| Issue |
A&A
Volume 553, May 2013
|
|
|---|---|---|
| Article Number | A113 | |
| Number of page(s) | 14 | |
| Section | Interstellar and circumstellar matter | |
| DOI | https://doi.org/10.1051/0004-6361/201321254 | |
| Published online | 17 May 2013 | |
Estimation of high-resolution dust column density maps
Comparison of modified black-body fits and radiative transfer modelling
Department of Physics, PO Box 64, 00014, University of Helsinki, Finland
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received: 7 February 2013
Accepted: 25 March 2013
Abstract
Context. Sub-millimetre dust emission is routinely used to derive the column density N of dense interstellar clouds. The observations consist of data at several wavelengths but also, with increasing wavelength, of poorer resolution. Procedures have been proposed for deriving higher resolution maps of N. In this paper the main ones are called Methods A and B. Method A uses low-resolution temperature estimates combined with higher resolution intensity data. Method B is a combination of column density estimates obtained using different wavelength ranges.
Aims. Our aim is to determine the accuracy of the proposed methods relative to the true column densities and to the estimates that could be obtained with radiative transfer modelling.
Methods. We used magnetohydrodynamical simulations and radiative transfer calculations to simulate sub-millimetre surface brightness observations at the wavelengths of the Herschel Space Observatory. The synthetic observations were analysed with the proposed methods and the results compared to the true column densities and to the results obtained with simple 3D radiative transfer modelling of the observations.
Results. Both methods give relatively reliable column density estimates at the resolution of 250 μm data while also making use of the longer wavelengths. In case of high signal-to-noise data, the results of Method B are better correlated with the true column density, while Method A is less sensitive to noise. When the cloud has internal heating sources, Method B gives results that are consistent with those that would be obtained if high-resolution data were available at all wavelengths. Because of line-of-sight temperature variations, these underestimate the true column density, and because of a favourable cancellation of errors, Method A can sometimes give more correct values. Radiative transfer modelling, even with very simple 3D cloud models, usually provides more accurate results. However, the complexity of the models that are required for improved results increases rapidly with the complexity and opacity of the clouds.
Conclusions. Method B provides reliable estimates of the column density, although in the case of internal heating, Method A can be less biased because of fortuitous cancellation of errors. For clouds with a simple density structure, improved column density estimates can be obtained even with simple radiative transfer modelling.
Key words: ISM: clouds / infrared: ISM / radiative transfer / submillimeter: ISM
© ESO, 2013
1. Introduction
Sub-millimetre and millimetre dust emission data are widely used to map the structure of dense interstellar clouds (Motte et al. 1998; André et al. 2000). The large surveys of Herschel are currently providing data on, for example, major nearby molecular clouds (André et al. 2010) and on the whole Galactic plane Molinari et al. (2010). The column densities derived from the emission depend not only on the strength of the emission but also on its spectrum. By covering the far-infrared part of the spectrum, Herschel observations are also sensitive to the dust temperature. Accurate estimates of the column density require accurate values of both temperature and dust opacity. In addition to being a tracer of cloud structure, the dust emission also carries information on the properties of the dust grains themselves. The properties are observed to change between clouds, which is associated with differences in the grain optical properties, the size distributions, the presence of ice mantles, and possibly even temperature-dependent optical characteristics (Ossenkopf & Henning 1994; Stepnik et al. 2003; Meny et al. 2007; Compiègne et al. 2011).
Measurements of dust emission can be complemented with information from other tracers. Both dust extinction and scattering can be observed using near-infrared (NIR) wavelengths. These would be valuable because they are independent of that dust temperature that is a major uncertainty in the interpretation of emission data. Additional data would also help constrain the dust properties; see, e.g., Goodman et al. (2009) and Malinen et al. (2012) for a comparison of the use of dust emission and extinction. Dust extinction has been mapped over large areas (Lombardi et al. 2006; Goodman et al. 2009; Schneider et al. 2011), but high resolution observations are expensive and restricted to small fields. The same applies to observations of NIR scattered light that still exist only for a few clouds (Lehtinen & Mattila 1996; Nakajima et al. 2003; Foster & Goodman 2006; Juvela et al. 2008; Nakajima et al. 2008; Malinen et al. in prep.). Measurements of scattered light are even rarer in the mid-infrared, and they probably tell more about the dust grains than the column density (Steinacker et al. 2010; Pagani et al. 2010). Therefore, in most cases one must rely on correct interpretation of the dust emission, preferably at far-infrared and longer wavelengths. Below 100 μm the situation is complicated by the contribution of transiently heated grains and by the sensitivity to the shorter wavelengths, for which the clouds are typically optically thick.
In addition to the uncertainty of the intrinsic grain properties, interpretation of dust emission data is affected by two main problems, the effect of noise and the effect temperature variations. The noise is particularly problematic if one tries to determine both the dust temperature and the dust emissivity spectral index β (Shetty et al. 2009a; Juvela & Ysard 2012a). Therefore, most estimates of cloud masses are derived by assuming a constant value of β. However, there is always dust with different temperatures along the line-of-sight and at different positions within the beam, and this affects the mass estimates (Shetty et al. 2009b; Malinen et al. 2011; Juvela & Ysard 2012b; Ysard et al. 2012). Because the emission of warm dust is stronger than the emission of colder dust of the same mass, the colour temperature derived from the observed intensities overestimates the mass-averaged temperature. The greater the temperature variations are, the more the dust mass is underestimated (Evans et al. 2001; Stamatellos & Whitworth 2003; Malinen et al. 2011; Ysard et al. 2012). The problem could be solved only if the temperature structure of the source were known so that the effect could be determined with modelling.
One would like to measure the density and temperature structure of the clouds not only as reliably as possible but also with as high a resolution as possible. The resolution depends on the telescope and the wavelengths used. For Herschel, the resolution varies from less than 8″ at 100 μm to ~37″ at 500 μm. The standard way to calculate a column density map is to convert all data first to the lowest common resolution. Thus, most of the input data has significantly higher resolution than the result. Therefore, it would be beneficial to find ways to combine the data in a way that, although all wavelengths are used, the final map would retain a resolution better than that of the longest waveband.
Juvela et al. (2012c) examined cloud filaments using column densities derived from Herschel 250 μm surface brightness data at ~20″ resolution and dust colour temperature at ~40″ resolution. It was argued that the effective resolution must be better than 40 ″ because, on small scales, the temperature changes are small. Palmeirim et al. (2013) presented a better justified method that combined Herschel data at 160, 250, 350, and 500 μm to produce high resolution column density maps. The methods may raise the question, what is the actual resolution of the maps. Furthermore, if one uses temperature maps of different resolution, they will be affected differently by the line-of-sight temperature variations and this could be reflected in the results. The aim of this paper is to investigate these questions. In the work we use the results of radiative transfer calculations, where the model clouds are the result of magnetohydrodynamical (MHD) simulations and the clouds may also contain point sources that introduce strong local temperature gradients. We compare the results of the above mentioned and similar methods (see Sect. 3) with the true column densities known from the models. We also examine the accuracy to which the column densities can be determined by carrying out radiative transfer modelling of the data. Such modelling has been applied, also recently, in the examination of the density and temperature structure of dense clouds (e.g. Ridderstad & Juvela 2010; Juvela et al. 2012b; Nielbock et al. 2012; Wilcock et al. 2012).
The content of the paper is the following. In Sect. 2 we present the cloud models and the calculation of the surface brightness maps. In Sect. 3 we describe the basic estimation of the colour temperatures and column densities and present the two methods that are used to convert surface brightness data back to high-resolution column density maps. In Sect. 4 we present the main results, comparing the column density estimates to the true column densities in the cloud models and to the column densities that would be recovered by higher resolution observations. In Sect. 5 we construct three-dimensional models that are adjusted to reproduce the surface brightness observations and in this way used to estimate the column densities. The column densities of these models are again compared to the column density in the original model cloud. The results are discussed in Sect. 6 where we also draw the final conclusions on the relative merits of the methods used.
2. Simulated observations
We use surface brightness maps calculated for two MHD models that are described in more detail in Malinen et al. (2011) and Juvela et al. (2012a). Cloud I corresponds to an isothermal MHD simulation carried out on a regular grid of 10003 cells (Padoan & Nordlund 2011). The calculations included self-gravity and the snapshot corresponds to situation before any significant core collapse. The cloud is scaled to a linear size of 6 pc and a mean density of n(H) = 222.0 cm-3, giving a mean visual extinction of 2m. The model is the same that was used in Juvela et al. (2012a) to study filamentary structures. Cloud II was calculated using the adaptive mesh refinement (AMR) code Enzo (Collins et al. 2010). The model has a base grid of 1283, four levels of refinement, and an effective resolution of 20483 cells. The model has been discussed in Collins et al. (2011) and in Malinen et al. (2011, called Model II in that paper). As in the case of Cloud I, the MHD calculations assumed an isothermal equation of state. The linear size and the mean density of the model are scaled to 10 pc and 400 cm-3. This gives an average column density of N(H) = 1.23 × 1022 cm-2 that corresponds to AV ~ 6.6mag. The extinction reaches 20m in less than 2% of the map pixels.
For the radiative transfer modelling, the density fields were resampled onto hierarchical grids. The gridding preserves the full resolution in the dense parts of the model clouds but, to speed up the calculations, the resolution is degraded in the low density regions. Occasionally the greater size of some cells along the line-of-sight produces noticeable artefacts in the surface brightness maps which, however, usually disappear when the data are convolved with the telescope beam. Because the parameters that are being compared (i.e., the true and the estimated column densities) refer to the same discretisation, possible discretisation errors do not directly affect this comparison.
A summary of the methods used for the estimation of column density.
The dust temperature distributions and the emerging dust continuum emission were calculated with the radiative transfer code described in Lunttila & Juvela (2012). The clouds are illuminated externally by an isotropic interstellar radiation field (ISRF, Mathis et al. 1983) and the dust properties correspond to those of the normal diffuse interstellar medium (Draine 2003) with a gas-to-dust ratio of 124 and RV = 3.1. The calculations are described in more detail in Malinen et al. (2011) and Juvela et al. (2012a). We refer to the densest sub-structures of the model clouds as cores. We will also examine a case where the cores of Cloud II, which already are known to be gravitationally bound, have internal heating sources. The properties of the sources and the procedures used in their modelling are described in Malinen et al. (2011). There are 34 sources with luminosities between 2.1 and 82 solar luminosities. For the present study, their main effect is how they modify the three-dimensional distribution of dust temperature and how that is reflected in the surface brightness measurements. With the assumed cloud distance of 500 pc, the sources can locally raise the dust colour temperature to 20−30 K when observed at the resolution of 40″.
We use the radiative transfer modelling to simulate observations by the Herschel Space Observatory (Pilbratt et al. 2010). The calculations result in synthetic surface brightness maps at 160, 250, 350, and 500 μm. The map size is 1000 × 1000 pixels for Cloud I and 2048 × 2048 pixels for Cloud II. As a default we assume noise levels of 3.7, 1.20, 0.85, and 0.35 M Jy sr-1 per beam for 160, 250, 350, and 500 μm, respectively. However, we also examine cases with noise 0.3 or 3.0 times these values.The pixel size of the maps is set to a value of 2.0″. During the analysis the maps are convolved with the assumed beam sizes of 12.0″, 18.3″, 24.9″, and 36.3″, for the four bands in the order of increasing wavelength. The values correspond to the approximate beam sizes of Herschel (Poglitsch et al. 2010; Griffin et al. 2010).
3. Analysis methods
In this section, we present the methods that are used to estimate the dust temperature and column density without resorting to full radiative transfer modelling. In particular, we recount the procedures used in Juvela et al. (2012c) and Palmeirim et al. (2013) to increase the spatial resolution of the column density maps. The methods are explained below and a summary of all the analytical combinations of individual column density estimates are summarised in Table 1.
3.1. Estimation of column density
The basic principles of the column density estimation are the same for all methods. The observed intensity Iν is approximated with a modified black body curve 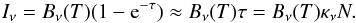 (1)The equation assumes that the medium can be described with a single temperature value. The included approximation of the exponential term is valid if the optical depth τ is much smaller than one. This is the case for the models and the wavelengths examined in this paper. The optical depth τ is the product of dust opacity at the frequency in question, κν, and the column density N. Thus, the equation can be used to estimate the column density, provided that the dust temperature T is known. If we assume for the opacity a frequency dependence of κν ∝ νβ with some fixed value of the emissivity spectral index β, the value of T can be estimated with observations of two or more wavelengths, the latter requiring a fit to the observed intensities. We carry out these as least squares fits. Whenever the source contains temperature variations, the colour temperature obtained from these fits is only an approximation of the mass averaged dust temperature (Shetty et al. 2009b; Malinen et al. 2011; Juvela & Ysard 2012b; Ysard et al. 2012). This is one of the main reason why the morphology of the derived column density maps (i.e., column density contrasts) deviate from the reality.
(1)The equation assumes that the medium can be described with a single temperature value. The included approximation of the exponential term is valid if the optical depth τ is much smaller than one. This is the case for the models and the wavelengths examined in this paper. The optical depth τ is the product of dust opacity at the frequency in question, κν, and the column density N. Thus, the equation can be used to estimate the column density, provided that the dust temperature T is known. If we assume for the opacity a frequency dependence of κν ∝ νβ with some fixed value of the emissivity spectral index β, the value of T can be estimated with observations of two or more wavelengths, the latter requiring a fit to the observed intensities. We carry out these as least squares fits. Whenever the source contains temperature variations, the colour temperature obtained from these fits is only an approximation of the mass averaged dust temperature (Shetty et al. 2009b; Malinen et al. 2011; Juvela & Ysard 2012b; Ysard et al. 2012). This is one of the main reason why the morphology of the derived column density maps (i.e., column density contrasts) deviate from the reality.
The least squares fits are carried out pixel by pixel, weighting the data points according to the observational noise. The fitted temperature and intensity are inserted to Eq. (1) for the calculation of an estimate of N. If data are available at more than two wavelengths, also the dust emissivity spectral index β could be determined. However, in this paper the value of β is kept fixed to the value of 2.0. In the dust model used in the radiative transfer calculations, the spectral index changes only a little as a function of wavelength and is ~2.08 between the wavelengths of 160 μm and 500 μm.
In the case of real observations, the absolute value of the opacity κν is a major source of uncertainty. In this paper, we are not interested in this factor and simply scale the median of the estimated column density maps to the median of the true column density that is known for the model clouds.
3.2. Higher resolution estimates: Method A
Juvela et al. (2012c) used Herschel observations to estimate the column density in the usual way, convolving all surface brightness data to the resolution of the 500 μm data. However, the paper also used alternative column density estimates that were obtained combining the colour temperatures at the 40″ resolution with 250 μm surface brightness data at a resolution of 20″. It was argued that the effective resolution of those maps would be close to 20″ because the variations in the surface brightness are stronger than the effects of colour temperature variations. It is not clear to what extent this is correct. This also depends on the difference between the colour temperature and the true mass averaged dust temperature. For example, a compact cold core can have a significantly lower physical temperature without a significant effect on the colour temperature that is dominated by emission from warmer regions. This means that although lower resolution of the temperature map does increase errors, these may not always be very significant.
3.3. Higher resolution estimates: Method B
In Palmeirim et al. (2013) a higher resolution column density map was obtained combining column density maps that were derived using different sets of wavelengths. The data consisted of Herschel at 160, 250, 350, and 500 μm. One starts by calculating column density maps N(250), N(350), and N(500) that are based on data up to the specified wavelength and convolved to the corresponding resolution. For example, N(350) is based on the 160 μm, 250 μm, and 350 μm maps that are convolved to the resolution of the 350 μm map, ~25″. If one convolves such a column density map to lower resolution, one also obtains estimates for the difference in the structures that are visible in the two versions. We use the notation N(λ1 → λ2) to denote a column density map that is first estimated using data at wavelengths λ ≤ λ1 and at the resolution of the observations at λ1 and is then convolved to the resolution of observations at wavelength λ2. The final estimate of the column densities is obtained as a combination ![Mathematical equation: \begin{eqnarray} N & = & N(500) + \left[ N(350) - N(350\rightarrow 500) \right] \nonumber \\ & & + \left[ N(250) - N(250\rightarrow 350) \right]. \label{eq:palmeirim} \end{eqnarray}](/articles/aa/full_html/2013/05/aa21254-13/aa21254-13-eq43.png) (2)N(500) is the best estimate of column density at low resolution. The other terms add information on structures that are visible at the resolution of 350 μm data but not at the resolution of 500 μm data and finally the structures that are visible at 250 μm but not at the resolution of the 350 μm data. In principle, the method thus provides estimates for the column density at the resolution of the 250 μm data, ~18″.
(2)N(500) is the best estimate of column density at low resolution. The other terms add information on structures that are visible at the resolution of 350 μm data but not at the resolution of 500 μm data and finally the structures that are visible at 250 μm but not at the resolution of the 350 μm data. In principle, the method thus provides estimates for the column density at the resolution of the 250 μm data, ~18″.
The estimates N(250), N(350), and N(500) will be different and not only because of the different resolution. By using different sets of wavelengths, one will not only have different noise levels but also the bias of each estimates will be different (Shetty et al. 2009b,a; Malinen et al. 2011). The biases are related to the temperature distribution of the source. In particular, without data at long wavelengths, one will be relatively insensitive to very cold dust. Of course, if the estimates were identical, one could use directly the N(250) map. With Eq. (2), one can include all the data although, of course, the correction terms [N(350) − N(350 → 500)] and [N(250) − N(250 → 350)] (i.e., estimates of small-scale structures) will be progressively more insensitive to cold emission.
3.4. Other higher resolution estimates
Because the bias of the column density estimates depends on the wavelengths used, it is possible that this particular combination of N(250), N(350), and N(500) is not optimal for the overall accuracy of the results. Therefore, we will later in Sect. 4 also examine some other linear and non-linear combinations. In particular, we will examine which linear combination of the terms N(500), [N(350) − N(350 → 500)], [N(250) − N(250 → 350)] gives the best correlation with the true column density. This will be called the Method C although, of course, in the case of real observations the values of these coefficients could not be estimated. Finally, to examine the effects of the wavelength-dependent biases further, we consider a linear combination of N(250 → 500), N(350 → 500), and N(500) where all surface brightness maps are first converted to the resolution of N(500). We call this Method D. Because already all the surface brightness data are convolved to a common resolution, Method D does not try to improve the spatial resolution of the column density map, only the correctness of the low resolution estimates.
The final analytical method includes one additional, non-linear term. The method is denoted by NL and, in addition to the terms already included in Method D, it contains a term [N(500) − N(250)]2. At this point this is examined only as one possible idea of taking the non-linear features introduced by the colour temperature bias into account.
3.5. Radiative transfer modelling
As an alternative to the “analytical” Methods A and B, we will also examine radiative transfer modelling as a tool for the column density determination. We construct a simple three-dimensional model for a source and carry out radiative transfer modelling to predict the dust emission at the observed wavelengths. The model is then adjusted until there is a satisfactory correspondence between the observed and the modelled intensities. The column density estimates are then read from the final model cloud.
In practice, we construct three-dimensional models where the density distribution is discretised onto a grid of 813 cells. The radiative transfer calculations are carried out with a Monte Carlo program (Juvela & Padoan 2003; Juvela 2005) using the same dust model as in the original calculations that were used to create the synthetic observations of Cloud I and Cloud II. Therefore, we exclude from consideration the errors that would be caused by wrong assumptions of dust opacity (and, consequently, of the dust emissivity spectral index). These errors are not included in the results of Methods A and B either. However, one must note that in the modelling we assume consistency not only at the sub-millimetre wavelengths but also at the short wavelengths where the dust grains are absorbing most of their energy. As the external radiation field we also used the same Mathis et al. (1983) model as in the original simulations but absolute level of the radiation field is not assumed to be known.
The cell size of the constructed 813 cell models is set equal to 4″. When the observations and the model are compared, the 160 μm and 250 μm data are convolved to the resolution of 18.3″ and the 350 μm and 500 μm data to the resolution of the observations, 24.9″ and 36.3″, respectively. The details of the assumed density distribution and the procedures used to update the model clouds are discussed in more detail in Sect. 5. However, because the column densities are adjusted directly based on the 250 μm data, the modelling should also provide column density estimates at the same resolution.
4. Results
4.1. Comparison of Methods A and B
Using the surface brightness maps at 160, 250, 350, and 500 μm resulting from the radiative transfer modelling (Sect. 2) we calculate column density maps using the Methods A and B (see Sect. 3). The results are compared with the true column density of the model clouds and with column density maps that are derived from synthetic observations with a uniform spatial resolution of 18.3 ″ and without observational noise.
 |
Fig. 1 Column densities estimated with Method A (black points) and Method B (red points) versus the true column density of Cloud I. The frames correspond to 0.3 or 3.0 times the default noise (see text). The numbers indicate the correlation coefficients r for Method A and Method B, respectively, for data with Ntrue > 5 × 1021 cm-2. For illustration, we have included in the lower frames the corresponding results obtained with a spectral index value of β = 1.7 instead of β = 2.0. |
 |
Fig. 2 Column density maps for a selected small region in Cloud I. Frame a) shows the true column density of the model cloud and the frames b) and c) the errors in the estimates of Method A and Method B, respectively (N(A) − Ntrue and N(B) − Ntrue). Frame d) shows the column density errors when estimates are calculated using data with 18.3″ resolution at all wavelengths, N(18.3) − Ntrue. The frames e–f) show the errors of Method A and Method B relative to the estimates from 18.3″ resolution data. The range of data values is given at the bottom of each frame. |
 |
Fig. 3 Column density profiles for a horizontal cut through the maps in Fig. 2. The noise levels are given in the frames. The lines show the true column density (black line), the column density derived from 18″ resolution surface brightness data (dotted line) and the results of Methods A and B (blue and red lines, respectively). |
4.1.1. Estimates on large scales: Cloud I
We start by examining Cloud I. Because we are mostly interested in the dense structures and because the bias is stronger at higher column densities, we restrict the analysis to regions with true column density Ntrue > 5 × 1021 cm-2. Figure 1 compares the results of Methods A and B to the true column density, including the Pearson correlation coefficients. On average, the methods give comparable results. For lower observational noise, Method B gives higher correlation with the true values. However, Method B is also more sensitive to the presence of noise and, in the case of three times the default noise level, the correlation coefficient is higher for Method A.
Figure 2 compares the results in a small region centred at a dense clump, i.e., concentrating on the highest column densities. The calculations are carried out with the default observational noise. In the figure, in the neighbourhood of the main peak, Method A now shows up to ~50% greater errors than Method B. This appears to be a direct consequence of the low resolution of the temperature information used by Method A. The figure also suggests that a large fraction of the errors in Method B map result from temperature variations that increase with the line-of-sight column density. Therefore, the availability of surface brightness data at the 18.3″ resolution would not result in lower errors. Figure 3 shows column density profiles for the same region, again comparing cases with 0.3 times at 3.0 times the default noise.
We also examine Method C that is an optimised version of Method B, a linear combination that results in the best correlation with the true column densities at the 18.3″ resolution. Finally, Method D is a similar linear combination of the N(250 → 500), N(350 → 500), and N(500) maps at the lower 36.3″ resolution. Figure 4 shows the correlations as scatter plots.
In these overall correlations, Method B is performing consistently slightly better than Method A. With its optimised linear coefficients, Method C produces still some improvement that is visible as a smaller scatter in Fig. 4. Even more interesting are the best coefficients that are obtained for the terms N(500), [N(350) − N(350 → 500)], [N(250) − N(250 → 350)] (see Table 2). In Method B these are by construction all equal to 1.0. However, in the case of Cloud I, both Method C and Method D have partly negative coefficients. The correlation coefficient with true values is highest for Method D, r = 0.977, partly also because of the lower resolution. The opposite signs and greater magnitude of the N(250) and N(350) coefficients mean that significant corrections are made based on the small differences between the individual column density estimates.
 |
Fig. 4 Correlations between column density estimates and the true column density for Methods A, B, C, and D in the case of Cloud I and the default noise level. The plots and the correlation coefficients listed in the frames correspond to column density estimates that are all convolved to a common resolution of 36.3″. |
The results are partly encouraging, suggesting that it might be possible to improve the accuracy of the column density estimates beyond those obtained assuming a single modified black body. However, the method should perform well for all clouds, not only for the one for which it is originally tuned. We repeated the previous analysis also using β = 1.7 instead of β = 2.0. This changes the coefficients of Methods C and D by some tens of percent but the correlations with the true column density are only slightly lower (less than 0.01). The main effect of a wrong spectral index value is, of course, bias in the absolute values of the column density estimates.
4.1.2. Estimates for cores: Cloud II
In this section, we concentrate on the densest structures of Cloud II (the cores) and their environment. We look first at all data between the column densities of 5 × 1021 cm-2 and 20 × 1021 cm-2, the selection being made using the true column densities at a resolution of 18.3″. The lower limit is the same as above while the upper limit is ~25% higher than the maximum column density of Cloud I. For these data all Methods A−D give a correlation coefficient r ~ 0.997 for the comparison with the true column density. This is probably due to the fact that in Cloud II these column densities still correspond to extended medium without strong dust temperature variations. In this situation the coefficients of Methods C and D are not very well defined.
In the column density range between 20 × 1021 cm-2 and 100 × 1021 cm-2, small differences again appear between the methods. The correlation coefficients are r = 0.972 for Method A, r = 0.978 for both Method B and Method C, and r = 0.987 for Method D. Unfortunately, for Method D, the coefficients found in Cloud I and Cloud II or between the column density intervals of Cloud II are not very similar (see Table 2). For Method C, the variation of the parameter values is smaller. Nevertheless, there is no single set of coefficients that could be used to improve the accuracy of the column density estimates for any cloud.
Linear coefficients of Methods C and D.
On large scales, the linear combinations of N(250), N(350), and N(500) did produce some improvement in the accuracy but not with universal coefficients. The usual column density estimates should be more biased at the locations of the dense cores where the line-of-sight temperature variations are the greatest. The small scale fidelity of the column density maps is crucial for the interpretation of the core properties. Therefore, we examine separately the neighbourhood of the cores in Cloud II. These are the same gravitationally bound regions as discussed in Malinen et al. (2011). We study pixels that fall within 2′ radius of the centre of each core.
Figure 5 compares the results at the 36.3″ resolution. All methods tend to underestimate the true column density, especially towards the column density peaks. This produces the strong flattening of column densities above ~1022 cm-2 and the greatest errors are close to a factor of three. The order of accuracy of Methods A–D is as in the case of the large scale correlations but the differences are more pronounced. At the highest column densities, the estimates given by Method D are twice the values of Methods A and B. Nevertheless, even Method D underestimates the true column density by up to ~50%. For this set of data, the correlation coefficients are 0.914, 0.921, 0.925, 0.964 for Methods A–D, respectively.
 |
Fig. 5 Correlations between column density estimates and the true column density. The figure compares the results of Methods A, B, C, and D using data around the cores of Cloud II. The estimates have been all convolved to a common resolution of 36.3″ and scaled so that the median values fall on the correct relation N = Ntrue (solid line). |
Malinen et al. (2011) noted that when the cores are extremely dense, internal heating will improve the accuracy of the column density estimates. However, the effect was small for the Cloud II (see their Fig. 11) and depends on how large regions around the cores are examined. We plot in Fig. 6 similar relation but for all pixels within the 2′ radius. The figure is thus similar to Fig. 5 but shows the situation after the addition of the internal heating sources.
The sources only have a little effect on the accuracy of the column density estimates when this is calculated at the resolution of the 500 μm data, the full width at half maximum (FWHM) corresponding to ~20 pixels. The bias shown by Methods A–C is very similar to Fig. 5 but the correlation coefficients are slightly lower. At the highest column densities, Method D manages to bring the column density estimates up by ~10% but below 100 × 1021 cm-2 the results show a greater scatter. The coefficients optimised for the cores differ from those derived on large scale but, on the other hand, the effect of the internal heating sources remains marginal (see Table 2).
 |
Fig. 7 Column density errors for Cloud II with internal sources. The upper frames show the true column density and the estimated colour temperature. The lower frames show, with different colour scales, the ratio of the column density estimates with and without internal sources. The maps show a 20′ × 20′ area of the full model. The estimates are calculated using 160–500 μm surface brightness maps with 18.3″ resolution. |
Figure 7 shows a 2.9 pc × 2.9 pc piece of Cloud II, looking at the column density estimates obtained from surface brightness data at a resolution of 18.3″. The area includes some filamentary structures and six sources that raise the colour temperature locally up to ~25 K. With the sources, the column density estimates of the main filament are higher by up to ~10%. This might be related to a higher average dust temperature that decreases the bias associated with line-of-sight temperature variations. At the very location of the sources the column density estimates are 10−30% lower. If the column density maps are convolved to a 2′ resolution, the internal sources are seen to increase (i.e., improve) the estimates of the average column density of the cores. The net effect is negative only for a few of the strongest sources. This is the case for the source in the lower left corner of Fig. 7) where, at the 2′ resolution, the estimate of the average column density of the region is still by ~7% lower because of the presence of the radiation source. At the 18.3″ resolution, the effect is 35% towards the source but goes to zero already at the distance of ~20″.
 |
Fig. 8 Comparison of column density estimates in a 0.5 pc × 0.5 pc area in Cloud II. Frame a) shows the true column density and frames d) and g) the errors for column density maps derived with all data at a resolution of 18.3″ or 36.3″. The second and the third columns show the difference between Method A and Method B relative to the true column density (first row) and the estimates obtained with all surface brightness data either at 18.3″ (second row) or 36.3″ resolution (third row). The numbers at the bottom of each frame show the range of values within the map. |
 |
Fig. 9 As Fig. 8 but showing the same 0.5 pc × 0.5 pc area of Cloud II with an added internal heating source in the middle of the field. The 33.7 solar luminosity source raises the dust colour temperature locally to ~27 K. |
 |
Fig. 10 Column density profiles for a horizontal cut through the maps Figs. 8−9. Shown are the true column density (solid black line; uppermost lines, convolved to 18.3″ resolution), the estimate derived from 18.3″ data at all wavelengths (black dotted line), Method A (blue solid line), and Method B (red solid line). The lower frames correspond to the case with an internal heating source. The noise is 0.3 times (frames a and c) or 3.0 times (frames b and d) times the default value. |
Figures 8−10 take a closer look at a ~0.5 × 0.5 pc area in Cloud II. The predictions of Method A and Method B are compared in Fig. 8 with the results obtained directly using surface brightness data at a resolution of 18.3″ or 36.3″. For the main clump in the field (containing a gravitationally bound core), the maximum error of Method A is about twice as large as for Method B. The results of Method B are very similar to the map derived from 18.3″ data. Both contain errors caused by the line-of-sight temperature variations. The maximum error is found at the position of a dense core in the upper right hand part of the figure where the error of Method B is ~37% greater than for the 18.3″ data. However, this error is still less than 20% when compared to the true column density. When the estimation is based on data at a resolution of 36.3″, the column density map appears smooth, because of the larger beam and because of the higher signal-to-noise ratio. In spite of the lower resolution, the maximum errors are greater than for either Method A or Method B at twice as high resolution.
Figure 9 shows the same area after the addition of an internal heating source. Because of stronger temperature variations, the column density errors are ~30%, the 36.3″ surface brightness data resulting in only slightly greater errors than the 18.3″ data. Compared to Method B, the errors of Method A are smaller at lower column densities (because of lower sensitivity to noise), greater in a ring around the main clump, and again smaller at the location of the heating source where the error is below 10%. Figure 10 shows the column density profiles for the main clump. For the quiescent core, the Method B gives a profile that is almost identical to that of high resolution data, this still slightly underestimating the true column density. In Method A, the low resolution of the temperature information results in too low column densities for the quiescent core but in the case of internally heated core this compensates the effect of temperature variations. In the case of internal heating, none of the methods is able to recover the actual column density profile of the clump. The result of Method B also is clearly impacted when the observational noise is increased.
 |
Fig. 11 The ratio of the column density estimates and the true values in the 19 cores of Cloud II with column densities N > 5 × 1022 cm-2. The results are shown separately for the case without internal heating (left frame) and with one radiation source inside each core (right frame). The estimates are calculated using 18.3″ resolution surface brightness data at all wavelengths 160–500 μm. |
4.2. Non-linear correction to column density estimates
In this section we examine non-linear combinations of the N(250), N(350), and N(500) values. The goal is to find a method that would better trace the relative column density variations around the dense cores.
Figure 11 shows the radial relative error of the column density estimates for all cores with peak column density exceeding 5 × 1022 cm-2. The values are calculated using data at 18.3″ resolution, i.e., the figure shows only the effect of the line-of-sight temperature variations on the estimates. The column density is underestimated up to 70% or, in the case of internal heating, up to ~60%. For most cores the errors are below 30%.
Figure 12 shows some examples of the radial profiles for the estimates N(250), N(350), and N(500) separately. Without internal heating, the behaviour is very predictable with N(250) < N(350) < N(500). Therefore, the difference between the estimates can be used to correct for the under-estimation of the column density. However, Fig. 12 also indicates that the fraction by which column density is under-estimated is not completely systematical relative to, for example, the ratio N(500) / N(250). With internal heating the situation becomes more complicated. Within the sample of six cores included in Fig. 12 (right frame), in two cases N(250) is larger than N(500). Such differences are to be expected, because the column density estimates depend in a complex way on the source luminosity and the geometry and optical depth of the cores.
 |
Fig. 12 The ratio of the column density estimates and the true values in a sample of six Cloud II cores with N > 5 × 1022 cm-2. The dotted, dashed, and solid lines correspond to N(250), N(350), and N(500), respectively, all calculated at the 18.3″ resolution. The results are shown for cores without (left frame) and with internal heating sources (right frame). |
As the simplest extension of Method D, we attempted a non-linear correction using the formula NNL = p1N(250 → 500) + p2N(350 → 500) + p3N(500) + p4[N(500) − N(250 → 500)]2. For the 2′ neighbourhoods of the gravitationally bound cores of Cloud II, the least-squares solution leads to the parameter values p1 = − 2.93, p2 = − 0.042, p3 = 4.10, and p4 = 0.62. As suggested by Fig. 12, the greater the difference in N(500) − N(250), the greater the upward correction of the column density estimates. The correction (see Fig. 13) increases the correlation coefficient between the true column density and the estimates from 0.924 for N(500) to 0.976 for NNL. The coefficients are largely determined by the two cores with the highest column densities. However, also in the range Ntrue = (10 − 60) × 1021 cm-2 the bias appears to be somewhat smaller and the correlation coefficient has risen, although only very marginally (from 0.992 to 0.993). Of course, the quadratic term in the formula of NNL does not take the sign of the N(500) − N(250) difference into account. In practice, the results would not change if the difference were replaced with max{ 0.0,N(500) − N(250) }. The use of an additional term [N(500) − N(350)]2 does not bring any further improvement.
 |
Fig. 13 Correlations between the true column density and the estimates N(500) (blue points) and NNL (red points, see text). The data consists of the 2′ radius environments of the cores in Cloud II. The resolution is 36.3″. The right hand frame shows a zoom-in to small column densities. |
When the same model is fitted to the data with internal sources, the parameters are p1 = − 3.03, p2 = 1.42, p3 = 2.79, and p4 = 0.48. The parameters p1, p3, and p4 are roughly similar as in the case without sources, but p2 has increased to a value of 1.42. With these parameters, the correlation with the true column density increases from 0.920 for N(500) to 0.982 for NNL. If we use directly the coefficients derived from the model without internal sources, the correlation coefficient for NNL becomes 0.977. This is still a clear improvement over N(500) but, with these coefficients, NNL overestimates the column densities beyond ~150 × 1021 cm-2, the error increasing to ~30% for the highest column densities. However, for these lines-of-sight N(500) underestimates the true values by a factor of three. This shows that the estimated non-linear correction could be useful in general, not only in the cloud where its coefficients were derived.
5. Radiative transfer modelling
The errors in the predictions of the previous methods are largely related to the temperature variations within the sources and the way the variations are reflected in observations at different wavelengths. By constructing three-dimensional models of the sources, one should be able to account for these effects. In this section, we examine how well this works in practice, especially in the case of high column densities. Our synthetic observations are themselves based on numerical simulations. In this section, we only use the resulting surface brightness data, not the information about the structure of the sources or the radiation field seen by the individual clumps.
5.1. The modelling procedures
We carry out radiative transfer modelling of the nine cores of Cloud II with the highest column densities. The modelling is done purely on the basis of the “observed” surface brightness maps, without using any information on the three-dimensional structure of the cloud. Each core separately is described with model of 813 4″ cells, the cell size corresponding to 0.0098 pc. Each model thus covers a projected area of 5.3′ × 5.3′ or 0.79 pc × 0.79 pc. The column density maps are shown in Fig. 14 with values obtained from the Cloud II density cube. Note that the term “observation” refers to the synthetic surface brightness maps obtained from Cloud II and the term “model” refers to the 813 cell models constructed for the regions around the selected cores.
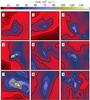 |
Fig. 14 Column density maps of the nine fields (cores) selected for radiative transfer modelling. The contours are at 10.0, 20.0, 50.0, 100.0, 200.0, and 400.0 times 1021 cm-2. |
Along the line-of-sight, the full extent of Cloud II is 10 pc, much greater than the size of the 813 cell models. Thus, the structures that are visible within these 5.3′ × 5.3′ maps may be physically connected or may be quite distant from each other. The lack of knowledge on the line-of-sight structure is one of the main sources of uncertainty in the modelling. To analyse the observations of Cloud II, we subtract from the surface brightness maps the local background that is defined with the position of minimum N(500) value within the 5.3′ × 5.3′ area. This eliminates the necessity of modelling the extended emission. In some fields surface brightness gradients result in large regions with negative residual signal. However, this has little effect on the actual cores that are much above the background. The line-of-sight density distribution is assumed to be Gaussian, with the FWHM set to 20% of the box size. The value is not tuned separately for each core but it is roughly consistent with the average core sizes in the plane of the sky. In the plane of the sky, the models are optimised by comparing the observed surface brightness maps and the corresponding maps produced by the models. The comparison is restricted to inner 2′ × 2′ area because the boundaries are affected by edge effects (because of the flat surfaces subjected to the full external field).
The modelled cores are embedded deep within Cloud II that has an average visual extinction of AV ~ 6.6mag. This means that the radiation field is different for each core. In the calculations, this is taken into account by illuminating the model cloud by an attenuated radiation field. The unattenuated radiation field corresponds to three times the Mathis et al. (1983) model of the ISRF, i.e., it is clearly higher than the actual field in the original simulations. The attenuation is parametrised by the visual extinction 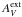 and is calculated using the extinction curve of the selected dust model. The attenuation is assumed to take place outside the model volume, by some external diffuse cloud component that would correspond to the diffuse component already subtracted from observations.
and is calculated using the extinction curve of the selected dust model. The attenuation is assumed to take place outside the model volume, by some external diffuse cloud component that would correspond to the diffuse component already subtracted from observations.
We carry out radiative transfer calculations to produce synthetic 81 × 81 pixel maps of surface brightness that are compared with the “observations” of Cloud II. The model column densities are adjusted according to the ratio of the observed and the modelled 250 μm values. This means that the density in each cell corresponding to a given map pixel is multiplied by the same number that depends on whether the current model is overestimating or underestimating the observed surface brightness. The procedure is iterated until the 250 μm errors are below 1% for the innermost 2′ × 2′ area.
5.1.1. Basic models
If we do not use any other spectral information, the column density estimates depend on the assumed intensity of the heating radiation. If the same value were used for all cores, the column densities would often be wrong by a factor of two, a result significantly worse than either of Methods A or B (comparing the estimates to the true column density in Cloud II). Therefore, we adjust the attenuation of the external field until the observed and modelled ratios of 160 μm and 500 μm surface brightness agree. The ratios are measured as the average within a 30″ radius of the core. Thus, both the intensity and shape of the emission spectral energy distribution (SED) should be correct at the location of the column density peak. Both attenuation and column densities (one value per map pixel) are adjusted iteratively until the relative errors are below 1%.
Figure 15 compares the column densities of the optimised models to the true column densities and to the estimates from Method B. Although the cores are not circularly-symmetric, we plot the azimuthally averaged column densities as the function of distance from the centre of the selected core. The error bars on the true column density correspond to the azimuthal variation. For cores 1−3, the modelling recovers the radial column density profiles quite accurately. For core 6, the fit is worse but still better than for Method B that underestimates the true values by a significant fraction. For core 8, the Method B and modelling are equally close to the truth, while in cores 5 and 9 the modelling overestimates the peak. For the sources with the highest column densities, cores number 4 and 7, the peak is missing for both methods. This is not surprising, as the very compact central object is almost invisible still at the wavelength of 250 μm.
If the external field is raised to five times the Mathis et al. (1983) values, the central column densities decrease by 5–10%. The higher level of the external field is compensated by a greater value of , which means that energy is absorbed mainly at longer wavelengths. This reduces temperature gradients, also reducing the estimated column density contrasts of the cores by a similar factor of ~10%.
 |
Fig. 15 Azimuthally-averaged column density profiles of the selected nine cores. The black symbols and error bars show the true column density and the variation in 4″ wide annuli. The blue solid curve is the estimate from Method B and the red solid curve the profile obtained from the constructed radiative transfer model. |
5.1.2. Asymmetric illumination
In the field number 4 the results of the modelling are completely wrong at greater distances (Fig.15). This is caused by the presence of a strong temperature gradient across the field. The SED is correct at the centre of the field but on one side of the map the same assumption of the external field strength is not enough to produce the observed 250 μm intensity. The column density increases to the point where the surface brightness saturates, leaving a spot where the 250 μm surface brightness is underestimated in spite of the model column density being far above the correct value. Fortunately, the problem is plainly visible in the surface brightness maps, i.e., is apparent for the observer. In the problem area, the model underestimates the 160 μm surface brightness by more than 50% and overestimates the 500 μm intensity by ~150%.
Temperature gradients are seen in a few fields and these can affect also the central column density because of the mutual shadowing of the regions. To make a first order correction for gradients in the plane of the sky, we added to each model an anisotropic radiation source that covers a circular area of the sky with an opening angle of 45 degrees. The centre of this sky area is in a direction perpendicular to the line of sight and at a position angle where, based on the previous results, the source will help to remove the residual colour gradients. The spectrum of the anisotropic component corresponds to the normal ISRF attenuated by AV = 2.0mag and its intensity is scaled to obtain a solution where, for data within the innermost one arcmin radius, the quantity ΔS(160 μm) − ΔS(500 μm) is no longer correlated with the distance along the original gradient direction. In the formula, ΔS stands for the difference of the observed and modelled surface brightness values.
The effect of asymmetric illumination is in most cores almost unnoticeable on the column density estimates. In core 3, the central column density increases by ~5% while in core 8 it decreases by the same amount. Clear effects are visible only in the case of the cores 4 and 7, the ones with the highest column density (see Fig. 16). In field 4, the model is now much closer to the correct column density values outside the central core. However, the constructed models still miss the high column density peaks of both fields 4 and 7. Figure 17 shows this for core 4. The densest core is invisible in the 160 μm map, not visible as a separate peak in the 500 μm surface brightness, and also missed by the model. The model was tuned so that the SED (250 μm surface brightness and the 160 μm/500 μm colour) on the average match the observations over an one arcmin circle. At the very centre, however, the residual errors are ~10% of the surface brightness and rise above 30% elsewhere in the field. The significance of these residuals suggests that further improvements in the models should be possible.
 |
Fig. 16 Azimuthally-averaged column density profiles of the selected nine cores. As Fig. 15 but including in the modelling anisotropic radiation field. |
 |
Fig. 17 Core 4 modelled with anisotropic radiation field. Frames a) and b) are the 160 μm and 500 μm surface brightness maps from Cloud II (the “observations”). The core is visible in the map of the true column density (frame c) but is missed by the constructed model (frame d). Frames e) and f) show the errors of the model predictions SModel relative to the observed surface brightness SObs at the wavelengths of 160 μm and 500 μm, respectively. |
5.1.3. Varying the line-of-sight mass distribution
The main problem for the modelling is that the cores are embedded in an optically thick cloud whose line-of-sight extent is two orders of magnitude longer than the typical core size. Any structure seen in a map can be a compact object also in three-dimensions, it may be elongated along the line-of-sight or may even consist of several unconnected structures within the 10 pc distance through the model cloud. This impacts the dust temperatures and, consequently, the column density estimates.
The previous models consisted of a smooth density distribution with a single FWHM for its line-of-sight extent. We can try to take some of the variations into account by modifying the FWHM values for each line-of-sight separately. A small FWHM value would corresponds to a compact and cold region, a greater FWHM to more diffuse region with a higher average temperature. We do not modify the FWHM at the core location where the data are already used to adjust the strength of the external radiation field. For any other line-of-sight, if the model predicts a too cold spectrum (low ratio of 160 μm and 500 μm intensities), the FWHM is increased (and vice versa). The final effect is complicated by shielding between the different regions.
This further modification helps to bring down the errors outside the densest core, e.g., in the field number 4 (see Fig. 18). The surface brightness residuals at 160 μm and 500 μm are mostly below 10% but raise up to 20% at the location of the column density peak. The column density estimate of the peak is close to that of the previous models. The situation is similar in field 7 where the peak value of ~120 × 1021 cm2 remains far below the correct number of ~800 × 1021 cm2.
Of the lower column density cores, the column density predictions were previously most erroneous in field 9 where the peak value was overestimated by ~35%. The adjustment of the line-of-sight extent of the clump has reduced this error only to ~28%. For the other cores, the effects are smaller. This shows that even the variation of the line-of-sight extent, as implemented, is not able to reproduce the complexity of these regions.
 |
Fig. 18 Core 4 modelled with anisotropic radiation field and varying line-of-sight width of the density distribution. The maps show the relative error of the model predictions at 160 μm (frame a) and at 500 μm (frame b). The contours are at intervals of 10%. |
5.2. Ellipsoidal model
For the final test, we return to a simple geometry and isotropic illumination. The cloud densities are generated as a three-dimensional ellipsoid with Gaussian density profiles and a ratio of 1:2:4 between the FWHM values along the main axes. The density field is sampled on a 813 Cartesian grid, first applying three 45 degree rotations to the density distribution. The resulting cloud has peak column densities of 21.5 × 1021 cm-2, 31.2 × 1021 cm-2, and 37.5 × 1021 cm-2 towards the three main axes (see Fig. 19). We calculate synthetic surface brightness maps with the default noise and ISRF. Based on these data, the column densities were then estimated with 3D modelling similar to that of Sect. 5.1.1. Thus, in the modelling only the column densities and the external isotropic field were adjusted. The results are compared only with the results of Method B because, as seen in Sect. 4, the differences in the accuracy of Methods A–D are not very significant.
When the 3D modelling was done with the correct level of the external fields but keeping its attenuation as a free parameter, the column densities were recovered with an accuracy of a couple of percent. The cloud has a density distribution that is consistent with the assumption of a Gaussian line-of-sight density distribution used in the modelling. However, the width of the distribution is not the same as in the modelling and, furthermore, varies by a factor of four depending on the viewing direction. This suggests that in this case the results are not very sensitive to the uncertainty of the line-of-sight extent.
The results of Method B and the 3D modelling are compared further in Fig. 19. In this case, the modelling is done with an external field that is twice as strong as the actual field used to produce the synthetic observations. Therefore, the field needs to be adjusted by introducing significant external attenuation. This correction is not exact because the attenuation changes not only the level but also the SED of the incoming radiation. After removing the shortest wavelengths, the remaining radiation penetrates deeper, making the cloud more isothermal. The resulting errors are visible in Fig. 19g−i where the column density is overestimated in the outer parts of the cloud and correspondingly underestimated at the centre. The errors rise over ~4% only at the centre and only when the cloud is viewed from the direction with the highest column density. The incorrect assumption of the ISRF spectrum is also visible in the residuals at 160 μm and 500 μm. Although the average colours are adjusted to be correct, at the cloud centre 160 μm intensity is overestimated by more than ~5% while the 500 μm intensity is underestimated by a couple of percent. This information could be used to further improve the accuracy of the model. For Method B the errors are stronger, column density being underestimated by up to ~10% percent. The relative bias is better visible in the radial profiles at the bottom of Fig. 19.
The sensitivity to noise is another important point. Unlike in the Cloud I and Cloud II, the observations of the outer parts of the clump are now dominated by noise. This affects Method B results already at ~4 × 1021 cm-2, mainly via the N(250) estimates. The modelling results in much lower statistical noise even when it does not use all the available data optimally and the column density distribution is adjusted using the 250 μm observations only. The low noise can be understood as a result of the strong intrinsic regularisation of the modelling procedure. In particular, this precludes unphysical temperature variations (i.e., those greater than allowed by the optical depths) and keeps the estimates reasonable even when the signal goes to zero.
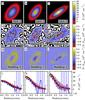 |
Fig. 19 Results for the ellipsoid model. The frames a)–c) show the true column densities towards three directions. The errors in the column density estimates of Method B and of the 3D modelling are shown in frames d)–f) and g)–i), respectively, with contours drawn at − 3 × 1021cm-2 and − 6 × 1021cm-2. The bottom frames show the radial column density profiles. The true column density is shown with a black solid line, the grey area indicating the 1σ variation in the averaged rings. The triangles correspond to Method B and the square symbols to the 3D modelling. The error bars indicate the corresponding 1σ variation in the averaged rings. |
6. Discussion
We have examined different ways of estimating the column density based on dust emission maps, especially using Herschel data in the bands between 160 μm and 500 μm. The methods A–C try to recover the column density at a resolution better than the lowest resolution of the input maps. These aim at a resolution of 18″ (the resolution of the 250 μm observations), a factor of two better than the resolution of the 500 μm data. The radiative transfer models also were constructed in a way that results in column density information at the same resolution.
In the tests with the extended emission (Sect. 4.1.1), Method B performed consistently better than Method A, the errors near dense clumps being smaller by up to ~50% (see Figs. 2 and 8). The difference remained clear even when estimates were compared at lower resolution, 36.3″, corresponding to the resolution of the 500 μm maps. Therefore, the difference is not limited to direct effects of resolution. Only in the case of internal heating Method A exhibited noticeably smaller bias. In those cases Method B was close to the results that would be obtained if data at all wavelengths were available at the same 18.3″ resolution. However, these estimates are biased because of the line-of-sight temperature variations that lead to overestimation of the dust temperature and underestimation of the column density. By underestimating the temperature variations that exist on small spatial scales, Method A was actually closer to the true column density at the location of internally heated clumps (see Figs. 9 and 10).
In Method B, there is some freedom to select the wavelengths that are used to derive the estimates N(500), N(350), etc. For example, if one assumes that SPIRE data give a more reliable picture of column density on large scales (or that they are less biased by temperature variations), one can base the N(500) estimate on data between 250 μm and 500 μm only. The other terms could include also the shorter wavelengths but, because in Method B these are high pass filtered correction terms, they would not be sensitive to large scale artefacts. For example, possible arteficial gradients or high pass filtering of the PACS maps themselves would have only a limited impact on the derived column density maps.
We also examined as Method C other linear combinations of the three constituent terms of Method B, N(500), [N(350) − N(350 → 500)], and [N(250) − N(250 → 350)]. By selecting optimal multipliers (Methods C and D), it was possible to increase the correlation with the true column density by a small but significant amount. The fact that those multipliers were not very similar for the two examined cloud models suggests that this may not be a viable method for general use. The best correspondence with the true column density was obtained with multipliers that were of different signs. This shows that, on large scales, the different biases of the N(250), N(350), and N(500) estimates have a significant effect on the final errors.
The differences between the methods were accentuated in the optically thick cores (Sect. 4.1.2). For cores with AV ≳ 50m or more, the central column densities can be underestimated by several tens of percent. The strongest errors observed for both Method A and B are a factor of three and the associated column density peaks are hardly visible in the surface brightness maps, even at 250 μm. The optimised linear combination of N(250), N(350), and N(500) improves the fit at the highest column densities, raising the column density estimates by up to a factor of two. However, because the errors behave in a very non-linear fashion (as a function of column density), this increases the errors at the lower column densities.
We also examined the possibility of making a non-linear combination of the N(250), N(350), and N(500) estimates. The bias depends on the wavelengths used and we found, as expected, that N(250) < N(350) < N(500). The differences increase as a function of column density. As a result, a non-linear combination of the estimates resulted in significant improvement in the accuracy of the column density predictions (see Fig. 13). It remains to be established whether the parameters are be stable enough, so that the method could be reliably applied to actual observations. The presence of internal heating sources was already seen to eliminate much of the systematic behaviour of N(250), N(350), and N(500) relative to each other.
 |
Fig. 20 The line-of-sight structure of the field number 9. The data consist of the density values within the modelled 5.3′ × 5.3′ area, along the full 10 pc distance through the Cloud II cloud. The upper image shows that density averaged over one direction perpendicular to the line-of-sight. The lower plot shows the mean density as the function of line-of-sight distance. The main structure is a filament with the long axis at ~30 degree angle with respect to the line-of-sight. |
As the final method, we examined 3D radiative transfer modelling as a way to estimate the column densities. In the case of Cloud II, this turned out to be quite challenging because of the high optical depths. Together with the complex density field this means that the radiation field illuminating the modelled core could be strongly asymmetric. The lack of information about the line-of-sight density structure is always a major problem and in this case, the line-of-sight extent was more that ten times the perpendicular extent of the modelled fields. Thus, also the radiation field could vary significantly along this extent. The dense material was seen to be distributed over long distances. This was in stark contrast with the assumed simple model where, for all lines of sight, the density always peaked in the mid-plane. This maximises the shadowing effect compared to the reality of isolated clumps (Fig. 21) or oblique filaments (Fig. 20).
In spite of these caveats, the modelling produced fair results. The model column density was adjusted based on the 250 μm observations and the attenuation of the external field was adjusted according to the 160 μm/500 μm colour in the central region. The accuracy of the results was typically slightly better than for Method B. For the cores with a simple geometry (e.g., cores 1–3, see Fig. 15) the basic modelling produced very accurate density profiles, while Method B underestimated the central column density by ~10%. For the most opaque cores the modelling required the inclusion of an anisotropic radiation field to avoid strong errors outside the central regions for which the radiation field was tuned. Because the different structures along the line-of-sight may be subjected to quite different radiation fields (e.g., of different intensity, SED, and anisotropy), it may be difficult improve the results much further, at least not without exhaustive examination of more complex models. The adjustment of the width of the density distribution along the line-of-sight direction did not produce very significant improvement.
It is possible to construct models that (at least in the case of such synthetic observations) reproduce all the observed surface brightness maps to within the observational noise. However, in the case of Cloud II this was already deemed too time consuming. The modelling procedure used in this paper was very simple and, apart from the column densities that were adjusted for each pixel separately, the number of free parameters was small. As a result, the solution was found in just some tens of iterations (run time of the order of one hour per model). Even when the line-of-sight extent of the density distribution was modified, all parameters could be updated relatively independently using heuristic rules based on the observed and modelled surface brightness maps. In more complex models (i.e., more complex parameterisation of the cloud structure) the link between the individual parameters and the surface brightness would be less obvious and the solution would have to be obtained through general optimisation. Depending on the number of parameters, this could be orders of magnitude more time consuming. However, as long as the models still exhibited systematic residuals (e.g., Fig. 18), further improvements remain possible.
Cloud II is rather extreme in its opacity. The dense cores in nearby molecular clouds would probably fall between Cloud II and the ellipsoidal cloud of Sect. 5.2 in complexity (Fig. 19). For the ellipsoidal cloud, if the external field was estimated correctly, the modelling recovered the column density to within a couple of percent. If the assumed ISRF was overestimated by a factor of two the errors remained below ~5% and the signature of the wrong radiation field was visible in the surface brightness maps. The same interpretation would be more difficult to make in the case of real, irregularly shaped clouds. However, the results suggest that for most of the clumps detected in nearby clouds one can, with careful modelling, determine the column density profiles to an accuracy of a few percent. Method B, possibly combined with a small bias correction, would result in an almost similar accuracy and with considerably less effort. One must also remember that we did not consider any of the uncertainties that are related to dust properties and are likely to be the dominant errors in the estimates of absolute column density.
 |
Fig. 21 The line-of-sight structure of the field number 4 (see Fig. 20 for the details). The mass distribution is dominated by a single, optically very thick core. |
7. Conclusions
We have compared different, previously presented, methods to calculate column density maps from dust emission, especially using the Herschel wavelengths 160–500 μm. Method A (Juvela et al. 2012c) uses low resolution temperature estimates combined with higher resolution intensity data. Method B (Palmeirim et al. 2013) uses a combination of column density estimates obtained using different wavelength ranges. The methods try to recover the column density at a resolution better than that of the lowest resolution input map. We also test other modifications of the methods and compare these with simple radiative transfer modelling that also is used to obtain the column densities.
We have found that
-
Both Methods A and B give relatively reliable column density estimates at the resolution of 250 μm data while also making use of the longer wavelengths.
-
By discarding temperature information on small scales, Method A shows greater errors for compact structures but is overall less sensitive to noise.
-
When the examined clumps have internal heating sources, Method B is consistent with results that would be obtained if high resolution data were available at all wavelengths. However, these underestimate the true column density and, because of favourable cancellation of errors, Method A is sometimes closer to the true column density.
-
Other linear combinations of the three terms of Method B can increase the correlation by a small but significant amount. However, this may not be a viable method for general use, as the multipliers may depend on the cloud properties.
-
Radiative transfer modelling even with very simple three-dimensional cloud models usually provides more accurate results. However, the complexity of the models that are required for improved results increases rapidly with the complexity and opacity of the clouds.
Acknowledgments
The authors acknowledge the support of the Academy of Finland grant No. 250741. T.L. acknowledges the support of the Academy of Finland grant No. 132291.
References
- André, P., Ward-Thompson, D., & Barsony, M. 2000, Protostars and Planets IV, 59 [Google Scholar]
- André, P., Men’shchikov, A., Bontemps, S., et al. 2010, A&A, 518, L102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Collins, D. C., Xu, H., Norman, M. L., Li, H., & Li, S. 2010, ApJS, 186, 308 [NASA ADS] [CrossRef] [Google Scholar]
- Collins, D. C., Padoan, P., Norman, M. L., & Xu, H. 2011, ApJ, 731, 59 [NASA ADS] [CrossRef] [Google Scholar]
- Compiègne, M., Verstraete, L., Jones, A., et al. 2011, A&A, 525, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Draine, B. T. 2003, ApJ, 598, 1017 [NASA ADS] [CrossRef] [Google Scholar]
- Evans, II, N. J., Rawlings, J. M. C., Shirley, Y. L., & Mundy, L. G. 2001, ApJ, 557, 193 [NASA ADS] [CrossRef] [Google Scholar]
- Foster, J. B., & Goodman, A. A. 2006, ApJ, 636, L105 [NASA ADS] [CrossRef] [Google Scholar]
- Goodman, A. A., Pineda, J. E., & Schnee, S. L. 2009, ApJ, 692, 91 [NASA ADS] [CrossRef] [Google Scholar]
- Griffin, M. J., Abergel, A., Abreu, A., et al. 2010, A&A, 518, L3 [Google Scholar]
- Juvela, M. 2005, A&A, 440, 531 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Juvela, M., & Padoan, P. 2003, A&A, 397, 201 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Juvela, M., & Ysard, N. 2012a, A&A, 541, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Juvela, M., & Ysard, N. 2012b, A&A, 539, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Juvela, M., Pelkonen, V.-M., Padoan, P., & Mattila, K. 2008, A&A, 480, 445 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Juvela, M., Malinen, J., & Lunttila, T. 2012a, A&A, 544, A141 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Juvela, M., Pelkonen, V.-M., White, G. J., et al. 2012b, A&A, 544, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Juvela, M., Ristorcelli, I., Pagani, L., et al. 2012c, A&A, 541, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lehtinen, K., & Mattila, K. 1996, A&A, 309, 570 [NASA ADS] [Google Scholar]
- Lombardi, M., Alves, J., & Lada, C. J. 2006, A&A, 454, 781 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lunttila, T., & Juvela, M. 2012, A&A, 544, A52 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Malinen, J., Juvela, M., Collins, D. C., Lunttila, T., & Padoan, P. 2011, A&A, 530, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Malinen, J., Juvela, M., Rawlings, M. G., et al. 2012, A&A, 544, A50 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mathis, J. S., Mezger, P. G., & Panagia, N. 1983, A&A, 128, 212 [NASA ADS] [Google Scholar]
- Meny, C., Gromov, V., Boudet, N., et al. 2007, A&A, 468, 171 [Google Scholar]
- Molinari, S., Swinyard, B., Bally, J., et al. 2010, A&A, 518, L100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Motte, F., Andre, P., & Neri, R. 1998, A&A, 336, 150 [NASA ADS] [Google Scholar]
- Nakajima, Y., Nagata, T., Sato, S., et al. 2003, AJ, 125, 1407 [NASA ADS] [CrossRef] [Google Scholar]
- Nakajima, Y., Kandori, R., Tamura, M., et al. 2008, PASJ, 60, 731 [NASA ADS] [Google Scholar]
- Nielbock, M., Launhardt, R., Steinacker, J., et al. 2012, A&A, 547, A11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ossenkopf, V., & Henning, T. 1994, A&A, 291, 943 [NASA ADS] [Google Scholar]
- Padoan, P., & Nordlund, Å. 2011, ApJ, 730, 40 [NASA ADS] [CrossRef] [Google Scholar]
- Pagani, L., Steinacker, J., Bacmann, A., Stutz, A., & Henning, T. 2010, Science, 329, 1622 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Palmeirim, P., André, P., Kirk, J., et al. 2013, A&A, 550, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pilbratt, G. L., Riedinger, J. R., Passvogel, T., et al. 2010, A&A, 518, L1 [CrossRef] [EDP Sciences] [Google Scholar]
- Poglitsch, A., Waelkens, C., Geis, N., et al. 2010, A&A, 518, L2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ridderstad, M., & Juvela, M. 2010, A&A, 520, A18 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schneider, N., Bontemps, S., Simon, R., et al. 2011, A&A, 529, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shetty, R., Kauffmann, J., Schnee, S., & Goodman, A. A. 2009a, ApJ, 696, 676 [NASA ADS] [CrossRef] [Google Scholar]
- Shetty, R., Kauffmann, J., Schnee, S., Goodman, A. A., & Ercolano, B. 2009b, ApJ, 696, 2234 [NASA ADS] [CrossRef] [Google Scholar]
- Stamatellos, D., & Whitworth, A. P. 2003, A&A, 407, 941 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Steinacker, J., Pagani, L., Bacmann, A., & Guieu, S. 2010, A&A, 511, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Stepnik, B., Abergel, A., Bernard, J., et al. 2003, A&A, 398, 551 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wilcock, L. A., Ward-Thompson, D., Kirk, J. M., et al. 2012, MNRAS, 424, 716 [NASA ADS] [CrossRef] [Google Scholar]
- Ysard, N., Juvela, M., Demyk, K., et al. 2012, A&A, 542, A21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
All Tables
All Figures
|
Fig. 1 Column densities estimated with Method A (black points) and Method B (red points) versus the true column density of Cloud I. The frames correspond to 0.3 or 3.0 times the default noise (see text). The numbers indicate the correlation coefficients r for Method A and Method B, respectively, for data with Ntrue > 5 × 1021 cm-2. For illustration, we have included in the lower frames the corresponding results obtained with a spectral index value of β = 1.7 instead of β = 2.0. |
| In the text | |
|
Fig. 2 Column density maps for a selected small region in Cloud I. Frame a) shows the true column density of the model cloud and the frames b) and c) the errors in the estimates of Method A and Method B, respectively (N(A) − Ntrue and N(B) − Ntrue). Frame d) shows the column density errors when estimates are calculated using data with 18.3″ resolution at all wavelengths, N(18.3) − Ntrue. The frames e–f) show the errors of Method A and Method B relative to the estimates from 18.3″ resolution data. The range of data values is given at the bottom of each frame. |
| In the text | |
|
Fig. 3 Column density profiles for a horizontal cut through the maps in Fig. 2. The noise levels are given in the frames. The lines show the true column density (black line), the column density derived from 18″ resolution surface brightness data (dotted line) and the results of Methods A and B (blue and red lines, respectively). |
| In the text | |
|
Fig. 4 Correlations between column density estimates and the true column density for Methods A, B, C, and D in the case of Cloud I and the default noise level. The plots and the correlation coefficients listed in the frames correspond to column density estimates that are all convolved to a common resolution of 36.3″. |
| In the text | |
|
Fig. 5 Correlations between column density estimates and the true column density. The figure compares the results of Methods A, B, C, and D using data around the cores of Cloud II. The estimates have been all convolved to a common resolution of 36.3″ and scaled so that the median values fall on the correct relation N = Ntrue (solid line). |
| In the text | |
 |
Fig. 6 As Fig. 5 but including internal heating of the cores. |
| In the text | |
|
Fig. 7 Column density errors for Cloud II with internal sources. The upper frames show the true column density and the estimated colour temperature. The lower frames show, with different colour scales, the ratio of the column density estimates with and without internal sources. The maps show a 20′ × 20′ area of the full model. The estimates are calculated using 160–500 μm surface brightness maps with 18.3″ resolution. |
| In the text | |
|
Fig. 8 Comparison of column density estimates in a 0.5 pc × 0.5 pc area in Cloud II. Frame a) shows the true column density and frames d) and g) the errors for column density maps derived with all data at a resolution of 18.3″ or 36.3″. The second and the third columns show the difference between Method A and Method B relative to the true column density (first row) and the estimates obtained with all surface brightness data either at 18.3″ (second row) or 36.3″ resolution (third row). The numbers at the bottom of each frame show the range of values within the map. |
| In the text | |
|
Fig. 9 As Fig. 8 but showing the same 0.5 pc × 0.5 pc area of Cloud II with an added internal heating source in the middle of the field. The 33.7 solar luminosity source raises the dust colour temperature locally to ~27 K. |
| In the text | |
|
Fig. 10 Column density profiles for a horizontal cut through the maps Figs. 8−9. Shown are the true column density (solid black line; uppermost lines, convolved to 18.3″ resolution), the estimate derived from 18.3″ data at all wavelengths (black dotted line), Method A (blue solid line), and Method B (red solid line). The lower frames correspond to the case with an internal heating source. The noise is 0.3 times (frames a and c) or 3.0 times (frames b and d) times the default value. |
| In the text | |
|
Fig. 11 The ratio of the column density estimates and the true values in the 19 cores of Cloud II with column densities N > 5 × 1022 cm-2. The results are shown separately for the case without internal heating (left frame) and with one radiation source inside each core (right frame). The estimates are calculated using 18.3″ resolution surface brightness data at all wavelengths 160–500 μm. |
| In the text | |
|
Fig. 12 The ratio of the column density estimates and the true values in a sample of six Cloud II cores with N > 5 × 1022 cm-2. The dotted, dashed, and solid lines correspond to N(250), N(350), and N(500), respectively, all calculated at the 18.3″ resolution. The results are shown for cores without (left frame) and with internal heating sources (right frame). |
| In the text | |
|
Fig. 13 Correlations between the true column density and the estimates N(500) (blue points) and NNL (red points, see text). The data consists of the 2′ radius environments of the cores in Cloud II. The resolution is 36.3″. The right hand frame shows a zoom-in to small column densities. |
| In the text | |
|
Fig. 14 Column density maps of the nine fields (cores) selected for radiative transfer modelling. The contours are at 10.0, 20.0, 50.0, 100.0, 200.0, and 400.0 times 1021 cm-2. |
| In the text | |
|
Fig. 15 Azimuthally-averaged column density profiles of the selected nine cores. The black symbols and error bars show the true column density and the variation in 4″ wide annuli. The blue solid curve is the estimate from Method B and the red solid curve the profile obtained from the constructed radiative transfer model. |
| In the text | |
|
Fig. 16 Azimuthally-averaged column density profiles of the selected nine cores. As Fig. 15 but including in the modelling anisotropic radiation field. |
| In the text | |
|
Fig. 17 Core 4 modelled with anisotropic radiation field. Frames a) and b) are the 160 μm and 500 μm surface brightness maps from Cloud II (the “observations”). The core is visible in the map of the true column density (frame c) but is missed by the constructed model (frame d). Frames e) and f) show the errors of the model predictions SModel relative to the observed surface brightness SObs at the wavelengths of 160 μm and 500 μm, respectively. |
| In the text | |
|
Fig. 18 Core 4 modelled with anisotropic radiation field and varying line-of-sight width of the density distribution. The maps show the relative error of the model predictions at 160 μm (frame a) and at 500 μm (frame b). The contours are at intervals of 10%. |
| In the text | |
|
Fig. 19 Results for the ellipsoid model. The frames a)–c) show the true column densities towards three directions. The errors in the column density estimates of Method B and of the 3D modelling are shown in frames d)–f) and g)–i), respectively, with contours drawn at − 3 × 1021cm-2 and − 6 × 1021cm-2. The bottom frames show the radial column density profiles. The true column density is shown with a black solid line, the grey area indicating the 1σ variation in the averaged rings. The triangles correspond to Method B and the square symbols to the 3D modelling. The error bars indicate the corresponding 1σ variation in the averaged rings. |
| In the text | |
|
Fig. 20 The line-of-sight structure of the field number 9. The data consist of the density values within the modelled 5.3′ × 5.3′ area, along the full 10 pc distance through the Cloud II cloud. The upper image shows that density averaged over one direction perpendicular to the line-of-sight. The lower plot shows the mean density as the function of line-of-sight distance. The main structure is a filament with the long axis at ~30 degree angle with respect to the line-of-sight. |
| In the text | |
|
Fig. 21 The line-of-sight structure of the field number 4 (see Fig. 20 for the details). The mass distribution is dominated by a single, optically very thick core. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.