| Issue |
A&A
Volume 683, March 2024
|
|
|---|---|---|
| Article Number | A165 | |
| Number of page(s) | 13 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/202348611 | |
| Published online | 15 March 2024 | |
Evaporation ages: A new dating method for young star clusters⋆
1
Institut de Ciències del Cosmos, Universitat de Barcelona, IEEC-UB, Martí i Franqués 1, 08028 Barcelona, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
University of Vienna, Department of Astrophysics, Türkenschanzstraße 17, 1180 Wien, Austria
3
ICREA, Pg. Lluís Companys 23, 08010 Barcelona, Spain
4
Department of Physics and Astronomy, Dartmouth College, 6127 Wilder Laboratory, Hanover, NH 03755, USA
Received:
14
November
2023
Accepted:
9
January
2024
Abstract
Context. The ages of young star clusters are fundamental clocks to constrain the formation and evolution of pre-main-sequence stars and their protoplanetary disks and exoplanets. However, dating methods for very young clusters often disagree, casting doubts on the accuracy of the derived ages.
Aims. We propose a new method to derive the kinematic age of star clusters based on the evaporation ages of their stars.
Methods. The method was validated and calibrated using hundreds of clusters identified in a supernova-driven simulation of the interstellar medium forming stars for approximately 40 Myr within a 250 pc region.
Results. We demonstrate that the clusters’ evaporation-age uncertainty can be as small as about 10% for clusters with a large enough number of evaporated stars and small but with realistic observational errors. We have obtained evaporation ages for a pilot sample of ten clusters, finding a good agreement with their published isochronal ages.
Conclusions. The evaporation ages will provide important constraints for modeling the pre-main-sequence evolution of low-mass stars, as well as allow for the star formation and gas-evaporation history of young clusters to be investigated. These ages can be more accurate than isochronal ages for very young clusters, for which observations and models are more uncertain.
Key words: stars: kinematics and dynamics / open clusters and associations: general / open clusters and associations: individual: β Pictoris / open clusters and associations: individual: Tucana-Horologium / open clusters and associations: individual: Ophiuchus / open clusters and associations: individual: Upper Scorpius
Full Table B.1 is available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/683/A165
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
The precise determination of stellar ages is a fundamental tool in cosmology and astrophysics. The ages of the oldest globular clusters provide a lower limit to the age of the universe (e.g., Chaboyer et al. 1996; Krauss & Chaboyer 2003; Jimenez et al. 2019), while at the other extreme, the ages of the youngest stars are fundamental clocks to time the evolution of protoplanetary disks and to guide our understanding of the origin of planets (e.g., Williams & Cieza 2011; Bell et al. 2013; Berger et al. 2023).
Stellar ages are derived by combining spectroscopic and photometric data with stellar evolution models (Soderblom 2010), with the most used methods being the lithium-depletion boundary (Basri et al. 1996; Stauffer et al. 1998; Barrado y Navascués et al. 1999; Manzi et al. 2008; Ramírez et al. 2012; Binks & Jeffries 2014; Galindo-Guil et al. 2022), gyrochronology (Barnes 2003, 2007; Meibom et al. 2009; Epstein & Pinsonneault 2014; Angus et al. 2015, 2019; Curtis et al. 2020; Lu et al. 2021; Van-Lane et al. 2023), asteroseismology (Lebreton & Goupil 2014; Aerts 2015; Silva Aguirre et al. 2017; Bellinger 2019; Murphy et al. 2021; Scutt et al. 2023), or isochrone fitting in the color–magnitude diagram (e.g., Naylor & Jeffries 2006; Mayne & Naylor 2008; Bonatto & Bica 2009; Da Rio et al. 2010; Glatt et al. 2010; Bell et al. 2015; Ying et al. 2023). The age accuracy is usually enhanced when such methods are used in combination with each other to date coeval stars in clusters, for example, when combining mass estimates from asteroseismology with isochrone fitting (e.g., Miglio et al. 2021; Wang et al. 2023). Because the cluster’s distance and stellar membership are crucial inputs in their age estimation, improved distance and membership determinations from the Gaia mission have resulted in the massive application of isochrone ages to large samples of young star clusters (Randich et al. 2018; Bossini et al. 2019; Cantat-Gaudin et al. 2020; Dias et al. 2021; Li & Shao 2022).
An alternative approach to determining the age of unbound star clusters, independent of stellar-evolution models, is the analysis of their kinematics. The first attempts to derive kinematic expansion ages, based on the correlation of the positions and motions, date from several decades ago (Blaauw 1964). A more sophisticated technique consists of tracing the positions of stars, members of a cluster, back in time using their current velocities and a Galactic potential. The dynamical traceback age is then the time corresponding to the highest stellar density. This technique requires the 3D positions and velocities of individual stars, which has been an observational limitation for years (Brown et al. 1997; Ortega et al. 2002; de la Reza et al. 2006; Ducourant et al. 2014; Donaldson et al. 2016; Miret-Roig et al. 2018). However, thanks to the precise astrometry of Gaia (Gaia Collaboration 2023) and extensive complementary radial velocity surveys like the Apache Point Observatory Galactic Evolution Experiment, APOGEE (Majewski et al. 2017), it is now possible to obtain significantly more precise kinematic ages (Crundall et al. 2019; Miret-Roig et al. 2020, 2022; Kerr et al. 2022a,b; Galli et al. 2023; Couture et al. 2023).
Although kinematic ages are too uncertain for old clusters, they have become complementary to the isochrone fitting method (hereafter CMD) for ages < 50 Myr. This is the age range for the clusters’ sample selected in this study. Very young clusters (< 5 Myr) may still be partly embedded in gas and dust from their parent cloud producing differential extinction on the cluster members, and they often display photometric variability widening the isochrone and the uncertainties on the age. CMD ages for the youngest clusters are also uncertain because the evolution of young accreting stars in the CMD is difficult to capture with standard evolutionary tracks where accretion is not appropriately modeled (Froebrich et al. 2006; Baraffe et al. 2009; Hosokawa et al. 2011; Jensen & Haugbølle 2018).
A detailed comparison of modern dynamical traceback and CMD ages, including observational uncertainties, has shown that there is a systematic difference between the two, with the former shorter than the latter (Miret-Roig et al. 2024). That study suggests that the two methods have a different “time zero”: a star cluster may be gravitationally bound before the dispersion of the parent gas cloud, so the time zero of the kinematic method that measures the expansion time would start a few million years after the time zero of the CMD method. If the timescale of cluster formation and gas dispersal were known, it would be possible to correct the dynamical traceback age to a similar time zero as the CMD age. Conversely, the age difference between the two methods may give us important clues about the cluster formation and gas dispersal processes.
This work proposes a new method of determining kinematic ages: instead of measuring the “expansion” age of the whole cluster, we evaluate the “evaporation” ages of its individual stars, and estimate the cluster age from that of the oldest evaporation ages. We subsequently show that this method results in ages on the order of the actual stellar ages, and we calibrated it using star clusters from a numerical simulation. We also applied the method to observational data, finding kinematic ages in reasonable agreement with the CMD ages.
In the following, the term “star cluster” is used to refer to both bound and unbound groups of stars, irrespective of their stellar density or total mass. In Sect. 2, we briefly describe the star formation simulation, and in Sect. 3 we characterize the clusters identified from the numerical data. The method is outlined in Sect. 4 and then we explain how it was validated and calibrated in Sect. 5 using the simulated clusters. In Sect. 6 we explain how we applied the method to observations of real star clusters, and we finally summarize our conclusions in Sect. 7.
2. Simulation
The kinematic-age method presented in this work is tested with star clusters from the same supernova (SN) driven magneto-hydrodynamic (MHD) simulation as in Padoan et al. (2017, 2020). The reader is referred to those papers for details of the numerical methods. The 3D MHD equations are solved with the Ramses adaptive-mesh-refinement (AMR) code (Teyssier 2002, 2007; Fromang et al. 2006) within a cubic region of size Lbox = 250 pc, total mass Mbox = 1.9 × 106 M⊙, and periodic boundary conditions. The initial conditions are taken from a SN-driven simulation that was integrated for 45 Myr without self-gravity (Padoan et al. 2016b) with a mean density nH, 0 = 5 cm−3 and a mean magnetic field B0 = 4.6 μG. The root mean square (rms) magnetic field generated by the turbulence has a value of 7.2 μG and an average of |B| of 6.0 μG, consistent with the value of 6.0 ± 1.8 μG derived from the “Millennium Arecibo 21-cm Absorption-Line Survey” by Heiles & Troland (2005).
The only driving force is from SN feedback, with SNe determined by the position and age of the massive sink particles formed when self-gravity is included (the SNe are randomly generated prior to star formation). When gravity is introduced, starting at t = 55.5 Myr from the initial conditions, the minimum cell size is dx = 0.0076 pc, obtained through a uniform root-grid of 5123 cells and six AMR levels. With this setup, the simulation is run for a period of approximately 40 Myr. To follow the collapse of prestellar cores, sink particles are created in cells where the gas density is larger than 106 cm−3, according to several criteria designed to avoid creating spurious sink particles in regions where the gas is not collapsing (see Haugbølle et al. 2018, for details). When a sink particle of mass larger than 7.5 M⊙ has an age equal to the corresponding stellar lifetime for that mass (Schaller et al. 1992), a sphere of 1051 erg of thermal energy is injected at the location of the sink particle to simulate the SN explosion Padoan et al. (2016b).
With a total mass of 1.9 × 106 M⊙, the mean column density of the simulation is 30 M⊙ pc−2, typical for spiral arms in the outer Galaxy (Heyer & Terebey 1998). In fact, a lower-resolution version of this simulation (Padoan et al. 2016b,a; Pan et al. 2016) has been shown to produce dense clouds with properties consistent with those of real molecular clouds in the 12CO FCRAO Outer Galaxy Survey (Heyer et al. 1998, 2001). These star-forming clouds are formed ab initio in the simulation, as a result of the large-scale dynamics driven by SNe. Although their disruption is also caused by SNe alone (HII regions and stellar winds are not included in the simulation yet), the clouds in the simulation have realistic lifetimes (Lu et al. 2020), comparable to estimates from observations of nearby galaxies (e.g., Chevance et al. 2022; Lee et al. 2023).
The simulation has generated ∼7000 stars with mass > 1.0 M⊙ and ∼600 stars with mass > 8 M⊙. The star formation is distributed over many different clouds with realistic values of the SFR, and the global SFR corresponds to a mean gas depletion time in the computational volume of almost 1 billion years, also realistic for a 250-pc scale (Padoan et al. 2017). Young stars are found inside the densest filaments, while older ones have already left their parent clouds. Most of the stars in the simulation are formed in clusters, some of which have cleared their surrounding gas thanks to SN explosions of their most massive members.
3. Identification of star clusters
For this work, we select six snapshots at time intervals of approximately 4.4 Myr, with the first one at 17.2 Myr after gravity is introduced in the simulation, and the final one at 39.2 Myr. This selection yields a total sample of 26 842 stars with mass > 1.0 M⊙. The stars in each snapshot are assigned into clusters using their 6D phase space information, using a Gaussian Mixing Model (GMM) from the Scikit-learn software (Pedregosa et al. 2011). We explored models with different numbers of Gaussians (between 1 and 70) and chose the one where the Bayesian information criterion (BIC) stabilized to a minimum value. This procedure results in a total of 339 star clusters (35, 42, 63, 67, 65, and 67 in each of the snapshots in chronological order).
The distributions of the overall properties of our sample of star clusters are shown in the histograms in Fig. 1, where the cluster age is defined as the median age of the stars and the radius as the median distance of the stars to the center of mass of the cluster. The age distribution has a median value of 13 Myr, is relatively flat in the range between approximately 1 and 20 Myr, and decreases between 20 and 30 Myr. The mass and radius distributions have median values of 217 M⊙ and 15.1 pc, and cover the approximate ranges from 20 to 2000 M⊙ and from 1 to 100 pc, respectively. The median rms velocity of the stars in the clusters is 2.9 km s−1, ranging from 1 to 10 km s−1. We compared our numbers to the Gaia DR3 all-sky cluster catalog made by Hunt & Reffert (2023), making a cut to high-reliability, young (< 50 Myr), nearby (< 500 pc) clusters. We found that the median age was comparable to ours at 17 Myr, while the radius was significantly smaller at 5 pc, which is not surprising as they have a large fraction of bound clusters. On the other hand, the clusters in our observational sample presented in Sect. 6 have a median radius of 7.3 pc but reach as high as 24 pc, comparable to that of the simulated clusters. Castro-Ginard et al. (2022) found a median velocity dispersion of 2.3 km s−1 for their class A open clusters, which is comparable to our median velocity dispersion of 2.9 km s−1.
 |
Fig. 1. Histograms (in red) of the ages, masses, radius, and rms velocities and scatter plots of the square root (to use the same scale as the histograms) of the ratio of kinetic and gravitational energies versus the same quantities (blue dots) of the 339 clusters identified in the six simulation snapshots used in this work. The black dashed line marks the value of Ek = Eg, showing that 5% of the clusters (17 of them) are gravitationally bound. |
The scatter plots in the panels of Fig. 1 show the square root of the ratio of kinetic and gravitational energies versus the age, mass, size, and rms velocity of the clusters. As can be seen from the Ek/Eg ratio and the sizes, the great majority of our systems are unbound clusters that have expanded to rather large sizes. However, we also have 17 bound clusters (5% of the total sample), and a few rather concentrated clusters with M ∼ 103 M⊙, R ∼ 1 pc and Ek/Eg ∼ 1. As mentioned above, in this work we refer to both bound and unbound star groups as clusters, and our evaporation-age method works for both types of clusters.
Because of the limited spatial resolution, the stellar initial mass function (IMF) in the simulation is incomplete below a few solar masses, and only stars > 1.0 M⊙ are used in this work. The lack of low-mass stars, as well as the incomplete binary statistics, may affect the early dynamical evolution of some of the densest clusters in the simulation, while its effect on most of the diffuse clusters is probably not significant. However, because our sample contains a large number of star clusters formed and evolved ab initio from a self-consistent simulation of a very large ISM region, it represents a significant improvement over previous ad hoc models of single star clusters from pure N-body simulations without gas-dynamics, or star formation simulations of very small regions of just a few pc that were used to test kinematic-age methods (e.g., Crundall et al. 2019). Although this should be tested with future simulations including low-mass stars, we do not expect the calibration of the method to be sensitive to details of the evolution of the clusters. If anything, the inclusion of low-mass stars would make the method even more successful than concluded here, due to improved statistics. A significant fraction of the low-mass stars would undergo early evaporation, so their inclusion would increase the number of reliable evaporation ages, improving the accuracy of the method, particularly in the case of bound clusters.
4. Evaporation-age method
The traditional way to determine the dynamical age of a star cluster assumes that the stars are coeval and that the cluster was never gravitationally bound, or at least started to expand very soon after its formation. The ages can then be derived by adopting a realistic Galactic potential and tracing the stellar orbits back in time to find the time of maximum stellar density (de la Reza et al. 2006; Miret-Roig et al. 2020), or using forward modeling of the stellar orbits to avoid propagation of observational errors (Crundall et al. 2019). Besides their uncertainties due to the observational errors, these methodologies have important limitations related to the above assumptions: (i) if the cluster is initially bound for a significant time relative to its age, the kinematic age largely underestimates its real age; (ii) if the cluster is still mostly gravitationally bound, the methods do not even apply (the cluster’s potential is dominant over the Galactic one); (iii) if the stars have a significant age dispersion relative to the age of the cluster (in the case of very young clusters) or if they become unbound at different times, the time zero of the methods is poorly defined.
To avoid these limitations, we propose a new method of determining dynamical ages: instead of measuring the expansion age of the whole cluster, we evaluate the evaporation ages of its individual stars, and identify the cluster’s age with that of the oldest evaporation ages. The evaporation age is the time since a star escaped the gravitational potential of the cluster. We define this time ignoring the cluster potential, as this requires careful modeling of the time evolution of both the gas and stars in the specific cluster, which is generally unknown, and the effect of the cluster potential is accounted for statistically when the method is calibrated with the simulated clusters. Younger evaporation ages may also correspond to the actual stellar ages if those stars were formed at a later time, or may represent a lower limit to the stellar ages if the stars had remained gravitationally bound to the system for a longer time and evaporated only more recently. For these reasons, we only use the oldest evaporation ages to establish the cluster age. However, the complete age and spatial distributions of the evaporated stars contain valuable information about the formation and dispersion process of a star cluster.
This method has a time zero comparable to that of the CMD method if the first evaporated stars are gravitationally bound to the cluster for a short time relative to their age, and if the observations can identify them, despite their large position and velocity dispersions. The time zero of the evaporation ages is independent of the duration of the bound phase of the cluster (even bound clusters undergo evaporation) and of its age dispersion. Therefore, this method can be applied to bound clusters as long as enough evaporated stars can be identified observationally. The method becomes increasingly uncertain for clusters of increasing age or increasing escape velocity, because of the increasing size of the spatial and velocity windows that must be explored to identify the oldest evaporated stars, and because the past trajectories become more uncertain.
The specific implementation of our evaporation-age method can be summarized by the following steps that are applied to each of the individual clusters identified by the GMM in the simulation snapshots. In the case of the clusters from the simulation, we assume constant velocities equal to the current values because the simulation does not include a Galactic potential. In general, when applied to real clusters, the orbits and the cluster center should be traced back in time accounting for the Galactic potential (see Sect. 6).
1. Rejection of divergent stars: We determine the position and velocity of a cluster’s center by taking the mean position and the mean velocity of all the stars in the cluster. The core radius, R50, is defined as the median distance of the stars from the center. We then trace each star back in time, until it reaches its closest 3D point to the center. As we do not know apriori the age of a real cluster, we go as far back in time as necessary. If both the star and this closest point are outside of the radius, we reject the star for the rest of the analysis.
2. Subclustering: It is not easy to find a single, optimal number of components for the GMM. The GMM sometimes fails to separate all the clusters, in particular younger clusters that are close together. In order to break these “joined clusters” apart to their actual individual clusters, we perform additional subclustering. We identify dense concentrations of stars, with five stars or more and a maximum mutual distance of 1 pc, as potential subcluster centers (see Appendix A for more details). The cluster’s center from the previous step is always included as the first subcluster center, too. This way, if there are no additional subclusters, the original cluster is treated as a single subcluster. We assign each star in the original cluster to the new potential subcluster it passes closest to. For each star member of the new subclusters, we calculate the closest distance to the subcluster center, the star evaporation age, defined as the time elapsed since the star was closest to the subcluster center, and the current distance to the center. With this step, a single GMM cluster may break into several subclusters, if a sufficiently high number of evaporated stars are found for more than one subcluster (see below).
3. Evaporation age: For each subcluster, we select all the stars of the subcluster that trace back inside its core radius and are currently located outside; we refer to the number of these evaporated stars as neva. We compute the 70th percentile of the star evaporation ages, t70, and remove any evaporated stars with evaporation age larger than 1.4 × t70 + 2 Myr, to reject potential outliers. We iterate until no more stars are removed and then select the stars with evaporation ages larger than the 70th percentile. We compute the evaporation age of the subcluster, teva, as the median of the evaporation ages of this selection of stars, and record the number of stars used to obtain this value, neva, 70. We only keep the subclusters with neva, 70 > 1.
The steps of the evaporation-age method are illustrated in Fig. 2, with one of the simulated clusters as an example. The top-left panel shows the current positions of the stars, where we have identified a few divergent stars (green triangles) that do not trace back (green vector) to the core radius. The other stars (blue diamonds and red stars, neva) trace back to the core radius (blue and red vectors) or are already inside (black points). In this particular example, we did not find subclusters, so we can directly plot the evaporation ages of individual stars as a function of the current distance, d, to the center, on the top-right panel. We used the stars outside the core radius to obtain the complete evaporation-age distribution, but only the stars with an evaporation age equal to or larger than the 70th percentile (red stars, neva, 70) are used to obtain the final evaporation-age of the cluster, teva. In this example, we did not find any outliers with the t70 criterion mentioned above, and the evaporation age that we determine (red line) is slightly underestimated compared to the simulation age (gray line). The two bottom panels show the positions of the stars that are currently outside the cluster’s core radius when traced back in time to half of tsim (bottom-left) and then by a full tsim (bottom-right). At tsim, only half of all the stars were born and they may have been gravitationally bound. Thus, some stars overshoot the radius, when traced back to a time before their evaporation time.
 |
Fig. 2. Example of the application of the evaporation-age method to a simulated cluster. a) Projected xz positions of the cluster members in the present (t0). Green triangles are initial cluster members rejected because they do not trace back into the cluster core (black circle). Black dots are cluster members in the cluster core in the present. Blue diamonds and red stars are evaporated cluster members. They are currently outside the cluster core but were inside in the past. Vectors show the 2D projected velocities back in time. b) The diagram illustrating the evaporation age determination. The x-axis is the current distance from the cluster center, d, with the gray vertical line showing the current core radius of the cluster, and the y-axis is the evaporation age, teva, for each star. Red stars are evaporated stars with teva higher than the 70th percentile of the teva distribution, and the red line is the median teva for these stars. Blue diamonds are evaporated stars with teva lower than the 70th percentile and are not used for the evaporation age determination. The gray horizontal line is the simulation age of the cluster, tsim. c) Projected XZ positions of evaporated stars at half tsim. d) Positions of evaporated stars at the beginning of the cluster. Only 50% of all the cluster stars had been born by this time. |
5. Validation and calibration of the method
5.1. Without observational errors
We define the evaporation age of a cluster, teva, as the median of the oldest evaporation ages of individual stars above the 70th percentile. Because different percentile values would give different ages, we need to calibrate the derived teva for the specific percentile value we have chosen. We calibrate and evaluate the accuracy of teva by comparison with the true age of the clusters in the simulation, tsim, which we define as the median age of all the stars in the cluster. We first perform this analysis by applying the method without adding position or velocity errors to the stars in the simulation. To ensure the quality of the evaporation ages, we consider only the clusters with teva > 2 Myr, as our tests showed that the accuracy decreases significantly with younger clusters.
The values of teva and tsim for all the clusters in the six snapshots of the simulation are plotted in Fig. 3, with the three panels showing clusters within three neva, 70 bins: 5–9, 10–19, and 20 or more, from left to right. The figure shows a strong correlation between teva and tsim, increasing with increasing values of neva, 70. In addition, the least-squares fit (black dashed lines) has a slope very close to unity, so we can calibrate the method by dividing the derived teva by a scaling factor, ϕeva, independent of cluster age, which we compute as the median of all the age ratios,
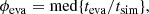 (1)
(1)
 |
Fig. 3. Evaporation age, teva, versus simulation age, tsim, for the clusters in the simulation within three different bins of the number of stars, neva, 70, from which the evaporation age was calculated. The left panel has 86 clusters, the middle one has 45 clusters, and the right one has 15 clusters. The dashdot red line corresponds to ϕeva, 0 tsim, where ϕeva, 0 is the median value of the age ratio teva/tsim (Eq. (1)) in each bin. The scatter, σeva, 0, is the standard deviation of the ratio of the corrected |
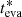
shown by the red dashed-dotted lines in Fig. 3. We will derive the full dependence of ϕeva on both neva, 70 and the size of the position and velocity errors in Sect. 5.2. For the three neva, 70 bins shown in Fig. 3, the calibration factor without observational noise, ϕeva, 0, varies from 0.81 to 0.93.
With the established calibration, the corrected evaporation age of a cluster, 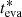 , is defined as
, is defined as
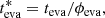 (2)
(2)
and the statistical uncertainty, σeva, is estimated as the standard deviation of the ratio of the individual corrected ages divided by their simulation ages, 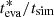 , a measure of the scatter in Fig. 3,
, a measure of the scatter in Fig. 3,
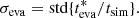 (3)
(3)
As seen in Fig. 3, this uncertainty is actually symmetrical in logarithmic space rather than in linear space. Thus, it should be interpreted as a factor: if σeva = 0.3, the upper 1σ limit should be 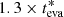 , while the lower limit should be
, while the lower limit should be 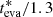 .
.
As the parameter ϕeva, σeva is also approximately independent of cluster age for teva > 2 Myr, and it only depends on the number of evaporated stars (neva, 70) and on the size of the position and velocity errors (see Sect. 5.2). For the three neva, 70 bins shown in Fig. 3, σeva is quite sensitive to neva, 70, decreasing from 35% to 9%. Thus, with sufficiently small observational errors, the evaporation-age method could in principle yield ages with a statistical error approaching 9%. Because neva, 70 is defined by the 70th percentile, achieving a 9% error or lower requires the identification of at least 67 stars outside of the cluster’s core radius with measured evaporation ages (stars tracing back to the cluster’s core), so a minimum of 134 stars in total (assuming no star is rejected). Figure 3 shows that only a few of the clusters in our sample have neva, 70 values large enough to achieve this high accuracy. However, if we had all the lower-mass stars in the simulation, our total number of stars would increase by ∼10, yielding a much larger number of clusters in the right panel of Fig. 3.
Figure 4 shows σeva, 0 (σeva without observational errors) as a function of neva, 70, where the clusters are binned according to their neva, 70 so that each bin has ten or more clusters, with the exception of the last bin that has 8 clusters. We do a least-squares fit in log-log space, which results in the fitting formula:
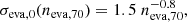 (4)
(4)
 |
Fig. 4. Scatter σeva, 0 as a function of neva, 70. The clusters are binned according to their neva, 70 so that each bin has ten or more clusters, with the exception of the last bin that has 8 clusters. The center of each bin is the mean of neva, 70 of the clusters in that bin. ϕeva and σeva are then derived for each bin using Eqs. (1) and (3). The least-squares fit to the [bin center, σeva] pairs (blue points) is done in log–log space (see the inset panel), weighing by the square root of the number of clusters in each bin, which results in a fit f(x) = 1.5 x−0.8 in linear space (red line). |
in linear space. This formula expresses the statistical error intrinsic to the method, that is in the absence of observational errors.
5.2. With position and velocity errors
In this section, we investigate the dependence of ϕeva and σeva on the observational errors in the positions and velocities. Assuming Gaussian error distributions, we added random errors to the current positions and velocities of the stars in the simulation, with six different 1σ values in both position and velocity, hence a 6 × 6 grid of 1σ error pairs (in the ranges 0.15–4.80 pc in positions and 0.15–4.80 km s−1 in velocities). These values represent the present errors achievable with Gaia only (astrometry and radial velocities) for nearby stars (< 500 pc) and also the Gaia astrometry complemented with ground-based high-resolution spectroscopy. For example, in Upper Scorpius, the tangential errors are around 0.2 km s−1, and with ground-based observations plus strict quality criteria (like the ones applied in our samples), it is possible to get radial velocity uncertainties of ≲1 km s−1. At the same time, the uncertainties of Gaia’s radial velocities are a few kilometers per second. We assumed that these error values, σp and σv, were the same in the three directions, σp = σp, x = σp, y = σp, z and σv = σv, x = σp, y = σp, z. In general, the observational errors in the line-of-sight direction are different (larger for nearby clusters) than in the 2D tangential plane. We have explored a case where the 1D error along the line-of-sight was three times the 1D error in another axis, and found differences in ϕeva and σeva of only 1–10% for the same 1D equivalent total errors, defined as:
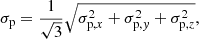 (5)
(5)
and
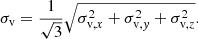 (6)
(6)
Thus, although the following calculations were carried out using equal errors in the three directions, the results hold valid for different error distributions with the same 1D equivalent total errors defined above. We performed 1000 Monte-Carlo runs for each of the 36 error pairs, but we computed the optimal number of clusters (the GMM procedure described in Sect. 3) only once for each error pair to reduce the computational time.
Figure 5 shows the impact of the observational errors on the fraction of clusters that we can identify, fGMM, compared to the case with no errors), the fraction of clusters for which we can compute an evaporation age, fages, the calibration factor, ϕeva, and statistical error, σeva, of the evaporation ages. All these values are the medians of the 1000 individual realizations of each observational error pair. The fraction of identified clusters decreases significantly with increasing σp and σv values, going down to nearly 50% with the largest error pair. The fraction of retained clusters, fages, decreases with increasing σv, but stays constant or increases with increasing σp. The increase is particularly noticeable in the cases with neva, 70 ≥ 10 and 20. The reason is two-fold. Firstly, the larger positional errors mean that GMM sorts all the stars into fewer clusters, as seen in the top row of Fig. 5, hence the individual clusters are bigger and retain more stars, so more clusters meet the minimum neva, 70 condition. Secondly, increasing random position errors cause a larger scatter of dense clumps of stars, reducing the chance that large GMM clusters get subclustered into smaller ones.
 |
Fig. 5. Impact of the observational errors. Top row: fraction of GMM clusters, fGMM, derived from the number of clusters found by GMM in each error pair, divided by the number of GMM clusters in the no errors case (339). Second row: fraction of clusters for which we derived ages, fages, normalized to 339. Red, blue, and black lines are for neva, 70 bins of 5–9, 10–19, and 20+ stars, respectively. Third row: ϕeva. Bottom row: σeva. Columns correspond to different 3D position errors, σp, and the x-axis is the 3D velocity error, σv. |
The calibration factor, ϕeva, is not very sensitive to the value of neva, 70 or σp, but decreases significantly with increasing σv, for σv > 1 km s−1. This is due to the shedding of the farthest and slowest evaporated stars: if a star is far away or has a low velocity, even a small deviation of its velocity may make it miss the cluster core and get rejected; if it is close to the cluster core or it has a high velocity the star is more likely retained. This results in a stronger reduction for the cluster’s evaporation age than for the cluster’s simulation age, as the latter is less sensitive to the loss of the oldest evaporated stars (they may not even be the oldest stars in the cluster). The value of the statistical age uncertainty, σeva, increases with increasing position and velocity errors, as expected, with some exceptions in the case of neva, 70 > 20, due to the poor statistics (too few clusters). As in the case without errors, σeva decreases with increasing neva, 70, approaching 10% for small enough observational errors and large enough number of stars. Histograms of ϕeva and σeva for all 36 error pairs are given in Appendix B, as well as the values of the medians of those histograms for five bins of neva, 70.
6. Results for observed clusters
6.1. Data and method
In this section, we apply the evaporation-age method to nine young (< 50 Myr), nearby (< 150 pc) clusters, namely, β Pictoris (Miret-Roig et al. 2020), Tucana-Horologium (Galli et al. 2023), and seven clusters in Upper Scorpius and Ophiucus detailed in Miret-Roig et al. (2022). We selected clusters for which we have a recent dynamical traceback age, tDT, obtained from Gaia astrometry plus a precise selection of radial velocities (errors ≲0.5 km s−1) from devoted ground-based observations, APOGEE, and Gaia. To obtain the 3D Cartesian heliocentric positions and velocities for the stars in our sample, we used the Gaia DR3 astrometry and the same radial velocities used for the dynamical traceback ages. This selection was carefully made to include only precise radial velocities (≲1 km s−1) and exclude potential binary stars which hinder the traceback.
A CMD age, tCMD, was also computed for these clusters, using the same stars as for the traceback analysis, and the isochrone-fitting methodology presented in Ratzenböck et al. (2023a), using the PARSEC v1.2S models (Marigo et al. 2017). For most clusters, the values of tCMD were presented in Miret-Roig et al. (2024), while for α Sco, π Sco and σ Sco they are reported here for the first time. The membership and dynamical traceback age for these three clusters are less accurate since α Sco contains two subclusters identified in Ratzenböck et al. (2023b), π Sco is incomplete, and σ Sco is more contaminated (Miret-Roig et al. 2022). In this work, we used the GMM code to separate α Sco into two subclusters, α Sco 1 and 2, by imposing a two-component solution on the original membership list, and apply the evaporation-age method to the two subclusters separately. The properties of all the clusters are summarized in Table 1.
Properties of the clusters considered in this study.
To apply the method described in Sect. 4, the orbits of the stars and the cluster center are traced back in time using a 3D Galactic potential. We tested three axisymmetric potentials, namely MWPotential14 (Bovy 2015), McMillan17 (McMillan 2017), and Irrgang13 (Irrgang et al. 2013). The differences in the evaporation ages between the Galactic potential models are very small, generally of < 1%, and only up to a few percent at most. The results that we report are obtained with the MWPotential14, following the orbits back by a maximum of 50 Myr (100 Myr in the case of Tuc-Hor), which is enough to find the evaporation ages. The initial number of stars used to determine the evaporation ages is the same as that used for the DT and the CMD ages (nstars in Table 1), except for the subclusters of α Sco, where the cluster was split in two. This sample is limited to stars with precise radial velocities, essential for the traceback analysis, but is only a lower limit to the total number of cluster members. Figure 6 shows the number of core, evaporated, and divergent stars for each cluster. Thanks to the careful selection of members (and 6D phase-space data) in these clusters, the number of stars rejected (divergent) in the evaporation-age method is relatively small (see Table 1). The exceptions are the α Sco and σ Sco clusters, which are likely more contaminated (see Miret-Roig et al. 2022), and ρ Oph and ν Sco, which are the youngest groups in the sample and might still be gravitationally bound. By contrast, the more isolated clusters β Pic and Tuc-Hor only have two divergent stars (in Tuc-Hor); this shows the impact of the proximity of other clusters to assigning the correct membership to the stars.
 |
Fig. 6. Number of stars in each of the ten observed clusters found within the core radius, ncore (blue), found outside of the core radius and tracing back to it, neva (orange), or not tracing back to it, ndiv (green). |
We derived the calibration factor, ϕeva, the corrected age, 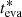 , and its uncertainty, σeva, using the 1D equivalent total observational errors and the values of neva, 70 as described in Sect. 5. All of these values are reported in Table 1. As explained in Sect. 5, the age uncertainty is symmetrical in logarithmic space, hence used as a factor to get the error bars in linear space.
, and its uncertainty, σeva, using the 1D equivalent total observational errors and the values of neva, 70 as described in Sect. 5. All of these values are reported in Table 1. As explained in Sect. 5, the age uncertainty is symmetrical in logarithmic space, hence used as a factor to get the error bars in linear space.
6.2. Evaporation ages
Figure 7 shows the distributions of the evaporation ages of individual stars (red histograms), obtained from the 1000 error realizations of each cluster. The corresponding cumulative distributions are also shown (gray curves), as well as the estimated age, 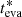 (black vertical lines). Because the method estimates the cluster age from the oldest evaporation ages of individual stars, the peak of the distribution is expected to be at younger ages than
(black vertical lines). Because the method estimates the cluster age from the oldest evaporation ages of individual stars, the peak of the distribution is expected to be at younger ages than 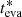 (to the left of the black vertical line), as shown in Fig. 7. The difference between the time of the peak and
(to the left of the black vertical line), as shown in Fig. 7. The difference between the time of the peak and 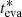 , typically a few Myr, is a rough estimate of the characteristic time during which the evaporated stars were bound to the cluster, which should increase over time, as more recently evaporated stars are gradually released from the cluster’s potential. In addition, the width of the distribution sets an upper limit to the actual age spread of the stars (it would be equal to the age spread only if the stars were never gravitationally bound to the cluster). Future studies should attempt a detailed analysis of the distributions of the evaporation ages of individual stars, including a comparison of the evaporation-age spread with the age spread inferred from the clusters’ CMD.
, typically a few Myr, is a rough estimate of the characteristic time during which the evaporated stars were bound to the cluster, which should increase over time, as more recently evaporated stars are gradually released from the cluster’s potential. In addition, the width of the distribution sets an upper limit to the actual age spread of the stars (it would be equal to the age spread only if the stars were never gravitationally bound to the cluster). Future studies should attempt a detailed analysis of the distributions of the evaporation ages of individual stars, including a comparison of the evaporation-age spread with the age spread inferred from the clusters’ CMD.
 |
Fig. 7. Histograms (peaks scaled to 1.0) of the evaporation ages of individual evaporated stars (red histograms) and the corresponding cumulative distributions (gray curves), from the 1000 Monte-Carlo error realizations and using stellar orbits computed with MWPotential14. The derived |
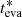
Figure 8 shows the comparison of the evaporation ages, 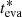 , with the CMD ages, tCMD (left panel), and the dynamical traceback ages, tDT (right panel). Nine out of ten clusters have an evaporation age compatible with the CMD age within the 1-σ uncertainty. Only for π Sco the evaporation age is not compatible with the CMD age. However, the census of π Sco is incomplete, limited to the stars inside the field of view analyzed in Miret-Roig et al. (2022). The truncation of the field of view leads to a shift of its center toward one side, reducing the stellar evaporation ages for the stars on that side and hence reducing the cluster’s evaporation age. This example stresses the importance of obtaining clusters’ membership lists as reliable and complete as possible.
, with the CMD ages, tCMD (left panel), and the dynamical traceback ages, tDT (right panel). Nine out of ten clusters have an evaporation age compatible with the CMD age within the 1-σ uncertainty. Only for π Sco the evaporation age is not compatible with the CMD age. However, the census of π Sco is incomplete, limited to the stars inside the field of view analyzed in Miret-Roig et al. (2022). The truncation of the field of view leads to a shift of its center toward one side, reducing the stellar evaporation ages for the stars on that side and hence reducing the cluster’s evaporation age. This example stresses the importance of obtaining clusters’ membership lists as reliable and complete as possible.
 |
Fig. 8. Comparison of the corrected evaporation ages, |
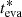
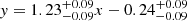
In the left panel of Fig. 8, we have performed a least-squares fit to the data in the logarithmic scale, discarding π Sco due to the previously stated reasons. We find a slope of 1.2, although the 1-to-1 line is still within the 1-sigma confidence of the fit. We caution that this slope is based on mainly the two lowest and the two highest age clusters. For the two young clusters, it is possible that we miss some of the evaporated cluster members due to the crowded nature of Upper Scorpius, or perhaps for these clusters there was a longer bound period before any stars were evaporated, either of which would easily explain the shift of about 1 Myr. Also, in all four cases, the clusters’ evaporation ages are relying on just 2–4 evaporated stars above the 70th percentile. Thus, the statistics are quite uncertain.
As shown in the right panel of Fig. 8, the evaporation ages are always larger than the dynamical traceback ages. This is expected since our method is designed to find the time when the first stars evaporated. In contrast, the dynamical traceback age is designed to find the overall expansion time of the cluster, which may start well after the evaporation of the first stars. The overall expansion is better represented by the evaporation of the overall stellar population, whose peak evaporation time (the peak of the red histograms in Fig. 7) is a few million years lower than the cluster’s age, 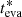 , as mentioned above. This result confirms the recent findings from the comparison between CMD and dynamical traceback ages by Miret-Roig et al. (2024).
, as mentioned above. This result confirms the recent findings from the comparison between CMD and dynamical traceback ages by Miret-Roig et al. (2024).
We have found that the evaporation-age method results in ages compatible with those from isochrone fitting in the CMD. With accurate enough observations (e.g., position errors < 0.6 pc and velocity errors < 0.6 km s−1) and a large enough number of stars (neva, 70 ≥ 20), the evaporation-age uncertainty could approach a value as low as 10%, comparable to the typical statistical uncertainty in tcmd from isochrone-fitting. The real uncertainty in tcmd, particularly for tcmd < 10 Myr, is significantly larger than 10%, due to uncertainties from pre-main sequence modeling, such as the effect of starspots and magnetic fields (e.g., Simon et al. 2019; Somers et al. 2020; Cao et al. 2022), or the effect of extended and variable accretion histories (e.g., Froebrich et al. 2006; Baraffe et al. 2009; Hosokawa et al. 2011; Jensen & Haugbølle 2018). However, the good correlation between our evaporation ages and the CMD ages may suggest that systematic errors in the latter may not be as large as the full range of age values allowed by the largest differences between evolutionary models. As follow-up observations continue to increase the samples of accurate radial velocities in young clusters, isochrone-fitting ages should be carefully compared with evaporation ages, making sure that the same stars are used in the two methods. This comparison may shed light on the pre-main-sequence evolution (e.g., the duration of the accretion phase), on the age spread within a cluster, and on the gas-dispersal mechanism.
7. Conclusions
We have presented a new method to measure the age of young star clusters, based on the evaporation age of their individual stars. The method has been validated and calibrated with hundreds of star clusters with ages between 2 and 30 Myr, taken from a star formation simulation in a region of 250 pc, evolved for approximately 40 Myr with self-consistent energy injection by SNe. It has also been applied to ten real clusters with previous estimates of CMD and dynamical traceback ages. Thanks to the simulated clusters, and to thousands of realizations of random observational errors, we have estimated the statistical uncertainty of the derived age, as well as a calibration factor to convert it into the median cluster age. The main conclusions of this study are listed in the following.
-
Using the clusters from the simulation, without adding observational errors, we find a strong correlation between the estimated age of a cluster and the median simulation age of its stars. We derive the ratio between estimated and real age, ϕeva, 0, which we use to calibrate the method’s age.
-
Using the simulation we also estimate the intrinsic (not due to observational errors) statistical uncertainty of the method, σeva, 0. We find it has no significant age dependence, and provide a fitting function for its dependence on the number of evaporated stars. We show that σeva, 0 can be as small as 9% for clusters with a large number of evaporated stars.
-
By adding observational errors to the simulated clusters, we derive both ϕeva and σeva as a function of both the number of evaporated stars and the observational errors in position and velocity, with σeva being the total uncertainty of the derived age, including both the intrinsic and observational random errors.
-
We find that, assuming small observational errors (σp < 1 pc and σv < 1 km s−1) similar to the ones achievable with Gaia astrometry plus complementary high-resolution spectroscopy, cluster ages have a 1-σ uncertainty < 30% for clusters with a minimum of ∼70 stars, and approaching 10% for clusters with ∼150 stars or more, if only a small fraction of the stars are rejected.
-
A pilot application to ten nearby clusters results in evaporation ages consistent with CMD ages, and larger than previously determined dynamical traceback ages. The uncertainties are currently significantly larger than 10%, due to the limited number of confirmed evaporated stars in the observational samples.
Given the large number of current and upcoming radial-velocity surveys complementing Gaia’s database, evaporation ages with accuracy close to 10% may become the norm in a few years. However, it will be necessary to explore rather wide space and velocity windows around each cluster, to capture a significant fraction of the evaporated stars, particularly the earliest ones. In practice, this will limit the method to relatively young clusters, probably with ages < 50–100 Myr, for which we can determine membership and precise stellar orbits back in time of their earliest evaporated stars. Because of theoretical uncertainties (e.g., magnetic fields and starspots) and stochasticity (e.g., extended and episodic accretion) of the pre-main sequence evolution of stars, CMD ages for very young clusters (< 10–20 Myr) are very uncertain, despite the often-quoted statistical error of ∼10% from isochrone fitting. As it is completely independent of stellar evolutionary models, and particularly suited for very young clusters, the evaporation-age method will provide important constraints for the modeling of pre-main sequence evolution.
Acknowledgments
We thank the anonymous referee for their helpful comments, leading to an improved and more clear presentation of our work. V.M.P. and P.P. acknowledge financial support by the grant PID2020-115892GB-I00, funded by MCIN/AEI/10.13039/501100011033 and by the grant CEX2019-000918-M funded by MCIN/AEI/10.13039/501100011033.
References
- Aerts, C. 2015, Astron. Nachr., 336, 477 [NASA ADS] [CrossRef] [Google Scholar]
- Angus, R., Aigrain, S., Foreman-Mackey, D., & McQuillan, A. 2015, MNRAS, 450, 1787 [Google Scholar]
- Angus, R., Morton, T. D., Foreman-Mackey, D., et al. 2019, AJ, 158, 173 [Google Scholar]
- Baraffe, I., Chabrier, G., & Gallardo, J. 2009, ApJ, 702, L27 [NASA ADS] [CrossRef] [Google Scholar]
- Barnes, S. A. 2003, ApJ, 586, 464 [Google Scholar]
- Barnes, S. A. 2007, ApJ, 669, 1167 [Google Scholar]
- Barrado y Navascués, D., Stauffer, J. R., Song, I., & Caillault, J. P. 1999, ApJ, 520, L123 [CrossRef] [Google Scholar]
- Basri, G., Marcy, G. W., & Graham, J. R. 1996, ApJ, 458, 600 [NASA ADS] [CrossRef] [Google Scholar]
- Bell, C. P. M., Naylor, T., Mayne, N. J., Jeffries, R. D., & Littlefair, S. P. 2013, MNRAS, 434, 806 [NASA ADS] [CrossRef] [Google Scholar]
- Bell, C. P. M., Mamajek, E. E., & Naylor, T. 2015, MNRAS, 454, 593 [Google Scholar]
- Bellinger, E. P. 2019, MNRAS, 486, 4612 [Google Scholar]
- Berger, T. A., Schlieder, J. E., & Huber, D. 2023, AJ, submitted [arXiv:2301.11338] [Google Scholar]
- Binks, A. S., & Jeffries, R. D. 2014, MNRAS, 438, L11 [NASA ADS] [CrossRef] [Google Scholar]
- Blaauw, A. 1964, ARA&A, 2, 213 [Google Scholar]
- Bonatto, C., & Bica, E. 2009, MNRAS, 394, 2127 [NASA ADS] [CrossRef] [Google Scholar]
- Bossini, D., Vallenari, A., Bragaglia, A., et al. 2019, A&A, 623, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bovy, J. 2015, ApJS, 216, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Brown, A. G. A., Dekker, G., & de Zeeuw, P. T. 1997, MNRAS, 285, 479 [NASA ADS] [CrossRef] [Google Scholar]
- Cantat-Gaudin, T., Anders, F., Castro-Ginard, A., et al. 2020, A&A, 640, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cao, L., Pinsonneault, M. H., Hillenbrand, L. A., & Kuhn, M. A. 2022, ApJ, 924, 84 [NASA ADS] [CrossRef] [Google Scholar]
- Chaboyer, B., Demarque, P., Kernan, P. J., & Krauss, L. M. 1996, Science, 271, 957 [NASA ADS] [CrossRef] [Google Scholar]
- Castro-Ginard, A., Jordi, C., Luri, X., et al. 2022, A&A, 661, A118 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chevance, M., Kruijssen, J. M. D., Krumholz, M. R., et al. 2022, MNRAS, 509, 272 [Google Scholar]
- Couture, D., Gagné, J., & Doyon, R. 2023, ApJ, 946, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Crundall, T. D., Ireland, M. J., Krumholz, M. R., et al. 2019, MNRAS, 489, 3625 [Google Scholar]
- Curtis, J. L., Agüeros, M. A., Matt, S. P., et al. 2020, ApJ, 904, 140 [Google Scholar]
- Da Rio, N., Gouliermis, D. A., & Gennaro, M. 2010, ApJ, 723, 166 [NASA ADS] [CrossRef] [Google Scholar]
- de la Reza, R., Jilinski, E., & Ortega, V. G. 2006, AJ, 131, 2609 [NASA ADS] [CrossRef] [Google Scholar]
- Dias, W. S., Monteiro, H., Moitinho, A., et al. 2021, MNRAS, 504, 356 [NASA ADS] [CrossRef] [Google Scholar]
- Donaldson, J. K., Weinberger, A. J., Gagné, J., et al. 2016, ApJ, 833, 95 [Google Scholar]
- Ducourant, C., Teixeira, R., Galli, P. A. B., et al. 2014, A&A, 563, A121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Epstein, C. R., & Pinsonneault, M. H. 2014, ApJ, 780, 159 [Google Scholar]
- Froebrich, D., Schmeja, S., Smith, M. D., & Klessen, R. S. 2006, MNRAS, 368, 435 [NASA ADS] [CrossRef] [Google Scholar]
- Fromang, S., Hennebelle, P., & Teyssier, R. 2006, A&A, 457, 371 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Galindo-Guil, F. J., Barrado, D., Bouy, H., et al. 2022, A&A, 664, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Galli, P. A. B., Miret-Roig, N., Bouy, H., Olivares, J., & Barrado, D. 2023, MNRAS, 520, 6245 [NASA ADS] [CrossRef] [Google Scholar]
- Glatt, K., Grebel, E. K., & Koch, A. 2010, A&A, 517, A50 [CrossRef] [EDP Sciences] [Google Scholar]
- Haugbølle, T., Padoan, P., & Nordlund, Å. 2018, ApJ, 854, 35 [CrossRef] [Google Scholar]
- Heiles, C., & Troland, T. H. 2005, ApJ, 624, 773 [NASA ADS] [CrossRef] [Google Scholar]
- Heyer, M. H., & Terebey, S. 1998, ApJ, 502, 265 [NASA ADS] [CrossRef] [Google Scholar]
- Heyer, M. H., Brunt, C., Snell, R. L., et al. 1998, ApJS, 115, 241 [NASA ADS] [CrossRef] [Google Scholar]
- Heyer, M. H., Carpenter, J. M., & Snell, R. L. 2001, ApJ, 551, 852 [NASA ADS] [CrossRef] [Google Scholar]
- Hosokawa, T., Offner, S. S. R., & Krumholz, M. R. 2011, ApJ, 738, 140 [NASA ADS] [CrossRef] [Google Scholar]
- Hunt, E. L., & Reffert, S. 2023, A&A, 673, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Irrgang, A., Wilcox, B., Tucker, E., & Schiefelbein, L. 2013, A&A, 549, A137 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jensen, S. S., & Haugbølle, T. 2018, MNRAS, 474, 1176 [Google Scholar]
- Jimenez, R., Cimatti, A., Verde, L., Moresco, M., & Wandelt, B. 2019, J. Cosmol. Astropart. Phys., 2019, 043 [CrossRef] [Google Scholar]
- Kerr, R., Kraus, A. L., Murphy, S. J., et al. 2022a, ApJ, 941, 143 [NASA ADS] [CrossRef] [Google Scholar]
- Kerr, R., Kraus, A. L., Murphy, S. J., et al. 2022b, ApJ, 941, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Krauss, L. M., & Chaboyer, B. 2003, Science, 299, 65 [Google Scholar]
- Lebreton, Y., & Goupil, M. J. 2014, A&A, 569, A21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lee, J. C., Sandstrom, K. M., Leroy, A. K., et al. 2023, ApJ, 944, L17 [NASA ADS] [CrossRef] [Google Scholar]
- Li, L., & Shao, Z. 2022, ApJ, 930, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Lu, Z.-J., Pelkonen, V.-M., Padoan, P., et al. 2020, ApJ, 904, 58 [NASA ADS] [CrossRef] [Google Scholar]
- Lu, Y. L., Angus, R., Curtis, J. L., David, T. J., & Kiman, R. 2021, AJ, 161, 189 [NASA ADS] [CrossRef] [Google Scholar]
- Majewski, S. R., Schiavon, R. P., Frinchaboy, P. M., et al. 2017, AJ, 154, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Manzi, S., Randich, S., de Wit, W. J., & Palla, F. 2008, A&A, 479, 141 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Marigo, P., Girardi, L., Bressan, A., et al. 2017, ApJ, 835, 77 [Google Scholar]
- Mayne, N. J., & Naylor, T. 2008, MNRAS, 386, 261 [NASA ADS] [CrossRef] [Google Scholar]
- McMillan, P. J. 2017, MNRAS, 465, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Meibom, S., Mathieu, R. D., & Stassun, K. G. 2009, ApJ, 695, 679 [Google Scholar]
- Miglio, A., Chiappini, C., Mackereth, J. T., et al. 2021, A&A, 645, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miret-Roig, N., Antoja, T., Romero-Gómez, M., & Figueras, F. 2018, A&A, 615, A51 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miret-Roig, N., Galli, P. A. B., Brandner, W., et al. 2020, A&A, 642, A179 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miret-Roig, N., Galli, P. A. B., Olivares, J., et al. 2022, A&A, 667, A163 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miret-Roig, N., Alves, J., Barrado, D., et al. 2024, Nat. Astron., 8, 216 [Google Scholar]
- Murphy, S. J., Joyce, M., Bedding, T. R., White, T. R., & Kama, M. 2021, MNRAS, 502, 1633 [NASA ADS] [CrossRef] [Google Scholar]
- Naylor, T., & Jeffries, R. D. 2006, MNRAS, 373, 1251 [Google Scholar]
- Ortega, V. G., de la Reza, R., Jilinski, E., & Bazzanella, B. 2002, ApJ, 575, L75 [NASA ADS] [CrossRef] [Google Scholar]
- Padoan, P., Juvela, M., Pan, L., Haugbølle, T., & Nordlund, Å. 2016a, ApJ, 826, 140 [NASA ADS] [CrossRef] [Google Scholar]
- Padoan, P., Pan, L., Haugbølle, T., & Nordlund, Å. 2016b, ApJ, 822, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Padoan, P., Haugbølle, T., Nordlund, Å., & Frimann, S. 2017, ApJ, 840, 48 [Google Scholar]
- Padoan, P., Pan, L., Juvela, M., Haugbølle, T., & Nordlund, Å. 2020, ApJ, 900, 82 [NASA ADS] [CrossRef] [Google Scholar]
- Pan, L., Padoan, P., Haugbølle, T., & Nordlund, Å. 2016, ApJ, 825, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Ramírez, I., Fish, J. R., Lambert, D. L., & Allende Prieto, C. 2012, ApJ, 756, 46 [CrossRef] [Google Scholar]
- Randich, S., Tognelli, E., Jackson, R., et al. 2018, A&A, 612, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ratzenböck, S., Großschedl, J. E., Alves, J., et al. 2023a, A&A, 678, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ratzenböck, S., Großschedl, J. E., Möller, T., et al. 2023b, A&A, 677, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schaller, G., Schaerer, D., Meynet, G., & Maeder, A. 1992, A&AS, 96, 269 [Google Scholar]
- Scutt, O. J., Murphy, S. J., Nielsen, M. B., et al. 2023, MNRAS, 525, 5235 [NASA ADS] [CrossRef] [Google Scholar]
- Silva Aguirre, V., Lund, M. N., Antia, H. M., et al. 2017, ApJ, 835, 173 [Google Scholar]
- Simon, M., Guilloteau, S., Beck, T. L., et al. 2019, ApJ, 884, 42 [NASA ADS] [CrossRef] [Google Scholar]
- Soderblom, D. R. 2010, ARA&A, 48, 581 [Google Scholar]
- Somers, G., Cao, L., & Pinsonneault, M. H. 2020, ApJ, 891, 29 [Google Scholar]
- Stauffer, J. R., Schultz, G., & Kirkpatrick, J. D. 1998, ApJ, 499, L199 [NASA ADS] [CrossRef] [Google Scholar]
- Teyssier, R. 2002, A&A, 385, 337 [CrossRef] [EDP Sciences] [Google Scholar]
- Teyssier, R. 2007, Geophys. Astrophys. Fluid Dyn., 101, 199 [NASA ADS] [CrossRef] [Google Scholar]
- Van-Lane, P., Speagle, J. S., & Douglas, S. 2023, arXiv e-prints [arXiv:2307.08753] [Google Scholar]
- Wang, C., Huang, Y., Zhou, Y., & Zhang, H. 2023, A&A, 675, A26 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Williams, J. P., & Cieza, L. A. 2011, ARA&A, 49, 67 [Google Scholar]
- Ying, J. M., Chaboyer, B., Boudreaux, E. M., et al. 2023, AJ, 166, 18 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Subclustering code
The subclustering code was written as a quick way to break apart mainly young, dense clusters in the simulation data that were clumped together by GMM. Thus, it is a simple code, trying to find alternative centers based on the overdensity of stars in 3D space.
-
Find centers: The first center by default is the mean location of all the stars in the cluster. After that, the code goes to each star, and finds how many stars are within 1 pc of it. This list of stars is then sorted by the number of stars: if the number of stars is higher than five, it is a possible center.
-
Refining the highest overdensity center: The code starts from the star with the highest number of neighbors, and recalculates the center coordinates based on those stars, iterating until the shift in coordinates is less than 0.1 pc to the previous center (originally centered on a star). Then the radius is allowed to grow from 1 pc in 0.1 pc increments, and as long as the volume average of the stars is higher than 1.25 stars/pc3, the radius continues to grow. This is to try to catch more of the stars that are on the outer edge of an overdensity. Once the criterion is no longer fulfilled, the center radius is set. Then the center position is iterated again, and then all the stars within the expanded radius are flagged as "used", so that they cannot provide new centers. We note that this radius is not the same as the core radius, R50, used in the traceback code.
-
Refining the other centers: The code goes through the next highest overdensity that remains, as in the previous step, until there are no overdensities with more than four stars within 1 pc.
-
Resulting list of centers: The list of centers and their coordinates is then passed on to the traceback code, where each star’s closest pass to every center position is calculated. The star is assigned to the center that it passes closest to, as explained in the main text.
Because the subclustering code is solely finding overdensities in 3D space, it cannot break apart two diffuse clusters. Obviously, more sophisticated clustering algorithms could be used, and in the case of individual clusters, the observers can be more careful with assigning cluster membership.
Appendix B: Determining ϕeva and σeva from Monte-Carlo runs
As explained in Sect. 5.2, we performed 1000 Monte-Carlo realizations of our simulation data for each error pair of position and velocity, σp and σv, in a six-by-six grid, assuming a Gaussian distribution of errors. Figures B.1 and B.2 show ϕeva and σeva in five bins of neva, 70. It is clear that for smaller neva, 70, the histograms in both cases are broader than for larger neva, 70. Also, while ϕeva peaks roughly at the same position, with the exception of neva, 70 ≥ 20 which tends to be slightly shifted toward 1, there is a clear trend in σeva becoming smaller with larger neva, 70.
 |
Fig. B.1. Histograms of ϕeva, shown in five bins of neva, 70. Only realizations that had at least two clusters in the bin are included. |
 |
Fig. B.2. Histograms of σeva, shown in five bins of neva, 70. Only realizations that had at least two clusters in the bin are included. |
Figure B.3 shows the medians of the previous ϕeva and σeva histograms in 2D maps as functions of σp and σv, for each five neva, 70 bins. The same information is provided in Table B.1. The values of ϕeva and σeva of the observed clusters are interpolated from these ten maps, using the observed σp and σv in linear space, and neva, 70 to select the correct bin (see Table 1).
 |
Fig. B.3. Maps of the medians of ϕeva (left column) and σeva (right column) histograms in the previous figures as functions of σv and σp, for five bins of neva, 70 (rows). |
Values of the medians of ϕeva and σeva for each error pair in the 1000 Monte-Carlo realizations, in five bins of neva, 70. Columns: (1) the lower limit of the neva, 70 bin, (2-3) the total observational error in position and velocity, (4) the scaling factor ϕeva, (5) the statistical uncertainty σeva. Here, we give only a small portion of the table, whose full version is available at the CDS.
All Tables
Values of the medians of ϕeva and σeva for each error pair in the 1000 Monte-Carlo realizations, in five bins of neva, 70. Columns: (1) the lower limit of the neva, 70 bin, (2-3) the total observational error in position and velocity, (4) the scaling factor ϕeva, (5) the statistical uncertainty σeva. Here, we give only a small portion of the table, whose full version is available at the CDS.
All Figures
|
Fig. 1. Histograms (in red) of the ages, masses, radius, and rms velocities and scatter plots of the square root (to use the same scale as the histograms) of the ratio of kinetic and gravitational energies versus the same quantities (blue dots) of the 339 clusters identified in the six simulation snapshots used in this work. The black dashed line marks the value of Ek = Eg, showing that 5% of the clusters (17 of them) are gravitationally bound. |
| In the text | |
|
Fig. 2. Example of the application of the evaporation-age method to a simulated cluster. a) Projected xz positions of the cluster members in the present (t0). Green triangles are initial cluster members rejected because they do not trace back into the cluster core (black circle). Black dots are cluster members in the cluster core in the present. Blue diamonds and red stars are evaporated cluster members. They are currently outside the cluster core but were inside in the past. Vectors show the 2D projected velocities back in time. b) The diagram illustrating the evaporation age determination. The x-axis is the current distance from the cluster center, d, with the gray vertical line showing the current core radius of the cluster, and the y-axis is the evaporation age, teva, for each star. Red stars are evaporated stars with teva higher than the 70th percentile of the teva distribution, and the red line is the median teva for these stars. Blue diamonds are evaporated stars with teva lower than the 70th percentile and are not used for the evaporation age determination. The gray horizontal line is the simulation age of the cluster, tsim. c) Projected XZ positions of evaporated stars at half tsim. d) Positions of evaporated stars at the beginning of the cluster. Only 50% of all the cluster stars had been born by this time. |
| In the text | |
|
Fig. 3. Evaporation age, teva, versus simulation age, tsim, for the clusters in the simulation within three different bins of the number of stars, neva, 70, from which the evaporation age was calculated. The left panel has 86 clusters, the middle one has 45 clusters, and the right one has 15 clusters. The dashdot red line corresponds to ϕeva, 0 tsim, where ϕeva, 0 is the median value of the age ratio teva/tsim (Eq. (1)) in each bin. The scatter, σeva, 0, is the standard deviation of the ratio of the corrected |
| In the text | |
|
Fig. 4. Scatter σeva, 0 as a function of neva, 70. The clusters are binned according to their neva, 70 so that each bin has ten or more clusters, with the exception of the last bin that has 8 clusters. The center of each bin is the mean of neva, 70 of the clusters in that bin. ϕeva and σeva are then derived for each bin using Eqs. (1) and (3). The least-squares fit to the [bin center, σeva] pairs (blue points) is done in log–log space (see the inset panel), weighing by the square root of the number of clusters in each bin, which results in a fit f(x) = 1.5 x−0.8 in linear space (red line). |
| In the text | |
|
Fig. 5. Impact of the observational errors. Top row: fraction of GMM clusters, fGMM, derived from the number of clusters found by GMM in each error pair, divided by the number of GMM clusters in the no errors case (339). Second row: fraction of clusters for which we derived ages, fages, normalized to 339. Red, blue, and black lines are for neva, 70 bins of 5–9, 10–19, and 20+ stars, respectively. Third row: ϕeva. Bottom row: σeva. Columns correspond to different 3D position errors, σp, and the x-axis is the 3D velocity error, σv. |
| In the text | |
|
Fig. 6. Number of stars in each of the ten observed clusters found within the core radius, ncore (blue), found outside of the core radius and tracing back to it, neva (orange), or not tracing back to it, ndiv (green). |
| In the text | |
|
Fig. 7. Histograms (peaks scaled to 1.0) of the evaporation ages of individual evaporated stars (red histograms) and the corresponding cumulative distributions (gray curves), from the 1000 Monte-Carlo error realizations and using stellar orbits computed with MWPotential14. The derived |
| In the text | |
|
Fig. 8. Comparison of the corrected evaporation ages, |
| In the text | |
|
Fig. B.1. Histograms of ϕeva, shown in five bins of neva, 70. Only realizations that had at least two clusters in the bin are included. |
| In the text | |
|
Fig. B.2. Histograms of σeva, shown in five bins of neva, 70. Only realizations that had at least two clusters in the bin are included. |
| In the text | |
|
Fig. B.3. Maps of the medians of ϕeva (left column) and σeva (right column) histograms in the previous figures as functions of σv and σp, for five bins of neva, 70 (rows). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.