| Issue |
A&A
Volume 609, January 2018
|
|
|---|---|---|
| Article Number | A103 | |
| Number of page(s) | 21 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201731410 | |
| Published online | 25 January 2018 | |
Chasing the peak: optimal statistics for weak shear analyses
Leiden Observatory, Leiden University, PO Box 9513, 2300 RA Leiden, The Netherlands
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received: 20 June 2017
Accepted: 9 October 2017
Abstract
Context. Weak gravitational lensing analyses are fundamentally limited by the intrinsic distribution of galaxy shapes. It is well known that this distribution of galaxy ellipticity is non-Gaussian, and the traditional estimation methods, explicitly or implicitly assuming Gaussianity, are not necessarily optimal.
Aims. We aim to explore alternative statistics for samples of ellipticity measurements. An optimal estimator needs to be asymptotically unbiased, efficient, and robust in retaining these properties for various possible sample distributions. We take the non-linear mapping of gravitational shear and the effect of noise into account. We then discuss how the distribution of individual galaxy shapes in the observed field of view can be modeled by fitting Fourier modes to the shear pattern directly. This allows scientific analyses using statistical information of the whole field of view, instead of locally sparse and poorly constrained estimates.
Methods. We simulated samples of galaxy ellipticities, using both theoretical distributions and data for ellipticities and noise. We determined the possible bias Δe, the efficiency η and the robustness of the least absolute deviations, the biweight, and the convex hull peeling (CHP) estimators, compared to the canonical weighted mean. Using these statistics for regression, we have shown the applicability of direct Fourier mode fitting.
Results. We find an improved performance of all estimators, when iteratively reducing the residuals after de-shearing the ellipticity samples by the estimated shear, which removes the asymmetry in the ellipticity distributions. We show that these estimators are then unbiased in the absence of noise, and decrease noise bias by more than ~30%. Our results show that the CHP estimator distribution is skewed, but still centered around the underlying shear, and its bias least affected by noise. We find the least absolute deviations estimator to be the most efficient estimator in almost all cases, except in the Gaussian case, where it’s still competitive (0.83 < η < 5.1) and therefore robust. These results hold when fitting Fourier modes, where amplitudes of variation in ellipticity are determined to the order of 10-3.
Conclusions. The peak of the ellipticity distribution is a direct tracer of the underlying shear and unaffected by noise, and we have shown that estimators that are sensitive to a central cusp perform more efficiently, potentially reducing uncertainties by more than 50% and significantly decreasing noise bias. These results become increasingly important, as survey sizes increase and systematic issues in shape measurements decrease.
Key words: gravitational lensing: weak / methods: data analysis / dark matter / large-scale structure of Universe / cosmological parameters / methods: statistical
© ESO, 2018
1. Introduction
Since the first gravitational shear detections (Tyson et al. 1990), the statistical analysis of weak gravitational lensing effects has become recognized as a competitive cosmological tool. With the advent of precision cosmology, meaningful interpretations of statistical agreement or tension between various models and datasets become increasingly important.
Weak gravitational lensing produces slight magnification and distortion effects by bending the paths of light rays. Although analyses of the former have produced important scientific results (e.g., Hildebrandt et al. 2009; Van Waerbeke et al. 2010) and it has in fact been demonstrated that combined analyses can give better constraints (Hildebrandt et al. 2011; Ford et al. 2012), most scientific information has come from the analysis of weak shear distortions. To access that information, one has to be able to (1) measure the shapes of lensed background sources accurately, (2) understand the intrinsic distribution of these shapes and the effects of shear and noise on statistical inference, and (3) obtain the statistical power to probe the subtle perturbations of this distribution by weak shear.
For the first part, a multitude of shape measurement methods have been explored, among which are foremost methods based on surface brightness moments (e.g., Kaiser et al. 1995; Rhodes et al. 2000) and model fitting methods (e.g., Kuijken 1999; Bernstein & Jarvis 2002; Hirata & Seljak 2003; Refregier & Bacon 2003; Kuijken 2006; Miller et al. 2007; Kitching et al. 2008), with various alternative or combined approaches (Bernstein & Armstrong 2014; Herbonnet et al. 2017; Zhang et al. 2015).
Community-driven projects for optimal and robust shape estimates (Heymans et al. 2006; Massey et al. 2007; Bridle et al. 2010; Kitching et al. 2012; Mandelbaum et al. 2015) have led to a further decrease in measurement variances and a better understanding of remaining systematic effects and biases (e.g., Voigt & Bridle 2010; Bernstein 2010; Kacprzak et al. 2012; Melchior & Viola 2012; Refregier et al. 2012).
For the last part, the last two and a half decades have also known dramatic improvements in statistical power. Surveys that are finished, ongoing, and planned such as COSMOS1 (Leauthaud et al. 2007), CFHTLenS2 (Heymans et al. 2012b), RCSLenS3 (Hildebrandt et al. 2016), KiDS4 (de Jong et al. 2013), DES5 (Dark Energy Survey Collaboration et al. 2016), LSST6 (Ivezic et al. 2008), Euclid7 (Laureijs et al. 2011) steadily increase in size (sky coverage and depth) and imaging quality, including a significant improvement in understanding and correcting for systematic effects (e.g., Heymans et al. 2012a,b,for CFHTLenS).
This increasing statistical power is necessary to overcome the inference limit set by the intrinsic galaxy shape distribution, known as shape noise. Unlike many forms of noise, such as measurement uncertainties that are often dominated by Poisson processes, there is no reason that the ellipticities of background galaxies follow a Gaussian distribution. In fact, studies of galaxy morphologies (Lambas et al. 1992; Rodríguez & Padilla 2013) suggest that late type galaxies may exhibit a roughly uniform axis ration distribution.
This departure from Gaussianity is clearly demonstrated in Sect. 2, when comparing the shape distribution of the CFHTLenS shape measurements catalog (Heymans et al. 2012b, Fig. 2) to a simulated Gaussian distribution (Fig. 1). This implies that commonly used Gaussian estimators, such as the (weighted) mean estimate of the central peak of the distribution or the variance for its width, are not necessarily optimal for the inference of the underlying gravitational shear.
For example, if the tails of the ellipticity distribution decline more slowly than the Gaussian exp(−x2), then more elliptical galaxies contribute more shape noise. There have been many weighting and clipping schemes suggested to minimize biases and uncertainties in weak shear inference (Bonnet & Mellier 1995; Van Waerbeke et al. 2000; Bernstein & Jarvis 2002). Alternative approaches include distribution symmetrization (Zhang & Zhang 2017), or using ensembles of galaxies in Bayesian analyses or nulling techniques (Bernstein & Armstrong 2014; Herbonnet et al. 2017), so that the step of individual shape measurement before inference of the underlying shear is bypassed.
In this article, we explore an alternative approach by reviewing statistical estimators that are more suited to a distribution with a pronounced central cusp and slowly declining tails. Estimator optimality would include a low or vanishing estimator bias and a high accuracy by a low spread in estimates. These aspects should be robust for various possible distributions, as samples of background galaxies are comprised of different populations.
We then highlight the use of these estimators in fitting the shear pattern in the field of view with Fourier modes (Fourier mode fitting, FMF). This approach provides an alternative to smoothed gridding and locally sparse and therefore poorly constrained estimates. It provides statistical information constrained by the whole field of view, and incorporates fluctuations in background number densities and estimated measurement uncertainties automatically. For subsequent scientific analyses, the Fourier model allows for relatively straightforward, analytic approach to fundamental quantities, such as a power spectrum or mass density reconstruction.
We note that we focus on the statistical inference from samples of measured shapes, for various possible intrinsic shape distributions, that is, the propagation of shape noise. This is a single but fundamental step in improving the accuracy and fidelity of weak lensing analyses. We do not perform a subsequent cosmological analysis, which would require addressing other well-known sources of bias and systematic effects. These include for example selection and detection biases (e.g., Hirata et al. 2004; Miller et al. 2013; Jarvis et al. 2016) among others on the instrumental and computational side. Other sources include physical effects that affects the interpretation of the measured signal, such as the effects of baryons, or the redshift distribution and intrinsic alignments of lensed background galaxies background sources. The shear signal we recover in this paper would represent a combined signal, which would then need to be interpreted.
The remainder of this paper is organized as follows. We will briefly review the necessary definitions of galaxy shapes and the weak lensing formalism in Sect. 2, referring the reader to excellent reviews such as Bartelmann & Schneider (2001), Schneider (2006), Hoekstra & Jain (2008), for more in-depth approaches. We review the necessary statistical framework in Sect. 3, where we discuss galaxy shape distributions and statistical estimators, including definitions for efficiency and bias, before expanding on FMF. In Sect. 4 we describe the various possible simulations and data, and analysis methods. In Sect. 5 we discuss the results and the scientific implications. Section 6 gives a summary of our conclusions.
 |
Fig. 1 Gaussian ellipticity distribution and corresponding axis ratio distribution. Top: a 2D histogram of ellipticities. Middle: histogram of the absolute ellipticity | e |. Bottom: histogram of the ellipse axis ratio q. |
 |
Fig. 2 Ellipticity and axis ratio distributions of the CFHTLenS catalog. Top: a 2D histogram of ellipticities. We note that the ring-like feature at e ≈ 0.8 is due to noisy outliers forced to a maximum e by the shape measurement pipeline, but see also Fig. 8. Middle: histogram of the absolute ellipticity | e |. Bottom: histogram of the ellipse axis ratio q. |
2. Weak lensing
Gravitational lensing is the effect of curved space-time on the paths of light rays from distant sources to the observer as they pass through the gravitational potential of foreground structures. This geometrical effect leads to a displacement of point sources on the projected plane of the sky. The differential effect on images I(x,y) of extended sources leads to magnification and distortion effects, know as the convergence κ and the shear γ = γ1 + iγ2, directly related to the surface mass density. This is commonly described as a coordinate transformation 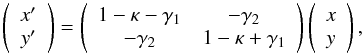 (1)resulting in the lensed image I(x′,y′).
(1)resulting in the lensed image I(x′,y′).
Weak lensing magnification analyses (e.g., Hildebrandt et al. 2009; Van Waerbeke et al. 2010) require the intrinsic (distribution of) source sizes or magnitudes. In weak shear analyses, the focus lies on the net distortion or reduced shear g = g1 + ig2 ≡ (γ1 + iγ2)/(1−κ): 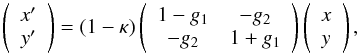 (2)where the transformation is written as a multiplication of (1−κ) (which leads to the magnification) and a traceless distortion matrix describing the alignment of lensed sources in the foreground potential.
(2)where the transformation is written as a multiplication of (1−κ) (which leads to the magnification) and a traceless distortion matrix describing the alignment of lensed sources in the foreground potential.
The distortion effect of weak lensing shear on images of background galaxies depends on their intrinsic shape distribution. While galaxies often have complex morphologies, it is adequate to describe images by their quadrupole brightness moments or their ellipticities, and the respective response to weak shear distortions.
A common definition of the shape of an image with elliptical isophotes is the ellipticity e = e1 + ie2, defined as the reduced shear needed to create this image from an image with circular isophotes (Bernstein & Jarvis 2002; Kuijken 2006). This gives an axis ratio 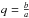 as
as 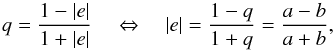 (3) and position angle θ via
(3) and position angle θ via 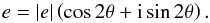 (4)As an example, we compare a Gaussian (e1,e2) distribution to the distribution observed in the CFHTLenS shape measurement catalog in Figs. 1 and 2.
(4)As an example, we compare a Gaussian (e1,e2) distribution to the distribution observed in the CFHTLenS shape measurement catalog in Figs. 1 and 2.
This complex notation gives a most straightforward formulation of the resulting ellipticity 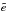 , after transforming an image with ellipticity e by a distortion g, by Seitz & Schneider (1997)
, after transforming an image with ellipticity e by a distortion g, by Seitz & Schneider (1997)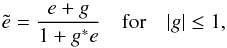 (5) with g* the complex conjugate of g.
(5) with g* the complex conjugate of g.
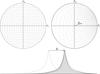 |
Fig. 3 Top: the non-linear mapping of ellipticities (with | e | ≤ 1) by an exaggerated gravitational shear of g = 0.33 + 0.11i. Bottom: the asymmetry introduced in the ellipticity distribution, highlighted for the e1-component. |
The non-linear effect of gravitational shear on the ellipticity parameters is shown in the top panel of Fig. 3. Through statistical estimation, we can attempt to infer from an ensemble of galaxy shapes the underlying shear, if we assume the intrinsic ellipticity distribution P(e) to be centered around zero ellipticity. In other words, one assumes no preferred direction on the sky.
This non-linear response to weak shear distortions gives rise to the asymmetry in the observed ellipticity distribution, as shown in the bottom panel of Fig. 3. The shifted central peak of the distribution is unaffected by this non-linearity and therefore a direct tracer of g.
The canonical approach is a weighted mean μ, where weighting schemes attempt to minimize systematic effects from noise, size and brightness. As observed by Seitz & Schneider (1997), the expectation value 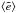 does not depend on P(e) in the absence of noise. The mean of an ensemble of measured ellipticities is then an asymptotically unbiased estimator for the underlying shear g.
does not depend on P(e) in the absence of noise. The mean of an ensemble of measured ellipticities is then an asymptotically unbiased estimator for the underlying shear g.
In the presence of noise, however, these estimations suffer from unavoidable biases in the estimated shear (Melchior & Viola 2012; Kacprzak et al. 2012). Furthermore, the variance of an estimator such as the mean, or more generally, the scale of the estimator distribution, does depend on the intrinsic ellipticity distribution P(e). Informally put, the smaller the estimator variance, the more “trustworthy” the estimates and the more efficient the estimator. A more efficient estimator reduces the uncertainties in and therefore the error bars or confidence intervals of parameter estimates.
The smearing of the sheared distribution by noise affects central value estimations, but the peak location itself is still an unbiased tracer of the shear.
3. Statistical framework
In this section, we discuss various estimators, after reflecting upon estimator properties, such as bias, efficiency, and robustness, and their interpretation. We then propose ways to apply this to fitting individual Fourier modes to a shear field.
3.1. Bias, efficiency and robustness
We will use the term bias, or Δe, when referring to the difference between the central value of an estimator, such as the expected value or mean ⟨ê⟩, and the population parameter e. We will use the term residuals, or ri = ei−ê, when talking about the differences between one sample estimate and the elements of that sample, that is, the individual measurements ei = ei,1 + iei,2.
We note that we write ri = ei−ê for simplicity throughout this paper, but we employ Eq. (5) to calculate the residuals, unless specifically noted otherwise. The absolute residual ellipticity of a single measurement with respect to the sample estimate is then the norm |ri|.
The difference Δe = ⟨ê⟩−e, commonly referred to as simply the bias of the estimator, is formally called the mean-bias μΔe. An estimator is then called asymptotically mean-unbiased, if for an increasing number of estimations ê, the mean estimate μê converges toward the parameter value of the underlying population. This is commonly simply referred to as unbiased. Here we have changed notation from ⟨ê⟩ to μê, to emphasize the method of determining the central value of a set of estimates.
We do this, because there are other possible definitions of unbiasedness, such as median-unbiasedness, in which case the median estimate M(ê) converges toward the true parameter value. By the central limit theorem, it is often appropriate to assume an asymptotically normal distribution of the estimator ê (not to be confused with the distribution P(e) of the population parameter e), when the number of estimations increases. This validates the general use of mean-unbiasedness. In practice, sample sizes needed for convergence toward a normal estimator distribution can be very large and one should take care when assuming asymptotic normality when making statistical inferences from a few measurements.
The efficiency of an estimator can be defined in terms of its variance. For unbiased estimators, this variance is bounded from below by the Cramér-Rao lower bound (Rao 1945; Cramér 1946), which in short means that there is an absolute maximum efficiency that can be obtained. For some distributions, such as the Gaussian distribution, this limit can be calculated analytically8. In other cases, it is useful to define a relative efficiency 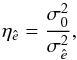 (6)where
(6)where 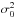 is the variance of a comparison estimator, such as the mean. Then, if for example ηê> 1, the estimator has a lower variance than the mean and is therefore more efficient in finding the central value of the population parameter distribution. An estimator that achieves the Cramér-Rao lower bound for all possible parameter values is for this reason also known as a minimum variance estimator.
is the variance of a comparison estimator, such as the mean. Then, if for example ηê> 1, the estimator has a lower variance than the mean and is therefore more efficient in finding the central value of the population parameter distribution. An estimator that achieves the Cramér-Rao lower bound for all possible parameter values is for this reason also known as a minimum variance estimator.
Again, if the assumption of asymptotic normality is not appropriate, another definition of the scale of distribution of the estimator can be used instead of the variance, such as the median absolute deviation (MAD). In such cases, care should be taken with the coverage of that scale, which is simply the percentage of estimates with lower residuals than the scale. In case of a Gaussian distribution, the standard deviation has a coverage of 68.3%. The MAD has, by definition, a coverage of 50%.
To avoid comparing apples with oranges, we will use chosen percentiles as scale, so the coverage is defined. For instance, we define the 68.3% scale s68.3 as the residual value for which 68.3% of the estimates has an equal or lower residual. In case of asymptotic normality, 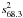 will converge to the same value as the estimator variance.
will converge to the same value as the estimator variance.
We note that we can do this, since in our simulations the true population parameter value e is known9. In general, the coverage of a definition of scale is not known, confusing the interpretation of any relative efficiency.
In conclusion, we define the efficiency of an estimator ê, relative to the mean μe, at a certain percentile coverage p, as 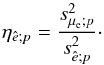 (7)Finally, we label an estimator ê as robust (in a qualitative manner), when ê retains low or zero bias and high efficiency in a wide range of possible distributions. A robust estimator is desirable, since it makes the choice of estimator for a parameter with unknown distribution more objective. As an example, the mean is optimally efficient in case of a Gaussian parameter distribution, but since the mean has low resistance against departures from Gaussianity (such as outliers), it is not the most robust.
(7)Finally, we label an estimator ê as robust (in a qualitative manner), when ê retains low or zero bias and high efficiency in a wide range of possible distributions. A robust estimator is desirable, since it makes the choice of estimator for a parameter with unknown distribution more objective. As an example, the mean is optimally efficient in case of a Gaussian parameter distribution, but since the mean has low resistance against departures from Gaussianity (such as outliers), it is not the most robust.
Since we work with relative efficiencies, a conclusive statement about robustness is not straightforward. We will therefore use robustness to indicate that an estimator is equally or more efficient than the Gaussian estimator in most or all cases.
3.2. Estimators
We have explored various alternatives for well known estimators, which are optimal under Gaussian assumptions, like the mean and variance. By definition, the mean êμ, or μe, minimizes the variance of the residuals, which makes it a least squares estimator.
In general, optimization estimators are solutions ê that minimize a loss function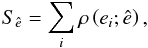 (8)such as
(8)such as 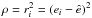 for the mean.
for the mean.
For this paper, we considered two other optimization estimators, the least absolute deviations estimator (LAD) and the biweight (BI) estimator, and an ordering estimator, namely convex hull peeling (CHP). In Sect. 3.3, we describe Fourier mode fitting (FM), using a LAD regression approach.
3.2.1. Least absolute deviations
LAD is an optimization approach where the loss function to be minimized is the sum of the absolute deviations, instead of the commonly used least squares minimization: 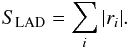 (9)In the one dimensional case, this is the median. In more than one dimension, we talk about the marginal median, when in each dimension the median is taken independently, or the spatial median, when minimizing the sum of the distances of measurements to a point. In many practical cases10, the spatial median is unique, contrary to the marginal median, which can have multiple solutions. This is one of the reasons we used the spatial median throughout the rest of the paper.
(9)In the one dimensional case, this is the median. In more than one dimension, we talk about the marginal median, when in each dimension the median is taken independently, or the spatial median, when minimizing the sum of the distances of measurements to a point. In many practical cases10, the spatial median is unique, contrary to the marginal median, which can have multiple solutions. This is one of the reasons we used the spatial median throughout the rest of the paper.
Another reason is that e1 and e2 should not be seen as independent parameters of the shape. An ellipticity is defined by an absolute elongation | e | and a position angle θ. The latter is defined within the context of a chosen frame of reference and therefore so are e1 and e2. In other words, using the marginal median would introduce an artificial anisotropy, as can be seen in Fig. 4.
In concreto, for a set of (ei,1,ei,2) measurements, the mean êμ as an estimator for the net reduced shear g1 + ig2 minimizes the squared residuals 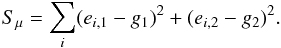 (10)A LAD estimate minimizes the absolute residuals,
(10)A LAD estimate minimizes the absolute residuals, 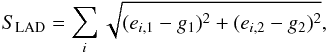 (11)which reduces the effect of outliers on the estimate. In one dimension, the LAD estimate arises as the central value maximum likelihood estimator of the Laplace distribution, which has a central cusp and more slowly declining tails.
(11)which reduces the effect of outliers on the estimate. In one dimension, the LAD estimate arises as the central value maximum likelihood estimator of the Laplace distribution, which has a central cusp and more slowly declining tails.
There is no general analytic solution for LAD optimization. LAD can however be formulated as a linear optimization problem for which several iterative methods exist (e.g., simplex-based methods, Barrodale & Roberts 1973). In practical weak shear analyses, convergence is generally rapid.
 |
Fig. 4 Comparison of the marginal median (left) to the spatial median, or LAD estimation (right). Plotted are the estimation biases Δe for 106 simulation runs, shown as a density in grayscale. Over-plotted are arbitrary contours of increasing density (equal in both plots), to highlight the anisotropy in P(Δe). Since e1 and e2 depend on the choice of reference frame, the marginal median introduces an artificial anisotropy. For the LAD estimations, the residual distances | ri | do not depend on the choice of reference frame. |
3.2.2. The biweight
An alternative optimization approach is a bi-square weighted loss function (Beaton & Tukey 1974), called the biweight for short, given by 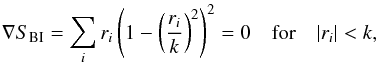 (12)where ri = (ei−ê) are again the residuals and k is a tuning parameter, usually determined by (an estimate of) the scale of the measured distribution.
(12)where ri = (ei−ê) are again the residuals and k is a tuning parameter, usually determined by (an estimate of) the scale of the measured distribution.
A robust choice for k is the MAD, setting k = c·MAD, where c = 6.0 is optimal for estimation of location for a broad range of distributions (Mosteller & Tukey 1977). A common approach is iteratively correcting an initial estimate M0 by the normalized sum in Eq. (12): 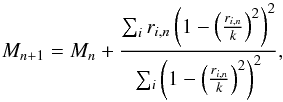 (13)which can be interpreted as a normalized weighting of the residuals. In this case, the weight of a certain measurement increases toward the (current) central estimate, which makes this estimator a useful complement to the mean and LAD estimators.
(13)which can be interpreted as a normalized weighting of the residuals. In this case, the weight of a certain measurement increases toward the (current) central estimate, which makes this estimator a useful complement to the mean and LAD estimators.
In turn, a robust choice for M0 is the (spatial) median. Note that measurements with residuals | ri,n | ≥ k have effectively zero weight, although these points are not “clipped” from the sample, since the residuals can change with each iteration. Convergence usually requires few iterations.
3.2.3. Convex hull peeling
The convex hull of a set of points X in Rn can be defined as the intersection of all convex sets in Rn that contain X. Informally put, the convex hull is the smallest subset of points that “surrounds” the rest of the set (see Fig. 5).
 |
Fig. 5 The method of CHP. The left panel shows a scatter plot with two outliers. The arithmetic mean is shown as a gray, solid line and the dotted line represents the mean without the two outliers. The middle panel shows the convex hull of the set of points, which is then removed from the set. The right panel shows the final result after repeating the process, until the final set of points is equal to its own convex hull. |
There exist various algorithms for determining the convex hull (e.g., Preparata & Shamos 1985). For this paper, we used Delaunay triangulation based on the divide-and-conquer method (Lee & Schachter 1980).
In the process of CHP, the convex hull of a set of data points is determined and subsequently “peeled” from the set, after which the process is repeated (Fig. 5). When the remaining set of points is equal to its own convex hull, the final estimate is determined from these points, for example using the mean or LAD. This makes CHP an ordering approach, much like obtaining the familiar median for the one-dimensional case by sorting the data, instead of optimization11. Among other aspects, it shares the resistance of the median against outliers.
In this paper, we are interested in the use of CHP in the two-dimensional case of (e1,e2) measurements in the complex plane, but CHP can be used in higher dimensions as well (see e.g., Lee 2007, for applications to SDSS quasar data).
3.2.4. Weighting and collinearity
When using real data, a weighting of ellipticity measurements is necessary to avoid or mitigate effects, such as noise or intrinsic size and ellipticity, that would confuse or bias the estimation of the underlying shear. For LAD and biweight optimization, weighting schemes are readily introduced, analogous to the weighted mean. For CHP, we suggest a possible weighting scheme, analogous to the one-dimensional weighted median, as follows.
The convex hull comprises a set of points in the (ei,1,ei,2)-plane, with wi the associated weights, given by the measurement pipeline. The minimum weight on the convex hull is then subtracted from these weights, after which all points with updated weight wi = 0 are peeled from the sample. Note that this removes at least one point per iteration, but can lead to point-by-point peeling and large computation times. A solution with lesser precision but increased speed would be given by binning the weights in discrete steps.
We also note a possible collinearity problem of multiple ellipticity measurements with finite precision coinciding. In that case, triangulation has no solution. By combining these points into one measurement by combining the weights, this problem is resolved.
3.3. Fourier mode fitting
One can model a signal, in our case a varying ellipticity, over a one-dimensional range −L < x < L, writing that signal as a linear superposition of waves, or (Fourier) modes, An·cos(knx ± φn), where An and φn are the amplitude and phase of the signal mode respectively, and 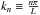 are the wave numbers of the modes, showing the periodicity over the range 2L.
are the wave numbers of the modes, showing the periodicity over the range 2L.
It is useful to rewrite this model linearly in its coefficients 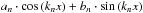 , where amplitude and the phase are now given by
, where amplitude and the phase are now given by 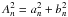 and via
and via 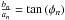 .
.
This one-dimensional model is readily extended to two dimensions, by considering that each coefficient depends similarly on y, giving αmn; ± = cos(kmx ± lny) and βmn; ± = cos(kmx ± lny), or  (14)where the wave numbers km and ln represent the spatial frequencies in the x and y directions, respectively. In two dimensions, we make a terminological distinction between a full Fourier mode, as given by Eq. (14), and the individual waves comprising it. The amplitude of the fluctuations in ellipticity are now given for each mode in m,n by
(14)where the wave numbers km and ln represent the spatial frequencies in the x and y directions, respectively. In two dimensions, we make a terminological distinction between a full Fourier mode, as given by Eq. (14), and the individual waves comprising it. The amplitude of the fluctuations in ellipticity are now given for each mode in m,n by 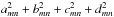 .
.
This linear model is fitted in a relatively straightforward manner to a sample of measured or simulated ellipticities. In the absence of noise and for a well-behaved field of view, each wave component of a Fourier mode is independent and can be fitted separately. We will discuss the effect of noise in Sect. 5.2.
3.3.1. Applying statistics
To apply these statistics to a shear field consisting of discrete Fourier modes, which by construction is centered around e = 0, the ellipticity measurements should be properly weighted by the model of the Fourier mode under consideration. We considered the information carried by an ellipticity measurement, which is proportional to the value of the fitted model M, where M(x,y) can for instance be a single wave like 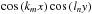 , or a full mode.
, or a full mode.
 |
Fig. 6 Ellipticity distribution of a superposition of 9 Fourier modes over the complex (e1,e2) plane, where we show how we recover a single (e1,e2) amplitude, indicated by the dotted lines. Left: the Fourier modes, centered around (0,0) (normalized number counts). Middle: the (e1,e2) points shifted by sgn(M), with M the model of the amplitude (normalized number counts). Right: the resulting distribution of weights over (e1,e2), showing a shift toward the amplitude under consideration. |
Measurements close to the nodes of a wave carry the least information, whereas measurement close to extrema, or antinodes, carry the most amplitude information. We considered that each ellipticity measurement ei theoretically infers an estimate of the amplitude A, where A ∈ { amn,bmn,cmn,dmn } by Âi = ei·M-1. In the case of Gaussian variations around the model, that is, measurement error distribution, the information scales as the inverse variance of that distribution, and therefore as the square of the model: 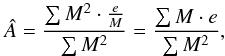 (15)where we recover the well known analytic LSQ form. This can be seen as an inverse variance weighting based on the model-to-noise ratio. For different error distributions, one can allow a general scaling of the information with the model by Mn, and therefore
(15)where we recover the well known analytic LSQ form. This can be seen as an inverse variance weighting based on the model-to-noise ratio. For different error distributions, one can allow a general scaling of the information with the model by Mn, and therefore 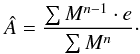 (16)For application with our proposed weighting scheme for CHP, it is instructive to view the multiplication by weights as shifting the data points, so the central data point(s) or CHP value matches the amplitude to be estimated. For this purpose, it is practical to write Eq. (16) as
(16)For application with our proposed weighting scheme for CHP, it is instructive to view the multiplication by weights as shifting the data points, so the central data point(s) or CHP value matches the amplitude to be estimated. For this purpose, it is practical to write Eq. (16) as 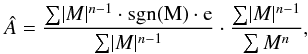 (17)where the (e1,e2) data points are first shifted by sgn(M), and then weighed by | M |, before the weighed estimate is normalized as usual. We show this in Fig. 6, where we plot the (e1,e2) values, the same (e1,e2) points shifted by sgn(M), with in this case
(17)where the (e1,e2) data points are first shifted by sgn(M), and then weighed by | M |, before the weighed estimate is normalized as usual. We show this in Fig. 6, where we plot the (e1,e2) values, the same (e1,e2) points shifted by sgn(M), with in this case 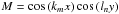 , and then the associated distribution of the weights | M | over the complex ellipticity plane as normalized 2D histograms.
, and then the associated distribution of the weights | M | over the complex ellipticity plane as normalized 2D histograms.
 |
Fig. 7 Ellipticity distributions for a uniform axis ratio distribution. Top: a 2D histogram of ellipticities. Middle: histogram of the absolute ellipticity | e |. Bottom: histogram of the ellipse axis ratio q. A cut-off near q ≈ 0.2 is suggested by observations and produces standard deviations in each ellipticity component of σe ≈ 0.25, comparable to most survey shape measurement catalogs. |
4. Simulations and data
For this paper, we tested various forms of P(e), using samples of random ellipticities, assumed to be centered around zero, which we sheared by Eq. (5). We have used several approaches to obtaining these samples.
Firstly, we simulated a uniform q distribution, which seems to fit real data adequately (e.g., Lambas et al. 1992; Rodríguez & Padilla 2013), without assuming any physical mechanism that would explain this distribution.
Secondly, we modeled background galaxies as randomly orientated triaxial ellipsoids, and derived the projected ellipticities following Stark (1977), using axis ratio distributions fitted to observed ellipticity distributions (Lambas et al. 1992).
In both cases, we compared our results to samples with added Gaussian noise, using real data shape measurement error distributions to simulate the effect of noise.
Thirdly, we sampled real data, using shape measurement catalogs from weak lensing observations.
Finally, we compared these various ellipticity distributions and the results from each estimator to results in case when P(e) follows a Gaussian distribution. We examined the behavior of bias and efficiency of each estimator under the effect of noise, the input shear and the sample size.
4.1. Simulated ellipticity distributions
4.1.1. Uniform samples
We produced random samples with a uniform q-distribution, as an ideal version of the observed distribution of spiral galaxies in for example Lambas et al. (1992), Rodríguez & Padilla (2013), henceforth referred to as a uniform sample. We used an axis ratio cut-off of q ≈ 0.2 to account for a finite galaxy thickness, following Lambas et al. (1992), which gives rise to standard deviations in each ellipticity component of σe ≈ 0.25, comparable to the samples drawn from data.
The resulting axis ratio and ellipticity distributions are shown in Fig. 7.
4.1.2. Projected ellipsoids
A triaxial ellipsoid with axes 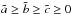 can be described by
can be described by 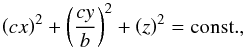 (18)with
(18)with 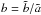 and
and 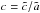 . As given by Stark (1977), such an ellipsoid is seen as an ellipse in projection, given by
. As given by Stark (1977), such an ellipsoid is seen as an ellipse in projection, given by 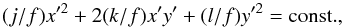 (19)where (x′,y′) are the coordinates in the projection plane and
(19)where (x′,y′) are the coordinates in the projection plane and 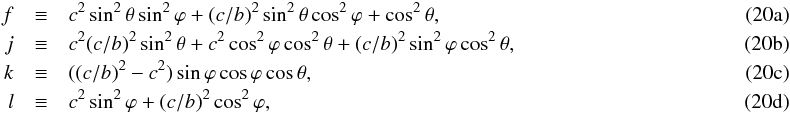 with ϕ and θ the first two orientation angles of the ellipsoid.
with ϕ and θ the first two orientation angles of the ellipsoid.
For simulations of projected ellipsoids, we assumed Gaussian distributions for b and c, following Lambas et al. (1992). For elliptical galaxies, we used b = 0.95 and c = 0.55 with standard deviations σb = 0.35 and σc = 0.2. For disk galaxies, we used b = 1.00 and c = 0.25 with standard deviations σb = 0.13 and σc = 0.12.
The axis ratio was then recovered via 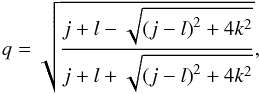 (21)and the ellipticity through Eq. (3). The orientation angles of the ellipsoids were randomly distributed. The resulting axis ratio and ellipticity distributions are shown in Fig. 8.
(21)and the ellipticity through Eq. (3). The orientation angles of the ellipsoids were randomly distributed. The resulting axis ratio and ellipticity distributions are shown in Fig. 8.
 |
Fig. 8 Ellipticity and axis ratio distributions for distribution of projected ellipsoids. Left: disk galaxies. Right: elliptical galaxies. Top: a 2D histogram of ellipticities. Note that the ring-like feature in the left panel is the result of a finite disk thickness. Middle: histogram of the absolute ellipticity | e |. Bottom: histogram of the ellipse axis ratio q. |
We will refer to these simulated samples as disk and elliptical samples. We also used combined samples with a disk to elliptical ratio derived from the CFHTLenS catalog. (See Table 1.)
4.2. Data: CFHTLenS
We used data from Canada-France-Hawaii Lensing Survey (CFHTLenS; Heymans et al. 2012b). The CFHTLenS survey analysis combined weak lensing data processing with theli (Erben et al. 2005, 2009, 2013), shear measurement with lensfit (Miller et al. 2007, 2013; Kitching et al. 2008), and Bayesian photometric redshift measurement (BPZ; Benítez 2000; Coe et al. 2006) with PSF-matched photometry (Hildebrandt et al. 2012). A full systematic error analysis of the shear measurements in combination with the photometric redshifts is presented in Heymans et al. (2012b), with additional error analyses of the photometric redshift measurements presented in Benjamin et al. (2013).
For our analyses, we selected 4.2 million objects that are well determined and resolved (lensfit fitclass = 0, non-zero lensfit weight, star_flag = 0, CLASS_STAR ≤ 0.5). We excluded objects that lie within a mask, with the exception of large, conservative masks around relatively faint stars and stellar haloes (MASK ≤ 1, see Erben et al. 2013).
The CFHTLenS shape catalog is not an exact representation of the ellipticity distribution of the observed galaxy population, as it includes measurement noise present in any real data set. Selecting sources on lensfit weight w or signal-to-noise ratio νSN could on the other hand introduce selection biases in the galaxy population we wanted to to study. We decided to use two sets of sources: the complete set, described above, to optimally sample the complete source population, and a conservative subset with w ≥ 15 and νSN ≥ 20, to reduce the uncertainty in observed ellipticity, at the possible cost of a bias in the selection.
For both sets, we split these sources by BPZ spectral type into red (TBPZ < 1.5) and blue (1.5 <TBPZ < 3.95) galaxies, with a further division between Sbc (1.5 < TBPZ < 2.5) and Scd (2.5 <TBPZ < 3.95). We found that our conservative selection reduced the number of galaxies to roughly 25%, almost independent of spectral bin for TBPZ < 3.1. For higher spectral types, the subset decreased linearly to roughly 10% for the highest spectral bin, which was an indication that our selection did indeed introduce a modest sample bias.
Table 1 gives an overview of the selected CFHTLenS data, while Fig. 9 shows the respective distributions.
We drew random subsets from the selected CFHTLenS ellipticities, which we then sheared by Eq. (5). This introduced the implicit assumption that, after the bias corrections described in Heymans et al. (2012b) and Miller et al. (2013), the central ellipticity was zero, and these random subsets were approximately drawn from an unsheared, noise-free background galaxy population.
 |
Fig. 9 Ellipticity and axis ratio distributions for CFHTLenS blue (left), red (right). Top: a 2D histogram of ellipticities. Note that the ring-like feature at e ≈ 0.8 is due to noisy outliers forced to a maximum e by the shape measurement pipeline, but see also Fig. 8. Middle: histogram of the absolute ellipticity | e |. Bottom: histogram of the ellipse axis ratio q. |
4.3. Simulated noise
In any realistic shape measurement catalog, ellipticities not only have shape noise due to a finite intrinsic distribution, but suffer from measurement uncertainties as well. For this reason, we wanted to study the effect of noise or our simulated, noiseless ellipticity samples.
Measurement uncertainties depend primarily on pixel noise and therefore vary with image size and brightness. This means that errors on the ellipticities are not drawn from a single distribution. To mimic the effect of a skewed composite error distribution for our simulated samples, we randomly sampled the CFHTLenS weight w.
Miller et al. (2013) calculated an approximately inverse-variance weight using the width of the ellipticity likelihood surface by![Mathematical equation: \begin{equation} \label{eq:cfhtls_w} w=\left[\frac{\sigma^2_ee^2_\mathrm{max}}{e^2_\mathrm{max}+2\sigma^2_e}+\sigma^2_\mathrm{pop}\right]^{-1} , \end{equation}](/articles/aa/full_html/2018/01/aa31410-17/aa31410-17-eq146.png) (22)where
(22)where 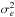 is the variance in ellipticity of the likelihood surface,
is the variance in ellipticity of the likelihood surface, 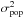 is the ellipticity variance of the galaxy population, and emax is a maximum ellipticity, to reflect a finite edge-on disk thickness.
is the ellipticity variance of the galaxy population, and emax is a maximum ellipticity, to reflect a finite edge-on disk thickness.
Overview of the CFHTLenS data used.
Using emax = 0.804 from Miller et al. (2013) and refining 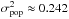 using the CFHTLenS catalog itself12, we obtained a distribution in ellipticity variance for each w. From this, we produced noise by assuming a Gaussian distribution with the ellipticity as mean and as variance.
using the CFHTLenS catalog itself12, we obtained a distribution in ellipticity variance for each w. From this, we produced noise by assuming a Gaussian distribution with the ellipticity as mean and as variance.
4.3.1. Estimation of errors
To assess errors on bias and efficiency from our simulations, we simply divided our simulations randomly in smaller subsets and determine the statistical variations, assuming t-distributions. While this approach may seem to lack finesse compared to a full bootstrap, the significance of our results is high enough for a proof of concept.
5. Results
5.1. Central value estimation
For each sample type, we produced 104 random samples of 100 ellipticities, which we distorted by an absolute reduced shear of g = 0.2, and determined relative efficiencies and possible biases. We then assessed the effect of varying the shear and the sample size.
5.1.1. Asymmetry and bias
Ideally, an estimator should be unbiased in the absence of noise. For the mean, this is the case (Seitz & Schneider 1997), but since the effect of shear on intrinsic ellipticities in non-linear, the resulting, observed ellipticity distribution 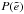 is asymmetric, or skewed, which can lead to mean-biases for various estimators.
is asymmetric, or skewed, which can lead to mean-biases for various estimators.
In Fig. 10, we show this effect on the CHP estimator for g = 0.3 in two directions. The distribution of the CHP estimator is clearly skewed, as shown by the convex hulls plotted, when the coverage within the current hull is equal to approximately1338.3%, 68.3%, 86.6%, and 95.4%. We note that this leads to a mean-biasedness, according to definition, but the center of the estimator distribution P(êCHP) seems significantly less biased. In other words, the CHP estimator seems “CHP-unbiased”.
A solution to this skewness in the estimator distribution, in the absence of noise, is iteratively improving estimates by correcting the observed ellipticities by the estimated shear, using Eq. (5), and then determining the updated residuals. We call this process of iteratively correcting the sample by the current estimate “de-shearing” (or “de-g”). Figure 10 shows how this symmetrized the estimator distribution P(ê), and slightly improved the efficiency as well (see Sect. 5.1.2). The latter seemed to be the case even for the mean êμ as estimator, but the difference was not statistically significant.
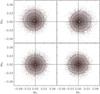 |
Fig. 10 The skewed êCHP distribution as an example of the effect of asymmetry in a sheared ellipticity distribution. Plotted are the estimation biases Δe for 105 simulation runs, shown as a density in grayscale. Over-plotted are the convex hulls at approximately 38.3%, 68.3%, 86.6%, and 95.4% coverage. The mean of the distribution is shown as a white plus. Top: estimation biases ΔeCHP for samples with an underlying shear of g = −0.21 + 0.21i (left) and g = 0.3 (right). Note that these estimator distributions are effectively mean-biased, because they are skewed, but still centered around Δe = 0, as indicated by the CHP estimation of the distributions. Bottom: ΔeCHP for the same samples, after iteratively de-shearing the samples until the final CHP estimate vanishes. These iterations remove asymptotic mean-bias and increase efficiency. |
In presence of noise, the mean is a biased estimator (Melchior & Viola 2012). Given that in reality systematic noise is always present, a form of bias is unavoidable, since the noise distribution is different14 from the (skewed) ellipticity distribution (see Fig. 3). This means that our method of de-shearing would introduce a noise bias for precisely the same reason, since we would not properly correct the asymmetry in the distribution.
We compared the results for simulated projected ellipsoids with and without simulated noise in Fig. 11 to assess the effect. In the appendix, we quantified the observed multiplicative bias in the form 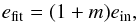 (23)where e stands for e1,2, and summarize the results in Table A.1.
(23)where e stands for e1,2, and summarize the results in Table A.1.
Without de-shearing, only the mean is a mean-unbiased estimator. We noted that all estimation methods could be made mean-unbiased in the noise-free case, when including de-shearing, but showed a mean-bias in the presence of noise, as expected. For the biweight estimator êBI, this was (within statistical significance) the same bias as for the mean. For the LAD and CHP estimators êLAD and êCHP, the biases were significantly reduced, up to ~ 30%, to below percent level for realistic weak shear.
This decrease in bias can be explained by realizing that the observed, sheared ellipticity distribution is skewed, but the location of the central peak of intrinsically round background sources is still an unbiased estimator of the underlying shear (which can be deduced from Eq. (5) and Fig. 3). It is the bias in determining the location of this peak that introduces the bias in the shear estimate. Likewise, the effect of noise changes the observed ellipticity distribution, but does not affect the location of that peak. Estimators that are more sensitive to a central cusp or peak in the distribution and less to high ellipticities in the tail, such as êLAD and êCHP, will therefore introduce a lower mean-bias.
We compared these results to the mean-bias in the upper panels of Fig. 10 and the observation that the central peak of the estimator distribution is in fact located at Δe ≈ 0. We found that the mean-bias arose due to the asymmetry in the estimator distribution and the CHP-bias vanished, unaffected by noise.
5.1.2. Estimator efficiencies
In Tables B.1−B.3 in the appendix, we summarized the full results for the relative efficiencies of each estimator. We applied de-shearing and note that this improves the efficiencies marginally at a similar marginal cost to the bias. We determined relative efficiencies for coverages of 25%, 50%, and 75%, corresponding to the MAD and the first and third quartiles, and 38.3%, 68.3%, 86.6%, and 95.4%, which would correspond to steps of 0.5σ in case of a Gaussian distribution with variance σ2.
In Fig. 12, we plot these results for a few distributions, namely Gaussian, uniform q, a combination of disk and elliptical projections and the conservative CFHTLenS catalog samples. We also plot the results for the samples with added noise and the full CFHTLenS samples.
 |
Fig. 11 Estimator mean-bias as a function of input shear for realistic combinations of simulated disk and elliptical samples, using projected ellipsoids. From left to right: all estimators without noise, without noise after iteratively de-shearing the samples, all estimators with noise, and with noise and after iteratively de-shearing the samples. Color coding: êμ (red), êLAD (blue), êCHP (green), and êBI (yellow). |
 |
Fig. 12 Relative efficiencies each estimator plotted at different coverages. From left to right: relative efficiencies in case of a Gaussian P(e) distribution, the CFHTLenS catalog P(e) distribution, a combination of disk and elliptical distributions using projected ellipsoids, and a uniform q distribution. Color coding: relative efficiencies for êLAD (blue), êBI (yellow), and êCHP (green). Solid lines: simulated samples without noise or using the CFHTLenS conservative subset. Dashed lines: including noise or using the complete CFHTLenS set. |
Not all estimators reached asymptotic normality. Especially CHP converged slower toward normality in the tails of the distribution, that is, at higher coverage. For LAD, this is noticeable mostly for the uniform q distribution.
The biweight is the most robust, as its relative efficiency doesn’t vary much across distributions. The biweight relative efficiency is however quite low, which means that this estimator offers little improvement. Even when P(e) follows a Gaussian distribution, ηBI is not significantly better or worse than the traditional mean.
Our results show that estimator efficiency is independent of input shear. This is the case, when we define the individual estimate biases similarly to the residuals, as noted in Sect. 3.1, that is, not as the difference ê−g, but as the extra shear needed over the input shear g to reach this difference, as determined by Eq. (5): 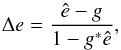 (24)with g∗ the complex conjugate of the input shear g of the simulations. Using that definition, this independence is demonstrated Fig. 13.
(24)with g∗ the complex conjugate of the input shear g of the simulations. Using that definition, this independence is demonstrated Fig. 13.
 |
Fig. 13 Efficiency for an arbitrary estimator and sample type versus input shear, ranging from g = 0.05 (left) to g = 0.35. Upper: simple difference ê−g between estimates and input shear, with s68.3 over-plotted. Lower: Δe, as defined by Eq. (24), with s68.3 over-plotted. |
As an aside: since the mean of the CHP estimator is displaced from the center, this necessarily increases the distribution scale. A more proper way to compare the scale with symmetric distributions would be comparing the surface within the convex hull at a certain coverage, as s2 is a measure of the (circular) surface around ê inside that scale. In this sense, efficiency is a figure of merit. We have not done so in this paper, which means the ηCHP are slightly underestimated, but not significantly.
In Fig. 14, we show the results for different samples sizes. In Table B.4 in the appendix, we summarize the quantitative results. In the limit of very small sample sizes, the difference between the various estimators is expected to vanish. We note that a potential improvement over the mean estimator remains even for a sample size of N = 10.
 |
Fig. 14 Relative efficiencies η68.3 plotted against sample sizes. From left to right: relative efficiencies in case of a Gaussian P(e) distribution, the CFHTLenS catalog P(e) distribution, a combination of disk and elliptical distributions using projected ellipsoids, and a uniform q distribution. Color coding: relative efficiencies for êLAD (blue), êBI (yellow), and êCHP (green). Solid lines: simulated samples without noise or using the CFHTLenS conservative subset. Dashed lines: including noise or using the complete CFHTLenS set. |
5.2. Fourier mode fitting
For samples of a combination of disk and elliptical distributions using projected ellipsoids, we produced 103 random square fields with 103 simulated ellipticities. For comparison, the average number of selected sources in a CFHTLenS field is roughly 2.5 × 104, ranging from 9525 to 37767, or 5.3 × 103, ranging from 2111 to 9525 for the more conservative sample.
Using Eq. (5), we distorted these intrinsic ellipticities by the total shear pattern of one or more full modes (as defined in Eq. (14)), then applied simulated measurement noise (as described in Sect. 4.3) as a final step.
We fitted amplitudes per individual wave using LSQ, LAD and CHP, and per mode using LSQ and LAD by simultaneously fitting all four amplitudes. We then determined relative efficiencies and possible biases of the recovered amplitudes in the same way as in Sect. 5.1.
In Fig. 15, we show the fitted shear field for a single realization, using in this case 104 simulated ellipticities. We fitted 16 different modes individually, using LSQ and LAD, and 64 individual amplitudes using LSQ, LAD, and CHP, and found the amplitude residuals, 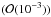 , to be two orders of magnitude less than the input values, which were constrained to g ≤ 0.25 for peak values at positive interference. Residuals in | e | for this realization varied between ± 0.075 for LSQ,± 0.066 for LAD and ± 0.14 for CHP.
, to be two orders of magnitude less than the input values, which were constrained to g ≤ 0.25 for peak values at positive interference. Residuals in | e | for this realization varied between ± 0.075 for LSQ,± 0.066 for LAD and ± 0.14 for CHP.
 |
Fig. 15 Shear field residuals when fitting 16 different modes, using simulated projected ellipsoids as intrinsic shapes, and including additional Gaussian noise. From left to right: input shear, LSQ fit and residuals, LAD fit and residuals, CHP it and residuals. Upper and lower row show e1 and e2 respectively. The color scale is the same in all plots for comparison and ranges between −0.247 ≤ e1,2 ≤ 0.247. Residuals for this realization vary between ± 0.075, ± 0.066, and ± 0.14, respectively. |
5.2.1. Bias and efficiency
The results from Sects. 5.1.1 and 5.1.2 carry over to estimates of Fourier amplitudes for LSQ and LAD. We found fitted values with standard deviations of the order of 10-3 for individual amplitudes. In Fig. 16, we show the consistency of the fitted values.
 |
Fig. 16 Consistency of the estimated Fourier amplitudes as defined in Eq. (14). Plotted are the input amplitudes amn, bmn, cmn, dmn vs. their estimates (Sect. 3.3.1) for LSQ (left), LAD (middle), and CHP (right). Top row: only simulated intrinsic shapes based on projected ellipsoids. Bottom row: the same, with added noise. Over plotted are the best-fitting mean-bias, as defined in Eq. (25). |
Over plotted in Fig. 16 are the best-fitting mean-bias, defined similar to Eq. (23) as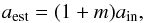 (25)where a stands for amn, bmn, cmn, and dmn as defined in Eq. (14). The uncertainties are too small to be visible. In Table C.1 in the appendix, we give the quantitative results.
(25)where a stands for amn, bmn, cmn, and dmn as defined in Eq. (14). The uncertainties are too small to be visible. In Table C.1 in the appendix, we give the quantitative results.
Similar to the results shown in Fig. 11, LSQ underestimates Fourier amplitudes by a few percent in the presence of noise. For LAD, we found an improvement on bias by ~ 20% in the presence of noise, when iteratively de-shearing the sample. Likewise, fitting for LAD without de-shearing slightly overestimated the amplitudes, again comparable to Fig. 11.
We note that in this case, adding noise did not seem to have a significant effect when fitting per mode. In most cases, we did notice a significant increase in bias when fitting per single amplitude. We did not see a change in bias between LSQ per mode and per amplitude.
We also found a slightly higher relative efficiency of η68.3 = 1.09 ± 0.07 for LSQ and η68.3 = 1.47 ± 0.09 for LAD, when fitting per mode, with or without added noise. It is not surprising that a model with four parameters (amplitudes) fits the estimates better than a model with one parameter, but the difference of this effect between LSQ and LAD is noteworthy.
Since CHP doesn’t fit a model to the data, but rather orders the (e1,e2) data points, there is no straightforward way to fit four amplitudes simultaneously with the necessary weighting (Sect. 3.2.4). We have not explored this option further in this paper.
The CHP estimator performs consistently, that is, convergent around the input values, but with a significant lower efficiency than for central value estimation of a cloud of (e1,e2) data points (Sect. 5.1). This is to be expected, since CHP is particularly sensitive to a (central) cusp in the distribution of data points. By shearing the intrinsic ellipticities by a model that varies over the field of view, as shown in Fig. 6, this peak will be smeared out, decreasing the effectiveness of CHP.
In conclusion, CHP is consistently the most sensitive to the central cuspiness of a distribution. The results of this section do serve as a proof of concept for applying alternative statistics to an observed field of weak shear measurements.
6. Conclusions and summary
6.1. Optimal estimators
Our main conclusion is that to evaluate a statistical estimator, one must be willing to look beyond the canonical terms of mean-bias and the Gaussian variance as efficiency. We have shown that these commonly used meta-analysis instruments do not always properly reflect how well weak shear estimator values are constrained around the true underlying shear values.
By discussing the statistical definitions and observing the behavior of estimators for various ellipticity distributions, we have proposed ways of comparing various estimators motivated by statistical theory. The conclusions of that comparison are as follows:
-
Since the central peak of the intrinsic ellipticity distributionP(e) is an unbiased tracer of the underlying shear, we find that the LAD and CHP estimators are less biased and more efficient than the standard mean.
-
When iteratively de-shearing the ellipticity sample by the estimated shear, the LAD estimator can reach a sub-percent bias for typical weak shear values, including noise. LAD is generally the most efficient of all estimators considered, potentially reducing uncertainties by more than 50% for samples simulated using a model of projected triaxial ellipsoids.
-
The CHP estimator is in terms of its mean-bias less affected by noise, as compared to the mean and, to a lesser extend, LAD. In fact, since the estimator distribution P(ê) is not symmetric, the actual center of that distribution, as opposed to the mean of that distribution, is unbiased in the presence of noise, within statistical significance. This makes CHP an important consideration, but it is less straightforward for adaptation for regression and requires careful assessment of uncertainties. Furthermore, CHP is computationally more demanding. In the presence of Gaussian noise, CHP is slightly less efficient than the mean (Fig. 12, panels 3 and 4), but defining efficiency in terms of a figure of merit can reduce this drawback compared to the gain in bias, as proposed in Sect. 5.1.2.
6.2. Direct Fourier mode fitting
Applying different statistics to fitting individual Fourier modes to the shear field directly, we found results consistent with our previous conclusions.
We have shown that the Fourier amplitudes can be recovered with sub-percent accuracy and a minimal bias, which is an important proof of concept. Since the periodic variations in underlying shear effectively smooth the central peak of the intrinsic ellipticity distribution, the gain in efficiency is slightly less for LAD and significantly less for CHP. It is possible that an alternative to our weighting scheme for FMF with CHP could improve results. At this point, the method of CHP seems more applicable to samples of expected (roughly) constant shear, for example when measuring tangential shear around a gravitational lens candidate in bins of distance.
We have also shown that the shear field can be recovered reliably, with residuals an the order of magnitude less than the variations of the shear over the field of view for LSQ and LAD, using 103 sources, which is conservative compared to a typical single CFHTLenS field.
6.3. Future considerations and possible applications
We have discussed alternative statistics for inference of shear from samples of background sources with various intrinsic ellipticity distributions, proposing methods that could improve biases and uncertainties arising from the shape noise. It is important to consider our results within the broader context of other sources of systematics, as mentioned in our introduction.
Firstly, our results for shape noise assume trustworthy shape measurements, not only per source, but also considering the effect of systematics in the shape measurement pipelines on the reproduced ellipticity distribution as a whole: the recovery of a central peak, the distribution of outliers, among others. Examples are the effect of constraining ellipticities to a certain “physical” maximum (e.g., emax = 0.804 for lensfit, Miller et al. 2013), as we see in Fig. 2, or conversely, the unphysical outliers with | e | > 1.0 arising from dividing two noisy quantities (often when correcting for the point spread function, or PSF), affecting the tails of the distribution. Any features in the recovered shape distribution could affect bias and efficiency of the statistic used. Optimizing statistics will place more stringent demands on shape measurements than performing excellent “on average”. Even methods that avoid individual shape measurements (Bernstein & Armstrong 2014), an ensemble inferred reduced shear could improve by considering the intrinsic shape distribution. Secondly, even with an accurately measured shape distribution, there will remain sources of systematic error in other steps of a cosmological analysis, as noted in our introduction. These effects still form a necessary part in a weak lensing analysis, but leave our statistical conclusions unaffected.
As survey sizes and image qualities increase, so will the demands on constraining systematic effects to a sub-dominant level, as described in for example Kuijken et al. (2015) and Mandelbaum et al. (2017) for the KiDS DR2 and HSC DR1, respectively. At the same time, it will be interesting to see measured ellipticity distributions converge as more sources are observed with higher signal-to-noise and measured with higher fidelity, due to increased depth of imaging, image quality and PSF control.
For now, we have given a proof of concept for alternative statistics in two cases: a sample of ellipticities with one underlying shear and the recovery of individual Fourier modes of the shear variation over a field of view. The first part has important applications when inferring a shear profile around lenses, both in recovering an accurate, less biased estimate and smaller error bars or confidence intervals. For the second part: since the amplitudes are well constrained by fitting individual Fourier modes, this provides a possible method toward estimation of the power spectrum. Furthermore, the shear field can be recovered in terms of its Fourier amplitudes, providing a powerful analytic model for mass reconstruction, without the need for smoothed gridding and incorporating variations in background source densities and estimated measurement uncertainties.
We will omit a more detailed discussion, since it’s applicable only to certain distributions and not (directly) relevant to this discussion.
More accurately, the underlying shear g is known.
Formally speaking: when the norm is strictly convex.
Indeed, in one dimension, both approaches to the median are the same.
Miller et al. (2013) cite 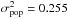 as prior, but this would lead to a negative for the maximum weight in the CFHTLenS catalog.
as prior, but this would lead to a negative for the maximum weight in the CFHTLenS catalog.
CHP is a discrete and not a continuous process, but this effect is negligible for 104 estimates.
Intrinsically, the effect of noise is symmetric, but the effect on a sample of sheared ellipticities depends on the shape measurement pipeline, as noted in Melchior & Viola (2012).
Acknowledgments
We thank the anonymous referee for useful comments and suggestions, which improved readability and reproducibility of this paper and its results.
M.S. acknowledges support from the Netherlands Organization for Scientific Research (NWO).
This work is based on observations obtained with MegaPrime/MegaCam, a joint project of CFHT and CEA/DAPNIA, at the Canada-France-Hawaii Telescope (CFHT) which is operated by the National Research Council (NRC) of Canada, the Institut National des Sciences de l’Univers of the Centre National de la Recherche Scientifique (CNRS) of France, and the University of Hawaii. This research used the facilities of the Canadian Astronomy Data Centre operated by the National Research Council of Canada with the support of the Canadian Space Agency. CFHTLenS data processing was made possible thanks to significant computing support from the NSERC Research Tools and Instruments grant program.
References
- Barrodale, I., & Roberts, F. D. K. 1973, SIAM J. Num. Anal., 10, 839 [NASA ADS] [CrossRef] [Google Scholar]
- Bartelmann, M., & Schneider, P. 2001, Phys. Rep., 340, 291 [NASA ADS] [CrossRef] [Google Scholar]
- Beaton, A. E., & Tukey, J. W. 1974, Outliers in Statistical Data (New York: Wiley) [Google Scholar]
- Benítez, N. 2000, ApJ, 536, 571 [NASA ADS] [CrossRef] [Google Scholar]
- Benjamin, J., Van Waerbeke, L., Heymans, C., et al. 2013, MNRAS, 431, 1547 [NASA ADS] [CrossRef] [Google Scholar]
- Bernstein, G. M. 2010, MNRAS, 406, 2793 [NASA ADS] [CrossRef] [Google Scholar]
- Bernstein, G. M., & Armstrong, R. 2014, MNRAS, 438, 1880 [NASA ADS] [CrossRef] [Google Scholar]
- Bernstein, G. M., & Jarvis, M. 2002, AJ, 123, 583 [NASA ADS] [CrossRef] [Google Scholar]
- Bonnet, H., & Mellier, Y. 1995, A&A, 303, 331 [NASA ADS] [Google Scholar]
- Bridle, S., Balan, S. T., Bethge, M., et al. 2010, MNRAS, 405, 2044 [NASA ADS] [Google Scholar]
- Coe, D., Benítez, N., Sánchez, S. F., et al. 2006, AJ, 132, 926 [NASA ADS] [CrossRef] [Google Scholar]
- Cramér, H. 1946, Mathematical Methods of Statistics, Princeton Mathematical Series (Princeton University Press) [Google Scholar]
- Dark Energy Survey Collaboration, Abbott, T., Abdalla, F. B., et al. 2016, MNRAS, 460, 1270 [NASA ADS] [CrossRef] [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Kuijken, K. H., & Valentijn, E. A. 2013, Exp.. Astron., 35, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Erben, T., Schirmer, M., Dietrich, J. P., et al. 2005, Astron. Nachr., 326, 432 [NASA ADS] [CrossRef] [Google Scholar]
- Erben, T., Hildebrandt, H., Lerchster, M., et al. 2009, A&A, 493, 1197 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Erben, T., Hildebrandt, H., Miller, L., et al. 2013, MNRAS, 433, 2545 [NASA ADS] [CrossRef] [Google Scholar]
- Ford, J., Hildebrandt, H., Van Waerbeke, L., et al. 2012, ApJ, 754, 143 [NASA ADS] [CrossRef] [Google Scholar]
- Herbonnet, R., Buddendiek, A., & Kuijken, K. 2017, A&A, 599, A73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heymans, C., Van Waerbeke, L., Bacon, D., et al. 2006, MNRAS, 368, 1323 [NASA ADS] [CrossRef] [Google Scholar]
- Heymans, C., Rowe, B., Hoekstra, H., et al. 2012a, MNRAS, 421, 381 [NASA ADS] [Google Scholar]
- Heymans, C., Van Waerbeke, L., Miller, L., et al. 2012b, MNRAS, 427, 146 [NASA ADS] [CrossRef] [Google Scholar]
- Hildebrandt, H., van Waerbeke, L., & Erben, T. 2009, A&A, 507, 683 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hildebrandt, H., Muzzin, A., Erben, T., et al. 2011, ApJ, 733, L30 [CrossRef] [Google Scholar]
- Hildebrandt, H., Erben, T., Kuijken, K., et al. 2012, MNRAS, 421, 2355 [NASA ADS] [CrossRef] [Google Scholar]
- Hildebrandt, H., Choi, A., Heymans, C., et al. 2016, MNRAS, 463, 635 [NASA ADS] [CrossRef] [Google Scholar]
- Hirata, C., & Seljak, U. 2003, MNRAS, 343, 459 [NASA ADS] [CrossRef] [Google Scholar]
- Hirata, C. M., Mandelbaum, R., Seljak, U., et al. 2004, MNRAS, 353, 529 [NASA ADS] [CrossRef] [Google Scholar]
- Hoekstra, H., & Jain, B. 2008, Ann. Rev. Nucl. Part. Sci., 58, 99 [Google Scholar]
- Ivezic, Z., Tyson, J. A., Abel, B., et al. 2008, ArXiv e-prints [arXiv:0805.2366] [Google Scholar]
- Jarvis, M., Sheldon, E., Zuntz, J., et al. 2016, MNRAS, 460, 2245 [NASA ADS] [CrossRef] [Google Scholar]
- Kacprzak, T., Zuntz, J., Rowe, B., et al. 2012, MNRAS, 427, 2711 [NASA ADS] [CrossRef] [Google Scholar]
- Kaiser, N., Squires, G., & Broadhurst, T. 1995, ApJ, 449, 460 [NASA ADS] [CrossRef] [Google Scholar]
- Kitching, T. D., Miller, L., Heymans, C. E., van Waerbeke, L., & Heavens, A. F. 2008, MNRAS, 390, 149 [NASA ADS] [CrossRef] [Google Scholar]
- Kitching, T. D., Balan, S. T., Bridle, S., et al. 2012, MNRAS, 423, 3163 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K. 1999, A&A, 352, 355 [NASA ADS] [Google Scholar]
- Kuijken, K. 2006, A&A, 456, 827 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kuijken, K., Heymans, C., Hildebrandt, H., et al. 2015, MNRAS, 454, 3500 [NASA ADS] [CrossRef] [Google Scholar]
- Lambas, D. G., Maddox, S. J., & Loveday, J. 1992, MNRAS, 258, 404 [NASA ADS] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Leauthaud, A., Massey, R., Kneib, J.-P., et al. 2007, ApJS, 172, 219 [NASA ADS] [CrossRef] [Google Scholar]
- Lee, H. 2007, in Statistical Challenges in Modern Astronomy IV, eds. G. J. Babu, & E. D. Feigelson, ASP Conf. Ser., 371, 425 [Google Scholar]
- Lee, D. T., & Schachter, B. J. 1980, Int. J. Comp. Inf. Sci., 9, 219 [Google Scholar]
- Mandelbaum, R., Rowe, B., Armstrong, R., et al. 2015, MNRAS, 450, 2963 [NASA ADS] [CrossRef] [Google Scholar]
- Mandelbaum, R., Miyatake, H., Hamana, T., et al. 2017, PASJ, in press, DOI: 10.1093/pasj/psx130 [Google Scholar]
- Massey, R., Heymans, C., Bergé, J., et al. 2007, MNRAS, 376, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Melchior, P., & Viola, M. 2012, MNRAS, 424, 2757 [NASA ADS] [CrossRef] [Google Scholar]
- Miller, L., Kitching, T. D., Heymans, C., Heavens, A. F., & van Waerbeke, L. 2007, MNRAS, 382, 315 [NASA ADS] [CrossRef] [Google Scholar]
- Miller, L., Heymans, C., Kitching, T. D., et al. 2013, MNRAS, 429, 2858 [Google Scholar]
- Mosteller, F., & Tukey, J. W. 1977, Data Analysis and Regression: a Second Course in Statistics (Reading, MA: Addison Wesley), 133 [Google Scholar]
- Preparata, F. P., & Shamos, M. I. 1985, Computational Geometry (New York: Springer), 95 [Google Scholar]
- Rao, C. R. 1945, Bull. Calcutta Math. Soc., 37, 81 [Google Scholar]
- Refregier, A., & Bacon, D. 2003, MNRAS, 338, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Refregier, A., Kacprzak, T., Amara, A., Bridle, S., & Rowe, B. 2012, MNRAS, 425, 1951 [NASA ADS] [CrossRef] [Google Scholar]
- Rhodes, J., Refregier, A., & Groth, E. J. 2000, ApJ, 536, 79 [NASA ADS] [CrossRef] [Google Scholar]
- Rodríguez, S., & Padilla, N. D. 2013, MNRAS, 434, 2153 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, P. 2006, in Saas-Fee Advanced Course 33: Gravitational Lensing: Strong, Weak and Micro, eds. G. Meylan, P. Jetzer, P. North, P. Schneider, et al., 269 [Google Scholar]
- Seitz, C., & Schneider, P. 1997, A&A, 318, 687 [NASA ADS] [Google Scholar]
- Stark, A. A. 1977, ApJ, 213, 368 [NASA ADS] [CrossRef] [Google Scholar]
- Tyson, J. A., Valdes, F., & Wenk, R. A. 1990, ApJ, 349, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Van Waerbeke, L., Mellier, Y., Erben, T., et al. 2000, A&A, 358, 30 [NASA ADS] [Google Scholar]
- Van Waerbeke, L., Hildebrandt, H., Ford, J., & Milkeraitis, M. 2010, ApJ, 723, L13 [NASA ADS] [CrossRef] [Google Scholar]
- Voigt, L. M., & Bridle, S. L. 2010, MNRAS, 404, 458 [NASA ADS] [Google Scholar]
- Zhang, J., Luo, W., & Foucaud, S. 2015, Cosmol. Astropart. Phys., 1, 024 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, J., Zhang, P., & Luo, W. 2017, ApJ, 834, 8 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Bias estimations
In Table A.1 are given the mean-bias and CHP-bias for each estimator, with and without de-shearing. This multiplicative bias m is defined by Eq. (23) as efit = (1 + m)ein.
Results for bias estimations for each estimator, with and without de-shearing.
Appendix B: Efficiency estimations
In Tables B.1−B.3, we summarize the full results for the relative efficiencies of each estimator. We determine relative efficiencies for coverages of 25%, 50%, and 75%, corresponding to the MAD and the first and third quartiles, and 38.3%, 68.3%, 86.6%, and 95.4%, which would correspond to steps of 0.5σ in case of a Gaussian distribution with variance σ2.
For easy reference, we also indicate how much the scale of the estimator distribution would improve, in percentages of the scale of the distribution of the mean estimator,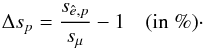 (B.1)Since a higher efficiency means a smaller scale and therefore a more “trustworthy” estimate, this is an intuitive, albeit rough indication of the change in error bars.
(B.1)Since a higher efficiency means a smaller scale and therefore a more “trustworthy” estimate, this is an intuitive, albeit rough indication of the change in error bars.
Results for scales of fixed coverage for LAD.
Results for scales of fixed coverage for the biweight.
Results for scales of fixed coverage for CHP.
Results for η68.3 for different sample sizes.
Appendix C: Estimations from Fourier mode fitting
In Table C.1 are given the mean-bias and efficiencies of the LSQ estimator, per mode and per individual amplitude, LAD estimator with and without de-shearing, per mode and per individual amplitude, and the CHP estimator, per individual amplitude. The mean-bias is again given in terms of a multiplicative component m as defined in Eq. (25).
Results for amplitude estimations for FMF, using different estimators (LSQ, LAD, and CHP) and models (per mode or per amplitude).
All Tables
Results for amplitude estimations for FMF, using different estimators (LSQ, LAD, and CHP) and models (per mode or per amplitude).
All Figures
|
Fig. 1 Gaussian ellipticity distribution and corresponding axis ratio distribution. Top: a 2D histogram of ellipticities. Middle: histogram of the absolute ellipticity | e |. Bottom: histogram of the ellipse axis ratio q. |
| In the text | |
|
Fig. 2 Ellipticity and axis ratio distributions of the CFHTLenS catalog. Top: a 2D histogram of ellipticities. We note that the ring-like feature at e ≈ 0.8 is due to noisy outliers forced to a maximum e by the shape measurement pipeline, but see also Fig. 8. Middle: histogram of the absolute ellipticity | e |. Bottom: histogram of the ellipse axis ratio q. |
| In the text | |
|
Fig. 3 Top: the non-linear mapping of ellipticities (with | e | ≤ 1) by an exaggerated gravitational shear of g = 0.33 + 0.11i. Bottom: the asymmetry introduced in the ellipticity distribution, highlighted for the e1-component. |
| In the text | |
|
Fig. 4 Comparison of the marginal median (left) to the spatial median, or LAD estimation (right). Plotted are the estimation biases Δe for 106 simulation runs, shown as a density in grayscale. Over-plotted are arbitrary contours of increasing density (equal in both plots), to highlight the anisotropy in P(Δe). Since e1 and e2 depend on the choice of reference frame, the marginal median introduces an artificial anisotropy. For the LAD estimations, the residual distances | ri | do not depend on the choice of reference frame. |
| In the text | |
|
Fig. 5 The method of CHP. The left panel shows a scatter plot with two outliers. The arithmetic mean is shown as a gray, solid line and the dotted line represents the mean without the two outliers. The middle panel shows the convex hull of the set of points, which is then removed from the set. The right panel shows the final result after repeating the process, until the final set of points is equal to its own convex hull. |
| In the text | |
|
Fig. 6 Ellipticity distribution of a superposition of 9 Fourier modes over the complex (e1,e2) plane, where we show how we recover a single (e1,e2) amplitude, indicated by the dotted lines. Left: the Fourier modes, centered around (0,0) (normalized number counts). Middle: the (e1,e2) points shifted by sgn(M), with M the model of the amplitude (normalized number counts). Right: the resulting distribution of weights over (e1,e2), showing a shift toward the amplitude under consideration. |
| In the text | |
|
Fig. 7 Ellipticity distributions for a uniform axis ratio distribution. Top: a 2D histogram of ellipticities. Middle: histogram of the absolute ellipticity | e |. Bottom: histogram of the ellipse axis ratio q. A cut-off near q ≈ 0.2 is suggested by observations and produces standard deviations in each ellipticity component of σe ≈ 0.25, comparable to most survey shape measurement catalogs. |
| In the text | |
|
Fig. 8 Ellipticity and axis ratio distributions for distribution of projected ellipsoids. Left: disk galaxies. Right: elliptical galaxies. Top: a 2D histogram of ellipticities. Note that the ring-like feature in the left panel is the result of a finite disk thickness. Middle: histogram of the absolute ellipticity | e |. Bottom: histogram of the ellipse axis ratio q. |
| In the text | |
|
Fig. 9 Ellipticity and axis ratio distributions for CFHTLenS blue (left), red (right). Top: a 2D histogram of ellipticities. Note that the ring-like feature at e ≈ 0.8 is due to noisy outliers forced to a maximum e by the shape measurement pipeline, but see also Fig. 8. Middle: histogram of the absolute ellipticity | e |. Bottom: histogram of the ellipse axis ratio q. |
| In the text | |
|
Fig. 10 The skewed êCHP distribution as an example of the effect of asymmetry in a sheared ellipticity distribution. Plotted are the estimation biases Δe for 105 simulation runs, shown as a density in grayscale. Over-plotted are the convex hulls at approximately 38.3%, 68.3%, 86.6%, and 95.4% coverage. The mean of the distribution is shown as a white plus. Top: estimation biases ΔeCHP for samples with an underlying shear of g = −0.21 + 0.21i (left) and g = 0.3 (right). Note that these estimator distributions are effectively mean-biased, because they are skewed, but still centered around Δe = 0, as indicated by the CHP estimation of the distributions. Bottom: ΔeCHP for the same samples, after iteratively de-shearing the samples until the final CHP estimate vanishes. These iterations remove asymptotic mean-bias and increase efficiency. |
| In the text | |
|
Fig. 11 Estimator mean-bias as a function of input shear for realistic combinations of simulated disk and elliptical samples, using projected ellipsoids. From left to right: all estimators without noise, without noise after iteratively de-shearing the samples, all estimators with noise, and with noise and after iteratively de-shearing the samples. Color coding: êμ (red), êLAD (blue), êCHP (green), and êBI (yellow). |
| In the text | |
|
Fig. 12 Relative efficiencies each estimator plotted at different coverages. From left to right: relative efficiencies in case of a Gaussian P(e) distribution, the CFHTLenS catalog P(e) distribution, a combination of disk and elliptical distributions using projected ellipsoids, and a uniform q distribution. Color coding: relative efficiencies for êLAD (blue), êBI (yellow), and êCHP (green). Solid lines: simulated samples without noise or using the CFHTLenS conservative subset. Dashed lines: including noise or using the complete CFHTLenS set. |
| In the text | |
|
Fig. 13 Efficiency for an arbitrary estimator and sample type versus input shear, ranging from g = 0.05 (left) to g = 0.35. Upper: simple difference ê−g between estimates and input shear, with s68.3 over-plotted. Lower: Δe, as defined by Eq. (24), with s68.3 over-plotted. |
| In the text | |
|
Fig. 14 Relative efficiencies η68.3 plotted against sample sizes. From left to right: relative efficiencies in case of a Gaussian P(e) distribution, the CFHTLenS catalog P(e) distribution, a combination of disk and elliptical distributions using projected ellipsoids, and a uniform q distribution. Color coding: relative efficiencies for êLAD (blue), êBI (yellow), and êCHP (green). Solid lines: simulated samples without noise or using the CFHTLenS conservative subset. Dashed lines: including noise or using the complete CFHTLenS set. |
| In the text | |
|
Fig. 15 Shear field residuals when fitting 16 different modes, using simulated projected ellipsoids as intrinsic shapes, and including additional Gaussian noise. From left to right: input shear, LSQ fit and residuals, LAD fit and residuals, CHP it and residuals. Upper and lower row show e1 and e2 respectively. The color scale is the same in all plots for comparison and ranges between −0.247 ≤ e1,2 ≤ 0.247. Residuals for this realization vary between ± 0.075, ± 0.066, and ± 0.14, respectively. |
| In the text | |
|
Fig. 16 Consistency of the estimated Fourier amplitudes as defined in Eq. (14). Plotted are the input amplitudes amn, bmn, cmn, dmn vs. their estimates (Sect. 3.3.1) for LSQ (left), LAD (middle), and CHP (right). Top row: only simulated intrinsic shapes based on projected ellipsoids. Bottom row: the same, with added noise. Over plotted are the best-fitting mean-bias, as defined in Eq. (25). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.