| Issue |
A&A
Volume 694, February 2025
|
|
|---|---|---|
| Article Number | A227 | |
| Number of page(s) | 21 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202453474 | |
| Published online | 18 February 2025 | |
Accelerating lensed quasar discovery and modeling with physics-informed variational autoencoders
1
Technical University of Munich, TUM School of Natural Sciences, Department of Physics, James-Franck-Str. 1, D-85748 Garching, Germany
2
Max-Planck-Institut für Astrophysik, Karl-Schwarzschild-Str. 1, D-85748 Garching, Germany
3
Dipartimento di Fisica, Università degli Studi di Milano, Via Celoria 16, I-20133 Milano, Italy
4
INAF – IASF Milano, Via A. Corti 12, I-20133 Milano, Italy
5
Academia Sinica Institute of Astronomy and Astrophysics (ASIAA), 11F of ASMAB, No. 1, Section 4, Roosevelt Road, Taipei 10617, Taiwan
6
Aix-Marseille Université, CNRS, CNES, LAM, Marseille, France
7
Department of Astrophysics, American Museum of Natural History, Central Park West and 79th Street, New York, NY 10024-5192, USA
8
Department of Physics and Astronomy, Lehman College of the CUNY, Bronx, NY 10468, USA
⋆ Corresponding author; irham.andika@tum.de
Received:
17
December
2024
Accepted:
17
January
2025
Strongly lensed quasars provide valuable insights into the rate of cosmic expansion, the distribution of dark matter in foreground deflectors, and the characteristics of quasar hosts. However, detecting them in astronomical images is difficult due to the prevalence of non-lensing objects. To address this challenge, we developed a generative deep learning model called VariLens, built upon a physics-informed variational autoencoder. This model seamlessly integrates three essential modules: image reconstruction, object classification, and lens modeling, offering a fast and comprehensive approach to strong lens analysis. VariLens is capable of rapidly determining both (1) the probability that an object is a lens system and (2) key parameters of a singular isothermal ellipsoid (SIE) mass model – including the Einstein radius (θE), lens center, and ellipticity – in just milliseconds using a single CPU. A direct comparison of VariLens estimates with traditional lens modeling for 20 known lensed quasars within the Subaru Hyper Suprime-Cam (HSC) footprint shows good agreement, with both results consistent within 2σ for systems with θE < 3″. To identify new lensed quasar candidates, we began with an initial sample of approximately 80 million sources, combining HSC data with multiwavelength information from Gaia, UKIRT, VISTA, WISE, eROSITA, and VLA. After applying a photometric preselection aimed at locating z > 1.5 sources, the number of candidates was reduced to 710 966. Subsequently, VariLens highlights 13 831 sources, each showing a high likelihood of being a lens. A visual assessment of these objects results in 42 promising candidates that await spectroscopic confirmation. These results underscore the potential of automated deep learning pipelines to efficiently detect and model strong lenses in large datasets, substantially reducing the need for manual inspection.
Key words: gravitational lensing: strong / methods: data analysis / galaxies: active / galaxies: high-redshift / quasars: general / quasars: supermassive black holes
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model.
Open access funding provided by Max Planck Society.
1. Introduction
Quasars serve as excellent tracers for investigating the assembly of supermassive black holes (SMBHs) and their host galaxies in the distant Universe (Inayoshi et al. 2020; Fan et al. 2023). When coupled with strong gravitational lensing, these systems offer unique perspectives on various astronomical phenomena. For instance, lensing can amplify the apparent flux and enhance the spatial resolution of target sources, allowing for the accurate characterization of quasar hosts that might otherwise be very faint or compact to observe (e.g., Ding et al. 2021; Yue et al. 2021; Stacey et al. 2022; Glikman et al. 2023). Lensing also allows us to investigate the foreground mass profile, offering valuable clues as to the dark matter characteristics and the mechanisms influencing the evolution of large-scale structures (Shajib et al. 2022). Furthermore, due to their variability, lensed quasars are exceptional tools for measuring the rate of cosmic expansion, quantified by the Hubble constant, H0, through time-delay cosmography (Refsdal 1964; Treu et al. 2022).
Previous studies have discovered hundreds of lensed quasars (e.g., Chan et al. 2022; Lemon et al. 2023; Dux et al. 2024, and the references within), but only a few tens of sources have been harnessed for time-delay analysis (Shajib et al. 2020; Wong et al. 2020). This is partly because only systems with a large enough separation (Δθ ≳ 1″), an adequate variability, and time delays ranging from weeks to years offer enhanced precision in H0 measurements (Rumbaugh et al. 2015; Millon et al. 2020; Ertl et al. 2023; Queirolo et al. 2023). Given the evident tension between H0 values calculated from the cosmic microwave background (CMB) radiation and those inferred from closer sources (e.g., Verde et al. 2019), expanding the number of cosmography-grade lensed quasars will help address this issue (Planck Collaboration VI 2020; Riess et al. 2022).
With the emergence of next-generation facilities such as the Vera C. Rubin Observatory’s Legacy Survey of Space and Time (LSST; Ivezić et al. 2019), scheduled to observe around 20 000 deg2 of the southern sky across six bandpasses, we foresee a significant rise in the number of lens candidates. To be precise, LSST is anticipated to unveil approximately 2000 lensed quasars, among which about 200 are expected to be quadruply lensed sources (Wong et al. 2020; Yue et al. 2022). However, locating them is challenging given that the fraction of strong lenses in all galaxies per unit area of the sky is as low as ≲10−3 (Oguri & Marshall 2010). This motivates us to develop a method capable of accurately identifying cosmography-grade systems amidst more numerous contaminants.
In our previous work, we introduced novel strategies for detecting galaxy-quasar lenses in multiband imaging surveys (Andika et al. 2023a,b). The method combines multiple convolutional neural networks (CNNs) and vision transformers (ViTs), resulting in a streamlined approach for locating lens candidates in the Hyper Suprime-Cam Subaru Strategic Program (hereafter HSC; Aihara et al. 2022) dataset with a low number of false positives. Considering the similarity between the HSC data and the anticipated quality of LSST images, we expect our model to perform at a comparable level with upcoming LSST data. Building upon our previous approach, we investigated the application of deep generative networks to refine our lens-finding strategy, specifically through the use of a physics-informed variational autoencoder. Additionally, we introduced two critical advancements in our method: (1) expanding the photometric preselection criteria to include more lensed quasar candidates, and (2) implementing fast, automated lens modeling to efficiently identify the most promising sources suitable for time-delay analysis. The latter point is crucial, given the anticipated rapid growth of photometric data in the coming years, contrasted with the limited availability of spectroscopic resources.
The structure of this paper is as follows. In Section 2, we describe the data collection process and detail the simulation used to generate mock galaxy-quasar lens systems, which serve as training data for our integrated lens-finding and modeling algorithm. Section 3 provides an in-depth look at the neural network architecture employed in this study. In Section 4, we evaluate the performance of our model and present the lensed quasar candidates identified through our analysis. Finally, Section 5 summarizes our findings and presents the conclusions drawn from this work.
All cosmological-related calculations were conducted using the ΛCDM model, where H0 = 72 km s−1 Mpc−1 and Ωm = 1 − ΩΛ = 0.3 (Bonvin et al. 2017; Planck Collaboration VI 2020). It is essential to mention that the mock lensed quasar images generated for the training dataset are independent of the exact value of H0. Additionally, the magnitudes are expressed using the AB convention. The reddening caused by Galactic extinction was corrected using the map from Schlegel et al. (1998) and filter adjustments from Fitzpatrick (1999) and Schlafly & Finkbeiner (2011). This correction was performed using the dustmaps1 library developed by Green (2018).
2. Data acquisition and training set construction
Our search for lensed quasars involves two stages. First, we will conduct data mining through a comprehensive analysis of multiband catalogs in this section. Next, we will assess the likelihood of candidates being lensed quasars as opposed to other types of sources using a deep learning classifier in Section 3.
In the first stage, our goal is to improve candidate purity by focusing on objects that, according to their photometric catalog data, have a higher chance of being lenses. This practice provides an efficient strategy to distinguish candidates from the majority of contaminants while minimizing computational resources. This section provides a detailed explanation of the initial phase of our search method. Additionally, we will discuss how the data is utilized to create the training dataset for the deep learning classifier through strong lens simulations.
2.1. Primary photometric catalog
To construct the main catalog, we utilize the wide-depth data from the third release of the public HSC survey dataset (Aihara et al. 2022). These data are acquired with the Hyper Suprime-Cam on the Subaru 8.2m telescope (Aihara et al. 2018, 2019), which captures 670 deg2 of the sky across five bands, reaching a depth of up to 26 mag (5σ for point sources), with a 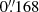 pixel scale and
pixel scale and  seeing. Including partially observed areas, the latest dataset extends to approximately 1300 deg2. This HSC data will be used to select the parent sample for our lensed quasar candidates.
seeing. Including partially observed areas, the latest dataset extends to approximately 1300 deg2. This HSC data will be used to select the parent sample for our lensed quasar candidates.
We choose all sources with 5σ detection in all bands, which corresponds to magnitude limits of [gri]< 26.0, z < 25.0, and y < 24.0. We then use the flux and magnitude values from the CModel photometry reported in the HSC pdr3_wide.forced table, which explicitly accounts for the point spread function (PSF) in the measurements. The following flags are applied to ensure reliable photometry:
-
[grizy]_sdsscentroid_flag is False
-
[grizy]_pixelflags_edge is False
-
[grizy]_pixelflags_interpolatedcenter is False
-
[grizy]_pixelflags_saturatedcenter is False
-
[grizy]_pixelflags_crcenter is False
-
[grizy]_pixelflags_bad is False
-
[grizy]_cmodel_flag is False.
After that, science images, each with 70 pixels on a side, along with their PSF models, are retrieved using the HSC data access tools2. At this stage, 86 792 741 unique sources, which constitute our parent sample, have passed our preliminary magnitude thresholds and flag criteria. To determine the spectroscopic classifications of these sources where available, we crossmatch this parent sample with databases of previously discovered quasars (Flesch 2021; Fan et al. 2023), stars/galaxies (Almeida et al. 2023), strong lenses3, and brown dwarfs4 (Best et al. 2018; Carnero Rosell et al. 2019).
2.2. Auxiliary data
Near-infrared (NIR) data are gathered from multiple surveys, including the VISTA Kilo-degree Infrared Galaxy Survey (VIKING; Edge et al. 2013), the VISTA Hemisphere Survey (VHS; McMahon et al. 2013), the United Kingdom Infrared Telescope (UKIRT) Infrared Deep Sky Survey (UKIDSS; Lawrence et al. 2007), and the UKIRT Hemisphere Survey (UHS; Dye et al. 2018). For this study, we utilize available photometry in the J, H, and K (or Ks) filters. Notably, VHS and VIKING cover a significant portion of the southern hemisphere, while UKIDSS and UHS cover vast regions of the northern sky. At the time of our search, data collection for both UKIDSS and VIKING had been completed. By comparison, UHS had only made J-band photometry available, whereas VHS had provided data in both the J and Ks filters across the majority of sky regions. Thus, the exact photometric data available for each object depends on its sky position.
In addition to the NIR data, the unWISE mid-infrared (MIR) measurements are used (Schlafly et al. 2019), which catalogs nearly two billion sources detected by the Wide-field Infrared Survey Explorer (WISE; Wright et al. 2010). With its ∼0.7 mag deeper imaging and enhanced source extraction in crowded regions, the unWISE catalog provides superior data quality compared to the original WISE survey. To merge the HSC data with the infrared (IR) catalogs mentioned above, we apply a 2″ crossmatching radius between corresponding targets.
Given that some quasars are X-ray bright, we incorporated data from the eROSITA telescope mounted on the Spektrum-Roentgen-Gamma (SRG) satellite. Specifically, we employed the first data release of the eROSITA All-Sky Survey (eRASS; Merloni et al. 2024), which provides soft X-ray measurements in the energy band 0.2−2.3 keV. The crossmatching process is then performed against our optical data using a radius of 15″.
Next, to identify radio-bright sources, we also included data from the Karl G. Jansky Very Large Array Sky Survey (VLASS; Lacy et al. 2020). VLASS is a radio survey designed to map the sky at 2−4 GHz (S-band). For this analysis, we looked for the radio counterparts of our optical sources within a radius of 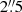 , using the second epoch of the VLASS Quick Look catalog (Gordon et al. 2020, 2021, 2023).
, using the second epoch of the VLASS Quick Look catalog (Gordon et al. 2020, 2021, 2023).
With the complete multiwavelength dataset in hand, we prioritized sources showing signal-to-noise ratio (S/N) of at least 3σ in the X-ray, IR, or radio. Ultimately, a total of 1 929 190 sources met this criterion. It is worth noting that the combination of multiwavelength information plays a crucial role in distinguishing between quasars, stars, and brown dwarfs (e.g., Andika et al. 2020, 2022). Additionally, this crossmatching method is effective for filtering out artifacts like cosmic rays or transient sources that appear in only one survey, helping to ensure cleaner data (e.g., Andika 2022). A summary of our selection criteria is provided in Table 1 for further details.
Overview of the selection criteria used to identify lensed quasar candidates.
2.3. Real galaxy and simulated quasar samples
The training dataset used in this study is adapted from Andika et al. (2023b). The mock lenses, are created by overlaying simulated point sources onto real galaxy images. The deflectors in this dataset are sourced from galaxy samples observed in the Sloan Digital Sky Survey Data Release 18 catalog (SDSS; Almeida et al. 2023). Specifically, we select objects classified as “GALAXY” by the SDSS spectroscopic pipeline having velocity dispersions of 50 ≤ σv ≤ 500 km s−1 and S/N of σv/σv, err > 5. This specific σv range is selected to exclude systems with measurements that are either too small, too large, or inaccurate. Furthermore, we restrict our selection to deflectors within redshift of z < 4 since the prevalence of the lensing optical depth for high-z quasars originates from ellipticals around z ∼ 1 (Mason et al. 2015; Pacucci & Loeb 2019). These selected deflectors are then cross-matched to our parent data with a search radius of 1″ to obtain their photometric measurements and image cutouts when available. As a result, we obtain a sample of 138 556 deflectors, predominantly made up of luminous red galaxies (LRGs) with typical velocity dispersions around σv ∼ 250 km s−1, extending to z ∼ 1.5 (see Figure 1).
 |
Fig. 1. Distribution of redshifts (zgal), stellar velocity dispersions (σv), Einstein radii (θE), and HSC i-band magnitudes (iHSC) for the galaxies used to simulate the lens systems. The orange histograms represent the mock lens configurations in all training, validation, and test datasets, while the mock lenses correctly identified by our classifier are highlighted with blue lines. |
To simulate the point-source emissions of background quasars, we generate a thousand quasar spectra, uniformly distributed across rest-frame 1450 Å absolute magnitudes ranging from M1450 = −30 to −20 and redshifts between z = 1.5 and 7.2. The simulation is performed using the SIMQSO5 module (McGreer et al. 2013), following the methodology outlined by Andika et al. (2023a, see their Sect. 2.2 for more information). Our quasar model is composed of a continuum emission characterized by a broken power-law shape. The continuum slopes (αν) follow a Gaussian function with means of −1.5 for rest wavelengths of λrest ≤ 1215 Å and −0.5 at λrest > 1215 Å, assuming a fixed dispersion of 0.3. The model further incorporates pseudo-continuum iron emissions using templates from Boroson & Green (1992) and Vestergaard & Wilkes (2001). Additionally, broad and narrow emission lines are included, adhering to the strengths, ratios, and widths observed in SDSS quasars (e.g., Dawson et al. 2013, 2016; Blanton et al. 2017).
Additionally, the generated spectra account for intergalactic medium (IGM) absorption through the Lyα forest along the line of sight (Songaila & Cowie 2010; Worseck & Prochaska 2011). For quasars with z ≳ 5.5, we apply the Lyα damping wing effect using the formula provided by Miralda-Escudé (1998), with a proximity zone size of 3 Mpc and neutral hydrogen fractions varying randomly between 0% and 10% (e.g., Euclid Collaboration: Barnett et al. 2019; Andika et al. 2020). Furthermore, internal reddening due to dust is applied to the spectra using the model from Calzetti et al. (2000), with E(B − V) values randomly chosen between −0.02 and 0.14. Negative reddening values are used to generate quasar models with bluer continua than the original templates provide. Photometry is subsequently derived from these mock data, and its uncertainty is computed using the magnitude–error relation specific to each survey (e.g., Yang et al. 2016).
2.4. Synthetic multiband lensed quasar images with strong lensing simulation
In the following stage, we use a singular isothermal ellipsoid (SIE) approximation to represent the profile of the lens mass (e.g., Barkana 1998; Rojas et al. 2022; Schuldt et al. 2023a). This model is characterized by 5 parameters: the Einstein radius (θE), the axis ratio (q), the position angle (ϕ), and the image centroid coordinates (x, y). The Einstein radius can be directly estimated from the observed galaxy velocity dispersion using the following equation:
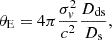
where c is the speed of light, and Dds is the angular diameter distance from the lens to the source, while Ds is the distance from the observer to the source. As shown by the distance ratio in Equation (1), the Einstein radius θE does not depend on H0.
The dimensionless surface mass density, or convergence, of the SIE profile used here can be described as
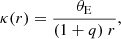
where r denotes the elliptical radius given by
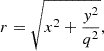
and q represents the axis ratio, defined as

where ex and ey are the components of the complex ellipticity in the coordinate plane of x − y of the lens system. These variables can also be expressed as
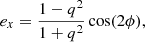
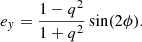
To account for extra mass beyond the observed image region, we include external shear parameters (γext, 1, γext, 2). These parameters are related to the total shear strength (γext), which is given by
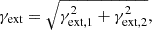
and the shear is oriented by
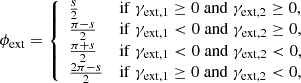
with s defined as
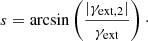
We determine the SIE parameters x, y, ex, and ey by modeling the light profile of each deflector using its HSC i-band data. This approach assumes that the mass profile follows the light distribution. Our fitting method utilizes a mixture of elliptical Sérsic and exponential light profiles, implemented in the PyAutoGalaxy6, a publicly available tool for studying galaxy morphologies (Nightingale et al. 2018, 2023). Afterward, we apply random external shears, with position angles selected randomly between 0 and 180 deg and strengths drawn from a Gaussian distribution with a mean of 0 and a standard deviation of 0.058 (e.g., Shu et al. 2022).
Next, images of simulated lenses are generated by combining each real galaxy with a randomly chosen mock quasar. The quasar is placed behind the lens at a random angular distance (β) within the range 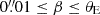 . The parameter β can be decomposed into its components (xs, ys) as follows:
. The parameter β can be decomposed into its components (xs, ys) as follows:
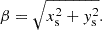
The background quasar image is then traced onto the lens plane, and the deflection angles and magnifications are calculated based on the lensing equation using PyAutoLens7 (version 2024.1.27.4; Nightingale et al. 2021). The resulting multiplied quasar images are then convolved with the HSC PSF model and overlaid onto the original HSC galaxy images.
The process of pairing and positioning quasars can be performed up to 500 times to determine a viable lens configuration that meets the following conditions: (1) the simulated image must exhibit a significant lensing effect with a magnification factor of > 5, (2) the maximum y-band flux of the lensed quasar must be detected at > 5σ above the median background noise, and (3) the y-band magnitude of the lensed quasar must be > 15 mag to prevent the inclusion of excessively bright objects or saturated images. If these conditions are not met, the current deflector is discarded, and the process continues with the next one. Additionally, systems with θE ≥ 5″ are excluded from consideration, as the largest Einstein radius observed in galaxy-scale lensing cases are not exceeding this limit (Belokurov et al. 2007; Schuldt et al. 2019, 2021). Ultimately, 137 552 mock lenses that meet our criteria are obtained from the preliminary pool of 138 556 deflectors and 1000 mock quasars.
Figure 1 illustrates the distribution of lens galaxy redshifts, velocity dispersions, Einstein radii, and i-band magnitudes used in our simulation. For the color images of the simulated lens systems, see Figure 2. Our deflector redshifts are primarily concentrated at z ≈ 0.5 and extend up to z ∼ 1.5, as noted earlier. There is a notable increase in the number of deflector galaxies up to i ≈ 19.5, followed by a sharp decline at fainter magnitudes. Consequently, our training dataset is biased to larger and brighter lens galaxies. This distribution pattern primarily reflects the selection criteria of SDSS for its spectroscopic targets, adhering to the selection set by Dawson et al. (2013, 2016) and Prakash et al. (2016) for studying large-scale structures in the Universe. Most of these targets are LRGs at z ≲ 1, which are particularly useful for examining baryon acoustic oscillations and, thus, understanding the Universe’s expansion (e.g., Woodfinden et al. 2022; Zhao et al. 2022). The magnitude limits for galaxies included in the spectroscopic surveys are i = 19.9 and 21.8 for SDSS III and IV, respectively.
 |
Fig. 2. Examples of mock lenses and other contaminants used for training the networks, with the inferred lens probability for each image indicated. By overlaying the multiply imaged source’s light following an SIE+γext lens configuration onto a real galaxy image, we are able to construct realistic galaxy-quasar lens mocks. |
3. Lens detection and parameter estimation with neural networks
3.1. Input data preparation and augmentation
Our training datasets are divided into two groups to align with the two distinct modules in our network architecture: regression and classification. The first group, hereafter DS1, is used to train the regressor and consists of all the simulated lensed quasars generated in the preceding section. The second dataset, named DS2, includes half of the previously created mock lenses and half of the real galaxies without lensed quasars, which will be used to train our classifier. Both DS1 and DS2 contain 137 552 objects each. Again, while DS1 is entirely composed of mock lenses, DS2 is a balanced mix of simulated lensed quasars and real galaxies.
Data augmentation is applied to both DS1 and DS2 but with different setups. For DS1, only translations of up to 3 pixels are used. Transformations such as rotations and flips are avoided, as they would modify the lensing configuration, requiring updates to the ground truth lens parameters and thereby increasing computational complexity. In contrast, for DS2, we apply random rotations of ±π/2, translations of up to 10 pixels, and vertical or horizontal flips on the fly during the training loop. In the case of the classification task, this approach boosts the number of training data and helps the network learn to correctly categorize different perspectives of the same image.
The training images are initially constructed from five HSC bands, each measuring 70 pixels per side, corresponding to an angular size of approximately 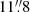 . After undergoing the augmentation process, we crop the images to 64 × 64 pixels, that is, equivalent to
. After undergoing the augmentation process, we crop the images to 64 × 64 pixels, that is, equivalent to 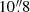 , to focus on the sources at the center. These image cutouts are then adjusted using min-max scaling to normalize fluxes between zero and one, followed by square-root stretching to enhance low-flux features and improve visual appearance (e.g., Cañameras et al. 2021; Andika et al. 2023b). This scaling is performed on each grizy image cube for every source, ensuring that the relative pixel brightness across different bandpasses is preserved, thereby retaining the colors of the sources.
, to focus on the sources at the center. These image cutouts are then adjusted using min-max scaling to normalize fluxes between zero and one, followed by square-root stretching to enhance low-flux features and improve visual appearance (e.g., Cañameras et al. 2021; Andika et al. 2023b). This scaling is performed on each grizy image cube for every source, ensuring that the relative pixel brightness across different bandpasses is preserved, thereby retaining the colors of the sources.
3.2. Physics-informed network architecture
Autoencoders (AEs) are neural networks designed to capture a compressed, or latent, representation of input data and then reconstruct the input from this representation (see, for example, Bank et al. 2020, and the references therein). Variational autoencoders (VAEs) extend the traditional AE by introducing a probabilistic approach to the latent space (Kingma & Welling 2019). Instead of mapping inputs to fixed points in the latent space, VAEs encode input data to a distribution over the latent space, typically modeled as a Gaussian. The encoder outputs parameters of this distribution (mean and variance), and the latent representation is sampled from this distribution during training. This probabilistic framework allows VAEs to create new data points by sampling from the distribution learned in the latent space and subsequently decoding these samples.
In this paper, we present a specialized version of VAE, which we name VariLens. This architecture integrates a physical model into the loss function to detect strongly lensed quasars and estimate the associated physical properties such as SIE+γext mass parameters, source positions, and redshifts. VariLens features an encoder with a branching structure designed for two distinct tasks, as illustrated in Figure 3. The primary branch connects directly to the decoder, following the conventional VAE framework where the encoded latent representations are utilized to reconstruct the input data. Meanwhile, the secondary branch, referred to as the regressor, diverges after the latent space representation, leading to a dense layer dedicated to predicting the physical parameters and their associated errors. More details of the VariLens networks can be found in Appendix A.
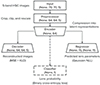 |
Fig. 3. Simplified overview of the VariLens architecture. The networks include three main components: the encoder, decoder, and regressor. The input consists of a batch of 5-band HSC images, initially sized at 70 × 70 pixels. The batch size is flexible, with “None” indicating it can vary based on user specifications. These images are cropped, clipped, and rescaled to standardize pixel values before reaching the encoder. The encoder subsequently takes the preprocessed 64 × 64 pixel images and compresses them into a 64-dimensional latent representation. The decoder then reconstructs this latent representation back into the original cropped 64 × 64 pixel images. At the same time, the regressor estimates lens and source parameters, guiding the latent distribution to ensure it is physics-informed. Once the networks are fully trained, the decoder and regressor are removed and replaced by a single dense layer serving as the classification head. Transfer learning is then applied to fine-tune the classifier, optimizing it to effectively distinguish between lensing and non-lensing systems. |
The encoder in VariLens consists of four convolutional layers with 16, 32, 64, and 128 filters, each paired with batch normalization (BN) and leaky ReLU activation layers. These convolutional layers employ strides of 2 and ‘same’ padding. Then, the compressed data is flattened, and a dense layer with 256 units is added, which also includes a BN layer and leaky ReLU activation. Following that, two dense layers, each with 64 units, are added to output two separate vectors: one for the mean and one for the variance of the latent variable distribution. During the training, the reparameterization trick is employed to sample from this distribution, allowing the gradient to be backpropagated through the network by treating the randomness as a separate step from the network’s parameters, thus enabling the network to learn both the mean and variance effectively (Kingma & Welling 2019).
The decoder in VariLens mirrors the encoder in its design but in reverse. It begins with a dense layer with 128 units, which is then batch normalized and leaky ReLU activated. After that, we reshape it into a tensor that matches the dimensions required for the subsequent transposed convolutional layers8. The tensor above is passed through four transposed convolutional layers with filter sizes of 128, 64, 32, and 16, each followed by a BN layer and a leaky ReLU activation. These layers are configured with strides of 2 and ‘same’ padding to progressively increase the spatial dimensions of the feature maps, ultimately reconstructing the original input size of 64 × 64 pixels. The final layer of the decoder is a convolutional layer with five filters and a sigmoid activation function, which outputs the reconstructed image. This layer ensures that the output image matches the original input format, with pixel values scaled to the appropriate range.
The optimization of the encoder and decoder is partly achieved using two loss functions. The first one is the reconstruction loss, parameterized using mean squared error (MSE), defined as:
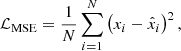
where xi and 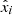 represent the i-th observed and reconstructed images, respectively, and N is the count of data points. Specifically, xi is a vector representing 5-bands image with dimensions of 64 × 64 pixels, resulting in N = 20 480 data points. This loss measures how well the decoder can reconstruct the input data from its latent space representation. Minimizing this term improves the accuracy of the reconstruction. The second component is the Kullback-Leibler divergence (KLD; Kingma & Welling 2019), given by:
represent the i-th observed and reconstructed images, respectively, and N is the count of data points. Specifically, xi is a vector representing 5-bands image with dimensions of 64 × 64 pixels, resulting in N = 20 480 data points. This loss measures how well the decoder can reconstruct the input data from its latent space representation. Minimizing this term improves the accuracy of the reconstruction. The second component is the Kullback-Leibler divergence (KLD; Kingma & Welling 2019), given by:
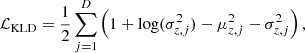
where μz, j and σz, j are the mean and standard deviation of the j-th latent variable, respectively, and D denotes dimensionality of the latent space. This term quantifies the divergence between the learned distribution of latent variables and a standard normal distribution. It regularizes the latent space by encouraging the latent variables to conform to the Gaussian prior distribution.
We then design the regressor to predict two values for each physical parameter using a Gaussian distribution (e.g., Perreault Levasseur et al. 2017; Schuldt et al. 2023a). This method yields not just a point estimate but also a mean value along with an uncertainty quantified at the 1σ level. To assess the regressor’s performance, we utilize the Gaussian negative log-likelihood (NLL) as the loss function, expressed as:
![$$ \begin{aligned} \mathcal{L} _{\mathrm{NLL} } = \frac{1}{M} \sum _{k=1}^{M} \left[\frac{\left(\eta _k^\mathrm{pred} - \eta _k^\mathrm{true}\right)^2}{2 \sigma _{\eta , k}^2} + \frac{1}{2} \log (2 \pi \sigma _{\eta , k}^2)\right], \end{aligned} $$](/articles/aa/full_html/2025/02/aa53474-24/aa53474-24-eq21.gif)
where ηkpred represents the vector of predicted parameters, ηktrue denotes the vector of true parameters, ση, k is the standard deviation for the k-th parameter, and M is the total number of parameters. The loss for a particular lens system is calculated by summing over the M parameters η and their corresponding uncertainties ση. These parameters encompass the properties of the foreground lens, including the mass center coordinates (xgal, ygal), complex ellipticities (ex, ey), Einstein radius (θE), external shear components (γext, 1, γext, 2), and deflector’s redshift (zgal). Additionally, η includes the redshift (zqso) of the background quasar and its position (xqso, yqso) in the source plane. In total, η comprises 11 physical parameters with its corresponding uncertainties ση also comprising 11 parameters.
The total loss for optimizing VariLens, denoted as ℒ, integrates three components:
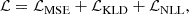
which ensure accurate data reconstruction, proper latent space regularization, and precise fitting of the regression output to the true parameters.
3.3. Normalization of parameters
Due to the differing ranges of different physical parameters, we apply min-max scaling to consistently map them to the range of [0, 1] using:
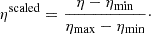
Here, η represents the original parameter value while ηmin (ηmax) is the minimum (maximum) value of the related parameter within the training dataset. This normalization ensures that each parameter contributes equally to the loss function, leading to improved optimization and model performance. Scaling back the network output back to the original ranges can be done by applying:
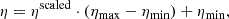
To revert the scaled uncertainties 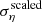 back to the original ση, we use:
back to the original ση, we use:
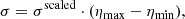
where the deviations are not shifted by ηmin since they are relative to the predicted median η. To ensure the regressor predicts values between 0 and 1, we include a sigmoid layer before splitting the outputs into 11 values for the median η and 11 values for the uncertainty ση.
Furthermore, to calibrate our model’s predicted uncertainties to match the expected Gaussian confidence intervals, we derive scaling factors for each parameter in ση by comparing the empirical percentiles of the absolute prediction errors with theoretical Gaussian percentiles (see also Schuldt et al. 2023a). Specifically, we first compute the absolute errors between our model’s predictions and the true values, then estimate the 68.3%, 95.4%, and 99.7% percentiles of these errors. The scaling factor is then defined as the average ratio of these error percentiles to the predicted uncertainty levels, ση, output by VariLens. This method effectively adjusts our model’s uncertainty estimates to better reflect the actual error distribution, ensuring that, on average, 68.3%, 95.4%, and 99.7% of predictions fall within 1, 2, and 3 standard deviations, respectively.
3.4. Model optimization
The VariLens training process is done in two phases: (1) simultaneous image reconstruction and physical parameter regression, and (2) classification. In the first phase, the physics-informed VAE network – which includes the encoder, decoder, and regressor – is optimized using DS1 with an initial learning rate of 10−4. The objective is to minimize the loss function specified in Equation (14). The training process consists of several critical steps, including dataset partitioning, batch processing, and iterative optimization. The dataset is divided into training, validation, and test sets in a 70:20:10 ratio to ensure comprehensive model evaluation and avoid overfitting. Further, the data is segmented into smaller batches of 128 samples, enabling efficient computational handling. During training, the network undergoes iterative forward and backward propagation. In the forward pass, input data is processed through the network to produce predictions, which are then evaluated against ground-truth labels using a predefined loss function. Backpropagation follows, where the loss function’s gradients are computed and utilized to adjust the model’s weights and biases through a stochastic gradient descent method like the adaptive moment estimation algorithm (Kingma & Ba 2014). This iterative refinement process systematically improves the model’s predictive accuracy and overall performance9.
In the second phase, we utilize the pretrained VariLens encoder as the base model for a downstream classification task. This is accomplished by adding a linear classifier, consisting of a single dense layer with one neuron and a sigmoid activation function, on top of the encoder. This dense layer serves as the classification head, tasked with differentiating between lens and non-lens categories through the use of a binary cross-entropy loss function. The process outlined above, known as transfer learning, comprises two main steps. First, all weights and biases in the pretrained encoder are frozen, and only the classification head is trained starting with a learning rate of 10−4. After optimizing the classification head, we proceed with fine-tuning the entire model by unfreezing all trainable parameters in both the encoder and the classification head, using a reduced initial learning rate of 10−5.
Throughout the training process, a learning rate scheduler is used to decrease the learning rate by a factor of 0.2 if the model’s performance does not improve over five consecutive epochs (e.g., Andika et al. 2023a). Additionally, early stopping is implemented to halt training if the loss does not decrease by at least 10−4 over 10 consecutive epochs. Usually, the training process requires between 100 and 200 epochs to converge, after which the optimized parameters are saved. Ultimately, the optimal model is determined by the set of weights and bias parameters that produce the minimum loss on the validation dataset.
A typical approach to assess the network’s learning capability is by analyzing the loss and accuracy curves over training epochs, as shown in Figure 4. In the case of VariLens optimization, both training and validation losses decrease and stabilize, following similar trends after several epochs. The absence of overfitting signatures – for example, the lack of a continued decline in training loss with a concurrent rise in validation loss – demonstrates that our networks generalize effectively. We note that the metrics discussed are not the only indicators of model performance. In the section that follows, we will present additional metrics that provide a more detailed evaluation of our model’s effectiveness in regression and classification tasks.
 |
Fig. 4. Loss and accuracy curves over training epochs for the VariLens model. The left panel shows optimizations for the physics-informed VAE, while the right panel displays the one for the classifier module. The metrics, evaluated on the training and validation datasets, are depicted by the blue and orange lines, respectively. For the classifier, the dashed black line indicates the epoch when network fine-tuning begins. Prior to fine-tuning, the VariLens classifier appeared to perform worse on the training dataset compared to the validation samples. This could be due to the model not having fully converged or found the optimal weights at that stage. |
4. Results and discussion
4.1. Image reconstruction and latent space exploration
As mentioned earlier, a key application of VariLens is its ability to perform image reconstruction. This process takes 5-band HSC images as inputs and effectively reconstructs them, reducing unnecessary details while preserving essential information. An illustration of this process is presented in Figure 5, where the decoder showcases good performance in reconstructing the input mock lensed quasars. A potential direction for the future development of VariLens is to upgrade the decoder for tasks beyond image reconstruction, including deblending foreground lenses and background sources, as well as noise reduction (e.g., Madireddy et al. 2019; Arcelin et al. 2021).
 |
Fig. 5. Image reconstruction examples. The original data containing mock lensed quasars, the reconstructed images predicted by VariLens, and the difference between them (i.e., residuals) are shown. These HSC grz images originate from sources within the test dataset. |
We then conduct unsupervised explorations of the latent space produced by VariLens to assess its potential for discriminating lensed quasars from non-lensed sources. This is achieved by employing two robust dimensionality reduction techniques. The first one is principal component analysis (PCA), which reduces the high-dimensional data onto a lower-dimensional space by identifying principal components – that is, the directions of maximum variance. Each principal component’s importance is quantified by its eigenvalue, which indicates the proportion of the total variance captured along that component. In other words, by analyzing these eigenvalues, we can assess how much of the overall data variance is explained by the selected components. This method effectively reveals underlying patterns and main axes of variation in the data. However, it is important to note that PCA relies on linear assumptions and may not effectively capture more complex, nonlinear relationships within the data.
The second technique we employ is t-distributed Stochastic Neighbor Embedding (t-SNE), a nonlinear dimensionality reduction method designed to maintain local structures within the data. This approach focuses on maintaining pairwise distances between data points, ensuring that similar points stay close together and dissimilar points are separated. Hence, t-SNE is especially effective for visualizing complex clusters and nonlinearly separable relationships. The results of the PCA and t-SNE visualizations are presented in Figures 6 and 7, respectively. While PCA provides little evidence of separability between lensed and non-lensed sources, the two-dimensional t-SNE indicates that these classes are reasonably distinguishable. This difference can be attributed to the linear nature of PCA, which may overlook nonlinear relations. In contrast, the nonlinear approach of t-SNE effectively captures and visualizes complex relationships, providing a more accurate description of class separation. This indicates that, although the VariLens encoder was initially trained on a dataset of only mock lenses, it effectively learns to organize the latent space in a way that distinguishes between lensed and non-lensed quasars.
 |
Fig. 6. Visualization of a subset of the data, including mock lensed quasars and contaminants, after dimensionality reduction using principal component analysis (PCA). The vertical dashed black lines in the left panels mark the number of principal components required to explain 95% of the variance and the corresponding eigenvalues. The right panels show the first three PCA components, which reveal minimal separability between lenses (red) and non-lenses (blue). |
 |
Fig. 7. Dimensionality reduction using two-dimensional t-distributed Stochastic Neighbor Embedding (t-SNE) on the encoded data. Projecting the high-dimensional data into two embedding components allows t-SNE to effectively visualize distinct clusters, with lensed quasars (red) and non-lensed sources (blue) showing clear separation. |
4.2. Fine-tuned classifier
The classifier module of VariLens provides probability estimates given the input data. A probability Plens = 1 signifies a high likelihood that the image features a lensed quasar. Conversely, Plens = 0 suggests that the image is unlikely to contain a lens and is more likely to include other types of sources, such as a ordinary galaxy, quasar, star, or even a photometric artifact.
To evaluate the overall performance of the trained model, we use the receiver operating characteristic (ROC) curve. The area under the ROC curve (AUROC) indicates the model’s ability to distinguish between two classes as the decision threshold is adjusted. In this assessment, lensed quasars are designated as positives (P), while non-lenses and other contaminating sources are defined as negatives (N). True positives (TP) represent instances where the model correctly identi fies lensed quasars, whereas true negatives (TN) are cases where non-lenses are accurately recognized. False positives (FP) occur when the model mistakenly classifies contaminants as lensed quasars, and false negatives (FN) are instances where the model fails to detect lensed quasars. The ROC curve visualizes the trade-off between the false-positive rate (FPR) and the true-positive rate (TPR) across different thresholds for the test dataset, where:
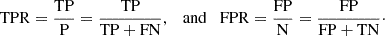
The ROC curve is generated by progressively increasing the probability threshold. A perfect classifier achieves an AUROC of 1, indicating flawless performance, while a random classifier yields an AUROC of 0.5. Our findings reveal an ROC curve with high AUROC values, demonstrating the classifier’s outstanding accuracy. To balance the TPR and FPR as depicted by the ROC curve, we use the geometric mean (G-mean)10. The optimal G-mean score determines the best Plens threshold that balances TPR and FPR, maximizing true positives while minimizing false positives. As illustrated in Figure 8, the optimal threshold for Plens in our model is 0.33, which corresponds to FPR and TPR values of 2% and 98%, respectively. It is crucial to note that lowering the Plens threshold below the optimal value significantly increases the number of candidates but at the cost of reduced quality, making visual inspection more challenging and less efficient. Therefore, it is essential to strike a balance between completeness and purity to ensure a manageable number of candidates for further observations.
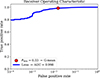 |
Fig. 8. Receiver operating characteristic (ROC) curve, depicted with a blue line, along with the corresponding area under the curve (AUC). The false positive rate and true positive rate at the chosen Plens threshold are marked with a red circle. |
4.3. Selection completeness
As previously discussed, the quasar samples in our simulation are uniformly distributed over a redshift range of 1.5 ≤ z ≤ 7.2 and an absolute magnitude range of −30 ≤ M1450 ≤ −20. Without the amplification provided by strong lensing, our classifier is capable of detecting only those quasars with M1450 ≲ −22 at redshifts z ≳ 6. However, lensing can push this detection threshold to lower luminosities, depending on the magnification factor. To explore this further, we quantify our selection function (or completeness) as the fraction of mock quasars with specified values of M1450, z, and spectral energy distributions (SEDs) that meet our selection criteria. The corresponding results are presented in Figure 9. Quasars with lower intrinsic brightness are only detectable if they undergo substantial magnification, which is relatively uncommon. Consequently, our completeness rate decreases for quasars with lower luminosity at any given redshift. Moreover, as discussed in Section 2.4, we exclude sources with y ≤ 15 mag to avoid unusually bright objects or saturated images. As a result, we do not recover extremely luminous quasars with M1450 ≲ −27 at lower redshifts (z ≲ 3), although such quasars may not even exist in reality.
 |
Fig. 9. Quasar selection function adopted in this work. The recovery rate percentage indicates the fraction of mock quasars within each (M1450, z) bin that our classifier successfully recognizes. |
As illustrated in Figure 1, our classifier successfully recovers the majority of lensing configurations with minimal bias. However, a slight reduction in the recovery rate is noticeable for systems where the deflector redshifts are zgal ≳ 1 and magnitudes are i ≳ 21. This decline is likely due to the fainter apparent fluxes of more distant lens galaxies, which makes them more challenging to detect. While these sources can still be identified when the lensed quasars are well separated, the detection becomes more challenging for compact lens systems with smaller masses. For example, Figure 1 indicates a modest decrease in the recovery rate for lenses with σv ≲ 100 km s−1 and 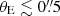 . This is expected, as the HSC data is constrained by seeing limits of
. This is expected, as the HSC data is constrained by seeing limits of 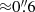 (Aihara et al. 2022). Consequently, any lensing configuration with θE smaller than this threshold would be difficult to resolve, complicating the inference of any lensing parameters.
(Aihara et al. 2022). Consequently, any lensing configuration with θE smaller than this threshold would be difficult to resolve, complicating the inference of any lensing parameters.
4.4. Inference of lens parameters
We evaluate here the performance of VariLens in determining the SIE+γext lens parameters, redshifts, and positions of the quasars. Figure 10 illustrates the comparison between predicted and actual values on the test dataset, featuring images that the network has not seen during training. For each parameter, we present the distribution of values using 2D colored histograms. Additionally, we assess the model’s quality using three key metrics: the coefficient of determination (R2), mean squared error (MSE), and mean absolute error (MAE). The definitions and calculations of these metrics can be found in Appendix B. Specifically, R2 indicates the proportion of variance in the dependent variable that can be explained by the independent variables, with values approaching 1 reflecting exceptional model accuracy. MSE measures the average of the squared differences between predicted and actual values, highlighting larger discrepancies. In contrast, MAE represents the average of the absolute differences, offering a more straightforward measure of prediction accuracy. Both MSE and MAE are lower for more accurate models, with MAE being less sensitive to outliers compared to MSE.
 |
Fig. 10. Comparison of true and predicted physical parameters. The metrics R2, MSE, and MAE for sources in the test dataset are displayed in each panel. Darker regions indicate higher concentrations of sources within the 2D histogram bins. The red dashed line represents the 1:1 relationship between the predicted and actual values. |
As illustrated in Figure 10, the network performs well in predicting most parameters, with the exception of the external shear. Predictions for the lens centers and complex ellipticities closely match the true values, showing no significant bias to either underestimation or overestimation. While the R2 scores for ellipticities are slightly lower than those for lens centers, this difference, although not substantial, indicates that measuring galaxy shapes may be more challenging than determining their positions within ground-based images. Nonetheless, the high R2 scores (≳0.8), along with MSE and MAE values near zero, demonstrate that VariLens accurately models the observed galaxies.
Regarding the Einstein radii, VariLens provides accurate estimates up to θE ≈ 2″. However, its performance declines beyond this range, likely due to the low amount of systems in the training dataset, leading to the underrepresentation of lenses with larger θE. As larger Einstein radii correspond to greater lens mass, this population of massive lensing galaxies is rare in the Universe. A similar issue is observed in the redshift predictions for deflector galaxies. The network performs well up to zgal ≈ 0.7 but struggles with higher redshifts. This decline in performance is due to the SDSS instrument’s limiting magnitude, which allows spectroscopic observations only for brighter galaxies at high redshifts, resulting in the exclusion of fainter deflectors (see also Section 2.3). Consequently, the number of samples at zgal ≳ 0.7 is significantly reduced, leading to the underrepresentation of high-z deflectors in the training dataset. One potential solution to address these issues is to resample the lenses to achieve a uniform distribution of θE and zgal, rather than relying on their natural distribution, as suggested in other studies (e.g., Schuldt et al. 2021). This approach would allow the network to be exposed to the entire spectrum of parameter values, thereby mitigating the effects of selection bias. However, we did not implement this correction in our current study and will consider it for future work.
A key innovation of VariLens is the incorporation of both source (quasar) redshift and positional measurements. While the network recovers source positions with high accuracy, there is notable scatter in redshift estimations for sources at z ≲ 3. The accuracy of redshift estimates improves significantly at higher redshifts. Notably, at z ≈ 3, the Lyα emission is redshifted to an observed wavelength of ≈4864 Å, while the mid-wavelength of the HSC g-band is ≈4798 Å. As the quasar’s Lyα emission moves out of the g-band and Lyα forest absorption becomes more pronounced, a phenomenon known as g-band dropout occurs – that is, the quasar appears very faint in the g-band while only bright enough in the redder bands. At even higher redshifts, this trend extends to producing dropouts in the r, i, and z filters, a phenomenon known as the Lyman break. The ability of VariLens to infer such a Lyman-break effect enhances its redshift estimation accuracy, demonstrating the network’s effectiveness in learning that complex phenomenon.
VariLens currently struggles to correctly estimate the external shear components (γext, 1, γext, 2), where it always predicts values close to zero. It seems that minor distortions caused by the external shear are not well captured in the HSC ground-based images, likely due to PSF variations across different lens systems being comparable to the shear effect. This challenge is also noted by Schuldt et al. (2023a), who faced similar difficulties in predicting shear in HSC data. Accurate shear measurement appears to be feasible only in more idealized datasets, where higher image resolution, stable PSFs, and prior lens light subtraction improve results (e.g., Morningstar et al. 2018). It is worth noting that the need for accurate external shear estimation depends on the specific scientific goals, as it has a negligible impact on the statistical studies of lens mass and quasar emissions conducted here.
Comparing the performance of VariLens to other modeling networks is challenging due to differences in underlying assumptions. While most previous studies, as discussed below, primarily focus on galaxy-galaxy lenses, our work complements them by specifically targeting lensed quasar cases. Nevertheless, we briefly summarize here the approaches taken in previous studies. The concept of harnessing CNNs to estimate SIE parameters such as ex, ey, and θE was initially raised by Hezaveh et al. (2017), who focused on mock datasets resembling those captured by the Hubble Space Telescope (HST). Their methodology involved subtracting the lens light prior to applying CNNs for lens parameter estimation. Further advancements on this idea were made by Perreault Levasseur et al. (2017), who presented estimations of uncertainty and external shear components. Later, Pearson et al. (2021) designed a model to deduce the lensing parameters, which they applied to simulated Euclid data with a resolution of 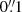 . Building on the work of Hezaveh et al. (2017), they incorporated error estimation techniques and introduced a hybrid method that combines neural networks with traditional, non-machine learning-based models to refine parameter inference.
. Building on the work of Hezaveh et al. (2017), they incorporated error estimation techniques and introduced a hybrid method that combines neural networks with traditional, non-machine learning-based models to refine parameter inference.
Variations in image resolution, type of bandpasses, quality of training datasets, and differing number of predicted parameters coupled with their intrinsic degeneracies make direct comparisons between the previous models with VariLens’s performance challenging. Schuldt et al. (2023a) presents the most similar work in terms of image properties, which employed a residual network (ResNet) to predict SIE+γext parameters for griz-bands of HSC data. However, their work primarily addresses galaxy-galaxy lensing, which exploits the detailed shape of the lensed arc rather than relying solely on the source position, as is common in lensed quasar studies. We evaluated VariLens on their test dataset of 31 lensed galaxies, but the results were suboptimal, with significant uncertainties in our predictions. This outcome underscores the distinct challenges between modeling lensed galaxies and quasars, particularly the added complexity and information provided by lensed arcs in galaxy-galaxy lensing.
Additionally, considerable progress has been made in the domain of automated modeling methods that do not rely on machine learning (e.g., Nightingale et al. 2018; Etherington et al. 2022; Rojas et al. 2022; Savary et al. 2022; Ertl et al. 2023; Gu et al. 2022; Schmidt et al. 2023; Schuldt et al. 2023b). These approaches generally surpass neural networks in accuracy and precision but are substantially more time-intensive, often requiring processing durations ranging from several hours to weeks. In contrast, the inference time of VariLens, along with other previously mentioned neural network-based methods, can be reduced to a fraction of a second, making them significantly more efficient than traditional lens modeling.
4.5. Evaluation with known lensed quasars
4.5.1. Classifier performance
We conduct further examination using a supplementary dataset containing confirmed lensed quasars provided by the GLQD (McMahon et al. 1992; Jackson et al. 1995, 2008; Inada et al. 2003, 2008, 2012; Oguri et al. 2004, 2008; Morokuma et al. 2007; Agnello et al. 2015, 2018; More et al. 2016; Williams et al. 2018; Spiniello et al. 2018; Lemon et al. 2018, 2019, 2020; Lemon et al. 2023; Krone-Martins et al. 2019; Chan et al. 2020; Jaelani et al. 2021).
HSC images are accessible for 22 of the 220 lenses cataloged in the database (see Figure 11). To evaluate the completeness and purity of our classifier, we combine these confirmed lenses with a sample of contaminants outlined in Section 2.1, consisting of galaxies, stars, and quasars. The non-lensed sources are anticipated to vastly outnumber the lens population by several thousand. Consequently, our model successfully identifies 16 of the known lensed quasars, resulting in a TPR (or completeness) of 73% and an FPR of 5%. Furthermore, we determine that the classifier achieves a purity11 of ≈1% in detecting lens candidates. There are several possible reasons why VariLens did not recover these known lensed quasars. In the case of COS5921+0638, the multiple images of the quasars are too faint to be detected by eyes unless the lens galaxy light is removed. Similarly, for SDSSJ1458−0202 and B1600+434, the quasar counterimages are also not easily visible. In the case of SDSSJ1452+4224, the colors of the quasar images appear slightly different, possibly due to reddening caused by dust in the foreground galaxy. Factors like this, among others, may influence the performance of our model. For KIDS1042+0023 and J1359+0128 the reasons behind the network’s failure to detect them are less clear. Further investigation is needed to better understand the network’s behavior, possibly using explainable artificial intelligence tools (e.g., Selvaraju et al. 2016; Simonyan et al. 2013; Sundararajan et al. 2017).
 |
Fig. 11. Lensed quasar samples compiled from GLQD (refer to the main text). The images are generated from HSC grz-band cutouts with dimensions of 64 × 64 pixels (approximately |
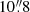
The VariLens classifier discussed in Section 4.2 demonstrates outstanding performance on the test dataset, with almost perfect AUROC and low FPR. Despite this, the classifier encounters difficulties in generalizing to real-world data, as indicated by the numerous spurious sources detected by the network. This limitation significantly increases the time required for the necessary visual inspection of lens candidates during later stages. A promising approach to mitigate this issue is probably to combine multiple networks with diverse architectures through model averaging, which could greatly reduce the number of candidates while maintaining high completeness (e.g., Andika et al. 2023b; Cañameras et al. 2024; More et al. 2024).
4.5.2. Regression performance
To evaluate the performance of our regression module compared to traditional, non-machine learning-based methods, we will utilize PyAutoLens for modeling the lensed quasars from GLQD. This process involves two stages: (1) performing light deblending to accurately determine the locations of the lensed source and foreground deflector in the image plane, along with the relevant morphological parameters of the deflector galaxy, and (2) modeling the lens system with an SIE+γext mass approximation.
While quasar emission is typically modeled as a point source, the PSF provided by the HSC database may exhibit slight off-centering or higher-order distortions, albeit minimal (Chan et al. 2024). To address this issue, we approximate the PSF using an elliptical Moffat profile (Moffat 1969). The number of required point source models is first manually determined by visually inspecting the multiband images of each lensed quasar. These point sources will have different positions and fluxes, but we restrict that their Moffat shapes should be the same within the observed image.
After that, we employ a Sérsic profile to fit the lens galaxy’s light (Sérsic 1963), assuming each system only contains one deflector galaxy. To simplify the optimization and prevent parameter degeneracy, we fix the Sérsic index to 4 (i.e., de Vaucouleurs profile), which approximates the profile of typical elliptical galaxies. For further details on these light profiles, we refer to Appendix C. Light profile fitting for each system is performed simultaneously across the grizy bands, assuming their positions and intrinsic shapes do not vary across different wavelengths. The main objective of this step is to infer the structural parameters of the system. Following the previous step, we perform SIE+γext lens modeling for the lensed quasars. To streamline the process, we fix the ellipticity and center of mass to match those of the galaxy’s light profile. Optimization is achieved by minimizing the χ2 statistics, comparing the predicted and observed positions of the sources (Oguri 2010; Chan et al. 2020, 2015). It is important to note that the number of data points for doubly imaged quasars in point-source lens modeling is insufficient to constrain the SIE+γext parameters, resulting in fitting degeneracy. Nonetheless, we adopt this approach for consistency in matching the output parameters predicted by VariLens.
The parameters derived from traditional lens modeling with PyAutoLens and those predicted by VariLens are reported in the tables provided in Appendix D. This comparison is further illustrated in Figure 12. Overall, key features like the Einstein radius, lens center, and source position are well-recovered, as these are relatively straightforward to infer directly from the multiband images. Consistent with tests on mock data, the Einstein radius estimated by VariLens closely matches that derived by the traditional approach for θE ≲ 2″. While our network significantly underestimates the Einstein radius for only one object with a large value, the remaining estimates fall within 2σ uncertainties. Hence, despite using simplistic light models and priors to deblend the foreground galaxy and background quasar, our traditional lens modeling method still produced a good result for determining the positions of both the deflector and the source. However, the simplicity of the PyAutoLens model may have led to imperfect deblending and inaccuracies in the estimation of morphological parameters, resulting in significant scatter in the predicted ellipticities of the lens galaxy. Improving this strategy might require higher-resolution data, which would allow us to relax the priors while avoiding fitting degeneracies. In addition, since VariLens is unable to accurately predict the external shear components, it becomes hard to compare its results with those obtained from traditional modeling. Nevertheless, the majority of the inferred parameters are consistent with each other within 2σ.
 |
Fig. 12. Comparison of the derived SIE+γext parameters from traditional lens modeling using PyAutoLens (labeled “Trad.”) and the deep learning-based approach with VariLens (“Net.”). Quadruply lensed quasars are indicated by red circles, while doubly lensed quasars are marked with blue circles. We also compare the redshifts inferred by VariLens with spectroscopic measurements. |
Our network provides adequate results in predicting the lens galaxy redshifts, although a noticeable scatter in zgal is observed. On the other hand, the network lacks precision in predicting the redshifts of the lensed sources, with a systematic overestimation of zqso being observed. One explanation for this might be the same reason presented in Figure 10. Our redshift predictions for the lensed quasars may only become accurate at z ≳ 3, where the Lyα forest absorption and break are more prominent, thereby improving the constraint on zqso. However, most of the GLQD samples are located at lower redshifts, where estimating redshifts is challenging without distinct features such as the Lyman-break effect. Thus, acquiring more samples of high-z lensed quasars will be critical for evaluating the accuracy of VariLens redshift estimates with real data. Overall, VariLens and PyAutoLens provide relatively consistent SIE lens models and source positions. In the future, integrating both approaches to refine the lens models could enhance the fitting process and yield more accurate estimates.
4.6. Lensed quasar candidates
4.6.1. Catalog-level preselection and image-based analysis
To identify lensed quasars, we begin with the approximately 80 million sources from our parent HSC catalog compiled in Section 2.1. Since most kpc-scale quasar pairs and lensed quasars typically have separations of ≲3″ (e.g., Yue et al. 2023), we narrow our selection to sources that indicate nearby companions within a 2″ radius. We acknowledge that this criterion might be overly stringent. For example, among 22 optically bright lensed quasars with spectroscopic confirmation listed in the HSC catalog (Chan et al. 2024), our preselection process only identifies 15, resulting in a recovery rate of 68%. The seven missed quasars likely lack detectable neighboring sources due to their faintness or issues with the HSC object deblending process. For this reason, we also take into account the spectroscopic classification of candidates, ensuring that known galaxies and quasars from the literature are not excluded, as detailed in Section 2.1. By selecting sources with a neighboring object within 2″ or with available spectroscopic data, we effectively narrow the candidate pool to a few million sources. This strategy reduces the number of candidates while retaining many known lenses, thereby minimizing contamination and computational requirements for subsequent analyses.
Subsequently, we apply a brightness cut across all HSC bands to ensure that each source is robustly detected with S/N levels of at least 5. Given our multiwavelength data, we then prioritize candidates that exhibit X-ray, IR, or radio detections. Adding multiwavelength information is helpful in eliminating unwanted sources, such as cosmic rays or moving objects that appear in one survey but not in others (e.g., Andika 2022). Following previous studies (e.g., Cañameras et al. 2021; Shu et al. 2022), we focus on foreground deflectors with an extended shape, specifically those with an i-band Kron radius 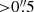 . At this stage, we have identified 710 966 candidates that have successfully passed our catalog-level preselection.
. At this stage, we have identified 710 966 candidates that have successfully passed our catalog-level preselection.
Next, we apply image-based analysis to evaluate the lens probability for each candidate using VariLens. This process yields 18 300 candidates with Plens > 0.3. To further refine our selection, we incorporate Gaia Data Release 3 (Gaia Collaboration 2023) catalog to filter out multiple stars that might mimic multiply imaged quasars. In this case, we evaluate the astrometric excess noise (AEN; Gaia Collaboration 2016) and proper motion significance (PMSIG; Lemon et al. 2019) when available. Elevated AEN numbers (> 10 mas) may indicate a probable star-forming galaxy, while high PMSIG values (> 10σ) strongly suggest the presence of a star within the system (Lemon et al. 2019). It is important to note that only about 30% of our candidates have these astrometric measurements. Nevertheless, we successfully narrow the selection to 13 831 sources.
4.6.2. Visual inspection
For the final selection step, we perform a visual inspection of the remaining targets, following a four-step procedure similar to the method detailed in Schuldt et al. (2025). In the first step, all candidates are inspected by two people through binary classification, where any systems flagged as a potential lens by at least one reviewer advance to the next stage. A calibration round is then conducted in the second step using 200 systems, including a subset of known lenses and contaminants, to align reviewer expectations and facilitate discussions on specific cases. Here, each system is graded on a scale of G = 0, 1, 2, or 3, corresponding to the classifications: not a lens, possible lens, probable lens, and definite lens. In the third step, four reviewers inspect all systems flagged as potential lenses in the initial round. Finally, in the fourth step, four additional reviewers inspect systems with an average grade of GN > 1 or GN ≤ 1 but with a standard deviation of σGN > 0.75, based on the assessments in round three.
To be specific, definite lenses (G = 3) are candidates that clearly exhibit multiple images, signs of a counter-image, a cross, or a complete Einstein ring. In other words, these systems have an obvious lensing configuration that a model would fit easily and do not require higher-resolution imaging for confirmation. Probable lenses (G = 2) are candidates displaying significant tangential distortion and a lensing-like configuration but require additional evidence. This is due to factors such as the absence of multiple images, arcs/images being clustered on one side of the galaxy, lack of signs of a counter-image, need for central galaxy removal, unusual lensing configurations, or the necessity for higher-resolution imaging to resolve uncertainties. These systems could also be mistaken for ring galaxies or spirals. Possible lenses (G = 1) are systems likely to consist of a single image with potential tangential flexion or distortion or a single arc situated far from the central galaxy. Finally, non-lenses (G = 0) are systems that lack convincing lensing features and are most likely single images with tangential flexion or distortion that could be mistaken for lensing features but are unlikely to be true lenses. This includes ring galaxies, spirals, merging galaxies, irregular systems, companions, or other unrelated sources.
Our visual examination results in 338 possible, probable, and definite lens candidates voted by eight independent reviewer, while all other systems are rejected during earlier stages of the process. We then define grade A lens candidates as systems with GN ≥ 2.5 and grade B lens candidates as those with 1.5 ≤ GN < 2.5. In total, we identify 8 grade A candidates and 34 grade B candidates, while the remaining 296 systems are classified as grade C. The tables describing the properties of these candidates are provided in Appendix E. As shown in Figure E.1, grade A candidates display a clear strong lensing configuration, such as detectable multiple images or a counter-image, without requiring higher-resolution imaging. Grade B candidates exhibit a lensing-like structure but lack visible multiple images or a counter-image. They often include single arcs or objects on one side of the central galaxy and are challenging to confirm without spectroscopic data, as chance alignments are possible. The majority of doubly lensed quasar candidates also fall into this category. Grade C candidates, as displayed in Figure E.2, resemble lenses but are likely false positives, such as ring galaxies, merging systems, double stars, or other ambiguous configurations. A detailed summary of our selection process, along with the number of candidates identified at each step, is provided in Table 1.
5. Summary and conclusion
In this research, we conduct a comprehensive search for lensed quasars within the redshift range 1.5 ≤ z ≤ 7.2 using data from the HSC PDR3. Our approach is organized into two primary phases. Initially, we filter potential candidates based on their photometric colors derived from catalog information, narrowing the pool from around 80 million sources to 710 966. Subsequently, we apply a physics-informed VAE network to assess the likelihood of each candidate being a lens or a contaminant, which yields 18 300 top candidates. It is noteworthy that the training data is created by overlaying deflected point-source light on actual HSC galaxy images. This method enables the generation of realistic strong-lens simulations and concentrates on identifying systems with Einstein radii of θE < 5″. After reviewing astrometric data when available and visually inspecting objects with a lens probability Plens > 0.3, we identify 42 grade A and B lens candidates. These findings illustrate that automated neural network-based classifiers, with minimal human supervision, are promising for detecting lensed quasars in extensive datasets.
The method described in this paper is highly adaptable for detecting galaxy-quasar lenses across a wide range of redshifts. It is particularly well-suited for upcoming surveys such as Euclid (Laureijs et al. 2011; Euclid Collaboration: Scaramella et al. 2022), which will deliver high-resolution NIR images covering extensive regions of the extragalactic sky, and the Rubin Observatory Legacy Survey of Space and Time (LSST; Ivezić et al. 2019), which will provide comprehensive optical multiband data. In order to achieve the best results on the network performance, adjustments to the bandpass profiles, seeing conditions, and image scales will be necessary. Furthermore, incorporating more sophisticated galaxy mass profiles beyond the SIE+γext model could enhance the performance of the classifier. To fully capitalize on the scientific value of our lens catalog, it is essential to perform spectroscopic observations to verify the redshifts of both deflectors and sources, along with high-resolution imaging to enable precise lens modeling.
Data availability
Additional appendices, which include the tables referenced in Appendices D and E, are available on the Zenodo repository at: https://doi.org/10.5281/zenodo.14718063
The previously identified galaxy-scale strong lens systems are gathered from two primary sources: the Master Lens Database (MLD; available online at https://test.masterlens.org/) and the Gravitationally Lensed Quasar Database (GLQD; accessible at https://research.ast.cam.ac.uk/lensedquasars/).
We utilized computers equipped with two Intel® Xeon® Processor E5 v4 Family CPUs, providing a total of 20 cores (hyperthreaded to 40) and 512 GB of RAM to optimize VariLens. The training process took approximately 8 hours to complete without utilizing GPU acceleration. During the inference phase, each source required only a few milliseconds to compute, yielding the predicted lens probability and SIE+γext parameters.
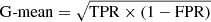
Acknowledgments
We thank Stefan Taubenberger for his participation in the visual inspection of lens candidates. SHS thanks the Max Planck Society for the support through the Max Planck Fellowship. SB acknowledges the funding provided by the Alexander von Humboldt Foundation. CG acknowledges support through grant MUR2020 SKSTHZ. Support for JHHC was provided by Schmidt Sciences. This research is supported in part by the Excellence Cluster ORIGINS which is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy – EXC-2094 – 390783311. SS has been funded by the European Union’s Horizon 2022 research and innovation program under the Marie Skłodowska-Curie grant agreement No 101105167 – FASTIDIoUS. This work is based on data collected at the Subaru Telescope and retrieved from the HSC data archive system, operated by the Subaru Telescope and Astronomy Data Center at the National Astronomical Observatory of Japan. The Hyper Suprime-Cam (HSC) collaboration includes the astronomical communities of Japan, Taiwan, and Princeton University. The HSC instrumentation and software were developed by the National Astronomical Observatory of Japan (NAOJ), the Kavli Institute for the Physics and Mathematics of the Universe (Kavli IPMU), the University of Tokyo, the High Energy Accelerator Research Organization (KEK), the Academia Sinica Institute for Astronomy and Astrophysics in Taiwan (ASIAA), and Princeton University. Funding was contributed by the FIRST program from the Japanese Cabinet Office, the Ministry of Education, Culture, Sports, Science and Technology (MEXT), the Japan Society for the Promotion of Science (JSPS), the Japan Science and Technology Agency (JST), the Toray Science Foundation, NAOJ, Kavli IPMU, KEK, ASIAA, and Princeton University. This paper makes use of software developed for the Large Synoptic Survey Telescope. We thank the LSST Project for making their code available as free software at http://dm.lsst.org. This project has included data from the Sloan Digital Sky Survey (SDSS). Funding for SDSS-IV has been provided by the Alfred P. Sloan Foundation, the U.S. Department of Energy Office of Science, and the Participating Institutions. SDSS-IV acknowledges support and resources from the Center for High-Performance Computing at the University of Utah. The SDSS website is https://www.sdss.org/. SDSS-IV is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS Collaboration. The unWISE catalog utilized in this paper is based on data products from the Wide-field Infrared Survey Explorer, which is a joint project of the University of California, Los Angeles, and NEOWISE, which is a project of the Jet Propulsion Laboratory/California Institute of Technology. WISE and NEOWISE are funded by the National Aeronautics and Space Administration. This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular, the institutions participating in the Gaia Multilateral Agreement. This work is based on data from eROSITA, the soft X-ray instrument aboard SRG, a joint Russian-German science mission supported by the Russian Space Agency (Roskosmos), in the interests of the Russian Academy of Sciences represented by its Space Research Institute (IKI), and the Deutsches Zentrum für Luft-und Raumfahrt (DLR). The SRG spacecraft was built by Lavochkin Association (NPOL) and its subcontractors, and is operated by NPOL with support from the Max Planck Institute for Extraterrestrial Physics (MPE). The development and construction of the eROSITA X-ray instrument was led by MPE, with contributions from the Dr. Karl Remeis Observatory Bamberg & ECAP (FAU Erlangen-Nuernberg), the University of Hamburg Observatory, the Leibniz Institute for Astrophysics Potsdam (AIP), and the Institute for Astronomy and Astrophysics of the University of Tübingen, with the support of DLR and the Max Planck Society. The Argelander Institute for Astronomy of the University of Bonn and the Ludwig Maximilians Universität Munich also participated in the science preparation for eROSITA. We acknowledge the use of the VHS, VIKING, UKIDSS, and UHS data. Facilities. eROSITA, ESO:VISTA (VIRCAM), Gaia, Sloan (eBOSS/BOSS), Subaru (HSC), UKIRT (WFCAM), WISE. Software. Astropy (Astropy Collaboration 2013, 2018), Dask (Rocklin 2015), EAZY (Brammer et al. 2008), Matplotlib (Caswell et al. 2021), NumPy (Harris et al. 2020), Pandas (Reback et al. 2022), PyAutoLens (Nightingale et al. 2021), Seaborn (Waskom 2021), SIMQSO (McGreer et al. 2013), TensorFlow (Abadi et al. 2016; TensorFlow Developers 2022), TOPCAT (Taylor 2005).
References
- Abadi, M., Barham, P., Chen, J., et al. 2016, ArXiv e-prints [arXiv:1605.08695] [Google Scholar]
- Agnello, A., Kelly, B. C., Treu, T., & Marshall, P. J. 2015, MNRAS, 448, 1446 [NASA ADS] [CrossRef] [Google Scholar]
- Agnello, A., Schechter, P. L., Morgan, N. D., et al. 2018, MNRAS, 475, 2086 [Google Scholar]
- Aihara, H., Armstrong, R., Bickerton, S., et al. 2018, PASJ, 70, S8 [NASA ADS] [Google Scholar]
- Aihara, H., AlSayyad, Y., Ando, M., et al. 2019, PASJ, 71, 114 [Google Scholar]
- Aihara, H., AlSayyad, Y., Ando, M., et al. 2022, PASJ, 74, 247 [NASA ADS] [CrossRef] [Google Scholar]
- Almeida, A., Anderson, S. F., Argudo-Fernández, M., et al. 2023, ApJS, 267, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Andika, I. T. 2022, Ph.D. Thesis, Max-Planck-Institute for Astronomy, Heidelberg, Germany [Google Scholar]
- Andika, I. T., Jahnke, K., Onoue, M., et al. 2020, ApJ, 903, 34 [Google Scholar]
- Andika, I. T., Jahnke, K., Bañados, E., et al. 2022, AJ, 163, 251 [NASA ADS] [CrossRef] [Google Scholar]
- Andika, I. T., Jahnke, K., van der Wel, A., et al. 2023a, ApJ, 943, 150 [NASA ADS] [CrossRef] [Google Scholar]
- Andika, I. T., Suyu, S. H., Cañameras, R., et al. 2023b, A&A, 678, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Arcelin, B., Doux, C., Aubourg, E., Roucelle, C., & LSST Dark Energy Science Collaboration 2021, MNRAS, 500, 531 [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Bank, D., Koenigstein, N., & Giryes, R. 2020, ArXiv e-prints [arXiv:2003.05991] [Google Scholar]
- Barkana, R. 1998, ApJ, 502, 531 [NASA ADS] [CrossRef] [Google Scholar]
- Belokurov, V., Evans, N. W., Moiseev, A., et al. 2007, ApJ, 671, L9 [NASA ADS] [CrossRef] [Google Scholar]
- Best, W. M. J., Magnier, E. A., Liu, M. C., et al. 2018, ApJS, 234, 1 [Google Scholar]
- Blanton, M. R., Bershady, M. A., Abolfathi, B., et al. 2017, AJ, 154, 28 [Google Scholar]
- Bonvin, V., Courbin, F., Suyu, S. H., et al. 2017, MNRAS, 465, 4914 [NASA ADS] [CrossRef] [Google Scholar]
- Boroson, T. A., & Green, R. F. 1992, ApJS, 80, 109 [Google Scholar]
- Brammer, G. B., van Dokkum, P. G., & Coppi, P. 2008, ApJ, 686, 1503 [Google Scholar]
- Calzetti, D., Armus, L., Bohlin, R. C., et al. 2000, ApJ, 533, 682 [NASA ADS] [CrossRef] [Google Scholar]
- Cañameras, R., Schuldt, S., Shu, Y., et al. 2021, A&A, 653, L6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cañameras, R., Schuldt, S., Shu, Y., et al. 2024, A&A, 692, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carnero Rosell, A., Santiago, B., dal Ponte, M., et al. 2019, MNRAS, 489, 5301 [NASA ADS] [CrossRef] [Google Scholar]
- Caswell, T. A., Droettboom, M., Lee, A., et al. 2021, https://doi.org/10.5281/zenodo.592536 [Google Scholar]
- Chan, J. H. H., Suyu, S. H., Chiueh, T., et al. 2015, ApJ, 807, 138 [NASA ADS] [CrossRef] [Google Scholar]
- Chan, J. H. H., Suyu, S. H., Sonnenfeld, A., et al. 2020, A&A, 636, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chan, J. H. H., Lemon, C., Courbin, F., et al. 2022, A&A, 659, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chan, J. H. H., Wong, K. C., Ding, X., et al. 2024, MNRAS, 527, 6253 [Google Scholar]
- Dawson, K. S., Schlegel, D. J., Ahn, C. P., et al. 2013, AJ, 145, 10 [Google Scholar]
- Dawson, K. S., Kneib, J.-P., Percival, W. J., et al. 2016, AJ, 151, 44 [Google Scholar]
- Ding, X., Treu, T., Birrer, S., et al. 2021, MNRAS, 501, 269 [Google Scholar]
- Dux, F., Lemon, C., Courbin, F., et al. 2024, A&A, 682, A47 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dye, S., Lawrence, A., Read, M. A., et al. 2018, MNRAS, 473, 5113 [Google Scholar]
- Edge, A., Sutherland, W., Kuijken, K., et al. 2013, The Messenger, 154, 32 [NASA ADS] [Google Scholar]
- Ertl, S., Schuldt, S., Suyu, S. H., et al. 2023, A&A, 672, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Etherington, A., Nightingale, J. W., Massey, R., et al. 2022, MNRAS, 517, 3275 [CrossRef] [Google Scholar]
- Euclid Collaboration (Barnett, R., et al.) 2019, A&A, 631, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Scaramella, R., et al.) 2022, A&A, 662, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fan, X., Bañados, E., & Simcoe, R. A. 2023, ARA&A, 61, 373 [NASA ADS] [CrossRef] [Google Scholar]
- Fitzpatrick, E. L. 1999, PASP, 111, 63 [Google Scholar]
- Flesch, E. W. 2021, ArXiv e-prints [arXiv:2105.12985] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Glikman, E., Rusu, C. E., Chen, G. C. F., et al. 2023, ApJ, 943, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Gordon, Y. A., Boyce, M. M., O’Dea, C. P., et al. 2020, Res. Notes Am. Astron. Soc., 4, 175 [Google Scholar]
- Gordon, Y. A., Boyce, M. M., O’Dea, C. P., et al. 2021, ApJS, 255, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Gordon, Y. A., Rudnick, L., Andernach, H., et al. 2023, ApJS, 267, 37 [NASA ADS] [CrossRef] [Google Scholar]
- Green, G. M. 2018, J. Open Source Softw., 3, 695 [Google Scholar]
- Gu, A., Huang, X., Sheu, W., et al. 2022, ApJ, 935, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Hezaveh, Y. D., Perreault Levasseur, L., & Marshall, P. J. 2017, Nature, 548, 555 [Google Scholar]
- Inada, N., Becker, R. H., Burles, S., et al. 2003, AJ, 126, 666 [NASA ADS] [CrossRef] [Google Scholar]
- Inada, N., Oguri, M., Becker, R. H., et al. 2008, AJ, 135, 496 [NASA ADS] [CrossRef] [Google Scholar]
- Inada, N., Oguri, M., Shin, M.-S., et al. 2012, AJ, 143, 119 [Google Scholar]
- Inayoshi, K., Visbal, E., & Haiman, Z. 2020, ARA&A, 58, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jackson, N., de Bruyn, A. G., Myers, S., et al. 1995, MNRAS, 274, L25 [NASA ADS] [CrossRef] [Google Scholar]
- Jackson, N., Ofek, E. O., & Oguri, M. 2008, MNRAS, 387, 741 [Google Scholar]
- Jaelani, A. T., Rusu, C. E., Kayo, I., et al. 2021, MNRAS, 502, 1487 [NASA ADS] [CrossRef] [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, ArXiv e-prints [arXiv:1412.6980] [Google Scholar]
- Kingma, D. P., & Welling, M. 2019, ArXiv e-prints [arXiv:1906.02691] [Google Scholar]
- Krone-Martins, A., Graham, M. J., Stern, D., et al. 2019, ArXiv e-prints [arXiv:1912.08977] [Google Scholar]
- Lacy, M., Baum, S. A., Chandler, C. J., et al. 2020, PASP, 132, 035001 [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Lawrence, A., Warren, S. J., Almaini, O., et al. 2007, MNRAS, 379, 1599 [Google Scholar]
- Lemon, C. A., Auger, M. W., McMahon, R. G., & Ostrovski, F. 2018, MNRAS, 479, 5060 [Google Scholar]
- Lemon, C. A., Auger, M. W., & McMahon, R. G. 2019, MNRAS, 483, 4242 [NASA ADS] [CrossRef] [Google Scholar]
- Lemon, C., Auger, M. W., McMahon, R., et al. 2020, MNRAS, 494, 3491 [NASA ADS] [CrossRef] [Google Scholar]
- Lemon, C., Anguita, T., Auger-Williams, M. W., et al. 2023, MNRAS, 520, 3305 [NASA ADS] [CrossRef] [Google Scholar]
- Madireddy, S., Ramachandra, N., Li, N., et al. 2019, ArXiv e-prints [arXiv:1911.03867] [Google Scholar]
- Mason, C. A., Treu, T., Schmidt, K. B., et al. 2015, ApJ, 805, 79 [NASA ADS] [CrossRef] [Google Scholar]
- McGreer, I. D., Jiang, L., Fan, X., et al. 2013, ApJ, 768, 105 [NASA ADS] [CrossRef] [Google Scholar]
- McMahon, R., Irwin, M., & Hazard, C. 1992, GEMINI Newsletter Royal Greenwich Observatory, 36, 1 [NASA ADS] [Google Scholar]
- McMahon, R. G., Banerji, M., Gonzalez, E., et al. 2013, The Messenger, 154, 35 [NASA ADS] [Google Scholar]
- Merloni, A., Lamer, G., Liu, T., et al. 2024, A&A, 682, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Millon, M., Courbin, F., Bonvin, V., et al. 2020, A&A, 640, A105 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miralda-Escudé, J. 1998, ApJ, 501, 15 [CrossRef] [Google Scholar]
- Moffat, A. F. J. 1969, A&A, 3, 455 [NASA ADS] [Google Scholar]
- More, A., Oguri, M., Kayo, I., et al. 2016, MNRAS, 456, 1595 [NASA ADS] [CrossRef] [Google Scholar]
- More, A., Cañameras, R., Jaelani, A. T., et al. 2024, MNRAS, 533, 525 [CrossRef] [Google Scholar]
- Morningstar, W. R., Hezaveh, Y. D., Perreault Levasseur, L., et al. 2018, ArXiv e-prints [arXiv:1808.00011] [Google Scholar]
- Morokuma, T., Inada, N., Oguri, M., et al. 2007, AJ, 133, 214 [NASA ADS] [CrossRef] [Google Scholar]
- Nightingale, J. W., Dye, S., & Massey, R. J. 2018, MNRAS, 478, 4738 [Google Scholar]
- Nightingale, J., Hayes, R., Kelly, A., et al. 2021, J. Open Source Softw., 6, 2825 [NASA ADS] [CrossRef] [Google Scholar]
- Nightingale, J., Amvrosiadis, A., Hayes, R., et al. 2023, J. Open Source Softw., 8, 4475 [Google Scholar]
- Oguri, M. 2010, PASJ, 62, 1017 [NASA ADS] [Google Scholar]
- Oguri, M., & Marshall, P. J. 2010, MNRAS, 405, 2579 [NASA ADS] [Google Scholar]
- Oguri, M., Inada, N., Castander, F. J., et al. 2004, PASJ, 56, 399 [NASA ADS] [Google Scholar]
- Oguri, M., Inada, N., Clocchiatti, A., et al. 2008, AJ, 135, 520 [NASA ADS] [CrossRef] [Google Scholar]
- Pacucci, F., & Loeb, A. 2019, ApJ, 870, L12 [NASA ADS] [CrossRef] [Google Scholar]
- Pearson, J., Maresca, J., Li, N., & Dye, S. 2021, MNRAS, 505, 4362 [CrossRef] [Google Scholar]
- Perreault Levasseur, L., Hezaveh, Y. D., & Wechsler, R. H. 2017, ApJ, 850, L7 [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Prakash, A., Licquia, T. C., Newman, J. A., et al. 2016, ApJS, 224, 34 [NASA ADS] [CrossRef] [Google Scholar]
- Queirolo, G., Seitz, S., Riffeser, A., et al. 2023, ArXiv e-prints [arXiv:2312.09311] [Google Scholar]
- Reback, J., McKinney, W., Van den Bossche, J., et al. 2022, https://doi.org/10.5281/zenodo.3509134 [Google Scholar]
- Refsdal, S. 1964, MNRAS, 128, 307 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G., Yuan, W., Macri, L. M., et al. 2022, ApJ, 934, L7 [NASA ADS] [CrossRef] [Google Scholar]
- Rocklin, M. 2015, in Proceedings of the 14th Python in Science Conference, eds. K. Huff, & J. Bergstra, 130 [Google Scholar]
- Rojas, K., Savary, E., Clément, B., et al. 2022, A&A, 668, A73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rumbaugh, N., Fassnacht, C. D., McKean, J. P., et al. 2015, MNRAS, 450, 1042 [NASA ADS] [CrossRef] [Google Scholar]
- Savary, E., Rojas, K., Maus, M., et al. 2022, A&A, 666, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schlafly, E. F., & Finkbeiner, D. P. 2011, ApJ, 737, 103 [Google Scholar]
- Schlafly, E. F., Meisner, A. M., & Green, G. M. 2019, ApJS, 240, 30 [Google Scholar]
- Schlegel, D. J., Finkbeiner, D. P., & Davis, M. 1998, ApJ, 500, 525 [Google Scholar]
- Schmidt, T., Treu, T., Birrer, S., et al. 2023, MNRAS, 518, 1260 [Google Scholar]
- Schuldt, S., Chirivì, G., Suyu, S. H., et al. 2019, A&A, 631, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuldt, S., Suyu, S. H., Meinhardt, T., et al. 2021, A&A, 646, A126 [EDP Sciences] [Google Scholar]
- Schuldt, S., Cañameras, R., Shu, Y., et al. 2023a, A&A, 671, A147 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuldt, S., Suyu, S. H., Cañameras, R., et al. 2023b, A&A, 673, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuldt, S., Canameras, R., Andika, I. T., et al. 2025, A&A, 693, A291 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Selvaraju, R. R., Cogswell, M., Das, A., et al. 2016, ArXiv e-prints [arXiv:1610.02391] [Google Scholar]
- Sérsic, J. L. 1963, Boletin de la Asociacion Argentina de Astronomia La Plata Argentina, 6, 41 [Google Scholar]
- Shajib, A. J., Birrer, S., Treu, T., et al. 2020, MNRAS, 494, 6072 [Google Scholar]
- Shajib, A. J., Vernardos, G., Collett, T. E., et al. 2022, ArXiv e-prints [arXiv:2210.10790] [Google Scholar]
- Shu, Y., Cañameras, R., Schuldt, S., et al. 2022, A&A, 662, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Simonyan, K., Vedaldi, A., & Zisserman, A. 2013, ArXiv e-prints [arXiv:1312.6034] [Google Scholar]
- Songaila, A., & Cowie, L. L. 2010, ApJ, 721, 1448 [NASA ADS] [CrossRef] [Google Scholar]
- Spiniello, C., Agnello, A., Napolitano, N. R., et al. 2018, MNRAS, 480, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Stacey, H. R., Costa, T., McKean, J. P., et al. 2022, MNRAS, 517, 3377 [NASA ADS] [CrossRef] [Google Scholar]
- Sundararajan, M., Taly, A., & Yan, Q. 2017, ArXiv e-prints [arXiv:1703.01365] [Google Scholar]
- Taylor, M. B. 2005, ASP Conf. Ser., 347, 29 [Google Scholar]
- TensorFlow Developers 2022, https://doi.org/10.5281/zenodo.4724125 [Google Scholar]
- Treu, T., Suyu, S. H., & Marshall, P. J. 2022, A&ARv, 30, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Verde, L., Treu, T., & Riess, A. G. 2019, Nat. Astron., 3, 891 [Google Scholar]
- Vestergaard, M., & Wilkes, B. J. 2001, ApJS, 134, 1 [Google Scholar]
- Waskom, M. 2021, J. Open Source Softw., 6, 3021 [CrossRef] [Google Scholar]
- Williams, P. R., Agnello, A., Treu, T., et al. 2018, MNRAS, 477, L70 [Google Scholar]
- Wong, K. C., Suyu, S. H., Chen, G. C. F., et al. 2020, MNRAS, 498, 1420 [Google Scholar]
- Woodfinden, A., Nadathur, S., Percival, W. J., et al. 2022, MNRAS, 516, 4307 [NASA ADS] [CrossRef] [Google Scholar]
- Worseck, G., & Prochaska, J. X. 2011, ApJ, 728, 23 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868 [Google Scholar]
- Yang, J., Wang, F., Wu, X.-B., et al. 2016, ApJ, 829, 33 [NASA ADS] [CrossRef] [Google Scholar]
- Yue, M., Yang, J., Fan, X., et al. 2021, ApJ, 917, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Yue, M., Fan, X., Yang, J., & Wang, F. 2022, AJ, 163, 139 [NASA ADS] [CrossRef] [Google Scholar]
- Yue, M., Fan, X., Yang, J., & Wang, F. 2023, AJ, 165, 191 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, C., Variu, A., He, M., et al. 2022, MNRAS, 511, 5492 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Network architecture overview
We present the detailed architecture of VariLens here, which is designed to process HSC images for detecting and modeling lensed quasars. The network is composed of distinct modules that handle regression and classification tasks through a combination of encoding and decoding techniques.
The overview of the VariLens architecture is already presented in Figure 3, which illustrates that the network consists of three key modules: the encoder, decoder, and regressor. As shown in Figure A.1, the encoder transforms the input images into a latent representation. The decoder, depicted in Figure A.2, reconstructs the latent distribution back into the original data. Meanwhile, the regressor, illustrated in Figure A.3, estimates the lens and source parameters while ensuring that the latent distribution remains physically meaningful. Due to space limitations, the batch normalization layers between the convolution and activation operations are not displayed in the figures. However, they are indeed present in the network architecture, similar to what is seen in the regression module, for example.
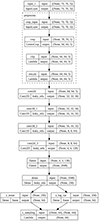 |
Fig. A.1. The encoder of VariLens. This module processes a batch of 5-band HSC images, each measuring 70 × 70 pixels, and compresses them into a latent representation of 64 dimensions. The batch size is flexible, with “None” meaning it can adapt based on user specifications. The leftmost column in the architecture diagram denotes the custom label and layer type, as defined by the TensorFlow deep learning framework. |
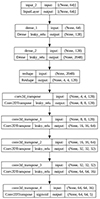 |
Fig. A.2. The decoder of VariLens. This module takes the latent representation generated by the encoder and reconstructs them back into the original images. This process retains only the most important information while smoothing out noise, effectively acting as a form of lossy compression-decompression that prioritizes essential features. |
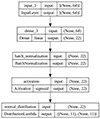 |
Fig. A.3. The regression module of VariLens. This regressor processes the latent representations produced by the encoder to estimate key lens and source parameters. Simultaneously, it helps the latent distribution align with physically meaningful constraints. |
Figure A.4 displays the classification module, where the network processes 5-band HSC images using an encoder and outputs the lens probability via a final dense layer with a sigmoid activation function. We note that the augmentation module within the classifier includes random flips, shifts, and rotations, which are applied only during the training phase but are not used during inference.
 |
Fig. A.4. The classification module of VariLens. This module leverages the pretrained encoder to process batches of 5-band HSC images, each with dimensions of 70 × 70 pixels. It outputs the probability of a lens through a final dense layer equipped with a sigmoid activation function, enabling binary classification of lens candidates. |
Appendix B: Regression metrics definition
The coefficient of determination, R2, can be computed as follows:
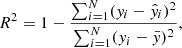
where 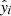 denotes the predicted value for the i-th sample, yi represents the true value of the i-th sample, and
denotes the predicted value for the i-th sample, yi represents the true value of the i-th sample, and 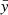 is the mean of the true values across all samples, computed as
is the mean of the true values across all samples, computed as 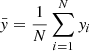 . The numerator,
. The numerator, 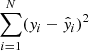 , is the residual sum of squares, which measures the variance of the prediction errors. The denominator,
, is the residual sum of squares, which measures the variance of the prediction errors. The denominator, 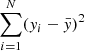 , is the total sum of squares, indicating the variance in the true values.
, is the total sum of squares, indicating the variance in the true values.
Additionally, the mean squared error (MSE) can be computed utilizing:
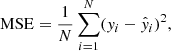
while the mean absolute error (MAE) is given by the expression as follows:
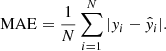
Here, N denotes the total data points. MSE provides the average of the squared differences between the true and predicted values, thereby emphasizing larger errors. In contrast, MAE calculates the average of the absolute differences, providing a simple metric of prediction accuracy that is less affected by outliers compared to MSE.
Appendix C: Quasar and galaxy light profiles
The elliptical Moffat profile, which we use to model the quasar’s light by approximating the point spread function (PSF), is given by:
![$$ \begin{aligned} I(x, y) = I_0 \left[ 1 + \left( \frac{r_{\mathrm{ell} }}{\alpha / \sqrt{q}} \right)^2 \right]^{-\beta }, \end{aligned} $$](/articles/aa/full_html/2025/02/aa53474-24/aa53474-24-eq42.gif)
where I(x, y) is the intensity at the location (x, y), I0 is the intensity normalization, α controls the overall size of the profile, and β adjusts the profile’s wing shape. The parameter q is the axis ratio of the ellipse – that is, expressed as q = b/a – where a and b are the semi-major and semi-minor axes, respectively. The elliptical radius rell is given by:
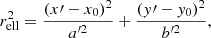
with (x′,y′) being the coordinates after rotation to align with the ellipse’s principal axes, and (x0, y0) representing the center of the profile. The quantities a′ and b′ denote the transformed semi-major and semi-minor axes, respectively, accounting for the ellipticity components e1 and e2. The components e1, e2, and q are connected to the orientation angle (ϕ) through the relations:
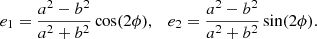
It is important to note that Equation C.1 is a reparameterization of the original expression proposed by Moffat (1969), as introduced by Nightingale et al. (2021) to improve numerical stability in lens modeling.
On the other hand, the mathematical equation for the Sérsic light distribution, used to model the lens galaxy’s light, is:
![$$ \begin{aligned} I(r) = I_0 \exp \left( -b_n \left[ \left(\frac{r}{R_e}\right)^{\frac{1}{n}} - 1 \right] \right) \end{aligned} $$](/articles/aa/full_html/2025/02/aa53474-24/aa53474-24-eq45.gif)
where I(r) denotes the intensity at the elliptical radius r, I0 represents the intensity at the effective radius Re, and n is the Sérsic index, which governs the concentration of the profile. The elliptical radius is defined as:
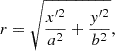
where a and b are the semi-major and semi-minor axes, and (x′,y′) are the coordinates in the rotated reference frame aligned with the galaxy’s major axis. The constant bn is a normalization factor that depends on n and is is typically approximated as:
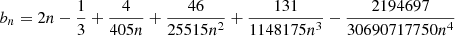
This constant bn ensures that Re contains half of the total intensity of the light profile.
Appendix D: Lens modeling results for GLQD sources
The result of the lens modeling for GLQD sources are stored on the Zenodo repository. This consists of tables containing the parameters obtained using the traditional approach with PyAutoLens and the ones inferred through the deep-learning based method with VariLens. A comparison of these estimates is illustrated in Figure 12.
Appendix E: Full List of Lens Candidates
The color images of our lens candidates are presented in Figure E.1 and E.2. These candidates were selected using the methodologies discussed in the main text. Comprehensive photometric data and the inferred physical parameters for each system can be accessed via Zenodo.
 |
Fig. E.1. The 64 × 64 pixels ( |
All Tables
All Figures
|
Fig. 1. Distribution of redshifts (zgal), stellar velocity dispersions (σv), Einstein radii (θE), and HSC i-band magnitudes (iHSC) for the galaxies used to simulate the lens systems. The orange histograms represent the mock lens configurations in all training, validation, and test datasets, while the mock lenses correctly identified by our classifier are highlighted with blue lines. |
| In the text | |
|
Fig. 2. Examples of mock lenses and other contaminants used for training the networks, with the inferred lens probability for each image indicated. By overlaying the multiply imaged source’s light following an SIE+γext lens configuration onto a real galaxy image, we are able to construct realistic galaxy-quasar lens mocks. |
| In the text | |
|
Fig. 3. Simplified overview of the VariLens architecture. The networks include three main components: the encoder, decoder, and regressor. The input consists of a batch of 5-band HSC images, initially sized at 70 × 70 pixels. The batch size is flexible, with “None” indicating it can vary based on user specifications. These images are cropped, clipped, and rescaled to standardize pixel values before reaching the encoder. The encoder subsequently takes the preprocessed 64 × 64 pixel images and compresses them into a 64-dimensional latent representation. The decoder then reconstructs this latent representation back into the original cropped 64 × 64 pixel images. At the same time, the regressor estimates lens and source parameters, guiding the latent distribution to ensure it is physics-informed. Once the networks are fully trained, the decoder and regressor are removed and replaced by a single dense layer serving as the classification head. Transfer learning is then applied to fine-tune the classifier, optimizing it to effectively distinguish between lensing and non-lensing systems. |
| In the text | |
|
Fig. 4. Loss and accuracy curves over training epochs for the VariLens model. The left panel shows optimizations for the physics-informed VAE, while the right panel displays the one for the classifier module. The metrics, evaluated on the training and validation datasets, are depicted by the blue and orange lines, respectively. For the classifier, the dashed black line indicates the epoch when network fine-tuning begins. Prior to fine-tuning, the VariLens classifier appeared to perform worse on the training dataset compared to the validation samples. This could be due to the model not having fully converged or found the optimal weights at that stage. |
| In the text | |
|
Fig. 5. Image reconstruction examples. The original data containing mock lensed quasars, the reconstructed images predicted by VariLens, and the difference between them (i.e., residuals) are shown. These HSC grz images originate from sources within the test dataset. |
| In the text | |
|
Fig. 6. Visualization of a subset of the data, including mock lensed quasars and contaminants, after dimensionality reduction using principal component analysis (PCA). The vertical dashed black lines in the left panels mark the number of principal components required to explain 95% of the variance and the corresponding eigenvalues. The right panels show the first three PCA components, which reveal minimal separability between lenses (red) and non-lenses (blue). |
| In the text | |
|
Fig. 7. Dimensionality reduction using two-dimensional t-distributed Stochastic Neighbor Embedding (t-SNE) on the encoded data. Projecting the high-dimensional data into two embedding components allows t-SNE to effectively visualize distinct clusters, with lensed quasars (red) and non-lensed sources (blue) showing clear separation. |
| In the text | |
|
Fig. 8. Receiver operating characteristic (ROC) curve, depicted with a blue line, along with the corresponding area under the curve (AUC). The false positive rate and true positive rate at the chosen Plens threshold are marked with a red circle. |
| In the text | |
|
Fig. 9. Quasar selection function adopted in this work. The recovery rate percentage indicates the fraction of mock quasars within each (M1450, z) bin that our classifier successfully recognizes. |
| In the text | |
|
Fig. 10. Comparison of true and predicted physical parameters. The metrics R2, MSE, and MAE for sources in the test dataset are displayed in each panel. Darker regions indicate higher concentrations of sources within the 2D histogram bins. The red dashed line represents the 1:1 relationship between the predicted and actual values. |
| In the text | |
|
Fig. 11. Lensed quasar samples compiled from GLQD (refer to the main text). The images are generated from HSC grz-band cutouts with dimensions of 64 × 64 pixels (approximately |
| In the text | |
|
Fig. 12. Comparison of the derived SIE+γext parameters from traditional lens modeling using PyAutoLens (labeled “Trad.”) and the deep learning-based approach with VariLens (“Net.”). Quadruply lensed quasars are indicated by red circles, while doubly lensed quasars are marked with blue circles. We also compare the redshifts inferred by VariLens with spectroscopic measurements. |
| In the text | |
|
Fig. A.1. The encoder of VariLens. This module processes a batch of 5-band HSC images, each measuring 70 × 70 pixels, and compresses them into a latent representation of 64 dimensions. The batch size is flexible, with “None” meaning it can adapt based on user specifications. The leftmost column in the architecture diagram denotes the custom label and layer type, as defined by the TensorFlow deep learning framework. |
| In the text | |
|
Fig. A.2. The decoder of VariLens. This module takes the latent representation generated by the encoder and reconstructs them back into the original images. This process retains only the most important information while smoothing out noise, effectively acting as a form of lossy compression-decompression that prioritizes essential features. |
| In the text | |
|
Fig. A.3. The regression module of VariLens. This regressor processes the latent representations produced by the encoder to estimate key lens and source parameters. Simultaneously, it helps the latent distribution align with physically meaningful constraints. |
| In the text | |
|
Fig. A.4. The classification module of VariLens. This module leverages the pretrained encoder to process batches of 5-band HSC images, each with dimensions of 70 × 70 pixels. It outputs the probability of a lens through a final dense layer equipped with a sigmoid activation function, enabling binary classification of lens candidates. |
| In the text | |
|
Fig. E.1. The 64 × 64 pixels ( |
| In the text | |
 |
Fig. E.2. Similar to Figure E.1, but for a subset of our grade C candidates. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.