| Issue |
A&A
Volume 676, August 2023
|
|
|---|---|---|
| Article Number | A142 | |
| Number of page(s) | 19 | |
| Section | Astronomical instrumentation | |
| DOI | https://doi.org/10.1051/0004-6361/202245099 | |
| Published online | 25 August 2023 | |
Studying X-ray instruments with galaxy clusters
1
Tartu Observatory, University of Tartu,
61602
Tõravere, Tartumaa, Estonia
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
INAF – IASF Milano,
via A. Corti 12,
20133
Milano, Italy
Received:
28
September
2022
Accepted:
5
May
2023
Abstract
Aims. Our aim is to apply a scientific approach to the problem of the effective area cross-calibration of the XMM-Newton EPIC instruments. Using a sample of galaxy clusters observed with XMM-Newton EPIC, we aim to quantify the effective area cross-calibration bias between the EPIC instruments as implemented in the public calibration database in November 2021 in the 0.5–6.1 keV energy band.
Methods. We tested two methods for evaluating the effective area cross-calibration bias for CCD-type X-ray instruments. Namely, we compared the evaluation of the cross-calibration bias by modelling it before the convolution of the spectral models with the redistribution matrix or by analysing the convolved products. We applied the methods to a sample of galaxy clusters observed with XMM-Newton/EPIC instruments. We invested significant efforts in controlling and keeping the systematic uncertainties of the cross-calibration bias below 1%. The statistical uncertainties are similar, and thus we can reliably measure effects at the 1% level.XMM.
Results. On average, the two methods differ very little; the only difference in the cross-calibration bias is at the highest energies, and by maximum of 3%. The effective area cross-calibration in the 0.5-6.1 keV band between MOS and pn is biased at a substantial level. The MOS/pn bias is systematic, suggesting that the MOS (pn) effective area may be calibrated too low (high), by ~3–27% on average depending on the instrument and energy band. The excellent agreement between the energy dependences (i.e. shapes) of the effective area of MOS2 and pn suggest that they are correctly calibrated, within in the 0.5–4.5 keV band. Comparison with an independent dataset of point sources (3XMM) confirms this. The cluster sample indicates that the MOS1/pn effective area shape cross-calibration has an approximately linear bias amounting to a maximum of ~10% in the 0.5–1.5 keV band.
Conclusions. The effective area cross-calibration of XMM-Newton/EPIC instruments in November 2021 in the 0.5–1.5 keV band was relatively successful. However, the cluster-to-cluster rms scatter of the bias is substantial compared to the median bias itself. Thus, a statistically robust implementation of the cross-calibration uncertainties to a scientific analysis of XMM-Newton/EPIC data should include the propagation of the scatter to the best-fit parameters, instead of a simple average bias correction of the effective area.
Key words: instrumentation: detectors / galaxies: clusters: intracluster medium / techniques: spectroscopic / X-rays: galaxies: clusters
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
In astronomical research, instruments are used to investigate astronomical objects. In the case of instrument calibration, we do the opposite: we use astronomical objects to investigate the instruments. In this work we use clusters of galaxies to investigate the effective area cross-calibration bias between the XMM-Newton/EPIC instruments.
Nearby clusters of galaxies are useful for X-ray calibration since they provide high numbers of counts with relatively short exposures with modern X-ray telescopes (e.g. Nevalainen et al. 2010, Kettula et al. 2013, Schellenberger et al. 2015). This enables a high statistical accuracy of the data, which in turn translates into a similarly high accuracy for the calibration results. Focusing on hotter clusters in particular is preferable, since they provide more counts towards the high energy end (~ 10 keV) of the typical CCD-type X-ray detectors, for example XMM-Newton/EPIC and Chandra/ACIS. Also, the line emission at ~1 keV energies is reduced when the hotter clusters are focused on, and thus the complications arising from the calibration accuracy of the energy redistribution are smaller. The number of hot nearby clusters is substantial, which enables large samples; this is necessary when attempting a statistically meaningful analysis.
Galaxy clusters are also useful for cross-calibration work because they are stable on human timescales. Thus, if one desires to compare the effective area cross-calibration between instruments of different missions, one can use observations performed at different epochs. This is different from the case of variable sources often used for cross-mission calibration. Obtaining a simultaneous cross-mission dataset of a single variable target is a huge effort, and consequently the samples are typically too small for robust statistical analyses of a given instrument pair (e.g. Madsen et al. 2017).
However, the extended nature of the galaxy clusters causes systematic uncertainties not present in the case of point sources. Our aim in this work is to control the systematics and limit their effect to below 1% of the cross-calibration bias. We aim to minimise each of the systematic uncertainty components by careful selecting the clusters, observations, spectrum extraction regions, and waveband.
2 The methods
We investigated two methods for evaluating the cross-calibration bias between the pn and MOS instruments on board XMM-Newton. Method 1 (post-convolution), used in several works (e.g. Kettula et al. 2013, Schellenberger et al. 2015, and Read et al. 2014), operates on the data that are obtained after convolution of the spectral models with the energy redistribution matrixes. We also examined Method 2 (pre-convolution) whereby the cross-calibration bias is modelled before the convolution (e.g. Smith et al. 20211). The latter method is more complex in the sense that the modelling of the reference instrument data has to be very accurate in order to maintain the pre-convolution aspect of the method. Otherwise, the inaccuracies of the modelling of the reference instrument data are applied outside the convolution, which is the problem we want to avoid with Method 2.
2.1 Method 1: Post-convolution
Our focus is the total effective area (i.e. essentially the product of the mirror effective area, the filter transmission, and the CCD quantum efficiency) in the 0.5–6.0 keV band. We chose EPIC-pn as a reference instrument, whose spectra we fit with absorbed thermal emission models (see Sect. 4.3 for the description of the required spectral analysis) obtaining the reference model (modelref,1). We use modelref,1 to form a prediction for the test instrument (MOS1 or MOS2) by multiplying it with the effective area function (arftest) of the test instrument and convolving the product with the energy redistribution matrix rmftest of the test instrument (see Eq. (1)). The parameter R1 (see Eq. (1)) compares the above prediction with the count rate data (datatest) (see Sect. 4.2 for the detailed description of the data reduction) in each spectral bin obtained with the test instrument, according to
 (1)
(1)
If the reference model was an accurate description of the data obtained with the reference instrument (dataref), a significant deviation of R1 (Eq. (1)) from the unity would indicate significant cross-calibration problems between the reference and test instruments. However, in the presence of calibration problems, it is difficult to obtain an acceptable match between the data and a physical model using the reference instrument in the first place. On the other hand, the accurate physical modelling is not necessary since we are interested in the relative accuracy between different instruments. Any numerical model that accurately describes the data of the reference instrument would suffice. We attempt to produce such a model by correcting the reference model (modelref,1 ) in Eq. (1) by dividing it by the residuals of the reference instrument (R2), according to
 (2)
(2)
Thus, the ratio R1/R2 yields the effective area cross-calibration bias parameter J1, that is,
 (3)
(3)
which is the focus of this work.
A limitation with correcting the reference model with the residuals as described in Eq. (3) is that it is done after the reference model is convolved with the test instrument response. By doing so effective area and redistribution issues are mixed with one another and the above approach provides only an approximate correction. We evaluate the effect of this approximation in Sect. 5.1.
If the prediction of the residual-corrected reference model on a test instrument deviates significantly from the data observed with the test instrument, then there is a significant cross-calibration bias between the reference instrument and test instrument. This bias manifests itself as a deviation of J1 (see Eq. (3)) from unity, and thus J1 serves directly as the bias factor. However, this approach involves another approximation, namely that we evaluate the cross-calibration bias by examining the convolved results while using it to represent the effective area bias that enters the spectral analysis before convolution with the redistribution matrix. We evaluate the effect of this approximation in Sect. 5.1.
One can also utilise J1 for investigating the accuracy of the cross-calibration of the energy dependence (i.e. the shape) of the effective area. Namely, in the case that there is no bias in the energy dependence, J1 is constant with energy (E). Thus, if dJ1/dE deviates significantly from zero, there is a significant bias in the cross-calibration of the energy dependence of the effective area. Thus, in the following we analyse the deviation of J and dJ/dE from unity and zero, respectively.
The statistical accuracy of the above correction to the reference model is set by the statistical uncertainties of the reference instrument data. Additionally, the statistics of the test instrument affect the accuracy of J1. Previous works, for example Schellenberger et al. (2015) and Nevalainen et al. (2010), have indicated ~10% effects in the effective area cross-calibration between XMM-Newton EPIC instruments. In order to meaningfully investigate the cross-calibration, we set as a requirement to maintain the statistical uncertainties of the sample mean cross-calibration bias data below the 1% level at each spectral bin (including the counting statistics of both the reference instrument and the test instrument).
Since we use the numerical model as a description of the data, the physical accuracy of the reference model does not matter (any deviation of the reference model from the data obtained by the reference instrument is corrected with residuals; see Eq. (3)). An important consequence is that we can include the spectrally very different cool cores (Hudson et al. 2010) and the hotter intermediate regions in a single extraction region and thus improve the signal-to-noise ratio. This approach also helps minimise the unwanted flux variation due to the point spread function (PSF) scatter (see Sect. 3.2).
2.2 Method 2: pre-convolution
Given that the above approach includes two potentially significant approximations we decided to compare the results obtained with Method 1 with those obtained with another method that does not include these approximations.
First, instead of using a purely thermal model (absorbed by the interstellar matter) for describing the reference instrument data, and correcting it with convolved residuals, we used a more complex model that describes the data very accurately. After experimenting, we settled on a hybrid model that includes an absorbed thermal component modified with cubic splines (piece-wise third-order polynomials; see the previous section for a justification of phenomenological modelling). We included three independent spline components with breaks at 0.5, 2.0, 4.0, and 6.1 keV. This is the reference model (modelref,2) when applying Method 2. We used here the optimal spectral bin size of 400 eV (see Sect. 3.1). The residuals are below 1% for each cluster and each spectral bin. Thus, the correction term R2 (Eq. (2)) is very close to unity and can be neglected in further analysis. This way we by-pass the first approximation. We propagate the statistical uncertainties of the reference instrument data to the following analysis.
Second, instead of studying the cross-calibration by analysing the data that have been convolved with the energy redistribution matrix, we modelled the effective area bias before convolution. After experimenting with different models, we settled on a single fourth-order polynomial in the 0.5–6.1 keV band,
 (4)
(4)
as the model for the cross-calibration bias (E is the photon energy in units of keV). This model is complex enough to describe the broad-band features (see Sect. 5 for details of the fitting) with a relatively small number of free parameters so that the complexity of the analysis is manageable. In practice we fit the test instrument data in XSPEC with a model consisting of (1) the hybrid spline-modified absorbed thermal component (modelref,2) whose all parameters are fixed to the best-fit values obtained when fitting the reference instrument data (see above), multiplied by (2) the model for the cross-calibration bias (Eq. (4)) whose coefficients are free parameters in the fit. We thus minimised the deviation of the ratio
 (5)
(5)
from unity. We used the same function (Eq. (4)) to model the cross-calibration bias values obtained with Method 1 (Eq. (3)) for direct comparison in Sect. 5.1.
3 Controlling the systematics
Our focus is on the calibration of the effective area. However, there are many aspects of the instrumentation (e.g. the possible bias of other calibration components and the dead detector area due to bad pixels, dominated by the CCD gaps) that can produce variation in the measured flux we erroneously attribute to effective area calibration effects. Our approach is to choose the clusters, observations, extraction regions and the wavebands in a manner that minimises the above effects. In particular we investigate energy redistribution, background, PSF, vignetting and bad pixels. We discuss these components below and define requirements and procedures for maintaining their effects (i.e. systematic uncertainties) below 1% of the cluster flux.
3.1 Energy redistribution
Due to the limitations of the energy resolution of detectors, a fraction of photons will be detected outside of the channel nominally corresponding to the energy of the incoming photon. Also, a given channel will get contribution from photons with true energy outside that channel. While this effect is modelled and taken into account in the data processing and analysis via the energy redistribution matrix, it has some degree of uncertainty. Thus, there will be additional redistributed flux in a given band that is not accounted for when modelling the data with the nominal energy redistribution matrix file (rmf in Eq. (3)) and consequently we interpreted the additional flux as being due to a bias of the effective area in that band.
As long as the spectral features are much broader than the width of a symmetric2 redistribution function, the scattered flux to and from the neighbouring bins cancels out very accurately, independently of the redistribution calibration. In the case of hot thermal plasma, to the first order the continuum is smooth over scales bigger than the full width at half maximum (FWHM) of the EPIC energy redistribution function (~100 eV) for the hot clusters at energies below 6 keV.
The emission lines are problematic in this context. The problem is most severe for the Fe XXV-XXVI lines of the hottest clusters, which dominate the total emission in the ~6–7 keV band. Since most of the useful clusters for our work have red-shifts below 0.1 due to photon counting statistics requirements (see below), the iron line flux and thus the possibly related problems are confined above 6 keV energies. Thus, we eliminate the effect by truncating the spectra at 6 keV.
The emission line complex at ~1 keV is less strong in hotter clusters, which our sample includes. Yet, for example, it produces ~5% of the total emission in the 0.8–1.2 keV band of the A1795 spectrum. Our approach is to minimise the redistribution between neighbouring bins by maximising the size of the spectral bins while maintaining useful spectral resolution for the cross-calibration study. We studied the effect of different spectral bin sizes for A1795 pn spectrum by comparing the fluxes in such bins obtained with the reference model by (1) applying the standard redistribution matrix (rmf-file produced by SAS toot rmfgen) and (2) diagonalising the above response using diagrsp – command in XSPEC. The latter approach produces fluxes assuming that the energy resolution is infinite, that is, assuming there is no redistribution to and from the neighbouring bins. After experimenting we chose a bin size of 400 eV, which exceeds the pn energy redistribution FWHM by a factor of 2(4) at 6 keV (1keV).
In most of the energy band studied in this work (0.5–6.1 keV) the net flux effect of the pn redistribution is at the few percent level (see Fig. 1). The larger effect at the low energy end can be understood via the complex energy-dependent interplay of the effective area, cluster emission, and asymmetric feature (soft tail) of the redistribution function, which is wider than 400 eV at the 1% level of the peak flux. Namely, the lost fraction of the flux originating from the 0.5–0.9 keV bin due to the soft wing will not be compensated for by the redistributed contributions originating from (1) the lower neighbouring energies due to the asymmetry (i.e. there is no hard wing) and (2) the neighbouring higher energies since the measured flux decreases with energy, which reduces the redistributed wing contribution. Thus, for A1795 the net redistribution effect in the 0.5–0.9 keV bin leads to a 15% flux loss for the pn.
At the highest energies the pn redistribution has an opposite effect: 15% net increase of flux in 5.7–6.1 keV band. While the soft wing is not significant at these energies, another asymmetry arises. Namely, the relatively quickly decreasing cluster emission at these energies will result in larger redistribution contribution originating from lower energy not being compensated for by smaller contribution from higher energy.
The effect on the MOS is different (except for the 0.5–0.9 keV bin); it is smaller than that in the pn and less strongly energy dependent. The drop in the MOS effective area above ~5 keV has an effect of producing an asymmetric situation resulting in redistributed flux excess towards higher energies. Yet, the net effect is smaller than that in pn, this can be ascribed to the better MOS energy resolution at higher energies. The difference of the pn and MOS at the highest energies results in energy-dependent rise of the redistribution effect on the MOS/pn flux ratio. This may be reflected in the differences of the results obtained with different treatments of the redistribution (Methods 1 and 2; see Sect. 5.1).
Assuming 3% uncertainty in the calibration of the EPIC redistribution (Haberl et al. 2010)3, the above estimates for the net redistribution effect with our 400 eV binning (i.e. a few percent of the total flux) yield a systematic redistribution effect that is a fraction of 1% of the flux in a given bin. This satisfies our criteria for the systematic uncertainty level.
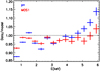 |
Fig. 1 Ratio of the spectral data of A1795 and the prediction of the best-fit hybrid model, i.e. the absorbed thermal model modified by the splines (modelref,2; see Sect. 2.2), after diagonalising the redistribution matrix for pn (blue) and MOS1 (red), shown with the crosses. |
3.2 Point spread function
The extended nature of galaxy clusters complicates the analysis. Namely, analogously to the energy redistribution phenomenon due to the limitations of the energy resolution (see Sect. 3.1), the limitations of the spatial resolution cause some of the intended flux to scatter out from the extraction region and some unwanted flux will scatter into our extraction region from outside the studied region. This is modelled as a point spread function (PSF). The XMM-Newton Science Analysis Software (SAS) has an option of considering the PSF scatter between the different studied regions of extended sources when computing the effective areas. The modelling of the PSF has some degree of uncertainty, and consequently there will be some level of flux variations that we would erroneously interpret as being due to effective area calibration problems.
Due to its wider PSF we conservatively used pn to estimate the EPIC PSF scatter effect. 90% of the energy entering the telescope in a single point is spread out within r ~ 1 arcmin circle in the pn detector. The brightness profiles of the non-cool-core clusters are relatively smooth and do not vary much at the 1 arcmin scale. Thus, the scattered flux to and from the neighbouring detector regions cancel out with high accuracy and the net PSF scatter effect for these clusters is negligible.
A particular problem related to clusters is the central brightness peak in the cool core clusters, analogous to a spectral line in the case of the energy redistribution. The brightness decreases rapidly with increasing radius at scales comparable to the PSF size. Thus, at these scales there will be significant net PSF scatter effect reducing the flux. Analogously to the energy redistribution case, our solution is to use extraction regions much bigger than the PSF scale and to include the central regions in our spectrum extraction region. By requiring a minimum of 3 arcmin radius for the extraction region (i.e. ~4 times the 90% energy encircled radius) we expect to minimise the variation of the extracted flux due to PSF scatter to and from the region outside below In such a case, the possible problems in the calibration of the PSF will yield an effect that is a fraction of 1% of the flux in our extraction region, satisfying our criteria.
Our expectation is supported by the work of Nevalainen et al. (2010) who examined the PSF scatter issue for a partially overlapping sample of galaxy clusters. They convolved the surface brightness profiles measured with Chandra with an analytical expression of the XMM-Newton/EPIC PSF obtaining that the PSF-scattered flux from the cool core to an annular region at ~ 1.5–3.0 arcmin distance from the cluster centre amounts to less than 1% of the flux originating from that region. In our case the fraction is much smaller since we include the cool core in the extraction region. Thus, an extraction radius of 3 arcmin is our very conservative lower limit for the extraction radius in order to minimise the PSF scatter.
3.3 Background
The data we utilise in our work (dataref and datatest in Eqs. (1), (2), (3), (5), and (6)) consist of the background-subtracted count rate of the cluster. The systematic uncertainties of the background modelling will introduce unwanted variation in our data. Our choice of the hottest nearby clusters and focusing on their bright central regions is our first order attempt to minimise the effect of the background in our data.
At the low energy end of the spectra the background is dominated by the Galactic emission and the cosmic X-ray background. However, the clusters are strong soft X-ray emitters and thus the background-to-source ratio is lowest at the soft X-rays.
The intrinsic emission of the clusters of galaxies decreases with higher energies in the X-ray band. Since the effective area behaves similarly, the net effect is that the number of source photons per keV decreases strongly with increasing photon energy in the XMM-Newton/EPIC waveband. Consequently, due to its much harder X-ray spectrum compared to the hottest clusters, the particle-induced background becomes more important at higher energies. We thus conservatively use the 4–6 keV band count rates to set the requirements for the background-to-source ratio.
Since the nearby clusters fill most of the EPIC field of view (FOV), we used blank sky and closed cover observations to estimate the background spectra (see Sect. 4.2) following Nevalainen et al. (2010). Comparison of the background spectrum estimate composed of the blank sky and closed cover samples with the individual blank sky observations yielded that, in the 4–6 keV band, the accuracy of such a background estimate for EPIC is ~5% at 1σ confidence (Nevalainen et al. 2005). While there are more up-to-date methods for more accurate background treatment (e.g. Marelli et al. 2021; Gastaldello et al. 2022) we prefer Nevalainen et al. (2005) method due to its simplicity and because its accuracy is adequate for our purposes. Thus, in order to maintain the uncertainty of the count rate due to the background subtraction below 1% of the source count rate at all wavelengths in the 0.5–6 keV band, we require that the background-to-source count rate ratio be smaller than 20% in the 4–6 keV band.
3.4 Vignetting
The extended nature of the galaxy clusters invokes a problem not present in the case of using on-axis point sources for effective area calibration studies. Namely, the effective area decreases with the off-axis angle due to partial obscuration of the mirror elements at such angles. The SAS tool arfgen calculates the effective area at a given energy by multiplying the on-axis value with the factor obtained by weighting the vignetting function at different positions of the extraction region with the surface brightness of the cluster. In this work, we are not interested in the calibration of the vignetting function but rather want to minimise the effect of its calibration problems.
Our solution is to keep the extraction radius small enough so that the vignetting effect stays small enough. The effect is stronger at higher energies, leading to ~20% effective area reduction at r = 6 arcmin for 6 keV photons. Due to the radially decreasing surface density of clusters, most of the photons in a r = 6 arcmin circle centred to the cluster centre originate from the less vignetted inner parts. An example calculation of the emission weighted vignetting factor of A1795 cluster within the central r = 6 arcmin region at 6 keV band yields a smaller than 10% total vignetting effect for the spectrum extracted within a circle of r = 6 arcmin. Allowing a very generous 10% uncertainty for the vignetting factor calibration (Lumb et al. 2003) results in systematic uncertainties of the effective area by a maximum of 1% at 6 keV when considering a central r = 6 arcmin region, satisfying our criteria. Thus, we set a maximal extraction region radius of 6 arcmin.
3.5 Obscuration by the bad pixels
On average, ~ 14% (~4–5%) of the full central r = 6 arcmin pn (MOS) region is obscured by the dysfunctional (i.e. bad) pixels, dominated by the CCD gaps (Nevalainen et al. 2021). This complicates the analysis of extended X-ray sources with non-uniform spatial flux distribution such as galaxy clusters. If not accurately accounted for, the bad pixel obscuration may cause significant variation of the flux, which is our essential observable (dataref and datatest in Eqs. (1), (2), (3), (5), and (6)). We summarise here the test of the accuracy of the CCD gap correction we performed in Nevalainen et al. (2021, see that work for the details of the test).
SAS includes an option for recovering the fraction of the flux obtained by a given EPIC instrument that has been lost due to bad pixel obscuration of the intended extraction region. Since version 17.0.0, SAS has included an option whereby the user can utilise the information of the spatial distribution of the flux (i.e. an image) of the same source observed with another instrument or via a synthetic model image. The procedure is implemented to arfgen whereby the effective area associated with the input spectrum is reduced by the lost flux fraction in the full intended extraction region, as informed by the supplementary image. This option is enabled by specifying badpixmaptype=dataset.
In Nevalainen et al. (2021), we compared the fluxes of the cluster sample presented in this paper recovered by the above procedure with those obtained with the simulated model images. We found that the accuracy of the recovery method as implemented to SAS18.0.0 is better than 0.1% on average while in individual cases the recovered flux may be uncertain by Thus, the accuracy of the procedure satisfies our requirement of maintaining the systematics at the 1% level.
In reality it is the flux, rather than the effective area, that is reduced, and thus we need to make sure that our study of the effective area is done in a correct way. We use pn (MOS2) images for applying the correction to MOS (pn) effective area. In Eqs. (2) and (3), arfref corresponds to the pn effective area reduced by the above procedure. Thus, when we fit the pn spectra, the best-fit model (modelref) will be scaled up corresponding to the full intended extraction region. The prediction for the reference instrument using the up-scaled model with the down-scaled effective area (modelref × ar ftest) corresponds to the partially obscured extraction region where the data are extracted from. Thus, the application of Eq. (2) with the CCD gap correction is valid.
We then use the up-scaled pn model to produce the prediction (modelref × ar ftest) for the test instrument (Eq. (1)). The effective area of the test instrument ar ftest is down-scaled due to CCD gap correction procedure and thus the model prediction for the test instrument corresponds to the same partially obscured region of the test instrument, where the test instrument data are extracted from. Thus, the application of Eq. (1) is also valid.
3.6 Summary of the criteria
We summarise here the above discussed requirements and procedures we employed in order to maintain the systematic effects of different calibration and instrumentation components on the cross-calibration bias below the 1% level in the studied energy band: (1) energy redistribution: minimal spectral bin size of 400 eV; (2) energy redistribution: maximal spectral bin energy of 6 keV; (3) background: maximal background-to-cluster count rate ratio at 4–6 keV of 20%; (4) PSF: minimal extraction region radius of 3 arcmin; and (5) vignetting: maximal extraction region radius of 6 arcmin.
4 X-ray data
4.1 The sample
The above requirements translate into selection criteria of the suitable clusters, observations and spectrum extraction regions. Since we want to minimise the statistical uncertainties of the spectra, we focused on relatively nearby clusters. In order to minimise the background-to-source count rate ratio, we prefer the hottest clusters since they provide intrinsically more counts at the critical higher energies.
In order to carry out a robust statistical analysis we need a substantial sample of cluster observations (we treat repeated observations of the same cluster as independent datasets). From the XMM-Newton observation archive we constructed a sample of 27 EPIC observations of galaxy clusters hotter than ~5 keV (see Table 1). These observations comply to an additional requirement that the pointing off-axis angle from the cluster X-ray peak must be smaller than 3 arcmin so that we do not fold in significant asymmetric vignetting features. The combined exposure time of the flare-filtered (see the next section) sample is ~600 ks, which renders the number of photons in the spectra in our adopted extraction region and bin size (400 eV) above 50 000 at each spectral bin. This renders the statistical uncertainty of the sample flux below 1% at each bin, that is to say, below the systematic uncertainty level.
Basic information of the EPIC data sample.
4.2 Reduction
We used SAS19.1.0 for processing the archival raw event files and producing the spectra and responses in November 2021, using the latest calibration files (CCFs) available at that date. We applied the SAS tools epchain and emchain with default parameters to the raw data in order to produce the event files for the observations and the simulated out-of-time4 (OOT) file for pn. We filtered the event files using patterns 0–4 for pn and 0–12 for MOS and applying expressions flag==0 for pn and #XMMEA_EM for MOS. We further filtered the event files to minimise the flares by accepting only such periods when the E > 10 keV band flux was within ±20% of the quiescent level.
We extracted the spectra at circular regions centred at the location of the X-ray peak. While a larger extraction radius improves the statistical precision of the spectrum, it also increases the background to source ratio. We adopted the extraction radius of 6 arcmin since this value satisfies the requirements due to PSF minimisation (not too small radius) and vignetting (not too large radius) and yields background-to-source ratio (see below) smaller than 20% in the 4–6 keV band in vast majority of the spectra (see Table 1).
We extracted the spectra in 5 eV bins and corrected the observational pn spectrum with the OOT spectrum. We produced the energy redistribution matrices (rmf) using rmfgen tool, using the image of the cluster for weighting. We produced the effective area files (arf) as described in Sect. 3.5. Importantly, we did not apply the average EPIC-MOS effective area correction described in the XMM-Newton calibration note XMM-CCF-REL-382 (see Sect. 8 for discussion on this approach in comparison to ours).
To investigate the origin of the possible calibration problems, we additionally used arfgen to separate the basic components of the total effective area: (1) the mirror effective area, (2) the quantum effciency (QE) of the detector and (3) the optical filter transmission. We used A1795 cluster for this exercise (see Fig. 2).
Following Nevalainen et al. (2005), we estimated the total and particle background spectra utilising a sample of blank sky and closed cover observations with XMM-Newton/EPIC. We extracted these spectra using the same detector region as applied to our cluster sample, a central circle with r = 6 arcmin, and co-added them in order to obtain single blank sky and closed cover spectra to be applied to all clusters (pn, MOS1 and MOS2 separately). The blank sky spectrum approximates the sum of the photon background and the quiescent particle background. We additionally extracted the background and cluster spectra in the full FOV in order to account for the variability of the residual particle flares entering our data despite our flare filtering. Namely, we obtained the normalisation of the residual flare spectrum (we assumed that its shape is that of the closed cover spectrum) for a given cluster observation by matching the E > 10 keV count rate (dominated by particles due to very low mirror effective area at these energies) of the full FOV particle background spectra with that of the full FOV cluster spectrum. We then subtracted such a normalised particle background spectrum from the cluster spectrum, together with the blank sky spectrum.
4.3 Spectral analysis
We used the XSPEC software (Arnaud 1996) to perform spectral analysis. We first binned the spectra to contain a minimum of 100 counts per bin. We modelled the background-subtracted (see Sect. 4.2) 0.5–6.0 keV band data of EPIC-pn (dataref in Eq. (2)) with a MEKAL emission model absorbed by phabs model in the case of Method 1. When following Method 2, the thermal model is modified by the splines (see Sect. 2.2). We adopted redshifts from NASA’s Extragalactic Database and the Galactic NH values from Willingale et al. (2013). We fixed the metal abundance to 0.3 Solar.
We formed the model prediction by multiplying the trial models with the effective area file (arf, including the bad pixel correction; see Sect. 3.5) and convolving the product with the redistribution matrix (rmf). We fitted the data with such a model prediction and the consequent best fit model corresponds to the reference model (modelref,1 and modelref,2 in Eqs.(1), (2), (3), (5), and (6)).
5 Results
When discussing the sample for a given instrument pair as a whole we prefer to use the sample median over the mean since the relatively small number of the data points in our sample does not allow a robust evaluation of the shape and in particular the symmetry of the distributions. Possible deviations from symmetry could bias the sample mean. We thus chose to use the more general sample median as a representative value of the distribution. This choice also mitigates the problem arising from the inhomogeneous statistical quality of the sample: the clusters with higher number of counts would bias the weighted mean. We adopted the error of the mean, multiplied by a factor of 1.3 (Sokal & Rohlf 1981) as the statistical uncertainty of the sample median.
 |
Fig. 2 Different components of instrumentation for A1795 observation 0723802101 for pn (red lines), MOS1 (black lines), and MOS2 (blue lines). The top-left panel shows the total effective area generated with arfgen (solid lines; for clarity, MOS1 is not shown). The dotted lines indicate the average correction to the effective area assuming that the other instrument is perfectly calibrated (see Sect. 6). The other panels show the mirror-only effective area (top right), the QE of the detector (bottom left), and the transmission of the optical filter (bottom right). |
5.1 Comparing the methods
Following the description in Sect. 2, we evaluated the MOS1/pn cross-calibration bias using Methods 1 and 2. The fourth-order polynomials yielded adequate fits to the full band (see Fig. 3 for the fit quality for MOS1/pn data of A1795 cluster). There are single spectral bins where the data deviate statistically significantly at the few percent level from the best-fit model. These features appear at the same energies and with similar magnitudes when using either of the two methods. They are hard to understand in terms of the effective area components (mirror effective area, filter transmission and detector QE). The apparently chaotic behaviour of the above isolated deviations with time and energy suggests that this issue could be due to the data processing and not inherent to the cross-calibration. The possible patterns of these features could be used to examine in detail the cause of such scatter, which is beyond the scope of this work.
We performed the comparison of the two methods in terms of the individual best-fit fourth-order polynomials (see Fig. 4). While the median J deviates by less than 1% at the lower energies, the deviations become larger at higher energy, reaching 3% at 6 keV. The models obtained via Method 2 tend to raise more sharply with energy while this is suppressed when analysing the convolved results via Method 1. Also, the cluster-to-cluster scatter is very similar in the two approaches except at the highest energies, where Method 2 has more scatter while it is somewhat suppressed when applied Method 1. These minor effects may be due to the difference of the relative net redistributed flux in the pn and MOS, reported in Sect. 3.1, which increases with energy.
While our requirement for the systematic uncertainty components is less than 1%, and since Method 1 may be underestimating the true scatter, we adopt Method 2 in the following when reporting most of the results. Due to practical reasons, in some instances when the small differences between Methods 1 and 2 are not important, we use Method 1 to highlight some aspects of the cross-calibration bias.
5.2 Measure of the cross-calibration bias
Before discussing in detail the results of modelling the cross-calibration bias with fourth-order polynomials, we want to visualise the cross-calibration signal we are modelling. The concept of the cross-calibration data is complex since in order to evaluate the cross-calibration bias between two instruments following Method 2, we fit two independent datasets, the X-ray spectra of the two instruments. Essentially the cross-calibration bias is a ratio of the data from the test instrument and the prediction of the model describing the reference instrument data. To obtain an observation-based measure of the cross-calibration bias we modified the function (Eq. (5)) used when finding the model for the cross-calibration bias by removing that model. The measure of the cross-calibration bias is thus given by
 (6)
(6)
Such a measure does not depend on the model as long as the model describes the data of the reference instrument accurately. Thus, we treat this measure in the following as data in order to examine the statistical properties of the cross-calibration bias J2 for MOS1/pn and MOS2/pn pairs (J2,MOS1/pn and J2,MOS2/pn) at each energy bin for each observation (see Fig. 5 and Table 2).
In this work, we focus on the cross-calibration between the pn and the MOS units by treating the pn as a reference instrument and the MOS units as test instruments. In order to obtain qualitative results for the cross-calibration status between the MOS units, for the discussion we divided the MOS1/pn cross-calibration bias curves by those of the MOS2/pn pair. A more robust quantitative evaluation of MOS1/MOS2 cross-calibration would require repeating the analysis reported in this work but replacing the pn as a reference instrument with one of the MOS units and using the other MOS unit as a test instrument.
The visual inspection of the results indicates that while the energy dependence of the median J2,MOS/pn values in the 0.5–4.5 keV is to the first order linear, there is a sharp upturn at ~5 keV (see Fig. 5). The visual inspection also indicates that while the individual J2 curves behave quite systematically with energy, there is a substantial scatter (see Fig. 5, upper panels). This is not driven by some outliers but seems to be present in the full sample, increasing with energy. We investigate these features in detail below.
 |
Fig. 3 Demonstration of the quality of the modelling of the MOS1/pn cross-calibration bias for A1795 using Method 1 (left panel) and Method 2 (right panel). When applying Method 1, we evaluate Eq. (3), i.e. we approximate the cross-calibration bias after the convolution (blue crosses in the upper-left panel). The best-fit model (Eq. (4)) to such data is shown as a red line. When applying Method 2, we fit the MOS1 spectra (blue symbols in the upper-right panel; the statistical uncertainty is smaller than the plot symbol) with a model consisting of a fixed component for accurate modelling of the pn data (see the main text for details), while the cross-calibration bias is modelled as a fourth-order polynomial (the total model is shown as a red line in the upper-right panel; see Eq. (5)). In both cases, the lower panel shows the ratio of the best-fit model to the data. |
 |
Fig. 4 Best-fit models for each individual cluster obtained by fitting the MOS1/pn cross-calibration data using Eq. (4) when applying Method 1 (left panel) or Method 2 (right panel). Each solid line connects the values of one cluster at the energy bin centres. The black symbols and vertical lines indicate the median and the standard deviation of the sample at each energy. The symbols from the right panel are repeated in the left panel in blue. The horizontal dashed line at unity indicates the expectation in the case of no cross-calibration bias. |
5.3 Scatter
We discuss next the substantial cluster-to-cluster scatter of the measure of the cross-calibration bias (see Fig. 5). The standard deviation of the individual J2 values of the full cluster sample amounts to ~2–13% of the median value in the studied energy range with an tendency to increase with the photon energy (see Fig. 5 and Table 2). The scatter exceeds the level of the known systematic uncertainties (see Sect. 3) by a factor of ~2–13. The statistical uncertainties of the individual clusters are much smaller than the scatter and may thus explain only a small fraction of the scatter. We demonstrated this by repeating the cross-calibration bias analysis using Method 1 for MOS2/pn, but this time using much bigger energy bins so that the statistical uncertainty of each individual cluster observation is below 1% at each bin (see Fig. 6). Yet, at a given photon energy, the scatter remains almost intact.
We investigated the possibility that the scatter is due to the random sampling of the parent population with a limited sample size. For a given statistical error of the sample mean (μ)5 and the number of data points in the sample (N), the expected standard deviation (σ) due to the statistical fluctuations in the sample is given by  . In our case, the standard deviation exceeds the statistical uncertainty of the sample median by a factor of 8–26 (MOS1/pn) and 9–28 (MOS2/pn) in the 0.5–6.0 keV band. Since we have N = 27, the standard deviation in our sample exceeds the expectation (
. In our case, the standard deviation exceeds the statistical uncertainty of the sample median by a factor of 8–26 (MOS1/pn) and 9–28 (MOS2/pn) in the 0.5–6.0 keV band. Since we have N = 27, the standard deviation in our sample exceeds the expectation ( ) by a factor of 1.6–5.0 (MOS1/pn) and 1.8–5.4 (MOS2/pn), depending on the photon energy. Thus, the scatter is significantly larger than expected by the sampling uncertainties.
) by a factor of 1.6–5.0 (MOS1/pn) and 1.8–5.4 (MOS2/pn), depending on the photon energy. Thus, the scatter is significantly larger than expected by the sampling uncertainties.
Our analysis of the bias factor using Method 1 in the 0.5−2.0 and 2.0–6.0 keV bands indicates no regular patterns in the behaviour as a function of the observation date (see Fig. 7). A more detailed analysis of the problem is out of the scope of this work. Expert knowledge on the XMM-Newton/EPIC instruments and SAS software would be needed to probe the cause of the substantial and significant scatter of the XMM-Newton/EPIC cross-calibration (which is not inherent to clusters; see Sect. 7.4).
 |
Fig. 5 Results obtained by analysing the measure of the cross-calibration bias (J2; see Eq. (6)). Upper panels: J2 for each observation for MOS1/pn (left panel) and MOS2/pn (middle panel) obtained via Method 2 (see the main text). Each line connects the values of one cluster at the energy bin centres. The black symbols and vertical lines indicate the median and the standard deviation of the sample at each energy. Lower panels: median J2 of the sample and their statistical (red crosses) and systematic (green crosses) uncertainties for MOS1/pn (left panel) and MOS2/pn (middle panel) pairs. The blue crosses indicate the standard deviation of the sample at a given energy (they are equal to the horizontal black lines in the upper panels). In all panels, the horizontal dashed line indicates the expectation (unity) in the case of no cross-calibration bias. Please note that the scales of the vertical axes are different in the upper and lower panels in order to better highlight the details. Right panels: approximative results for MOS1/MOS2 pair obtained by dividing the results of the left and middle panels. |
Statistical results of the measure of the cross-calibration bias obtained with Method 2 for the cluster sample.
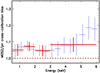 |
Fig. 6 Median cross-calibration bias parameter J1 (Eq. (3)), obtained with Method 1, of different observations and their standard deviation for the MOS2/pn pair for the standard energy binning used in the paper (blue crosses) and for a coarser binning (red crosses). In the latter case, the statistical uncertainties of each individual observation are below 1% in each bin. |
5.4 Normalisation
We started the analysis of the measures of the cross-calibration bias J2 (Eq. (6)) by investigating the normalisation of the cross-calibration using the sample medians. In particular, we examined deviations from the unity since J = 1 in the case of no bias in the normalisation of the effective area cross-calibration.
The approximative results for the MOS1/MOS2 pair (see Sect. 5.2) indicates in general J2 values closest to unity compared to pairs involving the pn (see Fig. 5). This is expected since the full light path entering MOS1 and MOS2 detectors are very similar and, apart from the mirror, very different from that of pn.
At all energies the bias factor between MOS and pn (J2,MOS1/pn and J2,MOS2/pn) is above unity. On average, J2,MOS1/pn ~1.12 and J2,MOS2/pn ~1.09, indicating a systematic normalisation bias in the effective area calibration in pn or MOS, or both (see Fig. 5). The MOS1/pn (MOS2/pn) deviations amount to ~27% (~22%) in maximum in the 0.5–6.0 keV band, indicating a similar maximal level of MOS/pn effective area normalisation problems.
If we assume first, for the sake of the argument, that the normalisation of the effective area of pn is accurately calibrated (i.e. the normalisation of modelref,2 in Eq. (6) is correct), since the MOS/pn measure of the cross-calibration (J2,MOS/pn) is above unity, it follows (see Eq. (6)) that the MOS prediction is too low (i.e. the MOS effective area normalisation is calibrated too low in this scenario; see Fig. 2). Assuming instead that the normalisation of the MOS effective area is accurately calibrated, that of pn is calibrated too high. In this scenario the standard spectral analysis of pn spectra would yields fluxes that are biased low.
The comparison with different works on the XMM-Newton/EPIC effective area cross-calibration is complicated because the implemented calibration information changes with time. Also, different methods and X-ray sources have different levels of systematics that are not always explicitly evaluated and reported. However, it appears that the above qualitative feature, namely the MOS yielding higher fluxes than the pn, has been consistently reported for the past 14 yr (e.g. Mateos et al. 2009, Nevalainen et al. 2010, Tsujimoto et al. 2011, Read et al. 2014, Schellenberger et al. 2015, Madsen et al. 2017, Plucinsky et al. 2017, Marshall et al. 2021, Fuerst 20226).
5.5 Energy dependence
We then studied the issue of the energy dependence as indicated by the measure of the cross-calibration.
5.5.1 MOS2/pn
Due to the issues of the MOS/pn pairs at the highest energies (see Sect. 5.2) we study first MOS/pn results in the 0.5–4.5 keV band. Visual investigation of the data indicated that the cross-calibration bias between MOS2 and pn is almost constant (see Fig. 8, middle panel). We examined this in more detail by fitting the individual curves of the measure of the cross-calibration (J2,MOS2/pn) for each cluster in the 0.5–4.5 keV band with a linear model. We used these models to construct a model describing the full sample by adopting such a linear model, whose parameters are the medians of those in the individual best-fit models. We approximated the uncertainty of the above parameters with the standard deviation of the best-fit parameters in the individual fits. The resulting median value of the best-fit linear coefficients is 0.002 ± 0.012; in other words, it does not deviate significantly from zero.
The median J2,MOS2/pn varies in the range ~1.05–1.08 in this band (see Fig. 8, middle panel). In most of the 0.5−4.5 keV band the linear model described above agrees with the data within the estimates of the systematic and statistical uncertainties. At 0.9−1.7 keV the data exceed the linear model by more than the estimated uncertainties (see Fig. 8, middle panel). However, the deviation amounts only to ~2–3%.
In such a wide band (0.5−4.5 keV) all the components of the effective area (filter transmission, detector QE and mirror effective area) vary substantially with the energy, and differently from each other (see Fig. 2). Thus, it is very unlikely that these components have calibration biases that cancel out the energy dependence of the cross-calibration bias. It is more likely that the energy dependences of the effective area components of MOS2 and pn in most of the 0.5–4.5 keV band as implemented in the public XMM-Newton calibration in November 2021 are very accurately modelled.
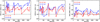 |
Fig. 7 Cross-calibration bias factor J1 using Method 1 (Eq. (3)) in the 0.5−2.0 keV band (red lines and symbols) and the 2.0−6.0 keV band (blue lines and symbols) as a function of the time (revolution number during which the given observation was performed) for MOS1/pn (left panel), MOS2/pn (middle panel), or MOS1/MOS2 (right panel) pairs. The dotted lines indicate the sample median. |
 |
Fig. 8 Median of the measures of cross-calibration bias, with statistical and systematic uncertainties (red and green symbols, repeated from the bottom panel of Fig. 5) for the MOS1/pn (left panel), MOS2/pn pair (middle panel), and MOS1/MOS2 pairs. The solid golden lines in the left and middle panels indicate the linear models whose parameters are the medians of those obtained by fitting the individual cluster data for MOS/pn pairs in the 0.5–4.5 keV band with a linear model. The dashed golden lines indicate the extrapolation of the above models to the 4.5–6.1 keV band. The MOS1/MOS2 data were fitted in the 0.5–6.1 keV band (right panel). In all panels, the horizontal dashed line indicates the expectation (unity) in the case of no cross-calibration bias. |
5.5.2 MOS1/pn
The situation is different for the MOS1/pn pair. J2,MOS1/pn increases approximately linearly from ~1.04 at 0.5 keV to ~1.11 at 4.5 keV (Fig. 8, left panel). The best-fit linear co-efficient is 0.018±0.013 (i.e. ~10 times larger than that in the case of MOS2/pn). Given the above MOS2/pn consistence this suggests that the MOS1 effective area energy dependence in the 0.5−4.5 keV band, as implemented in the XMM-Newton calibration in November 2021, has an approximately linear bias increasing with the photon energy (see Fig. 8, left panel). However, due to the large scatter described above, the linear coefficient of the best-fit linear model describing the MOS1/pn cross-calibration bias does not deviate very significantly from zero. Thus, the confirmation of this feature requires more work in the future.
5.5.3 MOS1/MOS2
Given that the MOS units behave differently in comparison to pn, there is some level of cross-calibration bias between MOS1 and MOS2. Using the approximative approach for the MOS1/MOS2 pair (see Sect. 5.2), the linear coefficient of the best-fit linear model to J2,MOS1/MOS2 data in the 0.5–6.0 keV band (0.015±0.005) deviates from zero by ~3 σ (Fig. 8, right panel). The deviation from zero is larger than that between MOS2 and pn derived earlier. This suggests, a bit surprisingly, that the cross-calibration of the energy dependence between MOS2 and pn is in better agreement than that between MOS1 and MOS2.
5.5.4 4.5–6.0 keV band
In the 4.5–6.1 keV band the MOS1/pn and MOS2/pn bias factors stand out from the linear trend extrapolated from the lower energies by ~30% at the maximum (see Fig. 8, left and middle panels). This feature is not present in the MOS1/MOS2 pair (see Fig. 8, right panel) Inspection of the individual J curves indicates that the above jump is a systematic feature and not driven by some extreme outliers.
While the mirror effective areas and filter transmissions of MOS and pn have similar energy dependence at these wavelengths, the QEs differ substantially (see Fig. 2); the QE of pn maintains at a rather constant level of 0.8 while that of MOS drops from 0.8 at 4 keV to 0.6 at 6 keV. If the drop has been overestimated so that the actual QEs of MOS1 and MOS2 would be harder, the MOS data/model ratio would actually be softer, and thus J2,MOS1/Pn and J2,MOS2/Pn would approach unity. This suggests there may be an issue in the QE calibration of MOS2 and even more so of MOS1.
5.6 Modelling the bias using Method 2
We then conducted a detailed analysis of the energy dependence of the cross-calibration bias obtained via Method 2 by modelling the MOS1/pn and MOS2/pn biases using a fourth-order polynomial. Given the larger than expected scatter (see Sect. 5.3), we fitted all the individual clusters separately (see Fig. 9). In this approach the statistical uncertainties dominate over the known systematic uncertainty level of 1% (discussed in Sect. 3). The best-fit MOS/pn models indicate a general behaviour whereby there is a small bump at 1–2 keV, a dip at 3 keV, and a sharp upturn above ~5 keV (see Fig. 9).
We then examined the resulting distributions of the best-fit coefficients of the fourth-order polynomial. This approach serves as an empirical evaluation of the effect of the unknown scatter to the cross-calibration bias. The distributions can be reasonably well approximated with Gaussian models (see Figs. 10 and 11 and Table 3).
There is significant correlation between the parameters (see Appendix A) and thus the best-fit parameters and the Gaussians widths of the parameter distributions reported in Figs. 10 and 11 and Table 3 are not alone sufficient to describe the statistical properties of the sample. We explore this further in Appendix A.
In order to produce useful information for the general user, we approximated the median curves of the cross-calibration bias for MOS1/pn and MOS2/pn pairs with fourth-order polynomials (see Fig. 9 and Table 4). These models describe the average MOS1/pn and MOS2/pn cross-calibration bias. They provide a quick quantitative way of understanding the effects of the cross-correlation bias to the first order. It should be noted that the proper treatment of the uncertainties includes a propagation of the scatter and requires the usage of parameter correlations, which are explored further in Appendices A and B.
 |
Fig. 9 Best-fit models for each individual cluster obtained by fitting the cross-calibration data of the MOS1/pn pair (left panel) or the MOS2/pn pair (right panel, repeated from the right panel of Fig. 3) using Method 2. Each solid line connects the values of one cluster at the energy bin centres. The black symbols and vertical lines indicate the median and the standard deviation of the sample at each energy level. The dashed blue lines indicate the fourth-order approximation of the median. The MOS1/pn curve is repeated in the right panel as a dashed white-red line. |
Statistical properties of the cross-calibration bias parameters.
Best-fit cross-calibration bias functions.
6 Application to scientific analysis
In this work we have evaluated and reported the significant systematic uncertainties in the XMM-Newton/EPIC instrument calibration. They will bias the derived physical parameters of the source under study at some level. This sets a limit to the accuracy of the parameters derived with XMM-Newton spectra that cannot be improved with higher photon counts obtained via longer exposures or by combining the pn and MOS data. In the case of Chandra/ACIS-S3 the limit is reached with ~104 counts (Drake et al. 2006).
We approached the problem by first playing the game of modifying the effective area of one instrument assuming that the other instrument is perfectly calibrated. This can be done by multiplying or dividing the effective area produced by SAS with the appropriate average bias function (i.e. fourth-order polynomial with parameters reported in Table 4). For this illustration we use the data from the observation of A1795 cluster (see Fig. 2, top-left panel for MOS2/pn pair). If pn (MOS) was perfectly calibrated, the effective area of MOS (pn) should be increased (reduced), with a factor that increases with the photon energy.
In principle, a general XMM-Newton user could apply the cross-calibration bias information presented in this paper by modifying the effective area column in an XMM-Newton/EPIC arf-file produced by the SAS software as demonstrated above and re-fitting the data. The change in the best-fit parameters would indicate the median systematic effective cross-calibration effect. However, in this this approach the scatter (discussed in Sect. 5.3) and the parameter correlations (see Appendix A) are omitted. The rms scatter is a substantial fraction of the bias itself, in some cases even exceeding it. Thus, a proper propagation of the substantial systematic uncertainties related to the effective area cross-calibration to the general XMM-Newton spectral analysis is not straightforward. It would include modifying the standard effective area with a large number of J curves derived via randomisation of the data according to the relevant cross-calibration model and the uncertainties of the model parameters, presented in Table 3. The resulting sample of modified effective areas could then be used to fit the user data. The scatter of the best-fit parameters would then yield the estimate for the systematic effect of the cross-calibration uncertainties (see Drake et al. 2006 for such application for Chandra/ACIS). We describe this procedure in more detail in Appendix A.
 |
Fig. 10 Distributions of the best-fit parameters of the fourth-order polynomials used for modelling the cross-calibration bias of single clusters for the MOS1/pn pair shown with the red histogram. The best-fit Gaussians to the above distributions are shown as a dashed blue line. The best-fit centroid of the Gaussian and the central interval containing 68% of the probability interval are indicated with a dashed black line and the yellow band, respectively. |
7 Comparison with 3XMM
An essential aspect of the current work is a strong control of the systematic uncertainties and their minimisation. In order to make sure that we have not underestimated the effect of the studied systematics and that we have not overlooked some remaining important cluster-related systematics, we repeated the analysis presented in this paper on a subsample (3XMM in short in the following) of 120 observations of point sources from the 3XMM-DR7 catalogue (Rosen et al. 2016). Due to practical reasons, we performed the comparison using Method 1. The slight difference at the highest energies compared to our preferred Method 2 does not affect significantly the comparison of the cluster and 3XMM samples. XMM-Newton calibration team has used 3XMM to investigate the cross-calibration between EPIC instruments (see Smith et al. 20217 for the details of the sample).
To ensure a meaningful comparison of the two datasets, we kept the data processing of 3XMM equal to that applied for the clusters to the maximal possible extent. Namely, we used the same SAS version, stage of public calibration, pattern choice, spectral bin size, and so on. (see Sect. 4). The essential difference between 3XMM and the cluster sample is that the objects in the former are point sources while the latter consists of extended sources.
The qualitative comparison of the cross-calibration bias parameter J1 (Eq. (3)) indicates similar features in 3XMM and cluster samples in the 0.5−4.5 keV band (see Fig. 12): (1) the MOS/pn data-to-model ratios are systematically above unity, (2) MOS1/pn bias increases with energy and (3) MOS2/pn bias is energy independent.
7.1 MOS2/pn 0.5−4.5 keV band
Quantitatively, there is an excellent agreement between clusters in the 0.5−4.5 keV band in terms of the MOS2/pn cross-calibration bias (see Fig. 12, right panel). The median J1 values of the cluster sample and 3XMM in each band differ on average by only ~1% and the differences are mostly consistent within the statistical and systematic uncertainties of the cluster data only. Rather than being a co-incidence we think this agreement serves as a proof that the systematics of both the clusters and 3XMM related to pn and MOS2 instruments affecting this band are well in control and minimised below 1% of the cross-calibration bias signal. This agreement gives strength to our cluster-based argumentation that the shape of the effective areas of pn and MOS2 are currently absolutely calibrated with accuracy of ~1%.
7.2 MOS1/pn 0.5−4.5 keV band
The situation is less clear for MOS1/pn pair. The median J1 values of 3XMM are systematically lower than those of the cluster sample in the 0.5−4.5 keV band, by ~3% on average, ~7% at maximum (see Fig. 12, left panel). The deviations are significant when considering the uncertainties of the cluster data. Currently we do not understand why the 3XMM and cluster sample results provide consistent results for the MOS2/pn analysis and significantly different results for the MOS1/pn analysis.
 |
Fig. 12 Median cross-calibration bias parameter, J1 (Eq. (3)), of different observations and their statistical uncertainties obtained using Method 1 shown as red crosses for the MOS1/pn (left panel) and MOS2/pn (right panel) pairs (at the lowest energies, the values are smaller than the plot symbol width). The blue crosses indicate the standard deviation of the cluster sample at a given energy. The black crosses indicate the medians and the range containing 68% of the values of the 3XMM sample. The horizontal dashed line indicates the expectation (unity) in the case of no cross-calibration bias. |
7.3 5–6 keV band
Towards the high end of our studied energy band, ~ 5−6 keV, there is another problem. The 3XMM data do not exhibit the steep rise of J values for MOS/pn pairs found in the cluster data (see Fig. 12). The estimates of the systematics related to the cluster sample, as presented in this work, are much smaller than the above difference. Similarly, the current understanding of the systematics related to 3XMM does not explain the difference. The solution to this problem requires more work, which is beyond the scope of this paper.
7.4 The scatter
The source-to-source scatter of the 3XMM data for MOS/pn pairs is substantial8 and comparable to that in the cluster sample (see Fig. 12). This confirms that the relatively large scatter we reported based on the cluster sample is not an inherent prob1em of clusters. It rather reflects some remaining problems in the common part of the analysis of the cluster sample and 3XMM when processing the data and/or estimating the effective area for a given observation.
8 Discussion
When producing the effective areas with the arfgen tool in the SAS software, the user has an option (applyxcaladjustment=yes) of adjusting the MOS effective area so that the spectral fit of the MOS data would yield results consistent with the pn on average. This correction has been derived by the XMM-Newton calibration team using the 3XMM sample (see the XMM-Newton calibration note CAL-SRN-0382). In order to avoid confusion between the above approach and the one we present in this paper, we discuss and compare the two below.
In Sect. 7, we show that the cluster sample and the 3XMM sample both indicated remaining inconsistencies of the calibration of the effective areas of MOS and pn (Fig. 12). We consider that the origin of the cross-calibration bias between the EPIC instruments needs to be understood before there can be scientifically justified progress on the issue of the inconsistence of the spectral fit parameters derived with the data from different EPIC instruments. Since the problem of the effective area cross-calibration bias is currently unresolved, we applied a scientific approach of considering it as a source of systematic uncertainty affecting the spectral fits. Our tools provide a practical way of evaluating and propagating these uncertainties to the results of the spectral analysis of the XMM-Newton/EPIC data.
The effective area cross-calibration bias measurements using the 3XMM and the cluster samples agree best at the lowest energies. However, the SAS implementation does not modify the effective area below 2 keV while our corrections are applicable down to 0.5 keV. On the other hand, there is a substantial difference between the medians of the two samples at the higher energies (above 4.5 keV). Thus, the average effective area correction for MOS will be different in the two approaches at some level.
The SAS implementation effectively assumes that the effective area calibration of the pn is very accurate and thus the effective area of MOS should be modified. Since there is no solid evidence for the above assumption, our tools allow the user to modify the effective area of any of the EPIC instruments.
Both the 3XMM sample and the cluster sample show that there is a substantial scatter in the evaluated cross-calibration bias between the individual objects (Sect. 7.4). The scatter is much larger than that allowed by the statistical uncertainties and the known systematic uncertainties. Thus, a single average correction for a random observation is not robust due to the ignored scatter. The reason for this scatter remains unknown and thus we consider it as an additional source of systematic uncertainties. Since there is currently no method for estimating accurately the cross-calibration bias for a given individual observation, we devised practical tools that allow the user to propagate the measured scatter to the spectral fit parameter uncertainties.
9 Summary and conclusions
We tested two methods for evaluating the effective area cross-calibration bias for CCD-type X-ray instruments. We applied the methods to a sample of clusters of galaxies observed with XMM-Newton/EPIC instruments and examined the cross-calibration of the total effective area as implemented in SAS19.1.0 in November 2021. We found and quantified the bias in the current effective area cross-calibration between the EPIC instruments. We repeated the analysis for objects in the 3XMM-DR7 catalogue to verify the robustness of the results. Our most important results are as follows:
We examined and compared the effect of performing the evaluation and analysis of the cross-calibration bias using the data before or after the convolution of the spectral models with the redistribution matrix. While the median cross-calibration bias obtained using the two methods deviates by less than 1% at the lower energies, the deviations become larger at higher energies, reaching 3% at 6 keV. Also, the cluster-to-cluster scatter is very similar in the two approaches except at the highest energies, where the post-convolution method suppresses the scatter somewhat;
The MOS/pn effective area cross-calibration bias factor in the 0.5–6.1 keV band deviates substantially from unity. The bias is systematic, suggesting that the MOS (pn) effective area may be calibrated too low (high), by ~3–27% depending on the instrument and energy band;
Our analysis suggests that the absolute energy dependences (i.e. shapes) of the effective area components of MOS2 and pn are correctly calibrated within ~1% in the 0.5−4.5 keV band. This is confirmed by the consistence with the 3XMM results;
The cluster analysis indicates that MOS1 stands out in the energy dependence comparison, suggesting that the absolute MOS1 effective area calibration has a significant bias that increases linearly with energy, amounting to ~5–10% in the 0.5−4.5 keV range;
The above results suggest, a bit surprisingly, that the effective area cross-calibration of the energy dependence between MOS2 and pn is in better agreement than that between MOS1 and MOS2;
In the 5–6 keV band, the abrupt behaviour of the bias in the cluster data between MOS and pn suggests that the drop in the MOS QE in this band has been overestimated. However, the 3XMM data do not confirm this;
The cluster-to-cluster rms scatter of the bias is substantial compared to the median bias itself. This is confirmed with 3XMM, and thus the scatter is not cluster-specific. The reasons for this effect and its random nature are beyond the scope of this work. Thus, a statistically robust implementation of the cross-calibration uncertainties in a scientific analysis of XMM-Newton/EPIC data should include the propagation of the scatter to the fit results (see Appendix B for the implementation) instead of simple average bias correction;
The study’s methods are powerful diagnostics tools for studying the effective area cross-calibration. We have demonstrated their applicability to galaxy cluster X-ray data, which reveals their potential for cross-mission effective area investigations: since clusters are stable over human timescales, non-simultaneous observations of the same clusters with different X-ray missions can be utilised.
On average the effective area cross-calibration of XMM-Newton/EPIC instruments in November 2021 in the 0.5−4.5 keV band was relatively successful. Future work is needed in order to understand the origins of the remaining cross-calibration bias and its substantial scatter.
Acknowledgements
The research leading to these results has received funding from the European Union’s Horizon 2020 Programme under the AHEAD2020 project (grant agreement no. 871158). Thanks to members of the XMM SOC for useful discussions and for making the 3XMM results available. We acknowledge the support by the Estonian Research Council grants PRG1006, and by the European Regional Development Fund (TK133).
Appendix A Parameter correlations
In this paper we have characterised the MOS/pn effective area cross-calibration bias and its statistical nature. In this section we provide practical information and procedures for the general user for treating the MOS/pn cross-calibration bias as a systematic uncertainty in the spectral analysis of the XMM-Newton/EPIC data.
The procedure is complicated in the case of significant correlations between the coefficients of the best-fit fourth-order polynomials we used to model the MOS/pn cross-calibration bias of the individual clusters (see Sect. 5.6 and Fig. 9). In order to understand better the correlations we computed the Pearson correlation coefficients between different pairs of the coefficients (ai, aj, where i,j = 0.4) of the above described fourth-order polynomials. The correlation matrices of the form
![Mathematical equation: ${\rm{corr}}\left( {{a_i},{a_j}} \right) = \left[ {\matrix{ {{a_0}} & \cdots & {{a_4}} \cr \vdots & \ddots & \vdots \cr {{a_4}} & \ldots & {{a_4}} \cr } } \right]$](/articles/aa/full_html/2023/08/aa45099-22/aa45099-22-eq9.png)
for MOS1/pn and MOS2/pn pairs yield
![Mathematical equation: ${\rm{cor}}{{\rm{r}}_{{{{\rm{MOS1}}} \mathord{\left/ {\vphantom {{{\rm{MOS1}}} {{\rm{pn}}}}} \right. \kern-\nulldelimiterspace} {{\rm{pn}}}}}}\left( {{a_i},{a_j}} \right) = \left[ {\matrix{ {1.00} & { - 0.95} & {0.87} & { - 0.75} & {0.61} \cr { - 0.95} & {1.00} & { - 0.97} & {0.89} & { - 0.78} \cr {0.87} & { - 0.97} & {1.00} & { - 0.97} & {0.91} \cr { - 0.75} & {0.89} & { - 0.97} & {1.00} & { - 0.98} \cr {0.61} & { - 0.78} & {0.91} & { - 0.98} & {1.00} \cr } } \right]$](/articles/aa/full_html/2023/08/aa45099-22/aa45099-22-eq10.png)
and
![Mathematical equation: ${\rm{cor}}{{\rm{r}}_{{{{\rm{MOS2}}} \mathord{\left/ {\vphantom {{{\rm{MOS2}}} {{\rm{pn}}}}} \right. \kern-\nulldelimiterspace} {{\rm{pn}}}}}}\left( {{a_i},{a_j}} \right) = \left[ {\matrix{ {1.00} & { - 0.98} & {0.93} & { - 0.85} & {0.74} \cr { - 0.98} & {1.00} & { - 0.98} & {0.92} & { - 0.84} \cr {0.93} & { - 0.98} & {1.00} & { - 0.98} & {0.93} \cr { - 0.85} & {0.92} & { - 0.98} & {1.00} & { - 0.98} \cr {0.74} & { - 0.84} & {0.93} & { - 0.98} & {1.00} \cr } } \right] $](/articles/aa/full_html/2023/08/aa45099-22/aa45099-22-eq11.png)
(respectively), indicating significant correlations between most of the parameters.
We visualised the correlations by plotting each parameter as a function of another one for each of the independent pair (see Figs. A.1 and A.2). We quantified these correlations by fitting the best-fit parameters of each pair of the coefficients (ai, aj) with a linear model aj· = A × ai + Β (see Fig. A.1 and Table A.1). Since our sample is not large enough to robustly sample the full parameter ranges, we cannot evaluate the scatter of the aj data at each value of ai. We thus assumed that the scatter is constant in the studied range of ai values and equal to the standard deviation of the difference of the ay data and the corresponding model predictions.
Consistently with the high degree of the correlations between the parameters, the scatter of the parameter correlations (σB in Table A.1) is small compared to the spread of the best-fit parameters (Table 3). Yet, ignoring the correlation scatter leads to underestimate of the final scatter of the modified effective areas when compared to data. A simple approach of allowing the parameters to vary within the correlation scatter leads to parameter combinations that are not consistent with the data. Due to the nature of the polynomial functions, many of these inconsistent parameter combinations produce models that deviate strongly from the data.
Thus, one would have to develop a more sophisticated method to properly incorporate the parameter correlations into the analysis. Instead, we devised an another method whereby we rely more on the data rather than the model. Namely, we use the statistical results for the cross-calibration bias in the cluster data sample (the medians and the standard deviations as reported in Table 2) to draw random cross-calibration bias data curves. This procedure ensures that we include the scatter of the data in the analysis. We then fit these datasets with fourth-order polynomials. In this manner the parameter correlations and their uncertainties are naturally propagated while the models remain consistent with the data.
 |
Fig. A.1 Correlations between the coefficients of the best-fit fourth-order polynomial models to the MOS1/pn cross-calibration data. The data are shown with blue symbols. The best-fit linear model and the variation characterised by the standard deviation of the differences between the Y-axis data and the corresponding model predictions are shown as dashed and dotted red lines, respectively. |
Parameters describing the correlations.
Appendix B Implementation
 |
Fig. B.1 Median (solid red line) and the variation as measured by the standard deviation (dashed red lines) of the cross-calibration bias parameter, J2, of the sample obtained by the procedure laid out in Appendix B. The blue symbols indicate the corresponding values obtained from the cluster data (repeated from Fig. 5). The results for the MOS1/pn and MOS2/pn pairs are shown in the left and right panels, respectively. The horizontal dashed line indicates the expectation (unity) in the case of no cross-calibration bias. |
We describe here in detail the procedure for the general user to implement the above information for X-ray spectral analyses of the XMM-Newton/EPIC data (these procedures are implemented in a public on-line tool9). (1) The work flow begins with the usual fitting of the X-ray spectrum with the standard SAS-produced arf. If the data being analysed are obtained with the pn instrument, the current implementation allows the user to choose whether to estimate the effect of the cross-calibration bias between pn and MOS1 or between pn and MOS2. If the user wishes to analyse the data obtained with MOS1 or MOS2, the procedure allows the evaluation of the effect of the cross-calibration bias between that instrument and the pn instrument. (2) Using the statistical results for the measure of the cross-calibration in the cluster sample corresponding to the choice of the instrument pair made in step 1 (Table 2) the user draws a random cross-calibration bias data curve. (3) The user fits the dataset obtained in step 2 with a fourth-order polynomial. (4) Depending on the choice of the instrument pair made in step 1, the user multiplies or divides the effective area column in the standard SAS-produced arf used in the beginning of the analysis with the best-fit fourth-order polynomial obtained in step 3. If, for example, the user wants to estimate the effect of the MOS1/pn cross-calibration bias on the spectral analysis of the MOS1 (pn) data, the fourth-order polynomial obtained in step 3 by fitting the randomised MOS1/pn cross-calibration bias data should be used to multiply (divide) the standard MOS1 effective area. (5) Steps 2–4 are repeated by a large number of times in order to produce a statistically meaningful sample of modified arf:s. (6) The spectral fit of step 1 is repeated, replacing each time the original arf with one of the arf:s generated by the above procedure. (7) The distribution of the best-fit parameters obtained with the modified arf:s can be analysed in order to evaluate the systematic uncertainty related to the cross-calibration bias.
We tested the above procedure by generating modified cross-calibration bias curves for MOS1/pn and MOS2/pn pairs. Using the distribution of the values at each energy we computed the sample median and the standard deviation. We found that using 1000 realisations, the median of the randomised sample agrees with that of the cluster data sample within 2% and the scatter, as measured by the standard deviation, is very similar in the two cases (see Fig B.1).
References
- Arnaud, K. A. 1996, in ASP Conf. Ser., 101, 17 [Google Scholar]
- Drake, J. J., Ratzlaff, P., Kashyap, V., et al. 2006, SPIE Conf. Ser., 6270, 62701I [NASA ADS] [Google Scholar]
- Gastaldello, F., Marelli, M., Molendi, S., et al. 2022, ApJ, 928, 168 [NASA ADS] [CrossRef] [Google Scholar]
- Hudson, D. S., Mittal, R., Reiprich, T. H., et al. 2010, A&A, 513, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kettula, K., Nevalainen, J., & Miller, E. D. 2013, A&A, 552, A47 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lumb, D. H., Finoguenov, A., Saxton, R., et al. 2003, Exp. Astron., 15, 89 [NASA ADS] [CrossRef] [Google Scholar]
- Madsen, K. K., Beardmore, A. P., Forster, K., et al. 2017, AJ, 153, 2 [Google Scholar]
- Marelli, M., Molendi, S., Rossetti, M., et al. 2021, ApJ, 908, 37 [CrossRef] [Google Scholar]
- Marshall, H. L., Chen, Y., Drake, J. J., et al. 2021, AJ, 162, 254 [NASA ADS] [CrossRef] [Google Scholar]
- Mateos, S., Saxton, R. D., Read, A. M., & Sembay, S. 2009, A&A, 496, 879 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nevalainen, J., Markevitch, M., & Lumb, D. 2005, ApJ, 629, 172 [CrossRef] [Google Scholar]
- Nevalainen, J., David, L., & Guainazzi, M. 2010, A&A, 523, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nevalainen, J., Valtchahov, I., Saxton, R. D., & Molendi, S. 2021, ArXiv e-prints, [arXiv:2103.01753] [Google Scholar]
- Plucinsky, P. P., Beardmore, A. P., Foster, A., et al. 2017, A&A, 597, A35 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Read, A. M., Guainazzi, M., & Sembay, S. 2014, A&A, 564, A75 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rosen, S. R., Webb, N. A., Watson, M. G., et al. 2016, A&A, 590, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schellenberger, G., Reiprich, T. H., Lovisari, L., Nevalainen, J., & David, L. 2015, A&A, 575, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sokal, R., & Rohlf, F. 1981, Biometry: The Principles and Practice of Statistics in Biological Research (San Francisco: W. H. Freeman) [Google Scholar]
- Tsujimoto, M., Guainazzi, M., Plucinsky, P. P., et al. 2011, A&A, 525, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Willingale, R., Starling, R. L. C., Beardmore, A. P., Tanvir, N. R., & O’Brien, P. T. 2013, MNRAS, 431, 394 [Google Scholar]
This assumption is not valid in the case of EPIC, and we investigate the effect below.
We replaced the error of the mean with the error of the median, as discussed in Sect. 5.
The scatter would be even larger when applying Method 2.
All Tables
Statistical results of the measure of the cross-calibration bias obtained with Method 2 for the cluster sample.
All Figures
|
Fig. 1 Ratio of the spectral data of A1795 and the prediction of the best-fit hybrid model, i.e. the absorbed thermal model modified by the splines (modelref,2; see Sect. 2.2), after diagonalising the redistribution matrix for pn (blue) and MOS1 (red), shown with the crosses. |
| In the text | |
|
Fig. 2 Different components of instrumentation for A1795 observation 0723802101 for pn (red lines), MOS1 (black lines), and MOS2 (blue lines). The top-left panel shows the total effective area generated with arfgen (solid lines; for clarity, MOS1 is not shown). The dotted lines indicate the average correction to the effective area assuming that the other instrument is perfectly calibrated (see Sect. 6). The other panels show the mirror-only effective area (top right), the QE of the detector (bottom left), and the transmission of the optical filter (bottom right). |
| In the text | |
|
Fig. 3 Demonstration of the quality of the modelling of the MOS1/pn cross-calibration bias for A1795 using Method 1 (left panel) and Method 2 (right panel). When applying Method 1, we evaluate Eq. (3), i.e. we approximate the cross-calibration bias after the convolution (blue crosses in the upper-left panel). The best-fit model (Eq. (4)) to such data is shown as a red line. When applying Method 2, we fit the MOS1 spectra (blue symbols in the upper-right panel; the statistical uncertainty is smaller than the plot symbol) with a model consisting of a fixed component for accurate modelling of the pn data (see the main text for details), while the cross-calibration bias is modelled as a fourth-order polynomial (the total model is shown as a red line in the upper-right panel; see Eq. (5)). In both cases, the lower panel shows the ratio of the best-fit model to the data. |
| In the text | |
|
Fig. 4 Best-fit models for each individual cluster obtained by fitting the MOS1/pn cross-calibration data using Eq. (4) when applying Method 1 (left panel) or Method 2 (right panel). Each solid line connects the values of one cluster at the energy bin centres. The black symbols and vertical lines indicate the median and the standard deviation of the sample at each energy. The symbols from the right panel are repeated in the left panel in blue. The horizontal dashed line at unity indicates the expectation in the case of no cross-calibration bias. |
| In the text | |
|
Fig. 5 Results obtained by analysing the measure of the cross-calibration bias (J2; see Eq. (6)). Upper panels: J2 for each observation for MOS1/pn (left panel) and MOS2/pn (middle panel) obtained via Method 2 (see the main text). Each line connects the values of one cluster at the energy bin centres. The black symbols and vertical lines indicate the median and the standard deviation of the sample at each energy. Lower panels: median J2 of the sample and their statistical (red crosses) and systematic (green crosses) uncertainties for MOS1/pn (left panel) and MOS2/pn (middle panel) pairs. The blue crosses indicate the standard deviation of the sample at a given energy (they are equal to the horizontal black lines in the upper panels). In all panels, the horizontal dashed line indicates the expectation (unity) in the case of no cross-calibration bias. Please note that the scales of the vertical axes are different in the upper and lower panels in order to better highlight the details. Right panels: approximative results for MOS1/MOS2 pair obtained by dividing the results of the left and middle panels. |
| In the text | |
|
Fig. 6 Median cross-calibration bias parameter J1 (Eq. (3)), obtained with Method 1, of different observations and their standard deviation for the MOS2/pn pair for the standard energy binning used in the paper (blue crosses) and for a coarser binning (red crosses). In the latter case, the statistical uncertainties of each individual observation are below 1% in each bin. |
| In the text | |
|
Fig. 7 Cross-calibration bias factor J1 using Method 1 (Eq. (3)) in the 0.5−2.0 keV band (red lines and symbols) and the 2.0−6.0 keV band (blue lines and symbols) as a function of the time (revolution number during which the given observation was performed) for MOS1/pn (left panel), MOS2/pn (middle panel), or MOS1/MOS2 (right panel) pairs. The dotted lines indicate the sample median. |
| In the text | |
|
Fig. 8 Median of the measures of cross-calibration bias, with statistical and systematic uncertainties (red and green symbols, repeated from the bottom panel of Fig. 5) for the MOS1/pn (left panel), MOS2/pn pair (middle panel), and MOS1/MOS2 pairs. The solid golden lines in the left and middle panels indicate the linear models whose parameters are the medians of those obtained by fitting the individual cluster data for MOS/pn pairs in the 0.5–4.5 keV band with a linear model. The dashed golden lines indicate the extrapolation of the above models to the 4.5–6.1 keV band. The MOS1/MOS2 data were fitted in the 0.5–6.1 keV band (right panel). In all panels, the horizontal dashed line indicates the expectation (unity) in the case of no cross-calibration bias. |
| In the text | |
|
Fig. 9 Best-fit models for each individual cluster obtained by fitting the cross-calibration data of the MOS1/pn pair (left panel) or the MOS2/pn pair (right panel, repeated from the right panel of Fig. 3) using Method 2. Each solid line connects the values of one cluster at the energy bin centres. The black symbols and vertical lines indicate the median and the standard deviation of the sample at each energy level. The dashed blue lines indicate the fourth-order approximation of the median. The MOS1/pn curve is repeated in the right panel as a dashed white-red line. |
| In the text | |
|
Fig. 10 Distributions of the best-fit parameters of the fourth-order polynomials used for modelling the cross-calibration bias of single clusters for the MOS1/pn pair shown with the red histogram. The best-fit Gaussians to the above distributions are shown as a dashed blue line. The best-fit centroid of the Gaussian and the central interval containing 68% of the probability interval are indicated with a dashed black line and the yellow band, respectively. |
| In the text | |
 |
Fig. 11 Same as for Fig. 10 but for the MOS2/pn pair. |
| In the text | |
|
Fig. 12 Median cross-calibration bias parameter, J1 (Eq. (3)), of different observations and their statistical uncertainties obtained using Method 1 shown as red crosses for the MOS1/pn (left panel) and MOS2/pn (right panel) pairs (at the lowest energies, the values are smaller than the plot symbol width). The blue crosses indicate the standard deviation of the cluster sample at a given energy. The black crosses indicate the medians and the range containing 68% of the values of the 3XMM sample. The horizontal dashed line indicates the expectation (unity) in the case of no cross-calibration bias. |
| In the text | |
|
Fig. A.1 Correlations between the coefficients of the best-fit fourth-order polynomial models to the MOS1/pn cross-calibration data. The data are shown with blue symbols. The best-fit linear model and the variation characterised by the standard deviation of the differences between the Y-axis data and the corresponding model predictions are shown as dashed and dotted red lines, respectively. |
| In the text | |
 |
Fig. A.2 Same as Fig. A.1 but for the MOS2/pn pair. |
| In the text | |
|
Fig. B.1 Median (solid red line) and the variation as measured by the standard deviation (dashed red lines) of the cross-calibration bias parameter, J2, of the sample obtained by the procedure laid out in Appendix B. The blue symbols indicate the corresponding values obtained from the cluster data (repeated from Fig. 5). The results for the MOS1/pn and MOS2/pn pairs are shown in the left and right panels, respectively. The horizontal dashed line indicates the expectation (unity) in the case of no cross-calibration bias. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.