inferring their existence in stellar evolution models, especially for stars of low metallicity, is clearly important for understanding IGW excitation mechanisms (Jermyn et al. 2022). From stellar evolution theory, it is expected that the size of sub-surface convection zone(s) grow from being negligible to relatively large fractions of a massive star’s radius as it evolves from the ZAMS to the TAMS. Hence, the contribution to SLF variability from sub-surface convection zones is plausibly also expected to increase as stars evolve. On the other hand, the increasing radius as stars evolve produces different contributing factors to the driving, damping and propagation of IGWs. Detailed (rotating) 3D full-sphere hydrodynamical simulations of massive stars at different masses and ages are needed to explore this transition and the relative importance of IGWs from both the core and sub-surface convection zones.
In this work we have tested and implemented the use of GP regression to infer the characteristic frequency, νchar of massive stars from TESS light curves using the CELERITE2 software package. We have demonstrated that a transition from a broad range of low-amplitude SLF variability to high-amplitude quasi-periodic variability exists between the ZAMS and TAMS. We postulate that the observed transition discovered in our work corresponds to an astrophysical scenario in which the dominant cause of SLF variability in massive stars transitions from core convection to sub-surface convection as stars evolve from the ZAMS to the TAMS, but larger sample sizes are needed to confirm this.
Other complementary methods to study SLF variability in astronomical time series data include low-order linear stochastic differential equations (e.g. Koen 2005), and continuous-time autoregressive moving average models (see Kelly et al. 2014). There are thus a variety of statistical tools discussed in the literature that can aid in unlocking the large quantity of TESS light curves of massive stars. In the future, we will expand our analysis to include such methods for inferring properties of the SLF variability in massive stars. We will also apply our methodology to additional stars observed by TESS to extract the morphology of their SLF variability. This will allow us to further populate Fig. 3 and study the origin of SLF variability and its correlation to stellar properties such as mass and age, but also macroturbulence as shown by Bowman et al. (2020). The TESS mission is ongoing and currently providing high precision light curves of thousands of massive stars, which also span much longer time spans than those considered in this initial study. In our next study, we will expand our method to apply it to a much larger sample and use it test if masses and radii can be reliably inferred from the light curves of massive stars.
Sometimes referred to as a low-frequency power excess or ‘red noise’ in the literature.
This is also sometimes referred to as the standard deviation of the variability process (e.g. Pereira et al. 2019).
This is certainly true for an asteroseismologist who usually prefers to inspect amplitude spectra rather than light curves when analysing stellar variability.
Acknowledgments
The authors acknowledge that this work was partially conducted on the traditional land of the first people of Seattle, the Duwamish People, past and present, and honours with gratitude the land itself and the Duwamish Tribe. We thank the anonymous referees for the constructive reports that improved the clarity of this work. D.M.B. gratefully acknowledges funding from the Research Foundation Flanders (FWO) by means of a senior postdoctoral fellowship (grant agreement No. 1286521N) and an FWO long stay travel grant (agreement No. V411621N). D.M.B. is also grateful to the staff and scientists at the Kavli Institute for Theoretical Physics, University of California, Santa Barbara, and to the organisers of the ‘Probes of Transport in Stars’ program, which hosted him during when part of this work was conducted. This research was supported in part by the National Science Foundation (NSF) under Grant Number NSF PHY-1748958. TZD-W gratefully acknowledges support from Grant Number NSF AST-1714285. The authors thank the TESS science team for the excellent data, which were obtained from the Mikulski Archive for Space Telescopes (MAST) at the Space Telescope Science Institute (STScI), which is operated by the Association of Universities for Research in Astronomy, Inc., under NASA contract NAS5-26555. Support to MAST for these data is provided by the NASA Office of Space Science via grant NAG5-7584 and by other grants and contracts. Funding for the TESS mission is provided by the NASA Explorer Program. This research has made use of the SIMBAD database, operated at CDS, Strasbourg, France; the SAO/NASA Astrophysics Data System; and the VizieR catalog access tool, CDS, Strasbourg, France. This research has made use of the following python software packages: MATPLOTLIB (Hunter 2007), Seaborn (Waskom 2021), Numpy (Oliphant 2006; van der Walt et al. 2011; Harris et al. 2020), astropy (Astropy Collaboration 2013, 2018), SciPy (Oliphant 2007; Virtanen et al. 2020), Pandas (McKinney 2010), celerite2 (Foreman-Mackey et al. 2017, 2019b; Foreman-Mackey 2018), exoplanet (Foreman-Mackey et al. 2019c, 2021), arviz (Kumar et al. 2019), corner (Foreman-Mackey 2016), and pymc3 (Salvatier et al. 2016).
References
- Aerts, C. 2021, Rev. Mod. Phys., 93, 015001 [Google Scholar]
- Aerts, C., & Rogers, T. M. 2015, ApJ, 806, L33 [Google Scholar]
- Aerts, C., Thoul, A., Daszyńska, J., et al. 2003, Science, 300, 1926 [Google Scholar]
- Aerts, C., Christensen-Dalsgaard, J., & Kurtz, D. W. 2010, Asteroseismology (Springer Science+Business Media B.V.) [Google Scholar]
- Aigrain, S., & Foreman-Mackey, D. 2022, ArXiv e-prints [arXiv:2209.08940] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Auvergne, M., Bodin, P., Boisnard, L., et al. 2009, A&A, 506, 411 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Barclay, T., Endl, M., Huber, D., et al. 2015, ApJ, 800, 46 [NASA ADS] [CrossRef] [Google Scholar]
- Blomme, R., Mahy, L., Catala, C., et al. 2011, A&A, 533, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Borucki, W. J., Koch, D., Basri, G., et al. 2010, Science, 327, 977 [Google Scholar]
- Bowman, D. M. 2020, Front. Astron. Space Sci., 7, 70 [Google Scholar]
- Bowman, D. M., & Michielsen, M. 2021, A&A, 656, A158 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bowman, D. M., Aerts, C., Johnston, C., et al. 2019a, A&A, 621, A135 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bowman, D. M., Burssens, S., Pedersen, M. G., et al. 2019b, Nat. Astron., 3, 760 [Google Scholar]
- Bowman, D. M., Burssens, S., Simón-Díaz, S., et al. 2020, A&A, 640, A36 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brewer, B. J., & Stello, D. 2009, MNRAS, 395, 2226 [NASA ADS] [CrossRef] [Google Scholar]
- Burssens, S., Simón-Díaz, S., Bowman, D. M., et al. 2020, A&A, 639, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Burssens, S., Bowman, D. M., Michielsen, M., et al. 2022, Nat. Astron., submitted [Google Scholar]
- Cantiello, M., Langer, N., Brott, I., et al. 2009, A&A, 499, 279 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cantiello, M., Lecoanet, D., Jermyn, A. S., & Grassitelli, L. 2021, ApJ, 915, 112 [NASA ADS] [CrossRef] [Google Scholar]
- Daszyńska-Daszkiewicz, J., Szewczuk, W., & Walczak, P. 2013, MNRAS, 431, 3396 [CrossRef] [Google Scholar]
- Deeming, T. J. 1975, Ap&SS, 36, 137 [Google Scholar]
- Degroote, P., Aerts, C., Ollivier, M., et al. 2009a, A&A, 506, 471 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Degroote, P., Briquet, M., Catala, C., et al. 2009b, A&A, 506, 111 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Degroote, P., Aerts, C., Baglin, A., et al. 2010, Nature, 464, 259 [Google Scholar]
- Dorn-Wallenstein, T. Z., Levesque, E. M., & Davenport, J. R. A. 2019, ApJ, 878, 155 [NASA ADS] [CrossRef] [Google Scholar]
- Dorn-Wallenstein, T. Z., Levesque, E. M., Neugent, K. F., et al. 2020, ApJ, 902, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Dziembowski, W. A., & Pamyatnykh, A. A. 1993, MNRAS, 262, 204 [CrossRef] [Google Scholar]
- Dziembowski, W. A., & Pamyatnykh, A. A. 2008, MNRAS, 385, 2061 [NASA ADS] [CrossRef] [Google Scholar]
- Dziembowski, W. A., Moskalik, P., & Pamyatnykh, A. A. 1993, MNRAS, 265, 588 [NASA ADS] [Google Scholar]
- Edelmann, P. V. F., Ratnasingam, R. P., Pedersen, M. G., et al. 2019, ApJ, 876, 4 [NASA ADS] [CrossRef] [Google Scholar]
- Elliott, A., Richardson, N. D., Pablo, H., et al. 2022, MNRAS, 509, 4246 [Google Scholar]
- Foreman-Mackey, D. 2016, J. Open Sour. Softw., 1, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D. 2018, Res. Notes Am. Astron. Soc., 2, 31 [NASA ADS] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Foreman-Mackey, D., Agol, E., Ambikasaran, S., & Angus, R. 2017, AJ, 154, 220 [Google Scholar]
- Foreman-Mackey, D., Farr, W., Sinha, M., et al. 2019a, J. Open Sour. Softw., 4, 1864 [Google Scholar]
- Foreman-Mackey, D., Agol, E., Angus, R., et al. 2019b, https://doi.org/10.5281/zenodo.2650526 [Google Scholar]
- Foreman-Mackey, D., Czekala, I., Agol, E., Luger, R., & Barclay, T. 2019c, https://doi.org/10.5281/zenodo.3595344 [Google Scholar]
- Foreman-Mackey, D., Luger, R., Agol, E., et al. 2021, J. Open Sour. Softw., 6, 3285 [NASA ADS] [CrossRef] [Google Scholar]
- Gelman, A., & Rubin, D. B. 1992, Stat. Sci., 7, 457 [Google Scholar]
- Grunblatt, S. K., Huber, D., Gaidos, E., et al. 2017, AJ, 154, 254 [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Harvey, J. 1985, in Future Missions in Solar, Heliospheric& Space Plasma Physics, eds. E. Rolfe, & B. Battrick, ESA Spec. Publ., 235 [Google Scholar]
- Herwig, F., Woodward, P. R., Mao, H., et al. 2022, MNRAS, submitted [Google Scholar]
- Horst, L., Edelmann, P. V. F., Andrássy, R., et al. 2020, A&A, 641, A18 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Howell, S. B., Sobeck, C., Haas, M., et al. 2014, PASP, 126, 398 [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Jermyn, A. S., Anders, E. H., & Cantiello, M. 2022, ApJ, 926, 221 [NASA ADS] [CrossRef] [Google Scholar]
- Jiang, Y.-F., Cantiello, M., Bildsten, L., Quataert, E., & Blaes, O. 2015, ApJ, 813, 74 [Google Scholar]
- Jiang, Y.-F., Cantiello, M., Bildsten, L., et al. 2018, Nature, 561, 498 [NASA ADS] [CrossRef] [Google Scholar]
- Kallinger, T., De Ridder, J., Hekker, S., et al. 2014, A&A, 570, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kelly, B. C., Becker, A. C., Sobolewska, M., Siemiginowska, A., & Uttley, P. 2014, ApJ, 788, 33 [NASA ADS] [CrossRef] [Google Scholar]
- Koch, D. G., Borucki, W. J., Basri, G., et al. 2010, ApJ, 713, L79 [Google Scholar]
- Koen, C. 2005, MNRAS, 361, 887 [NASA ADS] [CrossRef] [Google Scholar]
- Krtička, J., & Feldmeier, A. 2018, A&A, 617, A121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Krtička, J., & Feldmeier, A. 2021, A&A, 648, A79 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kumar, R., Carroll, C., Hartikainen, A., & Martin, O. 2019, J. Open Sour. Softw., 4, 1143 [NASA ADS] [CrossRef] [Google Scholar]
- Kurtz, D. W. 1985, MNRAS, 213, 773 [NASA ADS] [CrossRef] [Google Scholar]
- Langer, N., & Kudritzki, R. P. 2014, A&A, 564, A52 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lecoanet, D., Cantiello, M., Quataert, E., et al. 2019, ApJ, 886, L15 [Google Scholar]
- Lecoanet, D., Cantiello, M., Anders, E. H., et al. 2021, MNRAS, 508, 132 [NASA ADS] [CrossRef] [Google Scholar]
- Lenoir-Craig, G., St-Louis, N., Moffat, A. F. J., et al. 2022, ApJ, 925, 79 [NASA ADS] [CrossRef] [Google Scholar]
- Michielsen, M., Aerts, C., & Bowman, D. M. 2021, A&A, 650, A175 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miglio, A., Montalbán, J., & Dupret, M.-A. 2007, MNRAS, 375, L21 [CrossRef] [Google Scholar]
- Moravveji, E., Aerts, C., Pápics, P. I., Triana, S. A., & Vandoren, B. 2015, A&A, 580, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Moravveji, E., Townsend, R. H. D., Aerts, C., & Mathis, S. 2016, ApJ, 823, 130 [NASA ADS] [CrossRef] [Google Scholar]
- Nazé, Y., Rauw, G., & Gosset, E. 2021, MNRAS, 502, 5038 [CrossRef] [Google Scholar]
- Nicholson, B. A., & Aigrain, S. 2022, MNRAS, 515, 5251 [NASA ADS] [CrossRef] [Google Scholar]
- Oliphant, T. E. 2006, A Guide to NumPy (USA: Trelgol Publishing), 1 [Google Scholar]
- Oliphant, T. E. 2007, Comput. Sci. Eng., 9, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Pamyatnykh, A. A., Handler, G., & Dziembowski, W. A. 2004, MNRAS, 350, 1022 [NASA ADS] [CrossRef] [Google Scholar]
- Pedersen, M. G., Chowdhury, S., Johnston, C., et al. 2019, ApJ, 872, L9 [Google Scholar]
- Pedersen, M. G., Aerts, C., Pápics, P. I., et al. 2021, Nat. Astron., 5, 715 [NASA ADS] [CrossRef] [Google Scholar]
- Pereira, F., Campante, T. L., Cunha, M. S., et al. 2019, MNRAS, 489, 5764 [NASA ADS] [CrossRef] [Google Scholar]
- Press, W. H., & Rybicki, G. B. 1989, ApJ, 338, 277 [Google Scholar]
- Rasmussen, C. E., & Williams, C. K. I. 2006, Gaussian Processes for Machine Learning (Cambridge: Massachusetts Institute of Technology) [Google Scholar]
- Ratnasingam, R. P., Edelmann, P. V. F., & Rogers, T. M. 2020, MNRAS, 497, 4231 [NASA ADS] [CrossRef] [Google Scholar]
- Ricker, G. R., Winn, J. N., Vanderspek, R., et al. 2015, J. Astron. Telesc. Instrum. Syst., 1, 014003 [Google Scholar]
- Rogers, T. M. 2015, ApJ, 815, L30 [Google Scholar]
- Rogers, T. M., & McElwaine, J. N. 2017, ApJ, 848, L1 [CrossRef] [Google Scholar]
- Rogers, T. M., Lin, D. N. C., McElwaine, J. N., & Lau, H. H. B. 2013, ApJ, 772, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Salvatier, J., Wiecki, T. V., & Fonnesbeck, C. 2016, PeerJ Comput. Sci., 2, e55 [Google Scholar]
- Scargle, J. D. 1982, ApJ, 263, 835 [Google Scholar]
- Schultz, W. C., Bildsten, L., & Jiang, Y.-F. 2022, ApJ, 924, L11 [NASA ADS] [CrossRef] [Google Scholar]
- Simón-Díaz, S., Castro, N., Garcia, M., Herrero, A., & Markova, N. 2011, Bull. Soc. R. Sci. Liege, 80, 514 [Google Scholar]
- Szewczuk, W., & Daszyńska-Daszkiewicz, J. 2017, MNRAS, 469, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Szewczuk, W., & Daszyńska-Daszkiewicz, J. 2018, MNRAS, 478, 2243 [Google Scholar]
- Szewczuk, W., Walczak, P., Daszyńska-Daszkiewicz, J., & Moździerski, D. 2022, MNRAS, 511, 1529 [NASA ADS] [CrossRef] [Google Scholar]
- Thompson, W. R., Herwig, F., Woodward, P. R., et al. 2022, MNRAS, submitted [Google Scholar]
- van der Walt, S., Colbert, S. C., & Varoquaux, G. 2011, Comput. Sci. Eng., 13, 22 [Google Scholar]
- Vanon, R., Edelmann, P. V. F., Ratnasingam, R. P., Varghese, A., & Rogers, T. M. 2022, ApJ, submitted [Google Scholar]
- Varghese, A., Ratnasingam, R. P., Vanon, R., Edelmann, P. V. F., & Rogers, T. M. 2022, ArXiv e-prints [arXiv:2211.06432] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Meth., 17, 261 [Google Scholar]
- Waskom, M. L. 2021, J. Open Sour. Softw., 6, 3021 [NASA ADS] [CrossRef] [Google Scholar]
- McKinney, W. 2010, in Proceedings of the 9th Python in Science Conference, eds. S. van der Walt, & J. Millman, 56 [Google Scholar]
Appendix A: Light curve and power density spectra summary figures
Summary figures for the 30 galactic massive stars studied in this work containing the TESS light curve fitted using GP regression, the normalised power spectral density of the GP regression model, TESS data and the corresponding best-fit model determined by Bowman et al. (2020) are given in Figs. A.1, A.2, and A.3. We note that for all summary figures that the minimal informative frequency (i.e. resolution) of the data set is set by the inverse of the time span, which is well below the chosen 0.1 d−1 lower limit of the x-axes.
 |
Fig. A.1. Summary figures for selected massive stars analysed in this work. |
 |
Fig. A.2. Summary figures for selected massive stars analysed in this work. |
 |
Fig. A.3. Summary figures for selected massive stars analysed in this work. |
Appendix B: Extended data tables
The full parameter list of GP regression parameters including uncertainties determined by a Hamiltonian Monte-Carlo with no U-turn sampler are given in Table B.1 for the 30 massive stars studied in this work. In Table B.2, we provide the GP regression parameters for when a fixed input value of 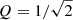 is used.
is used.
GP regression parameters for sample of massive stars studied in this work.
GP regression parameters for sample of massive stars studied in this work when fixed 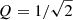 .
.
All Tables
Lower and upper limits of the four uniform logarithmic priors used in this work.
GP regression parameters for sample of massive stars studied in this work when fixed .
All Figures
|
Fig. 1. Histogram of inferred Q values from the GP regression colour coded by their spectroscopic effective luminosity. The determined values are clustered around |
| In the text | |
|
Fig. 2. Comparison of GP regression parameters determined in this work and equivalent parameters from Bowman et al. (2020). Top-left panel: νchar values colour coded by σA. Top-right panel: τdamp values from the GP regression and the steepness of the amplitude spectrum, γ, colour coded by σA. Bottom-left panel: νchar values colour coded by νdamp. Bottom-right panel: σA values from the GP regression and α0 colour coded by νdamp. |
| In the text | |
|
Fig. 3. Spectroscopic HR diagram of 30 O stars determined by Bowman et al. (2020) to be dominated by SLF variability in their TESS light curves (left panel) that we re-model using GP regression in this work (right panel), which are colour-coded by their corresponding νchar values. Evolutionary tracks from Burssens et al. (2020) are shown as solid grey lines and labelled in units of M⊙, and the dashed grey line represents the ZAMS. A typical spectroscopic error bar for the sample is shown in the top-left corner. |
| In the text | |
|
Fig. 4. Spectroscopic HR diagram of the same O stars as in Fig. 3 but colour-coded by the quality factor, Q, of the variability as determined in our GP regression. |
| In the text | |
|
Fig. 5. Results of GP regression and amplitude spectrum fitting for the noise-enhanced light curves of HD 112244 (TIC 406050497) and HD 96715 (TIC 306491594), which are typical yellow and blue subgroup members, are shown in the left and right columns, respectively. From top to bottom, increasingly larger amounts of white noise has been added. The blue and green shaded regions denote the 94% confidence interval for νchar for each method. The νchar values from the GP regression are more consistent, on average, than those from fitting the amplitude spectrum. |
| In the text | |
|
Fig. 6. Examples of results of GP regression and amplitude spectrum fitting for synthetic light curves. The left and right columns show three examples that resemble yellow and blue subgroup members in terms of their quality factor, respectively. The blue and green shaded regions denote the 94% confidence interval for νchar for each method. In all cases, the true input value of νchar is recovered well by the GP model with CELERITE2, whereas the MCMC method of Bowman et al. (2020) sometimes overestimates the value of νchar because of the more rigid profile imposed in the Fourier domain, as demonstrated by a comparison with the noiseless input SHO model. |
| In the text | |
|
Fig. A.1. Summary figures for selected massive stars analysed in this work. |
| In the text | |
|
Fig. A.2. Summary figures for selected massive stars analysed in this work. |
| In the text | |
|
Fig. A.3. Summary figures for selected massive stars analysed in this work. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.