| Issue |
A&A
Volume 571, November 2014
|
|
|---|---|---|
| Article Number | A71 | |
| Number of page(s) | 22 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201424181 | |
| Published online | 13 November 2014 | |
DIAMONDS: A new Bayesian nested sampling tool⋆
Application to peak bagging of solar-like oscillations
Instituut voor Sterrenkunde, KU Leuven, Celestijnenlaan 200D, 3001 Leuven, Belgium
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
,This email address is being protected from spambots. You need JavaScript enabled to view it.
Received: 11 May 2014
Accepted: 8 August 2014
Abstract
Context. Thanks to the advent of the space-based missions CoRoT and NASA’s Kepler, the asteroseismology of solar-like oscillations is now at the base of our understanding about stellar physics. The Kepler spacecraft, especially, is releasing excellent photometric observations of more than three years length in high duty cycle, which contain a large amount of information that has not yet been investigated.
Aims. To exploit the full potential of Kepler light curves, sophisticated and robust analysis tools are now required more than ever. Characterizing single stars with an unprecedented level of accuracy and subsequently analyzing stellar populations in detail are fundamental to further constrain stellar structure and evolutionary models.
Methods. We developed a new code, termed Diamonds, for Bayesian parameter estimation and model comparison by means of the nested sampling Monte Carlo (NSMC) algorithm, an efficient and powerful method very suitable for high-dimensional and multi-modal problems. A detailed description of the features implemented in the code is given with a focus on the novelties and differences with respect to other existing methods based on NSMC. Diamonds is then tested on the bright F8 V star KIC 9139163, a challenging target for peak-bagging analysis due to its large number of oscillation peaks observed, which are coupled to the blending that occurs between ℓ = 2,0 peaks, and the strong stellar background signal. We further strain the performance of the approach by adopting a 1147.5 days-long Kepler light curve, accounting for more than 840 000 data bins in the power spectrum of the star.
Results. The Diamonds code is able to provide robust results for the peak-bagging analysis of KIC 9139163, while preserving a considerable computational efficiency for identifying the solution at the same time. We test the detection of different astrophysical backgrounds in the star and provide a criterion based on the Bayesian evidence for assessing the peak significance of the detected oscillations in detail. We present results for 59 individual oscillation frequencies, amplitudes and linewidths and provide a detailed comparison to the existing values in the literature, from which significant deviations are found when a different background is used. Lastly, we successfully demonstrate an innovative approach to peak bagging that exploits the capability of Diamonds to sample multi-modal distributions, which is of great potential for possible future automatization of the analysis technique.
Key words: methods: data analysis / methods: statistical / stars: individual: KIC 9139163 / stars: solar-type / methods: numerical / stars: oscillations
Software package available at the Diamonds code website: https://fys.kuleuven.be/ster/Software/Diamonds/
© ESO, 2014
1. Introduction
The advent of the space-based photometric missions, CoRoT (Baglin et al. 2006; Michel et al. 2008) and NASA’s Kepler (Borucki et al. 2010; Koch et al. 2010), has revolutionized the asteroseismology of stars exhibiting solar-like oscillations, a type of stellar oscillation that is stochastically excited and intrinsically damped, which was observed for the first time in the Sun (e.g. see Bedding & Kjeldsen 2003, 2006, for a summary on solar-like oscillations).
Since May 2009, the Kepler spacecraft in particular has been providing an incredible amount of high-quality data, which allows us to study the asteroseismic properties of a large sample of low-mass stars (e.g. see García 2013, for a review). As a result, asteroseismology now confirms its key role in improving our understanding of stellar structure and evolution.
In addition to the ensemble studies of stellar populations, which became possible for the first time already from the beginning of the Kepler mission (Chaplin et al. 2011), the need for investigating detailed asteroseismic properties, such as frequencies, lifetimes and amplitudes of individual oscillations, is becoming even more important at present times. The increasing observing length of the Kepler light curves is opening up possibilities for extremely detailed data analysis and modeling of stars similar to our Sun. These studies are able to yield constraints on fundamental stellar properties, such as mass, radius, and age, the internal structure, and composition (e.g. Christensen-Dalsgaard 2004). Detailed modeling of some bright targets observed by Kepler have already been published (e.g. see Metcalfe et al. 2010, 2012).
However, measuring a complete set of characteristic asteroseismic parameters from informative power spectra that contain tens of resolved oscillations, while being able to retrieve results in a reasonable amount of time in parallel, is still a very challenging task to be accomplished. This analysis, often referred to as peak bagging (e.g. see Appourchaux 2003), involves fitting models in high-dimensional spaces and typically deals with pronounced degeneracies that convey a number of possible solutions. In addition, as peak bagging also implies the asteroseismic identification of the oscillation peak, the use of some model selection criterion is often required. For this purpose, Bayesian statistics offers a valuable choice (e.g. see Sivia & Skilling 2006; Trotta 2008; Benomar et al. 2009; Gruberbauer et al. 2009; Kallinger et al. 2010; Handberg & Campante 2011; Corsaro et al. 2013).
Nevertheless, Bayesian methods are typically more computationally demanding than standard classical approaches, such as maximum likelihood estimators (MLE; e.g. see Anderson et al. 1990; Toutain & Appourchaux 1994). Since the amount of asteroseismic data to be investigated is very large, adopting more efficient Bayesian techniques can significantly reduce the time required for performing an entire peak-bagging analysis.
In this paper, we present a new code termed Diamonds, based on the nested sampling Monte Carlo (NSMC, Skilling 2004, hereafter SK04), a powerful and efficient method for inference analyses of high-dimensional and multi-modal problems that incorporates a robust Bayesian approach (see also Mukherjee et al. 2006; Shaw et al. 2007; Feroz & Hobson 2008; Feroz et al. 2009; Feroz & Skilling 2013, hereafter M06, S07, FH08, F09, FS13, respectively). We show how the code can be used as a tool for the peak bagging of solar-like oscillations, ensuring a considerable computational speed and efficiency in performing the analysis.
2. Bayesian inference
The heart of the Diamonds code is Bayes’ theorem: 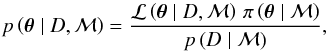 (1)where
(1)where 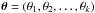 is the parameter vector, that is, the k-dimensional vector containing the free parameters that formalize a given model ℳ, and D is the dataset used for the inference. ℒ(θ | D,ℳ) (hereafter,
is the parameter vector, that is, the k-dimensional vector containing the free parameters that formalize a given model ℳ, and D is the dataset used for the inference. ℒ(θ | D,ℳ) (hereafter, 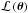 for simplicity) is the likelihood function, which represents the way we sample the data, while π(θ | ℳ) is the prior probability density function (PDF) that reflects our knowledge about the model parameters (see Sect. 4.2). The left-hand side of Eq. (1) is the posterior PDF, which has a key role in the parameter estimation problem as we shall discuss more in detail in Sect. 4.5.
for simplicity) is the likelihood function, which represents the way we sample the data, while π(θ | ℳ) is the prior probability density function (PDF) that reflects our knowledge about the model parameters (see Sect. 4.2). The left-hand side of Eq. (1) is the posterior PDF, which has a key role in the parameter estimation problem as we shall discuss more in detail in Sect. 4.5.
2.1. Model comparison
The denominator on the right-hand side of Eq. (1) is instead a normalization factor, generally known as the Bayesian evidence (or marginal likelihood), which is defined as 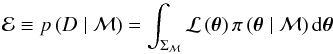 (2)with Σℳ the k-dimensional parameter space set by the prior PDF. The Bayesian evidence ℰ – namely, the likelihood distribution averaged over the parameter space set by the priors – plays no role in the parameter estimation because it does not depend upon the free parameters by definition, but it is nevertheless central for solving model selection problems as we shall show in Sect. 6 for the application of the peak bagging analysis.
(2)with Σℳ the k-dimensional parameter space set by the prior PDF. The Bayesian evidence ℰ – namely, the likelihood distribution averaged over the parameter space set by the priors – plays no role in the parameter estimation because it does not depend upon the free parameters by definition, but it is nevertheless central for solving model selection problems as we shall show in Sect. 6 for the application of the peak bagging analysis.
To perform the model comparison one considers the so-called odds ratio, that is the ratio of the posterior probabilities of the different models, which is defined as 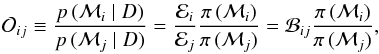 (3)which comprises both the Occam’s razor – consisting in a trade-off between fit quality of the model to the observations and the number of free parameters involved in the inference and represented by the Bayes factor ℬij – and our prior knowledge about the models investigated, π(ℳ), which is given as prior odds ratio here. When
(3)which comprises both the Occam’s razor – consisting in a trade-off between fit quality of the model to the observations and the number of free parameters involved in the inference and represented by the Bayes factor ℬij – and our prior knowledge about the models investigated, π(ℳ), which is given as prior odds ratio here. When 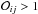 the model ℳi is favored over the model ℳj, and vice versa when Oij< 1.
the model ℳi is favored over the model ℳj, and vice versa when Oij< 1.
In most astrophysical applications, the model selection problem is addressed by setting π(ℳ) = const. for all models (e.g. see Corsaro et al. 2013), which means that we assign the same chance of being eligible a priori to all models. This assumption neutralizes the effect of the prior odds ratio and reduces Eq. (3) to 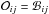 only, i.e. the ratio of the Bayesian evidences of the two models. Occasionally, the prior odds ratio may not be negligible and requires further consideration, see also Scott & Berger (2010). We also refer to the so-called Jeffreys’ scale of strength (Jeffreys 1961) for comparing the Bayes’ factor and conclude on whether a model ought to be preferred over its competitor.
only, i.e. the ratio of the Bayesian evidences of the two models. Occasionally, the prior odds ratio may not be negligible and requires further consideration, see also Scott & Berger (2010). We also refer to the so-called Jeffreys’ scale of strength (Jeffreys 1961) for comparing the Bayes’ factor and conclude on whether a model ought to be preferred over its competitor.
3. Nested sampling
Since Eq. (2) is a multi-dimensional integral, as the number of dimensions increases, its evaluation becomes quickly unsolvable both analytically and by numerical approximations. The NSMC algorithm was first developed by SK04, having not only the aim of an efficient evaluation of the Bayesian evidence for any dimensions but also the sampling of the posterior probability distribution (PPD) for parameter estimation as a straightforward by-product.
We follow SK04 by introducing the prior mass (or prior volume) dX = π(θ | ℳ) dθ such that 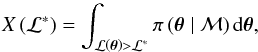 (4)with ℒ∗ being some fixed value of the likelihood distribution. Clearly, 0 ≤ X ≤ 1 because π(θ | ℳ) is a PDF. Equation (4) is therefore the fraction of volume under the prior PDF that is contained within the hard constraint
(4)with ℒ∗ being some fixed value of the likelihood distribution. Clearly, 0 ≤ X ≤ 1 because π(θ | ℳ) is a PDF. Equation (4) is therefore the fraction of volume under the prior PDF that is contained within the hard constraint 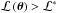 , hence the higher the constraining value and the smaller the prior mass considered. In other words, for a given ℒ∗, we are considering the parameter space delimited by the iso-likelihood contour ℒ(θ∗) = ℒ∗, which also includes the maximum value ℒmax.
, hence the higher the constraining value and the smaller the prior mass considered. In other words, for a given ℒ∗, we are considering the parameter space delimited by the iso-likelihood contour ℒ(θ∗) = ℒ∗, which also includes the maximum value ℒmax.
Considering the inverse function ℒ(X), i.e. ℒ(X(ℒ∗)) = ℒ∗, Eq. (2) becomes 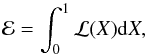 (5)reducing it to a one-dimensional integral. Assuming one has a set of Nnest pairs
(5)reducing it to a one-dimensional integral. Assuming one has a set of Nnest pairs 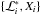 , where
, where 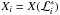 , with Xi + 1<Xi and
, with Xi + 1<Xi and 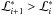 , Eq. (5) can be evaluated as
, Eq. (5) can be evaluated as 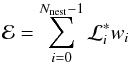 (6)with either
(6)with either 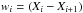 for a simple rectangular rule or
for a simple rectangular rule or 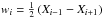 for a trapezoidal rule (see SK04 for some simple examples). For the sake of clarity, due to numerical reasons related to the implementation of the equations above, quantities such as evidence, prior mass, likelihood and prior probability density values are more conveniently considered in a logarithmic scale.
for a trapezoidal rule (see SK04 for some simple examples). For the sake of clarity, due to numerical reasons related to the implementation of the equations above, quantities such as evidence, prior mass, likelihood and prior probability density values are more conveniently considered in a logarithmic scale.
3.1. Drawing from the prior
What happens in practice is that we set a new likelihood constraint that is higher than the previous one at each iteration, and we peel off a thin shell of prior mass defined by the new iso-likelihood contour. This allows us to collect the evidence from that thin shell and cumulate it to the final value given by Eq. (6). Still following SK04, the right-hand side of Eq. (6) is computed as follows:
- 1.
Nlive “live” points are drawn uniformly from the original prior PDF π(θ | ℳ) by setting the initial prior mass X0 = 1.
- 2.
At the first iteration of the nested sampling, i = 0, the live point having the lowest likelihood is removed from the sample, its coordinates and its likelihood stored, the latter as the first likelihood constrain
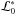 .
. - 3.
The missing point of the live sample is then replaced by a new one uniformly drawn from the prior PDF, having likelihood higher than the first constraint
. - 4.
The prior mass is reduced by a factor exp( − 1 /Nlive) according to the standard rule defined by SK04
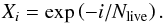 (7)
(7)
The entire process from point 2 to point 4 is repeated in the subsequent iterations until some stopping criterion is met. While the computation of the evidence is simple, the NSMC has the challenging drawback of requiring drawings from the prior with the hard constraint of the likelihood. This process becomes much more computationally demanding in the case of multi-modal PPDs, high-dimensional problems, and pronounced curving degeneracies. For these reasons, the drawing problem has been widely investigated and different solutions have been proposed, such as single ellipsoidal sampling (M06); clustered and simultaneous ellipsoidal sampling and improved versions with either k-means, X-means (S07, FH08), or an expectation-maximization algorithm (MultiNest code, by F09); Metropolis nested sampling (Sivia & Skilling 2006, FH08), artificial neural networks (Graff et al. 2012), and more recently Galilean Monte Carlo (GMC, by FS13).
In Sect. 4.1, we describe the details of another version of the simultaneous ellipsoidal sampling that adopts X-means, which was adopted in this work.
4. The DIAMONDS code
The Diamonds (high-DImensional And multi-MOdal NesteD Sampling) code presented in this work was developed in C++11 and structured in classes to be as much flexible and configurable as possible. The working scheme from a main function is as follows:
-
1.
reading an input dataset;
-
2.
setting up model, likelihood, and priors to be used in the Bayesian inference;
-
3.
setting up a drawing algorithm;
-
4.
configuring and starting the nested sampling;
-
5.
computation and printing of the results.
The code can be used for any application involving Bayesian parameter estimation and/or model selection in general. Users can supply new models, likelihood functions, and prior PDFs whenever needed by taking advantage of C++ class polymorphism and inheritance. Any new model, likelihood, and prior PDFs can be defined and implemented upon a basic template.
In addition, it is possible to feed the basic nested sampler with drawing methods based on different clustering algorithms (see section below).
4.1. Simultaneous ellipsoidal sampling
Simultaneous ellipsoidal sampling (SES) is a drawing algorithm based on a preliminary clustering of the set of live points at a given iteration of the nested sampling. The clustering is obtained in our case by using X-means (Pelleg & Moore 2000) with a number of clusters Nclust ranging from a minimum to a maximum value allowed. A good choice for most applications is given by 1 ≤ Nclust ≤ 6. The SES was developed by S07 and FH08, based on the first idea by M06, for gaining efficiency when dealing with multi-modal posteriors and pronounced curving degeneracies.
The SES algorithm proceeds as follows: once a number of clusters has been identified – i.e. the set of live points has been partitioned into subsets – ellipsoidal bounds for each of the clusters are constructed, and a new point is drawn from the inside of one of the ellipsoids exploiting a fast and exact method (see S07 for more details). Ellipsoids are intended to approximate the iso-likelihood contours, thus reducing the effective prior volume where the drawing has to take place. This considerably improves the speed of the NSMC because sampling from uninteresting regions of the PPD is in general avoided. This algorithm is in principle repeated at every iteration of the nested sampling (see also FH08).
 |
Fig. 1 Examples of 1000 points (red dots) drawn according to different prior distributions from a three-dimensional ellipsoid centered at coordinate (2.0,2.0,2.0) in the parameter space defined by θ1,θ2,θ3 ∈ [0.5,3.5]. Left panel: case of a uniform prior along each coordinate, |
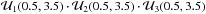
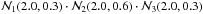
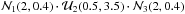
Below, we present the two main changes applied in the SES algorithm from the version described in Method 1 of FH08, the closest in spirit to the one adopted here. These changes were done to improve speed and efficiency of the drawing process.
The first difference is that we introduced two additional configuring parameters: (i) the number of nested iterations before executing the first clustering of the live points, Minit and (ii) the number of nested iterations with the same clustering, Msame, which is the number of iterations that do not involve any clustering of the live points. It is not required and conversely much more computationally expensive to perform the clustering at each iteration of the nested sampling. Point (i) addresses the problem of having X-means identifying one cluster during the early stages of the nesting process, where we do not yet expect any clustering of the live points to happen; and (ii) allows us to speed up the computation by a factor Msame, which is able to significantly reduce the run time of the NSMC, since X-means represents the bottleneck of this approach.
While the two additional parameters Minit and Msame complicate the configuration of the code to some extent, their tuning is not tricky because they do not critically affect the efficiency of the sampling. Intuitively, the more live points are being used, the more iterations can be treated with the same clustering. In general, adopting Minit~Nlive and Msame ~ 0.02 − 0.05Minit have provided a valuable choice for all the demos presented in Sect. 4.6 and for the peak bagging analysis discussed in Sect. 6. Ellipsoids are recomputed at each iteration because this process is not significantly influencing the speed of the NSMC.
The second relevant change applied to the original SES algorithm consists in another additional input parameter, Mattempts, which represents the maximum number of attempts in drawing from the prior with the hard constraint of the likelihood, and it is typically set to 104. On one hand, this parameter allows for a safer control of the drawing process, which can therefore be stopped if the number of attempts exceeds the given limit (meaning that the drawing is not efficient anymore). This avoids situations in which the sampling gets stuck in a flat region of the PPD, resulting in a prohibiting large number of drawing attempts. On the other hand, increasing Mattempts up to values, such as 105, can sometimes be useful to force more nested iterations and achieve more precision on the final value of the evidence. However, the larger the Mattempts, the slower the computation becomes toward the final iterations of the NSMC. It is important to note that the parameter Mattempts directly impacts the number of total likelihood computations done during the process. This is because every attempt done involves the drawing of a new point according to the prior PDF and the subsequent assessing of the likelihood constraint. As a result, the final number of sampling points only accounts for those attempts that were successful (hence useful according to the NSMC working criterion) and will always be smaller than the total number of likelihood evaluations that were practically done by the code.
Lastly, the SES implemented in Diamonds incorporates the dynamical enlargement of the ellipsoids as introduced by FH08, that is, for a given ith iteration and the kth ellipsoid 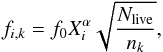 (8)where nk is the number of live points falling in the kth ellipsoid, while f0 ≥ 0 and 0 ≤ α ≤ 1 are the two additional configuring parameters, which represent the initial enlargement fraction and the shrinking rate of the ellipsoids, respectively.
(8)where nk is the number of live points falling in the kth ellipsoid, while f0 ≥ 0 and 0 ≤ α ≤ 1 are the two additional configuring parameters, which represent the initial enlargement fraction and the shrinking rate of the ellipsoids, respectively.
4.2. Likelihood and prior distributions
The code includes different likelihood functions, which are all implemented as a log-likelihood, 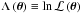 . The application exposed in this paper includes the exponential likelihood, which is required for describing Fourier power spectra as introduced by Duvall & Harvey (1986); Anderson et al. (1990) for data distributed according to a χ2 with two degrees of freedom. The log-likelihood reads
. The application exposed in this paper includes the exponential likelihood, which is required for describing Fourier power spectra as introduced by Duvall & Harvey (1986); Anderson et al. (1990) for data distributed according to a χ2 with two degrees of freedom. The log-likelihood reads ![Mathematical equation: \begin{equation} \Lambda \left( \dtheta \right) = - \sum^{\ndata}_{i=1} \left[\ln E_i \left( \dtheta \right) + \frac{O_i}{E_i \left( \dtheta \right)} \right], \label{eq:exponential_likelihood} \end{equation}](/articles/aa/full_html/2014/11/aa24181-14/aa24181-14-eq69.png) (9)where the functional form for
(9)where the functional form for 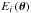 is described in Sects. 6.2 and 6.3.
is described in Sects. 6.2 and 6.3.
 |
Fig. 2 Examples of 20 000 points drawn from the 3D ellipsoid used in Fig. 1 but now according to the super-Gaussian priors |
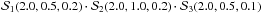
The SES algorithm does not put any particular restriction on the prior PDF that can be used when drawing a new point from an ellipsoid. Prior PDFs, as introduced in Eq. (1), allow us to draw a point more frequently from those regions inside the ellipsoid having higher prior probability density. This clearly encompasses our knowledge about the inferred parameters, and it is one of the key points of the Bayesian approach.
Differently from the implementation adopted by F09 in MultiNest, when using Diamonds prior distributions can be defined by the user by means of a separate module that implements a general template for any proper, or normalizable, prior.
The present code package comes with three different prior PDFs with each of them requiring input hyper parameters – i.e. the parameters defining the shape of the prior distribution – for their set-up. In the following, we briefly introduce them as defined for a single free parameter θj (hence in one dimension of the parameter space):
-
the uniform prior
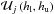 , where hl and hu are the hyper parameters defining lower and upper bounds, respectively, for the free parameter for which the prior is defined;
, where hl and hu are the hyper parameters defining lower and upper bounds, respectively, for the free parameter for which the prior is defined; -
the normal prior
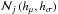 with hμ and hσ being the hyper parameters mean and standard deviation of the normal distribution for the free parameter considered, respectively;
with hμ and hσ being the hyper parameters mean and standard deviation of the normal distribution for the free parameter considered, respectively; -
the super-Gaussian prior
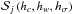 , consisting a plateau (flat prior) with symmetric Gaussian tails, as defined by the three hyper parameters hc as the center of the plateau region, hw the width of the plateau, and hσ the standard deviation of the Gaussian tails.
, consisting a plateau (flat prior) with symmetric Gaussian tails, as defined by the three hyper parameters hc as the center of the plateau region, hw the width of the plateau, and hσ the standard deviation of the Gaussian tails.
Each type of prior PDF can also be defined for set of free parameters, requiring an input vector of hyper parameters in which each element corresponds to one different dimension. The overall k-dimensional prior PDF is simply given as the product of the k prior PDFs defined for each coordinate.
Three examples for demonstrating the drawing process from a single ellipsoid in a three-dimensional parameter space according to different combinations of the prior PDFs and are shown in Fig. 1 with 1000 points drawn in each demo. In the first plot, the drawn points are uniformly distributed within the entire volume of the ellipsoid because a uniform prior was adopted for each coordinate. In the second plot, the points are concentrated around the center of the ellipsoid, occurring in the position (2,2,2), and are spread over the three directions since a normal prior was used for each coordinate. In the third plot, the samples are more concentrated along the direction of θ2 because of a uniform prior, while they are spread over the other two directions because two normal priors were used.
For demonstrating the super-Gaussian prior PDF instead, we show the histograms of the cumulated counts in each of the three directions, as seen in Fig. 2. For this demo, we used the same ellipsoid of Fig. 1 but drew 20 000 points from it to provide a more clear result in the histogram density. More details are mentioned in the figure caption.
The drawing from the ellipsoids is by default uniform, hence uniform priors ensure the most efficient drawing process. When using normal and/or super-Gaussian priors instead, it is recommended to put reasonably large standard deviations if one is not appreciably confident about the possible outcome of the free parameters involved in the inference. Moreover, drawing a new point using super-Gaussian priors is more computationally expensive than with normal priors. Especially in higher dimensions, it is often the slowest drawing among the three prior types considered.
4.3. Stopping criterion and total evidence
For the stopping criterion implemented in Diamonds, we considered the so-called mean live evidence (Keeton 2011, hereafter K11), defined at a given ith nested iteration as 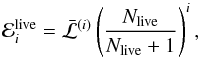 (10)where the product of the average likelihood estimated from the existing set of live points,
(10)where the product of the average likelihood estimated from the existing set of live points, 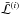 , by the remaining prior mass is expressed here as a simple power law of the number of live points because it is averaged over all possible realizations of prior mass distribution (see K11 for more details).
, by the remaining prior mass is expressed here as a simple power law of the number of live points because it is averaged over all possible realizations of prior mass distribution (see K11 for more details).
Once the nested sampling is terminated, we compute the total evidence as ℰtot = ℰ + ℰlive, where ℰlive is the remaining mean live evidence at the last iteration. This correction ensures that we have a more accurate estimate of the real evidence even in the case the algorithm is stopped prematurely. For achieving the same level of accuracy on the final evidence, fewer iterations might be required than if ℰ only is considered, thus representing an additional advantage for the computation.
The final uncertainty on lnℰtot can still be taken as the classical 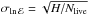 , which is suggested by SK04, where H is the final information gain (see Sivia & Skilling 2006, for more details) since the difference with respect to the total statistical uncertainty derived by K11 is negligible. In the remainder part of the paper, we shall refer to ℰtot only and adopt the symbol ℰ for simplicity.
, which is suggested by SK04, where H is the final information gain (see Sivia & Skilling 2006, for more details) since the difference with respect to the total statistical uncertainty derived by K11 is negligible. In the remainder part of the paper, we shall refer to ℰtot only and adopt the symbol ℰ for simplicity.
At this stage, it is important to introduce a change related to the stopping criterion of the NSMC implemented in Diamonds with respect to other existing codes using NSMC. As shown in the statistical work by K11, the evolving ratio 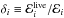 between the mean live evidence and the cumulated evidence at the ith iteration can be used as a criterion for terminating the NSMC. A ratio δfinal ≡ ℰlive/ ℰ < 1 is normally enough for obtaining both an accurate estimate of the total evidence and a good sampling of the PPD. This condition turns out to correspond reasonably well to that provided by SK04 by using the information theory; the latter gives an optimal number of iterations
between the mean live evidence and the cumulated evidence at the ith iteration can be used as a criterion for terminating the NSMC. A ratio δfinal ≡ ℰlive/ ℰ < 1 is normally enough for obtaining both an accurate estimate of the total evidence and a good sampling of the PPD. This condition turns out to correspond reasonably well to that provided by SK04 by using the information theory; the latter gives an optimal number of iterations 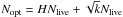 , where k is once again the number of dimensions in the problem and H the final information gain. The optimal number of iterations suggested by SK04 is also computed at the end of the process so that it can be used as a reference for the total number of iterations defined by the new stopping condition.
, where k is once again the number of dimensions in the problem and H the final information gain. The optimal number of iterations suggested by SK04 is also computed at the end of the process so that it can be used as a reference for the total number of iterations defined by the new stopping condition.
When a dense sampling of the modes in the PPD ought to be preferred, especially for multi-modal distributions, the stopping threshold can be lowered to a value δfinal< 0.1. Conversely, the threshold can also be set to higher values (>10) in case we have no much knowledge about the inferred parameters and, therefore, intend to test the validity of the prior boundaries. For the application of Diamonds presented in Sect. 6, we fix this parameter to δfinal = 0.01.
4.4. Reduction of the live points
As suggested by F09, reducing the number of live points as the NSMC process evolves may help in speeding up the whole computation, since fewer live points also imply fewer nested iterations for the algorithm to converge. This reduction could be needed especially in highly multi-modal problems, where a large number of live points is required at the beginning to ensure all the modes are properly detected. Nonetheless, the reduction of the prior mass with an evolving number of live points cannot be done with the standard rule given by Eq. (7), which assumes Nlive to be constant throughout the process, and the new approach requires some thoughts. This case was neither treated by SK04 for the basic algorithm nor explicitly discussed by F09, who proposed an empirical rule for reducing the live points based on the largest evidence contribution estimable at each iteration.
We explain below how we obtained the reduction rule for the prior mass with an evolving number of live points. We prove the result for one step only, as the principle can easily be generalized to an arbitrary number of reductions. Suppose we start with Nlive = N0 live points at the first nested iteration, i = 0. Applying Eq. (7), the remaining prior mass at the first iteration is given by 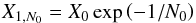 (11)with the subscript N0 indicating that it is based on N0 live points (X0 = 1 independently of the number of live points, hence no subscript is used). At the second iteration, i = 1, we reduce the number of live points to Nlive = N1 and once again reduce the prior mass. According to the standard reduction rule adopted for the case of N0 live points, we simply have for N1 that
(11)with the subscript N0 indicating that it is based on N0 live points (X0 = 1 independently of the number of live points, hence no subscript is used). At the second iteration, i = 1, we reduce the number of live points to Nlive = N1 and once again reduce the prior mass. According to the standard reduction rule adopted for the case of N0 live points, we simply have for N1 that 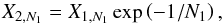 (12)where X1,N1 is the remaining prior mass from the first iteration given the number of live points is N1. Since we do not know X1,N1 a priori, we need to derive its relation to the old X1,N0, the latter being known already because it was computed at the previous iteration, i = 0. Without losing in generality, we can write
(12)where X1,N1 is the remaining prior mass from the first iteration given the number of live points is N1. Since we do not know X1,N1 a priori, we need to derive its relation to the old X1,N0, the latter being known already because it was computed at the previous iteration, i = 0. Without losing in generality, we can write 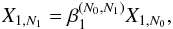 (13)where the factor
(13)where the factor 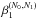 depends on both the previous and the new number of live points. By replacing the reduction rule for deriving X1 from X0, one obtains
depends on both the previous and the new number of live points. By replacing the reduction rule for deriving X1 from X0, one obtains 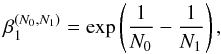 (14)which clearly shows that if N1<N0 then
(14)which clearly shows that if N1<N0 then 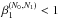 , thus resulting in a new remaining prior mass that is lower than the old one, as one would expect intuitively by adopting fewer live points. Iterating the result yields the generalized reduction rule; that is
, thus resulting in a new remaining prior mass that is lower than the old one, as one would expect intuitively by adopting fewer live points. Iterating the result yields the generalized reduction rule; that is 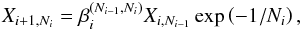 (15)where
(15)where 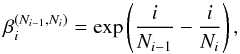 (16)i is the iteration in which the prior mass is updated and Ni is the number of live points to be used for the next iteration. Clearly, Eq. (15) reduces to the standard reduction rule expressed by Eq. (7) for Ni = Ni − 1 = Nlive.
(16)i is the iteration in which the prior mass is updated and Ni is the number of live points to be used for the next iteration. Clearly, Eq. (15) reduces to the standard reduction rule expressed by Eq. (7) for Ni = Ni − 1 = Nlive.
Equations (15) and (16) are implemented in the code, and two input parameters are therefore required: the initial number of live points, N0, and the minimum number of live points allowed in the computation, Nmin. In case the two values coincide, the reduction of the live points is turned off automatically.
For Diamonds, in addition to the empirical rule proposed by F09 we also implemented another one that allows for a different behavior of the reduction process. As shown from our testing phase the function adopted by F09 appears to reduce the number of live points only at the beginning of the computation. It could be convenient instead to start reducing live points at a later stage, especially if the modes in the PPD are difficult to detect. This choice is also supported by the slowing down of the computation when approaching the termination condition described in Sect. 4.3. This happens because it becomes more difficult to draw a new point that satisfies the likelihood constraint as we further rise up to the top of the likelihood distribution. Hence, the whole process would benefit more from removing live points at a later stage than in an early one since it ensures all the modes have been sampled efficiently in the previous steps.
Following the notation used above, our new relation for reducing live points can be expressed as 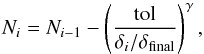 (17)where the final and evolving ratios of the live to the cumulated evidence introduced in Sect. 4.3 are adopted. The configuring parameter tol, which is the tolerance on the ratio δi/δfinal, determines the initiating nested iteration for the reduction process. The lower the tolerance, the later the stage at which the live points start to be reduced. The minimum value allowed is tol = 1, meaning that the reduction is not taking place. The exponent γ instead controls the speed of the reduction process. The default value is γ = 1 for a linear reduction. For γ> 1 the reduction is super-linear, hence faster, while it is sub-linear for 0 ≤ γ< 1, hence slower. In the case of γ = 0, Eq. (17) reduces to the simple form Ni = Ni − 1 − 1, which implies that the sample of live points is constantly reduced by one at each iteration.
(17)where the final and evolving ratios of the live to the cumulated evidence introduced in Sect. 4.3 are adopted. The configuring parameter tol, which is the tolerance on the ratio δi/δfinal, determines the initiating nested iteration for the reduction process. The lower the tolerance, the later the stage at which the live points start to be reduced. The minimum value allowed is tol = 1, meaning that the reduction is not taking place. The exponent γ instead controls the speed of the reduction process. The default value is γ = 1 for a linear reduction. For γ> 1 the reduction is super-linear, hence faster, while it is sub-linear for 0 ≤ γ< 1, hence slower. In the case of γ = 0, Eq. (17) reduces to the simple form Ni = Ni − 1 − 1, which implies that the sample of live points is constantly reduced by one at each iteration.
 |
Fig. 3 Shaded surfaces show Himmelblau’s function in the range θ1,θ2 ∈ [−5,5] (left), Rosenbrock’s function in the range θ1 ∈ [−3,4] and θ2 ∈ [−2,10] (middle left), Eggbox function in the range θ1,θ2 ∈ [0,10π] (middle right) and Rastrigin’s function in the range θ1,θ2 ∈ [−5.12,5.12] (right). Uniform priors over each coordinate were used for all the demos with stopping thresholds δfinal = 0.05,0.05,0.5, and 0.05, respectively. Upper panels: yellow dots represent (from left to right) the resulting Nnest = 8485, 8558, 8207, 10648 samples obtained with the code presented in Sect. 4 by using Nlive = 1000 points for each demo, as presented by FS13. Lower panels: green dots represent (from left to right) the resulting Nnest = 5286,5151,5874,6174 samples derived by additionally applying the reduction law given by Eq. (17) with tol = 100, γ = 0.4, N0 = 1000 and Nmin = 400 live points. |
Some caution when using the reduction process is nevertheless needed. In this case, properties such as prior mass, density of the sampling, and evidence collection, change considerably during the computation. Deviations from the standard method introduced by SK04 may hamper the goodness of the final result. This happens mostly when too many live points are removed over very few iterations. This bad condition can generally be caused by a strong reduction rate. In the testing phase, we could note some side effects of a bad reduction process, which we list below:
-
1.
The final sampling of the PPD may not correctly resemble thedensity of the probability function. This happens because whenlive points are removed, ellipsoids undergo an additionalenlargement according to Eq. (8), hence causingthe sampling to occur in a region of the parameter space that islarger than expected.
-
2.
The additional enlargement of the ellipsoids caused by having fewer live points also implies a loss in efficiency for the drawing algorithm.
-
3.
The evidence collection is affected by additional (systematic) uncertainties, since reducing the live points decreases Nnest, hence the number of contributing terms used in Eq. (6). This effect produces a significant underestimation of the final evidence.
Therefore, we recommend using the reduction of the live points with care and possibly only when it is really needed to speed up the inference analysis. We also advise not to use the reduction for computing evidences. Some examples on how to apply Eq. (17) for speeding up the computation are shown in Fig. 3 (see Sect. 4.6 for more discussion). We refer to Sect. 4.7 for a more suitable way of decreasing the computational time without directly affecting the number of live points during the process for both the models investigated.
4.5. Parameter estimation
Parameter estimation is addressed by a separate module of Diamonds. The module uses the sample of nested points, which are the points found to have the lowest likelihood at each iteration and collected during the computation. The sample includes the k coordinates of each nested point, and the corresponding likelihood value 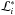 and weight wi, as defined in Sect. 3 for the case of the trapezoidal rule.
and weight wi, as defined in Sect. 3 for the case of the trapezoidal rule.
Posterior probability values (not densities) for each sampled point are calculated by 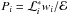 , as described by SK04. Since each free parameter θj of the k-dimensional parameter space Σℳ has Nnest sampled values, one can marginalize the posterior probability – i.e. integrate the posterior probability over the remainder (k − 1) coordinates – by simply sorting the Nnest sampled probabilities according to the ascending order of sampled values of the free parameter we want to estimate. Mean, median, and modal values of each free parameter θj, and the second moment (variance) of the marginalized distribution are then computed.
, as described by SK04. Since each free parameter θj of the k-dimensional parameter space Σℳ has Nnest sampled values, one can marginalize the posterior probability – i.e. integrate the posterior probability over the remainder (k − 1) coordinates – by simply sorting the Nnest sampled probabilities according to the ascending order of sampled values of the free parameter we want to estimate. Mean, median, and modal values of each free parameter θj, and the second moment (variance) of the marginalized distribution are then computed.
Upper and lower credible limits for the shortest Bayesian credible intervals (CI, e.g. see Sivia & Skilling 2006 for a definition) are also calculated and provided as an output with all the parameter estimation values discussed above. For the computation of the CI, a refined marginal probability distribution (MPD) is obtained for each free parameter θj by rebinning its Nnest sampled values according to the Scott’s normal rule and by adopting the averaged shifted histogram (ASH, Härdle 2004). The ASH is then interpolated by a grid that is ten times finer by means of a cubic spline interpolation. An example of this result is shown in Fig. 6 for the analysis presented in Sect. 6.2. The final interpolated ASH of the marginal distribution can also be stored in output ASCII files for possible usage after the computation.
4.6. Demos and comparison with MultiNest
For demonstrating the capability of Diamonds to sample challenging likelihood surfaces, we tested it with the four two-dimensional examples used by FS13 with the GMC algorithm applied to MultiNest. These two-dimensional surfaces prove to be difficult to explore with standard Markov chain Monte Carlo (MCMC) methods and they are:
-
the Himmelblau’s function
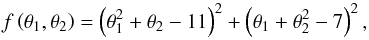 (18)which has four local minima at (3.0,2.0), (− 2.81,3.13), (− 3.78, − 3.28), and (3.58, − 1.85);
(18)which has four local minima at (3.0,2.0), (− 2.81,3.13), (− 3.78, − 3.28), and (3.58, − 1.85); -
the Rosenbrock’s function
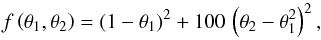 (19)having a global minimum at (1,1) hidden in a pronounced thin curving degeneracy;
(19)having a global minimum at (1,1) hidden in a pronounced thin curving degeneracy; -
the Eggbox function
![Mathematical equation: \begin{equation} f \left(\theta_1, \theta_2 \right) = - \left[2 + \cos \left( \frac{\theta_1}{2} \right) \cos \left( \frac{\theta_2}{2} \right) \right]^5, \end{equation}](/articles/aa/full_html/2014/11/aa24181-14/aa24181-14-eq158.png) (20)which presents identical local minima all equally spaced along each coordinate;
(20)which presents identical local minima all equally spaced along each coordinate; -
the Rastrigin’s function
![Mathematical equation: \begin{equation} f \left(\theta_1, \theta_2 \right) = 20 + \theta^2_1 + \theta^2_2 - 10 \left[\cos \, (2 \pi \theta_1) - \cos \, (2 \pi \theta_2) \right], \end{equation}](/articles/aa/full_html/2014/11/aa24181-14/aa24181-14-eq159.png) (21)having a global minimum at (0,0) hidden among a large number of local minima.
(21)having a global minimum at (0,0) hidden among a large number of local minima.
Following FS13, we adopted a log-likelihood 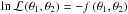 with θ1 and θ2 the coordinates identifying the two-dimensional parameter space. The results of the tests are shown in Fig. 3, where a fixed number of Nlive = 1000 points and uniform priors over each coordinate were adopted for all the demos for a more reliable comparison. We used uniform priors in the ranges specified in the caption of the figure. The code required Nnest< 104 samples for each demo to identify all the global maxima of the distributions. The number of iterations was about ten times fewer than in the case presented by FS13 for all the demos.
with θ1 and θ2 the coordinates identifying the two-dimensional parameter space. The results of the tests are shown in Fig. 3, where a fixed number of Nlive = 1000 points and uniform priors over each coordinate were adopted for all the demos for a more reliable comparison. We used uniform priors in the ranges specified in the caption of the figure. The code required Nnest< 104 samples for each demo to identify all the global maxima of the distributions. The number of iterations was about ten times fewer than in the case presented by FS13 for all the demos.
As already announced in Sect. 4.4, we also tested the same distributions by additionally applying a reduction of the live points according to Eq. (17). The samples, as visible in the green dots of Fig. 3, lower panels, resemble well the shape of the distributions and also allow for a correct identification of all the global maxima. In this case, the configuration adopted (see the caption of the figure for more details) yielded a final number of nested iterations reduced by up to 40%, resulting in a significant increase of speed in the computation. The evidence collected led to final values reduced by about 48% with respect to that obtained without the reduction process for all the demos considered.
4.7. Parallelization
Based on the suggestion by K11 and references therein, one could improve the goodness of the results by unifying different and independent runs having N1,N2, etc. live points with each, hence obtaining a joint run equivalent to a single one having Ntot = N1 + N2 +, etc. live points. The computation can be made parallel by running the split processes in several CPUs, hence merging the results in the end. The merging for the likelihood can be done by simply sorting the likelihood values from each independent run into a global ascending order. The merging of the parameters is done according to the sorting order of the corresponding likelihood values. For the prior mass, an easy re-computation based on Eq. (7) with a number of live points given by Ntot is required instead. The final evidence of the joint process can therefore be recomputed according to Eq. (6).
This simple parallelization allows us in principle to gain the same level of accuracy on the final result of that obtained by a single run with Ntot live points, while significantly reducing the run tine of the process at the same time. Another advantage of this parallelization is that the sampling of the PPD can be rendered much finer than that of a single process, even in a shorter computational time. As a side note, one should keep in mind that there the number of live points that can be used in each of the split processes has a lower limit, which is directly related to the complexity of the PPD and the number of dimensions for the given problem.
5. Observations and data
The Kepler satellite has monitored thousands of pulsating stars among the 150 000 observed in its field of view, exploiting a very high duty cycle and sampling time in two different modes, short cadence (SC, Gilliland et al. 2010), and long cadence (LC, Jenkins et al. 2010).
Among the initial ~550 stars showing solar-like oscillations and observed in SC during the first year of operation with Kepler, 61 of them were then selected for an extended observing time because they are bright and have higher signal-to-noise ratio (S/N) than other stars. The 61 final targets comprise G-type and F-type main-sequence (MS) and sub-giant stars, which were investigated by Appourchaux et al. (2012, hereafter A12), who measured their single p-mode frequencies.
For the purpose of our paper, we chose KIC 9139163 (HIP 92962), known also as Punto, one F-type MS star of the final sample. The selected star was studied in further detail in a subsequent analysis concerning oscillation linewidths and heights of a sub-sample of 23 targets, done by (Appourchaux et al. 2014, hereafter A14). In addition, Campante et al. (2014) also investigated the star concerning the effect of stellar activity on the amplitudes of solar-like oscillations. The object KIC 9139163 shows the largest number of individual oscillations (>50) among all the stars of the final sample. This peculiarity makes the star even more suitable for a high-dimensional and multi-modal problem.
A revised Hipparcos parallax for KIC 9139163, π = 9.49 ± 0.83 mas is provided by van Leeuwen (2007) and can be useful for accurately derive the stellar luminosity. We refer to Bruntt et al. (2012) for an estimate of the temperature from spectroscopy, Teff = 6375 ± 70 K, which is largely compatible within the error bars to the value Teff = 6405 ± 44 K derived by Pinsonneault et al. (2012) from SDSS photometry. Furthermore, the rotation and activity level of the star have been studied by Karoff et al. (2013b), who found a rotation period Prot = 6.5 ± 0.2 days by means of a periodogram analysis of the Kepler light curve, combined to asteroseismic and spectroscopic measurements.
Referring to the studies by A12 and A14, oscillation frequencies, linewidths, and heights already derived for several oscillations of the given star allow for a more fruitful comparison of the results presented in Sect. 6.6. We now exploit a more recent and larger dataset available for this star, which includes the Kepler observing quarters (Q) from 5 to 17, namely 1147.5 days of observations. These data were stitched together and corrected from instrumental instabilities and drifts following the procedures explained in García et al. (2011). Moreover, we have high-pass filtered the final light curve with triangular smoothing with a cut-off frequency at ~ 4 days. For minimizing the impact of the quasi-regular gaps due to the angular momentum desaturation of the Kepler spacecraft, we have interpolated the gaps of less than 1 h using a third order polynomial interpolation algorithm (García et al. 2014).
The new light curve used in this work is about 14 months longer than the one adopted by A14, who used Q5-Q12 light curves, hence ensuring higher accuracy and precision that allows for further constraint of the free parameters of the models investigated. For the inference problem presented in Sect. 6, we use a power spectral density (PSD) computed by means of a Lomb-Scargle algorithm (Scargle 1982) applied to the Kepler light curve. The new PSD has a frequency resolution of 0.01 μHz and contains a total of more than 840 000 bins. This remarkable amount of data points makes the peak bagging analysis even more challenging in terms of computational effort.
6. Application to peak bagging analysis
6.1. Introduction to solar-like oscillations
Before describing the details of the peak bagging analysis, it is useful to briefly introduce the physical quantities that we investigate. For a detailed description of the theory of solar-like oscillations, we refer the reader to Christensen-Dalsgaard (2004) for more insightful discussions. To avoid any ambiguity in terminology from now on, we shall refer to the individual oscillation mode as “peak”, while using the term “mode” to indicate the modal value of the outcome coming from the Bayesian inference analysis.
According to the asymptotic theory of solar-like oscillations (e.g. Tassoul 1980), acoustic standing waves (also known as pressure modes or simply p modes) with a low angular degree ℓ, the number of nodal lines on the stellar surface, and high radial order n, the number of nodes along the radial direction of the star, show a characteristic regular pattern in frequency, expressed by the asymptotic relation approximated at the first order, 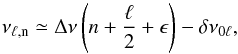 (22)where Δν is the main characteristic frequency spacing of p modes having different radial order, known as the large frequency separation, which scales roughly as the square root of the mean stellar density (Ulrich 1986). The phase shift ϵ is instead sensitive to the physics of the near-surface layers of the star (Christensen-Dalsgaard & Perez Hernandez 1992). The small frequency spacing δ0ℓ is related to the sound speed gradient in the stellar core, and it is defined for ℓ = 1,2 as
(22)where Δν is the main characteristic frequency spacing of p modes having different radial order, known as the large frequency separation, which scales roughly as the square root of the mean stellar density (Ulrich 1986). The phase shift ϵ is instead sensitive to the physics of the near-surface layers of the star (Christensen-Dalsgaard & Perez Hernandez 1992). The small frequency spacing δ0ℓ is related to the sound speed gradient in the stellar core, and it is defined for ℓ = 1,2 as 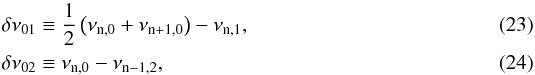 respectively.
respectively.
By plotting Eq. (22) as a function of the frequency modulo Δν, we obtain an échelle diagram where the oscillations having different angular degree align vertically to form separate ridges. In practice, it often happens that the ridges are curved, since the observed frequencies may depart from the first order approximation given by Eq. (22). Figure 4 shows an example of such a curvature effect with the échelle power spectrum of KIC 9139163 in a color-coded scale, computed in the same way as by Corsaro et al. (2012). For this plot, the PSD was normalized by the background level derived in Sect. 6.2, hence smoothed by a boxcar filter having width 1 μHz. Oscillation ridges for dipole peaks (ℓ = 1, left), quadrupole, and radial peaks (ℓ = 2,0, right) are visible over a frequency range of more than 1500 μHz. A large frequency separation Δν = 81.4 μHz, as derived by A12, was adopted.
6.2. Background modeling
 |
Fig. 4 Échelle power spectrum of KIC 9139163 on a colored scale for Δν = 81.4 μHz and smoothed by 1 μHz. On the left, we find the ℓ = 1 ridge of oscillation, while we have those corresponding to ℓ = 2,0 on the right. The plot makes the presence of a curvature of the ridges clear along the entire frequency range and the strong blending between quadrupole and radial peaks. |
A preliminary step for performing the peak bagging analysis consists in estimating the background level in the star’s PSD. Although fitting a background is a relatively low-dimensional problem, there is no universal model that can be used for all the stars as it closely depends on how many physical phenomena are involved, namely granulation (Harvey 1985; Aigrain et al. 2004; Michel et al. 2009), and the more recently investigated bright spots activity (faculae) (Chaplin et al. 2010; Karoff et al. 2010; Karoff 2012; Karoff et al. 2013a). As a consequence (since the asteroseismic analysis of the oscillations is sensitive to the stellar background components) assuming different models may sensibly change the final results (see the discussion by A14 concerning the impact of the background on the oscillation characteristic parameters).
For these reasons, it is essential to properly address this part of the analysis. With Bayesian statistics, this is achieved by exploiting the Bayesian evidence computed by Diamonds for testing different hypotheses through Eq. (3), as discussed in Sect. 2 already.
We therefore considered a general model based on those presented by Mathur et al. (2011) and by Karoff et al. (2013a), which can be expressed as ![Mathematical equation: \begin{equation} P \left(\nu \right) = W + R \left( \nu \right) \left[B\left( \nu \right) + G \left( \nu \right) \right], \label{eq:overall_bkg} \end{equation}](/articles/aa/full_html/2014/11/aa24181-14/aa24181-14-eq187.png) (25)where W is a constant noise (mainly photon noise),
(25)where W is a constant noise (mainly photon noise), 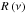 is the response function that considers the sampling rate of the observations,
is the response function that considers the sampling rate of the observations, 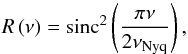 (26)where νNyq = 8496.36 μHz is the Nyquist frequency for Kepler SC data in our case. The background components are given by
(26)where νNyq = 8496.36 μHz is the Nyquist frequency for Kepler SC data in our case. The background components are given by 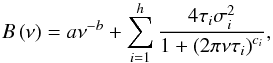 (27)and the power excess is described with
(27)and the power excess is described with ![Mathematical equation: \begin{equation} G\left(\nu\right) = H_\mathrm{osc} \exp \left[- \frac{ \left( \nu - \nu_\mathrm{max} \right)^2}{2 \sigma_\mathrm{env}^2} \right]\cdot \label{eq:env} \end{equation}](/articles/aa/full_html/2014/11/aa24181-14/aa24181-14-eq193.png) (28)The first term on the right-hand side of Eq. (27) is a power law that models slow variations caused by stellar activity, while the second term is a summation of h (either 1 or 2) as the Harvey-like profiles (Harvey 1985), τi being the characteristic timescale, σi the amplitude of the signature, and ci the corresponding exponent related to the decay time of the physical process involved (Harvey et al. 1993; Karoff 2012; Karoff et al. 2013a). We note that, in this formulation of the Harvey-like profiles the amplitudes ∗ ∗ σi are not the intrinsic amplitudes of the signatures, which can in turn be derived by multiplying each ∗ ∗ σi for a normalization factor as described by Karoff et al. (2013a), Sect. 3.2. The Gaussian component given by Eq. (28) models the power excess caused by solar-like oscillations with Hosc as the height of the oscillation envelope, and νmax and σenv as the corresponding frequency of maximum power and width, respectively. The component modeling the oscillation envelope is replaced afterwards by the global peak bagging model, as seen in Sect. 6.3, to fit the individual oscillation peaks.
(28)The first term on the right-hand side of Eq. (27) is a power law that models slow variations caused by stellar activity, while the second term is a summation of h (either 1 or 2) as the Harvey-like profiles (Harvey 1985), τi being the characteristic timescale, σi the amplitude of the signature, and ci the corresponding exponent related to the decay time of the physical process involved (Harvey et al. 1993; Karoff 2012; Karoff et al. 2013a). We note that, in this formulation of the Harvey-like profiles the amplitudes ∗ ∗ σi are not the intrinsic amplitudes of the signatures, which can in turn be derived by multiplying each ∗ ∗ σi for a normalization factor as described by Karoff et al. (2013a), Sect. 3.2. The Gaussian component given by Eq. (28) models the power excess caused by solar-like oscillations with Hosc as the height of the oscillation envelope, and νmax and σenv as the corresponding frequency of maximum power and width, respectively. The component modeling the oscillation envelope is replaced afterwards by the global peak bagging model, as seen in Sect. 6.3, to fit the individual oscillation peaks.
As already introduced in Sect. 4.2, the log-likelihood to be adopted for the inference analysis that involves a PSD is the exponential log-likelihood given by Eq. (9). In the context of the peak bagging analysis, the data point is now the observed PSD at a single frequency bin νi, namely 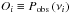 , while the corresponding prediction is given as
, while the corresponding prediction is given as 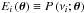 for the specific case of the background fitting, as expressed by Eq. (25). We used uniform priors for all the parameters of the model except for the parameter a, the amplitude of the slow variation in stellar activity. The indeterminacy on a is larger than that of the other parameters because a is mostly constrained by the PSD at very low frequencies. For this reason, we set up a Jeffreys’ prior
for the specific case of the background fitting, as expressed by Eq. (25). We used uniform priors for all the parameters of the model except for the parameter a, the amplitude of the slow variation in stellar activity. The indeterminacy on a is larger than that of the other parameters because a is mostly constrained by the PSD at very low frequencies. For this reason, we set up a Jeffreys’ prior 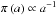 (Kass & Wasserman 1996), giving equal weight to different orders of magnitude. This was done in practice by adopting the new parameter lna, since the Jeffreys’ prior becomes uniform in logarithmic scale.
(Kass & Wasserman 1996), giving equal weight to different orders of magnitude. This was done in practice by adopting the new parameter lna, since the Jeffreys’ prior becomes uniform in logarithmic scale.
 |
Fig. 5 PSD of KIC 9139163 (gray) with overall background from Eq. (25) and median values reported in Table 1 (thick green line) with the additional Gaussian envelope included (dotted green line). The solid black line represents the smoothed PSD by 81.4 μHz. The single background components of constant photon noise (dotted), power law (dashed), granulation and faculae (dot-dashed), and Gaussian envelope (double-dot-dashed) are shown in blue. Upper panel: model ℳ1 accounting for one Harvey-like profile. The arrow indicates the presence of a kink that is not reproduced by the model. Lower panel: model ℳ2 accounting for two Harvey-like profiles. The winning model ℳ2 is strongly favored as it yields a Bayes’ factor lnℬ21 = 58.2 ± 0.2 over its competitor. |
Figure 5 shows the final results of the Bayesian inference for the background modeling of KIC 9139163 done by means of Diamonds (background without and with Gaussian envelope shown in figure and overlaid to the observed PSD and its smoothing by Δν). The figure presents both the case of the model including only one Harvey-like profile, which is the granulation signal component (h = 1), and the most likely model accounting for two Harvey-like profiles (h = 2), which represent the granulation signal and faculae activity of the star (see the caption of the figure for more details and Table 1 for a list of all the values derived from the Bayesian parameter estimation). By comparing the Bayesian evidence from the two competing models (ℳ1 for h = 1 and ℳ2 for h = 2), the resulting natural logarithm of the Bayes’ factor lnℬ21 = lnℰ2 − lnℰ1 = 58.2 ± 0.2 in favor of model ℳ2 suggests that an additional source of background signal coming from the faculae activity is strongly decisive for the model comparison. The model with two Harvey-like profiles thus ought to be preferred (strong evidence for lnℬ21 ≃ 5 in the Jeffreys’ scale of strength). More reliability is added to this conclusion since an error bar on the Bayes’ factor is also included, which is computed through error propagation of the statistical uncertainty on the final evidence given by the NSMC algorithm. The result of the model selection also agrees with the presence of a kink in the smoothed PSD (indicated by an arrow in the upper panel of Fig. 5) at the high-frequency side of the oscillation envelope. In Fig. 6, we plot an example of three correlation maps with likelihood values in a color-coded scale for the background parameters W and σgran and b of the winning model with the corresponding MPDs computed by Diamonds. We further provide three interesting cases of correlation maps for the background parameters characterizing the Harvey-like profile of the faculae activity, which are its amplitude σfac, timescale τfac, and height at zero frequency 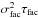 in PSD units, relative to the height of the oscillation envelope Hosc. As clearly visible, amplitude, timescale, and height of the faculae background are anti-correlated to Hosc, as one would expect, since the faculae component rises inside the oscillation region, while no significant correlation is found for the exponent cfac of the corresponding Harvey-like profile.
in PSD units, relative to the height of the oscillation envelope Hosc. As clearly visible, amplitude, timescale, and height of the faculae background are anti-correlated to Hosc, as one would expect, since the faculae component rises inside the oscillation region, while no significant correlation is found for the exponent cfac of the corresponding Harvey-like profile.
For the configuration of the code, the following set of parameters was used: f0 = 1.5, α = 0.02, Nlive = 1000, 1 ≤ Nclust ≤ 6, Mattempts = 104, Minit = Nlive, and Msame = 50. This has allowed us to maintain a good efficiency throughout the sampling process for both the models investigated.
 |
Fig. 6 Upper panels: examples of correlation maps of the three free parameters W, σgran, and b used in Eq. (27) using two Harvey-like profiles with color-coded likelihood values. Each point in the diagram is a sampling point that stems from the NSMC process. The plotted realization consists of ~27 000 samples. Lower panels: corresponding MPDs of the free parameters as computed by means of Diamonds. The shaded region indicates the portion of the distribution containing 68.3% of the total probability, defining the shortest credible intervals listed in Table 1. The dashed line indicates the mode of the distribution. |
 |
Fig. 7 Correlation maps for the parameters describing the Harvey-like profile related to the faculae activity – namely σfac, and τfac, their combination |
6.3. Characterization of p modes
It can be shown (e.g. see Kumar et al. 1988; Anderson et al. 1990) that the limit PSD for a series of Npeaks independent oscillations can be expressed by means of a Lorentzian mixture 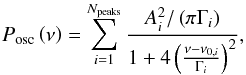 (29)where Ai is the amplitude of the ith oscillation peak in the PSD (expressed in ppm), ν0,i its central frequency, and Γi the linewidth, which is related to the oscillation lifetime τi by Γi = (πτi)-1. The quantities Ai, ν0,i, and Γi thus represent the free parameters characterizing one oscillation peak profile. We can easily assign uniform priors for each of these quantities by a quick look at the PSD.
(29)where Ai is the amplitude of the ith oscillation peak in the PSD (expressed in ppm), ν0,i its central frequency, and Γi the linewidth, which is related to the oscillation lifetime τi by Γi = (πτi)-1. The quantities Ai, ν0,i, and Γi thus represent the free parameters characterizing one oscillation peak profile. We can easily assign uniform priors for each of these quantities by a quick look at the PSD.
For the Bayesian inference, we adopt once again the exponential log-likelihood, but we now restrict the frequency range of the PSD to the interval 900 − 2800 μHz; namely, the region containing the oscillation peaks we intend to analyze, following the results by A12. Moreover, similar to the work done by A12 and by A14, we set a fixed background  and
and  by using the mean values of the corresponding parameters listed in Table 1. This choice is motivated by the fact that the background fitting is performed over the full-length PSD, thus providing the most precise and accurate result we can stem for the background from the given dataset. In addition, we adopt mean values since they are the optimal estimators post-data in the context of Bayesian statistics (Bolstad 2013), hence the most reliable outcomes of our fit.
by using the mean values of the corresponding parameters listed in Table 1. This choice is motivated by the fact that the background fitting is performed over the full-length PSD, thus providing the most precise and accurate result we can stem for the background from the given dataset. In addition, we adopt mean values since they are the optimal estimators post-data in the context of Bayesian statistics (Bolstad 2013), hence the most reliable outcomes of our fit.
Therefore, for the fitting and characterization of the individual oscillation peaks, the Lorentzian mixture model for solar-like oscillations described by Eq. (29) replaces the previous approximation of the power excess given by the Gaussian envelope  defined by Eq. (28), which yields the overall peak bagging model,
defined by Eq. (28), which yields the overall peak bagging model, ![Mathematical equation: \begin{equation} P \left(\nu \right) = \overline{W} + R \left( \nu \right) \left[\overline{B} \left( \nu \right) + P_\mathrm{osc} \left( \nu \right) \right] \label{eq:overall_pb} \end{equation}](/articles/aa/full_html/2014/11/aa24181-14/aa24181-14-eq257.png) (30)with
(30)with 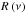 once again as the response function given by Eq. (26).
once again as the response function given by Eq. (26).
6.4. Rotation from ℓ= 1 peaks
The presence of rotation in a PSD lifts the (2ℓ + 1)-fold degeneracy of the frequency of non-radial peaks, hence directly measuring a mean angular velocity, Ω, of the star (Ledoux 1951) if the rotationally split peaks are properly resolved. For KIC 9139163, we exclude a priori the possibility of detecting rotation from the dipole (and therefore quadrupole) peaks since its surface rotation rate Prot-1 ≃ 1.78 μHz (Karoff et al. 2013b), as compared to the typical linewidth of the highest S/N ℓ = 1 peaks, where Γℓ = 1 ~ 4 μHz (this work, see Appendix A), satisfies the condition Prot-1< 2Γℓ = 1, hence this does not allows us to resolve multiplets coming from rotation (e.g. see Gizon & Solanki 2003). This is essentially related to the short oscillation lifetime of p modes occurring in the shallow convective regions of F-type stars. The result is even more enhanced if one considers the projection effect of the estimated inclination angle of the rotation axis of the star. By combining the spectroscopic vsini ≃ 4 km s-1 (Bruntt et al. 2012) and deriving the radius of the star through asteroseismology R ≃ 1.52 R⊙ (this work agrees within 2% with that stemmed by Karoff et al. 2013b) through the relation 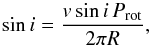 (31)one obtains i ≃ 20°. This low inclination angle implies a relative height of the central (non-split) component to that of the two split for the dipole oscillations (Gizon & Solanki 2003) of ~15.4, meaning that the split frequency peaks are almost undistinguishable from the background level. For all these reasons from now on, we assume there is no rotational effect observable in any of the dipole (and quadrupole) peaks of KIC 9139163.
(31)one obtains i ≃ 20°. This low inclination angle implies a relative height of the central (non-split) component to that of the two split for the dipole oscillations (Gizon & Solanki 2003) of ~15.4, meaning that the split frequency peaks are almost undistinguishable from the background level. For all these reasons from now on, we assume there is no rotational effect observable in any of the dipole (and quadrupole) peaks of KIC 9139163.
6.5. Peak significance and detection criterion
One of the main problems arising in the context of a peak bagging analysis consists in assessing the number of significative peaks to be fitted and/or accepted for the final result. In a frequentist-based approach, one would generally adopt a detection threshold based on either the estimated noise-level of the star or the maximum likelihood value of the fitted oscillation peak (e.g. see Appourchaux et al. 1998). In a Bayesian context, one computes instead a probability stating how reliable the given peak is, which may rely on either the null-hypothesis test or a direct estimate of the odds ratio given by Eq. (3) (e.g. see A12), as explained in Sect. 2. In this work, we exploit the Bayesian odds ratio, hence the Bayes’ factor, since its computation is straightforward within the NSMC process, as already shown earlier in the text. This allows us to statistically weight the peak detection in terms of both goodness-of-fit and model complexity, hence penalizing those peaks that have lower S/N. We apply this criterion in three different scenarios:
-
A single low-S/N peak arising from a background level. Thisdetection process involves the model comparison between twocompeting models, which we indicate asℳA when we exclude the peak in the fitting process and ℳB when we include the peak instead. This case is typically that of dipole peaks occurring in the wings of the oscillation envelope. The corresponding natural logarithm of the Bayes’ factor lnℬBA = lnℰB − lnℰA in favor of the model with a fitted peak, is therefore included in the final list of the results for all the ambiguous peak detections, to provide prompt confirmation of the outcome of the model comparison process. In addition, since assigning a quantitative probability value for the detection of an individual peak could be useful for weighting the reliability of the different detections, the Bayesian evidences ℰA and ℰB can be used to compute the detection probability as
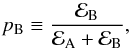 (32)or equivalently, the non-detection probability,
(32)or equivalently, the non-detection probability, 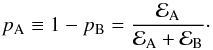 (33)
(33) -
Two high-S/N peaks appearing in a blended structure. This situation makes it ambiguous to distinguish between one or two different oscillation peaks. The issue is well represented by the duplet ℓ = 2,0 of F-type stars because their large oscillation linewidths can produce very strong blending, as shown in Fig. 8 for two oscillation peaks of KIC 9139163. For this case, we can once again assume two competing models, ℳB when only one peak (ℓ = 0) is fitted and ℳC when two peaks (both ℓ = 2 and 0) are fitted. We can thus compute the natural logarithm of the Bayes’ factor, lnℬCB = lnℰC − lnℰB in favor of the model with two peaks. Following Eqs. (32) and (33), we also define the probability of detecting two peaks, pC (or equivalently only one, pB ≡ 1 − pC).

Fig. 8 Example of an ambiguous detection of a high S/N duplet ℓ = 2,0 from the PSD of KIC 9139163. The solid line shows the resulting best-fit as computed by Diamonds, while the dashed line represents the mean background model as obtained in Sect. 6.2, according to Eq. (30). Upper panel: case of model ℳB where only ℓ = 0 is fitted. Lower panel: case of model ℳC where both ℓ = 2,0 are fitted. The resulting lnℬCB = 16.5 ± 0.1 strongly favors model ℳC, hence the presence of two peaks in the observed structure.

Fig. 9 Upper panel: resulting peak bagging best-fit for KIC 9139163 as derived by means of Diamonds by using Approach 1 based on the background that is estimated in Sect. 6.2 (red thick line) overlaid on the PSD smoothed by 0.25 μHz (gray). The mean background level is shown as a dashed blue line. Dotted vertical lines mark the oscillation peaks for which the detection probability is below 99% with labels indicating the corresponding peak identification, as reported in Table A.1 and as explained in Appendix A. Lower panel: ratio between the smoothed PSD and the resulting red line fit that is shown in the upper panel.
-
Two low-S/N peaks appearing in a blended structure. The typical example is given by the duplets ℓ = 2,0, which fall in the wings of the oscillation envelope. To properly address this event, one has to consider three possible competing models, namely ℳA, ℳB, and ℳC, as previously defined. We therefore compute the natural logarithm of the Bayes’ factors lnℬBA for checking whether a single peak (ℓ = 0) is detected or not, and lnℬCB for assessing the presence of two peaks (ℓ = 2,0) from the blended structure. The corresponding detection probabilities can be defined as
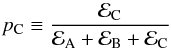 (34)for detecting two peaks;
(34)for detecting two peaks; 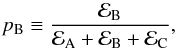 (35)for detecting one peak; and
(35)for detecting one peak; and 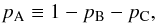 (36)for the case of just the background level.
(36)for the case of just the background level.
To apply the peak significance method and perform the Bayesian parameter estimation at the same time, we fit the PSD of KIC 9139163 as follows:
-
1.
When assessing and fitting a dipole oscillation, we consider achunk of PSD that contains a series of five consecutive oscillationpeaks having an angular degreeℓ = 2,0,1,2,0 in the order from left to right (hence with the dipole peak in the center of the selected PSD window). This allows the fit in the PSD to be stable for the central peak, hence comparing the models (cases ℳA and ℳB) accurately, and stemming parameter estimates more conveniently, since we adopt a maximum of k = 15 dimensions in the fit.
-
2.
When assessing and fitting a duplet of blended quadrupole and radial oscillations, we consider a chunk of PSD containing a series of four consecutive oscillation peaks having an angular degree ℓ = 1,2,0,1 in the order from left to right (hence with the duplet falling in the center of the selected PSD window). The reasoning is equivalent to that of the first case, allowing us to set the number of dimensions in the inference problem not beyond k = 12.
The choice of fitting windows in the PSD does not practically affect the parameter estimation process, since the oscillation peaks of the angular degrees ℓ = 2,0 are separated by those of angular degree ℓ = 1 by ~40 μHz, a value about ten times larger than the typical linewidth of the oscillations. For the blended ℓ = 2,0 oscillations, we instead always fit a duplet of Lorentzian profiles, since the two peaks cannot be separated from each other.
We note that in this work linewidths and amplitudes are fit independently for each individual oscillation peak, as expressed by Eq. (29), in contrast to a classical fitting method to peak bagging (e.g. see A12, A14). This implies that we drop both the assumption of the height ratios for oscillation peaks having a different angular degree (therefore using a single height per radial order) and the use of a common linewidth within a single radial order. A direct consequence of this approach is that the resulting PPD presents a uni-modal solution for any number of fit oscillation peaks, as we discuss in more detail in Sect. 6.7.
6.6. Results
All the results performed according to the approach based on the model as given by Eq. (29) and the peak significance as explained in Sect. 6.5 (hereafter Approach 1 for shortness) are listed in Table A.1 and documented in Appendix A. From a computational point of view, the configuration of Diamonds required the tuning of the parameters for the dynamical enlargement of the ellipsoids, as introduced in Sect. 4.1, and used values in the ranges 2.0 ≤ f0 ≤ 3.2 and 0.01 ≤ α ≤ 0.04. We adopted a fixed number of live points Nlive = 2000, as it ensured enough sampling points for the given problem. We allowed a number of clusters 1 ≤ Nclust ≤ 4, which proved to be enough to sample possible degeneracies in the PPD. Moreover, we set Mattempts = 104, Minit = Nlive, and Msame = 50, which is similar to the case of the background fitting presented in Sect. 6.2. The typical amount of final sampling points when analyzing each chunk of PSD settles to ~40 000.
The best-fit model based on Approach 1 is plotted in the upper panel of Fig. 9, which is overlaid to the PSD of KIC 9139163 and smoothed by 0.25 μHz for a visual comparison. The ratio between the smoothed PSD and the resulting fit is shown in the lower panel of the same figure. For clarity, the oscillation peaks that have a detection probability lower than 99% are indicated with mode identification (Peak #,ℓ) (see Appendix A). The background level shown corresponds to the mean background, as given in Eq. (30). Single dipole, and quadrupole oscillation parameters are shown in Fig. 10 for both amplitudes and linewidths. As it appears clear from the plot, the linewidths of the dipole peaks increase with the frequency position, while those of the quadrupole peaks are higher toward the center of the oscillation envelope, although they have a much larger scatter. Conversely, amplitudes visibly resemble the Gaussian envelope of the oscillation pattern for both angular degrees with a maximum occurring around νmax. The ℓ = 1 and 2 frequencies derived by means of Approach 1 agree within 0.1% and 0.3%, respectively, with those given by A12 for the full set of peaks.
For the case of the radial peaks derived with Approach 1, which is based on the background derived in Sect. 6.2, we instead refer to Fig. 11, where their amplitudes A0 and linewidths Γ0 as a function of their frequency position ν0 are directly confronted to those obtained by A14. The comparison underlines the presence of a significant difference in amplitude (on average ~24%) and in linewidth (on average ~42%), especially in the high-frequency side of the oscillation envelope (ν> 1900 μHz, see Sect. 7 for more discussion), which is caused by the different background adopted in this work with respect to that used by A14. The frequencies of the radial peaks estimated in this work and marked in Fig. 11 instead agree within 0.2% with those by A14 and within 0.7% with the previous set by A12 throughout all the frequency range.
To test the effect of a different background and compare our results to existing ones in a more favorable way, we have additionally performed the peak bagging of KIC 9139163 by adopting the background used in A14, thus applying Approach 1 to the same oscillation peaks as those presented in Table A.1. The results are presented in Appendix B and listed in Table B.1. As shown in Fig. 11, amplitudes and linewidths are now in good agreement with the previous results by A14 (up to 0.5%), which is well within the reported error bars for most of the cases.
 |
Fig. 10 Oscillation parameters for the dipole (red triangles) and quadrupole (orange squares) peaks of KIC 9139163 as derived by means of Diamonds by using Approach 1 based on the background derived in Sect. 6.2, for both amplitudes A (upper panel) and linewidths Γ (lower panel), as a function of the frequency position ν. All the results shown are the mean estimates from the Bayesian inference with corresponding 68.3% credible intervals overlaid. |
 |
Fig. 11 Comparison of the oscillation parameters for the radial peaks of KIC 9139163 between the results derived in this work by means of Diamonds (filled red circles, Approach 1 based on the background derived in Sect. 6.2 and, open red circles, Approach 1 based on A14 background) and those provided by A14 (gray squares) for both amplitudes A0 (upper panel), and linewidths Γ0 (lower panel), as a function of the frequency position ν0. The red circles represent the mean estimates coming from the Bayesian inference with their corresponding 68.3% credible intervals, while gray squares are the mean estimates from the MLE fit done by A14 and plotted with their error bars. The A0 values from Approach 1 shown in the plot are obtained by scaling down by a factor |
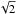
6.7. Exploiting the multi-modality of peak bagging
In the method termed Approach 1, described in Sect. 6.3 and Sect. 6.5, the number of dimensions of the parameter space scales linearly with the number of peaks in the PSD of the star. For example, fitting one peak in a narrow part of the PSD implies searching for one maximum of the PPD in a 3D parameter space (Γ, ν0, A). Fitting two peaks simultaneously implies searching for one maximum of the PPD in a 6D parameter space (Γ1, ν0,1, A1, Γ2, ν0,2, A2) and so on. In principle, one could try fitting one Lorentzian peak using a large part of the PSD and hope that the individual oscillation peaks pop up as several local maxima in the PPD. The advantage would clearly be a strongly reduced dimensionality of the parameter space to only 3D, irrespective of the number of oscillation peaks in the PSD. In practice, such an approach hardly works, because of a number of problems:
-
1.
The fitting algorithm can have the tendency to consider theentire spectrum as one peak with an extremely large width.
-
2.
The approach is prone to false maxima as it may consider local noise peaks also as an oscillation peak.
-
3.
Sampling a multi-modal parameter space and not missing local maxima is hard, especially with MCMC algorithms.
-
4.
Even if we do sample all the local maxima in the parameter space, it is still unclear how to extract the fit parameters for each oscillation peak individually.
In this section, we show how each of these problems can be solved, and we refer to the resulting method as Approach 2. This approach can be very useful in the process of automating the peak bagging analysis, thus providing a possible solution for performing the analysis on a large number of targets.
The first problem is easily solved by imposing a physically reasonable prior on the linewidth, so that the algorithm never diverges. Although the third problem, is hard to handle with standard MCMC algorithms, it is a lot easier with Diamonds, as shown in the demos presented in Sect. 4.6. We solved the second and fourth problems by letting the algorithm search for (i.e. fit) a pattern of three Lorentzian profiles, instead of fitting a single Lorentzian profile. Concretely, the model now becomes 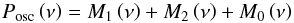 (37)where Mi corresponds to a Lorentzian profile of an oscillation peak with degree ℓ = i. This corresponds to nine fit parameters: (Γ1, ν1, A1, Γ2, ν2, A2, Γ0, ν0, A0). We replace, however, the parameters ν0 and ν2 with the frequency spacings δ10 ≡ νn,0 − νn − 1,1, which is analogous to the definition given in Eq. (23), and δ02 ≡ νn,0 − νn,2, as introduced in Eq. (24), hence having ν0 = ν1 + δν10 and ν2 = ν0 − δν02. The reason is that it is much easier to physically specify constraining priors for these frequency spacings within one radial order than it is for the individual frequencies ν0 and ν2. In summary, the frequency of the dipole peak, ν1, is the fit parameter used to locate the 3-peak pattern in the power spectrum, and the spacings δν10 and δν02 are used as fit parameters to determine the distances between the peaks inside the pattern. Each oscillation peak inside the 3-peak pattern has a separate fit parameter for the amplitude and the width, resulting in still nine fit parameters. The 9D posterior distribution shows local maxima, one for each 3-peak pattern identified in the PSD, which is one for each radial order. We found that fitting such a pattern is much less susceptible to noise than fitting a single Lorentzian profile.
(37)where Mi corresponds to a Lorentzian profile of an oscillation peak with degree ℓ = i. This corresponds to nine fit parameters: (Γ1, ν1, A1, Γ2, ν2, A2, Γ0, ν0, A0). We replace, however, the parameters ν0 and ν2 with the frequency spacings δ10 ≡ νn,0 − νn − 1,1, which is analogous to the definition given in Eq. (23), and δ02 ≡ νn,0 − νn,2, as introduced in Eq. (24), hence having ν0 = ν1 + δν10 and ν2 = ν0 − δν02. The reason is that it is much easier to physically specify constraining priors for these frequency spacings within one radial order than it is for the individual frequencies ν0 and ν2. In summary, the frequency of the dipole peak, ν1, is the fit parameter used to locate the 3-peak pattern in the power spectrum, and the spacings δν10 and δν02 are used as fit parameters to determine the distances between the peaks inside the pattern. Each oscillation peak inside the 3-peak pattern has a separate fit parameter for the amplitude and the width, resulting in still nine fit parameters. The 9D posterior distribution shows local maxima, one for each 3-peak pattern identified in the PSD, which is one for each radial order. We found that fitting such a pattern is much less susceptible to noise than fitting a single Lorentzian profile.
We note what we did not impose: we did not specify the number of radial orders in the PSD. This is an output of the algorithm: each local maximum detected in the PPD corresponds to an observed radial order in the PSD. We also did not impose the condition that the radial (or dipole) peaks in the PSD should be equidistant nor that they may show an oscillatory behavior due to acoustic glitches. This also will be an output of the algorithm: the different maxima found in the 9D PPD will show up as equidistant along the ν1 axis, hence disentangling the different radial orders without ambiguity.
To highlight two substantial differences between Approach 1 and Approach 2, as discussed in this section, we refer to an illustrative comparison shown in Fig. 12. In the top panel, we can observe the linear increasing trend of the number of fit parameters when using Approach 1 over an increasing number of radial orders of the star (nine new free parameters added for each new radial order included), as opposed to the constant number of nine free parameters used by Approach 2. In the bottom panel, we see that the number of local maxima obtained in the PPD increases linearly with Approach 2 when used over an increasing number of radial orders (one local maximum more for every additional radial order), leading to a multi-modal distribution when at least two radial orders are considered. The PPD remains instead uni-modal when using Approach 1, irrespective of the number of radial orders included in the fit. It is then clear that the two approaches have a reversed balance in terms of the number of free parameters and number of local maxima in the PPD, while they become essentially identical for the limiting case of one radial order.
 |
Fig. 12 Illustrative comparison between Approach 1 (red circles) and Approach 2 (blue squares) in terms of the number of free parameters used in the fit (top panel) and the number of local maxima identified in the final PPD (bottom panel), as a function of the number of radial orders considered. |
 |
Fig. 13 Resulting 43374 samples obtained by Diamonds by using Approach 2 applied to the PSD of KIC 9139163 in the frequency range 1280 − 2090 μHz, covering nine radial orders. Upper panel: distribution of the sampling points for the amplitude of dipole peaks, A1 and the corresponding frequency position, ν1. The islands marked in light blue represent the true positions of the dipole peaks, while those in gray are relative to the positions of the blended quadrupole-radial peaks, which are ignored. The red circles represent the mean Bayesian estimates derived from the MPDs of the light blue islands, while yellow triangles show the corresponding sampling average positions in both coordinates and are not related to the MPDs. Lower panel: corresponding histogram density along the direction of ν1, showing the number of counts occurring in each island. |
We tested Approach 2 by applying it to the PSD of KIC 9139163 in a frequency range containing nine radial orders (27 peaks), spanning ~800 μHz and centered around νmax. For configuring the code, we adopted the parameters f0 = 0.6, α = 0.04, Nlive = 2000, 1 ≤ Nclust ≤ 10, Mattempts = 104, Minit = 500, and Msame = 50. Figure 13 shows a sampling result of this multi-modal application, where we plot the fitted amplitude for dipole peaks, A1, against ν1, with an histogram density along the coordinate ν1. As it appears evident from the plot, the different islands sampled by Diamonds are regularly spaced in frequency, which clearly corresponds to the regular Tassoul comb-pattern of the solar-like oscillations observed in KIC 9139163. In particular, we identify two types of islands, those corresponding to the true position of the dipole peaks and those that occur where the duplets ℓ = 2,0 arise, in which the latter case is to be discarded, since it does not match the definition of the free parameter ν1. The result that the algorithm confuses ℓ = 1 peaks with ℓ = 0 peaks is particular for KIC 9139163, or for F-type solar-like oscillators in general, where the ℓ = 2 and ℓ = 0 peaks are blended, which makes it more difficult to recognize the typical Tassoul pattern. The position of the light blue islands along the direction of A1 decreases when moving from the center of the plot – i.e. the maximum power region – towards the wings, which agrees with the typical Gaussian modulation for the amplitudes of solar-like oscillations. We also notice that the left- and right-side light blue islands do not show an estimated Bayesian mean, though the position of the corresponding oscillation peaks can still be obtained by considering the sampling average position of the associated islands. This occurs because the side MPDs have a probability that is zero, as compared to that of the central MPDs, therefore, no Bayesian estimates could be computed for this case. As one can observe from the bottom panel of Fig. 13, the central peaks having higher amplitudes tend to be sampled about 100 times more than those falling in the wings of the range and having a lower amplitude. Since higher amplitude peaks produce higher likelihood regions in the parameter space, the NSMC algorithm tends to sample them more densely than the remainder regions that have lower likelihood values and, consequently for this case, lower posterior probabilities.
Figure 14 shows the resulting estimates, obtained by using Approach 2, for all the peaks compared to those derived by means of Approach 1, with sample average positions for each light blue island overlaid for completeness. The frequencies estimated by means of Approach 2 agree within 0.1% (for radial and dipole peaks) and within 0.2% (for quadrupole peaks) to those obtained by using Approach 1. Concerning amplitudes and linewidths instead, the agreement is more evident for the dipole peaks (where amplitudes match up to 0.5% and linewidths up to 0.8%), while it tends to be worse for radial and quadrupole peaks, especially in the wings, which produces discrepancies that can be up to 12% and 40% in amplitude and 18% and 75% in linewidths, respectively. These differences mainly rely on the result that Approach 2 is supposed to recognize the 3-peak pattern ℓ = 1,2,0, which for KIC 9139163 is often ambiguous, as already pointed out before. In addition, the total number of samples obtained for the lowest-amplitude modes in the multi-modal PPD might be too low to ensure accurate Bayesian estimates.
 |
Fig. 14 Comparison of the results for KIC 9139163 relative to the nine radial orders in the frequency range 1280 − 2090 μHz, obtained by Diamonds according to Approach 1 (red circles) and Approach 2 (blue squares). Panels from left to right show the amplitudes (upper panels) and linewidths (lower panels) against the frequency position of the full set of radial, ν0, dipole, ν1, and quadrupole oscillations, ν2, respectively. The red circles are the mean values as derived from the MPDs with their corresponding 68.3% shortest credible intervals, while the blue squares are the mean values from the MPDs of each blue island (see Fig. 13). The open triangles are the sample average positions (see Fig. 13) used for providing a frequency estimate for the two side peaks of each panel. Dotted vertical lines represent the frequency position of the red circles, as shown as a reference for the blue squares. |
7. Discussion
The fitting of the background models for KIC 9139163 is a challenging problem in terms of both computational speed and sampling efficiency of the resulting PPD. The estimated set of free parameters for the favored model that incorporates both granulation and faculae activity signal corresponds to a non-trivial combination of the different background components. This is mainly caused by the rising of the faculae component inside the region that contains the solar-like oscillations, which itself has not a prominent height if compared to the background level of the star. This leads to a S/N ~ 1.3 as measured from the PSD around νmax. The oscillation signal in the observed PSD is noisier due to the higher temperature of this target if compared to the solar value. The rising of the faculae signal beyond 1000 μHz agrees with the interpretation of the stellar background proposed by Harvey et al. (1993) and by Karoff (2012). In addition, the resulting Harvey-like profiles of both granulation and faculae activity are consistent with the findings by Karoff et al. (2013a) for other pulsating MS stars, for which we expect the faculae component to decay more rapidly with respect to that of the granulation. The decaying coefficients cgran and cfac estimated in this work, however, exceed by about 23% and 200%, respectively, from those measured for the Sun by Karoff et al. (2013a). The detection of a faculae signal in KIC 9139163 is even consistent with the presence of a stellar activity, as detected by Karoff et al. (2013b), while the estimated νmax from the global background fitting remains compatible within 0.5% with the value indicated by A12.
The selection of a proper background model plays a crucial role in estimating the asteroseismic parameters that characterize the individual oscillation peaks of the star. As outlined by A14, oscillation amplitudes and linewidths heavily depend on the background model adopted. A clear example of this behavior is depicted in Fig. 11 for the effect produced on the radial peaks (see Sect. 6.6 and below for more discussion). The model comparison of the different background models, as performed by means of the Bayesian evidence computed by Diamonds (see Sect. 6.2) has led to an unambiguous interpretation of the background. This addressed the problem of the choice of the background model and proved that the method could be applied very straightforwardly with an immediate result.
Concerning the outcomes of the peak bagging analysis based on Approach 1, as described in Sects. 6.3 and 6.5, we stress that all the frequencies derived in this work (see Tab. A.1) match remarkably well with those obtained in previous works by A12 and A14, showing an agreement level well below 1% (see Sect. 6.6 for more details). Significant discrepancies in the fitted amplitudes and linewidths of the radial oscillation peaks with respect to those measured by A14 are observed, especially for the region of the oscillation envelope beyond νmax (see Fig. 11). These new measurements from Approach 1 are on average ~1.36 and ~1.54 times smaller for amplitudes and linewidths respectively, as compared to the values provided by A14. As pointed out already, this relies on the different background adopted for this star, which is that of the granulation signal in the case of A14. The Harvey-like profile related to the faculae activity fitted in this work arises around 2000 μHz, as also clearly visible from Fig. 5. This is confirmed by the results presented in Table B.1, for which Approach 1 was adopted using a similar background fit to that considered in A14. The approach provided amplitude and linewidth estimates that are in good agreement with those reported by A14 (see Fig. 11 and Sect. 6.6 for more details). Moreover, as observed in Fig. 11, the increasing trend of the linewidths of the radial peaks with their frequency position tends to flatten in the region around νmax. This so-called linewidth depression, expected for radial peaks (e.g. see Belkacem et al. 2011, for a theoretical explanation) agrees with what observed by A14 for the same star (Fig. 11, lower panel). Finally, Approach 1 has led to a final set of 14 radial, 18 dipole, and 13 quadrupole peaks – as shown in Table A.1 from (3,0) to (16,0), from (1,1) to (17,1) and from (3,2) to (16,2) – whose detection probability is p ≥ 99%. The remainder peaks, except for (2,19), which was not detected, are marked in Fig. 9 and can still be considered valid, though keeping in mind that their detection probabilities are lower than 99% and even below 50% in some cases. Besides, the error bars on the frequencies appear to be about five times smaller than those provided by A12 and from 1.5 to 4 times smaller than those reported by A14 for amplitudes and linewidths. This is caused by the use of a longer dataset and also by their smaller values obtained in this work as compared to those reported by A14 in the particular case of the linewidths (see Toutain & Appourchaux 1994, for more details on the behavior of the error bar of the linewidth for a single oscillation).
We described a novel peak bagging method (Approach 2) in Sect. 6.7 (see Figs. 12 and 13, upper panel) based on multi-modality. The capability of the code to sample multi-modal PPDs has proven to be of great help for reducing the dimensionality of the peak bagging analysis, which succeeds in sampling 27 different oscillation peaks by means of only k = 9 free parameters. In particular, Approach 2 has allowed us to retrieve Bayesian estimates of the frequency position of 21 out of 27 peaks in the frequency range 1280 − 2090 μHz, which result in good agreement (well within 1%) with those derived by means of Approach 1 for all the three different angular degrees. The concordance weakens for the amplitudes and linewidths of radial and quadrupole peaks (see Fig. 14, left and right panels respectively), as detailed in Sect. 6.7, while still ensuring accurate estimates for the dipole modes (Fig. 14, central panels). Nevertheless, the method is sensitive to the configuration of the code parameters related to both the clustering and the ellipsoidal sampling algorithms. The process of identifying clusters in the PPD is much more tapped for Approach 2 (multi-modal) than for Approach 1 (uni-modal). In addition, as already described in Sect. 6.7, the NSMC algorithm samples more frequently those regions in the PPD having a higher likelihood value, which causes the final sampling to be sparser for those peaks that have a lower amplitude and fall in the wings of the oscillation envelope (see Fig. 13, lower panel). One feasible choice to overcome this problem is to avoid sampling peaks having too different amplitudes from one another, hence subdividing the process in chunks of PSD where the different oscillations are similar in terms of asteroseismic properties. In general, however, the merging of several runs, as explained in Sect. 4.7, tends to increase the total number of samples for all the islands, hence giving the possibility to improve the results also for the side peaks.
Importantly, Approach 2 can be further improved, optimized, and used for the automatization of the peak bagging analysis in MS stars exhibiting solar-like oscillations by adopting a two-step approach: (i) quickly estimating the asteroseismic parameters of several oscillation peaks by means of Approach 2, since it requires a low number of free parameters with a low constraint level of their corresponding prior PDFs, which can in turn be derived through simple asteroseismic scaling relations; (ii) fitting the PSD by using Approach 1, or another similar to it, where the prior PDFs are now set by the outcomes of Approach 2, to end up with more accurate results.
8. Conclusions
Based on the descriptions given in Sect. 4, we can summarize the new features implemented in Diamonds as follows:
-
A revised SES algorithm based on the clustering of the live pointsthat allows more control and speed in the drawing process of theNSMC;
-
The possibility to use different types of prior PDFs (either uniform, normal and super-Gaussian, or new user-defined types) for any free parameter of the inference problem and in any possible combination;
-
The inclusion of a flexible stopping criterion for the NSMC based on the amount of evidence coming from the remaining set of live points;
-
An improved computation of the final evidence based on the statistical work by K11;
-
A new relation for the reduction of the live points that allows better control of the reduction process.
As proven with the demos presented in Sect. 4.6 and especially with the application given in Sect. 6, the Diamonds code developed for this work shows great potential for fast and efficient Bayesian inferences of challenging high-dimensional and multi-modal problems, such as the peak bagging analysis of an F-type star, hence allowing for a direct model comparison aimed at measuring the reliability of the peak detection. In addition, we demonstrated that Diamonds is capable of making a valuable alternative to Approach 1 by sampling multiple peaks simultaneously and in terms of only a few free parameters (Approach 2), thus reducing the number of dimensions involved in the fitting process (Fig. 12) with a considerable gain in both computational power and speed. The automatization of the peak bagging analysis for the measurement of detailed asteroseismic parameters in thousands of observed pulsating low-mass MS stars will be crucial for testing theoretical models of stellar evolution and of asteroseismic inversion that is aimed at probing stellar structure. Therefore, Diamonds gives us the possibility to progress in the analysis of a large ensemble of asteroseismic datasets for the first time.
Acknowledgments
The research leading to these results has received funding from the European Research Council under the European Community’s Seventh Framework Programme (FP7/2007–2013) ERC grant agreement No. 227224 (PROSPERITY) and PEOPLE-IRSES No. 269194 (ASK), from the Fund for Scientific Research of Flanders (G.0728.11), and from the Belgian federal science policy office (C90291 Gaia-DPAC). E.C. acknowledges Rafael A. García for providing the new corrected Kepler data, Tiago Campante and Paul Beck for useful discussions that helped in improving the paper. The authors wish to thank the referee Thierry Appourchaux for the useful comments.
References
- Aigrain, S., Favata, F., & Gilmore, G. 2004, A&A, 414, 1139 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Anderson, E. R., Duvall, Jr., T. L., & Jefferies, S. M. 1990, ApJ, 364, 699 [NASA ADS] [CrossRef] [Google Scholar]
- Appourchaux, T. 2003, Ap&SS, 284, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Appourchaux, T., Gizon, L., & Rabello-Soares, M.-C. 1998, A&AS, 132, 107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Appourchaux, T., Chaplin, W. J., García, R. A., et al. 2012, A&A, 543, A54 (A12) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Appourchaux, T., Antia, H. M., Benomar, O., et al. 2014, A&A, 566, A20 (A14) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Baglin, A., Michel, E., Auvergne, M., & COROT Team. 2006, in Proc. SOHO 18/GONG 2006/HELAS I, Beyond the spherical Sun, ESA SP, 624 [Google Scholar]
- Bedding, T. R., & Kjeldsen, H. 2003, PASA, 20, 203 [Google Scholar]
- Bedding, T., & Kjeldsen, H. 2006, in ESA SP, 624, Proc. SOHO 18/GONG 2006/HELAS I, Beyond the spherical Sun [Google Scholar]
- Belkacem, K., Goupil, M. J., Dupret, M. A., et al. 2011, A&A, 530, A142 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Benomar, O., Appourchaux, T., & Baudin, F. 2009, A&A, 506, 15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bolstad, W. 2013, Introduction to Bayesian Statistics (Wiley) [Google Scholar]
- Borucki, W. J., Koch, D., Basri, G., et al. 2010, Science, 327, 977 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Bruntt, H., Basu, S., Smalley, B., et al. 2012, MNRAS, 423, 122 [NASA ADS] [CrossRef] [Google Scholar]
- Campante, T. L., Chaplin, W. J., Lund, M. N., et al. 2014, ApJ, 783, 123 [NASA ADS] [CrossRef] [Google Scholar]
- Chaplin, W. J., Appourchaux, T., Elsworth, Y., et al. 2010, ApJ, 713, L169 [NASA ADS] [CrossRef] [Google Scholar]
- Chaplin, W. J., Kjeldsen, H., Christensen-Dalsgaard, J., et al. 2011, Science, 332, 213 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Christensen-Dalsgaard, J. 2004, Sol. Phys., 220, 137 [NASA ADS] [CrossRef] [Google Scholar]
- Christensen-Dalsgaard, J., & Perez Hernandez, F. 1992, MNRAS, 257, 62 [NASA ADS] [CrossRef] [Google Scholar]
- Corsaro, E., Grundahl, F., Leccia, S., et al. 2012, A&A, 537, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Corsaro, E., Fröhlich, H.-E., Bonanno, A., et al. 2013, MNRAS, 430, 2313 [NASA ADS] [CrossRef] [Google Scholar]
- Duvall, Jr., T. L., & Harvey, J. W. 1986, in NATO ASIC Proc. 169: Seismology of the Sun and the Distant Stars, ed. D. O. Gough, 105 [Google Scholar]
- Feroz, F., & Hobson, M. P. 2008, MNRAS, 384, 449 (FH08) [NASA ADS] [CrossRef] [Google Scholar]
- Feroz, F., & Skilling, J. 2013, in AIP Conf. Ser. 1553, ed. U. von Toussaint, 106 (FS13) [Google Scholar]
- Feroz, F., Hobson, M. P., & Bridges, M. 2009, MNRAS, 398, 1601 (F09) [NASA ADS] [CrossRef] [Google Scholar]
- García, R. A. 2013, in Stellar Pulsations, eds. J. C. Suárez, R. Garrido, L. A. Balona, & J. Christensen-Dalsgaard, Astrophys. Space Sci. Proc. (Berlin, Heidelberg: Springer-Verlag), 31, 171 [Google Scholar]
- García, R. A., Hekker, S., Stello, D., et al. 2011, MNRAS, 414, L6 [NASA ADS] [CrossRef] [Google Scholar]
- García, R. A., Mathur, S., Pires, S., et al. 2014, A&A, 568, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gilliland, R. L., Jenkins, J. M., Borucki, W. J., et al. 2010, ApJ, 713, L160 [NASA ADS] [CrossRef] [Google Scholar]
- Gizon, L., & Solanki, S. K. 2003, ApJ, 589, 1009 [NASA ADS] [CrossRef] [Google Scholar]
- Graff, P., Feroz, F., Hobson, M. P., & Lasenby, A. 2012, MNRAS, 421, 169 [NASA ADS] [Google Scholar]
- Gruberbauer, M., Kallinger, T., Weiss, W. W., & Guenther, D. B. 2009, A&A, 506, 1043 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Handberg, R., & Campante, T. L. 2011, A&A, 527, A56 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Härdle, W. 2004, Nonparametric and Semiparametric Models, Springer Series in Statistics (Berlin, Heidelberg: Springer) [Google Scholar]
- Harvey, J. 1985, in Future Missions in Solar, Heliospheric, & Space Plasma Physics, eds. E. Rolfe, & B. Battrick, ESA SP, 235, 199 [Google Scholar]
- Harvey, J. W., Duvall, Jr., T. L.,Jefferies, S. M., & Pomerantz, M. A. 1993, in GONG 1992 Seismic Investigation of the Sun and Stars, ed. T. M. Brown, ASP Conf. Ser., 42, 111 [Google Scholar]
- Jeffreys, H. 1961, Theory of Probability, 3rd Ed. (Oxford: OUP) [Google Scholar]
- Jenkins, J. M., Caldwell, D. A., Chandrasekaran, H., et al. 2010, ApJ, 713, L120 [NASA ADS] [CrossRef] [Google Scholar]
- Kallinger, T., Weiss, W. W., Barban, C., et al. 2010, A&A, 509, A77 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Karoff, C. 2012, MNRAS, 421, 3170 [NASA ADS] [CrossRef] [Google Scholar]
- Karoff, C., Chaplin, W. J., Appourchaux, T., et al. 2010, Astron. Nachr., 331, 972 [NASA ADS] [CrossRef] [Google Scholar]
- Karoff, C., Campante, T. L., Ballot, J., et al. 2013a, ApJ, 767, 34 [NASA ADS] [CrossRef] [Google Scholar]
- Karoff, C., Metcalfe, T. S., Chaplin, W. J., et al. 2013b, MNRAS, 433, 3227 [NASA ADS] [CrossRef] [Google Scholar]
- Kass, R. E., & Wasserman, L. 1996, J. Am. Stat. Assoc., 91, 1343 [NASA ADS] [CrossRef] [Google Scholar]
- Keeton, C. R. 2011, MNRAS, 414, 1418 (K11) [NASA ADS] [CrossRef] [Google Scholar]
- Koch, D. G., Borucki, W. J., Basri, G., et al. 2010, ApJ, 713, L79 [NASA ADS] [CrossRef] [Google Scholar]
- Kumar, P., Franklin, J., & Goldreich, P. 1988, ApJ, 328, 879 [NASA ADS] [CrossRef] [Google Scholar]
- Ledoux, P. 1951, ApJ, 114, 373 [NASA ADS] [CrossRef] [Google Scholar]
- Mathur, S., Handberg, R., Campante, T. L., et al. 2011, ApJ, 733, 95 [NASA ADS] [CrossRef] [Google Scholar]
- Metcalfe, T. S., Monteiro, M. J. P. F. G., Thompson, M. J., et al. 2010, ApJ, 723, 1583 [NASA ADS] [CrossRef] [Google Scholar]
- Metcalfe, T. S., Chaplin, W. J., Appourchaux, T., et al. 2012, ApJ, 748, L10 [NASA ADS] [CrossRef] [Google Scholar]
- Michel, E., Baglin, A., Auvergne, M., et al. 2008, Science, 322, 558 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Michel, E., Samadi, R., Baudin, F., et al. 2009, A&A, 495, 979 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mukherjee, P., Parkinson, D., & Liddle, A. R. 2006, ApJ, 638, L51 (M06) [Google Scholar]
- Pelleg, D., & Moore, A. 2000, in Proc. Seventeenth Int. Conf. Machine Learning (San Francisco: Morgan Kaufmann), 727 [Google Scholar]
- Pinsonneault, M. H., An, D., Molenda-Żakowicz, J., et al. 2012, ApJS, 199, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Scargle, J. D. 1982, ApJ, 263, 835 [NASA ADS] [CrossRef] [Google Scholar]
- Scott, J. G., & Berger, J. O. 2010, Annals of Statistics, 38, 2587 [Google Scholar]
- Shaw, J. R., Bridges, M., & Hobson, M. P. 2007, MNRAS, 378, 1365 (S07) [NASA ADS] [CrossRef] [Google Scholar]
- Sivia, D., & Skilling, J. 2006, Data Analysis: A Bayesian Tutorial, Oxford science publications (Oxford: OUP) [Google Scholar]
- Skilling, J. 2004, AIP Conf. Proc., 735, 395 (SK04) [Google Scholar]
- Tassoul, M. 1980, ApJS, 43, 469 [NASA ADS] [CrossRef] [Google Scholar]
- Toutain, T., & Appourchaux, T. 1994, A&A, 289, 649 [NASA ADS] [Google Scholar]
- Trotta, R. 2008, Contemporary Physics, 49, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Ulrich, R. K. 1986, ApJ, 306, L37 [NASA ADS] [CrossRef] [Google Scholar]
- van Leeuwen, F. 2007, A&A, 474, 653 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: Results for peak bagging of KIC 9139163
All oscillation frequencies, amplitudes and linewidths, with the peak significance probabilities are listed in Table A.1. The peaks are labeled with increasing integer numbers, moving from low to high frequency, for each different angular degree, and use the same labels in both Tables. This, therefore, allows the reader to easily identify the single oscillation and all the corresponding information by using the notation  . The results presented in Table A.1 refer to the use of Approach 1 based on the background derived in Sect. 6.2, thus it includes the faculae activity component.
. The results presented in Table A.1 refer to the use of Approach 1 based on the background derived in Sect. 6.2, thus it includes the faculae activity component.
We note that we do not list any detection probability pA (which can possibly be assumed zero) for some peaks ℓ = 2,0 for which we performed the model comparison between models ℳC and ℳB. This is because they have a high S/N, and, therefore, assessing their significance over the background level was not needed. In addition, all the peaks labeled with the same number and having angular degrees ℓ = 0 and 2 have the same peak significance analysis. This happens since the model comparison is performed for the duplet 2-0 and not for the single peaks, separately. Whereas the model comparison favored the detection of one peak only (model ℳB), namely the ℓ = 0 peak, or alternatively just the background component (model ℳA), which has no peaks, it is also important to stress that we decided to show the resulting fit for the model fitting the duplet 2-0 (model ℳC), since the two peaks cannot be disentangled from one another and their characteristic parameters obtained from the fit might still be useful for subsequent investigations. When model ℳC is favored over ℳB, this results in detection probabilities pC> 0.5 and pB< 0.5. Conversely, when the model ℳB ought to be preferred, the corresponding detection probabilities
become pC< 0.5 and pB> 0.5. The same rule applies to the detection probabilities pA and pB. The reader can decide whether to consider the quadrupole peak (or even the radial one) or not if the corresponding detection probability pC (or even pB) is too low (e.g. below 50%).
Lastly, for most of the dipole peaks, we did not perform any peak significance analysis thanks to their high amplitude (ranging from ~3.5 to ~1.5 times that of the lowest amplitude peaks), which makes their detection unambiguous. For the dipole peaks falling in the wings of the oscillation envelope, we instead computed the model comparison between models ℳB and ℳA, hence listing the detection probabilities pA and pB. With similar arguments to those adopted for the duplets 2-0, we show the result of the model having the dipole peak included, ℳB, even when it is disfavored over its competitor when just the background level is considered.
Appendix B: Results for peak bagging of KIC 9139163 based on A14 background
In this Appendix, we report the same oscillation peaks as in Table A.1 but with frequencies, amplitudes, and linewidths, as obtained by means of Approach 1 that is based on a different fit of the background, following the formulation given by A14, which consists of a flat noise component and a granulation Harvey-like profile.
Median values with corresponding 68.3% shortest credible intervals for the oscillation frequencies, amplitudes and linewidths of KIC 9139163, as stemmed by Diamonds for the case of the background model adopted by A14.
All Tables
Median values with corresponding 68.3% shortest credible intervals for the oscillation frequencies, amplitudes and linewidths of KIC 9139163, as stemmed by Diamonds for the case of the background model adopted by A14.
All Figures
|
Fig. 1 Examples of 1000 points (red dots) drawn according to different prior distributions from a three-dimensional ellipsoid centered at coordinate (2.0,2.0,2.0) in the parameter space defined by θ1,θ2,θ3 ∈ [0.5,3.5]. Left panel: case of a uniform prior along each coordinate, |
| In the text | |
|
Fig. 2 Examples of 20 000 points drawn from the 3D ellipsoid used in Fig. 1 but now according to the super-Gaussian priors |
| In the text | |
|
Fig. 3 Shaded surfaces show Himmelblau’s function in the range θ1,θ2 ∈ [−5,5] (left), Rosenbrock’s function in the range θ1 ∈ [−3,4] and θ2 ∈ [−2,10] (middle left), Eggbox function in the range θ1,θ2 ∈ [0,10π] (middle right) and Rastrigin’s function in the range θ1,θ2 ∈ [−5.12,5.12] (right). Uniform priors over each coordinate were used for all the demos with stopping thresholds δfinal = 0.05,0.05,0.5, and 0.05, respectively. Upper panels: yellow dots represent (from left to right) the resulting Nnest = 8485, 8558, 8207, 10648 samples obtained with the code presented in Sect. 4 by using Nlive = 1000 points for each demo, as presented by FS13. Lower panels: green dots represent (from left to right) the resulting Nnest = 5286,5151,5874,6174 samples derived by additionally applying the reduction law given by Eq. (17) with tol = 100, γ = 0.4, N0 = 1000 and Nmin = 400 live points. |
| In the text | |
|
Fig. 4 Échelle power spectrum of KIC 9139163 on a colored scale for Δν = 81.4 μHz and smoothed by 1 μHz. On the left, we find the ℓ = 1 ridge of oscillation, while we have those corresponding to ℓ = 2,0 on the right. The plot makes the presence of a curvature of the ridges clear along the entire frequency range and the strong blending between quadrupole and radial peaks. |
| In the text | |
|
Fig. 5 PSD of KIC 9139163 (gray) with overall background from Eq. (25) and median values reported in Table 1 (thick green line) with the additional Gaussian envelope included (dotted green line). The solid black line represents the smoothed PSD by 81.4 μHz. The single background components of constant photon noise (dotted), power law (dashed), granulation and faculae (dot-dashed), and Gaussian envelope (double-dot-dashed) are shown in blue. Upper panel: model ℳ1 accounting for one Harvey-like profile. The arrow indicates the presence of a kink that is not reproduced by the model. Lower panel: model ℳ2 accounting for two Harvey-like profiles. The winning model ℳ2 is strongly favored as it yields a Bayes’ factor lnℬ21 = 58.2 ± 0.2 over its competitor. |
| In the text | |
|
Fig. 6 Upper panels: examples of correlation maps of the three free parameters W, σgran, and b used in Eq. (27) using two Harvey-like profiles with color-coded likelihood values. Each point in the diagram is a sampling point that stems from the NSMC process. The plotted realization consists of ~27 000 samples. Lower panels: corresponding MPDs of the free parameters as computed by means of Diamonds. The shaded region indicates the portion of the distribution containing 68.3% of the total probability, defining the shortest credible intervals listed in Table 1. The dashed line indicates the mode of the distribution. |
| In the text | |
|
Fig. 7 Correlation maps for the parameters describing the Harvey-like profile related to the faculae activity – namely σfac, and τfac, their combination |
| In the text | |
|
Fig. 8 Example of an ambiguous detection of a high S/N duplet ℓ = 2,0 from the PSD of KIC 9139163. The solid line shows the resulting best-fit as computed by Diamonds, while the dashed line represents the mean background model as obtained in Sect. 6.2, according to Eq. (30). Upper panel: case of model ℳB where only ℓ = 0 is fitted. Lower panel: case of model ℳC where both ℓ = 2,0 are fitted. The resulting lnℬCB = 16.5 ± 0.1 strongly favors model ℳC, hence the presence of two peaks in the observed structure. |
| In the text | |
|
Fig. 9 Upper panel: resulting peak bagging best-fit for KIC 9139163 as derived by means of Diamonds by using Approach 1 based on the background that is estimated in Sect. 6.2 (red thick line) overlaid on the PSD smoothed by 0.25 μHz (gray). The mean background level is shown as a dashed blue line. Dotted vertical lines mark the oscillation peaks for which the detection probability is below 99% with labels indicating the corresponding peak identification, as reported in Table A.1 and as explained in Appendix A. Lower panel: ratio between the smoothed PSD and the resulting red line fit that is shown in the upper panel. |
| In the text | |
|
Fig. 10 Oscillation parameters for the dipole (red triangles) and quadrupole (orange squares) peaks of KIC 9139163 as derived by means of Diamonds by using Approach 1 based on the background derived in Sect. 6.2, for both amplitudes A (upper panel) and linewidths Γ (lower panel), as a function of the frequency position ν. All the results shown are the mean estimates from the Bayesian inference with corresponding 68.3% credible intervals overlaid. |
| In the text | |
|
Fig. 11 Comparison of the oscillation parameters for the radial peaks of KIC 9139163 between the results derived in this work by means of Diamonds (filled red circles, Approach 1 based on the background derived in Sect. 6.2 and, open red circles, Approach 1 based on A14 background) and those provided by A14 (gray squares) for both amplitudes A0 (upper panel), and linewidths Γ0 (lower panel), as a function of the frequency position ν0. The red circles represent the mean estimates coming from the Bayesian inference with their corresponding 68.3% credible intervals, while gray squares are the mean estimates from the MLE fit done by A14 and plotted with their error bars. The A0 values from Approach 1 shown in the plot are obtained by scaling down by a factor |
| In the text | |
|
Fig. 12 Illustrative comparison between Approach 1 (red circles) and Approach 2 (blue squares) in terms of the number of free parameters used in the fit (top panel) and the number of local maxima identified in the final PPD (bottom panel), as a function of the number of radial orders considered. |
| In the text | |
|
Fig. 13 Resulting 43374 samples obtained by Diamonds by using Approach 2 applied to the PSD of KIC 9139163 in the frequency range 1280 − 2090 μHz, covering nine radial orders. Upper panel: distribution of the sampling points for the amplitude of dipole peaks, A1 and the corresponding frequency position, ν1. The islands marked in light blue represent the true positions of the dipole peaks, while those in gray are relative to the positions of the blended quadrupole-radial peaks, which are ignored. The red circles represent the mean Bayesian estimates derived from the MPDs of the light blue islands, while yellow triangles show the corresponding sampling average positions in both coordinates and are not related to the MPDs. Lower panel: corresponding histogram density along the direction of ν1, showing the number of counts occurring in each island. |
| In the text | |
|
Fig. 14 Comparison of the results for KIC 9139163 relative to the nine radial orders in the frequency range 1280 − 2090 μHz, obtained by Diamonds according to Approach 1 (red circles) and Approach 2 (blue squares). Panels from left to right show the amplitudes (upper panels) and linewidths (lower panels) against the frequency position of the full set of radial, ν0, dipole, ν1, and quadrupole oscillations, ν2, respectively. The red circles are the mean values as derived from the MPDs with their corresponding 68.3% shortest credible intervals, while the blue squares are the mean values from the MPDs of each blue island (see Fig. 13). The open triangles are the sample average positions (see Fig. 13) used for providing a frequency estimate for the two side peaks of each panel. Dotted vertical lines represent the frequency position of the red circles, as shown as a reference for the blue squares. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.