Fig. 6
Download original image
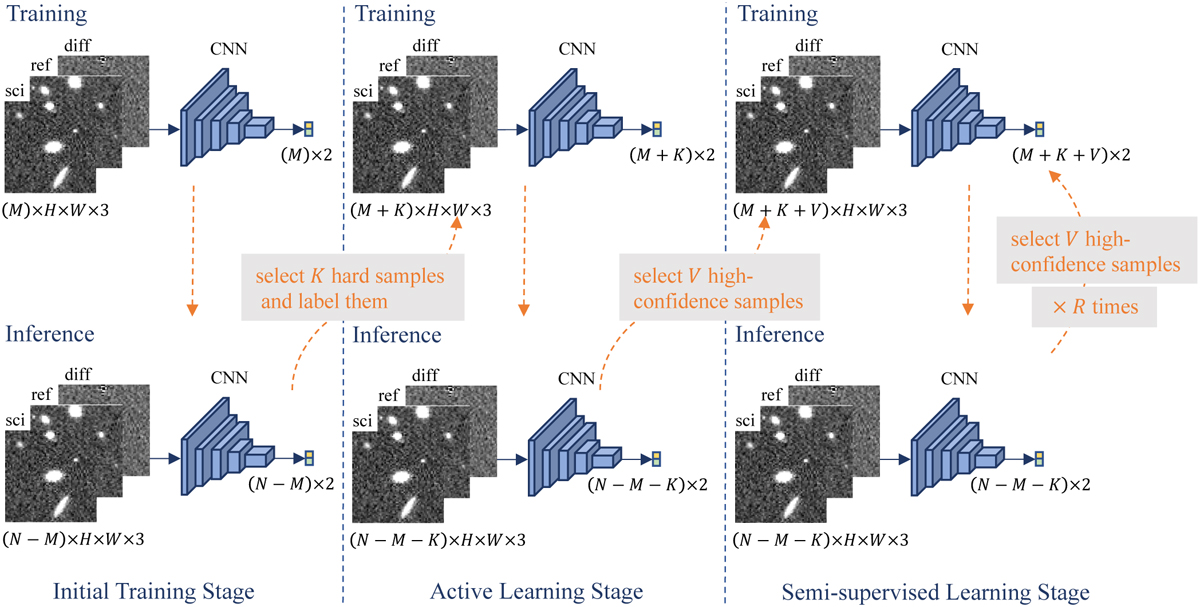
Architecture of our method. In the ITS, each labeled sample undergoes convolutional neural network processing to train an initial model. Subsequently, domain experts annotate the K most challenging samples, as determined by the initial model’s judgments. During the ALS, we employ the combined set of (M + K) labeled samples to train an active training model. From this model, we select the top V samples with high-confidence predictions and assign pseudo-labels to them. In the SSLS, we utilize the expanded dataset of (M + K + V) samples to train a semi-supervised training model. This process is repeated for a total of R iterations to obtain the final results.
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.