| Issue |
A&A
Volume 672, April 2023
|
|
|---|---|---|
| Article Number | A30 | |
| Number of page(s) | 39 | |
| Section | Interstellar and circumstellar matter | |
| DOI | https://doi.org/10.1051/0004-6361/202245461 | |
| Published online | 30 March 2023 | |
Analysing the SEDs of protoplanetary disks with machine learning★
1
Space Research Institute, Austrian Academy of Sciences,
Schmiedlstrasse 6,
8042
Graz, Austria
e-mail: till.kaeufer@oeaw.ac.at
2
Kapteyn Astronomical Institute, University of Groningen,
PO Box 800,
9700 AV
Groningen, The Netherlands
3
SRON Netherlands Institute for Space Research,
Niels Bohrweg 4,
2333CA
Leiden, The Netherlands
4
TU Graz, Fakultät für Mathematik, Physik und Geodäsie,
Petersgasse 16
8010
Graz, Austria
5
School of Physics and Astronomy, Monash University,
Clayton, Vic
3800, Australia
6
Université Grenoble-Alpes, CNRS Institut de Planétologie et d'Astrophyisque (IPAG),
38000
Grenoble, France
Received:
14
November
2022
Accepted:
23
January
2023
Context. The analysis of spectral energy distributions (SEDs) of protoplanetary disks to determine their physical properties is known to be highly degenerate. Hence, a full Bayesian analysis is required to obtain parameter uncertainties and degeneracies. The main challenge here is computational speed, as one proper full radiative transfer model requires at least a couple of CPU minutes to compute.
Aims. We performed a full Bayesian analysis for 30 well-known protoplanetary disks to determine their physical disk properties, including uncertainties and degeneracies. To circumvent the computational cost problem, we created neural networks (NNs) to emulate the SED generation process.
Methods. We created two sets of MCFOST Monte Carlo radiative transfer disk models to train and test two NNs that predict SEDs for continuous and discontinuous disks, with 18 and 26 free model parameters, respectively. A Bayesian analysis was then performed on 30 protoplanetary disks with SED data collected by the FP7-Space DIANA project to determine the posterior distributions of all parameters. We ran this analysis twice, (i) with old distances and additional parameter constraints as used in a previous study, to compare results, and (ii) with updated distances and free choice of parameters to obtain homogeneous and unbiased model parameters. We evaluated the uncertainties in the determination of physical disk parameters from SED analysis, and detected and quantified the strongest degeneracies.
Results. The NNs are able to predict SEDs within ~1 ms with uncertainties of about 5% compared to the true SEDs obtained by the radiative transfer code. We find parameter values and uncertainties that are significantly different from previous values obtained by χ2 fitting. Comparing the global evidence for continuous and discontinuous disks, we find that 26 out of 30 objects are better described by disks that have two distinct radial zones. The analysed sample shows a significant trend for massive disks to have small scale heights, which is consistent with lower midplane temperatures in massive disks. We find that the frequently used analytic relationship between disk dust mass and millimetre-flux systematically underestimates the dust mass for high-mass disks (dust mass ≥10−4 M⊙). We determine how well the dust mass can be determined with our method for different numbers of flux measurements. As a byproduct, we created an interactive graphical tool that instantly returns the SED predicted by our NNs for any parameter combination.
Key words: protoplanetary disks / methods: data analysis
Interactive graphical tool: https://tillkaeufer.github.io/sedpredictor
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
Spectral energy distributions (SEDs) are commonly used to determine the physical structure and the dust properties of protoplanetary disks (e.g. Andrews & Williams 2007; Ricci et al. 2011). To determine, for example, the mass and shape of the disk, or the properties of dust grains and polycyclic aromatic hydrocarbons (PAHs), radiative transfer (RT) models are usually applied which, after some fitting procedure, provide the values of these physical parameters.
However, SED analysis can be highly degenerate (e.g. Thamm et al. 1994; Heese et al. 2017). For example, simultaneous changes in disk mass and dust composition can lead to almost indistinguishable SEDs. Furthermore, dust particle settling and disk flaring may have very similar effects on the SED at (sub-)millimetre wavelengths. Such degeneracies can result in large uncertainties when the values of single physical parameters are determined.
One approach to address this problem is to combine SED fitting with other observations, for example, images at millimetre wavelengths to constrain the outer radius, which effectively reduces the number of free parameters. However, such a procedure will be very specific to a certain combination of multi-kind data, and it is often done only for one or a selected number of individual objects where that particular data exist (e.g. Pinte et al. 2008; Tannirkulam et al. 2008; Dong et al. 2012). Analysing larger samples entails substantial computational efforts (e.g. Sheehan et al. 2022).
The statistically correct way to take all the degeneracies in an analysis into account is to calculate the posterior distributions for all parameters via a full Bayesian analysis. However, this requires running at least a few million SED models. Due to the high computational cost of state-of-the-art 2D RT disk modelling tools, this process is computationally very demanding. Even though this has been done for single objects using very large computational resources, (e.g Pinte et al. 2008), it becomes computationally unfeasible when considering larger samples of objects. Another drawback of this brute-force method is that modellers are forced to use SED modelling approaches that are as fast as possible. Hence, they tend to avoid full RT models and fall back on simpler underlying disk models or allow only for a few physical parameters, in which case fewer degeneracies are found (e.g. Liu et al. 2015).
To circumvent the high computational cost, the modelling process can be emulated. Ribas et al. (2020) emulated the D'Alessio irradiated accelerator disk (DIAD) models (D’Alessio et al. 1998) using neural networks (NNs). DIAD assumes that the disk is geometrically thin, and that therefore the radial energy transport is negligible. Furthermore, the disks are assumed to be in a steady state, with a constant mass accretion rate, and in vertical hydrostatic equilibrium. In an iterative process, the vertical disk structure is solved under these assumptions. The NNs created by Ribas et al. (2020) predicted spectral fluxes with an estimated 1σ uncertainty of 10% compared to the true SEDs of the DIAD models. This enabled them to fit the SEDs of 23 objects, using the Markov chain Monte Carlo method to derive posterior parameter distributions. Their work focusses on confronting the α description (Shakura & Sunyaev 1973) with observations finding high accretion rates and viscosities for many sources.
The uncertainties of disk parameters are expected to increase with fewer observational constraints. Nevertheless, analytical relationships are often used to estimate individual disk parameters from limited sets of observations. In particular, the dust mass is often derived analytically from millimetre flux, assuming certain values for the dust absorption opacity and mean temperature, assuming the disk to be optically thin, and assuming the dust temperatures to be high enough to emit in the Rayleigh limit (Woitke et al. 2019). The disk dust masses derived this way have been shown to disagree with the masses derived from the full RT models, even when using the correct average dust temperature and opacity from the models (Ballering & Eisner 2019; Woitke et al. 2019). The Bayesian analysis carried out in this paper will allow us, for example, to quantify the inherent uncertainties in this disk mass determination method, and to confront these results with the frequently applied analytical relationship.
To do so, we generated a large set of SEDs using the Monte Carlo continuum RT code MCFOST (Pinte et al. 2006, 2009), and used NNs to emulate this process of creating SEDs from model parameters. The benefit of this process is the drastic decrease in computational cost to generate SEDs. This makes a full Bayesian analysis that is carried out for 30 well-known protoplanetary disks feasible.
This paper is structured as follows. Section 2 introduces the models, emulating process, and the fitting procedure including data selection, data preparation and the Bayesian framework. We present the results of this paper in Sect. 3 including the quality of the SED predictions, the overlap to the DIANA fitting results, the new fits, and the determination of the dust mass. These results are discussed in Sect. 4 with a focus on parameter trends in the sample, parameter uncertainties, and degeneracies. We conclude this paper in Sect. 5 with a summary of our main findings.
2 Method
We created large sets of more than 105 Monte Carlo continuum RT 2D disk SED models with MCFOST (Pinte et al. 2006, 2009), which cover the expected parameter space in an efficient way. We train a NN to reproduce these results from the values of the model parameters. The predicted SEDs are then used to perform a full Bayesian analysis on multiwavelength photometric and spectroscopic data sets of 30 well-known protoplanetary disks as published by Dionatos et al. (2019). We compare our new results for the physical disk properties with those previously obtained by Woitke et al. (2019), who used an evolutionary strategy to optimise χ2. In the next step, we refit these objects using updated Gaia distances (Gaia Collaboration 2021), fixing only the stellar parameters, and inclination. As a result, we obtain the most probable, up-to-date disk parameters for 30 well-known disks from the SED data, taking into account all uncertainties and degeneracies.
2.1 The SED forward model
All SEDs are calculated by the Monte Carlo radiative transfer code MCFOST 2.20.8 (Pinte et al. 2006, 2009). MCFOST solves the radiative transfer problem of a dusty disk being illuminated by a star. The disk is assumed to be passive, that is, we assume that all energy is coming from the central star and that at every point the radiative heating of the dust particles equals their radiative cooling. All relevant stellar, disk, and dust parameters for this problem, including disk shape, dust material, size distribution, and settling, are listed in Table 1 and are explained in Sect. 2.2. The meaning of these parameters is described in detail in Woitke et al. (2016).
MCFOST sets up a 2D density structure with a grid of 150 × 100 points concerning the radial and vertical directions, respectively. This structure is defined by various disk shape parameters. The material composition of the dust grains is assumed to be constant throughout the disk. A size distribution function is assumed and mapped onto 70 size bins. The opacities of these dust grains are pre-computed using Mie and effective mixing theory. We are using the so-called DIANA standard dust opacities, see Woitke et al. (2016). The grains in each size bin are then vertically redistributed, using the settling prescription of Dubrulle et al. (1995), and their opacities are co-added.
Photon packets are propagated in 3D from the stellar surface through the disk, while undergoing interactions with the dust on the 2D grid. The packets are traced until they exit the computational domain. Scattering events are modelled as a change of direction, dependent on the scattering angle, but without changing the wavelength. In case of absorption events, the packets are re-emitted isotropically with a wavelength distribution that is based on the local dust temperature (Bjorkman & Wood 2001). During the Monte Carlo modelling procedure, the grains heat up until radiative equilibrium is achieved. Packets that are absorbed by PAHs are stopped. At the end of the Monte Carlo run, the PAH temperature distribution is updated, and the absorbed packets are re-emitted. The procedure is iterated until convergence. We use 5 × 106 photon packages for the temperature determination phase. For more information, please see Pinte et al. (2006, 2009).
Once the temperature structure is computed using the above procedure, the SED is calculated in a subsequent step for a predefined set of 140 wavelength points. For this, a raytracing method is used, integrating the formal solution of the radiative transfer equation. The full wavelength dependent source function has to be known at each location in the disk. The thermal part of the source function is obtained from the temperature and emissivity of the grains. The scattering part of the source function is computed using a monochromatic Monte Carlo run. For doing so, photon packets are systematically generated by the star and by each cell. At each interaction, the weight of the package is reduced according to the probability of absorption, and only the scattered fraction is traced further after the direction has changed. From this procedure the angle dependent specific intensity is computed at each location in the disk which allows us to compute the contribution of scattering to the local source function. In this way, the raytraced SED is calculated for all inclination angles. The advantage of this separate raytracing step is that the generated SEDs contain only very little remaining Monte Carlo noise. In our setup, we have used 104 photon packages per wavelength point and 10 inclinations. These inclinations are equidistant in cosine space: 18.19°, 31.79°, 41.41°, 49.46°, 56.63°, 63.26°, 69.51°, 75.52°, 81.37°, and 87.13°.
The selected wavelengths are evenly distributed in logarithmic space, but with a denser coverage around the 10 µm and 20 µm silicate emission features, the mid-IR PAH emission features at 3.3 µm, 6.25 µm, 7.85 µm, 8.7 µm, 11.3 µm and 12.7 µm, and in the UV, see Fig. 1.
In total, the computation of one disk model, which generates ten SEDs, takes about 3-15 minutes on 8 processors. We have used MCFOST in this setup to calculate some 105 disk models, that is, a few 106 SEDs due to the 10 inclination angles, which are used for training and testing of the NNs, see Sect. 2.4.
All model parameters for single and two-zone models.
2.2 The free parameters
The star is described by four independent parameters Teff, L⋆, fUV and pUV. We use pre-main-sequence evolutionary tracks from Siess et al. (2000) to connect Teff and L⋆ to the mass M⋆ and age of the star. The photospheric spectrum is interpolated from the PHOENIX stellar atmosphere spectra (Brott & Hauschildt 2005) as function of effective temperature Teff and surface gravity log g. The surface gravity is calculated from the given photospheric luminosity L⋆ and the stellar mass M⋆. At UV wavelengths, a power law spectrum replaces the photo-spheric spectrum to account for the excess UV emission due to accretion and stellar activity. This power law is described by fUV and pUV, which are the total UV luminosity shortwards of 250 nm relative to L⋆, and the spectral slope in the UV, respectively.
The dust is described by five free parameters, using the DIANA standard dust opacities (see Woitke et al. 2016). The dust size distribution function before settling is assumed to be a power law, 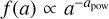 from a minimum size (αmin) to a maximum size (αmax), with power law index αpow. We assume the dust material to be a mixture of silicate Mg0.7 Fe0.3 SiO3 (Dorschner et al. 1995) and amorphous carbon (Zubko et al. 1996) with a fixed porosity of 25%. The opacity computations apply Mie-theory to a distribution of hollow spheres (DHS; Min et al. 2005) with a maximum volume fraction of the hollow core of 80%. The DHS provides a reasonable representation of the spectral properties of irregularly shaped aggregate dust grains, see Min et al. (2016). In addition to the three parameters of dust size, we have one additional free parameter for the dust material (the mixing ratio of amorphous carbon) and one additional parameter for dust settling αsettle.
from a minimum size (αmin) to a maximum size (αmax), with power law index αpow. We assume the dust material to be a mixture of silicate Mg0.7 Fe0.3 SiO3 (Dorschner et al. 1995) and amorphous carbon (Zubko et al. 1996) with a fixed porosity of 25%. The opacity computations apply Mie-theory to a distribution of hollow spheres (DHS; Min et al. 2005) with a maximum volume fraction of the hollow core of 80%. The DHS provides a reasonable representation of the spectral properties of irregularly shaped aggregate dust grains, see Min et al. (2016). In addition to the three parameters of dust size, we have one additional free parameter for the dust material (the mixing ratio of amorphous carbon) and one additional parameter for dust settling αsettle.
Polycyclic aromatic hydrocarbons can add multiple emission features to the SED at mid-IR wavelengths, in particular for central stars that are bright in the blue and soft-UV. We include PAHs in all models by means of two additional free parameters in the models, namely the PAH-abundance in comparison to the standard abundance in the interstellar medium (fPAH) and the ratio of charged to neutral PAHs (PAHcharged). We chose representative PAHs consisting of 54 carbon atoms and 18 hydrogen atoms. For details, see Woitke et al. (2016).
We are using two different types of disk structures (Fig. 2), single and two-zone models. While single zone models have a continuous radial surface density structure, two-zone models consist of two disk zones that can be connected or have a gap in between. This additional complexity is often used to improve the fit quality of SEDs, see, for example Woitke et al. (2019).
There are six free parameters that define the shape of every disk zone. The column density is assumed to decrease as a radial power law from an inner radius (Rin) to a tapering-off radius (Rtaper) beyond which the column density deceases with an exponential function, until the hydrogen nuclei column density reaches a threshold value of 1020 cm−2 which defines the outer radius, see Eq. (1) in Woitke et al. (2016). The exponent in the power law is assumed to be the same as in the exponential (γ = ϵ) in all models in this paper. The vertical extension of the gas density above the midplane is defined by a scale height (H0) at a reference radius and the flaring index (β), see Eq. (2) in Woitke et al. (2016). The gas mass in the disk zone (Mdisk) results from radial integration and is used to set the proportionality constant for the surface-density law.
The respective parameters for the inner disk zone in two-zone models have the same name, marked with a 2 (see Fig. 2 and Table 1). Additionally, the maximum dust size (αmax,2) and the PAH abundance (fPAH,2) in the inner zone are set independently. All other dust and PAH parameters are set globally.
In all disk models, we assume a gas to dust mass ratio of 100 in all disk zones. However, the gas mass influences only the settling efficiency in our models. Therefore, different gas to dust ratios can be simulated by changing the settling parameter accordingly. Additionally, we use an interstellar background radiation field composed of (i) the cosmic microwave background (CMB) modelled with a Planckian of temperature 2.7 K, plus (ii) a standard UV background (Draine 1978; Draine & Bertoldi 1996) χISM = 1. The number of free parameters (stellar, dust, PAHs, disk, and inclination) adds up to 18 and 26 for single and two-zone models, respectively.
 |
Fig. 1 Example of a predicted SED with strong PAH features for a single zone model of a A6 star that is part of the test sample compared to the true SED derived by the full RT code. The orange and blue points in the upper panel show the predicted and the true SEDs, respectively. The residual (orange) is shown in percent in the lower panel. |
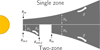 |
Fig. 2 Sketch of a single and two-zone disk structure. The shown parameters are explained in Table 1. |
2.3 Grid creation
We created two separate disk model grids to train the two NNs predicting the single zone and two-zone SEDs, respectively. The goal of both grids is to vary all model parameters that we want to use to fit SEDs, so that the NNs can learn the influence of these parameters. To find reasonable distributions for our model parameters, we analysed the parameter values found in the DIANA SED models (Woitke et al. 2019) and adjusted our parameter distributions for the grid production accordingly. Both grids are created similarly, but the two-zone grid has additional parameters for an inner disk zone. In this section, we describe the general idea behind the grid creation. A detailed explanation highlighting special parameters is attached in Appendix B.
We use the low-discrepancy Sobol sequence (Sobol 1967) to sample the parameter space. This results in a smooth quasi-random coverage, as seen in Fig. 3. A random distribution shows larger areas without any models and a more uneven distribution for every parameter compared to the Sobol sampling. Therefore, we think that the Sobol sampling improves the NN's ability to learn how the SEDs look like over the whole parameter space.
All parameters that vary for single and two-zone models are listed in Table 1. They are either uniformly or Gaussian distributed between a lower (xmin) and upper limit (xmax). The uniform distribution uses these minimal and maximal values to map the Sobol numbers (xsobol) that range from 0 to 1 to parameter values (xpara):
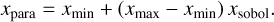 (1)
(1)
If we decided to sample a parameter with a Gaussian distribution, we used the inverse error function (erf−1) to map the Sobol numbers to the parameter value. The Gaussian distribution is defined by the mean value (xmean) and a standard deviation (xstd):
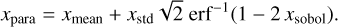 (2)
(2)
The Sobol numbers that result in values for xpara outside the limits of and xmax are discarded and uniformly distributed in the allowed range using Eq. (1). The values for xmin, xmax, xmean, and xstd are derived from the DIANA sample. We calculated the respective values of the sample, discarded eventual outliers, and influenced our decisions by knowledge of the physical meaning of all parameters. This knowledge resulted in stricter or looser limits for some parameters or in sampling the logarithm of a parameter instead of its linear value.
All values describing the parameter distributions are listed in Table 1, including the decisions whether or not to use logarithmic values and whether the sampling is even or Gaussian. In total, the single zone grid consists of 673378 SEDs. The two-zone grid consists of 1 195285 SEDs.
 |
Fig. 3 Two parameters sampled with 1000 points using random numbers (upper panel) and the Sobol sequence (lower panel). Both parameters are evenly distributed between 0 and 1. |
 |
Fig. 4 Chosen architecture of the neural network (NN) to predict single zone model's SEDs. The NN consists of an input layer (orange) with 18 neurons (18 free parameters), 6 hidden layers (blue circles) with 300 neurons each, and an output layer (red) with 140 neurons (the SED values at wavelength i of the 140 points (SED(λi)). All neurons are connected to every neuron in the adjacent layer. This sums up to 499 340 trainable parameters. |
2.4 Neural network
The NNs used in this paper consist of a number of layers, each with a number of nodes (see, e.g. Gangal et al. 2021 for an overview of different NNs). Each node or neuron is connected to every node in the adjacent layers (Fig. 4). The first layer, also called input layer, takes all input parameter values, one for each node. In the final layer, also called output layer, each node produces the spectral flux at a different wavelength. Both layers are connected through a number of hidden layers. Every connection between a neuron i in layer ℓ and a neuron j in the next layer ℓ + 1 has a weight wi,j,ℓ. These weights are optimised during the training process. The sum of the neurons' values ui,ℓ in layer ℓ, multiplied by the respective weights, plus a trainable constant bj,ℓ, called bias, is taken as input for the activation function f to get the output value of the neuron uj,ℓ+1 in the next layer:
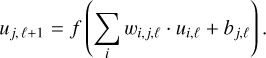 (3)
(3)
We use the rectified linear unit (relu) function f (u) = max(0, u) as the activation function for all neurons in all hidden layers. This function introduces non-linearities to the network, which is essential for the learning process. It enables a NN with just one hidden layer and a finite number of neurons to approximate any continuous function (Hornik et al. 1989). Multiple layers are used to reach convergence quicker.
We trained two different networks for the single-zone and the two-zone disk models. As input for both NNs, we take all model parameters. Therefore, the input layer of the NN to predict single zone models consists of 18 nodes, while the respective NN for two-zone models has 26 nodes. For all parameters that are logarithmically varied in the grid, we take the logarithm of their values as input for the network. The output predicted by the network is a vector with the logarithmic fluxes for the SED at the 140 wavelength points. Therefore, there is no knowledge about the relationship between the different wavelengths. Both input and output data are standardised by a scaler derived from the training data. This proved to be more successful than normalising the data (Appendix A). 70% of the data are taken for training, while the rest is used as a test set to determine the point at which the training does not improve any more. We made sure that all models that differ only in their inclination are part of the same set, to insure the independence of the test set. This is necessary, because the inclination is the only parameter not sampled randomly.
In the training process, the weights are changed using stochastic gradient descent to minimise the loss function. We decided to use the mean squared error between predicted and true logarithmic flux values as our loss function.
We use Keras (Chollet & Others 2015), which is part of the python package TensorFlow (Abadi et al. 2016), to build the multilayer feedforward NNs. Most hyperparameters are determined using hypergrids, which means running multiple NNs to find good settings. A summary of this process is shown in Appendix A. We are aware that we have not found the best combination of hyperparameters, but the change in quality turned out to be small for reasonable settings. This process results in an architecture of 6 hidden layers with 300 neurons for the single zone NN, a prediction of which is seen in Fig. 1. The two-zone NN has 7 layers with 400 neurons. Therefore, both NNs have a number of weights that is comparable to the size of the training sets (single zone: 499 340 weights and 470 379 SEDs in the training set; two-zone: 1 029 340 weights and 1 192 877 SEDs in the training set). For a detailed description of the training and determination of the hyperparameters, see Appendix A.
We trained the networks until the test loss function stopped improving for 100 epochs. Then we selected the state of the NN with the best test predictions. The loss value improves rapidly during the first epochs and converges quickly. Therefore, the test score does not improve any more after epoch 1615, and the training process is stopped.
2.5 Fitting process
In this section, we explain how we connect observations and the method to derive model parameters with their uncertainties for a sample of 30 protoplanetary disks.
2.5.1 The DIANA sample
We apply our machine learning SED-fitting method to a sample of 30 well-studied disks (the so-called DIANA sample, see Woitke et al. 2019), for which many multiwavelength observations (photometric fluxes and low-resolution spectra) are available and which have already been fitted using the same RT code (MCFOST). This will allow us to compare our results with a previous study. 27 of these objects are introduced in Woitke et al. (2019). However, here we expand this set by adding 3 more unpublished SED fits for DN Tau, CQ Tau and PDS 66, which have meanwhile been fitted as well using the same approach as described in Woitke et al. (2019)1. In this section, we introduce this sample and explain the modelling done by Woitke et al. (2019) briefly. For details on the data collection, see Dionatos et al. (2019) and Woitke et al. (2019) for details of the modelling.
The observational data for each object comprise photometric fluxes and low-resolution spectra (UV, ISO, Spitzer/IRS, Herschel/PACS, Herschel/SPIRE) that are individually selected. Measurement uncertainties smaller than 5% are set to 5% to account for calibration problems in the mix of different measurements.
The SED models for the DIANA sample in Woitke et al. (2019) are derived in a two-step approach. First, the stellar parameters are fitted and fixed afterwards. The stellar parameters (Teff, L⋆, Av, M⋆, age, and spectral type) are consistent with pre-main-sequence evolutionary tracks by Siess et al. (2000).
In a second modelling step, a disk model was fitted to the SED measurements for every object. This was done using an evolutionary strategy to minimise X2. For the modelling of each object, either a single or two-zone setup was selected by hand, which had a number of parameters fitted while other parameters were fixed using literature knowledge. This process resulted in the best fit for every object. We note that for a number of objects, the fits have recently been updated. The most up-to-date versions can be found online1.
For the three objects added to the DIANA sample in this paper, we exactly followed the same procedure, with the most up-to-date distances available at the time. We introduce these three objects briefly here, while referring to Woitke et al. (2019) for detailed information about the other objects.
CQ Tau. CQ Tau is a F5 star (Manoj et al. 2006) at a distance of about 163 pc (Gaia Collaboration 2018), and with an age of about 10 Myr, it is one of the oldest Herbig Ae/Be stars (Chapillon et al. 2008). We used a stellar luminosity of 13.81 L⊙, an effective temperature of 7231 K, a stellar mass of 1.25 M⊙, a visual extinction Av of 2.53, an age of 8.4 Myr, and a spectral type of A9 to fit the selected observations, roughly reproducing the literature values for age and spectral type. Gabellini et al. (2019) found a cavity between 15 AU and 25 AU. The disk is very similar to the TW Hydra system, due to its gas-rich disk with dust grains up to a few centimetres (Testi et al. 2003).
PDS 66. PDS 66 is a T Tauri-type K1 star (Pecaut & Mamajek 2016) at a distance of about 99 pc (Gaia Collaboration 2018). Depending on its membership to the Lower Centaurus Crux (LCC) subgroup or the eta Cha association, it is thought to have an age between 7 and 17 Myr (Wolff et al. 2016). The stellar fit by Gräfe & Wolf (2013) resulted in an age of 13 Myr. Despite the old age of the system, the inner rim of the disk is very close to the star (0.12″) in polarised light (Wolff et al. 2016). This is in line with Cortes et al. (2009), who find an inner radius of the disk consistent with the sublimation radius at 0.1 AU. This is peculiar, because normally the inner part of the disk is cleared at that time.
DN Tau. DN Tau in a classical T Tauri star of spectral type M0 (Long et al. 2018) at a distance of about 129 pc (Gaia Collaboration 2018). A fit to our photometric, UV and X-ray data collection (see Dionatos et al. 2019) finds an effective temperature of about 3990 K and a stellar luminosity of about 0.71 L⊙ with a reddening of Av ≈ 0.71, which according to the Siess tracks (Siess et al. 2000) corresponds to spectral type K7, a stellar mass of 0.69 M⊙ and an age of 2.4 Myrs. These stellar properties are close to the ones discussed for DN Tau in Robrade et al. (2014), even though our estimates use a slightly stronger reddening and hence larger luminosity, more in line with Ingleby et al. (2013). According to the ALMA observations by Long et al. (2018) the dusty disk of DN Tau shows a regular Gaussian intensity profile with only little evidence for rings. The apparent radius of the dusty disk at 1.3 mm is about 56 au, which makes DN Tau one to the smallest targets in the DSHARP sample.
The DIANA project used the observed UV spectra directly, whenever available. However, for the general fitting performed in this paper, we need to assume a power law in the UV with two input parameters. Therefore, we estimated pUV and fUV by an iterative process (resulting values in Tables C.1 and C.2), until the UV power law roughly fits the observed UV data. In case of RU Lup, the UV observations do not follow a power law. Hence, we opted for a power law that matches the UV luminosity from the DIANA fit instead. Additionally, there is no power law within the limitations of the grid setup that can reproduce the UV spectrum of DO Tau, due to the strong reddening of the object. We therefore opted for a power law that fits the data as good as possible. We do not expect these manipulations to have a large impact on the derived disk parameters, because the UV wavelength points are excluded from our likelihood function.
All model fits use the best distances available at that time. However, since all DIANA objects have meanwhile updated distances (Gaia Collaboration 2021), we scaled the luminosities to the new distances and used the evolutionary tracks from Siess et al. (2000) to update the stellar mass, age, and spectral type accordingly. A list of all stellar parameters are shown in Table 2. The resulting stellar spectra fit well to the observational data. Therefore, a completely new stellar fit is not necessary for the aims of this project.
This means that the reader will find two SED-fits for every object in this paper. The first fit uses old distance measurements and the same parameter constraints used in DIANA to compare the results to the previously published fits. The second fit uses up-to-date distances without any parameter constraints to derive new values with uncertainties for all disk parameters.
Assumed stellar parameters for the analysed sample.
2.5.2 Data preparation
To compare observations to the SEDs derived with our technique, a few in-between steps are needed. The NNs return SEDs for models that are at a distance of 100 pc, this has to be changed in post-processing by scaling the flux to the new distance.
Furthermore, the output of the NNs needs to be reddened. We use the reddening law by Fitzpatrick (1999) to derive the wavelength-dependent amount of interstellar extinction using two reddening parameters, EB-V and RV. In the last step, the reddened and distance-corrected SEDs are interpolated using a spline fit in log-log space to the wavelengths of the observations.
2.5.3 Bayesian analysis
We use MultiNest (Feroz & Hobson 2008; Feroz et al. 2009, Feroz et al. 2019) through the PyMultiNest Python package (Buchner et al. 2014) to compare the models with observations and determine the posterior distribution for the free parameters. MultiNest is a Bayesian inference tool. It uses a multimodal nested sampling algorithm to compute the Bayesian evidence and posterior distribution from a likelihood function. All details of the algorithm and the numerical implementation are described in the references given above.
We use the observational data selected by Woitke et al. (2019), which were introduced in Sect. 2.5.1. Since the goal of this study is to fit the disk parameters with reasonable assumptions about the star, we exclude all observations shortwards of 0.5 µm. The uncertainties for all (photometric and spectral) flux data points (σi,obs) is set to be at least 5% times the observed values, to account for calibration problems and stellar variability when using multiple instruments and multi-epoch data. As mentioned before, the model emulation by a NN introduces an error on the model prediction. To account for this, we add a model error of 5% of the predicted flux value (see Sect. 3.1).
The likelihood function ℒ accounts for the deviations of the interpolated model fluxes (yi,model = vF v,model) from the observational data (yi,obs = vF v,obs) considering all wavelength points i = 1… Nobs longwards of 0.5 µm, with respect to the uncertainties of model (σi,model) and observations (σi,obs):
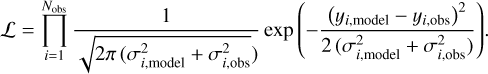 (4)
(4)
The low-resolution spectra consist of many more data points than the photometric measurements, which would make them dominate the likelihood value. Therefore, we reduce the influence of the spectra by weighting the logarithmic likelihood of spectral points. The weights are set to 10 divided by the spectral resolution. Therefore, the weight of every spectral point equals the weight a spectrum with a spectra resolution of 10 would have.
In addition to the likelihood function, we need to specify the prior probability distribution function for each object and parameter. We use the same parameter distributions that were used for the creation of the model grids as our prior distribution for all objects. We use additional constraints to ensure that the NNs cannot predict parameter values outside of the range used to create the training grid. We solved this problem by assigning a very small likelihood in all such cases. These constraints concern log10(Mdisc/M⋆), log10(Mdisc,2/Mdisc), log10(Rout,2/Rin), log10(amax,2/amax), log10(fPAH,2/fPAH), and Tsub, which are all checked for values outside of the limits xmin and xmax. We also use additional physical constraints to avoid the outer radii of all zones smaller than their respective inner radii, overlapping radial zones, and maximum dust sizes smaller than minimum dust sizes.
As described in Appendix B, we excluded SEDs from the training sample that have disks that occult the star (shielded SEDs). In those cases, the NNs are unable to predict this behaviour even if certain parameter combinations would lead to it. Hence, we also need to exclude these cases from the Bayesian analysis. To do so, we trained two NNs to distinguish between shielded and non-shielded SEDs with 2 and 4 hidden layers and 64 neurons per layer for single and two-zone models, respectively. These NNs were trained on all SEDs created during the grid creation. While all parameters (identical to the main NNs) are used as input, the output is a number between 0 and 1 that encodes the probability of this parameter set resulting in a shielded SED. Since we want to make sure that most shielded SEDs are excluded, we set the threshold to distinguish shielded and non-shielded SEDs to 0.0721 and 0.0577 for single and two-zone models, respectively. These values are chosen because they result in the detection of more than 99.9% of shielded SEDs while incorrectly classifying as non-shielded SEDs in about 1% of all test cases. We incorporated this classification into the likelihood in the same manner as previously shown, which hinders the Bayesian analysis to explore these areas of parameter space.
 |
Fig. 5 Quality distribution according to Eq. (5) of the predictions in the test set for the single zone (orange) and two-zone (blue) NN. The histogram shows how many predictions fall in each quality bin. The dashed, dashed-dotted, and dotted black lines show the 5%, 10%, and 20% difference, respectively. |
3 Results
3.1 SED predictions
In this section, we evaluate the quality of the NNs’ predictions. We use the relative deviations of predicted flux (Fpredict,λ) at a wavelength λ compared to the true flux calculated by the full RT code (Ftrue,λ) as our measure of quality for a predicted flux:
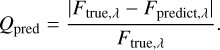 (5)
(5)
Figure 5 shows the quality distribution for every flux prediction of the single and two-zone SEDs in the respective test sets. The prediction quality for both networks peaks at similar values, with median/mean values of 2.2%/2.9% (single zone) and 2.3%/3.2% (two-zone).
Most predictions have similar qualities, with 68% of the predictions (1σ) being better than 3.4% and 3.6% for the single and two-zone NN, respectively. Therefore, we use a conservative value of 5% as the 1σ uncertainty for the NNs’ predictions in the Bayesian Analysis.
We note that both NNs predict a few models poorly, while the overwhelming majority are predicted well, with similar quality. We individually inspected the worst predictions and found common patterns. Individual wavelength points in the UV (0.1– 0.15 µm and ~0.42 µm) were sometimes poorly predicted. This can be explained by the many emission lines in the UV. A few wavelength points coincide with these lines. Therefore, the resulting flux at these points are hard to predict. Nevertheless, this does not affect the further analysis since the UV is not used in the Bayesian analysis. The second most common source for errors are the PAH features. Since the variation of the SED at these wavelengths is large, stars that show strong PAH features (high stellar luminosity and temperature) have the potential for slightly worse predictions.
Figure 1 shows an SED prediction for an A-type star from the single zone NN. This prediction has mean prediction quality for the 140 fluxes of this model of 2.9%, which is the mean value of the test sample. Therefore, the quality of this prediction is a good representation of the average prediction quality.
3.2 Reproducing DIANA fits
In a first step, we aim to reproduce the DIANA fits with parameter uncertainties. This means setting the same constraints to the model (fixed parameters and complexity) as done for the DIANA fits.
Regarding the complexity of the models, we opted for single or two-zone models according to the DIANA fits. Two-zone models exist in three settings (gap, no gap, and smooth transition). A gap exists if Rout,2 < Rin and there is no gap if Rout,2 = Rin. A smooth transition means that the flaring index and mass of the inner zone are adjusted so that the surface density and scale height are the same for the inner and outer disk zone at Rout,2 = Rin. The list of fixed parameters always included all stellar parameters (L⋆, Teff, fUV, and pUV) and the inclinations.
For one object, RECX 15, the dust-to-gas ratio is not 0.01 in the DIANA data. Since we cannot account for that with our setup, we adjusted the disk gas mass to a value that corresponds to the needed dust-to-gas ratio. Since the gas mass influences only the settling in our setup, we adjusted the settling parameter of that model to have the same settling efficiency.
For some objects, DIANA fixed the outer radius to values that do not fit into the relation we enforce between the outer radius and taper radius. Additionally, and exponent of the exponential function which decreases the column density outside Rtaper was sometimes fixed to values different from ϵ. Both of these effects, cannot be simulated with our neural networks. However, we expect the resulting differences of the SED to be minimal.
In Table C.1, all parameter values for single zone objects are listed with the values from Woitke et al. (2019) for comparison. If no value is given for a parameter for the fit from this study, it was fixed to the value used by DIANA. If no values are given for the PAH parameters in DIANA, this means that they were excluded from the model. In that case, we set fPAH = 0.001 and PAHcharged = 0.0. Even though this does not completely remove PAHs from our model, it makes them negligible.
In Table C.2, the parameter values for this work and DIANA are shown for all two-zone models. Again, values that are only listed for DIANA are fixed to that value in our study. For some object the PAH parameters are not listed meaning that PAHs were excluded for the respective zone in DIANA and set to fPAH = 0.001, fPAH,2 = 0.000001, and PAHcharged = 0.0 in this study to mimic this effect.
If the transition between zones is smooth, Mdisk,2 and β2 are adjusted accordingly. This is noted in Table C.2 as ’smooth’ at the relevant entries.
Now, we discuss the quantitative comparison of our fits and the DIANA fits. Figures 6 and 7 show how often the parameter values found in DIANA fall within different σ levels from the posterior for single and two-zone models, respectively.
For single zone models 23, 16, and 15 of the 72 parameter predictions fall within the 1σ, 2σ, and 3σ contour, with 18 DIANA parameter values outside the 3σ level. For the 317 two-zone model parameter predictions 103, 74, and 68 predictions fall within the respective contours, while 72 are outside the 3σ level.
A good agreement between DIANA and this study can have two causes. The parameter can be easy to constrain which makes it possible for DIANA to find these values, or the parameter uncertainties are very large and therefore many parameter prediction falls within a certain σ contour. We test the size of the uncertainties in Sect. 4.2. In general, there is little agreement between the DIANA parameter values and the derived posteriors for both single and two-zone models.
The best overlap for single zone parameters (Fig. 6) is found for amin, amax, αsettle, with 63%, 71%, and 63% of the fitted parameters within the 2σ level, respectively. Additionally, Rtaper and є are fitted only one time each with good agreement between the studies (within 1σ). Among the worst fitted parameters are amC-Zubko, Rin, H0, and ß.
The two-zone fits (Fig. 7) in this study find similar overlap compared to the single zone fits. Very often Rin values of DIANA are outside the uncertainties of this study. Similarly, there is little overlap for apow and Mdisk,2.
We constrain the Bayesian Analysis to only explore areas of the parameter space in which the NN’s predictions are valid. Therefore, it is not possible to predict values outside these restrictions. Even though, we informed our parameter space by the DIANA predictions, some parameter values that were found in DIANA are so extreme that we excluded them from our grid creation. As an example, it seems that the innermost radius causes some disagreement between DIANA and this study with 3 (6) predictions for single zone (two-zone) models outside the 3σ contour. 3 DIANA fit radii have temperatures that we exclude from our study. Therefore, our method does not explore this area of parameters space and these parameters are predetermined to be outside the 3σ contour.
The different levels of overlap are not equally distributed over all fitted objects. For example, the single zone fits of DN Tau and DF Tau and the two-zone fit for CQ Tau, HD 135344B and CY Tau find no > 3σ disagreements. On the other hand, the single zone DIANA fit for 49 Cet does end up in a completely different area of parameter space, resulting in > 3σ differences between both studies. The largest number of parameter disagreements for two-zone fits is found for AB Aur with 62% of parameters outside the 3σ level.
The differences between the parameter values derived in these two studies might be caused by the different quality metrics that are used. In this study, we use the likelihood defined in Sect. 2.5.3, while DIANA uses a wavelength weighted version of χ (DIANA-χ). We want to check if the fits found in this study are not just different from DIANA, but also of higher quality. To do that, we use DIANA-χ and calculate it for one representative model of the posterior distribution of every object. For this, we use the so-called median probability model, which we define as the model for which the parameters are closest to the median posterior values. This means that this model’s most extreme parameter value is within the percentile level closest to the median value of the posterior compared to all other models of the posterior (similar to Barbieri & Berger 2004). This model is a good representation of the posterior distribution, even though it is not the model with the maximum likelihood.
We calculate the DIANA-χ for SED predicted by the NNs of that model and also for the MCFOST model with the same parameters. Since data points shordwards of 0.5 µm are excluded from the Bayesian analysis, we exclude them from this calculation. As a comparison, we are calculating the DIANA-χ for the DIANA models also excluding the same observations. We find that the NN predicted SEDs for the median probable model results in a better DIANA-χ than the DIANA model for 17 of the 30 objects. We conclude that the better qualities are not due to the NNs’ deviations from the MCFOST models, because the MCFOST SEDs of the same models also result in better DIANA-χ values in 17 cases. Therefore, the optimisation strategy of DIANA did not converge to the optimal solution. This shows the advantages of exploring the parameter space with Bayesian analysis compared to simpler optimisation strategies.
The definition of the median probability model allows us to plot the density structure (see Fig. D.1). This shows that due to the fixing of some disk parameters and despite the parameter value differences, the disk structures of this work and the DIANA project show many similarities. Therefore, it is difficult to gain insights if one of the two disk structures is confirmed by other observations. In the next section, we evaluate the evidence for different disk structures (single zone and two-zone models). These structures are different enough that other observations can be used to distinguish between them.
 |
Fig. 6 Comparison between resulting parameter posterior distribution and the DIANA fits for single zone objects. The histograms show the fraction of DIANA models that have parameter values within the 1σ, 2σ, and 3σ contour or outside for that parameter. |
 |
Fig. 7 Comparison between resulting parameter posterior distribution and the DIANA fits for two-zone objects. The histograms show the fraction of DIANA models that have parameter values within the 1σ, 2σ, and 3σ contour or outside for that parameter. |
3.3 Consistent fits for all objects
After comparing our method to previous fits, we start to consistently fit all objects using a fully homogenised setup for both a single and a two-zone model. This effort was not possible in DIANA due to the computational cost. For doing so, we assume the stellar parameters listed in Table 2 and the inclination used in DIANA, which was always taken from literature values. This allows us to incorporate external knowledge for parameters that are hard to determine based on SEDs alone and for which we have known values for every object. All other parameters are free with the grid distribution imposed as a prior (Table 1). This results in 60 fits with 13 and 21 free parameters for every object’s single and two-zone model, respectively. The single zone parameter values with their uncertainties are shown in Table C.3, while the two-zone fit results are displayed in Table C.4.
This systematic approach allows us for the first time to evaluate the benefit of discontinuous disk models over simpler single zone models. We evaluate the significance by calculating the Bayes factor (B12) for every object between the two-zone model (M2) and the single zone model (M1). We calculate this factor as the difference of the Nested Sampling Global Log-Evidence for single (log(E(M1)) and two-zone models (log(E(M2)). According to Trotta (2008) B12 < 1, 1 < B12 < 2.5, 2.5 < B12 < 5, 5 < B12 < 11, and 11 < B12 correspond to no evidence, weak evidence, moderate evidence, strong evidence, and very strong evidence for a two-zone model over the single zone model, respectively. Negative values mean that single zone models are preferred with the corresponding evidence.
Table 3 list the Bayes factors for all objects with their interpretation. For 22 of the 30 objects, we find very strong evidence that a two-zone model reproduces the SED observations better. While some objects return inconclusive results, only 4 objects return negative Bayes factors, corresponding to evidence of a single zone model over a two-zone model. This dominance of two-zone models is also reflected in DIANA, where 22 objects used a two-zone fit. Nevertheless, we find very strong evidence for two-zone models for objects (49 Cet, MWC 480, RULup, DO Tau, FT Tau, and RECX 15) that are fitted with a single zone model in the DIANA project. On the other hand, we find weak evidence for a single zone model for TW Cha that is fitted with two-zones in DIANA.
For the objects with a complexity mismatch to DIANA, many disk parameters are similar between their single and two-zone fits (comparing Tables C.3 to C.4). This means, that even though SED fitting is very degenerate, certain parameters (e.g. disk mass and innermost radius) can be determined relatively well independently of the exact model.
This is also reflected in the single and two-zone density structures of the median probability models (see Fig. D.2). For many objects, the single zone and two-zone density distribution has a similar radial and vertical structure. This is very prominent for objects that do not have very strong evidence for one of the two structures. One example is CI Tau, which shows no evidence for either model complexities. The two density structures differ only in the two-zone model's gap at about 10 AU. Other examples for high similarities between the single and two-zone models are HD 142666 and AA Tau for which the two-zone model is preferred even though not strongly.
The resulting disk structures can be roughly compared with images of the objects. Even though we cannot expect the structures derived by SED fitting to reproduce the images well, we are interested if the preference of any disk structure can be confirmed by image data, especially if this study and DIANA prefer different disk complexities.
We find very strong evidence for MWC 480 to be described by a two-zone model, while DIANA used a single zone model to fit the object. Images by the Atacama Large Millimeter/submillimeter Array (ALMA) at 1.33 mm show a prominent disk gap at about 70 AU with a width of about 30 AU (Long et al. 2018). This is roughly consistent with the gap in the two-zone model, even though this gap is closer in (inner radius of the outer zone of about 45 AU). Therefore, we conclude that the evidence for a two-zone model to fit the SED is confirmed by image data in this case.
The images of CI Tau and FT Tau of the same study (Long et al. 2018) show four rings with corresponding gaps and one gap, respectively. Compared to MWC 480 these gaps have a much lower intensity contrast, which makes both disk structures plausible and does not give new insight in the complexity mismatch between our study and DIANA.
Figure D.3 shows the resulting SEDs of the posterior distribution. The SED contours are derived by using all models from the posterior, and calculating the 1σ (16th and 84 percentile), 2σ (2.5th and 97.5th percentile), and 3σ (0.05th and 99.95th percentile) level for every wavelength point. The single zone or two-zone fit is selected for every object based on their Bayes factor.
For all objects, either the single or the two-zone fit does reproduce the observations reasonably well. We point out a few notable cases. For two objects, the UV fits does not overlap the observations. RU Lup’s UV is not easily described by a power law that intersects with the stellar spectrum. Therefore, a power law that reproduces the UV flux is chosen. For DO Tau the reddened power law underestimates the UV flux compared to the observations. Due to DO Tau’s strong reddening, it is not possible to find a power law within the allowed range of fUV and pUV that overlaps with the observation and intersects the stellar spectrum.
The mid-IR wavelength region for every fit is shown in Fig. D.4. The silicate feature is well-fitted for all objects keeping in mind that a single parameter is used to describe the dust composition. For V 1149 Sco, Lk Ca 15, RY Lup, TW Cha, and GM Aur it seems, despite the overlap, the model's silicate feature peaks at a wavelength shorter than the peak wavelength of the observed feature. This hints that another dust composition could be a better representation for these objects, since this shift can be reproduced by changing the dust composition (see Fig. 4 in Min et al. 2007).
Additionally, we find that most PAH features are reproduced well by the models. Especially the strong features of HD 97048 and HD 169142 are well modelled and objects without PAH features are fitted by models without features.
Bayes factor between single and two-zone fits for all objects.
3.4 Determination of the dust mass
One of the most fundamental disk parameters is the dust mass of the disk. While full RT models that are used for SED fitting derive dust masses (even though without uncertainties), most often the dust mass is inferred from single flux measurements (e.g. Hildebrand 1983; Andrews & Williams 2005). The used analytical relation relies on many assumptions and literature values, which makes the relation often unreliable when comparing with full radiative transfer models (e.g. Woitke et al. 2019; Ballering & Eisner 2019).The dust mass 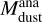 is connected to the observed flux (Fv) by:
is connected to the observed flux (Fv) by:
 (6)
(6)
The relation uses a flux measurement at a frequency v, the distance (d), the dust opacity ĸv (cm2 g−1 (dust)), and the Planck function (Bv) at the average dust temperature  . Assuming that the dust is optically thin and emits in the Rayleight-Jeans limit at the observed wavelength, the Rayleight-Jeans law approximates the Planck function using the speed of light c, the Boltzmann constant k, and the average dust temperature
. Assuming that the dust is optically thin and emits in the Rayleight-Jeans limit at the observed wavelength, the Rayleight-Jeans law approximates the Planck function using the speed of light c, the Boltzmann constant k, and the average dust temperature 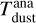 . Normally, flux measurements in the millimetre wavelength regime are used to ensure that the assumptions hold true. For comparison, often the same values are assumed in the literature for the average dust temperature and dust opacity (e.g. 20 K and 3.5 cm2 g−1 at 850 µm Andrews & Williams 2005).
. Normally, flux measurements in the millimetre wavelength regime are used to ensure that the assumptions hold true. For comparison, often the same values are assumed in the literature for the average dust temperature and dust opacity (e.g. 20 K and 3.5 cm2 g−1 at 850 µm Andrews & Williams 2005).
We show the analytical dust mass of Eq. (6) in comparison to the model dust mass in Fig. 8. The blue distribution shows all single and two-zone models that were produced during the grid creation. It is clearly visible that the distribution follows the unity line for about 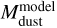 < 10−4 M⊙. For higher masses, the analytical expression systematically underpredicts the dust masses. This suggests that the assumptions of Eq. (6) break down. In particular, we suspect that for these high dust masses, disks become partly optically thick. This explains why an increase in model dust mass is not reflected any more in an increase in flux and therefore the analytical dust mass. This finding is consistent with a parameter study from Liu et al. (2022), which finds that the analytical method can underestimate the dust mass by a factor of up to hundreds for RT models.
< 10−4 M⊙. For higher masses, the analytical expression systematically underpredicts the dust masses. This suggests that the assumptions of Eq. (6) break down. In particular, we suspect that for these high dust masses, disks become partly optically thick. This explains why an increase in model dust mass is not reflected any more in an increase in flux and therefore the analytical dust mass. This finding is consistent with a parameter study from Liu et al. (2022), which finds that the analytical method can underestimate the dust mass by a factor of up to hundreds for RT models.
Over plotted in Fig. 8 are the fits for the sample (Sect. 3.3). For every object, the single or two-zone model is selected based on the Bayes factor (Sect. 3.3). The model masses and their uncertainties are directly obtained from the posteriors, with the error bars showing the 1σ level (based on its percentiles). The analytical dust masses are calculated using the interpolated model flux at 850 µm, Eq. (6), 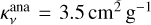 , and
, and 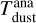 = 20 K. We note that the errors for the analytical dust masses, propagated from the flux uncertainties, are smaller than the used markers in Fig. 8. It can be seen that the majority of objects fall within the mass range in which the analytic expression starts to break down. Therefore, the dust mass is underestimated by the analytic formula for many high-mass objects.
= 20 K. We note that the errors for the analytical dust masses, propagated from the flux uncertainties, are smaller than the used markers in Fig. 8. It can be seen that the majority of objects fall within the mass range in which the analytic expression starts to break down. Therefore, the dust mass is underestimated by the analytic formula for many high-mass objects.
In a next step, we are evaluating the potential to estimate dust masses based on a limited number of mm-flux measurements without any analytical assumptions. We selected 100 random single zone models and used their mm-points as mock observations. The selected wavelength (combinations of 890 µm, 1.3 mm, and 3 mm) are seen in the first column of Table 4. The fluxes at these wavelengths are given a mock uncertainty of 1%, 5%, and 10% (first row of Table 4). These mock observations are then fitted with single zone models using a full Bayesian analysis for which the stellar parameters and the inclination are fixed to their correct model values. We used the resulting posterior distribution to estimate typical uncertainties for the disk mass. We compare the 84th (x+1σ) and 16th percentile (x-1σ) to derive a typical uncertainty factor ferr:
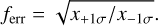 (7)
(7)
This factor is given in Table 4 for the different combinations of mock observational wavelength and uncertainties. The table shows the median mass uncertainty factor for the sample of 100 mock observations with the 84th and 16th percentile of the distribution given as uncertainties. Generally, the mass uncertainty decreases with more observations and with smaller flux uncertainties, which is to be expected. For a single observation at 890 µm with a flux uncertainty of 10%, the mass can be constrained by a median factor of 2.11, while three observations at 890 µm, 1.3 mm, and 3 mm, with uncertainties of 1% result in a median mass uncertainty factor of 1.67. Comparing only individual flux measurements, it comes clear that a measurement at longer wavelength can constrain the mass better than a measurement with the same uncertainty at shorter wavelength. This hints that parameters other than the disk mass are affecting the SED at longer wavelength less, which makes the fitting less degenerate and the mass determination more precise.
 |
Fig. 8 Calculated dust mass with Eq. (6) using the flux at 850 µm, |
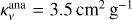
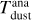
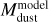
Mass uncertainty factors for mock observations.
4 Discussion
4.1 Related parameters in the sample
In this section, we examine the relations between different model parameters. Comparing all 30 objects, we analyse if a parameter difference between objects coincides with a change of another parameter. This gives insights into what kind of disks exist. Since the two-zone models are preferred for most object, we use these fits (Table C.4) for all objects to examine parameter relations. The values of selected parameters with their 1σ uncertainties are displayed in Fig. 9. The displayed parameter combinations are chosen based on the strength of their correlation and their physical importance. This correlation is quantified using the Pearson correlation coefficient, which is determined in an iterative process. The posterior of every object is projected on the to examine parameter combination. Then a random point from the posterior of every object is chosen and the correlation coefficient for this set of points is calculated. This process is repeated for a total of 10000 sets of parameter values from every object's posterior. The mean coefficient values with their standard deviation are displayed on top of every panel in Fig. 9.
The scale height (H0) and the disk mass (Mdisk) shows a Pearson coefficient of -0.38 ± 0.11. The negative value corresponds to more massive disks having smaller scale heights. The explanation for this dependency is that higher mass disks are optically thicker, resulting in lower midplane temperatures, which in hydrostatic equilibrium corresponds to flatter disks. It seems impossible to have both a massive disk and a large scale height, because such disks would extend vertically very high before they become optically thin.
This relation is also true for the inner disk zone, with a Pearson coefficient of -0.34 ± 0.09 between the disk mass Mdisk,2 and scale height H2 of the inner zone. We therefore argue that this correlation has a real physical origin in the disk structure, as described above.
The third panel in Fig. 9 shows the correlation between the dust size power law exponent apow and the scale height of the outer zone. High apow correspond to many small grains and only a few large once. The panel shows that no object with high values in H0 and apow exist in our sample (correlation coefficient of -0.26 ± 0.07). We argue similarly to the previous correlation, that small grains have higher opacities at shorter wavelength, which makes the disk more optically thick, decreasing the temperature and therefore the scale height.
The parameter combinations that are not displayed show some similar patterns. Firstly, some parameter combinations show correlations with high correlation coefficients, but they are enforced by our modelling process. For example, the inner radius (Rin) of the outer zone strongly correlates with the outer radius of the inner zone (Rout,2). This is a consequence of the constraint Rin ≥ Rout,2. Additionally, the stellar temperature strongly correlates with the stellar luminosity, which is a consequence of stellar evolution. Secondly, some parameter combinations have error bars for both parameters that are larger than the value differences between objects. An example of such a combination is the PAH abundance (fPAH) and its charge ratio (PAHcharged). This prohibits any strong correlation. Lastly, some parameter combinations have error bars that are smaller than the difference between objects, but there is nevertheless no clear correlation visible. This is, for example, the case for the mass of the disk and the dust composition. It is not always clear if a correlation is significant or not, therefore we decided to only show the most convincing ones.
 |
Fig. 9 Dependencies between selected physical two-zone disk parameters of all objects. Points with error bars denote the median values and the 84th and 16th percentiles resulting from the Bayesian analysis of two-zone fitted objects. The Pearson correlation coefficient is shown in the title of every plot. |
 |
Fig. 10 Violin plots showing the uncertainty distribution for all single zone parameters (Table C.3). For the left part of the plot (left of the dashed black line; linearly sampled parameters) the uncertainties are given in absolute values xerr according to Eq. (8) corresponding to the left axis. For the right part of the plot (logarithmically sampled parameters), the uncertainties are given as factors ferr (Eq. (7)) corresponding to the right axis. Every violin depicts the distribution of uncertainties for an individual parameter. The upper, middle, and lower line encode the maximal, median, and minimal uncertainty in the sample, respectively. |
4.2 Uncertainties of all disk parameters
One main objective of this study is to calculate the uncertainties for parameters derived from SED fitting, to provide general uncertainty estimates for SED fits. We determine the uncertainties of all parameters either in absolute values or in relative factors. Absolute values are used for parameters that were sampled on a linear scale, while factors are used for logarithmically sampled parameter. In both cases, we use the 84% (X+1σ) and the 16% (x-1σ) percentile level of the posterior probability distribution to derive the uncertainty.
For linearly sampled parameters, we define the absolute uncertainty xerr as:
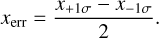 (8)
(8)
For example, the flaring index of AB Aur derived from a two-zone fit is 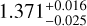 (see Table C.4), which according to Eq. (8) results in an absolute uncertainty xerr of 0.0205.
(see Table C.4), which according to Eq. (8) results in an absolute uncertainty xerr of 0.0205.
For logarithmically sampled parameters, the uncertainty is given as a factor according to Eq. (7). The same fit of AB Aur derives a disk mass of 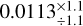 M⊙, which results in an uncertainty factor of
M⊙, which results in an uncertainty factor of 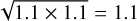 .
.
Figures 10 and 11 summarise the uncertainty distribution using violin plots for all single zone fits (Table C.3) and two-zone fits (Table C.4), respectively. The upper, middle, and lower lines encode the maximal, median, and minimal uncertainties of all fits (Sect. 3.3) for the parameters named on the x-axis. The width of the shaded area displays the distribution of all values.
For the single zone fits (Fig. 10), we first examine the parameters with absolute errors. The amount of amorphous carbon (amc-Zubko) has uncertainties between 0.001 and 0.05 with a median value of 0.02. The PAH charge ratio (PAHcharged) is among the worst constrained parameters compared to their allowed range. For many objects, no PAH features are visible, which explains an absolute uncertainty of the charge ratio of up to 0.34 with a median value of 0.31, which is large when considering the allowed parameter range of 1. For the best constrained charge ratio, the uncertainty drops to 0.038, which shows to what level it is possible to constrain this parameter if strong features are available. The scale height H0 is constrained by between 0.15 AU and 3.7 AU with a median uncertainty of 0.61 AU, which is small compared to the allowed parameter range of 32 AU. The best constrained linearly sampled parameter with respect to its allowed range is the flaring index (ß) which can have an uncertainty as low as 2.4 × 10−4 even though the range goes up to 0.5.
From the set of logarithmically sampled parameters, the inner radius (Rin) is the best constrained parameter. It has a maximum and median uncertainty factor in our sample of 1.18 and 1.10, respectively. Interestingly, the disk mass is determined by a factor of 1.33 (median) with the distribution ranging from 1.03 up to 2.69. This means that even though five orders of magnitudes of disk masses were allowed for every fit, SED fitting can constrain the mass very well. This is consistent with Ribas et al. (2020), who also find the disk mass well constrained for all objects. We note that the disk mass uncertainties from SED fitting are only slightly smaller than the once derived from fitting individual flux measurements (Sect. 3.4). The worst constrained logarithmically sampled parameters are the viscosity parameter (asettle) and the amount of PAHs (fPAH) which have maximal uncertainty factors of 5.8 and 6.2, respectively. The difference between these parameters is that the settling has a lower median (1.82 compared to 3.59) and minimal values (1.07 compared to 1.16). The minimal (amin) and maximal dust size (amax) are constrained by median factors of 2.1 and 1.5, respectively. The parameter constrained by the smallest factor is the best constrained fit of the taper radius (Rtaper), which is 1.007, while the worst constrained fit has the largest factor (7.22) of all parameters.
Overall, the parameter uncertainties vary greatly between different objects. This shows that different numbers of observations, different type of objects, or specific disk properties influence how well disk parameters can be determined. However, some parameters are better constrained than others.
Giving more degrees of freedom by adding multiple parameters for a two-zone model (Fig. 11) increases the uncertainties for parameters that are also used for single zone fits by a small factor. For example, the disk mass of the outer zone is constrained within a factor between 1.11 and 1.86 (median of 1.37), which is a slightly larger median value than the respective value for the single zone fits (Fig. 10). For the set of parameters describing the inner disk zone, the mass (Mdisk,2), maximum dust size (amax,2), and the PAH abundance (fpah,2) are most uncertain with median (maximal) factors of 3.20 (6.58), 5.93 (17.45), and 10.28 (16.03), respectively. While the mass and maximum dust size are constrained by small factors for individual objects, the PAH abundance of the inner zone is never better constrained than a factor of 6.28.
We note that a fraction of the parameter uncertainties originate from the assumed uncertainty for the NNs’ predictions. Therefore, a Bayesian analysis using the radiative model for every iteration will decrease the parameter uncertainties. The used prior will also affect the posterior. We rerun the Bayesian analysis with flat priors to estimate the influence of them. The uncertainties increase only slightly, showing that the given measurements predominantly determine the posterior.
The uncertainties derived in this study are roughly consistent with uncertainties estimated by Woitke et al. (2019) for three objects. For example, their estimated uncertainties for the dust parameter (amin, amax, apow, asett1e, and amC-Zubko) are well within the distributions displayed in Fig. 11.
 |
Fig. 11 Violin plots showing the uncertainty distribution for all two-zone parameters (Table C.4). For the left part of the plot (left of the dashed black line; linearly sampled parameters) the uncertainties are given in absolute values xerrr according to Eq. (8) corresponding to the left axis. For the right part of the plot (logarithmically sampled parameters), the uncertainties are given as factors ferrr (Eq. (7)) corresponding to the right axis. Every violin depicts the distribution of uncertainties for an individual parameter. The upper, middle, and lower line encode the maximal, median, and minimal uncertainty in the sample, respectively. |
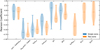 |
Fig. 12 Pearson correlation coefficients for selected combinations of model parameters. Values close to +1 and -1 denote strong positive and negative correlations, respectively, whereas 0 means no correlation. Every violin depicts the distribution of correlation coefficients for all single (blue) and two-zone (orange) models (Sect. 3.3). The upper, middle, and lower bars show the maximal, median, and minimal value, respectively. |
4.3 Degeneracies
In this section, we examine the degeneracies in SED-fitting that we have identified based on our full Bayesian analysis (Sect. 3.3). While SED-fitting is well-known to be degenerate, quantifying this effect is difficult due to the high computational cost.
We quantify a degeneracy between two parameters by the Pearson correlation coefficient of the joint posterior distributions using all single and two-zone models introduced in Sect. 3.3. In total, there are 78 single zone and 210 two-zone parameter relations to explore that represent all combinations of the 13 single zone and 21 two-zone parameters that were fitted. We display parameter combinations that show large positive or negative Pearson coefficients (mean absolute value larger than 0.35) in Fig. 12. The upper, middle, and lower bars encode the maximum, median, and minimum values for a certain parameter combination for all single (blue) and two-zone (orange) fits. The width of the shaded area corresponds to the value distribution. If a simultaneous increase in both parameters results in similar SEDs, the Pearson coefficient is positive, whereas, if an increase of one parameter can be counteracted by a decrease of another, the Pearson coefficient is negative. If no correlation is found, the Pearson coefficient is close to 0, and the two parameters are considered not to be degenerate.
The largest degeneracy is found between the disk mass, Mdisk, and the volume fraction of amorphous carbon in the dust grain material, amC-Zubko. This degeneracy shows that a higher disk mass in combination with less amorphous carbon can result in similar SEDs. Clearly, an increase of either of these two parameters results in more millimetre fluxes. However, Fig. 12 also shows that there are many objects where this Pearson coefficient is quite small. We explain this behaviour by the inclusion of mid-IR data, which measures the strength of the main silicate features at 10 µm and 20 µm. For objects which exhibit strong silicate emission features, the use of too much amorphous carbon results in too flat mid-IR dust opacities under the assumption that the dust composition does not vary as a function of altitude nor radius. This is a good example that some well-known degeneracies get smaller when additional data is taken into account.
For strong silicate emission features, we need the dust absorption opacity to be dominated by small (µm-sized) particles, for example, the power law exponent of the dust size distribution (apow) must be large. Otherwise, if apow is small, the grey opacities of the large dust particles flatten out the dust opacity at mid-IR wavelengths. This explains why apow is found to be positively degenerate with the amorphous carbon fraction amC-Zubko, which has a similar effect on the dust opacity in the mid-IR when increased.
The most degenerate of our disk parameters is the scale height of either disk zone (H0 and H2), which generally has a big impact on the SED. The scale height is found to be degenerate with apow, with the dust settling parameter asettle, with the disk flaring index ß and with the mass of the inner disk zone Mdisk,2 in case of a two-zone models. All these degeneracies have similar physical explanations. Larger scale heights, less dust settling, more disk mass and a steeper dust size power law all result in more grains high up in the disk, which affects the SED in similar ways.
Stronger disk flaring β reduces the scale heights inside the reference radius (100 AU for H0, and 1 AU for H2) and increases the scale heights outside of that radius. The positive Pearson coefficient between β and the scale height itself suggests that the inner parts of the disk are more important for the SED than the outer parts. The flaring indices β of both zones are also degenerate with the respective surface density exponent ϵ. Increasing either of these parameters changes the slope of the SED. An increase of ϵ and a decrease of β both increase the fluxes at short wavelengths (λ ≲ 10 µm) and decrease the fluxes at long wavelengths (λ ≳ 100 µm). However, the spread of the Pearson coefficients for these correlations is already quite large, indicating that the sign of the correlation can actually change with circumstances, depending on, for example, whether or not the outer disk zone is situated in the shadow cast by the inner disk.
Generally, parameters that exist for single and two-zone models show similar degeneracies. The degeneracies seen for the single zone models are mirrored by similar degeneracies for inner zone parameters in two-zone models. For example, is the degeneracy of β with ϵ and H0 similar to the degeneracy of β2 with ϵ2 and H2.
All found degeneracies are between parameters that have a large impact on the SED. Parameters that do not affect the SED strongly are poorly constrained, which makes them less degenerate.
Alonso-Albi et al. (2009) conclude that the slope of the SED at mm-wavelengths is for optically thin disks degenerate with the maximum dust size and the exponent of the dust size distribution. We do not see this degeneracy back in our SED fitting, which means that flux measurements at different wavelengths can break it.
4.4 Limitations of this method
In this section, we explore limitations and possible improvements of our method. After deriving the single zone (Table C.3) and two-zone (Table C.4) posteriors for every object, we selected 100 random models from every posterior to determine the quality of the NNs’ predictions at these points in parameter space. To calculate the prediction quality, the true SEDs must be known. Therefore, we run MCFOST of every selected model. The measure of quality is the relative flux difference between true and predicted SEDs as introduced in Eq. (5). Figure 13 shows the qualities for the selected models for the single zone and two-zone posterior of every object. Since wavelength points shortwards of 0.5 µm are not used to calculate the likelihood function, we excluded these points from the analysis.
68% (1σ) of these single zone and two-zone SED fluxes were predicted by our NNs with qualities better than 4.5% and 4.8%, respectively. Even though this is slightly worse than the achieved qualities of the test sets, 95% of single zone (two-zone) predicted SEDs have qualities better than 14% (13%). These errors, introduced by the necessity to use NNs for fast SED prediction, are generally small compared to the sum of measurement uncertainties and systematic problems inherent in SED fitting, such as source variability and systematic errors using multi-instrument data.
The worst predictions are often caused by models with parameter values close to the most extreme allowed values. This can be especially seen for the single zone predictions that do not describe the observations well and drift to extreme parameter values. We expect these predictions to be slightly worst, since the NNs have fewer training models in these areas of parameter space. This can be seen best in the case of 49 Cet, which is best fitted with inner radii as large as possible. The model from the two-zone posterior have an inner radius of the outer zone that is close to the maximum value of 70 AU allowed by the prior. For the single zone model the inner radius is sampled differently, which results for the given stellar parameters a tighter constraint of about 40 AU. This is why the two-zone model is strongly preferred based on the Bayes factor. This extreme configuration has two additional consequences. First, the two-zone model requires an inner zone, but since the object does not require this, it is close to the minimum possible mass. Second, the single zone posterior causes the strongest disagreements when calculating MCFOST models for the models of the posterior. This is because the area of parameter space that would be preferred to fit the model (large inner radii) is forbidden. This results in the Nested sampling algorithm searching and finding the part at which the NN’s predictions deviate the most from the RT runs and can explain the observations. This is reflected in the extreme choice also for many other fitted parameters of 49 Cet.
 |
Fig. 13 Quality distribution according to Eq. (5) of the flux predictions at wavelength longer than 0.5 µm for 100 random models from the single (orange) and two-zone (blue) posterior of every object. The histogram shows how many models fall in each quality bin. The dashed, dashed-dotted, and dotted black lines show the 5%, 10%, and 20% difference, respectively. |
5 Summary and conclusion
We used a Bayesian framework to fit the SEDs of 30 proto-planetary disks based on the observational data collected by the FP7 DIANA project2, based on single and two-zone full RT MCFOST models, emulated by NNs. The emulation decreases the SED computation time by a factor larger than 105. This web-page3 demonstrates the SED emulation process and (i) shows graphically how individual model parameters affect the SED, and (ii) can be used to compare models easily to observations getting first estimates for well-fitting disk parameters. The main conclusions of this paper are:
Our trained NNs can emulate the SEDs of single and two-zone disk models with flux errors of typically less than 5%. This acceleration enables us to fit a large set of objects using Bayesian analysis with or without using additional constraints on the disk properties.
We find significant differences between the parameter posterior distributions obtained in this study and the previously determined values based on a genetic χ2 optimisation (Woitke et al. 2019). For single and two-zone fits, the parameter values from Woitke et al. (2019) are outside the 3σ level of the posteriors derived in this study in about 25% and 22% of the cases, respectively.
We find significant statistical evidence that most objects are better described by a discontinuous (two-zone) disk structure compared to the continuous (single zone) models.
The disk dust masses derived from single mm-flux measurements systematically underpredict the true dust masses in the models for high-mass disks (dust mass ≥10−4 M⊙). Most objects fall into this mass range.
By an additional emulator-based Bayesian analysis, we have derived the uncertainties in disk mass determination from single mm-flux measurements. We show that this uncertainty decreases with the number and wavelength of the photometric fluxes used.
Our analysis shows a few clear, but not so well-known, correlations between disk parameters. In particular, high-mass disks have lower scale heights than their low-mass counter-parts. This is in line with vertical hydrostatic equilibrium based on cooler midplane temperatures in the high-mass disks.
We provide typical uncertainties for disk parameters derived with our method. We show that certain parameters are relatively well constrained (the dust mass of a single zone model is typically constrained by a factor of 1.3), while other parameters are poorly constrained (the minimal dust size has an uncertainty factor of 2.1).
SED fitting is known to be highly degenerate. Using our statistical framework, we are able, for the first time, to quantify these degeneracies. The disk mass and dust composition show the clearest degeneracy. Additionally, the scale height is degenerate with many parameters, like the dust size power law exponent and the flaring index.
This study has shown that a combination of complex RT disk models with novel machine learning techniques provide a powerful tool to analyse SED data including all degeneracies. We plan to use this method on more complex thermo-chemical disk models in the future. These models take about a factor of 100 longer than the dust RT models discussed in this paper, making the need for a faster generation of molecular emission spectra even greater.
Acknowledgements
We acknowledge funding from the European Union H2020-MSCA-ITN-2019 under grant agreement no. 860470 (CHAMELEON).
Appendix A Hypergrids
The training of a NN is an iterative process to minimise the loss function. This corresponds in general to predictions of the NN that are more similar to the true output, in our case the true SED of a model. The minimisation is done by adjusting the weights of the NN until the loss function converges. However, there are many NN architectures and other settings, so-called hyperpa- rameters, that change the NN or the training process. Finding good settings is a process of trail and error that involves running multiple NNs with different settings and comparing the results.
We used hypergrids to determine good values for the most important hyperparameters. Therefore, we trained multiple NNs with different settings and evaluated the quality of the predictions. The measure of quality (Q) is the mean difference between the logarithmic predicted (vFpredict) and true SED fluxes (vFtrue) averaged over all wavelength points Nλ and all models in the data set Nmodel:
![$Q = {1 \over {{N_{model}}}}\sum\limits_{j = 1}^{{N_{model}}} {\sqrt {\sum\limits_{i = 1}^{{N_\lambda }} {{{{{\left[ {{{\log }_{10}}\left( {{v_i}{F_{predict,i,j}}} \right) - {{\log }_{10}}\left( {{v_i}{F_{true,i,j}}} \right)} \right]}^2}} \over {{N_\lambda }}}} } }$](/articles/aa/full_html/2023/04/aa45461-22/aa45461-22-eq42.png) (A.1)
(A.1)
We examined 4 hyperparameters by running over 74 and 35 networks for single and two-zone predictions, respectively. While two of these hyperparameters (number of hidden layers and neurons per layer) determine the architecture of the NN, two others specify scaling (standardising or normalising) of the input and output data. Evaluating the influence of it is possible because the defined quality Q does not depend on the scaling of the SED, in contrast to the loss function.
The training was done on 70% of the data, with the rest used to evaluate the predictions. This is the same procedure used for the final NN. To increase comparability, the split in training and test set is the same for all NNs in all hypergrids.
To evaluate the effect of the scalers we trained a set of NNs with a learning rate of 0.1 for 400 epochs with different number of hidden layers (5,6), neurons per layer (100,128,150,200), and scaling (normalising and standardising) the input and output data resulting in 32 different NNs. Table A.1 shows the achieved average qualities for the test and training set for combinations of input and output scalers. We conclude that runs using standardised output achieve better qualities, while the different between normalising and standardising the input is small. Nevertheless, standardising the input gives slightly better predictions. Therefore, we choose to standardise input and output for all NNs, not just single zone NNs, but also for the two-zone NNs.
We trained more single zone NNs for 400 epochs to determine good architectures. Larger networks were additionally trained with 1000 epochs, to ensure that they converge. To increase comparability, every training that did not improve for 10 epochs was stopped. As seen in Fig. A.1, we ordered the NNs by the number of trainable parameters in it. This reveals that generally larger NNs perform better on our data. However, it also becomes clear that for larger NNs, the prediction quality for the test set becomes significantly worse than the same quality for the training set, which is a sign of overfitting.
Balanced between the quality of the predictions, overfitting, and the time needed for training, we decided on using 6 hidden layers with 300 neurons each. This gives a quality Q of 0.01618 and 0.017347 for the training and test set, which is close to the best quality (test score of 0.01678) in the hypergrid. Additionally, this network takes ~1 min to train per epoch on our machines and has with 499, 340 trainable parameters a reasonable size with respect to the size of the training set (470, 379 training SEDs).
Fig A.2 displays the quality of the predicted SEDs for two-zone NNs. We trained every network for 500 epochs. Again, larger NNs perform better, but while the training score improves steadily with size, the test score does not improve further for networks larger than ~1,000,000 trainable parameters which is roughly the number of SEDs used for the training (1,195,285 SEDs). Therefore, we choose a NN with 7 hidden layers with 400 neurons per layer (1,029,340 trainable parameters) as the best setup for two-zone predictions. This network is with a training score of 0.01662 close to the optimal scores of 0.016086, while the test score of 0.019649 is the best test score found in the hypergrid.
 |
Fig. A.1 Hypergrid to determine the best architecture of single zone NNs. The upper panel displays the quality Q of the test and training set for 37 different NNs as explained in Eq. A.1. The number of layers, neurons per layer, and the maximum number of epochs trained for every NN are shown in the lower panels. The lowest panel displays the number of trainable parameters in the NNs. The dashed line denotes the selected NN. |
 |
Fig. A.2 Hypergrid to determine the best architecture of two-zone NNs. The upper panel displays the quality Q of the test and training set for 35 different NNs as explained in Eq. A.1. The number of hidden layers and the number of neurons per layer for every NN are shown in the lower panels. The lowest panel displays the number of trainable parameters in the NNs. The dashed line denotes the selected NN. |
Hypergrid for input and output scaler.
Appendix B Detailed grid creation
After explaining the general idea of the grid creation (Sect. 2.3), this section focusses on individual parameters and their sampling, highlighting the physical knowledge that influences parameters. The four stellar parameters (M⋆, age, L⋆, and Teff) cannot be varied independently, since only certain combinations are physically possible. Therefore, we took two approaches, either sampling M⋆ and age or L⋆ and Teff and deriving the other two in a way that makes the stars consistent with pre-main- sequence tracks from Siess et al. (2000).
For single zone models, we sampled the stellar mass and age (limits in Tab 1). A small NN predicted the temperature and luminosity based on these parameters. This NN was trained on a subset of pre-main-sequence track points from Siess et al. (2000) and consists of 4 hidden layers with 32 neurons each. For a separated test set, the temperature predictions show a mean deviation of 0.18% with a maximal uncertainty of 2.11%. The luminosity predictions have a mean error of 1.94%. The resulting stellar distribution is shown in blue in the Hertzsprung-Russell diagram (HRD; Fig. B.1). When comparing this distribution to the DIANA sample, it comes clear that the grid has much fewer bright and hot stars.
The first tests with different NNs showed that this leads to worse prediction for stars that have such luminosities and temperatures. Therefore, another set of models was sampled uniformly in the log space of Teff and L⋆ for masses less than 2.5 M⊙, L⋆ > 4 L⊙, Teff > 5000 K, and ages between 0.5 Myr and 20 Myr to better populate this gap (green distribution in Fig. B.1).
For this adjusted grid, M⋆ is predicted by another NN trained on pre-main-sequence tracks using L⋆ and Teff. It consists of 6 layers with 32 neurons each. For a test set, it has a mean mass error of 0.39% and a maximal error of 4.19%.
The combination of both grids results in a distribution similar to the stellar parameters of the DIANA target stars. In total, 452, 444 SEDs are created using the mass and age sampling for the stars and 220, 934 to fix the lack of massive stars in the grid.
For the two-zone grid, and Teff are sampled with mass and age limits taken from the initial single zone grid, resulting in the stellar distribution shown in Fig. B.2. The mass is again predicted by the same NN as mentioned above.
The mass of the disk is sampled indirectly by the ratio of it to the mass of the star. This is done to avoid massive disks around low-mass stars.
The innermost radius (Rin for single zone models and Rin,2 for two-zone models) is determined by the temperature at this radius, with the idea to avoid disks that are too close to their star for dust to be stable. Therefore, we approximate the temperature (T(R0)) at the inner edge of the disk for all objects in the DIANA sample using a simple analytic formula. The temperature is derived using the stellar temperature (Teff), stellar radius (R⋆), and inner radius of the most inner disk zone (R0) for all objects in the DIANA sample using Eq. B.1 with a = 0.2 (Woitke 2015):
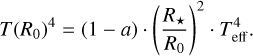 (B.1)
(B.1)
The distribution of temperatures for the sample is used to derive xmin, xmean, and xstd of the sample. The maximal limit (xmax) is set based on literature knowledge, to exclude unrealistically high temperatures.
Using the described setup, we run all MCFOST models and created SEDs for ten different inclinations. For high inclinations (edge-on disks), often the disks block large parts of the starlight. Since these SEDs look fundamentally different (see Fig. B.3), they were excluded from our sample. We identified these shielded SEDs by having at least one flux point at a wave-length shorter than 2µm lower than half the stellar flux. It is justified to exclude them, because such objects are not present in the DIANA sample, but make the training of a NN much more challenging.
 |
Fig. B.1 Hertzsprung-Russell diagram of the DIANA sample (orange markers) and all stars in the original single zone grid (blue) and the adjusted grid (green). The grey lines are the evolutionary tracks from (Siess et al. 2000) for different masses, and the coloured dashed lines are isochrones. The histograms show the distribution of values for luminosity and temperature for the sample and the grid in the same colours as used in the main plot. The sample's histogram is scaled to make a comparison easier. |
 |
Fig. B.2 HRD for two-zone models. Explanation is the same as for B.1. |
 |
Fig. B.3 Example of an MCFOST model with SEDs for all 10 different inclinations. The blue points show the stellar flux at different wavelengths between 0.1 µm and 2 µm (both shown as vertical blue lines). The blue line encode the limit, which is used to distinguish non- shielded inclinations (green SEDs) that were accepted for the sample and shielded inclinations (red SEDs) that were discarded. |
Appendix C Tables
Fits for all single zone objects comparable to DIANA. Notation a(+b) means a × 10b.
Fits for all two-zone objects comparable to DIANA
Fits for all objects with single zone models with all parameters fitted
Fits for all object with two-zone models with all parameters fitted
Appendix D Figures
 |
Fig. D.1 Density plots for every object’s median probable model to reproduce the DIANA results (Sect. 3.2). Every panel shows the density structure in number densities of Hydrogen per cubic centimetre (colour bar at the top) for the objects noted in the panel. The upper and lower half of every plot depict the model from this study and DIANA, respectively. The radial axis is different for every object. The inner zones of Usco J1604-2130 in this work has a radial extent smaller than the radial resolution of the plots. |
 |
Fig. D.2 Density plots for every object’s median probable model derived in this study (Sect. 3.3). Every panel shows the density structure in number densities of Hydrogen per cubic centimetre (colour bar at the top) for the objects noted in the panel. The upper and lower half of every plot depict the two-zone and single zone model, respectively. The radial axis is different for every object. The inner zone of the two-zone model of 49 Cet has densities lower than the minimum threshold of the picture. The inner zones of HD 169142 and Usco J1604-2130have a radial extent smaller than the radial resolution of the plots. |
 |
Fig. D.3 SEDs for all objects. The coloured points and lines indicate the observation listed in the legend. The SEDs from the posterior distribution are shown in black. The line denotes the median of all model SED, with the dark, medium, and light black areas denoting the 68%, 95%, and 99.9% percentiles, respectively. The name of the model and if it is fitted with a single or two-zone model is given in the title. |
 |
Fig. D.4 Mid-IR region of the SED for all objects. The coloured points and lines indicate the observation listed in the legend. The SEDs from the posterior distribution are shown in black. The line denotes the median of all model SED, with the dark, medium, and light black areas denoting the 68%, 95%, and 99.9% percentiles, respectively. The name of the model and if it is fitted with a single or two-zone model is given in the title. |
References
- Abadi, M., Barham, P., Chen, J., et al. 2016, in Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2016, 265 [Google Scholar]
- Alonso-Albi, T., Fuente, A., Bachiller, R., et al. 2009, A&A, 497, 117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Andrews, S.M., & Williams, J.P. 2005, ApJ, 631, 1134 [NASA ADS] [CrossRef] [Google Scholar]
- Andrews, S.M., & Williams, J.P. 2007, ApJ, 659, 705 [NASA ADS] [CrossRef] [Google Scholar]
- Ballering, N.P., & Eisner, J.A. 2019, AJ, 157, 144 [NASA ADS] [CrossRef] [Google Scholar]
- Barbieri, M.M., & Berger, J.O. 2004, Ann. Stat., 32, 870 [CrossRef] [Google Scholar]
- Bjorkman, J.E., & Wood, K. 2001, ApJ, 554, 615 [NASA ADS] [CrossRef] [Google Scholar]
- Brott, I., & Hauschildt, P.H. 2005, Proceedings of the Gaia Symposium “The Three-Dimensional Universe with Gaia”, eds C. Turon, K.S. O’Flaherty, & M.A.C. Perryman, 565 [Google Scholar]
- Buchner, Georgakakis, Nandra, et al. 2014, A&A, 564, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chapillon, E., Guilloteau, S., Dutrey, A., & Piétu, V. 2008, A&A, 488, 565 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chollet, F., & Others 2015, https://keras.io [Google Scholar]
- Cortes, S.R., Meyer, M.R., Carpenter, J.M., et al. 2009, ApJ, 697, 1305 [NASA ADS] [CrossRef] [Google Scholar]
- D’Alessio, P., Canto, J., Calvet, N., & Lizano, S. 1998, ApJ, 500, 411 [CrossRef] [Google Scholar]
- Dionatos, O., Woitke, P., Güdel, M., et al. 2019, A&A, 625, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dong, R., Hashimoto, J., Rafikov, R., et al. 2012, ApJ, 760, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Dorschner, J., Begemann, B., Henning, T., Jaeger, C., & Mutschke, H. 1995, A&A, 300, 503 [Google Scholar]
- Draine, B.T. 1978, ApJS, 36, 595 [NASA ADS] [CrossRef] [Google Scholar]
- Draine, B.T., & Bertoldi, F. 1996, ApJ, 468, 269 [NASA ADS] [CrossRef] [Google Scholar]
- Dubrulle, B., Morfill, G., & Sterzik, M. 1995, Icarus, 114, 237 [Google Scholar]
- Feroz, F., & Hobson, M.P. 2008, MNRAS, 384, 449 [NASA ADS] [CrossRef] [Google Scholar]
- Feroz, F., Hobson, M.P., & Bridges, M. 2009, MNRAS, 398, 1601 [NASA ADS] [CrossRef] [Google Scholar]
- Feroz, F., Hobson, M.P., Cameron, E., & Pettitt, A.N. 2019, Open J. Astrophys., 2 [Google Scholar]
- Fitzpatrick, E.L. 1999, PASP, 111, 63 [Google Scholar]
- Gabellini, M.G.U., Miotello, A., Facchini, S., et al. 2019, MNRAS, 486, 4638 [NASA ADS] [CrossRef] [Google Scholar]
- Gaia Collaboration (Brown, A.G.A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A.G.A., et al.) 2021, A&A, 649, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gangal, A., Kumar, P., Kumari, S., & Kumar, A. 2021, ArXiv e-prints [arXiv:2107.02744] [Google Scholar]
- Gräfe, C., & Wolf, S. 2013, A&A, 552, A88 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heese, S., Wolf, S., Dutrey, A., & Guilloteau, S. 2017, A&A, 604, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hildebrand, R.H. 1983, QJRAS, 24, 267 [Google Scholar]
- Hornik, K., Stinchcombe, M., & White, H. 1989, Neural Networks, 2, 359 [CrossRef] [Google Scholar]
- Ingleby, L., Calvet, N., Herczeg, G., et al. 2013, ApJ, 767, 112 [Google Scholar]
- Liu, Y., Joergens, V., Bayo, A., Nielbock, M., & Wang, H. 2015, A&A, 582, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liu, Y., Linz, H., Fang, M., et al. 2022, A&A, 668, A175 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Long, F., Pinilla, P., Herczeg, G.J., et al. 2018, ApJ, 869, 17 [NASA ADS] [CrossRef] [Google Scholar]
- Manoj, P., Bhatt, H.C., Maheswar, G., & Muneer, S. 2006, ApJ, 653, 657 [NASA ADS] [CrossRef] [Google Scholar]
- Min, M., Hovenier, J.W., & De Koter, A. 2005, A&A, 432, 909 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Min, M., Waters, L.B.F.M., de Koter, A., et al. 2007, A&A, 462, 667 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Min, M., Rab, C., Woitke, P., Dominik, C., & Ménard, F. 2016, A&A, 585, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pecaut, M.J., & Mamajek, E.E. 2016, MNRAS, 461, 794 [NASA ADS] [CrossRef] [Google Scholar]
- Pinte, C., Ménard, F., Duchêne, G., & Bastien, P. 2006, A&A, 459, 797 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pinte, C., Padgett, D.L., Ménard, F., et al. 2008, A&A, 489, 633 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pinte, C., Harries, T.J., Min, M., et al. 2009, A&A, 498, 967 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ribas, A., Espaillat, C.C., MacÍas, E., & Sarro, L.M. 2020, A&A, 642, A171 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ricci, L., Mann, R.K., Testi, L., et al. 2011, A&A, 525, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Robrade, J., Güdel, M., Günther, H.M., & Schmitt, J.H.M.M. 2014, A&A, 561, A124 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shakura, N.I., & Sunyaev, R.A. 1973, A&A, 24, 337 [Google Scholar]
- Sheehan, P.D., Tobin, J.J., Looney, L.W., & Megeath, S.T. 2022, ApJ, 929, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Siess, L., Dufour, E., & Forestini, M. 2000, A&A, 358, 593 [Google Scholar]
- Sobol, I. 1967, USSR Comput. Math. Math. Phys., 7, 86 [Google Scholar]
- Tannirkulam, A., Monnier, J.D., Harries, T.J., et al. 2008, ApJ, 689, 513 [NASA ADS] [CrossRef] [Google Scholar]
- Testi, L., Natta, A., Shepherd, D.S., & Wilner, D.J. 2003, A&A, 403, 323 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Thamm, E., Steinacker, J., & Henning, T. 1994, A&A, 287, 493 [NASA ADS] [Google Scholar]
- Trotta, R. 2008, Contemp. Phys., 49, 71 [Google Scholar]
- Woitke, P. 2015, EPJ Web Conf., 102, 1 [Google Scholar]
- Woitke, P., Min, M., Pinte, C., et al. 2016, A&A, 586, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Woitke, P., Kamp, I., Antonellini, S., et al. 2019, PASP, 131, 064301 [NASA ADS] [CrossRef] [Google Scholar]
- Wolff, S.G., Perrin, M., Millar-Blanchaer, M.A., et al. 2016, ApJ, 818, L15 [NASA ADS] [CrossRef] [Google Scholar]
- Zubko, V.G., Mennella, V., Colangeli, L., & Bussoletti, E. 1996, MNRAS, 282, 1321 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Fits for all single zone objects comparable to DIANA. Notation a(+b) means a × 10b.
All Figures
|
Fig. 1 Example of a predicted SED with strong PAH features for a single zone model of a A6 star that is part of the test sample compared to the true SED derived by the full RT code. The orange and blue points in the upper panel show the predicted and the true SEDs, respectively. The residual (orange) is shown in percent in the lower panel. |
| In the text | |
|
Fig. 2 Sketch of a single and two-zone disk structure. The shown parameters are explained in Table 1. |
| In the text | |
|
Fig. 3 Two parameters sampled with 1000 points using random numbers (upper panel) and the Sobol sequence (lower panel). Both parameters are evenly distributed between 0 and 1. |
| In the text | |
|
Fig. 4 Chosen architecture of the neural network (NN) to predict single zone model's SEDs. The NN consists of an input layer (orange) with 18 neurons (18 free parameters), 6 hidden layers (blue circles) with 300 neurons each, and an output layer (red) with 140 neurons (the SED values at wavelength i of the 140 points (SED(λi)). All neurons are connected to every neuron in the adjacent layer. This sums up to 499 340 trainable parameters. |
| In the text | |
|
Fig. 5 Quality distribution according to Eq. (5) of the predictions in the test set for the single zone (orange) and two-zone (blue) NN. The histogram shows how many predictions fall in each quality bin. The dashed, dashed-dotted, and dotted black lines show the 5%, 10%, and 20% difference, respectively. |
| In the text | |
|
Fig. 6 Comparison between resulting parameter posterior distribution and the DIANA fits for single zone objects. The histograms show the fraction of DIANA models that have parameter values within the 1σ, 2σ, and 3σ contour or outside for that parameter. |
| In the text | |
|
Fig. 7 Comparison between resulting parameter posterior distribution and the DIANA fits for two-zone objects. The histograms show the fraction of DIANA models that have parameter values within the 1σ, 2σ, and 3σ contour or outside for that parameter. |
| In the text | |
|
Fig. 8 Calculated dust mass with Eq. (6) using the flux at 850 µm, |
| In the text | |
|
Fig. 9 Dependencies between selected physical two-zone disk parameters of all objects. Points with error bars denote the median values and the 84th and 16th percentiles resulting from the Bayesian analysis of two-zone fitted objects. The Pearson correlation coefficient is shown in the title of every plot. |
| In the text | |
|
Fig. 10 Violin plots showing the uncertainty distribution for all single zone parameters (Table C.3). For the left part of the plot (left of the dashed black line; linearly sampled parameters) the uncertainties are given in absolute values xerr according to Eq. (8) corresponding to the left axis. For the right part of the plot (logarithmically sampled parameters), the uncertainties are given as factors ferr (Eq. (7)) corresponding to the right axis. Every violin depicts the distribution of uncertainties for an individual parameter. The upper, middle, and lower line encode the maximal, median, and minimal uncertainty in the sample, respectively. |
| In the text | |
|
Fig. 11 Violin plots showing the uncertainty distribution for all two-zone parameters (Table C.4). For the left part of the plot (left of the dashed black line; linearly sampled parameters) the uncertainties are given in absolute values xerrr according to Eq. (8) corresponding to the left axis. For the right part of the plot (logarithmically sampled parameters), the uncertainties are given as factors ferrr (Eq. (7)) corresponding to the right axis. Every violin depicts the distribution of uncertainties for an individual parameter. The upper, middle, and lower line encode the maximal, median, and minimal uncertainty in the sample, respectively. |
| In the text | |
|
Fig. 12 Pearson correlation coefficients for selected combinations of model parameters. Values close to +1 and -1 denote strong positive and negative correlations, respectively, whereas 0 means no correlation. Every violin depicts the distribution of correlation coefficients for all single (blue) and two-zone (orange) models (Sect. 3.3). The upper, middle, and lower bars show the maximal, median, and minimal value, respectively. |
| In the text | |
|
Fig. 13 Quality distribution according to Eq. (5) of the flux predictions at wavelength longer than 0.5 µm for 100 random models from the single (orange) and two-zone (blue) posterior of every object. The histogram shows how many models fall in each quality bin. The dashed, dashed-dotted, and dotted black lines show the 5%, 10%, and 20% difference, respectively. |
| In the text | |
|
Fig. A.1 Hypergrid to determine the best architecture of single zone NNs. The upper panel displays the quality Q of the test and training set for 37 different NNs as explained in Eq. A.1. The number of layers, neurons per layer, and the maximum number of epochs trained for every NN are shown in the lower panels. The lowest panel displays the number of trainable parameters in the NNs. The dashed line denotes the selected NN. |
| In the text | |
|
Fig. A.2 Hypergrid to determine the best architecture of two-zone NNs. The upper panel displays the quality Q of the test and training set for 35 different NNs as explained in Eq. A.1. The number of hidden layers and the number of neurons per layer for every NN are shown in the lower panels. The lowest panel displays the number of trainable parameters in the NNs. The dashed line denotes the selected NN. |
| In the text | |
|
Fig. B.1 Hertzsprung-Russell diagram of the DIANA sample (orange markers) and all stars in the original single zone grid (blue) and the adjusted grid (green). The grey lines are the evolutionary tracks from (Siess et al. 2000) for different masses, and the coloured dashed lines are isochrones. The histograms show the distribution of values for luminosity and temperature for the sample and the grid in the same colours as used in the main plot. The sample's histogram is scaled to make a comparison easier. |
| In the text | |
|
Fig. B.2 HRD for two-zone models. Explanation is the same as for B.1. |
| In the text | |
|
Fig. B.3 Example of an MCFOST model with SEDs for all 10 different inclinations. The blue points show the stellar flux at different wavelengths between 0.1 µm and 2 µm (both shown as vertical blue lines). The blue line encode the limit, which is used to distinguish non- shielded inclinations (green SEDs) that were accepted for the sample and shielded inclinations (red SEDs) that were discarded. |
| In the text | |
|
Fig. D.1 Density plots for every object’s median probable model to reproduce the DIANA results (Sect. 3.2). Every panel shows the density structure in number densities of Hydrogen per cubic centimetre (colour bar at the top) for the objects noted in the panel. The upper and lower half of every plot depict the model from this study and DIANA, respectively. The radial axis is different for every object. The inner zones of Usco J1604-2130 in this work has a radial extent smaller than the radial resolution of the plots. |
| In the text | |
|
Fig. D.2 Density plots for every object’s median probable model derived in this study (Sect. 3.3). Every panel shows the density structure in number densities of Hydrogen per cubic centimetre (colour bar at the top) for the objects noted in the panel. The upper and lower half of every plot depict the two-zone and single zone model, respectively. The radial axis is different for every object. The inner zone of the two-zone model of 49 Cet has densities lower than the minimum threshold of the picture. The inner zones of HD 169142 and Usco J1604-2130have a radial extent smaller than the radial resolution of the plots. |
| In the text | |
|
Fig. D.3 SEDs for all objects. The coloured points and lines indicate the observation listed in the legend. The SEDs from the posterior distribution are shown in black. The line denotes the median of all model SED, with the dark, medium, and light black areas denoting the 68%, 95%, and 99.9% percentiles, respectively. The name of the model and if it is fitted with a single or two-zone model is given in the title. |
| In the text | |
|
Fig. D.4 Mid-IR region of the SED for all objects. The coloured points and lines indicate the observation listed in the legend. The SEDs from the posterior distribution are shown in black. The line denotes the median of all model SED, with the dark, medium, and light black areas denoting the 68%, 95%, and 99.9% percentiles, respectively. The name of the model and if it is fitted with a single or two-zone model is given in the title. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.