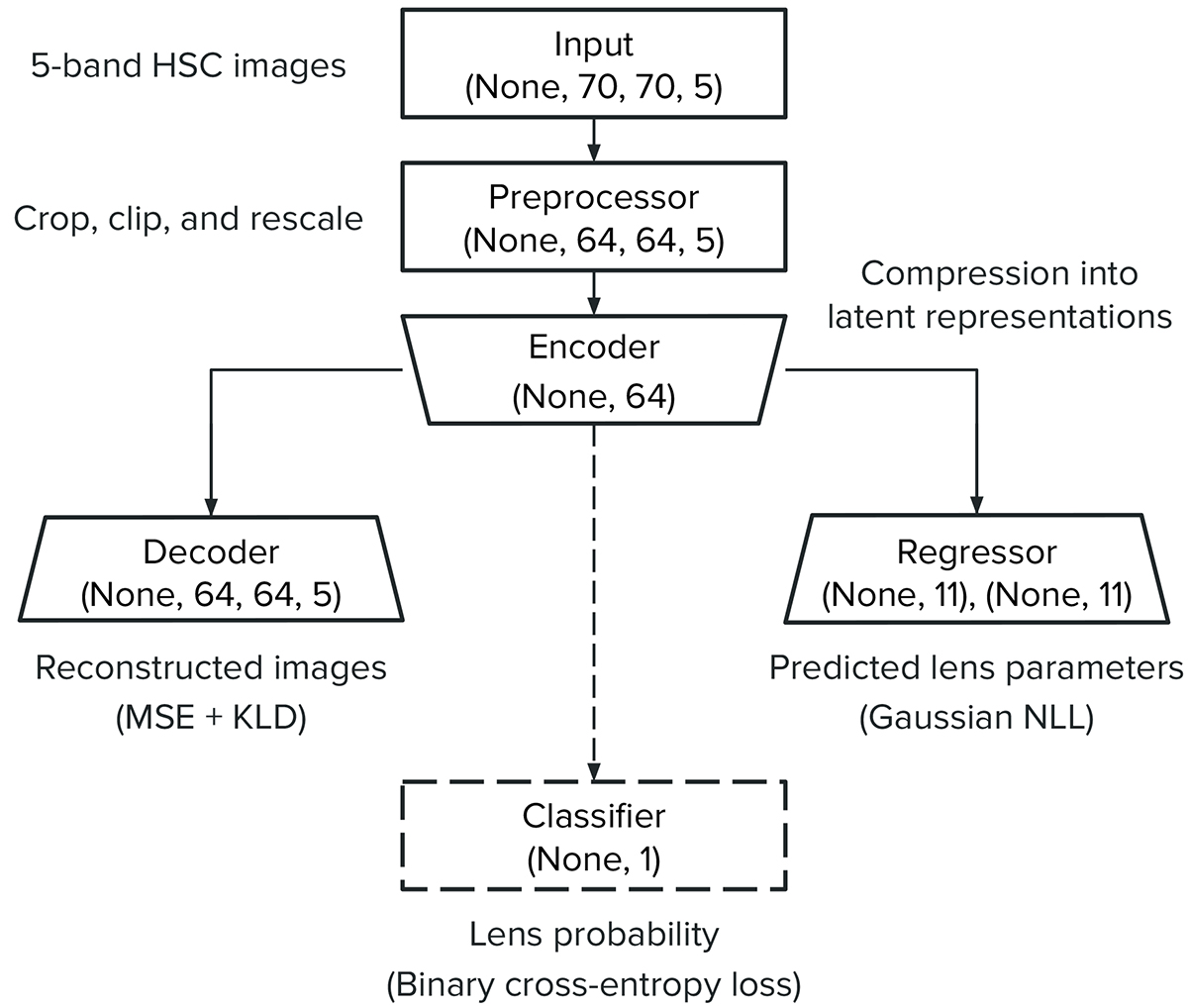
Fig. 3.
Download original image
Simplified overview of the VariLens architecture. The networks include three main components: the encoder, decoder, and regressor. The input consists of a batch of 5-band HSC images, initially sized at 70 × 70 pixels. The batch size is flexible, with “None” indicating it can vary based on user specifications. These images are cropped, clipped, and rescaled to standardize pixel values before reaching the encoder. The encoder subsequently takes the preprocessed 64 × 64 pixel images and compresses them into a 64-dimensional latent representation. The decoder then reconstructs this latent representation back into the original cropped 64 × 64 pixel images. At the same time, the regressor estimates lens and source parameters, guiding the latent distribution to ensure it is physics-informed. Once the networks are fully trained, the decoder and regressor are removed and replaced by a single dense layer serving as the classification head. Transfer learning is then applied to fine-tune the classifier, optimizing it to effectively distinguish between lensing and non-lensing systems.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.