| Issue |
A&A
Volume 673, May 2023
|
|
|---|---|---|
| Article Number | A130 | |
| Number of page(s) | 28 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202245618 | |
| Published online | 18 May 2023 | |
DESI mock challenge
Halo and galaxy catalogues with the bias assignment method
1
Instituto de Astrofísica de Canarias, s/n, 38205 La Laguna, Tenerife, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Departamento de Astrofísica, Universidad de La Laguna, 38206 La Laguna, Tenerife, Spain
3
Institue for Astronomy, Royal Observatory, University of Edinburgh, Edinburgh, UK
4
Tata Institue of Fundamental Research, Homi Bhabha Road, Mumbai 400005, India
5
Kavli Institute for Particle Astrophysics and Cosmology, Stanford University, 452 Lomita Mall, Stanford, CA 94305, USA
6
Shanghai Jiao Tong University, 800 Dongchuan Road, Shanghai 200233, PR China
7
Department of Physics and Astronomy, Università degli Studi di Padova, Vicolo dell’Osservatorio 3, Padova, Italy
8
Institute of Physics. Laboratory of astrophysics. École Polytechnique Fédérale de Lausanne, 1290 Lausanne, Switzerland
9
Department of Physics & Astronomy, University College London, Gower Street, London WC1E 6BT, UK
10
Instituto de Física, Universidad Nacional Autónoma de México, Cd. de México C.P., 04510 Mexico city, Mexico
11
Institut de Física d’Altes Energies, The Barcelona Institute of Science and Technology, Campus UAB, 08193 Bellaterra, Barcelona, Spain
12
Lawrence Berkeley National Laboratory, 1 Cyclotron Road, Berkeley, CA 94720, USA
13
Department of Physics, The Ohio State University, 191 West Woodruff Avenue, Columbus, OH 43210, USA
14
Center for Cosmology and AstroParticle Physics, The Ohio State University, 191 West Woodruff Avenue, Columbus, OH 43210, USA
15
Department of Physics, Southern Methodist University, 3215 Daniel Avenue, Dallas, TX 75275, USA
16
NSF’s NOIRLab, 950 N. Cherry Ave., Tucson, AZ 85719, USA
17
Institució Catalana de Recerca i Estudis Avançats, Passeig de Lluís Companys, 23, 08010 Barcelona, Spain
18
University of Michigan, Ann Arbor, MI 48109, USA
19
National Astronomical Observatories, Chinese Academy of Sciences, A20 Datun Rd., Chaoyang District, Beijing 100012, PR China
Received:
4
December
2022
Accepted:
16
March
2023
Abstract
Context. We present a novel approach to the construction of mock galaxy catalogues for large-scale structure analysis based on the distribution of dark matter halos obtained with effective bias models at the field level.
Aims. We aim to produce mock galaxy catalogues capable of generating accurate covariance matrices for a number of cosmological probes that are expected to be measured in current and forthcoming galaxy redshift surveys (e.g. two- and three-point statistics). The construction of the catalogues shown in this paper is part of a mock-comparison project within the Dark Energy Spectroscopic Instrument (DESI) collaboration.
Methods. We use the bias assignment method (BAM) to model the statistics of halo distribution through a learning algorithm using a few detailed N-body simulations, and approximated gravity solvers based on Lagrangian perturbation theory. We introduce cosmic-web-dependent corrections to modelling redshift-space distortions at the N-body level – both in the halo and galaxy distributions –, as well as a multi-scale approach for accurate assignment of halo properties. Using specific models of halo occupation distributions to populate halos, we generate galaxy mocks with the expected number density and central-satellite fraction of emission-line galaxies, which are a key target of the DESI experiment.
Results. BAM generates mock catalogues with per cent accuracy in a number of summary statistics, such as the abundance, the two- and three-point statistics of halo distributions, both in real and redshift space. In particular, the mock galaxy catalogues display ∼3%−10% accuracy in the multipoles of the power spectrum up to scales of k ∼ 0.4 h−1Mpc. We show that covariance matrices of two- and three-point statistics obtained with BAM display a similar structure to the reference simulation.
Conclusions. BAM offers an efficient way to produce mock halo catalogues with accurate two- and three-point statistics, and is able to generate a variety of multi-tracer catalogues with precise covariance matrices of several cosmological probes. We discuss future developments of the algorithm towards mock production in DESI and other galaxy-redshift surveys.
Key words: methods: numerical / Galaxy: halo / galaxies: statistics
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
The cosmological volume spanned by the nearly 40 million galaxies and quasars that are to be surveyed by the Dark Energy Spectroscopic Instrument (DESI Collaboration 2016a) poses unprecedented challenges for both theoretical and numerical cosmology. DESI is a robotic, fibre-fed, highly multiplexed spectroscopic surveyor operating on the Mayall 4 m telescope at Kitt Peak National Observatory (DESI Collaboration 2022). It can obtain simultaneous spectra of almost 5000 objects over a ∼3° field (DESI Collaboration 2016b; Silber et al. 2023, Miller et al., in prep.), and is currently conducting a five-year survey covering nearly one-third of the sky. DESI uses multiple supporting software pipelines and products, including significant imaging from the DESI Legacy Imaging Surveys (Zou et al. 2017; Dey et al. 2019, Schlegel et al., in prep.) as well as an extensive spectroscopic reduction pipeline (Guy et al., in prep.), a template-fitting pipeline to derive classifications and redshifts for each targeted source Bailey et al. (in prep.), a pipeline aimed to assign fibres to targets (Raichoor et al., in prep.), a pipeline to tile the survey and to plan and optimise observations as the campaign progresses (Schlafly et al., in prep.), and a pipeline to select targets for spectroscopic follow-up (Myers et al. 2023). The DESI target selection relies on the public Legacy Surveys (Dey et al. 2019), with preliminary target selection details published for the MWS (Allende Prieto et al. 2020), the LRGs sample (Zhou et al. 2020), BGS (Ruiz-Macias et al. 2020), ELGs (Raichoor et al. 2020), and QSOs (Yèche et al. 2020). Specific target selection approaches for DESI are varied and extensive. In particular, it is important that we mention the work describing the DESI Survey Validation (SV) phase (DESI collaboration, in prep.), two papers describing the process through which truth tables were produced via visual inspection of target spectra acquired during the SV phase and how these are used to inform target selection for the DESI Main Survey (Alexander et al. 2023; Lan et al. 2023), as well as a series of papers describing the selection of DESI bright-time and dark-time science targets (MWS, Cooper et al. 2023; BGS, Hahn et al. 2022; LRG, Zhou et al. 2023; ELG, Raichoor et al. 2023; QSO, Chaussidon et al. 2023). The Early DESI Data Release (DESI collaboration, in prep.) and the Siena Galaxy Atlas (SGA, Moustakas et al., in prep.) are forecast for 2023.
The precision of the measurements of the statistical properties of the spatial distribution and weak-lensing signals to be obtained from such an unprecedented number of tracers will shed light on the most intriguing features of the standard cosmological model; for example, the nature of dark energy (e.g. Levi et al. 2013; DESI Collaboration 2016a) and primordial non-gaussianities (see e.g. Vargas-Magana et al. 2019; Alam et al. 2021). The accomplishment of these goals depends heavily on access to precise and accurate covariance matrices for the statistical analysis of several cosmological probes, such as clustering, weak-lensing signals, redshift-space distortions, and baryon acoustic oscillations (e.g. Dodelson & Schneider 2013; Taylor et al. 2013; Percival et al. 2014; Paz & Sánchez 2015; Pearson & Samushia 2016; Howlett & Percival 2017; Lacasa 2018; O’Connell & Eisenstein 2019).
This paper is part of a mock challenge within the DESI collaboration (see e.g. Garrison et al. 2018; Grove et al. 2022; Ding et al. 2022) which is designed to establish a road map towards the construction of mock galaxy catalogues with per cent accuracy and precision in a number of statistical properties of the spatial distribution of galaxies. In particular, this article describes the application of a calibrated approach to producing mock catalogues, the so-called bias assignment method (BAM; Balaguera-Antolínez et al. 2019).
While a number of predictive methods (such as PThalos (Scoccimarro & Sheth 2002; Manera et al. 2013), MoLUSC (Sousbie et al. 2008), PINOCCHIO (Monaco et al. 2002, 2013; Munari et al. 2017; Berner et al. 2022), COLA (Tassev et al. 2013; Koda et al. 2016; Izard et al. 2018), QPM (White et al. 2014), L-PICCOLA (Howlett et al. 2015), FastPM (Feng et al. 2016), Peak-Patch (Bond & Myers 1996a,b,c; Stein et al. 2019), CoVMOS (Baratta et al. 2020, 2023) and analytical approaches (such as the log-normal approaches; e.g. Coles & Jones 1991; Xavier et al. 2016; Agrawal et al. 2017) have been designed as an alternative to highly detailed (e.g. Springel 2005; Potter et al. 2017; Weinberger et al. 2020; Springel et al. 2021), albeit time-consuming, N-body simulations (see e.g. Monaco 2016, for a review of some of these methods), the need for a step forward in terms of precision in the assessment of covariance matrices of cosmological observables has motivated the emergence of a new branch of techniques called calibrated methods; examples are HALOGEN Avila et al. (2015), EZmocks (Chuang et al. 2015a), and PATCHY Kitaura et al. (2014). The two latter methods were successfully used to generate accurate mock galaxy catalogues for clustering analysis (see e.g. Kitaura et al. 2016; Zhao et al. 2021) and were tested for analysis of forthcoming missions (see Chuang et al. 2015b; Lippich et al. 2019; Blot et al. 2019; Colavincenzo et al. 2018, for a likelihood comparison of some of these methods).
In recent years, machine-learning techniques have made an appearance in the cosmological scenario (see e.g. Dvorkin et al. 2022, for a recent review) with a number of different goals and applications. Among others, these techniques have been used to learn the spatial distribution of dark matter tracers from a large number of detailed N-body simulations (see e.g. Villaescusa-Navarro et al. 2021; Kreisch et al. 2022; Piras et al. 2023), generate corrections to the displacement field in Lagrangian perturbation theory (e.g. He et al. 2019), increase the mass resolution of fast and computationally cheap simulations (typically characterised by low mass resolutions, e.g. Li et al. 2021; Forero-Sánchez et al. 2022), learn the galaxy–dark matter connection from hydro-simulations (e.g. Zhang et al. 2019), and to provide a platform to obtain covariance matrices from fast and/or inaccurate sets of mocks (see e.g. Chartier et al. 2021; de Santi & Abramo 2022).
BAM is the latest of a class of algorithms designed to produce mock galaxy catalogues. Its unique combination of physical content and learning scheme means that it can be regarded as both a calibrated method and a physically supervised machine-learning approach to the production of mock galaxy catalogues. The method represents a step forward in precision as well as efficiency, as it has been demonstrated to provide covariance matrices of the halo power spectrum with per cent accuracy (with respect to an N-body simulation) and at low cost in terms of computing time as well as in the number of training sets (Balaguera-Antolínez et al. 2020). BAM has also been shown to be potentially useful to generating mock catalogues for Lyman-α and quasars by learning from hydro-dynamic simulations (Sinigaglia et al. 2021, 2022).
In this work, we present a methodology that uses BAM to generate ensembles of halo catalogues with phase-space coordinates. The methodology implemented for constructing halo catalogues presented here improves on previous approaches by including more precise recipes for the peculiar velocities and intrinsic properties of halos (such as virial mass and velocity dispersion). Building on the set of halo catalogues, we implement a halo occupation distribution (HOD) framework (e.g. Cooray 2002; Cooray & Sheth 2002; Berlind & Weinberg 2002; Kravtsov et al. 2004) to populate these halos with galaxies, and in particular emission line galaxies (ELGs), which are a key target of the DESI galaxy redshift survey (e.g. Raichoor et al. 2020). The strategy that we envisage for BAM allows us to implement more approaches to populate dark matter halos with galaxies, such as the sub-halo abundance matching (SHAM), (see e.g. Vale & Ostriker 2004; Kravtsov et al. 2004; Conroy et al. 2006; Favole et al. 2016), and to generate galaxy cluster catalogues (see e.g. Cai et al. 2009; Balaguera-Antolínez et al. 2012) based on different halo properties (Hearin et al. 2016; Wechsler & Tinker 2018). This provides high flexibility at the time of producing mock catalogues containing a number of different dark matter tracers with the same underlying dark matter density field. This is optimal for multi-tracer analyses (see e.g. Hamaus et al. 2012; Abramo & Leonard 2013; Abramo et al. 2016; Wang & Zhao 2020; Zhao et al. 2021) as expected to be performed in many experiments. Indeed, BAM is expected to provide halo and mock galaxy catalogues for several ongoing galaxy-redshift surveys, such as DESI Levi et al. (2013), EUCLID Amendola et al. (2018), J-PAS (Benitez et al. 2014), and the Nancy Grace Roman Space telescope Spergel et al. (2015).
The outline of this paper is as follows. In Sect. 2, we describe the BAM approach to calibrating the halo bias. In Sect. 2.4, we describe the reference N-body simulation and the different models of halo bias used in this work. Section Sect. 2.7 depicts the methodology used to learn the halo bias while Sect. 3 is devoted to the construction of halo catalogues. In Sect. 4, we present the HOD model used to generate galaxy catalogues and describe the main statistical properties of the resulting ensemble. We end with conclusions and a list of potential developments designed to improve our method.
2. Description of the bias-assignment method
2.1. The halo bias in BAM
The halo bias (i.e. the link between the halo and dark matter distribution) is a quantity of paramount relevance to the understanding of halo, and subsequently galaxy, clustering, as it represents the midpoint between the distribution of light (galaxies) and the distribution of the underlying dark matter in the Universe. It is very well established that the bias of dark matter tracers needs to be modelled beyond the standard linear scale-independent scheme: scale dependencies induced by the process of halo formation and merging, the non-linear evolution of the dark matter density field (see e.g. Matsubara 1999; Sigad et al. 2000; Somerville et al. 2001; Smith et al. 2007; Zentner 2007; Tinker et al. 2010; Valageas 2011; Pollack et al. 2012; Sheth et al. 2013; Ahn et al. 2015; Pujol et al. 2017; Desjacques et al. 2018; Han et al. 2019; Nasirudin et al. 2020, and references therein), and the discrete presentation of halo and matter density fields generalises the concept of halo bias to a non-local and stochastic quantity (see e.g. Fry & Gaztanaga 1993; Tegmark & Peebles 1998; Dekel & Lahav 1999; Blanton 2000; Simon 2005).
The BAM algorithm is designed to capture the aforementioned properties of the bias of dark matter tracers (halos in this case) at the field level by assuming that the number counts of dark matter halos in a cell of volume ∂V depends on a set of properties {Θdm} of the underlying dark matter (DM) density field evaluated on the same cells. This dependency is assumed to be represented by a probability distribution of halo occupation number Nh conditional to a set of 𝒩p properties of the underlying dark matter field. Accordingly, we represent the halo bias as a multi-dimensional histogram:
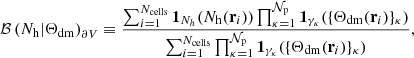 (1)
(1)
where γℓ ≡ [{Θdm}ℓ − Δℓ/2, {Θdm}ℓ + Δℓ/2) represents the set of bins (of width Δℓ) defined for the ℓ-th property (ℓ = 1, ⋯, 𝒩p) of the density field, with 1A(x) as the indicator function: 1A(x) = 1 if x ∈ A, and 0 otherwise. The quantity ℬ carries no information on the phases of the density fields, and therefore represents a statistical target that can be learned and mapped into a different realisation of the dark matter density field. Equation (1) approximates the true underlying halo bias, as it ignores key aspects such as the effects of the mass assignment and the correlation between pairs in different property bins, among others. The impact of these effects in the measurement of the halo bias is captured (and corrected for) within the iterative process, as discussed in Sect. 2.7.
2.2. The ingredients of BAM
The BAM machinery relies on a number of ingredients, which are mainly related to properties and outputs of detailed N-body simulations. These can be enumerated as follows:
-
Initial conditions (ICs) of a reference N-body simulation. These ICs are represented by an initial Gaussian random field built at a much lower resolution than that originally used by the N-body run. A subset of these ICs corresponds to down-sampled versions of the original ensemble, evolved by the N-body code to redshifts at which dark matter halo catalogues are identified and used in this analysis.
-
2.
A set of a few dark matter halo catalogues containing phase-space coordinates as well as halo properties that will be used for the assignment of galaxies by means of, for example, HOD prescription. These halos correspond to the ICs whose initial seeds are the same as those in the subset described in point (1).
-
3.
An approximated gravity solver (or surrogate) that evolves – in a fast way – the low-resolution IC to the redshift of the tracer catalogue.
Provided the above set of ingredients, the generation of mock galaxy catalogues in BAM is performed in four stages:
-
Stage I: Calibration: Learning process in which the halo bias (introduced in the previous section) and BAM kernel (introduced in Sect. 2.7) are calibrated using the two-point statistics of the reference as a target (or cost function).
-
2.
Stage II: Halo mock production: Generation of independent halo number count fields through the sampling of independent dark matter density fields using halo bias.
-
3.
Stage III: Phase-space coordinates and properties: (a) Assignment of position, (b) velocities, and (c) intrinsic properties to dark matter halos.
-
4.
Stage IV: Galaxy catalogues: Implementation of a HOD model to populate dark matter halos with galaxies.
We cover each of these steps throughout this article. To facilitate understanding of the processes involved in the method, we depict the different steps as a flow chart in Fig. 1.
 |
Fig. 1. Flow-chart representing the different stages involved in the generation of mock galaxy catalogues with BAM described in Sect. 2.2. The process is mainly divided into two sections: learning phase and mock production. In the learning phase, a number of kernels and halo biasses are calibrated from different realisations of the reference simulation and are stacked to generate one version of kernel and bias used in the mock production phase. The different colours in the arrows indicate the different stages involved in the process (e.g. calibration, generation of independent halo number counts, assignment of halo properties, construction of galaxy catalogues). |
2.3. Training set: Reference simulation and initial conditions
We use the Scinet LIghtCone Simulations (SLICSs) described by Harnois-Déraps et al. (2018), which consist of an ensemble of cosmological N-body simulations run in a comoving box of Lbox = 505 Mpc h−1 per side, following the non-linear evolution of 15363 particles initialised on a mesh of 30723 points, from an initial redshift of zini = 120 down to z = 0.
The original set of initial conditions of this simulation consist of about 1000 realisations in the form of particle positions and velocities, which need to be converted to density fields. A fraction of this set is to be used in particle mesh codes (such as FastPM Feng et al. 2016) as part of the mock-comparison project in DESI (Variu et al., in prep.). Accordingly, the initial density fields are obtained from the displacement field 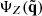 by reversing the Zeldovich displacement (Zel’dovich 1970) as
by reversing the Zeldovich displacement (Zel’dovich 1970) as 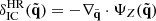 , where
, where 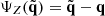 is computed from the particle positions
is computed from the particle positions 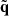 relative to a regular distribution with coordinates q on a
relative to a regular distribution with coordinates q on a 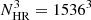 lattice (which we refer to as high-resolution, HR).
lattice (which we refer to as high-resolution, HR).
For applications to BAM, we adopted a resolution of 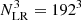 cells1 and applied an ideal (real) low-pass filter in order to obtain low-resolution initial conditions. The fiducial spatial resolution yields fields represented by a regular mesh with volume ∂V ∼ (2.6 Mpc h−1)3 and a Nyquist frequency of ∼1.2h Mpc−1. For comparison against the reference simulation, and according to DESI scientific requirements, we adopt a maximum wavenumber of ∼0.4h Mpc−1, which amounts to ∼30% of the Nyquist frequency. At those scales, mass assignment effects inherent to the interpolation of halos in a mesh are expected to be negligible (see e.g. Jing 2005).
cells1 and applied an ideal (real) low-pass filter in order to obtain low-resolution initial conditions. The fiducial spatial resolution yields fields represented by a regular mesh with volume ∂V ∼ (2.6 Mpc h−1)3 and a Nyquist frequency of ∼1.2h Mpc−1. For comparison against the reference simulation, and according to DESI scientific requirements, we adopt a maximum wavenumber of ∼0.4h Mpc−1, which amounts to ∼30% of the Nyquist frequency. At those scales, mass assignment effects inherent to the interpolation of halos in a mesh are expected to be negligible (see e.g. Jing 2005).
2.4. The reference halo catalogues
The corresponding halo catalogues from the SLICS consist of a set of virialised objects identified at z = 1.04 with a spherical overdensity algorithm (see e.g. Harnois-Déraps et al. 2013). We used a set of 80 realisations of halo catalogues2 to assess the accuracy of our mocks in terms of two and three-point statistics. A subset (of a maximum of 27 randomly selected3 references) was also used as part of the training set from which BAM learnt the halo bias (described in Sect. 2.7). The mass resolution of the SLICS is ∼2.8 × 109 M⊙h−1. We selected dark matter halos with masses above 2 × 1011 M⊙h−1, which agrees with the expected mass cut at which dark matter halos can host ELGs (see e.g. Alam et al. 2020). Number counts are generated over a mesh with our fiducial resolution of 1923 using the nearest grid-point mass assignment (Hockney & Eastwood 1988). Although the halo-finder algorithm allows the determination of different halo properties (e.g. mass, spin, concentration, velocity dispersion), the current set of reference catalogues involves only the virial mass and the velocity dispersion, along with halo coordinates and peculiar velocities, obtained from the position of the density used to identify each halo. These quantities are sufficient to apply an HOD prescription and populate halos with central and satellite galaxies. We note that the BAM method can be applied to reference halo catalogues built with different halo finders (see e.g. Balaguera-Antolínez et al. 2020).
2.5. Fast gravity solver
BAM relies on a combined Lagrangian and Eulerian perturbation theory approach, dubbed augmented Lagrangian perturbation theory (ALPT; see Kitaura & Hess 2013; Kitaura et al. 2014), to map the initial conditions represented by Lagrangian coordinates q (regularly spaced points at the redshift zini) into final (Eulerian) comoving coordinates r(z) via r(z) = q + Ψ(q, z), where Ψ(q, z) represents the displacement field. This displacement is assumed to be split into long and short-range components, Ψ(q, z) = Ψshort(q, z)+Ψlong(q, z). ALPT implements the displacement field from second-order Lagrangian perturbation theory (2LPT) to model the large-scale (long-range) displacement (see e.g. Buchert & Ehlers 1993; Bouchet et al. 1995; Bernardeau et al. 2002)
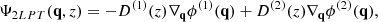 (2)
(2)
where D(1)(z) is the growth factor (see e.g. Heath 1977), 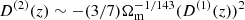 (Bouchet et al. 1995). The potentials ϕi(q) are the solutions of the Poisson equations
(Bouchet et al. 1995). The potentials ϕi(q) are the solutions of the Poisson equations 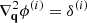 , where i = 1 is the linear density obtained in Sect. 2.3, and
, where i = 1 is the linear density obtained in Sect. 2.3, and
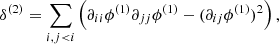 (3)
(3)
where we use the notation ∂ijϕ ≡ ∂2ϕ(q)/∂qi∂qj. Equation (3) shows how 2LPT takes into account the Hessian of the initial gravitational potential, and is therefore expected to develop the main features of the cosmic web on large scales. However, given that 2LPT is not accurate on small scales (see e.g. Kitaura & Hess 2013), its displacement is filtered with a Gaussian kernel 𝒢s(q), as Ψlong(q, z) = Ψ2LPT(q, z)⊗𝒢s(q), with a smoothing scale of rs = 20 Mpch−14.
While ALPT models the large scales using Lagrangian perturbation theory, it relies on Eulerian perturbation theory to model the small-scale clustering signal. In particular, the short-range displacement is written as Ψshort(q, z) = (1−𝒢s(q)) ⊗ Ψsc(q, z) where the displacement Ψsc(q, z) is derived within the spherical collapse (SC) approximation (see e.g. Bernardeau 1994; Bernardeau et al. 2002), ψsc(q, z) = ∇⋅Ψsc(q, z) where ψsc(q, z) is the solution to the Poison-like equation (see e.g. Mohayaee et al. 2006; Neyrinck 2013)
![Mathematical equation: $$ \begin{aligned} \nabla ^{2}\psi _{sc}({\mathbf{q}},z)=3\left( \left[1-\frac{2}{3}D^{(1)}(z)\delta ^{(1)}({\mathbf{q}})\right]^{1/2}-1\right). \end{aligned} $$](/articles/aa/full_html/2023/05/aa45618-22/aa45618-22-eq12.gif) (4)
(4)
The regular Lagrangian coordinates are then mapped into Eulerian coordinates using the total displacement:
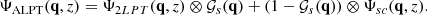 (5)
(5)
With dark matter particles evolved, a cloud-in-cell mass-assignment scheme is implemented to generate an approximated dark matter density field (A-DMDF) on the fiducial mesh. To improve the description of the non-linear dark matter field with a low number of particles, we implement the phase-space mapping technique (Abel et al. 2012; Hahn et al. 2013).
We note that the method can in principle implement any approximated gravity solver (with the correct large-scale clustering signal), given that the BAM kernel is meant to correct for missing power towards small scales, with the aim being to generate the correct tracer power spectrum through a learning procedure (further discussed in Sect. 2.7). Nevertheless, as long as we use the positions and velocities (see Sect. 3.3) from the dark matter particles computed from such approximated methods, along with the fact that the tidal field (see Eq. (3)) is a key ingredient of the method, the desired trade-off between precision, speed, and physical content means that we favour 2LPT or ALPT over, for example, the Zeldovich approximation (see White 2014, for a review on the Zeldovich approximation). Further developments designed to improve the precision without a significant increase in required computing time were recently presented by Kitaura et al. (2023) and will be implemented in the BAM machinery in future applications.
Finally, we highlight that the resulting mass of the dark matter particles (∼1014 M⊙h−1) used to define the cosmic web is nearly five times larger than in the reference N-body simulation (see Sect. 2.4).
2.6. Properties of the dark matter density field in BAM
BAM explicitly determines several properties {Θdm} of the underlying DM density field upon which the occupation number of dark matter halos is assumed to depend, as explained in Sect. 2. In general, such properties can be nominally divided into local and non-local, depending on the quantity used to infer them. While as a local property, we can readily use the dark matter overdensity at each cell (obtained using a given mass-assignment scheme), non-local properties (also dubbed as environmental) can be extracted from quantities defined on scales larger than the cell volume, such as the tidal field tensor 𝒯ij = ∂i∂jΦ (where Φ is the comoving gravitational potential satisfying the Poisson equation ∇2Φ = δdm). In particular, previous implementations of BAM used the cosmic-web classification (CWC), which relies on the value of the eigenvalues λi (i = 1, 2, 3) of the tidal field (see e.g. Hahn et al. 2007; van de Weygaert et al. 2009; Forero-Romero et al. 2009; Aragon-Calvo 2016; Yang et al. 2017; Paranjape et al. 2018) with respect to some arbitrary threshold λth. Similarly, the information of the velocity shear of the DM particles (see Bond et al. 1996; Libeskind et al. 2018; Kitaura et al. 2022) and its eigenvalues can be used to characterise the halo occupation number. In this work, we restrict ourselves to the CWC.
The CWC allows us to define the behaviour of the halo number counts in knots (labelled 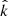 , λ1 > λth, λ2 > λth, λ3 > λth), filaments (
, λ1 > λth, λ2 > λth, λ3 > λth), filaments (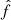 , λ1 < λth, λ2 > λth, λ3 > λth), sheets (
, λ1 < λth, λ2 > λth, λ3 > λth), sheets (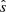 , λ1 < λth, λ2 < λth, λ3 > λth), and voids (
, λ1 < λth, λ2 < λth, λ3 > λth), and voids (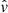 , with λ1 < λth, λ2 < λth and λ3 < λth)5. Furthermore, the CWC permits exploration of the dependency of halo occupancy on the mass Mk of collapsing regions, defined as the number of dark matter particles in sets (regions) formed by cells classified as knots. These regions are identified through a friend-of-friend percolation algorithm (Zhao et al. 2015).
, with λ1 < λth, λ2 < λth and λ3 < λth)5. Furthermore, the CWC permits exploration of the dependency of halo occupancy on the mass Mk of collapsing regions, defined as the number of dark matter particles in sets (regions) formed by cells classified as knots. These regions are identified through a friend-of-friend percolation algorithm (Zhao et al. 2015).
The set of properties (CWC+Mk) has been explored in previous BAM publications (see e.g. Balaguera-Antolínez et al. 2020), where it was shown that it is key to reconstructing the halo number counts based on the dark matter density field. In the same context, Kitaura et al. (2022) introduced the implementation of the invariants of the tidal field Ii in the definition of halo bias used in BAM (where I1 = δdm, I2 = λ1λ2 + λ1λ3 + λ2λ3 and I3 = λ1λ2λ3). This approach is designed to bridge a phenomenological description of the tidal field (e.g. with the CWC) and theoretical models of perturbation theory in which higher order terms can be written in terms of combinations of the eigenvalues of the tidal field.
In summary, we explore the following models for the reconstruction of halo density fields and the generation of mock catalogues:
-
TkWEB:
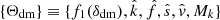 . Use the local density, cosmic-web types, and the mass of collapsing regions.
. Use the local density, cosmic-web types, and the mass of collapsing regions. -
IkWEB: {Θdm}≡{f1(δdm),f2(I2),f3(I3),Mk}. Use the invariants of the tidal field and the mass of collapsing regions.
-
TIWEB:
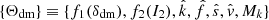 . Use the cosmic web classification and one invariant of the tidal field.
. Use the cosmic web classification and one invariant of the tidal field.
The functions fi(x) represent non-linear transformations designed to improve the extraction of the bias information in each variable x = {δdm, I2, I3}. We use f1(x) = log(2 + x) and f2(x) = f3(x) = 2(xα − γ)/(η − γ)−1 with γ ≡ min(xα), η ≡ max(xα) and α a free parameter (fixed to ∼0.11). The form of f1(x) has the usual form already used in (Balaguera-Antolínez et al. 2020), while the shape of f2, 3(x) is designed to map the (large) dynamic range spanned by the invariants I2, 3 to the interval [ − 1, 1], thus simplifying its binning. Other sets of properties, such as the eigenvalues of the tensor ∂i∂jδdm (see e.g. Peacock & Heavens 1985; Bardeen et al. 1986), can also be applied to characterise the bias of dark matter tracers (see e.g. Sinigaglia et al. 2021).
As previously mentioned, the physical motivation behind the choice of these models lies in the fact that local dark matter is not the only driver for halo clustering. Several works have already presented evidence of assembly bias in halos and galaxies (see e.g. Kauffmann et al. 1997; Sheth & Tormen 2004; Gao et al. 2005; Wechsler et al. 2006; Gao & White 2007; Croton et al. 2007; Angulo et al. 2008; Dalal et al. 2008; Faltenbacher & White 2010; Lee et al. 2017; Lazeyras et al. 2017; Montero-Dorta et al. 2017; Mao et al. 2018; Musso et al. 2018; Contreras et al. 2019; Xu et al. 2021). This type of bias not only includes the clustering of halos as a function of their intrinsic properties but also as a function of their environment (see e.g. Yang et al. 2017; Fisher & Faltenbacher 2018), a dependency that can be covered with approaches such as the TkWEB model. Furthermore, the inclusion of the mass of collapsing regions allows us to include short-range non-local bias, focusing on regions with a distinct (collapsing) dynamical state.
On the other hand, implementing the invariants of the tidal field (i.e. the IkWEB model) allows us to assess the halo bias of Eq. (1) in a more complete fashion. This can be understood from the degree of arbitrariness arising in the framework of the CWC, whose characterisation depends on the parameter λth. The invariants of the tidal field do not suffer from this freedom and therefore contain all the information in the cosmic-web decomposition. Also, and similarly important, the connection between the invariants of the tidal field and the different terms present in a perturbative approach (see e.g. McDonald & Roy 2009; Kitaura et al. 2022) allows BAM to explicitly include a non-negligible signal of non-local bias up to third order in perturbation theory, a signal that is expected to be measured in forthcoming experiments (see e.g. Goldstein et al. 2022). Finally, the TIWEB model is designed to use the information from the TkWEB, adding the information from one invariant of the tidal field or a function thereof. One such function is the so-called tidal anisotropy parameter defined as a function of the eigenvalues of the tidal field as α2 ∝ (λ1 − λ2)2 + (λ1 − λ3)2 + (λ3 − λ2)2 (e.g. Paranjape et al. 2018). This property is used in the assignment procedure for intrinsic halo properties, which is explained in Sect. 3.5.
Along with the models, the total number of bins adopted to discretise the information in the different dark matter properties (e.g. f1(δdm),Mk) is also important when assessing whether the process can fall into an over-fitting regime. This can be quantified by computing the ratio η between the total number of bins and the total number of spatial cells used in the field description of halos and dark matter. After a series of numerical tests (mainly focused on the ideal number of dark matter property bins needed to achieve the convergence of the method as explained in Sect. 2.7), we obtain η ∼ 0.02, 2.2, and 0.9, for TkWEB,IkWEB and TIWEB respectively. This implies that the IkWEB model is likely to incur overfitting6. This situation does not arise during the calibration procedure because the kernel and bias are applied to the same dark matter field from which these quantities are obtained. However, when implementing these products on independent dark matter density fields (as described in Sect. 3.2), the IkWEB model will be more sensitive to any difference in the dark matter distribution of the new field with respect to the reference. In that case, the algorithm generates biased estimates of the halo power spectrum for some realisations (e.g. those with density peaks not present in the reference), which leads to mode coupling in the covariance matrix of the power spectrum.
2.7. Learning phase: Iterative procedure and calibration of halo bias
The learning procedure in BAM is designed to generate two main outputs, namely, (i) the so-called BAM-kernel, and (ii) the corresponding (multi-dimensional) halo bias introduced by Eq. (1). The role of the halo bias is to assign the number of tracers in cells according to the underlying dark matter properties, keeping track of all the statistical anisotropies of the latter. The role of the kernel is twofold: it corrects for any effective large-scale contribution from non-local bias dependencies not accounted for in the set {Θdm}; and it also corrects for any aliasing effects caused by the representation of the DM field and the halo distribution on a mesh with respect to the original halo-finding algorithm used to construct the reference catalogue.
Let us now describe the procedure developed in the so-called learning phase of BAM. The main scope of the process is to modify the A-DMDF such that, when sampling it using the halo bias obtained with Eq. (1), we reconstruct the statistics of halo number counts to per cent precision up to the Nyquist frequency. Let us now focus on the i-th iteration: at this stage, the algorithm starts determining the properties 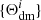 from a dark matter density field obtained as the convolution of the input A-DMDF with the so-called BAM-kernel (to be defined below) 𝒦7, which in turn is the result of the previous iteration:
from a dark matter density field obtained as the convolution of the input A-DMDF with the so-called BAM-kernel (to be defined below) 𝒦7, which in turn is the result of the previous iteration:
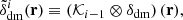 (6)
(6)
where the kernel is a Dirac’s delta function for the first iteration, and remains spherically symmetric in subsequent iterations. With this new density field, the halo bias 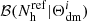 is measured using Eq. (1), and is then used to sample the density field
is measured using Eq. (1), and is then used to sample the density field 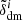 to obtain a new version of halo number counts (which we also refer to as the reconstructed field):
to obtain a new version of halo number counts (which we also refer to as the reconstructed field):
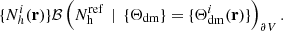 (7)
(7)
The main statistical property adopted as the target for the BAM algorithm is the halo power spectrum. This is obtained as an spherical average of the 3D Fourier transform of the new halo number count field, 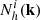 , performed in shells identified with a wavenumber kn,
, performed in shells identified with a wavenumber kn,
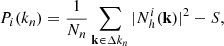 (8)
(8)
where Nn is the number of Fourier modes in the n-th shell (of width Δkn), and the sum incorporates all vector modes with magnitude in that shell. Here, 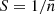 is the Poisson shot noise (Peebles 1980) of the reference halo catalogue. We then define a power transfer function,
is the Poisson shot noise (Peebles 1980) of the reference halo catalogue. We then define a power transfer function,
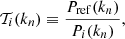 (9)
(9)
where Pref(kn) denotes the power spectrum of the reference halo catalogue (measured as in Eq. (8)). The sampling procedure of Eq. (7) is performed such that the new HDF not only contains the same number of objects as that of the reference but also shares its number-count statistics (number-count distribution function).
For each spherical shell in Fourier space, BAM implements a Metropolis-Hasting algorithm (see e.g. Heavens 2009, and references therein) to accept or reject the corresponding value of the transfer function defined in Eq. (9). As metric, BAM uses the quadratic difference between the mock and reference power spectra in units of the Gaussian variance (see e.g. Dodelson 2003) of the latter (the standardised Euclidean distance). That is, we define a mode-by-mode likelihood of the form
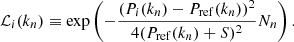 (10)
(10)
The algorithm maximises the function ℒi(kn) by accepting the new power spectrum – and therefore the corresponding transfer function 𝒯i(kn) – with a probability min(1,ℒi(kn)/ℒi − 1(kn)). If the transfer at a given mode is not accepted, the algorithm retains the previously accepted value. To express this fact, we define a set of weights ωi(kn) constructed according to the rejection criteria:
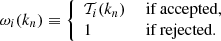 (11)
(11)
These weights are used to define (and to update) the BAM-kernel in Fourier space (which is isotropic, being only a function of kn), by making products of the weights at the current step with those from the preceding iterations (at the same shell kn):
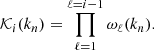 (12)
(12)
We use this new version of the kernel to convolve the input DM field, as in Eq. (6), from which a new iteration follows (in practice, the convolution with the kernel is done in Fourier-space). We note that the transfer function defined in Eq. (11) is applied to the dark matter density field, and not directly to the field we are trying to reconstruct. Hence, there is no explicit need to define it under a squared root (see e.g. Weinberg 1992).
The learning (or calibration) phase is considered to converge when the absolute residuals R, defined as
![Mathematical equation: $$ \begin{aligned} R_{i}[\%]\equiv \frac{100}{N_{\rm F}} \sum _{n=1}^{n=N_{\rm F}}|\mathcal{T} _{i}(k_{n}) -1 |, \end{aligned} $$](/articles/aa/full_html/2023/05/aa45618-22/aa45618-22-eq32.gif) (13)
(13)
(where NF is the number of spherical shells used to measure the power spectrum) reach the threshold ∼1%. We used 300 iterations, although with about 150 iterations, the calibration has already reached the sub-per cent residuals. In terms of computing time, at a 32-thread workstation, the calibration procedure (with 300 iterations) takes ∼1 h.
In order to verify that the outputs of the iterative process are independent of the realisation used as a reference, we repeated this procedure for a number of reference simulations (IC plus corresponding halo catalogues) available in the SLICS set. Figure 2 shows slices through the different density fields involved in the calibration procedure performed with one randomly selected reference simulation. In particular, we show the halo number counts on a mesh (second row) reconstructed using the three halo bias models described in Sect. 2.6.
 |
Fig. 2. Slices of 25 Mpc h−1 thick though different density fields involved in the calibration of the BAM products and its products. The bottom panel shows the reconstruction of the halo number density field using different models of halo bias (see Sect. 2.6). The rightmost column shows the galaxy density field from the reference and from BAM, built by populating halo catalogues with a model of halo occupation distribution (see Sect. 4). |
Figure 3 shows the summary statistics arising from the products of the iterative stage, using different models for the multidimensional halo bias of Eq. (1), and using one reference simulation. All the models shown are in a position to generate sub-per cent residuals in the calibration (see panel (a)) with reconstructed power spectra (panel (b)) within a 5% difference with respect to the reference (up to the Nyquist frequency). The models of halo bias shown display minor differences in their performances when explored at the level of the reconstructed power spectrum, as can be inferred from panel (c) of the previously mentioned figure, where we show the ratio of the power spectrum from the reconstructed field to that measured from the reference. It is only on the first Fourier mode that the differences with respect to the references are above 2%, while for the rest of the probed Fourier modes and up to the Nyquist frequency, the differences oscillate around ∼0.6%. We explicitly verified that similar trends are obtained when another realisation is used to perform the calibration. It is key to note that the fluctuations on large scales are not only a consequence of the small volume but are also linked to the stochastic nature of halo bias as expressed by Eq. (1).
 |
Fig. 3. Summary statistics of the calibration procedure in BAM based on one SLICS realisation. Panel (a): Residuals computed from the reference power spectrum and the halo power spectrum at different iterations within the calibration procedure. Absolute residuals (see Eq. (13)) show that the calibration leads to a precise (< 1%) reconstruction of the halo number counts and its two-point statistics, while relative values show that the deviation around the reference is randomly distributed, with a ∼0.15% amplitude. The different lines in each case show the behaviour under different models (TkWEB, IkWEB, TIWEB) of halo bias (see Sect. 2.6 for details). Panel (b) shows the power spectrum from the reconstructed halo number counts field in each of the halo models. Panel (c) shows the transfer function 𝒯i(k) computed as in Eq. (11), evaluated at the last iteration of the calibration procedure; the shaded area denotes the 3% deviation around unity. Panel (d) shows the BAM kernel computed using Eq. (12). |
The differences among the implemented models of halo bias can be observed in the shape of their corresponding kernel, as shown in panel (d) of Fig. 3. We note that the definition of the kernel implies that it does not explicitly encode any information on the anisotropies of the halo density field, which are clearly present in the large-scale distribution in the form of a filamentary structure. Indeed, the kernel in configuration space is fully symmetric, although the patterns can change according to the model of halo bias (and the type of mass-assignment scheme). The information on the anisotropies in the 3D halo distribution is instead statistically encoded in the halo bias, and as such, the model (i.e. the set of properties {Θ}) is key to reproducing higher order statistics, as we show below.
In general, the overall shape of the kernel agrees within all tested models: a constant amplitude towards large scales, with a scale dependency on small scales. The difference in the large-scale amplitude encodes the different content of information on the assembly bias8, and is accounted for as long as different non-local terms are included. That is, the higher the amount of information on halo bias, the closer the kernel is to unity on large scales. The constant amplitude of the kernel towards large scales is a property that can be used to generate mock catalogues on larger cosmological volumes. This will be the subject of forthcoming publications.
3. Construction of halo catalogues
In this section, we describe the steps followed to generate halo number counts on a cubic mesh starting from independent dark matter density fields and using the outputs described in Sect. 2.7. To compare the summary statistics of the mocks produced within BAM with those from the reference, we make all comparisons with a set of Nsim = 80 mocks. We test different models of halo bias, and based on the performance of the summary statistics obtained from the mocks constructed with these models, we adopt one of them to generate the final set of mock galaxy catalogues.
3.1. The halo bias and kernel
Based on the set of Nsim initial conditions described in Sect. 2.3, we generated the same number of realisations of (approximated) dark matter density fields 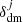 (j = 1, ⋯, Nsim) using the methods described in Sect. 2.5. These are convolved with the BAM-kernel (obtained from the learning phase, Sect. 2.7) to generate a new dark matter density field
(j = 1, ⋯, Nsim) using the methods described in Sect. 2.5. These are convolved with the BAM-kernel (obtained from the learning phase, Sect. 2.7) to generate a new dark matter density field 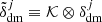 , after which the non-local properties (e.g. types of cosmic web) of the resulting field
, after which the non-local properties (e.g. types of cosmic web) of the resulting field 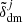 are determined. According to these properties, the algorithm populates these dark matter fields with a number of haloes in cells sampling as
are determined. According to these properties, the algorithm populates these dark matter fields with a number of haloes in cells sampling as
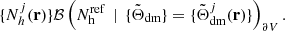 (14)
(14)
A previous analysis with BAM (Balaguera-Antolínez et al. 2019) showed that when using reference simulations probing larger cosmological volumes (e.g. approximately three times that of the SLICS), only one realisation (one member of the reference set) is sufficient to generate an ensemble of number counts with precise summary statistics (up to the four-point statistics). However, numerical tests with the current setup have shown that this procedure, which is based on one single calibration (i.e. based on a single realisation), can suffer from effects that are due to the relatively small volume of the reference simulation (cosmic variance). To circumvent this, we generalise the sampling procedure of Eq. (14) and allow each dark matter density field to be sampled with the bias and kernel independently inferred from one or more reference catalogues. That is, we calibrated Nref halo bias and kernels from the same number of SLICS references (as shown in Sect. 2.7) and constructed a total bias by ‘stacking’ the independent halo bias, along with a kernel, obtained as the average from those of each reference:
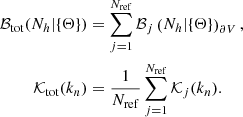 (15)
(15)
Adding the results of different calibrations as expressed by Eq. (15) is equivalent to increasing the volume of the reference simulation (keeping the same minimum tracer mass and spatial resolution) to an effective value 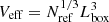 . However, we note that the stacked version of the halo bias ℬ will differ from that measured from an N-body simulation probing the volume Veff (with the same initial conditions) because of the absence of super-sample modes (e.g. Rimes & Hamilton 2006; Takada & Hu 2013) in the halo bias, with this difference manifesting as an underestimation of high-density peaks, leading to biased estimates of covariance matrices of clustering probes. This is not a problem for the present case because we apply the kernel and bias of Eq. (15) to the DM field with the volume of the reference simulation.
. However, we note that the stacked version of the halo bias ℬ will differ from that measured from an N-body simulation probing the volume Veff (with the same initial conditions) because of the absence of super-sample modes (e.g. Rimes & Hamilton 2006; Takada & Hu 2013) in the halo bias, with this difference manifesting as an underestimation of high-density peaks, leading to biased estimates of covariance matrices of clustering probes. This is not a problem for the present case because we apply the kernel and bias of Eq. (15) to the DM field with the volume of the reference simulation.
In Balaguera-Antolínez et al. (2019), it was also demonstrated that the implementation of a kernel along with its corresponding halo bias (i.e. the set of outputs obtained from the learning phase with a given IC) is key to delivering halo fields with accurate summary statistics, in particular, the covariance matrix of the power spectrum. Therefore, the implementation of Eq. (15) can be a potential source of inaccuracy because the resulting kernel 𝒦tot has not necessarily attached a halo bias represented by ℬtot. Instead, it is closer to what we can obtain using a reference simulation with fixed-amplitude initial conditions (Angulo & Pontzen 2016); that is, Eq. (15) is designed to suppress cosmic variance in the kernel while keeping it in the total halo bias. Accordingly, these two quantities are not physically (statistically) compatible because the abundance of massive halos (or high-density regions) present in the total bias is sensitive to the amount of cosmic variance of the corresponding IC (see e.g. Heß et al. 2013; Aragon-Calvo 2016), which is the same cosmic variance that an averaged kernel is designed to suppress. Keeping this in mind, we implemented Eq. (15) to assess whether or not increasing the effective volume can provide better statistics at the number-counts level. We discuss the results in the following section.
In Appendix D, we present the performance of BAM using larger cosmological simulations that were generated with an IC that was in turn generated with variance-suppressing methods (Chuang et al. 2019; Garrison et al. 2018; Maksimova et al. 2021). In forthcoming publications, we shall address this subject in more detail.
3.2. Stage II: Generation of halo number counts
According to the discussion of the previous section, we generated Nsim halo number-count fields, increasing the effective volume by a factor of 2 and 3, that is, using Nref = 23 and Nref = 33 calibrations obtained from the same number of references. To obtain a global picture of the performance of the different characterisations of the halo bias, we repeated this procedure for all the models proposed in Sect. 2.6. As an example, Fig. 4 shows a comparison between the summary statistics of 80 BAM mocks and the same number of realisations from the reference set. This shows that BAM can generate mock catalogues whose mean and variance of halo power spectrum are in 5% agreement with respect to the same statistics obtained from the reference set. We verified that similar results are obtained with the TiWEB model.
 |
Fig. 4. Power spectrum (left) and reduced bispectrum (right, isosceles configurations) computed from sets of mock halo number-count catalogues (of 80 realisations each) obtained from the calibration of BAM using the TkWEB model as described in Sect. 2.6. The first row shows the mean in each summary statistic. The second row shows the ratio of the mean statistics to that from the reference (RTRmean). The third row shows the variance in the respective statistics, and the fourth their respective ratio to the variance from the reference ensemble (RTRvar). The shaded area in the second row denotes the 5% deviation to unity. |
To further assess the level of accuracy with respect to the same statistics from the reference, we use the three-point statistics in Fourier space. In particular, we explore the reduced bi-spectrum (or hierarchical three-point amplitude) Q(θ12|k1, k2), (Peebles 1980), where θ12 is the cosine of the angle between the sides k1 and k2. We use estimates of the bispectrum to assess the precision of the method9 (see e.g. Pollack et al. 2012; Gil-Marín et al. 2012), using an isosceles configuration with k1 = k2 = 0.2h Mpc−1 as an example. We remind the reader that this quantity is not constrained in the calibration procedure and can therefore be used as a yardstick to determine which of the models (or amount of effective volume) provides the best scenario to generate mock catalogues in the form of halo number counts. In the case of the TkWEB model (Fig. 4), the signal of the reduced bispectrum is mostly within 5% of that of the reference, except for low values of θ12, where the difference can be of the order of 10%. The variance of the bispectrum for such a configuration is also within 5%−10% of that of the reference. We verified that the results based on the TIWEB model show the same general trend.
The correlation matrix 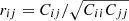 (where Cij is the covariance matrix) of the statistics under inspection (power spectrum in this case) for different halo bias models is shown in Fig. 5 along with a number of references used as training sets. In general, we can conclude that the TkWEB model generates correlation coefficients that are in good agreement with those from the reference. The TIWEB model displays extra coupling, which tends to decrease as the number of training references increases, which emphasises the need for larger cosmological volumes when one or two realisations are expected to be used as a training set and more detailed models are to be used. We have similarly verified that (as anticipated in Sect. 2.6) the IkWEB model displays strong mode coupling towards small scales even with Nref = 27, and we therefore discard it for the present applications. Such extra couplings are likely to be a consequence of the overfitting regime in which this model has been applied (as shown in Sect. 2.6), enhanced by the lack of compatibility between kernel and bias, as discussed in Sect. 3.1.
(where Cij is the covariance matrix) of the statistics under inspection (power spectrum in this case) for different halo bias models is shown in Fig. 5 along with a number of references used as training sets. In general, we can conclude that the TkWEB model generates correlation coefficients that are in good agreement with those from the reference. The TIWEB model displays extra coupling, which tends to decrease as the number of training references increases, which emphasises the need for larger cosmological volumes when one or two realisations are expected to be used as a training set and more detailed models are to be used. We have similarly verified that (as anticipated in Sect. 2.6) the IkWEB model displays strong mode coupling towards small scales even with Nref = 27, and we therefore discard it for the present applications. Such extra couplings are likely to be a consequence of the overfitting regime in which this model has been applied (as shown in Sect. 2.6), enhanced by the lack of compatibility between kernel and bias, as discussed in Sect. 3.1.
 |
Fig. 5. Correlation coefficients of the halo power spectrum obtained from a set of 80 realisations of halo number-counts using the SLICS and BAM mock catalogues, calibrated from the different number of references Nref and two characterisations of the properties of the dark matter density field (TkWEB and TIWEB). |
In terms of three-point statistics, Fig. 6 reveals that both the TkWEB and TIWEB models can generate sets of number counts whose noise in the correlation matrix of the reduced bispectrum (for isosceles configurations) qualitatively agrees with that observed from the reference simulation, especially Nref = 27. Figure 7 complements the presentation of the performance of the statistical properties of the halo mocks by showing the behaviour of the reduced bispectrum – in several configurations (using the TkWEB with Nref = 27) – in response to the corresponding signal from the reference: the left column shows ratios of the mean (solid lines) and variance (dashed lines) of the BAM ensemble to the results from the SLICS; the BAM mocks reproduce the mean reduced bispectrum, with average deviations (computed over the θ12-range) of ∼7%, while the variance shows an average deviation of ∼2% with respect to the reference. We expect that the implementation of improved gravity solvers, which provide a more accurate description of the underlying DM field (e.g. Kitaura et al. 2023), will help to reduce the difference in the mean signal.
 |
Fig. 6. Same as Fig. 5 but for the reduced bispectrum of dark matter halos using isosceles configuration k1 = k2 = 0.2 h Mpc−1. |
The right column of Fig. 7 shows two elements of the correlation matrix of the reduced bispectrum as obtained from the reference (solid lines) and the BAM set (dashed lines), showing that in general, the BAM approach is able to replicate the noise in the correlation matrix of three-point statistics (in real space).
 |
Fig. 7. Comparison of the signal of reduced bispectrum obtained from 80 mock catalogues generated with BAM (using the TkWEB model) and the same signal from the reference set, for several triangle configurations, which are specified in each panel. The left column shows the ratio to the reference (RTF) of the mean (solid lines) and variance (dashed lines); the shaded areas in the panels of this column denote a 20% deviation from unity. The right column shows two elements of the correlation coefficients of the bispectrum rij. |
Based on these results, we adopt the TkWEB model to generate independent realisations of halo number counts; this model will be used to generate the final set of halo catalogues as described in the following section. We used Nref = 27 references, but note that this particular model is already good enough to allow us to use the calibration from only one reference simulation.
3.3. Stage III-a: Assignment of halo coordinates
To transform the set of number counts obtained in Sect. 3.2 into an ensemble of discrete tracers, we assign coordinates and velocities following the approach of Kitaura et al. (2016), which consists in using the phase-space coordinates of dark matter particles generated by the approximated gravity solver (Sect. 2.5). The sampling of the halo number counts field is complemented with a set of random tracers (e.g. tracers with random coordinates within each cell), which are used when, at a given cell, the number of halos requested is larger than the available number of dark matter particles. The fraction of such random tracers depends on the redshift of the reference, and for the current setup represents ∼20% of the total number of tracers.
We use dark matter particles to sample the halo number count field in an attempt to maintain a precise clustering signal on scales below the fiducial cell size. As the randomly distributed tracers impact the shape of the power spectrum when analysed at higher Nyquist frequencies, BAM introduces a subgrid modelling based on the collapse of the random tracers towards their closest DM particles. This collapse is modulated by a fraction fcol of the separation between each random tracer and its nearest DM particle. That is, for a separation between a random particle and its closest DM particle dr, we displace the former towards the latter such that their new separation is the product fcoldr. This is depicted in Fig. 8. Numerical experiments (some of which are discussed in Appendix D) have shown that this parameter depends on the redshift and the nature of the approximated gravity solver (Balaguera-Antolínez et al., in prep.). For the current setup, fcol ∼ 0.35 provides a good description of the halo power spectrum. Furthermore, the parameter fcol can be generalised to depend on halo properties once these are assigned (Sect. 3.5).
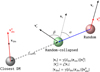 |
Fig. 8. Subgrid modelling for the assignment of coordinates in phase space. The coordinates of the random tracers are modulated by the fraction fcol such that if dr denotes the separation between the random particle and its closest dark matter particle, the new separation is fcoldr. Velocities are modified in two steps: (i) an isotropic density-dependent correction γ(δdm) is applied to the velocities of both random tracers and dark matter tracers ( |
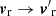
The panel (a) of Fig. 9 shows the mean real-space power spectrum obtained from an ensemble of 80 BAM halo catalogues with coordinates assigned as previously described. Each realisation is embedded in a 4003 cubic mesh using the triangular-shaped-cloud interpolation scheme (Hockney & Eastwood 1988)10. Panel (b) shows that the accuracy of the mean power from the BAM (with respect to the SLICS) is below 3% up to k ∼ 0.4 h Mpc−1.
 |
Fig. 9. Power spectrum of halo catalogues in real space P(k), (panels (a) and (b)) and redshift space, with the latter represented by the monopole P0(k), (panels (c) and (d)), the quadrupole P2(k), (panels (e) and (f)), and the hexadecapole P4(k), (panels (g) and (h)). Panels (a), (c), (e), and (g) show the mean power spectrum from the 80 SLICS realisations (grey dashed line) and the mean from the same number of BAM mocks (solid blue lines). Panels (b), (d), and (f) show the ratio (RTR) of the BAM mean spectrum to that of the reference. The shaded areas denote the standard deviation computed from the mean and variance of each set. |
3.4. Stage III-b: Assignment of halo velocities
The displacement obtained with ALPT (see Eq. (5)) provides the velocities of dark matter particles at their Eulerian coordinates r:
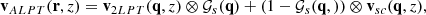 (16)
(16)
where the 2LPT velocity field is written as (see e.g. Buchert & Ehlers 1993; Kitaura et al. 2014)
![Mathematical equation: $$ \begin{aligned} \nonumber {\mathbf{v}}_{2LPT}({\mathbf{q}},z)=\left[-f^{(1)}D^{(1)}\nabla _{{\mathbf{q}}}\phi ^{(1)}({\mathbf{q}})+f^{(2)}D^{(2)}\nabla _{{\mathbf{q}}}\phi ^{(2)}({\mathbf{q}})\right]Ha. \end{aligned} $$](/articles/aa/full_html/2023/05/aa45618-22/aa45618-22-eq42.gif)
In this expression, f(i) ≡ f(i)(z) = dlnD(i)(a)/dlna are the growth indices computed as f(1)(z)∼Ωmat(z)5/9 and f(2)(z)∼2Ωmat(z)6/11 (see e.g. Lahav et al. 1991). The velocity field associated with the SC model is analogously derived as vsc(q, z) = ∇ψSC(q, z), where ψSC(q, z) is the solution of the Poisson equation
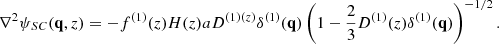
We assign peculiar velocities to dark matter halos in two steps. First, we generate a velocity field in Eulerian space using the velocities computed with Eq. (16) and implement an NGP interpolation scheme. It is well known that this kind of approach introduces sampling artefacts due to the fact that it relies on the particles to generate the velocity field (see e.g. Zheng et al. 2013; Zhang et al. 2015), which means cells without tracers are incorrectly assigned a null velocity. Alternatives such as the ‘nearest point’ (see e.g. Zhang et al. 2015; Chen et al. 2018) or more sophisticated algorithms such as the Delaunay Tesselation (see e.g. Romano-Díaz & van de Weygaert 2007) or the Kriging scheme (see e.g. Yu et al. 2015) are designed to reduce the spurious bias introduced by these sampling artefacts. We implement a hybrid approach and use NGP as the primary method, assigning to empty cells the average velocity computed from the first neighbour cells. A second step consists of a trilinear interpolation of the resulting velocity field at the position of both dark matter particles and random tracers (introduced in the previous section).
Figure 10 shows an example of the resulting distribution of the modulus of the halo peculiar velocity v = |v| from one realisation of SLICS and BAM sets (sharing the same seed). One strong feature arising from this comparison is the difference in the abundance (in terms of v) towards high velocities: above ∼300 km/s the abundance from the BAM halos (i.e. ALPT) is, in general, underestimated with respect to the reference. To correct this deviation, we introduce an isotropic correction to the i-th component of the velocity of each particle in the form 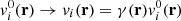 , where γ(r) = (1 + δdm(r))α. Numerical experiments have revealed that α ∼ 0.2 leads to good agreement in the halo velocity distribution, as is also presented in Fig. 10. We verified that this correction is indeed needed to obtain the good agreement between the clustering signal of the BAM mocks and that from the reference. We speculate that the origin of this correction is linked to the lack of small-scale modelling of coherent flows in ALPT combined with the resolution used in the analysis. A more detailed analysis (exploring e.g. redshift and cosmology dependencies) will be presented in future publications.
, where γ(r) = (1 + δdm(r))α. Numerical experiments have revealed that α ∼ 0.2 leads to good agreement in the halo velocity distribution, as is also presented in Fig. 10. We verified that this correction is indeed needed to obtain the good agreement between the clustering signal of the BAM mocks and that from the reference. We speculate that the origin of this correction is linked to the lack of small-scale modelling of coherent flows in ALPT combined with the resolution used in the analysis. A more detailed analysis (exploring e.g. redshift and cosmology dependencies) will be presented in future publications.
 |
Fig. 10. Example of the distribution of halo peculiar velocities v = |v| in one reference (solid black histogram) and one BAM (solid blue and filled histogram) halo catalogue, in different types of cosmic web (see Sect. 3.3). In all panels, the corrected histogram is obtained after applying the isotropic velocity correction described in Sect. 3.3. |
The second correction to the velocities is applied as part of the subgrid modelling, focusing again on the random tracers (as depicted in Fig. 8). In this case, along with the collapse towards the closest dark matter tracer (discussed in the previous section), we induce a rotation (or collapse) of the random velocities, modifying its orientation (through an angle β) and magnitude (through a parameter ζ), which can be a function of the tracer properties or local density. In this work, we empirically set this parameter to β = (1 − fcoll)(π − α) if α < π, and β = (1 − fcoll)(α − π) if α ≥ π, with ζ = 1; that is, we apply a rotation to the velocity vector to align it with the axis connecting the random particle and the dark matter particle, keeping its magnitude fixed. We verified that the effect of β ≠ 0 helps to improve the signal in redshift space towards small scales and leave a thorough study of their impact in the velocity field to a future study.
The performance of the velocity assignment in terms of the two-point statistics is presented in panels (c) to (h) of Fig. 9, where we show the mean halo power spectrum in redshift space. This signal is obtained by transforming the halo coordinates (x, y, z) along a line-of-sight axis (taken to be one of the three Cartesian coordinates, e.g. the z-direction) using the distant observer approximation to its redshift coordinate via z → s = z + vz/(aH(a)), (see e.g. Kaiser 1987). The clustering in this space is summarised through the Legendre decomposition which, according to the distant observer approximation, can be measured as (see e.g. Hamilton 1998)
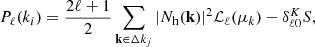 (17)
(17)
where the sum denotes averages in spherical shells, 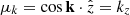 , |Nh(k)|2 is the three-dimensional halo power spectrum, ℒℓ(x) is the Legendre polynomial of order ℓ, and S is the Poisson shot noise (as in Eq. (8)). We measure the monopole (ℓ = 0), the quadrupole (ℓ = 2), and the hexadecapole (ℓ = 4) as main statistical probes of redshift-space distortions.
, |Nh(k)|2 is the three-dimensional halo power spectrum, ℒℓ(x) is the Legendre polynomial of order ℓ, and S is the Poisson shot noise (as in Eq. (8)). We measure the monopole (ℓ = 0), the quadrupole (ℓ = 2), and the hexadecapole (ℓ = 4) as main statistical probes of redshift-space distortions.
In general, the redshift-space power spectrum probed on scales up to k ∼ 0.4h Mpc−1 agrees within the 1σ uncertainty region with that of the reference, as is demonstrated by panels (c) to (h) in Fig. 9. Figure 11 shows the correlation coefficient of the halo power spectrum in real and redshift space computed from the halo distribution. The bottom panels of Fig. 11 show two elements of the correlation matrix, which reveal good agreement between the two compared sets, both in terms of the width of the correlation coefficients and the underlying noise. We verified that this agreement is also observed when using BAM realisations with seeds different from those of the reference set.
 |
Fig. 11. Correlation matrix of halo power spectrum with BAM. Top row: Correlation matrix |
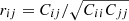
3.5. Stage III-c: Assignment of halo properties
Given that the BAM mock halo catalogues are to be considered as the building blocks of galaxy catalogues (though with the implementation of an HOD model), the BAM algorithm pays special attention to the assignment of halo properties such as the virial mass Mvir and the velocity dispersion σv. This step is indeed a critical and far-from-trivial task within the construction of BAM mock catalogues (Balaguera-Antolínez et al., in prep.), given that a simultaneous generation of precise clustering and halo properties would imply the assessment of the distribution of pairs in all possible bins of halo properties, a computation which goes openly against the need for speed in the generation of mock catalogues.
The procedure encoded in BAM finds its motivations in early methods developed by Zhao et al. (2015; see also Chuang et al. 2015a), which were envisaged to generate luminous red galaxy catalogues (see e.g Kitaura et al. 2016; Rodríguez-Torres et al. 2016). Those algorithms used the properties of the underlying dark matter density field, as in BAM. However, BAM takes the method to a greater level of detail, in which more properties of the dark matter and dark matter tracers are considered.
The assignment procedure in BAM (see Fig. 1) relies on a hierarchical approach in which a ‘main property’ is defined and assigned, followed by the assignment of secondary properties using the scaling relation with respect to the main property. To determine the main property, different options can be considered; for example, selecting the halo property with the tightest correlation with the underlying dark matter density field, or choosing the halo property that drives the main dependencies in the HOD framework. The latter option would lead us to treat the virial mass Mvir as the main property (which mainly determines galaxy number-count statistics in the HOD framework), followed by the velocity dispersion (which dictates the redshift space distribution of satellite galaxies). Nevertheless, given that BAM is designed to explore environmental dependencies (defined through the dark matter density field), we select the first option. Accordingly, while the correlation between virial mass and local dark matter density is ∼28%, the velocity dispersion displays tighter correlations (∼58%) with the local dark matter density. This is not surprising, as quantities directly derived from the dynamical properties of the dark matter particles in halos trace the depth of the potential wells very well (see Appendix A) and are less prone to ambiguities typical of the definition of the mass of a dark matter halo (see e.g. Skibba & Macciò 2011; Zehavi et al. 2019). In Appendix B, we describe the methodology implemented for the assignment of properties within BAM. Figure 12 shows the correlation between different halo properties with respect to the underlying dark matter density field, again for different cosmic-web types. We verified that the scaling relations between virial mass and velocity dispersion show an acceptable level of agreement with those from the reference set.
 |
Fig. 12. Joint probability distribution ℬ(x, δdm) of halo properties x (number counts, virial mass and velocity dispersion) and the underlying dark matter density, interpolated on a 1923 mesh using a CIC mass-assignment scheme and for different cosmic-web environments. Solid lines (and coloured regions) denote contours enclosing 98% and 68% of the total number of cells in a reference SLICS simulation. Dotted lines represent the same quantity obtained from one BAM halo catalogue. |
3.6. Results
Figure 13 shows the halo abundance as a function of the two assigned halo properties from a set of 80 realisations of BAM and the same number of SLICS simulations. We see good agreement in general, but this agreement partially breaks down for tracers with high velocity dispersion in low-density regions (voids) where BAM overestimates the abundance in terms of that particular property.
 |
Fig. 13. Cumulative halo abundance as a function of virial mass Mvir (left column) and velocity dispersion σv (right column) obtained in different cosmic-web types (normalised to the number of halos in each cosmic-web type). Error bars indicate the mean and standard deviations computed from 80 realisations. |
Similarly, we also verified that the multi-scaling approach generates better results than a direct assignment of properties. Although this approach naturally goes towards solving the problem of halo exclusion, it relies on the specification of the different thresholds, and we checked that the precision of the mean power spectrum of halos is sensitive to such figures, especially on the high-mass halo population. New alternatives are being explored and will be presented in forthcoming publications.
Figure 14 shows the ratio between the mean power spectra from the BAM set and that from the SLICS, both in real and redshift space and in three disjoint halo-mass bins. The area around that curve denotes the standard deviation. In general, the trend shown as a function of the halo mass is similar in the two sets of mock catalogues. However, closer inspection reveals ∼5% deviations towards small scales both in real and redshift space, and in particular, for the most massive halos.
 |
Fig. 14. Ratio (ratio-to-reference) between the mean power spectrum from the set of 80 BAM mock halo catalogues and that obtained from the same number of SLICS catalogues, both in real and redshift space (monopole ℓ = 0, quadrupole ℓ = 2, hexadecapole ℓ = 4), in three bins of halo virial mass. The shaded areas denote the 1σ region (standard deviation) computed from the means and their respective errors. |
Figure 15 shows the variance (left column) and correlation matrix (right column) of the halo power spectrum in real and redshift space for the full halo population. We can read from this figure that in real space, the BAM mocks display a closer correlation between modes on small scales compared to the reference simulation. The situation is mildly better in redshift space, where indeed the correlation matrix for the quadrupole agrees to a greater extent with the SLICS simulations. The most significant discrepancy appears when exploring the clustering as a function of the halo mass. In particular, high-mass halos display covariance matrices of the power spectrum with a strong mode coupling. Such coupling comes from realisations where the power spectra deviate considerably from the expected mean of the ensemble (i.e. that from the reference suite). These discrepancies originate from two different aspects of the BAM approach. On one hand, the assignment of halo properties turns out to be complex, especially for massive objects, where effects such as halo exclusion (see Appendix A) are not fully modelled. On the other hand, the deviations seen in redshift space are inherited from those in real space, plus any remaining deviation from the true halo velocity field from the velocity field generated from the ALPT. These two aspects mean that there is room for improvement in the assignment of coordinates, velocities, and properties of the halo population, especially towards small scales.
 |
Fig. 15. Correlation matrix of power spectrum. Left column: Ratio between the variance of the power spectrum from the BAM mocks and that measured from the SLICS in different halo-mass bins. Right column: Correlation coefficients obtained from the BAM mock halo catalogues and the SLICS references computed in real and redshift space, with the latter expressed through the monopole P0(k), the quadrupole P2(k), and the hexadecapole P4(k). Three bins of halo mass are shown (rows). |
With the procedures described in the previous sections, we generated 770 mock halo catalogues based on the same number of initial conditions. One of the great advantages of the method is the small computing-time requirements: the generation of this set of halo catalogues was achieved in ∼2 days (∼4 min per mock) using a work station with 128 threads and 256 Gb of random access memory (RAM).
4. Stage IV: Construction of galaxy catalogues
One of the main advantages of BAM is its capability to provide catalogues of different dark matter tracers, all sharing the same underlying dark matter and halo distribution. This is key to providing covariance matrices for multi-tracer analysis (see e.g. Hamaus et al. 2012; Abramo & Leonard 2013; Abramo et al. 2016; Wang & Zhao 2020; Zhao et al. 2021). While this is not a unique feature of this method (see e.g. Zhao et al. 2021), it represents an improvement over approaches that need to be calibrated with a particular galaxy population.
To assign galaxies to the dark matter halos of BAM, we implemented the HOD prescription based on the high-mass quenched model (see e.g. Alam et al. 2020), which describes the abundance of emission line galaxies (ELGs) in dark matter halos (see e.g. Gonzalez-Perez et al. 2018). This model suppresses the probability for the central ELG galaxies to be found in very massive dark matter halos. In particular, the probability that a halo of mass Mvir hosts a central ELG is expressed as
![Mathematical equation: $$ \begin{aligned} \langle N_{\rm c}|M_{\rm vir}\rangle = A\phi (M_{\rm vir})\Phi (\mathcal{M} ) +\frac{1}{2Q}\left[1+\mathrm{erf} \left( \log _{10} \left[\frac{M_{\rm vir}}{M_{c}}\right]^{1/\sigma _{M}} \right) \right] ,\end{aligned} $$](/articles/aa/full_html/2023/05/aa45618-22/aa45618-22-eq48.gif) (18)
(18)
where ϕ(x) = 𝒩(log10Mc, σM), ℳ ≡ γMvir, 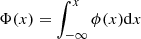 and A = 2(pmax − 1/Q)/max(2ϕ(x)Φ(x)). Here, Q denotes the quenching efficiency, pmax controls the saturation level of occupancy, and Mc is the cut-off mass for ELGs, which determines the maximum of the occupation distribution. The number of ELG satellites is generated from a Poisson realisation with a mean modelled as a power law with a lower cut-off:
and A = 2(pmax − 1/Q)/max(2ϕ(x)Φ(x)). Here, Q denotes the quenching efficiency, pmax controls the saturation level of occupancy, and Mc is the cut-off mass for ELGs, which determines the maximum of the occupation distribution. The number of ELG satellites is generated from a Poisson realisation with a mean modelled as a power law with a lower cut-off:
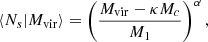 (19)
(19)
where M1 is a characteristic satellite mass, while the parameter κ defines a cut-off mass (in units of Mc) below which the occupancy of satellites drops to zero. The satellites are distributed within dark matter halos following an NFW density profile (Navarro et al. 1996). On the other hand, the random components of the velocities of the satellite galaxies are derived from a normal distribution, vs ↶ 𝒩(0, σv). The total velocity of the satellite galaxies is then given by the sum of the halo peculiar velocities of the parent halos and the random component. The velocities of the central galaxies are the same as those of their parent halos.
The HOD prescription of Eqs. (18) and (19) has been simultaneously applied to the SLICS and BAM halos to obtain their respective galaxy catalogues (see Alam et al. 2020, for the set of parameter {Q, γ, Mc, κ, α, σM, M1}). The performance of the BAM galaxy mocks in terms of the galaxy occupation distribution is presented in Fig. 16, where we observe how the larger deviations with respect to the reference are embodied in the satellite population at the high-halo mass end (∼60% difference at Mvir ∼ 4 × 1014 M⊙h−1, mass scale below which ≥99% of the sample is contained).
 |
Fig. 16. Mean number of galaxies (central and satellite) from the BAM and SLICS ensembles as a function of host halo mass. The points with error bars denote the mean and variance from each ensemble. |
Let us now summarise the performance of the mock galaxy catalogues produced with BAM through the assessment of different statistical probes.
Fourier space. Figure 17 shows the ratio of the mean power spectrum of galaxies in BAM with respect to the signal from the same type of populations in the reference simulation, both in real and redshift space. The most noticeable difference in real space comes from the clustering of satellites, which on small scales directly probes the density profile of the dark matter halo (see e.g. Cooray & Sheth 2002). As the two sets of mocks share the same density profile (by construction), the differences in the clustering pattern can be traced back to the assignment of halo masses, as this is a key property shaping the mass – concentration relation.
Similarly inherited from the parent halo population, the galaxy redshift-space power spectrum displays a lack of power towards small scales. We note that, contrary to the halo population in which such deviations can be solely tackled from the velocity field of the approximated gravity solver, at this stage we must also add – in addition to the velocity field of the dark matter particles – information on the halo properties used to derive galaxy coordinates in phase space.
Figures 18–20 show the variance and the correlation matrix of the mock galaxy catalogues, split into the two types of population and into different bins of (host) halo mass. In general, the covariance matrices show good agreement with the reference. The extra correlation in the high-halo-mass bins is inherited from the parent halo distribution but is only embodied within the statistics of the satellite population. The behaviour of the correlation matrices for central galaxies (in all host-mass bins) contrasts with that from the parent halo distribution, as it lacks the extra mode coupling presented in Fig. 19. The reason for this is that, as pointed out above, the HOD model applied here suppresses the abundance of central ELGs in high-mass halos, which negates the possible deviations coming from the combination of cosmic variance and inaccuracies in the kernel–bias connection (see Sect. 2).
Configuration space. We measure the standard correlation function (Peebles 1980) in real and redshift space (the latter similarly represented by the multipole decomposition) based on the natural estimator (e.g. Kerscher et al. 2000) ξ(s, μ)+1 = DD(s, μ)/RR(s, μ)11, where DD(s) (RR(s)) is the number of (random) galaxy pairs at a separation s in redshift space, and 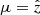 (according to the distant observer approximation; see Sect. 3.4). The multipoles of the two-point correlation function are obtained as a Legendre decomposition, in analogy to Eq. (17). Figure 21 shows the comparison of the two-point correlation function of the two data sets (see e.g. Favole et al. 2017, for a clustering analysis of ELGs). The picture observed in Fourier space (see Fig.17) is replicated here, in which a systematic bias (∼5%) can be seen in the quadrupole, albeit not statistically significant. The real space correlation function and its monopole in redshift space agrees very well with that of the reference. It is of paramount relevance for the quality validation of this suite to show how the position and the amplitude of the baryonic acoustic peak is well preserved in the BAM mocks.
(according to the distant observer approximation; see Sect. 3.4). The multipoles of the two-point correlation function are obtained as a Legendre decomposition, in analogy to Eq. (17). Figure 21 shows the comparison of the two-point correlation function of the two data sets (see e.g. Favole et al. 2017, for a clustering analysis of ELGs). The picture observed in Fourier space (see Fig.17) is replicated here, in which a systematic bias (∼5%) can be seen in the quadrupole, albeit not statistically significant. The real space correlation function and its monopole in redshift space agrees very well with that of the reference. It is of paramount relevance for the quality validation of this suite to show how the position and the amplitude of the baryonic acoustic peak is well preserved in the BAM mocks.
 |
Fig. 21. Galaxy correlation function in real space ξ(r), (top panel) and redshift space in the form of monopole ξ0(s), quadrupole ξ2(s), and hexadecapole ξ4(s). The solid line and shaded area denote the mean and sample variance from the SLICS simulation, respectively. |
Marked statistics. We can jointly assess the clustering properties and the quality of the assignment of halo properties using marked statistics in Fourier space (see e.g. Balaguera-Antolínez 2014) or in configuration space (see e.g. Sheth 2005; Sheth et al. 2005; Skibba et al. 2006; Satpathy et al. 2019). The marked correlation function can be regarded as a measure of the clustering of a given property (mark), defined as ℳα(s) = WWα(s)/DD(s) where WWα(s) represents the count pair of galaxies weighted with a given property α at separation s. Figure 22 shows the galaxy marked correlation function in real and redshift space, using the halo mass and velocity dispersion as marks, as obtained from the two suites of mocks. In general, the trend followed by the measurements from the two ensembles is consistent, showing how the BAM mocks can properly encode the information of galaxy bias as a function of different properties. Statistically significant differences are sizable when the halo mass is marked under inspection, especially on small separations, evidencing the trends observed in terms of the power spectrum of Fig. 17.
 |
Fig. 22. Galaxy marked correlation in real ℳ(r) and redshift space ℳ(s). The top panel show the result of using the halo virial mass as the mark. The middle panel uses the velocity dispersion and the third shows the results of using the cross-marked correlation function. |
Statistical compatibility with the reference suite. We verified the statistical compatibility between the two sets of mock catalogues by means of a Kolmogorov-Smirnov test (e.g. Press et al. 2002) based on the χ2 distributions of power spectra. The test, displaying p-values of ∼0.3, forecasts precise and accurate results (compared to those obtained from the reference N-body simulation) when the set of BAM mocks are subject to likelihood analysis (Chuang et al., in prep.).
The main body of this paper is devoted to the construction of galaxy catalogues based on the generation of halo catalogues endowed with intrinsic properties (such as virial mass and velocity dispersion) to which an HOD prescription is applied. This procedure allows us to discriminate between central and satellite galaxies, and paves the way towards the assignment of galaxy properties by linking them with the properties of their host halos (see e.g. de Santi et al. 2022). Nevertheless, if the main goal is to generate galaxy catalogues without further properties, we could similarly have applied the BAM machinery directly using a set of reference galaxy catalogues as the training set. In Appendix C, we discuss this option and present the results of such a direct approach.
5. Discussions and conclusions
In this paper, we present the construction of mock galaxy catalogues based on the bias assignment method (BAM), (Balaguera-Antolínez et al. 2019). We used the initial conditions of the reference N-body simulation (the SLICS simulation) Harnois-Déraps et al. (2018), down-sampled, and evolved it using augmented Lagrangian perturbation theory (Kitaura & Hess 2013). This approximated density field is accurate enough at scales of ∼0.4 h−1Mpc to robustly study the bias relation between the cosmic web and the halo number counts. The remaining differences between the approximate gravity solver and the exact solution from an N-body simulation (on scales above the mesh resolution) are automatically taken into account in the effective halo bias extracted from the reference simulation. In particular, the approximated density field is used along with the corresponding halo catalogue reference N-body simulation to iteratively learn the halo bias and a kernel, which are the main outputs of the learning phase of the method. We show how the characterisation of the halo bias as a function of cosmic-web type and the implementation of a number of realisations as a training data set (so as to increase the effective volume of the reference simulation) can generate ensembles of independent realisations of halo number counts with ∼2%−5% precision in the two- and three-point statistics, as well as in the variance obtained from the corresponding covariance matrices.
We describe a procedure to assign halo coordinates, velocities, and intrinsic properties, with the aim being to generate a set of 770 dark matter halos with the same number of properties as in the reference set. We assigned velocity dispersion and virial mass following a hierarchical and multi-scaling approach (see Sect. 3.5) designed to replicate the abundance as a function of these properties. The halo two-point statistics replicates that of the reference with 5% precision at k ∼ 0.4h Mpc−1, which is the maximum wave number adopted by the DESI mock challenge. We verified that covariance matrices of the two- and three-point statistics measured from the mock catalogues generated by BAM are in good qualitative agreement with those obtained from the reference N-body simulation. A thorough likelihood analysis using these covariance matrices will be performed by Chuang et al. (in prep.) as part of the DESI mock comparison project.
Based on this set of halo catalogues, we generated the same number of galaxy catalogues using an HOD prescription designed to replicate the abundance of emission-line galaxies. It is important to stress that the same HOD parameters were applied to both BAM and the N-body-based halo catalogues. The goodness of the suite of mocks is assessed not only in Fourier space but also in configuration space through the correlation function and the marked correlation function.
Despite the good performance of the method in terms of the different statistical probes explored, we identified a number of items in which BAM has to be improved to reduce the deviations observed with respect to a reference simulation. These are:
-
Peculiar velocities. Along with the density-dependent bias correction (described in Sect. 3.4), the small-scale clustering signal in redshift space demands the further treatment of the peculiar velocities. This treatment starts with a thorough analysis of the velocity assignment, especially for random tracers, as shown in Fig. 8. Generalisations of such an approach to taking into account halo properties and/or modification of the full population (dark matter and tracers) are part of this task. A deeper understanding of the origin of the different corrections in the velocities applied in this work is to be addressed in forthcoming publications.
-
Assignment of halo properties. A thorough approach to this task is to impose the pair distribution of tracers as a function of the different halo properties. However, this is a highly expensive task. Although the multi-scale algorithm described in Appendix B is an improvement with respect to previous algorithms, further developments need to be investigated and implemented. To that end, we are currently including a second learning phase and using marked statistics as the main diagnosis. The goal is to replicate the clustering pattern observed in the reference as a function of all halo properties.
In general, the accurate performance of BAM does not only depend on these planned improvements. It is also complemented by the characteristics of the reference simulation used as the training data set. The SLICS, with a relatively small cosmological volume, and initial conditions generated from Gaussian random fields, is highly prone to cosmic variance. This is reflected in the limited statistical information contained in a halo bias obtained from only one reference, which in turn can lead to inaccuracies in the generation of mock halo catalogues with different seeds. To take this into account, we pushed the method to the implementation of more than one reference simulation (see Eq. (15)) as the training data set.
In Appendix D, we describe our motivation to implement a reference simulation based on initial conditions with variance suppression (fixed amplitude initial conditions; see e.g. Angulo & Pontzen 2016; Chuang et al. 2019; Maion et al. 2022) covering larger cosmological volumes. This scenario can substantially improve the accuracy in the two- and three-point statistics, as well as the procedure to assign halo properties. Such a setup will also allow the method to extrapolate the generation of mock catalogues to volumes larger than that of the reference.
The present paper demonstrates the potential of BAM to speedily deliver mock halo catalogues – with a number of properties – that are both flexible and accurate enough to implement any mechanism to generate galaxy samples within the context of the halo model. The next step is the generation of larger sets of mock halo catalogues (larger cosmological volumes and light cones) with more halo properties (e.g. spin, concentration, maximum circular velocity) on which different methods for galaxy occupation and selection functions can be imposed to replicate the sky observed by different experiments.
This same resolution is adopted by EZmocks for the same DESI comparison project.
This corresponds to the available number of initial conditions with the corresponding halo catalogues, and represents a reasonable number of realisations to compute covariance matrices for comparison purposes.
The reason behind this figure is explained in Sect. 3.2.
We verified that smoothing scales in the range 10 − 20 Mpc h−1 lead to consistent results.
In this work, we use λth = 0.
Typically, for the TkWEB model, we use approximately 200 bins for the local density f1(δdm), about 200 bins for Mk, and the four types of cosmic web.
We use the same symbol for its Fourier or configuration space representation.
In this context, we use ‘halo assembly bias’ to refer to the clustering signal that is dependent on all possible effects not included within the description of halo bias of Sect. 2.6.
We used the code bispect https://github.com/cheng-zhao/pyEZmock
All power spectra are computed using the COPOWER code, https://github.com/balaguera/COPOWER
We measure the correlation function using the publicly available code at https://github.com/cheng-zhao/FCFC, Zhao et al. (2021).
Acknowledgments
We would like to thank Joachim Harnois-Deraps for making public the SLICS data, available at http://slics.roe.ac.uk/. ABA and FSK acknowledge the IAC facilities and the Spanish Ministry of Economy and Competitiveness (MINECO) under the Severo Ochoa program SEV-2015-0548, PID2020-120612GB-I00 and CEX2019-000920-S grants. FSK also thanks the RYC2015-18693 grant. ABA wishes to give deep thanks to Olga Alemán for her continuous support during this work. This research is supported by the Director, Office of Science, Office of High Energy Physics of the U.S. Department of Energy under Contract No. DE-AC02-05CH11231, and by the National Energy Research Scientific Computing Center, a DOE Office of Science User Facility under the same contract; additional support for DESI is provided by the U.S. National Science Foundation, Division of Astronomical Sciences under Contract No. AST-0950945 to the NSF’s National Optical-Infrared Astronomy Research Laboratory; the Science and Technologies Facilities Council of the United Kingdom; the Gordon and Betty Moore Foundation; the Heising-Simons Foundation; the French Alternative Energies and Atomic Energy Commission (CEA); the National Council of Science and Technology of Mexico (CONACYT); the Ministry of Science and Innovation of Spain (MICINN), and by the DESI Member Institutions: https://www.desi.lbl.gov/collaborating-institutions. The authors are honored to be permitted to conduct scientific research on Iolkam Du’ag (Kitt Peak), a mountain with particular significance to the Tohono O’odham Nation.
References
- Abel, T., Hahn, O., & Kaehler, R. 2012, MNRAS, 427, 61 [Google Scholar]
- Abramo, L. R., & Leonard, K. E. 2013, MNRAS, 432, 318 [NASA ADS] [CrossRef] [Google Scholar]
- Abramo, L. R., Secco, L. F., & Loureiro, A. 2016, MNRAS, 455, 3871 [NASA ADS] [CrossRef] [Google Scholar]
- Agrawal, A., Makiya, R., Chiang, C.-T., et al. 2017, J. Cosmol. Astropart. Phys., 2017, 003 [CrossRef] [Google Scholar]
- Ahn, K., Iliev, I. T., Shapiro, P. R., & Srisawat, C. 2015, MNRAS, 450, 1486 [CrossRef] [Google Scholar]
- Alam, S., Peacock, J. A., Kraljic, K., Ross, A. J., & Comparat, J. 2020, MNRAS, 497, 581 [NASA ADS] [CrossRef] [Google Scholar]
- Alam, S., Arnold, C., Aviles, A., et al. 2021, J. Cosmol. Astropart. Phys., 2021, 050 [CrossRef] [Google Scholar]
- Alexander, D. M., Davis, T. M., Chaussidon, E., et al. 2023, AJ, 165, 124 [NASA ADS] [CrossRef] [Google Scholar]
- Allende Prieto, C., Cooper, A. P., Dey, A., et al. 2020, Res. Notes Am. Astron. Soc., 4, 188 [Google Scholar]
- Amendola, L., Appleby, S., Avgoustidis, A., et al. 2018, Liv. Rev. Relativ., 21, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Angulo, R. E., & Pontzen, A. 2016, MNRAS, 462, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Angulo, R. E., Baugh, C. M., & Lacey, C. G. 2008, MNRAS, 387, 921 [NASA ADS] [CrossRef] [Google Scholar]
- Aragon-Calvo, M. A. 2016, MNRAS, 455, 438 [CrossRef] [Google Scholar]
- Avila, S., Murray, S. G., Knebe, A., et al. 2015, MNRAS, 450, 1856 [NASA ADS] [CrossRef] [Google Scholar]
- Balaguera-Antolínez, A. 2014, A&A, 563, A141 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Balaguera-Antolínez, A., Sánchez, A. G., Böhringer, H., & Collins, C. 2012, MNRAS, 425, 2244 [NASA ADS] [CrossRef] [Google Scholar]
- Balaguera-Antolínez, A., Kitaura, F.-S., Pellejero-Ibáñez, M., Zhao, C., & Abel, T. 2019, MNRAS, 483, L58 [CrossRef] [Google Scholar]
- Balaguera-Antolínez, A., Kitaura, F.-S., Pellejero-Ibáñez, M., et al. 2020, MNRAS, 491, 2565 [Google Scholar]
- Baldauf, T., Seljak, U., Smith, R. E., Hamaus, N., & Desjacques, V. 2013, Phys. Rev. D, 88, 083507 [NASA ADS] [CrossRef] [Google Scholar]
- Baratta, P., Bel, J., Plaszczynski, S., & Ealet, A. 2020, A&A, 633, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Baratta, P., Bel, J., Gouyou Beauchamps, S., & Carbone, C. 2023, A&A, 673, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bardeen, J. M., Bond, J. R., Kaiser, N., & Szalay, A. S. 1986, ApJ, 304, 15 [Google Scholar]
- Benitez, N., Dupke, R., Moles, M., et al. 2014, ArXiv e-prints [arXiv:1403.5237] [Google Scholar]
- Berlind, A. A., & Weinberg, D. H. 2002, ApJ, 575, 587 [Google Scholar]
- Bernardeau, F. 1994, ApJ, 427, 51 [NASA ADS] [CrossRef] [Google Scholar]
- Bernardeau, F., Colombi, S., Gaztañaga, E., & Scoccimarro, R. 2002, Phys. Rep., 367, 1 [Google Scholar]
- Berner, P., Refregier, A., Sgier, R., et al. 2022, J. Cosmol. Astropart. Phys., 2022, 002 [CrossRef] [Google Scholar]
- Blanton, M. 2000, ApJ, 544, 63 [Google Scholar]
- Blot, L., Crocce, M., Sefusatti, E., et al. 2019, MNRAS, 485, 500 [Google Scholar]
- Bond, J. R., & Myers, S. T. 1996a, ApJS, 103, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Bond, J. R., & Myers, S. T. 1996b, ApJS, 103, 41 [NASA ADS] [CrossRef] [Google Scholar]
- Bond, J. R., & Myers, S. T. 1996c, ApJS, 103, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Bond, J. R., Kofman, L., & Pogosyan, D. 1996, Nature, 380, 603 [NASA ADS] [CrossRef] [Google Scholar]
- Bouchet, F. R., Colombi, S., Hivon, E., & Juszkiewicz, R. 1995, A&A, 296, 575 [NASA ADS] [Google Scholar]
- Buchert, T., & Ehlers, J. 1993, MNRAS, 264, 375 [Google Scholar]
- Cai, Y.-C., Angulo, R. E., Baugh, C. M., et al. 2009, MNRAS, 395, 1185 [NASA ADS] [CrossRef] [Google Scholar]
- Chartier, N., Wandelt, B., Akrami, Y., & Villaescusa-Navarro, F. 2021, MNRAS, 503, 1897 [NASA ADS] [CrossRef] [Google Scholar]
- Chaussidon, E., Yèche, C., Palanque-Delabrouille, N., et al. 2023, ApJ, 944, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, J., Zhang, P., Zheng, Y., Yu, Y., & Jing, Y. 2018, ApJ, 861, 58 [NASA ADS] [CrossRef] [Google Scholar]
- Chuang, C.-H., Kitaura, F.-S., Prada, F., Zhao, C., & Yepes, G. 2015a, MNRAS, 446, 2621 [NASA ADS] [CrossRef] [Google Scholar]
- Chuang, C.-H., Zhao, C., Prada, F., et al. 2015b, MNRAS, 452, 686 [CrossRef] [Google Scholar]
- Chuang, C.-H., Yepes, G., Kitaura, F.-S., et al. 2019, MNRAS, 487, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Colavincenzo, M., Sefusatti, E., Monaco, P., et al. 2018, MNRAS, 482, 4883 [Google Scholar]
- Coles, P., & Jones, B. 1991, MNRAS, 248, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Conroy, C., Wechsler, R. H., & Kravtsov, A. V. 2006, ApJ, 647, 201 [Google Scholar]
- Contreras, S., Zehavi, I., Padilla, N., et al. 2019, MNRAS, 484, 1133 [NASA ADS] [CrossRef] [Google Scholar]
- Cooper, A. P., Koposov, S. E., Allende Prieto, C., et al. 2023, ApJ, 947, 37 [NASA ADS] [CrossRef] [Google Scholar]
- Cooray, A. 2002, ApJ, 576, L105 [NASA ADS] [CrossRef] [Google Scholar]
- Cooray, A., & Sheth, R. 2002, Phys. Rep., 372, 1 [Google Scholar]
- Crocce, M., & Scoccimarro, R. 2006, Phys. Rev. D, 73, 063520 [NASA ADS] [CrossRef] [Google Scholar]
- Croton, D. J., Gao, L., & White, S. D. M. 2007, MNRAS, 374, 1303 [Google Scholar]
- Dalal, N., White, M., Bond, J. R., & Shirokov, A. 2008, ApJ, 687, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Dekel, A., & Lahav, O. 1999, ApJ, 520, 24 [Google Scholar]
- de Santi, N. S. M., & Abramo, L. R. 2022, JCAP, 09, 013 [CrossRef] [Google Scholar]
- de Santi, N. S. M., Rodrigues, N. V. N., Montero-Dorta, A. D., et al. 2022, MNRAS, 514, 2463 [CrossRef] [Google Scholar]
- DESI Collaboration (Aghamousa, A., et al.) 2016a, ArXiv e-prints [arXiv:1611.00037] [Google Scholar]
- DESI Collaboration (Aghamousa, A., et al.) 2016b, ArXiv e-prints [arXiv:1611.00036] [Google Scholar]
- DESI Collaboration (Abareshi, B., et al.) 2022, AJ, 164, 207 [NASA ADS] [CrossRef] [Google Scholar]
- Desjacques, V., Jeong, D., & Schmidt, F. 2018, Phys. Rep., 733, 1 [Google Scholar]
- Dey, A., Schlegel, D. J., Lang, D., et al. 2019, AJ, 157, 168 [Google Scholar]
- Ding, Z., Chuang, C.-H., Yu, Y., et al. 2022, MNRAS, 514, 3308 [CrossRef] [Google Scholar]
- Dodelson, S. 2003, Modern Cosmology (Elsevier Science: Academic Press) [Google Scholar]
- Dodelson, S., & Schneider, M. D. 2013, Phys. Rev. D, 88, 063537 [Google Scholar]
- Dvorkin, C., Mishra-Sharma, S., Nord, B., et al. 2022, ArXiv e-prints [arXiv:2203.08056] [Google Scholar]
- Faltenbacher, A., & White, S. D. M. 2010, ApJ, 708, 469 [NASA ADS] [CrossRef] [Google Scholar]
- Favole, G., Comparat, J., Prada, F., et al. 2016, MNRAS, 461, 3421 [NASA ADS] [CrossRef] [Google Scholar]
- Favole, G., Rodríguez-Torres, S. A., Comparat, J., et al. 2017, MNRAS, 472, 550 [NASA ADS] [CrossRef] [Google Scholar]
- Feng, Y., Chu, M.-Y., Seljak, U., & McDonald, P. 2016, MNRAS, 463, 2273 [NASA ADS] [CrossRef] [Google Scholar]
- Fisher, J. D., & Faltenbacher, A. 2018, MNRAS, 473, 3941 [CrossRef] [Google Scholar]
- Forero-Romero, J. E., Hoffman, Y., Gottlöber, S., Klypin, A., & Yepes, G. 2009, MNRAS, 396, 1815 [Google Scholar]
- Forero-Sánchez, D., Chuang, C.-H., Rodríguez-Torres, S., et al. 2022, MNRAS, 513, 4318 [CrossRef] [Google Scholar]
- Fry, J. N., & Gaztanaga, E. 1993, ApJ, 413, 447 [NASA ADS] [CrossRef] [Google Scholar]
- Gao, L., & White, S. D. M. 2007, MNRAS, 377, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Gao, L., Springel, V., & White, S. D. M. 2005, MNRAS, 363, L66 [NASA ADS] [CrossRef] [Google Scholar]
- García, R., & Rozo, E. 2019, MNRAS, 489, 4170 [NASA ADS] [CrossRef] [Google Scholar]
- Garrison, L. H., Eisenstein, D. J., Ferrer, D., et al. 2018, ApJS, 236, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Gil-Marín, H., Wagner, C., Fragkoudi, F., Jimenez, R., & Verde, L. 2012, J. Cosmol. Astropart. Phys., 2012, 047 [CrossRef] [Google Scholar]
- Goldstein, S., Pandey, S., Slosar, A., et al. 2022, Phys. Rev. D, 105, 123518 [NASA ADS] [CrossRef] [Google Scholar]
- Gonzalez-Perez, V., Comparat, J., Norberg, P., et al. 2018, MNRAS, 474, 4024 [NASA ADS] [CrossRef] [Google Scholar]
- Grove, C., Chuang, C.-H., Devi, N. C., et al. 2022, MNRAS, 515, 1854 [NASA ADS] [CrossRef] [Google Scholar]
- Hahn, O., Porciani, C., Carollo, C. M., & Dekel, A. 2007, MNRAS, 375, 489 [NASA ADS] [CrossRef] [Google Scholar]
- Hahn, O., Abel, T., & Kaehler, R. 2013, MNRAS, 434, 1171 [Google Scholar]
- Hahn, C., Wilson, M. J., Ruiz-Macias, O., et al. 2022, AJ, submitted [arXiv:2208.08512] [Google Scholar]
- Hamaus, N., Seljak, U., & Desjacques, V. 2012, Phys. Rev. D, 86, 103513 [Google Scholar]
- Hamilton, A. J. S. 1998, Astrophys. Space Sci. Libr., 231, 185 [NASA ADS] [CrossRef] [Google Scholar]
- Han, J., Li, Y., Jing, Y., et al. 2019, MNRAS, 482, 1900 [NASA ADS] [CrossRef] [Google Scholar]
- Harnois-Déraps, J., Amon, A., Choi, A., et al. 2018, MNRAS, 481, 1337 [Google Scholar]
- Harnois-Déraps, J., Pen, U.-L., Iliev, I. T., et al. 2013, MNRAS, 436, 540 [Google Scholar]
- He, S., Li, Y., Feng, Y., et al. 2019, Proc. Nat. Academy Sci., 116, 13825 [NASA ADS] [CrossRef] [Google Scholar]
- Hearin, A. P., Zentner, A. R., van den Bosch, F. C., Campbell, D., & Tollerud, E. 2016, MNRAS, 460, 2552 [NASA ADS] [CrossRef] [Google Scholar]
- Heath, D. J. 1977, MNRAS, 179, 351 [NASA ADS] [CrossRef] [Google Scholar]
- Heavens, A. 2009, ArXiv e-prints [arXiv:0906.0664] [Google Scholar]
- Heß, S., Kitaura, F.-S., & Gottlöber, S. 2013, MNRAS, 435, 2065 [CrossRef] [Google Scholar]
- Hikage, C., & Yamamoto, K. 2016, MNRAS, 455, L77 [NASA ADS] [CrossRef] [Google Scholar]
- Hockney, R. W., & Eastwood, J. W. 1988, Computer Simulation Using Particles (CRC Press) [Google Scholar]
- Howlett, C., & Percival, W. J. 2017, MNRAS, 472, 4935 [NASA ADS] [CrossRef] [Google Scholar]
- Howlett, C., Manera, M., & Percival, W. J. 2015, Astron. Comput., 12, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Izard, A., Fosalba, P., & Crocce, M. 2018, MNRAS, 473, 3051 [NASA ADS] [CrossRef] [Google Scholar]
- Jing, Y. P. 2005, ApJ, 620, 559 [NASA ADS] [CrossRef] [Google Scholar]
- Kaiser, N. 1987, MNRAS, 227, 1 [Google Scholar]
- Kauffmann, G., Nusser, A., & Steinmetz, M. 1997, MNRAS, 286, 795 [NASA ADS] [CrossRef] [Google Scholar]
- Kerscher, M., Szapudi, I., & Szalay, A. S. 2000, ApJ, 535, L13 [NASA ADS] [CrossRef] [Google Scholar]
- Kitaura, F.-S., & Hess, S. 2013, MNRAS, 435, L78 [NASA ADS] [CrossRef] [Google Scholar]
- Kitaura, F.-S., Yepes, G., & Prada, F. 2014, MNRAS, 439, L21 [NASA ADS] [CrossRef] [Google Scholar]
- Kitaura, F.-S., Rodríguez-Torres, S., Chuang, C.-H., et al. 2016, MNRAS, 456, 4156 [NASA ADS] [CrossRef] [Google Scholar]
- Kitaura, F.-S., Balaguera-Antolínez, A., Sinigaglia, F., & Pellejero-Ibáñez, M. 2022, MNRAS, 512, 2245 [NASA ADS] [CrossRef] [Google Scholar]
- Kitaura, F. S., Sinigaglia, F., Balaguera-Antolínez, A., & Favole, G. 2023, ArXiv e-prints [arXiv:2301.03648] [Google Scholar]
- Klypin, A., & Prada, F. 2018, MNRAS, 478, 4602 [NASA ADS] [CrossRef] [Google Scholar]
- Koda, J., Blake, C., Beutler, F., Kazin, E., & Marin, F. 2016, MNRAS, 459, 2118 [NASA ADS] [CrossRef] [Google Scholar]
- Kravtsov, A. V., Berlind, A. A., Wechsler, R. H., et al. 2004, ApJ, 609, 35 [Google Scholar]
- Kreisch, C. D., Pisani, A., Villaescusa-Navarro, F., et al. 2022, ApJ, 935, 100 [NASA ADS] [CrossRef] [Google Scholar]
- Lacasa, F. 2018, A&A, 615, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lahav, O., Lilje, P. B., Primack, J. R., & Rees, M. J. 1991, MNRAS, 251, 128 [Google Scholar]
- Lan, T.-W., Tojeiro, R., Armengaud, E., et al. 2023, ApJ, 943, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Lazeyras, T., Musso, M., & Schmidt, F. 2017, J. Cosmol. Astropart. Phys., 2017, 059 [CrossRef] [Google Scholar]
- Lee, C. T., Primack, J. R., Behroozi, P., et al. 2017, MNRAS, 466, 3834 [CrossRef] [Google Scholar]
- Levi, M., Bebek, C., Beers, T., et al. 2013, ArXiv e-prints [arXiv:1308.0847] [Google Scholar]
- Li, Y., Ni, Y., Croft, R. A. C., et al. 2021, Proc. Nat. Academy Sci., 118, e2022038118 [CrossRef] [Google Scholar]
- Libeskind, N. I., van de Weygaert, R., Cautun, M., et al. 2018, MNRAS, 473, 1195 [NASA ADS] [CrossRef] [Google Scholar]
- Lippich, M., Sánchez, A. G., Colavincenzo, M., et al. 2019, MNRAS, 482, 1786 [NASA ADS] [CrossRef] [Google Scholar]
- Maion, F., Angulo, R. E., & Zennaro, M. 2022, JCAP, 10, 036 [CrossRef] [Google Scholar]
- Maksimova, N. A., Garrison, L. H., Eisenstein, D. J., et al. 2021, MNRAS, 508, 4017 [NASA ADS] [CrossRef] [Google Scholar]
- Manera, M., Scoccimarro, R., Percival, W. J., et al. 2013, MNRAS, 428, 1036 [Google Scholar]
- Mao, Y.-Y., Zentner, A. R., & Wechsler, R. H. 2018, MNRAS, 474, 5143 [NASA ADS] [CrossRef] [Google Scholar]
- Matsubara, T. 1999, ApJ, 525, 543 [NASA ADS] [CrossRef] [Google Scholar]
- McDonald, P., & Roy, A. 2009, J. Cosmol. Astropart. Phys., 8, 020 [CrossRef] [Google Scholar]
- Mohayaee, R., Mathis, H., Colombi, S., & Silk, J. 2006, MNRAS, 365, 939 [CrossRef] [Google Scholar]
- Monaco, P. 2016, Galaxies, 4, 53 [NASA ADS] [CrossRef] [Google Scholar]
- Monaco, P., Theuns, T., & Taffoni, G. 2002, MNRAS, 331, 587 [Google Scholar]
- Monaco, P., Sefusatti, E., Borgani, S., et al. 2013, MNRAS, 433, 2389 [NASA ADS] [CrossRef] [Google Scholar]
- Montero-Dorta, A. D., Pérez, E., Prada, F., et al. 2017, ApJ, 848, L2 [NASA ADS] [CrossRef] [Google Scholar]
- Munari, E., Monaco, P., Koda, J., et al. 2017, J. Cosmol. Astropart. Phys., 2017, 050 [CrossRef] [Google Scholar]
- Musso, M., Cadiou, C., Pichon, C., et al. 2018, MNRAS, 476, 4877 [Google Scholar]
- Myers, A. D., Moustakas, J., Bailey, S., et al. 2023, AJ, 165, 50 [NASA ADS] [CrossRef] [Google Scholar]
- Nasirudin, A., Iliev, I. T., & Ahn, K. 2020, MNRAS, 494, 3294 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1996, ApJ, 462, 563 [Google Scholar]
- Neyrinck, M. C. 2013, MNRAS, 428, 141 [NASA ADS] [CrossRef] [Google Scholar]
- O’Connell, R., & Eisenstein, D. J. 2019, MNRAS, 487, 2701 [CrossRef] [Google Scholar]
- Paranjape, A., Hahn, O., & Sheth, R. K. 2018, MNRAS, 476, 3631 [NASA ADS] [CrossRef] [Google Scholar]
- Paz, D. J., & Sánchez, A. G. 2015, MNRAS, 454, 4326 [NASA ADS] [CrossRef] [Google Scholar]
- Peacock, J. A., & Heavens, A. F. 1985, MNRAS, 217, 805 [NASA ADS] [CrossRef] [Google Scholar]
- Pearson, D. W., & Samushia, L. 2016, MNRAS, 457, 993 [NASA ADS] [CrossRef] [Google Scholar]
- Peebles, P. J. E. 1980, The large-scale Structure of the Universe (Princeton University Press) [Google Scholar]
- Percival, W. J., Ross, A. J., Sánchez, A. G., et al. 2014, MNRAS, 439, 2531 [NASA ADS] [CrossRef] [Google Scholar]
- Piras, D., Joachimi, B., & Villaescusa-Navarro, F. 2023, MNRAS, 520, 668 [Google Scholar]
- Pollack, J. E., Smith, R. E., & Porciani, C. 2012, MNRAS, 420, 3469 [NASA ADS] [CrossRef] [Google Scholar]
- Porciani, C., & Giavalisco, M. 2002, ApJ, 565, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Potter, D., Stadel, J., & Teyssier, R. 2017, Comput. Astrophys. Cosmol., 4, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Press, W. H., Teukolsky, S. A., Vetterling, W. T., & Flannery, B. P. 2002, Numerical Recipes in C++ : the art of Scientific Computing (Cambridge University Press) [Google Scholar]
- Pujol, A., Hoffmann, K., Jiménez, N., & Gaztañaga, E. 2017, A&A, 598, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Raichoor, A., Eisenstein, D. J., Karim, T., et al. 2020, Res. Notes AAS, 4, 180 [NASA ADS] [CrossRef] [Google Scholar]
- Raichoor, A., Moustakas, J., Newman, J. A., et al. 2023, AJ, 165, 126 [NASA ADS] [CrossRef] [Google Scholar]
- Rimes, C. D., & Hamilton, A. J. S. 2006, MNRAS, 371, 1205 [NASA ADS] [CrossRef] [Google Scholar]
- Rodríguez-Torres, S. A., Chuang, C.-H., Prada, F., et al. 2016, MNRAS, 460, 1173 [CrossRef] [Google Scholar]
- Romano-Díaz, E., & van de Weygaert, R. 2007, MNRAS, 382, 2 [CrossRef] [Google Scholar]
- Ruiz-Macias, O., Zarrouk, P., Cole, S., et al. 2020, Res. Notes Am. Astron. Soc., 4, 187 [Google Scholar]
- Satpathy, S., Croft, R. A. C., Ho, S., & Li, B. 2019, MNRAS, 484, 2148 [NASA ADS] [CrossRef] [Google Scholar]
- Scoccimarro, R., & Sheth, R. K. 2002, MNRAS, 329, 629 [NASA ADS] [CrossRef] [Google Scholar]
- Sheth, R. K. 2005, MNRAS, 364, 796 [NASA ADS] [CrossRef] [Google Scholar]
- Sheth, R. K., & Tormen, G. 2004, MNRAS, 350, 1385 [NASA ADS] [CrossRef] [Google Scholar]
- Sheth, R. K., Connolly, A. J., & Skibba, R. 2005, ArXiv e-prints [arXiv:astro-ph/0511773] [Google Scholar]
- Sheth, R. K., Chan, K. C., & Scoccimarro, R. 2013, Phys. Rev. D, 87, 083002 [NASA ADS] [CrossRef] [Google Scholar]
- Sigad, Y., Branchini, E., & Dekel, A. 2000, ApJ, 540, 62 [NASA ADS] [CrossRef] [Google Scholar]
- Silber, J. H., Fagrelius, P., Fanning, K., et al. 2023, AJ, 165, 9 [NASA ADS] [CrossRef] [Google Scholar]
- Simon, P. 2005, A&A, 430, 827 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sinigaglia, F., Kitaura, F.-S., Balaguera-Antolínez, A., et al. 2021, ApJ, 921, 66 [NASA ADS] [CrossRef] [Google Scholar]
- Sinigaglia, F., Kitaura, F.-S., Balaguera-Antolínez, A., et al. 2022, ApJ, 927, 230 [NASA ADS] [CrossRef] [Google Scholar]
- Skibba, R. A., & Macciò, A. V. 2011, MNRAS, 416, 2388 [NASA ADS] [CrossRef] [Google Scholar]
- Skibba, R., Sheth, R. K., Connolly, A. J., & Scranton, R. 2006, MNRAS, 369, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, R. E., Scoccimarro, R., & Sheth, R. K. 2007, Phys. Rev. D, 75, 063512 [NASA ADS] [CrossRef] [Google Scholar]
- Somerville, R. S., Lemson, G., Sigad, Y., et al. 2001, MNRAS, 320, 289 [Google Scholar]
- Sousbie, T., Courtois, H., Bryan, G., & Devriendt, J. 2008, ApJ, 678, 569 [NASA ADS] [CrossRef] [Google Scholar]
- Spergel, D., Gehrels, N., Baltay, C., et al. 2015, ArXiv e-prints [arXiv:1503.03757] [Google Scholar]
- Springel, V. 2005, MNRAS, 364, 1105 [Google Scholar]
- Springel, V., Pakmor, R., Zier, O., & Reinecke, M. 2021, MNRAS, 506, 2871 [NASA ADS] [CrossRef] [Google Scholar]
- Stein, G., Alvarez, M. A., & Bond, J. R. 2019, MNRAS, 483, 2236 [NASA ADS] [CrossRef] [Google Scholar]
- Takada, M., & Hu, W. 2013, Phys. Rev. D, 87, 123504 [NASA ADS] [CrossRef] [Google Scholar]
- Tassev, S., Zaldarriaga, M., & Eisenstein, D. J. 2013, J. Cosmol. Astropart. Phys., 6, 036 [CrossRef] [Google Scholar]
- Taylor, A., Joachimi, B., & Kitching, T. 2013, MNRAS, 432, 1928 [Google Scholar]
- Tegmark, M., & Peebles, P. J. E. 1998, ApJ, 500, L79 [Google Scholar]
- Tinker, J. L., Robertson, B. E., Kravtsov, A. V., et al. 2010, ApJ, 724, 878 [NASA ADS] [CrossRef] [Google Scholar]
- Valageas, P. 2011, A&A, 525, A98 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vale, A., & Ostriker, J. P. 2004, MNRAS, 353, 189 [Google Scholar]
- van de Weygaert, R., Aragon-Calvo, M. A., Jones, B. J. T., & Platen, E. 2009, ArXiv e-prints [arXiv:0912.3448] [Google Scholar]
- Vargas-Magana, M., Brooks, D. D., Levi, M. M., & Tarle, G. G. 2019, ArXiv e-prints [arXiv:1901.01581] [Google Scholar]
- Villaescusa-Navarro, F., Anglés-Alcázar, D., Genel, S., et al. 2021, ApJ, 915, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, Y., & Zhao, G.-B. 2020, Res. Astron. Astrophys., 20, 158 [Google Scholar]
- Wechsler, R. H., & Tinker, J. L. 2018, ARA&A, 56, 435 [NASA ADS] [CrossRef] [Google Scholar]
- Wechsler, R. H., Zentner, A. R., Bullock, J. S., Kravtsov, A. V., & Allgood, B. 2006, ApJ, 652, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Weinberg, D. H. 1992, MNRAS, 254, 315 [CrossRef] [Google Scholar]
- Weinberger, R., Springel, V., & Pakmor, R. 2020, ApJS, 248, 32 [Google Scholar]
- White, M. 2014, MNRAS, 439, 3630 [NASA ADS] [CrossRef] [Google Scholar]
- White, M., Tinker, J. L., & McBride, C. K. 2014, MNRAS, 437, 2594 [NASA ADS] [CrossRef] [Google Scholar]
- Xavier, H. S., Abdalla, F. B., & Joachimi, B. 2016, MNRAS, 459, 3693 [NASA ADS] [CrossRef] [Google Scholar]
- Xu, X., Zehavi, I., & Contreras, S. 2021, MNRAS, 502, 3242 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, X., Zhang, Y., Lu, T., et al. 2017, ApJ, 848, 60 [NASA ADS] [CrossRef] [Google Scholar]
- Yèche, C., Palanque-Delabrouille, N., Claveau, C.-A., et al. 2020, Res. Notes Am. Astron. Soc., 4, 179 [Google Scholar]
- Yu, Y., Zhang, J., Jing, Y., & Zhang, P. 2015, Phys. Rev. D, 92, 083527 [Google Scholar]
- Zehavi, I., Kerby, S. E., Contreras, S., et al. 2019, ApJ, 887, 17 [NASA ADS] [CrossRef] [Google Scholar]
- Zel’dovich, Y. B. 1970, A&A, 5, 84 [NASA ADS] [Google Scholar]
- Zentner, A. R. 2007, Int. J. Modern Phys. D, 16, 763 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, P., Zheng, Y., & Jing, Y. 2015, Phys. Rev. D, 91, 043522 [Google Scholar]
- Zhang, X., Wang, Y., Zhang, W., et al. 2019, ArXiv e-prints [arXiv:1902.05965] [Google Scholar]
- Zhao, C., Kitaura, F.-S., Chuang, C.-H., et al. 2015, MNRAS, 451, 4266 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, C., Chuang, C.-H., Bautista, J., et al. 2021, MNRAS, 503, 1149 [CrossRef] [Google Scholar]
- Zheng, Y., Zhang, P., Jing, Y., Lin, W., & Pan, J. 2013, Phys. Rev. D, 88, 103510 [NASA ADS] [CrossRef] [Google Scholar]
- Zheng, Y., Song, Y.-S., & Oh, M. 2019, J. Cosmol. Astropart. Phys., 2019, 013 [CrossRef] [Google Scholar]
- Zhou, R., Newman, J. A., Dawson, K. S., et al. 2020, Res. Notes Am. Astron. Soc., 4, 181 [Google Scholar]
- Zhou, R., Dey, B., Newman, J. A., et al. 2023, AJ, 165, 58 [NASA ADS] [CrossRef] [Google Scholar]
- Zou, H., Zhou, X., Fan, X., et al. 2017, PASP, 129, 064101 [CrossRef] [Google Scholar]
Appendix A: Hierarchy of properties
To motivate the hierarchical property assignment used in Sect. 3.5, we compute the Pearson correlation coefficient using the local dark matter density, virial mass, and velocity dispersion obtained in bins of local density and different cosmic-web type. The results shown in Fig. A.1 indicate that (i) the correlation between halo properties in different cosmic-web types (panel (a)) follows a similar trend in low and intermediate densities, reaching a maximum at δdm ∼ 0, and then decreasing towards high densities, where the correlation in knots becomes significantly dominant as compared to that in filaments; (ii) the correlation between velocity dispersion and dark matter displays (panel (b)) higher values, that is, of ∼30%, especially at high densities, and (iii) the correlations between virial mass and local density (panel (c)) are rather weak, with ≤15% on average over the density range, and no strong dependence on cosmic-web type. We note that the underlying dark matter density field used to compute these correlations is an approximated version of the original field (which has 512 times more particles) whose dark matter particles are used to define these halos. Hence, these measurements must not be taken as general claims as to the behaviour of halo properties, but instead a characterisation of the current setup within the BAM machinery. With this in mind, we adopt underlying dark matter density field as the main property with which to start the assignment procedure.
 |
Fig. A.1. Pearson correlation coefficients between halo properties (panel a), the local dark matter density with halo virial mass (panel b) and velocity dispersion (panel c), measured in bins of local density for different cosmic-web types, as obtained from the SLICS reference simulation. The error bars denote the standard deviation obtained from the set of catalogues. |
Appendix B: Multi-scaling assignment
One key aspect to take into account when sampling the halo number counts field with discrete tracers is, on one side, the need to preserve the large-scale clustering pattern according to that of the reference, and on the other hand, to avoid halo exclusion (see e.g. Porciani & Giavalisco 2002; Baldauf et al. 2013; García & Rozo 2019). The former is ensured by an appropriate choice of the gravity solver, while the latter can be addressed at the moment of assigning properties. To that aim, we envisaged a multi-scale assignment scheme, in which a given property (in this case, the velocity dispersion) is assigned in an ordered fashion, ensuring that the highest values are linked to tracers that are sufficiently far away to avoid exclusion (see also Zhao et al. 2015). Let us briefly describe the steps designed within the BAM algorithm to assign halo properties:
-
We randomly select one reference halo catalogue and define a threshold σth, above which the multi-scaling assignment will be performed.
-
For values of velocity dispersion above the threshold σth, we divide the σv range probed by the halo population into 𝒩 intervals. Each of these intervals is defined by a minimum and maximum value of velocity dispersion,
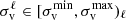 (ℓ = 1, ⋯𝒩).
(ℓ = 1, ⋯𝒩). -
Let Nℓ denote the number of tracers read from one reference simulation in each of these intervals. We construct a number of 𝒩 spatial meshes covering the cosmological volume of the BAM mocks, each of which is characterised by Nℓ cells, such that, on average, each cell is populated by one halo within the corresponding interval of σv.
-
We then select a number
 of reference halo catalogues. This number can be smaller than the figure used for the generation of halo number counts (i.e. Nref = 27). For the current setup, we randomly selected
of reference halo catalogues. This number can be smaller than the figure used for the generation of halo number counts (i.e. Nref = 27). For the current setup, we randomly selected  from the available set of SLICs catalogues.
from the available set of SLICs catalogues. -
From the set of
 catalogues, we identify the values of velocity dispersion {σv}ℓ({Θ}ref) as a function of the dark matter properties {Θ}ref, and sort these values top-down in each bin of {Θ}ref for all values above the minimum threshold
catalogues, we identify the values of velocity dispersion {σv}ℓ({Θ}ref) as a function of the dark matter properties {Θ}ref, and sort these values top-down in each bin of {Θ}ref for all values above the minimum threshold 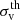 .
. -
We then proceed to the assignment of properties read from the reference to tracers in a BAM halo catalogue. The assignment starts with the interval containing the highest values of σv (this mesh is the least populated).
-
We then loop over the Nℓ cells in the mesh built over the BAM mock. In each step of this loop, the algorithm randomly selects one fiducial cell (i.e. defined by the nominal resolution 1923). To avoid the assignment of properties to tracers in adjacent cells, we previously randomise the order of the Nℓ cells.
-
Using the dark matter field of the current mock catalogue, we identify the corresponding set of properties {Θ}mock of the chosen fiducial cell.
-
We randomly choose one mock tracer in that fiducial cell (if any) and assign to it a value of σv from the list {σv}ℓ({Θ}mock = {Θ}ref). Given that this list is sorted, the first assignment (i.e. the first step in the loop over the Nℓ-cells) will correspond to the largest value of σv in the reference catalogue.
-
We then repeat the full loop until the number of requested tracers in the level are assigned with properties.
This procedure is repeated for the different levels ℳℓ. For values below the minimum threshold, the assignment is performed in the following way:
-
1.
We randomly select one tracer (without assigned property) from the mock, and then identify the fiducial cell where it resides and the corresponding set of properties {Θ}mock.
-
2.
Returning to the list {σv}({Θ}ref), we randomly assign any of the corresponding values still available (i.e. with
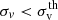 ).
).
Finally, if there are still tracers with no assigned properties (e.g. due to cosmic variance), BAM statistically assigns values of velocity dispersion by sampling the global halo abundance measured from one reference catalogue. This last case represents ∼5% of the total assignment, depending on the realisation. For the current case, we implemented 𝒩 = 3 levels with thresholds at 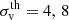 and 10 km/s.
and 10 km/s.
Once velocity dispersion is assigned, we measure the scaling relation 𝒫(Mvir|σv, {Θ}), (using one realisation of the reference set) to assign virial masses with
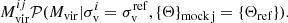 (B.1)
(B.1)
For this step, we implemented, along with the information of the velocity dispersion, the local dark matter density and the cosmic-web classification. The scheme can be generalised to any other set of halo properties tabulated in the reference catalogue (e.g. spin, concentration, maximum circular velocity).
Appendix C: Calibration using galaxy catalogues
In this Appendix, we assess the precision of mock galaxy catalogues built using the set of ELG catalogues described in Sect. 4 as a reference (i.e. SLICS halos plus HOD). Following the procedures described in Sect. 2.7 and § 3.2 and using the TkWEB model to characterise the galaxy bias in BAM, we generated 770 realisations of galaxy number counts. Coordinates of DM particles are used to define the positions of the galaxy-type tracers, while random tracers are similarly introduced, collapsing them towards their closest DM particles. Numerical tests indicate that for the current galaxy population, a fraction fcol = 0.05 has to be used to obtain a per cent accuracy in the real space mean power spectrum on small scales. We note that this collapsing fraction is smaller than that used for halos (∼0.35), and is expected as galaxies populate smaller scales than their parent halos, thus generating the need for a stronger collapse of the random set. The assignment of velocities to this set of tracers is not evident, as no clear identification of centrals or satellites is available, In order to match the large-scale clustering signal, bulk velocities can be assigned as shown in Sect. 3.4 with a constant velocity bias of ∼20%. On the other hand, small-scale clustering can be replicated by adding a random velocity component to the components of the bulk velocities from a normal distribution, with a width that can vary among the different cosmic-web types (see Sect. 3.4). Such a random component can be added to each component of the velocity (as would be the case of galaxies inside dark matter halos) or to the magnitude of the velocity, a situation that can be linked to parent halos in the mildly non-linear regime (Hikage & Yamamoto 2016; Zheng et al. 2019). Either of these options can be used to replicate the small-scale redshift space clustering signal up the k ∼ 0.4hMpc−1. For example, assigning a random component to each velocity component in knots demands a velocity dispersion of σ ∼ 350 km/s, while adding the noise and keeping the direction of the velocity of each tracer fixed demands σ ∼ 740 km/s. Here, we do not aim to precisely determine the best scenario for the assignment of random components to galaxy-like tracers. For the current test, we used σ = 350 km/s applied only to galaxies in knots. Figure C.1 shows the comparison of different summary statistics in Fourier space for the set of BAM galaxies generated from halo catalogues (BAMh) and the BAM set generated directly from the calibration to the SLICS galaxy catalogues (BAMg) described in Sect. 4. We can summarise the results of this comparison as follows:
-
In real space (first column of Fig. C.1), the BAMg set yields a more accurate description of the mean power spectrum, especially towards small scales (k ∼ 0.4hMpc−1). The variance of the power spectrum is also improved. With respect to the reference correlation matrix, this quantity displays less mode coupling for the BAMg than the BAMh set. In general, the improvement in real space of the set BAMg is due to the lack of inaccuracies in the galaxy distribution associated with the assignment of halo properties, as in the BAMh case.
-
The behaviour in redshift space from the BAMg is consistent with that from BAMh. Noticeable differences are (i) the mean of the quadrupole on scales k ≥ 0.2hMpc−1 and (ii) the correlation matrix, where the set BAMg displays less extra coupling than seen in BAMh.
 |
Fig. C.1. Comparison of the summary statistics of the set of BAM galaxies generated from the halo catalogues (BAMh) with those of the BAM galaxies generated from calibration (BAMg) obtained from the SLICS galaxy catalogue. The top row shows the ratios to the references (RTF) from the mean and variance of the power spectrum (real and redshift space). The middle row shows the absolute value of the difference between the correlation coefficients rij of the BAM sets (BAMg, upper diagonal, BAMh, lower diagonal) and those from the SLICS. The third row shows the elements of the correlation coefficients (in only one Fourier bin, to avoid clutter) from the three sets. |
These results are remarkable for two reasons: On one hand, the fact that the BAMh set is consistent with the BAMg highlights the ability of the method to generate galaxy catalogues with information on the hosting halos without a significant decrement in the precision of two-point statistics. On the other hand, the behaviour of the BAMg set shows how the method can be further adapted to generate galaxy catalogues by directly learning from a reference galaxy catalogue containing galaxy velocities based on theoretical models.
Appendix D: Forthcoming applications: Experiments with paired-fixed amplitude cosmological simulations
We show how the cosmological volume probed by the SLICS suite has imposed a limit on the precision and accuracy in the different summary statistics of the BAM halo catalogues when learning from one realisation. To circumvent this situation, we pushed the algorithm to learn from more than one reference simulation, effectively increasing the volume of the training set (see Sect. 3.1). Such an enlargement of the training set yields products (i.e halo bias and kernel) that, from a statistical perspective, are not fully compatible, as the averaged kernel defined in Eq. (15) effectively tries to reproduce the behaviour from a fixed-amplitude reference, that is, with reduced cosmic variance, while the stacked version of the halo bias enlarges the effective volume.
As pointed out in Sect. 3.1, a more convenient scenario for the calibration procedure and the generation of mock catalogues with BAM is the implementation of phase-inverted pairs of large cosmological simulations generated with fixed-amplitude initial conditions (see e.g. Angulo & Pontzen 2016; Chuang et al. 2019; Maion et al. 2022). In this section, we present results from numerical tests to motivate the implementation of BAM with that specific type of training set.
In our context, the advantages of N-body simulations with suppressed variance are straightforward. On one hand, the calibration with this type of IC allows the generation of kernels without any uncertainty from cosmic variance, which in turn allows an accurate extrapolation of this quantity towards smaller wavenumbers, with the aim being to generate halo catalogues in larger cosmological volumes (while learning from smaller ones). On the other hand, calibrating the method using the set of two-paired simulations (dubbed as the ‘normal’ and the ‘phase-inverted’) allows us to consistently extract halo bias, as in Eq. (15), which can then be used in conjunction with an average kernel, which (being phase-independent) is the same for the set of two paired references. This, complemented with larger cosmological volumes (and high mass resolution), provides a good statistical description of the dark matter density field (e.g. Crocce & Scoccimarro 2006; Klypin & Prada 2018), and in general, of the outputs from the learning phase.
To assess the performance of BAM in this scenario, we used the UNIT simulation Chuang et al. (2019). This suite is represented by a set of two pair-fixed realisations in a volume of 1(Gpch−1)3, run with 40963 dark matter particles and mass resolution of 1.2 × 109 M⊙h−1 and halo catalogues with a minimum (virial) mass of 3.6 × 1011 M⊙h−1. We use a number of snapshots in the redshift range 0 ≤ z ≤ 3 to generate the same number of kernels and halo bias for the normal and phase-inverted realisations. Following the procedure outlined in Sect. 2.3, the IC of the UNITsim is down-sampled to a lower resolution –in this case, 2563. For each of the snapshots, a kernel and a halo bias are produced following the steps of Sect. 2.7, based on the TkWEB model of halo bias (see Sect. 2.6). Figure D.1 shows the power spectrum, the kernel, and residuals at different cosmological redshifts, as obtained after the learning phase. The solid (dotted) lines in the middle panel show the kernel obtained from the normal (phase-inverted) realisations, while the bottom panel shows the residuals derived from the process with the two references.
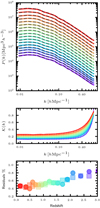 |
Fig. D.1. Summary statistics of mock halo catalogues generated with BAM using the UNITsim as reference. Top panels: Power spectrum P(k) obtained from learning phase (Sect. 2.7), (solid lines) compared to the same statistics from the reference (dashed lines). Colours indicate different snapshots of the UNIT simulation, ranging from z = 0 (red, upper curves) up to z = 3 (violet, bottom curves). The outputs and references at each redshift have been shifted by the same amount to facilitate the comparison. The middle panel shows the kernel 𝒦 and the bottom panels show the relative residuals in the power spectrum at the different redshifts, obtained from the normal (filled circles) and the phase-inverted (filled squares) reference catalogues. |
The procedure described in Sect. 3.2 is repeated to generate independent halo number counts. A number (∼1000) of ICs are generated using the FastPM code (Feng et al. 2016) with the same cosmological parameters and input power spectrum as the UNITsim, this time with allowing cosmic variance in the form of random Gaussian realisations. The same number of approximated dark matter density fields are accordingly generated. Figure D.2 shows the power spectrum of a number of halo number-count distributions at different redshifts compared with the reference power spectrum from (one of the two) paired references. As pointed out above, the results from the calibrations of the paired set are used to generate a total bias and an averaged kernel, as dictated by Eq. (15). An exhaustive analysis of the summary statistics from this set of mocks is out of the scope of this paper and will be presented in forthcoming publications. However, a simple visual analysis of the different spectra at different redshifts reveals good behaviour up to the Nyquist frequency (for this setup, ∼0.8 hMpc−1). Forthcoming work will be dedicated to applying the strategy described in this paper using larger simulations such as the Abacus-summit (Garrison et al. 2018).
 |
Fig. D.2. Halo power spectra of Nsim = 400 BAM-UNITsim-mock catalogues (grey lines) at different redshifts, obtained from the assignment of number counts. In each panel, the coloured lines represent the power spectrum of the reference halo catalogue at the respective redshift. |
All Figures
|
Fig. 1. Flow-chart representing the different stages involved in the generation of mock galaxy catalogues with BAM described in Sect. 2.2. The process is mainly divided into two sections: learning phase and mock production. In the learning phase, a number of kernels and halo biasses are calibrated from different realisations of the reference simulation and are stacked to generate one version of kernel and bias used in the mock production phase. The different colours in the arrows indicate the different stages involved in the process (e.g. calibration, generation of independent halo number counts, assignment of halo properties, construction of galaxy catalogues). |
| In the text | |
|
Fig. 2. Slices of 25 Mpc h−1 thick though different density fields involved in the calibration of the BAM products and its products. The bottom panel shows the reconstruction of the halo number density field using different models of halo bias (see Sect. 2.6). The rightmost column shows the galaxy density field from the reference and from BAM, built by populating halo catalogues with a model of halo occupation distribution (see Sect. 4). |
| In the text | |
|
Fig. 3. Summary statistics of the calibration procedure in BAM based on one SLICS realisation. Panel (a): Residuals computed from the reference power spectrum and the halo power spectrum at different iterations within the calibration procedure. Absolute residuals (see Eq. (13)) show that the calibration leads to a precise (< 1%) reconstruction of the halo number counts and its two-point statistics, while relative values show that the deviation around the reference is randomly distributed, with a ∼0.15% amplitude. The different lines in each case show the behaviour under different models (TkWEB, IkWEB, TIWEB) of halo bias (see Sect. 2.6 for details). Panel (b) shows the power spectrum from the reconstructed halo number counts field in each of the halo models. Panel (c) shows the transfer function 𝒯i(k) computed as in Eq. (11), evaluated at the last iteration of the calibration procedure; the shaded area denotes the 3% deviation around unity. Panel (d) shows the BAM kernel computed using Eq. (12). |
| In the text | |
|
Fig. 4. Power spectrum (left) and reduced bispectrum (right, isosceles configurations) computed from sets of mock halo number-count catalogues (of 80 realisations each) obtained from the calibration of BAM using the TkWEB model as described in Sect. 2.6. The first row shows the mean in each summary statistic. The second row shows the ratio of the mean statistics to that from the reference (RTRmean). The third row shows the variance in the respective statistics, and the fourth their respective ratio to the variance from the reference ensemble (RTRvar). The shaded area in the second row denotes the 5% deviation to unity. |
| In the text | |
|
Fig. 5. Correlation coefficients of the halo power spectrum obtained from a set of 80 realisations of halo number-counts using the SLICS and BAM mock catalogues, calibrated from the different number of references Nref and two characterisations of the properties of the dark matter density field (TkWEB and TIWEB). |
| In the text | |
|
Fig. 6. Same as Fig. 5 but for the reduced bispectrum of dark matter halos using isosceles configuration k1 = k2 = 0.2 h Mpc−1. |
| In the text | |
|
Fig. 7. Comparison of the signal of reduced bispectrum obtained from 80 mock catalogues generated with BAM (using the TkWEB model) and the same signal from the reference set, for several triangle configurations, which are specified in each panel. The left column shows the ratio to the reference (RTF) of the mean (solid lines) and variance (dashed lines); the shaded areas in the panels of this column denote a 20% deviation from unity. The right column shows two elements of the correlation coefficients of the bispectrum rij. |
| In the text | |
|
Fig. 8. Subgrid modelling for the assignment of coordinates in phase space. The coordinates of the random tracers are modulated by the fraction fcol such that if dr denotes the separation between the random particle and its closest dark matter particle, the new separation is fcoldr. Velocities are modified in two steps: (i) an isotropic density-dependent correction γ(δdm) is applied to the velocities of both random tracers and dark matter tracers ( |
| In the text | |
|
Fig. 9. Power spectrum of halo catalogues in real space P(k), (panels (a) and (b)) and redshift space, with the latter represented by the monopole P0(k), (panels (c) and (d)), the quadrupole P2(k), (panels (e) and (f)), and the hexadecapole P4(k), (panels (g) and (h)). Panels (a), (c), (e), and (g) show the mean power spectrum from the 80 SLICS realisations (grey dashed line) and the mean from the same number of BAM mocks (solid blue lines). Panels (b), (d), and (f) show the ratio (RTR) of the BAM mean spectrum to that of the reference. The shaded areas denote the standard deviation computed from the mean and variance of each set. |
| In the text | |
|
Fig. 10. Example of the distribution of halo peculiar velocities v = |v| in one reference (solid black histogram) and one BAM (solid blue and filled histogram) halo catalogue, in different types of cosmic web (see Sect. 3.3). In all panels, the corrected histogram is obtained after applying the isotropic velocity correction described in Sect. 3.3. |
| In the text | |
|
Fig. 11. Correlation matrix of halo power spectrum with BAM. Top row: Correlation matrix |
| In the text | |
|
Fig. 12. Joint probability distribution ℬ(x, δdm) of halo properties x (number counts, virial mass and velocity dispersion) and the underlying dark matter density, interpolated on a 1923 mesh using a CIC mass-assignment scheme and for different cosmic-web environments. Solid lines (and coloured regions) denote contours enclosing 98% and 68% of the total number of cells in a reference SLICS simulation. Dotted lines represent the same quantity obtained from one BAM halo catalogue. |
| In the text | |
|
Fig. 13. Cumulative halo abundance as a function of virial mass Mvir (left column) and velocity dispersion σv (right column) obtained in different cosmic-web types (normalised to the number of halos in each cosmic-web type). Error bars indicate the mean and standard deviations computed from 80 realisations. |
| In the text | |
|
Fig. 14. Ratio (ratio-to-reference) between the mean power spectrum from the set of 80 BAM mock halo catalogues and that obtained from the same number of SLICS catalogues, both in real and redshift space (monopole ℓ = 0, quadrupole ℓ = 2, hexadecapole ℓ = 4), in three bins of halo virial mass. The shaded areas denote the 1σ region (standard deviation) computed from the means and their respective errors. |
| In the text | |
|
Fig. 15. Correlation matrix of power spectrum. Left column: Ratio between the variance of the power spectrum from the BAM mocks and that measured from the SLICS in different halo-mass bins. Right column: Correlation coefficients obtained from the BAM mock halo catalogues and the SLICS references computed in real and redshift space, with the latter expressed through the monopole P0(k), the quadrupole P2(k), and the hexadecapole P4(k). Three bins of halo mass are shown (rows). |
| In the text | |
|
Fig. 16. Mean number of galaxies (central and satellite) from the BAM and SLICS ensembles as a function of host halo mass. The points with error bars denote the mean and variance from each ensemble. |
| In the text | |
 |
Fig. 17. Same as Fig. 14 but for the mock galaxy catalogues generated as explained in Sect. 4. |
| In the text | |
 |
Fig. 18. Same as Fig. 15 but for the galaxy population. |
| In the text | |
 |
Fig. 19. Same as Fig. 15 but for the central galaxy population. |
| In the text | |
 |
Fig. 20. Same as Fig. 15 but for the satellite galaxy population. |
| In the text | |
|
Fig. 21. Galaxy correlation function in real space ξ(r), (top panel) and redshift space in the form of monopole ξ0(s), quadrupole ξ2(s), and hexadecapole ξ4(s). The solid line and shaded area denote the mean and sample variance from the SLICS simulation, respectively. |
| In the text | |
|
Fig. 22. Galaxy marked correlation in real ℳ(r) and redshift space ℳ(s). The top panel show the result of using the halo virial mass as the mark. The middle panel uses the velocity dispersion and the third shows the results of using the cross-marked correlation function. |
| In the text | |
|
Fig. A.1. Pearson correlation coefficients between halo properties (panel a), the local dark matter density with halo virial mass (panel b) and velocity dispersion (panel c), measured in bins of local density for different cosmic-web types, as obtained from the SLICS reference simulation. The error bars denote the standard deviation obtained from the set of catalogues. |
| In the text | |
|
Fig. C.1. Comparison of the summary statistics of the set of BAM galaxies generated from the halo catalogues (BAMh) with those of the BAM galaxies generated from calibration (BAMg) obtained from the SLICS galaxy catalogue. The top row shows the ratios to the references (RTF) from the mean and variance of the power spectrum (real and redshift space). The middle row shows the absolute value of the difference between the correlation coefficients rij of the BAM sets (BAMg, upper diagonal, BAMh, lower diagonal) and those from the SLICS. The third row shows the elements of the correlation coefficients (in only one Fourier bin, to avoid clutter) from the three sets. |
| In the text | |
|
Fig. D.1. Summary statistics of mock halo catalogues generated with BAM using the UNITsim as reference. Top panels: Power spectrum P(k) obtained from learning phase (Sect. 2.7), (solid lines) compared to the same statistics from the reference (dashed lines). Colours indicate different snapshots of the UNIT simulation, ranging from z = 0 (red, upper curves) up to z = 3 (violet, bottom curves). The outputs and references at each redshift have been shifted by the same amount to facilitate the comparison. The middle panel shows the kernel 𝒦 and the bottom panels show the relative residuals in the power spectrum at the different redshifts, obtained from the normal (filled circles) and the phase-inverted (filled squares) reference catalogues. |
| In the text | |
|
Fig. D.2. Halo power spectra of Nsim = 400 BAM-UNITsim-mock catalogues (grey lines) at different redshifts, obtained from the assignment of number counts. In each panel, the coloured lines represent the power spectrum of the reference halo catalogue at the respective redshift. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.