| Issue |
A&A
Volume 661, May 2022
|
|
|---|---|---|
| Article Number | A63 | |
| Number of page(s) | 17 | |
| Section | Planets and planetary systems | |
| DOI | https://doi.org/10.1051/0004-6361/202142501 | |
| Published online | 17 May 2022 | |
Precise radial velocities of giant stars
XVI. Planet occurrence rates from the combined analysis of the Lick, EXPRESS, and PPPS giant star surveys
1
Landessternwarte, Zentrum für Astronomie der Universität Heidelberg,
Königstuhl 12,
69117
Heidelberg,
Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
European Southern Observatory,
Alonso de Córdova 3107, Vitacura, Casilla
19001
Santiago,
Chile
3
University of Southern Queensland, Centre for Astrophysics,
West Street,
Toowoomba,
QLD 4350
Australia
4
Departamento de Astronomía, Universidad de Chile,
Camino El Observatorio 1515,
Las Condes,
Santiago,
Chile
5
Centro de Astrofísica y Tecnologías Afines (CATA),
Casilla 36-D,
Santiago,
Chile
Received:
21
October
2021
Accepted:
11
February
2022
Abstract
Context. Radial velocity surveys of evolved stars allow us to probe a higher stellar mass range, on average, compared to main-sequence samples. Hence, differences between the planet populations around the two target classes can be caused by either the differing stellar mass or stellar evolution. To properly disentangle the effects of both variables, it is important to characterize the planet population around giant stars as accurately as possible.
Aims. Our goal is to investigate the giant planet occurrence rate around evolved stars and determine its dependence on stellar mass, metallicity, and orbital period.
Methods. We combine data from three different radial velocity surveys targeting giant stars: the Lick giant star survey, the radial velocity program EXoPlanets aRound Evolved StarS (EXPRESS), and the Pan-Pacific Planet Search (PPPS), yielding a sample of 482 stars and 37 planets. We homogeneously rederived the stellar parameters of all targets and accounted for varying observational coverage, precision and stellar noise properties by computing a detection probability map for each star via injection and retrieval of synthetic planetary signals. We then computed giant planet occurrence rates as a function of period, stellar mass, and metallicity, corrected for incompleteness.
Results. Our findings agree with previous studies that found a positive planet-metallicity correlation for evolved stars and identified a peak in the giant planet occurrence rate as a function of stellar mass, but our results place it at a slightly smaller mass of (1.68 ± 0.59) M⊙. The period dependence of the giant planet occurrence rate seems to follow a broken power-law or log-normal distribution peaking at (718 ± 226) days or (797 ± 455) days, respectively, which roughly corresponds to 1.6 AU for a 1 M⊙ star and 2.0 AU for a 2 M⊙ star. This peak could be a remnant from halted migration around intermediate-mass stars, caused by stellar evolution, or an artifact from contamination by false positives. The completeness-corrected global occurrence rate of giant planetary systems around evolved stars is 10.7%−1.6%+2.2% for the entire sample, while the evolutionary subsets of RGB and HB stars exhibit 14.2%−2.7%+4.1% and 6.6%−1.3%+2.1%, respectively. However, both subsets have different stellar mass distributions and we demonstrate that the stellar mass dependence of the occurrence rate suffices to explain the apparent change of occurrence with the evolutionary stage.
Key words: planets and satellites: detection / techniques: radial velocities / brown dwarfs / planetary systems
© ESO 2022
1 Introduction
To date, more than 4000 extrasolar planets have been discovered and several thousand candidates are still awaiting confirmation. And while they cover a large range of orbital parameters and are hosted by stars of many different types, a large portion of parameter space has yet to be explored in more depth.
Most of the known planet hosts have masses comparable to or smaller than that of the Sun because they are excellent targets for both radial-velocity (RV) and transit planet searches. In contrast, stars more massive than ~ 1.5 M⊙ are difficult targets for most of their lives: their size impedes detecting planetary transits, and the achievable RV precision is reduced because, compared to their lower-mass counterparts, A-F stars only show few absorption lines in their spectra (due to their higher surface temperatures) and they rotate faster leading to rotational broadening of the lines (Lagrange et al. 2009). But luckily, when these stars leave the main sequence, they cool down and rotate more slowly, becoming feasible targets for RV planet searches. Thus, evolved stars have been targeted by several RV surveys: the Lick giant star survey (Frink et al. 2001; Reffert et al. 2015), the Okayama Planet Search Program (Sato et al. 2005), the ESO planet search program (Setiawan et al. 2003), the Tautenburg Observatory Planet Search (Hatzes et al. 2005), the survey “Retired A Stars and Their Companions” (Johnson et al. 2007), the Penn State-Toruń Planet Search (Niedzielski et al. 2007) including its follow-up program “Tracking Advanced Planetary Systems” (Niedzielski et al. 2015), the BOAO K-giant survey (Han et al. 2010), the Pan-Pacific Planet Search (PPPS, Wittenmyer et al. 2011a), and the EXoPlanet aRound Evolved StarS project (EXPRESS, Jones et al. 2011). To date, more than 150 planets around evolved hosts have been discovered.
Addressing the dependence of planet occurrence on stellar mass, Johnson et al. (2010) studied a sample of main-sequence and subgiant stars with masses ranging from 0.2 to 2.0 M⊙ and found an approximately linear increase in the giant planet occurrence rate with stellar mass. These results were updated by Ghezzi et al. (2018). However, beyond ~2 M⊙, the occurrence rate appears to quickly decrease again (Reffert et al. 2015; Jones et al. 2016). Moreover, while several earlier studies found no evidence for a dependence of planet occurrence around giant stars on stellar metallicity (Pasquini et al. 2007; Takeda et al. 2008; Maldonado et al. 2013), other studies found that the well-known planet-metallicity correlation (Fischer & Valenti 2005), which states that giant planets are preferentially found around metal-rich host stars, also seems to hold for evolved host stars (Hekker & Meléndez 2007; Johnson et al. 2010; Reffert et al. 2015; Jones et al. 2016; Wittenmyer et al. 2017b).
Considering the properties of the planets hosted by postmain sequence stars, Bowler et al. (2010) found that the planet mass-period distribution is significantly different for their sample of subgiant hosts compared to the one derived for main-sequence stars (Cumming et al. 2008), while the orbital eccentricities are smaller for planets around evolved stars (Jones et al. 2014; Maldonado et al. 2013). The most notable difference is that close-in giant planets (Hot and Warm Jupiters with P < 90 days) are very rare (Johnson et al. 2007; Sato et al. 2008). While it was theorized that formation of these planets might be hindered for higher stellar masses due to faster disk dispersal and longer migration timescales (Kennedy & Kenyon 2008, 2009; Currie 2009), it now becomes apparent that Hot Jupiters do exist around A stars (see e.g., Siverd et al. 2018; Hellier et al. 2019; Rodríguez Martinez et al. 2020). Based on transit surveys, Zhou et al. (2019) find a Hot Jupiter occurrence rate of [0.26 ± 0.11]% for A stars, and compared to their values for G stars ([0.71 ± 0.31]%) and F stars ([0.43 ± 0.15]%), there seems to be a slight trend with stellar mass. In particular, the values for G and A stars differ at the 1σ level.
Hence, the observed paucity may be caused by stellar evolution which could have had an important impact on the architecture of the observed planetary systems, ultimately removing close-in planets by engulfment during expansion on the giant branch (Villaver & Livio 2009). Planet engulfment has also been discussed as a possible explanation for the unusually high Lithium abundances observed in a small fraction of giant stars (see, e.g., Adamów et al. 2012). However, stellar tides and mass loss are weaker for stars not undergoing a Helium-flash (M* ≳ 2 M⊙) and may not be efficient at removing Warm Jupiters (Kunitomo et al. 2011; Villaver et al. 2014); however, many uncertainties remain in the evolutionary simulations, and accurately characterizing the planet population around post-main sequence stars (and their progenitors of different masses) can be helpful to constrain the effect of stellar evolution on planetary orbits and theoretical models of planet engulfment.
In this study, we combine three of the previously mentioned RV surveys (the Lick giant star survey, EXPRESS, and PPPS) to investigate the planet population around evolved stars and its correlations with host star properties. In Sect. 2, we describe the observations of the three surveys. Section 3 presents the stellar sample, while we provide an overview of the detected substellar companions in Sect. 4. In Sect. 5, we summarize the derivation of detection probabilities for the combined sample. The global planet occurrence rate is computed in Sect. 6. Section 7 looks at the planet period distribution, while Sect. 8 analyzes the functional dependence of planet occurrence rate on stellar mass and metallicity. We finally conclude in Sect. 9.
2 Observational data
For our analysis, we combine observations from three RV surveys: the Lick giant star survey (Reffert et al. 2006), the EXo-Planets aRound Evolved StarS (EXPRESS) survey (Jones et al. 2011), and the Pan-Pacific Planet Search (PPPS, Wittenmyer et al. 2011a).
2.1 Lick observations
The Lick giant star survey targets 372 bright (V ≤ 6 mag) G and K giants. The survey started in 1999 with an initial sample size of 86 K giants with small photometric variability. One year later, 96 stars were added to the sample with relaxed constraints on photometric variability and three stars were removed as they turned out to be visual binaries. In 2004, another 194 G and K giant stars with on average higher masses and bluer colors (0.8 ≤ B - V ≤ 1.2) joined the sample. More details on the selection criteria are outlined in Frink et al. (2001) and Reffert et al. (2015). The stars were observed at UCO/Lick Observatory on Mount Hamilton in California using the 0.6 m Coudé Auxiliary Telescope (CAT) with the Hamilton High Resolution Echelle Spectrograph (R ~ 60000). RVs were extracted using the iodine cell technique (Butler et al. 1996), achieving a typical radial velocity precision of 5 m s-1 to 8 ms-1. Observations came to a preliminary halt in 2011 when the iodine cell at Lick broke; but they will be resumed in the near future with a new high resolution echelle spectrograph built for the 72 cm Waltz Telescope located at the Landessternwarte Königstuhl in Heidelberg (Tala et al. 2016). In the mean time, additional observations of the most interesting targets were made with the 1m Hertzsprung SONG telescope (Grundahl et al. 2007, 2017) on Tenerife (which are however not included in this analysis in order to keep the data more homogeneous).
2.2 EXPRESS observations
The EXPRESS survey began observing a sample of 164 bright (V ≤ 8 mag) giant stars in 2009 - for details on sample selection see Jones et al. (2011). Three different spectrographs were used within the survey: Early observations were made with the fiber echelle spectrograph (FECH; R ~ 45 000) at the 1.5 m telescope at the Cerro Tololo Inter-American Observatory (CTIO), which however only reach a long-term precision of ~20–30 m s–1 and are not considered in our analysis. In 2011, FECH was replaced by CHIRON (Tokovinin et al. 2013), which in turn is able to provide a resolution of R ~ 90000 and a mean RV precision of ~5 ms–1 and has been used for the EXPRESS observations since. An iodine cell is used for wavelength reference. Additional data have been obtained since 2010 with the Fiber-fed Extended Range Optical Spectrograph (FEROS; Kaufer et al. 1999) on the 2.2 m telescope at La Silla Observatory, which reaches a resolution of R ~ 48 000. RVs were computed from the FEROS spectra using the cross-correlation technique and the simultaneous calibration method (Baranne et al. 1996); more details on the data reduction are given in Jones et al. (2017). The FEROS data likewise reach a long-term precision of ~5 m s–1.
2.3 PPPS observations
The PPPS target list includes 164 evolved stars which were selected as a Southern hemisphere extension to the Lick & Keck Observatory survey of "retired A stars" (e.g., Johnson et al. 2010); for details see Wittenmyer et al. (2011a, Wittenmyer et al. 2016c).
Observations were taken between 2009 and 2015 using the University College London Echelle Spectrograph (UCLES; Diego et al. 1990) at the 3.9 m Anglo-Australian Telescope (AAT), which achieves a resolution of R ~ 45 000. Precise RVs are determined by the iodine-cell technique (Butler et al. 1996). While the survey as a whole has been discontinued, selected targets showing promising candidate planet signals are continued to be monitored as a “PPPS Legacy” program with the Minerva-Australis telescope array and with the SONG telescopes at Tenerife and Australia (Wittenmyer et al. 2018; Addison et al. 2019).
 |
Fig. 1 Stellar mass versus metallicity for the survey stars and histograms of both parameters. The complete sample is shown in gray; the 482 stars left after the homogenizing cuts (described in Sect. 3) are shown in blue, and the red points identify the 32 planet hosting stars within the sample. The mean uncertainties are shown in the upper right corner. The red and blue dotted lines indicate the mean stellar mass and metallicity for the targets with and without planets, respectively, for the following: planet hosts, |
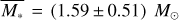
![Mathematical equation: $\overline {\left[{{\rm{Fe/H}}} \right]} = \left({0.06 \pm 0.14} \right)$](/articles/aa/full_html/2022/05/aa42501-21/aa42501-21-eq60.png)
![Mathematical equation: $\overline {\left[{{\rm{Fe/H}}} \right]} = \left({0.06 \pm 0.14} \right)$](/articles/aa/full_html/2022/05/aa42501-21/aa42501-21-eq5.png)
3 Stellar sample
Accounting for partial overlaps between the target lists of the three surveys (the EXPRESS and PPPS surveys share 37 stars, Lick and EXPRESS share 12 stars, and the PPPS and Lick target lists have one star in common), the combined sample comprises 650 stars. We homogeneously rederive the stellar parameters (mass, radius, age, surface gravity, effective temperature, and luminosity) using the method presented in Stock et al. (2018). A Python implementation of the original, unpublished IDL code applying the method of Stock et al. (2018), which is titled SP0G (Stellar Parameters of Giants), was recently made available by the author on github1. It relies on Bayesian inference to compare spectroscopic, photometric, and astrometric observables to grids of PARSEC evolutionary tracks (Bressan et al. 2012) while incorporating knowledge about evolutionary timescale and initial mass function as prior information into the analysis. There has been some controversy in the literature regarding the parameter determinations of evolved stars in RV planet searches. Criticism was raised that the stellar masses might be systematically overestimated (Lloyd 2011, 2013; Schlaufman & Winn 2013). Several other studies rebutted this, finding no evidence for a considerable systematic offset (Johnson et al. 2013; Ghezzi & Johnson 2015; North et al. 2017; Ghezzi et al. 2018). Indeed it seems that spectroscopic masses tend to be overestimated if not accounting for the evolutionary timescales in different regions of the Hertzsprung-Russell-Diagram. Stock et al. (2018) demonstrate the reliability of their method (which takes into account evolutionary timescales and the initial mass function, and fits the red-giant branch (RGB) and the horizontal branch (HB) separately) by applying the method to a test sample of 26 giant stars with available astroseismic mass determinations and find no indications for a significant overestimation in the determined stellar masses. The reliability is also confirmed by Malia et al. (2020), who note that the method by Stock et al. (2018) shows the smallest mass offset among their comparison of spectroscopic to asteroseismic mass estimates. We are therefore confident that the rederived parameters are suitable for determining the dependence of planet occurrence rate on stellar mass.
Recently, Soto et al. (2021) reanalyzed the stellar properties of the EXPRESS sample, incorporating a reselection of iron lines, newer extinction maps, and an improved interpolation between evolutionary tracks. For a subset of stars with available astroseismic parameters, they find an excellent agreement between their method and asteroseismology. Overall, the masses of the EXPRESS target stars are found to be on average 0.28 M⊙ smaller than previously determined (Jones et al. 2011). This is in good agreement with the results using the method from Stock et al. (2018): we find the mean difference between the old and new masses of the EXPRESS stars to be –0.45 + 0.25 M⊙, with the mean mass shifting from 1.86 + 0.52 M⊙ to 1.41 + 0.48 M⊙. Also the results for the evolutionary subsamples agree well: Soto et al. (2021) find a mean mass of 1.41 + 0.46 M⊙ and 1.87 + 0.53 M⊙, while we find 1.21 +0.17 M⊙ and 1.74 + 0.61 M⊙ for the RGB and HB stars, respectively.
The Bayesian inference method from Stock et al. (2018) supplies two probability distribution functions for each of the stellar parameters listed above, assuming the star is either ascending the RGB or has reached the HB, together with a probability estimate for the correct assignment to one of these evolutionary stages. In our analysis, we use the mode values of the distributions for the more probable evolutionary stage. The method requires the stellar metallicities as input which have been determined spectroscopically: for Lick by Hekker & Meléndez (2007), for EXPRESS by Jones et al. (2011), and for PPPS by Wittenmyer et al. (2016c). The distribution of stellar masses and metallicities of the sample stars is shown in Fig. 1 with stars which have been identified as planet hosting stars (see Sect. 4) marked in red. Figure 2 illustrates the positions of the sample stars in the Hertzsprung-Russell-Diagram with respect to three selected PARSEC evolutionary tracks. Again, the planet hosting stars are plotted in red.
In a further effort to obtain a more homogeneous sample for our analysis, we apply several cuts to the combined sample, which are presented in Fig. 3. We do not consider stars for our analysis that have a high stellar mass, M*, > 5 M⊙, have a high luminosity, L* ≥ 103 L⊙, are most likely supergiants, log(ɡ) ≤ 1.5, or have less than 10 observations, #RVs < 10. As very massive, very luminous, and supergiant stars can exhibit many (quasi-)periodic signals of stellar origin, the cuts also serve to exclude targets with a more complex RV behavior where planet detection is hampered from the outset and at the same time, the risk of false positives is larger. Overall, we are left with 482 stars for the detectability and occurrence rate analysis.
 |
Fig. 2 Hertzsprung-Russell diagram of the sample stars after cuts (blue). Planet hosting stars are shown in red. The green, dark-blue, and violet lines correspond to the PARSEC evolutionary tracks for the maximum (4.5 M⊙), mean (1.8 M⊙), and minimum mass (0.8 M⊙) among the target stars, respectively, and a metallicity of [Fe/H] = -0.05, which is the sample mean. |
4 Planet detections in the combined sample
In total, 48 planets in 42 systems have been detected and published around all 650 stars from the target lists of Lick, EXPRESS, and PPPS. They are listed in Table 1 including their detection reference. The stellar parameters given are the red-erived ones (see Sect. 3) and the minimum planet masses are based on the newly determined stellar masses. For confirmation of the planetary nature of the tabulated signals we refer to the listed discovery papers.
Notable discoveries made by the three surveys include the first planet detected around a giant star, ι Dra b (HIP 75458 b; Frink et al. 2002), the most eccentric planet hosted by an evolved star, HD 76920 b (HIP 43803 b; Wittenmyer et al. 2017a; Bergmann et al. 2021), an intriguing multiple system containing one of the shortest-period planets (P = 89 days, a = 0.4 AU) detected around a giant star and a cool Jupiter at 3.5 AU (HIP 67851; Jones et al. 2015a,b), the S-type planet HD 59686 Ab in an eccentric, close-separation binary system (HIP 36616; Ortiz et al. 2016), and several planets in mean motion resonances (MMR): η Cet b and c in a 2:1 MMR (HIP 5364; Trifonov et al. 2014), HD 33844 b and c in a 3:5 MMR (HIP 24275; Wittenmyer et al. 2016b), 7 CMa b and c in a 4:3 MMR (HIP 31592; Luque et al. 2019), and v Oph b and c in a 6:1 MMR (HIP 88048; Quirrenbach et al. 2019).
We note that we include companions beyond the deuterium burning limit at 13 MJup up to about 30 MJup in the category “planet”, as the high-order MMR of v Oph b and c with their minimum masses above 20 MJup strongly indicates that they formed in the circumstellar disk of v Oph (Quirrenbach et al. 2019). Within the combined sample, 79 stars have stellar binary companions (M > 100 MJup). They are not excluded from our analysis as HD 59686 Ab demonstrates that they can harbor detectable planetary systems.
Table 1 also contains planets published by other RV giant star surveys. For the sake of our occurrence rate analysis, we only consider these planets if their observational history within our combined survey allows for a detection with comparable confidence to the planets published within the framework of the Lick, EXPRESS, and PPPS programs. We therefore divide the entries in Table 1 into three blocks: the first block encompasses planets with clear evidence in our RV data and which are the basis for the occurrence rate analysis; 6 planets are hosted by stars that are removed from the sample by the homogenizing cuts described in Sect. 3 - these are assigned to the second block; the third block finally lists those planets without sufficient evidence in our data. While we do find hints of the signals from the third block, the observations are not enough to fully constrain the orbits and/or the false alarm probability is larger than 1%. Thus, they do not differ from other potential planets that might still be hidden in the data and we treat them as such.
Some candidates from the PPPS whose orbits are still unconstrained and follow-up observations are still needed to confirm them are presented in Wittenmyer et al. (2020). As the planets from block three and the candidates are only excluded due to insufficient observations, they should largely be automatically absorbed by the completeness correction for the occurrence rates.
In summary, we work with a sample of 37 planets in 32 systems (13.5% rate of observed multiples) in the following sections, spanning a range from 0.8 MJup to 24.4 MJup in minimum planet mass and from 89 days to 3168 days in period.
5 Detection probabilities
The observational coverage and the noise properties of each star differ considerably across the combined survey. Figure 4 illustrates how the number of data points and length of observation vary for the individual stars within the three surveys. To properly account for the imperfect observations, we use injection-recovery tests to determine the detection capabilities. Our method is a modification of the periodogram analysis used by, for example, Endl et al. (2002), Zechmeister et al. (2009), and Mayor et al. (2011), but accounting for quasi-periodic stellar noise, which several of our giant stars exhibit and which is distinct from the well-known p-mode oscillations (which have timescales of ~hours-days, are not resolved by our observing cadence, and therefore show up as noise). The origin of these longer-period oscillations is not yet well understood (see also Sect. 7).
5.1 Injection-recovery tests
We start by removing the Keplerians of all 37 confidently detected planets (first block in Table 1) and 79 binary companions from the RV time series of the respective host stars using the orbit-fitting routine RVLIN, which is based on a partial linearization of Kepler’s equations (Wright & Howard 2009, 2012). The resulting data can then be considered as pure noise, which can be caused by stellar “jitter”, measurement noise, yet undetected planets, or a combination thereof. Also the 4 planets from the third block of Table 1 are treated as part of this noise. In particular, we note that evolved stars often exhibit quasi-periodic variations (which can have a false-alarm-probability (FAP) of less than 1%) that we also consider as part of the noise and which require us to make some adaptations to the commonly used periodogram analysis.
Before adding synthetic planets with different periods and masses to the resulting residuals, we determine the power threshold in the GLS periodogram (Zechmeister & Kürster 2009) corresponding to a FAP level of 1% using bootstrap randomization (Kürster et al. 1997): For each star, we construct 10 000 bootstrapped data sets by shuffling the measured RV data points while keeping the observing times fixed. We then compute the GLS for each data set and record the maximum power. The 1% FAP level is given by the 99th percentile of the resulting distribution of maximum powers.
In the next step, we mimic planetary signals by adding sine waves with different periods, RV semi-amplitudes, and orbital phases to the residuals of each star. We limit our detectability analysis to circular orbits as the impact of the eccentricity on the resulting detection limits is relatively small for eccentricities up to about 0.5 (see Endl et al. 2002; Cumming et al. 2008; Cumming & Dragomir 2010). For each star, we probe 70 trial periods ranging from 70 days to 11000 days and 50 equidistant phases, increasing the signal’s semi-amplitude until the planet becomes detectable or an amplitude corresponding to a stellar mass companion (100 MJup) for the particular star is reached (Wittenmyer et al. 2011b). In order to deem a signal successfully recovered, we require the following criteria concerning peak height and position, as well as phase and amplitude recovery to be met.
We evaluate the peaks in the vicinity - defined as five times the average peak width in the periodogram, which is given by the inverse of the time base line (VanderPlas 2018) - of the trial period and require that the power of the peak closest to the trial period rises above the previously determined 1% FAP level, and that it is the highest peak in the region. This ensures that the synthetic peak rises above a potential peak in the vicinity corresponding to a (significant) stellar periodicity, whereas limiting the evaluated period range avoids spurious detections while the simulated signal is still small.
As mentioned already, evolved stars can exhibit stellar periodic signals with a FAP below 1%. If the injected signal’s period comes close to one of these noise periods, the first criterion may accept the signal as detected already at very small amplitudes because the stellar signal fulfills the requirements. Thus, it is essential to also test if the phase can be correctly retrieved. As the injected and recovered periods may differ slightly, the phase parameters cannot be compared directly. Instead, we determine the deviation of the recovered phase by finding the maximum separation between corresponding extrema of the two curves during the RV time series, while making sure that at least a time range of three periods is probed (which for long periods can extrapolate beyond the time base line). We then require that the deviation is smaller than 15% of the trial period.
If the signal is recovered in all 50 phases, we define the reached semi-amplitude as the 100% detection limit at the considered period. However, signals might still be detectable below this limit in a fraction of the tested phases due to fortunate sampling of the RV curve. We therefore assign detection probability levels of 10%, 20%, … to the semi-amplitudes where the signal first became detectable in 10%, 20%, … of phases. Yet again, it can happen that for low probabilities a stellar periodicity is recovered at small injected amplitudes when both period and phase are sufficiently similar (as we are probing a smaller range of phases). Hence, we additionally require that the recovered amplitude is within 30% of the simulated amplitude.
This procedure provides us with detection maps for every star in semi-amplitude space, which can be translated into planet mass space using the homogeneously determined stellar masses – an example is shown in Fig. 5. This star exhibits three peaks with FAP <1% in its periodogram of unclear, most likely stellar origin and which we therefore treat as noise. As can be seen in the figure, the detection probability curves rise around these periods indicating that a stronger planetary signal is necessary to clearly distinguish it from stellar noise. We note that this star constitutes an extreme example and is not representative of the entire sample, but serves as a good showcase for how our procedure deals with (quasi-)periodic noise.
 |
Fig. 3 Histograms to illustrate the homogenizing cuts applied to the target stars. Top left: distribution of the number of radial velocity data points, stars with 10 observations or less are excluded (the plot is truncated toward larger numbers; more than 50 stars have more than 70 RV data points). Top right: distribution of the stellar mass; stars as massive as 5 M⊙ or more are excluded. The mass distributions of the stars more likely to be on the RGB and HB are shown in green and orange, respectively. Bottom left: distribution of stellar surface gravity; stars with log(ɡ) equal to or less than 1.5 are excluded. Bottom right: distribution of stellar luminosity; stars as luminous as 1000 L⊙ or more are excluded. |
Planetary systems identified around stars from all three surveys.
 |
Fig. 4 Histograms to illustrate the inhomogeneous observational histories among all stars of the three surveys. Lick, EXPRESS, and PPPS are shown in violet, green, and orange, respectively. Left: distribution of the number of radial velocity data points per star. Right: distribution of the time base line, i.e., the time span covered by RV observations per star. |
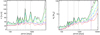 |
Fig. 5 Detection probability map for a target star affected by quasi-periodic oscillations; it exhibits three peaks (at 224d, 496d, and 875d) with FAP< 1% in the GLS periodogram; left: in period-RV semi-amplitude space, and right: in period-planet mass space. The black, green, light blue, yellow, blue, and red solid lines correspond to detection probabilities of 100%, 90%, 70%, 50%, 30%, and 10%, respectively. The detection probability level of, e.g., 10% gives the semi-amplitude (or planet mass) at which 10% of the tested phases can be recovered at the given period. The vertical black dotted lines show the positions of the three significant periodicities, while the vertical dashed blue line in the right plot delineates the time base line of observations for this star (the left plot is restricted to the time base line for better visibility). |
5.2 Survey completeness
The individual detection maps can be combined to illustrate the overall detection capabilities of the survey. The global survey efficiency (shown on the left side of Fig. 6) takes into account the upper limits of each star by counting for each period which fraction of the sample stars confidently excludes planets above a certain mass, that is planets above the 50% efficiency curve can be detected (or excluded) with a probability of 100% around 50% of the sample. The right side of Fig. 6 depicts the median detection probability curves which are computed by averaging each individual probability level over the entire sample, that is planets above the 50% mean probability curve have an overall probability of being detected of 50% across the sample (or are excluded with 50% confidence). The different global efficiency curves spread across a larger range in planetary masses than the mean detectability curves because they depend more strongly on individual stars and their observational history. Both versions of detectability curves can give an idea about how many planets might have been missed by our observations in different domains of the planet mass-period space. For instance, many of the detected planets with masses smaller than ~3MJup lie in regions of low probability indicating that more planets of this kind are to be expected and have remained elusive due to insufficient observations. Thus, their occurrence rate is considerably higher than the rate of detection alone suggests. In Sect. 7, we look at the planet occurrence across different regions of planet mass and period space in more detail.
6 Global giant planet occurrence around evolved stars
6.1 Global occurrence rate of the combined sample
If all stars in the sample were equally well observed and had the same noise properties, and the detected planets were all located above the upper detection limits, we could calculate the planet occurrence rate in the covered period and planet mass range simply by dividing the number of detections by the number of surveyed stars. As this is not the case, it is crucial to correct for incompleteness by estimating how many planets might have been missed using the detection probability maps from the injection-recovery tests. We follow the method for correction described by Wittenmyer et al. (2011b):
We start by computing the completeness fraction fc (Pi;, MP, i) which represents the mean detection probability across the sample for a planet i with given period P and minimum mass Mp,i:
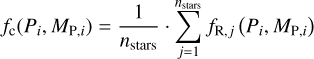 (1)
(1)
where nstars denotes the number of sample stars (after cuts) and fR, j (Pi, MP, i) is the recovery fraction of planet i around the star j, which is the probability for detecting planet if it was hosted by star j given the quality and quantity of our observations of star j. This fraction is determined from the individual detection maps by interpolating between the enclosing detection probability curves (which were recorded in steps of 10%) and the trial periods to obtain the probability corresponding to the values Pi and Mp, i. Both fc(Pi, MP, i) and fR(Pi, Mp, i) for all 37 planets can be found in Table 1.
We then combine the completeness fraction for each planet with the recovery fraction around its own host star, and sum over all host stars2 to calculate the number of planets missed due to insufficient observations:
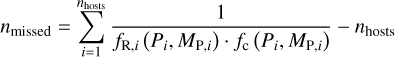 (2)
(2)
where nhosts is the number of stars hosting at least one planet. We find that about 19.7 planets have been missed across the combined sample.
Of the 482 stars in our sample (after cuts) 32 were found to host at least one giant planet (Mp ≥ 0.8 MJup). Using binomial statistics, we get a first estimate of the occurrence rate of planetary systems in our sample (including its 68% confidence interval from the beta distribution (Cameron 2011)) as 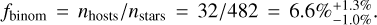 We then use the number of missed detections to boost this estimate and its uncertainties according to
We then use the number of missed detections to boost this estimate and its uncertainties according to
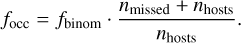 (3)
(3)
This finally gives us the corrected occurrence rate3 of planetary systems hosting at least one giant planet within our sample:
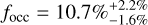
This agrees with the value of 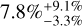 found for the PPPS sample alone (Wittenmyer et al. 2020).
found for the PPPS sample alone (Wittenmyer et al. 2020).
Cumming et al. (2008) estimate an occurrence rate of 6–9% for planets with masses MP = 1–10 MJup and periods in the range from 2 days to 10 years. Compared to these observational results for solar-mass, main-sequence stars, we find a slightly larger occurrence rate, which can be explained by the fact that our sample encompasses more massive stars (see Sect. 8). Our global occurrence rate is at the lower edge of the rate of 10–15% predicted by theoretical studies (Kennedy & Kenyon 2008), but we note that they look at gas giants in general and planets lighter than Jupiter are hardly detectable in our sample - so we expect our occurrence rate to be smaller.
Bowler et al. (2010) find the global planet occurrence of their subgiant sample to lie at, which is significantly higher than our estimate. However, Johnson et al. (2010) note that their sample of retired A stars is comparatively metal-rich which can cause a higher occurrence rate due to the planet-metallicity correlation. From Fig. 2 in Johnson et al. (2010), we can see that the average metallicity of the subgiant sample is around 0.15 dex, whereas our sample mean lies at –0.05 dex. We derive the exact shape of the planet-metallicity correlation for our sample in Sect. 8 (taking also the effect of the stellar mass into account) and show its functional form in Fig. 11. For 0.15 dex and –0.05 dex and the mean stellar mass of our sample, our model places the expected occurrence rates at 20.2% and 10.7%, respectively - hence our occurrence rate and the one derived by Bowler et al. (2010) are fully consistent when factoring in the different stellar metallicities.
Upon the publication of four newly discovered planets (see also Table 1), Jones et al. (2021) analyzed the fraction of stars hosting at least one giant planet in the common sample of EXPRESS and PPPS targets (37 stars, but four of them excluded from the analysis as they are compact binary systems; 11 planetary systems), finding a global occurrence rate of which again is significantly higher than what we find for our combined sample of three surveys4. In order to check whether the discrepancy can be explained by differing metallicity and/or stellar mass distributions between the common and the combined sample, we again anticipate our results from Sect. 8: we use the individual masses and metallicities to compute the expected occurrence rate for each of the 33 stars according to Eq. (6), then average these values to obtain the expected global occurrence rate, which yields 14.3%. So indeed, the parameter distributions are in favor of a higher occurrence rate, but the obtained value is still much smaller than the observed one. In principle, such a result could occur randomly due to the limited sample size. We can use the Poisson binomial distribution to assess the probability of obtaining this result. Given the set of individual success probabilities from Eq. (6), its peak indicates that the most probable outcome is that four planets are distributed among the 33 stars with a probability of 20% – but with a probability of more than 50%, the distribution function predicts a result of 5 or more planets in the subsample. However, the probability of 11 or more successes in 33 trials is only 0.4%. In other words, considering the mean of the distribution function at 4.72 and its standard deviation of 1.98, the observed result for the common sample lies just outside the 3σ confidence interval. We note that the stellar masses of the common sample are all ≤1.42 M⊙, and 14 out of the 33 stars and 8 out of the 11 planet hosts are found in the mass range of the bin with the highest occurrence rate depicted in Fig. 11 – and it is readily apparent that precisely this mass bin shows an excess of planet hosts with respect to the model prediction. Indeed, this excess is also visible in the Lick sample: Fig. 3 of Reffert et al. (2015) shows a high, narrow peak of ~40% in planet occurrence rate at metallicities around 0.2 and stellar masses just above 1.5 M⊙, which appears to be distinct from the pronounced peak they find at ~2.0 M⊙. While the underlying reason for the discrepancy remains elusive at the moment, it might hint at another process or effect that could be at work in this mass range, perhaps related to stellar evolution as all stars in the common sample are more likely to be RGB stars and seem to be at a fairly early stage in their evolution with radii smaller than 7.5 R⊙ and 3.4 ≥ log(ɡ) > 2.7, so some of them could even be subgiants,.
 |
Fig. 6 Two different ways to visualize detectability within the survey. Detected planets (see Table 1) are plotted in black. Left: global detection efficiency of the combined survey in period-planet mass space. Planets with Mp sin(i) above the, e.g., 50% limit can be detected around 50% of the stars in the sample at the given period. Right: median detection probabilities of the combined survey in period-planet mass space (the 50% median probability curve is computed by determining the median of all individual stars’ 50% level at each period). Planets with Mp sin(i) above the 50% limit have a median detection probability of 50% across the sample at the given period. |
6.2 Global occurrence rate as function of evolutionary stage
As mentioned before, stellar evolution can have an influence on orbiting bodies and may cause the planet occurrence rate to change. In our sample, 171 stars have a higher probability of still being on the first ascent of the red giant branch, while 311 stars are more likely to have already reached the horizontal branch. The planet hosts are divided equally: 16 of them are RGB stars (hosting in total 19 planets) and the other 16 are HB stars (hosting 18 planets). We derive the completeness corrected occurrence rate for both evolutionary stages as above and find:
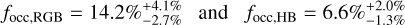
For the RGB and HB stars, 8.3 and 4.4 planets have been missed, respectively.
The occurrence rate of planetary systems on the RGB is more than twice as high as on the HB. In principle, this trend is in line with the expectation that the occurrence rate drops after a star has reached its maximum RGB radius as it could have engulfed potential close-in planets. Moreover, stellar mass loss can cause longer period orbits (that are too large to cause significant tidal interaction between star and companion) to expand leading to planets escaping detection. On the other hand, tides raised on the star by the accompanying body can cause orbits to shrink - the outcome strongly depends on the strength of dissipation within the star, which is not very well constrained. However, the RGB and HB stars in our sample differ from each other in another aspect that might affect the occurrence rate more than the evolutionary stage: The stellar mass distribution is different in both subsamples, which is illustrated in the top right plot of Fig. 3. The RGB stars are almost exclusively confined to masses <2 M⊙, with a mean mass of 1.3 M⊙ (standard deviation 0.4 M⊙), whereas the HB stars have a more uniform mass distribution between 1 M⊙ and about 3.5 M⊙ with a small peak at ~2.5 M⊙, the mean lies at 2.1 M⊙ (standard deviation 0.8 M⊙). These different mass distributions partly reflect the inherently different mass distributions of the observable population of RGB and HB stars in the Galaxy: stars with masses above the transition mass between degenerate and nondegenerate cores ascend the RGB significantly quicker than lower-mass stars as core contraction is not slowed by degeneracy pressure. At the same time, the HB lifetime peaks for stellar masses just above the transition mass while the RGB lifetime increases quickly toward lower masses (see e.g., Fig. 6 of Girardi et al. 2013). Thus, we are much more likely to observe an intermediate-mass star on the HB and a star below the transition mass on the RGB. The mass distributions in our sample however do not entirely follow those of the RGB and HB populations of the Galaxy, because the selection process involved limits on photometric stability and color -one subset in particular was specifically selected to contain the highest-mass giants causing these to be over-represented in our sample compared to the Galactic population.
As we show in Sect. 8, the planet occurrence rate around evolved stars peaks at ~1.7 M⊙, so the RGB stars are on average located closer to this maximum - which could also be an explanation for the higher planet occurrence rate around RGB stars. Hence, we investigate the effects of both mass and evolutionary stage in shaping the occurrence rate further in Sect. 8.
7 Planet occurrence as a function of period
7.1 Planet occurrence across the P-Mp sin(i) plane
To investigate how the occurrence of planets varies with planetary mass and orbital period, we divide the region in the MP sin(i) - P diagram covered by detected planets into nine domains equal in log(MP) and log(P) between 0.8 and 30 MJup and 80 and 3600 days, as shown in Fig. 7. For each domain, we determine the mean completeness fC, d by evaluating Eq. (1) for 2500 combinations of {P, MP sin(i)} across a 50 × 50 log-uniform grid. We then use this to compute the number of missed planets in this domain:, where ndet is the number of detected planets in the domain. As we are interested in the fraction of stars with at least one planet in the given domain, we count each planet of multiple systems in its respective domain. Additionally, we compute neff = nstars fC, d which estimates the effective number of stars whose observations exclude planets that would be located in this domain. Finally, the occurrence rate focc, d is given by Eq. (3) with the substitution of nhosts with ndet. Figure 7 reports all four values for each of the nine domains. As can be seen, the most common planets with masses above 0.8 MJup around evolved stars have masses below 3 MJup and are preferentially found at periods between several hundred days and ~1000 days. Furthermore, planets with long periods of a few thousand days are more abundant than periods below ~300 days in this mass regime. It seems that planets across the entire probed mass range are least common in the latter period regime, with planets above 10 MJup being decidedly rare. In fact, we did not find a single one in this domain even though our completeness is highest. From the binomial distribution, we derive a 1σ upper limit of focc ≤ 0.004 for zero detections around 476 stars.
Cumming et al. (2008) find that the orbital period distribution shows an increase in the occurrence rate of gas giants of a factor of 5 beyond P ~ 300 days. And indeed, if we collapse Fig. 7 along the mass axis, we find for the three bins: which corresponds to a factor of 5 increase between the first and the second. For periods above ~1000 days, the occurrence rate drops again by 40%.
 |
Fig. 7 Planet occurrence focc, d as a function of period and minimum planet mass. For each of the nine domains, we also give the number of detected planet ndet, the estimated number of missed planets due to incompleteness nmissed, the effective number of sample stars that are useful for constraining the occurrence rate in this domain neff, and the mean completeness within the domain fC, d. The light blue dots show the positions of the detected planets. |
 |
Fig. 8 Planet occurrence rate for planets with MP sin(i) > 0.8 MJup in five period bins. The blue histogram and blue dots correspond to the uncorrected rate, while the light blue histogram and black dots show the rate corrected for missed planets. Errors are derived from the binomial distribution. The log-normal fit is plotted in green, while the best-fit broken power-law is shown in red with a black dotted connector illustrating the 1σ uncertainty in Pbreak. |
7.2 Giant planet period distribution around evolved stars
To have a closer look at the period distribution, we divide the period range into five bins (which are large enough so that there are still 3 planets in the least populated bin), including the entire range of detected planet masses covered in Fig. 7 (0 8 - 30 MJup). We plot the resulting occurrence rates as a function of period including the completeness correction in Fig. 8, which clearly shows the rise and fall and the prominent peak in between, located at several hundred days. Fernandes et al. (2019) find a similar behavior in a reanalysis of the giant planet occurrence rate from the HARPS and CORALIE surveys (Mayor et al. 2011). Following their approach, we fit the period dependence of the occurrence rate with a broken power-law according to:
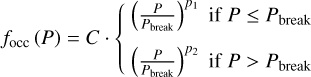 (4)
(4)
where focc(P) is the planet occurrence rate per period bin, C is a normalization constant, Pbreak is the position of the peak in the period distribution, and p1 and p2 are the power-law indices of the rising and falling slope, respectively. We perform a least-squares fit and find the best-fitting parameters as:
C = (5.48 ± 2.01)
Pbreak = (720 ± 223) days
P1 = (1.25 ± 0.46)
P2 = (–0.99 ± 0.81)
On a cautionary note, however, we remark that the x2 value of 0.22 points to considerable over-fitting (as to be expected with five data points and four free parameters).
Additionally, we fit a log-normal distribution function:
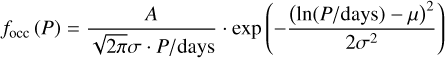 (5)
(5)
The least-squares fit yields:
A = (9988 ± 4166)
σ = (0.89 ± 0.19)
μ = (7.46 ± 0.45)
with a x2 value of 1.14. We obtain a second estimate of Pbreak from the mode of the log-normal distribution as:
Pbreak [days] = exp (μ – σ2) = 793 ± 443 which is in line with the value from the broken power-law. Figure 8 compares the result of both fits to the completeness-corrected occurrence rate in the period bins used for fitting the data.
Compared to the results from Fernandes et al. (2019), who deal with main-sequence solar-mass stars, our rising slope is much steeper (p1,F19 = 0.53 ± 0.09) while the power-law index for the decrease is comparable (p2, F19 = –1.22 ± 0.47). They find Pbreak to lie around 1200–2200 days which corresponds roughly to the position of the snow line (2.3–3.2 AU). As our sample is on average more massive and the snow line is thought to scale approximately linearly with stellar mass, we would expect Pbreak to lie at longer periods (for a 1 M⊙ star our Pbreak corresponds to 1.6 AU, and for a 2 M⊙ to 2 AU).
To investigate if the position of the break changes with stellar mass, we divide our sample into two subsamples with M* < 1.4 M⊙ and M*. ≥ 1.4 M⊙. This boundary mass apportions the planets roughly evenly among the two subsamples (20 vs. 17). Unfortunately, we cannot repeat the analysis from above due to increasingly severe small number statistics leaving some period bins devoid of planets. So instead, we look at the cumulative distribution in period for both subsamples in Fig. 9. Again, we can discern an increase in occurrence at around 300 days for both subsamples (and the entire sample). In general, the overall shape of the cumulative distribution is very similar between the subsamples, and neither deviates much from the whole sample. However, there is a noticeable bump for the higher-mass subsample at ~600days, which becomes even more apparent when we compare it to the cumulative period distribution of the RV-discovered giant planet population around main-sequence (log(ɡ) ≥ 4) stars (from the NASA Exoplanet Archive5) – for a better comparison, we limit the selected planets to similar planet masses and periods as found in our sample (Mp sin(i) ≥ 0.8 MJup and P > 89 days). A Kolmogorov-Smirnov (KS) test shows that the probability of our complete planet sample and the main-sequence sample being drawn from the same underlying period distribution is only 2.8% (KS statistic D = 0.258, Neff = 30.7). A more detailed look at the subsamples shows this is mostly caused by the higher-mass subsample: Comparing to the main-sequence stars, the KS test finds a probability of 42% (D = 0.2, Neff = 18.0) for the lower-mass subsample, and 2.5% (D = 0.362, Neff = 15.5) for the higher-mass subsam-ple, which is in line with the larger visual difference (i.e., the ~600 days bump) noted above. Both subsamples have a probability of 27% (D = 0.315, Neff = 9.2) to have been drawn from the same distribution.
In principle, this bump could cause an enhancement in the corresponding period bin and pull the peak of the occurrence rate to smaller periods. But in this case, the physical interpretation of the fitted Pbreak would need to change. In fact, the decrease in occurrence beyond the snow line identified by Fernandes et al. (2019) is still hinted at in Fig. 9 as all three depicted cumulative distributions seem to change slope again after ~ 1000 days. As for the origin of the enhancement at ~600days, there are several possibilities: as gas dispersal happens earlier during the formation of planets around higher-mass stars, it might be that giant planets get halted at these intermediate periods during their inward migration.
On the other hand, stellar evolution can affect the orbital separation of companions and as mentioned before, there is a correlation between stellar mass and evolutionary stage in our sample due to initial target selection (see Sect. 6). Therefore, we also look at two subsamples based on evolutionary stage (RGB vs HB) whose cumulative period distribution can be seen in Fig. 10. The enhancement seems to be more severe for the planets hosted by HB stars. The KS test gives a probability of 17.5% (D = 0.345, Neff = 9.2) that both the RGB and the HB distributions are drawn from the same underlying distribution, while compared to the main-sequence sample, the probabilities are 24% (D = 0.24, Neff = 17.2) and 6% (D = 0.317, Neff = 16.4) for RGB and HB stars, respectively. And indeed one would expect that planets around HB stars have been affected more severely by stellar evolution while their host was ascending the RGB. We note however that planets with host stars above 2 M0 are not thought to experience significant orbital changes during the first ascent of the red-giant branch because these stars do not experience a Helium flash at the tip of the RGB and hence expand much less during their ascent, weakening the effects of both stellar tides and mass loss on the planetary orbits (Kunitomo et al. 2011; Villaver et al. 2014). And due to the correlation between evolutionary stage and stellar mass in our sample, we cannot fully disentangle the influence either may have on the observed period distribution.
A third possibility for the origin of the enhancement could be a contamination with false positives. There are several notable examples in the literature of periodic signals around giant stars that were revealed through careful observations to be most likely of stellar origin. Hatzes et al. (2018) present the case of y Draco-nis showing coherent periodic RV variations with P = 702 days for seven years which then stopped only to pick up again after a few years, phase-shifted. Similar behavior has been detected in Aldebaran with a period of 629 days, based on more than 500 RV measurements (Reichert et al. 2019). Delgado Mena et al. (2018) find evidence against a planet interpretation for three giant stars with periodicities (P = 747 days, P = 699 days, P = 672 days) with two of these stars showing variations in the FWHM of the cross-correlation function with a similar period, and one exhibiting a correlation between RVs and bisector inverse slope in some observing windows. All these false positives have periods comparable to where we find a possible enhancement. Oscillatory convective modes in luminous giant stars (proposed in order to explain the origin of the long secondary period variables of the sequence D, Saio et al. 2015) have been invoked to explain the observed periods. The onset of these pulsations is associated with a minimum luminosity, the exact value however depends sensitively on the employed convection model. And considering that our HB stars are on average more luminous than our RGB stars, we cannot completely rule out a contamination with false positives.
In principle, near-infrared (IR) RV data can help identify false positives as the stellar phenomena potentially mimicking planet signals are expected to exhibit different amplitudes in the IR domain - see Trifonov et al. (2015), who obtained near-IR RVs with the CRIRES spectrograph at ESO’s VLT for eight of the planet-hosting giants in our sample (from the first block of Table 1) and confirmed the consistency between the orbital solutions from optical and IR data, with specific emphasis on a stable RV semi-amplitude. Unfortunately, similar analyses are not widely available for our target class at present.
 |
Fig. 9 Normalized cumulative distribution of orbital periods for planets with MPsin(i) ≥ 0.8 MJup. The black line corresponds to the entire sample, while the blue and red line show the distribution for subsam-ples with M, < 1.4 M⊙ and M* ≥ 1.4 M⊙, respectively. For comparison, the distribution for giant planets orbiting main-sequence stars with MP sin(i) ≥ 0.8 MJup and P > 89 days is shown (obtained from the NASA Exoplanet Archive, selecting only planets discovered via RV and around host stars with log(ɡ) ≥ 4). |
 |
Fig. 10 Same as Fig. 9 but the host stars were divided into two subsets based on their evolutionary stage. The blue line shows the period distribution of planets orbiting RGB stars, while the red line corresponds to planets hosted by HB stars. The green line again traces the giant planets around main-sequence stars. |
8 Planet occurrence as a function of stellar mass and metallicity
In this section, we investigate the dependence of the planet occurrence rate on stellar mass and metallicity. Figure 1 already shows a prominent concentration of planets at higher metallicities and stellar masses between 1–2 M⊙, while there are no planet hosting stars with masses larger than 3 M⊙. To robustly fit the functional dependence of the occurrence rate on the stellar parameters while avoiding binning of the data and accounting for uncertainties in stellar mass and metallicity determination, we use the Bayesian inference method detailed in Johnson et al. (2010), with a small variation to include the detection probabilities derived in Sect. 5:
We model the data as a series of Bernoulli trials with the success probability f depending on stellar mass M*. and metal-licity [Fe/H]. The number of trials is given by nstars = 482 and the number of successes by the number of identified planetary systems nhosts = 32 (hence nnonhosts= nstars – nhosts= 450), while d is the data and X the set of model parameters for the functional form of the occurrence rate f:
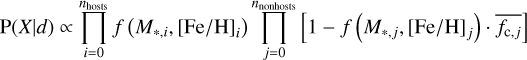
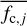 is the mean probability of detecting a planet similar to any of the planets in the sample6 around star j which is given by
is the mean probability of detecting a planet similar to any of the planets in the sample6 around star j which is given by
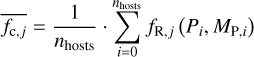
where fR,j (Pi, MP,i) is the recovery fraction of planet i around star j (see Sect. 5). This insertion of the mean detection probability allows for a larger f(M*.j, [Fe/H]j) for stars with low completeness for the detected planets and thus accounts for the fact that these stars may still host undetected planets of the same kind.
The likelihood is then given by:
![Mathematical equation: ${P_{{\rm{break}}}}\left[{{\rm{days}}} \right] = \exp \left({\mu - {\sigma ^2}} \right) = 793 \pm 443$](/articles/aa/full_html/2022/05/aa42501-21/aa42501-21-eq18.png)
We ignored P(X) in the last step as it does not affect the fitting result for uniform priors on the parameters X. To account for uncertainties in the mass and metallicity determination, we assume a Gaussian probability distribution function centered on {M*, i, [Fe/H]} and widths corresponding to their 1er errors and write ![Mathematical equation: $f\left({{M_{*,i,}}{{\left[{{\rm{Fe/H}}} \right]}_i}} \right)$](/articles/aa/full_html/2022/05/aa42501-21/aa42501-21-eq19.png) as:
as:
![Mathematical equation: ${\rm{P}}\left({X\left| d \right.} \right) \propto \prod\limits_{i = 0}^{{n_{{\rm{hosts}}}}} {f\left({{M_{*,i}},\,\,{{\left[{{\rm{Fe/H}}} \right]}_i}} \right)} \,\prod\limits_{j = 0}^{{n_{{\rm{nonhosts}}}}} {\left[{1 - f\left({{M_{*,i}},\,\,{{\left[{{\rm{Fe/H}}} \right]}_i}} \right) \cdot \overline {{f_{{\rm{c}},j}}}} \right]} $](/articles/aa/full_html/2022/05/aa42501-21/aa42501-21-eq20.png)
where we choose the 3e intervals as integration boundaries. We then determine the optimal model parameters by evaluating L numerically over a grid and finding the set of X that maximizes the likelihood. Following Reffert et al. (2015) and Jones et al. (2016), we model the dependence of the occurrence rate on stellar mass and metallicity as an exponential distribution in metallicity and a Gaussian distribution in stellar mass:
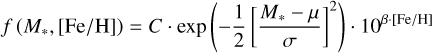 (6)
(6)
with the model parameters 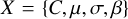 We find the values of maximum likelihood as
We find the values of maximum likelihood as
C = (0.128 ± 0.027)
μ = (1.68 ± 0.59) M⊙
σ = (0.70 ± 1.02) M⊙
ß = (1.38 ± 0.36)
where we estimated the errors from the one-dimensional marginal probability distribution functions (PDFs; see below) via the general definition of the standard deviation for a continuous random variable. We however note that this is only a point estimator and that the PDFs themselves give a better representation of the possible parameter spaces.
Figure 11 compares the fitted model to the observed planet rates in different stellar mass and metallicity bins. The highest probability for the presence of a planet is reached at 1.68 M⊙ with an occurrence rate of 12.8% at solar metallicity.
In order to show the distribution of possible values for the model parameters and potential correlations between them, we compute the one- and two-dimensional marginal PDFs according to:
![Mathematical equation: $\matrix{{{\cal L} = \log \left({{\rm{P}}\left({X\left| d \right.} \right)} \right) \propto \sum\limits_{i = 0}^{{n_{{\rm{hosts}}}}} {\log \,f\,\left({{M_{*,i}},{{\left[{{\rm{Fe/H}}} \right]}_i}} \right)}} \hfill \cr {\quad \quad \quad \quad \quad \quad \quad \quad + \sum\limits_{j = 0}^{{n_{{\rm{nonhosts}}}}} {\log \,\left[{1 - f\,\left({{M_{*,j}},{{\left[{{\rm{Fe/H}}} \right]}_i}} \right) \cdot \overline {{f_{{\rm{c}},j}}}} \right]}} \hfill \cr} $](/articles/aa/full_html/2022/05/aa42501-21/aa42501-21-eq23.png)
and
![Mathematical equation: $\matrix{{f\,\left({{M_{*,i}},{{\left[{{\rm{Fe/H}}} \right]}_i}} \right) = \int\!\!\!\int {f\,\left({{M_*},\left[{{\rm{Fe/H}}} \right]} \right)} \cdot} \hfill \cr {\,\,\exp \left[{- {{{M_*} - {M_{*,i}}} \over {2\sigma_{{M_*},i}^2}} - {{\left[{{\rm{Fe/H}}} \right] - {{\left[{{\rm{Fe/H}}} \right]}_i}} \over {2\sigma_{{{\left[{{\rm{Fe/H}}} \right]}_i}}^2}}} \right]d{M_*}\,{\rm{d}}\left[{{\rm{Fe/H}}} \right]} \hfill \cr} $](/articles/aa/full_html/2022/05/aa42501-21/aa42501-21-eq24.png)
with integration limits set by the uniform priors, and analogous for the remaining parameters and their combinations. All resulting PDFs are shown in Fig. 12. While there is no strong correlation between ß and any of the other parameters, the remaining three show some mutual correlations: Moving away from the maximum likelihood solution, there are regions in parameter space toward small μ and larger σ which are not excluded by the data. This could be an artifact due to the limited mass range covered by our sample with the smallest stellar mass being 0.8 M⊙ (hence in principle allowing the occurrence rate to peak outside this range if at the same time, σ is large and hence the occurrence rate only starts dropping significantly at intermediate masses). However, other studies have shown that the occurrence is monotonically increasing at these smaller stellar masses (Johnson et al. 2010; Ghezzi et al. 2018) and the plot for P(μ|d) in Fig. 12 still exhibits a clear peak at the maximum likelihood value for μ. Moreover, the plot for P(σ, μ|d) shows that around the best-fit μ, also σ is fairly well constrained to below 1 M⊙.
Additionally, we fit to our data a power-law distribution in stellar mass (Eq. (7), X = {C, α, β}) like the one found by Johnson et al. (2010). As their sample was restricted to stellar masses below -2 M⊙, the model does not include a decrease in occurrence to higher masses. Hence, we include a second version (Eq. (8), X = {C, α, M0, β}.) of the power-law distribution with an added exponential cut-off.
![Mathematical equation: $f\left({{M_*},\left[{{\rm{Fe/H}}} \right]} \right) = C \cdot \exp \left({- {1 \over 2}{{\left[{{{{M_*} - \mu} \over \sigma}} \right]}^2}} \right) \cdot {10^{\beta \cdot \left[{{\rm{Fe/H}}} \right]}}$](/articles/aa/full_html/2022/05/aa42501-21/aa42501-21-eq25.png) (7)
(7)
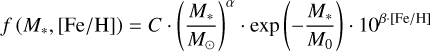 (8)
(8)
Ghezzi et al. (2018) present an update on the results of Johnson et al. (2010) using the same sample and find that the occurrence rate can also be well described by a power law of the combined quantity (M* × [Fe/H]), which can be considered as proportional to the amount of metals in the planet forming disk (Eq. (9), X = {C, ß}.). Again, we also consider a variation that includes an exponential cut-off (Eq. (10), X = {C, ß M0}.).
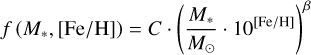 (9)
(9)
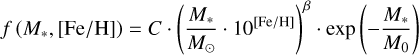 (10)
(10)
Finally, we also address the notion that the planet-metallicity correlation (PMC) might be absent for evolved stars (see Pasquini et al. 2007; Takeda et al. 2008; Maldonado et al. 2013) by testing two more functional forms based on Eqs. (6) and (8) but with ß set to zero, effectively removing the dependence of the occurrence rate on metallicity:
![Mathematical equation: $f\left({{M_*},\left[{{\rm{Fe/H}}} \right]} \right) = C \cdot {\left({{{{M_*}} \over {{M_ \odot}}}} \right)^\alpha} \cdot {10^{\beta \cdot \left[{{\rm{Fe/H}}} \right]}}$](/articles/aa/full_html/2022/05/aa42501-21/aa42501-21-eq29.png) (11)
(11)
![Mathematical equation: $f\left({{M_*},\left[{{\rm{Fe/H}}} \right]} \right) = C \cdot {\left({{{{M_*}} \over {{M_ \odot}}}} \right)^\alpha} \cdot \exp \left({- {{{M_*}} \over {{M_0}}}} \right) \cdot {10^{\beta \cdot \left[{{\rm{Fe/H}}} \right]}}$](/articles/aa/full_html/2022/05/aa42501-21/aa42501-21-eq30.png) (12)
(12)
Table 2 lists the maximum likelihood model parameters for all seven tested models. Following the procedure outlined in Mortier et al. (2013), we use the Bayes factor to compare the different functional forms and to quantify which one represents a better match to the data. It is given by
![Mathematical equation: $f\left({{M_*},\left[{{\rm{Fe/H}}} \right]} \right) = C \cdot {\left({{{{M_*}} \over {{M_ \odot}}} \cdot {{10}^{\left[{{\rm{Fe/H}}} \right]}}} \right)^\beta}$](/articles/aa/full_html/2022/05/aa42501-21/aa42501-21-eq31.png) (13)
(13)
We set Eq (6), which has the highest evidence, as fopt and therefore as a benchmark for comparison with the other models The Bayes factor is also listed in Table 2 Values larger than 10 indicate a strong evidence against the model, while values above 100 can be considered as decisive for model selection (Kass & Raftery 1995) Both Eq (8) and Eq (10) show evidence comparable to our benchmark model with B < 10 – our data are not sufficient to decide in favor of either of the three. On the other hand, the models 7 and 9 without exponential cut-off in the stellar mass dependence have ℬ > 10 providing strong evidence against a monotonically increasing occurrence rate with stellar mass and even decisive evidence against the functional form in Eq. (9). This can also be seen in Fig. 13 that compares the best-fits for the remaining models to the data. The stellar mass dependence in Eq. (7) even becomes negative, as for the masses present in our sample the drop in occurrence beyond the peak actually dominates over the increase at smaller masses.
Overall, our results strongly support a maximum of the planet occurrence rate at intermediate stellar masses and an exponential drop thereafter. This distinct peak in the occurrence rate was already noted by Reffert et al. (2015) for the Lick sample, and Jones et al. (2016) for the EXPRESS sample individually, with the peak placed at 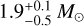 and
and 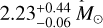 , respectively. Based on our larger sample, which also includes the PPPS data and a completeness correction based on a detectability analysis, we find the position of the peak to lie at 1.68 M⊙, which is consistent with the estimate from the Lick sample alone. The discrepancy to the value from Jones et al. (2016) is mainly caused by our new parameter determination: all EXPRESS targets are now thought to have smaller masses than determined previously (Jones et al. 2011); their mean stellar mass shifts from 1.86 M⊙ to 1.41 M⊙.
, respectively. Based on our larger sample, which also includes the PPPS data and a completeness correction based on a detectability analysis, we find the position of the peak to lie at 1.68 M⊙, which is consistent with the estimate from the Lick sample alone. The discrepancy to the value from Jones et al. (2016) is mainly caused by our new parameter determination: all EXPRESS targets are now thought to have smaller masses than determined previously (Jones et al. 2011); their mean stellar mass shifts from 1.86 M⊙ to 1.41 M⊙.
Regarding the PMC, the Bayes factor provides decisive evidence against the models shown in Eqs. (11) and (12) and hence strongly supports the presence of a dependence of planet occurrence rate on stellar metallicity. Our value for ß = 1.38 is smaller than found for main-sequence stars (Fischer & Valenti 2005: ß = 2) but in good agreement with other results for evolved stars (Johnson et al. 2010: ß = 1.2 ± 0.2; Reffert et al. 2015: 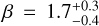 ; Jones et al. 2016:
; Jones et al. 2016: 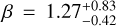 , though larger than the value of
, though larger than the value of 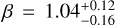 determined by Ghezzi et al. (2018). The question still remains as to why the PMC is weaker for evolved stars compared to what has been found for main-sequence samples. Several contributing factors could play a role: As noted by Ghezzi et al. (2018), the occurrence of giant planets could really be a function of the total amount of solids in the proto-planetary disk. In this case, lower metallicities may be compensated for by higher stellar masses (which are not present in the main-sequence samples). Furthermore, the PMC would also appear weaker if a fraction of our planet sample actually formed via gravitational instability, a formation channel that becomes more likely in massive disks, and which - in contrast to core accretion - is thought to be independent of metallicity. Moreover, it has been noted that there might be a period-metallicity correlation for giant planets (see e.g., Jenkins et al. 2017; Petigura et al. 2018), with metal-rich stars forming giant planets on closer orbits than metal-poor stars. During the radial expansion on the giant branch, planets around metal-rich stars would on average be more likely to get engulfed by their host star. Thereby, the PMC would appear weaker than it used to be when the stars were still on the main sequence. Finally, a contamination by false positives - if present - could also decrease the observed value of ß if it occurs independently of metallicity or is even favored by lower metallicity.
determined by Ghezzi et al. (2018). The question still remains as to why the PMC is weaker for evolved stars compared to what has been found for main-sequence samples. Several contributing factors could play a role: As noted by Ghezzi et al. (2018), the occurrence of giant planets could really be a function of the total amount of solids in the proto-planetary disk. In this case, lower metallicities may be compensated for by higher stellar masses (which are not present in the main-sequence samples). Furthermore, the PMC would also appear weaker if a fraction of our planet sample actually formed via gravitational instability, a formation channel that becomes more likely in massive disks, and which - in contrast to core accretion - is thought to be independent of metallicity. Moreover, it has been noted that there might be a period-metallicity correlation for giant planets (see e.g., Jenkins et al. 2017; Petigura et al. 2018), with metal-rich stars forming giant planets on closer orbits than metal-poor stars. During the radial expansion on the giant branch, planets around metal-rich stars would on average be more likely to get engulfed by their host star. Thereby, the PMC would appear weaker than it used to be when the stars were still on the main sequence. Finally, a contamination by false positives - if present - could also decrease the observed value of ß if it occurs independently of metallicity or is even favored by lower metallicity.
We also compare our results to those of Borgniet et al. (2019), who present occurrence rates from an RV survey of A and F stars for different period, planet mass, and stellar mass bins. The bin where we can best compare our results is for MP = 1–13 MJup and P = 100–1000 days. For stellar masses below 1.5 M⊙, they find 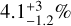 occurrence and in fact, all their detections are found in this subsample. For M* > 1.5 M⊙, they find an upper limit of ~3% (but the confidence limit goes up to Thus, their values are smaller than our global occurrence rate but we note that their sample only encompasses few stars in the range 1.6-1.7 M⊙, where we observed maximum planet occurrence. Based on our fit of the stellar mass dependence, we would expect to find about the same number of planets in bins above and below 1.5 M⊙ (assuming that there are equal numbers of stars in both bins which have a flat mass distribution), with a few more in the higher mass bin, as this basically means integrating from the peak down to either side of our occurrence rate function. Therefore, considering their large uncertainty in the higher stellar mass bin and limited completeness, as well as the fact that ~ 20% of our planets have periods larger than 1000 days, we consider our result consistent to theirs – so far. More observations will be necessary to unveil if the same dependence of occurrence rate on stellar mass holds for main-sequence stars, or if stellar evolution can significantly alter it in the considered period range P > 89 days.
occurrence and in fact, all their detections are found in this subsample. For M* > 1.5 M⊙, they find an upper limit of ~3% (but the confidence limit goes up to Thus, their values are smaller than our global occurrence rate but we note that their sample only encompasses few stars in the range 1.6-1.7 M⊙, where we observed maximum planet occurrence. Based on our fit of the stellar mass dependence, we would expect to find about the same number of planets in bins above and below 1.5 M⊙ (assuming that there are equal numbers of stars in both bins which have a flat mass distribution), with a few more in the higher mass bin, as this basically means integrating from the peak down to either side of our occurrence rate function. Therefore, considering their large uncertainty in the higher stellar mass bin and limited completeness, as well as the fact that ~ 20% of our planets have periods larger than 1000 days, we consider our result consistent to theirs – so far. More observations will be necessary to unveil if the same dependence of occurrence rate on stellar mass holds for main-sequence stars, or if stellar evolution can significantly alter it in the considered period range P > 89 days.
Lastly, we revisit the question as to whether the evolutionary stage significantly affects the planet occurrence rate when factoring in the different mass distributions of the RGB and HB subsets discussed in Sect. 6. For each subset, we compute the expected occurrence rate based on Eq. (6) using the masses and metallicities of the stars in the respective subset. This yields 7.4% and 11% for the HB and RGB stars, respectively. Compared to the results from Sect. 6, the estimate for the HB sample is in very good agreement and the result for the RGB sample lies only slightly below the lower boundary of the 1 σ error margin (11.5%). Hence at this point, the difference in planet occurrence between our evolutionary subsamples can be almost fully explained by their different mass distributions. However, fully disentangling the effects of mass and evolutionary stage on occurrence rates would require two carefully selected evolutionary subsets with comparable mass and metallicity distributions, which is beyond the scope of this paper.
 |
Fig. 11 Planet occurrence rate as a function of stellar mass (left) and metallicity (right). The black dotted histograms show the distribution of planets, while the solid black histograms show an estimate of the completeness correction performed for the individual bins according to the procedure outlined in Sect. 6. The blue solid line represents the fitted occurrence as a function of stellar mass (left) with the metallicity set to the sample mean of [Fe/H] = -0.05 and as a function of metallicity (right) with the mass set to the sample mean of M, = 1.81 M⊙. For a more precise prediction, the red dots give the average expected occurrence rate computed using the masses and metallicities of the stars in each bin. Note that we fit the dependence on stellar mass and metallicity simultaneously and that we show the histograms only for visualization, the fit does not rely on binning of the data. |
 |
Fig. 12 Marginal probability distributions functions (PDFs) from the maximum likelihood estimation for the set of model parameters from Eq. (6). The rightmost plot in each row shows the PDF of the indicated model parameter marginalized over the remaining three. The black dots show the grid values used for evaluating the likelihood, the blue line is a spline interpolation between them. The remaining plots show the different two-dimensional PDFs marginalized overtwo parameters with blue contours indicating levels from 95% down to 10% of the maximumprobability. The red dots and vertical red lines identify the parameter values corresponding to the maximum overall likelihood. Axes are limited to the chosen uniform prior ranges. |
Fitted model parameters, incl. uncertainties, of the seven tested functional forms for the stellar mass and metallicity dependence of the planet occurrence rate and the Bayes factor for comparing between them.
 |
Fig. 13 Similar to Fig. 11 but for the functional forms given in Eqs. (7)–(12). For the mass plots, we set the metallicity to the sample mean of –0.05 dex, and for the metallicity plots, we set the stellar mass to the sample mean of 1.81 M⊙. |
9 Summary
We presented an analysis of the combined data from the Lick, EXPRESS, and PPPS giant star RV surveys. In total, the sample consists of 482 stars hosting 37 giant planets in 32 systems, which span a range from 0.8 MJup to 24.4 MJup in minimum planet mass and from 89 days to 3168 days in period. The stellar parameters were homogeneously rederived using the method presented by Stock et al. (2018). We performed injection and retrieval tests of synthetic planetary signals and computed a detection probability map for each star, which we used to derive completeness corrected planet occurrence rates:
We find the global occurrence rate of planetary systems with at least one giant planet (MP,min > 0.8 MJup) around the evolved stars in our sample to be
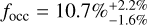
This estimate varies with evolutionary stage: for RGB stars and HB stars, we found
 , respectively. However, the stellar mass distribution differs between the two subsamples and we demonstrate that this is enough to explain the observed difference in occurrence between the evolutionary subsamples;
, respectively. However, the stellar mass distribution differs between the two subsamples and we demonstrate that this is enough to explain the observed difference in occurrence between the evolutionary subsamples;Our findings agree with previous studies that showed a positive planet-metallicity correlation for evolved stars (Wittenmyer et al. 2017b) and a distinct peak in the occurrence rate above 1.5 M⊙ with an exponential drop thereafter (Reffert et al. 2015; Jones et al. 2016), while placing these results on a more secure statistical footing. In our Bayesian fit, maximum planet occurrence is reached at a stellar mass of 1.68 M⊙, while the power-law exponent of the planet-metallicity correlation lies at ß = 1.38;
The period distribution of giant planets around evolved host stars seems to peak at several hundred days. A broken power-law fit places the position of the peak at (718 ± 226) days, a log-normal fit finds (797 ± 455) days. For main-sequence stars, this break is found to occur around the snow line at 1200-2200 days (Fernandes et al. 2019). As our stars are on average more massive, the break should lie even further out. This discrepancy could be a remnant from halted migration around intermediate-mass stars, caused by stellar evolution, or an artifact from contamination by false positives in this period range. It seems to be slightly more severe for higher stellar masses and later evolutionary stages.
In conclusion, we note that for evolved stars, age can be another factor with significant influence on the occurrence and architecture of planetary systems. Moreover, the planet period and mass distributions might vary with stellar mass (or metallicity) and a simultaneous fit to all four (or even five) parameters would be ideal and worthwhile to pursue for future studies.
Acknowledgements
V.W. and S.R. acknowledge the support of the DFG priority program SPP 1992 "Exploring the Diversity of Extrasolar Planets" (RE 2694/5–1). J.S.J. acknowledges support by FONDECYT grant 1201371, and partial support from CONICYT project Basal AFB-170002. We thank Stephan Stock for rederiving the stellar parameters of the combined sample and Paul Heeren for helpful discussions. This research has made use of the NASA Exoplanet Archive, which is operated by the California Institute of Technology, under contract with the National Aeronautics and Space Administration under the Exoplanet Exploration Program. Furthermore, this work has made use of NASA’s Astrophysics Data System (ADS); of the SIMBAD database (Wenger et al. 2000) and VizieR catalog access tool (Ochsenbein et al. 2000), operated at CDS, Strasbourg, France; and of the TOPCAT software (Taylor 2005).
References
- Adamów, M., Niedzielski, A., Villaver, E., Nowak, G., & Wolszczan, A. 2012, ApJ, 754, L15 [Google Scholar]
- Addison, B., Wright, D. J., Wittenmyer, R. A., et al. 2019, PASP, 131, 115003 [NASA ADS] [CrossRef] [Google Scholar]
- Baranne, A., Queloz, D., Mayor, M., et al. 1996, A&AS, 119, 373 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bergmann, C., Jones, M. I., Zhao, J., et al. 2021, Pub. Astron. Soc. Australia, 38, e019 [CrossRef] [Google Scholar]
- Borgniet, S., Lagrange, A. M., Meunier, N., et al. 2019, A&A, 621, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bowler, B. P., Johnson, J. A., Marcy, G. W., et al. 2010, ApJ, 709, 396 [Google Scholar]
- Bressan, A., Marigo, P., Girardi, L., et al. 2012, MNRAS, 427, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Butler, R. P., Marcy, G. W., Williams, E., et al. 1996, PASP, 108, 500 [Google Scholar]
- Cameron, E. 2011, PASA, 28, 128 [Google Scholar]
- Cumming, A., & Dragomir, D. 2010, MNRAS, 401, 1029 [NASA ADS] [CrossRef] [Google Scholar]
- Cumming, A., Butler, R. P., Marcy, G. W., et al. 2008, PASP, 120, 531 [CrossRef] [Google Scholar]
- Currie, T. 2009, ApJ, 694, L171 [Google Scholar]
- Delgado Mena, E., Lovis, C., Santos, N. C., et al. 2018, A&A, 619, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Diego, F., Charalambous, A., Fish, A. C., & Walker, D. D. 1990, SPIE Conf. Ser., 1235, 562 [NASA ADS] [Google Scholar]
- Endl, M., Kürster, M., Els, S., et al. 2002, A&A, 392, 671 [CrossRef] [EDP Sciences] [Google Scholar]
- Fernandes, R. B., Mulders, G. D., Pascucci, I., Mordasini, C., & Emsenhuber, A. 2019, ApJ, 874, 81 [NASA ADS] [CrossRef] [Google Scholar]
- Fischer, D. A., & Valenti, J. 2005, ApJ, 622, 1102 [NASA ADS] [CrossRef] [Google Scholar]
- Frink, S., Quirrenbach, A., Fischer, D., Röser, S., & Schilbach, E. 2001, PASP, 113, 173 [Google Scholar]
- Frink, S., Mitchell, D. S., Quirrenbach, A., et al. 2002, ApJ, 576, 478 [Google Scholar]
- Ghezzi, L., & Johnson, J. A. 2015, ApJ, 812, 96 [NASA ADS] [CrossRef] [Google Scholar]
- Ghezzi, L., Montet, B. T., & Johnson, J. A. 2018, ApJ, 860, 109 [Google Scholar]
- Girardi, L., Marigo, P., Bressan, A., & Rosenfield, P. 2013, ApJ, 777, 142 [Google Scholar]
- Grundahl, F., Kjeldsen, H., Christensen-Dalsgaard, J., Arentoft, T., & Frandsen, S. 2007, Commun. Asteroseismol., 150, 300 [NASA ADS] [CrossRef] [Google Scholar]
- Grundahl, F., Fredslund Andersen, M., Christensen-Dalsgaard, J., et al. 2017, ApJ, 836, 142 [Google Scholar]
- Han, I., Lee, B. C., Kim, K. M., et al. 2010, A&A, 509, A24 [CrossRef] [EDP Sciences] [Google Scholar]
- Hatzes, A. P., Guenther, E. W., Endl, M., et al. 2005, A&A, 437, 743 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hatzes, A. P., Cochran, W. D., Endl, M., et al. 2006, A&A, 457, 335 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hatzes, A. P., Endl, M., Cochran, W. D., et al. 2018, AJ, 155, 120 [NASA ADS] [CrossRef] [Google Scholar]
- Hekker, S., & Meléndez, J. 2007, A&A, 475, 1003 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hellier, C., Anderson, D. R., Barkaoui, K., et al. 2019, MNRAS, 490, 1479 [NASA ADS] [CrossRef] [Google Scholar]
- Jenkins, J. S., Jones, H. R. A., Tuomi, M., et al. 2017, MNRAS, 466, 443 [Google Scholar]
- Johnson, J. A., Fischer, D. A., Marcy, G. W., et al. 2007, ApJ, 665, 785 [Google Scholar]
- Johnson, J. A., Aller, K. M., Howard, A. W., & Crepp, J. R. 2010, PASP, 122, 905 [Google Scholar]
- Johnson, J. A., Morton, T. D., & Wright, J. T. 2013, ApJ, 763, 53 [Google Scholar]
- Jones, M. I., Jenkins, J. S., Rojo, P., & Melo, C. H. F. 2011, A&A, 536, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jones, M. I., Jenkins, J. S., Rojo, P., Melo, C. H. F., & Bluhm, P. 2013, A&A, 556, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jones, M. I., Jenkins, J. S., Bluhm, P., Rojo, P., & Melo, C. H. F. 2014, A&A, 566, A113 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jones, M. I., Jenkins, J. S., Rojo, P., Melo, C. H. F., & Bluhm, P. 2015a, A&A, 573, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jones, M. I., Jenkins, J. S., Rojo, P., Olivares, F., & Melo, C. H. F. 2015b, A&A, 580, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jones, M. I., Jenkins, J. S., Brahm, R., et al. 2016, A&A, 590, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jones, M. I., Brahm, R., Wittenmyer, R. A., et al. 2017, A&A, 602, A58 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jones, M. I., Wittenmyer, R., Aguilera-Gómez, C., et al. 2021, A&A, 646, A131 [EDP Sciences] [Google Scholar]
- Kass, R. E., & Raftery, A. E. 1995, J. Am. Stat. Assoc., 90, 773 [Google Scholar]
- Kaufer, A., Stahl, O., Tubbesing, S., et al. 1999, The Messenger, 95, 8 [Google Scholar]
- Kennedy, G. M., & Kenyon, S. J. 2008, ApJ, 673, 502 [Google Scholar]
- Kennedy, G. M., & Kenyon, S. J. 2009, ApJ, 695, 1210 [NASA ADS] [CrossRef] [Google Scholar]
- Kunitomo, M., Ikoma, M., Sato, B., Katsuta, Y., & Ida, S. 2011, ApJ, 737, 66 [Google Scholar]
- Kürster, M., Schmitt, J. H. M. M., Cutispoto, G., & Dennerl, K. 1997, A&A, 320, 831 [NASA ADS] [Google Scholar]
- Lagrange, A. M., Desort, M., Galland, F., Udry, S., & Mayor, M. 2009, A&A, 495, 335 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lee, B. C., Mkrtichian, D. E., Han, I., Kim, K. M., & Park, M. G. 2011, A&A, 529, A134 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lee, B. C., Han, I., Park, M. G., et al. 2014a, A&A, 566, A67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lee, B.-C., Han, I., Park, M.-G., et al. 2014b, J. Korean Astron. Soc., 47, 69 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, Y. J., Sato, B., Zhao, G., et al. 2008, ApJ, 672, 553 [NASA ADS] [CrossRef] [Google Scholar]
- Lloyd, J. P. 2011, ApJ, 739, L49 [Google Scholar]
- Lloyd, J. P. 2013, ApJ, 774, L2 [Google Scholar]
- Luque, R., Trifonov, T., Reffert, S., et al. 2019, A&A, 631, A136 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Maldonado, J., Villaver, E., & Eiroa, C. 2013, A&A, 554, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Malla, S. P., Stello, D., Huber, D., et al. 2020, MNRAS, 496, 5423 [NASA ADS] [CrossRef] [Google Scholar]
- Mayor, M., Marmier, M., Lovis, C., et al. 2011, ArXiv e-prints [arXiv:1109.2497] [Google Scholar]
- Mitchell, D. S., Reffert, S., Trifonov, T., Quirrenbach, A., & Fischer, D. A. 2013, A&A, 555, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mortier, A., Santos, N. C., Sousa, S., et al. 2013, A&A, 551, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Niedzielski, A., Konacki, M., Wolszczan, A., et al. 2007, ApJ, 669, 1354 [NASA ADS] [CrossRef] [Google Scholar]
- Niedzielski, A., Villaver, E., Wolszczan, A., et al. 2015, A&A, 573, A36 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- North, T. S. H., Campante, T. L., Miglio, A., et al. 2017, MNRAS, 472, 1866 [Google Scholar]
- Ochsenbein, F., Bauer, P., & Marcout, J. 2000, A&AS, 143, 23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ortiz, M., Reffert, S., Trifonov, T., et al. 2016, A&A, 595, A55 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pasquini, L., Döllinger, M. P., Weiss, A., et al. 2007, A&A, 473, 979 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Petigura, E. A., Marcy, G. W., Winn, J. N., et al. 2018, AJ, 155, 89 [Google Scholar]
- Quirrenbach, A. 2011, in AAS/Division for Extreme Solar Systems Abstracts [Google Scholar]
- Quirrenbach, A., Trifonov, T., Lee, M. H., & Reffert, S. 2019, A&A, 624, A18 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ramm, D. J., Pourbaix, D., Hearnshaw, J. B., & Komonjinda, S. 2009, MNRAS, 394, 1695 [Google Scholar]
- Ramm, D. J., Nelson, B. E., Endl, M., et al. 2016, MNRAS, 460, 3706 [Google Scholar]
- Reffert, S., Quirrenbach, A., Mitchell, D. S., et al. 2006, ApJ, 652, 661 [NASA ADS] [CrossRef] [Google Scholar]
- Reffert, S., Bergmann, C., Quirrenbach, A., Trifonov, T., & Künstler, A. 2015, A&A, 574, A116 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Reichert, K., Reffert, S., Stock, S., Trifonov, T., & Quirrenbach, A. 2019, A&A, 625, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rodríguez Martínez, R., Gaudi, B. S., Rodriguez, J. E., et al. 2020, AJ, 160, 111 [CrossRef] [Google Scholar]
- Saio, H., Wood, P. R., Takayama, M., & Ita, Y. 2015, MNRAS, 452, 3863 [Google Scholar]
- Sato, B., Kambe, E., Takeda, Y., et al. 2005, PASJ, 57, 97 [Google Scholar]
- Sato, B., Izumiura, H., Toyota, E., et al. 2007, ApJ, 661, 527 [NASA ADS] [CrossRef] [Google Scholar]
- Sato, B., Izumiura, H., Toyota, E., et al. 2008, PASJ, 60, 539 [NASA ADS] [Google Scholar]
- Sato, B., Omiya, M., Harakawa, H., et al. 2012, PASJ, 64, 135 [Google Scholar]
- Sato, B., Wang, L., Liu, Y.-J., et al. 2016, ApJ, 819, 59 [NASA ADS] [CrossRef] [Google Scholar]
- Schlaufman, K. C., & Winn, J. N. 2013, ApJ, 772, 143 [NASA ADS] [CrossRef] [Google Scholar]
- Setiawan, J., Pasquini, L., da Silva, L., von der Lühe, O., & Hatzes, A. 2003, A&A, 397, 1151 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Siverd, R. J., Collins, K. A., Zhou, G., et al. 2018, AJ, 155, 35 [Google Scholar]
- Soto, M. G., Jones, M. I., & Jenkins, J. S. 2021, A&A, 647, A157 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Stock, S., Reffert, S., & Quirrenbach, A. 2018, A&A, 616, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Takarada, T., Sato, B., Omiya, M., et al. 2018, PASJ, 70, 59 [NASA ADS] [CrossRef] [Google Scholar]
- Takeda, Y., Sato, B., & Murata, D. 2008, PASJ, 60, 781 [NASA ADS] [CrossRef] [Google Scholar]
- Tala, M., Heeren, P., Grill, M., et al. 2016, SPIE Conf. Ser., 9908, 99086O [NASA ADS] [Google Scholar]
- Tala Pinto, M., Reffert, S., Quirrenbach, A., et al. 2020, A&A, 644, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Taylor, M. B. 2005, in ASP Conf. Ser., 347, Astronomical Data Analysis Software and Systems XIV, eds. P. Shopbell, M. Britton, & R. Ebert, 29 [NASA ADS] [Google Scholar]
- Tokovinin, A., Fischer, D. A., Bonati, M., et al. 2013, PASP, 125, 1336 [NASA ADS] [CrossRef] [Google Scholar]
- Trifonov, T., Reffert, S., Tan, X., Lee, M. H., & Quirrenbach, A. 2014, A&A, 568, A64 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Trifonov, T., Reffert, S., Zechmeister, M., Reiners, A., & Quirrenbach, A. 2015, A&A, 582, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- VanderPlas, J. T. 2018, ApJS, 236, 16 [Google Scholar]
- Villaver, E., & Livio, M. 2009, ApJ, 705, L81 [Google Scholar]
- Villaver, E., Livio, M., Mustill, A. J., & Siess, L. 2014, ApJ, 794, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, S. X., Wright, J. T., Cochran, W., et al. 2012, ApJ, 761, 46 [NASA ADS] [CrossRef] [Google Scholar]
- Wenger, M., Ochsenbein, F., Egret, D., et al. 2000, A&AS, 143, 9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wittenmyer, R. A., Endl, M., Wang, L., et al. 2011a, ApJ, 743, 184 [NASA ADS] [CrossRef] [Google Scholar]
- Wittenmyer, R. A., Tinney, C. G., O’Toole, S. J., et al. 2011b, ApJ, 727, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Wittenmyer, R. A., Wang, L., Liu, F., et al. 2015, ApJ, 800, 74 [NASA ADS] [CrossRef] [Google Scholar]
- Wittenmyer, R. A., Butler, R. P., Wang, L., et al. 2016a, MNRAS, 455, 1398 [Google Scholar]
- Wittenmyer, R. A., Johnson, J. A., Butler, R. P., et al. 2016b, ApJ, 818, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Wittenmyer, R. A., Liu, F., Wang, L., et al. 2016c, AJ, 152, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Wittenmyer, R. A., Jones, M. I., Horner, J., et al. 2017a, AJ, 154, 274 [NASA ADS] [CrossRef] [Google Scholar]
- Wittenmyer, R. A., Jones, M. I., Zhao, J., et al. 2017b, AJ, 153, 51 [NASA ADS] [CrossRef] [Google Scholar]
- Wittenmyer, R. A., Horner, J., Carter, B. D., et al. 2018, ArXiv e-prints [arXiv:1806.09282] [Google Scholar]
- Wittenmyer, R. A., Butler, R. P., Horner, J., et al. 2020, MNRAS, 491, 5248 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, J. T., & Howard, A. W. 2009, ApJS, 182, 205 [Google Scholar]
- Wright, J., & Howard, A. 2012, RVLIN: Fitting Keplerian curves to radial velocity data [Google Scholar]
- Yılmaz, M., Sato, B., Bikmaev, I., et al. 2017, A&A, 608, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zechmeister, M., & Kürster, M. 2009, A&A, 496, 577 [CrossRef] [EDP Sciences] [Google Scholar]
- Zechmeister, M., Kürster, M., & Endl, M. 2009, A&A, 505, 859 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zhou, G., Huang, C. X., Bakos, G. Á., et al. 2019, AJ, 158, 141 [Google Scholar]
For stars hosting multiple planets, we use the recovery fraction of the most easily detectable planet.
Note that the corrected occurrence rate may also be computed directly: 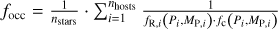
Correcting this value for completeness as described above, we even find 36:8%-0:1%. Only 1.16 planets are predicted to have been missed by the observations reflecting the fact that this common sample has been more thoroughly observed than the entire sample, on average.
As we are interested in the occurrence of planetary systems, we only consider the most easily detectable planet for multiple systems.
All Tables
Fitted model parameters, incl. uncertainties, of the seven tested functional forms for the stellar mass and metallicity dependence of the planet occurrence rate and the Bayes factor for comparing between them.
All Figures
|
Fig. 1 Stellar mass versus metallicity for the survey stars and histograms of both parameters. The complete sample is shown in gray; the 482 stars left after the homogenizing cuts (described in Sect. 3) are shown in blue, and the red points identify the 32 planet hosting stars within the sample. The mean uncertainties are shown in the upper right corner. The red and blue dotted lines indicate the mean stellar mass and metallicity for the targets with and without planets, respectively, for the following: planet hosts, |
| In the text | |
|
Fig. 2 Hertzsprung-Russell diagram of the sample stars after cuts (blue). Planet hosting stars are shown in red. The green, dark-blue, and violet lines correspond to the PARSEC evolutionary tracks for the maximum (4.5 M⊙), mean (1.8 M⊙), and minimum mass (0.8 M⊙) among the target stars, respectively, and a metallicity of [Fe/H] = -0.05, which is the sample mean. |
| In the text | |
|
Fig. 3 Histograms to illustrate the homogenizing cuts applied to the target stars. Top left: distribution of the number of radial velocity data points, stars with 10 observations or less are excluded (the plot is truncated toward larger numbers; more than 50 stars have more than 70 RV data points). Top right: distribution of the stellar mass; stars as massive as 5 M⊙ or more are excluded. The mass distributions of the stars more likely to be on the RGB and HB are shown in green and orange, respectively. Bottom left: distribution of stellar surface gravity; stars with log(ɡ) equal to or less than 1.5 are excluded. Bottom right: distribution of stellar luminosity; stars as luminous as 1000 L⊙ or more are excluded. |
| In the text | |
|
Fig. 4 Histograms to illustrate the inhomogeneous observational histories among all stars of the three surveys. Lick, EXPRESS, and PPPS are shown in violet, green, and orange, respectively. Left: distribution of the number of radial velocity data points per star. Right: distribution of the time base line, i.e., the time span covered by RV observations per star. |
| In the text | |
|
Fig. 5 Detection probability map for a target star affected by quasi-periodic oscillations; it exhibits three peaks (at 224d, 496d, and 875d) with FAP< 1% in the GLS periodogram; left: in period-RV semi-amplitude space, and right: in period-planet mass space. The black, green, light blue, yellow, blue, and red solid lines correspond to detection probabilities of 100%, 90%, 70%, 50%, 30%, and 10%, respectively. The detection probability level of, e.g., 10% gives the semi-amplitude (or planet mass) at which 10% of the tested phases can be recovered at the given period. The vertical black dotted lines show the positions of the three significant periodicities, while the vertical dashed blue line in the right plot delineates the time base line of observations for this star (the left plot is restricted to the time base line for better visibility). |
| In the text | |
|
Fig. 6 Two different ways to visualize detectability within the survey. Detected planets (see Table 1) are plotted in black. Left: global detection efficiency of the combined survey in period-planet mass space. Planets with Mp sin(i) above the, e.g., 50% limit can be detected around 50% of the stars in the sample at the given period. Right: median detection probabilities of the combined survey in period-planet mass space (the 50% median probability curve is computed by determining the median of all individual stars’ 50% level at each period). Planets with Mp sin(i) above the 50% limit have a median detection probability of 50% across the sample at the given period. |
| In the text | |
|
Fig. 7 Planet occurrence focc, d as a function of period and minimum planet mass. For each of the nine domains, we also give the number of detected planet ndet, the estimated number of missed planets due to incompleteness nmissed, the effective number of sample stars that are useful for constraining the occurrence rate in this domain neff, and the mean completeness within the domain fC, d. The light blue dots show the positions of the detected planets. |
| In the text | |
|
Fig. 8 Planet occurrence rate for planets with MP sin(i) > 0.8 MJup in five period bins. The blue histogram and blue dots correspond to the uncorrected rate, while the light blue histogram and black dots show the rate corrected for missed planets. Errors are derived from the binomial distribution. The log-normal fit is plotted in green, while the best-fit broken power-law is shown in red with a black dotted connector illustrating the 1σ uncertainty in Pbreak. |
| In the text | |
|
Fig. 9 Normalized cumulative distribution of orbital periods for planets with MPsin(i) ≥ 0.8 MJup. The black line corresponds to the entire sample, while the blue and red line show the distribution for subsam-ples with M, < 1.4 M⊙ and M* ≥ 1.4 M⊙, respectively. For comparison, the distribution for giant planets orbiting main-sequence stars with MP sin(i) ≥ 0.8 MJup and P > 89 days is shown (obtained from the NASA Exoplanet Archive, selecting only planets discovered via RV and around host stars with log(ɡ) ≥ 4). |
| In the text | |
|
Fig. 10 Same as Fig. 9 but the host stars were divided into two subsets based on their evolutionary stage. The blue line shows the period distribution of planets orbiting RGB stars, while the red line corresponds to planets hosted by HB stars. The green line again traces the giant planets around main-sequence stars. |
| In the text | |
|
Fig. 11 Planet occurrence rate as a function of stellar mass (left) and metallicity (right). The black dotted histograms show the distribution of planets, while the solid black histograms show an estimate of the completeness correction performed for the individual bins according to the procedure outlined in Sect. 6. The blue solid line represents the fitted occurrence as a function of stellar mass (left) with the metallicity set to the sample mean of [Fe/H] = -0.05 and as a function of metallicity (right) with the mass set to the sample mean of M, = 1.81 M⊙. For a more precise prediction, the red dots give the average expected occurrence rate computed using the masses and metallicities of the stars in each bin. Note that we fit the dependence on stellar mass and metallicity simultaneously and that we show the histograms only for visualization, the fit does not rely on binning of the data. |
| In the text | |
|
Fig. 12 Marginal probability distributions functions (PDFs) from the maximum likelihood estimation for the set of model parameters from Eq. (6). The rightmost plot in each row shows the PDF of the indicated model parameter marginalized over the remaining three. The black dots show the grid values used for evaluating the likelihood, the blue line is a spline interpolation between them. The remaining plots show the different two-dimensional PDFs marginalized overtwo parameters with blue contours indicating levels from 95% down to 10% of the maximumprobability. The red dots and vertical red lines identify the parameter values corresponding to the maximum overall likelihood. Axes are limited to the chosen uniform prior ranges. |
| In the text | |
|
Fig. 13 Similar to Fig. 11 but for the functional forms given in Eqs. (7)–(12). For the mass plots, we set the metallicity to the sample mean of –0.05 dex, and for the metallicity plots, we set the stellar mass to the sample mean of 1.81 M⊙. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.