| Issue |
A&A
Volume 697, May 2025
|
|
|---|---|---|
| Article Number | A119 | |
| Number of page(s) | 10 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202452880 | |
| Published online | 13 May 2025 | |
Tuning into the spatial frequency space
Satellite and space debris detection in the ZTF alert stream
1
Instituto de Astrofísica, Pontificia Universidad Católica de Chile,
Av. Vicuña Mackenna 4860, 7820436 Macul,
Santiago,
Chile
2
Millennium Institute of Astrophysics (MAS),
Nuncio Monsenor Sótero Sanz 100, Providencia,
Santiago,
Chile
3
Instituto de Alta Investigación, Universidad de Tarapacá,
Casilla 7D,
Arica,
Chile
4
Data Observatory,
Av. Eliodoro Yáñez 2990, oficina A5, Providencia,
Chile
5
Center for Mathematical Modeling (CMM), University of Chile,
AFB170001,
Santiago,
Chile
6
Data & Artificial Intelligence Initiative (ID&IA), University of Chile,
Santiago,
Chile
7
Centro de Astro-Ingeniería, Pontificia Universidad Católica de Chile,
Av. Vicuña Mackenna 4860, 7820436 Macul,
Santiago,
Chile
8
European Southern Observatory,
Karl-Schwarzschild-Strasse 2,
85748
Garching bei München,
Germany
9
Instituto de Estudios Astrofísicos, Facultad de Ingeniería y Ciencias, Universidad Diego Portales,
Av. Ejército Libertador 441,
Santiago,
Chile
10
Kavli Institute for Astronomy and Astrophysics, Peking University,
Beijing
100871,
China
★ Corresponding author: jcarvajal000@gmail.com
Received:
4
November
2024
Accepted:
1
April
2025
Context. A significant challenge in the study of transient astrophysical phenomena is the identification of bogus events, among which human-made Earth-orbiting satellites and debris remain major contaminants. Existing pipelines can effectively identify satellite trails, but they often miss more complex signatures, such as collections of satellite glints. In the Rubin Observatory era, the scale of operations will increase tenfold with respect to its precursor, the Zwicky Transient Facility (ZTF), requiring crucial improvements in classification purity, data compression for informative alerts, and pipeline speed.
Aims. We explore the use of a 2D Fast Fourier Transform (FFT) on difference images as a tool to improve satellite-detection machine learning algorithms.
Methods. Using the Automatic Learning for the Rapid Classification of Events (ALeRCE) single-stamp classifier as a baseline, we adapted its architecture to receive a cutout of the FFT of the difference image, in addition to the three (science, reference, difference) ZTF image cutouts (hereafter stamps). We explored various stamp sizes and resolutions, assessing the benefits of incorporating FFT images, particularly when data compression is critical due to alert size limitations and pipeline speed constraints (e.g., in large-scale surveys such as the Legacy Survey of Space and Time).
Results. The inclusion of the FFT can significantly improve satellite detection performance. The most notable improvement occurred in the smallest field-of-view model (16″), whose satellite classification accuracy increased from (72.0 ± 2.9)% to (87.8 ± 1.3)% after including the FFT, computed from the full 63″ difference images. This demonstrates the effectiveness of FFT in compressing and extracting relevant large-scale satellite features. However, the FFT alone did not fully match the accuracy achieved by the full 63″, (95.9 ± 1.3)% and multiscale (90.6 ± 0.8)% models, highlighting the complementary importance of contextual spatial information.
Conclusions. We show how FFTs can be leveraged to cull satellite and space debris signatures from alert streams.
Key words: methods: data analysis / techniques: image processing / techniques: photometric / surveys
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
Large étendue telescopes engaging in time-domain surveys, such as the Zwicky Transient Facility (ZTF; Bellm et al. 2018; Graham et al. 2019), have swiftly become a cornerstone of observational astrophysics. ZTF has revolutionized our ability to detect and characterize a wide variety of transients, active galaxies, and variable star phenomena (e.g., Chen et al. 2020; Perley et al. 2020; Carrasco-Davis et al. 2021; Sánchez-Sáez et al. 2021a, 2023), through both its 5σ difference-image alert stream and frequent data releases (Masci et al. 2019). Overall, ZTF distributes up to 106 alerts each night (with a median closer to ∼200 000), which equates to tens of GB of data per night (Patterson et al. 2018). The expected rates for the Legacy Survey of Space and Time (LSST; LSST Science Collaboration 2009; Ivezic’ et al. 2019) from the Vera C. Rubin Observatory will be an order of magnitude larger, with a single-visit depth almost four magnitudes deeper in the r band compared to ZTF. A handful of so-called community alert brokers have dedicated themselves to the distribution, filtering, and annotation of these massive alert volumes. These brokers ingest the alert streams and provide processed science products and services that enable the community to pursue their science goals without overloading the observatories’ infrastructure. Current full-stream community brokers for ZTF and future LSST include ALeRCE (Förster et al. 2021), AMPEL (Nordin et al. 2019), ANTARES (Matheson et al. 2021), Babamul, Fink (Möller et al. 2020), Lasair (Smith et al. 2019), and Pitt-Google1.
One of the persistent challenges is the identification and removal of contaminants (often referred to as “bogus” detections) from the observations and the transient event alert stream. Mitigation of bogus events is particularly important for robust early transient discovery and classification, such as identifying flash-ionization episodes in young supernovae (SNe) or short-lived kilonovae; this was a prime motivation for the development of the real-time first-stamp classifier by ALeRCE (Carrasco-Davis et al. 2021, hereafter, the “stamp classifier”). Notably, human-made satellites and space debris orbiting Earth can be particularly complicated contaminants to identify in realtime for existing algorithms and pipelines. Karpov & Peloton (2022, 2023) quantified the effect of satellite glints (see Fig. 1) that bypassed both the streak masking algorithm (Laher et al. 2014) and real-bogus classifier (Duev et al. 2019a) components of ZTF’s pipeline (Masci et al. 2019), finding at least ≈3000 glint-related alerts per month. For reference, this is ≈4.4 times the monthly rate of new transients detected by ZTF and reported to the Transient Name Server (TNS)2.
This challenge is already significant in the ZTF real-time alert stream and stands to become even more problematic in the LSST era due to the shift in stamp field of view (FoV), which is slated to go from 63″ × 63″ at a 1″/pixel resolution for ZTF (e.g., Fig. 1) to 6″ × 6″ at a 0.2″/pixel resolution for LSST, due to bandwidth limitations associated with increased image resolution. An upside of the increased resolution was recently highlighted by Tyson et al. (2024), demonstrating how glints from tumbling low-Earth orbit debris may become identifiable due to distinct de-focus and shape characteristics. This, however, does not completely alleviate the concerns, as glint-producing satellites occupy a wide range of orbits (Karpov & Peloton 2023). As discussed in Reyes-Jainaga et al. (2023, hereafter RJ23), a promising approach to mitigate the FoV reduction in LSST is to employ multiscale image stamps. These stamps capture a larger FoV with decreasing spatial resolution as the distance from the source center increases, effectively compressing data by preserving high-detail information in the central region, while also retaining relevant contextual information, such as flux from satellite trails, around the alert.
Motivated by the speed and potential for image compression, and by the unique glint signatures of satellites and space debris (hereafter, simply “satellites”), we explore the spatial frequency domain of the difference images via the fast Fourier transform (FFT) algorithm (Cooley & Tukey 1965). Satellite glints, presumably caused by rotating objects that reflect sunlight, exhibit a range of patterns from simple (e.g., Fig. 1, panel f) to complex (e.g., Fig. 1, panel g). Additionally, multiple glints from a single satellite may not be captured within the FoV of a single stamp (e.g., see Sect. 4.3). These glints generally consist of a periodic signal, dominated by the satellite’s rotation, aligned along an approximately straight line within the locality of the image. The signal is convolved with the point spread function (PSF) and, under this locality approximation, we can assume a relatively constant illumination geometry. Therefore, inspecting the spatial frequencies of these satellite glint variations is a natural path to explore. Central, point-like emission maps to very extended scales in Fourier space, while extended emission maps to more compact scales. Thus, in contrast with the multiscale approach of RJ23, the central portions of the Fourier map naturally tap into the extended emission, while imaging cropping effectively limits the minimum scales probed, rather than the maximum ones.
Building upon the approach in RJ23, we analyze the effect of including FFT information within the adapted architecture of the ALeRCE stamp classifier. The incorporation of the FFT slightly increases the model’s input size3, but more importantly, the efficiency of existing FFT implementations ensures that this addition incurs only a small computational cost, even in large-scale applications (see Appendix A). We aim to assess its potential for capturing extended spatial features in a compact form. We present the methods and results in Sects. 2 and 3, respectively. In Sect. 4, we analyze the results and discuss the future prospects for the FFT and how it can efficiently expand opportunities for improving streak detection algorithms (e.g., Duev et al. 2019b) to improve the performance with respect to satellite glints, while keeping inputs small. These aspects will be fundamental in the LSST era for both internal pipelines and downstream filtering.
 |
Fig. 1 Comparison of science image, difference image, and its FFT for various transient sources and contaminants in the ZTF alert stream. The full 63″ × 63″ science and difference stamps are shown, with the central 16″ × 16″ denoted in red. The FFT image stamp is cropped into the central 16 × 16 pixels. Panels (a)–(c) display astrophysical events: (a) variable star ZTF19abcqppk; (b) supernova ZTF20acogywb; and (c) asteroid ZTF18achatrx. Panel (d) shows a typical bogus event (ZTF18acgkbtq), characteristic of a bad subtraction. Panels (e)–(h) highlight different types of satellite signatures that reached the alert stream: (e) and (f), from alerts ZTF21abcjklk and ZTF21acaigul, show the typical regular glint signature with different separation among glints; (g) shows a satellite with irregular glints and an overall asymmetric signature; (h) shows a satellite with both a continuous signature and glints. This small portion of the Fourier space effectively captures the distinct extended signals of satellites. |
2 Enhancing the ALeRCE Stamp Classifier with FFT
The ALeRCE stamp classifier was first introduced in Carrasco-Davis et al. (2021), adopting a convolutional neural network (CNN) model that classifies individual ZTF alerts based on three-channel image cutouts (science, reference, and difference) and additional metadata (e.g., coordinates, flux and magnitude measurements, and seeing) into four distinct astrophysical sources and bogus. The effectiveness of this machine learning (ML) model is demonstrated by ALeRCE’s position as one of the top three reporting groups of transients to TNS, with ≲1% contamination among spectroscopically classified transients first reported by Förster et al. (2021).
In this work, we explore the effect of incorporating FFTs in the stamp classifier, building upon previous works. Our modifications start from the model architecture introduced in RJ23, where the “satellite” class was first introduced. The classifier categorizes alerts into six distinct classes: supernovae (SNe), variable stars, asteroids, active galactic nuclei (AGN), satellites, and bogus detections.
2.1 Preprocessing
After the ingestion of each alert, a preprocessing step takes place before the model run. A schematic is shown in Fig. 2. The detailed steps to go from the base ZTF stamps to the cropped stamp cube (blue box in the schematic), which serves as the input for the model, are the following:
In the rare cases, where the stamps do not have the original dimensions of 63 × 63 pixels (e.g., the object is by the edge of the CCD), the alert is dropped. The current necessity for the source to lie in the center of the stamp complicates such modifications. An attempt to “repair” these cases has yet to be implemented.
In each of the stamps, a boolean integrity mask is constructed, where infinite and NaN (Not a Number) values in the stamp are associated with a true (1), and finite values with a false (0).
The non-finite values in the masked stamp are then set to zero (0).
For computational efficiency, the normalization is performed separately for each stamp type (science, reference, difference) in batches. The maximum for the normalization is the 99th percentile of the absolute values. Then, the values are clipped to 2.0.
The normalized stamps are then concatenated with the integrity mask, ending up with a six-channel image. When employing the multiscale model, this process is repeated across four different scales, resulting in a 24-channel image.
-
Ultimately, the stamps are cropped or resized, depending on the model they will go into.
Beyond the preprocessing steps used in RJ23, we introduce new steps (highlighted in the red dashed box in Fig. 2) to incorporate the FFT calculation. Specifically, these steps are:
Starting from the complete (63 × 63 pixels) normalized difference image from step 5, we pad it to 128 pixels, filling with the median. The selection of the size was based on the efficiency of the FFT algorithm for sizes in powers of 2, with additional considerations explained below.
We then applied the 2D FFT and take the norm to obtain the amplitude.
Finally, we crop the central portion of the FFT. In our experiments, we kept the central 16 × 16 px region in all cases.
There are two reasons to apply the padding and both are associated with the nature of the FFT algorithm. First, since the transform maintains the sampling, padding allows us to increase the spatial frequency resolution. Second, the FFT algorithm is constructed under the assumption that the sequence to be transformed is infinitely periodic. Since this is not the case for these images, artifacts that might appear due to this inconsistency are mitigated by the padding. For these two reasons (i.e., achieving higher spatial frequency resolution and mitigating periodicity artifacts) the stamps were padded to 128 pixels instead of just 64. Increasing the padding beyond 128 pixels did not yield improvements in our early tests and would require larger cutouts to achieve the same coverage of spatial frequencies. Similar measures are taken in other fields that use the FFT, such as computational Fourier optics, to deal with such issues (e.g., Voelz 2011). Although the FFT is a complex field, we focus on the amplitude due to the potential for data compression. Alternatives to this approach are discussed in Sect. 4.3.
 |
Fig. 2 Schematic of the preprocessing for our FFT-enhanced Stamp Classifier. The red dashed box encloses the new steps for the inclusion of the FFT with respect to previous versions of the classifier (e.g., RJ23). |
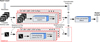 |
Fig. 3 Schematic view of the architecture of the ML models used in this work. The input includes the cropped stamp cube, the FFT cutout, and additional metadata. Both the stamp cube and FFT cutout undergo rotation and flip augmentation before being processed through separate convolutional blocks (red long-dashed boxes). The outputs are then concatenated with the metadata and passed through a fully connected block for prediction. The red short-dashed box highlights the addition of the FFT block to the architecture, which was included in models D, E, and F (see Sect. 2.2). |
2.2 Models
Figure 3 illustrates the architecture of the models evaluated in this study. The key components include the cropped stamp cube, the FFT cutout from the preprocessing step, and additional metadata (primarily the coordinates of the alert). These inputs are processed through distinct neural network blocks before being combined in a final fully connected layer that produces the model predictions.
In the architecture, the cropped stamp cube is passed through a convolutional block (referred to as the “stamp” convolutional block) that applies rotational and flip augmentations. After the convolutional layers, the images are flattened, averaged over the augmentation steps and passed through a dropout layer before being concatenated with the other features. While this block mirrors the structural design from RJ23, for the models that feature the FFT as an input (see the red short-dashed box in Fig. 3), the hyperparameters were re-optimized separately.
Parallel to this, the FFT convolutional block processes the FFT cutout. Similar to the stamp convolutional block, it includes rotation and flip augmentation followed by convolutional and pooling layers; finally, the output is flattened and concatenated with the other features. To assess the value of incorporating the FFT block, we compared models that included it with those that did not:
Full: the full 63″ × 63″ (63 × 63 px) FoV alert at 1″ resolution is used. The input consists of three images (science, reference, and difference) and their corresponding integrity masks, creating a six-channel image.
Multiscale: the stamp cube includes 8″, 16″, 32″, and 63″ FoV stamps at corresponding resolutions of 1″, 2″, 4″, and 8″. This produces a 24-channel image with four channels per image type.
Cropped-16: the alert is cropped to a 16″ FoV with the full 1″ resolution.
Full+FFT: combines the full 63″ FoV with the FFT block.
Multiscale+FFT: combines the multiscale stamp cube with the FFT block.
Cropped-16+FFT: combines the cropped 16″ FoV with the FFT block.
Model F (cropped-16+FFT) is particularly interesting due to its scalability. The amount of information in an image scales as the square of the number of pixels (N2). However, the FFT algorithm’s computational cost scales as N ⋆ log(N), making it significantly efficient, especially considering the subsequent cropping of the FFT to retain only the most relevant information. This efficiency enables model F to capture large-scale features of transient phenomena, such as satellite glints, while minimizing the inclusion of non-informative data (e.g., sky pixels in a science image) that would slow the pipelines.
For completeness, models D and E were also evaluated, although they did not show statistically significant improvements compared to models A and B. This is because the FFT block provided redundant information that was already captured by the larger FoVs in these models. The inclusion of the FFT block in these cases added complexity to the models, making them slower and complicating their optimization.
2.3 Data and training
We started from the same dataset used by RJ23 and closely followed the training procedure outlined therein. A detailed description of the dataset and its construction (by cross-matching with other databases) for all classes, except satellites, can be found in Carrasco-Davis et al. (2021) and Sánchez-Sáez et al. (2021b). Since RJ23, in the case of satellites, most of the alerts were flagged during the human inspection of ZTF alerts while searching for SNe candidates. While this approach limits the number of objects available, it ensures the purity of our sample, as multiple glints or a trail-like signal within the 63″×63″ FoV of the stamps are necessary to confidently classify the object as a satellite with only the alert information. One fundamental revision was made in this work. An inspection of the alerts that had been confused with each other in previous models prompted a manual review of all alerts labeled as “bogus” in the dataset. We found that a significant portion (∼3%) of the bogus-labeled alerts showed clear satellite trails and glints. Thus, we re-labeled them as satellites. We also added more satellites flagged during 2023–2024, increasing our sample of satellites to 1204. This manual revision significantly reduced contamination and improved the representativeness of our satellite class, thereby enhancing model reliability. Table 1 summarizes the number of alerts per class. To deal with the remaining class imbalance, we employed balanced training batches and class-balanced crossentropy loss for validation (see RJ23 for details). A limitation of this approach is discussed in Sect. 4.1.
The training process involved a hyperparameter (HP) search using Ray Tune (Liaw et al. 2018), optimizing parameters such as the number of filters in the convolutional layers, learning rate, dropout rate, the size of the first convolutional kernel, and the size of the last dense layer. Repeating the HP optimization for models A, B, and C after addressing bogus contamination resulted in moderate performance improvements, highlighting the value of this revision. For models D, E, and F (with the FFT block), we also ran a HP search, focusing on the FFT-specific convolutional layers. The search space for inherited parameters was narrowed to one-third of the original range, centered around the optimal values from models A, B, and C, while the FFT-specific parameters were searched within a broad range of values.
This approach ensured efficient HP optimization for the FFT models, with search times comparable to the non-FFT models. After identifying the optimal hyperparameters, each model was trained five times using the entire training set to compute the F1 score, precision, and recall (see Sect. 5.7.2. in Murphy 2012, for definitions), as well as to estimate their respective standard deviations and assess the significance of changes. The results are summarized in Table 2 for the test dataset.
Number of objects per class.
3 Results
In this section, we briefly introduce the model performance metrics, while interpretation follows in Sect. 4. Table 2 presents the performance metrics for each model. As in RJ23, the multiscale model outperforms the other non-FFT models. The inclusion of the FFT block in the full model (A) did not affect the F1 score, indicating that the FFT, while increasing the complexity of the model, did not compensate with additional useful information. In the case of the multiscale+FFT model (E), there was a marginal decrease in the F1 score, with no statistical significance, over the model (B). In contrast, the cropped-16+FFT model (F) showed significant improvements over cropped-16 (C) across all metrics, equal to the best-performing models in terms of F1 score.
Figure 4 shows the confusion matrices for the cropped-16 (C) and cropped-16+FFT (F) models. The addition of the FFT notably reduced misclassifications of satellites, bringing performance close to models A and B, as noted in Fig. 5. A detailed analysis of these results is given in the next section.
Performance metrics for each model.
4 Discussion
Here, we evaluate the impact of incorporating the FFT in satellite detection and explore potential applications for internal survey pipelines responsible for generating transient alerts. By enhancing the early detection and classification process, FFT-based methods may help streamline the flow of high-quality alerts in large-scale surveys. We first analyze the classification metrics and confusion matrices (Sect. 4.1), followed by an assessment of the satellite sample properties, potential biases, and limitations (Sect. 4.2), before discussing broader implications for future survey pipelines (Sect. 4.3).
4.1 The impact of the spatial frequency space
In the Fourier space, the distinct signatures of satellites, characterized by transient and extended features, become clear. Satellite glints, challenging to detect in the spatial domain, are efficiently isolated in the FFT space, enhancing the detection accuracy and providing a compact data representation for ML models.
To evaluate the benefits of FFT, we categorized the image information into three types (source, context, and satellite), which correspond to different spatial scales and play a critical role in classification tasks. Source information generally captures small-scale, transient, or variable objects such as SNe, AGN, variable stars, and asteroids, typically spanning only a few arcseconds in size. Satellites, however, are an important exception, as we discuss separately below. Context information provides larger-scale, unchanging environmental details, such as the position relative to nearby galaxies. The scale of this context information can vary; typical galaxy sizes range from a few arcseconds to several tens of arcminutes for extreme cases like the local Pinwheel Galaxy (M101). An important example is SN 2023ixf, discovered by amateur astronomer Koichi Itagaki (Itagaki 2023), within M101. Such a large host galaxy can complicate early classification efforts, as methods relying on context information, such as ALeRCE’s Stamp Classifier (Carrasco-Davis et al. 2021), might miss SNe in such contexts, as happened in this case, where it was mislabeled as bogus. This underscores the importance of a multiscale approach for capturing crucial contextual data. Satellite information, however, is distinct due to its large linear spread and transient nature, making the FFT particularly effective in isolating it.
Our experiment showed that the cropped-16 model (C) performed worse overall in the classification task compared to the full (A) or the multiscale (B) models (see Table 2). Since it contains less context information (smaller FoV), this is to be expected. It was particularly bad at identifying satellites, frequently confusing them with asteroids and SNe (see Fig. 4a and below for more details). By including the FFT Block in the cropped-16+FFT model (F), these issues were largely resolved, with satellite identification improving close to the accuracy of the best performing models (see Fig. 5). The confusion between satellites (true label), and asteroids and SNe was greatly reduced, despite the reduced context information.
These results suggest that the FFT of the difference image is highly effective for identifying satellites and capturing the periodic nature of glints, which are challenging to detect in the spatial domain. However, models incorporating more contextual information from wider FoVs in the science and reference images (such as the full and multiscale models) exhibit significantly less confusion in classifying SNe. This demonstrates that the FFT alone does not fully compensate for the contextual information gap, limiting the performance of the cropped-16+FFT model (F).
It is important to emphasize that the dataset is imbalanced, with significantly more bogus objects than satellites. Despite the efforts to mitigate class imbalance during model training (see Sect. 2.3), some residual effects of this may persist. In this context, comparing models F (Fig. 4b) and B (Fig. 5b), the former performs marginally better in terms of the bogus-satellite confusion (by 0.3% ± 0.1%), while the latter has a marginal edge in satellite-bogus confusion (by 2.1% ± 1.6%). Given the substantial class imbalance – with 12.7 times more bogus alerts than satellites – these percentages should be interpreted with caution.
In both cases, the accuracy for classifying satellites is less than that offered by model A (Fig. 5a), which includes more context from the complete stamp data. Overall, the 16″ FoV model F, enhanced by the inclusion of FFT, performs marginally below model B in satellite identification. The residual confusion with SNe likely arises from the reduced contextual information in the smaller FoV, which the FFT alone does not fully compensate for. Additionally, confusion with bogus detections can occur in crowded fields, where poor difference-image subtraction of extended features can mimic satellite-like FFT signatures, even when artifacts are not genuinely satellite-related.
 |
Fig. 4 Confusion matrices for the cropped and cropped+FFT models (C&F). The values are normalized by the “true” labels (rows). In parentheses are the standard deviations over five runs. |
4.2 Properties of sampled satellites
To assess potential biases and limitations in our classification methods, we characterized the properties of the detected satellites based on the available alert data, as access to the full images is not feasible in our setup. Specifically, we extracted two key parameters: the brightness of the central glint, taken from the magpsf value in the ZTF alert metadata and an estimated tumbling period derived from the spatial structure of the glints within the alert stamps.
The tumbling period is not directly measurable from the alert stamps due to the limited field of view (FoV) of 63″. Given that the ZTF exposure time is ∼30 s, a full trail could, in principle, provide a direct measurement of the satellite’s rotation period. However, within an individual alert stamp, we only observe a segment of the satellite’s light trail, imposing a fundamental limitation on how long a periodicity can be reliably measured. As a proxy, we estimated the glint period in arcseconds, namely, the characteristic spatial frequency of the satellite’s glinting pattern within the stamp. This is obtained by: (i) extracting the light profile along the direction of the trail, (ii) performing a 1D Lomb-Scargle periodogram to estimate the dominant periodicity in arcseconds. Given the stamp FoV, measurable glint periods are significantly limited to ≲30″ (if aligned with the edges) or ≲40″ (if diagonal). Longer periodicities arise only in special cases, such as objects displaying secondary glints of different brightness levels (e.g., Fig. 1, panel e) or irregular, extended trails (e.g., Fig. 1, panel h). This selection effect is visually represented by the shaded region in Fig. 6.
Figure 6 shows the joint distribution of magnitudes and estimated glint periods for our full satellite dataset. The magnitude distribution aligns well with previous studies (e.g., Karpov & Peloton 2022), with a peak around 19.5 mag and a decline at fainter magnitudes. While no prior references exist for the expected glint period distribution, our dataset serves as a useful baseline for evaluating classification biases. The test set (black outline) is representative of the full sample, ensuring that model performance can be assessed on a well-sampled population.
Overlaid on Fig. 6, we present the accuracy distributions for each classification model, averaged over the five training runs. Model A, with full-resolution and 63″ FoV, exhibits a uniform accuracy close to 1 across all magnitude and glint period bins, confirming the notion that access to the entire stamp preserves satellite properties without bias. The cropped-16 model (16″ FoV) exhibits significantly lower recovery rates, particularly around 19.5 mag, where a sharp drop is observed. The rest of the models (the multiscale and the FFT-enhanced) perform similarly across glint periods, showing no systematic bias. However, they exhibit a minor decline in accuracy at fainter magnitudes, decreasing to ∼0.8 at 20 mag. This suggests that while the FFT method successfully recovers satellite information, it begins to struggle at lower signal-to-noise ratios when the full context is not available.
Importantly, FFT-based approaches show no significant bias in glint-period recovery. This reinforces the suitability of FFT for encoding large-scale features, while maintaining sensitivity to periodic satellite glints.
 |
Fig. 6 Distribution of magnitudes and estimated glint periods for our satellite dataset. The central scatter plot presents the full sample, with marginal histograms (blue: full sample, black outline: test subset). Colored lines show classification accuracy per model, ranging from 0 (no recovery) to 1 (perfect recovery). Due to the limited 63″ stamp FoV, glint periods ≳30″ are incompletely sampled (shaded region, see Sect. 4.2). The full model shows consistently high accuracy, whereas the cropped-16 model accuracy drops notably at ∼19.5 mag. FFT-based models show no glint-period bias, with only minor accuracy reductions at faint magnitudes. |
4.3 Future prospects
In this study, we focus on the amplitude of the FFT, using it as a single additional channel for data compression. However, since the FFT provides a complex field, the phase information, while not considered here, may also prove valuable in distinguishing certain features. Future works could investigate alternative approaches, such as incorporating one-channel real-part FFT or two-channel real- and imaginary-part FFT components, to capture a wider range of spatial frequency features.
Beyond the technical aspects of the FFT, its practical applications in large-scale surveys such as LSST are worth exploring. Integrating FFT into internal pipelines could significantly improve the identification of satellite contaminants before the data reaches downstream (alert) processing. However, for the FFT to be most effective, the satellite trail must be well-centered in the image. Our experiments showed that even small offsets (e.g., five pixels within the 63″×63″ stamps) significantly distort the signal, regardless of whether the offset is along the trail direction or cross-trail. Larger offsets quickly cause the signal to disappear entirely. Although, in principle, a shift in the spatial domain corresponds to a phase modulation in Fourier space ![$\mathcal{F}[f(x + c)] = F(k) e^{i 2 \pi k c}$](/articles/aa/full_html/2025/05/aa52880-24/aa52880-24-eq1.png) , numerical effects in the FFT can degrade the signal. Therefore, we caution against relying on FFT for stamps with substantially offset satellite glints or trails.
, numerical effects in the FFT can degrade the signal. Therefore, we caution against relying on FFT for stamps with substantially offset satellite glints or trails.
Figure 7 demonstrates the application of FFT over a larger cutout (512 px), beyond the typical 63 px of ZTF alerts. The central portion of the image focuses on a satellite trail, initially mislabeled as bogus but correctly identified as a satellite by our FFT-enhanced model, later confirmed by human inspection using the ALeRCE Explorer4. Binning the FFT (right panel of Fig. 7) smooths out high-frequency details, allowing us to focus on large-scale variations that are more characteristic of satellite signatures. This approach demonstrates how FFTs could be implemented in internal pipelines, leveraging the information from very extended trails that produce apparently independent blobs at smaller scales, which may otherwise even fall below the detection threshold. Identifying and intelligently masking out these extended tracks could greatly reduce the number of complex satellite stamps, which currently pass into the alert stream.
When comparing our method to other approaches for satellite detection, several distinctions arise. For instance, Karpov & Peloton (2022, 2023) used tracklet reconstruction to identify satellites by correlating non-repeating transient sources geometrically. While this is effective and helped reveal the impact satellites have on surveys, our method offers the advantage of considering both the bright and low-brightness features of satellite trails, which could become increasingly important as the LSST’s deeper exposures reveal fainter satellite glints. Other approaches for detecting trails, mentioned in Sect. 1, involve analyzing images to search for elongated trail-like shapes (e.g., using the CREATETRACKIMAGE task from Laher et al. 2014) or employing CNNs (Duev et al. 2019b), similarly to this work. Unconnected blobs from satellite glints pose a challenge for the former method. Regarding the latter, a promising area for future development might be to incorporate FFTs into it, given the relative ease to include FFT in ALeRCE’s stamp classifier.
However, it is important to acknowledge that no single method is likely to completely address the problem of satellite contamination. While we have highlighted the strengths of the FFT approach, reducing the misclassification of satellite events will likely require a combination of techniques, each addressing different aspects of the contamination problem. Combining methods with complementary strengths, such as tracklet reconstruction, trail detection, CNN-based models, and FFT-enhanced classification, should offer more robust mitigation of satellite contamination in large-scale surveys like LSST.
Another promising avenue involves trail-fitting techniques like those used by Vereš et al. (2012) for asteroids, which could potentially be adapted to include light-curve estimation. This could allow for the subtraction of satellite signatures from images. Such trail-modeling could be crucial for distinguishing between human-made and natural fast-moving objects, as well as broader space pollution characterization.
As of this writing, the public plans for the Rubin Observatory’s data management facilities do not explicitly mention the use of graphics processing units (GPUs). However, given their widespread adoption in accelerating ML pipelines, GPUs would likely be a valuable addition to the survey’s infrastructure, either from the outset or as a future upgrade. GPU-optimized FFT algorithms, known for their scalability and efficiency (e.g., see Moreland & Angel 2003; NVIDIA Corporation 2023; Advanced Micro Devices, Inc. 2023, and Appendix A), offer an effective solution for processing the massive volumes of high-resolution data that LSST will generate. Their capacity for rapid FFT processing is essential to ensure that FFT-based feature extraction keeps up with the data flow in large-scale surveys like LSST (see Appendix A). Incorporating GPUs into LSST’s on-site computation facilities would significantly boost processing efficiency and scalability, though adapting existing pipelines to new hardware and software may pose challenges.
 |
Fig. 7 512 × 512 pixel cutouts from a ZTF full-chip image containing the alert-triggering object ZTF20aapfawc at the center. The satellite trail, highlighted with a red box, spans across the cutouts. Additional alerts raised by this satellite streak correspond to objects ZTF20aapfavz and ZTF20aapfavx, located 60″ to the bottom-left and 250″ to the top-right of the center, respectively, along the highlighted trail. The left and center panels display science and difference images, respectively, while the right panel shows the FFT of the difference image with an eight-pixel binning. In spatial frequency space, the satellite exhibits a distinctive fringe-like pattern, similar to the smaller stamps shown in Fig. 1. |
5 Conclusions
The study of transient astrophysical events in modern surveys such as ZTF and the LSST comes with several challenges, including managing the vast volumes of data and mitigating the presence of contaminants (e.g., CCD artifacts, template subtraction artifacts, and satellite trails). In the context of the burgeoning space industry, the latter is a rapidly growing problem that has yet to be adequately addressed by time-domain surveys (see, e.g., Catelan 2023, and references therein for a recent review). The current LSST bandwidth constraints on alert data volume may strongly limit the ability of downstream brokers and users to optimally filter out various contaminants. Thus, investigating efficient methods to improve the identification and filtering of contaminants early in the data stream or, alternatively, to compress the data information more effectively into alerts, will hopefully ensure that the most scientifically valuable information is retained and leveraged by end users.
In this study, we explore the utility of the FFT in enhancing the detection of satellite glints within astronomical survey data streams and its potential as an image compression tool. We specifically utilized ZTF data, while also anticipating the challenges of the upcoming LSST era. Our results demonstrate that the FFT effectively isolates the distinct signatures of satellite trails and glints, concentrating these features in a compact region of Fourier space. This compactness allows for efficient data compression, significantly reducing the amount of non-informative data.
Our experiment compared the performance of ML models using FoVs of different sizes for the three ZTF alert image stamps (science, reference, and difference) and assessed the impact of adding a central cutout of the FFT of the difference image as an input. As discussed in Sect. 4.1, incorporating the FFT block significantly improved the classification metrics of model C (which adopts a smaller 16″ FoV) to the levels achievable with the full 63″ FoV. In model F, using 16″ FoV stamps that include an FFT image, the overall F1 score increased to the level of the best performing models, with the most notable improvement on the classification of satellites. The confusion between SNe and asteroids, which can be the product of the small FoV, was not alleviated by the inclusion of the FFT. In this case, we found that the additional contextual information of larger FoVs was important, and the multiscale model introduced in RJ23 (model B here) did a better job, while keeping the size of the input low.
Beyond the immediate scope of this work, the FFT’s potential applications in internal data processing pipelines are vast. As discussed in Sect. 4.3, integrating FFTs into existing models could enable the analysis of larger image cutouts without a substantial increase in computational cost, facilitating more accurate and scalable contaminant detection. As shown in Appendix A, the GPU-based computation of the FFT would allow for the extraction of satellite signatures in 512×512 pixel images, instead of 64×64 pixel, at virtually no runtime cost. This approach could be particularly impactful for LSST, where efficient data handling and precise contamination filtering will be paramount.
Moving forward, this method opens several avenues for future optimization. For instance, since the signature of satellites in Fourier space is fringe-like, we found success in experiments aimed at reducing the images into 1D arrays (“spectra”). The possibility of deriving features related to this 1D frequency space spectra or even coefficients that could capture the 2D nature may be of relevance as information to include in alert packets in these data streams. Additionally, integrating this approach with real-time data processing pipelines could offer a substantial improvement in the purity and efficiency of alert systems, providing a more robust framework for upcoming large-scale surveys.
In conclusion, the FFT offers a powerful tool for both enhancing contaminant detection and improving data compression in astronomical surveys. By incorporating these techniques into future data processing pipelines, we can better prepare for the challenges of the LSST era and beyond, ultimately enabling more efficient and accurate astronomical research.
Acknowledgements
We acknowledge support from the National Agency for Research and Development (ANID) grants: Millennium Science Initiative ICN12_009 (FEB, AMMA, IRJ, MC) and AIM23-0001 (FEB, FF, MC), BASAL Center of Mathematical Modeling Grant FB210005 (FF, AMMA), BASAL projects ACE210002 (AB, MC) and FB210003 (JPC, FEB, AB, MC), FONDE-CYT Regular 1241005 (FEB), FONDECYT Regular 1231637 (MC), Beca de Doctorado Nacional (JPC). We also acknowledge the use of the Kultrún computing cluster at Universidad de Concepción, funded by Conicyt Quimal #170001, Anillo ACT172033, Fondecyt regular 1180291, Fondecyt Iniciacion 11170268, Basal AFB-170002, and Núcleo Milenio Titans NCN19-058. We are grateful to the anonymous referee for their careful review and valuable feedback, which significantly improved the clarity and robustness of this work.
References
- Advanced Micro Devices, Inc. 2023, AMD rocFFT Library, version 1.0.29, https://rocmdocs.amd.com/projects/rocFFT/en/latest/index.html [Google Scholar]
- Bellm, E. C., Kulkarni, S. R., Graham, M. J., et al. 2018, PASP, 131, 018002 [Google Scholar]
- Carrasco-Davis, R., Reyes, E., Valenzuela, C., et al. 2021, AJ, 162, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Catelan, M. 2023, Mem. Soc. Astron. It., 94, 56 [NASA ADS] [Google Scholar]
- Chen, X., Wang, S., Deng, L., et al. 2020, ApJS, 249, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Cooley, J. W., & Tukey, J. W. 1965, Math. Comput., 19, 297 [Google Scholar]
- Duev, D. A., Mahabal, A., Masci, F. J., et al. 2019a, MNRAS, 489, 3582 [NASA ADS] [CrossRef] [Google Scholar]
- Duev, D. A., Mahabal, A., Ye, Q., et al. 2019b, MNRAS, 486, 4158 [NASA ADS] [CrossRef] [Google Scholar]
- Förster, F., Cabrera-Vives, G., Castillo-Navarrete, E., et al. 2021, AJ, 161, 242 [CrossRef] [Google Scholar]
- Graham, M. J., Kulkarni, S. R., Bellm, E. C., et al. 2019, PASP, 131, 078001 [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Itagaki, K. 2023, Transient Name Server Discovery Report, 2023-1158, 1 [Google Scholar]
- Ivezic, Z., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Karpov, S., & Peloton, J. 2022, arXiv e-prints [arXiv:2202.05719] [Google Scholar]
- Karpov, S., & Peloton, J. 2023, Contrib. Astron. Observ. Skal. Pleso, 53, 69 [NASA ADS] [Google Scholar]
- Laher, R. R., Surace, J., Grillmair, C. J., et al. 2014, PASP, 126, 674 [NASA ADS] [Google Scholar]
- Liaw, R., Liang, E., Nishihara, R., et al. 2018, arXiv e-prints [arXiv:1807.05118] [Google Scholar]
- LSST Science Collaboration (Abell, P. A., et al.) 2009, arXiv e-prints [arXiv:0912.0201] [Google Scholar]
- Masci, F. J., Laher, R. R., Rusholme, B., et al. 2019, PASP, 131, 018003 [Google Scholar]
- Matheson, T., Stubens, C., Wolf, N., et al. 2021, AJ, 161, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Möller, A., Peloton, J., Ishida, E. E. O., et al. 2020, MNRAS, 501, 3272 [Google Scholar]
- Moreland, K., & Angel, E. 2003, in Graphics Hardware, eds. Doggett, M., Heidrich, W., Mark, W., & Schilling, A. (UK: The Eurographics Association) [Google Scholar]
- Murphy, K. P. 2012, Machine Learning: A Probabilistic Perspective, Adaptive Computation and Machine Learning Series (Cambridge, Massachusetts, London, England: MIT Press) [Google Scholar]
- Nordin, J., Brinnel, V., van Santen, J., et al. 2019, A&A, 631, A147 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- NVIDIA Corporation 2023, NVIDIA cuFFT Library, version 12.6, https://docs.nvidia.com/cuda/cufft/index.html [Google Scholar]
- Okuta, R., Unno, Y., Nishino, D., Hido, S., & Loomis, C. 2017, in Proceedings of Workshop on Machine Learning Systems (LearningSys) in The Thirty-first Annual Conference on Neural Information Processing Systems (NIPS), http://learningsys.org/nips17/assets/papers/paper_16.pdf https://www.goog [Google Scholar]
- Patterson, M. T., Bellm, E. C., Rusholme, B., et al. 2018, PASP, 131, 018001 [Google Scholar]
- Perley, D. A., Fremling, C., Sollerman, J., et al. 2020, ApJ, 904, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Reyes-Jainaga, I., Förster, F., Arancibia, A. M. M., et al. 2023, ApJ, 952, L43 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez-Sáez, P., Lira, H., Martí, L., et al. 2021a, AJ, 162, 206 [CrossRef] [Google Scholar]
- Sánchez-Sáez, P., Reyes, I., Valenzuela, C., et al. 2021b, AJ, 161, 141 [CrossRef] [Google Scholar]
- Sánchez-Sáez, P., Arredondo, J., Bayo, A., et al. 2023, A&A, 675, A195 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Smith, K. W., Williams, R. D., Young, D. R., et al. 2019, Res. Notes AAS, 3, 26 [Google Scholar]
- Tyson, J. A., Snyder, A., Polin, D., Rawls, M. L., & Ivezic, Ž. 2024, ApJ, 966, L38 [Google Scholar]
- Vereš, P., Jedicke, R., Denneau, L., et al. 2012, PASP, 124, 1197 [CrossRef] [Google Scholar]
- Voelz, D. G. 2011, Computational Fourier Optics, Tutorial Texts (Bellingham, WA: SPIE Press) [CrossRef] [Google Scholar]
Appendix A Computational benchmarking of FFT performance
 |
Fig. A.1 Scaling of 2D-FFT computation times with image size (CPU vs. GPU) and the runtime for each of our models as horizontal spans, with the width being the standard deviation between model runs. We provide the runtime for the models for perspective, but these do not vary stamp size. |
To evaluate the feasibility of integrating FFT-based preprocessing into real-time astronomical alert pipelines, we benchmarked the computational cost of FFT computations (both CPU- and GPU-based implementations) and compared it to the runtime of our deep learning models. This analysis provides a direct assessment of whether FFT processing introduces a significant computational overhead and whether it scales efficiently for larger images, such as those expected in upcoming surveys like LSST.
For consistency and reproducibility, both benchmarks were executed on the same computational system: a single NVIDIA RTX A4000 GPU for GPU benchmarks, and a single computational thread of an AMD EPYC 7773X CPU for CPU benchmarks.
FFT computation runtimes
We computed the 2D FFT on square stamps of various sizes (2n, n ∈ [6, 11]) using the numpy.fft.fft2 function for the CPU-based implementation (Harris et al. 2020), and the cupy.fft.fft2 for the GPU-based implementation (Okuta et al. 2017).
Each FFT computation was repeated 30 times per image size using different random cutouts from a single ZTF difference image to measure execution time and variability. The difference in performance between CPU and GPU implementations is significant: the GPU-based FFT is an order of magnitude faster at 512×512 pixels and two orders of magnitude faster at 2048×2048 pixels compared to CPU execution.
Machine learning model runtimes
To provide a meaningful baseline for interpreting FFT overhead, we also measured the inference time per alert for each of the six model architectures introduced in Sect. 2.2 (with GPU acceleration). For each model, we computed runtimes over five independent training runs, evaluated on the full 9,888-alert test set, and reported the mean and standard deviation. These results are shown as horizontal spans in Fig. A.1, where the width represents the standard deviation across runs.
FFT computation remains a fraction of the time required for CNN inference. On a GPU, FFT execution is sub-millisecond fast, even for 1024×1024 pixel images. These results confirm that FFT-based preprocessing is highly efficient and feasible for realtime pipelines of large-scale surveys such as ZTF and LSST.
All Tables
All Figures
|
Fig. 1 Comparison of science image, difference image, and its FFT for various transient sources and contaminants in the ZTF alert stream. The full 63″ × 63″ science and difference stamps are shown, with the central 16″ × 16″ denoted in red. The FFT image stamp is cropped into the central 16 × 16 pixels. Panels (a)–(c) display astrophysical events: (a) variable star ZTF19abcqppk; (b) supernova ZTF20acogywb; and (c) asteroid ZTF18achatrx. Panel (d) shows a typical bogus event (ZTF18acgkbtq), characteristic of a bad subtraction. Panels (e)–(h) highlight different types of satellite signatures that reached the alert stream: (e) and (f), from alerts ZTF21abcjklk and ZTF21acaigul, show the typical regular glint signature with different separation among glints; (g) shows a satellite with irregular glints and an overall asymmetric signature; (h) shows a satellite with both a continuous signature and glints. This small portion of the Fourier space effectively captures the distinct extended signals of satellites. |
| In the text | |
|
Fig. 2 Schematic of the preprocessing for our FFT-enhanced Stamp Classifier. The red dashed box encloses the new steps for the inclusion of the FFT with respect to previous versions of the classifier (e.g., RJ23). |
| In the text | |
|
Fig. 3 Schematic view of the architecture of the ML models used in this work. The input includes the cropped stamp cube, the FFT cutout, and additional metadata. Both the stamp cube and FFT cutout undergo rotation and flip augmentation before being processed through separate convolutional blocks (red long-dashed boxes). The outputs are then concatenated with the metadata and passed through a fully connected block for prediction. The red short-dashed box highlights the addition of the FFT block to the architecture, which was included in models D, E, and F (see Sect. 2.2). |
| In the text | |
|
Fig. 4 Confusion matrices for the cropped and cropped+FFT models (C&F). The values are normalized by the “true” labels (rows). In parentheses are the standard deviations over five runs. |
| In the text | |
 |
Fig. 5 Same as Fig. 4 but for the full and multiscale models. |
| In the text | |
|
Fig. 6 Distribution of magnitudes and estimated glint periods for our satellite dataset. The central scatter plot presents the full sample, with marginal histograms (blue: full sample, black outline: test subset). Colored lines show classification accuracy per model, ranging from 0 (no recovery) to 1 (perfect recovery). Due to the limited 63″ stamp FoV, glint periods ≳30″ are incompletely sampled (shaded region, see Sect. 4.2). The full model shows consistently high accuracy, whereas the cropped-16 model accuracy drops notably at ∼19.5 mag. FFT-based models show no glint-period bias, with only minor accuracy reductions at faint magnitudes. |
| In the text | |
|
Fig. 7 512 × 512 pixel cutouts from a ZTF full-chip image containing the alert-triggering object ZTF20aapfawc at the center. The satellite trail, highlighted with a red box, spans across the cutouts. Additional alerts raised by this satellite streak correspond to objects ZTF20aapfavz and ZTF20aapfavx, located 60″ to the bottom-left and 250″ to the top-right of the center, respectively, along the highlighted trail. The left and center panels display science and difference images, respectively, while the right panel shows the FFT of the difference image with an eight-pixel binning. In spatial frequency space, the satellite exhibits a distinctive fringe-like pattern, similar to the smaller stamps shown in Fig. 1. |
| In the text | |
|
Fig. A.1 Scaling of 2D-FFT computation times with image size (CPU vs. GPU) and the runtime for each of our models as horizontal spans, with the width being the standard deviation between model runs. We provide the runtime for the models for perspective, but these do not vary stamp size. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.