| Issue |
A&A
Volume 690, October 2024
|
|
|---|---|---|
| Article Number | A310 | |
| Number of page(s) | 15 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202449964 | |
| Published online | 17 October 2024 | |
Self-supervised learning on MeerKAT wide-field continuum images
1
Department of Computer Science, University of Geneva,
7 route de Drize,
1227
Carouge,
Switzerland
2
Department of Astronomy, University of Geneva,
51 Chemin Pegasi,
1290
Versoix,
Switzerland
★ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
13
March
2024
Accepted:
9
August
2024
Abstract
Context. Self-supervised learning (SSL) applied to natural images has demonstrated a remarkable ability to learn meaningful, low-dimension representations without labels, resulting in models that are adaptable to many different tasks. Until now, applications of SSL to astronomical images have been limited to Galaxy Zoo datasets, which require a significant amount of preprocessing to prepare sparse images centered on a single galaxy. With wide-field survey instruments at the forefront of the Square Kilometer Array (SKA) era, this approach to gathering training data is impractical.
Aims. We demonstrate that continuum images from surveys such as the MeerKAT Galactic Cluster Legacy Survey (MGCLS) can be successfully used with SSL, without extracting single-galaxy cutouts.
Methods. Using the SSL framework DINO, we experimented with various preprocessing steps, augmentations, and architectures to determine the optimal approach for this data. We trained both ResNet50 and Vision Transformer (ViT) backbones.
Results. Our models match state-of-the-art results (trained on Radio Galaxy Zoo) for FRI/FRII morphology classification. Furthermore, they predict the number of compact sources via linear regression with much higher accuracy. Open-source foundation models trained on natural images such as DINOv2 also excel at simple FRI/FRII classification; the advantage of domain-specific backbones is much smaller models trained on far less data. Smaller models are more efficient to fine-tune, and doing so results in a similar performance between our models, the state-of-the-art, and open-source models on multi-class morphology classification.
Conclusions. Using source-rich crops from wide-field images to train multi-purpose models is an easily scalable approach that significantly reduces data preparation time. For the tasks evaluated in this work, twenty thousand crops is sufficient training data for models that produce results similar to state-of-the-art. In the future, complex tasks like source detection and characterization, together with domain-specific tasks, ought to demonstrate the true advantages of training models with radio astronomy data over natural-image foundation models.
Key words: methods: data analysis / techniques: image processing / radio continuum: general
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Radio interferometer arrays are infamous for generating large quantities of data, and observations by the Square Kilometer Array (SKA, Dewdney et al. 2009) are expected to reach the exabyte scale. Even once these signals are correlated, processed into calibrated visibilities, and then drastically reduced in size via imaging, observations still require further analysis to bring the data to comprehensible levels. Currently, a majority of that work – finding sources and measuring their properties, classification or flagging as an unknown object – is done by experts in pursuit of a particular scientific goal. There is a significant overlap between these basic tasks and the capabilities of foundation models in computer vision. These networks are typically trained on massive datasets like ImageNet (Deng et al. 2009), and provide a foundation upon which more task-specific models can be built through fine-tuning.
Self-supervised learning (SSL) is an integral part of training foundation models, as it does not require any labels describing the data in order to learn. Especially in astrophysics, unla-beled data like images or spectra are more abundant than labeled data, such as cutouts of a single galaxy characterized by carefully calculated morphological or spectral parameters. Self-supervised learning enables models to learn rich, generalized representations from the data itself; its success is evident from works in the field of computer vision such as SwaV (Caron et al. 2020), SimCLR (Chen et al. 2020), BYOL (Grill et al. 2020), DINO vi and v2 (Caron et al. 2021; Oquab et al. 2024), and MSN (Assran et al. 2022).
Models like these have long since demonstrated incredible success when trained on natural images (e.g., Pathak et al. 2016); they can be used to detect and classify objects, estimate depth, find similar images, and detect copies, among many other tasks. Because general proprieties of images are encoded into a compressed dimension of latent representation, in which similar data points are close in Euclidian space, models can be quickly fine-tuned to specific tasks and datasets with relative ease. The ability to adapt to many different tasks is the most important characteristic of a foundation model, although Bommasani et al. (2021) additionally define foundation models as being trained on data with broad characteristics.
The application of foundation models in an out-of-the-box fashion to radio astronomy data has not been fully explored, with many simply assuming the need for domain-specific models because of the unique nature of radio images. Indeed, images from radio telescopes are fundamentally different from natural images. They are always reconstructions that start from an inverse Fourier transform of visibilities sampled in the uv-plane to the image plane. Weighting of the visibilities determines the trade-off between sensitivity and resolution. The resulting image product contains a number of radio sources, usually sparse relative to the field of view, some amount of noise, and artefacts from the image reconstruction. There can be a large dynamic range between the radio sources or the sources and the noise. Objects of many different scales can be present; most radio sources might be approximated by point sources, but diffuse emission and instrumental effects alike can occupy large areas.
Images from optical astronomy share many of these characteristics, and in recent years SSL was applied in this domain by Stein et al. (2021). Using 42 million images in three bands of individual optical galaxies from the Dark Energy Spectroscopic Instrument (DESI) Legacy Surveys, the authors trained a residual network (ResNet). They utilized an optical-specific set of data augmentations, such as reddening due to galactic extinction and a varying point spread function, to produce different views of a single image. Contrastive loss was then employed to minimize the distance in latent space between different views, while maximizing this distance between different images. To evaluate the performance of a SSL network, usually a smaller labeled portion of the dataset is used for some downstream task such as classification. With a completely unlabeled dataset, Stein et al. (2021) focused instead on instance-based retrieval, resulting in the Galaxy Finder tool. Hayat et al. (2021) used a similar approach for Sloan Digital Sky Survey (SDSS) data, which was labeled thanks to Galaxy Zoo. Their self-supervised approach outperformed state-of-the-art supervised models on the tasks of morphology classification and photometric redshift estimation.
Self-supervised learning was brought to radio astronomy by Slijepcevic et al. (2022) and further refined in Slijepcevic et al. (2024), using the yet-to-be-released Radio Galaxy Zoo (RGZ, Wong et al., in prep.) dataset assembled from the Very Large Array (VLA) FIRST survey (Becker et al. 1995). With the bootstrap your own latent (BYOL) method based on instance differentiation, they were able to find hybrid radio sources using similarity search, and to exceed baseline supervised binary classification performance. Unlike in the models from previous works mentioned, which used images from optical astronomy, the contrastive loss in BYOL is calculated without negative pairs; only different views of the same image are relevant.
These latest developments in both optical and radio astronomy have similarities not only in the networks used, but also in the core characteristics of the images. Training data are relatively small, typically 70–150 pixel cutouts centered on a single galaxy, meaning that the images are often very sparse. This postage-stamp format is a logical choice considering the goal of morphology classification or similarity search. However, it builds a reliance on data products from the very end of a traditional processing pipeline, which could take days or even months to reach. RGZ was assembled using archival survey data, which has the advantage of no additional waiting time for calibrating and processing data arriving from the interferometer; creating a similar dataset of individual galaxy cutouts from modern surveys from SKA precursors whose pipelines are not yet fully finalized would be a time-consuming endeavor.
The SKA-Mid precursors MeerKAT and Australian Square Kilometer Array Pathfinder (ASKAP) have been operating since 2018 and 2015, respectively. Observations from MeerKAT’s L-band (900–1670 MHz) are wide-field, with a single primary beam covering slightly more than one square degree (twice the area of the FIRST survey, from which RGZ takes its cutouts). At full resolution of ~8″, a single image will have a resolution close to 4K in pixels and contain up to ten thousand sources depending on the observation depth (Heywood et al. 2021). The other SKA-Mid precursor, ASKAP, has similar specifications. In the era of SKA, it will be impractical to process observations down to individual source cutouts before applying machine learning methods to simplify data analysis.
Even with the current state of the art, it is unfortunately still impractical to attempt to train vision networks with images as large as those produced by MeerKAT. Nevertheless, it is already important to explore the capabilities of SSL in order to extract generalized representations of larger, less sparse, non-object-centric scientific images from the next generation of radio interferometers. Should such an approach succeed, it would be built on an easily scalable method for assembling datasets for SSL training. Furthermore, if the learned representations from such data are capable of transferring to both large field-of-view tasks such as source detection and small field-of-view tasks like morphology classification, the model can confidently serve the purpose of a foundation model. This emphasis on wide-field images for SSL training does not negate the importance of Galaxy Zoo projects, which above all are useful because of labels provided by the efforts of large numbers of citizen scientists. Labeled datasets are essential for fine-tuning SSL-trained backbones to address specific tasks, as we demonstrate in this work.
The framework that we investigate is illustrated in Figure 1. The model f with parameters Φ is trained in a self-supervised fashion. Input data x is passed into this model with fixed parameters, 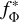 , resulting in a vector representation of the latent space, otherwise known as embeddings z. These embeddings are used by a trainable network 𝑔 with parameters θ, whose output is designed to address a specific downstream task, such as classification or regression. The primary focus of this work is to train the backbone model fΦ.
, resulting in a vector representation of the latent space, otherwise known as embeddings z. These embeddings are used by a trainable network 𝑔 with parameters θ, whose output is designed to address a specific downstream task, such as classification or regression. The primary focus of this work is to train the backbone model fΦ.
For our training data, we limit ourselves to only a fraction of publicly available MeerKAT observations – images from the L-band continuum. We show that the DINO framework with both ResNet and Vision Transformer backbones is capable of encoding important information into a small latent space. Emerging properties indicate that it can separate sources from background, and evaluation on downstream tasks shows it can retain both major statistical properties of the data and individual source morphologies.
The structure of the paper is as follows. In Section 2, we describe the data used for both training and evaluation, as well as preprocessing we performed. In Section 3, we describe the DINO framework for SSL, the network training process, and emerging properties of the trained networks. Evaluation results are presented and discussed within the context of other foundation models in Section 4, before our concluding remarks in Section 5.
 |
Fig. 1 Framework under investigation in this paper. Input data x is fed into the SSL-trained network with fixed parameters, |
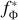
Datasets used in this work.
2 Data
To avoid confusion, we use the following terminology: a “field” is the target of a single MeerKAT observation, such as the COSMOS field or the galaxy cluster Abell 33; a “source” is a single (Gaussian or extended) radio source, usually a galaxy, in such a field; an “image” refers to the CLEAN reconstruction of the MeerKAT observed visibilities of an entire field; and a “crop” is a much smaller 2D cutout from such an image.
2.1 MeerKAT and MGCLS
The SKA precursor MeerKAT is a radio interferometer composed of 64 dishes that observes the sky below a declination of +45° (Jonas 2018). The L-band (900-1670 MHz) system, corresponding to SKA-Mid, has a primary beam FWHM of 1.2° at 1.28 GHz. The array’s layout features a dense core of antennas within a 1 km diameter and a maximum 7.7 km baseline, which enables high sensitivity to various angular scales. Full-resolution maps possess beam sizes of around 7.5–8″ and image noise levels of approximately 3–5 µJy/beam, capturing extended structures up to tens of arcminutes.
The MeerKAT Galaxy Cluster Legacy Survey (MGCLS, Knowles et al. 2022) began in 2018, accumulating 1000 hours of L-band observations. The targets were 115 galaxy clusters between −80° and 0° in declination (Dec) spread out over the full range of right ascension (RA). Knowles et al. 2022 calibrated and imaged the data, publicly providing CLEAN images and source catalogs in their first data release (DR1, SARAO 2021).
Each 8−12 hour observation was imaged by CLEANing to a depth of ~50 µJy/beam, using robust weighting of −1.5 for the full resolution of ~7.5–8″. These “basic” images were intended for visual inspection and source finding. Science-ready “enhanced” images were then corrected for primary beam effects at each frequency; these are the images we use for constructing our dataset. The final Stokes-I continuum images are the inner 1.2° × 1.2° portion of the fields (~3500 × 3500 pixels but varies according to field), showing brightness at the reference frequency of 1.28 GHz. Observations that include very strong sources (I > 100 mJy/beam) have limited dynamic range due to residual imaging artifacts. This and other data quality issues are discussed at length in Knowles et al. (2022) Section 4.4.
The survey team assigned data quality flags (DQF) as follows: 0 = good dynamic range; 1 = moderate dynamic range with some artefacts around bright sources; 2 = poor dynamic range with high contamination by bright source artefacts; 3 = poor dynamic range with ripples across image. Examples of images with each DQF are shown in Figure A.1.
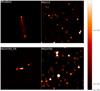 |
Fig. 2 Examples from datasets used in this work. Top left: FRII galaxy from MiraBest (VLA). Bottom left: a FRII galaxy from MIGHTEE (MeerKAT). Top right: 256 × 256 pixel cutout from Abell 209, a galaxy cluster observed as part of the MGCLS (MeerKAT). Bottom right: 256 × 256 pixel cutout from the COSMOS field, observed as part of MIGHTEE (MeerKAT). Yellow boxes indicate the extent of sources as given in the compact source catalogs. The color bar indicates the flux in mJy/beam for all images except MiraBest. |
2.2 Datasets
While MGCLS data was used for training, different datasets were used for the evaluation of various tasks. The datasets are summarized in Table 1. Sample images are shown in Figure 2. All the continuum images are centered at the corresponding observing band, and thus contain only one “channel” (in comparison to typical three-channel RGB images), containing values typically ranging from -10-10 to 10-3 mJy/beam.
2.2.1 Datasets for training
We trained the network on the MGCLS enhanced images, since the more challenging task of training on the basic images can be investigated once the SSL method is known to perform well on science-ready data. Similarly, we did not incorporate crops from other MeerKAT surveys into the training dataset, to avoid complications from observations of very different depth and sensitivity.
To make the wide-field MeerKAT images tractable for deep learning networks, images were subdivided into crops. In the field of computer vision, networks are often trained on small images, and for DINO, our deep learning framework of choice, input is by default randomly cropped to a size of 224 × 224 pixels. We chose a slightly larger crop size of 256 × 256 pixels, which allows for some slight variation in how the final crop is performed each time the data batch is loaded. Overlapping areas between adjacent crops were at maximum ten pixels on a side, since first we found the closest integer number of crops that fit in an image, and then arranged the crops such that overlap was minimized. No images were excluded from the training based on the data quality flag. Therefore, the full training dataset MGCLS_20k contains 19554 crops from the MGCLS DR1 dataset. A randomly selected 5000-crop subset named MGCLS_5k, containing at least one crop from each field, was used for hyperparameter optimization as well as for training the memory-intensive Vision Transformer backbone, whose attention mechanism is computationally more expensive than the convolutional operations that ResNet uses.
2.2.2 Datasets for evaluation
To evaluate network performance on compact source count prediction, we used portions of the MGCLS dataset as well as crops from the MeerKAT International GHz Tiered Extragalac-tic Explorations (MIGHTEE) survey (Heywood et al. 2022). Datasets used for the downstream task of galaxy morphology classification are the MiraBest dataset (Porter & Scaife 2023), 174 hand-labeled sources from the MIGHTEE survey (Scaife 2023), and Griese et al. (2022)’s FIRST dataset.
MIGHTEE was designed to reach the confusion limit in the total intensity continuum (Jarvis et al. 2018; Heywood et al. 2022). It is a deeper L-band survey than MGCLS, reaching a sensitivity of 2 µJy beam−1 via ~l·7 hours of on-source time. The Early Science data release (Heywood et al. 2021) contains continuum data products for two of the four observed fields: COSMOS andXMMLSS (XMM-Newton Large Scale Structure field). We took 256 × 256 pixel crops from these continuum images in the same way as for MGCLS, described in the previous section. These crops were taken from the Early Science images with a similar CLEAN weighting (robust −1.2) and the same resolution to MGCLS (8.6″ and 8.2″ for COSMOS and XMMLSS respectively). For the morphology classification dataset MIGH-TEE_FR, we simply made crops centered on the coordinates of the labeled galaxy.
MiraBest is a publicly available dataset manually labeled according to Fanaroff-Riley morphological classification (Fanaroff & Riley 1974), sourcing its data from the VLA’s NVSS and FIRST surveys. Because of this, there is some overlap between MiraBest and Radio Galaxy Zoo. Morphological labels are accompanied by a confidence parameter of either “confident” or “uncertain”. Crops have an angular scale of 270″. In the literature, it is common to use only the 729 “confident” samples.
Griese et al. (2022)’s RadioGalaxyDataset also comes from FIRST survey images, but includes two additional morphology classes: compact sources and bent-tailed galaxies.
2.3 Source catalog labels
Although images from the MGCLS and MIGHTEE surveys are unlabeled, certain useful characteristics can be inferred from the observation metadata and the extracted source catalogs. These can be treated as “noisy” labels, in that there is a certain degree of uncertainty associated with each label. Of key interest are the quantities calculated from the compact source catalog (a sample is given in Table 2 of Knowles et al. 2022): the number of sources per crop, their shapes, locations, and fluxes. For visualization purposes, metadata from both the FITS image headers and Table 1 of Knowles et al. (2022) are useful, although observation metadata describes the entire field rather than each individual crop. Two fields have additional labels available: Abell 209 and Abell S295 had an optical cross-match performed, and extended sources were identified by experts.
Both the MGCLS compact source catalog and the MIGH-TEE catalogs were obtained via PyBDSF (Mohan & Rafferty 2015), using the default parameters (island and source detection thresholds (3σlocal and 5σlocal respectively). Source detection on MGCLS was performed on CLEAN images with a robust weighting of −1.5, which is close to uniform weighting (robust −2), resulting in more system noise. MIGHTEE source detection was performed on the image with a robust of 0, which is an intermediate weighting scheme between natural and uniform weighting. MGCLS excluded sources detected within a certain radius of ultra-bright sources, while for the MIGHTEE survey such exclusion was based on visual inspection.
Referring to Figure 2, we can see some slight differences in the resulting source catalogs. MIGHTEE has detected some sources that overlap, shown in the upper, left-of-center part of that crop. This is not an uncommon occurrence in the MIGH-TEE source catalog; in fact, extended sources such as the FRII galaxy shown in the lower left of the figure would often have each component of this multi-Gaussian source included in the catalog. Multi-Gaussian components are excluded entirely from the MGCLS catalog, but not from MIGHTEE. Additionally, while even very faint areas of the MIGHTEE crop are designated sources, this does not appear to be the case for the MGCLS crop, where several faint blobs in the bottom central part of the image are not designated sources while one similar-looking one is.
PyBDSF has been shown to reach both purity and completeness of at least 90% for a signal-to-noise ratio (S/N) of source peak flux over image rms flux ≥4.3 using simulated, naturally weighted MeerKAT images (Vafaei Sadr et al. 2019). The same study suggests that, even on images consisting solely of point sources, completeness only approaches 100% near S/N = 6. Hence, we consider the source catalog entries as noisy labels, rather than ground truth, which for real data such as ours is additionally complicated by the presence of extended and overlapping sources.
2.4 Image preprocessing
A common problem when preparing scientific images for machine learning is correctly scaling the images. This is especially relevant for images which are not centered on a single, brightest source as are Galaxy Zoo images, but ones which may contain numerous sources of different magnitudes. The flux values in each crop could simply be normalized as is done in Galaxy Zoo; however, this removes certain context information.
Figure 3 illustrates the difference for 256 × 256 pixel crops near the center of the primary beam (left images) and near the edge (right images). There is about an order of magnitude difference between the brightest sources in the images on the left and the right, a characteristic that is not preserved by simple normalization. Additionally, the increase in noise near the edge of MeerKAT’s 1.2° primary beam is greatly exaggerated by such scaling. As we prepare for the full scale of SKA data we must assume that future deep learning techniques will be able to overcome the problem of images with more than 4000 pixels on a side, and possibly even neglect images altogether in favor of visibility data. Therefore we choose to apply scaling based on the image of each field rather than for each crop individually.
The distribution of noise and sources in an image is skewed towards the value of the noise, as sources are considerably more rare than background. This may not be the case in some individual crops, such as those containing a large portion of an extended source, but those are rare in this dataset. Knowles et al. (2022) estimate that the number of extended sources in each field is 35% of the number of compact sources, and of those, the angular extent required to occupy most of a crop would be 0.6°. Therefore, even for a single crop the flux brightness histogram should be strongly skewed towards the rms, with a long (not necessarily continuous) tail on the right indicating the presence of sources of various orders of magnitude. A good scaling technique should still have most counts centered around the image rms, while emphasizing the non-noise values of the sources.
Figure 4 compares several approaches to image scaling, utilizing different techniques from the fields of computer vision, astronomy, and particle physics. Due to the size of the full image of a single field, the y-axis is displayed on a log scale. The first method, z-scaling, originates from the need to calculate histograms based on a low number of samples, due to computing limitations. It is commonly employed in astronomy, and was used by Riggi et al. (2023) for the task of object detection, although they speculated that contrast stretching might have been more appropriate instead. Indeed, we see that contrast stretching (e.g., Negi & Bhandari 2014), a technique often used in computer vision to re-distribute values between a low and high percentile (generally 2% and 98%), results in a more desirable distribution compared to z-scaling; the majority of values are concentrated at a lower value, allowing more space for the long tail. Both these methods cause the brightest sources to be assigned the same maximum value, but the occurrence of such bright pixels can be seen to be extremely small through comparison with the histogram of normalized values.
Another method often used in cosmology and particle physics, scaling the data by sign(x) * log(|x| + 1) where x is the data vector or array, performs similarly to standard normalization, while adding some emphasis on the brighter pixels. For our data, the resulting distribution could be improved by replacing the very brightest pixels with a fixed value. However, the advantage of this method – being easily invertible without having to store the values of the low and high percentiles – would then be lost. Power law scaling is also useful in particle physics, accomplished by dividing by the maximum and then scaling to some power, usually 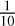 as is shown here (Drozdova et al. 2024). Similar to normalization, this causes the distribution to be dominated by the noise, although the scaling of the brighter pixels is much improved.
as is shown here (Drozdova et al. 2024). Similar to normalization, this causes the distribution to be dominated by the noise, although the scaling of the brighter pixels is much improved.
For this work, we chose to scale images with contrast stretching, since it results in a distribution that emphasizes the sources, can still be inverted, and is familiar to the computer vision community. MGCLS images were contrast stretched using the 2nd and 98th percentiles, while MIGHTEE images used the 2nd and 99.9th percentiles, due to the presence of a few spurious bright pixels.
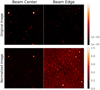 |
Fig. 3 Relative noise level and source brightness varying according to location in the primary beam, shown in this example from the MGCLS field Abell 209. Simple per-crop normalization distorts the perception of relative brightness of the sources. |
 |
Fig. 4 Various methods for scaling high dynamic range images for use with deep learning networks, applied to the image of Abell 209. Powerlaw scaling is done with a factor of |
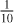
3 Method
3.1 DINO
DINO, which stands for knowledge distillation with no labels, is a SSL framework (Caron et al. 2021) that trains a student network to match the output of a teacher network. Like with BYOL, it does not use negative pairs; DINO inputs different views of an image into each network, rather than into a single encoder network. The student and teacher networks must have matching architectures, although this can take different forms, notably allowing use of Vision Transformers (ViT) as well as standard CNNs such as ResNet.
Using the standard DINO configuration, two global views, 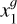 , and
, and 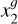 , are passed to the teacher network, while all global and local views V go to the student network. This design encourages the network to discover local-to-global correspondences. The loss across all views is as follows:
, are passed to the teacher network, while all global and local views V go to the student network. This design encourages the network to discover local-to-global correspondences. The loss across all views is as follows:
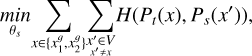 (1)
(1)
where θs are the parameters of the student network, and Pt and Ps are the network output probability distributions for the teacher and student networks respectively, and the cross-entropy loss H(a, b) = − a log b.
Parameters of the student network θs are learned using stochastic gradient descent. The teacher network’s parameters θt are updated using a momentum encoder, which acts as a form of model ensembling, allowing the teacher’s better performance to guide the training of the student.
The network that we refer to as the SSL-trained backbone model fΦ as in Figure 1 is the teacher network.
3.2 Data augmentations
DINO depends on data augmentations to distill knowledge from different parts of the input images. Data augmentation is commonly used in deep learning to build a more robust network, by distorting the data in ways likely to occur in the environment in which the data is collected, thereby enriching the training dataset. At the very basic level are the local and global views passed to the networks. Global views are large random crops of size 224 × 224 pixels, randomly re-scaled between 0.4 and 1. Local views are smaller 96 × 96 pixel crops from random areas of the input image, which also vary randomly in scale. In our work, we chose to use eight local crops and kept the default suggested scaling ranges of 0.05–0.14 for ResNet and 0.05–0.4 for ViT. Additional augmentations are applied to both local and global views in order to improve the robustness of the network.
The standard DINO image augmentations are optimized for natural images, and consist of a random horizontal flip, random color jitter, Gaussian blur, and solarization. Because MGCLS continuum images are single channel, we chose not to use color jitter and solarization, which are designed for RGB images. Other fields of physics have had great success with science-based augmentations (e.g., Strong 2020), which are slowly starting to be implemented for radio astronomy.
Previously, Slijepcevic et al. (2022) found that random resized cropping was the augmentation with most significant impact to BYOL performance, with rotation as the second most important. Random cropping at various scales is already a core part of creating DINO’s local crops, so we evaluate the effects of only random rotation, random autocontrast, and random power law scaling. For our non-object-centric data, with fluxes decreasing near the edge of the primary beam, as is shown in Figure 3, the latter two augmentations may improve the ability of the network to distinguish source from noise in low-contrast areas of the field.
We test the effectiveness of rotation, autocontrast, and power law scaling by adding one of these random augmentations at a time in addition to the standard ones of flipping and Gaussian blur, before trying different combinations. Using a ResNet50 backbone, we train for 100 epochs on the smaller MGCLS_5k dataset, and consider both the final training loss and the mean squared error (MSE) of our linear evaluation task (see Section 4.1) in determining the impact of additional augmentations. In this way, we find that the combination of rotation and power-law scaling gives the best results, performing better on the linear evaluation task than a network trained using the default augmentations, while having a similar final training loss.
DINO backbone parameters.
3.3 Training
We train backbones of two different architectures: a convolutional ResNet and a Vision Transformer. Because weights for a ResNet50 network pre-trained via DINO with ImageNet are publicly available, we use this same network depth. For the ViT backbone, we use the small 21-million parameter network with the DeiT implementation deit_small (Touvron et al. 2020). We use a patch size of 8, as this corresponds more closely to the average size of a compact source in the MGCLS catalog than the default patch size of 16. No pre-trained weights for this configuration were available, so we initialize both backbones with random weights.
We perform a small grid search to select certain hyperparameters: the learning rate, batch size, and momentum parameter for the teacher network. Recall that the teacher network updates via a momentum encoder, performing an exponential moving average on the weights of the student network. For training a ResNet, a constant weight decay was recommended, so we only include variations of this hyperparameter in the search for the ViT backbone, where memory limitations constrained the batch size of the ViT backbone to 8. In each training epoch, the network is exposed to the entire dataset, no matter the batch size. Networks are trained for 100 epochs on the MGCLS_5k dataset, and then evaluated on the linear regression task. Hyperparameters which minimize both the training loss and MSE are listed in Table 2 along with other network parameters. During training, the learning rate is scaled by the factor 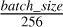 .
.
Our Resnet backbone is trained with the training split of the MGCLS_20k dataset simultaneously on 6 GPUs, which are either NVIDIA TITAN X or Tesla P100, depending on availability. We train a ViT backbone on the same cluster but using the smaller training dataset MGCLS_5k. The networks are evaluated every 25 epochs by performing linear regression to the compact source count. This is the only evaluation task that uses data from MGCLS rather than a different survey, so it is suitable as an initial evaluation task. Training of the linear regression is performed on a 70% split of the original training dataset, and validated with the remaining 30%. Finally, the MSE reported is that of the test set, which is a 20% split from the MGCLS_20k dataset that does not overlap with any samples in MGCLS_5k.
We consider the training loss to have converged if either the loss did not decrease by more than 1% in 100 epochs, or the source count linear regression MSE did not improve in the same period. Under this condition, we consider the 23-million parameter ResNet sufficiently trained after 425 epochs. Because it is trained with a smaller dataset, training loss for the ViT- small backbone keeps decreasing by more than 1%. Therefore, once the MSE no longer decreases, we stop training. The 21- million parameter ViT-small backbone converges at epoch 475 (see Figure 5).
 |
Fig. 5 Training loss and source count linear regression (see Section 4.1 for details) MSE per evaluation epoch, for both backbones. |
3.4 Emerging properties
To visualize emerging properties of the trained backbones, we employ the common dimensionality-reduction algorithm t-SNE and take advantage of the Vision Transformer architecture to show attention maps.
Figure 6 shows the features of both the MGCLS_20k and MIGHTEE datasets, extracted from our trained ResNet model, represented in two dimensions instead of the 2048 of the embedding layer. Different color-codings demonstrate how after training, the features are structured according to the dataset (top figure), observed field (middle), and number of compact sources per crop (bottom). It is clear that parts of the MIGHTEE dataset (COSMOS field in blue, XMMLSS field in magenta) are distinct from the MGCLS data; as a deeper, more sensitive survey this is unsurprising. Likewise, certain fields in the MGCLS_20k dataset are more unique than others (the group in light green on the bottom-right corner are all crops from the field J1248.7-4118, which has a DQF of 2, indicating contamination by bright source artefacts). MGCLS_20k itself is heterogeneous even without the addition of MIGHTEE, but even so the network can capture global properties of the individual crops, as evidenced by the last panel, showing the rough grouping of feature vectors according to the number of compact sources per crop.
While the t-SNE visualization can illustrate some global trends the model has learned, the details are revealed by visualizing the attention layers in the ViT network. Figure 7 illustrates this for two crops from the field Abell 209 – the top example is the same crop shown in Figure 2. Red contours show the 8x8 patches in the attention heads at the 90th percentile. Such pixels highlight areas in the image where a particular part of the network is focusing its attention.
In both these examples – one of a typical crop and another containing a large, bright, extended source – different attention heads pick out different attributes of the crops. Bright pixels or groups of pixels are more important to the attention heads visualized on the right side of the figure; darker areas, or areas bordering bright ones, are what is emphasized on the images on the left.
Although these visualizations are only a qualitative way of assessing the trained models, they give us some indication of the features learned by the networks.
 |
Fig. 6 Features extracted from our trained Resnet backbone, visualized via t-SNE in two dimensions. The top panel shows patterns by dataset; the middle by observation field, with COSMOS and XMMLSS in blue and magenta, respectively; and finally by the number of compact sources per crop. |
 |
Fig. 7 Attention maps overlaid on the crop of Abell 209 from Figure 2 (top) and an extended source from the same field (bottom). The left and right panels show maps from two of ViT-small’s six attention heads. As the network architecture has a patch size of eight, the 90th percentile of the attention maps shows the 8×8 patches that the specific attention head considers most important in the image. |
4 Evaluation and discussion
The choice of evaluation tasks is limited by the availability of labeled data, so most tasks involve transfer learning. Previously, we mentioned a simple linear regression task to predict the number of compact sources in a given crop, which helps determine training completion. This task is performed on MeerKAT data, using the available MGCLS and MIGHTEE compact source catalogs as labels. Therefore, the term “source count” simply refers to the total number of catalog-labeled sources in a single crop, as opposed to a stricter definition. In order to compare with previous works, we also evaluate binary classification of radio galaxy morphology using the public dataset MiraBest (Porter & Scaife 2023). We extend this classification problem to hand-labeled FRI and FRII galaxies in the MIGHTEE Early Science fields, as well as multi-class classification.
Unless specified, these evaluation tasks are performed without any fine-tuning of the backbone; following our notation from Figure 1, the backbone  is fixed. Therefore, for speed and efficiency, we start by extracting the latent space embeddings z for the dataset of interest x. The final dense layer of a ResNet or the CLS token at the end of the transformer layers are typically used as a summary of the input image content. Because these embeddings, also commonly called features, are of different shapes depending on the network architecture, we use PCA to reduce the size to a vector of length 1001 before using them as input to the trainable regression or classification models gθ, which consist of a single linear layer. These regression and classification models were then trained for 100 and 300 epochs, respectively, which thanks to the small shape of the input feature vectors took less than a minute on a single GPU.
is fixed. Therefore, for speed and efficiency, we start by extracting the latent space embeddings z for the dataset of interest x. The final dense layer of a ResNet or the CLS token at the end of the transformer layers are typically used as a summary of the input image content. Because these embeddings, also commonly called features, are of different shapes depending on the network architecture, we use PCA to reduce the size to a vector of length 1001 before using them as input to the trainable regression or classification models gθ, which consist of a single linear layer. These regression and classification models were then trained for 100 and 300 epochs, respectively, which thanks to the small shape of the input feature vectors took less than a minute on a single GPU.
This feature extraction approach, rather than attaching the classification or regression head directly, freezing the backbone, and performing the task, also allows us to easily compare with different backbones from the literature. The only modification necessary for extracting features was replication of the single-channel crops over the required number of channels (3 for backbones trained on natural images and 5 for optical Galaxy Zoo).
All the backbones evaluated in this section are listed in Table 3; these naming conventions will be used from here onwards. The training weights of last two are not publicly available, so extracted features shared by Mohale & Lochner (2024) were used, and the metric reported for RGZ VDVAE originates directly from the paper of Andrianomena & Tang (2024). All of these backbones were pre-trained in a self-supervised manner on datasets at least an order of magnitude larger than MGCLS_20k, from DINOv2’s 142 million images, to Galaxy Zoo and ImageNet’s 1.2 million and Radio Galaxy Zoo’s 108k images.
All results in tabular form can be found in Appendix B.
4.1 Compact source count prediction
Compact source count prediction is performed separately on both MGCLS and MIGHTEE crops. Feature vectors associated with source counts more than 3σ above or below the mean are considered outliers and not used for training or testing the model. This excludes 25 crops for MGCLS, and 4 for MIGHTEE. Selection of data by quality flag does not have a large effect on the chosen metric of mean squared error, so we do not exclude any crops for that reason. With the feature vectors extracted for each crop as input, the corresponding label is the total number of compact sources as per the catalog that are present in the crop.
Despite the catalog-derived quantities being “noisy” labels, this simple regression task is a good test of the backbone’s capabilities since it is a dataset-specific task, and can also be used as a linear probe to evaluate the network as it trains.
Similar to during training, we train and validate using a train/validation split of 70/30% of the MGCLS_20k training dataset before evaluating on the MGCLS_20k test set, which has only crops not present in the MGCLS_5k subset. Figure 8 shows the results when evaluated on both the MGCLS and MIGH- TEE datasets. The reported errors are calculated on the results of three independent training runs. On MGCLS, the MGCLS Resnet backbone achieves a MSE of 49.19 ± 0.06, while the MGCLS ViTS backbone does better with a MSE of 39.98 ± 0.05. For MIGHTEE, the MSEs are 37.73 ± 0.01 and 23.14 ± 0.01, respectively. Due to its attention mechanism, ViT is generally better at learning properties of data, so this result is expected.
Results in Figure 8 indicate that the models tend to underpredict source counts in the upper few percentiles. For MGCLs, 2% of crops have source counts exceeding 60, yet numbers greater than this were only predicted 0.15% of the time. This behavior is more evident with the MIGHTEE crops, where the upper ∼1% of crops with more than 50 compact sources is always predicted to have much fewer, and no prediction on the MIGHTEE data exceeds 50 compact sources per crop. As the distribution of source counts in these datasets is not normal but rather skewed towards the mid-range and lower end, it is understandable that linear regression would struggle to properly fit the under-represented upper tail of the distribution. The exact details of the source detection process might also have an impact, as was already discussed in Section 2.3.
We compare our results with the current state-of-the-art in both computer vision and astrophysics. Figure 9 illustrates how different backbones perform on compact source count prediction. It is clear that models trained with Galaxy Zoo datasets (GZ2 MoCo and RGZ BYOL) do not do well in this area, having not been exposed to images with such a variety of sources. It is interesting that the performance of DINOv2 VITG and DINO Resnet is much better than those models; perhaps the variety of images in their training data contributes to a more robust feature space. This is true when evaluated on the MIGHTEE observations as well; DINOv2’s largest foundation model ViTG also transfers well to this particular dataset and task. Finally, our networks perform this task well, although that is of little surprise as they trained on the same data (with the exception MGCLS ViTS which did not see any of the evaluation data during training).
Backbones referenced in this work.
 |
Fig. 8 Compact source count prediction via linear regression. |
 |
Fig. 9 Performance comparison of different backbones on the MGCLS (top) and MIGHTEE (bottom) compact source count linear regression task. |
 |
Fig. 10 Performance comparison of different backbones with FRI/FRII classification on MiraBest Confident. |
4.2 FRI/FRII classification
Since the release of the MiraBest labeled dataset, it has become standard to evaluate networks on this binary classification task. In the Fanarhoff-Riley classification scheme, radio galaxies of type I are brighter towards the central galaxy or quasar, while type II are both generally brighter and brighter towards their lobes rather than the central component. Galaxy morphology can be difficult for humans to classify even with this straightforward paradigm, and there are many cases in which labeling is uncertain. We perform this classification using a single linear layer on both the MiraBest Confident dataset and MIGHTEE_FR. Both datasets are relatively class-balanced; MiraBest Confident has 397 FRI and 437 FRII, while MIGHTEE_FR has 90 FRI and 87 FRII galaxies.
In order to easily compare with Slijepcevic et al. (2024), we report the test set error, which is one minus the test set accuracy. MGCLS ResNet reaches a test set error of 10% on MiraBest, while this is significantly worse for much smaller MIGHTEE_FR sample at 22%. The MGCLS ViTS backbone performs slightly worse, with a MiraBest test set error of 13.5% and 32% for MIGHTEE_FR. Using our evaluation pipeline of feature extraction, PCA, and classification with a single linear layer, the test set error for RGZ BYOL is 11% and 42% for MIGHTEE_FR. This demonstrates that our model, trained with 20K source-rich crops from wide-field images, can learn the same significant features as a model trained with 108K images from Radio Galaxy Zoo.
Figure 10 shows how binary classification of radio galaxies is easily done by models pre-trained on large datasets. Both DINOv2 ViTG and RGZ MoCo out-perform the state-of-the- art in the radio astronomy literature; ImageNet-trained DINO Resnet comes very close to the RGZ BYOL result.
If a model is considered versatile because it is able to adapt well to more than one task, then both DINOv2 ViTG and our models can be considered closer to foundation models than those trained on Galaxy Zoo. These results contradict the frequently cited need for domain-specific training data, since a 1,100-million parameter model trained on 142 million images out-performs the state-of-the-art model trained on Radio Galaxy Zoo.
However, we must acknowledge that neither source count prediction nor binary FRI/FRII classification are complex tasks. Standard benchmark tasks in computer vision literature, such as 1000-class classification with ImageNet, demand more flexibility from both backbone and classifier. A third class of hybrid galaxies is available in MiraBest, but there are only 19 confidently- labeled samples, so we evaluate multi-class classification on a different dataset from the same survey.
 |
Fig. 11 Confusion matrix comparison of different backbones with multiclass morphology classification on RadioGalaxyDataset (Griese et al. 2022). Each class in the test set has 50 samples. |
4.3 Multiclass classification with fine-tuning
In order to demonstrate adaptability to more complex tasks, we make use of Griese et al. (2022)’s RadioGalaxyDataset, a collection of FIRST survey images of four morphology types. Besides FRI and FRII, compact sources and bent-tailed galaxies are included. In total, there are 495 FRI, 924 FRII, 391 compact, and 348 bent galaxies. In the validation and test sets, the classes are perfectly balanced with 50 samples of each class.
Classification results using a single layer are poor for every class except compact sources, so fine-tuning is a necessity for this more complex task. In addition to comparing our models with RGZ BYOL, we also show the results of evaluating DINO Resnet. All layers of the ResNet backbones are allowed to finetune, as is the entire Vision Transformer backbone.
The best results out of three evaluation runs for each backbone are presented in Figure 11. All networks are capable of accurately identifying compact sources, although RGZ BYOL and MGCLS ViTS tend to misclassify these more often than the others. The addition of the bent-tailed galaxy class causes some confusion between that and the FRI/FRII morphologies, which can also feature extended emission. This is evident in the way that DINO Resnet classifies bent-tailed galaxies better than the others, but at the cost of FRI/FRII classification accuracy. Similarly, MGCLS ViTS errs in favor of FRII galaxies, at the cost of distinguishing bent and FRI galaxies poorly.
The end result, however, is only minor differences between the performances of different pre-trained ResNet backbones, after fine-tuning.
5 Summary
In this work, we demonstrate that source-rich crops from wide-field MeerKAT continuum images, which require minimal effort in selection and preprocessing, can be used to train a multipurpose backbone. The DINO framework for SSL, which encourages the backbone network to learn local-to-global correspondences within the data, lends itself especially well to these images as opposed to sparser, galaxy-centered ones. The results we achieve, depending on the evaluation task, are similar to or better than the current state-of-the-art.
This result has profound impacts on the scalability of domain-specific foundation models. Data straight from the calibration and imaging pipelines of modern telescopes can immediately be incorporated into such models, eliminating the need to wait for millions of single-galaxy cutouts to be collected into a Galaxy Zoo before applying SSL. Furthermore, a relatively small number of training samples may be sufficient. Our training dataset of twenty thousand crops is an order of magnitude smaller than Radio Galaxy Zoo, and even training with a five-thousand-sample subset of that data results in good performance on our chosen evaluation tasks. Many radio telescopes already have archived collections of pipeline data products that are at least of this magnitude; if our findings generalize well across different bandwidths and to observatory-specific tasks, then instrument-specific fine-tuned models are easily within reach.
Our findings also show that publicly available foundation models trained on natural images can perform radio astronomy classification and regression tasks, sometimes even better than models trained with astrophysical images. It is true that domain-specific data reduces by orders of magnitude the amount of training data and computing resources needed to achieve similar performance to the largest computer vision foundation models. From a practical perspective, it is extremely easy to initiate a network with the weights from pre-trained open-source models, so these remain a good starting point for approaching astrophysics tasks with deep learning. Even when allowing networks to fine-tune, the difference between natural image backbones and domain-specific ones is on the order of a few percent (see for example Table C.1).
However, these small advantages might become more significant once tasks become more complex and specific to astronomy or radio astronomy. The standard task of binary morphology classification is relatively simple, and even the additional source count task we use is easily done by linear regression. Other examples in the literature evaluate similarity search, although almost always qualitatively. The small variety of downstream tasks is due in part to a lack of labeled data. Hayat et al. (2021) were able to demonstrate performance on a number of different binary classification tasks as well as redshift estimation, thanks to the labeled Galaxy Zoo dataset. For tasks independent of channel, backbones trained with radio astronomy data could be evaluated on optical astronomy datasets. This has already been done in reverse; for example, in Mohale & Lochner (2024). With the emergence of new labeled datasets such as Gupta et al. (2024), tasks like source detection and parameter estimation should also become standard. It will be interesting to see if a complex, domain-specific task like this will clearly show the need for domain-specific training data or not.
In addition to adapting easily and accurately to perform tasks that are currently done by analytic pipelines, foundation models in radio astronomy should ideally be sensitive to features that allow room for discovery. This includes diffuse emission, which tends to be more evident in lower-resolution image reconstructions than the high-resolution ones that favor compact sources. The MGCLS survey alone contains many examples of diffuse emission, from radio relics spanning megaparsecs to mini-halos only ten to hundreds of kiloparsecs in size. Even the small sky area observed by the MIGHTEE survey has giant radio galaxies (Delhaize et al. 2021), one of which required a customized CLEAN weighting to properly image diffuse emission from the galaxy lobes. Models that are able to take full advantage of the high-dynamic range, wide-field images of telescopes like MeerKAT and ASKAP will almost certainly be more capable of discovery than standard computer vision models.
There are still many ways to leverage the uniqueness of radio astronomy data that have yet to be thoroughly explored. In the image plane, the inclusion of physics-driven data augmentations may turn out to be key; or the dependence on optimal augmentation schemes could simply be bypassed by using masking. With radio astronomy, there are also other modalities of the data to explore, such as spectral and temporal, or different stages of data processing at which SSL could be applied. Images directly from the automated processing pipelines, such as the MGCLS “basic” CLEAN images, dirty images more closely resembling the Fourier inversion of the measured visibilities, or the calibrated visibilities themselves are all representations of the same observation. Abandoning the reconstructed images in favor of the Fourier plane visibilities brings its own challenges, especially with data preparation. Some recent successes with source localization (Taran et al. 2023) and reconstruction (Vafaei Sadr et al. 2019; Drozdova et al. 2024) show promise in this area, an exciting direction for future research.
Data availability
All datasets used in this work are public, and the code and pre-trained checkpoints are available at https://github.com/elastufka/mgcls_dino.
Acknowledgements
This work has been done in partnership of the Swiss SKA consortium which is funded by the State Secretariat for Education, Research and Innovation (SERI). MGCLS data products were provided by the South African Radio Astronomy Observatory and the MGCLS team and were derived from observations with the MeerKAT radio telescope. The MeerKAT telescope is operated by the South African Radio Astronomy Observatory, which is a facility of the National Research Foundation, an agency of the Department of Science and Innovation. The authors would like to thank Prof. Anna Scaife and team for sharing their FRI/FRII classifications on the MIGHTEE survey, and Koketso Mohale for sharing extracted features from the work in Mohale & Lochner (2024). OB and DP were supported by the SNF Sinergia grant CRSII5-193826 “AstroSignals: A New Window on the Universe, with the New Generation of Large Radio-Astronomy Facilities”. MD and VK were supported by the SNF Sinergia project (CRSII5-193716), “Robust deep density models for high-energy particle physics and solar flare analysis (RODEM)”.
Appendix A MGCLS data quality illustration
Figure A.1 illustrates MGCLS images of various data quality. From left to right, they are: Abell 22, with DFQ 0, Abell 85 with DQF 1, Abell 168 wiht DQF 2, and J1653.0-5943 with DQF 3. Images are displayed without scaling, within the flux range of 1e-7 to 5e-5 mJy/beam.
 |
Fig. A.1 600×600 pixel crops from various MGCLS fields illustrating the Data Quality Flags (DQF). From left to right, they are: 0 = good dynamic range; 1 = moderate dynamic range with some artefacts around bright sources; 2 = poor dynamic range with high contamination by bright source artefacts; 3 = poor dynamic range with ripples across image. |
Appendix B Evaluation results
Appendix C Fine-tuning and label reduction results
C.1 Fine-tuning
For a more in-depth comparison with Slijepcevic et al. (2024) and to show how performance on binary classification can improve, we perform fine-tuning of all available Resnet backbones. The classification head attached to the backbone consists of a single input layer of shape (embedding_dimension, 512) and an output layer of shape (512, n_classes). This is to account for the different shape of the embedding layers between ResNets of different depths, such as our Resnet50 and RGZ BYOL’s Resnet18. Additionally, we use a slightly larger center crop in both the training and validation transforms (96 vs 70 pixels) and do not include an additional random small crop or Gaussian blur in the training transformations. Therefore, even though our training hyperparameters are similar, we do not reproduce the exact results reported in Slijepcevic et al. (2024).
Results showing test set error as a function of the number of fine-tuning layers is shown in Figure C.1a. For clarity, we only plot the fine-tuning results of our work, MGCLS Resnet, and RGZ BYOL; complete results are reported in Table C.1. Error bars are determined by the accuracies reported during the last ten epochs of training, rather than from the results of multiple training runs, due to the less efficient nature of fine-tuning.
Unlike the findings of Slijepcevic et al. (2024), we do not find significant benefit from fine-tuning all model layers. The difference in training data augmentation schemes may be key in this case; focusing even more strongly on the bright galaxy at the center of the image could result in better classification.
 |
Fig. C.1 Left: MiraBest Confident test set error according to number of labels present in the training data. As expected, performance improves significantly with more labeled data. Right: MiraBest Confident test set error according to number of fine-tuning layers. With our chosen training data augmentations and hyperparameters, performance does not improve significantly with additional depth in the model. |
C.2 Reducing number of labels
The impact that the number of labeled samples used for training can have is already evident from our single-layer FRI/FRII classification with MIGHTEE_FR, resulting in test set error of ~20 - 30%. With only 140 labeled samples in the training set, we can expect significant improvement with more data.
This is certainly the case with MiraBest; by steadily increasing the number of labels used for training, the accuracy of the classifier also increases. Figure C.1b shows the same trend as the result shown in Slijepcevic et al. (2024)’s figure 2. When even half the available labels are used, the accuracy of MGCLS Resnet backbone quickly approaches that RGZ BYOL. Complete results are reported in Table C.2.
Performance vs fine-tuned layers
Performance vs number of labels
Notes. Performance of each backbone on binary morphology classification with MiraBest Confident, as the number of labeled samples in the training set increases.
References
- Andrianomena, S., & Tang, H. 2024, J. Cosmol. Astropart. Phys., 2024, 034 [CrossRef] [Google Scholar]
- Assran, M., Caron, M., Misra, I., et al. 2022, in Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXI (Berlin, Heidelberg: Springer-Verlag), 456 [Google Scholar]
- Becker, R. H., White, R. L., & Helfand, D. J. 1995, ApJ, 450, 559 [Google Scholar]
- Bommasani, R., Hudson, D. A., Adeli, E., et al. 2021, arXiv e-prints [arXiv:2108.07258] [Google Scholar]
- Caron, M., Misra, I., Mairal, J., et al. 2020, Unsupervised Learning of Visual Features by Contrasting Cluster Assignments [Google Scholar]
- Caron, M., Touvron, H., Misra, I., et al. 2021, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 9630 [CrossRef] [Google Scholar]
- Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. 2020, A Simple Framework for Contrastive Learning of Visual Representations [Google Scholar]
- Delhaize, J., Heywood, I., Prescott, M., et al. 2021, MNRAS, 501, 3833 [Google Scholar]
- Deng, J., Dong, W., Socher, R., et al. 2009, in 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248 [CrossRef] [Google Scholar]
- Dewdney, P. E., Hall, P. J., Schilizzi, R. T., & Lazio, T. J. L. W. 2009, IEEE Proc., 97, 1482 [Google Scholar]
- Drozdova, M., Kinakh, V., Bait, O., et al. 2024, A&A, 683, A105 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fanaroff, B. L., & Riley, J. M. 1974, MNRAS, 167, 31 [Google Scholar]
- Griese, F., Kummer, J., & Rustige, L. 2022, https://doi.org/10.5281/zenodo.7120632 [Google Scholar]
- Grill, J.-B., Strub, F., Altché, F., et al. 2020, in Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20 (Red Hook, NY, USA: Curran Associates Inc.), 21271 [Google Scholar]
- Gupta, N., Hayder, Z., Norris, R. P., Huynh, M., & Petersson, L. 2024, PASA, 41, e001 [NASA ADS] [CrossRef] [Google Scholar]
- Hayat, M. A., Stein, G., Harrington, P., Lukic, Z., & Mustafa, M. 2021, ApJ, 911, L33 [NASA ADS] [CrossRef] [Google Scholar]
- Heywood, I., Jarvis, M. J., Hale, C. L., et al. 2021, MIGHTEE Early Science: image and catalogue products for the COSMOS/XMM-LSS fields [Google Scholar]
- Heywood, I., Jarvis, M. J., Hale, C. L., et al. 2022, MNRAS, 509, 2150 [Google Scholar]
- Jarvis, M., Taylor, R., Agudo, I., et al. 2018, PoS, MeerKAT2016, 006 [Google Scholar]
- Jonas, J. 2018, in Proceedings of MeerKAT Science: On the Pathway to the SKA – PoS(MeerKAT2016), 227, 001 [Google Scholar]
- Knowles, K., Cotton, W. D., Rudnick, L., et al. 2022, A&A, 657, A56 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mohale, K., & Lochner, M. 2024, MNRAS, 530, 1274 [NASA ADS] [CrossRef] [Google Scholar]
- Mohan, N., & Rafferty, D. 2015, Astrophysics Source Code Library [record ascl:1502.007] [Google Scholar]
- Negi, S. S., & Bhandari, Y. S. 2014, in International Conference on Recent Advances and Innovations in Engineering (ICRAIE-2014), 1 [Google Scholar]
- Oquab, M., Darcet, T., Moutakanni, T., et al. 2024, Trans. Mach. Learn. Res. [Google Scholar]
- Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., & Efros, A. A. 2016, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Las Vegas, NV, USA: IEEE), 2536 [CrossRef] [Google Scholar]
- Porter, F. A. M., & Scaife, A. M. M. 2023, RAS Tech. Instrum., 2, 293 [NASA ADS] [CrossRef] [Google Scholar]
- Riggi, S., Magro, D., Sortino, R., et al. 2023, Astron. Comput., 42, 100682 [NASA ADS] [CrossRef] [Google Scholar]
- SARAO 2021, MeerKAT Galaxy Cluster Legacy Survey Data Release 1 (MGCLS DR1) [Google Scholar]
- Scaife, A. M. M. 2023, mightee fr catalogue [Google Scholar]
- Slijepcevic, I. V., Scaife, A. M. M., Walmsley, M., & Bowles, M. 2022, arXiv e-prints [arXiv:2207.08666] [Google Scholar]
- Slijepcevic, I. V., Scaife, A. M. M., Walmsley, M., et al. 2024, RAS Tech. Instrum., 3, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Stein, G., Harrington, P., Blaum, J., Medan, T., & Lukic, Z. 2021, arXiv e-prints [arXiv:2110.13151] [Google Scholar]
- Strong, G. C. 2020, Mach. Learn. Sci. Technol., 1, 045006 [CrossRef] [Google Scholar]
- Taran, O., Bait, O., Dessauges-Zavadsky, M., et al. 2023, A&A, 674, A161 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Touvron, H., Cord, M., Douze, M., et al. 2020, Training data-efficient image transformers & distillation through attention [Google Scholar]
- Vafaei Sadr, A., Vos, E. E., Bassett, B. A., et al. 2019, MNRAS, 484, 2793 [CrossRef] [Google Scholar]
Interestingly, the fact that dimensionality reduction via PCA generally results in better performance indicates that features relevant to the chosen tasks occupy a small portion of the latent space.
All Tables
All Figures
|
Fig. 1 Framework under investigation in this paper. Input data x is fed into the SSL-trained network with fixed parameters, |
| In the text | |
|
Fig. 2 Examples from datasets used in this work. Top left: FRII galaxy from MiraBest (VLA). Bottom left: a FRII galaxy from MIGHTEE (MeerKAT). Top right: 256 × 256 pixel cutout from Abell 209, a galaxy cluster observed as part of the MGCLS (MeerKAT). Bottom right: 256 × 256 pixel cutout from the COSMOS field, observed as part of MIGHTEE (MeerKAT). Yellow boxes indicate the extent of sources as given in the compact source catalogs. The color bar indicates the flux in mJy/beam for all images except MiraBest. |
| In the text | |
|
Fig. 3 Relative noise level and source brightness varying according to location in the primary beam, shown in this example from the MGCLS field Abell 209. Simple per-crop normalization distorts the perception of relative brightness of the sources. |
| In the text | |
|
Fig. 4 Various methods for scaling high dynamic range images for use with deep learning networks, applied to the image of Abell 209. Powerlaw scaling is done with a factor of |
| In the text | |
|
Fig. 5 Training loss and source count linear regression (see Section 4.1 for details) MSE per evaluation epoch, for both backbones. |
| In the text | |
|
Fig. 6 Features extracted from our trained Resnet backbone, visualized via t-SNE in two dimensions. The top panel shows patterns by dataset; the middle by observation field, with COSMOS and XMMLSS in blue and magenta, respectively; and finally by the number of compact sources per crop. |
| In the text | |
|
Fig. 7 Attention maps overlaid on the crop of Abell 209 from Figure 2 (top) and an extended source from the same field (bottom). The left and right panels show maps from two of ViT-small’s six attention heads. As the network architecture has a patch size of eight, the 90th percentile of the attention maps shows the 8×8 patches that the specific attention head considers most important in the image. |
| In the text | |
|
Fig. 8 Compact source count prediction via linear regression. |
| In the text | |
|
Fig. 9 Performance comparison of different backbones on the MGCLS (top) and MIGHTEE (bottom) compact source count linear regression task. |
| In the text | |
|
Fig. 10 Performance comparison of different backbones with FRI/FRII classification on MiraBest Confident. |
| In the text | |
|
Fig. 11 Confusion matrix comparison of different backbones with multiclass morphology classification on RadioGalaxyDataset (Griese et al. 2022). Each class in the test set has 50 samples. |
| In the text | |
|
Fig. A.1 600×600 pixel crops from various MGCLS fields illustrating the Data Quality Flags (DQF). From left to right, they are: 0 = good dynamic range; 1 = moderate dynamic range with some artefacts around bright sources; 2 = poor dynamic range with high contamination by bright source artefacts; 3 = poor dynamic range with ripples across image. |
| In the text | |
|
Fig. C.1 Left: MiraBest Confident test set error according to number of labels present in the training data. As expected, performance improves significantly with more labeled data. Right: MiraBest Confident test set error according to number of fine-tuning layers. With our chosen training data augmentations and hyperparameters, performance does not improve significantly with additional depth in the model. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.