| Issue |
A&A
Volume 626, June 2019
|
|
|---|---|---|
| Article Number | A79 | |
| Number of page(s) | 17 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/201834265 | |
| Published online | 17 June 2019 | |
Do star clusters form in a completely mass-segregated way?⋆
1
Astronomical Institute of Charles University, Prague, Czech Republic
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Observatory and Planetarium of Prague, Prague, Czech Republic
3
Helmholtz-Institut für Strahlen- und Kernphysik (HISKP), Universität Bonn, Bonn, Germany
Received:
18
September
2018
Accepted:
13
May
2019
Abstract
Context. ALMA observations of the Serpens South star-forming region suggest that stellar protoclusters may be completely mass segregated at birth. Independent observations also suggest that embedded clusters form segregated by mass.
Aims. As the primordial mass segregation seems to be lost over time, we aim to study on which timescale an initially perfectly mass-segregated star cluster becomes indistinguishable from an initially not mass-segregated cluster. As an example, the Orion Nebula Cluster (ONC) is also discussed.
Methods. We used N-body simulations of star clusters with various masses and two different degrees of primordial mass segregation. We analysed their energy redistribution through two-body relaxation to quantify the time when the models agree in terms of mass segregation, which sets in only dynamically in the models that are primordially not mass segregated. A comprehensive cross-matched catalogue combining optical, infrared, and X-ray surveys of ONC members was also compiled and made available.
Results. The models evolve to a similar radial distribution of high-mass stars after the core collapse (about half a median two-body relaxation time, trh) and become observationally indistinguishable from the point of view of mass segregation at time τv ≈ 3.3 trh. In the case of the ONC, using the distribution of high-mass stars, we may not rule out either evolutionary scenario (regardless of whether they are initially mass segregated). When we account for extinction and elongation of the ONC, as reported elsewhere, an initially perfectly mass-segregated state seems to be more consistent with the observed cluster.
Key words: methods: numerical / methods: data analysis / galaxies: star clusters: individual: ONC / stars: formation
Full Table 3 is only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/626/A79
© ESO 2019
1. Introduction
According to gravothermal turbulence (Padoan & Nordlund 2002; Hennebelle & Chabrier 2008, 2011), star formation is largely a random process taking place in stochastically occurring density peaks in molecular clouds. Observations with the Herschel space telescope and with the ALMA facility have shown, however, that stars form in thin and long (≈0.1 pc wide and a few to many parsec long) kinematically coherent filaments of molecular material (André et al. 2010, 2014; Hacar et al. 2017, 2018; Mattern et al. 2018), suggesting instead that the formation of stars occurs in a non-turbulent and more constrained environment. In addition, if protostars throttle their accretion through the accretion-induced luminosity (Adams & Fatuzzo 1996; Matzner & McKee 2000), then a star’s mass depends on the accretion rate and thus on the inflow rate from the filament. A low-mass cloud core yielding a low accretion rate will terminate accretion sooner because a lower feedback energy will be required. Denser and more massive cores yielding higher accretion rates will allow the star to grow to a higher mass until the feedback energy can oppose the infall. In this case, star formation would be highly self-regulated. This scenario is naturally consistent with the relation mmax − Mcl (most massive star, stellar-cluster mass, respectively) observed in very young clusters (Weidner et al. 2010, 2013; Kirk & Myers 2011; Stephens et al. 2017; Ramírez Alegría et al. 2016).
One possible implication of these theoretical ideas is that embedded clusters may be less (if their formation is not self-regulated) or more segregated by mass primordially (if their formation is self-regulated). Studying primordial mass segregation is thus relevant for understanding the process of star formation. It is also important for understanding the evolution of star clusters because initially mass-segregated clusters tend to more quickly loose their low-mass stars across their tidal boundary when residual gas expulsion plays a role (Haghi et al. 2015). The mass-segregated clusters will eject their massive stars more quickly and efficiently as a result of the energetic encounters between massive stars in the cluster cores (Oh et al. 2015; Oh & Kroupa 2016; Kroupa et al. 2018; Wang et al. 2018). Primordial mass segregation also affects the dynamical evolution of a cluster through stellar evolutionary mass loss of the massive stars. Initial mass segregation may also lead to a different evolution of the radial dependence of the stellar mass function in the evolving star cluster when compared to a cluster not initially mass segregated (Webb et al. 2016).
It is therefore of interest to understand whether embedded star clusters are born segregated by mass, and how strong the mass segregation is. The stars in a star cluster in dynamical equilibrium that is completely mass segregated initially1 are almost perfectly arranged by mass and energy from the centre of the cluster outward (Baumgardt et al. 2008); another method for creating mass-segregated clusters, also developed in Bonn, uses interparticle potentials and binding energy to sort the stars (Šubr et al. 2008). Both methods imply2 that the most massive stars have the lowest energy (i.e. they are confined to the centre), while the least massive stars have the highest energy (i.e. they are on the widest orbits and are initially placed at the largest distance from the centre). This is consistent with the notion that the most massive stars in an embedded cluster need the highest densities to form (Vázquez-Semadeni et al. 2019). A star cluster that is not primordially mass segregated shows no relation between a star’s mass and its orbital energy or distance to the centre. In a system in which two-body relaxation plays no role, this state (complete or no mass segregation) persists for all time (ignoring stellar-evolutionary and tidal effects). In a system in which energy equipartition does play a role over its life time, the initially mass-segregated cluster will evolve away from the perfect initial mass segregation because stars exchange energy on a two-body relaxation timescale, while a cluster that initially is not mass segregated will evolve towards a state of statistical mass segregation because of the energy equipartition process (e.g. Aarseth 1966; Spitzer & Hart 1971a,b; Scaria & Bappu 1981; Stodolkiewicz 1982; Heggie & Hut 2003; Fragione et al. 2018). Both initial states are likely to become eventually indistinguishable.
Our work contributes to solving this problem. The type of test performed here has not been done before in that the initially perfectly mass-segregated configurations, which are consistent with the observed extremely young embedded clusters (e.g. the Serpens South by Plunkett et al. 2018), have not been considered in comparison with observational data. It has not been shown either on which timescale an initially perfectly mass-segregated model develops through the energy redistribution process as a result of two-body relaxation to a state that cannot be discerned at an observational level from an initially not mass-segregated state that evolves through the same process to a mass-segregated state.
We first consider the observational constraints by Plunkett et al. (2018), which suggest that embedded clusters that are younger than about a crossing time are perfectly mass segregated. We note that primordial mass segregation is also found by Kirk & Myers (2011) and Lane et al. (2016), who studied very young embedded clusters. We note in particular that the individual embedded clusters [or NESTS according to]Joncour2018 in the Taurus cloud are found by Kirk & Myers (2011) to be mass-segregated. Further evidence for primordial mass segregation in globular clusters (GCs) in the Milky Way was found by Haghi et al. (2014, 2015), and a high degree of primordial mass segregation seems to be necessary to form low-density GCs, such as Palomar 4 or 14 (Zonoozi et al. 2011, 2014, 2017). Using N-body simulations of idealised systems, we then compare a perfectly initially mass-segregated cluster to a not mass-segregated cluster to evaluate the timescale over which both approach the same degree of dynamical mass segregation. The initial conditions of both systems (mass segregated or not) were set up carefully such that the systems do not evolve in a violent manner. The two methods that we use (Šubr et al. 2008; Baumgardt et al. 2008) were tested to generate stable and reliable sets of initial conditions. The models used here differ in the degree of primordial mass segregation but have an identical number of stars, total mass, initial mass function (IMF), and initial density profile. Therefore, we do not have to evaluate the absolute measure of mass segregation for each one of them (e.g. through the method of the minimum spanning tree as in Allison et al. 2009), but we may use computationally less expensive methods to compare the models to each other and evaluate a relative difference in their mass segregation. Finally, we also compare the models to the observational data of the Orion Nebula Cluster (ONC), which is the only currently available very young cluster in which the stellar population from the hydrogen-burning limit to O-stars has been mapped, in order to understand whether its observed property of some mass segregation is consistent with perfect initial mass segregation or no initial mass segregation.
We note that the selected clusters used here (Serpens South and the ONC) are not two randomly chosen or extreme cases. The observed highly mass-segregated extremely young Serpens South cluster (observed and reported for the first time by Plunkett et al. 2018) is very useful concerning the question of primordial mass segregation. The ONC is not extreme, it is merely the closest very young cluster in which the full mass range of stars, from 0.1 to about 50 M⊙, has been observed.
2. Models
We performed numerical simulations of star clusters represented by N-body models (i.e. idealised mathematical models without gas or interstellar medium). Their initial conditions were set up using McLuster (Küpper et al. 2011) as follows. The positions of individual stars were distributed according to Plummer (1911), we used the canonical IMF (Kroupa 2001) with optimal sampling (Kroupa et al. 2013). The systems are isolated, and we did not consider any additional parameters, such as a primordial binary star population or stellar evolution. The models were integrated using the collisional code nbody6 (Aarseth 2003).
In terms of the number of stars, we created several models of young star clusters: (i) A low-mass one, containing 52 stars, see Table 1, which is to be compared with the sources of the Serpens South star cluster analysed by Plunkett et al. (2018). This comparison will establish whether the methods for creating initial conditions are realistic. (ii) A model with 2.4k stars, which resembles a young star cluster (see Table 2), also to be compared to the ONC. (iii) One lower mass model with 1.2k stars and two more massive models with 4.7k and 9.2k stars (see Table 2) that serve to verify the timescale on which the initially mass-segregated clusters evolve to a state comparable to pure dynamical mass segregation. The initial cluster size, that is, the half-mass radius (rh), of all models was determined from their masses based on the birth radius-mass relation of embedded clusters by Marks & Kroupa (2012). This radius-mass relation uses the observed binary star binding energy distribution functions in very young and open clusters to derive the allowed initial densities of the clusters, which are compared to molecular clump densities and the birth densities derived independently for globular clusters. These birth densities yield the birth radius-mass relation. The total mass of our clusters, Mcl, is identified with the total stellar mass, Mecl, from Marks & Kroupa (2012). The timescales listed in Tables 1 and 2 were calculated according to Aarseth (2003), that is,
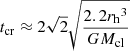 (1)
(1)
for the crossing time, where G ≈ 4.49 × 10−3 pc3 M⊙−1 Myr−2 is the gravitational constant, and
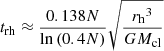 (2)
(2)
for the half-mass relaxation time (cf. Spitzer & Hart 1971a).
Initial parameters of the low-mass star cluster model: number of stars, mass of the cluster, half-mass radius, crossing time, and median relaxation time.
Initial parameters of the star cluster models: number of stars, mass of the cluster, half-mass radius, crossing time, and median relaxation time.
In all clusters, we analysed two extreme degrees of mass segregation, S, according to Baumgardt et al. (2008): no mass segregation (S = 0, models are labelled as non) and a fully mass segregated cluster (S = 1, labelled as seg). In the case of S = 1, stars with the highest mass are given the lowest total energy, which places them preferentially in the centre of the cluster, while lower mass stars are given higher energies, and they therefore are on higher orbits. The cluster then looks as if it were sorted by mass and energy from the centre outwards, see the initial conditions plotted in the left panels of Fig. 1. For S = 0, stars are positioned randomly and no additional sorting takes place, see the right panels of Fig. 1 where the non model average is localised in the energy space because each realisation is a random scatter. The properties of both the initially mass-segregated cluster and the initially non-segregated cluster are further discussed in Appendix A.
 |
Fig. 1. Initial distribution of masses (upper panels) and total energy (lower panels) with respect to the three-dimensional radial position of a star in the cluster. Three primordial mass segregations of our models containing 52 stars are shown: seg and Šubr are initially mass segregated with S = 1 and S = 0.5, respectively, and non is without any initial mass segregation (S = 0), see Sect. 2. The light crosses represent one realisation, and the darker lines are averages from all realisations. |
For a comparison of the methods we used, we also included an additional model with 52 stars using the method for mass segregation in energy by Šubr et al. (2008) with S = 0.5, which is a recommended maximum value. The energy space of the Šubr models (see Fig. 1) was sampled according to predefined rules as well, hence the average forms a line. We note that S has a considerably different meaning in Baumgardt et al. (2008) and Šubr et al. (2008).
In all models, the cluster centre is identified with the density centre provided by nbody6, that is, a numerically optimised method based on Casertano & Hut (1985). All clusters were generated in virial equilibrium.
3. Mass segregation
3.1. Initial conditions
First, we compare the small numerical model containing 52 stars with the data of the very young star cluster Serpens South observed by Plunkett et al. (2018), with the same number of sources. The reported age of the observed cluster is about 0.2 Myr and the reported crossing time is 0.6 Myr. We have integrated 100 realisations of each combination of the initial conditions (see Sect. 2) up to one crossing time of the models (see Table 1). We used this star cluster only to test the method of creating a young mass-segregated cluster, that is, whether the model is able to reproduce the observational data to a certain degree of accuracy. We note that real star clusters tend to be formed from converging filaments (André et al. 2014; Hacar et al. 2017, 2018), thus are neither spherically symmetric nor Plummer models, although the filament cross-sections have a Plummer-like profile (André et al. 2014), and that the choice of IMF could play a role as well. The evolution on a crossing timescale is sufficient to see also whether the methods we used can create reasonably stable initial conditions.
In Fig. 2 we indicate with crosses the projected radial coordinate of each star versus the ratio of its mass to the most massive star or source in the cluster for one realisation. As the IMF is optimally sampled, the masses of stars are the same in all 100 realisations. Thus, we also show the average position of a star of a given mass with a solid line. Because the models are spherically symmetric, there is no preferred plane of projection. Thus, we took the xy plane of coordinates of the model. First, we may see that the initial conditions are reasonably stable during the first crossing time (the averaged positions stayed almost the same). Although we tested only idealised models, we see after visually comparing the plots in Fig. 2 that our segregated models (two left panels) do represent the observations (right panel) better than the non-segregated model (middle right panel) at t = 0, 0.5 and even 1.0 tcr. This is also confirmed with a quantitative comparison of the power-law functions fitted to the data. The observed data have a power-law index of −1.4 ± 0.2 (Plunkett et al. 2018, verified here); in all time frames, the mean slope in the log-log plot of the seg model is −1.44 ± 0.13, and −2.46 ± 0.14 for the Šubr model; the non model has virtually a vertical slope, which makes the fitting ambiguous and the model not compatible at all with the observed data.
 |
Fig. 2. Three left upper panels: initial conditions of our models containing 52 stars: seg and Šubr are initially mass segregated with S = 1 and S = 0.5, respectively, and non is without any initial mass segregation (S = 0), see Sect. 2. Lower panels: models in a slightly evolved stage (at 0.5 tcr and 1.0 tcr). The solid line in each plot represents the average position for a star of a given mass in 100 realisations, whereas the lighter crosses are the positions from one random realisation. The power-law fit of both seg and Šubr models is shown by the grey dashed line. For comparison, right panels: observed data and the fitted slope (cf. Plunkett et al. 2018); the same dataset is used in all rows. We note that the horizontal axis of each plot is in projection to the xy plane. |
Hence, we conclude that the observational data of Plunkett et al. (2018) show a most impressive degree of mass segregation that is comparable to the perfectly mass-segregated models (S = 1). We note that independent authors also reported that very young embedded clusters are mass segregated (see Sect. 1).
3.2. Evolution
In the case of the star clusters with 1.2k stars, we have 20 realisations, for 2.4k, 4.7k, and 9.2k stars, we have integrated ten realisations of each combination of the initial conditions. The initial parameters are listed in Table 2. The whole cluster evolution can be visualised using the Lagrangian radii; the average over all realisations is plotted in Fig. 3 for each model. The mass-segregated models undergo core collapse slightly earlier than the non-segregated models, the latter lagging behind, which is due to the need of dynamical mass segregation to first gather massive stars in the core. This is most visible in the smallest model with 1.2k stars, where two-body encounters between massive stars have a higher impact on the whole system than in a larger model. During the core collapse, initial differences in the distribution of the most massive stars (>5 M⊙) of both seg and non models are smeared out. Thus, after the core collapse (at about 2.5–3 Myr), both seg and non Lagrangian radii appear to be the same in all models (except for random fluctuations, especially in the core region). Differences in the distribution of stars with lower masses still remain at this point, however. We further investigate this in each model in Appendix B.
 |
Fig. 3. Lagrangian radii of both segregated (blue) and non-segregated (red) models with 1.2k, 2.4k, 4.7k, and 9.2k stars (panels from top to bottom), averaged over all realisations of each model. The time axis reaches ≈10 trh, the corresponding mass fractions (10, 25, 50, 75, and 90 % from bottom to top) are on the right-hand side of each panel, and the half-mass radius is plotted with a dashed line. |
The difference between a collisional system that is and is not initially mass segregated gradually vanishes as the systems evolve. This is better illustrated using the radial mass distribution. In Fig. 4 we plot the mean mass contained in concentric spheres of radii (from above the core region to several rh) for each model from Table 2. Here, we merge all realisations of a particular model and divide the stars into logarithmically equidistant bins, that is, for a k-th bin at radius rk, the mean mass is
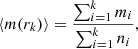 (3)
(3)
where ni and mi are the number of stars in an i-th bin and their total mass, respectively. Initially, we observe a clear difference because both models are generated with a different degree of mass segregation. Then, both cluster profiles approach each other due to energy redistribution; the non-segregated model gradually develops mass segregation, while the other model looses its primordial mass segregation. Visually, the distributions start to look similar at ≈2 trh. If we omit oscillations of the core region (i.e. close to 0.1 pc), the following evolution of both seg and non models looks the same for several relaxation times (in the case of the more populous clusters, it is almost perfectly synchronous).
 |
Fig. 4. Mean mass contained in a sphere of a given radius, see Eq. (3), of the models with 1.2k, 2.4k, 4.7k, and 9.2k stars (panels from top to bottom), averaged over all realisations of each model. Both initially mass-segregated (blue) and not mass-segregated clusters (red) of each model are plotted. Individual plots are separated by 2.0 trh. |
The fluctuations of the mean mass at low radii are higher for the most massive model, as can be seen in the lower panels of Fig. 4. In the more massive models, the seg and non curves of mean mass almost coincide and frequently cross, whereas in the lower mass models, they keep a fixed distance from each other.
In order to quantify the difference between the seg and non models, we compare the histograms given by Eq. (3) and presented in Fig. 4. The most important data that show mass segregation are at the smallest radii (i.e. near the cluster core). Because the histograms have equidistant bins in log-scale, large differences at small radii could be overshadowed by small differences at larger radii if we just summed their heights. Therefore, we weight each bin by its inverse width instead, which ensures that the bins at smaller radii become more important than the bins at larger radii, which gives us the parameter
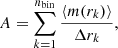 (4)
(4)
where Δrk is the width of the k-th bin (with logarithmically equidistant bins) and nbin is the total number of bins. In particular, r1 = 0.1 pc, rnbin = 10 pc and nbin = 50 for all models, as plotted in Fig. 4. A further discussion of the choice of binning and weights follows in Appendix C. At each time step, we evaluate the ratio Aseg/Anon of the initially mass-segregated and not mass-segregated clusters. This ratio, which is plotted for each model in Fig. 5, decreases initially and then settles at an almost constant value close to Aseg/Anon ≈ 1. Therefore, the initial difference of mass segregation almost vanishes (we denote this time τv). To derive the exact value of τv in each model, we fitted the time after which the data points correspond to a horizontal line (given the fluctuations of the data, the uncertainty of the fitted slope was set to ≲10−3 in the lower mass models and ≲10−2 in the higher mass models; these uncertainties correspond to the scatter that is evident in Fig. 5). The values that we obtained for each model are similar in units of the initial median relaxation times. Thus, we present an empirical estimate on the time when the primordial mass segregation vanishes in the range
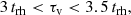 (5)
(5)
with the mean value around ⟨τv⟩ ≈ 3.3 trh which is also plotted for reference in Fig. 5. We note that the value of τv seems to be identical in all models.
 |
Fig. 5. Evolution of the ratio given by Eqs. (3) and (4) in time. The dashed line and the value ⟨τv⟩ (see Eq. (5)) represent the mean time when the slope of the data points turned zero. The slope itself is plotted by a grey line. |
The shallower potential well and lower escape velocity of the lower mass models implies that these clusters are more effective in ejecting stars from the central region as the individual two-body encounters are stronger. This is the case especially in the primordially mass-segregated clusters where the concentration of high-mass stars in the core is higher. On the other hand, in the higher-mass clusters, a collective effect of many two-body interactions is often needed to eject a star (cf. Oh et al. 2015). Consequently, the initially mass-segregated low-mass clusters inflate more than the non-segregated low-mass clusters or higher mass clusters. The mean mass will, therefore, decrease at smaller radii and increase at higher radii, and the values of ⟨m(rk)⟩ of an initially mass-segregated cluster will stay above those of an initially non-segregated cluster. This is also visible in the half-mass radii in Fig. 3, where the half-mass radius of the mass-segregated 1.2k cluster is above the non-segregated one even after 10 trh. Proceeding towards more massive models, this difference becomes less visible or disappears completely. Thus, the ratio of Aseg/Anon settles at a higher value than 1 in the lower mass models.
4. Orion Nebula Cluster
The question whether embedded star clusters form fully mass-segregated is approached here using the best observed (and nearest) case that formed stars from 0.1 M⊙ to the O-star regime: the ONC. It has been established for the present-day ONC that it is mass segregated in the range above 5 M⊙ by Hillenbrand (1997), which was later confirmed by Allison et al. (2009), who used the minimum spanning tree method on the data from Hillenbrand & Hartmann (1998). In this section, however, we focus on the possibility of a complete primordial mass segregation, as discussed in the preceding section.
4.1. Datasets
For the purpose of comparing our evolutionary models with the observational data, we used a publicly available database3. The sources of data are listed in Table 3. The structure of the ONC is complex: stars are surrounded and also partially covered by the interstellar medium (part of the Orion molecular cloud; Hillenbrand 1997; Hillenbrand & Hartmann 1998), which results in varying extinction in different wavelengths (Scandariato et al. 2011). Therefore, a combination of optical photometry and spectroscopy with X-ray and (near-)IR observations is used for more reliable results. We are also aware that our models are purely mathematical representations of the real ONC, nevertheless, we can use them to understand basic properties of dynamical evolution in the observed cluster.
Data of the ONC used in this work.
In order to construct the most complete dataset of the ONC, we combined several existing catalogues that are listed in Table 3. The main component is the optical dataset of Hillenbrand (1997), which offers a sample of 1576 stars in the Orion Nebula region. Masses are determined for 929 stars using the evolutionary models of D’Antona & Mazzitelli (1994), Swenson et al. (1994), and Ezer & Cameron (1967). The membership probability is based on proper motion (e.g. Jones & Walker 1988), and we excluded those labelled as probable non-members. Stars that were farther than 18.29′ from θ1 Ori were also excluded from the dataset (cf. Hillenbrand 1997); this left 1176 sources in total.
We also used all 1059 sources from Muench et al. (2002), who provided the most complete dataset of the ONC in the IR (K-band), that is, in the range from O and B stars down to near the deuterium-burning limit. The sources are already cross-identified with Hillenbrand (1997) and Hillenbrand & Carpenter (2000) observations. Stars that were labelled non-members by Hillenbrand (1997) but were labelled members by Muench et al. (2002) are included, using coordinates from the latter (this is mostly the case of sources with IDs from [H97b] 3000 to [H97b] 5999).
Flaccomio et al. (2003a,b) identified 742 objects in the X-ray band and 696 in the optical wavelengths. The masses of all stars from the optical sample were estimated, and the stars are likely ONC members. However, neither the X-ray nor the optical sources were cross-identified with earlier catalogues. Therefore, we used the CDS X-Match Service4 with the fixed distance criterion (d < 3″) to cross-identify these two datasets between each other and also with Hillenbrand (1997). Sources from the optical measurements that were identified with multiple counterparts were further distinguished based on their masses. In some cases, the optical data were identified with two X-ray sources (i.e. about ten cases); both are assigned to this one source (the entries are marked in column X2 in Tab. 3). Again, stars that were in the optical sample of Flaccomio et al. (2003a,b) but were marked non-members by Hillenbrand (1997) were returned to the dataset.
A majority of sources from the most complete X-ray survey of the Orion Nebula region, that is, COUP5 (Getman et al. 2005a), have been matched with previous optical (e.g. Hillenbrand 1997) near-IR or IR catalogues (e.g. Muench et al. 2002; Cutri et al. 2003). However, 16 new sources from COUP without counterparts were identified as ONC members by Getman et al. (2005b).
The young stellar objects were observed for instance by Prisinzano et al. (2008), who identified 45 sources in the ONC. Thirteen of these have no optical, IR, or X-ray counterparts. These sources were also added to our dataset.
The IR and optical dataset from Da Rio et al. (2009) has also previously been matched with previous catalogues, therefore we did not include these sources in our ONC dataset. However, we included brown dwarfs and pre-main-sequence stars from Da Rio et al. (2012) and used their cross-identification with Da Rio et al. (2009) in order to remove duplicates. Here, we also distinguished between probable members of the ONC and the foreground/background contamination based on reddening (Alves & Bouy 2012). This gave us additional 163 sources that have not been observed in the optical or IR wavelengths before. The masses of all of the sources from Da Rio et al. (2012) were deduced from the evolutionary tracks of D’Antona & Mazzitelli (1998) and Baraffe et al. (1998); a vast majority lie below 1 M⊙.
In total, our dataset of the ONC contains 2430 sources, see Table 3. Out of these, 995 have estimated masses. Nevertheless, we assume that all high-mass stars (i.e. m ≥ 5 M⊙) and even a majority of stars in the range from 1 to 5 M⊙ have known masses (cf. Hillenbrand 1997). Stars with an unknown mass are therefore assumed to be less massive than 5 M⊙. This is a reasonable assumption given that m > 1 M⊙ stars are the brightest and thus most conspicuous cluster members. In case of multiple mass estimates for one source, we took their mean value. Because the masses have very similar values and they never cross the boundary of 5 M⊙ (on which we focus here) in between different models, this is a valid assumption. Out of the most massive stars, we have 11 in total with m > 5 M⊙ (and 105 with 1 < m ≤ 5 M⊙).
Although there is evidence for stars in the ONC that are more than 5 Myr old (Huff & Stahler 2006) or even up to 12 Myr old (Warren & Hesser 1977), they were most likely captured by the cluster potential (Pflamm-Altenburg & Kroupa 2007). The age of the ONC, which is estimated from the time of the most active star formation (about 1–2 Myr ago), is about 2.5 Myr (Hillenbrand 1997; Palla & Stahler 1999). Nevertheless, we see that the ONC did not form in one burst (Palla et al. 2005). It has even been shown that the ONC is likely to contain three populations of stars that are younger than 3 Myr (Beccari et al. 2017; Kroupa et al. 2018; Wang et al. 2018).
To convert angular dimensions into a physical size scale, we need to know the distance to the ONC. We adopted the value (414 ± 7) pc of Menten et al. (2007), who measured trigonometric parallaxes of stars in the ONC. This value is consistent with previous works (cf. references in Menten et al. 2007) and also with the most recent astrometric observations of stars in the Orion A molecular cloud from the Gaia6 mission (Bailer-Jones et al. 2018), where Grossschedl et al. (2018) obtained a distance to the ONC between 400 pc and 410 pc. For 414 pc, the conversion between angular and proper separation reads 1′ = 0.1204 pc. This means that the ONC has a radius of approximately 2.5 pc (this corresponds to a Lagrangian radius of ≈90%).
The total number of sources in the ONC is comparable to our model with 2.4k stars. According to the results from Sect. 3.2 (ad Fig. 5), the expectation therefore is that the ONC has not yet reached an age such that a full primordial mass segregation becomes indistinguishable from an initially not segregated condition, that is, the time ⟨τv⟩ ≈ 8.4 Myr. If the ONC did form fully mass segregated, then it ought to still show evidence for this.
4.2. Mass segregation
We represent the ONC using our models with 2.4k stars. In order to compare the initially mass-segregated and non-segregated model to the observational data, we plot the averaged normalised cumulative distributions of stars in Fig. 9. Each model is plotted at three different times: the initial conditions at 0 Myr (for reference), at 1.5 Myr, and at 2.5 Myr, which is assumed to be the age of the ONC. The discussion in Appendix B shows that both of these extreme models evolve after 2.5 Myr (≈0.5 trh) to a stage where their high-mass stars (m ≥ 5 M⊙) are distributed almost identically. This holds even in projection, where the level of mass segregation is always lower than in 3D. The radial profiles of their low-mass stars (m < 5 M⊙) also seem to tend to the observed data as time proceeds, but at a much slower rate, and the shapes of the cumulative distributions are different. It is expected that less massive stars mix more slowly and thus lose their memory of the primordial mass segregation later than the more massive stars.
We evaluated the resemblance of the radial profiles of our models and the observational data using a two-sample Kolmogorov–Smirnov (KS) test7. From the results plotted in Fig. 7 from 0 to 5 Myr, it is evident that the observed data are not consistent with either of our models. Although the p-value of high-mass stars of both seg and non models increases above 0.8 after about 0.75 Myr and then stays very high, the p-value for lower mass stars is of the order of 10−4 and therefore the null hypothesis (seg or non) is not compatible with the data.
Several issues need to be discussed when we compare the models with observations, however. (i) The ONC is partially covered by a molecular cloud with extinction AV > 5 mag and in some areas even up to AV ≈ 11 mag (cf. Scandariato et al. 2011). This layer of opaque material extends from 0.5 to about 2 pc in approximately one quadrant of the nebula. The optical measurements in these parts of the cluster, for example, will therefore be always incomplete. This feature is visible even in the radial profile of low-mass stars (the dashed black line in Fig. 9), where the cumulative distribution suddenly changes slope above 0.5 pc. (ii) As documented by Hillenbrand & Hartmann (1998), the ONC is not spherically symmetric in the region beyond 0.5 pc from the centre. Therefore, it cannot be straightforwardly compared with a spherically symmetric model. (iii) Although we cross-correlated more than 20 years of observational data from the X-ray, optical, and (near-)IR wavelengths and compiled the possibly most complete dataset of the ONC so far, incompleteness in the form of observational bias may still play a role (cf. the data references). However, in comparison to the previous issues, this problem is minor.
In order to quantify the role of extinction and the non-spherical nature of the ONC, we evaluated these effects in two steps: (i) We introduced an artificial extinction in our projected data. All low-mass stars (m < 5 M⊙) in the area from 0.5 to 2 pc, where x < 0 and y > 0, were removed, see the hatched area in Fig. 6. The new radial profiles that include this extinction are plotted in the top panels of Fig. 10. When we compare them to the former radial profiles (Fig. 9), we see that the gap between the black and blue dashed curves is smaller. However, the KS test still shows no resemblance with the observational data, see Fig. 8. Because this extinction removes only up to 10 % of stars from the model, it is not the main responsible factor that would ensure that our model and the data are incompatible.
 |
Fig. 6. Schematic plot of the modifications made to the models in order to compare them to the ONC. The hatched area has artificial extinction of low-mass stars (i.e. stars with m < 5 M⊙ are removed), the dashed ellipse demonstrates the scaling of low-mass stars along the y-axis by a factor of 1.5, the dotted circle illustrates the isotropic scaling of all high-mass stars, and the grey circle covers the central region where low-mass stars are left without scaling. |
 |
Fig. 7. p-value of the two-sample KS test between the projected cumulative radial distribution of our models (based on ten realisations) and the real ONC. |
 |
Fig. 8. Same as in Fig. 7, but for the scaled model with artificial extinction (top panel), with scaling (middle panel), and with both scaling and extinction. When scaling is involved, time is given in the scaled units (tscl = st t), which are valid for all high- and low-mass stars above 0.5 pc. |
(ii) In addition to extinction, we also scaled the positions of low-mass stars (m < 5 M⊙) in the model beyond a radius of 0.5 pc along the y-axis by a factor of sy = 1.5 in order to achieve the same elongated shape as documented by Hillenbrand & Hartmann (1998, cf. their Fig. 3). The scaling is illustrated in Fig. 6. Given that this scaling is dynamically not self-consistent, the conclusions based on this should be seen only as suggestive. If the length scales by sr, the time must be scaled by 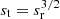 . Because we scale the projected data in only one direction, we define
. Because we scale the projected data in only one direction, we define
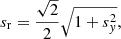 (6)
(6)
which gives, in particular, sr = 1.275 and st = 1.439. By doing so, we approximated the correct timescale for the low-mass stars in the outer cluster (>0.5 pc), but are slowed down their evolution of the central region (<0.5 pc). We scaled the x and y coordinates of high-mass stars equally in all directions by the factor sr from Eq. (6) because they are segregated towards the central region and no asymmetry in their distribution has been found (e.g. Hillenbrand 1997; Hillenbrand & Hartmann 1998). In Fig. 10 (middle and bottom panels), we also plot a comparison of the radial profiles with an artificial extinction and elongated shape at three times (in the panels with scaling, two time stamps are given: first, the real time of the simulation, which also corresponds to the central region of low-mass stars, then the time scaled by st, which is relevant for all high- and low-mass stars above 0.5 pc). Using the KS test, we found that scaling of our models (seg and non) alone is not able to describe the observational data of low-mass stars either (see the results in Fig. 8 and the radial profiles in Fig. 10). When we use the combination of both scaling and artificial extinction (see the radial profiles in the bottom middle panel of Fig. 10), however, the primordially mass-segregated model can describe the ONC: its p-value is above 0.05 between approximately 1.5 Myr and 3 Myr (see Fig. 8). The non-segregated model is still incompatible with the observational data even with all these modifications: its p-value is virtually zero.
 |
Fig. 9. Comparison of the average radial profiles (based on ten realisations of our models with 2.4k stars) of the projected models of segregated (blue) and non-segregated clusters (red) with the real ONC (black). In several time frames, we show two mass groups: m ≥ 5 M⊙ (solid line) and m < 5 M⊙ (dashed line). The corresponding statistic for each group can be found in Fig. 7, with the comparison even beyond the age of the ONC. |
 |
Fig. 10. Same as in Fig. 9, but for the model with artificial extinction (top row), with scaling of the low-mass stars along the y-axis (middle row) and with both scaling and extinction (bottom row). |
Although this last result is not conclusive because the scaling is not dynamically self-consistent, it is consistent with the results of Sect. 3.2: the time when the degree of mass segregation in this model is expected to become the same in the primordially mass-segregated and the initially not mass-segregated case is about 8.4 Myr. Although our models are also idealistic without a gaseous potential or other realistic features that very young star clusters tend to have (Kroupa et al. 2001; Šubr et al. 2012), these results are consistent with those reached by Bonnell & Davies (1998), who concluded that the ONC most likely formed segregated by mass.
5. Conclusions
Current existing data appear to suggest that embedded clusters may form completely mass segregated. More observational data of newborn and young star clusters are, however, needed to further establish this.
Using idealised numerical N-body models of star clusters with 1.2k, 2.4k, 4.7k, and 9.2k stars, we have found that the primordially fully mass-segregated models initially evolve faster (within the first several crossing times). During (or shortly after) the core collapse, the most massive stars (i.e. >5 M⊙ and even some stars with masses between 2 and 5 M⊙) loose all signs of primordial mass segregation. For the stars with decreasing mass, more time is needed to balance the degree of mass segregation between the primordially fully mass-segregated and non-segregated models. Using the radial distribution of mean mass in our models, we fitted the time when the primordial mass segregation vanishes, and such a model can no longer be observationally distinguished from an initially not mass-segregated model. The mean time is
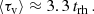
In the lower mass models a marginal difference can be still seen after τv, but more massive clusters are completely indistinguishable from this point onward.
We cross-matched existing observational data of the ONC from the past 30 years and more from the X-ray, (near-)IR, and optical wavelengths, and we compiled the most complete dataset of this cluster so far. It contains about 2400 sources from brown dwarfs and protostars to high-mass Trapezium stars. The numerical models with 2.4k stars were then used to study the degree of primordial mass segregation in the ONC. As the high-mass stars (>5 M⊙) evolve faster dynamically, their radial profiles quickly reach the observational data in this mass range. This holds for both models. However, neither model can describe the population of low-mass stars that we see in the ONC with a high confidence level (the p-value is virtually zero). Two factors were therefore considered in order to approach the observed ONC: (i) extinction and (ii) elongation, as documented in previous works. Although large extinction areas are present in the ONC, including it in the model has only a minor influence on the results and both models are still inconsistent with the data. With a geometrical modification of the modelled clusters according to the observed shape, however, the initially mass-segregated model fits the ONC significantly better at 1.5 ≲ t ≲ 3 Myr, which is about the current age of the ONC, even in the low-mass range (with p > 0.05). The initially not mass-segregated cluster is still incompatible with the observations. This result is expected because the estimated time when the 2.4k cluster should forget its primordial mass segregation is about 8.4 Myr, that is, well above the current age of the ONC. Thus, while not conclusive, the data suggest that the ONC may have formed fully segregated by mass. More theoretical and observational study of this intriguing possibility is needed. In the future, more detailed models that consider the evolution of non-spherical star clusters should be analysed. Other models of the ONC that take the three putative populations (Beccari et al. 2017) as well as a high initial binary population (Kroupa 1995; Kroupa et al. 2001; Belloni et al. 2017) into account should also be constructed.
This does not mean, however, that such a system is also in a state of energy equipartition.
The former strictly, the latter statistically.
Downloaded from Vizier and Simbad:
Chandra Orion Ultradeep Project.
Global astrometric interferometer for astrophysics.
The algorithm is implemented in the python library scipy.stats as ks_2samp().
Acknowledgments
This study was supported by Charles University through grants GAUK-186216 and SVV-260441. We sincerely thank the participants and organisers of the “M+3rd Aarseth N-Body Meeting” for a fruitful discussion about this topic. We also greatly appreciate access to the computing and storage facilities owned by parties and projects contributing to the National Grid Infrastructure MetaCentrum, provided under the programme “Projects of Large Research, Development, and Innovations Infrastructures” (CESNET LM2015042).
References
- Aarseth, S. J. 1966, MNRAS, 132, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Aarseth, S. J. 2003, Gravitational N-Body Simulations (Cambridge, UK: Cambridge University Press) [Google Scholar]
- Adams, F. C., & Fatuzzo, M. 1996, ApJ, 464, 256 [NASA ADS] [CrossRef] [Google Scholar]
- Allison, R. J., Goodwin, S. P., Parker, R. J., et al. 2009, MNRAS, 395, 1449 [Google Scholar]
- Alves, J., & Bouy, H. 2012, A&A, 547, 97 [Google Scholar]
- André, P., Men’shchikov, A., Bontemps, S., et al. 2010, A&A, 518, L102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- André, P., Di Francesco, J., Ward-Thompson, D., et al. 2014, Protostars and Planets VI, 27 [Google Scholar]
- Bailer-Jones, C. A. L., Rybizki, J., Fouesneau, M., Mantelet, G., & Andrae, R. 2018, AJ, 156, 58 [NASA ADS] [CrossRef] [Google Scholar]
- Baraffe, I., Chabrier, G., Allard, F., & Hauschildt, P. H. 1998, A&A, 337, 403 [NASA ADS] [Google Scholar]
- Baumgardt, H., De Marchi, G., & Kroupa, P. 2008, ApJ, 685, 247 [NASA ADS] [CrossRef] [Google Scholar]
- Beccari, G., Petr-Gotzens, M. G., Boffin, H. M. J., et al. 2017, A&A, 604, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Belloni, D., Askar, A., Giersz, M., Kroupa, P., & Rocha-Pinto, H. J. 2017, MNRAS, 471, 2812 [NASA ADS] [CrossRef] [Google Scholar]
- Bonnell, I. A., & Davies, M. B. 1998, MNRAS, 295, 691 [NASA ADS] [CrossRef] [Google Scholar]
- Casertano, S., & Hut, P. 1985, ApJ, 298, 80 [Google Scholar]
- Cutri, R. M., Skrutskie, M. F., van Dyk, S., et al. 2003, VizieR Online Data Catalog, II/246 [Google Scholar]
- D’Antona, F., & Mazzitelli, I. 1994, ApJS, 90, 467 [NASA ADS] [CrossRef] [Google Scholar]
- D’Antona, F., & Mazzitelli, I. 1998, in Brown Dwarfs and Extrasolar Planets, ASP Conf. Ser., 134, 442 [NASA ADS] [Google Scholar]
- Da Rio, N., Robberto, M., Soderblom, D. R., et al. 2009, ApJS, 183, 261 [NASA ADS] [CrossRef] [Google Scholar]
- Da Rio, N., Robberto, M., Hillenbrand, L. A., Henning, T., & Stassun, K. G. 2012, ApJ, 748, 14 [NASA ADS] [CrossRef] [Google Scholar]
- Ezer, D., & Cameron, A. G. W. 1967, Can. J. Phys., 45, 3429 [NASA ADS] [CrossRef] [Google Scholar]
- Flaccomio, E., Damiani, F., Micela, G., et al. 2003a, ApJ, 582, 382 [NASA ADS] [CrossRef] [Google Scholar]
- Flaccomio, E., Damiani, F., Micela, G., et al. 2003b, ApJ, 582, 398 [NASA ADS] [CrossRef] [Google Scholar]
- Fragione, G., Pavlík, V., & Banerjee, S. 2018, MNRAS, 480, 4955 [NASA ADS] [Google Scholar]
- Getman, K. V., Flaccomio, E., Broos, P. S., et al. 2005a, ApJS, 160, 319 [NASA ADS] [CrossRef] [Google Scholar]
- Getman, K. V., Feigelson, E. D., Grosso, N., et al. 2005b, ApJS, 160, 353 [NASA ADS] [CrossRef] [Google Scholar]
- Grossschedl, J. E., Alves, J., Meingast, S., et al. 2018, A&A, 619, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hacar, A., Tafalla, M., & Alves, J. 2017, A&A, 606, A123 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hacar, A., Tafalla, M., Forbrich, J., et al. 2018, A&A, 610, A77 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Haghi, H., Hoseini-Rad, S. M., Zonoozi, A. H., & Küpper, A. H. W. 2014, MNRAS, 444, 3699 [NASA ADS] [CrossRef] [Google Scholar]
- Haghi, H., Zonoozi, A. H., Kroupa, P., Banerjee, S., & Baumgardt, H. 2015, MNRAS, 454, 3872 [NASA ADS] [CrossRef] [Google Scholar]
- Heggie, D., & Hut, P. 2003, The Gravitational Million-Body Problem: A Multidisciplinary Approach to Star Cluster Dynamics (Cambridge, UK: Cambridge University Press) [CrossRef] [Google Scholar]
- Hennebelle, P., & Chabrier, G. 2008, ApJ, 684, 395 [NASA ADS] [CrossRef] [Google Scholar]
- Hennebelle, P., & Chabrier, G. 2011, ApJ, 743, L29 [NASA ADS] [CrossRef] [Google Scholar]
- Hillenbrand, L. A. 1997, AJ, 113, 1733 [NASA ADS] [CrossRef] [Google Scholar]
- Hillenbrand, L. A., & Carpenter, J. M. 2000, ApJ, 540, 236 [NASA ADS] [CrossRef] [Google Scholar]
- Hillenbrand, L. A., & Hartmann, L. W. 1998, ApJ, 492, 540 [NASA ADS] [CrossRef] [Google Scholar]
- Huff, E. M., & Stahler, S. W. 2006, ApJ, 644, 355 [NASA ADS] [CrossRef] [Google Scholar]
- Joncour, I., Duchêne, G., Moraux, E., & Motte, F. 2018, A&A, 620, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jones, B. F., & Walker, M. F. 1988, AJ, 95, 1755 [NASA ADS] [CrossRef] [Google Scholar]
- Kirk, H., & Myers, P. C. 2011, ApJ, 727, 64 [NASA ADS] [CrossRef] [Google Scholar]
- Kroupa, P. 1995, MNRAS, 277, 1507 [NASA ADS] [Google Scholar]
- Kroupa, P. 2001, MNRAS, 322, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Kroupa, P., Aarseth, S., & Hurley, J. 2001, MNRAS, 321, 699 [NASA ADS] [CrossRef] [Google Scholar]
- Kroupa, P., Jeřábková, T., Dinnbier, F., Beccari, G., & Yan, Z. 2018, A&A, 612, A74 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kroupa, P., Weidner, C., Pflamm-Altenburg, J., et al. 2013, in The Stellar and Sub-Stellar Initial Mass Function of Simple and Composite Populations, eds. T. D.Oswalt, & G.Gilmore, 115 [Google Scholar]
- Küpper, A. H. W., Maschberger, T., Kroupa, P., & Baumgardt, H. 2011, MNRAS, 417, 2300 [NASA ADS] [CrossRef] [Google Scholar]
- Lane, J., Kirk, H., Johnstone, D., et al. 2016, ApJ, 833, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Marks, M., & Kroupa, P. 2012, A&A, 543, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mattern, M., Kainulainen, J., Zhang, M., & Beuther, H. 2018, A&A, 616, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Matzner, C. D., & McKee, C. F. 2000, Am. Astron. Soc. Meeting Abstracts, 195, 135.07 [NASA ADS] [Google Scholar]
- Menten, K. M., Reid, M. J., Forbrich, J., & Brunthaler, A. 2007, A&A, 474, 515 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Muench, A. A., Lada, E. A., Lada, C. J., & Alves, J. 2002, ApJ, 573, 366 [NASA ADS] [CrossRef] [Google Scholar]
- Oh, S., & Kroupa, P. 2016, A&A, 590, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Oh, S., Kroupa, P., & Pflamm-Altenburg, J. 2015, ApJ, 805, 92 [NASA ADS] [CrossRef] [Google Scholar]
- Padoan, P., & Nordlund, Å. 2002, ApJ, 576, 870 [Google Scholar]
- Palla, F., & Stahler, S. W. 1999, ApJ, 525, 772 [NASA ADS] [CrossRef] [Google Scholar]
- Palla, F., Randich, S., Flaccomio, E., & Pallavicini, R. 2005, ApJ, 626, L49 [NASA ADS] [CrossRef] [Google Scholar]
- Pflamm-Altenburg, J., & Kroupa, P. 2007, MNRAS, 375, 855 [NASA ADS] [CrossRef] [Google Scholar]
- Plummer, H. C. 1911, MNRAS, 71, 460 [CrossRef] [Google Scholar]
- Plunkett, A. L., Fernández-López, M., Arce, H. G., et al. 2018, A&A, 615, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Prisinzano, L., Micela, G., Flaccomio, E., et al. 2008, ApJ, 677, 401 [NASA ADS] [CrossRef] [Google Scholar]
- Ramírez Alegría, S., Borissova, J., Chené, A. N., et al. 2016, A&A, 588, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Scandariato, G., Robberto, M., Pagano, I., & Hillenbrand, L. A. 2011, A&A, 533, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Scaria, K. K., & Bappu, M. K. V. 1981, JApA, 2, 215 [NASA ADS] [Google Scholar]
- Spitzer, Jr., L., & Hart, M. H. 1971a, ApJ, 164, 399 [NASA ADS] [CrossRef] [Google Scholar]
- Spitzer, Jr., L., & Hart, M. H. 1971b, ApJ, 166, 483 [NASA ADS] [CrossRef] [Google Scholar]
- Stephens, I. W., Gouliermis, D., Looney, L. W., et al. 2017, ApJ, 834, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Stodolkiewicz, J. S. 1982, Acta Astron., 32, 63 [NASA ADS] [Google Scholar]
- Šubr, L., Kroupa, P., & Baumgardt, H. 2008, MNRAS, 385, 1673 [NASA ADS] [CrossRef] [Google Scholar]
- Šubr, L., Kroupa, P., & Baumgardt, H. 2012, ApJ, 757, 37 [NASA ADS] [CrossRef] [Google Scholar]
- Swenson, F. J., Faulkner, J., Rogers, F. J., & Iglesias, C. A. 1994, ApJ, 425, 286 [NASA ADS] [CrossRef] [Google Scholar]
- Vázquez-Semadeni, E., Palau, A., Ballesteros-Paredes, J., Gómez, G. C., & Zamora-Avilés, M. 2019, MNRAS, submitted [arXiv:1903.11247] [Google Scholar]
- Wang, L., Kroupa, P., & Jerabkova, T. 2018, MNRAS, sty2232 [Google Scholar]
- Warren, Jr., W. H., & Hesser, J. E. 1977, ApJS, 34, 207 [NASA ADS] [CrossRef] [Google Scholar]
- Webb, J. J., & Vesperini, E. 2016, MNRAS, 463, 2383 [NASA ADS] [CrossRef] [Google Scholar]
- Weidner, C., Kroupa, P., & Bonnell, I. A. D. 2010, MNRAS, 401, 275 [NASA ADS] [CrossRef] [Google Scholar]
- Weidner, C., Kroupa, P., & Pflamm-Altenburg, J. 2013, MNRAS, 434, 84 [NASA ADS] [CrossRef] [Google Scholar]
- Zonoozi, A. H., Küpper, A. H. W., Baumgardt, H., et al. 2011, MNRAS, 411, 1989 [NASA ADS] [CrossRef] [Google Scholar]
- Zonoozi, A. H., Haghi, H., Küpper, A. H. W., et al. 2014, MNRAS, 440, 3172 [NASA ADS] [CrossRef] [Google Scholar]
- Zonoozi, A. H., Haghi, H., Kroupa, P., Küpper, A. H. W., & Baumgardt, H. 2017, MNRAS, 467, 758 [NASA ADS] [Google Scholar]
Appendix A: Information on the initial state of the clusters
All the models (1.2k, 2.4k, 4.7k, and 9.2k) were generated from the same distribution function of positions and velocities, IMF, and with the same two degrees of mass segregation according to Baumgardt et al. (2008). Therefore, only the most populous model with 9.2k stars is used for a further discussion of the initial conditions. As our models do not contain any primordial binary stars, the evolution towards thermal equilibrium due to the energy equipartition process is dominated by random two-body encounters.
A higher concentration of high-mass stars in the core of the initially mass-segregated cluster allows for sooner and more energetic interactions between them and consequently for a sooner expansion of the central region than in the initially not mass-segregated cluster. This property is discussed in Sect. 3.2 to explain the greater expansion of the 1.2k seg model. The early core expansion of the seg model is also visible in Fig. A.1, where we plot the mean positions of stars in five mass bins above 5 M⊙. In comparison to the non cluster, where the radii are almost stationary, the seg cluster stars move more abruptly. In this figure, we plot not only the radii with respect to the density centre (see Sect. 2), but also with respect to the rigid Cartesian coordinate system predefined at the beginning of each integration. For each bin, the two curves coincide. Thus, we conclude that this effect is dynamical and not produced by our choice of the coordinate system.
 |
Fig. A.1. Evolution of the radii of high-mass stars in time (up to 0.5 Myr, i.e. approximately 3.5 tcr) of the 9.2k model (one realisation each of seg and non is plotted). Colours represent stars in different mass bins (from 5 M⊙ < m ≤ 7 M⊙ up to m > 25 M⊙). The bins contain 39, 26, 18, 13, and 11 stars, respectively. The mean position within each bin is given. Radii with respect to the coordinate origin (dashed lines) and the density centre (solid lines) are plotted. |
The initial conditions of both mass-segregated and non-segregated models are also plotted in Fig. A.2, which shows the dependence of kinetic and potential energy on the masses of stars. By definition, high-mass stars of the seg model are concentrated more strongly than in the non model; as is visible in the lower panels of this figure, the stars in the seg model are arranged perfectly by mass and potential energy (the highest masses have the lowest potential energy), while in the non model we see a scatter. The distribution of kinetic energy (in the top panels) in both seg and non models is similar, except for the very low-mass range. This shows that the high-mass stars that are localised in the core in the initially mass-segregated model are not overcolled, even though there are no primordial binaries. This in turn means that the most massive component may expand immediately.
 |
Fig. A.2. Initial distribution of stellar kinetic energy (top panels) and potential energy (bottom panels) with respect to mass in the 9.2k model for both primordially mass-segregated and non-segregated clusters. The colour scale represents the mean number of stars based on ten realisations of this model. |
Appendix B: Additional figures: mass segregation
We further discuss mass segregation through the distribution of stars of different masses within each model. In Fig. B.1 we include the mean position of the most massive stars in each model whose masses add up to 10 % of the total mass. These curves are also averaged over all realisations of the model (the stellar masses were optimally sampled from the IMF in each realisation, so that we may average the positions of individual stars from different realisations). We note that after the core collapse, the most massive stars from both seg and non clusters expand at a very similar rate. In the smallest clusters, we can still see some difference in the rate of expansion of these stars, but with an increasing total mass of the model, any visual difference linked to the degree of primordial mass segregation disappears.
 |
Fig. B.1. Average positions of the most massive stars that are in the top 10 % of the total mass of the cluster (solid lines). Models with 1.2k, 2.4k, 4.7k, and 9.2k stars are plotted from top to bottom. The data are averaged over all realisations of a given model. For reference, we also plot the half-mass radius with a dashed line. Time extends to ≈18 Myr. |
The cumulative radial profiles that are plotted in Fig. B.2 provide other evidence that the initial mass segregation is gradually lost. Initially very distinct curves start to look similar; this occurs first for the most massive stars. At half a median relaxation time, that is, after the core collapse, there is no difference between the distribution of high-mass stars (>5 M⊙), and this seems to also be the case even in the mass range between 2 and 5 M⊙. The lower the masses of the stars, the longer before their radial distributions of the initially mass-segregated and not mass-segregated clusters coincide. This process becomes faster with higher total mass of the model.
 |
Fig. B.2. Cumulative distribution functions of stars in four different mass ranges in several key time frames (the initial conditions, t ≈ 0.5 τv, t ≈ τv and t ≈ 2 τv, given in the units of the median relaxation time, see also Fig. 5). Models with 1.2k, 2.4k, 4.7k, and 9.2k stars are plotted (from top to bottom). |
Although the curves plotted in Fig. B.2 show a slight difference, the p-value calculated from a two-sample KS test between the same mass groups from the seg and non models is higher than 0.4 (sometimes exceeding even 0.9) in the mass groups with m > 1 M⊙ by the time we reach τv; the mass groups with m > 5 M⊙ of the two models start to coincide even sooner and are completely indistinguishable at approximately 0.3 τv. We note that for p > 0.05, the hypothesis that two samples come from the same distribution cannot be excluded with more than 5 % confidence. The only problem arises in the low-mass range with m < 1 M⊙, where the p-value is much more dependent on the range of radii used for the KS test than in the other mass groups, especially the subgroup of masses m < 0.5 M⊙. When we include the radii only up to 5 pc, the p-value exceeds the critical value at about the time of the third panel (i.e. τv). When we include stars up to 10 pc, it becomes lower and oscillates around the critical value of 0.05. Nevertheless, given the spacial distributions of high-mass stars that dominate mass segregation, we conclude that the primordial mass segregation is lost by the time τv.
Appendix C: Bin-weighting of parameter A
In Sect. 3.2 we have defined a way of measuring the difference of mass segregation between models of the same initial mass and initial radius by the means of the bin-weighted sum of histogram heights, see Eq. (4). We chose to weight each bin by its inverse width Δrk (equidistant in the logarithmic scale) to emphasise the importance of mass segregation, which is visible especially at small radii. Generally, the weight Δrk may be raised to a non-negative power index q,
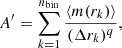 (C.1)
(C.1)
compare with Eq. (4). In Fig. C.1 we plot the ratio 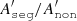 for the 1.2k model as an example to show how the choice of q influences the results (we set q = 0, 1, 2, and 10).
for the 1.2k model as an example to show how the choice of q influences the results (we set q = 0, 1, 2, and 10).
With an increasing index q, the initially large difference is increased and also renders the mass segregation decrease more visible. It is also evident that with a larger q the fluctuations in increase,  , especially after ⟨τv⟩. Nevertheless, the time ⟨τv⟩, when the information of the primordial mass segregation is forgotten, is invariant on the value of q. The choice of q = 1, as we presented in Sect 3.2, represents the first order. It was chosen arbitrarily, but the results do not loose generality.
, especially after ⟨τv⟩. Nevertheless, the time ⟨τv⟩, when the information of the primordial mass segregation is forgotten, is invariant on the value of q. The choice of q = 1, as we presented in Sect 3.2, represents the first order. It was chosen arbitrarily, but the results do not loose generality.
We note that in order to visualise differences between the values of q and the shape of  in Fig. C.1, the limits of the vertical axes were set to the same values. Therefore, the data point at t = 0, which symbolises the large initial difference between the mass-segregated and non-segregated model (e.g. see the panels for t = 0 in Fig. 4), is visible only in the plots of q = 0 and q = 1 but is outside the range of the plots of q = 2 and q = 10.
in Fig. C.1, the limits of the vertical axes were set to the same values. Therefore, the data point at t = 0, which symbolises the large initial difference between the mass-segregated and non-segregated model (e.g. see the panels for t = 0 in Fig. 4), is visible only in the plots of q = 0 and q = 1 but is outside the range of the plots of q = 2 and q = 10.
 |
Fig. C.1. Comparison of different values of the weight power index q from Eq. (C.1), which is set to 0, 1, 2, and 10 (from top to bottom). We compare only the data from the 1.2k model as an example. The mean time ⟨τv⟩ (see Eq. (5)) is also plotted for reference. The limits of the vertical axes are fixed. |
In the discussion of the lower mass models, we stated that the initially mass-segregated cluster inflates more than the non-segregated one. Therefore the ratio of 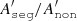 stays at a slightly higher value than 1. It might seem reasonable to try to lower this effect, for example, by normalising the radial distribution of the mean mass (in Fig. 4) by the current half-mass radius. For this method of comparing the mean masses to work, however, the bins must remain equally spaced throughout the whole cluster evolution. Because the half-mass radius evolves, we may not use it for normalisation. In principle, we could scale both models to their initial half-mass radius, but as its value for the primordially fully mass-segregated and non-segregated cluster is similar, we may also chose any other fixed units, for instance, parsecs. However, if we were about to compare clusters of different initial sizes, we would have to scale both to the same size for the method to work (e.g. again the initial half-mass radius).
stays at a slightly higher value than 1. It might seem reasonable to try to lower this effect, for example, by normalising the radial distribution of the mean mass (in Fig. 4) by the current half-mass radius. For this method of comparing the mean masses to work, however, the bins must remain equally spaced throughout the whole cluster evolution. Because the half-mass radius evolves, we may not use it for normalisation. In principle, we could scale both models to their initial half-mass radius, but as its value for the primordially fully mass-segregated and non-segregated cluster is similar, we may also chose any other fixed units, for instance, parsecs. However, if we were about to compare clusters of different initial sizes, we would have to scale both to the same size for the method to work (e.g. again the initial half-mass radius).
All Tables
Initial parameters of the low-mass star cluster model: number of stars, mass of the cluster, half-mass radius, crossing time, and median relaxation time.
Initial parameters of the star cluster models: number of stars, mass of the cluster, half-mass radius, crossing time, and median relaxation time.
All Figures
|
Fig. 1. Initial distribution of masses (upper panels) and total energy (lower panels) with respect to the three-dimensional radial position of a star in the cluster. Three primordial mass segregations of our models containing 52 stars are shown: seg and Šubr are initially mass segregated with S = 1 and S = 0.5, respectively, and non is without any initial mass segregation (S = 0), see Sect. 2. The light crosses represent one realisation, and the darker lines are averages from all realisations. |
| In the text | |
|
Fig. 2. Three left upper panels: initial conditions of our models containing 52 stars: seg and Šubr are initially mass segregated with S = 1 and S = 0.5, respectively, and non is without any initial mass segregation (S = 0), see Sect. 2. Lower panels: models in a slightly evolved stage (at 0.5 tcr and 1.0 tcr). The solid line in each plot represents the average position for a star of a given mass in 100 realisations, whereas the lighter crosses are the positions from one random realisation. The power-law fit of both seg and Šubr models is shown by the grey dashed line. For comparison, right panels: observed data and the fitted slope (cf. Plunkett et al. 2018); the same dataset is used in all rows. We note that the horizontal axis of each plot is in projection to the xy plane. |
| In the text | |
|
Fig. 3. Lagrangian radii of both segregated (blue) and non-segregated (red) models with 1.2k, 2.4k, 4.7k, and 9.2k stars (panels from top to bottom), averaged over all realisations of each model. The time axis reaches ≈10 trh, the corresponding mass fractions (10, 25, 50, 75, and 90 % from bottom to top) are on the right-hand side of each panel, and the half-mass radius is plotted with a dashed line. |
| In the text | |
|
Fig. 4. Mean mass contained in a sphere of a given radius, see Eq. (3), of the models with 1.2k, 2.4k, 4.7k, and 9.2k stars (panels from top to bottom), averaged over all realisations of each model. Both initially mass-segregated (blue) and not mass-segregated clusters (red) of each model are plotted. Individual plots are separated by 2.0 trh. |
| In the text | |
|
Fig. 5. Evolution of the ratio given by Eqs. (3) and (4) in time. The dashed line and the value ⟨τv⟩ (see Eq. (5)) represent the mean time when the slope of the data points turned zero. The slope itself is plotted by a grey line. |
| In the text | |
|
Fig. 6. Schematic plot of the modifications made to the models in order to compare them to the ONC. The hatched area has artificial extinction of low-mass stars (i.e. stars with m < 5 M⊙ are removed), the dashed ellipse demonstrates the scaling of low-mass stars along the y-axis by a factor of 1.5, the dotted circle illustrates the isotropic scaling of all high-mass stars, and the grey circle covers the central region where low-mass stars are left without scaling. |
| In the text | |
|
Fig. 7. p-value of the two-sample KS test between the projected cumulative radial distribution of our models (based on ten realisations) and the real ONC. |
| In the text | |
|
Fig. 8. Same as in Fig. 7, but for the scaled model with artificial extinction (top panel), with scaling (middle panel), and with both scaling and extinction. When scaling is involved, time is given in the scaled units (tscl = st t), which are valid for all high- and low-mass stars above 0.5 pc. |
| In the text | |
|
Fig. 9. Comparison of the average radial profiles (based on ten realisations of our models with 2.4k stars) of the projected models of segregated (blue) and non-segregated clusters (red) with the real ONC (black). In several time frames, we show two mass groups: m ≥ 5 M⊙ (solid line) and m < 5 M⊙ (dashed line). The corresponding statistic for each group can be found in Fig. 7, with the comparison even beyond the age of the ONC. |
| In the text | |
|
Fig. 10. Same as in Fig. 9, but for the model with artificial extinction (top row), with scaling of the low-mass stars along the y-axis (middle row) and with both scaling and extinction (bottom row). |
| In the text | |
|
Fig. A.1. Evolution of the radii of high-mass stars in time (up to 0.5 Myr, i.e. approximately 3.5 tcr) of the 9.2k model (one realisation each of seg and non is plotted). Colours represent stars in different mass bins (from 5 M⊙ < m ≤ 7 M⊙ up to m > 25 M⊙). The bins contain 39, 26, 18, 13, and 11 stars, respectively. The mean position within each bin is given. Radii with respect to the coordinate origin (dashed lines) and the density centre (solid lines) are plotted. |
| In the text | |
|
Fig. A.2. Initial distribution of stellar kinetic energy (top panels) and potential energy (bottom panels) with respect to mass in the 9.2k model for both primordially mass-segregated and non-segregated clusters. The colour scale represents the mean number of stars based on ten realisations of this model. |
| In the text | |
|
Fig. B.1. Average positions of the most massive stars that are in the top 10 % of the total mass of the cluster (solid lines). Models with 1.2k, 2.4k, 4.7k, and 9.2k stars are plotted from top to bottom. The data are averaged over all realisations of a given model. For reference, we also plot the half-mass radius with a dashed line. Time extends to ≈18 Myr. |
| In the text | |
|
Fig. B.2. Cumulative distribution functions of stars in four different mass ranges in several key time frames (the initial conditions, t ≈ 0.5 τv, t ≈ τv and t ≈ 2 τv, given in the units of the median relaxation time, see also Fig. 5). Models with 1.2k, 2.4k, 4.7k, and 9.2k stars are plotted (from top to bottom). |
| In the text | |
|
Fig. C.1. Comparison of different values of the weight power index q from Eq. (C.1), which is set to 0, 1, 2, and 10 (from top to bottom). We compare only the data from the 1.2k model as an example. The mean time ⟨τv⟩ (see Eq. (5)) is also plotted for reference. The limits of the vertical axes are fixed. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.