| Issue |
A&A
Volume 693, January 2025
|
|
|---|---|---|
| Article Number | A291 | |
| Number of page(s) | 18 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202450927 | |
| Published online | 28 January 2025 | |
HOLISMOKES
XIII. Strong-lens candidates at all mass scales and their environments from the Hyper-Suprime Cam and deep learning
1
Dipartimento di Fisica, Università degli Studi di Milano, Via Celoria 16, I-20133 Milano, Italy
2
INAF – IASF Milano, Via A. Corti 12, I-20133 Milano, Italy
3
Max-Planck-Institut für Astrophysik, Karl-Schwarzschild Straße 1, 85748 Garching, Germany
4
Technical University of Munich, TUM School of Natural Sciences, Physics Department, James-Franck-Straße 1, 85748 Garching, Germany
5
Aix Marseille Univ., CNRS, CNES, LAM, Marseille, France
6
Purple Mountain Observatory, No. 10 Yuanhua Road, Nanjing, Jiangsu 210033, People’s Republic of China
7
Academia Sinica Institute of Astronomy and Astrophysics (ASIAA), 11F of ASMAB, No. 1, Section 4, Roosevelt Road, Taipei 10617, Taiwan
⋆ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
30
May
2024
Accepted:
10
October
2024
Abstract
We performed a systematic search for strong gravitational lenses using Hyper Suprime-Cam (HSC) imaging data, focusing on galaxy-scale lenses combined with an environment analysis resulting in the identification of lensing clusters. To identify these lens candidates, we exploited our residual neural network from HOLISMOKES VI (Cañameras et al. 2021, A&A, 653, L6), trained on realistic gri mock-images as positive examples, and real HSC images as negative examples. Compared to our previous work, where we successfully applied the classifier to around 62.5 million galaxies having an i-Kron radius of ≥0.8″, we now lowered the i-Kron radius limit to ≥0.5″. The result in an increase by around 73 million sources, amounting to a total of over 135 million images. During our visual multi-stage grading of the network candidates, we also simultaneously inspected larger stamps (80″ × 80″) to identify large, extended arcs cropped in the 10″ × 10″ cutouts and also classify their overall environment. Here, we also re-inspected our previous lens candidates with i-Kron radii of ≥0.8″ and classified their environment. Using the 546 visually identified lens candidates, we further defined various criteria by exploiting extensive and complementary photometric redshift catalogs to select the candidates in overdensities. In total, we identified 24 grade A and 138 grade B exhibit either spatially-resolved multiple images or extended, distorted arcs in the new sample. Furthermore, combining our different techniques to determine overdensities, we identified a total 231/546 lens candidates by at least one of our three identification methods for overdensities. This new sample contains only 49 group- or cluster-scale re-discoveries, while 43 systems had been identified by all three procedures. Furthermore, we performed a statistical analysis by using the neural network from HOLISMOKES IX (Schuldt et al. 2023a, A&A, 671, A147) to model these systems as singular isothermal ellipsoids with external shear and to estimate their parameter values, making this the largest uniformly modeled sample to date. We find a tendency towards larger Einstein radii for galaxy-scale systems in overdense environments, while the other parameter values as well as the uncertainty distributions are consistent between those in overdense and non-overdense environments. These results demonstrate the feasibility of downloading and applying neural network classifiers to hundreds of million cutouts, which will be needed in the upcoming era of big data from deep, wide-field imaging surveys such as Euclid and the Rubin Observatory Legacy Survey of Space and Time. At the same time, it offers a sample size that can be visually inspected by humans. These deep learning pipelines, with false-positive rates of ∼0.01%, are very powerful tools to identify such rare galaxy-scale strong lensing systems, while also aiding in the discovery of new strong lensing clusters.
Key words: gravitational lensing: strong / methods: data analysis / catalogs / galaxies: clusters: general
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Strong gavitational lensing systems, both on galaxy and cluster scales, are very powerful tools used for probing the Universe’s properties in various fields, such as the study of the nature and distribution of dark matter (e.g., Schuldt et al. 2019; Shajib et al. 2021; Wang et al. 2022) and high-redshift systems (e.g., Lemon et al. 2018; Shu et al. 2018; Vanzella et al. 2021; Meštrić et al. 2022). In particular, galaxy-scale lensing systems in clusters are ideal for studying the galaxy mass distribution in the presence of a large-scale halo, as well as to constrain the subhalo density profiles or the inner mass structure of galaxies at the low-end of the stellar mass and velocity dispersion functions (e.g., Grillo et al. 2008, 2014; Parry et al. 2016; Granata et al. 2023; Despali et al. 2024). Furthermore, strong-lensing systems with time-variable objects, such as a quasar or supernova (SN), enable the measurement of the Hubble constant, H0, and the geometry of the Universe as proposed by Refsdal (1964). So far, mostly galaxy-scale systems with lensed quasars have been exploited for this (e.g., by the H0LiCOW and TDCOSMO collaborations, see e.g., Wong et al. 2020; Birrer et al. 2020; Shajib et al. 2022); however, this was also demonstrated on cluster scales (e.g., Acebron et al. 2022a,b), where the mass distribution is significantly more complicated. Extending this systematically to lensed SNe is one of the main scientific goals of our Highly Optimized Lensing Investigations of Supernovae, Microlensing Objects, and Kinematics of Ellipticals and Spirals (HOLISMOKES Suyu et al. 2020) program. To date, only very few lensed SNe have been found and, in fact, only two systems, SN Refsdal and SN H0pe (Kelly et al. 2015a,b; Frye et al. 2024), lensed by galaxy clusters have sufficiently precise time delays to enable measurements of the Hubble constant and the geometry of the universe (Grillo et al. 2018, 2020, 2024; Kelly et al. 2023; Pascale et al. 2024). A third lensed supernova is called SN Encore (Pierel et al. 2024), whose galaxy previously hosted SN Requiem (Rodney et al. 2021). It was discovered in November 2023 and the time-delay cosmography analyses with this system are ongoing (Ertl et al. in prep.; Suyu et al. in prep.).
With recently started and upcoming wide-field imaging surveys such as the Rubin Observatory Legacy Survey of Space and Time (LSST; Ivezic et al. 2008) from the ground, complemented by the Euclid (Laureijs et al. 2011) and Roman (Green et al. 2012) satellites from space, the amount of astronomical imaging data sets is expected to increase significantly in the optical and near-infrared wavelength range over the next few years. Thanks to their runtime and performance in image pattern recognition, supervised deep learning (DL) techniques such as convolutional neural networks (CNNs Lecun et al. 1998) are playing a significant role in the analysis of these data sets. Once trained, these networks can be applied to millions or billions of image cutouts within an acceptable amount of time. Beside exploiting supervised CNNs for photometric redshift estimation (D’Isanto & Polsterer 2018; Schuldt et al. 2021a; John William et al. 2023; Jones et al. 2024), modeling strong galaxy-scale lenses (e.g., Hezaveh et al. 2017; Pearson et al. 2019, 2021; Schuldt et al. 2021b, 2023a,b), detecting dark matter substructure (Tsang et al. 2024), estimating structural parameters of galaxies (Tuccillo et al. 2018; Tohill et al. 2021; Li et al. 2022), or classifying them according to their morphology (Dieleman et al. 2015; Walmsley et al. 2022), DL became the state of the art technique for lens classification (Metcalf et al. 2019). Although they have shared the same baseline of relying on DL, there are various projects that have targeted different image sets (e.g., Jacobs et al. 2017, 2019; Cañameras et al. 2020; Canameras et al. 2024; Savary et al. 2022) and are possibly limited to particular lens samples, such as lensed quasars (e.g., Andika et al. 2023), systems with high lens redshift (e.g., Shu et al. 2022), or those situated within a cluster environment (Angora et al. 2023). These CNNs are complementing previous non-DL algorithms (e.g., Chan et al. 2015; Sonnenfeld et al. 2018; Shu et al. 2016) with an overall better classification performance (Metcalf et al. 2019).
In Cañameras et al. (2021, hereafter C21), we presented a CNN trained on realistic mock images and applied it to gri multiband images from the Hyper-Suprime Cam Subaru Strategic Program (HSC-SSP; Aihara et al. 2018), complemented with a detailed performance test presented by Canameras et al. (2024). Avoiding any strict cuts on the catalog level, we applied it to 62.5 million image stamps from the HSC Wide layer corresponding to a lower limit on the i-band Kron radius of 0.8″. This is possible thanks to a false positive rate (FPR) of ∼0.01%. From the 9651 resulting systems, corresponding to 0.015% of the input catalog, we applied our visual inspection to identify 88 secure (grade A) and 379 probable (grade B) lens candidates. Given the high success rate, in this work we offer new lens candidates by lowering the limit on the i-Kron radius to 0.5″, which gives us an additional ∼73 million image stamps.
Since the scope of C21 was specifically set on the detection of new galaxy-scale lenses, we neglected, as is commonly done, possible group- or cluster-scale lensing features during our visual inspection. However, as previously reported in C21, our network was able to recover also group- and cluster-scale lenses. Therefore, we adjusted our visual inspection strategy and this time we also specifically report lenses in a significantly overdense environment, such as a galaxy cluster, by inspecting larger cutouts (80″ on a side). This was complemented by a re-inspection of the lens candidates from C21 to classify the environment.
While the deep learning-based identification of galaxy-scale lenses in the field has been well explored, only Angora et al. (2023) has developed a network to identify galaxy-scale lenses in galaxy clusters, which was trained on 4″ × 4″ high-resolution image cutouts in known clusters. In contrast, we used ∼12″ × 12″ ground-based image stamps from HSC, enabling the network to analyze the close environment and identify extended arcs influenced by a galaxy cluster. Furthermore, we applied it to any astronomical source targeted by HSC with i-Kron radius above 0.5″, which enabled the identification of new galaxy-scale lenses in the field as well.
Despite the scarcity of CNN-based searches for galaxy-scale systems in clusters, many known lensing clusters include also galaxy-scale systems. In fact, as shown by Meneghetti et al. (2020, 2022, 2023), around one order of magnitude more galaxy-scale systems in clusters have been observed than are expected based on hydrodynamic simulations in a ΛCDM cosmology.
Using the visually identified lens candidates in overdensities and lens candidates near known galaxy clusters, we have been able to define and test several selection criteria for their identification. These criteria are based on the photometric redshift distribution of their surrounding objects. Here, we focus specifically on our lens candidates, as lenses are already on average in slightly overdense environments (e.g., Wells et al. 2024). We exploited three complementing photometric redshift catalogs, providing more than a hundred million measurements in the targeted footprint. Thanks to the expected accurate and large photometric redshift catalog from ongoing and upcoming wide-field imaging surveys, these criteria can be used to identify lenses in significant overdensities, while also identifying galaxy clusters independent of their lensing nature.
Going beyond the identification of galaxy-scale systems, while separating them into systems in an overdensity from those in the field, we applied the neural network presented by Schuldt et al. (2023a) to all our grade A and B candidates. We show the distributions for all seven predicted parameters of the adopted singular isothermal ellipsoid (SIE) plus external shear profiles. We then discuss the differences between systems in an overdensity and in the field.
The paper is organized as follows. We first introduce the overall procedure in Sect. 2. Sect. 3 describes our visual inspection strategy and the identified lens candidates. In Sect. 4, we highlight our analysis of the lens environment and show a statistical analysis of their mass model parameters in Sect. 5. Finally, we conclude our findings in Sect. 6. Following C21, we have adopted the flat concordant ΛCDM cosmology with ΩM = 1 − ΩΛ = 0.308 (Planck Collaboration XIII 2016), and with H0 = 72 km s−1 Mpc−1 (Bonvin et al. 2017).
2. Methodology
We made use of the residual neural network presented by C21, and we refer to that publication as well as to Canameras et al. (2024), for further details. In the following, we give a short summary of the network architecture, the ground truth data set, and the training procedure.
2.1. Network architecture
Over time, neural networks have gotten more and more powerful thanks to the increasing extend of training sets, more powerful computing techniques that allows us to train deeper networks, improving their broad applicability, and other aspects. Consequently, different network architectures and algorithms were developed to optimize the performance. While the architecture for image processing tasks are overall still following the original setup of a simple CNN (Lecun et al. 1998), which consists of multiple convolutional layers followed by a number of fully connected layers, the depth of the network got significantly increased over time. In particular, the residual neural network (ResNet) concept (He et al. 2016a) introduces so-called skip-connections (preactivated bottleneck residual units in He et al. 2016b) to allow for deep CNNs, avoiding vanishing gradient, so that we can aptly optimize the first layers, while keeping the computational costs at an acceptable level. Such ResNets have obtained excellent results on the ImageNet Large Scale Visual Recognition Challenge 2015 (He et al. 2016a). In the recent past, these ResNets were also used for lens finding (e.g., Lanusse et al. 2018; Li et al. 2020; Huang et al. 2021) and outperformed classical CNNs from the lens finding challenge Metcalf et al. (2019).
We used a ResNet whose architecture setup is based on the ResNet-18 architecture (He et al. 2016a). It is composed of eight ResNet blocks with each two convolutional layers, batch normalization, and a ReLu activation function. These layers are followed by a fully connected layer with 16 neurons, before the last layer with a single neuron that outputs a score p in the range [0, 1] through to a sigmoid activation function.
2.2. Ground truth dataset
Our binary classification network is trained and validated on a set of images composed by 40 000 positive and 40 000 negative examples. As positive examples, we used simulated images of galaxy-scale lenses that are based on real HSC gri images of luminous red galaxies (LRGs). Following the procedure described in Cañameras et al. (2020) and Schuldt et al. (2021a), we added to those LRG images some arcs simulated with GLEE (Suyu & Halkola 2010; Suyu et al. 2012) from galaxy images of the Hubble Ultra Deep Field (Inami et al. 2017) as background sources. Here, we adopted a SIE profile and estimated the ellipticity based on that of the light distribution. The Einstein radius was inferred from the corresponding velocity dispersion and redshift measurement taken from the Sloan Digital Sky Survey program (SDSS, Abolfathi et al. 2018). Since it is important to have a uniform distribution in the training set, we increased the fraction of systems with wide image separations to obtain a sample with a uniform Einstein radius distribution in the range of 0.75″ to 2.5″. We also used a similar fraction of quadruply and doubly imaged systems.
This data set is complemented with negative examples, containing mostly spirals from Tadaki et al. (2020), isolated LRGs, and random galaxies with similar proportions. These were selected from random sky positions of the HSC Wide footprint to mitigate impact from small-scale and depth variations.
2.3. Training procedure
The data set described in Sect. 2.2 was split up into 80% training and 20% validation sets. The test sample and performance tests are summarized in Sect. 2.4.
After a random initialization, the network was trained over 100 epochs, while the network was saved at the epoch with the minimal binary-entropy loss on the validation set. We used mini-batch stochastic gradient descent with 128 images per batch, a learning rate of 0.0006, a weight decay of 0.001, and a momentum of 0.9. In each epoch all images were randomly shifted by up to ±5 pixels in x and y direction to improve the generalization.
2.4. Performance tests
We carried out several performance test of the network based on a test set with HSC Wide PDR2 images as described in detail by Canameras et al. (2024). In short, the completeness was tested with grade A or B galaxy-scale lenses from the Survey of Gravitationally-lensed Objects in HSC Imaging (SuGOHI, Sonnenfeld et al. 2018, 2019, 2020; Wong et al. 2020; Chan et al. 2020; Jaelani et al. 2020a, 2021, hereafter, SuGOHI sample). We excluded systems with high image separations (Einstein radius ≥4″) from this sample, which did not match our training data and would consequently be likely to be missed.
On the other hand, the FPR was estimated with a set of non-lens galaxies from the COSMOS field Scoville et al. (2007) by ensuring the exclusion of all known lenses and candidate lenses from the MasterLens database1, Faure et al. (2011), Pourrahmani et al. (2018), as well as systems from the SuGOHI sample. As shown in C21, using a threshold of p ≥ 0.1, we obtained a completeness above 50% on galaxy-scale systems and a FPR ≤ 0.01%. The obtained receiver operating characteristic curve is shown in Fig. 2 of C21. Examples of missed lenses are shown in Fig. 3 of C21 and Fig. B.2 of Canameras et al. (2024). These are typically lensing systems with atypical colors for the lens or source (e.g., red arcs), highly blended lenses, or lenses with significant contamination from other objects near the sightline.
Given our focus this time on lenses at all mass scales, approximately 25% of the grade A and B SuGOHI group and cluster-scale lenses are recovered in our list of candidates. This relatively low recovery rate is understandable given that the network is trained specifically on galaxy-scale systems, but highlights the possibility of new group- and cluster lens discoveries with this ResNet, as well as generally with automated algorithms.
3. Lens grading
The following section describes the visual inspection and grading procedure of the network candidates with i-Kron radii between 0.5″ and 0.8″. We further discuss the outcome and the effect of the individual steps, which will help in planning future visual inspection strategies. We offer a comparison between C21 and this work of the resulting numbers of network candidates, grade A, and B lens candidates in Table 1. Since we used the same network, the differences are coming from the different cut on the i-Kron radius when defining the parent sample.
Sample sizes at various stages of the analysis, including rediscoveries.
3.1. Network candidates
The trained network was applied to all ∼72 million images from the HSC Wide layer showing objects with an i-band Kron radius between 0.5″ and 0.8″, complementing the sample from C21 targeting objects with i-band Kron radii ≥0.8″. Based on the tests in C21, we considered all 11 816 objects (∼0.016% of the input catalog) with a network score p ≥ 0.1 as network candidates. The obtained fraction (see Table 1) is comparable to that achieved in C21, which indicates that the network has the capability to also handle objects that appear smaller or with some offset to the image center, as several times the central object is one of the possible lensed images or a compact object near the candidate lens system.
3.2. First cleaning through visual inspection
As in previous lens search studies, including C21, these network candidates have a significant fraction of false positives. Thus, we decided to carry out a visual inspection of these systems using pre-generated gri-color images. These images were inspected first by one person to exclude obvious non-lenses, reducing the candidates to 1475 systems. These false positives had mostly a low network score, such that a higher threshold would reduce the FPR significantly. However, in this case we would have missed several possible lens candidates. In fact, a threshold of 0.11 (instead of 0.1) would already exclude 12 grade B candidates, of which 8 are already known (see Table 2 and Sect. 3.4), justifying the relatively low threshold.
High-confidence lens candidates with ResNet scores p ≥ 0.1, and average grades G ≥ 1.5 from visual inspection.
3.3. Multiple grader inspection
According to Rojas et al. (2023, hereafter B23), the visual inspection should be done by at least six individual persons to ensure stable average grades, while the accuracy is still dropping with increasing number of graders (compare Fig. 15 in R23). To reduce the images that require inspection, we carried out a multi-step inspection with eight individuals2.
During the visual grading, we inspected gri-color images with a size of 10″ × 10″ to grade the central object and its close surrounding, showing possible arcs. In addition, which was done for the first time, we looked at larger images to classify their environment. Since 80″ corresponds to about 0.5 Mpc at z = 0.5, a typical lens cluster redshift (e.g., Bergamini et al. 2021; Acebron et al. 2022a,b; Schuldt et al. 2024), this size ensures that extended cluster-scale arcs remain within the images and enough of the cluster environment is included, while keeping the astronomical objects visible on the inspector’s screen. Therefore, our grading tool shows, in addition to three 10″ × 10″ gri-color images with different filter scalings, also three 80″ × 80″ cutouts centered at the small image stamp, again with different stretching factors.
Since CNNs are translation invariant and we specifically include off-centered systems in our training set, the network also identifies strong-lensing systems offset from the center as long as the lensing features remain within the cutout. Thus it is not guaranteed that the lens is the central object. Also, sometimes the reported coordinate is not precise as the central object is blended with a neighboring object. Since we want to report the lens center, we also incorporated in our grading tool an option to indicate if the lens galaxy is not the central object. This is particularly important in our case, as multiple lens candidates are centered at their possible arc or at a neighbouring objects given our selection criteria on more compact objects. We corrected these offsets manually after grading for the most probable lenses reported in Table 2.
Round #1: As initial step, we conducted a calibration round containing 200 systems inspected by everyone. We assigned to each system, as done in previous studies, an integer grade between zero and three, corresponding to “not a lens”, “possible lens”, “probable lens”, and “definite lens”. We then compared the 200 assigned grades from all eight individuals and discussed the systems with high discrepancies to understand the reasonings for giving different grades. This is crucial to calibrate the expectations and discuss individual systems to allow everyone to get familiar with the grading criteria and tool, as well as the specific images inspected (e.g., image resolution). Since lens candidates are sometimes ambiguous, especially for novice graders, even with a bullet-point list of criteria for the different grades, such discussions on the calibration set are helpful. The grades from round #1 are not taken into account for the final lens candidate compilation shown in Table 2.
Round #2: After calibration, we split ourselves into two teams of each four people. Each team graded 825 of the 1 475 network candidates, with an overlap of 175 random systems (hereafter, the overlap sample) that are graded by both teams for comparison. As expected from R23, we observe significant differences between the individual grades, but also between the two teams. In Fig. 1, we show a normalized histogram of the number of grades 0 (“not a lens”) and grades 1 (“possible lens”), for all possible team combinations of the graders. We clearly see significant differences between a single grader and a team of two people. Significant scatter remains for three and four graders, which is in agreement with results from R23, recommending to average over at least six individual grades.
 |
Fig. 1. Normalized histograms showing the distribution of 0 and 1 grades assigned in round #2 to network candidates from the overlap sample, containing 175 systems. We show all possible team combinations of the eight graders and only count systems that received a 0 or 1 by all graders of a particular team combination. Significant scatter is observed for small teams, which is expected and in agreement with R23. |
As mentioned above, we also observed differences between the two teams. This is shown in Fig. 2, where we plot the average grade GA from team A on the x-axis and the average grade GB from team B on the y-axis. Although each team contains four individuals, we see a tendency towards lower grades from team A. However, we note that the sample only contains 175 systems and thus, particularly at higher grades, the statistic is relatively poor. In detail, the top panel of Fig. 2 shows the results from round #2, while the middle panel displays the results from round #3, and the bottom panel from round #4, which we describe below.
 |
Fig. 2. Comparison between average grades from team A (x-axis) and team B (y-axis), containing four graders apiece, from round #2 (top), round #3 (middle), each with 175 systems (overlap sample), and round #4 (bottom), containing all 327 objects that received eight grades. |
Round #3: Both teams re-inspected the systems with strong discrepancy in the provided grades within each team (standard deviation above 0.75). Cases with high dispersion in visual grades often show ambiguous blue arcs that could either be lensed arcs from background galaxies (without clear counter-images), spiral arms, or tidal features. From Fig. 2, we see a slight improvement from round #2 to #3 in terms of agreement in the average grades from the two teams, although the discrepancy remains.
Round #4: To increase the number of examiners per object as recommended by R23, each team graded the systems with average grade above 1 obtained by the complementary team. This excludes a significant fraction of additional false-positive candidates and systems with not very clear lensing features. This consequently reduces the time required for round #4, while ensuring a stable average grade from eight inspectors per relevant object. We explicitly chose a slightly lower threshold than for the final compilation (see Sect. 3.4) to counterbalance the observed discrepancy and the effect of lower number of inspectors.
In the bottom panel of Fig. 2, we show the differences between the final average grades for all 327 systems that obtained eight grades, again split into the previous two teams for comparison. This highlights the good agreement between both teams for the relevant systems and shows a stabilization for more than four graders.
3.4. Final lens candidate compilation
Finally, we computed the average grade for all 1475 systems, where grades from earlier rounds are superseded by newer grades regardless of their value. As in previous lens search projects (e.g., Cañameras et al. 2020; Shu et al. 2022), we defined grade A lens candidates as systems with final average grade of G ≥ 2.5 and grade B systems with 2.5 > G ≥ 1.5. In total, we identified finally 24 grade-A candidates and 138 grade-B candidates. For 75 out of 162 lens candidates, we further correct manually the lens center, as we identified a significant offset here. This is crucial to correctly identify and monitor these lenses in the future. These candidates were selected often through an arc falling into our i-Kron range, such that the possible lens galaxy may have a higher i-Kron radius. All, if needed recentered, lens candidates are shown in Figs. 3 and A.1, and listed in Table 2. The absolute number of identified systems is slightly lower than obtained in previous programs (e.g., Jacobs et al. 2019; Shu et al. 2022, see also Table 1 for comparison to C21). However, they are still comparable with network based searches (e.g., Rojas et al. 2022; Savary et al. 2022) and depend on the used imaging survey and its footprint size as well. This is most likely due to the sample selection of low i-Kron radii systems, containing galaxies with lower mass, consequently less likely to act as strong lenses or creating overly small Einstein radii to be identified with the resolution from HSC (0.168″/pixel). While this is expected, it is also confirmed by the comparison to C21, as we can see from Table 1.
 |
Fig. 3. Recentered color-image stamps (12″ × 12″; north is up and east is left) of identified grade-A lens candidates using HSC gri multi-band imaging data. At the top of each panel, we list the ResNet scores, p, and the average grades, G, of eight graders, where ≥2.5 corresponds to grade A, from the visual inspection. At the bottom, we list the candidate name, displayed in white for new candidates, light blue if previously detected as grade C lens candidate, and green if previously known grade A or B lens candidate. Given the numerous lens search projects exploiting HSC data, only our grade-B systems (shown in Fig. A.1) include new identification highlighted additionally with orange boxes. All systems with their coordinates and further details such as the lens environment are listed in Table 2. |
3.5. Comparison with known systems
From our lens candidates listed in Table 2, 118 candidates are already known based on the current SLED (C. Lemon, private communication, May 2024) and our HOLISMOKES compilation (Suyu et al. 2020). From these systems, 12 and 60 from our grade A and B sample, respectively, match the grade from the literature. In contrast, 12 and 21 systems from our grade A and B sample, respectively, obtained higher grades than before. On the other hand, 8 published systems with grade A belong to the grade B class according to our grading. We missed a further 62 systems during the visual inspection (i.e., these obtained an average grade G ≤ 1.5 from us) of the 1475 network candidates, of which 43 have been published with a grade of C (mostly from the SuGOHI sample). Missing grade C candidates is expected as we compile only for grade A and B systems. In total, this shows that a strict grading is difficult as it also depends on the inspected image quality and resolution, filter amount, and possibly detection algorithm (especially for non-DL techniques such as modeling). However, it shows that the expectation on the lensing features are broadly consistent over the years and grading teams.
The relatively high number of known systems is expected since the HSC data set was targeted by multiple lens search projects, complemented by several other lens searches with data in the same footprint. Therefore, to reduce the number of systems during visual inspection, we propose to exclude previously graded systems in the future, regardless of their previous grade, unless the target sample, the data quality (e.g., high-resolution images from Euclid), or the detection algorithm (e.g., including lens deblending or modeling) changed significantly. However, a downside of excluding previously visually classified objects is that we cannot carry out a consistency check with grades from the literature as done above.
4. Environment analysis
Since the surrounding mass distribution of a galaxy-scale lens influences the lensing effect of that system, the characteristics of the environment are crucial and need to be taken into account when building a strong-lens mass model. In addition, galaxy-cluster lenses are modeled completely differently from galaxy-scale lenses and are particularly difficult to identify with autonomous algorithm because of their size, complexity, and peculiarity. However, cluster lenses have several advantages over galaxy-scale lenses, such as significantly longer time delays and higher magnifications, enabling several complementary studies to galaxy-scale systems. For these reasons, beside enlarging the sample to which we apply the network, we conduct an analysis of the lens candidate environment, which we describe in the following.
Here, we also re-considered our detected lens candidates from C21 and combined them with our new sample. After excluding duplicates, this leads to a total of 546 grade A or grade B lens candidates, based on our visual inspection described in Sect. 3 and C21.
4.1. Comparison with the literature
As a first step, we cross-matched our network candidates with a large sample of galaxy clusters without known strong-lensing features from the literature. In detail, we first used the catalog from Oguri (2014), containing 71 743 clusters identified by the Camira code using data from the SDSS Data Release 8 (York et al. 2000; Aihara et al. 2011) covering ∼11 960 deg2 of the sky, including the whole footprint of HSC-SSP DPR2 and thus all our lens candidates. This algorithm is based on stellar population synthesis models to predict colors of red sequence galaxies at a given redshift. The identified clusters cover a redshift range between 0.1 and 0.6 (Oguri 2014). This code was also directly applied to HSC data, resulting in the 1921 galaxy clusters presented by Oguri et al. (2018). Since the HSC images are significantly deeper than those from SDSS, this catalog extend the redshift range up to z ∼ 1.
We complemented both Camira catalogs with 1959 galaxy clusters detected by Wen & Han (2018) using SDSS and Wide-field Infrared Survey Explorer (WISE) data, along with 21 661 galaxy clusters published by Wen & Han (2021) exploiting HSC-SSP and WISE data. Wen & Han (2018, 2021) specifically targeted the high redshift range z ≥ 0.7, complementing ideally identifications by the Camira algorithm. The identifications in Wen & Han (2021) are based on photometric redshifts obtained from the seven-band photometric data from HSC and SDSS WISE using a nearest-neighbor algorithm.
This sums up to a total of more than 100 000 galaxy clusters with most systems in the targeted HSC Wide area. Thanks to the two complementary techniques, it also covers a broad redshift range, ensuring a roughly equal distribution over the HSC footprint and reduced selection biases.
The cross-match radius was selected based on the size of known lensing clusters. For instance, Schuldt et al. (2024) presented 308 securely identified cluster members of the lensing cluster MACS J1149.5+2223, one of the largest sample of cluster members. They are distributed over an area of around 160″ on a side, mostly limited by the area of available high-resolution imaging data. Therefore, to also include systems with significant offset to the BCG, we adopt a radius of 100″. This size corresponds to ∼0.65 Mpc at the lens cluster redshift of MACS J1149.5+2223 and roughly to the peak of the distribution of the reported R500 radii in Wen & Han (2021). The distribution of the reported R500 radii starts at around 0.36 Mpc, which corresponds to 100″ at a redshift of 0.25, and the distribution drops significantly until ∼0.8 Mpc, which is equal to 100″ at z = 0.9, supporting our selected radius of 100″.
In this way, we were able to identify 174 grade A or B lens candidates to be located within 100″ from a galaxy cluster centroid listed in the galaxy cluster catalogs. Out of these 174 systems, 63 systems are more than 50″ away from the reported cluster center, and only 44 are part of the SuGOHI group- or cluster scale lens sample. We indicate the possible overdense environment from the literature with ODlit in Tables 2 and 3 for the newly identified systems and those from C21, respectively. These cluster identifications are used in the following as a reference.
4.2. By visual inspection of the environment
As described in Sect. 3, we visually inspected all the newly detected network candidates. Here, we consider, besides 10″ × 10″ cutouts that are a typical size used for visual inspection, also stamps of 80″ × 80″ in size, displaying the larger environment (see Fig. 4). Since all galaxies that belong to a galaxy cluster are located at nearly the same redshift (the so-called cluster redshift) and mostly contain galaxies with similar morphologies, they have similar colors in the images, easing the identification of galaxy clusters based on color images. Consequently, large magnitude catalogs were used in the past to help identify galaxy clusters (e.g., Oguri 2014). Instead, we introduced a novel possibility to also indicate a cluster environment to our grading tool, which only slightly increases the required human time for the visual inspection, while offering additional crucial information on the lens candidate. To simplify the identification, we have focused on overdensities in general, which means we also report several group-scale lenses as well as lenses with high number of line-of-sight companions that might not be physically associated with the lens candidate. As a consequence, and analogously to the observed differences in the grades, we also observe some differences in the votes. In the rare case that only one or two graders (out of four or eight, see Sect. 3) indicated an overdensity, the lens candidate was inspected once more with a focus on the environment for a final decision. Lens candidates with more than two votes were directly indicated as being in a cluster-like environment based on the visual inspection. This is noted as ODvis in Tables 2 and 3.
 |
Fig. 4. New grade A or grade B lens candidates visually identified to be on group- or cluster-scale, excluding known group- or cluster lenses from the SuGOHI sample. Each panel is 80″ × 80″, and the insert on the top-left shows the 12″ × 12″ cutout analysed by the ResNet. The lens name is given in the bottom of each panel, in cyan if listed in the galaxy cluster catalogs, and otherwise white. Furthermore, the network score, average grade, and number of cluster votes during visual inspection is given in the top (first row), in orange if listed by C21, in cyan if listed in this work, and white if in both. This is followed by the photo-z characteristics Nmax, zlow, Ntot, and Nfrac (second row), and Npeak5, Apeak5, Npeak10, and Apeak10 (third row), colored green or red if passing or not passing the final limits (No. 46 in Table B.1), respectively. We note that lens candidates from C21 were only inspected by a single person for the group and cluster environment classifications and, thus, they have all only one vote. The figure continues in Appendix B. For all shown image stamps, north is up and east is left. |
Furthermore, one person re-inspected the network candidates reported in C21 regarding the environment, while we adopted the assigned average grades G on the lensing nature from C21 directly. This leads to an identification of additionally 47 (out of 467 grade A or B lens candidates in C21) to be in a significantly overdense environment, which are listed in Table 3. By combining both samples and removing duplicates, among the new candidates from Sect. 3 and those from C21 that we visually identified, out of 546 grade A or B lens candidates, 84 are found to be in an overdense environment. Interestingly, from these 84 lens candidates, only 31 were reported in the SuGOHI group- and cluster-scale sample. This demonstrates the necessity of further analysis of the lens environment to enlarge the sample of group- and cluster-scale lenses. In addition, only 54 of the 84 identified systems were reported in the considered galaxy cluster catalogs, and only 27 in both (the SuGOHI and the galaxy cluster catalogs). This highlights that several lens candidates recently identified with deep learning classifiers were lacking in terms of information on their environment.
4.3. By photometric redshifts
As a further characterization of the environment from our new lens candidates, as well as the lens candidates from C21, we obtained for each candidate the photometric redshift (hereafter photo-z) distribution within a given area, as detailed below. This analysis goes therefore beyond the analysis of simple magnitude catalogs and will be broadly applicable to upcoming wide field surveys such as Euclid and LSST, with large and accurate photo-z catalogs (e.g., Schmidt et al. 2020; Euclid Collaboration 2020, 2024). We elaborate possible criteria such as the height of the distribution peak and the sum of all objects with available photo-z value in the considered field to identify additional lenses in overdensities. In addition, the peak of the photo-z distribution indicates the cluster redshift and helps to determine whether the lens galaxy belongs to the cluster.
For this analysis, we use photometric redshift catalogs from three different and complementary codes that were broadly applied to objects from the HSC wide area. In detail, these codes are Mizuki (Tanaka et al. 2018), a template fitting code with Bayesian priors, DEmP (Hsieh & Yee 2014), a hybrid machine-learning code based on polynomial fitting, and NetZ (Schuldt et al. 2021b), a CNN-based code that infer the photo-z values directly from the HSC grizy-image stamps. All three catalogs obtained a very good performance against spectroscopic redshifts, and contain, after excluding duplicates defined by a distance of less than two pixels (≤0.336″), each on the order of several ten million redshifts. In case of duplicates, we took the simple average of all (typically two) photo-z values as well as the coordinates, and considered them as a single object. This ensures that we do not artificially overestimate the density of objects in a given area and expect to reduce the effect of catastrophic outliers. The relatively low threshold of only two pixels is chosen to not introduce wrong photo-z values through averaging. We further follow Schuldt et al. (2021b), and limit the catalogs to a photo-z range 0 < z < 5, given that the trustworthiness of photo-z values significantly decreases with increasing redshift. By combining the three catalogs, we ultimately obtained a photo-z catalog containing more than 115 million redshifts in the targeted footprint area.
Based on the size of known lensing clusters (compare with Sect. 4.1), we considered all objects within a 200″ × 200″ field, centered at the lens candidate in the analysis. Since the cluster member galaxies are typically within a redshift bin of around 0.03 to 0.06 (see e.g., Bergamini et al. 2021, 2023; Acebron et al. 2022a,b; Schuldt et al. 2024), we created a photo-z histogram for all lens candidates with a redshift bin width of 0.02. However, we note that the range of the cluster members in our distributions is broadened given the photo-z uncertainties. We show the histograms of two lens candidates, one visually identified to be in an overdense environment and one not, in Fig. B.1 as example.
For the selection of overdensities, we first exploited the extracted photo-z distributions directly and defined the following eight quantities that we used for the evaluation process:
-
Nmax: Since a higher peak of the photo-z distribution indicates a higher concentration of galaxies at a similar redshift, we introduce the absolute height of the photo-z distribution peak Nmax as a criterion.
-
Ntot: The second criterion is the total amount of objects in the adopted field, indicating the density of the field in general.
-
Nfrac: The third criterion is the ratio Nmax/Ntot, indicating the concentration of systems at the given redshift bin compared to the whole distribution.
-
Npeak5: Since, as noted above, we would expect a galaxy cluster to cover multiple neighboring redshift bins, we further introduce a criterion that gives the number of bins next to Nmax exceeding five counts.
-
Npeak10: Same criterion as Npeak5 but for 10 neighboring bins instead of five.
-
Apeak5: This criterion gives the sum of objects within Npeak5 bins, since a higher number of systems within the bounds above five indicate a significant overdensity.
-
Apeak10: This criterion gives, in analogy to Apeak5, the sum of objects within Npeak10 bins.
-
zlow: The lower redshift bound value of Nmax.
The first seven criteria rely on the fact that the different and complementary photometric redshift algorithms were applied broadly to the same footprint of the network candidates. These criteria are highlighted in the photo-z histograms shown in Fig. B.1. The criterion zlow was introduced since, based on the SuGOHI sample, galaxy clusters at very low redshift (z ≲ 0.1) or very high redshift (z ≳ 1) are very unlikely to create strong-lensing effects detectable in the HSC images that make up our target sample. In the case where two redshift bins have the exact same number of systems, Nmax, we used the lower redshift bin value as zlow since higher photometric redshifts are normally less accurate; consequently, a peak at higher redshift might be just due to photo-z outliers rather than an actual galaxy cluster. We note that this choice does not affect our first three criteria at all and that a combination of these criteria is crucial, as detailed below.
Since we are only interested in the characterization of strong-lensing systems, and because galaxy-scale lenses are in general located in fields with higher density (e.g., Wells et al. 2024), we limited the analysis to our 546 visually identified lens candidates. Nonetheless, we ran the photo-z analysis on the whole set of network candidates with p ≥ 0.1, as well as 10 000 random positions in the HSC footprint, for comparison and consistency checks. Based on the considered galaxy cluster catalogs and the visual inspection, this sample of 546 lens candidates contains, 174 and 84 systems, respectively, in a significantly overdense environment.
We show in Fig. 5 the distribution obtained for our eight introduced selection criteria. This highlights the difference between systems in overdensities (blue and green) compared to those in the field (orange and magenta), and consequently the effectiveness of our selection criteria. For comparison, we show in gray the inferred values from 10 000 random positions in the HSC footprint. This confirms also findings from Wells et al. (2024) that lenses are in general in overdense environments.
 |
Fig. 5. Normalized histograms of our eight introduced selection criteria. We distinguish between lens candidates visually identified to be in an overdensity (blue) or through the galaxy cluster catalogs (green), compared to those not in an overdensity (orange and magenta, respectively). We further show, for comparison, the distribution from 10 000 random positions in gray. Following the F1 criterion, we highlight the parameter range indicating overdensities in red (shaded regions for criteria No. 46 in Table B.1), which demonstrates that a combination of these different criteria is crucial to gain good performance. |
We then set different thresholds for these eight criteria and tested them against the visually identified lens candidates. While it is possible that we missed some clusters during our visual inspection, and we acknowledge the considered galaxy cluster catalogs may be incomplete, we treated these samples as the ground truth for inferring the best thresholds for our eight introduced criteria. This allowed us to define the true-positive (TP) and false-positive (FP) rates, which we listed for a representative selection of different limits. For comparison, we included, as No. 0, the full sample sizes of lens candidates (indicated by selection cuts that all candidates passes the criteria by definition).
Finally, we used the F1 criterion defined as
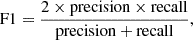 (1)
(1)
with
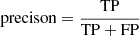 (2)
(2)
and
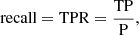 (3)
(3)
where P denotes the positive sample size (lens candidates in overdensity) to identify the best selection cuts. We list in Table B.1 the F1 values using the performance on the visually classification, denoted as F1vis, the cluster catalogs, denoted as F1lit, and their combination, denoted as F1tot.
Following the F1tot criterion, No. 46 shows the best performance. It also has the highest score for F1vis, while slightly outperformed according to F1lit. These selection cuts are indicated in Fig. 5 as red shades.
We test the individual selection cuts from No. 46 to see their selection effect, while keeping the cut of zlow ≥ 0.1 as this criterion rejects photo-z outliers rather than non-overdensities and is thus applied for all tested combinations. This clearly highlights the importance of the combination of multiple selection cuts to obtain a good performance.
Since the distribution of objects in a random field is not flat with respect to redshift, we also test our selection criteria using subtracted photo-z histograms. This means, we create the photo-z histograms for 10 000 random positions in the HSC footprint using our compiled photo-z catalog, and compute the median and the standard deviation per redshift bin. To obtain better statistics at these random positions, we consider here a bin width of 0.06. We now subtract the median histogram from that of all our lens candidates, and apply our criteria to the remaining distribution. As an alternative, we test also normalized histograms defined as the subtracted histograms divided by the standard deviation obtained from the 10 000 histograms at random positions. According to the F1 criterion, the selection on the original histograms performs better. This might be because of the relatively large considered area of 200″ × 200″, centered at the lens candidate, consequently including multiple foreground or background galaxies, such that, although we subtract the median of 10 000 random positions, compact galaxy groups do not obtain a prominent excess in the photo-z distribution of their surrounding objects.
4.4. Final cluster selection
Based on our comparison of different cuts on our eight introduced criteria, and taking into account the completeness and purity of the selection through the F1 criterion, we favor No. 46 in Table B.1. This gives a completeness rate on the visually identified systems of 58/84 ∼ 70%, while 87/174 = 50% are listed in the considered galaxy cluster catalogs. We recall that we flagged all overdensities during our visual inspection, including possible group-scale lenses and possible overdense fields not necessarily with most systems at a similar redshift. On the other hand, since the primary focus was the lens grading, the sample cannot be considered as complete. This is already evident from the considered catalogs, where we found 174 lens candidates less than 100″ away from a known galaxy cluster, although it is expected that the most distant matches might be missed as we inspected only 80″ × 80″ cutouts centered at the lens candidate. Therefore, it is understandable that we identified some candidates with our photo-z selection that had been missed either during the visual inspection or by the galaxy cluster catalogs, which are also incomplete. In contrast, the photo-z selection misses some candidates given their distance to the galaxy cluster or due to missing photo-z measurements around the lens candidate. For instance, this is the case for HSC J2329−0120, a grade-B lens candidate visually identified as cluster lens and listed in the galaxy cluster catalog from Wen & Han (2021), as well as the SuGOHI group- and cluster-scale lens sample. While the image stamps analyzed by the network are perfectly fine in all three bands, the g and r bands show ∼14″ to the north a 19″ broad stripe without observations. Consequently, in that area, no photometric redshifts are available, resulting in a lower number of galaxies in the field. Thus, it did not pass with a value of 395, our restriction on Ntot, while fulfilling the other criteria. These aspects help explain the missing lens candidates identified as lens clusters with other techniques. On the other hand, with selection No. 46, we found less than 15% contamination, namely lens candidates not identified as galaxy cluster that have nonetheless passed our photo-z criteria.
In total, we have 58 visually identified lens clusters that pass our criteria on the photo-z limits, which include 22 known systems from the SuGOHI group- and cluster-lens catalogs. From these 58 lens cluster candidates, only 15 are not listed in the galaxy cluster catalogs, highlighting the efficiency of the visual inspection in combination with our photo-z criteria. This implies that we identified 43 lens candidates that are (1) listed in the galaxy cluster catalogs, (2) visually identified as clusters, and (3) passing our photo-z criteria, while not being reported in the SuGOHI group- and cluster-scale sample. While these are the most secure newly identified cluster-lens candidates, we considered all lens candidates that pass one of these three criteria as a lens candidate in a significantly overdense environment, resulting in a total of 231/546 systems. For comparison, 136 of 546 lens candidates and 879 random fields from our 10 000 comparison sample, respectively, do indeed pass our photo-z criteria. This shows once more that lenses tend to be in an overdense environment compared to random galaxies, in agreement with the findings of e.g., Wells et al. (2024).
5. Mass models and their statistical analyses
As a further step of the lens candidate analysis, we exploited the residual neural network presented by Schuldt et al. (2023a) to model the mass distribution of all 546 grade A and B lens candidates, making this the largest sample that has been modeled in an uniform way and the first such statistical analysis overall. However, we note that this is only a first step towards a statistical analysis of a whole lens population and a detailed analysis is relegated to a further work.
The network has been trained on highly realistic HSC-based mock lens images generated with the same code as the mocks used in C21 to train the lens finding network that we exploited in this work (see Sect. 2). It predicts the mass model parameter values of a SIE mass profile with external shear and was tested on 31 confirmed HSC lenses, resulting in a good recovery for most of the mass model parameters, except the external shear (Schuldt et al. 2023b). The distribution of the estimated parameter values of our 546 lens systems is shown in the top row of Fig. 6, while the predicted uncertainties at the bottom. We give in Table 4 the median with 1σ values for the seven predicted parameters, which are also marked by vertical lines in Fig. 6. Here, we distinguish among the lens candidates flagged by any of our three criteria to identify an overdensity (literature, visual inspection, or photometric redshift) and those that are not flagged. Therefore, the overdensity sample includes also some group-scale lenses and some FPs, namely, galaxy-scale lenses (see also Table B.1), biasing the statistics towards the system of galaxy-scale lenses in the field. We further note that the modeling residual neural network was only trained for galaxy-scale systems and, thus, it is forced to predict an Einstein radius value between 0.5 and 5″, for instance.
 |
Fig. 6. Normalized histograms of the mass model parameter values (top row) with uncertainties (bottom row) predicted by the neural network of Schuldt et al. (2023a). From left to right: Predict values for the SIE profile (lens center, x and y, complex ellipticity, ex and ey, and Einstein radius, θE) and the external shear (γext, 1 and γext, 2). We applied the network to all grade A and B lens candidates identified in C21 and this work, and distinguish between those flagged by any overdensity criteria (blue) and those not (red). The median values and ±1 sigma ranges are indicated by dotted vertical lines for each parameter (see also Table 4). |
Median with their 1σ (86% percentile) values of the seven parameters predicted by the network of Schuldt et al. (2023a).
As expected, the predicted Einstein radii in an overdensity tend towards higher values (see particularly the +1σ bound), while being still compatible with galaxy-scale systems. We did not identify a significant difference for the other parameters, nor the predicted uncertainties. While we would expect a tendency towards higher external shear for systems in an overdensity, we argue that the consistency is due to the difficulties with this network to predict the external shear. This is a known issue (see Schuldt et al. 2023a,b) and likely a result of the image resolution and seeing in HSC images observed from the ground in contrast to high-resolution observations from space (e.g., with HST, JWST, or Euclid).
While we compared above systems flagged by any of our overdensity criteria to systems that did not get flagged, we also performed the comparison with systems that have been identified by all three of our criteria. This results in a very clean sample with only lens candidates in clear overdensities. In this case, we obtained an Einstein radius of 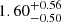 , which is significantly higher than that for the remaining systems and also notably higher than those reported in Table 4. This is in agreement with the expectation that the cluster environment does help to increase the size of the Einstein radius. All the other parameters are still consistent. However, we note that this value is based on a relatively small sample with only 43 systems.
, which is significantly higher than that for the remaining systems and also notably higher than those reported in Table 4. This is in agreement with the expectation that the cluster environment does help to increase the size of the Einstein radius. All the other parameters are still consistent. However, we note that this value is based on a relatively small sample with only 43 systems.
6. Conclusion and discussion
We extended our systematic search of galaxy-scale lenses by doubling our considered candidates to ∼135 million objects observed in the HSC Wide survey. We exploited the well tested residual neural network presented by C21 and obtained 11 816 network candidates from the new sample. To identify the most probable lens candidates and reject false positives, we carry out a multi-stage visual inspection with eight individual graders. This ensures stable average grades while limiting the workload though pre-selection with fewer graders. We discuss the procedure in detail, and elaborate recommendations for further visual inspections particularly on large samples such as those expected from the Euclid and Rubin LSST surveys. The proposed strategy is as follows:
-
Calibration round: every grader inspects the same small sample, which is then discussed to agree on the grading criteria. This is particularly crucial for new data sets or grading teams.
-
Given the high number of lens search projects carried out, we propose excluding all previously classified network candidates (i.e., candidates classified as lenses and non-lenses) to lower the number of systems that need inspection, unless the detection algorithm (e.g., modeling rather than CNNs) or data set (e.g., high resolution images from Euclid) has changed notably.
-
To reject a significant fraction of false positives, we propose a first inspection by a single person. The goal of this binary classification is to reject only the most obvious interlopers to lower the amount of systems that need to be inspected in the following steps, while keeping any system that require a closer look or system that may gain from a second opinion. In our case, this removed ∼90% of the network candidates, mostly images with, for instance, artefacts, or bright saturated stars that were not included in the training data.
-
A group of around four individuals inspect the remaining network candidates, providing grades between 0 and 3, and any additional classification flag included (e.g., indicating an offset of the lens, a cluster environment, a possible lensed quasar).
-
To further increase the grades per interesting object, but lowering the amount of human inspection, we propose to only collect additional grades for objects with average grade above 1, to finally average over at least seven grades per relevant object. While the threshold for interesting objects is G ≥ 1.5, we propose here a slightly lower threshold to allow for potential upgrading of candidates after acquiring more grades and to not exclude possible outliers in the grades.
-
Finally, a re-classification of systems with high-dispersion among the provided grades.
Following a similar approach, which is described in Sect. 3, we present 24 grade A lens candidates (average grade G ≥ 2.5) and 138 grade B lens candidates (2.5 > G ≥ 1.5) in Table 2, containing 118 recovered lens candidates that had already been identified by complementary algorithms.
While there have been a variety of lens search projects carried out, they are nearly always focusing on static, not time-varying, galaxy-scale lenses. Given the impact of the lens environment in their analysis and the advantages of cluster-scale lenses for various studies as well as the possibility of exploiting them to study galaxy cluster properties, we present a detailed analysis of their environment. Here, we consider also our previously identified network candidates from C21, enlarging the sample to 546 grade A or B lens candidates. For this, we visually inspected additionally larger image stamps as shown in Fig. 4 and classified their environment.
We further compiled and exploited a photo-z catalog obtained from three complementary techniques broadly applied to the HSC Wide survey area, ultimately providing more than 115 million photo-z values. The presented criteria enable a selection of cluster-lens candidates tested against our visual lens candidate identification and known galaxy clusters from the literature.
After their identification and environment analysis, we applied the neural network from Schuldt et al. (2023a) to all 546 analyzed grade A and B lens candidates, making it the largest sample that has been uniformly modeled so far. We discussed the parameter value and corresponding uncertainty distributions, while considering galaxy-scale systems in an overdensity separately from those in the field. We found a tendency towards larger Einstein radii for systems in an overdensity, while other parameters remain the same for the sample.
The proposed environment analysis and statistical modeling analysis pave the way to efficiently exploit larger samples of lens candidates in the upcoming era of wide-field imaging surveys. From this, we expect around 100 000 lenses, and which will bolster large and accurate photo-z catalogs, as well as offer a novel technique to identify new lensing clusters.
Data availability
Tables 2 and 3 are available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/693/A291
Significant part of Appendix B is also available on Zenodo here: https://zenodo.org/records/14501214
The visual inspectors are in alphabetical order by last name: I. T. A., S. B., R. C., A. M., S. S., Y. S., S. H. S., and S. T.
Acknowledgments
We thank C. Lemon for sharing the SLED compilation of known lens candidates and the anonymous referee for the helpful comments. SS has received funding from the European Union’s Horizon 2022 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 101105167 – FASTIDIoUS. We thank the Max Planck Society for support through the Max Planck Fellowship of SHS. This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (LENSNOVA: grant agreement No. 771776). This research is supported in part by the Excellence Cluster ORIGINS which is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy – EXC-2094 – 390783311. SB acknowledges the funding provided by the Alexander von Humboldt Foundation. CG acknowledges financial support through grants PRIN-MIUR 2017WSCC32 and 2020SKSTHZ. This paper is based on data collected at the Subaru Telescope and retrieved from the HSC data archive system, which is operated by Subaru Telescope and Astronomy Data Center at National Astronomical Observatory of Japan. The Hyper Suprime-Cam (HSC) collaboration includes the astronomical communities of Japan and Taiwan, and Princeton University. The HSC instrumentation and software were developed by the National Astronomical Observatory of Japan (NAOJ), the Kavli Institute for the Physics and Mathematics of the Universe (Kavli IPMU), the University of Tokyo, the High Energy Accelerator Research Organization (KEK), the Academia Sinica Institute for Astronomy and Astrophysics in Taiwan (ASIAA), and Princeton University. Funding was contributed by the FIRST program from Japanese Cabinet Office. the Ministry of Education. Culture, Sports, Science and Technology (MEXT), the Japan Society for the Promotion of Science (JSPS), Japan Science and Technology Agency (JST), the Toray Science Foundation, NAOJ, Kavli IPMU, KEK, ASIAA, and Princeton University. This work uses the following software packages: Astropy (Astropy Collaboration 2013, 2018), matplotlib (Hunter 2007), numpy (van der Walt et al. 2011; Harris et al. 2020), Python (Van Rossum & Drake 2009), Scipy (Virtanen et al. 2020). TOPCAT (Taylor 2005).
References
- Abolfathi, B., Aguado, D. S., Aguilar, G., et al. 2018, ApJS, 235, 42 [NASA ADS] [CrossRef] [Google Scholar]
- Acebron, A., Grillo, C., Bergamini, P., et al. 2022a, A&A, 668, A142 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Acebron, A., Grillo, C., Bergamini, P., et al. 2022b, ApJ, 926, 86 [NASA ADS] [CrossRef] [Google Scholar]
- Aihara, H., Allende Prieto, C., An, D., et al. 2011, ApJS, 193, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Aihara, H., Arimoto, N., Armstrong, R., et al. 2018, PASJ, 70, S4 [NASA ADS] [Google Scholar]
- Andika, I. T., Suyu, S. H., Cañameras, R., et al. 2023, A&A, 678, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Angora, G., Rosati, P., Meneghetti, M., et al. 2023, A&A, 676, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Bergamini, P., Rosati, P., Vanzella, E., et al. 2021, A&A, 645, A140 [EDP Sciences] [Google Scholar]
- Bergamini, P., Acebron, A., Grillo, C., et al. 2023, A&A, 670, A60 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Birrer, S., Shajib, A. J., Galan, A., et al. 2020, A&A, 643, A165 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bonvin, V., Courbin, F., Suyu, S. H., et al. 2017, MNRAS, 465, 4914 [NASA ADS] [CrossRef] [Google Scholar]
- Cañameras, R., Schuldt, S., Suyu, S. H., et al. 2020, A&A, 644, A163 [Google Scholar]
- Cañameras, R., Schuldt, S., Shu, Y., et al. 2021, A&A, 653, L6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Canameras, R., Schuldt, S., Shu, Y., et al. 2024, A&A, 692, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cao, X., Li, R., Shu, Y., et al. 2020, MNRAS, 499, 3610 [NASA ADS] [CrossRef] [Google Scholar]
- Chan, J. H. H., Suyu, S. H., Chiueh, T., et al. 2015, ApJ, 807, 138 [NASA ADS] [CrossRef] [Google Scholar]
- Chan, J. H. H., Suyu, S. H., Sonnenfeld, A., et al. 2020, A&A, 636, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Despali, G., Heinze, F. M., Fassnacht, C. D., et al. 2024, A&A, submitted [arXiv:2407.12910] [Google Scholar]
- Diehl, H. T., Buckley-Geer, E. J., Lindgren, K. A., et al. 2017, ApJS, 232, 15 [NASA ADS] [CrossRef] [Google Scholar]
- Dieleman, S., Willett, K. W., & Dambre, J. 2015, MNRAS, 450, 1441 [NASA ADS] [CrossRef] [Google Scholar]
- D’Isanto, A., & Polsterer, K. L. 2018, A&A, 609, A111 [Google Scholar]
- Euclid Collaboration (Desprez, G., et al.) 2020, A&A, 644, A31 [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Paltani, S., et al.) 2024, A&A, 681, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Faure, C., Anguita, T., Alloin, D., et al. 2011, A&A, 529, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Frye, B. L., Pascale, M., Pierel, J., et al. 2024, ApJ, 961, 171 [NASA ADS] [CrossRef] [Google Scholar]
- Gavazzi, R., Marshall, P. J., Treu, T., & Sonnenfeld, A. 2014, ApJ, 785, 144 [Google Scholar]
- Granata, G., Bergamini, P., Grillo, C., et al. 2023, A&A, 679, A124 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Green, J., Schechter, P., Baltay, C., et al. 2012, ArXiv e-prints [arXiv:1208.4012] [Google Scholar]
- Grillo, C., Lombardi, M., Rosati, P., et al. 2008, A&A, 486, 45 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Grillo, C., Gobat, R., Presotto, V., et al. 2014, ApJ, 786, 11 [Google Scholar]
- Grillo, C., Rosati, P., Suyu, S. H., et al. 2018, ApJ, 860, 94 [Google Scholar]
- Grillo, C., Rosati, P., Suyu, S. H., et al. 2020, ApJ, 898, 87 [Google Scholar]
- Grillo, C., Pagano, L., Rosati, P., & Suyu, S. H. 2024, A&A, 684, L23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2016a, 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770 [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2016b, ArXiv e-prints [arXiv:1603.05027] [Google Scholar]
- Hezaveh, Y. D., Perreault Levasseur, L., & Marshall, P. J. 2017, Nature, 548, 555 [Google Scholar]
- Hsieh, B. C., & Yee, H. K. C. 2014, ApJ, 792, 102 [Google Scholar]
- Huang, X., Bolton, A. S., Boone, K., et al. 2019, Confirming Strong Galaxy Gravitational Lenses in the DESI Legacy Imaging Surveys, HST Proposal [Google Scholar]
- Huang, X., Storfer, C., Ravi, V., et al. 2020, ApJ, 894, 78 [NASA ADS] [CrossRef] [Google Scholar]
- Huang, X., Storfer, C., Gu, A., et al. 2021, ApJ, 909, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Inami, H., Bacon, R., Brinchmann, J., et al. 2017, A&A, 608, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ivezic, Z., Axelrod, T., Brandt, W. N., et al. 2008, Serb. Astron. J., 176, 1 [Google Scholar]
- Jacobs, C., Glazebrook, K., Collett, T., More, A., & McCarthy, C. 2017, MNRAS, 471, 167 [Google Scholar]
- Jacobs, C., Collett, T., Glazebrook, K., et al. 2019, ApJS, 243, 17 [Google Scholar]
- Jaelani, A. T., More, A., Oguri, M., et al. 2020a, MNRAS, 495, 1291 [Google Scholar]
- Jaelani, A. T., More, A., Sonnenfeld, A., et al. 2020b, MNRAS, 494, 3156 [NASA ADS] [CrossRef] [Google Scholar]
- Jaelani, A. T., Rusu, C. E., Kayo, I., et al. 2021, MNRAS, 502, 1487 [NASA ADS] [CrossRef] [Google Scholar]
- Jaelani, A. T., More, A., Wong, K. C., et al. 2023, ArXiv e-prints [arXiv:2312.07333] [Google Scholar]
- John William, A., Jalan, P., Bilicki, M., & Hellwing, W. A. 2023, ArXiv e-prints [arXiv:2312.08043] [Google Scholar]
- Jones, E., Do, T., Li, Y. Q., et al. 2024, ApJ, 974, 159 [NASA ADS] [CrossRef] [Google Scholar]
- Kelly, P. L., Rodney, S. A., Brammer, G., et al. 2015a, ATel, 8402, 1 [NASA ADS] [Google Scholar]
- Kelly, P. L., Rodney, S. A., Treu, T., et al. 2015b, Science, 347, 1123 [Google Scholar]
- Kelly, P. L., Rodney, S., Treu, T., et al. 2023, ApJ, 948, 93 [NASA ADS] [CrossRef] [Google Scholar]
- Lanusse, F., Ma, Q., Li, N., et al. 2018, MNRAS, 473, 3895 [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Lecun, Y., Bottou, L., Bengio, Y., & Haffner, P. 1998, Proc. IEEE, 86, 2278 [Google Scholar]
- Lemon, C. A., Auger, M. W., McMahon, R. G., & Ostrovski, F. 2018, MNRAS, 479, 5060 [Google Scholar]
- Li, R., Napolitano, N. R., Tortora, C., et al. 2020, ApJ, 899, 30 [Google Scholar]
- Li, R., Napolitano, N. R., Roy, N., et al. 2022, ApJ, 929, 152 [NASA ADS] [CrossRef] [Google Scholar]
- Meneghetti, M., Davoli, G., Bergamini, P., et al. 2020, Science, 369, 1347 [Google Scholar]
- Meneghetti, M., Ragagnin, A., Borgani, S., et al. 2022, A&A, 668, A188 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meneghetti, M., Cui, W., Rasia, E., et al. 2023, A&A, 678, L2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Metcalf, R. B., Meneghetti, M., Avestruz, C., et al. 2019, A&A, 625, A119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meštrić, U., Vanzella, E., Zanella, A., et al. 2022, MNRAS, 516, 3532 [CrossRef] [Google Scholar]
- More, A., Verma, A., Marshall, P. J., et al. 2016, MNRAS, 455, 1191 [NASA ADS] [CrossRef] [Google Scholar]
- Oguri, M. 2014, MNRAS, 444, 147 [NASA ADS] [CrossRef] [Google Scholar]
- Oguri, M., Lin, Y.-T., Lin, S.-C., et al. 2018, PASJ, 70, S20 [NASA ADS] [Google Scholar]
- Parry, W. G., Grillo, C., Mercurio, A., et al. 2016, MNRAS, 458, 1493 [Google Scholar]
- Pascale, M., Frye, B. L., Pierel, J. D. R., et al. 2024, ArXiv e-prints [arXiv:2403.18902] [Google Scholar]
- Pearson, J., Li, N., & Dye, S. 2019, MNRAS, 488, 991 [Google Scholar]
- Pearson, J., Maresca, J., Li, N., & Dye, S. 2021, MNRAS, 505, 4362 [CrossRef] [Google Scholar]
- Petrillo, C. E., Tortora, C., Vernardos, G., et al. 2019, MNRAS, 484, 3879 [Google Scholar]
- Pierel, J. D. R., Newman, A. B., Dhawan, S., et al. 2024, ApJ, 967, L37 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration XIII. 2016, A&A, 594, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pourrahmani, M., Nayyeri, H., & Cooray, A. 2018, ApJ, 856, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Refsdal, S. 1964, MNRAS, 128, 307 [NASA ADS] [CrossRef] [Google Scholar]
- Rodney, S. A., Brammer, G. B., Pierel, J. D. R., et al. 2021, Nat. Astron., 5, 1118 [NASA ADS] [CrossRef] [Google Scholar]
- Rojas, K., Savary, E., Clément, B., et al. 2022, A&A, 668, A73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rojas, K., Collett, T. E., Ballard, D., et al. 2023, MNRAS, 523, 4413 [NASA ADS] [CrossRef] [Google Scholar]
- Savary, E., Rojas, K., Maus, M., et al. 2022, A&A, 666, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schmidt, S. J., Malz, A. I., Soo, J. Y. H., et al. 2020, MNRAS, 499, 1587 [Google Scholar]
- Schuldt, S., Chirivì, G., Suyu, S. H., et al. 2019, A&A, 631, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuldt, S., Suyu, S. H., Meinhardt, T., et al. 2021a, A&A, 646, A126 [EDP Sciences] [Google Scholar]
- Schuldt, S., Suyu, S. H., Cañameras, R., et al. 2021b, A&A, 651, A55 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuldt, S., Cañameras, R., Shu, Y., et al. 2023a, A&A, 671, A147 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuldt, S., Suyu, S. H., Cañameras, R., et al. 2023b, A&A, 673, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuldt, S., Grillo, C., Caminha, G. B., et al. 2024, A&A, 689, A42 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Scoville, N., Aussel, H., Brusa, M., et al. 2007, ApJS, 172, 1 [Google Scholar]
- Shajib, A. J., Treu, T., Birrer, S., & Sonnenfeld, A. 2021, MNRAS, 503, 2380 [Google Scholar]
- Shajib, A. J., Wong, K. C., Birrer, S., et al. 2022, A&A, 667, A123 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shu, Y., Bolton, A. S., Kochanek, C. S., et al. 2016, ApJ, 824, 86 [NASA ADS] [CrossRef] [Google Scholar]
- Shu, Y., Marques-Chaves, R., Evans, N. W., & Pérez-Fournon, I. 2018, MNRAS, 481, L136 [Google Scholar]
- Shu, Y., Cañameras, R., Schuldt, S., et al. 2022, A&A, 662, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Gavazzi, R., Suyu, S. H., Treu, T., & Marshall, P. J. 2013, ApJ, 777, 97 [Google Scholar]
- Sonnenfeld, A., Chan, J. H. H., Shu, Y., et al. 2018, PASJ, 70, S29 [Google Scholar]
- Sonnenfeld, A., Jaelani, A. T., Chan, J., et al. 2019, A&A, 630, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Verma, A., More, A., et al. 2020, A&A, 642, A148 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Suyu, S. H., & Halkola, A. 2010, A&A, 524, A94 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Suyu, S. H., Hensel, S. W., McKean, J. P., et al. 2012, ApJ, 750, 10 [Google Scholar]
- Suyu, S. H., Huber, S., Cañameras, R., et al. 2020, A&A, 644, A162 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tadaki, K.-I., Iye, M., Fukumoto, H., et al. 2020, MNRAS, 496, 4276 [NASA ADS] [CrossRef] [Google Scholar]
- Talbot, M. S., Brownstein, J. R., Dawson, K. S., Kneib, J.-P., & Bautista, J. 2021, MNRAS, 502, 4617 [NASA ADS] [CrossRef] [Google Scholar]
- Tanaka, M., Coupon, J., Hsieh, B.-C., et al. 2018, PASJ, 70, S9 [Google Scholar]
- Taylor, M. B. 2005, ASP Conf. Ser., 347, 29 [Google Scholar]
- Tohill, C., Ferreira, L., Conselice, C. J., Bamford, S. P., & Ferrari, F. 2021, ApJ, 916, 4 [NASA ADS] [CrossRef] [Google Scholar]
- Tsang, A., Çağan Şengül, A., & Dvorkin, C. 2024, ArXiv e-prints [arXiv:2401.16624] [Google Scholar]
- Tuccillo, D., Huertas-Company, M., Decencière, E., et al. 2018, MNRAS, 475, 894 [NASA ADS] [CrossRef] [Google Scholar]
- van der Walt, S., Colbert, S. C., & Varoquaux, G. 2011, Comput. Sci. Eng., 13, 22 [Google Scholar]
- Van Rossum, G., & Drake, F. L. 2009, Python 3 Reference Manual (Scotts Valley: CreateSpace) [Google Scholar]
- Vanzella, E., Caminha, G. B., Rosati, P., et al. 2021, A&A, 646, A57 [EDP Sciences] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Meth., 17, 261 [Google Scholar]
- Walmsley, M., Lintott, C., Géron, T., et al. 2022, MNRAS, 509, 3966 [Google Scholar]
- Wang, H., Cañameras, R., Caminha, G. B., et al. 2022, A&A, 668, A162 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wells, P. R., Fassnacht, C. D., Birrer, S., & Williams, D. 2024, A&A, 689, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wen, Z. L., & Han, J. L. 2018, MNRAS, 481, 4158 [CrossRef] [Google Scholar]
- Wen, Z. L., & Han, J. L. 2021, MNRAS, 500, 1003 [Google Scholar]
- Wong, K. C., Sonnenfeld, A., Chan, J. H. H., et al. 2018, ApJ, 867, 107 [Google Scholar]
- Wong, K. C., Suyu, S. H., Chen, G. C. F., et al. 2020, MNRAS, 498, 1420 [Google Scholar]
- York, D. G., Adelman, J., Anderson, J. E., et al. 2000, AJ, 120, 1579 [Google Scholar]
Appendix A: Overview of grade-B lens candidates
In this appendix, we show in Fig. A.1 recentered color-image stamps of our grade B candidates, in analogy to Fig. 3. The image stamps are 12″ on a side and we display the corresponding HSC name in the bottom of each panel, appearing white if discovered for the first time, and light blue if the candidate was previously classified as a grade C candidate. Names in green indicate re-discoveries with comparable grade. In the top we provide the network score p and the average grade G. Fully new discoveries are further highlighted with orange frames.
 |
Fig. A.1. Recentered color-image stamps of identified grade-B lens candidates. Same format as Fig. 3. |
 |
Fig. A.1. continued: Recentered color-image stamps of identified grade-B lens candidates. |
Appendix B: Details of lens candidates in overdensities
In this appendix, we provide in Table B.1 the details of our lens cluster selection regarding their environment described in Sect. 4. We provide further details of our lens cluster selection regarding their environment. In detail, Table B.2 gives, in analogy to Table B.1, the performance of photo-z cuts on the subtracted photo-z histograms, and shows that No. 43 lists the best criteria limits according to the F1tot value. We note that this selection is outperformed by No. 46 presented in Sect. 4.3 using the original histograms, instead of the subtracted ones.
In Fig. B.1 we show the photo-z histograms of two lens candidates as example, one visually identified to be in an overdense environment (HSC J0214-0206, red) and one not (HSC J0014+0041, blue). In detail, we show the original histograms (top panel), the subtracted histograms (middle panel), and the normalized histograms (bottom panel). The eight selection criteria, introduced in Sect. 4.3, are marked for visualization. For instance, HSC J0214-0206 has with the original histogram (top panel) a value for Npeak of 26 (horizontal dashed brown line) at zlow = 0.62 (vertical solid brown line). The sum of the red histogram results in Ntot = 810, and consequently Nfrac = 26/810 ∼ 0.032. In addition, this histogram shows Npeak5 = 26 and Npeak10 = 11 neighbouring redshift bins around zlow that exceeds 5 and 10 (horizontal solid brown line). The sums of objects in these redshift bins are 336 and 189, respectively, denoted as Apeak5 and Apeak10, that are shaded in light and solid red. Following the same style, we also indicate the values of the criteria for the other histograms.
Furthermore, Fig. B.2 visualizes the introduced criteria using the subtracted histograms, while Fig. B.3 shows them extracted from the normalized histograms. Finally, we show in Fig. B.4 80″ × 80″ image stamps of the remaining grade A and B lens candidates located in an overdense environment based on our visual inspection. This is the continuation of Fig. 4.
Comparison of true-positive (TP) and false-positive (FP) rates for different selection criteria using the photometric redshift distributions around the 546 grade A or B lens candidates.
All Tables
High-confidence lens candidates with ResNet scores p ≥ 0.1, and average grades G ≥ 1.5 from visual inspection.
Median with their 1σ (86% percentile) values of the seven parameters predicted by the network of Schuldt et al. (2023a).
Comparison of true-positive (TP) and false-positive (FP) rates for different selection criteria using the photometric redshift distributions around the 546 grade A or B lens candidates.
All Figures
|
Fig. 1. Normalized histograms showing the distribution of 0 and 1 grades assigned in round #2 to network candidates from the overlap sample, containing 175 systems. We show all possible team combinations of the eight graders and only count systems that received a 0 or 1 by all graders of a particular team combination. Significant scatter is observed for small teams, which is expected and in agreement with R23. |
| In the text | |
|
Fig. 2. Comparison between average grades from team A (x-axis) and team B (y-axis), containing four graders apiece, from round #2 (top), round #3 (middle), each with 175 systems (overlap sample), and round #4 (bottom), containing all 327 objects that received eight grades. |
| In the text | |
|
Fig. 3. Recentered color-image stamps (12″ × 12″; north is up and east is left) of identified grade-A lens candidates using HSC gri multi-band imaging data. At the top of each panel, we list the ResNet scores, p, and the average grades, G, of eight graders, where ≥2.5 corresponds to grade A, from the visual inspection. At the bottom, we list the candidate name, displayed in white for new candidates, light blue if previously detected as grade C lens candidate, and green if previously known grade A or B lens candidate. Given the numerous lens search projects exploiting HSC data, only our grade-B systems (shown in Fig. A.1) include new identification highlighted additionally with orange boxes. All systems with their coordinates and further details such as the lens environment are listed in Table 2. |
| In the text | |
|
Fig. 4. New grade A or grade B lens candidates visually identified to be on group- or cluster-scale, excluding known group- or cluster lenses from the SuGOHI sample. Each panel is 80″ × 80″, and the insert on the top-left shows the 12″ × 12″ cutout analysed by the ResNet. The lens name is given in the bottom of each panel, in cyan if listed in the galaxy cluster catalogs, and otherwise white. Furthermore, the network score, average grade, and number of cluster votes during visual inspection is given in the top (first row), in orange if listed by C21, in cyan if listed in this work, and white if in both. This is followed by the photo-z characteristics Nmax, zlow, Ntot, and Nfrac (second row), and Npeak5, Apeak5, Npeak10, and Apeak10 (third row), colored green or red if passing or not passing the final limits (No. 46 in Table B.1), respectively. We note that lens candidates from C21 were only inspected by a single person for the group and cluster environment classifications and, thus, they have all only one vote. The figure continues in Appendix B. For all shown image stamps, north is up and east is left. |
| In the text | |
|
Fig. 5. Normalized histograms of our eight introduced selection criteria. We distinguish between lens candidates visually identified to be in an overdensity (blue) or through the galaxy cluster catalogs (green), compared to those not in an overdensity (orange and magenta, respectively). We further show, for comparison, the distribution from 10 000 random positions in gray. Following the F1 criterion, we highlight the parameter range indicating overdensities in red (shaded regions for criteria No. 46 in Table B.1), which demonstrates that a combination of these different criteria is crucial to gain good performance. |
| In the text | |
|
Fig. 6. Normalized histograms of the mass model parameter values (top row) with uncertainties (bottom row) predicted by the neural network of Schuldt et al. (2023a). From left to right: Predict values for the SIE profile (lens center, x and y, complex ellipticity, ex and ey, and Einstein radius, θE) and the external shear (γext, 1 and γext, 2). We applied the network to all grade A and B lens candidates identified in C21 and this work, and distinguish between those flagged by any overdensity criteria (blue) and those not (red). The median values and ±1 sigma ranges are indicated by dotted vertical lines for each parameter (see also Table 4). |
| In the text | |
|
Fig. A.1. Recentered color-image stamps of identified grade-B lens candidates. Same format as Fig. 3. |
| In the text | |
|
Fig. A.1. continued: Recentered color-image stamps of identified grade-B lens candidates. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.