| Issue |
A&A
Volume 699, July 2025
|
|
|---|---|---|
| Article Number | A303 | |
| Number of page(s) | 15 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202553866 | |
| Published online | 17 July 2025 | |
Navigating AGN variability with self-organizing maps
1
INAF - Astronomical Observatory of Capodimonte, Via Moiariello 16, 80131 Napoli, Italy
2
Department of Physics “E. Pancini”, University Federico II of Napoli, Via Cinthia 21, 80126 Napoli, Italy
3
Millennium Institute of Astrophysics (MAS), Nuncio Monseñor Sotero Sanz 100, Providencia, Santiago, Chile
4
INFN section of Naples, via Cinthia 6, 80126 Napoli, Italy
5
European Southern Observatory, Karl-Schwarzschild-Strasse 2, 85748 Garching bei München, Germany
6
Intesa Sanpaolo S.p.A., Corso Inghilterra 3, 10138 Turin, Italy
★ Corresponding author
Received:
23
January
2025
Accepted:
12
June
2025
Abstract
Context. The classification of active galactic nuclei (AGNs) is a challenge in astrophysics. Variability features extracted from light curves offer a promising avenue for distinguishing AGNs and their subclasses. This approach would be very valuable in sight of the Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST).
Aims. Our goal is to utilize self-organizing maps (SOMs) to classify AGNs based on variability features and investigate how the use of different subsets of features impacts the purity and completeness of the resulting classifications.
Methods. We derived a set of variability features from light curves, similar to those employed in previous studies, and applied SOMs to explore the distribution of AGNs subclasses. We conducted a comparative analysis of the classifications obtained with different subsets of features, focusing on the ability to identify different AGNs types.
Results. Our analysis demonstrates that using SOMs with variability features yields a relatively pure AGNs sample, though completeness remains a challenge. In particular, Type 2 AGNs are the hardest to identify, as can be expected. These results represent a promising step toward the development of tools that may support AGNs selection in future large-scale surveys such as LSST.
Key words: methods: data analysis / methods: statistical / galaxies: active
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
The field of time-domain astronomy is next to the beginning of a revolutionary era, driven by the advent of a new generation of telescopes designed for wide, deep, and high-cadence sky surveys. This revolution will be led by the Legacy Survey of Space and Time (LSST; see, e.g., LSST Science Collaboration 2009; Ivezić et al. 2019). The LSST, to be conducted with the Simonyi Survey Telescope at the Vera C. Rubin Observatory, promises to dramatically enhance our understanding of active galactic nuclei (AGNs) in several key areas, such as the demography of AGNs, their luminosity function, their evolution, and the role they play in shaping their host galaxies (e.g., Brandt et al. 2018; Raiteri et al. 2022). Hopefully this will provide new insights into the physics and the structure behind the AGNs formation and evolution.
The primary LSST survey, known as the Wide-Fast-Deep (WFD) survey, will focus on an area of approximately 19.6 k square degrees. This vast region is expected to be surveyed around 800 times over a decade, utilizing a large amount of the available observing time. Beside that a portion of the time will be dedicated to ultra-deep surveys of well-known areas, collectively referred to as deep drilling fields (DDFs; e.g., Brandt et al. 2018; Scolnic et al. 2018). These DDFs are regions where extensive multiwavelength information is already available from previous surveys.
The initial 10-year observing program includes a proposal for high-cadence (up to ~ 14 000 visits) multiwavelength observations of an area of approximately 9.6 square degrees per DDF. These observations aim to reach impressive coadded depths of ~28.5 mag in the ugri bands, ~28 mag in the z band, and ~27.5 mag in the y band. Given these characteristics, the DDFs will serve as excellent laboratories for AGNs science.
The advent of wide-field surveys like LSST will push time domain astronomy in an era of unprecedented data volume, with information about millions of sources being collected nightly. This data deluge highlights the urgent need for scalable, automated, and effective methods to analyze sources, identify candidates, and characterize their physical properties.
To tackle similar challenges related to large and complex datasets, several other disciplines, such as healthcare (Tangaro et al. 2015; Pei et al. 2023), tourism (Solazzo et al. 2022), the banking sector (Maruccia et al. 2025), financial trading (Jaiswal & Kumar 2023), and environmental monitoring (Licen et al. 2023), have increasingly adopted machine learning (ML) algorithms. Astronomy is now following the same trend, with ML techniques becoming widely used across a variety of applications (e.g., Masters et al. 2015; Djorgovski et al. 2016; Cavuoti et al. 2017; Mahabal et al. 2017; D’Isanto et al. 2018; Baron 2019; Doorenbos et al. 2022; Soo et al. 2023; Angora et al. 2023; Cavuoti et al. 2024). Many of these ML algorithms rely on supervised training, utilizing “labeled” sets (LSs) of data. These LSs consist of samples of objects with known classifications, characterized by a set of features selected based on the properties of interest. The efficacy of the training process is heavily dependent on the chosen features and the balance of the selected LS, which should ideally provide the most complete and unbiased sampling possible of the source population to be studied, through broad and homogeneous coverage of the parameter space (though in practice this ideal is never fully achieved, often not even partially). In light of these limitations, the exploration of unsupervised methods (i.e., approaches that do not rely on a priori knowledge from LSs) has gained increasing interest in the astronomical community (e.g., Fotopoulou 2024, and literature inside). These techniques offer a complementary strategy to supervised learning, allowing for the identification of novel patterns, groups, or anomalies in complex datasets. For these reasons, exploring unsupervised methods represents a valuable and necessary complement to supervised approaches that is worth being accomplished.
Among the current selection of DDFs is the Cosmic Evolution Survey (COSMOS; Scoville et al. 2007b) field, renowned as one of the most thoroughly studied extragalactic survey regions in the sky. The present work is part of a series (e.g., De Cicco et al. 2015, 2019, 2021) focused on the identification of AGNs in a 1 square degree area in the COSMOS field making use of data from the VLT Survey Telescope (VST; Capaccioli & Schipani 2011). The selection is based on optical variability and the series of works overall also aims to assess the performance of variability selection in the DDFs. Variability is known to characterize AGNs at all wavelengths, with timescales and amplitudes depending on the observing waveband. Specifically, the VST-COSMOS dataset consists of 54 r-band visits from the SUpernova Diversity And Rate Evolution (SUDARE; Botticella et al. 2013) survey, originally designed to detect and characterize supernovae (Cappellaro et al. 2015; Botticella et al. 2017), and covering a 3.3-year baseline.
These characteristics allow us to explore regions of the variability parameter space that have been poorly investigated to date. Indeed, the VST-COSMOS dataset stands out as one of the few that combine both a considerable depth and a high observing cadence, two fundamental requirements for variability surveys that are often mutually exclusive in ground-based observations. For such reasons this dataset represents a benchmark in order to develop and test tools that will be then applied to the LSST data. De Cicco et al. (2021), in particular, made use of statistical derived parameters in order to train a random forest classifier (Breiman 2001).
As was mentioned before, the present work, is part of a series of studies in which our team has explored various approaches to AGNs identification, ranging from classical variability analysis (see De Cicco et al. (2015, 2019) to supervised ML methods (see De Cicco et al. 2021, 2025). In this work, we decided to investigate an unsupervised method to assess whether it could improve the results, at least for a specific subclass of AGNs. For this purpose, by using the same dataset and the extracted features as in De Cicco et al. (2021), we applied a self-organizing map (SOM, Kohonen 2001) in order to verify if it is possible to effectively separate different classes of astrophysical sources (AGNs, stars, and galaxies), without directly using the labels, which may be incomplete or biased. Labels were, however, utilized in order to interpret and validate the results of the network. SOMs can project high-dimensional data (such as light curve features and colors) onto a two-dimensional map while preserving topological relationships. This capability is particularly useful to visualize and somehow identify regions in which similar objects are falling. SOMs have been successfully employed in several astrophysical applications, including applications on stellar and galaxy spectra (e.g., Teimoorinia et al. 2022), classification of images (e.g., Gupta et al. 2022; Holwerda et al. 2022), estimation of physical parameters of galaxies (Hemmati et al. 2019; Davidzon et al. 2022), demonstrating their potential as a powerful tool for exploring complex and high-dimensional datasets.
In this perspective, we further explore the potential of the SOM to identify unlabeled sources with similar properties by leveraging their proximity to well-defined prototypes in the map, thus demonstrating its usefulness as a tool for unsupervised classification and label propagation in the presence of incomplete or uncertain labels.
The paper is organized as follows. In Sect. 2, we describe the data used for this work, while in Sect. 3 we present the methodology applied. In Sect. 4, we discuss the results, and finally in Sect. 5 we draw our conclusions.
2 Data
For our study, we utilized the same dataset as employed in several previous works (see for instance De Cicco et al. 2019, 2021, 2022 and Cavuoti et al. 2024). This dataset comprises r-band observations of the COSMOS field, obtained using the VST over three observing seasons from December 2011 to March 2015. These observations are part of a long-term initiative to monitor the LSST Deep Drilling Fields prior to the commencement of Vera Rubin Telescope operations.
The VST, a 2.6-meter optical telescope, covers a Field of View (FoV) of 1 square degree with a single pointing (pixel scale: 0.214″/pixel). The dataset encompasses a total of 54 visits across three observing seasons, with two intervening gaps.
The r-band observations were originally designed with a three-day observing cadence, although the actual cadence was subject to observational constraints. The single-visit depth reaches r ≲ 24.6 mag for point sources, at a ~5σ confidence level; this is comparable to the single-visit depth of r ~ 24.7 mag expected for LSST images, which makes our dataset particularly valuable for studies aimed at forecasting LSST performance. We note that, in spite of the mentioned single-visit depth, we limit our analysis to sources with r ≲ 23.5 mag in order to minimize the inclusion of sources with noise-affected light curves. For details on the reduction and combination of exposures, performed using the VST-Tube pipeline (Grado et al. 2012), as well as source extraction and sample assembly, we refer the reader to De Cicco et al. (2015). The VST-Tube magnitudes are expressed in the AB system.
Our sample contains 20 647 sources detected in at least 50% of the dataset visits (i.e., having a minimum of 27 points in their light curves), with an average magnitude of r ≤ 23.5 mag within a 1″-radius aperture. For a sub-sample of 2414 objects there is the availability of labels, and each object is labeled as Star, Galaxy or AGN. Beside that, we have additional subclassification available for 414 objects: this was obtained from several works from the literature and was already used in De Cicco et al. (2021, 2022). Specifically, we have the following labels, even if more than one of them can be associated to the same source: Type 1 (225 objects), Type 2 (122 objects), MIR AGNs (225 objects), variable (259 objects), and X-ray (362 objects). These labels reflect the technique used to identify our AGNs LS. Indeed, no AGNs selection technique is complete, and each one presents both strengths and limitations. Type 1 and Type 2 AGNs in this sample were identified via optical spectroscopy, but these sources are a subsample of the X-ray AGNs in this same LS, which come from the Chandra-COSMOS Legacy Catalog (Marchesi et al. 2016). Hence, these are X-ray emitting sources with an optical counterpart, and they were classified as either AGNs type on the basis of the presence (Type 1) or absence (Type 2) of broad (i.e., ≥2000 km s-1) emission lines in their spectra. This is quite a traditional criterion and, as such, it is quite strict, while we are now aware that the spectroscopic features of AGNs may change in time (e.g., MacLeod et al. 2016; Ricci & Trakhtenbrot 2023); nevertheless, this basic scheme is still widely used to broadly split these sources in two classes. The MIR AGNs sample was obtained via a selection criterion defined in Donley et al. (2012), where they identify a typical AGN locus in a diagram comparing the two MIR colors log(F[8.0] μm/F[4.5] μm) and log(F[5.8] μm/F[3.6] μm). In our work the MIR information was obtained from the mentioned COSMOS2015 catalog (Laigle et al. 2016), and the variable AGNs sample comes from De Cicco et al. (2021). See also Section 4 of De Cicco et al. 2019 for additional details. The most intriguing type of AGNs in the contest of this work are Type 2, since their optical emission is typically harder to detect compared to Type 1 AGNs. There is indeed a general consensus that AGNs possess a disk-like structure, and that their observed properties are, at least in part, the result of orientation effects (e.g., Antonucci 1993; Urry & Padovani 1995). Emission at different wavelengths arises from physically distinct regions located at varying distances from the central supermassive black hole (e.g., Netzer 2015, and references therein). Type 2 AGNs are viewed approximately edge-on, which implies that the opti-cal/UV emission from the accretion disk - typically responsible for the optical variability we are interested in - is at least partially obscured by the infrared-emitting dusty torus located farther out. While other selection methods may be more effective in identifying Type 2 AGNs, optical variability remains a powerful approach due to its ease of application in wide-field surveys.
We refer to the portion of the dataset with labels as the labeled set (LS) and to the remaining part as the unlabeled set (US). Following the approach of De Cicco et al. (2021), we made use of multiple features extracted as described in Sánchez-Sáez et al. (2021), and listed in Table 1.
In Figure 1, we show the distributions of four selected features: ηe, u-B, StetsonK, class_star_hst. These features were chosen to illustrate that, while certain AGNs occupy regions of the parameter space not populated by stars or galaxies, a substantial number of them remain indistinguishable based solely on a limited set of features. This highlights the need to consider the full multi-dimensional feature space, where class separability may be more pronounced.
 |
Fig. 1 The distributions of four features in the dataset: ηe, u-B, Stet-sonK, class_star_hst. |
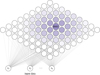 |
Fig. 2 Schematic representation of the SOM structure, where the input data vector is directly passed to the neurons through the weights, then the adaptation apply to the BMU and its neighbors. |
3 Method
We used a SOM (Kohonen 2001) to characterize the multidimensional feature space obtained as described in Section 2, adopting the python package MiniSOM (Vettigli 2018). ASOM is a helpful tool primarily used for dimensionality reduction and data visualization (Kohonen 2013), which belongs to the unsupervised learning domain. It projects the input parameter space onto a lower dimensional grid, a two-dimensional structure in its original form (Kohonen 2001), although some other topologies exist (e.g., Zin 2014). The grid consists of a m × n array of nodes, or neurons, as can be seen in Fig. 2. Each neuron is represented by a weight vector w that has the same dimension d of the input data. Unlike traditional neural networks using backpropagation, the SOM uses competitive learning to represent the dataset. For a given input vector x randomly chosen from the data, the best matching unit (BMU) is found as the neuron that “wins” the competition because its weight vector is closest to the input vector, given by:
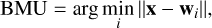 (1)
(1)
where ||·|| is the Euclidean norm. After finding the BMU, the weight vector of the BMU is updated in order to be dragged closer to the data point, together with the weight vectors of the
neurons within a “neighborhood radius”, which are also updated according to the neighborhood function adopted:
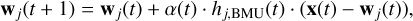 (2)
(2)
where wj(t) is the weight vector of neuron j at time t, α(t) is the learning rate at time t, hj,BMU(t) is the neighborhood function, which depends on the distance between neuron j and the BMU and decreases over time, x(t) is the input vector at time t. The idea behind this update is that neurons close to the BMU will absorb some of the information provided by the input stimulus, x, through a process of shifting (or migrating) their weights toward the input. This process is repeated for many iterations during which the magnitude of the change depends on how much all neurons are as close as possible to the input data, and decreases also with time. Since the objective of the training process is to position nodes with similar weights close to each other on the map, preserving the topological structure of the input space, for assessing the quality of a SOM it is useful to measure the quantization error and the topographical error. Quantization error is the average distance between the input data points and the corresponding BMU of the map (Kohonen et al. 2009):
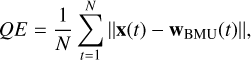 (3)
(3)
where x(t) represents the input data sample at the training t, wBMU(t) is the weight vector of the BMU associated with the input data x(t), N is the total number of input data, and ||·|| is the Euclidean norm. Lower values of the quantization error indicate a better accuracy of the represented data. Topographic error measures how well the topographic structure of the data is preserved on the map (Bauer et al. 1999; Kiviluoto 1996). The SOM is expected to maintain the neighborhood relationships of the input data, meaning that if two vectors are close in the input space then they should be mapped into neighboring neurons in the SOM. Mathematically, the topological error is the proportion of input vectors for which the first and the second BMUs are not adjacent in the SOM grid. It is given by the following expression:
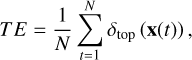 (4)
(4)
where N is the total number of input vectors, δtop(x(t)) is a step function δtop (x(t)) = 1 if the closest and the second closest BMU for x(t) are not adjacent, otherwise δtop(x(t)) = 0. Low topological errors means that the SOM preserves the structure of the input space better (Uriarte & Martín 2005).
The performance of the SOM could be affected by the choice of different hyper-parameters for the training, such as the number of neurons, the number of training iterations (or epochs), the learning rate, and so on. With a smaller number of epochs the SOM may not have enough time to properly adjust the neurons’ weights. This could lead to a poor representation of the input data, and both the quantization and topological errors would be high. On the contrary, an excessive number of epochs may lead to overfitting, where the map becomes too finely tuned to the training data, possibly capturing noise or small fluctuations that are not meaningful. Also adopting a large number of nodes the SOM may lead to overfitting, while with a lower number of nodes the SOM may lack sufficient resolution to properly represent the input data and may fail to preserve topological relationships, resulting in high quantization and topological errors.
As aforementioned, this process is unsupervised. Unlike traditional neural networks, where the weights are optimized in order to match output labels, the SOM learns to differentiate and distinguish features based on similarities, grouping them in a final lower-dimensional space. The presence of labeled data in our dataset is only used for easier interpretation of the SOM results. By identifying the labels of the input data which populate specific neurons of the SOM, one could establish the nature of the clusters, associating them with known categories. For this reason, the SOM can be used also as a tool for visualizing the dataset in a 2D representation, and as a canvas where the features distribution can be mapped on. Furthermore, once the SOM has been trained on the entire dataset, the labeled data can also be used to assign a likely label to each neuron of the map. This allows the neuron labels to be propagated to similar input vectors that have been mapped to the same neurons (Song & Hopke 1996). In this way, we can benefit of the advantages of both the unsupervised learning (i.e., identifying patterns and structures in the data) and the supervised learning (i.e., label prediction).
List of all the features used for the experiments.
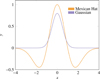 |
Fig. 3 Gaussian and Mexican hat functions. |
Identification of optimal hyper-parameters
In this section, we discuss the selection of hyper-parameters for the training of our SOM:
the number of epochs;
the neighborhood function;
the size of the map.
In particular, we performed a grid search to optimize two key hyper-parameters of the SOM: the map size and the number of training epochs. The map size is free to vary in the range 4-60 to explore different levels of resolution in the clustering structure, while the number of epochs ranged from 100 to 2000, in steps of 100, to ensure sufficient convergence without overfitting. To further evaluate the robustness of the training process, the grid search has been conducted using two commonly adopted neighborhood functions: the Gaussian and the Mexican hat (see Fig. 3). This systematic exploration allowed us to identify the configuration that provides the most stable and interpretable organization of the input space.
The Gaussian function is a common choice for a neighborhood function, where the influence of the BMU decreases gradually with the distance. Given its shape, this function is particularly beneficial when dealing with data that require a gradual transition between neighboring units, providing a more robust learning process. On the contrary, the Mexican hat:
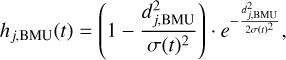 (5)
(5)
where dj,BMU is the distance between the neuron j and the BMU and σ(t) is the neighborhood radius that decreases over time, penalizes neighbors that are farther from the BMU: while the neurons close to the BMU are excited, those ones farther away experience negative influence, allowing for sharper boundaries between regions in the map. This function can have some advantages when working with datasets having distinct clusters, as it facilitates a more defined separation between them. However, it can also lead to instability when dealing with a sparse dataset.
For the purpose of this paper, we do not include all the plots of the results obtained with the grid search. Instead, we show a summary plot reporting the distribution of both quantization and topographic errors as a function of the SOM map size, evaluated for three different numbers of training epochs: 200, 1100, and 1700. These values have been selected to represent different regions of the tested range (100-2000 iterations), with 200 and 1700 close to the extremes and 1100 as it has been our final choice. Figure 4 displays these results assuming a Gaussian (top panel) and a Mexican hat (bottom panel) as neighborhood function. It is worth noting that the analysis performed shows that the Mexican hat does not fit well with our starting dataset, and this is particularly evident from the distribution of the topographic error which is almost always constant around one. Therefore, we decided to train a SOM on our dataset adopting a Gaussian function, the number of epochs equal to 1100, and a map size of 9 × 9, since the combination of these parameters seems to preserve the data topology and minimize the distance between data points and their corresponding BMUs.
 |
Fig. 4 Distribution of the quantization error (QE, represented in different shades of green) and topographic error (TE, represented in different shades of purple) as a function of the map size of the SOM, assuming as neighborhood function a Gaussian (top panel) and a Mexican hat (bottom panel). In each plot, the number of training epochs is set to 200 (diamond markers), 1100 (circles) and 1700 (squares), respectively. The dotted line represents the optimal SOM size for representing our dataset with 1100 training epochs. |
4 Experiments/results
In this section we present five experiments on the SOM behavior concerning the usage of different sets of features. The first experiment considers all the variability features with the addition of the optical colors (see Table 1). We refer to this experiment as the Main Experiment. This initial experiment establishes the reference framework for the construction of the other feature sets, as explained in detail in the following sections.
 |
Fig. 5 Activation map of the Main Experiment. A pie chart representing the distribution of labels has been overlaid on each cell of the map. For each cell, it has been indicated: the number of galaxies (GAL), the number of stars (STAR), and the number of AGNs, from the LS; the number of unlabeled objects (Δ); the total number of labeled and unlabeled objects (TOT). The background color intensity reflects the number of objects falling in the cell. |
4.1 Main Experiment
In this experiment, we ran a SOM on the whole dataset, labeled and unlabeled, using the parameters as explained in Section 3, and normalizing it using the MinMaxScaler1. The first output of the SOM is the activation map. In this map, each cell corresponds to a specific neuron of the SOM and the value indicates how frequently each neuron is selected as the BMU for the input data. The higher this value, the more times that neuron has been the BMU for some input data, meaning a higher similarity for these data points. On the contrary, lower values may represent outliers or less frequent patterns in the dataset. In Figure 5, we show the activation map obtained for the this set of features2. We overlaid a pie chart on each cell of the map, representing the distribution of labels for the portion of the dataset where the target is known. This allows one to visualize whether the cells contain objects that share the same label, and understanding the relationship between their features and the labels. Additionally, we specified the total number of the objects (labeled and unlabeled), and the unlabeled objects (Δ) falling into each cell. In this perspective, we can infer that unlabeled objects may receive the same label as those within the same neuron, by assuming that items within the same neuron may share similar characteristics and, therefore, the same label.
In this figure, it is possible to observe how most of the known AGNs are distributed in the lower right part of the map, remaining quite uncontaminated by stars and galaxies. Another isolated group of 22 AGNs is positioned in the neuron (2,5)3, contaminated by only one galaxy-type object, while only 3 more AGNs are positioned in the cell (0,7). For the remaining neurons, it is evident that the majority of stars are positioned in the left and central part of the map, while galaxies tend to occupy the opposite space.
It is interesting to investigate how the features are involved within each neuron. For this purpose, we calculated the mean and the standard deviation of each feature within the whole map, which we refer to as the global mean and the global standard deviation. Beside, we calculated the mean and the standard deviation of each feature within the single cell, and which we refer to as the local mean and the local standard deviation. Figure 6 shows the distributions of the feature means (hereinafter, FMD) in each neuron.
In particular, features are plotted in red if the local mean in that cell deviates from the global mean by twice the global standard deviation. A primary observation, based on the comparison between these figures and the corresponding activation maps (in Figure 5), is that in all the neurons where AGNs are present, the FMD presents many features in red, meaning that the values of the corresponding objects are highly different and far from the global average. In cells with a majority of AGNs, the photometric colors (which correspond to the last five features) never show a significant difference with respect to the other cells. It is worth noting that the distribution of the mean values of the five colors is quite different for cells with a majority of AGNs, galaxies and stars, respectively. Moreover, there are some features that never become red (thus, they remain within two times the standard deviations from the mean values), as can be seen in the second column of Table 2, corresponding to the Main Experiment row. In particular, they are: Pvar, indicating the probability that a source is intrinsically variable, AndersonDarling, indicating whether a sample of data comes from a population with a specific distribution, Skewness (Skew) and its medianbased measure (Gskew), the slope of a linear fit to the light curve (LinearTrend), the HST stellarity index (class_star_hst), and the four colors i-z, B-r, u-B, z-y. The method presented here seems to effectively separate galaxies from stars, as evidenced by Figure 5.
 |
Fig. 6 Main Experiment. Distribution of the feature means when considering all the features. In each neuron it is represented the local mean of each features, and the error bars correspond to the local standard deviations. The plotted features are in red when their local mean deviates from the corresponding global mean by twice the global standard deviation. The vertical dashed lines are placed after every five features (e.g., at feature 4,9,14...29) to facilitate reading the plot. Order of the features: 0) ASF, 1) γSF, 2) GP_DRW_τ, 3) GP_DRW_σ, 4) ExcessVar, 5) Pvar, 6) IARφ, 7) Amplitude, 8) AndersonDarling, 9) Autocor_length, 10) Beyond1Std, 11) ηe, 12) Gskew, 13) LinearTrend, 14) MaxSlope, 15) Meanvariance, 16) MedianAbsDev, 17) MedianBRP, 18) PeriodLS, 19) PairSlopeTrend, 20) PercentAmplitude, 21) Q31, 22) Period_fit, 23) ΨCS, 24) Ψη, 25) RCS, 26) Skew, 27) Std, 28) StetsonK, 29) class_star_hst, 30) i-z, 31) r-i, 32) B-r, 33) u-B, 34) z-y. |
“Never red features” and “Red features”.
4.2 Exploring different sets of features
Starting from the results obtained in the Main Experiment, we defined the following feature subsets to enable a more in-depth analysis. First, we selected as a subset only those features that, in the Main Experiment, appeared in red in the FMD. We refer to this subset as the Red Experiment.
Next, we examined the correlations among the features used in the Main Experiment (and shown in Fig. 7) and identified pairs of highly correlated features (absolute Pearson correlation > 90%). To reduce redundancy, we excluded the following features: PercentAmplitude, Meanvariance, Std, ExcessVar, and retained their correlated counterparts: Q31, Amplitude, Median-AbsDev, GP_DRW_sigma. Based on this selection, we defined two additional subsets: Main - correlated Experiment and Red - correlated Experiment.
Furthermore, we incorporated insights from De Cicco et al. (2019), where a random forest experiment identified a set of features as particularly relevant for the same dataset. As a fifth feature subset, we considered the union of the Red - correlated set and the top ten features from De Cicco et al. (2019), excluding any features that were among the previously identified highly correlated pairs part of highly correlated pairs. We refer to this combined set as Red - correlated + top Experiment.
Finally, we added the feature Ch21 (namely, the color obtained as Spitzer 4.5 μm (channel2) mag - 3.6 μm (chan-nel1) mag) as an extra feature to all the previous sets, to analyze its effect on the outcome of the experiments4. The comparative results will provide insights into the importance of colors and Ch21 in the context of AGNs detection.
Table 3 resumes the different sets of features adopted for the future experiments. Once the feature subsets have been defined, we ran the SOM on each of the datasets. To ensure the robustness of our results and reduce the impact of random initialization, we generated one hundred different random seeds and used them to initialize the SOM in each run. To objectively evaluate the performance of each experiment, we computed a set of key classification metrics during every run, focusing on four main indicators: Completeness Type 1, Completeness Type 2, Pureness AGNs, and Completeness AGNs. The boxplot shown in Figure 8 presents the distribution of metric values across the one hundred SOM seeds used in the analysis, providing an estimate of variability due to initialization. From the plot, it is evident that some experimental setups achieve both high median performance and low variability for multiple metrics. In contrast, other setups show more pronounced spread or lower overall performance, suggesting less stable or suboptimal behavior under the current feature subsets.
This comparative visualization clearly highlights the configurations that deliver the most consistent and high-performing results across repeated SOM initializations. Based on a thorough evaluation, we identified Red - corr. + top and Red - corr. + top + Ch21 as the most robust and effective feature sets, and therefore selected them for further analysis.
 |
Fig. 7 Matrix of correlations among all the features adopted in the Main Experiment. |
Sets of features adopted in the different experiments.
 |
Fig. 8 Distribution of the calculated metrics for each experimental configuration. Each colored box represents one of the four metrics: red for Completeness Type 1, green for Completeness Type 2, orange for Pureness AGNs, and blue for Completeness AGNs. Vertical dashed lines correspond to the median values obtained in the best selected experiment (Red - corr. + top Experiment), allowing a direct visual comparison. |
4.3 Red - corr. + top Experiment
Once the most suitable feature subsets for our analysis were identified, the next step was to select a representative random seed from those previously generated, in order to obtain results aligned with the average performance. As is shown in the boxplot in Figure 8, some seeds lead to either notably higher or lower metric values, potentially biasing the interpretation of the results. To mitigate this effect and ensure a fair representation, we selected seed = 188, which produced results closely matching the overall average, to initialize the SOM for subsequent analyses.
At this stage, we proceeded to run the SOM on the entire dataset, including both labeled and unlabeled data, using the same parameters adopted in the Main Experiment for consistency. The dataset was normalized using the MinMaxScaler. The top panel of Figure 9 shows the activation map obtained in this experiment, where each cell of the map is overlaid by a pie chart, representing the distribution of labels for the portion of the dataset where the target is known. As described in the previous sections, this representation is useful as it reveals distinct clusters that correspond to underlying patterns within the dataset.
In this panel, it can be seen that most of the known AGNs are clearly concentrated in the lower left region of the map, where they form a compact group with minimal contamination from stars and galaxies. This indicates that the SOM has effectively captured the key discriminative features that distinguish AGNs from the other classes, thereby providing a valuable region of interest for identifying potential AGN candidates among the unlabeled data. Beyond this AGN-rich zone, stars are predominantly grouped in well-defined clusters in the central part of the SOM. The distribution of the galaxies, on the other hand, is more scattered although some degree of local clustering is still observable, indicating some underlying substructure in the input feature space. Among them, four neurons are peculiar for their population: neurons (2,7) and (5,7), have inside only one labeled AGN each, with the rest of the objects being unlabeled. Additionally, neurons (4,6) and (5,8) host only two and four labeled sources, respectively, equally split between AGNs and galaxies, suggesting a more ambiguous region of the map where class boundaries might overlap.
With the bottom panel of Figure 9 it is possible to examine our results from another perspective. In this figure, in addition to the pie charts on the activation maps, we have specified the number of AGNs labeled as Type 1, Type 2, X-ray, MIR, and optically variable, respectively.
It is worth noting that, if we examine only cells with a majority of AGNs, Type 1 are quite separated from galaxies, as reported by De Cicco et al. (2021). In fact, we found that 212 Type 1 objects (~94%) are located in neurons mostly filled by AGNs, while only 31 Type 2 objects (~25%) are found in these cells. It is evident that the percentage of non-AGN objects is quite low (~2%). This indicates that contamination from non-AGN objects is minimal and, while the completeness for Type 2 objects is low, the completeness for Type 1 objects is remarkably high. A summary of these findings is reported in Table 4 (third column), along with a comparison to the average performance metrics obtained across the 100 random seed runs (second column).
As was previously discussed, we extended the experiment by including the Spitzer color Ch21 among the features. To ensure a fair comparison, the SOM was trained using the same configuration parameters as in the previous experiment, with the sole exception of the random seed. In this case, the seed was selected to produce results that closely align with the mean performance observed across the one hundred random initializations. For this purpose, we adopted seed = 2. In particular, 210 Type 1 objects (~93%) are located in neurons predominantly populated by AGNs, and only 31 Type 2 objects (~25%) are found in these cells. As in the previous experiment, the fraction of non-AGN objects remains low (~2%), suggesting a low contamination from stars and normal galaxies. These results are summarized in the last two columns of Table 4, where it is evident that the inclusion of Ch21 in the feature set does not lead to any significant improvement in the results. On the contrary, the metrics remain essentially unchanged, suggesting that the SOM does not exploit this additional feature to discriminate the different objects.
In this case we also built the FMD in order to verify the presence or absence of red features, i.e., those features whose values of the corresponding objects are strongly different and far from the global mean. As can be seen from the Figure 10, the red features are present in the cells with a majority of AGNs. The reader should note that this experiment had already started with the red features obtained from the Main Experiment (i.e., the one that included all the features at our disposal). Furthermore, only a group of this subset continues to become red, as can be seen in the Table 2 in correspondence of the Red - corr. + top Experiment.
After excluding the highly correlated features from the second feature set, and considering the addition of the most relevant features identified by De Cicco et al. (2021), several observations can be made. First, when comparing the features that never turn red in both experiments, it becomes evident that the color indices B-r and u-B consistently fall below the threshold used for highlighting features in red. The same can also be said for Pvar and class_star_hst, which similarly do not appear to reach the activation levels required for red marking in this context. Moreover, when using the reduced feature set, we observe that PairSlopeTrend also becomes a feature that is never marked as red. Lastly, within the group of red features in common across both the experiments, Period_fit and the color r-i emerge as shared key indicators, further reinforcing their relevance in the separation of the different object types.
For a better evaluation and analysis of these results, in Figure 11 we show the distribution of the mean values of both red and never red features, for cells mostly populated by AGNs. Features of neighboring cells have similar behaviors as expected from a SOM. However, neuron (0,0), which has a large fraction of Type 2, shows significant differences in some features. In particular, the objects populating this neuron show a significantly smaller value of class_star_hst (feature 19 in the radar plot) than the others. From an observational point of view, Type 2 sources are generally more extended, which is likely a selection effect, since the nucleus is often obscured by the surrounding dust near the accretion disk, limiting our ability to observe it clearly at high redshift. On the contrary, this feature exhibits high values for both AGNs- and stars- dominated cells. Moreover, the Pvar (feature 20) shows exceptionally high values in almost all cells with an AGNs majority, reflecting their inherent and significant luminosity variability driven by accretion processes around their supermassive black holes. Conversely, we observed very low values of Pvar for both stars and galaxies, as these objects are typically considered photometrically stable. Exceptions to these typical Pvar values observed in AGNs-dominated cells are found in neuron (2,7), and to a lesser extent in neuron (5,7). It is worth noting that neurons (2,7) and (5,7) each contain only one labeled AGN, implying limited statistical significance in evaluating their labeled composition. Nevertheless, from the same cells it can be noted how the behavior of the unlabeled objects is completely similar to the single labeled AGN. This highlights a key strength of the SOM as an unsupervised method: it allows one to capture and explore such patterns and similarities regardless of the availability of labeled data. A supervised approach, in contrast, would likely have required a larger number of labeled examples to recognize or validate these associations. Both cells exhibit feature patterns that are atypical from the rest of AGNs-dominated neurons, such as the missing structure in correspondence of ψCS (feature 13), ψη (feature 14), and RCS (feature 15). Most of the AGNs-dominated neurons shows, in fact, low values of ψη, a quite different behavior from the other cells in which stars and galaxies are dominant, suggesting that AGNs dominated sources typically exhibit less short-term variability (ψη low) but more coherent and wide-ranging longterm changes (ψCS and Rcs high) compared to others. Finally, neuron (5,7) shows higher values for the color r-i (feature 17), also observed in other star-dominated neurons (see, for example, the star component represented in orange in cell (2,1). This suggests that while AGNs typically exhibit bluer colors, these specific neurons are sensitive to objects where the contribution from redder and cooler populations is more prominent, further supporting the idea that these cells host peculiar sources isolated by the SOM.
The method presented here seems to effectively separate galaxies from stars, as evidenced by Figure 9. Remarkably, this separation persists even without incorporating the Spitzer color Ch21 information in the training process, suggesting that we can perform the classification based on variability and morphological features alone.
 |
Fig. 9 Activation maps of the Red - corr. + top Experiment, overlaid by a pie chart representing the distribution of labels (top panel) and the available subclasses for AGNs (bottom panel). |
Summary results of the experiments in terms of completeness of Type 1, Type 2, and purity of AGNs.
 |
Fig. 10 Red-corr. + top Experiment. Distribution of the feature means (FMD). In each neuron it is represented the local mean of each features, and the error bars correspond to the local standard deviations. The plotted features are in red when their local mean deviates from the corresponding global mean by twice the global standard deviation. The vertical dashed lines are placed after every five features (e.g., at feature 4, 9, 14, 19) to facilitate reading the plot. Order of the features: (0) ASF, (1) γSF, (2) ExcessVar, (3) IARφ, (4) Autocor_length, (5) Beyond1Std, (6) ηe, (7) MaxSlope, (8) MedianAbsDev, (9) MedianBRP, (10) PeriodLS, (11) PairSlopeTrend, (12) Period_fit, (13) Ψcs, (14) Ψη (15) RCS, (16) StetsonK, (17) r-i, (18) u-B, (19) class_star_hst, (20) Pvar, (21) B-r. |
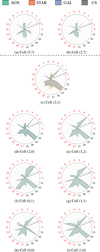 |
Fig. 11 Distribution of the mean values per neuron of both red and never red features. Results are reported for neurons with an AGNs majority. The top cells (2,7) and (5,7) are separated by the dotted line as they each contain only one labeled AGN. The reader should note that the feature order is chosen to separate red from never-red features. Indexes of features: 0) ASF, (1) γSF, (2) ExcessVar, (3) IARφ, (4) Autocor_length, (5) Beyond1Std, (6) ηe, (7) MaxSlope, (8) Medi-anAbsDev, (9) MedianBRP, (10) PeriodLS, (11) PairSlopeTrend, (12) Period_fit, (13) ΨCS, (14) Ψη, (15) Rcs, (16) StetsonK, (17) r-i, (18) u-B, (19) class_star_hst, (20) Pvar, (21) B-r. |
4.3.1 AGNs “stability” within the SOM
To strengthen the robustness of the results obtained in the Red -corr. + top Experiment, we conducted an analysis to determine which kind of objects consistently populate the cells dominated by AGNs. This assessment serves a dual purpose: first, to evaluate the stability and consistency of the experiment; second, to assess whether the presence of objects in the AGNs-majority cells is due to a systematic pattern or merely to random association.
Specifically, the analysis focused on identifying those Type 1 and Type 2 AGNs that, across 100 experiments performed with different random seeds, frequently appear in cells with a majority AGNs population. The results show that a significant number of Type 1 AGNs (198 objects) populate AGNs-majority cells in more than 90 out of the 100 experiments. An additional 9 Type 1 appear in AGNs-majority cells in 70-90 experiments, while only 15 Type 1 AGNs are found in such cells in fewer than 70 experiments. Once these objects were identified, we examined which cells they populate in the experiment presented above using seed = 188. Figure 12 maps their presence within the AGNs-majority cells, indicating how many of these objects populate each neuron. As can be seen, the AGNs-majority cells are mostly populated by the same Type 1 objects, while the more “unstable” ones are the objects that end up in cells contaminated by stars or galaxies. It should be noted that the totals reported per cell do not necessarily correspond to the number of Type 1 objects shown in Figure 9, as these frequencies pertain exclusively to cells that exhibited a majority of AGNs in all the 100 experiments.
Similarly, we performed the same analysis for Type 2 AGNs. The results show that only 29 Type 2 AGNs populate AGNs-majority cells in more than 90 out of the 100 experiments, none appear in AGNs-majority cells between 70 and 90 experiments, and 17 Type 2 AGNs are found in such cells in fewer than 70 experiments. Then, we mapped their distribution across AGNs-majority cells in the experiment with seed = 188. The results, shown in Figure 13, reveal that 13 of the 29 objects cluster together in the unique “uncontaminated” neuron with a Type 2-majority (0,0), while 7 of the objects identified in fewer than 70 experiments are grouped in cell (8,4). Although cell (8,4) is a Type-2 majority neuron (see bottom panel of Figure 9), it is notably populated by 65 known galaxies and 526 unlabeled objects (see top panel of Figure 9).
An analysis of the features for the 13 Type 2 and 6 Type 1 sources located in cell (0,0) reveals that their distributions are typically found in the tails, rather than near the peaks, of the corresponding LS distributions. Notably, they show particularly high values of both Pvar and IARφ, which are indicative of strong and structured variability. Such behavior may suggest the presence of highly active or irregular processes, potentially associated with obscured or atypical AGNs activity.
Overall, the analysis highlights a clear difference in behavior between Type 1 and Type 2 within the AGNs-majority cells. Type 1 AGNs exhibit a highly consistent presence, with the vast majority populating AGNs-majority neurons across almost all experiments, suggesting a robust and well-defined clustering pattern. In contrast, Type 2 AGNs show a more scattered distribution with fewer objects consistently associated with AGNs-majority cells, reflecting more complex intrinsic differences in the feature-based representation between Type 1 and Type 2.
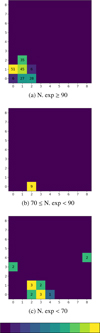 |
Fig. 12 Distribution of the most recurrent Type 1 AGNs within the AGNs-majority cells of the map obtained with seed = 188. The color scale indicates the number of such objects associated with each neuron. Top panel: Type 1 that populate AGNs-majority cells in more than 90 out of 100 experiments. Middle panel: Type 1 that populate AGNs-majority cells in 70 to 90 experiments. Bottom panel: Type 1 that populate AGNs-majority cells in fewer than 70 experiments. |
 |
Fig. 13 Distribution of the most recurrent Type 2 AGNs within the AGNs-majority cells of the map obtained with seed = 188. The color scale indicates the number of such objects associated with each neuron. Top panel: Type 2 that populate AGNs-majority cells in more than 90 out of 100 experiments. Bottom panel: Type 2 that populate AGNs-majority cells in fewer than 70 experiments. |
Distribution of sources across AGNs-majority cells of the SOM.
4.3.2 Label propagation in the AGNs dominated cells
Several cells predominantly containing AGNs also include unlabeled sources that exhibit AGN-like characteristics, particularly in their variability features. This pattern suggests that these unlabeled sources could potentially be AGNs, warranting further investigation.
As was previously mentioned, in a SOM, each cell corresponds to a neuron represented by a weight vector, whose length matches that of the input data (i.e., the number of features used for training). This weight vector acts as a prototype for all the objects for which the neuron is the BMU. To better characterize the AGNs-majority cells and strengthen the reliability of our analysis, it is useful to identify the object closest to the prototype for each neuron. After determining the prototypes for all cells, we identified both the closest labeled and unlabeled object to each prototype. For AGNs-majority cells, we then verified whether the labeled object was itself classified as an AGN, and, for the unlabeled objects, we searched the Simbad database5 to determine if any of these sources had been independently identified as AGN.
The results of this analysis are summarized in Table 5, which provides an overview of the distribution of both labeled and unlabeled sources across AGNs-majority cells. For each cell, we report the number of labeled objects, the coordinates and classification of the closest labeled source, as well as analogous information for the unlabeled population, including the SIMBAD classification. Sources marked with an asterisk indicate whether they are the overall closest to the prototype when considering both labeled and unlabeled data.
This detailed mapping allows us to validate the consistency of the SOM representation. In particular, the fact that the nearest labeled sources are predominantly AGNs strengthens our confidence in the ability of the map to capture meaningful structure in the feature space. Moreover, the identification of unlabeled sources with similar characteristics, and in some cases classified as confirmed AGNs in Simbad independent studies, opens the possibility for discovering new AGN candidates.
5 Conclusions
Our analysis explored the effectiveness of using SOMs to classify AGNs within the COSMOS field, examining the roles of different feature sets based on variability, as well as the impact of including the Spitzer color (Ch21) as an additional feature. Once the best feature subset (Red - corr. + top Experiment) have been defined through the study of four main indicator (Completeness Type 1, Completeness Type 2, Pureness AGNs, and Completeness AGNs), we ran the SOM with a fixed random seed and analyzed the results. Below are the primary insights and conclusions drawn from our experiments:
AGN completeness and Purity: In the Red - corr. + top Experiment with 100 random seeds, the SOM achieved a purity of (97.5 ± 1.6)%. Completeness rates varied by AGNs type, with Type 1 objects showing a high completeness of (93.2 ± 2.6)%, while Type 2 AGNs were less complete (25.0 ± 1.4)%, consistent with previous findings about the difficulty of distinguishing Type 2 AGNs without extensive spectral data.
Role of Ch21: While the addition of Ch21 provided subtle shifts in the results, it did not significantly alter the core results of all the experiments. This suggests that while Ch21 adds value, it does not distinctly impact AGNs classification when used in conjunction with other colors and variability features.
Anomalous cells: Cells containing AGNs showed a different behavior with respect to the cells containing non AGNs in some key features, consistent with AGNs behavior. The SOM cells which show outliering behavior in some features often contained primarily AGNs, demonstrating that our variability features are effective indicators within the feature space. This also implies that cells with unlabeled sources but significant difference in terms of features could contain still unknown AGN candidates.
Unlabeled set: Several cells with a majority of AGNs contained also unlabeled sources displaying hence AGN-like characteristics (e.g., similar variability features). This suggests they may indeed be AGNs, warranting further investigation. For such SOM cells we explored in literature, through the Simbad database, if the US sources closest to the prototypes of these cells have been flagged as AGN (see Table 5). The results show that most of them are AGNs, which supports the reliability of the classification in these cells and suggests that also the other sources falling in those cells maybe worth to be considered at least as candidate AGNs.
Comparative results: Compared to previous works (See Table 5 of De Cicco et al. 2021), our SOM-based classification method provides interesting results in purity, being able to achieve a result ~40% better at the price of a decrease in terms of completeness of about ~12%, mostly due to a decrease in completeness of ~5% of Type 2. This approach benefits from unsupervised learning’s ability to identify patterns without predefined labels, potentially enhancing AGNs detection rates and reducing contamination compared to traditional supervised methods, suffering also of the unbalancing of the data.
Summary: The SOM-based approach shows significant promise for AGNs classification in large, complex datasets, especially through the use of variability features. Our results demonstrate a relatively efficient separation of Type 1 AGNs, stars, and galaxies, while the identification of the more elusive Type 2 remains a challenge, reflecting a known limitation in AGNs studies. Future work will focus on refining the feature set and expanding the unlabeled dataset, with the aim of improving the representation of the full AGNs population and enhancing classification performance in preparation for next-generation large-scale surveys such as LSST.
Acknowledgements
The authors thank the anonymous referee for the valuable comments and suggestions that have improved the quality of this manuscript. This paper is supported by Italian Research Center on High Performance Computing Big Data and Quantum Computing (ICSC), project funded by European Union - NextGenerationEU - and National Recovery and Resilience Plan (NRRP) - Mission 4 Component 2 within the activities of Spoke 3 (Astrophysics and Cosmos Observations). DD acknowledges PON R&I 2021, CUP E65F21002880003. DD and MP also acknowledge the financial contribution from PRIN-MIUR 2022 and from the Timedomes grant within the “INAF 2023 Finanziamento della Ricerca Fondamentale”. MB, SC and GR acknoweldge the ASI-INAF TI agreement, 2018-23-HH.0 “Attività scientifica per la missione Euclid - fase D” SC and GR acknowledge support from PRIN MUR 2022 (20224MNC5A), “Life, death and after-death of massive stars”, funded by European Union - Next Generation EU. Topcat (Taylor 2005) and STILTS (Taylor 2006) have been used for this work. Some of the resources from Stutz (2022) has been used for this work. Some of the methods used in this work are part of the Scikit package (Pedregosa et al. 2011). The SOM used in this work is part of the python package MiniSOM (Vettigli 2018).
References
- Angora, G., Rosati, P., Meneghetti, M., et al. 2023, A&A, 676, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Antonucci, R. 1993, ARA&A, 31, 473 [Google Scholar]
- Baron, D. 2019, arXiv e-prints [arXiv:1904.07248] [Google Scholar]
- Bauer, H.-U., Herrmann, M., & Villmann, T. 1999, Neural Netw., 12, 659 [Google Scholar]
- Botticella, M. T., Cappellaro, E., Pignata, G., et al. 2013, TM, 151, 29 [Google Scholar]
- Botticella, M. T., Cappellaro, E., Greggio, L., et al. 2017, A&A, 598, A50 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brandt, W. N., Ni, Q., Yang, G., et al. 2018, arXiv e-prints [arXiv:1811.06542] [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [Google Scholar]
- Capaccioli, M., & Schipani, P. 2011, TM, 146, 2 [Google Scholar]
- Cappellaro, E., Botticella, M. T., Pignata, G., et al. 2015, A&A, 584, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cavuoti, S., Amaro, V., Brescia, M., et al. 2017, MNRAS, 465, 1959 [Google Scholar]
- Cavuoti, S., De Cicco, D., Doorenbos, L., et al. 2024, A&A, 687, A246 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Davidzon, I., Jegatheesan, K., Ilbert, O., et al. 2022, A&A, 665, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Cicco, D., Paolillo, M., Covone, G., et al. 2015, A&A, 574, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Cicco, D., Paolillo, M., Falocco, S., et al. 2019, A&A, 627, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Cicco, D., Bauer, F. E., Paolillo, M., et al. 2021, A&A, 645, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Cicco, D., Bauer, F. E., Paolillo, M., et al. 2022, A&A, 664, A117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- De Cicco, D., Zazzaro, G., Cavuoti, S., et al. 2025, A&A, 697, A204 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Djorgovski, S., Graham, M., Donalek, C., et al. 2016, Future Gener. Comput. Syst., 59, 95 [Google Scholar]
- Donley, J. L., Koekemoer, A. M., Brusa, M., et al. 2012, ApJ, 748, 142 [Google Scholar]
- Doorenbos, L., Torbaniuk, O., Cavuoti, S., et al. 2022, A&A, 666, A171 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- D’Isanto, A., Cavuoti, S., Gieseke, F., & Polsterer, K. L. 2018, A&A, 616, A97 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Eyheramendy, S., Elorrieta, F., & Palma, W. 2018, MNRAS, 481, 4311 [Google Scholar]
- Fotopoulou, S. 2024, Astron. Comput., 100851 [Google Scholar]
- Grado, A., Capaccioli, M., Limatola, L., & Getman, F. 2012, MemSAIt, 19, 362 [Google Scholar]
- Graham, M. J., Djorgovski, S. G., Drake, A. J., et al. 2017, MNRAS, 470, 4112 [NASA ADS] [CrossRef] [Google Scholar]
- Gupta, N., Huynh, M., Norris, R. P., et al. 2022, PASA, 39, e051 [Google Scholar]
- Hemmati, S., Capak, P., Pourrahmani, M., et al. 2019, ApJ, 881, L14 [NASA ADS] [CrossRef] [Google Scholar]
- Holwerda, B. W., Smith, D., Porter, L., et al. 2022, MNRAS, 513, 1972 [NASA ADS] [CrossRef] [Google Scholar]
- Huijse, P., Estévez, P. A., Förster, F., et al. 2018, ApJS, 236, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Z., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Jaiswal, A., & Kumar, R. 2023, Multimed. Tools Appl., 82, 18059 [Google Scholar]
- Kim, D.-W., Protopapas, P., Byun, Y.-I., et al. 2011, ApJ, 735, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Kim, D.-W., Protopapas, P., Bailer-Jones, C. A. L., et al. 2014, A&A, 566, A43 [CrossRef] [EDP Sciences] [Google Scholar]
- Kiviluoto, K. 1996, in Proceedings of International Conference on Neural Networks (ICNN’96), 1, IEEE, 294 [Google Scholar]
- Koekemoer, A. M., Aussel, H., Calzetti, D., et al. 2007, ApJS, 172, 196 [Google Scholar]
- Kohonen, T. 2001, Self-organizing Maps, 3rd edn., Springer Series in Information Sciences, 30 (Berlin: Springer) [Google Scholar]
- Kohonen, T. 2013, Neural Netw., 37, 52 [Google Scholar]
- Kohonen, T., Nieminen, I. T., & Honkela, T. 2009, in Advances in SelfOrganizing Maps: 7th International Workshop, WSOM 2009, St. Augustine, FL, USA, June 8-10, 2009. Proceedings 7 (Springer), 133 [Google Scholar]
- Laigle, C., McCracken, H. J., Ilbert, O., et al. 2016, ApJS, 224, 24 [Google Scholar]
- Licen, S., Astel, A., & Tsakovski, S. 2023, STOTEN, 878, 163084 [Google Scholar]
- LSST Science Collaboration (Abell, P. A., et al.) 2009, ArXiv e-prints [arXiv:0912.0201] [Google Scholar]
- MacLeod, C. L., Ross, N. P., Lawrence, A., et al. 2016, MNRAS, 457, 389 [Google Scholar]
- Mahabal, A., Sheth, K., Gieseke, F., et al. 2017, in 2017 IEEE Symposium Series on Computational Intelligence (SSCI), IEEE, 1 [Google Scholar]
- Marchesi, S., Civano, F., Elvis, M., et al. 2016, ApJ, 817, 34 [Google Scholar]
- Maruccia, Y., Cavuoti, S., Crupi, R., et al. 2025, Financ. Innov., submitted [Google Scholar]
- Masters, D., Capak, P., Stern, D., et al. 2015, ApJ, 813, 53 [Google Scholar]
- McLaughlin, M. A., Mattox, J. R., Cordes, J. M., & Thompson, D. J. 1996, ApJ, 473, 763 [Google Scholar]
- Nandra, K., George, I., Mushotzky, R., Turner, T., & Yaqoob, T. 1997, ApJ, 476, 70 [CrossRef] [Google Scholar]
- Netzer, H. 2015, ARA&A, 53, 365 [Google Scholar]
- Nun, I., Protopapas, P., Sim, B., et al. 2015, arXiv e-prints [arXiv:1506.00010] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, JMLR, 12, 2825 [Google Scholar]
- Pei, D., Luo, C., & Liu, X. 2023, Appl. Soft Comput., 134, 109972 [Google Scholar]
- Raiteri, C. M., Carnerero, M. I., Balmaverde, B., et al. 2022, ApJS, 258, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Ricci, C., & Trakhtenbrot, B. 2023, Nat. Astron., 7, 1282 [Google Scholar]
- Richards, J. W., Starr, D. L., Butler, N. R., et al. 2011, ApJ, 733, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez-Sáez, P., Reyes, I., Valenzuela, C., et al. 2021, AJ, 161, 141 [CrossRef] [Google Scholar]
- Schmidt, K. B., Marshall, P. J., Rix, H.-W., et al. 2010, ApJ, 714, 1194 [NASA ADS] [CrossRef] [Google Scholar]
- Scolnic, D. M., Lochner, M., Gris, P., et al. 2018, arXiv e-prints, [arXiv:1812.00516] [Google Scholar]
- Scoville, N., Abraham, R. G., Aussel, H., et al. 2007a, ApJS, 172, 38 [Google Scholar]
- Scoville, N., Aussel, H., Brusa, M., et al. 2007b, ApJS, 172, 1 [Google Scholar]
- Solazzo, G., Maruccia, Y., Ndou, V., & Del Vecchio, P. 2022, Serv. Bus., 16, 417 [Google Scholar]
- Song, X.-H., & Hopke, P. K. 1996, Anal. Chim. Acta., 334, 57 [Google Scholar]
- Soo, J. Y. H., Shuaili, I. Y. K. A., & Pathi, I. M. 2023, in First International Conference on Computational Science & Data Analytics: Incorporating the 1st South-East Asia Workshop on Computational Physics and Data Analytics (CPDAS 2021), 2756 (AIP Publishing), 040001 [Google Scholar]
- Stutz, D. 2022, Collection of LaTeX resources and examples, https://github.com/davidstutz/latex-resources, accessed on 01.01.2024 [Google Scholar]
- Tangaro, S., Amoroso, N., Brescia, M., et al. 2015, CMMM, 2015, https://doi.org/10.1155/2015/814104 [Google Scholar]
- Taylor, M. B. 2005, in Astronomical Society of the Pacific Conference Series, 347, Astronomical Data Analysis Software and Systems XIV, eds. P. Shopbell, M. Britton, & R. Ebert, 29 [Google Scholar]
- Taylor, M. B. 2006, in Astronomical Society of the Pacific Conference Series, 351, Astronomical Data Analysis Software and Systems XV, eds. C. Gabriel, C. Arviset, D. Ponz, & S. Enrique, 666 [Google Scholar]
- Teimoorinia, H., Archinuk, F., Woo, J., Shishehchi, S., & Bluck, A. F. 2022, AJ, 163, 71 [Google Scholar]
- Uriarte, E. A., & Martín, F. D. 2005, AMCS, 1, 19 [Google Scholar]
- Urry, C. M., & Padovani, P. 1995, PASP, 107, 803 [NASA ADS] [CrossRef] [Google Scholar]
- Vettigli, G. 2018, https://github.com/JustGlowing/minisom/ [Google Scholar]
- Zin, Z. M. 2014, in 2014 11th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), IEEE, 163 [Google Scholar]
In this plot and also in all the following ones, it can be noticed that some cells are empty. This means that none of the objects in the dataset choose this cell as BMU.
We define the notation for neurons on the SOM grid as (column, row).
We included this color since it appears important in the Feature Importance of De Cicco et al. (2021).
All Tables
Summary results of the experiments in terms of completeness of Type 1, Type 2, and purity of AGNs.
All Figures
|
Fig. 1 The distributions of four features in the dataset: ηe, u-B, Stet-sonK, class_star_hst. |
| In the text | |
|
Fig. 2 Schematic representation of the SOM structure, where the input data vector is directly passed to the neurons through the weights, then the adaptation apply to the BMU and its neighbors. |
| In the text | |
|
Fig. 3 Gaussian and Mexican hat functions. |
| In the text | |
|
Fig. 4 Distribution of the quantization error (QE, represented in different shades of green) and topographic error (TE, represented in different shades of purple) as a function of the map size of the SOM, assuming as neighborhood function a Gaussian (top panel) and a Mexican hat (bottom panel). In each plot, the number of training epochs is set to 200 (diamond markers), 1100 (circles) and 1700 (squares), respectively. The dotted line represents the optimal SOM size for representing our dataset with 1100 training epochs. |
| In the text | |
|
Fig. 5 Activation map of the Main Experiment. A pie chart representing the distribution of labels has been overlaid on each cell of the map. For each cell, it has been indicated: the number of galaxies (GAL), the number of stars (STAR), and the number of AGNs, from the LS; the number of unlabeled objects (Δ); the total number of labeled and unlabeled objects (TOT). The background color intensity reflects the number of objects falling in the cell. |
| In the text | |
|
Fig. 6 Main Experiment. Distribution of the feature means when considering all the features. In each neuron it is represented the local mean of each features, and the error bars correspond to the local standard deviations. The plotted features are in red when their local mean deviates from the corresponding global mean by twice the global standard deviation. The vertical dashed lines are placed after every five features (e.g., at feature 4,9,14...29) to facilitate reading the plot. Order of the features: 0) ASF, 1) γSF, 2) GP_DRW_τ, 3) GP_DRW_σ, 4) ExcessVar, 5) Pvar, 6) IARφ, 7) Amplitude, 8) AndersonDarling, 9) Autocor_length, 10) Beyond1Std, 11) ηe, 12) Gskew, 13) LinearTrend, 14) MaxSlope, 15) Meanvariance, 16) MedianAbsDev, 17) MedianBRP, 18) PeriodLS, 19) PairSlopeTrend, 20) PercentAmplitude, 21) Q31, 22) Period_fit, 23) ΨCS, 24) Ψη, 25) RCS, 26) Skew, 27) Std, 28) StetsonK, 29) class_star_hst, 30) i-z, 31) r-i, 32) B-r, 33) u-B, 34) z-y. |
| In the text | |
|
Fig. 7 Matrix of correlations among all the features adopted in the Main Experiment. |
| In the text | |
|
Fig. 8 Distribution of the calculated metrics for each experimental configuration. Each colored box represents one of the four metrics: red for Completeness Type 1, green for Completeness Type 2, orange for Pureness AGNs, and blue for Completeness AGNs. Vertical dashed lines correspond to the median values obtained in the best selected experiment (Red - corr. + top Experiment), allowing a direct visual comparison. |
| In the text | |
|
Fig. 9 Activation maps of the Red - corr. + top Experiment, overlaid by a pie chart representing the distribution of labels (top panel) and the available subclasses for AGNs (bottom panel). |
| In the text | |
|
Fig. 10 Red-corr. + top Experiment. Distribution of the feature means (FMD). In each neuron it is represented the local mean of each features, and the error bars correspond to the local standard deviations. The plotted features are in red when their local mean deviates from the corresponding global mean by twice the global standard deviation. The vertical dashed lines are placed after every five features (e.g., at feature 4, 9, 14, 19) to facilitate reading the plot. Order of the features: (0) ASF, (1) γSF, (2) ExcessVar, (3) IARφ, (4) Autocor_length, (5) Beyond1Std, (6) ηe, (7) MaxSlope, (8) MedianAbsDev, (9) MedianBRP, (10) PeriodLS, (11) PairSlopeTrend, (12) Period_fit, (13) Ψcs, (14) Ψη (15) RCS, (16) StetsonK, (17) r-i, (18) u-B, (19) class_star_hst, (20) Pvar, (21) B-r. |
| In the text | |
|
Fig. 11 Distribution of the mean values per neuron of both red and never red features. Results are reported for neurons with an AGNs majority. The top cells (2,7) and (5,7) are separated by the dotted line as they each contain only one labeled AGN. The reader should note that the feature order is chosen to separate red from never-red features. Indexes of features: 0) ASF, (1) γSF, (2) ExcessVar, (3) IARφ, (4) Autocor_length, (5) Beyond1Std, (6) ηe, (7) MaxSlope, (8) Medi-anAbsDev, (9) MedianBRP, (10) PeriodLS, (11) PairSlopeTrend, (12) Period_fit, (13) ΨCS, (14) Ψη, (15) Rcs, (16) StetsonK, (17) r-i, (18) u-B, (19) class_star_hst, (20) Pvar, (21) B-r. |
| In the text | |
|
Fig. 12 Distribution of the most recurrent Type 1 AGNs within the AGNs-majority cells of the map obtained with seed = 188. The color scale indicates the number of such objects associated with each neuron. Top panel: Type 1 that populate AGNs-majority cells in more than 90 out of 100 experiments. Middle panel: Type 1 that populate AGNs-majority cells in 70 to 90 experiments. Bottom panel: Type 1 that populate AGNs-majority cells in fewer than 70 experiments. |
| In the text | |
|
Fig. 13 Distribution of the most recurrent Type 2 AGNs within the AGNs-majority cells of the map obtained with seed = 188. The color scale indicates the number of such objects associated with each neuron. Top panel: Type 2 that populate AGNs-majority cells in more than 90 out of 100 experiments. Bottom panel: Type 2 that populate AGNs-majority cells in fewer than 70 experiments. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.