| Issue |
A&A
Volume 673, May 2023
|
|
|---|---|---|
| Article Number | A33 | |
| Number of page(s) | 60 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202244534 | |
| Published online | 03 May 2023 | |
HOLISMOKES
X. Comparison between neural network and semi-automated traditional modeling of strong lenses
1
Max-Planck-Institut für Astrophysik,
Karl-Schwarzschild Str. 1,
85748
Garching, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Technical University of Munich, TUM School of Natural Sciences, Department of Physics,
James-Franck-Str. 1,
85748
Garching, Germany
3
Academia Sinica Institute of Astronomy and Astrophysics (ASIAA),
11F of ASMAB, No.1, Section 4, Roosevelt Road,
Taipei
10617, Taiwan
4
Ruhr University Bochum, Faculty of Physics and Astronomy, Astronomical Institute (AIRUB), German Centre for Cosmological Lensing,
44780
Bochum, Germany
5
Pyörrekuja 5 A,
04300
Tuusula, Finland
Received:
18
July
2022
Accepted:
8
March
2023
Abstract
Modeling of strongly gravitationally lensed galaxies is often required in order to use them as astrophysical or cosmological probes. With current and upcoming wide-field imaging surveys, the number of detected lenses is increasing significantly such that automated and fast modeling procedures for ground-based data are urgently needed. This is especially pertinent to short-lived lensed transients in order to plan follow-up observations. Therefore, we present in a companion paper a neural network predicting the parameter values with corresponding uncertainties of a singular isothermal ellipsoid (SIE) mass profile with external shear. In this work, we also present a newly developed pipeline glee_auto.py that can be used to model any galaxy-scale lensing system consistently. In contrast to previous automated modeling pipelines that require high-resolution space-based images, glee_auto.py is optimized to work well on ground-based images such as those from the Hyper-Suprime-Cam (HSC) Subaru Strategic Program or the upcoming Rubin Observatory Legacy Survey of Space and Time. We further present glee_tools.py, a flexible automation code for individual modeling that has no direct decisions and assumptions implemented on the lens system setup or image resolution. Both pipelines, in addition to our modeling network, minimize the user input time drastically and thus are important for future modeling efforts. We applied the network to 31 real galaxy-scale lenses of HSC and compare the results to traditional, Markov chain Monte Carlo sampling-based models obtained from our semi-autonomous pipelines. In the direct comparison, we find a very good match for the Einstein radius. The lens mass center and ellipticity show reasonable agreement. The main discrepancies pretrain to the external shear, as is expected from our tests on mock systems where the neural network always predicts values close to zero for the complex components of the shear. In general, our study demonstrates that neural networks are a viable and ultra fast approach for measuring the lens-galaxy masses from ground-based data in the upcoming era with ~105 lenses expected.
Key words: gravitational lensing: strong / methods: data analysis
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model.
Open Access funding provided by Max Planck Society.
1 Introduction
Gravitational lensing, which means that the light of a background object is gravitationally deflected by a massive object in the foreground, gives us the opportunity to probe the Universe in various aspects. This includs the study of high-redshift systems (e.g., Dye et al. 2018; Lemon et al. 2018; McGreer et al. 2018; Rubin et al. 2018; Salmon et al. 2018; Shu et al. 2018), the study of the nature and distribution of dark matter (e.g., Schuldt et al. 2019; Baes & Camps 2021; Gilman et al. 2021; Shajib et al. 2021; Basak et al. 2022; Wang et al. 2022), and cosmological parameter measurements (e.g., Refsdal 1964; Chen et al. 2019; Birrer et al. 2020; Millon et al. 2020; Shajib et al. 2020, 2022; Wong et al. 2020).
Therefore, huge effort is spent on large strong lens detection surveys. So far only hundreds of lenses have been confirmed and thousands of candidates have been identified (e.g., Bolton et al. 2006; Cabanac et al. 2007; Treu et al. 2011; Brownstein et al. 2012; Sonnenfeld et al. 2015, 2018; Shu et al. 2016b, 2017; Cornachione et al. 2018; Wong et al. 2018; Chan et al. 2020; Jaelani et al. 2020a, 2021). Many lenses have been detected through deep learning networks scanning large image sets, from example, from the Panoramic Survey Telescope and Rapid Response System (Pan-STARRS; e.g., Cañameras et al. 2020), the Hyper Suprime-Cam Subaru Strategic Program (HSC-SSP; Cañameras et al. 2021; Shu et al. 2022; Jaelani et al., in prep.) the Dark Energy Survey (DES; Jacobs et al. 2019; Rojas et al. 2022), and the Canada-France Imaging Survey (CFIS; Savary et al. 2022). Besides the deep learning technique that has become popular over the last years thanks to the fast application to very large data sets, multiple other techniques have been used to identify strong lenses, including pattern-based searches (e.g., Cabanac et al. 2007; Gavazzi et al. 2012, 2014), spectroscopic searches (e.g., Bolton et al. 2006; Brownstein et al. 2012; Shu et al. 2016a; Talbot et al. 2018, 2021), and modeling searches (e.g., Sonnenfeld et al. 2018; Chan et al. 2020). In the near future, the Legacy Survey of Space and Time (LSST) at the Vera C. Rubin Observatory (Ivezic et al. 2008), which will cover around 18 000 deg2 in six filters (u, g, r, i, z, y), and the Euclid telescope (Laureijs et al. 2011), covering around 15 000 deg2 throughout its 6-yr-long mission, will provide billions of galaxy images including on the order of 100 000 additional lenses (Collett 2015).
After a lens system is detected, a mass model is necessary for nearly all further studies. Lens models are often described through parameterized profiles such as a Sérsic profile (De Vaucouleurs 1948; Sérsic 1963) for the lens light. There are different profiles assumed for the mass distribution, where the choice of profile depends on the image resolution and scientific goal. For ground-based images of galaxy-scale lensing systems, one typically adopts a singular isothermal sphere or singular isothermal ellipsoid (SIE) profile, possibly together with an external-shear γext component, while for high-resolution images, for example from the Hubble Space Telescope (HST), more complex profiles can be adopted. In that case, the dark matter component can be described independently through an NFW (Navarro et al. 1997) profile and the baryonic matter through a mass-follows-light profile or power-law profile (e.g., SPEMD profile; Barkana 1998). The best fitting parameter values are often obtained with Markov chain Monte Carlo (MCMC) sampling (e.g., Jullo et al. 2007; Suyu & Halkola 2010; Suyu et al. 2012; Fowlie et al. 2020; Sciortino et al. 2020) as it is able to sample a high-dimensional parameter space and yields the posterior distribution for the uncertainties and degeneracies. However, this method is very time and resource consuming due to its computational time and due to the required user inputs, such that the modeling of a single lens system can take weeks. Therefore the current techniques are already insufficient for the known lens candidates as well as for upcoming surveys such as LSST and Euclid.
One possibility is to automate the modeling procedure while still relying on Bayesian inference such as MCMC sampling (e.g., Nightingale et al. 2018; Rojas et al. 2022; Savary et al. 2022; Etherington et al. 2022; Gu et al. 2022; Ertl et al. 2023; Schmidt et al. 2023), which reduces the user input dramatically, resulting in an overall runtime on the order of days. A further speed-up can be achieved by using Graphical Processing Units (GPUs; e.g., Gu et al. 2022). Another option is to use machine learning (Hezaveh et al. 2017; Perreault Levasseur et al. 2017; Morningstar et al. 2018, 2019; Pearson et al. 2019, 2021; Schuldt et al. 2021b, 2023, hereafter S21b and S23, respectively). Convolutional neural networks (CNNs), including CNN-based residual networks (ResNets) have become one of the major tools in (astronomical) image processing on very large data sets (e.g., Paillassa et al. 2020; Wu 2020; Tohill et al. 2021; Tanoglidis et al. 2021; Cavanagh et al. 2021; Grover et al. 2021; Schuldt et al. 2021a; Vega-Ferrero et al. 2021) and thus also in recent lens detections (Jacobs et al. 2017, 2019; Petrillo et al. 2017; Lanusse et al. 2018; Schaefer et al. 2018; Davies et al. 2019; Metcalf et al. 2019; Cañameras et al. 2020, 2021; He et al. 2020; Huang et al. 2020; Li et al. 2020; Rojas et al. 2022; Savary et al. 2022; Shu et al. 2022; Jaelani et al., in prep.). The main requirement of neural networks (NNs) is a large enough training set on the order of a hundred thousand images. Since there are not that many known lenses so far, the training data need to be simulated. While the training data were previously completely simulated (Jacobs et al. 2017, 2019; Petrillo et al. 2017; Schaefer et al. 2018; Davies et al. 2019; Metcalf et al. 2019), recent efforts favor the use of real galaxy images and simulate only the lensing effect for the background object, that is paint the lensed arcs on top of a real galaxy image, which is then the lens galaxy (e.g., Cañameras et al. 2020, 2021; Savary et al. 2022; S21b; Shu et al. 2022; Jaelani et al., in prep.). Here the galaxies used as lens galaxies are typically limited to luminous red galaxies (LRGs) given their higher lensing cross section.
The main advantage of machine learning is the fully autonomous procedure and the huge speed-up compared to MCMC sampling methods since a trained network is able to predict the mass parameters within fraction of a second. The main challenges of this method are the requirement of a training, validation, and test set, which need to be, at least partly, simulated, and the difficulty in translating the model parameters into e.g., a χ2 for checks of their accuracy. Pearson et al. (2021) performed a detailed comparison between the network predictions and conventionally obtained models of a variety of complex mock lensing systems. This, however, still allows the question about the network performance on real observed lenses. Therefore, we apply the network described in S23 to a sample of grade A (i.e., secure) galaxy-scale lenses from the Survey of Gravitationally-lensed Objects in HSC Imaging (SuGOHI) program (Sonnenfeld et al. 2018, 2019, 2020; Wong et al. 2018; Chan et al. 2020; Jaelani et al. 2020a, Jaelani et al. 2021). This work, which is part of our ongoing Highly Optimized Lensing Investigations of Supernovae, Microlensing Objects, and Kinematics of Ellipticals and Spirals (HOLISMOKES; Suyu et al. 2020) program, is the first time a trained modeling network is applied to real ground-based images instead of mock images. Further, we compare each model predicted by the network to a model that we obtained with traditional MCMC sampling methods. For the traditional modeling, we have developed glee_auto.py, an automated code that is optimized for HSC-like ground-based images and thus will also be very helpful beyond this comparison project. Given the expected similarity in data quality, glee_auto.py can also be used to model lenses observed in the near future with LSST. For more specific and detailed follow-up modeling, we have developed glee_tools.py, a flexible code to automate optimization steps selected by the user without assuming anything on the lens system setup. Thanks to its flexibility, glee_tools.py will be very useful for many forthcoming projects including lens observations from LSST, but also from Euclid or the James Webb Space Telescope (Rigby et al. 2023).
The outline of the paper is as follows. In Sect. 2 we present the SuGOHI lenses used in this work. In Sect. 3 we describe glee_auto.py, our automated MCMC based modeling code for ground-based images, our flexible automation code glee_tools.py, and the resulting models. We then introduce our modeling network from S23 and present the output models from the network in Sect. 4. A detailed comparison of the mass models is given in Sect. 5, and of the predicted image positions and time delays in Sect. 6. We summarize our results in Sect. 7.
Throughout this work we assume a flat ACDM cosmology with a Hubble constant H0 = 72 km s−1 Mpc−1 (Bonvin et al. 2017) and Ωm = 1 − ΩΛ = 0.32 (Planck Collaboration VI 2020) for consistency with corresponding work presented in S21b and S23. Unless specified otherwise, each quoted parameter estimate is the median of its 1D marginalized posterior probability density function, and the quoted uncertainties show the 16th and 84th percentiles (i.e., the bounds of a 68% credible interval).
2 Comparison data set
For our comparison we use HSC images observed with the 8.2m Subaru Telescope in Hawaii. The HSC survey covers around 1400 deg2 in the second public data release wide layer in at least one filter. It provides images with very good quality and with a pixel size of 0.168" in different filters, including griz, which our network is trained on (S21b; S23). The quality is expected to match that from LSST such that our results should also hold for those images.
All lenses of our sample were detected as part of the SuGOHI program1, a large and extensive lens search in HSC data using various methods (Sonnenfeld et al. 2018, 2019, 2020; Wong et al. 2018; Chan et al. 2020; Jaelani et al. 2020a, 2021). For our comparison, we select only the grade A candidates detected by the SuGOHI program to have a very reliable, partly spectroscopically confirmed, sample without false-positive lens candidates. We further select galaxy-scale lenses as the network is trained for such systems. From the resulting sample, we reject systems HSCJ023307-043838 (More et al. 2012, 2016; 2013, 2019; Gavazzi et al. 2014; Jacobs et al. 2019; Chan et al. 2020), HSCJ144132-005358 (Sonnenfeld et al. 2020), and HSCJ135138+002839 (Wong et al. 2018) as those look more like cluster- or group-scale lenses based on their environment and image separation although they are listed as galaxy-scale systems on the webpage. This results in a sample of 31 lenses which we summarize in Table 1.
In the table, we also quote the spectroscopic redshifts of the lenses and – if available – of the sources. In case there is no spectroscopic lens redshift available, we report the photometric redshift in brackets. Since the SIE+γext parameters are independent of the redshifts, we can model all systems even if not all redshifts are measured yet. For our comparison we use images of the lenses in the four filters g, r, i, and z as our network was trained on these filters (S23). A mosaic of gri color images of our comparison sample is shown in Fig. 1.
Overview of all 31 SuGOHI lenses modeled with GLEE & GLAD for a direct comparison to the predictions of our ResNet.
 |
Fig. 1 Color images based on the gri filters of the 31 HSC SuGOHI lenses used for direct comparison. All images have the size of 64 × 64 pixels (i.e. ~10"× ~ 10″) and are oriented such that north is up and east is left. The name of each lens is given on the top of each image. |
3 Mass models through automated GLEE & GLAD software
For our comparison, we need a mass model of the 31 lens systems described in Sect. 2 that is obtained with a traditional, MCMC sampling method. A subset was already modeled by Sonnenfeld et al. (2013, 2019) for studies on the stellar initial mass function, but they adopted only an SIE profile parameterized by the lens-mass center x1 and y1, the axis ratio q1m with position angle ϕ1m, and an Einstein radius θΕ. Here, we also include an external-shear component parameterized by a shear strength γext and orientation ϕext to account for perturbations due to the environment of the lens system and to match the adopted parameterization of our neural network (see S23 and Sect. 4). Therefore, we model all 31 lenses using GLEE (Gravitational Lens Efficient Explorer; Suyu & Halkola 2010; Suyu et al. 2012) and its extension GLAD (Gravitational Lensing and Dynamics; Chirivì et al. 2020), which are both well tested modeling codes that provide several different parameterized profiles and optimization algorithms. These codes support e.g., MCMC sampling using the Metropolis Hastings algorithm (hereafter MCMC refers to Metropolis Hastings MCMC unless specified otherwise; Hastings 1970; Robert & Casella 2004), a highly parallelized ensemble sampler, EMCEE (Foreman-Mackey et al. 2013), simulated annealing, a generalized version called dual annealing2 (Tsallis 1988; Tsallis & Stariolo 1996; Xiang et al. 1997, 2013; Xiang & Gong 2000; Mullen 2014), and basin hopping3 (Wales & Doye 1997).
Such traditional modeling of lens systems is very time and resource consuming. Especially it requires a lot of input from a user with specific modeling expertise, e.g., to create the required input files, including a configuration file specifying the adopted light and mass profiles with the initial starting values, and the optimization details such as the chain length, step size, and range for the different sampling methods like MCMC and simulated annealing, the prior ranges on each parameter, and several other details. Each optimization run will lead to an updated configuration file with the newest best set of parameter values. After a possible update with e.g., the selection of varying parameters which get typically iteratively optimized, a new optimization run is started. This will be repeated until the sampled parameter values stabilize and represent the observation to an acceptable level. Thus, this procedure is a completely iterative process and thus the user input time is relatively high.
We develop glee_auto.py, a code to automate the modeling procedure and thus to minimize the user input time where we adapt partly the code and procedure presented in Ertl et al. (2023) who model high-resolution HST images of lensed quasars. The implemented procedure and decision criteria were extensively tested on the presented sample, such that the code is able to model a broad range of typical galaxy-scale lenses from ground-based surveys, where most of the lenses are detected. The final procedure and criteria are presented in Sect. 3.1.
Since each lensing system is special in its own way and thus requires specific treatment in the modeling, the presented automated code will not obtain for every lensing system a fit that perfectly represents the observation. This is expected because of the huge variety of galaxy light distribution, orientations, line-of-sight objects and similar aspects, but provides at least a very good initial model for further refinement of the parameter values with minimal user input and in an acceptable amount of computational run time. Since the main goal of this work is a direct comparison between network predictions and traditionally obtained models on real lenses, we conduct a specific follow-up modeling for several individual lenses of our sample to improve the fit. For this, we introduce glee_tools.py in Sect. 3.2, a code that automates individual optimization steps specified by the user but without its own decisions implemented. This allows full control of the modeling sequence while still reducing notable user input time.
The resulting best models are presented in Sect. 3.3 where we also discuss details of the code limitations. We compare glee_auto.py to other modeling codes in Sect. 3.4.
3.1 Automated modeling code glee_auto.py
Our newly developed automated modeling code glee_auto.py is divided into four individual parts (see also details in Appendix A). In the first step, the user simply prepares the input files which are used for the modeling. In the second step, the lens light distribution is modeled, where we adopt Sérsic profiles parameterized as
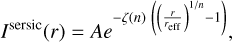 (1)
(1)
with an elliptical radius
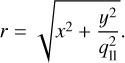 (2)
(2)
Here (x, y) are the coordinates aligned along the semi-major and semi-minor axis of the lens light, q11 is the lens-light axis ratio, and is the position angle. The amplitude is denoted as A and the effective radius as reff. The constant ζ(n) depends on the Sérsic index n and ensures that the effective radius encloses half of the projected light (Ciotti & Bertin 1999; Cardone 2004; Dutton et al. 2011). Therefore, the effective radius is also called half-light radius. For our modeling, we assume the same structural parameters (x1, y1, q11, ϕ11, reff,11, n11) across different filters, where (x1, y1) are the lens light center. This step is necessary to remove the light from the main lens and other line-of-sight objects (where the pixels associated with other line-of-sight objects are in the so-called lens mask and discarded in the light model fitting, see Fig. 2), resulting in an image of the arcs alone.
Before modeling the arcs on the pixel level, we include as the third step (see Fig. 2) a short optimization of the SIE mass parameters based on the multiple lensed image positions identified in Step 1. The convergence (also called dimensionless surface mass density) of the adopted SIE profile can be expressed as
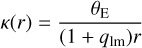 (3)
(3)
rotated by an angle ϕ1m, measured counterclockwise from the positive x-axis in our implementation, and with an elliptical radius defined in analogy to Eq. (2) with axis ratio q1m. Such an optimization is typically performed before the lens light model, but in our case we adopt the lens light center as the center of the SIE profile. This step only takes around a minute, but updates the initial mass parameter values such that the multiple images map to the same source position. This is crucial for the arc light modeling in step four. Additionally, it gives us a preliminary source position which is used as a starting value for the source light center. In this part, the external shear is neglected given the low number of constraints (four data points for a doubly and eight for a quadruply lensed system).
The arc light modeling and source light reconstruction is then performed as the fourth step, where the external shear is included. Here we assume one Sérsic profile to describe the source light distribution. A parameterized profile for the background source, which is supported only by GLAD, is preferred over the pixelized source surface brightness (SB) reconstruction implemented in GLEE, as we use ground-based images that only resolve the main structure of the arcs. This is the reason for making use of GLAD, even though we do not include dynamical modeling, which is the key part of GLAD. For the same reason, we adopt only one Sérsic profile instead of two as done for the lens light distribution. The input data with assumed nomenclature, the individual optimization steps and implemented criteria of the modeling routine are presented as a flow diagram in Fig. 2 and explained in more detail in Appendix A.
This procedure was developed through extensive tests on all our 31 SuGOHI lenses and is therefore optimized for ground-based observations with a parameterized source light distribution. The individual sequences typically consists of one MCMC or EMCEE chain to obtain a covariance matrix, and then alternate between either simulated annealing, dual annealing, or basin hopping, and an MCMC chain to obtain an updated covariance matrix but also optimized parameter values. The code is able to predict the lens-light model within a few hours, the source- and image-position model within around a minute, and the extended image model with source SB reconstruction within around a day. It runs on a single core and automatically launches 60-core parallelized jobs for the EMCEE optimizations. This allows a uniform modeling of a larger sample of galaxy-scale lenses without much user input to provide a basic model of the observations.
 |
Fig. 2 Diagram of glee_auto.py, our automated procedure for galaxy-scale lens modeling with GLEE & GLAD, which is divided into four main steps indicated on the top of each panel. For the optimization we make use of simulated annealing, basin hopping, dual annealing, and Metropolis Hastings MCMC sampling. The MCMC, and also EMCEE, are used to get an estimate of the sampling covariance matrix and provide the probability distribution used as decision criteria (indicated as logP). The "amplitude test" refers to a quick check of a newly included Sérsic profile's amplitude to determine the best order of magnitude to use as an initial starting point. This example lensing system has an identification number of 42 and the filter is denoted as R. Further details on the procedure can be found in Appendix A. |
3.2 Flexible modeling code glee_tools.py
Using the automated procedure described in Sect. 3.1, we modeled all 31 SuGOHI lenses uniformly. Because every lens system is peculiar in its own way, the automated procedure does not work perfectly for all of them. Since the main focus of this work is the comparison between network predictions and conventional methods rather than discussing the automation code limitations, we improved several models afterwards by hand until the residuals were acceptable and no further improvement was achieved. For this, we tested for lenses with stronger residuals the improvement when including additional profiles like a third Sérsic profile for the lens light or a second component for the source light. The automation code at least gives a very good starting point for further individual optimization with minimal user input time.
For the individual modeling, we developed glee_tools.py, a flexible GLEE-based code to automate several optimization steps when modeling with GLEE & GLAD. This means one provides as usual a configuration file to the code that specifies the data, the number of profiles, the varying parameters, starting values, the adopted cosmology, and other required information. One can then specify a list of optimization iterations that the code shall sequentially perform without further input from the user. This helps to reduce the user input time and waiting time for the start of the next iteration of optimization while giving the flexibility to assume any setup (e.g., number of filters or profiles, kinematic data, single or multiplane lensing etc.). The list of tasks can also include saving the best set of parameters from a MCMC or EMCEE chain as well as computing the covariance matrix and updating the configuration file, which are normally done always manually by hand.
Since the code does not include any decision criteria as the code presented in Sect. 3.1, glee_tools.py can be used for any lens system configuration and does not rely on the assumption of galaxy-scale lensing. This means, it can be used to model ground-based images like those from HSC or soon from LSST, but also high-resolution images from space or by using the adaptive optics technique. Moreover, it is independent of the mass scale (galaxy, galaxy group, or galaxy cluster), which means it is helpful for modeling any lensing system.
In addition to the sampling opportunities, glee_tools.py is equipped with several other frequently needed tools for e.g., visualization of the obtained fits (compare Figs. B.1–B.31) with GLEE & GLAD4, running the amplitude test used in glee_auto.py (see Appendix A), updating all linked parameters within the configuration file, generating masks such as the required arc mask and lens mask5, and converting the complex ellipticity and external shear with their uncertainties into the normal parameterization (axis ratio and shear strength with corresponding position angles) or vice versa (see also Sect. 4).
3.3 Results and discussion of MCMC modeling
We model each of the presented lenses in the sample with glee_auto.py. Depending on the χ2, MCMC chain convergence, and residuals, we improve the models further manually where we make extensive use of glee_tools.py. Since we are mainly interested in the comparison to the network predictions instead of demonstrating the power of our automated code, we only give a short quantitative summary of the performance of our automated pipeline here and afterwards report the results of the final models in detail.
For 29 out of 31 systems, we obtain a 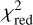 over all four bands of less than 2 directly with glee_auto.py, and for 15 out of 31 systems a
over all four bands of less than 2 directly with glee_auto.py, and for 15 out of 31 systems a 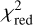 of less than 1.5. As usual,
of less than 1.5. As usual, 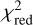 is defined as χ2 divided by the number of degrees of freedom (the number of modeled pixels minus the number of free parameters) with
is defined as χ2 divided by the number of degrees of freedom (the number of modeled pixels minus the number of free parameters) with
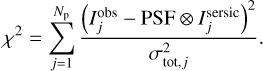 (4)
(4)
In this equation, Np denotes the number of pixels, σtot,j the total noise of pixel j provided by the HSC error map, ⊗ represents the convolution of the point spread function (PSF) and the predicted intensity 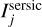 from Eq. (1) including both lens galaxy and the lensed source galaxy, and
from Eq. (1) including both lens galaxy and the lensed source galaxy, and 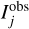 describes the observed intensity of pixel j.
describes the observed intensity of pixel j.
When visually inspecting the residuals, we identified six systems where glee_auto.py produced inadequate model or failed completely, while for seven systems (nearly) no further improvement was necessary to obtain our final model presented below (compare also Figs. B.1–B.31). However, a 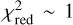 does not necessarily mean that the model is good as the code sometimes predicted unrealistic parameter values (e.g., very low axis ratio values of <0.1) but low residuals which might come from known degeneracies and relatively large prior ranges. For reducing this possibility, stronger priors would help (e.g., on the Sérsic index or mass axis ratio).
does not necessarily mean that the model is good as the code sometimes predicted unrealistic parameter values (e.g., very low axis ratio values of <0.1) but low residuals which might come from known degeneracies and relatively large prior ranges. For reducing this possibility, stronger priors would help (e.g., on the Sérsic index or mass axis ratio).
The median values with 1σ uncertainties computed from our final MCMC chain for the SIE and the external shear parameters, i.e. after possible manual refinement with glee_tools.py, are reported in Table B.1 (white background). We further quote in Table B.1 the χ2 and the 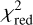 values (compare Eq. (4)), which give an indication of how good the obtained GLEE & GLAD model is. From this list, we see that the
values (compare Eq. (4)), which give an indication of how good the obtained GLEE & GLAD model is. From this list, we see that the 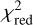 is above 1.5 for only five of the 31 lenses (HSCJ020141−030946, HSCJ023322−020530, HSCJ135138+002839, HSCJ150112+ 422113, HSCJ230521−000211). Nonetheless, we included them in our comparison as the fits are overall still reasonable.
is above 1.5 for only five of the 31 lenses (HSCJ020141−030946, HSCJ023322−020530, HSCJ135138+002839, HSCJ150112+ 422113, HSCJ230521−000211). Nonetheless, we included them in our comparison as the fits are overall still reasonable.
In contrast to the network, we model with the traditional method directly the lens light and source light as Sérsic profiles, which also influence the quoted χ2 and 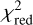 . The resulting parameter values are given in Appendix B. The best fit values for the Sérsic parameters of the lens light are listed in Table B.3, and of the source light in Table B.4. We further show all 31 final models as Figs. B.1–B.31. Each plot shows from left to right the observed image, the model, and the normalized residuals. The four rows correspond to the four different filters in the order g, r, i, and z.
. The resulting parameter values are given in Appendix B. The best fit values for the Sérsic parameters of the lens light are listed in Table B.3, and of the source light in Table B.4. We further show all 31 final models as Figs. B.1–B.31. Each plot shows from left to right the observed image, the model, and the normalized residuals. The four rows correspond to the four different filters in the order g, r, i, and z.
In the course of the modeling, we have made several observations which we discuss in the following.
In general, the lens center, which is assumed to be the same for the light and mass distribution, is in all models very well constrained (1σ ~ 0.001″). The offsets with respect to the image center are also relatively small, only seven systems have a difference larger than half a pixel (0.084″) and none has an offset larger than one pixel (0.168″). The source center is not as well constrained as the lens center with a typical 1σ uncertainty of <0.1".
The estimated Einstein radius is, apart from the lens HSCJ015618–010747 with θΕ = 0.99″, always above 1″. The lens HSCJ150021–004936 has the largest Einstein radius with 3.063″, followed by system HSCJ135138+002839 with 2.216". All other systems have an Einstein radius between 1″ and 2″.
When comparing the lens axis ratio between light q11 and mass q1m, we find notable differences, especially that some mass distributions seem to be very elongated. A quantitative comparison to lens models from the Strong Lensing Legacy Survey (SL2S) program (Sonnenfeld et al. 2013) reveals similar differences, although there a simple SIE profile was adopted by default and an external shear component was included only when the SIE-only model led to strong residuals. Given that Arneson et al. (2012) observed no bias for the axis ratio with spectroscopically identified lenses, this might be an effect of the imaging selection process used in SL2S and SuGOHI. Also, several sources seem to be very elongated; twelve out of 31 have an axis ratio below 0.2 and 24 out of 31 below 0.5. This could be because of the lens search strategy from SuGOHI. Since the arcs must be bright, galaxies with higher surface area are more likely to be detected sources. These are then typically edge-on galaxies, i.e. they have very low q. This is in agreement with a relative low Sérsic index; 16 out of 31 systems have ns < 1. Additionally, it is known that some of these parameters are degenerate. Therefore, it might be necessary to reconsider whether more stringent prior ranges than our broad and flat priors would be better for images of ground-based resolution. For instance, there could be a Gaussian prior for the lens mass axis ratio q1m centered on the lens light axis ratio q11, or for the shear strength or the source and/or lens Sérsic index. Although we generally consider these models to be more trustworthy than the network predictions, this demonstrates that also the models from GLEE & GLAD cannot be considered as true reference models and include some inaccuracies also from parameter degeneracies.
In the following we discuss aspects of individual lens systems that were not mentioned above.
HSCJ023322−020530: This lens system has one very bright source, potentially an active galactic nucleus, which is doubly lensed. Since those two lensed images are extremely compact, this configuration is very hard to model with GLAD, which is optimal for modeling extended sources but not point-like objects. Additionally, it seems that the PSF is not perfectly symmetric, leading to significant residuals of the point-like images. Since there is another fainter source lensed into extended arcs, we manually included here a second source at the same redshift. However, even with this second source included, visible residuals remain, resulting in a relatively high
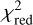 of 1.87. We tried several different options such as including additional profiles or relaxing assumptions on the structural parameters but obtained no notable improvement that would justify the increase in model complexity.
of 1.87. We tried several different options such as including additional profiles or relaxing assumptions on the structural parameters but obtained no notable improvement that would justify the increase in model complexity.HSCJ090429–010228: The lens system HSCJ090429–010228 appears also like a point-source such as an active galactic nucleus. However, based on Jaelani et al. (2020b), it is a compact Lyman alpha break galaxy. As mentioned already above, GLAD works best for extended sources such that residuals are expected. Interestingly, we find only moderate residuals in the i band but nearly no residuals in the other filters and obtain a good
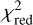 of 1.22.
of 1.22.HSCJ135138+002839: This lens system has overall relatively low residuals, resulting in a good χ2. The somewhat higher reduced χ2 of 1.65 is related to the relatively large part of the image in the south-west (bottom-right) that is masked out due to luminous objects. This reduces the number of modeled pixels and thus the number of degrees of freedom. Although those masked pixel are not taken into account when computing the χ2, the reduction in the number of degrees of freedom effectively increases the
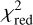 , which needs to be taken into account when comparing it to the
, which needs to be taken into account when comparing it to the 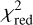 of other lens systems. There are two additional areas in the image that have been masked, one on the south-east of the lens and the other on the north-west. Given the orientation, shape and color (compare Fig. 1), this could be from a second source behind the lens. To confirm this, either a further multiplane model analysis, which is beyond of the scope of this work, or spectroscopic observations would be needed.
of other lens systems. There are two additional areas in the image that have been masked, one on the south-east of the lens and the other on the north-west. Given the orientation, shape and color (compare Fig. 1), this could be from a second source behind the lens. To confirm this, either a further multiplane model analysis, which is beyond of the scope of this work, or spectroscopic observations would be needed.HSCJ141815+015832: Two images (g and r bands) of this lensing system are unfortunately slightly corrupted, which also leads to the wrongly colored stripes in the color image shown in Fig. 1. Nonetheless, we modeled this system masking out the affected regions. We find that the remaining lensing information is still enough to constrain the parameter values and provide a reasonable fit, most likely as we model the different filters simultaneously and assume that they have the same structural parameters for the lens light. This was previously not obvious as the corrupted pixels belong to the most relevant filters and both masked areas go directly through the lens and arcs.
HSCJ150112+422113: The best model of this system represents the observed structure in lens and arcs relatively well, but shows still notable residuals, both in the lens light as well as in the arcs, which results in a higher reduced χ2of 1.63. To improve the model a flexible lens and source center across the different bands might help.
HSCJ230521−000211: The final model of this lens system reproduces the observed structure in lens and arcs, but has slight differences especially also in the positions. A different lens light center for each band might improve the fit slightly but is incompatible with the uniform modeling needed for our comparison in Sect. 4.
3.4 Comparison to other automated modeling codes
In this section we compare the main properties of the two modeling pipelines glee_auto.py (Sect. 3.1) and glee_tools.py (Sect. 3.2) with those of other similar approaches from the literature. While there are no assumptions on the lensing system, prior ranges, or profiles in glee_tools.py, glee_auto.py is dedicated to model galaxy-scale lenses, preferentially in ground-based data given our parameterized source SB. This is the main difference to previous investigations done for instance by Nightingale et al. (2018) and Etherington et al. (2022), which both assumed HST image resolution, but focused also on galaxy-scale lenses. For instance, Etherington et al. (2022) modeled 59 high-resolution systems from the SLACS (Bolton et al. 2006; Auger et al. 2010) and GALLERY (Shu et al. 2016a,b) sample fully autonomously and achieved a physically plausible fit for 54 of the 59 systems without further changes in e.g., the data preprocessing steps. Given the good data quality, they assumed a power-law mass distribution with external shear, i.e. they had an additional a slope parameter to constrain. In an attempt to accelerate the modeling, Gu et al. (2022) presented Giga-Lens, a modeling code tested on simulated HST-like lenses that still relies on a Bayesian framework but is much faster through the use of GPUs, high parallelization, and implementations in TensorFlow (Abadi et al. 2015) and Jax (Bradbury et al. 2018). In contrast to those codes for lensed galaxies, Schmidt et al. (2023) and Ertl et al. (2023) have developed both modeling pipelines that are dedicated to HST images of strongly lensed quasars to derive mass models more rapidly which is necessary to predict time delays and give a good initial model with minimal user input required for cosmological analysis.
Besides these codes for high-resolution images, Rojas et al. (2022) and Savary et al. (2022), who carried out dedicated galaxy-lens search programs in DES and CFIS, respectively, presented a modeling pipeline based on MCMC sampling and a particle swarm optimizer. This code was used to model their best candidates for further refinement. Their code is fully automated, whereas in our pipelines the initial preparation of input files such as the masks and lens/arcs identification is still manual. The advantage of a fully autonomous procedure is clearly the further speed up and also the applicability to much larger samples (hundreds to thousands of lenses if the run time permits). The drawback is the risk of further inaccuracies and miss-identifications for some models, as already pointed out by Rojas et al. (2022) and Savary et al. (2022). Therefore, we prefer a non-fully automated procedure given our sample size of 31 lenses and the aim to obtain very good models for the comparison to the neural network modeling. But even beyond this immediate objective, glee_auto.py will be very helpful for future modeling as it is perfectly suited for observations from LSST. In addition, glee_tools.py will be useful for further refinement, as already in this work, independent of the image quality or type of lensing system.
3.5 Comparison to previously published models
As mentioned in the beginning of this section, 17 of our lensing systems were already modeled by Sonnenfeld et al. (2013, 2019) adopting an SIE profile for describing the lens mass distribution, and a single De Vaucouleurs profile (De Vaucouleurs 1948) or a single Sérsic profile (Sérsic 1963) for describing the lens light distribution. Despite these differences, we compare briefly the values obtained for the Einstein radius 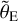 , the lens-mass axis ratio q1m, and the position angle ϕ1m in Fig. 3. Here we adopt the parameterization of Sonnenfeld et al. (2013, 2019), i.e. we convert our Einstein radius θΕ to
, the lens-mass axis ratio q1m, and the position angle ϕ1m in Fig. 3. Here we adopt the parameterization of Sonnenfeld et al. (2013, 2019), i.e. we convert our Einstein radius θΕ to
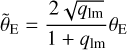 (5)
(5)
as this leads to an Einstein radius that should be more independent of the axis ratio. In this comparison, we exclude the lens system HSCJ094427−014742 with its very faint counter image, as Sonnenfeld et al. (2019) adopted here the lens mass model parameter values measured by Brownstein et al. (2012) using HST data since it was not possible for them to obtain a robust model with HSC.
In the comparison panels in Fig. 3, we color code the points by either the external shear strength or the axis ratio as possible reasons for the differences between our results and that of Sonnenfeld et al. (2013, 2019). In particular, we color code the first three panels in Fig. 3 by the external shear strength γext since a higher external shear in our models could explain differences in the reconstructed parameters. Furthermore, since an axis ratio q1m ~ 1 leads to no constraints on the position angle, we show the comparison of the position angle, in the fourth panel, color-coded by the axis ratio q1m either from GLEE & GLAD or Sonnenfeld et al. (2013, 2019), whichever is higher. We obtain a median offset of 0.097" in the Einstein radius (corresponding to 0.58 pixels) while the largest difference is 0.28" (1.7 pixels) for a system with a high external shear of around 0.1. For better comparison to the pixel size, we show a gray band corresponding to the range of 1 pixel (i.e. 0.168″). The axis ratio shows stronger differences (median offset 0.16, highest offset 0.57). Interestingly, the systems with the largest discrepancies do not have high external shear. For the position angle we obtain a median offset of 0.76 radians and the highest difference is 1.49 radians (corresponding to 43.5° and 85.1°, respectively), but we see a stronger correlation to the external shear and axis ratio that explains the larger differences. In other words, if γext ≤ 0.05 and q1m ≤ 0.85, the position angle matches very well with a median offset of 0.25 radians (14°) and a maximum of 0.30 radians (17.3°).
All in all, these differences demonstrate that the lens mass model parameter values depend to some extent on the modeling assumptions, such as the mass and light profiles and relations between mass and light. Parameter degeneracies, such as that between the external shear and axis ratio, also affect the resulting parameter constraints. We therefore should keep in mind these scatters in the parameter values obtained with GLEE & GLAD for our model parameter comparison in Sect. 5 between the traditional and neural network modeling results. Nonetheless, the Einstein radius is overall well recovered within ~0.1″, irrespective of differences in modeling assumptions.
 |
Fig. 3 Comparison of the SIE parameter values obtained with GLEE & GLAD using SIE+γext to those values from Sonnenfeld et al. (2013, 2019) adopting mainly SIE-only. The gray shaded region in the first panel indicates the 1 pixel range. The discrepancy is mostly due to the difference in the adopted mass model in this work and in Sonnenfeld et al. (2013, 2019). |
4 Mass models predicted by the neural network
In S23, we present a ResNet to model galaxy-scale lens images of HSC quality. It was trained on simulated images using real HSC LRGs as lens images and galaxies from the Hubble ultra deep field (HUDF) as background sources. The lens redshift, peaking at z ~ 0.5, and velocity dispersion, ranging from ~100 km s−1 to ~500 km s−1 and peaking at ~280 km s−1, are taken from SDSS, while the redshifts for the sources are directly provided by HUDF. Details on the simulation procedure and network training are in S21b and S23. We now apply this network to our sample of 31 known real lenses. Within few seconds, the network predicts the full set of parameter values with corresponding 1σ uncertainties for all lenses in the sample. This set of parameters includes the SIE mass parameters, namely the lens mass center x1 and y1, the ellipticity ex and ey, and the Einstein radius θΕ. The complex ellipticity of the lens mass can be converted into the axis ratio
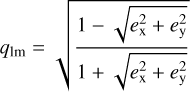 (6)
(6)
and into the position angle
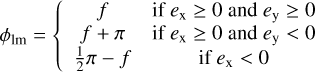 (7)
(7)
with
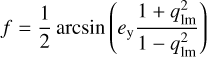 (8)
(8)
and
![Mathematical equation: $f \in \left[ { - \pi /4, + \pi /4} \right].$](/articles/aa/full_html/2023/05/aa44534-22/aa44534-22-eq23.png) (9)
(9)
The network further predicts the external shear γext,1 and γext,2, which can be translated into a shear strength
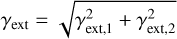 (10)
(10)
that is rotated by
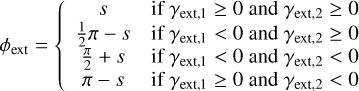 (11)
(11)
with
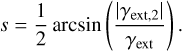 (12)
(12)
We report in Table B.1 the network-predicted values and uncertainties, which we converted to the parameterization of GLEE & GLAD (i.e. γext, ϕext, q1m, ϕ1m). We provide the values in complex notation, as directly obtained from the network, in Table B.2 as well, where we also include the converted values obtained with GLEE & GLAD. While the median values are directly convertible through Eqs. (10) and (11), this is not straightforward for the uncertainties. Therefore, we implemented in glee_tools.py the option to convert values with Gaussian uncertainties. To this end, a sample of values is internally generated based on the given median and σ width, which is then converted into the complex notation. From that new, converted sample, the median and 1σ values are computed. Given the constraint 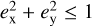 to obtain physically possible values in Eq. (6), we exclude all nonphysical values, if any, from the sample. Because of the conversion, the uncertainties are no longer symmetric about the median value and are thus reported individually.
to obtain physically possible values in Eq. (6), we exclude all nonphysical values, if any, from the sample. Because of the conversion, the uncertainties are no longer symmetric about the median value and are thus reported individually.
5 Comparison and discussion
After modeling our lens sample in the traditional way with GLEE & GLAD and with our ResNet from S23, we compare directly the obtained SIE+γext parameter values. Figure 4 shows them as histograms (left) and plotted against each other (right), with the traditional obtained values on the x-axis and the network predictions on the y-axis. We further show the difference between the traditional and network-based values as histograms in Fig. 5.
As we can see from Fig. 4, the Einstein radius is very well determined through the traditional procedure because the image positions used at the beginning already constrained the Einstein radius very well and then further refined through the extended image modeling. Also the ResNet performs overall well on our comparison sample (see also Fig. 5). For θΕ ≲ 2, we find overall a good match between both methods, although a few are not within the 1σ range. In agreement with S23, the network underpredicts the Einstein radius for system HSCJ150021−004936 with θE = 1.8″, notably lower than the θE = 3.1" obtained with GLEE & GLAD. Since the number of systems with θE ≥ 2″ is significantly lower than the number of systems with θΕ ≤ 2″ in the training set, the network shows a bias towards lower separations on the test set.
The coordinates of the lens mass center x1 and y1 are very well constrained by both methods but we observe some differences between these two methods. The traditional modeling predicts a lens center very close to the image center, i.e. within ± 1 pixel. Here we have to remember that we assume the light center to be coincident with the lens mass center. S26ce the lens light has a relatively large influence on the χ2 and thus on the lens center, the predicted value will be highly influenced by the lens light. A possible offset to the true mass center can be compensated through a change in the external shear. This could be a reason why the network predicts for several systems a larger offset to the image center. The largest offset is 0.484" for lens HSCJ021737−051329, corresponding to nearly three pixels. The fact that we can model nearly all lenses with GLEE & GLAD by assuming a coincident lens light and mass center, implies that we could also adopt this assumption when generating our network training data. Moreover, if we assume the traditionally obtained value to be more accurate, a lens-center offset of ±1 pixel instead of the currently used ±3 pixels would be enough when creating the mocks. This could simplify the task for the network and thus increase the performance on the lens center and also on the other parameters. On the other hand, for most of the lens systems, a slight offset with respect to the cutout center were found with the traditional procedure. Therefore, depending on the science goal, it can be important to include a variable lens center and to predict all five parameters of the SIE profile, instead of assuming that the lens light and mass center fall exactly on the cutout center and thus predicting only three parameters (ellipticity and Einstein radius) as done in other modeling networks (e.g., Hezaveh et al. 2017; Perreault Levasseur et al. 2017; Pearson et al. 2019, 2021).
The ellipticity shows better agreement between traditional and network-based modeling than the lens centroids. In general, the network predicts values closer to zero than the traditional modeling, which was expected from the performance on the test data (compare S23). This is most likely the result of having nearly two orders of magnitude more systems with ellipticity ~ 0 than ~±0.5 in the training sample. A further possible reason is that SuGOHI lenses tend to have more elliptical mass distributions than the training set in S23, since the inner caustic covers a larger area when the mass distribution is more elliptical, leading to a higher magnification that makes the elliptical lenses easier to detect. Because the ellipticity in our training data is set by real observations of LRGs, a flatter distribution, which would most likely lead to an improvement on the currently underrepresented values, is difficult to achieve.
Finally, the external shear is very difficult to estimate. This is especially true for the ResNet, but also the traditionally obtained error bars for are relatively large, especially γext,1, indicating the difficulty to constrain that parameter. Nonetheless, it is interesting to see that the shear orientation is roughly recovered, even if the network predicts relatively large uncertainties.
While the conventional method is considered to give more accurate estimations in general, some of the models show significant residuals in their fit as can be seen from Figs. B.1–B.31, resulting in a higher 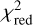 as noted in Sect. 3.3. We therefore compare the θΕ inference as a function of
as noted in Sect. 3.3. We therefore compare the θΕ inference as a function of  in the top panel of Fig. 6. We do not see a direct correlation between the overall accuracy of the GLEE & GLAD model and the agreement of the Einstein radius between the traditional and the network-based approach. On the other hand, we find a small correlation between the signal-to-noise ratio (S/N) of the arcs and the Einstein radius (see Fig. 6, bottom panel, especially for systems with θEtrad ~ 1″) or the S/N and the complex ellipticity. This is not too surprising, as systems with higher S/N have arcs that are more prominent and thus both methods can better constrain the parameters. This fact could be used in the future as an additional criterion to probe the trustworthiness of the predicted parameter values, e.g. with a limit of (S /N)arc > 10.
in the top panel of Fig. 6. We do not see a direct correlation between the overall accuracy of the GLEE & GLAD model and the agreement of the Einstein radius between the traditional and the network-based approach. On the other hand, we find a small correlation between the signal-to-noise ratio (S/N) of the arcs and the Einstein radius (see Fig. 6, bottom panel, especially for systems with θEtrad ~ 1″) or the S/N and the complex ellipticity. This is not too surprising, as systems with higher S/N have arcs that are more prominent and thus both methods can better constrain the parameters. This fact could be used in the future as an additional criterion to probe the trustworthiness of the predicted parameter values, e.g. with a limit of (S /N)arc > 10.
Apart from these general trends, we note again that HSCJ023322−020530 was difficult to model in the automated, uniform way as it shows two very bright objects, for which we had to adopt a third Sérsic profile for the underlying extended background source to describe the observation with acceptable accuracy. Moreover, the extended, relatively faint arcs seem to originate from another source as the one giving the bright images, such that we modeled those arcs with a separate Sérsic component. Nonetheless, the modeling resulted in visible residuals (see Fig. B.9) and a higher  as noted above.
as noted above.
Special consideration is also required for HSCJ141815+015832, as it has corrupted data, which we tried to avoid in the training of the network. As noted in Sect. 3.3, the traditional modeling worked quite well regardless of the missing data. Surprisingly this holds also for the network, although only the position angle and the shear orientation are within 1 σ. The lens center is quite off with a difference of ~2.5 pixels in the x direction, which can be due to the stripe artifact along the x-axis in the g and r bands, falling in the r band directly on top of the lens center. The axis ratio and also the Einstein radius are both well recovered without larger uncertainties than in other systems. This demonstrates that our network is able to handle even such cases which it was not trained on.
6 Image position and time delay comparison
Since the computational time of the network is extremely low, it would be perfectly suited to predict the next appearing image(s) and corresponding time delay(s)6 for a supernova in the background galaxy. In S21b and S23, we therefore included a comparison based on the simulated test data set to see whether the precision of the network is sufficient. For completeness, we now also compute the image positions and time delays for our 31 SuGOHI lenses. Explicitly, we use the mass model and source position 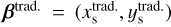 obtained with GLEE & GLAD to predict the image positions θtrad., the corresponding Fermat potential differences Δτtrad. and time delays Δttrad. defined as
obtained with GLEE & GLAD to predict the image positions θtrad., the corresponding Fermat potential differences Δτtrad. and time delays Δttrad. defined as
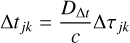 (13)
(13)
with the Fermat potential
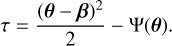 (14)
(14)
Here c is the speed of light, Ψ the lens potential, and DΔt the time-delay distance which depends on the lens redshift zd and source redshift zs, where we assume the redshifts noted in Table 1 or zs = 1 if the source redshift is unknown. For simplicity, we assume the supernova event is located directly in the center of the source galaxy when calculating their corresponding image positions based on the GLEE & GLAD model. For the time-delay and image-position predictions based on the ResNet, we replace the mass model of GLEE & GLAD by that of the neural network and predict the source position βnet using the position of the first appearing image predicted by GLEE & GLAD. This means we obtain a coincident first appearing image, i.e.  , which would be the observed image position. From the obtained source position βnet, we can then predict with the ResNet mass model the other image positions θnet, Fermat potential differences Δτnet and time delays Δtnet. Since the image multiplicity depends on the source position and mass model, the number of images can differ between the network and GLEE & GLAD prediction. When the predicted number of image positions N matches, the obtained image positions are sorted in order to minimize
, which would be the observed image position. From the obtained source position βnet, we can then predict with the ResNet mass model the other image positions θnet, Fermat potential differences Δτnet and time delays Δtnet. Since the image multiplicity depends on the source position and mass model, the number of images can differ between the network and GLEE & GLAD prediction. When the predicted number of image positions N matches, the obtained image positions are sorted in order to minimize
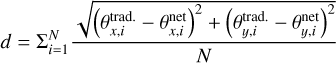 (15)
(15)
to facilitate a direct comparison.
The obtained image positions and source positions are reported in Table C.1. The Fermat potential differences and time delays are sorted accordingly and reported in Table C.2. When comparing the different quantities for our sample, we unfortunately find that the scatter is slightly larger than on the test set in S21b and S23. Figure 7 shows the differences of the obtained image positions and the obtained values d for visualization. For most of the lens systems, 36 find significant differences in the predicted time delays between the traditional and ResNet models. Therefore, the network prediction on the basis of ground-based data is unfortunately not good enough for accurate time-delay predictions. However, it could give a good starting model for further optimization with GLEE & GLAD, e.g. in a fully automated way, as it could replace the creation of the region file marking lens position and ellipticity (compare Sect. 3.1, step 1 in glee_auto.py). We note that the values obtained with GLEE & GLAD are more accurate and precise, but not necessarily the true values (like in test set) and also have inaccuracies given the obtained model parameter value uncertainties. Nonetheless, we consider the image positions and time delays inferred from our GLEE & GLAD model as more trustworthy.
 |
Fig. 4 Comparison of the SIE+γext values obtained with the traditional GLEE & GLAD method (orange histogram) and our ResNet (blue histogram). We further include a comparison where the GLEE & GLAD values are plotted against the ResNet values. |
 |
Fig. 5 Difference of the SIE+γext values obtained with the traditional method using GLEE & GLAD and our ResNet. |
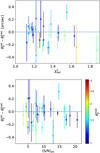 |
Fig. 6 Dependency of the Einstein radius difference on the |
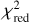
 |
Fig. 7 Comparison of the next appearing image positions (θx,θy) predicted by adopting the traditional GLEE & GLAD model and the mass model of the ResNet in case of matching image mutliplicity. The first image A of each lensing system is excluded because of our assumption of a coincident first image. |
7 Summary and conclusion
In this paper, we compared the predictions of the residual neural network presented in S23 to the SIE+γext parameter values obtained through modeling with GLEE & GLAD. For this comparison, we selected known galaxy-scale lenses detected in HSC, as the network is trained for these kind of lenses and for this image quality. This resulted in a sample of 31 grade-A lenses, which we presented in Sect. 2.
We modeled the full sample of 31 lenses with GLEE & GLAD, a software based on Bayesian optimization algorithms such as simulated annealing and MCMC sampling and thus referred to as traditional, non-machine learning technique. Because of the iterative sampling, this procedure is very time- and resource-consuming. To minimize the user input, we automated most of the modeling steps and developed glee_auto.py, a dedicated procedure to model galaxy-scale strong-lensing systems in optionally multiple filters simultaneously. The code autonomously fits the lens light with Sérsic profiles, before including an SIE+γext profile to describe the lens mass distribution. After a quick optimization based on the user-identified image positions, the code performs a source SB reconstruction by fitting to the full image cutout. Because glee_auto.py is specifically optimized for ground-based observations like those in our comparison sample, we adopted a parameterized source SB reconstruction rather than a pixelated reconstruction. This means we adopt one Sérsic profile to describe the light distribution of the background source.
Since each lens with its environment is unique, the presented uniform modeling sequence did not produce a good fit for all lenses. We therefore further refined some of the models manually. To this end, we developed glee_tools.py, a software package that accepts any configuration file for GLEE & GLAD and a list of optimization algorithms. The specified optimization steps are then performed one after the other without any further input of the user. Since glee_tools.py has no criteria on the modeling procedure incorporated, it has a very broad applicability. With the two codes, we were able to model all 31 lens systems with satisfactory quality and in an acceptable amount of time.
For the comparison, we applied our trained network to the same sample of lenses. We find very good agreement with the traditional models for the Einstein radiusalthough differences appear for systems with larger Einstein radii (θΕ ≳ 2″, i.e. HSCJ150021−004936. This is expected given the performance on the test set (compare S23) because of the under-representation of these systems in the training set. The predicted Einstein radius from the traditional modeling is comparatively well constrained, which comes at least partly from using our visually identified image positions as constraints to get a first estimate.
For the lens center, all values predicted through the traditional modeling procedure are within ± 1 pixel with respect to the cutout center, while the network predicts larger offsets for some systems. This can be explained by our assumption of a coincidence between lens light and mass center for the traditional modeling on the one hand and the rather generous ±3 pixel shift adopted when generating the training data for our network on the other hand. The ellipticity is relatively well constrained by both techniques, but the network tends to predict a more spherical mass distribution (i.e., values closer to zero in complex parameterization) compared to GLEE & GLAD. This is in agreement with the network performance on the test set in S23, and a result of a realistic, but non-uniform distribution in the training sample. For future networks, it might thus make sense to enforce a more evenly distributed ellipticity in the training set, which could be achieved through data augmentation of more elliptical lenses and/or limiting the number of rounder systems. Finally, as expected, the external shear is not well predicted by the network, resulting in the prediction of large uncertainties.
All in all, the performance of the network is very good, especially when taking into account the minimal user input and extremely low computational time. We were able to predict all seven SIE+γext values for the full sample within a fraction of a minute, while the traditional modeling, even with our automated code, requires a few days per lens in addition to possible follow-up modeling. We confirm with our comparison that the network performs similarly well on real lenses as it does on the test set. This demonstrates that the mock images in S23 are indeed realistic and that we can expect a similar performance on a large sample of hundreds to thousands of systems, which can be modeled easily with our network. This would allow a detailed statistical analysis of lens mass properties, especially for systems with θΕ ≳ 1.5" or with S/N in the arcs above ~10. In contrast to that, we are able to model a sample of dozens of lenses with our automated traditional pipeline to better accuracy and we can also evaluate the quality of the fit in terms of a χ2, which is not possible for the network output. The glee_tools.py code enables us to further refine the models obtained with our fully automated procedure or also other dedicated automated modeling codes (e.g., Hezaveh et al. 2017; Perreault Levasseur et al. 2017; Nightingale et al. 2018, Nightingale et al. 2021a,b; Pearson et al. 2019, 2021; Adam et al. 2022; Etherington et al. 2022; Ertl et al. 2023; Schmidt et al. 2023). The combination of all three codes enables us to handle different sample sizes of lenses, and thus takes us a huge step forward in handling the newly detected lenses in current and upcoming wide-field imaging surveys such as LSST and Euclid.
Acknowledgements
We thank J. H. H. Chan for good discussions and helpful comments. We further thank the referee A. Sonnenfeld for the constructive and helpful comments. SS, SHS, RC and SE thank the Max Planck Society for support through the Max Planck Research Group for SHS. This project has received funding from the European Research Council (ERC) under the European Unions Horizon 2020 research and innovation programme (LENSNOVA: grant agreement No 771776). This research is supported in part by the Excellence Cluster ORIGINS which is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany's Excellence Strategy - EXC-2094 - 390783311. YS acknowledges support from the Alexander von Humboldt Foundation in the framework of the Max Planck-Humboldt Research Award endowed by the Federal Ministry of Education and Research. The Hyper Suprime-Cam (HSC) collaboration includes the astronomical communities of Japan and Taiwan, and Princeton University. The HSC instrumentation and software were developed by the National Astronomical Observatory of Japan (NAOJ), the Kavli Institute for the Physics and Mathematics of the Universe (Kavli IPMU), the University of Tokyo, the High Energy Accelerator Research Organization (KEK), the Academia Sinica Institute for Astronomy and Astrophysics in Taiwan (ASIAA), and Princeton University. Funding was contributed by the FIRST program from Japanese Cabinet Office, the Ministry of Education, Culture, Sports, Science and Technology (MEXT), the Japan Society for the Promotion of Science (JSPS), Japan Science and Technology Agency (JST), the Toray Science Foundation, NAOJ, Kavli IPMU, KEK, ASIAA, and Princeton University. This paper makes use of software developed for the Rubin Observatory Legacy Survey in Space and Time (LSST). We thank the LSST Project for making their code available as free software at http://dm.lsst.org. This paper is based in part on data collected at the Subaru Telescope and retrieved from the HSC data archive system, which is operated by Subaru Telescope and Astronomy Data Center (ADC) at National Astronomical Observatory of Japan. Data analysis was in part carried out with the cooperation of Center for Computational Astrophysics (CfCA), National Astronomical Observatory of Japan. We make partly use of the data collected at the Subaru Telescope and retrieved from the HSC data archive system, which is operated by Subaru Telescope and Astronomy Data Center at National Astronomical Observatory of Japan. Software Citations: This work uses the following software packages: Astropy (Astropy Collaboration 2013, 2018), matplotlib (Hunter 2007), NumPy (van der Walt et al. 2011; Harris et al. 2020), Python (Van Rossum & Drake 2009), Scipy (Virtanen et al. 2020), torch (Paszke et al. 2019).
Appendix A Detailed description of glee_auto.py
In the following we describe in detail the model sequence of glee_auto.py, our automated modeling pipeline for galaxy-scale lenses introduced in Sect. 3. Because of the relatively long runtime of the last part, glee_auto.py can be re-started from several different steps indicated with m, for instance if the code gets aborted or the model needs to be refined.
Preparation of input files
Creation of lens and arc masks, shown in Fig. 2 as the top-left and top-middle insert of the corresponding box. These masks specify the region to be modeled and can be different for each filter.
Creation of a region file with the ds9 software7 (Joye & Mandel 2003) as shown in the top-right insert of the corresponding box in Fig. 2. Here one specifies the cutouts size, the lens center and the lens ellipticity, the image positions, and if needed a region to subtract the image background σbkgr.
Renaming of all files according to the assumptions of the modeling code displayed on the bottom of each insert. Both, the alphanumerical ID specifying the lensing system, which is 42 in our example, and a name to distinguish between the filters, which is R in our example, are chosen by the user.
Lens light modeling with GLEE
Read in the provided files, crop the lens image and error map, subtract the background if specified and save the new image and error map cutout to disk.
The code now creates automatically the initial GLEE configuration file for the first filter. The starting values for the lens center and ellipticity are determined from the region file provided. At this stage one Sérsic profile with the following parameters and prior ranges is adopted: lens light center coordinates x1 ∈ [x1,i − 2″, x1,i + 2″] and y1 ∈ [y1,i − 2″, y1,i + 2″], axis ratio q11 ∈ [0.3,1], position angle ϕ11 ∈ [−π, +π], the amplitude A11 ∈ [0,100], the effective radius reff,ll ∈ [0.01″, 10″], and the Sérsic index n11 ∈ [1, 5]. The initial starting values (x1,i, y1,i, q11,i, ϕ11,i, A11,i, reff,i, n11,i) are extracted from the region file created by the user in step one.
Since the Sérsic amplitude A11 is not known a priori, the code evaluates automatically each order of magnitude between 10−5 and 105 and selects the correct order of magnitude defined through the minimal; χ2. The code then updates the upper limit of the prior range to 100 times the estimated amplitude. If the new upper parameter range limit is lower than 10, it is set to 10. In this work, we refer to that procedure as amplitude test.
-
If the reduced; χ2,
 , is above 2, optimize the model by running
, is above 2, optimize the model by running
a simulated annealing optimization and
then an MCMC chain to use the best model of the chain as new model parameters and to include a covariance matrix in the next optimization sequence.
Redo both optimization steps until the MCMC chain passes the criterion of Δ log P ≤ 20 where P is the likelihood probability of the corresponding MCMC chain.
Add now iteratively the other filters in the order specified by the user. Assume the same structural parameters across the different filters, which means only the amplitude is added as a new parameter for each filter.
For each new filter run first an amplitude test as described above, and
then a simulated annealing optimization,
followed by an MCMC chain to continue with the best set of parameter values of that chain.
-
After adding all filters and if
 , optimize all filters simultaneously further by alternating between
, optimize all filters simultaneously further by alternating between
an MCMC run and
a simulated annealing run
until Δ log P ≤ 5.
If still
 , which is normally the case, the code adds a second but concentric Sérsic profile for each filter, assuming again the same structural parameters across the different filters.
, which is normally the case, the code adds a second but concentric Sérsic profile for each filter, assuming again the same structural parameters across the different filters.Determine again the order of magnitude of each new amplitude and set the prior range as specified above.
-
Optimize the model further by alternating between
an MCMC run and
a simulated annealing optimization
until Δ log P ≤ 5.
Accept this as final lens light model obtained with GLEE.
Source and image position modeling with GLEE:
This optimization step of the SIE profile parameters is based on the multiple image positions identified by the user during the preparation stage. The mass parameters are now optimized to reproduce these image positions.
As starting values for the SIE central coordinates, use the obtained lens light center as lens mass center and keep it fixed for now to reduce the number of free parameters. Adopt the axis ratio and position angle from the lens light fit as well, and vary them only if three or more image positions are specified to not under-constrain the model. The Einstein radius is estimated from the identified image positions and always allowed to vary. Assume no shear for now to minimize the number of free parameters.
optimize the model based on the source position with simulated annealing. Perform up to three optimizations, stopping earlier if
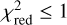 .
.optimize the model based on the image positions with simulated annealing. Perform up to three optimizations, stopping earlier if
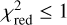 .
.
Arc light modeling with GLEE & GLAD:
Transfer the best fit values to a GLAD configuration file. Assume the source profile to be located at the predicted weighted source position (xs,i, ys,i) obtained from the image position model.
-
(m = 1) Perform again a quick lens-light-only optimization, to reduce the minimal differences in the model arising though differences between GLEE and GLAD in subsampling the PSF and the usage of the masks8.
To this end, first run an EMCEE chain to obtain a new covariance matrix.
Alternate then between
a basin-hopping iteration and
an MCMC chain to obtain a new covariance matrix and also to update the parameter values to the new best set from the chain.
until Δ log P ≤ 2 is achieved in the MCMC chain.
(m = 2) Fix now all lens-light parameters to the best values obtained in the previous modeling sequence. Instead, allow now the source-light axis ratio qs ∈ [0.5, 1], the position angle ϕs ∈ [−π, +π], the amplitude As ∈ [0, 50], and the effective radius reff,s e [0.01, 10] to vary in the specified prior ranges, but assume again the same structural parameters across the different bands. Since the source Sérsic parameters cannot be easily estimated by the user, the initial starting values are qs,i = 0.9, ϕs,i·≡ 0, reff,i ≡ 0.5, and ns,i ≡ 3. The amplitudes, which are different for each filter, are again determined from an amplitude test. Include from now on also the regions specified in the arc mask in the optimization which were previously excluded to fit only to the light from the lens.
Run an EMCEE chain to update the covariance matrix.
Perform a dual annealing optimization, followed by
an MCMC chain and
a basin-hopping optimization.
(m = 3) Allow the coordinates of the source light center xs ∈ [xs,i − 1″, xs,i + 1″] and ys ∈ [ys,i − 1″, ys,i + 1″] to vary. Increase additionally the prior range of the source axis ratio to qs ∈ [0.01,1]. Optimize now the model until reaching Δ log P ≤ 2 by a repeated sequence of
a basin-hopping optimization,
an EMCEE chain to update the covariance matrix (max 10 times in total) and
an MCMC chain to save the new best set of parameter values and update the covariance matrix.
(m = 4) After optimizing the lens light and source light, allow now, in addition to the source light, the lens-mass axis ratio q1m ∈ [0.3,1], the position angle ϕ1m ∈ [−π, +π], and the Einstein radius θΕ ∈ [0.5″, 10″] to vary. Moreover, include from now on also an external shear component with γext ∈ [0, 0.2] and ϕext ∈ [−π, +π]. Optimize until Δ log P ≤ 2 through a repeated sequence of
a dual annealing iteration,
an EMCEE chain to update the covariance matrix (max 15 times in total), and
an MCMC chain to save the new best set of parameters and update the covariance matrix.
-
(m = 5) Vary now additionally the source Sérsic index ns ∈ [0.5, 6], which was previously fixed to 3.
Run an EMCEE chain to obtain a covariance matrix for the new set of varying parameters.
Optimize then all varying parameters through a repeated sequence consisting of
a dual annealing iteration, and
an MCMC chain to save the best set of parameter values and update the covariance matrix
until Δ log P ≤ 2 is reached.
-
(m = 6) After all parameters were optimized at least once, refine once more the lens light parameters which were fixed during the last optimization steps. For this, allow the lens light to vary again, but fix all other parameters, i.e the lens mass, external shear, and the source light components.
Run one EMCEE chain to obtain a first covariance matrix.
Optimize then until Δ log P ≤ 2 through a repeated sequence of
a dual annealing iteration and
an MCMC chain to save the best values and update the covariance matrix.
-
(m = 7) Fix again all lens light parameters and vary again the source light, lens mass and external shear by using the same prior ranges as before, but update the parameter range for the source light center to be again xs ∈
![Mathematical equation: $\left[ {x_{{\rm{s}},i}^{^\prime } - 1'',x_{{\rm{s}},i}^{^\prime } + 1''} \right]$](/articles/aa/full_html/2023/05/aa44534-22/aa44534-22-eq42.png) and ys ∈
and ys ∈ ![Mathematical equation: $\left[ {y_{{\rm{s}},i}^{^\prime } - 1'',y_{{\rm{s}},i}^{^\prime } + 1''} \right]$](/articles/aa/full_html/2023/05/aa44534-22/aa44534-22-eq43.png) with (
with (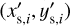 ) being the previously best source position.
) being the previously best source position.
Run first one EMCEE chain to obtain a new covariance matrix.
Optimize until Δ log P ≤ 2 through a repeated sequence of
a dual annealing iteration and
an MCMC chain to save the best parameter set and update the covariance matrix.
(m = 8) Double the length of the MCMC chains to 400,000 and run them until they are fully converged based on the power spectrum (Dunkley et al. 2005). Always take the best set of parameter values of the chain and update the covariance matrix. In case the tenth MCMC chain of this optimization sequence did not converge, the number of sampling steps is increased to 600,000.
Appendix B Details of the 31 HSC models
In this section we provide details of the individual lens models. Tab. B.1 lists the values of the SIE profile and external shear as obtained with GLEE & GLAD and the converted values from the network. In analogy, Tab. B.2 lists these values in complex notation as predicted directly by the network and the converted values from GLEE & GLAD models. We further report the values from GLEE & GLAD for the lens light (Tab. B.3) and source light (Tab. B.4) parameters, which are not obtained with the network. Furthermore, we show images of the 31 GLEE & GLAD models in all four filters in separate rows (Figs. B.1 – B.31), with the observed image (left column), predicted image (middle), and normalized residuals in the range [−5σ, +5σ] (right).
Shear and mass parameter values from our ResNet and GLEE & GLAD for the 31 HSC SuGOHI lenses. Columns 3 and 4 report, respectively, the χ2 and 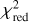 for the GLEE & GLAD-based model. This is followed by the lens (light and mass) center x1 and y1 (with respect to the image cutout center), the lens mass axis ratio q1m, its orientation ϕ1m, the Einstein radius θE, the external shear strength γext, and its orientation φext. The angles φ1m and φext are measured counterclockwise from the positive x-axis. This means φ1m = 0 corresponds to a lens mass distribution with major-axis along x and φext = 0 corresponds to a shear of the lensed images along the x-axis.
for the GLEE & GLAD-based model. This is followed by the lens (light and mass) center x1 and y1 (with respect to the image cutout center), the lens mass axis ratio q1m, its orientation ϕ1m, the Einstein radius θE, the external shear strength γext, and its orientation φext. The angles φ1m and φext are measured counterclockwise from the positive x-axis. This means φ1m = 0 corresponds to a lens mass distribution with major-axis along x and φext = 0 corresponds to a shear of the lensed images along the x-axis.
SIE mass and external shear parameter values obtained by modeling with GLEE & GLAD (converted to complex quantities) or with our neural network (column 2, method) for the 31 HSC SuGOHI lenses used for the direct comparison. The quoted SIE mass parameters are the lens mass center x1 and y1, the complex lens mass ellipticity ex and ey, and the Einstein radius θE. We further give values for γext,1 and γext,2.
Lens light parameter values obtained with GLEE & GLAD. We give, respectively for both the first and second Sérsic profile (column 2), the axis ratio q11, its orientation ϕ11, the effective radius reff,11, the Sérsic index n11, and the amplitudes A11 for the four different filters griz. The lens light center is assumed to match the lens mass center and is thus only quoted in Table B.2
Reconstructed source-light parameter values obtained with GLEE & GLAD. For each Sérsic profile as specified in column 2 (component c), we list the unlensed source center coordinates xs and ys, the axis ratio qs, its orientation ϕs, the effective radius reffs, the Sérsic index ns, and the amplitudes As for the four different filters griz.
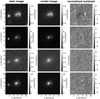 |
Fig. B.1 Fit of lens HSCJ015618−010747. Top to bottom: griz filters. |
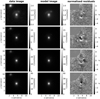 |
Fig. B.2 Fit of lens HSCJ020141−030946. Top to bottom: griz filters. |
 |
Fig. B.3 Fit of lens HSCJ020241−064611. Top to bottom: griz filters. |
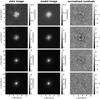 |
Fig. B.4 Fit of lens HSCJ020955−024442. Top to bottom: griz filters. |
 |
Fig. B.5 Fit of lens HSCJ021737−051329. Top to bottom: griz filters. |
 |
Fig. B.6 Fit of lens HSCJ022346−053418. Top to bottom: griz filters. |
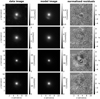 |
Fig. B.7 Fit of lens HSCJ022610−042011. Top to bottom: griz filters. |
 |
Fig. B.8 Fit of lens HSCJ023217−021703. Top to bottom: griz filters. |
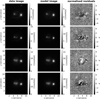 |
Fig. B.9 Fit of lens HSCJ023322−020530. Top to bottom: griz filters. |
 |
Fig. B.10 Fit of lens HSCJ085046+00390. Top to bottom: griz filters. |
 |
Fig. B.11 Fit of lens HSCJ085855−010208. Top to bottom: griz filters. |
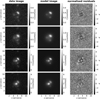 |
Fig. B.12 Fit of lens HSCJ090429−010228. Top to bottom: griz filters. |
 |
Fig. B.13 Fit of lens HSCJ094427−014742. Top to bottom: griz filters. |
 |
Fig. B.14 Fit of lens HSCJ120623+001507. Top to bottom: griz filters. |
 |
Fig. B.15 Fit of lens HSCJ121052−011905. Top to bottom: griz filters. |
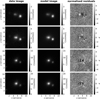 |
Fig. B.16 Fit of lens HSCJ121504+004726. Top to bottom: griz filters. |
 |
Fig. B.17 Fit of lens HSCJ124320−004517. Top to bottom: griz filters. |
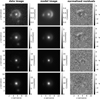 |
Fig. B.18 Fit of lens HSCJ125254+004356. Top to bottom: griz filters. |
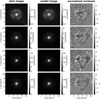 |
Fig. B.19 Fit of lens HSCJ135138+002839. Top to bottom: griz filters. |
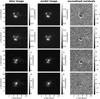 |
Fig. B.20 Fit of lens HSCJ141136−010215. Top to bottom: griz filters. |
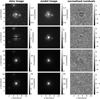 |
Fig. B.21 Fit of lens HSCJ141815+015832. Top to bottom: griz filters. |
 |
Fig. B.22 Fit of lens HSCJ142720+001916. Top to bottom: griz filters. |
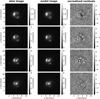 |
Fig. B.23 Fit of lens HSCJ144320−012537. Top to bottom: griz filters. |
 |
Fig. B.24 Fit of lens HSCJ145242+425731. Top to bottom: griz filters. |
 |
Fig. B.25 Fit of lens HSCJ150021−004936. Top to bottom: griz filters. |
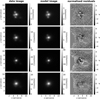 |
Fig. B.26 Fit of lens HSCJ150112+422113. Top to bottom: griz filters. |
 |
Fig. B.27 Fit of lens HSCJ223733+005015. Top to bottom: griz filters. |
 |
Fig. B.28 Fit of lens HSCJ230335+003703. Top to bottom: griz filters. |
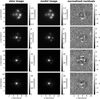 |
Fig. B.29 Fit of lens HSCJ230521−000211. Top to bottom: griz filters. |
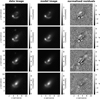 |
Fig. B.30 Fit of lens HSCJ233130+003733. Top to bottom: griz filters. |
 |
Fig. B.31 Fit of lens HSCJ233146+013845. Top to bottom: griz filters. |
Appendix C Predicted image positions, Fermat potential, and time delays
Tab. C.1 lists the predicted image positions for all 31 lenses using both the mass model obtained with GLEE & GLAD and obtained with the network. We further report the distance d (see Eq. (15)) and the source positions. For the GLEE & GLAD model, the latter is the magnification-weighted mean position of the final MCMC chain, and for the network the obtained source position from the first appearing image, both with respect to the image center. The corresponding Fermat potential differences and time delays of the predicted images are reported in Tab. C.2.
Resulting image positions and source position obtained with the GLEE & GLAD model and predicted by the network.
Resulting time delays and Fermat potential differences.
References
- Abadi, M., Agarwal, A., Barham, P., et al. 2015, TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems, software available from tensorflow.org [Google Scholar]
- Adam, A., Perreault-Levasseur, L., & Hezaveh, Y. 2022, ArXiv e-prints [arXiv:2207.01073] [Google Scholar]
- Arneson, R. A., Brownstein, J. R., & Bolton, A. S. 2012, ApJ, 753, 4 [CrossRef] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Auger, M. W., Treu, T., Bolton, A. S., et al. 2010, ApJ, 724, 511 [NASA ADS] [CrossRef] [Google Scholar]
- Baes, M., & Camps, P. 2021, MNRAS, 503, 2955 [NASA ADS] [CrossRef] [Google Scholar]
- Barkana, R. 1998, ApJ, 502, 531 [NASA ADS] [CrossRef] [Google Scholar]
- Basak, S., Ganguly, A., Haris, K., et al. 2022, ApJ, 926, L28 [NASA ADS] [CrossRef] [Google Scholar]
- Birrer, S., Shajib, A. J., Galan, A., et al. 2020, A&A, 643, A165 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bolton, A. S., Burles, S., Koopmans, L. V. E., Treu, T., & Moustakas, L. A. 2006, ApJ, 638, 703 [NASA ADS] [CrossRef] [Google Scholar]
- Bonvin, V., Courbin, F., Suyu, S. H., et al. 2017, MNRAS, 465, 4914 [NASA ADS] [CrossRef] [Google Scholar]
- Bradbury, J., Frostig, R., Hawkins, P., et al. 2018, JAX: composable transformations of Python+NumPy programs [Google Scholar]
- Brownstein, J. R., Bolton, A. S., Schlegel, D. J., et al. 2012, ApJ, 744, 41 [NASA ADS] [CrossRef] [Google Scholar]
- Cañameras, R., Schuldt, S., Suyu, S. H., et al. 2020, A&A, 644, A163 [Google Scholar]
- Cañameras, R., Schuldt, S., Shu, Y., et al. 2021, A&A, 653, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cabanac, R. A., Alard, C., Dantel-Fort, M., et al. 2007, A&A, 461, 813 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cardone, V. F. 2004, A&A, 415, 839 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cavanagh, M. K., Bekki, K., & Groves, B. A. 2021, MNRAS, 506, 659 [NASA ADS] [CrossRef] [Google Scholar]
- Chan, J. H. H., Suyu, S. H., Sonnenfeld, A., et al. 2020, A&A, 636, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chen, G. C. F., Fassnacht, C. D., Suyu, S. H., et al. 2019, MNRAS, 490, 1743 [NASA ADS] [CrossRef] [Google Scholar]
- Chirivì, G., Yildirim, A., Suyu, S. H., & Halkola, A. 2020, A&A, 643, A135 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ciotti, L., & Bertin, G. 1999, A&A, 352, 447 [NASA ADS] [Google Scholar]
- Collett, T. E. 2015, ApJ, 811, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Cornachione, M. A., Bolton, A. S., Shu, Y., et al. 2018, ApJ, 853, 148 [NASA ADS] [CrossRef] [Google Scholar]
- Davies, A., Serjeant, S., & Bromley, J. M. 2019, MNRAS, 487, 5263 [NASA ADS] [CrossRef] [Google Scholar]
- De Vaucouleurs, G. 1948, Compte rend. Acad. Sci. Paris, 227, 586 [Google Scholar]
- Dunkley, J., Bucher, M., Ferreira, P. G., Moodley, K., & Skordis, C. 2005, MNRAS, 356, 925 [Google Scholar]
- Dutton, A. A., Brewer, B. J., Marshall, P. J., et al. 2011, MNRAS, 417, 1621 [NASA ADS] [CrossRef] [Google Scholar]
- Dye, S., Furlanetto, C., Dunne, L., et al. 2018, MNRAS, 476, 4383 [Google Scholar]
- Ertl, S., Schuldt, S., Suyu, S. H., et al. 2023, A&A, 672, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Etherington, A., Nightingale, J. W., Massey, R., et al. 2022, MNRAS, 517, 3275 [CrossRef] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Fowlie, A., Handley, W., & Su, L. 2020, MNRAS, 497, 5256 [Google Scholar]
- Gavazzi, R., Treu, T., Marshall, P. J., Brault, F., & Ruff, A. 2012, ApJ, 761, 170 [Google Scholar]
- Gavazzi, R., Marshall, P. J., Treu, T., & Sonnenfeld, A. 2014, ApJ, 785, 144 [Google Scholar]
- Gilman, D., Bovy, J., Treu, T., et al. 2021, MNRAS, 507, 2432 [NASA ADS] [CrossRef] [Google Scholar]
- Grover, H., Bait, O., Wadadekar, Y., & Mishra, P. K. 2021, MNRAS, 506, 3313 [NASA ADS] [CrossRef] [Google Scholar]
- Gu, A., Huang, X., Sheu, W., et al. 2022, ApJ, 935, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357-362 [NASA ADS] [CrossRef] [Google Scholar]
- Hastings, W. K. 1970, Biometrika, 57, 97 [Google Scholar]
- He, Z., Er, X., Long, Q., et al. 2020, MNRAS, 497, 556 [NASA ADS] [CrossRef] [Google Scholar]
- Hezaveh, Y. D., Perreault Levasseur, L., & Marshall, P. J. 2017, Nature, 548, 555 [Google Scholar]
- Huang, X., Storfer, C., Ravi, V., et al. 2020, ApJ, 894, 78 [NASA ADS] [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Computing in Science & Engineering, 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezic, Z., Axelrod, T., Brandt, W. N., et al. 2008, Serb. Astron. J., 176, 1 [Google Scholar]
- Jacobs, C., Glazebrook, K., Collett, T., More, A., & McCarthy, C. 2017, MNRAS, 471, 167 [Google Scholar]
- Jacobs, C., Collett, T., Glazebrook, K., et al. 2019, ApJS, 243, 17 [Google Scholar]
- Jaelani, A. T., More, A., Oguri, M., et al. 2020a, MNRAS, 495, 1291 [Google Scholar]
- Jaelani, A. T., More, A., Sonnenfeld, A., et al. 2020b, MNRAS, 494, 3156 [NASA ADS] [CrossRef] [Google Scholar]
- Jaelani, A. T., Rusu, C. E., Kayo, I., et al. 2021, MNRAS, 502, 1487 [NASA ADS] [CrossRef] [Google Scholar]
- Joye, W. A., & Mandel, E. 2003, ASP Conf. Ser., 295, 489 [Google Scholar]
- Jullo, E., Kneib, J. P., Limousin, M., et al. 2007, New J. Physics, 9, 447 [NASA ADS] [CrossRef] [Google Scholar]
- Lanusse, F., Ma, Q., Li, N., et al. 2018, MNRAS, 473, 3895 [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Lemon, C. A., Auger, M. W., McMahon, R. G., & Ostrovski, F. 2018, MNRAS, 479, 5060 [Google Scholar]
- Li, R., Napolitano, N. R., Tortora, C., et al. 2020, ApJ, 899, 30 [Google Scholar]
- McGreer, I. D., Clément, B., Mainali, R., et al. 2018, MNRAS, 479, 435 [Google Scholar]
- Metcalf, R. B., Meneghetti, M., Avestruz, C., et al. 2019, A&A, 625, A119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Millon, M., Courbin, F., Bonvin, V., et al. 2020, A&A, 642, A193 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- More, A., Cabanac, R., More, S., et al. 2012, ApJ, 749, 38 [NASA ADS] [CrossRef] [Google Scholar]
- More, A., Verma, A., Marshall, P. J., et al. 2016, MNRAS, 455, 1191 [NASA ADS] [CrossRef] [Google Scholar]
- Morningstar, W. R., Hezaveh, Y. D., Perreault Levasseur, L., et al. 2018, ArXiv e-prints [arXiv:1808.00011] [Google Scholar]
- Morningstar, W. R., Perreault Levasseur, L., Hezaveh, Y. D., et al. 2019, ApJ, 883, 14 [Google Scholar]
- Mullen, K. M. 2014, J. Stat. Softw., 60, 1 [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [Google Scholar]
- Nightingale, J. W., Dye, S., & Massey, R. J. 2018, MNRAS, 478, 4738 [Google Scholar]
- Nightingale, J., Hayes, R., & Griffiths, M. 2021a, J. Open Source Softw., 6, 2550 [NASA ADS] [CrossRef] [Google Scholar]
- Nightingale, J., Hayes, R., Kelly, A., et al. 2021b, J. Open Source Softw., 6, 2825 [NASA ADS] [CrossRef] [Google Scholar]
- Paillassa, M., Bertin, E., & Bouy, H. 2020, A&A, 634, A48 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, in Advances in Neural Information Processing Systems 32 (Curran Associates, Inc.), 8024 [Google Scholar]
- Pearson, J., Li, N., & Dye, S. 2019, MNRAS, 488, 991 [Google Scholar]
- Pearson, J., Maresca, J., Li, N., & Dye, S. 2021, MNRAS, 505, 4362 [CrossRef] [Google Scholar]
- Perreault Levasseur, L., Hezaveh, Y. D., & Wechsler, R. H. 2017, ApJ, 850, L7 [Google Scholar]
- Petrillo, C. E., Tortora, C., Chatterjee, S., et al. 2017, MNRAS, 472, 1129 [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Refsdal, S. 1964, MNRAS, 128, 307 [NASA ADS] [CrossRef] [Google Scholar]
- Rigby, J., Perrin, M., McElwain, M., et al. 2023, PASP, 135, 048001 [NASA ADS] [CrossRef] [Google Scholar]
- Robert, C. P., & Casella, G. 2004, Monte Carlo Statistical Methods, 2nd edn. (New York: Springer), 677 [Google Scholar]
- Rojas, K., Savary, E., Clément, B., et al. 2022, A&A, 668, A73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rubin, D., Hayden, B., Huang, X., et al. 2018, ApJ, 866, 65 [Google Scholar]
- Salmon, B., Coe, D., Bradley, L., et al. 2018, ApJ, 864, L22 [Google Scholar]
- Savary, E., Rojas, K., Maus, M., et al. 2022, A&A, 666, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schaefer, C., Geiger, M., Kuntzer, T., & Kneib, J. P. 2018, A&A, 611, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schmidt, T., Treu, T., Birrer, S., et al. 2023, MNRAS, 518, 1260 [Google Scholar]
- Schuldt, S., Chirivì, G., Suyu, S. H., et al. 2019, A&A, 631, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuldt, S., Suyu, S. H., Cañameras, R., et al. 2021a, A&A, 651, A55 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuldt, S., Suyu, S. H., Meinhardt, T., et al. 2021b, A&A, 646, A126 [EDP Sciences] [Google Scholar]
- Schuldt, S., Cañameras, R., Shu, Y., et al. 2023, A&A, 671, A147 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sciortino, F., Howard, N. T., Marmar, E. S., et al. 2020, Nuclear Fusion, 60, 126014 [NASA ADS] [CrossRef] [Google Scholar]
- Sérsic, J. L. 1963, BAAA, 6, 41 [Google Scholar]
- Shajib, A. J., Birrer, S., Treu, T., et al. 2020, MNRAS, 494, 6072 [Google Scholar]
- Shajib, A. J., Treu, T., Birrer, S., & Sonnenfeld, A. 2021, MNRAS, 503, 2380 [Google Scholar]
- Shajib, A. J., Wong, K. C., Birrer, S., et al. 2022, A&A, 667, A123 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shu, Y., Bolton, A. S., Kochanek, C. S., et al. 2016a, ApJ, 824, 86 [NASA ADS] [CrossRef] [Google Scholar]
- Shu, Y., Bolton, A. S., Mao, S., et al. 2016b, ApJ, 833, 264 [Google Scholar]
- Shu, Y., Brownstein, J. R., Bolton, A. S., et al. 2017, ApJ, 851, 48 [Google Scholar]
- Shu, Y., Marques-Chaves, R., Evans, N. W., & Pérez-Fournon, I. 2018, MNRAS, 481, L136 [Google Scholar]
- Shu, Y., Cañameras, R., Schuldt, S., et al. 2022, A&A, 662, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Gavazzi, R., Suyu, S. H., Treu, T., & Marshall, P. J. 2013, ApJ, 777, 97 [Google Scholar]
- Sonnenfeld, A., Treu, T., Marshall, P. J., et al. 2015, ApJ, 800, 94 [Google Scholar]
- Sonnenfeld, A., Chan, J. H. H., Shu, Y., et al. 2018, PASJ, 70, S29 [Google Scholar]
- Sonnenfeld, A., Jaelani, A. T., Chan, J., et al. 2019, A&A, 630, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sonnenfeld, A., Verma, A., More, A., et al. 2020, A&A, 642, A148 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Suyu, S. H., & Halkola, A. 2010, A&A, 524, A94 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Suyu, S. H., Hensel, S. W., McKean, J. P., et al. 2012, ApJ, 750, 10 [Google Scholar]
- Suyu, S. H., Huber, S., Cañameras, R., et al. 2020, A&A, 644, A162 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Talbot, M. S., Brownstein, J. R., Bolton, A. S., et al. 2018, MNRAS, 477, 195 [NASA ADS] [CrossRef] [Google Scholar]
- Talbot, M. S., Brownstein, J. R., Dawson, K. S., Kneib, J.-P., & Bautista, J. 2021, MNRAS, 502, 4617 [NASA ADS] [CrossRef] [Google Scholar]
- Tanoglidis, D., Drlica-Wagner, A., Wei, K., et al. 2021, ApJS, 252, 18 [Google Scholar]
- Tohill, C., Ferreira, L., Conselice, C. J., Bamford, S. P., & Ferrari, F. 2021, ApJ, 916, 4 [NASA ADS] [CrossRef] [Google Scholar]
- Treu, T., Dutton, A. A., Auger, M. W., et al. 2011, MNRAS, 417, 1601 [Google Scholar]
- Tsallis, C. 1988, J. Statist. Phys., 52, 479 [CrossRef] [Google Scholar]
- Tsallis, C., & Stariolo, D. A. 1996, Physica A, 233, 395 [NASA ADS] [CrossRef] [Google Scholar]
- van der Walt, S., Colbert, S. C., & Varoquaux, G. 2011, Comput. Sci. Eng., 13, 22 [Google Scholar]
- Van Rossum, G. & Drake, F. L. 2009, Python 3 Reference Manual (Scotts Valley, CA: CreateSpace) [Google Scholar]
- Vega-Ferrero, J., Domínguez Sánchez, H., Bernardi, M., et al. 2021, MNRAS, 506, 1927 [NASA ADS] [CrossRef] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Wales, D. J., & Doye, J. P. K. 1997, J. Phys. Chem. A, 101, 5111 [CrossRef] [Google Scholar]
- Wang, H., Cañameras, R., Caminha, G. B., et al. 2022, A&A, 668, A162 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wong, K. C., Sonnenfeld, A., Chan, J. H. H., et al. 2018, ApJ, 867, 107 [Google Scholar]
- Wong, K. C., Suyu, S. H., Chen, G. C. F., et al. 2020, MNRAS, 498, 1420 [Google Scholar]
- Wu, J. F. 2020, ApJ, 900, 142 [NASA ADS] [CrossRef] [Google Scholar]
- Xiang, Y., & Gong, X. G. 2000, Phys. Rev. E, 62, 4473 [NASA ADS] [CrossRef] [Google Scholar]
- Xiang, Y., Sun, D. Y., Fan, W., & Gong, X. G. 1997, Phys. Lett. A, 233, 216 [NASA ADS] [CrossRef] [Google Scholar]
- Xiang, Y., Gubian, S., Suomela, B., & Hoeng, J. 2013, R Journal, 5, 13 [Google Scholar]
Python Package available here: https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.dual_annealing.html
Python Package available here: https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.basinhopping.html
This plotting tool is adapted from a code developed by Dr. Giulia Chirivì with the GLAD extension (Chirivì et al. 2020).
This tool was written by Dr. Yiping Shu (Shu et al. 2016b).
Hereafter we use always the plural for the image position(s), time delay(s), and Fermat potential difference(s) for better readability of the text.
GLEE excludes directly all pixels that are specified in the mask when summing up the χ2, while in GLAD the masked regions are incorporated implicitly in the error map through significantly boosting of their uncertainty values such that they contribute effectively nothing to the χ2.
All Tables
Overview of all 31 SuGOHI lenses modeled with GLEE & GLAD for a direct comparison to the predictions of our ResNet.
Shear and mass parameter values from our ResNet and GLEE & GLAD for the 31 HSC SuGOHI lenses. Columns 3 and 4 report, respectively, the χ2 and for the GLEE & GLAD-based model. This is followed by the lens (light and mass) center x1 and y1 (with respect to the image cutout center), the lens mass axis ratio q1m, its orientation ϕ1m, the Einstein radius θE, the external shear strength γext, and its orientation φext. The angles φ1m and φext are measured counterclockwise from the positive x-axis. This means φ1m = 0 corresponds to a lens mass distribution with major-axis along x and φext = 0 corresponds to a shear of the lensed images along the x-axis.
SIE mass and external shear parameter values obtained by modeling with GLEE & GLAD (converted to complex quantities) or with our neural network (column 2, method) for the 31 HSC SuGOHI lenses used for the direct comparison. The quoted SIE mass parameters are the lens mass center x1 and y1, the complex lens mass ellipticity ex and ey, and the Einstein radius θE. We further give values for γext,1 and γext,2.
Lens light parameter values obtained with GLEE & GLAD. We give, respectively for both the first and second Sérsic profile (column 2), the axis ratio q11, its orientation ϕ11, the effective radius reff,11, the Sérsic index n11, and the amplitudes A11 for the four different filters griz. The lens light center is assumed to match the lens mass center and is thus only quoted in Table B.2
Reconstructed source-light parameter values obtained with GLEE & GLAD. For each Sérsic profile as specified in column 2 (component c), we list the unlensed source center coordinates xs and ys, the axis ratio qs, its orientation ϕs, the effective radius reffs, the Sérsic index ns, and the amplitudes As for the four different filters griz.
Resulting image positions and source position obtained with the GLEE & GLAD model and predicted by the network.
All Figures
|
Fig. 1 Color images based on the gri filters of the 31 HSC SuGOHI lenses used for direct comparison. All images have the size of 64 × 64 pixels (i.e. ~10"× ~ 10″) and are oriented such that north is up and east is left. The name of each lens is given on the top of each image. |
| In the text | |
|
Fig. 2 Diagram of glee_auto.py, our automated procedure for galaxy-scale lens modeling with GLEE & GLAD, which is divided into four main steps indicated on the top of each panel. For the optimization we make use of simulated annealing, basin hopping, dual annealing, and Metropolis Hastings MCMC sampling. The MCMC, and also EMCEE, are used to get an estimate of the sampling covariance matrix and provide the probability distribution used as decision criteria (indicated as logP). The "amplitude test" refers to a quick check of a newly included Sérsic profile's amplitude to determine the best order of magnitude to use as an initial starting point. This example lensing system has an identification number of 42 and the filter is denoted as R. Further details on the procedure can be found in Appendix A. |
| In the text | |
|
Fig. 3 Comparison of the SIE parameter values obtained with GLEE & GLAD using SIE+γext to those values from Sonnenfeld et al. (2013, 2019) adopting mainly SIE-only. The gray shaded region in the first panel indicates the 1 pixel range. The discrepancy is mostly due to the difference in the adopted mass model in this work and in Sonnenfeld et al. (2013, 2019). |
| In the text | |
|
Fig. 4 Comparison of the SIE+γext values obtained with the traditional GLEE & GLAD method (orange histogram) and our ResNet (blue histogram). We further include a comparison where the GLEE & GLAD values are plotted against the ResNet values. |
| In the text | |
|
Fig. 5 Difference of the SIE+γext values obtained with the traditional method using GLEE & GLAD and our ResNet. |
| In the text | |
|
Fig. 6 Dependency of the Einstein radius difference on the |
| In the text | |
|
Fig. 7 Comparison of the next appearing image positions (θx,θy) predicted by adopting the traditional GLEE & GLAD model and the mass model of the ResNet in case of matching image mutliplicity. The first image A of each lensing system is excluded because of our assumption of a coincident first image. |
| In the text | |
|
Fig. B.1 Fit of lens HSCJ015618−010747. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.2 Fit of lens HSCJ020141−030946. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.3 Fit of lens HSCJ020241−064611. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.4 Fit of lens HSCJ020955−024442. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.5 Fit of lens HSCJ021737−051329. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.6 Fit of lens HSCJ022346−053418. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.7 Fit of lens HSCJ022610−042011. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.8 Fit of lens HSCJ023217−021703. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.9 Fit of lens HSCJ023322−020530. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.10 Fit of lens HSCJ085046+00390. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.11 Fit of lens HSCJ085855−010208. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.12 Fit of lens HSCJ090429−010228. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.13 Fit of lens HSCJ094427−014742. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.14 Fit of lens HSCJ120623+001507. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.15 Fit of lens HSCJ121052−011905. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.16 Fit of lens HSCJ121504+004726. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.17 Fit of lens HSCJ124320−004517. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.18 Fit of lens HSCJ125254+004356. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.19 Fit of lens HSCJ135138+002839. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.20 Fit of lens HSCJ141136−010215. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.21 Fit of lens HSCJ141815+015832. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.22 Fit of lens HSCJ142720+001916. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.23 Fit of lens HSCJ144320−012537. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.24 Fit of lens HSCJ145242+425731. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.25 Fit of lens HSCJ150021−004936. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.26 Fit of lens HSCJ150112+422113. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.27 Fit of lens HSCJ223733+005015. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.28 Fit of lens HSCJ230335+003703. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.29 Fit of lens HSCJ230521−000211. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.30 Fit of lens HSCJ233130+003733. Top to bottom: griz filters. |
| In the text | |
|
Fig. B.31 Fit of lens HSCJ233146+013845. Top to bottom: griz filters. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.