| Issue |
A&A
Volume 678, October 2023
|
|
|---|---|---|
| Article Number | A71 | |
| Number of page(s) | 20 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/202346901 | |
| Published online | 06 October 2023 | |
The star formation history of the Sco-Cen association
Coherent star formation patterns in space and time⋆,⋆⋆
1
University of Vienna, Department of Astrophysics, Türkenschanzstraße 17, 1180 Vienna, Austria
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
University of Vienna, Research Network Data Science at Uni Vienna, Kolingasse 14-16, 1090 Vienna, Austria
3
University of Vienna, Faculty of Computer Science, Währinger Straße 29/S6, 1090 Vienna, Austria
4
University of Vienna, ISOR/VCOR, Oskar-Morgenstern-Platz 1, 1090 Vienna, Austria
5
School of Physical and Chemical Sciences – Te Kura Matū, University of Canterbury, Christchurch 9150, New Zealand
6
Center for Computational Astrophysics, Flatiron Institute, 162 5th Avenue, New York, NY 10010, USA
7
Harvard-Smithsonian Center for Astrophysics, 60 Garden Street, MS- 42, Cambridge, MA 02138, USA
8
Department of Astronomy and Astrophysics, University of California, Santa Cruz, CA, USA
9
Institute for Advanced Studies, Tsinghua University, Beijing, PR China
10
Space Telescope Science Institute, 3700 San Martin Drive, Baltimore, MD 21218, USA
Received:
14
May
2023
Accepted:
7
July
2023
Abstract
We reconstructed the star formation history of the Sco-Cen OB association using a novel high-resolution age map of the region. We developed an approach to produce robust ages for Sco-Cen’s recently identified 37 stellar clusters using the SigMA algorithm. The Sco-Cen star formation timeline reveals four periods of enhanced star formation activity, or bursts, remarkably separated by about 5 Myr. Of these, the second burst, which occurred about 15 million years ago, is by far the dominant one, and most of Sco-Cen’s stars and clusters were in place by the end of this burst. The formation of stars and clusters in Sco-Cen is correlated but not linearly, implying that more stars were formed per cluster during the peak of the star formation rate. Most of the clusters that are large enough to have supernova precursors were formed during the second burst around 15 Myr ago. Star and cluster formation activity has been continuously declining since then. We have clear evidence that Sco-Cen formed from the inside out and that it contains 100-pc long chains of contiguous clusters exhibiting well-defined age gradients, from massive older clusters to smaller young clusters. These observables suggest an important role for feedback in forming about half of Sco-Cen stars, although follow-up work is needed to quantify this statement. Finally, we confirm that the Upper-Sco age controversy discussed in the literature during the last decades is solved: the nine clusters previously lumped together as Upper-Sco, a benchmark region for planet formation studies, exhibit a wide range of ages from 3 to 19 Myr.
Key words: Hertzsprung–Russell and C–M diagrams / methods: statistical / astrometry / stars: statistics / stars: evolution / open clusters and associations: individual: Sco-Cen
Interactive versions of Figs. 1, 2, and 4 are available at https://www.aanda.org.
Full Table 1 is available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/678/A71
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Reconstructing the star formation history of a star-forming region is essential for gaining insight into the complex and out-of-equilibrium process of star formation. Insights into the underlying physical mechanisms driving star formation can be obtained from a timeline of when and where different subpopulations form. For instance, understanding whether the star formation rate in a collapsing cloud accelerates until gas consumption, if star formation leaves discernible spatio-temporal patterns, or if it is a chaotic process. Moreover, investigating whether the observed patterns of progression are intrinsic to the process or influenced by an external agent. Additionally, exploring how variations in the star formation rate may directly relate to fundamental properties of the resulting stellar population, such as the formation of gravitationally bound clusters as opposed to loose stellar associations. Star formation history encodes much of the information needed to address these questions. It is crucial for developing accurate star formation models and interpreting observations of star-forming regions across the Universe.
Unfortunately, recognizing distinct populations in a star-forming region is challenging, particularly for loose stellar associations that quickly disperse into the surrounding Galactic field, making them difficult to identify. Moreover, as they are formed from the same molecular cloud complex, the velocities and age differences between different subpopulations are small and, therefore, hard to measure. Despite the growing evidence that subpopulations exist inside the same star formation region (e.g., Alves & Bouy 2012; Jerabkova et al. 2019; Chen et al. 2020; Großschedl et al. 2021; Kerr et al. 2021; Luhman 2022a; Miret-Roig et al. 2022b), there is little evidence so far for large-scale star formation patterns (Wright et al. 2022).
The Scorpius-Centaurus OB association (Sco-Cen; Blaauw 1946, 1964) is the closest OB association to Earth. The full association is a large, roughly 200-pc-wide complex that still includes molecular clouds with ongoing star formation. It is an ideal laboratory for studying various aspects of star, planet, and stellar cluster formation and evolution. It was well established early on that Sco-Cen includes subpopulations with ages from about 1 Myr to about 20 Myr. (e.g., de Geus et al. 1989; de Geus 1992; de Bruijne 1999; Preibisch & Zinnecker 1999; de Zeeuw et al. 1999, 2001; Lépine & Sartori 2003; Preibisch et al. 2008; Makarov 2007a,b; Diehl et al. 2010; Pöppel et al. 2010; Rizzuto et al. 2011; Pecaut et al. 2012; Pecaut & Mamajek 2016; Krause et al. 2018; Forbes et al. 2021). The availability of Gaia data (Gaia Collaboration 2016) has generated a series of Sco-Cen studies that aim to determine the structure of the association with the superb astrometric and photometric data (e.g., Wright & Mamajek 2018; Villa Vélez et al. 2018; Goldman et al. 2018; Damiani et al. 2019; Luhman & Esplin 2020; Grasser et al. 2021; Kerr et al. 2021; Squicciarini et al. 2021; Schmitt et al. 2022; Luhman 2022a; Miret-Roig et al. 2022b; Ratzenböck et al. 2023; Briceño-Morales & Chanamé 2023).
Recently, Ratzenböck et al. (2023) presented results from a novel clustering algorithm called Significance Mode Analysis (SigMA), which interprets density peaks separated by dips as significant clusters. Using a graph-based approach, the technique detects peaks and dips directly in the 5D multidimensional phase space. The method can identify cospatial and comoving clusters with nonconvex shapes and variable densities with a measure of significance. The application of SigMA to Gaia Data Release 3 (DR3) data (Gaia Collaboration 2023) of stars in and around the Sco-Cen association led to the discovery of multiple clusters1, reaching stellar volume densities as low as 0.01 sources pc−3 and tangential velocity differences of about 0.5 km s−1 between different clusters. This level of accuracy is unprecedented and has unveiled 37 stellar clusters inside Sco-Cen. The SigMA algorithm opens new possibilities for a detailed look at the star formation history of Sco-Cen and other nearby star formation complexes.
The goal of this paper is to derive robust ages for the 37 stellar Sco-Cen clusters identified by Ratzenböck et al. (2023; hereafter Paper I) with the SigMA algorithm and reconstruct the star formation history of this important region. Given SigMA’s ability to disentangle young populations in Sco-Cen, adding robust ages to these clusters should enable the construction of a high-resolution age map of the region. The paper is structured as follows. In Sect. 2, we present the data and the quality criteria applied. In Sect. 3 we roughly summarize our methods to determine robust isochronal ages, while we outline the methods in detail in Appendix A. In Sect. 4, we present our results, which we then discuss in Sect. 5. In Sect. 6, we summarize our conclusions.
2. Data
For this study, we determined robust isochronal ages for the 37 SigMA clusters in Sco-Cen, which contain 13 103 candidate Sco-Cen members. A detailed description of the process used to select the cluster sample can be found in Paper I (SigMA algorithm), and an overview of the clusters is presented in Table 1. The clusters are assigned to traditional subregions within Sco-Cen, including the classical Blaauw (1946) definition (see details in Paper I and Table 1). However, we point out that these borders were drawn initially in 2D on the plane of the sky and should not be seen as physically meaningful entities. They should instead be used for orientation and comparisons with previous works.
Isochronal ages for the 37 stellar groups in Sco-Cen as selected with SigMA in Ratzenböck et al. (2023).
To determine the ages of the Sco-Cen clusters, we utilized two different evolutionary model families: PARSEC v1.2S (hereafter PARSEC; Bressan et al. 2012; Chen et al. 2015; Marigo et al. 2017) and Baraffe et al. (2015; hereafter BHAC15). These models are outlined in more detail in Appendix A. We also use two different color-absolute magnitude diagrams (CMDs) based on Gaia photometric systems: (MG vs. GBP − GRP) and (MG vs. G − GRP), which are abbreviated as BPRP and GRP, respectively. The absolute magnitude MG was calculated using the distance modulus using the inverse of the parallax as distance, which is reasonable for sources with Sco-Cen distances and low uncertainties, as discussed in Paper I.
We applied a set of photometric quality criteria to the Gaia DR3 photometry to achieve more reliable isochronal age fitting. The influence of photometric uncertainties is highlighted in Fig. C.1. We use the corrected flux excess factor C* as described in Riello et al. (2021). As noted in Evans et al. (2018), large values of the flux excess factor are the result of issues in the GBP or GRP photometry. Additionally, we cut photometric flux errors Gerr, GBP, err, and GRP, err, as well as RUWE, which (preferentially) removes unresolved binaries in the sample (Lindegren et al. 2018, 2021). The parameters used are summarized in Eq. (1) and the quality criteria in Eq. (2).
 (1)
(1)
Our sample is restricted to sources that satisfy the following photometric quality criteria:
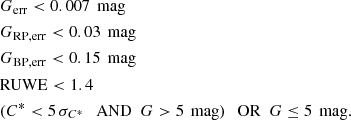 (2)
(2)
We use these criteria for the BPRP CMD, while we exclude the GBP, err condition when using the GRP CMD. We visually confirm that these quality criteria reduce the scatter around isochrones significantly, especially in the low-mass regime (see Fig. C.1). We further constrain the absolute magnitude range of the sample, using different cuts for the two model families.
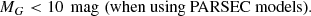 (3)
(3)
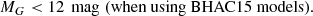 (4)
(4)
These cuts are motivated by our observation of areas in the CMD with varying degrees of overlap between data and model isochrones (see Figs. C.2–C.5). Furthermore, the PARSEC and BHAC15 isochrones start to disagree with each other toward the faint end, while the BHAC15 models tend to agree better with the data fainter than MG ≳ 10 mag compared to PARSEC models. Therefore, we cut at MG < 10 mag to reduce systematic age shifts determined with PARSEC. This choice is also supported by the mass coverage of the PARSEC isochrones, which are cut off at 0.09 M⊙, while BHAC15 includes low-mass objects down to 0.01 M⊙. The magnitude limit for the BHAC15 models is motivated by the larger uncertainties of the observations in the faint regime, which increases the scatter in the CMD below 12 mag (see Fig. C.1).
Applying the photometric quality criteria from Eq. (2) to the Sco-Cen sample of 13 103 stars, there are 9249 sources (71%) remaining in the BPRP CMD, and 9593 (73%) in the GRP CMD (see Fig. C.1). When applying the additional magnitude limits in Eq. (3), there are 5257 (∼40%) sources left in both CMDs for PARSEC-BPRP and PARSEC-GRP. For BHAC15-BPRP and BHAC15-GRP there are 8514 and 8521 sources left, respectively (∼65% each), after applying the magnitude cut from Eq. (4). The BHAC15 isochrones do not cover the upper main-sequence, since the models stop at around MG ∼ 4 mag (at 1.4 M⊙). However, this is not an issue for the age fitting method, since the method uses only sources until the maximum brightness of each fit isochrone. This also reduces the number of sources used for fitting to BHAC15 isochrones, depending on the maximum MG.
3. Method
Determining an accurate age for each cluster is critical for our goal of distinguishing small age differences between clusters and creating a high-resolution Sco-Cen age map. Our isochrone fitting procedure is summarized here, with a comprehensive description in Appendix A.
Rather than simply minimizing the sum of squares between data points and isochronal curves, we aim to account for observational trends such as unresolved binaries and extinction. We assume a simple model in which data are generated along isochrones with noise contributions drawn independently from skewed Cauchy distributions with zero means to model nonsymmetric noise sources. The influence of reddening and unresolved binaries on the displacement of sources in the CMD is different for each cluster. Instead of fixing the skewness and scale parameters of the skewed Cauchy distribution, we let them be free parameters of the model, which are obtained during Bayesian inference alongside astrophysical parameters such as cluster age and dust extinction. This age fitting technique is explained in detail in Appendix A.
4. Results
We present robust isochronal ages for the 37 SigMA clusters in Sco-Cen as selected in Paper I. We provide four different age estimates for the clusters, determined with PARSEC-BPRP, PARSEC-GRP, BHAC15-BPRP, and BHAC15-GRP, as outlined in Sect. 2 and Appendix A. The ages determined in this fashion are listed in Table 1. In Appendix B, we compare our ages in more detail to the cluster sample by Kerr et al. (2021), who found a similar substructure in Sco-Cen, while with lower numbers statistics. The clusters in Kerr et al. (2021) appear to be systematically older compared to our age estimates, while we do not (yet) have a clear explanation for this behavior.
In Appendix C, we provide the CMDs showing the best-fitting isochrone models for each cluster and the four different age-fitting results. Unless otherwise noted, we adopt the PARSEC-BPRP ages in our analysis. These isochrones seem robust within the errors compared to the PARSEC-GRP and BHAC15-GRP ages. Furthermore, the combination of PARSEC-BPRP is often used in the literature, which facilitates comparison to previous work (e.g., Bossini et al. 2019; Dias et al. 2019; Cantat-Gaudin et al. 2020; Kerr et al. 2021).
We exclude three clusters from the original SigMA sample of 37 clusters, namely Norma-North (Norma-N), Oph-Southeast (Oph-SE), and Oph-NorthFar (Oph-NF), leaving 34 clusters for further discussion in Sect. 5.1. Norma-N is excluded, as it is substantially older (∼40 Myr) than the nominal upper age limit of Sco-Cen, which is about 20 Myr. Moreover, Norma-N, Oph-SE, and Oph-NF appear to be kinematically unrelated as suggested by the trace-backs of the cluster orbits, which is discussed in more detail in a follow-up paper (Großschedl et al., in prep.).
Figure 1 presents the spatial distribution of the surfaces enveloping the 34 clusters, color-coded by cluster ages. This figure can be investigated as an interactive 3D plot2, which best illustrates the spatial arrangement of Sco-Cen’s clusters. It provides important insight into how the complex was assembled. At first glance, it is easy to see that the center of the association contains the oldest clusters, while the youngest clusters, appearing in blue, tend to be at the outskirts of the association. The existence of patterns of age gradients across contiguously located clusters is also evident.
 |
Fig. 1. 3D distribution of 34 clusters in the Sco-Cen association found by SigMA. The Sun is at (0,0,0) and the Z = 0 plane is parallel to the Galactic plane. The surfaces of the cluster volumes are shown, color-coded by age, from dark blue (2 Myr) to dark red (21 Myr). For more details, see the interactive 3D version online or at https://homepage.univie.ac.at/sebastian.ratzenboeck/wp-content/uploads/2023/05/scocen_age.html. |
Figure 2 highlights the age gradients, which are particularly clear toward two quasi-vertical, approximately 100 pc long chains of clusters. These contiguous cluster chains connect the older clusters at the (older) center of the association with the younger clusters at the (younger) outskirts. The first one comprises the traditional Blaauw’s LCC (from here on, LCC chain), while the second connects CrA to the center of the association (from here on, CrA chain). They are remarkable structures for being a contiguous series of clusters following a coherent age gradient. The LCC chain clusters comprise, from old to young and north to south: σ Cen, Acrux, Musca-foreground, ϵ Cham, and η Cham. The member clusters toward the CrA chain are less clear and are tentatively arranged as follows, from old to young: ϕ Lup, η Lup, (V1062 Sco, μ Sco)3, Sco-Body, Sco-Sting, CrA-North, and CrA-Main.
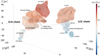 |
Fig. 2. Star formation progression along approximately 100 pc long chains of clusters. We find age gradients along these cluster chains. In Sco-Cen, we find two cluster chains: one comprising clusters in the traditional LCC region (LCC chain) and a second chain connecting down to CrA (CrA chain). For more details, see the interactive 3D version online or at https://homepage.univie.ac.at/sebastian.ratzenboeck/wp-content/uploads/2023/06/scocen_ages-3D_chains_online.html. |
Toward the Galactic northeast, the main body of Sco-Cen is connected to USco in a similar manner to the cluster chains (see Fig. 4), forming a third chain of clusters, albeit more complex. Recent attempts to reconstruct the star formation history of the USco region also reveal a more complex substructure compared to the LCC or CrA chains (e.g, Squicciarini et al. 2021; Miret-Roig et al. 2022b; Briceño-Morales & Chanamé 2023). This could possibly be explained by a different original gas distribution and by the number and distribution of massive stars located within USco itself or the older clusters in Sco-Cen (e.g., Diehl et al. 2010; Robitaille et al. 2018; Krause et al. 2018; Neuhäuser et al. 2020; Forbes et al. 2021). The origin of USco warrants a dedicated analysis beyond the scope of this paper, but it seems clear from Fig. 4 that USco is the third chain of clusters. These three chains started to form about 10 Myr ago, and are likely induced or enhanced by the feedback generated by the massive clusters formed about 15 Myr ago.
Figure 3 presents the age distribution within the Sco-Cen complex. In the upper panel, we show the distribution of cluster ages using the selected 34 SigMA clusters. In the lower panel, we display the age distribution for the stellar members by assigning each star the age of the parent cluster. We employ a kernel density estimate (KDE) technique to examine the age distribution of clusters and stars, focusing on uncovering the modality structure of the probability density function (PDF). To account for age uncertainty, we implemented an adaptive KDE in which the kernels’ size reflects the determined age variance of the samples (see age uncertainties in Table 1). We have standardized the area under the curves to represent the number of clusters and stars for the respective PDFs.
 |
Fig. 3. Star formation history of Sco-Cen. Top: age distribution of the 34 clusters in Sco-Cen traces four main star formation events in the history of the association. Bottom: stellar age distribution in Sco-Cen shows a similar pattern. To study the age distribution of clusters and stars, we used a kernel density estimate with an adaptive bandwidth corresponding to the age uncertainty of each sample. The formation of stars and clusters is correlated, but not linearly, meaning that, when compared to the average in the association, more stars were formed per cluster during the peak of star formation rate, about 15 Myr ago. |
The distribution of cluster ages in Fig. 3 exhibits a significant multimodality. When applying the calibrated dip test (Hartigan & Hartigan 1985; Cheng & Hall 1998) to the cluster ages, we find a strong indication (p < 0.05) for multiple modes in the data. To locate the modes, we apply the excess of mass test (Müller & Sawitzki 1991; Cheng & Hall 1998), which finds two modes in the following age ranges: (8.5, 10.2), (14.4, 15.9) Myr (see Fig. 3, upper panel). Together they make up the two main modes of star formation in the evolution of Sco-Cen, in which over 60% of stars have been formed. The adaptive KDE in Fig. 3 reveals a small third and fourth peak at around 4 Myr and 21 Myr, respectively. The four peaks in star formation rate are summarized in Table 2.
5. Discussion
We first examine the spatial-temporal patterns in Sco-Cen revealed by isochrone fitting for the individual clusters (Sect. 5.1) and consider potential explanations for the observed age patterns (Sect. 5.2). In Sect. 5.3, we provide a solution to the Upper-Sco age controversy that has perplexed the literature for decades, clarified by Gaia data.
5.1. Spatial-temporal patterns in Sco-Cen
The spatial-temporal arrangement of the clusters in Fig. 1 indicates that star formation in Sco-Cen did not proceed chaotically. Figure 4 shows groups of clusters associated with the star formation rate peaks from Fig. 3 and Table 2. This figure shows a clear relationship between age and position of Sco-Cen clusters, with the older clusters (age > 15 Myr) toward the association’s center and the younger cluster toward the outskirts of the association. This spatial arrangement implies an inside-out star formation scenario for Sco-Cen and evokes a feedback-driven scenario reminiscent of the canonical triggering scenario in Elmegreen & Lada (1977).
 |
Fig. 4. Star formation progression in Sco-Cen, shown with the same orientation in XYZ and color-scaling as in Fig. 1. By separating the clusters in age bins, following the peaks in Fig. 3 and Table 2, one can appreciate a consistent inside-out progression of star formation from older to younger clusters. For more details, see the interactive 3D version online or at https://homepage.univie.ac.at/sebastian.ratzenboeck/wp-content/uploads/2023/05/scocen_age.html. |
Although we could speculate that the oldest clusters in the association’s center (e Lup and ϕ Lup) provided the supernovae (SNe) for the initial trigger, the masses of these clusters suggest that they might have produced only a few SNe, assuming a normal initial mass function (IMF). A dedicated model, like the forward modeling done for the Ophiuchus region by Forbes et al. (2021), is warranted to test this suggestion. Perhaps more impressive is the likely number of SNe provided by the 15 Myr star formation burst, which could be in the tens of SNe when integrating over the massive clusters formed during this high star formation rate period. These SNe, together with stellar winds, ionizing radiation, and mass loss events, would have injected substantial energy and momentum into the primeval gas in the Sco-Cen region, likely pushing part of it to collapse.
Figure 5 displays the ages as a function of the number of stars per cluster, color-coded by age and scaled by the number of stars per cluster. This visualization facilitates linking individual clusters to peaks in the star formation history of the region. Similarly to Fig. 3, we can see that a peak at around 15 Myr ago contributed the largest numbers of stars and the most massive clusters to the association. Since then, star formation has been declining, although periods of increased star formation rate seem to appear about every ∼5 Myr (Fig. 3). Small clusters have formed throughout the entire history of Sco-Cen.
 |
Fig. 5. Timeline of the formation of clusters in Sco-Cen, color-coded by age (same as in Fig. 1) and scaled by cluster size. The horizontal lines represent age uncertainties. While Sco-Cen has been forming small clusters (≤250 stars) continuously since its formation 20–25 Myr ago, its large clusters (≳1000 stars) were all formed during the peak of the star formation rate, around 15 Myr ago. Regarding their absolute numbers, most of the stars and clusters we can observe today in the Sco-Cen region were formed around 15 Myr ago. Since then, star formation has been declining. The peaks of star and cluster formation rate seem to be periodically distributed (every ∼5 Myr, see also Fig. 3). |
By using the distribution and ages of the SigMA clusters, star formation in Sco-Cen can be described as follows: The first Sco-Cen stars were formed about 20–25 Myr ago in the primordial Sco-Cen giant molecular cloud. At around 15 Myr ago, there was a burst of star and cluster formation where most stars in the association formed. This burst aligns with a scenario presented in Zucker et al. (2022), which suggests that the Local Bubble was triggered by massive stellar feedback originating from Sco-Cen. Zucker et al. (2022) suggest that the first SNe that powered the Local Bubble happened about 14 Myr ago, which is roughly compatible with feedback from the oldest stellar populations in Sco-Cen. Considering that the most massive stars require a few million years to explode as SNe, the likely first Sco-Cen SNe originated in the oldest clusters presented in this work, particularly e Lup and ϕ Lup. The feedback of possible SNe at that time may have triggered the Sco-Cen 15 Myr burst, which created the most massive clusters in the association. Subsequently, SNe originating from the 15 Myr clusters likely continue feeding the Local Bubble’s expansion, with the last SNe taking place about 2 Myr ago (Fuchs et al. 2006; Breitschwerdt et al. 2016; Feige et al. 2017; Krause et al. 2018; Neuhäuser et al. 2020).
While we propose that feedback played a crucial role in the formation of Sco-Cen, it is hard to quantify how crucial it was. At this point, we have no evidence that the formation of the first stars in Sco-Cen was induced by feedback or any external factor to a collapsing molecular cloud. The same can be argued for the origin of the 15 Myr burst. While tempting to invoke e Lup or ϕ Lup as the potential progenitors of this burst, this is tentative and modeling is required to make a stronger statement. Still, what is clear now is that star formation since the peak of star formation rate about 15 Myr ago formed coherent patterns that are best explained as the direct product of feedback. Clusters younger than 10 Myr are arranged in quasi-linear radial structures with coherent age gradients from old in the center to younger in the outskirts of the association. The observed “chains of clusters” (the LCC, CrA, and the USco chain) are clear examples.
5.2. The “Octopus” model
In their study, Krause et al. (2018) proposed a “Surround and Squash” scenario for the formation history of Sco-Cen, suggesting that the region formed from a long connected cloud, shaped as an elongated sheet. They argued that superbubbles continuously broke out of this sheet to surround and squash the denser parts of the cloud (while small cloud fractions initially survive in-between), inducing further star formation and creating several shells and superbubbles. The authors also confirmed the existence of a large super-shell around the entire OB association and a nested filamentary super-shell. Krause et al. (2018) suggested that the first SNe occurred at the center of the primordial Sco-Cen cloud, which agrees with our results. They proposed that possible SNe originating from the oldest clusters compressed the surrounding gas, which could have caused the 15 Myr burst.
The Surround and Squash model was designed to explain the age ranking of the subgroups, with UCL being the oldest and USco the youngest. The main assumption of this model is that the Sco-Cen population is described by the three main Blaauw subgroups, which we now know is an oversimplified description of the association. Our results instead point to an Octopus model, where most stars and clusters are formed at the head of the octopus, and several arms extend radially outward, containing the younger stars and clusters in the association. There is no obvious need for a Surround and Squash scenario to explain the observations. Although we do not have sufficient evidence to state the likely role of feedback in the formation of the head, the formation of the arms is very likely a product of the feedback from the massive stellar population in the head.
In conclusion, the star formation patterns described in this work (combined with earlier evidence for massive stellar feedback) suggest an important role for feedback-driven star formation in a manner similar to the classical sequential star formation scenario of Elmegreen & Lada (1977). The observed octopus-like inside-out formation of Sco-Cen provides a simpler explanation compared to the Surround and Squash model, while both are feedback driven. Our results for the Sco-Cen OB association suggest a generally significant role for feedback in the formation and evolution of OB associations. Similar evidence can be found in the Orion OB1 association, where also an important role for massive stellar feedback has been found (e.g., Brown et al. 1994, 1995; Ochsendorf et al. 2015; Großschedl et al. 2021; Swiggum et al. 2021; Foley et al. 2023), as well as in Vela (e.g., Cantat-Gaudin et al. 2019; Armstrong et al. 2022), Cygnus (e.g., Quintana & Wright 2021, 2022), or Cepheus (e.g., Kun et al. 1987; Szilágyi et al. 2023).
5.3. Upper-Sco age controversy
There has been a long discussion in the literature about the age of the Upper-Sco Association (USco). Due to its young age, richness, and proximity to Earth, USco is a unique laboratory for early stellar evolution and planet formation studies. Therefore, getting the correct age for USco (or, better said, the ensemble of different coeval clusters that were previously taken as the single population USco) is critical for multiple research fields across astronomical scales.
Traditionally, the stellar populations toward USco were often substructured into two parts, ρ Oph (partially embedded young stellar objects in the Ophiuchus cloud), and USco. The age determinations for USco in the literature from the last decades (pre-Gaia) fall broadly around two estimates: 5 Myr and 10–12 Myr. de Geus et al. (1989) used the massive stars in USco to determine an age of about 5 Myr, an estimate confirmed in Preibisch et al. (2002), using the full stellar mass spectrum of USco. Pecaut et al. (2012) on the other hand determined an age of about 10–12 Myr using intermediate to high-mass stars. Sullivan & Kraus (2021) find an age gradient in USco, suggesting that the observed mass-dependent age gradient can be explained by a population of undetected binary stars. They argue their result supports the previously suggested 10 Myr age for USco, with a small intrinsic age spread.
Since the release of Gaia data, several updated cluster catalogs have been published for the USco association, including cluster samples by Squicciarini et al. (2021), Kerr et al. (2021), Miret-Roig et al. (2022b), Briceño-Morales & Chanamé (2023), and the SigMA sample from Paper I. The new view of USco reveals multiple clusters projected on the same region of the sky and the previous ages of 5 or 10 Myr for USco are now superseded. The ages for the overlapping clusters along the same line-of-sight range from 3 to 19 Myr (see Table 1).
Fang et al. (2017; hereafter F17) discuss a sample of stars in the USco region compiled from several sources in the literature (Preibisch & Zinnecker 1999; Ardila et al. 2000; Slesnick et al. 2006; Preibisch et al. 2002; Luhman & Mamajek 2012; Rizzuto et al. 2015; Pecaut & Mamajek 2016). The sample includes known stellar parameters, such as spectral types, temperatures, and stellar luminosities, allowing for age analysis in the Hertzsprung–Russell diagram (HRD). However, for their discussion, F17 assume that the stars belong to a single population. Treating this sample as a single population generates a large spread in the HRD (see their Fig. 5 and our CMD in Fig. 6), making it impossible to reliably determine the age. For example, isochrones from about 3–15 Myr all provide good fits to the data, depending on the spectral type.
 |
Fig. 6. Gaia BPRP CMD displaying members of the 12 stellar clusters that have matches with USco members from F17. The blue dots are all sources in the 12 SigMA clusters that pass additional photometric quality criteria (see text). The red dots indicate sources that are both in SigMA and F17. Two PARSEC isochrones are shown for 5 Myr (solid) and 10 Myr (dashed), marking the earlier assumed nominal ages of USco. The arrow shows an extinction vector with a length of AG = 1 mag. See Fig. C.6 for an overview of the separate CMDs of the individual 12 clusters. |
The fact that the SigMA clusters4 and the mentioned other recent clustering studies using Gaia data show narrow CMD sequences (hence, better-constrained ages) highlights the high value of the high precision astrometry of the Gaia satellite. We can now revisit the F17 sample cross-matching it with the SigMA clusters5 to investigate the USco age controversy. We find that there are about 500 cross-matches of F17 with SigMA, which are contained in 12 of the SigMA clusters with different ages. Stars from all 12 clusters are projected toward the traditional USco region, while nine out of the 12 clusters have been assigned to the USco clusters and the remaining three clusters have been assigned to the UCL clusters (see Table 1).
Figure 6 shows all stellar members of the 12 clusters in the Gaia BRPR CMD and Fig. C.6 displays the individual clusters separately. In these figures, the blue symbols represent all stellar members from the 12 clusters as selected in Paper I, with additional photometric quality criteria from Eq. (2), but excluding the RUWE cut. The red dots represent the sources that are in both samples, Paper I and F17. The isochrones in Figs. 6 and C.6 are PARSEC isochrones for the Gaia DR3 passbands with solar metallicity and no extinction. It becomes now clear that previous USco age estimates have been using a mix of different populations at different evolutionary stages and different locations along the line-of-sight. Such a mixture will naturally broaden the HRD or CMD sequence, as is apparent in Fig. 6.
A possible mixture of populations was already pointed out by F17, while the available data at that time did not allow a clear separation of the stellar clusters, as was achieved with Gaia data. Evidently, separating the F17 sample into coeval clusters, as done by SigMA and other recent studies, solves the age controversy.
6. Conclusions
In this paper, we reconstruct the star formation history of the closest OB association to Earth, Sco-Cen, by deriving robust isochronal ages for 37 clusters selected with the SigMA algorithm on Gaia DR3 data (Ratzenböck et al. 2023). The ages of the 37 coeval stellar clusters, some previously unrecognized, reveal the complex star formation history of Sco-Cen and are compared with previous work. The main results of this work can be summarized as follows:
-
Sco-Cen’s star formation history is dominated by a brief period of intense star and cluster formation rate about 15 Myr ago. This is consistent with previous works. Most of Sco-Cen stars and clusters were in place after this intense formation period. The production of stars and clusters has been slowly declining since this burst.
-
We identified four discernible stages during the formation of Sco-Cen associated with elevated star formation activity. They are, approximately, the 20 Myr, 15 Myr, 10 Myr, and 5 Myr bursts. Remarkably, these elevated star formation activity periods seem periodic, separated by spans of about 5 Myr.
-
The formation of stars and clusters is correlated throughout the entire star formation history of Sco-Cen. Still, after the initial burst 20 Myr ago, the star formation rate more than doubles during the main 15 Myr burst. This implies that the formation of the large majority of clusters with supernova precursors (clusters containing more than about 500 stars) took place during the peak of the star- and cluster-formation rate.
-
Sco-Cen was formed inside out, meaning that there is a correlation between the age of a cluster and its distance to the oldest cluster in the association. Older clusters from the 20 Myr and 15 Myr bursts are located in the center of the association, while younger clusters are located toward the outskirts of the association.
-
We find well-defined patterns of star formation progression in space and time. In particular, two 100-pc long chains (LCC and CrA chains) of contiguously located clusters exhibit a well-defined age gradient, from massive older clusters to smaller younger ones. The simplest explanation for these long chains of correlated clusters is feedback acting on a diminishing gas reservoir. These patterns are reminiscent of the classic Elmegreen & Lada (1977) scenario, suggesting an important role for feedback on the formation of the Sco-Cen population. Morphologically, the formation appears to have been “Octopus-like”, with most older stars in the head and younger stars in the radial arms, the quasi-linear chains of clusters.
-
We confirm the post-Gaia view from recent studies that USco is not a single cluster, which solves the Upper-Sco age controversy. What was taken in the literature of the last decades as the USco stellar population consists instead of up to nine clusters with ages between 3 and 19 Myr, naturally explaining the wide age spread and conflicting results in earlier studies. This realization applies to all Blaauw’s subgroups (USco, UCL, and LCC). It directly impacts planet formation studies in Sco-Cen, a benchmark laboratory for planet formation, calling for a revision of disk ages.
Gaia studies of Sco-Cen are revealing a new set of captivating stellar substructures. The classical Blaauw subgroups (USco, UCL, and LCC), originally defined on the plane of the sky in 2D, do not capture the richness of structure and the many stellar populations in Sco-Cen. Separation into three main regions is obsolete and does not encapsulate the more complex, but more revealing star-formation history of this association. Tracebacks of the different Sco-Cen clusters will test the main conclusions of this work, and they will be able to test and characterize the existence of well-defined chains of clusters in OB associations.
Interactive Figures
Two interactive images associated with Figs. 1, 2, and 4 (scocen_age and scocen_ages-3D_chains_online) Access Supplementary Material
Henceforth, we use the word “cluster” in the statistical sense, namely, an enhancement over a background, as extracted with SigMA. This avoids creating a new word for the spatially and kinematically coherent structures in Sco-Cen. None of the Sco-Cen clusters are expected to be gravitationally bound.
See the interactive 3D version online or at https://homepage.univie.ac.at/sebastian.ratzenboeck/wp-content/uploads/2023/05/scocen_age.html.
V1062 Sco and μ Sco are located slightly off from the chain, toward the back of Sco-Cen. Future work is needed to understand the true connections between clusters.
The SigMA algorithm does not use any age or color information, only the phase-space density.
Using the clustered substructure from Squicciarini et al. (2021), Kerr et al. (2021), Miret-Roig et al. (2022b) or Briceño-Morales & Chanamé (2023) would deliver similar results.
Stellar evolution models are also parameterized by the initial mass of a star. We consider an isochrone model the curve resulting from varying the mass between 0.1 ≤ M/M⊙ < 50.
Isochronal models are available on a grid in age and metallicity (Δτ = 0.2, see Table A.1 for units), which we interpolate linearly between equal-mass grid points. For a given age-metallicity tuple, we move the isochrone in the CMD based on a given dust extinction value ϵ, assuming a constant extinction law for each Gaia filter.
To a first approximation, the scale parameter s handles differential reddening effects. This allows us to work with a single extinction value, although more complex reddening effects might exist. In practice, the inference finds approximately the minimum extinction value throughout the cluster, while the scale parameter s takes higher differential reddening into account (to some degree).
We determined the bandwidth by employing Scott’s rule (Scott 1979).
KRK21 analyzed the data at three different levels of detail. The coarsest level was obtained by selecting a large threshold below which clusters cannot fragment resulting in the TLC groups. In a second step, this threshold was drastically reduced allowing for more substructures to appear. In this second run, KRK21 used HDBSCANS’s excess of mass method (EOM) to merge smaller clusters producing the “EOM” result and also recorded clusters with the “leaf” method which represents the maximally fragmented clustering solution.
They use the selected clusters as “signposts” (training sets) to select additional potential cluster members with HDBSCAN, with similar spatial and kinematic properties, to reintroduce potentially older members, older than their original age selection of < 50 Myr.
Acknowledgments
S. Ratzenböck acknowledges funding by the Federal Ministry Republic of Austria for Climate Action, Environment, Energy, Mobility, Innovation and Technology (BMK, https://www.bmk.gv.at/) and the Austrian Research Promotion Agency (FFG, https://www.ffg.at/) under project number FO999892674. J. Großschedl acknowledges funding by the Austrian Research Promotion Agency (FFG) under project number 873708. Co-funded by the European Union (ERC, ISM-FLOW, 101055318). Views and opinions expressed are, however, those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council. Neither the European Union nor the granting authority can be held responsible for them. This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular, the institutions participating in the Gaia Multilateral Agreement. This research has used Python, https://www.python.org; Astropy, a community-developed core Python package for Astronomy (Astropy Collaboration 2013, 2018); NumPy (van der Walt et al. 2011); Matplotlib (Hunter 2007); and Plotly (Plotly Technologies Inc. 2015). This research has made use of the SIMBAD database operated at CDS, Strasbourg, France (Wenger et al. 2000); of the VizieR catalog access tool, CDS, Strasbourg, France (Ochsenbein et al. 2000); and of “Aladin sky atlas” developed at CDS, Strasbourg Observatory, France (Bonnarel et al. 2000; Boch & Fernique 2014). This research has made use of TOPCAT, an interactive graphical viewer and editor for tabular data (Taylor 2005).
References
- Alves, J., & Bouy, H. 2012, A&A, 547, A97 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ardila, D., Martín, E., & Basri, G. 2000, AJ, 120, 479 [NASA ADS] [CrossRef] [Google Scholar]
- Armstrong, J. J., Wright, N. J., Jeffries, R. D., Jackson, R. J., & Cantat-Gaudin, T. 2022, MNRAS, 517, 5704 [NASA ADS] [CrossRef] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Baraffe, I., Homeier, D., Allard, F., & Chabrier, G. 2015, A&A, 577, A42 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Beaton, A. E., & Tukey, J. W. 1974, Technometrics, 16, 147 [CrossRef] [Google Scholar]
- Blaauw, A. 1946, Publ. Kapteyn Astron. Lab. Groningen, 52, 1 [NASA ADS] [Google Scholar]
- Blaauw, A. 1964, ARA&A, 2, 213 [Google Scholar]
- Boch, T., & Fernique, P. 2014, ASP Conf. Ser., 485, 277 [Google Scholar]
- Bonnarel, F., Fernique, P., Bienaymé, O., et al. 2000, A&AS, 143, 33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bossini, D., Vallenari, A., Bragaglia, A., et al. 2019, A&A, 623, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Breitschwerdt, D., Feige, J., Schulreich, M. M., et al. 2016, Nature, 532, 73 [NASA ADS] [CrossRef] [Google Scholar]
- Bressan, A., Marigo, P., Girardi, L., et al. 2012, MNRAS, 427, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Briceño-Morales, G., & Chanamé, J. 2023, MNRAS, 522, 1288 [CrossRef] [Google Scholar]
- Brown, A. G. A., de Geus, E. J., & de Zeeuw, P. T. 1994, A&A, 289, 101 [NASA ADS] [Google Scholar]
- Brown, A. G. A., Hartmann, D., & Burton, W. B. 1995, A&A, 300, 903 [NASA ADS] [Google Scholar]
- Cantat-Gaudin, T., & Anders, F. 2020, A&A, 633, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cantat-Gaudin, T., Mapelli, M., Balaguer-Núñez, L., et al. 2019, A&A, 621, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cantat-Gaudin, T., Anders, F., Castro-Ginard, A., et al. 2020, A&A, 640, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chen, B., D’Onghia, E., Alves, J., & Adamo, A. 2020, A&A, 643, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chen, Y., Bressan, A., Girardi, L., et al. 2015, MNRAS, 452, 1068 [Google Scholar]
- Cheng, M.-Y., & Hall, P. 1998, J. R. Stat. Soc. Ser. B, 60, 579 [CrossRef] [Google Scholar]
- Damiani, F., Prisinzano, L., Pillitteri, I., Micela, G., & Sciortino, S. 2019, A&A, 623, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Avillez, M. A., & Mac Low, M.-M. 2002, ApJ, 581, 1047 [NASA ADS] [CrossRef] [Google Scholar]
- de Bruijne, J. H. J. 1999, MNRAS, 310, 585 [NASA ADS] [CrossRef] [Google Scholar]
- de Geus, E. J. 1992, A&A, 262, 258 [NASA ADS] [Google Scholar]
- de Geus, E. J., de Zeeuw, P. T., & Lub, J. 1989, A&A, 216, 44 [NASA ADS] [Google Scholar]
- de Zeeuw, P. T., Hoogerwerf, R., de Bruijne, J. H. J., Brown, A. G. A., & Blaauw, A. 1999, AJ, 117, 354 [Google Scholar]
- de Zeeuw, P. T., Hoogerwerf, R., de Bruijne, J., Brown, A., & Blaauw, A. 2001, in Encyclopedia of Astronomy and Astrophysics, ed. P. Murdin (IOP Publishing Ltd), 1915 [Google Scholar]
- Dias, W. S., Monteiro, H., Lépine, J. R. D., & Barros, D. A. 2019, MNRAS, 486, 5726 [NASA ADS] [CrossRef] [Google Scholar]
- Diehl, R., Lang, M. G., Martin, P., et al. 2010, A&A, 522, A51 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Elmegreen, B. G., & Lada, C. J. 1977, ApJ, 214, 725 [Google Scholar]
- Evans, D. W., Riello, M., De Angeli, F., et al. 2018, A&A, 616, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fang, Q., Herczeg, G. J., & Rizzuto, A. 2017, ApJ, 842, 123 [Google Scholar]
- Feige, J., Breitschwerdt, D., Wallner, A., et al. 2017, in 14th International Symposium on Nuclei in the Cosmos (NIC2016), eds. S. Kubono, T. Kajino, S. Nishimura, et al., 010304 [Google Scholar]
- Fischler, M. A., & Bolles, R. C. 1981, Commu. ACM, 24, 381 [CrossRef] [Google Scholar]
- Foley, M. M., Goodman, A., Zucker, C., et al. 2023, ApJ, 947, 66 [NASA ADS] [CrossRef] [Google Scholar]
- Forbes, J. C., Alves, J., & Lin, D. N. C. 2021, Nat. Astron., 5, 1009 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Fuchs, B., Breitschwerdt, D., de Avillez, M. A., Dettbarn, C., & Flynn, C. 2006, MNRAS, 373, 993 [NASA ADS] [CrossRef] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2016, A&A, 595, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goldman, B., Röser, S., Schilbach, E., Moór, A. C., & Henning, T. 2018, ApJ, 868, 32 [Google Scholar]
- Grasser, N., Ratzenböck, S., Alves, J., et al. 2021, A&A, 652, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Großschedl, J. E., Alves, J., Meingast, S., & Herbst-Kiss, G. 2021, A&A, 647, A91 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hampel, F., Ronchetti, E., Rousseeuw, P., & Stahel, W. 2011, Wiley Series in Probability and Statistics (John Wiley& Sons, Inc.), 503 [Google Scholar]
- Hartigan, J. A., & Hartigan, P. M. 1985, Ann. Stat., 13, 70 [Google Scholar]
- Huber, P. J. 1964, Ann. Math. Stat., 35, 73 [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Jerabkova, T., Boffin, H. M. J., Beccari, G., & Anderson, R. I. 2019, MNRAS, 489, 4418 [Google Scholar]
- Kerr, R. M. P., Rizzuto, A. C., Kraus, A. L., & Offner, S. S. R. 2021, ApJ, 917, 23 [NASA ADS] [CrossRef] [Google Scholar]
- Kerr, R. M. P., Kraus, A. L., Murphy, S. J., et al. 2022, ApJ, 941, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Krause, M. G. H., Burkert, A., Diehl, R., et al. 2018, A&A, 619, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kun, M., Balazs, L. G., & Toth, I. 1987, Ap&SS, 134, 211 [NASA ADS] [CrossRef] [Google Scholar]
- Lépine, J. R. D., & Sartori, M. J. 2003, Astrophys. Space Sci. Lib., 299, 63 [Google Scholar]
- Lindegren, L., Hernández, J., Bombrun, A., et al. 2018, A&A, 616, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lindegren, L., Klioner, S. A., Hernández, J., et al. 2021, A&A, 649, A2 [EDP Sciences] [Google Scholar]
- Luhman, K. L. 2022a, AJ, 163, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Luhman, K. L., & Esplin, T. L. 2020, AJ, 160, 44 [Google Scholar]
- Luhman, K. L., & Mamajek, E. E. 2012, ApJ, 758, 31 [Google Scholar]
- Makarov, V. V. 2007a, ApJS, 169, 105 [NASA ADS] [CrossRef] [Google Scholar]
- Makarov, V. V. 2007b, ApJ, 670, 1225 [NASA ADS] [CrossRef] [Google Scholar]
- Marigo, P., Girardi, L., Bressan, A., et al. 2017, ApJ, 835, 77 [Google Scholar]
- Miret-Roig, N., Galli, P. A. B., Olivares, J., et al. 2022b, A&A, 667, A163 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Müller, D. W., & Sawitzki, G. 1991, J. Am. Stat. Assoc., 86, 738 [Google Scholar]
- Neuhäuser, R., Gießler, F., & Hambaryan, V. V. 2020, MNRAS, 498, 899 [CrossRef] [Google Scholar]
- Ochsenbein, F., Bauer, P., & Marcout, J. 2000, A&AS, 143, 23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ochsendorf, B. B., Brown, A. G. A., Bally, J., & Tielens, A. G. G. M. 2015, ApJ, 808, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Pecaut, M. J., & Mamajek, E. E. 2016, MNRAS, 461, 794 [Google Scholar]
- Pecaut, M. J., Mamajek, E. E., & Bubar, E. J. 2012, ApJ, 746, 154 [Google Scholar]
- Plotly Technologies Inc. 2015, Collaborative Data Science, Montreal, QC [Google Scholar]
- Pöppel, W. G. L., Bajaja, E., Arnal, E. M., & Morras, R. 2010, A&A, 512, A83 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Preibisch, T., & Mamajek, E. 2008, in Handbook of Star Forming Regions, Volume II, ed. B. Reipurth, 5, 235 [NASA ADS] [Google Scholar]
- Preibisch, T., & Zinnecker, H. 1999, AJ, 117, 2381 [NASA ADS] [CrossRef] [Google Scholar]
- Preibisch, T., Brown, A. G. A., Bridges, T., Guenther, E., & Zinnecker, H. 2002, AJ, 124, 404 [NASA ADS] [CrossRef] [Google Scholar]
- Quintana, A. L., & Wright, N. J. 2021, MNRAS, 508, 2370 [NASA ADS] [CrossRef] [Google Scholar]
- Quintana, A. L., & Wright, N. J. 2022, MNRAS, 515, 687 [NASA ADS] [CrossRef] [Google Scholar]
- Ratzenböck, S., Großschedl, J. E., Möller, T., et al. 2023, A&A, 677, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Riello, M., De Angeli, F., Evans, D. W., et al. 2021, A&A, 649, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rizzuto, A. C., Ireland, M. J., & Robertson, J. G. 2011, MNRAS, 416, 3108 [Google Scholar]
- Rizzuto, A. C., Ireland, M. J., & Kraus, A. L. 2015, MNRAS, 448, 2737 [NASA ADS] [CrossRef] [Google Scholar]
- Robitaille, J. F., Scaife, A. M. M., Carretti, E., et al. 2018, A&A, 617, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rousseeuw, P. J. 1984, J. Am. Stat. Assoc., 79, 871 [CrossRef] [Google Scholar]
- Rousseeuw, P. J., & Leroy, A. M. 2005, Robust Regression and Outlier Detection (John Wiley& sons) [Google Scholar]
- Schmitt, J. H. M. M., Czesla, S., Freund, S., Robrade, J., & Schneider, P. C. 2022, A&A, 661, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Scott, D. W. 1979, Biometrika, 66, 605 [CrossRef] [Google Scholar]
- Slesnick, C. L., Carpenter, J. M., & Hillenbrand, L. A. 2006, AJ, 131, 3016 [NASA ADS] [CrossRef] [Google Scholar]
- Soderblom, D. R. 2010, ARA&A, 48, 581 [Google Scholar]
- Squicciarini, V., Gratton, R., Bonavita, M., & Mesa, D. 2021, MNRAS, 507, 1381 [NASA ADS] [CrossRef] [Google Scholar]
- Sullivan, K., & Kraus, A. L. 2021, ApJ, 912, 137 [NASA ADS] [CrossRef] [Google Scholar]
- Swiggum, C., D’Onghia, E., Alves, J., et al. 2021, ApJ, 917, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Szilágyi, M., Kun, M., Ábrahám, P., & Marton, G. 2023, MNRAS, 520, 1390 [CrossRef] [Google Scholar]
- Taylor, M. B. 2005, ASP Conf. Ser., 347, 29 [Google Scholar]
- van der Walt, S., Colbert, S. C., & Varoquaux, G. 2011, Comput. Sci. Eng., 13, 22 [Google Scholar]
- Viana Almeida, P., Santos, N. C., Melo, C., et al. 2009, A&A, 501, 965 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Villa Vélez, J. A., Brown, A. G. A., & Kenworthy, M. A. 2018, Res. Notes Am. Astron. Soc., 2, 58 [Google Scholar]
- Wenger, M., Ochsenbein, F., Egret, D., et al. 2000, A&AS, 143, 9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wright, N. J., & Mamajek, E. E. 2018, MNRAS, 476, 381 [Google Scholar]
- Wright, N. J., Goodwin, S., Jeffries, R. D., Kounkel, M., & Zari, E. 2022, ArXiv e-prints [arXiv:2203.10007] [Google Scholar]
- Zucker, C., Goodman, A. A., Alves, J., et al. 2022, Nature, 601, 334 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Fitting isochrones to photometric data
We fit model isochrones to the 37 extracted SigMA clusters to infer cluster ages. Isochronal age estimates are an effective tool for studying relative ages and age sequences in the CMD, as consistent shifts in the position of pre–main-sequence (PMS) objects relative to the main-sequence (MS), precise photometry, and parallax measurements from Gaia provide reliable evidence for relative age differences between populations. These systematic shifts are especially pronounced in young populations (≤100 Myr). As older populations reach the main sequence, the changes in the isochrones below the turn-off become almost imperceptible due to the long-lasting, stable process of hydrogen burning, which keeps the CMD distribution virtually stagnant (Soderblom 2010).
Although relative age sequences become apparent when comparing young populations in the CMD, determining absolute ages is a process that is prone to biasing effects of systematic uncertainties. Such uncertainties, for instance, arise from the use of different isochronal model families (see e.g., Kerr et al. 2022). To mitigate the systematic effect of different evolutionary models on our method, we employ two model families: PARSEC and BHAC15 (Sect. 2).
Another systematic uncertainty is introduced by the choice of the fitting technique itself, as different fitting approaches are accompanied by disparate assumptions about the underlying data distribution of the measurements. For example, the popular and often used least squares (LS) method is based on the expectation that the data exhibit Gaussian uncertainties around the regression curve. However, assuming a Gaussian distribution of the data may not be entirely justified in the first place, as it is well-established that observational trends such as the unresolved binary sequence appear brighter compared to the single-star main sequence. At the same time, extinction skews the source distribution toward fainter magnitudes and redder colors. As a result, a fit of the (bluer) left-main ridge of the data in the CMD is often the preferred location for an isochrone, as it is believed to represent the underlying data more accurately. This can, for example, be achieved with fitting techniques that do not implicitly assume Gaussian distribution (see Sect. A.2).
As susceptibility to outliers is a general problem (and not specifically related to LS), we aim to curb their influence by applying photometric quality filters (see Sect. 2 for a detailed outline of the applied quality criteria) and employing robust fitting techniques. Robust fitting techniques are less sensitive to the influence of outliers in the data (Rousseeuw & Leroy 2005). As we still observed outliers in the CMD distributions after applying our quality cuts, we aim to use techniques that decrease their influence, producing more stable and reliable results. In the following, we briefly discuss robust methods and the choice of an appropriate method depending on the specific characteristics of the data.
A.1. Robust fitting methods
Among the different robust methods available, two prominent approaches to robust fitting include employing nonparametric methods, which aim to reduce the impact of outliers on observations that otherwise have an underlying normal distribution, and using a (more) robust loss function for regression. Which of these two options is generally better depends on the specific context and objectives of the scientific analysis.
Nonparametric methods for robust regression are a class of statistical techniques that do not make any assumptions about the underlying distribution of the data. These methods are typically less sensitive to outliers and are often employed when the underlying distribution is unknown. Commonly used methods include Least Trimmed Squares (LTS, Rousseeuw 1984) and RANdom SAmple Consensus (RANSAC, Fischler & Bolles 1981). LTS works by iteratively removing a predefined fraction of the data that exhibit the largest residuals and then minimizing the sum of squared residuals over the remaining subset. The RANSAC algorithm works by iteratively selecting and fitting random subsets of the data and determining their outlier fraction. The best fit minimizes the number of outliers. The subset size and the outlier threshold are critical parameters of LTS and RANSAC, respectively, which depend on the inherent fraction of outliers in the data and their approximate distance from the remaining “inliers”. If not set carefully, they can affect the resulting model and lead to poor results.
Robust loss functions are less sensitive to outliers than the traditionally used normal distribution due to their utilization of heavy-tailed distributions. Their heavy tail effectively assigns a smaller weight to data points that deviate significantly from the overall trend, decreasing the influence of outliers. Prominent candidates include the Huber loss (Huber 1964) and the Tukey biweight loss (Beaton & Tukey 1974). Both methods combine the mean squared error loss with a lesser penalizing loss for outlying observations. The difference between respective loss functions is that the Huber loss scales linearly with outliers above a given threshold. In contrast, Tukey’s loss is even less sensitive to outliers, as it flattens to a constant value at the given outlier threshold.
Generally, both nonparametric and parametric regression techniques try to reduce the impact of outliers while simultaneously fitting a least-sum of squares model to normal observations. In other words, they assume a symmetric data distribution of inliers around the “true” model. As mentioned, CMD data are known to deviate from this assumption and show a skewed distribution (toward fainter and cooler stars) of sources due to the appearance of reddening and unresolved objects in the data. To solve this predicament, we chose to approximate the data distribution with a skewed Cauchy likelihood function to capture the source distribution around the isochrone better.
A.2. Statistical model
Applying quality filters (see Sect. 2) drastically reduces the data size and range of photometric uncertainties (see also Fig. C.1). We generally do not observe strong heteroscedasticity within the sample. On the contrary, in the case of outliers, the reported uncertainties are often too inconsequential to explain large observed deviations from theoretical isochrones. As mentioned, observational data may be biased by reddening or resolution limits. Moreover, cluster selections could be influenced by contamination from older sources, which, however, is generally low for the used sample (∼6%), as determined in Paper I. Still, even more effects, such as small intra-cluster metallicity variations or stellar rotation, can result in a departure from the regression curve of a given model. We are generally unable to determine the exact nature of each data point’s deviation, and we have to account for all these effects in our choice of model as best as possible.
The skewed Cauchy distribution extends the standard Cauchy distribution, allowing for skewness. The standard Cauchy distribution is a heavy-tailed distribution known for its robustness to outliers and ability to model data with many outliers (Hampel et al. 2011). The PDF of the zero-centered skewed Cauchy distribution is defined by a scale parameter s, with s ∈ ℝ+, which controls the width of the distribution, and a skewness parameter a, with a ∈ ( − 1, 1):
![Mathematical equation: $$ \begin{aligned} f(x; s, a) = \left[s\pi \left( 1 + \frac{x^2}{s^2 (1 + a\, sign(x))^2} \right) \right]^{-1} \end{aligned} $$](/articles/aa/full_html/2023/10/aa46901-23/aa46901-23-eq7.gif) (A.1)
(A.1)
Setting a = 0 yields the standard Cauchy distribution.
A.2.1. Likelihood
For a given set of model parameters ⃗θ = (τ, ζ, ϵ) denoting age, metallicity, and dust extinction, respectively, the stellar evolution model predicts a set of magnitudes that characterize a coeval single-stellar population6. The astrophysical parameter equivalent to the model parameter vector is (logAge, [Fe/H], AV). It describes age in log10 years, metallicity in log10 of the iron to hydrogen ratio (calibrated to the sun), and extinction measured in the V band in magnitudes, see Table A.1.
Description of the parameters and flat prior ranges.
To describe the observations, we assume a simple model in which the data 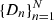 (of size N) is generated along isochrones with noise contributions en drawn independently from skewed Cauchy distributions with zero means. We consider the models in the CMD as tuples of colors c and magnitudes m. The expected color and magnitude of an observed star n, conditioned on model parameters ⃗θ, is determined by the theoretical point on the isochrone7, which minimizes the distance to the observed star’s color cn and magnitude mn. Their signed distance d(⃗θ) is defined as follows:
(of size N) is generated along isochrones with noise contributions en drawn independently from skewed Cauchy distributions with zero means. We consider the models in the CMD as tuples of colors c and magnitudes m. The expected color and magnitude of an observed star n, conditioned on model parameters ⃗θ, is determined by the theoretical point on the isochrone7, which minimizes the distance to the observed star’s color cn and magnitude mn. Their signed distance d(⃗θ) is defined as follows:
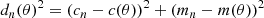 (A.2)
(A.2)
The sign of d(⃗θ) is determined according to whether the observed star is redder or bluer than the isochrone.
For simplicity, we assume that every data point is drawn from the same constant-noise model. Further, we treat nonsymmetric noise sources such as unresolved binaries and reddening effects as mass-independent. Thus, we employ a constant scale parameter s. Depending on the location and distribution of sources relative to the interstellar medium (ISM), reddening effects can vary widely among clusters, which translates to different scales s of the skewed Cauchy distribution8. Instead of fixing s, it becomes a free parameter of the model, and its value is obtained during Bayesian inference. Similarly, the skewness parameter a is determined during inference. The distribution p(Dn ∣ ⃗θ, s, a) of the data points Dn becomes the following:
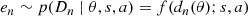 (A.3)
(A.3)
By combining the isochrone parameters ⃗θ and the noise distribution parameters (s, a) into Θ = (τ, ζ, ϵ, s, a), we can write the likelihood as:
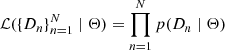 (A.4)
(A.4)
A.2.2. Posterior probability
Applying Bayes’ theorem, we obtain the posterior PDF of the parameters Θ, conditional on the data 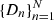 :
:
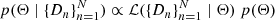 (A.5)
(A.5)
The PDF p(Θ) represents our prior knowledge of the parameters Θ, which we summarize in Table A.1. We employ flat priors and limit the isochrone parameters to ages between 1–100 Myr, dust extinction in the V band to AV ∈ [0, 2], and set the metallicity to [Fe/H] = 0 (solar metallicity). Due to the high degeneracy between age and metallicity, fixing the metallicity to the solar value reduces ambiguity in age. However, one must be careful when omitting the metallicity parameter from the fit due to its impact on absolute isochronal ages. In the solar neighborhood, assuming solar metallicity is a common approximation appropriate for Sco-Cen (Viana Almeida et al. 2009) and consistent with the short mixing timescales measured in supernova-driven ISM simulations (de Avillez & Mac Low 2002).
The prior ranges of PDF parameters are established through maximum likelihood fits of Eq. (A.1) to data around best-fitting isochrones found by Bossini et al. (2019) and Dias et al. (2019). To ensure comparability, we apply the same quality criteria discussed in Sect. 2 and restrict the sample to clusters within 500 pc and to ages < 100 Myr to create similar CMD conditions as Sco-Cen subclusters. We assume flat priors between the minimum and maximum of the obtained parameter values. Since different colors have different value ranges, we determine separate scale ranges for GBP − GRP and G − GRP.
We use the Markov Chain Monte Carlo (MCMC) method implemented within the public code emcee (Foreman-Mackey et al. 2013) to generate samples from the posterior PDF in Eq. (A.5). For each parameter, we compute the marginal PDF, its maximum a posteriori (MAP) position, and the 1σ credible interval determined via computing the 68% high-density interval (HDI) to represent the fitting results and uncertainties, respectively.
A.3. Validation
To validate our methodology, we selected a subset of clusters from Cantat-Gaudin & Anders (2020) that are within 500 pc and with more than 100 members. This selection results in 35 clusters, which have ages determined by Bossini et al. (2019), Dias et al. (2019), and Cantat-Gaudin et al. (2020) in the age range 7< logAge < 9. We apply our age fitting to the same data using the PARSEC models and the BPRP CMD, also used by the mentioned literature. The differences between the ages determined in this work and these studies are consistently within the boundaries of one standard deviation (see Fig. A.1). The differences in logAge have an average of 0.02 dex, and a standard deviation of 0.09 dex when compared to Bossini et al. (2019). Compared to Dias et al. (2019), the mean deviation is -0.07 dex, and the standard deviation is 0.14 dex. For Cantat-Gaudin et al. (2020), the mean difference is 0.05 dex, and the standard deviation is 0.1 dex. The top panel of Fig. A.2 displays the distribution of logAge differences between this study and the studies by Bossini et al. (2019), Dias et al. (2019), and Cantat-Gaudin et al. (2020). These are represented by blue, orange, and purple colors, respectively. We have used a KDE9 to approximate the shape of the distribution. The bottom three panels show the distribution of logAge differences for the remaining surveys against the other three, respectively. We find similar uncertainties across all surveys; thus, there seem to be no significant systematic differences across these four age estimates.
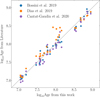 |
Fig. A.1. Comparison between our age estimates and ages determined in two previous studies for 35 nearby (< 500 pc) open clusters (see legend). |
 |
Fig. A.2. Distribution of logAge differences between this study (in black) and the studies by Bossini et al. (2019) (in blue), Dias et al. (2019) (in orange), and Cantat-Gaudin et al. (2020) (in purple). The distributions are obtained via a KDE, using Scott’s rule (Scott 1979) to determine the bandwidth. The bottom three panels show the distribution of logAge differences for the remaining surveys against the other three, respectively. Using this comparison, we find no systematic differences in estimated ages across the four presented methods. |
A.4. Age dependency on model families and photometric systems
In this section, we discuss the sources of systematic uncertainty between determined ages as introduced by different model isochrone families and photometric systems. For a detailed summary of the inferred ages, see Table 1. It also includes 1σ confidence intervals determined via the highest density interval (HDI) from the marginalized posterior PDF.
Figure A.3 compares the four determined cluster ages. We find good agreement between different color spaces (BPRP, GRP) when employing PARSEC isochrones with systematic uncertainties in the order of ≲1 Myr. Different isochrone model families (PARSEC, BHAC15) also agree well when using GRP colors. Comparing BHAC15-GRP to the PARSEC solutions, we find that older populations tend to be about 1.8 ± 1.6 Myr younger when estimated with the BHAC15-GRP. At the same time, we do not identify a bias for young populations (< 10 Myr) in the inferred age (estimated ages agree within ≲1 Myr). The most significant systematic trend is introduced when estimating ages with BHAC15 models in BPRP colors. We identify an approximately linear trend between BHAC15-BPRP ages and the other model families and color spaces, which leads to an underestimation of the ages by roughly 60%, compared to the other results.
 |
Fig. A.3. Comparison of the cluster ages (in Myr) as determined with different model families (PARSEC and BHAC15) and different Gaia CMDs (BPRP and GRP). We observe strong agreement between ages determined with PARSEC BPRP, PARSEC GRP, and BHAC15 GRP isochrones. In contrast, BHAC15 BPRP model fits seem to suggest systematically younger ages. |
Appendix B: Comparison to Kerr et al. (2021)
In Paper I, we compare the SigMA clustering results in more detail with the results of Kerr et al. (2021; hereafter, KRK21), who use HDBSCAN to select young clusters within 333 pc from the Sun, including the Sco-Cen association. We find a similar extent and clustered substructure in the Sco-Cen region. However, the individual SigMA clusters are significantly larger in size and numbers of stars compared to KRK21 (see Table E.3 in Paper I).
Figure B.1 compares the age estimates from KRK21 to ages as determined in this work using the PARSEC-BPRP ages if sufficient overlap between individual clusters is present. KRK21 also uses the PARSEC-BPRP models with solar metallicity, allowing direct comparison. We require that at least 10% of the sources of a matching SigMA cluster need to be part of the corresponding KRK21 cluster and that at least 60% of the sources of one KRK21 cluster need to be part of the same SigMA cluster. The different fractions are chosen since the individual KRK21 clusters are significantly smaller in size compared to SigMA, in particular when considering subclusterings which are themselves parts of KRK21’s top-level clusterings (TLC) to extract more substructure (subclustered by KRK21 with different subcluster aggregation strategies10).
 |
Fig. B.1. Comparison of the cluster ages from this work (using PARSEC-BPRP) to ages from KRK21. Only clusters with sufficient overlap between the two samples are shown (see text for more information). The solid gray line is a one-to-one line, and the black dashed line is a linear fit to the data points, as given in the panel. Individual clusters are marked with different colors and symbols (see legend), including error bars. |
In Figure B.1 there appears to be a trend with growing age in that KRK21 ages are systematically older as a function of our ages, affecting in particular clusters with older ages (≳10 Myr). This trend is puzzling because both studies use the same isochrone models. The imperfect overlap between the two samples could create different outcomes in the age fitting; however, possible imperfect matches of clusters would not create a trend. Another difference is the use of Gaia DR2 in KRK21 versus Gaia DR3 in Paper I. A likely culprit for the age-difference trend seems to be the age correction done in KRK21, which might be biasing their age estimate as a function of age (with their correction procedure, they will necessarily get more field stars for the older clusters)11. Moreover, as outlined in the methods section, selecting an appropriate fitting method is crucial since the scatter of sources in a CMD is not distributed normally around the best fitting isochrone (see the explanations in Appendix A).
The age-difference trend highlights the importance of careful age determination when using isochronal models. It should caution against comparing ages from different works at face value without considering possible biases that the various methods and fitting approaches could introduce.
Appendix C: Additional figures
Figure C.1 displays the members of all 37 SigMA clusters in the BRPB and GRP CMDs (lightgray dots). After applying the quality criteria from Sect. 2, the scatter of sources in the CMD reduces (colored dots), particularly affecting low-mass sources. There is a trend such that inferior photometry tends to get shifted to the left in the BPRP CMD and to the right in the GRP CMD (see the scatter of the lightgray dots). The reliability of a source’s cluster membership, as selected with SigMA, can be estimated via a stability value ranging from 0%–100%, which indicates how often individual sources appear throughout the ensemble of clustering solutions per cluster. We color-code the sources by their stability value. It can be seen that sources, which appear on an older age sequence, generally have lower stability and are, therefore, more unreliable members. In this work, we do not remove sources based on a stability cut since our isochrone fitting method is tuned to deal with outliers.
 |
Fig. C.1. Gaia CMDs for the BPRP (left) and GRP (right) colors. The gray sources are all Sco-Cen members from Paper I. Sources that remain after applied quality criteria (see Sect. 2) are color-coded in copper for stability. The scatter of the gray sources compared to the colored sources highlights the influence of photometric uncertainties. PARSEC and BHAC15 isochrones are over-plotted for 5 Myr and 20 Myr. We mark the two magnitude limits at MG > 10 mag and MG > 12 mag in light-purple as used for PARSEC and BHAC15 isochrone fitting, respectively. |
Figures C.2–C.5 show the Gaia CMDs for each cluster with over-plotted isochrones from the best fitting PARSEC and BHAC15 models, both for BPRP and GRP CMDs. The sources are again color-coded for stability. The maximum stability varies per cluster, while the stellar members of the more massive clusters tend to have higher stability up to 100%, while some smaller scale clusters have a maximum only at around 10%, like Cen-Far or Oph-NF. This does not indicate that such clusters are not real, while their identification in the sea of noise was less pronounced compared to more massive clusters. Therefore, we vary the upper limits of the color scale individually per cluster, using the mean stability per cluster, which is given in the legend of each panel.
 |
Fig. C.2. Gaia BPRP CMDs for the SigMA clusters 1–20. Only cluster members, which pass the photometric quality criteria from Eq. (2) are plotted, with the remaining number of sources given in the legend (Phot-cut). The dots are color-coded for stability with lower limits set to 2.5% (orange) and upper limits (dark) are varied per cluster, as given in the legend (Stab-limit, %). The magenta and blue solid lines show the best-fitting PARSEC (P) and BHAC15 (B) isochrones, respectively, as determined for BPRP, and the dashed lines show the upper and lower age limits (age limits are given in parenthesis in the legend). The horizontal solid and dashed light-gray lines give the magnitude limits at MG > 10 mag and MG > 12 mag for PARSEC and BHAC15, respectively, used to exclude sources from the age fitting. |
 |
Fig. C.4. Similar as Fig. C.2, but showing the GRP CMD for the SigMA clusters 1–20. The best fitting PARSEC isochrone is shown as determined with GRP. |
Figure C.6 shows the 12 clusters, which have matches with the USco sample from Fang et al. (2017) (see Sect. 5.3), first shown in Fig. 6. The separation of the clusters into individual CMDs highlights the different ages of stellar clusters that are located toward USco, which were often treated as one population in the past.
 |
Fig. C.6. Gaia BPRP CMD showing the 12 SigMA clusters that have matches with sources from F17. Similar to Fig. 6, but now the individual clusters are displayed in separate panels. The sample includes nine clusters from USco and three clusters from UCL (bottom row), as assigned based on traditional borders (see Paper I). The three UCL clusters have only a few matches since they only partially reach into the USco region. The blue dots are the SigMA members of the respective clusters with additional photometric quality criteria (see Sect. 5.3). The red dots mark the sources that match with the F17 sample. We do not use the RUWE cut for this overview, which reveals some binary sequences. The dashed black line shows the PARSEC isochrone for the cluster age as estimated in this work (see legends). |
All Tables
Isochronal ages for the 37 stellar groups in Sco-Cen as selected with SigMA in Ratzenböck et al. (2023).
All Figures
|
Fig. 1. 3D distribution of 34 clusters in the Sco-Cen association found by SigMA. The Sun is at (0,0,0) and the Z = 0 plane is parallel to the Galactic plane. The surfaces of the cluster volumes are shown, color-coded by age, from dark blue (2 Myr) to dark red (21 Myr). For more details, see the interactive 3D version online or at https://homepage.univie.ac.at/sebastian.ratzenboeck/wp-content/uploads/2023/05/scocen_age.html. |
| In the text | |
|
Fig. 2. Star formation progression along approximately 100 pc long chains of clusters. We find age gradients along these cluster chains. In Sco-Cen, we find two cluster chains: one comprising clusters in the traditional LCC region (LCC chain) and a second chain connecting down to CrA (CrA chain). For more details, see the interactive 3D version online or at https://homepage.univie.ac.at/sebastian.ratzenboeck/wp-content/uploads/2023/06/scocen_ages-3D_chains_online.html. |
| In the text | |
|
Fig. 3. Star formation history of Sco-Cen. Top: age distribution of the 34 clusters in Sco-Cen traces four main star formation events in the history of the association. Bottom: stellar age distribution in Sco-Cen shows a similar pattern. To study the age distribution of clusters and stars, we used a kernel density estimate with an adaptive bandwidth corresponding to the age uncertainty of each sample. The formation of stars and clusters is correlated, but not linearly, meaning that, when compared to the average in the association, more stars were formed per cluster during the peak of star formation rate, about 15 Myr ago. |
| In the text | |
|
Fig. 4. Star formation progression in Sco-Cen, shown with the same orientation in XYZ and color-scaling as in Fig. 1. By separating the clusters in age bins, following the peaks in Fig. 3 and Table 2, one can appreciate a consistent inside-out progression of star formation from older to younger clusters. For more details, see the interactive 3D version online or at https://homepage.univie.ac.at/sebastian.ratzenboeck/wp-content/uploads/2023/05/scocen_age.html. |
| In the text | |
|
Fig. 5. Timeline of the formation of clusters in Sco-Cen, color-coded by age (same as in Fig. 1) and scaled by cluster size. The horizontal lines represent age uncertainties. While Sco-Cen has been forming small clusters (≤250 stars) continuously since its formation 20–25 Myr ago, its large clusters (≳1000 stars) were all formed during the peak of the star formation rate, around 15 Myr ago. Regarding their absolute numbers, most of the stars and clusters we can observe today in the Sco-Cen region were formed around 15 Myr ago. Since then, star formation has been declining. The peaks of star and cluster formation rate seem to be periodically distributed (every ∼5 Myr, see also Fig. 3). |
| In the text | |
|
Fig. 6. Gaia BPRP CMD displaying members of the 12 stellar clusters that have matches with USco members from F17. The blue dots are all sources in the 12 SigMA clusters that pass additional photometric quality criteria (see text). The red dots indicate sources that are both in SigMA and F17. Two PARSEC isochrones are shown for 5 Myr (solid) and 10 Myr (dashed), marking the earlier assumed nominal ages of USco. The arrow shows an extinction vector with a length of AG = 1 mag. See Fig. C.6 for an overview of the separate CMDs of the individual 12 clusters. |
| In the text | |
|
Fig. A.1. Comparison between our age estimates and ages determined in two previous studies for 35 nearby (< 500 pc) open clusters (see legend). |
| In the text | |
|
Fig. A.2. Distribution of logAge differences between this study (in black) and the studies by Bossini et al. (2019) (in blue), Dias et al. (2019) (in orange), and Cantat-Gaudin et al. (2020) (in purple). The distributions are obtained via a KDE, using Scott’s rule (Scott 1979) to determine the bandwidth. The bottom three panels show the distribution of logAge differences for the remaining surveys against the other three, respectively. Using this comparison, we find no systematic differences in estimated ages across the four presented methods. |
| In the text | |
|
Fig. A.3. Comparison of the cluster ages (in Myr) as determined with different model families (PARSEC and BHAC15) and different Gaia CMDs (BPRP and GRP). We observe strong agreement between ages determined with PARSEC BPRP, PARSEC GRP, and BHAC15 GRP isochrones. In contrast, BHAC15 BPRP model fits seem to suggest systematically younger ages. |
| In the text | |
|
Fig. B.1. Comparison of the cluster ages from this work (using PARSEC-BPRP) to ages from KRK21. Only clusters with sufficient overlap between the two samples are shown (see text for more information). The solid gray line is a one-to-one line, and the black dashed line is a linear fit to the data points, as given in the panel. Individual clusters are marked with different colors and symbols (see legend), including error bars. |
| In the text | |
|
Fig. C.1. Gaia CMDs for the BPRP (left) and GRP (right) colors. The gray sources are all Sco-Cen members from Paper I. Sources that remain after applied quality criteria (see Sect. 2) are color-coded in copper for stability. The scatter of the gray sources compared to the colored sources highlights the influence of photometric uncertainties. PARSEC and BHAC15 isochrones are over-plotted for 5 Myr and 20 Myr. We mark the two magnitude limits at MG > 10 mag and MG > 12 mag in light-purple as used for PARSEC and BHAC15 isochrone fitting, respectively. |
| In the text | |
|
Fig. C.2. Gaia BPRP CMDs for the SigMA clusters 1–20. Only cluster members, which pass the photometric quality criteria from Eq. (2) are plotted, with the remaining number of sources given in the legend (Phot-cut). The dots are color-coded for stability with lower limits set to 2.5% (orange) and upper limits (dark) are varied per cluster, as given in the legend (Stab-limit, %). The magenta and blue solid lines show the best-fitting PARSEC (P) and BHAC15 (B) isochrones, respectively, as determined for BPRP, and the dashed lines show the upper and lower age limits (age limits are given in parenthesis in the legend). The horizontal solid and dashed light-gray lines give the magnitude limits at MG > 10 mag and MG > 12 mag for PARSEC and BHAC15, respectively, used to exclude sources from the age fitting. |
| In the text | |
 |
Fig. C.3. Same as Fig. C.2, but for the SigMA clusters 21–37. |
| In the text | |
|
Fig. C.4. Similar as Fig. C.2, but showing the GRP CMD for the SigMA clusters 1–20. The best fitting PARSEC isochrone is shown as determined with GRP. |
| In the text | |
 |
Fig. C.5. Same as Fig. C.4, but for the SigMA clusters 21–37. |
| In the text | |
|
Fig. C.6. Gaia BPRP CMD showing the 12 SigMA clusters that have matches with sources from F17. Similar to Fig. 6, but now the individual clusters are displayed in separate panels. The sample includes nine clusters from USco and three clusters from UCL (bottom row), as assigned based on traditional borders (see Paper I). The three UCL clusters have only a few matches since they only partially reach into the USco region. The blue dots are the SigMA members of the respective clusters with additional photometric quality criteria (see Sect. 5.3). The red dots mark the sources that match with the F17 sample. We do not use the RUWE cut for this overview, which reveals some binary sequences. The dashed black line shows the PARSEC isochrone for the cluster age as estimated in this work (see legends). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.