| Issue |
A&A
Volume 699, July 2025
|
|
|---|---|---|
| Article Number | A291 | |
| Number of page(s) | 22 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/202554863 | |
| Published online | 17 July 2025 | |
Studying stellar populations in Omega Centauri with phylogenetics
1
Instituto de Estudios Astrofísicos, Facultad de Ingeniería y Ciencias, Universidad Diego Portales,
Ejército Libertador 441,
Santiago,
Chile
2
Millennium Nucleus ERIS,
Chile
3
Instituto de Astrofísica, Pontificia Universidad Católica de Chile,
Av. Vicuña Mackenna 4860,
782-0436
Macul,
Santiago,
Chile
4
Millennium Institute for Integrative Biology (iBio),
Santiago,
Chile
5
Centro de Genómica y Bioinformática, Facultad de Ciencias, Ingeniería y Tecnología, Universidad Mayor,
Santiago,
Chile
6
Departamento de Biología, Facultad de Química y Biología, Universidad de
Santiago de,
Chile
7
School of Mathematics and Physics, University of Surrey,
Guildford,
Surrey,
GU2 7XH,
UK
8
Mathematical Sciences Institute, Australian National University,
Canberra ACT
2601,
Australia
9
Centre for Astrophysics Research, University of Hertfordshire,
Hatfield,
AL10 9AB,
UK
10
Inria Chile Research Center,
Av. Apoquindo
2827, piso 12,
Las Condes,
Santiago,
Chile
11
Departamento de Ingeniería Matemática, Facultad de Ciencias Físicas y Matemáticas, Universidad de Chile,
Av. Beauchef 851,
8370458
Santiago,
Chile
12
Centro de Astroingeniería, Pontificia Universidad Católica de Santiago,
Av. Vicuña Makenna
4860,
Santiago,
Chile
13
Departamento de Física, Universidad de Santiago de Chile,
Av. Victor Jara
3659,
Santiago,
Chile
14
Millenium Institute of Astrophysics (MAS),
Av. Vicuña Mackenna
4860, 82-0436 Macul,
Santiago,
Chile
15
Center for Interdisciplinary Research in Astrophysics and Space Exploration (CIRAS), Universidad de Santiago de Chile,
Santiago,
Chile
16
Institute of Astronomy, University of Cambridge, Madingley Road,
CB3 OHA,
Cambridge,
UK
17
Institute of Astrophysics,
FORTH Cert, N. Plastira 100,
GR-70013
Vassilika Vouton,
Crete,
Greece
18
Leverhulme Centre for Human Evolutionary Studies, Department of Archaeology, University of Cambridge,
Fitzwilliam Street,
Cambridge
CB2 1QH,
UK
★ Corresponding author: paula.jofre@mail.udp.cl
Received:
29
March
2025
Accepted:
2
June
2025
Context. The nature and formation history of our Galaxy’s largest and most enigmatic stellar cluster, known as Omega Centauri (ω Cen) remains debated.
Aims. Here, we offer a novel approach to disentangling the complex stellar populations within ω Cen based on phylogenetics methodologies from evolutionary biology.
Methods. These include the Gaussian mixture model and neighbor-joining clustering algorithms applied to a set of chemical abundances of ω Cen stellar members. Instead of using the classical approach in astronomy of grouping them into separate populations, we focused on how the stars are related to each other.
Results. We could identify stars that likely formed in globular clusters versus those originating from prolonged in-situ star formation and how these stars interconnect.
Conclusions. Our analysis supports the hypothesis that ω Cen might be a nuclear star cluster of a galaxy accreted by the Milky Way with a mass of about 109 M⊙. Furthermore, we revealed the existence of a previously unidentified in-situ stellar population with a distinct chemical pattern unlike any known population found in the Milky Way to date. Our analysis of ω Cen is an example of the success of cross-disciplinary research and shows the vast potential of applying evolutionary biology tools to astronomical datasets, opening new avenues for understanding the chemical evolution of complex stellar systems.
Key words: methods: statistical / stars: abundances / globular clusters: general / galaxies: star clusters: general
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
Omega Centauri (ω Cen) is the largest nearby stellar cluster, but its origin remains unresolved. Among such stellar clusters, globular clusters (GCs) are very old and dense, and tend to live in the halos of galaxies. While GCs were once expected to be be composed of a simple coeval stellar population with homogeneous chemical compositions, ω Cen, like many other massive globular star clusters, hosts multiple stellar populations covering a wide range of iron abundances. A possible hypothesis is that ω Cen might be a nuclear star cluster (NSC) that originated at the center of a galaxy accreted by the Milky Way (Bekki & Freeman 2003; Alvarez Garay et al. 2024), making ω Cen a remnant of this galaxy.
Understanding how NSCs form and evolve is an active field of research in astrophysics (Neumayer et al. 2020). These clusters form in the centers of galaxies, where the environment is extremely dense, packed with stars, GCs, and gas. Critically, an NSC is at the base of a very much deeper gravitational potential well than that of an isolated star cluster-forming molecular cloud. Thus much more complex, and longer duration evolutionary sequences will be encoded. Depending on the mass of the progenitor galaxy, NSCs are believed to be assembled via accretion of GCs or in-situ star formation fuelled by infalling gas (Tremaine et al. 1975; Milosavljević 2004; Fahrion et al. 2021). Nonetheless, neither the relative contribution of either channel nor the dependence on host galaxy properties is fully understood (Fahrion et al. 2021). Disentangling the various evolutionary pathways can shed light on the assembly mechanisms of NSCs. In this context, ω Cen, as an NSC candidate, provides a unique opportunity to study resolved stellar populations in an NSC in great detail. Such an analysis is not feasible for the Milky Way’s galactic center or other nearby NSCs like M54 because of their large distances as well as high levels of crowding and extinction, which make it observationally very expensive to obtain high-resolution spectra for a large number of stars in a comparable way to ω Cen. More generally, ω Cen is a prototype of multipopulation globular clusters, a class of important astrophysical systems whose evolution remains to be understood.
Chemical elements created inside stars, or during stellar explosions, and ejected into the interstellar medium on varying timescales and in different amounts (Kobayashi et al. 2020; Cowan et al. 2021). These ejected elements can then become locked back into new stars, formed from this chemically-enriched interstellar gas. The chemical abundances of low-mass (long-lived) stars therefore serve as a fossil record of their birth environments, and, as such, are essential for studying galactic evolution (Freeman & Bland-Hawthorn 2002; Tissera et al. 2012). Critically, chemical abundances in stars trace all the key nucleosynthetic element-creation paths, namely α-capture, iron-peak, and various neutron-capture modes. Thus, the more chemical elements we have available for analysis in each star in these fossil records, the better we can disentangle the evolutionary timescales and processes (Griffith et al. 2025). Today, there are many different chemical abundance measurements of thousands of individual stars in ω Cen published (Johnson & Pilachowski 2010; Mészáros et al. 2021). From these datasets, many studies have attempted to use clustering methods to find groups in these stars and chemical elements to interpret the main characteristics (Mészáros et al. 2021; Alvarez Garay et al. 2024), yet no definitive conclusions regarding the history of ω Cen’s populations have been reached. One reason might be because these studies are rather focused to separate the stars into distinct groups, and not necessarily designed to study how these groups connect in an evolutionary and historical sense and are thus related to each other in an astrophysically viable evolutionary sequence.
Biology has an extensive track record developing and implementing phylogenetic tools to study relationships among species and so reconstruct their histories. Phylogenetic trees study the accumulation of small modifications passed from one generation to the next to build a model of their relationships as they developed over time (Baum et al. 2005). The key assumption in the use of trees is that there is a level of heritability between generations. In biology that heritability is provided by DNA. Indeed, it is the fact that DNA is shared across all organisms that allows the reconstruction of relationships across all of life, and the expansion of genomics techniques has revolutionized phylogenetic methods (Yang 2014). DNA carries information about shared ancestry, and large genomic datasets have been used to model and analyze trees in evolutionary biology.
However, although DNA is the basis for most phylogenetic reconstructions in biology, as long as there is a mechanism of heritability then other systems can be used (O’Brien et al. 2025). All that is required is some means by which information (and traits) are transmitted from one generation to another. For example, languages are inherited (and subject to modification from generation to generation), and have been analyzed phylo-genetically (Bromham et al. 2022). Archaeologists increasingly use these techniques to reconstruct cultural history from non-biological materials (O’Brien et al. 2025). Phylogenetic methods have also been applied to nearby stars using chemical abundances as heritable traits (Jofré et al. 2017). Indeed, stars generate new chemical elements themselves, which are expelled into the interstellar medium upon their death. New stars form from this chemically enriched interstellar medium, inheriting its chemical pattern. This fullfills the heritability condition required for phylogenetic methods. Some low-mass stars survive for as long as the age of the Universe, and their chemical pattern serves as the fossil record and heritable marker of the evolving interstellar medium (Freeman & Bland-Hawthorn 2002). It is thus possible to build on approaches from evolutionary biology, adapt tools to reconstruct the history of galaxies by using the chemical patterns of stars as the heritable marker, and illustrate the power and opportunity of such inter-disciplinary approach (Jofré et al. 2017; Jackson et al. 2021; de Brito Silva et al. 2024). The complex nature of ω Cen, and the wealth of available stellar abundance data, make it an ideal case for such research.
In Sect. 2 we present the data used in this work, which we take from published catalogs. In Sect. 3 we explain the phylogenetic methods used to analyse ω Cen, and in Sect. 4 we provide an astrophysical interpretation of these results. We conclude our work in Sect. 5.
2 Data
In this work we use two published datasets of stars from ω Cen, both containing data of chemical abundances obtained from high resolution spectral analysis. The idea to use both datasets here is to further investigate the impact of the choice of data on our conclusion. These datasets come from Johnson & Pilachowski (2010, hereafter Optical) and Mészáros et al. (2021, hereafter Infrared) and we explain them in more detail below. Additionally, we checked that both the Optical and Infrared datasets with detailed abundances are highly probable members of ω Cen, according to Vasiliev & Baumgardt (2021). This is based on the updated Gaia EDR3 kinematic properties of Milky Way clusters. Both datasets (IDs, brightness, and abundances) are listed in the CDS tables.
2.1 Optical sample
Johnson & Pilachowski (2010) published stellar parameters and abundances for 855 red giants determined from spectra taken from Cerro Tololo Inter-American Observatory (CTIO) using the Blanco 4 m telescope equipped with the Hydra multifiber positioner and bench spectrograph. The spectra cover the wavelength range of 6135 − 6365 Å and ∼ 6500 − 6800 Å, and have a resolving power of R ∼ 18 000. The long exposure of the observations yielded high signal-to-noise spectra of about 200. The authors performed a spectroscopic analysis based on equivalent width methods to determine abundances of Fe, Na, Si, Ca, Sc, Ti, Ni, and Eu. Abundances of O, Al, and La were determined using synthesis fitting. For Sc abundances of both ScI and ScII were provided, which we take the mean of. Among these 855 stars, 122 stars have abundances measured for all the elements. We consider this subsample for our analysis.
Photometry, coordinates, and membership probabilities for all stars in that study were taken from van Leeuwen et al. (2000). This is before the Gaia era, thus the proper motions were derived using photographic plates from the years 1931, 1937, 1978, and 1983. Because of this, obtaining updated photometry and astrometric information from Gaia for these stars was possible for only 710 stars, including all our 122 selected stars. The stars are in the red giant branch, except a few outliers (see the study of multiple red giant branches in ω Cen by Pancino et al. 2000).
 |
Fig. 1 Abundance ratios against [Fe/H] of all elements in both optical (in blue squares) and IR (in red circles) samples. Some of the element abundances are measured in both samples, and some are measured in only one of the samples. Shaded contours correspond to the Gaussian kernel density estimation of the datapoints. |
2.2 IR sample
This sample is taken from Mészáros et al. (2021), who analyzed stars observed with SDSS-IV/APOGEE-2 (Ahumada et al. 2020). It consists of 775 stars with APOGEE observations, which use an infrared spectrograph in the H band with a resolving power of R ∼ 22 000 covering a range of 1.514–1.696 micrometers installed in the du Pont Telescope at Las Campanas Observatory. The data for ω Cen has a signal-to-noise of about 70. Using the code BACCHUS (Masseron et al. 2016), Mészáros et al. (2021) published abundances of Fe, C, N, O, Mg, Al, Si, K, Ca, and Ce. The subset which has measurements for all elements contains 137 stars and this is the set we use for our analysis. In this work we remove C and N abundances because in red giants they change as stars experience their dredge up (Salaris et al. 2015; Mészáros et al. 2021), making the photospheric abundances of these stars not a suitable heritable tracer.
Cluster membership for these stars is based on RV and proper motions from Gaia DR2 (Baumgardt & Hilker 2018). The cross-match of this sample with Gaia DR3 yields 676 stars, with the 137 stars with detailed abundances included. As the Optical sample, they follow the red giant branch. There are a few stars in the Infrared sample which are hotter and of lower luminosity compared to the Optical sample, but both datasets are otherwise comparable.
2.3 Chemical abundances
Figure 1 displays the chemical abundance ratios for all elements analyzed in this work in various panels. The panels show the distribution of each abundance ratio [X/Fe] as a function of [Fe/H]. In blue squares we plot the abundances for the Optical sample, and in red circles we plot the abundances for the Infrared sample. A total of 12 abundance ratios, in addition to the metallicity [Fe/H] are included in this analysis.
With the exception of a few stars from the Optical reaching values up to [Fe/H] = − 0.3 dex, both samples cover a comparable metallicity range between − 2 and − 1 dex. We only have abundances of O, Al, Si, and Ca for both samples. All these elements are mainly produced in core-collapse Type II super-nova (Nomoto et al. 2013), although Al is very dependent on the progenitor metallicity (Weinberg et al. 2019; Vasini et al. 2024) and has a different behaviour compared to the α−capture elements like O, Si, and Ca. Mg, which is another α− capture element is only included in the IR sample, while Ti, which shows the trends of an α− capture element in the Milky Way, is only included as part of the optical sample. Ca, Mg, and Si, the other α− capture elements of the sample, show a flatter trend as a function of metallicity. We remark that among these elements, O, Na, Mg, Al, and Si are those that show high levels of depletion or enhancement due to the internal stellar evolution processes of the CNO, NeNA, MgAl cycles that are suspected to produce the anticorrelations in GCs (Gratton et al. 2019).
Al, Si, and Ca agree well in both samples, showing similar trends and absolute values. This is not the case for O, which shows a positive trend with [Fe/H] and very high abundances in the Infrared sample, while the [O/Fe] trend with [Fe/H] decreases with [Fe/H] in the Optical sample. This discrepancy is discussed further the next section. The high [O/Fe] abundances of some stars from the Infrared sample and its increasing trend with metallicity have also seen in the independent analysis of Marino et al. (2012), who analyzed a sample of ω Cen stars observed with optical spectra. We recall that it is not expected that the plausible NSC nature of ω Cen has similar abundance patterns as the Milky Way or disrupted dwarf galaxies. Indeed, Romano et al. (2007) predict high [O/Fe] abundance ratios in ω Cen, although with a decreasing trend with metallicity. Star formation bursts can cause an increase for [O/Fe] in dense systems, this was recently shown in the EDGE simulation of a NSC by Gray et al. (2025). We keep thus all [O/Fe] for our analysis.
The Optical sample includes, in addition to Fe, the iron-peak abundance ratios Sc and Ni. Both Sc and Ni show flat trends and a small dispersion with [Fe/H], although Sc displays a small decrease over metallicity as it is being mostly produced by corecollapse supernovae (Kobayashi et al. 2020). Other elements produced in massive stars, which are only included in the Optical sample are Na and Eu. Both show trends with [Fe/H] and a high dispersion. Europium however is also produced by neutron star mergers (Cowan et al. 2021; Arcones & Thielemann 2023), which are able to enrich entire dwarf galaxies with high levels of Eu in one episode of star formation. Finally, both samples have one neutron capture element produced by the s − process and expelled to the interstellar medium via asymptotic giant branch (AGB) winds (see for instance Lugaro et al. 2003, 2012; Cseh et al. 2018; Magrini et al. 2018). The Optical sample includes La, and the Infrared sample includes Ce. Both elements show comparable trends, such as increasing with [Fe/H] from about − 0.5 to 1 dex. This is expected (Bisterzo et al. 2014) because such elements produced in AGB stars are typically released after SNIa elements. Their trends indicates an extended star formation history.
 |
Fig. 2 Comparison of abundance ratios for the 16 stars in common between both datasets. The mean and the standard deviation of the comparison is indicated in each panel. The diagonal red line indicates the 1-1 relation. Only [Fe/H] and [O/Fe] show significant systematic offsets. |
2.4 Comparison of common stars between samples
Our cross-match with Gaia allows us to identify stars in common between both samples, finding 16 stars. Their IDs and Gaia magnitudes are listed in Table A.1. In addition to the Source ID from Gaia, we include the APOGEE ID used by Mészáros et al. (2021), the LEID ID used in Johnson & Pilachowski (2010), and our own IDs, which we call SIR for the Infrared sample, and SOP for the Optical sample.
The direct comparison for the abundances in common can be found in Fig. 2. The x axis show the abundances as reported by Mészáros et al. (2021) and the y axis show the abundances of the same stars as reported by Johnson & Pilachowski (2010) for [Fe/H], [O/Fe], [Al/Fe], [Si/Fe], and [Ca/Fe]. We overplot the one-to-one line in red and write in each panel the mean of the differences and the standard deviation of the differences. We note the small errors reported for Al. Indeed, for most stars, no Al errors are reported in Johnson & Pilachowski (2010). This is because in that work errors are the scatter among lines. Measuring Al from optical spectra is very challenging (see for instance Buder et al. 2022), the Al abundances here come mostly form one line, which is why no errors were reported. While the agreement for Al, Si, and Ca are within the scatter, there is a systematic offset of 0.15 dex in metallicity between both samples, and a significant offset in [O/Fe] of 0.4 dex. The large difference in [O/Fe] between optical and infrared measurements in metal-poor stars has been already identified in the literature (Griffith et al. 2019). While applying a shift might bring into better agreement both samples in the [Fe/H] - [O/Fe] plane, the trends still would go on opposite directions. It is thus not possible to fully attribute the differences in oxygen between samples to a systematic effect; the difference might also be due to a selection effect of stars.
3 Phylogenetic analysis
Our goal is to use chemical abundances to study the assembly history of stars in ω Cen. This is analogous to biologists studying the genealogical history of a biological population, such as asking if a human population is descended from one or multiple sources through migrations and admixture1 (Hellenthal et al. 2014). This approach that biologists commonly use can be adapted to study the ancestry of stars. This process usually starts with a principal component analysis (PCA) to visualize the variability in the data, followed by a mixture model to detect distinct groups in the data, and finalized by a phylogenetic analysis to reconstruct when and where migration and admixture events happened (Nespolo et al. 2020; Price et al. 2006; Tian et al. 2008; Solovieff et al. 2010). In this study, we adapt this approach to help us understand the formation of ω Cen. We focus our analysis and discussion on the results obtained from the Optical dataset, but the parallel results for the Infrared sample can be found in the appendixes.
First, we apply PCA to our dataset. This is to ensure that there is chemical diversity in the dataset to detect distinct groups Buckley et al. (2024) and to understand which elements are responsible for this diversity. PCA has been done with chemical data of Milky Way stars (Ting et al. 2012; Andrews et al. 2012; Signor et al. 2024; Buckley et al. 2024; Griffith et al. 2025). In Fig. 3 we show the distribution of 122 ω Cen stars in the space defined by the first three principle components (PCs), and the contribution of significant chemical abundances to each PC. The left-hand panel shows the first and second component, while the right-hand panel shows the first and the third component. A similar plot but for the Infrared sample can be found in Fig. B.3. Each star is represented by a gray circle. The arrows of each abundance ratio are overplotted in the diagrams whose length and color correspond to the contribution in these dimensions while the direction of the vector corresponds to where the stars have a higher abundance ratio in each PC. These planes in a way summarize Fig. 5 of Buckley et al. (2024), who plotted the first and second component of the PCA color coded by different abundance ratios in nine panels.
The plane shows that an anticorrelation of aluminum and oxygen, as well as sodium and oxygen, have an important impact on the variance of the data. This can be seen through the [Na/Fe] and [Al/Fe] vectors pointing in the opposite direction to the [O/Fe] vectors. Indeed, the Na-O and Al-O anticorrelations are typical of GCs (Carretta et al. 2009), whose nature remains unresolved (Bastian & Lardo 2018; Gratton et al. 2019), and have been studied in ω Cen (Johnson & Pilachowski 2010; Alvarez Garay et al. 2024). We see long arrows for those elements pointing to opposite directions. The first PC captures 34.8% of the variability among stars in their chemical composition, which is mostly driven by the Na-O anticorrelation, with some influence from La, Si, Ca, Ti, and Fe (see Appendix B.1). The second PC (Y axis of left hand panel), captures 17.9% of the variance and separates the stars mostly by their α-capture (O, Ca), iron-peak (Ni) elements and aluminum. The third dimension (Y axis of right-hand panel) contributes 14.9% to the variance and separates the stars in neutron-capture (Eu) abundance ratios as well as iron. For more in-depth analysis of the PCA, as well as the PCA using the Infrared sample, we refer the reader to the Appendix B.1. When using the Infrared sample (see Fig. B.3, the [O/Fe] and [Al/Fe] vectors point in the opposite directions to the Optical sample (reflecting the different trends with [Fe/H]), but the O-Al anticorrelation still holds. We conclude that we need to consider all available elements because they all contribute mean-ingfully to at least one of the three most significant principal components.
 |
Fig. 3 PC space with the direction and contribution of each chemical element in the first three principal components. Stars are dots in the space and arrows indicate the direction in which the abundance ratios are higher in these planes. The color of an arrow shows the overall contribution of the chemical element to both PCs. The first two components show how α-elements and [Al/Fe] dominate the variance. These arrows point in opposite directions in the space. This is due to the anticorrelation of these elements in the chemical space. The third component illustrates that [Fe/H] and [Eu/Fe] become important. |
3.1 Stellar population bar plot
Given that we have found that our data is chemically diverse, we proceed to cluster the stars using all abundance ratios, [X/Fe], with Gaussian mixture models (GMM). The Bayesian Information Criterion (BIC) scores indicate that the optimal number of units or groups in this dataset is three (see Appendix B.2). In Fig. 4 we show the GMM classification for three groups for all stars. This plot is similar to the STRUCTURE bar plot, which is a popular tool for studying population structure in biology (Pritchard et al. 2000). While STRUCTURE uses a mixture model for DNA, which is a categorical variable, we adapt the idea to describe stellar populations by using GMM for chemical abundance ratios. We call our approach stellar population bar plot.
The main difference between the stellar population bar plot and how astrophysicists usually use GMM (Das et al. 2020; Buckley et al. 2024; Buder et al. 2022) is that we do not only select stars with high probability of belonging to a certain GMM group for further analyses. Instead, the bar plot includes stars with all levels of probabilities. This is because stars with a low probability of belonging to a certain group offers us the opportunity to study mixing between groups (Villarreal et al. 2022; Nespolo et al. 2020). This is similar to the STRUCTURE bar plot where low probability can be indicative of migration or admixture events, for example when a particular population is descended from multiple ancestral populations (Peter 2016). If the majority of stars have a 100% probability of belonging to one GMM group, then the distribution of chemical abundances over stars is discrete, suggesting that each GMM group is likely to have evolved independently. But if the majority of stars have a low probability of belonging to a single group, then the distribution of chemical abundances over stars is continuous. This suggests strong mixing among groups, for example, the chemical elements from one group is mixed with the interstellar medium that forms the other group.
Most of the stars with a high probability of being in Group_O1 (orange) have very low probabilities of being in another group. This suggests that Group_O1 has evolved independently of the other groups. This independency might be spatially or temporally, namely this group could have formed far away from the other groups and/or before the other groups existed. On the other hand, the gray group has a handful of stars with more than 20% of contribution from the orange and purple groups, suggesting that the gray group could be more related to the others. This interpretation is in any case subject to the uncertainties of the abundance measurements, as well as the latent chemical space considered for the clustering (Buder et al. 2022; Buckley et al. 2024), and also the number of GMM groups. To draw firm conclusions, we would need validate with simulated data, such as Gray et al. (2025), where the history is known. Various key abundance ratio planes color-coded by the GMM groups can be found in Appendix B.3, where they are discussed at length.
 |
Fig. 4 Stellar population bar plot. Each star, whose name is indicated in the X axis, is shown as a bar with the cumulative probability of the star belonging to a specific group. The Y axis shows the probability of the star belonging to the groups, which are assigned using a Gaussian mixture model of three components. The stellar population bar plot allows us to appreciate the clustering, and to identify which groups might be more related to each other, as reflected by the level of mixing between them. |
3.2 Phylogenetic tree of ω Cen
While phylogenetic trees can show when and where migration or admixture events happened in the history of a biological population, they also carry important information on the history of star formation. In particular, using simulations of galaxy evolution de Brito Silva et al. (2024) showed that an isolated galaxy generates stars that form a special tree topology, known as the ‘caterpillar’ tree, where all tips are incident to the same branch. We can therefore use this result as the benchmark to compare the tree of ω Cen stars with the null hypothesis that ω Cen evolved in isolation.
3.2.1 Building NJ trees
Following de Brito Silva et al. (2024), we built trees using the empirical distance method and the agglomerative neighbor-joining (NJ) clustering algorithm (Saitou & Nei 1987), which does not rely on an evolutionary model to find the best tree from a given dataset. This is important when borrowing tools from a different discipline, as we must avoid making assumptions that might not apply to astrophysics. The NJ algorithm arranges chemically similar stars nearer to one another in the tree while placing those more different further apart. The branch lengths correspond to the overall chemical differences between stars (see also Sect. 3 of Jofré et al. 2017). The chemical distance is taken from a distance matrix, which is symmetric and of the dimension of the number of stars. In this case, following Jofré et al. (2017), we computed Manhattan distances based on stellar abundances. The pairwise distance matrix was calculated using the [X/H] abundance ratios available to us, namely [O/H], [Na/H], [Al/H], [Si/H], [Ca/H], [Sc/H], [Ti/H], [Fe/H], [Ni/H], [La/H], and [Eu/H].
To assess the robustness of our tree topology we calculate the node support by considering the uncertainties in our abunsdances. We sampled 1000 distance matrices, by perturbing the abundances with their uncertainties. From these distance matrices we calculated 1000 NJ trees. The node support corresponds to the percentage of occurrence of a given node in all other sampled trees. This is calculated by counting the occurrence of nodes in all trees (see Jackson et al. 2021; Walsen et al. 2024, for more details about node support in stellar trees).
3.2.2 Stellar phylogenies
Figure 5 shows the tree in circular form and allows us to realize that the tree shows similar results to the GMM analysis in the sense that purple and gray stars form two ‘caterpillar’ trees, suggesting they evolved independently. Since these branches contain stars from the different GMM groups, we have labeled with new names, which are explained in detail in the next Section. The branches are highlighted in the yellow and cyan boxes.
The remaining stars, highlighed in the pink box, form a more ‘star-like’ tree, suggesting that they either mixed a lot, are from different sources, or the data is too uncertain for the NJ method to resolve the hierarchical differences there. The nodes of the figure have pie charts overplotted, which indicate the proportion of trees that have this node in blue given the uncertainties in the abundance measurements (this is the node support). Due to uncertainties in abundance measurements, multiple pair-wise distances between stars in their chemical composition are possible, which translates in an uncertain tree topology. It is possible to see that the orange stars, which belong to the Group_O1 from the GMM and are mostly part of the pink and the deep nodes of the Block box, have nodes with low support. This is because these stars are so similar to each other that the NJ algorithm is not able to assign them to a specific node given the uncertainties. Indeed, here we find ourselves with a limitation of the NJ method, already discussed in Walsen et al. (2024). By construction, the NJ has to assign every star into a different branch, assuming each of them represents a different star formation episode. When analyzing observed stars, we cannot rule out the possibility that two stars belong to the same star formation episode. While the GMM will put them together in the same group (because they might have the same chemical signature), the NJ algorithm has to place them in distinct leaves. The overall support of 35% is similar to Walsen et al. (2024), which is expected since this is the support due to uncertainties in the stellar chemical data.
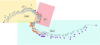 |
Fig. 5 Circular Optical tree. The colors of the tips correspond to the GMM groups. The pie charts on the nodes correspond to the percentage of occurrence of the node in 1000 random generated trees considering the abundance uncertainties (node support), indicating that the tree has an overall support of 35%. |
4 The assembly of populations in ω Cen
When the root, that is, the ancestral node, is set, and assuming the choice of root is sensible (Yang 2014), the phylogenetic tree reveals more information on star formation history. The resulting rooted tree is displayed in Fig. 6. We set the root at the star with the lowest [Ca/H] abundance ratio. This assumes that chemical abundances increases with time, so the lowest abundances in a dataset should reflect the earliest time and therefore a root for the tree. We choose [Ca/H] instead of [Fe/H] in this case because of its excellent consistency in the abundance measurements with the Infrared sample, which allows us to use the same criterion to root the Infrared tree. Furthermore, the PCA revealed that Ca had a similar effect on the chemical diversity of both samples. This enables a better comparison between trees and so a better interpretation of our results (see Sect. 4.2).
Our analysis revealed that stars with pink labels stars, that is, stars whose probability to belong to a specific group is lower than 90%, do not have a preferred location in the tree. Changing the threshold for this definition does not affect our interpretation. In this section we interpret the astrophysical meaning of the branches and groups found in our phylogenetic analysis, and so discuss the possible history of assembly of ω Cen.
4.1 The Block, Child and GC branches of the tree
Figures 5 and 6 show two big branches, each with a clear ‘caterpillar’ topology. We call these two branches Block and Child. The remaining tips are closer to the root of the tree and show a more star-like topology, which we call GC. Considering our null hypothesis (de Brito Silva et al. 2024), the Block and Child branches likely evolved independently, while group GC likely consists of stars well mixed or from different origins. The chemical patterns in Block, Child, and GC groups are not only distinct, but also suggest their possible history. The next four panels to the right of Fig. 6 show the distribution of [Fe/H], [O/Fe], [Al/Fe], and [La/Fe] along the branches. Evidence supporting Block and Child having independent star formation histories is that the two branches have different [O/Fe], [Al/Fe], and [La/Fe] trends. Also, the majority of purple stars, grouped by GMM, are in the Block branch and the majority of gray stars are in the Child branch. In contrast, GC stars have a narrow [Fe/H] and [La/Fe] ranges, and present the Al-O, Na-O anticorrelation, which is typical in globular clusters, and so we call this population GC-Cen.
The population of stars from the Block branch shows a classical [O/Fe] trend with metallicity, namely the [O/Fe]- [Fe/H] relation with a [O/Fe] plateau at 0.4 dex, which is the signature of SNII and presenting a potential [O/Fe] knee at [Fe/H] ∼ − 1.3, which results from the pollution of [Fe/H] due to SNIa. This is consistent with the chemical evolution of a dwarf galaxy (Matteucci & Brocato 1990). The increasing trend of [La/Fe] with [Fe/H] is also found in dwarf galaxies. Since La is a neutron-capture element produced via the slow-process mechanism in AGB stars, reaching the high [La/Fe] abundance ratios is possible only after a few Gyr (Bisterzo et al. 2014; Romano et al. 2023). [Al/Fe] is notably more enhanced than in typical dwarf galaxies, which are normally subsolar and lower compared to the Milky Way trend (Das et al. 2020; Hasselquist et al. 2021). We note however that recent discoveries of Milky Way metal-poor ancient structures, such as Shiva and Shakti (Malhan & Rix 2024), as well as the G3/G5 groups from the GALAH sample by Buckley et al. (2024), have significantly higher [Al/Fe] than the better-known disrupted galaxies in the halo of comparable metallicities. Such systems were proposed by Malhan & Rix (2024) to have formed from gas clumps in a massive and/or dense progenitor. The abundance patterns of the Block branch could be thus associated with a building block population or a proto-galaxy, equivalent to Shiva and Shakti of the Milky Way. We thus call this population Block-Cen and attribute it to the building block of the progenitor galaxy that formed ω Cen.
The Child branch has an anticorrelation between Al and O like the GC branch, although [Fe/H] has a significant increasing trend, as does [La/Fe]. This points towards an extended star formation history, perhaps a result of in-situ star formation from material that has been enriched by the stars within ω Cen, henceforth its designation as Child-Cen. Indeed, the G_O2-gray stars has slightly more admixture with G_O1-orange and G_O3-purple in the stellar population bar plot, suggesting that this group is somehow more related to the other populations. This admixture is driven by [Ca/Fe] and [La/Fe] abundances (see Fig. B.7).
The anticorrelations of stellar abundances such as [O/Fe] and [Al/Fe] are among the most challenging features of globular clusters to be explained (see Gratton et al. 2019, for extensive review). While there are strong arguments in favor of an inheritance process due to the CNO and MgAl cycles inside massive stars, which pollute the ISM in the AGB phase via winds (D’Ercole et al. 2012; Gratton et al. 2019), there are still many theoretical aspects on stellar nucleosynthesis and GC formation that are not understood and therefore the observations of such abundance ratios cannot be fully reproduced for all GCs (Bastian & Lardo 2018). The case of ω Cen offers additional complexities due to the extended range of [Fe/H] and s-process elements, which suggest timescales of Gyr for star formation compared to the few Myr of the CNO, NeNA, and MgAl cycles of massive stars. The peculiar abundance patterns of Child-Cen, namely the very low [O/Fe], and high [Al/Fe], cannot be directly associated with the (unexplained) O-Al anticorrelation of classical GCs, because of the different timescales needed to simultaneously describe the pollution mechanisms of the anticorrelations and the chemical enrichment of the Fe and La trends. A stellar population with such characteristics has not been found in the Galactic field, or in mono-metallic clusters. The chemical pattern of Child-Cen would therefore need a new explanation.
 |
Fig. 6 Neighbor-joining tree of ω Cen stars. Tips are colored based on the GMM group to which each star has the highest probability of belonging to in Fig. 4. The tree shows three main branches, whose [Fe/H], [O/Fe], [Al/Fe], and [La/Fe] are shown in the right-hand panels. The GC branch has properties similar to globular clusters. The Block and Child branches have extended metallicity and [La/Fe] distributions, supporting in-situ star formation for a prolonged duration. However, their [O/Fe] and [Al/Fe] trends are distinct, suggesting that they had different star formation histories and explaining why they are placed on different branches and GMM groups. |
4.2 Assessing systematic differences with common stars
To understand further the similarities and the differences in the populations and branches found between both datasets (see Appendix C for the tree obtained from the Infrared sample), as well as the tree shapes, we build trees of the stars in common between both datasets. The trees are seen in Fig. 7. The left hand trees correspond to the Optical dataset and the right hand ones to the Infrared dataset. Same stars are connected through lines. The top trees are a subset of the trees from Figs. 6 and C.2, that is, they are built using all abundance ratios but only for the 16 stars of Table A.1. Rooting the tree by the star with lowest [Ca/H], which is one of the elements with best agreement between both datasets, allows us to use the same root for both trees. But the topology does not agree among both datasets, as seen by the various crossed lines. This suggests the choice of abundances ratios used affects the order of the tips in the tree. This conflict of branches thus causes the GC/Block blue and the GC red branches of the Infrared tree to be placed at locations that are not expected from the Optical tree.
To quantify the difference, we calculate the normalized Robinson-Foulds distances (RFD), following de Brito Silva et al. (2024). RFD = 0 means trees have identical branching pattern, and RFD = 1 means trees have totally different branching patterns. An extensive explanation of this distance measure and its pros and cons in using it can be found in Yang (2014). Between the two upper trees of Fig. 7, we obtain RFD = 0.63. The lower panels of Fig. 7 are trees built using only the common abundance between the two (see the elements plotted in Fig. 2). The ranking of the tips between both trees agrees better, but the trees still differ by RFD = 0.57. There are only a few stars that are strongly disordered, with 38% of the stars ordered identically. And, if we remove SOP_29/SIR_58, that increases to 60%. This seems like a large improvement on the all-abundance tree comparison, but the RFD score remains quite similar. This might be due to the uncertainties of the abundance measurements, which are driving significant scatter in the tree shapes, as noted by the averaged 35% of node support discussed above. However, we need to consider the limitations of the RFD distance metric, which only focuses on the topology of the tree and counts the number of common nodal position between trees (see Yang 2014). We discuss this issue further below.
It is actually interesting that these RFDs are not significantly different when using the full abundance dataset or only the common abundances. In order to assess if this similarity is significant given the uncertainties of the measurements, we can estimate the minimum expected difference for the same tree, given its uncertainties. To do so, we run another Monte Carlo simulation to calculate random distance matrices considering the abundances and the reported uncertainty. We then build NJ trees and compare them. We do this 1000 times and estimate the mean RFD and its standard deviation for the Optical and for the Infrared sample independently. This was done using the common abundances between two samples, as well as the full set of abundances.
For the common set of abundances, we obtain that, given the uncertainties, the Optical samples are consistent among each other with a mean RFD = 0.42 ± 0.11. The Infrared samples are consistent among each other with a mean of RFD = 0.39 ± 0.1. Thus, the value of RFD = 0.57 for the difference of the Optical versus Infrared tree computed using the common set of abundances, which is displayed in the lower panel of Fig. 7, can be attributed to the systematic differences of the abundances of each dataset and not only to the random uncertainties of the data.
For the full set of abundances, that is Fe, O, Na, Al, Si, Ca, Sc, Ti, Ni, La, and Eu for the Optical and Fe, O, Mg, Al, Si, Ca, and Ce for the Infrared, we obtain that trees are similar among each other on average by RFD = 0.31 ± 0.11 and RFD = 0.35 ± 0.1, respectively. These numbers are similar to each other, and comparable to the 35% of the nodal support. In both cases, adding abundances increases the robustness of the tree topology accounting for abundance measurement errors, since RFD decreases. We note that the improvement of the Infrared RFD is very small. This is because only two additional elements, namely Mg and Ce, have been added to the distance matrix. The value of RFD = 0.63 for the difference of the Optical and the Infrared tree using all the abundances displayed in the upper panel of Fig. 7 is also the result of more precise trees and therefore the difference can not be explained only due to errors.
It is worth referring to to the discussion of Kuhner & Yamato (2014). The RFD metric counts the number of branch partitions that appear in one tree but not the other, scoring one for each non-matched partition. This means that the RFD metric does not consider differences in branch lengths, only tree topology. Furthermore, a rooted-tree has a maximum of number of nodes of 2(n − 2), where n is the number of tips. This means RFD has 2(n − 2) partitions to score. In our case, n = 16 implies we score 28 partitions only, which is not a very large number to quantify significant differences between the trees here.
Even considering these caveats, we find that the Optical and Infrared trees are different to each other. This difference is dominated by the systematic uncertainties of the measurements rather than the election of elements used in the distance matrix. A reason for this result could be that even if the full Optical and Infrared sample consider different elements, these elements overlap in three nucleosynthetic channels, namely, CCSNe, SNe-Ia, and AGB winds. In both datasets α− capture, iron-peak, and neutron-capture elements are included. We note that the Optical sample includes Eu, which is an r-process element produced by neutron star mergers, but Eu has a weaker contribution to the variance of the Optical data, according to the PCA (see Appendix B.1). Indeed, by removing for instance Fe from the Infrared sample, the RFD between the Optical and the Infrared sample increases to a mean of RFD = 0.92 ± 0.01. Removing Ce has a much smaller impact on the RFD estimate. This could be related to the fact that Fe is a more significant driver of the variance in the abundance space compared to Ce, as discussed in Appendix B.1.
Branching patterns, phylogenetic analyses and history reconstructions are thus highly dependent on the elements employed, but most importantly, on the abundance accuracy and precision estimates. Better interpretation on this kind of analysis will be possible once abundances reach higher level of accuracy and precision, or once simulations reach the numerical precision to model individual stars and abundances in objects like ω Cen.
 |
Fig. 7 Comparison of rooted tree color coded by groups for common stars. Top Panel shows the comparison among trees when all abundances are considered for building the tree, while lower panel shows the comparison when elements in common are used. The agreement between trees is slightly better when the same chemical abundances are used, but differences persist. This can be attributed to the uncertainties in the data. |
4.3 Connecting branches and populations through common stars
The interpretations regarding the nature of the populations found in the Optical sample depend on the dataset and the selection of stars, but using a different dataset does not contradict our results. We can reach that conclusion by studying the groups of stars in common. The trees in Fig. 7 show that purple stars in the Optical typically appear alongside yellow and red stars in the Infrared, while orange stars in the Optical are either yellow or blue infrared. Looking at the positions of these stars in Figs. 6 and C.2 allows us to conclude that the orange-purple Optical branch, as well as the yellow-red-magenta branch in the Infrared, correspond to Block-Cen, where stars show signatures of in-situ star formation.
GC-Cen stars, dominated mainly by orange stars in the Optical, are divided into blue and red stars in the Infrared. The GMM model prefers two groups for this population, which are divided into two branches in the Infrared tree. While the metallicity range is comparable in these branches, the O-Al anticorrelation is quite different. Indeed, among the three stars in the bottom red branch of the Infrared sample which are included in the Optical sample, SIR_61 is colored purple, while SIR_19 and SIR_45 are colored gray. These three stars are actually in the Child-Cen branch in the Optical tree, but SIR_45 is mixed with orange, and SIR_61 is at the bottom of the gray branch. We could thus attribute the red branch to Child-Cen instead of GC-Cen, but the metallicity trend and distribution are quite narrow. The Infrared Stellar population bar plot shows that the blue, magenta and yellow groups are more related to each other than the red, suggesting that indeed the red is a more independent population, such as GCs falling into the potential well of the NSC.
It might be possible that the Infrared sample has other stars belonging to Child-Cen. We need to consider that we do not have the same information for both trees. We have abundances of different species, which are measured using various methods and data. Furthermore, we have only 20% of stars that both samples have in common. If the Infrared dataset includes Child-Cen, it does not cover a large range in s-process and metallicity to be assigned to a different “caterpillar” branch or a new GMM group. It would be worthwhile to see if some of the most metal-rich stars observed in Mészáros et al. (2021) indeed follow the chemical trends of the Optical sample. To do so, Optical spectroscopic follow-up observations are needed.
It is worth commenting on the recent discussions about the anticorrelations of ω Cen, which tend to become weaker with higher metallicity (Alvarez Garay et al. 2024; Mészáros et al. 2021). The Child-Cen anticorrelation we observe for the highest metallicity stars could be the consequence of a channel that is different from the MgAl nucleosynthetic chain of globular clusters (Alvarez Garay et al. 2024). Indeed, Romano et al. (2023) studied various chemical evolution models to understand the chemical pattern of Terzan 5, which was found to host multiple populations similar to ω Cen, and is in the bulge of the Milky Way. In such a dense environment, the [Fe/H] spread, the age spread, and the chemical pattern of Terzan 5 is used to conclude that Terzan 5 can have multiple populations only because of insitu star formation. Through a combination of star formation bursts with different duration and efficiency (which is dependent on the temperature of the gas, which might further depend on the temperature of the surroundings) and the ability to retain remnant stars for later Fe-peak production from SNe-Ia, it is possible to have an impact on the relative abundance ratios in such systems.
Under the hypothesis that ω Cen is a NSC, we are able to identify both its main formation channels, namely GC accretion and in-situ formation (Neumayer et al. 2020). Using Fig. 6 of Fahrion et al. (2021), which relates the formation channels and the NSC progenitor galaxy’s mass, we conclude that the progenitor galaxy of ω Cen could have a mass of about 109M⊙. This mass has been measured for the galaxy of the largest major merger event (Das et al. 2020), namely Gaia-Enceladus Sausage (GES; Helmi et al. 2018; Belokurov et al. 2018). Our analysis thus provides evidence to support previous claims of Bekki & Freeman (2003) and Pfeffer et al. (2021), that ω Cen might be the NSC of the GES. Indeed, among all clusters that are dynamically associated with the GES, according to Massari et al. (2019), ω Cen is the one with the highest binding energy (see also the extensive discussion from Limberg et al. 2022, about this scenario).
We note that the connection between the GES and ω Cen does not need to imply a chemical similarity between the ω Cen populations and the field accreted stars that have been associated with GES by various works in the literature. Indeed, these stars are more α− poor, Al-poor, and Eu-rich compared to ω Cen (see also Fig. B.7 to see some elements; Matsuno et al. 2021; Carrillo et al. 2022; Nissen & Schuster 2011; Das et al. 2020; da Silva & Smiljanic 2023). The chemical similarity between GES and ω Cen might be expected if ω Cen were a typical GC, such as NGC1261, which Massari et al. (2019) have attributed be part of GES. Indeed, Koch-Hansen et al. (2021) provided evidence of its chemical similarity with GES. But expecting stars from a NSC and the field of the parent galaxy sharing the same chemical composition might imply they share the same star formation history, which does not need to be true (Neumayer et al. 2020).
Let us furthermore consider the current belief that M54 is the NSC of the Sagittarius (Sgr) galaxy (Alfaro-Cuello et al. 2019). The chemical abundance analysis of M54 and the Sgr performed by Carretta et al. (2010) showed a continuation of α elements between M54 and the Sgr core, but the metallicity of both populations did not overlap. Abundances such as O, Na, Al differ due to the anticorrelations present in M54, which are not in the field. In Vitali et al. (2025), more metal-poor stars were included in the analysis of the field stars, overlapping better with the M54 metallicity coverage of Carretta et al. (2010). The overlap shows that α− abundances of Sgr’s core at a [Fe/H] ∼ − 1.5 is of the order of 0.2 dex, while the abundances of M54 is of the order of 0.4 − 0.5 dex, although this comparison is subject to uncertainties due to the different methods employed in these independent works. This difference is consistent with what is found between GES and ω Cen. More discussions about the chemical connection between GES stars and ω Cen and the role of europium can be further found in Appendix D.
4.4 The history of the formation and evolution of ω Cen
We assume that NSCs are dense stellar systems, which contain stellar populations formed in different ways. Under the hypothesis that ω Cen is a NSC, whose host galaxy has been disrupted by its accretion on to the Milky Way, we can use the various populations of ω Cen to understand not only its formation history, but also the properties of ω Cen’s parent galaxy.
Our phylogenetic analysis using NJ trees allows us to study how our GMM groups are distributed and related to each other, enabling us to deduce that ω Cen appears to have formed via multiple formation channels: accretion of globular clusters, accretion of gas and stars belonging to primordial building blocks of galaxies, as well as in-situ star formation. GC-like stars belonging to G_O1-orange, are the most metal-poor and probably the most ancient ones in our dataset. Furthermore, the [La/Fe] abundances of these stars are low compared to the rest of the sample, and have a narrow distribution as well. This is consistent with a population formed rapidly and early on. They might be the relics of GC accretion onto ω Cen. Because GC-Cen is mono-metallic, with a rather small dispersion, our data does not support a contribution of a large number of GCs contributing to the formation of this NSC. The other stellar populations in ω Cen show signatures of being the result of prolonged star formation. These populations belong mostly to G_O2-gray and G_O3-purple but some belong to G_O1-orange and are separated in two ‘caterpillar’ branches in the NJ tree.
The metallicity distribution of Block-Cen, as well as its [O/Fe] and [La/Fe] trends, are consistent with chemical evolution models of Romano et al. (2023), which are specifically designed to replicate abundance patterns in dense and old environments, in their case, Terzan 5. Among the various abundance ratios, the [Al/Fe] enhancement has been found in potential ancient building blocks of the Milky Way (Malhan & Rix 2024; Buckley et al. 2024). The fact that Block-Cen is enhanced in [Al/Fe] might thus be the result of a primordial population formed at the center of ω Cen’s progenitor galaxy, which was accreted early on to form the NSC along with the accreted globular clusters. It is possible that both stars and gas were accreted onto ω Cen.
The second population, Child-Cen, corresponds to the branch with gray stars. Its [Fe/H] as well as [La/Fe] reach values that are very enhanced. [Al/Fe] is also very enhanced in this population, whereas the [O/Fe] values are very depleted. The low [O/Fe] might be a signature of pristine gas accretion onto ω Cen (D’Ercole et al. 2012). While a combination of star formation bursts and interactions with the surrounding gas of a dense environment might yield an abundance pattern like the one found here, the pattern of a population like Child-Cen has not been intentionally modeled so far. The abundance trends of this branch are not like those observed in globular clusters, dwarf galaxies or in the populations of the Milky Way as discussed above, therefore we attribute it to a population that formed in situ. Our phylogenetic analysis has allowed us to discover abundance trends that would require new models to explain them.
As a final note, we point to the recent independent analysis of Mason et al. (2025), which was announced at the same time as this work. That work used a different dataset and different methods to reach a remarkably consistent conclusions about the three populations of ω Cen: P1 (our Block-Cen), P2 (our Child-Cen), and IM (our GC-Cen). While the similarities and differences of the exact properties and abundance patterns of these populations need to be further studied, it seems that new data and methods are converging into disentangling the populations of ω Cen and revealing its nature as a NSC.
5 Concluding remarks
Our interdisciplinary methodology is able to provide more sophisticated analyses of the astrophysical evolution of a complex stellar system such as ω Cen than has been viable using traditional, purely astronomy approaches. Our interpretation that ω Cen might have built up from the merging of at least one metal-poor GC and more metal-rich populations whose broad metallicity distribution could be the result of prolonged star formation agrees well with the recent conclusions of Alvarez Garay et al. (2024) and the overall recent literature about the theoretical connection between ω Cen and NSCs (Brown et al. 2018; Pfeffer et al. 2021; Gray et al. 2025). Alvarez Garay et al. (2024) claim to reach their conclusions because of the improved precision in their abundance measurements compared to Johnson & Pilachowski (2010). Here, however, we use these seemingly less precise datasets, but are still able to reach similar conclusions to Alvarez Garay et al. (2024). This is thanks to the novel methods we employ, adapted from evolutionary biology, which has an established history in performing population analysis reconstructions
Nuclear star clusters might result from GC mergers, accretion of ancient building blocks, and in-situ star formation (Neumayer et al. 2020). Our analysis presents new evidence in favor ofω Cen being a nuclear star cluster. We find that its stellar populations have different chemical abundance pathways and relationships. The chemical pattern of the various branches in our NJ trees suggest that, in contrast to regular galaxies or genuine globular clusters, the ω Cen chemical history has been impacted by other processes, such as strong accretion and mixing. The multiple-channel formation scenario of NSCs can indeed account for the large variety of abundance patterns observed in ω Cen. Our phylogenetic analysis enables us to navigate the multidimensional chemical dataset produced by these formation pathways and disentangle the contributions of each channel. Furthermore, our analysis allows us to connect all these populations and reconstruct a possible shared history.
The presence of more than one ‘caterpillar’ branch in our tree thus rejects the hypothesis that ω Cen had an isolated evolutionary history. In fact, our branches could be associated with stellar populations of different origins: (1) GC-Cen: a globular cluster population; (2) Block-Cen: a stellar population that experienced star formation for more than one Gyr, with similar properties and perhaps origins to ancient clumpy populations found in dense environments such as the center of our Milky Way. (3) Child-Cen: a population with in-situ star formation, which could have formed inside ω Cen, but its chemical pattern has not been seen before so explaining it requires tailored modeling. Whether these are the true and only origins of the stellar populations of ω Cen, however, remains to be seen with more data, high resolution simulations of NSCs, or with more detailed spectroscopic analysis of other NSCs.
With this work, we demonstrate the large prospects of applying phylogenetics to studying the historical processes in our cosmic surroundings. As long as heritable markers are present in our data, phylogenetic methods can be used. As we come to appreciate the full complexity of the evolution of the cosmic bodies such as the emblematic Omega Centauri, we must be willing to expand our horizons, even beyond astronomy, to further advance our understanding.
Data availability
Tables with abundance determination as introduced in Sect. 2 are available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/699/A291.
Acknowledgements
This paper accomplishes one of the main scientific objectives of the interdisciplinary project Millennium Nucleus for the Evolutionary Reconstruction of the InterStellar medium (ERIS NCN2021_017). This work has been supported through student thesis fellowships of P.S, and K.W, in addition to funding for travel for P.J and K.W to visit or invite P.D, R.Y and X.H in several occasions. P.J. and C.A.G. thank Keaghan Yaxley, Sven Buder, Joshua Povick and Nicole Buckley for fruitful suggestions and exploratory analyses on this paper. P.J. and F.C warmly thank Macarena Concha for introducing us to each other. P.J furthermore thanks FONDECYT REGULAR 1231057. C.A.G. acknowledges support from FONDECYT Iniciación 11230741. P.V and P.C acknowledge Milenio – ICN17_022 and NCN2024_040. P.D is supported by a UKRI Future Leaders Fellowship (grant reference MR/S032223/1). S.V. thanks ANID Beca Doctorado Nacional, 21220489). P.B.T acknowledges FONDECYT Regular 1240465. P.B.T and E.J. acknowledge support from ANID Basal Project FB210003. This project has received funding from the European Union Horizon 2020 Research and Innovation Programme under the Marie Sklodowska-Curie grant agreement No 734374-LACEGAL. A.R.A. acknowledges support from DICYT through grant 062319RA FONDECYT Regular 1230731. GG acknowledges support from the Leverhulme Trust under grant EM-2025-007. The authors warmly thank the referee for the constructive and respectful feedback.
Appendix A Stars in common between Optical and Infrared sample
Table A.1 lists the stars in common between both samples. The identification number from Gaia DR3, the APOGEE ID and the Leid ID are indicated for these stars, in addition to our own designation. We add the Gaia G apparent magnitude for reference.
IDs and Gaia magnitude of stars in common between both samples
Appendix B Principal component analysis and Gaussian mixture models
B.1 PCA
Figure B.1 illustrates the PCA outcomes, with the Optical sample displayed in blue on the left and the Infrared sample in red on the right. The histograms show the percentage of the variances of each principal component (dimension). We first focus on the Optical sample, which has abundance ratios of 11 elements. While the first three components explain 67% of the variance, with the second and the third dimensions contributing to a similar percentage (between 15 and 18%), a total of six dimensions are needed to explain 87% of the variance in the chemical space.
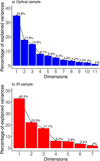 |
Fig. B.1 Contributions to the chemical variance of each PCA component for the Optical (a) and Infrared (b) samples. |
The situation is slightly different regarding the Infrared sample, which has fewer abundances measured than the Optical sample. The first two components already explain more than 60% of the variance, and the first three components explain 80% of it. We comment that even though the Infrared sample is more limited in several elements, the sample also includes iron-peak, α− capture, and neutron-capture elements. However, it lacks the heavy r-process neutron-capture elements. The percentages cannot be directly compared to the Optical sample, since they are normalized to their own dataset.
Figure B.2 shows the contribution of the individual elements in each principal component, with the dashed horizontal line indicating the threshold of 50% of contribution. The upper panels show the Optical sample and the lower panels show the Infrared sample.
For the Optical sample, we obtain that Na, La, Si, Ca, Ti, and Fe are the elements that most contribute to the first component. O, Ni, Ca, and Al contribute most to the second component, and Fe, Eu, Al, and Sc contribute to the third component. We thus find that elements coming from different nucleosynthetic paths are combined in each principal component. The Infrared sample shows a similar situation. The most influential elements in the first component are O, Mg, and Ce, in the second component are Al, Si, and Ca, and the third component involves Fe, Ce, and Ca.
In Fig. B.3 we plot the PC planes of the Infrared sample, in a similar way to Fig. 3 for the Optical sample. The left-hand panel, focused on the first and second PC of the Infrared sample, shows a similar picture to the Optical first and second PCs, in the sense that [Al/Fe] and [O/Fe] arrows point towards opposite directions, indicating that they anticorrelate. [O/Fe] has a long and purple arrow, showing the dominance of [O/Fe] in the variance of the Infrared sample. Another arrow that points in the same direction but is shorter than the [O/Fe] one is the [Mg/Fe] arrow. This element is responsible for this dataset’s anticorrelation with [Al/Fe] Mészáros et al. (2021). The fact that Mg and O have similar direction means they correlate. This is expected, based on that they have similar trends in Fig. 1.
The third principal component, in the right-hand panel of Fig. B.3 shows the importance of the iron-peak and the neutron-capture elements in the variance, in a similar way than in the Optical case. We further note that Ca never plays a similar role in importance to the Optical case. Si and Ca arrows are orthogonal to O and Al in both samples, which indicates that these α− capture elements do not correlate with O in ω Cen. The s-process element Ce, and the iron-peak element Fe, although showing a small contribution by their shorter and greener arrows, they all point in the same direction, which is to the right in these planes. In fact, in these planes only O and Al have opposite directions from the Optical sample.
B.2 Identification of populations with Gaussian mixture models
We define populations by groups that are chemically coherent. To do so, we perform Gaussian mixture models (GMM) on the stellar abundance data considering all elements and the element space, because from the PCA exploration we found that all elements contribute to the variance and that abundances are not so correlated with each other. We use the scikit-learn python package (Pedregosa et al. 2011) and explore the Bayesian Information Criterion (BIC) scores, which finds a tradeoff between the number of parameters and the model to fit (see Buckley et al. 2024, for extensive discussions about GMM applied to metal-poor stars). BIC scores provide a way to perform a model selection using a penalty proportional to the number of estimated parameters, which help us avoid overfitted solutions. The minimum BIC scores represent the optimal combination of estimated parameters in the GMM model. We thus calculate the BIC scores for different number of groups considering each Gaussian has its own diagonal covariance matrix. The BIC scores are plotted in Fig. B.4. The upper panel shows the Optical sample in blue, and the lower panel shows the Infrared sample in red.
The Optical sample supports three groups, which corresponds to the lowest BIC scores. The Infrared sample supports four groups. The populations found from the metallicity distribution of ω Cen by Mészáros et al. (2021) (using more stars from the same Infrared sample as us), Sollima et al. (2005), as well as Alvarez Garay et al. (2024), yield four groups. This number is however smaller than the five populations found from the metallicity distribution analyzed by Johnson & Pilachowski (2010), who used a larger version of our Optical sample, or the seven populations found clustering the chemical space using the entire sample of our Infrared sample by Mészáros et al. (2021). This is a further argument against attempting to establish a number of populations in ω Cen, because it heavily depends on the data, method, and the information used. See also further recent discussions on GMM for ω Cen chemical abundances in Pagnini et al. (2025). In fact the GMM analysis on chemical GALAH data by Buder et al. (2022) shows that the BIC scores and the optimal number of groups have a significant impact when varying the abundance ratios considered for the GMM. In this paper we thus use GMM to see how the various groups might be related to each other and which abundances might be causing the separation of the groups.
 |
Fig. B.2 Contributions to the first principal components from each element. In blue the Optical Sample, in red the Infrared sample. The dashed red horizontal line delineates the 50% of contribution, helping us to see which elements contribute most each PC. |
Figure B.5 shows the stellar population bar plot for the Infrared sample, with four groups colored with red, blue, magenta, and yellow. As in the case of the Optical sample, the admixture between groups is low, especially for the Group_I1-red. A lightly higher admixture between the Group_I2-blue, Group_I3-magenta, and Group_I4-yellow is seen. Following the arguments used for the Optical sample, we can interpret this stellar population bar plot by claiming that Group_I1-red might have had a more distinct history than Group_I2-blue, Group_I3-magenta, and Group_I4-yellow, which are more related to each other.
B.3 Chemical distributions of the populations
We present a description of the groups general properties. We focus our description on their chemical properties and their stellar parameters only. Regarding the kinematical properties, we investigated the proper motions from Gaia and did not find any particular evidence that some group had different kinematical properties than the other. Regarding the ages, we attempted to estimate ages of the individual stars, but our results could not be validated and thus we could not trust them. Acknowledging that He, C, N, and O abundances in ω Cen are peculiar (Mészáros et al. 2021; Romano et al. 2007; Tailo et al. 2016) and that we do not have He abundances for our stars, we decided not to consider ages in this analysis. Indeed, Marino et al. (2012) and Sollima et al. (2005) extensively discuss on the caveats of using ages to study ω Cen given these element abundance peculiarities.
The anticorrelations Na-O and Al-O for the Optical sample are plotted in the top panels of Fig. B.6. The lower panel shows the anticorrelations Al-Mg and Al-O for the Infrared sample. The right-hand panels are the color magnitude diagrams, this allows a 1-1 comparison between the samples because the parameters come from the same source. This time the stars are colored by the population with highest frequency for each star, and symbols correspond to if the stars are pure (probability of belonging to the GMM group of more than 90%) or mixed (probability of belonging to the group of less than 90%). Changing this threshold does not change our interpretation, since the admixture of the stellar population bar plot is in general very low.
The GMM finds that the populations found are well separated in the anticorrelations. This is expected since already from the PCA we could see that the anticorrelations were dominating the variance of the data (see Fig. 3 and B.3). Regarding the Optical sample, G_O2-gray stars have high [Na/Fe] and high [Al/Fe] but low [O/Fe] abundances. G_O3-purple has very high [Na/Fe] but normal [Al/Fe] and [O/Fe]. We note they do not overlap in the red giant branch like the other stars. Pancino et al. (2000) showed that ω Cen has multiple red giant branches, with the faintest branch being the most metal and calcium rich one. The high [Na/Fe] ratio can be related to a metal-rich progenitor since Na production has a strong dependency of metallicity (Brown et al. 2018). G_O1-orange mix in Na, Al, O, and the color-magnitude diagram, belonging to the low-Na, low-Al, and high-O side of the anticorrelation. Mixed stars are at the central parts of the diagrams.
Regarding the Infrared sample, we see in the bottom panels of Fig. B.6 that G_I1-red populates the high-Al low-Mg and low-O part of the anticorrelation. G_I3-magenta has the highest Mg and O abundances, but Al is not particularly low. In fact, G_I2-blue and G_I4-yellow dominate the low-Al, high-Mg side of the anticorrelation. All these stars overlap in these diagrams, as well as in the color-magnitude diagram of the bottom right panel. As in the Optical sample, mixed stars appear at the central parts of the diagrams, where populations overlap.
 |
Fig. B.3 PCA planes with the direction and contribution of each chemical element in the first three most significant components of the Infrared sample. Stars are distributed in the planes and arrows indicate the direction to which the abundance ratios are higher in these planes. Colors indicate the contribution to the PCA of the abundance ratios. The first two dimensions show how [O/Fe] and [Al/Fe] dominate the variance, contributing to opposite directions in these planes. This is due to the anticorrelation of these elements. |
We further explore the chemical abundance trends as a function of metallicity for our populations in Fig. B.7. The Optical sample is displayed in the left-hand panels, and the Infrared sample is shown in the right-hand panels. We show the [O/Fe], [Ca/Fe], and the s-process [La/Fe] or [Ce/Fe] abundances.
We first realize that the populations found with our GMM method are not the same as those found from the metallicity distribution peaks by Mészáros et al. (2021), Johnson & Pila-chowski (2010) or by Sollima et al. (2005) and Alvarez Garay et al. (2024). While our groups separate in [Fe/H], some over-lap significantly. They result in different GMMs because of the other elements considered in this analysis. Further discussions on GMM using different abundance planes can be found in Buder et al. (2022) and how to separate groups better using GMM with PCA can be found in Buckley et al. (2024).
 |
Fig. B.4 BIC Scores for the Gaussian mixture models as a function of number of groups for the Optical sample (upper panel) and the Infrared one (lower panel). The Optical sample prefers three Gaussians and the Infrared sample prefers four Gaussians. |
In the diagrams of Fig. B.7 we find that G_O3-purple is the most metal-rich population of the Optical sample. The correlation between Na and Fe is thus expected (Brown et al. 2018), as well as the position of the magenta stars in the color-magnitude diagram (see also Pancino et al. 2000). Both G_O2 and G_O3 have high [Ca/Fe] and [La/Fe] abundances. Pancino et al. (2000) also points to the [Ca/H]-rich stars being Ba enriched due to AGB pollution. This is consistent with the mangenta stars having high levels of enhancement in [La/Fe]. If intermediate-mass AGB pollution is responsible for these enhancements, then some timespan of at least 0.5 Gyr is needed for this enrichment to happen. This suggests that these a stars might have formed at a later time compared to the G_O1 stars.
It is quite interesting to note that there are G_O3-gray stars that are also metal-rich and [Na/Fe] rich, but they follow the red giant branch of the CMD diagram, are considerably bluer and brighter compared to the purple stars. This can be explained by their difference in oxygen, but this could be also a result of ages, with the gray stars being younger than the purple ones. We are unable to determine individual ages to quantify this difference, given the strong chemical peculiarities of these stars.
The G_I3-magenta stars of the Infrared sample are the most O, Ca, and Ce-rich ones, and span a wide range of [Fe/H]. Their location in the color-magnitude diagram is mixed with the rest of the stars, but this could be a selection effect of stellar parameters between these and the Optical sample. G_I4-yellow stars have middle Ca and Ce abundances. G_I1-red, on the other hand, while being those with the highest Al abundances do not have significantly high Ce abundances. G_I2-blue have similar properties to G_O1-orange from the Optical sample, namely low metallicities, O and Ca abundances of the order of 0.4 dex, and low Ce s-process abundances.
We plot in the lowest left panel of Fig. B.7 the distribution of [Eu/Fe] vs [Fe/H] for the stars colocoloredred by the GMM groups. One can see that the lowest metallicity stars, regardless of the GMM group, have higher [Eu/Fe]. The decreasing trend with [Fe/H] can be noticed, but the scatter is large. This scatter, as well as negative trend with [Fe/H], explains why Eu is important in the PCA (see Fig. 3).
 |
Fig. B.5 Stellar population bar plot of the Infrared sample. Same as Fig. 4 but using four groups, which is the optimal number for the Infrared sample from the GMM analysis. |
 |
Fig. B.6 Anticorrelations colored by groups following GMM classification and color scheme of of the GMM models. Each star is colored by the group which has the maximum probability. The right hand panels show the Color Magnitude Diagrams. Top row: optical sample. Bottom row: near infrared sample. Shaded contours represent the KDE of the datapoints. |
 |
Fig. B.7 Chemical trends colored by groups following classification and color scheme of Fig. 4 and Fig. B.6. |
Appendix C Infrared sample tree
Figure C.1 is the equivalent to Fig. 5, and allows us to see the more significant branches and their support. As in the optical sample, the overall node support in this dataset is 35%, which is not surprising if the reported abundance uncertainties are comparable to the Optical sample (see more discussions below).
Figure C.2 shows the Infrared tree in the same way as the Optical tree of Fig. 6, which is colored based on the GMM groups illustrated in Fig. B.5. The Infrared tree features more sub-branches than the Optical tree, but only one significant “caterpillar” branch, colored with yellow and magenta. However, we categorize these branches according to the populations identified in the Optical tree, which maps the connections of the stars shared between the two datasets (see sections below). The reason for fewer ‘caterpillar’ long branches in this tree compared to the Optical one might be that this dataset uses fewer abundance ratios, making it harder to divide the tree into populations with different histories. We recall that the stellar population bar plot of the Infrared sample shows a higher proportion of mixed stars compared to the Optical sample and the GMM model prefers four groups instead of three. It is, of course, also possible that the difference in the number of branches is due to selection effects, because we do not have the same stars in both samples, but our analysis of stars in common does not support this idea.
Indeed, stars in common with the Optical sample allow us to associate the magenta and yellow stars with Block-Cen, blue with a mix of Block and GC, and red with the GC-Cen stars (see below). This is how we can divide the tree of Fig. C.2 into the upper yellow ‘caterpillar’ branch corresponding to the population Block-Cen, a middle blue branch being a mix between Block and GC-Cen, and a lower branch of GC-Cen stars. Block-Cen shows similar chemical properties to the Optical one, namely it has an extended metallicity distribution, with a trend form the lowest metallicity at the root to the highest metallicity at the tip. [O/Fe] and [Al/Fe] decrease with metallicity with comparable values to the Optical branch, and the s-process element ratio [Ce/Fe] increases with metallicity such as [La/Fe]. The scatter in this case is higher, but Ce abundances are uncertain to estimate from the data used in the Infrared sample (Mészáros et al. 2021; Hayes et al. 2022). In general, the trends here have more outliers, such as those red stars at the tip of the lower subbranch.
The blue branch is composed of both GC and Block stars. Here, no metallicity distribution, as well as no anticorrelation in O-Al is found. Indeed, the blue stars that are also part of the Optical dataset belong to G_O1-orange, and are thus located at the bottom of the Block branch. This branch may correspond to the first generation of GC stars. The bottom GC branch, colored in red, has no significant metallicity distribution, but shows an anticorrelation, and a [Ce/Fe] positive trend with metallicity. Stars in common between this branch and the Optical suggest they belong to the GC-Cen population although one star (SIR_019) is associated with Child-Cen and it is located at the end of the bottom branch.
As in the Optical case, this tree is not consistent with a single ‘caterpillar’ tree expected from an isolated galaxy evolving like the one analyzed by de Brito Silva et al. (2024). This provides stronger evidence that ω Cen is likely the result of more than one history, or/and the result of a complex star formation history.
Appendix D Europium abundances and the connection of ω Cen with GES
In Fig. D.1 we plot the same data as in Fig. 6 but the panels show the trends of [Fe/H], [Eu/Fe], [Eu/Si], and [La/Eu] along the branches. In consistency with the scatter plot discussed above, the negative trend of [Eu/Fe] is seen for both, Block-Cen and Child-Cen. The trends of [Eu/Fe] however are not so distinct in both branches one another as in the case of [O/Fe] or [Al/Fe] (see Fig. 6), which can be explained by the fact that [Eu/Fe] becomes important only in the third PC of the PCA, unlike O and Al, which matter in the first and the second PC most. The similarity in the [Eu/Fe] abundances in ω Cen has already been reported by Johnson & Pilachowski (2010) Block-Cen and could mean that r-process elements might not necessarily have been produced inside ω Cen in large quantities.
The [La/Eu] and [Eu/Si] trends serve to put in context the possible association of ω Cen as NSC of the GES. As extensively discussed in the literature, the GES shows significant enhancement of [Eu/Fe] abundances of above 0.5 and even 0.7 dex (Aguado et al. 2021; Matsuno et al. 2021; Carrillo et al. 2022), explained by the r-process produced through a neutron star merger (NSM), which can pollute with Eu an entire dwarf galaxy. The ratio of r/s and r/α elements, such as [Eu/La] and [Eu/Si] can be used to study the importance and the time delay of the r-process pollution, because of the different lifetimes of the different progenitors. In fact, Matsuno et al. (2021) found that GES has a flat trend of [La/Eu] with scatter, in agreement with the trends of [Ba/Eu] of Aguado et al. (2021), consistent with Eu being produced by a NSM event. Because GES has low abundances of α− elements compared to the in-situ halo, Monty et al. (2024) uses [Eu/Si] to distinguish between accreted and in-situ stars, showing that accreted stars have significantly higher [Eu/Si] compared to in-situ stars. This includes the globular clusters.
 |
Fig. D.1 Optical tree. Same as Fig. 6 but showing the trends of [Eu/Fe], [La/Eu], and [Eu/Si] along the branches |
Figure D.1 shows that all branches and GMM groups have comparable distributions in [Eu/Fe], and have values that are below the reported ones for GES. The Block-Cen and the Child-Cen branches have increasing [La/Eu] trends with metallicity, suggesting that s-process is important in these populations. [Eu/Si] is low in Block-Cen and has a decreasing trend with metallicity, while for Child-Cen we can not identify a clear trend. The GC-Cen has solar-values for [Eu/Si], and no trend. These abundance trends might rule out the chemical connection of ω Cen with the GES, but only if we believe that the NSC of the GES has to follow the same chemical trends as the rest of the galaxy, which is not established so far. Indeed, if there was a time-delay to pollute the GES with r-process abundances from a NSM, then it is possible that Block-Cen and GC-Cen formed before this event happened. We recall that α− capture element abundances of this population are higher than the typical GES ones. The fact that the Eu abundances do not increase in Child-Cen might also suggest that no other NSM event happened inside ω Cen.
References
- Aguado, D. S., Belokurov, V., Myeong, G. C., et al. 2021, ApJ, 908, L8 [NASA ADS] [CrossRef] [Google Scholar]
- Ahumada, R., Allende Prieto, C., Almeida, A., et al. 2020, ApJS, 249, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Alfaro-Cuello, M., Kacharov, N., Neumayer, N., et al. 2019, ApJ, 886, 57 [Google Scholar]
- Alvarez Garay, D. A., Mucciarelli, A., Bellazzini, M., Lardo, C., & Ventura, P. 2024, A&A, 681, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Andrews, B. H., Weinberg, D. H., Johnson, J. A., Bensby, T., & Feltzing, S. 2012, Acta Astron., 62, 269 [Google Scholar]
- Arcones, A., & Thielemann, F.-K. 2023, A&A Rev., 31, 1 [Google Scholar]
- Bastian, N., & Lardo, C. 2018, ARA&A, 56, 83 [Google Scholar]
- Baum, D. A., Smith, S. D., & Donovan, S. S. 2005, Science, 310, 979 [Google Scholar]
- Baumgardt, H., & Hilker, M. 2018, MNRAS, 478, 1520 [Google Scholar]
- Bekki, K., & Freeman, K. C. 2003, MNRAS, 346, L11 [Google Scholar]
- Belokurov, V., Erkal, D., Evans, N. W., Koposov, S. E., & Deason, A. J. 2018, MNRAS, 478, 611 [Google Scholar]
- Bisterzo, S., Travaglio, C., Gallino, R., Wiescher, M., & Käppeler, F. 2014, ApJ, 787, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Bromham, L., Dinnage, R., Skirgård, H., et al. 2022, Nat. Ecol. Evol., 6, 163 [Google Scholar]
- Brown, G., Gnedin, O. Y., & Li, H. 2018, ApJ, 864, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Buckley, N., Das, P., Jofré, P., Yates, R. M., & Hawkins, K. 2024, MNRAS, 534, 1985 [Google Scholar]
- Buder, S., Lind, K., Ness, M. K., et al. 2022, MNRAS, 510, 2407 [NASA ADS] [CrossRef] [Google Scholar]
- Carretta, E., Bragaglia, A., Gratton, R. G., et al. 2009, A&A, 505, 117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carretta, E., Bragaglia, A., Gratton, R. G., et al. 2010, A&A, 520, A95 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carrillo, A., Hawkins, K., Jofré, P., et al. 2022, MNRAS, 513, 1557 [CrossRef] [Google Scholar]
- Cowan, J. J., Sneden, C., Lawler, J. E., et al. 2021, Rev. Mod. Phys., 93, 015002 [Google Scholar]
- Cseh, B., Lugaro, M., D’Orazi, V., et al. 2018, A&A, 620, A146 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- da Silva, A. R., & Smiljanic, R. 2023, A&A, 677, A74 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Das, P., Hawkins, K., & Jofré, P. 2020, MNRAS, 493, 5195 [NASA ADS] [CrossRef] [Google Scholar]
- de Brito Silva, D., Jofré, P., Tissera, P. B., et al. 2024, ApJ, 962, 154 [Google Scholar]
- D’Ercole, A., D’Antona, F., Carini, R., Vesperini, E., & Ventura, P. 2012, MNRAS, 423, 1521 [Google Scholar]
- Fahrion, K., Lyubenova, M., van de Ven, G., et al. 2021, A&A, 650, A137 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Freeman, K., & Bland-Hawthorn, J. 2002, ARA&A, 40, 487 [Google Scholar]
- Gratton, R., Bragaglia, A., Carretta, E., et al. 2019, A&A Rev., 27, 8 [Google Scholar]
- Gray, E. I., Read, J. I., Taylor, E., et al. 2025, MNRAS, 539, 1167 [Google Scholar]
- Griffith, E., Johnson, J. A., & Weinberg, D. H. 2019, ApJ, 886, 84 [Google Scholar]
- Griffith, E. J., Hogg, D. W., Hasselquist, S., et al. 2025, AJ, 169, 280 [Google Scholar]
- Hasselquist, S., Hayes, C. R., Lian, J., et al. 2021, ApJ, 923, 172 [NASA ADS] [CrossRef] [Google Scholar]
- Hayes, C. R., Masseron, T., Sobeck, J., et al. 2022, ApJS, 262, 34 [NASA ADS] [CrossRef] [Google Scholar]
- Hellenthal, G., Busby, G. B., Band, G., et al. 2014, Science, 343, 747 [Google Scholar]
- Helmi, A., Babusiaux, C., Koppelman, H. H., et al. 2018, Nature, 563, 85 [Google Scholar]
- Jackson, H., Jofré, P., Yaxley, K., et al. 2021, MNRAS, 502, 32 [Google Scholar]
- Jofré, P., Das, P., Bertranpetit, J., & Foley, R. 2017, MNRAS, 467, 1140 [CrossRef] [Google Scholar]
- Johnson, C. I., & Pilachowski, C. A. 2010, ApJ, 722, 1373 [NASA ADS] [CrossRef] [Google Scholar]
- Kobayashi, C., Karakas, A. I., & Lugaro, M. 2020, ApJ, 900, 179 [Google Scholar]
- Koch-Hansen, A. J., Hansen, C. J., & McWilliam, A. 2021, A&A, 653, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kuhner, M. K., & Yamato, J. 2014, Syst. Biol., 64, 205 [Google Scholar]
- Limberg, G., Souza, S. O., Pérez-Villegas, A., et al. 2022, ApJ, 935, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Lugaro, M., Davis, A. M., Gallino, R., et al. 2003, ApJ, 593, 486 [NASA ADS] [CrossRef] [Google Scholar]
- Lugaro, M., Karakas, A. I., Stancliffe, R. J., & Rijs, C. 2012, ApJ, 747, 2 [Google Scholar]
- Magrini, L., Spina, L., Randich, S., et al. 2018, A&A, 617, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Malhan, K., & Rix, H.-W. 2024, ApJ, 964, 104 [NASA ADS] [CrossRef] [Google Scholar]
- Marino, A. F., Milone, A. P., Piotto, G., et al. 2012, ApJ, 746, 14 [CrossRef] [Google Scholar]
- Mason, A. C., Schiavon, R. P., Kamann, S., et al. 2025, arXiv e-prints [arXiv:2504.06341] [Google Scholar]
- Massari, D., Koppelman, H. H., & Helmi, A. 2019, A&A, 630, L4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Masseron, T., Merle, T., & Hawkins, K. 2016, Astrophysics Source Code Library [record ascl:1605.004] [Google Scholar]
- Matsuno, T., Hirai, Y., Tarumi, Y., et al. 2021, A&A, 650, A110 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Matteucci, F., & Brocato, E. 1990, ApJ, 365, 539 [CrossRef] [Google Scholar]
- Mészáros, S., Masseron, T., Fernández-Trincado, J. G., et al. 2021, MNRAS, 505, 1645 [Google Scholar]
- Milosavljević, M. 2004, ApJ, 605, L13 [Google Scholar]
- Monty, S., Belokurov, V., Sanders, J. L., et al. 2024, MNRAS, 533, 2420 [NASA ADS] [CrossRef] [Google Scholar]
- Nespolo, R. F., Villarroel, C. A., Oporto, C. I., et al. 2020, PLoS Genetics, 16, e1008777 [Google Scholar]
- Neumayer, N., Seth, A., & Böker, T. 2020, A&A Rev., 28, 4 [Google Scholar]
- Nissen, P. E., & Schuster, W. J. 2011, A&A, 530, A15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nomoto, K., Kobayashi, C., & Tominaga, N. 2013, ARA&A, 51, 457 [CrossRef] [Google Scholar]
- O’Brien, M. J., Vidiella, B., Duran-Nebreda, S., Bentley, R. A., & Valverde, S. 2025, Biological Theory (Berlin: Springer), 1 [Google Scholar]
- Pagnini, G., Di Matteo, P., Haywood, M., et al. 2025, A&A, 693, A155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pancino, E., Ferraro, F. R., Bellazzini, M., Piotto, G., & Zoccali, M. 2000, ApJ, 534, L83 [NASA ADS] [CrossRef] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Peter, B. M. 2016, Genetics, 202, 1485 [Google Scholar]
- Pfeffer, J., Lardo, C., Bastian, N., Saracino, S., & Kamann, S. 2021, MNRAS, 500, 2514 [Google Scholar]
- Price, A. L., Patterson, N. J., Plenge, R. M., et al. 2006, Nat. Genetics, 38, 904 [Google Scholar]
- Pritchard, J. K., Stephens, M., & Donnelly, P. 2000, Genetics, 155, 945 [Google Scholar]
- Romano, D., Matteucci, F., Tosi, M., et al. 2007, MNRAS, 376, 405 [Google Scholar]
- Romano, D., Ferraro, F. R., Origlia, L., et al. 2023, ApJ, 951, 85 [NASA ADS] [CrossRef] [Google Scholar]
- Saitou, N., & Nei, M. 1987, Mol. Biol. Evol., 4, 406 [Google Scholar]
- Salaris, M., Pietrinferni, A., Piersimoni, A. M., & Cassisi, S. 2015, A&A, 583, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Signor, T., Jofré, P., Martí, L., & Sánchez-Pi, N. 2024, A&A, 688, A165 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sollima, A., Pancino, E., Ferraro, F. R., et al. 2005, ApJ, 634, 332 [NASA ADS] [CrossRef] [Google Scholar]
- Solovieff, N., Hartley, S. W., Baldwin, C. T., et al. 2010, BMC genetics, 11, 1 [Google Scholar]
- Tailo, M., Di Criscienzo, M., D’Antona, F., Caloi, V., & Ventura, P. 2016, MNRAS, 457, 4525 [CrossRef] [Google Scholar]
- Tian, C., Gregersen, P. K., & Seldin, M. F. 2008, Human Mol. Genetics, 17, R143 [Google Scholar]
- Ting, Y.-S., Freeman, K. C., Kobayashi, C., De Silva, G. M., & Bland-Hawthorn, J. 2012, MNRAS, 421, 1231 [NASA ADS] [CrossRef] [Google Scholar]
- Tissera, P. B., White, S. D. M., & Scannapieco, C. 2012, MNRAS, 420, 255 [NASA ADS] [CrossRef] [Google Scholar]
- Tremaine, S. D., Ostriker, J. P., & Spitzer, Jr., L. 1975, ApJ, 196, 407 [NASA ADS] [CrossRef] [Google Scholar]
- van Leeuwen, F., Le Poole, R. S., Reijns, R. A., Freeman, K. C., & de Zeeuw, P. T. 2000, A&A, 360, 472 [NASA ADS] [Google Scholar]
- Vasiliev, E., & Baumgardt, H. 2021, MNRAS, 505, 5978 [NASA ADS] [CrossRef] [Google Scholar]
- Vasini, A., Spitoni, E., & Matteucci, F. 2024, A&A, 683, A121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Villarreal, P., Quintrel, P. A., Olivares-Muñoz, S., et al. 2022, Yeast, 39, 128 [Google Scholar]
- Vitali, S., Rojas-Arriagada, A., Jofré, P., et al. 2025, A&A, 699, A163 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Walsen, K., Jofré, P., Buder, S., et al. 2024, MNRAS, 529, 2946 [Google Scholar]
- Weinberg, D. H., Holtzman, J. A., Hasselquist, S., et al. 2019, ApJ, 874, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, Z. 2014, Molecular Evolution: a Statistical Approach (Oxford: Oxford University Press) [Google Scholar]
In population genetics, migration refers to the movement of genes from one population to another. This can occur when individuals migrate and introduce their genetic material into a new population. Admixture refers to the mixture of previously isolated populations. This can happen between different species (hybridization) or within the same species.
All Tables
All Figures
|
Fig. 1 Abundance ratios against [Fe/H] of all elements in both optical (in blue squares) and IR (in red circles) samples. Some of the element abundances are measured in both samples, and some are measured in only one of the samples. Shaded contours correspond to the Gaussian kernel density estimation of the datapoints. |
| In the text | |
|
Fig. 2 Comparison of abundance ratios for the 16 stars in common between both datasets. The mean and the standard deviation of the comparison is indicated in each panel. The diagonal red line indicates the 1-1 relation. Only [Fe/H] and [O/Fe] show significant systematic offsets. |
| In the text | |
|
Fig. 3 PC space with the direction and contribution of each chemical element in the first three principal components. Stars are dots in the space and arrows indicate the direction in which the abundance ratios are higher in these planes. The color of an arrow shows the overall contribution of the chemical element to both PCs. The first two components show how α-elements and [Al/Fe] dominate the variance. These arrows point in opposite directions in the space. This is due to the anticorrelation of these elements in the chemical space. The third component illustrates that [Fe/H] and [Eu/Fe] become important. |
| In the text | |
|
Fig. 4 Stellar population bar plot. Each star, whose name is indicated in the X axis, is shown as a bar with the cumulative probability of the star belonging to a specific group. The Y axis shows the probability of the star belonging to the groups, which are assigned using a Gaussian mixture model of three components. The stellar population bar plot allows us to appreciate the clustering, and to identify which groups might be more related to each other, as reflected by the level of mixing between them. |
| In the text | |
|
Fig. 5 Circular Optical tree. The colors of the tips correspond to the GMM groups. The pie charts on the nodes correspond to the percentage of occurrence of the node in 1000 random generated trees considering the abundance uncertainties (node support), indicating that the tree has an overall support of 35%. |
| In the text | |
|
Fig. 6 Neighbor-joining tree of ω Cen stars. Tips are colored based on the GMM group to which each star has the highest probability of belonging to in Fig. 4. The tree shows three main branches, whose [Fe/H], [O/Fe], [Al/Fe], and [La/Fe] are shown in the right-hand panels. The GC branch has properties similar to globular clusters. The Block and Child branches have extended metallicity and [La/Fe] distributions, supporting in-situ star formation for a prolonged duration. However, their [O/Fe] and [Al/Fe] trends are distinct, suggesting that they had different star formation histories and explaining why they are placed on different branches and GMM groups. |
| In the text | |
|
Fig. 7 Comparison of rooted tree color coded by groups for common stars. Top Panel shows the comparison among trees when all abundances are considered for building the tree, while lower panel shows the comparison when elements in common are used. The agreement between trees is slightly better when the same chemical abundances are used, but differences persist. This can be attributed to the uncertainties in the data. |
| In the text | |
|
Fig. B.1 Contributions to the chemical variance of each PCA component for the Optical (a) and Infrared (b) samples. |
| In the text | |
|
Fig. B.2 Contributions to the first principal components from each element. In blue the Optical Sample, in red the Infrared sample. The dashed red horizontal line delineates the 50% of contribution, helping us to see which elements contribute most each PC. |
| In the text | |
|
Fig. B.3 PCA planes with the direction and contribution of each chemical element in the first three most significant components of the Infrared sample. Stars are distributed in the planes and arrows indicate the direction to which the abundance ratios are higher in these planes. Colors indicate the contribution to the PCA of the abundance ratios. The first two dimensions show how [O/Fe] and [Al/Fe] dominate the variance, contributing to opposite directions in these planes. This is due to the anticorrelation of these elements. |
| In the text | |
|
Fig. B.4 BIC Scores for the Gaussian mixture models as a function of number of groups for the Optical sample (upper panel) and the Infrared one (lower panel). The Optical sample prefers three Gaussians and the Infrared sample prefers four Gaussians. |
| In the text | |
|
Fig. B.5 Stellar population bar plot of the Infrared sample. Same as Fig. 4 but using four groups, which is the optimal number for the Infrared sample from the GMM analysis. |
| In the text | |
|
Fig. B.6 Anticorrelations colored by groups following GMM classification and color scheme of of the GMM models. Each star is colored by the group which has the maximum probability. The right hand panels show the Color Magnitude Diagrams. Top row: optical sample. Bottom row: near infrared sample. Shaded contours represent the KDE of the datapoints. |
| In the text | |
|
Fig. B.7 Chemical trends colored by groups following classification and color scheme of Fig. 4 and Fig. B.6. |
| In the text | |
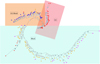 |
Fig. C.1 Circular Infrared tree. Same as Fig. 5 |
| In the text | |
 |
Fig. C.2 Same as Fig. 6 but for the Infrared sample. |
| In the text | |
|
Fig. D.1 Optical tree. Same as Fig. 6 but showing the trends of [Eu/Fe], [La/Eu], and [Eu/Si] along the branches |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.