| Issue |
A&A
Volume 689, September 2024
|
|
|---|---|---|
| Article Number | A58 | |
| Number of page(s) | 11 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202449909 | |
| Published online | 30 August 2024 | |
Deriving the star formation histories of galaxies from spectra with simulation-based inference
1
Instituto de Astrofísica de Canarias, C/ Vía Láctea s/n, 38205 La Laguna, Tenerife, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Departamento de Astrofísica, Universidad de La Laguna, 38200 La Laguna, Tenerife, Spain
3
Observatoire de Paris, LERMA, PSL University, 61 Avenue de l’Observatoire, 75014 Paris, France
4
Université Paris-Cité, 5 Rue Thomas Mann, 75014 Paris, France
5
Department of Physics, Faculty of Engineering and Physical Sciences, University of Surrey, GU2 7XH Guildford, UK
Received:
8
March
2024
Accepted:
23
June
2024
Abstract
High-resolution galaxy spectra encode information about the stellar populations within galaxies. The properties of the stars, such as their ages, masses, and metallicities, provide insights into the underlying physical processes that drive the growth and transformation of galaxies over cosmic time. We explore a simulation-based inference (SBI) workflow to infer from optical absorption spectra the posterior distributions of metallicities and the star formation histories (SFHs) of galaxies (i.e. the star formation rate as a function of time). We generated a dataset of synthetic spectra to train and test our model using the spectroscopic predictions of the MILES stellar population library and non-parametric SFHs. We reliably estimate the mass assembly of an integrated stellar population with well-calibrated uncertainties. Specifically, we reach a score of 0.97 R2 for the time at which a given galaxy from the test set formed 50% of its stellar mass, obtaining samples of the posteriors in only 10−4 s. We then applied the pipeline to real observations of massive elliptical galaxies, recovering the well-known relationship between the age and the velocity dispersion, and show that the most massive galaxies (σ ∼ 300 km s−1) built up to 90% of their total stellar masses within 1 Gyr of the Big Bang. The inferred properties also agree with the state-of-the-art inversion codes, but the inference is performed up to five orders of magnitude faster. This SBI approach coupled with machine learning and applied to full spectral fitting makes it possible to address large numbers of galaxies while performing a thick sampling of the posteriors. It will allow both the deterministic trends and the inherent uncertainties of the highly degenerated inversion problem to be estimated for large and complex upcoming spectroscopic surveys, such as DESI, WEAVE, or 4MOST.
Key words: galaxies: evolution / galaxies: star formation / galaxies: statistics
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Understanding the physical processes that regulate star formation over cosmic time is one of the main challenges of galaxy studies, as their evolution depends on a balance between processes that trigger star formation and others that prevent it by expelling or heating gas (e.g. Franx & Illingworth 1990; Silk & Mamon 2012; Lilly et al. 2013; Martín-Navarro et al. 2020). Reconstructing star formation histories (SFHs) is thus a fundamental step towards understanding galaxy evolution. However, inferring them from observed spectra for a statistically significant sample of galaxies is a complex inverse problem subject to a large number of degeneracies that are not well understood (e.g. Worthey et al. 1992; Ocvirk et al. 2006; Conroy et al. 2009).
Stellar population synthesis (SPS) models are normally used, built from simple stellar population (SSP) templates. SSPs describe the evolution in time of the spectrum of a single stellar burst of fixed metallicity and chemical abundance and require three basic inputs: (i) stellar evolution theory in the form of isochrones, for example Padova (Girardi et al. 2000), BaSTI (Pietrinferni et al. 2006), or MIST (Choi et al. 2016), (ii) empirical or theoretical stellar spectral libraries, for example CaT (Cenarro et al. 2001), MILES (Vazdekis et al. 2010), or XSL (Gonneau et al. 2020), and (iii) an initial mass function (IMF; Salpeter 1955; Kroupa 2001; Chabrier 2003). Each of these three inputs can in principle depend on the metallicity and/or elemental abundance patterns. Composite stellar populations differ from simple ones because they contain stars with a range of ages (as given by their SFHs) and metallicities (as given by their time-dependent metallicity distribution function, P([M/H]1, t)).
To connect a model with observations, a statistical inference framework is required. Full spectral fitting algorithms are a popular tool for inferring stellar population properties from integrated spectra, generally based on a backward comparison between data and models (e.g. Fernandes et al. 2005; Ocvirk et al. 2006; Tojeiro et al. 2007; Wilkinson et al. 2017; Cappellari 2023). The success and reliability of this method depend on the quality of the template spectra and the robustness of the fitting algorithm. In parallel, stellar population inversion algorithms have evolved into Bayesian statistics (e.g. Martín-Navarro et al. 2019; Johnson et al. 2021; Maksymowicz-Maciata et al. 2024; Wang et al. 2024), with the Markov chain Monte Carlo (MCMC) method primarily used for sampling the posterior distributions, which are assumed to be Gaussian, allowing an efficient exploration of the degeneracies associated with the large parameter space.
Existing Bayesian spectral modelling approaches, however, require a substantial computational investment, ranging from 10 to 100 CPU hours per galaxy (Carnall et al. 2019; Tacchella et al. 2022). This computational demand is already high for current datasets, like the Sloan Digital Sky Survey (SDSS; York et al. 2000) or the Cosmic Evolution Survey (COSMOS; Scoville et al. 2007), which contain hundreds of thousands of galaxy spectral energy distributions, and it will become a prohibitive bottleneck for upcoming surveys. Over the next decade, the Dark Energy Spectroscopic Instrument (DESI; Hahn et al. 2023a), the William Herschel Telescope Enhanced Area Velocity Explorer (WEAVE; Dalton et al. 2012), the 4-m Multi-Object Spectroscopic Telescope (4MOST; de Jong 2011), and the Multi-Object Optical and Near-infrared Spectrograph (MOONS; Cirasuolo et al. 2020) will capture spectra from billions of galaxies, which would imply tens or hundreds of billions of CPU hours.
Machine-learning-based models are becoming more popular in astronomy (e.g. Huertas-Company et al. 2023; Woo et al. 2024; Moser et al. 2024; Hunt et al. 2024). In contrast with traditional full-spectral fitting, where SFHs are built by combining SSPs to recover the observed spectra, machine learning models directly learn the implicit relation between the spectra and the SFHs. Its systematic uncertainties are thus different from those from classical spectral fitting, complementing and strengthening the measurements (Lovell et al. 2019). On the other hand, neural density estimators have recently been introduced to address the computational challenge of Bayesian methods (e.g. Papamakarios & Murray 2016; Alsing et al. 2018; Kwon & Hahn 2024), demonstrating a significant acceleration in spectral energy distribution model evaluations of up to five orders of magnitude (Hahn & Melchior 2022), so the posterior inference for each galaxy now takes only seconds.
In this work we explore a novel approach based on probabilistic machine learning and simulation-based inference (SBI) to estimate the SFHs of galaxies from their optical absorption spectra. We followed the initial steps laid out for this method for full-spectral fitting by Khullar et al. (2022). The main differences from classical Bayesian inference methods are that the SBI approach does not require an explicit functional form for the likelihood, typically considered Gaussian, and that once the model is trained, it can be evaluated on different observations with minimal computational cost. In this paper, which essentially describes a proof of concept, we do not include noise or emission lines, although we discuss the way to generalise the method in the future to include these features.
The outline of the paper is as follows: In Sect. 2 we describe the Bayesian inference framework, using SPS (Sect. 2.1), an encoder of the spectra (Sect. 2.2.1), and a neural density estimator (Sect. 2.2.2). In Sect. 3 we test the model with both mocked observations and stacks of early-type galaxies (ETGs) from SDSS. We further discuss the details of the model and the inferred galaxy properties in Sect. 4.
2. Methods
When applied to spectral fitting, Bayesian algorithms aim to infer the posterior probability distributions P(θ ∣ x) of galaxy properties, θ, given observations, x. For a specific θ and x, one typically evaluates the posterior using Bayes’ rule, P(θ ∣ x)∝P(θ) P(x ∣ θ), where P(θ) denotes the prior distribution and P(x ∣ θ) the likelihood. As this last distribution is typically intractable, conventional statistical approaches assume fixed functional forms for it, attempting to be consistent both with the empirical data and the theoretical models.
Simulation-based inference, also known as likelihood-free inference, offers an alternative that does not require an explicit form for the likelihood. It consists of creating synthetic data, in the often called the forward model, and then fitting them like real observations, in the backward model, comparing against a known “truth”. Therefore, SBI uses a generative model (i.e. a simulation F) to generate mock data x′ given parameters θ′:F(θ′) = x′. It uses a large number of simulated pairs (θ′,x′), which can be considered as samples of the implicit likelihood distribution, to directly estimate the posterior P(θ ∣ x), the likelihood P(x ∣ θ), or the joint distribution of the parameters and data P(θ, x). This technique has already been successfully applied to several Bayesian parameter inference problems in astronomy (e.g. Cameron & Pettitt 2012; Mishra-Sharma 2022; Hahn et al. 2023b; Zhang et al. 2023).
As most real observations are unbalanced and affected by selection effects, we typically do not have the kind of broad and uniform dataset required by inference algorithms. We can achieve this parameter space coverage with the forward model, although the inference will be more biased in those areas of the parameter space with fewer observations. On the other hand, SBI is especially useful when testing single-effect biases (e.g. parametrisations of SFHs or noise) as it enables complexity to be layered in the simulation. In contrast, it is likely to present problems of domain shifts when generalising results to real observations. Modelling considerations, like priors, wavelength coverage, or resolution, can have a significant impact on inferred galaxy properties (Leja et al. 2019; Hahn & Melchior 2022; Alsing et al. 2024) and must be carefully selected.
2.1. Forward model
The first step is to generate a synthetic dataset to train and test our model, for which the spectrum, the SFH, and the metallicity are known. As mentioned before, in this toy model we do not include emission features or noise. We worked with MILES SPS models (Vazdekis et al. 2010). These fully empirical SSP templates provide medium resolution (FWHM = 2.51 Å, Falcón-Barroso et al. 2011) predictions for a wide range of ages (from 0.03 Gyr to 14.00 Gyr) and metallicities ([M/H] moving from −2.27 to 0.40). We selected a Kroupa universal IMF and BaSTI isochrones, in the wavelength range [3540.5, 7409.6] Å, and used the so-called base models for [α/Fe], following the abundance pattern of the solar neighbourhood.
We built non-parametric SFHs with Dense Basis (Iyer & Gawiser 2017), specifically the module GP-SFH. These SFHs allow complex behaviours, like rejuvenation events, bursts, or sudden quenching, and do not rely on a fixed functional form. The selected prior assumes that the fractional specific star formation rate (sSFR; i.e. the star formation rate normalised by the stellar mass), for three equally spaced time bins, follows a Dirichlet distribution with a concentration parameter α = 1. This prior for the SFHs has been studied in detail in Leja et al. (2019). Moreover, a uniform prior is included for the logarithm of the total stellar mass, 8.0 ≤ log(M*/M⊙)≤12.0, and for the logarithm of the sSFR at z = 0, −17.0 ≤ log(sSFR/yr−1)≤ − 7.5. We believe that these priors are general enough not to impose strong effects on the inferred galaxy properties; however, they will always play a role in the model estimations.
For simplicity, we assumed that there is no time evolution in metallicity, so each SFH was assigned a single value of [M/H]. We interpolated MILES spectra in time to obtain a SSP spectrum each 0.01347 Gyr, with cosmic time in the range [0.00, 13.47] Gyr (1000 time bins). On the other hand, using unequally spaced metallicities imposes a non-uniform prior on [M/H], which would bias the inference. To avoid this, we interpolated the spectra in [M/H] too, obtaining 15 equally spaced values of this parameter in the range [ − 2.3, 0.4]. For each artificial SFH, given a value of [M/H], all the MILES interpolated spectra (corresponding to different ages and with that metallicity) are combined as
![Mathematical equation: $$ \begin{aligned} F_{\mathrm{gal} } \left(\lambda , M_{\mathrm{tot} }, \mathrm{[M/H]}, [\alpha /\mathrm{Fe}]_{\mathrm{Base} }\right) = \sum _{t_i} \frac{M(t_i)}{M_{\mathrm{tot} }} \cdot F_{\mathrm{SSP} } \left(\lambda , t_i, \mathrm{[M/H]}, [\alpha /\mathrm{Fe}]_{\mathrm{Base} }\right).\nonumber \\[-1pc] \end{aligned} $$](/articles/aa/full_html/2024/09/aa49909-24/aa49909-24-eq1.gif) (1)
(1)
Finally, each spectrum was normalised by its median. In total, we obtained 10 000 SFHs for each value of [M/H], so: 10 000 SFHs x 15 bins of metallicity = 150 000 spectra, for which SFHs and metallicities are known. Examples of the mock SFHs and their corresponding spectra are shown in Fig. 1.
 |
Fig. 1. Samples of the simulated dataset, each in a different colour. In the left plot we show their mocked SFHs: in the upper panel the star formation rate normalised by the total stellar mass in Gyr−1 and in the lower one the nine stellar mass percentiles, together with three dashed grey lines indicating when 25%, 50%, and 75% of the total stellar mass has been formed. In the right plot, we show the simulated normalised spectra corresponding to these SFHs (same colours) for two different values of metallicity: in the upper panel we fix [M/H] = −2.3, and in the lower one [M/H] = 0.4, which are respectively the minimum and maximum bins of [M/H] in the simulation. |
Stellar mass curves (i.e. the star formation rate as a function of time) are integrated to get nine stellar mass percentiles. We thus focused on the cosmic time (the time since the Big Bang) at which 10%, 20%, …90% of the total stellar mass of the galaxy has been formed. These quantities are more robust than their non-cumulative analogues, as only the features in the SFHs that contribute meaningfully to the total stellar mass of the galaxy play a role. This approach decreases the dimensionality of the SFHs without relying on standard parametric shapes, and mitigates the impact of possible artefacts in the synthetic SFHs.
2.2. Backward model
2.2.1. Encoding the spectra
High-quality absorption spectra typically cover at least 1000 Å, described by a similar number of pixels. However, the widespread adoption of template libraries suggests that galaxy spectra in fact occupy a low-dimensional manifold. In particular, Portillo et al. (2020) demonstrated that a high-fidelity reconstruction can be achieved by an autoencoder (AE) architecture (Hinton & Salakhutdinov 2006), a non-linear dimensionality reduction technique, with a latent space of just six dimensions. Teimoorinia et al. (2022) and Melchior et al. (2023) improved the method by introducing convolutional elements into the AE to aid the extraction of correlated features from the spectra. In short, AEs are feed-forward neural networks that learn efficient encodings of data in an unsupervised manner. They consist of two parts: an encoder, which takes data as input and compresses it to produce a low-dimensional latent representation, and a decoder, which takes the latent representations and decompresses them to reconstruct the original data. Due to their non-linear behaviour, AEs can capture non-linear features, such as line widths, with fewer parameters than principal component analysis (Kramer 1991; Portillo et al. 2020), one of the most commonly used techniques. Moreover, unlike line-ratio diagnosis, AEs use the continuum information in the spectra, resulting in an interpretable latent space where galaxies of the same type are grouped together, even though the AEs were never given these classifications in training.
We took advantage of this approach to obtain low-dimensional representations of the spectra, using the encoder part of the architecture implemented by Melchior et al. (2023) (https://github.com/pmelchior/spender.git2). These representations are more suitable than the full spectrum to be introduced into a Bayesian inference model for a fully probabilistic treatment, as they provide summary statistics of the spectra by reducing the dimensionality and disentangling correlations. The size of the latent representations is a tunable parameter and depends on what information in the spectrum is relevant to determine the SFHs and metallicity, as well as on the dimension of the spectrum and the performance required. During this work, it is set to 16, as most of the details of the spectra that contain information relevant to the early star formation of galaxies are extremely subtle.
Our network consists of a three-layer convolutional neural network (moving to wider kernels and including max-pooling), plus an attention module (dot-product) and a three-layer multi-layer perceptron to obtain the latent vectors. Furthermore, an additional two-layer multi-layer perceptron has been included to optimise the encoding for our final task: to obtain stellar mass percentiles and a value of [M/H]. We thus incorporated a log-cosh loss function3 that computes the difference between the predicted and real values, driving the evolution of the training. We selected this loss function because it combines the robustness to outliers of the mean absolute error function and the smoothness and differentiability of the mean squared error function (Saleh & Ehsanes Saleh 2022).
The encoder was trained with the training and validation sets (80% and 10% of the total number of samples), and the training was stopped when the validation loss reached a plateau, after 250 epochs approximately. Then, the model was applied to test data (the remaining 10% of the total number of samples, never seen before by the network), producing not only the latent vectors we used as summary statistics for the Bayesian inference, but also an initial prediction for the mass percentiles and metallicity. These predictions will not be used once we have trained the encoder, as we only require them to drive the training process towards latent representations that preserve the information of these properties, while their probabilistic inference will be done by the neural density estimator, as detailed below.
2.2.2. Posterior estimation
We used a neural density estimator known as Normalising Flows to estimate the posterior probability distribution for each of the stellar mass percentiles, and for the metallicity. In a few words, variables (z) described by a simple base distribution P(z), such as a multivariate Gaussian, are transformed through a parameterised invertible transformation x = f(z), which has a tractable Jacobian. The target density Pf(x) is then given by the change-of-variables formula as a product of the base density and the determinant of the transformation’s Jacobian:
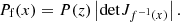 (2)
(2)
Several such steps can be stacked, with the probability density “flowing” through the successive variable transformations. The parameters of the transformations during the training of the model are estimated by maximising the log likelihood of the transformed data under the Gaussian distribution P(z), which is indeed tractable:
 (3)
(3)
Otherwise, it would not be possible to compute the loss since P(x) is unknown. Following this pipeline, Normalising Flows have been generalised to model a conditional density such as the posterior P(θ ∣ x). Following the choice of Hahn & Melchior (2022), we developed a masked autoregressive flow (MAF; Papamakarios et al. 2017), implemented with the module SBI (Tejero-Cantero et al. 2020), with five Masked Autoencoder for Distribution Estimation (MADE) blocks, each of them with two hidden layers of 128 hidden units. In total, the model has a set of 50 560 free parameters, ϕ. Our goal is to determine the ϕ for the MAF model, so that given galaxy properties θ and summary statistics of the observations x, Pϕ(θ∣x) accurately estimates the posterior probability distribution P(θ∣x). In practice, we divided the training data into training and validation sets with a 90/10 split. We used the Adam optimiser with a learning rate of 5 × 10−4. To prevent overfitting, we evaluated the likelihood of the data points under the base distribution, using the validation data at every training epoch, and stopping the training when that validation likelihood fails to increase after 20 epochs.
By using this workflow, we trained our model with mock synthetic data and then applied it to real observations to obtain promptly posteriors for the SFHs and metallicity, which was possible thanks to its amortised nature (i.e. it is not focused on any particular observation, as once we have a trained model, new data can be evaluated without repeating the training, the computationally expensive step). We are making two key assumptions. First, the simulator F must generate mock data, x′, that are nearly identical to the real data, x. Therefore, we should include all possible features one can find in spectra, such as noise or outliers, in the forward model. Second, the neural density estimator must well trained, so Pf(θ ∣ x′) provides a reliable approximation of P(θ ∣ x′), and consequently of P(θ ∣ x). As opposed to standard variational inference, we are not assuming any functional form for the posterior, and since neural networks are universal approximators, we could therefore estimate the posterior with an arbitrarily small error.
3. Results
The results are presented as follows. First, in Sect. 3.1, the performance of the model is tested by comparing the derived posteriors with the true values of the physical properties. We compute the time it takes for the full model (encoder and neural density estimator) to obtain the distributions given one spectrum. We also check the uncertainty estimation with a test of statistical coverage (Talts et al. 2018) in Sect. 3.2. Finally, we further validate our model in Sect. 3.3 by inferring the SFHs and the metallicity for 18 stacks of ETGs (La Barbera et al. 2013), and in Sect. 3.4 by comparing them with the results obtained through a consolidated spectral fitting method (Cappellari 2023).
3.1. Recovering the properties of synthetic galaxies
We encoded the spectra to obtain 16-component latent representations, optimised to introduce them in the Bayesian inference model by preserving the relevant information to determine the SFHs and metallicity. Once the encoder is trained, the latent representations for the full dataset are obtained. We study in detail the structure of this latent space in Appendix A.
Then, the neural density estimator is trained with 90% of the generated samples (x = latent vectors, θ = nine stellar mass percentiles, [M/H]), with 10% of these composing the validation set. Once the training is finished (∼4 h: 1 h for the encoder and 3 h for the Normalising Flows), the remaining 10% of the samples is used to test its performance, by obtaining probability distributions for the values of each percentile and [M/H] from their latent representations, and comparing the distributions with the true values. Each posterior estimation for the test set is performed with 1000 samples, taking ∼0.4 s to get the predictions for the 10 quantities of each galaxy.
All the time estimations have been made using a NVIDIA Tesla P100 PCIe GPU with 12 GB.
Figure 2 shows five examples of synthetic SFHs from the test set, presenting the true values for the mass percentiles, the recovered medians of the posteriors, and the 1 and 2σ confidence intervals. It its clear that the model can recover from the latent vectors SFHs that are fully consistent with the ground truth within the expected uncertainties. In Fig. 3, we plot the median values of the posterior distributions predicted for the 15 000 test galaxies against the true values, for the percentiles 10%, 50%, and 90% (in cosmic time), and for the metallicity. Both agree, close to the one-to-one relation, reaching high R2 values4 of 0.88, 0.97, 0.98, and 0.96, respectively. A larger scatter is observed for earlier percentiles, which is expected as the luminosity of young stars “outshines” the spectra, hiding the information of the oldest ones. This is properly captured by the width of the posteriors, with systematically higher uncertainties for earlier percentiles.
 |
Fig. 2. Percentile predictions for five synthetic galaxies. The cumulative mass curves indicate the time at which the nine stellar mass percentiles are achieved over cosmic time. The solid lines correspond to the true values, and the dashed ones to the predictions (medians of the posterior distributions). The σ and 2σ intervals of confidence are shaded dark and light, respectively. The model yields reliable reconstructions for all five galaxies. |
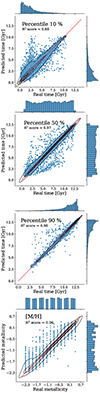 |
Fig. 3. Median values of the posterior distributions estimated for the percentiles 10%, 50%, and 90% and [M/H], compared to the true values. The R2 score achieved for each prediction is 0.88, 0.97, 0.98, and 0.96, respectively. Each blue dot is a different sample from the test set. The red line shows the one-to-one relation, the histograms at the right of each panel show the marginal distributions of the predictions, and the histograms of the real data are shown at the top. Kernel density estimation contours are drawn in black at iso-proportions of the density of samples. |
Posterior distributions for the percentiles 10%, 50%, and 90%, and for the metallicity are shown as a corner plot in Fig. 4, for a single galaxy from the test set. These have been computed with 10 000 samples. They deviate slightly from Gaussian functions, showing multi-modalities associated with the degeneracy between the age (in particular the percentile 90%) and the metallicity, but in perfect agreement with the true values. Figures 2–4 confirm that the model is indeed capable of recovering the stellar mass growth and metallicity, with uncertainties associated with the complexity of the inversion problem, due to the very nature of the spectra and to the observational imprints left by galaxies on them.
 |
Fig. 4. Corner plot with the posterior distributions for a simulated galaxy, drawn with 10 000 samples for the percentiles 10%, 50%, and 90% (in Gyr) and for [M/H]. Kernel density estimation contours are shown with different shades at iso-proportions of the density of samples. The solid lines correspond to the true values. The distributions deviate slightly from Gaussian functions, showing multi-modalities associated with the degeneracy of the parameter space, but are in perfect agreement with the true values. |
3.2. Simulation-based calibration
A key point is ensuring that the estimated posterior distributions are well calibrated. We used simulation-based calibration (SBC) as described in Talts et al. (2018) to examine the distribution of the rank statistics of the true parameter values within the marginalised posteriors, which must be uniform if the posterior samples are consistent with the prior used to generate the spectra in the forward model. The only requirement of this test is that we have a generative model for our data, so that we are able to simulate observations from the physical parameters we inferred. However, the original simulation includes more free parameters than the stellar mass percentiles and metallicity, as we used 1000 points of the SFHs (i.e. a linear combination of 1000 SSP spectra). To carry out this test, we repeated the model training with a simulation that only takes the nine percentiles and metallicities into consideration, performing the linear combination with nine spectra so that with the posteriors provided by the model we are able to recover unequivocally the synthetic observations.
Figure 5 shows a histogram from an ensemble of rank statistics of 1000 prior samples relative to the corresponding posterior samples, for the percentiles 10%, 50%, and 90%, and for [M/H]. Each histogram is complemented with a grey band indicating 99% of the variation expected from a uniform histogram. Additionally, in Fig. 6 we include the empirical cumulative distribution function (CDF), together with the diagonal expected from a well-calibrated posterior. Both plots show uniformly distributed ranks, and consequently an optimal overall performance, except for the metallicity, where we detect a slight ∩ shape. This symmetric deviation, related with the wide binning of Δ[M/H] = 0.1929 we used throughout the work5, implies that the computed posterior will be wider than the true posterior, allowing us to estimate an upper limit for the uncertainty of the parameter. This is strictly true in the simulated dataset, but not in real observations with finite S/N, where the posteriors may underestimate the uncertainty as we have not taken the observational noise into account.
 |
Fig. 5. SBC test of the posteriors for 1000 synthetic test observations. The red histograms in each panel represent the distribution of the rank statistic of the true value within the marginalised posterior for the percentiles 10%, 50%, and 90% and for [M/H]. For a well-calibrated posterior, the rank statistics will have a uniform distribution (dashed black line). The grey band indicates 99% of the variation expected from a uniform histogram. The rank statistic distributions of our posteriors are nearly uniform for all four parameters, and therefore, the model provides unbiased and accurate posteriors. |
 |
Fig. 6. Empirical CDFs for the percentiles 10%, 50%, and 90% and for the [M/H] obtained with 1000 synthetic test observations. If the posteriors are well calibrated, the nominal coverage probability (the fraction of the probability volume), on the x-axis, will be equal to the coverage probability (the fraction of actual values in such a volume), on the y-axis, making the CDF diagonal (dashed black line). Our CDFs closely follow the diagonal, indicating that the posteriors are properly computed. |
3.3. Testing with observations
To test the method, we inferred the SFHs and metallicity for 18 stacks of ETGs at z ∼ 0 from SDSS spectra (with velocity dispersion in the range 100 − 320 km s−1), whose stellar populations have been studied in detail in La Barbera et al. (2013). We highlight that the main advantage of working with these stacks is their very high S/N, and the absence of emission features, which is important because no noise models or emission lines have been incorporated in the simulation.
First, we convolved all the observations to emulate the maximum velocity dispersion of the dataset. Then, we clipped the wavelength range to [4023, 6000] Å, the maximum window that is common to all stacks. We also processed the MILES spectra used for training to simulate the conditions of the observations. Once all the artificial spectra had the same resolution and wavelength range as the observations, we repeated the training and then tested the model again, analysing the impact of these changes on the performance.
As a result of the processing, the R2 score on the synthetic test set decreases to 0.72, 0.95, and 0.96 for the estimation of the percentiles 10%, 50%, and 90%, respectively, and to 0.96 for the metallicity. These losses in performance, mainly for the first percentiles, are a direct consequence of reducing the resolution in the spectral lines, and clipping the Balmer jump in the bluer region of the spectra.
We then applied the trained model to the spectra of the stacks, generating 10 000 samples from the posteriors. In Fig. 7, we show the median values of the inferred distributions for the mass percentiles, as a function of cosmic time and redshift6, using a colour map based on the velocity dispersions. The most massive galaxies (highest velocity dispersions) build up their stellar masses more abruptly, up to 90% of their total stellar mass by 1 Gyr after the Big Bang, while the growth of stellar mass is softened as we move to less massive ones.
 |
Fig. 7. Median values of the posterior distributions obtained for the stellar mass percentiles of 18 stacks, as a function of cosmic time (in Gyr) and redshift, coloured according to their velocity dispersions (in km s−1). Redder colours indicate higher velocity dispersions (more massive galaxies), and bluer ones lower velocity dispersions (less massive ones). In the inset, we plot the observed spectra, normalised and in the wavelength range [4023, 6000] Å, with the same colour map. |
For a more detailed analysis, the median values of the posterior predictions, together with their uncertainties given by one standard deviation, are included in Table 1, for all 18 observations. The quantities shown are the times by which 10%, 50%, and 90% of the total stellar mass have been formed, as well as the metallicity. We do not find a clear trend between the metallicity and the velocity dispersion, but the margin of uncertainty is too large to make any further assumptions, mainly due to the wide binning in [M/H] of 0.1929 dex for the simulated sample. This is consistent with the results of La Barbera et al. (2013), who reported a variation of ∼0.2 dex in metallicity from the least massive to the most massive stack.
Inferred properties for 18 stacks of ETGs.
Finally, we carried out a spectral reconstruction with our model in Fig. 8, for the stacks with velocity dispersions 105, 205, and 300 km s−1. This test is usually referred to as posterior predictive check (Talts et al. 2018), and allows us to verify that the properties we infer are indeed compatible with the observed spectra. These observed and reconstructed spectra must be close to each other in the latent space, but a priori this proximity is not trivial in the wavelength space, since we did not minimise the differences with respect to the observed spectra as in more traditional approaches, but performed the Bayesian inference on the latent representations. Even so, it is the most direct way we have of determining the reliability of the inference, and we did it by performing a linear combination of nine SSP MILES spectra of ages obtained from the percentiles of stellar mass, and metallicity fixed and equal to the predicted value. According to the definition of the percentiles, all nine spectra are weighted with 1/9. The results are very positive, showing mean residuals of 1.7% between the fit and the observations, averaging over all 18 stacks and wavelengths. The uncertainties are propagated into the spectra, within the grey-shadowed stripe in Fig. 8 corresponding to the interval of two standard deviations.
 |
Fig. 8. Reconstructions of the observed spectra for the stacks with velocity dispersion 105, 205, and 300 km s−1. In red we show the observed spectra, normalised by the median, in the wavelength range [4023, 6000] Å. In blue, we show the spectra obtained as a linear combination of MILES SSP spectra according to our model, using the median values of the posteriors predicted. We repeated the procedure for the median ±2σ to get the grey-shadowed stripe, which shows how the uncertainties in the quantities are manifested in the spectra. In green, we plot the spectra obtained with the weights given by pPXF. In the lower panels, we include the residuals between the observed spectra and those reconstructed from the percentiles and metallicity predicted by our model (solid black line), and between the observed spectra and the one recovered by pPXF (dashed black line). The dotted line indicates the zero level. The typical value of the residuals of our method (1.7%) is very similar to the average value obtained with pPXF (1.5%), although in the first case the inference is performed in the latent space, without directly trying to reproduce the observed spectra. |
3.4. Comparison with existing codes
We include another reconstruction of the spectra in Fig. 8, namely a linear combination of the same MILES templates of 34 different ages and 12 different metallicities (408 templates in total), where the weights are given by the Penalized PiXel-Fitting code (pPXF; Cappellari & Emsellem 2004). The purpose of this comparison is to benchmark our amortised inference against this well-known optimisation method. In order to do that, we used the same wavelength range as before without any continuum correction. The average of the residuals between the observed spectra and the pPXF fitting is 1.5%. The observed spectra, our reconstructions from the percentiles and the reconstructions made with the weights of pPXF are in close agreement, not only in the latent space, but also in the wavelength space. We find that our method generally fits the spectra as accurately as pPXF despite, again, not being designed to reproduce them.
On the other hand, the pPXF fitting takes ∼30 s for each stack, and since it does not provide an uncertainty, this measurement would be equivalent to a sample of the posteriors obtained with our model, which take 4 × 10−4 s per stack. Thanks to this acceleration of five orders of magnitude, our model can easily produce 103 or 104 samples of the posteriors for each observation and thus, always under the assumptions of the simulation, obtain a proper calibration of the uncertainty.
4. Discussion
We have developed a new approach to estimating the SFHs of galaxies from their optical absorption spectra, using SBI to obtain posteriors in a fully probabilistic treatment. From interpretable latent representations of the spectra, we inferred the stellar mass growth and metallicity, reaching high accuracy for the synthetic sample, as well as properly calibrated uncertainties, evaluated through a SBC test. It requires less than half a second to generate 1000 samples from the posteriors for each galaxy. This not only makes it possible to address a large dataset, but also to increase the number of samples from the posteriors, raising the precision of the inferred galaxy properties and their uncertainties.
4.1. Model considerations
Although our SBI framework is substantially faster than other Bayesian inference methods, such as MCMC, and provides well-calibrated uncertainties, unlike classical inversion methods applied to spectral fitting, it is subject to different systematics and modelling assumptions. One of the obvious limitations is the use of a forward model to train the network, because as our understanding of galaxy evolution is incomplete, the considerations taken when generating the synthetic data will never be fully constrained by a typical galaxy spectrum. Therefore, the prior, set by the distribution of parameters in the training set, will always have at least a moderate role in determining the answer.
In particular, the simplifications made in terms of chemical evolution, by combining MILES SSP spectra with a fixed metallicity (instead of taking into account the metallicity histories) and working with base α-enhancement models, may affect the reliability of our model predictions, given the intrinsic degeneration between the age and the metal content in the spectra. Moreover, there is currently no consensus on the stellar evolution (Conroy et al. 2009) or on the IMF of galaxies (Martín-Navarro et al. 2015), and our model training has been restricted to a specific set of isochrones assuming a particular IMF parametrisation. This limits the range of the training data, and dooms our model to fail in observations of galaxies that differ from these considerations. Nevertheless, MCMC-based approaches also suffer from these forward model mis-specifications. As shown in Acquaviva et al. (2011), both the values of the physical parameters and their uncertainties may depend on the assumptions made in the SPS modelling. The main difference is that as SBI uses a neural network to estimate the posterior, the inference is potentially more sensitive to the discrepancies between the training dataset and the true observations.
It is known that the SFHs have a strong impact on the predicted posteriors, as shown by Leja et al. (2019), and models that mimic the breadth distribution of SFR(t) in the real Universe are required. In this work, in the pipeline provided by the GP-SFH module, we selected a dispersive prior: a Dirichlet distribution with α = 1.0 for the fractional sSFR in each of the three equally spaced time bins, positioning ourselves in favour of short-term variations in the SFHs (with smaller characteristic times). However, this selection must be explored with caution in future works.
4.2. Observations
We inferred the SFH and the metallicity for stacks of SDSS spectra of ETGs. The model recovers the well-known relationship between age and velocity dispersion, showing that the most massive galaxies (σ ∼ 300 km s−1) build up their stellar masses more abruptly, up to 90% of their total stellar mass by 1 Gyr after the Big Bang, while the growth of stellar mass is softened in less massive galaxies. How these massive galaxies, up to M∗ ∼ 1012 M⊙ for the highest velocity dispersion stack, can form most of their masses so early is a question that is still open, given that a priori it requires a very high star formation efficiency. These galaxies are rare in the known Universe, with rapid bursts of star formation and followed by rapid quenching. The stars we see may have formed in different progenitor galaxies, which were located in the highest-density peaks of the Cosmic Web, and later assembled in major mergers (Conselice 2008). To attend to these processes, hierarchical assembly models are necessary, commonly studied through large-scale cosmological simulations (e.g. Angeloudi et al. 2023).
As future work, we propose studying the SFHs and metallicities for late-type galaxies, for which we expect modelling difficulties due to the larger number of emission lines and potential “over-shining” effects when recovering the metallicity and ages of their first stars to form. So far we have not incorporated emission lines, noise models or dust attenuation, but including these aspects in the future is essential to manage a wide range of observations. We can model the emission lines with specialised libraries (e.g. Ferland et al. 1998; Cardoso et al. 2019), or with data-driven approaches, training a neural network to directly learn the relation between the continuum and the emission features in real observed spectra. This last method can also be extended to apply realistic noise to the spectra in the simulation, matching the uncertainty distributions in observations, and possibly introducing both the synthetic noisy spectra and the uncertainties for the fluxes into the encoder, resulting in noise-aware latent representations. In this way, we can condition the Bayesian inference with the noise.
Our approach can contribute, given its speed and error handling, to study the biases that produce aspects of the forward model that have traditionally been assumed in similar analyses. We can do that by studying the differences we obtain in the posteriors when changing the specifications and ranges of the parameters in the SPS model. An example would be to change the IMF, which was fixed in this work. By using templates with a bottom-heavy IMF, as expected at least at some stages of the life of massive ETGs (Weidner et al. 2013; De Masi et al. 2019; Martín-Navarro et al. 2023), we obtain a smoother growth of stellar mass for the stacked spectra we analysed, slightly relaxing the requirement of an extremely high star formation efficiency in the first years after the Big Bang.
Apart from performing model selection, and following the first steps taken in this project for the SDSS spectra, we plan to expand our model to perform a deep sampling of current or upcoming spectroscopic surveys such as DESI (Hahn et al. 2023a), WEAVE (Dalton et al. 2012), 4MOST (de Jong 2011), or MOONS (Cirasuolo et al. 2020), which will observe billions of galaxies and produce more than 108 TB of data (Smith & Geach 2023).
5. Summary and outlook
By analysing the spectrum of a galaxy, one can infer physical properties such as its stellar mass, star formation rates, and chemical abundances, key ingredients for our understanding of galaxy evolution. State-of-the-art spectral fitting methods use MCMC sampling to perform Bayesian statistical inference, deriving the posterior probability distributions of galaxy properties from observations. However, obtaining a posterior with these methods can take ≳10 − 100 CPU hours per galaxy and thus implies a major bottleneck for addressing large galaxy surveys.
We demonstrate in this work that an amortised SBI, with a previous encoding of the spectra, provides an alternative approach for spectral fitting through a neural density estimator. By using MILES templates and non-parametric SFHs, we have constructed a flexible model that recovers SFHs and metallicities with their uncertainties for observed stacks of spectra from the SDSS, taking ∼4 s per galaxy to generate 10 000 samples from the posteriors for the ten quantities we estimate. The key results of our project are as follows.
First, we constructed a model composed of an encoder for the spectra based on a dot-product attention model, plus a MAF, to estimate the posterior distributions for the cosmic times at which nine stellar mass percentiles are reached, and for the metallicity. We trained it over ∼4 h with 135 000 synthetic samples obtained from SSP MILES templates and non-parametric SFHs from the GP-SFH module.
Second, we tested the model with 15 000 synthetic samples, reaching an R2 score of 0.88, 0.97, 0.98, and 0.96 when estimating the percentiles 10%, 50%, and 90% and the metallicity, respectively. The model recovers uncertainties associated with the degeneration of the inversion problem. It struggles more in assessing the first percentiles in galaxies with recent star formation but reflects these difficulties adequately in the posteriors, as indicated by an SBC test.
Third, we estimated with our model the SFHs and metallicities of 18 stacks of ETGs from the SDSS with velocity dispersions in the range 105 − 300 km s−1, as well as reliable uncertainties for the inferred properties. We uncover very early bursts of star formation in the most massive galaxies and a smoother growth of stellar mass when moving to intermediate masses, recovering the well-known relation between age and velocity dispersion. Moreover, we accurately reconstructed the spectra from MILES templates using the nine ages and the mean metallicity measured, in good agreement with the real spectra, with an averaged error of 1.7%.
In the future, we plan to explore different sets of assumptions for the isochrones, the stellar library, and the IMF, as well as the effects of the priors introduced by the selection of SFHs and metallicity ranges. To simulate the spectra of young stellar populations, a data-driven approach, possibly a neural network, can be used to directly learn the emission features from observed spectra. This methodology can also be extended to model the noise. To obtain noise-aware representations, the encoder can use both the uncertainties in the fluxes and the noisy spectra. At that stage, the optimal dimension of the latent vectors must be studied again. Such a complete model would allow one to analyse massive sets of galaxy spectra in a highly efficient and reliable manner.
The entire pipeline, including the scripts for the simulation and the Bayesian inference framework, is publicly available at https://github.com/patriglesias/SBISFHs.git7.
I.e. metals over hydrogen, defined as ![Mathematical equation: $ \mathrm{[M/H]}=\log \left(\frac{M}{\mathrm{H}}\right)-\log \left(\frac{M}{\mathrm{H}}\right)_{\odot} $](/articles/aa/full_html/2024/09/aa49909-24/aa49909-24-eq4.gif) .
.
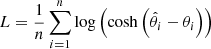 .
.
Also known as coefficient of determination  , not to be confused with the square of the Pearson’s coefficient.
, not to be confused with the square of the Pearson’s coefficient.
A finer binning is always possible, but at the cost of a larger training set and longer training time.
Assuming a Planck13 cosmology (Planck Collaboration XVI 2014).
Acknowledgments
Co-funded by the European Union. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union. Neither the European Union nor the granting authority can be held responsible for them. M.H.C. and P.I.N. acknowledge financial support from the State Research Agency of the Spanish Ministry of Science and Innovation (AEI-MCINN) under the grants “Galaxy Evolution with Artificial Intelligence” with reference PGC2018-100852-A-I00 and “BASALT” with reference PID2021-126838NB-I00. I.M.N. acknowledges support from AEI-MCINN under the grant “B-CycleS” with reference PID2022-140869NB-I00. J.H.K. acknowledges support from AEI-MCINN under the grant “The structure and evolution of galaxies and their outer regions” and the European Regional Development Fund (ERDF) with reference PID2022-136505NB-I00/10.13039/501100011033. E.P. acknowledges support from the Turing Scheme.
References
- Acquaviva, V., Gawiser, E., & Guaita, L. 2011, ApJ, 737, 47 [NASA ADS] [CrossRef] [Google Scholar]
- Alsing, J., Wandelt, B., & Feeney, S. 2018, MNRAS, 477, 2874 [NASA ADS] [CrossRef] [Google Scholar]
- Alsing, J., Thorp, S., Deger, S., et al., 2024, ApJS, Submitted [arXiv:2402.00935] [Google Scholar]
- Angeloudi, E., Falcón-Barroso, J., Huertas-Company, M., et al. 2023, MNRAS, 523, 5408 [CrossRef] [Google Scholar]
- Cameron, E., & Pettitt, A. N. 2012, MNRAS, 425, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Cappellari, M. 2023, MNRAS, 526, 3273 [NASA ADS] [CrossRef] [Google Scholar]
- Cappellari, M., & Emsellem, E. 2004, PASP, 116, 138 [Google Scholar]
- Cardoso, L. S. M., Gomes, J. M., & Papaderos, P. 2019, A&A, 622, A56 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carnall, A. C., Leja, J., Johnson, B. D., et al. 2019, ApJ, 873, 44 [Google Scholar]
- Cenarro, A. J., Cardiel, N., Gorgas, J., et al. 2001, MNRAS, 326, 959 [NASA ADS] [CrossRef] [Google Scholar]
- Cervantes, J. L., & Vazdekis, A. 2008, MNRAS, 392, 691 [Google Scholar]
- Chabrier, G. 2003, PASP, 115, 763 [Google Scholar]
- Choi, J., Dotter, A., Conroy, C., et al. 2016, ApJ, 823, 102 [Google Scholar]
- Cirasuolo, M., Fairley, A., Rees, P., et al. 2020, The Messenger, 180, 10 [NASA ADS] [Google Scholar]
- Conroy, C. 2013, ARA&A, 51, 393 [NASA ADS] [CrossRef] [Google Scholar]
- Conroy, C., Gunn, J. E., & White, M. 2009, ApJ, 699, 486 [Google Scholar]
- Conselice, C. J. 2008, ASP Conf. Ser., 390, 403 [NASA ADS] [Google Scholar]
- Dalton, G., Trager, S. C., Abrams, D. C., et al. 2012, in Ground-based and Airborne Instrumentation for Astronomy IV, eds. I. S. McLean, S. K. Ramsay, & H. Takami, SPIE Conf. Ser., 8446, 84460P [NASA ADS] [Google Scholar]
- de Jong, R. 2011, The Messenger, 145, 14 [NASA ADS] [Google Scholar]
- De Masi, C., Vincenzo, F., Matteucci, F., et al. 2019, MNRAS, 483, 2217 [CrossRef] [Google Scholar]
- Falcón-Barroso, J., Sánchez-Blázquez, P., Vazdekis, A., et al. 2011, A&A, 532, A95 [Google Scholar]
- Ferland, G. J., Korista, K. T., Verner, D. A., et al. 1998, PASP, 110, 761 [Google Scholar]
- Fernandes, R. C., Mateus, A., Sodré, L., Stasińska, G., & Gomes, J. M. 2005, MNRAS, 358, 363 [CrossRef] [Google Scholar]
- Franx, M., & Illingworth, G. 1990, ApJ, 359, L41 [NASA ADS] [CrossRef] [Google Scholar]
- Girardi, L., Bressan, A., Bertelli, G., & Chiosi, C. 2000, A&AS, 141, 371 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gonneau, A., Lyubenova, M., Lancon, A., et al. 2020, A&A, 634, A133 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hahn, C., & Melchior, P. 2022, ApJ, 938, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Hahn, C., Kwon, K. J., Tojeiro, R., et al. 2023a, ApJ, 945, 16 [NASA ADS] [CrossRef] [Google Scholar]
- Hahn, C., Eickenberg, M., Ho, S., et al. 2023b, JCAP, 2023, 010 [CrossRef] [Google Scholar]
- Hinton, G. E., & Salakhutdinov, R. R. 2006, Science, 313, 504 [Google Scholar]
- Huertas-Company, M., Sarmiento, R., & Knapen, J. H. 2023, RAS Tech. Instrum., 2, 441 [NASA ADS] [CrossRef] [Google Scholar]
- Hunt, L. J., Pimbblet, K. A., & Benoit, D. M. 2024, MNRAS, 529, 479 [CrossRef] [Google Scholar]
- Iyer, K., & Gawiser, E. 2017, ApJ, 838, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Johnson, B. D., Leja, J., Conroy, C., & Speagle, J. S. 2021, ApJS, 254, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Khullar, G., Nord, B., Ćiprijanović, A., Poh, J., & Xu, F. 2022, Mach. Learn. Sci. Technol., 3, 04LT04 [CrossRef] [Google Scholar]
- Kramer, M. A. 1991, AIChE J., 37, 233 [CrossRef] [Google Scholar]
- Kroupa, P. 2001, MNRAS, 322, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Kwon, K. J., & Hahn, C. 2024, ApJ, submitted [arXiv:2401.12318] [Google Scholar]
- La Barbera, F., Ferreras, I., Vazdekis, A., et al. 2013, MNRAS, 433, 3017 [Google Scholar]
- Leja, J., Carnall, A. C., Johnson, B. D., Conroy, C., & Speagle, J. S. 2019, ApJ, 876, 3 [Google Scholar]
- Lilly, S. J., Carollo, C. M., Pipino, A., Renzini, A., & Peng, Y. 2013, ApJ, 772, 119 [NASA ADS] [CrossRef] [Google Scholar]
- Lovell, C. C., Acquaviva, V., Thomas, P. A., et al. 2019, MNRAS, 490, 5503 [NASA ADS] [CrossRef] [Google Scholar]
- Maksymowicz-Maciata, M., Spiniello, C., Martín-Navarro, I., et al. 2024, MNRAS, 531, 2864 [Google Scholar]
- Martín-Navarro, I., La Barbera, F., Vazdekis, A., Falcón-Barroso, J., & Ferreras, I. 2015, MNRAS, 447, 1033 [Google Scholar]
- Martín-Navarro, I., van de Ven, G., & Yıldırım, A. 2019, MNRAS, 487, 4939 [CrossRef] [Google Scholar]
- Martín-Navarro, I., Burchett, J. N., & Mezcua, M. 2020, MNRAS, 491, 1311 [Google Scholar]
- Martín-Navarro, I., Spiniello, C., Tortora, C., et al. 2023, MNRAS, 521, 1408 [CrossRef] [Google Scholar]
- McInnes, L., Healy, J., Saul, N., & Großberger, L. 2018, J. Open Source Softw., 3, 861 [CrossRef] [Google Scholar]
- Melchior, P., Liang, Y., Hahn, C., & Goulding, A. 2023, AJ, 166, 74 [NASA ADS] [CrossRef] [Google Scholar]
- Mishra-Sharma, S. 2022, Mach. Learn. Sci. Technol., 3, 01LT03 [CrossRef] [Google Scholar]
- Moser, B., Kacprzak, T., Fischbacher, S., et al. 2024, JCAP, 05, 049 [CrossRef] [Google Scholar]
- Ocvirk, P., Pichon, C., Lançon, A., & Thiébaut, E. 2006, MNRAS, 365, 74 [Google Scholar]
- Papamakarios, G., & Murray, I., ArXiv e-prints [arXiv:1605.06376] [Google Scholar]
- Papamakarios, G., Pavlakou, T., & Murray, I. 2017, ArXiv e-prints [arXiv:1705.07057] [Google Scholar]
- Pietrinferni, A., Cassisi, S., Salaris, M., & Castelli, F. 2006, ApJ, 642, 797 [Google Scholar]
- Planck Collaboration XVI. 2014, A&A, 571, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Portillo, S. K. N., Parejko, J. K., Vergara, J. R., & Connolly, A. J. 2020, ApJ, 160, 45 [Google Scholar]
- Saleh, R. A., & Ehsanes Saleh, A. K. M. 2022, ArXiv e-prints [arXiv:2208.04564] [Google Scholar]
- Salpeter, E. E. 1955, ApJ, 121, 161 [Google Scholar]
- Scoville, N., Aussel, H., Brusa, M., et al. 2007, ApJS, 172, 1 [Google Scholar]
- Silk, J., & Mamon, G. A. 2012, Res. Astron. Astrophys., 12, 917 [Google Scholar]
- Smith, M. J., & Geach, J. E. 2023, R. Soc. Open Sci., 10, 221454 [NASA ADS] [CrossRef] [Google Scholar]
- Tacchella, S., Conroy, C., Faber, S. M., et al. 2022, ApJ, 926, 134 [NASA ADS] [CrossRef] [Google Scholar]
- Talts, S., Betancourt, M., Simpson, D., Vehtari, A., & Gelman, A. 2018, ArXiv e-prints [arXiv:1804.06788] [Google Scholar]
- Teimoorinia, H., Archinuk, F., Woo, J., Shishehchi, S., & Bluck, A. F. L. 2022, ApJ, 163, 71 [Google Scholar]
- Tejero-Cantero, A., Boelts, J., Deistler, M., et al. 2020, J. Open Source Softw., 5, 2505 [NASA ADS] [CrossRef] [Google Scholar]
- Thomas, D., Maraston, C., & Bender, R. 2003, MNRAS, 339, 897 [NASA ADS] [CrossRef] [Google Scholar]
- Tojeiro, R., Heavens, A. F., Jimenez, R., & Panter, B. 2007, MNRAS, 381, 1252 [NASA ADS] [CrossRef] [Google Scholar]
- Vazdekis, A., Sánchez-Blázquez, P., Falcón-Barroso, J., et al. 2010, MNRAS, 404, 1639 [NASA ADS] [Google Scholar]
- Wang, B., Leja, J., Labbé, I., et al. 2024, ApJS, 270, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Weidner, C., Ferreras, I., Vazdekis, A., & La Barbera, F. 2013, MNRAS, 435, 2274 [NASA ADS] [CrossRef] [Google Scholar]
- Wilkinson, D. M., Maraston, C., Goddard, D., Thomas, D., & Parikh, T. 2017, MNRAS, 472, 4297 [Google Scholar]
- Woo, J., Walters, D., Archinuk, F., et al. 2024, MNRAS, 530, 4260 [NASA ADS] [CrossRef] [Google Scholar]
- Worthey, G., Faber, S. M., & Gonzalez, J. J. 1992, ApJ, 398, 69 [Google Scholar]
- York, D. G., Adelman, J., Anderson, J. E., et al. 2000, AJ, 120, 1579 [Google Scholar]
- Zhang, K., Jayasinghe, T., & Bloom, J. 2023, Machine Learning for Astrophysics. Workshop at the Fortieth International Conference on Machine Learning (ICML 2023), 39 [Google Scholar]
Appendix A: Low-dimensional representations of the spectra
We did a sanity check to verify whether the encoder is well trained and performs a reliable summary statistics of the spectra and the physical properties. A uniform manifold approximation and projection (UMAP) of the latent vectors is shown in Fig. A.1, only for visualisation purposes. It uses a non-linear dimensionality reduction technique that produces two-dimensional maps topologically equivalent to the latent vectors of 16 components (see McInnes et al. 2018). The shape of the UMAP, where each dot corresponds to a synthetic galaxy from the test sample, can be intuitively explained according to the physical quantities we want to recover, demonstrating an optimal encoding of the spectral information. The map is shown using five different colour maps: the value of the cosmic time for the 10% and 90% stellar mass percentiles, the metallicity, and the line indices Hβo (Cervantes & Vazdekis 2008) and [MgFe]′ (Thomas et al. 2003).
 |
Fig. A.1. UMAP embedding for the latent representations. Each dot corresponds to a synthetic galaxy from the test sample. The closer two galaxies are on the map, the more similar are their latent representations. Different colour maps are set according to the cosmic time at which 10% (top left) and 90% (top middle) of the total stellar mass is reached, the [M/H] (top right), and the two line indices Hβo (lower left) and [MgFe]′ (lower right). Clear trends can be observed, demonstrating that the information encoded in the latent vectors is optimal for recovering the SFHs and metallicities. |
First, the percentile 10% plot show how galaxies clustered on the left started forming their stars late (large cosmic time for the percentile 10%), while on the centre and right of the UMAP there are located galaxies that started forming stars early (small cosmic time for the percentile 10%). Focusing now on the percentile 90% and Hβo plots, we observe that last episodes of star formation take place at larger values of the cosmic time for the left and upper clusters, while the galaxies in the lower right have stopped forming stars earlier. In short, if we divide the UMAP into left, upper, and right zones, we see that the galaxies on the left have a short and recent star formation, those on the top have extended and recent star formation, and those on the right have old star formation. Furthermore, in the right region there are two clusters with no difference in age, but in metallicity, splitting galaxies without recent star formation into two groups: the upper one, metal-rich, and the lower one, metal-poor (see the metallicity and [MgFe]′ plots). Finally, we highlight that in the galaxies with more recent star formation, there is no clear distinction in metallicity. The complexity of measuring metallicity in young populations is already known (Conroy 2013) and is based on stellar physics, as the high temperatures of the atmospheres of massive stars cause the metallic lines to be very faint, and the parameter that fundamentally governs the spectra is age. The network, without any constraints in the input, naturally recovers the underlying physics of spectral fitting, as well as the fundamental role of the absorption lines used in measurements of the indices (Vazdekis et al. 2010).
All Tables
All Figures
|
Fig. 1. Samples of the simulated dataset, each in a different colour. In the left plot we show their mocked SFHs: in the upper panel the star formation rate normalised by the total stellar mass in Gyr−1 and in the lower one the nine stellar mass percentiles, together with three dashed grey lines indicating when 25%, 50%, and 75% of the total stellar mass has been formed. In the right plot, we show the simulated normalised spectra corresponding to these SFHs (same colours) for two different values of metallicity: in the upper panel we fix [M/H] = −2.3, and in the lower one [M/H] = 0.4, which are respectively the minimum and maximum bins of [M/H] in the simulation. |
| In the text | |
|
Fig. 2. Percentile predictions for five synthetic galaxies. The cumulative mass curves indicate the time at which the nine stellar mass percentiles are achieved over cosmic time. The solid lines correspond to the true values, and the dashed ones to the predictions (medians of the posterior distributions). The σ and 2σ intervals of confidence are shaded dark and light, respectively. The model yields reliable reconstructions for all five galaxies. |
| In the text | |
|
Fig. 3. Median values of the posterior distributions estimated for the percentiles 10%, 50%, and 90% and [M/H], compared to the true values. The R2 score achieved for each prediction is 0.88, 0.97, 0.98, and 0.96, respectively. Each blue dot is a different sample from the test set. The red line shows the one-to-one relation, the histograms at the right of each panel show the marginal distributions of the predictions, and the histograms of the real data are shown at the top. Kernel density estimation contours are drawn in black at iso-proportions of the density of samples. |
| In the text | |
|
Fig. 4. Corner plot with the posterior distributions for a simulated galaxy, drawn with 10 000 samples for the percentiles 10%, 50%, and 90% (in Gyr) and for [M/H]. Kernel density estimation contours are shown with different shades at iso-proportions of the density of samples. The solid lines correspond to the true values. The distributions deviate slightly from Gaussian functions, showing multi-modalities associated with the degeneracy of the parameter space, but are in perfect agreement with the true values. |
| In the text | |
|
Fig. 5. SBC test of the posteriors for 1000 synthetic test observations. The red histograms in each panel represent the distribution of the rank statistic of the true value within the marginalised posterior for the percentiles 10%, 50%, and 90% and for [M/H]. For a well-calibrated posterior, the rank statistics will have a uniform distribution (dashed black line). The grey band indicates 99% of the variation expected from a uniform histogram. The rank statistic distributions of our posteriors are nearly uniform for all four parameters, and therefore, the model provides unbiased and accurate posteriors. |
| In the text | |
|
Fig. 6. Empirical CDFs for the percentiles 10%, 50%, and 90% and for the [M/H] obtained with 1000 synthetic test observations. If the posteriors are well calibrated, the nominal coverage probability (the fraction of the probability volume), on the x-axis, will be equal to the coverage probability (the fraction of actual values in such a volume), on the y-axis, making the CDF diagonal (dashed black line). Our CDFs closely follow the diagonal, indicating that the posteriors are properly computed. |
| In the text | |
|
Fig. 7. Median values of the posterior distributions obtained for the stellar mass percentiles of 18 stacks, as a function of cosmic time (in Gyr) and redshift, coloured according to their velocity dispersions (in km s−1). Redder colours indicate higher velocity dispersions (more massive galaxies), and bluer ones lower velocity dispersions (less massive ones). In the inset, we plot the observed spectra, normalised and in the wavelength range [4023, 6000] Å, with the same colour map. |
| In the text | |
|
Fig. 8. Reconstructions of the observed spectra for the stacks with velocity dispersion 105, 205, and 300 km s−1. In red we show the observed spectra, normalised by the median, in the wavelength range [4023, 6000] Å. In blue, we show the spectra obtained as a linear combination of MILES SSP spectra according to our model, using the median values of the posteriors predicted. We repeated the procedure for the median ±2σ to get the grey-shadowed stripe, which shows how the uncertainties in the quantities are manifested in the spectra. In green, we plot the spectra obtained with the weights given by pPXF. In the lower panels, we include the residuals between the observed spectra and those reconstructed from the percentiles and metallicity predicted by our model (solid black line), and between the observed spectra and the one recovered by pPXF (dashed black line). The dotted line indicates the zero level. The typical value of the residuals of our method (1.7%) is very similar to the average value obtained with pPXF (1.5%), although in the first case the inference is performed in the latent space, without directly trying to reproduce the observed spectra. |
| In the text | |
|
Fig. A.1. UMAP embedding for the latent representations. Each dot corresponds to a synthetic galaxy from the test sample. The closer two galaxies are on the map, the more similar are their latent representations. Different colour maps are set according to the cosmic time at which 10% (top left) and 90% (top middle) of the total stellar mass is reached, the [M/H] (top right), and the two line indices Hβo (lower left) and [MgFe]′ (lower right). Clear trends can be observed, demonstrating that the information encoded in the latent vectors is optimal for recovering the SFHs and metallicities. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.