| Issue |
A&A
Volume 678, October 2023
|
|
|---|---|---|
| Article Number | A103 | |
| Number of page(s) | 28 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202347332 | |
| Published online | 11 October 2023 | |
Streamlined lensed quasar identification in multiband images via ensemble networks
1
Technical University of Munich, TUM School of Natural Sciences, Department of Physics,
James-Franck-Str. 1,
85748
Garching,
Germany
e-mail: irham.andika@tum.de
2
Max-Planck-Institut für Astrophysik,
Karl-Schwarzschild-Str. 1,
85748
Garching,
Germany
3
Academia Sinica Institute of Astronomy and Astrophysics (ASIAA),
11F of ASMAB, No.1, Section 4, Roosevelt Road,
Taipei
10617,
Taiwan
4
Dipartimento di Fisica, Università degli Studi di Milano,
via Celoria 16,
20133
Milano,
Italy
5
Purple Mountain Observatory,
No. 10 Yuanhua Road,
Nanjing, Jiangsu,
210033,
PR China
6
MIT Kavli Institute for Astrophysics and Space Research,
77 Massachusetts Ave.,
Cambridge, MA
02139,
USA
7
Astronomy Research Group and Bosscha Observatory, FMIPA, Institut Teknologi Bandung,
Jl. Ganesha 10,
Bandung
40132,
Indonesia
8
U-CoE AI-VLB, Institut Teknologi Bandung,
Jl. Ganesha 10,
Bandung
40132,
Indonesia
Received:
30
June
2023
Accepted:
10
August
2023
Quasars experiencing strong lensing offer unique viewpoints on subjects related to the cosmic expansion rate, the dark matter profile within the foreground deflectors, and the quasar host galaxies. Unfortunately, identifying them in astronomical images is challenging since they are overwhelmed by the abundance of non-lenses. To address this, we have developed a novel approach by ensembling cutting-edge convolutional networks (CNNs) - for instance, ResNet, Inception, NASNet, MobileNet, EfficientNet, and RegNet – along with vision transformers (ViTs) trained on realistic galaxy-quasar lens simulations based on the Hyper Suprime-Cam (HSC) multiband images. While the individual model exhibits remarkable performance when evaluated against the test dataset, achieving an area under the receiver operating characteristic curve of >97.3% and a median false positive rate of 3.6%, it struggles to generalize in real data, indicated by numerous spurious sources picked by each classifier. A significant improvement is achieved by averaging these CNNs and ViTs, resulting in the impurities being downsized by factors up to 50. Subsequently, combining the HSC images with the UKIRT, VISTA, and unWISE data, we retrieve approximately 60 million sources as parent samples and reduce this to 892 609 after employing a photometry preselection to discover z > 1.5 lensed quasars with Einstein radii of θE < 5″. Afterward, the ensemble classifier indicates 3080 sources with a high probability of being lenses, for which we visually inspect, yielding 210 prevailing candidates awaiting spectroscopic confirmation. These outcomes suggest that automated deep learning pipelines hold great potential in effectively detecting strong lenses in vast datasets with minimal manual visual inspection involved.
Key words: galaxies: active / quasars: general / quasars: supermassive black holes / gravitational lensing: strong / methods: data analysis
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model.
Open Access funding provided by Max Planck Society.
1 Introduction
Quasars are fueled by matter accretion onto supermassive black holes (SMBHs) and are among the most luminous objects in the universe, emitting enormous amounts of energy. This attribute makes them ideal probes for studying the distant universe and the physical processes that govern the emergence of the SMBHs and their host galaxies across cosmic time (e.g., Inayoshi et al. 2020; Fan et al. 2023).
In rare occurrences, the presence of a nearby galaxy in the observer’s line of sight can distort the light originating from a distant quasar in the background, resulting in so-called gravitational lensing (Schneider 2015). In the event of strong lensing, where highly magnified and multiple images of the quasar are produced, the mass distribution of the deflectors can be examined by analyzing the observed lens configuration, providing insights into the dark matter profile and the processes that drive the mass assembly of galaxies and clusters (e.g., Shajib et al. 2022, and references therein).
Lensed quasars also serve as crucial tracers for understanding the fundamental physics of our universe. For example, the cosmic expansion rate, age, and critical density are related to the Hubble constant (H0), which can be inferred via lens mass distribution modeling and time delay analysis of lensed quasar images (e.g., Refsdal 1964; Treu et al. 2022). Considering the current tension of H0 values inferred from the different late and early universe probes, independent methods using the lensed quasars analysis are critically important (see e.g., Wong et al. 2020), and more precise measurement is expected with higher number statistics. In addition, lensing could provide flux magnification and increase the effective spatial resolution of the target of interest that would otherwise be too faint (compact) to be detected (resolved). This effect enables us to study quasars with intrinsically lower luminosity along with their host galaxies in unprecedented detail (Yue et al. 2021; Stacey et al. 2022; Glikman et al. 2023).
At the time of writing, around 300 lensed quasars have been discovered through various observational techniques, including locating multiple point sources with quasar-like colors or selecting objects with unusual shapes consistent with lensing configurations. In the early days, for example, the Cosmic Lens All-Sky Survey identified many multiply-imaged flat-spectrum radio sources, which are then confirmed as radio-loud lensed quasars (Myers et al. 2003; Browne et al. 2003). Shortly after, in the optical wavelength, the Sloan Digital Sky Survey Quasar Lens Search confirmed a few tens of lenses based on the morphological analysis and color selection of spectroscopically classified quasars (Oguri et al. 2006; Inada et al. 2008, 2010, 2012).
Over time, modern wide-field sky surveys can reach deeper limiting magnitudes and deliver great data quality, making it feasible to select more lensed quasar candidates via imaging data alone without the need for spectroscopic preselection. For instance, data mining on photometric catalogs to detect multiple quasar sources allows for the discovery of lensed quasars in numerous projects, such as the Dark Energy Survey (Shu et al. 2018; Anguita et al. 2018; Agnello & Spiniello 2019; Lemon et al. 2020), the Kilo-Degree Survey (Spiniello et al. 2018; Khramtsov et al. 2019), and the Dark Energy Spectro-scopic Instrument Legacy Imaging Surveys (Dawes et al. 2022; He et al. 2023). In addition, complementing optical data with infrared photometry and adding astrometric measurements could further reduce the number of false detections (Krone-Martins et al. 2018; Ducourant et al. 2018; Lemon et al. 2018, 2019, 2023; Shu et al. 2019; Desira et al. 2022). We note that despite the high success rates of the previous lensed-finding approaches, they still face a substantial challenge: the inevitability of human involvement in time-consuming and exhaustive visual inspection stages to acquire a final list of candidates with high purity (e.g., Chan et al. 2023; Yue et al. 2023).
Over the past few years, automated lens-finding methods, either using conventional point sources and lens arcs finder or state-of-the-art machine learning algorithms - for example, convolutional neural network (CNN), variational autoencoder (VAE), and vision transformer (ViT) – are being explored to reduce human interventions further (Cheng et al. 2020; Rezaei et al. 2022; Akhazhanov et al. 2022). However, more optimizations are still required since applying these classifiers to real survey data frequently yields samples dominated by false detections. Often, manual visual inspection still needs to be done at the final stage on more than ten thousand candidates recommended by automated classifiers to select high-grade lenses and remove the contaminants (e.g., Chan et al. 2022). This hassle might be caused by the need for more realistic training datasets to improve the classifier performance, coupled with complications caused by the very low fraction (≲10−3) of strong lenses in all galaxies per sky area (see, for example, Oguri & Marshall 2010).
Although machine learnings are now widely used for finding galaxy-galaxy strong lenses and performing lens modeling to those systems (e.g., Hezaveh et al. 2017; Shu et al. 2022; Schuldt et al. 2023), their use case for lenses containing galaxy-quasar pairs is still limited and has not been explored much. They might have worked well for lensed galaxies since these sources display extended lens arcs that can be distinguished from other astronomical sources. On the other hand, lensed quasars often show only two or more point sources that outshine the light from the lensing galaxy. They are also overwhelmed by visually identical impurities such as binary stars or quasar-star projections.
As mentioned earlier, previous lensed quasar searches are proven to be effective, but they might not be efficient enough and not scalable in larger datasets. Specifically, current estimations for the upcoming data from the next-generation surveys such as Euclid (Laureijs et al. 2011; Euclid Collaboration 2022) and Vera C. Rubin Observatory’s Legacy Survey of Space and Time (LSST; Ivezic et al. 2019) expect that these projects would expand the number of candidates for strong lenses by at least a few orders of magnitude (Collett 2015; Yue et al. 2022a; Taak & Treu 2023). Therefore, developing a highly efficient, automated lensed quasar selection algorithm is very much indispensable.
Here, we develop a novel lens finder using the ensemble of state-of-the-art convolutional and transformer-based neural networks (e.g., Sultana et al. 2018; Dosovitskiy et al. 2020). Our classifier is particularly optimized to detect lensed quasars in multiband images of the Hyper Suprime-Cam Subaru Strategic Program (HSC-SSP; Aihara et al. 2022), extending the selection space to higher redshift ranges that might be missed by previous surveys. Complementing the primary optical data with infrared photometry, we further apply spectral color modeling to obtain lensed quasar candidates with minimal contaminants.
This paper is presented as follows. Section 2 begins with a description of data collection and target preselection using photometric color cuts. Section 3 explains the simulation for understanding the color and morphology of the galaxy-quasar lens systems. Section 4 then goes through the specifics of lens detection using automated classifiers, including the datasets utilized for training and evaluating the neural networks. Section 5 then discusses the classification outputs and the lensed quasar candidates. Section 6 completes with a summary and our conclusions.
Throughout this paper, we employ the ACDM cosmological model where ΩΛ = 1 − Ωm = 0.685 to simulate lensed images in the training set (Planck Collaboration VI 2020). It is worth noting that the resulting lensed images do not depend on the exact value of H0. In addition, the written magnitudes are reported using the AB system.
2 Dataset and preselection
Our lensed quasar hunt comprises two steps: (1) selecting candidates based on their photometric color using multiband data, and (2) calculating the relative likelihoods of the candidates being a lens or contaminant utilizing a machine learning classifier. In this first step, we want to increase the purity of the candidates by restricting the search to objects that we suspect, based on catalog-level photometry, are more likely to be lenses. This approach offers a strategy for efficiently distinguishing the candidates from the majority of the contaminants while requiring the least amount of computer resources. The following section will describe the first part of our search method in more detail.
2.1 Primary optical photometric data
As the primary catalog in the optical regime, we make use of the wide-layer data of HSC-SSP Public Data Release 3 (shortened to HSC; Aihara et al. 2022). The observations are conducted by utilizing the Hyper Suprime-Cam mounted on the Subaru 8.2m telescope (Aihara et al. 2018, 2019), capturing the sky image of 670 deg2 wide in five bands (grizy) at the full depth of ~26 mag (5σ for point sources), a pixel scale of 0″.168, and seeing of 0″.6– 0″.8. It should be noted that if we also account for the partially observed areas, the current data release covers up to approximately 1300 deg2 instead. This larger HSC footprint will be used to construct the parent sample of our lensed quasar candidates selection.
To begin the initial selection, we pick all sources detected in the i, z, and y bandpasses with signal-to-noise ratio (S/N) values of more than 3, 5, and 8, respectively. These sources should also have g and r images in the HSC data, but we do not impose any S/N cuts for these bands. As a note, these S/N cut values are derived based on our lens simulation, which will be discussed in the later section. Also, in this case, we adopt the flux and magnitude measurements within the 2″ (≈12 pixels) aperture diameter from the HSC pdr3_wide.summary1 catalog entries. This table incorporates forced photometry on stacked images containing frequently-selected columns of primary objects. Furthermore, we apply the flags: (1) [grizy]_apertureflux_20_flag is False, and (2) [grizy]_is_clean_centerpixels is True, to retrieve only the sources with reliable photometry. The science images with a size of 72 × 72 pixels and their corresponding point spread function (PSF) cutouts are subsequently downloaded using the HSC data access tools2. At this point, 57 464 157 unique sources, defined as our parent sample, pass our preliminary S/N cuts and flag criteria, implying that a lot of computing power is required to process them all. As additional information, the summary of our selection criteria will be reported in Table 1.
After that, since most kpc-scale quasar pairs and lensed quasars have separations of ≲ 3″ (e.g., Yue et al. 2023), we try to narrow the selection to sources that show the presence of nearby companions within a 2″ radius. We are aware that this choice might be too strict. As an illustration, out of 22 optically bright lensed quasars with spectroscopic confirmation in the HSC catalog (Chan et al. 2023), we only recover 15 of them via the above preselection - that is, a recovery rate of 68%. Seven lensed quasars are missed due to the absence of neighboring sources in their vicinity, probably because they are too faint or some failures in the HSC object deblending process. Nevertheless, this method managed to reduce the number of selected objects significantly while keeping many known lenses to be recovered with minimal contaminations and required computational power later. We then crossmatch our parent sample with catalogs of known quasars (Flesch 2021; Fan et al. 2023), galaxies/stars (Almeida et al. 2023), strong lenses3, and brown dwarfs4 (Best et al. 2018; Carnero Rosell et al. 2019) to identify the spectroscopic classification of these sources when available. In the end, after selecting only sources that: (1) have at least one neighboring source within a 2″ radius or (2) have spectroscopic classifications, we managed to reduce the number of objects to only 4 854 831.
Summary of the selection criteria applied to find the lensed quasar candidates.
2.2 Infrared photometry from public surveys
The near-infrared (NIR) data is then acquired from the catalogs of the UKIRT Infrared Deep Sky Survey (UKIDSS; Lawrence et al. 2007), the UKIRT Hemisphere Survey (UHS; Dye et al. 2018), the VISTA Hemisphere Survey (VHS; McMahon et al. 2013), and the VISTA Kilo-degree Infrared Galaxy (VIKING) Survey (Edge et al. 2013). We use here the photometry in the J, H, and K (or Ks) bands, when available. As a note, most of the southern hemisphere is covered by VHS and VIKING, while UKIDSS and UHS capture a large sky area in the north. When we began the candidate selection, UKIDSS and VIKING had completed their observations. However, UHS had only published its J-band photometry, while VHS had only provided its J and Ks-band photometry for most sky regions. As a consequence, the precise photometry accessible for each source is determined by its location in the sky. We also exploit mid-infrared (MIR) observations from the unWISE catalog (Schlafly et al. 2019), which contains about two billion objects identified by the Wide-field Infrared Survey Explorer (WISE; Wright et al. 2010) throughout the whole sky. With its ≈0.7 magnitudes of deeper imaging data and better source extraction in crowded sky areas, unWISE data surpasses the quality of the predecessor WISE catalog.
To combine the HSC data with the compiled infrared catalogs, we use a crossmatching radius of 2″ between the sources. Together with the NIR photometry, the MIR W1 (3.4 µm) and W2 (4.6 µm) bands from unWISE are highly valuable for determining if the sources are quasars, stars, or brown dwarfs (e.g., Andika et al. 2020, 2022). This crossmatching technique also works for removing unwanted sources, such as cosmic rays or moving sources that are present in one survey but not in others (e.g., Andika 2022). Subsequently, we retrieve the candidates with fluxes of respectively at least 5σ and 3σ in the W1 and W2 bands, as well as having the color of 0.1 < y − W1 < 3.6 and −0.7 < W1 − W2 < 0.7, resulting in a remaining 911 263 sources. The NIR color cut is then conducted by keeping the sources with J-band S/N > 3, leaving us only 621 713 candidates. Further cut is made by taking only sources with −0.8 < z − y < 3.9 and −0.2 < y − J < 2.8, which yields 601 277 objects. We note that the criteria we employed so far are derived empirically and managed to preserve 68% previously discovered lensed quasars and 57% known unlensed quasars within the HSC footprint while removing 93% and 28% of contaminating stars and galaxies.
Next, we will focus on sources that present the existence of nearby companions within a 2″ radius, reducing the number of candidates further to 389 263. Since a lens candidate could have one, two, or more detected companions, we also need to take account of the neighbors around the primary targets, so the total number of sources that will be analyzed at the next stage is 892 609. At the end of this preselection, we are still able to recover all of the 15 known lensed quasars mentioned before. As a reminder, Table 1 contains an overview of all the selection steps employed up to this point. It is also worth mentioning that all photometric measurements have been corrected from Galactic reddening employing the dust map from Schlegel et al. (1998) and with the updated bandpass corrections from Fitzpatrick (1999) and Schlafly & Finkbeiner (2011) extinction relation, implemented via the dustmaps library of Green (2018).
3 Simulating the lenses
To find lensed quasar candidates based on their multiband images, we need to understand their spectral energy distribution (SED) and morphology, composed by the addition of lights between the galaxy in the foreground and the quasar in the background. Following some lensing configurations, we can ray trace the lights and produce highly-realistic mock lens images by overlaying the lights of deflected point sources, representing the background quasar emission, over the real deflector images. These mock images will serve as input for the training dataset for building our neural networks model at the later selection step. As a brief illustration, the outline of our simulation workflow is presented in Fig. 1. More details on (1) the deflector galaxies data retrieval, (2) the mock quasar spectra generation, and (3) the galaxy-quasar lens image production are explained in this part of the paper.
3.1 Assembling the deflector galaxy samples
We first need to look for a sample of spectroscopically verified galaxies in the Sloan Digital Sky Survey Data Release 18 catalog (hereafter SDSS; Almeida et al. 2023), accessible through the CasJobs5 website, to assemble the deflectors for our lens simulation. Since the velocity dispersion (συ) is a critical metric for computing the lensing effect later, we pick all pipeline-classified “GALAXY” sources and narrow our search to those with the ratio of velocity dispersion to its error of συ/συ,err > 5 to retrieve samples with accurate measurements. We also exclude galaxies with συ < 50 km s−1 to discard lenses with too small or potentially inaccurate mass.
Furthermore, because the bulk of the lensing optical depth for high-z sources originates from the early-type lens galaxies at a redshift of z ~ 1 (Mason et al. 2015; Pacucci & Loeb 2019), we limit our selection to deflectors at z = 0.05 to 4 (see Fig. 2 as a reference). The resulting samples are then matched to the HSC catalog, with a radius of search of 1″, to get their associated magnitudes and image cutouts when present. As a result, we acquire a sample of 78 619 deflectors dominated by the luminous red galaxies (LRGs) population, peaked at z ~ 0.5 and συ ~ 250 km s−1, extending out to z ≲ 1.5.
3.2 Generating the quasar spectral colors
We proceed now to create simulated quasar emissions by generating a thousand quasar spectra, distributed uniformly at red-shifts of 1.5 ≤ z ≤ 7.2 and absolute magnitudes of −30 ≤ M1450 ≤ −20 at the rest-frame wavelength of 1450 Å. The simulation is done using the SIMQSO6 module (McGreer et al. 2013), following the prescription of Andika et al. (2023, see their Sect. 2.2 for details). This kind of simulation has been proven to mimic the SDSS quasar colors in high accuracy while also frequently used to assess the completeness of various quasar surveys (e.g., Yang et al. 2016; McGreer et al. 2018).
As a quick summary, the foundation of our quasar spectral model consists of continuum emission, represented by a broken power-law function. The slopes of the continuum (αv) follow a Gaussian distribution with mean values of −1.5 and −0.5 for the wavelengths at ≤1215 Å and >1215 Å, respectively, while each of their dispersions is fixed to 0.3. Afterward, the series of iron emissions at the rest wavelengths of <2200 Å, 2200–3500 Å, and 3500–7500 Å are consecutively appended to the model following the templates from Vestergaard & Wilkes (2001), Boroson & Green (1992). The broad and narrow lines are then added to the spectra, complying with the ratio and width distributions of SDSS quasars (e.g., Dawson et al. 2013, 2016; Blanton et al. 2017). Furthermore, the mock spectra incorporate the intergalactic medium (IGM) absorption by the Lyα forest in the sightline (Songaila & Cowie 2010; Worseck & Prochaska 2011). On top of that, for z ≳ 5.5 quasars, we apply the Lyα damping wing effect based on the theoretical approximation proposed by Miralda-Escudé (1998), with a fixed proximity zone size of 3 Mpc and a randomly assigned neutral hydrogen fractions of 0–10% (e.g., Euclid Collaboration 2019; Andika et al. 2020). Finally, using the Calzetti et al. (2000) model and randomly picked E(B – V) values of −0.02 to 0.14, the internal reddening effect from the dust is applied to the spectra. The negative reddening parameters are for creating quasar models with bluer continua than the original templates can accommodate. The photometry is then estimated from the mock spectra, and the associated errors are calculated using the magnitude-error relations of each survey (e.g., Yang et al. 2016).
 |
Fig. 1 Simulation workflow that we adopt for generating the mock lensed quasar images. The cutouts are based on the HSC images with 72 × 72 pixels wide (≈12″ on a side). The real galaxy, acting as a lens, is shown in the upper left panel. On the other hand, the quasar, which serves as a background source, is depicted in the lower left panel as a Gaussian light profile. The deflected source’s light convolved with the respective HSC PSF model is shown in the lower middle panel, which is determined based on the associated lens arrangement. Ultimately, we paint the multiply-imaged sources on top of the galaxy image and display it in the upper right panel. Below each panel, the lens parameters (in arcseconds, β and θE) and the photometry is reported. In this case, we construct mock images for all HSC bandpasses – namely, grizy bands. |
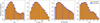 |
Fig. 2 Redshiſts (zgal), stellar velocity dispersions (συ), Einstein radii (θE), and HSC i-band magnitudes (iHSC) distributions of the galaxies used for making the mock lenses. These configurations are utilized to create mock lenses and are shown as orange histograms. The distribution of recovered lenses predicted by our ensemble network classifier is presented with blue lines. |
3.3 Producing the multiband images of lensed quasars
As the next step, we adopt a singular isothermal ellipsoid (SIE; Barkana 1998) model to characterize the lens mass profile, which is specified by the Einstein radius (θE), axis ratio translated into a complex ellipticity, position angle, and image centroid (e.g., Rojas et al. 2022). Subsequently, the Einstein radius can be calculated from συ enclosed by the gravitational potential using:
 (1)
(1)
where the light speed is c, while the angular diameter distances of the lens to source is Dds and the observer to source is Ds. Given the ratio of distances in Eq. (1), θE is independent of H0. Nonetheless, for computing each of the distances, a value of H0 = 67.4 km s−1 Mpc−1 is used (e.g., Planck Collaboration VI 2020). The SIE axis ratio, centroid, and position angle are then estimated directly by fitting the light distribution of each deflector on its HSC i-band image. Here, we perform the light profile fitting using the combination of elliptical Sérsic and exponential functions implemented in the PyAutoGalaxy7, an open-source library for investigating the galaxy morphologies and structures in multiwavelength data (Nightingale et al. 2018, 2023). The external shears are then added at random following a Gaussian distribution with a mean strength of 0 and a standard deviation of 0.058 (e.g., Shu et al. 2022), while the corresponding position angles are selected randomly in the range of 0–180 deg.
Next, the simulated lens images are generated by coupling each real galaxy with a mock quasar taken at random. The quasar is then randomly positioned behind the lens within 0″. 01 ≤ β ≤ θE, where β is the true angular position of the respective source. After that, the source image is projected onto the lens plane, while the magnification and deflection angle are traced based on the lensing structure using the PyAutoLens8 code (Nightingale et al. 2021). We also convolve the deflected quasar lights with the associated HSC PSF model before overlaying them to the original HSC galaxy images.
The quasar pairing and placement can be repeated up to 500 times to find a suitable lens configuration that satisfies the following criteria: (1) the mock image has a strong lensing effect with a magnification factor of µ > 5, (2) the lensed quasar y-band peak flux is detected at ≥ 5σ against the mean background noise, and (3) its y-band magnitude is > 15 mag to exclude unusually bright objects or saturated images. Otherwise, we drop the current deflector and move to the next one. Throughout this simulation, we also exclude systems with θE ≥ 5″ since the largest Einstein radius detected so far in the cases of galaxy-scale lensing corresponds to that limit (Belokurov et al. 2007; Schuldt et al. 2021). At last, we acquire 72 626 surviving lens configurations that fit our criteria from the initial 78 619 deflectors and 1000 mock quasars.
Figure 2 depicts the distribution of the lens galaxy red-shifts, velocity dispersions, Einstein radii, and i-band magnitudes adopted in our simulation. We also refer to Fig. 3 for the resulting grz-band color images of the previously created mock lens systems. It is apparent that the redshifts of our deflectors peak at z ≈ 0.5 and extend out to z ≲ 1.5, as mentioned before. Concerning the i-band magnitudes, we witness a spike in the deflector galaxy numbers up to iHSC ≈ 19.5, followed by an abrupt decrease near the faint end. As a result, our training dataset is weighted toward brighter and larger lens galaxies. This occurrence is mostly produced by how SDSS picks its target galaxies for spectroscopy, which fulfills the guidelines outlined by Dawson et al. (2013, 2016) and Prakash et al. (2016) to investigate the universe’s large-scale structure. The majority of the targets are luminous elliptical galaxies at z < 1, which are ideal tracers for studying the baryon acoustic oscillation signal and, hence, the expansion of our cosmos (e.g., Woodfinden et al. 2022; Zhao et al. 2022). The magnitude boundaries for galaxies selected for spectroscopic surveys are i = 19.9 for the SDSS III and i = 21.8 for the SDSS IV projects (Prakash et al. 2016).
 |
Fig. 3 HSC grz-band images of the unlensed galaxies, quasars, and stars as the negatives, along with the mock lenses as the positive examples. The square-root stretching is applied to the cutouts with a size of 72 × 72 pixels (≈12″ on a side) to emphasize features with low fluxes and improve the visual appearance. We also present the ground-truth labels and the estimated lens probability for each source in the figure. |
4 Lens finding with deep neural networks
The second step of our lensed quasar search strategy involves supervised, deep neural network classification, requiring realistic training datasets as inputs to function. CNNs, for example, have been demonstrated to be successful in pattern recognition, such as discovering gravitational lenses in enormous sets of data (e.g., Metcalf et al. 2019; Bom et al. 2022; Gentile et al. 2022; Wilde et al. 2022; Thuruthipilly et al. 2022). While the exact design of the CNNs is generally determined by the challenge at hand, it typically consists of images as data inputs, which are subsequently processed by a sequence of convolutional, fully connected, and output layers. In this part, we describe our automated classifier that has been trained to distinguish lensed quasars from non-lensed sources. The section that follows will discuss the principles of our approach.
4.1 Preparing the input data
The inputs used to train our classifier will be divided into four categories: (1) the mock lensed quasars created in the previous section, (2) the real HSC galaxies that are not picked for the lensing simulation (Almeida et al. 2023), (3) previously discovered quasars from the local universe up to z ~ 7 (Flesch 2021; Fan et al. 2023), and (4) a sample of stars and brown dwarfs (Best et al. 2018; Carnero Rosell et al. 2019). Here, the distribution is balanced so that each class contains around 60 000 objects, and in sum, we use approximately 240 000 sources.
As later explained in Sect. 5.1, we will build and train the classifier iteratively, where some false positives identified by our lens finder – for instance, ring galaxies, spiral arms, irregular galaxies, CCD artifacts, and groups of multiple sources that imitate lensing arcs – will be also included the in the training dataset. About 90% of them are galaxies, and the rest are labeled as either quasars or stars, depending on their spectro-scopic classification when available. In total, there are 9562 of these additional negative examples. It should be noted that the images utilized for the training inputs have been built based on the grizy bands of HSC cutouts with a size of 72 pixels on a side, which is comparable to an angular dimension of ≈12″.
Next, the images are min-max adjusted so that the fluxes vary from zero to one and are square-root stretched to boost features with low fluxes and enhance the visual appearance. The relative pixel brightnesses across bandpasses are maintained, and therefore the colors of the associated sources are retained. The images are subsequently augmented with random ± π/2 rotations, 7-pixel translations, and horizontal or vertical flips on the fly each time they are called for training. This strategy will expand the quantity of training data while increasing the possibility that the network will properly categorize several perspectives of the same image.
4.2 Network architectures
Ensemble networks, which combine the predictions of multiple classifiers (e.g., CNNs or ViTs), have been shown to outperform individual models in various machine-learning tasks (Ganaie et al. 2022). There are several reasons why this approach is often superior. First, we can leverage the diversity of individual models. Each classifier in the ensemble is trained with a different initialization, architecture variation, or data augmentation scheme, leading to diverse learned representations. By combining these diverse models, the grouped networks can capture a broader range of patterns and variations in the data, improving overall generalization performance. Second, ensemble networks can reduce overfitting, mitigate the impact of individual model biases or errors, and offer improved performance stability. By averaging the predictions of multiple classifiers, they compensate for these biases and reduce the impact of individual errors, resulting in more reliable and robust predictions. Therefore, several network models will be discussed in this section to assemble our ensemble network architecture.
4.2.1 Baseline convolutional network
We start with creating a simple CNN as a baseline, dubbed as BaseNet, following the same model presented by Andika et al. (2023) and motivated by other classical network designs (e.g., Lecun et al. 1998; Simonyan & Zisserman 2014; Krizhevsky et al. 2017). BaseNet has three convolutional layers containing kernels with sizes of 3 × 3 × C, with C = 32, 64, and 64 for the first, second, and third layers, respectively, along with a stride of 1 × 1 and the same padding9. Each convolutional layer is then followed by a max pooling with the stride of 2 × 2, the size of 2 × 2, and the same padding. At the end of this sequence, a fully connected layer of 128 neurons is appended, and the final output layer is attached to retrieve four outputs – specifically, the chances of a target being a lensed quasar, a galaxy, an unlensed quasar, and a star. The dropout regularizations are utilized everywhere, where the drop rates are set to 0.2 and 0.5 for convolutional and fully connected layers, respectively. At the start, the learning rate is adjusted to 10−4 while the bias and weight of each neuron are set randomly and subsequently updated during the training. The activation functions based on the Rectified Linear Unit (ReLU) are utilized throughout the networks, except for the output layer, which employs the softmax activation. The TensorFlow10 deep learning platform is used to carry out all training procedures and CNN modeling (Abadi et al. 2016; TensorFlow Developers 2022).
After establishing the baseline network, additional classifiers will be added to the ensemble model, and an overview of each network architecture will be discussed. However, here we only provide a concise, high-level understanding and comparisons of the network architectures while acknowledging that in-depth information, technical specifications, and implementation details can be found in the respective cited references (also see, e.g., Chen et al. 2021, for a review).
4.2.2 Residual learning network
Residual network, which is often abbreviated as ResNet, is a deep CNN architecture familiarized by He et al. (2015). The core idea of ResNet is based on the observation that deeper networks could suffer from diminishing performance or even degradation due to vanishing/exploding gradients. The introduction of skip connections bypasses certain layers, allowing the network to learn residual functions or the difference between the input and the desired output. This strategy enables the model to focus on learning the residual information, which is often easier to optimize.
Further progress is made with the introduction of ResNetV2, which follows the original ResNet designs but integrates the bottleneck residual blocks (He et al. 2016). It also presents the concept of identity shortcuts to handle the skip connections, enhancing the overall network performance. Another variant of this family is ResNetRS, which incorporates the Squeeze-and-Excitation (SE) modules into the residual blocks, aiming to capture channel-wise dependencies and recalibrate the feature maps adaptively (Bello et al. 2021). By selectively amplifying informative features, these modules enhance the representation capacity of the network and improve its discriminative ability. Here, ResNet50V2 and ResNetRS50, which have 50 layers, will be picked as our choices for building the ensemble model components. This starting point is also chosen since deeper ResNet with 101 or 152 layers did not improve classification performance for the tiny image cutouts we studied.
4.2.3 Inception network
Inception is an architecture that is developed by Szegedy et al. (2014) to handle the challenges of effectively capturing multi-scale features and reducing computational complexity in deep neural networks. The central notion behind the Inception model is to employ parallel convolutional filters of different sizes within a single layer, allowing the network to grasp features at different spatial scales. These filters are usually composed of 1 × 1, 3 × 3, or 5 × 5 convolutions, along with a 3 × 3 max pooling operation. By combining these different-sized filters and pooling operations, Inception enables the network to apprehend both fine-grained details and broader contextual information simultaneously.
The Inception family has undergone several improvements over time, leading to subsequent versions such as InceptionV3, Xception, and InceptionResNetV2 (Szegedy et al. 2015, 2016; Chollet 2016). These variants, which we will utilize in this work, incorporated additional design elements, including factorized convolutions, depthwise separable convolutions, batch normalization, or residual connections, to further enhance the gradient flow and training stability.
4.2.4 Neural architecture search network
Neural architecture search network, or NASNet, is a category of CNNs that revolutionizes network modeling, developed by Zoph et al. (2018). Its ability to automatically discover high-performing architectures has remarkably reduced the need for human expertise and computational resources in the design process. The idea behind NASNet is to utilize a reinforcement learning-based search algorithm to explore a vast search space of potential models. NASNet is composed of diverse essential elements. The main building block is a “cell” structure, represented by a directed acyclic graph, which captures the connectivity pattern of the neural network. The search algorithm learns to discover the optimal cell structure, which is then repeated multiple times to construct the complete network. A notable characteristic of NASNet is the incorporation of skip connections, or residual connections, within its cell structure. These connections allow for seamless information flow and facilitate gradient propagation during training, leading to more effective learning. Additionally, NASNet introduces reduction cells that downsample feature maps spatially, enabling the network to handle larger input images and capture high-level spatial information. Here, we consider a smaller variant of the NASNet family called NASNetMobile.
4.2.5 MobileNet
MobileNet is a class of lightweight CNNs designed for mobile and embedded devices. MobileNetV3, developed by Howard et al. (2019), brings several critical improvements over its predecessors – namely, MobileNetV1 (Howard et al. 2017) and MobileNetV2 (Sandler et al. 2018) – to deliver enhanced performance while maintaining efficiency, catering to the limitations of resource-constrained devices. The architecture of MobileNetV3 incorporates an efficient backbone structure consisting of various lightweight layers, including depthwise separable convolutions, pointwise convolutions, and linear bottleneck layers. SE blocks are also employed to recalibrate channel-wise features adaptively, emphasizing their importance and improving the model capacity. In addition, the use of hard-swish activation functions introduces non-linearity while keeping the computational cost low. By leveraging these components, MobileNetV3 reduces complexity while retaining the ability to capture crucial visual features. Additionally, the adoption of neural architecture search (NAS) allows it to automatically discover the optimal architecture through an algorithmic exploration of a vast search space. MobileNetV3 is available in different versions, and in this case, we employ the MobileNetV3Large, aiming to achieve higher accuracy with a sacrifice of slightly larger model size and calculation requirements compared to its smaller variant.
4.2.6 EfficientNet
EfficientNet is a family of CNN architectures presented by Tan & Le (2019) that has demonstrated outstanding performance across various computer vision tasks, including image classification, object detection, and semantic segmentation. The EfficientNet models are designed to attain cutting-edge performance while being computationally efficient, requiring fewer parameters and computations compared to other architectures. The pivotal innovation behind EfficientNet is the concept of compound scaling, which uniformly scales the network’s depth, width, and resolution, allowing for an optimal trade-off between model size and performance. The EfficientNet models also employ other techniques to enhance performance, such as the use of mobile inverted bottleneck convolutional (MBConv) layers and a compound coefficient for controlling the number of channels in each layer. Further improvement is then proposed by Tan & Le (2021) by introducing a new convolutional operation called “Fused-MBConv”, combining depthwise separable convolutions with inverted bottleneck residual connections. These approaches additionally improve the efficiency and effectiveness of the models. Here, we adopt the simplest form of EfficientNet, represented by EfficientNetB0 and EfficientNetV2B0. Other variants of this family (B1–B7, S–XL, etc.) introduce progressive scaling to increase the model sizes and complexity.
4.2.7 Regularized network
Regularized Network, hereafter RegNet, is a family of CNNs introduced by Radosavovic et al. (2020) to address the challenge of network scaling by promoting a design principle that improves both accuracy and efficiency, utilizing adaptive regularization of weights and adjustment of scaling coefficients. This approach applies regularization proportional to the magnitude of network weights, which helps prevent overfitting and improves generalization performance (Dollar et al. 2021). RegNet architectures also comprise a channel-wise group convolution technique, effectively reducing the computational cost without significantly sacrificing accuracy.
We will implement here two of the smallest RegNet variants. The first one is RegNetX002, which emphasizes the model depth as the primary scaling factor, has deeper layers, and aims to capture more complex patterns in the data. The second one is RegNetY002, which prioritizes the model width as the scaling factor, has a wider network and seeks to capture more fine-grained details in the data with increasing feature diversity.
4.2.8 Vision transformer
Vision transformer, shortened as ViT, is a state-of-the-art deep learning architecture introduced by Dosovitskiy et al. (2020). It brings the powerful transformer-based architecture, originally designed for natural language processing, to the field of computer vision. It also represents a significant departure from traditional CNNs by relying solely on self-attention mechanisms without any convolutional layers. The principal concept of ViT is to treat an image as a sequence of patches, where each patch is regarded as a token. These image patches are flattened and fed into a transformer encoder consisting of multiple stacked self-attention layers and feed-forward neural networks. The self-attention mechanism allows the model to capture global dependencies and relationships between different patches in the image, enabling it to learn contextual information and high-level representations. Since the transformer architecture does not inherently encode spatial information, positional encoding is introduced to provide the model with the relative positions of the image patches. This information helps the model understand the spatial structure of the image and retain spatial relationships between different patches during the self-attention process.
However, ViT has shown to be more data-hungry, meaning it typically requires larger amounts of labeled training data to achieve competitive performance compared to CNNs. This phenomenon is partly due to its reliance on self-attention mechanisms and the challenges in capturing fine-grained spatial details. The combination of ViT with Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA) is an alternative modification that aims to improve the efficiency and effectiveness of ViT models (Lee et al. 2021). SPT shift the image patches by half of their size horizontally and vertically. This method improves the alignment between the patches and the objects in the image, enhancing the model’s ability to capture accurate spatial information. On the other hand, LSA restricts the network attention to a local neighborhood of tokens instead of attending to all of them, significantly reducing the computational cost while still capturing relevant contextual information. Hence, we will use the original ViT model (dubbed as ViT-Vanilla) and ViT with the implementation of SPT and LSA (named as ViT-Lite) for constructing our ensemble network.
4.3 Training the network models
The CNN and ViT models discussed before need to be separately trained first. Once the optimum parameters for each classifier are obtained, we will combine them to construct the ensemble networks. This strategy aims to improve predictive power by averaging the forecasts of multiple instances into a unified and robust decision-making framework. One shortcoming of this technique is that each model contributes the same proportion to the ensemble forecast, irrespective of how well the network performs. A weighted average ensemble is a version of this strategy that weights the role of every ensemble member by its performance on the test dataset. This scheme allows high-performing classifiers to contribute more while low-performing models influence less. This technique may be further generalized by substituting the linear weighted sum model used to integrate the sub-model predictions with any learning algorithm and correspondingly known as layered generalization or stacking. A stacked generalization ensemble, as compared to a weighted average ensemble, can utilize the set of forecasts as a context and dynamically select how to weigh the input predictions, possibly leading to higher performance (Ganaie et al. 2022). However, for simplicity and considering that: (1) manually assigning each of the model contributions in the weighted average ensemble is not straightforward and (2) the stacked generalization ensemble usually needs more independent datasets for its training to prevent overfitting, we will use the model averaging ensemble without the weighing approach instead, as shown in Fig. 4.
Training the network models involves several steps, including data splitting, batch subdivision, and iterative forward and backward propagation. In this case, the input data is split into training, validation, and test datasets using a ratio of 70:20:10, allowing for proper evaluation and testing of the trained models. The dataset is further subdivided into smaller batches consisting of 128 samples to facilitate efficient computation by processing a subset of the data at a time. During the training process, the models undergo iterative forward and backward propagation. Forward propagation involves passing the input data through the network and generating predictions. These calculations are then compared to the ground-truth labels using the sparse categorical cross-entropy11, a loss function that is often used for multilabel classification tasks. The backpropagation step estimates the gradients of the loss function, which are then utilized to update the corresponding weights and biases employing a stochastic gradient descent technique (e.g., Adam optimizer; Kingma & Ba 2014). This optimization process allows the models to iteratively adjust their parameters, improving their predictions and overall performance.
The training and validation losses need to be monitored to check whether the model is able to learn or if overfitting occurs – in other words, where the network becomes too specialized to the training data and fails to generalize well to new, unseen data. In an attempt to prevent overfitting and achieve more accurate predictions, we randomly shuffle the training and validation data after each epoch. At the start, the learning rate is adjusted to 10−4 while the bias and weight of each neuron are set randomly and subsequently updated during the training. When learning becomes stagnant, the network models often benefit from reducing the learning rate by a factor of 2–10. Due to this reason, we apply a callback function, which lowers the model learning rate by a factor of ten if the loss curve shows a plateau for five consecutive epochs. After numerous epochs, we stop the training if the lowest average validation loss over multiple runs is reached, or to put it another way, early stopping is applied if the loss difference fails to decrease below 10−4 over ten consecutive epochs. Typically, the training cycle could reach 50 to 100 epochs before the optimization is converged, and the classifier performance cannot be improved further (see Fig. 5 as reference). The best model is then stored, which corresponds to the combination of the weights and other parameters that generate the lowest cross-entropy loss tested in the validation dataset.
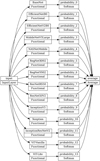 |
Fig. 4 Architecture of our ensemble network, which produces 4 outcomes as the end product – to be exact, the probability of a candidate being a lensed quasar, a galaxy, an unlensed quasar, and a star – is shown here. The input layer takes the HSC grizy-band images and passes them to the functional layers containing 12 CNN and 2 ViT models. Each model produces 4 output logits, which are then transformed into a probability distribution that sums to unity using the softmax layer. Subsequently, we average the softmax outputs of these 14 networks to produce only 4 final probabilities. |
 |
Fig. 5 Example of accuracy and loss curves as a function of the training epoch of ViT-Lite, one of the top-performing models, is displayed in the upper and lower panels. The other classifiers also show a similar increasing accuracy and decreasing loss trend, indicating that they are able to learn. These metrics are inferred by testing the network on the training and validation datasets, which are subsequently depicted as blue and orange lines, respectively. |
4.4 Classifier performance evaluation
Each of our classifiers will return the probability estimates for an individual tensor that is passed into the networks, indicating whether the respective images contain a lensed quasar, an unlensed galaxy, an ordinary quasar, or a star – to be exact, Plens, Pgalaxy, Pquasar, and Pstar – where the sum of this probabilities equals to unity. The predicted category is then allocated by selecting the class with the highest likelihood score. It is worth noting that Plens = 1 indicates that there is a strong probability that the categorized images include a lensed quasar. Plens = 0, on the other hand, indicates that the cutouts do not comprise a lensed quasar and are more likely to contain contaminating sources.
As commonly perceived, the excellent accuracy achieved in the training process might have been attributed to overfitting. Naturally, we then examine the accuracy-loss learning curves obtained by assessing network predictions on validation and training datasets (see Fig. 5 for an example). The training and validation losses are settling and maintaining the same trends after declining for numerous epochs. The absence of any overfitting signals – specifically, the training loss stays to decline while the validation loss starts rising after several epochs – gives us confidence that our classifier can generalize and learn well.
In order to evaluate the overall performance of the trained models further, another commonly used metric is the receiver operating characteristic (ROC) curve. The area under the ROC curve (AUROC) provides insights into how effectively a binary classifier distinguishes between two classes as the decision threshold is adjusted. Therefore, to utilize the ROC curve and calculate the AUROC, we mark lenses as the positive (P) and non-lenses or contaminating sources as the negative (N) cases. True positives (TP) are instances in which the model properly predicts the lenses, distinct from true negatives (TN), which are accurate identifications of non-lenses. False positives (FP) emerge when the classifier wrongly labels contaminants as lenses. Finally, false negatives (FN) are occasions in which the model incorrectly rejects lenses. The ROC curve compares the false-positive rate (FPR) to the true-positive rate (TPR) for the unseen test dataset, where:
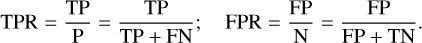 (2)
(2)
The ROC curve is then made by gradually raising the probability cutoff from 0 to 1. This result in AUROC = 1 for a flawless classifier, while AUROC = 0.5 for a classifier that only predicts randomly. Since we have four categories for classifying the candidates (i.e., a multilabel classification), we have to binarize each network’s prediction using the so-called “one versus all” framework. As a result, we generate four ROC curves constructed based on the evaluation of the classifier using a previously unseen test dataset and display them in Fig. 6, which encompasses the following scenarios: (1) distinguishing lensed quasars from galaxies and other point-source contaminants, represented by the solid blue line; (2) discriminating galaxies from lens systems and other contaminating sources, symbolized by the dashed magenta line; (3) separating stars from other sources, illustrated by the dashed yellow line; and (4) classifying quasars with respect to lenses, galaxies, and other sources, expressed by the dashed cyan line. Notably, these curves exhibit high AUROC values, indicating the exceptional performance of the classifier in these scenarios. We then employ the geometric mean or G-mean12 metric to find a balance of the TPR and FPR ratios based on the ROC curves. The highest G-mean score shows an ideal Plens threshold for maximizing TPR while reducing FPR. In this situation, the reasonable Plens and the resulting FPR and TPR for each network model and the combined classifiers are reported in Table 2.
It is noteworthy to mention that below the previously mentioned Plens limit, the amount of candidates increases rapidly while their quality declines, which means that the visual assessment required at the next stage will be more tedious and less practical. Concerning the compromise involving completeness and purity, we have to strike a balance in which the quantity of candidates is reasonable for follow-up observations at the next step.
 |
Fig. 6 Curves of the receiver operating characteristic and its area under the curve (AUC) calculation are presented. A solid blue line indicates the curve for categorizing lensed quasars. The curves for classifying galaxies, quasars, and stars, are also illustrated as magenta, yellow, and cyan dashed lines, respectively. Finally, a red circle represents the FPR and TPR values for the chosen Plens limit. |
Performances of the individual and ensemble network models evaluated on the test dataset are reported here.
5 Results and discussion
5.1 Final list of lens candidates
After the catalog-level preselection explained before and employing our ensemble network classification, we obtained 3080 surviving targets with Plens > 0.3. To further remove the contaminating sources from this list, we consider the relevant astrometric excess noise (AEN; Gaia Collaboration 2016) and proper motion significance (PMSIG; Lemon et al. 2019) parameters when the astrometry of these lens candidates is available in the Gaia Data Release 3 catalog (Gaia Collaboration 2023). We note that only about 30% of our candidates have this astrometric information. A high value of AEN (≳ 10 mas) could point to a potential star-forming galaxy, while a significant PMSIG number (≳ 10σ) strongly implies that the system includes a star (Lemon et al. 2019). These additional criteria manage to select 2604 sources (1801 unique systems/groups), which are then visually inspected, yielding 210 remaining candidates with high lens probabilities.
We further split these candidates into A and B grades. Grade A is assigned when the cutout exhibits a definite configuration of strong lensing, even without the assistance of a higher-resolution image. This case implies the presence of multiple-imaged sources or the indication of a counter-image, along with the existence of a possible lens galaxy. On the other hand, grade B means that the candidates display a potentially lensing-like configuration, although visual identification of multiple images is not feasible. This category includes scenarios where multiple objects or a single arc-like object are positioned on one side of the central galaxy without a clear counter-image visible on the opposite. In addition, we performed a random check on some sources with Plens ≤ 0.3 and found that on some occasions, they show lensing features and are missed by our classifier. Accordingly, we mark these objects with grade A* or B*, depending on their visual-based quality. We stress that the list in this category might be incomplete since not all sources with Plens ≤ 0.3 are inspected.
Interestingly, our compilation of candidates encompasses not only lensed quasars but also galaxy-galaxy lenses. These strongly lensed galaxies are not included explicitly in the training dataset. However, the lensed point-source lights from the multiply-imaged quasars sometimes could mimic the extended arcs of the galaxy-galaxy lens systems and confuse our ensemble classifier. Therefore, more information beyond the optical images is required to discriminate between these systems, and we will attempt to check their SEDs later (see Appendix A). In addition, we provide the complete list of our lens candidates in Table B.1.
Based on the evaluation applied to the test dataset and reported in Table 2, our ensemble classifier appears to have an FPR as low as 1.6% for recognizing lensed quasars at z = 1.5– 7.2. Yet, how many lensed quasars that we expect to discover? Using the latest estimate from Yue et al. (2022a), assuming an i-band 5σ depth of ≈26 mag, and sky coverage of around 1300 deg2, we expect to find about 153 lensed quasars, including 13 quadruply-imaged sources, within the HSC wide-layer footprint. Approximately 80% (50%) of these systems have a separation greater than 0″.5 (1″). We remark that this number is about two to three times lower compared to the earlier model from Oguri & Marshall (2010), primarily caused by the discrepancy in the details of the simulated quasars. Oguri & Marshall (2010) adopt a steeper faint-end slope of the quasar luminosity function, do not impose an absolute magnitude cut, and disregard redshift evolution of the deflector velocity dispersion function (VDF; Choi et al. 2007). On the other hand, an improvement from Yue et al. (2022a) is made by considering quasars with i-band absolute magnitude of Mi < −20 and employing a new VDF that decreases with redshift (Korytov et al. 2019).
While our current strategy appears to yield reasonable candidate samples, we believe there is an opportunity for optimization. The occurrence of FP-classified sources is, at present, not zero. Fortunately, trained astronomers can swiftly rule out the spurious sources in this candidate list, as presented in Fig. 7. Based on our visual inspection, they are highly improbable to be lenses or have no apparent indicators of strong lensing characteristics. Moreover, they have a variety of visible forms, such as irregular galaxies, spiral arms, or groups of multiple sources that imitate lensing arcs. Aside from that, sources with unusual morphologies that do not belong to either category in the data used for the training can get unexpected network-based classification scores. Due to these reasons, our network models have been trained iteratively by including the sample of identified FPs to keep improving the classifier performances.
 |
Fig. 7 FP sources, or contaminants, identified by our classifier and their lens probabilities are shown here. The images are created based on the HSC grz-band cutouts with 72 pixels (≈12″) on a side, colorized, and square-root stretched. |
5.2 Selection of high-redshift lensed quasars
Lensed quasars at z ≳ 6 is another intriguing case we want to explore because so far, only 2 lenses have been found at this distance among ≈300 known quasars throughout the whole sky (Fan et al. 2019; Yue et al. 2023). Subsequently, we expect to discover at least 2 lensed quasars in the current dataset if we consider the high-z lensed quasar fraction of ≈1% (Yue et al. 2022b) among ~ 150 quasars at z ≳ 6 that have been found within the HSC footprint (Matsuoka et al. 2022). However, this estimate could be much larger, depending on the chosen model. For example, Pacucci & Loeb (2019) suggest a lens fraction of >4%, which results in the expected number of lenses of more than 6. This tension might be the result of unaccounted-for biases that have not been thoroughly examined, in particular, the disparity between the adopted quasar luminosity function and deflector VDF used by Yue et al. (2022b) and Pacucci & Loeb (2019).
In retrospect, the reasons why many lenses are left undiscovered might be very evident. Most methods to select quasar candidates have included extra magnitude cuts or full “dropout” criteria at all bandpasses bluer than the Lya emission (e.g., Matsuoka et al. 2022; Fan et al. 2023, and reference therein). This approach makes sense because the light emitted by z ≳ 6 quasars at wavelengths shorter of Lya is severely absorbed by the foreground IGM, forming a prominent break in the spectrum and thus a primary marker for the quasar preselection. To put it another way, we are not anticipating any substantial flux emanating from the g or r bands for quasars at these redshifts. This characteristic, however, is not true if the lens galaxies exist at 0.1 ≲ z ≳ 1.5, which might produce substantial emission at the observed wavelengths of λobs ≳ 8000.
Testing our methodology against prior quasar selection approaches validates the expanded selection space. If we imposed an extra cut of S/N(g, r) < 5, or the dropout criterion, none of the mock lenses generated in Sect. 3 would survive. In simpler terms, we would overlook all lens systems featuring luminous galaxies as deflectors. Hence, to include prospective lens systems, we have eliminated such dropout requirements in our photometric preselection. Instead, we exploit the whole spatial and color information by using the associated multiband images and process them with our deep learning classifier.
The intersection with earlier search methods occurs when the deflectors are fainter and less massive, resulting in compact lenses with small θE and image separations. These systems are expected to have quasar-dominated light and may exhibit a slightly extended shape in ground-based images. However, when their lensing mass is below a certain threshold, conventional quasar search techniques can still detect them, but demonstrating their true lensing nature becomes challenging. Employing higher-resolution, space-based imaging would greatly widen the range of parameters accessible for this diagnostic.
Accordingly, as an effort to: (1) detect compact, faint lenses with the light dominated by bright z ≳ 6 quasars, (2) identify quasars in the cases that they are well separated (≳ 0″.5) from the associated foreground deflectors, and (3) recognize unwanted sources (e.g., binary stars and quasar-star pairs) solely using their catalog-level photometric information, we also implement a standard object classification using the SED fitting method. Our approach involves pinpointing candidates of quasars, galaxies, and stars based on their multiwavelength data, estimating photometric redshifts, and reassessing our final list of targets (see Appendix A for more details). However, we did not discover any new z ≳ 6 quasars using the current dataset and selection method. Instead, all of our lens candidates are located at lower redshifts. In future work, we aim to relax the current photometric preselection to uncover high-z lensed quasars.
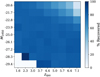 |
Fig. 8 Model of the quasar selection function that we make use of in this work. The percentage of recovery rate corresponds to the number of mock quasars in each (M1450, z) bin that is successfully recovered by our selection method. |
5.3 Quasar selection completeness
As previously stated, the parent population of quasars in our simulation follows a uniform distribution within the redshifts of 1.5 ≤ z ≤ 7.2 and absolute magnitudes of −30 ≤ M1450 ≤ − 20. Without the contribution of strong gravitational lensing, our ensemble network classifier can only discover quasars with M1450 ≲ −22 at z ≳ 6. Fortunately, the lensing event could shift this boundary towards a lower luminosity territory, depending on the factor of magnification values. To examine this in more depth, we initially define our selection function (or completeness) as the proportion of simulated quasars with specific M1450, z, and intrinsic SEDs that are successfully identified by our selection criteria. The outcomes are displayed in Fig. 8. Quasars with inherently low brightness can only be detected if they experience a substantial magnification boost from gravitational lensing, and such occasions are relatively rare. Therefore, as the quasars possess inherently lower luminosity, our completeness rate diminishes at a given redshift. As an extra note, since in Sect. 3 we exclude sources with y-band magnitude > 15 mag to discard unusually bright objects or saturated images, we missed all intrinsically luminous quasars with M1450 ≲ −27 at low redshifts (z ≲ 3), which might not even exist in the real universe.
Then, looking at Fig. 2, our classifier could recover most of the lensing configurations without a significant bias. A slight decrease in recovery rate is apparent in the cases of systems with deflector redshifts of zgal ≲ 1 and magnitudes of i ≲ 21, which might be caused by farther lens galaxies having fainter apparent fluxes and more challenging to be detected. Though these sources could still be identified if the lensed quasars are well separated, these phenomena can be exacerbated for the lens systems that are too compact due to small lens masses. For example, we notice a slight drop in lens recovery rate in Fig. 2 for systems with συ ≲ 100 km s−1 and θE ≲ 0″.5.
5.4 Evaluation with independent datasets
We also conduct a supplementary test with an alternative dataset assembled using the list of known quasars compiled in the GLQD (McMahon et al. 1992; Jackson et al. 1995, 2008; Inada et al. 2003, 2008, 2012; Oguri et al. 2004, 2008; Morokuma et al. 2007; Agnello et al. 2015, 2018; More et al. 2016; Spiniello et al. 2018; Williams et al. 2018; Lemon et al. 2018, 2019, 2020, 2023; Krone-Martins et al. 2019; Chan et al. 2020; Jaelani et al. 2021). In this case, HSC images are available for about 22 of the 220 lenses in the database (see Fig. 9). To evaluate the completeness and purity of our ensemble classifier, we first combine these known lenses with a sample of contaminants compiled in Sect. 4.1, which includes galaxies, stars, and quasars, with the non-lensed sources expected to outweigh the lens population by a factor of a few thousand. As an outcome, our model correctly identifies 16 known lensed quasars, resulting in a TPR (or completeness) of 72.7% and an FPR of 1.6%. In addition, we discover that the classifier has a purity13 of 5.6% in identifying the lens candidates.
Other individual model explained in Sect. 4.2 demonstrates impressive performance when assessed against the test dataset, with an AUROC exceeding 97.3% and a median false positive rate as low as 3.6%. However, they still encounter difficulties in generalizing to real-world data. This thing is evident from the presence of numerous spurious sources identified by each classifier. For example, InceptionResNetV2, ResNet50V2, and EfficientNetB0 are three best-performing classifiers, recovering 18 to 19 known lensed quasars - that is, a completeness of 81.8– 86.4%. Yet, these networks give high scores to more than a hundred thousand sources, making the required visual inspection for the resulting lens candidates at the later stage extremely time-consuming. Better selection purity is achieved by ViT-Vanilla and ViT-Lite, which have a completeness of 72.7% while keeping the number of lens candidates in the order of ten to twenty thousand. Then, a much better improvement is uncovered by ensembling the predictions of all of the CNNs and ViTs via model averaging, leading to a reduction in impurities by up to a factor of ≈ 50. This ensemble network manages to reduce the number of candidates to just a few thousand while maintaining the completeness of 72.7%.
When evaluated against real lens systems, the model seems to perform worse than when tested against simulated lenses, which is indicated by the declining TPR from 96.3% to 72.7% (see Table 2). This lower performance is somewhat expected and might be attributed to the uniqueness of some of the lens systems that are not taken into account by our simulation. Some missed lenses might contain arcs or counter images that are too dim to be recognized, contamination of the bright deflector lights, compact lenses, saturated images, or other factors. Still, our classifier can generalize and obtain a high enough accuracy for our objectives, where the purpose of our network-based classification is to reduce the false candidates as much as possible before proceeding with the visual inspection and compiling the final list of targets.
In addition, to assess the flexibility of our ensemble model when applied to the next-generation ground-based survey data, we perform one more test using a mock dataset that closely resembles the LSST photometry (Ivezić et al. 2019). This dataset, kindly provided by Yue et al. (2022a), encompasses 3628 strongly-lensed quasars at z ≳ 5. Employing our ensemble model directly, we successfully identified 3095 systems of the parent sample, yielding a completeness of 85.3%. We expect that applying transfer learning by retraining our classifier on a subset of this dataset could increase the network performance further (e.g., Thuruthipilly et al. 2022; Bom et al. 2022). This outcome illustrates the adaptability and robustness of our ensemble model, showcasing its ability to excel in the upcoming LSST data.
 |
Fig. 9 Example of discovered lenses compiled from the literature (see main text). The images are generated using 48 × 48 pixels (≈8″ on a side) of HSC grz cutouts, colorized, and square-root stretched. The lens probabilities, assigned by our ensemble classifier, of each system are also shown in the figure. |
6 Summary and conclusion
In this paper, we conduct a systematic hunt for lensed quasars at 1.5 ≤ z ≤ 7.2 by exploiting the HSC, UKIRT, VISTA, unWISE, and Gaia data. Our approach is divided into two key stages. First, we use catalog-level information to preselect the candidates based on their photometric color, decreasing the number of sources from ~60 million to only 892 609. Second, we use an ensemble of CNN and ViT classifiers to assess the relative likelihood of each source being a lens or contaminant, yielding 3080 prevailing candidates. It is worth noting that the training input is created by overlaying deflected point-source lights on the images of real HSC galaxies. This strategy allows us to generate realistic strong-lens simulations and concentrate on identifying systems within the Einstein radii of θE < 5″. We then obtain 210 newly found lens candidates after inspecting their astrometric data when available and visually evaluating the objects with the lens probability of Plens > 0.3. These findings indicate that automated neural network-based classifiers, with minimal human involvement, are promising for spotting lensed quasars in big datasets.
The technique presented in this paper is readily applicable to seeking out galaxy-quasar lenses across a wide range of red-shifts. It also appears to be suitable for next-generation surveys such as Euclid (Laureijs et al. 2011; Euclid Collaboration 2022), which will provide high-resolution NIR imagery over a large portion of the extragalactic sky, and Rubin Observatory Legacy Survey of Space and Time (Ivezić et al. 2019), which will have extensive optical multiband data. In this case, modifications to the bandpass profiles, seeing values, and image scale will be essential to obtain optimal results. In addition, adopting more complex galaxy mass profiles beyond the SIE model might also help to enhance the classifier performance. To fully exploit the scientific potential of our catalog of lenses, it is essential to conduct spectroscopic observations to confirm the redshifts of the deflectors and sources, along with high-resolution imaging to perform accurate lens modeling.
Acknowledgements
We thank Alessandro Sonnenfeld, the referee of this paper, for his constructive and insightful comments. We are also grateful to James Chan and Simona Vegetti for their valuable contributions and fruitful discussions, which have significantly improved the quality of this manuscript. This research is supported in part by the Excellence Cluster ORIGINS, which is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy − EXC-2094 − 390783311. S.H.S. thanks the Max Planck Society for support through the Max Planck Fellowship. This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (LENSNOVA: grant agreement No 771776). S.S. acknowledges financial support through grants PRIN-MIUR 2017WSCC32 and 2020SKSTHZ. Y.S. acknowledges the support from the China Manned Spaced Project (No. CMS-CSST-2021-A07 and CMS-CSST-2021-A12). A.T.J. is supported by the Program Riset ITB 2023. This work is based on data collected at the Subaru Telescope and retrieved from the HSC data archive system, operated by the Subaru Telescope and Astronomy Data Center at the National Astronomical Observatory of Japan. The Hyper Suprime-Cam (HSC) collaboration includes the astronomical communities of Japan, Taiwan, and Princeton University. The HSC instrumentation and software were developed by the National Astronomical Observatory of Japan (NAOJ), the Kavli Institute for the Physics and Mathematics of the Universe (Kavli IPMU), the University of Tokyo, the High Energy Accelerator Research Organization (KEK), the Academia Sinica Institute for Astronomy and Astrophysics in Taiwan (ASIAA), and Princeton University. Funding was contributed by the FIRST program from the Japanese Cabinet Office, the Ministry of Education, Culture, Sports, Science and Technology (MEXT), the Japan Society for the Promotion of Science (JSPS), the Japan Science and Technology Agency (JST), the Toray Science Foundation, NAOJ, Kavli IPMU, KEK, ASIAA, and Princeton University. This paper makes use of software developed for the Large Synoptic Survey Telescope. We thank the LSST Project for making their code available as free software at http://dm.lsst.org. This project has included data from the Sloan Digital Sky Survey (SDSS). Funding for SDSS-IV has been provided by the Alfred P. Sloan Foundation, the U.S. Department of Energy Office of Science, and the Participating Institutions. SDSS-IV acknowledges support and resources from the Center for High-Performance Computing at the University of Utah. The SDSS website is https://www.sdss.org/. SDSS-IV is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS Collaboration. The unWISE catalog utilized in this paper is based on data products from the Wide-field Infrared Survey Explorer, which is a joint project of the University of California, Los Angeles, and NEOWISE, which is a project of the Jet Propulsion Laboratory/California Institute of Technology. WISE and NEOWISE are funded by the National Aeronautics and Space Administration. We acknowledge the use of the VHS, VIKING, UKIDSS, and UHS data. This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular, the institutions participating in the Gaia Multilateral Agreement. Facilities: ESO:VISTA (VIRCAM), Gaia, Sloan (eBOSS/BOSS), Subaru (HSC), UKIRT (WFCAM), WISE. Software: Astropy (Astropy Collaboration 2013, 2018), EAZY (Brammer et al. 2008), Matplotlib (Caswell et al. 2021), NumPy (Harris et al. 2020), Pandas (Reback et al. 2022), PyAutoLens (Nightingale et al. 2021), SIMQSO (McGreer et al. 2013), TensorFlow (Abadi et al. 2016; TensorFlow Developers 2022).
Appendix A Eliminating spurious sources with spectral modeling
We implement SED fitting as an additional practice to discover unresolved lens systems with the light dominated by the background quasar and to remove spurious sources in our lens search. In principle, we want to separate the candidates of quasars, galaxies, and stars based on their multiwavelength data and estimate the associated photometric redshifts. Therefore, the eazy-py14 module, a Pythonic photometric redshift tool based on EAZY (Brammer et al. 2008), will be used to implement the SED modeling. The way it works is by going across a grid of spectral templates, matching them to the photometry of the targets, and trying to discover the best model. Here, we select the best models with the lowest reduced chi-square (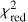 ) as solutions. The candidates with a high likelihood of being quasars are chosen based on the derived
) as solutions. The candidates with a high likelihood of being quasars are chosen based on the derived 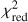 of the quasar (
of the quasar (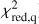 ) galaxy (
) galaxy (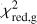 ) brown dwarf (
) brown dwarf (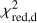 ), and star (
), and star (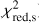 ) templates along with their associated ratios. Hence, the sources which are best fitted with models of stars or brown dwarfs will be removed from our list of lens candidates.
) templates along with their associated ratios. Hence, the sources which are best fitted with models of stars or brown dwarfs will be removed from our list of lens candidates.
To establish the templates, we first compile the brown dwarf spectra from the SpeX Prism Library15 (Burgasser 2014). This database contains 360 spectra of M5–M9, L0–L9, and T0–T8 stars with wavelength spanning from 0.625 µm to 2.55 µm. Following the prescription of Andika et al. (2020), we then extend these templates into the wavelength covered by unWISE bands – namely, W1 (3.4 µm) and W2 (4.6 µm). We also add the stellar models16 provided by Pickles (1998), which contains 131 spectra in the range of 1150–25 000 Å to include the SED of main sequence stars.
After that, we utilize the latest version of the XMM-COSMOS galaxy and active galactic nucleus (AGN) SEDs (Polletta et al. 2007; Salvato et al. 2009, 2011). These templates are discussed in detail by Ananna et al. (2017) as part of their work on estimating the redshift of X-ray AGNs. Similar to what has been done by Duncan et al. (2021), we then apply the dust reddening by employing the attenuation levels of 0 ≤ AV ≤ 2, following the Calzetti et al. (2000) extinction law. While the original template list covers a wide range of galaxy spectral types, we only pick the SEDs of luminous quasars dominated by the continuum and broad-line emissions for our purpose.
Next, to ascertain that our targets do not resemble unlensed galaxies, we fit them with the set of SEDs established from the Flexible Stellar Population Synthesis code (FSPS; Conroy et al. 2009, 2010; Conroy & Gunn 2010b,a). These templates are composed of a combination of stellar lights, nebular lines, and MIR dust-reprocessed emissions. They also encompass ultraviolet to infrared wavelengths and contain information about stellar population properties, such as ages, metallicities, and initial mass functions.
A grid of SED sets is then assembled by distributing the quasar and galaxy templates in the redshifts of 0 ≤ z ≤ 8 with a step size of Δz = 0.005. We have to note that in these SED models, we incorporate the attenuation produced by the H I in the IGM using the analytical approximation from Inoue et al. (2014). While the star, brown dwarf, and quasar templates are fitted utilizing the single template mode in eazy-py, the galaxy models are matched to each source’s photometry with non-negative linear combinations, allowing each component to contribute to the fit. An example of our SED fitting result is displayed in Fig. A.1.
 |
Fig. A.1 SED fitting result for a lensed quasar candidate is presented. In the main panel, the observed photometry of the source is depicted as red circles with error bars modeled with three distinct templates. The best-fit quasar spectral template is represented by a blue line, while the synthesized photometry is illustrated with blue circles. The yellow and magenta colors indicate the best-fit models using non-lensed star and galaxy templates, respectively. The right panel showcases the photometric redshift probability density functions obtained by fitting the data to templates of unlensed quasars (cyan line) and galaxies (magenta line). |
Appendix B Complete list of lens candidates
We present here the complete list of our lens candidates selected in the main text. The photometry measured within a 2″ aperture diameter of each system is reported in Table B.1, while the associated color images are displayed in Fig. B.1.
List of rediscovered strong lenses and newly found lensed quasar candidates.
 |
Fig. B.1 The 12″ × 12″ ɡrz-color images of our lens candidates are shown. To enhance the visual contrast of each HSC cutout, we apply a square-root stretch to the fluxes. We also display the grade determined from our visual inspection and the identification number of each target on top of the panel. At the bottom side, we report the lens probability inferred by our automated classifier. Newly discovered sources in this work, along with some candidates that are also independently published by Chan et al. (2023) that are not listed in the MLD and GLQD, are marked with red rectangles. |
References
- Abadi, M., Barham, P., Chen, J., et al. 2016, ArXiv e-prints [arXiv: 1605.08695] [Google Scholar]
- Agnello, A., & Spiniello, C. 2019, MNRAS, 489, 2525 [Google Scholar]
- Agnello, A., Kelly, B. C., Treu, T., & Marshall, P. J. 2015, MNRAS, 448, 1446 [NASA ADS] [CrossRef] [Google Scholar]
- Agnello, A., Schechter, P. L., Morgan, N. D., et al. 2018, MNRAS, 475, 2086 [Google Scholar]
- Aihara, H., Armstrong, R., Bickerton, S., et al. 2018, PASJ, 70, S8 [NASA ADS] [Google Scholar]
- Aihara, H., AlSayyad, Y., Ando, M., et al. 2019, PASJ, 71, 114 [Google Scholar]
- Aihara, H., AlSayyad, Y., Ando, M., et al. 2022, PASJ, 74, 247 [NASA ADS] [CrossRef] [Google Scholar]
- Akhazhanov, A., More, A., Amini, A., et al. 2022, MNRAS, 513, 2407 [NASA ADS] [CrossRef] [Google Scholar]
- Almeida, A., Anderson, S. F., Argudo-Fernández, M., et al. 2023, ApJS, 267, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Ananna, T. T., Salvato, M., LaMassa, S., et al. 2017, ApJ, 850, 66 [Google Scholar]
- Andika, I. T. 2022, Ph.D. Thesis, Max-Planck-Institute for Astronomy, Heidelberg, Germany [Google Scholar]
- Andika, I. T., Jahnke, K., Onoue, M., et al. 2020, ApJ, 903, 34 [Google Scholar]
- Andika, I. T., Jahnke, K., Bañados, E., et al. 2022, AJ, 163, 251 [NASA ADS] [CrossRef] [Google Scholar]
- Andika, I. T., Jahnke, K., van der Wel, A., et al. 2023, ApJ, 943, 150 [NASA ADS] [CrossRef] [Google Scholar]
- Anguita, T., Schechter, P. L., Kuropatkin, N., et al. 2018, MNRAS, 480, 5017 [NASA ADS] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Barkana, R. 1998, ApJ, 502, 531 [NASA ADS] [CrossRef] [Google Scholar]
- Bello, I., Fedus, W., Du, X., et al. 2021, ArXiv e-prints [arXiv: 2103.07579] [Google Scholar]
- Belokurov, V., Evans, N. W., Moiseev, A., et al. 2007, ApJ, 671, L9 [NASA ADS] [CrossRef] [Google Scholar]
- Best, W. M. J., Magnier, E. A., Liu, M. C., et al. 2018, ApJS, 234, 1 [Google Scholar]
- Blanton, M. R., Bershady, M. A., Abolfathi, B., et al. 2017, AJ, 154, 28 [Google Scholar]
- Bom, C. R., Fraga, B. M. O., Dias, L. O., et al. 2022, MNRAS, 515, 5121 [Google Scholar]
- Boroson, T. A., & Green, R. F. 1992, ApJS, 80, 109 [Google Scholar]
- Brammer, G. B., van Dokkum, P. G., & Coppi, P. 2008, ApJ, 686, 1503 [Google Scholar]
- Browne, I. W. A., Wilkinson, P. N., Jackson, N. J. F., et al. 2003, MNRAS, 341, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Burgasser, A. J. 2014, ASI Conf. Ser., 11, 7 [Google Scholar]
- Calzetti, D., Armus, L., Bohlin, R. C., et al. 2000, ApJ, 533, 682 [NASA ADS] [CrossRef] [Google Scholar]
- Cañameras, R., Schuldt, S., Shu, Y., et al. 2021, A&A, 653, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carnero Rosell, A., Santiago, B., dal Ponte, M., et al. 2019, MNRAS, 489, 5301 [NASA ADS] [CrossRef] [Google Scholar]
- Caswell, T. A., Droettboom, M., Lee, A., et al. 2021, https://zenodo.org/record/5773480 [Google Scholar]
- Chan, J. H. H., Suyu, S. H., Sonnenfeld, A., et al. 2020, A&A, 636, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chan, J. H. H., Lemon, C., Courbin, F., et al. 2022, A&A, 659, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chan, J. H. H., Wong, K. C., Ding, X., et al. 2023, ArXiv e-prints [arXiv: 2304.05425] [Google Scholar]
- Chen, L., Li, S., Bai, Q., et al. 2021, Rem. Sensing, 13, 4712 [NASA ADS] [CrossRef] [Google Scholar]
- Cheng, T.-Y., Li, N., Conselice, C. J., et al. 2020, MNRAS, 494, 3750 [NASA ADS] [CrossRef] [Google Scholar]
- Choi, Y.-Y., Park, C., & Vogeley, M. S. 2007, ApJ, 658, 884 [NASA ADS] [CrossRef] [Google Scholar]
- Collett, T. E. 2015, ApJ, 811, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Chollet, F. 2016, ArXiv e-prints [arXiv: 1610.02357] [Google Scholar]
- Conroy, C., & Gunn, J. E. 2010a, Astrophysics Source Code Library [record ascl:1010.043] [Google Scholar]
- Conroy, C., & Gunn, J. E. 2010b, ApJ, 712, 833 [Google Scholar]
- Conroy, C., Gunn, J. E., & White, M. 2009, ApJ, 699, 486 [Google Scholar]
- Conroy, C., White, M., & Gunn, J. E. 2010, ApJ, 708, 58 [NASA ADS] [CrossRef] [Google Scholar]
- Dawes, C., Storfer, C., Huang, X., et al. 2022, ArXiv e-prints [arXiv: 2208.06356] [Google Scholar]
- Dawson, K. S., Schlegel, D. J., Ahn, C. P., et al. 2013, AJ, 145, 10 [Google Scholar]
- Dawson, K. S., Kneib, J.-P., Percival, W. J., et al. 2016, AJ, 151, 44 [Google Scholar]
- Desira, C., Shu, Y., Auger, M. W., et al. 2022, MNRAS, 509, 738 [Google Scholar]
- Dollar, P., Singh, M., & Girshick, R. 2021, ArXiv e-prints [arXiv: 2103.06877] [Google Scholar]
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al. 2020, ArXiv e-prints [arXiv: 2010.11929] [Google Scholar]
- Ducourant, C., Wertz, O., Krone-Martins, A., et al. 2018, A&A, 618, A56 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Duncan, K. J., Kondapally, R., Brown, M. J. I., et al. 2021, A&A, 648, A4 [EDP Sciences] [Google Scholar]
- Dye, S., Lawrence, A., Read, M. A., et al. 2018, MNRAS, 473, 5113 [Google Scholar]
- Edge, A., Sutherland, W., Kuijken, K., et al. 2013, The Messenger, 154, 32 [NASA ADS] [Google Scholar]
- Euclid Collaboration (Barnett, R., et al.) 2019, A&A, 631, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Scaramella, R., et al.) 2022, A&A, 662, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fan, X., Wang, F., Yang, J., et al. 2019, ApJ, 870, L11 [Google Scholar]
- Fan, X., Bañados, E., & Simcoe, R. A. 2023, ARA&A, 61, 373 [NASA ADS] [CrossRef] [Google Scholar]
- Fitzpatrick, E. L. 1999, PASP, 111, 63 [Google Scholar]
- Flesch, E. W. 2021, ArXiv e-prints [arXiv: 2105.12985] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ganaie, M. A., Hu, M., Malik, A. K., Tanveer, M., & Suganthan, P. N. 2022, Eng. Appl. Artif. Intell., 115, 105151 [CrossRef] [Google Scholar]
- Gentile, F., Tortora, C., Covone, G., et al. 2022, MNRAS, 510, 500 [Google Scholar]
- Glikman, E., Rusu, C. E., Chen, G. C. F., et al. 2023, ApJ, 943, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Green, G. M. 2018, J. Open Source Softw., 3, 695 [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2015, ArXiv e-prints [arXiv: 1512.03385] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2016, ArXiv e-prints [arXiv: 1603.05027] [Google Scholar]
- He, Z., Li, N., Cao, X., et al. 2023, A&A, 672, A123 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hezaveh, Y. D., Perreault Levasseur, L., & Marshall, P. J. 2017, Nature, 548, 555 [Google Scholar]
- Howard, A. G., Zhu, M., Chen, B., et al. 2017, ArXiv e-prints [arXiv: 1704.04861] [Google Scholar]
- Howard, A., Sandler, M., Chu, G., et al. 2019, ArXiv e-prints [arXiv: 1905.02244] [Google Scholar]
- Huang, X., Storfer, C., Ravi, V., et al. 2020, ApJ, 894, 78 [NASA ADS] [CrossRef] [Google Scholar]
- Inada, N., Becker, R. H., Burles, S., et al. 2003, AJ, 126, 666 [NASA ADS] [CrossRef] [Google Scholar]
- Inada, N., Oguri, M., Becker, R. H., et al. 2008, AJ, 135, 496 [NASA ADS] [CrossRef] [Google Scholar]
- Inada, N., Oguri, M., Shin, M.-S., et al. 2010, AJ, 140, 403 [NASA ADS] [CrossRef] [Google Scholar]
- Inada, N., Oguri, M., Shin, M.-S., et al. 2012, AJ, 143, 119 [Google Scholar]
- Inayoshi, K., Visbal, E., & Haiman, Z. 2020, ARA&A, 58, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Inoue, A. K., Shimizu, I., Iwata, I., & Tanaka, M. 2014, MNRAS, 442, 1805 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jackson, N., de Bruyn, A. G., Myers, S., et al. 1995, MNRAS, 274, L25 [NASA ADS] [CrossRef] [Google Scholar]
- Jackson, N., Ofek, E. O., & Oguri, M. 2008, MNRAS, 387, 741 [Google Scholar]
- Jacobs, C., Collett, T., Glazebrook, K., et al. 2019, ApJS, 243, 17 [Google Scholar]
- Jaelani, A. T., More, A., Oguri, M., et al. 2020, MNRAS, 495, 1291 [Google Scholar]
- Jaelani, A. T., Rusu, C. E., Kayo, I., et al. 2021, MNRAS, 502, 1487 [NASA ADS] [CrossRef] [Google Scholar]
- Khramtsov, V., Sergeyev, A., Spiniello, C., et al. 2019, A&A, 632, A56 [EDP Sciences] [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, ArXiv e-prints [arXiv: 1412.6980] [Google Scholar]
- Korytov, D., Hearin, A., Kovacs, E., et al. 2019, ApJS, 245, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. 2017, Commun. ACM, 60, 84 [CrossRef] [Google Scholar]
- Krone-Martins, A., Delchambre, L., Wertz, O., et al. 2018, A&A, 616, L11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Krone-Martins, A., Graham, M. J., Stern, D., et al. 2019, ArXiv e-prints [arXiv: 1912.08977] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv: 1110.3193] [Google Scholar]
- Lawrence, A., Warren, S. J., Almaini, O., et al. 2007, MNRAS, 379, 1599 [Google Scholar]
- Lecun, Y., Bottou, L., Bengio, Y., & Haffner, P. 1998, Proc. IEEE, 86, 2278 [Google Scholar]
- Lee, S. H., Lee, S., & Song, B. C. 2021, ArXiv e-prints [arXiv: 2112.13492] [Google Scholar]
- Lemon, C. A., Auger, M. W., McMahon, R. G., & Ostrovski, F. 2018, MNRAS, 479, 5060 [Google Scholar]
- Lemon, C. A., Auger, M. W., & McMahon, R. G. 2019, MNRAS, 483, 4242 [NASA ADS] [CrossRef] [Google Scholar]
- Lemon, C. A., Auger, M. W., McMahon, R., et al. 2020, MNRAS, 494, 3491 [NASA ADS] [CrossRef] [Google Scholar]
- Lemon, C., Anguita, T., Auger-Williams, M. W., et al. 2023, MNRAS, 520, 3305 [NASA ADS] [CrossRef] [Google Scholar]
- Li, R., Napolitano, N. R., Tortora, C., et al. 2020, ApJ, 899, 30 [Google Scholar]
- Mason, C. A., Treu, T., Schmidt, K. B., et al. 2015, ApJ, 805, 79 [NASA ADS] [CrossRef] [Google Scholar]
- Matsuoka, Y., Iwasawa, K., Onoue, M., et al. 2022, ApJS, 259, 18 [NASA ADS] [CrossRef] [Google Scholar]
- McGreer, I. D., Jiang, L., Fan, X., et al. 2013, ApJ, 768, 105 [NASA ADS] [CrossRef] [Google Scholar]
- McGreer, I. D., Fan, X., Jiang, L., & Cai, Z. 2018, AJ, 155, 131 [NASA ADS] [CrossRef] [Google Scholar]
- McMahon, R., Irwin, M., & Hazard, C. 1992, GEMINI Newslett. Roy. Greenwich Observatory, 36, 1 [Google Scholar]
- McMahon, R. G., Banerji, M., Gonzalez, E., et al. 2013, The Messenger, 154, 35 [NASA ADS] [Google Scholar]
- Metcalf, R. B., Meneghetti, M., Avestruz, C., et al. 2019, A&A, 625, A119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miralda-Escudé, J. 1998, ApJ, 501, 15 [CrossRef] [Google Scholar]
- More, A., Oguri, M., Kayo, I., et al. 2016, MNRAS, 456, 1595 [NASA ADS] [CrossRef] [Google Scholar]
- Morokuma, T., Inada, N., Oguri, M., et al. 2007, AJ, 133, 214 [NASA ADS] [CrossRef] [Google Scholar]
- Myers, S. T., Jackson, N. J., Browne, I. W. A., et al. 2003, MNRAS, 341, 1 [Google Scholar]
- Nightingale, J. W., Dye, S., & Massey, R. J. 2018, MNRAS, 478, 4738 [Google Scholar]
- Nightingale, J., Hayes, R., Kelly, A., et al. 2021, J. Open Source Softw., 6, 2825 [NASA ADS] [CrossRef] [Google Scholar]
- Nightingale, J., Amvrosiadis, A., Hayes, R., et al. 2023, J. Open Source Softw., 8, 4475 [Google Scholar]
- Oguri, M., & Marshall, P. J. 2010, MNRAS, 405, 2579 [NASA ADS] [Google Scholar]
- Oguri, M., Inada, N., Castander, F. J., et al. 2004, PASJ, 56, 399 [NASA ADS] [Google Scholar]
- Oguri, M., Inada, N., Pindor, B., et al. 2006, AJ, 132, 999 [Google Scholar]
- Oguri, M., Inada, N., Clocchiatti, A., et al. 2008, AJ, 135, 520 [NASA ADS] [CrossRef] [Google Scholar]
- Pacucci, F., & Loeb, A. 2019, ApJ, 870, L12 [NASA ADS] [CrossRef] [Google Scholar]
- Petrillo, C. E., Tortora, C., Vernardos, G., et al. 2019, MNRAS, 484, 3879 [Google Scholar]
- Pickles, A. J. 1998, PASP, 110, 863 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Polletta, M., Tajer, M., Maraschi, L., et al. 2007, ApJ, 663, 81 [NASA ADS] [CrossRef] [Google Scholar]
- Prakash, A., Licquia, T. C., Newman, J. A., et al. 2016, ApJS, 224, 34 [NASA ADS] [CrossRef] [Google Scholar]
- Radosavovic, I., Prateek Kosaraju, R., Girshick, R., He, K., & Dollár, P. 2020, ArXiv e-prints [arXiv: 2003.13678] [Google Scholar]
- Reback, J., Jbrockmendel, McKinney, W., et al. 2022, https://zenodo.org/record/6408044 [Google Scholar]
- Refsdal, S. 1964, MNRAS, 128, 307 [NASA ADS] [CrossRef] [Google Scholar]
- Rezaei, S., McKean, J. P., Biehl, M., de Roo, W., & Lafontaine, A. 2022, MNRAS, 517, 1156 [NASA ADS] [CrossRef] [Google Scholar]
- Rojas, K., Savary, E., Clément, B., et al. 2022, A&A, 668, A73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Salvato, M., Hasinger, G., Ilbert, O., et al. 2009, ApJ, 690, 1250 [CrossRef] [Google Scholar]
- Salvato, M., Ilbert, O., Hasinger, G., et al. 2011, ApJ, 742, 61 [Google Scholar]
- Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., & Chen, L.-C. 2018, ArXiv e-prints [arXiv: 1801.04381] [Google Scholar]
- Schlafly, E. F., & Finkbeiner, D. P. 2011, ApJ, 737, 103 [Google Scholar]
- Schlafly, E. F., Meisner, A. M., & Green, G. M. 2019, ApJS, 240, 30 [Google Scholar]
- Schlegel, D. J., Finkbeiner, D. P., & Davis, M. 1998, ApJ, 500, 525 [Google Scholar]
- Schneider, P. 2015, Extragalactic Astronomy and Cosmology: An Introduction (Berlin: Springer) [CrossRef] [Google Scholar]
- Schuldt, S., Suyu, S. H., Meinhardt, T., et al. 2021, A&A, 646, A126 [EDP Sciences] [Google Scholar]
- Schuldt, S., Cañameras, R., Shu, Y., et al. 2023, A&A, 671, A147 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shajib, A. J., Vernardos, G., Collett, T. E., et al. 2022, ArXiv e-prints [arXiv: 2210.10790] [Google Scholar]
- Shu, Y., Marques-Chaves, R., Evans, N. W., & Pérez-Fournon, I. 2018, MNRAS, 481, L136 [Google Scholar]
- Shu, Y., Koposov, S. E., Evans, N. W., et al. 2019, MNRAS, 489, 4741 [Google Scholar]
- Shu, Y., Cañameras, R., Schuldt, S., et al. 2022, A&A, 662, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Simonyan, K., & Zisserman, A. 2014, ArXiv e-prints [arXiv: 1409.1556] [Google Scholar]
- Songaila, A., & Cowie, L. L. 2010, ApJ, 721, 1448 [NASA ADS] [CrossRef] [Google Scholar]
- Sonnenfeld, A., Chan, J. H. H., Shu, Y., et al. 2018, PASJ, 70, S29 [Google Scholar]
- Sonnenfeld, A., Verma, A., More, A., et al. 2020, A&A, 642, A148 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spiniello, C., Agnello, A., Napolitano, N. R., et al. 2018, MNRAS, 480, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Stacey, H. R., Costa, T., McKean, J. P., et al. 2022, MNRAS, 517, 3377 [NASA ADS] [CrossRef] [Google Scholar]
- Stein, G., Blaum, J., Harrington, P., Medan, T., & Lukić, Z. 2022, ApJ, 932, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Storfer, C., Huang, X., Gu, A., et al. 2022, ArXiv e-prints [arXiv: 2206.02764] [Google Scholar]
- Sultana, F., Sufian, A., & Dutta, P. 2018, Fourth International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN), Kolkata, India, 122 [Google Scholar]
- Szegedy, C., Liu, W., Jia, Y., et al. 2014, ArXiv e-prints [arXiv: 1409.4842] [Google Scholar]
- Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. 2015, ArXiv e-prints [arXiv: 1512.00567] [Google Scholar]
- Szegedy, C., Ioffe, S., Vanhoucke, V., & Alemi, A. 2016, ArXiv e-prints [arXiv: 1602.07261] [Google Scholar]
- Taak, Y. C., & Treu, T. 2023, MNRAS, 524, 5446 [Google Scholar]
- Tan, M., & Le, Q. V. 2019, ArXiv e-prints [arXiv: 1905.11946] [Google Scholar]
- Tan, M., & Le, Q. V. 2021, ArXiv e-prints [arXiv: 2104.00298] [Google Scholar]
- TensorFlow Developers 2022, https://zenodo.org/record/8118033 [Google Scholar]
- Thuruthipilly, H., Zadrozny, A., Pollo, A., & Biesiada, M. 2022, A&A, 664, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Treu, T., Suyu, S. H., & Marshall, P. J. 2022, A&ARv, 30, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Vestergaard, M., & Wilkes, B. J. 2001, ApJS, 134, 1 [Google Scholar]
- Wilde, J., Serjeant, S., Bromley, J. M., et al. 2022, MNRAS, 512, 3464 [Google Scholar]
- Williams, P. R., Agnello, A., Treu, T., et al. 2018, MNRAS, 477, L70 [Google Scholar]
- Wong, K. C., Suyu, S. H., Chen, G. C. F., et al. 2020, MNRAS, 498, 1420 [Google Scholar]
- Wong, K. C., Chan, J. H. H., Chao, D. C. Y., et al. 2022, PASJ, 74, 1209 [CrossRef] [Google Scholar]
- Woodfinden, A., Nadathur, S., Percival, W. J., et al. 2022, MNRAS, 516, 4307 [NASA ADS] [CrossRef] [Google Scholar]
- Worseck, G., & Prochaska, J. X. 2011, ApJ, 728, 23 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868 [Google Scholar]
- Yang, J., Wang, F., Wu, X.-B., et al. 2016, ApJ, 829, 33 [NASA ADS] [CrossRef] [Google Scholar]
- Yue, M., Yang, J., Fan, X., et al. 2021, ApJ, 917, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Yue, M., Fan, X., Yang, J., & Wang, F. 2022a, AJ, 163, 139 [NASA ADS] [CrossRef] [Google Scholar]
- Yue, M., Fan, X., Yang, J., & Wang, F. 2022b, ApJ, 925, 169 [NASA ADS] [CrossRef] [Google Scholar]
- Yue, M., Fan, X., Yang, J., & Wang, F. 2023, AJ, 165, 191 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, C., Variu, A., He, M., et al. 2022, MNRAS, 511, 5492 [NASA ADS] [CrossRef] [Google Scholar]
- Zoph, B., Vasudevan, V., Shlens, J., & Le, Q. V. 2018, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 8697 [Google Scholar]
The list of previously published lens systems is compiled from the Master Lens Database (hereafter MLD; https://test.masterlens.org/) and the Gravitationally Lensed Quasar Database (dubbed as GLQD; https://research.ast.cam.ac.uk/lensedquasars/).
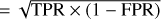
All Tables
Performances of the individual and ensemble network models evaluated on the test dataset are reported here.
All Figures
|
Fig. 1 Simulation workflow that we adopt for generating the mock lensed quasar images. The cutouts are based on the HSC images with 72 × 72 pixels wide (≈12″ on a side). The real galaxy, acting as a lens, is shown in the upper left panel. On the other hand, the quasar, which serves as a background source, is depicted in the lower left panel as a Gaussian light profile. The deflected source’s light convolved with the respective HSC PSF model is shown in the lower middle panel, which is determined based on the associated lens arrangement. Ultimately, we paint the multiply-imaged sources on top of the galaxy image and display it in the upper right panel. Below each panel, the lens parameters (in arcseconds, β and θE) and the photometry is reported. In this case, we construct mock images for all HSC bandpasses – namely, grizy bands. |
| In the text | |
|
Fig. 2 Redshiſts (zgal), stellar velocity dispersions (συ), Einstein radii (θE), and HSC i-band magnitudes (iHSC) distributions of the galaxies used for making the mock lenses. These configurations are utilized to create mock lenses and are shown as orange histograms. The distribution of recovered lenses predicted by our ensemble network classifier is presented with blue lines. |
| In the text | |
|
Fig. 3 HSC grz-band images of the unlensed galaxies, quasars, and stars as the negatives, along with the mock lenses as the positive examples. The square-root stretching is applied to the cutouts with a size of 72 × 72 pixels (≈12″ on a side) to emphasize features with low fluxes and improve the visual appearance. We also present the ground-truth labels and the estimated lens probability for each source in the figure. |
| In the text | |
|
Fig. 4 Architecture of our ensemble network, which produces 4 outcomes as the end product – to be exact, the probability of a candidate being a lensed quasar, a galaxy, an unlensed quasar, and a star – is shown here. The input layer takes the HSC grizy-band images and passes them to the functional layers containing 12 CNN and 2 ViT models. Each model produces 4 output logits, which are then transformed into a probability distribution that sums to unity using the softmax layer. Subsequently, we average the softmax outputs of these 14 networks to produce only 4 final probabilities. |
| In the text | |
|
Fig. 5 Example of accuracy and loss curves as a function of the training epoch of ViT-Lite, one of the top-performing models, is displayed in the upper and lower panels. The other classifiers also show a similar increasing accuracy and decreasing loss trend, indicating that they are able to learn. These metrics are inferred by testing the network on the training and validation datasets, which are subsequently depicted as blue and orange lines, respectively. |
| In the text | |
|
Fig. 6 Curves of the receiver operating characteristic and its area under the curve (AUC) calculation are presented. A solid blue line indicates the curve for categorizing lensed quasars. The curves for classifying galaxies, quasars, and stars, are also illustrated as magenta, yellow, and cyan dashed lines, respectively. Finally, a red circle represents the FPR and TPR values for the chosen Plens limit. |
| In the text | |
|
Fig. 7 FP sources, or contaminants, identified by our classifier and their lens probabilities are shown here. The images are created based on the HSC grz-band cutouts with 72 pixels (≈12″) on a side, colorized, and square-root stretched. |
| In the text | |
|
Fig. 8 Model of the quasar selection function that we make use of in this work. The percentage of recovery rate corresponds to the number of mock quasars in each (M1450, z) bin that is successfully recovered by our selection method. |
| In the text | |
|
Fig. 9 Example of discovered lenses compiled from the literature (see main text). The images are generated using 48 × 48 pixels (≈8″ on a side) of HSC grz cutouts, colorized, and square-root stretched. The lens probabilities, assigned by our ensemble classifier, of each system are also shown in the figure. |
| In the text | |
|
Fig. A.1 SED fitting result for a lensed quasar candidate is presented. In the main panel, the observed photometry of the source is depicted as red circles with error bars modeled with three distinct templates. The best-fit quasar spectral template is represented by a blue line, while the synthesized photometry is illustrated with blue circles. The yellow and magenta colors indicate the best-fit models using non-lensed star and galaxy templates, respectively. The right panel showcases the photometric redshift probability density functions obtained by fitting the data to templates of unlensed quasars (cyan line) and galaxies (magenta line). |
| In the text | |
|
Fig. B.1 The 12″ × 12″ ɡrz-color images of our lens candidates are shown. To enhance the visual contrast of each HSC cutout, we apply a square-root stretch to the fluxes. We also display the grade determined from our visual inspection and the identification number of each target on top of the panel. At the bottom side, we report the lens probability inferred by our automated classifier. Newly discovered sources in this work, along with some candidates that are also independently published by Chan et al. (2023) that are not listed in the MLD and GLQD, are marked with red rectangles. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.