| Issue |
A&A
Volume 679, November 2023
|
|
|---|---|---|
| Article Number | A101 | |
| Number of page(s) | 24 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202245770 | |
| Published online | 06 December 2023 | |
Selection of powerful radio galaxies with machine learning
1
Instituto de Astrofísica e Ciências do Espaço, Universidade de Lisboa, OAL, Tapada da Ajuda, 1349-018 Lisbon, Portugal
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Departamento de Física, Faculdade de Ciências, Universidade de Lisboa, Edifício C8, Campo Grande, 1749-016 Lisbon, Portugal
3
School of Science, Western Sydney University, Locked Bag 1797, Penrith, NSW 2751, Australia
4
CSIRO Space & Astronomy, Australia Telescope National Facility, PO Box 76, Epping, NSW 1710, Australia
5
CSIRO Data61, PO Box 76, Epping, NSW 1710, Australia
6
European Southern Observatory, Karl-Schwarzschild-Straße 2, 85748 Garching bei München, Germany
7
Instituto de Astrofísica e Ciências do Espaço, Universidade do Porto, CAUP, Rua das Estrelas, 4150-762 Porto, Portugal
8
Departamento de Física e Astronomia, Faculdade de Ciências, Universidade do Porto, Rua do Campo Alegre 687, 4169-007 Porto, Portugal
9
DTx – Digital Transformation CoLAB, Building 1, Azurém Campus, University of Minho, 4800-058 Guimarães, Portugal
10
Joint ALMA Observatory, Alonso de Córdova 3107, Vitacura, 763-0355 Santiago, Chile
11
European Southern Observatory, Alonso de Córdova 3107, Vitacura, Casilla, 19001 Santiago de Chile, Chile
12
Institut de Radioastronomie Millimétrique (IRAM), Avenida Divina Pastora 7, Local 20, 18012 Granada, Spain
13
Closer Consultoria Lda, Av. Eng. Duarte Pacheco, Torre 1, 15 o, 1070-101 Lisboa, Portugal
Received:
22
December
2022
Accepted:
13
August
2023
Abstract
Context. The study of active galactic nuclei (AGNs) is fundamental to discern the formation and growth of supermassive black holes (SMBHs) and their connection with star formation and galaxy evolution. Due to the significant kinetic and radiative energy emitted by powerful AGNs, they are prime candidates to observe the interplay between SMBH and stellar growth in galaxies.
Aims. We aim to develop a method to predict the AGN nature of a source, its radio detectability, and redshift purely based on photometry. The use of such a method will increase the number of radio AGNs, allowing us to improve our knowledge of accretion power into an SMBH, the origin and triggers of radio emission, and its impact on galaxy evolution.
Methods. We developed and trained a pipeline of three machine learning (ML) models than can predict which sources are more likely to be an AGN and to be detected in specific radio surveys. Also, it can estimate redshift values for predicted radio-detectable AGNs. These models, which combine predictions from tree-based and gradient-boosting algorithms, have been trained with multi-wavelength data from near-infrared-selected sources in the Hobby-Eberly Telescope Dark Energy Experiment (HETDEX) Spring field. Training, testing, calibration, and validation were carried out in the HETDEX field. Further validation was performed on near-infrared-selected sources in the Stripe 82 field.
Results. In the HETDEX validation subset, our pipeline recovers 96% of the initially labelled AGNs and, from AGNs candidates, we recover 50% of previously detected radio sources. For Stripe 82, these numbers are 94% and 55%. Compared to random selection, these rates are two and four times better for HETDEX, and 1.2 and 12 times better for Stripe 82. The pipeline can also recover the redshift distribution of these sources with σNMAD = 0.07 for HETDEX (σNMAD = 0.09 for Stripe 82) and an outlier fraction of 19% (25% for Stripe 82), compatible with previous results based on broad-band photometry. Feature importance analysis stresses the relevance of near- and mid-infrared colours to select AGNs and identify their radio and redshift nature.
Conclusions. Combining different algorithms in ML models shows an improvement in the prediction power of our pipeline over a random selection of sources. Tree-based ML models (in contrast to deep learning techniques) facilitate the analysis of the impact that features have on the predictions. This prediction can give insight into the potential physical interplay between the properties of radio AGNs (e.g. mass of black hole and accretion rate).
Key words: galaxies: active / radio continuum: galaxies / galaxies: high-redshift / catalogs / methods: statistical
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Active galactic nuclei (AGNs) are instrumental in determining the nature, growth, and evolution of supermassive black holes (SMBHs). Their strong emission allows us to study the close environment within the hosting galaxies and, at a larger scale, the intergalactic medium (e.g. Padovani et al. 2017; Bianchi et al. 2022). Feedback due to AGN energetics, which most prominently manifest in the form of jetted radio emission, might play a fundamental role in regulating stellar growth and the overall evolution of hosts and their environments (Alatalo et al. 2015; Villar-Martín et al. 2017; Hardcastle & Croston 2020).
Although radio emission can trace high star formation (SF) in galaxies, above certain luminosities (e.g. log L1.4 GHz > 25 W Hz−1, Jarvis et al. 2021), it is a prime tracer of the powerful jet emission triggered by the SMBH in AGNs (radio galaxies, Heckman & Best 2014). Traditionally, these powerful radio galaxies (RGs) were used to pinpoint AGN activity, but they have been superseded in the last decades by optical, near-infrared (NIR), and X-ray surveys. In fact, RGs in the high redshift Universe (z > 2) have been identified and studied mostly through the follow-up of AGNs selected at shorter wavelengths (optical, NIR, millimetre, and X-rays, e.g. McGreer et al. 2006; Pensabene et al. 2020; Delhaize et al. 2021). The landscape is quickly changing and the advent of new radio instruments and surveys has allowed the detection of larger numbers of RGs (e.g. Williams et al. 2018; Capetti et al. 2020). Some of these surveys are: the National Radio Astronomy Observatory (NRAO) Very Large Array (VLA) Sky Survey (NVSS; Condon et al. 1998), the Faint Images of the Radio Sky at Twenty-Centimetres (FIRST; Helfand et al. 2015), the Evolutionary Map of the Universe (EMU; Norris et al. 2011), the Very Large Array Sky Survey (VLASS; Gordon et al. 2020), and the Low Frequency Array (LOFAR) Two-metre Sky Survey (LoTSS; Shimwell et al. 2019).
One of the ultimate goals is to detect powerful RGs in the Epoch of Reionisation (EoR), which could be used to trace the neutral gas distribution during this critical phase of the Universe (e.g. Carilli et al. 2004; Jensen et al. 2013). Simulations have shown that as much as a few hundreds of RGs per deg2 could be present in the EoR (Amarantidis et al. 2019; Bonaldi et al. 2019; Thomas et al. 2021) and detectable with present and future deep observations, for example the Square Kilometre Array (SKA), which is projected to have μJy point-source sensitivity levels (SKA1-Mid is expected to reach close to 2 μJy in 1-h continuum observations at ν ≳ 1 GHz; Prandoni & Seymour 2015; Braun et al. 2019). Most recent observational compilations (e.g. Inayoshi et al. 2020; Ross & Cross 2020; Bosman 2022; Fan et al. 2023) show that around 300 AGNs have been confirmed to exist at redshifts higher than z ∼ 6 over thousands of square degrees. This disagreement highlights the uncertainties present in simulations, mainly due to our lack of knowledge of the triggering mechanisms and duty cycle for jetted emission in AGNs (Afonso et al. 2015; Pierce et al. 2022).
The selection of AGN candidates has had success in the X-rays and radio wavebands as they dominate the emission above certain luminosities. Unfortunately, deep X-ray surveys are limited in area and only of the order of 10% of AGNs have strong radio emissions linked to jets (i.e. radio-loud sources) at any given time with variations, going from ∼6% up to ∼30%, correlated to optical and X-ray luminosities, as well as with redshift (e.g. Padovani 1993; della Ceca et al. 1994; Jiang et al. 2007; Storchi-Bergmann & Schnorr-Müller 2019; Gürkan et al. 2019; Macfarlane et al. 2021; Gloudemans et al. 2021, 2022; Best et al. 2023)1.
The largest number of AGN candidates has been selected through the compilation of multi-wavelength spectral energy distributions (SED) for millions of sources (Hickox & Alexander 2018; Pouliasis 2020). Of particular relevance for AGNs are the mid-infrared (mid-IR) colours where Spitzer (Werner et al. 2004) and especially the Wide-field Infrared Survey Explorer (WISE; Wright et al. 2010) have opened a window for the detection of AGNs over the whole sky, including the elusive fraction of heavily obscured ones (e.g. Stern et al. 2012; Mateos et al. 2012; Jarrett et al. 2017; Assef et al. 2018; Barrows et al. 2021).
Currently, extensive spectroscopic follow-up measurements have allowed the confirmation of the estimated redshifts for more than 800 000 AGNs over large areas of the sky (Flesch 2021). Spectroscopic surveys have also contributed to the detection of AGN activity through the analysis of the line ratio as is the case of the Baldwin-Phillips-Terlevich (BPT) diagram (Baldwin et al. 1981). However, their determination can take long integration times and require high-quality observations, rendering them ill-suited for most sources in large-sky catalogues. Photometric classification and redshifts (photo-z) are a viable option to understand the source nature and distribution across cosmic time (Baum 1957; Salvato et al. 2019). Photometric redshift estimations have been obtained for galaxies (e.g. Hernán-Caballero et al. 2021) and AGNs (e.g. Ananna et al. 2017). Template-fitting photo-z estimations are computationally expensive and require high-performance computing facilities for large catalogues (≳107 elements, Gilda et al. 2021). At the expense of redshift precision, the use of drop-out techniques offer a more computationally efficient solution to generate and study high-redshift sources or candidates that, otherwise, would not have enough information to produce a precise redshift value (e.g. Bouwens et al. 2020; Carvajal et al. 2020; Shobhana et al. 2023).
Alternative statistical and computational methods can analyse a large number of elements and find relevant trends among their properties. One branch of these techniques is machine learning (ML; Samuel 1959), which can, using previously modelled data, predict the behaviour that new data will have, that is, the values of their properties. In astronomy, ML has been used with much success in a wide range of subjects, such as redshift determination, morphological classification, emission prediction, anomaly detection, observations planning, and more (e.g. Ball & Brunner 2010; Baron 2019). Traditional ML models are, in general, only fed with measurements and not with physical assumptions (Desai & Strachan 2021), and they do not need to check the consistency of the predictions or the results they provide. As a consequence, prediction times of traditional ML methods are typically less than those from physically based methods.
Despite the large number of applications it might have, one important criticism that ML has received is related to the lack of interpretability – or ‘explainability’, as it is called in ML jargon – of the derived models, trends, and correlations. Most ML models, after taking a series of measurements and properties as input, deliver a prediction of a different property. But they cannot provide coefficients or an analytical expression that might allow one to find an equation for future predictions (Goebel et al. 2018). An important counterexample of this fact is the use of symbolic regression (e.g. Cranmer et al. 2020; Villaescusa-Navarro et al. 2021; Cranmer 2023). This implies that, for most ML models, it is not a simple task to understand which properties, and to what extent they help predict and interpret another attribute. This fact hinders our capability of understanding the results in physical terms.
Recent work has been done to overcome the lack of explainability in ML models. The most widely used assessment is done with feature importance (Casalicchio et al. 2019; Roscher et al. 2020), both global and local (Saarela & Jauhiainen 2021). Game-theory-based analyses, such as the Shapley analysis (Shapley 1953), have also been used to understand the importance of features in astrophysics (e.g. Machado Poletti Valle et al. 2021; Carvajal et al. 2021; Dey et al. 2022; Anbajagane et al. 2022; Alegre et al. 2022).
A further complication is that astronomical data can be very heterogeneous. Surveys and instruments gather data from many different areas in the sky with very different sensitivities and observational properties. This heterogeneity severely complicates most astronomical analyses, but in particular ML methods, as they are completely driven by data most of the time. This issue can be alleviated using observations in large, and homogeneous, surveys. Currently, among others, VLA, LOFAR, and the Giant Metrewave Radio Telescope (GMRT) allow such measurements to be obtained. Next-generation observatories and surveys – such as SKA and the Vera C. Rubin Observatory – will also help in this regard, where observations will be carried out homogeneously over very large areas.
From a pure ML-based standpoint, several techniques used to lessen the effect of data heterogeneity have been developed (i.e. data cleansing and homogenisation). Some of them include discarding sources that add noise to the overall data distribution (Ilyas & Rekatsinas 2022). This can be extended to vetoing sources from specific areas in the sky (due to, for example, bad data reduction). Opposite to that, and when possible, previously mentioned techniques can be combined by increasing the survey area as a way to reduce possible biases. After selecting the data sample to be used for modelling, it is also possible to homogenise the measured ranges of observed properties. This procedure implies, for instance, that normalising or standardising measured values can help ML models extract trends and connections among features more easily (Singh & Singh 2020).
Future observatories and surveys will deliver immense datasets. One option to analyse such observations and confirm their radio-AGN nature is through visual inspection (e.g. Banfield et al. 2015). The use of such a technique over large areas can have a very high cost. An alternative is using already-available multi-wavelength data and template-fitting tools to determine the likelihood of an AGN of being detected in radio wavelengths (see, for instance, Pacifici et al. 2023). With the use of existing data, ML can help to speed this process up via the training of models that can detect counterparts in large radio surveys (see, for example, the efforts made to achieve this goal, Hopkins et al. 2015; Bonaldi et al. 2021).
Building upon the work presented by Carvajal et al. (2021), we aim to identify candidates of high-redshift radio-detectable AGNs that can be extracted from heterogeneous large-area surveys. We developed a series of ML models to predict, separately, the detection of AGNs, the detection of the radio signal from AGNs, and the redshift values of radio-detectable AGNs using non-radio photometric data. In this way, it might be possible to avoid the direct analysis of large numbers of radio detections. Furthermore, we tested the performance of these models without applying a large number of previous cleaning steps, which might reduce the size of the training sets considerably. The compiled catalogue of candidates can help to use data from future large-sky surveys more efficiently, as observational and analytical efforts can be focussed on the areas in which AGNs have been predicted to exist. We seek, therefore, to test the generalisation power of such models by applying them in a different area from the training field with data that are not necessarily of the same quality.
The structure of this article is as follows. In Sect. 2, we present the data and its preparation for ML training. The selection of models and the metrics used to assess their results are shown in Sect. 3. In Sect. 4, the results of model training and validation are provided as well as the predictions using the ML pipeline for radio AGN detections. We present the discussion of our results in Sect. 5. Finally, in Sect. 6, we summarise our work.
2. Data
A large area with deep and homogeneous quality radio observations is needed to train and validate our models and predictions for RGs with already existent observations. As training field we selected the area of the Hobby-Eberly Telescope Dark Energy Experiment Spring field (HETDEX; Hill et al. 2008) covered by the first data release of the LOFAR Two-metre Sky Survey (LoTSS-DR1; Shimwell et al. 2019). The LoTSS-DR1 survey covers 424 deg2 in the HETDEX Spring field (hereafter, HETDEX field) with LOFAR (van Haarlem et al. 2013) 150 MHz observations that have a median sensitivity of 71 μJy/beam and an angular resolution of 6″. HETDEX provides as well multi-wavelength homogeneous coverage as described below.
In order to test the performance of the models when applied to different areas of the sky, and with different coverages from radio surveys, we selected the Sloan Digital Sky Survey (SDSS; York et al. 2000) Stripe 82 field (S82; Annis et al. 2014; Jiang et al. 2014). For S82, we collected data from the same surveys as with the HETDEX (see the following section) field but with one important caveat: no LoTSS-DR1 data is available in the field and, thus, we gathered the radio information from the VLA SDSS Stripe 82 Survey (VLAS82; Hodge et al. 2011). VLAS82 covers an area of 92 deg2 with a median rms noise of 52 μJy/beam at 1.4 GHz with an angular resolution of  . We selected the S82 field (and, in particular, the area covered by VLAS82) given that it presents deep radio observations but taken with a different instrument than LOFAR. This difference allows us to test the suitability of our models and procedures in conditions that are different from the training circumstances.
. We selected the S82 field (and, in particular, the area covered by VLAS82) given that it presents deep radio observations but taken with a different instrument than LOFAR. This difference allows us to test the suitability of our models and procedures in conditions that are different from the training circumstances.
2.1. Data collection
The base survey from which all the studied sources have been drawn is the CatWISE2020 catalogue (CW; Marocco et al. 2021). It lists NIR-detected elements selected from WISE (Wright et al. 2010) and the Near-Earth Object Wide-field Infrared Survey Explorer Reactivation Mission (NEOWISE; Mainzer et al. 2011, 2014) over the entire sky at 3.4 and 4.6 μm (W1 and W2 bands, respectively). This catalogue includes sources detected at 5σ in either of the used bands (i.e. W1 ∼ 17.43 and W2 ∼ 16.47 magVega respectively). The HETDEX field contains 15 136 878 sources listed in CW. Conversely, in the S82 field, there are 3 590 306 of them.
Multi-wavelength counterparts for CW sources were found on other catalogues applying a 5″search criteria. These catalogues include the Panoramic Survey Telescope and Rapid Response System (Pan-STARRS DR1, hereafter PS1, Chambers et al. 2016; Flewelling et al. 2020), the Two Micron All-Sky Survey (2MASS All-Sky, hereafter 2M; Skrutskie et al. 2006; Cutri et al. 2003a,b), and AllWISE (AW; Cutri et al. 2013)2. The adopted search radius corresponds to the distance that has been used by Wright et al. (2010) to match radio sources to Pan-STARRS and WISE observations. Nevertheless, the source density of the radio (LOFAR and VLA) and 2MASS catalogues imply a low statistical (< 1%) spurious counterpart association, this is not the case for PS1, where the source density is higher. For this reason, and to maintain a statistically low spurious association between CW and PS1, we limited our search radius to  . This distance corresponds to the smallest point-spread function (PSF) size of the bands included in PS1 (Chambers et al. 2016).
. This distance corresponds to the smallest point-spread function (PSF) size of the bands included in PS1 (Chambers et al. 2016).
For the purposes of this work, observations in LoTSS and VLAS82 are only used to determine whether a source is radio detected, or not. In particular, no check has been performed on whether a selected source is extended or not in any of the radio surveys. A single Boolean feature is created from the radio measurements (see Sect. 2.2) and no further analyses were performed regarding the detection levels that might be found.
Additionally, we discarded the measurement errors of all bands. Traditionally, ML algorithms cannot incorporate uncertainties in a straightforward way and, thus, we opted to avoid attempting to use them for training. One significant counterexample corresponds to Gaussian processes (GPs; Rasmussen & Williams 2006), where measurement uncertainties are needed by the algorithm to generate predictions. Additionally, the astronomical community has attempted to modify existing techniques to include uncertainties in their ML studies. Some examples include the works by Ball et al. (2008), Reis et al. (2019), Shy et al. (2022). Furthermore, Euclid Collaboration (2023a) have shown that, in specific cases, the inclusion of measurement errors does not add new information to the training of the models and can be even detrimental to the prediction metrics. The degradation of the model by including uncertainties can likely be related to the fact that, by virtue of the large number of sources included in the training stages, the uncertainties are already encoded in the dataset in the form of scatter.
Following the same argument of measurement errors, upper limit values have been removed and a missing value is assumed instead. In general, ML methods (and their underlying statistical methods) cannot work with catalogues that have empty entries (Allison 2001). For that reason, we used single imputation (a review on the use of this method, which is part of data cleansing, in astronomy can be seen in Chattopadhyay 2017) to replace these missing values, and those fainter than 5-σ limits, with meaningful quantities that represent the lack of a measurement. We opted for the inclusion of the same 5-σ limiting magnitudes as the value to impute with. This method of imputation with some variations, has been successfully applied and tested, recently, by Arsioli & Dedin (2020), Carvajal et al. (2021), Curran (2022), and Curran et al. (2022). In particular, Curran (2022) tested several data imputation methods. Among those which replaced all missing values in a wavelength band with a single, constant value, using the 5-σ limiting magnitudes showed the best performance.
In this way, observations from 12 non-radio bands were gathered (as listed in Table 1). The magnitude density distribution for the sample from the HETDEX and S82 fields, without any imputation, is shown in Fig. 1. After imputation, the distribution of magnitudes changes, as shown in Fig. 2. Each panel of the figure shows the number of sources which have a measurement above its 5-σ limit in such band. Additionally, a representation of the observational 5-σ limits of the bands and surveys used in this work is presented in Fig. 3. It is worth noting the depth difference between VLAS82 and LoTSS-DR1 is ∼1.5 mag for a typical synchrotron emitting source (Fν ∝ να with α = −0.8), allowing the latter survey to reach fainter sources.
 |
Fig. 1. Histograms of base collected, non-imputed, non-radio bands for HETDEX (clean, background histograms) and S82 (empty, brown histograms). Each panel shows the distribution of measured magnitudes of detected sources divided by the total area of the field. Dashed, vertical lines represent the 5-σ magnitude limit for each band. The number in the upper right corner of each panel shows the number of measured magnitudes included in their corresponding histogram. |
 |
Fig. 2. Histograms of base collected non-radio bands for HETDEX (clean, background histograms) and S82 (empty, brown histograms) fields. Description as in Fig. 1. The number in the upper right corner of each panel shows number of sources with magnitudes originally measured above the 5-σ limit included in their corresponding histogram for each field (i.e. sources that have not been imputed or replaced). |
 |
Fig. 3. Flux and magnitude depths (5-σ) from the surveys and bands used in this work. Limiting magnitudes and fluxes were obtained from the description of the surveys, as referenced in Sect. 2.1. In purple, rest-frame SED from Mrk231 (z = 0.0422; Brown et al. 2019) is displayed as an example AGN. Redshifted (from z = 0.001 to z = 7) versions of this SED are shown in dashed grey lines. |
Bands available for model training in our dataset.
AGN labels and redshift information were obtained by cross-matching (with a  search radius) the catalogue with the Million Quasar Catalog3 (MQC, v7.4d; Flesch 2021), which lists information from more than 1 500 000 objects that have been classified as optical quasi-stellar objects (QSOs), AGNs, or Blazars. Sources listed in the MQC may have additional counterpart information, including radio or X-ray associations. For the purposes of this work, only sources with secure spectroscopic redshifts were used. The matching yielded 50 538 spectroscopically confirmed AGNs in HETDEX and 17 743 confirmed AGNs in S82.
search radius) the catalogue with the Million Quasar Catalog3 (MQC, v7.4d; Flesch 2021), which lists information from more than 1 500 000 objects that have been classified as optical quasi-stellar objects (QSOs), AGNs, or Blazars. Sources listed in the MQC may have additional counterpart information, including radio or X-ray associations. For the purposes of this work, only sources with secure spectroscopic redshifts were used. The matching yielded 50 538 spectroscopically confirmed AGNs in HETDEX and 17 743 confirmed AGNs in S82.
Similarly, the sources in our parent catalogue were cross-matched with the Sloan Digital Sky Survey Data Release 16 (SDSS-DR16; Ahumada et al. 2020). This cross-match was done solely to determine which sources have been spectroscopically classified as galaxies (spClass == GALAXY). For most of these galaxies, SDSS-DR16 lists a spectroscopic redshift value, which will be used in some stages of this work. In the HETDEX field, SDSS-DR16 provides 68 196 spectroscopically confirmed galaxies. In the S82 field, SDSS-DR16 identifies 4085 galaxies spectroscopically. Given that MQC has access to more AGN detection methods than SDSS, when sources were identified as both galaxies (in SDSS-DR16) and AGNs (in the MQC), a final label of AGN was given. A description of the number of elements in each field and the multi-wavelength counterparts found for them is presented in Table 2. From Table 2, it is possible to see that the numbers and ratios of AGNs and galaxies in both fields are dissimilar. S82 has been subject to a larger number of observations, which have allowed the detection of a larger fraction of AGNs than in the HETDEX field (see, for instance, Lyke et al. 2020), which does not have such number of dedicated studies.
Composition of initial catalogue and number of cross matches with additional surveys and catalogues.
Attending to the intrinsic differences between ML algorithms, not all of them have the same performance when being trained with features spanning a wide range of values (i.e. several orders of magnitude). For this reason, it is customary to re-scale the available values to either be contained within the range [0, 1] or to have similar distributions. We applied a version of the latter transformation to our features (not the targets) as to have a mean value of μ = 0 and a standard deviation of σ = 1 for each feature. Additionally, these new values were power-transformed to resemble a Gaussian distribution. This transformation helps the models avoid using the distribution of values as additional information for the training. For this work, a Yeo-Johnson transformation (Yeo & Johnson 2000) was applied.
2.2. Feature pool
The initial pool of features that have been selected or engineered to use in our analysis is briefly described here. A full list of the features created for this work and their representation in the code and in some of the figures is presented in Table A.1.
Most of the features used in this work come from photometry, both measured and imputed, in the form of AB magnitudes for a total of 12 bands. Also, all available colours from measured and imputed magnitudes were considered. In total, there are 66 colours, resulting from all available combinations of two magnitudes between the 12 selected bands. These colours are labelled in the form X_Y where X and Y are the respective magnitudes.
Additionally, the number of non-radio bands in which a source has valid measurements (band_num) has been used. This feature could be, very loosely, attributed to the total flux a source can display. A higher band_num will imply that such source can be detected in more bands, hinting a higher flux (regardless of redshift). The use of features with counting or aggregation of elements in the studied dataset is well established in ML (see, for example, Zheng & Casari 2018; Duboue 2020; Sánchez-Sáez et al. 2021; Euclid Collaboration 2023a).
Finally, as categorical features, we included an AGN-galaxy classification Boolean flag named class and a radio Boolean flag LOFAR_detect. This feature flags whether sources have counterparts in the radio catalogues (LoTSS or VLAS82).
3. Machine learning training
In an attempt to extract the largest available amount of information from the data, and let ML algorithms improve their predictions, we decided to perform our training and predictions through a series of sequential steps, which we refer to as ‘models’ henceforth. We started with the training and prediction of the class of sources (AGNs or galaxies). The next model predicts whether an AGN could be detected in radio at the depth used during training (LoTSS). A final model will predict the redshift values of radio-predicted AGNs. A visual representation of this process can be seen in Fig. 4. Creating separate models gives us the opportunity to select the best subset of features for training as well as the best combination of ML algorithms for training in each step.
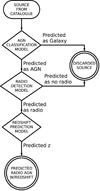 |
Fig. 4. Flowchart representing the prediction pipeline used to predict the presence of radio-detectable AGNs and their redshift values. At the beginning of each model step, the most relevant features are selected as described in Sect. 3.1. |
In broad terms, our goal with the classification models is to recover the largest number of elements from the positive classes (i.e. class = 1 and LOFAR_detect = 1). For the regression model, we aim to retrieve predictions as close as the originally fed redshift values.
In general, classification models provide a final score in the range [0, 1], which can only be associated with a true probability after a careful calibration (Kull et al. 2017a,b). Calibration of these scores can be done by applying a transformation to their values. For our work, we decided to apply a Beta transformation4. This type of transformation allows us to re-distribute the scores of an uncalibrated classifier allowing them to get closer to the definition of probability. Further details of the calibration process are given in the Appendix C.
Given that we need to be able to compare the results from the training and application of the ML models with values obtained independently (i.e. ground truth), we divided our dataset into labelled and unlabelled sources. Labelled sources are all elements of our catalogue that have been classified as either AGNs or galaxies. Unlabelled sources are those which lack such classification and that will only be subject to the prediction of our models, not taking part in any training step.
Before any calculation or transformation is applied to the data from the HETDEX field, we split the labelled dataset into training, validation, calibration, and testing subsets. The early creation of these subsets helps avoid information leakage from the test subset into the models. Initially, a 20% of the dataset has been reserved as testing data. Of the remaining elements, an 80% of them have been used for training, and the rest of the data has been divided equally between calibration and validation subsets (i.e. a 10% each). The splitting process and the number of elements for each subset are shown in Fig. 5. Depending on the model, the needed sources are selected from each of the subsets that have been already created. The training set will be used to select algorithms for each step and to optimise their hyperparameters. The inclusion of the validation subset helps in the parameter optimisation of the models. The probability calibration of the trained model is performed over the calibration subset and, finally, the completed models are tested on the test subset. The use of these subsets will be expanded in Sects. 3.3 and 3.4.
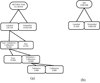 |
Fig. 5. Composition of datasets used for the different steps of this work. (a) HETDEX field. (b) S82. |
All the following transformations (feature selection, standardisation, and power transform of features) were applied to the training and validation subsets before the training of the algorithms and models. The calibration and testing subsets were subject to the same transformations after the modelling stage.
3.1. Feature selection
Machine learning algorithms, as with most data analysis tools, require execution times which increase at least linearly with the size of the datasets. In order to reduce training times without losing relevant information for the model, the most important features were selected at each step through a process called feature selection.
To avoid redundancy, the process starts discarding features that have a high correlation with another property of the dataset. For discarding features, we calculated Pearson’s correlation matrix for the full train+validation dataset only and selected the pairs of features that showed a correlation factor higher than ρ = 0.75, in absolute values5. From each pair, we discarded the feature with the lowest relative standard deviation (RSD; Johnson & Leone 1964). The RSD is defined as the ratio between the standard deviation of a set and its mean value. A feature which covers a small portion of its probable values (i.e. low coverage of parameter space, and lower RSD) will give less information to a model than one with largely spread values.
For each model, the process of feature selection begins with 79 base features and three targets (class, LOFARdetect, and Z). Feature selection is run, independently, for each trained model (i.e. AGN-galaxy classification, radio detection, and redshift predictions), delivering three different sets of features.
3.2. Metrics
A set of metrics will be used to understand the reliability of the results and put them in context with results in the literature. Since our work includes the use of classification and regression models, we briefly discuss the appropriate metrics in the following sections.
3.2.1. Classification metrics
The main tool to assess the performance of classification methods is the confusion (or error) matrix. It is a two-dimension (predicted vs. true) matrix where the true and predicted class(es) are compared and results stored in cells with the rate of true positives (TP), true negative (TN), false positives (FP), and false gegatives (FN). As mentioned earlier in Sect. 3, we seek to maximise the number of positive-class sources that are recovered as such. Using the elements of the confusion matrix, this aim can be translated into the maximisation of TP and, consequently, the minimisation of FN.
From the elements of the confusion matrix, we can obtain additional metrics, such as the F1 and Fβ scores (Dice 1945; Sørenson 1948; van Rijsbergen 1979), and the Matthews correlation coefficient (MCC; Yule 1912; Cramér 1946; Matthews 1975 which are better suited for unbalanced data as they take into account the behaviour and correlations among all elements of the confusion matrix. As such, the F1 coefficient is defined as the following:
 (1)
(1)
The values of F1 can go from 0 (no prediction of positive instances) to 1 (perfect prediction of elements with positive labels). This definition assigns equal weight (importance) to both the number of FN and FP. An extension to the F1 score, which adds a non-negative parameter, β, to increase, the importance given to each one of them is the F score (Fβ), defined as follows:
 (2)
(2)
Using β > 1, more relevance is given to the optimisation of FN. When 0 ≤ β < 1, the optimisation of FP is more relevant. If β = 1, the initial definition of F1 is recovered. As with F1, Fβ values can be in the range [0, 1]. As we seek to minimise the number of FN detection, we adopt a conservative value of β = 1.1, giving more significance to their reduction without removing the aim for FP. Also, this value is close enough to β = 1, which will allow us to compare our scores to those produced in previous works.
The MCC metric is defined as
 (3)
(3)
which includes also the information about the TN elements. The values of MCC can range from −1 (total disagreement between true and predicted values) to +1 (perfect prediction) with 0 representing a prediction analogous to a random guess.
The recall, or true positive rate (TPR, also called completeness, or sensitivity; Yerushalmy 1947) corresponds to the rate of relevant, or correct, elements that have been recovered by a process. Using the elements from the confusion matrix, it can be defined as the following:
 (4)
(4)
and it can go from 0 to 1, with a value of 1 meaning that the model can recover all the true instances.
The last metric used is precision (also known as purity), which can be defined as the ratio between the number of correctly classified elements and the number of sources in the positive class (AGN or radio detectable):
 (5)
(5)
and their values can range from 0 to 1 where higher values show that more real positive instances of the studied set were retrieved as such by the model.
In order to establish a baseline from which the aforementioned metrics can be assessed, it is possible to obtain them in the case of a random, or no-skill prediction. Following, for instance, the derivations and notation from Poisot (2023), no-skill versions of classification metrics (Eqs. (2)–(5)) are the following:
 (6)
(6)
 (7)
(7)
 (8)
(8)
 (9)
(9)
where p corresponds to the ratio between the elements of the positive class and the total number of elements involved in the prediction.
3.2.2. Regression metrics
For the case of individual redshift value determination, two commonly used metrics are the difference between predicted and true redshift,
 (10)
(10)
and its normalised difference,
 (11)
(11)
If the comparison is made over a larger sample of elements, the bias of the redshift is used (Dahlen et al. 2013), with the median of the quantities instead of its mean to avoid the strong influence of extreme values. This bias can be written as
 (12)
(12)
 (13)
(13)
Using the previous definitions, four additional metrics can be calculated. These are the median absolute deviation (MAD, σMAD) and normalised median absolute deviation (NMAD, σNMAD; Hoaglin et al. 1983; Ilbert et al. 2009), which are less sensitive to outliers. Also, the standard deviation of the predictions, σz, and its normalised version,  are typically used. They are defined as
are typically used. They are defined as
 (14)
(14)
 (15)
(15)
 (16)
(16)
 (17)
(17)
with d being the number of elements in the studied sample (i.e. its size).
Also, the outlier fraction (η, as used in Dahlen et al. 2013; Lima et al. 2022) is considered, which is defined as the fraction sources with a predicted redshift difference (|#x0394;zN|, Eq. (11)) larger than a previously set value. Taking the results from Ilbert et al. (2009) and Hildebrandt et al. (2010), we selected this threshold to be 0.15, leaving the definition of the outlier fraction as follows:
 (18)
(18)
where # symbolises the number of sources fulfilling the described relation, and d corresponds to the size of the selected sample.
3.2.3. Calibration metrics
One of the most used analytical metrics to assess calibration of a model is the Brier score (BS; Brier 1950). It measures the mean square difference between the predicted probability of an element and its true class. If the total number of elements in the studied sample is d, the BS can be written (for binary classification problems, as the ones studied in this work) as
 (19)
(19)
where ℂ is the predicted class and class corresponds the true class of each of the elements in the sample (0 or 1). The BS can range between 0 and 1 with 0 representing a model that is completely reliable in its predictions. Additionally, the BS can be used to compare the reliability (or calibration) between a model and a reference using the Brier skill score (BSS; e.g. Glahn & Jorgensen 1970), which can be defined as the following:
 (20)
(20)
In our case, BSref corresponds to the value calculated from the uncalibrated model. The BSS can take values between −1 and +1. The closer the BSS gets to 1, the more reliable the analysed model is. These values include the case where BSS ≈ 0, in which both models perform similarly in terms of calibration.
For our pipeline, after a model has been fully trained, a calibrated version of their scores will be obtained. With both of them, the BSS will be calculated and, if it is not much lower than 0, that calibrated transformation will be used as the final scores from the prediction.
3.3. Model selection
By design, each ML algorithm has been developed and tuned to work better with certain data conditions. For instance, balance of target categories and ranges of base features. The predicting power of different algorithms can be combined with the use of meta learners (Vanschoren et al. 2019). Meta learners use the properties or predictions from other algorithms (base learners) as additional information during their training stages. A simple implementation of this procedure is called generalised stacking (Wolpert 1992) which can be interpreted as the addition of priors to the model training stage. Generalised stacking has been applied in several astrophysical problems. That is the case of Zitlau et al. (2016), Cunha & Humphrey (2022), and Euclid Collaboration (2023a,b).
Base and meta learners have been selected based upon the metrics described in Sect. 3.2. We trained five algorithms with the training subset and calculated the metrics for all of them using a 10-fold cross-validation approach (e.g. Stone 1974; Allen 1974) over the same training subset. For each metric, the learners have been given a rank (from 1 to 5) and a mean value has been obtained from them. Out of the analysed algorithms, the one with the best overall performance (i.e. best mean rank) is selected to be the meta learner while the remaining four are used as base learners.
For the AGN-galaxy classification and radio detection problems, we tested five classification algorithms: Random Forest (RF; Breiman 2001), Gradient Boosting Classifier (GBC; Friedman 2001), Extra Trees (ET; Geurts et al. 2006), Extreme Gradient Boosting (XGBoost, v1.5.1; Chen & Guestrin 2016), and Category Boosting (CatBoost, v1.0.5; Prokhorenkova et al. 2018; Dorogush et al. 2018). For the redshift prediction problem, we tested five regressors as well: RF, ET, XGBoost, CatBoost, and Gradient Boosting Regressor (GBR; Friedman 2001). We used the Python implementations of these algorithms and, in particular for RF, ET, GBC, and GBR, the versions offered by the package scikit-learn6 (v0.23.2; Pedregosa et al. 2011). These algorithms were selected given that they offer tools to interpret the global and local influence of the input features in the training and predictions (cf. Sects. 1 and 5.3).
All the algorithms selected for this work fall into the broad family of tree-based models. Forest models (RF and ET) rely on a collection of decision trees to, after applying a majority vote, predict either a class or a continuum value. Each of these decision trees uses a different, randomly selected subset of features to make a decision on the training set (Breiman 2001). Opposite to forests, gradient boosting models (GBC, GBR, XGBoost and CatBoost) apply decision trees sequentially to improve the quality of the previous predictions (Friedman 2001, 2002).
3.4. Training of models
The procedure described in Sect. 3.3 includes an initial fit of the selected algorithms to the training data (including the selected features) to optimise their parameters. The stacking step includes a new optimisation of the parameters of the meta learner using 10-fold cross-validation on the training data with the addition of the output from the base learners, which are treated as regular features. Then, the hyperparameters of the stacked models are optimised over the training subset (a brief description of this step is presented in Appendix D).
The final step involves a last parameter fitting instance but using, this time, the combined train+validation subset, which includes the output of the base algorithms, to ensure wider coverage of the parameter space and better-performing models. Consequently, only the testing set is available for assessing the quality of the predictions made by the models.
3.5. Probability calibration
The calibration procedure was performed in the calibration subset. In this way, we avoid influencing the process with information from the training and validation steps. A broader description of the calibration process and the results obtained for our models are presented in Appendix C. Thus, from this point onwards, and with the sole exception of some of the outcomes shown in Sect. 5.3, all results from classifications will be based on the calibrated probabilities.
3.6. Optimisation of classification thresholds
As mentioned in the first paragraphs of Sect. 3, classification models deliver a range of probabilities for which a threshold is needed to separate their predictions between negative and positive classes. By default, these models set a threshold at 0.5 in score7 but, in principle, and given the characteristics of the problem, a different optimal threshold might be needed.
In our case, we want to optimise (increase) the number of recovered elements in each model (i.e. AGNs or radio-detectable sources). This maximisation corresponds to obtaining thresholds that optimise the recall given a specific precision limit. We did that with the use of the statistical tool called precision-recall (PR) curve. A deeper description of this method and the results obtained from our work are presented in Appendix E8.
4. Results
In the present section, we report the results from the training of the different models in the HETDEX field. All metrics are evaluated using the testing subset. The metrics are also computed on labelled AGNs in the S82 field. As no training is done on S82 data, it offers a way to test the validity of the pipeline on data that, despite having similar optical-to-NIR photometric properties, presents distinct radio information and location in the sky.
The three models are chained afterwards in sequential mode to create a pipeline, and related metrics, for the prediction of radio-AGN activity. Novel predictions were obtained from the application of such pipeline to unlabelled sources from both the HETDEX and S82 fields.
4.1. AGN-galaxy classification
Feature selection was applied to the train+validation subset with 85 488 confirmed elements (galaxies from SDSS DR16 and AGNs from MQC, i.e. class == 0 or class == 1). After the selection procedure described in Sect. 3.1, 18 features were selected for training: bandnum, W4mag, gr, ri, rJ, iz, iy, zy, zW2, yJ, yW1, yW2, JH, HK, HW3, W1W2, W1W3, and W3W4. The target feature is class.
The results of model testing for the AGN-galaxy classification are reported in Table 3. The CatBoost algorithm provides the best metric values (highest mean rank) and is therefore selected as the meta model. XGBoost, RF, ET, and GBC were used as base learners.
Best performing models for the AGN-galaxy classification.
The optimisation of the PR curve for the calibrated predictor provides an optimal threshold for this algorithm of 0.34895. This value was used for the AGN-galaxy model throughout this work.
The results of the application of the stacked and calibrated model for the testing subset and the labelled sources in S82 are presented in Table 4. The metrics are shown for the use of two different thresholds, the naive value of 0.5 and the PR-derived value of 0.34895. The confusion matrix (calculated on the testing dataset) is shown in the upper left panel of Fig. 6.
 |
Fig. 6. Performance of individual models (AGN-galaxy classification, radio-detectability classification and redshift regression) when applied to the HETDEX test subset. (a) Confusion matrix for AGN-galaxy classification. (b) Same as (a), but for radio detection. (c) Density plot comparison between original and the predicted redshifts. Grey, dashed line shows the 1:1 relation while dot-dashed lines show the limits for outliers (cf. Eq. (18)). Inset displays the distribution of #x0394;zN with a < #x0394;zN > = 0.0442. |
Overall, the model is able to separate AGNs from galaxies with a very high (recall ≳94%) success rate. A comparison with traditional colour-colour criteria for AGNs selection is presented in Sect. 5.1.1. Our classification model can recover, in the HETDEX field, 15% and 59% more AGNs than said formulae. In the S82 field, these differences range between 17% and 61%. Such differences highlight the fact that most of the information that separates AGNs from galaxies is traced by the selected features (mostly colours). Also, the increase in the recovery rate underlines the importance of using photometric information from several bands for such task, as opposed to traditional colour-colour criteria.
4.2. Radio detection
Training of the radio detection model was applied only to sources confirmed to be AGN (class == 1). Feature selection was applied to the train+validation subset, with 36 387 confirmed AGNs. The target feature is LOFARdetect and the base of selected features are: bandnum, W4mag, gr, gi, ri, rz, iz, zy, zW1, yJ, yW1, JH, HK, KW3, KW4, W1W2, and W2W3.
The performance of the tested algorithms is shown in Table 5. In this case, GBC shows the highest mean rank. For this reason, we used it as the meta learner and XGBoost, CatBoost, RF, and ET were selected as base learners. The optimal threshold for this model is found to be ∼0.20460. Finally, the stacked model metrics and confusion matrix are shown in Table 6, for PR-optimised and naive thresholds, and in Fig. 6 respectively.
Best performing models the radio detection classification.
4.3. Redshift predictions
The redshift value prediction model was applied to sources confirmed to be radio-detected AGN (i.e. class == 1 and radio_detect == 1). Feature selection (cf. Sect. 3.1) was applied to the train+validation subset, with 4612 sources, leading to the selection of 17 features. The target feature is Z and the selected base features are bandnum, W4mag, gr, gW3, ri, rz, iz, iy, zy, yJ, yW1, JH, HK, KW3, KW4, W1W2, and W2W3.
For the redshift prediction, the tested algorithms performed as shown in Table 7. Based on their mean rank values, RF, CatBoost, XGBoost, and GBR were selected as base learners and ET (which shows the best σMAD value of the two models with the best rank) was used as meta learner. The redshift regression metrics of the stacked model are presented in Table 8. Likewise, the comparison between the original and predicted redshifts is shown in the lower panel of Fig. 6.
Results of initial fit for redshift value prediction.
4.4. Prediction pipeline
The sequential combination of the models described in Sect. 3 defines the pipeline for the prediction of radio-detectable AGNs and their redshift. As separate tasks, the pipeline was applied to the labelled sources in the HETDEX testing subset, to the labelled sources in S82, and to all unlabelled sources across both fields. S82 provides an independent test of the pipeline as no data in this field was used for training the different models. A full candidate catalogue is extracted from this exercise and based on the unlabelled datasets.
As the metrics discussed in the previous sections correspond to each individual model, new – combined – metrics, based on the knowledge for labelled sources, are calculated for HETDEX and S82 and presented in Fig. 7 and Tables 8 and 9. Overall, we observe worse combined metrics with respect to the ones calculated for individual models (e.g. recall of 45% for HETDEX and 47% for S82). This degradation might be understood by the fact that the pipeline is composed of three sequential models. Each additional step is fed with sources classified by the previous algorithm. And some of these sources might not be similar, in terms of features, to those used for training, thus adding noise to the output of such model. A small sample of the output of the pipeline for five high-z labelled radio AGN sources in HETDEX and S82 are shown in Tables 10 and 11 respectively.
 |
Fig. 7. Combined confusion matrices and True/predicted redshift density plot for the full radio AGN detection prediction computed using the testing subset from HETDEX (panels a and b) and the known labelled sources from S82 (panels c and d). |
Results of application of radio AGN prediction pipeline to the labelled sources in the HETDEX and S82 fields.
Predicted and original properties for the 5 sources in testing subset with the highest redshift predicted radio AGNs.
Predicted and original properties for the 5 sources in S82 with the highest predicted redshift on the labelled sources predicted to be radio AGNs.
The application of the prediction pipeline to the unlabelled sources from the HETDEX field led to 9 974 990 predicted AGNs, from which 68 252 were predicted to be radio detectable. The pipeline predicts, as well, 2 073 997 AGNs in the unlabelled data from S82, being 22 445 of them candidates to be detected in the radio (to the detection level of LoTSS). The distribution of the predicted redshifts for radio AGNs in HETDEX and S82 is presented in Fig. 8. The pipeline outputs for a small sample of the predicted radio AGNs are presented in Tables 12 and 13 for HETDEX and S82 respectively. Section 5 explores the comparison of these results with previous works in the literature and discusses the main drivers (i.e. features) for the detection of these radio AGNs.
 |
Fig. 8. Redshift density distribution of the predicted radio AGNs within the unlabelled sources (clean histograms) in HETDEX (ochre histograms) and S82 (blue histograms) and true redshifts from labelled radio AGNs (dashed histograms). |
Predicted and original properties for the 5 sources in the HETDEX field with the highest predicted redshift on the unlabelled sources predicted to be radio AGNs.
Predicted and original properties for the 5 sources in S82 with the highest predicted redshift on the unlabelled sources predicted to be radio AGNs.
4.5. No-skill classification
As presented in Sect. 3.2.1, Eqs. (6)–(9) show the base results for a classification with no skill. Table 14 presents the scores generated by using this technique. These values are the base from which any improvement can be assessed.
Results of no-skill selection of sources in different stages of pipeline to the labelled sources in the HETDEX test subset and S82 fields.
Subsets and prediction modes displayed in Table 14 coincide with those exhibited in Tables 4, 6, and 9. For instance, in the test HETDEX sub-sample, ∼43% of sources are labelled as AGNs. From all AGNs, ∼13% of them have radio detections. This can be summarised stating that ∼6% of all sources in the test sub-sample are radio-detected AGNs.
5. Discussion
5.1. Comparison with previous prediction or detection works
In this subsection, we provide a few examples of related published works as well as plausible explanations for observed discrepancies when these are present. This comparison attempts to be representative of the literature on the subject but does not intends to be complete in any way.
5.1.1. AGN detection prediction
In order to understand the significance of our results and ways for future improvement, we separate the comparison with previous works in two parts. First, we present previously published results from traditional methodologies. In second place, we offer a comparison with ML methods.
Traditional AGN selection methods are based on the comparison of the measured SED photometry to a template library (Walcher et al. 2011). A recent example of its application is presented by Thorne et al. (2022) where best fit classifications were calculated for more than 700 000 galaxies in the D10 field of the Deep Extragalactic VIsible Legacy Survey (DEVILS; Davies et al. 2018) and the Galaxy and Mass Assembly survey (GAMA; Driver et al. 2011; Liske et al. 2015). The 91% recovery rate of AGNs, selected through various means (X-ray measurements, narrow and broad emission lines, and mid-IR colours), is very much in line with our findings in S82, where our rate (recall) reaches 89%.
Traditional methods also encompass the colour-based selection of AGNs. While less precise, they provide access to a much larger base of candidates with a very low computational cost. We implemented some of the most common colour criteria on the data from S82. Of particular interest is the predicting power of the mid-IR colour selection due to its potential to detect hidden or heavily obscured AGN activity.
Based on WISE (Wright et al. 2010) data, Stern et al. (2012, hereafter S12) proposed a threshold at W1–W2 ≥ 0.8 to separate AGNs from non-AGNs using data from AGNs in the Cosmic Evolution Survey (COSMOS) field (Scoville et al. 2007). A more stringent criterion was developed by Mateos et al. (2012, hereafter M12), the AGN wedge, which can be defined by the sources located inside the region defined by the relations W1–W2 < 0.315 × (W2–W3)+ 0.791, W1 - W2 > 0.315 × (W2– W3) – 0.222, and W1–W2 > –3.172 × (W2–W3) + 7.624. In order to define this wedge, they used data from X-ray selected AGNs over an area of 44.43 deg2 in the northern sky. Mingo et al. (2016, hereafter M16) cross-correlated data from WISE observations with X-ray and radio surveys creating a sample of star-forming galaxies and AGNs in the northern sky. They developed individual relations to separate classes of galaxies and AGNs in the W1–W2, W2–W3 space and, for AGNs the criterion, the relation is W1–W2 ≥ 0.5 and W2–W3 < 4.4. More recently, Blecha et al. (2018, hereafter B18) analysed the quality of mid-IR colour selection methods for the identification of obscured AGNs involved in mergers. Using hydrodynamic simulations for the evolution of AGNs in galaxy mergers, they developed a selection criterion from WISE colours which is shown to be able to separate, with high reliability, starburst galaxies from AGNs. The expressions have the form W1–W2 > 0.5, W2–W3 > 2.2, and W1–W2 > 2 × (W2–W3) −8.9. The results from the application of these criteria to our samples in the testing subset and in the labelled sources of S82 field are summarised in Table 15 and a graphical representation of the boundaries they create in their respective parameter spaces is presented in Fig. 9.
 |
Fig. 9. W1–W2, W2–W3 colour-colour diagrams for sources in the testing subset, from HETDEX, and labelled sources from S82 given their position in the AGN-galaxy confusion matrix (see, for HETDEX, rightmost panel of Fig. 7). In the background, density plot of all CW-detected sources in the full HETDEX field sample is displayed. Colour of each square represents the number of sources in that position of parameter space, with darker squares having more sources (as defined in the colourbar of the upper-right panel). Contours represent distribution of sources for each of the aforementioned subsets at 1, 2, 3, and 4σ levels (shades of blue, for testing set and shades of red for labelled S82 sources). Coloured, solid lines display limits from the criteria for the detection of AGNs described in Sect. 5.1.1. |
Results of application of several AGN detection criteria to our testing subset and the labelled sources from the S82 field.
Table 15 shows that previous colour-colour criteria have been designed and calibrated to have very high precision values. Most of the sources deemed to be AGN by them are, indeed, of such class. Despite being tuned to maximise their recall (and Fβ to a lesser extent), our classifier, and the criterion derived from it, still show precision values compatible with those of such criteria. This result underlines the power of ML methods. They can be on a par with traditional colour-colour criteria and excel in additional metrics.
Figure 9 is constructed as a confusion matrix, plotting in each quadrant the whole WISE population in the background and in colour contours the corresponding fraction of the testing set (TP, TN, FP, and FN, see Fig. 6a and Sect. 3.2.1). As expected, our pipeline is able to separate with high confidence sources which are closer to the AGN or the galaxy loci (TP and TN) while sources in the FN and FP quadrant show a different situation. Active galactic nuclei predicted to be galaxies (FN, 1.6% of sources for HETDEX, and 4.9% for S82) are located in the galaxy region of the colour-colour diagram. On the opposite corner of the plot, galaxies predicted to be AGNs (FP, 2.4% of sources for HETDEX, and 4.2% for S82) cover the areas of AGNs and galaxies uniformly. False negative sources might be sources that are identified as AGNs by means not included in our feature set (e.g. X-ray, radio emission). Sources in the FP quadrant, alternatively, might be galaxies with extreme properties, similar to AGNs.
For the case of ML-based models for AGN-galaxy classification, several analyses have been published in recent years. An example of their application is provided in Clarke et al. (2020) where a random forest model for the classification of stars, galaxies and AGNs using photometric data was trained from more than 3 000 000 sources in the SDSS (DR15; Aguado et al. 2019) and WISE with associated spectroscopic observations. Close to 400 000 sources have a quasar spectroscopic label and from the application of their model to a validation subset, they obtain a recall of 0.929 and F1 score of 0.943 for the quasar classification. These scores are of the same order as the ones obtained when applying our AGN-galaxy model to the testing set (see Table 4). Thus, and despite using an order of magnitude fewer sources for the full training and validation process, our model can achieve equivalently good scores.
Expanding on Clarke et al. (2020), Cunha & Humphrey (2022) built a ML pipeline, SHEEP, for the classification of sources into stars, galaxies and QSOs. In contrast to Clarke et al. (2020) or the pipeline described here, the first step in their analysis is the redshift prediction, which is used as part of the training features by the subsequent classifiers. They extracted WISE and SDSS (DR15; Aguado et al. 2019) photometric data for almost 3 500 000 sources classified as stars, galaxies or QSOs. The application of their pipeline to sources predicted to be QSOs leads to a recall of 0.960 and an F1 score of 0.967. The improved scores in their pipeline might be a consequence not only of the slightly larger pool of sources, but also the inclusion of the coordinates of the sources (right ascension, declination) and the predicted redshift values as features in the training.
A test with a larger number of ML methods was performed by Poliszczuk et al. (2021). For training, they used optical and infrared data from close to 1500 sources (galaxies and AGNs) located at the AKARI North Ecliptic Pole (NEP) Wide-field (Lee et al. 2009; Kim et al. 2012) covering a 5.4 deg2 area. They tested LR, SVM, RF, ET, and XGBoost including the possibility of generalised stacking. In general, they obtain results with F1 scores between 0.60–0.70 and recall values in the range of 50%–80%. These values, lower than the works described here, can be fully understood given the small size of their training sample. A larger photometric sample covers a wider range of the parameter space which significantly helps the metrics of any given model.
5.1.2. Radio detection prediction
We have not found in the literature any work attempting the prediction of AGN radio detection at any level and therefore this is the first attempt at doing so. In the literature we do find several correlations between the AGN radio emission (flux) and that at other wavelengths (e.g. with infrared emission, Helou et al. 1985; Condon 1992) and substantial effort has been done towards classifying RGs based upon their morphology (e.g. Aniyan & Thorat 2017; Wu et al. 2019) and its connection to environment (Miley & De Breuck 2008; Magliocchetti 2022). None of these extensive works has directly focussed on the a priori presence or absence of radio emission above a certain threshold. Therefore, the results presented here are the first attempt at such an effort.
The ∼2x success rate of the pipeline to identify radio emission in AGNs (∼44.61% recall and ∼32.20% precision; see Table 9) with the respect to a no-skill selection (⪅30%), provides the opportunity to understand what the model has learned from the data and, therefore, gain some insight into the nature or triggering mechanisms of the radio emission. We, therefore, reserve the discussion of the most important features, and the linked physical processes, driving the pipeline improved predictions to Sect. 5.3.1.
5.1.3. Redshift value prediction
We compare our results to that of Ananna et al. (2017; Stripe 82X) where the authors analysed multi-wavelength data from more than 6 100 X-ray detected AGNs from the 31.3 deg2 of the Stripe 82X survey. They obtained photometric redshifts for almost 6000 of these sources using the template-based fitting code LePhare (Arnouts et al. 1999; Ilbert et al. 2006). Their results present a normalised median absolute deviation of σNMAD = 0.062 and an outlier fraction of η = 13.69%, values which are similar to our results in HETDEX and S82 except for a better outlier fraction (as shown in Table 8, we obtain ηS82 = 25.18%,  , and ηHETDEX = 18.9%).
, and ηHETDEX = 18.9%).
On the ML side, we compare our results to those produced by Carvajal et al. (2021) in S82, with σNMAD = 0.1197 and η = 29.72%, and find that our redshift prediction model improves by at least 25% for any given metric. The source of improvement is probably many-fold. First, it might be related to the different sets of features used (colours vs. ratios) and, second, the more specific population of radio AGN used to train our models. Carvajal et al. (2021) used a limited set of colours to train their model, while we allowed the use of all available combinations of magnitudes (Sect. 2.2). Additionally, their redshift model was trained on all available AGNs in HETDEX, while we trained (and tested) it only with radio-detected AGNs. Using a more constrained sample reduces the likelihood of handling sources that are too different in the parameter space.
Another example of the use of ML for AGN redshift prediction has been presented by Luken et al. (2019). They studied the use of the k-nearest neighbours algorithm KNN (Cover & Hart 1967), a non-parametric supervised learning approach, to derive redshift values for radio-detectable sources. They combined 1.4 GHz radio measurements, infrared, and optical photometry in the European Large Area Infrared Space Observatory (ISO) Survey-South 1 (ELAIS-S1; Oliver et al. 2000) and extended Chandra Deep Field South (eCDFS; Lehmer et al. 2005) fields, matching their sensitivities and depths to the expected values in the Evolutionary Map of the Universe (EMU; Norris et al. 2011). From the different experiments they run, their resulting NMAD values are in the range σNMAD = 0.05 − 0.06, and their outlier fraction can be found between η = 7.35% and η = 13.88%. As an extension to the previous results, Luken et al. (2022) analysed multi-wavelength data from radio-detected sources the eCDFS and the ELAIS-S1 fields. Using KNN and RF methods to predict the redshifts of more than 1300 RGs, they developed regression methods that show NMAD values between σNMAD = 0.03 and σNMAD = 0.06, σz = 0.10 − 0.19, and outlier fractions of η = 6.36% and η = 12.75%.
In addition to the previous work, Norris et al. (2019) compared a number of methodologies, mostly related with ML but also LePhare, for predicting redshift values for radio sources. They used more than 45 photometric measurements (including 1.4 GHz fluxes) from different surveys in the COSMOS field. From several settings of features, sensitivities, and parameters, they retrieve redshift predictions with NMAD values between σNMAD = 0.054 and σNMAD = 0.48 and outlier fractions that range between η = 7% and η = 80%. The broad span of obtained values might be due to the combinations of properties for each individual training set (including the use of radio or X-ray measurements, the selection depth, and others) and to the size of these sets, which was small for ML purposes (less than 400 sources). The slightly better results can be understood given the heavily populated photometric data available in COSMOS.
Specifically related to HETDEX, it is possible to compare our results to those from Duncan et al. (2019). They use a hybrid photometric redshift approach combining traditional template fitting redshift determination and ML-based methods. In particular, they implemented a GP algorithm, which is able to model both the intrinsic noise and the uncertainties of the training features. Their redshift prediction analysis of AGN sources with a spectroscopic redshift detected in the LoTSS DR1 (6, 811 sources) recovers a NMAD value of σNMAD = 0.102 and an outlier fraction of η = 26.6%. The differences between these results and those obtained from the application of our models (individually and as part of the prediction pipeline) might be due to the differences in the creation of the training sets. Duncan et al. (2019) used information from all available sources in the HETDEX field for training the redshift GP whilst our redshift model has been only trained on radio-detected AGNs, giving it the opportunity to focus its parameter exploration only on these sources.
Finally, Cunha & Humphrey (2022) also produced photometric redshift predictions for almost 3 500 000 sources (stars, galaxies, and QSOs) as part of their pipeline (see Sect. 5.1.1). They combined three algorithms for their predictions: XGBoost, CatBoost, and LightGBM (Ke et al. 2017). This procedure leads to σNMAD = 0.018 and η = 2%. As with previous examples, the differences with our results can be a consequence of the number of training samples. Also, in the case of Cunha & Humphrey (2022), they applied an additional post-processing step to the redshift predictions attempting to predict and understand the appearance of catastrophic outliers.
5.2. Influence of data imputation
One effect which might influence the training of the models and, consequently, the prediction for new sources is related to the imputation of missing values (cf. Sect. 2.1). In Fig. 10, we plotted the distributions of predicted scores (for classification models) and predicted redshift values as a function of the number of measured bands (band_num) for each step of the pipeline as applied to sources predicted to be of each class in the test subset.
 |
Fig. 10. Evolution of predicted probabilities (top: probability to be AGN, middle: probability of AGNs to be detected in radio) and redshift values for radio-detectable AGNs (bottom panel) as a function of the number of observed bands for sources in test set. In top panel, sources have been divided between those predicted to be AGN and galaxy. In middle panel, sources are divided between predicted AGN that are predicted to be detected in radio and those predicted to not have radio detection. Background density plots (following colour coding in colourbars) show location of predicted values. Overlaid boxplots display main statistics for each number of measured bands. Black rectangles encompass sources in second and third quartiles. Vertical lines show the place of sources from first and fourth quartiles. Orange lines represent median value of sample and dashed, green lines indicate their mean values. Dashed, grey lines show PR thresholds for AGN-galaxy and radio detection classifications. Close to each boxplot, written values correspond to the number of sources considered to create each set of statistics. |
The top panel of Fig. 10 shows the influence of the degree of imputation in the classification between AGNs and galaxies. For most of the bins, probabilities for predicted galaxies are distributed close to 0.0, without any noticeable trend. In the case of predicted AGNs, the combination of low number of sources and high degree of imputation (band_num < 5) lead to low mean probabilities.
The case of radio detection classification is somewhat different. Given the number and distribution of sources per bin, it is not possible to extract any strong trend for the probabilities of radio-predicted sources. The absence of evolution with the number of observed bands is stronger for sources predicted to be devoid of radio detection.
Finally, a stronger effect can be seen with the evolution of predicted redshift values for radio-detectable AGNs. Despite the lower number of available sources, it is possible to recognise that sources with higher number of available measurements are predicted to have lower redshift values. Sources that are closer to us have higher probabilities to be detected in a large number of bands. Thus, it is expected that our model predicts lower redshift values for the most measured sources in the field.
In consequence, Fig. 10 allows us to understand the influence of imputation over the predictions. The most highly affected quantity is the redshift, where large fractions of measured magnitudes are needed to obtain scores that are in line with previous results (cf. Sect. 5.1.3). The AGN-galaxy and radio detection classifications show a mild influence of imputation in their results.
5.3. Model explanations
Given the success of the models and pipeline in classifying AGNs, their radio detectability and redshift with the provided set of observables, knowing the relative weights that they have in the decision-making process is of utmost relevance. In this way, physical insight might be gained about the triggers of AGN and radio activity and its connection to their host. Therefore, we estimated both local and global feature importances for the individual models and the combined pipeline. Global importances were retrieved using the so-called ‘decrease in impurity’ approach (see, for example, Breiman 2001). Local importances have been determined via Shapley values. A more detailed description of what these importances are and how they are calculated is given in the following sections.
5.3.1. Global feature importances
Overall, mean or global feature importances can be retrieved from models that are based on decision trees (e.g. random forests and boosting models, Breiman 2001, 2003). All algorithms selected in this work (RF, CatBoost, XGBoost, ET, GBR, and GBC) belong to these two classes. For each feature, the decrease in impurity (a term frequently used in the literature related to machine learning) of the dataset is calculated for all the nodes of the tree in which that feature is used. Features with the highest impurity decrease will be more important for the model (Louppe et al. 2013)9.
Insight into the decision-making of the pipeline can only rely on the specific weight of the original set of features (see Sect. 3.1). Table 16 presents the ranked combined importances from the observables selected in each of the three sequential models that compose the pipeline. They have been combined using the importances from the meta learner (as shown in Table 17) and that of base learners. The derived importances will be dependent on the dataset used, including any imputation for the missing data, and the details of the models (i.e. algorithms used and stacking procedure). We first notice in Table 16 that the order of the features is different for all three models. This difference reinforces the need, as stated in Sect. 3, of developing separate models for each of the prediction stages of this work that would evaluate the best feature weights for the related classification or regression task.
Relative importances (rescaled to add to 100) for observed features from the three models combined between meta and base models.
Relative feature importances (rescaled to add to 100) for base algorithms in each prediction step.
For the AGN-galaxy classification model, it is very interesting to note that the most important feature for the predicted probability of a source to be an AGN is the WISE colour W1–W2 (as well as W1–W3). This colour is indeed one of the axes of the widely used WISE colour-colour selection, with the second axis being the W2–W3 colour (cf. Sect 5.1.1). The WISE W3 photometry is though significantly less sensitive than W1, W2 or PS1 (see Fig. 3) and a significant number of sources will be represented as upper limits in such plot (see Table 2). From the importances in Table 16 and the values presented in Fig. 1 we infer that using optical colours could in principle create selection criteria with metrics equivalent to those shown in Table 15 but for a much larger number of sources (100 000 sources for colour plots using W3 vs. 4 700 000 sources for colours based in r, i or z magnitudes). We tested this hypothesis and derived a selection criterion in the g–r vs. W1–W2 colour-colour plot shown in Fig. 11 using the labelled sources in the test subset of the HETDEX field. The results of the application of this criterion to the testing data and to the labelled sources in S82 is presented in the last row of Table 15. Their limits are defined by the following expressions:
 (21)
(21)
 (22)
(22)
 (23)
(23)
 |
Fig. 11. AGN classification colour-colour plot in the HETDEX field using CW (W1, W2) and PS1 (g, r) passbands. Grey-scale density plot include all CW detected and non-imputed sources. Red contours highlight the density distribution of the AGNs in the Million QSO catalogue (MQC) and blue contours show the density distribution for the galaxies from SDSS DR16. Contours are located at 1, 2, and 3σ levels. |
where W1, W2, g, and r are Vega magnitudes. Our colour criteria provides better and more homogeneous scores across the different metrics with purity (precision) and completeness (recall) above 87%. Avoiding the use of the longer WISE wavelength (W3 and W4), the criteria can be applied to a much larger dataset.
One of the main potential uses of the pipeline is its capability to pinpoint radio-detectable AGNs. The global features analysis for the radio detection model shows a high dependence on the near- and mid-IR magnitudes and colours, especially those coming from WISE. As a useful outcome similar to the AGN-galaxy classification, we can use the most relevant features to build useful plots for the pre-selection of these sources and get insight into the origin of the radio emission. This is the case for the W4 histogram, shown in Fig. 12, where sources predicted to be radio-emitting AGNs extend to brighter measured W4 magnitudes. This added mid-IR flux might be simply due to an increased star formation rates (SFR) in these sources. In fact the 24 μm flux is often used, together with that of Hα as a proxy for SFR (Kennicutt et al. 2009). The radio detection for these sources might have a strong component linked to the ongoing SF, especially for the sources with real or predicted redshift below z ∼ 1.5. A detailed exploration of the implications that these dependencies might have in our understanding of the triggering of radio emission on AGNs, whether related to SF or jets, is left for a future publication (Carvajal et al., in prep.).
 |
Fig. 12. W4 magnitudes density distribution of the newly predicted radio AGNs (clean histograms) in HETDEX (ochre histograms) and S82 (blue histograms) and W4 magnitudes from predicted AGNs that are predicted to not have radio detection (dashed histograms). |
Finally, the redshift prediction model shows again that the final estimate is mostly driven by the results of the base learners, accounting for ∼82% of the predicting power. The overall combined importance of features shows also in this case a strong dependence on several near-IR colours of which y–W1 and W1–W2 are the most relevant ones. The model still relies, to a lesser extent, on a broad range of optical features needed to trace the broad range of redshift possibilities (z ∈ [0, 6]).
5.3.2. Local feature importances: Shapley values
As opposed to the global (mean) assessment of feature importances derived from the decrease in impurity, local (i.e. source by source) information on the performance of such features can be obtained from Shapley values. This is a method from coalitional game theory that tells us how to fairly distribute the dividends (the prediction in our case) among the features (Shapley 1953). The previous statement means that the relative influence of each property from the dataset can be derived for individual predictions in the decision made by the model (which is not the same as obtaining causal correlations between features and the target; Ma & Tourani 2020). The combination of Shapley values with several other model explanation methods was used by Lundberg & Lee (2017) to create the SHapley Additive exPlanations (SHAP) values. In this work, SHAP values were calculated using the python package SHAP10 and, in particular, its module for tree-based predictors (Lundberg et al. 2020). To speed calculations up, the package FastTreeSHAP11 (v0.1.2; Yang 2021) was also used, which allows the user to run multi-thread computations.
One way to display these SHAP values is through the so-called decision plots. They can show how individual predictions are driven by the inclusion of each feature. Besides determining the most relevant properties that help the model make a decision, it is possible to detect sources that follow different prediction paths which could be, eventually and upon further examination, labelled as outliers. An example of this decision plot, linked to the AGN-galaxy classification, is shown in Fig. 13 for a subsample of the high-redshift (z ≥ 4.0) spectroscopically classified AGNs in the HETDEX field (121 sources, regardless of them being part of any subset involved in the training or validation of the models). The different features used by the meta learner are stacked on the vertical axis with increasing weight and these final weight are summarised in Table 18. Similarly, SHAP decision plots for the radio detection and redshift prediction are presented in Figs. 14 and 15, respectively.
 |
Fig. 13. Decision plot from SHAP values for AGN-galaxy classification from the 121 high redshift (z ≥ 4) spectroscopically confirmed AGNs in HETDEX. Horizontal axis represents the model’s output with a starting value for each source centred on the selected naive threshold for classification. Vertical axis shows features used in the model sorted, from top to bottom, by decreasing mean absolute SHAP value. Each prediction is represented by a coloured line corresponding to its final predicted value as shown by the colourbar at the top. Moving from the bottom of the plot to the top, SHAP values for each feature are added to the previous value in order to highlight how each feature contributes to the overall prediction. Predictions for sources detected by LOFAR are highlighted with a dotted, dashed line. |
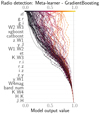 |
Fig. 14. Decision plot from the SHAP values for all features from the radio detection model in the 121 high redshift (z ≥ 4) spectroscopically confirmed AGNs from HETDEX. Description as in Fig. 13. |
 |
Fig. 15. Decision plot from the SHAP values for all features from the redshift prediction model in the 121 high redshift (z ≥ 4) spectroscopically confirmed AGNs from HETDEX. Description as in Fig. 13. |
SHAP values (rescaled to add to 100) for base algorithms in each prediction step for observed features using 121 spectroscopically confirmed AGNs at high redshift values (z > 4).
As it can be seen, for the three models, base learners are amongst the features with the highest influence. This result raises the question of what drives these individual base predictions. Appendix F includes SHAP decision plots for all base learners used in this work. Additionally, and to be able to compare these results with the features importances from Sect. 5.3.1, we constructed Table 19, which displays the combined SHAP values of base and meta learners but, in this case, for the same 121 high-redshift confirmed AGNs (with 29 of them detected by LoTSS). Table 19 shows, as Table 16, that the colour W1–W2 is the most important discriminator between AGNs and galaxies for this specific set of sources. The importance of the rest of the features is mixed: similar colours are located on the top spots (e.g. g–r, W1–W3 or r–i).
Combined and normalised (rescaled to add to 100) mean absolute SHAP values for observed features from the three models using 121 spectroscopically confirmed AGNs at high redshift values (z ≥ 4).
For the radio classification step of the pipeline, we find that features linked to those 121 high-z AGNs perform at the same level as for the overall population. The improved metrics with respect to those obtained from the no-skill selection do indicate that the model has learned some connections between the data and the radio emission. Feature importance has changed when compared to the overall population. If the radio emission observed from these sources were exclusively due to SF, this connection would imply SFR of several hundred M⊙ yr−1. This explanation can not be completely ruled out from the model side but some contribution of radio emission from the AGN is expected. The detailed analysis of the exact contribution for the SF and AGN component will be left for a forthcoming publication (Carvajal et al., in prep.).
6. Summary and conclusions
With the ultimate intention of better understanding the triggering of radio emission in AGNs, in this paper, we have shown that it is possible to build a pipeline to detect AGNs, determine their detectability in radio, within a given flux limit, and predict their redshift value. Most importantly, we have described a series of methodologies to understand the driving properties of the different decisions, in particular for the radio detection which is, to our best knowledge, the first attempt at doing so.
We have trained the models using multi-wavelength photometry from almost 120 000 spectroscopically identified infrared-detected sources in the HETDEX field and created stacked models with them. These models were applied, sequentially, to 15 018 144 infrared detections in the HETDEX Spring field, leading to the creation of 68 252 radio AGNs candidates with their corresponding predicted redshift values. Additionally, we applied the models to 3 568 478 infrared detections in the S82 field, obtaining 22 445 new radio AGNs candidates with their predicted redshift values.
We then applied a number of analyses to the models to understand the influence of the observed properties over the predictions and their confidence levels. In particular, the use of SHAP values gives the opportunity to extract the influence that the feature set has for each individual prediction. From the application of the prediction pipeline on labelled and unlabelled sources and the analysis of the predictions and the models themselves, the following conclusions can be drawn.
-
Generalised stacking is a useful procedure which collects results from individual ML algorithms into a single model that can outperform each of the individual models, while preventing the inclusion of biases from individual algorithms. Proper selection of models and input features, together with detailed probability and threshold calibration, maximises the metrics of the final model.
-
Classification between AGNs and galaxies derived from our model is in line with previous works. Our pipeline is able to retrieve a high fraction of previously classified AGNs from HETDEX (recall = 0.9621, precision = 0.9449) and from the S82 field (recall = 0.9401, precision = 0.9481).
-
Radio detection classification for predicted AGNs has proven to be highly demanding in terms of the data needed for creating the models. Thanks to the use of the techniques shown in this article (i.e. feature creation and selection, generalised stacking, probability calibration, and threshold optimisation), we were able to retrieve previously known radio-detectable AGNs in the HETDEX field (recall = 0.5216, precision = 0.3528) and in the S82 field (recall = 0.5816, precision = 0.1229). These rates improve significantly upon a purely random selection (4 times better for the HETDEX field and 13 times better for S82), showing the power of ML methods for obtaining new RG candidates.
-
The prediction of redshift values for sources classified as radio-detectable AGNs can deliver results that are in line with works that use either traditional or ML methods. The good quality of these predictions is achieved despite the fact of them being produced after two previous ML steps (the two classifications of the pipeline), which might introduce large uncertainties to their values.
-
Our models (classification and regression) can be applied to areas of the sky that have different radio coverage from that used for training without a strong degradation of the prediction results. This feature can lead to the use of our pipeline over very distinct datasets (in radio and multi-wavelength coverage) expecting to recover the sources predicted to be radio-detectable AGNs with a high probability.
-
Machine-learning models cannot be only used for a direct prediction of a value (or a set of values). They can also be subject to analyses that allow additional results to be extracted. We took advantage of this fact by using global and local feature importances to derive novel colour-colour AGN selection methods.
The next generation of observatories is already producing source catalogues with an order of magnitude better sensitivity over large areas of the sky than was previously the case. Some examples of these catalogues and surveys include the Rapid ASKAP Continuum Survey (RACS; McConnell et al. 2020), EMU (Norris et al. 2011), and the MeerKAT International GHz Tiered Extragalactic Exploration (MIGHTEE; Jarvis et al. 2016). With the increased number of radio detections, the need to understand the fraction of those detections related to AGNs and to determine counterparts across wavelengths is more necessary than ever.
Although we developed the pipeline as a tool to better understand the aforementioned issues, we foresee additional possibilities in which the pipeline can be of great use. The first possibility involves the use of the pipeline to assist with the selection of radio-detectable AGNs within any set of observations. This application might turn out to be particularly valuable in recent surveys carried out with MeerKAT (Jonas & MeerKAT Team 2016) or the future SKA where the population at the faintest sources will be dominated by star-forming galaxies. This change needs to use the corresponding data in the training set.
Future developments of the pipeline will concentrate on minimising the existent biases in the training sample as well as in increasing the coverage of the parameter space. We also plan to generalise the pipeline to make it useful for non-radio or galaxy-related research communities. These developments include, for instance, the capability to carry the full analysis for the galactic and stellar populations (i.e. models to determine if a galaxy can be detected in the radio and to predict redshift values for galaxies and non-radio AGNs).
In order to increase the parameter space of our training sets, we plan to include information from radio surveys with different properties in terms of covered area and multi-wavelength coverage. In particular, we aim to include far-IR, X-ray, and multi-survey radio measurements from larger areas. The inclusion of a larger, and possibly deeper, set of measurements makes part of our goal to improve detections, not only in radio, but in additional, wavelengths.
Depending on the dataset, a random selection of AGNs would lead to a rate of radio-detectable AGNs in the range 6 − 30%. We call this random choice a ‘no-skill’ selection.
For the purposes of the analyses, and except when clearly stated otherwise, photometric measurements are converted to AB magnitudes.
Beta transformation functions have the general form  , with S being the score from the classifier and a, b, c, free parameters to be optimised.
, with S being the score from the classifier and a, b, c, free parameters to be optimised.
A value of ρ = 0.75 is a compromise between stringent thresholds (e.g. ρ = 0.5) and more relaxed values (e.g. ρ ≈ 0.9). For an explanation on the selection of correlation values, see, for instance Ratner (2009).
Throughout this work, we call this a naive threshold.
Thresholds derived from the PR curves are labelled as PR.
For some models not based on decision trees, feature importances can be obtained from the coefficients delivered by the training process. These coefficients are related to the level to which each quantity is scaled to obtain a final prediction (as in the coefficients from a polynomial regression).
Acknowledgments
We thank the anonymous referee for their valuable comments and constructive suggestions which have greatly improved the manuscript. The authors would also like to thank insightful comments from P. Papaderos and B. Arsioli. This work was supported by Fundação para a Ciência e a Tecnologia (FCT) through research grants PTDC/FIS-AST/29245/2017, EXPL/FIS-AST/1085/2021, UID/FIS/04434/2019, UIDB/04434/2020, and UIDP/04434/2020. R.C. acknowledges support from the Fundação para a Ciência e a Tecnologia (FCT) through the Fellowship PD/BD/150455/2019 (PhD:SPACE Doctoral Network PD/00040/2012) and POCH/FSE (EC). I.M. acknowledges support from DL 57/2016 (P2461) from the ‘Departamento de Física, Faculdade de Ciências da Universidade de Lisboa’. A.H. acknowledges support from contract DL 57/2016/CP1364/CT0002 and an FCT-CAPES funded Transnational Cooperation project “Strategic Partnership in Astrophysics Portugal-Brazil”. P.A.C.C. acknowledges financial support by the Fundação para a Ciência e a Tecnologia (FCT) through the grant 2022.11477.BD. D.B. acknowledges support from the Fundação para a Ciência e a Tecnologia (FCT) through the Fellowship UI/BD/152315/2021. H.M. acknowledges support from the Fundação para a Ciência e a Tecnologia (FCT) through the PhD Fellowship 2022.12891.BD. A.P.A. acknowledges support from the Fundação para a Ciência e a Tecnologia (FCT) through the work Contract No. 2020.03946.CEECIND. C.P. acknowledges support from DL 57/2016 (P2460) from the ‘Departamento de Física, Faculdade de Ciências da Universidade de Lisboa’. This publication makes use of data products from the Wide-field Infrared Survey Explorer, which is a joint project of the University of California, Los Angeles, and the Jet Propulsion Laboratory/California Institute of Technology, funded by the National Aeronautics and Space Administration. LOFAR data products were provided by the LOFAR Surveys Key Science project (LSKSP, https://lofar-surveys.org/) and were derived from observations with the International LOFAR Telescope (ILT). LOFAR (van Haarlem et al. 2013) is the Low Frequency Array designed and constructed by ASTRON. It has observing, data processing, and data storage facilities in several countries, which are owned by various parties (each with their own funding sources), and which are collectively operated by the ILT foundation under a joint scientific policy. The efforts of the LSKSP have benefited from funding from the European Research Council, NOVA, NWO, CNRS-INSU, the SURF Co-operative, the UK Science and Technology Funding Council and the Jülich Supercomputing Centre. The Pan-STARRS1 Surveys (PS1) and the PS1 public science archive have been made possible through contributions by the Institute for Astronomy, the University of Hawaii, the Pan-STARRS Project Office, the Max-Planck Society and its participating institutes, the Max Planck Institute for Astronomy, Heidelberg and the Max Planck Institute for Extraterrestrial Physics, Garching, The Johns Hopkins University, Durham University, the University of Edinburgh, the Queen’s University Belfast, the Harvard-Smithsonian Center for Astrophysics, the Las Cumbres Observatory Global Telescope Network Incorporated, the National Central University of Taiwan, the Space Telescope Science Institute, the National Aeronautics and Space Administration under Grant No. NNX08AR22G issued through the Planetary Science Division of the NASA Science Mission Directorate, the National Science Foundation Grant No. AST-1238877, the University of Maryland, Eötvös Loránd University (ELTE), the Los Alamos National Laboratory, and the Gordon and Betty Moore Foundation. This publication makes use of data products from the Two Micron All Sky Survey, which is a joint project of the University of Massachusetts and the Infrared Processing and Analysis Center/California Institute of Technology, funded by the National Aeronautics and Space Administration and the National Science Foundation. This work made use of public data from the Sloan Digital Sky Survey, Data Release 16. Funding for the Sloan Digital Sky Survey IV has been provided by the Alfred P. Sloan Foundation, the U.S. Department of Energy Office of Science, and the Participating Institutions. SDSS-IV acknowledges support and resources from the Center for High Performance Computing at the University of Utah. The SDSS website is www.sdss.org. SDSS-IV is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS Collaboration including the Brazilian Participation Group, the Carnegie Institution for Science, Carnegie Mellon University, Center for Astrophysics | Harvard & Smithsonian, the Chilean Participation Group, the French Participation Group, Instituto de Astrofísica de Canarias, The Johns Hopkins University, Kavli Institute for the Physics and Mathematics of the Universe (IPMU)/University of Tokyo, the Korean Participation Group, Lawrence Berkeley National Laboratory, Leibniz Institut für Astrophysik Potsdam (AIP), Max-Planck-Institut für Astronomie (MPIA Heidelberg), Max-Planck-Institut für Astrophysik (MPA Garching), Max-Planck-Institut für Extraterrestrische Physik (MPE), National Astronomical Observatories of China, New Mexico State University, New York University, University of Notre Dame, Observatário Nacional/MCTI, The Ohio State University, Pennsylvania State University, Shanghai Astronomical Observatory, United Kingdom Participation Group, Universidad Nacional Autónoma de México, University of Arizona, University of Colorado Boulder, University of Oxford, University of Portsmouth, University of Utah, University of Virginia, University of Washington, University of Wisconsin, Vanderbilt University, and Yale University. This research has made use of NASA’s Astrophysics Data System, TOPCAT (http://www.star.bris.ac.uk/~mbt/topcat/; Taylor 2005), JupyterLab (https://www.jupyter.org; Kluyver et al. 2016, ‘Aladin sky atlas’ (v11.0.24; Bonnarel et al. 2000) developed at CDS, Strasbourg Observatory, France, and the VizieR catalogue access tool, CDS, Strasbourg, France (DOI: 10.26093/cds/vizier). The original description of the VizieR service was published in Ochsenbein et al. (2000). This work made extensive use of the Python packages PyCaret (v2.3.10, https://pycaret.org; Ali 2020), scikit-learn (v0.23.2; Pedregosa et al. 2011), pandas (v1.4.2, https://pandas.pydata.org; McKinney et al. 2010), Astropy (https://www.astropy.org), a community-developed core Python package for Astronomy (v5.0; Astropy Collaboration 2013, 2018, 2022), Matplotlib (v3.5.1; Hunter 2007), betacal (v1.1.0, https://betacal.github.io), and CMasher (v1.6.3, https://github.com/1313e/CMasher; van der Velden 2020).
References
- Afonso, J., Casanellas, J., Prandoni, I., et al. 2015, Advancing Astrophysics with the Square Kilometre Array (AASKA14), 71 [Google Scholar]
- Aguado, D. S., Ahumada, R., Almeida, A., et al. 2019, ApJS, 240, 23 [Google Scholar]
- Ahumada, R., Prieto, C. A., Almeida, A., et al. 2020, ApJS, 249, 3 [Google Scholar]
- Alatalo, K., Lacy, M., Lanz, L., et al. 2015, ApJ, 798, 31 [Google Scholar]
- Alegre, L., Sabater, J., Best, P., et al. 2022, MNRAS, 516, 4716 [NASA ADS] [CrossRef] [Google Scholar]
- Ali, M. 2020, PyCaret: An Open Source, Low-code Machine Learning Library in Python, pyCaret version 2.3 [Google Scholar]
- Allen, D. M. 1974, Technometrics, 16, 125 [CrossRef] [Google Scholar]
- Allison, P. 2001, Missing Data, Quantitative Applications in the Social Sciences (SAGE Publications) [Google Scholar]
- Amarantidis, S., Afonso, J., Messias, H., et al. 2019, MNRAS, 485, 2694 [Google Scholar]
- Ananna, T. T., Salvato, M., LaMassa, S., et al. 2017, ApJ, 850, 66 [Google Scholar]
- Anbajagane, D., Evrard, A. E., & Farahi, A. 2022, MNRAS, 509, 3441 [Google Scholar]
- Aniyan, A. K., & Thorat, K. 2017, ApJS, 230, 20 [Google Scholar]
- Annis, J., Soares-Santos, M., Strauss, M. A., et al. 2014, ApJ, 794, 120 [Google Scholar]
- Arnouts, S., Cristiani, S., Moscardini, L., et al. 1999, MNRAS, 310, 540 [Google Scholar]
- Arsioli, B., & Dedin, P. 2020, MNRAS, 498, 1750 [CrossRef] [Google Scholar]
- Assef, R. J., Stern, D., Noirot, G., et al. 2018, ApJS, 234, 23 [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Baldwin, J. A., Phillips, M. M., & Terlevich, R. 1981, PASP, 93, 5 [Google Scholar]
- Ball, N. M., & Brunner, R. J. 2010, Int. J. Mod. Phys. D, 19, 1049 [Google Scholar]
- Ball, N. M., Brunner, R. J., Myers, A. D., et al. 2008, ApJ, 683, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Banfield, J. K., Wong, O. I., Willett, K. W., et al. 2015, MNRAS, 453, 2326 [Google Scholar]
- Baron, D. 2019, ArXiv e-prints [arXiv:1904.07248] [Google Scholar]
- Barrows, R. S., Comerford, J. M., Stern, D., & Assef, R. J. 2021, ApJ, 922, 179 [NASA ADS] [CrossRef] [Google Scholar]
- Baum, W. A. 1957, AJ, 62, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Best, P. N., Kondapally, R., Williams, W. L., et al. 2023, MNRAS, 523, 1729 [NASA ADS] [CrossRef] [Google Scholar]
- Bianchi, S., Chiaberge, M., Laor, A., et al. 2022, MNRAS, 516, 5775 [NASA ADS] [CrossRef] [Google Scholar]
- Blecha, L., Snyder, G. F., Satyapal, S., & Ellison, S. L. 2018, MNRAS, 478, 3056 [Google Scholar]
- Bonaldi, A., Bonato, M., Galluzzi, V., et al. 2019, MNRAS, 482, 2 [Google Scholar]
- Bonaldi, A., An, T., Brüggen, M., et al. 2021, MNRAS, 500, 3821 [Google Scholar]
- Bonnarel, F., Fernique, P., Bienaymé, O., et al. 2000, A&AS, 143, 33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bosman, S. E. I. 2022, The Continuously Updated Webpage is Hosted, http://www.sarahbosman.co.uk/list_of_all_quasars [Google Scholar]
- Bouwens, R., González-López, J., Aravena, M., et al. 2020, ApJ, 902, 112 [NASA ADS] [CrossRef] [Google Scholar]
- Braun, R., Bonaldi, A., Bourke, T., Keane, E., & Wagg, J. 2019, ArXiv e-prints [arXiv:1912.12699] [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [Google Scholar]
- Breiman, L. 2003, Statistics Department University of California Berkeley (CA,USA) [Google Scholar]
- Brier, G. W. 1950, Mon. Weather Rev., 78, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Bröcker, J., & Smith, L. A. 2007, Weather Forecasting, 22, 651 [CrossRef] [Google Scholar]
- Brown, M. J. I., Duncan, K. J., Landt, H., et al. 2019, MNRAS, 489, 3351 [Google Scholar]
- Capetti, A., Brienza, M., Baldi, R. D., et al. 2020, A&A, 642, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carilli, C. L., Furlanetto, S., Briggs, F., et al. 2004, New Astron. Rev., 48, 1029 [CrossRef] [Google Scholar]
- Carvajal, R., Bauer, F. E., Bouwens, R. J., et al. 2020, A&A, 633, A160 [EDP Sciences] [Google Scholar]
- Carvajal, R., Matute, I., Afonso, J., et al. 2021, Galaxies, 9, 86 [NASA ADS] [CrossRef] [Google Scholar]
- Casalicchio, G., Molnar, C., & Bischl, B. 2019, in Machine Learning and Knowledge Discovery in Databases, eds. M. Berlingerio, F. Bonchi, T. Gärtner, N. Hurley, & G. Ifrim (Cham: Springer International Publishing), 655 [Google Scholar]
- Chambers, K. C., Magnier, E. A., Metcalfe, N., et al. 2016, ArXiv e-prints [arXiv:1612.05560] [Google Scholar]
- Chattopadhyay, A. K. 2017, Incomplete Data in Astrostatistics (American Cancer Society), 1 [Google Scholar]
- Chen, T., & Guestrin, C. 2016, Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16 (New York, NY, USA: ACM), 785 [CrossRef] [Google Scholar]
- Clarke, A. O., Scaife, A. M. M., Greenhalgh, R., & Griguta, V. 2020, A&A, 639, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Condon, J. J. 1992, ARA&A, 30, 575 [Google Scholar]
- Condon, J. J., Cotton, W. D., Greisen, E. W., et al. 1998, AJ, 115, 1693 [Google Scholar]
- Cover, T., & Hart, P. 1967, IEEE Trans. Inf. Theory, 13, 21 [CrossRef] [Google Scholar]
- Cramér, H. 1946, Mathematical Methods of Statistics (Princeton University Press), 575 [Google Scholar]
- Cranmer, M. 2023, ArXiv e-prints [arXiv:2305.01582] [Google Scholar]
- Cranmer, M., Sanchez-Gonzalez, A., Battaglia, P., et al. 2020, Adv. Neural Inf. Proc. Syst., 33, 17429 [Google Scholar]
- Cunha, P. A. C., & Humphrey, A. 2022, A&A, 666, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Curran, S. J. 2022, MNRAS, 512, 2099 [NASA ADS] [CrossRef] [Google Scholar]
- Curran, S. J., Moss, J. P., & Perrott, Y. C. 2022, MNRAS, 514, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Cutri, R. M., Skrutskie, M. F., van Dyk, S., et al. 2003a, in 2MASS All Sky Catalog of Point Sources [Google Scholar]
- Cutri, R. M., Skrutskie, M. F., van Dyk, S., et al. 2003b, VizieR Online Data Catalog: II/246 [Google Scholar]
- Cutri, R. M., Wright, E. L., Conrow, T., et al. 2013, Explanatory Supplement to the AllWISE Data Release Products [Google Scholar]
- Dahlen, T., Mobasher, B., Faber, S. M., et al. 2013, ApJ, 775, 93 [Google Scholar]
- Davies, L. J. M., Robotham, A. S. G., Driver, S. P., et al. 2018, MNRAS, 480, 768 [NASA ADS] [CrossRef] [Google Scholar]
- Delhaize, J., Heywood, I., Prescott, M., et al. 2021, MNRAS, 501, 3833 [Google Scholar]
- della Ceca, R., Lamorani, G., Maccacaro, T., et al. 1994, ApJ, 430, 533 [NASA ADS] [CrossRef] [Google Scholar]
- Desai, S., & Strachan, A. 2021, Sci. Rep., 11, 12761 [NASA ADS] [CrossRef] [Google Scholar]
- Dey, B., Andrews, B. H., Newman, J. A., et al. 2022, MNRAS, 515, 5285 [NASA ADS] [CrossRef] [Google Scholar]
- Dice, L. R. 1945, Ecology, 26, 297 [CrossRef] [Google Scholar]
- Dorogush, A. V., Ershov, V., & Gulin, A. 2018, ArXiv e-prints [arXiv:1810.11363] [Google Scholar]
- Driver, S. P., Hill, D. T., Kelvin, L. S., et al. 2011, MNRAS, 413, 971 [Google Scholar]
- Duboue, P. 2020, The Art of Feature Engineering: Essentials for Machine Learning (Cambridge University Press) [Google Scholar]
- Duncan, K. J., Sabater, J., Röttgering, H. J. A., et al. 2019, A&A, 622, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Humphrey, A., et al.) 2023a, A&A, 671, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Bisigello, L., et al.) 2023b, MNRAS, 520, 3529 [NASA ADS] [CrossRef] [Google Scholar]
- Fan, X., Bañados, E., & Simcoe, R. A. 2023, ARA&A, 61, 373 [NASA ADS] [CrossRef] [Google Scholar]
- Flesch, E. W. 2021, ArXiv e-prints [arXiv:2105.12985] [Google Scholar]
- Flewelling, H. A., Magnier, E. A., Chambers, K. C., et al. 2020, ApJS, 251, 7 [NASA ADS] [CrossRef] [Google Scholar]
- Friedman, J. H. 2001, Ann. Stat., 29, 1189 [Google Scholar]
- Friedman, J. H. 2002, Comput. Stat. Data Anal., 38, 367 [CrossRef] [Google Scholar]
- Geurts, P., Ernst, D., & Wehenkel, L. 2006, Mach. Learn., 63, 3 [Google Scholar]
- Gilda, S., Lower, S., & Narayanan, D. 2021, ApJ, 916, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Glahn, H. R., & Jorgensen, D. L. 1970, Mon. Weather Rev., 98, 136 [NASA ADS] [CrossRef] [Google Scholar]
- Gloudemans, A. J., Duncan, K. J., Röttgering, H. J. A., et al. 2021, A&A, 656, A137 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gloudemans, A. J., Duncan, K. J., Saxena, A., et al. 2022, A&A, 668, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goebel, R., Chander, A., Holzinger, K., et al. 2018, in International Cross-domain Conference for Machine Learning and Knowledge Extraction (Springer International Publishing), 295 [CrossRef] [Google Scholar]
- Gordon, Y. A., Boyce, M. M., O’Dea, C. P., et al. 2020, Res. Notes Am. Astron. Soc., 4, 175 [Google Scholar]
- Gürkan, G., Hardcastle, M. J., Best, P. N., et al. 2019, A&A, 622, A11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hardcastle, M. J., & Croston, J. H. 2020, New Astron. Rev., 88, 101539 [Google Scholar]
- Head, T., Kumar, M., Nahrstaedt, H., Louppe, G., & Shcherbatyi, I. 2021, https://doi.org/10.5281/zenodo.5565057 [Google Scholar]
- Heckman, T. M., & Best, P. N. 2014, ARA&A, 52, 589 [Google Scholar]
- Helfand, D. J., White, R. L., & Becker, R. H. 2015, ApJ, 801, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Helou, G., Soifer, B. T., & Rowan-Robinson, M. 1985, ApJ, 298, L7 [Google Scholar]
- Hernán-Caballero, A., Varela, J., López-Sanjuan, C., et al. 2021, A&A, 654, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hickox, R. C., & Alexander, D. M. 2018, ARA&A, 56, 625 [Google Scholar]
- Hildebrandt, H., Arnouts, S., Capak, P., et al. 2010, A&A, 523, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hill, G. J., Gebhardt, K., Komatsu, E., et al. 2008, ASP Conf. ser., 399, 115 [Google Scholar]
- Hoaglin, D., Mosteller, F., Tukey, J., et al. 1983, Understanding Robust and Exploratory Data Analysis, Wiley Series in Probability and Statistics: Probability and Statistics Section Series (John Wiley& Sons) [Google Scholar]
- Hodge, J. A., Becker, R. H., White, R. L., Richards, G. T., & Zeimann, G. R. 2011, AJ, 142, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Hopkins, A. M., Whiting, M. T., Seymour, N., et al. 2015, PASA, 32, e037 [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Ilbert, O., Arnouts, S., McCracken, H. J., et al. 2006, A&A, 457, 841 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ilbert, O., Capak, P., Salvato, M., et al. 2009, ApJ, 690, 1236 [NASA ADS] [CrossRef] [Google Scholar]
- Ilyas, I. F., & Rekatsinas, T. J. 2022, J. Data Inf. Qual., 14, 13 [Google Scholar]
- Inayoshi, K., Visbal, E., & Haiman, Z. 2020, ARA&A, 58, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Jarrett, T. H., Cluver, M. E., Magoulas, C., et al. 2017, ApJ, 836, 182 [Google Scholar]
- Jarvis, M., Taylor, R., Agudo, I., et al. 2016, in MeerKAT Science: On the Pathway to the SKA, 6 [Google Scholar]
- Jarvis, M. E., Harrison, C. M., Mainieri, V., et al. 2021, MNRAS, 503, 1780 [NASA ADS] [CrossRef] [Google Scholar]
- Jensen, H., Datta, K. K., Mellema, G., et al. 2013, MNRAS, 435, 460 [CrossRef] [Google Scholar]
- Jiang, L., Fan, X., Ivezić, Ž., et al. 2007, ApJ, 656, 680 [Google Scholar]
- Jiang, L., Fan, X., Bian, F., et al. 2014, ApJS, 213, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Johnson, N., & Leone, F. 1964, Statistics and Experimental Design in Engineering and the Physical Sciences, 2, 125 [Google Scholar]
- Jonas, J., & MeerKAT Team 2016, in MeerKAT Science: On the Pathway to the SKA, 1 [Google Scholar]
- Ke, G., Meng, Q., Finley, T., et al. 2017, in Advances in Neural Information Processing Systems, eds. I. Guyon, U. V. Luxburg, S. Bengio, et al. (Curran Associates, Inc.), 30 [Google Scholar]
- Kennicutt, R. C., Jr, Hao, C.-N., Calzetti, D., et al. 2009, ApJ, 703, 1672 [NASA ADS] [CrossRef] [Google Scholar]
- Kim, S. J., Lee, H. M., Matsuhara, H., et al. 2012, A&A, 548, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kluyver, T., Ragan-Kelley, B., Pérez, F., et al. 2016, in Positioning and Powerin Academic Publishing: Players, Agents and Agendas, eds. F. Loizides, & B. Schmidt (IOS Press), 87 [Google Scholar]
- Kull, M., Filho, T. M. S., & Flach, P. 2017a, Electron. J Stat., 11, 5052 [CrossRef] [Google Scholar]
- Kull, M., Filho, T. S., & Flach, P. 2017b, Proc. Mach. Learn. Res., 54, 623 [Google Scholar]
- Lee, H. M., Kim, S. J., Im, M., et al. 2009, PASJ, 61, 375 [NASA ADS] [Google Scholar]
- Lehmer, B. D., Brandt, W. N., Alexander, D. M., et al. 2005, ApJS, 161, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Lichtenstein, S., Fischhoff, B., & Phillips, L. D. 1982, in Calibration of probabilities: The state of the art to 1980, eds. D. Kahneman, P. Slovic, & A. Tversky (Cambridge University Press), 306 [Google Scholar]
- Lima, E. V. R., Sodré, L., Bom, C. R., et al. 2022, Astron. Comput., 38, 100510 [NASA ADS] [CrossRef] [Google Scholar]
- Liske, J., Baldry, I. K., Driver, S. P., et al. 2015, MNRAS, 452, 2087 [Google Scholar]
- Louppe, G., Wehenkel, L., Sutera, A., & Geurts, P. 2013, in Advances in Neural Information Processing Systems, eds. C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, & K. Q. Weinberger (Curran Associates, Inc.), 26 [Google Scholar]
- Luken, K. J., Norris, R. P., & Park, L. A. F. 2019, PASP, 131, 108003 [NASA ADS] [CrossRef] [Google Scholar]
- Luken, K., Norris, R., Park, L., Wang, X., & Filipović, M. 2022, Astron. Comput., 39, 100557 [NASA ADS] [CrossRef] [Google Scholar]
- Lundberg, S. M., & Lee, S.-I. 2017, in Advances in Neural Information Processing Systems, eds. I. Guyon, U. V. Luxburg, S. Bengio, et al. (Curran Associates, Inc.), 4765 [Google Scholar]
- Lundberg, S. M., Erion, G., Chen, H., et al. 2020, Nat. Mach. Intell., 2, 2522 [Google Scholar]
- Lyke, B. W., Higley, A. N., McLane, J. N., et al. 2020, ApJS, 250, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Ma, S., & Tourani, R. 2020, in Proceedings of the 2020 KDD Workshop on Causal Discovery (PMLR), 127, 23 [Google Scholar]
- Macfarlane, C., Best, P. N., Sabater, J., et al. 2021, MNRAS, 506, 5888 [NASA ADS] [CrossRef] [Google Scholar]
- Machado Poletti Valle, L. F., Avestruz, C., Barnes, D. J., et al. 2021, MNRAS, 507, 1468 [CrossRef] [Google Scholar]
- Magliocchetti, M. 2022, A&ARv, 30, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Mainzer, A., Bauer, J., Grav, T., et al. 2011, ApJ, 731, 53 [Google Scholar]
- Mainzer, A., Bauer, J., Cutri, R. M., et al. 2014, ApJ, 792, 30 [Google Scholar]
- Marocco, F., Eisenhardt, P. R. M., Fowler, J. W., et al. 2021, ApJS, 253, 8 [Google Scholar]
- Mateos, S., Alonso-Herrero, A., Carrera, F. J., et al. 2012, MNRAS, 426, 3271 [Google Scholar]
- Matthews, B. 1975, Biochimica et Biophysica Acta (BBA) - Protein Structure, 405, 442 [CrossRef] [Google Scholar]
- McConnell, D., Hale, C. L., Lenc, E., et al. 2020, PASA, 37, e048 [Google Scholar]
- McGreer, I. D., Becker, R. H., Helfand, D. J., & White, R. L. 2006, ApJ, 652, 157 [Google Scholar]
- McKinney, W. 2010, in Proceedings of the 9th Python in Science Conference, eds. S. van der Walt, & J. Millman, 56 [Google Scholar]
- Miley, G., & De Breuck, C. 2008, A&ARv, 15, 67 [Google Scholar]
- Mingo, B., Watson, M. G., Rosen, S. R., et al. 2016, MNRAS, 462, 2631 [NASA ADS] [CrossRef] [Google Scholar]
- Norris, R. P., Hopkins, A. M., Afonso, J., et al. 2011, PASA, 28, 215 [Google Scholar]
- Norris, R. P., Salvato, M., Longo, G., et al. 2019, PASP, 131, 108004 [Google Scholar]
- Ochsenbein, F., Bauer, P., & Marcout, J. 2000, A&AS, 143, 23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Oliver, S., Rowan-Robinson, M., Alexander, D. M., et al. 2000, MNRAS, 316, 749 [Google Scholar]
- Pacifici, C., Iyer, K. G., Mobasher, B., et al. 2023, ApJ, 944, 141 [NASA ADS] [CrossRef] [Google Scholar]
- Padovani, P. 1993, MNRAS, 263, 461 [NASA ADS] [Google Scholar]
- Padovani, P., Alexander, D. M., Assef, R. J., et al. 2017, A&ARv, 25, 2 [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Pensabene, A., Carniani, S., Perna, M., et al. 2020, A&A, 637, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pierce, J. C. S., Tadhunter, C. N., Gordon, Y., et al. 2022, MNRAS, 510, 1163 [Google Scholar]
- Poisot, T. 2023, Methods Ecol. Evol., 14, 1333 [NASA ADS] [CrossRef] [Google Scholar]
- Poliszczuk, A., Pollo, A., Małek, K., et al. 2021, A&A, 651, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pouliasis, E. 2020, Ph.D. Thesis, IAASARS, National Observatory of Athens, Greece [Google Scholar]
- Prandoni, I., & Seymour, N. 2015, Advancing Astrophysics with the Square Kilometre Array (AASKA14), 67 [Google Scholar]
- Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. 2018, in Advances in Neural Information Processing Systems, eds. S. Bengio, H. Wallach, H. Larochelle, et al. (Curran Associates, Inc.), 31 [Google Scholar]
- Rasmussen, C., & Williams, C. 2006, Gaussian Processes for Machine Learning, Adaptative Computation and Machine Learning Series (University Press Group Limited), 31 [Google Scholar]
- Ratner, B. 2009, J. Target Meas. Anal. Market., 17, 139 [CrossRef] [Google Scholar]
- Reis, I., Baron, D., & Shahaf, S. 2019, AJ, 157, 16 [Google Scholar]
- Roscher, R., Bohn, B., Duarte, M. F., & Garcke, J. 2020, IEEE Access, 8, 42200 [NASA ADS] [CrossRef] [Google Scholar]
- Ross, N. P., & Cross, N. J. G. 2020, MNRAS, 494, 789 [NASA ADS] [CrossRef] [Google Scholar]
- Saarela, M., & Jauhiainen, S. 2021, SN Appl. Sci., 3, 272 [CrossRef] [Google Scholar]
- Salvato, M., Ilbert, O., & Hoyle, B. 2019, Nat. Astron., 3, 212 [NASA ADS] [CrossRef] [Google Scholar]
- Samuel, A. L. 1959, IBM J. Res. Dev., 3, 210 [CrossRef] [Google Scholar]
- Sánchez-Sáez, P., Reyes, I., Valenzuela, C., et al. 2021, AJ, 161, 141 [CrossRef] [Google Scholar]
- Scoville, N., Aussel, H., Brusa, M., et al. 2007, ApJS, 172, 1 [Google Scholar]
- Shapley, L. S. 1953, A Value for n-Person Games (Princeton University Press), 1, 307 [Google Scholar]
- Shimwell, T. W., Tasse, C., Hardcastle, M. J., et al. 2019, A&A, 622, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shobhana, D., Norris, R. P., Filipović, M. D., et al. 2023, MNRAS, 519, 4902 [NASA ADS] [CrossRef] [Google Scholar]
- Shy, S., Tak, H., Feigelson, E. D., Timlin, J. D., & Babu, G. J. 2022, AJ, 164, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Silva Filho, T., Song, H., Perello-Nieto, M., et al. 2023, Mach. Learn., 112, 3211 [CrossRef] [Google Scholar]
- Singh, D., & Singh, B. 2020, Appl. Soft Comput., 97, 105524 [CrossRef] [Google Scholar]
- Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, 131, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Sørenson, T. 1948, A Method of Establishing Groups of Equal Amplitude in Plant Sociology Based on Similarity of Species Content, Biologiske skrifter (I kommission hos E. Munksgaard) [Google Scholar]
- Stern, D., Assef, R. J., Benford, D. J., et al. 2012, ApJ, 753, 30 [Google Scholar]
- Stone, M. 1974, J. R. Stat. Soc. Ser. B (Method.), 36, 111 [Google Scholar]
- Storchi-Bergmann, T., & Schnorr-Müller, A. 2019, Nat. Astron., 3, 48 [Google Scholar]
- Taylor, M. B. 2005, ASP Conf. Ser., 347, 29 [Google Scholar]
- Thomas, N., Davé, R., Jarvis, M. J., & Anglés-Alcázar, D. 2021, MNRAS, 503, 3492 [NASA ADS] [CrossRef] [Google Scholar]
- Thorne, J. E., Robotham, A. S. G., Davies, L. J. M., et al. 2022, MNRAS, 509, 4940 [Google Scholar]
- Van Calster, B., McLernon, D. J., van Smeden, M., et al. 2019, BMC Med., 17, 230 [CrossRef] [Google Scholar]
- van der Velden, E. 2020, J. Open Source Softw., 5, 2004 [Google Scholar]
- van Haarlem, M. P., Wise, M. W., Gunst, A. W., et al. 2013, A&A, 556, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van Rijsbergen, C. J. 1979, Information Retrieval, 2nd edn. (USA: Butterworth-Heinemann) [Google Scholar]
- Vanschoren, J. 2019, in Meta-Learning, eds. F. Hutter, L. Kotthoff, & J. Vanschoren (Cham: Springer International Publishing) [Google Scholar]
- Villaescusa-Navarro, F., Anglés-Alcázar, D., Genel, S., et al. 2021, ApJ, 915, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Villar-Martín, M., Emonts, B., Cabrera Lavers, A., et al. 2017, MNRAS, 472, 4659 [Google Scholar]
- Walcher, J., Groves, B., Budavári, T., & Dale, D. 2011, Ap&SS, 331, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Werner, M. W., Roellig, T. L., Low, F. J., et al. 2004, ApJS, 154, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Williams, W. L., Calistro Rivera, G., Best, P. N., et al. 2018, MNRAS, 475, 3429 [NASA ADS] [CrossRef] [Google Scholar]
- Wolpert, D. H. 1992, Neural Networks, 5, 241 [CrossRef] [Google Scholar]
- Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868 [Google Scholar]
- Wu, C., Wong, O. I., Rudnick, L., et al. 2019, MNRAS, 482, 1211 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, J. 2021, ArXiv e-prints [arXiv:2109.09847] [Google Scholar]
- Yeo, I., & Johnson, R. A. 2000, Biometrika, 87, 954 [CrossRef] [Google Scholar]
- Yerushalmy, J. 1947, Public Health Reports (1896–1970), 62, 1432 [CrossRef] [Google Scholar]
- York, D. G., Adelman, J., Anderson, J. E., et al. 2000, AJ, 120, 1579 [Google Scholar]
- Yule, G. U. 1912, J. R. Stat. Soc., 75, 579 [CrossRef] [Google Scholar]
- Zheng, A., & Casari, A. 2018, Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists (O’Reilly) [Google Scholar]
- Zitlau, R., Hoyle, B., Paech, K., et al. 2016, MNRAS, 460, 3152 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Column names in this study
Table A.1 presents the names (and what they represent) of the features, used in throughout this work. This information can be read in combination with the columns presented in Appendix G.
Names of columns or features used in the code and what they represent.
Appendix B: Non-imputed magnitudes
The number of valid measurements in Fig. 1 for each field and band can be used to determine the relative difference of density of sources between both fields. This density can be obtained by dividing the number of valid measurements over the effective area of each field (Sect. 2). Table B.1 shows these densities.
Density of detected sources (in units of sources per square degree) per band and field.
Appendix C: From scores to probabilities
In general, classifiers deliver scores in the range [0, 1], which could be associated to the probability of a studied source being part of the relevant class (in our work, AGN or radio detectable). The classifier uses a threshold above which, any predicted element would be considered a positive instance.
With the exception of few algorithms (including the family of logistic regressions), scores from classifiers cannot be directly used as probabilities. As a consequence of this inability, such values cannot be compared from one type of model to some other and can not be combined to obtain a joint score. Therefore, in order to retrieve joint scores and treat them as probabilities, scores (and, by extension, the classifiers) need to be calibrated. This calibration means that, when taking all predictions with a probability P of being of a class, a fraction P of them really belong to that class (e.g. Lichtenstein et al. 1982; Silva Filho et al. 2023).
Calibration of these scores can be done by applying a transformation to their values. For our work, we will apply a Beta transformation. It allows one to re-distribute the scores of a classifier allowing them to get closer to the definition of probability (Kull et al. 2017a,b). Calibration steps in our workflow have been applied using the Python package betacal. In the case of the radio detection model, the new scores have a wider range than the original, uncalibrated scores.
When obtaining the BSS values for both classification, the AGN-galaxy classifier has a score of BSS = −0.002, demonstrating that no major changes were applied to the distribution of scores. For the radio detection classifier, the score is BSS = −0.434. Even though the BSS value is slightly negative for the AGN-galaxy classifier, we keep it since its range of values now can be compared and combined with additional probabilities. In the case of the radio detection classifier, the BSS shows a degradation of the calibration, but we will keep the calibrated model given that it provides, overall, better values for the remaining metrics. This effect can be seen, more strongly, with recall.
Calibration (or reliability) plots show how well calibrated the predicted scores of a classifier are by displaying the fraction of sources that are part of a given class as a function of the predicted probability. A perfectly calibrated classifier would have all its prediction lying in the x = y line. The magnitude of the deviations from that line give information of the miscalibration a model has (see, for instance, Bröcker & Smith 2007; Van Calster et al. 2019). In Fig. C.1, we present the reliability curves for the uncalibrated classifiers and, in Fig. C.2, for their calibrated versions.
 |
Fig. C.1. Reliability curves for uncalibrated classifiers. Each line represents the calibration curve for each subset in HETDEX field. Data has been binned and each bin (represented by the points) has the same number of elements per curve. Dashed line represents a perfectly calibrated model. (a) AGN-galaxy classification model. (b) Radio detection model. |
 |
Fig. C.2. Reliability curves for calibrated classifiers. (a) AGN-galaxy classification model. (b) Radio detection model. Details as in Fig. C.1. |
Appendix D: Meta learners hyperparameters
In Table D.1, we present the optimised hyperparameters from our meta learners. For all three instances of modelling (AGN-galaxy, radio detection, and redshift), hyperparameters were optimised using the SkoptSearch algorithm embedded in the package tune-sklearn12 (v0.4.1; Head et al. 2021), which implements a Bayesian search in the hyperparameter space.
Values of Hyperparameters for meta learners after tuning.
Appendix E: PR curve threshold optimisation
By maximising the recall (Eq. 4), we improve the number of recovered elements in each classifier. This can be done by decreasing the threshold by which a source is classified as a positive instances. Setting this threshold to its minimum, 0.0, would increase the recall. But every source would be predicted to be an AGN or detected on the radio regardless of their properties.
One statistical tool designed to optimise the classification threshold taking into account the overall model performance is the PR curve. It can help to understand the behaviour of a classifier as a function of its threshold. Both quantities, precision (Eq. 5) and recall, show an inverse correlation, and both depend on the selected threshold. Thus, they can be used to retrieve the score value for which both quantities are balanced. This optimisation is done by finding the threshold that maximises the Fβ score (Eq. 2). This operation is performed over the union of training and validation sets, which have been used to create and train each model. PR curves for all subsets used in our classification models are shown in Fig. E.1.
 |
Fig. E.1. Precision-recall curves for the (a) AGN-galaxy and (b) radio detection classification models. |
Appendix F: SHAP values for base models
Figures F.1, F.3, and F.2 show the decision plots for each base learners used in the prediction models of our pipeline (Sect. 5.3.2). For the classification algorithms, the starting point of their predictions corresponds to the naive threshold (0.5) since no threshold optimisation was applied to them and only the scores are included in the stacking step, not the final probabilities. In the case of the redshift predictors, decision plots start at the value z = 0, as presented for the meta learner.
 |
Fig. F.1. SHAP decision plots for base AGN-galaxy algorithms. Details as described in Figs. 13. Starting point of predictions is the naive classification threshold. From left to right and from top to bottom, each panel shows the results from XGBoost, RF, ET, and GBC. |
 |
Fig. F.2. SHAP decision plots from base radio algorithms. Details as Figs. 13 and F.1. Each panel with results for XGBoost, CatBoost, RF, and ET. |
 |
Fig. F.3. SHAP decision plots from base z algorithms. Details as in Fig 13. Each panel shows results for ET, CatBoost, XGBoost, and GBR. |
Appendix G: Prediction results for radio AGNs
The columns shown in the prediction results for sources in both HETDEX and S82 fields are described as follows.
-
ID: Internal identification number.
-
RA_ICRS: Right Ascension (in degrees) of source in CW.
-
DE_ICRS: Declination (in degrees) of source in CW.
-
Name: Name of the source as it appears in the CW catalogue.
-
band_num: Number of non-radio bands with a valid measurement per source (cf. Sect. 2.2).
-
class: 1 if a source is a confirmed AGN by the MQC. 0 if it has been spectroscopically confirmed as a galaxy in SDSS DR16. Sources with no value do not have a spectroscopic classification in this catalogue.
-
Sint_LOFAR (or Fint_VLAS82): Imputed integrated flux (in mJy) of source from LOFAR or VLAS82.
-
Sint_LOFAR_non_imp (or Fint_VLAS82_non_imp): Non-imputed integrated flux (in mJy) of source from LOFAR or VLAS82.
-
W1mproPM: Imputed W1 magnitude of source.
-
W2mproPM: Imputed W2 magnitude of source.
-
gmag: Imputed g magnitude of source.
-
rmag: Imputed r magnitude of source.
-
imag: Imputed i magnitude of source.
-
zmag: Imputed z magnitude of source.
-
ymag: Imputed y magnitude of source.
-
W3mag: Imputed W3 magnitude of source.
-
W4mag: Imputed W4 magnitude of source.
-
Jmag: Imputed J magnitude of source.
-
Hmag: Imputed H magnitude of source.
-
Kmag: Imputed Ks magnitude of source.
-
Score_AGN: Score from the meta AGN-galaxy classifier for a prediction to be an AGN.
-
Prob_AGN: Probability from the calibrated meta AGN-galaxy classifier for a prediction to be an AGN.
-
LOFAR_detect: 1 if a source has been detected on the LoTSS survey or in their analogue surveys for fields different to HETDEX (see Sect. 2.1). 0 otherwise.
-
Score_radio_AGN: Score from the meta radio detection model for a prediction to be detected in the radio.
-
Prob_radio_AGN: Probability, from the calibrated radio detection model for a prediction to be detected in the radio.
-
radio_AGN: class × LOFAR_detect. 1 if a source is an AGN and has been detected in the radio. 0 otherwise.
-
Score_rAGN: Score_AGN × Score_radio. Score of a source for it to be an AGN detected in the radio.
-
Prob_rAGN: Prob_AGN × Prob_radio. Probability of a source for it to be an AGN detected in the radio.
-
Z: Spectroscopic redshift as listed by the MQC (if available).
-
pred_Z: Redshift value predicted by our model.
All Tables
Composition of initial catalogue and number of cross matches with additional surveys and catalogues.
Results of application of radio AGN prediction pipeline to the labelled sources in the HETDEX and S82 fields.
Predicted and original properties for the 5 sources in testing subset with the highest redshift predicted radio AGNs.
Predicted and original properties for the 5 sources in S82 with the highest predicted redshift on the labelled sources predicted to be radio AGNs.
Predicted and original properties for the 5 sources in the HETDEX field with the highest predicted redshift on the unlabelled sources predicted to be radio AGNs.
Predicted and original properties for the 5 sources in S82 with the highest predicted redshift on the unlabelled sources predicted to be radio AGNs.
Results of no-skill selection of sources in different stages of pipeline to the labelled sources in the HETDEX test subset and S82 fields.
Results of application of several AGN detection criteria to our testing subset and the labelled sources from the S82 field.
Relative importances (rescaled to add to 100) for observed features from the three models combined between meta and base models.
Relative feature importances (rescaled to add to 100) for base algorithms in each prediction step.
SHAP values (rescaled to add to 100) for base algorithms in each prediction step for observed features using 121 spectroscopically confirmed AGNs at high redshift values (z > 4).
Combined and normalised (rescaled to add to 100) mean absolute SHAP values for observed features from the three models using 121 spectroscopically confirmed AGNs at high redshift values (z ≥ 4).
Density of detected sources (in units of sources per square degree) per band and field.
All Figures
|
Fig. 1. Histograms of base collected, non-imputed, non-radio bands for HETDEX (clean, background histograms) and S82 (empty, brown histograms). Each panel shows the distribution of measured magnitudes of detected sources divided by the total area of the field. Dashed, vertical lines represent the 5-σ magnitude limit for each band. The number in the upper right corner of each panel shows the number of measured magnitudes included in their corresponding histogram. |
| In the text | |
|
Fig. 2. Histograms of base collected non-radio bands for HETDEX (clean, background histograms) and S82 (empty, brown histograms) fields. Description as in Fig. 1. The number in the upper right corner of each panel shows number of sources with magnitudes originally measured above the 5-σ limit included in their corresponding histogram for each field (i.e. sources that have not been imputed or replaced). |
| In the text | |
|
Fig. 3. Flux and magnitude depths (5-σ) from the surveys and bands used in this work. Limiting magnitudes and fluxes were obtained from the description of the surveys, as referenced in Sect. 2.1. In purple, rest-frame SED from Mrk231 (z = 0.0422; Brown et al. 2019) is displayed as an example AGN. Redshifted (from z = 0.001 to z = 7) versions of this SED are shown in dashed grey lines. |
| In the text | |
|
Fig. 4. Flowchart representing the prediction pipeline used to predict the presence of radio-detectable AGNs and their redshift values. At the beginning of each model step, the most relevant features are selected as described in Sect. 3.1. |
| In the text | |
|
Fig. 5. Composition of datasets used for the different steps of this work. (a) HETDEX field. (b) S82. |
| In the text | |
|
Fig. 6. Performance of individual models (AGN-galaxy classification, radio-detectability classification and redshift regression) when applied to the HETDEX test subset. (a) Confusion matrix for AGN-galaxy classification. (b) Same as (a), but for radio detection. (c) Density plot comparison between original and the predicted redshifts. Grey, dashed line shows the 1:1 relation while dot-dashed lines show the limits for outliers (cf. Eq. (18)). Inset displays the distribution of #x0394;zN with a < #x0394;zN > = 0.0442. |
| In the text | |
|
Fig. 7. Combined confusion matrices and True/predicted redshift density plot for the full radio AGN detection prediction computed using the testing subset from HETDEX (panels a and b) and the known labelled sources from S82 (panels c and d). |
| In the text | |
|
Fig. 8. Redshift density distribution of the predicted radio AGNs within the unlabelled sources (clean histograms) in HETDEX (ochre histograms) and S82 (blue histograms) and true redshifts from labelled radio AGNs (dashed histograms). |
| In the text | |
|
Fig. 9. W1–W2, W2–W3 colour-colour diagrams for sources in the testing subset, from HETDEX, and labelled sources from S82 given their position in the AGN-galaxy confusion matrix (see, for HETDEX, rightmost panel of Fig. 7). In the background, density plot of all CW-detected sources in the full HETDEX field sample is displayed. Colour of each square represents the number of sources in that position of parameter space, with darker squares having more sources (as defined in the colourbar of the upper-right panel). Contours represent distribution of sources for each of the aforementioned subsets at 1, 2, 3, and 4σ levels (shades of blue, for testing set and shades of red for labelled S82 sources). Coloured, solid lines display limits from the criteria for the detection of AGNs described in Sect. 5.1.1. |
| In the text | |
|
Fig. 10. Evolution of predicted probabilities (top: probability to be AGN, middle: probability of AGNs to be detected in radio) and redshift values for radio-detectable AGNs (bottom panel) as a function of the number of observed bands for sources in test set. In top panel, sources have been divided between those predicted to be AGN and galaxy. In middle panel, sources are divided between predicted AGN that are predicted to be detected in radio and those predicted to not have radio detection. Background density plots (following colour coding in colourbars) show location of predicted values. Overlaid boxplots display main statistics for each number of measured bands. Black rectangles encompass sources in second and third quartiles. Vertical lines show the place of sources from first and fourth quartiles. Orange lines represent median value of sample and dashed, green lines indicate their mean values. Dashed, grey lines show PR thresholds for AGN-galaxy and radio detection classifications. Close to each boxplot, written values correspond to the number of sources considered to create each set of statistics. |
| In the text | |
|
Fig. 11. AGN classification colour-colour plot in the HETDEX field using CW (W1, W2) and PS1 (g, r) passbands. Grey-scale density plot include all CW detected and non-imputed sources. Red contours highlight the density distribution of the AGNs in the Million QSO catalogue (MQC) and blue contours show the density distribution for the galaxies from SDSS DR16. Contours are located at 1, 2, and 3σ levels. |
| In the text | |
|
Fig. 12. W4 magnitudes density distribution of the newly predicted radio AGNs (clean histograms) in HETDEX (ochre histograms) and S82 (blue histograms) and W4 magnitudes from predicted AGNs that are predicted to not have radio detection (dashed histograms). |
| In the text | |
|
Fig. 13. Decision plot from SHAP values for AGN-galaxy classification from the 121 high redshift (z ≥ 4) spectroscopically confirmed AGNs in HETDEX. Horizontal axis represents the model’s output with a starting value for each source centred on the selected naive threshold for classification. Vertical axis shows features used in the model sorted, from top to bottom, by decreasing mean absolute SHAP value. Each prediction is represented by a coloured line corresponding to its final predicted value as shown by the colourbar at the top. Moving from the bottom of the plot to the top, SHAP values for each feature are added to the previous value in order to highlight how each feature contributes to the overall prediction. Predictions for sources detected by LOFAR are highlighted with a dotted, dashed line. |
| In the text | |
|
Fig. 14. Decision plot from the SHAP values for all features from the radio detection model in the 121 high redshift (z ≥ 4) spectroscopically confirmed AGNs from HETDEX. Description as in Fig. 13. |
| In the text | |
|
Fig. 15. Decision plot from the SHAP values for all features from the redshift prediction model in the 121 high redshift (z ≥ 4) spectroscopically confirmed AGNs from HETDEX. Description as in Fig. 13. |
| In the text | |
|
Fig. C.1. Reliability curves for uncalibrated classifiers. Each line represents the calibration curve for each subset in HETDEX field. Data has been binned and each bin (represented by the points) has the same number of elements per curve. Dashed line represents a perfectly calibrated model. (a) AGN-galaxy classification model. (b) Radio detection model. |
| In the text | |
|
Fig. C.2. Reliability curves for calibrated classifiers. (a) AGN-galaxy classification model. (b) Radio detection model. Details as in Fig. C.1. |
| In the text | |
|
Fig. E.1. Precision-recall curves for the (a) AGN-galaxy and (b) radio detection classification models. |
| In the text | |
|
Fig. F.1. SHAP decision plots for base AGN-galaxy algorithms. Details as described in Figs. 13. Starting point of predictions is the naive classification threshold. From left to right and from top to bottom, each panel shows the results from XGBoost, RF, ET, and GBC. |
| In the text | |
|
Fig. F.2. SHAP decision plots from base radio algorithms. Details as Figs. 13 and F.1. Each panel with results for XGBoost, CatBoost, RF, and ET. |
| In the text | |
|
Fig. F.3. SHAP decision plots from base z algorithms. Details as in Fig 13. Each panel shows results for ET, CatBoost, XGBoost, and GBR. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.