| Issue |
A&A
Volume 691, November 2024
|
|
|---|---|---|
| Article Number | A28 | |
| Number of page(s) | 27 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/202449828 | |
| Published online | 29 October 2024 | |
Tidal tails of open clusters
Faculty of mathematics and physics, University of Ljubljana, Jadranska 19, 1000 Ljubljana, Slovenia
⋆ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
1
March
2024
Accepted:
27
June
2024
Abstract
Context. Open clusters that emerged from the star-forming regions as gravitationally bound structures are subjected to star evaporation, ejection, and tidal forces throughout the rest of their lives. Consequently, they form tidal tails that can stretch kiloparsecs along the cluster’s orbit.
Aims. Cluster members are typically found by searching for overdensities in some parameter space (positions and velocities or sometimes actions and orbital parameters of stars). However, this method is not effective at identifying stars located in the tidal tails far from the open cluster cores. We present a probabilistic method for finding distant cluster members without relying on a search for overdensities and apply it to 476 open clusters.
Methods. First, we simulated the dissolution of a cluster and obtained a probability distribution (likelihood) describing where cluster members are to be found. The distribution of stars from the Gaia DR3 catalogue in high likelihood regions was then compared to the simulated stellar population of the Galaxy to define the membership probability of each star.
Results. The survey of cluster members included all stars with a magnitude of G < 17.5 and larger clusters with an age of > 100 Myr within 3 kpc from the Sun. We successfully found stars with high membership probabilities in the tidal tails of most clusters. The recovered tidal tails stretch more than a kiloparsec from the cluster cores in some cases. We analysed the morphological properties of the tidal tails and demonstrated how properly normalised membership probabilities aid systematic studies of open clusters. Finally, we have published a catalogue of stars found in the tidal tails.
Key words: methods: statistical / surveys / stars: kinematics and dynamics / open clusters and associations: general
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Tidal tails of open clusters were predicted long ago (Bok 1934; Spitzer 1940) (also Küpper et al. 2008, and references therein), but their observational confirmation has only recently been possible with the precise positions and motions of stars obtained by the Gaia mission (Meingast & Alves 2019; Röser et al. 2019). Unlike globular clusters and dwarf galaxies, many of which possess well-studied tidal tails (e.g. Odenkirchen et al. 2001; Belokurov et al. 2006; Ibata et al. 2019), open clusters are around a thousand times smaller than globular clusters and are found in the environment around a thousand times more densely populated with stars than the Galactic halo. Hence the tidal tails of open clusters do not form a statistically significant overdensity in space. Stars in tidal tails can only be found with algorithms designed for the specific task (unlike general algorithms for finding clusters and streams, such as OC finder Castro-Ginard et al. 2018 or STREAMFINDER Malhan & Ibata 2018) and in datasets with small enough uncertainties, so stars in the tail can be delineated from the field stars with some certainty.
So far, only about a dozen open clusters in the literature have known tidal tails. The first stars in tidal tails well past the cluster tidal radius were found in Hyades. Stars were found in the 6D position-velocity space (Meingast & Alves 2019) as well as in 5D position-proper motion space (Röser et al. 2019), accounting for the projection effects with the convergent point method (van Leeuwen 2009). Hyades has been extensively researched since then, with studies revealing more stars in the tails stretching up to 800 pc and showing some structure and overdensities in the tail (Jerabkova et al. 2021). The shape of the tails and the overdensities are used to infer the best models of cluster evolution in the Galactic gravitational potential and the interaction with giant molecular clouds or spiral arms (Oh & Evans 2020; Jerabkova et al. 2021; Evans & Oh 2022; Thomas et al. 2023).
Tidal tails and coronae or haloes of ten open clusters were found by Meingast et al. (2021) using a convergent-point technique and machine learning. Only a few more clusters were found to have observed tidal tails: M67 (Gao 2020a), NGC 2506 (Gao 2020b), NGC 752 (Boffin et al. 2022), IC 4756 (Ye et al. 2021), and Coma (Tang et al. 2019). Some more clusters were found to have member stars known outside their core yet not in extended tidal tails (Bhattacharya et al. 2022; Tarricq et al. 2021). Recently, many already disintegrated structures have also been found (Kounkel & Covey 2019), and many of them stretch along distances similar to those expected for the tails of dissolving open clusters (e.g. Andrews et al. 2022). However, most of the structures have been disputed as representing stars with a common origin (Zucker et al. 2022).
It is common to all the discoveries of tidal tails in the existing literature that only stars based on high likelihood are found (as opposed to stars with high membership probability). Likelihood is the probability that a star originating from the cluster is found at some coordinate in some parameter space occupied by a cluster. Such selection of most-likely cluster members can be reliable (Bouma et al. 2021), but this is hard to verify without additional observations of radial velocities, asteroseismic parameters, and chemistry of stellar atmospheres, among other aspects. Membership probability is the probability that a star at some coordinate in some parameter space is a cluster member. Stars with high likelihood do not necessarily have high membership probability if, for example, they lie in the Galactic plane, where many field stars pass the likelihood threshold as well. To these stars, we can assign some low membership probability, although it would be impossible to know which of the stars are cluster members and which are not – it would just be known that the ensemble of stars has some membership probability. The membership probability would be proportional (or equal, if correctly normalised) to the fraction of the stars that we expect to be cluster members.
Not being able to estimate membership probabilities is a strong drawback of existing approaches to finding tidal tails of open clusters. First, there is no objective threshold for the likelihood that delineates members from non-members. This also holds for machine learning techniques, where some internal parameter or a variable dictates the size of found groups. Second, with the maximum likelihood type of methods, it is always possible to find some tidal tails if the underlying model predicts them. This means that there will always be a model for the shape of tidal tails that matches the observations. Hence it is impossible to perform model matching to observed distributions of possible tidal tail stars if membership probabilities cannot be estimated and the effect of the background population of stars cannot be evaluated.
Our work avoids the use of clustering algorithms and machine learning. Instead, we rely on clear and discrete criteria for the selection of possible cluster members, that is, the stars that pass some likelihood threshold. This, together with a plain selection function, allows us to apply the same selection criteria to the observed stars and to a simulated Galactic population in order to calculate normalised cluster membership probabilities. With these probabilities, we can analyse the distribution of stars and the shapes of the tidal tails, even in areas far away from the cluster centres where only low-probability members may be present in available data.
The shape and structure of tidal tails are influenced by the cluster formation processes, the gravitational field of the Galaxy, and gravitational perturbations experienced throughout the cluster’s lifetime. The positions of the tail (Dinnbier et al. 2022) and epicyclic overdensities (Küpper et al. 2010; Jerabkova et al. 2021) are the easiest to measure, while the prominence of the tail (or length) is the hardest, due to uncertainties in membership probabilities far from the cluster core. Observations of tidal tails can shed light on several processes and phenomena discussed below and have been proposed in the literature, some of which are analogous to tidal tails observed in the Galactic halo.
Unlike the tidal tails observed in the Galactic halo, the tidal tails of open clusters can be used to probe the gravitational potential of the inner Galaxy. This offers a unique opportunity to study the inner Galaxy by tracing the kinematical processes, such as the dissolution of clusters, rather than just observing a static distribution of stars or their orbital parameters. Open clusters in the solar neighbourhood are affected by the gravitational potential of the Galactic bar, and their orbits offer insights into the bar’s rotation and pattern speed. The pattern speed of the bar primarily affects the shape of the tidal tails due to resonances (Thomas et al. 2023). Clusters offer a unique insight into the rotation of the bar in the last 2 Gyr, possibly revealing the pattern speed of the bar slowing down (Chiba & Schönrich 2021). Due to a wide range of ages and orbits, even open clusters in the solar neighbourhood offer a unique insight into temporal variations of gravitational potentials involved in tidal tail formation.
In addition to the tidal forces, the clusters are regularly perturbed by the gravitational effects of structures they encounter along their orbits, mostly the giant molecular clouds (GMCs). Such interactions have been explored as the reason for asymmetric tidal tails in Hyades (Jerabkova et al. 2021). It is expected that such interactions are common and should be a dominant source of perturbation when a cluster passes through the Galactic plane (Gieles et al. 2006; Martinez-Medina et al. 2017).
The shape of the tidal tails also depends on the gravitational potential of the cluster itself, particularly during the gas expulsion phase immediately after the cluster and star formation (Dinnbier & Kroupa 2020). Early phases of cluster lives can thus be explored indirectly with a large sample of clusters (to avoid degeneracy between early processes and later perturbation). Cluster rotation (Guilherme-Garcia et al. 2023) is another internal factor that can affect the shape and prominence of the tidal tails. The evolution of the tidal tails can also be affected by massive objects in the cluster, such as OB stars and black holes (Wang & Jerabkova 2021).
The initial mass function for stars, often measured in (young) open clusters, is the critical parameter relating the theories of star formation to observed stellar populations (Krumholz et al. 2019). The formation of tidal tails can skew the observed mass function if some stars are not accounted for (Gieles 2009). Therefore, a more complete census of stars in the tidal tails can contribute to observed mass functions of open clusters being less affected by mass segregation. This will allow the initial mass function of older clusters to be more accurately inferred.
In this paper, we focus on finding stars in tidal tails of open clusters and only briefly discuss the implications of found structures for the study of physical processes involved in their formation. We acknowledge that further research would require more precise N-body simulations and careful matching of tested models to observations. We offer a method of finding normalised probabilities for stars in the tidal tails being members of open clusters. This method is necessary for comparing different models.
This paper first describes the parameter space in which we searched for cluster members and tidal tails (Sect. 2). Then we present the simulations of the dissolution of open clusters in Sect. 3, and in Sect. 4, we describe our method for assigning membership probabilities to stars found in the tidal tails. Products and results of our analysis are presented in Sect. 5. We also provide online tables at the CDS with parameters of analysed clusters and stars as well as figures illustrating the tidal tails of each cluster. In Sect. 6, we compare our results for four clusters with already known tidal tails and discuss some initial findings on the morphology and physics of tidal tails. Discussion on how to use our catalogue is also included in the latter section. Section 7 finishes with conclusions.
2. Projected parameter space
Ideally, the cluster members would be searched for in a parameter space where members form as tight of a group as possible, while field stars are scattered widely. Actions and orbital parameters are often used to construct a parameter space. This works extremely well for finding stellar streams (Helmi 2020) and moving groups (Antoja et al. 2008), and is in principle a good method for finding open clusters as well (Krumholz et al. 2019). However, very precise positions and velocities are needed in practice. Clusters in action and orbital parameter space are blurred mostly due to uncertainties in distance and radial velocity measurements. Distances almost always have uncertainties much larger than the size of the cluster, and the radial velocities are not always available and are additionally distorted by binary stars. Therefore a dataset of good enough quality to support finding tidal tails of open clusters in the mentioned parameter spaces would be rather small, limited to brighter and nearby stars, and would have a complicated selection function.
In this work, we aim to find individual stars in the tails of known open clusters. These stars are sparse and a dataset with the emphasis on quantity over quality suits us much better. To derive membership probabilities we also need a simple and well-known selection function. Hence we can only search for cluster members in parameter spaces that can be constructed without accounting for the radial velocity of stars.
We can use the five observables, which include two positions on the sky, two proper motions, and parallax, as the parameter space for finding cluster members in the cluster cores (Castro-Ginard et al. 2018). Naturally, stars in the tidal tails do not form a concentrated cluster in this parameter space, but can sometimes be recovered by cluster finding algorithms that search for extended structures (Meingast et al. 2021). The shape of the clusters in the observables parameter space can be further deformed by projection effects. These can be untangled with the convergent point method (de Bruijne 1999; Röser et al. 2019) to find members further away from the cluster cores. The general structure of tidal tails can also be accounted for (if known from N-body simulations for example) by a so-called compact convergent point algorithm (Jerabkova et al. 2021).
Similarly to the convergent point methods, we search for cluster members in a transformed parameter space. Using Astropy’s SkyOffsetFrame function that perform coordinate and velocity conversions via Euler angles (e.g. Tatum 2023), we can calculate the distance of a star from the cluster centre, the position of the star in a coordinate system with the cluster in the origin, and the velocities in this coordinate system, which are the velocity of the star in the radial direction from the cluster centre (v∥) and in the orthogonal direction (v⊥), defined as
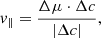 (1)
(1)
and
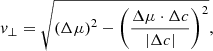 (2)
(2)
where vector Δμ contains proper motions translated into the system where the cluster is at the origin, and Δc is a vector of celestial coordinates in the same translated system.
It is obvious that in the absence of projection effects and long tidal tails, the stars that were ejected from the cluster must have v∥ proportional to the distance from the cluster (d), and v⊥ must be close to zero. Projection effects cause the relation between d, v∥, and v⊥ to bend away from a straight line, and forces shaping the tidal tails can make the relationship between the above quantities even more complicated. However, the stars in the cluster, or originating in the cluster, will always form a coherent and continuous shape in the projected parameter space if the perturbation comes only from tidal forces. The stars will also occupy a smaller region of the projected parameter space (form a tighter group) than in the observed proper motion space. The projected parameter space is illustrated in Sect. 4.2 for an example of NGC 2516.
3. Modelling dissolution of clusters
The first step in our algorithm for finding distant cluster members is defining a likelihood that describes where in a parameter space we expect to find cluster members. This is done by a simulation, where we take the positional and kinematic parameters of a known cluster, integrate the orbit of the cluster centre back in time, populate a cluster with stars and then do a simulation of the cluster evolution forwards in time to the present age. The result is a simulated cluster that samples the wanted likelihood. It is essential that the likelihood is sampled with sufficient density, which in our case, where cluster members are searched for in a 5D parameter space, means up to one million samples per cluster, depending on the size of the tidal tails. We note that the positions of simulated stars in each dimension are well correlated, so simulating only ∼15 stars per dimension still produces enough samples.
3.1. Initial conditions
For clusters younger than 750 Myr we simulate their dissolution throughout their whole life. At most, this takes roughly three revolutions around the Galaxy. In simulations, the clusters with the age of 750 Myr develop tidal tails the length of a few kiloparsecs. It is extremely unlikely that we would be able to find any cluster members at these distances either due to error propagation, a large size of the parameter space, or a small number of members that should exist at these distances in the first place. We therefore only simulated the last 750 Myr of dissolution for older clusters. For longer simulations, we would have to account for different Galactic gravitational potentials, as small variations can have a significant impact on the orbit after a while. This would produce a spread-out likelihood distribution that favours many stars as members, but all with tiny probabilities. We do not have any mechanism at hand that would reduce such a large amount of low probable members into a useful or applicable sample. Even the simulation of the last 750 Myr can be significantly uncertain for the shape of the orbits > 1 kpc from the cluster centre.
3.1.1. Galactic potential
To simulate the orbits of clusters we constructed a 4 component Galactic potential. The halo is described by a Navarro–Frenk–White potential (scale radius R = 16.244 kpc, normalised so its rotation curve peaks at rmax = 35.13 kpc with vmax = 169.0 km s−1), a bar with a softened needle bar potential (mass m = 1010 M⊙, bar half length a = 3.5 kpc, prolate softening length c = 1.0 kpc, pattern speed Ωb = 1.85, and position angle at present time ϕPA = 0.4), bulge with a Plummer potential (mass m = 2.0 109 M⊙, scale c = 0.25 kpc), and the disc is described by a Miyamoto Nagai potential (mass m = 6.0 1010 M⊙, scale radius R = 3.0 kpc, scale height h = 0.28 kpc). Figure 1 illustrates the gravitational potential used in this work. The code to produce the potential is given in Appendix G.
 |
Fig. 1. Illustration of Galactic potentials used in the simulation of stellar orbits. The left column shows the complete gravitational potential, and the following columns show the potential of the bar, disc and the halo. The black line shows the orbit of the Sun for the last 750 Myr. A small dip close to the present position of the Sun is the gravitational potential of a simulated cluster, amplified one million times. Magnitudes of different potentials are not plotted to scale. |
Potentials, distances and velocities are normalised or converted to natural units using R⊙ = 8.122 kpc for the Sun’s distance to the Galactic centre (GRAVITY Collaboration 2018) and v⊙ = 233.4 km s−1 for the circular velocity of the LSR (Drimmel & Poggio 2018), i.e. the values used by default in ASTROPY for coordinate system conversions. Orbits are then integrated using GALPY package.
To find the initial conditions for the cluster centre, we integrate its centre back in time using the potential mentioned above. For the actual simulation of cluster’s dissolution, we add the gravitational potential of the cluster and populate it with massless particles.
3.1.2. Clusters parameters
To simulate a cluster we use the position and velocity of a cluster at the present time and integrate back the orbit of the cluster’s centre. There we initialise the cluster and simulate the kinematics of its stars. The positions, proper motions, distances, and ages (also used to generate an isochrone and calculate stellar masses) of clusters are taken from Cantat-Gaudin et al. (2020). We analyse all clusters from this catalogue with age > 100 Myr, distance < 3 kpc, with more than 45 stars found by Cantat-Gaudin et al. (2020) (parameter nbstars07 > 45) and with available radial velocities (see below). Open clusters analysed in this study therefore exclude any poorly defined structures, large dissolved groups or associations. Additionally to 475 clusters that satisfy the above conditions, we analysed Pleiades (Melotte 22). Pleiades have an age of 77.6 Myr in Cantat-Gaudin et al. (2020). However, in the literature their age is usually 100 Myr or more (e.g. Gossage et al. 2018; Bouvier et al. 2018; Murphy et al. 2022; Hunt & Reffert 2023). Because Pleiades is a commonly studied cluster, also in the context of tidal tails (Meingast et al. 2021), we include Pleiades in our analysis. Age and parameters from Cantat-Gaudin et al. (2020) were used in simulations and analysis for Pleiades, same as for all other clusters.
We take radial velocities from Simbad. Clusters in the above catalogue with no radial velocity in Simbad were not analysed. The source of the radial velocity is given in the online table of cluster parameters (Clusters table). Radial velocity sources are Conrad et al. (2014, 2017), Loktin & Popova (2017), Gaia Collaboration (2018), Kos et al. (2018), Soubiran et al. (2018), Carrera et al. (2019, 2022), Casali et al. (2019), Dias et al. (2019, 2021), Monteiro & Dias (2019), Donor et al. (2020), Zhong et al. (2020), Magrini et al. (2021), Tarricq et al. (2021). For 43 clusters we repeated the simulation with our radial velocities obtained from stars initially found as members with the Simbad’s radial velocity (see Sect. 5.1).
Coordinate conversion between the celestial and Galactic coordinate systems was done by ASTROPY using (U, V, W)⊙ = ( − 12.9, 245.6, 7.78) km s−1 (Drimmel & Poggio 2018), R⊙ = 8.122 kpc (GRAVITY Collaboration 2018), and z⊙ = 20.8 pc (Bennett & Bovy 2019).
3.1.3. Cluster initialisation
Because we are not interested in the dynamical properties of stars inside the cluster, but rather just the stars very far away from the cluster core, we did not intend to simulate the core itself. Kinematics in the core are dominated by multi-body interactions, which would require a precise and computationally slow simulation, possibly involving stellar evolution as well. Motions of stars far away from the cluster core are completely dominated by the Galactic gravitational potential. Once the star is ejected or stripped from the cluster, the intra-cluster dynamics are irrelevant to the star’s future orbit. Therefore, we only aimed to simulate well the ejection of stars from cluster core, tidal evaporation and the subsequent orbit of a star in the Galactic potential. We also neglect any gravitational effects of spiral arms or giant molecular clouds, as their evolution throughout the last 750 Myr is mostly unknown.
All clusters are initialised in the same way, regardless of their age, mass or star counts; we create a Plummer potential well centred at the cluster with a scale parameter (radius) of 2 pc and a mass of 5000 M⊙. We populate this potential with one million point masses, following the recipe in Aarseth et al. (1974), so they form a stable distribution that would give rise to the original Plummer potential. Masses of bodies are irrelevant, as our simulation has no body-body interactions.
3.1.4. Ejection and tidal evaporation
Stars are removed from a cluster by two mechanisms: tidal evaporation and two- or three-body interactions. We simulated the former but not the latter. Tidal evaporation works on edges of the cluster close to the cluster – Galactic centre line (Lagrange points, Fukushige & Heggie 2000) on long timescales. Because the initial conditions for a cluster are stable (the cluster is gravitationally bound), we expect very little tidal evaporation. Because a gravitationally bound cluster is not the most realistic representation of known open clusters, and to move more stars into tidal tails, we initialise a mass loss from the Plummer potential. All clusters start with a mass of 5000 M⊙ and lose 4000 M⊙ by the present time. We note that such a simplification does not simulate the velocity distribution in the cluster core well.
Two- or three-body interactions are more common at the beginning of the cluster’s life and are random in terms of direction. They cause mass segregation, mix the initial velocity distribution and cause fast ejections of stars. We do not simulate these processes directly, but instead assume and analytically model a velocity distribution and rate for ejected stars. These stars will be the only ones that can end up far away from the cluster core of young clusters and allow us to sample the distribution of stars in the halo or corona of the cluster.
The ejection velocities are random in direction, but the amplitude changes with time as
![Mathematical equation: $$ \begin{aligned} v_\mathrm{eject} =\left[300.0\left(\frac{t}{{\mathrm{Myr} }}\right)^{-1.7}+1.0\right]\,\mathrm {km\,s} ^{-1}. \end{aligned} $$](/articles/aa/full_html/2024/11/aa49828-24/aa49828-24-eq3.gif) (3)
(3)
This function approximates the results of a simulation in Moyano Loyola & Hurley (2013). The rate of ejected stars changes with time as
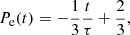 (4)
(4)
where Pe(t) is the probability that a star is ejected at time t, and τ is the age of the cluster. Half of the stars in the cluster will get the kick described above once in the simulation. Again, this is not realistic, but sends more stars into the tidal tails and the cluster’s halo, where we want to sample the likelihood as well as possible.
For each star we calculated when and how it should be ejected and later simulated it in two parts. First we simulated the orbit until the ejection time. At this point, we added the kick and then simulated the rest of the orbit.
3.2. Orbit integration
When simulated stars are initialised, we integrate their orbits in the combined gravitational potential of the Galaxy and the cluster, where the gravitational potential of the cluster is moving along the pre-calculated orbit and is getting shallower with time, as described in the previous section.
Orbits are integrated with a Runge-Kutta type of algorithm with a relative precision of 10−3 and absolute precision of 10−6 R⊙. This is sufficient, so no energy is lost while simulating the dynamics of tidal tails. Such a simulation is fast enough that it can be performed for one million bodies in hundreds of clusters in a reasonable time on one node of a cluster computer.
3.3. Constructing the membership likelihood distribution
The result of a cluster dissolution simulation is a sampled probability distribution for the present location of cluster members. We call this probability distribution membership likelihood. It tells us where we expect to find cluster members, but not yet the membership probability of a found star, as the likelihood does not account for any underlying structure of the Galaxy and distribution of field stars.
Gaia stars for which we want to calculate membership likelihoods are affected by observational uncertainties. Ideally, the likelihood for each star would be calculated by multiplying the membership likelihood distribution with the distribution describing the measured parameters of a star. This is computationally too expensive, so instead we convolve the simulated likelihood distribution with Gaia’s mean observational uncertainties (Fabricius et al. 2021; Katz et al. 2023). The simulated likelihood was re-sampled with a multivariate Gaussian kernel using the following uncertainties (multiple values indicate a sum of multiple Gaussian kernels with given widths):
 (5)
(5)
Only 9% of the samples were convolved with a vr = 150 km s−1 uncertainty and only 1% with a vr = 300 km s−1 uncertainty, both of which represent unresolved binaries. The rest of the samples are evenly divided between multiple uncertainties listed above. The uncertainties represent well the Gaia’s observational uncertainties for stars up to magnitude G < 17.5. Simulated stars that sample the likelihood have no mass or magnitude attributed to them, so all can be re-sampled using the same mean uncertainties.
3.4. Defining likelihoods for Gaia stars
To calculate the likelihood of each Gaia star from the sampled likelihood distribution we first have to parameterise the sampled likelihood distribution. We use a parameter space of three positions and two projected velocities, so we need to define a joined five-dimensional parameterisation. This is done by making a five-dimensional grid encompassing the bulk of the distribution of simulated stars and calculating a histogram of star counts on this grid. The number of samples in each bin is proportional to the likelihood (ℒ) value in that bin:
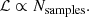 (6)
(6)
For each Gaia star we find its corresponding bin as well and assign it the likelihood of that bin. All Gaia stars in a single bin therefore have the same membership likelihood. Likelihood is reported in the Members table under the keyword likelihood. There is no need for any normalisation of likelihoods, as we only used the likelihood for relative comparisons between Gaia stars that are more or less likely to be members of one cluster.
The five-dimensional space is binned with constant steps of 20 pc in X and Y, 15 pc in Z, and 1 mas yr−1 in v∥ and v⊥. For a small number of clusters, we used proper motions instead of projected proper motions, which were binned in steps of 1.5 mas yr−1.
For stars with existing radial velocities, we calculate another likelihood, where v∥ and v⊥ are calculated from three cartesian velocities, which are calculated from proper motions and the radial velocity (i.e. from the six-dimensional position and velocity vector). This likelihood is reported in the table Members under the keyword likelihood_6d. We note that this likelihood is still calculated in five dimensions because the simulation would have to be much larger to fill the six-dimensional space compared to a five-dimensional space. 6D likelihood was calculated with the same binning, we just updated v∥ and v⊥ with values incorporating the radial velocities.
4. Assigning cluster membership probabilities
Membership likelihood defines a region in the parameter space where stars originating from the cluster are expected to be found. A probability that an actual star is indeed a cluster member depends on the likelihood at the position of the star and the probability of finding a star at that position in the population of field stars alone. In this section we calculate likelihoods of individual stars in the Gaia DR3 catalogue and combine them with a model of the Galactic stellar population to derive cluster membership probabilities.
4.1. Data
The Gaia data release 3 data (Gaia Collaboration 2016, 2023) was downloaded from the gaia_source table for all stars with G < 17.5 in some regions around the cluster and its tidal tails. An example of the query is given in Appendix E. No quality cuts were made initially, as low-quality or flagged data represents only a small fraction of the stars, but subjective quality cuts can impact the selection function. Completeness is an important issue in our algorithm, so all quality cuts were made only after the members were found, if necessary.
We split the Galaxy into regions 18 × 9 deg2 large on the sky and further split into 30 distance bins to the distance of 5 kpc. For each cluster, we only downloaded regions with more than 50 simulated stars. Each region has a low enough number of Gaia stars in it so the query on the Gaia’s server can be performed and all the provided data can be downloaded. At the same time, we refrain from downloading regions where we are unlikely to find cluster members to save time and computer memory. For each cluster, we end up with an order of one million stars from which we will select cluster members. In rare cases (clusters with very long tails and clusters in the direction towards the inner parts of the Galaxy), the number of stars is larger than 10 million.
To calculate distances from parallaxes we used a direct inversion without any priors. The first reason is that geometric or photometric priors do not account for congregates of cluster stars (Bailer-Jones et al. 2021). The second reason is that the simulations of the Galactic stellar population are made with distance as the parameter, but Gaia queries are made in respect to the parallax. We solve the discrepancy in possible star counts by calculating the parallax of simulated field stars using the uncertainties given in Sect. 3.3 and simulate an appropriately larger region.
4.2. Non-probabilistic method for finding cluster members
In Sect. 2 we describe how a parameter space of projected velocities is constructed. In this section, we show an example of the parameter space and illustrate the basic principles of using projected velocities by finding cluster members in NGC 2516 using simple selection criteria in the parameter space. The example also demonstrates the limitations of a non-probabilistic approach to finding cluster members far away from the cluster cores.
The non-probabilistic approach demonstrated here is similar to the traditional approach, where we search for cluster members in some parameter space (like (α, δ, μα, μδ, ϖ) or any similar combination of coordinates) by selecting the region around the cluster, which then delineates cluster members from non-members. The advantage of this approach is speed, clear selection function, and repeatability. Such a method is incapable of finding very distant cluster members with high confidence if we try to expand the boundaries defining the cluster. It is also impossible to define normalised membership probabilities for found stars without some further effort. We must note that such a method works much better when all three positions and all three velocities of the stars are known, as one can then search for cluster members in a cartesian parameter space unaffected by projection effects.
From the simulation of the cluster dissolution (shown with contours in Fig. 2) we can deduce the projection effects: NGC 2516 is receding from us fast enough that it appears to be shrinking when motions of the stars are projected onto the sky. This is evident from the v∥ vs. distance panel in Fig. 2. We can select the cluster members following the shape predicted by the simulation. We did the same for v⊥, and then further constrained the extent of the cluster on the sky (radius d2D) and the range of the parallax to find members of NGC 2516. The complete selection criterion is
 |
Fig. 2. Members of NGC 2516 found with a simple non-probabilistic method (green) and shown in the parameter space explored in this work. Simulated field stars found with the same selection as used for finding the members are shown in blue. Black contours show the likelihood for the position of cluster members predicted by a simulation of a dissolving open cluster. Contours are log-spaced. Top row: XY Galactic plane, proper motions space, colour-magnitude diagram. Middle row: Position along the main axis of the tidal tails (D) and density of stars along this line, two projected proper motions, v⊥ projected motion as a function of distance from the cluster. Bottom row: Position on the sky, radial velocity as a function of distance from the cluster, and v∥ projected motion as a function of distance from the cluster. |
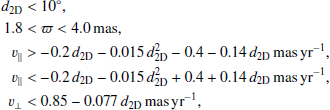 (7)
(7)
where d2D is given in degrees. Members found by the non-probabilistic method in Fig. 2 are shown in green. We applied the same selection on a simulated population of stars that does not include any clusters (see Sect. 4.3). These stars are shown in blue. From Fig. 2, one can learn that
-
Projection effects are complicated in the proper motions plane (the contours originate from the core of the cluster and wrap outside the panel into the convergent point at (μα, μδ) = (2, −5) mas yr−1). The projection effects are simpler, mostly monotonic in the projected velocity space.
-
Cluster members occupy a smaller portion of the projected velocity space compared to the proper motion space, i.e. they are better clustered.
-
Members found furthest from the cluster core are not reliable. This is best illustrated by the histogram in the second panel on the left, where in some regions we find almost as many simulated stars as real stars. Only a small fraction of those stars can be members.
-
Using the radial velocities would let us make a better selection by removing stars that have radial velocity measured but do not follow the predicted distribution of radial velocities.
-
Same could be done using the photometric information and removing the stars that do not follow the isochrone. We note that some scatter around the isochrone is normal due to differential reddening.
Our analysis of NGC 2516 shows results similar to Tarricq et al. (2022) – we find an oblong distribution of stars around the core and some halo members, but we are unable to find longer tidal tails like Meingast et al. (2021). To use the full information of the simulated likelihood and simulated Galactic population of stars we use probabilistic methods described in the next section. Then we are able to find cluster members with high certainty even in the region where field stars dominate the selection of stars in the above example.
4.3. GALAXIA simulations
To generate a synthetic survey of the Galaxy we use the GALAXIA code (Sharma et al. 2011) and populate the exact same space that was queried in Gaia with a synthetic population of stars. The Besancon analytical model of the Galaxy (Robin et al. 2003) that is used is smooth, so there are no clusters in the synthetic population. We note that the stars representing the age, chemical composition and kinematics of the clusters are in the model. They are just not put into clusters but still exist in the general region of the synthetic Galaxy. GALAXIA uses PADOVA isochrones (Bressan et al. 2012) and can provide magnitudes of synthetic stars in Gaia DR3 passbands (Riello et al. 2021). The latter is important for the selection function of the simulated stars to be as well matched as possible to Gaia’s selection function.
To avoid low-number statistics in some regions of the simulated space guiding the calculation of membership probabilities, we also oversample the GALAXIA simulation by a factor of five. The accuracy of calculated membership probabilities benefits greatly from an oversampled simulation, although an even higher oversampling was not feasible due to computer memory limitations.
Absolute magnitudes, distance, and interstellar reddening are given by GALAXIA for simulated stars. For the simulated population to be comparable to the observed one, we have to correct the magnitudes for the extinction in selected bands ourselves. We used bandpasses from Riello et al. (2021) to convert GALAXIA’s absolute magnitudes to apparent magnitudes using the extinction law with RV = 3.15 and calibration factors from Sharma et al. (2011). While Gaia has extinction measured for most stars, we find much more compatible star counts between Gaia and GALAXIA if we correct the latter. This is illustrated in Fig. 3 where completeness is compared when no extinction correction is done (blue histograms), when Gaia’s magnitudes are corrected for Gaia’s extinction (orange histogram), and when GALAXIA’s magnitudes are corrected for extinction modelled by GALAXIA (green histogram). The figure shows the case for one cluster, but correcting GALAXIA’s magnitudes is always preferred.
 |
Fig. 3. Completeness of the GALAXIA simulation versus the Gaia star counts. Histograms show the number of stars per magnitude bin in the region of NGC 2516. Blue shows the distribution when no reddening correction is done to the apparent magnitudes. Orange is the distribution when Gaia’s magnitudes are corrected for Gaia’s extinction, and Green is when GALAXIA absolute magnitudes are converted to apparent magnitudes with GALAXIA’s extinction taken into account. We used the latter magnitudes in this study. Points together with the axis on the right show the number of stars in Gaia per magnitude bin downloaded in the region of this cluster. |
An ideal simulation of synthetic stars would match the star counts by Gaia in some broad region around the cluster. We find that this is rarely the case and the star counts can vary by up to 20% (see Fig. 3). Gaia is, for all practical reasons, complete between magnitudes G = 12 and 17. Incompleteness is negligible for our case at G = 17.5 (Fabricius et al. 2021), the limiting magnitude of this study, as well as at the bright end. Hence the discrepancy between Gaia and GALAXIA star counts is due to the simulation not encasing the complexity of the real Galaxy. We take this incompleteness into account when we later calculate membership probabilities by scaling all GALAXIA counts by the incompleteness value.
The likelihood of GALAXIA stars being members of a cluster were calculated in the same way as the likelihoods for Gaia stars in Sect. 3.4. Consequently, all Gaia or GALAXIA stars have the same likelihood if they are found in the same bin of the 5D parameter space.
4.4. Calculating cluster membership probabilities
We aim to assign a membership probability to all stars in Gaia DR3 catalogue that pass a threshold of likelihood for being members of one of the studied clusters. The likelihoods of stars in each cluster have discrete values, as the likelihoods are proportional to the number of simulated stars in each 5D histogram bin. We selected the likelihood threshold so no more than 5000 Gaia stars make the selection, and then lower the threshold by one discrete step. This cut in likelihoods was done once for each cluster before the star counts described in the next sections were made.
4.4.1. Definitions
In Sect. 3.4 we described how to assign membership likelihoods to Gaia stars. Based on the likelihood, we can select candidates for cluster members. Within a region of the parameter space, the probability that a star is indeed a cluster member equals
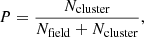 (8)
(8)
where Ncluster is the number of cluster stars in that region, and Nfield is the number of field stars (all other stars that are not members of the particular cluster) in the same region of the parameter space. We call P the membership probability. Of course, the Ncluster and Nfield are not known. What we do know is the observed number of stars (called NGaia), which is the sum of stars in the cluster and the field stars:
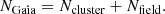 (9)
(9)
Ncluster and Nfield cannot be measured, so we assume that Nfield equals the number of simulated stars NGalaxia. Subsequently, we can derive Ncluster and calculate the membership probability from Eq. (8). However, one must be careful, as all numbers above are in reality just one sample taken from a Poisson distribution. The consequence is that even if NGaia = NGalaxia, for example, there is some chance that the Gaia stars are members of the cluster and we just got unlucky with the sampling of the distribution.
The probability that a star is a cluster member can be calculated for any combination of NGaia and NGalaxia. Formally this involves operating with cumulative distributions of the Poisson distribution, so instead we simulated the membership probability for any combination of NGaia and NGalaxia. It is evident from Eq. (9) that the same NGaia can be obtained from different combinations of Ncluster and Nfield. We follow Eq. (8) to calculate the probabilities for all combinations of Ncluster and NGalaxia, and save them into a tableau. We then convert Ncluster and NGalaxia to NGaia and average probabilities from the tableau for the same combination of NGaia and NGalaxia. The resulting table is illustrated in Fig. 4. We also account for the oversampling of the GALAXIA simulation when calculating the probabilities. We query a lookup table for each bin of the parameter space, which is faster than calculating the probabilities from an equation.
 |
Fig. 4. Membership probability lookup table given the number of observed stars (NGaia) and the number of simulated stars (NGalaxia) in any region of the parameter space. The left panel shows a detail of the right panel for a small number of observed or simulated stars. |
4.4.2. Integrated and binned membership probabilities
There are several ways of binning the parameter space to get the numbers for NGaia and NGalaxia and consequently the membership probabilities for stars in that bin. Ideally, all methods would give the same probabilities, but in reality, this is not true either due to the simulation lacking small scale structure, or due to the small number statistics. We report two different membership probabilities called integrated probability and binned probability (called probability_int and probability_bin in the Members table).
To calculated the integrated probability, we use the same bins as defined in Sect. 3.4 for calculating likelihoods of stars. We then iterate through the likelihoods in log steps of logℒ = 0.0385 and count NGaia and NGalaxia stars with likelihood between logℒi < logℒ < logℒi + 0.0385. Thus we add the star counts from all 5D histogram bins that correspond to the same range of likelihoods to obtain NGaia and NGalaxia. We than follow Eq. (8) an derivation in Sect. 4.4.1 to calculate membership probabilities from star counts NGaia and NGalaxia.
To calculate the binned membership probability, we count NGaia and NGalaxia in each individual 5D bin, regardless the likelihood. Because the number of Gaia or GALAXIA stars in each bin is almost always low (orders of magnitude lower than the number of simulated stars used to calculate likelihoods), we re-bin the data with bins twice the size (32 times the volume) of the bins used for likelihood calculations. Even after re-binning, the most common number of stars in each bin is zero, and it is also most likely that Gaia and GALAXIA stars are distributed sparsely with only one of either type of stars in one bin. Hence we re-bin the space further by merging the neighbouring bins, until there is at least one Gaia star in each bin, and there are no empty bins. Then we count the number of Gaia and GALAXIA stars in each bin and calculate the membership probability for stars in that bin. The re-binned space is essentially a discrete Voronoi tessellation in five dimensions with Gaia stars defining the cell centres.
5. Results
We provide the analysis of 476 open clusters and a catalogue of 1 026 079 stars found in their tidal tails. A small selection of clusters showing the diversity of found tidal tails is plotted in Fig. 5
 |
Fig. 5. A selection of 12 clusters from this work displayed in the Galactic XY plane. Darker coloured points show stars with higher membership probability. The purple markings show the position of the Sun. The Galactic centre is towards the right and the Galaxy rotates towards positive Y values. Stretching of the cluster core, most notable in Ruprecht 171 and NGC 6134, is due to distance uncertainties of individual stars that smear the distribution along the line of sight. |
We also produce an array of diagnostic plots for each cluster1 (like Figs. A.1, A.2, A.3, and A.4). All diagnostic plots show the same panels described here: Black contours show the log-density obtained from the simulation of cluster dissolution. Points are the stars with the highest likelihood, whereas the colour marks the membership probability. The purple dot (where visible) is the position of the Sun. The top-left plot shows the members in the XY plane. Below it is the view in the Galactic plane, where D is the dimension along the major axis of the cluster (defined for each cluster in Table 1). The histogram on the bottom of this panel shows star counts in 25 pc bins along the L axis. Bins of different membership probabilities are stacked on top of each other, and the solid line is the star count obtained as the sum of all membership probabilities (e.g. two stars with a membership probability of 0.5 count as a value of one on the black histogram). Grey-shaded rectangles above the histogram mark the region used to calculate the asymmetry of the cluster. Moving one panel down, the colour-magnitude diagram shows the isochrone as the solid line for the age given in the right of the panel (sourced from Cantat-Gaudin et al. 2020) and for the Solar metallicity. The dashed line is its binary sequence. The grey background represents the CMD of the general area around the cluster. The black arrow on the right (where visible) is the mean reddening vector. Positions of stars on the CMD were corrected for reddening and extinction as given in Gaia DR3. On the bottom-left is a panel showing the mass function of the cluster. The histogram is stacked in the same way as the one two panels above. Blue line is the fitted de Marchi mass function. It was fitted onto the black histogram in the region that is plotted as a solid line. Dashed blue line is the extrapolation of the fitted function. Red and orange symbols show the degree of segregation (see Sect. 5.3.4) for stars of the same or higher mass than the position of the symbol. Colours denote two different selections of stars (mass segregation based on members with P > 0.9 or with P > 0.66). In the right column, we show the position of the stars on the sky. Grey silhouette marks the shape of the Milky Way. Below is the proper motion diagram. Second from the bottom is the plot of radial velocities as a function of the distance of the star from the cluster centre projected on the sky. The bottom-right plot shows the two projected velocities (defined in Sect. 2).
Schema for the Clusters table.
5.1. Radial velocities of cluster centres
When comparing simulated clusters with found cluster members we noted many clusters that have wrong radial velocities reported in the literature. We obtained the radial velocities of clusters from Simbad (CDS), which collects them from many different sources (see Sect. 3.1.2). Errors are mostly caused by using a too small sample of stars and by low-precision spectroscopy with large radial velocity uncertainties. Because we did not use radial velocities to find cluster members, we are somewhat immune to the erroneous radial velocity assumed for the cluster. This holds at least for the cluster cores, while the shape and position of the tidal tail depend on the radial velocity as well.
In addition to the literature values, we calculated our own radial velocities of all clusters with at least 10 members with membership probability P > 0.5 within 5° of the literature’s cluster centre. When our radial velocity was more than 10 km s−1 and three standard deviations different from the literature value, we simulated the cluster dissolution again, now using our radial velocities. This was done for 43 clusters. Revised radial velocities are collected in Table 2, where columns show the name of the cluster, number of members with membership probability P > 0.5 used to calculate the radial velocity, radial velocity given in Simbad, source of Simbad’s radial velocity, and the radial velocity measured by us with one standard deviation uncertainty. These clusters have no radial velocity source in the Clusters table, and the value of radial_velocity is the one we measured for the cluster in the initial analysis and then used for the dissolution simulation. It can differ from the value of radial_velocity_measured, which we calculated after the final analysis, with the repeated simulation. For every cluster with at least 10 members with existing Gaia’s radial velocities with membership probability P > 0.5 within 5° of the literature’s cluster centre, we combine Gaia’s radial velocity measurements. When combining the measurements, we reject one third of the most extreme values (to mitigate the problem of binaries) and then report the average weighted by the Gaia’s uncertainty and the standard deviation of the remaining sample. These values are reported in the Clusters table in columns radial_velocity_measured and radial_velocity_std, respectively.
Clusters with revised radial velocities.
5.2. Mass functions
To fit a mass function for hundreds of clusters, one needs to parameterise it with a flexible function that is still simple and practical to fit. We chose the de Marchi mass function (De Marchi et al. 2005, 2010), which is a tapered power law of the form
![Mathematical equation: $$ \begin{aligned} \frac{dN}{dm}\propto m^\alpha \left[ 1 - \exp \left(-\left(\frac{m}{m_\mathrm{c} }\right)^\beta \right) \right]. \end{aligned} $$](/articles/aa/full_html/2024/11/aa49828-24/aa49828-24-eq10.gif) (10)
(10)
The mass function is defined by the index of the power law (α), describing the Salpeter-like mass function for most massive stars, characteristic mass mc, and the tapering exponent β that describes the mass function at the low mass end, below mc.
We fit the observed mass distribution of every cluster with the de Marchi mass function with some additional restrictions: the integrated mass function must be finite, the index of power law must (α) be close to −2.4, and the characteristic mass (mc) must be between 0.25 and 0.85 M⊙. To fit the mass function we use stars with all membership probabilities. The beauty of properly normalised membership probabilities is that we can add them together to get the star counts weighted with the membership probability. For example, ten stars with a membership probability of 0.1 together count for one star. This means that we do not have to truncate the star counts at some membership probability. The benefit is particularly obvious in mass functions. The mass function for Hyades or NGC 752 in Figs. A.1 and A.4 is completely unrealistic if only high membership probability stars are used. When we add star counts for all stars, including low probability members, the mass functions look as expected (clear peak at around 0.7 M⊙ and power law index of around −2.4).
5.3. Morphology parameters
We calculated or fitted some parameters that describe the shape of the cluster and its tidal tails. These morphology parameters do not necessarily correspond to any physical parameters and must be used with caution when interpreted as such. We mainly use them to find clusters with particular properties in the database.
5.3.1. Tail lengths
Tidal tails stretch along the orbit of the cluster, and at scales of 1 kpc, they can hardly be approximated with a simple curve. We avoid using a different, complicated orbit in the analysis of the obtained distribution of stars in each cluster. Instead we define a straight line that we call a ‘major axis’ that traverses the centre of the cluster and the extreme ends of both tidal tails. The major axis is calculated by fitting a line through the positions of cluster members in the (X, Y, Z) space. Stars are weighted by their membership probabilities, and only stars in the top 10 percentile of the distance from the cluster centre are considered. This asures us that the major axis is fitted through the tails’ ends. The parameters of the major axis are given in the Clusters table. We use the major axis when it is beneficial to project the position of stars onto a single line, like in the calculation of the length of the tidal tails or cusp index in the next section, or when plots with the same orientation of the tails must be made for several clusters.
We calculate the total length of the tidal tails as the length along the major axis between the most extreme points with at least one star per 25 pc in star counts calculated as the sum of all membership probabilities projected onto the major axis, i.e. the distance between the extreme bins with the value of ≥1 on the black histogram in the second panel on the diagnostic plots. We note that the tidal tails are curved, so the length of the tails measured along the orbit would be slightly larger.
5.3.2. Cusp index
The cusp index parameterises the shape of the cluster system close to the core. Small numbers (∼0.3) indicate a concentrated and distinct core with a steep density drop towards the tidal tails (e.g. Hyades in Fig. A.1). Large numbers (∼1.5) indicate a bulky cluster with a gradual density drop towards (usually short) tails (e.g. COIN-Gaia 13 in Fig. A.3).
Cusp index (cusp_index in the Clusters table) is calculated by fitting a generalised normal distribution to the logarithm of star counts (obtained as the sum of all membership probabilities) along the system’s major axis. The generalised normal distribution has the form
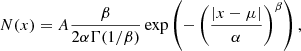 (11)
(11)
where Γ is the gamma function. The mean value μ is always set to zero, and A, α, and β are free parameters, the latter being the cusp index.
Because the shape of the system can be distorted by the combination of distance uncertainties and projection to the major axis, we only calculate the cusp index for clusters closer than 1 kpc.
5.3.3. Tail asymmetry
Tail asymmetry is calculated as the ratio of the number of stars in tidal tails on each side of the cluster centre, more precisely as
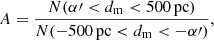 (12)
(12)
where α′ = 0.5 α2, and α is defined in Eq. (11) and dm is the position along the major axis. By counting stars from some distance away from the cluster centre we avoid making the asymmetry index too dependent on the star counts in the cluster core. Cutting off the star counts at 500 pc from the cluster centre we avoid the inclusion of stars at the end of the tails, where a large number of stars with small and possibly unreliable membership probabilities can add up to a significant star count. For clusters without the fitted α we assume a value of α = 100 pc.
We note that the tails that pass close to the Sun might be poorly surveyed by us and can therefore show some asymmetry due to incompleteness.
We find that the distribution of asymmetries of tidal tails is normally distributed around the index A = 1, so neither leading nor trailing tails are unevenly populated by stars. The distribution of asymmetry indexes is illustrated in Fig. 6. One-third of the clusters have an asymmetry index such that one tail contains more than twice the number of stars as the opposite tail.
 |
Fig. 6. Distribution of asymmetry indexes of all clusters analysed in this work. |
5.3.4. Mass segregation index
We calculate the degree of mass segregation from the minimum spanning tree method as described in Allison et al. (2009). The size of a minimum spanning tree is calculated for stars with mass larger than some value (mass ceiling). The size of this tree is compared with the average size of a minimum spanning tree calculated from the same number of randomly selected stars. If the two sizes are different, this indicates that the distribution of massive stars is different from the mean distribution of stars.
We calculate the degree of mass segregation for a range of mass ceilings. The results are plotted on the bottom left panel in the diagnostics plots. The degree of mass segregation can be calculated for stars with different membership probability thresholds. We chose thresholds of P > 0.9 and P > 0.66 for the plots. We note that membership probabilities of individual stars cannot be used in the method described in Allison et al. (2009), so we chose two thresholds that might represent the majority of stars with high membership probability. If there is mass segregation in the cluster system, the degree of mass segregation is expected to increase as a function of the mass ceiling. In the Clusters table we indicate a possible trend with a single value: the ratio of the highest to the lowest degree of mass segregation.
We only report the mass segregation index when mass segregation is calculated with P > 0.9 stars. If there are no high-probability stars in the tails, the mass segregation index can be recalculated using any probability threshold from the masses of stars reported in the Members table (see table schema in Table 3). It is not possible to use membership probabilities to combine the contribution of many low-probability stars in this case, because the minimum spanning tree can only be constructed for distinct stars.
Schema for the Members table.
6. Discussions
6.1. Clusters previously analysed in the literature
6.1.1. Hyades
Hyades have some of the longest known tidal tails of any open cluster. Tails have been found with several different methods (Meingast & Alves 2019; Röser et al. 2019; Jerabkova et al. 2021). Hyades is one of the most convenient clusters for finding tidal tails because they are old enough to have developed long tails and they are one of the nearest clusters, so distances are precise, and radial velocities are available for many stars. However, no work in the literature attempts to estimate membership probabilities for Hyades stars, only finding members with the maximum likelihood.
Our results for Hyades in general agree with the literature; we are able to find the same stars as in the literature, although the number of stars can differ depending on the likelihood threshold we adopt. Our goal is not to find the best likelihood threshold but to assign membership probabilities to stars. In Fig. 7 we show a detailed comparison of our results with Jerabkova et al. (2021). Unfortunately, the stars outside the cluster core that we have in common with Jerabkova et al. (2021) are mostly low-probability members. The stars just outside of the cluster core are the ones where probability is the hardest to estimate, as they cover a large region in the parameter space that we then bin into small segments. In such regions even a small variation in the GALAXIA star counts can change the membership probability by a lot. Hyades is the nearest open cluster to the Sun, so this effect is the largest. Consequently, the Hyades is not the best cluster to compare the results of our method with the ones using maximum likelihood to define cluster members.
 |
Fig. 7. Comparison between the stars found in this work (solid symbols) and those found by Jerabkova et al. (2021) (black circles) in Hyades and its tidal tails. Only stars with G < 17.5 in Jerabkova et al. (2021) are shown. |
Stars with membership probability P > 0.5 found by us stretch for 800 pc between the tips of the tidal tails, the same length as uncovered in Jerabkova et al. (2021). We also provide a selection of less probable members up to 750 pc from the core in each tail. The probability of finding a member at this extreme distance is around 5 stars per 25 pc of the tail length. This probability rises to around 10 stars per 25 pc at 500 pc distance from the core. The number of stars with nonzero likelihood at these distances is an order of magnitude higher than the number of expected member stars, so finding reliable members in these regions is hard and would require careful use of radial velocities and ideally chemical information as well.
We also observe asymmetry in star counts close to the cluster core, same as Jerabkova et al. (2021). However, the excess of stars in the leading tail is only apparent if membership probabilities are ignored. If counting only high-probability members, or summing all the membership probabilities, the asymmetry is reversed with more stars in the trailing tail.
Hyades is one of the hardest clusters for determining membership probabilities. Their stars occupy a huge parameter space, so statistics is completely governed by low number star counts. When calculating likelihoods we can mitigate this by using more stars in the cluster dissolution simulation. However, in the Galaxia simulation, this is not possible, as we already oversample the simulated population by a factor of five, and any significant increase in oversampling would need too much computer memory. The GALAXIA simulation also lacks any fine structure that might affect star-count differences between observation and simulation close to the Sun. The same problem occurs with a handful of other clusters that are very close to the Sun or have tidal tails that pass close to the Sun. In the latter case, only the region closest to the Sun might be affected.
6.1.2. NGC 2516
NGC 2516 is the cluster with the longest tidal tail in Meingast et al. (2021) measuring 380 pc from the end of the trailing to the end of the leading tidal tail. We find stars with membership probability P > 0.5 stretching almost 500 pc. From Fig. 8 we see that our members match well with stars found in Meingast et al. (2021) between Y = −0.45 and −0.25 kpc. Further in the leading tail the literature members only match with our low membership probability stars. The reason could be that closer to the Sun the tail covers a large region in the parameter space, so we cannot find any high membership probability stars there. However, in the trailing tail, we find high membership probability stars further away than Meingast et al. (2021), consequently making our tidal tails more symmetric. Our complete results for NGC 2516 are illustrated in Fig. A.2.
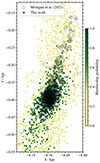 |
Fig. 8. Comparison between the stars found in this work (solid symbols) and those found by Meingast et al. (2021) (black circles) in NGC 2516 and its tidal tails. Only stars with G < 17.5 in Meingast et al. (2021) are shown. There are more high probability members found by us outside of the plotted range (see Fig. A.2). |
6.1.3. COIN-Gaia 13
COIN-Gaia 13, or Theia 456 is the cluster with the longest confirmed tidal tail in Kounkel & Covey (2019), Andrews et al. (2022) spanning 200 pc. The cluster is completely dissolved, showing no clear core, although a concentration of stars is observed at around α = 83.186°, δ = 42.087°, μαcosδ = −3.828 mas yr−1, μδ = −1.676 mas yr−1, and ϖ = 1.927 mas (Cantat-Gaudin et al. 2020). We detect stars with membership probability P > 0.5 in a 700 pc long region stretching 50° on the sky. Figure 9 shows that our member selections match well, although on the western part of the tail, the Andrews et al. (2022) stars match with a mix of our high and low membership probability stars. We also detect the same asymmetry as Kounkel & Covey (2019) and Andrews et al. (2022), showing more stars in the leading tail.
 |
Fig. 9. Comparison between the stars found in this work (solid symbols) and those found by Andrews et al. (2022) (black circles) in COIN-Gaia 13 and its tidal tails. Only stars with G < 17.5 in Andrews et al. (2022) are shown. There are more high probability members found by us outside of the plotted range (see Fig. A.3). |
We note that in COIN-Gaia 13 we found two giant stars with high membership probability. Based on their position in the HR diagram (Fig. A.3), they are not likely to be cluster members. They indeed have a negligible likelihood when their radial velocities are taken into account. Such occurrences are expected for stars with the membership probability lower than one. Our complete results for COIN-Gaia 13 are illustrated in Fig. A.3.
6.1.4. NGC 752
Boffin et al. (2022) claim that they possibly found stars in tidal tails of NGC 752 stretching along several kpc. It is unlikely that many stars several kpc from the cluster core are indeed members, as we cannot find any high membership probability stars at these distances. Hence in Fig. 10 we only compare a smaller sample of stars found by DBSCAN in Boffin et al. (2022) with ours. Both our selections of stars match well close to the cluster core, but in the western tail, we cannot confirm most stars found by Boffin et al. (2022). However, in the eastern tail, the match is very good and most high probability members found by us are also included in Boffin et al. (2022). We also find stars with membership probability P > 0.5 along a 1.5 kpc long stretch of the tidal tails. However, many of these stars that have radial velocities measured, would be excluded as high-likelihood members based on their radial velocities. In this case, we conclude that stars found by us at the extreme distances in the tidal tails of NGC 752 have overestimated membership probabilities. Our complete results for NGC 752 are illustrated in Fig. A.4.
 |
Fig. 10. Comparison between the stars found in this work (solid symbols) and those found by Boffin et al. (2022) (black circles) in NGC 752 and its tidal tails. Only stars with G < 17.5 in Boffin et al. (2022) are shown. There are more high probability members found by us outside of the plotted range (see Fig. A.4). |
6.2. Completeness
We analysed 476 clusters selected based on their age, distance, size, and availability of their mean radial velocity. From our input catalogue for clusters data (Cantat-Gaudin et al. 2020), we removed 34 clusters that had no known radial velocity in the literature after reducing the list of clusters by 223 clusters, which were removed for being too small in terms of star counts. Therefore, the clusters analysed in this work represent well the population of larger clusters in the solar neighbourhood, not the complete population. Clusters with fewer members in Cantat-Gaudin et al. (2020) might be interesting for our analysis if the low star counts are due to most stars already being moved into the tidal tails.
In terms of the stellar content, our study is complete across the whole sky for all stars with G < 17.5, as long as they are in the Gaia DR3 catalogue. Particularly some bright stars might be missing, even if they are known cluster members. This should happen very rarely, so the effect for example on the mass function at the most massive end is negligible.
We are confident that our results show observational evidence that almost all analysed clusters form tidal tails. The exceptions are most distant clusters where observational uncertainties blur the structures to such a degree that stars in the tidal tails cannot be found with any meaningful certainty. We refrain from giving a metric that would delineate clusters with recovered and non-recovered tidal tails. First reason is that there is no definition of what constitutes a tidal tail in terms of length or star density. Second reason is that the shape and properties of the tidal tails are determined by the stars found in them. Therefore, we put our effort into computing the membership probabilities, which can be used for a variety of subsequent studies. It must be noted that a metric defining a well recovered tail would be extremely beneficial, as it would allow us to quantify which models and parameters constrain the position and shape of the tidal tails best, i.e. which models fit best the real distributions of stars.
6.3. Dynamics of tidal tails
Asymmetric tidal tails were first observed in Hyades (Meingast & Alves 2019; Jerabkova et al. 2021), for which different causes were proposed. With our systematic study of 476 open clusters, we can confirm that asymmetric tidal tails are extremely common. However, we cannot confirm any bias in the asymmetry direction previously suggested in the literature (Kroupa et al. 2022). Leading and trailing tidal tails show the same degree of asymmetry (see Fig. 6), even when we remove clusters where our survey is incomplete due to one of the tails passing close to the Sun.
Some clusters we analysed show evidence of epicyclic overdensities in their tails (the best examples being Alessi 3 and IC 4651). For some clusters, more than one knot is observed. The structure of epicyclic overdensities depends on the orbit of the cluster, the position of the cluster on the orbit and the gravitational potential providing the tidal force (Just et al. 2009). Together with the position and velocity of the cluster, the structure of overdensities offers a unique opportunity to study the gravitational potential of the Galaxy with some temporal resolution (Nibauer et al. 2023). Similar conclusions can be inferred from the position of tidal tails far away from the clusters. The latter would benefit from more model testing to find which gravitational potential in the cluster dissolution simulations produces the most reliable tidal tails at large distances. Some differences in the position of tidal tails can be seen in Fig. 7, probably due to Jerabkova et al. (2021) and us using a different model of the Galactic gravitational potential (the main difference is the absence of the bar in Jerabkova et al. 2021). The shape of the tidal tails might also depend on the mass of the cluster and the mass loss rate, which could be revealed by model testing. Model testing is out of the scope of this paper, as it would require more realistic N-body simulations. It would be best performed on a small number of clusters where we show that stars in the tidal tails can be found most reliably.
Epicyclic overdensities, tail orientations, and asymmetries are properties that arise due to many different physical processes. Before conclusions are made about what is responsible for the particular shape of a tidal tail it is best to verify the memberships through other means than just kinematics. Photometry and to some extent, radial velocities are readily available. However, chemical analysis, such as predicted lithium abundance in younger clusters or some degree of chemical homogeneity among the found stars, offers a good independent confirmation of cluster memberships (Casamiquela et al. 2020; Bouma et al. 2021).
6.4. Using the catalogue
6.4.1. Table schema
Resulting memberships and cluster parameters are collected in two tables (called ‘Clusters’ and ‘Members’) with schemas described in Tables 1 and 3. The Clusters table contains one entry per cluster with basic properties of the cluster, parameters used in our membership search and derived parameters. The Members table contains one entry per star per cluster with basic stellar parameters and our derived likelihoods and probabilities.
6.4.2. Using photometry for membership selection
No photometric information apart from the cut in G magnitude was used in the selection of possible cluster members or calculation of membership probabilities. We can then use HR diagrams to examine the performance of our methods, expecting the cluster members to be arranged on or close to the theoretical isochrone. The HR diagrams can be used to further clean the list of members for example to produce a better mass function at the high mass end, as a small number of stars misclassified as members can spoil the statistics (see for example Fig. A.2 where we found too many massive giants).
While we expect the found members to lie close to the theoretical isochrones, there are many caveats. Binary stars are found, which can lie up to 0.75 magnitudes above the isochrone. The ages of clusters can have high uncertainty and consequently, the correct isochrone cannot be determined well. Clusters between the age of 100 and ∼300 Myr are the most affected because they don’t have any pre-main-sequence stars left, and at the same time, there are only a small number of stars close to the turn-off point – the position of both of these stellar types are the most sensitive to age. Finally, the biggest deviation from stars being nicely arranged on an isochrone is the differential interstellar extinction. Because we are finding stars that sometimes stretch along several kiloparsecs in space, the measured magnitudes are affected by a significantly varying range of extinctions. To mitigate this, we use Gaia’s extinctions and reddenings for individual stars when plotting HR diagrams. An alternative would be to produce the PADOVA isochrones with a mean extinction applied, which would not solve the issue of differential reddening. Extinction and reddening are not always consistently measured across different regions on the sky or across different stellar types, which is most evident for clusters with high extinctions (for example cluster King 1). There is also an issue of theoretical PADOVA isochrones not matching well with observations (for example in Hyades between 2 < BP − RP < 3). The precision of measured magnitudes is not an issue for stars with G < 17.5, apart from the stars with bad quality data.
6.4.3. Caveats
Here we list several suggestions on how to use the tables effectively. We also warn the users about the correct interpretation of several parameters found in Clusters and Members tables.
-
The user should not use likelihood to select members, unless they will be using an additional algorithm for finding the most probable members, such as clustering algorithms, or using more parameters, such as radial velocity or photometry.
-
The catalogue is not complete. While we tried to provide a complete selection of members above some likelihood threshold, we failed to do so in cases where the tidal tails pass close to the Sun. Those stars occupy a large region in the parameter space, which makes it difficult to calculate likelihoods or membership probabilities.
-
Stars can have a large likelihood (or even probability) to be in more than one cluster. This happens when nearby clusters move along similar orbits. In practice, such stars can be assigned to the cluster with the highest likelihood. We leave stars with multiple cluster memberships in the tables for the user to decide what to do with them. There are almost 12 000 such stars, but almost always one cluster has a much higher membership probability (most typically by a factor of 10). For a few percent of stars where the membership probability is similar for bots clusters, both probabilities are low (almost always < 0.2). Stars can also belong to clusters not analysed in this work (for example UPK 537 contains stars from (probably co-natal) UBC 480).
-
We report membership probabilities computed by two different methods (see Sect. 4.4.2). We recommend the integrated probability to be used over the binned probability, as the latter is more susceptible to small number statistics and can thus vary a lot in the most extreme parts of the tidal tails.
-
Membership probabilities are always calculated for small groups of stars. While such a probability might be reliable for the whole ensemble of stars, one must be careful when interpreting the value for each individual star. E.g. a group of high probability stars (but with probability < 1) probably includes members and some nonmembers. Concluding that all high probability stars are indeed members of a cluster is therefore wrong (see Appendix C for more discussion).
-
We include in our analysis all Gaia stars, regardless of the quality of the measured parameters (given by RUWE, for example). This is necessary to achieve completeness, which is necessary to reliably measure membership probabilities. The user must be careful to avoid the stars with poor data quality, as their parameters reported in this work might be erroneous.
7. Conclusions
In the third data release of Gaia, the astrometric parameters have become precise enough to enable the discovery of stars that have escaped the potential of the core of open clusters. These stars form tidal tails under the influence of the Galactic gravitational forces. Tidal tails of open clusters were long predicted to exist, but we offer the first systematic study that shows that they are common and can be recovered to a large extent.
We have derived normalised membership probabilities, which give the probability that a star is a cluster member – as opposed to likelihoods, which are usually used in the literature and give the probability that cluster members are found at some location. We show that correctly normalised membership probabilities are extremely beneficial for statistical studies of tidal structures in regions where cluster membership cannot be determined with absolute certainty. This aids in recovering the extent of tidal tails and accounts for stars in tidal tails in mass functions, for example. The rich and diverse structures that we observed in tidal tails of 476 analysed clusters indicate that many different physical processes can be studied in the future based on the structure of tidal tails.
To perform a more reliable and precise search of tidal tails in future studies, it will be essential to use radial velocities, provided that the selection function for stars with available radial velocities can be derived. A better known selection function for fainter stars and for binaries would also be needed to extend the search towards fainter stars. To reliably estimate the membership probabilities, we also seek the models of the Galactic stellar population that are more realistic on smaller scales.
It should also be possible to include masses of stars into the likelihood calculation if some IMF and degree of mass segregation could be assumed. Any additional parameter that can increase the dimension of the parameter space is beneficial to the likelihood calculation. Stellar mass is already a parameter in the synthetic models of the stellar population, so calculating membership probabilities using stellar masses is not a problem. However, the IMF and mass segregation can depend a lot on the conditions during the star formation and on perturbations that a cluster encounters in its lifetime. Dedicated cluster-specific simulations would then need to be done instead of the one-size-fits-all type of simulation of a cluster dissolution that we used in this work.
Data availability
Data described in Tables 1 and 3 (i. e. parameters of analysed clusters and a list of cluster members) are available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/691/A28.
Diagnostic plots for all clusters are available at https://zenodo.org/records/12699372. Simulations of cluster dissolution will be shared via private communication with a reasonable request.
Plots for all clusters are available at https://zenodo.org/records/12699372
Acknowledgments
JK is supported by the Slovenian Research Agency ARIS grants P1-0188. JK thanks Sanjib Sharma for all the useful discussions and for the use of the most recent version of the GALAXIA code with Gaia’s photometric filters. JK is most thankful to the anonymous referee, who provided many valuable comments and initiated several highly appreciated discussions that have undoubtedly enhanced this work. This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement. The data used in this paper are available from the Gaia DR3 science archive, at gea.esac.esa.int. Queries used to duplicate the dataset used in this work are described in Appendix E.
References
- Aarseth, S. J., Henon, M., & Wielen, R. 1974, A&A, 37, 183 [NASA ADS] [Google Scholar]
- Allison, R. J., Goodwin, S. P., Parker, R. J., et al. 2009, MNRAS, 395, 1449 [Google Scholar]
- Andrews, J. J., Curtis, J. L., Chanamé, J., et al. 2022, AJ, 163, 275 [Google Scholar]
- Antoja, T., Figueras, F., Fernández, D., & Torra, J. 2008, A&A, 490, 135 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bailer-Jones, C. A. L., Rybizki, J., Fouesneau, M., Demleitner, M., & Andrae, R. 2021, AJ, 161, 147 [Google Scholar]
- Belokurov, V., Zucker, D. B., Evans, N. W., et al. 2006, ApJ, 642, L137 [Google Scholar]
- Bennett, M., & Bovy, J. 2019, MNRAS, 482, 1417 [NASA ADS] [CrossRef] [Google Scholar]
- Bhattacharya, S., Rao, K. K., Agarwal, M., Balan, S., & Vaidya, K. 2022, MNRAS, 517, 3525 [CrossRef] [Google Scholar]
- Boffin, H. M. J., Jerabkova, T., Beccari, G., & Wang, L. 2022, MNRAS, 514, 3579 [NASA ADS] [CrossRef] [Google Scholar]
- Bok, B. J. 1934, Harvard College Observatory Circular, 384, 1 [Google Scholar]
- Bouma, L. G., Curtis, J. L., Hartman, J. D., Winn, J. N., & Bakos, G. Á. 2021, AJ, 162, 197 [NASA ADS] [CrossRef] [Google Scholar]
- Bouvier, J., Barrado, D., Moraux, E., et al. 2018, A&A, 613, A63 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bressan, A., Marigo, P., Girardi, L., et al. 2012, MNRAS, 427, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Cantat-Gaudin, T., Anders, F., Castro-Ginard, A., et al. 2020, A&A, 640, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carrera, R., Bragaglia, A., Cantat-Gaudin, T., et al. 2019, A&A, 623, A80 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carrera, R., Casamiquela, L., Carbajo-Hijarrubia, J., et al. 2022, A&A, 658, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casali, G., Magrini, L., Tognelli, E., et al. 2019, A&A, 629, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casamiquela, L., Tarricq, Y., Soubiran, C., et al. 2020, A&A, 635, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Castro-Ginard, A., Jordi, C., Luri, X., et al. 2018, A&A, 618, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chiba, R., & Schönrich, R. 2021, MNRAS, 505, 2412 [NASA ADS] [CrossRef] [Google Scholar]
- Conrad, C., Scholz, R. D., Kharchenko, N. V., et al. 2014, A&A, 562, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Conrad, C., Scholz, R. D., Kharchenko, N. V., et al. 2017, A&A, 600, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Bruijne, J. H. J. 1999, MNRAS, 306, 381 [Google Scholar]
- De Marchi, G., Paresce, F., & Portegies Zwart, S. 2005, Astrophys. Space Sci. Lib., 327, 77 [NASA ADS] [CrossRef] [Google Scholar]
- De Marchi, G., Paresce, F., & Portegies Zwart, S. 2010, ApJ, 718, 105 [NASA ADS] [CrossRef] [Google Scholar]
- Dias, W. S., Monteiro, H., Lépine, J. R. D., & Barros, D. A. 2019, MNRAS, 486, 5726 [NASA ADS] [CrossRef] [Google Scholar]
- Dias, W. S., Monteiro, H., Moitinho, A., et al. 2021, MNRAS, 504, 356 [NASA ADS] [CrossRef] [Google Scholar]
- Dinnbier, F., & Kroupa, P. 2020, A&A, 640, A84 [EDP Sciences] [Google Scholar]
- Dinnbier, F., Kroupa, P., Šubr, L., & Jeřábková, T. 2022, ApJ, 925, 214 [NASA ADS] [CrossRef] [Google Scholar]
- Donor, J., Frinchaboy, P. M., Cunha, K., et al. 2020, AJ, 159, 199 [NASA ADS] [CrossRef] [Google Scholar]
- Drimmel, R., & Poggio, E. 2018, Res. Notes Am. Astron. Soc., 2, 210 [Google Scholar]
- Evans, N. W., & Oh, S. 2022, MNRAS, 512, 3846 [NASA ADS] [CrossRef] [Google Scholar]
- Fabricius, C., Luri, X., Arenou, F., et al. 2021, A&A, 649, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fukushige, T., & Heggie, D. C. 2000, MNRAS, 318, 753 [CrossRef] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Babusiaux, C., et al.) 2018, A&A, 616, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gao, X. 2020a, PASJ, 72, 47 [NASA ADS] [CrossRef] [Google Scholar]
- Gao, X. 2020b, ApJ, 894, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Gieles, M. 2009, MNRAS, 394, 2113 [NASA ADS] [CrossRef] [Google Scholar]
- Gieles, M., Portegies Zwart, S. F., Baumgardt, H., et al. 2006, MNRAS, 371, 793 [Google Scholar]
- Gossage, S., Conroy, C., Dotter, A., et al. 2018, ApJ, 863, 67 [Google Scholar]
- GRAVITY Collaboration (Abuter, R., et al.) 2018, A&A, 615, L15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Guilherme-Garcia, P., Krone-Martins, A., & Moitinho, A. 2023, A&A, 673, A128 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Helmi, A. 2020, ARA&A, 58, 205 [Google Scholar]
- Hunt, E. L., & Reffert, S. 2023, A&A, 673, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ibata, R. A., Malhan, K., & Martin, N. F. 2019, ApJ, 872, 152 [Google Scholar]
- Jerabkova, T., Boffin, H. M. J., Beccari, G., et al. 2021, A&A, 647, A137 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Just, A., Berczik, P., Petrov, M. I., & Ernst, A. 2009, MNRAS, 392, 969 [Google Scholar]
- Katz, D., Sartoretti, P., Guerrier, A., et al. 2023, A&A, 674, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kos, J., de Silva, G., Buder, S., et al. 2018, MNRAS, 480, 5242 [Google Scholar]
- Kounkel, M., & Covey, K. 2019, AJ, 158, 122 [Google Scholar]
- Kroupa, P., Jerabkova, T., Thies, I., et al. 2022, MNRAS, 517, 3613 [CrossRef] [Google Scholar]
- Krumholz, M. R., McKee, C. F., & Bland-Hawthorn, J. 2019, ARA&A, 57, 227 [NASA ADS] [CrossRef] [Google Scholar]
- Küpper, A. H. W., MacLeod, A., & Heggie, D. C. 2008, MNRAS, 387, 1248 [Google Scholar]
- Küpper, A. H. W., Kroupa, P., Baumgardt, H., & Heggie, D. C. 2010, MNRAS, 401, 105 [Google Scholar]
- Loktin, A. V., & Popova, M. E. 2017, Astrophys. Bull., 72, 257 [NASA ADS] [CrossRef] [Google Scholar]
- Magrini, L., Lagarde, N., Charbonnel, C., et al. 2021, A&A, 651, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Malhan, K., & Ibata, R. A. 2018, MNRAS, 477, 4063 [Google Scholar]
- Martinez-Medina, L. A., Pichardo, B., Peimbert, A., & Moreno, E. 2017, ApJ, 834, 58 [Google Scholar]
- Meingast, S., & Alves, J. 2019, A&A, 621, L3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meingast, S., Alves, J., & Rottensteiner, A. 2021, A&A, 645, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Monteiro, H., & Dias, W. S. 2019, MNRAS, 487, 2385 [Google Scholar]
- Moyano Loyola, G. R. I., & Hurley, J. R. 2013, MNRAS, 434, 2509 [CrossRef] [Google Scholar]
- Murphy, S. J., Bedding, T. R., White, T. R., et al. 2022, MNRAS, 511, 5718 [NASA ADS] [CrossRef] [Google Scholar]
- Nibauer, J., Bonaca, A., & Johnston, K. V. 2023, ApJ, 954, 195 [NASA ADS] [CrossRef] [Google Scholar]
- Odenkirchen, M., Grebel, E. K., Rockosi, C. M., et al. 2001, ApJ, 548, L165 [Google Scholar]
- Oh, S., & Evans, N. W. 2020, MNRAS, 498, 1920 [Google Scholar]
- Pelupessy, F. I., van Elteren, A., de Vries, N., et al. 2013, A&A, 557, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Portegies Zwart, S., & McMillan, S. 2018, Astrophysical Recipes; The art of AMUSE (Bristol, UK: IOP Publishing) [Google Scholar]
- Portegies Zwart, S., McMillan, S., Harfst, S., et al. 2009, New Astron., 14, 369 [Google Scholar]
- Portegies Zwart, S., McMillan, S. L. W., van Elteren, E., Pelupessy, I., & de Vries, N. 2013, Comput. Phys. Commun., 184, 456 [Google Scholar]
- Riello, M., De Angeli, F., Evans, D. W., et al. 2021, A&A, 649, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Robin, A. C., Reylé, C., Derrière, S., & Picaud, S. 2003, A&A, 409, 523 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Röser, S., Schilbach, E., & Goldman, B. 2019, A&A, 621, L2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sharma, S., Bland-Hawthorn, J., Johnston, K. V., & Binney, J. 2011, ApJ, 730, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Soubiran, C., Cantat-Gaudin, T., Romero-Gómez, M., et al. 2018, A&A, 619, A155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spitzer, L., Jr. 1940, MNRAS, 100, 396 [NASA ADS] [CrossRef] [Google Scholar]
- Tang, S.-Y., Pang, X., Yuan, Z., et al. 2019, ApJ, 877, 12 [Google Scholar]
- Tarricq, Y., Soubiran, C., Casamiquela, L., et al. 2021, A&A, 647, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tarricq, Y., Soubiran, C., Casamiquela, L., et al. 2022, A&A, 659, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tatum, J. B. 2023, Celestial Mechanics, https://www.astro.uvic.ca/~tatum/celmechs.html [Google Scholar]
- Thomas, G. F., Famaey, B., Monari, G., et al. 2023, A&A, 678, A180 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van Leeuwen, F. 2009, A&A, 497, 209 [CrossRef] [EDP Sciences] [Google Scholar]
- Wang, L., & Jerabkova, T. 2021, A&A, 655, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ye, X., Zhao, J., Zhang, J., Yang, Y., & Zhao, G. 2021, AJ, 162, 171 [NASA ADS] [CrossRef] [Google Scholar]
- Zhong, J., Chen, L., Wu, D., et al. 2020, A&A, 640, A127 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zucker, C., Peek, J. E. G., & Loebman, S. 2022, ApJ, 936, 160 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Full parameter space plots
Figures A.1 to A.4 show the full parameter space plotted for four clusters discussed in more detail in Sect. 6.1.
 |
Fig. A.1. Membership probability of stars in Hyades displayed across the parameter space. See Sect. 5 for the description of this figure. |
 |
Fig. A.2. Membership probability of stars in NGC 2516 displayed across the parameter space. See Sect. 5 for the description of this figure. |
 |
Fig. A.3. Membership probability of stars in COIN-Gaia 13 displayed across the parameter space. See Sect. 5 for the description of this figure. |
 |
Fig. A.4. Membership probability of stars in NGC 752 displayed across the parameter space. See Sect. 5 for the description of this figure. |
Appendix B: Accuracy of simplified cluster dissolution simulations
B.1. Two-body interactions
Our simulations of cluster dissolution use an empirical gravitational potential that represents the mass distribution in an open cluster. Simulated stars are then massless particles that do not interact with each other and only feel the combined gravitational potential of the Galaxy and the cluster. This is a simplification that allows us to compute simulations faster and also imposes no selection functions (based on stellar masses or spectral types) that we would have to account for in the observed samples. In order to verify that a simplified simulation can reproduce the same structures that an N-body simulation would, we ran an independent N-body simulation of the cluster NGC 2516.
The N-body simulation initialises a cluster with a Plummer gravitational potential with a radius of 2 pc, and 3500 particles with a Kroupa mass function (corresponding to a total mass of around 1300 M⊙). The initial position of the cluster is such that the centre of the cluster ends at the observed position and velocity when simulated to the present time. The simulation did not contain any binary stars. We used the AMUSE2 framework (Portegies Zwart et al. 2009, 2013; Pelupessy et al. 2013; Portegies Zwart & McMillan 2018) to combine the BHTREE N-body simulation code with the same gravitational potential of the Galaxy as used in the simplified simulations. The simulation was repeated 50 times to produce enough samples to compare it to a larger simplified simulation.
Comparison between a simplified simulation and an N-body simulation is shown in Fig. B1 for two spatial and two kinematic dimensions of cluster NGC 2516. Two simulations produce the exact same structures with the same positions and orientations in the parameter space. The only notable difference is a somewhat slower drop in density in the XY plane for the N-body simulation. We conject that using such a simulation in the calculation of membership likelihoods would result in a similar final selection of stars, as low-likelihood stars do not make the selection as possible cluster members. Processes not simulated in either of the two simulations (like interactions with GMCs and spiral arms) probably have larger impact on the shape of the tidal tails than is the discrepancy between the two simulations displayed in Fig. B1.
B.2. Cluster mass
Massless particles in our simplified simulations are contained in a Plummer potential that moves on a fixed orbit around the Galaxy. The mass of the Plummer potential, which represents the mass of the cluster decreases with time (see Sect. 3.1.2).
We tested whether the initial cluster mass has any effect on the shape of the tidal tails. Figure B2 shows three simulations for cluster NGC 2516 with different initial cluster masses. Initial masses of Minit = 5000 and 3000 M⊙ exhibit no significant difference, while the initial mass of Minit = 1000 M⊙ produces slightly shorter tails. Shorter tails are also reflected in the distribution of stars in the simulated proper motion plot (right-hand-side plots in figures in this section), where there are almost no stars around the convergent point at (μα, μδ) = (0, −6) mas yr−1.
B.3. Cluster size
While the mass of the Plummer potential decreases through the simulation, the radius of the Plummer potential is kept constant at RCl = 2 pc. Figure B3 shows the sensitivity of the simulation results on the varying cluster radius. The simulation of cluster dissolution was made with three cluster radii. Shown is the expected shape at the present time for cluster NGC 2516. The corona of the cluster is more puffed-up for smaller clusters, and the tails are slightly shorter in the case of RCl = 6 pc. The shape and orientation of the tidal tails are the same for all cases. We conclude that adopted cluster sizes and masses have negligible effect on the large-scale structure of the tidal tails unravelled in this work.
Appendix C: Robustness of derived membership probabilities
We derive membership probabilities under the assumption that the model for cluster dissolution is correct. The model assumes a Galactic gravitational potential, bar pattern speed, shape of the cluster and its initial velocity dispersion, Gaia’s selection function, and a model for the Galactic stellar population – all of which are findings of a broad part of modern astrophysics. We use models and parameters that are widely accepted as most probable values for state-of-the-art models. It is well beyond the scope of a single paper to verify the assumed models and explore their effects on the tidal tails of open clusters, let alone marginalise the probabilities calculated in this work over all possible variations of the assumed models. It is also impossible to include a number of secondary perturbations, like interaction of clusters with spiral arms and giant molecular clouds into the simulations, as their interaction with stars and clusters throughout the last 100s million years is largely unknown. While such perturbations have certainly affected some clusters and their tidal tails (signs of which we point out in this work), they would have to be studied case-by-case. Hence we emphasis that the results presented in this work are produced under the assumption of one set of models.
 |
Fig. C.1. Comparison between the simulated tidal tails in a simplified simulation and in an N-body simulation. Simplified simulation (blue contours) is used throughout this work. A collisional N-body simulation (orange contours) of the same cluster NGC 2516 shows the same shape of tidal tails in the spatial (left panel) and kinematic (right panel) parameter spaces. The distributions plotted in this figure are not convolved with observational uncertainties. Contours are log-spaced. |
 |
Fig. C.2. Comparison between simulations with different initial cluster masses. All simulations are made for cluster NGC 2516 with a cluster radius of 2 pc. The distributions plotted in this figure are not convolved with observational uncertainties. Contours are log-spaced. |
 |
Fig. C.3. Comparison between simulations with different cluster radii. All simulations are made for cluster NGC 2516 with an initial mass of 5000 M⊙. The distributions plotted in this figure are not convolved with observational uncertainties. Contours are log-spaced. |
 |
Fig. C.4. Star counts and membership probabilities in the core and tails of cluster Collinder 350 if simulated with different positions of the cluster. Top: Mean membership probability of stars that have membership probability P > 0.6 in our original calculation after recomputing them with different cluster models. Shades show 16th and 84th percentiles and the silid lines show the 50th percentile. Bottom: Number of stars with P > 0.6 in the core (blue) and tails (orange) is shown with solid lines for the original cluster model and five different deviations from the model. Dashed lines show the number of stars that do not appear in the selection made with the original cluster model. All models deviated from the original in the position of the cluster centre in galactic latitude. |
In this section we explore the sensitivity of our selection of stars in tidal tails on the variations in underlying models. In this test we try to find tidal tails of imaginary clusters, i.e. clusters for which we made up some arbitrary positions and motions. We start with a real cluster and vary the proper motion and the position of the cluster centre in our simulation, until they represent a nonexistent cluster, well beyond the uncertainty of the parameters defining the cluster centre. Figures C1 and C2 quantify the results for one cluster (Collinder 350). We found members and recalculated their membership probabilities when pretending that the cluster centre is between 1.4° and 7° from the real one. First we traced how the membership probability of stars found in the original calculation (with cluster’s centre unchanged) varies in subsequent computations with a shifted cluster centre. First, we selected all stars with membership probability above 0.6 in the original calculation. In the top panel of Fig. C1 we show the 16th to 84th percentile of recalculated memberships of these stars in subsequent simulations. Stars that initially had a high membership probability, become low membership probability stars or are completely absent in the computations with a shifted cluster centre. We also plot the total number of high probability stars (P > 0.6 hereafter) in each individual computation (solid line, bottom panel of Fig. C1) and a number of high probability stars that appear in computations with shifted cluster centre that do not exist in the original computation. These are expected to be stars that we serendipitously find to be high probability members, but are obviously not, as they only appear in computations with a shifted cluster centre. We repeated the analysis for the cluster centre at the original position, but this time with the proper motion of the cluster shifted between 0.5 and 2.5 mas yr−1 as illustrated in Fig. C2.
It is expected that by shifting the alleged cluster centre away from the real one, we loose the original cluster members. This transition happens at the shift of around 2° or 1.5 mas yr−1 for the cluster core. This is around twice the standard deviation of the core’s size in position and proper motion. The loss of original stars is more rapid in the tails, also because the membership probabilities in the tail are lower in average and closer to the threshold of P = 0.6, as used in the aforementioned exercise. More informative are the star counts. The number of high probability stars in the tails drops from 20 in the original computation to 9 in the computations with the most extreme shift. Almost all stars in the tail at large shifts are stars with a zero membership probability in the original computation. Given that probabilities of stars found in the tails are usually less than one, we expect that some are just coincidental stars that we could not have rejected as cluster members using only five observables. By the same logic, it is expected that for a computation with a shifted cluster centre, we find stars that satisfy the condition to be a cluster member. The fact that the number of stars in the tidal tails drops by a significant fraction when we move the proposed cluster centre from the real one, confirms that the calculated probabilities are sensible. Although it must be noted that the number of stars found in the tails of shifted alleged clusters is not zero. A drop from 20 to nine stars indicates that the stars in the tidal tails that had membership probabilities > 0.6 for the computation for a real cluster should have somewhat lower probabilities. If 9 out of 20 stars are impostors, as the above experiment suggests, the membership probabilities of the initial 20 stars should be 0.55 in average.
A test presented in this section would have to be repeated for a large number of clusters in order to get a good overview of the discussed behaviour elsewhere in the Galaxy. It must be noted that the number of stars we might find in imaginary clusters can depend on the position in the Galaxy and on the parameters of the cluster. A quick estimate that suggests that the probabilities might be slightly overestimated would likewise need a thorough analysis. However, it is expected that the probabilities derived from low number statistics are only our best estimates. Repeating the analysis for all clusters would be a computationally expensive exercise, which we are not able to perform.
Appendix D: List of analysed clusters
A list of all clusters is given in Table D.1 with celestial coordinates and a number of found members. A table with all reported parameters is available at the CDS (see description in Sect. 6.4.1 and Table 1).
All analysed clusters. NP > 0.9 is the number of stars with membership probability > 90%. A table with more parameters is available online at the CDS.
Appendix E: Gaia queries
The volume we analysed was divided into sections. We conducted separate Gaia data queries for each section. The ADQL query for one section is:
SELECT gaiadr3.gaia_source.source_id, gaiadr3.gaia_source.ra, gaiadr3.gaia_source.dec, gaiadr3.gaia_source.pmra, gaiadr3.gaia_source.pmdec, gaiadr3.gaia_source.parallax, gaiadr3.gaia_source.radial_velocity, gaiadr3.gaia_source.phot_g_mean_mag, gaiadr3.gaia_source.phot_rp_mean_mag, gaiadr3.gaia_source.phot_bp_mean_mag, external.gaiaedr3_distance.r_med_geo, gaiadr3.astrophysical_parameters.teff_gspspec, gaiadr3.astrophysical_parameters.logg_gspspec, gaiadr3.astrophysical_parameters.mh_gspspec, gaiadr3.astrophysical_parameters.alphafe_gspspec, gaiadr3.gaia_source.ag_gspphot, gaiadr3.gaia_source.ebpminrp_gspphot, gaiadr3.gaia_source.ruwe FROM gaiadr3.gaia_source LEFT JOIN external.gaiaedr3_distance ON gaiadr3.gaia_source.source_id = external.gaiaedr3_distance.source_id LEFT JOIN gaiadr3.astrophysical_parameters ON gaiadr3.gaia_source.source_id = gaiadr3.astrophysical_parameters.source_id WHERE gaiadr3.gaia_source.ra >= 94.73684210526315 AND gaiadr3.gaia_source.ra < 113.68421052631578 AND gaiadr3.gaia_source.dec >= -33.15789473684211 AND gaiadr3.gaia_source.dec < -23.684210526315795 AND gaiadr3.gaia_source.parallax >= 0.36291930060041844 AND gaiadr3.gaia_source.parallax < 0.3806079094531518 AND gaiadr3.gaia_source.phot_g_mean_mag < 17.5 AND gaiadr3.gaia_source.phot_bp_mean_mag < 20 AND gaiadr3.gaia_source.phot_rp_mean_mag < 20
The limits for ra, dec, and parallax were different for each section, and the numbers above only serve as placeholders.
Appendix F: GALAXIA parameters
Below is the parameter file for one GALAXIA simulation.
outputFile galaxia_2947 modelFile Model/population_parameters_mrtd5.ebf outputDir ./galaxia_cache_all photoSys parsec1/GAIADR2_TMASS magcolorNames gaia_g,gaia_gbp-gaia_grp appMagLimits[0] -10 appMagLimits[1] 17.5 absMagLimits[0] -1000 absMagLimits[1] 1000 colorLimits[0] -1000 colorLimits[1] 1000 geometryOption 1 longitude 239.15335157491867 latitude -11.453305872563032 surveyArea 281.3196664594758 fSample 5.0 popID -1 warpFlareOn 1 seed 1 r_max 2.755433503662073 starType 0 photoError 0
We note that the GALAXIA simulation can only be run within a cone, while Gaia queries were done within sections limited by α, δ. For each section we ran the GALAXIA simulation within a cone covering the whole section and later discarded the stars outside that section. GALAXIA can be run for the whole sky, but our computer did not have enough memory to run such a simulation with sufficient oversampling.
Appendix G: GALPY gravitational potential of the Galaxy
Below is the code to construct the gravitational potential of the Galaxy used in this work from GALPY potentials in PYTHON.
from galpy import potential RO = 8.122 #kpc diskp = potential.MiyamotoNagaiPotential(normalize = 0.54, a = 3.0/RO, b = 0.28/RO) halop = potential.NFWPotential(normalize = 0.35, a = 2.0) sbp = potential.SoftenedNeedleBarPotential(normalize = 0.1, a = 3.5/RO, c = 1.0/RO, omegab = 1.85) npot = potential.PlummerPotential(normalize = 0.01, b = 0.25/RO) pot = [diskp, halop, npot, sbp]
All Tables
All analysed clusters. NP > 0.9 is the number of stars with membership probability > 90%. A table with more parameters is available online at the CDS.
All Figures
|
Fig. 1. Illustration of Galactic potentials used in the simulation of stellar orbits. The left column shows the complete gravitational potential, and the following columns show the potential of the bar, disc and the halo. The black line shows the orbit of the Sun for the last 750 Myr. A small dip close to the present position of the Sun is the gravitational potential of a simulated cluster, amplified one million times. Magnitudes of different potentials are not plotted to scale. |
| In the text | |
|
Fig. 2. Members of NGC 2516 found with a simple non-probabilistic method (green) and shown in the parameter space explored in this work. Simulated field stars found with the same selection as used for finding the members are shown in blue. Black contours show the likelihood for the position of cluster members predicted by a simulation of a dissolving open cluster. Contours are log-spaced. Top row: XY Galactic plane, proper motions space, colour-magnitude diagram. Middle row: Position along the main axis of the tidal tails (D) and density of stars along this line, two projected proper motions, v⊥ projected motion as a function of distance from the cluster. Bottom row: Position on the sky, radial velocity as a function of distance from the cluster, and v∥ projected motion as a function of distance from the cluster. |
| In the text | |
|
Fig. 3. Completeness of the GALAXIA simulation versus the Gaia star counts. Histograms show the number of stars per magnitude bin in the region of NGC 2516. Blue shows the distribution when no reddening correction is done to the apparent magnitudes. Orange is the distribution when Gaia’s magnitudes are corrected for Gaia’s extinction, and Green is when GALAXIA absolute magnitudes are converted to apparent magnitudes with GALAXIA’s extinction taken into account. We used the latter magnitudes in this study. Points together with the axis on the right show the number of stars in Gaia per magnitude bin downloaded in the region of this cluster. |
| In the text | |
|
Fig. 4. Membership probability lookup table given the number of observed stars (NGaia) and the number of simulated stars (NGalaxia) in any region of the parameter space. The left panel shows a detail of the right panel for a small number of observed or simulated stars. |
| In the text | |
|
Fig. 5. A selection of 12 clusters from this work displayed in the Galactic XY plane. Darker coloured points show stars with higher membership probability. The purple markings show the position of the Sun. The Galactic centre is towards the right and the Galaxy rotates towards positive Y values. Stretching of the cluster core, most notable in Ruprecht 171 and NGC 6134, is due to distance uncertainties of individual stars that smear the distribution along the line of sight. |
| In the text | |
|
Fig. 6. Distribution of asymmetry indexes of all clusters analysed in this work. |
| In the text | |
|
Fig. 7. Comparison between the stars found in this work (solid symbols) and those found by Jerabkova et al. (2021) (black circles) in Hyades and its tidal tails. Only stars with G < 17.5 in Jerabkova et al. (2021) are shown. |
| In the text | |
|
Fig. 8. Comparison between the stars found in this work (solid symbols) and those found by Meingast et al. (2021) (black circles) in NGC 2516 and its tidal tails. Only stars with G < 17.5 in Meingast et al. (2021) are shown. There are more high probability members found by us outside of the plotted range (see Fig. A.2). |
| In the text | |
|
Fig. 9. Comparison between the stars found in this work (solid symbols) and those found by Andrews et al. (2022) (black circles) in COIN-Gaia 13 and its tidal tails. Only stars with G < 17.5 in Andrews et al. (2022) are shown. There are more high probability members found by us outside of the plotted range (see Fig. A.3). |
| In the text | |
|
Fig. 10. Comparison between the stars found in this work (solid symbols) and those found by Boffin et al. (2022) (black circles) in NGC 752 and its tidal tails. Only stars with G < 17.5 in Boffin et al. (2022) are shown. There are more high probability members found by us outside of the plotted range (see Fig. A.4). |
| In the text | |
|
Fig. A.1. Membership probability of stars in Hyades displayed across the parameter space. See Sect. 5 for the description of this figure. |
| In the text | |
|
Fig. A.2. Membership probability of stars in NGC 2516 displayed across the parameter space. See Sect. 5 for the description of this figure. |
| In the text | |
|
Fig. A.3. Membership probability of stars in COIN-Gaia 13 displayed across the parameter space. See Sect. 5 for the description of this figure. |
| In the text | |
|
Fig. A.4. Membership probability of stars in NGC 752 displayed across the parameter space. See Sect. 5 for the description of this figure. |
| In the text | |
|
Fig. C.1. Comparison between the simulated tidal tails in a simplified simulation and in an N-body simulation. Simplified simulation (blue contours) is used throughout this work. A collisional N-body simulation (orange contours) of the same cluster NGC 2516 shows the same shape of tidal tails in the spatial (left panel) and kinematic (right panel) parameter spaces. The distributions plotted in this figure are not convolved with observational uncertainties. Contours are log-spaced. |
| In the text | |
|
Fig. C.2. Comparison between simulations with different initial cluster masses. All simulations are made for cluster NGC 2516 with a cluster radius of 2 pc. The distributions plotted in this figure are not convolved with observational uncertainties. Contours are log-spaced. |
| In the text | |
|
Fig. C.3. Comparison between simulations with different cluster radii. All simulations are made for cluster NGC 2516 with an initial mass of 5000 M⊙. The distributions plotted in this figure are not convolved with observational uncertainties. Contours are log-spaced. |
| In the text | |
|
Fig. C.4. Star counts and membership probabilities in the core and tails of cluster Collinder 350 if simulated with different positions of the cluster. Top: Mean membership probability of stars that have membership probability P > 0.6 in our original calculation after recomputing them with different cluster models. Shades show 16th and 84th percentiles and the silid lines show the 50th percentile. Bottom: Number of stars with P > 0.6 in the core (blue) and tails (orange) is shown with solid lines for the original cluster model and five different deviations from the model. Dashed lines show the number of stars that do not appear in the selection made with the original cluster model. All models deviated from the original in the position of the cluster centre in galactic latitude. |
| In the text | |
 |
Fig. C.5. Same as Fig. C1 but for model deviation in proper motion. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.