| Issue |
A&A
Volume 674, June 2023
|
|
|---|---|---|
| Article Number | A173 | |
| Number of page(s) | 13 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202245622 | |
| Published online | 19 June 2023 | |
A non-parametric approach to the relation between the halo mass function and internal dark matter structure of haloes
1
Laboratoire Univers et Théories, Observatoire de Paris, Université PSL, Université de Paris Cité, CNRS, 92190 Meudon, France
e-mail: tamara.richardson@obspm.fr
2
Université, CNRS, UMR 7095, Institut d’Astrophysique de Paris, 98 bis bd Arago, 75014 Paris, France
Received:
5
December
2022
Accepted:
11
April
2023
Context. Galaxy cluster masses are usually defined as the mass within a spherical region enclosing a given matter overdensity (in units of the critical density). Converting masses from one overdensity definition to another can have several useful applications.
Aims. In this article we present a generic non-parametric formalism that allows one to accurately map the halo mass function between two different mass overdensity definitions using the distribution of halo sparsities defined as the ratio of the two masses. We show that changing mass definitions reduces to modelling the distribution of halo sparsities.
Methods. Using standard transformation rules of random variates, we derive relations between the halo mass function at different overdensities and the distribution of halo sparsities.
Results. We show that these relations reproduce the N-body halo mass functions from the Uchuu simulation within the statistical errors at a few percent level. Furthermore, these relations allow the halo mass functions at different overdensities to be related to parametric descriptions of the halo density profile. In particular, we discuss the case of the concentration-mass relation of the Navarro-Frenk-White profile. Finally, we show that the use of such relations allows us to predict the distribution of sparsities of a sample of haloes of a given mass, thus opening the way to inferring cosmological constraints from individual galaxy cluster sparsity measurements.
Key words: methods: analytical / cosmology: theory / galaxies: clusters: general / cosmological parameters
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1. Introduction
It is now well established that estimates of the abundance of galaxy clusters in the universe can be used to test the standard cosmological scenario (Allen et al. 2011; Kravtsov & Borgani 2012). Over the past decade, surveys dedicated to the detection of galaxy clusters have provided complete samples that have enabled numerous cosmological parameter inference analyses using cluster number count measurements (Rozo et al. 2010; Mantz et al. 2015; de Haan et al. 2016; Planck Collaboration XXIV 2016; Schellenberger & Reiprich 2017; Pacaud et al. 2018; Bocquet et al. 2019; Abbott et al. 2020). In the near future, a new generation of surveys such as Euclid (Laureijs et al. 2011; Euclid Collaboration 2022) and the Rubin Observatory’s LSST (Ivezić et al. 2019) will provide larger cluster samples that have the potential to improve current constraints so as to be complementary to those inferred from other cosmic probes.
Key to the success of such analyses will be, on the one hand, the ability to control the impact of systematic uncertainties and, on the other hand, the availability of accurate predictions of the halo mass function (HMF) because galaxy clusters are hosted in massive dark matter haloes that are the ultimate result of the hierarchical bottom-up process of cosmic structure formation. Formally, the HMF is the number density of dark matter haloes per unit volume per unit mass, dn/dM, which can be written in the following factorised form (see e.g., Press & Schechter 1974; Bond et al. 1991):
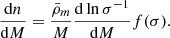
Here 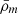 is the mean cosmic matter density, σ is the root-mean-square fluctuation of the linear matter density field smoothed on a spherical region enclosing a mass M, and f(σ) is the multiplicity function. The last encodes information on the distribution of halo masses resulting from the non-linear gravitational collapse of matter density fluctuations that leads to the assembly of haloes. However, because of the complexity of this process, predictions of the multiplicity function, and consequently of the HMF, entirely rely on the analysis of cosmological N-body simulations. Numerically calibrated parametrisations of f(σ) have been provided in a vast literature (Jenkins et al. 2001; Sheth et al. 2001; Reed et al. 2003; Warren et al. 2006; Lukić et al. 2007; Tinker et al. 2008; Courtin et al. 2011; Angulo et al. 2012; Bocquet et al. 2016; Despali et al. 2016; Diemer 2020; Seppi et al. 2021). However, obtaining accurate HMF predictions from numerical simulations poses three main challenges. First of all, simulations must cover large cosmic volumes to resolve with sufficient statistics the high-mass end of the HMF (see e.g., Ishiyama et al. 2021), and possibly to account for the impact of the baryons. In the latter case, this requires the use of N-body or hydrodynamical simulations (e.g., Martizzi et al. 2014; Cui et al. 2014; Velliscig et al. 2014; Bocquet et al. 2016; Castro et al. 2021). Secondly, simulations with different cosmological parameter set-ups are necessary to evaluate the cosmological dependence (or lack thereof) of the multiplicity function (Jenkins et al. 2001; Tinker et al. 2008; Courtin et al. 2011; Despali et al. 2016; McClintock et al. 2019; Nishimichi et al. 2019; Diemer 2020; Bocquet et al. 2020; Ondaro-Mallea et al. 2022). Finally, the results depend on the criteria used to detect haloes in the simulations. This is usually done using either the friends-of-friends (FoF; Davis et al. 1985) or spherical overdensity (SO; Lacey & Cole 1994) algorithms. In the first case, haloes are defined as group of particles characterised by an intra-particle distance smaller than a given linking length parameter. In the second case, haloes correspond to particles within a spherical region that encloses a given overdensity (with respect to the critical or background density). The mass of SO haloes is closer to the definition of mass that is measured from observations of galaxy clusters.
is the mean cosmic matter density, σ is the root-mean-square fluctuation of the linear matter density field smoothed on a spherical region enclosing a mass M, and f(σ) is the multiplicity function. The last encodes information on the distribution of halo masses resulting from the non-linear gravitational collapse of matter density fluctuations that leads to the assembly of haloes. However, because of the complexity of this process, predictions of the multiplicity function, and consequently of the HMF, entirely rely on the analysis of cosmological N-body simulations. Numerically calibrated parametrisations of f(σ) have been provided in a vast literature (Jenkins et al. 2001; Sheth et al. 2001; Reed et al. 2003; Warren et al. 2006; Lukić et al. 2007; Tinker et al. 2008; Courtin et al. 2011; Angulo et al. 2012; Bocquet et al. 2016; Despali et al. 2016; Diemer 2020; Seppi et al. 2021). However, obtaining accurate HMF predictions from numerical simulations poses three main challenges. First of all, simulations must cover large cosmic volumes to resolve with sufficient statistics the high-mass end of the HMF (see e.g., Ishiyama et al. 2021), and possibly to account for the impact of the baryons. In the latter case, this requires the use of N-body or hydrodynamical simulations (e.g., Martizzi et al. 2014; Cui et al. 2014; Velliscig et al. 2014; Bocquet et al. 2016; Castro et al. 2021). Secondly, simulations with different cosmological parameter set-ups are necessary to evaluate the cosmological dependence (or lack thereof) of the multiplicity function (Jenkins et al. 2001; Tinker et al. 2008; Courtin et al. 2011; Despali et al. 2016; McClintock et al. 2019; Nishimichi et al. 2019; Diemer 2020; Bocquet et al. 2020; Ondaro-Mallea et al. 2022). Finally, the results depend on the criteria used to detect haloes in the simulations. This is usually done using either the friends-of-friends (FoF; Davis et al. 1985) or spherical overdensity (SO; Lacey & Cole 1994) algorithms. In the first case, haloes are defined as group of particles characterised by an intra-particle distance smaller than a given linking length parameter. In the second case, haloes correspond to particles within a spherical region that encloses a given overdensity (with respect to the critical or background density). The mass of SO haloes is closer to the definition of mass that is measured from observations of galaxy clusters.
In principle, the mass of a galaxy cluster at a given overdensity can be converted to another overdensity if the underlying matter density profile is known. This is the approach originally developed by Hu & Kravtsov (2003), in which the mapping between the mass at two different overdensity values is obtained by assuming the Navarro-Frenk-White (NFW; Navarro et al. 1997) profile with a given concentration-mass relation. The possibility of mapping halo masses at different overdensities can have several practical applications. As an example, it allows a numerical HMF calibrated for a given overdensity to be transformed into a different one. More specifically, suppose that we have a sample of galaxy clusters with measurements of their spherical mass M500c at an overdensity Δ = 500ρc, from which we can estimate the halo mass function, dn/dM500c. Suppose that we also have predictions of the HMF for a numerically calibrated multiplicity function f200c(σ) using SO halo masses M200c at an overdensity Δ = 200ρc. Then, we can still make a prediction for dn/dM500c by performing a simple variable transformation:
![$$ \begin{aligned} \frac{\mathrm{d} n}{\mathrm{d} M_{500\mathrm{c}}}\equiv \frac{\mathrm{d} n}{\mathrm{d} M_{200\mathrm{c}}}\frac{\mathrm{d} M_{200\mathrm{c}}}{\mathrm{d} M_{500\mathrm{c}}}=\left[\frac{\bar{\rho }_m}{M_{500\mathrm{c}}}\frac{\mathrm{d} \ln {\sigma ^{-1}}}{\mathrm{d} M_{500\mathrm{c}}}f_{200\mathrm{c}}(\sigma )\right]\frac{M_{500\mathrm{c}}}{M_{200\mathrm{c}}}. \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq3.gif)
As we can see, this transformation depends crucially on the ratio of the halo masses at two different overdensities. Parametric fits from the analyses of numerical halo catalogues have been provided in the literature for different mass ratios, which have the advantage of being affected by a smaller scatter than the transformation based on the concentration-mass relation (see Bocquet et al. 2016; Ragagnin et al. 2021). However, these ratios are not deterministic variables, as implicitly assumed in these studies. Quite the opposite, they are stochastic variables that probe the mass profile of haloes. Dubbed halo sparsities, these ratios were originally investigated in Balmès et al. (2014), who showed that the ratio of halo masses at two different overdensities provides a proxy of the level of sparsity of the mass distribution inside a halo. Subsequent studies have shown that these ratios encode a considerable amount of cosmological (Corasaniti et al. 2018, 2021, 2022) and astrophysical (Richardson & Corasaniti 2022) information.
In this work we present a generic formalism that allows us to accurately map between halo mass functions with different mass overdensity definitions using the distribution of halo sparsities. More specifically, we show that the problem of changing mass definition can be recast into a problem of modelling the distribution of halo sparsities, thus showing the deep connection between the halo mass function at different overdensities and the mass profile of dark matter haloes. This enables us to connect this formalism to the vast literature devoted to the study of the concentration-mass relation of the NFW profile (Navarro et al. 1997). Most importantly, we show that such a formalism allows us to accurately predict the distributions of halo sparsities at a given mass using calibrated HMF fitting formula at different overdensities. We demonstrate that this can provide stronger constraints on cosmological parameters than those inferred using average sparsity measurements.
The article is organised as follows. In Sect. 2 we briefly describe the N-body simulation halo catalogues used as a validation dataset. In Sect. 3 we introduce the formalism to map the HMF across different mass overdensity definitions using halo sparsity statistics. We test the accuracy of the formalism against the simulation data and compare to existing results in the literature. In Sect. 4 we present the general methodology to convert any model for the internal structure of haloes into a sparsity model and describe the results of specific applications to the NFW profile. In Sect. 5 we describe a novel method to retrieve cosmological information from a sample of galaxy clusters using measurements of cluster sparsities as function of mass. Finally, in Sect. 6 we present our conclusions.
2. Simulation data
We used halo catalogues from the Uchuu suite of N-body simulations (Ishiyama et al. 2021), which were run with the GreeM code (Ishiyama et al. 2009, 2012). In particular, we considered haloes with masses M200c > 1013h−1 M⊙ from the large volume (2h−1Gpc)3 run with 12 8003 particles (equivalent to a mass resolution of mp = 3.27 × 108 h−1 M⊙), for which the cosmological parameters were set to the values of the Planck-CMB 2015 analysis (Planck Collaboration XIII 2016): Ωm = 0.3089, Ωb = 0.0486, h = 0.6774, ns = 0.9667, and σ8 = 0.8159.
Halo catalogues were generated with the ROCKSTAR code (Behroozi et al. 2013a,b), which implements a six-dimensional FoF halo finder. The publicly available datasets contain, for each halo in the catalogues, the spherical overdensity halo masses M200c, M500c, and M2500c at overdensities Δ = 200, 500, and 2500, respectively (in units of the critical overdensity). We used these data to compute the sparsities s200, 500, s200, 2500, and s500, 2500 for each halo in the catalogues. Then, we estimated the corresponding conditional sparsity distributions ρs(sΔ1, Δ2|MΔ2), the marginal sparsity distributions ρs(sΔ1, Δ2), and the halo mass functions dn/dMΔ. We find the last to be consistent with those presented in the first Uchuu data release (Ishiyama et al. 2021). This dataset is used for all the practical applications of the methods presented hereafter.
3. Relating sparsity to the halo mass function
In this section we introduce our probabilistic approach to map the HMF from one mass definition to another using halo sparsity. Sparsity is formally defined as (Balmès et al. 2014)
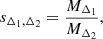
where MΔ1 and MΔ2 are spherical masses enclosing overdensities1Δ1 and Δ2, respectively (with Δ2 > Δ1). In this context each variable in this expression is treated as a random variable, such that each can be expressed as the product or ratio of two others: MΔ2 = sΔ1, Δ2MΔ1 or MΔ1 = MΔ2/sΔ1, Δ2. Hence, a mapping of the HMF from any of these two mass definitions to the other can be performed using the transformation rules of random variates, which we briefly review in Appendix A.
3.1. Halo mass conversion
Suppose we want to reconstruct the HMF at the higher overdensity Δ2 from the HMF at the lower overdensity Δ1, which we refer to as inward reconstruction. We let the masses MΔ1 and MΔ2 be drawn from dn/dMΔ1 and dn/dMΔ2, respectively, and let the sparsity2 (s) be drawn from the distribution ρs(s|MΔ1) conditional to the mass MΔ1. We note that this distribution is only defined over the interval 1 < s < ∞. Then, as MΔ2 can be written as the ratio of MΔ1 to sΔ1, Δ2, the HMF at Δ2 can be written as a ratio distribution of the two other variables:
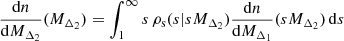
(see Eq. (A.9) for a detailed derivation). We note that if we assume that the sparsity distribution is independent of the mass at the outer density MΔ1, this relation changes only by replacing the conditional distribution of sparsity ρs(s|sMΔ2) by its marginal distribution ρs(s). As such, the only requirement to relate both mass functions is the sparsity distribution.
We now consider the inverse case in which we aim to reconstruct the HMF at the lower density Δ1 from the HMF at the higher overdensity Δ2, which we refer to as outward reconstruction. Using the definition of the product distribution, see Eq. (A.7), we obtain
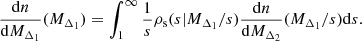
Thus, the combination of Eqs. (4) and (5) allow us to describe the HMF at a given overdensity contrast as a function of the HMF at any other overdensity.
3.2. Validation with N-body halo mass functions
We test the accuracy of the inward and outward reconstruction given by Eqs. (4) and (5) against the HMF estimated from the Uchuu halo catalogues at z = 0 for different overdensity contrasts. To do so we numerically estimate the conditional sparsity distributions, ρs(sΔ1, Δ2|MΔ1) and ρs(sΔ1, Δ2|MΔ2), and their marginalised counterparts, from the same halo catalogues used to estimate the HMFs at the two overdensities. These are then used to estimate both sides of Eqs. (4) and (5), which we compare in Fig. 1. In the left panel we plot the N-body mass function at Δ = 200 (top curve), 500 (middle curve), and 2500 (bottom curve) in units of the critical density against the inward (M200c → M500c, M200c → M2500c, and M500c → M2500c) and outward (M2500c → M500c, M2500c → M200c, and M500c → M200c) reconstructed HMFs assuming the conditional (solid lines) and marginal (dashed lines) sparsity distributions, respectively. As already mentioned, the latter is equivalent to assuming that the sparsity distribution is independent of the mass at the starting density contrast. In the right panel of Fig. 1, we plot the relative differences with respect to the N-body mass functions at the different overdensities. The shaded areas in both panels correspond to the 1σ statistical error on the N-body mass functions that we have computed as the standard deviation over 103 bootstrap iterations.
 |
Fig. 1. Comparison of the accuracy of the mass dependent HMF transfer formalism with the marginalised formalism. The latter provides poor reconstructions while accounting for the mass dependence results with predictions that are exact to the level of statistical uncertainty. Left panel: estimated HMFs (purple shaded area) at z = 0 from the Uchuu halo catalogues for overdensities Δ = 200, 500, and 2500 (in units of the critical density) plotted against the inward (200 → 500, 200 → 2500, and 500 → 2500) and outward (2500 → 500, 2500 → 200, and 500 → 200) reconstructed HMFs from Eqs. (4) and (5), respectively, assuming the marginal sparsity distribution (dashed lines) and conditional distribution (solid lines). Right panels: relative error between the reconstructions and the measured HMF at Δ = 200 (top panel), Δ = 500 (mid panel), and Δ = 2500 (bottom panel). The shaded areas around the measured HMFs represents the statistical error on the measurement estimated as the standard deviation over 103 bootstrap iterations. |
We can see that using the conditional sparsity distributions nicely reproduces the N-body HMFs within the statistical errors at a few percent level. It is also worth noting that the inward reconstructions outperform their outward counterparts at the low-mass end because in the latter case the integration boundaries are below the mass interval over which the HMFs are estimated. This does not occur at the high-mass end due to the presence of the exponential cut-off in the HMFs. In contrast, we find that using the marginal sparsity distribution (i.e. assuming independence), leads to less accurate reconstructed HMFs, which results in relative errors that can exceed the 10% level. In such a case the shape of the recovered HMF more closely resembles that of the one that appears in the integrand of Eq. (4) or Eq. (5). Hence, in the case of the inward reconstruction, this results in an underestimation of the reconstructed HMF at low masses and an overestimation at the high-mass end, while the opposite occurs when reconstructing outwards. In Appendix B we present similar tests performed using the Uchuu catalogues at z = 0.5 and 1. We find similar trends to those shown in Fig. 1.
3.3. Validation with analytical results
The general formalism presented above allows us to better understand the relation between halo sparsity and halo mass functions at different overdensities and reproduce past results from the literature. As an example, from our formalism we recover a mapping of the form of Eq. (2) considered in Bocquet et al. (2016) and Ragagnin et al. (2021). Such a mapping is equivalent to the inward reconstruction given by Eq. (4) with the additional assumption that the sparsity distribution is highly peaked about the mean sparsity (i.e. ⟨sΔ1, Δ2⟩). Thus, we approximate the sparsity distribution by a Dirac delta function:
![$$ \begin{aligned} \rho _{\rm s}(s|M_{\Delta _1}) \approx \delta _\text{D}[s - \langle s_{\Delta _1,\Delta _2}\rangle (M_{\Delta _1})]. \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq7.gif)
Consequently, the integral in Eq. (4) results in
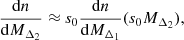
where s0 is the root of the argument of the Dirac function (i.e. s0 − ⟨sΔ1, Δ2⟩ = 0). If the mean sparsity does not vary significantly as function of the halo mass (i.e. d⟨sΔ1, Δ2⟩/dMΔ1 ≃ 0), then s0 ≃ ⟨sΔ1, Δ2⟩. Thus, after some cumbersome algebra, we can write Eq. (7) as
![$$ \begin{aligned} \frac{\mathrm{d} n}{\mathrm{d} M_{\Delta _2}}=\left[\frac{\bar{\rho }_m}{M_{\Delta _2}}\frac{\mathrm{d} \ln {\sigma ^{-1}}}{\mathrm{d} M_{\Delta _2}}f(\sigma )\right]\frac{1}{\langle s_{\Delta _1,\Delta _2}\rangle }, \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq9.gif)
where σ is the root-mean-square fluctuation of the linear density field on the mass scale MΔ1 = ⟨sΔ1, Δ2⟩MΔ2. As we can see, for Δ1 = 200ρc and Δ2 = 500ρc we recover Eq. (2). The only fundamental difference is the presence of the expectation value.
Another result we are able to recover is that of the seminal work of Balmès et al. (2014), which relates the average sparsity to the halo mass functions, thus providing a quantitative set-up to predict the mean sparsity of a cluster sample and to perform cosmological parameter inference analyses (see Corasaniti et al. 2018, 2021, 2022). Specifically, given the halo mass function at masses MΔ1 and MΔ2, one can infer the value of the average sparsity sΔ1, Δ2 by solving the integral equation
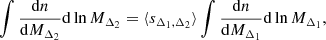
where we have omitted the integration boundaries only for ease of reading.
We can derive this equation by simply integrating both sides of Eq. (4) over lnMΔ2. Then, assuming that sparsity is independent from MΔ1, we can replace the conditional distribution ρs(s|sMΔ2) with the marginal sparsity distribution, ρs(s) to obtain the following equation:
![$$ \begin{aligned} \int \frac{\mathrm{d} n}{\mathrm{d} M_{\Delta _2}}\mathrm{d} \ln {M_{\Delta _2}}=\int _{1}^{\infty }s\rho _{\rm s}(s)\left[\int \frac{\mathrm{d} n}{\mathrm{d} M_{\Delta _1}}(s M_{\Delta _2}) \mathrm{d} \ln {M_{\Delta _2}}\right]\mathrm{d} s. \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq11.gif)
If the marginal sparsity distribution is peaked around the mean, then we can again approximate, ρs(s) = δD(s − ⟨sΔ1, Δ2⟩). Finally, by performing the integral over s we recover Eq. (9).
We conclude this section by emphasising that Eq. (7) is the mass dependent version of Eq. (9). On the one hand, this shows the deep link between the halo mass function at different overdensities and the halo mass profile. On the other hand, it suggests the possibility of predicting halo sparsity at a given mass from the HMFs. However, rather than using Eq. (7), this can be done more accurately (as shown by the validation plots of Fig. 1), by assuming an analytical model for the conditional sparsity distribution (e.g., a Gaussian with unknown mean and variance) and solving simultaneously Eqs. (4) and (5) for these two variables as function of halo mass. As we discuss in Sect. 5, this allows us to predict the likelihood of individual cluster sparsities that can potentially provide constraints on the cosmological parameters stronger than those inferred using average sparsity measurements.
4. Halo density profiles
Halo sparsity is a non-parametric proxy of the halo mass profile. As such, it does not make any assumption on the specific shape of the dark matter density profile. On the other hand, parametric profile parameters can be mapped onto sparsities. Using this in conjunction with its relation to the HMFs, one can map any parametric halo density profile to the HMF at different overdensities. In the following, we investigate this in the specific case of the NFW profile.
4.1. Sparsities from the Navarro-Frenk-White profile
Numerical simulation studies have shown that the density profile of dark matter haloes is described well by a two-parameter fitting function called the NFW profile (Navarro et al. 1997),
![$$ \begin{aligned} \rho _\text{NFW}(r) = \frac{M_{200\text{ c}}}{4\pi \left[\ln (1+c) - c/(1+c)\right]}\times \frac{1}{r\left(\frac{r_{200\text{ c}}}{c}+r\right)^2}, \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq12.gif)
where M200c is the mass enclosing the overdensity Δ = 200 (in units of the critical density) and c = r200c/rs is the concentration parameter, which is the ratio of the radius of the spherical region enclosing the mass M200c to the scale radius rs at which the radial slope of the NFW profile changes from ∝r−1 (r ≲ rs) to ∝r−3 (r ≳ rs). The concentration parameter provides a simplified description of the radial distribution of mass within haloes since all the information related to a halo’s mass assembly history is compressed into a single stochastic variate. It has been the subject of numerous studies in the literature that have investigated its dependence on halo mass, redshift, and cosmology (Bullock et al. 2001; Wechsler et al. 2002; Zhao et al. 2003a, 2009; Dolag et al. 2004; Macciò et al. 2007; Prada et al. 2012; Diemer & Kravtsov 2015; Ludlow et al. 2016; Diemer & Joyce 2019; Ishiyama et al. 2021; López-Cano et al. 2022) and its relation to the halo assembly history (see e.g., Zhao et al. 2003b, 2009; Li et al. 2007; Neto et al. 2007; Giocoli et al. 2012; Ludlow et al. 2012, 2016; Wang et al. 2020).
Integrating Eq. (11) for a given mass M200c and concentration parameter c, one can compute the halo mass at any overdensity Δ, and thus compute the corresponding sparsity from the mass ratio. Hence, as shown in Balmès et al. (2014), there is a one-to-one relation between the concentration parameter of the NFW profile and the halo sparsity 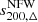 . Specifically, this leads to
. Specifically, this leads to
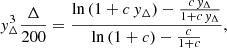
where yΔ = rΔ/r200c, with rΔ being the radius of a sphere enclosing an overdensity Δ, in units of the critical density. Then, solving for yΔ, the corresponding sparsity is given by
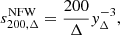
for any value of Δ and c. We note that by solving this relation for two distinct overdensities, one can calculate any sparsity 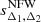 . Moreover, this particular relation entails the existence of a continuous differentiable function
. Moreover, this particular relation entails the existence of a continuous differentiable function
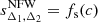
and its inverse
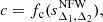
as shown in Fig. 7 of Balmès et al. (2014). Hence, given that the concentration parameter is a random variate drawn from the conditional distribution ρc(c|MΔ1), we can derive the conditional distribution of the NFW sparsity:
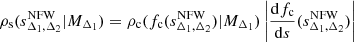
(see Eq. (A.1) for the derivation).
The distribution of the concentration parameter is usually modelled as a log-normal density function, whose mean is given by the c − M relation, and a width parameter ≈0.25 (see e.g., Bullock et al. 2001; Dolag et al. 2004; Macciò et al. 2007). Thus, given a model for the distribution of the NFW concentration, one can compute the corresponding distribution of the NFW sparsity using Eq. (16).
In Fig. 2 we plot iso-contours of the conditional sparsity distribution as function of M200c obtained from the estimated sparsities of the Uchuu halo catalogue at z = 0 (top panel), the NFW sparsities obtained from the measured concentrations on the same haloes (middle panel), and the NFW sparsities predicted assuming a log-normal concentration distribution for which the mean is given by the concentration-mass relation measured from the analysis of Uchuu haloes (Ishiyama et al. 2021) and width parameter σ = 0.25 (bottom panel). The solid lines correspond to the mean values of the distributions: red for the measured sparsities, orange for those inferred from the measured concentrations, and yellow from the log-normal distribution.
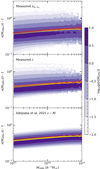 |
Fig. 2. Iso-contours of the conditional density distribution of the halo sparsity, ρ(s200,500|M200,c). Measurements are from the Uchuu halo catalogue at z = 0, (top panel), estimated from the distribution of measured concentrations (central panel), and predicted assuming a log-normal distribution of the concentration parameter for which the mean is given by the c − M relation of Ishiyama et al. (2021) calibrated on the Uchuu catalogues and width paramter σ = 0.25 (bottom panel). The coloured lines correspond to the mean of the distribution of measured sparsities (red), and that inferred from the measured concentrations (orange) and from the log-normal distribution (yellow). |
We can see that the last two cases accurately reproduce the mean of the distribution of the sparsities measured from the N-body haloes. However they do not accurately reproduce the scatter around the latter. In particular, we can see that the measured concentrations underestimate the level of scatter for low sparsity values, this is inherently due to assuming a specific shape of the profile, which leads to a loss of information. Moreover, further assuming that the concentration follows a log-normal distribution results in a suppression of the scatter on the high-sparsity tail. This is because the log-normal distribution underestimates the distribution of concentrations at low values, which is primarily sourced by mergers (Richardson & Corasaniti 2022).
4.2. Halo mass conversions from concentration-mass relations
Given the relation between halo sparsity and halo concentration, we can map the HMF at different overdensities by combining both the reconstruction procedure presented above in Eqs. (4) and (5) with models of the distribution of NFW concentrations from the literature, which are converted into sparsities using using Eq. (16). This leads to an inward,
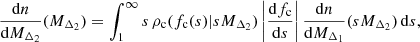
and outward,
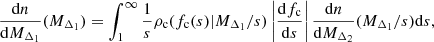
reconstruction of the HMF assuming the NFW profile and a c − M relation model. In a similar fashion to how we derived Eq. (8), assuming that the concentration distribution is highly peaked around the c − M relation
![$$ \begin{aligned} \rho _{\rm c}(c|M_{\Delta _1}) \simeq \delta _D\left[c - \bar{c}(M_{\Delta _1},z)\right], \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq22.gif)
one can show that the leading order contributions to Eqs. (17) and (18) reduce to the formulation of Hu & Kravtsov (2003). Thus, it is clear that the formulation presented above generalises widely used results by including the stochastic natures of the parameters at play, which allows the study of a wider variety of models within a unified framework.
In Fig. 3 we perform an inward reconstruction of the HMF at Δ2 = 500 starting from the HMF estimated from the Uchuu catalogue at Δ1 = 200 assuming 1) the marginal sparsity distribution; 2) the conditional sparsity distribution; 3) the conditional sparsity distribution computed from measured concentrations; and 4) the sparsity distribution predicted assuming a log-normal distribution of the concentration with σ = 0.25 and the mean specified by different c − M relations from Bullock et al. (2001), Zhao et al. (2009), Prada et al. (2012), Diemer & Kravtsov (2015), Ludlow et al. (2016), Diemer & Joyce (2019), Ishiyama et al. (2021). In addition, we plot the mass functions estimated from the Uchuu halo catalogues against the reconstructed ones at M500c (left panel) and the relative differences (right panel). As in Fig. 1, the shaded areas correspond to the 1σ statistical error on the N-body mass function estimated as the standard deviation of 103 bootstrap iterations. Again, in the case of the sparsity-based reconstructions, we find that using the conditional sparsity distribution results in a reconstructed HMF that is consistent with that estimated from the N-body halo catalogue within statistical uncertainties with deviations at the sub-percent level up to M500c ≈ 1014 M⊙h−1. Instead, using the marginal distribution leads to differences that exceed the 10% level. In the concentration-based reconstructions, we can see that in the case of the c − M relation from Prada et al. (2012) the reconstructed HMF deviates from the N-body HMF by more than 10% for M500c ≳ 1014 M⊙h−1, while in the other cases deviations are within the 1 − 10% level over the entire mass range. This could be the consequence of a number of factors, such as assumptions in the way the halo concentrations are estimated and the level of scatter we assume in the reconstruction.
 |
Fig. 3. Measuring the effectiveness of transforming the halo mass function from one density contrast to another assuming a c − M relation. Left panel: HMF at Δ1 = 200 (dark magenta line) and Δ2 = 500 (light magenta line) from the Uchuu halo catalogue at z = 0 against the reconstructed HMF at Δ2 = 500 obtained for the different c − M relation models shown in the legend (see text for further information). Right panel: relative error on these reconstructions. As in Fig. 1, the shaded areas around the measured HMFs represent the statistical error on the measurement estimated as the standard deviation over 103 bootstrap iterations. |
To estimate the goodness of the reconstruction for each of the models considered, we compute
![$$ \begin{aligned} \chi ^2 = \sum _{i=0}^N \frac{1}{\sigma _i^2}\left[\frac{\mathrm{d} n_{\rm rec}}{\mathrm{d} M_{500\mathrm{c}}}\left(M^i_{500\mathrm{c}}\right)-\frac{\mathrm{d}n_{N-\mathrm {body}}}{\mathrm{d} M_{500\mathrm{c}}}\left(M^i_{500\mathrm{c}}\right)\right]^2, \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq23.gif)
where the index i runs over the N mass bins at which the HMF is estimated from the Uchuu haloes and σi is the corresponding statistical error. We evaluated the goodness-of-fit of the different models at z = 0.00, 0.25, 0.50, 1.00, and 2.00; the results are quoted in Table 1. We find that using the conditional sparsity distribution results in an inward reconstruction that performs significantly better than all other cases at all redshifts. We also find that all reconstructions based on the concentration, including those using the empirical distribution of c from the N-body halo catalogues, exhibit a percent level bias on the reconstruction. We conclude that this bias originates from discrepancies between the true profile and the assumed NFW profile of each halo. Furthermore, we note that among the reconstructions based on the use of c − M relations, the model of Zhao et al. (2009) outperforms the others at low redshifts including the case of Ishiyama et al. (2021), which was obtained from the analysis of the same simulations.
χ2 statistics of the reconstructed HMFs at Δ2 = 500 and z = 0.00, 0.25, 0.50, 1.00, and 2.00 for different reconstruction model assumptions.
4.3. Concentration-mass relation from halo mass functions
An interesting byproduct is the ability to predict the concentration-mass relation from the HMFs at two different overdensities. This can be done using the relation between halo sparsity and HMFs, as well as the relation between the conditional sparsity distribution and that of the concentration. More specifically, in the same fashion used to transform the conditional concentration distribution into the conditional sparsity distribution with Eq. (16), we perform the inverse operation,
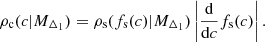
Analogously to Sect. 3.3, by assuming that the distribution of sparsities is peaked around the mean sparsity value we have
![$$ \begin{aligned} \rho _{\rm s}(s|M_{\Delta _1}) \approx \delta _{\rm D}\left[s - \langle s_{\Delta _1, \Delta _2}\rangle (M_{\Delta _1})\right]. \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq25.gif)
Hence, this results in a conditional distribution of concentrations that is also peaked around a value given by
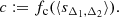
Furthermore, using Eq. (5) we derive an outward relation between the HMFs and the mean sparsity3:
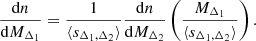
Henceforth, given a functional form of the HMFs, we can numerically solve the above equation to obtain ⟨sΔ1, Δ2⟩(MΔ1); when substituted in Eq. (23), this allows us to predict the c − M relation from the HMFs.
We plot in Fig. 4 the mean concentration c200c as a function of M200c from the Uchuu halo catalogue at z = 0 (solid orange line) with iso-contours of the conditional concentration distribution against the mean c200c − M200c relation obtained from the mean sparsity mass relation ⟨s200, 500⟩(M200c) measured from the same halo catalogue (solid blue), and that predicted by the HMFs at Δ = 200ρc and Δ = 500ρc from Tinker et al. (2008), Watson et al. (2013), Bocquet et al. (2016), Despali et al. (2016) and measured HMFs respectively the green, red, pink, yellow, and grey lines.
 |
Fig. 4. Comparison of the concentration distribution inside the Uchuu simulation, measured c − M relation, and model predictions. Top panel: iso-contours of the conditional concentration c200c from the Uchuu halo catalogues at z = 0 as a function of M200c. The solid lines correspond to the mean c − M relation measured from the concentration (orange line) and mean sparsity s200, 500 (blue line) of the N-body haloes, and predicted from the measure HMF (grey lines) and HMFs models by Tinker et al. (2008) (green line), Watson et al. (2013) (red line), Bocquet et al. (2016) (pink line), and Despali et al. (2016) (yellow line). Middle and bottom panels: relative difference between the concentration mass relation predicted from the measured mean sparsity and that measured or predicted using other methods. The shaded area around each model represents one standard deviation around the latter assuming the statistical uncertainty of the HMF measured in the Uchuu simulation. Dashed lines represent the concentration-mass relation predicted from the median sparsity and concentration. |
We find that the predicted mean c − M relations deviates by 10 − 30% with respect to that estimated from the concentration of the N-body haloes. Upon closer inspection we see considerable scatter between the predictions of different HMF prescriptions. This scatter results from the compound effect of model choices, particularly at low masses, and statistical uncertainty on model calibration, especially at high masses, as can be seen in the lower panels of Fig. 4, where we show the relative difference between the c − M relation from measured mean sparsity and those predicted under our assumptions. The shaded areas in this figure correspond to the standard deviation around each model prediction estimated using 103 bootstrap iterations assuming the statistical error on the HMF models is similar to that from the Uchuu simulation.
In addition, we see that the predicted c − M relation from the measured mean sparsity is significantly offset from the prediction from the measured HMF; this is due to our assumption that the distribution is highly peaked around the mean, when it is in fact a wide and highly skewed distribution. We can see this clearly when repeating the same process but using the median instead of the mean. The median, which is closer to the mode of the distribution, is indeed much closer to the prediction from the HMF and is contained within the statistical error around this prediction. This suggests that, when performing a cosmological parameter inference based upon a prediction of the internal structure of haloes as we do in the following section, the choice of a particular HMF model and the type of statistics considered (i.e. sample mean or median) may introduce systematic errors on the inferred cosmological parameters.
It should be noted that the relations between halo mass functions at different overdensities and the parameters of the parametrised halo density profile discussed here are not limited to the NFW profile, but can be generalised to any parametric profile. For example in Appendix C, we discuss the case of the Einasto profile (Einasto 1965).
5. Forecasting cosmological constraints from individual sparsity measurements
Cosmological analyses based on cluster sparsity measurements have so far relied on estimates of the ensemble average sparsity of cluster samples at different redshifts (see Corasaniti et al. 2018, 2021, 2022). However, as shown in Sect. 3.3, by adopting a parametrised form of the conditional sparsity distribution and a parametrisation of the HMFs at two different overdensities, it is possible to predict the mean sparsity and its variance at a given mass and redshift. This provides a quantitative framework to infer cosmological parameter constraints from individual sparsity measurements of galaxy clusters, which may carry more cosmological information than that encoded in the cluster ensemble average, since in the latter case the cosmological signal may be diluted when averaging over the cluster sample.
We note that while the constraints from sparsity measurements rely on prior theoretical modelling of the HMF, they are to be considered separately from those inferred from number count data analyses. The latter probes the cosmological imprint encoded in the evolution of the shape and amplitude of the calibrated HMF at the overdensity definition of the cluster observations, while the former tests the differential evolution of the HMF at two overdensities of interest. Formally this is indicated by the presence of the integration variable within Eqs. (4) and (5) linking the HMF and sparsity distribution. In essence, the distribution of sparsities controls the difference in the shapes and relative height of the HMFs. Furthermore, studies of the halo concentration (see e.g., Zhao et al. 2003b, 2009; Li et al. 2007; Neto et al. 2007; Giocoli et al. 2012; Ludlow et al. 2012, 2016; Wang et al. 2020) strongly indicate that the internal structures of haloes is linked to their assembly history. Sparsity constraints are thus complementary to number counts, and combining the two probes provides further improvements to those obtained from sparsity-only analyses. We leave a detailed study of the constraints that can be inferred from the combination of the two probes to future work.
In the following, we assume that the conditional sparsity distribution, ρs(sΔ1, Δ2|MΔ2), is a Gaussian with mean s0 and standard deviation σs. Then, given a parametrised form of the HMFs at redshift z and overdensities Δ1 and Δ2, we can simultaneously solve Eqs. (4) and (5) to derive a prediction for the value of 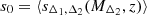 and
and 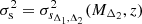 . It is worth noting that this particular choice implies that we use the same conditional sparsity distribution for the inward and outward constraints, which in full generality should not be the case. In addition, the distribution of sparsities measured from the N-body halo catalogues appears to be strongly skewed towards high values, and moreover should by definition be 0 for all values sΔ1, Δ2 < 1. While this is far from being verified with our assumptions, the Gaussian distribution is the only distribution that yields a unique solution for this choice of constraints, making it robust to the first guess used to initialise the gradient decent algorithm.
. It is worth noting that this particular choice implies that we use the same conditional sparsity distribution for the inward and outward constraints, which in full generality should not be the case. In addition, the distribution of sparsities measured from the N-body halo catalogues appears to be strongly skewed towards high values, and moreover should by definition be 0 for all values sΔ1, Δ2 < 1. While this is far from being verified with our assumptions, the Gaussian distribution is the only distribution that yields a unique solution for this choice of constraints, making it robust to the first guess used to initialise the gradient decent algorithm.
In Fig. 5 we plot the mean sparsity s200, 500 and its variance 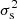 in bins of mass M500c, as obtained from the analysis of the Uchuu halo catalogue at z = 0, against the prediction obtained from the HMFs measured from the same sample at Δ1 = 200 and Δ2 = 500 in units of the critical density and assuming the analytical fit from Despali et al. (2016). We can see that s0 is accurate to the order of a few percent when recovering the sample mean. However, we see that the reconstructed variance is significantly biased at high masses. What can be seen is that the variance has only a weak dependency on halo mass while the reconstructed variance increases with mass. This effect is most likely a consequence of the assumptions made on the shape of the probability distribution function since there is no significant difference between using an analytical model for the HMFs and that estimated from the N-body haloes we are trying to reproduce.
in bins of mass M500c, as obtained from the analysis of the Uchuu halo catalogue at z = 0, against the prediction obtained from the HMFs measured from the same sample at Δ1 = 200 and Δ2 = 500 in units of the critical density and assuming the analytical fit from Despali et al. (2016). We can see that s0 is accurate to the order of a few percent when recovering the sample mean. However, we see that the reconstructed variance is significantly biased at high masses. What can be seen is that the variance has only a weak dependency on halo mass while the reconstructed variance increases with mass. This effect is most likely a consequence of the assumptions made on the shape of the probability distribution function since there is no significant difference between using an analytical model for the HMFs and that estimated from the N-body haloes we are trying to reproduce.
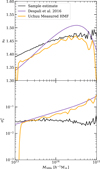 |
Fig. 5. Parameters s0 and |
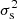
We can now test the level of constraints that can be inferred on the cosmological parameters when using individual sparsity measurements of galaxy clusters. To this end, we generated a synthetic dataset consisting of 118 cluster-scale haloes (M200c > 1014h−1 M⊙) randomly selected over all Uchuu catalogues up to z = 0.63. This particular selection was done so as to have a crude resemblance to the CHEX-MATE cluster sample (CHEX-MATE Collaboration 2021). For each of these haloes we computed the sparsity s200, 500. We compared the constraints from the individual sparsity measurements to those from the ensemble average estimates at different redshifts (see e.g., Corasaniti et al. 2018). For this purpose we split the synthetic sample into Nz = 6 independent redshift bins and computed the average sparsity in each of them.
In order to evaluate the differences between the two approaches, we first consider an ideal case in which we neglect uncertainties on the sparsity measurements and assume a Gaussian likelihood function:
![$$ \begin{aligned} \ln \mathcal{L} = -\frac{1}{2}\sum _{i = 1}^N\left\{ \ln \left[2\pi \,\sigma _{\rm s}^2(M_i, z_i)\right] + \frac{\left[s_i - s_0(M_i, z_i)\right]^2}{\sigma _{\rm s}^2(M_i, z_i)}\right\} . \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq32.gif)
Here si is the sparsity of the ith synthetic data point with N = 118, s0(Mi, zi) and 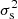 (Mi, zi) are respectively the mean and variance of sparsities at a given mass and redshift as predicted for a given set of cosmological parameters by simultaneously solving Eqs. (4) and (5), with HMFs given by the analytical fit of Despali et al. (2016) and assuming, ρs(x|Mi, zi), to be Gaussian with mean, s0(Mi, zi), and variance
(Mi, zi) are respectively the mean and variance of sparsities at a given mass and redshift as predicted for a given set of cosmological parameters by simultaneously solving Eqs. (4) and (5), with HMFs given by the analytical fit of Despali et al. (2016) and assuming, ρs(x|Mi, zi), to be Gaussian with mean, s0(Mi, zi), and variance 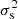 (Mi, zi). The cosmology dependence of the likelihood is captured through that of the HMF at the density contrasts of interest. In the case of Despali et al. (2016) this dependence is embodied by the variation of the fit parameters with the virial overdensity contrast. Moreover, this choice is motivated by the need of a HMF definition compatible with matched haloes. In the case of the ensemble average sparsity measurements, the sum in Eq. (25) runs over the redshift bins (i.e. N = 6), and the average sparsities are compared to the theoretical expectation (Corasaniti et al. 2018) through a Gaussian likelihood with variance σ2 = 0.22. We focus on Ωm and σ8 and use affine invariant Markov chain Monte Carlo sampling (Goodman & Weare 2010; Foreman-Mackey et al. 2013) of the log-likelihood with uniform priors 0.1 < Ωm < 0.6 and 0.3 < σ8 < 1.3.
(Mi, zi). The cosmology dependence of the likelihood is captured through that of the HMF at the density contrasts of interest. In the case of Despali et al. (2016) this dependence is embodied by the variation of the fit parameters with the virial overdensity contrast. Moreover, this choice is motivated by the need of a HMF definition compatible with matched haloes. In the case of the ensemble average sparsity measurements, the sum in Eq. (25) runs over the redshift bins (i.e. N = 6), and the average sparsities are compared to the theoretical expectation (Corasaniti et al. 2018) through a Gaussian likelihood with variance σ2 = 0.22. We focus on Ωm and σ8 and use affine invariant Markov chain Monte Carlo sampling (Goodman & Weare 2010; Foreman-Mackey et al. 2013) of the log-likelihood with uniform priors 0.1 < Ωm < 0.6 and 0.3 < σ8 < 1.3.
In Fig. 6 we show the resulting posterior distributions. In both cases we see that the Uchuu simulation’s fiducial cosmology is recovered within the 1σ contour of each posterior. Moreover, consistently with results from previous studies, the sparsity constraints line up along the 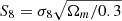 degeneracy curve. We may also find that using individual sparsity measurements rather than the ensemble averages at different redshifts leads to much stronger constraints. This is due to avoiding the information loss caused by binning and calculating the mean sparsity in each redshift bin. However, this comes at the cost of increased run time resulting from the complexity of the likelihood evaluation.
degeneracy curve. We may also find that using individual sparsity measurements rather than the ensemble averages at different redshifts leads to much stronger constraints. This is due to avoiding the information loss caused by binning and calculating the mean sparsity in each redshift bin. However, this comes at the cost of increased run time resulting from the complexity of the likelihood evaluation.
 |
Fig. 6. Posterior distributions resulting from the analysis of 118 randomly selected haloes from the Uchuu simulation. Shown in purple is the methodology of Corasaniti et al. (2018) that calculates the mean sparsity in Nz = 6 redshift bins and in orange the method where the haloes are treated as an individual data point (see Sect. 5). In both cases the same input information is used (i.e. the same 118 haloes and using the HMF definition of Despali et al. 2016). There is a clear increase in the constraining power when using the second method, this is simply due to avoiding the information loss that occurs when binning and calculating the mean sparsity. |
In order to account for sparsity measurement errors due to observational uncertainties of the cluster masses, we now assume for simplicity that individual mass measurements are drawn from independent log-normal distributions of mean MΔi and variance 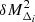 . From this, we obtain the joint distribution of errors on the sparsity, s200, 500 and the inner mass, M500c, using a ratio distribution, Eq. (A.9), over which we marginalise the likelihood function. This simple approach is sufficient when the errors on the masses are small, typically a few percent; however, if the errors are larger, the resulting error distribution assigns significant probabilities to sparsities s200, 500 < 1, a non-physical regime. This has the systematic effect of assigning weight to low sparsities and greatly biasing the likelihood towards large values of S8. Accurate error modelling, in particular the correlation between the errors, is therefore crucial to avoid this statistical induced bias.
. From this, we obtain the joint distribution of errors on the sparsity, s200, 500 and the inner mass, M500c, using a ratio distribution, Eq. (A.9), over which we marginalise the likelihood function. This simple approach is sufficient when the errors on the masses are small, typically a few percent; however, if the errors are larger, the resulting error distribution assigns significant probabilities to sparsities s200, 500 < 1, a non-physical regime. This has the systematic effect of assigning weight to low sparsities and greatly biasing the likelihood towards large values of S8. Accurate error modelling, in particular the correlation between the errors, is therefore crucial to avoid this statistical induced bias.
With the intent of diminishing this effect we add the following prior to our error model,
![$$ \begin{aligned} \rho _{\rm p}(s) = 1- \exp \left[-\frac{1}{2}\frac{(s - 1)^2}{s_i^2(\delta M_{200 \mathrm{c}, i}^2/M_{200 \mathrm{c}, i}^2 + \delta M_{500 \mathrm{c}, i}^2/M_{500 \mathrm{c}, i}^2)}\right], \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq37.gif)
which reduces the non-physical weight placed on low sparsities to produce the posteriors of Fig. 7. We note the distinction between si (the measured sparsity) and s (the variable over which we marginalise the error distribution). We chose to adapt the width of this prior with the magnitude of the errors so as to correct the low-mass error regime as little as possible. We produce posterior distributions for four error models. In blue we show the case of cluster mass errors estimated by Corasaniti et al. (2022) for the CHEX-MATE sample, δM200c, i/M200c, i = 0.23, δM500c, i/M500c, i = 0.15; in purple is shown the case where we halve these errors; for the orange contours we have reduced the original errors by a factor of 4; and in pink we use percent level errors. What can be clearly seen is the effect of the bias induced by the crude modelling of errors. This bias is naturally reduced when we consider smaller errors on the cluster masses, with the case with the smallest errors recovering the contours obtained in the ideal case (i.e. with no mass measurement uncertainties).
 |
Fig. 7. Posterior distributions resulting from the analysis of a sample of 118 randomly selected haloes from the Uchuu simulation modelling measurement errors. Each contour corresponds to a model for the relative errors on clusters masses (δM200c, i/M200c, i, δM500c, i/M500c, i): in blue (23%, 15%) the magnitude of errors estimated for the CHEX-MATE sample; in purple (11.5%, 7.5%); in orange (5.7%, 3.7%); and in pink (1%, 1%). For the smallest errors the posterior from Fig. 6 is recovered where errors were neglected. Also seen is that a naive modelling of errors induces a bias towards increasingly large values of S8. |
While it is difficult to conclude on the case with the largest errors as the prior strongly influences this specific result, we do note that models with errors comparable to those of upcoming missions already produce stronger constraints than if we consider only the ensemble average sparsity. It is also worth noting that the simplifying assumptions that produced these forecasts can be alleviated with known methodologies. For example, we could replace the analytical form of the sparsity distribution with one predicted by a cosmological emulator trained over a large sample of cosmological simulations. Moreover, accurately modelling the mass measurement errors can further improve the cosmological constraints providing a new avenue for testing cosmology.
6. Conclusions
It is currently widely accepted that observations of galaxy clusters provide exceptional opportunities to study both cosmology and astrophysics. While recent cosmological studies using galaxy clusters have been primarily focused on cluster number counts, the internal structure of dark matter haloes, as probed by halo sparsity, has proven to be a new and useful probe for both cosmology (Balmès et al. 2014; Corasaniti et al. 2018, 2021, 2022) and the astrophysics of galaxy clusters (Richardson & Corasaniti 2022), thanks to current and upcoming observations of galaxy clusters reaching the level of precision required to extract this information encoded in the mass profile of clusters.
In this paper we investigated how sparsity statistics can be further used to map the relation between two halo mass functions estimated at two distinct density contrasts. Within a probabilistic framework we were able to exactly relate both halo mass functions using only the distribution of sparsities conditional to halo mass. In particular, we showed that with additional assumptions on this distribution we were able to recover formulations previously used in the literature. Moreover, we demonstrated that it is also possible to retrieve information about the sparsity distribution directly from the halo mass functions.
The non-parametric nature of halo sparsity also allowed us to express the mapping between halo mass functions in terms of any parameters describing the density profiles of haloes. To this end, we examined the specific case of NFW concentration. Thus, we showed that using the relation between sparsity and concentration it is possible to map the halo mass function to any density contrast simply by assuming a c − M relation, and inversely to predict a c − M relation given the HMF at two overdensity contrasts.
Finally, we showed that our method for predicting the distribution of sparsities at any mass, redshift, and cosmology can be directly applied to perform cosmological inference analyses and provide significantly stronger constraints than current methods based on the use of ensemble average sparsity measurements. However, the method presented here can be further expanded through the use of emulators and more accurate handling of the cluster mass measurement errors.
This project made use of publicly available data from the Skies and Universes database4. In addition, many of the Python codes and transformed data products used throughout this project are made publicly available online5.
As shown in Balmès et al. (2014), the properties of halo sparsity are independent of whether overdensities are defined in units of the critical or background density.
As opposed to the inward relation, Eq. (7).
Acknowledgments
We thank Yann Rasera, Amandine Le Brun and the anonymous referee for their insightful comments on this manuscript. This work has made use of the Infinity Cluster hosted by Institut d’Astrophysique de Paris. We thank Stephane Rouberol for running smoothly this cluster for us. We thank Instituto de Astrofisica de Andalucia (IAA-CSIC), Centro de Supercomputacion de Galicia (CESGA) and the Spanish academic and research network (RedIRIS) in Spain for hosting Uchuu DR1 and DR2 in the Skies & Universes site for cosmological simulations. The Uchuu simulations were carried out on Aterui II supercomputer at Center for Computational Astrophysics, CfCA, of National Astronomical Observatory of Japan, and the K computer at the RIKEN Advanced Institute for Computational Science. The Uchuu DR1 and DR2 effort has made use of the skun@IAA_RedIRIS and skun6@IAA computer facilities managed by the IAA-CSIC in Spain (MICINN EU-Feder grant EQC2018-004366-P). We thank the developers and maintainers of the colossus package Diemer (2018) that was used in this work.
References
- Abbott, T. M. C., Aguena, M., Alarcon, A., et al. 2020, Phys. Rev. D, 102, 023509 [Google Scholar]
- Allen, S. W., Evrard, A. E., & Mantz, A. B. 2011, ARA&A, 49, 409 [Google Scholar]
- Angulo, R. E., Springel, V., White, S. D. M., et al. 2012, MNRAS, 426, 2046 [NASA ADS] [CrossRef] [Google Scholar]
- Balmès, I., Rasera, Y., Corasaniti, P. S., & Alimi, J. M. 2014, MNRAS, 437, 2328 [CrossRef] [Google Scholar]
- Behroozi, P. S., Wechsler, R. H., & Wu, H.-Y. 2013a, ApJ, 762, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Behroozi, P. S., Wechsler, R. H., Wu, H.-Y., et al. 2013b, ApJ, 763, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Bocquet, S., Saro, A., Dolag, K., & Mohr, J. J. 2016, MNRAS, 456, 2361 [Google Scholar]
- Bocquet, S., Dietrich, J. P., Schrabback, T., et al. 2019, ApJ, 878, 55 [Google Scholar]
- Bocquet, S., Heitmann, K., Habib, S., et al. 2020, ApJ, 901, 5 [Google Scholar]
- Bond, J. R., Cole, S., Efstathiou, G., & Kaiser, N. 1991, ApJ, 379, 440 [NASA ADS] [CrossRef] [Google Scholar]
- Bullock, J. S., Kolatt, T. S., Sigad, Y., et al. 2001, MNRAS, 321, 559 [Google Scholar]
- Castro, T., Borgani, S., Dolag, K., et al. 2021, MNRAS, 500, 2316 [Google Scholar]
- CHEX-MATE Collaboration (Arnaud, M., et al.) 2021, A&A, 650, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Corasaniti, P. S., Ettori, S., Rasera, Y., et al. 2018, ApJ, 862, 40 [CrossRef] [Google Scholar]
- Corasaniti, P.-S., Sereno, M., & Ettori, S. 2021, ApJ, 911, 82 [NASA ADS] [CrossRef] [Google Scholar]
- Corasaniti, P. S., Le Brun, A. M. C., Richardson, T. R. G., et al. 2022, MNRAS, 516, 437 [NASA ADS] [CrossRef] [Google Scholar]
- Courtin, J., Rasera, Y., Alimi, J. M., et al. 2011, MNRAS, 410, 1911 [NASA ADS] [Google Scholar]
- Cui, W., Borgani, S., & Murante, G. 2014, MNRAS, 441, 1769 [NASA ADS] [CrossRef] [Google Scholar]
- Davis, M., Efstathiou, G., Frenk, C. S., & White, S. D. M. 1985, ApJ, 292, 371 [Google Scholar]
- de Haan, T., Benson, B. A., Bleem, L. E., et al. 2016, ApJ, 832, 95 [NASA ADS] [CrossRef] [Google Scholar]
- Despali, G., Giocoli, C., Angulo, R. E., et al. 2016, MNRAS, 456, 2486 [NASA ADS] [CrossRef] [Google Scholar]
- Diemer, B. 2018, ApJS, 239, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Diemer, B. 2020, ApJ, 903, 87 [NASA ADS] [CrossRef] [Google Scholar]
- Diemer, B., & Joyce, M. 2019, ApJ, 871, 168 [NASA ADS] [CrossRef] [Google Scholar]
- Diemer, B., & Kravtsov, A. V. 2015, ApJ, 799, 108 [Google Scholar]
- Dolag, K., Bartelmann, M., Perrotta, F., et al. 2004, A&A, 416, 853 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Einasto, J. 1965, Trudy Astrofizicheskogo Instituta Alma-Ata, 5, 87 [NASA ADS] [Google Scholar]
- Euclid Collaboration (Scaramella, R., et al.) 2022, A&A, 662, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Giocoli, C., Tormen, G., & Sheth, R. K. 2012, MNRAS, 422, 185 [NASA ADS] [CrossRef] [Google Scholar]
- Goodman, J., & Weare, J. 2010, Commun. Appl. Math. Comput. Sci., 5, 65 [Google Scholar]
- Hu, W., & Kravtsov, A. V. 2003, ApJ, 584, 702 [Google Scholar]
- Ishiyama, T., Fukushige, T., & Makino, J. 2009, PASJ, 61, 1319 [NASA ADS] [CrossRef] [Google Scholar]
- Ishiyama, T., Nitadori, K., & Makino, J. 2012, ArXiv e-prints [arXiv:1211.4406] [Google Scholar]
- Ishiyama, T., Prada, F., Klypin, A. A., et al. 2021, MNRAS, 506, 4210 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jenkins, A., Frenk, C. S., White, S. D. M., et al. 2001, MNRAS, 321, 372 [Google Scholar]
- Kravtsov, A. V., & Borgani, S. 2012, ARA&A, 50, 353 [Google Scholar]
- Lacey, C., & Cole, S. 1994, MNRAS, 271, 676 [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Li, Y., Mo, H. J., van den Bosch, F. C., & Lin, W. P. 2007, MNRAS, 379, 689 [CrossRef] [Google Scholar]
- López-Cano, D., Angulo, R. E., Ludlow, A. D., et al. 2022, MNRAS, 517, 2000 [CrossRef] [Google Scholar]
- Ludlow, A. D., Navarro, J. F., Li, M., et al. 2012, MNRAS, 427, 1322 [NASA ADS] [CrossRef] [Google Scholar]
- Ludlow, A. D., Bose, S., Angulo, R. E., et al. 2016, MNRAS, 460, 1214 [Google Scholar]
- Lukić, Z., Heitmann, K., Habib, S., Bashinsky, S., & Ricker, P. M. 2007, ApJ, 671, 1160 [CrossRef] [Google Scholar]
- Macciò, A. V., Dutton, A. A., van den Bosch, F. C., et al. 2007, MNRAS, 378, 55 [Google Scholar]
- Mantz, A. B., von der Linden, A., Allen, S. W., et al. 2015, MNRAS, 446, 2205 [Google Scholar]
- Martizzi, D., Mohammed, I., Teyssier, R., & Moore, B. 2014, MNRAS, 440, 2290 [NASA ADS] [CrossRef] [Google Scholar]
- McClintock, T., Rozo, E., Becker, M. R., et al. 2019, ApJ, 872, 53 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [Google Scholar]
- Neto, A. F., Gao, L., Bett, P., et al. 2007, MNRAS, 381, 1450 [NASA ADS] [CrossRef] [Google Scholar]
- Nishimichi, T., Takada, M., Takahashi, R., et al. 2019, ApJ, 884, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Ondaro-Mallea, L., Angulo, R. E., Zennaro, M., Contreras, S., & Aricò, G. 2022, MNRAS, 509, 6077 [Google Scholar]
- Pacaud, F., Pierre, M., Melin, J. B., et al. 2018, A&A, 620, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XIII. 2016, A&A, 594, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXIV. 2016, A&A, 594, A24 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Prada, F., Klypin, A. A., Cuesta, A. J., Betancort-Rijo, J. E., & Primack, J. 2012, MNRAS, 423, 3018 [NASA ADS] [CrossRef] [Google Scholar]
- Press, W. H., & Schechter, P. 1974, ApJ, 187, 425 [Google Scholar]
- Ragagnin, A., Saro, A., Singh, P., & Dolag, K. 2021, MNRAS, 500, 5056 [Google Scholar]
- Reed, D., Gardner, J., Quinn, T., et al. 2003, MNRAS, 346, 565 [NASA ADS] [CrossRef] [Google Scholar]
- Richardson, T. R. G., & Corasaniti, P. S. 2022, MNRAS, 513, 4951 [NASA ADS] [CrossRef] [Google Scholar]
- Rozo, E., Wechsler, R. H., Rykoff, E. S., et al. 2010, ApJ, 708, 645 [Google Scholar]
- Schellenberger, G., & Reiprich, T. H. 2017, MNRAS, 471, 1370 [Google Scholar]
- Seppi, R., Comparat, J., Nandra, K., et al. 2021, A&A, 652, A155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sheth, R. K., Mo, H. J., & Tormen, G. 2001, MNRAS, 323, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Tinker, J., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [Google Scholar]
- Velliscig, M., van Daalen, M. P., Schaye, J., et al. 2014, MNRAS, 442, 2641 [Google Scholar]
- Wang, K., Mao, Y.-Y., Zentner, A. R., et al. 2020, MNRAS, 498, 4450 [NASA ADS] [CrossRef] [Google Scholar]
- Warren, M. S., Abazajian, K., Holz, D. E., & Teodoro, L. 2006, ApJ, 646, 881 [NASA ADS] [CrossRef] [Google Scholar]
- Watson, W. A., Iliev, I. T., D’Aloisio, A., et al. 2013, MNRAS, 433, 1230 [Google Scholar]
- Wechsler, R. H., Bullock, J. S., Primack, J. R., Kravtsov, A. V., & Dekel, A. 2002, ApJ, 568, 52 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, D. H., Jing, Y. P., Mo, H. J., & Börner, G. 2003a, ApJ, 597, L9 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, D. H., Mo, H. J., Jing, Y. P., & Börner, G. 2003b, MNRAS, 339, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, D. H., Jing, Y. P., Mo, H. J., & Börner, G. 2009, ApJ, 707, 354 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Transformation of random variates
Throughout this work we treat halo properties as random variables. As such, each variable is associated with a probability distribution function (PDF). When we apply a transformation to the random variable, the PDF must also be transformed.
We let X and Y be two random variates drawn respectively from ρx(x) and ρy(y) and related through a deterministic function, Y = f(X). Due to the conservation of probability, ρy(y)dy = ρx(x)dx, we can relate the two PDFs,
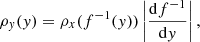
assuming the transformation to be invertible.
Within the context of this work we are interested in transformations involving two random variates: Z = f(X, Y). Relating the PDF of Z to the joint distribution, ρxy(x, y) of X and Y, requires additional thought compared to the one-dimensional case. In most cases the function f(X, Y) will not be invertible. However, this can be circumvented through the introduction of a fourth variable W. We define two column vectors,
![$$ \begin{aligned} \left[\begin{matrix} Z \\ W \end{matrix}\right] = \boldsymbol{f}(X,Y) = \left[\begin{matrix} f_Z(X,Y) \\ f_W(X,Y) \end{matrix}\right] \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq39.gif)
and
![$$ \begin{aligned} \left[\begin{matrix} X \\ Y \end{matrix}\right] = \boldsymbol{g}(Z,W) = \left[\begin{matrix} g_X(Z,W) \\ g_Y(Z,W) \end{matrix}\right] ,\end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq40.gif)
as the transformations between these variables. Through the conservation of probability, the joint distribution, ρzw(Z, W), can be written as
![$$ \begin{aligned} \rho _{zw}(z,w) = \rho _{xy}[g_X(z,w), g_Y(z,w)]\left| \begin{matrix} \partial _z g_X&\partial _w g_X\\ \partial _z g_Y&\partial _w g_Y \end{matrix}\right|. \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq41.gif)
The distribution for Z can then be obtained by marginalising over W:
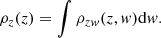
In this work we are particularly interested in the PDF of the product, Z = XY, and ratio, 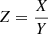 , of two random variables. In the case of the product, we define
, of two random variables. In the case of the product, we define
![$$ \begin{aligned} \left[\begin{matrix} Z \\ W \end{matrix}\right] = \left[\begin{matrix} XY \\ Y \end{matrix}\right] \;\text{ and}\; \left[\begin{matrix} X \\ Y \end{matrix}\right] = \left[\begin{matrix} Z/W \\ W \end{matrix}\right] \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq44.gif)
as the transformation between the four random variables. We can then write
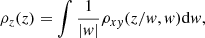
the PDF of Z. The ratio Z = X/Y similarly leads to
![$$ \begin{aligned} \left[\begin{matrix} Z \\ W \end{matrix}\right] = \left[\begin{matrix} X/Y \\ Y \end{matrix}\right] \;\text{ and}\; \left[\begin{matrix} X \\ Y \end{matrix}\right] = \left[\begin{matrix} ZW \\ W \end{matrix}\right]. \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq46.gif)
This results in the ratio distribution
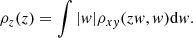
Appendix B: Validation against N-body halo catalogues at z > 0
In Section 3.2 we test the validity of the inward and outward HMF reconstructions using the halo Uchuu catalogue at z = 0. Here we present the results of similar analyses for the halo catalogues at z = 0.5 and 1. These are summarised in the plots shown in Fig. B.1 and Fig. B.2, respectively. We find the same trends as shown in Fig. 1. In particular, we note again that the use of the conditional sparsity distribution results in reconstructed HMFs that are within the statistical errors of those estimated from the N-body catalogues. This is not the case of the inward and outward reconstructions obtained using the sparsity marginal distribution.
Appendix C: Profiles with more than one parameter
Within this work we present an in-depth exploration of the relation between the distributions of NFW concentrations and sparsities. This methodology can be extended to profiles with more than one parameter describing the shape. Here we take the example of another widely used profile, the Einasto profile (Einasto 1965)
![$$ \begin{aligned} \rho (r) = \rho _{-2}\exp \left\{ -\frac{2}{\alpha }\left[\left(\frac{r}{r_{-2}}\right)^{-\alpha } - 1\right]\right\} , \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq48.gif)
which has gained significant traction over the last decade. This profile is able to fit the density profiles of dark matter haloes to a greater acuracy than the NFW profile, even accounting for the fact that it has an additional parameter. However, using the Einasto profile comes with the added complexity that the mass profile can only be expressed numerically and not analytically.
Here the additional parameter increases the complexity of the transformation between the two parameters describing the shape of the profile, (r−2, α), and sparsity. For each pair (r−2, α) we fix ρ−2 by fixing M200c. Taking into account this constraint, we calculate the sparsity by solving

for both values of Δ. This results in a mass dependent transformation between the Einasto parameters and sΔ1, Δ2.
To transform the distribution of Einasto profile parameters into a distribution of sparsities we choose, in the conventions of Appendix A, Z = sΔ1, Δ2, X = r−2, and W = Y = α, which considerably simplifies the expression of the Jacobian,
![$$ \begin{aligned} \rho _{s, \alpha }(s,\alpha ) = \rho _{r_{-2},\alpha }[g_{r_{-2}}(s,\alpha ), \alpha ]\left|\partial _s g_{r_{-2}}\right|, \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq50.gif)
where, as for the mass profile, the expression gr−2(s, α) has to be estimated numerically. This function can simply be seen as the value of r−2 for a given value of sΔ1, Δ2 and α. The PDF of sparsity is then
![$$ \begin{aligned} \rho _{\rm s}(s) = \int \rho _{r_{-2},\alpha }[g_{r_{-2}}(s,\alpha ), \alpha ]\left|\partial _s g_{r_{-2}}\right|\mathrm{d} \alpha . \end{aligned} $$](/articles/aa/full_html/2023/06/aa45622-22/aa45622-22-eq51.gif)
This methodology can be extended to any number of parameters, however with the complexity of having n − 1 dimensional integrals for a profile with n parameters.
All Tables
χ2 statistics of the reconstructed HMFs at Δ2 = 500 and z = 0.00, 0.25, 0.50, 1.00, and 2.00 for different reconstruction model assumptions.
All Figures
|
Fig. 1. Comparison of the accuracy of the mass dependent HMF transfer formalism with the marginalised formalism. The latter provides poor reconstructions while accounting for the mass dependence results with predictions that are exact to the level of statistical uncertainty. Left panel: estimated HMFs (purple shaded area) at z = 0 from the Uchuu halo catalogues for overdensities Δ = 200, 500, and 2500 (in units of the critical density) plotted against the inward (200 → 500, 200 → 2500, and 500 → 2500) and outward (2500 → 500, 2500 → 200, and 500 → 200) reconstructed HMFs from Eqs. (4) and (5), respectively, assuming the marginal sparsity distribution (dashed lines) and conditional distribution (solid lines). Right panels: relative error between the reconstructions and the measured HMF at Δ = 200 (top panel), Δ = 500 (mid panel), and Δ = 2500 (bottom panel). The shaded areas around the measured HMFs represents the statistical error on the measurement estimated as the standard deviation over 103 bootstrap iterations. |
| In the text | |
|
Fig. 2. Iso-contours of the conditional density distribution of the halo sparsity, ρ(s200,500|M200,c). Measurements are from the Uchuu halo catalogue at z = 0, (top panel), estimated from the distribution of measured concentrations (central panel), and predicted assuming a log-normal distribution of the concentration parameter for which the mean is given by the c − M relation of Ishiyama et al. (2021) calibrated on the Uchuu catalogues and width paramter σ = 0.25 (bottom panel). The coloured lines correspond to the mean of the distribution of measured sparsities (red), and that inferred from the measured concentrations (orange) and from the log-normal distribution (yellow). |
| In the text | |
|
Fig. 3. Measuring the effectiveness of transforming the halo mass function from one density contrast to another assuming a c − M relation. Left panel: HMF at Δ1 = 200 (dark magenta line) and Δ2 = 500 (light magenta line) from the Uchuu halo catalogue at z = 0 against the reconstructed HMF at Δ2 = 500 obtained for the different c − M relation models shown in the legend (see text for further information). Right panel: relative error on these reconstructions. As in Fig. 1, the shaded areas around the measured HMFs represent the statistical error on the measurement estimated as the standard deviation over 103 bootstrap iterations. |
| In the text | |
|
Fig. 4. Comparison of the concentration distribution inside the Uchuu simulation, measured c − M relation, and model predictions. Top panel: iso-contours of the conditional concentration c200c from the Uchuu halo catalogues at z = 0 as a function of M200c. The solid lines correspond to the mean c − M relation measured from the concentration (orange line) and mean sparsity s200, 500 (blue line) of the N-body haloes, and predicted from the measure HMF (grey lines) and HMFs models by Tinker et al. (2008) (green line), Watson et al. (2013) (red line), Bocquet et al. (2016) (pink line), and Despali et al. (2016) (yellow line). Middle and bottom panels: relative difference between the concentration mass relation predicted from the measured mean sparsity and that measured or predicted using other methods. The shaded area around each model represents one standard deviation around the latter assuming the statistical uncertainty of the HMF measured in the Uchuu simulation. Dashed lines represent the concentration-mass relation predicted from the median sparsity and concentration. |
| In the text | |
|
Fig. 5. Parameters s0 and |
| In the text | |
|
Fig. 6. Posterior distributions resulting from the analysis of 118 randomly selected haloes from the Uchuu simulation. Shown in purple is the methodology of Corasaniti et al. (2018) that calculates the mean sparsity in Nz = 6 redshift bins and in orange the method where the haloes are treated as an individual data point (see Sect. 5). In both cases the same input information is used (i.e. the same 118 haloes and using the HMF definition of Despali et al. 2016). There is a clear increase in the constraining power when using the second method, this is simply due to avoiding the information loss that occurs when binning and calculating the mean sparsity. |
| In the text | |
|
Fig. 7. Posterior distributions resulting from the analysis of a sample of 118 randomly selected haloes from the Uchuu simulation modelling measurement errors. Each contour corresponds to a model for the relative errors on clusters masses (δM200c, i/M200c, i, δM500c, i/M500c, i): in blue (23%, 15%) the magnitude of errors estimated for the CHEX-MATE sample; in purple (11.5%, 7.5%); in orange (5.7%, 3.7%); and in pink (1%, 1%). For the smallest errors the posterior from Fig. 6 is recovered where errors were neglected. Also seen is that a naive modelling of errors induces a bias towards increasingly large values of S8. |
| In the text | |
 |
Fig. B.1. Same as Fig. 1, but at redshift z = 0.5. |
| In the text | |
 |
Fig. B.2. Same as Fig. 1, but at redshift z = 1. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.