| Issue |
A&A
Volume 693, January 2025
|
|
|---|---|---|
| Article Number | A105 | |
| Number of page(s) | 14 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202348581 | |
| Published online | 09 January 2025 | |
Classification of real and bogus transients using active learning and semi-supervised learning
1
School of Artificial Intelligence and Data Science, University of Science and Technology of China,
Hefei
230026,
China
2
CAS Key Laboratory for Research in Galaxies and Cosmology, Department of Astronomy, University of Science and Technology of China,
Hefei
230026,
China
3
School of Astronomy and Space Science, University of Science and Technology of China,
Hefei
230026,
China
4
Deep Space Exploration Laboratory,
Hefei
230088,
China
5
McWilliams Center for Cosmology, Department of Physics, Carnegie Mellon University,
5000 Forbes Ave,
Pittsburgh,
15213,
PA,
USA
6
Shanghai AI Laboratory,
Shanghai
200232,
China
7
Purple Mountain Observatory,
Nanjing
210023,
China
★ Corresponding authors; This email address is being protected from spambots. You need JavaScript enabled to view it.
; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
13
November
2023
Accepted:
1
December
2024
Abstract
Context. The mounting data stream of large time-domain surveys renders the visual inspections of a huge set of transient candidates impractical. Techniques based on deep learning-based are popular solutions for minimizing human intervention in the time domain community. The classification of real and bogus transients is a fundamental component in real-time data processing systems and is critical to enabling rapid follow-up observations. Most existing methods (supervised learning) require sufficiently large training samples with corresponding labels, which involve costly human labeling and are challenging in the early stages of a time-domain survey. One method that can make use of training samples with access to only a limited amount of labels is highly desirable for future large time-domain surveys. These include the forthcoming 2.5-meter Wide-Field Survey Telescope (WFST) six-year survey and the Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST).
Aims. Deep-learning-based methods have been favored in astrophysics owing to their adaptability and remarkable performance. They have been applied to the task of the classification of real and bogus transients. Unlike most existing approaches, which necessitate massive and expensive annotated data, we aim to leverage training samples with only 1000 labels and discover real sources that vary in brightness over time in the early stages of the WFST six-year survey.
Methods. We present a novel deep learning method that combines active learning and semi-supervised learning to construct a competitive real-bogus classifier. Our method incorporates an active learning stage, where we actively select the most informative or uncertain samples for annotation. This stage aims to achieve higher model performance by leveraging fewer labeled samples, thus reducing annotation costs and improving the overall learning process efficiency. Furthermore, our approach involves a semi-supervised learning stage that exploits the unlabeled data to enhance the model’s performance and achieve superior results, compared to using only the limited labeled data.
Results. Our proposed methodology capitalizes on the potential of active learning and semi-supervised learning. To demonstrate the efficacy of our approach, we constructed three newly compiled datasets from the Zwicky Transient Facility, achieving average accuracies of 98.8, 98.8, and 98.6% across these three datasets. It is important to note that our newly compiled datasets only work in terms of testing our deep learning methodology and there may be a potential bias between our datasets and the complete data stream. Therefore, the observed performance on these datasets cannot be assumed to directly translate to the general alert stream for general transient detection in actual scenarios. The algorithm will be integrated into the WFST pipeline, enabling an efficient and effective classification of transients in the early period of a time-domain survey.
Key words: techniques: image processing
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Large-scale surveys are generating considerable data that record abundant dynamic events in the sky, as exemplified by Panoramic Survey Telescope and Rapid Response System (Pan-STARRS; Chambers et al. 2016), High Cadence Transient Survey (HiTS; Förster et al. 2016), Dark Energy Survey (DES; Dark Energy Survey Collaboration 2005), Zwicky Transient Facility (ZTF; Bellm et al. 2018), forthcoming 2.5-meter Wide-Field Survey Telescope (WFST; Wang et al. 2023) six-year survey, and Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST; Abell et al. 2009). Real detections that interest astronomers are events that vary in brightness over time, including variable, transient, and moving sources. It is critical to discover these real sources to enable rapid follow-up scientific observations (e.g., Hu et al. 2022).
In most surveys, three images are utilized to discover real detections (Ayyar et al. 2022; Duev et al. 2019; Reyes-Jainaga et al. 2023): (1) a reference image, which is an archival observation of the sky; (2) a science image, which is a recent image of the same sky area and the same band as the reference image; and (3) a difference image, which is the result of subtracting the reference image from the science image. In principle, real detections can be discovered by the difference image with brightness residual (Hosenie et al. 2021). However, most of the detection candidates detected by brightness residual are bogus detections caused by poor image subtraction, atmospheric dispersion, optical ghosting, etc. To filter out these bogus sources, an effective real-bogus classifier is essential for large sky surveys.
The mounting data stream of large time-domain surveys renders astronomers unable to visually inspect source candidates manually (Killestein et al. 2021; Makhlouf et al. 2022), requiring new tools to process the overwhelming data (Bailey et al. 2007; Brink et al. 2013; Goldstein et al. 2015; Sedaghat et al. 2017; Wright et al. 2015). Deep-learning-based techniques have led to great progress in computer vision (He et al. 2017; Ren et al. 2015) and serve as popular solutions for minimizing human intervention in the time-domain community (Duev et al. 2019; Gomez et al. 2020; Turpin et al. 2020). There are some methods (Cavanagh et al. 2021; Goode et al. 2022; Reyes et al. 2018) using deep learning to tackle this real-bogus classification task to detect real sources. Several approaches have constructed their neural network architectures such as BRAAI (Duev et al. 2019), MeerCRAB (Hosenie et al. 2021), and Deep-HiTS (Cabrera-Vives et al. 2017). Moreover, some works have presented integrated systems, such as combining classifications from volunteers participating in the science project with those from a convolutional neural network (Wright et al. 2017), including majority voting of boosting, random forest, and deep neural networks (Morii et al. 2016). The aforementioned works in the real-bogus classification task displayed a commendable performance, but they are still supervised learning approaches built on sufficiently large training samples with corresponding labels. This means they require costly human annotation and are challenging in the early period of a time-domain survey. Furthermore, the model trained on data from another telescope should not be used directly, because data from different telescopes violate independent and identically distributed (i.i.d) which limits the consistency and high performance of classification (Hosenie et al. 2021). Therefore, a method that can utilize training samples with only a few available labels is highly desirable for future large time-domain surveys such as the WFST and the LSST.
In this paper, we propose RB-C1000, a novel deep learning method using active learning and semi-supervised learning that obtains competitive real-bogus classifier results with only 1000 labels. We also have constructed three new datasets from the ZTF to demonstrate the effectiveness of our approach. It should be acknowledged that the three datasets only work in testing our deep learning method. Therefore, the observed performance on these datasets may not accurately represent real world scenarios. The remaining parts of our paper are organized as follows. In Section 2, we describe the construction pipeline of newly compiled datasets. Afterward, we provide a brief introduction to active learning and semi-supervised learning and we present the architecture of our novel deep learning method RB-C1000 in Section 3. The experimental results are provided in Section 4. Finally, we summarize our work in the last section.
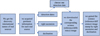 |
Fig. 1 Process of collecting real sources. The outputs of this process are real sources and each real detection includes a 63 × 63 science image stamp, the corresponding 63 × 63 reference image stamp, and the corresponding 63 × 63 difference image stamp. |
2 Data
We have constructed new real-bogus classification datasets from the Zwicky Transient Facility (ZTF) to verify the effectiveness of our approach. To explore the effect of bands on the real-bogus results, we collected two single-band datasets (ZTF-NEWg: g-band, ZTF-NEWr: r-band) and one mixed-band dataset (ZTF- NEWm: taking half of the g-band data and half of the r-band data). The data collection process is divided into real source collection and bogus detection collection. The construction pipeline of newly compiled datasets is presented below.
Real sources: To obtain real detections, we curated the discovery international names1 of real sources discovered by the ZTF from March 1, 2019 to March 1, 2022, such as ZTF20acmvsdj, ZTF21acjanhz. Through the collected names, we acquired pertinent information2 for each real source, including detection dates (observation UT date and time), right ascension, and declination. Generally, each real detection is observed and detected by ZTF multiple times during its lifetime. To prevent information leaks during the data partitioning process for training and evaluation, we chose one of the detection dates for each real source (Reyes-Jainaga et al. 2023). Subsequently, we downloaded the corresponding science (reference and difference) image3 of the specific detection date we chose and gained the science (reference and difference) image stamp (Bertin 2010) by the right ascension and the declination. The process of collecting real sources is shown in Figure 1. Finally, we obtained a total of 13 055 g-band real sources and 13 006 r-band real sources. We randomly removed 55 sources from the 13 055 g-band real sources to obtain the exact 13 000 g-band real detections as the real part of the ZTF-NEWg dataset. Similarly, we randomly deleted six detections from 13 006 r-band real sources as the real part of the ZTF-NEWr dataset. To increase the challenge of our datasets, out of 13 000 real sources collected in the g-band, 4000 sources were dated with their first detection dates, as sources from the initial detection date are typically fainter. The remaining 9000 sources were dated with their randomly sampled detection dates. The collection of real detections in the r-band followed the same pattern.
Bogus detections: Initially, we downloaded the science (reference and difference) images on a specific day of specific fields in the g-band and r-band. We chose fields 774 to 780 on January 2, 2021 for the purposes of this paper. Each field contains 64 triplet images per band, with each triplet comprising a two-degree science image, its corresponding two-degree reference image, and the corresponding two-degree difference image, resulting in 896 sets of triplet images. Each downloaded image had dimensions of 3080 pixels × 3072 pixels. Subsequently, we obtained the pairs of right ascension and declination for detection candidates in each difference image by source extractor (Bertin & Arnouts 1996). We gained the science (reference and difference) image stamps centered at the obtained coordinates and the size of each science (reference and difference) image stamp is 63 pixels × 63 pixels. To ensure the diversity of bogus sources, we conducted a random selection process. From the thousands of stamp candidates available for each two-degree triplet, we randomly chose approximately 75 triplet image stamps. The ratio of bogus detections to real detections in each two-degree triplet is overwhelmingly skewed, with bogus detections comprising approximately 99 percent of the total (Killestein et al. 2021). Given this significant disparity, the chosen sampling approach is justified. The pipeline of collecting bogus detections is shown in Figure 2.
After completing the above steps, we obtained a g-band dataset (ZTF-NEWg) and a r-band dataset (ZTF-NEWr) respectively. The mixed-band dataset selected half of the samples from the ZTF-NEWg and the ZTF-NEWr (shown in Figure 3). The three newly compiled datasets for the real-bogus classification task, each with 13 000 real sources and 30 000 bogus detections, as shown in Figure 4. The top left part of the figure depicts two real sources in g-band and each row represents a real detection, showing the science image stamp, the reference image stamp, and the difference image stamp of the real detection from left to right respectively. Similarly, the bottom left, the top right, and the bottom right of this figure display two real detections in the r-band, two bogus detections in the g-band, and two bogus detections in the r-band, respectively. The distribution of magnitudes for real and bogus sources of the three datasets are shown in Figure 5.
It should be noted that there is a potential bias between our datasets and the complete data stream, which exists in both real and bogus sources. Regarding real sources, the kinds of real detection are not diverse. They only consist of supernovas (SNe) as reported to the Transient Name Server (TNS) and lack large stellar flares, AGN variability, SNe below the nominal detection limit, and so on. For bogus detections, they might contain a few real detections, since they are randomly drawn from detection candidates. Our newly compiled datasets only work in terms of testing our deep-learning algorithm, as well as the effectiveness of each component in our method. Therefore, the performance of the three datasets cannot be assumed to apply to the general alert stream for detecting general transients in actual sky surveys.
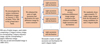 |
Fig. 2 Pipeline of gathering bogus sources. The outputs of this pipeline are bogus detections and each bogus detection includes a 63 × 63 science image stamp, the corresponding 63 × 63 reference image stamp, and the corresponding 63 × 63 difference image stamp. |
3 Method
3.1 Active learning and semi-supervised learning
Active learning: the purpose of active learning (Prince 2004; Settles 2009) is to use as few sample annotations as possible to achieve the best performance of the model. In many cases, it is impractical to obtain a large number of labeled samples due to limited resources. Active learning addresses this challenge by selecting the most informative samples for annotation to maximize the performance of the model. Specifically, there are a few labeled samples in the whole dataset, M << N, where M and N represent the number of labeled and total samples in the dataset, respectively. The active learning process begins by training an initial model using all available labeled samples. Then experts annotate the K most challenging samples from the unlabeled data, as determined by the initial model’s predictions. Finally, we leverage the (M + K) labeled samples to train a supervised or semi-supervised model. By selectively annotating the most informative samples, active learning integrates artificial experience and additional expert knowledge into the model, leading to improving the model’s ability to make accurate predictions.
Semi-supervised learning: Semi-supervised learning (Zhu 2005; Chapelle et al. 2009) has received increasing attention in recent years because human annotation is costly. The goal of semi-supervised methods is to enhance experimental outcomes by using unlabeled samples, as these data provide valuable distributional information. To be specific, regardless of whether the samples are labeled or not, they all originate from the same distribution. Numerous classic approaches have emerged in the field of semi-supervised learning such as semi-supervised support vector machines (Bennett & Demiriz 1998; Joachims 1999) and graph-based semi-supervised learning (Yang et al. 2016). In this article, we employ the technique of pseudo-labeling. Concretely, after training a model by (M + K) labeled samples, the model assigns a pseudo-label and a corresponding confidence score to each remaining sample in the dataset. And then a new model is retrained using both the labeled samples and the unlabeled data whose confidence scores exceed a predetermined threshold. By leveraging the power of unlabeled data, the retrained model can effectively harness the valuable information present in the unlabeled samples, leading to enhanced performance without incurring additional labor costs.
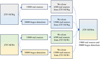 |
Fig. 3 Construction pipeline of the ZTF-NEWm dataset. Both the ZTF-NEWg dataset and the ZTF-NEWr dataset contain 13 000 real sources and 30 000 bogus sources. We selected 6500 real sources from the ZTF-NEWg dataset and 6500 real detections from the ZTF-NEWr dataset. The 13 000 selected samples were combined to form the real source component of the ZTF-NEWm dataset and above them contained at least 4000 first detection sources. Similarly, we randomly chose 15 000 bogus sources from the ZTF-NEWg dataset and 15 000 bogus detections from the ZTF- NEWr dataset. These chosen samples were then combined to create the bogus detection component of the ZTF-NEWm dataset. By combining the real source and bogus detection components, we obtained a dataset (ZTF-NEWm) consisting of 13 000 real sources and 30 000 bogus detections. |
 |
Fig. 4 Examples of 63 pixels × 63 pixels triplet image stamps of our compiled datasets. The top-left part of the figure depicts two real sources in g-band and each row represents a real detection, showing the science image stamp, the reference image stamp, and the difference image stamp of the real detection from left to right respectively. Similarly, the bottom-left, top-right, and bottom-right of this figure display two real detections in the r-band, two bogus detections in the g-band, and two bogus detections in the r-band respectively. |
 |
Fig. 5 Distribution of magnitudes for real and bogus sources of the three datasets. |
 |
Fig. 6 Architecture of our method. In the ITS, each labeled sample undergoes convolutional neural network processing to train an initial model. Subsequently, domain experts annotate the K most challenging samples, as determined by the initial model’s judgments. During the ALS, we employ the combined set of (M + K) labeled samples to train an active training model. From this model, we select the top V samples with high-confidence predictions and assign pseudo-labels to them. In the SSLS, we utilize the expanded dataset of (M + K + V) samples to train a semi-supervised training model. This process is repeated for a total of R iterations to obtain the final results. |
3.2 RB-C1000 architecture
The pipeline of our approach is shown in Figure 6. Distinguishing itself from other methods, our approach is tailored to scenarios, where only a limited number of labeled samples are available (M ≪ N, where M and N represent the number of labeled and total samples in the dataset respectively). Inspired by active learning and semi-supervised learning, our novel deeplearning method, RB-C1000, consists of three components: the initial training stage (ITS), the active learning stage (ALS), and the semi-supervised learning stage (SSLS). To minimize manual annotation, the ITS utilizes the idea of active learning which aims to label the K hardest samples from the pool of unlabeled data as determined by the initial model’s predictions. The objective of the ALS is to search for the V most confident samples from unlabeled data, as assessed by the active training model, to aid the training process in the SSLS. During the SSLS, we iterate the training of a semi-supervised model multiple times to obtain promising and accurate results. Each module works together to achieve performance improvements and further details of each stage are elaborated as follows:
Initial training stage: In the ITS, every labeled sample is passed through a convolutional neural network (CNN; LeCun et al. 2016) to train an initial supervised model. Following the training process, the remaining (N − M) samples are sent into the initial model, producing (N − M) 2-dimensional results, as the left of Figure 6 shows. The first and the second dimensions of each result represent the probability of bogus detection and real detection respectively, with their sum being equal to 1. Subsequently, we collected the maximum value from each 2dimensional result of the (N−test − M) unlabeled samples and get (N−test − M) one-dimensional (1D) results. These (N−test − M) 1-dimensional results represent the confidence of the initial model’s prediction and we arrange these results in ascending order. Here, N−test denotes the count of the dataset excluding test samples. Finally, we selected the top K samples, which are determined to be the hardest by our initial model (i.e., the samples with probabilities of bogus source and real detection both tending toward 0.5), and annotate them, integrating the artificial experience. Although the initial model may not achieve high performance with only a few labeled samples, it guides us in identifying challenging samples, thereby reducing the cost of expert labeling. The annotation process is illustrated by the first arrow in Figure 7.
Active learning stage: After obtaining the labels for the K hard samples, we used the (M + K) labeled data to train an active training model, which has the same structure as the initial model, during the ALS. Following the training phase, we infer the results for the remaining (N − M − K) samples as well. Unlike the ITS, we extracted the higher dimension of each two-dimensional (2D) result as a confidence score. However, for the (N−test − M − K) 1-dimensional scores, we arrange them in descending order. As illustrated in the second arrow in Figure 7, We chose the top V samples, which correspond to the highest confidence samples according to the active training model (i.e., the samples with probabilities of bogus detection or real source trending toward 1) to assign pseudo-labels. These pseudo-labels are predicted labels generated by the active training model. The overall operation in the ALS is illustrated in the middle of Figure 6. Although the active training model may not achieve satisfactory results with only (M + K) labeled samples, it exhibits a certain discriminative ability. Therefore, the pseudo-labels of the samples with confidence scores surpassing a predetermined threshold τ can be considered correct judgments.
Semi-supervised learning stage: During the SSLS, the (M + K + V) samples are employed to train a semi-supervised training model, as illustrated in the right portion of Figure 6. This model has been designed with the same structure as the initial model and the active training model. Following the training process, the (N − M − K) unlabeled samples are sent to the semi-supervised training model to obtain the final predicted results. This stage can be iterated for R times, as depicted in the right section of Figure 7. Specifically, after training the semisupervised training model in the r-th iteration, we selected the samples from the (N−test − M − K) unlabeled data that surpass a predetermined threshold τ and assigned them pseudo-labels. Subsequently, we retrained the semi-supervised training model from scratch in the (r + 1)-th iteration. By selecting the best R iterations, we have been able to achieve competitive results. Algorithm 1 summarizes our RB-C1000.
By adopting this comprehensive approach, we can leverage the strengths of both initial model training, active learning, and semi-supervised learning. This iterative process allows us to refine the model’s performance and enhance the accuracy and reliability of the final classification results.
 |
Fig. 7 Process of labeling or pseudo-labeling for unlabeled samples. Following the training phase in the ITS, we select K hard samples from the pool of (N−test − M) unlabeled data and label them with expert annotations. Subsequently, after the training phase in the ALS, we choose V over-threshold samples from (N−test − M − K) unlabeled data to assign pseudo-labels. Moving forward, after the training process in SSLS in the r-th iteration, we again select V samples from the pool of (N−test − M − K) unlabeled data that exceed the predetermined threshold and assign pseudo labels. In the (r + 1)-th iteration, we retrain the semi-supervised training model from scratch, refining the performance of our models in subsequent iterations. |
4 Experiments
In this section, we provide a brief overview of the experimental settings used in our experiments. We then describe the metric used for evaluating the performance of our classification task. Finally, we show the results of our real-bogus classifier, which leverages both active learning and semi-supervised learning techniques.
4.1 Experimental settings
We utilized three new complied datasets we collected to demonstrate the effectiveness of our method. Each dataset comprises 43 000 samples, consisting of 13 000 real sources and 30 000 bogus detections. Specifically, the ZTF-NEWg dataset, which consists of 43 000 g-band triplet image stamps, and the ZTF- NEWr dataset, which comprises 43 000 r-band triplet image stamps. Additionally, the ZTF-NEWm dataset contains a combination of 21 500 g-band triplet image stamps and 21 500 r-band triplet image stamps which are randomly sampled by the ZTF-NEWg and the ZTF-NEWr, respectively. Each triplet image stamp within the datasets consists of three components: a 63 pixels × 63 pixels science image stamp, the corresponding 63 pixels × 63 pixels reference image stamp, and the corresponding 63 pixels × 63 pixels difference image stamp. Here, each pixel corresponds to 1.012 arcseconds.
// ****************************************
// The initial training stage
// ****************************************
Input: Initial supervised model: finit; Data: total N samples, M labeled samples, Ntest test samples, (N−test − M) unlabeled samples, the count of challenging samples K
Training the initial supervised model finit with
Output: The K hard samples from (N−test − M) unlabeled data judged based on finit ; The results of Ntest test samples
// ****************************************
// The active learning stage
// ****************************************
Input: Active training model: fact; predetermined threshold τ; Data: total N samples, M labeled samples, Ntest test samples, the
Training the active training model fact with (
M +K ) labeled dataSelecting the V samples from (N−test − M − K) unlabeled data with confidence scores surpassing a predetermined threshold τ based on fact and assign pseudo-labels to them
Output: The V highest confidence samples and their corresponding pseudo labels; The results of Ntest test samples
// ****************************************
// The semi-supervised learning stage
// ****************************************
Input: Semi-supervised training model: fsemi ; predetermined threshold τ; Data: total N samples, (M + K) labeled samples, Ntest test samples, The
for r = 1; r ≤ R; r + + do

Output: The results of Ntest test samples
In our active and semi-supervised setting, we allocated 10% of each dataset for testing (Ntest = 4300). The amount of initial labeled data and the count of challenging samples are M = 900 and K = 100, respectively. We partitioned the (M + K) = 1000 samples into training and validation sets, with 60% for training and 40% for validation. The validation set serves as a tool for selecting model parameters during the training process of a real and bogus classification model. By evaluating the model’s performance on the validation set, we can identify the model parameters that yield the best results on the validation set and save these optimal parameters as the final real and bogus classification model parameters.
We implemented our method based on the Pytorch (Paszke et al. 2017) and adopted a Nvidia Tesla v100 GPU with a batch size of 256 for training. For the backbone architecture, we employed ResNet-18 (He et al. 2016) and made appropriate modifications to adjust the output dimension for the classification of real and bogus transients. Each sample from the datasets has a size of H × W × 3, where H and W represent the height and width of image stamps respectively. Here, the number 3 represents the count of channels, corresponding to the science image stamp, the reference image stamp, and the difference image stamp, each contributing one channel. We used H = 63 pixels and W = 63 pixels here. To adapt the images to the input dimension of ResNet-18, we interpolated all images to a uniform size of 224 pixels × 224 pixels × 3. To improve the flipping invariance, we applied two data augmentation operation schemes on the training samples. One is random horizontal flipping, the other is random vertical flipping. Both operations have a probability of 0.5. We train the model by cross entropy loss in 100 epochs with an Adam optimizer whose learning rate is 2e-4. The predetermined threshold τ is 95%. We repeated the SSLS stage R = 3 times.
We have observed that achieving the classification of real and bogus transients is possible by solely utilizing the difference image stamp or by employing the two-channel image stamp (the one-channel science image stamp and the one-channel reference image stamp). The existing approach (Acero-Cuellar et al. 2022) on the real-bogus classifier provides evidence that a higher number of channels leads to improved classification performance. In our approach, we aim to obtain more precise results during the early stage of time-domain surveys. Therefore, we conduct experiments in our method using three-channel images. A summary of the basic parameters is presented in Table 1.
4.2 Performance indicators
The essence of the classification of real and bogus transients is a classification problem. Thus, we can evaluate the performance with precision, accuracy, recall, F1 score, Matthews correlation coefficient (MCC), and average precision (AP), which are commonly used in classification problems. AP is the area under the precision-recall (PR) curve, and the specific formulas for precision, accuracy, recall, F1 score, and MCC are as follows:
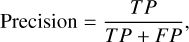 (1)
(1)
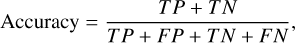 (2)
(2)
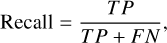 (3)
(3)
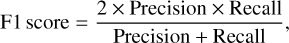 (4)
(4)
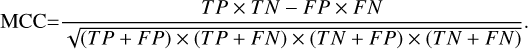 (5)
(5)
where T P (true positive) indicates the real sources which are correctly classified as real and FN (false negative) denotes the real sources that are classified as bogus; FP (false positive) means the bogus detections that are classified as real and TN (true negative) indicates the bogus detections which are correctly classified as bogus. The definitions of TN, FP, FN, and T P are shown in Figure 8.
Precision is the probability of real sources among the real sources judged by our network. Accuracy indicates the percentage of correctly classified in the total data. Recall represents the proportion of real sources in the whole dataset that are identified by our network. F1 score and MCC are comprehensive evaluation indices. The closer all these performance indicators are to 1, the better the method’s performance.
A summary of the basic parameters in Section 4.1.
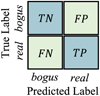 |
Fig. 8 Definitions of TN, FP, FN, and TP. |
4.3 Test results
We evaluated the performance of our method on three newly compiled datasets. To verify the effectiveness of our algorithm, each experiment was repeated five times. Both the mean and standard deviation of the results obtained over the five trials were then reported.
The performance results of our model are presented in Table A.1, where we offer the precision, accuracy, recall, F1 score, Matthews correlation coefficient (MCC), and average precision (AP) as performance measurement indicators. The overall performance measurement was obtained by summing the values of these six indicators, as depicted in the last column of Table A.1. Taking the ZTF-NEWg dataset as an example, we see that in the initial training stage (ITS), using 900 labeled samples, our model achieved an overall performance of 572.2%; the accuracy and recall were 96.7 and 95.5%, respectively. This result demonstrates that our model can effectively distinguish real detections and bogus sources with a limited number of labeled data. In the active learning stage (ALS), we incorporated an additional set of the K challenging samples, which were determined by the model trained in the ITS. These K samples were labeled by experts. By utilizing the (M + K = 1000) labeled samples for training in the ALS, the overall performance increased by 13.9% compared to the overall result of the ITS. We note that the observed improvement of 13.9% cannot be solely attributed to active learning, as increasing the amount of training data itself may also contribute to enhanced performance. The effect of active learning is depicted in the next paragraph and the experiment of active learning is shown in Table A.2. In the semi-supervised learning stage (SSLS), we employed V high- confidence samples, in addition to the labeled (M + K) samples, to train the semi-supervised training model. By repeating the SSLS process for R = 1,2, 3, 4, and 5 iterations, we achieved respective overall performance indicators of 588.2, 589.9, 590.2, 589.8, and 589.9%. This iterative process in the SSLS allowed us to refine the model’s performance and enhance the accuracy and reliability of the final classification results. We notice that SSLS (R = 3) often shows the best performance on the overall indicator on these three datasets we collected, so we set R = 3 in this paper and the remaining experiments (in Tables A.2, A.3, A.5, A.4, and A.7) are all based on the condition R = 3.
Effect of active learning: we evaluated the improvement made by active learning in Table A.2. For each dataset, the results (given in rows 1 and 2) were obtained by randomly selecting K samples and selecting K hard samples from (N−test − M) unlabeled data, respectively. The overall performance result in the last column shows an improvement of 1.4 %, 3.4 %, and 7.2% for the ZTF-NEWg, the ZTF-NEWr, and the ZTF-NEWm, respectively, by active learning. Therefore, by selectively annotating the most informative samples, active learning aims to achieve higher model performance by leveraging fewer labeled samples, thus reducing annotation costs and improving the overall learning process efficiency.
Effect of semi-supervised learning: We aim to quantify the contribution of semi-supervised learning. The results (presented in rows 2 and 5 of each dataset in Table A.1) demonstrate the gains achieved through the SSLS. We observe improvements of 4.1, 8.7, and 7.3% in the overall performance of the three datasets, respectively. These results indicate that the SSLS effectively utilizes the unlabeled data to enhance the model’s performance, surpassing the performance obtained using only the limited labeled data. The iterative process employed in the SSLS allows for a continuous refinement of the model’s performance, ultimately improving accuracy and reliability in the final classification results.
Effect of the count of unlabeled data usage: As we know, the number of samples of each dataset is N = 43 000, where 10% (Ntest = 4300) is reserved for testing. The count of labeled samples for initial training and the number of challenging samples are M = 900 and K = 100, respectively. All other 33 770 samples except Ntest , M, and K are unlabeled data. We explored the effect of the amount of unlabeled data usage on performance. We utilized 5000 samples (the remaining 28 770 unlabeled samples are not used), 10 000 samples (the remaining 23 770 unlabeled samples are not used), 15 000 samples (the remaining 18 770 unlabeled samples are not used), and 20 000 samples (the remaining 13 770 unlabeled samples were not used) of the unlabeled 33 770 samples. The results (depicted in Table A.3) demonstrate the overall performance achieved on the ZTF- NEWg dataset, namely, is 589.7, 590.2, 589.6, and 586.1%, respectively. Similarly, for the ZTF-NEWr dataset, we obtained the overall performance score of 589.7, 590.1, 590.5, and 588.1%. The overall performance results are 587.5, 587.5, 586.7, and 587.0% on the ZTF-NEWm dataset. For the ZTF-NEWg, utilizing 10 000 unlabeled samples offered the best performance. Using 15 000 unlabeled data offered the best overall indicator on the ZTF-NEWr. For the ZTF-NEWm, 5000 unlabeled samples or 10 000 unlabeled samples achieved competitive results. It can be seen from experiments that 10 000 unlabeled sample usage size often give the best results. Note that for each additional usage of 5000 unlabeled data, the training time experiences an approximate increase of half an hour. Given this consideration, it is feasible to select either 5000 or 10 000 unlabeled data usage. All other experimental results (presented in Tables A.1, A.2, A.5, A.4, and A.7) were obtained using the case of 10 000 unlabeled data usage. This choice strikes a reasonable balance between leveraging the benefits of unlabeled data and managing the associated training time.
Effect of the labeled sample quantity (M + K): We explore the impact of the labeled sample quantity (M + K) on performance, as presented in Table A.5 and depicted in the left part of Figure 9. It can be seen that no matter which dataset, an increasing quantity of (M + K) leads to a progressive improvement in overall performance. The overall performance experiences a significant enhancement when the number of annotations rises from 200 to 500. However, once the annotation count surpasses 1000, the rate of improvement in overall performance begins to slow down. Therefore, we opt for an overall number of tags of (M + K) = 1000, taking into consideration both the labeling cost and performance factors. All experiments presented in Tables A.1, A.2, A.3, A.4, and A.7 are all based on the condition (M + K) = 1000.
Effect of stability on different selections of M and K: We tested our model’s stability on the ZTF-NEWm dataset as an example, which is the most challenging one of our three datasets. We explore different selections of M and K, which represent the initial labeled quantity and most challenging labeled samples’ quantity, respectively, as shown in Table A.5 and Figure 9. It can be shown that our algorithm’s results tend to stabilize once M ≥ 400. The highest overall performance is achieved at ratios of 0.9, resulting in performances of 587.5%. Therefore, we choose a ratio of 0.9, which is employed in Tables A.1, A.2, A.3, A.5, and A.7.
The efficiency of our approach: We explored the extent to which annotations from fully supervised techniques can match the performance of RB-C1000. We also used ZTF-NEWm as an example. We trained a fully supervised model using ResNet18 while maintaining the test set size equivalent to RB-C1000. We conducted fully supervised experiments with randomly labeled sets comprising 1000, 1500, 2000, 2500, and 3000 annotations, while maintaining the ratio of real to bogus samples, with the results shown in Table A.6. Our methodology yields results surpassing those of the fully supervised model employing 2500 annotations, despite using only 1000 labels available. The efficiency of our RB-C1000 is significantly higher than the random annotation of the fully supervised model.
Effect of bands on performance: We evaluated the impact of bands on performance. Tables A.1 and A.2 demonstrate that the impact of our method on the ZTF-NEWm dataset is more pronounced compared to the single-band datasets. The transition from a single-band dataset to a dual-band dataset introduces higher diversity and complexity. Our approach proves to be more effective for challenging data. Additionally, we conducted an evaluation of the performance when training on the g-band and r-band datasets separately, and then testing on the opposite band. Specifically, for each model trained on the g-band dataset, we randomly selected 10% of the data from the r-band dataset as the test samples, and vice versa. The results (presented in Table A.7) demonstrate that the performance is satisfactory when training on the g-band and testing on the r-band; conversely, the performance is notably poorer. These results show the importance of not directly applying a model trained on one band to another band. The discrepancy in performance between training and testing on different bands suggests that the models trained on one specific band are not robust enough to be aptly generalized to the other band.
Discussion: Our RB-C1000 is improved by active learning and semi-supervised learning. For the ZTF-NEWg, the ZTF- NEWr, and the ZTF-NEWm, the improvement made by active learning is 1.4, 3.4, and 7.2% respectively and the improvement made by semi-supervised learning is 4.1, 8.7, and 7.3% respectively. The efficiency of our RB-C1000 is significantly higher than the random annotation of the fully supervised model. Our methodology yields results surpassing those of the fully supervised model employing 2500 annotations, despite using only 1000 labels available. We note that the performance of the second row of ZTF-NEWr in Table A.1 is slightly worse than that of the first row. We realize that adding difficult samples may degrade the performance, but after adding active learning and semi-supervised learning, the advantage of difficult samples on performance is revealed again.
We present the results of the confusion matrices obtained using RB-C1000 on the three collected datasets, namely ZTF- NEWg, ZTF-NEWr, and ZTF-NEWm, in Figure 10. The upper half of Figure 10 showcases the unnormalized results, while the lower half displays the normalized results. The unnormalized results provide a direct representation of the raw classification outcomes, while the normalized results offer a normalized view, accounting for the distribution of TP (true positive), FN (false negative), FP (false positive), and FN (false negative) predictions. It is important to note that, as mentioned in Section 2, there may be a potential bias between our datasets and the complete data stream. Therefore, the performance observed on these datasets may not directly generalize to real-world scenarios involving general transient detection. Our RB-C1000, which incorporates active learning and semi-supervised learning techniques, demonstrates significant potential in effectively classifying real and bogus sources. Active learning empowers deep learning algorithms to actively acquire new labeled data, leading to improved model performance, reduced labeling effort, and more cost-effective data annotation. Semi-supervised learning provides an effective approach for leveraging large amounts of unlabeled data, improving model performance, and reducing labeling effort and costs. The active-learning technique and the semi-supervised learning technique are valuable techniques in situations where the availability of labeled data is limited.
 |
Fig. 9 (a) Relationship between the quantity of labeled samples (M + K) and the overall performance. (b) Relationship between different selections of M and K and the overall results in the ZTF-NEWm. Figures (a) and (b) only display the mean value of the overall performance. |
 |
Fig. 10 Results of confusion matrices using RB-C1000 on our three datasets. The top half of this figure represents the unnormalized results, which provide a direct representation of the raw classification outcomes. The lower half of this figure displays the normalized results. |
5 Summary and conclusion
In this paper, we propose RB-C1000, a novel deep-learning method using active learning and semi-supervised learning, which obtains a highly promising real-bogus classifier capability with only 1000 labels. The algorithm facilitates efficient and effective classification of transients in the early period of a time-domain survey. A module based on our method will be incorporated into the data processing pipeline of the upcoming 2.5-meter Wide-Field Survey Telescope (WFST) six-year survey, aimed at discovering and monitoring various transient events. To verify the applicability of our approach, we constructed three new datasets (ZTF-NEWg, ZTF-NEWr, and ZTF-NEWm) from the Zwicky Transient Facility (ZTF). Our RB-C1000 model achieves an average accuracy of 98.8, 98.8, and 98.6% on these datasets, respectively. It’s crucial to note that there may be a potential bias between our datasets and the complete data stream. Therefore, these resulting performances may not represent the performance of our approach in real-world sky surveys involving general transient detection. Our newly complied datasets only work in terms of testing our approach, as well as the effectiveness of each component such as the active learning and semi-supervised learning parts. In practice, by using RB- C1000, we can significantly reduce the consumption of human annotation and obtain a competitive model by leveraging training samples with only 1000 labels available. We adopted a Nvidia Tesla v100 GPU with a batch size of 256 for training. The total time taken for the training procedure was approximately 1.5 hours. RB-C1000 is a flexible algorithm that can also be applied to next-generation telescopes, such as the Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST), to address the real-source detection issue in the early stage of a time-domain survey.
Data availability
The code and three datasets we collected are available at https://github.com/cherry0116/RB-C1000.
Acknowledgements
We are grateful to the anonymous referee for providing many useful comments. This work is supported by the National Key Research and Development Program of China (2023YFA1608100) and the Strategic Priority Research Program of the Chinese Academy of Sciences, Grant No. XDB 41000000. We gratefully acknowledge the support of the National Natural Science Foundation of China (NSFC, grant No. 12173037, 12233008), the CAS Project for Young Scientists in Basic Research (No. YSBR-092), the Fundamental Research Funds for the Central Universities (WK3440000006), and Cyrus Chun Ying Tang Foundations.
Appendix A Additional tables
Performance on three datasets we collected.
Improved results through active learning.
Effect of the amount of unlabeled data usage.
Effect of our model’s stability by different selections of M and K.
Impact of the labeled sample quantity (M + K).
Efficiency of our approach.
Evaluation of the performance when training on the g-band and r-band datasets separately, and then testing on the opposite band.
References
- Abell, P. A., Allison, J., Anderson, S. F., et al. 2009, arXiv e-prints [arXiv:0912.0201] [Google Scholar]
- Acero-Cuellar, T., Bianco, F., Dobler, G., et al. 2022, AJ, 166, 115 [Google Scholar]
- Ayyar, V., Knop Jr, R., Awbrey, A., et al. 2022, arXiv e-prints [arXiv:2203.09908] [Google Scholar]
- Bailey, S., Aragon, C., Romano, R., et al. 2007, AJ, 665, 1246 [NASA ADS] [Google Scholar]
- Bellm, E. C., Kulkarni, S. R., Graham, M. J., et al. 2018, PASP, 131, 018002 [Google Scholar]
- Bennett, K., & Demiriz, A. 1998, NeurIPS, 11 [Google Scholar]
- Bertin E. (2010) SWarp: resampling and co-adding FITS images together[J]. Astrophysics Source Code Library: [record ascl:1010.068] [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, ApJS, 117, 393 [Google Scholar]
- Brink, H., Richards, J. W., Poznanski, D., et al. 2013, MNRAS, 435, 1047 [NASA ADS] [CrossRef] [Google Scholar]
- Cabrera-Vives, G., Reyes, I., Förster, F., et al. 2017, AJ, 836, 97 [NASA ADS] [Google Scholar]
- Cavanagh, M. K., Bekki, K., & Groves, B. A. 2021, MNRAS, 506, 659 [NASA ADS] [CrossRef] [Google Scholar]
- Chambers, K. C., Magnier, E. A., Metcalfe, N., et al. 2016, arXiv e-prints [arXiv:1612.05560] [Google Scholar]
- Chapelle, O., Scholkopf, B., & Zien, A. 2009, IEEE Trans. Neural Netw., 20, 542 [Google Scholar]
- Dark Energy Survey Collaboration 2005, Int. J. Mod. Phys. A, 20, 3121 [CrossRef] [Google Scholar]
- Duev, D. A., Mahabal, A., Masci, F. J., et al. 2019, MNRAS, 489, 3582 [NASA ADS] [CrossRef] [Google Scholar]
- Förster, F., Maureira, J. C., San Martín, J., et al. 2016, AJ, 832, 155 [Google Scholar]
- Goldstein, D. A., D’Andrea, C. B., Fischer, J. A., et al. 2015, AJ, 150, 82 [Google Scholar]
- Gomez, C., Neira, M., Hernández Hoyos, M., et al. 2017, MNRAS, 499, 3130 [Google Scholar]
- Goode, S., Cooke, J., Zhang, J., et al. 2022, MNRAS, 513, 1742 [NASA ADS] [CrossRef] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2016, arXiv e-prints [arXiv:1512.03385] [Google Scholar]
- He, K., Gkioxari, G., Dollár, P., & Girshick, R. 2017, arXiv e-prints [arXiv:1703.06870] [Google Scholar]
- Hosenie, Z., Bloemen, S., Groot, P., et al. 2021, Exp. Astron., 51, 319 [CrossRef] [Google Scholar]
- Hu, M., Hu, L., Jiang, J., et al. 2022, Universe, 9, 7 [NASA ADS] [CrossRef] [Google Scholar]
- Joachims, T. 1999, ICML, 99, 200 [Google Scholar]
- Killestein, T. L., Lyman, J., Steeghs, D., et al. 2021, MNRAS, 503, 4838 [NASA ADS] [CrossRef] [Google Scholar]
- LeCun, Y., Boser, B., Denker, J. S. 1989, Neural Comput., 1, 541 [NASA ADS] [CrossRef] [Google Scholar]
- Makhlouf, K., Turpin, D., Corre, D., et al. 2022, A&A 664, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Morii, M., Ikeda, S., Tominaga, N., et al. 2016, PASJ, 68, 104 [NASA ADS] [CrossRef] [Google Scholar]
- Paszke, A., Gross, S., Chintala, S., et al. 2017, Automatic differentiation in pytorch, 31st Conference on Neural Information Processing Systems (NIPS 2017) [Google Scholar]
- Prince, M. 2004, J. Eng. Educ., 93, 223 [CrossRef] [Google Scholar]
- Ren, S., He, K., Girshick, R., & Sun, J. 2015, arXiv e-prints [arXiv: 1506.01497] [Google Scholar]
- Reyes, E., Estévez, P. A., Reyes, I., et al. 2018, arXiv e-prints [arXiv: 1808.03626] [Google Scholar]
- Reyes-Jainaga, I., Förster, F., Muñoz Arancibia, A. M., et al. 2023, ApJ, 952, L43 [NASA ADS] [CrossRef] [Google Scholar]
- Sedaghat, N., & Mahabal, A. 2017, arXiv e-prints [arXiv:1710.01422] [Google Scholar]
- Settles, B. 2009, Active learning literature survey, Tech. Rep., TR1648 [Google Scholar]
- Turpin, D., Ganet, M., Antier, S., et al. 2020, MNRAS, 497, 2641 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, T., Liu, G., and Cai, Z., et al. 2023, Sci.China Phys. Mech., 66, 109512 [CrossRef] [Google Scholar]
- Wright, D. E., Smartt, S. J., Smith, K. W., et al. 2015, MNRAS, 449, 451 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, D. E., Lintott, C. J., Smartt, S. J., et al. 2017, MNRAS, 472, 1315 [CrossRef] [Google Scholar]
- Yang, Z., Cohen, W., & Salakhudinov, R. 2016, Proc. Mach. Learn. Res., 48, 40 [NASA ADS] [Google Scholar]
- Zhu, X. J. 2005, Semi-supervised learning literature survey, Tech. Rep. 1530, Computer Science, University of Wisconsin-Madison, USA [Google Scholar]
All Tables
Evaluation of the performance when training on the g-band and r-band datasets separately, and then testing on the opposite band.
All Figures
|
Fig. 1 Process of collecting real sources. The outputs of this process are real sources and each real detection includes a 63 × 63 science image stamp, the corresponding 63 × 63 reference image stamp, and the corresponding 63 × 63 difference image stamp. |
| In the text | |
|
Fig. 2 Pipeline of gathering bogus sources. The outputs of this pipeline are bogus detections and each bogus detection includes a 63 × 63 science image stamp, the corresponding 63 × 63 reference image stamp, and the corresponding 63 × 63 difference image stamp. |
| In the text | |
|
Fig. 3 Construction pipeline of the ZTF-NEWm dataset. Both the ZTF-NEWg dataset and the ZTF-NEWr dataset contain 13 000 real sources and 30 000 bogus sources. We selected 6500 real sources from the ZTF-NEWg dataset and 6500 real detections from the ZTF-NEWr dataset. The 13 000 selected samples were combined to form the real source component of the ZTF-NEWm dataset and above them contained at least 4000 first detection sources. Similarly, we randomly chose 15 000 bogus sources from the ZTF-NEWg dataset and 15 000 bogus detections from the ZTF- NEWr dataset. These chosen samples were then combined to create the bogus detection component of the ZTF-NEWm dataset. By combining the real source and bogus detection components, we obtained a dataset (ZTF-NEWm) consisting of 13 000 real sources and 30 000 bogus detections. |
| In the text | |
|
Fig. 4 Examples of 63 pixels × 63 pixels triplet image stamps of our compiled datasets. The top-left part of the figure depicts two real sources in g-band and each row represents a real detection, showing the science image stamp, the reference image stamp, and the difference image stamp of the real detection from left to right respectively. Similarly, the bottom-left, top-right, and bottom-right of this figure display two real detections in the r-band, two bogus detections in the g-band, and two bogus detections in the r-band respectively. |
| In the text | |
|
Fig. 5 Distribution of magnitudes for real and bogus sources of the three datasets. |
| In the text | |
|
Fig. 6 Architecture of our method. In the ITS, each labeled sample undergoes convolutional neural network processing to train an initial model. Subsequently, domain experts annotate the K most challenging samples, as determined by the initial model’s judgments. During the ALS, we employ the combined set of (M + K) labeled samples to train an active training model. From this model, we select the top V samples with high-confidence predictions and assign pseudo-labels to them. In the SSLS, we utilize the expanded dataset of (M + K + V) samples to train a semi-supervised training model. This process is repeated for a total of R iterations to obtain the final results. |
| In the text | |
|
Fig. 7 Process of labeling or pseudo-labeling for unlabeled samples. Following the training phase in the ITS, we select K hard samples from the pool of (N−test − M) unlabeled data and label them with expert annotations. Subsequently, after the training phase in the ALS, we choose V over-threshold samples from (N−test − M − K) unlabeled data to assign pseudo-labels. Moving forward, after the training process in SSLS in the r-th iteration, we again select V samples from the pool of (N−test − M − K) unlabeled data that exceed the predetermined threshold and assign pseudo labels. In the (r + 1)-th iteration, we retrain the semi-supervised training model from scratch, refining the performance of our models in subsequent iterations. |
| In the text | |
|
Fig. 8 Definitions of TN, FP, FN, and TP. |
| In the text | |
|
Fig. 9 (a) Relationship between the quantity of labeled samples (M + K) and the overall performance. (b) Relationship between different selections of M and K and the overall results in the ZTF-NEWm. Figures (a) and (b) only display the mean value of the overall performance. |
| In the text | |
|
Fig. 10 Results of confusion matrices using RB-C1000 on our three datasets. The top half of this figure represents the unnormalized results, which provide a direct representation of the raw classification outcomes. The lower half of this figure displays the normalized results. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.